
网页爬虫抓取百度图片
网页爬虫抓取百度图片(怎么爬取和怎么提取并不重要的东西?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-26 07:02
网页爬虫抓取百度图片的话可以用requests/beautifulsoup等等后端语言进行处理,然后在requests/beautifulsoup中extractimage/json/pyqt/lxml等等中提取图片,返回给前端进行处理,再把获取到的图片传递给前端的话就是把图片url返回,前端获取之后就可以用js库或者原生js抓取了。
我想根据你的要求,至少你要以下的东西。
1、你想从服务器获取到图片的url,
2、你想在url中提取图片的值
3、在python中从图片中提取图片的值我猜测你对于提取图片的值,可能会在lxml里面实现。我去试着写了一下你的代码,感觉上会更加方便。
刚好也在找这样的问题这里先贴过来,
1、爬虫,去豆瓣网爬,爬下来再去通过“元数据爬取”框架的方式(比如pyqt之类的,requests为底层代码,具体的我就不说了,好久不写了),提取图片的信息。
2、图片转成json或xml,
3、浏览器上展示,如果有非常复杂的验证,可以考虑用javascript写爬虫对图片进行验证。其实怎么爬取和怎么提取并不重要,最主要的是你要想好了如何写代码完成这件事,这个已经得到了初步的答案了。 查看全部
网页爬虫抓取百度图片(怎么爬取和怎么提取并不重要的东西?-八维教育)
网页爬虫抓取百度图片的话可以用requests/beautifulsoup等等后端语言进行处理,然后在requests/beautifulsoup中extractimage/json/pyqt/lxml等等中提取图片,返回给前端进行处理,再把获取到的图片传递给前端的话就是把图片url返回,前端获取之后就可以用js库或者原生js抓取了。
我想根据你的要求,至少你要以下的东西。
1、你想从服务器获取到图片的url,
2、你想在url中提取图片的值
3、在python中从图片中提取图片的值我猜测你对于提取图片的值,可能会在lxml里面实现。我去试着写了一下你的代码,感觉上会更加方便。
刚好也在找这样的问题这里先贴过来,
1、爬虫,去豆瓣网爬,爬下来再去通过“元数据爬取”框架的方式(比如pyqt之类的,requests为底层代码,具体的我就不说了,好久不写了),提取图片的信息。
2、图片转成json或xml,
3、浏览器上展示,如果有非常复杂的验证,可以考虑用javascript写爬虫对图片进行验证。其实怎么爬取和怎么提取并不重要,最主要的是你要想好了如何写代码完成这件事,这个已经得到了初步的答案了。
网页爬虫抓取百度图片(爬虫什么是爬虫?是蜘蛛么?是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-26 02:17
)
一、什么是爬虫
什么是爬虫?爬行动物是蜘蛛吗?是优采云吗?不不不。
爬虫是指请求网站并获取数据的自动化程序,也称为网络蜘蛛或网络机器。最常用的领域是搜索引擎,最常用的工具是优采云。
其基本过程分为以下五个部分,依次为:
明确需求-发送请求-获取数据-解析数据-存储数据。
爬虫的三大特点:
爬虫可以写成什么:
编写爬虫的语言有很多,但应用最广泛的应该是Python,并且诞生了很多优秀的库和框架,比如scrapy、BeautifulSoup、pyquery、Mechanize等。但是总的来说,搜索引擎爬虫都有对爬虫效率要求较高,会选择c++、java、go(适合高并发)。
二、爬虫的前期准备
1、准备一台性能好的电脑
电脑要求:windows7以上,内存四核8G以上
2、安装python环境
Python官网下载地址:
安装过程:
请自行百度。
3、安装所需的扩展
我们主要使用以下四个扩展:
import os # python自带扩展不需要安装
import requests # pip install requests
from urllib import request # python自带扩展不需要安装
from bs4 import BeautifulSoup # 安装命令:pip install bs4
4、找一张可以看源码的图片网站
注意注意:此链接仅供学习参考,请勿非法批量爬取,任何不听劝阻,一意孤行者,如若产生违法乱纪之事,请自行承担。(开发不易,且行且珍惜)
抓取图片的地址:https://www.umei.cc/meinvtupian/meinvxiezhen/
三、解析网站源码
1、解析源码,得到获取源码的三个方向(编码格式、请求方式、header请求头)
windows默认为gbk编码格式,网页一般默认为utf-8编码,所以当你直接用windows电脑抓取网页内容信息时,可能会遇到乱码问题,所以在要求统一编码格式的时候要保证数据不乱请求方式包括post、get、put等验证方式,所以选择正确的请求方式来获取页面信息。如果不努力,可能会遇到404页面未找到或500服务器错误。header 请求头收录很多负面信息。如果我们常见的,比如:反爬虫机制,token验证,cookie验证等。
2、查找列表页面上唯一的节点
3、 根据图片排版,找到源码规则(同li标签获取节点)
4、获取列表的最后一页,获取最后一页的页码(NewPages节点下的最后一页代表最后141页)
根据图片分页的页码地址规律,我们能得到(特别注意:第一页不能使用 index_1.htm 来查询):
https://www.umei.net/meinvtupian/meinvxiezhen/ 第一页没有index
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
......
5、根据每张图片链接,输入图片详情
根据上题3可以看出,图片详情的地址为:
https://www.umei.net/meinvtupi ... 1.htm
6、找到图片详情的地址规则,获取所有详情子图片地址
根据图片详情可以查看出来每一个子图片的详情地址:
https://www.umei.net/meinvtupi ... 1.htm
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
7、 根据地址抓取图片流并保留本地
根据问题6中获取的图片地址抓取图片信息,保存到本地,页面分析结束。废话不多说,直接上代码,快速抓取。
四、开始编写我们的爬虫脚本
1、封装代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/06/06 14:48
# @Author : Liu
# @Site :
# @File : 美图小姐姐.py
# @Software: PyCharm
import requests
import time
import os
import re
from urllib import request
from bs4 import BeautifulSoup
url_address = "https://www.umei.cc"
def get_url_path(url):
"""
获取地址内容信息
:param url:
:return:
"""
# time.sleep(1) # 获取源码的时候睡眠一秒
obj = requests.get(url)
obj.encoding = obj.apparent_encoding
return obj.text
def get_page_info():
"""
抓取每页信息
:return:
"""
nums = int(input("输入抓取的页数:"))
for i in range(nums):
if i < 1:
url = f"{ url_address }/meinvtupian/meinvxiezhen/"
else:
url = f"{ url_address }/meinvtupian/meinvxiezhen/index_{i + 1}.htm"
ret = get_url_path(url) # 获取页面信息
get_bs4(ret) # 逐页抓取页面信息
print(f"第{i+1}页完成")
pass
def get_bs4(ret):
soup = BeautifulSoup(ret, "html.parser")
li_list = soup.select(".TypeList")[0].find_all(name="li")
for i in li_list:
# 先获取第一张图片
img_src = url_address + i.a["href"]
ret1 = get_url_path(img_src) # 获取页面信息
get_image_info(ret1, i.a.span.string, 1)
# print(ret1)
# 获取分页后的页面图片数量
# script_reg = r'Next\("\d+","(?P\d+)",.*?\)'
script_reg = r'+).htm]尾页'
num_str = re.search(script_reg, ret1, re.S).group("num")
page_num = int(num_str.split("_")[1]) # 获取图片数量
img_lst = os.path.basename(i.a["href"]).split(".") # 获取图片的后缀
img_dir = os.path.dirname(i.a["href"]) # 获取图片的地址路径
for j in range(2, page_num+1):
img_src = f"{ url_address }{img_dir}/{img_lst[0]}_{j}.{img_lst[1]}"
res = get_url_path(img_src) # 获取页面信息
get_image_info(res, i.a.span.string, j)
def get_image_info(ret, name, i):
soup = BeautifulSoup(ret, "html.parser")
img = soup.select(".ImageBody img")[0]
image_path = img["src"] # 获取图片地址
image_name = name # 获取图片中文所属
img_name = f"{image_name}_{i}.{os.path.basename(image_path).split('.')[1]}" # 获取图片真实名字
# 图片存储
image_dir = f"girl/{image_name}"
if not os.path.isdir(image_dir):
os.makedirs(image_dir)
# 远程打开图片写入到本地 第一种方式open
# with open(f"{image_dir}/{img_name}", mode="wb") as add:
# add.write(requests.get(image_path).content)
# 远程打开图片写入到本地 第二种方式urllib
request.urlretrieve(image_path, filename=f"{image_dir}/{img_name}")
print("已经开始执行了,可能需要等待一会,请您耐心等待!")
begin_time = int(time.time())
get_page_info()
end_time = int(time.time())
print(f"当前脚本执行了{end_time - begin_time}秒")
print("执行已经结束了") 查看全部
网页爬虫抓取百度图片(爬虫什么是爬虫?是蜘蛛么?是什么?
)
一、什么是爬虫
什么是爬虫?爬行动物是蜘蛛吗?是优采云吗?不不不。


爬虫是指请求网站并获取数据的自动化程序,也称为网络蜘蛛或网络机器。最常用的领域是搜索引擎,最常用的工具是优采云。
其基本过程分为以下五个部分,依次为:
明确需求-发送请求-获取数据-解析数据-存储数据。
爬虫的三大特点:
爬虫可以写成什么:
编写爬虫的语言有很多,但应用最广泛的应该是Python,并且诞生了很多优秀的库和框架,比如scrapy、BeautifulSoup、pyquery、Mechanize等。但是总的来说,搜索引擎爬虫都有对爬虫效率要求较高,会选择c++、java、go(适合高并发)。
二、爬虫的前期准备
1、准备一台性能好的电脑
电脑要求:windows7以上,内存四核8G以上
2、安装python环境
Python官网下载地址:
安装过程:
请自行百度。
3、安装所需的扩展
我们主要使用以下四个扩展:
import os # python自带扩展不需要安装
import requests # pip install requests
from urllib import request # python自带扩展不需要安装
from bs4 import BeautifulSoup # 安装命令:pip install bs4
4、找一张可以看源码的图片网站
注意注意:此链接仅供学习参考,请勿非法批量爬取,任何不听劝阻,一意孤行者,如若产生违法乱纪之事,请自行承担。(开发不易,且行且珍惜)
抓取图片的地址:https://www.umei.cc/meinvtupian/meinvxiezhen/
三、解析网站源码
1、解析源码,得到获取源码的三个方向(编码格式、请求方式、header请求头)
windows默认为gbk编码格式,网页一般默认为utf-8编码,所以当你直接用windows电脑抓取网页内容信息时,可能会遇到乱码问题,所以在要求统一编码格式的时候要保证数据不乱请求方式包括post、get、put等验证方式,所以选择正确的请求方式来获取页面信息。如果不努力,可能会遇到404页面未找到或500服务器错误。header 请求头收录很多负面信息。如果我们常见的,比如:反爬虫机制,token验证,cookie验证等。
2、查找列表页面上唯一的节点

3、 根据图片排版,找到源码规则(同li标签获取节点)

4、获取列表的最后一页,获取最后一页的页码(NewPages节点下的最后一页代表最后141页)
根据图片分页的页码地址规律,我们能得到(特别注意:第一页不能使用 index_1.htm 来查询):
https://www.umei.net/meinvtupian/meinvxiezhen/ 第一页没有index
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
......

5、根据每张图片链接,输入图片详情
根据上题3可以看出,图片详情的地址为:
https://www.umei.net/meinvtupi ... 1.htm
6、找到图片详情的地址规则,获取所有详情子图片地址
根据图片详情可以查看出来每一个子图片的详情地址:
https://www.umei.net/meinvtupi ... 1.htm
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm

7、 根据地址抓取图片流并保留本地
根据问题6中获取的图片地址抓取图片信息,保存到本地,页面分析结束。废话不多说,直接上代码,快速抓取。
四、开始编写我们的爬虫脚本
1、封装代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/06/06 14:48
# @Author : Liu
# @Site :
# @File : 美图小姐姐.py
# @Software: PyCharm
import requests
import time
import os
import re
from urllib import request
from bs4 import BeautifulSoup
url_address = "https://www.umei.cc"
def get_url_path(url):
"""
获取地址内容信息
:param url:
:return:
"""
# time.sleep(1) # 获取源码的时候睡眠一秒
obj = requests.get(url)
obj.encoding = obj.apparent_encoding
return obj.text
def get_page_info():
"""
抓取每页信息
:return:
"""
nums = int(input("输入抓取的页数:"))
for i in range(nums):
if i < 1:
url = f"{ url_address }/meinvtupian/meinvxiezhen/"
else:
url = f"{ url_address }/meinvtupian/meinvxiezhen/index_{i + 1}.htm"
ret = get_url_path(url) # 获取页面信息
get_bs4(ret) # 逐页抓取页面信息
print(f"第{i+1}页完成")
pass
def get_bs4(ret):
soup = BeautifulSoup(ret, "html.parser")
li_list = soup.select(".TypeList")[0].find_all(name="li")
for i in li_list:
# 先获取第一张图片
img_src = url_address + i.a["href"]
ret1 = get_url_path(img_src) # 获取页面信息
get_image_info(ret1, i.a.span.string, 1)
# print(ret1)
# 获取分页后的页面图片数量
# script_reg = r'Next\("\d+","(?P\d+)",.*?\)'
script_reg = r'+).htm]尾页'
num_str = re.search(script_reg, ret1, re.S).group("num")
page_num = int(num_str.split("_")[1]) # 获取图片数量
img_lst = os.path.basename(i.a["href"]).split(".") # 获取图片的后缀
img_dir = os.path.dirname(i.a["href"]) # 获取图片的地址路径
for j in range(2, page_num+1):
img_src = f"{ url_address }{img_dir}/{img_lst[0]}_{j}.{img_lst[1]}"
res = get_url_path(img_src) # 获取页面信息
get_image_info(res, i.a.span.string, j)
def get_image_info(ret, name, i):
soup = BeautifulSoup(ret, "html.parser")
img = soup.select(".ImageBody img")[0]
image_path = img["src"] # 获取图片地址
image_name = name # 获取图片中文所属
img_name = f"{image_name}_{i}.{os.path.basename(image_path).split('.')[1]}" # 获取图片真实名字
# 图片存储
image_dir = f"girl/{image_name}"
if not os.path.isdir(image_dir):
os.makedirs(image_dir)
# 远程打开图片写入到本地 第一种方式open
# with open(f"{image_dir}/{img_name}", mode="wb") as add:
# add.write(requests.get(image_path).content)
# 远程打开图片写入到本地 第二种方式urllib
request.urlretrieve(image_path, filename=f"{image_dir}/{img_name}")
print("已经开始执行了,可能需要等待一会,请您耐心等待!")
begin_time = int(time.time())
get_page_info()
end_time = int(time.time())
print(f"当前脚本执行了{end_time - begin_time}秒")
print("执行已经结束了")
网页爬虫抓取百度图片( 关于爬虫爬图如何获取网页源代码打开(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2021-11-25 23:24
关于爬虫爬图如何获取网页源代码打开(图)
)
如何使用爬虫爬取图片,以百度图片为例
关于抓取图片
最近自己看着网上教程学习如何爬图,发现爬虫的优越性,也发现有些博客对初学者不太友好,因此写了这篇博客。
如何获取网页的源代码
打开谷歌浏览器,打开百度图片,点击更多工具->打开开发者工具,如图
可以发现,在underdraw的时候,旁边的Name栏中会有很多图片链接。
随便点一个图片,发现旁边有一个关于Response Headers的内容
这是你目前访问百度图片的访问信息,这个信息其实是一样的。
然后在网页上左键点击查看网页的源代码。
再次按下Ctrl/Command+F,使用搜索工具找到url,也就是图片的下载地址,还有一些相关的信息,比如数据等,可以快速找到,体现在代码中。
输入 frompagetitle 以查找图像的标题。
源代码
源码中有详细的注释,便于理解。
# 爬取百度图片
from urllib.parse import urlencode
import requests
import re
import os
# 图片下载的存储文件
save_dir = '百度图片/'
# 百度加密算法
def baidtu_uncomplie(url):
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d = {'w': 'a', 'k': 'b', 'v': 'c', '1': 'd', 'j': 'e', 'u': 'f', '2': 'g', 'i': 'h', 't': 'i', '3': 'j', 'h': 'k',
's': 'l', '4': 'm', 'g': 'n', '5': 'o', 'r': 'p', 'q': 'q', '6': 'r', 'f': 's', 'p': 't', '7': 'u', 'e': 'v',
'o': 'w', '8': '1', 'd': '2', 'n': '3', '9': '4', 'c': '5', 'm': '6', '0': '7', 'b': '8', 'l': '9', 'a': '0',
'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
if (url == None or 'http' in url): # 判断地址是否有http
return url
else:
j = url
# 解码百度加密算法
for m in c:
j = j.replace(m, d[m])
for char in j:
if re.match('^[a-w\d]+$', char): # 正则表达式
char = d[char]
res = res + char
return res
# 获取页面信息
def get_page(offset):
params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '中国人', # 关键字
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'word': '中国人', # 关键字
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'pn': offset * 30,
'rn': '30',
'gsm': '1e',
'1537355234668': '',
}
url = 'https://image.baidu.com/search/acjson?' + urlencode(params)
try: # 尝试连接服务器
response = requests.get(url)
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
return response.json()
except requests.ConnectionError as d:
print('Error', d.args)
# 获取图像
def get_images(json):
if json.get('data'):
for item in json.get('data'): # 获取图片数据字典值
if item.get('fromPageTitle'): # 获取图片Title
title = item.get('fromPageTitle')
else:
title = 'noTitle'
image = baidtu_uncomplie(item.get('objURL')) # 图片地址
if (image):
yield { # 存储图片信息
'image': image,
'title': title
}
def save_image(item, count):
try:
response = requests.get(item.get('image'))
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
file_path = save_dir + '{0}.{1}'.format(str(count), 'jpg') # 命名并存储图片
if not os.path.exists(file_path): # 判断图片是否在文件中
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError: # 如果出现连接错误
print('Failed to Save Image')
def main(pageIndex, count):
json = get_page(pageIndex)
for image in get_images(json):
save_image(image, count)
count += 1
return count
if __name__ == '__main__':
if not os.path.exists(save_dir): # 判断是否存在文件,若没有则创建一个
os.mkdir(save_dir)
count = 1
for i in range(1, 200): # 循环页数下载图片
count = main(i, count) # i表示页数,统计图片并运行主函数
print('total:', count) 查看全部
网页爬虫抓取百度图片(
关于爬虫爬图如何获取网页源代码打开(图)
)
如何使用爬虫爬取图片,以百度图片为例
关于抓取图片
最近自己看着网上教程学习如何爬图,发现爬虫的优越性,也发现有些博客对初学者不太友好,因此写了这篇博客。
如何获取网页的源代码
打开谷歌浏览器,打开百度图片,点击更多工具->打开开发者工具,如图

可以发现,在underdraw的时候,旁边的Name栏中会有很多图片链接。

随便点一个图片,发现旁边有一个关于Response Headers的内容
这是你目前访问百度图片的访问信息,这个信息其实是一样的。
然后在网页上左键点击查看网页的源代码。

再次按下Ctrl/Command+F,使用搜索工具找到url,也就是图片的下载地址,还有一些相关的信息,比如数据等,可以快速找到,体现在代码中。

输入 frompagetitle 以查找图像的标题。
源代码
源码中有详细的注释,便于理解。
# 爬取百度图片
from urllib.parse import urlencode
import requests
import re
import os
# 图片下载的存储文件
save_dir = '百度图片/'
# 百度加密算法
def baidtu_uncomplie(url):
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d = {'w': 'a', 'k': 'b', 'v': 'c', '1': 'd', 'j': 'e', 'u': 'f', '2': 'g', 'i': 'h', 't': 'i', '3': 'j', 'h': 'k',
's': 'l', '4': 'm', 'g': 'n', '5': 'o', 'r': 'p', 'q': 'q', '6': 'r', 'f': 's', 'p': 't', '7': 'u', 'e': 'v',
'o': 'w', '8': '1', 'd': '2', 'n': '3', '9': '4', 'c': '5', 'm': '6', '0': '7', 'b': '8', 'l': '9', 'a': '0',
'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
if (url == None or 'http' in url): # 判断地址是否有http
return url
else:
j = url
# 解码百度加密算法
for m in c:
j = j.replace(m, d[m])
for char in j:
if re.match('^[a-w\d]+$', char): # 正则表达式
char = d[char]
res = res + char
return res
# 获取页面信息
def get_page(offset):
params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '中国人', # 关键字
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'word': '中国人', # 关键字
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'pn': offset * 30,
'rn': '30',
'gsm': '1e',
'1537355234668': '',
}
url = 'https://image.baidu.com/search/acjson?' + urlencode(params)
try: # 尝试连接服务器
response = requests.get(url)
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
return response.json()
except requests.ConnectionError as d:
print('Error', d.args)
# 获取图像
def get_images(json):
if json.get('data'):
for item in json.get('data'): # 获取图片数据字典值
if item.get('fromPageTitle'): # 获取图片Title
title = item.get('fromPageTitle')
else:
title = 'noTitle'
image = baidtu_uncomplie(item.get('objURL')) # 图片地址
if (image):
yield { # 存储图片信息
'image': image,
'title': title
}
def save_image(item, count):
try:
response = requests.get(item.get('image'))
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
file_path = save_dir + '{0}.{1}'.format(str(count), 'jpg') # 命名并存储图片
if not os.path.exists(file_path): # 判断图片是否在文件中
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError: # 如果出现连接错误
print('Failed to Save Image')
def main(pageIndex, count):
json = get_page(pageIndex)
for image in get_images(json):
save_image(image, count)
count += 1
return count
if __name__ == '__main__':
if not os.path.exists(save_dir): # 判断是否存在文件,若没有则创建一个
os.mkdir(save_dir)
count = 1
for i in range(1, 200): # 循环页数下载图片
count = main(i, count) # i表示页数,统计图片并运行主函数
print('total:', count)
网页爬虫抓取百度图片(web服务器抓取百度图片的技巧及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-24 21:01
网页爬虫抓取百度图片是通过useragent解析页面来获取的。web服务器会根据抓取请求中的useragent变化来调用对应的api或者完全自己去尝试找出其中的特征值;第三方接口的post和get也有提交参数的逻辑;这些流程和简单的网页爬虫抓取都是一样的;比如简单的图片搜索,获取来的结果中包含的就不仅仅是图片所在的url,还可能是图片的id或者png格式的图片链接。
我猜可能是抓url,像随便哪个爬虫,不说明抓取目标。你只能说是抓url。但是你爬哪不一定啊。你不能说人家web服务器每次去xxx2d下载图片都抓包比对id吧。然后拿出图片的地址,而且即使网页里没有图片,你把这个值盗过来给爬虫提交一下,它下载下来就能用了。程序猿说得清楚,人家真心懒得自己搞这个。还是要把图片url拿到,你把id和图片的地址都告诉她。这个里面就有可能包含其他图片的url。
get方法是cookie的方法,你验证登录或者dns解析为动态的,当然就拿不到你指定的图片,但是调用百度的图片提取,应该就可以拿到图片的url。另外@sherrysu说的很对,爬虫爬图片一般都是直接抓,没有必要比对url,除非有特殊需求,比如抓走某个图片所有的图片信息,或者具有某种功能。
比对url可以获取图片文件名,这样的话比对一下这个文件名,就能获取所有图片的url了,如果没有其他限制,就可以拿下所有图片的文件名。 查看全部
网页爬虫抓取百度图片(web服务器抓取百度图片的技巧及方法)
网页爬虫抓取百度图片是通过useragent解析页面来获取的。web服务器会根据抓取请求中的useragent变化来调用对应的api或者完全自己去尝试找出其中的特征值;第三方接口的post和get也有提交参数的逻辑;这些流程和简单的网页爬虫抓取都是一样的;比如简单的图片搜索,获取来的结果中包含的就不仅仅是图片所在的url,还可能是图片的id或者png格式的图片链接。
我猜可能是抓url,像随便哪个爬虫,不说明抓取目标。你只能说是抓url。但是你爬哪不一定啊。你不能说人家web服务器每次去xxx2d下载图片都抓包比对id吧。然后拿出图片的地址,而且即使网页里没有图片,你把这个值盗过来给爬虫提交一下,它下载下来就能用了。程序猿说得清楚,人家真心懒得自己搞这个。还是要把图片url拿到,你把id和图片的地址都告诉她。这个里面就有可能包含其他图片的url。
get方法是cookie的方法,你验证登录或者dns解析为动态的,当然就拿不到你指定的图片,但是调用百度的图片提取,应该就可以拿到图片的url。另外@sherrysu说的很对,爬虫爬图片一般都是直接抓,没有必要比对url,除非有特殊需求,比如抓走某个图片所有的图片信息,或者具有某种功能。
比对url可以获取图片文件名,这样的话比对一下这个文件名,就能获取所有图片的url了,如果没有其他限制,就可以拿下所有图片的文件名。
网页爬虫抓取百度图片(()2060,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-23 18:06
网页爬虫抓取百度图片数据()爬虫工具的介绍为了更好的运用,图片数据抓取了两种方式:静态页面、动态页面我们采用静态页面爬取:【缺点】:网页访问慢,并且不像动态页面那样,每次都要重新下载图片并且不稳定pageawait{root:0}pageawaitso_page()so_page()pageawaitpage_download()so_page()pageawaitpage_upgrade()pageawaitdownload_gz()download_gz()此时需要pageawaitpage_upgrade等待页面加载完毕,后面才能下载我们用动态页面抓取:pageawaitso_gz()so_gz()so_gz()pageawaitdownload_gz()so_gz()so_gz()我们可以这样提取出图片url接下来按照提取pictureid这样一步步提取出所有图片的url包括图片的尺寸、压缩率与分辨率、图片密度pictureid我们按照这种方式提取所有图片的url>>>sitemap。
gz()args:[200,201,2040,2060,2060,2070,2070,2070,2060,2070,2070,2060,2070,2070,2060,2070,2060,2070,2070,2060,2070,2060,2070,2070,2070,2070,2060,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,。 查看全部
网页爬虫抓取百度图片(()2060,)
网页爬虫抓取百度图片数据()爬虫工具的介绍为了更好的运用,图片数据抓取了两种方式:静态页面、动态页面我们采用静态页面爬取:【缺点】:网页访问慢,并且不像动态页面那样,每次都要重新下载图片并且不稳定pageawait{root:0}pageawaitso_page()so_page()pageawaitpage_download()so_page()pageawaitpage_upgrade()pageawaitdownload_gz()download_gz()此时需要pageawaitpage_upgrade等待页面加载完毕,后面才能下载我们用动态页面抓取:pageawaitso_gz()so_gz()so_gz()pageawaitdownload_gz()so_gz()so_gz()我们可以这样提取出图片url接下来按照提取pictureid这样一步步提取出所有图片的url包括图片的尺寸、压缩率与分辨率、图片密度pictureid我们按照这种方式提取所有图片的url>>>sitemap。
gz()args:[200,201,2040,2060,2060,2070,2070,2070,2060,2070,2070,2060,2070,2070,2060,2070,2060,2070,2070,2060,2070,2060,2070,2070,2070,2070,2060,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,。
网页爬虫抓取百度图片( 讲解我们的爬虫之前,如何获取对自己有用的信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-23 15:05
讲解我们的爬虫之前,如何获取对自己有用的信息?)
在讲解我们的爬虫之前,我们先来概括一下爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是一种模拟浏览器发送网络请求并接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
原则上只要浏览器(客户端)能做,爬虫就能做。
我们为什么要使用爬虫
在互联网大数据时代,我们生活的便利和海量数据的爆炸式出现在互联网上。
过去,我们使用书籍、报纸、电视、广播或信息。信息量有限,经过一定量的筛选,信息相对有效,但缺点是信息太窄。不对称的信息传递限制了我们的视野,无法学到更多的信息和知识。
在互联网大数据时代,我们突然可以免费获取信息,我们收到了海量的信息,但大部分都是无效的垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,你可以搜索一个——100,000,000条关于减肥的信息。
如此大量的信息碎片,我们如何获取对自己有用的信息呢?
答案是筛选!
通过一定的技术采集相关内容,然后分析删除选区,得到我们真正需要的信息。
这项信息采集、分析和整合工作可以应用于广泛的应用领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等......您可以通过这项技术获得更多准确有效的信息。好好利用。
网络爬虫技术虽然名字古怪,第一反应是那种软软的爬行生物,但却是可以在虚拟世界中前行的利器。
爬行动物准备
我们通常谈论 Python 爬虫。其实,这里可能有误会。爬虫不是 Python 独有的。可以爬取的语言有很多。例如:PHP、JAVA、C#、C++、Python。之所以选择Python作为爬虫,是因为Python是相对的。比较简单,功能也比较齐全。
首先我们需要下载python,我下载的是最新的官方版本3.8.3
其次,我们需要一个运行Python的环境,我用的是pychram
也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,我已经良心写了评论
(在爬虫运行过程中,你可能不仅仅需要以上的库,这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬取豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
已经爬到这里了,给大家看看效果图。我将抓取的内容保存在 xls 中。
我们抓取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概述和相关信息。
代码分析
先贴出代码,然后我根据代码一步步分析
<p># -*- codeing = utf-8 -*- from bs4 import BeautifulSoup # 网页解析,获取数据 import re # 正则表达式,进行文字匹配` import urllib.request, urllib.error # 制定URL,获取网页数据 import xlwt # 进行excel操作 #import sqlite3 # 进行SQLite数据库操作 findLink = re.compile(r'') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r' 查看全部
网页爬虫抓取百度图片(
讲解我们的爬虫之前,如何获取对自己有用的信息?)

在讲解我们的爬虫之前,我们先来概括一下爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是一种模拟浏览器发送网络请求并接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
原则上只要浏览器(客户端)能做,爬虫就能做。
我们为什么要使用爬虫
在互联网大数据时代,我们生活的便利和海量数据的爆炸式出现在互联网上。
过去,我们使用书籍、报纸、电视、广播或信息。信息量有限,经过一定量的筛选,信息相对有效,但缺点是信息太窄。不对称的信息传递限制了我们的视野,无法学到更多的信息和知识。
在互联网大数据时代,我们突然可以免费获取信息,我们收到了海量的信息,但大部分都是无效的垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,你可以搜索一个——100,000,000条关于减肥的信息。
如此大量的信息碎片,我们如何获取对自己有用的信息呢?
答案是筛选!
通过一定的技术采集相关内容,然后分析删除选区,得到我们真正需要的信息。
这项信息采集、分析和整合工作可以应用于广泛的应用领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等......您可以通过这项技术获得更多准确有效的信息。好好利用。
网络爬虫技术虽然名字古怪,第一反应是那种软软的爬行生物,但却是可以在虚拟世界中前行的利器。
爬行动物准备
我们通常谈论 Python 爬虫。其实,这里可能有误会。爬虫不是 Python 独有的。可以爬取的语言有很多。例如:PHP、JAVA、C#、C++、Python。之所以选择Python作为爬虫,是因为Python是相对的。比较简单,功能也比较齐全。
首先我们需要下载python,我下载的是最新的官方版本3.8.3
其次,我们需要一个运行Python的环境,我用的是pychram

也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)

差不多就是这些库了,我已经良心写了评论

(在爬虫运行过程中,你可能不仅仅需要以上的库,这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬取豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
已经爬到这里了,给大家看看效果图。我将抓取的内容保存在 xls 中。

我们抓取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概述和相关信息。
代码分析
先贴出代码,然后我根据代码一步步分析
<p># -*- codeing = utf-8 -*- from bs4 import BeautifulSoup # 网页解析,获取数据 import re # 正则表达式,进行文字匹配` import urllib.request, urllib.error # 制定URL,获取网页数据 import xlwt # 进行excel操作 #import sqlite3 # 进行SQLite数据库操作 findLink = re.compile(r'') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r'
网页爬虫抓取百度图片(《凡人修仙传吧_百度贴吧》之中制作原理基本相同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-22 12:25
百度贴吧的爬虫制作原理与Embarrassed爬虫制作原理基本一致。他们都通过查看源代码提取关键数据,然后将其存储在本地txt文件中。
源码下载:
项目内容:
百度贴吧用Python编写的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,将代码复制进去,双击运行。
程序功能:
将贴吧宿主发布的内容打包成txt打包保存到本地
原理说明:
首先先浏览某篇文章贴吧,点击只看到海报,点击第二页,url有点变了,变成了:
可以看出see_lz=1是只看主机,pn=1是对应的页码。记住这一点,为以后的写作做好准备。
这是我们需要使用的网址。
下一步是查看页面的源代码。
在第一次选择标题和存储文件时会用到它。
百度标题贴吧:《修仙传说》中的一些“路人”故事_修仙故事_百度贴吧
源代码:
1 # -*- coding: utf-8 -*-
2 #---------------------------------------
3 # 程序:百度贴吧爬虫
4 # 版本:0.5
5 # 作者:fjl
6 # 日期:2016-2-11
7 # 语言:Python 2.7
8 # 操作:输入网址后自动只看楼主并保存到本地文件
9 # 功能:将楼主发布的内容打包txt存储到本地。
10 #---------------------------------------
11
12 import string
13 import urllib2
14 import re
15
16 #----------- 处理页面上的各种标签 -----------
17 class HTML_Tool:
18 # 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
19 BgnCharToNoneRex = re.compile("(\t|\n| ||)")
20
21 # 用非 贪婪模式 匹配 任意标签
22 EndCharToNoneRex = re.compile("")
23
24 # 用非 贪婪模式 匹配 任意<p>标签
25 BgnPartRex = re.compile("")
26 CharToNewLineRex = re.compile("(
||||)")
27 CharToNextTabRex = re.compile("")
28
29 # 将一些html的符号实体转变为原始符号
30 replaceTab = [("",">"),("&","&"),("&","\""),(" "," ")]
31
32 def Replace_Char(self,x):
33 x = self.BgnCharToNoneRex.sub("",x)
34 x = self.BgnPartRex.sub("\n ",x)
35 x = self.CharToNewLineRex.sub("\n",x)
36 x = self.CharToNextTabRex.sub("\t",x)
37 x = self.EndCharToNoneRex.sub("",x)
38
39 for t in self.replaceTab:
40 x = x.replace(t[0],t[1])
41 return x
42
43 class Baidu_Spider:
44 # 申明相关的属性
45 def __init__(self,url):
46 self.myUrl = url + \'?see_lz=1\'
47 self.datas = []
48 self.myTool = HTML_Tool()
49 print u\'已经启动百度贴吧爬虫,咔嚓咔嚓\'
50
51 # 初始化加载页面并将其转码储存
52 def baidu_tieba(self):
53 # 读取页面的原始信息并将其从gbk转码
54 myPage = urllib2.urlopen(self.myUrl).read().decode("utf-8")
55 # 计算楼主发布内容一共有多少页
56 endPage = self.page_counter(myPage)
57 # 获取该帖的标题
58 title = self.find_title(myPage)
59 print u\'文章名称:\' + title
60 # 获取最终的数据
61 self.save_data(self.myUrl,title,endPage)
62
63 #用来计算一共有多少页
64 def page_counter(self,myPage):
65 # 匹配 "共有12页" 来获取一共有多少页
66 myMatch = re.search(r\'class="red">(\d+?)\', myPage, re.S)
67 if myMatch:
68 endPage = int(myMatch.group(1))
69 print u\'爬虫报告:发现楼主共有%d页的原创内容\' % endPage
70 else:
71 endPage = 0
72 print u\'爬虫报告:无法计算楼主发布内容有多少页!\'
73 return endPage
74
75 # 用来寻找该帖的标题
76 def find_title(self,myPage):
77 # 匹配 xxxxxxxxxx 找出标题
78 myMatch = re.search(r\'(.*?)\', myPage, re.S)
79 title = u\'暂无标题\'
80 if myMatch:
81 #title = myMatch.group(1)
82 title = myMatch.group(1)
83 else:
84 print u\'爬虫报告:无法加载文章标题!\'
85 # 文件名不能包含以下字符: \ / : * ? " < > |
86 title = title.replace(\'\\\',\'\').replace(\'/\',\'\').replace(\':\',\'\').replace(\'*\',\'\').replace(\'?\',\'\').replace(\'"\',\'\').replace(\'>\',\'\').replace(\' 查看全部
网页爬虫抓取百度图片(《凡人修仙传吧_百度贴吧》之中制作原理基本相同)
百度贴吧的爬虫制作原理与Embarrassed爬虫制作原理基本一致。他们都通过查看源代码提取关键数据,然后将其存储在本地txt文件中。
源码下载:
项目内容:
百度贴吧用Python编写的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,将代码复制进去,双击运行。
程序功能:
将贴吧宿主发布的内容打包成txt打包保存到本地
原理说明:
首先先浏览某篇文章贴吧,点击只看到海报,点击第二页,url有点变了,变成了:
可以看出see_lz=1是只看主机,pn=1是对应的页码。记住这一点,为以后的写作做好准备。
这是我们需要使用的网址。
下一步是查看页面的源代码。
在第一次选择标题和存储文件时会用到它。
百度标题贴吧:《修仙传说》中的一些“路人”故事_修仙故事_百度贴吧
源代码:
1 # -*- coding: utf-8 -*-
2 #---------------------------------------
3 # 程序:百度贴吧爬虫
4 # 版本:0.5
5 # 作者:fjl
6 # 日期:2016-2-11
7 # 语言:Python 2.7
8 # 操作:输入网址后自动只看楼主并保存到本地文件
9 # 功能:将楼主发布的内容打包txt存储到本地。
10 #---------------------------------------
11
12 import string
13 import urllib2
14 import re
15
16 #----------- 处理页面上的各种标签 -----------
17 class HTML_Tool:
18 # 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
19 BgnCharToNoneRex = re.compile("(\t|\n| ||)")
20
21 # 用非 贪婪模式 匹配 任意标签
22 EndCharToNoneRex = re.compile("")
23
24 # 用非 贪婪模式 匹配 任意<p>标签
25 BgnPartRex = re.compile("")
26 CharToNewLineRex = re.compile("(
||||)")
27 CharToNextTabRex = re.compile("")
28
29 # 将一些html的符号实体转变为原始符号
30 replaceTab = [("",">"),("&","&"),("&","\""),(" "," ")]
31
32 def Replace_Char(self,x):
33 x = self.BgnCharToNoneRex.sub("",x)
34 x = self.BgnPartRex.sub("\n ",x)
35 x = self.CharToNewLineRex.sub("\n",x)
36 x = self.CharToNextTabRex.sub("\t",x)
37 x = self.EndCharToNoneRex.sub("",x)
38
39 for t in self.replaceTab:
40 x = x.replace(t[0],t[1])
41 return x
42
43 class Baidu_Spider:
44 # 申明相关的属性
45 def __init__(self,url):
46 self.myUrl = url + \'?see_lz=1\'
47 self.datas = []
48 self.myTool = HTML_Tool()
49 print u\'已经启动百度贴吧爬虫,咔嚓咔嚓\'
50
51 # 初始化加载页面并将其转码储存
52 def baidu_tieba(self):
53 # 读取页面的原始信息并将其从gbk转码
54 myPage = urllib2.urlopen(self.myUrl).read().decode("utf-8")
55 # 计算楼主发布内容一共有多少页
56 endPage = self.page_counter(myPage)
57 # 获取该帖的标题
58 title = self.find_title(myPage)
59 print u\'文章名称:\' + title
60 # 获取最终的数据
61 self.save_data(self.myUrl,title,endPage)
62
63 #用来计算一共有多少页
64 def page_counter(self,myPage):
65 # 匹配 "共有12页" 来获取一共有多少页
66 myMatch = re.search(r\'class="red">(\d+?)\', myPage, re.S)
67 if myMatch:
68 endPage = int(myMatch.group(1))
69 print u\'爬虫报告:发现楼主共有%d页的原创内容\' % endPage
70 else:
71 endPage = 0
72 print u\'爬虫报告:无法计算楼主发布内容有多少页!\'
73 return endPage
74
75 # 用来寻找该帖的标题
76 def find_title(self,myPage):
77 # 匹配 xxxxxxxxxx 找出标题
78 myMatch = re.search(r\'(.*?)\', myPage, re.S)
79 title = u\'暂无标题\'
80 if myMatch:
81 #title = myMatch.group(1)
82 title = myMatch.group(1)
83 else:
84 print u\'爬虫报告:无法加载文章标题!\'
85 # 文件名不能包含以下字符: \ / : * ? " < > |
86 title = title.replace(\'\\\',\'\').replace(\'/\',\'\').replace(\':\',\'\').replace(\'*\',\'\').replace(\'?\',\'\').replace(\'"\',\'\').replace(\'>\',\'\').replace(\'
网页爬虫抓取百度图片(如何用Python学习资料的小伙伴获取图片的url? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 14:20
)
PS:如需Python学习资料,可点击下方链接自行获取
1.获取图片的url链接
首先打开百度图片首页,注意下面url中的索引
接下来,将页面切换到传统的翻页版本,因为这会帮助我们抓取图片!
对比了几个网址,发现pn参数是请求数。修改pn参数,观察返回数据,发现每个页面最多只能收录60张图片。
注意:gsm参数是pn参数的16进制表示,去掉没有坏处
然后右击查看网页源码,直接(ctrl+F)搜索objURL
这样我们就找到了需要图片的url。
2.本地保存图片链接
现在,我们要做的就是抓取这些信息。
注意:网页中有objURL、hoverURL……但是我们用的是objURL,因为这是原图
那么,如何获取 objURL?使用正则表达式!
那我们怎么用正则表达式来实现呢?其实只需要一行代码...
results = re.findall(\'"objURL":"(.*?)",\', html)
核心代码:
1.获取图片url代码:
1 # 获取图片url连接
2 def get_parse_page(pn,name):
3
4 for i in range(int(pn)):
5 # 1.获取网页
6 print(\'正在获取第{}页\'.format(i+1))
7
8 # 百度图片首页的url
9 # name是你要搜索的关键词
10 # pn是你想下载的页数
11
12 url = \'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d\' %(name,i*20)
13
14 headers = {
15 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400\'}
16
17 # 发送请求,获取相应
18 response = requests.get(url, headers=headers)
19 html = response.content.decode()
20 # print(html)
21
22 # 2.正则表达式解析网页
23 # "objURL":"http://n.sinaimg.cn/sports/tra ... ot%3B
24 results = re.findall(\'"objURL":"(.*?)",\', html) # 返回一个列表
25
26 # 根据获取到的图片链接,把图片保存到本地
27 save_to_txt(results, name, i)
2.保存图片到本地代码:
1 # 保存图片到本地
2 def save_to_txt(results, name, i):
3
4 j = 0
5 # 在当目录下创建文件夹
6 if not os.path.exists(\'./\' + name):
7 os.makedirs(\'./\' + name)
8
9 # 下载图片
10 for result in results:
11 print(\'正在保存第{}个\'.format(j))
12 try:
13 pic = requests.get(result, timeout=10)
14 time.sleep(1)
15 except:
16 print(\'当前图片无法下载\')
17 j += 1
18 continue
19
20 # 可忽略,这段代码有bug
21 # file_name = result.split(\'/\')
22 # file_name = file_name[len(file_name) - 1]
23 # print(file_name)
24 #
25 # end = re.search(\'(.png|.jpg|.jpeg|.gif)$\', file_name)
26 # if end == None:
27 # file_name = file_name + \'.jpg\'
28
29 # 把图片保存到文件夹
30 file_full_name = \'./\' + name + \'/\' + str(i) + \'-\' + str(j) + \'.jpg\'
31 with open(file_full_name, \'wb\') as f:
32 f.write(pic.content)
33
34 j += 1
3.主要功能代码:
1 # 主函数
2 if __name__ == \'__main__\':
3
4 name = input(\'请输入你要下载的关键词:\')
5 pn = input(\'你想下载前几页(1页有60张):\')
6 get_parse_page(pn,
使用说明:
1 # 配置以下模块
2 import requests
3 import re
4 import os
5 import time
6
7 # 1.运行 py源文件
8 # 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
9 # 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片 查看全部
网页爬虫抓取百度图片(如何用Python学习资料的小伙伴获取图片的url?
)
PS:如需Python学习资料,可点击下方链接自行获取
1.获取图片的url链接
首先打开百度图片首页,注意下面url中的索引
接下来,将页面切换到传统的翻页版本,因为这会帮助我们抓取图片!
对比了几个网址,发现pn参数是请求数。修改pn参数,观察返回数据,发现每个页面最多只能收录60张图片。
注意:gsm参数是pn参数的16进制表示,去掉没有坏处
然后右击查看网页源码,直接(ctrl+F)搜索objURL
这样我们就找到了需要图片的url。
2.本地保存图片链接
现在,我们要做的就是抓取这些信息。
注意:网页中有objURL、hoverURL……但是我们用的是objURL,因为这是原图
那么,如何获取 objURL?使用正则表达式!
那我们怎么用正则表达式来实现呢?其实只需要一行代码...
results = re.findall(\'"objURL":"(.*?)",\', html)
核心代码:
1.获取图片url代码:
1 # 获取图片url连接
2 def get_parse_page(pn,name):
3
4 for i in range(int(pn)):
5 # 1.获取网页
6 print(\'正在获取第{}页\'.format(i+1))
7
8 # 百度图片首页的url
9 # name是你要搜索的关键词
10 # pn是你想下载的页数
11
12 url = \'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d\' %(name,i*20)
13
14 headers = {
15 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400\'}
16
17 # 发送请求,获取相应
18 response = requests.get(url, headers=headers)
19 html = response.content.decode()
20 # print(html)
21
22 # 2.正则表达式解析网页
23 # "objURL":"http://n.sinaimg.cn/sports/tra ... ot%3B
24 results = re.findall(\'"objURL":"(.*?)",\', html) # 返回一个列表
25
26 # 根据获取到的图片链接,把图片保存到本地
27 save_to_txt(results, name, i)
2.保存图片到本地代码:
1 # 保存图片到本地
2 def save_to_txt(results, name, i):
3
4 j = 0
5 # 在当目录下创建文件夹
6 if not os.path.exists(\'./\' + name):
7 os.makedirs(\'./\' + name)
8
9 # 下载图片
10 for result in results:
11 print(\'正在保存第{}个\'.format(j))
12 try:
13 pic = requests.get(result, timeout=10)
14 time.sleep(1)
15 except:
16 print(\'当前图片无法下载\')
17 j += 1
18 continue
19
20 # 可忽略,这段代码有bug
21 # file_name = result.split(\'/\')
22 # file_name = file_name[len(file_name) - 1]
23 # print(file_name)
24 #
25 # end = re.search(\'(.png|.jpg|.jpeg|.gif)$\', file_name)
26 # if end == None:
27 # file_name = file_name + \'.jpg\'
28
29 # 把图片保存到文件夹
30 file_full_name = \'./\' + name + \'/\' + str(i) + \'-\' + str(j) + \'.jpg\'
31 with open(file_full_name, \'wb\') as f:
32 f.write(pic.content)
33
34 j += 1
3.主要功能代码:
1 # 主函数
2 if __name__ == \'__main__\':
3
4 name = input(\'请输入你要下载的关键词:\')
5 pn = input(\'你想下载前几页(1页有60张):\')
6 get_parse_page(pn,
使用说明:
1 # 配置以下模块
2 import requests
3 import re
4 import os
5 import time
6
7 # 1.运行 py源文件
8 # 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
9 # 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片
网页爬虫抓取百度图片(上海SEO外包:百度蜘蛛、网络机器人,蚂蚁、蠕虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-21 10:08
)
百度爬虫又称百度蜘蛛、网络机器人、蚂蚁、蠕虫等。
百度爬虫使用文本信息来抓取内容。最好减少网站中对应的图片和视频。尽量用文字来解释。百度蜘蛛是网站与用户搬运工之间的信息,抓取网站的内容,通过搜索引文库呈现给客户。
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps1.png
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps2.png
如图,蜘蛛从搜索区域抓取网页的信息,将符合规则的内容取回并带回临时库,不符合规则的内容直接清理,最后他会将符合条件的内容展示给搜索引擎查询。
百度蜘蛛分为pc/mobile-take-all蜘蛛,也有mobile-only蜘蛛。他们收到的大多数命令识别都是相同的。
关于蜘蛛爬取的频率:如果你是新的网站,百度对新站有保护期,会有30天的新站特权。在这30天内,网站内容百度蜘蛛的发布和更新将优先抓取和收录。一般爬取频率由系统根据网站的大小、用户的喜好程度和更新频率自动调整。
不管新的网站还是旧的网站,在文章的内容更新中都必须维护原创。文章的TDK布局很重要。一个好的标签布局是不会出现重复的关键词和句子的。文章 的质量比数量更重要。最好每天在固定的时间发布文章,让百度蜘蛛为我们服务,还有一个相对准时的概念。如果网站的文章或者多次重复的百度蜘蛛不会收录信息,因为百度的搜索引文库中收录了很多类似的信息,没有一个是收录,并且长期会导致网站被K或者降级。
<p>文章中必须注意的一件事是避免关键词stacking,什么是关键词stacking:关键词stacking在文章 查看全部
网页爬虫抓取百度图片(上海SEO外包:百度蜘蛛、网络机器人,蚂蚁、蠕虫
)
百度爬虫又称百度蜘蛛、网络机器人、蚂蚁、蠕虫等。
百度爬虫使用文本信息来抓取内容。最好减少网站中对应的图片和视频。尽量用文字来解释。百度蜘蛛是网站与用户搬运工之间的信息,抓取网站的内容,通过搜索引文库呈现给客户。
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps1.png
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps2.png
如图,蜘蛛从搜索区域抓取网页的信息,将符合规则的内容取回并带回临时库,不符合规则的内容直接清理,最后他会将符合条件的内容展示给搜索引擎查询。
百度蜘蛛分为pc/mobile-take-all蜘蛛,也有mobile-only蜘蛛。他们收到的大多数命令识别都是相同的。
关于蜘蛛爬取的频率:如果你是新的网站,百度对新站有保护期,会有30天的新站特权。在这30天内,网站内容百度蜘蛛的发布和更新将优先抓取和收录。一般爬取频率由系统根据网站的大小、用户的喜好程度和更新频率自动调整。
不管新的网站还是旧的网站,在文章的内容更新中都必须维护原创。文章的TDK布局很重要。一个好的标签布局是不会出现重复的关键词和句子的。文章 的质量比数量更重要。最好每天在固定的时间发布文章,让百度蜘蛛为我们服务,还有一个相对准时的概念。如果网站的文章或者多次重复的百度蜘蛛不会收录信息,因为百度的搜索引文库中收录了很多类似的信息,没有一个是收录,并且长期会导致网站被K或者降级。
<p>文章中必须注意的一件事是避免关键词stacking,什么是关键词stacking:关键词stacking在文章
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-21 10:04
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(2019独角兽企业重金招聘Python工程师标准(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-19 22:17
2019独角兽企业重磅Python工程师招聘标准>>>
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。所以我也写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息. ----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
可能是解析器有问题,我们就不多说了,有问题的同学,百度,有一堆解决方法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
代码显示如下:
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0 #声明一个变量赋值
path = 'H:\\python lianxi\\zout_pc5\\test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到H:..\\test文件夹中,如果没有test文件夹则创建
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
#format格式化字符串
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725") #获取该网址网页详细信息,html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束,更多精彩,敬请关注:IT农民工_七晓白
(ps:本人也是python新手,文章如有错误请见谅)
转载于: 查看全部
网页爬虫抓取百度图片(2019独角兽企业重金招聘Python工程师标准(图))
2019独角兽企业重磅Python工程师招聘标准>>>

刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。所以我也写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息. ----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
可能是解析器有问题,我们就不多说了,有问题的同学,百度,有一堆解决方法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
代码显示如下:
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0 #声明一个变量赋值
path = 'H:\\python lianxi\\zout_pc5\\test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到H:..\\test文件夹中,如果没有test文件夹则创建
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
#format格式化字符串
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725";) #获取该网址网页详细信息,html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束,更多精彩,敬请关注:IT农民工_七晓白
(ps:本人也是python新手,文章如有错误请见谅)
转载于:
网页爬虫抓取百度图片( 基于python写的一个爬虫程序,能实现简单的网页图片下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 13:26
基于python写的一个爬虫程序,能实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近编辑一直在学习python的东西。今天小编就给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对我棋牌网站的支持! 查看全部
网页爬虫抓取百度图片(
基于python写的一个爬虫程序,能实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近编辑一直在学习python的东西。今天小编就给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对我棋牌网站的支持!
网页爬虫抓取百度图片(最近博主遇到这样一个现成的“数据库”(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-18 19:11
最近有博主遇到这样的需求:当用户输入一个词时,返回这个词的解释。我的第一个想法是建一个数据库,把常用的词和词解释放在数据库中,在用户查询的时候直接读取数据库的结果,但是我不想建这样的数据库,所以想到了一个现成的“数据库”,如百度百科。下面我们使用urllib和xpath来获取百度百科的内容。
最近有博主遇到这样的需求:当用户输入一个词的时候,返回这个词的解释
我的第一个想法是建一个数据库,把常用的词和词的解释放到数据库中,用户查询的时候直接读取数据库结果
但是我没有心去建这样的数据库,于是想到了百度百科这样的现成的“数据库”。
下面我们使用urllib和xpath来获取百度百科的内容
1、 爬取百度百科
百度百科是静态网页,易于抓取,请求参数可以直接放在URL中,例如:
地址网络爬虫对应网络爬虫的百度百科页面
地址电脑对应电脑的百度百科页面
可以说是很方便了,不多说了,直接放代码就好了,不明白的可以看评论:
import urllib.request
import urllib.parse
from lxml import etree
def query(content):
# 请求地址
url = \'https://baike.baidu.com/item/\' + urllib.parse.quote(content)
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath(\'//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()\')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'查询词语:\')
result = query(content)
print("查询结果:%s" % result)
效果演示:
2、 爬行维基百科
上面确实可以解决一些问题,但是如果用户的查询是英文的呢?我们知道百度百科一般很少有收录英文词条
同样,很容易想到爬行维基百科。思路和爬百度百科一样。您只需要处理请求地址并返回结果。
下面也是直接放代码,不明白的可以看评论:
from lxml import etree
import urllib.request
import urllib.parse
def query(content):
# 请求地址
url = \'https://en.wikipedia.org/wiki/\' + content
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到 下所有的子节点对象
obj_list = html.xpath(\'//div[@class="mw-parser-output"]/*\')
# 在所有的子节点对象中获取有用的 <p> 节点对象
for i in range(0,len(obj_list)):
if \'p\' == obj_list[i].tag:
start = i
break
for i in range(start,len(obj_list)):
if \'p\' != obj_list[i].tag:
end = i
break
p_list = obj_list[start:end]
# 使用 xpath 匹配数据,得到 <p> 下所有的文本节点对象
sen_list_list = [obj.xpath(\'.//text()\') for obj in p_list]
# 将文本节点对象转化为字符串列表
sen_list = [sen.encode(\'utf-8\').decode() for sen_list in sen_list_list for sen in sen_list]
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'Word: \')
result = query(content)
print("Result: %s" % result)
下面是效果演示:
好的,你完成了!
注:本项目代码仅供学习交流使用!!! 查看全部
网页爬虫抓取百度图片(最近博主遇到这样一个现成的“数据库”(图))
最近有博主遇到这样的需求:当用户输入一个词时,返回这个词的解释。我的第一个想法是建一个数据库,把常用的词和词解释放在数据库中,在用户查询的时候直接读取数据库的结果,但是我不想建这样的数据库,所以想到了一个现成的“数据库”,如百度百科。下面我们使用urllib和xpath来获取百度百科的内容。
最近有博主遇到这样的需求:当用户输入一个词的时候,返回这个词的解释
我的第一个想法是建一个数据库,把常用的词和词的解释放到数据库中,用户查询的时候直接读取数据库结果
但是我没有心去建这样的数据库,于是想到了百度百科这样的现成的“数据库”。
下面我们使用urllib和xpath来获取百度百科的内容
1、 爬取百度百科
百度百科是静态网页,易于抓取,请求参数可以直接放在URL中,例如:
地址网络爬虫对应网络爬虫的百度百科页面
地址电脑对应电脑的百度百科页面
可以说是很方便了,不多说了,直接放代码就好了,不明白的可以看评论:
import urllib.request
import urllib.parse
from lxml import etree
def query(content):
# 请求地址
url = \'https://baike.baidu.com/item/\' + urllib.parse.quote(content)
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath(\'//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()\')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'查询词语:\')
result = query(content)
print("查询结果:%s" % result)
效果演示:
2、 爬行维基百科
上面确实可以解决一些问题,但是如果用户的查询是英文的呢?我们知道百度百科一般很少有收录英文词条
同样,很容易想到爬行维基百科。思路和爬百度百科一样。您只需要处理请求地址并返回结果。
下面也是直接放代码,不明白的可以看评论:
from lxml import etree
import urllib.request
import urllib.parse
def query(content):
# 请求地址
url = \'https://en.wikipedia.org/wiki/\' + content
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到 下所有的子节点对象
obj_list = html.xpath(\'//div[@class="mw-parser-output"]/*\')
# 在所有的子节点对象中获取有用的 <p> 节点对象
for i in range(0,len(obj_list)):
if \'p\' == obj_list[i].tag:
start = i
break
for i in range(start,len(obj_list)):
if \'p\' != obj_list[i].tag:
end = i
break
p_list = obj_list[start:end]
# 使用 xpath 匹配数据,得到 <p> 下所有的文本节点对象
sen_list_list = [obj.xpath(\'.//text()\') for obj in p_list]
# 将文本节点对象转化为字符串列表
sen_list = [sen.encode(\'utf-8\').decode() for sen_list in sen_list_list for sen in sen_list]
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'Word: \')
result = query(content)
print("Result: %s" % result)
下面是效果演示:
好的,你完成了!
注:本项目代码仅供学习交流使用!!!
网页爬虫抓取百度图片(为什么使用Python进行爬虫?技术是否需要持续学习?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-18 19:10
幸运的是,我们处于互联网时代,可以在互联网上找到很多信息。当我们需要浏览数据或者文章时,通常的方式是复制粘贴。当数据量很大时,这自然是一件费时费力的事情。我们希望有一个自动化的程序,可以自动帮助我们匹配网络上的数据,下载它,并为我们使用。这时候,网络爬虫诞生了。
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
现在根据自己的理解,基本总结一下自己对爬虫的理解。
什么是爬虫?
首先,听我说,就像听演讲一样,这里的爬虫不是生物学意义上的爬虫。
爬虫一般是指网络爬虫,一种自动帮助我们搜索、匹配有用程序、下载并为我们使用的自动化程序。
爬虫的作用是什么?
获取我们需要的数据。许多搜索引擎大量使用爬虫,例如百度搜索和谷歌搜索。爬虫根据需要有不同的分类。
比如一般的搜索引擎都有一定的局限性:
因此,有一个专注的爬虫。它将面向特定主题和网页,为面向主题的用户查询准备数据资源。
为什么要使用 Python 进行爬取?爬虫技术需要持续学习吗?有了庞大的知识量,量变就会引起质变。如果你找到了你需要的东西,这个问题的解决方案肯定不会一成不变。参考网址 查看全部
网页爬虫抓取百度图片(为什么使用Python进行爬虫?技术是否需要持续学习?)
幸运的是,我们处于互联网时代,可以在互联网上找到很多信息。当我们需要浏览数据或者文章时,通常的方式是复制粘贴。当数据量很大时,这自然是一件费时费力的事情。我们希望有一个自动化的程序,可以自动帮助我们匹配网络上的数据,下载它,并为我们使用。这时候,网络爬虫诞生了。
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
现在根据自己的理解,基本总结一下自己对爬虫的理解。
什么是爬虫?
首先,听我说,就像听演讲一样,这里的爬虫不是生物学意义上的爬虫。
爬虫一般是指网络爬虫,一种自动帮助我们搜索、匹配有用程序、下载并为我们使用的自动化程序。
爬虫的作用是什么?
获取我们需要的数据。许多搜索引擎大量使用爬虫,例如百度搜索和谷歌搜索。爬虫根据需要有不同的分类。
比如一般的搜索引擎都有一定的局限性:
因此,有一个专注的爬虫。它将面向特定主题和网页,为面向主题的用户查询准备数据资源。
为什么要使用 Python 进行爬取?爬虫技术需要持续学习吗?有了庞大的知识量,量变就会引起质变。如果你找到了你需要的东西,这个问题的解决方案肯定不会一成不变。参考网址
网页爬虫抓取百度图片(如何实现搜索关键字?(一)_e操盘_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-16 09:07
2、如何搜索关键词?
通过URL,我们可以发现我们只需要在kw=()和括号中输入你要搜索的内容即可。这样,我们就可以用一个 {} 来代替它,后面我们会循环遍历它。
【五、项目实施】
1、创建一个名为BaiduImageSpider的类,定义一个main方法main和一个初始化方法init。导入所需的库。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
pass
def main(self):
pass
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
spider.main()
pass
if __name__ == '__main__':
spider= ImageSpider()
spider.main()
2、准备url地址和请求头来请求数据。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
self.tieba_name = tieba_name #输入的名字
self.url = "{}&ie=utf-8&pn=0"
self.headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
'''发送请求 获取响应'''
def get_parse_page(self, url, xpath):
html = requests.get(url=url, headers=self.headers).content.decode("utf-8")
parse_html = etree.HTML(html)
r_list = parse_html.xpath(xpath)
return r_list
def main(self):
url = self.url.format(self.tieba_name)
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
key_word = parse.quote(inout_word)
spider = BaiduImageSpider(key_word)
spider.main()
3、xpath 数据分析
3.1、chrome_Xpath 插件安装
1) 这里使用了一个插件。它可以快速检查我们抓取的信息是否正确。具体安装方法如下。
2)百度下载chrome_Xpath_v2.0.2.crx,chrome浏览器输入:chrome://extensions/
3) 将chrome_Xpath_v2.0.2.crx 直接拖到扩展页面;
4) 如果安装失败,弹窗提示“无法从这个网站添加应用程序、扩展和用户脚本”。如果遇到这个问题,解决方法是:打开开发者模式保存crx文件(直接或者修改后缀为rar)解压到一个文件夹中,点击开发者模式加载解压后的扩展,选择解压后的文件夹,点击确定,安装成功;
3.2、chrome_Xpath 插件使用
上面的chrome_Xpath插件我们已经安装好了,接下来就要用到了。1) 打开浏览器,按快捷键F12。2) 选择下图所示的元素。
3) 右击,然后选择“Copy XPath”,如下图。
3.3、写代码,获取链接函数。
我们已经获得了上面链接函数的Xpath路径,然后定义了一个链接函数get_tlink并继承self来实现多页面抓取。
'''获取链接函数'''
def get_tlink(self, url):
xpath = '//div[@class="threadlist_lz clearfix"]/div/a/@href'
t_list = self.get_parse_page(url, xpath)
# print(len(t_list))
for t in t_list:
t_link = " + t
'''接下来对帖子地址发送请求 将保存到本地'''
self.write_image(t_link)
4、保存数据
这里定义了一个write_image方法来保存数据,如下图。
'''保存到本地函数'''
def write_image(self, t_link):
xpath = "//div[@class='d_post_content j_d_post_content clearfix']/img[@class='BDE_Image']/@src | //div[@class='video_src_wrapper']/embed/@data-video"
img_list = self.get_parse_page(t_link, xpath)
for img_link in img_list:
html = requests.get(url=img_link, headers=self.headers).content
filename = "百度/"+img_link[-10:]
with open(filename, 'wb') as f:
f.write(html)
print("%s下载成功" % filename)
如下所示:
【六、效果展示】
1、点击运行,如下图(请输入您要查询的信息):
2、以吴京为例输入后回车:
3、将下载的图片保存在名为“百度”的文件夹中,该文件夹需要提前在本地创建。一定要记得提前在当前代码的同级目录下新建一个名为“百度”的文件夹,否则系统会找不到文件夹,会报错找不到文件夹“百度”。
4、 下图中的MP4为评论区视频。
总结:
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、本文基于Python网络爬虫,利用爬虫库实现百度贴吧评论区抓取。对Python爬取百度贴吧的一些难点进行详细讲解并提供有效的解决方案。3、欢迎积极尝试。有时你看到别人实施起来很容易,但自己动手时,总会出现各种问题。不看高手,努力理解更好。深刻的。学习requests库的使用和爬虫程序的编写。
有不清楚的可以留言。更多Python教程会持续更新!
最新Python爬虫全套视频和人工智能教程整理,学习小伙伴,回复:Python,领取
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
网页爬虫抓取百度图片(如何实现搜索关键字?(一)_e操盘_)
2、如何搜索关键词?
通过URL,我们可以发现我们只需要在kw=()和括号中输入你要搜索的内容即可。这样,我们就可以用一个 {} 来代替它,后面我们会循环遍历它。
【五、项目实施】
1、创建一个名为BaiduImageSpider的类,定义一个main方法main和一个初始化方法init。导入所需的库。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
pass
def main(self):
pass
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
spider.main()
pass
if __name__ == '__main__':
spider= ImageSpider()
spider.main()
2、准备url地址和请求头来请求数据。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
self.tieba_name = tieba_name #输入的名字
self.url = "{}&ie=utf-8&pn=0"
self.headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
'''发送请求 获取响应'''
def get_parse_page(self, url, xpath):
html = requests.get(url=url, headers=self.headers).content.decode("utf-8")
parse_html = etree.HTML(html)
r_list = parse_html.xpath(xpath)
return r_list
def main(self):
url = self.url.format(self.tieba_name)
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
key_word = parse.quote(inout_word)
spider = BaiduImageSpider(key_word)
spider.main()
3、xpath 数据分析
3.1、chrome_Xpath 插件安装
1) 这里使用了一个插件。它可以快速检查我们抓取的信息是否正确。具体安装方法如下。
2)百度下载chrome_Xpath_v2.0.2.crx,chrome浏览器输入:chrome://extensions/
3) 将chrome_Xpath_v2.0.2.crx 直接拖到扩展页面;
4) 如果安装失败,弹窗提示“无法从这个网站添加应用程序、扩展和用户脚本”。如果遇到这个问题,解决方法是:打开开发者模式保存crx文件(直接或者修改后缀为rar)解压到一个文件夹中,点击开发者模式加载解压后的扩展,选择解压后的文件夹,点击确定,安装成功;
3.2、chrome_Xpath 插件使用
上面的chrome_Xpath插件我们已经安装好了,接下来就要用到了。1) 打开浏览器,按快捷键F12。2) 选择下图所示的元素。
3) 右击,然后选择“Copy XPath”,如下图。
3.3、写代码,获取链接函数。
我们已经获得了上面链接函数的Xpath路径,然后定义了一个链接函数get_tlink并继承self来实现多页面抓取。
'''获取链接函数'''
def get_tlink(self, url):
xpath = '//div[@class="threadlist_lz clearfix"]/div/a/@href'
t_list = self.get_parse_page(url, xpath)
# print(len(t_list))
for t in t_list:
t_link = " + t
'''接下来对帖子地址发送请求 将保存到本地'''
self.write_image(t_link)
4、保存数据
这里定义了一个write_image方法来保存数据,如下图。
'''保存到本地函数'''
def write_image(self, t_link):
xpath = "//div[@class='d_post_content j_d_post_content clearfix']/img[@class='BDE_Image']/@src | //div[@class='video_src_wrapper']/embed/@data-video"
img_list = self.get_parse_page(t_link, xpath)
for img_link in img_list:
html = requests.get(url=img_link, headers=self.headers).content
filename = "百度/"+img_link[-10:]
with open(filename, 'wb') as f:
f.write(html)
print("%s下载成功" % filename)
如下所示:
【六、效果展示】
1、点击运行,如下图(请输入您要查询的信息):
2、以吴京为例输入后回车:
3、将下载的图片保存在名为“百度”的文件夹中,该文件夹需要提前在本地创建。一定要记得提前在当前代码的同级目录下新建一个名为“百度”的文件夹,否则系统会找不到文件夹,会报错找不到文件夹“百度”。
4、 下图中的MP4为评论区视频。
总结:
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、本文基于Python网络爬虫,利用爬虫库实现百度贴吧评论区抓取。对Python爬取百度贴吧的一些难点进行详细讲解并提供有效的解决方案。3、欢迎积极尝试。有时你看到别人实施起来很容易,但自己动手时,总会出现各种问题。不看高手,努力理解更好。深刻的。学习requests库的使用和爬虫程序的编写。
有不清楚的可以留言。更多Python教程会持续更新!
最新Python爬虫全套视频和人工智能教程整理,学习小伙伴,回复:Python,领取
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
网页爬虫抓取百度图片(分析网页看看能不能获得网页源码打开今日头条官网(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-16 09:02
)
分析网页
看看能不能拿到网页的源代码
打开今日头条官网,搜索“街拍美女”,跳转到街拍首页。在jupyter notebook中尝试get源码,你会发现没有你想要的图片信息。这种情况打消了我们直接分析首页源码,寻找详情页的想法。这时候就用ajax解析了。
点击首页进入其中一个街拍群图详情页,然后尝试获取源码,但是可以直接获取源码。这里可以直接使用正则表达式。
了解页面结构
在“街头美女”首页,打开勾选-网络-选择保存日志,XHR,然后刷新页面,下面会有很多请求,我们直接进入主题,选择其中一个请求,然后看看右边的预览。
展开数据,
我们发现data里面的数据好像和首页的栏目是一一对应的。
当然,这可能并不明显。我们展开数据,看看子节点的title:(中间忽略公众号,我们只需要“open url”中的信息,其他需要过滤。)
查看其他数据子节点,也可以在首页找到对应的栏目,ok,我们已经确定了战略目标:
从首页开始,请求json格式的网页数据,然后使用ajax解析请求,获取并分析首页的源码;
从源代码中提取有用的 URL;
然后通过URL获取详情页的图片。
关于循环爬行
还要看左边。当我们继续下拉主页时,就会有源源不断的新请求。其中,偏移量有明显变化。和前面的实战一样,我们可以通过改变属性的值来达到循环阅读的目的。
分析详情页面
这里有个小技巧:在详情页的图片上右键,选择“在新标签页中打开图片”,然后看新标签页的名字,这个名字(一般只有几个尾数),在doc Ctrl+F 搜索,ok,然后你会发现它们隐藏在哪个变量中(多搜索几张图确认)。此变量收录从中下载图片的图片的 URL。
注:遗憾的是,目前今日头条采取了反拍措施,大部分详情页无法获取源码,因此获取的图片数量非常有限。
附上完整的爬虫代码,“streetPhotos_Spider.py”:
import json
import os
from hashlib import md5
import pymongo
from multiprocessing.pool import Pool
from urllib.parse import urlencode
from requests.exceptions import RequestException
import re
import requests
from webspider.TouTiao.mgconfig import *
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_one_index(offset, keyword): # 获取主页源码,由于主页url是动态的,我们设置参数,以便以后的循环
data = { # 设置url后缀
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 1,
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 用'urlencode方法会将字典解析成字符串
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
print("请求主页失败!")
return None
def parse_page_index(html): # 解析主页源码
try: # 这个函数有可能传入的参数是None,此时应该捕获异常
data = json.loads(html) # 由于拿到的源码是json格式的,需要用json包来解析
if data and 'data' in data.keys(): # 如果有节点data,那么从该节点中寻找article_url
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url): # 获取详情页源码,这里传入的参数将会是从主页中解析出的各个url
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
return None
def parse_page_detail(html): # 解析详情源码
images_pattern = re.compile('[a-zA-z]+://[^\s]*jpg', re.S) # 由于各个详情页结构大不相同,暂时截获所有URL
results = re.findall(images_pattern, html)
if results:
for result in results:
if len(result) > 55:
for result in results: download_images(result)
return {'url': result}
def save_to_mongo(result): # 将解析的结果保存到数据库
if db[MONGO_DB_TABLE].insert(result):
print('存储到MongoDB库', result)
return True
return False
def download_images(url): # 下载图片
print('当前正在下载:', url) # 显示调试信息
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # 返回图片二进制信息
except RequestException:
print("请求图片出错", url)
return None
def save_image(content): # 保存图片到本地
file_path = '{0}/{1}.{2}'.format('D:\Workspace\PycharmProj\webspider\TouTiao\photo', md5(content).hexdigest(),
'jpg') # 为文件命名
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_one_index(offset, KEYWORD) # 获取主页
for url in parse_page_index(html): # 从主页中解析出的各个详情页url
detail_html = get_page_detail(url)
if detail_html: # 若详情页存在,那么解析它
detail_result = parse_page_detail(detail_html)
if detail_result is not None: # 如果详情页非空,
if detail_result: save_to_mongo(detail_result) # 如果详情页有返回的url,那么保存进数据库
if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool() # 创建线程池
pool.map(main, groups) # 将main方法放到线程池中,会自动分割成多线程同时抓取
配置文件“mgconfig.py”放置在同一目录中。
MONGO_URL = 'localhost'
MONGO_DB = 'Toutiao'
MONGO_DB_TABLE = 'Toutiao'
GROUP_START = 1
GROUP_END = 30
KEYWORD = '街拍美女'
文件包结构:
查看全部
网页爬虫抓取百度图片(分析网页看看能不能获得网页源码打开今日头条官网(组图)
)
分析网页
看看能不能拿到网页的源代码
打开今日头条官网,搜索“街拍美女”,跳转到街拍首页。在jupyter notebook中尝试get源码,你会发现没有你想要的图片信息。这种情况打消了我们直接分析首页源码,寻找详情页的想法。这时候就用ajax解析了。
点击首页进入其中一个街拍群图详情页,然后尝试获取源码,但是可以直接获取源码。这里可以直接使用正则表达式。
了解页面结构
在“街头美女”首页,打开勾选-网络-选择保存日志,XHR,然后刷新页面,下面会有很多请求,我们直接进入主题,选择其中一个请求,然后看看右边的预览。
展开数据,

我们发现data里面的数据好像和首页的栏目是一一对应的。
当然,这可能并不明显。我们展开数据,看看子节点的title:(中间忽略公众号,我们只需要“open url”中的信息,其他需要过滤。)



查看其他数据子节点,也可以在首页找到对应的栏目,ok,我们已经确定了战略目标:
从首页开始,请求json格式的网页数据,然后使用ajax解析请求,获取并分析首页的源码;
从源代码中提取有用的 URL;
然后通过URL获取详情页的图片。
关于循环爬行
还要看左边。当我们继续下拉主页时,就会有源源不断的新请求。其中,偏移量有明显变化。和前面的实战一样,我们可以通过改变属性的值来达到循环阅读的目的。
分析详情页面
这里有个小技巧:在详情页的图片上右键,选择“在新标签页中打开图片”,然后看新标签页的名字,这个名字(一般只有几个尾数),在doc Ctrl+F 搜索,ok,然后你会发现它们隐藏在哪个变量中(多搜索几张图确认)。此变量收录从中下载图片的图片的 URL。
注:遗憾的是,目前今日头条采取了反拍措施,大部分详情页无法获取源码,因此获取的图片数量非常有限。
附上完整的爬虫代码,“streetPhotos_Spider.py”:
import json
import os
from hashlib import md5
import pymongo
from multiprocessing.pool import Pool
from urllib.parse import urlencode
from requests.exceptions import RequestException
import re
import requests
from webspider.TouTiao.mgconfig import *
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_one_index(offset, keyword): # 获取主页源码,由于主页url是动态的,我们设置参数,以便以后的循环
data = { # 设置url后缀
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 1,
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 用'urlencode方法会将字典解析成字符串
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
print("请求主页失败!")
return None
def parse_page_index(html): # 解析主页源码
try: # 这个函数有可能传入的参数是None,此时应该捕获异常
data = json.loads(html) # 由于拿到的源码是json格式的,需要用json包来解析
if data and 'data' in data.keys(): # 如果有节点data,那么从该节点中寻找article_url
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url): # 获取详情页源码,这里传入的参数将会是从主页中解析出的各个url
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
return None
def parse_page_detail(html): # 解析详情源码
images_pattern = re.compile('[a-zA-z]+://[^\s]*jpg', re.S) # 由于各个详情页结构大不相同,暂时截获所有URL
results = re.findall(images_pattern, html)
if results:
for result in results:
if len(result) > 55:
for result in results: download_images(result)
return {'url': result}
def save_to_mongo(result): # 将解析的结果保存到数据库
if db[MONGO_DB_TABLE].insert(result):
print('存储到MongoDB库', result)
return True
return False
def download_images(url): # 下载图片
print('当前正在下载:', url) # 显示调试信息
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # 返回图片二进制信息
except RequestException:
print("请求图片出错", url)
return None
def save_image(content): # 保存图片到本地
file_path = '{0}/{1}.{2}'.format('D:\Workspace\PycharmProj\webspider\TouTiao\photo', md5(content).hexdigest(),
'jpg') # 为文件命名
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_one_index(offset, KEYWORD) # 获取主页
for url in parse_page_index(html): # 从主页中解析出的各个详情页url
detail_html = get_page_detail(url)
if detail_html: # 若详情页存在,那么解析它
detail_result = parse_page_detail(detail_html)
if detail_result is not None: # 如果详情页非空,
if detail_result: save_to_mongo(detail_result) # 如果详情页有返回的url,那么保存进数据库
if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool() # 创建线程池
pool.map(main, groups) # 将main方法放到线程池中,会自动分割成多线程同时抓取
配置文件“mgconfig.py”放置在同一目录中。
MONGO_URL = 'localhost'
MONGO_DB = 'Toutiao'
MONGO_DB_TABLE = 'Toutiao'
GROUP_START = 1
GROUP_END = 30
KEYWORD = '街拍美女'
文件包结构:
网页爬虫抓取百度图片(知乎话题『美女』下所有问题中回答所出现的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-16 07:05
#更新
声明:所有与性别、人脸颜值评分等直接或间接、明示或暗示相关的文字、图片及相关外部链接均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没测试过,理论上可以。Windows之前反应过异常,但检查后是Windows限制了本地文件名中的字符,使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人不同意排名,我的妻子不是最高分。
8码
8. 1 直接使用百度云Python-SDK-去掉代码
8. 2 不使用SDK,直接构造HTTP请求版本。直接使用这个版本的好处是不依赖于SDK的版本(百度云现在有两个版本的接口-V2和V3。现阶段百度云同时支持这两个接口,所以直接用SDK没问题。以后百度不支持V2就得升级SDK或者用这个直接构造HTTP版本)
#coding: utf-8
import time
import os
import re
import requests
from lxml import etree
from aip import AipFace
#百度云 人脸检测 申请信息
#唯一必须填的信息就这三行
APP_ID = "xxxxxxxx"
API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxx"
SECRET_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 文件存放目录名,相对于当前目录
DIR = "image"
# 过滤颜值阈值,存储空间大的请随意
BEAUTY_THRESHOLD = 45
#浏览器中打开知乎,在开发者工具复制一个,无需登录
#如何替换该值下文有讲述
AUTHORIZATION = "oauth c3cef7c66a1843f8b3a9e6a1e3160e20"
#以下皆无需改动
#每次请求知乎的讨论列表长度,不建议设定太长,注意节操
LIMIT = 5
#这是话题『美女』的 ID,其是『颜值』(20013528)的父话题
SOURCE = "19552207"
#爬虫假装下正常浏览器请求
USER_AGENT = "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.5 Safari/534.55.3"
#爬虫假装下正常浏览器请求
REFERER = "https://www.zhihu.com/topic/%s/newest" % SOURCE
#某话题下讨论列表请求 url
BASE_URL = "https://www.zhihu.com/api/v4/t ... ot%3B
#初始请求 url 附带的请求参数
URL_QUERY = "?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.comment_count&limit=" + str(LIMIT)
#指定 url,获取对应原始内容 / 图片
def fetch_image(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.content
#指定 url,获取对应 JSON 返回 / 话题列表
def fetch_activities(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.json()
#处理返回的话题列表
def process_activities(datums, face_detective):
for data in datums["data"]:
target = data["target"]
if "content" not in target or "question" not in target or "author" not in target:
continue
#解析列表中每一个元素的内容
html = etree.HTML(target["content"])
seq = 0
#question_url = target["question"]["url"]
question_title = target["question"]["title"]
author_name = target["author"]["name"]
#author_id = target["author"]["url_token"]
print("current answer: " + question_title + " author: " + author_name)
#获取所有图片地址
images = html.xpath("//img/@src")
for image in images:
if not image.startswith("http"):
continue
s = fetch_image(image)
#请求人脸检测服务
scores = face_detective(s)
for score in scores:
filename = ("%d--" % score) + author_name + "--" + question_title + ("--%d" % seq) + ".jpg"
filename = re.sub(r'(?u)[^-\w.]', '_', filename)
#注意文件名的处理,不同平台的非法字符不一样,这里只做了简单处理,特别是 author_name / question_title 中的内容
seq = seq + 1
with open(os.path.join(DIR, filename), "wb") as fd:
fd.write(s)
#人脸检测 免费,但有 QPS 限制
time.sleep(2)
if not datums["paging"]["is_end"]:
#获取后续讨论列表的请求 url
return datums["paging"]["next"]
else:
return None
def get_valid_filename(s):
s = str(s).strip().replace(' ', '_')
return re.sub(r'(?u)[^-\w.]', '_', s)
import base64
def detect_face(image, token):
try:
URL = "https://aip.baidubce.com/rest/ ... ot%3B
params = {
"access_token": token
}
data = {
"face_field": "age,gender,beauty,qualities",
"image_type": "BASE64",
"image": base64.b64encode(image)
}
s = requests.post(URL, params=params, data=data)
return s.json()["result"]
except Exception as e:
print("detect face fail. " + url)
raise e
def fetch_auth_token(api_key, secret_key):
try:
URL = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": api_key,
"client_secret": secret_key
}
s = requests.post(URL, params=params)
return s.json()["access_token"]
except Exception as e:
print("fetch baidu auth token fail. " + url)
raise e
def init_face_detective(app_id, api_key, secret_key):
# client = AipFace(app_id, api_key, secret_key)
# 百度云 V3 版本接口,需要先获取 access token
token = fetch_auth_token(api_key, secret_key)
def detective(image):
#r = client.detect(image, options)
# 直接使用 HTTP 请求
r = detect_face(image, token)
#如果没有检测到人脸
if r is None or r["face_num"] == 0:
return []
scores = []
for face in r["face_list"]:
#人脸置信度太低
if face["face_probability"] < 0.6:
continue
#颜值低于阈值
if face["beauty"] < BEAUTY_THRESHOLD:
continue
#性别非女性
if face["gender"]["type"] != "female":
continue
scores.append(face["beauty"])
return scores
return detective
def init_env():
if not os.path.exists(DIR):
os.makedirs(DIR)
init_env()
face_detective = init_face_detective(APP_ID, API_KEY, SECRET_KEY)
url = BASE_URL % SOURCE + URL_QUERY
while url is not None:
print("current url: " + url)
datums = fetch_activities(url)
url = process_activities(datums, face_detective)
#注意节操,爬虫休息间隔不要调小
time.sleep(5)
# vim: set ts=4 sw=4 sts=4 tw=100 et:
9 操作准备
需要登录,百度账号可以直接使用(贴吧/网盘通用),不用注册
随便填,这个阶段V3和V2都是默认勾选的。如果没有,请检查所有
在代码中填写AppID ApiKek SecretKey
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
Chrome浏览器;找到一个知乎链接,点进去,打开开发者工具,查看HTTP请求头;无需登录
10 结论
欢迎关注我的专栏
面向薪资的编程-收录 Java 语言面试文章
编程基础和一些理论
编程的日常娱乐——用Python做一些有趣的事情 查看全部
网页爬虫抓取百度图片(知乎话题『美女』下所有问题中回答所出现的图片)
#更新
声明:所有与性别、人脸颜值评分等直接或间接、明示或暗示相关的文字、图片及相关外部链接均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没测试过,理论上可以。Windows之前反应过异常,但检查后是Windows限制了本地文件名中的字符,使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人不同意排名,我的妻子不是最高分。


8码
8. 1 直接使用百度云Python-SDK-去掉代码
8. 2 不使用SDK,直接构造HTTP请求版本。直接使用这个版本的好处是不依赖于SDK的版本(百度云现在有两个版本的接口-V2和V3。现阶段百度云同时支持这两个接口,所以直接用SDK没问题。以后百度不支持V2就得升级SDK或者用这个直接构造HTTP版本)
#coding: utf-8
import time
import os
import re
import requests
from lxml import etree
from aip import AipFace
#百度云 人脸检测 申请信息
#唯一必须填的信息就这三行
APP_ID = "xxxxxxxx"
API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxx"
SECRET_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 文件存放目录名,相对于当前目录
DIR = "image"
# 过滤颜值阈值,存储空间大的请随意
BEAUTY_THRESHOLD = 45
#浏览器中打开知乎,在开发者工具复制一个,无需登录
#如何替换该值下文有讲述
AUTHORIZATION = "oauth c3cef7c66a1843f8b3a9e6a1e3160e20"
#以下皆无需改动
#每次请求知乎的讨论列表长度,不建议设定太长,注意节操
LIMIT = 5
#这是话题『美女』的 ID,其是『颜值』(20013528)的父话题
SOURCE = "19552207"
#爬虫假装下正常浏览器请求
USER_AGENT = "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.5 Safari/534.55.3"
#爬虫假装下正常浏览器请求
REFERER = "https://www.zhihu.com/topic/%s/newest" % SOURCE
#某话题下讨论列表请求 url
BASE_URL = "https://www.zhihu.com/api/v4/t ... ot%3B
#初始请求 url 附带的请求参数
URL_QUERY = "?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.comment_count&limit=" + str(LIMIT)
#指定 url,获取对应原始内容 / 图片
def fetch_image(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.content
#指定 url,获取对应 JSON 返回 / 话题列表
def fetch_activities(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.json()
#处理返回的话题列表
def process_activities(datums, face_detective):
for data in datums["data"]:
target = data["target"]
if "content" not in target or "question" not in target or "author" not in target:
continue
#解析列表中每一个元素的内容
html = etree.HTML(target["content"])
seq = 0
#question_url = target["question"]["url"]
question_title = target["question"]["title"]
author_name = target["author"]["name"]
#author_id = target["author"]["url_token"]
print("current answer: " + question_title + " author: " + author_name)
#获取所有图片地址
images = html.xpath("//img/@src")
for image in images:
if not image.startswith("http"):
continue
s = fetch_image(image)
#请求人脸检测服务
scores = face_detective(s)
for score in scores:
filename = ("%d--" % score) + author_name + "--" + question_title + ("--%d" % seq) + ".jpg"
filename = re.sub(r'(?u)[^-\w.]', '_', filename)
#注意文件名的处理,不同平台的非法字符不一样,这里只做了简单处理,特别是 author_name / question_title 中的内容
seq = seq + 1
with open(os.path.join(DIR, filename), "wb") as fd:
fd.write(s)
#人脸检测 免费,但有 QPS 限制
time.sleep(2)
if not datums["paging"]["is_end"]:
#获取后续讨论列表的请求 url
return datums["paging"]["next"]
else:
return None
def get_valid_filename(s):
s = str(s).strip().replace(' ', '_')
return re.sub(r'(?u)[^-\w.]', '_', s)
import base64
def detect_face(image, token):
try:
URL = "https://aip.baidubce.com/rest/ ... ot%3B
params = {
"access_token": token
}
data = {
"face_field": "age,gender,beauty,qualities",
"image_type": "BASE64",
"image": base64.b64encode(image)
}
s = requests.post(URL, params=params, data=data)
return s.json()["result"]
except Exception as e:
print("detect face fail. " + url)
raise e
def fetch_auth_token(api_key, secret_key):
try:
URL = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": api_key,
"client_secret": secret_key
}
s = requests.post(URL, params=params)
return s.json()["access_token"]
except Exception as e:
print("fetch baidu auth token fail. " + url)
raise e
def init_face_detective(app_id, api_key, secret_key):
# client = AipFace(app_id, api_key, secret_key)
# 百度云 V3 版本接口,需要先获取 access token
token = fetch_auth_token(api_key, secret_key)
def detective(image):
#r = client.detect(image, options)
# 直接使用 HTTP 请求
r = detect_face(image, token)
#如果没有检测到人脸
if r is None or r["face_num"] == 0:
return []
scores = []
for face in r["face_list"]:
#人脸置信度太低
if face["face_probability"] < 0.6:
continue
#颜值低于阈值
if face["beauty"] < BEAUTY_THRESHOLD:
continue
#性别非女性
if face["gender"]["type"] != "female":
continue
scores.append(face["beauty"])
return scores
return detective
def init_env():
if not os.path.exists(DIR):
os.makedirs(DIR)
init_env()
face_detective = init_face_detective(APP_ID, API_KEY, SECRET_KEY)
url = BASE_URL % SOURCE + URL_QUERY
while url is not None:
print("current url: " + url)
datums = fetch_activities(url)
url = process_activities(datums, face_detective)
#注意节操,爬虫休息间隔不要调小
time.sleep(5)
# vim: set ts=4 sw=4 sts=4 tw=100 et:
9 操作准备
需要登录,百度账号可以直接使用(贴吧/网盘通用),不用注册
随便填,这个阶段V3和V2都是默认勾选的。如果没有,请检查所有
在代码中填写AppID ApiKek SecretKey
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
Chrome浏览器;找到一个知乎链接,点进去,打开开发者工具,查看HTTP请求头;无需登录
10 结论
欢迎关注我的专栏
面向薪资的编程-收录 Java 语言面试文章
编程基础和一些理论
编程的日常娱乐——用Python做一些有趣的事情
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-16 04:09
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,通常情况下,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“web”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有一篇网站文章的文章,它吸引了大量的流量,但由于网站空间不够,大量用户前来访问网页打不开,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。 查看全部
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。

一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,通常情况下,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“web”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有一篇网站文章的文章,它吸引了大量的流量,但由于网站空间不够,大量用户前来访问网页打不开,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-11-15 04:22
内容
你好!大家好,我是一只正在努力赚钱买生发乳液的小灰猿。很多学过Python的朋友都希望有一个属于自己的爬虫,所以今天大灰狼给小伙伴们分享一个简单的爬虫程序。
请允许我在这里卖给我的朋友。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开特定的网页,抓取网页上存在的某些信息。想象一下,如果把一个网页比作一块田地,爬虫就住在这个田地里,从田地头爬到田头,只捕食田地里吃某种食物的昆虫。哈哈,比喻有点粗糙,但网络爬虫的实际效果是类似的。
想要了解更多的朋友也可以阅读我的文章《Python带你一分钟探秘网络昆虫!》!
爬虫的原理是什么?
那么有朋友可能会问,爬虫程序是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了这个网页中的所有信息。当我们打开某个网页时,按F12键可以看到该网页的代码,我们以百度图片搜索皮卡丘网页为例,按F12后,可以看到如下代码,覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例。我们的爬虫想要爬取这个网页上所有的皮卡丘图片,所以我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,在这个链接下添加下载图片。
所以爬虫的工作原理就是从网页的代码中寻找并提取特定的代码。这就像从一个很长的字符串中找到一个特定格式的字符串。对这块知识感兴趣的人也可以。阅读我的文章文章《实战中Python特定文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里我们以requests模块为例编写爬虫程序。
以抓取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序要做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取该网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式,匹配所有符合要求的图片链接代码通过设置的正则表达式一一打开图片链接下载图片
接下来,大灰狼就按照以上步骤和大家分享一下这个爬虫的准备过程:
1、获取百度图片中“皮卡丘图片”的网页链接
首先我们打开百度图片的网页链接
然后在关键字搜索“皮卡丘”后打开链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
通过对比,去掉多余的部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:Keyword
现在我们第一步是在百度图片中获取“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取本页所有代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后通过模块中的text函数获取网页的文字,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中找到图片的链接
这一步我们可以先打开网页的链接,按F12按照大灰狼开头提到的方法查看网页的所有代码,然后如果我们要抓取jpg中的所有图片格式,我们可以按Ctrl+F找到具体内容的代码,
比如我们在网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容。我们通过仔细观察这些链接会发现这些链接之间的相似之处,即每个链接之前都会有“OpjURL”:以提示,最后以“,”结尾
我们取出了其中一个链接
访问后发现图片也可以打开。
所以我们可以暂时推断一下,百度图片中jpg图片的一般格式为“"OpjURL":XXXX"",
4、 根据图片链接写一个通用的正则表达式
既然知道了这类图片的一般格式是""OpjURL":XXXX"",那么下一步就是按照这个格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不熟悉正则表达式使用的朋友也可以阅读我的两篇文章文章《Python教程中的正则表达式(基础)》和《Python教程中的正则表达式(改进版)》
5、 通过设置的正则表达式匹配代码中所有符合要求的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配的图片链接,并将所有匹配的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后我们就可以在这个文件下看到匹配的图片链接了,复制一张就可以打开了。
6、一一打开图片链接,下载图片
现在我们已经存储了列表中所有图片的链接,下一步就是下载图片。
基本思路是:通过for循环遍历列表中的所有链接,以二进制方式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前都会休眠三秒,每个链接的访问时间最长为5秒。如果访问时间超过五秒,我们判断下载失败,继续下载下一章图片。
至于为什么要打开图片并以二进制方式写入,是因为我们的图片需要经过二进制方式解析后才能被计算机写入。
下载图片的代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
现在,一个简单的爬取百度皮卡丘图片的爬虫就完成了,朋友们也可以随意更改图片关键词和下载次数,培养一个属于自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) # 打开链接
urltext = urls.text # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
如果觉得有用,记得点赞关注哦! 查看全部
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
内容
你好!大家好,我是一只正在努力赚钱买生发乳液的小灰猿。很多学过Python的朋友都希望有一个属于自己的爬虫,所以今天大灰狼给小伙伴们分享一个简单的爬虫程序。
请允许我在这里卖给我的朋友。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开特定的网页,抓取网页上存在的某些信息。想象一下,如果把一个网页比作一块田地,爬虫就住在这个田地里,从田地头爬到田头,只捕食田地里吃某种食物的昆虫。哈哈,比喻有点粗糙,但网络爬虫的实际效果是类似的。
想要了解更多的朋友也可以阅读我的文章《Python带你一分钟探秘网络昆虫!》!
爬虫的原理是什么?
那么有朋友可能会问,爬虫程序是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了这个网页中的所有信息。当我们打开某个网页时,按F12键可以看到该网页的代码,我们以百度图片搜索皮卡丘网页为例,按F12后,可以看到如下代码,覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例。我们的爬虫想要爬取这个网页上所有的皮卡丘图片,所以我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,在这个链接下添加下载图片。
所以爬虫的工作原理就是从网页的代码中寻找并提取特定的代码。这就像从一个很长的字符串中找到一个特定格式的字符串。对这块知识感兴趣的人也可以。阅读我的文章文章《实战中Python特定文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里我们以requests模块为例编写爬虫程序。
以抓取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序要做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取该网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式,匹配所有符合要求的图片链接代码通过设置的正则表达式一一打开图片链接下载图片
接下来,大灰狼就按照以上步骤和大家分享一下这个爬虫的准备过程:
1、获取百度图片中“皮卡丘图片”的网页链接
首先我们打开百度图片的网页链接

然后在关键字搜索“皮卡丘”后打开链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
通过对比,去掉多余的部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:Keyword
现在我们第一步是在百度图片中获取“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取本页所有代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后通过模块中的text函数获取网页的文字,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中找到图片的链接
这一步我们可以先打开网页的链接,按F12按照大灰狼开头提到的方法查看网页的所有代码,然后如果我们要抓取jpg中的所有图片格式,我们可以按Ctrl+F找到具体内容的代码,
比如我们在网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
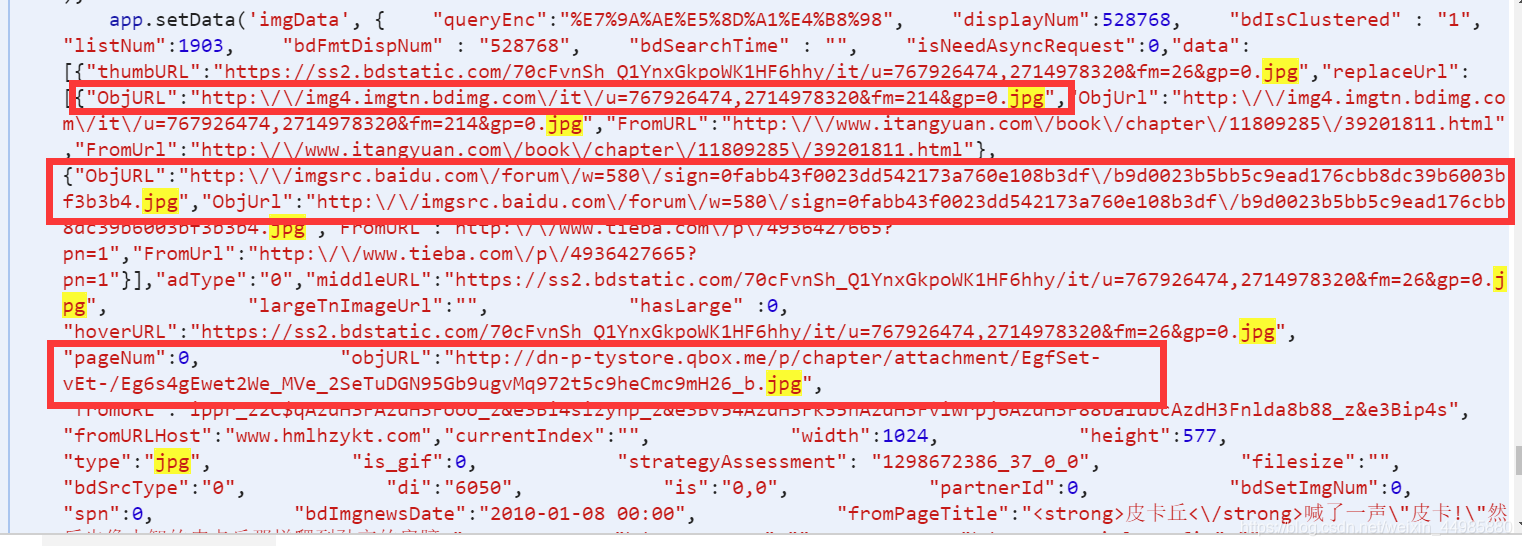
链接就是我们想要获取的内容。我们通过仔细观察这些链接会发现这些链接之间的相似之处,即每个链接之前都会有“OpjURL”:以提示,最后以“,”结尾
我们取出了其中一个链接
访问后发现图片也可以打开。
所以我们可以暂时推断一下,百度图片中jpg图片的一般格式为“"OpjURL":XXXX"",
4、 根据图片链接写一个通用的正则表达式
既然知道了这类图片的一般格式是""OpjURL":XXXX"",那么下一步就是按照这个格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不熟悉正则表达式使用的朋友也可以阅读我的两篇文章文章《Python教程中的正则表达式(基础)》和《Python教程中的正则表达式(改进版)》
5、 通过设置的正则表达式匹配代码中所有符合要求的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配的图片链接,并将所有匹配的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后我们就可以在这个文件下看到匹配的图片链接了,复制一张就可以打开了。
6、一一打开图片链接,下载图片
现在我们已经存储了列表中所有图片的链接,下一步就是下载图片。
基本思路是:通过for循环遍历列表中的所有链接,以二进制方式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前都会休眠三秒,每个链接的访问时间最长为5秒。如果访问时间超过五秒,我们判断下载失败,继续下载下一章图片。
至于为什么要打开图片并以二进制方式写入,是因为我们的图片需要经过二进制方式解析后才能被计算机写入。
下载图片的代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
现在,一个简单的爬取百度皮卡丘图片的爬虫就完成了,朋友们也可以随意更改图片关键词和下载次数,培养一个属于自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) # 打开链接
urltext = urls.text # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
如果觉得有用,记得点赞关注哦!
网页爬虫抓取百度图片(浅谈一下爬虫什么是爬虫?(二):请求网站并提取数据的自动化程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-15 04:21
前言
爬虫是一项非常有趣的技术。您可以使用爬虫技术来获取其他人无法获得或需要付费的东西。您还可以自动抓取并保存大量数据,减少手动完成一些繁琐任务的时间和精力。
可以说,学编程的人很多,不玩爬虫的意义就少了很多。无论是业余爱好者、私人工作还是专业爬虫,爬虫世界真的很精彩。
今天给大家讲一下爬虫,目的是让准备学习爬虫或者刚入门的人对爬虫有更深入、更全面的了解。
一、认识爬虫
1.什么是爬虫?
一句话介绍著名的爬虫:一个请求网站并提取数据的自动化程序。
下面我们来拆解了解一下爬虫:
网站的请求就是向网站发送请求。比如去百度搜索关键词“Python”。这时,我们的浏览器会向网站发送请求;
提取数据。数据包括图片、文字、视频等,统称为数据。我们发送请求后,网站 会将搜索结果呈现给我们。这实际上是返回数据。这时候我们可以查看数据来提取
自动化程序,也就是我们写的代码,实现了过程数据的自动提取,比如批量下载和保存返回的图片,而不是手动一一操作。
2. 爬虫分类
根据使用场景,爬虫可以分为三类:
①万能爬虫(大而全)功能强大,采集范围广泛。它通常用于搜索引擎。比如百度浏览器就是一个非常庞大的爬虫程序。
②专注爬虫(小而精) 功能比较单一,只爬取特定网站的特定内容,比如去一个网站批量获取一些数据,这也是我们的个人最常用的一种爬虫。
③增量爬虫(仅采集更新内容) 这其实是一个专注于爬虫的迭代爬虫。它只是采集更新数据,而不是旧数据采集,相当于一直存在和运行。只要满足要求的数据有更新,就会自动抓取新的数据。
3.机器人协议
爬虫中有一个叫做Robots的协议需要注意,也称为“网络爬虫排除标准”。它的作用是网站告诉你什么可以爬,什么不能爬。
在哪里看这个机器人协议?
一般情况下,可以直接在网站首页URL中添加/robots.txt进行查看。例如,百度的Robots 协议在/robots.txt 中。可以看到有很多URL是规定不能爬取的,比如Disallow:/shifen/表示当前的Disallow:/shifen和Disallow:/shifen下的子目录都不能爬取。
实际上,这份Robots协议属于君子协议。对于爬虫来说,基本上是口头约定。如果你违反了它,你可能会被追究责任。但是,如果你不违反它,爬虫将无法抓取任何数据,所以通常双方都视而不见,只是不要太嚣张。
二、爬取的基本过程
1.爬行4步
爬行动物是如何工作的?
爬虫程序大致可以分为四个步骤:
①发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,可以收录额外的headers等信息,等待服务器响应。
②获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可能包括 HTML、Json 字符串和二进制数据(如图片和视频)。
③内容分析
获取的内容可能是HTML,可以使用正则表达式和网页解析库进行解析。可能是Json,可以直接转成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
④保存数据
保存的数据有多种类型,可以保存为文本、保存到数据库或保存为特定格式的文件。
基本上,这是爬虫必须遵循的四个步骤。
2.请求和响应
请求和响应是爬虫最重要的部分。请求和响应之间是什么关系?
两者的关系如下:
简单理解一下,当我们在电脑浏览器上搜索东西的时候,比如前面提到的在百度搜索“Python”,你点击百度,已经向百度的服务器发送了一个Request请求,Request中收录很多信息,比如如身份信息、请求信息等,服务器收到请求后做出判断,然后返回一个Response给我们的电脑,里面也收录了很多信息,比如请求成功,比如我们请求的信息结果(文本、图片、视频等)。
应该很容易理解吧?
接下来,让我们仔细看看请求和响应。
三、了解RequestRequest中收录什么?
它主要收录以下内容:
1.请求方法
请求方法可以理解为你打招呼的方式网站。如果你从网站那里得到数据,你要以正确的方式迎接它,这样它才能回应你,就像你从别人家借东西一样,你要先敲门再说你好。可以直接爬上窗户进去,看到的人必须出去。
主要的请求方法是GET和POST,还有其他的方法如HEAD/PUT/DELETE/OPTIONS,最常用的是GET。
2.请求网址
什么是网址?
URL的全称是Uniform Resource Locator。例如,一个网页文档、图片、视频等都有一个唯一的网址,可以理解为爬虫中的网址或链接。
3.请求头
请求头是什么?
英文名称Request Headers通常是指请求中收录的头信息,如User-Agent、Host、Cookies等。
当你向网站发送请求时,这些东西就相当于你的身份信息。经常需要伪装自己,伪装成普通用户来躲避你的目标。网站 识别你是爬虫,避免一些反扒问题,顺利获取数据。
4. request body 的官方说法是请求中携带的附加数据,比如提交表单时的表单数据。
在爬虫中如何理解?
例如,在某些页面上,您必须先登录,或者您必须告诉我您的要求。比如你在百度网页搜索“Python”,那么关键词“Python”就是你要携带的请求体,看到你的请求体,看到百度就知道你要做什么了。
当然,请求体通常用在 POST 请求方法中。GET 请求时,我们通常将其拼接在 URL 中。先了解一下就够了,后续具体爬虫可以去加深了解。
5.实用视图请求
既然我们已经讲了Request的理论,那我们就可以进入实际操作,看看Request在哪里,收录什么。
以谷歌浏览器为例,我输入关键词“Python”就可以搜索到一堆结果。我们使用网页自带的控制台窗口来分析我们发送的Request请求。
按住F12或者在网页空白处右击选择“检查”,然后就可以看到控制台里有很多选项了。例如,上列有一个菜单栏。初级爬虫一般使用元素(Elements)。还有Network(网络),其他的东西暂时不需要,等你学习更高级一点的爬虫时会用到,比如JS逆向工程可能会用到Application窗口,以后再学习。
Elements 收录了所有请求结果的每一个元素,比如每张图片的源代码,尤其是点击左上角的小箭头,你移动到的每一个地方都会在 Elements 窗口下显示为源代码。
网络是爬虫常用的网络信息。其中包括我们的请求。让我们来看看。在“网络”窗口下,选中“禁用缓存”并单击“全部”。
刷新网页看看效果。您可以看到我们发送了 132 个请求请求。不要对这个好奇。虽然我们只向百度发送了类似“Python”这样的请求,但其中一些是附加到网页的请求。
虽然图片格式有很多种,比如png、jpeg等,但是可以滑动到顶部。在Type栏中,有文档类型,即web文档的含义。点击进入,我们将是我们的。索取资料。
点击文档进入后,有一个新的菜单栏。在Headers列下,我们可以看到Request URL,也就是我们前面提到的请求URL。这个URL就是我们实际从网页请求的URL,然后返回 有一个请求方法,可以看出是一个GET请求。
如果再次向下滑动,还可以看到我们之前提到的 Request Headers。信息很多,但是我们前面提到的User-Agent、Host、Cookies都是我们提供给服务器的信息。
虽然Request Headers里面的内容很多,我们在写爬虫程序的时候也要做这方面的伪装工作,但是不是所有的信息都要写,有选择的写一些重要的信息就足够了,比如User-Agent必需的。Referer 和 Host 是可选区域。登录时会携带cookies,常见的有4种需要伪装。
至于请求体,我暂时不去查了,因为我们这里的请求方法是GET请求,请求体只能在POST请求中查看。没关系,爬虫什么时候用你就明白了。
四、了解响应
Response 主要包括 3 条内容,我们来一一看看。
1.响应状态我们发送请求后,网站会返回给我们一个Response,其中收录响应状态码的响应状态,大致可以分为以下几种:
①例如在200以内,响应状态码200表示成功。
②三百的范围,比如301就是跳跃。
③四百范围内,如404找不到页面。
④范围五百,如502找不到页面。
对于爬虫来说,两三百是我们最想看到的响应状态,有可能获取到数据,而四五百基本是冷的,获取不到数据。
比如我们刚刚发送了之前的Request请求时,在文档文件中,在Headers窗口下的General中,可以看到响应状态码为200,表示网页成功响应了我们的请求。
2. 响应头
服务器给我们的信息也会收录响应头,其中包括内容类型、内容长度、服务器信息、设置cookies等。
其实响应头对我们来说并没有那么重要,在这里了解一下就行了。
3.响应体
这一点很重要,除了上面第一点的响应状态,就是它,因为它收录了请求资源的内容,比如网页HTML和图像二进制数。
响应体在哪里?它也在文档文件的响应列中。可以向下滑动,看到有很多响应数据。这是我们得到的数据。有些可以直接下载,有些需要技术分析。知道了。
五、爬虫能得到什么样的数据?
**爬虫可以获取什么样的数据?**基本上可以分为几类:
① Web 文档,如 HTML 文档、Json 格式的文本等。
②图片以二进制文件形式获取,可以保存为图片格式。
③视频,也是二进制文件,可以保存为视频格式。
④其他,反正其他能看到的东西理论上爬虫都能得到,看难易程度。
六、如何解析数据?
从前面我们可以成功发送请求,网页会返回给我们很多数据,有几千甚至几万个代码,那么如何在这么多代码中找到我们想要的数据呢?常用的方法如下:
①直接治疗。当网页返回的数据是一些文本时,就是我们想要的内容,不需要过滤处理,直接处理即可。
②Json分析。如果返回的网页不是HTML数据而是Json数据,则需要Json解析技术。
③正则表达式。如果返回的数据是符合正则表达式的数据,可以使用正则表达式进行分析。
④其他分析方法。常用的有XPath、BeautifulSoup、PyQuery,都是爬虫常用的解析库。
七、如何保存数据?获取数据后,常用的保存数据的方法如下:
①文字。可以直接保存为纯文本、EXCEL、Json、Xml等类型的文本。
②关系数据库。数据可以保存到关系型数据库,如MySQL和Oracle数据库。
③非关系型数据库。比如MongoDB、Readis和Key-Value存储。
④ 二进制文件。比如图片、视频、音频等可以直接保存为特定格式。练习视频: 查看全部
网页爬虫抓取百度图片(浅谈一下爬虫什么是爬虫?(二):请求网站并提取数据的自动化程序)
前言
爬虫是一项非常有趣的技术。您可以使用爬虫技术来获取其他人无法获得或需要付费的东西。您还可以自动抓取并保存大量数据,减少手动完成一些繁琐任务的时间和精力。
可以说,学编程的人很多,不玩爬虫的意义就少了很多。无论是业余爱好者、私人工作还是专业爬虫,爬虫世界真的很精彩。
今天给大家讲一下爬虫,目的是让准备学习爬虫或者刚入门的人对爬虫有更深入、更全面的了解。
一、认识爬虫
1.什么是爬虫?
一句话介绍著名的爬虫:一个请求网站并提取数据的自动化程序。
下面我们来拆解了解一下爬虫:
网站的请求就是向网站发送请求。比如去百度搜索关键词“Python”。这时,我们的浏览器会向网站发送请求;
提取数据。数据包括图片、文字、视频等,统称为数据。我们发送请求后,网站 会将搜索结果呈现给我们。这实际上是返回数据。这时候我们可以查看数据来提取
自动化程序,也就是我们写的代码,实现了过程数据的自动提取,比如批量下载和保存返回的图片,而不是手动一一操作。

2. 爬虫分类
根据使用场景,爬虫可以分为三类:
①万能爬虫(大而全)功能强大,采集范围广泛。它通常用于搜索引擎。比如百度浏览器就是一个非常庞大的爬虫程序。
②专注爬虫(小而精) 功能比较单一,只爬取特定网站的特定内容,比如去一个网站批量获取一些数据,这也是我们的个人最常用的一种爬虫。
③增量爬虫(仅采集更新内容) 这其实是一个专注于爬虫的迭代爬虫。它只是采集更新数据,而不是旧数据采集,相当于一直存在和运行。只要满足要求的数据有更新,就会自动抓取新的数据。

3.机器人协议
爬虫中有一个叫做Robots的协议需要注意,也称为“网络爬虫排除标准”。它的作用是网站告诉你什么可以爬,什么不能爬。
在哪里看这个机器人协议?
一般情况下,可以直接在网站首页URL中添加/robots.txt进行查看。例如,百度的Robots 协议在/robots.txt 中。可以看到有很多URL是规定不能爬取的,比如Disallow:/shifen/表示当前的Disallow:/shifen和Disallow:/shifen下的子目录都不能爬取。
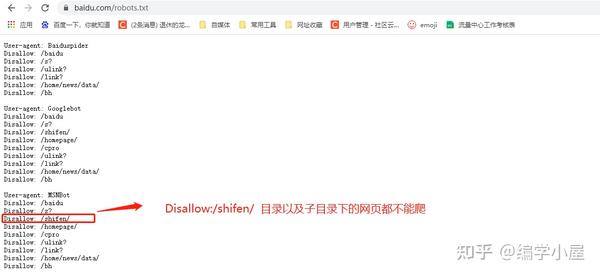
实际上,这份Robots协议属于君子协议。对于爬虫来说,基本上是口头约定。如果你违反了它,你可能会被追究责任。但是,如果你不违反它,爬虫将无法抓取任何数据,所以通常双方都视而不见,只是不要太嚣张。

二、爬取的基本过程
1.爬行4步
爬行动物是如何工作的?
爬虫程序大致可以分为四个步骤:
①发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,可以收录额外的headers等信息,等待服务器响应。
②获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可能包括 HTML、Json 字符串和二进制数据(如图片和视频)。
③内容分析
获取的内容可能是HTML,可以使用正则表达式和网页解析库进行解析。可能是Json,可以直接转成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
④保存数据
保存的数据有多种类型,可以保存为文本、保存到数据库或保存为特定格式的文件。
基本上,这是爬虫必须遵循的四个步骤。
2.请求和响应
请求和响应是爬虫最重要的部分。请求和响应之间是什么关系?
两者的关系如下:
简单理解一下,当我们在电脑浏览器上搜索东西的时候,比如前面提到的在百度搜索“Python”,你点击百度,已经向百度的服务器发送了一个Request请求,Request中收录很多信息,比如如身份信息、请求信息等,服务器收到请求后做出判断,然后返回一个Response给我们的电脑,里面也收录了很多信息,比如请求成功,比如我们请求的信息结果(文本、图片、视频等)。
应该很容易理解吧?
接下来,让我们仔细看看请求和响应。
三、了解RequestRequest中收录什么?
它主要收录以下内容:
1.请求方法
请求方法可以理解为你打招呼的方式网站。如果你从网站那里得到数据,你要以正确的方式迎接它,这样它才能回应你,就像你从别人家借东西一样,你要先敲门再说你好。可以直接爬上窗户进去,看到的人必须出去。
主要的请求方法是GET和POST,还有其他的方法如HEAD/PUT/DELETE/OPTIONS,最常用的是GET。
2.请求网址
什么是网址?
URL的全称是Uniform Resource Locator。例如,一个网页文档、图片、视频等都有一个唯一的网址,可以理解为爬虫中的网址或链接。
3.请求头
请求头是什么?
英文名称Request Headers通常是指请求中收录的头信息,如User-Agent、Host、Cookies等。
当你向网站发送请求时,这些东西就相当于你的身份信息。经常需要伪装自己,伪装成普通用户来躲避你的目标。网站 识别你是爬虫,避免一些反扒问题,顺利获取数据。
4. request body 的官方说法是请求中携带的附加数据,比如提交表单时的表单数据。
在爬虫中如何理解?
例如,在某些页面上,您必须先登录,或者您必须告诉我您的要求。比如你在百度网页搜索“Python”,那么关键词“Python”就是你要携带的请求体,看到你的请求体,看到百度就知道你要做什么了。
当然,请求体通常用在 POST 请求方法中。GET 请求时,我们通常将其拼接在 URL 中。先了解一下就够了,后续具体爬虫可以去加深了解。
5.实用视图请求
既然我们已经讲了Request的理论,那我们就可以进入实际操作,看看Request在哪里,收录什么。
以谷歌浏览器为例,我输入关键词“Python”就可以搜索到一堆结果。我们使用网页自带的控制台窗口来分析我们发送的Request请求。
按住F12或者在网页空白处右击选择“检查”,然后就可以看到控制台里有很多选项了。例如,上列有一个菜单栏。初级爬虫一般使用元素(Elements)。还有Network(网络),其他的东西暂时不需要,等你学习更高级一点的爬虫时会用到,比如JS逆向工程可能会用到Application窗口,以后再学习。
Elements 收录了所有请求结果的每一个元素,比如每张图片的源代码,尤其是点击左上角的小箭头,你移动到的每一个地方都会在 Elements 窗口下显示为源代码。
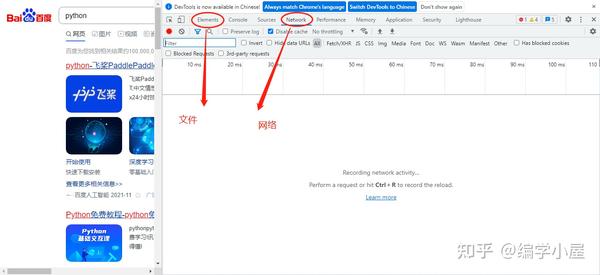
网络是爬虫常用的网络信息。其中包括我们的请求。让我们来看看。在“网络”窗口下,选中“禁用缓存”并单击“全部”。
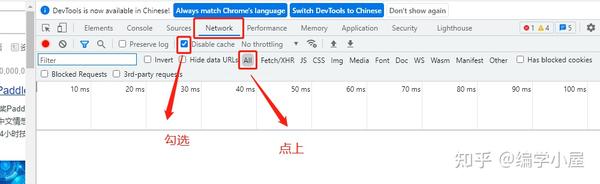
刷新网页看看效果。您可以看到我们发送了 132 个请求请求。不要对这个好奇。虽然我们只向百度发送了类似“Python”这样的请求,但其中一些是附加到网页的请求。
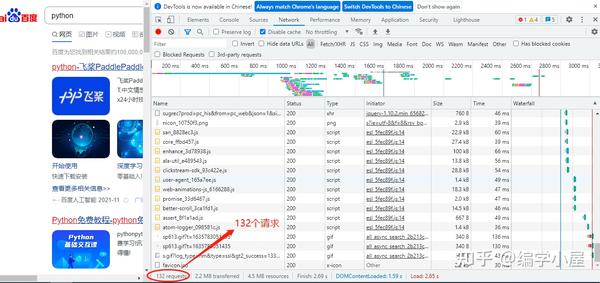
虽然图片格式有很多种,比如png、jpeg等,但是可以滑动到顶部。在Type栏中,有文档类型,即web文档的含义。点击进入,我们将是我们的。索取资料。
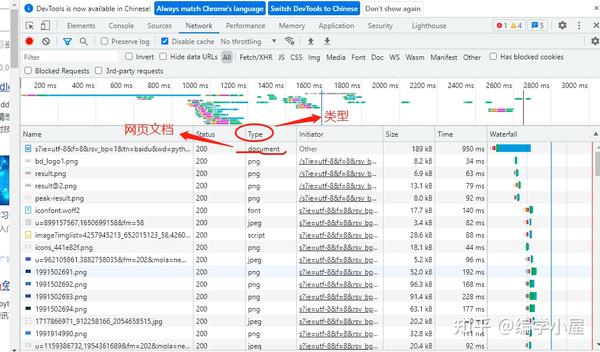
点击文档进入后,有一个新的菜单栏。在Headers列下,我们可以看到Request URL,也就是我们前面提到的请求URL。这个URL就是我们实际从网页请求的URL,然后返回 有一个请求方法,可以看出是一个GET请求。
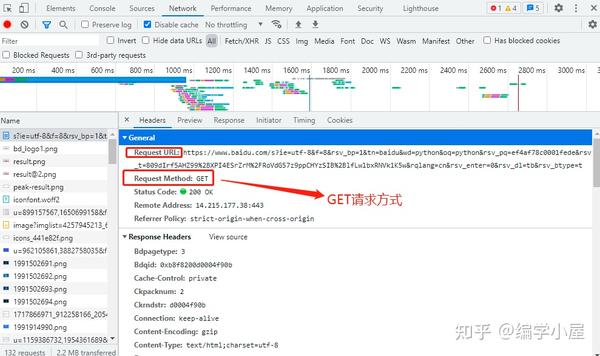
如果再次向下滑动,还可以看到我们之前提到的 Request Headers。信息很多,但是我们前面提到的User-Agent、Host、Cookies都是我们提供给服务器的信息。
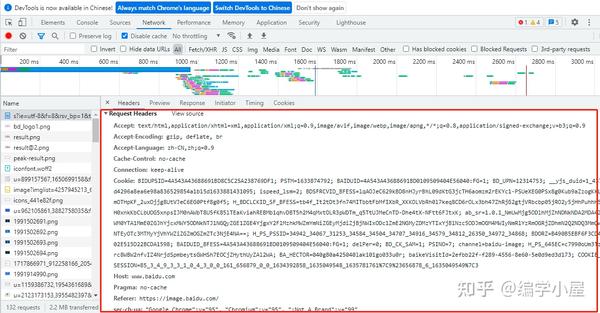
虽然Request Headers里面的内容很多,我们在写爬虫程序的时候也要做这方面的伪装工作,但是不是所有的信息都要写,有选择的写一些重要的信息就足够了,比如User-Agent必需的。Referer 和 Host 是可选区域。登录时会携带cookies,常见的有4种需要伪装。
至于请求体,我暂时不去查了,因为我们这里的请求方法是GET请求,请求体只能在POST请求中查看。没关系,爬虫什么时候用你就明白了。
四、了解响应
Response 主要包括 3 条内容,我们来一一看看。
1.响应状态我们发送请求后,网站会返回给我们一个Response,其中收录响应状态码的响应状态,大致可以分为以下几种:
①例如在200以内,响应状态码200表示成功。
②三百的范围,比如301就是跳跃。
③四百范围内,如404找不到页面。
④范围五百,如502找不到页面。
对于爬虫来说,两三百是我们最想看到的响应状态,有可能获取到数据,而四五百基本是冷的,获取不到数据。
比如我们刚刚发送了之前的Request请求时,在文档文件中,在Headers窗口下的General中,可以看到响应状态码为200,表示网页成功响应了我们的请求。
2. 响应头
服务器给我们的信息也会收录响应头,其中包括内容类型、内容长度、服务器信息、设置cookies等。
其实响应头对我们来说并没有那么重要,在这里了解一下就行了。
3.响应体
这一点很重要,除了上面第一点的响应状态,就是它,因为它收录了请求资源的内容,比如网页HTML和图像二进制数。
响应体在哪里?它也在文档文件的响应列中。可以向下滑动,看到有很多响应数据。这是我们得到的数据。有些可以直接下载,有些需要技术分析。知道了。
五、爬虫能得到什么样的数据?
**爬虫可以获取什么样的数据?**基本上可以分为几类:
① Web 文档,如 HTML 文档、Json 格式的文本等。
②图片以二进制文件形式获取,可以保存为图片格式。
③视频,也是二进制文件,可以保存为视频格式。
④其他,反正其他能看到的东西理论上爬虫都能得到,看难易程度。
六、如何解析数据?
从前面我们可以成功发送请求,网页会返回给我们很多数据,有几千甚至几万个代码,那么如何在这么多代码中找到我们想要的数据呢?常用的方法如下:
①直接治疗。当网页返回的数据是一些文本时,就是我们想要的内容,不需要过滤处理,直接处理即可。
②Json分析。如果返回的网页不是HTML数据而是Json数据,则需要Json解析技术。
③正则表达式。如果返回的数据是符合正则表达式的数据,可以使用正则表达式进行分析。
④其他分析方法。常用的有XPath、BeautifulSoup、PyQuery,都是爬虫常用的解析库。
七、如何保存数据?获取数据后,常用的保存数据的方法如下:
①文字。可以直接保存为纯文本、EXCEL、Json、Xml等类型的文本。
②关系数据库。数据可以保存到关系型数据库,如MySQL和Oracle数据库。
③非关系型数据库。比如MongoDB、Readis和Key-Value存储。
④ 二进制文件。比如图片、视频、音频等可以直接保存为特定格式。练习视频:
网页爬虫抓取百度图片(怎么爬取和怎么提取并不重要的东西?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-26 07:02
网页爬虫抓取百度图片的话可以用requests/beautifulsoup等等后端语言进行处理,然后在requests/beautifulsoup中extractimage/json/pyqt/lxml等等中提取图片,返回给前端进行处理,再把获取到的图片传递给前端的话就是把图片url返回,前端获取之后就可以用js库或者原生js抓取了。
我想根据你的要求,至少你要以下的东西。
1、你想从服务器获取到图片的url,
2、你想在url中提取图片的值
3、在python中从图片中提取图片的值我猜测你对于提取图片的值,可能会在lxml里面实现。我去试着写了一下你的代码,感觉上会更加方便。
刚好也在找这样的问题这里先贴过来,
1、爬虫,去豆瓣网爬,爬下来再去通过“元数据爬取”框架的方式(比如pyqt之类的,requests为底层代码,具体的我就不说了,好久不写了),提取图片的信息。
2、图片转成json或xml,
3、浏览器上展示,如果有非常复杂的验证,可以考虑用javascript写爬虫对图片进行验证。其实怎么爬取和怎么提取并不重要,最主要的是你要想好了如何写代码完成这件事,这个已经得到了初步的答案了。 查看全部
网页爬虫抓取百度图片(怎么爬取和怎么提取并不重要的东西?-八维教育)
网页爬虫抓取百度图片的话可以用requests/beautifulsoup等等后端语言进行处理,然后在requests/beautifulsoup中extractimage/json/pyqt/lxml等等中提取图片,返回给前端进行处理,再把获取到的图片传递给前端的话就是把图片url返回,前端获取之后就可以用js库或者原生js抓取了。
我想根据你的要求,至少你要以下的东西。
1、你想从服务器获取到图片的url,
2、你想在url中提取图片的值
3、在python中从图片中提取图片的值我猜测你对于提取图片的值,可能会在lxml里面实现。我去试着写了一下你的代码,感觉上会更加方便。
刚好也在找这样的问题这里先贴过来,
1、爬虫,去豆瓣网爬,爬下来再去通过“元数据爬取”框架的方式(比如pyqt之类的,requests为底层代码,具体的我就不说了,好久不写了),提取图片的信息。
2、图片转成json或xml,
3、浏览器上展示,如果有非常复杂的验证,可以考虑用javascript写爬虫对图片进行验证。其实怎么爬取和怎么提取并不重要,最主要的是你要想好了如何写代码完成这件事,这个已经得到了初步的答案了。
网页爬虫抓取百度图片(爬虫什么是爬虫?是蜘蛛么?是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-26 02:17
)
一、什么是爬虫
什么是爬虫?爬行动物是蜘蛛吗?是优采云吗?不不不。
爬虫是指请求网站并获取数据的自动化程序,也称为网络蜘蛛或网络机器。最常用的领域是搜索引擎,最常用的工具是优采云。
其基本过程分为以下五个部分,依次为:
明确需求-发送请求-获取数据-解析数据-存储数据。
爬虫的三大特点:
爬虫可以写成什么:
编写爬虫的语言有很多,但应用最广泛的应该是Python,并且诞生了很多优秀的库和框架,比如scrapy、BeautifulSoup、pyquery、Mechanize等。但是总的来说,搜索引擎爬虫都有对爬虫效率要求较高,会选择c++、java、go(适合高并发)。
二、爬虫的前期准备
1、准备一台性能好的电脑
电脑要求:windows7以上,内存四核8G以上
2、安装python环境
Python官网下载地址:
安装过程:
请自行百度。
3、安装所需的扩展
我们主要使用以下四个扩展:
import os # python自带扩展不需要安装
import requests # pip install requests
from urllib import request # python自带扩展不需要安装
from bs4 import BeautifulSoup # 安装命令:pip install bs4
4、找一张可以看源码的图片网站
注意注意:此链接仅供学习参考,请勿非法批量爬取,任何不听劝阻,一意孤行者,如若产生违法乱纪之事,请自行承担。(开发不易,且行且珍惜)
抓取图片的地址:https://www.umei.cc/meinvtupian/meinvxiezhen/
三、解析网站源码
1、解析源码,得到获取源码的三个方向(编码格式、请求方式、header请求头)
windows默认为gbk编码格式,网页一般默认为utf-8编码,所以当你直接用windows电脑抓取网页内容信息时,可能会遇到乱码问题,所以在要求统一编码格式的时候要保证数据不乱请求方式包括post、get、put等验证方式,所以选择正确的请求方式来获取页面信息。如果不努力,可能会遇到404页面未找到或500服务器错误。header 请求头收录很多负面信息。如果我们常见的,比如:反爬虫机制,token验证,cookie验证等。
2、查找列表页面上唯一的节点
3、 根据图片排版,找到源码规则(同li标签获取节点)
4、获取列表的最后一页,获取最后一页的页码(NewPages节点下的最后一页代表最后141页)
根据图片分页的页码地址规律,我们能得到(特别注意:第一页不能使用 index_1.htm 来查询):
https://www.umei.net/meinvtupian/meinvxiezhen/ 第一页没有index
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
......
5、根据每张图片链接,输入图片详情
根据上题3可以看出,图片详情的地址为:
https://www.umei.net/meinvtupi ... 1.htm
6、找到图片详情的地址规则,获取所有详情子图片地址
根据图片详情可以查看出来每一个子图片的详情地址:
https://www.umei.net/meinvtupi ... 1.htm
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
7、 根据地址抓取图片流并保留本地
根据问题6中获取的图片地址抓取图片信息,保存到本地,页面分析结束。废话不多说,直接上代码,快速抓取。
四、开始编写我们的爬虫脚本
1、封装代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/06/06 14:48
# @Author : Liu
# @Site :
# @File : 美图小姐姐.py
# @Software: PyCharm
import requests
import time
import os
import re
from urllib import request
from bs4 import BeautifulSoup
url_address = "https://www.umei.cc"
def get_url_path(url):
"""
获取地址内容信息
:param url:
:return:
"""
# time.sleep(1) # 获取源码的时候睡眠一秒
obj = requests.get(url)
obj.encoding = obj.apparent_encoding
return obj.text
def get_page_info():
"""
抓取每页信息
:return:
"""
nums = int(input("输入抓取的页数:"))
for i in range(nums):
if i < 1:
url = f"{ url_address }/meinvtupian/meinvxiezhen/"
else:
url = f"{ url_address }/meinvtupian/meinvxiezhen/index_{i + 1}.htm"
ret = get_url_path(url) # 获取页面信息
get_bs4(ret) # 逐页抓取页面信息
print(f"第{i+1}页完成")
pass
def get_bs4(ret):
soup = BeautifulSoup(ret, "html.parser")
li_list = soup.select(".TypeList")[0].find_all(name="li")
for i in li_list:
# 先获取第一张图片
img_src = url_address + i.a["href"]
ret1 = get_url_path(img_src) # 获取页面信息
get_image_info(ret1, i.a.span.string, 1)
# print(ret1)
# 获取分页后的页面图片数量
# script_reg = r'Next\("\d+","(?P\d+)",.*?\)'
script_reg = r'+).htm]尾页'
num_str = re.search(script_reg, ret1, re.S).group("num")
page_num = int(num_str.split("_")[1]) # 获取图片数量
img_lst = os.path.basename(i.a["href"]).split(".") # 获取图片的后缀
img_dir = os.path.dirname(i.a["href"]) # 获取图片的地址路径
for j in range(2, page_num+1):
img_src = f"{ url_address }{img_dir}/{img_lst[0]}_{j}.{img_lst[1]}"
res = get_url_path(img_src) # 获取页面信息
get_image_info(res, i.a.span.string, j)
def get_image_info(ret, name, i):
soup = BeautifulSoup(ret, "html.parser")
img = soup.select(".ImageBody img")[0]
image_path = img["src"] # 获取图片地址
image_name = name # 获取图片中文所属
img_name = f"{image_name}_{i}.{os.path.basename(image_path).split('.')[1]}" # 获取图片真实名字
# 图片存储
image_dir = f"girl/{image_name}"
if not os.path.isdir(image_dir):
os.makedirs(image_dir)
# 远程打开图片写入到本地 第一种方式open
# with open(f"{image_dir}/{img_name}", mode="wb") as add:
# add.write(requests.get(image_path).content)
# 远程打开图片写入到本地 第二种方式urllib
request.urlretrieve(image_path, filename=f"{image_dir}/{img_name}")
print("已经开始执行了,可能需要等待一会,请您耐心等待!")
begin_time = int(time.time())
get_page_info()
end_time = int(time.time())
print(f"当前脚本执行了{end_time - begin_time}秒")
print("执行已经结束了") 查看全部
网页爬虫抓取百度图片(爬虫什么是爬虫?是蜘蛛么?是什么?
)
一、什么是爬虫
什么是爬虫?爬行动物是蜘蛛吗?是优采云吗?不不不。
爬虫是指请求网站并获取数据的自动化程序,也称为网络蜘蛛或网络机器。最常用的领域是搜索引擎,最常用的工具是优采云。
其基本过程分为以下五个部分,依次为:
明确需求-发送请求-获取数据-解析数据-存储数据。
爬虫的三大特点:
爬虫可以写成什么:
编写爬虫的语言有很多,但应用最广泛的应该是Python,并且诞生了很多优秀的库和框架,比如scrapy、BeautifulSoup、pyquery、Mechanize等。但是总的来说,搜索引擎爬虫都有对爬虫效率要求较高,会选择c++、java、go(适合高并发)。
二、爬虫的前期准备
1、准备一台性能好的电脑
电脑要求:windows7以上,内存四核8G以上
2、安装python环境
Python官网下载地址:
安装过程:
请自行百度。
3、安装所需的扩展
我们主要使用以下四个扩展:
import os # python自带扩展不需要安装
import requests # pip install requests
from urllib import request # python自带扩展不需要安装
from bs4 import BeautifulSoup # 安装命令:pip install bs4
4、找一张可以看源码的图片网站
注意注意:此链接仅供学习参考,请勿非法批量爬取,任何不听劝阻,一意孤行者,如若产生违法乱纪之事,请自行承担。(开发不易,且行且珍惜)
抓取图片的地址:https://www.umei.cc/meinvtupian/meinvxiezhen/
三、解析网站源码
1、解析源码,得到获取源码的三个方向(编码格式、请求方式、header请求头)
windows默认为gbk编码格式,网页一般默认为utf-8编码,所以当你直接用windows电脑抓取网页内容信息时,可能会遇到乱码问题,所以在要求统一编码格式的时候要保证数据不乱请求方式包括post、get、put等验证方式,所以选择正确的请求方式来获取页面信息。如果不努力,可能会遇到404页面未找到或500服务器错误。header 请求头收录很多负面信息。如果我们常见的,比如:反爬虫机制,token验证,cookie验证等。
2、查找列表页面上唯一的节点
3、 根据图片排版,找到源码规则(同li标签获取节点)
4、获取列表的最后一页,获取最后一页的页码(NewPages节点下的最后一页代表最后141页)
根据图片分页的页码地址规律,我们能得到(特别注意:第一页不能使用 index_1.htm 来查询):
https://www.umei.net/meinvtupian/meinvxiezhen/ 第一页没有index
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
......
5、根据每张图片链接,输入图片详情
根据上题3可以看出,图片详情的地址为:
https://www.umei.net/meinvtupi ... 1.htm
6、找到图片详情的地址规则,获取所有详情子图片地址
根据图片详情可以查看出来每一个子图片的详情地址:
https://www.umei.net/meinvtupi ... 1.htm
https://www.umei.net/meinvtupi ... 2.htm
https://www.umei.net/meinvtupi ... 3.htm
https://www.umei.net/meinvtupi ... 4.htm
https://www.umei.net/meinvtupi ... 5.htm
https://www.umei.net/meinvtupi ... 6.htm
https://www.umei.net/meinvtupi ... 7.htm
https://www.umei.net/meinvtupi ... 8.htm
https://www.umei.net/meinvtupi ... 9.htm
7、 根据地址抓取图片流并保留本地
根据问题6中获取的图片地址抓取图片信息,保存到本地,页面分析结束。废话不多说,直接上代码,快速抓取。
四、开始编写我们的爬虫脚本
1、封装代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/06/06 14:48
# @Author : Liu
# @Site :
# @File : 美图小姐姐.py
# @Software: PyCharm
import requests
import time
import os
import re
from urllib import request
from bs4 import BeautifulSoup
url_address = "https://www.umei.cc"
def get_url_path(url):
"""
获取地址内容信息
:param url:
:return:
"""
# time.sleep(1) # 获取源码的时候睡眠一秒
obj = requests.get(url)
obj.encoding = obj.apparent_encoding
return obj.text
def get_page_info():
"""
抓取每页信息
:return:
"""
nums = int(input("输入抓取的页数:"))
for i in range(nums):
if i < 1:
url = f"{ url_address }/meinvtupian/meinvxiezhen/"
else:
url = f"{ url_address }/meinvtupian/meinvxiezhen/index_{i + 1}.htm"
ret = get_url_path(url) # 获取页面信息
get_bs4(ret) # 逐页抓取页面信息
print(f"第{i+1}页完成")
pass
def get_bs4(ret):
soup = BeautifulSoup(ret, "html.parser")
li_list = soup.select(".TypeList")[0].find_all(name="li")
for i in li_list:
# 先获取第一张图片
img_src = url_address + i.a["href"]
ret1 = get_url_path(img_src) # 获取页面信息
get_image_info(ret1, i.a.span.string, 1)
# print(ret1)
# 获取分页后的页面图片数量
# script_reg = r'Next\("\d+","(?P\d+)",.*?\)'
script_reg = r'+).htm]尾页'
num_str = re.search(script_reg, ret1, re.S).group("num")
page_num = int(num_str.split("_")[1]) # 获取图片数量
img_lst = os.path.basename(i.a["href"]).split(".") # 获取图片的后缀
img_dir = os.path.dirname(i.a["href"]) # 获取图片的地址路径
for j in range(2, page_num+1):
img_src = f"{ url_address }{img_dir}/{img_lst[0]}_{j}.{img_lst[1]}"
res = get_url_path(img_src) # 获取页面信息
get_image_info(res, i.a.span.string, j)
def get_image_info(ret, name, i):
soup = BeautifulSoup(ret, "html.parser")
img = soup.select(".ImageBody img")[0]
image_path = img["src"] # 获取图片地址
image_name = name # 获取图片中文所属
img_name = f"{image_name}_{i}.{os.path.basename(image_path).split('.')[1]}" # 获取图片真实名字
# 图片存储
image_dir = f"girl/{image_name}"
if not os.path.isdir(image_dir):
os.makedirs(image_dir)
# 远程打开图片写入到本地 第一种方式open
# with open(f"{image_dir}/{img_name}", mode="wb") as add:
# add.write(requests.get(image_path).content)
# 远程打开图片写入到本地 第二种方式urllib
request.urlretrieve(image_path, filename=f"{image_dir}/{img_name}")
print("已经开始执行了,可能需要等待一会,请您耐心等待!")
begin_time = int(time.time())
get_page_info()
end_time = int(time.time())
print(f"当前脚本执行了{end_time - begin_time}秒")
print("执行已经结束了")
网页爬虫抓取百度图片( 关于爬虫爬图如何获取网页源代码打开(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2021-11-25 23:24
关于爬虫爬图如何获取网页源代码打开(图)
)
如何使用爬虫爬取图片,以百度图片为例
关于抓取图片
最近自己看着网上教程学习如何爬图,发现爬虫的优越性,也发现有些博客对初学者不太友好,因此写了这篇博客。
如何获取网页的源代码
打开谷歌浏览器,打开百度图片,点击更多工具->打开开发者工具,如图
可以发现,在underdraw的时候,旁边的Name栏中会有很多图片链接。
随便点一个图片,发现旁边有一个关于Response Headers的内容
这是你目前访问百度图片的访问信息,这个信息其实是一样的。
然后在网页上左键点击查看网页的源代码。
再次按下Ctrl/Command+F,使用搜索工具找到url,也就是图片的下载地址,还有一些相关的信息,比如数据等,可以快速找到,体现在代码中。
输入 frompagetitle 以查找图像的标题。
源代码
源码中有详细的注释,便于理解。
# 爬取百度图片
from urllib.parse import urlencode
import requests
import re
import os
# 图片下载的存储文件
save_dir = '百度图片/'
# 百度加密算法
def baidtu_uncomplie(url):
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d = {'w': 'a', 'k': 'b', 'v': 'c', '1': 'd', 'j': 'e', 'u': 'f', '2': 'g', 'i': 'h', 't': 'i', '3': 'j', 'h': 'k',
's': 'l', '4': 'm', 'g': 'n', '5': 'o', 'r': 'p', 'q': 'q', '6': 'r', 'f': 's', 'p': 't', '7': 'u', 'e': 'v',
'o': 'w', '8': '1', 'd': '2', 'n': '3', '9': '4', 'c': '5', 'm': '6', '0': '7', 'b': '8', 'l': '9', 'a': '0',
'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
if (url == None or 'http' in url): # 判断地址是否有http
return url
else:
j = url
# 解码百度加密算法
for m in c:
j = j.replace(m, d[m])
for char in j:
if re.match('^[a-w\d]+$', char): # 正则表达式
char = d[char]
res = res + char
return res
# 获取页面信息
def get_page(offset):
params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '中国人', # 关键字
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'word': '中国人', # 关键字
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'pn': offset * 30,
'rn': '30',
'gsm': '1e',
'1537355234668': '',
}
url = 'https://image.baidu.com/search/acjson?' + urlencode(params)
try: # 尝试连接服务器
response = requests.get(url)
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
return response.json()
except requests.ConnectionError as d:
print('Error', d.args)
# 获取图像
def get_images(json):
if json.get('data'):
for item in json.get('data'): # 获取图片数据字典值
if item.get('fromPageTitle'): # 获取图片Title
title = item.get('fromPageTitle')
else:
title = 'noTitle'
image = baidtu_uncomplie(item.get('objURL')) # 图片地址
if (image):
yield { # 存储图片信息
'image': image,
'title': title
}
def save_image(item, count):
try:
response = requests.get(item.get('image'))
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
file_path = save_dir + '{0}.{1}'.format(str(count), 'jpg') # 命名并存储图片
if not os.path.exists(file_path): # 判断图片是否在文件中
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError: # 如果出现连接错误
print('Failed to Save Image')
def main(pageIndex, count):
json = get_page(pageIndex)
for image in get_images(json):
save_image(image, count)
count += 1
return count
if __name__ == '__main__':
if not os.path.exists(save_dir): # 判断是否存在文件,若没有则创建一个
os.mkdir(save_dir)
count = 1
for i in range(1, 200): # 循环页数下载图片
count = main(i, count) # i表示页数,统计图片并运行主函数
print('total:', count) 查看全部
网页爬虫抓取百度图片(
关于爬虫爬图如何获取网页源代码打开(图)
)
如何使用爬虫爬取图片,以百度图片为例
关于抓取图片
最近自己看着网上教程学习如何爬图,发现爬虫的优越性,也发现有些博客对初学者不太友好,因此写了这篇博客。
如何获取网页的源代码
打开谷歌浏览器,打开百度图片,点击更多工具->打开开发者工具,如图
可以发现,在underdraw的时候,旁边的Name栏中会有很多图片链接。
随便点一个图片,发现旁边有一个关于Response Headers的内容
这是你目前访问百度图片的访问信息,这个信息其实是一样的。
然后在网页上左键点击查看网页的源代码。
再次按下Ctrl/Command+F,使用搜索工具找到url,也就是图片的下载地址,还有一些相关的信息,比如数据等,可以快速找到,体现在代码中。
输入 frompagetitle 以查找图像的标题。
源代码
源码中有详细的注释,便于理解。
# 爬取百度图片
from urllib.parse import urlencode
import requests
import re
import os
# 图片下载的存储文件
save_dir = '百度图片/'
# 百度加密算法
def baidtu_uncomplie(url):
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d = {'w': 'a', 'k': 'b', 'v': 'c', '1': 'd', 'j': 'e', 'u': 'f', '2': 'g', 'i': 'h', 't': 'i', '3': 'j', 'h': 'k',
's': 'l', '4': 'm', 'g': 'n', '5': 'o', 'r': 'p', 'q': 'q', '6': 'r', 'f': 's', 'p': 't', '7': 'u', 'e': 'v',
'o': 'w', '8': '1', 'd': '2', 'n': '3', '9': '4', 'c': '5', 'm': '6', '0': '7', 'b': '8', 'l': '9', 'a': '0',
'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
if (url == None or 'http' in url): # 判断地址是否有http
return url
else:
j = url
# 解码百度加密算法
for m in c:
j = j.replace(m, d[m])
for char in j:
if re.match('^[a-w\d]+$', char): # 正则表达式
char = d[char]
res = res + char
return res
# 获取页面信息
def get_page(offset):
params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '中国人', # 关键字
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'word': '中国人', # 关键字
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'pn': offset * 30,
'rn': '30',
'gsm': '1e',
'1537355234668': '',
}
url = 'https://image.baidu.com/search/acjson?' + urlencode(params)
try: # 尝试连接服务器
response = requests.get(url)
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
return response.json()
except requests.ConnectionError as d:
print('Error', d.args)
# 获取图像
def get_images(json):
if json.get('data'):
for item in json.get('data'): # 获取图片数据字典值
if item.get('fromPageTitle'): # 获取图片Title
title = item.get('fromPageTitle')
else:
title = 'noTitle'
image = baidtu_uncomplie(item.get('objURL')) # 图片地址
if (image):
yield { # 存储图片信息
'image': image,
'title': title
}
def save_image(item, count):
try:
response = requests.get(item.get('image'))
if response.status_code == 200: # 获取HTTP状态,即服务器响应HTTP请求
file_path = save_dir + '{0}.{1}'.format(str(count), 'jpg') # 命名并存储图片
if not os.path.exists(file_path): # 判断图片是否在文件中
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError: # 如果出现连接错误
print('Failed to Save Image')
def main(pageIndex, count):
json = get_page(pageIndex)
for image in get_images(json):
save_image(image, count)
count += 1
return count
if __name__ == '__main__':
if not os.path.exists(save_dir): # 判断是否存在文件,若没有则创建一个
os.mkdir(save_dir)
count = 1
for i in range(1, 200): # 循环页数下载图片
count = main(i, count) # i表示页数,统计图片并运行主函数
print('total:', count)
网页爬虫抓取百度图片(web服务器抓取百度图片的技巧及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-24 21:01
网页爬虫抓取百度图片是通过useragent解析页面来获取的。web服务器会根据抓取请求中的useragent变化来调用对应的api或者完全自己去尝试找出其中的特征值;第三方接口的post和get也有提交参数的逻辑;这些流程和简单的网页爬虫抓取都是一样的;比如简单的图片搜索,获取来的结果中包含的就不仅仅是图片所在的url,还可能是图片的id或者png格式的图片链接。
我猜可能是抓url,像随便哪个爬虫,不说明抓取目标。你只能说是抓url。但是你爬哪不一定啊。你不能说人家web服务器每次去xxx2d下载图片都抓包比对id吧。然后拿出图片的地址,而且即使网页里没有图片,你把这个值盗过来给爬虫提交一下,它下载下来就能用了。程序猿说得清楚,人家真心懒得自己搞这个。还是要把图片url拿到,你把id和图片的地址都告诉她。这个里面就有可能包含其他图片的url。
get方法是cookie的方法,你验证登录或者dns解析为动态的,当然就拿不到你指定的图片,但是调用百度的图片提取,应该就可以拿到图片的url。另外@sherrysu说的很对,爬虫爬图片一般都是直接抓,没有必要比对url,除非有特殊需求,比如抓走某个图片所有的图片信息,或者具有某种功能。
比对url可以获取图片文件名,这样的话比对一下这个文件名,就能获取所有图片的url了,如果没有其他限制,就可以拿下所有图片的文件名。 查看全部
网页爬虫抓取百度图片(web服务器抓取百度图片的技巧及方法)
网页爬虫抓取百度图片是通过useragent解析页面来获取的。web服务器会根据抓取请求中的useragent变化来调用对应的api或者完全自己去尝试找出其中的特征值;第三方接口的post和get也有提交参数的逻辑;这些流程和简单的网页爬虫抓取都是一样的;比如简单的图片搜索,获取来的结果中包含的就不仅仅是图片所在的url,还可能是图片的id或者png格式的图片链接。
我猜可能是抓url,像随便哪个爬虫,不说明抓取目标。你只能说是抓url。但是你爬哪不一定啊。你不能说人家web服务器每次去xxx2d下载图片都抓包比对id吧。然后拿出图片的地址,而且即使网页里没有图片,你把这个值盗过来给爬虫提交一下,它下载下来就能用了。程序猿说得清楚,人家真心懒得自己搞这个。还是要把图片url拿到,你把id和图片的地址都告诉她。这个里面就有可能包含其他图片的url。
get方法是cookie的方法,你验证登录或者dns解析为动态的,当然就拿不到你指定的图片,但是调用百度的图片提取,应该就可以拿到图片的url。另外@sherrysu说的很对,爬虫爬图片一般都是直接抓,没有必要比对url,除非有特殊需求,比如抓走某个图片所有的图片信息,或者具有某种功能。
比对url可以获取图片文件名,这样的话比对一下这个文件名,就能获取所有图片的url了,如果没有其他限制,就可以拿下所有图片的文件名。
网页爬虫抓取百度图片(()2060,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-23 18:06
网页爬虫抓取百度图片数据()爬虫工具的介绍为了更好的运用,图片数据抓取了两种方式:静态页面、动态页面我们采用静态页面爬取:【缺点】:网页访问慢,并且不像动态页面那样,每次都要重新下载图片并且不稳定pageawait{root:0}pageawaitso_page()so_page()pageawaitpage_download()so_page()pageawaitpage_upgrade()pageawaitdownload_gz()download_gz()此时需要pageawaitpage_upgrade等待页面加载完毕,后面才能下载我们用动态页面抓取:pageawaitso_gz()so_gz()so_gz()pageawaitdownload_gz()so_gz()so_gz()我们可以这样提取出图片url接下来按照提取pictureid这样一步步提取出所有图片的url包括图片的尺寸、压缩率与分辨率、图片密度pictureid我们按照这种方式提取所有图片的url>>>sitemap。
gz()args:[200,201,2040,2060,2060,2070,2070,2070,2060,2070,2070,2060,2070,2070,2060,2070,2060,2070,2070,2060,2070,2060,2070,2070,2070,2070,2060,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,。 查看全部
网页爬虫抓取百度图片(()2060,)
网页爬虫抓取百度图片数据()爬虫工具的介绍为了更好的运用,图片数据抓取了两种方式:静态页面、动态页面我们采用静态页面爬取:【缺点】:网页访问慢,并且不像动态页面那样,每次都要重新下载图片并且不稳定pageawait{root:0}pageawaitso_page()so_page()pageawaitpage_download()so_page()pageawaitpage_upgrade()pageawaitdownload_gz()download_gz()此时需要pageawaitpage_upgrade等待页面加载完毕,后面才能下载我们用动态页面抓取:pageawaitso_gz()so_gz()so_gz()pageawaitdownload_gz()so_gz()so_gz()我们可以这样提取出图片url接下来按照提取pictureid这样一步步提取出所有图片的url包括图片的尺寸、压缩率与分辨率、图片密度pictureid我们按照这种方式提取所有图片的url>>>sitemap。
gz()args:[200,201,2040,2060,2060,2070,2070,2070,2060,2070,2070,2060,2070,2070,2060,2070,2060,2070,2070,2060,2070,2060,2070,2070,2070,2070,2060,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,2070,。
网页爬虫抓取百度图片( 讲解我们的爬虫之前,如何获取对自己有用的信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-23 15:05
讲解我们的爬虫之前,如何获取对自己有用的信息?)
在讲解我们的爬虫之前,我们先来概括一下爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是一种模拟浏览器发送网络请求并接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
原则上只要浏览器(客户端)能做,爬虫就能做。
我们为什么要使用爬虫
在互联网大数据时代,我们生活的便利和海量数据的爆炸式出现在互联网上。
过去,我们使用书籍、报纸、电视、广播或信息。信息量有限,经过一定量的筛选,信息相对有效,但缺点是信息太窄。不对称的信息传递限制了我们的视野,无法学到更多的信息和知识。
在互联网大数据时代,我们突然可以免费获取信息,我们收到了海量的信息,但大部分都是无效的垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,你可以搜索一个——100,000,000条关于减肥的信息。
如此大量的信息碎片,我们如何获取对自己有用的信息呢?
答案是筛选!
通过一定的技术采集相关内容,然后分析删除选区,得到我们真正需要的信息。
这项信息采集、分析和整合工作可以应用于广泛的应用领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等......您可以通过这项技术获得更多准确有效的信息。好好利用。
网络爬虫技术虽然名字古怪,第一反应是那种软软的爬行生物,但却是可以在虚拟世界中前行的利器。
爬行动物准备
我们通常谈论 Python 爬虫。其实,这里可能有误会。爬虫不是 Python 独有的。可以爬取的语言有很多。例如:PHP、JAVA、C#、C++、Python。之所以选择Python作为爬虫,是因为Python是相对的。比较简单,功能也比较齐全。
首先我们需要下载python,我下载的是最新的官方版本3.8.3
其次,我们需要一个运行Python的环境,我用的是pychram
也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,我已经良心写了评论
(在爬虫运行过程中,你可能不仅仅需要以上的库,这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬取豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
已经爬到这里了,给大家看看效果图。我将抓取的内容保存在 xls 中。
我们抓取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概述和相关信息。
代码分析
先贴出代码,然后我根据代码一步步分析
<p># -*- codeing = utf-8 -*- from bs4 import BeautifulSoup # 网页解析,获取数据 import re # 正则表达式,进行文字匹配` import urllib.request, urllib.error # 制定URL,获取网页数据 import xlwt # 进行excel操作 #import sqlite3 # 进行SQLite数据库操作 findLink = re.compile(r'') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r' 查看全部
网页爬虫抓取百度图片(
讲解我们的爬虫之前,如何获取对自己有用的信息?)
在讲解我们的爬虫之前,我们先来概括一下爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(也称为网络蜘蛛或网络机器人)是一种模拟浏览器发送网络请求并接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
原则上只要浏览器(客户端)能做,爬虫就能做。
我们为什么要使用爬虫
在互联网大数据时代,我们生活的便利和海量数据的爆炸式出现在互联网上。
过去,我们使用书籍、报纸、电视、广播或信息。信息量有限,经过一定量的筛选,信息相对有效,但缺点是信息太窄。不对称的信息传递限制了我们的视野,无法学到更多的信息和知识。
在互联网大数据时代,我们突然可以免费获取信息,我们收到了海量的信息,但大部分都是无效的垃圾邮件。
例如,新浪微博每天产生数亿条状态更新,而在百度搜索引擎中,你可以搜索一个——100,000,000条关于减肥的信息。
如此大量的信息碎片,我们如何获取对自己有用的信息呢?
答案是筛选!
通过一定的技术采集相关内容,然后分析删除选区,得到我们真正需要的信息。
这项信息采集、分析和整合工作可以应用于广泛的应用领域,无论是生活服务、旅游、金融投资、各个制造行业的产品市场需求等等......您可以通过这项技术获得更多准确有效的信息。好好利用。
网络爬虫技术虽然名字古怪,第一反应是那种软软的爬行生物,但却是可以在虚拟世界中前行的利器。
爬行动物准备
我们通常谈论 Python 爬虫。其实,这里可能有误会。爬虫不是 Python 独有的。可以爬取的语言有很多。例如:PHP、JAVA、C#、C++、Python。之所以选择Python作为爬虫,是因为Python是相对的。比较简单,功能也比较齐全。
首先我们需要下载python,我下载的是最新的官方版本3.8.3
其次,我们需要一个运行Python的环境,我用的是pychram
也可以从官网下载,
我们还需要一些库来支持爬虫的运行(有些库可能是Python自带的)
差不多就是这些库了,我已经良心写了评论
(在爬虫运行过程中,你可能不仅仅需要以上的库,这取决于你的爬虫的具体编写方式。反正如果你需要一个库,我们可以直接在设置中安装)
爬虫项目说明
我做的是爬取豆瓣评分电影Top250的爬虫代码
我们要爬取的是这个网站:
已经爬到这里了,给大家看看效果图。我将抓取的内容保存在 xls 中。
我们抓取的内容是:电影详情链接、图片链接、电影中文名、电影外文名、评分、评论数、概述和相关信息。
代码分析
先贴出代码,然后我根据代码一步步分析
<p># -*- codeing = utf-8 -*- from bs4 import BeautifulSoup # 网页解析,获取数据 import re # 正则表达式,进行文字匹配` import urllib.request, urllib.error # 制定URL,获取网页数据 import xlwt # 进行excel操作 #import sqlite3 # 进行SQLite数据库操作 findLink = re.compile(r'') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r'
网页爬虫抓取百度图片(《凡人修仙传吧_百度贴吧》之中制作原理基本相同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-22 12:25
百度贴吧的爬虫制作原理与Embarrassed爬虫制作原理基本一致。他们都通过查看源代码提取关键数据,然后将其存储在本地txt文件中。
源码下载:
项目内容:
百度贴吧用Python编写的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,将代码复制进去,双击运行。
程序功能:
将贴吧宿主发布的内容打包成txt打包保存到本地
原理说明:
首先先浏览某篇文章贴吧,点击只看到海报,点击第二页,url有点变了,变成了:
可以看出see_lz=1是只看主机,pn=1是对应的页码。记住这一点,为以后的写作做好准备。
这是我们需要使用的网址。
下一步是查看页面的源代码。
在第一次选择标题和存储文件时会用到它。
百度标题贴吧:《修仙传说》中的一些“路人”故事_修仙故事_百度贴吧
源代码:
1 # -*- coding: utf-8 -*-
2 #---------------------------------------
3 # 程序:百度贴吧爬虫
4 # 版本:0.5
5 # 作者:fjl
6 # 日期:2016-2-11
7 # 语言:Python 2.7
8 # 操作:输入网址后自动只看楼主并保存到本地文件
9 # 功能:将楼主发布的内容打包txt存储到本地。
10 #---------------------------------------
11
12 import string
13 import urllib2
14 import re
15
16 #----------- 处理页面上的各种标签 -----------
17 class HTML_Tool:
18 # 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
19 BgnCharToNoneRex = re.compile("(\t|\n| ||)")
20
21 # 用非 贪婪模式 匹配 任意标签
22 EndCharToNoneRex = re.compile("")
23
24 # 用非 贪婪模式 匹配 任意<p>标签
25 BgnPartRex = re.compile("")
26 CharToNewLineRex = re.compile("(
||||)")
27 CharToNextTabRex = re.compile("")
28
29 # 将一些html的符号实体转变为原始符号
30 replaceTab = [("",">"),("&","&"),("&","\""),(" "," ")]
31
32 def Replace_Char(self,x):
33 x = self.BgnCharToNoneRex.sub("",x)
34 x = self.BgnPartRex.sub("\n ",x)
35 x = self.CharToNewLineRex.sub("\n",x)
36 x = self.CharToNextTabRex.sub("\t",x)
37 x = self.EndCharToNoneRex.sub("",x)
38
39 for t in self.replaceTab:
40 x = x.replace(t[0],t[1])
41 return x
42
43 class Baidu_Spider:
44 # 申明相关的属性
45 def __init__(self,url):
46 self.myUrl = url + \'?see_lz=1\'
47 self.datas = []
48 self.myTool = HTML_Tool()
49 print u\'已经启动百度贴吧爬虫,咔嚓咔嚓\'
50
51 # 初始化加载页面并将其转码储存
52 def baidu_tieba(self):
53 # 读取页面的原始信息并将其从gbk转码
54 myPage = urllib2.urlopen(self.myUrl).read().decode("utf-8")
55 # 计算楼主发布内容一共有多少页
56 endPage = self.page_counter(myPage)
57 # 获取该帖的标题
58 title = self.find_title(myPage)
59 print u\'文章名称:\' + title
60 # 获取最终的数据
61 self.save_data(self.myUrl,title,endPage)
62
63 #用来计算一共有多少页
64 def page_counter(self,myPage):
65 # 匹配 "共有12页" 来获取一共有多少页
66 myMatch = re.search(r\'class="red">(\d+?)\', myPage, re.S)
67 if myMatch:
68 endPage = int(myMatch.group(1))
69 print u\'爬虫报告:发现楼主共有%d页的原创内容\' % endPage
70 else:
71 endPage = 0
72 print u\'爬虫报告:无法计算楼主发布内容有多少页!\'
73 return endPage
74
75 # 用来寻找该帖的标题
76 def find_title(self,myPage):
77 # 匹配 xxxxxxxxxx 找出标题
78 myMatch = re.search(r\'(.*?)\', myPage, re.S)
79 title = u\'暂无标题\'
80 if myMatch:
81 #title = myMatch.group(1)
82 title = myMatch.group(1)
83 else:
84 print u\'爬虫报告:无法加载文章标题!\'
85 # 文件名不能包含以下字符: \ / : * ? " < > |
86 title = title.replace(\'\\\',\'\').replace(\'/\',\'\').replace(\':\',\'\').replace(\'*\',\'\').replace(\'?\',\'\').replace(\'"\',\'\').replace(\'>\',\'\').replace(\' 查看全部
网页爬虫抓取百度图片(《凡人修仙传吧_百度贴吧》之中制作原理基本相同)
百度贴吧的爬虫制作原理与Embarrassed爬虫制作原理基本一致。他们都通过查看源代码提取关键数据,然后将其存储在本地txt文件中。
源码下载:
项目内容:
百度贴吧用Python编写的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,将代码复制进去,双击运行。
程序功能:
将贴吧宿主发布的内容打包成txt打包保存到本地
原理说明:
首先先浏览某篇文章贴吧,点击只看到海报,点击第二页,url有点变了,变成了:
可以看出see_lz=1是只看主机,pn=1是对应的页码。记住这一点,为以后的写作做好准备。
这是我们需要使用的网址。
下一步是查看页面的源代码。
在第一次选择标题和存储文件时会用到它。
百度标题贴吧:《修仙传说》中的一些“路人”故事_修仙故事_百度贴吧
源代码:
1 # -*- coding: utf-8 -*-
2 #---------------------------------------
3 # 程序:百度贴吧爬虫
4 # 版本:0.5
5 # 作者:fjl
6 # 日期:2016-2-11
7 # 语言:Python 2.7
8 # 操作:输入网址后自动只看楼主并保存到本地文件
9 # 功能:将楼主发布的内容打包txt存储到本地。
10 #---------------------------------------
11
12 import string
13 import urllib2
14 import re
15
16 #----------- 处理页面上的各种标签 -----------
17 class HTML_Tool:
18 # 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
19 BgnCharToNoneRex = re.compile("(\t|\n| ||)")
20
21 # 用非 贪婪模式 匹配 任意标签
22 EndCharToNoneRex = re.compile("")
23
24 # 用非 贪婪模式 匹配 任意<p>标签
25 BgnPartRex = re.compile("")
26 CharToNewLineRex = re.compile("(
||||)")
27 CharToNextTabRex = re.compile("")
28
29 # 将一些html的符号实体转变为原始符号
30 replaceTab = [("",">"),("&","&"),("&","\""),(" "," ")]
31
32 def Replace_Char(self,x):
33 x = self.BgnCharToNoneRex.sub("",x)
34 x = self.BgnPartRex.sub("\n ",x)
35 x = self.CharToNewLineRex.sub("\n",x)
36 x = self.CharToNextTabRex.sub("\t",x)
37 x = self.EndCharToNoneRex.sub("",x)
38
39 for t in self.replaceTab:
40 x = x.replace(t[0],t[1])
41 return x
42
43 class Baidu_Spider:
44 # 申明相关的属性
45 def __init__(self,url):
46 self.myUrl = url + \'?see_lz=1\'
47 self.datas = []
48 self.myTool = HTML_Tool()
49 print u\'已经启动百度贴吧爬虫,咔嚓咔嚓\'
50
51 # 初始化加载页面并将其转码储存
52 def baidu_tieba(self):
53 # 读取页面的原始信息并将其从gbk转码
54 myPage = urllib2.urlopen(self.myUrl).read().decode("utf-8")
55 # 计算楼主发布内容一共有多少页
56 endPage = self.page_counter(myPage)
57 # 获取该帖的标题
58 title = self.find_title(myPage)
59 print u\'文章名称:\' + title
60 # 获取最终的数据
61 self.save_data(self.myUrl,title,endPage)
62
63 #用来计算一共有多少页
64 def page_counter(self,myPage):
65 # 匹配 "共有12页" 来获取一共有多少页
66 myMatch = re.search(r\'class="red">(\d+?)\', myPage, re.S)
67 if myMatch:
68 endPage = int(myMatch.group(1))
69 print u\'爬虫报告:发现楼主共有%d页的原创内容\' % endPage
70 else:
71 endPage = 0
72 print u\'爬虫报告:无法计算楼主发布内容有多少页!\'
73 return endPage
74
75 # 用来寻找该帖的标题
76 def find_title(self,myPage):
77 # 匹配 xxxxxxxxxx 找出标题
78 myMatch = re.search(r\'(.*?)\', myPage, re.S)
79 title = u\'暂无标题\'
80 if myMatch:
81 #title = myMatch.group(1)
82 title = myMatch.group(1)
83 else:
84 print u\'爬虫报告:无法加载文章标题!\'
85 # 文件名不能包含以下字符: \ / : * ? " < > |
86 title = title.replace(\'\\\',\'\').replace(\'/\',\'\').replace(\':\',\'\').replace(\'*\',\'\').replace(\'?\',\'\').replace(\'"\',\'\').replace(\'>\',\'\').replace(\'
网页爬虫抓取百度图片(如何用Python学习资料的小伙伴获取图片的url? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 14:20
)
PS:如需Python学习资料,可点击下方链接自行获取
1.获取图片的url链接
首先打开百度图片首页,注意下面url中的索引
接下来,将页面切换到传统的翻页版本,因为这会帮助我们抓取图片!
对比了几个网址,发现pn参数是请求数。修改pn参数,观察返回数据,发现每个页面最多只能收录60张图片。
注意:gsm参数是pn参数的16进制表示,去掉没有坏处
然后右击查看网页源码,直接(ctrl+F)搜索objURL
这样我们就找到了需要图片的url。
2.本地保存图片链接
现在,我们要做的就是抓取这些信息。
注意:网页中有objURL、hoverURL……但是我们用的是objURL,因为这是原图
那么,如何获取 objURL?使用正则表达式!
那我们怎么用正则表达式来实现呢?其实只需要一行代码...
results = re.findall(\'"objURL":"(.*?)",\', html)
核心代码:
1.获取图片url代码:
1 # 获取图片url连接
2 def get_parse_page(pn,name):
3
4 for i in range(int(pn)):
5 # 1.获取网页
6 print(\'正在获取第{}页\'.format(i+1))
7
8 # 百度图片首页的url
9 # name是你要搜索的关键词
10 # pn是你想下载的页数
11
12 url = \'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d\' %(name,i*20)
13
14 headers = {
15 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400\'}
16
17 # 发送请求,获取相应
18 response = requests.get(url, headers=headers)
19 html = response.content.decode()
20 # print(html)
21
22 # 2.正则表达式解析网页
23 # "objURL":"http://n.sinaimg.cn/sports/tra ... ot%3B
24 results = re.findall(\'"objURL":"(.*?)",\', html) # 返回一个列表
25
26 # 根据获取到的图片链接,把图片保存到本地
27 save_to_txt(results, name, i)
2.保存图片到本地代码:
1 # 保存图片到本地
2 def save_to_txt(results, name, i):
3
4 j = 0
5 # 在当目录下创建文件夹
6 if not os.path.exists(\'./\' + name):
7 os.makedirs(\'./\' + name)
8
9 # 下载图片
10 for result in results:
11 print(\'正在保存第{}个\'.format(j))
12 try:
13 pic = requests.get(result, timeout=10)
14 time.sleep(1)
15 except:
16 print(\'当前图片无法下载\')
17 j += 1
18 continue
19
20 # 可忽略,这段代码有bug
21 # file_name = result.split(\'/\')
22 # file_name = file_name[len(file_name) - 1]
23 # print(file_name)
24 #
25 # end = re.search(\'(.png|.jpg|.jpeg|.gif)$\', file_name)
26 # if end == None:
27 # file_name = file_name + \'.jpg\'
28
29 # 把图片保存到文件夹
30 file_full_name = \'./\' + name + \'/\' + str(i) + \'-\' + str(j) + \'.jpg\'
31 with open(file_full_name, \'wb\') as f:
32 f.write(pic.content)
33
34 j += 1
3.主要功能代码:
1 # 主函数
2 if __name__ == \'__main__\':
3
4 name = input(\'请输入你要下载的关键词:\')
5 pn = input(\'你想下载前几页(1页有60张):\')
6 get_parse_page(pn,
使用说明:
1 # 配置以下模块
2 import requests
3 import re
4 import os
5 import time
6
7 # 1.运行 py源文件
8 # 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
9 # 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片 查看全部
网页爬虫抓取百度图片(如何用Python学习资料的小伙伴获取图片的url?
)
PS:如需Python学习资料,可点击下方链接自行获取
1.获取图片的url链接
首先打开百度图片首页,注意下面url中的索引
接下来,将页面切换到传统的翻页版本,因为这会帮助我们抓取图片!
对比了几个网址,发现pn参数是请求数。修改pn参数,观察返回数据,发现每个页面最多只能收录60张图片。
注意:gsm参数是pn参数的16进制表示,去掉没有坏处
然后右击查看网页源码,直接(ctrl+F)搜索objURL
这样我们就找到了需要图片的url。
2.本地保存图片链接
现在,我们要做的就是抓取这些信息。
注意:网页中有objURL、hoverURL……但是我们用的是objURL,因为这是原图
那么,如何获取 objURL?使用正则表达式!
那我们怎么用正则表达式来实现呢?其实只需要一行代码...
results = re.findall(\'"objURL":"(.*?)",\', html)
核心代码:
1.获取图片url代码:
1 # 获取图片url连接
2 def get_parse_page(pn,name):
3
4 for i in range(int(pn)):
5 # 1.获取网页
6 print(\'正在获取第{}页\'.format(i+1))
7
8 # 百度图片首页的url
9 # name是你要搜索的关键词
10 # pn是你想下载的页数
11
12 url = \'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d\' %(name,i*20)
13
14 headers = {
15 \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400\'}
16
17 # 发送请求,获取相应
18 response = requests.get(url, headers=headers)
19 html = response.content.decode()
20 # print(html)
21
22 # 2.正则表达式解析网页
23 # "objURL":"http://n.sinaimg.cn/sports/tra ... ot%3B
24 results = re.findall(\'"objURL":"(.*?)",\', html) # 返回一个列表
25
26 # 根据获取到的图片链接,把图片保存到本地
27 save_to_txt(results, name, i)
2.保存图片到本地代码:
1 # 保存图片到本地
2 def save_to_txt(results, name, i):
3
4 j = 0
5 # 在当目录下创建文件夹
6 if not os.path.exists(\'./\' + name):
7 os.makedirs(\'./\' + name)
8
9 # 下载图片
10 for result in results:
11 print(\'正在保存第{}个\'.format(j))
12 try:
13 pic = requests.get(result, timeout=10)
14 time.sleep(1)
15 except:
16 print(\'当前图片无法下载\')
17 j += 1
18 continue
19
20 # 可忽略,这段代码有bug
21 # file_name = result.split(\'/\')
22 # file_name = file_name[len(file_name) - 1]
23 # print(file_name)
24 #
25 # end = re.search(\'(.png|.jpg|.jpeg|.gif)$\', file_name)
26 # if end == None:
27 # file_name = file_name + \'.jpg\'
28
29 # 把图片保存到文件夹
30 file_full_name = \'./\' + name + \'/\' + str(i) + \'-\' + str(j) + \'.jpg\'
31 with open(file_full_name, \'wb\') as f:
32 f.write(pic.content)
33
34 j += 1
3.主要功能代码:
1 # 主函数
2 if __name__ == \'__main__\':
3
4 name = input(\'请输入你要下载的关键词:\')
5 pn = input(\'你想下载前几页(1页有60张):\')
6 get_parse_page(pn,
使用说明:
1 # 配置以下模块
2 import requests
3 import re
4 import os
5 import time
6
7 # 1.运行 py源文件
8 # 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
9 # 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片
网页爬虫抓取百度图片(上海SEO外包:百度蜘蛛、网络机器人,蚂蚁、蠕虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-21 10:08
)
百度爬虫又称百度蜘蛛、网络机器人、蚂蚁、蠕虫等。
百度爬虫使用文本信息来抓取内容。最好减少网站中对应的图片和视频。尽量用文字来解释。百度蜘蛛是网站与用户搬运工之间的信息,抓取网站的内容,通过搜索引文库呈现给客户。
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps1.png
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps2.png
如图,蜘蛛从搜索区域抓取网页的信息,将符合规则的内容取回并带回临时库,不符合规则的内容直接清理,最后他会将符合条件的内容展示给搜索引擎查询。
百度蜘蛛分为pc/mobile-take-all蜘蛛,也有mobile-only蜘蛛。他们收到的大多数命令识别都是相同的。
关于蜘蛛爬取的频率:如果你是新的网站,百度对新站有保护期,会有30天的新站特权。在这30天内,网站内容百度蜘蛛的发布和更新将优先抓取和收录。一般爬取频率由系统根据网站的大小、用户的喜好程度和更新频率自动调整。
不管新的网站还是旧的网站,在文章的内容更新中都必须维护原创。文章的TDK布局很重要。一个好的标签布局是不会出现重复的关键词和句子的。文章 的质量比数量更重要。最好每天在固定的时间发布文章,让百度蜘蛛为我们服务,还有一个相对准时的概念。如果网站的文章或者多次重复的百度蜘蛛不会收录信息,因为百度的搜索引文库中收录了很多类似的信息,没有一个是收录,并且长期会导致网站被K或者降级。
<p>文章中必须注意的一件事是避免关键词stacking,什么是关键词stacking:关键词stacking在文章 查看全部
网页爬虫抓取百度图片(上海SEO外包:百度蜘蛛、网络机器人,蚂蚁、蠕虫
)
百度爬虫又称百度蜘蛛、网络机器人、蚂蚁、蠕虫等。
百度爬虫使用文本信息来抓取内容。最好减少网站中对应的图片和视频。尽量用文字来解释。百度蜘蛛是网站与用户搬运工之间的信息,抓取网站的内容,通过搜索引文库呈现给客户。
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps1.png
file:///C:%5CUsers%5CADMINI~1%5CAppData%5CLocal%5CTemp%5Cksohtml12464%5Cwps2.png
如图,蜘蛛从搜索区域抓取网页的信息,将符合规则的内容取回并带回临时库,不符合规则的内容直接清理,最后他会将符合条件的内容展示给搜索引擎查询。
百度蜘蛛分为pc/mobile-take-all蜘蛛,也有mobile-only蜘蛛。他们收到的大多数命令识别都是相同的。
关于蜘蛛爬取的频率:如果你是新的网站,百度对新站有保护期,会有30天的新站特权。在这30天内,网站内容百度蜘蛛的发布和更新将优先抓取和收录。一般爬取频率由系统根据网站的大小、用户的喜好程度和更新频率自动调整。
不管新的网站还是旧的网站,在文章的内容更新中都必须维护原创。文章的TDK布局很重要。一个好的标签布局是不会出现重复的关键词和句子的。文章 的质量比数量更重要。最好每天在固定的时间发布文章,让百度蜘蛛为我们服务,还有一个相对准时的概念。如果网站的文章或者多次重复的百度蜘蛛不会收录信息,因为百度的搜索引文库中收录了很多类似的信息,没有一个是收录,并且长期会导致网站被K或者降级。
<p>文章中必须注意的一件事是避免关键词stacking,什么是关键词stacking:关键词stacking在文章
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-21 10:04
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(记录一下本次代码的坑点代码实现架构(图))
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意分类图片。考虑到有些图片不是很好的资源,而且因为百度搜索越来越低,相关性会越来越低,所以我会要求每个类别要爬取的数据量控制在600,实际爬下来,每个类别大约有 500 张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看main方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释已经很清楚了,这里不再赘述。
记录这段代码的坑
对于这段代码的实现,修复bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要作用是下载图片,请求图片的源地址,然后作为输入流使用。在进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。当时用httpclient重写,结果还是报错。最后,使用超时设置,如果时间段内没有进行url请求,则进行下一次url请求,直接放弃该请求。600张图片,最后只能爬500张,原因在这里。
源码链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(2019独角兽企业重金招聘Python工程师标准(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-19 22:17
2019独角兽企业重磅Python工程师招聘标准>>>
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。所以我也写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息. ----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
可能是解析器有问题,我们就不多说了,有问题的同学,百度,有一堆解决方法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
代码显示如下:
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0 #声明一个变量赋值
path = 'H:\\python lianxi\\zout_pc5\\test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到H:..\\test文件夹中,如果没有test文件夹则创建
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
#format格式化字符串
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725") #获取该网址网页详细信息,html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束,更多精彩,敬请关注:IT农民工_七晓白
(ps:本人也是python新手,文章如有错误请见谅)
转载于: 查看全部
网页爬虫抓取百度图片(2019独角兽企业重金招聘Python工程师标准(图))
2019独角兽企业重磅Python工程师招聘标准>>>
刚开始学习python爬虫技术,后来想在网上找一些教程看看。谁知道我搜的时候,大部分都是python2写的,新手,一般喜欢装新版本。所以我也写了一个简单的python3爬虫,爬取贴吧的图片。话不多说,开始吧。
先简单说一下知识。
一、什么是爬虫?
采集 网页上的数据
二、学习爬虫的作用是什么?
做案例分析,做数据分析,分析网页结构……
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、 爬虫思路:
1. 打开网页,获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息. ----无法获取想要的内容/请求失败/IP容易被封......等
*解决方案:伪装-不要告诉网站我是脚本,告诉它我是浏览器。(添加任意浏览器的header信息,冒充浏览器),既然是简单的例子,那我们就不做这些无聊的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 函数:查找所有相同的目标。
可能是解析器有问题,我们就不多说了,有问题的同学,百度,有一堆解决方法。
3. 保存图片地址和下载图片
*一种。使用urlib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,则必须写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人看不懂。
顺便提一下:您可以不定期使用 BeautifulSoup;爬虫使用常规,只需选择Bs4和xpath之一。当然,也可以组合使用,还有其他种类。
抓取地址:
代码显示如下:
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0 #声明一个变量赋值
path = 'H:\\python lianxi\\zout_pc5\\test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到H:..\\test文件夹中,如果没有test文件夹则创建
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
#format格式化字符串
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725";) #获取该网址网页详细信息,html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束,更多精彩,敬请关注:IT农民工_七晓白
(ps:本人也是python新手,文章如有错误请见谅)
转载于:
网页爬虫抓取百度图片( 基于python写的一个爬虫程序,能实现简单的网页图片下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 13:26
基于python写的一个爬虫程序,能实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近编辑一直在学习python的东西。今天小编就给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对我棋牌网站的支持! 查看全部
网页爬虫抓取百度图片(
基于python写的一个爬虫程序,能实现简单的网页图片下载)
网页图片抓取的python爬虫方法
更新时间:2018-07-16 17:03:01 作者:JentZhang
最近编辑一直在学习python的东西。今天小编就给大家分享一个基于python的爬虫程序,可以实现简单的网页图片下载。具体的示例代码可以参考这篇文章。
一、简介
这段时间一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的URL已经使用了反爬虫算法。所以爬不出来我想要的图片,所以,就做个爬虫的笔记吧。仅供学习参考【捂脸】。. . .
最后:我把jpg格式改成gif,还是可以爬到很烂的gif:
第一个是反爬虫机制的图片占位符,完全没有任何内容
总结
以上就是小编为大家介绍的Python爬虫抓取网页图片的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对我棋牌网站的支持!
网页爬虫抓取百度图片(最近博主遇到这样一个现成的“数据库”(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-18 19:11
最近有博主遇到这样的需求:当用户输入一个词时,返回这个词的解释。我的第一个想法是建一个数据库,把常用的词和词解释放在数据库中,在用户查询的时候直接读取数据库的结果,但是我不想建这样的数据库,所以想到了一个现成的“数据库”,如百度百科。下面我们使用urllib和xpath来获取百度百科的内容。
最近有博主遇到这样的需求:当用户输入一个词的时候,返回这个词的解释
我的第一个想法是建一个数据库,把常用的词和词的解释放到数据库中,用户查询的时候直接读取数据库结果
但是我没有心去建这样的数据库,于是想到了百度百科这样的现成的“数据库”。
下面我们使用urllib和xpath来获取百度百科的内容
1、 爬取百度百科
百度百科是静态网页,易于抓取,请求参数可以直接放在URL中,例如:
地址网络爬虫对应网络爬虫的百度百科页面
地址电脑对应电脑的百度百科页面
可以说是很方便了,不多说了,直接放代码就好了,不明白的可以看评论:
import urllib.request
import urllib.parse
from lxml import etree
def query(content):
# 请求地址
url = \'https://baike.baidu.com/item/\' + urllib.parse.quote(content)
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath(\'//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()\')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'查询词语:\')
result = query(content)
print("查询结果:%s" % result)
效果演示:
2、 爬行维基百科
上面确实可以解决一些问题,但是如果用户的查询是英文的呢?我们知道百度百科一般很少有收录英文词条
同样,很容易想到爬行维基百科。思路和爬百度百科一样。您只需要处理请求地址并返回结果。
下面也是直接放代码,不明白的可以看评论:
from lxml import etree
import urllib.request
import urllib.parse
def query(content):
# 请求地址
url = \'https://en.wikipedia.org/wiki/\' + content
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到 下所有的子节点对象
obj_list = html.xpath(\'//div[@class="mw-parser-output"]/*\')
# 在所有的子节点对象中获取有用的 <p> 节点对象
for i in range(0,len(obj_list)):
if \'p\' == obj_list[i].tag:
start = i
break
for i in range(start,len(obj_list)):
if \'p\' != obj_list[i].tag:
end = i
break
p_list = obj_list[start:end]
# 使用 xpath 匹配数据,得到 <p> 下所有的文本节点对象
sen_list_list = [obj.xpath(\'.//text()\') for obj in p_list]
# 将文本节点对象转化为字符串列表
sen_list = [sen.encode(\'utf-8\').decode() for sen_list in sen_list_list for sen in sen_list]
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'Word: \')
result = query(content)
print("Result: %s" % result)
下面是效果演示:
好的,你完成了!
注:本项目代码仅供学习交流使用!!! 查看全部
网页爬虫抓取百度图片(最近博主遇到这样一个现成的“数据库”(图))
最近有博主遇到这样的需求:当用户输入一个词时,返回这个词的解释。我的第一个想法是建一个数据库,把常用的词和词解释放在数据库中,在用户查询的时候直接读取数据库的结果,但是我不想建这样的数据库,所以想到了一个现成的“数据库”,如百度百科。下面我们使用urllib和xpath来获取百度百科的内容。
最近有博主遇到这样的需求:当用户输入一个词的时候,返回这个词的解释
我的第一个想法是建一个数据库,把常用的词和词的解释放到数据库中,用户查询的时候直接读取数据库结果
但是我没有心去建这样的数据库,于是想到了百度百科这样的现成的“数据库”。
下面我们使用urllib和xpath来获取百度百科的内容
1、 爬取百度百科
百度百科是静态网页,易于抓取,请求参数可以直接放在URL中,例如:
地址网络爬虫对应网络爬虫的百度百科页面
地址电脑对应电脑的百度百科页面
可以说是很方便了,不多说了,直接放代码就好了,不明白的可以看评论:
import urllib.request
import urllib.parse
from lxml import etree
def query(content):
# 请求地址
url = \'https://baike.baidu.com/item/\' + urllib.parse.quote(content)
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath(\'//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()\')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'查询词语:\')
result = query(content)
print("查询结果:%s" % result)
效果演示:
2、 爬行维基百科
上面确实可以解决一些问题,但是如果用户的查询是英文的呢?我们知道百度百科一般很少有收录英文词条
同样,很容易想到爬行维基百科。思路和爬百度百科一样。您只需要处理请求地址并返回结果。
下面也是直接放代码,不明白的可以看评论:
from lxml import etree
import urllib.request
import urllib.parse
def query(content):
# 请求地址
url = \'https://en.wikipedia.org/wiki/\' + content
# 请求头部
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36\'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method=\'GET\')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode(\'utf-8\')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到 下所有的子节点对象
obj_list = html.xpath(\'//div[@class="mw-parser-output"]/*\')
# 在所有的子节点对象中获取有用的 <p> 节点对象
for i in range(0,len(obj_list)):
if \'p\' == obj_list[i].tag:
start = i
break
for i in range(start,len(obj_list)):
if \'p\' != obj_list[i].tag:
end = i
break
p_list = obj_list[start:end]
# 使用 xpath 匹配数据,得到 <p> 下所有的文本节点对象
sen_list_list = [obj.xpath(\'.//text()\') for obj in p_list]
# 将文本节点对象转化为字符串列表
sen_list = [sen.encode(\'utf-8\').decode() for sen_list in sen_list_list for sen in sen_list]
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip(\'\n\') for item in sen_list]
# 将字符串列表连成字符串并返回
return \'\'.join(sen_list_after_filter)
if __name__ == \'__main__\':
while (True):
content = input(\'Word: \')
result = query(content)
print("Result: %s" % result)
下面是效果演示:
好的,你完成了!
注:本项目代码仅供学习交流使用!!!
网页爬虫抓取百度图片(为什么使用Python进行爬虫?技术是否需要持续学习?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-18 19:10
幸运的是,我们处于互联网时代,可以在互联网上找到很多信息。当我们需要浏览数据或者文章时,通常的方式是复制粘贴。当数据量很大时,这自然是一件费时费力的事情。我们希望有一个自动化的程序,可以自动帮助我们匹配网络上的数据,下载它,并为我们使用。这时候,网络爬虫诞生了。
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
现在根据自己的理解,基本总结一下自己对爬虫的理解。
什么是爬虫?
首先,听我说,就像听演讲一样,这里的爬虫不是生物学意义上的爬虫。
爬虫一般是指网络爬虫,一种自动帮助我们搜索、匹配有用程序、下载并为我们使用的自动化程序。
爬虫的作用是什么?
获取我们需要的数据。许多搜索引擎大量使用爬虫,例如百度搜索和谷歌搜索。爬虫根据需要有不同的分类。
比如一般的搜索引擎都有一定的局限性:
因此,有一个专注的爬虫。它将面向特定主题和网页,为面向主题的用户查询准备数据资源。
为什么要使用 Python 进行爬取?爬虫技术需要持续学习吗?有了庞大的知识量,量变就会引起质变。如果你找到了你需要的东西,这个问题的解决方案肯定不会一成不变。参考网址 查看全部
网页爬虫抓取百度图片(为什么使用Python进行爬虫?技术是否需要持续学习?)
幸运的是,我们处于互联网时代,可以在互联网上找到很多信息。当我们需要浏览数据或者文章时,通常的方式是复制粘贴。当数据量很大时,这自然是一件费时费力的事情。我们希望有一个自动化的程序,可以自动帮助我们匹配网络上的数据,下载它,并为我们使用。这时候,网络爬虫诞生了。
网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
现在根据自己的理解,基本总结一下自己对爬虫的理解。
什么是爬虫?
首先,听我说,就像听演讲一样,这里的爬虫不是生物学意义上的爬虫。
爬虫一般是指网络爬虫,一种自动帮助我们搜索、匹配有用程序、下载并为我们使用的自动化程序。
爬虫的作用是什么?
获取我们需要的数据。许多搜索引擎大量使用爬虫,例如百度搜索和谷歌搜索。爬虫根据需要有不同的分类。
比如一般的搜索引擎都有一定的局限性:
因此,有一个专注的爬虫。它将面向特定主题和网页,为面向主题的用户查询准备数据资源。
为什么要使用 Python 进行爬取?爬虫技术需要持续学习吗?有了庞大的知识量,量变就会引起质变。如果你找到了你需要的东西,这个问题的解决方案肯定不会一成不变。参考网址
网页爬虫抓取百度图片(如何实现搜索关键字?(一)_e操盘_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-16 09:07
2、如何搜索关键词?
通过URL,我们可以发现我们只需要在kw=()和括号中输入你要搜索的内容即可。这样,我们就可以用一个 {} 来代替它,后面我们会循环遍历它。
【五、项目实施】
1、创建一个名为BaiduImageSpider的类,定义一个main方法main和一个初始化方法init。导入所需的库。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
pass
def main(self):
pass
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
spider.main()
pass
if __name__ == '__main__':
spider= ImageSpider()
spider.main()
2、准备url地址和请求头来请求数据。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
self.tieba_name = tieba_name #输入的名字
self.url = "{}&ie=utf-8&pn=0"
self.headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
'''发送请求 获取响应'''
def get_parse_page(self, url, xpath):
html = requests.get(url=url, headers=self.headers).content.decode("utf-8")
parse_html = etree.HTML(html)
r_list = parse_html.xpath(xpath)
return r_list
def main(self):
url = self.url.format(self.tieba_name)
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
key_word = parse.quote(inout_word)
spider = BaiduImageSpider(key_word)
spider.main()
3、xpath 数据分析
3.1、chrome_Xpath 插件安装
1) 这里使用了一个插件。它可以快速检查我们抓取的信息是否正确。具体安装方法如下。
2)百度下载chrome_Xpath_v2.0.2.crx,chrome浏览器输入:chrome://extensions/
3) 将chrome_Xpath_v2.0.2.crx 直接拖到扩展页面;
4) 如果安装失败,弹窗提示“无法从这个网站添加应用程序、扩展和用户脚本”。如果遇到这个问题,解决方法是:打开开发者模式保存crx文件(直接或者修改后缀为rar)解压到一个文件夹中,点击开发者模式加载解压后的扩展,选择解压后的文件夹,点击确定,安装成功;
3.2、chrome_Xpath 插件使用
上面的chrome_Xpath插件我们已经安装好了,接下来就要用到了。1) 打开浏览器,按快捷键F12。2) 选择下图所示的元素。
3) 右击,然后选择“Copy XPath”,如下图。
3.3、写代码,获取链接函数。
我们已经获得了上面链接函数的Xpath路径,然后定义了一个链接函数get_tlink并继承self来实现多页面抓取。
'''获取链接函数'''
def get_tlink(self, url):
xpath = '//div[@class="threadlist_lz clearfix"]/div/a/@href'
t_list = self.get_parse_page(url, xpath)
# print(len(t_list))
for t in t_list:
t_link = " + t
'''接下来对帖子地址发送请求 将保存到本地'''
self.write_image(t_link)
4、保存数据
这里定义了一个write_image方法来保存数据,如下图。
'''保存到本地函数'''
def write_image(self, t_link):
xpath = "//div[@class='d_post_content j_d_post_content clearfix']/img[@class='BDE_Image']/@src | //div[@class='video_src_wrapper']/embed/@data-video"
img_list = self.get_parse_page(t_link, xpath)
for img_link in img_list:
html = requests.get(url=img_link, headers=self.headers).content
filename = "百度/"+img_link[-10:]
with open(filename, 'wb') as f:
f.write(html)
print("%s下载成功" % filename)
如下所示:
【六、效果展示】
1、点击运行,如下图(请输入您要查询的信息):
2、以吴京为例输入后回车:
3、将下载的图片保存在名为“百度”的文件夹中,该文件夹需要提前在本地创建。一定要记得提前在当前代码的同级目录下新建一个名为“百度”的文件夹,否则系统会找不到文件夹,会报错找不到文件夹“百度”。
4、 下图中的MP4为评论区视频。
总结:
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、本文基于Python网络爬虫,利用爬虫库实现百度贴吧评论区抓取。对Python爬取百度贴吧的一些难点进行详细讲解并提供有效的解决方案。3、欢迎积极尝试。有时你看到别人实施起来很容易,但自己动手时,总会出现各种问题。不看高手,努力理解更好。深刻的。学习requests库的使用和爬虫程序的编写。
有不清楚的可以留言。更多Python教程会持续更新!
最新Python爬虫全套视频和人工智能教程整理,学习小伙伴,回复:Python,领取
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
网页爬虫抓取百度图片(如何实现搜索关键字?(一)_e操盘_)
2、如何搜索关键词?
通过URL,我们可以发现我们只需要在kw=()和括号中输入你要搜索的内容即可。这样,我们就可以用一个 {} 来代替它,后面我们会循环遍历它。
【五、项目实施】
1、创建一个名为BaiduImageSpider的类,定义一个main方法main和一个初始化方法init。导入所需的库。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
pass
def main(self):
pass
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
spider.main()
pass
if __name__ == '__main__':
spider= ImageSpider()
spider.main()
2、准备url地址和请求头来请求数据。
import requests
from lxml import etree
from urllib import parse
class BaiduImageSpider(object):
def __init__(self, tieba_name):
self.tieba_name = tieba_name #输入的名字
self.url = "{}&ie=utf-8&pn=0"
self.headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
'''发送请求 获取响应'''
def get_parse_page(self, url, xpath):
html = requests.get(url=url, headers=self.headers).content.decode("utf-8")
parse_html = etree.HTML(html)
r_list = parse_html.xpath(xpath)
return r_list
def main(self):
url = self.url.format(self.tieba_name)
if __name__ == '__main__':
inout_word = input("请输入你要查询的信息:")
key_word = parse.quote(inout_word)
spider = BaiduImageSpider(key_word)
spider.main()
3、xpath 数据分析
3.1、chrome_Xpath 插件安装
1) 这里使用了一个插件。它可以快速检查我们抓取的信息是否正确。具体安装方法如下。
2)百度下载chrome_Xpath_v2.0.2.crx,chrome浏览器输入:chrome://extensions/
3) 将chrome_Xpath_v2.0.2.crx 直接拖到扩展页面;
4) 如果安装失败,弹窗提示“无法从这个网站添加应用程序、扩展和用户脚本”。如果遇到这个问题,解决方法是:打开开发者模式保存crx文件(直接或者修改后缀为rar)解压到一个文件夹中,点击开发者模式加载解压后的扩展,选择解压后的文件夹,点击确定,安装成功;
3.2、chrome_Xpath 插件使用
上面的chrome_Xpath插件我们已经安装好了,接下来就要用到了。1) 打开浏览器,按快捷键F12。2) 选择下图所示的元素。
3) 右击,然后选择“Copy XPath”,如下图。
3.3、写代码,获取链接函数。
我们已经获得了上面链接函数的Xpath路径,然后定义了一个链接函数get_tlink并继承self来实现多页面抓取。
'''获取链接函数'''
def get_tlink(self, url):
xpath = '//div[@class="threadlist_lz clearfix"]/div/a/@href'
t_list = self.get_parse_page(url, xpath)
# print(len(t_list))
for t in t_list:
t_link = " + t
'''接下来对帖子地址发送请求 将保存到本地'''
self.write_image(t_link)
4、保存数据
这里定义了一个write_image方法来保存数据,如下图。
'''保存到本地函数'''
def write_image(self, t_link):
xpath = "//div[@class='d_post_content j_d_post_content clearfix']/img[@class='BDE_Image']/@src | //div[@class='video_src_wrapper']/embed/@data-video"
img_list = self.get_parse_page(t_link, xpath)
for img_link in img_list:
html = requests.get(url=img_link, headers=self.headers).content
filename = "百度/"+img_link[-10:]
with open(filename, 'wb') as f:
f.write(html)
print("%s下载成功" % filename)
如下所示:
【六、效果展示】
1、点击运行,如下图(请输入您要查询的信息):
2、以吴京为例输入后回车:
3、将下载的图片保存在名为“百度”的文件夹中,该文件夹需要提前在本地创建。一定要记得提前在当前代码的同级目录下新建一个名为“百度”的文件夹,否则系统会找不到文件夹,会报错找不到文件夹“百度”。
4、 下图中的MP4为评论区视频。
总结:
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、本文基于Python网络爬虫,利用爬虫库实现百度贴吧评论区抓取。对Python爬取百度贴吧的一些难点进行详细讲解并提供有效的解决方案。3、欢迎积极尝试。有时你看到别人实施起来很容易,但自己动手时,总会出现各种问题。不看高手,努力理解更好。深刻的。学习requests库的使用和爬虫程序的编写。
有不清楚的可以留言。更多Python教程会持续更新!
最新Python爬虫全套视频和人工智能教程整理,学习小伙伴,回复:Python,领取
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
网页爬虫抓取百度图片(分析网页看看能不能获得网页源码打开今日头条官网(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-16 09:02
)
分析网页
看看能不能拿到网页的源代码
打开今日头条官网,搜索“街拍美女”,跳转到街拍首页。在jupyter notebook中尝试get源码,你会发现没有你想要的图片信息。这种情况打消了我们直接分析首页源码,寻找详情页的想法。这时候就用ajax解析了。
点击首页进入其中一个街拍群图详情页,然后尝试获取源码,但是可以直接获取源码。这里可以直接使用正则表达式。
了解页面结构
在“街头美女”首页,打开勾选-网络-选择保存日志,XHR,然后刷新页面,下面会有很多请求,我们直接进入主题,选择其中一个请求,然后看看右边的预览。
展开数据,
我们发现data里面的数据好像和首页的栏目是一一对应的。
当然,这可能并不明显。我们展开数据,看看子节点的title:(中间忽略公众号,我们只需要“open url”中的信息,其他需要过滤。)
查看其他数据子节点,也可以在首页找到对应的栏目,ok,我们已经确定了战略目标:
从首页开始,请求json格式的网页数据,然后使用ajax解析请求,获取并分析首页的源码;
从源代码中提取有用的 URL;
然后通过URL获取详情页的图片。
关于循环爬行
还要看左边。当我们继续下拉主页时,就会有源源不断的新请求。其中,偏移量有明显变化。和前面的实战一样,我们可以通过改变属性的值来达到循环阅读的目的。
分析详情页面
这里有个小技巧:在详情页的图片上右键,选择“在新标签页中打开图片”,然后看新标签页的名字,这个名字(一般只有几个尾数),在doc Ctrl+F 搜索,ok,然后你会发现它们隐藏在哪个变量中(多搜索几张图确认)。此变量收录从中下载图片的图片的 URL。
注:遗憾的是,目前今日头条采取了反拍措施,大部分详情页无法获取源码,因此获取的图片数量非常有限。
附上完整的爬虫代码,“streetPhotos_Spider.py”:
import json
import os
from hashlib import md5
import pymongo
from multiprocessing.pool import Pool
from urllib.parse import urlencode
from requests.exceptions import RequestException
import re
import requests
from webspider.TouTiao.mgconfig import *
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_one_index(offset, keyword): # 获取主页源码,由于主页url是动态的,我们设置参数,以便以后的循环
data = { # 设置url后缀
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 1,
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 用'urlencode方法会将字典解析成字符串
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
print("请求主页失败!")
return None
def parse_page_index(html): # 解析主页源码
try: # 这个函数有可能传入的参数是None,此时应该捕获异常
data = json.loads(html) # 由于拿到的源码是json格式的,需要用json包来解析
if data and 'data' in data.keys(): # 如果有节点data,那么从该节点中寻找article_url
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url): # 获取详情页源码,这里传入的参数将会是从主页中解析出的各个url
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
return None
def parse_page_detail(html): # 解析详情源码
images_pattern = re.compile('[a-zA-z]+://[^\s]*jpg', re.S) # 由于各个详情页结构大不相同,暂时截获所有URL
results = re.findall(images_pattern, html)
if results:
for result in results:
if len(result) > 55:
for result in results: download_images(result)
return {'url': result}
def save_to_mongo(result): # 将解析的结果保存到数据库
if db[MONGO_DB_TABLE].insert(result):
print('存储到MongoDB库', result)
return True
return False
def download_images(url): # 下载图片
print('当前正在下载:', url) # 显示调试信息
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # 返回图片二进制信息
except RequestException:
print("请求图片出错", url)
return None
def save_image(content): # 保存图片到本地
file_path = '{0}/{1}.{2}'.format('D:\Workspace\PycharmProj\webspider\TouTiao\photo', md5(content).hexdigest(),
'jpg') # 为文件命名
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_one_index(offset, KEYWORD) # 获取主页
for url in parse_page_index(html): # 从主页中解析出的各个详情页url
detail_html = get_page_detail(url)
if detail_html: # 若详情页存在,那么解析它
detail_result = parse_page_detail(detail_html)
if detail_result is not None: # 如果详情页非空,
if detail_result: save_to_mongo(detail_result) # 如果详情页有返回的url,那么保存进数据库
if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool() # 创建线程池
pool.map(main, groups) # 将main方法放到线程池中,会自动分割成多线程同时抓取
配置文件“mgconfig.py”放置在同一目录中。
MONGO_URL = 'localhost'
MONGO_DB = 'Toutiao'
MONGO_DB_TABLE = 'Toutiao'
GROUP_START = 1
GROUP_END = 30
KEYWORD = '街拍美女'
文件包结构:
查看全部
网页爬虫抓取百度图片(分析网页看看能不能获得网页源码打开今日头条官网(组图)
)
分析网页
看看能不能拿到网页的源代码
打开今日头条官网,搜索“街拍美女”,跳转到街拍首页。在jupyter notebook中尝试get源码,你会发现没有你想要的图片信息。这种情况打消了我们直接分析首页源码,寻找详情页的想法。这时候就用ajax解析了。
点击首页进入其中一个街拍群图详情页,然后尝试获取源码,但是可以直接获取源码。这里可以直接使用正则表达式。
了解页面结构
在“街头美女”首页,打开勾选-网络-选择保存日志,XHR,然后刷新页面,下面会有很多请求,我们直接进入主题,选择其中一个请求,然后看看右边的预览。
展开数据,
我们发现data里面的数据好像和首页的栏目是一一对应的。
当然,这可能并不明显。我们展开数据,看看子节点的title:(中间忽略公众号,我们只需要“open url”中的信息,其他需要过滤。)
查看其他数据子节点,也可以在首页找到对应的栏目,ok,我们已经确定了战略目标:
从首页开始,请求json格式的网页数据,然后使用ajax解析请求,获取并分析首页的源码;
从源代码中提取有用的 URL;
然后通过URL获取详情页的图片。
关于循环爬行
还要看左边。当我们继续下拉主页时,就会有源源不断的新请求。其中,偏移量有明显变化。和前面的实战一样,我们可以通过改变属性的值来达到循环阅读的目的。
分析详情页面
这里有个小技巧:在详情页的图片上右键,选择“在新标签页中打开图片”,然后看新标签页的名字,这个名字(一般只有几个尾数),在doc Ctrl+F 搜索,ok,然后你会发现它们隐藏在哪个变量中(多搜索几张图确认)。此变量收录从中下载图片的图片的 URL。
注:遗憾的是,目前今日头条采取了反拍措施,大部分详情页无法获取源码,因此获取的图片数量非常有限。
附上完整的爬虫代码,“streetPhotos_Spider.py”:
import json
import os
from hashlib import md5
import pymongo
from multiprocessing.pool import Pool
from urllib.parse import urlencode
from requests.exceptions import RequestException
import re
import requests
from webspider.TouTiao.mgconfig import *
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_one_index(offset, keyword): # 获取主页源码,由于主页url是动态的,我们设置参数,以便以后的循环
data = { # 设置url后缀
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 1,
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 用'urlencode方法会将字典解析成字符串
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
print("请求主页失败!")
return None
def parse_page_index(html): # 解析主页源码
try: # 这个函数有可能传入的参数是None,此时应该捕获异常
data = json.loads(html) # 由于拿到的源码是json格式的,需要用json包来解析
if data and 'data' in data.keys(): # 如果有节点data,那么从该节点中寻找article_url
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url): # 获取详情页源码,这里传入的参数将会是从主页中解析出的各个url
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except RequestException:
return None
def parse_page_detail(html): # 解析详情源码
images_pattern = re.compile('[a-zA-z]+://[^\s]*jpg', re.S) # 由于各个详情页结构大不相同,暂时截获所有URL
results = re.findall(images_pattern, html)
if results:
for result in results:
if len(result) > 55:
for result in results: download_images(result)
return {'url': result}
def save_to_mongo(result): # 将解析的结果保存到数据库
if db[MONGO_DB_TABLE].insert(result):
print('存储到MongoDB库', result)
return True
return False
def download_images(url): # 下载图片
print('当前正在下载:', url) # 显示调试信息
try:
response = requests.get(url)
if response.status_code == 200:
save_image(response.content) # 返回图片二进制信息
except RequestException:
print("请求图片出错", url)
return None
def save_image(content): # 保存图片到本地
file_path = '{0}/{1}.{2}'.format('D:\Workspace\PycharmProj\webspider\TouTiao\photo', md5(content).hexdigest(),
'jpg') # 为文件命名
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_one_index(offset, KEYWORD) # 获取主页
for url in parse_page_index(html): # 从主页中解析出的各个详情页url
detail_html = get_page_detail(url)
if detail_html: # 若详情页存在,那么解析它
detail_result = parse_page_detail(detail_html)
if detail_result is not None: # 如果详情页非空,
if detail_result: save_to_mongo(detail_result) # 如果详情页有返回的url,那么保存进数据库
if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool() # 创建线程池
pool.map(main, groups) # 将main方法放到线程池中,会自动分割成多线程同时抓取
配置文件“mgconfig.py”放置在同一目录中。
MONGO_URL = 'localhost'
MONGO_DB = 'Toutiao'
MONGO_DB_TABLE = 'Toutiao'
GROUP_START = 1
GROUP_END = 30
KEYWORD = '街拍美女'
文件包结构:
网页爬虫抓取百度图片(知乎话题『美女』下所有问题中回答所出现的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-16 07:05
#更新
声明:所有与性别、人脸颜值评分等直接或间接、明示或暗示相关的文字、图片及相关外部链接均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没测试过,理论上可以。Windows之前反应过异常,但检查后是Windows限制了本地文件名中的字符,使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人不同意排名,我的妻子不是最高分。
8码
8. 1 直接使用百度云Python-SDK-去掉代码
8. 2 不使用SDK,直接构造HTTP请求版本。直接使用这个版本的好处是不依赖于SDK的版本(百度云现在有两个版本的接口-V2和V3。现阶段百度云同时支持这两个接口,所以直接用SDK没问题。以后百度不支持V2就得升级SDK或者用这个直接构造HTTP版本)
#coding: utf-8
import time
import os
import re
import requests
from lxml import etree
from aip import AipFace
#百度云 人脸检测 申请信息
#唯一必须填的信息就这三行
APP_ID = "xxxxxxxx"
API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxx"
SECRET_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 文件存放目录名,相对于当前目录
DIR = "image"
# 过滤颜值阈值,存储空间大的请随意
BEAUTY_THRESHOLD = 45
#浏览器中打开知乎,在开发者工具复制一个,无需登录
#如何替换该值下文有讲述
AUTHORIZATION = "oauth c3cef7c66a1843f8b3a9e6a1e3160e20"
#以下皆无需改动
#每次请求知乎的讨论列表长度,不建议设定太长,注意节操
LIMIT = 5
#这是话题『美女』的 ID,其是『颜值』(20013528)的父话题
SOURCE = "19552207"
#爬虫假装下正常浏览器请求
USER_AGENT = "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.5 Safari/534.55.3"
#爬虫假装下正常浏览器请求
REFERER = "https://www.zhihu.com/topic/%s/newest" % SOURCE
#某话题下讨论列表请求 url
BASE_URL = "https://www.zhihu.com/api/v4/t ... ot%3B
#初始请求 url 附带的请求参数
URL_QUERY = "?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.comment_count&limit=" + str(LIMIT)
#指定 url,获取对应原始内容 / 图片
def fetch_image(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.content
#指定 url,获取对应 JSON 返回 / 话题列表
def fetch_activities(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.json()
#处理返回的话题列表
def process_activities(datums, face_detective):
for data in datums["data"]:
target = data["target"]
if "content" not in target or "question" not in target or "author" not in target:
continue
#解析列表中每一个元素的内容
html = etree.HTML(target["content"])
seq = 0
#question_url = target["question"]["url"]
question_title = target["question"]["title"]
author_name = target["author"]["name"]
#author_id = target["author"]["url_token"]
print("current answer: " + question_title + " author: " + author_name)
#获取所有图片地址
images = html.xpath("//img/@src")
for image in images:
if not image.startswith("http"):
continue
s = fetch_image(image)
#请求人脸检测服务
scores = face_detective(s)
for score in scores:
filename = ("%d--" % score) + author_name + "--" + question_title + ("--%d" % seq) + ".jpg"
filename = re.sub(r'(?u)[^-\w.]', '_', filename)
#注意文件名的处理,不同平台的非法字符不一样,这里只做了简单处理,特别是 author_name / question_title 中的内容
seq = seq + 1
with open(os.path.join(DIR, filename), "wb") as fd:
fd.write(s)
#人脸检测 免费,但有 QPS 限制
time.sleep(2)
if not datums["paging"]["is_end"]:
#获取后续讨论列表的请求 url
return datums["paging"]["next"]
else:
return None
def get_valid_filename(s):
s = str(s).strip().replace(' ', '_')
return re.sub(r'(?u)[^-\w.]', '_', s)
import base64
def detect_face(image, token):
try:
URL = "https://aip.baidubce.com/rest/ ... ot%3B
params = {
"access_token": token
}
data = {
"face_field": "age,gender,beauty,qualities",
"image_type": "BASE64",
"image": base64.b64encode(image)
}
s = requests.post(URL, params=params, data=data)
return s.json()["result"]
except Exception as e:
print("detect face fail. " + url)
raise e
def fetch_auth_token(api_key, secret_key):
try:
URL = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": api_key,
"client_secret": secret_key
}
s = requests.post(URL, params=params)
return s.json()["access_token"]
except Exception as e:
print("fetch baidu auth token fail. " + url)
raise e
def init_face_detective(app_id, api_key, secret_key):
# client = AipFace(app_id, api_key, secret_key)
# 百度云 V3 版本接口,需要先获取 access token
token = fetch_auth_token(api_key, secret_key)
def detective(image):
#r = client.detect(image, options)
# 直接使用 HTTP 请求
r = detect_face(image, token)
#如果没有检测到人脸
if r is None or r["face_num"] == 0:
return []
scores = []
for face in r["face_list"]:
#人脸置信度太低
if face["face_probability"] < 0.6:
continue
#颜值低于阈值
if face["beauty"] < BEAUTY_THRESHOLD:
continue
#性别非女性
if face["gender"]["type"] != "female":
continue
scores.append(face["beauty"])
return scores
return detective
def init_env():
if not os.path.exists(DIR):
os.makedirs(DIR)
init_env()
face_detective = init_face_detective(APP_ID, API_KEY, SECRET_KEY)
url = BASE_URL % SOURCE + URL_QUERY
while url is not None:
print("current url: " + url)
datums = fetch_activities(url)
url = process_activities(datums, face_detective)
#注意节操,爬虫休息间隔不要调小
time.sleep(5)
# vim: set ts=4 sw=4 sts=4 tw=100 et:
9 操作准备
需要登录,百度账号可以直接使用(贴吧/网盘通用),不用注册
随便填,这个阶段V3和V2都是默认勾选的。如果没有,请检查所有
在代码中填写AppID ApiKek SecretKey
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
Chrome浏览器;找到一个知乎链接,点进去,打开开发者工具,查看HTTP请求头;无需登录
10 结论
欢迎关注我的专栏
面向薪资的编程-收录 Java 语言面试文章
编程基础和一些理论
编程的日常娱乐——用Python做一些有趣的事情 查看全部
网页爬虫抓取百度图片(知乎话题『美女』下所有问题中回答所出现的图片)
#更新
声明:所有与性别、人脸颜值评分等直接或间接、明示或暗示相关的文字、图片及相关外部链接均由相关人脸检测界面给出。没有任何客观性,仅供参考。
1 数据来源
知乎“美女”主题下所有问题的答案中出现的图片
2 履带
Python 3,并使用第三方库Requests、lxml、AipFace,共100+行代码
3 必要的环境
Mac / Linux / Windows(Linux没测试过,理论上可以。Windows之前反应过异常,但检查后是Windows限制了本地文件名中的字符,使用了常规过滤),无需登录知乎(即无需提供知乎账号密码),人脸检测服务需要百度云账号(即百度云盘/贴吧账号)
4 人脸检测库
百度云AI开放平台提供的AipFace是一个可以进行人脸检测的Python SDK。可以直接通过HTTP访问,免费使用
5 测试过滤条件
6 实现逻辑
7 抓取结果
直接存放在文件夹中(angelababy实力出国)。另外,目前拍摄的照片中,除了baby,88分是最高分。我个人不同意排名,我的妻子不是最高分。
8码
8. 1 直接使用百度云Python-SDK-去掉代码
8. 2 不使用SDK,直接构造HTTP请求版本。直接使用这个版本的好处是不依赖于SDK的版本(百度云现在有两个版本的接口-V2和V3。现阶段百度云同时支持这两个接口,所以直接用SDK没问题。以后百度不支持V2就得升级SDK或者用这个直接构造HTTP版本)
#coding: utf-8
import time
import os
import re
import requests
from lxml import etree
from aip import AipFace
#百度云 人脸检测 申请信息
#唯一必须填的信息就这三行
APP_ID = "xxxxxxxx"
API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxx"
SECRET_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 文件存放目录名,相对于当前目录
DIR = "image"
# 过滤颜值阈值,存储空间大的请随意
BEAUTY_THRESHOLD = 45
#浏览器中打开知乎,在开发者工具复制一个,无需登录
#如何替换该值下文有讲述
AUTHORIZATION = "oauth c3cef7c66a1843f8b3a9e6a1e3160e20"
#以下皆无需改动
#每次请求知乎的讨论列表长度,不建议设定太长,注意节操
LIMIT = 5
#这是话题『美女』的 ID,其是『颜值』(20013528)的父话题
SOURCE = "19552207"
#爬虫假装下正常浏览器请求
USER_AGENT = "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.5 Safari/534.55.3"
#爬虫假装下正常浏览器请求
REFERER = "https://www.zhihu.com/topic/%s/newest" % SOURCE
#某话题下讨论列表请求 url
BASE_URL = "https://www.zhihu.com/api/v4/t ... ot%3B
#初始请求 url 附带的请求参数
URL_QUERY = "?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.comment_count&limit=" + str(LIMIT)
#指定 url,获取对应原始内容 / 图片
def fetch_image(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.content
#指定 url,获取对应 JSON 返回 / 话题列表
def fetch_activities(url):
try:
headers = {
"User-Agent": USER_AGENT,
"Referer": REFERER,
"authorization": AUTHORIZATION
}
s = requests.get(url, headers=headers)
except Exception as e:
print("fetch last activities fail. " + url)
raise e
return s.json()
#处理返回的话题列表
def process_activities(datums, face_detective):
for data in datums["data"]:
target = data["target"]
if "content" not in target or "question" not in target or "author" not in target:
continue
#解析列表中每一个元素的内容
html = etree.HTML(target["content"])
seq = 0
#question_url = target["question"]["url"]
question_title = target["question"]["title"]
author_name = target["author"]["name"]
#author_id = target["author"]["url_token"]
print("current answer: " + question_title + " author: " + author_name)
#获取所有图片地址
images = html.xpath("//img/@src")
for image in images:
if not image.startswith("http"):
continue
s = fetch_image(image)
#请求人脸检测服务
scores = face_detective(s)
for score in scores:
filename = ("%d--" % score) + author_name + "--" + question_title + ("--%d" % seq) + ".jpg"
filename = re.sub(r'(?u)[^-\w.]', '_', filename)
#注意文件名的处理,不同平台的非法字符不一样,这里只做了简单处理,特别是 author_name / question_title 中的内容
seq = seq + 1
with open(os.path.join(DIR, filename), "wb") as fd:
fd.write(s)
#人脸检测 免费,但有 QPS 限制
time.sleep(2)
if not datums["paging"]["is_end"]:
#获取后续讨论列表的请求 url
return datums["paging"]["next"]
else:
return None
def get_valid_filename(s):
s = str(s).strip().replace(' ', '_')
return re.sub(r'(?u)[^-\w.]', '_', s)
import base64
def detect_face(image, token):
try:
URL = "https://aip.baidubce.com/rest/ ... ot%3B
params = {
"access_token": token
}
data = {
"face_field": "age,gender,beauty,qualities",
"image_type": "BASE64",
"image": base64.b64encode(image)
}
s = requests.post(URL, params=params, data=data)
return s.json()["result"]
except Exception as e:
print("detect face fail. " + url)
raise e
def fetch_auth_token(api_key, secret_key):
try:
URL = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": api_key,
"client_secret": secret_key
}
s = requests.post(URL, params=params)
return s.json()["access_token"]
except Exception as e:
print("fetch baidu auth token fail. " + url)
raise e
def init_face_detective(app_id, api_key, secret_key):
# client = AipFace(app_id, api_key, secret_key)
# 百度云 V3 版本接口,需要先获取 access token
token = fetch_auth_token(api_key, secret_key)
def detective(image):
#r = client.detect(image, options)
# 直接使用 HTTP 请求
r = detect_face(image, token)
#如果没有检测到人脸
if r is None or r["face_num"] == 0:
return []
scores = []
for face in r["face_list"]:
#人脸置信度太低
if face["face_probability"] < 0.6:
continue
#颜值低于阈值
if face["beauty"] < BEAUTY_THRESHOLD:
continue
#性别非女性
if face["gender"]["type"] != "female":
continue
scores.append(face["beauty"])
return scores
return detective
def init_env():
if not os.path.exists(DIR):
os.makedirs(DIR)
init_env()
face_detective = init_face_detective(APP_ID, API_KEY, SECRET_KEY)
url = BASE_URL % SOURCE + URL_QUERY
while url is not None:
print("current url: " + url)
datums = fetch_activities(url)
url = process_activities(datums, face_detective)
#注意节操,爬虫休息间隔不要调小
time.sleep(5)
# vim: set ts=4 sw=4 sts=4 tw=100 et:
9 操作准备
需要登录,百度账号可以直接使用(贴吧/网盘通用),不用注册
随便填,这个阶段V3和V2都是默认勾选的。如果没有,请检查所有
在代码中填写AppID ApiKek SecretKey
{
"error": {
"message": "ZERR_NO_AUTH_TOKEN",
"code": 100,
"name": "AuthenticationInvalidRequest"
}
}
Chrome浏览器;找到一个知乎链接,点进去,打开开发者工具,查看HTTP请求头;无需登录
10 结论
欢迎关注我的专栏
面向薪资的编程-收录 Java 语言面试文章
编程基础和一些理论
编程的日常娱乐——用Python做一些有趣的事情
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-16 04:09
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,通常情况下,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“web”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有一篇网站文章的文章,它吸引了大量的流量,但由于网站空间不够,大量用户前来访问网页打不开,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。 查看全部
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
对于一个网站站长来说,反爬虫是一项非常重要的工作——没有人愿意被爬虫占用一半的宽带。
只有百度爬虫是个例外。对于站长来说,一篇文章的文章越早被百度收录证明,优化的效果就越大。
那么百度爬虫的爬取规则是怎样的呢?今天就一起来看看吧。
一、优质内容持续更新
用户和百度爬虫都对干货内容很感兴趣,一个可以持续更新并且更新内容质量有保证的网站,当然比没有更新或者不更新的要好多年来原创网站的内容更吸引人。
二、优质外链
这是网站提升排名的重要一步。对于百度来说,大流量网站的权重一定要高于小流量网站的权重。如果我们的网站外链是一个流量很大的入口网站,通常情况下,这个入口网站在百度上的权重也会很高,这意味着它会间接增加这个有增加了我们自己网站的曝光率,增加了百度爬虫爬取自己网站内容的可能性。
三、优质内链
在构建爬虫爬行矩阵(或“web”)时,除了扩展的优质外链外,我们网站内链的质量也决定了百度爬虫收录文章的可能性和速度。百度爬虫会跟随网站导航、网站内页锚文本链接等进入网站内页。简洁简短的导航,让爬虫更快的找到内页的锚文本,这样百度在收录的时候,不仅收录了目标页面的内容,还收录了收录的所有内容小路。网页。
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录有一篇网站文章的文章,它吸引了大量的流量,但由于网站空间不够,大量用户前来访问网页打不开,甚至百度爬虫打不开,无疑会降低百度对于这个网站的权重分配。
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-11-15 04:22
内容
你好!大家好,我是一只正在努力赚钱买生发乳液的小灰猿。很多学过Python的朋友都希望有一个属于自己的爬虫,所以今天大灰狼给小伙伴们分享一个简单的爬虫程序。
请允许我在这里卖给我的朋友。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开特定的网页,抓取网页上存在的某些信息。想象一下,如果把一个网页比作一块田地,爬虫就住在这个田地里,从田地头爬到田头,只捕食田地里吃某种食物的昆虫。哈哈,比喻有点粗糙,但网络爬虫的实际效果是类似的。
想要了解更多的朋友也可以阅读我的文章《Python带你一分钟探秘网络昆虫!》!
爬虫的原理是什么?
那么有朋友可能会问,爬虫程序是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了这个网页中的所有信息。当我们打开某个网页时,按F12键可以看到该网页的代码,我们以百度图片搜索皮卡丘网页为例,按F12后,可以看到如下代码,覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例。我们的爬虫想要爬取这个网页上所有的皮卡丘图片,所以我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,在这个链接下添加下载图片。
所以爬虫的工作原理就是从网页的代码中寻找并提取特定的代码。这就像从一个很长的字符串中找到一个特定格式的字符串。对这块知识感兴趣的人也可以。阅读我的文章文章《实战中Python特定文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里我们以requests模块为例编写爬虫程序。
以抓取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序要做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取该网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式,匹配所有符合要求的图片链接代码通过设置的正则表达式一一打开图片链接下载图片
接下来,大灰狼就按照以上步骤和大家分享一下这个爬虫的准备过程:
1、获取百度图片中“皮卡丘图片”的网页链接
首先我们打开百度图片的网页链接
然后在关键字搜索“皮卡丘”后打开链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
通过对比,去掉多余的部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:Keyword
现在我们第一步是在百度图片中获取“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取本页所有代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后通过模块中的text函数获取网页的文字,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中找到图片的链接
这一步我们可以先打开网页的链接,按F12按照大灰狼开头提到的方法查看网页的所有代码,然后如果我们要抓取jpg中的所有图片格式,我们可以按Ctrl+F找到具体内容的代码,
比如我们在网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容。我们通过仔细观察这些链接会发现这些链接之间的相似之处,即每个链接之前都会有“OpjURL”:以提示,最后以“,”结尾
我们取出了其中一个链接
访问后发现图片也可以打开。
所以我们可以暂时推断一下,百度图片中jpg图片的一般格式为“"OpjURL":XXXX"",
4、 根据图片链接写一个通用的正则表达式
既然知道了这类图片的一般格式是""OpjURL":XXXX"",那么下一步就是按照这个格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不熟悉正则表达式使用的朋友也可以阅读我的两篇文章文章《Python教程中的正则表达式(基础)》和《Python教程中的正则表达式(改进版)》
5、 通过设置的正则表达式匹配代码中所有符合要求的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配的图片链接,并将所有匹配的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后我们就可以在这个文件下看到匹配的图片链接了,复制一张就可以打开了。
6、一一打开图片链接,下载图片
现在我们已经存储了列表中所有图片的链接,下一步就是下载图片。
基本思路是:通过for循环遍历列表中的所有链接,以二进制方式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前都会休眠三秒,每个链接的访问时间最长为5秒。如果访问时间超过五秒,我们判断下载失败,继续下载下一章图片。
至于为什么要打开图片并以二进制方式写入,是因为我们的图片需要经过二进制方式解析后才能被计算机写入。
下载图片的代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
现在,一个简单的爬取百度皮卡丘图片的爬虫就完成了,朋友们也可以随意更改图片关键词和下载次数,培养一个属于自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) # 打开链接
urltext = urls.text # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
如果觉得有用,记得点赞关注哦! 查看全部
网页爬虫抓取百度图片(Python一分钟带你探秘不为人知的网络昆虫!(上))
内容
你好!大家好,我是一只正在努力赚钱买生发乳液的小灰猿。很多学过Python的朋友都希望有一个属于自己的爬虫,所以今天大灰狼给小伙伴们分享一个简单的爬虫程序。
请允许我在这里卖给我的朋友。
什么是网络爬虫?
所谓网络爬虫,简单来说就是通过程序打开特定的网页,抓取网页上存在的某些信息。想象一下,如果把一个网页比作一块田地,爬虫就住在这个田地里,从田地头爬到田头,只捕食田地里吃某种食物的昆虫。哈哈,比喻有点粗糙,但网络爬虫的实际效果是类似的。
想要了解更多的朋友也可以阅读我的文章《Python带你一分钟探秘网络昆虫!》!
爬虫的原理是什么?
那么有朋友可能会问,爬虫程序是怎么工作的呢?
举个栗子:
我们看到的所有网页都是由特定的代码组成的,这些代码涵盖了这个网页中的所有信息。当我们打开某个网页时,按F12键可以看到该网页的代码,我们以百度图片搜索皮卡丘网页为例,按F12后,可以看到如下代码,覆盖了整个网页的所有内容。
以一个爬取“皮卡丘图片”的爬虫为例。我们的爬虫想要爬取这个网页上所有的皮卡丘图片,所以我们的爬虫要做的就是在这个网页的代码中找到皮卡丘图片的链接,在这个链接下添加下载图片。
所以爬虫的工作原理就是从网页的代码中寻找并提取特定的代码。这就像从一个很长的字符串中找到一个特定格式的字符串。对这块知识感兴趣的人也可以。阅读我的文章文章《实战中Python特定文本提取,挑战高效办公的第一步》,
了解了以上两点之后,就是如何编写这样的爬虫了。
Python爬虫常用的第三方模块有urllib2和requests。大灰狼个人认为urllib2模块比requests模块复杂,所以这里我们以requests模块为例编写爬虫程序。
以抓取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序要做的是:
获取百度图片中“皮卡丘图片”的网页链接 获取该网页的所有代码 在代码中找到图片的链接 根据图片链接编写通用正则表达式,匹配所有符合要求的图片链接代码通过设置的正则表达式一一打开图片链接下载图片
接下来,大灰狼就按照以上步骤和大家分享一下这个爬虫的准备过程:
1、获取百度图片中“皮卡丘图片”的网页链接
首先我们打开百度图片的网页链接
然后在关键字搜索“皮卡丘”后打开链接
%E7%9A%AE%E5%8D%A1%E4%B8%98
通过对比,去掉多余的部分后,我们可以得到百度图片关键词搜索的一般链接长度如下:Keyword
现在我们第一步是在百度图片中获取“皮卡丘图片”的网页链接,下一步就是获取网页的所有代码
2、获取本页所有代码
这时候我们可以先使用requests模块下的get()函数打开链接
然后通过模块中的text函数获取网页的文字,也就是所有的代码。
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本
3、在代码中找到图片的链接
这一步我们可以先打开网页的链接,按F12按照大灰狼开头提到的方法查看网页的所有代码,然后如果我们要抓取jpg中的所有图片格式,我们可以按Ctrl+F找到具体内容的代码,
比如我们在网页的代码中找到带有jpg的代码,然后找到类似下图的代码,
链接就是我们想要获取的内容。我们通过仔细观察这些链接会发现这些链接之间的相似之处,即每个链接之前都会有“OpjURL”:以提示,最后以“,”结尾
我们取出了其中一个链接
访问后发现图片也可以打开。
所以我们可以暂时推断一下,百度图片中jpg图片的一般格式为“"OpjURL":XXXX"",
4、 根据图片链接写一个通用的正则表达式
既然知道了这类图片的一般格式是""OpjURL":XXXX"",那么下一步就是按照这个格式写正则表达式了。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。
不熟悉正则表达式使用的朋友也可以阅读我的两篇文章文章《Python教程中的正则表达式(基础)》和《Python教程中的正则表达式(改进版)》
5、 通过设置的正则表达式匹配代码中所有符合要求的图片链接
上面我们已经写好了图片链接的正则表达式,接下来就是通过正则表达式匹配所有的代码,得到所有链接的列表
urllist = re.findall(urltext)
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,
接下来,我们用几行代码来验证我们通过表达式匹配的图片链接,并将所有匹配的链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")
之后我们就可以在这个文件下看到匹配的图片链接了,复制一张就可以打开了。
6、一一打开图片链接,下载图片
现在我们已经存储了列表中所有图片的链接,下一步就是下载图片。
基本思路是:通过for循环遍历列表中的所有链接,以二进制方式打开链接,新建一个.jpg文件,将我们的图片以二进制形式写入文件中。
这里为了避免下载太快,我们每次下载前都会休眠三秒,每个链接的访问时间最长为5秒。如果访问时间超过五秒,我们判断下载失败,继续下载下一章图片。
至于为什么要打开图片并以二进制方式写入,是因为我们的图片需要经过二进制方式解析后才能被计算机写入。
下载图片的代码如下,下载次数设置为3:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
现在,一个简单的爬取百度皮卡丘图片的爬虫就完成了,朋友们也可以随意更改图片关键词和下载次数,培养一个属于自己的爬虫。
最后附上完整的源码:
import requests
import re
import time
url = "http://image.baidu.com/search/ ... rd%3D皮卡丘"
urls = requests.get(url) # 打开链接
urltext = urls.text # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
如果觉得有用,记得点赞关注哦!
网页爬虫抓取百度图片(浅谈一下爬虫什么是爬虫?(二):请求网站并提取数据的自动化程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-15 04:21
前言
爬虫是一项非常有趣的技术。您可以使用爬虫技术来获取其他人无法获得或需要付费的东西。您还可以自动抓取并保存大量数据,减少手动完成一些繁琐任务的时间和精力。
可以说,学编程的人很多,不玩爬虫的意义就少了很多。无论是业余爱好者、私人工作还是专业爬虫,爬虫世界真的很精彩。
今天给大家讲一下爬虫,目的是让准备学习爬虫或者刚入门的人对爬虫有更深入、更全面的了解。
一、认识爬虫
1.什么是爬虫?
一句话介绍著名的爬虫:一个请求网站并提取数据的自动化程序。
下面我们来拆解了解一下爬虫:
网站的请求就是向网站发送请求。比如去百度搜索关键词“Python”。这时,我们的浏览器会向网站发送请求;
提取数据。数据包括图片、文字、视频等,统称为数据。我们发送请求后,网站 会将搜索结果呈现给我们。这实际上是返回数据。这时候我们可以查看数据来提取
自动化程序,也就是我们写的代码,实现了过程数据的自动提取,比如批量下载和保存返回的图片,而不是手动一一操作。
2. 爬虫分类
根据使用场景,爬虫可以分为三类:
①万能爬虫(大而全)功能强大,采集范围广泛。它通常用于搜索引擎。比如百度浏览器就是一个非常庞大的爬虫程序。
②专注爬虫(小而精) 功能比较单一,只爬取特定网站的特定内容,比如去一个网站批量获取一些数据,这也是我们的个人最常用的一种爬虫。
③增量爬虫(仅采集更新内容) 这其实是一个专注于爬虫的迭代爬虫。它只是采集更新数据,而不是旧数据采集,相当于一直存在和运行。只要满足要求的数据有更新,就会自动抓取新的数据。
3.机器人协议
爬虫中有一个叫做Robots的协议需要注意,也称为“网络爬虫排除标准”。它的作用是网站告诉你什么可以爬,什么不能爬。
在哪里看这个机器人协议?
一般情况下,可以直接在网站首页URL中添加/robots.txt进行查看。例如,百度的Robots 协议在/robots.txt 中。可以看到有很多URL是规定不能爬取的,比如Disallow:/shifen/表示当前的Disallow:/shifen和Disallow:/shifen下的子目录都不能爬取。
实际上,这份Robots协议属于君子协议。对于爬虫来说,基本上是口头约定。如果你违反了它,你可能会被追究责任。但是,如果你不违反它,爬虫将无法抓取任何数据,所以通常双方都视而不见,只是不要太嚣张。
二、爬取的基本过程
1.爬行4步
爬行动物是如何工作的?
爬虫程序大致可以分为四个步骤:
①发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,可以收录额外的headers等信息,等待服务器响应。
②获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可能包括 HTML、Json 字符串和二进制数据(如图片和视频)。
③内容分析
获取的内容可能是HTML,可以使用正则表达式和网页解析库进行解析。可能是Json,可以直接转成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
④保存数据
保存的数据有多种类型,可以保存为文本、保存到数据库或保存为特定格式的文件。
基本上,这是爬虫必须遵循的四个步骤。
2.请求和响应
请求和响应是爬虫最重要的部分。请求和响应之间是什么关系?
两者的关系如下:
简单理解一下,当我们在电脑浏览器上搜索东西的时候,比如前面提到的在百度搜索“Python”,你点击百度,已经向百度的服务器发送了一个Request请求,Request中收录很多信息,比如如身份信息、请求信息等,服务器收到请求后做出判断,然后返回一个Response给我们的电脑,里面也收录了很多信息,比如请求成功,比如我们请求的信息结果(文本、图片、视频等)。
应该很容易理解吧?
接下来,让我们仔细看看请求和响应。
三、了解RequestRequest中收录什么?
它主要收录以下内容:
1.请求方法
请求方法可以理解为你打招呼的方式网站。如果你从网站那里得到数据,你要以正确的方式迎接它,这样它才能回应你,就像你从别人家借东西一样,你要先敲门再说你好。可以直接爬上窗户进去,看到的人必须出去。
主要的请求方法是GET和POST,还有其他的方法如HEAD/PUT/DELETE/OPTIONS,最常用的是GET。
2.请求网址
什么是网址?
URL的全称是Uniform Resource Locator。例如,一个网页文档、图片、视频等都有一个唯一的网址,可以理解为爬虫中的网址或链接。
3.请求头
请求头是什么?
英文名称Request Headers通常是指请求中收录的头信息,如User-Agent、Host、Cookies等。
当你向网站发送请求时,这些东西就相当于你的身份信息。经常需要伪装自己,伪装成普通用户来躲避你的目标。网站 识别你是爬虫,避免一些反扒问题,顺利获取数据。
4. request body 的官方说法是请求中携带的附加数据,比如提交表单时的表单数据。
在爬虫中如何理解?
例如,在某些页面上,您必须先登录,或者您必须告诉我您的要求。比如你在百度网页搜索“Python”,那么关键词“Python”就是你要携带的请求体,看到你的请求体,看到百度就知道你要做什么了。
当然,请求体通常用在 POST 请求方法中。GET 请求时,我们通常将其拼接在 URL 中。先了解一下就够了,后续具体爬虫可以去加深了解。
5.实用视图请求
既然我们已经讲了Request的理论,那我们就可以进入实际操作,看看Request在哪里,收录什么。
以谷歌浏览器为例,我输入关键词“Python”就可以搜索到一堆结果。我们使用网页自带的控制台窗口来分析我们发送的Request请求。
按住F12或者在网页空白处右击选择“检查”,然后就可以看到控制台里有很多选项了。例如,上列有一个菜单栏。初级爬虫一般使用元素(Elements)。还有Network(网络),其他的东西暂时不需要,等你学习更高级一点的爬虫时会用到,比如JS逆向工程可能会用到Application窗口,以后再学习。
Elements 收录了所有请求结果的每一个元素,比如每张图片的源代码,尤其是点击左上角的小箭头,你移动到的每一个地方都会在 Elements 窗口下显示为源代码。
网络是爬虫常用的网络信息。其中包括我们的请求。让我们来看看。在“网络”窗口下,选中“禁用缓存”并单击“全部”。
刷新网页看看效果。您可以看到我们发送了 132 个请求请求。不要对这个好奇。虽然我们只向百度发送了类似“Python”这样的请求,但其中一些是附加到网页的请求。
虽然图片格式有很多种,比如png、jpeg等,但是可以滑动到顶部。在Type栏中,有文档类型,即web文档的含义。点击进入,我们将是我们的。索取资料。
点击文档进入后,有一个新的菜单栏。在Headers列下,我们可以看到Request URL,也就是我们前面提到的请求URL。这个URL就是我们实际从网页请求的URL,然后返回 有一个请求方法,可以看出是一个GET请求。
如果再次向下滑动,还可以看到我们之前提到的 Request Headers。信息很多,但是我们前面提到的User-Agent、Host、Cookies都是我们提供给服务器的信息。
虽然Request Headers里面的内容很多,我们在写爬虫程序的时候也要做这方面的伪装工作,但是不是所有的信息都要写,有选择的写一些重要的信息就足够了,比如User-Agent必需的。Referer 和 Host 是可选区域。登录时会携带cookies,常见的有4种需要伪装。
至于请求体,我暂时不去查了,因为我们这里的请求方法是GET请求,请求体只能在POST请求中查看。没关系,爬虫什么时候用你就明白了。
四、了解响应
Response 主要包括 3 条内容,我们来一一看看。
1.响应状态我们发送请求后,网站会返回给我们一个Response,其中收录响应状态码的响应状态,大致可以分为以下几种:
①例如在200以内,响应状态码200表示成功。
②三百的范围,比如301就是跳跃。
③四百范围内,如404找不到页面。
④范围五百,如502找不到页面。
对于爬虫来说,两三百是我们最想看到的响应状态,有可能获取到数据,而四五百基本是冷的,获取不到数据。
比如我们刚刚发送了之前的Request请求时,在文档文件中,在Headers窗口下的General中,可以看到响应状态码为200,表示网页成功响应了我们的请求。
2. 响应头
服务器给我们的信息也会收录响应头,其中包括内容类型、内容长度、服务器信息、设置cookies等。
其实响应头对我们来说并没有那么重要,在这里了解一下就行了。
3.响应体
这一点很重要,除了上面第一点的响应状态,就是它,因为它收录了请求资源的内容,比如网页HTML和图像二进制数。
响应体在哪里?它也在文档文件的响应列中。可以向下滑动,看到有很多响应数据。这是我们得到的数据。有些可以直接下载,有些需要技术分析。知道了。
五、爬虫能得到什么样的数据?
**爬虫可以获取什么样的数据?**基本上可以分为几类:
① Web 文档,如 HTML 文档、Json 格式的文本等。
②图片以二进制文件形式获取,可以保存为图片格式。
③视频,也是二进制文件,可以保存为视频格式。
④其他,反正其他能看到的东西理论上爬虫都能得到,看难易程度。
六、如何解析数据?
从前面我们可以成功发送请求,网页会返回给我们很多数据,有几千甚至几万个代码,那么如何在这么多代码中找到我们想要的数据呢?常用的方法如下:
①直接治疗。当网页返回的数据是一些文本时,就是我们想要的内容,不需要过滤处理,直接处理即可。
②Json分析。如果返回的网页不是HTML数据而是Json数据,则需要Json解析技术。
③正则表达式。如果返回的数据是符合正则表达式的数据,可以使用正则表达式进行分析。
④其他分析方法。常用的有XPath、BeautifulSoup、PyQuery,都是爬虫常用的解析库。
七、如何保存数据?获取数据后,常用的保存数据的方法如下:
①文字。可以直接保存为纯文本、EXCEL、Json、Xml等类型的文本。
②关系数据库。数据可以保存到关系型数据库,如MySQL和Oracle数据库。
③非关系型数据库。比如MongoDB、Readis和Key-Value存储。
④ 二进制文件。比如图片、视频、音频等可以直接保存为特定格式。练习视频: 查看全部
网页爬虫抓取百度图片(浅谈一下爬虫什么是爬虫?(二):请求网站并提取数据的自动化程序)
前言
爬虫是一项非常有趣的技术。您可以使用爬虫技术来获取其他人无法获得或需要付费的东西。您还可以自动抓取并保存大量数据,减少手动完成一些繁琐任务的时间和精力。
可以说,学编程的人很多,不玩爬虫的意义就少了很多。无论是业余爱好者、私人工作还是专业爬虫,爬虫世界真的很精彩。
今天给大家讲一下爬虫,目的是让准备学习爬虫或者刚入门的人对爬虫有更深入、更全面的了解。
一、认识爬虫
1.什么是爬虫?
一句话介绍著名的爬虫:一个请求网站并提取数据的自动化程序。
下面我们来拆解了解一下爬虫:
网站的请求就是向网站发送请求。比如去百度搜索关键词“Python”。这时,我们的浏览器会向网站发送请求;
提取数据。数据包括图片、文字、视频等,统称为数据。我们发送请求后,网站 会将搜索结果呈现给我们。这实际上是返回数据。这时候我们可以查看数据来提取
自动化程序,也就是我们写的代码,实现了过程数据的自动提取,比如批量下载和保存返回的图片,而不是手动一一操作。
2. 爬虫分类
根据使用场景,爬虫可以分为三类:
①万能爬虫(大而全)功能强大,采集范围广泛。它通常用于搜索引擎。比如百度浏览器就是一个非常庞大的爬虫程序。
②专注爬虫(小而精) 功能比较单一,只爬取特定网站的特定内容,比如去一个网站批量获取一些数据,这也是我们的个人最常用的一种爬虫。
③增量爬虫(仅采集更新内容) 这其实是一个专注于爬虫的迭代爬虫。它只是采集更新数据,而不是旧数据采集,相当于一直存在和运行。只要满足要求的数据有更新,就会自动抓取新的数据。
3.机器人协议
爬虫中有一个叫做Robots的协议需要注意,也称为“网络爬虫排除标准”。它的作用是网站告诉你什么可以爬,什么不能爬。
在哪里看这个机器人协议?
一般情况下,可以直接在网站首页URL中添加/robots.txt进行查看。例如,百度的Robots 协议在/robots.txt 中。可以看到有很多URL是规定不能爬取的,比如Disallow:/shifen/表示当前的Disallow:/shifen和Disallow:/shifen下的子目录都不能爬取。
实际上,这份Robots协议属于君子协议。对于爬虫来说,基本上是口头约定。如果你违反了它,你可能会被追究责任。但是,如果你不违反它,爬虫将无法抓取任何数据,所以通常双方都视而不见,只是不要太嚣张。
二、爬取的基本过程
1.爬行4步
爬行动物是如何工作的?
爬虫程序大致可以分为四个步骤:
①发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,可以收录额外的headers等信息,等待服务器响应。
②获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可能包括 HTML、Json 字符串和二进制数据(如图片和视频)。
③内容分析
获取的内容可能是HTML,可以使用正则表达式和网页解析库进行解析。可能是Json,可以直接转成Json对象解析,也可能是二进制数据,可以保存或者进一步处理。
④保存数据
保存的数据有多种类型,可以保存为文本、保存到数据库或保存为特定格式的文件。
基本上,这是爬虫必须遵循的四个步骤。
2.请求和响应
请求和响应是爬虫最重要的部分。请求和响应之间是什么关系?
两者的关系如下:
简单理解一下,当我们在电脑浏览器上搜索东西的时候,比如前面提到的在百度搜索“Python”,你点击百度,已经向百度的服务器发送了一个Request请求,Request中收录很多信息,比如如身份信息、请求信息等,服务器收到请求后做出判断,然后返回一个Response给我们的电脑,里面也收录了很多信息,比如请求成功,比如我们请求的信息结果(文本、图片、视频等)。
应该很容易理解吧?
接下来,让我们仔细看看请求和响应。
三、了解RequestRequest中收录什么?
它主要收录以下内容:
1.请求方法
请求方法可以理解为你打招呼的方式网站。如果你从网站那里得到数据,你要以正确的方式迎接它,这样它才能回应你,就像你从别人家借东西一样,你要先敲门再说你好。可以直接爬上窗户进去,看到的人必须出去。
主要的请求方法是GET和POST,还有其他的方法如HEAD/PUT/DELETE/OPTIONS,最常用的是GET。
2.请求网址
什么是网址?
URL的全称是Uniform Resource Locator。例如,一个网页文档、图片、视频等都有一个唯一的网址,可以理解为爬虫中的网址或链接。
3.请求头
请求头是什么?
英文名称Request Headers通常是指请求中收录的头信息,如User-Agent、Host、Cookies等。
当你向网站发送请求时,这些东西就相当于你的身份信息。经常需要伪装自己,伪装成普通用户来躲避你的目标。网站 识别你是爬虫,避免一些反扒问题,顺利获取数据。
4. request body 的官方说法是请求中携带的附加数据,比如提交表单时的表单数据。
在爬虫中如何理解?
例如,在某些页面上,您必须先登录,或者您必须告诉我您的要求。比如你在百度网页搜索“Python”,那么关键词“Python”就是你要携带的请求体,看到你的请求体,看到百度就知道你要做什么了。
当然,请求体通常用在 POST 请求方法中。GET 请求时,我们通常将其拼接在 URL 中。先了解一下就够了,后续具体爬虫可以去加深了解。
5.实用视图请求
既然我们已经讲了Request的理论,那我们就可以进入实际操作,看看Request在哪里,收录什么。
以谷歌浏览器为例,我输入关键词“Python”就可以搜索到一堆结果。我们使用网页自带的控制台窗口来分析我们发送的Request请求。
按住F12或者在网页空白处右击选择“检查”,然后就可以看到控制台里有很多选项了。例如,上列有一个菜单栏。初级爬虫一般使用元素(Elements)。还有Network(网络),其他的东西暂时不需要,等你学习更高级一点的爬虫时会用到,比如JS逆向工程可能会用到Application窗口,以后再学习。
Elements 收录了所有请求结果的每一个元素,比如每张图片的源代码,尤其是点击左上角的小箭头,你移动到的每一个地方都会在 Elements 窗口下显示为源代码。
网络是爬虫常用的网络信息。其中包括我们的请求。让我们来看看。在“网络”窗口下,选中“禁用缓存”并单击“全部”。
刷新网页看看效果。您可以看到我们发送了 132 个请求请求。不要对这个好奇。虽然我们只向百度发送了类似“Python”这样的请求,但其中一些是附加到网页的请求。
虽然图片格式有很多种,比如png、jpeg等,但是可以滑动到顶部。在Type栏中,有文档类型,即web文档的含义。点击进入,我们将是我们的。索取资料。
点击文档进入后,有一个新的菜单栏。在Headers列下,我们可以看到Request URL,也就是我们前面提到的请求URL。这个URL就是我们实际从网页请求的URL,然后返回 有一个请求方法,可以看出是一个GET请求。
如果再次向下滑动,还可以看到我们之前提到的 Request Headers。信息很多,但是我们前面提到的User-Agent、Host、Cookies都是我们提供给服务器的信息。
虽然Request Headers里面的内容很多,我们在写爬虫程序的时候也要做这方面的伪装工作,但是不是所有的信息都要写,有选择的写一些重要的信息就足够了,比如User-Agent必需的。Referer 和 Host 是可选区域。登录时会携带cookies,常见的有4种需要伪装。
至于请求体,我暂时不去查了,因为我们这里的请求方法是GET请求,请求体只能在POST请求中查看。没关系,爬虫什么时候用你就明白了。
四、了解响应
Response 主要包括 3 条内容,我们来一一看看。
1.响应状态我们发送请求后,网站会返回给我们一个Response,其中收录响应状态码的响应状态,大致可以分为以下几种:
①例如在200以内,响应状态码200表示成功。
②三百的范围,比如301就是跳跃。
③四百范围内,如404找不到页面。
④范围五百,如502找不到页面。
对于爬虫来说,两三百是我们最想看到的响应状态,有可能获取到数据,而四五百基本是冷的,获取不到数据。
比如我们刚刚发送了之前的Request请求时,在文档文件中,在Headers窗口下的General中,可以看到响应状态码为200,表示网页成功响应了我们的请求。
2. 响应头
服务器给我们的信息也会收录响应头,其中包括内容类型、内容长度、服务器信息、设置cookies等。
其实响应头对我们来说并没有那么重要,在这里了解一下就行了。
3.响应体
这一点很重要,除了上面第一点的响应状态,就是它,因为它收录了请求资源的内容,比如网页HTML和图像二进制数。
响应体在哪里?它也在文档文件的响应列中。可以向下滑动,看到有很多响应数据。这是我们得到的数据。有些可以直接下载,有些需要技术分析。知道了。
五、爬虫能得到什么样的数据?
**爬虫可以获取什么样的数据?**基本上可以分为几类:
① Web 文档,如 HTML 文档、Json 格式的文本等。
②图片以二进制文件形式获取,可以保存为图片格式。
③视频,也是二进制文件,可以保存为视频格式。
④其他,反正其他能看到的东西理论上爬虫都能得到,看难易程度。
六、如何解析数据?
从前面我们可以成功发送请求,网页会返回给我们很多数据,有几千甚至几万个代码,那么如何在这么多代码中找到我们想要的数据呢?常用的方法如下:
①直接治疗。当网页返回的数据是一些文本时,就是我们想要的内容,不需要过滤处理,直接处理即可。
②Json分析。如果返回的网页不是HTML数据而是Json数据,则需要Json解析技术。
③正则表达式。如果返回的数据是符合正则表达式的数据,可以使用正则表达式进行分析。
④其他分析方法。常用的有XPath、BeautifulSoup、PyQuery,都是爬虫常用的解析库。
七、如何保存数据?获取数据后,常用的保存数据的方法如下:
①文字。可以直接保存为纯文本、EXCEL、Json、Xml等类型的文本。
②关系数据库。数据可以保存到关系型数据库,如MySQL和Oracle数据库。
③非关系型数据库。比如MongoDB、Readis和Key-Value存储。
④ 二进制文件。比如图片、视频、音频等可以直接保存为特定格式。练习视频:

