
网页爬虫抓取百度图片
网页爬虫抓取百度图片(网站快速被蜘蛛方法网站及页面权重具权威性、权威性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-28 00:17
1.关键词 是重中之重
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。因此,关键词是SEO优化的核心。
2.外链也会影响权重
外链是SEO优化的过程之一,其作用是间接影响网站的权重。常用的链接有:锚文本链接、纯文本链接和图片链接。
3.如何被爬虫爬取?
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。比如百度的蜘蛛在抓取网页时需要定义网页,对网页数据进行过滤和分析。
对于页面来说,爬取是收录的前提,越爬越多收录。如果网站页面更新频繁,爬虫会频繁访问该页面,优质内容,尤其是原创,是爬虫喜欢爬取的目标。
网站快被蜘蛛爬到
1.网站 和页面权重
权威高权重老网站享受VIP级待遇。这类网站爬取频率高,爬取页面多,爬取深度高,收录页面相对较多,就是这样的区别对待。
2.网站服务器
网站服务器是访问网站的基石。如果长时间打不开门,就相当于敲了很久的门。如果没有人回应,访客会因为无法进入而陆续离开。蜘蛛访问也是访客之一。如果服务器不稳定,蜘蛛每次抓取页面都会受到阻碍,蜘蛛对网站的印象会越来越差,导致评分越来越低,自然排名也越来越低。
3.网站的更新频率
网站内容更新频繁,会更频繁地吸引蜘蛛访问。定期更新文章,蜘蛛会定期访问。每次爬虫爬取时,页面数据都存入库中,分析后收录页面。如果每次爬虫都发现收录的内容完全一样,爬虫就会判断网站,从而减少网站的爬取。
原创 4.文章 的性别
蜘蛛存在的根本目的是寻找有价值的“新”事物,所以原创的优质内容对蜘蛛的吸引力是巨大的。如果你能得到蜘蛛之类的东西,你自然会把网站标记为“优秀”,并定期爬取网站。
5.展平网站结构
蜘蛛爬行有自己的规则。如果藏得太深,蜘蛛就找不到路了。爬虫程序是个直截了当的东西,所以网站结构不要太复杂。
6.网站节目
在网站的构建中,程序会产生大量的页面。页面一般是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成内容大量重复,影响蜘蛛抓取。如果一个页面对应多个 URL,尝试通过 301 重定向、Canonical 标签或机器人进行处理,以确保蜘蛛只抓取一个标准 URL。
7.外链搭建
对于新站来说,在建设初期,人流量比较少,蜘蛛的光顾也比较少。外链可以增加网站页面的曝光率,增加蜘蛛的爬取,但是要注意外链的质量。
8.内链构造 查看全部
网页爬虫抓取百度图片(网站快速被蜘蛛方法网站及页面权重具权威性、权威性)
1.关键词 是重中之重
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。因此,关键词是SEO优化的核心。
2.外链也会影响权重
外链是SEO优化的过程之一,其作用是间接影响网站的权重。常用的链接有:锚文本链接、纯文本链接和图片链接。
3.如何被爬虫爬取?
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。比如百度的蜘蛛在抓取网页时需要定义网页,对网页数据进行过滤和分析。
对于页面来说,爬取是收录的前提,越爬越多收录。如果网站页面更新频繁,爬虫会频繁访问该页面,优质内容,尤其是原创,是爬虫喜欢爬取的目标。
网站快被蜘蛛爬到
1.网站 和页面权重
权威高权重老网站享受VIP级待遇。这类网站爬取频率高,爬取页面多,爬取深度高,收录页面相对较多,就是这样的区别对待。
2.网站服务器
网站服务器是访问网站的基石。如果长时间打不开门,就相当于敲了很久的门。如果没有人回应,访客会因为无法进入而陆续离开。蜘蛛访问也是访客之一。如果服务器不稳定,蜘蛛每次抓取页面都会受到阻碍,蜘蛛对网站的印象会越来越差,导致评分越来越低,自然排名也越来越低。
3.网站的更新频率
网站内容更新频繁,会更频繁地吸引蜘蛛访问。定期更新文章,蜘蛛会定期访问。每次爬虫爬取时,页面数据都存入库中,分析后收录页面。如果每次爬虫都发现收录的内容完全一样,爬虫就会判断网站,从而减少网站的爬取。
原创 4.文章 的性别
蜘蛛存在的根本目的是寻找有价值的“新”事物,所以原创的优质内容对蜘蛛的吸引力是巨大的。如果你能得到蜘蛛之类的东西,你自然会把网站标记为“优秀”,并定期爬取网站。
5.展平网站结构
蜘蛛爬行有自己的规则。如果藏得太深,蜘蛛就找不到路了。爬虫程序是个直截了当的东西,所以网站结构不要太复杂。
6.网站节目
在网站的构建中,程序会产生大量的页面。页面一般是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成内容大量重复,影响蜘蛛抓取。如果一个页面对应多个 URL,尝试通过 301 重定向、Canonical 标签或机器人进行处理,以确保蜘蛛只抓取一个标准 URL。
7.外链搭建
对于新站来说,在建设初期,人流量比较少,蜘蛛的光顾也比较少。外链可以增加网站页面的曝光率,增加蜘蛛的爬取,但是要注意外链的质量。
8.内链构造
网页爬虫抓取百度图片(西安网站多少钱,推荐阅读(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-28 00:17
我所在的网站是一个很大的网站,百度收录3000万,百度爬取总次数约为每天500w次,百度收录单页率80%,看起来是个不错的数据,但是如果分析详细的日志文件,还是可以发现一些问题,
1.大规模网站列表页面通常会设置多个过滤条件(Facet Navigation),以方便用户找到需要的信息,但爬虫还不够智能,无法独立判断哪些条件可以组合和哪些条件 把它们结合起来是没有意义的。只要代码中有链接,就会被爬取,导致百度爬虫在列表过滤页面上耗费大量资源。分析1个月的数据发现百度30%的爬取量消耗在列表页上,但列表页带来的百度自然流量只占百度所有自然流量的2%,所以< @网站 也就是说,爬虫的输入输出很低。西安网站多少钱,推荐阅读>>
2.重复爬取现象严重。我个人认为对于网站来说,爬虫只爬过一次(Distinct Crawl)的页面是最有价值的,因为对于内容质量好的页面,只要爬过一次, 收录 几率超过 80%。如果页面本身质量不好,就算爬了几十次,也不会是收录。继续分析我们的网站的数据,我们发现百度爬虫每天500万次的爬取中,有一半以上是同一页面的多次爬取。如果这些重复爬取能够转移到那些一次性爬取的页面上,对于网站来说无疑更有价值。网站制作公司西安,做网站
如何解决这两个问题?
让我们谈谈第一个。对于过滤页面消耗爬虫资源的问题,很多人建议使用nofollow标签告诉爬虫不要继续给这些页面分配权重,我们已经这样做了。然而,事实证明,百度爬虫对nofollow并不敏感。使用后,爬虫依然在疯狂爬行,同时也没有将权重从筛选页面转移到规范页面。
无奈之下,我们不得不考虑使用 SEO 的大杀手:Robots 文件来禁止所有被过滤的页面。我们之前之所以没有使用robots禁止爬取,是担心如果爬虫被禁止爬取列表,是否会被禁止爬虫爬取列表。其他页面也爬不上去?毕竟列表过滤页还是会为单页贡献很多条目,但是基于我们的网站单页收录还不错的现状,我们决定试一试. 西安网站施工推荐读物>>>智能使用机器人避开蜘蛛黑洞-百度站长平台资讯,
事实证明,效果非常明显。新版robots上线三天后,列表页爬虫的爬取量已经下降到15%;同时,之前令人担忧的问题也没有出现。大约在同一时间,单个页面的爬取量也增加了 20%,这算是达到了我们预期的目标:将浪费在列表页面上的爬虫资源转移到其他需要爬取的页面上。
但是如何证明爬取的资源被转移到了需要爬取的页面上,这恰好是前面提到的第二个问题,我们看的是唯一爬取率(只爬取一次的页面数/总数爬取率)从 50% 提高到 74%,这意味着爬虫在读取 robots 文件后,对爬虫资源进行了更合理的分配,爬取的单页也更多。西安做网站推荐阅读>>>带你玩转机器人协议,新手必玩,
总结:相对于其他方法,Robots文件可以在比较短的时间内优化百度爬虫的资源分配,但这必须基于网站本身结构好,传递内容。同时,最重要的是要通过对实际情况的日志分析,反复测试和调整以达到最佳效果。来自百度站长社区 查看全部
网页爬虫抓取百度图片(西安网站多少钱,推荐阅读(组图))
我所在的网站是一个很大的网站,百度收录3000万,百度爬取总次数约为每天500w次,百度收录单页率80%,看起来是个不错的数据,但是如果分析详细的日志文件,还是可以发现一些问题,
1.大规模网站列表页面通常会设置多个过滤条件(Facet Navigation),以方便用户找到需要的信息,但爬虫还不够智能,无法独立判断哪些条件可以组合和哪些条件 把它们结合起来是没有意义的。只要代码中有链接,就会被爬取,导致百度爬虫在列表过滤页面上耗费大量资源。分析1个月的数据发现百度30%的爬取量消耗在列表页上,但列表页带来的百度自然流量只占百度所有自然流量的2%,所以< @网站 也就是说,爬虫的输入输出很低。西安网站多少钱,推荐阅读>>
2.重复爬取现象严重。我个人认为对于网站来说,爬虫只爬过一次(Distinct Crawl)的页面是最有价值的,因为对于内容质量好的页面,只要爬过一次, 收录 几率超过 80%。如果页面本身质量不好,就算爬了几十次,也不会是收录。继续分析我们的网站的数据,我们发现百度爬虫每天500万次的爬取中,有一半以上是同一页面的多次爬取。如果这些重复爬取能够转移到那些一次性爬取的页面上,对于网站来说无疑更有价值。网站制作公司西安,做网站
如何解决这两个问题?
让我们谈谈第一个。对于过滤页面消耗爬虫资源的问题,很多人建议使用nofollow标签告诉爬虫不要继续给这些页面分配权重,我们已经这样做了。然而,事实证明,百度爬虫对nofollow并不敏感。使用后,爬虫依然在疯狂爬行,同时也没有将权重从筛选页面转移到规范页面。
无奈之下,我们不得不考虑使用 SEO 的大杀手:Robots 文件来禁止所有被过滤的页面。我们之前之所以没有使用robots禁止爬取,是担心如果爬虫被禁止爬取列表,是否会被禁止爬虫爬取列表。其他页面也爬不上去?毕竟列表过滤页还是会为单页贡献很多条目,但是基于我们的网站单页收录还不错的现状,我们决定试一试. 西安网站施工推荐读物>>>智能使用机器人避开蜘蛛黑洞-百度站长平台资讯,
事实证明,效果非常明显。新版robots上线三天后,列表页爬虫的爬取量已经下降到15%;同时,之前令人担忧的问题也没有出现。大约在同一时间,单个页面的爬取量也增加了 20%,这算是达到了我们预期的目标:将浪费在列表页面上的爬虫资源转移到其他需要爬取的页面上。
但是如何证明爬取的资源被转移到了需要爬取的页面上,这恰好是前面提到的第二个问题,我们看的是唯一爬取率(只爬取一次的页面数/总数爬取率)从 50% 提高到 74%,这意味着爬虫在读取 robots 文件后,对爬虫资源进行了更合理的分配,爬取的单页也更多。西安做网站推荐阅读>>>带你玩转机器人协议,新手必玩,
总结:相对于其他方法,Robots文件可以在比较短的时间内优化百度爬虫的资源分配,但这必须基于网站本身结构好,传递内容。同时,最重要的是要通过对实际情况的日志分析,反复测试和调整以达到最佳效果。来自百度站长社区
网页爬虫抓取百度图片(网站如何快速被百度蜘蛛快速和抓取方法蜘蛛抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-28 00:14
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就为大家介绍一下网站如何让百度蜘蛛快速爬取及爬取方法。
网站如何被爬虫快速抓取1、关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO优化的核心,也是网站在搜索引擎中排名的重要因素。
2、外部链接也会影响权重
网站入站链接也是优化网站的一个非常重要的过程,而外部链接可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3、如何被爬虫爬取
爬虫和蜘蛛其实是同一个东西,只是名字不同而已。是一个自动提取网页的程序,比如百度蜘蛛、360蜘蛛、搜狗蜘蛛等。如果你想让你的网站中的页面多为收录,收录中的网页@网站 必须先被蜘蛛爬行。
如果你的网站页面更新频繁,爬虫会更频繁地访问你的页面,优质的内容页面是蜘蛛喜欢爬取的目标,尤其是原创内容。 查看全部
网页爬虫抓取百度图片(网站如何快速被百度蜘蛛快速和抓取方法蜘蛛抓取)
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。

可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就为大家介绍一下网站如何让百度蜘蛛快速爬取及爬取方法。
网站如何被爬虫快速抓取1、关键词是重中之重

我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO优化的核心,也是网站在搜索引擎中排名的重要因素。
2、外部链接也会影响权重
网站入站链接也是优化网站的一个非常重要的过程,而外部链接可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3、如何被爬虫爬取
爬虫和蜘蛛其实是同一个东西,只是名字不同而已。是一个自动提取网页的程序,比如百度蜘蛛、360蜘蛛、搜狗蜘蛛等。如果你想让你的网站中的页面多为收录,收录中的网页@网站 必须先被蜘蛛爬行。
如果你的网站页面更新频繁,爬虫会更频繁地访问你的页面,优质的内容页面是蜘蛛喜欢爬取的目标,尤其是原创内容。
网页爬虫抓取百度图片(2021-10-20认识爬虫网络爬虫(又称为网页蜘蛛))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-27 06:05
2021-10-20 认识爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫也分为“好爬虫”和“恶意爬虫”,比如谷歌、百度等,每天都有大量的网站,满足用户的需求,这既是用户又是网站非常喜欢,所以被称为善良的爬虫,但像一些“抢票软件”和“非VIP下载”,有时不仅会增加网站的压力,还会导致一些资源隐私泄露,所以我们也称之为“恶意爬虫”。
简单地说,爬虫是一个模拟人类请求网站的行为的程序。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
项目效益
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。所以现在最常见的就是用Python写爬虫,我们可以爬取图片、视频、文字。大数据背后,我们称之为“数据挖掘”,做数据分析,没有数据怎么行。
应用范围广,优势突出。今年疫情的背后,我们依靠大数据的力量进行数据挖掘和清洗,保障了很多人的生命安全。通过大数据,可以跟踪查询人员的行踪,从海量的人员数据中提取有价值的东西。这就是爬行动物的高级用途。
基本思想
发送请求 - 获取页面 - 解析页面 - 存储有价值的信息
每一步都需要扎实的语法基础和使用爬虫库的概念。我们知道如何理解其他代码,知道如何改进别人的缺点,以及如何移植代码来执行我们自己的一些操作。
二是学习阅读第三方库的一些语法,知道如何安装第三方库非常重要。
写好爬虫项目,作为初学者,是非常困难的。一定要读很多别人的优质代码,爬虫项目,懂得改进和优化。这是我们学习的最终目的。当然,在这之前一定要学习一些知识点,不然看不懂代码,怎么优化,哈哈哈哈!
履带技术步骤
爬虫
网络爬虫是自动访问网页的脚本或机器人,它的作用是从网页中抓取原创数据——最终用户在屏幕上看到的各种元素(字符、图片)。它的工作方式就像一个机器人,在网页上带有 ctrl+a(全选)、ctrl+c(复制内容)、ctrl+v(粘贴内容)按钮(当然本质上没那么简单)。
通常,爬虫不会停留在网页上,而是会根据某些预定逻辑在停止之前爬取一系列 URL。例如,它可能会跟踪它找到的每个链接,然后抓取该 网站。当然,在这个过程中,你需要优先考虑你抓取的 网站 的数量,以及你可以为任务投入的资源数量(存储、处理、带宽等)。
解析
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以轻松访问它们并用于其他操作。要将网页转换为对研究或分析真正有用的数据,我们需要以一种使数据易于搜索、排序和基于定义的参数集提供服务的方式对其进行解析。
存储和检索
最后,在获得所需的数据并分解成有用的组件后,有一种可扩展的方法将所有提取和解析的数据存储在数据库或集群中,然后创建一个数据库或集群,让用户能够及时找到相关的数据集方式或提取的特征。
爬行动物是做什么的
1、网络数据采集
使用爬虫自动采集互联网上的信息(图片、文字、链接等),返回后采集进行相应的存储和处理。并根据一定的规则和筛选标准,将数据分类成一个数据库文件的形成过程。但是在这个过程中,你首先需要明确采集你想要什么信息。当你足够准确地采集采集的条件时,采集的内容会更接近你想要的。
2、大数据分析
在大数据时代,要进行数据分析,首先要有数据源,而其他很多数据源都可以通过爬虫技术获取。在进行大数据分析或数据挖掘时,数据源可以从一些提供数据统计的网站中获取,也可以从某些文献或内部数据中获取,但从这些获取数据的方式有时很难满足我们的需求为数据。这时,我们可以利用爬虫技术从互联网上自动获取所需的数据内容,并将这些数据内容作为数据源,进行更深层次的数据分析。
3、网页分析
通过爬取网页数据采集,在获取网站流量、客户登陆页面、网页关键词权重等基础数据的情况下,分析网页数据,找到出访问者访问网站的规律和特点,并将这些规律与网络营销策略相结合,从而发现当前网络营销活动和运营中可能存在的问题和机会,为进一步修正或重新提供依据-制定战略
建议
学习爬虫前的技术准备
Python基础语法:基础语法、运算符、数据类型、过程控制、函数、对象模块、文件操作、多线程、网络编程等。
W3C 标准:HTML、CSS、JavaScript、Xpath、JSON 查看全部
网页爬虫抓取百度图片(2021-10-20认识爬虫网络爬虫(又称为网页蜘蛛))
2021-10-20 认识爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫也分为“好爬虫”和“恶意爬虫”,比如谷歌、百度等,每天都有大量的网站,满足用户的需求,这既是用户又是网站非常喜欢,所以被称为善良的爬虫,但像一些“抢票软件”和“非VIP下载”,有时不仅会增加网站的压力,还会导致一些资源隐私泄露,所以我们也称之为“恶意爬虫”。
简单地说,爬虫是一个模拟人类请求网站的行为的程序。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
项目效益
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。所以现在最常见的就是用Python写爬虫,我们可以爬取图片、视频、文字。大数据背后,我们称之为“数据挖掘”,做数据分析,没有数据怎么行。
应用范围广,优势突出。今年疫情的背后,我们依靠大数据的力量进行数据挖掘和清洗,保障了很多人的生命安全。通过大数据,可以跟踪查询人员的行踪,从海量的人员数据中提取有价值的东西。这就是爬行动物的高级用途。
基本思想
发送请求 - 获取页面 - 解析页面 - 存储有价值的信息
每一步都需要扎实的语法基础和使用爬虫库的概念。我们知道如何理解其他代码,知道如何改进别人的缺点,以及如何移植代码来执行我们自己的一些操作。
二是学习阅读第三方库的一些语法,知道如何安装第三方库非常重要。
写好爬虫项目,作为初学者,是非常困难的。一定要读很多别人的优质代码,爬虫项目,懂得改进和优化。这是我们学习的最终目的。当然,在这之前一定要学习一些知识点,不然看不懂代码,怎么优化,哈哈哈哈!
履带技术步骤
爬虫
网络爬虫是自动访问网页的脚本或机器人,它的作用是从网页中抓取原创数据——最终用户在屏幕上看到的各种元素(字符、图片)。它的工作方式就像一个机器人,在网页上带有 ctrl+a(全选)、ctrl+c(复制内容)、ctrl+v(粘贴内容)按钮(当然本质上没那么简单)。
通常,爬虫不会停留在网页上,而是会根据某些预定逻辑在停止之前爬取一系列 URL。例如,它可能会跟踪它找到的每个链接,然后抓取该 网站。当然,在这个过程中,你需要优先考虑你抓取的 网站 的数量,以及你可以为任务投入的资源数量(存储、处理、带宽等)。
解析
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以轻松访问它们并用于其他操作。要将网页转换为对研究或分析真正有用的数据,我们需要以一种使数据易于搜索、排序和基于定义的参数集提供服务的方式对其进行解析。
存储和检索
最后,在获得所需的数据并分解成有用的组件后,有一种可扩展的方法将所有提取和解析的数据存储在数据库或集群中,然后创建一个数据库或集群,让用户能够及时找到相关的数据集方式或提取的特征。
爬行动物是做什么的
1、网络数据采集
使用爬虫自动采集互联网上的信息(图片、文字、链接等),返回后采集进行相应的存储和处理。并根据一定的规则和筛选标准,将数据分类成一个数据库文件的形成过程。但是在这个过程中,你首先需要明确采集你想要什么信息。当你足够准确地采集采集的条件时,采集的内容会更接近你想要的。
2、大数据分析
在大数据时代,要进行数据分析,首先要有数据源,而其他很多数据源都可以通过爬虫技术获取。在进行大数据分析或数据挖掘时,数据源可以从一些提供数据统计的网站中获取,也可以从某些文献或内部数据中获取,但从这些获取数据的方式有时很难满足我们的需求为数据。这时,我们可以利用爬虫技术从互联网上自动获取所需的数据内容,并将这些数据内容作为数据源,进行更深层次的数据分析。
3、网页分析
通过爬取网页数据采集,在获取网站流量、客户登陆页面、网页关键词权重等基础数据的情况下,分析网页数据,找到出访问者访问网站的规律和特点,并将这些规律与网络营销策略相结合,从而发现当前网络营销活动和运营中可能存在的问题和机会,为进一步修正或重新提供依据-制定战略
建议
学习爬虫前的技术准备
Python基础语法:基础语法、运算符、数据类型、过程控制、函数、对象模块、文件操作、多线程、网络编程等。
W3C 标准:HTML、CSS、JavaScript、Xpath、JSON
网页爬虫抓取百度图片(现阶段深度学习有关的安装对应版本介绍参考网站如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-26 02:08
2022-01-07
我正忙着找工作,现阶段我在同一个家庭。诚然,同事都是老板,我讲解了很多关于深度学习的知识。不过,我是菜鸟,因为公司的人工智能工作需要更多的图片。而我目前只知道爬虫,所以现阶段由公司的爬虫负责抓图。当然,百度图片很好抓。我还写了一个很好的代码来捕获。如有需要,您可以留言。作者在这里提供了完整的代码,这里就不分享百度图片的截图了。谷歌图片爬虫的作者还是想在这里分享一下,因为毕竟我花了一点时间才做出来的。
之所以要分享源码,是因为我发现网上关于爬取谷歌图片的介绍很少,而且有一个分享代码是加密收费mmp的。不要在意它是否有点低。废话不多说,直接说代码吧。
准备一:
对应版本的Chromedriver安装请参考网站如下:
https://blog.csdn.net/yoyocat9 ... 80066 # 参考版本【转载yoyocat915】
http://chromedriver.storage.go ... .html # 对应版本下载
因为我之前的工作中没有硒,所以我今天才用它
2. 准备2:
上网准备,如果贵公司有,就不用买了。不想科学上网的可以去这个网站买一波广告。
https://e.2333.tn/ #购买的过程在这里就不介绍了
购买后调试。在这里,笔者被公司外网坑了不少。他直接提议在那儿坑,免得你被坑。
第一步:先调试成全局模式,否则只有谷歌可以访问外网,所以不能用其他浏览器访问外网(个人理解)
第 2 步:检查您使用的端口
ok 到这里几步就可以开始编码了,接下来分析下如何使用selenium+chrome进行抓图。共享代码如下。如果你对selenium的使用不是很熟练,基础教程就不在这里分享了,因为我也在学习过程中。代码流共享如下:
在此之前先介绍一下图片存储的用法:
urllib.request.urlretrieve(图片的路径.jpg结尾\图片的base64编码,‘储存的位置)
可以参考博客:https://blog.csdn.net/wuguangb ... 80058
好的初始代码版本 1.0
import os
import time
import urllib
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window()
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url: #仅仅就第一页可以,其他误判这个代码不是完整的是作者的错代码。
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
这里遇到的坑如下:
截图一:
前20张图片的src显示的是base64编码,所以可以直接用上面的代码解决,但是你后面的图片的src是什么?如下所示
这里既不是 base64 也不是 .jpg。我如何在这里保存它?你用
self.browser.get(图片的地址)
img_source = self.browser.page_source
继续经历这个?如果你这样想,那你就错了,因为我们还是拿到了完整的页面,那么这个时候我们该怎么办呢?想到我们最初使用requests来请求图片地址,这时候作者就简单的尝试着拿出一个单独的图片src去请求,不加代理就错了。因此,添加代理会导致以下结果:
import time
import requests
proxy = {"https": "https://127.0.0.1:8787"} //端口作者在前边的坑已经介绍了需要外网的端口
response = requests.get(
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTwwkW09Hrnq5DOzSYAKqrxv3uGjbQzoCRP28AOF03pzJ2uFObS',
proxies=proxy, verify=False)
with open('./image%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
结果就是想要的结果
那么你知道如何修改上面的代码吗?哈哈哈可能有点乱
修改代码如下:
import os
import time
import urllib
import requests
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.proxy = {"https": "https://127.0.0.1:8787"} #初始化代理
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window() #最大的适应屏幕
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url:
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
else: #在这里添加一个不久行了吗?如果图片的链接不是base64的
response = requests.get(each_url,proxies=self.proxy, verify=False)
with open('D:\GoogleImgDownLoad\%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
以上就是分享的结束。当然,直接使用requests模块+代理更方便。百度的爬虫这里就不分享了。如果你想联系源代码的作者,我会分享给你。当然,美中不足的是,这里不需要对图片进行去重,非常简单。不知道你有没有什么想法。无论如何,作者在这里有想法。已经是深夜了,我们睡个午觉吧。
分类:
技术要点:
相关文章: 查看全部
网页爬虫抓取百度图片(现阶段深度学习有关的安装对应版本介绍参考网站如下)
2022-01-07
我正忙着找工作,现阶段我在同一个家庭。诚然,同事都是老板,我讲解了很多关于深度学习的知识。不过,我是菜鸟,因为公司的人工智能工作需要更多的图片。而我目前只知道爬虫,所以现阶段由公司的爬虫负责抓图。当然,百度图片很好抓。我还写了一个很好的代码来捕获。如有需要,您可以留言。作者在这里提供了完整的代码,这里就不分享百度图片的截图了。谷歌图片爬虫的作者还是想在这里分享一下,因为毕竟我花了一点时间才做出来的。
之所以要分享源码,是因为我发现网上关于爬取谷歌图片的介绍很少,而且有一个分享代码是加密收费mmp的。不要在意它是否有点低。废话不多说,直接说代码吧。
准备一:
对应版本的Chromedriver安装请参考网站如下:
https://blog.csdn.net/yoyocat9 ... 80066 # 参考版本【转载yoyocat915】
http://chromedriver.storage.go ... .html # 对应版本下载
因为我之前的工作中没有硒,所以我今天才用它
2. 准备2:
上网准备,如果贵公司有,就不用买了。不想科学上网的可以去这个网站买一波广告。
https://e.2333.tn/ #购买的过程在这里就不介绍了
购买后调试。在这里,笔者被公司外网坑了不少。他直接提议在那儿坑,免得你被坑。
第一步:先调试成全局模式,否则只有谷歌可以访问外网,所以不能用其他浏览器访问外网(个人理解)
第 2 步:检查您使用的端口
ok 到这里几步就可以开始编码了,接下来分析下如何使用selenium+chrome进行抓图。共享代码如下。如果你对selenium的使用不是很熟练,基础教程就不在这里分享了,因为我也在学习过程中。代码流共享如下:
在此之前先介绍一下图片存储的用法:
urllib.request.urlretrieve(图片的路径.jpg结尾\图片的base64编码,‘储存的位置)
可以参考博客:https://blog.csdn.net/wuguangb ... 80058
好的初始代码版本 1.0
import os
import time
import urllib
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window()
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url: #仅仅就第一页可以,其他误判这个代码不是完整的是作者的错代码。
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
这里遇到的坑如下:
截图一:
前20张图片的src显示的是base64编码,所以可以直接用上面的代码解决,但是你后面的图片的src是什么?如下所示
这里既不是 base64 也不是 .jpg。我如何在这里保存它?你用
self.browser.get(图片的地址)
img_source = self.browser.page_source
继续经历这个?如果你这样想,那你就错了,因为我们还是拿到了完整的页面,那么这个时候我们该怎么办呢?想到我们最初使用requests来请求图片地址,这时候作者就简单的尝试着拿出一个单独的图片src去请求,不加代理就错了。因此,添加代理会导致以下结果:
import time
import requests
proxy = {"https": "https://127.0.0.1:8787"} //端口作者在前边的坑已经介绍了需要外网的端口
response = requests.get(
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTwwkW09Hrnq5DOzSYAKqrxv3uGjbQzoCRP28AOF03pzJ2uFObS',
proxies=proxy, verify=False)
with open('./image%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
结果就是想要的结果
那么你知道如何修改上面的代码吗?哈哈哈可能有点乱
修改代码如下:
import os
import time
import urllib
import requests
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.proxy = {"https": "https://127.0.0.1:8787"} #初始化代理
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window() #最大的适应屏幕
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url:
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
else: #在这里添加一个不久行了吗?如果图片的链接不是base64的
response = requests.get(each_url,proxies=self.proxy, verify=False)
with open('D:\GoogleImgDownLoad\%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
以上就是分享的结束。当然,直接使用requests模块+代理更方便。百度的爬虫这里就不分享了。如果你想联系源代码的作者,我会分享给你。当然,美中不足的是,这里不需要对图片进行去重,非常简单。不知道你有没有什么想法。无论如何,作者在这里有想法。已经是深夜了,我们睡个午觉吧。
分类:
技术要点:
相关文章:
网页爬虫抓取百度图片(我们先来直接分析代码:[python]__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-26 02:04
2022-01-07
在上一次爬虫中,主要是使用第三方Beautifulsoup库来爬取数据,然后通过选择器在网页中找到每一个具体的数据,每个类别都有一个select方法。接触过网页的人都知道,很多有用的数据都放在一个共同的父节点上,但它的子节点却不同。在上一次爬虫中,每类数据都必须从其父类(包括其父节点的父节点)中找到ROI数据所在的子节点,这会使爬虫非常臃肿,因为很多数据具有相同的父节点,每次都必须重复找到。这种爬行动物效率低下。
因此,作者在上次的基础上改进了爬取策略,并举例说明。
如图,作者这次爬取了百度音乐的页面,爬取的内容就是上面列表下的所有内容(歌名、歌手、排名)。如果按照最后一个爬虫的方式,就得写三个select方法来分别抓取歌名、歌手、排名,但是作者观察到这三个数据都放在了一个li标签中,如图:
这样,我们是不是直接抓取ul标签,然后分析里面的数据,得到所有的数据呢?答案当然是。
但是 Beaufulsoup 不能直接提供这样的方法,但是 Python 是无所不能的,而 Python 自带的 re 模块是我见过的最引人入胜的模块之一。它可以在字符串中找到我们让我们 roi 的区域。上面的 li 标签收录了我们需要的歌曲名称、歌手和排名数据。我们只需要使用 li 标签中的 re.findall() 方法就可以找到它。我们需要的数据。这样可以大大提高我们爬虫的效率。
我们直接分析代码:
[python]viewplain
defparse_one_page(html):soup=BeautifulSoup(html,'lxml')data=soup.select('div.ranklist-wrapper.clearfixdiv.bdul.song-listli')pattern1=pile(r'(.*?)
.*?title="(.*?)".*?title="(.*?)".*?',re.S)pattern2=pile(r'(.*?) 查看全部
网页爬虫抓取百度图片(我们先来直接分析代码:[python]__)
2022-01-07
在上一次爬虫中,主要是使用第三方Beautifulsoup库来爬取数据,然后通过选择器在网页中找到每一个具体的数据,每个类别都有一个select方法。接触过网页的人都知道,很多有用的数据都放在一个共同的父节点上,但它的子节点却不同。在上一次爬虫中,每类数据都必须从其父类(包括其父节点的父节点)中找到ROI数据所在的子节点,这会使爬虫非常臃肿,因为很多数据具有相同的父节点,每次都必须重复找到。这种爬行动物效率低下。
因此,作者在上次的基础上改进了爬取策略,并举例说明。
如图,作者这次爬取了百度音乐的页面,爬取的内容就是上面列表下的所有内容(歌名、歌手、排名)。如果按照最后一个爬虫的方式,就得写三个select方法来分别抓取歌名、歌手、排名,但是作者观察到这三个数据都放在了一个li标签中,如图:
这样,我们是不是直接抓取ul标签,然后分析里面的数据,得到所有的数据呢?答案当然是。
但是 Beaufulsoup 不能直接提供这样的方法,但是 Python 是无所不能的,而 Python 自带的 re 模块是我见过的最引人入胜的模块之一。它可以在字符串中找到我们让我们 roi 的区域。上面的 li 标签收录了我们需要的歌曲名称、歌手和排名数据。我们只需要使用 li 标签中的 re.findall() 方法就可以找到它。我们需要的数据。这样可以大大提高我们爬虫的效率。
我们直接分析代码:
[python]viewplain
defparse_one_page(html):soup=BeautifulSoup(html,'lxml')data=soup.select('div.ranklist-wrapper.clearfixdiv.bdul.song-listli')pattern1=pile(r'(.*?)
.*?title="(.*?)".*?title="(.*?)".*?',re.S)pattern2=pile(r'(.*?)
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-25 15:09
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片html
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,只是请求方法比较简单,还有一些正则表达式
不要忘记爬虫的基本思想:函数
1.指定要抓取的连接然后抓取网站源码网站
2.提取你想要的内容,比如你想爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签的方法代码
3.循环获取要爬取的内容列表,保存文件url
这里的代码和我博客前几章的代码区别(图片爬虫系列一)是:spa
1.reques库代码用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀为htm
3.保存图片时不要使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片博客
具体代码如下图所示:
1 # 使用requests、bs4库下载华侨大学主页上的全部图片
2 import os
3 import requests
4 from bs4 import BeautifulSoup
5 import shutil
6 from pathlib import Path # 关于文件路径操做的库,这里主要为了获得图片后缀名
7
8
9 # 该方法传入url,返回url的html的源代码
10 def getHtmlCode(url):
11 # 假装请求的头部来隐藏本身
12 headers = {
13 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0'
14 }
15 # 获取网页
16 r = requests.get(url, headers=headers)
17 # 指定网页解析的编码格式
18 r.encoding = 'UTF-8'
19 # 获取url页面的源代码字符串文本
20 page = r.text
21 return page
22
23
24 # 该方法传入html的源代码,经过截取其中的img标签,将图片保存到本机
25 def getImg(page, localPath):
26 # 判断文件夹是否存在,存在则删除,最后都要从新新的文件夹
27 if os.path.exists(localPath):
28 shutil.rmtree(localPath)
29 os.mkdir(localPath)
30
31 # 按照Html格式解析页面
32 soup = BeautifulSoup(page, 'html.parser')
33 # 返回的是一个包含全部img标签的列表
34 imgList = soup.find_all('img')
35 x = 0
36 # 循环url列表
37 for imgUrl in imgList:
38 try:
39 # 获得img标签中的src具体内容
40 imgUrl_src = imgUrl.get('src')
41 # 排除 src='' 的状况
42 if imgUrl_src != '':
43 print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src))
44 # 判断图片是不是从绝对路径https开始,具体为何这样操做能够看下图所示
45 if "https://" not in imgUrl_src:
46 m = 'https://www.hqu.edu.cn/' + imgUrl_src
47 print('正在下载: %s' % m)
48 # 获取图片
49 ir = requests.get(m)
50 else:
51 ir = requests.get(imgUrl_src)
52 # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名
53 p = Path(imgUrl_src)
54 # 获得后缀,返回的是如 '.jpg'
55 p_suffix = p.suffix
56 # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称
57 open(localPath + str(x) + p_suffix, 'wb').write(ir.content)
58 x = x + 1
59 except:
60 continue
61
62
63 if __name__ == '__main__':
64 # 指定爬取图片连接
65 url = 'https://www.hqu.edu.cn/index.htm'
66 # 指定存储图片路径
67 localPath = './img/'
68 # 获得网页源代码
69 page = getHtmlCode(url)
70 # 保存图片
71 getImg(page, localPath)
注意我们之所以判断图片链接是否从“https://”开始,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一张图片,然后点击html所在的代码。 ,鼠标悬停,可以看到绝对路径,然后根据这个绝对路径设置要添加的缺失部分,如下图:
查看全部
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生)
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片html
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,只是请求方法比较简单,还有一些正则表达式
不要忘记爬虫的基本思想:函数
1.指定要抓取的连接然后抓取网站源码网站
2.提取你想要的内容,比如你想爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签的方法代码
3.循环获取要爬取的内容列表,保存文件url
这里的代码和我博客前几章的代码区别(图片爬虫系列一)是:spa
1.reques库代码用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀为htm
3.保存图片时不要使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片博客
具体代码如下图所示:
1 # 使用requests、bs4库下载华侨大学主页上的全部图片
2 import os
3 import requests
4 from bs4 import BeautifulSoup
5 import shutil
6 from pathlib import Path # 关于文件路径操做的库,这里主要为了获得图片后缀名
7
8
9 # 该方法传入url,返回url的html的源代码
10 def getHtmlCode(url):
11 # 假装请求的头部来隐藏本身
12 headers = {
13 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0'
14 }
15 # 获取网页
16 r = requests.get(url, headers=headers)
17 # 指定网页解析的编码格式
18 r.encoding = 'UTF-8'
19 # 获取url页面的源代码字符串文本
20 page = r.text
21 return page
22
23
24 # 该方法传入html的源代码,经过截取其中的img标签,将图片保存到本机
25 def getImg(page, localPath):
26 # 判断文件夹是否存在,存在则删除,最后都要从新新的文件夹
27 if os.path.exists(localPath):
28 shutil.rmtree(localPath)
29 os.mkdir(localPath)
30
31 # 按照Html格式解析页面
32 soup = BeautifulSoup(page, 'html.parser')
33 # 返回的是一个包含全部img标签的列表
34 imgList = soup.find_all('img')
35 x = 0
36 # 循环url列表
37 for imgUrl in imgList:
38 try:
39 # 获得img标签中的src具体内容
40 imgUrl_src = imgUrl.get('src')
41 # 排除 src='' 的状况
42 if imgUrl_src != '':
43 print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src))
44 # 判断图片是不是从绝对路径https开始,具体为何这样操做能够看下图所示
45 if "https://" not in imgUrl_src:
46 m = 'https://www.hqu.edu.cn/' + imgUrl_src
47 print('正在下载: %s' % m)
48 # 获取图片
49 ir = requests.get(m)
50 else:
51 ir = requests.get(imgUrl_src)
52 # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名
53 p = Path(imgUrl_src)
54 # 获得后缀,返回的是如 '.jpg'
55 p_suffix = p.suffix
56 # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称
57 open(localPath + str(x) + p_suffix, 'wb').write(ir.content)
58 x = x + 1
59 except:
60 continue
61
62
63 if __name__ == '__main__':
64 # 指定爬取图片连接
65 url = 'https://www.hqu.edu.cn/index.htm'
66 # 指定存储图片路径
67 localPath = './img/'
68 # 获得网页源代码
69 page = getHtmlCode(url)
70 # 保存图片
71 getImg(page, localPath)
注意我们之所以判断图片链接是否从“https://”开始,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一张图片,然后点击html所在的代码。 ,鼠标悬停,可以看到绝对路径,然后根据这个绝对路径设置要添加的缺失部分,如下图:

网页爬虫抓取百度图片(如何做好SEO更是更是企业上下都面临的一个重要问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-23 04:19
我们都知道,在这个互联网时代,人们想要购买新品时,首先会在互联网上查找相关信息,看看哪个品牌的评价更好。这时候,在搜索引擎排名靠前的产品具有绝对优势。因此,SEO对企业和产品至关重要。
而如何做好SEO,是企业自上而下面临的重要课题。SEO是一项说起来简单的工作,但需要极大的耐心和细心。我们见过的很多SEO方法都很笼统,有些新手可能不知道从哪里入手。今天,我们先来讨论爬虫如何快速爬取你的网站。为了让你的网站更多页面成为收录,你必须先让网页被爬虫爬取。在此之前,让我们来看看爬行动物。
网络爬虫,也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常被称为网络追逐者,是根据一定的规则自动从万维网上爬取信息的程序或脚本。使用的其他名称是 ant、autoindex、emulator 或 worm。
简单来说,爬虫就是一个检测机器。它的基本操作是模拟人类的行为,去各种网站行走,点击按钮,查看数据,或者背诵它看到的信息。就像一只在建筑物周围不知疲倦地爬行的虫子。
那么如何让爬虫快速爬取我们的网站呢?我们将一一解释 网站 构造的各个方面。
1、网站 的基础 - 网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那说明你关了门,爬虫就来不及了。爬虫也是 网站 的访问者。如果你的服务器不稳定或卡顿,爬虫每次都很难爬到,有时只能爬到页面的一部分。你的体验越来越差,你的网站分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
2、网站 导航 - 建筑 网站 地图
爬虫真的很喜欢 网站maps,而 网站maps 是所有 网站links 的容器。许多 网站 链接很深,蜘蛛很难爬取。@网站 的架构,所以构建一个网站 地图,不仅可以提高爬取率,还可以得到爬虫的青睐。
3、网站 的结构 – 扁平化 网站 的结构
爬虫也有自己的线路。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取以下页面。.
4、网站 的栅栏 - 检查机器人文件
很多网站直接屏蔽了百度或者网站robots文件中的一些页面,有意无意,却在寻找爬虫整天爬不上我的页面的原因。你能怪爬虫吗?它是密封的,爬虫如何收录你的网页?所以需要时常检查网站robots文件,看是否正常。 查看全部
网页爬虫抓取百度图片(如何做好SEO更是更是企业上下都面临的一个重要问题)
我们都知道,在这个互联网时代,人们想要购买新品时,首先会在互联网上查找相关信息,看看哪个品牌的评价更好。这时候,在搜索引擎排名靠前的产品具有绝对优势。因此,SEO对企业和产品至关重要。
而如何做好SEO,是企业自上而下面临的重要课题。SEO是一项说起来简单的工作,但需要极大的耐心和细心。我们见过的很多SEO方法都很笼统,有些新手可能不知道从哪里入手。今天,我们先来讨论爬虫如何快速爬取你的网站。为了让你的网站更多页面成为收录,你必须先让网页被爬虫爬取。在此之前,让我们来看看爬行动物。

网络爬虫,也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常被称为网络追逐者,是根据一定的规则自动从万维网上爬取信息的程序或脚本。使用的其他名称是 ant、autoindex、emulator 或 worm。
简单来说,爬虫就是一个检测机器。它的基本操作是模拟人类的行为,去各种网站行走,点击按钮,查看数据,或者背诵它看到的信息。就像一只在建筑物周围不知疲倦地爬行的虫子。
那么如何让爬虫快速爬取我们的网站呢?我们将一一解释 网站 构造的各个方面。
1、网站 的基础 - 网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那说明你关了门,爬虫就来不及了。爬虫也是 网站 的访问者。如果你的服务器不稳定或卡顿,爬虫每次都很难爬到,有时只能爬到页面的一部分。你的体验越来越差,你的网站分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
2、网站 导航 - 建筑 网站 地图
爬虫真的很喜欢 网站maps,而 网站maps 是所有 网站links 的容器。许多 网站 链接很深,蜘蛛很难爬取。@网站 的架构,所以构建一个网站 地图,不仅可以提高爬取率,还可以得到爬虫的青睐。
3、网站 的结构 – 扁平化 网站 的结构
爬虫也有自己的线路。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取以下页面。.
4、网站 的栅栏 - 检查机器人文件
很多网站直接屏蔽了百度或者网站robots文件中的一些页面,有意无意,却在寻找爬虫整天爬不上我的页面的原因。你能怪爬虫吗?它是密封的,爬虫如何收录你的网页?所以需要时常检查网站robots文件,看是否正常。
网页爬虫抓取百度图片(如何让百度爬虫多来多来爬取你的卡盟?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-23 04:17
作为一个关注搜索引擎的站长,也许是一个优化关键词排名的seoer,对爬虫非常重视。每天,我都会查看联盟日志,看看爬虫爬了哪些页面,喜欢哪些内容,来了多少次。其他情况分析。今天德玛主要讲的是如何提高百度爬虫的爬取频率,也就是如何让百度爬虫更多的爬取你的卡盟。
看过百度分享帮助的人都知道,安装百度分享会提高百度爬虫的爬取速度和频率。下面是截图:
从这张图可以看出,要提高百度爬虫的爬取频率,必须从外部链接和设备百度分享入手。其实德玛个人觉得,优质原创内容更新频率的提升,也有利于爬虫爬虫的爬取频率。进步。
1、添加高质量的反向链接
这位德玛想,很多人都知道,优质的外链越多,卡牌联盟的百度快照更新的越快。为什么我们在这里谈论高质量的外部链接?如果有很多浪费的外部链接,那就没什么用了。由于百度爬虫很少爬垃圾外链,通过垃圾外链进入你的卡联盟的机会也很少。.
2、设备百度分享
从百度分享的协助可以看出,用户的分享动作将网页的URL发送给百度爬虫,这样百度爬虫就有更多的机会来。如果每天有很多人分享,那么发送百度爬虫的机会就更多了,它的爬取频率自然会提高。
3、高质量原创 内容多久更新一次
我们都知道,如果卡盟的更新有规则,百度爬虫来卡盟的时间也是有规则的,那我们就有规则提高优质原创内容的更新频率,自然百度爬虫也会有规则。更多爬行。为什么它是高质量的原创?高质量是用户喜欢的东西。用户一旦喜欢,自然会分享你的卡盟内容,对第二种情况有利。原创 是百度爬虫喜欢的东西。Dema 的博客基本上类似于 原创。即使一周只更新一条内容,也能秒收到,说明原创内容可以被爬虫抓取,因为它错过了你这里的好东西。随着您的发布频率增加,
如果以上三点都做到了,并且定期坚持了一段时间,再看卡的日志,你会发现百度爬虫的频率提升了很多。其实养爬虫并不难,难的是需要坚持和执行。百度分享刚出来的时候,很多人评论会不会影响排名。德玛想说的是,没有证明百度分享会影响排名,但是已经证明了百度分享会影响爬虫的爬取频率。所以建议各位站长还是在自己的卡联盟上安装一个百度分享,安装这个不会影响你的卡联盟速度。 查看全部
网页爬虫抓取百度图片(如何让百度爬虫多来多来爬取你的卡盟?(图))
作为一个关注搜索引擎的站长,也许是一个优化关键词排名的seoer,对爬虫非常重视。每天,我都会查看联盟日志,看看爬虫爬了哪些页面,喜欢哪些内容,来了多少次。其他情况分析。今天德玛主要讲的是如何提高百度爬虫的爬取频率,也就是如何让百度爬虫更多的爬取你的卡盟。
看过百度分享帮助的人都知道,安装百度分享会提高百度爬虫的爬取速度和频率。下面是截图:
从这张图可以看出,要提高百度爬虫的爬取频率,必须从外部链接和设备百度分享入手。其实德玛个人觉得,优质原创内容更新频率的提升,也有利于爬虫爬虫的爬取频率。进步。
1、添加高质量的反向链接
这位德玛想,很多人都知道,优质的外链越多,卡牌联盟的百度快照更新的越快。为什么我们在这里谈论高质量的外部链接?如果有很多浪费的外部链接,那就没什么用了。由于百度爬虫很少爬垃圾外链,通过垃圾外链进入你的卡联盟的机会也很少。.
2、设备百度分享
从百度分享的协助可以看出,用户的分享动作将网页的URL发送给百度爬虫,这样百度爬虫就有更多的机会来。如果每天有很多人分享,那么发送百度爬虫的机会就更多了,它的爬取频率自然会提高。
3、高质量原创 内容多久更新一次
我们都知道,如果卡盟的更新有规则,百度爬虫来卡盟的时间也是有规则的,那我们就有规则提高优质原创内容的更新频率,自然百度爬虫也会有规则。更多爬行。为什么它是高质量的原创?高质量是用户喜欢的东西。用户一旦喜欢,自然会分享你的卡盟内容,对第二种情况有利。原创 是百度爬虫喜欢的东西。Dema 的博客基本上类似于 原创。即使一周只更新一条内容,也能秒收到,说明原创内容可以被爬虫抓取,因为它错过了你这里的好东西。随着您的发布频率增加,
如果以上三点都做到了,并且定期坚持了一段时间,再看卡的日志,你会发现百度爬虫的频率提升了很多。其实养爬虫并不难,难的是需要坚持和执行。百度分享刚出来的时候,很多人评论会不会影响排名。德玛想说的是,没有证明百度分享会影响排名,但是已经证明了百度分享会影响爬虫的爬取频率。所以建议各位站长还是在自己的卡联盟上安装一个百度分享,安装这个不会影响你的卡联盟速度。
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-21 06:18
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然。它也比其他社区论坛更易于使用。注册容易,甚至不注册,发布也容易。但是,栏目创建的参差不齐,内容千奇百怪。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,我们可以看到贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
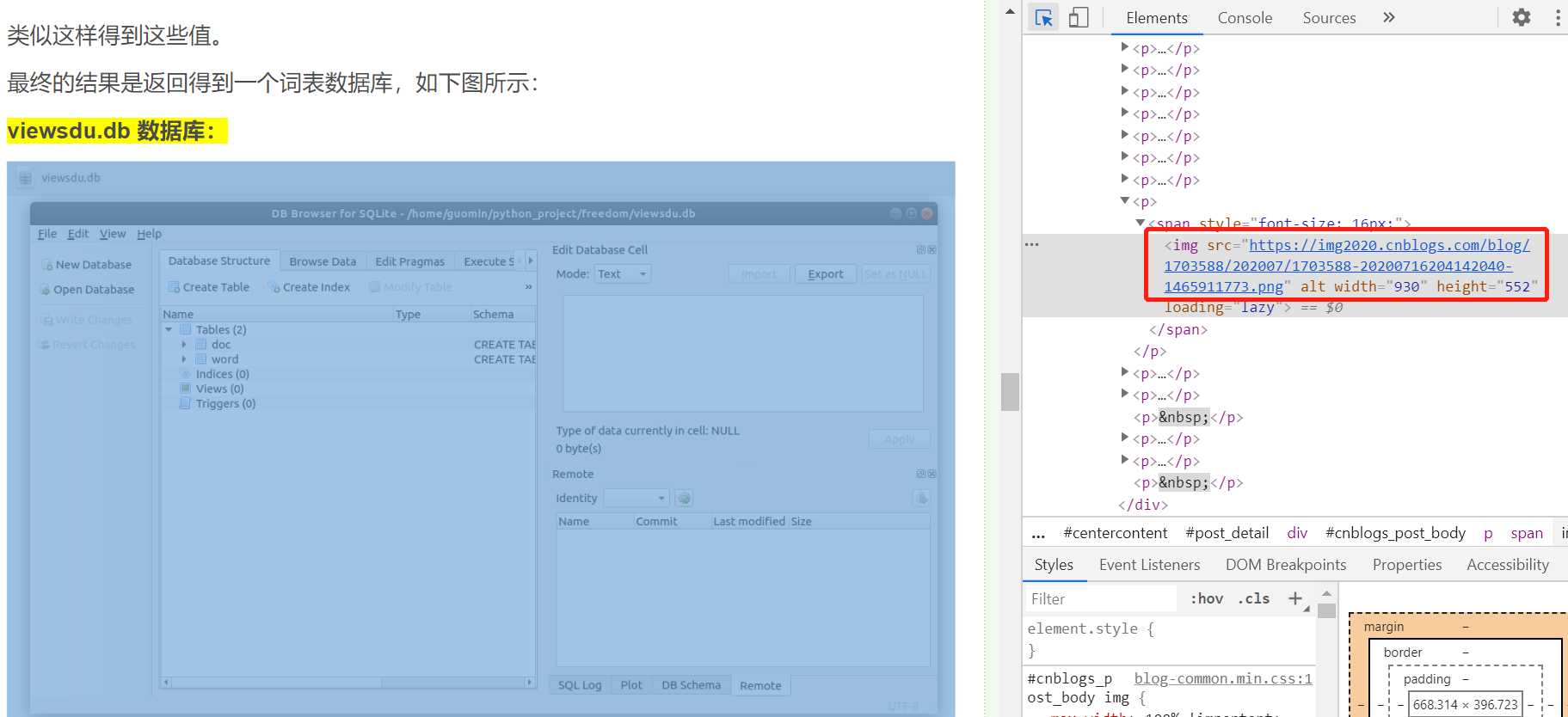
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
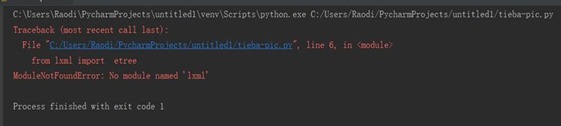
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
图 5-1 错误解决流程
2、 有时候需要模拟浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
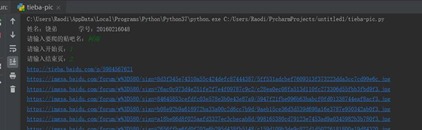
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage) 查看全部
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四)
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然。它也比其他社区论坛更易于使用。注册容易,甚至不注册,发布也容易。但是,栏目创建的参差不齐,内容千奇百怪。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,我们可以看到贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1

图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)

(三)爬虫运行结果



(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。

图 5-1 错误解决流程
2、 有时候需要模拟浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-21 06:12
)
这篇文章是针对初学者的。我将用最简单的案例告诉你如何开始使用python爬虫!
上手Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫,其实叫网络数据采集,比较好理解。
就是通过编程向Web服务器请求数据(HTML表单),然后解析HTML提取出你想要的数据。
可以概括为四个步骤:
根据url获取HTML数据,解析HTML,获取目标信息并存储数据,重复第一步
这将涉及数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全、图像处理等等。但是对于初学者来说,没有必要掌握这么多。
二、你有多想学python
如果你不会python,你需要先学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非就是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。这会很无聊,但学起来并不难。
刚开始学爬虫,甚至不需要学习python的类、多线程、模块等稍有难度的内容。找一本初学者的教材或者网上教程,用了十多天,可以对python的基础有了三四点的了解,然后就可以玩爬虫了!
当然,前提是这十天一定要仔细敲代码,反复咀嚼语法逻辑。比如列表、字典、字符串、if语句、for循环等最核心的东西,一定要心手可得。
教材选择更多。我个人推荐官方的python文档和简洁的python教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面说过,爬虫要爬取的数据隐藏在网页中的HTML中,有点混乱!
这就是维基百科解释 HTML 的方式
超文本标记语言(英文:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。HTML 是一种底层技术,许多 网站 使用 CSS 来设计网页、Web 应用程序和移动应用程序的用户界面[3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视网页。HTML 描述了 网站 的结构语义作为提示,使其成为一种标记语言而不是一种编程语言。
综上所述,HTML是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并渲染到我们看到的网页中。
所以我们会先爬取HTML,然后解析数据,因为数据是隐藏在HTML中的。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则,这里是一个大概的介绍。
HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如 .
在这些成对的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图片等),有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,用尖括号括起来,如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。带有文本内容的元素放置在这些标签之间。
四、了解python网络爬虫的基本原理
编写python爬虫时,只需要做两件事:
对于这两件事,python有相应的库来帮助你,你只需要知道如何使用它们。
五、使用python库爬取百度首页标题和图片
首先,发送HTML数据请求,可以使用python的内置库urllib,里面有一个urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页“”的HTML内容
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看看效果:
下面我们来看看真正的百度主页html是什么样子的。如果你使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:
对比一下就知道刚才python程序得到的html和网页中的html是一样的!
获取到HTML之后,接下来就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种手段提取出需要的数据。
Python 还提供了很多强大的库来帮助你解析 HTML。这里使用著名的python库BeautifulSoup作为解析上面已经获取的HTML的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。您可以从命令行使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需从结构化标签中提取数据即可:
比如我想获取百度首页的标题“百度,我会知道”,该怎么做?
这个标题被两个标签包围,一个是一级标签,另一个是二级标签,所以只需从标签中取出信息
# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
查看结果:
这样就完成了,成功提取了百度首页的标题。
如果我想下载百度主页logo图片怎么办?
第一步是获取网页的所有图片标签和网址。这可以使用 BeautifulSoup 的 findAll 方法,该方法可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll(“img”)来获取所有图片的信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
查看结果:
打印出所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高。
有一张百度主页logo的图片,图片的class(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:
获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
urlretrieve(logo_url, 'logo.png')
最终图像保存在“logo.png”中
六、结束语
本文以爬取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是一个比较基础的爬虫知识,后面还有很多优秀的python爬虫库和框架等着学习。
当然,如果你掌握了本文提到的知识点,你就已经开始上手python爬虫了。来吧,少年!
##最后
这里我整理了2022年最新版本的全套python资料,你想要的我都有,有需要的可以添加领取。
查看全部
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫
)
这篇文章是针对初学者的。我将用最简单的案例告诉你如何开始使用python爬虫!
上手Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫,其实叫网络数据采集,比较好理解。
就是通过编程向Web服务器请求数据(HTML表单),然后解析HTML提取出你想要的数据。
可以概括为四个步骤:
根据url获取HTML数据,解析HTML,获取目标信息并存储数据,重复第一步
这将涉及数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全、图像处理等等。但是对于初学者来说,没有必要掌握这么多。
二、你有多想学python
如果你不会python,你需要先学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非就是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。这会很无聊,但学起来并不难。
刚开始学爬虫,甚至不需要学习python的类、多线程、模块等稍有难度的内容。找一本初学者的教材或者网上教程,用了十多天,可以对python的基础有了三四点的了解,然后就可以玩爬虫了!
当然,前提是这十天一定要仔细敲代码,反复咀嚼语法逻辑。比如列表、字典、字符串、if语句、for循环等最核心的东西,一定要心手可得。
教材选择更多。我个人推荐官方的python文档和简洁的python教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面说过,爬虫要爬取的数据隐藏在网页中的HTML中,有点混乱!
这就是维基百科解释 HTML 的方式
超文本标记语言(英文:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。HTML 是一种底层技术,许多 网站 使用 CSS 来设计网页、Web 应用程序和移动应用程序的用户界面[3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视网页。HTML 描述了 网站 的结构语义作为提示,使其成为一种标记语言而不是一种编程语言。
综上所述,HTML是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并渲染到我们看到的网页中。
所以我们会先爬取HTML,然后解析数据,因为数据是隐藏在HTML中的。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则,这里是一个大概的介绍。
HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如 .
在这些成对的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图片等),有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,用尖括号括起来,如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。带有文本内容的元素放置在这些标签之间。
四、了解python网络爬虫的基本原理
编写python爬虫时,只需要做两件事:
对于这两件事,python有相应的库来帮助你,你只需要知道如何使用它们。
五、使用python库爬取百度首页标题和图片
首先,发送HTML数据请求,可以使用python的内置库urllib,里面有一个urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页“”的HTML内容
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/";)
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看看效果:

下面我们来看看真正的百度主页html是什么样子的。如果你使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:

对比一下就知道刚才python程序得到的html和网页中的html是一样的!
获取到HTML之后,接下来就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种手段提取出需要的数据。
Python 还提供了很多强大的库来帮助你解析 HTML。这里使用著名的python库BeautifulSoup作为解析上面已经获取的HTML的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。您可以从命令行使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需从结构化标签中提取数据即可:

比如我想获取百度首页的标题“百度,我会知道”,该怎么做?
这个标题被两个标签包围,一个是一级标签,另一个是二级标签,所以只需从标签中取出信息

# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
查看结果:

这样就完成了,成功提取了百度首页的标题。
如果我想下载百度主页logo图片怎么办?
第一步是获取网页的所有图片标签和网址。这可以使用 BeautifulSoup 的 findAll 方法,该方法可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll(“img”)来获取所有图片的信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
查看结果:

打印出所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高。
有一张百度主页logo的图片,图片的class(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:

获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
urlretrieve(logo_url, 'logo.png')
最终图像保存在“logo.png”中

六、结束语
本文以爬取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是一个比较基础的爬虫知识,后面还有很多优秀的python爬虫库和框架等着学习。
当然,如果你掌握了本文提到的知识点,你就已经开始上手python爬虫了。来吧,少年!
##最后
这里我整理了2022年最新版本的全套python资料,你想要的我都有,有需要的可以添加领取。

网页爬虫抓取百度图片(《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)中爬虫应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-21 03:00
标签:宽度标签,除了按 defmic 源 %sapp
摘自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)在爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
实现爬取指定网页中图片的代码如下:
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样
9 # headers = {
10 # ‘User-Agent‘: ‘Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 # AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36‘
12 # }
13 # # 将headers头部添加到url,模拟浏览器访问
14 # url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(‘UTF-8‘)
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 imageList = re.findall(r‘(https:[^\s]*?(jpg|png|gif))"‘, page)
27 x = 0
28 # 循环列表
29 for imageUrl in imageList:
30 try:
31 print(‘正在下载: %s‘ % imageUrl[0])
32 # 这个image文件夹需要先创建好才能看到结果
33 image_save_path = ‘./image/%d.png‘ % x
34 # 下载图片并且保存到指定文件夹中
35 urllib.request.urlretrieve(imageUrl[0], image_save_path)
36 x = x + 1
37 except:
38 continue
39
40 pass
41
42
43 if __name__ == ‘__main__‘:
44 # 指定要爬取的网站
45 url = "https://www.cnblogs.com/ttweix ... ot%3B
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
50 # print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这段内容,怎么设计正则表达式需要根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
python爬取指定页面中的图片
标签:宽度标签,除了按 defmic 源 %sapp 查看全部
网页爬虫抓取百度图片(《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)中爬虫应用)
标签:宽度标签,除了按 defmic 源 %sapp
摘自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)在爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
实现爬取指定网页中图片的代码如下:
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样
9 # headers = {
10 # ‘User-Agent‘: ‘Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 # AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36‘
12 # }
13 # # 将headers头部添加到url,模拟浏览器访问
14 # url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(‘UTF-8‘)
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 imageList = re.findall(r‘(https:[^\s]*?(jpg|png|gif))"‘, page)
27 x = 0
28 # 循环列表
29 for imageUrl in imageList:
30 try:
31 print(‘正在下载: %s‘ % imageUrl[0])
32 # 这个image文件夹需要先创建好才能看到结果
33 image_save_path = ‘./image/%d.png‘ % x
34 # 下载图片并且保存到指定文件夹中
35 urllib.request.urlretrieve(imageUrl[0], image_save_path)
36 x = x + 1
37 except:
38 continue
39
40 pass
41
42
43 if __name__ == ‘__main__‘:
44 # 指定要爬取的网站
45 url = "https://www.cnblogs.com/ttweix ... ot%3B
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
50 # print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这段内容,怎么设计正则表达式需要根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
python爬取指定页面中的图片
标签:宽度标签,除了按 defmic 源 %sapp
网页爬虫抓取百度图片(《Python爬虫开发与项目实战》——第3章(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 22:18
阿里云 > 云栖社区 > 主题地图 > W > 网络爬虫的网络爬取算法
推荐活动:
更多优惠>
当前主题: 网络爬虫的网络爬取算法 添加到采集夹
相关话题:
Web Crawler Web Scraping Algorithms 相关博客 查看更多博客
浅谈网络爬虫中的深度优先算法及简单代码实现
作者:python进阶1029人查看评论:13年前
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。当 网站 的 URL 太多时,我们
阅读全文
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实践》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解
作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:03年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
网络爬虫基本原理(一)
作者:xumaojun978 浏览评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下
阅读全文
网络爬虫基本原理(一)
作者:nothingfinal690 观众评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图:网络爬虫
阅读全文 查看全部
网页爬虫抓取百度图片(《Python爬虫开发与项目实战》——第3章(组图))
阿里云 > 云栖社区 > 主题地图 > W > 网络爬虫的网络爬取算法

推荐活动:
更多优惠>
当前主题: 网络爬虫的网络爬取算法 添加到采集夹
相关话题:
Web Crawler Web Scraping Algorithms 相关博客 查看更多博客
浅谈网络爬虫中的深度优先算法及简单代码实现


作者:python进阶1029人查看评论:13年前
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。当 网站 的 URL 太多时,我们
阅读全文
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述

作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实践》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解

作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
网络爬虫的实现


作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现


作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现

作者:maojunxu558 浏览评论:03年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
网络爬虫基本原理(一)

作者:xumaojun978 浏览评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下
阅读全文
网络爬虫基本原理(一)

作者:nothingfinal690 观众评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图:网络爬虫
阅读全文
网页爬虫抓取百度图片(Java实现的爬虫抓取图片并保存操作技巧汇总(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-20 22:12
本篇文章主要介绍Java实现的抓取图片并保存的爬虫。涉及到Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文的例子描述了java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MoZyyxlKalformedURLException;
import java.net.URL;
import java.net.URLConnection;
impooZyyxlKrt java.util.ArrayList;
import java.util.List;
import java.util.reghttp://www.cppcns.comex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public stati编程客栈c String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL 编程客栈url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
本文标题:Java实现的爬虫抓取图片保存操作示例 查看全部
网页爬虫抓取百度图片(Java实现的爬虫抓取图片并保存操作技巧汇总(二))
本篇文章主要介绍Java实现的抓取图片并保存的爬虫。涉及到Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文的例子描述了java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MoZyyxlKalformedURLException;
import java.net.URL;
import java.net.URLConnection;
impooZyyxlKrt java.util.ArrayList;
import java.util.List;
import java.util.reghttp://www.cppcns.comex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public stati编程客栈c String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL 编程客栈url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:

对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
本文标题:Java实现的爬虫抓取图片保存操作示例
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-18 23:00
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然,比其他社区论坛更容易使用。注册容易,甚至不注册,发布也容易。但是,栏目创建不均,内容五花八门。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,可以看出贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
图 5-1 错误解决流程
2、 有时候你要模拟一个浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage) 查看全部
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四)
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然,比其他社区论坛更容易使用。注册容易,甚至不注册,发布也容易。但是,栏目创建不均,内容五花八门。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,可以看出贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
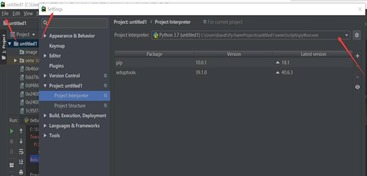
图 5-1 错误解决流程
2、 有时候你要模拟一个浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
网页爬虫抓取百度图片( Control的异步和回调知识的逻辑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-18 12:10
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路及抓取百度图片的例子分享
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本篇文章主要介绍Node.js编写爬虫的基本思路和抓取百度图片的例子分享。作者提到了GBK转码需要特别注意的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(和我基础不够扎实,也没有认真研究过node.js有很大关系)。主要原因是node.js的异步和回调知识没有完全掌握,导致在编写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像写PHP一样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以有必要一开始就分析一下这个爬虫需要实现的功能。,大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用数据,返回一个对象
持久性模块,接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一个下午的问题:模块之间的异步调用导致数据错误。其实我还是不太明白是什么问题,因为脚本语言的调试功能不方便,所以还没有深入研究过。
还有一点需要注意的是,在模块化的时候,尽量谨慎的使用全局对象来存储数据,因为可能你的模块的某个功能还没有结束,而全局变量已经被修改了。
控制流
这个东西很难翻译,直译就叫控制流(?)。众所周知,node.js的核心思想是异步,但是如果异步多了,就会有好几层嵌套,代码真的很难看。此时,您需要借助一些控制流模块重新排列逻辑。这里我们推荐 async.js(),它在开发社区中非常活跃且易于使用。
async提供了很多实用的方法,我主要在写爬虫的时候使用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景,需要向数据库中插入多条数据(属于同一个学生),并且需要在插入所有数据后返回结果,那么如何保证所有的插入操作都结束了? 它只能通过回调层来保证。使用 async.parallel 要方便得多。
这里还要提一件事,本来是为了保证所有的insert都完成,这个操作可以在SQL层实现,也就是transaction,但是node-mysql在我使用的时候还是不能很好的支持transaction,所以只能用代码手动保证。
解析 HTML
解析过程中也遇到了一些问题,记录在这里。
发送 HTTP 请求获取 HTML 代码最基本的方法是使用 node 自带的 http.request 函数。如果是抓取简单的内容,比如获取指定id元素的内容(常用于抓取商品价格),那么正则就足够完成任务了。但是对于复杂的页面,尤其是数据项很多的页面,使用 DOM 会更加方便和高效。
node.js 的最佳 DOM 实现是cheerio()。其实,cheerio 应该算是 jQuery 的一个子集,针对 DOM 操作进行了优化和精简,包括了 DOM 操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在爬取数据时,我们可能还需要下载图片。其实下载图片的方式和普通网页没有太大区别,但是有一点让我很苦恼。
请注意下面代码中的起泡注释,这是我年轻时犯的错误......
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得解释的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会走弯路。这是所有的源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i 查看全部
网页爬虫抓取百度图片(
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路及抓取百度图片的例子分享
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本篇文章主要介绍Node.js编写爬虫的基本思路和抓取百度图片的例子分享。作者提到了GBK转码需要特别注意的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(和我基础不够扎实,也没有认真研究过node.js有很大关系)。主要原因是node.js的异步和回调知识没有完全掌握,导致在编写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像写PHP一样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以有必要一开始就分析一下这个爬虫需要实现的功能。,大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用数据,返回一个对象
持久性模块,接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一个下午的问题:模块之间的异步调用导致数据错误。其实我还是不太明白是什么问题,因为脚本语言的调试功能不方便,所以还没有深入研究过。
还有一点需要注意的是,在模块化的时候,尽量谨慎的使用全局对象来存储数据,因为可能你的模块的某个功能还没有结束,而全局变量已经被修改了。
控制流
这个东西很难翻译,直译就叫控制流(?)。众所周知,node.js的核心思想是异步,但是如果异步多了,就会有好几层嵌套,代码真的很难看。此时,您需要借助一些控制流模块重新排列逻辑。这里我们推荐 async.js(),它在开发社区中非常活跃且易于使用。
async提供了很多实用的方法,我主要在写爬虫的时候使用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景,需要向数据库中插入多条数据(属于同一个学生),并且需要在插入所有数据后返回结果,那么如何保证所有的插入操作都结束了? 它只能通过回调层来保证。使用 async.parallel 要方便得多。
这里还要提一件事,本来是为了保证所有的insert都完成,这个操作可以在SQL层实现,也就是transaction,但是node-mysql在我使用的时候还是不能很好的支持transaction,所以只能用代码手动保证。
解析 HTML
解析过程中也遇到了一些问题,记录在这里。
发送 HTTP 请求获取 HTML 代码最基本的方法是使用 node 自带的 http.request 函数。如果是抓取简单的内容,比如获取指定id元素的内容(常用于抓取商品价格),那么正则就足够完成任务了。但是对于复杂的页面,尤其是数据项很多的页面,使用 DOM 会更加方便和高效。
node.js 的最佳 DOM 实现是cheerio()。其实,cheerio 应该算是 jQuery 的一个子集,针对 DOM 操作进行了优化和精简,包括了 DOM 操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在爬取数据时,我们可能还需要下载图片。其实下载图片的方式和普通网页没有太大区别,但是有一点让我很苦恼。
请注意下面代码中的起泡注释,这是我年轻时犯的错误......
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得解释的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会走弯路。这是所有的源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i
网页爬虫抓取百度图片(2016年7月26日(周四)、、上一步公告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-18 08:03
第二步:输入关键字,页面加载完毕后,按F12进入开发者模式,因为百度图片ajax是动态加载的,点击网络标签,刷新页面,查看XHR数据,截图如下:
p>
第 3 步:分析多个 XHR 并获取规则。每个页面请求的url携带的参数只有pn、rn、gsm(不关心),它们是不同的,其中pn代表当前页面。 , rn 表示一个页面有几条数据,如下截图所示:
第四步:分析完上一步url的规则后,我们找到图片的隐藏位置,点击任意XHR,从0到29,一共30条数据,图片的信息存储在每个字典中,其中'thumbURL'存储地址,截图如下:
第五步:上一步已经分析了图片存放的地方,接下来我们来写代码,代码如下:
import requests
import os
class Image():
url = 'https://image.baidu.com/search/acjson'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'
}
varlist = []
dir = './images'
params = {}
def __init__(self):
global page_num,keywords
page_num = int(input('请输入要抓取的页数:\n'))
keywords = input('请输入关键字:\n')
if self.catch_page():
self.writeData()
else:
print('抓取页面失败')
def catch_page(self):
for i in range(0,page_num * 30,30):
self.params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keywords,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'hd': '',
'latest': '',
'copyright': '',
'word': keywords,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': i,
'rn': '30',
'gsm': '',
'1584010126096': ''
}
res = requests.get(url = self.url,params = self.params).json()['data']
for j in range(0,30):
self.varlist.append(res[j]['thumbURL'])
if self.varlist != None:
return True
return False
def writeData(self):
# 判读是否存在文件,不存在则创建
if not os.path.exists(self.dir):
os.mkdir(self.dir)
for i in range(0,page_num * 30):
print(f'正在下载第{i}条数据')
images = requests.get(url = self.varlist[i])
open(f'./images/{i}.jpg','wb').write(images.content)
if __name__ == '__main__':
Image()
第6步:完成插花 查看全部
网页爬虫抓取百度图片(2016年7月26日(周四)、、上一步公告)
第二步:输入关键字,页面加载完毕后,按F12进入开发者模式,因为百度图片ajax是动态加载的,点击网络标签,刷新页面,查看XHR数据,截图如下:
p>
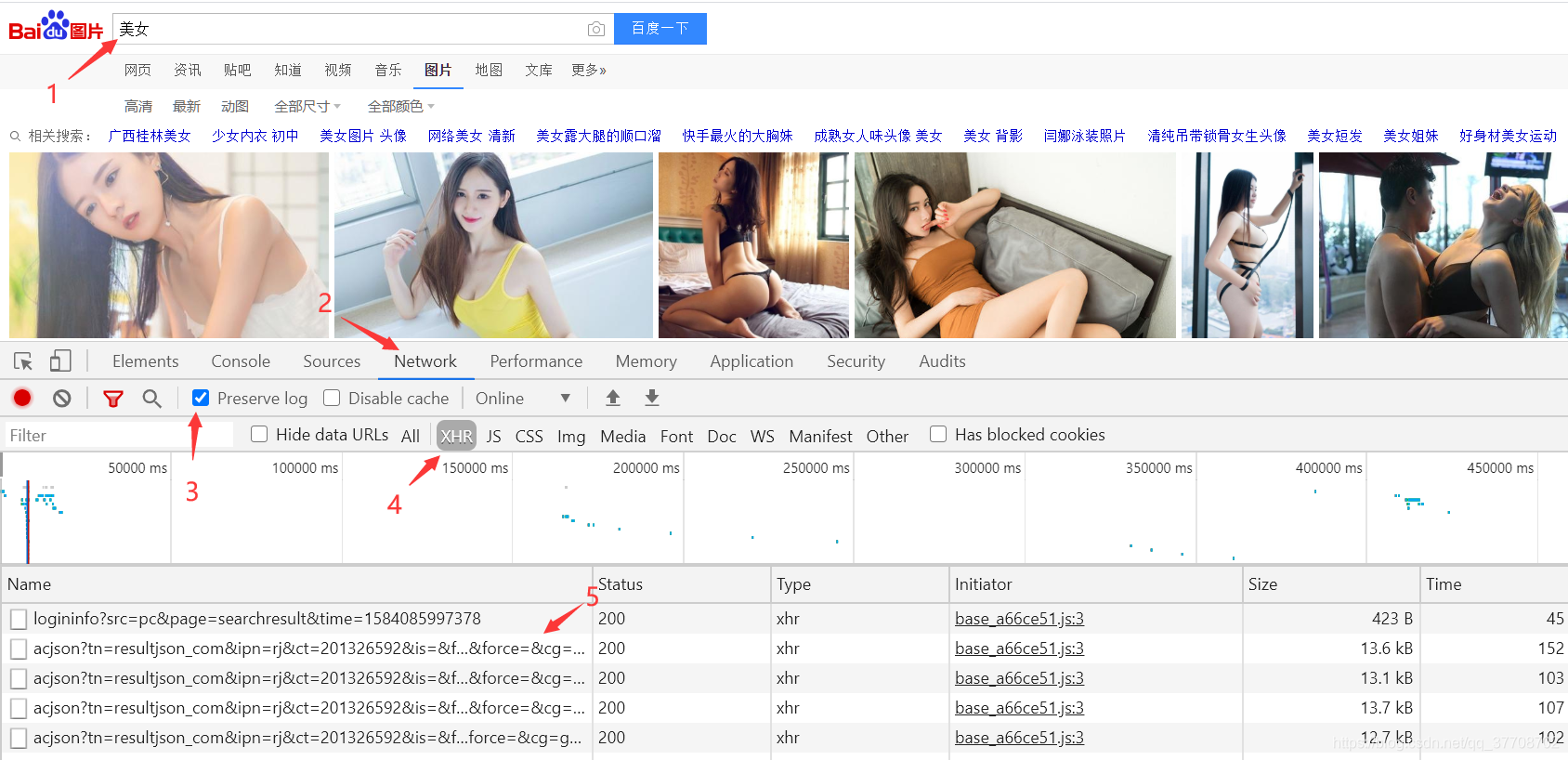
第 3 步:分析多个 XHR 并获取规则。每个页面请求的url携带的参数只有pn、rn、gsm(不关心),它们是不同的,其中pn代表当前页面。 , rn 表示一个页面有几条数据,如下截图所示:


第四步:分析完上一步url的规则后,我们找到图片的隐藏位置,点击任意XHR,从0到29,一共30条数据,图片的信息存储在每个字典中,其中'thumbURL'存储地址,截图如下:
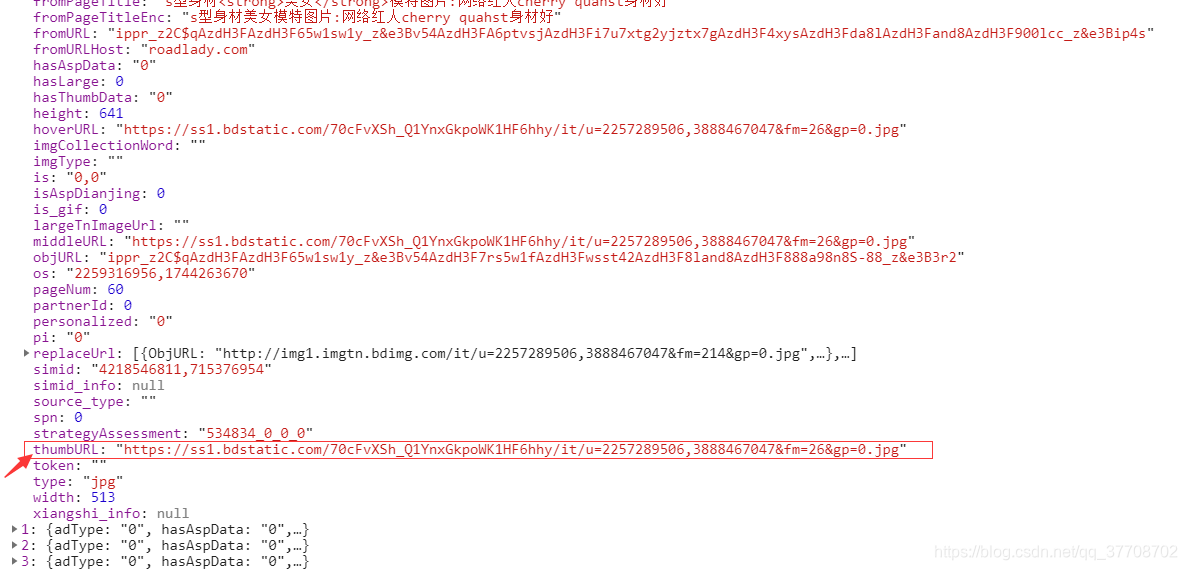
第五步:上一步已经分析了图片存放的地方,接下来我们来写代码,代码如下:
import requests
import os
class Image():
url = 'https://image.baidu.com/search/acjson'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'
}
varlist = []
dir = './images'
params = {}
def __init__(self):
global page_num,keywords
page_num = int(input('请输入要抓取的页数:\n'))
keywords = input('请输入关键字:\n')
if self.catch_page():
self.writeData()
else:
print('抓取页面失败')
def catch_page(self):
for i in range(0,page_num * 30,30):
self.params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keywords,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'hd': '',
'latest': '',
'copyright': '',
'word': keywords,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': i,
'rn': '30',
'gsm': '',
'1584010126096': ''
}
res = requests.get(url = self.url,params = self.params).json()['data']
for j in range(0,30):
self.varlist.append(res[j]['thumbURL'])
if self.varlist != None:
return True
return False
def writeData(self):
# 判读是否存在文件,不存在则创建
if not os.path.exists(self.dir):
os.mkdir(self.dir)
for i in range(0,page_num * 30):
print(f'正在下载第{i}条数据')
images = requests.get(url = self.varlist[i])
open(f'./images/{i}.jpg','wb').write(images.content)
if __name__ == '__main__':
Image()
第6步:完成插花
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-18 02:20
内容
你好!大家好,我是一只为了赚钱买发水的小灰猿。很多学过Python的小伙伴都希望拥有一个属于自己的爬虫,那么今天大灰狼就给小伙伴们分享一个简单的爬虫程序。.
请允许我在这里为我的朋友出售通行证。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开一个特定的网页,对网页上存在的一些信息进行爬取。想象一下,如果把一个网页比作一片田地,爬行动物就是生活在这片田地里的昆虫,从田地的头到尾爬行,只捕食田地里的某一种食物。哈哈,比喻有点粗略,但是网络爬虫的实际作用和这个差不多。
想了解更多的朋友也可以看我的文章文章《Python一分钟带你探索不为人知的网虫!》它!
爬虫的原理是什么?
那么有的朋友可能会问,爬虫是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了网页中的所有信息。当我们打开一个网页时,按 F12 键可以查看该页面的内容。代码已准备就绪。我们以百度图片搜索皮卡丘的网页为例。按下 F12 后,可以看到下面的代码覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例,我们的爬虫想要爬取这个网页上所有的皮卡丘图片,那么我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,并且从此链接下载图片。
所以爬虫的工作原理就是从网页的代码中找到并提取特定的代码,就像从很长的字符串中找到特定格式的字符串一样,对这块知识感兴趣的朋友也可以阅读我的文章文章《Python实战中的具体文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里以requests模块为例编写爬虫程序。
以爬取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序应该做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式 匹配代码中所有符合要求的图片链接通过设置的正则表达式一张一张打开图片链接下载图片
接下来大灰狼就按照上面的步骤跟大家分享一下这个爬虫的准备工作:
1、获取百度图片中“皮卡丘图片”的网址
首先我们打开百度图片的网页链接
然后打开关键字搜索“皮卡丘”后的链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
作为对比,去掉多余部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:
现在我们的第一步是获取百度图片中“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取此页面的完整代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后,通过模块中的text函数获取网页的文本,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中查找图片链接
这一步我们可以先打开网页的链接,按大灰狼开头说的方法,按F12查看网页的所有代码,然后如果我们要爬取jpg中的所有图片格式,我们可以按 Ctrl+F 代码来查找特定的东西,
比如我们在这个网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容,如果我们仔细观察这些链接,会发现它们是相似的,即每个链接前都会有“OpjURL”:提示,最后以“,
我们取出其中一个链接
访问,发现图片也可以打开。
所以我们可以暂时推断出百度图片中jpg图片的一般格式为“”OpjURL“:XXXX”,
4、根据图片链接写一个通用的正则表达式
既然我们知道了这类图片的一般格式是“"OpjURL":XXXX"”,那么接下来就是按照这种格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不知道如何使用正则表达式的同学,也可以看看我的两篇文章文章《Python 中的正则表达式教程(基础)》和《Python 教程中的正则表达式(改进)》
5、通过设置的正则表达式匹配代码中所有匹配的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配到的图片链接,并将所有匹配到的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后,我们可以在这个文件下看到匹配的图片链接,复制任意一个即可打开。
6、一一打开图片链接,下载图片
现在我们已经将所有图片的链接存储在列表中,下一步就是下载图片了。
基本思路是:通过一个for循环遍历列表中的所有链接,以二进制形式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前休眠3秒,每个链接的访问时间最多5秒。如果访问时间超过五秒,我们将判断下载失败,继续下载下一章。图片。
至于为什么我们用二进制打开和写入图片,我们的图片需要经过二进制解析才能被计算机写入。
图片下载代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
至此,一个简单的爬取百度皮卡丘图片的爬虫就完成了,小伙伴们还可以随意更改图片关键词和下载次数,来培养自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
s = requests.session()
s.headers['User-Agent']='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
urls = s.get(url).content.decode('utf-8')
# urls = requests.get(url) # 打开链接
# requests.get(url="https://www.baidu.com/")
urltext = urls # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout=5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i + 1), urlimg))
imgs.write(img) # 将图片写入
i += 1
if i == 5: # 为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
觉得有用的话记得点赞关注哦! 查看全部
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
内容
你好!大家好,我是一只为了赚钱买发水的小灰猿。很多学过Python的小伙伴都希望拥有一个属于自己的爬虫,那么今天大灰狼就给小伙伴们分享一个简单的爬虫程序。.
请允许我在这里为我的朋友出售通行证。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开一个特定的网页,对网页上存在的一些信息进行爬取。想象一下,如果把一个网页比作一片田地,爬行动物就是生活在这片田地里的昆虫,从田地的头到尾爬行,只捕食田地里的某一种食物。哈哈,比喻有点粗略,但是网络爬虫的实际作用和这个差不多。
想了解更多的朋友也可以看我的文章文章《Python一分钟带你探索不为人知的网虫!》它!
爬虫的原理是什么?
那么有的朋友可能会问,爬虫是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了网页中的所有信息。当我们打开一个网页时,按 F12 键可以查看该页面的内容。代码已准备就绪。我们以百度图片搜索皮卡丘的网页为例。按下 F12 后,可以看到下面的代码覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例,我们的爬虫想要爬取这个网页上所有的皮卡丘图片,那么我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,并且从此链接下载图片。
所以爬虫的工作原理就是从网页的代码中找到并提取特定的代码,就像从很长的字符串中找到特定格式的字符串一样,对这块知识感兴趣的朋友也可以阅读我的文章文章《Python实战中的具体文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里以requests模块为例编写爬虫程序。
以爬取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序应该做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式 匹配代码中所有符合要求的图片链接通过设置的正则表达式一张一张打开图片链接下载图片
接下来大灰狼就按照上面的步骤跟大家分享一下这个爬虫的准备工作:
1、获取百度图片中“皮卡丘图片”的网址
首先我们打开百度图片的网页链接

然后打开关键字搜索“皮卡丘”后的链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
作为对比,去掉多余部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:
现在我们的第一步是获取百度图片中“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取此页面的完整代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后,通过模块中的text函数获取网页的文本,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中查找图片链接
这一步我们可以先打开网页的链接,按大灰狼开头说的方法,按F12查看网页的所有代码,然后如果我们要爬取jpg中的所有图片格式,我们可以按 Ctrl+F 代码来查找特定的东西,
比如我们在这个网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容,如果我们仔细观察这些链接,会发现它们是相似的,即每个链接前都会有“OpjURL”:提示,最后以“,
我们取出其中一个链接
访问,发现图片也可以打开。
所以我们可以暂时推断出百度图片中jpg图片的一般格式为“”OpjURL“:XXXX”,
4、根据图片链接写一个通用的正则表达式
既然我们知道了这类图片的一般格式是“"OpjURL":XXXX"”,那么接下来就是按照这种格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不知道如何使用正则表达式的同学,也可以看看我的两篇文章文章《Python 中的正则表达式教程(基础)》和《Python 教程中的正则表达式(改进)》
5、通过设置的正则表达式匹配代码中所有匹配的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配到的图片链接,并将所有匹配到的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后,我们可以在这个文件下看到匹配的图片链接,复制任意一个即可打开。
6、一一打开图片链接,下载图片
现在我们已经将所有图片的链接存储在列表中,下一步就是下载图片了。
基本思路是:通过一个for循环遍历列表中的所有链接,以二进制形式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前休眠3秒,每个链接的访问时间最多5秒。如果访问时间超过五秒,我们将判断下载失败,继续下载下一章。图片。
至于为什么我们用二进制打开和写入图片,我们的图片需要经过二进制解析才能被计算机写入。
图片下载代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
至此,一个简单的爬取百度皮卡丘图片的爬虫就完成了,小伙伴们还可以随意更改图片关键词和下载次数,来培养自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
s = requests.session()
s.headers['User-Agent']='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
urls = s.get(url).content.decode('utf-8')
# urls = requests.get(url) # 打开链接
# requests.get(url="https://www.baidu.com/";)
urltext = urls # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout=5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i + 1), urlimg))
imgs.write(img) # 将图片写入
i += 1
if i == 5: # 为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
觉得有用的话记得点赞关注哦!
网页爬虫抓取百度图片(一下网络爬虫的大概论述和介绍,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-17 08:07
上午我们了解了网络爬虫的一般讨论和介绍,了解了网络爬虫的现状和现状。在这篇博文中,我们将通过学习一个爬虫示例来了解更多关于如何使用网络爬虫的知识,并使其对我们更好。更有趣的工作。
例子的目的:通过分析特定的url,下载url路径下的所有图片。由于学习水平有限,本例中没有对url进行循环爬取。
爬取工作主要分为三个步骤:
1、获取页面源代码
2、分析源码,找到源码中的图片标签
3、网络编程,下载图片
首先,我们来看看项目的整体结构:
示例如下:
package cn.edu.lnu.crawler;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Util {
// 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
// 获取html内容
public static String getHTML(String srcUrl) throws Exception {
URL url = new URL(srcUrl);
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line = null;
StringBuffer buffer = new StringBuffer();
while ((line = br.readLine()) != null) {
buffer.append(line);
buffer.append("\n");
}
br.close();
isr.close();
is.close();
return buffer.toString();
}
// 获取image url地址
public static List getImageURL(String html) {
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List list = new ArrayList();
while (matcher.find()) {
list.add(matcher.group());
}
return list;
}
// 获取image src地址
public static List getImageSrc(List listUrl) {
List listSrc = new ArrayList();
for (String img : listUrl) {
Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(img);
while (matcher.find()) {
listSrc.add(matcher.group().substring(0,
matcher.group().length() - 1));
}
}
return listSrc;
}
// 下载图片
private static void Download(List listImgSrc) {
try {
// 开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
// 开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1,
url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File(imageName));// 文件输出流
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
// 关闭流
in.close();
fo.close();
System.out.println(imageName + "下载完成");
// 结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
public static void main(String[] args) throws Exception {
String html = getHTML(URL);
List listUrl = getImageURL(html);
/*
* for(String img : listUrl){ System.out.println(img); }
*/
List listSrc = getImageSrc(listUrl);
/*
* for(String img : listSrc){ System.out.println(img); }
*/
Download(listSrc);
}
}
下载结果如下图所示:
接下来我会继续研究爬虫技术,把我的学习总结记录在博客上。欢迎来到我的下一个博客。 查看全部
网页爬虫抓取百度图片(一下网络爬虫的大概论述和介绍,你了解多少?)
上午我们了解了网络爬虫的一般讨论和介绍,了解了网络爬虫的现状和现状。在这篇博文中,我们将通过学习一个爬虫示例来了解更多关于如何使用网络爬虫的知识,并使其对我们更好。更有趣的工作。
例子的目的:通过分析特定的url,下载url路径下的所有图片。由于学习水平有限,本例中没有对url进行循环爬取。
爬取工作主要分为三个步骤:
1、获取页面源代码
2、分析源码,找到源码中的图片标签
3、网络编程,下载图片
首先,我们来看看项目的整体结构:

示例如下:
package cn.edu.lnu.crawler;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Util {
// 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
// 获取html内容
public static String getHTML(String srcUrl) throws Exception {
URL url = new URL(srcUrl);
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line = null;
StringBuffer buffer = new StringBuffer();
while ((line = br.readLine()) != null) {
buffer.append(line);
buffer.append("\n");
}
br.close();
isr.close();
is.close();
return buffer.toString();
}
// 获取image url地址
public static List getImageURL(String html) {
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List list = new ArrayList();
while (matcher.find()) {
list.add(matcher.group());
}
return list;
}
// 获取image src地址
public static List getImageSrc(List listUrl) {
List listSrc = new ArrayList();
for (String img : listUrl) {
Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(img);
while (matcher.find()) {
listSrc.add(matcher.group().substring(0,
matcher.group().length() - 1));
}
}
return listSrc;
}
// 下载图片
private static void Download(List listImgSrc) {
try {
// 开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
// 开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1,
url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File(imageName));// 文件输出流
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
// 关闭流
in.close();
fo.close();
System.out.println(imageName + "下载完成");
// 结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
public static void main(String[] args) throws Exception {
String html = getHTML(URL);
List listUrl = getImageURL(html);
/*
* for(String img : listUrl){ System.out.println(img); }
*/
List listSrc = getImageSrc(listUrl);
/*
* for(String img : listSrc){ System.out.println(img); }
*/
Download(listSrc);
}
}
下载结果如下图所示:


接下来我会继续研究爬虫技术,把我的学习总结记录在博客上。欢迎来到我的下一个博客。
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-15 08:19
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量都控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量都控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(网站快速被蜘蛛方法网站及页面权重具权威性、权威性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-28 00:17
1.关键词 是重中之重
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。因此,关键词是SEO优化的核心。
2.外链也会影响权重
外链是SEO优化的过程之一,其作用是间接影响网站的权重。常用的链接有:锚文本链接、纯文本链接和图片链接。
3.如何被爬虫爬取?
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。比如百度的蜘蛛在抓取网页时需要定义网页,对网页数据进行过滤和分析。
对于页面来说,爬取是收录的前提,越爬越多收录。如果网站页面更新频繁,爬虫会频繁访问该页面,优质内容,尤其是原创,是爬虫喜欢爬取的目标。
网站快被蜘蛛爬到
1.网站 和页面权重
权威高权重老网站享受VIP级待遇。这类网站爬取频率高,爬取页面多,爬取深度高,收录页面相对较多,就是这样的区别对待。
2.网站服务器
网站服务器是访问网站的基石。如果长时间打不开门,就相当于敲了很久的门。如果没有人回应,访客会因为无法进入而陆续离开。蜘蛛访问也是访客之一。如果服务器不稳定,蜘蛛每次抓取页面都会受到阻碍,蜘蛛对网站的印象会越来越差,导致评分越来越低,自然排名也越来越低。
3.网站的更新频率
网站内容更新频繁,会更频繁地吸引蜘蛛访问。定期更新文章,蜘蛛会定期访问。每次爬虫爬取时,页面数据都存入库中,分析后收录页面。如果每次爬虫都发现收录的内容完全一样,爬虫就会判断网站,从而减少网站的爬取。
原创 4.文章 的性别
蜘蛛存在的根本目的是寻找有价值的“新”事物,所以原创的优质内容对蜘蛛的吸引力是巨大的。如果你能得到蜘蛛之类的东西,你自然会把网站标记为“优秀”,并定期爬取网站。
5.展平网站结构
蜘蛛爬行有自己的规则。如果藏得太深,蜘蛛就找不到路了。爬虫程序是个直截了当的东西,所以网站结构不要太复杂。
6.网站节目
在网站的构建中,程序会产生大量的页面。页面一般是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成内容大量重复,影响蜘蛛抓取。如果一个页面对应多个 URL,尝试通过 301 重定向、Canonical 标签或机器人进行处理,以确保蜘蛛只抓取一个标准 URL。
7.外链搭建
对于新站来说,在建设初期,人流量比较少,蜘蛛的光顾也比较少。外链可以增加网站页面的曝光率,增加蜘蛛的爬取,但是要注意外链的质量。
8.内链构造 查看全部
网页爬虫抓取百度图片(网站快速被蜘蛛方法网站及页面权重具权威性、权威性)
1.关键词 是重中之重
关键词的具体作用是在搜索引擎中排名,让用户尽快找到我的网站。因此,关键词是SEO优化的核心。
2.外链也会影响权重
外链是SEO优化的过程之一,其作用是间接影响网站的权重。常用的链接有:锚文本链接、纯文本链接和图片链接。
3.如何被爬虫爬取?
网络爬虫是一种自动提取网页的程序,是搜索引擎的重要组成部分。比如百度的蜘蛛在抓取网页时需要定义网页,对网页数据进行过滤和分析。
对于页面来说,爬取是收录的前提,越爬越多收录。如果网站页面更新频繁,爬虫会频繁访问该页面,优质内容,尤其是原创,是爬虫喜欢爬取的目标。
网站快被蜘蛛爬到
1.网站 和页面权重
权威高权重老网站享受VIP级待遇。这类网站爬取频率高,爬取页面多,爬取深度高,收录页面相对较多,就是这样的区别对待。
2.网站服务器
网站服务器是访问网站的基石。如果长时间打不开门,就相当于敲了很久的门。如果没有人回应,访客会因为无法进入而陆续离开。蜘蛛访问也是访客之一。如果服务器不稳定,蜘蛛每次抓取页面都会受到阻碍,蜘蛛对网站的印象会越来越差,导致评分越来越低,自然排名也越来越低。
3.网站的更新频率
网站内容更新频繁,会更频繁地吸引蜘蛛访问。定期更新文章,蜘蛛会定期访问。每次爬虫爬取时,页面数据都存入库中,分析后收录页面。如果每次爬虫都发现收录的内容完全一样,爬虫就会判断网站,从而减少网站的爬取。
原创 4.文章 的性别
蜘蛛存在的根本目的是寻找有价值的“新”事物,所以原创的优质内容对蜘蛛的吸引力是巨大的。如果你能得到蜘蛛之类的东西,你自然会把网站标记为“优秀”,并定期爬取网站。
5.展平网站结构
蜘蛛爬行有自己的规则。如果藏得太深,蜘蛛就找不到路了。爬虫程序是个直截了当的东西,所以网站结构不要太复杂。
6.网站节目
在网站的构建中,程序会产生大量的页面。页面一般是通过参数来实现的。一定要保证一个页面对应一个URL,否则会造成内容大量重复,影响蜘蛛抓取。如果一个页面对应多个 URL,尝试通过 301 重定向、Canonical 标签或机器人进行处理,以确保蜘蛛只抓取一个标准 URL。
7.外链搭建
对于新站来说,在建设初期,人流量比较少,蜘蛛的光顾也比较少。外链可以增加网站页面的曝光率,增加蜘蛛的爬取,但是要注意外链的质量。
8.内链构造
网页爬虫抓取百度图片(西安网站多少钱,推荐阅读(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-28 00:17
我所在的网站是一个很大的网站,百度收录3000万,百度爬取总次数约为每天500w次,百度收录单页率80%,看起来是个不错的数据,但是如果分析详细的日志文件,还是可以发现一些问题,
1.大规模网站列表页面通常会设置多个过滤条件(Facet Navigation),以方便用户找到需要的信息,但爬虫还不够智能,无法独立判断哪些条件可以组合和哪些条件 把它们结合起来是没有意义的。只要代码中有链接,就会被爬取,导致百度爬虫在列表过滤页面上耗费大量资源。分析1个月的数据发现百度30%的爬取量消耗在列表页上,但列表页带来的百度自然流量只占百度所有自然流量的2%,所以< @网站 也就是说,爬虫的输入输出很低。西安网站多少钱,推荐阅读>>
2.重复爬取现象严重。我个人认为对于网站来说,爬虫只爬过一次(Distinct Crawl)的页面是最有价值的,因为对于内容质量好的页面,只要爬过一次, 收录 几率超过 80%。如果页面本身质量不好,就算爬了几十次,也不会是收录。继续分析我们的网站的数据,我们发现百度爬虫每天500万次的爬取中,有一半以上是同一页面的多次爬取。如果这些重复爬取能够转移到那些一次性爬取的页面上,对于网站来说无疑更有价值。网站制作公司西安,做网站
如何解决这两个问题?
让我们谈谈第一个。对于过滤页面消耗爬虫资源的问题,很多人建议使用nofollow标签告诉爬虫不要继续给这些页面分配权重,我们已经这样做了。然而,事实证明,百度爬虫对nofollow并不敏感。使用后,爬虫依然在疯狂爬行,同时也没有将权重从筛选页面转移到规范页面。
无奈之下,我们不得不考虑使用 SEO 的大杀手:Robots 文件来禁止所有被过滤的页面。我们之前之所以没有使用robots禁止爬取,是担心如果爬虫被禁止爬取列表,是否会被禁止爬虫爬取列表。其他页面也爬不上去?毕竟列表过滤页还是会为单页贡献很多条目,但是基于我们的网站单页收录还不错的现状,我们决定试一试. 西安网站施工推荐读物>>>智能使用机器人避开蜘蛛黑洞-百度站长平台资讯,
事实证明,效果非常明显。新版robots上线三天后,列表页爬虫的爬取量已经下降到15%;同时,之前令人担忧的问题也没有出现。大约在同一时间,单个页面的爬取量也增加了 20%,这算是达到了我们预期的目标:将浪费在列表页面上的爬虫资源转移到其他需要爬取的页面上。
但是如何证明爬取的资源被转移到了需要爬取的页面上,这恰好是前面提到的第二个问题,我们看的是唯一爬取率(只爬取一次的页面数/总数爬取率)从 50% 提高到 74%,这意味着爬虫在读取 robots 文件后,对爬虫资源进行了更合理的分配,爬取的单页也更多。西安做网站推荐阅读>>>带你玩转机器人协议,新手必玩,
总结:相对于其他方法,Robots文件可以在比较短的时间内优化百度爬虫的资源分配,但这必须基于网站本身结构好,传递内容。同时,最重要的是要通过对实际情况的日志分析,反复测试和调整以达到最佳效果。来自百度站长社区 查看全部
网页爬虫抓取百度图片(西安网站多少钱,推荐阅读(组图))
我所在的网站是一个很大的网站,百度收录3000万,百度爬取总次数约为每天500w次,百度收录单页率80%,看起来是个不错的数据,但是如果分析详细的日志文件,还是可以发现一些问题,
1.大规模网站列表页面通常会设置多个过滤条件(Facet Navigation),以方便用户找到需要的信息,但爬虫还不够智能,无法独立判断哪些条件可以组合和哪些条件 把它们结合起来是没有意义的。只要代码中有链接,就会被爬取,导致百度爬虫在列表过滤页面上耗费大量资源。分析1个月的数据发现百度30%的爬取量消耗在列表页上,但列表页带来的百度自然流量只占百度所有自然流量的2%,所以< @网站 也就是说,爬虫的输入输出很低。西安网站多少钱,推荐阅读>>
2.重复爬取现象严重。我个人认为对于网站来说,爬虫只爬过一次(Distinct Crawl)的页面是最有价值的,因为对于内容质量好的页面,只要爬过一次, 收录 几率超过 80%。如果页面本身质量不好,就算爬了几十次,也不会是收录。继续分析我们的网站的数据,我们发现百度爬虫每天500万次的爬取中,有一半以上是同一页面的多次爬取。如果这些重复爬取能够转移到那些一次性爬取的页面上,对于网站来说无疑更有价值。网站制作公司西安,做网站
如何解决这两个问题?
让我们谈谈第一个。对于过滤页面消耗爬虫资源的问题,很多人建议使用nofollow标签告诉爬虫不要继续给这些页面分配权重,我们已经这样做了。然而,事实证明,百度爬虫对nofollow并不敏感。使用后,爬虫依然在疯狂爬行,同时也没有将权重从筛选页面转移到规范页面。
无奈之下,我们不得不考虑使用 SEO 的大杀手:Robots 文件来禁止所有被过滤的页面。我们之前之所以没有使用robots禁止爬取,是担心如果爬虫被禁止爬取列表,是否会被禁止爬虫爬取列表。其他页面也爬不上去?毕竟列表过滤页还是会为单页贡献很多条目,但是基于我们的网站单页收录还不错的现状,我们决定试一试. 西安网站施工推荐读物>>>智能使用机器人避开蜘蛛黑洞-百度站长平台资讯,
事实证明,效果非常明显。新版robots上线三天后,列表页爬虫的爬取量已经下降到15%;同时,之前令人担忧的问题也没有出现。大约在同一时间,单个页面的爬取量也增加了 20%,这算是达到了我们预期的目标:将浪费在列表页面上的爬虫资源转移到其他需要爬取的页面上。
但是如何证明爬取的资源被转移到了需要爬取的页面上,这恰好是前面提到的第二个问题,我们看的是唯一爬取率(只爬取一次的页面数/总数爬取率)从 50% 提高到 74%,这意味着爬虫在读取 robots 文件后,对爬虫资源进行了更合理的分配,爬取的单页也更多。西安做网站推荐阅读>>>带你玩转机器人协议,新手必玩,
总结:相对于其他方法,Robots文件可以在比较短的时间内优化百度爬虫的资源分配,但这必须基于网站本身结构好,传递内容。同时,最重要的是要通过对实际情况的日志分析,反复测试和调整以达到最佳效果。来自百度站长社区
网页爬虫抓取百度图片(网站如何快速被百度蜘蛛快速和抓取方法蜘蛛抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-28 00:14
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就为大家介绍一下网站如何让百度蜘蛛快速爬取及爬取方法。
网站如何被爬虫快速抓取1、关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO优化的核心,也是网站在搜索引擎中排名的重要因素。
2、外部链接也会影响权重
网站入站链接也是优化网站的一个非常重要的过程,而外部链接可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3、如何被爬虫爬取
爬虫和蜘蛛其实是同一个东西,只是名字不同而已。是一个自动提取网页的程序,比如百度蜘蛛、360蜘蛛、搜狗蜘蛛等。如果你想让你的网站中的页面多为收录,收录中的网页@网站 必须先被蜘蛛爬行。
如果你的网站页面更新频繁,爬虫会更频繁地访问你的页面,优质的内容页面是蜘蛛喜欢爬取的目标,尤其是原创内容。 查看全部
网页爬虫抓取百度图片(网站如何快速被百度蜘蛛快速和抓取方法蜘蛛抓取)
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。调查显示,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。下面小编就为大家介绍一下网站如何让百度蜘蛛快速爬取及爬取方法。
网站如何被爬虫快速抓取1、关键词是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO优化的核心,也是网站在搜索引擎中排名的重要因素。
2、外部链接也会影响权重
网站入站链接也是优化网站的一个非常重要的过程,而外部链接可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
3、如何被爬虫爬取
爬虫和蜘蛛其实是同一个东西,只是名字不同而已。是一个自动提取网页的程序,比如百度蜘蛛、360蜘蛛、搜狗蜘蛛等。如果你想让你的网站中的页面多为收录,收录中的网页@网站 必须先被蜘蛛爬行。
如果你的网站页面更新频繁,爬虫会更频繁地访问你的页面,优质的内容页面是蜘蛛喜欢爬取的目标,尤其是原创内容。
网页爬虫抓取百度图片(2021-10-20认识爬虫网络爬虫(又称为网页蜘蛛))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-27 06:05
2021-10-20 认识爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫也分为“好爬虫”和“恶意爬虫”,比如谷歌、百度等,每天都有大量的网站,满足用户的需求,这既是用户又是网站非常喜欢,所以被称为善良的爬虫,但像一些“抢票软件”和“非VIP下载”,有时不仅会增加网站的压力,还会导致一些资源隐私泄露,所以我们也称之为“恶意爬虫”。
简单地说,爬虫是一个模拟人类请求网站的行为的程序。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
项目效益
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。所以现在最常见的就是用Python写爬虫,我们可以爬取图片、视频、文字。大数据背后,我们称之为“数据挖掘”,做数据分析,没有数据怎么行。
应用范围广,优势突出。今年疫情的背后,我们依靠大数据的力量进行数据挖掘和清洗,保障了很多人的生命安全。通过大数据,可以跟踪查询人员的行踪,从海量的人员数据中提取有价值的东西。这就是爬行动物的高级用途。
基本思想
发送请求 - 获取页面 - 解析页面 - 存储有价值的信息
每一步都需要扎实的语法基础和使用爬虫库的概念。我们知道如何理解其他代码,知道如何改进别人的缺点,以及如何移植代码来执行我们自己的一些操作。
二是学习阅读第三方库的一些语法,知道如何安装第三方库非常重要。
写好爬虫项目,作为初学者,是非常困难的。一定要读很多别人的优质代码,爬虫项目,懂得改进和优化。这是我们学习的最终目的。当然,在这之前一定要学习一些知识点,不然看不懂代码,怎么优化,哈哈哈哈!
履带技术步骤
爬虫
网络爬虫是自动访问网页的脚本或机器人,它的作用是从网页中抓取原创数据——最终用户在屏幕上看到的各种元素(字符、图片)。它的工作方式就像一个机器人,在网页上带有 ctrl+a(全选)、ctrl+c(复制内容)、ctrl+v(粘贴内容)按钮(当然本质上没那么简单)。
通常,爬虫不会停留在网页上,而是会根据某些预定逻辑在停止之前爬取一系列 URL。例如,它可能会跟踪它找到的每个链接,然后抓取该 网站。当然,在这个过程中,你需要优先考虑你抓取的 网站 的数量,以及你可以为任务投入的资源数量(存储、处理、带宽等)。
解析
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以轻松访问它们并用于其他操作。要将网页转换为对研究或分析真正有用的数据,我们需要以一种使数据易于搜索、排序和基于定义的参数集提供服务的方式对其进行解析。
存储和检索
最后,在获得所需的数据并分解成有用的组件后,有一种可扩展的方法将所有提取和解析的数据存储在数据库或集群中,然后创建一个数据库或集群,让用户能够及时找到相关的数据集方式或提取的特征。
爬行动物是做什么的
1、网络数据采集
使用爬虫自动采集互联网上的信息(图片、文字、链接等),返回后采集进行相应的存储和处理。并根据一定的规则和筛选标准,将数据分类成一个数据库文件的形成过程。但是在这个过程中,你首先需要明确采集你想要什么信息。当你足够准确地采集采集的条件时,采集的内容会更接近你想要的。
2、大数据分析
在大数据时代,要进行数据分析,首先要有数据源,而其他很多数据源都可以通过爬虫技术获取。在进行大数据分析或数据挖掘时,数据源可以从一些提供数据统计的网站中获取,也可以从某些文献或内部数据中获取,但从这些获取数据的方式有时很难满足我们的需求为数据。这时,我们可以利用爬虫技术从互联网上自动获取所需的数据内容,并将这些数据内容作为数据源,进行更深层次的数据分析。
3、网页分析
通过爬取网页数据采集,在获取网站流量、客户登陆页面、网页关键词权重等基础数据的情况下,分析网页数据,找到出访问者访问网站的规律和特点,并将这些规律与网络营销策略相结合,从而发现当前网络营销活动和运营中可能存在的问题和机会,为进一步修正或重新提供依据-制定战略
建议
学习爬虫前的技术准备
Python基础语法:基础语法、运算符、数据类型、过程控制、函数、对象模块、文件操作、多线程、网络编程等。
W3C 标准:HTML、CSS、JavaScript、Xpath、JSON 查看全部
网页爬虫抓取百度图片(2021-10-20认识爬虫网络爬虫(又称为网页蜘蛛))
2021-10-20 认识爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常称为网络追踪器)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫也分为“好爬虫”和“恶意爬虫”,比如谷歌、百度等,每天都有大量的网站,满足用户的需求,这既是用户又是网站非常喜欢,所以被称为善良的爬虫,但像一些“抢票软件”和“非VIP下载”,有时不仅会增加网站的压力,还会导致一些资源隐私泄露,所以我们也称之为“恶意爬虫”。
简单地说,爬虫是一个模拟人类请求网站的行为的程序。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
项目效益
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。所以现在最常见的就是用Python写爬虫,我们可以爬取图片、视频、文字。大数据背后,我们称之为“数据挖掘”,做数据分析,没有数据怎么行。
应用范围广,优势突出。今年疫情的背后,我们依靠大数据的力量进行数据挖掘和清洗,保障了很多人的生命安全。通过大数据,可以跟踪查询人员的行踪,从海量的人员数据中提取有价值的东西。这就是爬行动物的高级用途。
基本思想
发送请求 - 获取页面 - 解析页面 - 存储有价值的信息
每一步都需要扎实的语法基础和使用爬虫库的概念。我们知道如何理解其他代码,知道如何改进别人的缺点,以及如何移植代码来执行我们自己的一些操作。
二是学习阅读第三方库的一些语法,知道如何安装第三方库非常重要。
写好爬虫项目,作为初学者,是非常困难的。一定要读很多别人的优质代码,爬虫项目,懂得改进和优化。这是我们学习的最终目的。当然,在这之前一定要学习一些知识点,不然看不懂代码,怎么优化,哈哈哈哈!
履带技术步骤
爬虫
网络爬虫是自动访问网页的脚本或机器人,它的作用是从网页中抓取原创数据——最终用户在屏幕上看到的各种元素(字符、图片)。它的工作方式就像一个机器人,在网页上带有 ctrl+a(全选)、ctrl+c(复制内容)、ctrl+v(粘贴内容)按钮(当然本质上没那么简单)。
通常,爬虫不会停留在网页上,而是会根据某些预定逻辑在停止之前爬取一系列 URL。例如,它可能会跟踪它找到的每个链接,然后抓取该 网站。当然,在这个过程中,你需要优先考虑你抓取的 网站 的数量,以及你可以为任务投入的资源数量(存储、处理、带宽等)。
解析
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以轻松访问它们并用于其他操作。要将网页转换为对研究或分析真正有用的数据,我们需要以一种使数据易于搜索、排序和基于定义的参数集提供服务的方式对其进行解析。
存储和检索
最后,在获得所需的数据并分解成有用的组件后,有一种可扩展的方法将所有提取和解析的数据存储在数据库或集群中,然后创建一个数据库或集群,让用户能够及时找到相关的数据集方式或提取的特征。
爬行动物是做什么的
1、网络数据采集
使用爬虫自动采集互联网上的信息(图片、文字、链接等),返回后采集进行相应的存储和处理。并根据一定的规则和筛选标准,将数据分类成一个数据库文件的形成过程。但是在这个过程中,你首先需要明确采集你想要什么信息。当你足够准确地采集采集的条件时,采集的内容会更接近你想要的。
2、大数据分析
在大数据时代,要进行数据分析,首先要有数据源,而其他很多数据源都可以通过爬虫技术获取。在进行大数据分析或数据挖掘时,数据源可以从一些提供数据统计的网站中获取,也可以从某些文献或内部数据中获取,但从这些获取数据的方式有时很难满足我们的需求为数据。这时,我们可以利用爬虫技术从互联网上自动获取所需的数据内容,并将这些数据内容作为数据源,进行更深层次的数据分析。
3、网页分析
通过爬取网页数据采集,在获取网站流量、客户登陆页面、网页关键词权重等基础数据的情况下,分析网页数据,找到出访问者访问网站的规律和特点,并将这些规律与网络营销策略相结合,从而发现当前网络营销活动和运营中可能存在的问题和机会,为进一步修正或重新提供依据-制定战略
建议
学习爬虫前的技术准备
Python基础语法:基础语法、运算符、数据类型、过程控制、函数、对象模块、文件操作、多线程、网络编程等。
W3C 标准:HTML、CSS、JavaScript、Xpath、JSON
网页爬虫抓取百度图片(现阶段深度学习有关的安装对应版本介绍参考网站如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-26 02:08
2022-01-07
我正忙着找工作,现阶段我在同一个家庭。诚然,同事都是老板,我讲解了很多关于深度学习的知识。不过,我是菜鸟,因为公司的人工智能工作需要更多的图片。而我目前只知道爬虫,所以现阶段由公司的爬虫负责抓图。当然,百度图片很好抓。我还写了一个很好的代码来捕获。如有需要,您可以留言。作者在这里提供了完整的代码,这里就不分享百度图片的截图了。谷歌图片爬虫的作者还是想在这里分享一下,因为毕竟我花了一点时间才做出来的。
之所以要分享源码,是因为我发现网上关于爬取谷歌图片的介绍很少,而且有一个分享代码是加密收费mmp的。不要在意它是否有点低。废话不多说,直接说代码吧。
准备一:
对应版本的Chromedriver安装请参考网站如下:
https://blog.csdn.net/yoyocat9 ... 80066 # 参考版本【转载yoyocat915】
http://chromedriver.storage.go ... .html # 对应版本下载
因为我之前的工作中没有硒,所以我今天才用它
2. 准备2:
上网准备,如果贵公司有,就不用买了。不想科学上网的可以去这个网站买一波广告。
https://e.2333.tn/ #购买的过程在这里就不介绍了
购买后调试。在这里,笔者被公司外网坑了不少。他直接提议在那儿坑,免得你被坑。
第一步:先调试成全局模式,否则只有谷歌可以访问外网,所以不能用其他浏览器访问外网(个人理解)
第 2 步:检查您使用的端口
ok 到这里几步就可以开始编码了,接下来分析下如何使用selenium+chrome进行抓图。共享代码如下。如果你对selenium的使用不是很熟练,基础教程就不在这里分享了,因为我也在学习过程中。代码流共享如下:
在此之前先介绍一下图片存储的用法:
urllib.request.urlretrieve(图片的路径.jpg结尾\图片的base64编码,‘储存的位置)
可以参考博客:https://blog.csdn.net/wuguangb ... 80058
好的初始代码版本 1.0
import os
import time
import urllib
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window()
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url: #仅仅就第一页可以,其他误判这个代码不是完整的是作者的错代码。
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
这里遇到的坑如下:
截图一:
前20张图片的src显示的是base64编码,所以可以直接用上面的代码解决,但是你后面的图片的src是什么?如下所示
这里既不是 base64 也不是 .jpg。我如何在这里保存它?你用
self.browser.get(图片的地址)
img_source = self.browser.page_source
继续经历这个?如果你这样想,那你就错了,因为我们还是拿到了完整的页面,那么这个时候我们该怎么办呢?想到我们最初使用requests来请求图片地址,这时候作者就简单的尝试着拿出一个单独的图片src去请求,不加代理就错了。因此,添加代理会导致以下结果:
import time
import requests
proxy = {"https": "https://127.0.0.1:8787"} //端口作者在前边的坑已经介绍了需要外网的端口
response = requests.get(
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTwwkW09Hrnq5DOzSYAKqrxv3uGjbQzoCRP28AOF03pzJ2uFObS',
proxies=proxy, verify=False)
with open('./image%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
结果就是想要的结果
那么你知道如何修改上面的代码吗?哈哈哈可能有点乱
修改代码如下:
import os
import time
import urllib
import requests
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.proxy = {"https": "https://127.0.0.1:8787"} #初始化代理
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window() #最大的适应屏幕
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url:
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
else: #在这里添加一个不久行了吗?如果图片的链接不是base64的
response = requests.get(each_url,proxies=self.proxy, verify=False)
with open('D:\GoogleImgDownLoad\%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
以上就是分享的结束。当然,直接使用requests模块+代理更方便。百度的爬虫这里就不分享了。如果你想联系源代码的作者,我会分享给你。当然,美中不足的是,这里不需要对图片进行去重,非常简单。不知道你有没有什么想法。无论如何,作者在这里有想法。已经是深夜了,我们睡个午觉吧。
分类:
技术要点:
相关文章: 查看全部
网页爬虫抓取百度图片(现阶段深度学习有关的安装对应版本介绍参考网站如下)
2022-01-07
我正忙着找工作,现阶段我在同一个家庭。诚然,同事都是老板,我讲解了很多关于深度学习的知识。不过,我是菜鸟,因为公司的人工智能工作需要更多的图片。而我目前只知道爬虫,所以现阶段由公司的爬虫负责抓图。当然,百度图片很好抓。我还写了一个很好的代码来捕获。如有需要,您可以留言。作者在这里提供了完整的代码,这里就不分享百度图片的截图了。谷歌图片爬虫的作者还是想在这里分享一下,因为毕竟我花了一点时间才做出来的。
之所以要分享源码,是因为我发现网上关于爬取谷歌图片的介绍很少,而且有一个分享代码是加密收费mmp的。不要在意它是否有点低。废话不多说,直接说代码吧。
准备一:
对应版本的Chromedriver安装请参考网站如下:
https://blog.csdn.net/yoyocat9 ... 80066 # 参考版本【转载yoyocat915】
http://chromedriver.storage.go ... .html # 对应版本下载
因为我之前的工作中没有硒,所以我今天才用它
2. 准备2:
上网准备,如果贵公司有,就不用买了。不想科学上网的可以去这个网站买一波广告。
https://e.2333.tn/ #购买的过程在这里就不介绍了
购买后调试。在这里,笔者被公司外网坑了不少。他直接提议在那儿坑,免得你被坑。
第一步:先调试成全局模式,否则只有谷歌可以访问外网,所以不能用其他浏览器访问外网(个人理解)
第 2 步:检查您使用的端口
ok 到这里几步就可以开始编码了,接下来分析下如何使用selenium+chrome进行抓图。共享代码如下。如果你对selenium的使用不是很熟练,基础教程就不在这里分享了,因为我也在学习过程中。代码流共享如下:
在此之前先介绍一下图片存储的用法:
urllib.request.urlretrieve(图片的路径.jpg结尾\图片的base64编码,‘储存的位置)
可以参考博客:https://blog.csdn.net/wuguangb ... 80058
好的初始代码版本 1.0
import os
import time
import urllib
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window()
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url: #仅仅就第一页可以,其他误判这个代码不是完整的是作者的错代码。
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
这里遇到的坑如下:
截图一:
前20张图片的src显示的是base64编码,所以可以直接用上面的代码解决,但是你后面的图片的src是什么?如下所示
这里既不是 base64 也不是 .jpg。我如何在这里保存它?你用
self.browser.get(图片的地址)
img_source = self.browser.page_source
继续经历这个?如果你这样想,那你就错了,因为我们还是拿到了完整的页面,那么这个时候我们该怎么办呢?想到我们最初使用requests来请求图片地址,这时候作者就简单的尝试着拿出一个单独的图片src去请求,不加代理就错了。因此,添加代理会导致以下结果:
import time
import requests
proxy = {"https": "https://127.0.0.1:8787"} //端口作者在前边的坑已经介绍了需要外网的端口
response = requests.get(
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTwwkW09Hrnq5DOzSYAKqrxv3uGjbQzoCRP28AOF03pzJ2uFObS',
proxies=proxy, verify=False)
with open('./image%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
结果就是想要的结果
那么你知道如何修改上面的代码吗?哈哈哈可能有点乱
修改代码如下:
import os
import time
import urllib
import requests
from scrapy import Selector
from selenium import webdriver
class GoogleImgCrawl:
def __init__(self):
self.proxy = {"https": "https://127.0.0.1:8787"} #初始化代理
self.browser = webdriver.Chrome('F:\MyDownloads\chromedriver.exe')
self.browser.maximize_window() #最大的适应屏幕
self.key_world = input('Please input the content of the picture you want to grab >:')
self.img_path = r'D:\GoogleImgDownLoad' # 下载到的本地目录
if not os.path.exists(self.img_path): # 路径不存在时创建一个
os.makedirs(self.img_path)
def start_crawl(self):
self.browser.get('https://www.google.com/search?q=%s' % self.key_world)
self.browser.implicitly_wait(3) # 隐形等待时间
self.browser.find_element_by_xpath('//a[@class="iu-card-header"]').click() # 找到图片的链接点击进去
time.sleep(3) # 休眠3秒使其加载完毕
img_source = self.browser.page_source
img_source = Selector(text=img_source)
self.img_down(img_source) # 第一次下载图片
self.slide_down() # 向下滑动继续加载图片
def slide_down(self):
for i in range(7, 20): # 自己可以任意设置
pos = i * 500 # 每次向下滑动500
js = "document.documentElement.scrollTop=%s" % pos
self.browser.execute_script(js)
time.sleep(3)
img_source = Selector(text=self.browser.page_source)
self.img_down(img_source)
def img_down(self, img_source):
img_url_list = img_source.xpath('//div[@class="THL2l"]/../img/@src').extract()
for each_url in img_url_list:
if 'https' not in each_url:
# print(each_url)
each_img_source = urllib.request.urlretrieve(each_url,
'%s/%s.jpg' % (self.img_path, time.time())) # 储存图片
else: #在这里添加一个不久行了吗?如果图片的链接不是base64的
response = requests.get(each_url,proxies=self.proxy, verify=False)
with open('D:\GoogleImgDownLoad\%s.jpg' % time.time(), 'wb')as f:
f.write(response.content)
if __name__ == '__main__':
google_img = GoogleImgCrawl()
google_img.start_crawl()
以上就是分享的结束。当然,直接使用requests模块+代理更方便。百度的爬虫这里就不分享了。如果你想联系源代码的作者,我会分享给你。当然,美中不足的是,这里不需要对图片进行去重,非常简单。不知道你有没有什么想法。无论如何,作者在这里有想法。已经是深夜了,我们睡个午觉吧。
分类:
技术要点:
相关文章:
网页爬虫抓取百度图片(我们先来直接分析代码:[python]__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-26 02:04
2022-01-07
在上一次爬虫中,主要是使用第三方Beautifulsoup库来爬取数据,然后通过选择器在网页中找到每一个具体的数据,每个类别都有一个select方法。接触过网页的人都知道,很多有用的数据都放在一个共同的父节点上,但它的子节点却不同。在上一次爬虫中,每类数据都必须从其父类(包括其父节点的父节点)中找到ROI数据所在的子节点,这会使爬虫非常臃肿,因为很多数据具有相同的父节点,每次都必须重复找到。这种爬行动物效率低下。
因此,作者在上次的基础上改进了爬取策略,并举例说明。
如图,作者这次爬取了百度音乐的页面,爬取的内容就是上面列表下的所有内容(歌名、歌手、排名)。如果按照最后一个爬虫的方式,就得写三个select方法来分别抓取歌名、歌手、排名,但是作者观察到这三个数据都放在了一个li标签中,如图:
这样,我们是不是直接抓取ul标签,然后分析里面的数据,得到所有的数据呢?答案当然是。
但是 Beaufulsoup 不能直接提供这样的方法,但是 Python 是无所不能的,而 Python 自带的 re 模块是我见过的最引人入胜的模块之一。它可以在字符串中找到我们让我们 roi 的区域。上面的 li 标签收录了我们需要的歌曲名称、歌手和排名数据。我们只需要使用 li 标签中的 re.findall() 方法就可以找到它。我们需要的数据。这样可以大大提高我们爬虫的效率。
我们直接分析代码:
[python]viewplain
defparse_one_page(html):soup=BeautifulSoup(html,'lxml')data=soup.select('div.ranklist-wrapper.clearfixdiv.bdul.song-listli')pattern1=pile(r'(.*?)
.*?title="(.*?)".*?title="(.*?)".*?',re.S)pattern2=pile(r'(.*?) 查看全部
网页爬虫抓取百度图片(我们先来直接分析代码:[python]__)
2022-01-07
在上一次爬虫中,主要是使用第三方Beautifulsoup库来爬取数据,然后通过选择器在网页中找到每一个具体的数据,每个类别都有一个select方法。接触过网页的人都知道,很多有用的数据都放在一个共同的父节点上,但它的子节点却不同。在上一次爬虫中,每类数据都必须从其父类(包括其父节点的父节点)中找到ROI数据所在的子节点,这会使爬虫非常臃肿,因为很多数据具有相同的父节点,每次都必须重复找到。这种爬行动物效率低下。
因此,作者在上次的基础上改进了爬取策略,并举例说明。
如图,作者这次爬取了百度音乐的页面,爬取的内容就是上面列表下的所有内容(歌名、歌手、排名)。如果按照最后一个爬虫的方式,就得写三个select方法来分别抓取歌名、歌手、排名,但是作者观察到这三个数据都放在了一个li标签中,如图:
这样,我们是不是直接抓取ul标签,然后分析里面的数据,得到所有的数据呢?答案当然是。
但是 Beaufulsoup 不能直接提供这样的方法,但是 Python 是无所不能的,而 Python 自带的 re 模块是我见过的最引人入胜的模块之一。它可以在字符串中找到我们让我们 roi 的区域。上面的 li 标签收录了我们需要的歌曲名称、歌手和排名数据。我们只需要使用 li 标签中的 re.findall() 方法就可以找到它。我们需要的数据。这样可以大大提高我们爬虫的效率。
我们直接分析代码:
[python]viewplain
defparse_one_page(html):soup=BeautifulSoup(html,'lxml')data=soup.select('div.ranklist-wrapper.clearfixdiv.bdul.song-listli')pattern1=pile(r'(.*?)
.*?title="(.*?)".*?title="(.*?)".*?',re.S)pattern2=pile(r'(.*?)
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-25 15:09
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片html
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,只是请求方法比较简单,还有一些正则表达式
不要忘记爬虫的基本思想:函数
1.指定要抓取的连接然后抓取网站源码网站
2.提取你想要的内容,比如你想爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签的方法代码
3.循环获取要爬取的内容列表,保存文件url
这里的代码和我博客前几章的代码区别(图片爬虫系列一)是:spa
1.reques库代码用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀为htm
3.保存图片时不要使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片博客
具体代码如下图所示:
1 # 使用requests、bs4库下载华侨大学主页上的全部图片
2 import os
3 import requests
4 from bs4 import BeautifulSoup
5 import shutil
6 from pathlib import Path # 关于文件路径操做的库,这里主要为了获得图片后缀名
7
8
9 # 该方法传入url,返回url的html的源代码
10 def getHtmlCode(url):
11 # 假装请求的头部来隐藏本身
12 headers = {
13 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0'
14 }
15 # 获取网页
16 r = requests.get(url, headers=headers)
17 # 指定网页解析的编码格式
18 r.encoding = 'UTF-8'
19 # 获取url页面的源代码字符串文本
20 page = r.text
21 return page
22
23
24 # 该方法传入html的源代码,经过截取其中的img标签,将图片保存到本机
25 def getImg(page, localPath):
26 # 判断文件夹是否存在,存在则删除,最后都要从新新的文件夹
27 if os.path.exists(localPath):
28 shutil.rmtree(localPath)
29 os.mkdir(localPath)
30
31 # 按照Html格式解析页面
32 soup = BeautifulSoup(page, 'html.parser')
33 # 返回的是一个包含全部img标签的列表
34 imgList = soup.find_all('img')
35 x = 0
36 # 循环url列表
37 for imgUrl in imgList:
38 try:
39 # 获得img标签中的src具体内容
40 imgUrl_src = imgUrl.get('src')
41 # 排除 src='' 的状况
42 if imgUrl_src != '':
43 print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src))
44 # 判断图片是不是从绝对路径https开始,具体为何这样操做能够看下图所示
45 if "https://" not in imgUrl_src:
46 m = 'https://www.hqu.edu.cn/' + imgUrl_src
47 print('正在下载: %s' % m)
48 # 获取图片
49 ir = requests.get(m)
50 else:
51 ir = requests.get(imgUrl_src)
52 # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名
53 p = Path(imgUrl_src)
54 # 获得后缀,返回的是如 '.jpg'
55 p_suffix = p.suffix
56 # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称
57 open(localPath + str(x) + p_suffix, 'wb').write(ir.content)
58 x = x + 1
59 except:
60 continue
61
62
63 if __name__ == '__main__':
64 # 指定爬取图片连接
65 url = 'https://www.hqu.edu.cn/index.htm'
66 # 指定存储图片路径
67 localPath = './img/'
68 # 获得网页源代码
69 page = getHtmlCode(url)
70 # 保存图片
71 getImg(page, localPath)
注意我们之所以判断图片链接是否从“https://”开始,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一张图片,然后点击html所在的代码。 ,鼠标悬停,可以看到绝对路径,然后根据这个绝对路径设置要添加的缺失部分,如下图:
查看全部
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生)
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片html
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,只是请求方法比较简单,还有一些正则表达式
不要忘记爬虫的基本思想:函数
1.指定要抓取的连接然后抓取网站源码网站
2.提取你想要的内容,比如你想爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签的方法代码
3.循环获取要爬取的内容列表,保存文件url
这里的代码和我博客前几章的代码区别(图片爬虫系列一)是:spa
1.reques库代码用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀为htm
3.保存图片时不要使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片博客
具体代码如下图所示:
1 # 使用requests、bs4库下载华侨大学主页上的全部图片
2 import os
3 import requests
4 from bs4 import BeautifulSoup
5 import shutil
6 from pathlib import Path # 关于文件路径操做的库,这里主要为了获得图片后缀名
7
8
9 # 该方法传入url,返回url的html的源代码
10 def getHtmlCode(url):
11 # 假装请求的头部来隐藏本身
12 headers = {
13 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0'
14 }
15 # 获取网页
16 r = requests.get(url, headers=headers)
17 # 指定网页解析的编码格式
18 r.encoding = 'UTF-8'
19 # 获取url页面的源代码字符串文本
20 page = r.text
21 return page
22
23
24 # 该方法传入html的源代码,经过截取其中的img标签,将图片保存到本机
25 def getImg(page, localPath):
26 # 判断文件夹是否存在,存在则删除,最后都要从新新的文件夹
27 if os.path.exists(localPath):
28 shutil.rmtree(localPath)
29 os.mkdir(localPath)
30
31 # 按照Html格式解析页面
32 soup = BeautifulSoup(page, 'html.parser')
33 # 返回的是一个包含全部img标签的列表
34 imgList = soup.find_all('img')
35 x = 0
36 # 循环url列表
37 for imgUrl in imgList:
38 try:
39 # 获得img标签中的src具体内容
40 imgUrl_src = imgUrl.get('src')
41 # 排除 src='' 的状况
42 if imgUrl_src != '':
43 print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src))
44 # 判断图片是不是从绝对路径https开始,具体为何这样操做能够看下图所示
45 if "https://" not in imgUrl_src:
46 m = 'https://www.hqu.edu.cn/' + imgUrl_src
47 print('正在下载: %s' % m)
48 # 获取图片
49 ir = requests.get(m)
50 else:
51 ir = requests.get(imgUrl_src)
52 # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名
53 p = Path(imgUrl_src)
54 # 获得后缀,返回的是如 '.jpg'
55 p_suffix = p.suffix
56 # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称
57 open(localPath + str(x) + p_suffix, 'wb').write(ir.content)
58 x = x + 1
59 except:
60 continue
61
62
63 if __name__ == '__main__':
64 # 指定爬取图片连接
65 url = 'https://www.hqu.edu.cn/index.htm'
66 # 指定存储图片路径
67 localPath = './img/'
68 # 获得网页源代码
69 page = getHtmlCode(url)
70 # 保存图片
71 getImg(page, localPath)
注意我们之所以判断图片链接是否从“https://”开始,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一张图片,然后点击html所在的代码。 ,鼠标悬停,可以看到绝对路径,然后根据这个绝对路径设置要添加的缺失部分,如下图:
网页爬虫抓取百度图片(如何做好SEO更是更是企业上下都面临的一个重要问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-23 04:19
我们都知道,在这个互联网时代,人们想要购买新品时,首先会在互联网上查找相关信息,看看哪个品牌的评价更好。这时候,在搜索引擎排名靠前的产品具有绝对优势。因此,SEO对企业和产品至关重要。
而如何做好SEO,是企业自上而下面临的重要课题。SEO是一项说起来简单的工作,但需要极大的耐心和细心。我们见过的很多SEO方法都很笼统,有些新手可能不知道从哪里入手。今天,我们先来讨论爬虫如何快速爬取你的网站。为了让你的网站更多页面成为收录,你必须先让网页被爬虫爬取。在此之前,让我们来看看爬行动物。
网络爬虫,也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常被称为网络追逐者,是根据一定的规则自动从万维网上爬取信息的程序或脚本。使用的其他名称是 ant、autoindex、emulator 或 worm。
简单来说,爬虫就是一个检测机器。它的基本操作是模拟人类的行为,去各种网站行走,点击按钮,查看数据,或者背诵它看到的信息。就像一只在建筑物周围不知疲倦地爬行的虫子。
那么如何让爬虫快速爬取我们的网站呢?我们将一一解释 网站 构造的各个方面。
1、网站 的基础 - 网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那说明你关了门,爬虫就来不及了。爬虫也是 网站 的访问者。如果你的服务器不稳定或卡顿,爬虫每次都很难爬到,有时只能爬到页面的一部分。你的体验越来越差,你的网站分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
2、网站 导航 - 建筑 网站 地图
爬虫真的很喜欢 网站maps,而 网站maps 是所有 网站links 的容器。许多 网站 链接很深,蜘蛛很难爬取。@网站 的架构,所以构建一个网站 地图,不仅可以提高爬取率,还可以得到爬虫的青睐。
3、网站 的结构 – 扁平化 网站 的结构
爬虫也有自己的线路。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取以下页面。.
4、网站 的栅栏 - 检查机器人文件
很多网站直接屏蔽了百度或者网站robots文件中的一些页面,有意无意,却在寻找爬虫整天爬不上我的页面的原因。你能怪爬虫吗?它是密封的,爬虫如何收录你的网页?所以需要时常检查网站robots文件,看是否正常。 查看全部
网页爬虫抓取百度图片(如何做好SEO更是更是企业上下都面临的一个重要问题)
我们都知道,在这个互联网时代,人们想要购买新品时,首先会在互联网上查找相关信息,看看哪个品牌的评价更好。这时候,在搜索引擎排名靠前的产品具有绝对优势。因此,SEO对企业和产品至关重要。
而如何做好SEO,是企业自上而下面临的重要课题。SEO是一项说起来简单的工作,但需要极大的耐心和细心。我们见过的很多SEO方法都很笼统,有些新手可能不知道从哪里入手。今天,我们先来讨论爬虫如何快速爬取你的网站。为了让你的网站更多页面成为收录,你必须先让网页被爬虫爬取。在此之前,让我们来看看爬行动物。
网络爬虫,也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常被称为网络追逐者,是根据一定的规则自动从万维网上爬取信息的程序或脚本。使用的其他名称是 ant、autoindex、emulator 或 worm。
简单来说,爬虫就是一个检测机器。它的基本操作是模拟人类的行为,去各种网站行走,点击按钮,查看数据,或者背诵它看到的信息。就像一只在建筑物周围不知疲倦地爬行的虫子。
那么如何让爬虫快速爬取我们的网站呢?我们将一一解释 网站 构造的各个方面。
1、网站 的基础 - 网站服务器
网站服务器是网站的基石。如果网站服务器长时间打不开,那说明你关了门,爬虫就来不及了。爬虫也是 网站 的访问者。如果你的服务器不稳定或卡顿,爬虫每次都很难爬到,有时只能爬到页面的一部分。你的体验越来越差,你的网站分数会越来越低,自然会影响你的网站抢,所以一定要愿意选择空间服务器,有没有好的基础,房子再好。
2、网站 导航 - 建筑 网站 地图
爬虫真的很喜欢 网站maps,而 网站maps 是所有 网站links 的容器。许多 网站 链接很深,蜘蛛很难爬取。@网站 的架构,所以构建一个网站 地图,不仅可以提高爬取率,还可以得到爬虫的青睐。
3、网站 的结构 – 扁平化 网站 的结构
爬虫也有自己的线路。你之前已经为它铺平了道路。网站 结构不要太复杂,链接层次不要太深。如果链接级别太深,蜘蛛将难以抓取以下页面。.
4、网站 的栅栏 - 检查机器人文件
很多网站直接屏蔽了百度或者网站robots文件中的一些页面,有意无意,却在寻找爬虫整天爬不上我的页面的原因。你能怪爬虫吗?它是密封的,爬虫如何收录你的网页?所以需要时常检查网站robots文件,看是否正常。
网页爬虫抓取百度图片(如何让百度爬虫多来多来爬取你的卡盟?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-23 04:17
作为一个关注搜索引擎的站长,也许是一个优化关键词排名的seoer,对爬虫非常重视。每天,我都会查看联盟日志,看看爬虫爬了哪些页面,喜欢哪些内容,来了多少次。其他情况分析。今天德玛主要讲的是如何提高百度爬虫的爬取频率,也就是如何让百度爬虫更多的爬取你的卡盟。
看过百度分享帮助的人都知道,安装百度分享会提高百度爬虫的爬取速度和频率。下面是截图:
从这张图可以看出,要提高百度爬虫的爬取频率,必须从外部链接和设备百度分享入手。其实德玛个人觉得,优质原创内容更新频率的提升,也有利于爬虫爬虫的爬取频率。进步。
1、添加高质量的反向链接
这位德玛想,很多人都知道,优质的外链越多,卡牌联盟的百度快照更新的越快。为什么我们在这里谈论高质量的外部链接?如果有很多浪费的外部链接,那就没什么用了。由于百度爬虫很少爬垃圾外链,通过垃圾外链进入你的卡联盟的机会也很少。.
2、设备百度分享
从百度分享的协助可以看出,用户的分享动作将网页的URL发送给百度爬虫,这样百度爬虫就有更多的机会来。如果每天有很多人分享,那么发送百度爬虫的机会就更多了,它的爬取频率自然会提高。
3、高质量原创 内容多久更新一次
我们都知道,如果卡盟的更新有规则,百度爬虫来卡盟的时间也是有规则的,那我们就有规则提高优质原创内容的更新频率,自然百度爬虫也会有规则。更多爬行。为什么它是高质量的原创?高质量是用户喜欢的东西。用户一旦喜欢,自然会分享你的卡盟内容,对第二种情况有利。原创 是百度爬虫喜欢的东西。Dema 的博客基本上类似于 原创。即使一周只更新一条内容,也能秒收到,说明原创内容可以被爬虫抓取,因为它错过了你这里的好东西。随着您的发布频率增加,
如果以上三点都做到了,并且定期坚持了一段时间,再看卡的日志,你会发现百度爬虫的频率提升了很多。其实养爬虫并不难,难的是需要坚持和执行。百度分享刚出来的时候,很多人评论会不会影响排名。德玛想说的是,没有证明百度分享会影响排名,但是已经证明了百度分享会影响爬虫的爬取频率。所以建议各位站长还是在自己的卡联盟上安装一个百度分享,安装这个不会影响你的卡联盟速度。 查看全部
网页爬虫抓取百度图片(如何让百度爬虫多来多来爬取你的卡盟?(图))
作为一个关注搜索引擎的站长,也许是一个优化关键词排名的seoer,对爬虫非常重视。每天,我都会查看联盟日志,看看爬虫爬了哪些页面,喜欢哪些内容,来了多少次。其他情况分析。今天德玛主要讲的是如何提高百度爬虫的爬取频率,也就是如何让百度爬虫更多的爬取你的卡盟。
看过百度分享帮助的人都知道,安装百度分享会提高百度爬虫的爬取速度和频率。下面是截图:
从这张图可以看出,要提高百度爬虫的爬取频率,必须从外部链接和设备百度分享入手。其实德玛个人觉得,优质原创内容更新频率的提升,也有利于爬虫爬虫的爬取频率。进步。
1、添加高质量的反向链接
这位德玛想,很多人都知道,优质的外链越多,卡牌联盟的百度快照更新的越快。为什么我们在这里谈论高质量的外部链接?如果有很多浪费的外部链接,那就没什么用了。由于百度爬虫很少爬垃圾外链,通过垃圾外链进入你的卡联盟的机会也很少。.
2、设备百度分享
从百度分享的协助可以看出,用户的分享动作将网页的URL发送给百度爬虫,这样百度爬虫就有更多的机会来。如果每天有很多人分享,那么发送百度爬虫的机会就更多了,它的爬取频率自然会提高。
3、高质量原创 内容多久更新一次
我们都知道,如果卡盟的更新有规则,百度爬虫来卡盟的时间也是有规则的,那我们就有规则提高优质原创内容的更新频率,自然百度爬虫也会有规则。更多爬行。为什么它是高质量的原创?高质量是用户喜欢的东西。用户一旦喜欢,自然会分享你的卡盟内容,对第二种情况有利。原创 是百度爬虫喜欢的东西。Dema 的博客基本上类似于 原创。即使一周只更新一条内容,也能秒收到,说明原创内容可以被爬虫抓取,因为它错过了你这里的好东西。随着您的发布频率增加,
如果以上三点都做到了,并且定期坚持了一段时间,再看卡的日志,你会发现百度爬虫的频率提升了很多。其实养爬虫并不难,难的是需要坚持和执行。百度分享刚出来的时候,很多人评论会不会影响排名。德玛想说的是,没有证明百度分享会影响排名,但是已经证明了百度分享会影响爬虫的爬取频率。所以建议各位站长还是在自己的卡联盟上安装一个百度分享,安装这个不会影响你的卡联盟速度。
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-21 06:18
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然。它也比其他社区论坛更易于使用。注册容易,甚至不注册,发布也容易。但是,栏目创建的参差不齐,内容千奇百怪。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,我们可以看到贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
图 5-1 错误解决流程
2、 有时候需要模拟浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage) 查看全部
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四)
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然。它也比其他社区论坛更易于使用。注册容易,甚至不注册,发布也容易。但是,栏目创建的参差不齐,内容千奇百怪。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,我们可以看到贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
图 5-1 错误解决流程
2、 有时候需要模拟浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-21 06:12
)
这篇文章是针对初学者的。我将用最简单的案例告诉你如何开始使用python爬虫!
上手Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫,其实叫网络数据采集,比较好理解。
就是通过编程向Web服务器请求数据(HTML表单),然后解析HTML提取出你想要的数据。
可以概括为四个步骤:
根据url获取HTML数据,解析HTML,获取目标信息并存储数据,重复第一步
这将涉及数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全、图像处理等等。但是对于初学者来说,没有必要掌握这么多。
二、你有多想学python
如果你不会python,你需要先学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非就是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。这会很无聊,但学起来并不难。
刚开始学爬虫,甚至不需要学习python的类、多线程、模块等稍有难度的内容。找一本初学者的教材或者网上教程,用了十多天,可以对python的基础有了三四点的了解,然后就可以玩爬虫了!
当然,前提是这十天一定要仔细敲代码,反复咀嚼语法逻辑。比如列表、字典、字符串、if语句、for循环等最核心的东西,一定要心手可得。
教材选择更多。我个人推荐官方的python文档和简洁的python教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面说过,爬虫要爬取的数据隐藏在网页中的HTML中,有点混乱!
这就是维基百科解释 HTML 的方式
超文本标记语言(英文:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。HTML 是一种底层技术,许多 网站 使用 CSS 来设计网页、Web 应用程序和移动应用程序的用户界面[3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视网页。HTML 描述了 网站 的结构语义作为提示,使其成为一种标记语言而不是一种编程语言。
综上所述,HTML是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并渲染到我们看到的网页中。
所以我们会先爬取HTML,然后解析数据,因为数据是隐藏在HTML中的。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则,这里是一个大概的介绍。
HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如 .
在这些成对的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图片等),有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,用尖括号括起来,如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。带有文本内容的元素放置在这些标签之间。
四、了解python网络爬虫的基本原理
编写python爬虫时,只需要做两件事:
对于这两件事,python有相应的库来帮助你,你只需要知道如何使用它们。
五、使用python库爬取百度首页标题和图片
首先,发送HTML数据请求,可以使用python的内置库urllib,里面有一个urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页“”的HTML内容
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看看效果:
下面我们来看看真正的百度主页html是什么样子的。如果你使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:
对比一下就知道刚才python程序得到的html和网页中的html是一样的!
获取到HTML之后,接下来就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种手段提取出需要的数据。
Python 还提供了很多强大的库来帮助你解析 HTML。这里使用著名的python库BeautifulSoup作为解析上面已经获取的HTML的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。您可以从命令行使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需从结构化标签中提取数据即可:
比如我想获取百度首页的标题“百度,我会知道”,该怎么做?
这个标题被两个标签包围,一个是一级标签,另一个是二级标签,所以只需从标签中取出信息
# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
查看结果:
这样就完成了,成功提取了百度首页的标题。
如果我想下载百度主页logo图片怎么办?
第一步是获取网页的所有图片标签和网址。这可以使用 BeautifulSoup 的 findAll 方法,该方法可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll(“img”)来获取所有图片的信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
查看结果:
打印出所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高。
有一张百度主页logo的图片,图片的class(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:
获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
urlretrieve(logo_url, 'logo.png')
最终图像保存在“logo.png”中
六、结束语
本文以爬取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是一个比较基础的爬虫知识,后面还有很多优秀的python爬虫库和框架等着学习。
当然,如果你掌握了本文提到的知识点,你就已经开始上手python爬虫了。来吧,少年!
##最后
这里我整理了2022年最新版本的全套python资料,你想要的我都有,有需要的可以添加领取。
查看全部
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫
)
这篇文章是针对初学者的。我将用最简单的案例告诉你如何开始使用python爬虫!
上手Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫,其实叫网络数据采集,比较好理解。
就是通过编程向Web服务器请求数据(HTML表单),然后解析HTML提取出你想要的数据。
可以概括为四个步骤:
根据url获取HTML数据,解析HTML,获取目标信息并存储数据,重复第一步
这将涉及数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全、图像处理等等。但是对于初学者来说,没有必要掌握这么多。
二、你有多想学python
如果你不会python,你需要先学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非就是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。这会很无聊,但学起来并不难。
刚开始学爬虫,甚至不需要学习python的类、多线程、模块等稍有难度的内容。找一本初学者的教材或者网上教程,用了十多天,可以对python的基础有了三四点的了解,然后就可以玩爬虫了!
当然,前提是这十天一定要仔细敲代码,反复咀嚼语法逻辑。比如列表、字典、字符串、if语句、for循环等最核心的东西,一定要心手可得。
教材选择更多。我个人推荐官方的python文档和简洁的python教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面说过,爬虫要爬取的数据隐藏在网页中的HTML中,有点混乱!
这就是维基百科解释 HTML 的方式
超文本标记语言(英文:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。HTML 是一种底层技术,许多 网站 使用 CSS 来设计网页、Web 应用程序和移动应用程序的用户界面[3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视网页。HTML 描述了 网站 的结构语义作为提示,使其成为一种标记语言而不是一种编程语言。
综上所述,HTML是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并渲染到我们看到的网页中。
所以我们会先爬取HTML,然后解析数据,因为数据是隐藏在HTML中的。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则,这里是一个大概的介绍。
HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如 .
在这些成对的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图片等),有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,用尖括号括起来,如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。带有文本内容的元素放置在这些标签之间。
四、了解python网络爬虫的基本原理
编写python爬虫时,只需要做两件事:
对于这两件事,python有相应的库来帮助你,你只需要知道如何使用它们。
五、使用python库爬取百度首页标题和图片
首先,发送HTML数据请求,可以使用python的内置库urllib,里面有一个urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页“”的HTML内容
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/";)
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看看效果:
下面我们来看看真正的百度主页html是什么样子的。如果你使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:
对比一下就知道刚才python程序得到的html和网页中的html是一样的!
获取到HTML之后,接下来就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种手段提取出需要的数据。
Python 还提供了很多强大的库来帮助你解析 HTML。这里使用著名的python库BeautifulSoup作为解析上面已经获取的HTML的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。您可以从命令行使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需从结构化标签中提取数据即可:
比如我想获取百度首页的标题“百度,我会知道”,该怎么做?
这个标题被两个标签包围,一个是一级标签,另一个是二级标签,所以只需从标签中取出信息
# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
查看结果:
这样就完成了,成功提取了百度首页的标题。
如果我想下载百度主页logo图片怎么办?
第一步是获取网页的所有图片标签和网址。这可以使用 BeautifulSoup 的 findAll 方法,该方法可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll(“img”)来获取所有图片的信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
查看结果:
打印出所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高。
有一张百度主页logo的图片,图片的class(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:
获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
urlretrieve(logo_url, 'logo.png')
最终图像保存在“logo.png”中
六、结束语
本文以爬取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是一个比较基础的爬虫知识,后面还有很多优秀的python爬虫库和框架等着学习。
当然,如果你掌握了本文提到的知识点,你就已经开始上手python爬虫了。来吧,少年!
##最后
这里我整理了2022年最新版本的全套python资料,你想要的我都有,有需要的可以添加领取。
网页爬虫抓取百度图片(《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)中爬虫应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-21 03:00
标签:宽度标签,除了按 defmic 源 %sapp
摘自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)在爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
实现爬取指定网页中图片的代码如下:
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样
9 # headers = {
10 # ‘User-Agent‘: ‘Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 # AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36‘
12 # }
13 # # 将headers头部添加到url,模拟浏览器访问
14 # url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(‘UTF-8‘)
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 imageList = re.findall(r‘(https:[^\s]*?(jpg|png|gif))"‘, page)
27 x = 0
28 # 循环列表
29 for imageUrl in imageList:
30 try:
31 print(‘正在下载: %s‘ % imageUrl[0])
32 # 这个image文件夹需要先创建好才能看到结果
33 image_save_path = ‘./image/%d.png‘ % x
34 # 下载图片并且保存到指定文件夹中
35 urllib.request.urlretrieve(imageUrl[0], image_save_path)
36 x = x + 1
37 except:
38 continue
39
40 pass
41
42
43 if __name__ == ‘__main__‘:
44 # 指定要爬取的网站
45 url = "https://www.cnblogs.com/ttweix ... ot%3B
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
50 # print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这段内容,怎么设计正则表达式需要根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
python爬取指定页面中的图片
标签:宽度标签,除了按 defmic 源 %sapp 查看全部
网页爬虫抓取百度图片(《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)中爬虫应用)
标签:宽度标签,除了按 defmic 源 %sapp
摘自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)在爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表,反复抓取和保存内容
实现爬取指定网页中图片的代码如下:
1 # 第一个简单的爬取图片的程序
2 import urllib.request # python自带的爬操作url的库
3 import re # 正则表达式
4
5
6 # 该方法传入url,返回url的html的源代码
7 def getHtmlCode(url):
8 # 以下几行注释的代码在本程序中有加没加效果一样
9 # headers = {
10 # ‘User-Agent‘: ‘Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
11 # AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36‘
12 # }
13 # # 将headers头部添加到url,模拟浏览器访问
14 # url = urllib.request.Request(url, headers=headers)
15
16 # 将url页面的源代码保存成字符串
17 page = urllib.request.urlopen(url).read()
18 # 字符串转码
19 page = page.decode(‘UTF-8‘)
20 return page
21
22
23 # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
24 def getImage(page):
25 # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
26 imageList = re.findall(r‘(https:[^\s]*?(jpg|png|gif))"‘, page)
27 x = 0
28 # 循环列表
29 for imageUrl in imageList:
30 try:
31 print(‘正在下载: %s‘ % imageUrl[0])
32 # 这个image文件夹需要先创建好才能看到结果
33 image_save_path = ‘./image/%d.png‘ % x
34 # 下载图片并且保存到指定文件夹中
35 urllib.request.urlretrieve(imageUrl[0], image_save_path)
36 x = x + 1
37 except:
38 continue
39
40 pass
41
42
43 if __name__ == ‘__main__‘:
44 # 指定要爬取的网站
45 url = "https://www.cnblogs.com/ttweix ... ot%3B
46 # 得到该网站的源代码
47 page = getHtmlCode(url)
48 # 爬取该网站的图片并且保存
49 getImage(page)
50 # print(page)
注意代码中需要修改的是 imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这段内容,怎么设计正则表达式需要根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
python爬取指定页面中的图片
标签:宽度标签,除了按 defmic 源 %sapp
网页爬虫抓取百度图片(《Python爬虫开发与项目实战》——第3章(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 22:18
阿里云 > 云栖社区 > 主题地图 > W > 网络爬虫的网络爬取算法
推荐活动:
更多优惠>
当前主题: 网络爬虫的网络爬取算法 添加到采集夹
相关话题:
Web Crawler Web Scraping Algorithms 相关博客 查看更多博客
浅谈网络爬虫中的深度优先算法及简单代码实现
作者:python进阶1029人查看评论:13年前
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。当 网站 的 URL 太多时,我们
阅读全文
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实践》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解
作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:03年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
网络爬虫基本原理(一)
作者:xumaojun978 浏览评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下
阅读全文
网络爬虫基本原理(一)
作者:nothingfinal690 观众评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图:网络爬虫
阅读全文 查看全部
网页爬虫抓取百度图片(《Python爬虫开发与项目实战》——第3章(组图))
阿里云 > 云栖社区 > 主题地图 > W > 网络爬虫的网络爬取算法
推荐活动:
更多优惠>
当前主题: 网络爬虫的网络爬取算法 添加到采集夹
相关话题:
Web Crawler Web Scraping Algorithms 相关博客 查看更多博客
浅谈网络爬虫中的深度优先算法及简单代码实现
作者:python进阶1029人查看评论:13年前
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。当 网站 的 URL 太多时,我们
阅读全文
《Python爬虫开发与项目实践》——第3章Web爬虫入门3.1 Web爬虫概述
作者:华章电脑 3956人浏览评论:04年前
本章节选自华章计算机《Python爬虫开发与项目实践》一书第3章3.1节,作者:范传辉。更多章节请访问云栖社区“华章计算机”查看公众号第3章网络爬虫入门本章将正式涉及Python爬虫的开发。本章主要分为两部分:一部分是网络
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解
作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
网络爬虫的实现
作者:xumaojun933 浏览评论:03年前
作者:古普塔,P。乔哈里,K。印度 Linagay 大学 文章 发表于:工程技术新兴趋势 (ICETET),2009 年第 2 次实习生
阅读全文
网络爬虫的实现
作者:nothingfinal1246 浏览评论:23 年前
通过古普塔,P。乔哈里,K。Linagay's Univ., India 文章发表于:工程和技术的新兴趋势 (ICETET),2009 年第二届国际
阅读全文
网络爬虫的实现
作者:maojunxu558 浏览评论:03年前
作者:古普塔,P。乔哈里,K。Linagay 大学,印度文章发表于:工程技术新兴趋势 (ICETET),2009 年第二届实习生
阅读全文
网络爬虫基本原理(一)
作者:xumaojun978 浏览评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下
阅读全文
网络爬虫基本原理(一)
作者:nothingfinal690 观众评论:03年前
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程一般网络爬虫的框架如图:网络爬虫
阅读全文
网页爬虫抓取百度图片(Java实现的爬虫抓取图片并保存操作技巧汇总(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-20 22:12
本篇文章主要介绍Java实现的抓取图片并保存的爬虫。涉及到Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文的例子描述了java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MoZyyxlKalformedURLException;
import java.net.URL;
import java.net.URLConnection;
impooZyyxlKrt java.util.ArrayList;
import java.util.List;
import java.util.reghttp://www.cppcns.comex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public stati编程客栈c String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL 编程客栈url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
本文标题:Java实现的爬虫抓取图片保存操作示例 查看全部
网页爬虫抓取百度图片(Java实现的爬虫抓取图片并保存操作技巧汇总(二))
本篇文章主要介绍Java实现的抓取图片并保存的爬虫。涉及到Java对页面URL访问、获取、字符串匹配、文件下载等的相关操作技巧,有需要的朋友可以参考以下
本文的例子描述了java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MoZyyxlKalformedURLException;
import java.net.URL;
import java.net.URLConnection;
impooZyyxlKrt java.util.ArrayList;
import java.util.List;
import java.util.reghttp://www.cppcns.comex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public stati编程客栈c String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL 编程客栈url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
本文标题:Java实现的爬虫抓取图片保存操作示例
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-18 23:00
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然,比其他社区论坛更容易使用。注册容易,甚至不注册,发布也容易。但是,栏目创建不均,内容五花八门。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,可以看出贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
图 5-1 错误解决流程
2、 有时候你要模拟一个浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage) 查看全部
网页爬虫抓取百度图片(项目工具Python3.7.1、JetBrainsPyCharm三、项目过程(四)
)
需要编写的程序可以在任意一个贴吧页面获取帖子链接,抓取用户在帖子中发布的图片。在这个过程中,通过用户代理进行伪装和轮换,解决了爬虫ip被目标网站封禁的问题。熟悉基本的网页和url分析,能灵活使用Xmind工具分析Python爬虫(网络爬虫)的流程图。
一、项目分析
1. 网络分析
贴吧页面简洁,所有内容一目了然,比其他社区论坛更容易使用。注册容易,甚至不注册,发布也容易。但是,栏目创建不均,内容五花八门。
2. 网址解析
分析贴吧中post链接的拼接形式,在程序中重构post链接。
比如在本例的实验中,多次输入不同的贴吧后,可以看出贴吧的链接组成为:fullurl=url+key。其中 fullurl 表示 贴吧 总链接
url为贴吧链接的社区:
关键是urlencode编码的贴吧中文名
使用 xpath_helper_2_0_2.crx 浏览器插件,帖子的链接条目可以归结为:
"//li/div[@class="t_con cleafix"]/div/div/div/a/@href",用户在帖子中张贴的图片链接表达式为:"//img··[@class = "BDE_Image"]/@src"
二、项目工具
Python 3.7.1,JetBrains PyCharm 2018.3.2
三、项目流程
(一)使用Xmind工具分析Python爬虫(网络爬虫)的流程图,绘制程序逻辑框架图如图4-1
图 4-1 程序逻辑框架图
(二)爬虫调试过程的Bug描述(截图)
(三)爬虫运行结果
(四)项目经历
本次实验的经验总结如下:
1、 当程序运行结果提示错误:ModuleNotFoundError: No module named 'lxml'时,最好的解决办法是先检查lxml是否安装,再检查lxml是否导入。在本次实验中,由于项目可以成功导入lxml,解决方案如图5-1所示。在“Project Interperter”中选择python安装目录。
图 5-1 错误解决流程
2、 有时候你要模拟一个浏览器,否则做过反爬的网站 会知道你是机器人
例如,对于浏览器的限制,我们可以设置 User-Agent 头。对于防盗链限制,我们可以设置Referer头。一些网站使用cookies进行限制,主要涉及登录和限流。没有通用的方法,只看能不能自动登录或者分析cookies的问题。
3、 第一步,我们可以从主界面的html代码中提取出这组图片的链接地址。显然,我们需要使用正则表达式来提取这些不同的地址。然后,有了每组图片的起始地址后,我们进入子页面,刷新网页,观察它的加载过程。
四、项目源码
贴吧pic.py
from urllib import request,parse
import ssl
import random
import time
from lxml import etree
ua_list=[
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
def loadPage(url):
userAgent=random.choice(ua_list)
headers={"User-Agent":userAgent}
req =request.Request(url,headers=headers)
context=ssl._create_unverified_context()
response=request.urlopen(req,context=context)
html=response.read()
content=etree.HTML(html)
link_list=content.xpath('//li/div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fullurl='http://tieba.baidu.com'+link
print(fullurl)
loadImge(fullurl)
def loadImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
html = response.read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImge(link)
def writeImge(url):
req = request.Request(url)
context = ssl._create_unverified_context()
response = request.urlopen(req, context=context)
image = response.read()
filename=url[-12:]
f=open(filename,'wb')
f.write(image)
f.close()
def tiebaSpider(url,beginPage,endPage):
for page in range(beginPage,endPage+100):
pn=(page-1)*50
fullurl=url+"&pn="+str(pn)
loadPage(fullurl)
if __name__=="__main__":
print("测试成功!")
kw=input("请输入要爬的贴吧名:")
beginPage=int(input("请输入开始页:"))
endPage = int(input("请输入结束页:"))
url="http://tieba.baidu.com/f?"
key=parse.urlencode({"kw":kw})
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
网页爬虫抓取百度图片( Control的异步和回调知识的逻辑 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-18 12:10
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路及抓取百度图片的例子分享
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本篇文章主要介绍Node.js编写爬虫的基本思路和抓取百度图片的例子分享。作者提到了GBK转码需要特别注意的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(和我基础不够扎实,也没有认真研究过node.js有很大关系)。主要原因是node.js的异步和回调知识没有完全掌握,导致在编写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像写PHP一样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以有必要一开始就分析一下这个爬虫需要实现的功能。,大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用数据,返回一个对象
持久性模块,接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一个下午的问题:模块之间的异步调用导致数据错误。其实我还是不太明白是什么问题,因为脚本语言的调试功能不方便,所以还没有深入研究过。
还有一点需要注意的是,在模块化的时候,尽量谨慎的使用全局对象来存储数据,因为可能你的模块的某个功能还没有结束,而全局变量已经被修改了。
控制流
这个东西很难翻译,直译就叫控制流(?)。众所周知,node.js的核心思想是异步,但是如果异步多了,就会有好几层嵌套,代码真的很难看。此时,您需要借助一些控制流模块重新排列逻辑。这里我们推荐 async.js(),它在开发社区中非常活跃且易于使用。
async提供了很多实用的方法,我主要在写爬虫的时候使用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景,需要向数据库中插入多条数据(属于同一个学生),并且需要在插入所有数据后返回结果,那么如何保证所有的插入操作都结束了? 它只能通过回调层来保证。使用 async.parallel 要方便得多。
这里还要提一件事,本来是为了保证所有的insert都完成,这个操作可以在SQL层实现,也就是transaction,但是node-mysql在我使用的时候还是不能很好的支持transaction,所以只能用代码手动保证。
解析 HTML
解析过程中也遇到了一些问题,记录在这里。
发送 HTTP 请求获取 HTML 代码最基本的方法是使用 node 自带的 http.request 函数。如果是抓取简单的内容,比如获取指定id元素的内容(常用于抓取商品价格),那么正则就足够完成任务了。但是对于复杂的页面,尤其是数据项很多的页面,使用 DOM 会更加方便和高效。
node.js 的最佳 DOM 实现是cheerio()。其实,cheerio 应该算是 jQuery 的一个子集,针对 DOM 操作进行了优化和精简,包括了 DOM 操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在爬取数据时,我们可能还需要下载图片。其实下载图片的方式和普通网页没有太大区别,但是有一点让我很苦恼。
请注意下面代码中的起泡注释,这是我年轻时犯的错误......
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得解释的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会走弯路。这是所有的源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i 查看全部
网页爬虫抓取百度图片(
Control的异步和回调知识的逻辑
)
Node.js写爬虫的基本思路及抓取百度图片的例子分享
更新时间:2016-03-12 17:32:27 作者:qiaolevip
本篇文章主要介绍Node.js编写爬虫的基本思路和抓取百度图片的例子分享。作者提到了GBK转码需要特别注意的转码问题。有需要的朋友可以参考以下
其实写爬虫的思路很简单:
但是当我真正写这个爬虫的时候,还是遇到了很多问题(和我基础不够扎实,也没有认真研究过node.js有很大关系)。主要原因是node.js的异步和回调知识没有完全掌握,导致在编写代码的过程中走了不少弯路。
模块化的
模块化对于 node.js 程序非常重要。不能像写PHP一样把所有代码都扔到一个文件里(当然这只是我个人的恶习),所以有必要一开始就分析一下这个爬虫需要实现的功能。,大致分为三个模块。
主程序,调用爬虫模块和持久化模块,实现完整的爬虫功能
爬虫模块根据传入的数据发送请求,解析HTML并提取有用数据,返回一个对象
持久性模块,接受一个对象并将其内容存储在数据库中
模块化也带来了一个困扰我一个下午的问题:模块之间的异步调用导致数据错误。其实我还是不太明白是什么问题,因为脚本语言的调试功能不方便,所以还没有深入研究过。
还有一点需要注意的是,在模块化的时候,尽量谨慎的使用全局对象来存储数据,因为可能你的模块的某个功能还没有结束,而全局变量已经被修改了。
控制流
这个东西很难翻译,直译就叫控制流(?)。众所周知,node.js的核心思想是异步,但是如果异步多了,就会有好几层嵌套,代码真的很难看。此时,您需要借助一些控制流模块重新排列逻辑。这里我们推荐 async.js(),它在开发社区中非常活跃且易于使用。
async提供了很多实用的方法,我主要在写爬虫的时候使用
这些控制流方式给爬虫的开发带来了极大的便利。考虑这样一个应用场景,需要向数据库中插入多条数据(属于同一个学生),并且需要在插入所有数据后返回结果,那么如何保证所有的插入操作都结束了? 它只能通过回调层来保证。使用 async.parallel 要方便得多。
这里还要提一件事,本来是为了保证所有的insert都完成,这个操作可以在SQL层实现,也就是transaction,但是node-mysql在我使用的时候还是不能很好的支持transaction,所以只能用代码手动保证。
解析 HTML
解析过程中也遇到了一些问题,记录在这里。
发送 HTTP 请求获取 HTML 代码最基本的方法是使用 node 自带的 http.request 函数。如果是抓取简单的内容,比如获取指定id元素的内容(常用于抓取商品价格),那么正则就足够完成任务了。但是对于复杂的页面,尤其是数据项很多的页面,使用 DOM 会更加方便和高效。
node.js 的最佳 DOM 实现是cheerio()。其实,cheerio 应该算是 jQuery 的一个子集,针对 DOM 操作进行了优化和精简,包括了 DOM 操作的大部分内容,去掉了其他不必要的内容。使用cheerio,您可以像使用普通的jQuery 选择器一样选择您需要的内容。
下载图片
在爬取数据时,我们可能还需要下载图片。其实下载图片的方式和普通网页没有太大区别,但是有一点让我很苦恼。
请注意下面代码中的起泡注释,这是我年轻时犯的错误......
var req = http.request(options, function(res){
//初始化数据!!!
var binImage = '';
res.setEncoding('binary');
res.on('data', function(chunk){
binImage += chunk;
});
res.on('end', function(){
if (!binImage) {
console.log('image data is null');
return null;
}
fs.writeFile(imageFolder + filename, binImage, 'binary', function(err){
if (err) {
console.log('image writing error:' + err.message);
return null;
}
else{
console.log('image ' + filename + ' saved');
return filename;
}
});
});
res.on('error', function(e){
console.log('image downloading response error:' + e.message);
return null;
});
});
req.end();
GBK转码
另一个值得解释的问题是node.js爬虫爬取GBK编码内容时的转码问题。其实这个问题很容易解决,只是新手可能会走弯路。这是所有的源代码:
var req = http.request(options, function(res) {
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function(){
//转换编码
html = iconv.decode(html, 'gbk');
});
});
req.end();
我这里使用的转码库是iconv-lite(),完美支持GBK、GB2312等双字节编码。
示例:爬虫批量下载百度图片
<p>
var fs = require('fs'),
path = require('path'),
util = require('util'), // 以上为Nodejs自带依赖包
request = require('request'); // 需要npm install的包
// main函数,使用 node main执行即可
patchPreImg();
// 批量处理图片
function patchPreImg() {
var tag1 = '摄影', tag2 = '国家地理',
url = 'http://image.baidu.com/data/imgs?pn=%s&rn=60&p=channel&from=1&col=%s&tag=%s&sort=1&tag3=',
url = util.format(url, 0, tag1, tag2),
url = encodeURI(url),
dir = 'D:/downloads/images/',
dir = path.join(dir, tag1, tag2),
dir = mkdirSync(dir);
request(url, function(error, response, html) {
var data = JSON.parse(html);
if (data && Array.isArray(data.imgs)) {
var imgs = data.imgs;
imgs.forEach(function(img) {
if (Object.getOwnPropertyNames(img).length > 0) {
var desc = img.desc || ((img.owner && img.owner.userName) + img.column);
desc += '(' + img.id + ')';
var downloadUrl = img.downloadUrl || img.objUrl;
downloadImg(downloadUrl, dir, desc);
}
});
}
});
}
// 循环创建目录
function mkdirSync(dir) {
var parts = dir.split(path.sep);
for (var i = 1; i
网页爬虫抓取百度图片(2016年7月26日(周四)、、上一步公告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-18 08:03
第二步:输入关键字,页面加载完毕后,按F12进入开发者模式,因为百度图片ajax是动态加载的,点击网络标签,刷新页面,查看XHR数据,截图如下:
p>
第 3 步:分析多个 XHR 并获取规则。每个页面请求的url携带的参数只有pn、rn、gsm(不关心),它们是不同的,其中pn代表当前页面。 , rn 表示一个页面有几条数据,如下截图所示:
第四步:分析完上一步url的规则后,我们找到图片的隐藏位置,点击任意XHR,从0到29,一共30条数据,图片的信息存储在每个字典中,其中'thumbURL'存储地址,截图如下:
第五步:上一步已经分析了图片存放的地方,接下来我们来写代码,代码如下:
import requests
import os
class Image():
url = 'https://image.baidu.com/search/acjson'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'
}
varlist = []
dir = './images'
params = {}
def __init__(self):
global page_num,keywords
page_num = int(input('请输入要抓取的页数:\n'))
keywords = input('请输入关键字:\n')
if self.catch_page():
self.writeData()
else:
print('抓取页面失败')
def catch_page(self):
for i in range(0,page_num * 30,30):
self.params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keywords,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'hd': '',
'latest': '',
'copyright': '',
'word': keywords,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': i,
'rn': '30',
'gsm': '',
'1584010126096': ''
}
res = requests.get(url = self.url,params = self.params).json()['data']
for j in range(0,30):
self.varlist.append(res[j]['thumbURL'])
if self.varlist != None:
return True
return False
def writeData(self):
# 判读是否存在文件,不存在则创建
if not os.path.exists(self.dir):
os.mkdir(self.dir)
for i in range(0,page_num * 30):
print(f'正在下载第{i}条数据')
images = requests.get(url = self.varlist[i])
open(f'./images/{i}.jpg','wb').write(images.content)
if __name__ == '__main__':
Image()
第6步:完成插花 查看全部
网页爬虫抓取百度图片(2016年7月26日(周四)、、上一步公告)
第二步:输入关键字,页面加载完毕后,按F12进入开发者模式,因为百度图片ajax是动态加载的,点击网络标签,刷新页面,查看XHR数据,截图如下:
p>
第 3 步:分析多个 XHR 并获取规则。每个页面请求的url携带的参数只有pn、rn、gsm(不关心),它们是不同的,其中pn代表当前页面。 , rn 表示一个页面有几条数据,如下截图所示:
第四步:分析完上一步url的规则后,我们找到图片的隐藏位置,点击任意XHR,从0到29,一共30条数据,图片的信息存储在每个字典中,其中'thumbURL'存储地址,截图如下:
第五步:上一步已经分析了图片存放的地方,接下来我们来写代码,代码如下:
import requests
import os
class Image():
url = 'https://image.baidu.com/search/acjson'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36'
}
varlist = []
dir = './images'
params = {}
def __init__(self):
global page_num,keywords
page_num = int(input('请输入要抓取的页数:\n'))
keywords = input('请输入关键字:\n')
if self.catch_page():
self.writeData()
else:
print('抓取页面失败')
def catch_page(self):
for i in range(0,page_num * 30,30):
self.params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keywords,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'hd': '',
'latest': '',
'copyright': '',
'word': keywords,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': i,
'rn': '30',
'gsm': '',
'1584010126096': ''
}
res = requests.get(url = self.url,params = self.params).json()['data']
for j in range(0,30):
self.varlist.append(res[j]['thumbURL'])
if self.varlist != None:
return True
return False
def writeData(self):
# 判读是否存在文件,不存在则创建
if not os.path.exists(self.dir):
os.mkdir(self.dir)
for i in range(0,page_num * 30):
print(f'正在下载第{i}条数据')
images = requests.get(url = self.varlist[i])
open(f'./images/{i}.jpg','wb').write(images.content)
if __name__ == '__main__':
Image()
第6步:完成插花
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-18 02:20
内容
你好!大家好,我是一只为了赚钱买发水的小灰猿。很多学过Python的小伙伴都希望拥有一个属于自己的爬虫,那么今天大灰狼就给小伙伴们分享一个简单的爬虫程序。.
请允许我在这里为我的朋友出售通行证。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开一个特定的网页,对网页上存在的一些信息进行爬取。想象一下,如果把一个网页比作一片田地,爬行动物就是生活在这片田地里的昆虫,从田地的头到尾爬行,只捕食田地里的某一种食物。哈哈,比喻有点粗略,但是网络爬虫的实际作用和这个差不多。
想了解更多的朋友也可以看我的文章文章《Python一分钟带你探索不为人知的网虫!》它!
爬虫的原理是什么?
那么有的朋友可能会问,爬虫是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了网页中的所有信息。当我们打开一个网页时,按 F12 键可以查看该页面的内容。代码已准备就绪。我们以百度图片搜索皮卡丘的网页为例。按下 F12 后,可以看到下面的代码覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例,我们的爬虫想要爬取这个网页上所有的皮卡丘图片,那么我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,并且从此链接下载图片。
所以爬虫的工作原理就是从网页的代码中找到并提取特定的代码,就像从很长的字符串中找到特定格式的字符串一样,对这块知识感兴趣的朋友也可以阅读我的文章文章《Python实战中的具体文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里以requests模块为例编写爬虫程序。
以爬取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序应该做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式 匹配代码中所有符合要求的图片链接通过设置的正则表达式一张一张打开图片链接下载图片
接下来大灰狼就按照上面的步骤跟大家分享一下这个爬虫的准备工作:
1、获取百度图片中“皮卡丘图片”的网址
首先我们打开百度图片的网页链接
然后打开关键字搜索“皮卡丘”后的链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
作为对比,去掉多余部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:
现在我们的第一步是获取百度图片中“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取此页面的完整代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后,通过模块中的text函数获取网页的文本,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中查找图片链接
这一步我们可以先打开网页的链接,按大灰狼开头说的方法,按F12查看网页的所有代码,然后如果我们要爬取jpg中的所有图片格式,我们可以按 Ctrl+F 代码来查找特定的东西,
比如我们在这个网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容,如果我们仔细观察这些链接,会发现它们是相似的,即每个链接前都会有“OpjURL”:提示,最后以“,
我们取出其中一个链接
访问,发现图片也可以打开。
所以我们可以暂时推断出百度图片中jpg图片的一般格式为“”OpjURL“:XXXX”,
4、根据图片链接写一个通用的正则表达式
既然我们知道了这类图片的一般格式是“"OpjURL":XXXX"”,那么接下来就是按照这种格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不知道如何使用正则表达式的同学,也可以看看我的两篇文章文章《Python 中的正则表达式教程(基础)》和《Python 教程中的正则表达式(改进)》
5、通过设置的正则表达式匹配代码中所有匹配的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配到的图片链接,并将所有匹配到的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后,我们可以在这个文件下看到匹配的图片链接,复制任意一个即可打开。
6、一一打开图片链接,下载图片
现在我们已经将所有图片的链接存储在列表中,下一步就是下载图片了。
基本思路是:通过一个for循环遍历列表中的所有链接,以二进制形式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前休眠3秒,每个链接的访问时间最多5秒。如果访问时间超过五秒,我们将判断下载失败,继续下载下一章。图片。
至于为什么我们用二进制打开和写入图片,我们的图片需要经过二进制解析才能被计算机写入。
图片下载代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
至此,一个简单的爬取百度皮卡丘图片的爬虫就完成了,小伙伴们还可以随意更改图片关键词和下载次数,来培养自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
s = requests.session()
s.headers['User-Agent']='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
urls = s.get(url).content.decode('utf-8')
# urls = requests.get(url) # 打开链接
# requests.get(url="https://www.baidu.com/")
urltext = urls # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout=5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i + 1), urlimg))
imgs.write(img) # 将图片写入
i += 1
if i == 5: # 为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
觉得有用的话记得点赞关注哦! 查看全部
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
内容
你好!大家好,我是一只为了赚钱买发水的小灰猿。很多学过Python的小伙伴都希望拥有一个属于自己的爬虫,那么今天大灰狼就给小伙伴们分享一个简单的爬虫程序。.
请允许我在这里为我的朋友出售通行证。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开一个特定的网页,对网页上存在的一些信息进行爬取。想象一下,如果把一个网页比作一片田地,爬行动物就是生活在这片田地里的昆虫,从田地的头到尾爬行,只捕食田地里的某一种食物。哈哈,比喻有点粗略,但是网络爬虫的实际作用和这个差不多。
想了解更多的朋友也可以看我的文章文章《Python一分钟带你探索不为人知的网虫!》它!
爬虫的原理是什么?
那么有的朋友可能会问,爬虫是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了网页中的所有信息。当我们打开一个网页时,按 F12 键可以查看该页面的内容。代码已准备就绪。我们以百度图片搜索皮卡丘的网页为例。按下 F12 后,可以看到下面的代码覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例,我们的爬虫想要爬取这个网页上所有的皮卡丘图片,那么我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,并且从此链接下载图片。
所以爬虫的工作原理就是从网页的代码中找到并提取特定的代码,就像从很长的字符串中找到特定格式的字符串一样,对这块知识感兴趣的朋友也可以阅读我的文章文章《Python实战中的具体文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里以requests模块为例编写爬虫程序。
以爬取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序应该做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式 匹配代码中所有符合要求的图片链接通过设置的正则表达式一张一张打开图片链接下载图片
接下来大灰狼就按照上面的步骤跟大家分享一下这个爬虫的准备工作:
1、获取百度图片中“皮卡丘图片”的网址
首先我们打开百度图片的网页链接
然后打开关键字搜索“皮卡丘”后的链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
作为对比,去掉多余部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:
现在我们的第一步是获取百度图片中“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取此页面的完整代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后,通过模块中的text函数获取网页的文本,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中查找图片链接
这一步我们可以先打开网页的链接,按大灰狼开头说的方法,按F12查看网页的所有代码,然后如果我们要爬取jpg中的所有图片格式,我们可以按 Ctrl+F 代码来查找特定的东西,
比如我们在这个网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容,如果我们仔细观察这些链接,会发现它们是相似的,即每个链接前都会有“OpjURL”:提示,最后以“,
我们取出其中一个链接
访问,发现图片也可以打开。
所以我们可以暂时推断出百度图片中jpg图片的一般格式为“”OpjURL“:XXXX”,
4、根据图片链接写一个通用的正则表达式
既然我们知道了这类图片的一般格式是“"OpjURL":XXXX"”,那么接下来就是按照这种格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不知道如何使用正则表达式的同学,也可以看看我的两篇文章文章《Python 中的正则表达式教程(基础)》和《Python 教程中的正则表达式(改进)》
5、通过设置的正则表达式匹配代码中所有匹配的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配到的图片链接,并将所有匹配到的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后,我们可以在这个文件下看到匹配的图片链接,复制任意一个即可打开。
6、一一打开图片链接,下载图片
现在我们已经将所有图片的链接存储在列表中,下一步就是下载图片了。
基本思路是:通过一个for循环遍历列表中的所有链接,以二进制形式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前休眠3秒,每个链接的访问时间最多5秒。如果访问时间超过五秒,我们将判断下载失败,继续下载下一章。图片。
至于为什么我们用二进制打开和写入图片,我们的图片需要经过二进制解析才能被计算机写入。
图片下载代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
至此,一个简单的爬取百度皮卡丘图片的爬虫就完成了,小伙伴们还可以随意更改图片关键词和下载次数,来培养自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
s = requests.session()
s.headers['User-Agent']='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
urls = s.get(url).content.decode('utf-8')
# urls = requests.get(url) # 打开链接
# requests.get(url="https://www.baidu.com/";)
urltext = urls # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout=5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i + 1), urlimg))
imgs.write(img) # 将图片写入
i += 1
if i == 5: # 为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
觉得有用的话记得点赞关注哦!
网页爬虫抓取百度图片(一下网络爬虫的大概论述和介绍,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-17 08:07
上午我们了解了网络爬虫的一般讨论和介绍,了解了网络爬虫的现状和现状。在这篇博文中,我们将通过学习一个爬虫示例来了解更多关于如何使用网络爬虫的知识,并使其对我们更好。更有趣的工作。
例子的目的:通过分析特定的url,下载url路径下的所有图片。由于学习水平有限,本例中没有对url进行循环爬取。
爬取工作主要分为三个步骤:
1、获取页面源代码
2、分析源码,找到源码中的图片标签
3、网络编程,下载图片
首先,我们来看看项目的整体结构:
示例如下:
package cn.edu.lnu.crawler;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Util {
// 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
// 获取html内容
public static String getHTML(String srcUrl) throws Exception {
URL url = new URL(srcUrl);
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line = null;
StringBuffer buffer = new StringBuffer();
while ((line = br.readLine()) != null) {
buffer.append(line);
buffer.append("\n");
}
br.close();
isr.close();
is.close();
return buffer.toString();
}
// 获取image url地址
public static List getImageURL(String html) {
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List list = new ArrayList();
while (matcher.find()) {
list.add(matcher.group());
}
return list;
}
// 获取image src地址
public static List getImageSrc(List listUrl) {
List listSrc = new ArrayList();
for (String img : listUrl) {
Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(img);
while (matcher.find()) {
listSrc.add(matcher.group().substring(0,
matcher.group().length() - 1));
}
}
return listSrc;
}
// 下载图片
private static void Download(List listImgSrc) {
try {
// 开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
// 开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1,
url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File(imageName));// 文件输出流
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
// 关闭流
in.close();
fo.close();
System.out.println(imageName + "下载完成");
// 结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
public static void main(String[] args) throws Exception {
String html = getHTML(URL);
List listUrl = getImageURL(html);
/*
* for(String img : listUrl){ System.out.println(img); }
*/
List listSrc = getImageSrc(listUrl);
/*
* for(String img : listSrc){ System.out.println(img); }
*/
Download(listSrc);
}
}
下载结果如下图所示:
接下来我会继续研究爬虫技术,把我的学习总结记录在博客上。欢迎来到我的下一个博客。 查看全部
网页爬虫抓取百度图片(一下网络爬虫的大概论述和介绍,你了解多少?)
上午我们了解了网络爬虫的一般讨论和介绍,了解了网络爬虫的现状和现状。在这篇博文中,我们将通过学习一个爬虫示例来了解更多关于如何使用网络爬虫的知识,并使其对我们更好。更有趣的工作。
例子的目的:通过分析特定的url,下载url路径下的所有图片。由于学习水平有限,本例中没有对url进行循环爬取。
爬取工作主要分为三个步骤:
1、获取页面源代码
2、分析源码,找到源码中的图片标签
3、网络编程,下载图片
首先,我们来看看项目的整体结构:
示例如下:
package cn.edu.lnu.crawler;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Util {
// 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
// 获取html内容
public static String getHTML(String srcUrl) throws Exception {
URL url = new URL(srcUrl);
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line = null;
StringBuffer buffer = new StringBuffer();
while ((line = br.readLine()) != null) {
buffer.append(line);
buffer.append("\n");
}
br.close();
isr.close();
is.close();
return buffer.toString();
}
// 获取image url地址
public static List getImageURL(String html) {
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List list = new ArrayList();
while (matcher.find()) {
list.add(matcher.group());
}
return list;
}
// 获取image src地址
public static List getImageSrc(List listUrl) {
List listSrc = new ArrayList();
for (String img : listUrl) {
Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(img);
while (matcher.find()) {
listSrc.add(matcher.group().substring(0,
matcher.group().length() - 1));
}
}
return listSrc;
}
// 下载图片
private static void Download(List listImgSrc) {
try {
// 开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
// 开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1,
url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File(imageName));// 文件输出流
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
// 关闭流
in.close();
fo.close();
System.out.println(imageName + "下载完成");
// 结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
public static void main(String[] args) throws Exception {
String html = getHTML(URL);
List listUrl = getImageURL(html);
/*
* for(String img : listUrl){ System.out.println(img); }
*/
List listSrc = getImageSrc(listUrl);
/*
* for(String img : listSrc){ System.out.println(img); }
*/
Download(listSrc);
}
}
下载结果如下图所示:
接下来我会继续研究爬虫技术,把我的学习总结记录在博客上。欢迎来到我的下一个博客。
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-15 08:19
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量都控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量都控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片

