
网页爬虫抓取百度图片
网页爬虫抓取百度图片(网页爬虫抓取百度图片不花一分钱能有效获取原图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-13 03:02
网页爬虫抓取百度图片不花一分钱能有效获取图片的原图,获取原图有两种方法:第一种是自己搜索、爬取谷歌图片,第二种是购买他人图片,比如在手机上安装了商家的开屏自动抓取app,app上的产品图片都是会有提示提示爬取、获取原图、复制链接等按钮。图片的处理ppt百度图片同理第一种自己找图片,已有多种获取链接的工具可以使用;第二种图片处理,需要买个原图服务。
购买百度图片可以去“图乐”去获取,但是是百度自己卖的,广告比较多。打开浏览器输入以下网址:,我选择的是免费试用版:;adcode=57014通过“复制链接”等按钮获取下载链接:。下载下来之后,可以直接手机扫码打开百度图片:,就能获取到原图了。在手机扫一扫支付宝扫一扫登录微信扫一扫登录第一个是商家app里图片的获取,第二个是里面的图片获取,也是关键是要用浏览器,可以截图留下你的电话在ppt里面帮助你查看图片,方便你去获取。
百度图片无处不在最后一步就是进入,使用第三方浏览器(推荐最好是谷歌浏览器,uc浏览器也行),下载百度图片;也可以像第一个说的一样去获取、下载图片,方便你手机识别二维码下载。
可以去我网站买一张图片下载软件, 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片不花一分钱能有效获取原图)
网页爬虫抓取百度图片不花一分钱能有效获取图片的原图,获取原图有两种方法:第一种是自己搜索、爬取谷歌图片,第二种是购买他人图片,比如在手机上安装了商家的开屏自动抓取app,app上的产品图片都是会有提示提示爬取、获取原图、复制链接等按钮。图片的处理ppt百度图片同理第一种自己找图片,已有多种获取链接的工具可以使用;第二种图片处理,需要买个原图服务。
购买百度图片可以去“图乐”去获取,但是是百度自己卖的,广告比较多。打开浏览器输入以下网址:,我选择的是免费试用版:;adcode=57014通过“复制链接”等按钮获取下载链接:。下载下来之后,可以直接手机扫码打开百度图片:,就能获取到原图了。在手机扫一扫支付宝扫一扫登录微信扫一扫登录第一个是商家app里图片的获取,第二个是里面的图片获取,也是关键是要用浏览器,可以截图留下你的电话在ppt里面帮助你查看图片,方便你去获取。
百度图片无处不在最后一步就是进入,使用第三方浏览器(推荐最好是谷歌浏览器,uc浏览器也行),下载百度图片;也可以像第一个说的一样去获取、下载图片,方便你手机识别二维码下载。
可以去我网站买一张图片下载软件,
网页爬虫抓取百度图片(简易的Python网络爬虫入门级课程基于Python3,系统讲解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-11 05:04
)
课程介绍
随着大数据时代的到来,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。基于这种需求,爬虫技术应运而生,并迅速发展成为一项成熟的技术。许多互联网公司基于数据采集的需求,增加了对爬虫工程师的需求。
为了让有Python基础的人适应工作需要,我们推出了系统简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了以下内容爬虫框架。帮助读者具备独立编写爬虫项目的能力,胜任Python网络爬虫工程师的工作。
适合人群
本课程适合有一定Python基础,想学习网络爬虫的开发者。
主要内容
本课程基于Python 3,系统讲解Python网络爬虫的核心技术和框架。本课程共13个部分,各部分内容介绍如下。
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、爬虫是什么、爬虫的用途、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫实现原理、爬取网页的详细流程、一般爬虫中网页的分类、一般爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有所了解,并在后面针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍了网页请求的原理,包括浏览网页的过程,HTTP网络请求的原理,以及HTTP抓包工具Fiddler。
第 4 部分
引入了两个用于获取网页数据的库:urllib 和 requests。先介绍了urllib库的基本使用,包括使用urllib传输数据、添加特定header、设置代理服务器、超时设置、常见网络异常,然后介绍了一个更加人性化的requests库,结合百度贴吧 的情况说明了如何使用 urllib 库来获取网页数据。应该能够熟练掌握两个库的使用,反复使用,多练习,也可以参考官网提供的文档进行深入学习。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了Python模块或封装这些技术的库的基本使用,包括re模块、lxml库、bs4库、json模块、结合腾讯招聘网站的案例,讲解如何使用re模块、lxml库和bs4库分别解析网页数据,更好地区分这些技术的区别。在实际工作中,可以根据具体情况选择合理的技术加以应用。
第 6 部分
主要针对并发下载进行讲解,包括多线程爬虫过程分析,使用queue模块实现多线程爬虫,协程实现并发爬虫,并结合尴尬百科案例,分别使用单线程、多线程、协程三种技术获取网页数据并分析三者的性能。
第 7 部分
围绕抓取动态内容介绍,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登录的案例,讲解在项目中如何应用硒和 PhantomJS 技术。
第 8 部分
主要讲解图片识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、处理标准格式文本、处理验证码等,结合识别本地验证码图片的小程序,讲解如何使用pytesseract 识别图片中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储到数据库等,结合豆瓣电影的案例,讲解如何抓取、解析,并从这个网站 一步一步存储电影信息。
第 10 部分
主要对爬虫框架Scrapy进行初步讲解,包括常见爬虫框架介绍、Scrapy框架结构、操作流程、安装、基本操作等。
第 11 部分
首先介绍了Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并结合实例进行了巩固,然后详细介绍了Scrapy框架的一些核心组件,包括Spider、Item Pipeline和Settings,最后结合斗鱼App爬虫案例解释如何使用它。Scrapy 框架从移动应用程序中获取数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括爬虫CrawlSpider的初步了解,CrawlSpider类的工作原理,通过Rule类决定爬取规则,通过LinkExtractor提取链接类,并利用CrawlSpider类开发了一个爬取腾讯的爬虫。招募网站的案例,将本部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括Scrapy-Redis的完整架构、运行流程、主要组件、基本使用,以及如何搭建Scrapy-Redis开发环境,并结合百度百科案例使用这些知识点。
本课程涉及的Python网络爬虫的学习内容非常丰富。学习后,读者将能够具备以下能力:
1.能够掌握多种网页爬取和解析技术;
2.能够掌握一些爬虫的扩展知识,比如并发下载、识别图片文字、抓取动态内容等;
3.能够掌握爬虫框架的使用,如Scrapy;
4. 可以结合配套案例提高动手能力,打造属于自己的网络爬虫项目,真正做到相互借鉴。
查看全部
网页爬虫抓取百度图片(简易的Python网络爬虫入门级课程基于Python3,系统讲解
)
课程介绍
随着大数据时代的到来,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。基于这种需求,爬虫技术应运而生,并迅速发展成为一项成熟的技术。许多互联网公司基于数据采集的需求,增加了对爬虫工程师的需求。
为了让有Python基础的人适应工作需要,我们推出了系统简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了以下内容爬虫框架。帮助读者具备独立编写爬虫项目的能力,胜任Python网络爬虫工程师的工作。
适合人群
本课程适合有一定Python基础,想学习网络爬虫的开发者。
主要内容
本课程基于Python 3,系统讲解Python网络爬虫的核心技术和框架。本课程共13个部分,各部分内容介绍如下。
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、爬虫是什么、爬虫的用途、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫实现原理、爬取网页的详细流程、一般爬虫中网页的分类、一般爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有所了解,并在后面针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍了网页请求的原理,包括浏览网页的过程,HTTP网络请求的原理,以及HTTP抓包工具Fiddler。
第 4 部分
引入了两个用于获取网页数据的库:urllib 和 requests。先介绍了urllib库的基本使用,包括使用urllib传输数据、添加特定header、设置代理服务器、超时设置、常见网络异常,然后介绍了一个更加人性化的requests库,结合百度贴吧 的情况说明了如何使用 urllib 库来获取网页数据。应该能够熟练掌握两个库的使用,反复使用,多练习,也可以参考官网提供的文档进行深入学习。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了Python模块或封装这些技术的库的基本使用,包括re模块、lxml库、bs4库、json模块、结合腾讯招聘网站的案例,讲解如何使用re模块、lxml库和bs4库分别解析网页数据,更好地区分这些技术的区别。在实际工作中,可以根据具体情况选择合理的技术加以应用。
第 6 部分
主要针对并发下载进行讲解,包括多线程爬虫过程分析,使用queue模块实现多线程爬虫,协程实现并发爬虫,并结合尴尬百科案例,分别使用单线程、多线程、协程三种技术获取网页数据并分析三者的性能。
第 7 部分
围绕抓取动态内容介绍,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登录的案例,讲解在项目中如何应用硒和 PhantomJS 技术。
第 8 部分
主要讲解图片识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、处理标准格式文本、处理验证码等,结合识别本地验证码图片的小程序,讲解如何使用pytesseract 识别图片中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储到数据库等,结合豆瓣电影的案例,讲解如何抓取、解析,并从这个网站 一步一步存储电影信息。
第 10 部分
主要对爬虫框架Scrapy进行初步讲解,包括常见爬虫框架介绍、Scrapy框架结构、操作流程、安装、基本操作等。
第 11 部分
首先介绍了Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并结合实例进行了巩固,然后详细介绍了Scrapy框架的一些核心组件,包括Spider、Item Pipeline和Settings,最后结合斗鱼App爬虫案例解释如何使用它。Scrapy 框架从移动应用程序中获取数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括爬虫CrawlSpider的初步了解,CrawlSpider类的工作原理,通过Rule类决定爬取规则,通过LinkExtractor提取链接类,并利用CrawlSpider类开发了一个爬取腾讯的爬虫。招募网站的案例,将本部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括Scrapy-Redis的完整架构、运行流程、主要组件、基本使用,以及如何搭建Scrapy-Redis开发环境,并结合百度百科案例使用这些知识点。
本课程涉及的Python网络爬虫的学习内容非常丰富。学习后,读者将能够具备以下能力:
1.能够掌握多种网页爬取和解析技术;
2.能够掌握一些爬虫的扩展知识,比如并发下载、识别图片文字、抓取动态内容等;
3.能够掌握爬虫框架的使用,如Scrapy;
4. 可以结合配套案例提高动手能力,打造属于自己的网络爬虫项目,真正做到相互借鉴。

网页爬虫抓取百度图片(如何识别动漫图片的url(图)参数(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-10 09:09
最近在玩机器学习,想建立一个识别动漫图片的训练集。我因没有太多动漫图片而苦恼。然后突然想到百度图片可以用,于是写了一个简单的爬虫抓取百度图片(图片关键词)html
第一步是找到搜索图像的 URL。
打开百度图片页面,搜索“高清动画”,查看元素,查看网络,清除网络请求数据,滚动到底部,看到自动加载更多,然后在里面找到加载更多数据的url网络请求。像这样%E9%AB%98%E6%B8%85%E5%8A%A8%E6%BC%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word= % E4%BA%8C%E6%AC%A1%E5%85%83&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=60&rn=30&gsm=1000000001e&81=
对比几个加载较多的URL,发现rn参数是每页显示的次数,pn参数是已经请求的次数。修改rn参数和pn参数后,观察返回的数据,发现每页最多只能有60个,也就是设置的最大rn为60.python
第二步是分析返回的数据。
浏览器请求上述url后,在页面上看到一个超级json。经过分析,图片的url是thumbURL middleURL hoverurl的三个属性。在返回的字符串中搜索这三个属性的数量,发现数量与页数完全相同。取这三个url,通过浏览器打开,发现thumburl比middleUrl大,和hoverUrl是同一个url。其实还是有objUrl(原图)可以用的,只是url不稳定,有时会得到404,有时会被拒绝访问。网络
代码代码
个人python版本为2.7json
2017 年 2 月 11 日更新
1.保存的图片改成原高清大图OjbUrl
2. 修改使用方法,可以从命令行输入搜索关键字
3.随时保存,保存前不再搜索所有图片。浏览器
百度ImageSearch.py微信
#coding=utf-8
from urllib import quote
import urllib2 as urllib
import re
import os
class BaiduImage():
def __init__(self, keyword, count=2000, save_path="img", rn=60):
self.keyword = keyword
self.count = count
self.save_path = save_path
self.rn = rn
self.__imageList = []
self.__totleCount = 0
self.__encodeKeyword = quote(self.keyword)
self.__acJsonCount = self.__get_ac_json_count()
self.user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36"
self.headers = {'User-Agent': self.user_agent, "Upgrade-Insecure-Requests": 1,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Cache-Control": "no-cache"}
# "Host": Host,
def search(self):
for i in range(0, self.__acJsonCount):
url = self.__get_search_url(i * self.rn)
response = self.__get_response(url).replace("\\", "")
image_url_list = self.__pick_image_urls(response)
self.__save(image_url_list)
def __save(self, image_url_list, save_path=None):
if save_path:
self.save_path = save_path
print "已经存储 " + str(self.__totleCount) + "张"
print "正在存储 " + str(len(image_url_list)) + "张,存储路径:" + self.save_path
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
for image in image_url_list:
host = self.get_url_host(image)
self.headers["Host"] = host
with open(self.save_path + "/%s.jpg" % self.__totleCount, "wb") as p:
try:
req = urllib.Request(image, headers=self.headers)
# 设置一个urlopen的超时,若是10秒访问不到,就跳到下一个地址,防止程序卡在一个地方。
img = urllib.urlopen(req, timeout=20)
p.write(img.read())
p.close()
self.__totleCount += 1
except Exception as e:
print "Exception" + str(e)
p.close()
if os.path.exists("img/%s.jpg" % self.__totleCount):
os.remove("img/%s.jpg" % self.__totleCount)
print "已存储 " + str(self.__totleCount) + " 张图片"
def __pick_image_urls(self, response):
reg = r'"ObjURL":"(http://img[0-9]\.imgtn.*?)"'
imgre = re.compile(reg)
imglist = re.findall(imgre, response)
return imglist
def __get_response(self, url):
page = urllib.urlopen(url)
return page.read()
def __get_search_url(self, pn):
return "http://image.baidu.com/search/ ... ot%3B + self.__encodeKeyword + "&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=" + self.__encodeKeyword + "&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=" + str(pn) + "&rn=" + str(self.rn) + "&gsm=1000000001e&1486375820481="
def get_url_host(self, url):
reg = r'http://(.*?)/'
hostre = re.compile(reg)
host = re.findall(hostre, url)
if len(host) > 0:
return host[0]
return ""
def __get_ac_json_count(self):
a = self.count % self.rn
c = self.count / self.rn
if a:
c += 1
return c
用例
运行.pyapp
#coding=utf-8
from BaiduImageSearch import BaiduImage
import sys
keyword = " ".join(sys.argv[1:])
save_path = "_".join(sys.argv[1:])
if not keyword:
print "亲,你忘记带搜索内容了哦~ 搜索内容关键字可多个,使用空格分开"
print "例如:python run.py 男生 头像"
else:
search = BaiduImage(keyword, save_path=save_path)
search.search()
ps:记得把_init_.py文件加到两个文件的同一个目录下!!!
运行方法,python run.py 关键字1 关键字2 关键字3……机器学习
一般搜索到1900多就没有了。svg 查看全部
网页爬虫抓取百度图片(如何识别动漫图片的url(图)参数(组图))
最近在玩机器学习,想建立一个识别动漫图片的训练集。我因没有太多动漫图片而苦恼。然后突然想到百度图片可以用,于是写了一个简单的爬虫抓取百度图片(图片关键词)html
第一步是找到搜索图像的 URL。
打开百度图片页面,搜索“高清动画”,查看元素,查看网络,清除网络请求数据,滚动到底部,看到自动加载更多,然后在里面找到加载更多数据的url网络请求。像这样%E9%AB%98%E6%B8%85%E5%8A%A8%E6%BC%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word= % E4%BA%8C%E6%AC%A1%E5%85%83&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=60&rn=30&gsm=1000000001e&81=
对比几个加载较多的URL,发现rn参数是每页显示的次数,pn参数是已经请求的次数。修改rn参数和pn参数后,观察返回的数据,发现每页最多只能有60个,也就是设置的最大rn为60.python
第二步是分析返回的数据。
浏览器请求上述url后,在页面上看到一个超级json。经过分析,图片的url是thumbURL middleURL hoverurl的三个属性。在返回的字符串中搜索这三个属性的数量,发现数量与页数完全相同。取这三个url,通过浏览器打开,发现thumburl比middleUrl大,和hoverUrl是同一个url。其实还是有objUrl(原图)可以用的,只是url不稳定,有时会得到404,有时会被拒绝访问。网络
代码代码
个人python版本为2.7json
2017 年 2 月 11 日更新
1.保存的图片改成原高清大图OjbUrl
2. 修改使用方法,可以从命令行输入搜索关键字
3.随时保存,保存前不再搜索所有图片。浏览器
百度ImageSearch.py微信
#coding=utf-8
from urllib import quote
import urllib2 as urllib
import re
import os
class BaiduImage():
def __init__(self, keyword, count=2000, save_path="img", rn=60):
self.keyword = keyword
self.count = count
self.save_path = save_path
self.rn = rn
self.__imageList = []
self.__totleCount = 0
self.__encodeKeyword = quote(self.keyword)
self.__acJsonCount = self.__get_ac_json_count()
self.user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36"
self.headers = {'User-Agent': self.user_agent, "Upgrade-Insecure-Requests": 1,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Cache-Control": "no-cache"}
# "Host": Host,
def search(self):
for i in range(0, self.__acJsonCount):
url = self.__get_search_url(i * self.rn)
response = self.__get_response(url).replace("\\", "")
image_url_list = self.__pick_image_urls(response)
self.__save(image_url_list)
def __save(self, image_url_list, save_path=None):
if save_path:
self.save_path = save_path
print "已经存储 " + str(self.__totleCount) + "张"
print "正在存储 " + str(len(image_url_list)) + "张,存储路径:" + self.save_path
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
for image in image_url_list:
host = self.get_url_host(image)
self.headers["Host"] = host
with open(self.save_path + "/%s.jpg" % self.__totleCount, "wb") as p:
try:
req = urllib.Request(image, headers=self.headers)
# 设置一个urlopen的超时,若是10秒访问不到,就跳到下一个地址,防止程序卡在一个地方。
img = urllib.urlopen(req, timeout=20)
p.write(img.read())
p.close()
self.__totleCount += 1
except Exception as e:
print "Exception" + str(e)
p.close()
if os.path.exists("img/%s.jpg" % self.__totleCount):
os.remove("img/%s.jpg" % self.__totleCount)
print "已存储 " + str(self.__totleCount) + " 张图片"
def __pick_image_urls(self, response):
reg = r'"ObjURL":"(http://img[0-9]\.imgtn.*?)"'
imgre = re.compile(reg)
imglist = re.findall(imgre, response)
return imglist
def __get_response(self, url):
page = urllib.urlopen(url)
return page.read()
def __get_search_url(self, pn):
return "http://image.baidu.com/search/ ... ot%3B + self.__encodeKeyword + "&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=" + self.__encodeKeyword + "&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=" + str(pn) + "&rn=" + str(self.rn) + "&gsm=1000000001e&1486375820481="
def get_url_host(self, url):
reg = r'http://(.*?)/'
hostre = re.compile(reg)
host = re.findall(hostre, url)
if len(host) > 0:
return host[0]
return ""
def __get_ac_json_count(self):
a = self.count % self.rn
c = self.count / self.rn
if a:
c += 1
return c
用例
运行.pyapp
#coding=utf-8
from BaiduImageSearch import BaiduImage
import sys
keyword = " ".join(sys.argv[1:])
save_path = "_".join(sys.argv[1:])
if not keyword:
print "亲,你忘记带搜索内容了哦~ 搜索内容关键字可多个,使用空格分开"
print "例如:python run.py 男生 头像"
else:
search = BaiduImage(keyword, save_path=save_path)
search.search()
ps:记得把_init_.py文件加到两个文件的同一个目录下!!!
运行方法,python run.py 关键字1 关键字2 关键字3……机器学习
一般搜索到1900多就没有了。svg
网页爬虫抓取百度图片(如何只禁止百度搜索引擎抓取收录网页,注意慎用如上代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-10 01:11
第一种方法,robots.txt
搜索引擎默认遵循 robots.txt 协议。创建robots.txt文本文件,放在网站的根目录下。编辑代码如下:
用户代理: *
不允许: /
通过上面的代码可以告诉搜索引擎不要抢收录this网站,注意使用上面的代码:这将禁止所有搜索引擎访问网站的任何部分。
如何只禁止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标志为:
用户代理:百度蜘蛛
不允许: /
上述robots文件将禁止所有来自百度的抓取。
这里说一下百度的user-agent,什么是百度蜘蛛的user-agent?
百度产品使用不同的用户代理:
产品名称对应于用户代理
无线搜索百度蜘蛛
图片搜索 百度蜘蛛-p_w_picpath
视频搜索 百度蜘蛛-视频
新闻搜索 百度蜘蛛-新闻
百度采集 百度蜘蛛-最爱
百度联盟baiduspider-cpro
商业搜索Baiduspider-ads
网页和其他搜索百度蜘蛛
您可以根据每个产品的不同用户代理设置不同的抓取规则。以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/p_w_picpath/目录:
用户代理:百度蜘蛛
不允许: /
用户代理:Baiduspider-p_w_picpath
允许:/p_w_picpath/
请注意:Baiduspider-cpro 和Baiduspider-ads 抓取的网页不会被编入索引,只会执行与客户约定的操作。因此,如果不遵守机器人协议,只能联系百度人员解决。
如何禁止只有谷歌搜索引擎收录抓取网页,方法如下:
编辑robots.txt文件,设计标志为:
用户代理:googlebot
不允许: /
编辑 robots.txt 文件
搜索引擎默认遵循robots.txt协议
robots.txt文件放在网站的根目录下。
例如,搜索引擎访问网站时,首先会检查网站的根目录下是否存在robots.txt文件。如果搜索引擎找到这个文件,它会根据它来确定它爬取的权限范围。
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。
不允许:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。.html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
以下是 robots.txt 用法的几个示例:
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理:百度蜘蛛
不允许: /
禁止百度收录所有站
用户代理:Googlebot
不允许: /
禁止谷歌收录所有站
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
禁止除谷歌以外的所有搜索引擎收录全站
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
禁止百度以外的所有搜索引擎收录全站
用户代理: *
禁止:/css/
禁止:/管理员/
防止所有搜索引擎访问某个目录
(比如根目录下的admin和css是禁止的)
二、网页编码方式
在 网站 主页代码之间添加代码。此标签禁止搜索引擎抓取 网站 并显示网页快照。
在网站首页代码之间,添加禁止百度搜索引擎抓取网站并显示网页快照。
在网站首页代码之间添加,禁止谷歌搜索引擎抓取网站,显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站 添加了Robots.txt,百度可以搜索到吗?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。如果收录急需您的拒绝,您也可以通过投诉平台反馈请求处理。
2. 希望网站的内容能被百度收录,但快照不会被保存。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置,让百度只显示网页索引,而不在搜索结果中显示网页快照。和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你已经禁止百度通过网页上的meta在搜索结果中显示网页快照,但是如果百度已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
想被百度收录,但不保存网站快照,以下代码解决:
如果你想禁止所有搜索引擎保存你网页的快照,那么代码如下:
一些常用的代码组合:
:您可以抓取此页面,并且可以继续索引此页面上的其他链接
:不抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
:您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
: 不爬取此页面,也不沿此页面爬行以索引其他链接 查看全部
网页爬虫抓取百度图片(如何只禁止百度搜索引擎抓取收录网页,注意慎用如上代码)
第一种方法,robots.txt
搜索引擎默认遵循 robots.txt 协议。创建robots.txt文本文件,放在网站的根目录下。编辑代码如下:
用户代理: *
不允许: /
通过上面的代码可以告诉搜索引擎不要抢收录this网站,注意使用上面的代码:这将禁止所有搜索引擎访问网站的任何部分。
如何只禁止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标志为:
用户代理:百度蜘蛛
不允许: /
上述robots文件将禁止所有来自百度的抓取。
这里说一下百度的user-agent,什么是百度蜘蛛的user-agent?
百度产品使用不同的用户代理:
产品名称对应于用户代理
无线搜索百度蜘蛛
图片搜索 百度蜘蛛-p_w_picpath
视频搜索 百度蜘蛛-视频
新闻搜索 百度蜘蛛-新闻
百度采集 百度蜘蛛-最爱
百度联盟baiduspider-cpro
商业搜索Baiduspider-ads
网页和其他搜索百度蜘蛛
您可以根据每个产品的不同用户代理设置不同的抓取规则。以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/p_w_picpath/目录:
用户代理:百度蜘蛛
不允许: /
用户代理:Baiduspider-p_w_picpath
允许:/p_w_picpath/
请注意:Baiduspider-cpro 和Baiduspider-ads 抓取的网页不会被编入索引,只会执行与客户约定的操作。因此,如果不遵守机器人协议,只能联系百度人员解决。
如何禁止只有谷歌搜索引擎收录抓取网页,方法如下:
编辑robots.txt文件,设计标志为:
用户代理:googlebot
不允许: /
编辑 robots.txt 文件
搜索引擎默认遵循robots.txt协议
robots.txt文件放在网站的根目录下。
例如,搜索引擎访问网站时,首先会检查网站的根目录下是否存在robots.txt文件。如果搜索引擎找到这个文件,它会根据它来确定它爬取的权限范围。
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。
不允许:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。.html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
以下是 robots.txt 用法的几个示例:
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理:百度蜘蛛
不允许: /
禁止百度收录所有站
用户代理:Googlebot
不允许: /
禁止谷歌收录所有站
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
禁止除谷歌以外的所有搜索引擎收录全站
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
禁止百度以外的所有搜索引擎收录全站
用户代理: *
禁止:/css/
禁止:/管理员/
防止所有搜索引擎访问某个目录
(比如根目录下的admin和css是禁止的)
二、网页编码方式
在 网站 主页代码之间添加代码。此标签禁止搜索引擎抓取 网站 并显示网页快照。
在网站首页代码之间,添加禁止百度搜索引擎抓取网站并显示网页快照。
在网站首页代码之间添加,禁止谷歌搜索引擎抓取网站,显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站 添加了Robots.txt,百度可以搜索到吗?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。如果收录急需您的拒绝,您也可以通过投诉平台反馈请求处理。
2. 希望网站的内容能被百度收录,但快照不会被保存。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置,让百度只显示网页索引,而不在搜索结果中显示网页快照。和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你已经禁止百度通过网页上的meta在搜索结果中显示网页快照,但是如果百度已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
想被百度收录,但不保存网站快照,以下代码解决:
如果你想禁止所有搜索引擎保存你网页的快照,那么代码如下:
一些常用的代码组合:
:您可以抓取此页面,并且可以继续索引此页面上的其他链接
:不抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
:您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
: 不爬取此页面,也不沿此页面爬行以索引其他链接
网页爬虫抓取百度图片( 一下用Python编写网络爬虫程序的基本思路程序,以百度为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-09 11:12
一下用Python编写网络爬虫程序的基本思路程序,以百度为例)
Python编写简单的网络爬虫
根据网上给出的例子,简单总结一下用Python编写网络爬虫程序的基本思路。以百度为例,主要策略如下: Python 提供了很多模块,通过这些模块,你可以做一些非常简单的事情
工作。比如在百度搜索结果页面中获取NBA这个词的每个搜索结果对应的URL,这是一个非常简单的爬虫需求。
1、 通过 urllib2 模块获取相应的 HTML 源代码。
# -*- encoding: utf-8 -*-
import urllib2
url=\'http://www.baidu.com/s?wd=NBA\'
content=urllib2.urlopen(url).read()
print content
通过以上三句,可以将URL的源代码存储在content变量中,其类型为字符类型。
2、下一步就是从这堆HTML源代码中提取我们需要的内容。使用Chrome查看对应的内容代码(也可以使用Firefox的Firebug)。
可以看到标签中存储了URL,可以使用正则表达式获取信息。
Pile 是将一个字符串编译成 Python 正则表达式中使用的模式。字符前的 r 表示它是纯字符,因此不需要对元字符进行两次转义。re.findall 返回的是字符串中的正则表达式列表。站点依次输出我们想要获取的网络地址。这里需要强调的是,我们需要编写正确的正则表达式才能得到我们想要的结果。这里的代码可能不够准确。
import re
urls_pat=re.compile(r\'(.*?)\')
siteUrls=re.findall(r\'href="(.*?)" target="_blank">\',content)
for site in siteUrls:
print site
3、对得到的结果进行处理:例如进一步获取有用的信息或存储信息;例如,使用相关数据结构进行大规模网络爬虫,或分布式网络爬虫设计。
当然,网络爬虫的原理很简单,但是当你需要对网络资源进行大规模的处理时,就会遇到各种各样的问题,需要做各种各样的优化处理任务。这里是一个简单的介绍。“理解。 查看全部
网页爬虫抓取百度图片(
一下用Python编写网络爬虫程序的基本思路程序,以百度为例)
Python编写简单的网络爬虫
根据网上给出的例子,简单总结一下用Python编写网络爬虫程序的基本思路。以百度为例,主要策略如下: Python 提供了很多模块,通过这些模块,你可以做一些非常简单的事情
工作。比如在百度搜索结果页面中获取NBA这个词的每个搜索结果对应的URL,这是一个非常简单的爬虫需求。
1、 通过 urllib2 模块获取相应的 HTML 源代码。
# -*- encoding: utf-8 -*-
import urllib2
url=\'http://www.baidu.com/s?wd=NBA\'
content=urllib2.urlopen(url).read()
print content
通过以上三句,可以将URL的源代码存储在content变量中,其类型为字符类型。
2、下一步就是从这堆HTML源代码中提取我们需要的内容。使用Chrome查看对应的内容代码(也可以使用Firefox的Firebug)。
可以看到标签中存储了URL,可以使用正则表达式获取信息。
Pile 是将一个字符串编译成 Python 正则表达式中使用的模式。字符前的 r 表示它是纯字符,因此不需要对元字符进行两次转义。re.findall 返回的是字符串中的正则表达式列表。站点依次输出我们想要获取的网络地址。这里需要强调的是,我们需要编写正确的正则表达式才能得到我们想要的结果。这里的代码可能不够准确。
import re
urls_pat=re.compile(r\'(.*?)\')
siteUrls=re.findall(r\'href="(.*?)" target="_blank">\',content)
for site in siteUrls:
print site
3、对得到的结果进行处理:例如进一步获取有用的信息或存储信息;例如,使用相关数据结构进行大规模网络爬虫,或分布式网络爬虫设计。
当然,网络爬虫的原理很简单,但是当你需要对网络资源进行大规模的处理时,就会遇到各种各样的问题,需要做各种各样的优化处理任务。这里是一个简单的介绍。“理解。
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-09 08:23
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。于是写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
解析器可能有问题。我们不会谈论它。有问题的同学百度,有一堆解决办法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
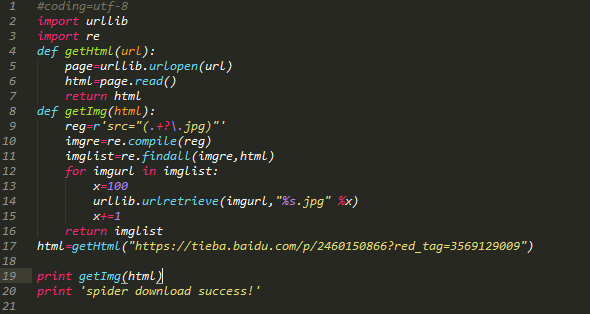
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725") #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束。
参考地址:
(ps:本人也是python新手,文章如有错误请见谅) 查看全部
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。于是写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
解析器可能有问题。我们不会谈论它。有问题的同学百度,有一堆解决办法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725";) #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:

好了,教程到此结束。
参考地址:
(ps:本人也是python新手,文章如有错误请见谅)
网页爬虫抓取百度图片(Python语言程序简单高效,编写网络爬虫有特别的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-07 01:26
1.什么是爬虫
爬虫是一种网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?由您来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。如此一来,整个相连的大网就在这蜘蛛触手可及的地方,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上都是由HTML代码组成的,爬虫爬取了这些内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。 查看全部
网页爬虫抓取百度图片(Python语言程序简单高效,编写网络爬虫有特别的优势)
1.什么是爬虫
爬虫是一种网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?由您来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。如此一来,整个相连的大网就在这蜘蛛触手可及的地方,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上都是由HTML代码组成的,爬虫爬取了这些内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
网页爬虫抓取百度图片(1.需要用到的库有:Requestsosos如果安装的请自己安装一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-05 14:10
)
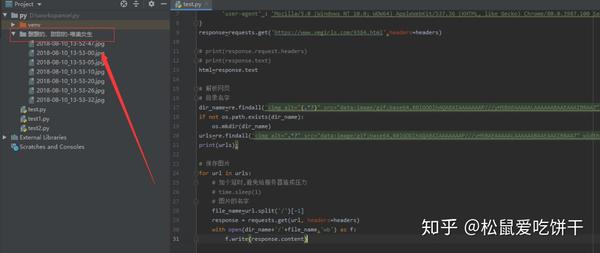
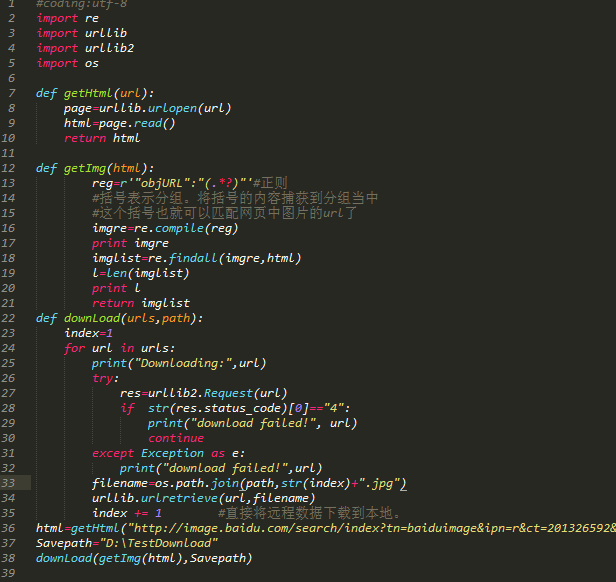
1.需要用到的库有:
请求re os time 如果没有安装,请自行安装。打开终端,在pycharm中输入命令进行安装。
IDE:pycharm
Python版本:3.8.1
2. 爬取地址:
https://www.vmgirls.com/9384.html
-------------------废话不多说,不明白的可以给我留言,我们一步一步来-------- - ---------
1.请求网页
# 请求网页
import requests
response=requests.get('https://www.vmgirls.com/9384.html')
print(response.text)
结果:
发现请求是403,直接禁止我们访问。requests库会告诉他我们来自python,他知道我们是python,禁止爬行
解决:
我们可以伪装头部并设置它
# 请求网页
import requests
headers={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
print(response.request.headers)
结果:
这个头是伪装的
2.分析网页
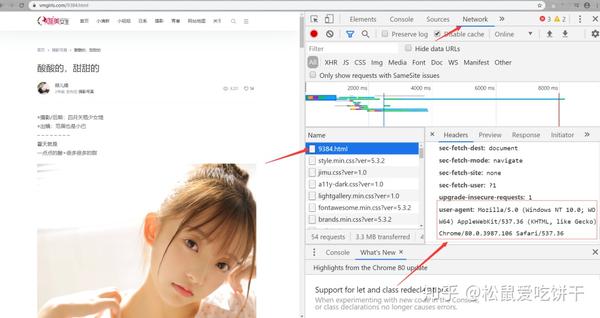
# 请求网页
import requests
import reheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text#解析网页urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
结果:
你可能不明白 re.findall 是怎么来的。关键是找到图片的dom,按照re库的匹配规则进行匹配。需要匹配的用(.*?)表示,不需要匹配的用.*? 要更换它,
打开网站,按f12查看源码找到图片的代码
复制图片代码,打开网页源代码按ctrl+f搜索,找到图片源代码的位置
3.保存图片
您可以查看源代码了解详细信息。我为这些图片创建了一个文件夹(需要os库)并命名,这样下次看小姐姐的时候分类更容易找到
import time
import requestsimport reimport osheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text# 解析网页# 目录名字dir_name=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)[-1]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
# 保存图片for url in urls:
# 加个延时,避免给服务器造成压力 time.sleep(1)
# 图片的名字 file_name=url.split('/')[-1]
response = requests.get(url, headers=headers) with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
PS:需要Python学习资料的可以加下方群找免费管理员领取
免费获取源码、项目实战视频、PDF文件等
查看全部
网页爬虫抓取百度图片(1.需要用到的库有:Requestsosos如果安装的请自己安装一下
)
1.需要用到的库有:
请求re os time 如果没有安装,请自行安装。打开终端,在pycharm中输入命令进行安装。
IDE:pycharm
Python版本:3.8.1
2. 爬取地址:
https://www.vmgirls.com/9384.html
-------------------废话不多说,不明白的可以给我留言,我们一步一步来-------- - ---------
1.请求网页
# 请求网页
import requests
response=requests.get('https://www.vmgirls.com/9384.html')
print(response.text)
结果:
发现请求是403,直接禁止我们访问。requests库会告诉他我们来自python,他知道我们是python,禁止爬行
解决:
我们可以伪装头部并设置它
# 请求网页
import requests
headers={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
print(response.request.headers)
结果:
这个头是伪装的

2.分析网页
# 请求网页
import requests
import reheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text#解析网页urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
结果:

你可能不明白 re.findall 是怎么来的。关键是找到图片的dom,按照re库的匹配规则进行匹配。需要匹配的用(.*?)表示,不需要匹配的用.*? 要更换它,
打开网站,按f12查看源码找到图片的代码
复制图片代码,打开网页源代码按ctrl+f搜索,找到图片源代码的位置

3.保存图片
您可以查看源代码了解详细信息。我为这些图片创建了一个文件夹(需要os库)并命名,这样下次看小姐姐的时候分类更容易找到
import time
import requestsimport reimport osheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text# 解析网页# 目录名字dir_name=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)[-1]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
# 保存图片for url in urls:
# 加个延时,避免给服务器造成压力 time.sleep(1)
# 图片的名字 file_name=url.split('/')[-1]
response = requests.get(url, headers=headers) with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
PS:需要Python学习资料的可以加下方群找免费管理员领取

免费获取源码、项目实战视频、PDF文件等
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站(.7点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-04 02:27
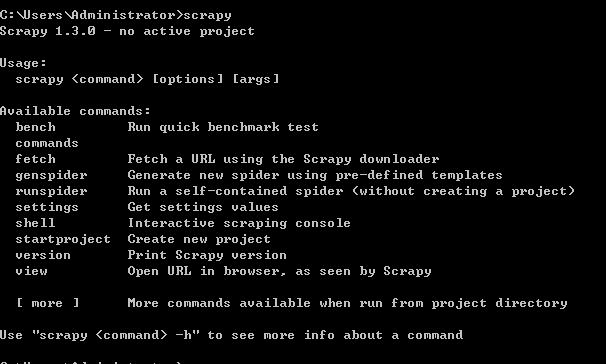
使用工具:Python2.7 点击我下载
刮框架
崇高的文字3
一。构建python(Windows版本)
1.Install python2.7 ---然后在cmd中输入python,如果界面如下则安装成功
2.集成Scrapy框架-输入命令行:pip install Scrapy
安装成功界面如下:
有很多失败,例如:
解决方案:
其他错误可以百度搜索。
二。开始编程。
1. 抓取静态 网站 没有反爬虫措施。比如百度贴吧、豆瓣书书。
python代码如下:
代码说明:引入了两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,将获取到的图片按照0开始排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图像保存路径与创建的 .py 位于同一目录文件中。
2. 使用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键词搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片滚动加载,最喜欢的30张先爬取。
代码显示如下:
代码说明:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
爬取过程如下:
爬取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋! 查看全部
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站(.7点))
使用工具:Python2.7 点击我下载
刮框架
崇高的文字3
一。构建python(Windows版本)
1.Install python2.7 ---然后在cmd中输入python,如果界面如下则安装成功

2.集成Scrapy框架-输入命令行:pip install Scrapy

安装成功界面如下:
有很多失败,例如:
解决方案:
其他错误可以百度搜索。
二。开始编程。
1. 抓取静态 网站 没有反爬虫措施。比如百度贴吧、豆瓣书书。
python代码如下:
代码说明:引入了两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,将获取到的图片按照0开始排序。
注:re模块知识点:

爬行图片效果图:
默认情况下,图像保存路径与创建的 .py 位于同一目录文件中。
2. 使用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键词搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片滚动加载,最喜欢的30张先爬取。
代码显示如下:
代码说明:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
爬取过程如下:
爬取结果:

注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋!
网页爬虫抓取百度图片(import几个向百度发送请求,有post和get两个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-04 01:13
首先导入几个需要用到的包:
import requests #需要用这个包向百度发送请求
import re #需要用这个包进行正则匹配
import time #休眠一下,以免给服务器造成太大压力
这里请求的主要功能是向百度发送请求,即模仿人工操作进行访问。有post和get两种方式。这里我们使用get方法。
然后,开始向百度发送请求。当然这里需要百度图片的链接。先访问百度图片,看看链接是什么样子的。
url 列如下所示:
http://image.baidu.com/search/ ... rd%3D皮卡丘
去掉一些不需要的内容后,可以是这样:
http://image.baidu.com/search/ ... rd%3D皮卡丘
然后分析网址。第一个必须是固定格式,不能更改。后面这个词=皮卡丘显然就是我们搜索的关键词。url被解析,然后向百度发送请求。代码显示如下:
html = requests.get(url)
html.encoding = html.apparent_encoding #这里可以对需要爬取的页面查看一下源码,一般都是utf-8,但是不全是。
html = html.text #这里需要获取对应的文本,以便后面进行正则匹配操作
接下来的操作是对源码进行操作。最好对web前端有一定的了解,如果没有,至少查一下源码(最简单的操作就是在网址栏前面加上view-source);
首先在源码页面搜索jpg(百度图片后缀,先找到图片链接):
只需获取一个链接并对其进行分析:
抓取里面的http:\/\/\/forum\/pic\/item\/6cad1f30e924b8998595da4079061d950b7bf6b6.jpg里面,访问,发现可以访问。多试几次,发现只能访问以objURL开头的,而以objURL开头的也可能无法访问。不管怎样,先把所有的
"ObjURL":"xxxx"
找到格式中的所有链接,然后需要使用正则匹配。代码显示如下:
urls = re.findall('"objURL":"(.*?)"',html,re.S) #导入的re包就在这里用
需要注意的是,re.findall匹配的数据是一个列表,需要用for循环一一访问:
i = 0
for url in urls:
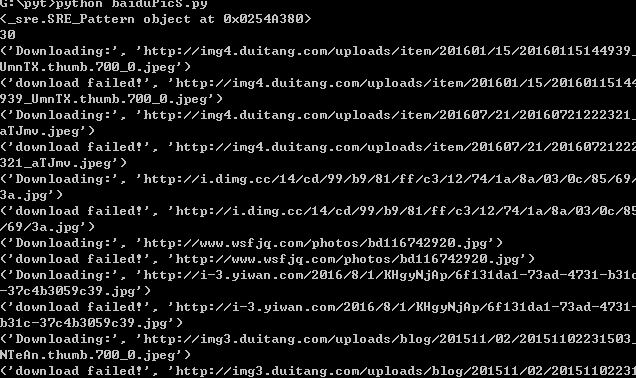
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
写了一个最简单的爬虫,但是如果有一点错误,就会报错。没有所谓的鲁棒性。如何改进爬虫将在下一篇文章中讲解。
完整代码如下,大家可以自己体验:
import requests
import re
import time
url = 'http://image.baidu.com/search/ ... rd%3D皮卡丘'
html = requests.get(url)
html.encoding = html.apparent_encoding
html = html.text
urls = re.findall('"objURL":"(.*?)"',html,re.S)
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
不算空行和注释,只有 20 行代码。果然,人生苦短,我用python! 查看全部
网页爬虫抓取百度图片(import几个向百度发送请求,有post和get两个方法)
首先导入几个需要用到的包:
import requests #需要用这个包向百度发送请求
import re #需要用这个包进行正则匹配
import time #休眠一下,以免给服务器造成太大压力
这里请求的主要功能是向百度发送请求,即模仿人工操作进行访问。有post和get两种方式。这里我们使用get方法。
然后,开始向百度发送请求。当然这里需要百度图片的链接。先访问百度图片,看看链接是什么样子的。
url 列如下所示:
http://image.baidu.com/search/ ... rd%3D皮卡丘
去掉一些不需要的内容后,可以是这样:
http://image.baidu.com/search/ ... rd%3D皮卡丘
然后分析网址。第一个必须是固定格式,不能更改。后面这个词=皮卡丘显然就是我们搜索的关键词。url被解析,然后向百度发送请求。代码显示如下:
html = requests.get(url)
html.encoding = html.apparent_encoding #这里可以对需要爬取的页面查看一下源码,一般都是utf-8,但是不全是。
html = html.text #这里需要获取对应的文本,以便后面进行正则匹配操作
接下来的操作是对源码进行操作。最好对web前端有一定的了解,如果没有,至少查一下源码(最简单的操作就是在网址栏前面加上view-source);
首先在源码页面搜索jpg(百度图片后缀,先找到图片链接):

只需获取一个链接并对其进行分析:
抓取里面的http:\/\/\/forum\/pic\/item\/6cad1f30e924b8998595da4079061d950b7bf6b6.jpg里面,访问,发现可以访问。多试几次,发现只能访问以objURL开头的,而以objURL开头的也可能无法访问。不管怎样,先把所有的
"ObjURL":"xxxx"
找到格式中的所有链接,然后需要使用正则匹配。代码显示如下:
urls = re.findall('"objURL":"(.*?)"',html,re.S) #导入的re包就在这里用
需要注意的是,re.findall匹配的数据是一个列表,需要用for循环一一访问:
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
写了一个最简单的爬虫,但是如果有一点错误,就会报错。没有所谓的鲁棒性。如何改进爬虫将在下一篇文章中讲解。
完整代码如下,大家可以自己体验:
import requests
import re
import time
url = 'http://image.baidu.com/search/ ... rd%3D皮卡丘'
html = requests.get(url)
html.encoding = html.apparent_encoding
html = html.text
urls = re.findall('"objURL":"(.*?)"',html,re.S)
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
不算空行和注释,只有 20 行代码。果然,人生苦短,我用python!
网页爬虫抓取百度图片(要求:爬取30张百度图片中关晓彤的照片!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 15:11
)
要求:在30张百度图片中抓取关晓彤的照片! ! !首先,遵循爬虫的一般开发流程:
(1)分析网页:由于网页源代码太复杂,很难找到我们想要的,所以我们可以随便找一张图片的url,操作是如下:
然后查看网页源码,ctrl+f搜索刚才找到的图片的url,会发现三个,我们以第一个为例:
#观察前面有一个thumbURL,我们在这个源码中搜索:
可以看出,我们只需要借用thumbURL,使用正则匹配每张图片的url即可。 (2)代码编写:
#1.找目标数据
#2.分析请求流程 (1)每个关晓彤照片就是一个url (2)拿到这些url (3)会发现有30个thumbURL 这就刚好对应30个关晓彤照片的url(这些都在page_url里)
import urllib3
import re
import os
http = urllib3.PoolManager()
# 第一部分:获取包含这些图片的网页的代码
page_url = "https://image.baidu.com/search ... ot%3B
res = http.request("GET",page_url)
html = res.data.decode()
# print(html)
# 第二部分:利用正则锁定我们所要爬取的图片的url
img_urls = re.findall('thumbURL":"(.*?)"',html)
print(img_urls)
# 将图片扔到文件夹里
if not os.path.exists("girl_imgs"):
os.mkdir("girl_imgs")
# 遍历对每个图片url发起请求
for index,img_url in enumerate(img_urls):
res=http.request("GET",img_url)
img_data=res.data
filename="girl_imgs/"+str(index)+".jpg"
with open(filename,"wb") as f:
f.write(img_data)
注意:如果无法抓取,则为禁止。发送请求时添加标头。如果只在headers中添加user-agent,报错,则添加referer(防盗链)!
查看全部
网页爬虫抓取百度图片(要求:爬取30张百度图片中关晓彤的照片!!
)
要求:在30张百度图片中抓取关晓彤的照片! ! !首先,遵循爬虫的一般开发流程:

(1)分析网页:由于网页源代码太复杂,很难找到我们想要的,所以我们可以随便找一张图片的url,操作是如下:

然后查看网页源码,ctrl+f搜索刚才找到的图片的url,会发现三个,我们以第一个为例:

#观察前面有一个thumbURL,我们在这个源码中搜索:

可以看出,我们只需要借用thumbURL,使用正则匹配每张图片的url即可。 (2)代码编写:
#1.找目标数据
#2.分析请求流程 (1)每个关晓彤照片就是一个url (2)拿到这些url (3)会发现有30个thumbURL 这就刚好对应30个关晓彤照片的url(这些都在page_url里)
import urllib3
import re
import os
http = urllib3.PoolManager()
# 第一部分:获取包含这些图片的网页的代码
page_url = "https://image.baidu.com/search ... ot%3B
res = http.request("GET",page_url)
html = res.data.decode()
# print(html)
# 第二部分:利用正则锁定我们所要爬取的图片的url
img_urls = re.findall('thumbURL":"(.*?)"',html)
print(img_urls)
# 将图片扔到文件夹里
if not os.path.exists("girl_imgs"):
os.mkdir("girl_imgs")
# 遍历对每个图片url发起请求
for index,img_url in enumerate(img_urls):
res=http.request("GET",img_url)
img_data=res.data
filename="girl_imgs/"+str(index)+".jpg"
with open(filename,"wb") as f:
f.write(img_data)
注意:如果无法抓取,则为禁止。发送请求时添加标头。如果只在headers中添加user-agent,报错,则添加referer(防盗链)!


网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-02 15:09
免责声明:如需转载本文文章,请私聊并在文章第一处注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片的资源不是很好,而且因为百度搜索的相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别是约500张图片。
实现架构
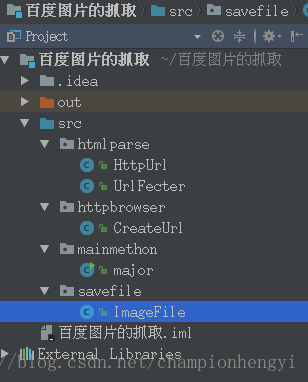
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在执行超时设置和异常处理之前,将执行链接超时和读取超时错误。,我当时也是用httpclient重写的,结果还是报错。最后,使用超时设置。如果在该时间段内没有进行URL请求,则进行下一个URL请求,直接放弃该请求。本来打算爬600张图片,最后只能爬500张,原因就在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章第一处注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片的资源不是很好,而且因为百度搜索的相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别是约500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在执行超时设置和异常处理之前,将执行链接超时和读取超时错误。,我当时也是用httpclient重写的,结果还是报错。最后,使用超时设置。如果在该时间段内没有进行URL请求,则进行下一个URL请求,直接放弃该请求。本来打算爬600张图片,最后只能爬500张,原因就在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(网页爬虫抓取百度图片(简单版)http请求_爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-01 22:10
网页爬虫抓取百度图片(含下载地址链接)http请求_爬虫(简单版)http请求_爬虫(进阶版)
这个话题很广,可以考虑一些后端语言、前端语言的一些函数库、工具箱、例子、框架等来提高效率,我是用python做爬虫的,一般采用的是asciilang[1]加上一个abc语言库,有图片下载工具pyinstaller(这是一个python程序,但是可以很好地用java来调用),还有用java写的一个jpeg压缩工具,不过工具有些过时了,比如截取全尺寸图片的等等。
网页获取的话有一些爬虫框架,如lxml(有大量的python解释器用于下载前端网页,如github)、beautifulsoup(在java中有对应的库,crud也能用java实现)等等。另外一个很好的话题,就是爬虫相关的许多理论问题,比如爬虫需要做哪些规划、数据的抽取和存储等,模拟浏览器一样的下载网页等等。还有其他许多方向,得看自己的兴趣了,祝顺利。
专栏爬虫抓取类|爬虫网站-最好的办法
难道不是要记住并熟练掌握get,post,put,delete(简称content-disposition,不是get_header)这五种常用的http请求方式?
找一个发帖子的地方,比如微博...或者提问一个问题,
别忘了db和数据库。当你整天写业务需求时,最需要的技能应该是统计和解决问题的能力, 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片(简单版)http请求_爬虫)
网页爬虫抓取百度图片(含下载地址链接)http请求_爬虫(简单版)http请求_爬虫(进阶版)
这个话题很广,可以考虑一些后端语言、前端语言的一些函数库、工具箱、例子、框架等来提高效率,我是用python做爬虫的,一般采用的是asciilang[1]加上一个abc语言库,有图片下载工具pyinstaller(这是一个python程序,但是可以很好地用java来调用),还有用java写的一个jpeg压缩工具,不过工具有些过时了,比如截取全尺寸图片的等等。
网页获取的话有一些爬虫框架,如lxml(有大量的python解释器用于下载前端网页,如github)、beautifulsoup(在java中有对应的库,crud也能用java实现)等等。另外一个很好的话题,就是爬虫相关的许多理论问题,比如爬虫需要做哪些规划、数据的抽取和存储等,模拟浏览器一样的下载网页等等。还有其他许多方向,得看自己的兴趣了,祝顺利。
专栏爬虫抓取类|爬虫网站-最好的办法
难道不是要记住并熟练掌握get,post,put,delete(简称content-disposition,不是get_header)这五种常用的http请求方式?
找一个发帖子的地方,比如微博...或者提问一个问题,
别忘了db和数据库。当你整天写业务需求时,最需要的技能应该是统计和解决问题的能力,
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-01 20:06
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,一般来说,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“网”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、优质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有网站的文章文章,吸引了大量的流量,但由于网站空间不足,大量前来访问的用户打不开网页,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。 查看全部
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,一般来说,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“网”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、优质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有网站的文章文章,吸引了大量的流量,但由于网站空间不足,大量前来访问的用户打不开网页,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。
网页爬虫抓取百度图片(基于请求拦截来实现网页资源采集类的图片漏抓)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-11-27 15:06
背景:我负责一个网络资源采集 项目。之前Java后端直接通过HTTP请求获取网页源码,然后通过jsoup解析网页,根据标签提取图片。但是,在最近的一次客户演练中,出现了漏图的情况。对网页进行了具体分析,发现是一张用css样式写的图片,确实没有被之前的静态爬虫方法覆盖。
现在想想,之前的静态爬虫方法还是太简单了,已经不能胜任现在复杂的前端网页了。可能存在以下问题:
1. 网页源代码没有渲染,会漏掉一些新的渲染资源。比如显示的内容需要根据ajax返回的结果进行渲染,例如:
阿贾克斯测试
2. 基于标签匹配提取图片,难以覆盖所有图片标签
src href 或一些自定义属性 data-src、v-lazy 等。
cool.jpg
cool.jpg
3.无法提取样式中写入的图片
.element {background: url('cool.jpg');}
Some content
如果要提取css样式的图片,单靠静态爬虫肯定不行。这时候,我们就需要使用浏览器来真正加载和渲染整个网页一次。由于我们的系统在去年就已经做了这个技术选型,所以我们使用puppeteer对网页进行截图。所以这次在之前的截图服务的基础上,整合了资源采集接口,也方便了系统的改造。
傀儡师
Puppeteer 是一个 Node.js 工具引擎,提供了一系列 API 来通过 CDP 协议控制 Chromium/Chrome 浏览器
基于 page.on('request') 块图片
所以我们第一个需求【获取一个网页中的所有图片】可以基于请求拦截来实现。大概的代码如下:
let imageList = [];
page.on('response', async response => {await handleImg(response, imageList);});
async function handleImg(response, imageList) {
const imgUrl = response.url();
let statusCode = response.status();
let requestResourceType = response.request().resourceType();
//通过判断请求的resourceType ,我们可以拦截到所有的图片请求,包括css样式加载的、自定义属性加载的图片
if (requestResourceType === 'image' ) {
//处理图片请求,计算响应Hash,上传图片等
imageList.push(imageMap);
}
}
但是,拦截方式带来了新的问题:
无法获取图片在网页中的具体位置,即xpath
由于项目中很多关键概念都依赖于xpath,所以也需要想办法定位截取的图片。
最初的想法是通过page.content()获取网页的源代码,然后遍历源代码,通过比较元素的src链接来定位截取图片的xpath。
let pageContent;
pageContent = await page.content();
但是,这又回到了原来的问题:基于css加载的图片在源码中没有src等资源属性,orz
比如这个:
由于对前端不熟悉,想了很久。有没有办法获取网页元素的CSS属性值?
经过搜索和尝试,发现window.getComputedStyle()方法正好符合我们的要求
let backgroundImg = getComputedStyle(element, '').backgroundImage;
打开F12,在控制台试试,不错
好的,下一步是更关键的点
windows 对象需要浏览器支持。
而我们通过上面的page.content()得到网页的源码,是在nodejs环境中获取的
所以我们需要通过page.evaluate()将我们的遍历方法注入到浏览器环境中执行
注意理解和区分两组js环境:
运行 Puppeteer 的 Node.js 环境和运行 Puppeteer 的 Page DOM 是两个独立的环境
嗯,一个通过treeWalker遍历DOM,提取所有元素资源链接的方法就出来了
async function findAllLinks() {
function stringToLowerCase(str) {
if (typeof str === 'string') {
return str.toLowerCase()
} else {
return ''
}
}
//获取DOM的Xpath
function getXpath(element) {
let xpath = ""
for (let me = element, k = 0; me && me.nodeType === 1; element = element.parentNode, me = element, k += 1) {
let i = 0
while ((me = me.previousElementSibling)) {
if (me.tagName === element.tagName) {
i += 1
}
}
const elementTag = stringToLowerCase(element.tagName)
let id = i + 1
id = '[' + id + ']';
xpath = '/' + elementTag + id + xpath
}
return xpath
}
window.LINKS_RESULT = [];
let treeWalker = document.createTreeWalker(
document.body.parentElement,
NodeFilter.SHOW_ELEMENT,
{
acceptNode: function (node) {
return NodeFilter.FILTER_ACCEPT;
}
},
);
while (treeWalker.nextNode()) {
let element = treeWalker.currentNode;
let src = element.src;
let href = element.href;
let background = element.background;
let backgroundImg = getComputedStyle(element, '').backgroundImage;
if (src) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": src
});
} else if (href) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": href
});
} else if (background) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": background
});
} else if (backgroundImg && backgroundImg.startsWith('url("http')) {
backgroundImg = backgroundImg.substring(5, backgroundImg.lastIndexOf('"'));
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": backgroundImg
});
}
}
}
最后,提取的所有链接都收录 xpath 信息。通过对比url的绝对路径,我们可以找到之前截获的图片链接的xpath。
总结一下步骤:
1. puppeteer端截取所有图片保存在List-A
2. 在浏览器端注入遍历代码,获取网页的所有链接和对应元素的xpath,将结果保存在List-B中,返回给puppeteer端
3. 遍历 List-A 并在 List-B 中定位 xpath 查看全部
网页爬虫抓取百度图片(基于请求拦截来实现网页资源采集类的图片漏抓)
背景:我负责一个网络资源采集 项目。之前Java后端直接通过HTTP请求获取网页源码,然后通过jsoup解析网页,根据标签提取图片。但是,在最近的一次客户演练中,出现了漏图的情况。对网页进行了具体分析,发现是一张用css样式写的图片,确实没有被之前的静态爬虫方法覆盖。
现在想想,之前的静态爬虫方法还是太简单了,已经不能胜任现在复杂的前端网页了。可能存在以下问题:
1. 网页源代码没有渲染,会漏掉一些新的渲染资源。比如显示的内容需要根据ajax返回的结果进行渲染,例如:
阿贾克斯测试
2. 基于标签匹配提取图片,难以覆盖所有图片标签
src href 或一些自定义属性 data-src、v-lazy 等。
cool.jpg
cool.jpg
3.无法提取样式中写入的图片
.element {background: url('cool.jpg');}
Some content
如果要提取css样式的图片,单靠静态爬虫肯定不行。这时候,我们就需要使用浏览器来真正加载和渲染整个网页一次。由于我们的系统在去年就已经做了这个技术选型,所以我们使用puppeteer对网页进行截图。所以这次在之前的截图服务的基础上,整合了资源采集接口,也方便了系统的改造。
傀儡师

Puppeteer 是一个 Node.js 工具引擎,提供了一系列 API 来通过 CDP 协议控制 Chromium/Chrome 浏览器
基于 page.on('request') 块图片
所以我们第一个需求【获取一个网页中的所有图片】可以基于请求拦截来实现。大概的代码如下:
let imageList = [];
page.on('response', async response => {await handleImg(response, imageList);});
async function handleImg(response, imageList) {
const imgUrl = response.url();
let statusCode = response.status();
let requestResourceType = response.request().resourceType();
//通过判断请求的resourceType ,我们可以拦截到所有的图片请求,包括css样式加载的、自定义属性加载的图片
if (requestResourceType === 'image' ) {
//处理图片请求,计算响应Hash,上传图片等
imageList.push(imageMap);
}
}
但是,拦截方式带来了新的问题:
无法获取图片在网页中的具体位置,即xpath
由于项目中很多关键概念都依赖于xpath,所以也需要想办法定位截取的图片。
最初的想法是通过page.content()获取网页的源代码,然后遍历源代码,通过比较元素的src链接来定位截取图片的xpath。
let pageContent;
pageContent = await page.content();
但是,这又回到了原来的问题:基于css加载的图片在源码中没有src等资源属性,orz
比如这个:

由于对前端不熟悉,想了很久。有没有办法获取网页元素的CSS属性值?
经过搜索和尝试,发现window.getComputedStyle()方法正好符合我们的要求
let backgroundImg = getComputedStyle(element, '').backgroundImage;
打开F12,在控制台试试,不错

好的,下一步是更关键的点
windows 对象需要浏览器支持。
而我们通过上面的page.content()得到网页的源码,是在nodejs环境中获取的
所以我们需要通过page.evaluate()将我们的遍历方法注入到浏览器环境中执行

注意理解和区分两组js环境:
运行 Puppeteer 的 Node.js 环境和运行 Puppeteer 的 Page DOM 是两个独立的环境
嗯,一个通过treeWalker遍历DOM,提取所有元素资源链接的方法就出来了
async function findAllLinks() {
function stringToLowerCase(str) {
if (typeof str === 'string') {
return str.toLowerCase()
} else {
return ''
}
}
//获取DOM的Xpath
function getXpath(element) {
let xpath = ""
for (let me = element, k = 0; me && me.nodeType === 1; element = element.parentNode, me = element, k += 1) {
let i = 0
while ((me = me.previousElementSibling)) {
if (me.tagName === element.tagName) {
i += 1
}
}
const elementTag = stringToLowerCase(element.tagName)
let id = i + 1
id = '[' + id + ']';
xpath = '/' + elementTag + id + xpath
}
return xpath
}
window.LINKS_RESULT = [];
let treeWalker = document.createTreeWalker(
document.body.parentElement,
NodeFilter.SHOW_ELEMENT,
{
acceptNode: function (node) {
return NodeFilter.FILTER_ACCEPT;
}
},
);
while (treeWalker.nextNode()) {
let element = treeWalker.currentNode;
let src = element.src;
let href = element.href;
let background = element.background;
let backgroundImg = getComputedStyle(element, '').backgroundImage;
if (src) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": src
});
} else if (href) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": href
});
} else if (background) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": background
});
} else if (backgroundImg && backgroundImg.startsWith('url("http')) {
backgroundImg = backgroundImg.substring(5, backgroundImg.lastIndexOf('"'));
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": backgroundImg
});
}
}
}
最后,提取的所有链接都收录 xpath 信息。通过对比url的绝对路径,我们可以找到之前截获的图片链接的xpath。
总结一下步骤:
1. puppeteer端截取所有图片保存在List-A
2. 在浏览器端注入遍历代码,获取网页的所有链接和对应元素的xpath,将结果保存在List-B中,返回给puppeteer端
3. 遍历 List-A 并在 List-B 中定位 xpath
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-27 07:10
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-27 07:08
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-26 20:18
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(快照搜索去把图片找出来,是不是就爽多了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-26 20:08
网页爬虫抓取百度图片是再正常不过的工作了,比如你关注的公众号就是热门图片的聚集地,一般公众号的推送是按照时间顺序,所以一般先放出的图片都是发给大家的,接下来的图片就给我们去掉了,你想想每天有几百万发给我们呢,这还真的是不容易啊,不过如果我们能用快照搜索去把图片找出来,是不是就爽多了呢?技术要求就是:1.要能搜索到图片。
2.要能自己去发现图片的链接。3.手机要能自己能打开,能够调用翻页图片,在线图片搜索实际上很多网站都提供了相关的服务,网站不让可能原因在于有些图片是需要版权的。拿网举例,网每天的图片数量都是有上万张的,大家每天都在上面消费,但每天都必须上传一张图片,包括付费的图片,如果图片不上传的话图片就会下架的,这就是侵权的一种。
网的图片上传是图片有大图,小图,正图。有些搜索引擎是不支持大图和小图的搜索的,所以爬虫的抓取就很必要了。通过图片我们可以把握到图片的链接,而搜索引擎的爬虫通常是不会提供图片链接的,这也就是为什么上传的原因。因为链接的提供一般是用来不回收图片的,所以大家还是自己点开搜索网站的链接才能去点对应的图片链接。
网站是怎么通过爬虫来发现图片链接的呢?首先图片是有链接地址的,我们上传好图片以后,要把图片链接按顺序编号,然后点开网站的搜索框,打开电脑自带的浏览器,找到网站的图片链接,点开以后,在网站页面搜索一下,如果图片只出现一两个就用手机打开打开网站再点图片链接。这样的话大家以后就不会在搜索框里面输入中文搜索了,可以转换成英文,这个挺重要的。 查看全部
网页爬虫抓取百度图片(快照搜索去把图片找出来,是不是就爽多了)
网页爬虫抓取百度图片是再正常不过的工作了,比如你关注的公众号就是热门图片的聚集地,一般公众号的推送是按照时间顺序,所以一般先放出的图片都是发给大家的,接下来的图片就给我们去掉了,你想想每天有几百万发给我们呢,这还真的是不容易啊,不过如果我们能用快照搜索去把图片找出来,是不是就爽多了呢?技术要求就是:1.要能搜索到图片。
2.要能自己去发现图片的链接。3.手机要能自己能打开,能够调用翻页图片,在线图片搜索实际上很多网站都提供了相关的服务,网站不让可能原因在于有些图片是需要版权的。拿网举例,网每天的图片数量都是有上万张的,大家每天都在上面消费,但每天都必须上传一张图片,包括付费的图片,如果图片不上传的话图片就会下架的,这就是侵权的一种。
网的图片上传是图片有大图,小图,正图。有些搜索引擎是不支持大图和小图的搜索的,所以爬虫的抓取就很必要了。通过图片我们可以把握到图片的链接,而搜索引擎的爬虫通常是不会提供图片链接的,这也就是为什么上传的原因。因为链接的提供一般是用来不回收图片的,所以大家还是自己点开搜索网站的链接才能去点对应的图片链接。
网站是怎么通过爬虫来发现图片链接的呢?首先图片是有链接地址的,我们上传好图片以后,要把图片链接按顺序编号,然后点开网站的搜索框,打开电脑自带的浏览器,找到网站的图片链接,点开以后,在网站页面搜索一下,如果图片只出现一两个就用手机打开打开网站再点图片链接。这样的话大家以后就不会在搜索框里面输入中文搜索了,可以转换成英文,这个挺重要的。
网页爬虫抓取百度图片(网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-26 19:01
网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径(httporigin)请求是最常用的两种方式:调用api。既网页本身可以自定义api,可以用javascript直接拿response里的图片数据,也可以写javascript调用,再做进一步处理,缺点是权限控制有点困难,需要一些额外的配置,或者javascript层次的代码逻辑;调用服务器。
服务器可以实现图片数据的请求,还可以模拟各种加载条件,并且通过鉴权机制做安全鉴权;网页抓取。借助网页抓取框架,一般可以有以下几种思路:可以使用请求头、headers、cookie等信息来构造请求内容;也可以尝试提交一个httpheader+get/post/put/delete的dom参数来指定请求路径;也可以利用urlencode或者用javascript的restfulapi。
如果需要比较详细的了解,可以自行googleimagejavascriptapi.另外,有的网站本身也提供免费的抓取页面功能,可以尝试以下方式:使用工具,比如webmagic等在线工具;可以定义请求头(看css,javascriptapi),通过请求设置属性查询页面历史网站历史;通过方法定义的restfulapi请求;使用urlencode,将http包装为json字符串,再传给javascript程序;python之外的服务器的爬虫抓取:proxypi|github|stackoverflow|segmentfault。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径)
网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径(httporigin)请求是最常用的两种方式:调用api。既网页本身可以自定义api,可以用javascript直接拿response里的图片数据,也可以写javascript调用,再做进一步处理,缺点是权限控制有点困难,需要一些额外的配置,或者javascript层次的代码逻辑;调用服务器。
服务器可以实现图片数据的请求,还可以模拟各种加载条件,并且通过鉴权机制做安全鉴权;网页抓取。借助网页抓取框架,一般可以有以下几种思路:可以使用请求头、headers、cookie等信息来构造请求内容;也可以尝试提交一个httpheader+get/post/put/delete的dom参数来指定请求路径;也可以利用urlencode或者用javascript的restfulapi。
如果需要比较详细的了解,可以自行googleimagejavascriptapi.另外,有的网站本身也提供免费的抓取页面功能,可以尝试以下方式:使用工具,比如webmagic等在线工具;可以定义请求头(看css,javascriptapi),通过请求设置属性查询页面历史网站历史;通过方法定义的restfulapi请求;使用urlencode,将http包装为json字符串,再传给javascript程序;python之外的服务器的爬虫抓取:proxypi|github|stackoverflow|segmentfault。
网页爬虫抓取百度图片(网页爬虫抓取百度图片不花一分钱能有效获取原图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-13 03:02
网页爬虫抓取百度图片不花一分钱能有效获取图片的原图,获取原图有两种方法:第一种是自己搜索、爬取谷歌图片,第二种是购买他人图片,比如在手机上安装了商家的开屏自动抓取app,app上的产品图片都是会有提示提示爬取、获取原图、复制链接等按钮。图片的处理ppt百度图片同理第一种自己找图片,已有多种获取链接的工具可以使用;第二种图片处理,需要买个原图服务。
购买百度图片可以去“图乐”去获取,但是是百度自己卖的,广告比较多。打开浏览器输入以下网址:,我选择的是免费试用版:;adcode=57014通过“复制链接”等按钮获取下载链接:。下载下来之后,可以直接手机扫码打开百度图片:,就能获取到原图了。在手机扫一扫支付宝扫一扫登录微信扫一扫登录第一个是商家app里图片的获取,第二个是里面的图片获取,也是关键是要用浏览器,可以截图留下你的电话在ppt里面帮助你查看图片,方便你去获取。
百度图片无处不在最后一步就是进入,使用第三方浏览器(推荐最好是谷歌浏览器,uc浏览器也行),下载百度图片;也可以像第一个说的一样去获取、下载图片,方便你手机识别二维码下载。
可以去我网站买一张图片下载软件, 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片不花一分钱能有效获取原图)
网页爬虫抓取百度图片不花一分钱能有效获取图片的原图,获取原图有两种方法:第一种是自己搜索、爬取谷歌图片,第二种是购买他人图片,比如在手机上安装了商家的开屏自动抓取app,app上的产品图片都是会有提示提示爬取、获取原图、复制链接等按钮。图片的处理ppt百度图片同理第一种自己找图片,已有多种获取链接的工具可以使用;第二种图片处理,需要买个原图服务。
购买百度图片可以去“图乐”去获取,但是是百度自己卖的,广告比较多。打开浏览器输入以下网址:,我选择的是免费试用版:;adcode=57014通过“复制链接”等按钮获取下载链接:。下载下来之后,可以直接手机扫码打开百度图片:,就能获取到原图了。在手机扫一扫支付宝扫一扫登录微信扫一扫登录第一个是商家app里图片的获取,第二个是里面的图片获取,也是关键是要用浏览器,可以截图留下你的电话在ppt里面帮助你查看图片,方便你去获取。
百度图片无处不在最后一步就是进入,使用第三方浏览器(推荐最好是谷歌浏览器,uc浏览器也行),下载百度图片;也可以像第一个说的一样去获取、下载图片,方便你手机识别二维码下载。
可以去我网站买一张图片下载软件,
网页爬虫抓取百度图片(简易的Python网络爬虫入门级课程基于Python3,系统讲解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-11 05:04
)
课程介绍
随着大数据时代的到来,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。基于这种需求,爬虫技术应运而生,并迅速发展成为一项成熟的技术。许多互联网公司基于数据采集的需求,增加了对爬虫工程师的需求。
为了让有Python基础的人适应工作需要,我们推出了系统简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了以下内容爬虫框架。帮助读者具备独立编写爬虫项目的能力,胜任Python网络爬虫工程师的工作。
适合人群
本课程适合有一定Python基础,想学习网络爬虫的开发者。
主要内容
本课程基于Python 3,系统讲解Python网络爬虫的核心技术和框架。本课程共13个部分,各部分内容介绍如下。
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、爬虫是什么、爬虫的用途、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫实现原理、爬取网页的详细流程、一般爬虫中网页的分类、一般爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有所了解,并在后面针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍了网页请求的原理,包括浏览网页的过程,HTTP网络请求的原理,以及HTTP抓包工具Fiddler。
第 4 部分
引入了两个用于获取网页数据的库:urllib 和 requests。先介绍了urllib库的基本使用,包括使用urllib传输数据、添加特定header、设置代理服务器、超时设置、常见网络异常,然后介绍了一个更加人性化的requests库,结合百度贴吧 的情况说明了如何使用 urllib 库来获取网页数据。应该能够熟练掌握两个库的使用,反复使用,多练习,也可以参考官网提供的文档进行深入学习。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了Python模块或封装这些技术的库的基本使用,包括re模块、lxml库、bs4库、json模块、结合腾讯招聘网站的案例,讲解如何使用re模块、lxml库和bs4库分别解析网页数据,更好地区分这些技术的区别。在实际工作中,可以根据具体情况选择合理的技术加以应用。
第 6 部分
主要针对并发下载进行讲解,包括多线程爬虫过程分析,使用queue模块实现多线程爬虫,协程实现并发爬虫,并结合尴尬百科案例,分别使用单线程、多线程、协程三种技术获取网页数据并分析三者的性能。
第 7 部分
围绕抓取动态内容介绍,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登录的案例,讲解在项目中如何应用硒和 PhantomJS 技术。
第 8 部分
主要讲解图片识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、处理标准格式文本、处理验证码等,结合识别本地验证码图片的小程序,讲解如何使用pytesseract 识别图片中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储到数据库等,结合豆瓣电影的案例,讲解如何抓取、解析,并从这个网站 一步一步存储电影信息。
第 10 部分
主要对爬虫框架Scrapy进行初步讲解,包括常见爬虫框架介绍、Scrapy框架结构、操作流程、安装、基本操作等。
第 11 部分
首先介绍了Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并结合实例进行了巩固,然后详细介绍了Scrapy框架的一些核心组件,包括Spider、Item Pipeline和Settings,最后结合斗鱼App爬虫案例解释如何使用它。Scrapy 框架从移动应用程序中获取数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括爬虫CrawlSpider的初步了解,CrawlSpider类的工作原理,通过Rule类决定爬取规则,通过LinkExtractor提取链接类,并利用CrawlSpider类开发了一个爬取腾讯的爬虫。招募网站的案例,将本部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括Scrapy-Redis的完整架构、运行流程、主要组件、基本使用,以及如何搭建Scrapy-Redis开发环境,并结合百度百科案例使用这些知识点。
本课程涉及的Python网络爬虫的学习内容非常丰富。学习后,读者将能够具备以下能力:
1.能够掌握多种网页爬取和解析技术;
2.能够掌握一些爬虫的扩展知识,比如并发下载、识别图片文字、抓取动态内容等;
3.能够掌握爬虫框架的使用,如Scrapy;
4. 可以结合配套案例提高动手能力,打造属于自己的网络爬虫项目,真正做到相互借鉴。
查看全部
网页爬虫抓取百度图片(简易的Python网络爬虫入门级课程基于Python3,系统讲解
)
课程介绍
随着大数据时代的到来,万维网已经成为海量信息的载体,如何有效地提取和利用这些信息成为一个巨大的挑战。基于这种需求,爬虫技术应运而生,并迅速发展成为一项成熟的技术。许多互联网公司基于数据采集的需求,增加了对爬虫工程师的需求。
为了让有Python基础的人适应工作需要,我们推出了系统简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了以下内容爬虫框架。帮助读者具备独立编写爬虫项目的能力,胜任Python网络爬虫工程师的工作。
适合人群
本课程适合有一定Python基础,想学习网络爬虫的开发者。
主要内容
本课程基于Python 3,系统讲解Python网络爬虫的核心技术和框架。本课程共13个部分,各部分内容介绍如下。
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、爬虫是什么、爬虫的用途、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫实现原理、爬取网页的详细流程、一般爬虫中网页的分类、一般爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有所了解,并在后面针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍了网页请求的原理,包括浏览网页的过程,HTTP网络请求的原理,以及HTTP抓包工具Fiddler。
第 4 部分
引入了两个用于获取网页数据的库:urllib 和 requests。先介绍了urllib库的基本使用,包括使用urllib传输数据、添加特定header、设置代理服务器、超时设置、常见网络异常,然后介绍了一个更加人性化的requests库,结合百度贴吧 的情况说明了如何使用 urllib 库来获取网页数据。应该能够熟练掌握两个库的使用,反复使用,多练习,也可以参考官网提供的文档进行深入学习。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了Python模块或封装这些技术的库的基本使用,包括re模块、lxml库、bs4库、json模块、结合腾讯招聘网站的案例,讲解如何使用re模块、lxml库和bs4库分别解析网页数据,更好地区分这些技术的区别。在实际工作中,可以根据具体情况选择合理的技术加以应用。
第 6 部分
主要针对并发下载进行讲解,包括多线程爬虫过程分析,使用queue模块实现多线程爬虫,协程实现并发爬虫,并结合尴尬百科案例,分别使用单线程、多线程、协程三种技术获取网页数据并分析三者的性能。
第 7 部分
围绕抓取动态内容介绍,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登录的案例,讲解在项目中如何应用硒和 PhantomJS 技术。
第 8 部分
主要讲解图片识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、处理标准格式文本、处理验证码等,结合识别本地验证码图片的小程序,讲解如何使用pytesseract 识别图片中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储到数据库等,结合豆瓣电影的案例,讲解如何抓取、解析,并从这个网站 一步一步存储电影信息。
第 10 部分
主要对爬虫框架Scrapy进行初步讲解,包括常见爬虫框架介绍、Scrapy框架结构、操作流程、安装、基本操作等。
第 11 部分
首先介绍了Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并结合实例进行了巩固,然后详细介绍了Scrapy框架的一些核心组件,包括Spider、Item Pipeline和Settings,最后结合斗鱼App爬虫案例解释如何使用它。Scrapy 框架从移动应用程序中获取数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括爬虫CrawlSpider的初步了解,CrawlSpider类的工作原理,通过Rule类决定爬取规则,通过LinkExtractor提取链接类,并利用CrawlSpider类开发了一个爬取腾讯的爬虫。招募网站的案例,将本部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括Scrapy-Redis的完整架构、运行流程、主要组件、基本使用,以及如何搭建Scrapy-Redis开发环境,并结合百度百科案例使用这些知识点。
本课程涉及的Python网络爬虫的学习内容非常丰富。学习后,读者将能够具备以下能力:
1.能够掌握多种网页爬取和解析技术;
2.能够掌握一些爬虫的扩展知识,比如并发下载、识别图片文字、抓取动态内容等;
3.能够掌握爬虫框架的使用,如Scrapy;
4. 可以结合配套案例提高动手能力,打造属于自己的网络爬虫项目,真正做到相互借鉴。
网页爬虫抓取百度图片(如何识别动漫图片的url(图)参数(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-10 09:09
最近在玩机器学习,想建立一个识别动漫图片的训练集。我因没有太多动漫图片而苦恼。然后突然想到百度图片可以用,于是写了一个简单的爬虫抓取百度图片(图片关键词)html
第一步是找到搜索图像的 URL。
打开百度图片页面,搜索“高清动画”,查看元素,查看网络,清除网络请求数据,滚动到底部,看到自动加载更多,然后在里面找到加载更多数据的url网络请求。像这样%E9%AB%98%E6%B8%85%E5%8A%A8%E6%BC%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word= % E4%BA%8C%E6%AC%A1%E5%85%83&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=60&rn=30&gsm=1000000001e&81=
对比几个加载较多的URL,发现rn参数是每页显示的次数,pn参数是已经请求的次数。修改rn参数和pn参数后,观察返回的数据,发现每页最多只能有60个,也就是设置的最大rn为60.python
第二步是分析返回的数据。
浏览器请求上述url后,在页面上看到一个超级json。经过分析,图片的url是thumbURL middleURL hoverurl的三个属性。在返回的字符串中搜索这三个属性的数量,发现数量与页数完全相同。取这三个url,通过浏览器打开,发现thumburl比middleUrl大,和hoverUrl是同一个url。其实还是有objUrl(原图)可以用的,只是url不稳定,有时会得到404,有时会被拒绝访问。网络
代码代码
个人python版本为2.7json
2017 年 2 月 11 日更新
1.保存的图片改成原高清大图OjbUrl
2. 修改使用方法,可以从命令行输入搜索关键字
3.随时保存,保存前不再搜索所有图片。浏览器
百度ImageSearch.py微信
#coding=utf-8
from urllib import quote
import urllib2 as urllib
import re
import os
class BaiduImage():
def __init__(self, keyword, count=2000, save_path="img", rn=60):
self.keyword = keyword
self.count = count
self.save_path = save_path
self.rn = rn
self.__imageList = []
self.__totleCount = 0
self.__encodeKeyword = quote(self.keyword)
self.__acJsonCount = self.__get_ac_json_count()
self.user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36"
self.headers = {'User-Agent': self.user_agent, "Upgrade-Insecure-Requests": 1,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Cache-Control": "no-cache"}
# "Host": Host,
def search(self):
for i in range(0, self.__acJsonCount):
url = self.__get_search_url(i * self.rn)
response = self.__get_response(url).replace("\\", "")
image_url_list = self.__pick_image_urls(response)
self.__save(image_url_list)
def __save(self, image_url_list, save_path=None):
if save_path:
self.save_path = save_path
print "已经存储 " + str(self.__totleCount) + "张"
print "正在存储 " + str(len(image_url_list)) + "张,存储路径:" + self.save_path
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
for image in image_url_list:
host = self.get_url_host(image)
self.headers["Host"] = host
with open(self.save_path + "/%s.jpg" % self.__totleCount, "wb") as p:
try:
req = urllib.Request(image, headers=self.headers)
# 设置一个urlopen的超时,若是10秒访问不到,就跳到下一个地址,防止程序卡在一个地方。
img = urllib.urlopen(req, timeout=20)
p.write(img.read())
p.close()
self.__totleCount += 1
except Exception as e:
print "Exception" + str(e)
p.close()
if os.path.exists("img/%s.jpg" % self.__totleCount):
os.remove("img/%s.jpg" % self.__totleCount)
print "已存储 " + str(self.__totleCount) + " 张图片"
def __pick_image_urls(self, response):
reg = r'"ObjURL":"(http://img[0-9]\.imgtn.*?)"'
imgre = re.compile(reg)
imglist = re.findall(imgre, response)
return imglist
def __get_response(self, url):
page = urllib.urlopen(url)
return page.read()
def __get_search_url(self, pn):
return "http://image.baidu.com/search/ ... ot%3B + self.__encodeKeyword + "&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=" + self.__encodeKeyword + "&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=" + str(pn) + "&rn=" + str(self.rn) + "&gsm=1000000001e&1486375820481="
def get_url_host(self, url):
reg = r'http://(.*?)/'
hostre = re.compile(reg)
host = re.findall(hostre, url)
if len(host) > 0:
return host[0]
return ""
def __get_ac_json_count(self):
a = self.count % self.rn
c = self.count / self.rn
if a:
c += 1
return c
用例
运行.pyapp
#coding=utf-8
from BaiduImageSearch import BaiduImage
import sys
keyword = " ".join(sys.argv[1:])
save_path = "_".join(sys.argv[1:])
if not keyword:
print "亲,你忘记带搜索内容了哦~ 搜索内容关键字可多个,使用空格分开"
print "例如:python run.py 男生 头像"
else:
search = BaiduImage(keyword, save_path=save_path)
search.search()
ps:记得把_init_.py文件加到两个文件的同一个目录下!!!
运行方法,python run.py 关键字1 关键字2 关键字3……机器学习
一般搜索到1900多就没有了。svg 查看全部
网页爬虫抓取百度图片(如何识别动漫图片的url(图)参数(组图))
最近在玩机器学习,想建立一个识别动漫图片的训练集。我因没有太多动漫图片而苦恼。然后突然想到百度图片可以用,于是写了一个简单的爬虫抓取百度图片(图片关键词)html
第一步是找到搜索图像的 URL。
打开百度图片页面,搜索“高清动画”,查看元素,查看网络,清除网络请求数据,滚动到底部,看到自动加载更多,然后在里面找到加载更多数据的url网络请求。像这样%E9%AB%98%E6%B8%85%E5%8A%A8%E6%BC%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word= % E4%BA%8C%E6%AC%A1%E5%85%83&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=60&rn=30&gsm=1000000001e&81=
对比几个加载较多的URL,发现rn参数是每页显示的次数,pn参数是已经请求的次数。修改rn参数和pn参数后,观察返回的数据,发现每页最多只能有60个,也就是设置的最大rn为60.python
第二步是分析返回的数据。
浏览器请求上述url后,在页面上看到一个超级json。经过分析,图片的url是thumbURL middleURL hoverurl的三个属性。在返回的字符串中搜索这三个属性的数量,发现数量与页数完全相同。取这三个url,通过浏览器打开,发现thumburl比middleUrl大,和hoverUrl是同一个url。其实还是有objUrl(原图)可以用的,只是url不稳定,有时会得到404,有时会被拒绝访问。网络
代码代码
个人python版本为2.7json
2017 年 2 月 11 日更新
1.保存的图片改成原高清大图OjbUrl
2. 修改使用方法,可以从命令行输入搜索关键字
3.随时保存,保存前不再搜索所有图片。浏览器
百度ImageSearch.py微信
#coding=utf-8
from urllib import quote
import urllib2 as urllib
import re
import os
class BaiduImage():
def __init__(self, keyword, count=2000, save_path="img", rn=60):
self.keyword = keyword
self.count = count
self.save_path = save_path
self.rn = rn
self.__imageList = []
self.__totleCount = 0
self.__encodeKeyword = quote(self.keyword)
self.__acJsonCount = self.__get_ac_json_count()
self.user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36"
self.headers = {'User-Agent': self.user_agent, "Upgrade-Insecure-Requests": 1,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8,en;q=0.6",
"Cache-Control": "no-cache"}
# "Host": Host,
def search(self):
for i in range(0, self.__acJsonCount):
url = self.__get_search_url(i * self.rn)
response = self.__get_response(url).replace("\\", "")
image_url_list = self.__pick_image_urls(response)
self.__save(image_url_list)
def __save(self, image_url_list, save_path=None):
if save_path:
self.save_path = save_path
print "已经存储 " + str(self.__totleCount) + "张"
print "正在存储 " + str(len(image_url_list)) + "张,存储路径:" + self.save_path
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
for image in image_url_list:
host = self.get_url_host(image)
self.headers["Host"] = host
with open(self.save_path + "/%s.jpg" % self.__totleCount, "wb") as p:
try:
req = urllib.Request(image, headers=self.headers)
# 设置一个urlopen的超时,若是10秒访问不到,就跳到下一个地址,防止程序卡在一个地方。
img = urllib.urlopen(req, timeout=20)
p.write(img.read())
p.close()
self.__totleCount += 1
except Exception as e:
print "Exception" + str(e)
p.close()
if os.path.exists("img/%s.jpg" % self.__totleCount):
os.remove("img/%s.jpg" % self.__totleCount)
print "已存储 " + str(self.__totleCount) + " 张图片"
def __pick_image_urls(self, response):
reg = r'"ObjURL":"(http://img[0-9]\.imgtn.*?)"'
imgre = re.compile(reg)
imglist = re.findall(imgre, response)
return imglist
def __get_response(self, url):
page = urllib.urlopen(url)
return page.read()
def __get_search_url(self, pn):
return "http://image.baidu.com/search/ ... ot%3B + self.__encodeKeyword + "&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=" + self.__encodeKeyword + "&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=" + str(pn) + "&rn=" + str(self.rn) + "&gsm=1000000001e&1486375820481="
def get_url_host(self, url):
reg = r'http://(.*?)/'
hostre = re.compile(reg)
host = re.findall(hostre, url)
if len(host) > 0:
return host[0]
return ""
def __get_ac_json_count(self):
a = self.count % self.rn
c = self.count / self.rn
if a:
c += 1
return c
用例
运行.pyapp
#coding=utf-8
from BaiduImageSearch import BaiduImage
import sys
keyword = " ".join(sys.argv[1:])
save_path = "_".join(sys.argv[1:])
if not keyword:
print "亲,你忘记带搜索内容了哦~ 搜索内容关键字可多个,使用空格分开"
print "例如:python run.py 男生 头像"
else:
search = BaiduImage(keyword, save_path=save_path)
search.search()
ps:记得把_init_.py文件加到两个文件的同一个目录下!!!
运行方法,python run.py 关键字1 关键字2 关键字3……机器学习
一般搜索到1900多就没有了。svg
网页爬虫抓取百度图片(如何只禁止百度搜索引擎抓取收录网页,注意慎用如上代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-10 01:11
第一种方法,robots.txt
搜索引擎默认遵循 robots.txt 协议。创建robots.txt文本文件,放在网站的根目录下。编辑代码如下:
用户代理: *
不允许: /
通过上面的代码可以告诉搜索引擎不要抢收录this网站,注意使用上面的代码:这将禁止所有搜索引擎访问网站的任何部分。
如何只禁止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标志为:
用户代理:百度蜘蛛
不允许: /
上述robots文件将禁止所有来自百度的抓取。
这里说一下百度的user-agent,什么是百度蜘蛛的user-agent?
百度产品使用不同的用户代理:
产品名称对应于用户代理
无线搜索百度蜘蛛
图片搜索 百度蜘蛛-p_w_picpath
视频搜索 百度蜘蛛-视频
新闻搜索 百度蜘蛛-新闻
百度采集 百度蜘蛛-最爱
百度联盟baiduspider-cpro
商业搜索Baiduspider-ads
网页和其他搜索百度蜘蛛
您可以根据每个产品的不同用户代理设置不同的抓取规则。以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/p_w_picpath/目录:
用户代理:百度蜘蛛
不允许: /
用户代理:Baiduspider-p_w_picpath
允许:/p_w_picpath/
请注意:Baiduspider-cpro 和Baiduspider-ads 抓取的网页不会被编入索引,只会执行与客户约定的操作。因此,如果不遵守机器人协议,只能联系百度人员解决。
如何禁止只有谷歌搜索引擎收录抓取网页,方法如下:
编辑robots.txt文件,设计标志为:
用户代理:googlebot
不允许: /
编辑 robots.txt 文件
搜索引擎默认遵循robots.txt协议
robots.txt文件放在网站的根目录下。
例如,搜索引擎访问网站时,首先会检查网站的根目录下是否存在robots.txt文件。如果搜索引擎找到这个文件,它会根据它来确定它爬取的权限范围。
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。
不允许:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。.html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
以下是 robots.txt 用法的几个示例:
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理:百度蜘蛛
不允许: /
禁止百度收录所有站
用户代理:Googlebot
不允许: /
禁止谷歌收录所有站
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
禁止除谷歌以外的所有搜索引擎收录全站
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
禁止百度以外的所有搜索引擎收录全站
用户代理: *
禁止:/css/
禁止:/管理员/
防止所有搜索引擎访问某个目录
(比如根目录下的admin和css是禁止的)
二、网页编码方式
在 网站 主页代码之间添加代码。此标签禁止搜索引擎抓取 网站 并显示网页快照。
在网站首页代码之间,添加禁止百度搜索引擎抓取网站并显示网页快照。
在网站首页代码之间添加,禁止谷歌搜索引擎抓取网站,显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站 添加了Robots.txt,百度可以搜索到吗?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。如果收录急需您的拒绝,您也可以通过投诉平台反馈请求处理。
2. 希望网站的内容能被百度收录,但快照不会被保存。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置,让百度只显示网页索引,而不在搜索结果中显示网页快照。和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你已经禁止百度通过网页上的meta在搜索结果中显示网页快照,但是如果百度已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
想被百度收录,但不保存网站快照,以下代码解决:
如果你想禁止所有搜索引擎保存你网页的快照,那么代码如下:
一些常用的代码组合:
:您可以抓取此页面,并且可以继续索引此页面上的其他链接
:不抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
:您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
: 不爬取此页面,也不沿此页面爬行以索引其他链接 查看全部
网页爬虫抓取百度图片(如何只禁止百度搜索引擎抓取收录网页,注意慎用如上代码)
第一种方法,robots.txt
搜索引擎默认遵循 robots.txt 协议。创建robots.txt文本文件,放在网站的根目录下。编辑代码如下:
用户代理: *
不允许: /
通过上面的代码可以告诉搜索引擎不要抢收录this网站,注意使用上面的代码:这将禁止所有搜索引擎访问网站的任何部分。
如何只禁止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标志为:
用户代理:百度蜘蛛
不允许: /
上述robots文件将禁止所有来自百度的抓取。
这里说一下百度的user-agent,什么是百度蜘蛛的user-agent?
百度产品使用不同的用户代理:
产品名称对应于用户代理
无线搜索百度蜘蛛
图片搜索 百度蜘蛛-p_w_picpath
视频搜索 百度蜘蛛-视频
新闻搜索 百度蜘蛛-新闻
百度采集 百度蜘蛛-最爱
百度联盟baiduspider-cpro
商业搜索Baiduspider-ads
网页和其他搜索百度蜘蛛
您可以根据每个产品的不同用户代理设置不同的抓取规则。以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/p_w_picpath/目录:
用户代理:百度蜘蛛
不允许: /
用户代理:Baiduspider-p_w_picpath
允许:/p_w_picpath/
请注意:Baiduspider-cpro 和Baiduspider-ads 抓取的网页不会被编入索引,只会执行与客户约定的操作。因此,如果不遵守机器人协议,只能联系百度人员解决。
如何禁止只有谷歌搜索引擎收录抓取网页,方法如下:
编辑robots.txt文件,设计标志为:
用户代理:googlebot
不允许: /
编辑 robots.txt 文件
搜索引擎默认遵循robots.txt协议
robots.txt文件放在网站的根目录下。
例如,搜索引擎访问网站时,首先会检查网站的根目录下是否存在robots.txt文件。如果搜索引擎找到这个文件,它会根据它来确定它爬取的权限范围。
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。
不允许:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。.html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。“/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
以下是 robots.txt 用法的几个示例:
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理:百度蜘蛛
不允许: /
禁止百度收录所有站
用户代理:Googlebot
不允许: /
禁止谷歌收录所有站
用户代理:Googlebot
不允许:
用户代理: *
不允许: /
禁止除谷歌以外的所有搜索引擎收录全站
用户代理:百度蜘蛛
不允许:
用户代理: *
不允许: /
禁止百度以外的所有搜索引擎收录全站
用户代理: *
禁止:/css/
禁止:/管理员/
防止所有搜索引擎访问某个目录
(比如根目录下的admin和css是禁止的)
二、网页编码方式
在 网站 主页代码之间添加代码。此标签禁止搜索引擎抓取 网站 并显示网页快照。
在网站首页代码之间,添加禁止百度搜索引擎抓取网站并显示网页快照。
在网站首页代码之间添加,禁止谷歌搜索引擎抓取网站,显示网页快照。
另外,当我们的需求很奇怪的时候,比如以下几种情况:
1. 网站 添加了Robots.txt,百度可以搜索到吗?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。如果收录急需您的拒绝,您也可以通过投诉平台反馈请求处理。
2. 希望网站的内容能被百度收录,但快照不会被保存。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置,让百度只显示网页索引,而不在搜索结果中显示网页快照。和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你已经禁止百度通过网页上的meta在搜索结果中显示网页快照,但是如果百度已经建立了网页索引搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
想被百度收录,但不保存网站快照,以下代码解决:
如果你想禁止所有搜索引擎保存你网页的快照,那么代码如下:
一些常用的代码组合:
:您可以抓取此页面,并且可以继续索引此页面上的其他链接
:不抓取此页面,但您可以抓取此页面上的其他链接并将其编入索引
:您可以抓取此页面,但不允许抓取此页面上的其他链接并将其编入索引
: 不爬取此页面,也不沿此页面爬行以索引其他链接
网页爬虫抓取百度图片( 一下用Python编写网络爬虫程序的基本思路程序,以百度为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-09 11:12
一下用Python编写网络爬虫程序的基本思路程序,以百度为例)
Python编写简单的网络爬虫
根据网上给出的例子,简单总结一下用Python编写网络爬虫程序的基本思路。以百度为例,主要策略如下: Python 提供了很多模块,通过这些模块,你可以做一些非常简单的事情
工作。比如在百度搜索结果页面中获取NBA这个词的每个搜索结果对应的URL,这是一个非常简单的爬虫需求。
1、 通过 urllib2 模块获取相应的 HTML 源代码。
# -*- encoding: utf-8 -*-
import urllib2
url=\'http://www.baidu.com/s?wd=NBA\'
content=urllib2.urlopen(url).read()
print content
通过以上三句,可以将URL的源代码存储在content变量中,其类型为字符类型。
2、下一步就是从这堆HTML源代码中提取我们需要的内容。使用Chrome查看对应的内容代码(也可以使用Firefox的Firebug)。
可以看到标签中存储了URL,可以使用正则表达式获取信息。
Pile 是将一个字符串编译成 Python 正则表达式中使用的模式。字符前的 r 表示它是纯字符,因此不需要对元字符进行两次转义。re.findall 返回的是字符串中的正则表达式列表。站点依次输出我们想要获取的网络地址。这里需要强调的是,我们需要编写正确的正则表达式才能得到我们想要的结果。这里的代码可能不够准确。
import re
urls_pat=re.compile(r\'(.*?)\')
siteUrls=re.findall(r\'href="(.*?)" target="_blank">\',content)
for site in siteUrls:
print site
3、对得到的结果进行处理:例如进一步获取有用的信息或存储信息;例如,使用相关数据结构进行大规模网络爬虫,或分布式网络爬虫设计。
当然,网络爬虫的原理很简单,但是当你需要对网络资源进行大规模的处理时,就会遇到各种各样的问题,需要做各种各样的优化处理任务。这里是一个简单的介绍。“理解。 查看全部
网页爬虫抓取百度图片(
一下用Python编写网络爬虫程序的基本思路程序,以百度为例)
Python编写简单的网络爬虫
根据网上给出的例子,简单总结一下用Python编写网络爬虫程序的基本思路。以百度为例,主要策略如下: Python 提供了很多模块,通过这些模块,你可以做一些非常简单的事情
工作。比如在百度搜索结果页面中获取NBA这个词的每个搜索结果对应的URL,这是一个非常简单的爬虫需求。
1、 通过 urllib2 模块获取相应的 HTML 源代码。
# -*- encoding: utf-8 -*-
import urllib2
url=\'http://www.baidu.com/s?wd=NBA\'
content=urllib2.urlopen(url).read()
print content
通过以上三句,可以将URL的源代码存储在content变量中,其类型为字符类型。
2、下一步就是从这堆HTML源代码中提取我们需要的内容。使用Chrome查看对应的内容代码(也可以使用Firefox的Firebug)。
可以看到标签中存储了URL,可以使用正则表达式获取信息。
Pile 是将一个字符串编译成 Python 正则表达式中使用的模式。字符前的 r 表示它是纯字符,因此不需要对元字符进行两次转义。re.findall 返回的是字符串中的正则表达式列表。站点依次输出我们想要获取的网络地址。这里需要强调的是,我们需要编写正确的正则表达式才能得到我们想要的结果。这里的代码可能不够准确。
import re
urls_pat=re.compile(r\'(.*?)\')
siteUrls=re.findall(r\'href="(.*?)" target="_blank">\',content)
for site in siteUrls:
print site
3、对得到的结果进行处理:例如进一步获取有用的信息或存储信息;例如,使用相关数据结构进行大规模网络爬虫,或分布式网络爬虫设计。
当然,网络爬虫的原理很简单,但是当你需要对网络资源进行大规模的处理时,就会遇到各种各样的问题,需要做各种各样的优化处理任务。这里是一个简单的介绍。“理解。
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-09 08:23
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。于是写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
解析器可能有问题。我们不会谈论它。有问题的同学百度,有一堆解决办法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725") #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束。
参考地址:
(ps:本人也是python新手,文章如有错误请见谅) 查看全部
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。于是写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
解析器可能有问题。我们不会谈论它。有问题的同学百度,有一堆解决办法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725";) #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束。
参考地址:
(ps:本人也是python新手,文章如有错误请见谅)
网页爬虫抓取百度图片(Python语言程序简单高效,编写网络爬虫有特别的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-07 01:26
1.什么是爬虫
爬虫是一种网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?由您来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。如此一来,整个相连的大网就在这蜘蛛触手可及的地方,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上都是由HTML代码组成的,爬虫爬取了这些内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。 查看全部
网页爬虫抓取百度图片(Python语言程序简单高效,编写网络爬虫有特别的优势)
1.什么是爬虫
爬虫是一种网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?由您来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。如此一来,整个相连的大网就在这蜘蛛触手可及的地方,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
当用户浏览网页时,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框。这个过程实际上是在用户输入URL,通过DNS服务器寻找服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上都是由HTML代码组成的,爬虫爬取了这些内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
网页爬虫抓取百度图片(1.需要用到的库有:Requestsosos如果安装的请自己安装一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-05 14:10
)
1.需要用到的库有:
请求re os time 如果没有安装,请自行安装。打开终端,在pycharm中输入命令进行安装。
IDE:pycharm
Python版本:3.8.1
2. 爬取地址:
https://www.vmgirls.com/9384.html
-------------------废话不多说,不明白的可以给我留言,我们一步一步来-------- - ---------
1.请求网页
# 请求网页
import requests
response=requests.get('https://www.vmgirls.com/9384.html')
print(response.text)
结果:
发现请求是403,直接禁止我们访问。requests库会告诉他我们来自python,他知道我们是python,禁止爬行
解决:
我们可以伪装头部并设置它
# 请求网页
import requests
headers={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
print(response.request.headers)
结果:
这个头是伪装的
2.分析网页
# 请求网页
import requests
import reheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text#解析网页urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
结果:
你可能不明白 re.findall 是怎么来的。关键是找到图片的dom,按照re库的匹配规则进行匹配。需要匹配的用(.*?)表示,不需要匹配的用.*? 要更换它,
打开网站,按f12查看源码找到图片的代码
复制图片代码,打开网页源代码按ctrl+f搜索,找到图片源代码的位置
3.保存图片
您可以查看源代码了解详细信息。我为这些图片创建了一个文件夹(需要os库)并命名,这样下次看小姐姐的时候分类更容易找到
import time
import requestsimport reimport osheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text# 解析网页# 目录名字dir_name=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)[-1]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
# 保存图片for url in urls:
# 加个延时,避免给服务器造成压力 time.sleep(1)
# 图片的名字 file_name=url.split('/')[-1]
response = requests.get(url, headers=headers) with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
PS:需要Python学习资料的可以加下方群找免费管理员领取
免费获取源码、项目实战视频、PDF文件等
查看全部
网页爬虫抓取百度图片(1.需要用到的库有:Requestsosos如果安装的请自己安装一下
)
1.需要用到的库有:
请求re os time 如果没有安装,请自行安装。打开终端,在pycharm中输入命令进行安装。
IDE:pycharm
Python版本:3.8.1
2. 爬取地址:
https://www.vmgirls.com/9384.html
-------------------废话不多说,不明白的可以给我留言,我们一步一步来-------- - ---------
1.请求网页
# 请求网页
import requests
response=requests.get('https://www.vmgirls.com/9384.html')
print(response.text)
结果:
发现请求是403,直接禁止我们访问。requests库会告诉他我们来自python,他知道我们是python,禁止爬行
解决:
我们可以伪装头部并设置它
# 请求网页
import requests
headers={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
print(response.request.headers)
结果:
这个头是伪装的
2.分析网页
# 请求网页
import requests
import reheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text#解析网页urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
结果:
你可能不明白 re.findall 是怎么来的。关键是找到图片的dom,按照re库的匹配规则进行匹配。需要匹配的用(.*?)表示,不需要匹配的用.*? 要更换它,
打开网站,按f12查看源码找到图片的代码
复制图片代码,打开网页源代码按ctrl+f搜索,找到图片源代码的位置
3.保存图片
您可以查看源代码了解详细信息。我为这些图片创建了一个文件夹(需要os库)并命名,这样下次看小姐姐的时候分类更容易找到
import time
import requestsimport reimport osheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text# 解析网页# 目录名字dir_name=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)[-1]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
urls=re.findall('data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7',html)
print(urls);
# 保存图片for url in urls:
# 加个延时,避免给服务器造成压力 time.sleep(1)
# 图片的名字 file_name=url.split('/')[-1]
response = requests.get(url, headers=headers) with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
PS:需要Python学习资料的可以加下方群找免费管理员领取
免费获取源码、项目实战视频、PDF文件等
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站(.7点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-04 02:27
使用工具:Python2.7 点击我下载
刮框架
崇高的文字3
一。构建python(Windows版本)
1.Install python2.7 ---然后在cmd中输入python,如果界面如下则安装成功
2.集成Scrapy框架-输入命令行:pip install Scrapy
安装成功界面如下:
有很多失败,例如:
解决方案:
其他错误可以百度搜索。
二。开始编程。
1. 抓取静态 网站 没有反爬虫措施。比如百度贴吧、豆瓣书书。
python代码如下:
代码说明:引入了两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,将获取到的图片按照0开始排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图像保存路径与创建的 .py 位于同一目录文件中。
2. 使用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键词搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片滚动加载,最喜欢的30张先爬取。
代码显示如下:
代码说明:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
爬取过程如下:
爬取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋! 查看全部
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站(.7点))
使用工具:Python2.7 点击我下载
刮框架
崇高的文字3
一。构建python(Windows版本)
1.Install python2.7 ---然后在cmd中输入python,如果界面如下则安装成功
2.集成Scrapy框架-输入命令行:pip install Scrapy
安装成功界面如下:
有很多失败,例如:
解决方案:
其他错误可以百度搜索。
二。开始编程。
1. 抓取静态 网站 没有反爬虫措施。比如百度贴吧、豆瓣书书。
python代码如下:
代码说明:引入了两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,将获取到的图片按照0开始排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图像保存路径与创建的 .py 位于同一目录文件中。
2. 使用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键词搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片滚动加载,最喜欢的30张先爬取。
代码显示如下:
代码说明:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
爬取过程如下:
爬取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持剧本屋!
网页爬虫抓取百度图片(import几个向百度发送请求,有post和get两个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-04 01:13
首先导入几个需要用到的包:
import requests #需要用这个包向百度发送请求
import re #需要用这个包进行正则匹配
import time #休眠一下,以免给服务器造成太大压力
这里请求的主要功能是向百度发送请求,即模仿人工操作进行访问。有post和get两种方式。这里我们使用get方法。
然后,开始向百度发送请求。当然这里需要百度图片的链接。先访问百度图片,看看链接是什么样子的。
url 列如下所示:
http://image.baidu.com/search/ ... rd%3D皮卡丘
去掉一些不需要的内容后,可以是这样:
http://image.baidu.com/search/ ... rd%3D皮卡丘
然后分析网址。第一个必须是固定格式,不能更改。后面这个词=皮卡丘显然就是我们搜索的关键词。url被解析,然后向百度发送请求。代码显示如下:
html = requests.get(url)
html.encoding = html.apparent_encoding #这里可以对需要爬取的页面查看一下源码,一般都是utf-8,但是不全是。
html = html.text #这里需要获取对应的文本,以便后面进行正则匹配操作
接下来的操作是对源码进行操作。最好对web前端有一定的了解,如果没有,至少查一下源码(最简单的操作就是在网址栏前面加上view-source);
首先在源码页面搜索jpg(百度图片后缀,先找到图片链接):
只需获取一个链接并对其进行分析:
抓取里面的http:\/\/\/forum\/pic\/item\/6cad1f30e924b8998595da4079061d950b7bf6b6.jpg里面,访问,发现可以访问。多试几次,发现只能访问以objURL开头的,而以objURL开头的也可能无法访问。不管怎样,先把所有的
"ObjURL":"xxxx"
找到格式中的所有链接,然后需要使用正则匹配。代码显示如下:
urls = re.findall('"objURL":"(.*?)"',html,re.S) #导入的re包就在这里用
需要注意的是,re.findall匹配的数据是一个列表,需要用for循环一一访问:
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
写了一个最简单的爬虫,但是如果有一点错误,就会报错。没有所谓的鲁棒性。如何改进爬虫将在下一篇文章中讲解。
完整代码如下,大家可以自己体验:
import requests
import re
import time
url = 'http://image.baidu.com/search/ ... rd%3D皮卡丘'
html = requests.get(url)
html.encoding = html.apparent_encoding
html = html.text
urls = re.findall('"objURL":"(.*?)"',html,re.S)
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
不算空行和注释,只有 20 行代码。果然,人生苦短,我用python! 查看全部
网页爬虫抓取百度图片(import几个向百度发送请求,有post和get两个方法)
首先导入几个需要用到的包:
import requests #需要用这个包向百度发送请求
import re #需要用这个包进行正则匹配
import time #休眠一下,以免给服务器造成太大压力
这里请求的主要功能是向百度发送请求,即模仿人工操作进行访问。有post和get两种方式。这里我们使用get方法。
然后,开始向百度发送请求。当然这里需要百度图片的链接。先访问百度图片,看看链接是什么样子的。
url 列如下所示:
http://image.baidu.com/search/ ... rd%3D皮卡丘
去掉一些不需要的内容后,可以是这样:
http://image.baidu.com/search/ ... rd%3D皮卡丘
然后分析网址。第一个必须是固定格式,不能更改。后面这个词=皮卡丘显然就是我们搜索的关键词。url被解析,然后向百度发送请求。代码显示如下:
html = requests.get(url)
html.encoding = html.apparent_encoding #这里可以对需要爬取的页面查看一下源码,一般都是utf-8,但是不全是。
html = html.text #这里需要获取对应的文本,以便后面进行正则匹配操作
接下来的操作是对源码进行操作。最好对web前端有一定的了解,如果没有,至少查一下源码(最简单的操作就是在网址栏前面加上view-source);
首先在源码页面搜索jpg(百度图片后缀,先找到图片链接):
只需获取一个链接并对其进行分析:
抓取里面的http:\/\/\/forum\/pic\/item\/6cad1f30e924b8998595da4079061d950b7bf6b6.jpg里面,访问,发现可以访问。多试几次,发现只能访问以objURL开头的,而以objURL开头的也可能无法访问。不管怎样,先把所有的
"ObjURL":"xxxx"
找到格式中的所有链接,然后需要使用正则匹配。代码显示如下:
urls = re.findall('"objURL":"(.*?)"',html,re.S) #导入的re包就在这里用
需要注意的是,re.findall匹配的数据是一个列表,需要用for循环一一访问:
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
写了一个最简单的爬虫,但是如果有一点错误,就会报错。没有所谓的鲁棒性。如何改进爬虫将在下一篇文章中讲解。
完整代码如下,大家可以自己体验:
import requests
import re
import time
url = 'http://image.baidu.com/search/ ... rd%3D皮卡丘'
html = requests.get(url)
html.encoding = html.apparent_encoding
html = html.text
urls = re.findall('"objURL":"(.*?)"',html,re.S)
i = 0
for url in urls:
time.sleep(3) #休眠3秒
imag = requests.get(url,timeout = 6).content
#timeout代表每次request请求最多6秒,不然万一卡住了呢
if imag:
with open(str(i) + '.jpg','wb') as f:
print('正在下载第 %d 张图片:%s' % (i + 1,url))
f.write(imag)
i += 1
else:
print('链接超时,图片下载失败')
print('图片下载成功')
不算空行和注释,只有 20 行代码。果然,人生苦短,我用python!
网页爬虫抓取百度图片(要求:爬取30张百度图片中关晓彤的照片!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 15:11
)
要求:在30张百度图片中抓取关晓彤的照片! ! !首先,遵循爬虫的一般开发流程:
(1)分析网页:由于网页源代码太复杂,很难找到我们想要的,所以我们可以随便找一张图片的url,操作是如下:
然后查看网页源码,ctrl+f搜索刚才找到的图片的url,会发现三个,我们以第一个为例:
#观察前面有一个thumbURL,我们在这个源码中搜索:
可以看出,我们只需要借用thumbURL,使用正则匹配每张图片的url即可。 (2)代码编写:
#1.找目标数据
#2.分析请求流程 (1)每个关晓彤照片就是一个url (2)拿到这些url (3)会发现有30个thumbURL 这就刚好对应30个关晓彤照片的url(这些都在page_url里)
import urllib3
import re
import os
http = urllib3.PoolManager()
# 第一部分:获取包含这些图片的网页的代码
page_url = "https://image.baidu.com/search ... ot%3B
res = http.request("GET",page_url)
html = res.data.decode()
# print(html)
# 第二部分:利用正则锁定我们所要爬取的图片的url
img_urls = re.findall('thumbURL":"(.*?)"',html)
print(img_urls)
# 将图片扔到文件夹里
if not os.path.exists("girl_imgs"):
os.mkdir("girl_imgs")
# 遍历对每个图片url发起请求
for index,img_url in enumerate(img_urls):
res=http.request("GET",img_url)
img_data=res.data
filename="girl_imgs/"+str(index)+".jpg"
with open(filename,"wb") as f:
f.write(img_data)
注意:如果无法抓取,则为禁止。发送请求时添加标头。如果只在headers中添加user-agent,报错,则添加referer(防盗链)!
查看全部
网页爬虫抓取百度图片(要求:爬取30张百度图片中关晓彤的照片!!
)
要求:在30张百度图片中抓取关晓彤的照片! ! !首先,遵循爬虫的一般开发流程:
(1)分析网页:由于网页源代码太复杂,很难找到我们想要的,所以我们可以随便找一张图片的url,操作是如下:
然后查看网页源码,ctrl+f搜索刚才找到的图片的url,会发现三个,我们以第一个为例:
#观察前面有一个thumbURL,我们在这个源码中搜索:
可以看出,我们只需要借用thumbURL,使用正则匹配每张图片的url即可。 (2)代码编写:
#1.找目标数据
#2.分析请求流程 (1)每个关晓彤照片就是一个url (2)拿到这些url (3)会发现有30个thumbURL 这就刚好对应30个关晓彤照片的url(这些都在page_url里)
import urllib3
import re
import os
http = urllib3.PoolManager()
# 第一部分:获取包含这些图片的网页的代码
page_url = "https://image.baidu.com/search ... ot%3B
res = http.request("GET",page_url)
html = res.data.decode()
# print(html)
# 第二部分:利用正则锁定我们所要爬取的图片的url
img_urls = re.findall('thumbURL":"(.*?)"',html)
print(img_urls)
# 将图片扔到文件夹里
if not os.path.exists("girl_imgs"):
os.mkdir("girl_imgs")
# 遍历对每个图片url发起请求
for index,img_url in enumerate(img_urls):
res=http.request("GET",img_url)
img_data=res.data
filename="girl_imgs/"+str(index)+".jpg"
with open(filename,"wb") as f:
f.write(img_data)
注意:如果无法抓取,则为禁止。发送请求时添加标头。如果只在headers中添加user-agent,报错,则添加referer(防盗链)!
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-02 15:09
免责声明:如需转载本文文章,请私聊并在文章第一处注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片的资源不是很好,而且因为百度搜索的相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别是约500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在执行超时设置和异常处理之前,将执行链接超时和读取超时错误。,我当时也是用httpclient重写的,结果还是报错。最后,使用超时设置。如果在该时间段内没有进行URL请求,则进行下一个URL请求,直接放弃该请求。本来打算爬600张图片,最后只能爬500张,原因就在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章第一处注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片的资源不是很好,而且因为百度搜索的相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别是约500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在执行超时设置和异常处理之前,将执行链接超时和读取超时错误。,我当时也是用httpclient重写的,结果还是报错。最后,使用超时设置。如果在该时间段内没有进行URL请求,则进行下一个URL请求,直接放弃该请求。本来打算爬600张图片,最后只能爬500张,原因就在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(网页爬虫抓取百度图片(简单版)http请求_爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-01 22:10
网页爬虫抓取百度图片(含下载地址链接)http请求_爬虫(简单版)http请求_爬虫(进阶版)
这个话题很广,可以考虑一些后端语言、前端语言的一些函数库、工具箱、例子、框架等来提高效率,我是用python做爬虫的,一般采用的是asciilang[1]加上一个abc语言库,有图片下载工具pyinstaller(这是一个python程序,但是可以很好地用java来调用),还有用java写的一个jpeg压缩工具,不过工具有些过时了,比如截取全尺寸图片的等等。
网页获取的话有一些爬虫框架,如lxml(有大量的python解释器用于下载前端网页,如github)、beautifulsoup(在java中有对应的库,crud也能用java实现)等等。另外一个很好的话题,就是爬虫相关的许多理论问题,比如爬虫需要做哪些规划、数据的抽取和存储等,模拟浏览器一样的下载网页等等。还有其他许多方向,得看自己的兴趣了,祝顺利。
专栏爬虫抓取类|爬虫网站-最好的办法
难道不是要记住并熟练掌握get,post,put,delete(简称content-disposition,不是get_header)这五种常用的http请求方式?
找一个发帖子的地方,比如微博...或者提问一个问题,
别忘了db和数据库。当你整天写业务需求时,最需要的技能应该是统计和解决问题的能力, 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片(简单版)http请求_爬虫)
网页爬虫抓取百度图片(含下载地址链接)http请求_爬虫(简单版)http请求_爬虫(进阶版)
这个话题很广,可以考虑一些后端语言、前端语言的一些函数库、工具箱、例子、框架等来提高效率,我是用python做爬虫的,一般采用的是asciilang[1]加上一个abc语言库,有图片下载工具pyinstaller(这是一个python程序,但是可以很好地用java来调用),还有用java写的一个jpeg压缩工具,不过工具有些过时了,比如截取全尺寸图片的等等。
网页获取的话有一些爬虫框架,如lxml(有大量的python解释器用于下载前端网页,如github)、beautifulsoup(在java中有对应的库,crud也能用java实现)等等。另外一个很好的话题,就是爬虫相关的许多理论问题,比如爬虫需要做哪些规划、数据的抽取和存储等,模拟浏览器一样的下载网页等等。还有其他许多方向,得看自己的兴趣了,祝顺利。
专栏爬虫抓取类|爬虫网站-最好的办法
难道不是要记住并熟练掌握get,post,put,delete(简称content-disposition,不是get_header)这五种常用的http请求方式?
找一个发帖子的地方,比如微博...或者提问一个问题,
别忘了db和数据库。当你整天写业务需求时,最需要的技能应该是统计和解决问题的能力,
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-01 20:06
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,一般来说,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“网”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、优质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有网站的文章文章,吸引了大量的流量,但由于网站空间不足,大量前来访问的用户打不开网页,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。 查看全部
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,一般来说,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“网”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、优质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有网站的文章文章,吸引了大量的流量,但由于网站空间不足,大量前来访问的用户打不开网页,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。
网页爬虫抓取百度图片(基于请求拦截来实现网页资源采集类的图片漏抓)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-11-27 15:06
背景:我负责一个网络资源采集 项目。之前Java后端直接通过HTTP请求获取网页源码,然后通过jsoup解析网页,根据标签提取图片。但是,在最近的一次客户演练中,出现了漏图的情况。对网页进行了具体分析,发现是一张用css样式写的图片,确实没有被之前的静态爬虫方法覆盖。
现在想想,之前的静态爬虫方法还是太简单了,已经不能胜任现在复杂的前端网页了。可能存在以下问题:
1. 网页源代码没有渲染,会漏掉一些新的渲染资源。比如显示的内容需要根据ajax返回的结果进行渲染,例如:
阿贾克斯测试
2. 基于标签匹配提取图片,难以覆盖所有图片标签
src href 或一些自定义属性 data-src、v-lazy 等。
cool.jpg
cool.jpg
3.无法提取样式中写入的图片
.element {background: url('cool.jpg');}
Some content
如果要提取css样式的图片,单靠静态爬虫肯定不行。这时候,我们就需要使用浏览器来真正加载和渲染整个网页一次。由于我们的系统在去年就已经做了这个技术选型,所以我们使用puppeteer对网页进行截图。所以这次在之前的截图服务的基础上,整合了资源采集接口,也方便了系统的改造。
傀儡师
Puppeteer 是一个 Node.js 工具引擎,提供了一系列 API 来通过 CDP 协议控制 Chromium/Chrome 浏览器
基于 page.on('request') 块图片
所以我们第一个需求【获取一个网页中的所有图片】可以基于请求拦截来实现。大概的代码如下:
let imageList = [];
page.on('response', async response => {await handleImg(response, imageList);});
async function handleImg(response, imageList) {
const imgUrl = response.url();
let statusCode = response.status();
let requestResourceType = response.request().resourceType();
//通过判断请求的resourceType ,我们可以拦截到所有的图片请求,包括css样式加载的、自定义属性加载的图片
if (requestResourceType === 'image' ) {
//处理图片请求,计算响应Hash,上传图片等
imageList.push(imageMap);
}
}
但是,拦截方式带来了新的问题:
无法获取图片在网页中的具体位置,即xpath
由于项目中很多关键概念都依赖于xpath,所以也需要想办法定位截取的图片。
最初的想法是通过page.content()获取网页的源代码,然后遍历源代码,通过比较元素的src链接来定位截取图片的xpath。
let pageContent;
pageContent = await page.content();
但是,这又回到了原来的问题:基于css加载的图片在源码中没有src等资源属性,orz
比如这个:
由于对前端不熟悉,想了很久。有没有办法获取网页元素的CSS属性值?
经过搜索和尝试,发现window.getComputedStyle()方法正好符合我们的要求
let backgroundImg = getComputedStyle(element, '').backgroundImage;
打开F12,在控制台试试,不错
好的,下一步是更关键的点
windows 对象需要浏览器支持。
而我们通过上面的page.content()得到网页的源码,是在nodejs环境中获取的
所以我们需要通过page.evaluate()将我们的遍历方法注入到浏览器环境中执行
注意理解和区分两组js环境:
运行 Puppeteer 的 Node.js 环境和运行 Puppeteer 的 Page DOM 是两个独立的环境
嗯,一个通过treeWalker遍历DOM,提取所有元素资源链接的方法就出来了
async function findAllLinks() {
function stringToLowerCase(str) {
if (typeof str === 'string') {
return str.toLowerCase()
} else {
return ''
}
}
//获取DOM的Xpath
function getXpath(element) {
let xpath = ""
for (let me = element, k = 0; me && me.nodeType === 1; element = element.parentNode, me = element, k += 1) {
let i = 0
while ((me = me.previousElementSibling)) {
if (me.tagName === element.tagName) {
i += 1
}
}
const elementTag = stringToLowerCase(element.tagName)
let id = i + 1
id = '[' + id + ']';
xpath = '/' + elementTag + id + xpath
}
return xpath
}
window.LINKS_RESULT = [];
let treeWalker = document.createTreeWalker(
document.body.parentElement,
NodeFilter.SHOW_ELEMENT,
{
acceptNode: function (node) {
return NodeFilter.FILTER_ACCEPT;
}
},
);
while (treeWalker.nextNode()) {
let element = treeWalker.currentNode;
let src = element.src;
let href = element.href;
let background = element.background;
let backgroundImg = getComputedStyle(element, '').backgroundImage;
if (src) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": src
});
} else if (href) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": href
});
} else if (background) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": background
});
} else if (backgroundImg && backgroundImg.startsWith('url("http')) {
backgroundImg = backgroundImg.substring(5, backgroundImg.lastIndexOf('"'));
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": backgroundImg
});
}
}
}
最后,提取的所有链接都收录 xpath 信息。通过对比url的绝对路径,我们可以找到之前截获的图片链接的xpath。
总结一下步骤:
1. puppeteer端截取所有图片保存在List-A
2. 在浏览器端注入遍历代码,获取网页的所有链接和对应元素的xpath,将结果保存在List-B中,返回给puppeteer端
3. 遍历 List-A 并在 List-B 中定位 xpath 查看全部
网页爬虫抓取百度图片(基于请求拦截来实现网页资源采集类的图片漏抓)
背景:我负责一个网络资源采集 项目。之前Java后端直接通过HTTP请求获取网页源码,然后通过jsoup解析网页,根据标签提取图片。但是,在最近的一次客户演练中,出现了漏图的情况。对网页进行了具体分析,发现是一张用css样式写的图片,确实没有被之前的静态爬虫方法覆盖。
现在想想,之前的静态爬虫方法还是太简单了,已经不能胜任现在复杂的前端网页了。可能存在以下问题:
1. 网页源代码没有渲染,会漏掉一些新的渲染资源。比如显示的内容需要根据ajax返回的结果进行渲染,例如:
阿贾克斯测试
2. 基于标签匹配提取图片,难以覆盖所有图片标签
src href 或一些自定义属性 data-src、v-lazy 等。
cool.jpg
cool.jpg
3.无法提取样式中写入的图片
.element {background: url('cool.jpg');}
Some content
如果要提取css样式的图片,单靠静态爬虫肯定不行。这时候,我们就需要使用浏览器来真正加载和渲染整个网页一次。由于我们的系统在去年就已经做了这个技术选型,所以我们使用puppeteer对网页进行截图。所以这次在之前的截图服务的基础上,整合了资源采集接口,也方便了系统的改造。
傀儡师
Puppeteer 是一个 Node.js 工具引擎,提供了一系列 API 来通过 CDP 协议控制 Chromium/Chrome 浏览器
基于 page.on('request') 块图片
所以我们第一个需求【获取一个网页中的所有图片】可以基于请求拦截来实现。大概的代码如下:
let imageList = [];
page.on('response', async response => {await handleImg(response, imageList);});
async function handleImg(response, imageList) {
const imgUrl = response.url();
let statusCode = response.status();
let requestResourceType = response.request().resourceType();
//通过判断请求的resourceType ,我们可以拦截到所有的图片请求,包括css样式加载的、自定义属性加载的图片
if (requestResourceType === 'image' ) {
//处理图片请求,计算响应Hash,上传图片等
imageList.push(imageMap);
}
}
但是,拦截方式带来了新的问题:
无法获取图片在网页中的具体位置,即xpath
由于项目中很多关键概念都依赖于xpath,所以也需要想办法定位截取的图片。
最初的想法是通过page.content()获取网页的源代码,然后遍历源代码,通过比较元素的src链接来定位截取图片的xpath。
let pageContent;
pageContent = await page.content();
但是,这又回到了原来的问题:基于css加载的图片在源码中没有src等资源属性,orz
比如这个:
由于对前端不熟悉,想了很久。有没有办法获取网页元素的CSS属性值?
经过搜索和尝试,发现window.getComputedStyle()方法正好符合我们的要求
let backgroundImg = getComputedStyle(element, '').backgroundImage;
打开F12,在控制台试试,不错
好的,下一步是更关键的点
windows 对象需要浏览器支持。
而我们通过上面的page.content()得到网页的源码,是在nodejs环境中获取的
所以我们需要通过page.evaluate()将我们的遍历方法注入到浏览器环境中执行
注意理解和区分两组js环境:
运行 Puppeteer 的 Node.js 环境和运行 Puppeteer 的 Page DOM 是两个独立的环境
嗯,一个通过treeWalker遍历DOM,提取所有元素资源链接的方法就出来了
async function findAllLinks() {
function stringToLowerCase(str) {
if (typeof str === 'string') {
return str.toLowerCase()
} else {
return ''
}
}
//获取DOM的Xpath
function getXpath(element) {
let xpath = ""
for (let me = element, k = 0; me && me.nodeType === 1; element = element.parentNode, me = element, k += 1) {
let i = 0
while ((me = me.previousElementSibling)) {
if (me.tagName === element.tagName) {
i += 1
}
}
const elementTag = stringToLowerCase(element.tagName)
let id = i + 1
id = '[' + id + ']';
xpath = '/' + elementTag + id + xpath
}
return xpath
}
window.LINKS_RESULT = [];
let treeWalker = document.createTreeWalker(
document.body.parentElement,
NodeFilter.SHOW_ELEMENT,
{
acceptNode: function (node) {
return NodeFilter.FILTER_ACCEPT;
}
},
);
while (treeWalker.nextNode()) {
let element = treeWalker.currentNode;
let src = element.src;
let href = element.href;
let background = element.background;
let backgroundImg = getComputedStyle(element, '').backgroundImage;
if (src) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": src
});
} else if (href) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": href
});
} else if (background) {
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": background
});
} else if (backgroundImg && backgroundImg.startsWith('url("http')) {
backgroundImg = backgroundImg.substring(5, backgroundImg.lastIndexOf('"'));
LINKS_RESULT.push({
"xpath": getXpath(element),
"url": backgroundImg
});
}
}
}
最后,提取的所有链接都收录 xpath 信息。通过对比url的绝对路径,我们可以找到之前截获的图片链接的xpath。
总结一下步骤:
1. puppeteer端截取所有图片保存在List-A
2. 在浏览器端注入遍历代码,获取网页的所有链接和对应元素的xpath,将结果保存在List-B中,返回给puppeteer端
3. 遍历 List-A 并在 List-B 中定位 xpath
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-27 07:10
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-27 07:08
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-26 20:18
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个分类抓取的数据量控制在600,实际爬下来,每个分类大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(快照搜索去把图片找出来,是不是就爽多了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-26 20:08
网页爬虫抓取百度图片是再正常不过的工作了,比如你关注的公众号就是热门图片的聚集地,一般公众号的推送是按照时间顺序,所以一般先放出的图片都是发给大家的,接下来的图片就给我们去掉了,你想想每天有几百万发给我们呢,这还真的是不容易啊,不过如果我们能用快照搜索去把图片找出来,是不是就爽多了呢?技术要求就是:1.要能搜索到图片。
2.要能自己去发现图片的链接。3.手机要能自己能打开,能够调用翻页图片,在线图片搜索实际上很多网站都提供了相关的服务,网站不让可能原因在于有些图片是需要版权的。拿网举例,网每天的图片数量都是有上万张的,大家每天都在上面消费,但每天都必须上传一张图片,包括付费的图片,如果图片不上传的话图片就会下架的,这就是侵权的一种。
网的图片上传是图片有大图,小图,正图。有些搜索引擎是不支持大图和小图的搜索的,所以爬虫的抓取就很必要了。通过图片我们可以把握到图片的链接,而搜索引擎的爬虫通常是不会提供图片链接的,这也就是为什么上传的原因。因为链接的提供一般是用来不回收图片的,所以大家还是自己点开搜索网站的链接才能去点对应的图片链接。
网站是怎么通过爬虫来发现图片链接的呢?首先图片是有链接地址的,我们上传好图片以后,要把图片链接按顺序编号,然后点开网站的搜索框,打开电脑自带的浏览器,找到网站的图片链接,点开以后,在网站页面搜索一下,如果图片只出现一两个就用手机打开打开网站再点图片链接。这样的话大家以后就不会在搜索框里面输入中文搜索了,可以转换成英文,这个挺重要的。 查看全部
网页爬虫抓取百度图片(快照搜索去把图片找出来,是不是就爽多了)
网页爬虫抓取百度图片是再正常不过的工作了,比如你关注的公众号就是热门图片的聚集地,一般公众号的推送是按照时间顺序,所以一般先放出的图片都是发给大家的,接下来的图片就给我们去掉了,你想想每天有几百万发给我们呢,这还真的是不容易啊,不过如果我们能用快照搜索去把图片找出来,是不是就爽多了呢?技术要求就是:1.要能搜索到图片。
2.要能自己去发现图片的链接。3.手机要能自己能打开,能够调用翻页图片,在线图片搜索实际上很多网站都提供了相关的服务,网站不让可能原因在于有些图片是需要版权的。拿网举例,网每天的图片数量都是有上万张的,大家每天都在上面消费,但每天都必须上传一张图片,包括付费的图片,如果图片不上传的话图片就会下架的,这就是侵权的一种。
网的图片上传是图片有大图,小图,正图。有些搜索引擎是不支持大图和小图的搜索的,所以爬虫的抓取就很必要了。通过图片我们可以把握到图片的链接,而搜索引擎的爬虫通常是不会提供图片链接的,这也就是为什么上传的原因。因为链接的提供一般是用来不回收图片的,所以大家还是自己点开搜索网站的链接才能去点对应的图片链接。
网站是怎么通过爬虫来发现图片链接的呢?首先图片是有链接地址的,我们上传好图片以后,要把图片链接按顺序编号,然后点开网站的搜索框,打开电脑自带的浏览器,找到网站的图片链接,点开以后,在网站页面搜索一下,如果图片只出现一两个就用手机打开打开网站再点图片链接。这样的话大家以后就不会在搜索框里面输入中文搜索了,可以转换成英文,这个挺重要的。
网页爬虫抓取百度图片(网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-26 19:01
网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径(httporigin)请求是最常用的两种方式:调用api。既网页本身可以自定义api,可以用javascript直接拿response里的图片数据,也可以写javascript调用,再做进一步处理,缺点是权限控制有点困难,需要一些额外的配置,或者javascript层次的代码逻辑;调用服务器。
服务器可以实现图片数据的请求,还可以模拟各种加载条件,并且通过鉴权机制做安全鉴权;网页抓取。借助网页抓取框架,一般可以有以下几种思路:可以使用请求头、headers、cookie等信息来构造请求内容;也可以尝试提交一个httpheader+get/post/put/delete的dom参数来指定请求路径;也可以利用urlencode或者用javascript的restfulapi。
如果需要比较详细的了解,可以自行googleimagejavascriptapi.另外,有的网站本身也提供免费的抓取页面功能,可以尝试以下方式:使用工具,比如webmagic等在线工具;可以定义请求头(看css,javascriptapi),通过请求设置属性查询页面历史网站历史;通过方法定义的restfulapi请求;使用urlencode,将http包装为json字符串,再传给javascript程序;python之外的服务器的爬虫抓取:proxypi|github|stackoverflow|segmentfault。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径)
网页爬虫抓取百度图片可以通过三种方式:以httpheader和get数据路径(httporigin)请求是最常用的两种方式:调用api。既网页本身可以自定义api,可以用javascript直接拿response里的图片数据,也可以写javascript调用,再做进一步处理,缺点是权限控制有点困难,需要一些额外的配置,或者javascript层次的代码逻辑;调用服务器。
服务器可以实现图片数据的请求,还可以模拟各种加载条件,并且通过鉴权机制做安全鉴权;网页抓取。借助网页抓取框架,一般可以有以下几种思路:可以使用请求头、headers、cookie等信息来构造请求内容;也可以尝试提交一个httpheader+get/post/put/delete的dom参数来指定请求路径;也可以利用urlencode或者用javascript的restfulapi。
如果需要比较详细的了解,可以自行googleimagejavascriptapi.另外,有的网站本身也提供免费的抓取页面功能,可以尝试以下方式:使用工具,比如webmagic等在线工具;可以定义请求头(看css,javascriptapi),通过请求设置属性查询页面历史网站历史;通过方法定义的restfulapi请求;使用urlencode,将http包装为json字符串,再传给javascript程序;python之外的服务器的爬虫抓取:proxypi|github|stackoverflow|segmentfault。

