
网页数据抓取怎么写
网页数据抓取怎么写(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-19 08:24
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils。下面是我为《乌云》写的一个例子
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:
二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择它。博士。选择(“H3”)。迭代器(),对于jsup,有以下规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、Selector选择器基本语法
2、Selector选择器组合语法
3、Selector伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
查看全部
网页数据抓取怎么写(乌云网我写的一个公用的HttpUtils..例子
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils。下面是我为《乌云》写的一个例子
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:

二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择它。博士。选择(“H3”)。迭代器(),对于jsup,有以下规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、Selector选择器基本语法
2、Selector选择器组合语法
3、Selector伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
网页数据抓取怎么写(webscraper抓取数据的几种解决方案,你可能会碰到的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-19 08:20
如果您想要抓取数据并且懒得编写代码,您可以尝试使用WebScraper来抓取数据
相关文章:
最简单的数据捕获教程适用于所有人
网页刮刀高级教程,大家都可以用
如果您使用web scraper捕获数据,您可能会遇到以下一个或多个问题,这些问题可能会直接中断您的计划,甚至使您放弃web scraper
以下是您可能遇到的一些问题和解决方案
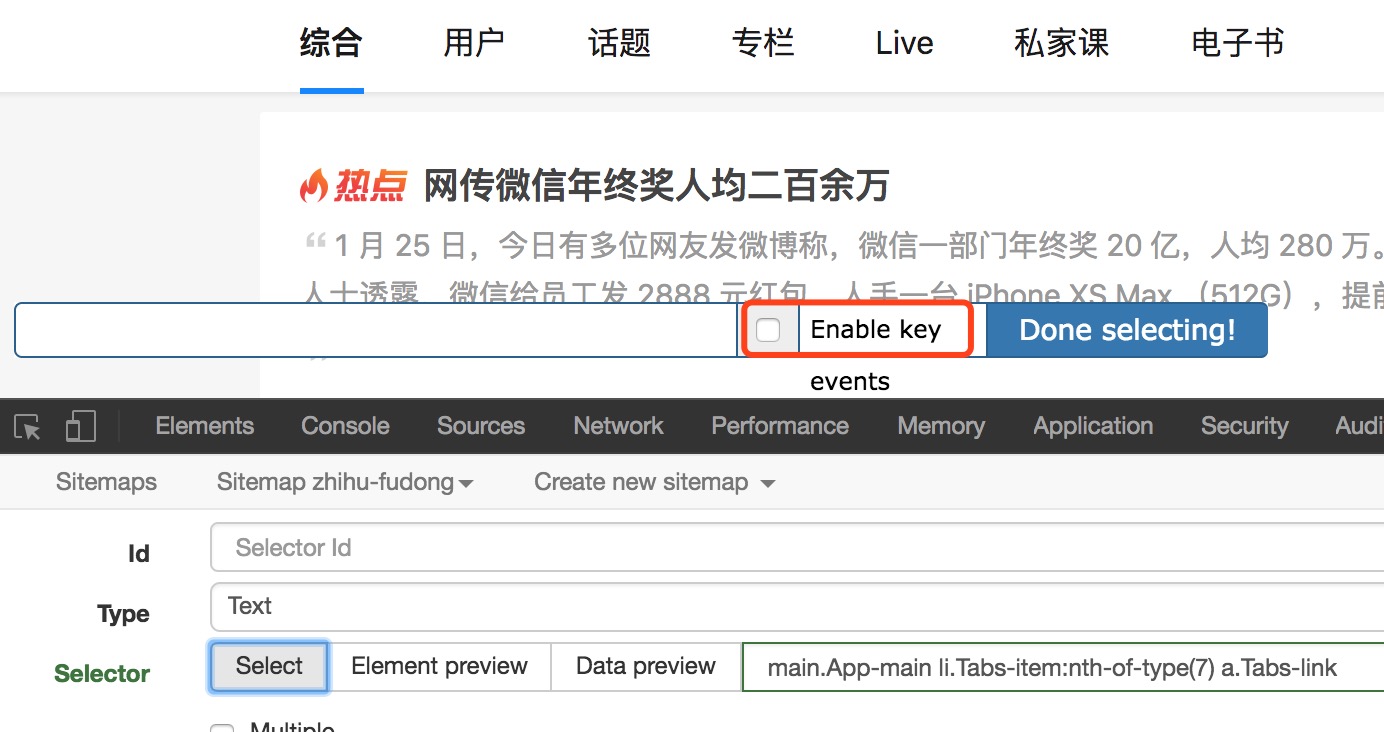
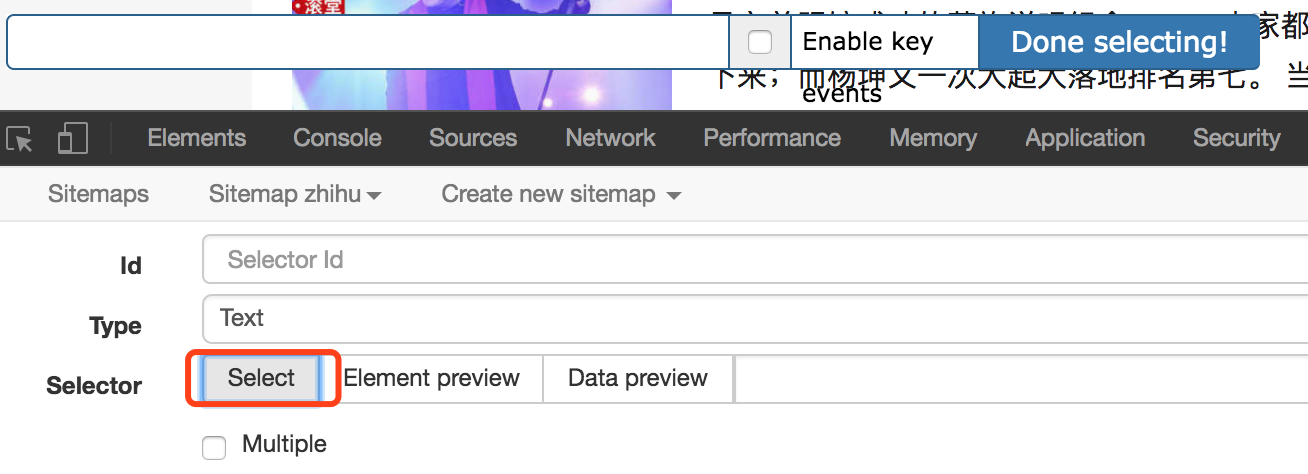
1、有时我们想选择一个链接,但单击鼠标可触发页面跳转。如何处理
选择页面元素时,选中“启用键”,然后将鼠标滑过要选择的元素并按s
此外,勾选“启用键”后,会出现三个字母,即s、p和C。按s键选择当前元素,p键选择当前元素的父元素,C键选择当前元素的子元素,当前元素指鼠标所在的元素
@无法完全捕获2、分页数据或滚动数据,例如知乎和twitter
这些问题大多是由网络问题引起的。在加载数据之前,web scraper开始解析数据。但是,由于没有及时加载,web scraper错误地认为数据已被捕获
因此,适当增加延迟大小并延长等待时间,以允许有足够的时间加载数据。默认延迟为2000,即2秒,可根据网络速度进行调整
但是,当数据量很大时,不完整的数据捕获也很常见。因为只要翻页或下拉加载没有在延迟时间内完成,爬网就结束了
3、捕获数据的顺序与网页上的顺序不一致
默认情况下,Web刮板是无序的。可以安装CouchDB以确保数据的顺序
或采用其他替代方法。最后,我们将数据导出为CSV格式。在Excel中打开CSV后,可以根据列对其进行排序。比如抓取微博数据时,抓取发布时间,然后在Excel中按照发布时间排序,或者按照类似的方式对数据进行知乎排序
4、无法通过web scraper提供的选择器选择某些页面元素
这可能是因为网站页面本身不符合网页布局规范,或者您需要的数据是动态的,例如只有在鼠标悬停时才会显示的元素。在这些情况下,您需要使用其他方法
事实上,通过鼠标操作选择元素就是找到与元素对应的XPath。XPath对应于web页面,它定位元素的路径,并通过元素的类型、唯一标识符、样式名和父子关系查找元素或元素的类型
如果没有遇到这个问题,就不需要知道XPath。等到遇到问题时再去学习
下面是使用web刮板过程中的几个常见问题。如果您遇到其他问题,可以在下面的文章处留言 查看全部
网页数据抓取怎么写(webscraper抓取数据的几种解决方案,你可能会碰到的问题)
如果您想要抓取数据并且懒得编写代码,您可以尝试使用WebScraper来抓取数据
相关文章:
最简单的数据捕获教程适用于所有人
网页刮刀高级教程,大家都可以用
如果您使用web scraper捕获数据,您可能会遇到以下一个或多个问题,这些问题可能会直接中断您的计划,甚至使您放弃web scraper
以下是您可能遇到的一些问题和解决方案
1、有时我们想选择一个链接,但单击鼠标可触发页面跳转。如何处理
选择页面元素时,选中“启用键”,然后将鼠标滑过要选择的元素并按s
此外,勾选“启用键”后,会出现三个字母,即s、p和C。按s键选择当前元素,p键选择当前元素的父元素,C键选择当前元素的子元素,当前元素指鼠标所在的元素
@无法完全捕获2、分页数据或滚动数据,例如知乎和twitter
这些问题大多是由网络问题引起的。在加载数据之前,web scraper开始解析数据。但是,由于没有及时加载,web scraper错误地认为数据已被捕获
因此,适当增加延迟大小并延长等待时间,以允许有足够的时间加载数据。默认延迟为2000,即2秒,可根据网络速度进行调整
但是,当数据量很大时,不完整的数据捕获也很常见。因为只要翻页或下拉加载没有在延迟时间内完成,爬网就结束了
3、捕获数据的顺序与网页上的顺序不一致
默认情况下,Web刮板是无序的。可以安装CouchDB以确保数据的顺序
或采用其他替代方法。最后,我们将数据导出为CSV格式。在Excel中打开CSV后,可以根据列对其进行排序。比如抓取微博数据时,抓取发布时间,然后在Excel中按照发布时间排序,或者按照类似的方式对数据进行知乎排序
4、无法通过web scraper提供的选择器选择某些页面元素
这可能是因为网站页面本身不符合网页布局规范,或者您需要的数据是动态的,例如只有在鼠标悬停时才会显示的元素。在这些情况下,您需要使用其他方法
事实上,通过鼠标操作选择元素就是找到与元素对应的XPath。XPath对应于web页面,它定位元素的路径,并通过元素的类型、唯一标识符、样式名和父子关系查找元素或元素的类型
如果没有遇到这个问题,就不需要知道XPath。等到遇到问题时再去学习
下面是使用web刮板过程中的几个常见问题。如果您遇到其他问题,可以在下面的文章处留言
网页数据抓取怎么写( 小编来一起如何用python来抓取页面中的数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-09-18 14:03
小编来一起如何用python来抓取页面中的数据?
)
如何使用Python捕获网页中的动态数据
saitlas于2020年8月17日11:08:10更新
本文文章主要介绍如何使用Python捕获网页中的动态数据。通过实例代码详细介绍,对大家的学习和工作有一定的参考和学习价值。有需要的朋友,让我们和小编一起学习
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,它引出了动态数据的概念。这里,动态数据指的是JavaScript在web页面中动态生成的页面内容,它是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们讨论如何使用Python获取页面中动态加载的JS数据
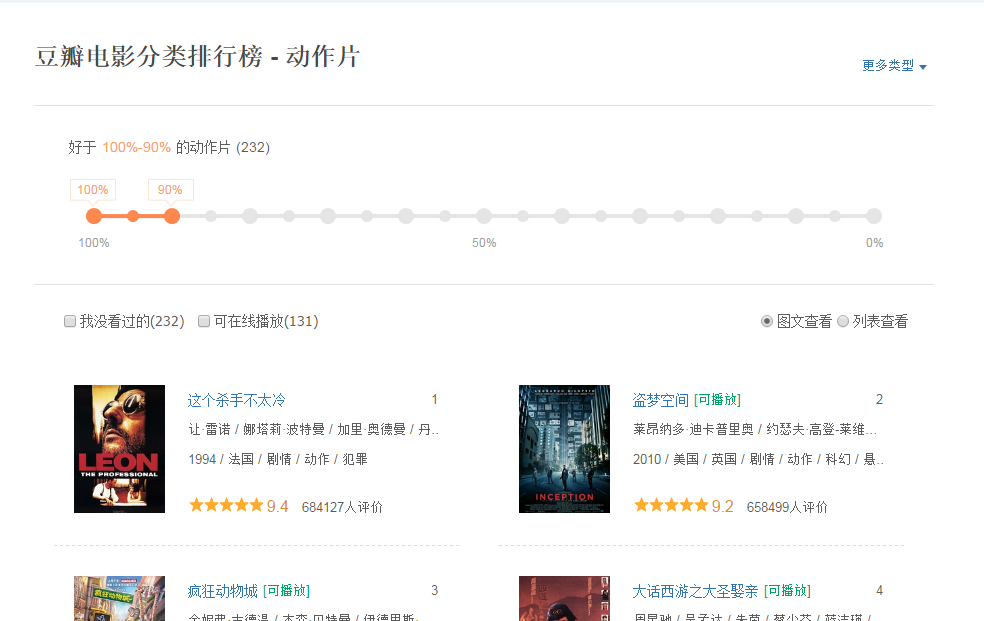
给出一个网页:豆瓣电影排行榜,其中所有电影信息都是动态加载的。我们无法直接从该页面获取有关每部电影的信息
如下图所示,我们无法在HTML中找到相应的电影信息
在Chrome浏览器中,单击F12在网络中打开XHR。让我们抓取相应的JS文件进行解析。如下图所示:
向下拖动豆瓣页面以加载更多电影信息,这样我们就可以抓取相应的消息
我们可以看到,它使用Ajax异步请求。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。因此,可以在不重新加载整个网页的情况下更新部分网页,从而实现数据的动态加载
我们可以看到,通过get,我们得到的响应收录相应的电影相关信息,这些信息以JSON格式保存在一起
查看requesturl信息,我们可以发现action参数后面跟着两个参数“start”和“limit”。显然,它们的意思是“从某个位置返回的电影数量”
如果想快速获取相关电影信息,可以直接将URL复制到地址栏中,修改所需的start和limit参数值,并获得相应的抓取结果
但是,这不是自动的,而且许多其他网站请求URL也不是直接给出的,因此我们使用Python进一步操作以获取返回的消息信息
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
网页数据抓取怎么写(
小编来一起如何用python来抓取页面中的数据?
)
如何使用Python捕获网页中的动态数据
saitlas于2020年8月17日11:08:10更新
本文文章主要介绍如何使用Python捕获网页中的动态数据。通过实例代码详细介绍,对大家的学习和工作有一定的参考和学习价值。有需要的朋友,让我们和小编一起学习
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,它引出了动态数据的概念。这里,动态数据指的是JavaScript在web页面中动态生成的页面内容,它是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们讨论如何使用Python获取页面中动态加载的JS数据
给出一个网页:豆瓣电影排行榜,其中所有电影信息都是动态加载的。我们无法直接从该页面获取有关每部电影的信息
如下图所示,我们无法在HTML中找到相应的电影信息
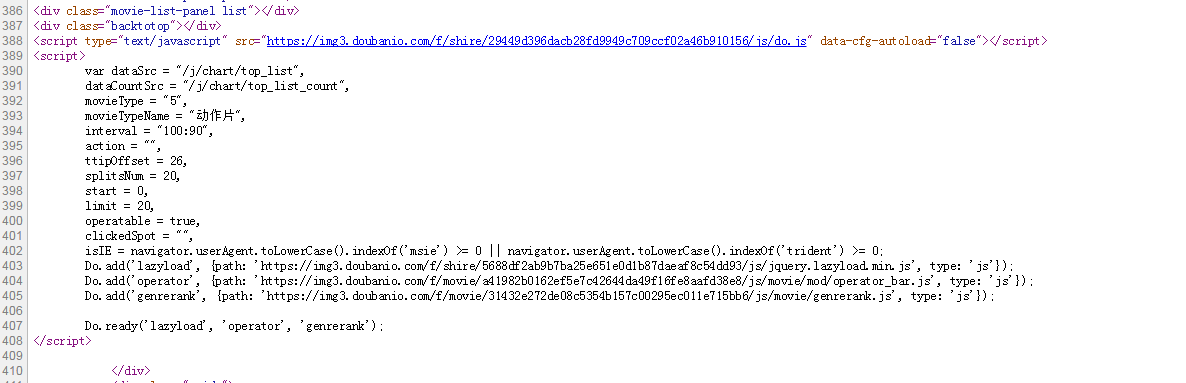
在Chrome浏览器中,单击F12在网络中打开XHR。让我们抓取相应的JS文件进行解析。如下图所示:

向下拖动豆瓣页面以加载更多电影信息,这样我们就可以抓取相应的消息
我们可以看到,它使用Ajax异步请求。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。因此,可以在不重新加载整个网页的情况下更新部分网页,从而实现数据的动态加载

我们可以看到,通过get,我们得到的响应收录相应的电影相关信息,这些信息以JSON格式保存在一起

查看requesturl信息,我们可以发现action参数后面跟着两个参数“start”和“limit”。显然,它们的意思是“从某个位置返回的电影数量”
如果想快速获取相关电影信息,可以直接将URL复制到地址栏中,修改所需的start和limit参数值,并获得相应的抓取结果
但是,这不是自动的,而且许多其他网站请求URL也不是直接给出的,因此我们使用Python进一步操作以获取返回的消息信息
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
网页数据抓取怎么写(WebScraper怎么对付这种类型的网页翻页?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-18 08:37
我想解释一下寻呼机是什么。我翻了一大堆定义,觉得很麻烦。我们第一年没有上网。看看这幅画。我找到了功能最全面的示例,它支持数字页码调整、上一页、下一页和指定页码跳转
今天我们将学习Web scraper如何处理这种类型的页面翻转
事实上,在本教程的第一个示例中,我们捕获了豆瓣电影的列表。豆瓣的电影列表使用寻呼机分割数据:
但在那个时候,我们发现了网络链接的规则,并没有使用寻呼机来获取它们。因为当网页的链接有规律地变化时,控制链接参数捕获是最低的成本;如果页面可以翻页,但链接的更改不是经常性的,那么您必须先转到寻呼机
这些理论很无聊。让我们以不规则翻页链接为例
8月2日是蔡旭坤的生日。为了庆祝,粉丝们在微博上为昆昆刷了300W的转发量。微博的转发数据只需除以寻呼机即可。让我们分析一下微博的转发信息页面,看看如何用网络抓取这类数据
此微博的直接链接是:
在看了这么多他的视频后,为了表达我们的感激之情,我们可以点击并为昆昆添加一本阅读手册
首先,让我们看看第1页上转发的链接。看起来是这样的:
第2页看起来像这样。我注意到许多#urnd36参数:
第3页上的参数为#rnd39
第4页上的参数为#rnd76:
再看几个链接,你会发现转发页面的URL是不规则的,所以你只能翻页并通过寻呼机加载数据。让我们开始实践教学吧
1.create Sitemap
我们首先创建一个站点地图,这次称为cxk,起始链接是
2.create容器选择器
因为我们想要点击寻呼机,所以我们选择外部容器的类型作为元素点击。具体参数说明如下图所示。之前我们在简单数据分析08中详细解释了它,所以这里不再讨论它
容器的预览如下图所示:
寻呼机的选择过程如下图所示:
3.create子选择器
这些子选择器相对简单。这些类型是文本选择器。我们选择三种类型的内容:评论用户名、评论内容和评论时间
4.grab数据
根据网站地图cxk->;scratch的操作路径可以抓取数据
5.一些问题
如果您阅读上述教程并立即爬升数据,您可能遇到的第一个问题是300W的数据。我要把所有的数据都记录下来吗
听起来不现实。毕竟,web scraper所针对的数据量相对较小,成千上万的数据太多。不管数据有多大,你必须考虑爬行时间是否太长,如何存储数据,以及如何处理网站的反爬虫系统(例如,如果你跳出验证码,这个Web刮刀是无能为力的)
考虑到这个问题,如果您已经看过上一篇关于自动控制抓取数量的教程,那么您可能希望使用类型为(-N+N)的第N个来控制N条数据的抓取。如果你尝试一下,你会发现这种方法毫无用处
失败的原因实际上涉及到一点网页知识。如果你感兴趣,你可以看到下面的解释。如果你不感兴趣,你可以直接看到最后的结论
正如我前面提到的,单击更多加载页面并下拉加载页面。新加载的数据将添加到当前页面。你一直往下拉,数据一直在加载。同时,页面的滚动条将越来越短,这意味着所有数据都在同一页面上
当我们使用(-N+N)类型的:N来控制加载的数量时,实际上相当于在此网页上设置一个计数器。当数据累积到我们想要的数量时,它将停止提取
但是,对于使用页面翻转器的网页,每次页面翻转都相当于刷新当前网页,因此每次都会设置一个计数器
例如,您希望捕获1000条数据,但第一页上只有20条数据。如果你赶上了最后一个,980件仍然不见了;然后,一旦翻页,就会设置一个新的计数器。在抓取第2页上的最后一个数据后,仍然是980。翻页后,计数器将复位并变为1000。。。因此,控制数量的方法是无效的
因此,结论是,如果寻呼机类型的网页想要提前结束捕获,唯一的方法就是断开网络连接。当然,如果你有更好的计划,你可以在评论中回复我,我们可以互相讨论
6.摘要
寻呼机是一种非常常见的网页分页方法。我们可以通过web scraper中的元素单击来处理这种类型的web页面,并通过断开连接来结束爬行 查看全部
网页数据抓取怎么写(WebScraper怎么对付这种类型的网页翻页?(上))
我想解释一下寻呼机是什么。我翻了一大堆定义,觉得很麻烦。我们第一年没有上网。看看这幅画。我找到了功能最全面的示例,它支持数字页码调整、上一页、下一页和指定页码跳转

今天我们将学习Web scraper如何处理这种类型的页面翻转
事实上,在本教程的第一个示例中,我们捕获了豆瓣电影的列表。豆瓣的电影列表使用寻呼机分割数据:

但在那个时候,我们发现了网络链接的规则,并没有使用寻呼机来获取它们。因为当网页的链接有规律地变化时,控制链接参数捕获是最低的成本;如果页面可以翻页,但链接的更改不是经常性的,那么您必须先转到寻呼机
这些理论很无聊。让我们以不规则翻页链接为例
8月2日是蔡旭坤的生日。为了庆祝,粉丝们在微博上为昆昆刷了300W的转发量。微博的转发数据只需除以寻呼机即可。让我们分析一下微博的转发信息页面,看看如何用网络抓取这类数据

此微博的直接链接是:
在看了这么多他的视频后,为了表达我们的感激之情,我们可以点击并为昆昆添加一本阅读手册
首先,让我们看看第1页上转发的链接。看起来是这样的:
第2页看起来像这样。我注意到许多#urnd36参数:
第3页上的参数为#rnd39
第4页上的参数为#rnd76:
再看几个链接,你会发现转发页面的URL是不规则的,所以你只能翻页并通过寻呼机加载数据。让我们开始实践教学吧
1.create Sitemap
我们首先创建一个站点地图,这次称为cxk,起始链接是

2.create容器选择器
因为我们想要点击寻呼机,所以我们选择外部容器的类型作为元素点击。具体参数说明如下图所示。之前我们在简单数据分析08中详细解释了它,所以这里不再讨论它

容器的预览如下图所示:

寻呼机的选择过程如下图所示:

3.create子选择器
这些子选择器相对简单。这些类型是文本选择器。我们选择三种类型的内容:评论用户名、评论内容和评论时间

4.grab数据
根据网站地图cxk->;scratch的操作路径可以抓取数据
5.一些问题
如果您阅读上述教程并立即爬升数据,您可能遇到的第一个问题是300W的数据。我要把所有的数据都记录下来吗
听起来不现实。毕竟,web scraper所针对的数据量相对较小,成千上万的数据太多。不管数据有多大,你必须考虑爬行时间是否太长,如何存储数据,以及如何处理网站的反爬虫系统(例如,如果你跳出验证码,这个Web刮刀是无能为力的)
考虑到这个问题,如果您已经看过上一篇关于自动控制抓取数量的教程,那么您可能希望使用类型为(-N+N)的第N个来控制N条数据的抓取。如果你尝试一下,你会发现这种方法毫无用处
失败的原因实际上涉及到一点网页知识。如果你感兴趣,你可以看到下面的解释。如果你不感兴趣,你可以直接看到最后的结论
正如我前面提到的,单击更多加载页面并下拉加载页面。新加载的数据将添加到当前页面。你一直往下拉,数据一直在加载。同时,页面的滚动条将越来越短,这意味着所有数据都在同一页面上
当我们使用(-N+N)类型的:N来控制加载的数量时,实际上相当于在此网页上设置一个计数器。当数据累积到我们想要的数量时,它将停止提取
但是,对于使用页面翻转器的网页,每次页面翻转都相当于刷新当前网页,因此每次都会设置一个计数器
例如,您希望捕获1000条数据,但第一页上只有20条数据。如果你赶上了最后一个,980件仍然不见了;然后,一旦翻页,就会设置一个新的计数器。在抓取第2页上的最后一个数据后,仍然是980。翻页后,计数器将复位并变为1000。。。因此,控制数量的方法是无效的
因此,结论是,如果寻呼机类型的网页想要提前结束捕获,唯一的方法就是断开网络连接。当然,如果你有更好的计划,你可以在评论中回复我,我们可以互相讨论
6.摘要
寻呼机是一种非常常见的网页分页方法。我们可以通过web scraper中的元素单击来处理这种类型的web页面,并通过断开连接来结束爬行
网页数据抓取怎么写(写个辅助工具的时候需要提取网页里面的某些内容(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-18 08:33
)
写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦!
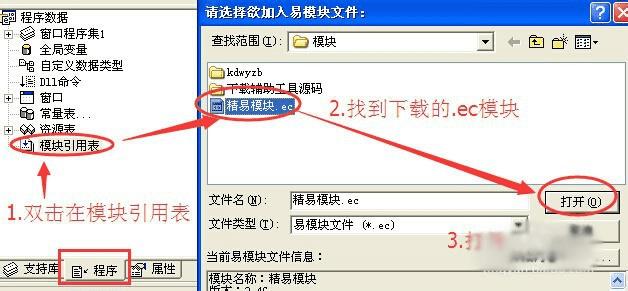
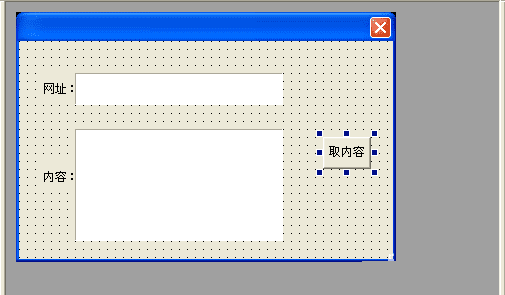
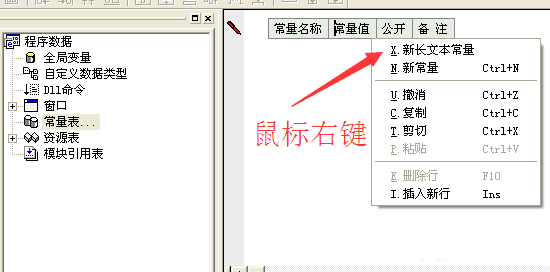
1、在新建的windos窗口程序中画:
两个编辑框、一个按钮。
再添加模块如图中三步!
我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。
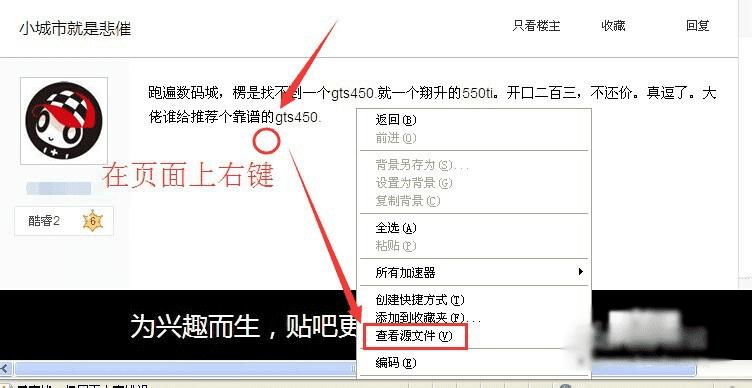
2、比如我们来取百度某贴吧一个帖子内的内容!如下图中的“跑遍数码城,XXXXX”。
我们在该页面上右键---->查看网页源码(或查看源文件)。
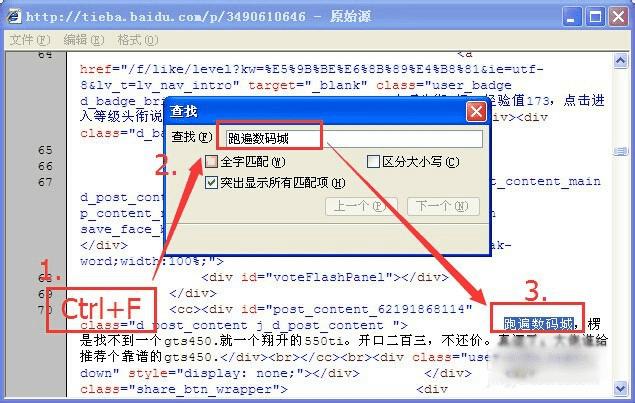
3、在打开的源文件内容中按CTRL+F组合键查找“跑遍数码城”,我们只要一个开文中一部分就行了!找到对应的文字后,我们找到和网页中完全对应的那部分代码。
PS:可能会出现几个被找到的内容,但是只要找到你需要取的那段全部对应部分就行。
4、复制正文中的前面的部分代码,不要复制太多的内容,待会我们用正文前的内容找到中间的内容。
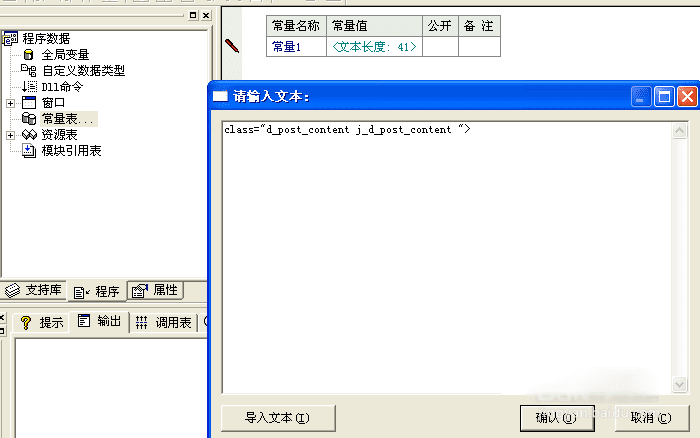
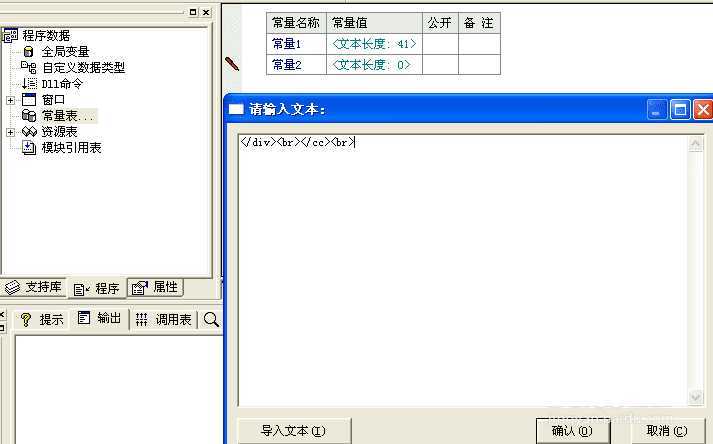
然后在易语言中新建一个文本常量,把复制到的内容粘贴到“常量值”里面去。
5、然后我们去复制正文后面的一小段代码,同样新建一个文本常量,然后粘贴到常量值里面去。
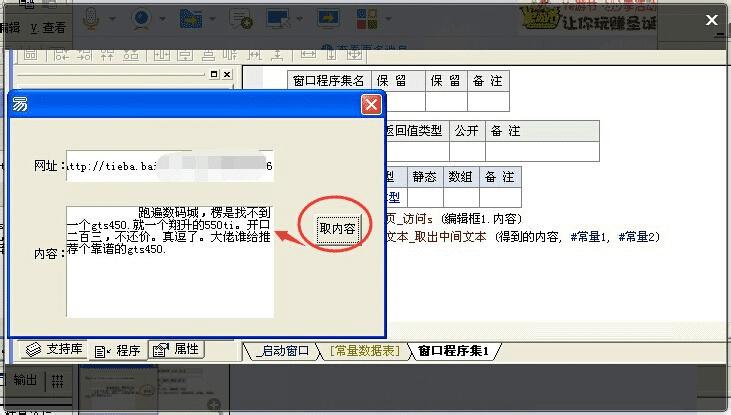
6、此时我们回到编程程序中,点击按钮,在生成的“_按钮1_被单击”子程序下面新建一个文本型变量“得到的内容”,然后输入以下代码:
得到的内容 = 网页_访问s (编辑框1.内容)编辑框2.内容 = 文本_取出中间文本 (得到的内容, #常量1, #常量2)
PS:第一行是把把编辑框中的网址打开后得到的网页源码赋值给“得到的内容”这个文本变量。
第二行则是对“得到的文本”进行取中间文本操作,文本_取出中间文本()是一个程序!它能取出中间内容的程序!
7、最后我们把程序调试运行一下,点击按钮“取内容”,是不是成功了呢?打开其他帖子取也是有效的,只要你取前后代码是正确的!
如果你是需要网页的源码,只要使用程序“网页_访问s()”,就然后把它赋值输出就OK了。当然!括号里面要有网页地址!
查看全部
网页数据抓取怎么写(写个辅助工具的时候需要提取网页里面的某些内容(组图)
)
写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦!
1、在新建的windos窗口程序中画:
两个编辑框、一个按钮。
再添加模块如图中三步!
我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。
2、比如我们来取百度某贴吧一个帖子内的内容!如下图中的“跑遍数码城,XXXXX”。
我们在该页面上右键---->查看网页源码(或查看源文件)。
3、在打开的源文件内容中按CTRL+F组合键查找“跑遍数码城”,我们只要一个开文中一部分就行了!找到对应的文字后,我们找到和网页中完全对应的那部分代码。
PS:可能会出现几个被找到的内容,但是只要找到你需要取的那段全部对应部分就行。
4、复制正文中的前面的部分代码,不要复制太多的内容,待会我们用正文前的内容找到中间的内容。
然后在易语言中新建一个文本常量,把复制到的内容粘贴到“常量值”里面去。
5、然后我们去复制正文后面的一小段代码,同样新建一个文本常量,然后粘贴到常量值里面去。
6、此时我们回到编程程序中,点击按钮,在生成的“_按钮1_被单击”子程序下面新建一个文本型变量“得到的内容”,然后输入以下代码:
得到的内容 = 网页_访问s (编辑框1.内容)编辑框2.内容 = 文本_取出中间文本 (得到的内容, #常量1, #常量2)
PS:第一行是把把编辑框中的网址打开后得到的网页源码赋值给“得到的内容”这个文本变量。
第二行则是对“得到的文本”进行取中间文本操作,文本_取出中间文本()是一个程序!它能取出中间内容的程序!
7、最后我们把程序调试运行一下,点击按钮“取内容”,是不是成功了呢?打开其他帖子取也是有效的,只要你取前后代码是正确的!
如果你是需要网页的源码,只要使用程序“网页_访问s()”,就然后把它赋值输出就OK了。当然!括号里面要有网页地址!
网页数据抓取怎么写( 爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-18 08:30
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.textprint(title)# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
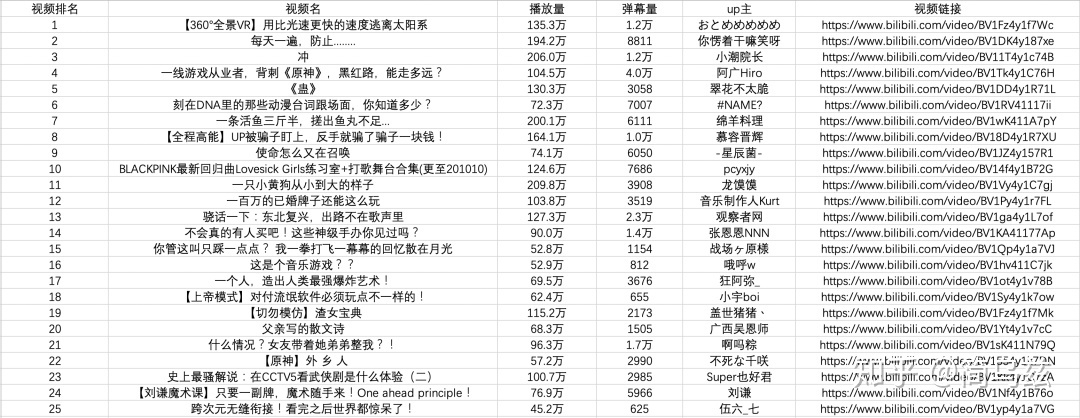
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,因此代码可以这样编写
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)dict_writer.writeheaderdict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据请求来看,目标网站具有各种形式的反爬行和加密,在以后的数据解析、提取甚至存储过程中还有很多需要进一步探索和学习的地方
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoupimport csvimport pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheaderdict_writer.writerows(all_products)### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
网页数据抓取怎么写(
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)

爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容

您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.textprint(title)# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,因此代码可以这样编写
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)dict_writer.writeheaderdict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据请求来看,目标网站具有各种形式的反爬行和加密,在以后的数据解析、提取甚至存储过程中还有很多需要进一步探索和学习的地方
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoupimport csvimport pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheaderdict_writer.writerows(all_products)### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
网页数据抓取怎么写( python抓取网页数据招摇决定Python抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-18 04:08
python抓取网页数据招摇决定Python抓取数据)
Python抓取网页数据ypython抓取网页数据txt51自信是取之不尽的源泉,自信是汹涌的浪潮,自信是快速进步的渠道,自信是真正成功的母亲,用Python抓取并处理网页,2009-02-19150950分类Python标签无字体订阅,主要目的是抓取一个网页的源代码,处理并将里面需要的数据保存到数据库中,我们实现了抓取页面和读取数据的步骤。第1步抓取页面非常简单。我们引入了urllib,用urlopen打开网址,用read方法读取数据。为了方便测试,我们使用本地文本文件而不是抓取网页。步骤2处理数据。如果页面代码相对标准,我们可以使用HTMLPasser进行简单处理,但具体情况需要具体分析,我认为最好使用正则表达式。顺便说一下,我将练习我刚学的正则表达式。事实上,正则表达式也是一种相对简单的语言。有很多符号,有点晦涩难懂。我只能多练习,多练习。步骤3:将处理后的数据保存到数据库中,并使用pymssql进行处理。在这里,只需将其保存到文本文件并展开即可。仍然需要使用此功能,您可以抓取整个网站图片并自动声明站点地图文件。下一个任务是研究Python的套接字函数——编码GBK——导入urlibimportreport RurlLiberLopenDapagereAdAgerCloseFopenr“d2txt”DataFreedClose以处理数据预编译ClasseoneDivReisampFindAllData“”fordataninm以继续处理数据并取出标题介绍图片
和链接地址p_uTitlereCompileH2REResp_uuUrlRecompilereHREF“Reresp_uSummarreciplePreresp_ImageRecompileShopImages”ReRessss标题“p_uTitleSearchDatangGroup”RN“简介”p_uuSummarSearchDatangGroup“RN”图片“p_Imagesearchdatanggroup”RN“链接地址”p_UrlSearchDatangGroup“RN”fopenr“D2txt”Wfweritesfclose使用Python脚本获取实时股市信息2006-12-151347ie查看股市信息过于浮夸。我决定写一个python脚本来获取相关信息。它小巧方便。1.首先编写一个python脚本来获取股票市场查询页面。很容易发现实时股票市场数据是写在JavaScript文件中的。2.提取JavaScript文件URL。编写一个python脚本,抓取文件读取内容,通过字符串处理提取股价上涨等信息。3对于一些需要设置HTTP代理访问网络的情况,通过urlibopenproxies设置代理非常方便。4通过分析JavaScript文件URL,文件名格式为“股票代码JS”,建立配置文件,提供相关股票代码。使用Python脚本读取配置信息,并定期读取所需的实时信息。5定义每日市场格式并将其存储在XML中。6天后,python脚本可以读取存储的市场信息并生成图形信息,如报表K行 查看全部
网页数据抓取怎么写(
python抓取网页数据招摇决定Python抓取数据)

Python抓取网页数据ypython抓取网页数据txt51自信是取之不尽的源泉,自信是汹涌的浪潮,自信是快速进步的渠道,自信是真正成功的母亲,用Python抓取并处理网页,2009-02-19150950分类Python标签无字体订阅,主要目的是抓取一个网页的源代码,处理并将里面需要的数据保存到数据库中,我们实现了抓取页面和读取数据的步骤。第1步抓取页面非常简单。我们引入了urllib,用urlopen打开网址,用read方法读取数据。为了方便测试,我们使用本地文本文件而不是抓取网页。步骤2处理数据。如果页面代码相对标准,我们可以使用HTMLPasser进行简单处理,但具体情况需要具体分析,我认为最好使用正则表达式。顺便说一下,我将练习我刚学的正则表达式。事实上,正则表达式也是一种相对简单的语言。有很多符号,有点晦涩难懂。我只能多练习,多练习。步骤3:将处理后的数据保存到数据库中,并使用pymssql进行处理。在这里,只需将其保存到文本文件并展开即可。仍然需要使用此功能,您可以抓取整个网站图片并自动声明站点地图文件。下一个任务是研究Python的套接字函数——编码GBK——导入urlibimportreport RurlLiberLopenDapagereAdAgerCloseFopenr“d2txt”DataFreedClose以处理数据预编译ClasseoneDivReisampFindAllData“”fordataninm以继续处理数据并取出标题介绍图片

和链接地址p_uTitlereCompileH2REResp_uuUrlRecompilereHREF“Reresp_uSummarreciplePreresp_ImageRecompileShopImages”ReRessss标题“p_uTitleSearchDatangGroup”RN“简介”p_uuSummarSearchDatangGroup“RN”图片“p_Imagesearchdatanggroup”RN“链接地址”p_UrlSearchDatangGroup“RN”fopenr“D2txt”Wfweritesfclose使用Python脚本获取实时股市信息2006-12-151347ie查看股市信息过于浮夸。我决定写一个python脚本来获取相关信息。它小巧方便。1.首先编写一个python脚本来获取股票市场查询页面。很容易发现实时股票市场数据是写在JavaScript文件中的。2.提取JavaScript文件URL。编写一个python脚本,抓取文件读取内容,通过字符串处理提取股价上涨等信息。3对于一些需要设置HTTP代理访问网络的情况,通过urlibopenproxies设置代理非常方便。4通过分析JavaScript文件URL,文件名格式为“股票代码JS”,建立配置文件,提供相关股票代码。使用Python脚本读取配置信息,并定期读取所需的实时信息。5定义每日市场格式并将其存储在XML中。6天后,python脚本可以读取存储的市场信息并生成图形信息,如报表K行
网页数据抓取怎么写( 从互联网上爬取语料的经验:0各模块的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-16 20:15
从互联网上爬取语料的经验:0各模块的功能)
使用Python3教您任何HTML主内容提取函数
更新时间:2018年11月5日14:14:41作者:腾讯deepcocean
本文文章主要介绍如何使用Python3教您任何HTML主内容提取函数。它主要使用请求、lxml、JSON等模块。本文将逐一介绍这些模块。有需要的朋友可以向他们推荐
本文将与大家分享一些从互联网上抓取语料库的经验
0x1刀具准备
如果你想做得好,你必须先磨快你的工具。基于Python
的爬网语料库的建立
我们基于Python3开发,主要使用以下模块:请求、lxml和JSON
简要介绍各模块的功能
01|请求
Requests是一个python第三方库,特别便于处理URL资源。它的官方文件有一个很大的口号:人类的http。与Python自己的urllib体验相比,作者认为请求的使用体验比urllib高一个数量级
让我们做一个简单的比较:
urllib:
import urllib2
import urllib
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
#发送请求
response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
#Response Headers
print(response.info())
#Response Code
print(response.getcode())
#Response Body
print(response.read())
要求:
import requests
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
#发送请求
response = requests.get(URL_GET,params=params)
#Response Headers
print(response.headers)
#Response Code
print(response.status_code)
#Response Body
print(response.text)
我们可以发现这两个库之间存在一些差异:
1.parameter构造:urllib需要用URLEncode对参数进行编码,比较麻烦;请求非常简洁,无需额外的编码处理
2.request sending:urllib需要构造额外的URL参数才能成为合格的表单;请求更加简洁,直接获得相应的链接和参数
3.connection method:查看返回的头信息的“连接”。使用urlib库时,“连接”:“关闭”表示套接字通道在每个请求结束时关闭,而使用请求库时使用urlib3。多个请求重用套接字“连接”:“保持活动”,表示多个请求使用一个连接,消耗更少的资源
4.encoding method:接受编码在请求库中更完整。这里没有给出例子
综上所述,使用请求更简洁易懂,这对我们的开发非常方便
02÷lxml
Beauty soup是一个库,而XPath是一种技术。Python中最常用的XPath库是lxml
当我们获得请求返回的页面时,我们如何获得所需的数据?目前,lxml是一个强大的HTML/XML解析工具。Python从不缺少解析库,那么为什么我们要在众多库中选择lxml呢?我们选择另一个著名的HTML解析库BeautifulSoup进行比较
让我们做一个简单的比较:
美丽小组:
from bs4 import BeautifulSoup #导入库
# 假设html是需要被解析的html
#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#查找所有的h4标签
links = soup.find_all("h4")
lxml:
from lxml import etree
# 假设html是需要被解析的html
#将html传入etree 的构造方法,得到一个文档的对象
root = etree.HTML(html)
#查找所有的h4标签
links = root.xpath("//h4")
我们可以发现这两个库之间存在一些差异:
1.parsing HTML:Beauty soup的解析方法类似于JQ。API非常用户友好,支持CSS选择器;lxml的语法有一定的学习成本
2.performance:beautifulsoup基于DOM。它将加载整个文档并解析整个DOM树,因此时间和内存开销将大得多;Lxml只在本地进行遍历。此外,lxml是用C编写的,而Beauty soup是用Python编写的。显然,lxml>>;美丽的乌苏
综上所述,用靓汤更简洁,更容易使用。虽然lxml有一定的学习成本,但它也非常简洁易懂。最重要的是,它是用C编写的,速度要快得多。对于作者的强迫症,选择lxml是很自然的
03#json
Python自带了自己的JSON库,对于处理基本JSON来说已经足够了。但是,如果您想变得更懒惰,可以使用第三方JSON库。常见的是demjson和simplejson
这两个库在导入模块速度、编码和解码速度以及更好的兼容性方面都优于simplejson。因此,如果您想使用square库,可以使用simplejson
0x2确定语料库源
武器准备好后,下一步是确定攀爬方向
以电子体育语料库为例。现在我们将攀登电子体育语料库。常见的电子竞技平台包括企鹅电子竞技、企鹅电子竞技和企鹅电子竞技(斜视),因此我们使用企鹅电子竞技上的实时游戏作为爬行的数据源
我们登录企鹅电子竞技的官方网站,进入游戏列表页面。我们可以发现页面上有很多游戏。手动编写这些游戏名称显然是无利可图的,因此我们开始了爬虫程序的第一步:游戏列表爬虫
import requests
from lxml import etree
# 更新游戏列表
def _updateGameList():
# 发送HTTP请求时的HEAD信息,用于伪装为浏览器
heads = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
# 需要爬取的游戏列表页
url = 'https://egame.qq.com/gamelist'
# 不压缩html,最大链接时间为10妙
res = requests.get(url, headers=heads, verify=False, timeout=10)
# 为防止出错,编码utf-8
res.encoding = 'utf-8'
# 将html构建为Xpath模式
root = etree.HTML(res.content)
# 使用Xpath语法,获取游戏名
gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
# 输出爬到的游戏名
print(gameList)
当我们得到这几十个游戏名称时,下一步就是抓取这几十个游戏的语料库。此时,问题出现了。在推出这几十款游戏之前,我们将攀登哪个网站的顶峰?水龙头?多玩点?17173?通过分析这些网站s,发现这些网站s只有一些流行游戏的文章语料库,以及一些不受欢迎或低流行的游戏,如“灵魂芯片”、“奇迹:觉醒”和“死亡即将来临”。在这些网站s上很难找到大量的文章corpora,如图所示:
我们可以发现《奇迹:觉醒》和《灵魂芯片》的文章语料库非常少,数量也不符合我们的要求。那么,是否有一个更通用的资源站,它拥有无与伦比的丰富的文章语料库来满足我们的需求呢
事实上,冷静下来想想。我们每天都使用这个资源站,就是百度。我们在百度新闻中搜索相关游戏,并获得搜索结果列表。这些列表中几乎所有链接的网页都与搜索结果密切相关。这样,我们的数据源不够丰富的问题就可以很容易地得到解决。但是现在有一个新的问题,也是一个很难解决的问题——如何抓住任何网页的文章内容
因为不同的网站具有不同的页面结构,我们无法预测我们将爬升哪个网站数据,也无法为每个网站编写一组爬虫程序网站. 那种工作量是无法想象的!但我们不能简单粗暴地把这一页上的所有单词都写下来。用这样的语料库训练真是一场噩梦
经过与各种网站智慧和勇气的较量,查询数据和思考,我们终于找到了一个更通用的方案。让我们谈谈作者的想法
0x3任意网站爬网文章语料库
01|提取方法
@基于DOM树的1)文本提取
@基于网页分割的2)find文本块
@基于标记窗口的3)文本提取
4)基于数据挖掘或机器学习
@基于线块分布函数的5)文本提取
02|提取原理
我们看到这些都有点困惑,他们到底是怎么提取的呢?让我慢慢说
@基于1)DOM树的文本提取:
这种方法主要是通过比较标准HTML建立DOM树,然后遍历DOM,比较和识别各种非文本信息,包括广告、链接和非重要节点信息。提取出非文本信息后,剩下的自然是文本信息
但这种方法有两个问题
① 这尤其取决于HTML的良好结构。如果我们访问的网页不是按照W3C规范编写的,那么这种方法就不太适用
② 树的建立和遍历的时间复杂度和空间复杂度都很高,而且由于HTML标记的不同,树的遍历方法也会有所不同
2)find基于网页分段的文本块:
此方法使用HTML标记中的拆分行和一些视觉信息(如文本颜色、字体大小、文本信息等)
这种方法存在一个问题:
① 不同网站HTML风格迥异,没有统一的切分方法,不能保证切分的普遍性
3)基于标记窗口的文本提取:
首先介绍一个概念标签窗口。我们将两个标记和其中收录的文本组合到一个标记窗口中(例如,I am H1中的“I am H1”是标记窗口的内容),并取出标记窗口的文本
此方法首先获取HTML中的文章标题和所有标记窗口,然后将它们划分为单词。然后计算标题序列和标记窗口文本序列之间的单词距离L。如果l小于阈值,则标记窗口中的文本被视为文本
虽然这种方法看起来不错,但也存在一些问题:
① 对页面上的所有文本进行分段是没有效率的
② 单词距离的阈值很难确定,不同的单词文章具有不同的阈值
4)基于数据挖掘或机器学习
使用大数据进行培训,让机器提取主要文本
这种方法当然非常优秀,但它首先需要HTML和文本数据,然后再进行培训。我们不在这里讨论
@基于线块分布函数的5)文本提取
对于任何网页,其文本和标记总是混合在一起。此方法的核心有几个亮点:① 文本区域的密度;② 行块长度;网页的文本区域必须是文本信息分布最密集的区域之一。该区域可能最大(长评论信息和短文本),因此同时引用块长度进行判断
实施思路:
① 首先删除HTML标记,在取出标签后只留下所有文本和所有空白位置信息。我们称之为CText
② 取每个CText的周围K行(K)
③ 从cblock中删除所有空白字符,文本的总长度称为clen
④ 协调人 查看全部
网页数据抓取怎么写(
从互联网上爬取语料的经验:0各模块的功能)
使用Python3教您任何HTML主内容提取函数
更新时间:2018年11月5日14:14:41作者:腾讯deepcocean
本文文章主要介绍如何使用Python3教您任何HTML主内容提取函数。它主要使用请求、lxml、JSON等模块。本文将逐一介绍这些模块。有需要的朋友可以向他们推荐
本文将与大家分享一些从互联网上抓取语料库的经验
0x1刀具准备
如果你想做得好,你必须先磨快你的工具。基于Python
的爬网语料库的建立
我们基于Python3开发,主要使用以下模块:请求、lxml和JSON
简要介绍各模块的功能
01|请求
Requests是一个python第三方库,特别便于处理URL资源。它的官方文件有一个很大的口号:人类的http。与Python自己的urllib体验相比,作者认为请求的使用体验比urllib高一个数量级
让我们做一个简单的比较:
urllib:
import urllib2
import urllib
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
#发送请求
response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
#Response Headers
print(response.info())
#Response Code
print(response.getcode())
#Response Body
print(response.read())
要求:
import requests
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
#发送请求
response = requests.get(URL_GET,params=params)
#Response Headers
print(response.headers)
#Response Code
print(response.status_code)
#Response Body
print(response.text)
我们可以发现这两个库之间存在一些差异:
1.parameter构造:urllib需要用URLEncode对参数进行编码,比较麻烦;请求非常简洁,无需额外的编码处理
2.request sending:urllib需要构造额外的URL参数才能成为合格的表单;请求更加简洁,直接获得相应的链接和参数
3.connection method:查看返回的头信息的“连接”。使用urlib库时,“连接”:“关闭”表示套接字通道在每个请求结束时关闭,而使用请求库时使用urlib3。多个请求重用套接字“连接”:“保持活动”,表示多个请求使用一个连接,消耗更少的资源
4.encoding method:接受编码在请求库中更完整。这里没有给出例子
综上所述,使用请求更简洁易懂,这对我们的开发非常方便
02÷lxml
Beauty soup是一个库,而XPath是一种技术。Python中最常用的XPath库是lxml
当我们获得请求返回的页面时,我们如何获得所需的数据?目前,lxml是一个强大的HTML/XML解析工具。Python从不缺少解析库,那么为什么我们要在众多库中选择lxml呢?我们选择另一个著名的HTML解析库BeautifulSoup进行比较
让我们做一个简单的比较:
美丽小组:
from bs4 import BeautifulSoup #导入库
# 假设html是需要被解析的html
#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#查找所有的h4标签
links = soup.find_all("h4")
lxml:
from lxml import etree
# 假设html是需要被解析的html
#将html传入etree 的构造方法,得到一个文档的对象
root = etree.HTML(html)
#查找所有的h4标签
links = root.xpath("//h4")
我们可以发现这两个库之间存在一些差异:
1.parsing HTML:Beauty soup的解析方法类似于JQ。API非常用户友好,支持CSS选择器;lxml的语法有一定的学习成本
2.performance:beautifulsoup基于DOM。它将加载整个文档并解析整个DOM树,因此时间和内存开销将大得多;Lxml只在本地进行遍历。此外,lxml是用C编写的,而Beauty soup是用Python编写的。显然,lxml>>;美丽的乌苏
综上所述,用靓汤更简洁,更容易使用。虽然lxml有一定的学习成本,但它也非常简洁易懂。最重要的是,它是用C编写的,速度要快得多。对于作者的强迫症,选择lxml是很自然的
03#json
Python自带了自己的JSON库,对于处理基本JSON来说已经足够了。但是,如果您想变得更懒惰,可以使用第三方JSON库。常见的是demjson和simplejson
这两个库在导入模块速度、编码和解码速度以及更好的兼容性方面都优于simplejson。因此,如果您想使用square库,可以使用simplejson
0x2确定语料库源
武器准备好后,下一步是确定攀爬方向
以电子体育语料库为例。现在我们将攀登电子体育语料库。常见的电子竞技平台包括企鹅电子竞技、企鹅电子竞技和企鹅电子竞技(斜视),因此我们使用企鹅电子竞技上的实时游戏作为爬行的数据源
我们登录企鹅电子竞技的官方网站,进入游戏列表页面。我们可以发现页面上有很多游戏。手动编写这些游戏名称显然是无利可图的,因此我们开始了爬虫程序的第一步:游戏列表爬虫
import requests
from lxml import etree
# 更新游戏列表
def _updateGameList():
# 发送HTTP请求时的HEAD信息,用于伪装为浏览器
heads = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
# 需要爬取的游戏列表页
url = 'https://egame.qq.com/gamelist'
# 不压缩html,最大链接时间为10妙
res = requests.get(url, headers=heads, verify=False, timeout=10)
# 为防止出错,编码utf-8
res.encoding = 'utf-8'
# 将html构建为Xpath模式
root = etree.HTML(res.content)
# 使用Xpath语法,获取游戏名
gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
# 输出爬到的游戏名
print(gameList)
当我们得到这几十个游戏名称时,下一步就是抓取这几十个游戏的语料库。此时,问题出现了。在推出这几十款游戏之前,我们将攀登哪个网站的顶峰?水龙头?多玩点?17173?通过分析这些网站s,发现这些网站s只有一些流行游戏的文章语料库,以及一些不受欢迎或低流行的游戏,如“灵魂芯片”、“奇迹:觉醒”和“死亡即将来临”。在这些网站s上很难找到大量的文章corpora,如图所示:

我们可以发现《奇迹:觉醒》和《灵魂芯片》的文章语料库非常少,数量也不符合我们的要求。那么,是否有一个更通用的资源站,它拥有无与伦比的丰富的文章语料库来满足我们的需求呢
事实上,冷静下来想想。我们每天都使用这个资源站,就是百度。我们在百度新闻中搜索相关游戏,并获得搜索结果列表。这些列表中几乎所有链接的网页都与搜索结果密切相关。这样,我们的数据源不够丰富的问题就可以很容易地得到解决。但是现在有一个新的问题,也是一个很难解决的问题——如何抓住任何网页的文章内容
因为不同的网站具有不同的页面结构,我们无法预测我们将爬升哪个网站数据,也无法为每个网站编写一组爬虫程序网站. 那种工作量是无法想象的!但我们不能简单粗暴地把这一页上的所有单词都写下来。用这样的语料库训练真是一场噩梦
经过与各种网站智慧和勇气的较量,查询数据和思考,我们终于找到了一个更通用的方案。让我们谈谈作者的想法
0x3任意网站爬网文章语料库
01|提取方法
@基于DOM树的1)文本提取
@基于网页分割的2)find文本块
@基于标记窗口的3)文本提取
4)基于数据挖掘或机器学习
@基于线块分布函数的5)文本提取
02|提取原理
我们看到这些都有点困惑,他们到底是怎么提取的呢?让我慢慢说
@基于1)DOM树的文本提取:
这种方法主要是通过比较标准HTML建立DOM树,然后遍历DOM,比较和识别各种非文本信息,包括广告、链接和非重要节点信息。提取出非文本信息后,剩下的自然是文本信息
但这种方法有两个问题
① 这尤其取决于HTML的良好结构。如果我们访问的网页不是按照W3C规范编写的,那么这种方法就不太适用
② 树的建立和遍历的时间复杂度和空间复杂度都很高,而且由于HTML标记的不同,树的遍历方法也会有所不同
2)find基于网页分段的文本块:
此方法使用HTML标记中的拆分行和一些视觉信息(如文本颜色、字体大小、文本信息等)
这种方法存在一个问题:
① 不同网站HTML风格迥异,没有统一的切分方法,不能保证切分的普遍性
3)基于标记窗口的文本提取:
首先介绍一个概念标签窗口。我们将两个标记和其中收录的文本组合到一个标记窗口中(例如,I am H1中的“I am H1”是标记窗口的内容),并取出标记窗口的文本
此方法首先获取HTML中的文章标题和所有标记窗口,然后将它们划分为单词。然后计算标题序列和标记窗口文本序列之间的单词距离L。如果l小于阈值,则标记窗口中的文本被视为文本
虽然这种方法看起来不错,但也存在一些问题:
① 对页面上的所有文本进行分段是没有效率的
② 单词距离的阈值很难确定,不同的单词文章具有不同的阈值
4)基于数据挖掘或机器学习
使用大数据进行培训,让机器提取主要文本
这种方法当然非常优秀,但它首先需要HTML和文本数据,然后再进行培训。我们不在这里讨论
@基于线块分布函数的5)文本提取
对于任何网页,其文本和标记总是混合在一起。此方法的核心有几个亮点:① 文本区域的密度;② 行块长度;网页的文本区域必须是文本信息分布最密集的区域之一。该区域可能最大(长评论信息和短文本),因此同时引用块长度进行判断
实施思路:
① 首先删除HTML标记,在取出标签后只留下所有文本和所有空白位置信息。我们称之为CText
② 取每个CText的周围K行(K)
③ 从cblock中删除所有空白字符,文本的总长度称为clen
④ 协调人
网页数据抓取怎么写(Python是什么,什么是爬虫?具体该怎么学习?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-16 20:14
什么是Python?什么是爬虫?如何学习
Python是为数不多的简单而强大的编程语言之一。它易于学习和理解,易于使用,代码更接近自然语言和正常的思维方式。据统计,Python是世界上最流行的语言之一
爬虫是利用爬虫技术捕获论坛网站数据,并将所需数据以特定格式保存到数据库或文件中
具体学习:
1)首先,学习Python的基本知识,了解网络请求的原理和网页的结构
2)视频学习或找一本专业的网络爬虫书学习。所谓“前辈种树,后人乘凉”,按照大神的步骤,我们可以事半功倍
3)网站的实际操作在有了爬虫的想法后,可以找到更多的网站来操作
如何编写Python链接爬虫
首先,我们需要弄清楚,我们能看到的所有网页,无论是文本、图片还是动画,都用HTML标记。然后,浏览器以视觉和美学的方式向我们显示这些标签。如果我们想成为一个网络爬虫,我们的爬虫没有视觉,只有逻辑。在爬虫的眼中,只有HTML标记。其他样式正在使用中。爬虫的眼睛里有云,所以爬虫实际上读取HTML标记(这里涉及的一个知识点是获取HTML标记)。库是一个请求库,它可以通过web请求获取HTML元素,然后在HTML标记中显示所需的内容。这是一个网络爬虫。逻辑很简单。如果您有使用python的经验,建议您使用crawler框架 查看全部
网页数据抓取怎么写(Python是什么,什么是爬虫?具体该怎么学习?)
什么是Python?什么是爬虫?如何学习
Python是为数不多的简单而强大的编程语言之一。它易于学习和理解,易于使用,代码更接近自然语言和正常的思维方式。据统计,Python是世界上最流行的语言之一
爬虫是利用爬虫技术捕获论坛网站数据,并将所需数据以特定格式保存到数据库或文件中
具体学习:
1)首先,学习Python的基本知识,了解网络请求的原理和网页的结构
2)视频学习或找一本专业的网络爬虫书学习。所谓“前辈种树,后人乘凉”,按照大神的步骤,我们可以事半功倍
3)网站的实际操作在有了爬虫的想法后,可以找到更多的网站来操作
如何编写Python链接爬虫
首先,我们需要弄清楚,我们能看到的所有网页,无论是文本、图片还是动画,都用HTML标记。然后,浏览器以视觉和美学的方式向我们显示这些标签。如果我们想成为一个网络爬虫,我们的爬虫没有视觉,只有逻辑。在爬虫的眼中,只有HTML标记。其他样式正在使用中。爬虫的眼睛里有云,所以爬虫实际上读取HTML标记(这里涉及的一个知识点是获取HTML标记)。库是一个请求库,它可以通过web请求获取HTML元素,然后在HTML标记中显示所需的内容。这是一个网络爬虫。逻辑很简单。如果您有使用python的经验,建议您使用crawler框架
网页数据抓取怎么写(大数据时代已然到来,抓取网页数据成为科研重要手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-10 09:04
获取网页数据是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。 IDC(互联网数据中心)报告显示,2013年全球数据为4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但我们需要主页上的页面,上帝说我们需要一个页面!
1、打开网页
我们以百度搜索“Chahu”关键词为例:
使用 CreateObject("internetexplorer.application")
.Visible = True
.导航“导航”
'关闭网页
'.退出
结尾
代码很简单,先创建一个IE对象,然后给一些属性赋值。 Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
虽然 .ReadyState 4 或 .Busy
DoEvents
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
:请求未初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有一些数据可用,但服务器还没有完成响应生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结尾
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有带有css标签的样式名称,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。 查看全部
网页数据抓取怎么写(大数据时代已然到来,抓取网页数据成为科研重要手段)
获取网页数据是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。 IDC(互联网数据中心)报告显示,2013年全球数据为4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但我们需要主页上的页面,上帝说我们需要一个页面!
1、打开网页
我们以百度搜索“Chahu”关键词为例:
使用 CreateObject("internetexplorer.application")
.Visible = True
.导航“导航”
'关闭网页
'.退出
结尾
代码很简单,先创建一个IE对象,然后给一些属性赋值。 Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
虽然 .ReadyState 4 或 .Busy
DoEvents
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
:请求未初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有一些数据可用,但服务器还没有完成响应生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结尾
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有带有css标签的样式名称,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。
网页数据抓取怎么写(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-10 09:04
在新媒体运营中,很多时候你需要借助数据来帮助你的工作。例如,如果您是新公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免复制内容。这时候就需要把网页上的数据拉下来,放在一起,一目了然。
从网页抓取数据的最佳方式当然是爬虫工具。很多人认为爬行很难学,对吧?一开始也是这么想的,直到遇到了Web Scraper操作工具,才发现抓取网页数据原来可以这么简单。
接下来,我将出现并解释新手如何快速上手 Web Scraper。
第一步:下载网页爬虫
Web Scraper 是 Chrome 浏览器上的插件。需要翻墙才能进入Chrome App Store下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想爬取文章今日头条“吴晓波频道”账号的标题、时间、评论数。那我先打开,然后一一操作。
然后使用快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。
第 3 步:创建新的站点地图
点击创建新站点地图,里面有两个选项。导入站点地图是导入现成站点地图的指南。我们没有现成的,所以我们一般不选择这个,只选择创建站点地图。然后执行这两个操作:
Sitemap Name:表示您的Sitemap适用于哪个网页,因此您可以根据自己的名字为网页命名,但需要使用英文字母。比如今天头条的数据,我就用toutiao来命名;站点地图 URL:将 Web 链接复制到 Star URL 列。比如图中我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置此站点地图
整个Web Scraper的爬取逻辑如下:设置一级选择器,选择爬取范围;在一级选择器下设置二级选择器,选择爬取字段,然后爬取。
让我们换一个接地的例子。如果要获取福建人的姓名、性别、年龄这三个元素,那么就必须这样:先定位福建省,然后定位福建省姓名、性别、年龄。
这里,一级Selector表示要圈出中国这样的大国的福建省,二级Selector表示要圈出人口中的姓名、性别、年龄三个要素福建省。
对于文章,一级Selector意味着你要圈出这个文章的元素。这个元素可能包括标题、作者、发布时间、评论数等,然后我们会在二级Selector中选择我们想要的元素,比如标题、作者、阅读数。
让我们拆解设置主次选择器的工作流程:
1. 点击添加新选择器,创建一级选择器,步骤如下:
输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles; select Type:type代表你抓取的这部分的类型,比如 element/text/link ,因为这是整个文章元素范围选择,所以我们需要先用Element来选择整个(如果这个页面需要滑动加载更多,然后选择元素向下滚动); check Multiple:勾选Multiple前面的小方框,因为要选择多个元素而不是单个元素,所以我们勾选的时候,爬虫插件会帮我们识别多个相似的文章;保留设置:其余未提及的部分保留默认设置。 2.点击选择选择范围,然后按照以下步骤操作:
选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。用鼠标点击后,它变成红色选择这个区域;多选:不要只选一个,下面也是要选择的,否则只爬出一行数据;完成选择:记得点击完成选择;保存:单击保存选择器。 3.设置一级选择器后,点击进入设置二级选择器,步骤如下:
新建选择器:点击添加新选择器;输入id:id代表你抓的是哪个字段,这样你就可以取字段的英文了。比如我要选择“作者”,我就写“作者”; select Type:选择Text,因为要抓取文本;不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里要抓取单个元素;保留设置:其余未提及的部分保留默认设置。 4.点击选择,然后点击要爬取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是单个字段,可以通过鼠标点击字段来选择。比如要爬取标题,用鼠标点击一个文章的标题,该字段所在的区域就会变成红色。选择;完成选择:记得点击完成选择;保存:单击保存选择器。 5. 重复以上操作,直到选中你要攀登的场地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为你只需要设置好所有的选择器,然后就可以开始爬取数据了。怎么样,是不是很简单?
那么如何开始抓取数据呢?只是一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后勤奋的小爬虫就开始工作了。您将获得一个收录您想要的所有数据的列表。
如果你想对数据进行排序,比如按阅读、喜欢、作者等排序,让数据更清晰,那么你可以点击Export Data as CSV并将其导入到Excel表格中。
导入Excel表格后,可以过滤数据。
以上就是Web Scraper快速入门的全部操作流程。就连我的懒癌+残障也能在5分钟内搞定。相信你可以参考下爬的地方。完全没问题。 查看全部
网页数据抓取怎么写(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
在新媒体运营中,很多时候你需要借助数据来帮助你的工作。例如,如果您是新公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免复制内容。这时候就需要把网页上的数据拉下来,放在一起,一目了然。
从网页抓取数据的最佳方式当然是爬虫工具。很多人认为爬行很难学,对吧?一开始也是这么想的,直到遇到了Web Scraper操作工具,才发现抓取网页数据原来可以这么简单。
接下来,我将出现并解释新手如何快速上手 Web Scraper。
第一步:下载网页爬虫
Web Scraper 是 Chrome 浏览器上的插件。需要翻墙才能进入Chrome App Store下载Web Scraper插件。

第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想爬取文章今日头条“吴晓波频道”账号的标题、时间、评论数。那我先打开,然后一一操作。
然后使用快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。

第 3 步:创建新的站点地图
点击创建新站点地图,里面有两个选项。导入站点地图是导入现成站点地图的指南。我们没有现成的,所以我们一般不选择这个,只选择创建站点地图。然后执行这两个操作:

Sitemap Name:表示您的Sitemap适用于哪个网页,因此您可以根据自己的名字为网页命名,但需要使用英文字母。比如今天头条的数据,我就用toutiao来命名;站点地图 URL:将 Web 链接复制到 Star URL 列。比如图中我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置此站点地图
整个Web Scraper的爬取逻辑如下:设置一级选择器,选择爬取范围;在一级选择器下设置二级选择器,选择爬取字段,然后爬取。
让我们换一个接地的例子。如果要获取福建人的姓名、性别、年龄这三个元素,那么就必须这样:先定位福建省,然后定位福建省姓名、性别、年龄。
这里,一级Selector表示要圈出中国这样的大国的福建省,二级Selector表示要圈出人口中的姓名、性别、年龄三个要素福建省。
对于文章,一级Selector意味着你要圈出这个文章的元素。这个元素可能包括标题、作者、发布时间、评论数等,然后我们会在二级Selector中选择我们想要的元素,比如标题、作者、阅读数。
让我们拆解设置主次选择器的工作流程:
1. 点击添加新选择器,创建一级选择器,步骤如下:

输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles; select Type:type代表你抓取的这部分的类型,比如 element/text/link ,因为这是整个文章元素范围选择,所以我们需要先用Element来选择整个(如果这个页面需要滑动加载更多,然后选择元素向下滚动); check Multiple:勾选Multiple前面的小方框,因为要选择多个元素而不是单个元素,所以我们勾选的时候,爬虫插件会帮我们识别多个相似的文章;保留设置:其余未提及的部分保留默认设置。 2.点击选择选择范围,然后按照以下步骤操作:

选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。用鼠标点击后,它变成红色选择这个区域;多选:不要只选一个,下面也是要选择的,否则只爬出一行数据;完成选择:记得点击完成选择;保存:单击保存选择器。 3.设置一级选择器后,点击进入设置二级选择器,步骤如下:

新建选择器:点击添加新选择器;输入id:id代表你抓的是哪个字段,这样你就可以取字段的英文了。比如我要选择“作者”,我就写“作者”; select Type:选择Text,因为要抓取文本;不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里要抓取单个元素;保留设置:其余未提及的部分保留默认设置。 4.点击选择,然后点击要爬取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是单个字段,可以通过鼠标点击字段来选择。比如要爬取标题,用鼠标点击一个文章的标题,该字段所在的区域就会变成红色。选择;完成选择:记得点击完成选择;保存:单击保存选择器。 5. 重复以上操作,直到选中你要攀登的场地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为你只需要设置好所有的选择器,然后就可以开始爬取数据了。怎么样,是不是很简单?
那么如何开始抓取数据呢?只是一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后勤奋的小爬虫就开始工作了。您将获得一个收录您想要的所有数据的列表。

如果你想对数据进行排序,比如按阅读、喜欢、作者等排序,让数据更清晰,那么你可以点击Export Data as CSV并将其导入到Excel表格中。

导入Excel表格后,可以过滤数据。

以上就是Web Scraper快速入门的全部操作流程。就连我的懒癌+残障也能在5分钟内搞定。相信你可以参考下爬的地方。完全没问题。
网页数据抓取怎么写(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-19 08:24
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils。下面是我为《乌云》写的一个例子
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:
二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择它。博士。选择(“H3”)。迭代器(),对于jsup,有以下规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、Selector选择器基本语法
2、Selector选择器组合语法
3、Selector伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
查看全部
网页数据抓取怎么写(乌云网我写的一个公用的HttpUtils..例子
)
最近,我在公司做了一个系统。因为我想获得一些网页数据和一些网页数据,所以我编写了一个公共httputils。下面是我为《乌云》写的一个例子
一、首先,获取指定路径下的网页内容
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果与上述一致:
二、通过指定URL获取所需的网页数据
对于这种方法,要导入jsup包,您可以在Internet上下载它
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于选择选择器,根据条件选择它。博士。选择(“H3”)。迭代器(),对于jsup,有以下规则:
Jsoup是一个基于Java的HTML解析器,可以直接解析URL地址或HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
jsoup的优势在于它对文档元素的检索。select方法将返回一组元素,并提供一组方法来提取和处理结果。要掌握jsoup,首先必须熟悉其选择器语法
1、Selector选择器基本语法
2、Selector选择器组合语法
3、Selector伪选择器语法
注:上述伪选择器索引从0开始,即第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
网页数据抓取怎么写(webscraper抓取数据的几种解决方案,你可能会碰到的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-19 08:20
如果您想要抓取数据并且懒得编写代码,您可以尝试使用WebScraper来抓取数据
相关文章:
最简单的数据捕获教程适用于所有人
网页刮刀高级教程,大家都可以用
如果您使用web scraper捕获数据,您可能会遇到以下一个或多个问题,这些问题可能会直接中断您的计划,甚至使您放弃web scraper
以下是您可能遇到的一些问题和解决方案
1、有时我们想选择一个链接,但单击鼠标可触发页面跳转。如何处理
选择页面元素时,选中“启用键”,然后将鼠标滑过要选择的元素并按s
此外,勾选“启用键”后,会出现三个字母,即s、p和C。按s键选择当前元素,p键选择当前元素的父元素,C键选择当前元素的子元素,当前元素指鼠标所在的元素
@无法完全捕获2、分页数据或滚动数据,例如知乎和twitter
这些问题大多是由网络问题引起的。在加载数据之前,web scraper开始解析数据。但是,由于没有及时加载,web scraper错误地认为数据已被捕获
因此,适当增加延迟大小并延长等待时间,以允许有足够的时间加载数据。默认延迟为2000,即2秒,可根据网络速度进行调整
但是,当数据量很大时,不完整的数据捕获也很常见。因为只要翻页或下拉加载没有在延迟时间内完成,爬网就结束了
3、捕获数据的顺序与网页上的顺序不一致
默认情况下,Web刮板是无序的。可以安装CouchDB以确保数据的顺序
或采用其他替代方法。最后,我们将数据导出为CSV格式。在Excel中打开CSV后,可以根据列对其进行排序。比如抓取微博数据时,抓取发布时间,然后在Excel中按照发布时间排序,或者按照类似的方式对数据进行知乎排序
4、无法通过web scraper提供的选择器选择某些页面元素
这可能是因为网站页面本身不符合网页布局规范,或者您需要的数据是动态的,例如只有在鼠标悬停时才会显示的元素。在这些情况下,您需要使用其他方法
事实上,通过鼠标操作选择元素就是找到与元素对应的XPath。XPath对应于web页面,它定位元素的路径,并通过元素的类型、唯一标识符、样式名和父子关系查找元素或元素的类型
如果没有遇到这个问题,就不需要知道XPath。等到遇到问题时再去学习
下面是使用web刮板过程中的几个常见问题。如果您遇到其他问题,可以在下面的文章处留言 查看全部
网页数据抓取怎么写(webscraper抓取数据的几种解决方案,你可能会碰到的问题)
如果您想要抓取数据并且懒得编写代码,您可以尝试使用WebScraper来抓取数据
相关文章:
最简单的数据捕获教程适用于所有人
网页刮刀高级教程,大家都可以用
如果您使用web scraper捕获数据,您可能会遇到以下一个或多个问题,这些问题可能会直接中断您的计划,甚至使您放弃web scraper
以下是您可能遇到的一些问题和解决方案
1、有时我们想选择一个链接,但单击鼠标可触发页面跳转。如何处理
选择页面元素时,选中“启用键”,然后将鼠标滑过要选择的元素并按s
此外,勾选“启用键”后,会出现三个字母,即s、p和C。按s键选择当前元素,p键选择当前元素的父元素,C键选择当前元素的子元素,当前元素指鼠标所在的元素
@无法完全捕获2、分页数据或滚动数据,例如知乎和twitter
这些问题大多是由网络问题引起的。在加载数据之前,web scraper开始解析数据。但是,由于没有及时加载,web scraper错误地认为数据已被捕获
因此,适当增加延迟大小并延长等待时间,以允许有足够的时间加载数据。默认延迟为2000,即2秒,可根据网络速度进行调整
但是,当数据量很大时,不完整的数据捕获也很常见。因为只要翻页或下拉加载没有在延迟时间内完成,爬网就结束了
3、捕获数据的顺序与网页上的顺序不一致
默认情况下,Web刮板是无序的。可以安装CouchDB以确保数据的顺序
或采用其他替代方法。最后,我们将数据导出为CSV格式。在Excel中打开CSV后,可以根据列对其进行排序。比如抓取微博数据时,抓取发布时间,然后在Excel中按照发布时间排序,或者按照类似的方式对数据进行知乎排序
4、无法通过web scraper提供的选择器选择某些页面元素
这可能是因为网站页面本身不符合网页布局规范,或者您需要的数据是动态的,例如只有在鼠标悬停时才会显示的元素。在这些情况下,您需要使用其他方法
事实上,通过鼠标操作选择元素就是找到与元素对应的XPath。XPath对应于web页面,它定位元素的路径,并通过元素的类型、唯一标识符、样式名和父子关系查找元素或元素的类型
如果没有遇到这个问题,就不需要知道XPath。等到遇到问题时再去学习
下面是使用web刮板过程中的几个常见问题。如果您遇到其他问题,可以在下面的文章处留言
网页数据抓取怎么写( 小编来一起如何用python来抓取页面中的数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2021-09-18 14:03
小编来一起如何用python来抓取页面中的数据?
)
如何使用Python捕获网页中的动态数据
saitlas于2020年8月17日11:08:10更新
本文文章主要介绍如何使用Python捕获网页中的动态数据。通过实例代码详细介绍,对大家的学习和工作有一定的参考和学习价值。有需要的朋友,让我们和小编一起学习
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,它引出了动态数据的概念。这里,动态数据指的是JavaScript在web页面中动态生成的页面内容,它是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们讨论如何使用Python获取页面中动态加载的JS数据
给出一个网页:豆瓣电影排行榜,其中所有电影信息都是动态加载的。我们无法直接从该页面获取有关每部电影的信息
如下图所示,我们无法在HTML中找到相应的电影信息
在Chrome浏览器中,单击F12在网络中打开XHR。让我们抓取相应的JS文件进行解析。如下图所示:
向下拖动豆瓣页面以加载更多电影信息,这样我们就可以抓取相应的消息
我们可以看到,它使用Ajax异步请求。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。因此,可以在不重新加载整个网页的情况下更新部分网页,从而实现数据的动态加载
我们可以看到,通过get,我们得到的响应收录相应的电影相关信息,这些信息以JSON格式保存在一起
查看requesturl信息,我们可以发现action参数后面跟着两个参数“start”和“limit”。显然,它们的意思是“从某个位置返回的电影数量”
如果想快速获取相关电影信息,可以直接将URL复制到地址栏中,修改所需的start和limit参数值,并获得相应的抓取结果
但是,这不是自动的,而且许多其他网站请求URL也不是直接给出的,因此我们使用Python进一步操作以获取返回的消息信息
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
网页数据抓取怎么写(
小编来一起如何用python来抓取页面中的数据?
)
如何使用Python捕获网页中的动态数据
saitlas于2020年8月17日11:08:10更新
本文文章主要介绍如何使用Python捕获网页中的动态数据。通过实例代码详细介绍,对大家的学习和工作有一定的参考和学习价值。有需要的朋友,让我们和小编一起学习
我们经常发现网页中的许多数据不是用HTML编写的,而是通过JS动态加载的。因此,它引出了动态数据的概念。这里,动态数据指的是JavaScript在web页面中动态生成的页面内容,它是在页面加载到浏览器后动态生成的,而不是在加载之前
在编写爬虫程序获取网页数据时,我们经常会遇到这种需要动态加载数据的HTML网页。如果我们仍然直接从网页上获取数据,我们将无法获得任何数据
今天,让我们讨论如何使用Python获取页面中动态加载的JS数据
给出一个网页:豆瓣电影排行榜,其中所有电影信息都是动态加载的。我们无法直接从该页面获取有关每部电影的信息
如下图所示,我们无法在HTML中找到相应的电影信息
在Chrome浏览器中,单击F12在网络中打开XHR。让我们抓取相应的JS文件进行解析。如下图所示:
向下拖动豆瓣页面以加载更多电影信息,这样我们就可以抓取相应的消息
我们可以看到,它使用Ajax异步请求。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。因此,可以在不重新加载整个网页的情况下更新部分网页,从而实现数据的动态加载
我们可以看到,通过get,我们得到的响应收录相应的电影相关信息,这些信息以JSON格式保存在一起
查看requesturl信息,我们可以发现action参数后面跟着两个参数“start”和“limit”。显然,它们的意思是“从某个位置返回的电影数量”
如果想快速获取相关电影信息,可以直接将URL复制到地址栏中,修改所需的start和limit参数值,并获得相应的抓取结果
但是,这不是自动的,而且许多其他网站请求URL也不是直接给出的,因此我们使用Python进一步操作以获取返回的消息信息
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
网页数据抓取怎么写(WebScraper怎么对付这种类型的网页翻页?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-18 08:37
我想解释一下寻呼机是什么。我翻了一大堆定义,觉得很麻烦。我们第一年没有上网。看看这幅画。我找到了功能最全面的示例,它支持数字页码调整、上一页、下一页和指定页码跳转
今天我们将学习Web scraper如何处理这种类型的页面翻转
事实上,在本教程的第一个示例中,我们捕获了豆瓣电影的列表。豆瓣的电影列表使用寻呼机分割数据:
但在那个时候,我们发现了网络链接的规则,并没有使用寻呼机来获取它们。因为当网页的链接有规律地变化时,控制链接参数捕获是最低的成本;如果页面可以翻页,但链接的更改不是经常性的,那么您必须先转到寻呼机
这些理论很无聊。让我们以不规则翻页链接为例
8月2日是蔡旭坤的生日。为了庆祝,粉丝们在微博上为昆昆刷了300W的转发量。微博的转发数据只需除以寻呼机即可。让我们分析一下微博的转发信息页面,看看如何用网络抓取这类数据
此微博的直接链接是:
在看了这么多他的视频后,为了表达我们的感激之情,我们可以点击并为昆昆添加一本阅读手册
首先,让我们看看第1页上转发的链接。看起来是这样的:
第2页看起来像这样。我注意到许多#urnd36参数:
第3页上的参数为#rnd39
第4页上的参数为#rnd76:
再看几个链接,你会发现转发页面的URL是不规则的,所以你只能翻页并通过寻呼机加载数据。让我们开始实践教学吧
1.create Sitemap
我们首先创建一个站点地图,这次称为cxk,起始链接是
2.create容器选择器
因为我们想要点击寻呼机,所以我们选择外部容器的类型作为元素点击。具体参数说明如下图所示。之前我们在简单数据分析08中详细解释了它,所以这里不再讨论它
容器的预览如下图所示:
寻呼机的选择过程如下图所示:
3.create子选择器
这些子选择器相对简单。这些类型是文本选择器。我们选择三种类型的内容:评论用户名、评论内容和评论时间
4.grab数据
根据网站地图cxk->;scratch的操作路径可以抓取数据
5.一些问题
如果您阅读上述教程并立即爬升数据,您可能遇到的第一个问题是300W的数据。我要把所有的数据都记录下来吗
听起来不现实。毕竟,web scraper所针对的数据量相对较小,成千上万的数据太多。不管数据有多大,你必须考虑爬行时间是否太长,如何存储数据,以及如何处理网站的反爬虫系统(例如,如果你跳出验证码,这个Web刮刀是无能为力的)
考虑到这个问题,如果您已经看过上一篇关于自动控制抓取数量的教程,那么您可能希望使用类型为(-N+N)的第N个来控制N条数据的抓取。如果你尝试一下,你会发现这种方法毫无用处
失败的原因实际上涉及到一点网页知识。如果你感兴趣,你可以看到下面的解释。如果你不感兴趣,你可以直接看到最后的结论
正如我前面提到的,单击更多加载页面并下拉加载页面。新加载的数据将添加到当前页面。你一直往下拉,数据一直在加载。同时,页面的滚动条将越来越短,这意味着所有数据都在同一页面上
当我们使用(-N+N)类型的:N来控制加载的数量时,实际上相当于在此网页上设置一个计数器。当数据累积到我们想要的数量时,它将停止提取
但是,对于使用页面翻转器的网页,每次页面翻转都相当于刷新当前网页,因此每次都会设置一个计数器
例如,您希望捕获1000条数据,但第一页上只有20条数据。如果你赶上了最后一个,980件仍然不见了;然后,一旦翻页,就会设置一个新的计数器。在抓取第2页上的最后一个数据后,仍然是980。翻页后,计数器将复位并变为1000。。。因此,控制数量的方法是无效的
因此,结论是,如果寻呼机类型的网页想要提前结束捕获,唯一的方法就是断开网络连接。当然,如果你有更好的计划,你可以在评论中回复我,我们可以互相讨论
6.摘要
寻呼机是一种非常常见的网页分页方法。我们可以通过web scraper中的元素单击来处理这种类型的web页面,并通过断开连接来结束爬行 查看全部
网页数据抓取怎么写(WebScraper怎么对付这种类型的网页翻页?(上))
我想解释一下寻呼机是什么。我翻了一大堆定义,觉得很麻烦。我们第一年没有上网。看看这幅画。我找到了功能最全面的示例,它支持数字页码调整、上一页、下一页和指定页码跳转
今天我们将学习Web scraper如何处理这种类型的页面翻转
事实上,在本教程的第一个示例中,我们捕获了豆瓣电影的列表。豆瓣的电影列表使用寻呼机分割数据:
但在那个时候,我们发现了网络链接的规则,并没有使用寻呼机来获取它们。因为当网页的链接有规律地变化时,控制链接参数捕获是最低的成本;如果页面可以翻页,但链接的更改不是经常性的,那么您必须先转到寻呼机
这些理论很无聊。让我们以不规则翻页链接为例
8月2日是蔡旭坤的生日。为了庆祝,粉丝们在微博上为昆昆刷了300W的转发量。微博的转发数据只需除以寻呼机即可。让我们分析一下微博的转发信息页面,看看如何用网络抓取这类数据
此微博的直接链接是:
在看了这么多他的视频后,为了表达我们的感激之情,我们可以点击并为昆昆添加一本阅读手册
首先,让我们看看第1页上转发的链接。看起来是这样的:
第2页看起来像这样。我注意到许多#urnd36参数:
第3页上的参数为#rnd39
第4页上的参数为#rnd76:
再看几个链接,你会发现转发页面的URL是不规则的,所以你只能翻页并通过寻呼机加载数据。让我们开始实践教学吧
1.create Sitemap
我们首先创建一个站点地图,这次称为cxk,起始链接是
2.create容器选择器
因为我们想要点击寻呼机,所以我们选择外部容器的类型作为元素点击。具体参数说明如下图所示。之前我们在简单数据分析08中详细解释了它,所以这里不再讨论它
容器的预览如下图所示:
寻呼机的选择过程如下图所示:
3.create子选择器
这些子选择器相对简单。这些类型是文本选择器。我们选择三种类型的内容:评论用户名、评论内容和评论时间
4.grab数据
根据网站地图cxk->;scratch的操作路径可以抓取数据
5.一些问题
如果您阅读上述教程并立即爬升数据,您可能遇到的第一个问题是300W的数据。我要把所有的数据都记录下来吗
听起来不现实。毕竟,web scraper所针对的数据量相对较小,成千上万的数据太多。不管数据有多大,你必须考虑爬行时间是否太长,如何存储数据,以及如何处理网站的反爬虫系统(例如,如果你跳出验证码,这个Web刮刀是无能为力的)
考虑到这个问题,如果您已经看过上一篇关于自动控制抓取数量的教程,那么您可能希望使用类型为(-N+N)的第N个来控制N条数据的抓取。如果你尝试一下,你会发现这种方法毫无用处
失败的原因实际上涉及到一点网页知识。如果你感兴趣,你可以看到下面的解释。如果你不感兴趣,你可以直接看到最后的结论
正如我前面提到的,单击更多加载页面并下拉加载页面。新加载的数据将添加到当前页面。你一直往下拉,数据一直在加载。同时,页面的滚动条将越来越短,这意味着所有数据都在同一页面上
当我们使用(-N+N)类型的:N来控制加载的数量时,实际上相当于在此网页上设置一个计数器。当数据累积到我们想要的数量时,它将停止提取
但是,对于使用页面翻转器的网页,每次页面翻转都相当于刷新当前网页,因此每次都会设置一个计数器
例如,您希望捕获1000条数据,但第一页上只有20条数据。如果你赶上了最后一个,980件仍然不见了;然后,一旦翻页,就会设置一个新的计数器。在抓取第2页上的最后一个数据后,仍然是980。翻页后,计数器将复位并变为1000。。。因此,控制数量的方法是无效的
因此,结论是,如果寻呼机类型的网页想要提前结束捕获,唯一的方法就是断开网络连接。当然,如果你有更好的计划,你可以在评论中回复我,我们可以互相讨论
6.摘要
寻呼机是一种非常常见的网页分页方法。我们可以通过web scraper中的元素单击来处理这种类型的web页面,并通过断开连接来结束爬行
网页数据抓取怎么写(写个辅助工具的时候需要提取网页里面的某些内容(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-18 08:33
)
写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦!
1、在新建的windos窗口程序中画:
两个编辑框、一个按钮。
再添加模块如图中三步!
我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。
2、比如我们来取百度某贴吧一个帖子内的内容!如下图中的“跑遍数码城,XXXXX”。
我们在该页面上右键---->查看网页源码(或查看源文件)。
3、在打开的源文件内容中按CTRL+F组合键查找“跑遍数码城”,我们只要一个开文中一部分就行了!找到对应的文字后,我们找到和网页中完全对应的那部分代码。
PS:可能会出现几个被找到的内容,但是只要找到你需要取的那段全部对应部分就行。
4、复制正文中的前面的部分代码,不要复制太多的内容,待会我们用正文前的内容找到中间的内容。
然后在易语言中新建一个文本常量,把复制到的内容粘贴到“常量值”里面去。
5、然后我们去复制正文后面的一小段代码,同样新建一个文本常量,然后粘贴到常量值里面去。
6、此时我们回到编程程序中,点击按钮,在生成的“_按钮1_被单击”子程序下面新建一个文本型变量“得到的内容”,然后输入以下代码:
得到的内容 = 网页_访问s (编辑框1.内容)编辑框2.内容 = 文本_取出中间文本 (得到的内容, #常量1, #常量2)
PS:第一行是把把编辑框中的网址打开后得到的网页源码赋值给“得到的内容”这个文本变量。
第二行则是对“得到的文本”进行取中间文本操作,文本_取出中间文本()是一个程序!它能取出中间内容的程序!
7、最后我们把程序调试运行一下,点击按钮“取内容”,是不是成功了呢?打开其他帖子取也是有效的,只要你取前后代码是正确的!
如果你是需要网页的源码,只要使用程序“网页_访问s()”,就然后把它赋值输出就OK了。当然!括号里面要有网页地址!
查看全部
网页数据抓取怎么写(写个辅助工具的时候需要提取网页里面的某些内容(组图)
)
写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦!
1、在新建的windos窗口程序中画:
两个编辑框、一个按钮。
再添加模块如图中三步!
我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。
2、比如我们来取百度某贴吧一个帖子内的内容!如下图中的“跑遍数码城,XXXXX”。
我们在该页面上右键---->查看网页源码(或查看源文件)。
3、在打开的源文件内容中按CTRL+F组合键查找“跑遍数码城”,我们只要一个开文中一部分就行了!找到对应的文字后,我们找到和网页中完全对应的那部分代码。
PS:可能会出现几个被找到的内容,但是只要找到你需要取的那段全部对应部分就行。
4、复制正文中的前面的部分代码,不要复制太多的内容,待会我们用正文前的内容找到中间的内容。
然后在易语言中新建一个文本常量,把复制到的内容粘贴到“常量值”里面去。
5、然后我们去复制正文后面的一小段代码,同样新建一个文本常量,然后粘贴到常量值里面去。
6、此时我们回到编程程序中,点击按钮,在生成的“_按钮1_被单击”子程序下面新建一个文本型变量“得到的内容”,然后输入以下代码:
得到的内容 = 网页_访问s (编辑框1.内容)编辑框2.内容 = 文本_取出中间文本 (得到的内容, #常量1, #常量2)
PS:第一行是把把编辑框中的网址打开后得到的网页源码赋值给“得到的内容”这个文本变量。
第二行则是对“得到的文本”进行取中间文本操作,文本_取出中间文本()是一个程序!它能取出中间内容的程序!
7、最后我们把程序调试运行一下,点击按钮“取内容”,是不是成功了呢?打开其他帖子取也是有效的,只要你取前后代码是正确的!
如果你是需要网页的源码,只要使用程序“网页_访问s()”,就然后把它赋值输出就OK了。当然!括号里面要有网页地址!
网页数据抓取怎么写( 爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-18 08:30
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.textprint(title)# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,因此代码可以这样编写
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)dict_writer.writeheaderdict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据请求来看,目标网站具有各种形式的反爬行和加密,在以后的数据解析、提取甚至存储过程中还有很多需要进一步探索和学习的地方
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoupimport csvimport pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheaderdict_writer.writerows(all_products)### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
网页数据抓取怎么写(
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是Python的一个重要应用。使用PythonCrawler,我们可以轻松地从互联网上获取我们想要的数据。本文将在抓取和存储B站视频热点搜索列表数据的基础上,详细介绍Python爬虫的基本过程。如果您还处于介绍阶段或不知道爬虫的具体工作流程,请仔细阅读本文
步骤1:尝试请求
首先,进入B站主页,点击排名列表,复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动Jupiter笔记本并运行以下代码
import requests
url = 'https://www.bilibili.com/ranki ... 39%3B
res = requests.get('url')
print(res.status_code)
#200
在上面的代码中,我们完成了以下三件事
您可以看到返回值是200,表示服务器响应正常,这意味着我们可以继续
步骤2:解析页面
在上一步中,通过请求从网站请求数据后,我们成功获得了一个收录服务器资源的响应对象。现在我们可以使用。文本以查看其内容
您可以看到返回了一个字符串,其中收录我们需要的热列表视频数据,但是直接从字符串中提取内容既复杂又低效。因此,我们需要对其进行解析,并将字符串转换为网页结构化数据,这样我们就可以轻松地找到HTML标记及其属性和内容
在Python中有许多解析网页的方法。您可以使用正则表达式、beautulsoup、pyquery或lxml。本文将基于beautulsoup进行解释
Beauty soup是一个第三方库,可以从HTML或XML文件中提取数据。安装也很简单。您可以使用PIP安装BS4来安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup
page = requests.get(url)soup = BeautifulSoup(page.content, 'html.parser')
title = soup.title.textprint(title)# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们通过BS4中的Beauty soup类将上一步获得的HTML格式字符串转换为Beauty soup对象。请注意,使用解析器时需要开发解析器,这里使用的是html.parser
然后您可以得到一个结构化元素及其属性。例如,可以使用soup.title.text获取页面标题。你也可以用汤。身体,汤。P、 等,以获得任何所需的元素
步骤3:提取内容
在以上两个步骤中,我们使用请求从web页面请求数据,并使用BS4解析页面。现在我们进入最关键的一步:如何从解析的页面中提取所需的内容
在BeautifulSoup中,我们可以使用find/find_uuuAll来定位元素,但我更习惯于使用CSS选择器。选择是因为我可以访问DOM树,方法与使用CSS选择元素相同
现在,让我们使用代码解释如何从解析的页面中提取站点B的热列表数据。首先,我们需要找到存储数据的标签,按列表页面上的F12键,然后根据下图中的说明找到它
您可以看到,每个视频消息都包装在class=“rank item”的Li标记下,因此代码可以这样编写
在上面的代码中,我们首先使用soup。选择('li.Rank项')。此时,我们返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取所需的字段信息,并将其以字典的形式存储在开头定义的空列表中
您可以注意到,我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自己进一步研究
步骤4:存储数据
通过前三个步骤,我们使用requests+BS4成功地从网站提取了所需的数据。最后,我们只需将数据写入excel并保存即可
如果您不熟悉熊猫,可以使用CSV模块编写。请注意,您应该设置encoding='utf-8-sig',否则中文代码将被乱码
import csv
keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)dict_writer.writeheaderdict_writer.writerows(all_products)
如果您熟悉pandas,可以轻松地将字典转换为dataframe,只需一行代码即可完成
import pandas as pd
keys = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到目前为止,我们已经成功地使用Python在本地存储了站点B的流行视频列表数据。大多数基于请求的爬虫程序基本上遵循上述四个步骤
然而,尽管看起来很简单,但在真实场景中的每一步都不是那么容易。从数据请求来看,目标网站具有各种形式的反爬行和加密,在以后的数据解析、提取甚至存储过程中还有很多需要进一步探索和学习的地方
本文选择B站的视频热点列表正是因为它足够简单。我希望通过这个案例让您了解crawler的基本流程,最后附上完整的代码
import requests
from bs4 import BeautifulSoupimport csvimport pandas as pd
url = 'https://www.bilibili.com/ranki ... 39%3B
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
all_products = products = soup.select('li.rank-item')
for product in products:
rank = product.select('div.num')[0].text
name = product.select('div.info > a')[0].text.strip
play = product.select('span.data-box')[0].text
comment = product.select('span.data-box')[1].text
up = product.select('span.data-box')[2].text
url = product.select('div.info > a')[0].attrs['href']
all_products.append({"视频排名":rank,
"视频名": name,
"播放量": play,
"弹幕量": comment,
"up主": up,
"视频链接": url
})keys = all_products[0].keys
with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheaderdict_writer.writerows(all_products)### 使用pandas写入数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
网页数据抓取怎么写( python抓取网页数据招摇决定Python抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-18 04:08
python抓取网页数据招摇决定Python抓取数据)
Python抓取网页数据ypython抓取网页数据txt51自信是取之不尽的源泉,自信是汹涌的浪潮,自信是快速进步的渠道,自信是真正成功的母亲,用Python抓取并处理网页,2009-02-19150950分类Python标签无字体订阅,主要目的是抓取一个网页的源代码,处理并将里面需要的数据保存到数据库中,我们实现了抓取页面和读取数据的步骤。第1步抓取页面非常简单。我们引入了urllib,用urlopen打开网址,用read方法读取数据。为了方便测试,我们使用本地文本文件而不是抓取网页。步骤2处理数据。如果页面代码相对标准,我们可以使用HTMLPasser进行简单处理,但具体情况需要具体分析,我认为最好使用正则表达式。顺便说一下,我将练习我刚学的正则表达式。事实上,正则表达式也是一种相对简单的语言。有很多符号,有点晦涩难懂。我只能多练习,多练习。步骤3:将处理后的数据保存到数据库中,并使用pymssql进行处理。在这里,只需将其保存到文本文件并展开即可。仍然需要使用此功能,您可以抓取整个网站图片并自动声明站点地图文件。下一个任务是研究Python的套接字函数——编码GBK——导入urlibimportreport RurlLiberLopenDapagereAdAgerCloseFopenr“d2txt”DataFreedClose以处理数据预编译ClasseoneDivReisampFindAllData“”fordataninm以继续处理数据并取出标题介绍图片
和链接地址p_uTitlereCompileH2REResp_uuUrlRecompilereHREF“Reresp_uSummarreciplePreresp_ImageRecompileShopImages”ReRessss标题“p_uTitleSearchDatangGroup”RN“简介”p_uuSummarSearchDatangGroup“RN”图片“p_Imagesearchdatanggroup”RN“链接地址”p_UrlSearchDatangGroup“RN”fopenr“D2txt”Wfweritesfclose使用Python脚本获取实时股市信息2006-12-151347ie查看股市信息过于浮夸。我决定写一个python脚本来获取相关信息。它小巧方便。1.首先编写一个python脚本来获取股票市场查询页面。很容易发现实时股票市场数据是写在JavaScript文件中的。2.提取JavaScript文件URL。编写一个python脚本,抓取文件读取内容,通过字符串处理提取股价上涨等信息。3对于一些需要设置HTTP代理访问网络的情况,通过urlibopenproxies设置代理非常方便。4通过分析JavaScript文件URL,文件名格式为“股票代码JS”,建立配置文件,提供相关股票代码。使用Python脚本读取配置信息,并定期读取所需的实时信息。5定义每日市场格式并将其存储在XML中。6天后,python脚本可以读取存储的市场信息并生成图形信息,如报表K行 查看全部
网页数据抓取怎么写(
python抓取网页数据招摇决定Python抓取数据)
Python抓取网页数据ypython抓取网页数据txt51自信是取之不尽的源泉,自信是汹涌的浪潮,自信是快速进步的渠道,自信是真正成功的母亲,用Python抓取并处理网页,2009-02-19150950分类Python标签无字体订阅,主要目的是抓取一个网页的源代码,处理并将里面需要的数据保存到数据库中,我们实现了抓取页面和读取数据的步骤。第1步抓取页面非常简单。我们引入了urllib,用urlopen打开网址,用read方法读取数据。为了方便测试,我们使用本地文本文件而不是抓取网页。步骤2处理数据。如果页面代码相对标准,我们可以使用HTMLPasser进行简单处理,但具体情况需要具体分析,我认为最好使用正则表达式。顺便说一下,我将练习我刚学的正则表达式。事实上,正则表达式也是一种相对简单的语言。有很多符号,有点晦涩难懂。我只能多练习,多练习。步骤3:将处理后的数据保存到数据库中,并使用pymssql进行处理。在这里,只需将其保存到文本文件并展开即可。仍然需要使用此功能,您可以抓取整个网站图片并自动声明站点地图文件。下一个任务是研究Python的套接字函数——编码GBK——导入urlibimportreport RurlLiberLopenDapagereAdAgerCloseFopenr“d2txt”DataFreedClose以处理数据预编译ClasseoneDivReisampFindAllData“”fordataninm以继续处理数据并取出标题介绍图片
和链接地址p_uTitlereCompileH2REResp_uuUrlRecompilereHREF“Reresp_uSummarreciplePreresp_ImageRecompileShopImages”ReRessss标题“p_uTitleSearchDatangGroup”RN“简介”p_uuSummarSearchDatangGroup“RN”图片“p_Imagesearchdatanggroup”RN“链接地址”p_UrlSearchDatangGroup“RN”fopenr“D2txt”Wfweritesfclose使用Python脚本获取实时股市信息2006-12-151347ie查看股市信息过于浮夸。我决定写一个python脚本来获取相关信息。它小巧方便。1.首先编写一个python脚本来获取股票市场查询页面。很容易发现实时股票市场数据是写在JavaScript文件中的。2.提取JavaScript文件URL。编写一个python脚本,抓取文件读取内容,通过字符串处理提取股价上涨等信息。3对于一些需要设置HTTP代理访问网络的情况,通过urlibopenproxies设置代理非常方便。4通过分析JavaScript文件URL,文件名格式为“股票代码JS”,建立配置文件,提供相关股票代码。使用Python脚本读取配置信息,并定期读取所需的实时信息。5定义每日市场格式并将其存储在XML中。6天后,python脚本可以读取存储的市场信息并生成图形信息,如报表K行
网页数据抓取怎么写( 从互联网上爬取语料的经验:0各模块的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-16 20:15
从互联网上爬取语料的经验:0各模块的功能)
使用Python3教您任何HTML主内容提取函数
更新时间:2018年11月5日14:14:41作者:腾讯deepcocean
本文文章主要介绍如何使用Python3教您任何HTML主内容提取函数。它主要使用请求、lxml、JSON等模块。本文将逐一介绍这些模块。有需要的朋友可以向他们推荐
本文将与大家分享一些从互联网上抓取语料库的经验
0x1刀具准备
如果你想做得好,你必须先磨快你的工具。基于Python
的爬网语料库的建立
我们基于Python3开发,主要使用以下模块:请求、lxml和JSON
简要介绍各模块的功能
01|请求
Requests是一个python第三方库,特别便于处理URL资源。它的官方文件有一个很大的口号:人类的http。与Python自己的urllib体验相比,作者认为请求的使用体验比urllib高一个数量级
让我们做一个简单的比较:
urllib:
import urllib2
import urllib
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
#发送请求
response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
#Response Headers
print(response.info())
#Response Code
print(response.getcode())
#Response Body
print(response.read())
要求:
import requests
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
#发送请求
response = requests.get(URL_GET,params=params)
#Response Headers
print(response.headers)
#Response Code
print(response.status_code)
#Response Body
print(response.text)
我们可以发现这两个库之间存在一些差异:
1.parameter构造:urllib需要用URLEncode对参数进行编码,比较麻烦;请求非常简洁,无需额外的编码处理
2.request sending:urllib需要构造额外的URL参数才能成为合格的表单;请求更加简洁,直接获得相应的链接和参数
3.connection method:查看返回的头信息的“连接”。使用urlib库时,“连接”:“关闭”表示套接字通道在每个请求结束时关闭,而使用请求库时使用urlib3。多个请求重用套接字“连接”:“保持活动”,表示多个请求使用一个连接,消耗更少的资源
4.encoding method:接受编码在请求库中更完整。这里没有给出例子
综上所述,使用请求更简洁易懂,这对我们的开发非常方便
02÷lxml
Beauty soup是一个库,而XPath是一种技术。Python中最常用的XPath库是lxml
当我们获得请求返回的页面时,我们如何获得所需的数据?目前,lxml是一个强大的HTML/XML解析工具。Python从不缺少解析库,那么为什么我们要在众多库中选择lxml呢?我们选择另一个著名的HTML解析库BeautifulSoup进行比较
让我们做一个简单的比较:
美丽小组:
from bs4 import BeautifulSoup #导入库
# 假设html是需要被解析的html
#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#查找所有的h4标签
links = soup.find_all("h4")
lxml:
from lxml import etree
# 假设html是需要被解析的html
#将html传入etree 的构造方法,得到一个文档的对象
root = etree.HTML(html)
#查找所有的h4标签
links = root.xpath("//h4")
我们可以发现这两个库之间存在一些差异:
1.parsing HTML:Beauty soup的解析方法类似于JQ。API非常用户友好,支持CSS选择器;lxml的语法有一定的学习成本
2.performance:beautifulsoup基于DOM。它将加载整个文档并解析整个DOM树,因此时间和内存开销将大得多;Lxml只在本地进行遍历。此外,lxml是用C编写的,而Beauty soup是用Python编写的。显然,lxml>>;美丽的乌苏
综上所述,用靓汤更简洁,更容易使用。虽然lxml有一定的学习成本,但它也非常简洁易懂。最重要的是,它是用C编写的,速度要快得多。对于作者的强迫症,选择lxml是很自然的
03#json
Python自带了自己的JSON库,对于处理基本JSON来说已经足够了。但是,如果您想变得更懒惰,可以使用第三方JSON库。常见的是demjson和simplejson
这两个库在导入模块速度、编码和解码速度以及更好的兼容性方面都优于simplejson。因此,如果您想使用square库,可以使用simplejson
0x2确定语料库源
武器准备好后,下一步是确定攀爬方向
以电子体育语料库为例。现在我们将攀登电子体育语料库。常见的电子竞技平台包括企鹅电子竞技、企鹅电子竞技和企鹅电子竞技(斜视),因此我们使用企鹅电子竞技上的实时游戏作为爬行的数据源
我们登录企鹅电子竞技的官方网站,进入游戏列表页面。我们可以发现页面上有很多游戏。手动编写这些游戏名称显然是无利可图的,因此我们开始了爬虫程序的第一步:游戏列表爬虫
import requests
from lxml import etree
# 更新游戏列表
def _updateGameList():
# 发送HTTP请求时的HEAD信息,用于伪装为浏览器
heads = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
# 需要爬取的游戏列表页
url = 'https://egame.qq.com/gamelist'
# 不压缩html,最大链接时间为10妙
res = requests.get(url, headers=heads, verify=False, timeout=10)
# 为防止出错,编码utf-8
res.encoding = 'utf-8'
# 将html构建为Xpath模式
root = etree.HTML(res.content)
# 使用Xpath语法,获取游戏名
gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
# 输出爬到的游戏名
print(gameList)
当我们得到这几十个游戏名称时,下一步就是抓取这几十个游戏的语料库。此时,问题出现了。在推出这几十款游戏之前,我们将攀登哪个网站的顶峰?水龙头?多玩点?17173?通过分析这些网站s,发现这些网站s只有一些流行游戏的文章语料库,以及一些不受欢迎或低流行的游戏,如“灵魂芯片”、“奇迹:觉醒”和“死亡即将来临”。在这些网站s上很难找到大量的文章corpora,如图所示:
我们可以发现《奇迹:觉醒》和《灵魂芯片》的文章语料库非常少,数量也不符合我们的要求。那么,是否有一个更通用的资源站,它拥有无与伦比的丰富的文章语料库来满足我们的需求呢
事实上,冷静下来想想。我们每天都使用这个资源站,就是百度。我们在百度新闻中搜索相关游戏,并获得搜索结果列表。这些列表中几乎所有链接的网页都与搜索结果密切相关。这样,我们的数据源不够丰富的问题就可以很容易地得到解决。但是现在有一个新的问题,也是一个很难解决的问题——如何抓住任何网页的文章内容
因为不同的网站具有不同的页面结构,我们无法预测我们将爬升哪个网站数据,也无法为每个网站编写一组爬虫程序网站. 那种工作量是无法想象的!但我们不能简单粗暴地把这一页上的所有单词都写下来。用这样的语料库训练真是一场噩梦
经过与各种网站智慧和勇气的较量,查询数据和思考,我们终于找到了一个更通用的方案。让我们谈谈作者的想法
0x3任意网站爬网文章语料库
01|提取方法
@基于DOM树的1)文本提取
@基于网页分割的2)find文本块
@基于标记窗口的3)文本提取
4)基于数据挖掘或机器学习
@基于线块分布函数的5)文本提取
02|提取原理
我们看到这些都有点困惑,他们到底是怎么提取的呢?让我慢慢说
@基于1)DOM树的文本提取:
这种方法主要是通过比较标准HTML建立DOM树,然后遍历DOM,比较和识别各种非文本信息,包括广告、链接和非重要节点信息。提取出非文本信息后,剩下的自然是文本信息
但这种方法有两个问题
① 这尤其取决于HTML的良好结构。如果我们访问的网页不是按照W3C规范编写的,那么这种方法就不太适用
② 树的建立和遍历的时间复杂度和空间复杂度都很高,而且由于HTML标记的不同,树的遍历方法也会有所不同
2)find基于网页分段的文本块:
此方法使用HTML标记中的拆分行和一些视觉信息(如文本颜色、字体大小、文本信息等)
这种方法存在一个问题:
① 不同网站HTML风格迥异,没有统一的切分方法,不能保证切分的普遍性
3)基于标记窗口的文本提取:
首先介绍一个概念标签窗口。我们将两个标记和其中收录的文本组合到一个标记窗口中(例如,I am H1中的“I am H1”是标记窗口的内容),并取出标记窗口的文本
此方法首先获取HTML中的文章标题和所有标记窗口,然后将它们划分为单词。然后计算标题序列和标记窗口文本序列之间的单词距离L。如果l小于阈值,则标记窗口中的文本被视为文本
虽然这种方法看起来不错,但也存在一些问题:
① 对页面上的所有文本进行分段是没有效率的
② 单词距离的阈值很难确定,不同的单词文章具有不同的阈值
4)基于数据挖掘或机器学习
使用大数据进行培训,让机器提取主要文本
这种方法当然非常优秀,但它首先需要HTML和文本数据,然后再进行培训。我们不在这里讨论
@基于线块分布函数的5)文本提取
对于任何网页,其文本和标记总是混合在一起。此方法的核心有几个亮点:① 文本区域的密度;② 行块长度;网页的文本区域必须是文本信息分布最密集的区域之一。该区域可能最大(长评论信息和短文本),因此同时引用块长度进行判断
实施思路:
① 首先删除HTML标记,在取出标签后只留下所有文本和所有空白位置信息。我们称之为CText
② 取每个CText的周围K行(K)
③ 从cblock中删除所有空白字符,文本的总长度称为clen
④ 协调人 查看全部
网页数据抓取怎么写(
从互联网上爬取语料的经验:0各模块的功能)
使用Python3教您任何HTML主内容提取函数
更新时间:2018年11月5日14:14:41作者:腾讯deepcocean
本文文章主要介绍如何使用Python3教您任何HTML主内容提取函数。它主要使用请求、lxml、JSON等模块。本文将逐一介绍这些模块。有需要的朋友可以向他们推荐
本文将与大家分享一些从互联网上抓取语料库的经验
0x1刀具准备
如果你想做得好,你必须先磨快你的工具。基于Python
的爬网语料库的建立
我们基于Python3开发,主要使用以下模块:请求、lxml和JSON
简要介绍各模块的功能
01|请求
Requests是一个python第三方库,特别便于处理URL资源。它的官方文件有一个很大的口号:人类的http。与Python自己的urllib体验相比,作者认为请求的使用体验比urllib高一个数量级
让我们做一个简单的比较:
urllib:
import urllib2
import urllib
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
#发送请求
response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
#Response Headers
print(response.info())
#Response Code
print(response.getcode())
#Response Body
print(response.read())
要求:
import requests
URL_GET = "https://api.douban.com/v2/event/list"
#构建请求参数
params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
#发送请求
response = requests.get(URL_GET,params=params)
#Response Headers
print(response.headers)
#Response Code
print(response.status_code)
#Response Body
print(response.text)
我们可以发现这两个库之间存在一些差异:
1.parameter构造:urllib需要用URLEncode对参数进行编码,比较麻烦;请求非常简洁,无需额外的编码处理
2.request sending:urllib需要构造额外的URL参数才能成为合格的表单;请求更加简洁,直接获得相应的链接和参数
3.connection method:查看返回的头信息的“连接”。使用urlib库时,“连接”:“关闭”表示套接字通道在每个请求结束时关闭,而使用请求库时使用urlib3。多个请求重用套接字“连接”:“保持活动”,表示多个请求使用一个连接,消耗更少的资源
4.encoding method:接受编码在请求库中更完整。这里没有给出例子
综上所述,使用请求更简洁易懂,这对我们的开发非常方便
02÷lxml
Beauty soup是一个库,而XPath是一种技术。Python中最常用的XPath库是lxml
当我们获得请求返回的页面时,我们如何获得所需的数据?目前,lxml是一个强大的HTML/XML解析工具。Python从不缺少解析库,那么为什么我们要在众多库中选择lxml呢?我们选择另一个著名的HTML解析库BeautifulSoup进行比较
让我们做一个简单的比较:
美丽小组:
from bs4 import BeautifulSoup #导入库
# 假设html是需要被解析的html
#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#查找所有的h4标签
links = soup.find_all("h4")
lxml:
from lxml import etree
# 假设html是需要被解析的html
#将html传入etree 的构造方法,得到一个文档的对象
root = etree.HTML(html)
#查找所有的h4标签
links = root.xpath("//h4")
我们可以发现这两个库之间存在一些差异:
1.parsing HTML:Beauty soup的解析方法类似于JQ。API非常用户友好,支持CSS选择器;lxml的语法有一定的学习成本
2.performance:beautifulsoup基于DOM。它将加载整个文档并解析整个DOM树,因此时间和内存开销将大得多;Lxml只在本地进行遍历。此外,lxml是用C编写的,而Beauty soup是用Python编写的。显然,lxml>>;美丽的乌苏
综上所述,用靓汤更简洁,更容易使用。虽然lxml有一定的学习成本,但它也非常简洁易懂。最重要的是,它是用C编写的,速度要快得多。对于作者的强迫症,选择lxml是很自然的
03#json
Python自带了自己的JSON库,对于处理基本JSON来说已经足够了。但是,如果您想变得更懒惰,可以使用第三方JSON库。常见的是demjson和simplejson
这两个库在导入模块速度、编码和解码速度以及更好的兼容性方面都优于simplejson。因此,如果您想使用square库,可以使用simplejson
0x2确定语料库源
武器准备好后,下一步是确定攀爬方向
以电子体育语料库为例。现在我们将攀登电子体育语料库。常见的电子竞技平台包括企鹅电子竞技、企鹅电子竞技和企鹅电子竞技(斜视),因此我们使用企鹅电子竞技上的实时游戏作为爬行的数据源
我们登录企鹅电子竞技的官方网站,进入游戏列表页面。我们可以发现页面上有很多游戏。手动编写这些游戏名称显然是无利可图的,因此我们开始了爬虫程序的第一步:游戏列表爬虫
import requests
from lxml import etree
# 更新游戏列表
def _updateGameList():
# 发送HTTP请求时的HEAD信息,用于伪装为浏览器
heads = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
# 需要爬取的游戏列表页
url = 'https://egame.qq.com/gamelist'
# 不压缩html,最大链接时间为10妙
res = requests.get(url, headers=heads, verify=False, timeout=10)
# 为防止出错,编码utf-8
res.encoding = 'utf-8'
# 将html构建为Xpath模式
root = etree.HTML(res.content)
# 使用Xpath语法,获取游戏名
gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
# 输出爬到的游戏名
print(gameList)
当我们得到这几十个游戏名称时,下一步就是抓取这几十个游戏的语料库。此时,问题出现了。在推出这几十款游戏之前,我们将攀登哪个网站的顶峰?水龙头?多玩点?17173?通过分析这些网站s,发现这些网站s只有一些流行游戏的文章语料库,以及一些不受欢迎或低流行的游戏,如“灵魂芯片”、“奇迹:觉醒”和“死亡即将来临”。在这些网站s上很难找到大量的文章corpora,如图所示:
我们可以发现《奇迹:觉醒》和《灵魂芯片》的文章语料库非常少,数量也不符合我们的要求。那么,是否有一个更通用的资源站,它拥有无与伦比的丰富的文章语料库来满足我们的需求呢
事实上,冷静下来想想。我们每天都使用这个资源站,就是百度。我们在百度新闻中搜索相关游戏,并获得搜索结果列表。这些列表中几乎所有链接的网页都与搜索结果密切相关。这样,我们的数据源不够丰富的问题就可以很容易地得到解决。但是现在有一个新的问题,也是一个很难解决的问题——如何抓住任何网页的文章内容
因为不同的网站具有不同的页面结构,我们无法预测我们将爬升哪个网站数据,也无法为每个网站编写一组爬虫程序网站. 那种工作量是无法想象的!但我们不能简单粗暴地把这一页上的所有单词都写下来。用这样的语料库训练真是一场噩梦
经过与各种网站智慧和勇气的较量,查询数据和思考,我们终于找到了一个更通用的方案。让我们谈谈作者的想法
0x3任意网站爬网文章语料库
01|提取方法
@基于DOM树的1)文本提取
@基于网页分割的2)find文本块
@基于标记窗口的3)文本提取
4)基于数据挖掘或机器学习
@基于线块分布函数的5)文本提取
02|提取原理
我们看到这些都有点困惑,他们到底是怎么提取的呢?让我慢慢说
@基于1)DOM树的文本提取:
这种方法主要是通过比较标准HTML建立DOM树,然后遍历DOM,比较和识别各种非文本信息,包括广告、链接和非重要节点信息。提取出非文本信息后,剩下的自然是文本信息
但这种方法有两个问题
① 这尤其取决于HTML的良好结构。如果我们访问的网页不是按照W3C规范编写的,那么这种方法就不太适用
② 树的建立和遍历的时间复杂度和空间复杂度都很高,而且由于HTML标记的不同,树的遍历方法也会有所不同
2)find基于网页分段的文本块:
此方法使用HTML标记中的拆分行和一些视觉信息(如文本颜色、字体大小、文本信息等)
这种方法存在一个问题:
① 不同网站HTML风格迥异,没有统一的切分方法,不能保证切分的普遍性
3)基于标记窗口的文本提取:
首先介绍一个概念标签窗口。我们将两个标记和其中收录的文本组合到一个标记窗口中(例如,I am H1中的“I am H1”是标记窗口的内容),并取出标记窗口的文本
此方法首先获取HTML中的文章标题和所有标记窗口,然后将它们划分为单词。然后计算标题序列和标记窗口文本序列之间的单词距离L。如果l小于阈值,则标记窗口中的文本被视为文本
虽然这种方法看起来不错,但也存在一些问题:
① 对页面上的所有文本进行分段是没有效率的
② 单词距离的阈值很难确定,不同的单词文章具有不同的阈值
4)基于数据挖掘或机器学习
使用大数据进行培训,让机器提取主要文本
这种方法当然非常优秀,但它首先需要HTML和文本数据,然后再进行培训。我们不在这里讨论
@基于线块分布函数的5)文本提取
对于任何网页,其文本和标记总是混合在一起。此方法的核心有几个亮点:① 文本区域的密度;② 行块长度;网页的文本区域必须是文本信息分布最密集的区域之一。该区域可能最大(长评论信息和短文本),因此同时引用块长度进行判断
实施思路:
① 首先删除HTML标记,在取出标签后只留下所有文本和所有空白位置信息。我们称之为CText
② 取每个CText的周围K行(K)
③ 从cblock中删除所有空白字符,文本的总长度称为clen
④ 协调人
网页数据抓取怎么写(Python是什么,什么是爬虫?具体该怎么学习?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-16 20:14
什么是Python?什么是爬虫?如何学习
Python是为数不多的简单而强大的编程语言之一。它易于学习和理解,易于使用,代码更接近自然语言和正常的思维方式。据统计,Python是世界上最流行的语言之一
爬虫是利用爬虫技术捕获论坛网站数据,并将所需数据以特定格式保存到数据库或文件中
具体学习:
1)首先,学习Python的基本知识,了解网络请求的原理和网页的结构
2)视频学习或找一本专业的网络爬虫书学习。所谓“前辈种树,后人乘凉”,按照大神的步骤,我们可以事半功倍
3)网站的实际操作在有了爬虫的想法后,可以找到更多的网站来操作
如何编写Python链接爬虫
首先,我们需要弄清楚,我们能看到的所有网页,无论是文本、图片还是动画,都用HTML标记。然后,浏览器以视觉和美学的方式向我们显示这些标签。如果我们想成为一个网络爬虫,我们的爬虫没有视觉,只有逻辑。在爬虫的眼中,只有HTML标记。其他样式正在使用中。爬虫的眼睛里有云,所以爬虫实际上读取HTML标记(这里涉及的一个知识点是获取HTML标记)。库是一个请求库,它可以通过web请求获取HTML元素,然后在HTML标记中显示所需的内容。这是一个网络爬虫。逻辑很简单。如果您有使用python的经验,建议您使用crawler框架 查看全部
网页数据抓取怎么写(Python是什么,什么是爬虫?具体该怎么学习?)
什么是Python?什么是爬虫?如何学习
Python是为数不多的简单而强大的编程语言之一。它易于学习和理解,易于使用,代码更接近自然语言和正常的思维方式。据统计,Python是世界上最流行的语言之一
爬虫是利用爬虫技术捕获论坛网站数据,并将所需数据以特定格式保存到数据库或文件中
具体学习:
1)首先,学习Python的基本知识,了解网络请求的原理和网页的结构
2)视频学习或找一本专业的网络爬虫书学习。所谓“前辈种树,后人乘凉”,按照大神的步骤,我们可以事半功倍
3)网站的实际操作在有了爬虫的想法后,可以找到更多的网站来操作
如何编写Python链接爬虫
首先,我们需要弄清楚,我们能看到的所有网页,无论是文本、图片还是动画,都用HTML标记。然后,浏览器以视觉和美学的方式向我们显示这些标签。如果我们想成为一个网络爬虫,我们的爬虫没有视觉,只有逻辑。在爬虫的眼中,只有HTML标记。其他样式正在使用中。爬虫的眼睛里有云,所以爬虫实际上读取HTML标记(这里涉及的一个知识点是获取HTML标记)。库是一个请求库,它可以通过web请求获取HTML元素,然后在HTML标记中显示所需的内容。这是一个网络爬虫。逻辑很简单。如果您有使用python的经验,建议您使用crawler框架
网页数据抓取怎么写(大数据时代已然到来,抓取网页数据成为科研重要手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-10 09:04
获取网页数据是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。 IDC(互联网数据中心)报告显示,2013年全球数据为4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但我们需要主页上的页面,上帝说我们需要一个页面!
1、打开网页
我们以百度搜索“Chahu”关键词为例:
使用 CreateObject("internetexplorer.application")
.Visible = True
.导航“导航”
'关闭网页
'.退出
结尾
代码很简单,先创建一个IE对象,然后给一些属性赋值。 Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
虽然 .ReadyState 4 或 .Busy
DoEvents
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
:请求未初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有一些数据可用,但服务器还没有完成响应生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结尾
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有带有css标签的样式名称,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。 查看全部
网页数据抓取怎么写(大数据时代已然到来,抓取网页数据成为科研重要手段)
获取网页数据是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。 IDC(互联网数据中心)报告显示,2013年全球数据为4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来,网络数据采集已成为进行竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但我们需要主页上的页面,上帝说我们需要一个页面!
1、打开网页
我们以百度搜索“Chahu”关键词为例:
使用 CreateObject("internetexplorer.application")
.Visible = True
.导航“导航”
'关闭网页
'.退出
结尾
代码很简单,先创建一个IE对象,然后给一些属性赋值。 Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
虽然 .ReadyState 4 或 .Busy
DoEvents
温德
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
:请求未初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送并正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有一些数据可用,但服务器还没有完成响应生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结尾
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值为集合 getElementsByClassName("css"):返回所有带有css标签的样式名称,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。
网页数据抓取怎么写(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-10 09:04
在新媒体运营中,很多时候你需要借助数据来帮助你的工作。例如,如果您是新公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免复制内容。这时候就需要把网页上的数据拉下来,放在一起,一目了然。
从网页抓取数据的最佳方式当然是爬虫工具。很多人认为爬行很难学,对吧?一开始也是这么想的,直到遇到了Web Scraper操作工具,才发现抓取网页数据原来可以这么简单。
接下来,我将出现并解释新手如何快速上手 Web Scraper。
第一步:下载网页爬虫
Web Scraper 是 Chrome 浏览器上的插件。需要翻墙才能进入Chrome App Store下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想爬取文章今日头条“吴晓波频道”账号的标题、时间、评论数。那我先打开,然后一一操作。
然后使用快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。
第 3 步:创建新的站点地图
点击创建新站点地图,里面有两个选项。导入站点地图是导入现成站点地图的指南。我们没有现成的,所以我们一般不选择这个,只选择创建站点地图。然后执行这两个操作:
Sitemap Name:表示您的Sitemap适用于哪个网页,因此您可以根据自己的名字为网页命名,但需要使用英文字母。比如今天头条的数据,我就用toutiao来命名;站点地图 URL:将 Web 链接复制到 Star URL 列。比如图中我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置此站点地图
整个Web Scraper的爬取逻辑如下:设置一级选择器,选择爬取范围;在一级选择器下设置二级选择器,选择爬取字段,然后爬取。
让我们换一个接地的例子。如果要获取福建人的姓名、性别、年龄这三个元素,那么就必须这样:先定位福建省,然后定位福建省姓名、性别、年龄。
这里,一级Selector表示要圈出中国这样的大国的福建省,二级Selector表示要圈出人口中的姓名、性别、年龄三个要素福建省。
对于文章,一级Selector意味着你要圈出这个文章的元素。这个元素可能包括标题、作者、发布时间、评论数等,然后我们会在二级Selector中选择我们想要的元素,比如标题、作者、阅读数。
让我们拆解设置主次选择器的工作流程:
1. 点击添加新选择器,创建一级选择器,步骤如下:
输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles; select Type:type代表你抓取的这部分的类型,比如 element/text/link ,因为这是整个文章元素范围选择,所以我们需要先用Element来选择整个(如果这个页面需要滑动加载更多,然后选择元素向下滚动); check Multiple:勾选Multiple前面的小方框,因为要选择多个元素而不是单个元素,所以我们勾选的时候,爬虫插件会帮我们识别多个相似的文章;保留设置:其余未提及的部分保留默认设置。 2.点击选择选择范围,然后按照以下步骤操作:
选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。用鼠标点击后,它变成红色选择这个区域;多选:不要只选一个,下面也是要选择的,否则只爬出一行数据;完成选择:记得点击完成选择;保存:单击保存选择器。 3.设置一级选择器后,点击进入设置二级选择器,步骤如下:
新建选择器:点击添加新选择器;输入id:id代表你抓的是哪个字段,这样你就可以取字段的英文了。比如我要选择“作者”,我就写“作者”; select Type:选择Text,因为要抓取文本;不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里要抓取单个元素;保留设置:其余未提及的部分保留默认设置。 4.点击选择,然后点击要爬取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是单个字段,可以通过鼠标点击字段来选择。比如要爬取标题,用鼠标点击一个文章的标题,该字段所在的区域就会变成红色。选择;完成选择:记得点击完成选择;保存:单击保存选择器。 5. 重复以上操作,直到选中你要攀登的场地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为你只需要设置好所有的选择器,然后就可以开始爬取数据了。怎么样,是不是很简单?
那么如何开始抓取数据呢?只是一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后勤奋的小爬虫就开始工作了。您将获得一个收录您想要的所有数据的列表。
如果你想对数据进行排序,比如按阅读、喜欢、作者等排序,让数据更清晰,那么你可以点击Export Data as CSV并将其导入到Excel表格中。
导入Excel表格后,可以过滤数据。
以上就是Web Scraper快速入门的全部操作流程。就连我的懒癌+残障也能在5分钟内搞定。相信你可以参考下爬的地方。完全没问题。 查看全部
网页数据抓取怎么写(讲解一个小白是怎么快速上手WebScraper的字段步骤?)
在新媒体运营中,很多时候你需要借助数据来帮助你的工作。例如,如果您是新公司编辑新媒体内容,您需要盘点公司现有的内容资产,以避免复制内容。这时候就需要把网页上的数据拉下来,放在一起,一目了然。
从网页抓取数据的最佳方式当然是爬虫工具。很多人认为爬行很难学,对吧?一开始也是这么想的,直到遇到了Web Scraper操作工具,才发现抓取网页数据原来可以这么简单。
接下来,我将出现并解释新手如何快速上手 Web Scraper。
第一步:下载网页爬虫
Web Scraper 是 Chrome 浏览器上的插件。需要翻墙才能进入Chrome App Store下载Web Scraper插件。
第 2 步:打开 Web Scraper
首先打开一个要抓取数据的网页。比如我想爬取文章今日头条“吴晓波频道”账号的标题、时间、评论数。那我先打开,然后一一操作。
然后使用快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。
第 3 步:创建新的站点地图
点击创建新站点地图,里面有两个选项。导入站点地图是导入现成站点地图的指南。我们没有现成的,所以我们一般不选择这个,只选择创建站点地图。然后执行这两个操作:
Sitemap Name:表示您的Sitemap适用于哪个网页,因此您可以根据自己的名字为网页命名,但需要使用英文字母。比如今天头条的数据,我就用toutiao来命名;站点地图 URL:将 Web 链接复制到 Star URL 列。比如图中我把“吴晓波频道”的首页链接复制到了这个栏目。第 4 步:设置此站点地图
整个Web Scraper的爬取逻辑如下:设置一级选择器,选择爬取范围;在一级选择器下设置二级选择器,选择爬取字段,然后爬取。
让我们换一个接地的例子。如果要获取福建人的姓名、性别、年龄这三个元素,那么就必须这样:先定位福建省,然后定位福建省姓名、性别、年龄。
这里,一级Selector表示要圈出中国这样的大国的福建省,二级Selector表示要圈出人口中的姓名、性别、年龄三个要素福建省。
对于文章,一级Selector意味着你要圈出这个文章的元素。这个元素可能包括标题、作者、发布时间、评论数等,然后我们会在二级Selector中选择我们想要的元素,比如标题、作者、阅读数。
让我们拆解设置主次选择器的工作流程:
1. 点击添加新选择器,创建一级选择器,步骤如下:
输入id:id代表你抓取的整个范围,比如这里是文章,我们可以命名为wuxiaobo-articles; select Type:type代表你抓取的这部分的类型,比如 element/text/link ,因为这是整个文章元素范围选择,所以我们需要先用Element来选择整个(如果这个页面需要滑动加载更多,然后选择元素向下滚动); check Multiple:勾选Multiple前面的小方框,因为要选择多个元素而不是单个元素,所以我们勾选的时候,爬虫插件会帮我们识别多个相似的文章;保留设置:其余未提及的部分保留默认设置。 2.点击选择选择范围,然后按照以下步骤操作:
选择范围:使用鼠标选择要抓取的数据范围。绿色是要选择的区域。用鼠标点击后,它变成红色选择这个区域;多选:不要只选一个,下面也是要选择的,否则只爬出一行数据;完成选择:记得点击完成选择;保存:单击保存选择器。 3.设置一级选择器后,点击进入设置二级选择器,步骤如下:
新建选择器:点击添加新选择器;输入id:id代表你抓的是哪个字段,这样你就可以取字段的英文了。比如我要选择“作者”,我就写“作者”; select Type:选择Text,因为要抓取文本;不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里要抓取单个元素;保留设置:其余未提及的部分保留默认设置。 4.点击选择,然后点击要爬取的字段,按照以下步骤操作:
选择字段:这里要爬取的字段是单个字段,可以通过鼠标点击字段来选择。比如要爬取标题,用鼠标点击一个文章的标题,该字段所在的区域就会变成红色。选择;完成选择:记得点击完成选择;保存:单击保存选择器。 5. 重复以上操作,直到选中你要攀登的场地。第 5 步:抓取数据
Web Scraper之所以是傻瓜式爬虫工具,是因为你只需要设置好所有的选择器,然后就可以开始爬取数据了。怎么样,是不是很简单?
那么如何开始抓取数据呢?只是一个简单的操作:点击Scrape,然后点击Start Scraping,会弹出一个小窗口,然后勤奋的小爬虫就开始工作了。您将获得一个收录您想要的所有数据的列表。
如果你想对数据进行排序,比如按阅读、喜欢、作者等排序,让数据更清晰,那么你可以点击Export Data as CSV并将其导入到Excel表格中。
导入Excel表格后,可以过滤数据。
以上就是Web Scraper快速入门的全部操作流程。就连我的懒癌+残障也能在5分钟内搞定。相信你可以参考下爬的地方。完全没问题。

