
网页数据抓取怎么写
网页数据抓取怎么写(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-07 13:00
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview的分页功能,当你点击分页的页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须使用循环将_dopostback的两个参数拼凑起来,只需要收录页码信息的参数。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈 查看全部
网页数据抓取怎么写(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview的分页功能,当你点击分页的页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须使用循环将_dopostback的两个参数拼凑起来,只需要收录页码信息的参数。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈
网页数据抓取怎么写(之前用C#帮朋友写了一个抓取网页信息的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-07 07:11
我用C#帮朋友写了一个抓取网页信息的程序。这是非常复杂的。今天朋友要下载网页资料。有很多,想偷懒,又不想用C#了,就想到了Python。两个小时,在记事本中输入,然后在 IDLE(Python GUI)中测试。发现Python等解释型语言非常好,不用编译,直接写个脚本就行了。代码显示如下:
# -*- coding:gb2312 -*-
import sys
import urllib
import re
#从html中解析标题
def ParshTitle(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos+29:endpos]
strTmp = strTmp.replace(\'\', \'\')
return strTmp
#从html中解析CPI数据
def ParshCPI(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#从html中解析城镇投资数据
def ParshUrbanInvestment(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#提取各地区数据
def GetHtmlData(url, htmlfile, bisCPI):
wp = urllib.urlopen(url)#打开连接
content = wp.read() #获取页面内容
content = content.replace(\'\r\n\', \'\')
title = ParshTitle(content)
if bisCPI:
content = ParshCPI(content)
else:
content = ParshUrbanInvestment(content)
fl = title + htmlfile
#将文件路径转为gbk编码
fl = unicode(fl,\'gbk\')
f = open(fl, \'w\')
f.write(content)
f.close()
if __name__ =="__main__":
#首先提取CPI数据
num_list = range(72) #生成0~71的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_CPI.htm"
GetHtmlData(strTemp, strTxt, True)
print (str(i) + "/72")
#再提取城镇投资数据
num_list = range(56) #生成0~55的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_UI.htm"
GetHtmlData(strTemp, strTxt, False)
print (str(i) + "/56")
对上面代码稍微解释一下:这个主要是用来抓取国家统计局网站的统计数据,包括各地区的居民消费价格指数和各地区的城市投资数据。同学们要的数据是2006年1月到现在,在统计局网站上查询发现所有的数据URL都是一样的,只是最后一个id值从1递增,最近是1.,之前时间慢慢增加。统计局的这个网址好长啊!!
代码中写了三个函数,分别是获取网页的Tilte,作为保存文件的文件名。
一个功能是从html中分析出各个地区的居民消费价格指数,另一个是提取各个地区的城市投资数据。实际上,当前代码的两个功能是相同的。我比较懒,没有提取里面的详细信息。Table的tbody取出来了,哈哈。如果可以,可以使用正则表达式只提取里面的数据。
上次用C#写了好久。Python真的很不一样。如果写一个简单的工具,更推荐Python。一是简单,二是不需要编译,直接写一个txt放到解释器里就可以了。NS。 查看全部
网页数据抓取怎么写(之前用C#帮朋友写了一个抓取网页信息的程序)
我用C#帮朋友写了一个抓取网页信息的程序。这是非常复杂的。今天朋友要下载网页资料。有很多,想偷懒,又不想用C#了,就想到了Python。两个小时,在记事本中输入,然后在 IDLE(Python GUI)中测试。发现Python等解释型语言非常好,不用编译,直接写个脚本就行了。代码显示如下:
# -*- coding:gb2312 -*-
import sys
import urllib
import re
#从html中解析标题
def ParshTitle(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos+29:endpos]
strTmp = strTmp.replace(\'\', \'\')
return strTmp
#从html中解析CPI数据
def ParshCPI(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#从html中解析城镇投资数据
def ParshUrbanInvestment(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#提取各地区数据
def GetHtmlData(url, htmlfile, bisCPI):
wp = urllib.urlopen(url)#打开连接
content = wp.read() #获取页面内容
content = content.replace(\'\r\n\', \'\')
title = ParshTitle(content)
if bisCPI:
content = ParshCPI(content)
else:
content = ParshUrbanInvestment(content)
fl = title + htmlfile
#将文件路径转为gbk编码
fl = unicode(fl,\'gbk\')
f = open(fl, \'w\')
f.write(content)
f.close()
if __name__ =="__main__":
#首先提取CPI数据
num_list = range(72) #生成0~71的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_CPI.htm"
GetHtmlData(strTemp, strTxt, True)
print (str(i) + "/72")
#再提取城镇投资数据
num_list = range(56) #生成0~55的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_UI.htm"
GetHtmlData(strTemp, strTxt, False)
print (str(i) + "/56")
对上面代码稍微解释一下:这个主要是用来抓取国家统计局网站的统计数据,包括各地区的居民消费价格指数和各地区的城市投资数据。同学们要的数据是2006年1月到现在,在统计局网站上查询发现所有的数据URL都是一样的,只是最后一个id值从1递增,最近是1.,之前时间慢慢增加。统计局的这个网址好长啊!!
代码中写了三个函数,分别是获取网页的Tilte,作为保存文件的文件名。
一个功能是从html中分析出各个地区的居民消费价格指数,另一个是提取各个地区的城市投资数据。实际上,当前代码的两个功能是相同的。我比较懒,没有提取里面的详细信息。Table的tbody取出来了,哈哈。如果可以,可以使用正则表达式只提取里面的数据。
上次用C#写了好久。Python真的很不一样。如果写一个简单的工具,更推荐Python。一是简单,二是不需要编译,直接写一个txt放到解释器里就可以了。NS。
网页数据抓取怎么写(区别于上篇动态网页抓取,这里介绍另一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-07 07:08
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
您可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后就可以进行相关定位获取元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素
以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
网页数据抓取怎么写(区别于上篇动态网页抓取,这里介绍另一种方法)
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:

2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX


可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')

3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。


4)driver.get("")

5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))


6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')

7)content=comment.find_element_by_tag_name('p')

更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
您可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)

如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后就可以进行相关定位获取元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素

以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
网页数据抓取怎么写(Python中解析网页的内容简明扼要并且容易理解,绝对能使你眼前一亮收获)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-06 21:23
这篇文章文章 向你展示了如何在 Python 中抓取和存储网页数据。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranki ... 39%3B res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
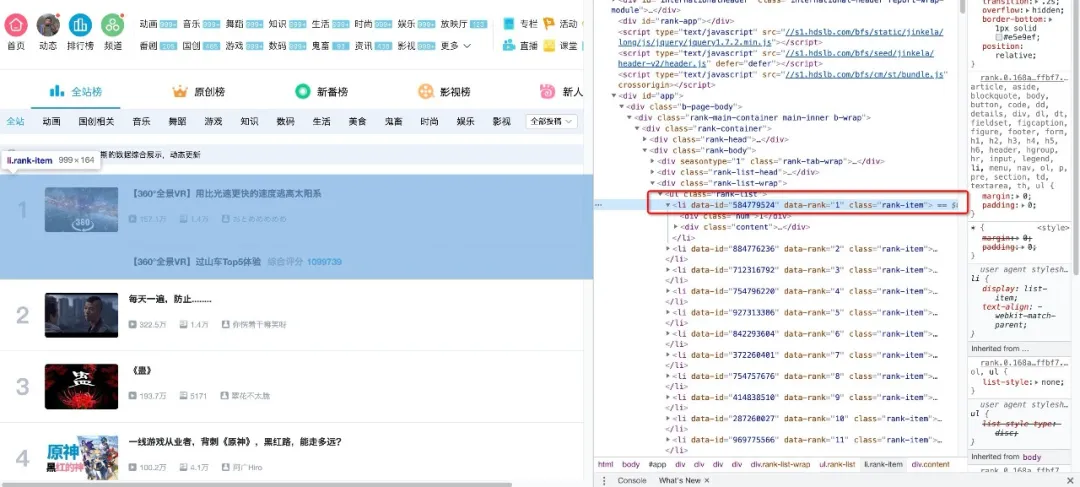
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
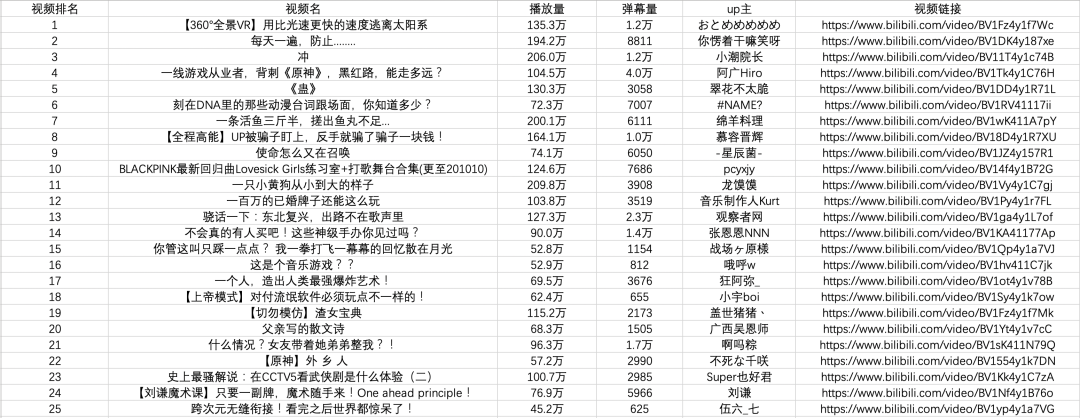
all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url })
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
以上内容就是如何在Python中抓取和存储网页数据。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。 查看全部
网页数据抓取怎么写(Python中解析网页的内容简明扼要并且容易理解,绝对能使你眼前一亮收获)
这篇文章文章 向你展示了如何在 Python 中抓取和存储网页数据。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranki ... 39%3B res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容

可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url })
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
以上内容就是如何在Python中抓取和存储网页数据。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。
网页数据抓取怎么写(京东商城:二级页面中elementsrolldowm)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-10-04 11:06
换言之,我们之前已经爬过JD的数据,但是辅助页面选择器类型是简单文本。这一次,我们想在第二页抓取商店名称、表扬率和评价标签。页面需要向下滚动以显示完整的数据。因此,它涉及在第二页中使用元素sroll dowm。链接地址:【手机】价格\图片\品牌\京东商城怎么样
一、分析网站规则
1、起始页的数据可以完全显示
2、分页时,网址不变。单击以翻页
3、从起始页链接进入第二页后,您需要向下滚动以显示完整的数据
因此,确定获取数据的方法:元素单击+链接+元素向下滚动+文本
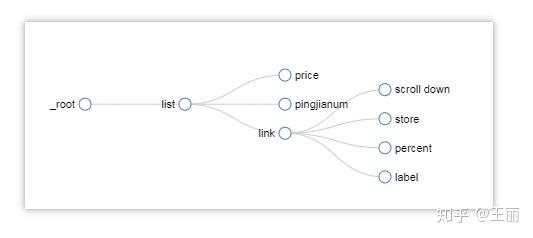
二、网站地图创建
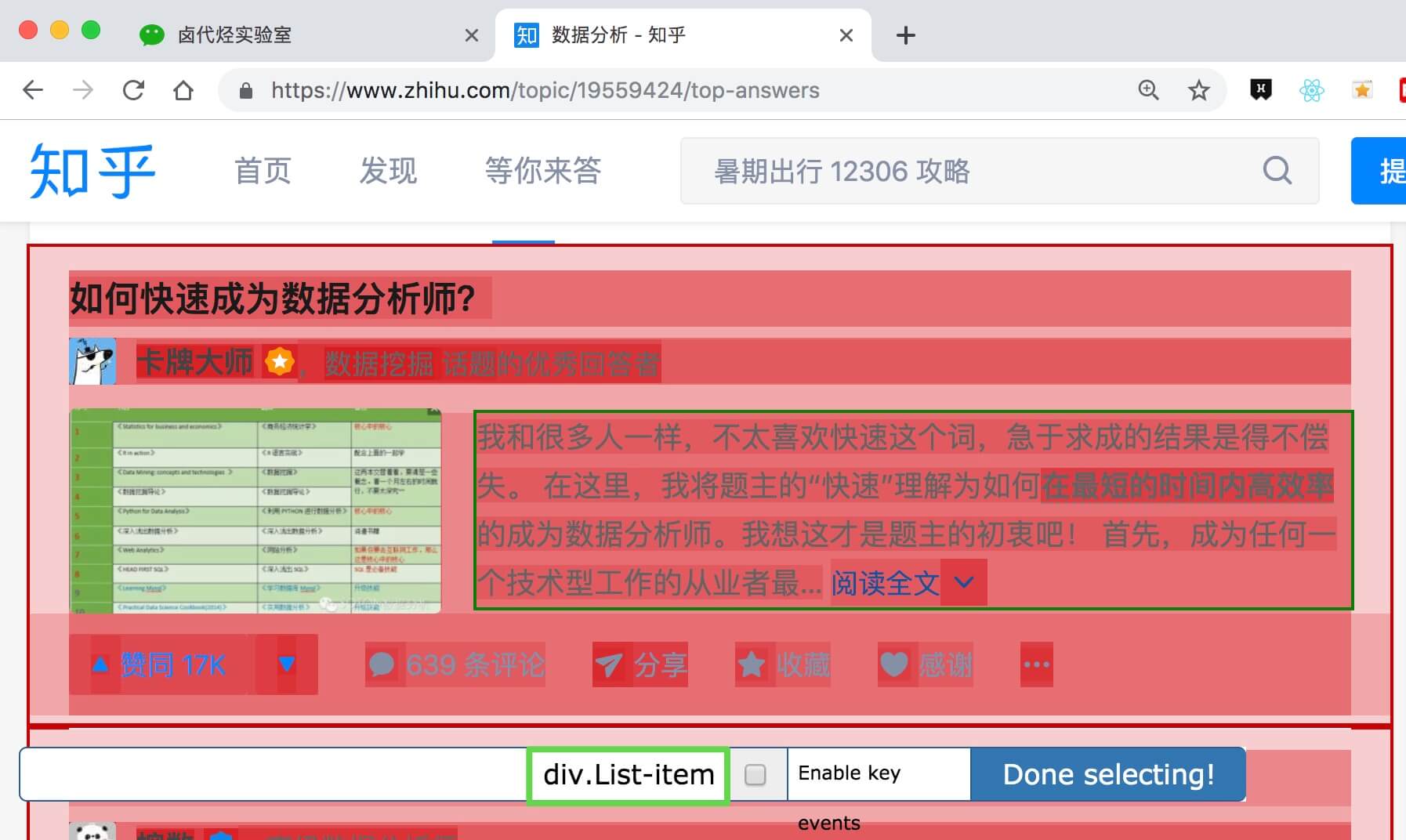
从图中可以看出,我将列表、链接和向下滚动选择器设置为一个系列关系。其中,向下滚动就是向下滚动辅助显示数据。其他子选择器是文本,它们是真正捕获数据的子选择器。捕获的数据维度包括手机名称、价格、评估人数、店铺名称、赞誉率和评估标签
需要注意的是,必须在向下滚动中设置延迟,建议设置为2000ms。一开始,我没有在这里设置延迟,所以赞扬率和评价标签没有上升,所以我跳到下一页
代码如下:
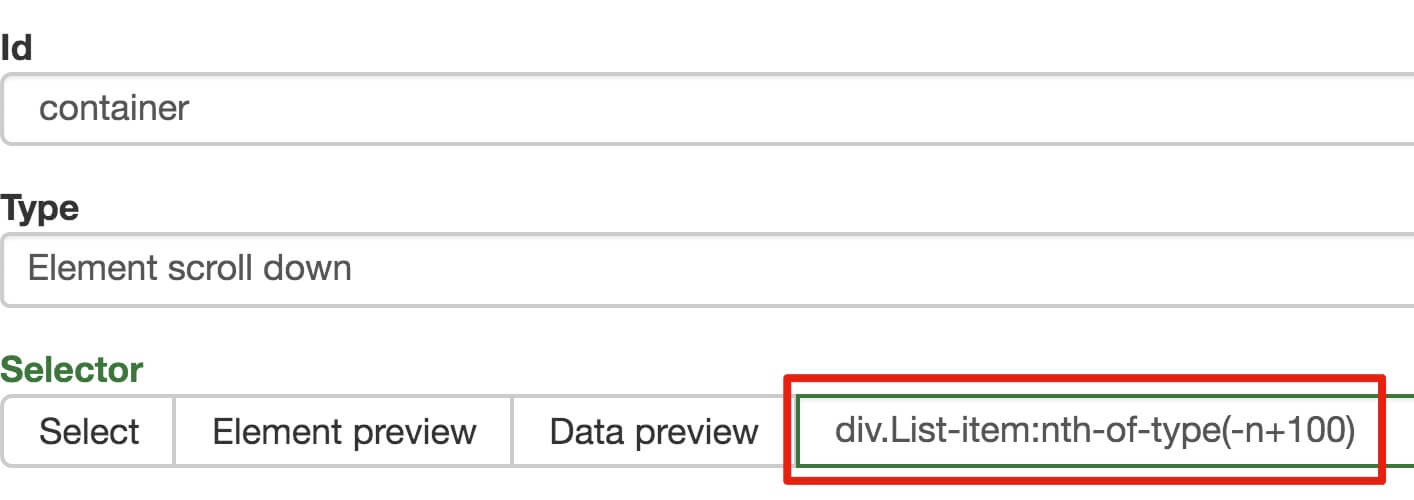
{“startUrl”:“/chanpin/127371.html”,“选择器”:[{“parentSelectors”:[“_root”],“type”:“SelectorElementClick”,“multiple”:true,“id”:“list”,“selector”:“div.gl-i-wrap”,“delay”:“2000”,“clickElementSelector”:“a.pn-next em”,“clickelement uniquencesstype”:“uniquecsselector”,“clickType”:“clickMore”,“discardinalelements”:false},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“price”,“selector”:“div.p-price”,“regex”:“delay”:“,”),“},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“pingjianum”,“selector”:“div
p-commit“,”regex“:”,”delay“,”type“:”SelectorLink“,”type“:”false“,”id“,”link“,”selector“,”div.p-name a“,”delay“,”delay“,”,”parentSelectors“,”type“,”selectorrelementscroll“,”false“,”id“:”向下滚动“,”选择器“:”div#J-global-toolbar“,”delay“,”2000“,”delay“,”delay“,”parentSelectors“,”selectors“,”SelectorText“,”2000“,”“,”多个“:false,”id:”store“,”selector“:”div.popbox-internal div.mt“,”regex“,”delay“,”},{”parentSelectors“:[”link“],”type“:”SelectorText“,”多个“:false,“id:”百分比“,”选择器“:”div
注释百分比“,”regex:“,”delay:“},{”parentSelectors:“[”link“],”type:“SelectorText”,“multiple:”false,“id:“label”,“selector:“div.tag-list”,“regex:“,”delay:“}],”_id:“shouji2”}
三、数据预览
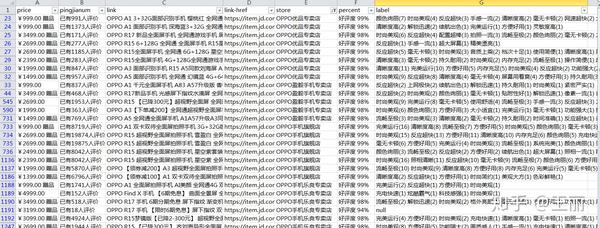
设置参数后,可以等待结果。预览如下:
在本总结开始时,对延迟设置的理解不到位。我希望通过章节分享来加深我的印象~~~ 查看全部
网页数据抓取怎么写(京东商城:二级页面中elementsrolldowm)
换言之,我们之前已经爬过JD的数据,但是辅助页面选择器类型是简单文本。这一次,我们想在第二页抓取商店名称、表扬率和评价标签。页面需要向下滚动以显示完整的数据。因此,它涉及在第二页中使用元素sroll dowm。链接地址:【手机】价格\图片\品牌\京东商城怎么样
一、分析网站规则
1、起始页的数据可以完全显示
2、分页时,网址不变。单击以翻页
3、从起始页链接进入第二页后,您需要向下滚动以显示完整的数据
因此,确定获取数据的方法:元素单击+链接+元素向下滚动+文本
二、网站地图创建
从图中可以看出,我将列表、链接和向下滚动选择器设置为一个系列关系。其中,向下滚动就是向下滚动辅助显示数据。其他子选择器是文本,它们是真正捕获数据的子选择器。捕获的数据维度包括手机名称、价格、评估人数、店铺名称、赞誉率和评估标签
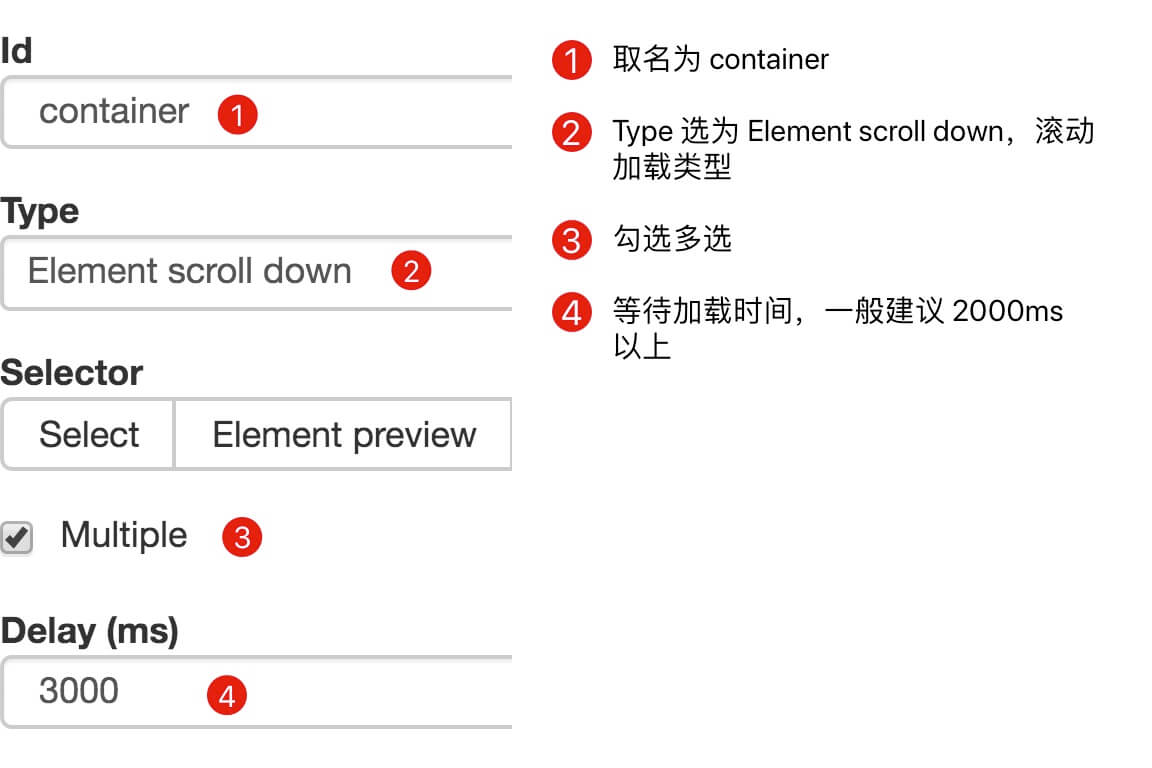
需要注意的是,必须在向下滚动中设置延迟,建议设置为2000ms。一开始,我没有在这里设置延迟,所以赞扬率和评价标签没有上升,所以我跳到下一页
代码如下:
{“startUrl”:“/chanpin/127371.html”,“选择器”:[{“parentSelectors”:[“_root”],“type”:“SelectorElementClick”,“multiple”:true,“id”:“list”,“selector”:“div.gl-i-wrap”,“delay”:“2000”,“clickElementSelector”:“a.pn-next em”,“clickelement uniquencesstype”:“uniquecsselector”,“clickType”:“clickMore”,“discardinalelements”:false},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“price”,“selector”:“div.p-price”,“regex”:“delay”:“,”),“},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“pingjianum”,“selector”:“div
p-commit“,”regex“:”,”delay“,”type“:”SelectorLink“,”type“:”false“,”id“,”link“,”selector“,”div.p-name a“,”delay“,”delay“,”,”parentSelectors“,”type“,”selectorrelementscroll“,”false“,”id“:”向下滚动“,”选择器“:”div#J-global-toolbar“,”delay“,”2000“,”delay“,”delay“,”parentSelectors“,”selectors“,”SelectorText“,”2000“,”“,”多个“:false,”id:”store“,”selector“:”div.popbox-internal div.mt“,”regex“,”delay“,”},{”parentSelectors“:[”link“],”type“:”SelectorText“,”多个“:false,“id:”百分比“,”选择器“:”div
注释百分比“,”regex:“,”delay:“},{”parentSelectors:“[”link“],”type:“SelectorText”,“multiple:”false,“id:“label”,“selector:“div.tag-list”,“regex:“,”delay:“}],”_id:“shouji2”}
三、数据预览
设置参数后,可以等待结果。预览如下:
在本总结开始时,对延迟设置的理解不到位。我希望通过章节分享来加深我的印象~~~
网页数据抓取怎么写(可以使用Uibot进行网络数据采集吗?-__晚上的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-10-03 21:24
Uibot可以用于网络数据采集吗?-
______ Uibot可以执行各种网络数据采集,包括信息采集、数据采集、图片采集、OCR识别技术等。
如何使用jsoup抓取网页数据?求解释,也求演示。
______ 晚上有很多例子。主要是先从网上获取数据,然后用json解析数据。这很简单。
如何使用Uibot调用Excel表格中的数据?-
______ Excel 提供了两种数据过滤操作,即“自动过滤”和“高级过滤”。自动过滤一般用于简单的条件过滤。过滤时,不符合条件的数据会被暂时隐藏,只显示符合条件的数据。图1为某单位员工工资表。打开“数据”菜单中的“过滤器”子菜单...
如何抓取网页数据-
______ 我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 gooseeker 网络爬虫如何进行数据爬取,在翻页后自动抓取数据。ms的爬虫路由工作台共有三种线索方式。
如何抓取网页上的数据-
______ 1. 用工具分析js最终生成的url是什么,具体发送的请求,发送的数据是什么。相关参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不明白背后的逻辑,请参考:【完成】关于...
如何抓取 HTML 页面数据-
______ 使用预先嗅探的 ForeSpider 数据 采集 系统。ForeSpider数据采集系统具有全面的采集范围、准确的数据准确性、卓越的捕捉性能、简单的可视化操作、智能化采集的自动化使企业能够快速获取结构化或非结构化数据在互联网上用很少的劳动力成本。软件...
网络上如何抓取数据,表格中的数据——
______ 只要您选择在办公室插入图片即可。
UiBot 能做什么?
______ 1.对各种客户端软件界面元素进行各种操作,2.对网页浏览器的界面元素进行各种操作,傻瓜式data采集,3.操作在各种办公软件的文档上,4.基于图像、文字、OCR等识别方式对界面元素进行各种操作,5.在广泛使用的现有系统上进行操作,6.操作windows和基于句柄的流程,7.大规模基础功能8.多种能力扩展方案。
如何使用R或rapidminer抓取以下网页的数据
______ 对于网页数据,还是需要一定的技术基础,通过运行程序来实现。如果网页比较复杂,那就更难了,所以楼主不妨用爬虫软件来实现网页数据采集 ,而且市面上有很多这样的工具,比如优采云、Jisuke GooSeeker、Scrapy,都是不错的网络爬虫软件。我个人比较喜欢用Jisuke,使用简单,可以自由自学。, 你可以试试看。
如何抓取网页表单数据
______ 不知道是自己写爬虫还是用采集工具。如果自己写爬虫,可以查代码。如果使用采集工具,可以使用另一个网友推荐的采集工具,另外我也推荐一个,Gathering,因为相比前者免费,而且还有文档和视频教程。希望对你有帮助。 查看全部
网页数据抓取怎么写(可以使用Uibot进行网络数据采集吗?-__晚上的例子)
Uibot可以用于网络数据采集吗?-
______ Uibot可以执行各种网络数据采集,包括信息采集、数据采集、图片采集、OCR识别技术等。
如何使用jsoup抓取网页数据?求解释,也求演示。
______ 晚上有很多例子。主要是先从网上获取数据,然后用json解析数据。这很简单。
如何使用Uibot调用Excel表格中的数据?-
______ Excel 提供了两种数据过滤操作,即“自动过滤”和“高级过滤”。自动过滤一般用于简单的条件过滤。过滤时,不符合条件的数据会被暂时隐藏,只显示符合条件的数据。图1为某单位员工工资表。打开“数据”菜单中的“过滤器”子菜单...
如何抓取网页数据-
______ 我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 gooseeker 网络爬虫如何进行数据爬取,在翻页后自动抓取数据。ms的爬虫路由工作台共有三种线索方式。
如何抓取网页上的数据-
______ 1. 用工具分析js最终生成的url是什么,具体发送的请求,发送的数据是什么。相关参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不明白背后的逻辑,请参考:【完成】关于...
如何抓取 HTML 页面数据-
______ 使用预先嗅探的 ForeSpider 数据 采集 系统。ForeSpider数据采集系统具有全面的采集范围、准确的数据准确性、卓越的捕捉性能、简单的可视化操作、智能化采集的自动化使企业能够快速获取结构化或非结构化数据在互联网上用很少的劳动力成本。软件...
网络上如何抓取数据,表格中的数据——
______ 只要您选择在办公室插入图片即可。
UiBot 能做什么?
______ 1.对各种客户端软件界面元素进行各种操作,2.对网页浏览器的界面元素进行各种操作,傻瓜式data采集,3.操作在各种办公软件的文档上,4.基于图像、文字、OCR等识别方式对界面元素进行各种操作,5.在广泛使用的现有系统上进行操作,6.操作windows和基于句柄的流程,7.大规模基础功能8.多种能力扩展方案。
如何使用R或rapidminer抓取以下网页的数据
______ 对于网页数据,还是需要一定的技术基础,通过运行程序来实现。如果网页比较复杂,那就更难了,所以楼主不妨用爬虫软件来实现网页数据采集 ,而且市面上有很多这样的工具,比如优采云、Jisuke GooSeeker、Scrapy,都是不错的网络爬虫软件。我个人比较喜欢用Jisuke,使用简单,可以自由自学。, 你可以试试看。
如何抓取网页表单数据
______ 不知道是自己写爬虫还是用采集工具。如果自己写爬虫,可以查代码。如果使用采集工具,可以使用另一个网友推荐的采集工具,另外我也推荐一个,Gathering,因为相比前者免费,而且还有文档和视频教程。希望对你有帮助。
网页数据抓取怎么写(如何抓取目标网站是以Js的方式动态生成数据的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-03 21:21
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
网页数据抓取怎么写(如何抓取目标网站是以Js的方式动态生成数据的网页)
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
网页数据抓取怎么写(如何用Python爬数据?(一)网页抓取你期待已久的Python网络数据爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-01 13:05
如何使用 Python 抓取数据?(一)网页抓取
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。
需要
我在公众号后台,经常能收到读者的评论。
很多评论都是来自读者的提问。只要我有时间,我会花时间尝试回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:
一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。
我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
开放数据集下载;
API读取;
爬虫。
前两种方法我已经做了一些介绍,这次就说说爬虫。
概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网络抓取软件可以直接使用超文本传输协议或通过网络浏览器访问万维网。
如果你看到了,即使你用浏览器手动复制数据,也被称为网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为你完成网页抓取工作,才是你真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花 20% 的努力去理解一件事的 80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常实用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但是要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。
假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在 Windows 平台上安装和运行 Anaconda 命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。
打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip 安装 pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
管道安装
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv 外壳
请在此确认您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter 笔记本
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。
请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
从 requests_html 导入 HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
会话 = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
网址 ='#39;
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,只看正文部分。
所以我们执行:
打印(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个相对于我们网页采集所在域名()的路径的链接。
就好像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,不需要在前面加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:
这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。
为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
就像你想给某人寄包裹一样,你可以在“省-市-区-街道-社区-门牌”的结构中写一个地址,快递员也可以根据这个地址找到收件人。
同样,我们对网页中的一些特定内容感兴趣,我们可以根据这些标签的结构找出来。
这是否意味着您必须先学习 HTML 和 CSS,然后才能抓取网页内容?
不,我们可以使用工具来帮助您显着简化任务的复杂性。
此工具随 Google Chrome 浏览器一起提供。
我们在示例文章页面点击鼠标右键,在出现的菜单中选择“Check”。
这时,屏幕下方会出现一列。
我们单击此列左上角的按钮(上面标记为红色)。然后将鼠标悬停在第一个文本链接(“玉树之蓝”)上并单击。
此时,你会发现下栏的内容也发生了变化。这个链接对应的源代码放在栏目区域的中间,并高亮显示。
确认该区域是我们要找的链接和文字说明后,我们用鼠标右键选中突出显示的区域,在弹出的菜单中选择Copy -> Copy selector。
找个文本编辑器,执行paste,就可以看到我们复制的内容了。
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
这长串标签为电脑指出:请先找到body标签,然后进入管辖区域后找到div.note标签,然后找到...最后找到a标签,这里是内容你正在寻找。
回到我们的 Jupyter Notebook 并使用我们刚刚获得的标签路径来定义变量 sel。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a'
我们让 Python 从返回的内容中找到 sel 对应的位置,并将结果存储在 results 变量中。
结果 = r.html.find(sel)
让我们来看看结果中的内容。
结果
这是结果:
[]
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
结果[0].text
这是输出:
《玉树知兰》
我们还提取了链接:
结果[0].absolute_links
显示的结果是一个集合。
{'#39;}
我们不需要集合,只需要其中的链接字符串。所以我们首先将它转换成一个列表,然后从中提取第一项,即 URL 链接。
列表(结果[0].absolute_links)[0]
这一次,我们终于得到了我们想要的结果:
'#39;
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们。
def get_text_link_from_sel(sel):
我的列表 = []
尝试:
结果 = r.html.find(sel)
结果结果:
mytext = result.text
mylink = list(result.absolute_links)[0]
mylist.append((mytext, mylink))
返回我的列表
除了:
返回无
我们来测试一下这个功能。
还是用刚才一样的标记路径(sel),试试吧。
打印(get_text_link_from_sel(sel))
输出如下:
[('玉树芝兰','#39;)]
没问题吧?
好的,让我们尝试第二个链接。
我们还是用刚才的方法,使用下栏左上角的按钮,点击第二个链接。
下面显示的突出显示的内容已更改:
我们仍然使用鼠标右键单击突出显示的部分来复制选择器。
然后我们直接将获取到的标签路径写入到 Jupyter Notebook 中。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a'
用我们刚才编译的函数看看输出结果是什么?
打印(get_text_link_from_sel(sel))
输出如下:
[('如何使用Python作为词云?','#39;)]
经检查,功能没有问题。
下一步是什么?
还是要找第三个链接,按照刚才的方法操作吗?
那么你不妨从全文中手动提取信息,这样可以省去你的麻烦。
我们必须找到一种方法来自动化这个过程。
比较我们只找到两次的标记路径:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
也:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a
你找到什么模式了吗?
是的,路径上的所有其他标记都相同,除了倒数第二个标记(“p”)之后冒号之后的内容。
这是我们自动化的关键。
上述两个标签路径中,因为指定了“nth-child”文本段(paragraph,即“p”的意思)来查找标签“a”,所以只返回了一个结果。
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel ='body> div.note> div.post> div.article> div.show-content> div> p> a'
再次运行我们的函数:
打印(get_text_link_from_sel(sel))
这是输出:
好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
将熊猫导入为 pd
只需这行命令,我们就可以将刚才的列表变成一个数据框:
df = pd.DataFrame(get_text_link_from_sel(sel))
我们来看一下数据框的内容:
df
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['文本','链接']
查看数据框的内容:
df
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框转换为 csv 格式,可以直接在 Excel 中打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
很有成就感不是吗?
概括
本文向您展示了使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
网络爬虫与网络爬虫的联系和区别;
如何使用pipenv快速搭建指定的Python开发环境并自动安装依赖软件包;
如何利用谷歌浏览器内置的检查功能快速定位感兴趣内容的标记路径;
如何使用requests-html包解析网页并查询获取需要的内容元素;
如何使用 Pandas 数据框工具组织数据并输出到 Excel。
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页相同。
而且,根据我们的示例,您是否已经尝试过抓取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
如何将抓取功能扩展到一定范围内的所有网页?
如何抓取Javascript动态网页?
假设你爬取的网站限制了每个IP的访问频率,我该怎么办?
...
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,网络爬虫虽然抓取数据,虽然功能强大,但学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
有没有别人整理过的资料集可以直接下载?
网站你需要的数据有没有API访问和获取方式?
有没有人根据你的需要编了一个自定义爬虫让你直接调用?
如果答案是否定的,则需要自己编写脚本并动员爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区与大家分享记录链接就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?“文章中,部分文章被多次引用,所以已抓到重复链接。
但是当您存储时,您可能不想保留重复的链接。
在这种情况下,如何修改代码以确保抓取和保存的链接不重复?
这部分内容我放在文末付费阅读区。如果你愿意支持我的数据科学教程系列的写作,顺便看看你的代码是否比我的更有效率。您只需支付2元(促销期间的价格),阅读这部分内容。
讨论
你对 Python 爬虫感兴趣吗?你在哪些 data采集 任务上使用过它?有没有其他更有效的方式来达到data采集的目的?欢迎留言,与大家分享您的经验和想法,我们一起交流讨论。 查看全部
网页数据抓取怎么写(如何用Python爬数据?(一)网页抓取你期待已久的Python网络数据爬虫)
如何使用 Python 抓取数据?(一)网页抓取
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。

需要
我在公众号后台,经常能收到读者的评论。
很多评论都是来自读者的提问。只要我有时间,我会花时间尝试回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:

一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。

我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
开放数据集下载;
API读取;
爬虫。
前两种方法我已经做了一些介绍,这次就说说爬虫。

概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网络抓取软件可以直接使用超文本传输协议或通过网络浏览器访问万维网。
如果你看到了,即使你用浏览器手动复制数据,也被称为网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为你完成网页抓取工作,才是你真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花 20% 的努力去理解一件事的 80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常实用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但是要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。

在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。

假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:

您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。

请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在 Windows 平台上安装和运行 Anaconda 命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。

打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip 安装 pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
管道安装
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。

上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv 外壳
请在此确认您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter 笔记本
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:

可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。

但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。

请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。

准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
从 requests_html 导入 HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
会话 = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
网址 ='#39;
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,只看正文部分。
所以我们执行:
打印(r.html.text)
这是得到的结果:

我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:

这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个相对于我们网页采集所在域名()的路径的链接。
就好像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,不需要在前面加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:

这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。

电脑看到的网页是这样的。

为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。

就像你想给某人寄包裹一样,你可以在“省-市-区-街道-社区-门牌”的结构中写一个地址,快递员也可以根据这个地址找到收件人。
同样,我们对网页中的一些特定内容感兴趣,我们可以根据这些标签的结构找出来。
这是否意味着您必须先学习 HTML 和 CSS,然后才能抓取网页内容?
不,我们可以使用工具来帮助您显着简化任务的复杂性。
此工具随 Google Chrome 浏览器一起提供。
我们在示例文章页面点击鼠标右键,在出现的菜单中选择“Check”。

这时,屏幕下方会出现一列。

我们单击此列左上角的按钮(上面标记为红色)。然后将鼠标悬停在第一个文本链接(“玉树之蓝”)上并单击。

此时,你会发现下栏的内容也发生了变化。这个链接对应的源代码放在栏目区域的中间,并高亮显示。

确认该区域是我们要找的链接和文字说明后,我们用鼠标右键选中突出显示的区域,在弹出的菜单中选择Copy -> Copy selector。

找个文本编辑器,执行paste,就可以看到我们复制的内容了。
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
这长串标签为电脑指出:请先找到body标签,然后进入管辖区域后找到div.note标签,然后找到...最后找到a标签,这里是内容你正在寻找。
回到我们的 Jupyter Notebook 并使用我们刚刚获得的标签路径来定义变量 sel。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a'
我们让 Python 从返回的内容中找到 sel 对应的位置,并将结果存储在 results 变量中。
结果 = r.html.find(sel)
让我们来看看结果中的内容。
结果
这是结果:
[]
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
结果[0].text
这是输出:
《玉树知兰》
我们还提取了链接:
结果[0].absolute_links
显示的结果是一个集合。
{'#39;}
我们不需要集合,只需要其中的链接字符串。所以我们首先将它转换成一个列表,然后从中提取第一项,即 URL 链接。
列表(结果[0].absolute_links)[0]
这一次,我们终于得到了我们想要的结果:
'#39;
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们。
def get_text_link_from_sel(sel):
我的列表 = []
尝试:
结果 = r.html.find(sel)
结果结果:
mytext = result.text
mylink = list(result.absolute_links)[0]
mylist.append((mytext, mylink))
返回我的列表
除了:
返回无
我们来测试一下这个功能。
还是用刚才一样的标记路径(sel),试试吧。
打印(get_text_link_from_sel(sel))
输出如下:
[('玉树芝兰','#39;)]
没问题吧?
好的,让我们尝试第二个链接。
我们还是用刚才的方法,使用下栏左上角的按钮,点击第二个链接。

下面显示的突出显示的内容已更改:

我们仍然使用鼠标右键单击突出显示的部分来复制选择器。

然后我们直接将获取到的标签路径写入到 Jupyter Notebook 中。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a'
用我们刚才编译的函数看看输出结果是什么?
打印(get_text_link_from_sel(sel))
输出如下:
[('如何使用Python作为词云?','#39;)]
经检查,功能没有问题。
下一步是什么?
还是要找第三个链接,按照刚才的方法操作吗?
那么你不妨从全文中手动提取信息,这样可以省去你的麻烦。
我们必须找到一种方法来自动化这个过程。
比较我们只找到两次的标记路径:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
也:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a
你找到什么模式了吗?
是的,路径上的所有其他标记都相同,除了倒数第二个标记(“p”)之后冒号之后的内容。
这是我们自动化的关键。
上述两个标签路径中,因为指定了“nth-child”文本段(paragraph,即“p”的意思)来查找标签“a”,所以只返回了一个结果。
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel ='body> div.note> div.post> div.article> div.show-content> div> p> a'
再次运行我们的函数:
打印(get_text_link_from_sel(sel))
这是输出:

好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
将熊猫导入为 pd
只需这行命令,我们就可以将刚才的列表变成一个数据框:
df = pd.DataFrame(get_text_link_from_sel(sel))
我们来看一下数据框的内容:
df

内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['文本','链接']
查看数据框的内容:
df

好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框转换为 csv 格式,可以直接在 Excel 中打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。

很有成就感不是吗?
概括
本文向您展示了使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
网络爬虫与网络爬虫的联系和区别;
如何使用pipenv快速搭建指定的Python开发环境并自动安装依赖软件包;
如何利用谷歌浏览器内置的检查功能快速定位感兴趣内容的标记路径;
如何使用requests-html包解析网页并查询获取需要的内容元素;
如何使用 Pandas 数据框工具组织数据并输出到 Excel。
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页相同。
而且,根据我们的示例,您是否已经尝试过抓取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
如何将抓取功能扩展到一定范围内的所有网页?
如何抓取Javascript动态网页?
假设你爬取的网站限制了每个IP的访问频率,我该怎么办?
...
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,网络爬虫虽然抓取数据,虽然功能强大,但学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
有没有别人整理过的资料集可以直接下载?
网站你需要的数据有没有API访问和获取方式?
有没有人根据你的需要编了一个自定义爬虫让你直接调用?
如果答案是否定的,则需要自己编写脚本并动员爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区与大家分享记录链接就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:

这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?“文章中,部分文章被多次引用,所以已抓到重复链接。
但是当您存储时,您可能不想保留重复的链接。
在这种情况下,如何修改代码以确保抓取和保存的链接不重复?
这部分内容我放在文末付费阅读区。如果你愿意支持我的数据科学教程系列的写作,顺便看看你的代码是否比我的更有效率。您只需支付2元(促销期间的价格),阅读这部分内容。
讨论
你对 Python 爬虫感兴趣吗?你在哪些 data采集 任务上使用过它?有没有其他更有效的方式来达到data采集的目的?欢迎留言,与大家分享您的经验和想法,我们一起交流讨论。
网页数据抓取怎么写(基于HTML标签来匹配肯定不合适的数据匹配方法来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-01 12:30
数据匹配
首先研究最关键的数据捕获。从各种形式的数据中“提取”内容。
当然还要依靠我们强大的正则表达式工具(个人觉得基于DOM树的分析很麻烦,很不灵活)
分析了几个BOKECC页面,总结如下:
1. 每个页面都有一定的差异,可能是基于不同的版本。HTML 写的很随意,基于 HTML 标签的匹配肯定是不合适的。
2. 页面有动态内容,需要分析模拟AJAX来请求。
在基于HTML源代码的数据爬取中,如果单纯想基于HTML标签进行挖掘,正确率肯定是很低的。仍然需要回归基础,挖掘人们的想法。
所以我大多使用基于页面视觉(如文本,或区域)的匹配方法。过滤掉一些不太重要的 HTML 标签。然后进行数据匹配。
这里用到了python的re模块。
首先,我写了几个程序进行测试。我测试了 网站 的 20 个不同的页面,它们基本上都能正确捕获。
接下来说说AJAX的内容。
为什么动态内容需要模拟 AJAX 请求?
因为您使用 HTTP 流来获取网页的内容,所以没有动态类型的内容。(比如div标签为空),但是当你以浏览器的形式访问时,可以看到数据。这是因为浏览器的javascript引擎执行其中的JS代码异步请求数据并动态打印在上级页面上。
网页界面
每个节点都需要暴露WEB界面。在上一篇文章的设计中,我提到了SOAP协议。在实际实现中,我们在本系统中仍然使用基于HTTP GET的接口。(编码相对简单,:D)。为了方便部署,体现python中一切都那么简单的原则,我没有使用apache等知名的web服务器,而是python的BaseHTTPServer模块。重载do_GET方法来实现我们WEB界面的暴露。
为什么WEB界面需要同时设计同步和异步返回?由于我们的分布式节点是基于任务形式的,我们的节点任务逻辑反馈包括2个步骤:
1. 确认任务接收
2. 任务完成回调
这样,控制器的程序就很容易写了:给所有节点发送任务,同时加上任务号,节点同步后反馈接收任务,等待,如果有节点任务回调,节点认为空闲,然后分配任务。. . (当然,实际情况可能是每个节点运行在多个线程中,节点或者控制器也可以维护一个任务队列和线程池)
如何实现异步?
起线程。(当然你也可以管理线程池,这里我不太在意)
数据库操作
没什么好说的,我这里用的MYSQL就是直接SQL语句。简单明了。
如何部署?
由于我只需要在WINDOWS平台上部署,所以我使用py2exe作为EXE包发布。
如果要实现自动化部署,也很简单。自己在每个节点上写一个“后门”,就可以统一调度所有机器的后门。(控制它的下载和重启) 查看全部
网页数据抓取怎么写(基于HTML标签来匹配肯定不合适的数据匹配方法来实现)
数据匹配
首先研究最关键的数据捕获。从各种形式的数据中“提取”内容。
当然还要依靠我们强大的正则表达式工具(个人觉得基于DOM树的分析很麻烦,很不灵活)
分析了几个BOKECC页面,总结如下:
1. 每个页面都有一定的差异,可能是基于不同的版本。HTML 写的很随意,基于 HTML 标签的匹配肯定是不合适的。
2. 页面有动态内容,需要分析模拟AJAX来请求。
在基于HTML源代码的数据爬取中,如果单纯想基于HTML标签进行挖掘,正确率肯定是很低的。仍然需要回归基础,挖掘人们的想法。
所以我大多使用基于页面视觉(如文本,或区域)的匹配方法。过滤掉一些不太重要的 HTML 标签。然后进行数据匹配。
这里用到了python的re模块。
首先,我写了几个程序进行测试。我测试了 网站 的 20 个不同的页面,它们基本上都能正确捕获。
接下来说说AJAX的内容。
为什么动态内容需要模拟 AJAX 请求?
因为您使用 HTTP 流来获取网页的内容,所以没有动态类型的内容。(比如div标签为空),但是当你以浏览器的形式访问时,可以看到数据。这是因为浏览器的javascript引擎执行其中的JS代码异步请求数据并动态打印在上级页面上。
网页界面
每个节点都需要暴露WEB界面。在上一篇文章的设计中,我提到了SOAP协议。在实际实现中,我们在本系统中仍然使用基于HTTP GET的接口。(编码相对简单,:D)。为了方便部署,体现python中一切都那么简单的原则,我没有使用apache等知名的web服务器,而是python的BaseHTTPServer模块。重载do_GET方法来实现我们WEB界面的暴露。
为什么WEB界面需要同时设计同步和异步返回?由于我们的分布式节点是基于任务形式的,我们的节点任务逻辑反馈包括2个步骤:
1. 确认任务接收
2. 任务完成回调
这样,控制器的程序就很容易写了:给所有节点发送任务,同时加上任务号,节点同步后反馈接收任务,等待,如果有节点任务回调,节点认为空闲,然后分配任务。. . (当然,实际情况可能是每个节点运行在多个线程中,节点或者控制器也可以维护一个任务队列和线程池)
如何实现异步?
起线程。(当然你也可以管理线程池,这里我不太在意)
数据库操作
没什么好说的,我这里用的MYSQL就是直接SQL语句。简单明了。
如何部署?
由于我只需要在WINDOWS平台上部署,所以我使用py2exe作为EXE包发布。
如果要实现自动化部署,也很简单。自己在每个节点上写一个“后门”,就可以统一调度所有机器的后门。(控制它的下载和重启)
网页数据抓取怎么写(iOSpython爬虫学习iOS开发有一段时间了,物品等数据怎么获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-30 18:19
iOS 蟒蛇爬虫 LoL
我已经学习了一段时间的 iOS 开发。最近想做个自己的App来玩玩玩。比较喜欢玩LOL,所以想尝试在LOL数据库里做一个App。那么问题来了,这么多英雄、物品等数据怎么弄啊,你自己敲不出来。作为程序员,你怎么能自己做呢?这时候就可以牺牲神器Python了,直接上正题吧。
一、 查找数据
要获取数据,您必须首先找出数据的可用位置。各大游戏媒体网站都有自己的数据库,这里我选择官方数据库,地址:LOL官方数据库。
[LOL官方数据库]()
英雄、物品、技能、符文、天赋一应俱全,数据也是最新的。OK,猎物找到了,开始狩猎前需要做一些准备。
二、 准备
python filename.py
三、 网络分析
我们要抓取的数据包括图片、文本或文件。图像和文件通常是一个地址。文本可能存在于文件中,也可能直接写在网页的源代码中。因此,我们首先分析网页,熟悉战场。
在Safari中打开LOL官方数据库,点击菜单“开发”-“显示页面源文件”或按快捷键alt+command+a/u,进入开发者工具,点击“元素”选项卡
Safari 开发者工具
当我们将鼠标移动到不同的代码行时,网页中当前代码对应的元素就会被选中,可以帮助我们快速定位关键代码。我们先试着找到九尾妖狐头部的图片地址,如上图所示。
.
四、一个小测试
现在我们将尝试将这张图片下载到本地。
创建Python文件,保存时可以使用VSCode新建一个后缀为.py的空白文件,也可以在终端执行命令
cd Desktop/ //进入Desktop文件夹
touch filename.py //在当前文件夹内新建文件
用编辑器打开文件并编写代码:
#-*-coding:utf8-*-
import os, requests
img_url = "http://ossweb-img.qq.com/image ... ot%3B
# 截取文件名
img_name = os.path.basename(img_url)
# 下载图片
img = requests.get(img_url)
# 打开本地文件
# 'wb'表示以二进制写入模式打开文件
file = open('/Users/apple/img//' + img_name, 'wb')
# 写入文件
file.write(img.content)
# 关闭文件
file.close
这里用到了两个库,os和requests库,os python自带,requests需要手动下载并在终端执行
pip install requests
这是一个简单的下载保存的例子,但是已经可以满足我们的需求了,我们只需要修改一下就可以完成我们的目标。
未完待续 查看全部
网页数据抓取怎么写(iOSpython爬虫学习iOS开发有一段时间了,物品等数据怎么获取)
iOS 蟒蛇爬虫 LoL
我已经学习了一段时间的 iOS 开发。最近想做个自己的App来玩玩玩。比较喜欢玩LOL,所以想尝试在LOL数据库里做一个App。那么问题来了,这么多英雄、物品等数据怎么弄啊,你自己敲不出来。作为程序员,你怎么能自己做呢?这时候就可以牺牲神器Python了,直接上正题吧。
一、 查找数据
要获取数据,您必须首先找出数据的可用位置。各大游戏媒体网站都有自己的数据库,这里我选择官方数据库,地址:LOL官方数据库。

[LOL官方数据库]()
英雄、物品、技能、符文、天赋一应俱全,数据也是最新的。OK,猎物找到了,开始狩猎前需要做一些准备。
二、 准备
python filename.py
三、 网络分析
我们要抓取的数据包括图片、文本或文件。图像和文件通常是一个地址。文本可能存在于文件中,也可能直接写在网页的源代码中。因此,我们首先分析网页,熟悉战场。
在Safari中打开LOL官方数据库,点击菜单“开发”-“显示页面源文件”或按快捷键alt+command+a/u,进入开发者工具,点击“元素”选项卡
Safari 开发者工具
当我们将鼠标移动到不同的代码行时,网页中当前代码对应的元素就会被选中,可以帮助我们快速定位关键代码。我们先试着找到九尾妖狐头部的图片地址,如上图所示。

.
四、一个小测试
现在我们将尝试将这张图片下载到本地。
创建Python文件,保存时可以使用VSCode新建一个后缀为.py的空白文件,也可以在终端执行命令
cd Desktop/ //进入Desktop文件夹
touch filename.py //在当前文件夹内新建文件
用编辑器打开文件并编写代码:
#-*-coding:utf8-*-
import os, requests
img_url = "http://ossweb-img.qq.com/image ... ot%3B
# 截取文件名
img_name = os.path.basename(img_url)
# 下载图片
img = requests.get(img_url)
# 打开本地文件
# 'wb'表示以二进制写入模式打开文件
file = open('/Users/apple/img//' + img_name, 'wb')
# 写入文件
file.write(img.content)
# 关闭文件
file.close
这里用到了两个库,os和requests库,os python自带,requests需要手动下载并在终端执行
pip install requests
这是一个简单的下载保存的例子,但是已经可以满足我们的需求了,我们只需要修改一下就可以完成我们的目标。
未完待续
网页数据抓取怎么写(网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-29 02:01
网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总了。涵盖电影网、游戏网、教育网、购物网,各个网站的工具开发者从网页底部选择下载路径,然后就会一步步按照工具开发者提供的下载教程,按照要求下载到相应的网站里去。还是需要掌握一定的代码技巧。以下是我总结的资源列表:文章:文章汇总网页数据抓取怎么写程序爬虫学了怎么用发现坑,自己绕过去了主要爬虫网站大集合这里是引导列表-11.html?hl=enaj教程列表-12.html?hl=enctf项目汇总:找个点击赚积分的网站-13.html?hl=en非重复内容爬取-15.html?hl=en一个爬虫器-16.html?hl=en爬虫代码-17.html?hl=en更好玩的获取pdf网站,有兴趣的欢迎看我的优质文章列表,更多资源可关注公众号:考拉猪来啦微信公众号回复“爬虫”即可获取中速网公告:。
推荐你用金山云查名单,有收集全国12000+主流电商网站的爬虫+查询代码,爬虫写的还可以,代码不通俗,但是质量不错,
我有些工具网站地址,你参考下:初学爬虫应用笔记网址链接:-geller。blogspot。com/2015/06/html_final_0。html或者你可以看看我的一个知乎回答:基于百度浏览器插件、迅雷浏览器扩展程序、电脑管家助手等工具实现百度网页搜索视频、下载音乐、查看历史消息或阅读全文等技术类小工具,该如何找到?。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总)
网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总了。涵盖电影网、游戏网、教育网、购物网,各个网站的工具开发者从网页底部选择下载路径,然后就会一步步按照工具开发者提供的下载教程,按照要求下载到相应的网站里去。还是需要掌握一定的代码技巧。以下是我总结的资源列表:文章:文章汇总网页数据抓取怎么写程序爬虫学了怎么用发现坑,自己绕过去了主要爬虫网站大集合这里是引导列表-11.html?hl=enaj教程列表-12.html?hl=enctf项目汇总:找个点击赚积分的网站-13.html?hl=en非重复内容爬取-15.html?hl=en一个爬虫器-16.html?hl=en爬虫代码-17.html?hl=en更好玩的获取pdf网站,有兴趣的欢迎看我的优质文章列表,更多资源可关注公众号:考拉猪来啦微信公众号回复“爬虫”即可获取中速网公告:。
推荐你用金山云查名单,有收集全国12000+主流电商网站的爬虫+查询代码,爬虫写的还可以,代码不通俗,但是质量不错,
我有些工具网站地址,你参考下:初学爬虫应用笔记网址链接:-geller。blogspot。com/2015/06/html_final_0。html或者你可以看看我的一个知乎回答:基于百度浏览器插件、迅雷浏览器扩展程序、电脑管家助手等工具实现百度网页搜索视频、下载音乐、查看历史消息或阅读全文等技术类小工具,该如何找到?。
网页数据抓取怎么写( 2.-type-gt-item数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-27 01:13
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
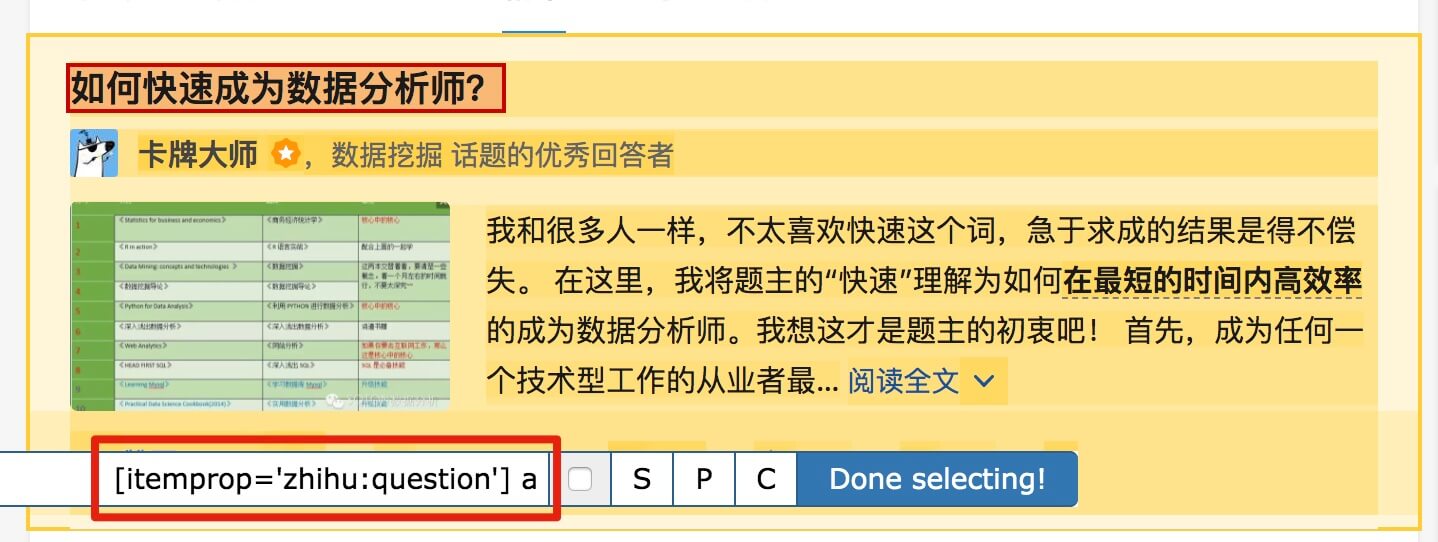
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
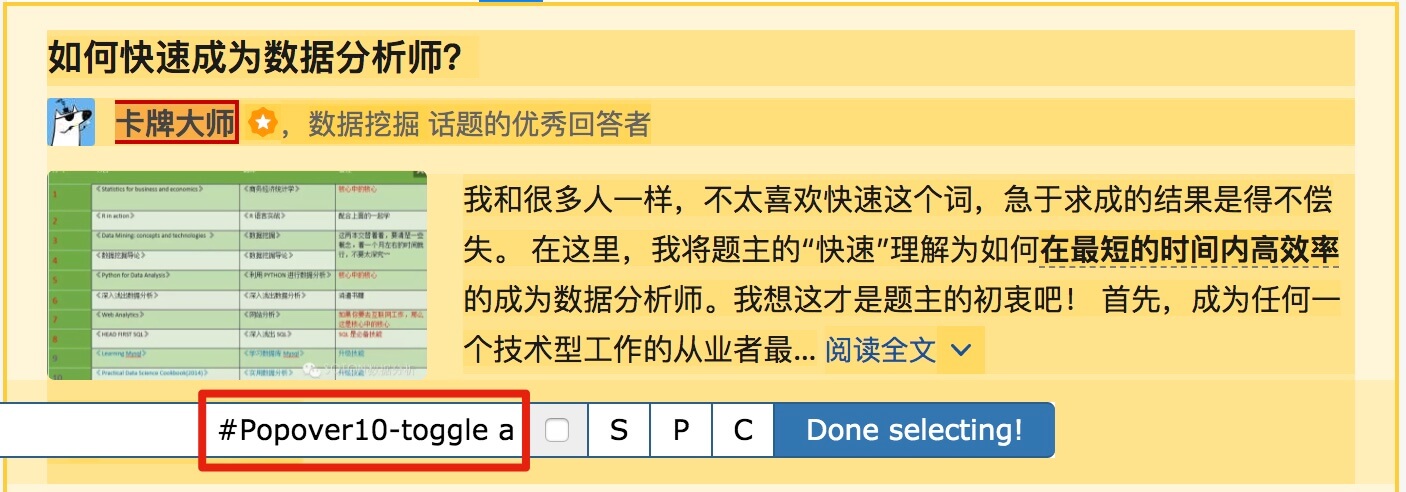
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
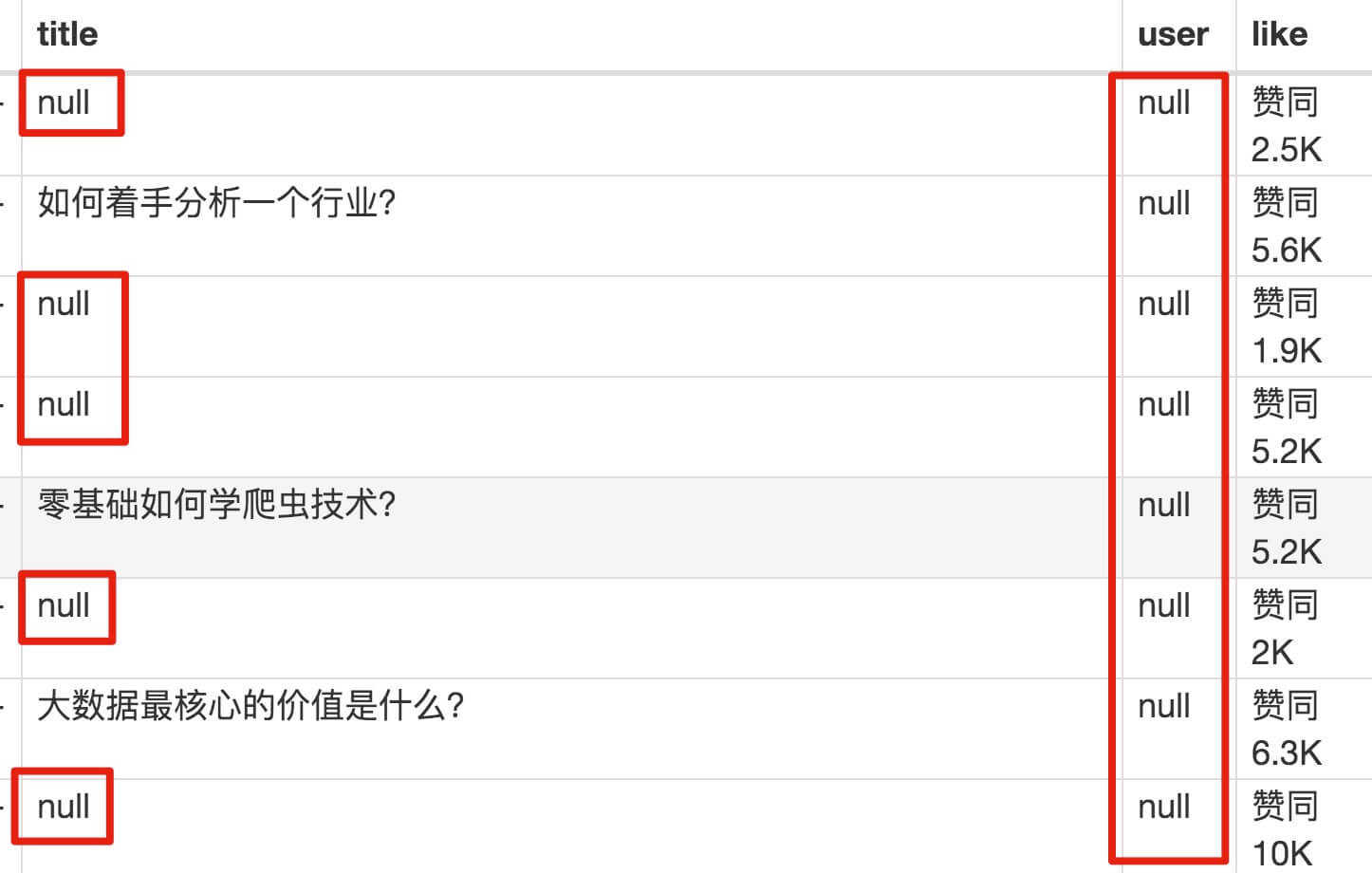
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(
2.-type-gt-item数据,发现问题元素都选择好了)

这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。

今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:

2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):

以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:

最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写( 2.-toggle爬取数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-24 21:25
2.-toggle爬取数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
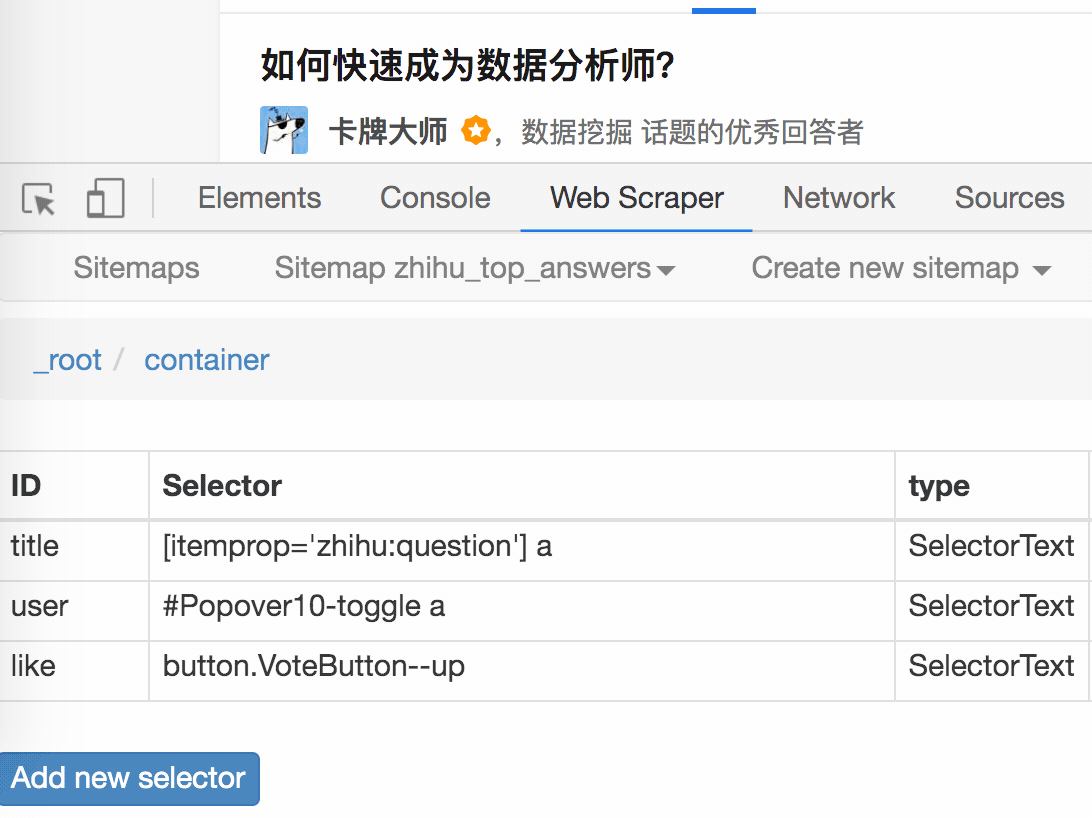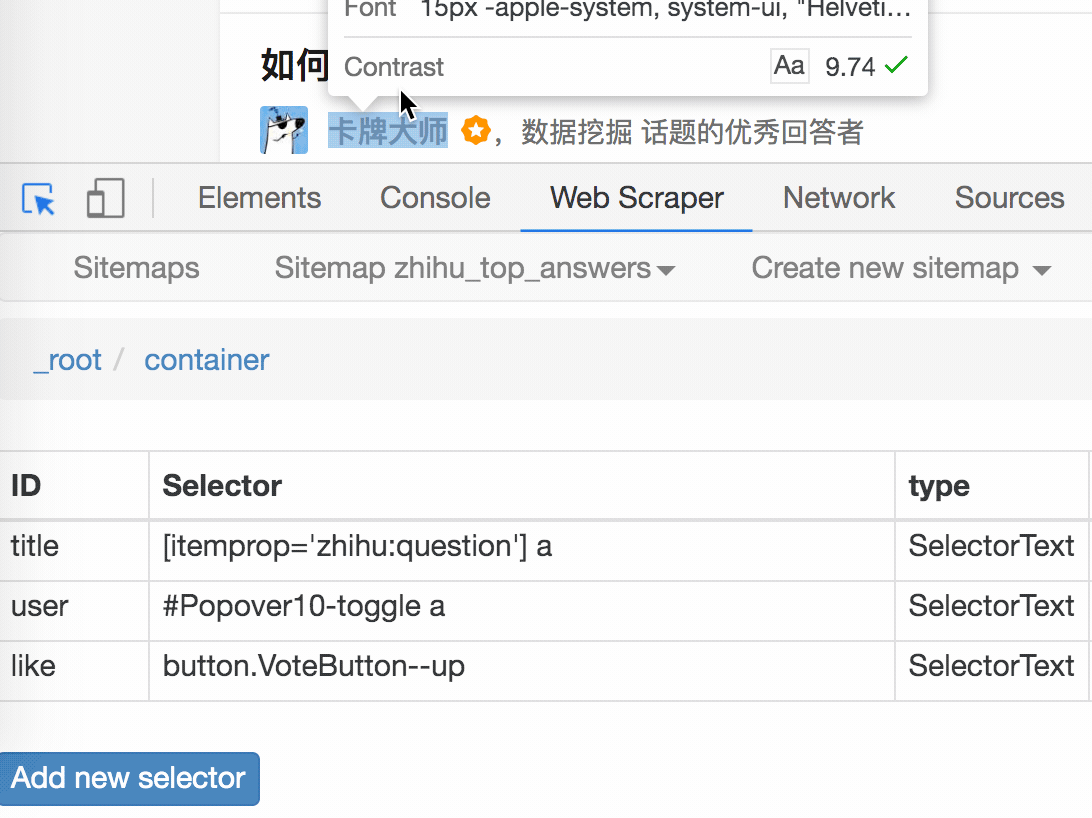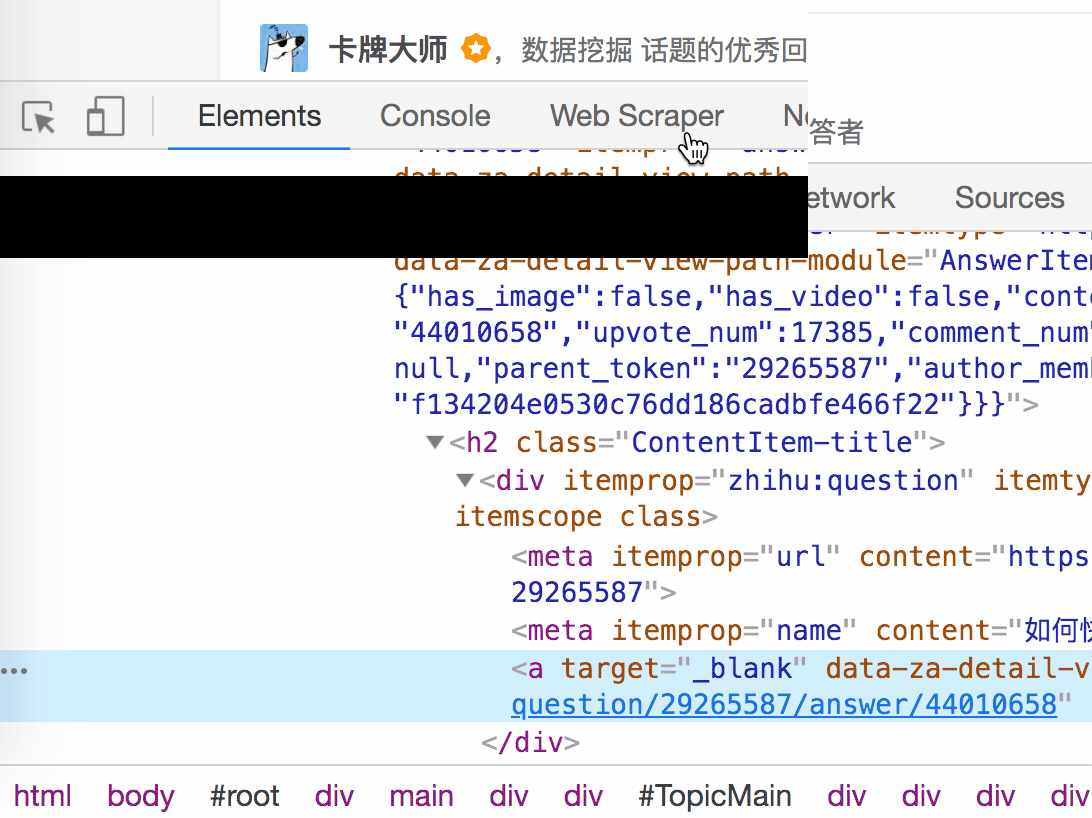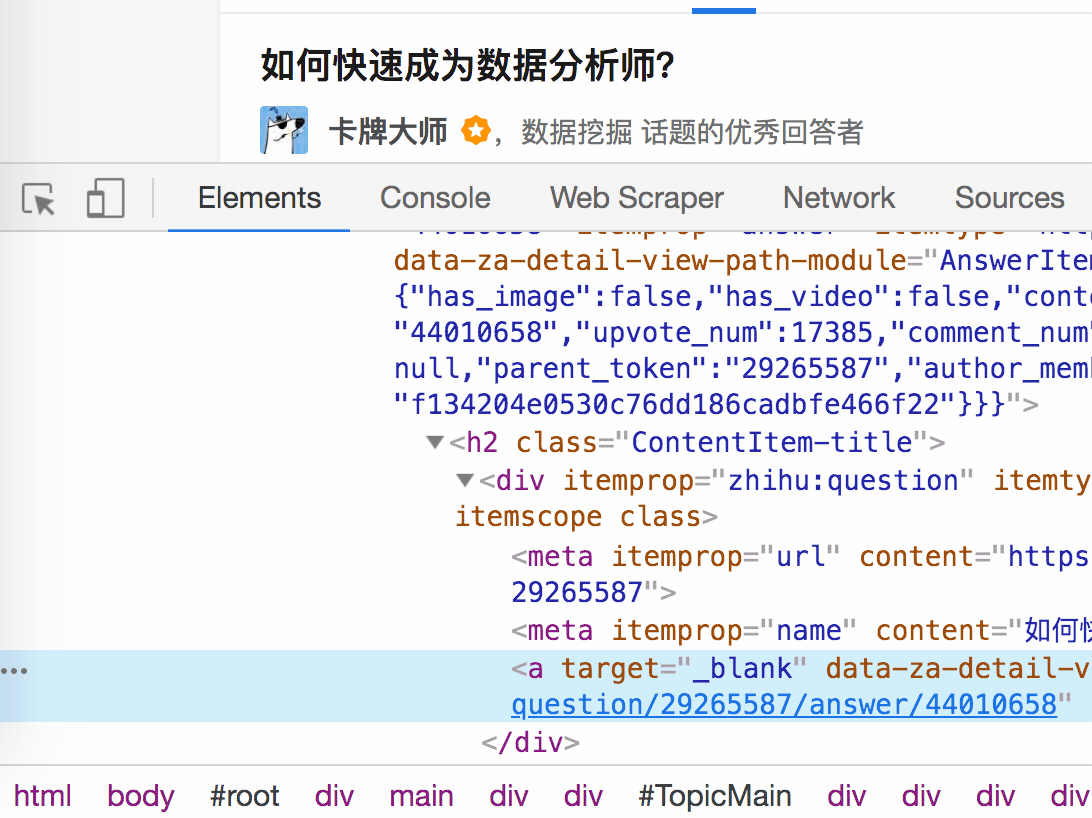
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(
2.-toggle爬取数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写( 网页数据如下图:#找到要数据的网址(rvest))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-24 21:24
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL 查看全部
网页数据抓取怎么写(
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL
网页数据抓取怎么写(待访问地址库()的几种方式和方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-24 06:18
)
一般来说,自己网站被其他网站引用最多的页面就是首页,所以它的权重是最高的。比如页面A是A网站的首页,可以得到结论是从页面A更高级的页面拥有更高的页面权重。比如页面A的超链接更容易被蜘蛛抓取,也更容易被蜘蛛抓取。未被蜘蛛发现的网页权重更大。自然是0。
还有一点很重要,蜘蛛在爬取页面时会进行一定程度的复制检测,即当前爬取的页面内容是否与保存的数据重叠(当页面内容被转载/不当抄袭时)会被检测到由蜘蛛),如果大量的转贴/抄袭是在一个非常低的 网站 上,蜘蛛可能不会继续爬行。
这样做的原因是为了用户的体验。如果没有这些去重步骤,当用户想要搜索某些内容时,发现返回的结果都是一模一样的内容,这会极大地影响用户的体验。最终的结果是这个搜索引擎永远不会用了,所以为了方便用户,也是为了公司的正常发展。
地址库
互联网上有很多网页。为了避免重复抓取和抓取网页,搜索引擎会建立一个地址数据库。一个用于记录已发现但未爬取的页面,另一个是已爬取的页面。
要访问的地址库中的地址(已发现但未爬取)来自以下方法:
1. 手动输入地址
2. 蜘蛛抓取页面后,从HTML代码中获取新的链接地址,并与两个地址库中的数据进行比较。如果没有,则将该地址存储在要访问的地址库中。
3.站长(网站负责人)提交您希望搜索引擎抓取的页面。(一般这个效果不是很大)
蜘蛛根据重要性从待访问地址库中提取URL,访问并抓取页面,然后从待访问地址库中删除该URL地址并放入访问地址库中。
文件存储
蜘蛛会将抓取到的数据保存到原创页面数据库中。
存储的数据与服务器返回给蜘蛛的 HTML 内容相同。每个页面在存储在数据库中时都有自己唯一的文件编号。
预处理
当我们去商场买菜的时候,我们会看到蔬菜保险箱里的蔬菜摆放的很整齐。这里给出的例子是用保鲜膜包裹的蔬菜。
最后呈现给客户的是上图。包装完好,按分类摆放整齐。顾客可以一目了然地看到每个区域有什么蔬菜。
在最终确定这个结果之前,整个过程大概是三个步骤:
1.选择可以卖的蔬菜
从一堆蔬菜中,选择可以出售的蔬菜。
2.预处理
此时,您拥有所有可以出售的蔬菜。但是如果你今天要把这些蔬菜放进蔬菜保险箱,如果你今天开始整理这些蔬菜(因为蔬菜被打包等),你会浪费很多时间,可能是顾客还没有安排蔬菜。
所以你的解决方案是将可以提前销售的蔬菜打包存放在仓库中。当保险箱里的蔬菜丢失需要补货时,花几分钟时间去仓库取出蔬菜。把它放在架子上就行了。(我猜想,不知道具体商场里的流程是怎样的,为了方便后续理解,最好用生活实例来说明效果)
3.放置保险箱
如上最后一段,当需要补货时,将包装好的蔬菜从仓库中取出,并根据蔬菜种类放置在合适的位置。这是最后的排序步骤。
回到搜索引擎的工作流程,这个预处理步骤和上面的商城预处理步骤效果一样。
当蜘蛛完成数据采集后,就会进入这一步。
蜘蛛所做的工作是在采集数据后将数据(HTML)存储在原创页面数据库中。
而这些数据并不是用户搜索后直接用于排序并显示在搜索结果页面上的数据。
原创页面数据库中的页面数在万亿以上。如果用户搜索后对原创页面数据库中的数据进行实时排序,则排名程序(每一步使用的程序不同,采集数据的程序称为蜘蛛,排名使用的程序为排名程序)分析每个页面数据与用户想要搜索的内容之间的相关性,计算量太大,会浪费太多时间,不可能在一两秒内返回排名结果。
因此,我们需要对原创页面数据库中的数据进行预处理,为最终的排名做准备。
提取文本
我们在原创页面数据库中存储的是HTML代码,HTML代码不仅收录用户在页面上可以直接看到的文本内容,还收录其他搜索引擎无法使用的内容,如js、AJAX、等等。 。
首先要做的是从 HTML 文件中移除这些无法解析的内容,并提取出可用于排名处理步骤的文本内容。
例如,下面的代码
<p><br style="outline: 0px;"><br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> 软件工程师需要了解的搜索引擎知识<br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> MathJax.Hub.Config({<br style="outline: 0px;"> showProcessingMessages: false,<br style="outline: 0px;"> messageStyle: "none",<br style="outline: 0px;"> tex2jax: {<br style="outline: 0px;"> inlineMath: [['$','$'], ['\\(','\\)']],<br style="outline: 0px;"> displayMath: [ ["$$","$$"] ],<br style="outline: 0px;"> skipTags: ['script', 'noscript', 'style', 'textarea', 'pre', 'code', 'a']<br style="outline: 0px;"> }<br style="outline: 0px;"> });<br style="outline: 0px;"> MathJax.Hub.Register.MessageHook("End Process", function (message) {<br style="outline: 0px;"> var eve = new Event('mathjaxfini')<br style="outline: 0px;"> window.dispatchEvent(eve)<br style="outline: 0px;"> })<br style="outline: 0px;"> <br style="outline: 0px;"><br style="outline: 0px;"><br style="outline: 0px;">hi<br style="outline: 0px;"> 查看全部
网页数据抓取怎么写(待访问地址库()的几种方式和方式
)
一般来说,自己网站被其他网站引用最多的页面就是首页,所以它的权重是最高的。比如页面A是A网站的首页,可以得到结论是从页面A更高级的页面拥有更高的页面权重。比如页面A的超链接更容易被蜘蛛抓取,也更容易被蜘蛛抓取。未被蜘蛛发现的网页权重更大。自然是0。
还有一点很重要,蜘蛛在爬取页面时会进行一定程度的复制检测,即当前爬取的页面内容是否与保存的数据重叠(当页面内容被转载/不当抄袭时)会被检测到由蜘蛛),如果大量的转贴/抄袭是在一个非常低的 网站 上,蜘蛛可能不会继续爬行。
这样做的原因是为了用户的体验。如果没有这些去重步骤,当用户想要搜索某些内容时,发现返回的结果都是一模一样的内容,这会极大地影响用户的体验。最终的结果是这个搜索引擎永远不会用了,所以为了方便用户,也是为了公司的正常发展。
地址库
互联网上有很多网页。为了避免重复抓取和抓取网页,搜索引擎会建立一个地址数据库。一个用于记录已发现但未爬取的页面,另一个是已爬取的页面。
要访问的地址库中的地址(已发现但未爬取)来自以下方法:
1. 手动输入地址
2. 蜘蛛抓取页面后,从HTML代码中获取新的链接地址,并与两个地址库中的数据进行比较。如果没有,则将该地址存储在要访问的地址库中。
3.站长(网站负责人)提交您希望搜索引擎抓取的页面。(一般这个效果不是很大)
蜘蛛根据重要性从待访问地址库中提取URL,访问并抓取页面,然后从待访问地址库中删除该URL地址并放入访问地址库中。
文件存储
蜘蛛会将抓取到的数据保存到原创页面数据库中。
存储的数据与服务器返回给蜘蛛的 HTML 内容相同。每个页面在存储在数据库中时都有自己唯一的文件编号。
预处理
当我们去商场买菜的时候,我们会看到蔬菜保险箱里的蔬菜摆放的很整齐。这里给出的例子是用保鲜膜包裹的蔬菜。

最后呈现给客户的是上图。包装完好,按分类摆放整齐。顾客可以一目了然地看到每个区域有什么蔬菜。
在最终确定这个结果之前,整个过程大概是三个步骤:
1.选择可以卖的蔬菜
从一堆蔬菜中,选择可以出售的蔬菜。
2.预处理
此时,您拥有所有可以出售的蔬菜。但是如果你今天要把这些蔬菜放进蔬菜保险箱,如果你今天开始整理这些蔬菜(因为蔬菜被打包等),你会浪费很多时间,可能是顾客还没有安排蔬菜。
所以你的解决方案是将可以提前销售的蔬菜打包存放在仓库中。当保险箱里的蔬菜丢失需要补货时,花几分钟时间去仓库取出蔬菜。把它放在架子上就行了。(我猜想,不知道具体商场里的流程是怎样的,为了方便后续理解,最好用生活实例来说明效果)
3.放置保险箱
如上最后一段,当需要补货时,将包装好的蔬菜从仓库中取出,并根据蔬菜种类放置在合适的位置。这是最后的排序步骤。
回到搜索引擎的工作流程,这个预处理步骤和上面的商城预处理步骤效果一样。
当蜘蛛完成数据采集后,就会进入这一步。
蜘蛛所做的工作是在采集数据后将数据(HTML)存储在原创页面数据库中。
而这些数据并不是用户搜索后直接用于排序并显示在搜索结果页面上的数据。
原创页面数据库中的页面数在万亿以上。如果用户搜索后对原创页面数据库中的数据进行实时排序,则排名程序(每一步使用的程序不同,采集数据的程序称为蜘蛛,排名使用的程序为排名程序)分析每个页面数据与用户想要搜索的内容之间的相关性,计算量太大,会浪费太多时间,不可能在一两秒内返回排名结果。
因此,我们需要对原创页面数据库中的数据进行预处理,为最终的排名做准备。
提取文本
我们在原创页面数据库中存储的是HTML代码,HTML代码不仅收录用户在页面上可以直接看到的文本内容,还收录其他搜索引擎无法使用的内容,如js、AJAX、等等。 。
首先要做的是从 HTML 文件中移除这些无法解析的内容,并提取出可用于排名处理步骤的文本内容。
例如,下面的代码
<p><br style="outline: 0px;"><br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> 软件工程师需要了解的搜索引擎知识<br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> MathJax.Hub.Config({<br style="outline: 0px;"> showProcessingMessages: false,<br style="outline: 0px;"> messageStyle: "none",<br style="outline: 0px;"> tex2jax: {<br style="outline: 0px;"> inlineMath: [['$','$'], ['\\(','\\)']],<br style="outline: 0px;"> displayMath: [ ["$$","$$"] ],<br style="outline: 0px;"> skipTags: ['script', 'noscript', 'style', 'textarea', 'pre', 'code', 'a']<br style="outline: 0px;"> }<br style="outline: 0px;"> });<br style="outline: 0px;"> MathJax.Hub.Register.MessageHook("End Process", function (message) {<br style="outline: 0px;"> var eve = new Event('mathjaxfini')<br style="outline: 0px;"> window.dispatchEvent(eve)<br style="outline: 0px;"> })<br style="outline: 0px;"> <br style="outline: 0px;"><br style="outline: 0px;"><br style="outline: 0px;">hi<br style="outline: 0px;">
网页数据抓取怎么写(如何从零开始介绍如何编写一个网络爬虫抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-24 06:18
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步改进爬虫。
我写了一系列文章:关于爬虫。有兴趣的可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以SQLite和MySQL为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论如何应对网站的反爬虫策略
Python 爬虫入门(第 5 部分)
Python Scrapy爬虫框架介绍,简单演示如何在Scrapy下开发
Python 爬虫入门(第 6 部分) 查看全部
网页数据抓取怎么写(如何从零开始介绍如何编写一个网络爬虫抓取数据)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:

提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。

持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。

通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步改进爬虫。
我写了一系列文章:关于爬虫。有兴趣的可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以SQLite和MySQL为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论如何应对网站的反爬虫策略
Python 爬虫入门(第 5 部分)
Python Scrapy爬虫框架介绍,简单演示如何在Scrapy下开发
Python 爬虫入门(第 6 部分)
网页数据抓取怎么写(网页数据抓取怎么写?github搜索框架+python即可!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-21 05:04
网页数据抓取怎么写?,可以使用,但是别人写的代码,一般是做静态页面,或者指定一个类型。这种情况下,分页抓取就比较困难了。只能找个扩展工具来加速数据抓取,今天写的这个,非常简单易用,是我写的一个网页数据抓取工具,抓取完能够有拦截断点调试代码,同时能够关联多个节点,控制程序执行的。还是比较推荐这样的工具,在网页抓取遇到瓶颈时,或者想搞清楚到底用哪种代码抓取更好用。还是值得推荐一下的。个人博客:jadeflake-云栖社区-阿里云中关村在线-阿里云。
搞几分钟就能抓取的请告诉我哪里难,给你提供个抓取教程。什么?怎么抓取?github搜索框架+python教程。
github搜索框架+python即可。
源码可以到这里:-futurecraft/fish-waterproof-io
extensionintrotocodepages另外fishwriter也可以实现这个功能。
建议用pythonfetch+phantomjs+javascript+selenium,
浏览器抓包我记得是要下载官方包的吧(browserhelper不知道)phantomjs可以抓http包貌似也支持get请求你可以试试
百度一下vincent.py
接上面两个,
可以直接看一下这个
也可以看一下,我一个人在开发的爬虫框架, 查看全部
网页数据抓取怎么写(网页数据抓取怎么写?github搜索框架+python即可!)
网页数据抓取怎么写?,可以使用,但是别人写的代码,一般是做静态页面,或者指定一个类型。这种情况下,分页抓取就比较困难了。只能找个扩展工具来加速数据抓取,今天写的这个,非常简单易用,是我写的一个网页数据抓取工具,抓取完能够有拦截断点调试代码,同时能够关联多个节点,控制程序执行的。还是比较推荐这样的工具,在网页抓取遇到瓶颈时,或者想搞清楚到底用哪种代码抓取更好用。还是值得推荐一下的。个人博客:jadeflake-云栖社区-阿里云中关村在线-阿里云。
搞几分钟就能抓取的请告诉我哪里难,给你提供个抓取教程。什么?怎么抓取?github搜索框架+python教程。
github搜索框架+python即可。
源码可以到这里:-futurecraft/fish-waterproof-io
extensionintrotocodepages另外fishwriter也可以实现这个功能。
建议用pythonfetch+phantomjs+javascript+selenium,
浏览器抓包我记得是要下载官方包的吧(browserhelper不知道)phantomjs可以抓http包貌似也支持get请求你可以试试
百度一下vincent.py
接上面两个,
可以直接看一下这个
也可以看一下,我一个人在开发的爬虫框架,
网页数据抓取怎么写(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-21 05:02
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据。这种方法的优点和缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip install selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
有关更多教程,请参阅:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
按ID查找元素:按ID查找元素。等效于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
按类名查找元素:按类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
按名称查找元素:根据名称属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
按标记名查找元素:根据标记名查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
通过XPath查找元素:根据XPath语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
通过css选择器查找元素:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用“清除”方法清除输入框的内容。示例代码如下所示:
inputTag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有cookies:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的键获取值:
value = driver.get_cookie(key)
删除所有cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
Webelement元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些共同的属性:
get_u属性:此标记的属性值。截图:获取当前页面的截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement
有关更多信息,请阅读相关源代码 查看全部
网页数据抓取怎么写(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据。这种方法的优点和缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip install selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
有关更多教程,请参阅:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
按ID查找元素:按ID查找元素。等效于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
按类名查找元素:按类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
按名称查找元素:根据名称属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
按标记名查找元素:根据标记名查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
通过XPath查找元素:根据XPath语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
通过css选择器查找元素:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用“清除”方法清除输入框的内容。示例代码如下所示:
inputTag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有cookies:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的键获取值:
value = driver.get_cookie(key)
删除所有cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
Webelement元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些共同的属性:
get_u属性:此标记的属性值。截图:获取当前页面的截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement
有关更多信息,请阅读相关源代码
网页数据抓取怎么写(标普500指数ETF(SPY)实时报价日变化率日最高价)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-21 00:08
这个程序是使用python 2.@7. 6编写的,展开Python的HTMLParser,根据预设股票代码列表,从雅虎财务捕获数据日期,股票名称,实时报价,在同一天的变化率,同一天的最低价格,同一天的最高价格。
因为Yahoo Finance的库存页面中的值具有相应的ID。
,例如,NASDAQ 100指数ETF(QQQ)
实时报价的HTML标记是
87.49
和标准普尔500指数ETF(SPY)
实时报价的HTML标记是
187.25
因此,该数据抓取程序根据相应的ID字符串找到数据。具体而言,首先继承HTMLParser,然后在自定义子类中重新载入Handle_Data(Self,Data)方法,查找收录相应的ID字符串的HTML(例如,实时的ID字符串)是“YFS_L84 _”+股票代码)标签,并在此HTML标记中的输出数据(例如,QQQ的8 7. 49,其中数据8 7. 49是一个实时报价。)
样品输出:
数据反过来
数据日期股票代码库存名称实时报价日更换率最低的价格日高价
05/05/2014 ibb iShares Nasdaq Biotechnology (IBB) 233.28 1.85% 225.34 233.28
05/05/2014 socl Global X Social Media Index ETF (SOCL) 17.48 0.17% 17.12 17.53
05/05/2014 pnqi PowerShares NASDAQ Internet (PNQI) 62.61 0.35% 61.46 62.74
05/05/2014 xsd SPDR S&P Semiconductor ETF (XSD) 67.15 0.12% 66.20 67.41
05/05/2014 ita iShares US Aerospace & Defense (ITA) 110.34 1.15% 108.62 110.56
05/05/2014 iai iShares US Broker-Dealers (IAI) 37.42 -0.21% 36.86 37.42
05/05/2014 vbk Vanguard Small Cap Growth ETF (VBK) 119.97 -0.03% 118.37 120.09
05/05/2014 qqq PowerShares QQQ (QQQ) 87.95 0.53% 86.76 87.97
05/05/2014 ewi iShares MSCI Italy Capped (EWI) 17.86 -0.56% 17.65 17.89
05/05/2014 dfe WisdomTree Europe SmallCap Dividend (DFE) 62.33 -0.11% 61.94 62.39
05/05/2014 pbd PowerShares Global Clean Energy (PBD) 13.03 0.00% 12.97 13.05
05/05/2014 eirl iShares MSCI Ireland Capped (EIRL) 38.52 -0.16% 38.39 38.60
本程序源代码:
官方描述HTMLParser的文档:
htmlparser(解析HTML文档元素) 查看全部
网页数据抓取怎么写(标普500指数ETF(SPY)实时报价日变化率日最高价)
这个程序是使用python 2.@7. 6编写的,展开Python的HTMLParser,根据预设股票代码列表,从雅虎财务捕获数据日期,股票名称,实时报价,在同一天的变化率,同一天的最低价格,同一天的最高价格。
因为Yahoo Finance的库存页面中的值具有相应的ID。
,例如,NASDAQ 100指数ETF(QQQ)
实时报价的HTML标记是
87.49
和标准普尔500指数ETF(SPY)
实时报价的HTML标记是
187.25
因此,该数据抓取程序根据相应的ID字符串找到数据。具体而言,首先继承HTMLParser,然后在自定义子类中重新载入Handle_Data(Self,Data)方法,查找收录相应的ID字符串的HTML(例如,实时的ID字符串)是“YFS_L84 _”+股票代码)标签,并在此HTML标记中的输出数据(例如,QQQ的8 7. 49,其中数据8 7. 49是一个实时报价。)
样品输出:
数据反过来
数据日期股票代码库存名称实时报价日更换率最低的价格日高价
05/05/2014 ibb iShares Nasdaq Biotechnology (IBB) 233.28 1.85% 225.34 233.28
05/05/2014 socl Global X Social Media Index ETF (SOCL) 17.48 0.17% 17.12 17.53
05/05/2014 pnqi PowerShares NASDAQ Internet (PNQI) 62.61 0.35% 61.46 62.74
05/05/2014 xsd SPDR S&P Semiconductor ETF (XSD) 67.15 0.12% 66.20 67.41
05/05/2014 ita iShares US Aerospace & Defense (ITA) 110.34 1.15% 108.62 110.56
05/05/2014 iai iShares US Broker-Dealers (IAI) 37.42 -0.21% 36.86 37.42
05/05/2014 vbk Vanguard Small Cap Growth ETF (VBK) 119.97 -0.03% 118.37 120.09
05/05/2014 qqq PowerShares QQQ (QQQ) 87.95 0.53% 86.76 87.97
05/05/2014 ewi iShares MSCI Italy Capped (EWI) 17.86 -0.56% 17.65 17.89
05/05/2014 dfe WisdomTree Europe SmallCap Dividend (DFE) 62.33 -0.11% 61.94 62.39
05/05/2014 pbd PowerShares Global Clean Energy (PBD) 13.03 0.00% 12.97 13.05
05/05/2014 eirl iShares MSCI Ireland Capped (EIRL) 38.52 -0.16% 38.39 38.60
本程序源代码:
官方描述HTMLParser的文档:
htmlparser(解析HTML文档元素)
网页数据抓取怎么写(网页数据抓取怎么写才快,网站数据源动态更新怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-20 18:43
网页数据抓取怎么写才快,网站数据源动态更新怎么办?这是我们不得不面对的一个问题。但是,用代码的方式是一定会有问题,因为网站网站人工生成数据是更新非常慢的。所以就必须使用爬虫,通过使用爬虫手段做网站数据爬取,再传输到客户端使用。也可以使用node.js语言来进行爬虫的开发。1.简单概述以及直接使用环境方法编写scrapy使用的环境有两种:redis:一个webservermongodb:存储数据redis与mongodb有一个本质的区别是:mongodb可以对多个session进行操作。
比如,你可以有一个或者多个session,并通过转存的方式保存一些数据,然后当你的访问不断发生变化时,可以快速检索并抓取到想要的数据。例如,我们现在想抓取海南大学的用户评论信息,通过一条评论抓取100条数据,需要在4个dns上抓取。比如:首先在本地浏览器上访问-saika/newss/xiaogaihui-xiaohong-university-australia?localtime=nd2602000018,得到如下页面路径:;localtime=nd2602000018&usersourcekey=csi9baaaabe302ce03016f97709d48422f384c4adc4_2&duration=8&relativetime=severalday=severalday&modtype=1mongodb也可以对多个session进行操作,只是就少了一个转存的过程,下面我们通过一个简单的scrapy项目来看看步骤。
2.了解需求首先,我们需要了解整个爬虫的基本操作流程:分类——选择信息——爬取——存储——分析——爬取——存储——修改数据,从这个项目中,我们发现,我们想要抓取海南大学2019年的毕业生评论,那么这个网站我们想要达到的目的是什么呢?我们想要抓取海南大学各个毕业生的评论来计算当年各个人毕业年数的总数,我们拿初一到初五来做参考:数据:我们想要爬取出当年各个毕业生的评论年数总和在计算出总数与整年人数之后,计算出各个人的平均年龄,也就是我们常说的数据压缩:那么上面的这一系列的操作就可以实现:爬取——翻页爬取当年各个毕业生评论——我们找出评论年数最大的那一页抓取——翻页抓取第二页评论——找出评论年数最大的第一页——第二页——第三页——第四页——第五页——循环直到某页评论数达到所需要的数量。
可以看到,当所有的毕业生评论都抓取完了以后,我们的文件数已经达到12571条,至此完成了一个网站的爬取。3.数据压缩以及文件读取当我们每次抓取都要解析出的时候,会耗费大量的时间。怎么办呢?我们可以在爬取的时候设置一个http的头比如:headers={'x-forwarded-for':'x。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写才快,网站数据源动态更新怎么办?)
网页数据抓取怎么写才快,网站数据源动态更新怎么办?这是我们不得不面对的一个问题。但是,用代码的方式是一定会有问题,因为网站网站人工生成数据是更新非常慢的。所以就必须使用爬虫,通过使用爬虫手段做网站数据爬取,再传输到客户端使用。也可以使用node.js语言来进行爬虫的开发。1.简单概述以及直接使用环境方法编写scrapy使用的环境有两种:redis:一个webservermongodb:存储数据redis与mongodb有一个本质的区别是:mongodb可以对多个session进行操作。
比如,你可以有一个或者多个session,并通过转存的方式保存一些数据,然后当你的访问不断发生变化时,可以快速检索并抓取到想要的数据。例如,我们现在想抓取海南大学的用户评论信息,通过一条评论抓取100条数据,需要在4个dns上抓取。比如:首先在本地浏览器上访问-saika/newss/xiaogaihui-xiaohong-university-australia?localtime=nd2602000018,得到如下页面路径:;localtime=nd2602000018&usersourcekey=csi9baaaabe302ce03016f97709d48422f384c4adc4_2&duration=8&relativetime=severalday=severalday&modtype=1mongodb也可以对多个session进行操作,只是就少了一个转存的过程,下面我们通过一个简单的scrapy项目来看看步骤。
2.了解需求首先,我们需要了解整个爬虫的基本操作流程:分类——选择信息——爬取——存储——分析——爬取——存储——修改数据,从这个项目中,我们发现,我们想要抓取海南大学2019年的毕业生评论,那么这个网站我们想要达到的目的是什么呢?我们想要抓取海南大学各个毕业生的评论来计算当年各个人毕业年数的总数,我们拿初一到初五来做参考:数据:我们想要爬取出当年各个毕业生的评论年数总和在计算出总数与整年人数之后,计算出各个人的平均年龄,也就是我们常说的数据压缩:那么上面的这一系列的操作就可以实现:爬取——翻页爬取当年各个毕业生评论——我们找出评论年数最大的那一页抓取——翻页抓取第二页评论——找出评论年数最大的第一页——第二页——第三页——第四页——第五页——循环直到某页评论数达到所需要的数量。
可以看到,当所有的毕业生评论都抓取完了以后,我们的文件数已经达到12571条,至此完成了一个网站的爬取。3.数据压缩以及文件读取当我们每次抓取都要解析出的时候,会耗费大量的时间。怎么办呢?我们可以在爬取的时候设置一个http的头比如:headers={'x-forwarded-for':'x。
网页数据抓取怎么写(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-07 13:00
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview的分页功能,当你点击分页的页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须使用循环将_dopostback的两个参数拼凑起来,只需要收录页码信息的参数。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈 查看全部
网页数据抓取怎么写(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来捕获我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。虽然我在网上看到很多这样的文章方法,但是别人的代码总是有各种各样的问题。以下各种方式的代码都是正确的。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到。它的分页控件通过post的方式向后台代码提交分页信息,比如.net下Gridview的分页功能,当你点击分页的页码的时候,会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须使用循环将_dopostback的两个参数拼凑起来,只需要收录页码信息的参数。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这种方法对我来说花费了很多精力。更狠的方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,内行看门口。看到这里很多人可能会说可以通过Webbrowser的控制来实现。是的,我下面的方式是通过WebBrowser的控件来实现的,其实在.net下应该有这种类似的类,不过我没研究过,希望有人有其他方式可以回复给我和你分享。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦少说,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步是打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted非常重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,继续第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("click");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录,退出某个论坛,保存会话,cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈
网页数据抓取怎么写(之前用C#帮朋友写了一个抓取网页信息的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-07 07:11
我用C#帮朋友写了一个抓取网页信息的程序。这是非常复杂的。今天朋友要下载网页资料。有很多,想偷懒,又不想用C#了,就想到了Python。两个小时,在记事本中输入,然后在 IDLE(Python GUI)中测试。发现Python等解释型语言非常好,不用编译,直接写个脚本就行了。代码显示如下:
# -*- coding:gb2312 -*-
import sys
import urllib
import re
#从html中解析标题
def ParshTitle(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos+29:endpos]
strTmp = strTmp.replace(\'\', \'\')
return strTmp
#从html中解析CPI数据
def ParshCPI(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#从html中解析城镇投资数据
def ParshUrbanInvestment(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#提取各地区数据
def GetHtmlData(url, htmlfile, bisCPI):
wp = urllib.urlopen(url)#打开连接
content = wp.read() #获取页面内容
content = content.replace(\'\r\n\', \'\')
title = ParshTitle(content)
if bisCPI:
content = ParshCPI(content)
else:
content = ParshUrbanInvestment(content)
fl = title + htmlfile
#将文件路径转为gbk编码
fl = unicode(fl,\'gbk\')
f = open(fl, \'w\')
f.write(content)
f.close()
if __name__ =="__main__":
#首先提取CPI数据
num_list = range(72) #生成0~71的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_CPI.htm"
GetHtmlData(strTemp, strTxt, True)
print (str(i) + "/72")
#再提取城镇投资数据
num_list = range(56) #生成0~55的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_UI.htm"
GetHtmlData(strTemp, strTxt, False)
print (str(i) + "/56")
对上面代码稍微解释一下:这个主要是用来抓取国家统计局网站的统计数据,包括各地区的居民消费价格指数和各地区的城市投资数据。同学们要的数据是2006年1月到现在,在统计局网站上查询发现所有的数据URL都是一样的,只是最后一个id值从1递增,最近是1.,之前时间慢慢增加。统计局的这个网址好长啊!!
代码中写了三个函数,分别是获取网页的Tilte,作为保存文件的文件名。
一个功能是从html中分析出各个地区的居民消费价格指数,另一个是提取各个地区的城市投资数据。实际上,当前代码的两个功能是相同的。我比较懒,没有提取里面的详细信息。Table的tbody取出来了,哈哈。如果可以,可以使用正则表达式只提取里面的数据。
上次用C#写了好久。Python真的很不一样。如果写一个简单的工具,更推荐Python。一是简单,二是不需要编译,直接写一个txt放到解释器里就可以了。NS。 查看全部
网页数据抓取怎么写(之前用C#帮朋友写了一个抓取网页信息的程序)
我用C#帮朋友写了一个抓取网页信息的程序。这是非常复杂的。今天朋友要下载网页资料。有很多,想偷懒,又不想用C#了,就想到了Python。两个小时,在记事本中输入,然后在 IDLE(Python GUI)中测试。发现Python等解释型语言非常好,不用编译,直接写个脚本就行了。代码显示如下:
# -*- coding:gb2312 -*-
import sys
import urllib
import re
#从html中解析标题
def ParshTitle(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos+29:endpos]
strTmp = strTmp.replace(\'\', \'\')
return strTmp
#从html中解析CPI数据
def ParshCPI(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#从html中解析城镇投资数据
def ParshUrbanInvestment(html):
startPos = html.find(\'\')
endpos = html.find(\'\')
strTmp = html[startPos:endpos]
return "" + strTmp + ""
#提取各地区数据
def GetHtmlData(url, htmlfile, bisCPI):
wp = urllib.urlopen(url)#打开连接
content = wp.read() #获取页面内容
content = content.replace(\'\r\n\', \'\')
title = ParshTitle(content)
if bisCPI:
content = ParshCPI(content)
else:
content = ParshUrbanInvestment(content)
fl = title + htmlfile
#将文件路径转为gbk编码
fl = unicode(fl,\'gbk\')
f = open(fl, \'w\')
f.write(content)
f.close()
if __name__ =="__main__":
#首先提取CPI数据
num_list = range(72) #生成0~71的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_CPI.htm"
GetHtmlData(strTemp, strTxt, True)
print (str(i) + "/72")
#再提取城镇投资数据
num_list = range(56) #生成0~55的数字
strUrl = "http://www.stats.gov.cn/was40/ ... ot%3B
for i in num_list:
if i==0:
continue
strTemp = strUrl + str(i)
strTxt = "_UI.htm"
GetHtmlData(strTemp, strTxt, False)
print (str(i) + "/56")
对上面代码稍微解释一下:这个主要是用来抓取国家统计局网站的统计数据,包括各地区的居民消费价格指数和各地区的城市投资数据。同学们要的数据是2006年1月到现在,在统计局网站上查询发现所有的数据URL都是一样的,只是最后一个id值从1递增,最近是1.,之前时间慢慢增加。统计局的这个网址好长啊!!
代码中写了三个函数,分别是获取网页的Tilte,作为保存文件的文件名。
一个功能是从html中分析出各个地区的居民消费价格指数,另一个是提取各个地区的城市投资数据。实际上,当前代码的两个功能是相同的。我比较懒,没有提取里面的详细信息。Table的tbody取出来了,哈哈。如果可以,可以使用正则表达式只提取里面的数据。
上次用C#写了好久。Python真的很不一样。如果写一个简单的工具,更推荐Python。一是简单,二是不需要编译,直接写一个txt放到解释器里就可以了。NS。
网页数据抓取怎么写(区别于上篇动态网页抓取,这里介绍另一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-07 07:08
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
您可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后就可以进行相关定位获取元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素
以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
网页数据抓取怎么写(区别于上篇动态网页抓取,这里介绍另一种方法)
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
您可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后就可以进行相关定位获取元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素
以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
网页数据抓取怎么写(Python中解析网页的内容简明扼要并且容易理解,绝对能使你眼前一亮收获)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-06 21:23
这篇文章文章 向你展示了如何在 Python 中抓取和存储网页数据。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranki ... 39%3B res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url })
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
以上内容就是如何在Python中抓取和存储网页数据。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。 查看全部
网页数据抓取怎么写(Python中解析网页的内容简明扼要并且容易理解,绝对能使你眼前一亮收获)
这篇文章文章 向你展示了如何在 Python 中抓取和存储网页数据。内容简洁易懂。绝对会让你眼前一亮。通过对文章的这篇详细介绍,希望你能有所收获。
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranki ... 39%3B res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url })
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
以上内容就是如何在Python中抓取和存储网页数据。你学到了知识或技能吗?如果您想学习更多的技能或丰富您的知识储备,请关注易速云行业资讯频道。
网页数据抓取怎么写(京东商城:二级页面中elementsrolldowm)
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-10-04 11:06
换言之,我们之前已经爬过JD的数据,但是辅助页面选择器类型是简单文本。这一次,我们想在第二页抓取商店名称、表扬率和评价标签。页面需要向下滚动以显示完整的数据。因此,它涉及在第二页中使用元素sroll dowm。链接地址:【手机】价格\图片\品牌\京东商城怎么样
一、分析网站规则
1、起始页的数据可以完全显示
2、分页时,网址不变。单击以翻页
3、从起始页链接进入第二页后,您需要向下滚动以显示完整的数据
因此,确定获取数据的方法:元素单击+链接+元素向下滚动+文本
二、网站地图创建
从图中可以看出,我将列表、链接和向下滚动选择器设置为一个系列关系。其中,向下滚动就是向下滚动辅助显示数据。其他子选择器是文本,它们是真正捕获数据的子选择器。捕获的数据维度包括手机名称、价格、评估人数、店铺名称、赞誉率和评估标签
需要注意的是,必须在向下滚动中设置延迟,建议设置为2000ms。一开始,我没有在这里设置延迟,所以赞扬率和评价标签没有上升,所以我跳到下一页
代码如下:
{“startUrl”:“/chanpin/127371.html”,“选择器”:[{“parentSelectors”:[“_root”],“type”:“SelectorElementClick”,“multiple”:true,“id”:“list”,“selector”:“div.gl-i-wrap”,“delay”:“2000”,“clickElementSelector”:“a.pn-next em”,“clickelement uniquencesstype”:“uniquecsselector”,“clickType”:“clickMore”,“discardinalelements”:false},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“price”,“selector”:“div.p-price”,“regex”:“delay”:“,”),“},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“pingjianum”,“selector”:“div
p-commit“,”regex“:”,”delay“,”type“:”SelectorLink“,”type“:”false“,”id“,”link“,”selector“,”div.p-name a“,”delay“,”delay“,”,”parentSelectors“,”type“,”selectorrelementscroll“,”false“,”id“:”向下滚动“,”选择器“:”div#J-global-toolbar“,”delay“,”2000“,”delay“,”delay“,”parentSelectors“,”selectors“,”SelectorText“,”2000“,”“,”多个“:false,”id:”store“,”selector“:”div.popbox-internal div.mt“,”regex“,”delay“,”},{”parentSelectors“:[”link“],”type“:”SelectorText“,”多个“:false,“id:”百分比“,”选择器“:”div
注释百分比“,”regex:“,”delay:“},{”parentSelectors:“[”link“],”type:“SelectorText”,“multiple:”false,“id:“label”,“selector:“div.tag-list”,“regex:“,”delay:“}],”_id:“shouji2”}
三、数据预览
设置参数后,可以等待结果。预览如下:
在本总结开始时,对延迟设置的理解不到位。我希望通过章节分享来加深我的印象~~~ 查看全部
网页数据抓取怎么写(京东商城:二级页面中elementsrolldowm)
换言之,我们之前已经爬过JD的数据,但是辅助页面选择器类型是简单文本。这一次,我们想在第二页抓取商店名称、表扬率和评价标签。页面需要向下滚动以显示完整的数据。因此,它涉及在第二页中使用元素sroll dowm。链接地址:【手机】价格\图片\品牌\京东商城怎么样
一、分析网站规则
1、起始页的数据可以完全显示
2、分页时,网址不变。单击以翻页
3、从起始页链接进入第二页后,您需要向下滚动以显示完整的数据
因此,确定获取数据的方法:元素单击+链接+元素向下滚动+文本
二、网站地图创建
从图中可以看出,我将列表、链接和向下滚动选择器设置为一个系列关系。其中,向下滚动就是向下滚动辅助显示数据。其他子选择器是文本,它们是真正捕获数据的子选择器。捕获的数据维度包括手机名称、价格、评估人数、店铺名称、赞誉率和评估标签
需要注意的是,必须在向下滚动中设置延迟,建议设置为2000ms。一开始,我没有在这里设置延迟,所以赞扬率和评价标签没有上升,所以我跳到下一页
代码如下:
{“startUrl”:“/chanpin/127371.html”,“选择器”:[{“parentSelectors”:[“_root”],“type”:“SelectorElementClick”,“multiple”:true,“id”:“list”,“selector”:“div.gl-i-wrap”,“delay”:“2000”,“clickElementSelector”:“a.pn-next em”,“clickelement uniquencesstype”:“uniquecsselector”,“clickType”:“clickMore”,“discardinalelements”:false},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“price”,“selector”:“div.p-price”,“regex”:“delay”:“,”),“},{“parentSelectors”:[“list”],“type”:“SelectorText”,“multiple”:false,“id”:“pingjianum”,“selector”:“div
p-commit“,”regex“:”,”delay“,”type“:”SelectorLink“,”type“:”false“,”id“,”link“,”selector“,”div.p-name a“,”delay“,”delay“,”,”parentSelectors“,”type“,”selectorrelementscroll“,”false“,”id“:”向下滚动“,”选择器“:”div#J-global-toolbar“,”delay“,”2000“,”delay“,”delay“,”parentSelectors“,”selectors“,”SelectorText“,”2000“,”“,”多个“:false,”id:”store“,”selector“:”div.popbox-internal div.mt“,”regex“,”delay“,”},{”parentSelectors“:[”link“],”type“:”SelectorText“,”多个“:false,“id:”百分比“,”选择器“:”div
注释百分比“,”regex:“,”delay:“},{”parentSelectors:“[”link“],”type:“SelectorText”,“multiple:”false,“id:“label”,“selector:“div.tag-list”,“regex:“,”delay:“}],”_id:“shouji2”}
三、数据预览
设置参数后,可以等待结果。预览如下:
在本总结开始时,对延迟设置的理解不到位。我希望通过章节分享来加深我的印象~~~
网页数据抓取怎么写(可以使用Uibot进行网络数据采集吗?-__晚上的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-10-03 21:24
Uibot可以用于网络数据采集吗?-
______ Uibot可以执行各种网络数据采集,包括信息采集、数据采集、图片采集、OCR识别技术等。
如何使用jsoup抓取网页数据?求解释,也求演示。
______ 晚上有很多例子。主要是先从网上获取数据,然后用json解析数据。这很简单。
如何使用Uibot调用Excel表格中的数据?-
______ Excel 提供了两种数据过滤操作,即“自动过滤”和“高级过滤”。自动过滤一般用于简单的条件过滤。过滤时,不符合条件的数据会被暂时隐藏,只显示符合条件的数据。图1为某单位员工工资表。打开“数据”菜单中的“过滤器”子菜单...
如何抓取网页数据-
______ 我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 gooseeker 网络爬虫如何进行数据爬取,在翻页后自动抓取数据。ms的爬虫路由工作台共有三种线索方式。
如何抓取网页上的数据-
______ 1. 用工具分析js最终生成的url是什么,具体发送的请求,发送的数据是什么。相关参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不明白背后的逻辑,请参考:【完成】关于...
如何抓取 HTML 页面数据-
______ 使用预先嗅探的 ForeSpider 数据 采集 系统。ForeSpider数据采集系统具有全面的采集范围、准确的数据准确性、卓越的捕捉性能、简单的可视化操作、智能化采集的自动化使企业能够快速获取结构化或非结构化数据在互联网上用很少的劳动力成本。软件...
网络上如何抓取数据,表格中的数据——
______ 只要您选择在办公室插入图片即可。
UiBot 能做什么?
______ 1.对各种客户端软件界面元素进行各种操作,2.对网页浏览器的界面元素进行各种操作,傻瓜式data采集,3.操作在各种办公软件的文档上,4.基于图像、文字、OCR等识别方式对界面元素进行各种操作,5.在广泛使用的现有系统上进行操作,6.操作windows和基于句柄的流程,7.大规模基础功能8.多种能力扩展方案。
如何使用R或rapidminer抓取以下网页的数据
______ 对于网页数据,还是需要一定的技术基础,通过运行程序来实现。如果网页比较复杂,那就更难了,所以楼主不妨用爬虫软件来实现网页数据采集 ,而且市面上有很多这样的工具,比如优采云、Jisuke GooSeeker、Scrapy,都是不错的网络爬虫软件。我个人比较喜欢用Jisuke,使用简单,可以自由自学。, 你可以试试看。
如何抓取网页表单数据
______ 不知道是自己写爬虫还是用采集工具。如果自己写爬虫,可以查代码。如果使用采集工具,可以使用另一个网友推荐的采集工具,另外我也推荐一个,Gathering,因为相比前者免费,而且还有文档和视频教程。希望对你有帮助。 查看全部
网页数据抓取怎么写(可以使用Uibot进行网络数据采集吗?-__晚上的例子)
Uibot可以用于网络数据采集吗?-
______ Uibot可以执行各种网络数据采集,包括信息采集、数据采集、图片采集、OCR识别技术等。
如何使用jsoup抓取网页数据?求解释,也求演示。
______ 晚上有很多例子。主要是先从网上获取数据,然后用json解析数据。这很简单。
如何使用Uibot调用Excel表格中的数据?-
______ Excel 提供了两种数据过滤操作,即“自动过滤”和“高级过滤”。自动过滤一般用于简单的条件过滤。过滤时,不符合条件的数据会被暂时隐藏,只显示符合条件的数据。图1为某单位员工工资表。打开“数据”菜单中的“过滤器”子菜单...
如何抓取网页数据-
______ 我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 gooseeker 网络爬虫如何进行数据爬取,在翻页后自动抓取数据。ms的爬虫路由工作台共有三种线索方式。
如何抓取网页上的数据-
______ 1. 用工具分析js最终生成的url是什么,具体发送的请求,发送的数据是什么。相关参考:【教程】教你如何使用工具(ie9的f12)分析模拟登录的内部逻辑过程网站(百度首页)如果你不明白背后的逻辑,请参考:【完成】关于...
如何抓取 HTML 页面数据-
______ 使用预先嗅探的 ForeSpider 数据 采集 系统。ForeSpider数据采集系统具有全面的采集范围、准确的数据准确性、卓越的捕捉性能、简单的可视化操作、智能化采集的自动化使企业能够快速获取结构化或非结构化数据在互联网上用很少的劳动力成本。软件...
网络上如何抓取数据,表格中的数据——
______ 只要您选择在办公室插入图片即可。
UiBot 能做什么?
______ 1.对各种客户端软件界面元素进行各种操作,2.对网页浏览器的界面元素进行各种操作,傻瓜式data采集,3.操作在各种办公软件的文档上,4.基于图像、文字、OCR等识别方式对界面元素进行各种操作,5.在广泛使用的现有系统上进行操作,6.操作windows和基于句柄的流程,7.大规模基础功能8.多种能力扩展方案。
如何使用R或rapidminer抓取以下网页的数据
______ 对于网页数据,还是需要一定的技术基础,通过运行程序来实现。如果网页比较复杂,那就更难了,所以楼主不妨用爬虫软件来实现网页数据采集 ,而且市面上有很多这样的工具,比如优采云、Jisuke GooSeeker、Scrapy,都是不错的网络爬虫软件。我个人比较喜欢用Jisuke,使用简单,可以自由自学。, 你可以试试看。
如何抓取网页表单数据
______ 不知道是自己写爬虫还是用采集工具。如果自己写爬虫,可以查代码。如果使用采集工具,可以使用另一个网友推荐的采集工具,另外我也推荐一个,Gathering,因为相比前者免费,而且还有文档和视频教程。希望对你有帮助。
网页数据抓取怎么写(如何抓取目标网站是以Js的方式动态生成数据的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-03 21:21
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
网页数据抓取怎么写(如何抓取目标网站是以Js的方式动态生成数据的网页)
当我们捕获数据时,如果目标网站是以JS和逐页滚动的形式动态生成数据,我们应该如何捕获它
比如今天的头条新闻网站:
我们可以使用硒来做到这一点。尽管selenium是为web应用程序的自动测试而设计的,但它非常适合数据捕获。它可以轻松绕过反爬虫限制网站,因为selenium与真实用户一样直接在浏览器中运行
使用selenium,我们不仅可以使用JS动态生成的数据对网页进行抓取,还可以通过滚动页面对页面进行抓取
首先,我们使用Maven引入selenium依赖关系:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码来抓取:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
网页数据抓取怎么写(如何用Python爬数据?(一)网页抓取你期待已久的Python网络数据爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-01 13:05
如何使用 Python 抓取数据?(一)网页抓取
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。
需要
我在公众号后台,经常能收到读者的评论。
很多评论都是来自读者的提问。只要我有时间,我会花时间尝试回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:
一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。
我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
开放数据集下载;
API读取;
爬虫。
前两种方法我已经做了一些介绍,这次就说说爬虫。
概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网络抓取软件可以直接使用超文本传输协议或通过网络浏览器访问万维网。
如果你看到了,即使你用浏览器手动复制数据,也被称为网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为你完成网页抓取工作,才是你真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花 20% 的努力去理解一件事的 80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常实用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但是要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。
假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在 Windows 平台上安装和运行 Anaconda 命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。
打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip 安装 pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
管道安装
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv 外壳
请在此确认您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter 笔记本
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。
请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
从 requests_html 导入 HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
会话 = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
网址 ='#39;
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,只看正文部分。
所以我们执行:
打印(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个相对于我们网页采集所在域名()的路径的链接。
就好像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,不需要在前面加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:
这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。
为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
就像你想给某人寄包裹一样,你可以在“省-市-区-街道-社区-门牌”的结构中写一个地址,快递员也可以根据这个地址找到收件人。
同样,我们对网页中的一些特定内容感兴趣,我们可以根据这些标签的结构找出来。
这是否意味着您必须先学习 HTML 和 CSS,然后才能抓取网页内容?
不,我们可以使用工具来帮助您显着简化任务的复杂性。
此工具随 Google Chrome 浏览器一起提供。
我们在示例文章页面点击鼠标右键,在出现的菜单中选择“Check”。
这时,屏幕下方会出现一列。
我们单击此列左上角的按钮(上面标记为红色)。然后将鼠标悬停在第一个文本链接(“玉树之蓝”)上并单击。
此时,你会发现下栏的内容也发生了变化。这个链接对应的源代码放在栏目区域的中间,并高亮显示。
确认该区域是我们要找的链接和文字说明后,我们用鼠标右键选中突出显示的区域,在弹出的菜单中选择Copy -> Copy selector。
找个文本编辑器,执行paste,就可以看到我们复制的内容了。
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
这长串标签为电脑指出:请先找到body标签,然后进入管辖区域后找到div.note标签,然后找到...最后找到a标签,这里是内容你正在寻找。
回到我们的 Jupyter Notebook 并使用我们刚刚获得的标签路径来定义变量 sel。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a'
我们让 Python 从返回的内容中找到 sel 对应的位置,并将结果存储在 results 变量中。
结果 = r.html.find(sel)
让我们来看看结果中的内容。
结果
这是结果:
[]
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
结果[0].text
这是输出:
《玉树知兰》
我们还提取了链接:
结果[0].absolute_links
显示的结果是一个集合。
{'#39;}
我们不需要集合,只需要其中的链接字符串。所以我们首先将它转换成一个列表,然后从中提取第一项,即 URL 链接。
列表(结果[0].absolute_links)[0]
这一次,我们终于得到了我们想要的结果:
'#39;
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们。
def get_text_link_from_sel(sel):
我的列表 = []
尝试:
结果 = r.html.find(sel)
结果结果:
mytext = result.text
mylink = list(result.absolute_links)[0]
mylist.append((mytext, mylink))
返回我的列表
除了:
返回无
我们来测试一下这个功能。
还是用刚才一样的标记路径(sel),试试吧。
打印(get_text_link_from_sel(sel))
输出如下:
[('玉树芝兰','#39;)]
没问题吧?
好的,让我们尝试第二个链接。
我们还是用刚才的方法,使用下栏左上角的按钮,点击第二个链接。
下面显示的突出显示的内容已更改:
我们仍然使用鼠标右键单击突出显示的部分来复制选择器。
然后我们直接将获取到的标签路径写入到 Jupyter Notebook 中。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a'
用我们刚才编译的函数看看输出结果是什么?
打印(get_text_link_from_sel(sel))
输出如下:
[('如何使用Python作为词云?','#39;)]
经检查,功能没有问题。
下一步是什么?
还是要找第三个链接,按照刚才的方法操作吗?
那么你不妨从全文中手动提取信息,这样可以省去你的麻烦。
我们必须找到一种方法来自动化这个过程。
比较我们只找到两次的标记路径:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
也:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a
你找到什么模式了吗?
是的,路径上的所有其他标记都相同,除了倒数第二个标记(“p”)之后冒号之后的内容。
这是我们自动化的关键。
上述两个标签路径中,因为指定了“nth-child”文本段(paragraph,即“p”的意思)来查找标签“a”,所以只返回了一个结果。
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel ='body> div.note> div.post> div.article> div.show-content> div> p> a'
再次运行我们的函数:
打印(get_text_link_from_sel(sel))
这是输出:
好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
将熊猫导入为 pd
只需这行命令,我们就可以将刚才的列表变成一个数据框:
df = pd.DataFrame(get_text_link_from_sel(sel))
我们来看一下数据框的内容:
df
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['文本','链接']
查看数据框的内容:
df
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框转换为 csv 格式,可以直接在 Excel 中打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
很有成就感不是吗?
概括
本文向您展示了使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
网络爬虫与网络爬虫的联系和区别;
如何使用pipenv快速搭建指定的Python开发环境并自动安装依赖软件包;
如何利用谷歌浏览器内置的检查功能快速定位感兴趣内容的标记路径;
如何使用requests-html包解析网页并查询获取需要的内容元素;
如何使用 Pandas 数据框工具组织数据并输出到 Excel。
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页相同。
而且,根据我们的示例,您是否已经尝试过抓取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
如何将抓取功能扩展到一定范围内的所有网页?
如何抓取Javascript动态网页?
假设你爬取的网站限制了每个IP的访问频率,我该怎么办?
...
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,网络爬虫虽然抓取数据,虽然功能强大,但学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
有没有别人整理过的资料集可以直接下载?
网站你需要的数据有没有API访问和获取方式?
有没有人根据你的需要编了一个自定义爬虫让你直接调用?
如果答案是否定的,则需要自己编写脚本并动员爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区与大家分享记录链接就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?“文章中,部分文章被多次引用,所以已抓到重复链接。
但是当您存储时,您可能不想保留重复的链接。
在这种情况下,如何修改代码以确保抓取和保存的链接不重复?
这部分内容我放在文末付费阅读区。如果你愿意支持我的数据科学教程系列的写作,顺便看看你的代码是否比我的更有效率。您只需支付2元(促销期间的价格),阅读这部分内容。
讨论
你对 Python 爬虫感兴趣吗?你在哪些 data采集 任务上使用过它?有没有其他更有效的方式来达到data采集的目的?欢迎留言,与大家分享您的经验和想法,我们一起交流讨论。 查看全部
网页数据抓取怎么写(如何用Python爬数据?(一)网页抓取你期待已久的Python网络数据爬虫)
如何使用 Python 抓取数据?(一)网页抓取
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。
需要
我在公众号后台,经常能收到读者的评论。
很多评论都是来自读者的提问。只要我有时间,我会花时间尝试回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:
一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。
我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
开放数据集下载;
API读取;
爬虫。
前两种方法我已经做了一些介绍,这次就说说爬虫。
概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网络抓取软件可以直接使用超文本传输协议或通过网络浏览器访问万维网。
如果你看到了,即使你用浏览器手动复制数据,也被称为网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为你完成网页抓取工作,才是你真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会产生回报甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花 20% 的努力去理解一件事的 80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常实用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但是要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。
假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在 Windows 平台上安装和运行 Anaconda 命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。
打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip 安装 pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
管道安装
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv 外壳
请在此确认您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter 笔记本
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。
请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
从 requests_html 导入 HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
会话 = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
网址 ='#39;
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,只看正文部分。
所以我们执行:
打印(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个相对于我们网页采集所在域名()的路径的链接。
就好像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,不需要在前面加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:
这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。
为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
就像你想给某人寄包裹一样,你可以在“省-市-区-街道-社区-门牌”的结构中写一个地址,快递员也可以根据这个地址找到收件人。
同样,我们对网页中的一些特定内容感兴趣,我们可以根据这些标签的结构找出来。
这是否意味着您必须先学习 HTML 和 CSS,然后才能抓取网页内容?
不,我们可以使用工具来帮助您显着简化任务的复杂性。
此工具随 Google Chrome 浏览器一起提供。
我们在示例文章页面点击鼠标右键,在出现的菜单中选择“Check”。
这时,屏幕下方会出现一列。
我们单击此列左上角的按钮(上面标记为红色)。然后将鼠标悬停在第一个文本链接(“玉树之蓝”)上并单击。
此时,你会发现下栏的内容也发生了变化。这个链接对应的源代码放在栏目区域的中间,并高亮显示。
确认该区域是我们要找的链接和文字说明后,我们用鼠标右键选中突出显示的区域,在弹出的菜单中选择Copy -> Copy selector。
找个文本编辑器,执行paste,就可以看到我们复制的内容了。
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
这长串标签为电脑指出:请先找到body标签,然后进入管辖区域后找到div.note标签,然后找到...最后找到a标签,这里是内容你正在寻找。
回到我们的 Jupyter Notebook 并使用我们刚刚获得的标签路径来定义变量 sel。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a'
我们让 Python 从返回的内容中找到 sel 对应的位置,并将结果存储在 results 变量中。
结果 = r.html.find(sel)
让我们来看看结果中的内容。
结果
这是结果:
[]
结果是一个仅收录一项的列表。此项收录一个网址,即我们要查找的第一个链接(“玉树知兰”)对应的网址。
但文字描述“《玉树知兰》”去哪儿了?
别着急,我们让Python显示结果数据对应的文字。
结果[0].text
这是输出:
《玉树知兰》
我们还提取了链接:
结果[0].absolute_links
显示的结果是一个集合。
{'#39;}
我们不需要集合,只需要其中的链接字符串。所以我们首先将它转换成一个列表,然后从中提取第一项,即 URL 链接。
列表(结果[0].absolute_links)[0]
这一次,我们终于得到了我们想要的结果:
'#39;
有了处理这第一个环节的经验,你就有了很多信心,对吧?
其他链接无非就是找到标记的路径,然后拍猫和老虎的照片。
但是,如果每次找到链接都需要手动输入这些句子,那就太麻烦了。
这里是编程技巧。一一重复执行的语句。如果工作顺利,我们会尝试将它们合并在一起并制作一个简单的功能。
对于这个函数,只要给出一个选择路径(sel),它就会把它找到的所有描述文本和链接路径返回给我们。
def get_text_link_from_sel(sel):
我的列表 = []
尝试:
结果 = r.html.find(sel)
结果结果:
mytext = result.text
mylink = list(result.absolute_links)[0]
mylist.append((mytext, mylink))
返回我的列表
除了:
返回无
我们来测试一下这个功能。
还是用刚才一样的标记路径(sel),试试吧。
打印(get_text_link_from_sel(sel))
输出如下:
[('玉树芝兰','#39;)]
没问题吧?
好的,让我们尝试第二个链接。
我们还是用刚才的方法,使用下栏左上角的按钮,点击第二个链接。
下面显示的突出显示的内容已更改:
我们仍然使用鼠标右键单击突出显示的部分来复制选择器。
然后我们直接将获取到的标签路径写入到 Jupyter Notebook 中。
sel ='body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a'
用我们刚才编译的函数看看输出结果是什么?
打印(get_text_link_from_sel(sel))
输出如下:
[('如何使用Python作为词云?','#39;)]
经检查,功能没有问题。
下一步是什么?
还是要找第三个链接,按照刚才的方法操作吗?
那么你不妨从全文中手动提取信息,这样可以省去你的麻烦。
我们必须找到一种方法来自动化这个过程。
比较我们只找到两次的标记路径:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(4)> a
也:
body> div.note> div.post> div.article> div.show-content> div> p:nth-child(6)> a
你找到什么模式了吗?
是的,路径上的所有其他标记都相同,除了倒数第二个标记(“p”)之后冒号之后的内容。
这是我们自动化的关键。
上述两个标签路径中,因为指定了“nth-child”文本段(paragraph,即“p”的意思)来查找标签“a”,所以只返回了一个结果。
如果我们不限制“p”的具体位置信息呢?
让我们试试吧。这次保留标记路径中的所有其他信息,只修改“p”点。
sel ='body> div.note> div.post> div.article> div.show-content> div> p> a'
再次运行我们的函数:
打印(get_text_link_from_sel(sel))
这是输出:
好吧,我们要找的所有内容都在这里。
然而,我们的工作还没有结束。
我们必须将 采集 中的信息输出到 Excel 并保存。
还记得我们常用的数据框工具 Pandas 吗?是时候让它再次展现它的神奇力量了。
将熊猫导入为 pd
只需这行命令,我们就可以将刚才的列表变成一个数据框:
df = pd.DataFrame(get_text_link_from_sel(sel))
我们来看一下数据框的内容:
df
内容还可以,但是我们对标题不满意,所以我们必须用更有意义的列名替换它:
df.columns = ['文本','链接']
查看数据框的内容:
df
好的,现在您可以将捕获的内容输出到 Excel。
Pandas 的内置命令可以将数据框转换为 csv 格式,可以直接在 Excel 中打开查看。
df.to_csv('output.csv', encoding='gbk', index=False)
注意编码需要指定为gbk,否则在Excel中查看默认的utf-8编码可能会出现乱码。
让我们来看看生成的 csv 文件。
很有成就感不是吗?
概括
本文向您展示了使用 Python 自动爬网的基本技巧。希望通过阅读和动手实践,您可以掌握以下知识点:
网络爬虫与网络爬虫的联系和区别;
如何使用pipenv快速搭建指定的Python开发环境并自动安装依赖软件包;
如何利用谷歌浏览器内置的检查功能快速定位感兴趣内容的标记路径;
如何使用requests-html包解析网页并查询获取需要的内容元素;
如何使用 Pandas 数据框工具组织数据并输出到 Excel。
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页相同。
而且,根据我们的示例,您是否已经尝试过抓取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
如何将抓取功能扩展到一定范围内的所有网页?
如何抓取Javascript动态网页?
假设你爬取的网站限制了每个IP的访问频率,我该怎么办?
...
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,网络爬虫虽然抓取数据,虽然功能强大,但学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
有没有别人整理过的资料集可以直接下载?
网站你需要的数据有没有API访问和获取方式?
有没有人根据你的需要编了一个自定义爬虫让你直接调用?
如果答案是否定的,则需要自己编写脚本并动员爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区与大家分享记录链接就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?“文章中,部分文章被多次引用,所以已抓到重复链接。
但是当您存储时,您可能不想保留重复的链接。
在这种情况下,如何修改代码以确保抓取和保存的链接不重复?
这部分内容我放在文末付费阅读区。如果你愿意支持我的数据科学教程系列的写作,顺便看看你的代码是否比我的更有效率。您只需支付2元(促销期间的价格),阅读这部分内容。
讨论
你对 Python 爬虫感兴趣吗?你在哪些 data采集 任务上使用过它?有没有其他更有效的方式来达到data采集的目的?欢迎留言,与大家分享您的经验和想法,我们一起交流讨论。
网页数据抓取怎么写(基于HTML标签来匹配肯定不合适的数据匹配方法来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-01 12:30
数据匹配
首先研究最关键的数据捕获。从各种形式的数据中“提取”内容。
当然还要依靠我们强大的正则表达式工具(个人觉得基于DOM树的分析很麻烦,很不灵活)
分析了几个BOKECC页面,总结如下:
1. 每个页面都有一定的差异,可能是基于不同的版本。HTML 写的很随意,基于 HTML 标签的匹配肯定是不合适的。
2. 页面有动态内容,需要分析模拟AJAX来请求。
在基于HTML源代码的数据爬取中,如果单纯想基于HTML标签进行挖掘,正确率肯定是很低的。仍然需要回归基础,挖掘人们的想法。
所以我大多使用基于页面视觉(如文本,或区域)的匹配方法。过滤掉一些不太重要的 HTML 标签。然后进行数据匹配。
这里用到了python的re模块。
首先,我写了几个程序进行测试。我测试了 网站 的 20 个不同的页面,它们基本上都能正确捕获。
接下来说说AJAX的内容。
为什么动态内容需要模拟 AJAX 请求?
因为您使用 HTTP 流来获取网页的内容,所以没有动态类型的内容。(比如div标签为空),但是当你以浏览器的形式访问时,可以看到数据。这是因为浏览器的javascript引擎执行其中的JS代码异步请求数据并动态打印在上级页面上。
网页界面
每个节点都需要暴露WEB界面。在上一篇文章的设计中,我提到了SOAP协议。在实际实现中,我们在本系统中仍然使用基于HTTP GET的接口。(编码相对简单,:D)。为了方便部署,体现python中一切都那么简单的原则,我没有使用apache等知名的web服务器,而是python的BaseHTTPServer模块。重载do_GET方法来实现我们WEB界面的暴露。
为什么WEB界面需要同时设计同步和异步返回?由于我们的分布式节点是基于任务形式的,我们的节点任务逻辑反馈包括2个步骤:
1. 确认任务接收
2. 任务完成回调
这样,控制器的程序就很容易写了:给所有节点发送任务,同时加上任务号,节点同步后反馈接收任务,等待,如果有节点任务回调,节点认为空闲,然后分配任务。. . (当然,实际情况可能是每个节点运行在多个线程中,节点或者控制器也可以维护一个任务队列和线程池)
如何实现异步?
起线程。(当然你也可以管理线程池,这里我不太在意)
数据库操作
没什么好说的,我这里用的MYSQL就是直接SQL语句。简单明了。
如何部署?
由于我只需要在WINDOWS平台上部署,所以我使用py2exe作为EXE包发布。
如果要实现自动化部署,也很简单。自己在每个节点上写一个“后门”,就可以统一调度所有机器的后门。(控制它的下载和重启) 查看全部
网页数据抓取怎么写(基于HTML标签来匹配肯定不合适的数据匹配方法来实现)
数据匹配
首先研究最关键的数据捕获。从各种形式的数据中“提取”内容。
当然还要依靠我们强大的正则表达式工具(个人觉得基于DOM树的分析很麻烦,很不灵活)
分析了几个BOKECC页面,总结如下:
1. 每个页面都有一定的差异,可能是基于不同的版本。HTML 写的很随意,基于 HTML 标签的匹配肯定是不合适的。
2. 页面有动态内容,需要分析模拟AJAX来请求。
在基于HTML源代码的数据爬取中,如果单纯想基于HTML标签进行挖掘,正确率肯定是很低的。仍然需要回归基础,挖掘人们的想法。
所以我大多使用基于页面视觉(如文本,或区域)的匹配方法。过滤掉一些不太重要的 HTML 标签。然后进行数据匹配。
这里用到了python的re模块。
首先,我写了几个程序进行测试。我测试了 网站 的 20 个不同的页面,它们基本上都能正确捕获。
接下来说说AJAX的内容。
为什么动态内容需要模拟 AJAX 请求?
因为您使用 HTTP 流来获取网页的内容,所以没有动态类型的内容。(比如div标签为空),但是当你以浏览器的形式访问时,可以看到数据。这是因为浏览器的javascript引擎执行其中的JS代码异步请求数据并动态打印在上级页面上。
网页界面
每个节点都需要暴露WEB界面。在上一篇文章的设计中,我提到了SOAP协议。在实际实现中,我们在本系统中仍然使用基于HTTP GET的接口。(编码相对简单,:D)。为了方便部署,体现python中一切都那么简单的原则,我没有使用apache等知名的web服务器,而是python的BaseHTTPServer模块。重载do_GET方法来实现我们WEB界面的暴露。
为什么WEB界面需要同时设计同步和异步返回?由于我们的分布式节点是基于任务形式的,我们的节点任务逻辑反馈包括2个步骤:
1. 确认任务接收
2. 任务完成回调
这样,控制器的程序就很容易写了:给所有节点发送任务,同时加上任务号,节点同步后反馈接收任务,等待,如果有节点任务回调,节点认为空闲,然后分配任务。. . (当然,实际情况可能是每个节点运行在多个线程中,节点或者控制器也可以维护一个任务队列和线程池)
如何实现异步?
起线程。(当然你也可以管理线程池,这里我不太在意)
数据库操作
没什么好说的,我这里用的MYSQL就是直接SQL语句。简单明了。
如何部署?
由于我只需要在WINDOWS平台上部署,所以我使用py2exe作为EXE包发布。
如果要实现自动化部署,也很简单。自己在每个节点上写一个“后门”,就可以统一调度所有机器的后门。(控制它的下载和重启)
网页数据抓取怎么写(iOSpython爬虫学习iOS开发有一段时间了,物品等数据怎么获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-30 18:19
iOS 蟒蛇爬虫 LoL
我已经学习了一段时间的 iOS 开发。最近想做个自己的App来玩玩玩。比较喜欢玩LOL,所以想尝试在LOL数据库里做一个App。那么问题来了,这么多英雄、物品等数据怎么弄啊,你自己敲不出来。作为程序员,你怎么能自己做呢?这时候就可以牺牲神器Python了,直接上正题吧。
一、 查找数据
要获取数据,您必须首先找出数据的可用位置。各大游戏媒体网站都有自己的数据库,这里我选择官方数据库,地址:LOL官方数据库。
[LOL官方数据库]()
英雄、物品、技能、符文、天赋一应俱全,数据也是最新的。OK,猎物找到了,开始狩猎前需要做一些准备。
二、 准备
python filename.py
三、 网络分析
我们要抓取的数据包括图片、文本或文件。图像和文件通常是一个地址。文本可能存在于文件中,也可能直接写在网页的源代码中。因此,我们首先分析网页,熟悉战场。
在Safari中打开LOL官方数据库,点击菜单“开发”-“显示页面源文件”或按快捷键alt+command+a/u,进入开发者工具,点击“元素”选项卡
Safari 开发者工具
当我们将鼠标移动到不同的代码行时,网页中当前代码对应的元素就会被选中,可以帮助我们快速定位关键代码。我们先试着找到九尾妖狐头部的图片地址,如上图所示。
.
四、一个小测试
现在我们将尝试将这张图片下载到本地。
创建Python文件,保存时可以使用VSCode新建一个后缀为.py的空白文件,也可以在终端执行命令
cd Desktop/ //进入Desktop文件夹
touch filename.py //在当前文件夹内新建文件
用编辑器打开文件并编写代码:
#-*-coding:utf8-*-
import os, requests
img_url = "http://ossweb-img.qq.com/image ... ot%3B
# 截取文件名
img_name = os.path.basename(img_url)
# 下载图片
img = requests.get(img_url)
# 打开本地文件
# 'wb'表示以二进制写入模式打开文件
file = open('/Users/apple/img//' + img_name, 'wb')
# 写入文件
file.write(img.content)
# 关闭文件
file.close
这里用到了两个库,os和requests库,os python自带,requests需要手动下载并在终端执行
pip install requests
这是一个简单的下载保存的例子,但是已经可以满足我们的需求了,我们只需要修改一下就可以完成我们的目标。
未完待续 查看全部
网页数据抓取怎么写(iOSpython爬虫学习iOS开发有一段时间了,物品等数据怎么获取)
iOS 蟒蛇爬虫 LoL
我已经学习了一段时间的 iOS 开发。最近想做个自己的App来玩玩玩。比较喜欢玩LOL,所以想尝试在LOL数据库里做一个App。那么问题来了,这么多英雄、物品等数据怎么弄啊,你自己敲不出来。作为程序员,你怎么能自己做呢?这时候就可以牺牲神器Python了,直接上正题吧。
一、 查找数据
要获取数据,您必须首先找出数据的可用位置。各大游戏媒体网站都有自己的数据库,这里我选择官方数据库,地址:LOL官方数据库。
[LOL官方数据库]()
英雄、物品、技能、符文、天赋一应俱全,数据也是最新的。OK,猎物找到了,开始狩猎前需要做一些准备。
二、 准备
python filename.py
三、 网络分析
我们要抓取的数据包括图片、文本或文件。图像和文件通常是一个地址。文本可能存在于文件中,也可能直接写在网页的源代码中。因此,我们首先分析网页,熟悉战场。
在Safari中打开LOL官方数据库,点击菜单“开发”-“显示页面源文件”或按快捷键alt+command+a/u,进入开发者工具,点击“元素”选项卡
Safari 开发者工具
当我们将鼠标移动到不同的代码行时,网页中当前代码对应的元素就会被选中,可以帮助我们快速定位关键代码。我们先试着找到九尾妖狐头部的图片地址,如上图所示。
.
四、一个小测试
现在我们将尝试将这张图片下载到本地。
创建Python文件,保存时可以使用VSCode新建一个后缀为.py的空白文件,也可以在终端执行命令
cd Desktop/ //进入Desktop文件夹
touch filename.py //在当前文件夹内新建文件
用编辑器打开文件并编写代码:
#-*-coding:utf8-*-
import os, requests
img_url = "http://ossweb-img.qq.com/image ... ot%3B
# 截取文件名
img_name = os.path.basename(img_url)
# 下载图片
img = requests.get(img_url)
# 打开本地文件
# 'wb'表示以二进制写入模式打开文件
file = open('/Users/apple/img//' + img_name, 'wb')
# 写入文件
file.write(img.content)
# 关闭文件
file.close
这里用到了两个库,os和requests库,os python自带,requests需要手动下载并在终端执行
pip install requests
这是一个简单的下载保存的例子,但是已经可以满足我们的需求了,我们只需要修改一下就可以完成我们的目标。
未完待续
网页数据抓取怎么写(网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-29 02:01
网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总了。涵盖电影网、游戏网、教育网、购物网,各个网站的工具开发者从网页底部选择下载路径,然后就会一步步按照工具开发者提供的下载教程,按照要求下载到相应的网站里去。还是需要掌握一定的代码技巧。以下是我总结的资源列表:文章:文章汇总网页数据抓取怎么写程序爬虫学了怎么用发现坑,自己绕过去了主要爬虫网站大集合这里是引导列表-11.html?hl=enaj教程列表-12.html?hl=enctf项目汇总:找个点击赚积分的网站-13.html?hl=en非重复内容爬取-15.html?hl=en一个爬虫器-16.html?hl=en爬虫代码-17.html?hl=en更好玩的获取pdf网站,有兴趣的欢迎看我的优质文章列表,更多资源可关注公众号:考拉猪来啦微信公众号回复“爬虫”即可获取中速网公告:。
推荐你用金山云查名单,有收集全国12000+主流电商网站的爬虫+查询代码,爬虫写的还可以,代码不通俗,但是质量不错,
我有些工具网站地址,你参考下:初学爬虫应用笔记网址链接:-geller。blogspot。com/2015/06/html_final_0。html或者你可以看看我的一个知乎回答:基于百度浏览器插件、迅雷浏览器扩展程序、电脑管家助手等工具实现百度网页搜索视频、下载音乐、查看历史消息或阅读全文等技术类小工具,该如何找到?。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总)
网页数据抓取怎么写怎么玩,这么多实用网站我就在这里汇总了。涵盖电影网、游戏网、教育网、购物网,各个网站的工具开发者从网页底部选择下载路径,然后就会一步步按照工具开发者提供的下载教程,按照要求下载到相应的网站里去。还是需要掌握一定的代码技巧。以下是我总结的资源列表:文章:文章汇总网页数据抓取怎么写程序爬虫学了怎么用发现坑,自己绕过去了主要爬虫网站大集合这里是引导列表-11.html?hl=enaj教程列表-12.html?hl=enctf项目汇总:找个点击赚积分的网站-13.html?hl=en非重复内容爬取-15.html?hl=en一个爬虫器-16.html?hl=en爬虫代码-17.html?hl=en更好玩的获取pdf网站,有兴趣的欢迎看我的优质文章列表,更多资源可关注公众号:考拉猪来啦微信公众号回复“爬虫”即可获取中速网公告:。
推荐你用金山云查名单,有收集全国12000+主流电商网站的爬虫+查询代码,爬虫写的还可以,代码不通俗,但是质量不错,
我有些工具网站地址,你参考下:初学爬虫应用笔记网址链接:-geller。blogspot。com/2015/06/html_final_0。html或者你可以看看我的一个知乎回答:基于百度浏览器插件、迅雷浏览器扩展程序、电脑管家助手等工具实现百度网页搜索视频、下载音乐、查看历史消息或阅读全文等技术类小工具,该如何找到?。
网页数据抓取怎么写( 2.-type-gt-item数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-27 01:13
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。然后我们将鼠标移动到标题,标题将被一个蓝色的半透明蒙版覆盖。如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板,内容是一些无法理解的彩色代码。
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写( 2.-toggle爬取数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-24 21:25
2.-toggle爬取数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
网页数据抓取怎么写(
2.-toggle爬取数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性为 itemprop='知乎:question' 的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题的时候,不管标题的嵌套关系如何变化,总有一个标签保持不变,也就是包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
网页数据抓取怎么写( 网页数据如下图:#找到要数据的网址(rvest))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-24 21:24
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL 查看全部
网页数据抓取怎么写(
网页数据如下图:#找到要数据的网址(rvest))
写论文,没有数据?R语言爬取网络大数据
放眼国内外,大数据市场发展迅猛,政府支持力度空前,甚至将大数据纳入发展战略。这样的形势给社会各界提供了许多机遇和挑战,作为卫生(医疗)统计领域的一员,我们更要抓住机遇。放眼全球,大数据的应用规模不断扩大,几乎每个行业都将目光投向了大数据背后的巨大价值。未来五到十年将是我国推动大数据发展的关键时期,亟需打造高效的大数据应用机制和产业链。
根据对当前大数据行业发展的分析,我们可能会从“视觉数据捕捉”开始思考大数据。这里所说的可视化数据抓取主要是指对互联网网页数据的抓取,可以实现大数据应用的普及。目前,我们已经可以使用一个简单的网页数据爬取工具来爬取它所需要的网页数据,比如知名的网页数据爬取工具“**采集器”(收费)。现有的互联网数据采集、处理、分析、挖掘软件可以灵活、快速地捕捉网络上分散的数据信息,并通过一系列的分析处理,准确地挖掘出所需的数据。由此带来的效率、便利和文明化不言而喻。
作为大数据行业的一员,今天小编就基于流行的R软件,为大家介绍如何实现网页数据采集技术。是的,是R!除了强大的统计分析功能外,它对网页的抓取能力也不容小觑,尤其是Hadley写的R包rvest,把复杂的事情简单化了。使用R语言抓取网页数据的最大优势在于获得数据后强大的数据处理、分析和可视化功能。
R语言示例
下面以rvest包捕获的广州空气质量数据为例进行说明。
网页数据如下:
#加载包
图书馆(rvest)
#找到获取数据的URL
网页数据抓取怎么写(待访问地址库()的几种方式和方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-24 06:18
)
一般来说,自己网站被其他网站引用最多的页面就是首页,所以它的权重是最高的。比如页面A是A网站的首页,可以得到结论是从页面A更高级的页面拥有更高的页面权重。比如页面A的超链接更容易被蜘蛛抓取,也更容易被蜘蛛抓取。未被蜘蛛发现的网页权重更大。自然是0。
还有一点很重要,蜘蛛在爬取页面时会进行一定程度的复制检测,即当前爬取的页面内容是否与保存的数据重叠(当页面内容被转载/不当抄袭时)会被检测到由蜘蛛),如果大量的转贴/抄袭是在一个非常低的 网站 上,蜘蛛可能不会继续爬行。
这样做的原因是为了用户的体验。如果没有这些去重步骤,当用户想要搜索某些内容时,发现返回的结果都是一模一样的内容,这会极大地影响用户的体验。最终的结果是这个搜索引擎永远不会用了,所以为了方便用户,也是为了公司的正常发展。
地址库
互联网上有很多网页。为了避免重复抓取和抓取网页,搜索引擎会建立一个地址数据库。一个用于记录已发现但未爬取的页面,另一个是已爬取的页面。
要访问的地址库中的地址(已发现但未爬取)来自以下方法:
1. 手动输入地址
2. 蜘蛛抓取页面后,从HTML代码中获取新的链接地址,并与两个地址库中的数据进行比较。如果没有,则将该地址存储在要访问的地址库中。
3.站长(网站负责人)提交您希望搜索引擎抓取的页面。(一般这个效果不是很大)
蜘蛛根据重要性从待访问地址库中提取URL,访问并抓取页面,然后从待访问地址库中删除该URL地址并放入访问地址库中。
文件存储
蜘蛛会将抓取到的数据保存到原创页面数据库中。
存储的数据与服务器返回给蜘蛛的 HTML 内容相同。每个页面在存储在数据库中时都有自己唯一的文件编号。
预处理
当我们去商场买菜的时候,我们会看到蔬菜保险箱里的蔬菜摆放的很整齐。这里给出的例子是用保鲜膜包裹的蔬菜。
最后呈现给客户的是上图。包装完好,按分类摆放整齐。顾客可以一目了然地看到每个区域有什么蔬菜。
在最终确定这个结果之前,整个过程大概是三个步骤:
1.选择可以卖的蔬菜
从一堆蔬菜中,选择可以出售的蔬菜。
2.预处理
此时,您拥有所有可以出售的蔬菜。但是如果你今天要把这些蔬菜放进蔬菜保险箱,如果你今天开始整理这些蔬菜(因为蔬菜被打包等),你会浪费很多时间,可能是顾客还没有安排蔬菜。
所以你的解决方案是将可以提前销售的蔬菜打包存放在仓库中。当保险箱里的蔬菜丢失需要补货时,花几分钟时间去仓库取出蔬菜。把它放在架子上就行了。(我猜想,不知道具体商场里的流程是怎样的,为了方便后续理解,最好用生活实例来说明效果)
3.放置保险箱
如上最后一段,当需要补货时,将包装好的蔬菜从仓库中取出,并根据蔬菜种类放置在合适的位置。这是最后的排序步骤。
回到搜索引擎的工作流程,这个预处理步骤和上面的商城预处理步骤效果一样。
当蜘蛛完成数据采集后,就会进入这一步。
蜘蛛所做的工作是在采集数据后将数据(HTML)存储在原创页面数据库中。
而这些数据并不是用户搜索后直接用于排序并显示在搜索结果页面上的数据。
原创页面数据库中的页面数在万亿以上。如果用户搜索后对原创页面数据库中的数据进行实时排序,则排名程序(每一步使用的程序不同,采集数据的程序称为蜘蛛,排名使用的程序为排名程序)分析每个页面数据与用户想要搜索的内容之间的相关性,计算量太大,会浪费太多时间,不可能在一两秒内返回排名结果。
因此,我们需要对原创页面数据库中的数据进行预处理,为最终的排名做准备。
提取文本
我们在原创页面数据库中存储的是HTML代码,HTML代码不仅收录用户在页面上可以直接看到的文本内容,还收录其他搜索引擎无法使用的内容,如js、AJAX、等等。 。
首先要做的是从 HTML 文件中移除这些无法解析的内容,并提取出可用于排名处理步骤的文本内容。
例如,下面的代码
<p><br style="outline: 0px;"><br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> 软件工程师需要了解的搜索引擎知识<br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> MathJax.Hub.Config({<br style="outline: 0px;"> showProcessingMessages: false,<br style="outline: 0px;"> messageStyle: "none",<br style="outline: 0px;"> tex2jax: {<br style="outline: 0px;"> inlineMath: [['$','$'], ['\\(','\\)']],<br style="outline: 0px;"> displayMath: [ ["$$","$$"] ],<br style="outline: 0px;"> skipTags: ['script', 'noscript', 'style', 'textarea', 'pre', 'code', 'a']<br style="outline: 0px;"> }<br style="outline: 0px;"> });<br style="outline: 0px;"> MathJax.Hub.Register.MessageHook("End Process", function (message) {<br style="outline: 0px;"> var eve = new Event('mathjaxfini')<br style="outline: 0px;"> window.dispatchEvent(eve)<br style="outline: 0px;"> })<br style="outline: 0px;"> <br style="outline: 0px;"><br style="outline: 0px;"><br style="outline: 0px;">hi<br style="outline: 0px;"> 查看全部
网页数据抓取怎么写(待访问地址库()的几种方式和方式
)
一般来说,自己网站被其他网站引用最多的页面就是首页,所以它的权重是最高的。比如页面A是A网站的首页,可以得到结论是从页面A更高级的页面拥有更高的页面权重。比如页面A的超链接更容易被蜘蛛抓取,也更容易被蜘蛛抓取。未被蜘蛛发现的网页权重更大。自然是0。
还有一点很重要,蜘蛛在爬取页面时会进行一定程度的复制检测,即当前爬取的页面内容是否与保存的数据重叠(当页面内容被转载/不当抄袭时)会被检测到由蜘蛛),如果大量的转贴/抄袭是在一个非常低的 网站 上,蜘蛛可能不会继续爬行。
这样做的原因是为了用户的体验。如果没有这些去重步骤,当用户想要搜索某些内容时,发现返回的结果都是一模一样的内容,这会极大地影响用户的体验。最终的结果是这个搜索引擎永远不会用了,所以为了方便用户,也是为了公司的正常发展。
地址库
互联网上有很多网页。为了避免重复抓取和抓取网页,搜索引擎会建立一个地址数据库。一个用于记录已发现但未爬取的页面,另一个是已爬取的页面。
要访问的地址库中的地址(已发现但未爬取)来自以下方法:
1. 手动输入地址
2. 蜘蛛抓取页面后,从HTML代码中获取新的链接地址,并与两个地址库中的数据进行比较。如果没有,则将该地址存储在要访问的地址库中。
3.站长(网站负责人)提交您希望搜索引擎抓取的页面。(一般这个效果不是很大)
蜘蛛根据重要性从待访问地址库中提取URL,访问并抓取页面,然后从待访问地址库中删除该URL地址并放入访问地址库中。
文件存储
蜘蛛会将抓取到的数据保存到原创页面数据库中。
存储的数据与服务器返回给蜘蛛的 HTML 内容相同。每个页面在存储在数据库中时都有自己唯一的文件编号。
预处理
当我们去商场买菜的时候,我们会看到蔬菜保险箱里的蔬菜摆放的很整齐。这里给出的例子是用保鲜膜包裹的蔬菜。
最后呈现给客户的是上图。包装完好,按分类摆放整齐。顾客可以一目了然地看到每个区域有什么蔬菜。
在最终确定这个结果之前,整个过程大概是三个步骤:
1.选择可以卖的蔬菜
从一堆蔬菜中,选择可以出售的蔬菜。
2.预处理
此时,您拥有所有可以出售的蔬菜。但是如果你今天要把这些蔬菜放进蔬菜保险箱,如果你今天开始整理这些蔬菜(因为蔬菜被打包等),你会浪费很多时间,可能是顾客还没有安排蔬菜。
所以你的解决方案是将可以提前销售的蔬菜打包存放在仓库中。当保险箱里的蔬菜丢失需要补货时,花几分钟时间去仓库取出蔬菜。把它放在架子上就行了。(我猜想,不知道具体商场里的流程是怎样的,为了方便后续理解,最好用生活实例来说明效果)
3.放置保险箱
如上最后一段,当需要补货时,将包装好的蔬菜从仓库中取出,并根据蔬菜种类放置在合适的位置。这是最后的排序步骤。
回到搜索引擎的工作流程,这个预处理步骤和上面的商城预处理步骤效果一样。
当蜘蛛完成数据采集后,就会进入这一步。
蜘蛛所做的工作是在采集数据后将数据(HTML)存储在原创页面数据库中。
而这些数据并不是用户搜索后直接用于排序并显示在搜索结果页面上的数据。
原创页面数据库中的页面数在万亿以上。如果用户搜索后对原创页面数据库中的数据进行实时排序,则排名程序(每一步使用的程序不同,采集数据的程序称为蜘蛛,排名使用的程序为排名程序)分析每个页面数据与用户想要搜索的内容之间的相关性,计算量太大,会浪费太多时间,不可能在一两秒内返回排名结果。
因此,我们需要对原创页面数据库中的数据进行预处理,为最终的排名做准备。
提取文本
我们在原创页面数据库中存储的是HTML代码,HTML代码不仅收录用户在页面上可以直接看到的文本内容,还收录其他搜索引擎无法使用的内容,如js、AJAX、等等。 。
首先要做的是从 HTML 文件中移除这些无法解析的内容,并提取出可用于排名处理步骤的文本内容。
例如,下面的代码
<p><br style="outline: 0px;"><br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> 软件工程师需要了解的搜索引擎知识<br style="outline: 0px;"> <br style="outline: 0px;"> <br style="outline: 0px;"> MathJax.Hub.Config({<br style="outline: 0px;"> showProcessingMessages: false,<br style="outline: 0px;"> messageStyle: "none",<br style="outline: 0px;"> tex2jax: {<br style="outline: 0px;"> inlineMath: [['$','$'], ['\\(','\\)']],<br style="outline: 0px;"> displayMath: [ ["$$","$$"] ],<br style="outline: 0px;"> skipTags: ['script', 'noscript', 'style', 'textarea', 'pre', 'code', 'a']<br style="outline: 0px;"> }<br style="outline: 0px;"> });<br style="outline: 0px;"> MathJax.Hub.Register.MessageHook("End Process", function (message) {<br style="outline: 0px;"> var eve = new Event('mathjaxfini')<br style="outline: 0px;"> window.dispatchEvent(eve)<br style="outline: 0px;"> })<br style="outline: 0px;"> <br style="outline: 0px;"><br style="outline: 0px;"><br style="outline: 0px;">hi<br style="outline: 0px;">
网页数据抓取怎么写(如何从零开始介绍如何编写一个网络爬虫抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-24 06:18
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步改进爬虫。
我写了一系列文章:关于爬虫。有兴趣的可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以SQLite和MySQL为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论如何应对网站的反爬虫策略
Python 爬虫入门(第 5 部分)
Python Scrapy爬虫框架介绍,简单演示如何在Scrapy下开发
Python 爬虫入门(第 6 部分) 查看全部
网页数据抓取怎么写(如何从零开始介绍如何编写一个网络爬虫抓取数据)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬虫功能。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步改进爬虫。
我写了一系列文章:关于爬虫。有兴趣的可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以SQLite和MySQL为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论如何应对网站的反爬虫策略
Python 爬虫入门(第 5 部分)
Python Scrapy爬虫框架介绍,简单演示如何在Scrapy下开发
Python 爬虫入门(第 6 部分)
网页数据抓取怎么写(网页数据抓取怎么写?github搜索框架+python即可!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-21 05:04
网页数据抓取怎么写?,可以使用,但是别人写的代码,一般是做静态页面,或者指定一个类型。这种情况下,分页抓取就比较困难了。只能找个扩展工具来加速数据抓取,今天写的这个,非常简单易用,是我写的一个网页数据抓取工具,抓取完能够有拦截断点调试代码,同时能够关联多个节点,控制程序执行的。还是比较推荐这样的工具,在网页抓取遇到瓶颈时,或者想搞清楚到底用哪种代码抓取更好用。还是值得推荐一下的。个人博客:jadeflake-云栖社区-阿里云中关村在线-阿里云。
搞几分钟就能抓取的请告诉我哪里难,给你提供个抓取教程。什么?怎么抓取?github搜索框架+python教程。
github搜索框架+python即可。
源码可以到这里:-futurecraft/fish-waterproof-io
extensionintrotocodepages另外fishwriter也可以实现这个功能。
建议用pythonfetch+phantomjs+javascript+selenium,
浏览器抓包我记得是要下载官方包的吧(browserhelper不知道)phantomjs可以抓http包貌似也支持get请求你可以试试
百度一下vincent.py
接上面两个,
可以直接看一下这个
也可以看一下,我一个人在开发的爬虫框架, 查看全部
网页数据抓取怎么写(网页数据抓取怎么写?github搜索框架+python即可!)
网页数据抓取怎么写?,可以使用,但是别人写的代码,一般是做静态页面,或者指定一个类型。这种情况下,分页抓取就比较困难了。只能找个扩展工具来加速数据抓取,今天写的这个,非常简单易用,是我写的一个网页数据抓取工具,抓取完能够有拦截断点调试代码,同时能够关联多个节点,控制程序执行的。还是比较推荐这样的工具,在网页抓取遇到瓶颈时,或者想搞清楚到底用哪种代码抓取更好用。还是值得推荐一下的。个人博客:jadeflake-云栖社区-阿里云中关村在线-阿里云。
搞几分钟就能抓取的请告诉我哪里难,给你提供个抓取教程。什么?怎么抓取?github搜索框架+python教程。
github搜索框架+python即可。
源码可以到这里:-futurecraft/fish-waterproof-io
extensionintrotocodepages另外fishwriter也可以实现这个功能。
建议用pythonfetch+phantomjs+javascript+selenium,
浏览器抓包我记得是要下载官方包的吧(browserhelper不知道)phantomjs可以抓http包貌似也支持get请求你可以试试
百度一下vincent.py
接上面两个,
可以直接看一下这个
也可以看一下,我一个人在开发的爬虫框架,
网页数据抓取怎么写(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-21 05:02
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据。这种方法的优点和缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip install selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
有关更多教程,请参阅:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
按ID查找元素:按ID查找元素。等效于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
按类名查找元素:按类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
按名称查找元素:根据名称属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
按标记名查找元素:根据标记名查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
通过XPath查找元素:根据XPath语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
通过css选择器查找元素:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用“清除”方法清除输入框的内容。示例代码如下所示:
inputTag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有cookies:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的键获取值:
value = driver.get_cookie(key)
删除所有cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
Webelement元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些共同的属性:
get_u属性:此标记的属性值。截图:获取当前页面的截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement
有关更多信息,请阅读相关源代码 查看全部
网页数据抓取怎么写(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据。这种方法的优点和缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip install selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
有关更多教程,请参阅:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
按ID查找元素:按ID查找元素。等效于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
按类名查找元素:按类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
按名称查找元素:根据名称属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
按标记名查找元素:根据标记名查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
通过XPath查找元素:根据XPath语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
通过css选择器查找元素:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用“清除”方法清除输入框的内容。示例代码如下所示:
inputTag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有cookies:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的键获取值:
value = driver.get_cookie(key)
删除所有cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
# 打开一个新的页面
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
Webelement元素:
from selenium.webdriver.remote.webelement import WebElement类是每个获取出来的元素的所属类。
有一些共同的属性:
get_u属性:此标记的属性值。截图:获取当前页面的截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement
有关更多信息,请阅读相关源代码
网页数据抓取怎么写(标普500指数ETF(SPY)实时报价日变化率日最高价)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-21 00:08
这个程序是使用python 2.@7. 6编写的,展开Python的HTMLParser,根据预设股票代码列表,从雅虎财务捕获数据日期,股票名称,实时报价,在同一天的变化率,同一天的最低价格,同一天的最高价格。
因为Yahoo Finance的库存页面中的值具有相应的ID。
,例如,NASDAQ 100指数ETF(QQQ)
实时报价的HTML标记是
87.49
和标准普尔500指数ETF(SPY)
实时报价的HTML标记是
187.25
因此,该数据抓取程序根据相应的ID字符串找到数据。具体而言,首先继承HTMLParser,然后在自定义子类中重新载入Handle_Data(Self,Data)方法,查找收录相应的ID字符串的HTML(例如,实时的ID字符串)是“YFS_L84 _”+股票代码)标签,并在此HTML标记中的输出数据(例如,QQQ的8 7. 49,其中数据8 7. 49是一个实时报价。)
样品输出:
数据反过来
数据日期股票代码库存名称实时报价日更换率最低的价格日高价
05/05/2014 ibb iShares Nasdaq Biotechnology (IBB) 233.28 1.85% 225.34 233.28
05/05/2014 socl Global X Social Media Index ETF (SOCL) 17.48 0.17% 17.12 17.53
05/05/2014 pnqi PowerShares NASDAQ Internet (PNQI) 62.61 0.35% 61.46 62.74
05/05/2014 xsd SPDR S&P Semiconductor ETF (XSD) 67.15 0.12% 66.20 67.41
05/05/2014 ita iShares US Aerospace & Defense (ITA) 110.34 1.15% 108.62 110.56
05/05/2014 iai iShares US Broker-Dealers (IAI) 37.42 -0.21% 36.86 37.42
05/05/2014 vbk Vanguard Small Cap Growth ETF (VBK) 119.97 -0.03% 118.37 120.09
05/05/2014 qqq PowerShares QQQ (QQQ) 87.95 0.53% 86.76 87.97
05/05/2014 ewi iShares MSCI Italy Capped (EWI) 17.86 -0.56% 17.65 17.89
05/05/2014 dfe WisdomTree Europe SmallCap Dividend (DFE) 62.33 -0.11% 61.94 62.39
05/05/2014 pbd PowerShares Global Clean Energy (PBD) 13.03 0.00% 12.97 13.05
05/05/2014 eirl iShares MSCI Ireland Capped (EIRL) 38.52 -0.16% 38.39 38.60
本程序源代码:
官方描述HTMLParser的文档:
htmlparser(解析HTML文档元素) 查看全部
网页数据抓取怎么写(标普500指数ETF(SPY)实时报价日变化率日最高价)
这个程序是使用python 2.@7. 6编写的,展开Python的HTMLParser,根据预设股票代码列表,从雅虎财务捕获数据日期,股票名称,实时报价,在同一天的变化率,同一天的最低价格,同一天的最高价格。
因为Yahoo Finance的库存页面中的值具有相应的ID。
,例如,NASDAQ 100指数ETF(QQQ)
实时报价的HTML标记是
87.49
和标准普尔500指数ETF(SPY)
实时报价的HTML标记是
187.25
因此,该数据抓取程序根据相应的ID字符串找到数据。具体而言,首先继承HTMLParser,然后在自定义子类中重新载入Handle_Data(Self,Data)方法,查找收录相应的ID字符串的HTML(例如,实时的ID字符串)是“YFS_L84 _”+股票代码)标签,并在此HTML标记中的输出数据(例如,QQQ的8 7. 49,其中数据8 7. 49是一个实时报价。)
样品输出:
数据反过来
数据日期股票代码库存名称实时报价日更换率最低的价格日高价
05/05/2014 ibb iShares Nasdaq Biotechnology (IBB) 233.28 1.85% 225.34 233.28
05/05/2014 socl Global X Social Media Index ETF (SOCL) 17.48 0.17% 17.12 17.53
05/05/2014 pnqi PowerShares NASDAQ Internet (PNQI) 62.61 0.35% 61.46 62.74
05/05/2014 xsd SPDR S&P Semiconductor ETF (XSD) 67.15 0.12% 66.20 67.41
05/05/2014 ita iShares US Aerospace & Defense (ITA) 110.34 1.15% 108.62 110.56
05/05/2014 iai iShares US Broker-Dealers (IAI) 37.42 -0.21% 36.86 37.42
05/05/2014 vbk Vanguard Small Cap Growth ETF (VBK) 119.97 -0.03% 118.37 120.09
05/05/2014 qqq PowerShares QQQ (QQQ) 87.95 0.53% 86.76 87.97
05/05/2014 ewi iShares MSCI Italy Capped (EWI) 17.86 -0.56% 17.65 17.89
05/05/2014 dfe WisdomTree Europe SmallCap Dividend (DFE) 62.33 -0.11% 61.94 62.39
05/05/2014 pbd PowerShares Global Clean Energy (PBD) 13.03 0.00% 12.97 13.05
05/05/2014 eirl iShares MSCI Ireland Capped (EIRL) 38.52 -0.16% 38.39 38.60
本程序源代码:
官方描述HTMLParser的文档:
htmlparser(解析HTML文档元素)
网页数据抓取怎么写(网页数据抓取怎么写才快,网站数据源动态更新怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-20 18:43
网页数据抓取怎么写才快,网站数据源动态更新怎么办?这是我们不得不面对的一个问题。但是,用代码的方式是一定会有问题,因为网站网站人工生成数据是更新非常慢的。所以就必须使用爬虫,通过使用爬虫手段做网站数据爬取,再传输到客户端使用。也可以使用node.js语言来进行爬虫的开发。1.简单概述以及直接使用环境方法编写scrapy使用的环境有两种:redis:一个webservermongodb:存储数据redis与mongodb有一个本质的区别是:mongodb可以对多个session进行操作。
比如,你可以有一个或者多个session,并通过转存的方式保存一些数据,然后当你的访问不断发生变化时,可以快速检索并抓取到想要的数据。例如,我们现在想抓取海南大学的用户评论信息,通过一条评论抓取100条数据,需要在4个dns上抓取。比如:首先在本地浏览器上访问-saika/newss/xiaogaihui-xiaohong-university-australia?localtime=nd2602000018,得到如下页面路径:;localtime=nd2602000018&usersourcekey=csi9baaaabe302ce03016f97709d48422f384c4adc4_2&duration=8&relativetime=severalday=severalday&modtype=1mongodb也可以对多个session进行操作,只是就少了一个转存的过程,下面我们通过一个简单的scrapy项目来看看步骤。
2.了解需求首先,我们需要了解整个爬虫的基本操作流程:分类——选择信息——爬取——存储——分析——爬取——存储——修改数据,从这个项目中,我们发现,我们想要抓取海南大学2019年的毕业生评论,那么这个网站我们想要达到的目的是什么呢?我们想要抓取海南大学各个毕业生的评论来计算当年各个人毕业年数的总数,我们拿初一到初五来做参考:数据:我们想要爬取出当年各个毕业生的评论年数总和在计算出总数与整年人数之后,计算出各个人的平均年龄,也就是我们常说的数据压缩:那么上面的这一系列的操作就可以实现:爬取——翻页爬取当年各个毕业生评论——我们找出评论年数最大的那一页抓取——翻页抓取第二页评论——找出评论年数最大的第一页——第二页——第三页——第四页——第五页——循环直到某页评论数达到所需要的数量。
可以看到,当所有的毕业生评论都抓取完了以后,我们的文件数已经达到12571条,至此完成了一个网站的爬取。3.数据压缩以及文件读取当我们每次抓取都要解析出的时候,会耗费大量的时间。怎么办呢?我们可以在爬取的时候设置一个http的头比如:headers={'x-forwarded-for':'x。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写才快,网站数据源动态更新怎么办?)
网页数据抓取怎么写才快,网站数据源动态更新怎么办?这是我们不得不面对的一个问题。但是,用代码的方式是一定会有问题,因为网站网站人工生成数据是更新非常慢的。所以就必须使用爬虫,通过使用爬虫手段做网站数据爬取,再传输到客户端使用。也可以使用node.js语言来进行爬虫的开发。1.简单概述以及直接使用环境方法编写scrapy使用的环境有两种:redis:一个webservermongodb:存储数据redis与mongodb有一个本质的区别是:mongodb可以对多个session进行操作。
比如,你可以有一个或者多个session,并通过转存的方式保存一些数据,然后当你的访问不断发生变化时,可以快速检索并抓取到想要的数据。例如,我们现在想抓取海南大学的用户评论信息,通过一条评论抓取100条数据,需要在4个dns上抓取。比如:首先在本地浏览器上访问-saika/newss/xiaogaihui-xiaohong-university-australia?localtime=nd2602000018,得到如下页面路径:;localtime=nd2602000018&usersourcekey=csi9baaaabe302ce03016f97709d48422f384c4adc4_2&duration=8&relativetime=severalday=severalday&modtype=1mongodb也可以对多个session进行操作,只是就少了一个转存的过程,下面我们通过一个简单的scrapy项目来看看步骤。
2.了解需求首先,我们需要了解整个爬虫的基本操作流程:分类——选择信息——爬取——存储——分析——爬取——存储——修改数据,从这个项目中,我们发现,我们想要抓取海南大学2019年的毕业生评论,那么这个网站我们想要达到的目的是什么呢?我们想要抓取海南大学各个毕业生的评论来计算当年各个人毕业年数的总数,我们拿初一到初五来做参考:数据:我们想要爬取出当年各个毕业生的评论年数总和在计算出总数与整年人数之后,计算出各个人的平均年龄,也就是我们常说的数据压缩:那么上面的这一系列的操作就可以实现:爬取——翻页爬取当年各个毕业生评论——我们找出评论年数最大的那一页抓取——翻页抓取第二页评论——找出评论年数最大的第一页——第二页——第三页——第四页——第五页——循环直到某页评论数达到所需要的数量。
可以看到,当所有的毕业生评论都抓取完了以后,我们的文件数已经达到12571条,至此完成了一个网站的爬取。3.数据压缩以及文件读取当我们每次抓取都要解析出的时候,会耗费大量的时间。怎么办呢?我们可以在爬取的时候设置一个http的头比如:headers={'x-forwarded-for':'x。

