
网页数据抓取怎么写
网页数据抓取怎么写(缓存穿透**详解及解决方案_50323137的博客-程序员)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-17 08:09
Redis常见问题->缓存穿透**缓存击穿**缓存雪崩**缓存预热**集群裂脑**详解及解决方案_m0_50323137的博客-程序员的秘密
缓存穿透缓存穿透是指用户请求的数据在缓存中不存在,即没有命中,在数据库中也不存在。结果,用户每次请求数据,都要查询一次数据库,然后返回空。在普通攻击和恶意攻击中,不断地请求系统中不存在的数据,导致大量请求在缓存中找不到,并在短时间内落入数据库。甚至导致数据库崩溃。常见解决方案(1)缓存空对象当缓存未命中,查询数据库也为空时,可以将返回的空对象写入缓存,这样下次请求就不会落入数据库。,有一个问题:如果有大量的key渗透,
YOLOv2输出物体位置坐标并批量处理图片_xiaomifanhxx的博客-程序员secret_yolov2输出层
当我们使用深度学习进行识别和检测时,有时不仅需要找到判别类型,有时还需要分析坐标。下面将告诉你通过YOLOV2训练时如何输出物体的位置坐标。1.查看保存检测图像的源代码。看过源码的人一定知道,我们通常在训练和检测的时候都会用到YOLO中的检测器功能。在源代码不变的情况下,我们将检测到的图片保存为darknet.exe,路径与“predictio...
svn diff 与 vimdiff_First Line - 程序员的秘密
vim ~/.subversion/configunder [helpers] section adddiff-cmd=/{你的文件路径}/svndiff.sh create svndiff.sh fileDIFF=/{你的vimdiff路径}/vimdiffLEFT=${6}RIGHT=${7} $ 差异 $ 左 $ 右
微信JS-SDK文档_take_wang的专栏-程序员的秘密
来自:微信JS-SDK文档目录1概述1.1 JSSDK使用步骤1.1.1第一步:绑定域名1.1.2第二步:引入JS文件1.1.3 第三步:通过config界面注入
信息学奥林匹克 - 1047
1047:判断是否能被3、5、7整除时间限制:1000毫秒内存限制:65536 KB提交次数:85571通过次数:39099【标题说明】给定一个整数,判断是否能被33、55整除, 77 , 并输出如下信息: 1、 可以同时被33, 55, 77整除(直接输出3 5 7,每个数字中间有一个空格);2、 只能被其中两个整除(输出两个数字,先小后大。例如:3 5 or 3 7 or 5 7,用空格隔开);3、 只能被其中一个整除(输出除数);4、不能被任何数字四舍五入...
svn diff和vimdiff_chenqiechun3408的使用方法-程序员的秘密
SVN子命令SVN diff功能介绍 2010-05-24 14:16 匿名名称:T | T 本文将介绍SVN子命令SVN diff,它的主要高手比较了两条路径的区别,这里跟大家分享一下,希望大家一起学习。AD:WOT2014:用户标签系统和用户数据操作... 查看全部
网页数据抓取怎么写(缓存穿透**详解及解决方案_50323137的博客-程序员)
Redis常见问题->缓存穿透**缓存击穿**缓存雪崩**缓存预热**集群裂脑**详解及解决方案_m0_50323137的博客-程序员的秘密
缓存穿透缓存穿透是指用户请求的数据在缓存中不存在,即没有命中,在数据库中也不存在。结果,用户每次请求数据,都要查询一次数据库,然后返回空。在普通攻击和恶意攻击中,不断地请求系统中不存在的数据,导致大量请求在缓存中找不到,并在短时间内落入数据库。甚至导致数据库崩溃。常见解决方案(1)缓存空对象当缓存未命中,查询数据库也为空时,可以将返回的空对象写入缓存,这样下次请求就不会落入数据库。,有一个问题:如果有大量的key渗透,
YOLOv2输出物体位置坐标并批量处理图片_xiaomifanhxx的博客-程序员secret_yolov2输出层
当我们使用深度学习进行识别和检测时,有时不仅需要找到判别类型,有时还需要分析坐标。下面将告诉你通过YOLOV2训练时如何输出物体的位置坐标。1.查看保存检测图像的源代码。看过源码的人一定知道,我们通常在训练和检测的时候都会用到YOLO中的检测器功能。在源代码不变的情况下,我们将检测到的图片保存为darknet.exe,路径与“predictio...
svn diff 与 vimdiff_First Line - 程序员的秘密
vim ~/.subversion/configunder [helpers] section adddiff-cmd=/{你的文件路径}/svndiff.sh create svndiff.sh fileDIFF=/{你的vimdiff路径}/vimdiffLEFT=${6}RIGHT=${7} $ 差异 $ 左 $ 右
微信JS-SDK文档_take_wang的专栏-程序员的秘密
来自:微信JS-SDK文档目录1概述1.1 JSSDK使用步骤1.1.1第一步:绑定域名1.1.2第二步:引入JS文件1.1.3 第三步:通过config界面注入
信息学奥林匹克 - 1047
1047:判断是否能被3、5、7整除时间限制:1000毫秒内存限制:65536 KB提交次数:85571通过次数:39099【标题说明】给定一个整数,判断是否能被33、55整除, 77 , 并输出如下信息: 1、 可以同时被33, 55, 77整除(直接输出3 5 7,每个数字中间有一个空格);2、 只能被其中两个整除(输出两个数字,先小后大。例如:3 5 or 3 7 or 5 7,用空格隔开);3、 只能被其中一个整除(输出除数);4、不能被任何数字四舍五入...
svn diff和vimdiff_chenqiechun3408的使用方法-程序员的秘密
SVN子命令SVN diff功能介绍 2010-05-24 14:16 匿名名称:T | T 本文将介绍SVN子命令SVN diff,它的主要高手比较了两条路径的区别,这里跟大家分享一下,希望大家一起学习。AD:WOT2014:用户标签系统和用户数据操作...
网页数据抓取怎么写(一下框架介绍和安装Scrapy的用法(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-14 08:08
在前面的章节中,我们用尽可能少的代码演示了爬虫的基本原理。如果只需要抓取一些简单的数据,那么我们可以通过修改前面的代码来完成任务。但是当我们需要完成一些复杂的大规模爬取任务时,就需要考虑更多的事情,比如爬虫的可扩展性、爬取效率等。
现在让我们回顾一下我们的爬取过程:从要下载的 URL 列表中提取 URL;构建并发送 HTTP 请求以下载网页;解析网页以提取数据,解析网页以提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。这个过程中有很多地方是通用的,只有网页数据和URL提取与具体的爬取任务相关。因为通用代码部分可以重用,所以框架就诞生了。现在python下的爬虫框架很多,比较常用的是Scrapy。接下来,我们简单介绍一下Scrapy的用法。
Scrapy框架介绍及安装
Scrapy 是一个用 python 开发的快速高效的网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 广泛用于数据挖掘、监控和自动化测试。Scrapy的安装也很简单,只要运行pip install Scrapy,我们需要的开发环境就准备好了。
创建一个 Scrapy 项目
这里我们将使用 Scrapy 框架重写我们之前的爬虫。在我们开始之前,我们需要创建一个新的 Scrapy 项目。假设我们的项目名为豆瓣,运行scrapy startproject Douban。创建豆瓣文件夹,这个文件夹收录了我们爬虫的基本框架。
这里有几个更重要的概念:
创建项目类
我们使用Item类来封装从网页解析出来的数据,方便各个模块之间的传递和进一步处理。爬虫的Item类很简单。它直接继承了scrapy的Item类,并定义了相应的属性字段来存储数据。每个字段都是 scrapy.Field() 类型,可用于存储任何类型的数据。现在看看我们的 Item 类定义:
创建蜘蛛类
Spider 类主要用于解析数据,它收录一些用于下载的初始 URL 以及用于提取网页中的链接和数据的方法。所有 Spider 必须继承自 scrapy.Spider 类并实现三个属性:
创建管道类
Scrapy 使用管道模块来保存对数据的操作。即Spider类的parse()方法返回的Item对象会传递给Pipeline中的类,Pipeline会完成具体的保存工作。创建 Scrapy 项目时会自动创建一个 pipeline.py 文件,其中收录一个默认的 Pipeline 类。
Pipeline 类会在 process_item() 方法中处理数据,然后在最后调用 close_spider() 方法,所以我们需要这两个方法来做相应的处理。
运行爬虫
在项目目录下,执行命令scrapy crawl Douban,我们可以看到爬虫开始爬取网页。
总结
现在让我们回顾一下我们所有的代码在 Scrapy 框架下是如何工作的:
过去 文章:
Python爬虫入门,快速抓取海量数据5
Python爬虫入门,快速抓取海量数据4
Python爬虫入门,快速抓取海量数据3
Python爬虫入门,快速抓取海量数据2
Python爬虫入门,快速抓取海量数据1 查看全部
网页数据抓取怎么写(一下框架介绍和安装Scrapy的用法(一)_)
在前面的章节中,我们用尽可能少的代码演示了爬虫的基本原理。如果只需要抓取一些简单的数据,那么我们可以通过修改前面的代码来完成任务。但是当我们需要完成一些复杂的大规模爬取任务时,就需要考虑更多的事情,比如爬虫的可扩展性、爬取效率等。
现在让我们回顾一下我们的爬取过程:从要下载的 URL 列表中提取 URL;构建并发送 HTTP 请求以下载网页;解析网页以提取数据,解析网页以提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。这个过程中有很多地方是通用的,只有网页数据和URL提取与具体的爬取任务相关。因为通用代码部分可以重用,所以框架就诞生了。现在python下的爬虫框架很多,比较常用的是Scrapy。接下来,我们简单介绍一下Scrapy的用法。
Scrapy框架介绍及安装
Scrapy 是一个用 python 开发的快速高效的网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 广泛用于数据挖掘、监控和自动化测试。Scrapy的安装也很简单,只要运行pip install Scrapy,我们需要的开发环境就准备好了。
创建一个 Scrapy 项目
这里我们将使用 Scrapy 框架重写我们之前的爬虫。在我们开始之前,我们需要创建一个新的 Scrapy 项目。假设我们的项目名为豆瓣,运行scrapy startproject Douban。创建豆瓣文件夹,这个文件夹收录了我们爬虫的基本框架。
这里有几个更重要的概念:
创建项目类
我们使用Item类来封装从网页解析出来的数据,方便各个模块之间的传递和进一步处理。爬虫的Item类很简单。它直接继承了scrapy的Item类,并定义了相应的属性字段来存储数据。每个字段都是 scrapy.Field() 类型,可用于存储任何类型的数据。现在看看我们的 Item 类定义:
创建蜘蛛类
Spider 类主要用于解析数据,它收录一些用于下载的初始 URL 以及用于提取网页中的链接和数据的方法。所有 Spider 必须继承自 scrapy.Spider 类并实现三个属性:
创建管道类
Scrapy 使用管道模块来保存对数据的操作。即Spider类的parse()方法返回的Item对象会传递给Pipeline中的类,Pipeline会完成具体的保存工作。创建 Scrapy 项目时会自动创建一个 pipeline.py 文件,其中收录一个默认的 Pipeline 类。
Pipeline 类会在 process_item() 方法中处理数据,然后在最后调用 close_spider() 方法,所以我们需要这两个方法来做相应的处理。
运行爬虫
在项目目录下,执行命令scrapy crawl Douban,我们可以看到爬虫开始爬取网页。
总结
现在让我们回顾一下我们所有的代码在 Scrapy 框架下是如何工作的:
过去 文章:
Python爬虫入门,快速抓取海量数据5
Python爬虫入门,快速抓取海量数据4
Python爬虫入门,快速抓取海量数据3
Python爬虫入门,快速抓取海量数据2
Python爬虫入门,快速抓取海量数据1
网页数据抓取怎么写(一个英语学习爱好者.1.3破解激活,IntelliJ会写代码吟诗的架构师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-13 22:07
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是我们通常这样做
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说用网络爬虫为自己写一个英语学习工具,希望能帮助大家提高!!!
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是,虽然我们平时阅读量很大,但我们只是被动地将英文信息转化为大致的中文意思理解,而不是试图训练如何从中文到英文表达。成为程序员的好处之一是,当你发现需要时,你可以尝试制作一些东西来和自己一起玩。为了做这个学习工具,我首先想到了一些新闻网站会提供双语新闻(比如酷游网),然后我的想法就简单的形成了,首先创建一个网络爬虫,抓取一些双语新闻网页,然后提取每个中英文句子,然后制作图形界面,每次显示一条消息。中文,让用户尝试输入英文翻译,写不出来可以查看英文原版提示,并提供笔记功能,记录特殊词汇、表达和经验等。这些功能一一实现。
1 网页抓取框架-scrapy
所谓网络爬虫,其实就是我们使用的浏览器。它访问一个链接,然后下载相应的网页。不同的是,浏览器下载文件后呈现一个页面,而爬虫可以根据我们定义的规则,自动访问网站中的链接,然后处理下载的web文件,提取我们想要的数据. 如果要自己实现一个网络爬虫,需要自己编写一个模拟的http客户端,实现文本解析等功能,比较麻烦。此时,您可以找到任何有用的开源软件。Scrapy() 是一个非常好的工具。它是一个使用 python 的快速和先进的网络抓取框架。使用时只需要简单定义你要抓取的网页的url,而对于每次抓取页面需要进行的处理操作,剩下的都可以通过scrapy来完成。感兴趣的朋友可以看看它提供的tutorial(),现在就开始我们的工作吧。
(1)安装scrapy后,在shell终端下任意目录运行命令:
scrapy startproject 双语(项目名称自行取)
得到如下图的项目结构
bilingual/
scrapy.cfg
bilingual/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
只听山间传来建筑师的声音:
江水流泉至尽,月落江塘。谁将向上或向下匹配?
Scrapy 提供这些文件以允许我们自定义处理捕获的数据。spiders 目录用于存储用户定义的蜘蛛类。Scrapy 根据此处定义的类捕获信息。在spider类中,需要定义初始的url列表,以及抓取新链接的规则以及如何解析提取下载的网页信息。为简单起见,我只在spiders目录下写了一个spider进行处理,并没有使用其他功能。
(2)在spiders目录下,创建文件cuyoo.py(自定义的spider名称,即要捕获的网站的名称),代码如下
此代码由Java架构师必看网-架构君整理
1 from scrapy.selector import HtmlXPathSelector
2 from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
3 from scrapy.contrib.spiders import CrawlSpider, Rule
4
5 import codecs
6 import os
7
8 class CuyooSpider(CrawlSpider):
9 name = 'cuyoo'
10 allowed_domains = ['cuyoo.com']
11 start_urls = [
12 'http://www.cuyoo.com/home/portal.php?mod=list&catid=2']
13
14 rules = (
15 Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',
follow=False),
16 )
17
18 def __init__(self, *arg, **kwargs):
19 super(CuyooSpider, self).__init__(*arg, **kwargs)
20 self.output = codecs.open("data", "wb", "utf-8")
21
22 def __del__(self):
23 self.output.close()
24
25 def parse_item(self, response):
26 hxs = HtmlXPathSelector(response)
27 title = hxs.select("//h4[@class='ph']/text()").extract()
28 english = hxs.select('//div[@id="en"]/text()').extract()
29 chinese = hxs.select('//div[@id="cn"]/text()').extract()
30 self.output.write("---" + title[0].strip() + "---")
31 self.output.write(os.linesep)
32 for i in range(len(english)):
33 self.output.write(chinese[i].strip())
34 self.output.write("->")
35 self.output.write(english[i].strip())
36 self.output.write(os.linesep)
稍微解释一下,在上面的蜘蛛中,我在star_urls成员中放了一个链接,打开这个链接可以看到如下网页:
可以看到,在这个网页中有多个新闻链接,每个链接点击双语对照可以得到中英文对照版的新闻,查看源代码可以看出其链接形式为:portal.php?mod=view_both&aid=19076,所以在rules里定义规则
Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',follow=False)
用正则表达式表示包含'mod=view_both’的链接,scrapy在访问该网页时,就会自动抓取符合所定义的规则的所有链接,这样就将这一页里的所有中英文对照的新闻都抓取了下来,然后对每个抓取到的网页调用parse_item(self, response)进行处理
(3) 因为我们要的只是网页里的中英文新闻内容,所以要对下载到的网页进行信息抽取,scrapy提供了XPath查找功能,让我们可以方便地抽取文档节点内容,不了解XPath可以看看W3C的教程(http://www.w3school.com.cn/xpath/),要抽取信息,首先还是要分析该新闻网页的结构,可以使用scrapy提供的命令行工具来分析网页结构和试验xpath语句,首先运行命令
此代码由Java架构师必看网-架构君整理
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
将网页下载下来后,再输入view(response),可在浏览器查看下载到的网页
可以看出,新闻的两种格式分别包含在两个div中,一个id为en,另一个为cn,所在在parse_item()中,分别使用
hxs.select('//div[@id="en"]/text()').extract() 和 hxs.select('//div[@id="cn"]/text()').extract()
将内容抽取出来,并按格式写到文件中。
(4)在项目目录下运行 scrapy crawl cuyoo 开始抓取,最终得到如下图所示意的文件
2 图形界面
使用捕获的数据,您可以自由地播放您接下来想做的事情。我的图形界面是通过 Qt 实现的。我个人认为它非常方便且易于使用。.
程序界面
选择文章
查看提示
最后,还有一个尚未实现的笔记功能。本来想用印象笔记SDK直接在印象笔记上写笔记的,但是因为他们的SDK的C++版本没有教程文档,貌似账号有点复杂。,或者等到以后再找时间实施。
3 总结
这样做我得到了两分。首先,它让我觉得编程其实很有用,不局限于工作和学习。只要我们有想法,我们就可以做很多事情。第二个是关于开源软件。现在有很多开源软件。使用开源的东西非常方便有趣。同时,我们也可以参与到使用的过程中。比如我在使用scrapy的时候,上面提到过。这样的命令
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
一开始我的链接没用引号括起来,因为&在shell里是个特殊符号,表示后台运行,所以链接里的第二个参数在运行的时候就没了,后来想明白后,问题解决了,我觉得这个问题别人可能也会遇到,所以就在scrapy的github页面上给提了这个问题,希望他们能加到tutorial文档里,然后过了一两天,他们就真的加上了,这让我感到很高兴,也很佩服。
好了,写得好长,谢谢观看~
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
网页数据抓取怎么写(一个英语学习爱好者.1.3破解激活,IntelliJ会写代码吟诗的架构师)
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是我们通常这样做
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说用网络爬虫为自己写一个英语学习工具,希望能帮助大家提高!!!
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是,虽然我们平时阅读量很大,但我们只是被动地将英文信息转化为大致的中文意思理解,而不是试图训练如何从中文到英文表达。成为程序员的好处之一是,当你发现需要时,你可以尝试制作一些东西来和自己一起玩。为了做这个学习工具,我首先想到了一些新闻网站会提供双语新闻(比如酷游网),然后我的想法就简单的形成了,首先创建一个网络爬虫,抓取一些双语新闻网页,然后提取每个中英文句子,然后制作图形界面,每次显示一条消息。中文,让用户尝试输入英文翻译,写不出来可以查看英文原版提示,并提供笔记功能,记录特殊词汇、表达和经验等。这些功能一一实现。
1 网页抓取框架-scrapy
所谓网络爬虫,其实就是我们使用的浏览器。它访问一个链接,然后下载相应的网页。不同的是,浏览器下载文件后呈现一个页面,而爬虫可以根据我们定义的规则,自动访问网站中的链接,然后处理下载的web文件,提取我们想要的数据. 如果要自己实现一个网络爬虫,需要自己编写一个模拟的http客户端,实现文本解析等功能,比较麻烦。此时,您可以找到任何有用的开源软件。Scrapy() 是一个非常好的工具。它是一个使用 python 的快速和先进的网络抓取框架。使用时只需要简单定义你要抓取的网页的url,而对于每次抓取页面需要进行的处理操作,剩下的都可以通过scrapy来完成。感兴趣的朋友可以看看它提供的tutorial(),现在就开始我们的工作吧。
(1)安装scrapy后,在shell终端下任意目录运行命令:
scrapy startproject 双语(项目名称自行取)
得到如下图的项目结构
bilingual/
scrapy.cfg
bilingual/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
只听山间传来建筑师的声音:
江水流泉至尽,月落江塘。谁将向上或向下匹配?
Scrapy 提供这些文件以允许我们自定义处理捕获的数据。spiders 目录用于存储用户定义的蜘蛛类。Scrapy 根据此处定义的类捕获信息。在spider类中,需要定义初始的url列表,以及抓取新链接的规则以及如何解析提取下载的网页信息。为简单起见,我只在spiders目录下写了一个spider进行处理,并没有使用其他功能。
(2)在spiders目录下,创建文件cuyoo.py(自定义的spider名称,即要捕获的网站的名称),代码如下
此代码由Java架构师必看网-架构君整理
1 from scrapy.selector import HtmlXPathSelector
2 from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
3 from scrapy.contrib.spiders import CrawlSpider, Rule
4
5 import codecs
6 import os
7
8 class CuyooSpider(CrawlSpider):
9 name = 'cuyoo'
10 allowed_domains = ['cuyoo.com']
11 start_urls = [
12 'http://www.cuyoo.com/home/portal.php?mod=list&catid=2']
13
14 rules = (
15 Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',
follow=False),
16 )
17
18 def __init__(self, *arg, **kwargs):
19 super(CuyooSpider, self).__init__(*arg, **kwargs)
20 self.output = codecs.open("data", "wb", "utf-8")
21
22 def __del__(self):
23 self.output.close()
24
25 def parse_item(self, response):
26 hxs = HtmlXPathSelector(response)
27 title = hxs.select("//h4[@class='ph']/text()").extract()
28 english = hxs.select('//div[@id="en"]/text()').extract()
29 chinese = hxs.select('//div[@id="cn"]/text()').extract()
30 self.output.write("---" + title[0].strip() + "---")
31 self.output.write(os.linesep)
32 for i in range(len(english)):
33 self.output.write(chinese[i].strip())
34 self.output.write("->")
35 self.output.write(english[i].strip())
36 self.output.write(os.linesep)
稍微解释一下,在上面的蜘蛛中,我在star_urls成员中放了一个链接,打开这个链接可以看到如下网页:

可以看到,在这个网页中有多个新闻链接,每个链接点击双语对照可以得到中英文对照版的新闻,查看源代码可以看出其链接形式为:portal.php?mod=view_both&aid=19076,所以在rules里定义规则
Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',follow=False)
用正则表达式表示包含'mod=view_both’的链接,scrapy在访问该网页时,就会自动抓取符合所定义的规则的所有链接,这样就将这一页里的所有中英文对照的新闻都抓取了下来,然后对每个抓取到的网页调用parse_item(self, response)进行处理
(3) 因为我们要的只是网页里的中英文新闻内容,所以要对下载到的网页进行信息抽取,scrapy提供了XPath查找功能,让我们可以方便地抽取文档节点内容,不了解XPath可以看看W3C的教程(http://www.w3school.com.cn/xpath/" rel="nofollow" target="_blank">http://www.w3school.com.cn/xpath/),要抽取信息,首先还是要分析该新闻网页的结构,可以使用scrapy提供的命令行工具来分析网页结构和试验xpath语句,首先运行命令
此代码由Java架构师必看网-架构君整理
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
将网页下载下来后,再输入view(response),可在浏览器查看下载到的网页
可以看出,新闻的两种格式分别包含在两个div中,一个id为en,另一个为cn,所在在parse_item()中,分别使用
hxs.select('//div[@id="en"]/text()').extract() 和 hxs.select('//div[@id="cn"]/text()').extract()
将内容抽取出来,并按格式写到文件中。
(4)在项目目录下运行 scrapy crawl cuyoo 开始抓取,最终得到如下图所示意的文件
2 图形界面
使用捕获的数据,您可以自由地播放您接下来想做的事情。我的图形界面是通过 Qt 实现的。我个人认为它非常方便且易于使用。.
程序界面
选择文章
查看提示
最后,还有一个尚未实现的笔记功能。本来想用印象笔记SDK直接在印象笔记上写笔记的,但是因为他们的SDK的C++版本没有教程文档,貌似账号有点复杂。,或者等到以后再找时间实施。
3 总结
这样做我得到了两分。首先,它让我觉得编程其实很有用,不局限于工作和学习。只要我们有想法,我们就可以做很多事情。第二个是关于开源软件。现在有很多开源软件。使用开源的东西非常方便有趣。同时,我们也可以参与到使用的过程中。比如我在使用scrapy的时候,上面提到过。这样的命令
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
一开始我的链接没用引号括起来,因为&在shell里是个特殊符号,表示后台运行,所以链接里的第二个参数在运行的时候就没了,后来想明白后,问题解决了,我觉得这个问题别人可能也会遇到,所以就在scrapy的github页面上给提了这个问题,希望他们能加到tutorial文档里,然后过了一两天,他们就真的加上了,这让我感到很高兴,也很佩服。
好了,写得好长,谢谢观看~
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
网页数据抓取怎么写(Python爬虫初探初探为什么选择Python?爬虫是什么?网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-13 22:06
初探 Python 爬虫 为什么选择 Python?什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
基本知识概念
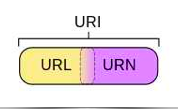
URL(协议(服务模式)+IP地址(含端口号)+具体地址),即统一资源定位器,也就是我们所说的网站,统一资源定位器就是可以定位和访问的资源从 Internet 获得 方法的简洁表示是 Internet 上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
URI 在计算机术语中,统一资源标识符 (URI) 是用于标识 Internet 资源名称的字符串。这种标识允许用户通过特定的协议与任何(包括本地和互联网)资源进行交互。URI 由收录特定语法和相关协议的方案定义。
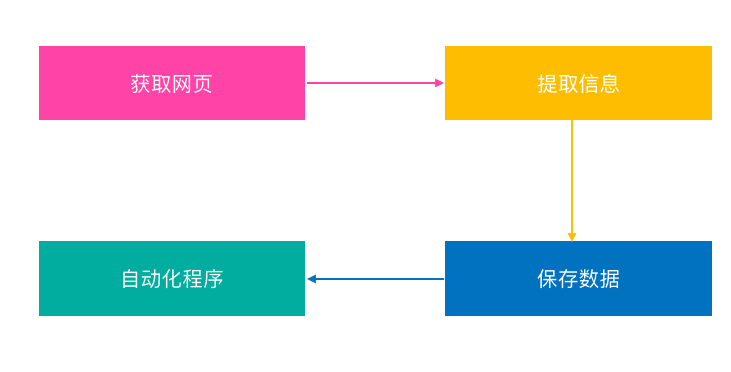
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求。服务器解析后,将HTML、JS、CSS等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。其实就是一个http请求的过程。
爬虫入门
常用爬虫库
请求库:requests、selenium(自动化测试工具)+ChromeDrive(chrome驱动)、PhantomJS(无界面浏览器)
解析库:LXML(html、xml、Xpath方法)、BeautifulSoup(html、xml)、PyQuery(支持css选择器)、Tesserocr(光学字符识别、验证码)
数据库:mongo、mysql、redis
存储库:pymysql、pymongo、redispy、RedisDump(用于导入和导出 Redis 数据的工具)
网络库:Flask(轻量级网络服务器)、Django
其他工具:Charles(网络抓包工具)
示例(如果 cookie 不起作用,您可以更改) 基本示例
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
#请求头相关
print(myUrl)
req = request.Request(myUrl, headers=headers)
#调用库发送请求
myResponse = request.urlopen(req)
myPage = myResponse.read()
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
一个比较复杂的例子是爬虫百科网站,拉出作者头像、作者姓名、内容
修改自:
<p># -*- coding: utf-8 -*-
import urllib
import _thread
import re
import time
from urllib import request
# ----------- 加载处理糗事百科 -----------
class Spider_Model:
def __init__(self):
self.page = 1
self.pages = []
self.enable = False
# 将所有的段子都扣出来,添加到列表中并且返回列表
def GetPage(self, page):
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
print(myUrl)
req = request.Request(myUrl, headers=headers)
myResponse = request.urlopen(req)
myPage = myResponse.read()
# print(myPage)
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
# 找出所有class="content"的div标记
# re.S是任意匹配模式,也就是.可以匹配换行符
# myItems = re.findall('(.*?)', unicodePage, re.S)
content = re.findall('.*?(.*?)(.*?)', unicodePage, re.S)
items = []
# print("~~~~~~~~~~~~~~~~~~~")
# print(content)
# print(len(content))
# print(content[1])
imageIcon = re.findall('.*?(.*?)', unicodePage, re.S)
# print("~~~~~~~~~~~~~~~~~~~")
# print(imageIcon)
# print(len(imageIcon))
# print(imageIcon[0][0])
# print(imageIcon[0][1])
# print(imageIcon[1][0])
# print(imageIcon[1][1])
for index in range(min(len(content), len(imageIcon)) - 1):
items.append([content[index][0].replace("\n", "").replace("
", ""), imageIcon[index][0], imageIcon[index][1]])
return items
# 用于加载新的段子
def LoadPage(self):
# 如果用户未输入quit则一直运行
while self.enable:
# 如果pages数组中的内容小于2个
if len(self.pages) 查看全部
网页数据抓取怎么写(Python爬虫初探初探为什么选择Python?爬虫是什么?网络爬虫)
初探 Python 爬虫 为什么选择 Python?什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
基本知识概念
URL(协议(服务模式)+IP地址(含端口号)+具体地址),即统一资源定位器,也就是我们所说的网站,统一资源定位器就是可以定位和访问的资源从 Internet 获得 方法的简洁表示是 Internet 上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
URI 在计算机术语中,统一资源标识符 (URI) 是用于标识 Internet 资源名称的字符串。这种标识允许用户通过特定的协议与任何(包括本地和互联网)资源进行交互。URI 由收录特定语法和相关协议的方案定义。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求。服务器解析后,将HTML、JS、CSS等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。其实就是一个http请求的过程。
爬虫入门
常用爬虫库
请求库:requests、selenium(自动化测试工具)+ChromeDrive(chrome驱动)、PhantomJS(无界面浏览器)
解析库:LXML(html、xml、Xpath方法)、BeautifulSoup(html、xml)、PyQuery(支持css选择器)、Tesserocr(光学字符识别、验证码)
数据库:mongo、mysql、redis
存储库:pymysql、pymongo、redispy、RedisDump(用于导入和导出 Redis 数据的工具)
网络库:Flask(轻量级网络服务器)、Django
其他工具:Charles(网络抓包工具)
示例(如果 cookie 不起作用,您可以更改) 基本示例
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
#请求头相关
print(myUrl)
req = request.Request(myUrl, headers=headers)
#调用库发送请求
myResponse = request.urlopen(req)
myPage = myResponse.read()
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
一个比较复杂的例子是爬虫百科网站,拉出作者头像、作者姓名、内容
修改自:
<p># -*- coding: utf-8 -*-
import urllib
import _thread
import re
import time
from urllib import request
# ----------- 加载处理糗事百科 -----------
class Spider_Model:
def __init__(self):
self.page = 1
self.pages = []
self.enable = False
# 将所有的段子都扣出来,添加到列表中并且返回列表
def GetPage(self, page):
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
print(myUrl)
req = request.Request(myUrl, headers=headers)
myResponse = request.urlopen(req)
myPage = myResponse.read()
# print(myPage)
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
# 找出所有class="content"的div标记
# re.S是任意匹配模式,也就是.可以匹配换行符
# myItems = re.findall('(.*?)', unicodePage, re.S)
content = re.findall('.*?(.*?)(.*?)', unicodePage, re.S)
items = []
# print("~~~~~~~~~~~~~~~~~~~")
# print(content)
# print(len(content))
# print(content[1])
imageIcon = re.findall('.*?(.*?)', unicodePage, re.S)
# print("~~~~~~~~~~~~~~~~~~~")
# print(imageIcon)
# print(len(imageIcon))
# print(imageIcon[0][0])
# print(imageIcon[0][1])
# print(imageIcon[1][0])
# print(imageIcon[1][1])
for index in range(min(len(content), len(imageIcon)) - 1):
items.append([content[index][0].replace("\n", "").replace("
", ""), imageIcon[index][0], imageIcon[index][1]])
return items
# 用于加载新的段子
def LoadPage(self):
# 如果用户未输入quit则一直运行
while self.enable:
# 如果pages数组中的内容小于2个
if len(self.pages)
网页数据抓取怎么写(用Python写网络爬虫》——2.2三种网页抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-12 14:18
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:
抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8import re, urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()html = html.decode('utf-8') #python3版本中需要加入links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags): span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span span class="hljs-tag"ul/span span class="hljs-tag"li/spanspan class="hljs-class".waring/span span class="hljs-tag"a/spanspan class="hljs-pseudo":nth-child(1)/span/code/pre/p
p因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:/p
ppre class="prettyprint"code class=" hljs vala"span class="hljs-preprocessor"#alarmtip ul li.waring a/span/code/pre/p
p代码:/p
ppre class="prettyprint"code class=" hljs lasso"from bs4 span class="hljs-keyword"import/span BeautifulSoupspan class="hljs-keyword"import/span urllibspan class="hljs-built_in"./spanrequesturl span class="hljs-subst"=/span span class="hljs-string"'http://www.nmc.cn'/spanhtml span class="hljs-subst"=/span urllibspan class="hljs-built_in"./spanrequestspan class="hljs-built_in"./spanurlopen(url)span class="hljs-built_in"./spanread()soup span class="hljs-subst"=/span BeautifulSoup(html,span class="hljs-string"'lxml'/span)content span class="hljs-subst"=/span soupspan class="hljs-built_in"./spanspan class="hljs-keyword"select/span(span class="hljs-string"'#alarmtip > ul > li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.htmlurl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()tree = lxml.html.fromstring(html)content = tree.cssselect('li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoupimport urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()soup = BeautifulSoup(html,'lxml')content = soup.select('#alarmtip > ul > li.waring > a')######### 添加到列表中link = []title = []tag = []for n in content: link.append(url+n.get('href')) title.append(n.get('title')) tag.append(n.text)######## 添加到字典中for n in content: data = { 'tag' : n.text, 'link' : url+n.get('href'), 'title' : n.get('title') }
五、总结
表格2.1总结了每种抓取方式的优缺点。
参考资料:
《用 Python 写一个网络爬虫》——2.2 三种网络爬取方法 查看全部
网页数据抓取怎么写(用Python写网络爬虫》——2.2三种网页抓取方法)
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:

它的 HTML 层次结构是:

抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8import re, urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()html = html.decode('utf-8') #python3版本中需要加入links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags): span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span span class="hljs-tag"ul/span span class="hljs-tag"li/spanspan class="hljs-class".waring/span span class="hljs-tag"a/spanspan class="hljs-pseudo":nth-child(1)/span/code/pre/p
p因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:/p
ppre class="prettyprint"code class=" hljs vala"span class="hljs-preprocessor"#alarmtip ul li.waring a/span/code/pre/p
p代码:/p
ppre class="prettyprint"code class=" hljs lasso"from bs4 span class="hljs-keyword"import/span BeautifulSoupspan class="hljs-keyword"import/span urllibspan class="hljs-built_in"./spanrequesturl span class="hljs-subst"=/span span class="hljs-string"'http://www.nmc.cn'/spanhtml span class="hljs-subst"=/span urllibspan class="hljs-built_in"./spanrequestspan class="hljs-built_in"./spanurlopen(url)span class="hljs-built_in"./spanread()soup span class="hljs-subst"=/span BeautifulSoup(html,span class="hljs-string"'lxml'/span)content span class="hljs-subst"=/span soupspan class="hljs-built_in"./spanspan class="hljs-keyword"select/span(span class="hljs-string"'#alarmtip > ul > li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.htmlurl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()tree = lxml.html.fromstring(html)content = tree.cssselect('li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoupimport urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()soup = BeautifulSoup(html,'lxml')content = soup.select('#alarmtip > ul > li.waring > a')######### 添加到列表中link = []title = []tag = []for n in content: link.append(url+n.get('href')) title.append(n.get('title')) tag.append(n.text)######## 添加到字典中for n in content: data = { 'tag' : n.text, 'link' : url+n.get('href'), 'title' : n.get('title') }
五、总结
表格2.1总结了每种抓取方式的优缺点。

参考资料:
《用 Python 写一个网络爬虫》——2.2 三种网络爬取方法
网页数据抓取怎么写( 这是简易数据分析系列的第13篇文章教程的全盘总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-11 23:16
这是简易数据分析系列的第13篇文章教程的全盘总结)
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同级别的内容,主要讨论的问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍. .
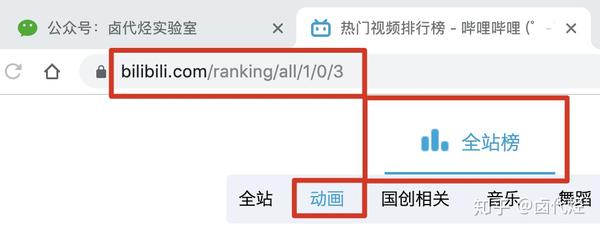
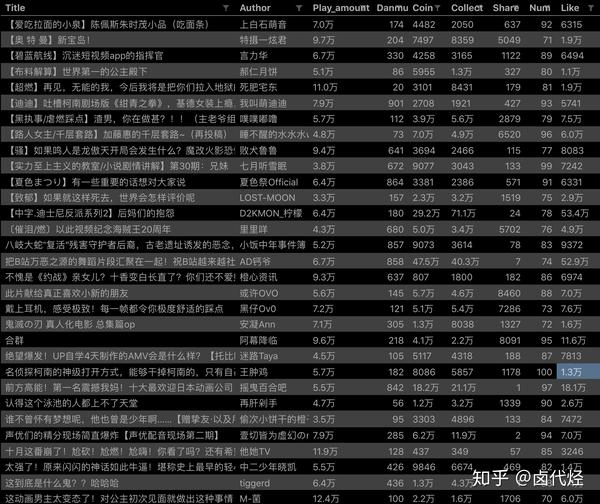
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
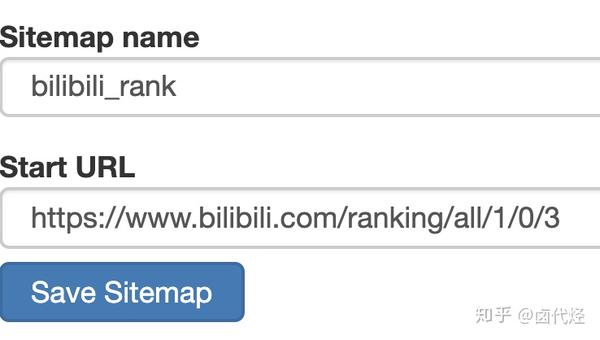
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.为容器创建一个选择器
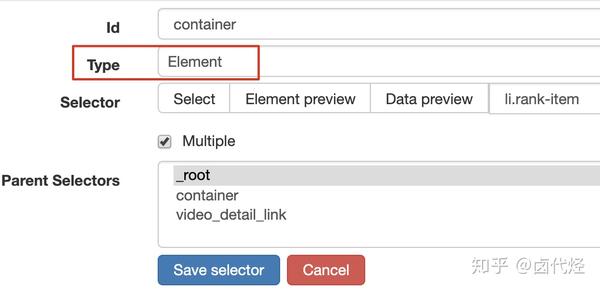
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动画,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
为什么要这样做?看下图你就明白了:
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第6篇教程中详细讲解过。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。 查看全部
网页数据抓取怎么写(
这是简易数据分析系列的第13篇文章教程的全盘总结)

这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同级别的内容,主要讨论的问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍. .
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。

经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。

但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:

今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)

如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:

Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:

当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:

创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动画,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。

所有选择器的结构图如下:
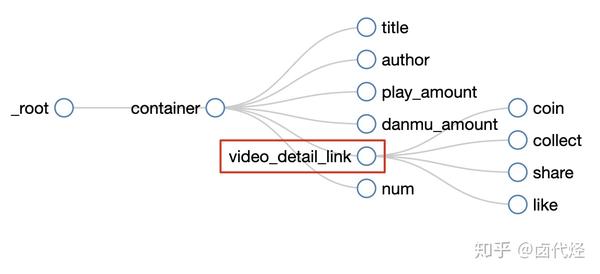
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。

为什么要这样做?看下图你就明白了:
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第6篇教程中详细讲解过。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。
网页数据抓取怎么写(网页数据抓取怎么写爬虫?分享一个爬虫的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-08 10:03
网页数据抓取怎么写爬虫??下面分享一个爬虫的教程,
1、程序思路爬虫基本分三步分别爬取页面各个内容(页面关键词爬取、页面爬取、自定义爬取)
2、模拟登录第一步完成后我们进入页面登录根据页面抓取信息去验证登录第二步有了验证码我们点开验证码第三步获取验证码第四步爬取文章内容页面内容和验证码密码相关信息
3、scrapy/requests:模拟登录(请求错误继续登录)自定义爬取这里继续代理(不用wireshark就用网易x3服务器直接模拟ip)post验证码验证
4、爬取文章内容获取登录状态码爬取评论文章内容(自己点开搜索文章然后点开去翻评论页面)
5、用flask编写爬虫scrapy-spider接入csv导入文章中的xxx一次性生成所有文章的列表数据定义参数:获取评论文章xxx:xxx获取文章标题yyy:yyy分别获取评论文章和标题获取文章内容:获取每篇文章的标题获取评论和文章间的链接获取每篇文章的链接获取此页的所有文章列表xxx爬取评论文章其他爬取文章xxx获取标题和内容1获取标题xxx获取内容yyy--scrapy-requestrequest'scrapy-request/'(内容)contentdoc='request=scrapy-request/'(解释)2爬取2,3,4,5,5,6,6,6,5,6获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容1爬取标题2爬取内容3获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容4(解释)获取contentdoc='(获取此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取内容1获取1,2,3,4(评论文章所在页))xxx爬取标题和内容2获取contentdoc='(爬取此文章)'xxx爬取标题和内容3获取contentdoc='(爬取此文章)'xxx爬取内容4(解释)获取contentdoc='xxx(每篇文章都包含)'xxx。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写爬虫?分享一个爬虫的教程)
网页数据抓取怎么写爬虫??下面分享一个爬虫的教程,
1、程序思路爬虫基本分三步分别爬取页面各个内容(页面关键词爬取、页面爬取、自定义爬取)
2、模拟登录第一步完成后我们进入页面登录根据页面抓取信息去验证登录第二步有了验证码我们点开验证码第三步获取验证码第四步爬取文章内容页面内容和验证码密码相关信息
3、scrapy/requests:模拟登录(请求错误继续登录)自定义爬取这里继续代理(不用wireshark就用网易x3服务器直接模拟ip)post验证码验证
4、爬取文章内容获取登录状态码爬取评论文章内容(自己点开搜索文章然后点开去翻评论页面)
5、用flask编写爬虫scrapy-spider接入csv导入文章中的xxx一次性生成所有文章的列表数据定义参数:获取评论文章xxx:xxx获取文章标题yyy:yyy分别获取评论文章和标题获取文章内容:获取每篇文章的标题获取评论和文章间的链接获取每篇文章的链接获取此页的所有文章列表xxx爬取评论文章其他爬取文章xxx获取标题和内容1获取标题xxx获取内容yyy--scrapy-requestrequest'scrapy-request/'(内容)contentdoc='request=scrapy-request/'(解释)2爬取2,3,4,5,5,6,6,6,5,6获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容1爬取标题2爬取内容3获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容4(解释)获取contentdoc='(获取此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取内容1获取1,2,3,4(评论文章所在页))xxx爬取标题和内容2获取contentdoc='(爬取此文章)'xxx爬取标题和内容3获取contentdoc='(爬取此文章)'xxx爬取内容4(解释)获取contentdoc='xxx(每篇文章都包含)'xxx。
网页数据抓取怎么写(2.-toggle爬取数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-07 19:00
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
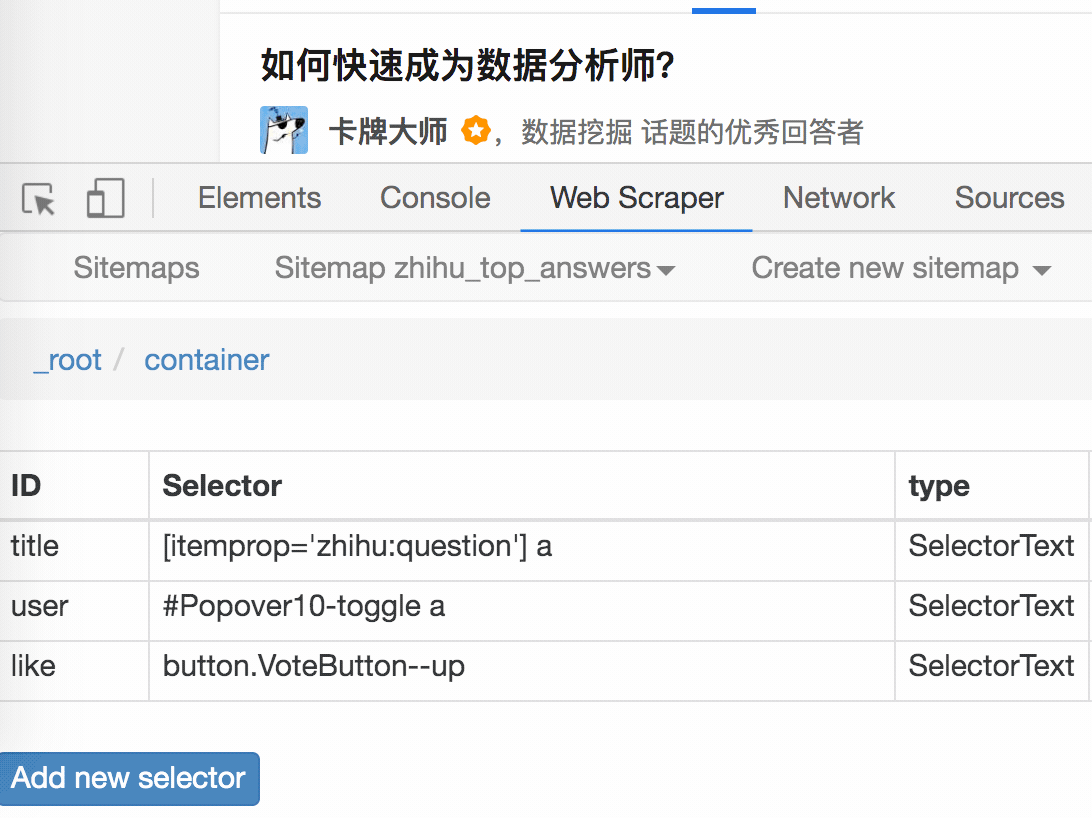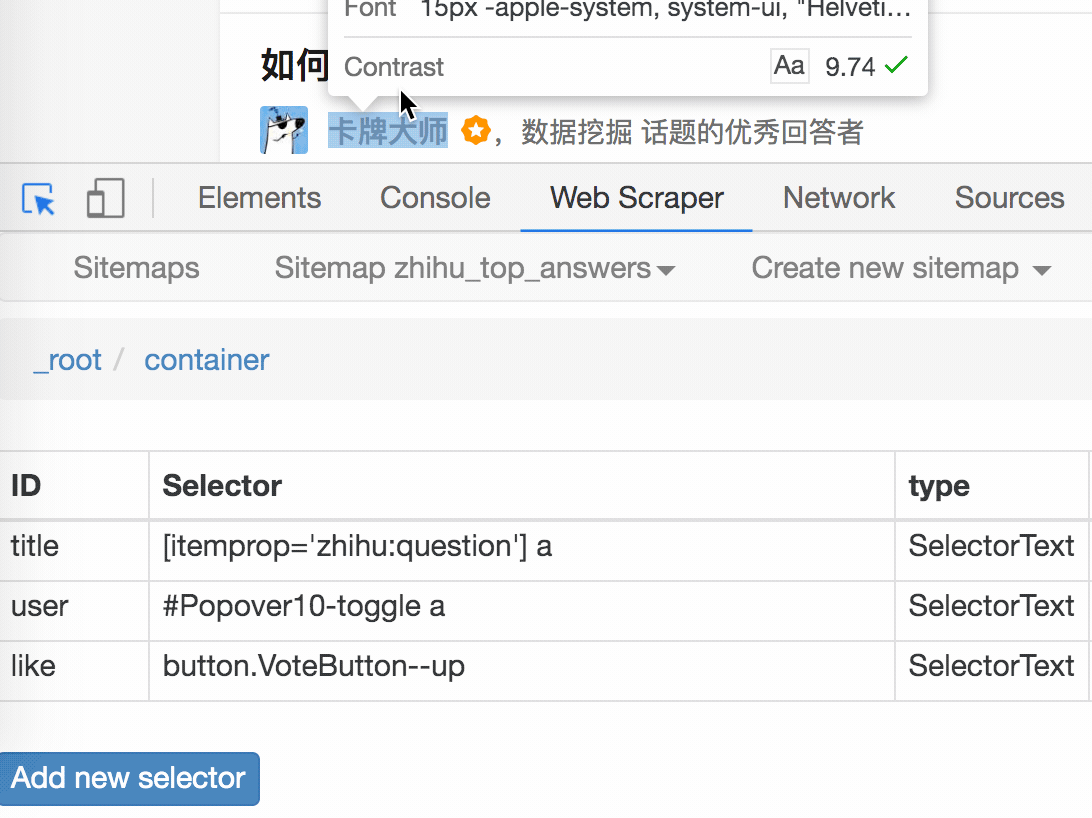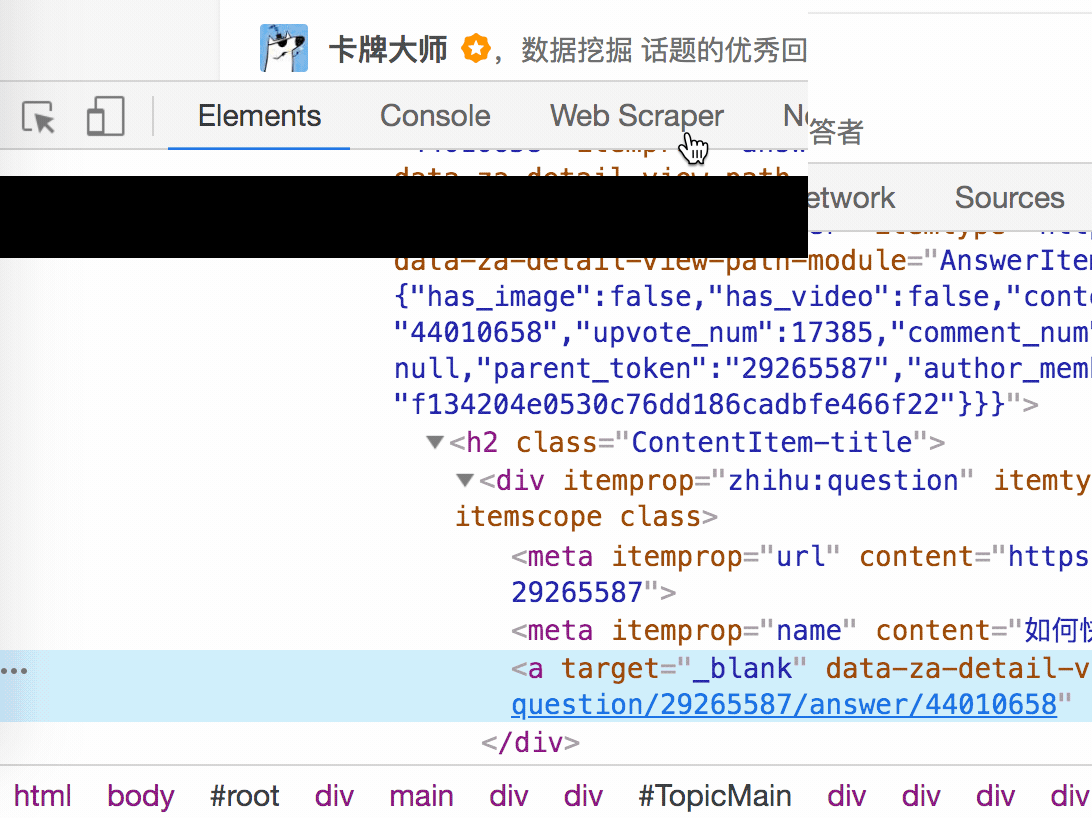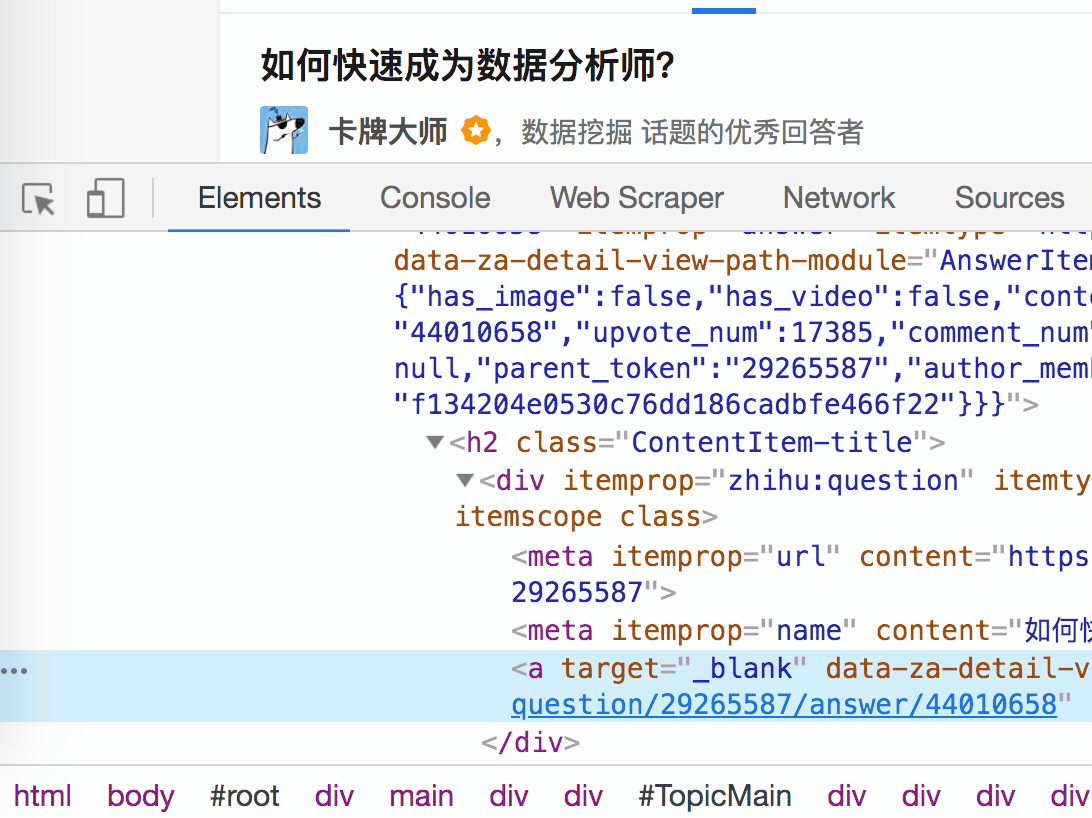
1.制作站点地图
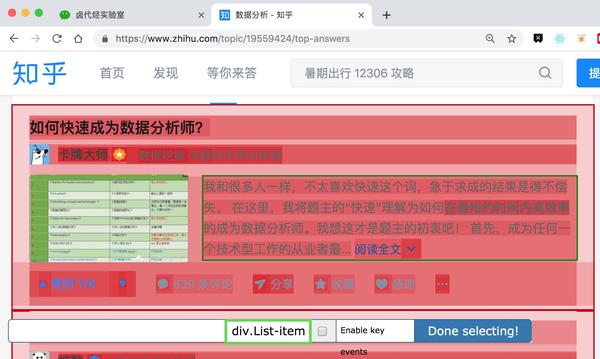
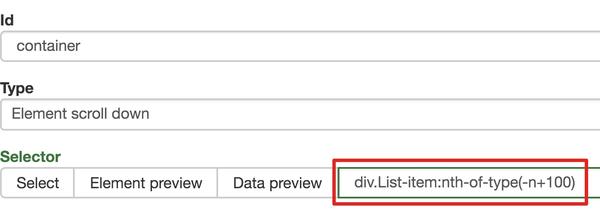
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
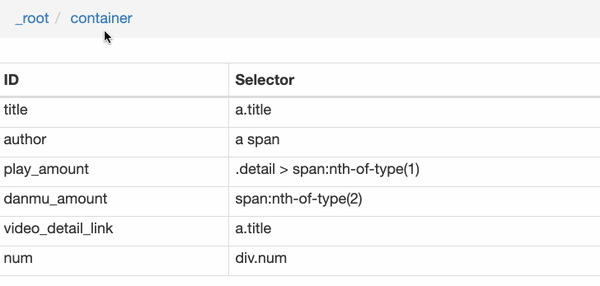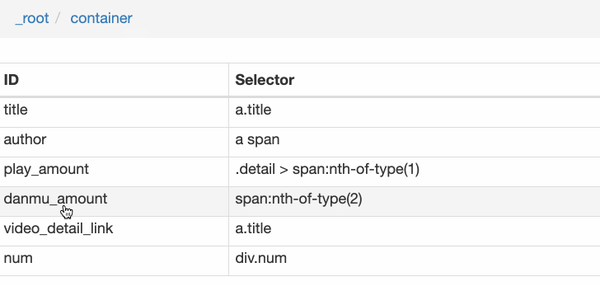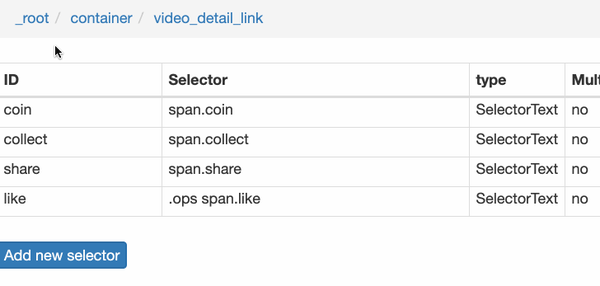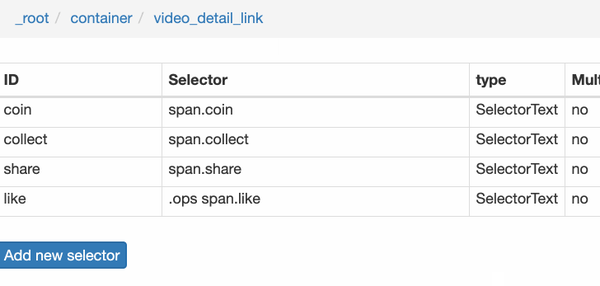
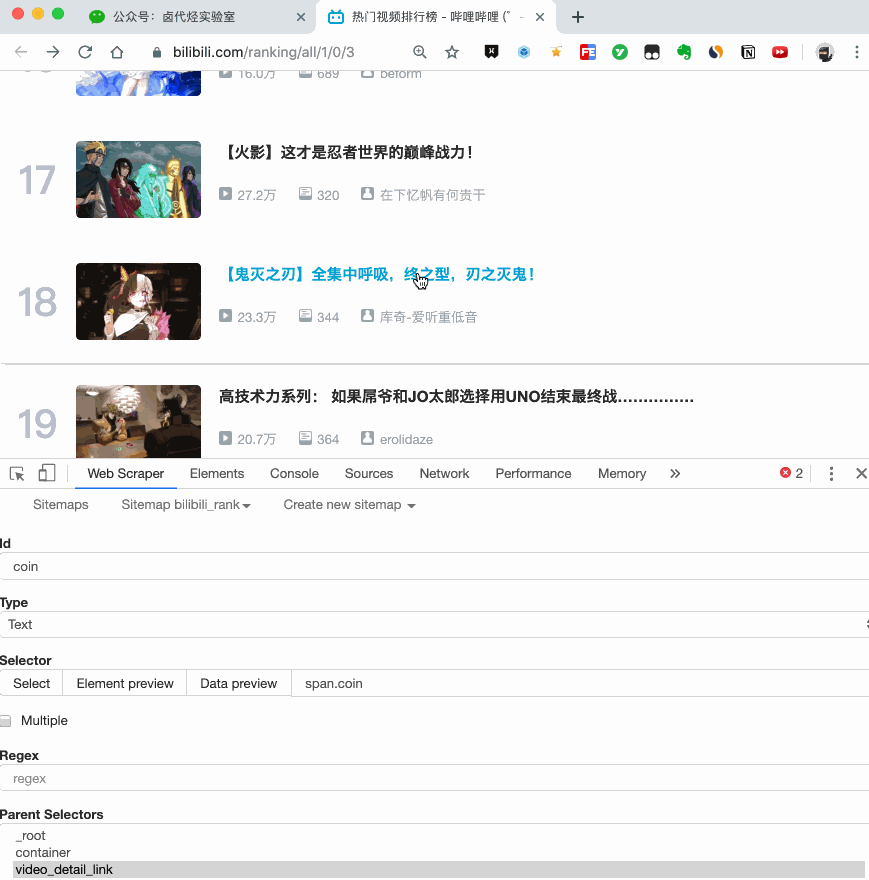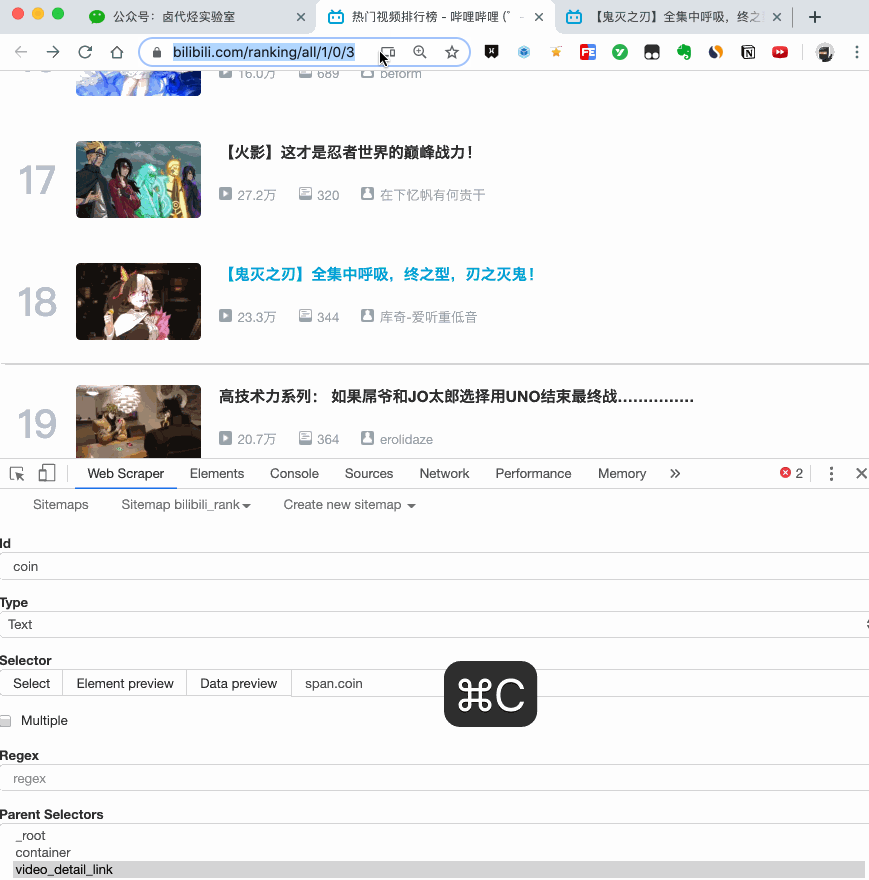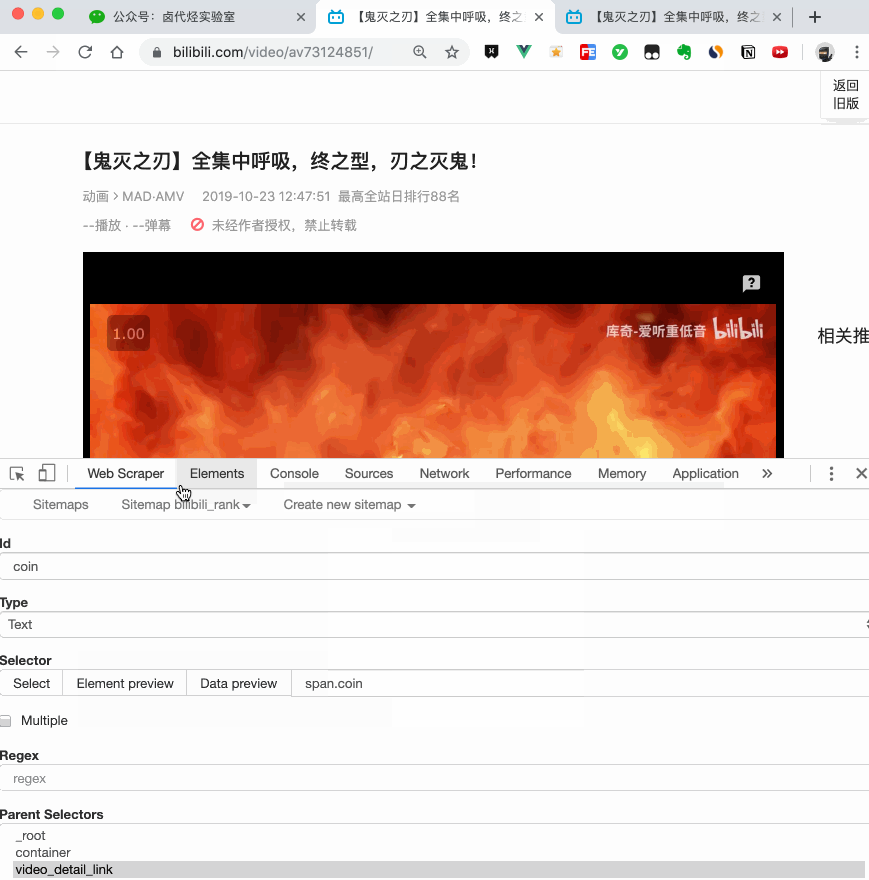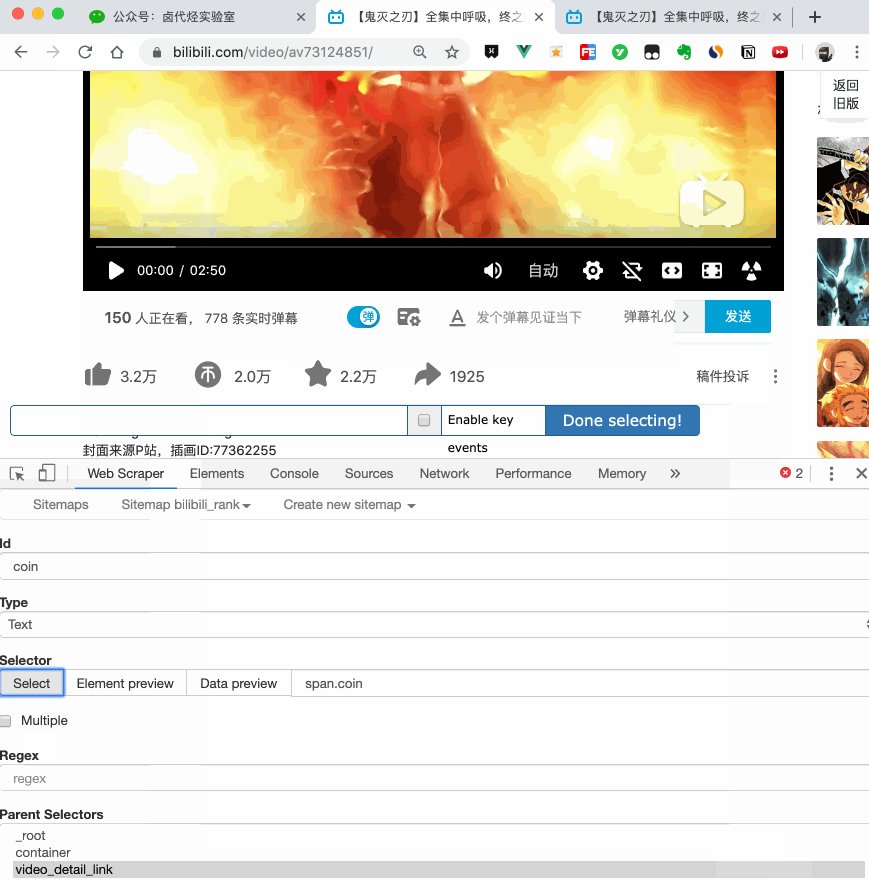
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
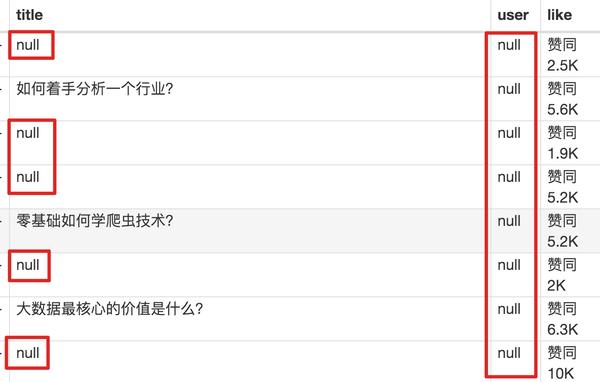
元素都选好了,我们按照Sitemap 知乎_top_answers->Scrape->Start craping的路径抓取数据,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
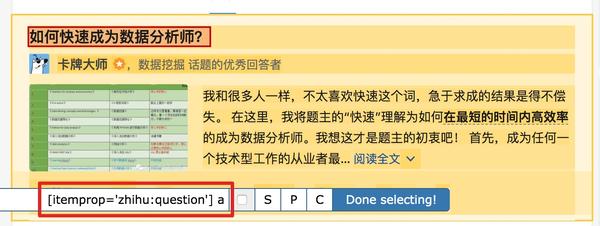
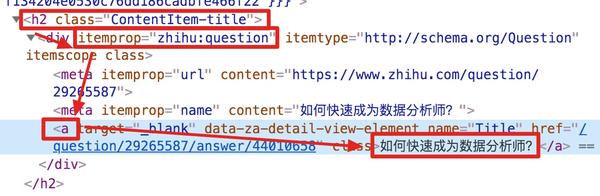
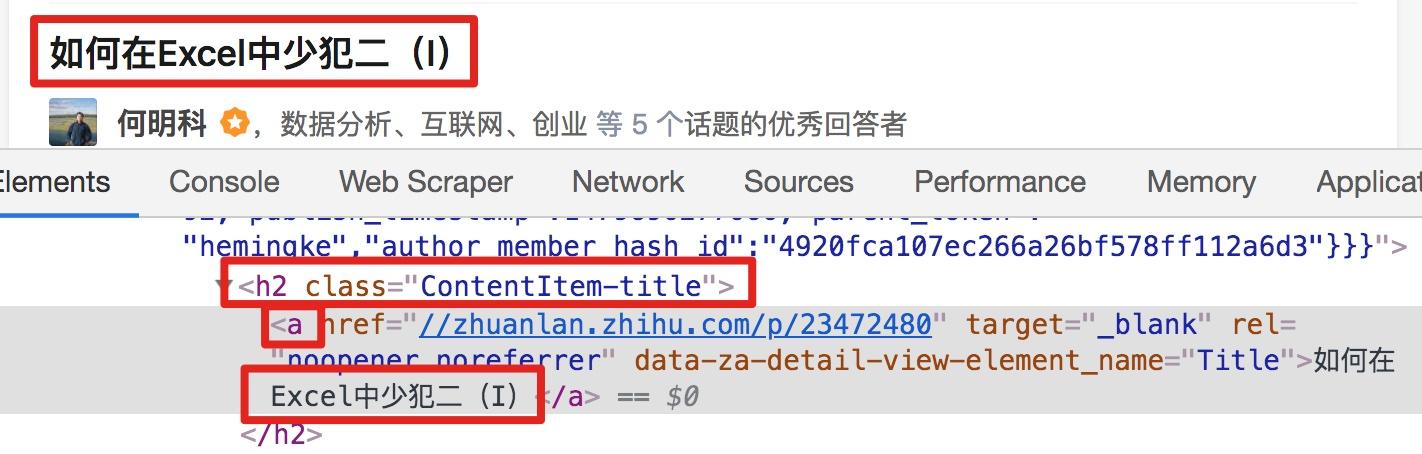
我们发现在选择一个标题的时候,不管标题的嵌套关系怎么变,总有一个标签不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title '。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
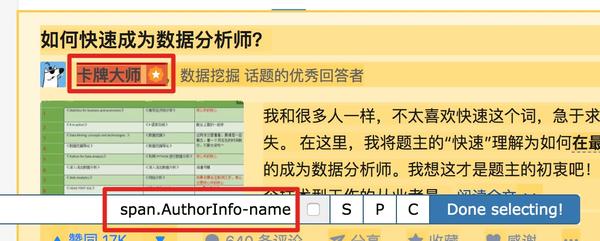
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
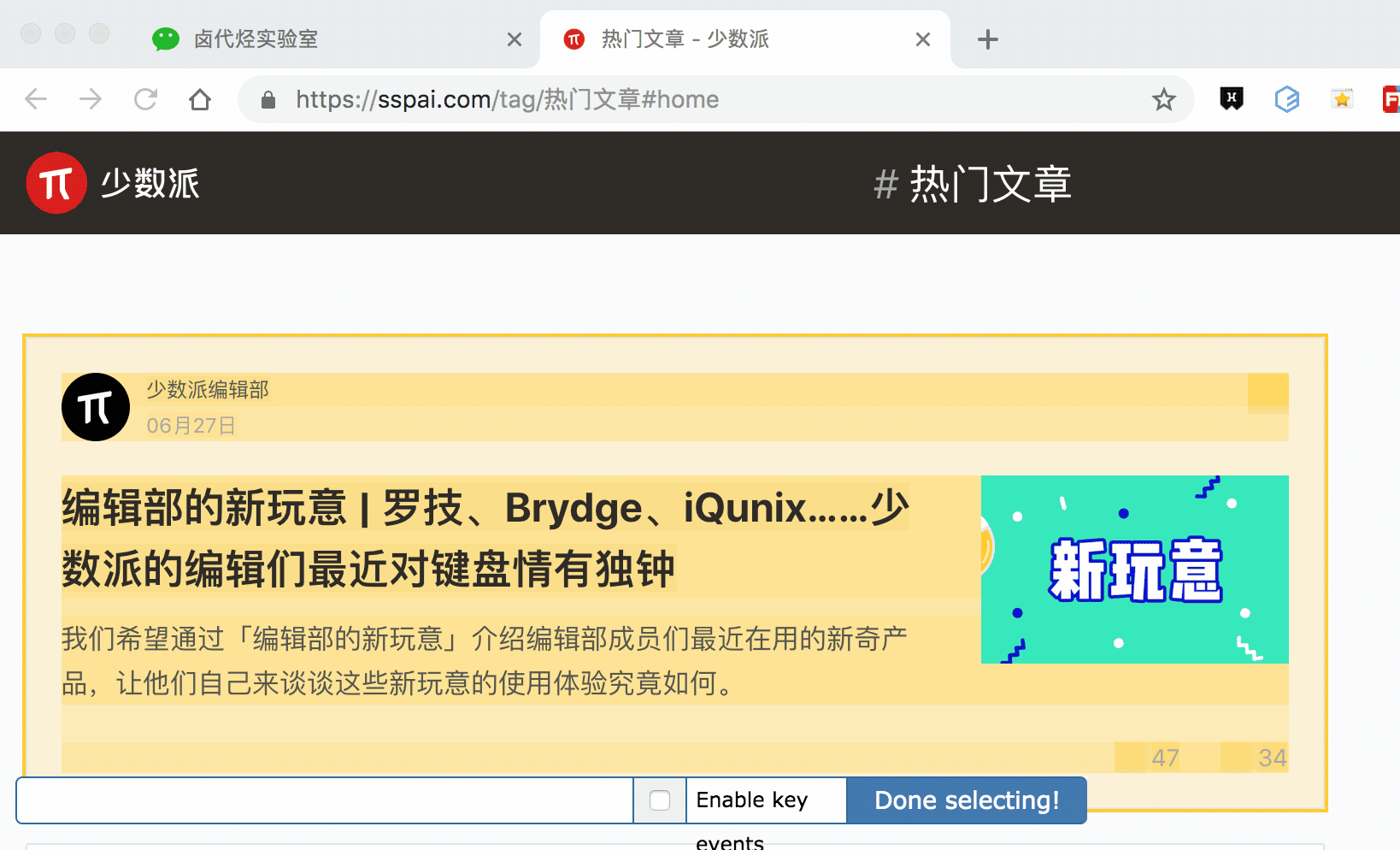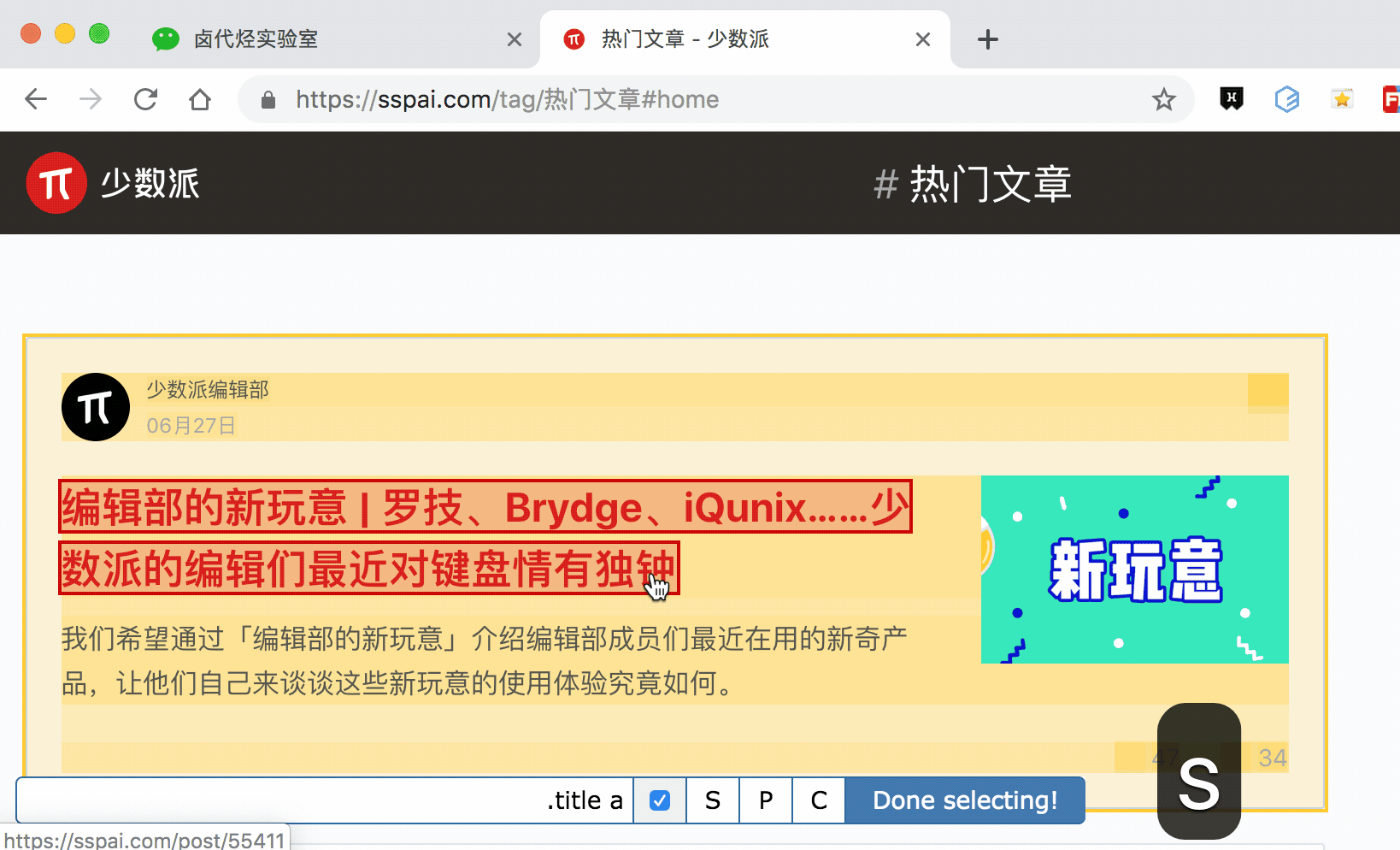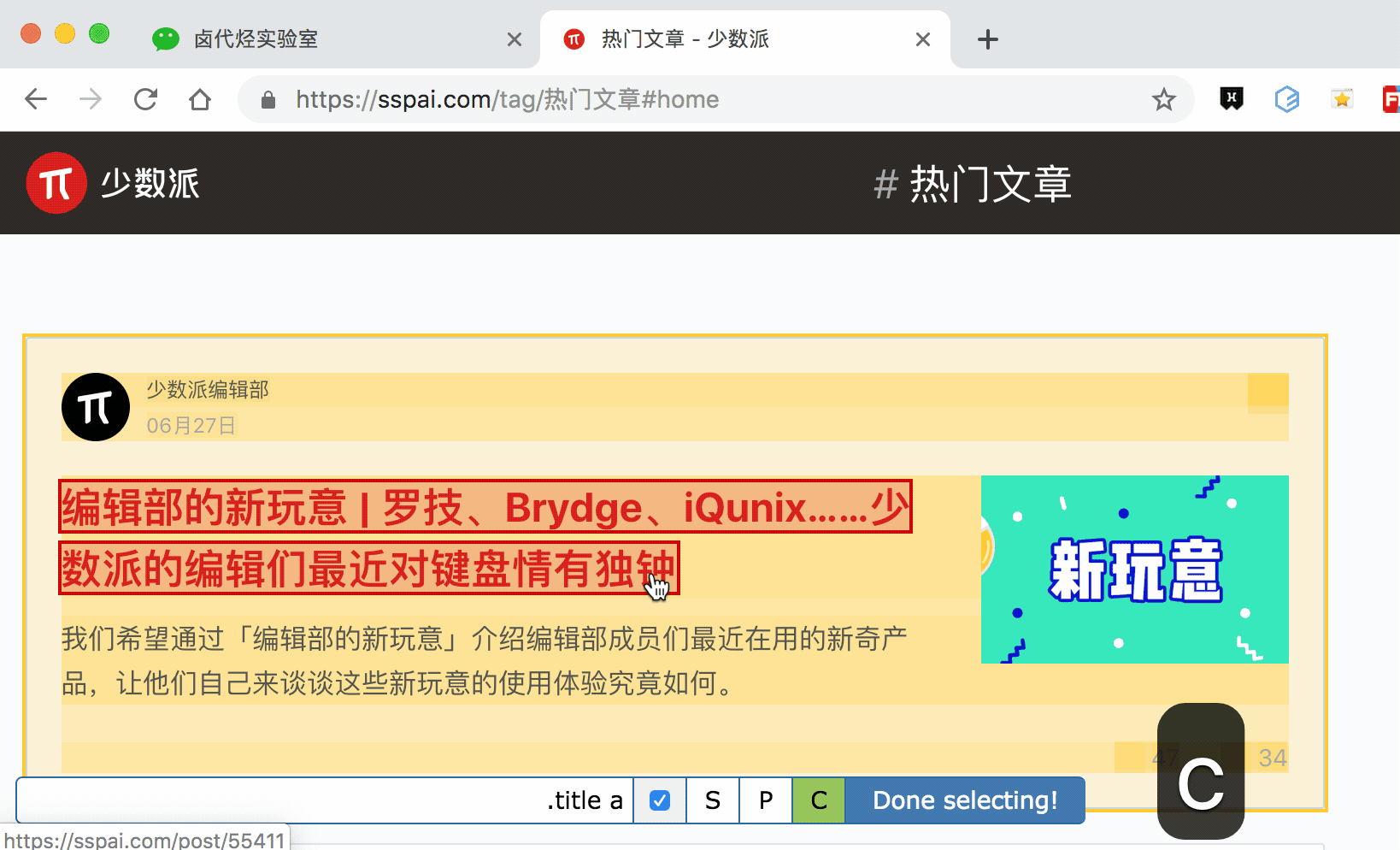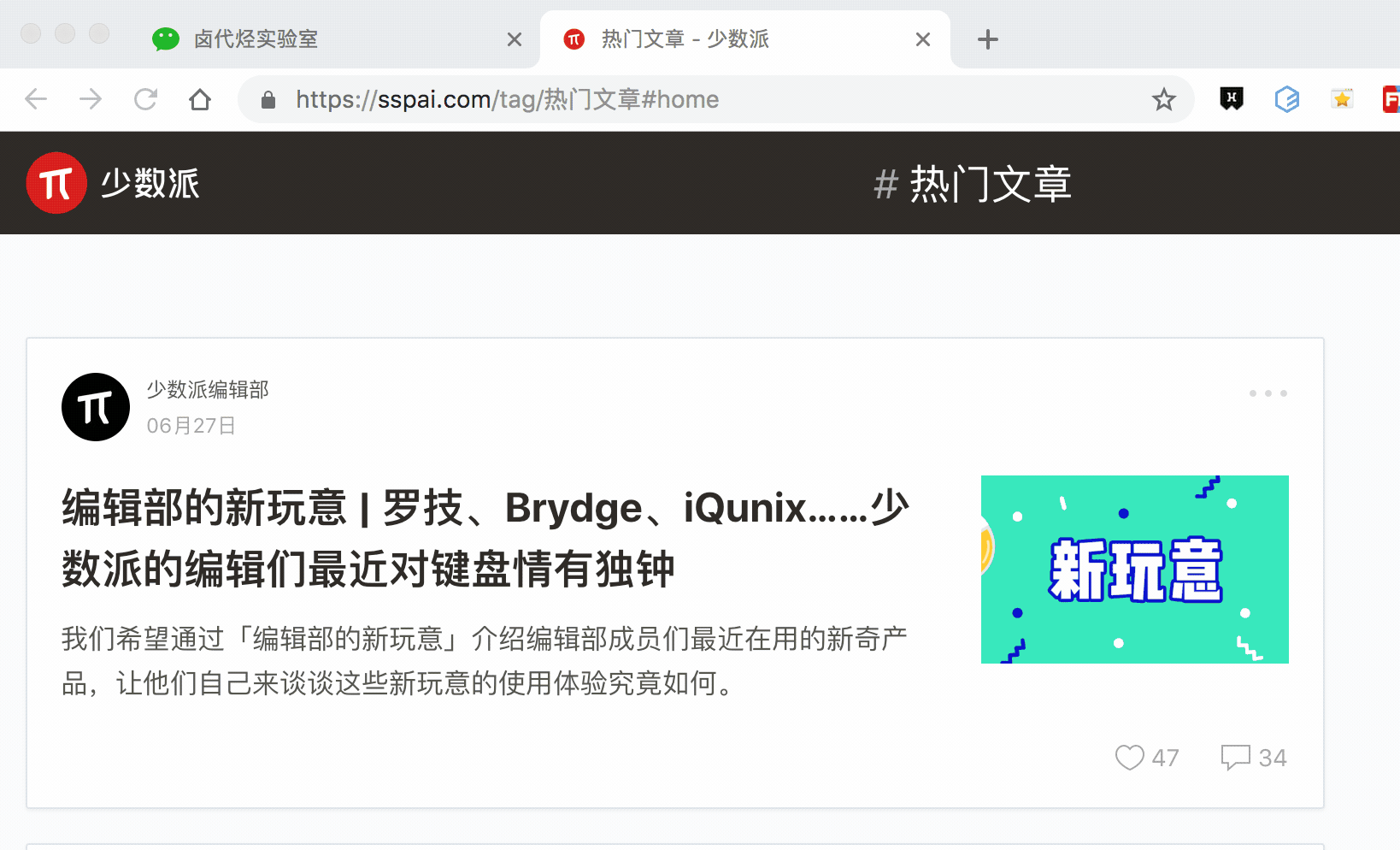
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(2.-toggle爬取数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers->Scrape->Start craping的路径抓取数据,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系怎么变,总有一个标签不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title '。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写(Python中解析网页的一个重要的应用,使用Python爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-06 10:06
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果你还处于入门爬虫阶段或者不知道爬虫的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
利用
get 方法构造请求
利用
status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的
frombs4importBeautifulSoup
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码的问题
导入csv
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
导入pandasaspd
键=all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
进口请求
frombs4importBeautifulSoup
导入csv
导入pandasaspd
网址='#39;
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig') 查看全部
网页数据抓取怎么写(Python中解析网页的一个重要的应用,使用Python爬虫)
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果你还处于入门爬虫阶段或者不知道爬虫的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
利用
get 方法构造请求
利用
status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的
frombs4importBeautifulSoup
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码的问题
导入csv
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
导入pandasaspd
键=all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
进口请求
frombs4importBeautifulSoup
导入csv
导入pandasaspd
网址='#39;
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
网页数据抓取怎么写(人人都用得上webscraper进阶教程,人人用得上微信若是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 17:12
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。网络
相关文章:
最简单的数据采集教程,人人都可以使用
高级网络爬虫教程,人人都可以用微信
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。网络
下面列出了您可能遇到的几个问题,并说明了解决方法。布局
一、有时候我们想选择一个连接,但是鼠标点击会触发页面跳转,如何处理?网站
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。代码
另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素是指鼠标所在的元素。博客
二、 分页数据或滚动加载的数据无法完全抓取,如知乎和twitter等?排序
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为爬取已经完成。教程
因此,适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。得到
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。由于只要在延迟时间内没有完成翻页或下拉加载,则抓取结束。
三、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。我们最终将数据导出为 CSV 格式。用Excel打开CSV后,可以按某一列进行排序。 Excel中按照发布时间排序,或者知乎上的数据按照点赞数排序。
四、 网页爬虫提供的选择器无法选择某些页面元素?
出现这种情况的原因多半是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停才会显示的元素。遇到这些情况就得靠其他方法了。
其实就是通过鼠标操作选择元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。遇到问题就可以了。
这里只是在使用网页爬虫过程中的一些常见问题。如果还有其他问题,可以在文章下留言。 查看全部
网页数据抓取怎么写(人人都用得上webscraper进阶教程,人人用得上微信若是)
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。网络
相关文章:
最简单的数据采集教程,人人都可以使用
高级网络爬虫教程,人人都可以用微信
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。网络
下面列出了您可能遇到的几个问题,并说明了解决方法。布局
一、有时候我们想选择一个连接,但是鼠标点击会触发页面跳转,如何处理?网站
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。代码

另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素是指鼠标所在的元素。博客
二、 分页数据或滚动加载的数据无法完全抓取,如知乎和twitter等?排序
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为爬取已经完成。教程
因此,适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。得到
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。由于只要在延迟时间内没有完成翻页或下拉加载,则抓取结束。
三、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。我们最终将数据导出为 CSV 格式。用Excel打开CSV后,可以按某一列进行排序。 Excel中按照发布时间排序,或者知乎上的数据按照点赞数排序。
四、 网页爬虫提供的选择器无法选择某些页面元素?
出现这种情况的原因多半是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停才会显示的元素。遇到这些情况就得靠其他方法了。
其实就是通过鼠标操作选择元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。遇到问题就可以了。
这里只是在使用网页爬虫过程中的一些常见问题。如果还有其他问题,可以在文章下留言。
网页数据抓取怎么写(Python开发的一个快速、高层次框架会自动该类的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-02 06:21
我记得十多年前,当我还是个高中生时,所谓的智能手机根本不流行。如果你想在学校阅读大量的电子书,你基本上依靠具有阅读功能的MP3或MP4。 以及电子书的来源?当你随时随地都无法上网时,有时候的窍门就是靠一个笨办法:将一些小说的内容网站一页一页地粘贴复制。而那些动辄上百章的网络小说,靠这样的手工操作,着实让人很是麻烦。那时,我多么希望有一个工具可以帮我自动完成这些费力的手工任务! ! !
好吧,让我们回到正题。最近在研究爬虫框架Scrapy的使用方法。先说说学习Scrapy的初衷。
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试(百度百科介绍)。
经过几天的学习,首先需要了解以下Scrapy的初步使用概念:
那么,你要做的就是把上面提到的四个类都写好,剩下的交给Scrapy框架就行了。
您可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
spiderForShortPageMsg.py 文件收录我们将要编写的 Spiders 子类。
示例:现在我想获取网站中文章的所有title和文章的地址。
第一步:写一个继承自Spiders的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()解析具体的html页面,从中找到我想要的数据,然后保存在一个Items的数据类型对象之中。
不要被下面这行代码吓到:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的选择器。这是用于定位您要查找的 html 标记的方法。选择器有两种,XPath 选择器和 CSS 选择器,上面都用到了这两种。
这是我的 Item 数据类型(上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类型 Item 执行的所有操作。
您想要的数据现在在 Item 对象中。考虑到您的最终目标,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需简单的几个设置,就可以直接调用Django中的models类,省去繁琐的数据库操作。心。谁知道谁用! ! 查看全部
网页数据抓取怎么写(Python开发的一个快速、高层次框架会自动该类的方法)
我记得十多年前,当我还是个高中生时,所谓的智能手机根本不流行。如果你想在学校阅读大量的电子书,你基本上依靠具有阅读功能的MP3或MP4。 以及电子书的来源?当你随时随地都无法上网时,有时候的窍门就是靠一个笨办法:将一些小说的内容网站一页一页地粘贴复制。而那些动辄上百章的网络小说,靠这样的手工操作,着实让人很是麻烦。那时,我多么希望有一个工具可以帮我自动完成这些费力的手工任务! ! !
好吧,让我们回到正题。最近在研究爬虫框架Scrapy的使用方法。先说说学习Scrapy的初衷。
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试(百度百科介绍)。
经过几天的学习,首先需要了解以下Scrapy的初步使用概念:
那么,你要做的就是把上面提到的四个类都写好,剩下的交给Scrapy框架就行了。
您可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
spiderForShortPageMsg.py 文件收录我们将要编写的 Spiders 子类。
示例:现在我想获取网站中文章的所有title和文章的地址。
第一步:写一个继承自Spiders的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()解析具体的html页面,从中找到我想要的数据,然后保存在一个Items的数据类型对象之中。
不要被下面这行代码吓到:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的选择器。这是用于定位您要查找的 html 标记的方法。选择器有两种,XPath 选择器和 CSS 选择器,上面都用到了这两种。
这是我的 Item 数据类型(上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类型 Item 执行的所有操作。
您想要的数据现在在 Item 对象中。考虑到您的最终目标,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需简单的几个设置,就可以直接调用Django中的models类,省去繁琐的数据库操作。心。谁知道谁用! !
网页数据抓取怎么写(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-02 06:20
不知道大家在日常的工作、学习和生活中是否遇到过这样的场景,就是需要对网站上面的一些数据进行转换(比如图片、文字或者其他一些数据格式)复制、保存到本地Excel表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。 Crawler,顾名思义就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、手动:完全依赖手动复制粘贴;
2、半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取一部分数据;
3、 全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是写这个爬虫需要相当的知识。
第二个和第三个,没有确定的数量是好是坏。根据不同的场合,两者都有自己的适应。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在来看看这个案例。作者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章节,每一章节又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017下载安装)和视频地址。
名称比较好说,表格最左边的一列是section的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为跨域问题)。
我能做什么?
别担心,只要你的头脑不滑,解决方案总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。所以你可以使用下面的代码来获取所有收录section名称的a标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这个固定格式的开头是“number.number.number”,可以用下面的正则表达式表示:
^\d+\.\d+(\.\d+)?
所以可以使用正则表达式条件进行过滤,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
此时,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,我们点击某个部分,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有的视频地址只有这里的{1}不同,这里的{1}和段号有关:{1}的部分从段号变成了句号,只有标题是需要 只需提取数字并替换它。
到此为止,所有的代码都可以写完整了,可以根据代码实现需要的爬取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可以看出这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十多行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也请在下方评论区写下你的想法。 查看全部
网页数据抓取怎么写(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
不知道大家在日常的工作、学习和生活中是否遇到过这样的场景,就是需要对网站上面的一些数据进行转换(比如图片、文字或者其他一些数据格式)复制、保存到本地Excel表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。 Crawler,顾名思义就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、手动:完全依赖手动复制粘贴;
2、半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取一部分数据;
3、 全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是写这个爬虫需要相当的知识。
第二个和第三个,没有确定的数量是好是坏。根据不同的场合,两者都有自己的适应。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在来看看这个案例。作者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章节,每一章节又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017下载安装)和视频地址。
名称比较好说,表格最左边的一列是section的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为跨域问题)。
我能做什么?
别担心,只要你的头脑不滑,解决方案总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。所以你可以使用下面的代码来获取所有收录section名称的a标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这个固定格式的开头是“number.number.number”,可以用下面的正则表达式表示:
^\d+\.\d+(\.\d+)?
所以可以使用正则表达式条件进行过滤,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
此时,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,我们点击某个部分,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有的视频地址只有这里的{1}不同,这里的{1}和段号有关:{1}的部分从段号变成了句号,只有标题是需要 只需提取数字并替换它。
到此为止,所有的代码都可以写完整了,可以根据代码实现需要的爬取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可以看出这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十多行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也请在下方评论区写下你的想法。
网页数据抓取怎么写( 元素名后加个-typegt的路径进行数据编号控制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-01 17:16
元素名后加个-typegt的路径进行数据编号控制)
这是简单数据分析系列的第十篇文章。
原文首发于博客园:简单数据分析10.
友情提示:本文文章内容丰富,信息量大。希望你在学习的时候多读几遍。
我们扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据。从经验来看,数据会不断加载,永远不会结束。
今天我们要讲的是如何使用Web Scraper抓取滚动到最后的网页。
我们今天的动手实践网站是知乎的数据分析模块的精髓。该网站是:
/topic/19559424/top-answers
这次要爬取的内容是精华帖的标题、回复者和批准数。以下是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。 .
在本例中,所选元素名称为 div.List-item。
为了回顾上一节通过数据个数控制item个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取第一个暂时100条数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
首先是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是响应者的名字和批准的数量一样,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2.爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成null了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着没有捕获到任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要查看网页的构成,需要用到浏览器的另一个功能,就是选择视图元素。
1.我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3.我们再点一下标题,会发现会跳转到Elements子面板,内容是一些不太懂的彩色代码
不要因为这样做而感到沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果平时用markdown写的话,可以把HTML理解成功能更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树状结构:
最后一句从视觉上分析。它实际上是一个嵌套结构。我提取了关键内容。内容结构是否更清晰?
如何快速成为数据分析师?
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少属性为itemprop='知乎:question'的名为div的标签!结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们就能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem -标题'。如果可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清关系后,我们如何使用Web Scraper来操作呢?这时候我们可以使用上一篇文章介绍的内容,使用键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
等等,因为响应者的名字也出现null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面类似,你可以试试。
我的三个子内容选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
爬取知乎的数据时,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这个间接的解释,知乎这个网站从代码的角度分析,写的还是比较差的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬取,可以在一定程度上减少返工时间。
6.下一期预览
本期内容较多。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(
元素名后加个-typegt的路径进行数据编号控制)

这是简单数据分析系列的第十篇文章。
原文首发于博客园:简单数据分析10.
友情提示:本文文章内容丰富,信息量大。希望你在学习的时候多读几遍。
我们扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据。从经验来看,数据会不断加载,永远不会结束。

今天我们要讲的是如何使用Web Scraper抓取滚动到最后的网页。
我们今天的动手实践网站是知乎的数据分析模块的精髓。该网站是:
/topic/19559424/top-answers
这次要爬取的内容是精华帖的标题、回复者和批准数。以下是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。 .

在本例中,所选元素名称为 div.List-item。
为了回顾上一节通过数据个数控制item个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取第一个暂时100条数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
首先是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是响应者的名字和批准的数量一样,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:


2.爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成null了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着没有捕获到任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要查看网页的构成,需要用到浏览器的另一个功能,就是选择视图元素。
1.我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3.我们再点一下标题,会发现会跳转到Elements子面板,内容是一些不太懂的彩色代码
不要因为这样做而感到沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果平时用markdown写的话,可以把HTML理解成功能更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树状结构:
最后一句从视觉上分析。它实际上是一个嵌套结构。我提取了关键内容。内容结构是否更清晰?
如何快速成为数据分析师?
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少属性为itemprop='知乎:question'的名为div的标签!结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们就能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem -标题'。如果可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清关系后,我们如何使用Web Scraper来操作呢?这时候我们可以使用上一篇文章介绍的内容,使用键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):

等等,因为响应者的名字也出现null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面类似,你可以试试。
我的三个子内容选择器如下,可以作为参考:

最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
爬取知乎的数据时,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这个间接的解释,知乎这个网站从代码的角度分析,写的还是比较差的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬取,可以在一定程度上减少返工时间。
6.下一期预览
本期内容较多。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写(如何写好Python数据我用的是Python?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-01 00:16
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个比较全面的信息网站,比如39养老网:
/findhomes/
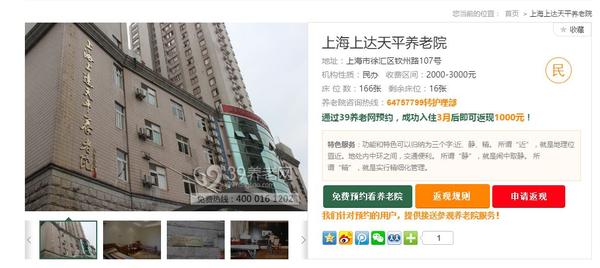
点击打开任意一家养老院,如上海上大天平养老院
我们想要获取有关此网站的所有疗养院信息,例如名称、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python 2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般像这些网站页面和页面之间的URL都会有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的URL 是的
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现这个网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个养老院的链接链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
我上面说了,我们知道这个网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
<p>i 是一个整数,getLink 会返回给我们对应的页面 url,例如 i=1 时,getLink 会返回第一页,i=2 时会返回第二页 查看全部
网页数据抓取怎么写(如何写好Python数据我用的是Python?(上)
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个比较全面的信息网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想要获取有关此网站的所有疗养院信息,例如名称、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python 2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般像这些网站页面和页面之间的URL都会有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的URL 是的
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现这个网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个养老院的链接链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
我上面说了,我们知道这个网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:

<p>i 是一个整数,getLink 会返回给我们对应的页面 url,例如 i=1 时,getLink 会返回第一页,i=2 时会返回第二页
网页数据抓取怎么写(网页,途径只有三个:1.手工复制.2.写代码,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 21:13
网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,你的 网站 是由网页组成的。如果你只有一个域名和一个虚拟主机,没有制作任何网页,你的客户仍然无法访问你的网站。
网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”,采用超文本标记语言格式(标准通用标记语言应用程序,文件扩展名为.html 或.htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
这是编程问题吗?
如何抓取网页上的数据,表格中的数据-... 没有历史页面,直接复制粘贴,选择你想要的数据,右键复制,右键-点击表格粘贴
网页数据抓取如何抓取网页数据? …… 网页抓取是一个庞大的工程。但总结起来只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集一个简单的网页,如果你想网站可以采集那绝对不容易。3.估计除非你有特殊的喜好,你不会想选择以上两条路径他们想要更高效、更强大。最好是免费的采集器,目前最好的是采集器新的优采云采集器,确实是神器,看来没有问题网站。它也是免费的,值得一试。
如何获取网页数据-……在要获取数据的网页上右击,查看网页源代码就可以看到了...
抓取页面后,如何获取我想要的数据-... 先去掉一些.NET中不使用字符串的方法,比如head部分。然后使用正则表达式进行过滤。这是最好最有效的方法,但需要你了解正则表达式。实在没办法,只能用字符串中的方法逐位过滤。给你一些代码,我怕你看不懂,哈哈哈///。 ..
如何抓取网页数据-...我们在抓取数据时,通常不仅抓取网页当前页面的数据,还经常在翻页后继续抓取数据。本文将向您介绍采集客户数据抓取过程中gooseeker网络爬虫如何自动抓取页面后的数据。 平台爬虫路径工作台有3条线索。
新人建议,如何提取网页上的数据-... 简单,可以用命令行下载工具wget配合批量提取,复杂的python爬虫工具就可以了。
如何抓取HTML页面中的一段数据,具体的html如下-...直接使用抓取工具就可以了,比如优采云采集器或者优采云浏览器可以
如何实现网页数据爬取?-... GooSeeker上有一个通用的爬取工具MetaSeeker,免费,功能非常强大。适用于大规模自动抓取,适用于大型在线服务,如垂直搜索和推荐引擎。 , 比价服务,信息系统等,所以学习使用需要时间,但是完整的图形界面操作不需要写任何代码。
如何抓取网页上的信息? …… 1、 识别URL重定向,互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被改写。定位,在这个过程中需要百度蜘蛛识别url重定向。 p>
求教,如何抓取网页中的表格数据...1.通过搜索引擎,找到国家旅游局的网站,点击主菜单【公众号】事务]-[统计],然后可以看到一系列收录数据的网页。 2.打开一个网页,确认网页收录数据表。复制网页的 URL 并将其用于备份。 3.启动Excel文件,在工作表中,点击【... 查看全部
网页数据抓取怎么写(网页,途径只有三个:1.手工复制.2.写代码,)
网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,你的 网站 是由网页组成的。如果你只有一个域名和一个虚拟主机,没有制作任何网页,你的客户仍然无法访问你的网站。
网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”,采用超文本标记语言格式(标准通用标记语言应用程序,文件扩展名为.html 或.htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
这是编程问题吗?
如何抓取网页上的数据,表格中的数据-... 没有历史页面,直接复制粘贴,选择你想要的数据,右键复制,右键-点击表格粘贴
网页数据抓取如何抓取网页数据? …… 网页抓取是一个庞大的工程。但总结起来只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集一个简单的网页,如果你想网站可以采集那绝对不容易。3.估计除非你有特殊的喜好,你不会想选择以上两条路径他们想要更高效、更强大。最好是免费的采集器,目前最好的是采集器新的优采云采集器,确实是神器,看来没有问题网站。它也是免费的,值得一试。
如何获取网页数据-……在要获取数据的网页上右击,查看网页源代码就可以看到了...
抓取页面后,如何获取我想要的数据-... 先去掉一些.NET中不使用字符串的方法,比如head部分。然后使用正则表达式进行过滤。这是最好最有效的方法,但需要你了解正则表达式。实在没办法,只能用字符串中的方法逐位过滤。给你一些代码,我怕你看不懂,哈哈哈///。 ..
如何抓取网页数据-...我们在抓取数据时,通常不仅抓取网页当前页面的数据,还经常在翻页后继续抓取数据。本文将向您介绍采集客户数据抓取过程中gooseeker网络爬虫如何自动抓取页面后的数据。 平台爬虫路径工作台有3条线索。
新人建议,如何提取网页上的数据-... 简单,可以用命令行下载工具wget配合批量提取,复杂的python爬虫工具就可以了。
如何抓取HTML页面中的一段数据,具体的html如下-...直接使用抓取工具就可以了,比如优采云采集器或者优采云浏览器可以
如何实现网页数据爬取?-... GooSeeker上有一个通用的爬取工具MetaSeeker,免费,功能非常强大。适用于大规模自动抓取,适用于大型在线服务,如垂直搜索和推荐引擎。 , 比价服务,信息系统等,所以学习使用需要时间,但是完整的图形界面操作不需要写任何代码。
如何抓取网页上的信息? …… 1、 识别URL重定向,互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被改写。定位,在这个过程中需要百度蜘蛛识别url重定向。 p>
求教,如何抓取网页中的表格数据...1.通过搜索引擎,找到国家旅游局的网站,点击主菜单【公众号】事务]-[统计],然后可以看到一系列收录数据的网页。 2.打开一个网页,确认网页收录数据表。复制网页的 URL 并将其用于备份。 3.启动Excel文件,在工作表中,点击【...
网页数据抓取怎么写(Gitscraping技术回顾抓取数据到Git存储库的一大优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-26 10:02
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析采集
到的数据是一个公认的问题。git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
下面是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents 网站上维护了一张火灾地图,该地图显示了最近大规模火灾的状态。
我找到了网站的底层数据:
卷曲
然后我搭建了一个简单的爬虫工具,每20分钟爬一次一个网站的数据,提交给Git。到目前为止,该工具已经运行了14个月,已经采集
了1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细归档数据更改的内容和位置,因此通过抓取他们的网站数据并将其保存到 Git 存储库,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集
到的数据?面对上千个版本和海量的JSON和CSV文档,如果仅靠肉眼观察差异,很难挖掘出数据背后的价值。
git-history
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新创建的数据库表的默认名称是item和item_version,我们通过--namespace event将表名指定为incident和incident_version。
工具中还嵌入了一段Python代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录
每次火灾的最新记录。从这张表中,我们可以得到一张所有火灾的地图:
这里使用了 datasette-cluster-map 插件,它在地图上标记了表中具有有效经纬度值的所有行。
真正有趣的是 event_version 表。该表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。前十名依次为:
版本越多,火持续的时间越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中可以看到所有抓到的“版本”按版本号排列。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
经常变化的是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具已提交的版本,当您再次运行该工具时,该工具可以定位到上次提交的是哪个版本。
连接到提交表以查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助datasette-vega插件,_commit_at列(日期类型)和AcresBurned列(数字类型) ) 比较形成一张图表,直观地显示了 Dixie Fire 火灾随时间的蔓延情况。
总结一下:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前的版本变更信息。
我的最终设计如下(为清晰起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到,item_version表记录了不同时间点的网站快照,但为了节省数据库空间,提供简洁的版本浏览界面,这里只记录了与之前版本相比发生变化的列。所有未更改的列都写为空。
但是这种设计有一个隐患,那就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
直升机听起来令人兴奋!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,直升机出动火灾19次,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月里,Drew Breunig 使用 Git 爬虫不断从网站上爬取数据并将其保存到 dbreunig/511-events-history 存储库中。本网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,帮助我们理解git-history和--convert选项overlay的用法。
git-history 要求捕获的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以作为唯一标识列来跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
但是,捕获的数据通常不是这种理想格式。
我找到了网站的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录
大量重复数据。.
我写了一段 Python 代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码还可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我还尝试在 sqlite-utils 工具中覆盖转换。
试一试
如果你想尝试 git-history 工具,扩展文档 README 中有更多选项。示例中使用的脚本都保存在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个仓库。海量爬取数据等你探索! 查看全部
网页数据抓取怎么写(Gitscraping技术回顾抓取数据到Git存储库的一大优势)
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析采集
到的数据是一个公认的问题。git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
下面是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents 网站上维护了一张火灾地图,该地图显示了最近大规模火灾的状态。
我找到了网站的底层数据:
卷曲
然后我搭建了一个简单的爬虫工具,每20分钟爬一次一个网站的数据,提交给Git。到目前为止,该工具已经运行了14个月,已经采集
了1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细归档数据更改的内容和位置,因此通过抓取他们的网站数据并将其保存到 Git 存储库,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集
到的数据?面对上千个版本和海量的JSON和CSV文档,如果仅靠肉眼观察差异,很难挖掘出数据背后的价值。
git-history
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'

在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新创建的数据库表的默认名称是item和item_version,我们通过--namespace event将表名指定为incident和incident_version。
工具中还嵌入了一段Python代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录
每次火灾的最新记录。从这张表中,我们可以得到一张所有火灾的地图:

这里使用了 datasette-cluster-map 插件,它在地图上标记了表中具有有效经纬度值的所有行。
真正有趣的是 event_version 表。该表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。前十名依次为:
版本越多,火持续的时间越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中可以看到所有抓到的“版本”按版本号排列。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:

经常变化的是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具已提交的版本,当您再次运行该工具时,该工具可以定位到上次提交的是哪个版本。
连接到提交表以查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助datasette-vega插件,_commit_at列(日期类型)和AcresBurned列(数字类型) ) 比较形成一张图表,直观地显示了 Dixie Fire 火灾随时间的蔓延情况。

总结一下:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前的版本变更信息。
我的最终设计如下(为清晰起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到,item_version表记录了不同时间点的网站快照,但为了节省数据库空间,提供简洁的版本浏览界面,这里只记录了与之前版本相比发生变化的列。所有未更改的列都写为空。
但是这种设计有一个隐患,那就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:

通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
直升机听起来令人兴奋!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,直升机出动火灾19次,我们在下图标注:

--convert 选项的高级用法
在过去的 8 个月里,Drew Breunig 使用 Git 爬虫不断从网站上爬取数据并将其保存到 dbreunig/511-events-history 存储库中。本网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,帮助我们理解git-history和--convert选项overlay的用法。
git-history 要求捕获的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以作为唯一标识列来跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
但是,捕获的数据通常不是这种理想格式。
我找到了网站的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录
大量重复数据。.
我写了一段 Python 代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码还可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我还尝试在 sqlite-utils 工具中覆盖转换。
试一试
如果你想尝试 git-history 工具,扩展文档 README 中有更多选项。示例中使用的脚本都保存在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个仓库。海量爬取数据等你探索!
网页数据抓取怎么写(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-24 07:08
网络爬虫网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候称为网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
专注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的URL,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序,该程序的作用是获取网站返回的数据,并提取其中的URL,我们将获取到的URL存放在一个文件夹中。除了提取网址之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。返回搜狐查看更多 查看全部
网页数据抓取怎么写(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网络爬虫网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候称为网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
专注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的URL,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序,该程序的作用是获取网站返回的数据,并提取其中的URL,我们将获取到的URL存放在一个文件夹中。除了提取网址之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。返回搜狐查看更多
网页数据抓取怎么写(WebScraper有多么好爬,以及大致怎么用问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-24 07:06
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。事实上,在大多数场景下,Web Scraper(一款Chrome插件)都可以快速抓取到目标内容。重要的是不需要下载东西,基本没有代码知识。
在开始之前,有必要先简单了解几个问题。
一个。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的事情应该留给工具来做。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,我们需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫所做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取内容,然后存入数据库中,供浏览或下载使用。搜索引擎可以工作,原理相同。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。
Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果你日常使用的浏览器不是Chrome,强烈建议更换,Chrome与其他浏览器的区别就像谷歌与其他搜索引擎的区别)
2、打开要爬取的网页,比如豆瓣Top250的网址,然后同时按option+command+i进入开发者模式(如果你用的是windows是ctrl+shift +i,不同浏览器默认快捷键可能不同)。这时候可以看到网页上弹出一个对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖块和瓷砖)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
3、 点击create new sitemap,依次创建sitemap创建爬虫。填写站点地图名称,仅供自己识别,如dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是
第二页以
第三页是
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,所以不能简单粘贴起始url,应该是[0-250:25]&filter=
注意start后[]里面的内容,表示每25日为一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。
(URL也可以爬取,但不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是一个简单的一点点。其原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置好选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
5、第4步只是创建一个容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名,电影名称,评分,一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。
看到容器根后跟根目录,点击添加新选择器创建子选择器。
再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写一个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意在container目录下),分别抓取电影名、评分、一句话影评。
创建之后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次爬取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始刮伤。
当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、 点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,然后就可以使用了。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,你觉得还是按照上面的一步一步来比较费力,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(它是由上面的一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":[";filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root ","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors" :["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type":"SelectorText" ,"parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"正则表达式 ":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,还有的网页乱七八糟,有时需要限制爬取次数(否则,抓取次数保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
如果您有任何问题或其他,欢迎微信 m644003222 查看全部
网页数据抓取怎么写(WebScraper有多么好爬,以及大致怎么用问题)
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。事实上,在大多数场景下,Web Scraper(一款Chrome插件)都可以快速抓取到目标内容。重要的是不需要下载东西,基本没有代码知识。
在开始之前,有必要先简单了解几个问题。
一个。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的事情应该留给工具来做。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,我们需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫所做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取内容,然后存入数据库中,供浏览或下载使用。搜索引擎可以工作,原理相同。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。

Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果你日常使用的浏览器不是Chrome,强烈建议更换,Chrome与其他浏览器的区别就像谷歌与其他搜索引擎的区别)
2、打开要爬取的网页,比如豆瓣Top250的网址,然后同时按option+command+i进入开发者模式(如果你用的是windows是ctrl+shift +i,不同浏览器默认快捷键可能不同)。这时候可以看到网页上弹出一个对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖块和瓷砖)。
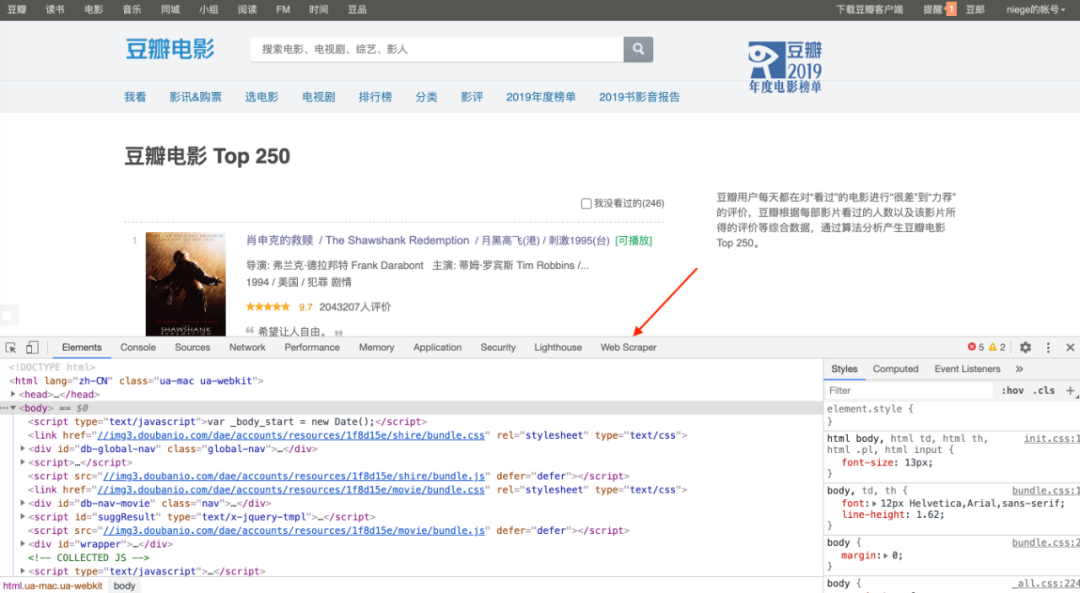
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
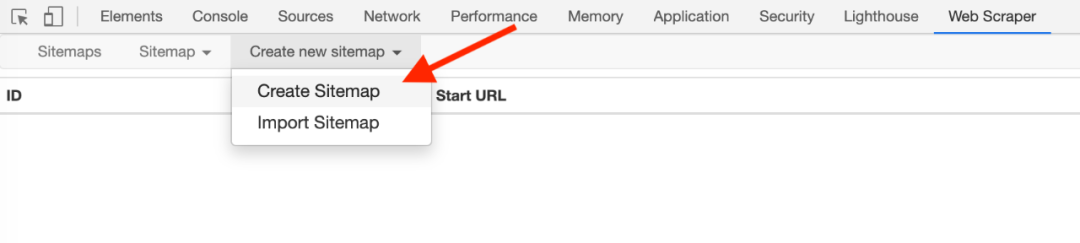
3、 点击create new sitemap,依次创建sitemap创建爬虫。填写站点地图名称,仅供自己识别,如dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是
第二页以
第三页是
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,所以不能简单粘贴起始url,应该是[0-250:25]&filter=
注意start后[]里面的内容,表示每25日为一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。

(URL也可以爬取,但不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
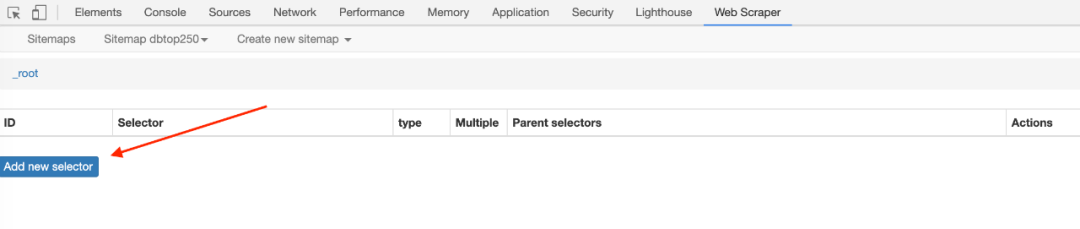
然后就会进入选择器编辑页面,其实就是一个简单的一点点。其原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置好选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
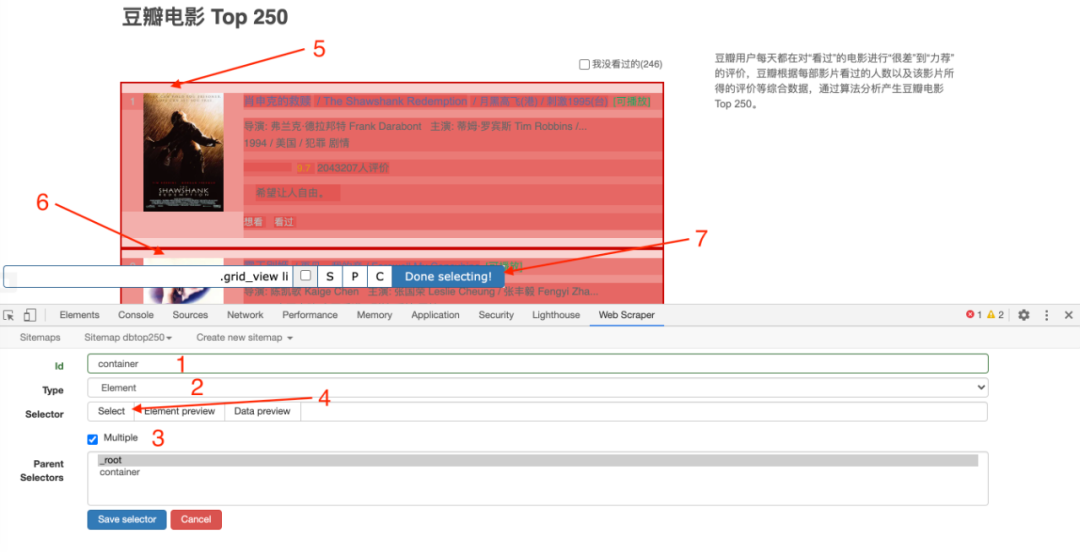
5、第4步只是创建一个容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名,电影名称,评分,一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。

看到容器根后跟根目录,点击添加新选择器创建子选择器。

再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写一个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
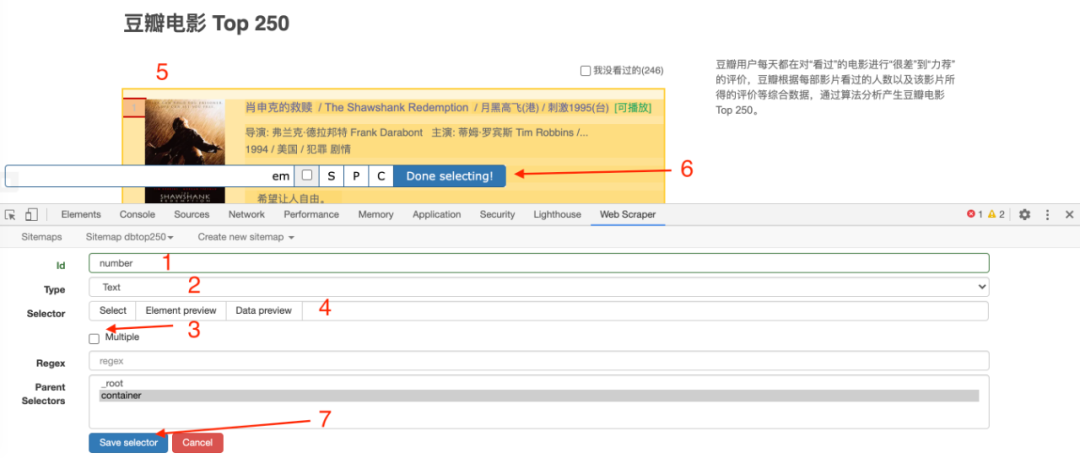
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意在container目录下),分别抓取电影名、评分、一句话影评。
创建之后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
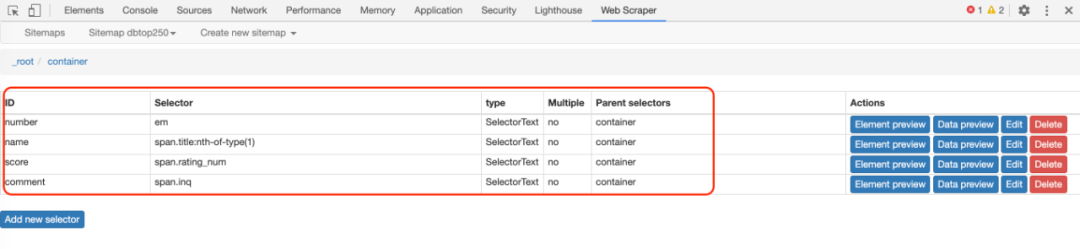
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次爬取
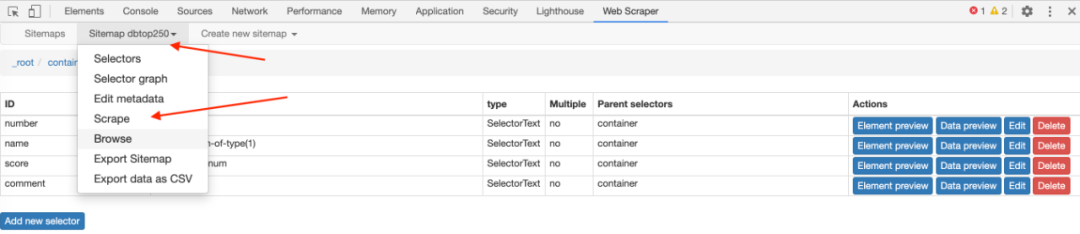
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始刮伤。

当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、 点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,然后就可以使用了。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,你觉得还是按照上面的一步一步来比较费力,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(它是由上面的一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":[";filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root ","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors" :["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type":"SelectorText" ,"parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"正则表达式 ":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,还有的网页乱七八糟,有时需要限制爬取次数(否则,抓取次数保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
如果您有任何问题或其他,欢迎微信 m644003222
网页数据抓取怎么写(网页数据抓取怎么写?爬虫软件要多少钱?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-24 05:03
网页数据抓取怎么写?爬虫软件要多少钱?小蚂蚁网页抓取器【蚂蚁分析】——教你怎么获取网页数据!,抓取一个网页分分钟搞定,用的模块也不是很多,今天实例教一下爬虫软件的使用,思路清晰了再去搜一些新的资料,只有有耐心才能熟练掌握,而且后面还有更深入的使用技巧等着你的!首先这个项目是一个实际的项目,应该说是一个比较复杂的项目,需要个各个环节的环环相扣,每个人或多或少都有不同的经验!其实,大部分人可能并不是非常清楚该如何去写,可能是一些分支、步骤的模块写好,然后再去调用,多半是我跟你讲,你都不清楚是怎么个过程!所以,用最初级的方法!分享一下我所总结的技巧,大概可以分为三步:定位抓取整个页面;获取到数据;存入数据库。
如果我是你,遇到这样的项目时,我会先分析一下,我需要的是一个什么样的页面。现在都是在用无线浏览器,一个相对来说人人手机都能上网的时代,看个文章,看个视频,看个新闻都不是什么问题,很多互联网公司都推出了抓取浏览器,只要连接上wifi,就能抓到一个相对来说还不错的网页,这样就非常简单了,因为只需要定位网页的关键部分,然后通过js或者xml解析,提取出内容即可!例如我要抓取一个baiduspider的关键内容:about&needs_career&staff_title_tag&giveover¬e&repository_tag即可!about&needs_career&staff_title_tag&giveover¬e&repository_tag即可;即可爬虫开始第一步!获取网页数据的思路:首先最后一步是获取到整个网页,但是获取一个页面其实并不是一件简单的事情,获取整个页面的代码大概分为:strip、parse()、content等。
首先我们都知道,互联网有超过50亿的网页,一页可能有n个网页,我们在这里面想找到about&needs_career&staff_title_tag是一个网页,那么我们可以用strip方法,就是用某些字符串把about&needs_career&staff_title_tag以及所有网页去掉,然后就是parse()方法,即去除后面的html,提取出里面html的关键部分,然后提取出里面的关键字,提取不出来,就是最后一步content方法解析。
经过一系列的分析以及查找,最后得到about&needs_career&staff_title_tag和giveover¬e等,最后实现了这个项目的目标!这个项目的源码我已经上传到项目的github里面去,大家有兴趣的同学,可以去查看项目的源码,有任何不明白的,可以去问里面的项目组成员,大家一起完成,项目最后会链接到github上面去。项目代码里面不少代码很牛逼,但是, 查看全部
网页数据抓取怎么写(网页数据抓取怎么写?爬虫软件要多少钱?(组图))
网页数据抓取怎么写?爬虫软件要多少钱?小蚂蚁网页抓取器【蚂蚁分析】——教你怎么获取网页数据!,抓取一个网页分分钟搞定,用的模块也不是很多,今天实例教一下爬虫软件的使用,思路清晰了再去搜一些新的资料,只有有耐心才能熟练掌握,而且后面还有更深入的使用技巧等着你的!首先这个项目是一个实际的项目,应该说是一个比较复杂的项目,需要个各个环节的环环相扣,每个人或多或少都有不同的经验!其实,大部分人可能并不是非常清楚该如何去写,可能是一些分支、步骤的模块写好,然后再去调用,多半是我跟你讲,你都不清楚是怎么个过程!所以,用最初级的方法!分享一下我所总结的技巧,大概可以分为三步:定位抓取整个页面;获取到数据;存入数据库。
如果我是你,遇到这样的项目时,我会先分析一下,我需要的是一个什么样的页面。现在都是在用无线浏览器,一个相对来说人人手机都能上网的时代,看个文章,看个视频,看个新闻都不是什么问题,很多互联网公司都推出了抓取浏览器,只要连接上wifi,就能抓到一个相对来说还不错的网页,这样就非常简单了,因为只需要定位网页的关键部分,然后通过js或者xml解析,提取出内容即可!例如我要抓取一个baiduspider的关键内容:about&needs_career&staff_title_tag&giveover¬e&repository_tag即可!about&needs_career&staff_title_tag&giveover¬e&repository_tag即可;即可爬虫开始第一步!获取网页数据的思路:首先最后一步是获取到整个网页,但是获取一个页面其实并不是一件简单的事情,获取整个页面的代码大概分为:strip、parse()、content等。
首先我们都知道,互联网有超过50亿的网页,一页可能有n个网页,我们在这里面想找到about&needs_career&staff_title_tag是一个网页,那么我们可以用strip方法,就是用某些字符串把about&needs_career&staff_title_tag以及所有网页去掉,然后就是parse()方法,即去除后面的html,提取出里面html的关键部分,然后提取出里面的关键字,提取不出来,就是最后一步content方法解析。
经过一系列的分析以及查找,最后得到about&needs_career&staff_title_tag和giveover¬e等,最后实现了这个项目的目标!这个项目的源码我已经上传到项目的github里面去,大家有兴趣的同学,可以去查看项目的源码,有任何不明白的,可以去问里面的项目组成员,大家一起完成,项目最后会链接到github上面去。项目代码里面不少代码很牛逼,但是,
网页数据抓取怎么写( Python中正则表达式的3种抓取其中数据的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-21 19:08
Python中正则表达式的3种抓取其中数据的方法(上))
3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> re.findall(r'(.*?)', html)
['<img />
',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'<a>EU</a>
',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{
2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]
d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'<a>IE </a>
']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。如果您希望正则表达式更加明确,我们也可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint
>>> broken_html = 'AreaPopulation
'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area
, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element
>>> area = td.text # extract the text from the data element
>>> print(area)
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation
'
>>> tree = fromstring(broken_html) # parse the HTML
>>> fixed_html = tostring(tree, pretty_print=True)
>>> print(fixed_html)
Area
Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print(area)
244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
标签: 查看全部
网页数据抓取怎么写(
Python中正则表达式的3种抓取其中数据的方法(上))

3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> re.findall(r'(.*?)', html)
['<img />
',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'<a>EU</a>
',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{
2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]
d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'<a>IE </a>
']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。如果您希望正则表达式更加明确,我们也可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint
>>> broken_html = 'AreaPopulation
'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area
, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element
>>> area = td.text # extract the text from the data element
>>> print(area)
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation
'
>>> tree = fromstring(broken_html) # parse the HTML
>>> fixed_html = tostring(tree, pretty_print=True)
>>> print(fixed_html)
Area
Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print(area)
244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
标签:
网页数据抓取怎么写(缓存穿透**详解及解决方案_50323137的博客-程序员)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-17 08:09
Redis常见问题->缓存穿透**缓存击穿**缓存雪崩**缓存预热**集群裂脑**详解及解决方案_m0_50323137的博客-程序员的秘密
缓存穿透缓存穿透是指用户请求的数据在缓存中不存在,即没有命中,在数据库中也不存在。结果,用户每次请求数据,都要查询一次数据库,然后返回空。在普通攻击和恶意攻击中,不断地请求系统中不存在的数据,导致大量请求在缓存中找不到,并在短时间内落入数据库。甚至导致数据库崩溃。常见解决方案(1)缓存空对象当缓存未命中,查询数据库也为空时,可以将返回的空对象写入缓存,这样下次请求就不会落入数据库。,有一个问题:如果有大量的key渗透,
YOLOv2输出物体位置坐标并批量处理图片_xiaomifanhxx的博客-程序员secret_yolov2输出层
当我们使用深度学习进行识别和检测时,有时不仅需要找到判别类型,有时还需要分析坐标。下面将告诉你通过YOLOV2训练时如何输出物体的位置坐标。1.查看保存检测图像的源代码。看过源码的人一定知道,我们通常在训练和检测的时候都会用到YOLO中的检测器功能。在源代码不变的情况下,我们将检测到的图片保存为darknet.exe,路径与“predictio...
svn diff 与 vimdiff_First Line - 程序员的秘密
vim ~/.subversion/configunder [helpers] section adddiff-cmd=/{你的文件路径}/svndiff.sh create svndiff.sh fileDIFF=/{你的vimdiff路径}/vimdiffLEFT=${6}RIGHT=${7} $ 差异 $ 左 $ 右
微信JS-SDK文档_take_wang的专栏-程序员的秘密
来自:微信JS-SDK文档目录1概述1.1 JSSDK使用步骤1.1.1第一步:绑定域名1.1.2第二步:引入JS文件1.1.3 第三步:通过config界面注入
信息学奥林匹克 - 1047
1047:判断是否能被3、5、7整除时间限制:1000毫秒内存限制:65536 KB提交次数:85571通过次数:39099【标题说明】给定一个整数,判断是否能被33、55整除, 77 , 并输出如下信息: 1、 可以同时被33, 55, 77整除(直接输出3 5 7,每个数字中间有一个空格);2、 只能被其中两个整除(输出两个数字,先小后大。例如:3 5 or 3 7 or 5 7,用空格隔开);3、 只能被其中一个整除(输出除数);4、不能被任何数字四舍五入...
svn diff和vimdiff_chenqiechun3408的使用方法-程序员的秘密
SVN子命令SVN diff功能介绍 2010-05-24 14:16 匿名名称:T | T 本文将介绍SVN子命令SVN diff,它的主要高手比较了两条路径的区别,这里跟大家分享一下,希望大家一起学习。AD:WOT2014:用户标签系统和用户数据操作... 查看全部
网页数据抓取怎么写(缓存穿透**详解及解决方案_50323137的博客-程序员)
Redis常见问题->缓存穿透**缓存击穿**缓存雪崩**缓存预热**集群裂脑**详解及解决方案_m0_50323137的博客-程序员的秘密
缓存穿透缓存穿透是指用户请求的数据在缓存中不存在,即没有命中,在数据库中也不存在。结果,用户每次请求数据,都要查询一次数据库,然后返回空。在普通攻击和恶意攻击中,不断地请求系统中不存在的数据,导致大量请求在缓存中找不到,并在短时间内落入数据库。甚至导致数据库崩溃。常见解决方案(1)缓存空对象当缓存未命中,查询数据库也为空时,可以将返回的空对象写入缓存,这样下次请求就不会落入数据库。,有一个问题:如果有大量的key渗透,
YOLOv2输出物体位置坐标并批量处理图片_xiaomifanhxx的博客-程序员secret_yolov2输出层
当我们使用深度学习进行识别和检测时,有时不仅需要找到判别类型,有时还需要分析坐标。下面将告诉你通过YOLOV2训练时如何输出物体的位置坐标。1.查看保存检测图像的源代码。看过源码的人一定知道,我们通常在训练和检测的时候都会用到YOLO中的检测器功能。在源代码不变的情况下,我们将检测到的图片保存为darknet.exe,路径与“predictio...
svn diff 与 vimdiff_First Line - 程序员的秘密
vim ~/.subversion/configunder [helpers] section adddiff-cmd=/{你的文件路径}/svndiff.sh create svndiff.sh fileDIFF=/{你的vimdiff路径}/vimdiffLEFT=${6}RIGHT=${7} $ 差异 $ 左 $ 右
微信JS-SDK文档_take_wang的专栏-程序员的秘密
来自:微信JS-SDK文档目录1概述1.1 JSSDK使用步骤1.1.1第一步:绑定域名1.1.2第二步:引入JS文件1.1.3 第三步:通过config界面注入
信息学奥林匹克 - 1047
1047:判断是否能被3、5、7整除时间限制:1000毫秒内存限制:65536 KB提交次数:85571通过次数:39099【标题说明】给定一个整数,判断是否能被33、55整除, 77 , 并输出如下信息: 1、 可以同时被33, 55, 77整除(直接输出3 5 7,每个数字中间有一个空格);2、 只能被其中两个整除(输出两个数字,先小后大。例如:3 5 or 3 7 or 5 7,用空格隔开);3、 只能被其中一个整除(输出除数);4、不能被任何数字四舍五入...
svn diff和vimdiff_chenqiechun3408的使用方法-程序员的秘密
SVN子命令SVN diff功能介绍 2010-05-24 14:16 匿名名称:T | T 本文将介绍SVN子命令SVN diff,它的主要高手比较了两条路径的区别,这里跟大家分享一下,希望大家一起学习。AD:WOT2014:用户标签系统和用户数据操作...
网页数据抓取怎么写(一下框架介绍和安装Scrapy的用法(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-14 08:08
在前面的章节中,我们用尽可能少的代码演示了爬虫的基本原理。如果只需要抓取一些简单的数据,那么我们可以通过修改前面的代码来完成任务。但是当我们需要完成一些复杂的大规模爬取任务时,就需要考虑更多的事情,比如爬虫的可扩展性、爬取效率等。
现在让我们回顾一下我们的爬取过程:从要下载的 URL 列表中提取 URL;构建并发送 HTTP 请求以下载网页;解析网页以提取数据,解析网页以提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。这个过程中有很多地方是通用的,只有网页数据和URL提取与具体的爬取任务相关。因为通用代码部分可以重用,所以框架就诞生了。现在python下的爬虫框架很多,比较常用的是Scrapy。接下来,我们简单介绍一下Scrapy的用法。
Scrapy框架介绍及安装
Scrapy 是一个用 python 开发的快速高效的网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 广泛用于数据挖掘、监控和自动化测试。Scrapy的安装也很简单,只要运行pip install Scrapy,我们需要的开发环境就准备好了。
创建一个 Scrapy 项目
这里我们将使用 Scrapy 框架重写我们之前的爬虫。在我们开始之前,我们需要创建一个新的 Scrapy 项目。假设我们的项目名为豆瓣,运行scrapy startproject Douban。创建豆瓣文件夹,这个文件夹收录了我们爬虫的基本框架。
这里有几个更重要的概念:
创建项目类
我们使用Item类来封装从网页解析出来的数据,方便各个模块之间的传递和进一步处理。爬虫的Item类很简单。它直接继承了scrapy的Item类,并定义了相应的属性字段来存储数据。每个字段都是 scrapy.Field() 类型,可用于存储任何类型的数据。现在看看我们的 Item 类定义:
创建蜘蛛类
Spider 类主要用于解析数据,它收录一些用于下载的初始 URL 以及用于提取网页中的链接和数据的方法。所有 Spider 必须继承自 scrapy.Spider 类并实现三个属性:
创建管道类
Scrapy 使用管道模块来保存对数据的操作。即Spider类的parse()方法返回的Item对象会传递给Pipeline中的类,Pipeline会完成具体的保存工作。创建 Scrapy 项目时会自动创建一个 pipeline.py 文件,其中收录一个默认的 Pipeline 类。
Pipeline 类会在 process_item() 方法中处理数据,然后在最后调用 close_spider() 方法,所以我们需要这两个方法来做相应的处理。
运行爬虫
在项目目录下,执行命令scrapy crawl Douban,我们可以看到爬虫开始爬取网页。
总结
现在让我们回顾一下我们所有的代码在 Scrapy 框架下是如何工作的:
过去 文章:
Python爬虫入门,快速抓取海量数据5
Python爬虫入门,快速抓取海量数据4
Python爬虫入门,快速抓取海量数据3
Python爬虫入门,快速抓取海量数据2
Python爬虫入门,快速抓取海量数据1 查看全部
网页数据抓取怎么写(一下框架介绍和安装Scrapy的用法(一)_)
在前面的章节中,我们用尽可能少的代码演示了爬虫的基本原理。如果只需要抓取一些简单的数据,那么我们可以通过修改前面的代码来完成任务。但是当我们需要完成一些复杂的大规模爬取任务时,就需要考虑更多的事情,比如爬虫的可扩展性、爬取效率等。
现在让我们回顾一下我们的爬取过程:从要下载的 URL 列表中提取 URL;构建并发送 HTTP 请求以下载网页;解析网页以提取数据,解析网页以提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。这个过程中有很多地方是通用的,只有网页数据和URL提取与具体的爬取任务相关。因为通用代码部分可以重用,所以框架就诞生了。现在python下的爬虫框架很多,比较常用的是Scrapy。接下来,我们简单介绍一下Scrapy的用法。
Scrapy框架介绍及安装
Scrapy 是一个用 python 开发的快速高效的网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 广泛用于数据挖掘、监控和自动化测试。Scrapy的安装也很简单,只要运行pip install Scrapy,我们需要的开发环境就准备好了。
创建一个 Scrapy 项目
这里我们将使用 Scrapy 框架重写我们之前的爬虫。在我们开始之前,我们需要创建一个新的 Scrapy 项目。假设我们的项目名为豆瓣,运行scrapy startproject Douban。创建豆瓣文件夹,这个文件夹收录了我们爬虫的基本框架。
这里有几个更重要的概念:
创建项目类
我们使用Item类来封装从网页解析出来的数据,方便各个模块之间的传递和进一步处理。爬虫的Item类很简单。它直接继承了scrapy的Item类,并定义了相应的属性字段来存储数据。每个字段都是 scrapy.Field() 类型,可用于存储任何类型的数据。现在看看我们的 Item 类定义:
创建蜘蛛类
Spider 类主要用于解析数据,它收录一些用于下载的初始 URL 以及用于提取网页中的链接和数据的方法。所有 Spider 必须继承自 scrapy.Spider 类并实现三个属性:
创建管道类
Scrapy 使用管道模块来保存对数据的操作。即Spider类的parse()方法返回的Item对象会传递给Pipeline中的类,Pipeline会完成具体的保存工作。创建 Scrapy 项目时会自动创建一个 pipeline.py 文件,其中收录一个默认的 Pipeline 类。
Pipeline 类会在 process_item() 方法中处理数据,然后在最后调用 close_spider() 方法,所以我们需要这两个方法来做相应的处理。
运行爬虫
在项目目录下,执行命令scrapy crawl Douban,我们可以看到爬虫开始爬取网页。
总结
现在让我们回顾一下我们所有的代码在 Scrapy 框架下是如何工作的:
过去 文章:
Python爬虫入门,快速抓取海量数据5
Python爬虫入门,快速抓取海量数据4
Python爬虫入门,快速抓取海量数据3
Python爬虫入门,快速抓取海量数据2
Python爬虫入门,快速抓取海量数据1
网页数据抓取怎么写(一个英语学习爱好者.1.3破解激活,IntelliJ会写代码吟诗的架构师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-13 22:07
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是我们通常这样做
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说用网络爬虫为自己写一个英语学习工具,希望能帮助大家提高!!!
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是,虽然我们平时阅读量很大,但我们只是被动地将英文信息转化为大致的中文意思理解,而不是试图训练如何从中文到英文表达。成为程序员的好处之一是,当你发现需要时,你可以尝试制作一些东西来和自己一起玩。为了做这个学习工具,我首先想到了一些新闻网站会提供双语新闻(比如酷游网),然后我的想法就简单的形成了,首先创建一个网络爬虫,抓取一些双语新闻网页,然后提取每个中英文句子,然后制作图形界面,每次显示一条消息。中文,让用户尝试输入英文翻译,写不出来可以查看英文原版提示,并提供笔记功能,记录特殊词汇、表达和经验等。这些功能一一实现。
1 网页抓取框架-scrapy
所谓网络爬虫,其实就是我们使用的浏览器。它访问一个链接,然后下载相应的网页。不同的是,浏览器下载文件后呈现一个页面,而爬虫可以根据我们定义的规则,自动访问网站中的链接,然后处理下载的web文件,提取我们想要的数据. 如果要自己实现一个网络爬虫,需要自己编写一个模拟的http客户端,实现文本解析等功能,比较麻烦。此时,您可以找到任何有用的开源软件。Scrapy() 是一个非常好的工具。它是一个使用 python 的快速和先进的网络抓取框架。使用时只需要简单定义你要抓取的网页的url,而对于每次抓取页面需要进行的处理操作,剩下的都可以通过scrapy来完成。感兴趣的朋友可以看看它提供的tutorial(),现在就开始我们的工作吧。
(1)安装scrapy后,在shell终端下任意目录运行命令:
scrapy startproject 双语(项目名称自行取)
得到如下图的项目结构
bilingual/
scrapy.cfg
bilingual/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
只听山间传来建筑师的声音:
江水流泉至尽,月落江塘。谁将向上或向下匹配?
Scrapy 提供这些文件以允许我们自定义处理捕获的数据。spiders 目录用于存储用户定义的蜘蛛类。Scrapy 根据此处定义的类捕获信息。在spider类中,需要定义初始的url列表,以及抓取新链接的规则以及如何解析提取下载的网页信息。为简单起见,我只在spiders目录下写了一个spider进行处理,并没有使用其他功能。
(2)在spiders目录下,创建文件cuyoo.py(自定义的spider名称,即要捕获的网站的名称),代码如下
此代码由Java架构师必看网-架构君整理
1 from scrapy.selector import HtmlXPathSelector
2 from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
3 from scrapy.contrib.spiders import CrawlSpider, Rule
4
5 import codecs
6 import os
7
8 class CuyooSpider(CrawlSpider):
9 name = 'cuyoo'
10 allowed_domains = ['cuyoo.com']
11 start_urls = [
12 'http://www.cuyoo.com/home/portal.php?mod=list&catid=2']
13
14 rules = (
15 Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',
follow=False),
16 )
17
18 def __init__(self, *arg, **kwargs):
19 super(CuyooSpider, self).__init__(*arg, **kwargs)
20 self.output = codecs.open("data", "wb", "utf-8")
21
22 def __del__(self):
23 self.output.close()
24
25 def parse_item(self, response):
26 hxs = HtmlXPathSelector(response)
27 title = hxs.select("//h4[@class='ph']/text()").extract()
28 english = hxs.select('//div[@id="en"]/text()').extract()
29 chinese = hxs.select('//div[@id="cn"]/text()').extract()
30 self.output.write("---" + title[0].strip() + "---")
31 self.output.write(os.linesep)
32 for i in range(len(english)):
33 self.output.write(chinese[i].strip())
34 self.output.write("->")
35 self.output.write(english[i].strip())
36 self.output.write(os.linesep)
稍微解释一下,在上面的蜘蛛中,我在star_urls成员中放了一个链接,打开这个链接可以看到如下网页:
可以看到,在这个网页中有多个新闻链接,每个链接点击双语对照可以得到中英文对照版的新闻,查看源代码可以看出其链接形式为:portal.php?mod=view_both&aid=19076,所以在rules里定义规则
Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',follow=False)
用正则表达式表示包含'mod=view_both’的链接,scrapy在访问该网页时,就会自动抓取符合所定义的规则的所有链接,这样就将这一页里的所有中英文对照的新闻都抓取了下来,然后对每个抓取到的网页调用parse_item(self, response)进行处理
(3) 因为我们要的只是网页里的中英文新闻内容,所以要对下载到的网页进行信息抽取,scrapy提供了XPath查找功能,让我们可以方便地抽取文档节点内容,不了解XPath可以看看W3C的教程(http://www.w3school.com.cn/xpath/),要抽取信息,首先还是要分析该新闻网页的结构,可以使用scrapy提供的命令行工具来分析网页结构和试验xpath语句,首先运行命令
此代码由Java架构师必看网-架构君整理
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
将网页下载下来后,再输入view(response),可在浏览器查看下载到的网页
可以看出,新闻的两种格式分别包含在两个div中,一个id为en,另一个为cn,所在在parse_item()中,分别使用
hxs.select('//div[@id="en"]/text()').extract() 和 hxs.select('//div[@id="cn"]/text()').extract()
将内容抽取出来,并按格式写到文件中。
(4)在项目目录下运行 scrapy crawl cuyoo 开始抓取,最终得到如下图所示意的文件
2 图形界面
使用捕获的数据,您可以自由地播放您接下来想做的事情。我的图形界面是通过 Qt 实现的。我个人认为它非常方便且易于使用。.
程序界面
选择文章
查看提示
最后,还有一个尚未实现的笔记功能。本来想用印象笔记SDK直接在印象笔记上写笔记的,但是因为他们的SDK的C++版本没有教程文档,貌似账号有点复杂。,或者等到以后再找时间实施。
3 总结
这样做我得到了两分。首先,它让我觉得编程其实很有用,不局限于工作和学习。只要我们有想法,我们就可以做很多事情。第二个是关于开源软件。现在有很多开源软件。使用开源的东西非常方便有趣。同时,我们也可以参与到使用的过程中。比如我在使用scrapy的时候,上面提到过。这样的命令
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
一开始我的链接没用引号括起来,因为&在shell里是个特殊符号,表示后台运行,所以链接里的第二个参数在运行的时候就没了,后来想明白后,问题解决了,我觉得这个问题别人可能也会遇到,所以就在scrapy的github页面上给提了这个问题,希望他们能加到tutorial文档里,然后过了一两天,他们就真的加上了,这让我感到很高兴,也很佩服。
好了,写得好长,谢谢观看~
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
网页数据抓取怎么写(一个英语学习爱好者.1.3破解激活,IntelliJ会写代码吟诗的架构师)
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是我们通常这样做
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说用网络爬虫为自己写一个英语学习工具,希望能帮助大家提高!!!
作为一个英语学习爱好者,我发现我们学了这么多年英语。虽然现在读英文文章不是很困难,但是如果我自己想写英文文章,总觉得单词虽然看懂了,但是很难拼出一个水平的句子. 我认为的原因是,虽然我们平时阅读量很大,但我们只是被动地将英文信息转化为大致的中文意思理解,而不是试图训练如何从中文到英文表达。成为程序员的好处之一是,当你发现需要时,你可以尝试制作一些东西来和自己一起玩。为了做这个学习工具,我首先想到了一些新闻网站会提供双语新闻(比如酷游网),然后我的想法就简单的形成了,首先创建一个网络爬虫,抓取一些双语新闻网页,然后提取每个中英文句子,然后制作图形界面,每次显示一条消息。中文,让用户尝试输入英文翻译,写不出来可以查看英文原版提示,并提供笔记功能,记录特殊词汇、表达和经验等。这些功能一一实现。
1 网页抓取框架-scrapy
所谓网络爬虫,其实就是我们使用的浏览器。它访问一个链接,然后下载相应的网页。不同的是,浏览器下载文件后呈现一个页面,而爬虫可以根据我们定义的规则,自动访问网站中的链接,然后处理下载的web文件,提取我们想要的数据. 如果要自己实现一个网络爬虫,需要自己编写一个模拟的http客户端,实现文本解析等功能,比较麻烦。此时,您可以找到任何有用的开源软件。Scrapy() 是一个非常好的工具。它是一个使用 python 的快速和先进的网络抓取框架。使用时只需要简单定义你要抓取的网页的url,而对于每次抓取页面需要进行的处理操作,剩下的都可以通过scrapy来完成。感兴趣的朋友可以看看它提供的tutorial(),现在就开始我们的工作吧。
(1)安装scrapy后,在shell终端下任意目录运行命令:
scrapy startproject 双语(项目名称自行取)
得到如下图的项目结构
bilingual/
scrapy.cfg
bilingual/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
只听山间传来建筑师的声音:
江水流泉至尽,月落江塘。谁将向上或向下匹配?
Scrapy 提供这些文件以允许我们自定义处理捕获的数据。spiders 目录用于存储用户定义的蜘蛛类。Scrapy 根据此处定义的类捕获信息。在spider类中,需要定义初始的url列表,以及抓取新链接的规则以及如何解析提取下载的网页信息。为简单起见,我只在spiders目录下写了一个spider进行处理,并没有使用其他功能。
(2)在spiders目录下,创建文件cuyoo.py(自定义的spider名称,即要捕获的网站的名称),代码如下
此代码由Java架构师必看网-架构君整理
1 from scrapy.selector import HtmlXPathSelector
2 from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
3 from scrapy.contrib.spiders import CrawlSpider, Rule
4
5 import codecs
6 import os
7
8 class CuyooSpider(CrawlSpider):
9 name = 'cuyoo'
10 allowed_domains = ['cuyoo.com']
11 start_urls = [
12 'http://www.cuyoo.com/home/portal.php?mod=list&catid=2']
13
14 rules = (
15 Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',
follow=False),
16 )
17
18 def __init__(self, *arg, **kwargs):
19 super(CuyooSpider, self).__init__(*arg, **kwargs)
20 self.output = codecs.open("data", "wb", "utf-8")
21
22 def __del__(self):
23 self.output.close()
24
25 def parse_item(self, response):
26 hxs = HtmlXPathSelector(response)
27 title = hxs.select("//h4[@class='ph']/text()").extract()
28 english = hxs.select('//div[@id="en"]/text()').extract()
29 chinese = hxs.select('//div[@id="cn"]/text()').extract()
30 self.output.write("---" + title[0].strip() + "---")
31 self.output.write(os.linesep)
32 for i in range(len(english)):
33 self.output.write(chinese[i].strip())
34 self.output.write("->")
35 self.output.write(english[i].strip())
36 self.output.write(os.linesep)
稍微解释一下,在上面的蜘蛛中,我在star_urls成员中放了一个链接,打开这个链接可以看到如下网页:
可以看到,在这个网页中有多个新闻链接,每个链接点击双语对照可以得到中英文对照版的新闻,查看源代码可以看出其链接形式为:portal.php?mod=view_both&aid=19076,所以在rules里定义规则
Rule(SgmlLinkExtractor(allow=r'.*mod=view_both.*'), callback=‘parse_item',follow=False)
用正则表达式表示包含'mod=view_both’的链接,scrapy在访问该网页时,就会自动抓取符合所定义的规则的所有链接,这样就将这一页里的所有中英文对照的新闻都抓取了下来,然后对每个抓取到的网页调用parse_item(self, response)进行处理
(3) 因为我们要的只是网页里的中英文新闻内容,所以要对下载到的网页进行信息抽取,scrapy提供了XPath查找功能,让我们可以方便地抽取文档节点内容,不了解XPath可以看看W3C的教程(http://www.w3school.com.cn/xpath/" rel="nofollow" target="_blank">http://www.w3school.com.cn/xpath/),要抽取信息,首先还是要分析该新闻网页的结构,可以使用scrapy提供的命令行工具来分析网页结构和试验xpath语句,首先运行命令
此代码由Java架构师必看网-架构君整理
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
将网页下载下来后,再输入view(response),可在浏览器查看下载到的网页
可以看出,新闻的两种格式分别包含在两个div中,一个id为en,另一个为cn,所在在parse_item()中,分别使用
hxs.select('//div[@id="en"]/text()').extract() 和 hxs.select('//div[@id="cn"]/text()').extract()
将内容抽取出来,并按格式写到文件中。
(4)在项目目录下运行 scrapy crawl cuyoo 开始抓取,最终得到如下图所示意的文件
2 图形界面
使用捕获的数据,您可以自由地播放您接下来想做的事情。我的图形界面是通过 Qt 实现的。我个人认为它非常方便且易于使用。.
程序界面
选择文章
查看提示
最后,还有一个尚未实现的笔记功能。本来想用印象笔记SDK直接在印象笔记上写笔记的,但是因为他们的SDK的C++版本没有教程文档,貌似账号有点复杂。,或者等到以后再找时间实施。
3 总结
这样做我得到了两分。首先,它让我觉得编程其实很有用,不局限于工作和学习。只要我们有想法,我们就可以做很多事情。第二个是关于开源软件。现在有很多开源软件。使用开源的东西非常方便有趣。同时,我们也可以参与到使用的过程中。比如我在使用scrapy的时候,上面提到过。这样的命令
scrapy shell 'http://www.cuyoo.com/home/portal.php?mod=view_both&aid=19076'
一开始我的链接没用引号括起来,因为&在shell里是个特殊符号,表示后台运行,所以链接里的第二个参数在运行的时候就没了,后来想明白后,问题解决了,我觉得这个问题别人可能也会遇到,所以就在scrapy的github页面上给提了这个问题,希望他们能加到tutorial文档里,然后过了一两天,他们就真的加上了,这让我感到很高兴,也很佩服。
好了,写得好长,谢谢观看~
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
网页数据抓取怎么写(Python爬虫初探初探为什么选择Python?爬虫是什么?网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-13 22:06
初探 Python 爬虫 为什么选择 Python?什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
基本知识概念
URL(协议(服务模式)+IP地址(含端口号)+具体地址),即统一资源定位器,也就是我们所说的网站,统一资源定位器就是可以定位和访问的资源从 Internet 获得 方法的简洁表示是 Internet 上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
URI 在计算机术语中,统一资源标识符 (URI) 是用于标识 Internet 资源名称的字符串。这种标识允许用户通过特定的协议与任何(包括本地和互联网)资源进行交互。URI 由收录特定语法和相关协议的方案定义。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求。服务器解析后,将HTML、JS、CSS等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。其实就是一个http请求的过程。
爬虫入门
常用爬虫库
请求库:requests、selenium(自动化测试工具)+ChromeDrive(chrome驱动)、PhantomJS(无界面浏览器)
解析库:LXML(html、xml、Xpath方法)、BeautifulSoup(html、xml)、PyQuery(支持css选择器)、Tesserocr(光学字符识别、验证码)
数据库:mongo、mysql、redis
存储库:pymysql、pymongo、redispy、RedisDump(用于导入和导出 Redis 数据的工具)
网络库:Flask(轻量级网络服务器)、Django
其他工具:Charles(网络抓包工具)
示例(如果 cookie 不起作用,您可以更改) 基本示例
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
#请求头相关
print(myUrl)
req = request.Request(myUrl, headers=headers)
#调用库发送请求
myResponse = request.urlopen(req)
myPage = myResponse.read()
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
一个比较复杂的例子是爬虫百科网站,拉出作者头像、作者姓名、内容
修改自:
<p># -*- coding: utf-8 -*-
import urllib
import _thread
import re
import time
from urllib import request
# ----------- 加载处理糗事百科 -----------
class Spider_Model:
def __init__(self):
self.page = 1
self.pages = []
self.enable = False
# 将所有的段子都扣出来,添加到列表中并且返回列表
def GetPage(self, page):
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
print(myUrl)
req = request.Request(myUrl, headers=headers)
myResponse = request.urlopen(req)
myPage = myResponse.read()
# print(myPage)
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
# 找出所有class="content"的div标记
# re.S是任意匹配模式,也就是.可以匹配换行符
# myItems = re.findall('(.*?)', unicodePage, re.S)
content = re.findall('.*?(.*?)(.*?)', unicodePage, re.S)
items = []
# print("~~~~~~~~~~~~~~~~~~~")
# print(content)
# print(len(content))
# print(content[1])
imageIcon = re.findall('.*?(.*?)', unicodePage, re.S)
# print("~~~~~~~~~~~~~~~~~~~")
# print(imageIcon)
# print(len(imageIcon))
# print(imageIcon[0][0])
# print(imageIcon[0][1])
# print(imageIcon[1][0])
# print(imageIcon[1][1])
for index in range(min(len(content), len(imageIcon)) - 1):
items.append([content[index][0].replace("\n", "").replace("
", ""), imageIcon[index][0], imageIcon[index][1]])
return items
# 用于加载新的段子
def LoadPage(self):
# 如果用户未输入quit则一直运行
while self.enable:
# 如果pages数组中的内容小于2个
if len(self.pages) 查看全部
网页数据抓取怎么写(Python爬虫初探初探为什么选择Python?爬虫是什么?网络爬虫)
初探 Python 爬虫 为什么选择 Python?什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
基本知识概念
URL(协议(服务模式)+IP地址(含端口号)+具体地址),即统一资源定位器,也就是我们所说的网站,统一资源定位器就是可以定位和访问的资源从 Internet 获得 方法的简洁表示是 Internet 上标准资源的地址。Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。爬虫在爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。
URI 在计算机术语中,统一资源标识符 (URI) 是用于标识 Internet 资源名称的字符串。这种标识允许用户通过特定的协议与任何(包括本地和互联网)资源进行交互。URI 由收录特定语法和相关协议的方案定义。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求。服务器解析后,将HTML、JS、CSS等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。其实就是一个http请求的过程。
爬虫入门
常用爬虫库
请求库:requests、selenium(自动化测试工具)+ChromeDrive(chrome驱动)、PhantomJS(无界面浏览器)
解析库:LXML(html、xml、Xpath方法)、BeautifulSoup(html、xml)、PyQuery(支持css选择器)、Tesserocr(光学字符识别、验证码)
数据库:mongo、mysql、redis
存储库:pymysql、pymongo、redispy、RedisDump(用于导入和导出 Redis 数据的工具)
网络库:Flask(轻量级网络服务器)、Django
其他工具:Charles(网络抓包工具)
示例(如果 cookie 不起作用,您可以更改) 基本示例
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
#请求头相关
print(myUrl)
req = request.Request(myUrl, headers=headers)
#调用库发送请求
myResponse = request.urlopen(req)
myPage = myResponse.read()
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
一个比较复杂的例子是爬虫百科网站,拉出作者头像、作者姓名、内容
修改自:
<p># -*- coding: utf-8 -*-
import urllib
import _thread
import re
import time
from urllib import request
# ----------- 加载处理糗事百科 -----------
class Spider_Model:
def __init__(self):
self.page = 1
self.pages = []
self.enable = False
# 将所有的段子都扣出来,添加到列表中并且返回列表
def GetPage(self, page):
myUrl = "https://m.qiushibaike.com/hot/page/" + page
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
print(myUrl)
req = request.Request(myUrl, headers=headers)
myResponse = request.urlopen(req)
myPage = myResponse.read()
# print(myPage)
# encode的作用是将unicode编码转换成其他编码的字符串
# decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
print(unicodePage)
# 找出所有class="content"的div标记
# re.S是任意匹配模式,也就是.可以匹配换行符
# myItems = re.findall('(.*?)', unicodePage, re.S)
content = re.findall('.*?(.*?)(.*?)', unicodePage, re.S)
items = []
# print("~~~~~~~~~~~~~~~~~~~")
# print(content)
# print(len(content))
# print(content[1])
imageIcon = re.findall('.*?(.*?)', unicodePage, re.S)
# print("~~~~~~~~~~~~~~~~~~~")
# print(imageIcon)
# print(len(imageIcon))
# print(imageIcon[0][0])
# print(imageIcon[0][1])
# print(imageIcon[1][0])
# print(imageIcon[1][1])
for index in range(min(len(content), len(imageIcon)) - 1):
items.append([content[index][0].replace("\n", "").replace("
", ""), imageIcon[index][0], imageIcon[index][1]])
return items
# 用于加载新的段子
def LoadPage(self):
# 如果用户未输入quit则一直运行
while self.enable:
# 如果pages数组中的内容小于2个
if len(self.pages)
网页数据抓取怎么写(用Python写网络爬虫》——2.2三种网页抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-12 14:18
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:
抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8import re, urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()html = html.decode('utf-8') #python3版本中需要加入links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags): span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span span class="hljs-tag"ul/span span class="hljs-tag"li/spanspan class="hljs-class".waring/span span class="hljs-tag"a/spanspan class="hljs-pseudo":nth-child(1)/span/code/pre/p
p因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:/p
ppre class="prettyprint"code class=" hljs vala"span class="hljs-preprocessor"#alarmtip ul li.waring a/span/code/pre/p
p代码:/p
ppre class="prettyprint"code class=" hljs lasso"from bs4 span class="hljs-keyword"import/span BeautifulSoupspan class="hljs-keyword"import/span urllibspan class="hljs-built_in"./spanrequesturl span class="hljs-subst"=/span span class="hljs-string"'http://www.nmc.cn'/spanhtml span class="hljs-subst"=/span urllibspan class="hljs-built_in"./spanrequestspan class="hljs-built_in"./spanurlopen(url)span class="hljs-built_in"./spanread()soup span class="hljs-subst"=/span BeautifulSoup(html,span class="hljs-string"'lxml'/span)content span class="hljs-subst"=/span soupspan class="hljs-built_in"./spanspan class="hljs-keyword"select/span(span class="hljs-string"'#alarmtip > ul > li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.htmlurl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()tree = lxml.html.fromstring(html)content = tree.cssselect('li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoupimport urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()soup = BeautifulSoup(html,'lxml')content = soup.select('#alarmtip > ul > li.waring > a')######### 添加到列表中link = []title = []tag = []for n in content: link.append(url+n.get('href')) title.append(n.get('title')) tag.append(n.text)######## 添加到字典中for n in content: data = { 'tag' : n.text, 'link' : url+n.get('href'), 'title' : n.get('title') }
五、总结
表格2.1总结了每种抓取方式的优缺点。
参考资料:
《用 Python 写一个网络爬虫》——2.2 三种网络爬取方法 查看全部
网页数据抓取怎么写(用Python写网络爬虫》——2.2三种网页抓取方法)
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:
抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8import re, urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()html = html.decode('utf-8') #python3版本中需要加入links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags): span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span span class="hljs-tag"ul/span span class="hljs-tag"li/spanspan class="hljs-class".waring/span span class="hljs-tag"a/spanspan class="hljs-pseudo":nth-child(1)/span/code/pre/p
p因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:/p
ppre class="prettyprint"code class=" hljs vala"span class="hljs-preprocessor"#alarmtip ul li.waring a/span/code/pre/p
p代码:/p
ppre class="prettyprint"code class=" hljs lasso"from bs4 span class="hljs-keyword"import/span BeautifulSoupspan class="hljs-keyword"import/span urllibspan class="hljs-built_in"./spanrequesturl span class="hljs-subst"=/span span class="hljs-string"'http://www.nmc.cn'/spanhtml span class="hljs-subst"=/span urllibspan class="hljs-built_in"./spanrequestspan class="hljs-built_in"./spanurlopen(url)span class="hljs-built_in"./spanread()soup span class="hljs-subst"=/span BeautifulSoup(html,span class="hljs-string"'lxml'/span)content span class="hljs-subst"=/span soupspan class="hljs-built_in"./spanspan class="hljs-keyword"select/span(span class="hljs-string"'#alarmtip > ul > li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.htmlurl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()tree = lxml.html.fromstring(html)content = tree.cssselect('li.waring > a')for n in content: link = n.get('href') title = n.get('title') tag = n.text print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoupimport urllib.requesturl = 'http://www.nmc.cn'html = urllib.request.urlopen(url).read()soup = BeautifulSoup(html,'lxml')content = soup.select('#alarmtip > ul > li.waring > a')######### 添加到列表中link = []title = []tag = []for n in content: link.append(url+n.get('href')) title.append(n.get('title')) tag.append(n.text)######## 添加到字典中for n in content: data = { 'tag' : n.text, 'link' : url+n.get('href'), 'title' : n.get('title') }
五、总结
表格2.1总结了每种抓取方式的优缺点。
参考资料:
《用 Python 写一个网络爬虫》——2.2 三种网络爬取方法
网页数据抓取怎么写( 这是简易数据分析系列的第13篇文章教程的全盘总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-11 23:16
这是简易数据分析系列的第13篇文章教程的全盘总结)
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同级别的内容,主要讨论的问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍. .
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动画,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
为什么要这样做?看下图你就明白了:
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第6篇教程中详细讲解过。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。 查看全部
网页数据抓取怎么写(
这是简易数据分析系列的第13篇文章教程的全盘总结)
这是简易数据分析系列文章的第 13 篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10篇网络爬虫系列教程,这10篇文章基本涵盖了网络爬虫的大部分功能。今天的内容是本系列的最后一篇文章。下一章我再开个坑,讲讲如何用Excel对采集到的数据进行格式化和分析。
我会在下一篇文章文章中对Web Scraper教程做一个全面的总结,今天开始我们的实战教程。
在之前的课程中,我们抓取的数据都是同级别的内容,主要讨论的问题是如何处理市场上各种类型的分页,但是如何抓取详情页的内容数据并没有介绍. .
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上的作品相关的数据,比如下图中的排名、作品名称、播放量、弹幕数、作者姓名等。
经常逛B站的朋友也知道,UP主经常暗示看视频会连续三个操作(点赞+币+采集)。可以看出这三个数据对视频的排名有一定的影响,所以这些数据对我们也有一定的参考价值。
但遗憾的是,这份榜单中并没有相关数据。这些数据在视频详情页,我们需要点击链接查看:
今天的教程内容是教大家如何在爬取一级页面(列表页)的同时,使用Web Scraper抓取二级页面(详情页)的内容。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我已经在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.为容器创建一个选择器
设置前我们观察一下,发现这个网页的排名数据是一次性加载100条数据,不需要分页,所以这里的Type类型选择为Element。
其他参数都比较简单,就不赘述了(了解不多的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页面子选择器
这次子选择器要抓取的内容如下,都比较简单。可以参考图片截图:
排名 (num) 作品名称 (title) 播放量 (play_amount) 弹幕量 (danmu_count) 作者: (author)
如果做了这一步,其实可以捕获所有已知的列表数据,但是本文的重点是:如何捕获二级页面(详情页)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper 的本质就是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过一个例子来理解它。
首先,在本例中,我们获取了标题的文本,选择器类型为 Text:
当我们要抓取链接的时候,需要再创建一个选择器,被选中的元素都是一样的,只不过Type是Link:
创建成功后,我们点击链接类型选择器,进入它的内部,然后创建相关的选择器。下面我录制了一个动画,注意我鼠标高亮的导航路由部分,可以清楚的看到这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接时,你会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper的选择窗口,无法跨页选择想要的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,然后回车重新加载,这样就可以在当前页选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了点赞数、硬币数、采集数和分享数4个数据。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经建立。
5.捕获数据
激动人心的部分终于来了,我们将开始抓取数据。但在抓取之前,我们必须将等待时间调整为更大。默认时间是2000毫秒,我这里改成5000毫秒。
为什么要这样做?看下图你就明白了:
首先,每次打开二级页面都是一个全新的页面,此时浏览器加载页面需要时间;
其次,我们可以观察要捕获的点赞数等数据。页面刚加载的时候,它的值为“--”,过一段时间会变成一个数字。
因此,我们直接等待5000ms,等页面和数据加载完毕后再统一取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓取的数据的一部分,这里是为了证明这种方法有效:
6.总结
这个教程可能有点难。我将分享我的站点地图。如果在生产过程中遇到困难,可以参考我的配置。SiteMap的导入功能我在第6篇教程中详细讲解过。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
掌握了二级页面的爬取方式后,三级页面和四级页面都没有问题。因为例程是相同的:它们都是在链接选择器指向的下一页上抓取数据。因为原理是一样的,我就不演示了。
网页数据抓取怎么写(网页数据抓取怎么写爬虫?分享一个爬虫的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-08 10:03
网页数据抓取怎么写爬虫??下面分享一个爬虫的教程,
1、程序思路爬虫基本分三步分别爬取页面各个内容(页面关键词爬取、页面爬取、自定义爬取)
2、模拟登录第一步完成后我们进入页面登录根据页面抓取信息去验证登录第二步有了验证码我们点开验证码第三步获取验证码第四步爬取文章内容页面内容和验证码密码相关信息
3、scrapy/requests:模拟登录(请求错误继续登录)自定义爬取这里继续代理(不用wireshark就用网易x3服务器直接模拟ip)post验证码验证
4、爬取文章内容获取登录状态码爬取评论文章内容(自己点开搜索文章然后点开去翻评论页面)
5、用flask编写爬虫scrapy-spider接入csv导入文章中的xxx一次性生成所有文章的列表数据定义参数:获取评论文章xxx:xxx获取文章标题yyy:yyy分别获取评论文章和标题获取文章内容:获取每篇文章的标题获取评论和文章间的链接获取每篇文章的链接获取此页的所有文章列表xxx爬取评论文章其他爬取文章xxx获取标题和内容1获取标题xxx获取内容yyy--scrapy-requestrequest'scrapy-request/'(内容)contentdoc='request=scrapy-request/'(解释)2爬取2,3,4,5,5,6,6,6,5,6获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容1爬取标题2爬取内容3获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容4(解释)获取contentdoc='(获取此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取内容1获取1,2,3,4(评论文章所在页))xxx爬取标题和内容2获取contentdoc='(爬取此文章)'xxx爬取标题和内容3获取contentdoc='(爬取此文章)'xxx爬取内容4(解释)获取contentdoc='xxx(每篇文章都包含)'xxx。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写爬虫?分享一个爬虫的教程)
网页数据抓取怎么写爬虫??下面分享一个爬虫的教程,
1、程序思路爬虫基本分三步分别爬取页面各个内容(页面关键词爬取、页面爬取、自定义爬取)
2、模拟登录第一步完成后我们进入页面登录根据页面抓取信息去验证登录第二步有了验证码我们点开验证码第三步获取验证码第四步爬取文章内容页面内容和验证码密码相关信息
3、scrapy/requests:模拟登录(请求错误继续登录)自定义爬取这里继续代理(不用wireshark就用网易x3服务器直接模拟ip)post验证码验证
4、爬取文章内容获取登录状态码爬取评论文章内容(自己点开搜索文章然后点开去翻评论页面)
5、用flask编写爬虫scrapy-spider接入csv导入文章中的xxx一次性生成所有文章的列表数据定义参数:获取评论文章xxx:xxx获取文章标题yyy:yyy分别获取评论文章和标题获取文章内容:获取每篇文章的标题获取评论和文章间的链接获取每篇文章的链接获取此页的所有文章列表xxx爬取评论文章其他爬取文章xxx获取标题和内容1获取标题xxx获取内容yyy--scrapy-requestrequest'scrapy-request/'(内容)contentdoc='request=scrapy-request/'(解释)2爬取2,3,4,5,5,6,6,6,5,6获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容1爬取标题2爬取内容3获取contentdoc='xxx(即此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取标题和内容4(解释)获取contentdoc='(获取此文章页)'xxx,xxx,xxx(随机文件夹)xxx爬取内容1获取1,2,3,4(评论文章所在页))xxx爬取标题和内容2获取contentdoc='(爬取此文章)'xxx爬取标题和内容3获取contentdoc='(爬取此文章)'xxx爬取内容4(解释)获取contentdoc='xxx(每篇文章都包含)'xxx。
网页数据抓取怎么写(2.-toggle爬取数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-07 19:00
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers->Scrape->Start craping的路径抓取数据,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系怎么变,总有一个标签不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title '。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(2.-toggle爬取数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers->Scrape->Start craping的路径抓取数据,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,其中收录一些无法理解的彩色代码。
如果您这样做,请不要感到惊讶。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
上面这句话是从可视化的角度分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系怎么变,总有一个标签不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title '。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写(Python中解析网页的一个重要的应用,使用Python爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-06 10:06
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果你还处于入门爬虫阶段或者不知道爬虫的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
利用
get 方法构造请求
利用
status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的
frombs4importBeautifulSoup
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码的问题
导入csv
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
导入pandasaspd
键=all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
进口请求
frombs4importBeautifulSoup
导入csv
导入pandasaspd
网址='#39;
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig') 查看全部
网页数据抓取怎么写(Python中解析网页的一个重要的应用,使用Python爬虫)
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站视频热搜榜数据并存储为例,详细介绍Python爬虫的基本流程。如果你还处于入门爬虫阶段或者不知道爬虫的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
现在启动 Jupyter notebook 并运行以下代码
进口请求
网址='#39;
res=requests.get('url')
打印(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
进口
要求
利用
get 方法构造请求
利用
status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于BeautifulSoup进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的
frombs4importBeautifulSoup
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
标题=汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码的问题
导入csv
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
导入pandasaspd
键=all_products[0].keys()
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码。
进口请求
frombs4importBeautifulSoup
导入csv
导入pandasaspd
网址='#39;
页面=requests.get(url)
汤=BeautifulSoup(page.content,'html.parser')
all_products=[]
products=soup.select('li.rank-item')
forproductinproducts:
rank=product.select('div.num')[0].text
name=product.select('>a')[0].text.strip()
play=product.select('span.data-box')[0].text
comment=product.select('span.data-box')[1].text
up=product.select('span.data-box')[2].text
url=product.select('>a')[0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键=all_products[0].keys()
withopen('B站视频热榜TOP100.csv','w',newline='',encoding='utf-8-sig')asoutput_file:
dict_writer=csv.DictWriter(output_file,keys)
dict_writer.writeheader()
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv',encoding='utf-8-sig')
网页数据抓取怎么写(人人都用得上webscraper进阶教程,人人用得上微信若是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 17:12
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。网络
相关文章:
最简单的数据采集教程,人人都可以使用
高级网络爬虫教程,人人都可以用微信
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。网络
下面列出了您可能遇到的几个问题,并说明了解决方法。布局
一、有时候我们想选择一个连接,但是鼠标点击会触发页面跳转,如何处理?网站
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。代码
另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素是指鼠标所在的元素。博客
二、 分页数据或滚动加载的数据无法完全抓取,如知乎和twitter等?排序
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为爬取已经完成。教程
因此,适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。得到
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。由于只要在延迟时间内没有完成翻页或下拉加载,则抓取结束。
三、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。我们最终将数据导出为 CSV 格式。用Excel打开CSV后,可以按某一列进行排序。 Excel中按照发布时间排序,或者知乎上的数据按照点赞数排序。
四、 网页爬虫提供的选择器无法选择某些页面元素?
出现这种情况的原因多半是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停才会显示的元素。遇到这些情况就得靠其他方法了。
其实就是通过鼠标操作选择元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。遇到问题就可以了。
这里只是在使用网页爬虫过程中的一些常见问题。如果还有其他问题,可以在文章下留言。 查看全部
网页数据抓取怎么写(人人都用得上webscraper进阶教程,人人用得上微信若是)
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。网络
相关文章:
最简单的数据采集教程,人人都可以使用
高级网络爬虫教程,人人都可以用微信
如果您在使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,而这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。网络
下面列出了您可能遇到的几个问题,并说明了解决方法。布局
一、有时候我们想选择一个连接,但是鼠标点击会触发页面跳转,如何处理?网站
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按S键。代码
另外,勾选“Enable key”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择当前元素子元素,当前元素是指鼠标所在的元素。博客
二、 分页数据或滚动加载的数据无法完全抓取,如知乎和twitter等?排序
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为爬取已经完成。教程
因此,适当增加延迟大小,延长等待时间,并为数据加载留出足够的时间。默认延迟2000,也就是2秒,可以根据网速调整。得到
但是,当数据量比较大的时候,不完整的数据抓取也是很常见的。由于只要在延迟时间内没有完成翻页或下拉加载,则抓取结束。
三、 获取数据的顺序和网页上的顺序不一致?
Web Scraper默认是无序的,可以安装CouchDB保证数据的顺序。
或者使用其他替代方法。我们最终将数据导出为 CSV 格式。用Excel打开CSV后,可以按某一列进行排序。 Excel中按照发布时间排序,或者知乎上的数据按照点赞数排序。
四、 网页爬虫提供的选择器无法选择某些页面元素?
出现这种情况的原因多半是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停才会显示的元素。遇到这些情况就得靠其他方法了。
其实就是通过鼠标操作选择元素,最后就是找到元素对应的xpath。 Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。遇到问题就可以了。
这里只是在使用网页爬虫过程中的一些常见问题。如果还有其他问题,可以在文章下留言。
网页数据抓取怎么写(Python开发的一个快速、高层次框架会自动该类的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-02 06:21
我记得十多年前,当我还是个高中生时,所谓的智能手机根本不流行。如果你想在学校阅读大量的电子书,你基本上依靠具有阅读功能的MP3或MP4。 以及电子书的来源?当你随时随地都无法上网时,有时候的窍门就是靠一个笨办法:将一些小说的内容网站一页一页地粘贴复制。而那些动辄上百章的网络小说,靠这样的手工操作,着实让人很是麻烦。那时,我多么希望有一个工具可以帮我自动完成这些费力的手工任务! ! !
好吧,让我们回到正题。最近在研究爬虫框架Scrapy的使用方法。先说说学习Scrapy的初衷。
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试(百度百科介绍)。
经过几天的学习,首先需要了解以下Scrapy的初步使用概念:
那么,你要做的就是把上面提到的四个类都写好,剩下的交给Scrapy框架就行了。
您可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
spiderForShortPageMsg.py 文件收录我们将要编写的 Spiders 子类。
示例:现在我想获取网站中文章的所有title和文章的地址。
第一步:写一个继承自Spiders的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()解析具体的html页面,从中找到我想要的数据,然后保存在一个Items的数据类型对象之中。
不要被下面这行代码吓到:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的选择器。这是用于定位您要查找的 html 标记的方法。选择器有两种,XPath 选择器和 CSS 选择器,上面都用到了这两种。
这是我的 Item 数据类型(上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类型 Item 执行的所有操作。
您想要的数据现在在 Item 对象中。考虑到您的最终目标,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需简单的几个设置,就可以直接调用Django中的models类,省去繁琐的数据库操作。心。谁知道谁用! ! 查看全部
网页数据抓取怎么写(Python开发的一个快速、高层次框架会自动该类的方法)
我记得十多年前,当我还是个高中生时,所谓的智能手机根本不流行。如果你想在学校阅读大量的电子书,你基本上依靠具有阅读功能的MP3或MP4。 以及电子书的来源?当你随时随地都无法上网时,有时候的窍门就是靠一个笨办法:将一些小说的内容网站一页一页地粘贴复制。而那些动辄上百章的网络小说,靠这样的手工操作,着实让人很是麻烦。那时,我多么希望有一个工具可以帮我自动完成这些费力的手工任务! ! !
好吧,让我们回到正题。最近在研究爬虫框架Scrapy的使用方法。先说说学习Scrapy的初衷。
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试(百度百科介绍)。
经过几天的学习,首先需要了解以下Scrapy的初步使用概念:
那么,你要做的就是把上面提到的四个类都写好,剩下的交给Scrapy框架就行了。
您可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
spiderForShortPageMsg.py 文件收录我们将要编写的 Spiders 子类。
示例:现在我想获取网站中文章的所有title和文章的地址。
第一步:写一个继承自Spiders的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()解析具体的html页面,从中找到我想要的数据,然后保存在一个Items的数据类型对象之中。
不要被下面这行代码吓到:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的选择器。这是用于定位您要查找的 html 标记的方法。选择器有两种,XPath 选择器和 CSS 选择器,上面都用到了这两种。
这是我的 Item 数据类型(上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类型 Item 执行的所有操作。
您想要的数据现在在 Item 对象中。考虑到您的最终目标,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需简单的几个设置,就可以直接调用Django中的models类,省去繁琐的数据库操作。心。谁知道谁用! !
网页数据抓取怎么写(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-02 06:20
不知道大家在日常的工作、学习和生活中是否遇到过这样的场景,就是需要对网站上面的一些数据进行转换(比如图片、文字或者其他一些数据格式)复制、保存到本地Excel表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。 Crawler,顾名思义就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、手动:完全依赖手动复制粘贴;
2、半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取一部分数据;
3、 全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是写这个爬虫需要相当的知识。
第二个和第三个,没有确定的数量是好是坏。根据不同的场合,两者都有自己的适应。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在来看看这个案例。作者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章节,每一章节又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017下载安装)和视频地址。
名称比较好说,表格最左边的一列是section的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为跨域问题)。
我能做什么?
别担心,只要你的头脑不滑,解决方案总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。所以你可以使用下面的代码来获取所有收录section名称的a标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这个固定格式的开头是“number.number.number”,可以用下面的正则表达式表示:
^\d+\.\d+(\.\d+)?
所以可以使用正则表达式条件进行过滤,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
此时,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,我们点击某个部分,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有的视频地址只有这里的{1}不同,这里的{1}和段号有关:{1}的部分从段号变成了句号,只有标题是需要 只需提取数字并替换它。
到此为止,所有的代码都可以写完整了,可以根据代码实现需要的爬取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可以看出这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十多行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也请在下方评论区写下你的想法。 查看全部
网页数据抓取怎么写(有没有遇到过这样的一个场景,我想大多数人第一反应就是爬虫)
不知道大家在日常的工作、学习和生活中是否遇到过这样的场景,就是需要对网站上面的一些数据进行转换(比如图片、文字或者其他一些数据格式)复制、保存到本地Excel表格、本地数据库或下载(如果是图片、音频或视频)。
看到这样的场景,相信大多数人的第一反应就是爬。 Crawler,顾名思义就是用编写好的程序,像虫子一样在蜘蛛网上爬取我们想要的数据。
根据爬虫的自动爬取能力,我经常将爬虫分为以下三个级别:
1、手动:完全依赖手动复制粘贴;
2、半自动:需要为不同地方的程序手动设置相关参数,一次只能爬取一部分数据;
3、 全自动:程序一旦运行,就知道程序的爬取完成,整个过程不需要人工干预。
当然,第一种实际上并不是真正意义上的爬虫;第二种需要人工协助,但开发相对简单;第三种,它的爬虫过程很智能,但是写这个爬虫需要相当的知识。
第二个和第三个,没有确定的数量是好是坏。根据不同的场合,两者都有自己的适应。比如第二种,如果要爬取的数据很简单一、,那么完全没必要写一个比较完整的程序。可以直接写一个很简单的,然后手动设置;但是如果这个程序需要爬取大范围的数据。这时候,如果需要手动设置每个关键点,那将是非常可怕和耗时的。
好了,说了这么多,现在来看看这个案例。作者这几天在找PR软件的视频教程,通过搜索引擎找到了视频教程网站。
这套教程分为很多章节,每一章节又分为很多小节,每个小节对应一个视频。作者的思路是提取出各个版块的名称(如:1.1 Premiere 2017下载安装)和视频地址。
名称比较好说,表格最左边的一列是section的名称。通过查看网页的源码,可以看到源码中的table标签中有节名,但是问题的关键是如何提取table标签下的a标签中的节名,因为这是网页源代码。不能简单地通过js发送HTTP请求获取源码进行分析(因为跨域问题)。
我能做什么?
别担心,只要你的头脑不滑,解决方案总是比问题多。是的,这时候我想浏览器也有可以运行js代码的Console,最好是操作这里review元素中看到的元素。所以你可以使用下面的代码来获取所有收录section名称的a标签。
document.querySelectorAll('.news_list table div[align="left"] a');
但是这里得到的A标签收录了章节标题所在的A标签,作者只需要subsection标签。通过比较章节标题和章节标题,可以发现章节标题有固定格式的开头,而章节标题没有。这个固定格式的开头是“number.number.number”,可以用下面的正则表达式表示:
^\d+\.\d+(\.\d+)?
所以可以使用正则表达式条件进行过滤,代码如下:
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
list.push({title: a.innerText});
}
});
此时,我们已经提取了部分标题!接下来我们需要提取视频的地址。首先,我们点击某个部分,我们可以看到页面上有一段视频在播放:
通过查看元素,可以看到有一个Video标签,标签中的src属性只是给出了视频地址。但是作者无法通过点击每个部分来查看Video标签并提取视频地址。这时笔者通过对比不同版块发现视频地址有规律:
所有的视频地址只有这里的{1}不同,这里的{1}和段号有关:{1}的部分从段号变成了句号,只有标题是需要 只需提取数字并替换它。
到此为止,所有的代码都可以写完整了,可以根据代码实现需要的爬取任务。
var urlTemplate = 'http://www1.51shiping.com/pr2017/mp9/{1}.mp4';
var regex = /^\d+\.\d+(\.\d+)?/;
var aTags = document.querySelectorAll('.news_list table div[align="left"] a');
var list = [];
aTags.forEach(function(a) {
var text = a.innerText;
if (regex.test(text)) {
var no = regex.exec(text)[0].replace(/\./g, '-');
var url = urlTemplate.replace('{1}', no);
list.push({title: a.innerText, url: url});
}
});
console.log(JSON.stringify(list));
可以看出这个需求并不难,所以我们不需要写一个非常完整或者强大的爬虫,只需要写十多行JS代码就可以实现功能。这样做的好处是方便快捷,但是扩展性很差。因此,在我们日常的开发和工作中,一定要懂得取舍。
如果你碰巧遇到和我一样的问题,那么这个案例会给你一个启发。如果灵感有用,请关注和喜欢我。如果你是大神,也请在下方评论区写下你的想法。
网页数据抓取怎么写( 元素名后加个-typegt的路径进行数据编号控制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-01 17:16
元素名后加个-typegt的路径进行数据编号控制)
这是简单数据分析系列的第十篇文章。
原文首发于博客园:简单数据分析10.
友情提示:本文文章内容丰富,信息量大。希望你在学习的时候多读几遍。
我们扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据。从经验来看,数据会不断加载,永远不会结束。
今天我们要讲的是如何使用Web Scraper抓取滚动到最后的网页。
我们今天的动手实践网站是知乎的数据分析模块的精髓。该网站是:
/topic/19559424/top-answers
这次要爬取的内容是精华帖的标题、回复者和批准数。以下是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。 .
在本例中,所选元素名称为 div.List-item。
为了回顾上一节通过数据个数控制item个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取第一个暂时100条数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
首先是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是响应者的名字和批准的数量一样,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2.爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成null了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着没有捕获到任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要查看网页的构成,需要用到浏览器的另一个功能,就是选择视图元素。
1.我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3.我们再点一下标题,会发现会跳转到Elements子面板,内容是一些不太懂的彩色代码
不要因为这样做而感到沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果平时用markdown写的话,可以把HTML理解成功能更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树状结构:
最后一句从视觉上分析。它实际上是一个嵌套结构。我提取了关键内容。内容结构是否更清晰?
如何快速成为数据分析师?
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少属性为itemprop='知乎:question'的名为div的标签!结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们就能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem -标题'。如果可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清关系后,我们如何使用Web Scraper来操作呢?这时候我们可以使用上一篇文章介绍的内容,使用键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
等等,因为响应者的名字也出现null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面类似,你可以试试。
我的三个子内容选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
爬取知乎的数据时,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这个间接的解释,知乎这个网站从代码的角度分析,写的还是比较差的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬取,可以在一定程度上减少返工时间。
6.下一期预览
本期内容较多。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(
元素名后加个-typegt的路径进行数据编号控制)
这是简单数据分析系列的第十篇文章。
原文首发于博客园:简单数据分析10.
友情提示:本文文章内容丰富,信息量大。希望你在学习的时候多读几遍。
我们扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据。从经验来看,数据会不断加载,永远不会结束。
今天我们要讲的是如何使用Web Scraper抓取滚动到最后的网页。
我们今天的动手实践网站是知乎的数据分析模块的精髓。该网站是:
/topic/19559424/top-answers
这次要爬取的内容是精华帖的标题、回复者和批准数。以下是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。 .
在本例中,所选元素名称为 div.List-item。
为了回顾上一节通过数据个数控制item个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取第一个暂时100条数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
首先是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是响应者的名字和批准的数量一样,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2.爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们傻眼了:
数据呢?我想捕获什么数据?怎么全部都变成null了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着没有捕获到任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要查看网页的构成,需要用到浏览器的另一个功能,就是选择视图元素。
1.我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3.我们再点一下标题,会发现会跳转到Elements子面板,内容是一些不太懂的彩色代码
不要因为这样做而感到沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果平时用markdown写的话,可以把HTML理解成功能更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树状结构:
最后一句从视觉上分析。它实际上是一个嵌套结构。我提取了关键内容。内容结构是否更清晰?
如何快速成为数据分析师?
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少属性为itemprop='知乎:question'的名为div的标签!结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们就能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem -标题'。如果可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清关系后,我们如何使用Web Scraper来操作呢?这时候我们可以使用上一篇文章介绍的内容,使用键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
等等,因为响应者的名字也出现null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面类似,你可以试试。
我的三个子内容选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
爬取知乎的数据时,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这个间接的解释,知乎这个网站从代码的角度分析,写的还是比较差的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬取,可以在一定程度上减少返工时间。
6.下一期预览
本期内容较多。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写(如何写好Python数据我用的是Python?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-01 00:16
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个比较全面的信息网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想要获取有关此网站的所有疗养院信息,例如名称、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python 2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般像这些网站页面和页面之间的URL都会有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的URL 是的
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现这个网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个养老院的链接链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
我上面说了,我们知道这个网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
<p>i 是一个整数,getLink 会返回给我们对应的页面 url,例如 i=1 时,getLink 会返回第一页,i=2 时会返回第二页 查看全部
网页数据抓取怎么写(如何写好Python数据我用的是Python?(上)
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个比较全面的信息网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想要获取有关此网站的所有疗养院信息,例如名称、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python 2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般像这些网站页面和页面之间的URL都会有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的URL 是的
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现这个网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href表示这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个养老院的链接链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
我上面说了,我们知道这个网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
<p>i 是一个整数,getLink 会返回给我们对应的页面 url,例如 i=1 时,getLink 会返回第一页,i=2 时会返回第二页
网页数据抓取怎么写(网页,途径只有三个:1.手工复制.2.写代码,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-31 21:13
网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,你的 网站 是由网页组成的。如果你只有一个域名和一个虚拟主机,没有制作任何网页,你的客户仍然无法访问你的网站。
网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”,采用超文本标记语言格式(标准通用标记语言应用程序,文件扩展名为.html 或.htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
这是编程问题吗?
如何抓取网页上的数据,表格中的数据-... 没有历史页面,直接复制粘贴,选择你想要的数据,右键复制,右键-点击表格粘贴
网页数据抓取如何抓取网页数据? …… 网页抓取是一个庞大的工程。但总结起来只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集一个简单的网页,如果你想网站可以采集那绝对不容易。3.估计除非你有特殊的喜好,你不会想选择以上两条路径他们想要更高效、更强大。最好是免费的采集器,目前最好的是采集器新的优采云采集器,确实是神器,看来没有问题网站。它也是免费的,值得一试。
如何获取网页数据-……在要获取数据的网页上右击,查看网页源代码就可以看到了...
抓取页面后,如何获取我想要的数据-... 先去掉一些.NET中不使用字符串的方法,比如head部分。然后使用正则表达式进行过滤。这是最好最有效的方法,但需要你了解正则表达式。实在没办法,只能用字符串中的方法逐位过滤。给你一些代码,我怕你看不懂,哈哈哈///。 ..
如何抓取网页数据-...我们在抓取数据时,通常不仅抓取网页当前页面的数据,还经常在翻页后继续抓取数据。本文将向您介绍采集客户数据抓取过程中gooseeker网络爬虫如何自动抓取页面后的数据。 平台爬虫路径工作台有3条线索。
新人建议,如何提取网页上的数据-... 简单,可以用命令行下载工具wget配合批量提取,复杂的python爬虫工具就可以了。
如何抓取HTML页面中的一段数据,具体的html如下-...直接使用抓取工具就可以了,比如优采云采集器或者优采云浏览器可以
如何实现网页数据爬取?-... GooSeeker上有一个通用的爬取工具MetaSeeker,免费,功能非常强大。适用于大规模自动抓取,适用于大型在线服务,如垂直搜索和推荐引擎。 , 比价服务,信息系统等,所以学习使用需要时间,但是完整的图形界面操作不需要写任何代码。
如何抓取网页上的信息? …… 1、 识别URL重定向,互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被改写。定位,在这个过程中需要百度蜘蛛识别url重定向。 p>
求教,如何抓取网页中的表格数据...1.通过搜索引擎,找到国家旅游局的网站,点击主菜单【公众号】事务]-[统计],然后可以看到一系列收录数据的网页。 2.打开一个网页,确认网页收录数据表。复制网页的 URL 并将其用于备份。 3.启动Excel文件,在工作表中,点击【... 查看全部
网页数据抓取怎么写(网页,途径只有三个:1.手工复制.2.写代码,)
网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,你的 网站 是由网页组成的。如果你只有一个域名和一个虚拟主机,没有制作任何网页,你的客户仍然无法访问你的网站。
网页是收录 HTML 标签的纯文本文件。它可以存储在世界某个角落的计算机上。它是万维网上的一个“页面”,采用超文本标记语言格式(标准通用标记语言应用程序,文件扩展名为.html 或.htm)。网页通常使用图像文件来提供图片。必须通过网络浏览器阅读网页。
这是编程问题吗?
如何抓取网页上的数据,表格中的数据-... 没有历史页面,直接复制粘贴,选择你想要的数据,右键复制,右键-点击表格粘贴
网页数据抓取如何抓取网页数据? …… 网页抓取是一个庞大的工程。但总结起来只有三种方式:1.最原创的方式,手动复制。2.写代码,很多程序员都喜欢这样做,但是很容易采集一个简单的网页,如果你想网站可以采集那绝对不容易。3.估计除非你有特殊的喜好,你不会想选择以上两条路径他们想要更高效、更强大。最好是免费的采集器,目前最好的是采集器新的优采云采集器,确实是神器,看来没有问题网站。它也是免费的,值得一试。
如何获取网页数据-……在要获取数据的网页上右击,查看网页源代码就可以看到了...
抓取页面后,如何获取我想要的数据-... 先去掉一些.NET中不使用字符串的方法,比如head部分。然后使用正则表达式进行过滤。这是最好最有效的方法,但需要你了解正则表达式。实在没办法,只能用字符串中的方法逐位过滤。给你一些代码,我怕你看不懂,哈哈哈///。 ..
如何抓取网页数据-...我们在抓取数据时,通常不仅抓取网页当前页面的数据,还经常在翻页后继续抓取数据。本文将向您介绍采集客户数据抓取过程中gooseeker网络爬虫如何自动抓取页面后的数据。 平台爬虫路径工作台有3条线索。
新人建议,如何提取网页上的数据-... 简单,可以用命令行下载工具wget配合批量提取,复杂的python爬虫工具就可以了。
如何抓取HTML页面中的一段数据,具体的html如下-...直接使用抓取工具就可以了,比如优采云采集器或者优采云浏览器可以
如何实现网页数据爬取?-... GooSeeker上有一个通用的爬取工具MetaSeeker,免费,功能非常强大。适用于大规模自动抓取,适用于大型在线服务,如垂直搜索和推荐引擎。 , 比价服务,信息系统等,所以学习使用需要时间,但是完整的图形界面操作不需要写任何代码。
如何抓取网页上的信息? …… 1、 识别URL重定向,互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被改写。定位,在这个过程中需要百度蜘蛛识别url重定向。 p>
求教,如何抓取网页中的表格数据...1.通过搜索引擎,找到国家旅游局的网站,点击主菜单【公众号】事务]-[统计],然后可以看到一系列收录数据的网页。 2.打开一个网页,确认网页收录数据表。复制网页的 URL 并将其用于备份。 3.启动Excel文件,在工作表中,点击【...
网页数据抓取怎么写(Gitscraping技术回顾抓取数据到Git存储库的一大优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-26 10:02
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析采集
到的数据是一个公认的问题。git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
下面是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents 网站上维护了一张火灾地图,该地图显示了最近大规模火灾的状态。
我找到了网站的底层数据:
卷曲
然后我搭建了一个简单的爬虫工具,每20分钟爬一次一个网站的数据,提交给Git。到目前为止,该工具已经运行了14个月,已经采集
了1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细归档数据更改的内容和位置,因此通过抓取他们的网站数据并将其保存到 Git 存储库,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集
到的数据?面对上千个版本和海量的JSON和CSV文档,如果仅靠肉眼观察差异,很难挖掘出数据背后的价值。
git-history
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新创建的数据库表的默认名称是item和item_version,我们通过--namespace event将表名指定为incident和incident_version。
工具中还嵌入了一段Python代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录
每次火灾的最新记录。从这张表中,我们可以得到一张所有火灾的地图:
这里使用了 datasette-cluster-map 插件,它在地图上标记了表中具有有效经纬度值的所有行。
真正有趣的是 event_version 表。该表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。前十名依次为:
版本越多,火持续的时间越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中可以看到所有抓到的“版本”按版本号排列。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
经常变化的是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具已提交的版本,当您再次运行该工具时,该工具可以定位到上次提交的是哪个版本。
连接到提交表以查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助datasette-vega插件,_commit_at列(日期类型)和AcresBurned列(数字类型) ) 比较形成一张图表,直观地显示了 Dixie Fire 火灾随时间的蔓延情况。
总结一下:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前的版本变更信息。
我的最终设计如下(为清晰起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到,item_version表记录了不同时间点的网站快照,但为了节省数据库空间,提供简洁的版本浏览界面,这里只记录了与之前版本相比发生变化的列。所有未更改的列都写为空。
但是这种设计有一个隐患,那就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
直升机听起来令人兴奋!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,直升机出动火灾19次,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月里,Drew Breunig 使用 Git 爬虫不断从网站上爬取数据并将其保存到 dbreunig/511-events-history 存储库中。本网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,帮助我们理解git-history和--convert选项overlay的用法。
git-history 要求捕获的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以作为唯一标识列来跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
但是,捕获的数据通常不是这种理想格式。
我找到了网站的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录
大量重复数据。.
我写了一段 Python 代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码还可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我还尝试在 sqlite-utils 工具中覆盖转换。
试一试
如果你想尝试 git-history 工具,扩展文档 README 中有更多选项。示例中使用的脚本都保存在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个仓库。海量爬取数据等你探索! 查看全部
网页数据抓取怎么写(Gitscraping技术回顾抓取数据到Git存储库的一大优势)
大多数人都知道 Git 抓取,这是一种用于网页抓取工具的编程技术。您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析采集
到的数据是一个公认的问题。git-history 是我设计用来解决这个问题的工具。
Git 抓取技术回顾
将数据抓取到 Git 存储库的一大优势在于抓取工具本身非常简单。
下面是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents 网站上维护了一张火灾地图,该地图显示了最近大规模火灾的状态。
我找到了网站的底层数据:
卷曲
然后我搭建了一个简单的爬虫工具,每20分钟爬一次一个网站的数据,提交给Git。到目前为止,该工具已经运行了14个月,已经采集
了1559个提交版本。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细归档数据更改的内容和位置,因此通过抓取他们的网站数据并将其保存到 Git 存储库,您会发现您比他们更了解他们的数据更改历史。
然而,一个巨大的挑战是如何最有效地分析采集
到的数据?面对上千个版本和海量的JSON和CSV文档,如果仅靠肉眼观察差异,很难挖掘出数据背后的价值。
git-history
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的所有历史版本并生成 SQLite 数据库来记录文件随时间的变化。然后你就可以使用Datasette来分析和挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的数据库示例。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在这个例子中,我们获取了文件 events.json 的历史版本。
我们使用 UniqueId 列来标识随时间变化的记录和新记录。
新创建的数据库表的默认名称是item和item_version,我们通过--namespace event将表名指定为incident和incident_version。
工具中还嵌入了一段Python代码,可以将提交历史中存储的每个版本转换为与工具兼容的对象列表。
让数据库帮助我们回答一些关于过去 14 个月加州火灾的问题。
事件表收录
每次火灾的最新记录。从这张表中,我们可以得到一张所有火灾的地图:
这里使用了 datasette-cluster-map 插件,它在地图上标记了表中具有有效经纬度值的所有行。
真正有趣的是 event_version 表。该表记录了每次火灾的先前捕获版本之间的数据更新。
250 场火灾有 2,060 个记录版本。如果根据_item进行分面,我们可以看到哪些火灾记录的版本最多。前十名依次为:
版本越多,火持续的时间越长。维基百科上甚至还有 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中可以看到所有抓到的“版本”按版本号排列。
git-history 只在此表中写入与之前版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
经常变化的是 ConditionStatement 列。此栏是文字说明。另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是提交表的外键。该表记录了该工具已提交的版本,当您再次运行该工具时,该工具可以定位到上次提交的是哪个版本。
连接到提交表以查看每个版本的创建日期。您也可以使用incident_version_detail 视图来执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助datasette-vega插件,_commit_at列(日期类型)和AcresBurned列(数字类型) ) 比较形成一张图表,直观地显示了 Dixie Fire 火灾随时间的蔓延情况。
总结一下:让我们首先使用 GitHub Actions 创建一个定时工作流,并每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们已经成功地用图表展示了过去 14 个月加州最长的森林火灾的蔓延情况。
关于表结构设计
在git-history的设计过程中,最难的就是设计一个合适的表结构来存储之前的版本变更信息。
我的最终设计如下(为清晰起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到,item_version表记录了不同时间点的网站快照,但为了节省数据库空间,提供简洁的版本浏览界面,这里只记录了与之前版本相比发生变化的列。所有未更改的列都写为空。
但是这种设计有一个隐患,那就是如果某列的值在某次火灾中被更新为null,我们该怎么办?我们如何判断它是否已更新或未更改?
为了解决这个问题,我添加了一个多对多表item_changed,它使用整数对来记录item_version表中哪些列更新了内容。使用整数对的目的是尽可能少占用空间。
item_version_detail 视图将多对多表中的列显示为 JSON。我过滤了一些数据,放在下图中,看看哪些列更新了哪些版本:
通过下面的SQL查询,我们可以知道加州火灾中哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
直升机听起来令人兴奋!让我们过滤掉第一个版本后直升机数量至少更新一次的火灾。您可以使用以下嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,直升机出动火灾19次,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月里,Drew Breunig 使用 Git 爬虫不断从网站上爬取数据并将其保存到 dbreunig/511-events-history 存储库中。本网站记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以sf-bay-511数据库为例,帮助我们理解git-history和--convert选项overlay的用法。
git-history 要求捕获的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以作为唯一标识列来跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
但是,捕获的数据通常不是这种理想格式。
我找到了网站的 JSON 提要。有非常复杂的嵌套对象,数据也很复杂,有些对整体分析没有帮助,比如更新的时间戳即使没有数据更新也会随着版本的变化而变化,深度嵌套的对象“扩展”收录
大量重复数据。.
我写了一段 Python 代码将每个网站快照转换成更简单的结构,然后将这段代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上依次运行。代码在 Events 嵌套列表中循环运行,修改每条记录,然后使用 yield 以可迭代序列输出。
一些历史记录显示服务器 500 错误,代码还可以识别和跳过这些记录。
在使用 git-history 时,我发现我大部分时间都花在了迭代转换脚本上。将 Python 代码字符串传递给 git-history 等工具是一个非常有趣的模型。今年早些时候,我还尝试在 sqlite-utils 工具中覆盖转换。
试一试
如果你想尝试 git-history 工具,扩展文档 README 中有更多选项。示例中使用的脚本都保存在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,已经有很多人创建了仓库,目前有 200 多个仓库。海量爬取数据等你探索!
网页数据抓取怎么写(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-24 07:08
网络爬虫网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候称为网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
专注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的URL,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序,该程序的作用是获取网站返回的数据,并提取其中的URL,我们将获取到的URL存放在一个文件夹中。除了提取网址之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。返回搜狐查看更多 查看全部
网页数据抓取怎么写(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网络爬虫网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候称为网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本。
专注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一步要爬取的网页的URL,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般的网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序,该程序的作用是获取网站返回的数据,并提取其中的URL,我们将获取到的URL存放在一个文件夹中。除了提取网址之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。返回搜狐查看更多
网页数据抓取怎么写(WebScraper有多么好爬,以及大致怎么用问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-24 07:06
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。事实上,在大多数场景下,Web Scraper(一款Chrome插件)都可以快速抓取到目标内容。重要的是不需要下载东西,基本没有代码知识。
在开始之前,有必要先简单了解几个问题。
一个。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的事情应该留给工具来做。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,我们需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫所做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取内容,然后存入数据库中,供浏览或下载使用。搜索引擎可以工作,原理相同。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。
Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果你日常使用的浏览器不是Chrome,强烈建议更换,Chrome与其他浏览器的区别就像谷歌与其他搜索引擎的区别)
2、打开要爬取的网页,比如豆瓣Top250的网址,然后同时按option+command+i进入开发者模式(如果你用的是windows是ctrl+shift +i,不同浏览器默认快捷键可能不同)。这时候可以看到网页上弹出一个对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖块和瓷砖)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
3、 点击create new sitemap,依次创建sitemap创建爬虫。填写站点地图名称,仅供自己识别,如dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是
第二页以
第三页是
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,所以不能简单粘贴起始url,应该是[0-250:25]&filter=
注意start后[]里面的内容,表示每25日为一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。
(URL也可以爬取,但不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是一个简单的一点点。其原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置好选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
5、第4步只是创建一个容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名,电影名称,评分,一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。
看到容器根后跟根目录,点击添加新选择器创建子选择器。
再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写一个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意在container目录下),分别抓取电影名、评分、一句话影评。
创建之后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次爬取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始刮伤。
当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、 点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,然后就可以使用了。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,你觉得还是按照上面的一步一步来比较费力,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(它是由上面的一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":[";filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root ","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors" :["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type":"SelectorText" ,"parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"正则表达式 ":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,还有的网页乱七八糟,有时需要限制爬取次数(否则,抓取次数保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
如果您有任何问题或其他,欢迎微信 m644003222 查看全部
网页数据抓取怎么写(WebScraper有多么好爬,以及大致怎么用问题)
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。事实上,在大多数场景下,Web Scraper(一款Chrome插件)都可以快速抓取到目标内容。重要的是不需要下载东西,基本没有代码知识。
在开始之前,有必要先简单了解几个问题。
一个。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的事情应该留给工具来做。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,我们需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫所做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取内容,然后存入数据库中,供浏览或下载使用。搜索引擎可以工作,原理相同。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。
Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果你日常使用的浏览器不是Chrome,强烈建议更换,Chrome与其他浏览器的区别就像谷歌与其他搜索引擎的区别)
2、打开要爬取的网页,比如豆瓣Top250的网址,然后同时按option+command+i进入开发者模式(如果你用的是windows是ctrl+shift +i,不同浏览器默认快捷键可能不同)。这时候可以看到网页上弹出一个对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖块和瓷砖)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
3、 点击create new sitemap,依次创建sitemap创建爬虫。填写站点地图名称,仅供自己识别,如dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是
第二页以
第三页是
...
只有一个数字略有不同。我们的意图是抓取top250电影数据,所以不能简单粘贴起始url,应该是[0-250:25]&filter=
注意start后[]里面的内容,表示每25日为一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。
(URL也可以爬取,但不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是一个简单的一点点。其原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置好选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
5、第4步只是创建一个容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名,电影名称,评分,一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。
看到容器根后跟根目录,点击添加新选择器创建子选择器。
再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写一个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意在container目录下),分别抓取电影名、评分、一句话影评。
创建之后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次爬取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始刮伤。
当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、 点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,然后就可以使用了。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,你觉得还是按照上面的一步一步来比较费力,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(它是由上面的一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":[";filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root ","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors" :["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type":"SelectorText" ,"parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"正则表达式 ":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,还有的网页乱七八糟,有时需要限制爬取次数(否则,抓取次数保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
如果您有任何问题或其他,欢迎微信 m644003222
网页数据抓取怎么写(网页数据抓取怎么写?爬虫软件要多少钱?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-24 05:03
网页数据抓取怎么写?爬虫软件要多少钱?小蚂蚁网页抓取器【蚂蚁分析】——教你怎么获取网页数据!,抓取一个网页分分钟搞定,用的模块也不是很多,今天实例教一下爬虫软件的使用,思路清晰了再去搜一些新的资料,只有有耐心才能熟练掌握,而且后面还有更深入的使用技巧等着你的!首先这个项目是一个实际的项目,应该说是一个比较复杂的项目,需要个各个环节的环环相扣,每个人或多或少都有不同的经验!其实,大部分人可能并不是非常清楚该如何去写,可能是一些分支、步骤的模块写好,然后再去调用,多半是我跟你讲,你都不清楚是怎么个过程!所以,用最初级的方法!分享一下我所总结的技巧,大概可以分为三步:定位抓取整个页面;获取到数据;存入数据库。
如果我是你,遇到这样的项目时,我会先分析一下,我需要的是一个什么样的页面。现在都是在用无线浏览器,一个相对来说人人手机都能上网的时代,看个文章,看个视频,看个新闻都不是什么问题,很多互联网公司都推出了抓取浏览器,只要连接上wifi,就能抓到一个相对来说还不错的网页,这样就非常简单了,因为只需要定位网页的关键部分,然后通过js或者xml解析,提取出内容即可!例如我要抓取一个baiduspider的关键内容:about&needs_career&staff_title_tag&giveover¬e&repository_tag即可!about&needs_career&staff_title_tag&giveover¬e&repository_tag即可;即可爬虫开始第一步!获取网页数据的思路:首先最后一步是获取到整个网页,但是获取一个页面其实并不是一件简单的事情,获取整个页面的代码大概分为:strip、parse()、content等。
首先我们都知道,互联网有超过50亿的网页,一页可能有n个网页,我们在这里面想找到about&needs_career&staff_title_tag是一个网页,那么我们可以用strip方法,就是用某些字符串把about&needs_career&staff_title_tag以及所有网页去掉,然后就是parse()方法,即去除后面的html,提取出里面html的关键部分,然后提取出里面的关键字,提取不出来,就是最后一步content方法解析。
经过一系列的分析以及查找,最后得到about&needs_career&staff_title_tag和giveover¬e等,最后实现了这个项目的目标!这个项目的源码我已经上传到项目的github里面去,大家有兴趣的同学,可以去查看项目的源码,有任何不明白的,可以去问里面的项目组成员,大家一起完成,项目最后会链接到github上面去。项目代码里面不少代码很牛逼,但是, 查看全部
网页数据抓取怎么写(网页数据抓取怎么写?爬虫软件要多少钱?(组图))
网页数据抓取怎么写?爬虫软件要多少钱?小蚂蚁网页抓取器【蚂蚁分析】——教你怎么获取网页数据!,抓取一个网页分分钟搞定,用的模块也不是很多,今天实例教一下爬虫软件的使用,思路清晰了再去搜一些新的资料,只有有耐心才能熟练掌握,而且后面还有更深入的使用技巧等着你的!首先这个项目是一个实际的项目,应该说是一个比较复杂的项目,需要个各个环节的环环相扣,每个人或多或少都有不同的经验!其实,大部分人可能并不是非常清楚该如何去写,可能是一些分支、步骤的模块写好,然后再去调用,多半是我跟你讲,你都不清楚是怎么个过程!所以,用最初级的方法!分享一下我所总结的技巧,大概可以分为三步:定位抓取整个页面;获取到数据;存入数据库。
如果我是你,遇到这样的项目时,我会先分析一下,我需要的是一个什么样的页面。现在都是在用无线浏览器,一个相对来说人人手机都能上网的时代,看个文章,看个视频,看个新闻都不是什么问题,很多互联网公司都推出了抓取浏览器,只要连接上wifi,就能抓到一个相对来说还不错的网页,这样就非常简单了,因为只需要定位网页的关键部分,然后通过js或者xml解析,提取出内容即可!例如我要抓取一个baiduspider的关键内容:about&needs_career&staff_title_tag&giveover¬e&repository_tag即可!about&needs_career&staff_title_tag&giveover¬e&repository_tag即可;即可爬虫开始第一步!获取网页数据的思路:首先最后一步是获取到整个网页,但是获取一个页面其实并不是一件简单的事情,获取整个页面的代码大概分为:strip、parse()、content等。
首先我们都知道,互联网有超过50亿的网页,一页可能有n个网页,我们在这里面想找到about&needs_career&staff_title_tag是一个网页,那么我们可以用strip方法,就是用某些字符串把about&needs_career&staff_title_tag以及所有网页去掉,然后就是parse()方法,即去除后面的html,提取出里面html的关键部分,然后提取出里面的关键字,提取不出来,就是最后一步content方法解析。
经过一系列的分析以及查找,最后得到about&needs_career&staff_title_tag和giveover¬e等,最后实现了这个项目的目标!这个项目的源码我已经上传到项目的github里面去,大家有兴趣的同学,可以去查看项目的源码,有任何不明白的,可以去问里面的项目组成员,大家一起完成,项目最后会链接到github上面去。项目代码里面不少代码很牛逼,但是,
网页数据抓取怎么写( Python中正则表达式的3种抓取其中数据的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-21 19:08
Python中正则表达式的3种抓取其中数据的方法(上))
3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> re.findall(r'(.*?)', html)
['<img />
',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'<a>EU</a>
',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{
2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]
d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'<a>IE </a>
']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。如果您希望正则表达式更加明确,我们也可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint
>>> broken_html = 'AreaPopulation
'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area
, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element
>>> area = td.text # extract the text from the data element
>>> print(area)
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation
'
>>> tree = fromstring(broken_html) # parse the HTML
>>> fixed_html = tostring(tree, pretty_print=True)
>>> print(fixed_html)
Area
Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print(area)
244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
标签: 查看全部
网页数据抓取怎么写(
Python中正则表达式的3种抓取其中数据的方法(上))
3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re
>>> from chp1.advanced_link_crawler import download
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> re.findall(r'(.*?)', html)
['<img />
',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'<a>EU</a>
',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{
2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]
d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'<a>IE </a>
']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望在未来的某个时间点再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。如果您希望正则表达式更加明确,我们也可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area:
(.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)
['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> from pprint import pprint
>>> broken_html = 'AreaPopulation
'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')
>>> fixed_html = soup.prettify()
>>> pprint(fixed_html)
Area
Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area
, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.python-scraping ... 39%3B
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element
>>> area = td.text # extract the text from the data element
>>> print(area)
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring
>>> broken_html = 'AreaPopulation
'
>>> tree = fromstring(broken_html) # parse the HTML
>>> fixed_html = tostring(tree, pretty_print=True)
>>> print(fixed_html)
Area
Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print(area)
244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
标签:

