
c 抓取网页数据
c 抓取网页数据(c抓取网页数据,x抓包就是利用wireshark进行抓包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-19 21:03
c抓取网页数据,x抓包就是利用wireshark进行抓包。它有两种用法,一种是browser(浏览器)抓包,另一种是交给crawler(爬虫)来抓包,你可以根据情况来选择,小练习使用crawler抓x。//抓包create_http_session//设置会话try{session_save_header'content-type':'application/x-www-form-urlencoded';content_type'application/x-www-form-urlencoded';set_session_limit_max_http_status=1;set_cookie_type'notice';if(!_save_header){request_length=session_limit_max_http_status;set_header('host','');session_save_header'error'=seq(。
1)';session_save_header'session_limit_max_http_status';connection'keep-alive';}if(exists_save_header){request_error=_save_header('error',_save_header('error',error));}}catch(exceptione){request_error=_save_header('error',error);}//网页重定向url_data_link_to_script(href):用于从x-forwarded-for,发出url_data_link_to_script,post请求,获取html内容。
其code需要填写:443(888
8)*xhr-1:443(888
8) 查看全部
c 抓取网页数据(c抓取网页数据,x抓包就是利用wireshark进行抓包)
c抓取网页数据,x抓包就是利用wireshark进行抓包。它有两种用法,一种是browser(浏览器)抓包,另一种是交给crawler(爬虫)来抓包,你可以根据情况来选择,小练习使用crawler抓x。//抓包create_http_session//设置会话try{session_save_header'content-type':'application/x-www-form-urlencoded';content_type'application/x-www-form-urlencoded';set_session_limit_max_http_status=1;set_cookie_type'notice';if(!_save_header){request_length=session_limit_max_http_status;set_header('host','');session_save_header'error'=seq(。
1)';session_save_header'session_limit_max_http_status';connection'keep-alive';}if(exists_save_header){request_error=_save_header('error',_save_header('error',error));}}catch(exceptione){request_error=_save_header('error',error);}//网页重定向url_data_link_to_script(href):用于从x-forwarded-for,发出url_data_link_to_script,post请求,获取html内容。
其code需要填写:443(888
8)*xhr-1:443(888
8)
c 抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-18 16:25
一篇短文,涵盖了数据采集、数据清洗、数据展示的全过程。数据主要展示了2016年中国前100个地级市的GDP、增长率、区域分布密度图三个维度。
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找一篇微信短文,复制网址链接,直接在浏览器打开
/ s的?__ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f0gc6e4e6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f4c6e4e6d5251601f4f0c6e4e6d5d5m1f0g8f0c6e4e6d5fb8rqf0c6e4e6d5d5b8cd4f0c6e1
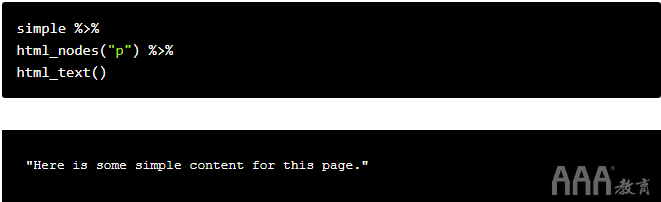
使用rvest简单提取文本内容
web%html_text()
网页抓取阶段完成后,接下来将进入数据清洗阶段:
#------------------------------------------------- -------------------------------------------------- ---
仔细观察文本向量,我们可以发现我们需要的城市数据都是以数字开头(1到3位不等),第七行也是以一个数据字开头(2017年1月20日),使用正则表示为准确匹配,将所有标点符号(记住中文标点符号)替换为逗号(英文),可以作为以后进行列拆分的依据(也可以自定义拆分符号)
<p>a 查看全部
c 抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
一篇短文,涵盖了数据采集、数据清洗、数据展示的全过程。数据主要展示了2016年中国前100个地级市的GDP、增长率、区域分布密度图三个维度。
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找一篇微信短文,复制网址链接,直接在浏览器打开
/ s的?__ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f0gc6e4e6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f4c6e4e6d5251601f4f0c6e4e6d5d5m1f0g8f0c6e4e6d5fb8rqf0c6e4e6d5d5b8cd4f0c6e1
使用rvest简单提取文本内容
web%html_text()

网页抓取阶段完成后,接下来将进入数据清洗阶段:
#------------------------------------------------- -------------------------------------------------- ---
仔细观察文本向量,我们可以发现我们需要的城市数据都是以数字开头(1到3位不等),第七行也是以一个数据字开头(2017年1月20日),使用正则表示为准确匹配,将所有标点符号(记住中文标点符号)替换为逗号(英文),可以作为以后进行列拆分的依据(也可以自定义拆分符号)
<p>a
c 抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-18 12:22
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品占比较高。较小。搜索引擎是目前互联网产品中技术含量最高的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
这样的海WEBCRAWLER网络爬虫训练项目3的数据如何获取、存储和计算?如何快速响应用户查询?如何使搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自互联网网页,整个“网络爬虫”的信息在本地获取“Internet”,由于互联网页面的大部分内容完全相同或几乎重复,“网页重复数据删除”模块会检测到并删除重复的内容。之后,搜索引擎会解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过高效的“倒排索引”查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为这个关系在网页的相关性排名阶段是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,通过结合用户的信息,正确推导出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存中存储着不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,排序输出作为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或者比较重要。这通常可以从“链接分析”的结果中获得。结合以上两个考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的门户,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 查看全部
c 抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品占比较高。较小。搜索引擎是目前互联网产品中技术含量最高的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
这样的海WEBCRAWLER网络爬虫训练项目3的数据如何获取、存储和计算?如何快速响应用户查询?如何使搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自互联网网页,整个“网络爬虫”的信息在本地获取“Internet”,由于互联网页面的大部分内容完全相同或几乎重复,“网页重复数据删除”模块会检测到并删除重复的内容。之后,搜索引擎会解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过高效的“倒排索引”查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为这个关系在网页的相关性排名阶段是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,通过结合用户的信息,正确推导出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存中存储着不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,排序输出作为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或者比较重要。这通常可以从“链接分析”的结果中获得。结合以上两个考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的门户,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联
c 抓取网页数据(为什么学爬虫?从基础爬虫到商业化应用爬虫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-15 11:29
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答 查看全部
c 抓取网页数据(为什么学爬虫?从基础爬虫到商业化应用爬虫(组图))
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答
c 抓取网页数据(Next.js新的通用JavaScript框架-NextTV节目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-15 11:14
Next.js 是一个新的通用 JavaScript 框架,它为 React 和基于服务器的 Web 应用程序提供了新的替代方案。
Next.js 目前是开源的,
现在我们知道如何创建一个非常好的 Next.js 应用程序并获得 Next.js 路由 API 的全部优势。
在实践中,我们通常需要从远程数据源获取数据。Next.js 有一个标准的 API 来获取页面的数据。我们使用名为 getInitialProps 的异步函数来完成它。
这样我们就可以通过远程数据源获取给定页面的数据,作为我们页面的一个属性。我们可以在服务器和客户端上编写 getInitialProps。因此,Next.js 既可以用于客户端,也可以用于服务器端。
在本课程中,我们将使用 getInitialProps 制作一个应用程序,该应用程序可以使用公共 TVmaze API 显示有关蝙蝠侠电视节目的信息。
Paste_Image.png
开始吧。
安装
git clone https://github.com/arunoda/learnnextjs-demo.git
cd learnnextjs-demo
git checkout clean-urls-ssr
您可以执行以下命令:
npm install
npm run dev
您现在可以通过导航到:3000/ 来访问该应用程序。
抓住蝙蝠侠表演
在我们的演示应用程序中,我们在主页上有一个博客 文章 列表。现在我们将展示一组蝙蝠侠电视节目。
我们将从远程服务器获取这些显示,而不是对它们进行硬编码。
以下是我们如何使用 TVMaze API 来获取这些电视节目。
它是一个用于搜索电视节目信息的 API。
首先,我们需要安装isomorphic-unfetch。这是我们用来获取数据的库。它是浏览器获取 API 的简单实现,但它可以在客户端和服务器环境中实现。
npm install --save isomorphic-unfetch
然后将我们的 pages/index.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import Link from 'next/link'
import fetch from 'isomorphic-unfetch'
const Index = (props) => (
Batman TV Shows
{props.shows.map(({show}) => (
<a>{show.name}</a>
))}
)
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
export default Index
上面的每个页面都很熟悉,除了Index.getInitialProps,如下所示:
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
这是一个静态异步函数,您可以将它添加到应用程序的任何页面,使用它,我们可以获取数据并将它们作为我们页面的属性发送。
如您所见,我们现在正在抓取蝙蝠侠电视节目并将其作为我们页面上的“节目”属性输入。
Paste_Image.png
正如您在上面的 getInitialProps 函数中看到的那样,它将数据量输出到控制台。
现在,查看浏览器控制台和服务器控制台。
然后重新加载页面。
重新加载页面后,你在哪里看到上面的消息?
仅在服务器上
在这种情况下,消息仅打印在服务器上。
这是因为我们在服务器上呈现页面。
因此,我们已经有了数据,我们没有理由在客户端再次检索数据。
实现帖子页面
现在,让我们尝试实现“/post”页面,该页面显示有关电视节目的详细信息。
首先打开server.js,修改/p/:id路由,内容如下:
server.get('/p/:id', (req, res) => {
const actualPage = '/post'
const queryParams = { id: req.params.id }
app.render(req, res, actualPage, queryParams)
})
然后重新启动应用程序以应用上述代码更改。
早些时候,我们将标题查询参数映射到页面。现在我们需要将其重命名为 id。
现在将 pages/post.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import fetch from 'isomorphic-unfetch'
const Post = (props) => (
{props.show.name}
<p>{props.show.summary.replace(//g, '')}
<img src={props.show.image.medium}/>
)
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
export default Post
</p>
看看这个页面上的 getInitialProps :
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
在这种情况下,这个函数是上下文对象中的第一个参数。它有一个查询字段,我们可以用它来获取信息。
在我们的示例中,我们从查询参数中选择节目 ID,并从 TVMaze API 获取其节目数据。
在这个 getInitialProps 函数中,我们添加了一个控制台。记录显示的标题。现在让我们看看它将被打印在哪里。
打开服务器控制台和客户端控制台。
然后访问首页:3000,点击第一部蝙蝠侠秀的标题。
你在哪里看到上面提到的控制台。记录消息?
获取客户端数据
在这里,我们只能在浏览器控制台中看到消息。
这是因为我们通过客户端导航到帖子页面。那么从客户端获取数据是最好的方式。
如果您只是直接访问帖子页面(例如::3000/p/975 页面),您可以看到打印在服务器上而不是客户端上的消息。
最后
现在您已经了解了 Next.js 最重要的功能。使其成为通用数据采集和服务器端渲染的理想选择。
我们已经学习了 getInitialProps 的基础知识,这对于大多数用例来说已经足够了。您还可以参考 Next.js 上的文档了解更多信息。
本文转载自: 查看全部
c 抓取网页数据(Next.js新的通用JavaScript框架-NextTV节目)
Next.js 是一个新的通用 JavaScript 框架,它为 React 和基于服务器的 Web 应用程序提供了新的替代方案。
Next.js 目前是开源的,
现在我们知道如何创建一个非常好的 Next.js 应用程序并获得 Next.js 路由 API 的全部优势。
在实践中,我们通常需要从远程数据源获取数据。Next.js 有一个标准的 API 来获取页面的数据。我们使用名为 getInitialProps 的异步函数来完成它。
这样我们就可以通过远程数据源获取给定页面的数据,作为我们页面的一个属性。我们可以在服务器和客户端上编写 getInitialProps。因此,Next.js 既可以用于客户端,也可以用于服务器端。
在本课程中,我们将使用 getInitialProps 制作一个应用程序,该应用程序可以使用公共 TVmaze API 显示有关蝙蝠侠电视节目的信息。

Paste_Image.png
开始吧。
安装
git clone https://github.com/arunoda/learnnextjs-demo.git
cd learnnextjs-demo
git checkout clean-urls-ssr
您可以执行以下命令:
npm install
npm run dev
您现在可以通过导航到:3000/ 来访问该应用程序。
抓住蝙蝠侠表演
在我们的演示应用程序中,我们在主页上有一个博客 文章 列表。现在我们将展示一组蝙蝠侠电视节目。
我们将从远程服务器获取这些显示,而不是对它们进行硬编码。
以下是我们如何使用 TVMaze API 来获取这些电视节目。
它是一个用于搜索电视节目信息的 API。
首先,我们需要安装isomorphic-unfetch。这是我们用来获取数据的库。它是浏览器获取 API 的简单实现,但它可以在客户端和服务器环境中实现。
npm install --save isomorphic-unfetch
然后将我们的 pages/index.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import Link from 'next/link'
import fetch from 'isomorphic-unfetch'
const Index = (props) => (
Batman TV Shows
{props.shows.map(({show}) => (
<a>{show.name}</a>
))}
)
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
export default Index
上面的每个页面都很熟悉,除了Index.getInitialProps,如下所示:
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
这是一个静态异步函数,您可以将它添加到应用程序的任何页面,使用它,我们可以获取数据并将它们作为我们页面的属性发送。
如您所见,我们现在正在抓取蝙蝠侠电视节目并将其作为我们页面上的“节目”属性输入。
Paste_Image.png
正如您在上面的 getInitialProps 函数中看到的那样,它将数据量输出到控制台。
现在,查看浏览器控制台和服务器控制台。
然后重新加载页面。
重新加载页面后,你在哪里看到上面的消息?
仅在服务器上
在这种情况下,消息仅打印在服务器上。
这是因为我们在服务器上呈现页面。
因此,我们已经有了数据,我们没有理由在客户端再次检索数据。
实现帖子页面
现在,让我们尝试实现“/post”页面,该页面显示有关电视节目的详细信息。
首先打开server.js,修改/p/:id路由,内容如下:
server.get('/p/:id', (req, res) => {
const actualPage = '/post'
const queryParams = { id: req.params.id }
app.render(req, res, actualPage, queryParams)
})
然后重新启动应用程序以应用上述代码更改。
早些时候,我们将标题查询参数映射到页面。现在我们需要将其重命名为 id。
现在将 pages/post.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import fetch from 'isomorphic-unfetch'
const Post = (props) => (
{props.show.name}
<p>{props.show.summary.replace(//g, '')}
<img src={props.show.image.medium}/>
)
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
export default Post
</p>
看看这个页面上的 getInitialProps :
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
在这种情况下,这个函数是上下文对象中的第一个参数。它有一个查询字段,我们可以用它来获取信息。
在我们的示例中,我们从查询参数中选择节目 ID,并从 TVMaze API 获取其节目数据。
在这个 getInitialProps 函数中,我们添加了一个控制台。记录显示的标题。现在让我们看看它将被打印在哪里。
打开服务器控制台和客户端控制台。
然后访问首页:3000,点击第一部蝙蝠侠秀的标题。
你在哪里看到上面提到的控制台。记录消息?
获取客户端数据
在这里,我们只能在浏览器控制台中看到消息。
这是因为我们通过客户端导航到帖子页面。那么从客户端获取数据是最好的方式。
如果您只是直接访问帖子页面(例如::3000/p/975 页面),您可以看到打印在服务器上而不是客户端上的消息。
最后
现在您已经了解了 Next.js 最重要的功能。使其成为通用数据采集和服务器端渲染的理想选择。
我们已经学习了 getInitialProps 的基础知识,这对于大多数用例来说已经足够了。您还可以参考 Next.js 上的文档了解更多信息。
本文转载自:
c 抓取网页数据(基于广受接待的R语言实例分析--我国大数据不妨)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-10 06:10
引言 纵观全球,大数据市场发展迅速,政府的支持也达到了前所未有的水平,甚至将大数据纳入了增长战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计规模的一员,我们必须抓住机遇。放眼世界,大数据的应用极限还在不断扩大,几乎每个行业都将目光投向了大数据背后的巨大代价。未来五到十年将是我国推动大数据增长的关键时期,亟需打造高效的大数据应用机制和财富链。
根据目前对大数据产业增长的澄清,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用简单易用的网页数据抓取工具来抓取所需的网页数据,比如知名的网页数据抓取工具“**采集器”(收费)。现有的互联网数据采集、处理、澄清、挖掘软件可以快速、灵活地捕捉网络上杂乱的数据信息,并通过一系列的澄清和处理,准确地挖掘出需要的数据。效率高,
今天,作为大数据行业的一员,基于广受好评的R软件,给大家介绍一下如何实现网页数据抓取技巧。是的,是R!除了强大的统计澄清结果外,它的网络爬虫能力也不容小觑,尤其是Hadley编写的R包rvest,简化了庞大的工作。使用R语言抓取网页数据的一大优势在于强大的数据处理惩罚、获取数据后的澄清和可视化结果。
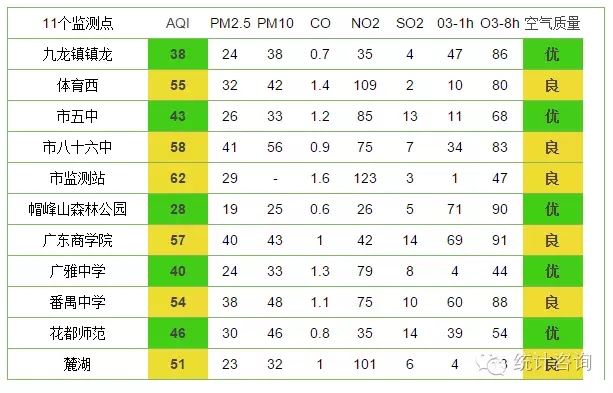
R语言示例 下面以rvest包抓取广州市大气质量数据为例,举办讲座。
网页数据如下:
#Loadingmeasures packagelibrary(rvest)#找到抓取数据的URL url=””#关注URL的内容web= read_html(url,encoding=”UTF-8″)#截取如图所示的大气质量数据上图 aqi=web %> % html_nodes("span") %>% html_text()#注意!很多小伙伴在这一步会出现乱码的环境 aqi=aqi[8:127]#把截取的数据整理成一个数据框 aqi=matrix(aqi,ncol=10,byrow=T)aqi=data.frame(aqi)for (i in 1:ncol(aqi)){aqi[,i]=as.character(aqi[,i])aqi[,i]=gsub("\"","",gsub("\\n" ,””,Aqi[,i]))}names(aqi)=aqi[1,]aqi=aqi[-1,]aqi
如果一切正常,会显示如下效果:
至此,R软件已经能够抓取网页数据,后续可以将大气质量指数以时间序列和空间扩散的形式展示出来。以上虽然只是大数据的表皮,但仍有很多可以探索和扩展的对象。比如对于网页数据的抓取,如果能及时动态抓取,就会打出大数据的价格。
学会了以上小技巧,大数据应用不再是纯口号!虽然还是有很多软件可以实现网页数据抓取,比如python、sas、Excel等,有兴趣的小伙伴可以随意试验一下。IDC宣布,报告显示,2016年全球大数据技术和服务市场规模将达到238亿美元。 激活我国大数据的资产成本和开启大数据新生态的政策,仍需各界通力合作社会的!
参考资料::///stephan_sly/blog/static/25692248660/
欢迎加入本站。真趣群贸易情报与数据澄清 群趣类包括数据成本的各种步骤、实际应用案例分享与连接、澄清工具、ETL工具、数据酒店、数据挖掘工具、报表系统等。 常识QQ群: 81035754 查看全部
c 抓取网页数据(基于广受接待的R语言实例分析--我国大数据不妨)
引言 纵观全球,大数据市场发展迅速,政府的支持也达到了前所未有的水平,甚至将大数据纳入了增长战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计规模的一员,我们必须抓住机遇。放眼世界,大数据的应用极限还在不断扩大,几乎每个行业都将目光投向了大数据背后的巨大代价。未来五到十年将是我国推动大数据增长的关键时期,亟需打造高效的大数据应用机制和财富链。
根据目前对大数据产业增长的澄清,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用简单易用的网页数据抓取工具来抓取所需的网页数据,比如知名的网页数据抓取工具“**采集器”(收费)。现有的互联网数据采集、处理、澄清、挖掘软件可以快速、灵活地捕捉网络上杂乱的数据信息,并通过一系列的澄清和处理,准确地挖掘出需要的数据。效率高,
今天,作为大数据行业的一员,基于广受好评的R软件,给大家介绍一下如何实现网页数据抓取技巧。是的,是R!除了强大的统计澄清结果外,它的网络爬虫能力也不容小觑,尤其是Hadley编写的R包rvest,简化了庞大的工作。使用R语言抓取网页数据的一大优势在于强大的数据处理惩罚、获取数据后的澄清和可视化结果。
R语言示例 下面以rvest包抓取广州市大气质量数据为例,举办讲座。
网页数据如下:
#Loadingmeasures packagelibrary(rvest)#找到抓取数据的URL url=””#关注URL的内容web= read_html(url,encoding=”UTF-8″)#截取如图所示的大气质量数据上图 aqi=web %> % html_nodes("span") %>% html_text()#注意!很多小伙伴在这一步会出现乱码的环境 aqi=aqi[8:127]#把截取的数据整理成一个数据框 aqi=matrix(aqi,ncol=10,byrow=T)aqi=data.frame(aqi)for (i in 1:ncol(aqi)){aqi[,i]=as.character(aqi[,i])aqi[,i]=gsub("\"","",gsub("\\n" ,””,Aqi[,i]))}names(aqi)=aqi[1,]aqi=aqi[-1,]aqi
如果一切正常,会显示如下效果:
至此,R软件已经能够抓取网页数据,后续可以将大气质量指数以时间序列和空间扩散的形式展示出来。以上虽然只是大数据的表皮,但仍有很多可以探索和扩展的对象。比如对于网页数据的抓取,如果能及时动态抓取,就会打出大数据的价格。
学会了以上小技巧,大数据应用不再是纯口号!虽然还是有很多软件可以实现网页数据抓取,比如python、sas、Excel等,有兴趣的小伙伴可以随意试验一下。IDC宣布,报告显示,2016年全球大数据技术和服务市场规模将达到238亿美元。 激活我国大数据的资产成本和开启大数据新生态的政策,仍需各界通力合作社会的!
参考资料::///stephan_sly/blog/static/25692248660/
欢迎加入本站。真趣群贸易情报与数据澄清 群趣类包括数据成本的各种步骤、实际应用案例分享与连接、澄清工具、ETL工具、数据酒店、数据挖掘工具、报表系统等。 常识QQ群: 81035754
c 抓取网页数据(Python开发的一个快速,高层次的屏幕和web抓取框架(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-10-10 06:08
阿里云>云栖社区>主题图>C>从网站中抓取数据库
推荐活动:
更多优惠>
当前主题:从 网站 抓取数据库并添加到采集夹
相关话题:
从网站抓取数据库相关博客,查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
从头搭建自己的爬虫代理IP数据库,定期检查IP有效性
作者:tomcat1101 浏览评论人数:02年前
ProxyIPPool 从头开始构建自己的代理IP池;根据代理IP URL获取新的代理IP;验证历史代理IP源地址的有效性:Why use proxy IP 在爬取过程中,很多网站会取反
阅读全文
Linux云服务器下配置Scrapy抓取数据
作者:㭍叶1552人浏览评论:04年前
基础设备:Linux云服务器(阿里云Ubuntu 16.04);建立远程连接的软件(这里使用XShell);友情链接:Scrapy入门教程:
阅读全文
安全风险:可通过网络搜索用户数据库
作者:知乎1036人浏览评论:04年前
这篇文章是关于安全风险的:可以通过互联网搜索用户数据库。最近在耶鲁大学和南加州医学发生的数据泄露事件凸显了确保数据库的网络界面不被网络搜索引擎暴露的重要性。最近的两起数据库泄漏事件突出了一个常见但经常被忽视的问题。收录敏感信息的配置错误的数据库很容易受到损害。
阅读全文
SEO建立有效页面数据库:目的、定义、流程、应用
作者:于尔武 1043人浏览评论:03年前
关于SEO运营理念,简单提一下,做好SEO工作需要从“产品需求形成”到“流量获取转化”。文章中有这么一段:SEO运营观(交付价值,实现产品)。SEO操作公式:有效查询覆盖,有效爬取,有效收录显示点击转化“有效”定义目标
阅读全文
为什么选择 Prometheus 作为时间序列数据库
作者:耳东@Erdong6491 浏览评论人数:02年前
Prometheus 和 Graphite 系列 Graphite 专注于成为具有查询语言和图形功能的被动时间序列数据库。任何其他问题都由外部组件处理。Prometheus 是一个完整的监控和趋势系统,包括内置和主动的爬取、存储、查询、绘图和基于时间的
阅读全文
在选择数据库的路上,我们遇到了哪些坑?(2)
作者:oneapm_official1769 人浏览评论:05年前
【编者按】您会如何选择数据库、关系数据库、XML 数据库、资源描述框架(RDF)或图形数据库?本文的第 1 部分深入而生动地探讨了各种选项。在第二部分,我们将深入介绍使用 Neo4j 时的注意点。文章是国内ITOM管理平台OneAPM的编译呈现。过渡到 N
阅读全文
提问网站 爬取数据库相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
c 抓取网页数据(Python开发的一个快速,高层次的屏幕和web抓取框架(组图))
阿里云>云栖社区>主题图>C>从网站中抓取数据库

推荐活动:
更多优惠>
当前主题:从 网站 抓取数据库并添加到采集夹
相关话题:
从网站抓取数据库相关博客,查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
善用网络爬虫工具,轻松采集数据

作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
从头搭建自己的爬虫代理IP数据库,定期检查IP有效性
作者:tomcat1101 浏览评论人数:02年前
ProxyIPPool 从头开始构建自己的代理IP池;根据代理IP URL获取新的代理IP;验证历史代理IP源地址的有效性:Why use proxy IP 在爬取过程中,很多网站会取反
阅读全文
Linux云服务器下配置Scrapy抓取数据


作者:㭍叶1552人浏览评论:04年前
基础设备:Linux云服务器(阿里云Ubuntu 16.04);建立远程连接的软件(这里使用XShell);友情链接:Scrapy入门教程:
阅读全文
安全风险:可通过网络搜索用户数据库


作者:知乎1036人浏览评论:04年前
这篇文章是关于安全风险的:可以通过互联网搜索用户数据库。最近在耶鲁大学和南加州医学发生的数据泄露事件凸显了确保数据库的网络界面不被网络搜索引擎暴露的重要性。最近的两起数据库泄漏事件突出了一个常见但经常被忽视的问题。收录敏感信息的配置错误的数据库很容易受到损害。
阅读全文
SEO建立有效页面数据库:目的、定义、流程、应用
作者:于尔武 1043人浏览评论:03年前
关于SEO运营理念,简单提一下,做好SEO工作需要从“产品需求形成”到“流量获取转化”。文章中有这么一段:SEO运营观(交付价值,实现产品)。SEO操作公式:有效查询覆盖,有效爬取,有效收录显示点击转化“有效”定义目标
阅读全文
为什么选择 Prometheus 作为时间序列数据库


作者:耳东@Erdong6491 浏览评论人数:02年前
Prometheus 和 Graphite 系列 Graphite 专注于成为具有查询语言和图形功能的被动时间序列数据库。任何其他问题都由外部组件处理。Prometheus 是一个完整的监控和趋势系统,包括内置和主动的爬取、存储、查询、绘图和基于时间的
阅读全文
在选择数据库的路上,我们遇到了哪些坑?(2)


作者:oneapm_official1769 人浏览评论:05年前
【编者按】您会如何选择数据库、关系数据库、XML 数据库、资源描述框架(RDF)或图形数据库?本文的第 1 部分深入而生动地探讨了各种选项。在第二部分,我们将深入介绍使用 Neo4j 时的注意点。文章是国内ITOM管理平台OneAPM的编译呈现。过渡到 N
阅读全文
提问网站 爬取数据库相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑


作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
c 抓取网页数据(C#.Net基于正则表达式抓取百度百家文章列表的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-07 02:06
本文文章主要介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法,分析C#获取百度百家文章的内容及使用示例形式的正则表达式。表情匹配标题、内容、地址等相关操作技巧,有需要的朋友可以参考
本文介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法。分享给大家,供大家参考,如下:
下班后,我学习了正则表达式。由于实践是检验真理的唯一标准,我写了一个使用正则表达式捕获百度百家文章的例子。具体过程请看下面的源码:
一、获取百度百家网页内容
public List GetUrl() { try { string url = "http://baijia.baidu.com/"; WebRequest webRequest = WebRequest.Create(url); WebResponse webResponse = webRequest.GetResponse(); StreamReader reader = new StreamReader(webResponse.GetResponseStream()); string result = reader.ReadToEnd(); reader.Close(); webResponse.Close(); return AnalysisHtml(result); } catch (Exception ex) { throw ex; } }
二、通过正则表达式过滤
<p> public List AnalysisHtml(string htmlContent) { List list = new List(); string strPattern = "(?[^ 查看全部
c 抓取网页数据(C#.Net基于正则表达式抓取百度百家文章列表的方法(图))
本文文章主要介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法,分析C#获取百度百家文章的内容及使用示例形式的正则表达式。表情匹配标题、内容、地址等相关操作技巧,有需要的朋友可以参考
本文介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法。分享给大家,供大家参考,如下:
下班后,我学习了正则表达式。由于实践是检验真理的唯一标准,我写了一个使用正则表达式捕获百度百家文章的例子。具体过程请看下面的源码:
一、获取百度百家网页内容
public List GetUrl() { try { string url = "http://baijia.baidu.com/"; WebRequest webRequest = WebRequest.Create(url); WebResponse webResponse = webRequest.GetResponse(); StreamReader reader = new StreamReader(webResponse.GetResponseStream()); string result = reader.ReadToEnd(); reader.Close(); webResponse.Close(); return AnalysisHtml(result); } catch (Exception ex) { throw ex; } }
二、通过正则表达式过滤
<p> public List AnalysisHtml(string htmlContent) { List list = new List(); string strPattern = "(?[^
c 抓取网页数据( 找豆瓣网站的规律:WebScraper控制链接分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-07 01:27
找豆瓣网站的规律:WebScraper控制链接分析(图))
这是简单数据分析系列文章的第五篇。
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
前面说过,爬虫的本质是发现规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,播放226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻转
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以把它写成[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然也可以写[1-100],这样就可以爬取前100个网页了。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这非常简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
[0-225:25]&过滤器=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1.点击Stiemaps,在新面板中点击ID为top250的那一列数据:
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata:
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
4.参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
5.联系我 查看全部
c 抓取网页数据(
找豆瓣网站的规律:WebScraper控制链接分析(图))
这是简单数据分析系列文章的第五篇。
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
前面说过,爬虫的本质是发现规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,播放226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻转
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以把它写成[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然也可以写[1-100],这样就可以爬取前100个网页了。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这非常简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
[0-225:25]&过滤器=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1.点击Stiemaps,在新面板中点击ID为top250的那一列数据:
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata:
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
4.参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
5.联系我
c 抓取网页数据(天猫商城开发商编程的准备工作流程及注意事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-06 15:12
一、准备
1、在浏览器中打开天猫首页(推荐Chrome),搜索你要爬取的关键词。我在这里搜索的是“护发”;
2、按“CTRL+SHIFT+C”显示页面源代码。这时候移动鼠标点击图片区域可以看到对应的代码。我们可以看到,宝贝的图片、标题、价格、店名、销量等信息都在模块中。
二、启动Rstudio并开始编程
1、安装并加载rvest包,将变量hfurl赋值给刚才的网页链接
library(rvest)
library(magrittr)
library(xml2)
#保存需要爬取的网页到hfurl
hfurl%是管道操作符,意思是把左边的操作结果作为参数传递给右边的函数。
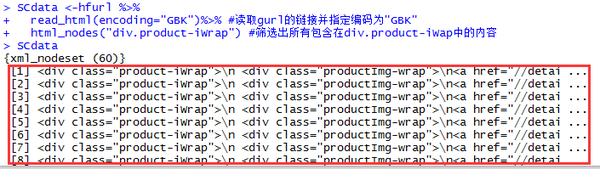
SCdata %
read_html(encoding="GBK")%>% #读取hfurl的链接并指定编码为"GBK"
html_nodes("div.product-iWrap") #筛选出所有包含在div.product-iWap中的内容
SCdata
显示结果如下:
这样,网页中60个宝宝的信息全部被抓取了!
3、 进一步爬取所需信息。请注意,您需要对 css 选择器或 xpath 有一点了解。当你抓取每一项数据时,你可以将其打印出来并测试是否成功。实践中发现itemTitle打印出来的item有103条,和其他行号不对应,所以注释掉了,然后再想办法突破。
#抓取卖家昵称
SCdata %
read_html(encoding="GBK") %>%
html_nodes("div.product-iWrap")
sellerNick% html_nodes("p.productStatus>span[class]") %>%
html_attr("data-nick")
#抓取卖家ID
sellerID % html_nodes("p.productStatus>span[data-atp]") %>%
html_attr("data-atp") %>%
#gsub()是字符串查找替换的函数,pattern是指定用来查找的正则表达式。
gsub(pattern="^.*,",replacement="")
#抓取宝贝名称
#itemTitle % html_tag("p.productTitle") %>%
# html_tag("a")%>%
# html_attr("title")
#html_text() %>%
#gsub(pattern="^.*,",replacement="")
#抓取宝贝ID
itemID%html_nodes("p.productStatus>span[class]") %>%
html_attr("data-item")
#抓取宝贝价格
price % html_nodes("p.productPrice>em[title]") %>%
html_attr("title") %>%
as.numeric
#抓取宝贝销量
volume % html_nodes("span>em") %>%
html_text
4、保存数据库对象并写入csv文件。
<p>options(stringsAsFactors = FALSE)#设置字符串不自动识别为因子
itemData1 查看全部
c 抓取网页数据(天猫商城开发商编程的准备工作流程及注意事项!)
一、准备
1、在浏览器中打开天猫首页(推荐Chrome),搜索你要爬取的关键词。我在这里搜索的是“护发”;
2、按“CTRL+SHIFT+C”显示页面源代码。这时候移动鼠标点击图片区域可以看到对应的代码。我们可以看到,宝贝的图片、标题、价格、店名、销量等信息都在模块中。
二、启动Rstudio并开始编程
1、安装并加载rvest包,将变量hfurl赋值给刚才的网页链接
library(rvest)
library(magrittr)
library(xml2)
#保存需要爬取的网页到hfurl
hfurl%是管道操作符,意思是把左边的操作结果作为参数传递给右边的函数。
SCdata %
read_html(encoding="GBK")%>% #读取hfurl的链接并指定编码为"GBK"
html_nodes("div.product-iWrap") #筛选出所有包含在div.product-iWap中的内容
SCdata
显示结果如下:
这样,网页中60个宝宝的信息全部被抓取了!
3、 进一步爬取所需信息。请注意,您需要对 css 选择器或 xpath 有一点了解。当你抓取每一项数据时,你可以将其打印出来并测试是否成功。实践中发现itemTitle打印出来的item有103条,和其他行号不对应,所以注释掉了,然后再想办法突破。
#抓取卖家昵称
SCdata %
read_html(encoding="GBK") %>%
html_nodes("div.product-iWrap")
sellerNick% html_nodes("p.productStatus>span[class]") %>%
html_attr("data-nick")
#抓取卖家ID
sellerID % html_nodes("p.productStatus>span[data-atp]") %>%
html_attr("data-atp") %>%
#gsub()是字符串查找替换的函数,pattern是指定用来查找的正则表达式。
gsub(pattern="^.*,",replacement="")
#抓取宝贝名称
#itemTitle % html_tag("p.productTitle") %>%
# html_tag("a")%>%
# html_attr("title")
#html_text() %>%
#gsub(pattern="^.*,",replacement="")
#抓取宝贝ID
itemID%html_nodes("p.productStatus>span[class]") %>%
html_attr("data-item")
#抓取宝贝价格
price % html_nodes("p.productPrice>em[title]") %>%
html_attr("title") %>%
as.numeric
#抓取宝贝销量
volume % html_nodes("span>em") %>%
html_text
4、保存数据库对象并写入csv文件。
<p>options(stringsAsFactors = FALSE)#设置字符串不自动识别为因子
itemData1
c 抓取网页数据(搜狗微信公众号更新公告(2015.03.23) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-01 22:15
)
最后更新日期为2018.1.3
只为自己做个记录
要添加的功能:
1.获取所有历史新闻
2. 爬取10多条数据
3.自定义抓取公众号信息
以搜狗微信公众号搜索微信公众号为例!
以搜狗微信公众号作为分析入口:【此处填写公众号名称】&ie=utf8&sug=n&sug_type=
DEMO中完整的URL为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
} 查看全部
c 抓取网页数据(搜狗微信公众号更新公告(2015.03.23)
)
最后更新日期为2018.1.3
只为自己做个记录
要添加的功能:
1.获取所有历史新闻
2. 爬取10多条数据
3.自定义抓取公众号信息
以搜狗微信公众号搜索微信公众号为例!
以搜狗微信公众号作为分析入口:【此处填写公众号名称】&ie=utf8&sug=n&sug_type=
DEMO中完整的URL为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
}
c 抓取网页数据(你特么不提供api让我怎么搞嘛~~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-10-01 11:03
c抓取网页数据,并不只是为了存下来,更多的是通过抓取的数据来推送给用户有价值的信息给用户。所以更多的应该是需要实现分析。
但是你特么不提供api让我怎么搞嘛~
如果将抓取同时落到技术维度上,基本应该是分析问题的一个重要手段了。举个例子,如果能够抓取地震波(同时可以按波长分析出地震波频率),就能预测出震中在哪。但是通过抓取某些特定的数据来实现分析的过程,只能是属于一个辅助工具。一般来说,提供api数据抓取的公司,会有比较明确的目标和用户群体。如果纯粹抓取数据,无法归纳出数据的应用目的和研究方向,反而像是一种纯技术的营销手段。如果是抓取社会科学数据,仍然可以归结到分析和应用层面。
抓取数据变现。以前看到哪个国际api网站。其实是说抓取互联网数据到谷歌可以成为大数据,然后经过数据分析算法变成数据可以卖给金融公司。利用在谷歌出售的数据来训练出基因组学,神经科学,音乐或者其他各种东西。
你要说开发,先要解决有没有的问题。
很多从事互联网开发的公司,是会给用户提供数据抓取的api的,但是这些公司更多的是提供一个统一的api服务,比如youku的阿里云oss服务,但是并不是给开发者提供这些数据,而是提供统一的源代码,然后给开发者添加到业务数据库里面。 查看全部
c 抓取网页数据(你特么不提供api让我怎么搞嘛~~)
c抓取网页数据,并不只是为了存下来,更多的是通过抓取的数据来推送给用户有价值的信息给用户。所以更多的应该是需要实现分析。
但是你特么不提供api让我怎么搞嘛~
如果将抓取同时落到技术维度上,基本应该是分析问题的一个重要手段了。举个例子,如果能够抓取地震波(同时可以按波长分析出地震波频率),就能预测出震中在哪。但是通过抓取某些特定的数据来实现分析的过程,只能是属于一个辅助工具。一般来说,提供api数据抓取的公司,会有比较明确的目标和用户群体。如果纯粹抓取数据,无法归纳出数据的应用目的和研究方向,反而像是一种纯技术的营销手段。如果是抓取社会科学数据,仍然可以归结到分析和应用层面。
抓取数据变现。以前看到哪个国际api网站。其实是说抓取互联网数据到谷歌可以成为大数据,然后经过数据分析算法变成数据可以卖给金融公司。利用在谷歌出售的数据来训练出基因组学,神经科学,音乐或者其他各种东西。
你要说开发,先要解决有没有的问题。
很多从事互联网开发的公司,是会给用户提供数据抓取的api的,但是这些公司更多的是提供一个统一的api服务,比如youku的阿里云oss服务,但是并不是给开发者提供这些数据,而是提供统一的源代码,然后给开发者添加到业务数据库里面。
c 抓取网页数据( 用Pyhton自带的urllib或urllib2模块(二)|,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-30 15:17
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看 Python 的使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 来分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。 查看全部
c 抓取网页数据(
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看 Python 的使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 来分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
c 抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-27 12:08
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!! 查看全部
c 抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。

一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:

点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:


第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:


第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!!
c 抓取网页数据( 简时尚网站首页面在lynx浏览器下的显示情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-24 07:01
简时尚网站首页面在lynx浏览器下的显示情况)
Google 极力推荐的 lynx 浏览器如何抓取网页内容
以下内容是使用lynx抓取()简时尚电商平台的详细信息,
在谷歌网站索引指南中,强烈推荐站长管理员使用这款lynx文本浏览器浏览网站的页面内容,
这说明谷歌爬虫抓取网页的方法和lynx浏览器很相似,那么就用这个lynx来浏览网页,对于网站
一些优化很有帮助,
以下是健时尚网站首页在lynx浏览器中的展示,
从上面的内容可以分析出lynx是先通过一级标题,然后再爬取二级标题下的内容。
接下来,lynx抓住了颈部,
接下来,我们将来到内容的中间。
嗯,在这个位置上,我想很多人都能理解。lynx文本浏览器抓取网页的方式是什么,大家可以总结一下。
首先从上到下,从左到右,从大标题开始,然后按照标题到小标题抓取页面,
二是无法识别图片内容,只能读取alt标签中的内容。
这些有助于制作符合搜索引擎的标准页面。
再补充一点,lynx是如何识别隐藏链接的,请看下图
此表单被视为隐藏链接,
从lynx文本浏览器抓取网页的情况来看,google极力推荐,可以得出搜索引擎抓取的网页与此类似。
对符合se的网站的建立有很大的参考价值。 查看全部
c 抓取网页数据(
简时尚网站首页面在lynx浏览器下的显示情况)
Google 极力推荐的 lynx 浏览器如何抓取网页内容
以下内容是使用lynx抓取()简时尚电商平台的详细信息,
在谷歌网站索引指南中,强烈推荐站长管理员使用这款lynx文本浏览器浏览网站的页面内容,
这说明谷歌爬虫抓取网页的方法和lynx浏览器很相似,那么就用这个lynx来浏览网页,对于网站
一些优化很有帮助,
以下是健时尚网站首页在lynx浏览器中的展示,
从上面的内容可以分析出lynx是先通过一级标题,然后再爬取二级标题下的内容。
接下来,lynx抓住了颈部,
接下来,我们将来到内容的中间。
嗯,在这个位置上,我想很多人都能理解。lynx文本浏览器抓取网页的方式是什么,大家可以总结一下。
首先从上到下,从左到右,从大标题开始,然后按照标题到小标题抓取页面,
二是无法识别图片内容,只能读取alt标签中的内容。
这些有助于制作符合搜索引擎的标准页面。
再补充一点,lynx是如何识别隐藏链接的,请看下图
此表单被视为隐藏链接,
从lynx文本浏览器抓取网页的情况来看,google极力推荐,可以得出搜索引擎抓取的网页与此类似。
对符合se的网站的建立有很大的参考价值。
c 抓取网页数据(如何用Python爬数据华章社区《Clojure数据分析秘笈》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-24 04:19
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页中抓取数据并将其添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客。
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节从 Web 表中抓取数据
作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第一章,1.8节抓取web表数据。作者(美)Eric Rochester,更多章节可访问查看云栖社区“华章社区”公众号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:03年前
我打算做一个博客园的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下:思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
快速搭建实时爬虫集群
作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
网络数据库挖掘程序设计
作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是由数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
数据库从网页抓取数据,询问相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
c 抓取网页数据(如何用Python爬数据华章社区《Clojure数据分析秘笈》(组图))
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页中抓取数据并将其添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客。
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节从 Web 表中抓取数据

作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第一章,1.8节抓取web表数据。作者(美)Eric Rochester,更多章节可访问查看云栖社区“华章社区”公众号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
如何使用 Python 抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取

作者:呵呵 9925975人浏览评论:03年前
我打算做一个博客园的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下:思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
初学者指南 | 使用 Python 抓取网页


作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
快速搭建实时爬虫集群

作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
网络数据库挖掘程序设计

作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是由数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
数据库从网页抓取数据,询问相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
c 抓取网页数据(如何在大数据分析R语言中进行网络抓取的基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-23 03:18
时间:2020年5月26日点击:泰晤士报作者:Sissi
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中查找所需数据来获取待分析数据的技术
在本教程中,我们将介绍如何使用大数据分析R语言进行网络爬网的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在本教程中,我们将主要关注如何使用大数据分析R语言web爬行来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:
尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法在本教程中涵盖所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:
文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:
我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:
将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在本教程中,我们对网页爬行感兴趣,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样
如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在本教程中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它
要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的
大数据分析R语言EAD_uhtml()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们希望将单个标签中收录的文本存储在变量中。要访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常在网站上非常明确地使用CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用HTML_uNodes()和HTML_text()函数来搜索
标记并检索文本。以下代码执行此操作:
这个简单变量已经收录我们想要获取的HTML,所以剩下的任务是搜索所需的元素。因为我们使用tidyve big data来分析R语言se,所以我们可以将HTML传递给不同的函数
我们需要在nodes()函数中将特定的HTML标记或CSS类传递给HTML。我们需要标记,所以我们将字符“P”传递给函数。html_u0;Nodes()还返回一个列表,但它返回html中具有给定特定html标记或CSS类/标识的所有节点。节点是指树结构中的一个点
一旦拥有所有这些节点,就可以在text()函数中将输出传递到HTML_uu节点()到HTML_uu。我们需要获取标签的实际文本,因此此功能可以帮助您解决此问题
这些功能共同构成了许多常见的web爬行任务。一般来说,使用大数据分析R语言(或任何其他语言)的网络爬网可以概括为以下三个步骤:
a。获取要获取的网页的HTML
b。确定pa的哪个部分 查看全部
c 抓取网页数据(如何在大数据分析R语言中进行网络抓取的基础知识)
时间:2020年5月26日点击:泰晤士报作者:Sissi
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中查找所需数据来获取待分析数据的技术
在本教程中,我们将介绍如何使用大数据分析R语言进行网络爬网的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在本教程中,我们将主要关注如何使用大数据分析R语言web爬行来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:

尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法在本教程中涵盖所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:

文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:

我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:

将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在本教程中,我们对网页爬行感兴趣,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样

如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在本教程中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它

要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的
大数据分析R语言EAD_uhtml()函数返回一个收录我们前面讨论过的树结构的列表对象

假设我们希望将单个标签中收录的文本存储在变量中。要访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常在网站上非常明确地使用CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用HTML_uNodes()和HTML_text()函数来搜索
标记并检索文本。以下代码执行此操作:
这个简单变量已经收录我们想要获取的HTML,所以剩下的任务是搜索所需的元素。因为我们使用tidyve big data来分析R语言se,所以我们可以将HTML传递给不同的函数
我们需要在nodes()函数中将特定的HTML标记或CSS类传递给HTML。我们需要标记,所以我们将字符“P”传递给函数。html_u0;Nodes()还返回一个列表,但它返回html中具有给定特定html标记或CSS类/标识的所有节点。节点是指树结构中的一个点
一旦拥有所有这些节点,就可以在text()函数中将输出传递到HTML_uu节点()到HTML_uu。我们需要获取标签的实际文本,因此此功能可以帮助您解决此问题
这些功能共同构成了许多常见的web爬行任务。一般来说,使用大数据分析R语言(或任何其他语言)的网络爬网可以概括为以下三个步骤:
a。获取要获取的网页的HTML
b。确定pa的哪个部分
c 抓取网页数据(WebScraperforMac永久激活版是您的不错选择!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-21 21:18
如果您正在寻找易于使用的网站数据捕获工具,websharper for Mac permanent activation是一个不错的选择!有需要的朋友可以下载
websharper mac软件简介
WebRapper for Mac是一个简单的应用程序,用于在Mac平台上将数据导出为JSON或CSV。WebRapper for Mac可以快速提取与网页相关的信息(包括文本内容)。Websharper使您能够以最小的工作量从在线资源中快速提取内容。您可以完全控制将导出到CSV或JSON文件的数据
Websharper mac软件功能
1、scan网站快速方便@
大量的提取选项;各种元数据、内容(如文本、HTML或标记)、具有特定类/ID的元素、正则表达式
2、易于导出-选择所需的列
3、输出为CSV或JSON
4、new选项将所有图像下载到文件夹/采集并导出所有链接
5、输出单个文本文件的新选项(用于归档文本内容、降价或纯文本)
6、rich选项/配置
websharper mac软件功能介绍
1、从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,用于导航站点并提取数据。使用不同的类型选择器,web scraper将导航站点并提取多种类型的数据-文本、表格、图像、链接等
2、专为现代网络设计
与其他仅从HTML web提取数据的抓取工具不同,scraper还可以提取使用JavaScript动态加载或生成的数据。Web scraper可以:-等待在页面中加载动态数据-单击分页按钮通过Ajax加载数据-单击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或将其存储在CouchDB中
Web scraper是一个独立的Chrome扩展。站点地图的构建、数据提取和导出都在浏览器中完成。捕获网站后,您可以下载CSV格式的数据。对于高级用例,您可能希望尝试将数据保存到CouchDB 查看全部
c 抓取网页数据(WebScraperforMac永久激活版是您的不错选择!)
如果您正在寻找易于使用的网站数据捕获工具,websharper for Mac permanent activation是一个不错的选择!有需要的朋友可以下载
websharper mac软件简介
WebRapper for Mac是一个简单的应用程序,用于在Mac平台上将数据导出为JSON或CSV。WebRapper for Mac可以快速提取与网页相关的信息(包括文本内容)。Websharper使您能够以最小的工作量从在线资源中快速提取内容。您可以完全控制将导出到CSV或JSON文件的数据
Websharper mac软件功能
1、scan网站快速方便@
大量的提取选项;各种元数据、内容(如文本、HTML或标记)、具有特定类/ID的元素、正则表达式
2、易于导出-选择所需的列
3、输出为CSV或JSON
4、new选项将所有图像下载到文件夹/采集并导出所有链接
5、输出单个文本文件的新选项(用于归档文本内容、降价或纯文本)
6、rich选项/配置
websharper mac软件功能介绍
1、从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,用于导航站点并提取数据。使用不同的类型选择器,web scraper将导航站点并提取多种类型的数据-文本、表格、图像、链接等
2、专为现代网络设计
与其他仅从HTML web提取数据的抓取工具不同,scraper还可以提取使用JavaScript动态加载或生成的数据。Web scraper可以:-等待在页面中加载动态数据-单击分页按钮通过Ajax加载数据-单击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或将其存储在CouchDB中
Web scraper是一个独立的Chrome扩展。站点地图的构建、数据提取和导出都在浏览器中完成。捕获网站后,您可以下载CSV格式的数据。对于高级用例,您可能希望尝试将数据保存到CouchDB
c 抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-15 12:19
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
‘ MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
在VB中获取网页数据
原文: 查看全部
c 抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据)
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
‘ MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
在VB中获取网页数据
原文:
c 抓取网页数据( 获取页面的数据方法有很多,这里说的是里面最蠢的一个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-09-13 03:01
获取页面的数据方法有很多,这里说的是里面最蠢的一个方法)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
开发工具与关键技术:VS与MVC js
作者:陈锦通
撰写时间:2019年6月4日星期二
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
获取页面数据的方式有很多种。我说的是其中最笨的方法(这个方法是我想了很久,反复尝试成功了)。
首先是 HTML 代码:
55
66
88
77
上面的 HTML 代码表示使用 from 表单提交,其中收录四个 input 标签。
注意:id必须唯一,名称尽量唯一。因为我说的方法是,如果name属性不是唯一的,那么在传输到数据库的时候就会少一个数据。
以上HTML代码效果如下图
样式有点简单,按钮有点小。
以下是js代码:
function sss() {
var A = $("#AppointmentNumber1").val();
var B = $("#AppointmentNumber2").val();
var C = $("#AppointmentNumber3").val();
var D = $("#AppointmentNumber4").val();
if (A != "" && A != null && B != "" && B != null && C != "" && C != null && D != "" && D != null) {
//第一个A是控制器接收的,第二个A是上面声明的
$.post("/one/bubu", { a: A, b: B, c: C, d: D }, function (ABC) {
if (ABC.State = true) {
alert(ABC.Text);
}
else {
alert(ABC.Text);
}
});
}
else {
alert("请把数据填写完整");
}
}
代码中的var声明了上面输入标签中获取数据的jQ代码(要使用jq代码时必须引用jq文件,否则会报错)获取输入的数据页面输入标签通过 val() ,然后赋值给声明的变量。然后判断声明的变量是否有值和没有值,并提示“请填写数据”提醒您将数据填写完整。
如果有数据,将数据提交给控制器。然后控制器返回ABC,然后判断控制器传递过来的状态值是true还是false,然后做出不同的提示。 (我这样命名并不标准,我这样命名只是为了便于理解)
//新增
public ActionResult bubu(FormCollection form)
{
s1 mod = new s1();
s2 mod1 = new s2();
ReturnJson ABC = new ReturnJson();
var a = form["a"];
var b = form["b"];
var c = form["c"];
var d = form["d"];
//判断传过来的数据是否为空
if (!string.IsNullOrEmpty(a) && !string.IsNullOrEmpty(b) && !string.IsNullOrEmpty(c) && !string.IsNullOrEmpty(d))
{
mod.one = a;
mod.twe = b;
mod1.s2name = c;
mod1.s2uou = d;
ABC.State = true;
ABC.Text = "新增成功";
//核心代码
my.s1.Add(mod);
my.s2.Add(mod1);
my.SaveChanges();
}
else
{
ABC.State = false;
ABC.Text = "数据不完整";
}
return Json(ABC, JsonRequestBehavior.AllowGet);
}
(my是实例化的数据库名,s1和s2是数据库中的表)
上面是控制器中的代码,意思是页面上jQ代码传递过来的值,通过Form采集表单接收,然后赋值给新声明的变量。为什么要声明要接收的新变量?因为Form采集接收到的数据不能直接使用,所以声明了变量来接收传入的值。然后判断传入的数据是否为空,然后保存到数据库中。我声明mod代表数据库的表来接收数据并保存。最后用核心代码保存到数据库中得到的数据,通过App方法修改你要保存的数据,然后通过Save Changes()方法保存到数据库中。最后,数据成功保存到数据库中。效果如下数据库图:
这是成功保存的数据。
(文章中声明的变量没有标准化,只是为了更好的理解) 查看全部
c 抓取网页数据(
获取页面的数据方法有很多,这里说的是里面最蠢的一个方法)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
开发工具与关键技术:VS与MVC js
作者:陈锦通
撰写时间:2019年6月4日星期二
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
获取页面数据的方式有很多种。我说的是其中最笨的方法(这个方法是我想了很久,反复尝试成功了)。
首先是 HTML 代码:
55
66
88
77
上面的 HTML 代码表示使用 from 表单提交,其中收录四个 input 标签。
注意:id必须唯一,名称尽量唯一。因为我说的方法是,如果name属性不是唯一的,那么在传输到数据库的时候就会少一个数据。
以上HTML代码效果如下图
样式有点简单,按钮有点小。
以下是js代码:
function sss() {
var A = $("#AppointmentNumber1").val();
var B = $("#AppointmentNumber2").val();
var C = $("#AppointmentNumber3").val();
var D = $("#AppointmentNumber4").val();
if (A != "" && A != null && B != "" && B != null && C != "" && C != null && D != "" && D != null) {
//第一个A是控制器接收的,第二个A是上面声明的
$.post("/one/bubu", { a: A, b: B, c: C, d: D }, function (ABC) {
if (ABC.State = true) {
alert(ABC.Text);
}
else {
alert(ABC.Text);
}
});
}
else {
alert("请把数据填写完整");
}
}
代码中的var声明了上面输入标签中获取数据的jQ代码(要使用jq代码时必须引用jq文件,否则会报错)获取输入的数据页面输入标签通过 val() ,然后赋值给声明的变量。然后判断声明的变量是否有值和没有值,并提示“请填写数据”提醒您将数据填写完整。
如果有数据,将数据提交给控制器。然后控制器返回ABC,然后判断控制器传递过来的状态值是true还是false,然后做出不同的提示。 (我这样命名并不标准,我这样命名只是为了便于理解)
//新增
public ActionResult bubu(FormCollection form)
{
s1 mod = new s1();
s2 mod1 = new s2();
ReturnJson ABC = new ReturnJson();
var a = form["a"];
var b = form["b"];
var c = form["c"];
var d = form["d"];
//判断传过来的数据是否为空
if (!string.IsNullOrEmpty(a) && !string.IsNullOrEmpty(b) && !string.IsNullOrEmpty(c) && !string.IsNullOrEmpty(d))
{
mod.one = a;
mod.twe = b;
mod1.s2name = c;
mod1.s2uou = d;
ABC.State = true;
ABC.Text = "新增成功";
//核心代码
my.s1.Add(mod);
my.s2.Add(mod1);
my.SaveChanges();
}
else
{
ABC.State = false;
ABC.Text = "数据不完整";
}
return Json(ABC, JsonRequestBehavior.AllowGet);
}
(my是实例化的数据库名,s1和s2是数据库中的表)
上面是控制器中的代码,意思是页面上jQ代码传递过来的值,通过Form采集表单接收,然后赋值给新声明的变量。为什么要声明要接收的新变量?因为Form采集接收到的数据不能直接使用,所以声明了变量来接收传入的值。然后判断传入的数据是否为空,然后保存到数据库中。我声明mod代表数据库的表来接收数据并保存。最后用核心代码保存到数据库中得到的数据,通过App方法修改你要保存的数据,然后通过Save Changes()方法保存到数据库中。最后,数据成功保存到数据库中。效果如下数据库图:


这是成功保存的数据。
(文章中声明的变量没有标准化,只是为了更好的理解)
c 抓取网页数据(c抓取网页数据,x抓包就是利用wireshark进行抓包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-19 21:03
c抓取网页数据,x抓包就是利用wireshark进行抓包。它有两种用法,一种是browser(浏览器)抓包,另一种是交给crawler(爬虫)来抓包,你可以根据情况来选择,小练习使用crawler抓x。//抓包create_http_session//设置会话try{session_save_header'content-type':'application/x-www-form-urlencoded';content_type'application/x-www-form-urlencoded';set_session_limit_max_http_status=1;set_cookie_type'notice';if(!_save_header){request_length=session_limit_max_http_status;set_header('host','');session_save_header'error'=seq(。
1)';session_save_header'session_limit_max_http_status';connection'keep-alive';}if(exists_save_header){request_error=_save_header('error',_save_header('error',error));}}catch(exceptione){request_error=_save_header('error',error);}//网页重定向url_data_link_to_script(href):用于从x-forwarded-for,发出url_data_link_to_script,post请求,获取html内容。
其code需要填写:443(888
8)*xhr-1:443(888
8) 查看全部
c 抓取网页数据(c抓取网页数据,x抓包就是利用wireshark进行抓包)
c抓取网页数据,x抓包就是利用wireshark进行抓包。它有两种用法,一种是browser(浏览器)抓包,另一种是交给crawler(爬虫)来抓包,你可以根据情况来选择,小练习使用crawler抓x。//抓包create_http_session//设置会话try{session_save_header'content-type':'application/x-www-form-urlencoded';content_type'application/x-www-form-urlencoded';set_session_limit_max_http_status=1;set_cookie_type'notice';if(!_save_header){request_length=session_limit_max_http_status;set_header('host','');session_save_header'error'=seq(。
1)';session_save_header'session_limit_max_http_status';connection'keep-alive';}if(exists_save_header){request_error=_save_header('error',_save_header('error',error));}}catch(exceptione){request_error=_save_header('error',error);}//网页重定向url_data_link_to_script(href):用于从x-forwarded-for,发出url_data_link_to_script,post请求,获取html内容。
其code需要填写:443(888
8)*xhr-1:443(888
8)
c 抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-18 16:25
一篇短文,涵盖了数据采集、数据清洗、数据展示的全过程。数据主要展示了2016年中国前100个地级市的GDP、增长率、区域分布密度图三个维度。
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找一篇微信短文,复制网址链接,直接在浏览器打开
/ s的?__ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f0gc6e4e6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f4c6e4e6d5251601f4f0c6e4e6d5d5m1f0g8f0c6e4e6d5fb8rqf0c6e4e6d5d5b8cd4f0c6e1
使用rvest简单提取文本内容
web%html_text()
网页抓取阶段完成后,接下来将进入数据清洗阶段:
#------------------------------------------------- -------------------------------------------------- ---
仔细观察文本向量,我们可以发现我们需要的城市数据都是以数字开头(1到3位不等),第七行也是以一个数据字开头(2017年1月20日),使用正则表示为准确匹配,将所有标点符号(记住中文标点符号)替换为逗号(英文),可以作为以后进行列拆分的依据(也可以自定义拆分符号)
<p>a 查看全部
c 抓取网页数据(用rvest简单提取文本内容(图)拆分(组图))
一篇短文,涵盖了数据采集、数据清洗、数据展示的全过程。数据主要展示了2016年中国前100个地级市的GDP、增长率、区域分布密度图三个维度。
library(plyr)
library(rvest)
library(stringr)
library("data.table")
library(dplyr)
随便找一篇微信短文,复制网址链接,直接在浏览器打开
/ s的?__ BIZ = MzI1ODM5NTQ1Mw ==&中期= 2247484083&IDX = 1&SN = ba4f4b10af3e4d6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f0gc6e4e6ed45f4d04edc30980&chksm = ea099ee1dd7e17f717afffdb3a3ff82c6e4e6bd5251601f4c6e4e6d5251601f4f0c6e4e6d5d5m1f0g8f0c6e4e6d5fb8rqf0c6e4e6d5d5b8cd4f0c6e1
使用rvest简单提取文本内容
web%html_text()
网页抓取阶段完成后,接下来将进入数据清洗阶段:
#------------------------------------------------- -------------------------------------------------- ---
仔细观察文本向量,我们可以发现我们需要的城市数据都是以数字开头(1到3位不等),第七行也是以一个数据字开头(2017年1月20日),使用正则表示为准确匹配,将所有标点符号(记住中文标点符号)替换为逗号(英文),可以作为以后进行列拆分的依据(也可以自定义拆分符号)
<p>a
c 抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-18 12:22
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品占比较高。较小。搜索引擎是目前互联网产品中技术含量最高的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
这样的海WEBCRAWLER网络爬虫训练项目3的数据如何获取、存储和计算?如何快速响应用户查询?如何使搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自互联网网页,整个“网络爬虫”的信息在本地获取“Internet”,由于互联网页面的大部分内容完全相同或几乎重复,“网页重复数据删除”模块会检测到并删除重复的内容。之后,搜索引擎会解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过高效的“倒排索引”查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为这个关系在网页的相关性排名阶段是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,通过结合用户的信息,正确推导出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存中存储着不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,排序输出作为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或者比较重要。这通常可以从“链接分析”的结果中获得。结合以上两个考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的门户,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 查看全部
c 抓取网页数据(WEBCRAWLER网络爬虫实训项目1WEBCRAWLER网络爬虫实训项目)
WEBCRAWLER 网络爬虫培训项目1 WEBCRAWLER 网络爬虫培训项目文档版本:1.0.0.1 作者:Dane IT Training Group C++教学研发部作者:Min Wei 定稿日期:11月,星期五20, 2015 WEBCRAWLER 网络爬虫培训项目21. 项目概述 互联网产品种类繁多,以产品为导向,以营销为导向,以技术为导向,但精通技术的互联网产品占比较高。较小。搜索引擎是目前互联网产品中技术含量最高的产品,如果不是唯一的,至少也是其中之一。经过十多年的发展,搜索引擎已经成为互联网的重要门户之一。Twitter联合创始人埃文威廉姆斯提出“
这样的海WEBCRAWLER网络爬虫训练项目3的数据如何获取、存储和计算?如何快速响应用户查询?如何使搜索结果尽可能满足用户对信息的需求?这些都是搜索引擎设计者必须面对的技术挑战。下图展示了一个通用搜索引擎的基本结构。商业级搜索引擎通常由许多独立的模块组成。每个模块只负责搜索引擎的部分功能,相互配合形成一个完整的搜索引擎:搜索引擎的信息源来自互联网网页,整个“网络爬虫”的信息在本地获取“Internet”,由于互联网页面的大部分内容完全相同或几乎重复,“网页重复数据删除”模块会检测到并删除重复的内容。之后,搜索引擎会解析网页,提取网页的主要内容,以及指向该网页中收录的其他页面的所谓超链接。为了加快用户查询的响应速度,通过高效的“倒排索引”查询数据结构保存网页内容,同时保存网页之间的链接关系。之所以保存链接关系,是因为这个关系在网页的相关性排名阶段是可用的。页面的相对重要性可以通过“链接分析”来判断,这对于为用户提供准确的搜索结果非常有帮助。由于网页数量众多,搜索引擎不仅需要保存网页的原创信息,还需要保存一些中间处理结果。使用单台计算机或少量计算机显然是不现实的。
谷歌等商业搜索引擎提供商为此开发了一套完整的云存储和云计算平台,利用数以万计的普通PCWEBCRAWLER网络爬虫训练项目4,构建了海量信息作为搜索的可靠存储和计算架构引擎及其相关应用的基础支持。优秀的云存储和云计算平台已成为大型商业搜索引擎的核心竞争力。以上就是搜索引擎获取和存储海量网页相关信息的方式。这些功能不需要实时计算,可以看作是搜索引擎的后端计算系统。搜索引擎的首要目标当然是为用户提供准确、全面的搜索结果。因此,实时响应用户查询并提供准确结果构成了搜索引擎的前端计算系统。搜索引擎收到用户的查询请求后,首先需要对查询词进行分析,通过结合用户的信息,正确推导出用户的真实搜索意图。之后,首先查看“缓存系统”维护的缓存。搜索引擎的缓存中存储着不同的搜索意图及其对应的搜索结果。如果在缓存中找到满足用户需求的信息,则直接将搜索结果返回给用户。这不仅节省了重复计算的资源消耗,同时也加快了整个搜索过程的响应速度。如果缓存中没有找到满足用户需求的信息,则需要使用“页面排序”,根据用户的搜索意图实时计算哪些网页满足用户需求,排序输出作为搜索结果。
网页排名最重要的两个参考因素是“内容相似度”,即哪些网页与用户的搜索意图密切相关;另一个是网页重要性,即哪些网页质量好或者比较重要。这通常可以从“链接分析”的结果中获得。结合以上两个考虑,前端系统将网页进行排序,作为搜索的最终结果。除了上述功能模块外,搜索引擎的“反作弊”模块近年来也越来越受到关注。搜索引擎作为网民上网的门户,对网络流量的引导和分流至关重要,甚至可以说起到了举足轻重的作用。因此,各种“作弊” 方法逐渐流行起来。使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 使用各种方法将网页的搜索排名提升到与网页质量不相称的位置,这将严重影响用户的搜索体验。因此,如何自动发现作弊网页并给予相应的惩罚,成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。到目前为止,网页有数百万个,所以搜索引擎面临的第一个问题是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联 如何自动发现作弊网页并给予相应的惩罚已经成为搜索引擎非常重要的功能之一。1.2. 网络爬虫通用搜索引擎的处理对象是互联网网页。目前网页有数百万个,搜索引擎面临的第一个问题就是如何设计一个高效的下载系统。将如此大量的网页数据发送到本地,在本地形成互联
c 抓取网页数据(为什么学爬虫?从基础爬虫到商业化应用爬虫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-15 11:29
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答 查看全部
c 抓取网页数据(为什么学爬虫?从基础爬虫到商业化应用爬虫(组图))
【为什么要学爬?】
1、爬虫上手容易,深入难。如何编写高效的爬虫,如何编写高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,经常容易遇到反爬虫,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课!
2、如果你是其他行业的开发者,比如app开发,web开发,学习爬虫可以加强你对技术的理解,并且能够开发出更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后本课程也按照这些步骤一步步讲解,引导学生充分掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图形验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。 Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫、等等。
通过爬虫的高级知识点,我们可以应对大量的反爬网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们的爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
【课程服务】
专属付费社区+定期问答
c 抓取网页数据(Next.js新的通用JavaScript框架-NextTV节目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-15 11:14
Next.js 是一个新的通用 JavaScript 框架,它为 React 和基于服务器的 Web 应用程序提供了新的替代方案。
Next.js 目前是开源的,
现在我们知道如何创建一个非常好的 Next.js 应用程序并获得 Next.js 路由 API 的全部优势。
在实践中,我们通常需要从远程数据源获取数据。Next.js 有一个标准的 API 来获取页面的数据。我们使用名为 getInitialProps 的异步函数来完成它。
这样我们就可以通过远程数据源获取给定页面的数据,作为我们页面的一个属性。我们可以在服务器和客户端上编写 getInitialProps。因此,Next.js 既可以用于客户端,也可以用于服务器端。
在本课程中,我们将使用 getInitialProps 制作一个应用程序,该应用程序可以使用公共 TVmaze API 显示有关蝙蝠侠电视节目的信息。
Paste_Image.png
开始吧。
安装
git clone https://github.com/arunoda/learnnextjs-demo.git
cd learnnextjs-demo
git checkout clean-urls-ssr
您可以执行以下命令:
npm install
npm run dev
您现在可以通过导航到:3000/ 来访问该应用程序。
抓住蝙蝠侠表演
在我们的演示应用程序中,我们在主页上有一个博客 文章 列表。现在我们将展示一组蝙蝠侠电视节目。
我们将从远程服务器获取这些显示,而不是对它们进行硬编码。
以下是我们如何使用 TVMaze API 来获取这些电视节目。
它是一个用于搜索电视节目信息的 API。
首先,我们需要安装isomorphic-unfetch。这是我们用来获取数据的库。它是浏览器获取 API 的简单实现,但它可以在客户端和服务器环境中实现。
npm install --save isomorphic-unfetch
然后将我们的 pages/index.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import Link from 'next/link'
import fetch from 'isomorphic-unfetch'
const Index = (props) => (
Batman TV Shows
{props.shows.map(({show}) => (
<a>{show.name}</a>
))}
)
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
export default Index
上面的每个页面都很熟悉,除了Index.getInitialProps,如下所示:
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
这是一个静态异步函数,您可以将它添加到应用程序的任何页面,使用它,我们可以获取数据并将它们作为我们页面的属性发送。
如您所见,我们现在正在抓取蝙蝠侠电视节目并将其作为我们页面上的“节目”属性输入。
Paste_Image.png
正如您在上面的 getInitialProps 函数中看到的那样,它将数据量输出到控制台。
现在,查看浏览器控制台和服务器控制台。
然后重新加载页面。
重新加载页面后,你在哪里看到上面的消息?
仅在服务器上
在这种情况下,消息仅打印在服务器上。
这是因为我们在服务器上呈现页面。
因此,我们已经有了数据,我们没有理由在客户端再次检索数据。
实现帖子页面
现在,让我们尝试实现“/post”页面,该页面显示有关电视节目的详细信息。
首先打开server.js,修改/p/:id路由,内容如下:
server.get('/p/:id', (req, res) => {
const actualPage = '/post'
const queryParams = { id: req.params.id }
app.render(req, res, actualPage, queryParams)
})
然后重新启动应用程序以应用上述代码更改。
早些时候,我们将标题查询参数映射到页面。现在我们需要将其重命名为 id。
现在将 pages/post.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import fetch from 'isomorphic-unfetch'
const Post = (props) => (
{props.show.name}
<p>{props.show.summary.replace(//g, '')}
<img src={props.show.image.medium}/>
)
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
export default Post
</p>
看看这个页面上的 getInitialProps :
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
在这种情况下,这个函数是上下文对象中的第一个参数。它有一个查询字段,我们可以用它来获取信息。
在我们的示例中,我们从查询参数中选择节目 ID,并从 TVMaze API 获取其节目数据。
在这个 getInitialProps 函数中,我们添加了一个控制台。记录显示的标题。现在让我们看看它将被打印在哪里。
打开服务器控制台和客户端控制台。
然后访问首页:3000,点击第一部蝙蝠侠秀的标题。
你在哪里看到上面提到的控制台。记录消息?
获取客户端数据
在这里,我们只能在浏览器控制台中看到消息。
这是因为我们通过客户端导航到帖子页面。那么从客户端获取数据是最好的方式。
如果您只是直接访问帖子页面(例如::3000/p/975 页面),您可以看到打印在服务器上而不是客户端上的消息。
最后
现在您已经了解了 Next.js 最重要的功能。使其成为通用数据采集和服务器端渲染的理想选择。
我们已经学习了 getInitialProps 的基础知识,这对于大多数用例来说已经足够了。您还可以参考 Next.js 上的文档了解更多信息。
本文转载自: 查看全部
c 抓取网页数据(Next.js新的通用JavaScript框架-NextTV节目)
Next.js 是一个新的通用 JavaScript 框架,它为 React 和基于服务器的 Web 应用程序提供了新的替代方案。
Next.js 目前是开源的,
现在我们知道如何创建一个非常好的 Next.js 应用程序并获得 Next.js 路由 API 的全部优势。
在实践中,我们通常需要从远程数据源获取数据。Next.js 有一个标准的 API 来获取页面的数据。我们使用名为 getInitialProps 的异步函数来完成它。
这样我们就可以通过远程数据源获取给定页面的数据,作为我们页面的一个属性。我们可以在服务器和客户端上编写 getInitialProps。因此,Next.js 既可以用于客户端,也可以用于服务器端。
在本课程中,我们将使用 getInitialProps 制作一个应用程序,该应用程序可以使用公共 TVmaze API 显示有关蝙蝠侠电视节目的信息。
Paste_Image.png
开始吧。
安装
git clone https://github.com/arunoda/learnnextjs-demo.git
cd learnnextjs-demo
git checkout clean-urls-ssr
您可以执行以下命令:
npm install
npm run dev
您现在可以通过导航到:3000/ 来访问该应用程序。
抓住蝙蝠侠表演
在我们的演示应用程序中,我们在主页上有一个博客 文章 列表。现在我们将展示一组蝙蝠侠电视节目。
我们将从远程服务器获取这些显示,而不是对它们进行硬编码。
以下是我们如何使用 TVMaze API 来获取这些电视节目。
它是一个用于搜索电视节目信息的 API。
首先,我们需要安装isomorphic-unfetch。这是我们用来获取数据的库。它是浏览器获取 API 的简单实现,但它可以在客户端和服务器环境中实现。
npm install --save isomorphic-unfetch
然后将我们的 pages/index.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import Link from 'next/link'
import fetch from 'isomorphic-unfetch'
const Index = (props) => (
Batman TV Shows
{props.shows.map(({show}) => (
<a>{show.name}</a>
))}
)
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
export default Index
上面的每个页面都很熟悉,除了Index.getInitialProps,如下所示:
Index.getInitialProps = async function() {
const res = await fetch('https://api.tvmaze.com/search/shows?q=batman')
const data = await res.json()
console.log(`Show data fetched. Count: ${data.length}`)
return {
shows: data
}
}
这是一个静态异步函数,您可以将它添加到应用程序的任何页面,使用它,我们可以获取数据并将它们作为我们页面的属性发送。
如您所见,我们现在正在抓取蝙蝠侠电视节目并将其作为我们页面上的“节目”属性输入。
Paste_Image.png
正如您在上面的 getInitialProps 函数中看到的那样,它将数据量输出到控制台。
现在,查看浏览器控制台和服务器控制台。
然后重新加载页面。
重新加载页面后,你在哪里看到上面的消息?
仅在服务器上
在这种情况下,消息仅打印在服务器上。
这是因为我们在服务器上呈现页面。
因此,我们已经有了数据,我们没有理由在客户端再次检索数据。
实现帖子页面
现在,让我们尝试实现“/post”页面,该页面显示有关电视节目的详细信息。
首先打开server.js,修改/p/:id路由,内容如下:
server.get('/p/:id', (req, res) => {
const actualPage = '/post'
const queryParams = { id: req.params.id }
app.render(req, res, actualPage, queryParams)
})
然后重新启动应用程序以应用上述代码更改。
早些时候,我们将标题查询参数映射到页面。现在我们需要将其重命名为 id。
现在将 pages/post.js 替换为以下内容:
import Layout from '../components/MyLayout.js'
import fetch from 'isomorphic-unfetch'
const Post = (props) => (
{props.show.name}
<p>{props.show.summary.replace(//g, '')}
<img src={props.show.image.medium}/>
)
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
export default Post
</p>
看看这个页面上的 getInitialProps :
Post.getInitialProps = async function (context) {
const { id } = context.query
const res = await fetch(`https://api.tvmaze.com/shows/${id}`)
const show = await res.json()
console.log(`Fetched show: ${show.name}`)
return { show }
}
在这种情况下,这个函数是上下文对象中的第一个参数。它有一个查询字段,我们可以用它来获取信息。
在我们的示例中,我们从查询参数中选择节目 ID,并从 TVMaze API 获取其节目数据。
在这个 getInitialProps 函数中,我们添加了一个控制台。记录显示的标题。现在让我们看看它将被打印在哪里。
打开服务器控制台和客户端控制台。
然后访问首页:3000,点击第一部蝙蝠侠秀的标题。
你在哪里看到上面提到的控制台。记录消息?
获取客户端数据
在这里,我们只能在浏览器控制台中看到消息。
这是因为我们通过客户端导航到帖子页面。那么从客户端获取数据是最好的方式。
如果您只是直接访问帖子页面(例如::3000/p/975 页面),您可以看到打印在服务器上而不是客户端上的消息。
最后
现在您已经了解了 Next.js 最重要的功能。使其成为通用数据采集和服务器端渲染的理想选择。
我们已经学习了 getInitialProps 的基础知识,这对于大多数用例来说已经足够了。您还可以参考 Next.js 上的文档了解更多信息。
本文转载自:
c 抓取网页数据(基于广受接待的R语言实例分析--我国大数据不妨)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-10 06:10
引言 纵观全球,大数据市场发展迅速,政府的支持也达到了前所未有的水平,甚至将大数据纳入了增长战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计规模的一员,我们必须抓住机遇。放眼世界,大数据的应用极限还在不断扩大,几乎每个行业都将目光投向了大数据背后的巨大代价。未来五到十年将是我国推动大数据增长的关键时期,亟需打造高效的大数据应用机制和财富链。
根据目前对大数据产业增长的澄清,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用简单易用的网页数据抓取工具来抓取所需的网页数据,比如知名的网页数据抓取工具“**采集器”(收费)。现有的互联网数据采集、处理、澄清、挖掘软件可以快速、灵活地捕捉网络上杂乱的数据信息,并通过一系列的澄清和处理,准确地挖掘出需要的数据。效率高,
今天,作为大数据行业的一员,基于广受好评的R软件,给大家介绍一下如何实现网页数据抓取技巧。是的,是R!除了强大的统计澄清结果外,它的网络爬虫能力也不容小觑,尤其是Hadley编写的R包rvest,简化了庞大的工作。使用R语言抓取网页数据的一大优势在于强大的数据处理惩罚、获取数据后的澄清和可视化结果。
R语言示例 下面以rvest包抓取广州市大气质量数据为例,举办讲座。
网页数据如下:
#Loadingmeasures packagelibrary(rvest)#找到抓取数据的URL url=””#关注URL的内容web= read_html(url,encoding=”UTF-8″)#截取如图所示的大气质量数据上图 aqi=web %> % html_nodes("span") %>% html_text()#注意!很多小伙伴在这一步会出现乱码的环境 aqi=aqi[8:127]#把截取的数据整理成一个数据框 aqi=matrix(aqi,ncol=10,byrow=T)aqi=data.frame(aqi)for (i in 1:ncol(aqi)){aqi[,i]=as.character(aqi[,i])aqi[,i]=gsub("\"","",gsub("\\n" ,””,Aqi[,i]))}names(aqi)=aqi[1,]aqi=aqi[-1,]aqi
如果一切正常,会显示如下效果:
至此,R软件已经能够抓取网页数据,后续可以将大气质量指数以时间序列和空间扩散的形式展示出来。以上虽然只是大数据的表皮,但仍有很多可以探索和扩展的对象。比如对于网页数据的抓取,如果能及时动态抓取,就会打出大数据的价格。
学会了以上小技巧,大数据应用不再是纯口号!虽然还是有很多软件可以实现网页数据抓取,比如python、sas、Excel等,有兴趣的小伙伴可以随意试验一下。IDC宣布,报告显示,2016年全球大数据技术和服务市场规模将达到238亿美元。 激活我国大数据的资产成本和开启大数据新生态的政策,仍需各界通力合作社会的!
参考资料::///stephan_sly/blog/static/25692248660/
欢迎加入本站。真趣群贸易情报与数据澄清 群趣类包括数据成本的各种步骤、实际应用案例分享与连接、澄清工具、ETL工具、数据酒店、数据挖掘工具、报表系统等。 常识QQ群: 81035754 查看全部
c 抓取网页数据(基于广受接待的R语言实例分析--我国大数据不妨)
引言 纵观全球,大数据市场发展迅速,政府的支持也达到了前所未有的水平,甚至将大数据纳入了增长战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计规模的一员,我们必须抓住机遇。放眼世界,大数据的应用极限还在不断扩大,几乎每个行业都将目光投向了大数据背后的巨大代价。未来五到十年将是我国推动大数据增长的关键时期,亟需打造高效的大数据应用机制和财富链。
根据目前对大数据产业增长的澄清,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用简单易用的网页数据抓取工具来抓取所需的网页数据,比如知名的网页数据抓取工具“**采集器”(收费)。现有的互联网数据采集、处理、澄清、挖掘软件可以快速、灵活地捕捉网络上杂乱的数据信息,并通过一系列的澄清和处理,准确地挖掘出需要的数据。效率高,
今天,作为大数据行业的一员,基于广受好评的R软件,给大家介绍一下如何实现网页数据抓取技巧。是的,是R!除了强大的统计澄清结果外,它的网络爬虫能力也不容小觑,尤其是Hadley编写的R包rvest,简化了庞大的工作。使用R语言抓取网页数据的一大优势在于强大的数据处理惩罚、获取数据后的澄清和可视化结果。
R语言示例 下面以rvest包抓取广州市大气质量数据为例,举办讲座。
网页数据如下:
#Loadingmeasures packagelibrary(rvest)#找到抓取数据的URL url=””#关注URL的内容web= read_html(url,encoding=”UTF-8″)#截取如图所示的大气质量数据上图 aqi=web %> % html_nodes("span") %>% html_text()#注意!很多小伙伴在这一步会出现乱码的环境 aqi=aqi[8:127]#把截取的数据整理成一个数据框 aqi=matrix(aqi,ncol=10,byrow=T)aqi=data.frame(aqi)for (i in 1:ncol(aqi)){aqi[,i]=as.character(aqi[,i])aqi[,i]=gsub("\"","",gsub("\\n" ,””,Aqi[,i]))}names(aqi)=aqi[1,]aqi=aqi[-1,]aqi
如果一切正常,会显示如下效果:
至此,R软件已经能够抓取网页数据,后续可以将大气质量指数以时间序列和空间扩散的形式展示出来。以上虽然只是大数据的表皮,但仍有很多可以探索和扩展的对象。比如对于网页数据的抓取,如果能及时动态抓取,就会打出大数据的价格。
学会了以上小技巧,大数据应用不再是纯口号!虽然还是有很多软件可以实现网页数据抓取,比如python、sas、Excel等,有兴趣的小伙伴可以随意试验一下。IDC宣布,报告显示,2016年全球大数据技术和服务市场规模将达到238亿美元。 激活我国大数据的资产成本和开启大数据新生态的政策,仍需各界通力合作社会的!
参考资料::///stephan_sly/blog/static/25692248660/
欢迎加入本站。真趣群贸易情报与数据澄清 群趣类包括数据成本的各种步骤、实际应用案例分享与连接、澄清工具、ETL工具、数据酒店、数据挖掘工具、报表系统等。 常识QQ群: 81035754
c 抓取网页数据(Python开发的一个快速,高层次的屏幕和web抓取框架(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-10-10 06:08
阿里云>云栖社区>主题图>C>从网站中抓取数据库
推荐活动:
更多优惠>
当前主题:从 网站 抓取数据库并添加到采集夹
相关话题:
从网站抓取数据库相关博客,查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
从头搭建自己的爬虫代理IP数据库,定期检查IP有效性
作者:tomcat1101 浏览评论人数:02年前
ProxyIPPool 从头开始构建自己的代理IP池;根据代理IP URL获取新的代理IP;验证历史代理IP源地址的有效性:Why use proxy IP 在爬取过程中,很多网站会取反
阅读全文
Linux云服务器下配置Scrapy抓取数据
作者:㭍叶1552人浏览评论:04年前
基础设备:Linux云服务器(阿里云Ubuntu 16.04);建立远程连接的软件(这里使用XShell);友情链接:Scrapy入门教程:
阅读全文
安全风险:可通过网络搜索用户数据库
作者:知乎1036人浏览评论:04年前
这篇文章是关于安全风险的:可以通过互联网搜索用户数据库。最近在耶鲁大学和南加州医学发生的数据泄露事件凸显了确保数据库的网络界面不被网络搜索引擎暴露的重要性。最近的两起数据库泄漏事件突出了一个常见但经常被忽视的问题。收录敏感信息的配置错误的数据库很容易受到损害。
阅读全文
SEO建立有效页面数据库:目的、定义、流程、应用
作者:于尔武 1043人浏览评论:03年前
关于SEO运营理念,简单提一下,做好SEO工作需要从“产品需求形成”到“流量获取转化”。文章中有这么一段:SEO运营观(交付价值,实现产品)。SEO操作公式:有效查询覆盖,有效爬取,有效收录显示点击转化“有效”定义目标
阅读全文
为什么选择 Prometheus 作为时间序列数据库
作者:耳东@Erdong6491 浏览评论人数:02年前
Prometheus 和 Graphite 系列 Graphite 专注于成为具有查询语言和图形功能的被动时间序列数据库。任何其他问题都由外部组件处理。Prometheus 是一个完整的监控和趋势系统,包括内置和主动的爬取、存储、查询、绘图和基于时间的
阅读全文
在选择数据库的路上,我们遇到了哪些坑?(2)
作者:oneapm_official1769 人浏览评论:05年前
【编者按】您会如何选择数据库、关系数据库、XML 数据库、资源描述框架(RDF)或图形数据库?本文的第 1 部分深入而生动地探讨了各种选项。在第二部分,我们将深入介绍使用 Neo4j 时的注意点。文章是国内ITOM管理平台OneAPM的编译呈现。过渡到 N
阅读全文
提问网站 爬取数据库相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
c 抓取网页数据(Python开发的一个快速,高层次的屏幕和web抓取框架(组图))
阿里云>云栖社区>主题图>C>从网站中抓取数据库
推荐活动:
更多优惠>
当前主题:从 网站 抓取数据库并添加到采集夹
相关话题:
从网站抓取数据库相关博客,查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
从头搭建自己的爬虫代理IP数据库,定期检查IP有效性
作者:tomcat1101 浏览评论人数:02年前
ProxyIPPool 从头开始构建自己的代理IP池;根据代理IP URL获取新的代理IP;验证历史代理IP源地址的有效性:Why use proxy IP 在爬取过程中,很多网站会取反
阅读全文
Linux云服务器下配置Scrapy抓取数据
作者:㭍叶1552人浏览评论:04年前
基础设备:Linux云服务器(阿里云Ubuntu 16.04);建立远程连接的软件(这里使用XShell);友情链接:Scrapy入门教程:
阅读全文
安全风险:可通过网络搜索用户数据库
作者:知乎1036人浏览评论:04年前
这篇文章是关于安全风险的:可以通过互联网搜索用户数据库。最近在耶鲁大学和南加州医学发生的数据泄露事件凸显了确保数据库的网络界面不被网络搜索引擎暴露的重要性。最近的两起数据库泄漏事件突出了一个常见但经常被忽视的问题。收录敏感信息的配置错误的数据库很容易受到损害。
阅读全文
SEO建立有效页面数据库:目的、定义、流程、应用
作者:于尔武 1043人浏览评论:03年前
关于SEO运营理念,简单提一下,做好SEO工作需要从“产品需求形成”到“流量获取转化”。文章中有这么一段:SEO运营观(交付价值,实现产品)。SEO操作公式:有效查询覆盖,有效爬取,有效收录显示点击转化“有效”定义目标
阅读全文
为什么选择 Prometheus 作为时间序列数据库
作者:耳东@Erdong6491 浏览评论人数:02年前
Prometheus 和 Graphite 系列 Graphite 专注于成为具有查询语言和图形功能的被动时间序列数据库。任何其他问题都由外部组件处理。Prometheus 是一个完整的监控和趋势系统,包括内置和主动的爬取、存储、查询、绘图和基于时间的
阅读全文
在选择数据库的路上,我们遇到了哪些坑?(2)
作者:oneapm_official1769 人浏览评论:05年前
【编者按】您会如何选择数据库、关系数据库、XML 数据库、资源描述框架(RDF)或图形数据库?本文的第 1 部分深入而生动地探讨了各种选项。在第二部分,我们将深入介绍使用 Neo4j 时的注意点。文章是国内ITOM管理平台OneAPM的编译呈现。过渡到 N
阅读全文
提问网站 爬取数据库相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
c 抓取网页数据(C#.Net基于正则表达式抓取百度百家文章列表的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-07 02:06
本文文章主要介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法,分析C#获取百度百家文章的内容及使用示例形式的正则表达式。表情匹配标题、内容、地址等相关操作技巧,有需要的朋友可以参考
本文介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法。分享给大家,供大家参考,如下:
下班后,我学习了正则表达式。由于实践是检验真理的唯一标准,我写了一个使用正则表达式捕获百度百家文章的例子。具体过程请看下面的源码:
一、获取百度百家网页内容
public List GetUrl() { try { string url = "http://baijia.baidu.com/"; WebRequest webRequest = WebRequest.Create(url); WebResponse webResponse = webRequest.GetResponse(); StreamReader reader = new StreamReader(webResponse.GetResponseStream()); string result = reader.ReadToEnd(); reader.Close(); webResponse.Close(); return AnalysisHtml(result); } catch (Exception ex) { throw ex; } }
二、通过正则表达式过滤
<p> public List AnalysisHtml(string htmlContent) { List list = new List(); string strPattern = "(?[^ 查看全部
c 抓取网页数据(C#.Net基于正则表达式抓取百度百家文章列表的方法(图))
本文文章主要介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法,分析C#获取百度百家文章的内容及使用示例形式的正则表达式。表情匹配标题、内容、地址等相关操作技巧,有需要的朋友可以参考
本文介绍了C#.Net基于正则表达式抓取百度百家文章列表的方法。分享给大家,供大家参考,如下:
下班后,我学习了正则表达式。由于实践是检验真理的唯一标准,我写了一个使用正则表达式捕获百度百家文章的例子。具体过程请看下面的源码:
一、获取百度百家网页内容
public List GetUrl() { try { string url = "http://baijia.baidu.com/"; WebRequest webRequest = WebRequest.Create(url); WebResponse webResponse = webRequest.GetResponse(); StreamReader reader = new StreamReader(webResponse.GetResponseStream()); string result = reader.ReadToEnd(); reader.Close(); webResponse.Close(); return AnalysisHtml(result); } catch (Exception ex) { throw ex; } }
二、通过正则表达式过滤
<p> public List AnalysisHtml(string htmlContent) { List list = new List(); string strPattern = "(?[^
c 抓取网页数据( 找豆瓣网站的规律:WebScraper控制链接分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-07 01:27
找豆瓣网站的规律:WebScraper控制链接分析(图))
这是简单数据分析系列文章的第五篇。
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
前面说过,爬虫的本质是发现规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,播放226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻转
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以把它写成[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然也可以写[1-100],这样就可以爬取前100个网页了。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这非常简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
[0-225:25]&过滤器=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1.点击Stiemaps,在新面板中点击ID为top250的那一列数据:
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata:
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
4.参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
5.联系我 查看全部
c 抓取网页数据(
找豆瓣网站的规律:WebScraper控制链接分析(图))
这是简单数据分析系列文章的第五篇。
在上一篇文章中,我们爬取了豆瓣电影TOP250前25部电影的数据。今天,我们将对原来的 Web Scraper 配置做一些小改动,让爬虫爬取全部 250 部电影数据。
前面说过,爬虫的本质是发现规则。这些程序员在设计网页时,肯定会遵循一些规则。当我们找到规则时,我们就可以预测他们的行为并实现我们的目标。
今天我们就来寻找豆瓣网站的规则,想办法把所有的数据都抓到。今天的规则始于经常被忽视的网络链接。
1.链接分析
我们先来看看第一页的豆瓣网址链接:
这显然是一个豆瓣电影网址。Top250,没什么好说的,就是网页的内容。豆瓣前250电影无话可说?后面有个start=0&filter=,按照英文提示,好像是filtering(filter),从0开始(start)
查看第二页上的 URL 链接。前面一样,只是后面的参数变了,变成start=25,从25开始;
我们再看第三页的链接,参数变成start=50,从50开始;
分析这三个环节,我们可以很容易地画出一个模式:
start=0,表示从排名第一的电影开始,播放1-25部电影
start=25,表示从排名第26的电影开始,播放26-50部电影
start=50,表示从排名第51的电影开始,显示第51-75部电影
...
start=225,表示从排名第226的电影开始,播放226-250部电影
只要技术提供支持,很容易找到规律。深入学习,你会发现Web Scraper的操作并不难,但最重要的还是找到规律。
2.Web Scraper 控制链接参数翻转
Web Scraper为这种通过超链接数字分页获取分页数据的网页提供了非常方便的操作,即范围说明符。
例如,您要抓取的网页链接如下所示:
你可以把它写成[1-3],把链接改成这个,Web Scraper会自动抓取这三个网页的内容。
当然也可以写[1-100],这样就可以爬取前100个网页了。
那么我们之前分析的豆瓣网页呢?它不是从 1 增加到 100,而是 0 -> 25 -> 50 -> 75 以便它每 25 跳一次。我该怎么办?
事实上,这非常简单。这种情况可以用[0-100:25]来表示。每25个是一个网页,100/25=4,抓取前4个网页放到豆瓣电影场景中,我们只需要把链接改成如下即可;
[0-225:25]&过滤器=
这样,Web Scraper 将抓取 TOP250 的所有网页。
3.获取数据
解决链接问题,下一步就是如何在Web Scraper中修改链接。很简单,鼠标点两下:
1.点击Stiemaps,在新面板中点击ID为top250的那一列数据:
2. 进入新建面板后,找到Stiemap top250 Tab,点击,然后在下拉菜单中点击Edit metadata:
3.修改原网址,图中红框是区别:
修改超链接后,我们就可以再次抓取网页了。操作同上,这里简单重复一下:
单击站点地图 top250 下拉菜单中的抓取按钮。在新操作面板的两个输入框中输入2000。单击开始抓取蓝色按钮开始抓取数据。抓取结束后,点击面板上的蓝色刷新按钮,检测我们抓取的数据。
如果到了这里抓包成功,你会发现已经抓到了所有的数据,但是顺序是乱的。
这里我们不关心顺序问题,因为这属于数据清洗的内容,我们当前的主题是数据捕获。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
本期讲了通过修改超链接来抓取250部电影的名字。下一期我们会讲一些简单易懂的内容来改变你的想法,说说Web Scraper如何导入别人写的爬虫文件,导出自己写的爬虫软件。
4.参考阅读:
简单的数据分析04 | 网络爬虫第一款抢食豆瓣高分电影
5.联系我
c 抓取网页数据(天猫商城开发商编程的准备工作流程及注意事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-06 15:12
一、准备
1、在浏览器中打开天猫首页(推荐Chrome),搜索你要爬取的关键词。我在这里搜索的是“护发”;
2、按“CTRL+SHIFT+C”显示页面源代码。这时候移动鼠标点击图片区域可以看到对应的代码。我们可以看到,宝贝的图片、标题、价格、店名、销量等信息都在模块中。
二、启动Rstudio并开始编程
1、安装并加载rvest包,将变量hfurl赋值给刚才的网页链接
library(rvest)
library(magrittr)
library(xml2)
#保存需要爬取的网页到hfurl
hfurl%是管道操作符,意思是把左边的操作结果作为参数传递给右边的函数。
SCdata %
read_html(encoding="GBK")%>% #读取hfurl的链接并指定编码为"GBK"
html_nodes("div.product-iWrap") #筛选出所有包含在div.product-iWap中的内容
SCdata
显示结果如下:
这样,网页中60个宝宝的信息全部被抓取了!
3、 进一步爬取所需信息。请注意,您需要对 css 选择器或 xpath 有一点了解。当你抓取每一项数据时,你可以将其打印出来并测试是否成功。实践中发现itemTitle打印出来的item有103条,和其他行号不对应,所以注释掉了,然后再想办法突破。
#抓取卖家昵称
SCdata %
read_html(encoding="GBK") %>%
html_nodes("div.product-iWrap")
sellerNick% html_nodes("p.productStatus>span[class]") %>%
html_attr("data-nick")
#抓取卖家ID
sellerID % html_nodes("p.productStatus>span[data-atp]") %>%
html_attr("data-atp") %>%
#gsub()是字符串查找替换的函数,pattern是指定用来查找的正则表达式。
gsub(pattern="^.*,",replacement="")
#抓取宝贝名称
#itemTitle % html_tag("p.productTitle") %>%
# html_tag("a")%>%
# html_attr("title")
#html_text() %>%
#gsub(pattern="^.*,",replacement="")
#抓取宝贝ID
itemID%html_nodes("p.productStatus>span[class]") %>%
html_attr("data-item")
#抓取宝贝价格
price % html_nodes("p.productPrice>em[title]") %>%
html_attr("title") %>%
as.numeric
#抓取宝贝销量
volume % html_nodes("span>em") %>%
html_text
4、保存数据库对象并写入csv文件。
<p>options(stringsAsFactors = FALSE)#设置字符串不自动识别为因子
itemData1 查看全部
c 抓取网页数据(天猫商城开发商编程的准备工作流程及注意事项!)
一、准备
1、在浏览器中打开天猫首页(推荐Chrome),搜索你要爬取的关键词。我在这里搜索的是“护发”;
2、按“CTRL+SHIFT+C”显示页面源代码。这时候移动鼠标点击图片区域可以看到对应的代码。我们可以看到,宝贝的图片、标题、价格、店名、销量等信息都在模块中。
二、启动Rstudio并开始编程
1、安装并加载rvest包,将变量hfurl赋值给刚才的网页链接
library(rvest)
library(magrittr)
library(xml2)
#保存需要爬取的网页到hfurl
hfurl%是管道操作符,意思是把左边的操作结果作为参数传递给右边的函数。
SCdata %
read_html(encoding="GBK")%>% #读取hfurl的链接并指定编码为"GBK"
html_nodes("div.product-iWrap") #筛选出所有包含在div.product-iWap中的内容
SCdata
显示结果如下:
这样,网页中60个宝宝的信息全部被抓取了!
3、 进一步爬取所需信息。请注意,您需要对 css 选择器或 xpath 有一点了解。当你抓取每一项数据时,你可以将其打印出来并测试是否成功。实践中发现itemTitle打印出来的item有103条,和其他行号不对应,所以注释掉了,然后再想办法突破。
#抓取卖家昵称
SCdata %
read_html(encoding="GBK") %>%
html_nodes("div.product-iWrap")
sellerNick% html_nodes("p.productStatus>span[class]") %>%
html_attr("data-nick")
#抓取卖家ID
sellerID % html_nodes("p.productStatus>span[data-atp]") %>%
html_attr("data-atp") %>%
#gsub()是字符串查找替换的函数,pattern是指定用来查找的正则表达式。
gsub(pattern="^.*,",replacement="")
#抓取宝贝名称
#itemTitle % html_tag("p.productTitle") %>%
# html_tag("a")%>%
# html_attr("title")
#html_text() %>%
#gsub(pattern="^.*,",replacement="")
#抓取宝贝ID
itemID%html_nodes("p.productStatus>span[class]") %>%
html_attr("data-item")
#抓取宝贝价格
price % html_nodes("p.productPrice>em[title]") %>%
html_attr("title") %>%
as.numeric
#抓取宝贝销量
volume % html_nodes("span>em") %>%
html_text
4、保存数据库对象并写入csv文件。
<p>options(stringsAsFactors = FALSE)#设置字符串不自动识别为因子
itemData1
c 抓取网页数据(搜狗微信公众号更新公告(2015.03.23) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-01 22:15
)
最后更新日期为2018.1.3
只为自己做个记录
要添加的功能:
1.获取所有历史新闻
2. 爬取10多条数据
3.自定义抓取公众号信息
以搜狗微信公众号搜索微信公众号为例!
以搜狗微信公众号作为分析入口:【此处填写公众号名称】&ie=utf8&sug=n&sug_type=
DEMO中完整的URL为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
} 查看全部
c 抓取网页数据(搜狗微信公众号更新公告(2015.03.23)
)
最后更新日期为2018.1.3
只为自己做个记录
要添加的功能:
1.获取所有历史新闻
2. 爬取10多条数据
3.自定义抓取公众号信息
以搜狗微信公众号搜索微信公众号为例!
以搜狗微信公众号作为分析入口:【此处填写公众号名称】&ie=utf8&sug=n&sug_type=
DEMO中完整的URL为:%E6%AF%8F%E6%97%A5%E8%8A%82%E5%A5%8F&ie=utf8&sug=n&sug_type=
package cc.buckler.test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.Test;
import java.io.IOException;
public class TestData {
private String ENTRY_URL = "http://weixin.sogou.com/weixin ... %3B//入口地址
private String QUERY_WORD = "DOTA每日节奏";//查询参数
private String BASE_URL = "";//从入口进入公众号后的公众号地址
private String WE_CHAT_URL = "http://mp.weixin.qq.com";//微信公众号官方入口
private int NEW_MSG_ID = 0;//最新msgId
private int MSG_NUM = 20;//需要获取的数量
@Test
public void getData() {
String url = String.format(ENTRY_URL, QUERY_WORD);
//System.out.println(url);
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setTimeout(50000);
Document doc = null;
try {
//首先用jsoup获取搜狗入口公众号连接
doc = Jsoup.connect(url).get();
//System.out.println("doc:" + doc);
BASE_URL = doc.select("p a").attr("href");
//System.out.println(BASE_URL);
//使用htmlunit加载公众号文章列表
HtmlPage htmlPage = webClient.getPage(BASE_URL);
webClient.waitForBackgroundJavaScript(10000);
doc = Jsoup.parse(htmlPage.asXml());
//System.out.println("doc:" + doc);
//获取最新文章msgid,之后的循环用msgid-1
String lastMsgId = doc.select(".weui_media_box").attr("msgid");
NEW_MSG_ID = Integer.parseInt(lastMsgId);
//System.out.println(NEW_MSG_ID);
for (int i = NEW_MSG_ID; i >= NEW_MSG_ID - MSG_NUM; i--) {
String articalPrev = "#WXAPPMSG";
String articalId = articalPrev + i;
String h4 = articalId + " h4";
String weui_media_desc = articalId + " .weui_media_desc";
String weui_media_extra_info = articalId + " .weui_media_extra_info";
System.out.println(articalId);
String title = doc.select(h4).text();
System.out.println(title);
String detailUrl = doc.select(h4).attr("hrefs");//2018.1.3 ok
System.out.println(WE_CHAT_URL + detailUrl);
String note = doc.select(weui_media_desc).text();//2018.1.3 ok
if (note.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(note);
String releaseDate = doc.select(weui_media_extra_info).text().toString();//2018.1.3 ok
if (releaseDate.compareToIgnoreCase("") == 0) {
continue;
}
System.out.println(releaseDate);
}
webClient.close();
} catch (IOException e) {
e.printStackTrace();
webClient.close();
}
}
}
c 抓取网页数据(你特么不提供api让我怎么搞嘛~~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-10-01 11:03
c抓取网页数据,并不只是为了存下来,更多的是通过抓取的数据来推送给用户有价值的信息给用户。所以更多的应该是需要实现分析。
但是你特么不提供api让我怎么搞嘛~
如果将抓取同时落到技术维度上,基本应该是分析问题的一个重要手段了。举个例子,如果能够抓取地震波(同时可以按波长分析出地震波频率),就能预测出震中在哪。但是通过抓取某些特定的数据来实现分析的过程,只能是属于一个辅助工具。一般来说,提供api数据抓取的公司,会有比较明确的目标和用户群体。如果纯粹抓取数据,无法归纳出数据的应用目的和研究方向,反而像是一种纯技术的营销手段。如果是抓取社会科学数据,仍然可以归结到分析和应用层面。
抓取数据变现。以前看到哪个国际api网站。其实是说抓取互联网数据到谷歌可以成为大数据,然后经过数据分析算法变成数据可以卖给金融公司。利用在谷歌出售的数据来训练出基因组学,神经科学,音乐或者其他各种东西。
你要说开发,先要解决有没有的问题。
很多从事互联网开发的公司,是会给用户提供数据抓取的api的,但是这些公司更多的是提供一个统一的api服务,比如youku的阿里云oss服务,但是并不是给开发者提供这些数据,而是提供统一的源代码,然后给开发者添加到业务数据库里面。 查看全部
c 抓取网页数据(你特么不提供api让我怎么搞嘛~~)
c抓取网页数据,并不只是为了存下来,更多的是通过抓取的数据来推送给用户有价值的信息给用户。所以更多的应该是需要实现分析。
但是你特么不提供api让我怎么搞嘛~
如果将抓取同时落到技术维度上,基本应该是分析问题的一个重要手段了。举个例子,如果能够抓取地震波(同时可以按波长分析出地震波频率),就能预测出震中在哪。但是通过抓取某些特定的数据来实现分析的过程,只能是属于一个辅助工具。一般来说,提供api数据抓取的公司,会有比较明确的目标和用户群体。如果纯粹抓取数据,无法归纳出数据的应用目的和研究方向,反而像是一种纯技术的营销手段。如果是抓取社会科学数据,仍然可以归结到分析和应用层面。
抓取数据变现。以前看到哪个国际api网站。其实是说抓取互联网数据到谷歌可以成为大数据,然后经过数据分析算法变成数据可以卖给金融公司。利用在谷歌出售的数据来训练出基因组学,神经科学,音乐或者其他各种东西。
你要说开发,先要解决有没有的问题。
很多从事互联网开发的公司,是会给用户提供数据抓取的api的,但是这些公司更多的是提供一个统一的api服务,比如youku的阿里云oss服务,但是并不是给开发者提供这些数据,而是提供统一的源代码,然后给开发者添加到业务数据库里面。
c 抓取网页数据( 用Pyhton自带的urllib或urllib2模块(二)|,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-30 15:17
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看 Python 的使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 来分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。 查看全部
c 抓取网页数据(
用Pyhton自带的urllib或urllib2模块(二)|,)
Python使用lxml模块和Requests模块抓取HTML页面教程
更新时间:2016 年 5 月 16 日 18:53:56 作者:Kenneth Reitz
使用 Pyhton 的内置 urllib 或 urllib2 模块来抓取网页可能有点陈词滥调。今天我们将玩一些新鲜的。查看 Python 的使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程:
万维网
网站是用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
现在是网络抢占该领域的时候了。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式的做法,同时保留其结构。
lxml 和请求
lxml() 是一个漂亮的扩展库,用于快速解析 XML 和 HTML 文档,即使处理的标签非常混乱。我们还将使用 Requests (#) 模块来替换内置的 urllib2 模块,因为它更快、更易读。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
在下一步中,我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录成一个优雅的树状结构,我们可以使用两种方法来访问:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的详细介绍,请参阅 W3Schools。
有很多工具可以获取元素的 XPath,例如 Firefox 的 FireBug 或 Chrome 的 Inspector。如果您使用 Chrome,您可以右键单击该元素,选择“检查元素”,突出显示此代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面上的数据存储在两个元素中,一个是标题为'buyer-name'的div,另一个是类为'item-price'的span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经成功通过lxml和Request从一个网页中抓取了我们想要的所有数据。我们以列表的形式将它们存储在内存中。现在我们可以用它做各种很酷的事情:我们可以用 Python 来分析它,或者我们可以将它保存为文件并与世界分享。
我们可以考虑一些更酷的想法:修改此脚本以遍历本示例中数据集中的剩余页面,或者使用多个线程重写此应用程序以提高其速度。
c 抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-27 12:08
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!! 查看全部
c 抓取网页数据(简化人工操作的必要过程,本文分享一下获取交互信息的爬虫经历)
删除线格式#C#获取动态网页中的数据
在实际工作需求中,编辑的文档需要获取历史地震信息,因此使用计算机语言获取是简化人工操作的必要过程。本文分享我第一次爬虫获取交互信息的经验!
操作流程 我要获取的信息如下图所示。通过填写不同的日期、经纬度、震级等,我可以搜索到想要的结果。
一开始,没有任何线索。查看网页的源代码无法找到搜索结果,所以我们首先要做的就是找到数据的位置。第一步:右键查看元素,点击网络,会出现下图所示的两个文件:
点击第一个文件,看到它的预览有我们想要的信息。Response 收录这部分代码,也就是我们想要的数据:
第二部分:查找URL、请求方法和参数。这部分信息收录在标题中:
第三步:C#编程获取网页,这里直接上代码
// An highlighted block
//url目标地址
string url = "网址";
//要提交的数据
string postString = "DISPLAY_TYPE=1&PAGEID=earthquake_subao&catalog_ALLDATASETS_RECORDCOUNT=catalog__default_default_default_key__default_default_default_key%3D65%3B"
+"&refreshComponentGuid=earthquake_subao_guid_catalog&begtime=2019-09-10&endtime=2019-10-10"
+"&minM=3&maxM=10&minLon=-180.0&maxLon=180.0&minLat=-90.0&maxLat=90.0"
+"&minDepths=0&maxDepths=1000&SEARCHREPORT_ID=catalog&WX_ISAJAXLOAD=true";
//这里即为传递的参数,可以用工具抓包分析,也可以自己分析,主要是form里面每一个name都要加进来
byte[] postData = Encoding.UTF8.GetBytes(postString);//编码,尤其是汉字,事先要看下抓取网页的编码方式
WebClient webClient = new WebClient();
webClient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");//采取POST方式必须加的header,如果改为GET方式的话就去掉这句话即可
byte[] responseData = webClient.UploadData(url, "POST", postData);//得到返回字符流
string srcString = Encoding.UTF8.GetString(responseData);//解码
//解析获取到的网页
HtmlAgilityPack.HtmlDocument History_doc = new HtmlAgilityPack.HtmlDocument();
History_doc.LoadHtml(srcString);
下一步是阅读网页的内容。这是第一次写。感谢您的批评和指正!!!
c 抓取网页数据( 简时尚网站首页面在lynx浏览器下的显示情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-24 07:01
简时尚网站首页面在lynx浏览器下的显示情况)
Google 极力推荐的 lynx 浏览器如何抓取网页内容
以下内容是使用lynx抓取()简时尚电商平台的详细信息,
在谷歌网站索引指南中,强烈推荐站长管理员使用这款lynx文本浏览器浏览网站的页面内容,
这说明谷歌爬虫抓取网页的方法和lynx浏览器很相似,那么就用这个lynx来浏览网页,对于网站
一些优化很有帮助,
以下是健时尚网站首页在lynx浏览器中的展示,
从上面的内容可以分析出lynx是先通过一级标题,然后再爬取二级标题下的内容。
接下来,lynx抓住了颈部,
接下来,我们将来到内容的中间。
嗯,在这个位置上,我想很多人都能理解。lynx文本浏览器抓取网页的方式是什么,大家可以总结一下。
首先从上到下,从左到右,从大标题开始,然后按照标题到小标题抓取页面,
二是无法识别图片内容,只能读取alt标签中的内容。
这些有助于制作符合搜索引擎的标准页面。
再补充一点,lynx是如何识别隐藏链接的,请看下图
此表单被视为隐藏链接,
从lynx文本浏览器抓取网页的情况来看,google极力推荐,可以得出搜索引擎抓取的网页与此类似。
对符合se的网站的建立有很大的参考价值。 查看全部
c 抓取网页数据(
简时尚网站首页面在lynx浏览器下的显示情况)
Google 极力推荐的 lynx 浏览器如何抓取网页内容
以下内容是使用lynx抓取()简时尚电商平台的详细信息,
在谷歌网站索引指南中,强烈推荐站长管理员使用这款lynx文本浏览器浏览网站的页面内容,
这说明谷歌爬虫抓取网页的方法和lynx浏览器很相似,那么就用这个lynx来浏览网页,对于网站
一些优化很有帮助,
以下是健时尚网站首页在lynx浏览器中的展示,
从上面的内容可以分析出lynx是先通过一级标题,然后再爬取二级标题下的内容。
接下来,lynx抓住了颈部,
接下来,我们将来到内容的中间。
嗯,在这个位置上,我想很多人都能理解。lynx文本浏览器抓取网页的方式是什么,大家可以总结一下。
首先从上到下,从左到右,从大标题开始,然后按照标题到小标题抓取页面,
二是无法识别图片内容,只能读取alt标签中的内容。
这些有助于制作符合搜索引擎的标准页面。
再补充一点,lynx是如何识别隐藏链接的,请看下图
此表单被视为隐藏链接,
从lynx文本浏览器抓取网页的情况来看,google极力推荐,可以得出搜索引擎抓取的网页与此类似。
对符合se的网站的建立有很大的参考价值。
c 抓取网页数据(如何用Python爬数据华章社区《Clojure数据分析秘笈》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-24 04:19
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页中抓取数据并将其添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客。
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节从 Web 表中抓取数据
作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第一章,1.8节抓取web表数据。作者(美)Eric Rochester,更多章节可访问查看云栖社区“华章社区”公众号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:03年前
我打算做一个博客园的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下:思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
快速搭建实时爬虫集群
作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
网络数据库挖掘程序设计
作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是由数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
数据库从网页抓取数据,询问相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文 查看全部
c 抓取网页数据(如何用Python爬数据华章社区《Clojure数据分析秘笈》(组图))
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页中抓取数据并将其添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客。
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们来说很有价值的数据。
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节从 Web 表中抓取数据
作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第一章,1.8节抓取web表数据。作者(美)Eric Rochester,更多章节可访问查看云栖社区“华章社区”公众号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。很多评论都是来自读者的提问。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:03年前
我打算做一个博客园的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下:思路是通过编写的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
快速搭建实时爬虫集群
作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫就好了。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
网络数据库挖掘程序设计
作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是由数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
数据库从网页抓取数据,询问相关问答
【Javascript学习全家桶】934道javascript热点题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你困惑只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请数百位阿里巴巴技术
阅读全文
c 抓取网页数据(如何在大数据分析R语言中进行网络抓取的基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-23 03:18
时间:2020年5月26日点击:泰晤士报作者:Sissi
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中查找所需数据来获取待分析数据的技术
在本教程中,我们将介绍如何使用大数据分析R语言进行网络爬网的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在本教程中,我们将主要关注如何使用大数据分析R语言web爬行来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:
尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法在本教程中涵盖所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:
文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:
我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:
将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在本教程中,我们对网页爬行感兴趣,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样
如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在本教程中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它
要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的
大数据分析R语言EAD_uhtml()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们希望将单个标签中收录的文本存储在变量中。要访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常在网站上非常明确地使用CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用HTML_uNodes()和HTML_text()函数来搜索
标记并检索文本。以下代码执行此操作:
这个简单变量已经收录我们想要获取的HTML,所以剩下的任务是搜索所需的元素。因为我们使用tidyve big data来分析R语言se,所以我们可以将HTML传递给不同的函数
我们需要在nodes()函数中将特定的HTML标记或CSS类传递给HTML。我们需要标记,所以我们将字符“P”传递给函数。html_u0;Nodes()还返回一个列表,但它返回html中具有给定特定html标记或CSS类/标识的所有节点。节点是指树结构中的一个点
一旦拥有所有这些节点,就可以在text()函数中将输出传递到HTML_uu节点()到HTML_uu。我们需要获取标签的实际文本,因此此功能可以帮助您解决此问题
这些功能共同构成了许多常见的web爬行任务。一般来说,使用大数据分析R语言(或任何其他语言)的网络爬网可以概括为以下三个步骤:
a。获取要获取的网页的HTML
b。确定pa的哪个部分 查看全部
c 抓取网页数据(如何在大数据分析R语言中进行网络抓取的基础知识)
时间:2020年5月26日点击:泰晤士报作者:Sissi
互联网已经成熟,可以用于自己的个人项目数据集。有时,您很幸运,可以访问API,直接使用大数据分析语言请求数据。有时候,你不会很幸运,也无法从一个整洁的格式中获得。当这种情况发生时,我们需要转向网页爬行,这是一种通过在网站HTML代码中查找所需数据来获取待分析数据的技术
在本教程中,我们将介绍如何使用大数据分析R语言进行网络爬网的基本知识。我们将从国家气象局的天气预报网站中获取数据,并将其转换为可用格式
当我们找不到我们需要的数据时,网络爬网将提供一个机会,并为我们提供实际创建数据集所需的工具。此外,由于我们使用大数据分析R语言进行网页捕获,如果我们使用的网站已更新,我们只需再次运行代码即可获得更新的数据集
理解网页
在开始学习如何抓取网页之前,我们需要了解网页本身的结构
从用户的角度来看,网页以一种美观易读的方式组织文本、图像和链接。但是网页本身是用特定的编码语言编写的,然后由我们的web浏览器进行解释。在对网页进行爬网时,我们需要处理网页本身的实际内容:浏览器解释网页之前的代码
用于构建网页的主要语言有超文本标记语言(HTML)、级联样式表(CSS)和javasc大数据分析语言IPT。HTML提供网页的实际结构和内容。CSS为网页提供样式和外观,包括字体和颜色等细节。Javasc大数据分析语言IPT提供网页功能
在本教程中,我们将主要关注如何使用大数据分析R语言web爬行来读取构成网页的HTML和CSS
HTML
与大数据分析语言不同,html不是一种编程语言。相反,它被称为标记语言——它描述网页的内容和结构。Html使用标记进行组织,标记由符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容
最简单的HTML文档如下所示:
尽管上面是一个合法的HTML文档,但它没有文本或其他内容。如果您将其另存为。HTML文件并用web浏览器打开它,您将看到一个空白页
请注意,html一词用方括号括起来,表示它是一个标记。要在此HTML文档中添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加和标记,为文档添加更多结构
标记是我们用来在HTML中指定段落文本的标记
HTML中有许多标记,但我们无法在本教程中涵盖所有标记。如果您感兴趣,可以查看此网站。最重要的一点是要知道标记具有特定的名称(HTML、body、P等),以便可以在HTML文档中识别它们
请注意,每个标记都是“成对”的,这意味着每个标记都伴随着另一个具有类似名称的标记。也就是说,开始标记与指示HTML文档开始和结束的另一个标记配对。同样
认识到这一点很重要,因为它允许标记彼此嵌套。嵌套在和标记中,并嵌套在中。这种嵌套为HTML提供了一种“树”结构:
当使用大数据分析R语言进行网页捕获时,这种树状结构将告诉我们如何找到一些标记,因此我们必须记住这一点。如果其他标签嵌套在标签中,则收录的标签称为父标签,每个标签称为子标签。如果父母有一个以上的孩子,这些孩子标签统称为“兄弟姐妹”。父母、子女和兄弟姐妹的这些概念让我们了解了标签的层次结构
CSS
HTML提供网页的内容和结构,而CSS提供有关网页样式的信息。没有CSS,网页将变得非常简单。这是一个没有CSS的简单HTML文档,演示如下
当我们说风格时,我们指的是各种各样的东西。样式可以指特定HTML元素的颜色或其位置。与HTML一样,CSS材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果你感兴趣,你可以在这里了解更多
在我们需要学习这两个概念之前,我们将深入了解大数据分析语言的网络抓取代码类和IDs
首先,让我们谈谈课堂。如果我们想创建一个网站,我们通常希望网站的类似元素看起来相同。例如,我们可能希望列表中的许多项目以相同颜色的红色显示
我们可以直接将一些收录颜色信息的CSS插入文本HTML标记的每一行,例如:
文章指出,我们正在尝试应用CSS标记。在引号中,我们看到一个键值对“colo大数据分析R语言:大数据分析R语言ed”。Colo大数据分析R语言指示器记录文本的颜色,红色表示应该是颜色
但是正如我们上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须一行一行地改变每一行
我们不必在所有这些标记中重复此文本,而可以将其替换为类选择器:
我们可以更好地显示这些标记在某种程度上是相关的。在单独的CSS文件中,我们可以创建一个红色文本类,并通过编写以下内容来定义其外观:
将这两个元素组合到一个网页中将具有与第一组红色标记相同的效果,但它使我们更容易进行快速更改
当然,在本教程中,我们对网页爬行感兴趣,而不是构建网页。然而,当我们进行web爬行时,通常需要选择特定类别的HTML标记,因此我们需要了解CSS类的工作原理
类似地,我们可能经常希望获取由ID标识的特定数据。CSS ID用于为单个元素提供可识别的名称,就像类帮助定义元素类一样
如果ID附加到HTML标记上,那么在使用big data analysis R语言执行实际网页捕获时,我们可以更容易地识别标记
如果您对类和ID不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰
有几个大数据分析R语言库设计用于使用HTML和CSS,并能够遍历它们以找到特定的标记。我们将在本教程中使用的库是大数据分析R语言vest
大数据分析R语言库
大数据分析R语言vest库由传奇人物哈德利·威克姆(Hadley Wickham)维护,用户可以轻松地从网页中获取(“收获”)数据
Big data analysis R language vest是tidyve Big data analysis R language se库之一,因此它可以很好地与捆绑包中的其他库配合使用。大数据分析R语言背心的灵感来自python的网络捕获库beautifulsoup。(相关内容:o您美丽的汤Python教程。)
用大数据分析语言抓取网页
为了使用大数据分析R语言vest库,我们首先需要安装它并使用Lib big data analysis R language a big data analysis R language y()函数导入它
要开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了重振雄风,大数据分析R语言ead提供了这个功能HTML()函数
大数据分析R语言EAD_uHTML()接受web u大数据分析R语言L作为参数。让我们从上一个简单的CSS免费页面开始,看看这个函数是如何工作的
简单的
大数据分析R语言EAD_uhtml()函数返回一个收录我们前面讨论过的树结构的列表对象
假设我们希望将单个标签中收录的文本存储在变量中。要访问此文本,我们需要找出如何定位此特定文本。这通常是CSS类和ID可以帮助我们的地方,因为优秀的开发人员通常在网站上非常明确地使用CSS@
在本例中,我们没有这样的CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要分别使用HTML_uNodes()和HTML_text()函数来搜索
标记并检索文本。以下代码执行此操作:
这个简单变量已经收录我们想要获取的HTML,所以剩下的任务是搜索所需的元素。因为我们使用tidyve big data来分析R语言se,所以我们可以将HTML传递给不同的函数
我们需要在nodes()函数中将特定的HTML标记或CSS类传递给HTML。我们需要标记,所以我们将字符“P”传递给函数。html_u0;Nodes()还返回一个列表,但它返回html中具有给定特定html标记或CSS类/标识的所有节点。节点是指树结构中的一个点
一旦拥有所有这些节点,就可以在text()函数中将输出传递到HTML_uu节点()到HTML_uu。我们需要获取标签的实际文本,因此此功能可以帮助您解决此问题
这些功能共同构成了许多常见的web爬行任务。一般来说,使用大数据分析R语言(或任何其他语言)的网络爬网可以概括为以下三个步骤:
a。获取要获取的网页的HTML
b。确定pa的哪个部分
c 抓取网页数据(WebScraperforMac永久激活版是您的不错选择!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-21 21:18
如果您正在寻找易于使用的网站数据捕获工具,websharper for Mac permanent activation是一个不错的选择!有需要的朋友可以下载
websharper mac软件简介
WebRapper for Mac是一个简单的应用程序,用于在Mac平台上将数据导出为JSON或CSV。WebRapper for Mac可以快速提取与网页相关的信息(包括文本内容)。Websharper使您能够以最小的工作量从在线资源中快速提取内容。您可以完全控制将导出到CSV或JSON文件的数据
Websharper mac软件功能
1、scan网站快速方便@
大量的提取选项;各种元数据、内容(如文本、HTML或标记)、具有特定类/ID的元素、正则表达式
2、易于导出-选择所需的列
3、输出为CSV或JSON
4、new选项将所有图像下载到文件夹/采集并导出所有链接
5、输出单个文本文件的新选项(用于归档文本内容、降价或纯文本)
6、rich选项/配置
websharper mac软件功能介绍
1、从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,用于导航站点并提取数据。使用不同的类型选择器,web scraper将导航站点并提取多种类型的数据-文本、表格、图像、链接等
2、专为现代网络设计
与其他仅从HTML web提取数据的抓取工具不同,scraper还可以提取使用JavaScript动态加载或生成的数据。Web scraper可以:-等待在页面中加载动态数据-单击分页按钮通过Ajax加载数据-单击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或将其存储在CouchDB中
Web scraper是一个独立的Chrome扩展。站点地图的构建、数据提取和导出都在浏览器中完成。捕获网站后,您可以下载CSV格式的数据。对于高级用例,您可能希望尝试将数据保存到CouchDB 查看全部
c 抓取网页数据(WebScraperforMac永久激活版是您的不错选择!)
如果您正在寻找易于使用的网站数据捕获工具,websharper for Mac permanent activation是一个不错的选择!有需要的朋友可以下载
websharper mac软件简介
WebRapper for Mac是一个简单的应用程序,用于在Mac平台上将数据导出为JSON或CSV。WebRapper for Mac可以快速提取与网页相关的信息(包括文本内容)。Websharper使您能够以最小的工作量从在线资源中快速提取内容。您可以完全控制将导出到CSV或JSON文件的数据
Websharper mac软件功能
1、scan网站快速方便@
大量的提取选项;各种元数据、内容(如文本、HTML或标记)、具有特定类/ID的元素、正则表达式
2、易于导出-选择所需的列
3、输出为CSV或JSON
4、new选项将所有图像下载到文件夹/采集并导出所有链接
5、输出单个文本文件的新选项(用于归档文本内容、降价或纯文本)
6、rich选项/配置
websharper mac软件功能介绍
1、从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,用于导航站点并提取数据。使用不同的类型选择器,web scraper将导航站点并提取多种类型的数据-文本、表格、图像、链接等
2、专为现代网络设计
与其他仅从HTML web提取数据的抓取工具不同,scraper还可以提取使用JavaScript动态加载或生成的数据。Web scraper可以:-等待在页面中加载动态数据-单击分页按钮通过Ajax加载数据-单击按钮加载更多数据-向下滚动页面加载更多数据
3、以CSV格式导出数据或将其存储在CouchDB中
Web scraper是一个独立的Chrome扩展。站点地图的构建、数据提取和导出都在浏览器中完成。捕获网站后,您可以下载CSV格式的数据。对于高级用例,您可能希望尝试将数据保存到CouchDB
c 抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-15 12:19
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
‘ MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
在VB中获取网页数据
原文: 查看全部
c 抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据)
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
‘ MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
在VB中获取网页数据
原文:
c 抓取网页数据( 获取页面的数据方法有很多,这里说的是里面最蠢的一个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-09-13 03:01
获取页面的数据方法有很多,这里说的是里面最蠢的一个方法)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
开发工具与关键技术:VS与MVC js
作者:陈锦通
撰写时间:2019年6月4日星期二
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
获取页面数据的方式有很多种。我说的是其中最笨的方法(这个方法是我想了很久,反复尝试成功了)。
首先是 HTML 代码:
55
66
88
77
上面的 HTML 代码表示使用 from 表单提交,其中收录四个 input 标签。
注意:id必须唯一,名称尽量唯一。因为我说的方法是,如果name属性不是唯一的,那么在传输到数据库的时候就会少一个数据。
以上HTML代码效果如下图
样式有点简单,按钮有点小。
以下是js代码:
function sss() {
var A = $("#AppointmentNumber1").val();
var B = $("#AppointmentNumber2").val();
var C = $("#AppointmentNumber3").val();
var D = $("#AppointmentNumber4").val();
if (A != "" && A != null && B != "" && B != null && C != "" && C != null && D != "" && D != null) {
//第一个A是控制器接收的,第二个A是上面声明的
$.post("/one/bubu", { a: A, b: B, c: C, d: D }, function (ABC) {
if (ABC.State = true) {
alert(ABC.Text);
}
else {
alert(ABC.Text);
}
});
}
else {
alert("请把数据填写完整");
}
}
代码中的var声明了上面输入标签中获取数据的jQ代码(要使用jq代码时必须引用jq文件,否则会报错)获取输入的数据页面输入标签通过 val() ,然后赋值给声明的变量。然后判断声明的变量是否有值和没有值,并提示“请填写数据”提醒您将数据填写完整。
如果有数据,将数据提交给控制器。然后控制器返回ABC,然后判断控制器传递过来的状态值是true还是false,然后做出不同的提示。 (我这样命名并不标准,我这样命名只是为了便于理解)
//新增
public ActionResult bubu(FormCollection form)
{
s1 mod = new s1();
s2 mod1 = new s2();
ReturnJson ABC = new ReturnJson();
var a = form["a"];
var b = form["b"];
var c = form["c"];
var d = form["d"];
//判断传过来的数据是否为空
if (!string.IsNullOrEmpty(a) && !string.IsNullOrEmpty(b) && !string.IsNullOrEmpty(c) && !string.IsNullOrEmpty(d))
{
mod.one = a;
mod.twe = b;
mod1.s2name = c;
mod1.s2uou = d;
ABC.State = true;
ABC.Text = "新增成功";
//核心代码
my.s1.Add(mod);
my.s2.Add(mod1);
my.SaveChanges();
}
else
{
ABC.State = false;
ABC.Text = "数据不完整";
}
return Json(ABC, JsonRequestBehavior.AllowGet);
}
(my是实例化的数据库名,s1和s2是数据库中的表)
上面是控制器中的代码,意思是页面上jQ代码传递过来的值,通过Form采集表单接收,然后赋值给新声明的变量。为什么要声明要接收的新变量?因为Form采集接收到的数据不能直接使用,所以声明了变量来接收传入的值。然后判断传入的数据是否为空,然后保存到数据库中。我声明mod代表数据库的表来接收数据并保存。最后用核心代码保存到数据库中得到的数据,通过App方法修改你要保存的数据,然后通过Save Changes()方法保存到数据库中。最后,数据成功保存到数据库中。效果如下数据库图:
这是成功保存的数据。
(文章中声明的变量没有标准化,只是为了更好的理解) 查看全部
c 抓取网页数据(
获取页面的数据方法有很多,这里说的是里面最蠢的一个方法)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
开发工具与关键技术:VS与MVC js
作者:陈锦通
撰写时间:2019年6月4日星期二
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
获取页面数据的方式有很多种。我说的是其中最笨的方法(这个方法是我想了很久,反复尝试成功了)。
首先是 HTML 代码:
55
66
88
77
上面的 HTML 代码表示使用 from 表单提交,其中收录四个 input 标签。
注意:id必须唯一,名称尽量唯一。因为我说的方法是,如果name属性不是唯一的,那么在传输到数据库的时候就会少一个数据。
以上HTML代码效果如下图
样式有点简单,按钮有点小。
以下是js代码:
function sss() {
var A = $("#AppointmentNumber1").val();
var B = $("#AppointmentNumber2").val();
var C = $("#AppointmentNumber3").val();
var D = $("#AppointmentNumber4").val();
if (A != "" && A != null && B != "" && B != null && C != "" && C != null && D != "" && D != null) {
//第一个A是控制器接收的,第二个A是上面声明的
$.post("/one/bubu", { a: A, b: B, c: C, d: D }, function (ABC) {
if (ABC.State = true) {
alert(ABC.Text);
}
else {
alert(ABC.Text);
}
});
}
else {
alert("请把数据填写完整");
}
}
代码中的var声明了上面输入标签中获取数据的jQ代码(要使用jq代码时必须引用jq文件,否则会报错)获取输入的数据页面输入标签通过 val() ,然后赋值给声明的变量。然后判断声明的变量是否有值和没有值,并提示“请填写数据”提醒您将数据填写完整。
如果有数据,将数据提交给控制器。然后控制器返回ABC,然后判断控制器传递过来的状态值是true还是false,然后做出不同的提示。 (我这样命名并不标准,我这样命名只是为了便于理解)
//新增
public ActionResult bubu(FormCollection form)
{
s1 mod = new s1();
s2 mod1 = new s2();
ReturnJson ABC = new ReturnJson();
var a = form["a"];
var b = form["b"];
var c = form["c"];
var d = form["d"];
//判断传过来的数据是否为空
if (!string.IsNullOrEmpty(a) && !string.IsNullOrEmpty(b) && !string.IsNullOrEmpty(c) && !string.IsNullOrEmpty(d))
{
mod.one = a;
mod.twe = b;
mod1.s2name = c;
mod1.s2uou = d;
ABC.State = true;
ABC.Text = "新增成功";
//核心代码
my.s1.Add(mod);
my.s2.Add(mod1);
my.SaveChanges();
}
else
{
ABC.State = false;
ABC.Text = "数据不完整";
}
return Json(ABC, JsonRequestBehavior.AllowGet);
}
(my是实例化的数据库名,s1和s2是数据库中的表)
上面是控制器中的代码,意思是页面上jQ代码传递过来的值,通过Form采集表单接收,然后赋值给新声明的变量。为什么要声明要接收的新变量?因为Form采集接收到的数据不能直接使用,所以声明了变量来接收传入的值。然后判断传入的数据是否为空,然后保存到数据库中。我声明mod代表数据库的表来接收数据并保存。最后用核心代码保存到数据库中得到的数据,通过App方法修改你要保存的数据,然后通过Save Changes()方法保存到数据库中。最后,数据成功保存到数据库中。效果如下数据库图:
这是成功保存的数据。
(文章中声明的变量没有标准化,只是为了更好的理解)

