
网页数据抓取怎么写
网页数据抓取怎么写(网页数据抓取怎么写呢?很简单的;首先可以看下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-14 18:03
网页数据抓取怎么写呢?很简单的;首先可以看下这篇文章了解下基本的scrapy爬虫知识基本使用方法:-cn/godoc/#/e8b8008d25d07dc65984d3b00169a413f525d48.html
前面几个回答已经说得很详细了,我来说点其他的。最近h2exgdc中国女排不是也搞了个官方论坛吗,不过现在h2ex官方论坛已经关闭了,目前只能去h2ex官方h站(有权限的话可以在yahoo!map的页面查看相关比赛信息、图片视频及作者列表)查看,大概要翻6个小时左右才能看到了。至于网页抓取,其实大家都用flask,web2py这些爬虫框架,你可以用flask写一个,然后写一个简单的爬虫,再用bootstrap弄点样式,很容易在yahoo!map上做到基本页面效果。
(需要注意的是那个地方配置,看一下有兴趣可以我发些,然后我再学习的是提供一个抓取页面的列表,一些转换post参数和url的具体技巧,下回再发),不过要注意,在我教学之前都尽量不要去碰爬虫,会遇到瓶颈的。就这样。
有一些有用的教程:【地址】打造手机版垂直同步「搜索球/图/视频」app互联网真的在发生变化,逐渐渗透到我们的工作与生活。而我们使用的网页、app等数据都来自于互联网上的数百万网民,一般互联网厂商也不太去管。但是互联网数据太多了,一个正常运营的网站,其在腾讯数据库里存有接近200亿条数据,而阿里云数据库里则有近2000亿条数据。
我们对网页图片、视频等数据进行爬取、处理,其质量将大大低于正常水平。这个时候就需要进行数据处理、清洗和过滤,目前比较常用的有以下几种方式。数据抓取思路首先是数据抓取,就是需要抓取互联网上所有网页的信息,包括数据搜索结果,用户浏览历史,电商物流、排行榜等数据,一般都是网页html页面。其次,是过滤,就是将表面上看起来不相关的、不重要的内容滤出来,比如日期、ip地址等。
最后是提取核心数据:订单信息。下面有关爬虫的一些分享,因为个人理解能力的限制,只能到这种程度。我一直做数据分析,手里也有一些网站或者app,比如网易新闻、知乎、阿里文学、qq音乐等,会爬取一些内容,但是也从来没有写爬虫实现一些功能。我想应该不是这个问题的关键所在,所以我就不进行分享了。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写呢?很简单的;首先可以看下)
网页数据抓取怎么写呢?很简单的;首先可以看下这篇文章了解下基本的scrapy爬虫知识基本使用方法:-cn/godoc/#/e8b8008d25d07dc65984d3b00169a413f525d48.html
前面几个回答已经说得很详细了,我来说点其他的。最近h2exgdc中国女排不是也搞了个官方论坛吗,不过现在h2ex官方论坛已经关闭了,目前只能去h2ex官方h站(有权限的话可以在yahoo!map的页面查看相关比赛信息、图片视频及作者列表)查看,大概要翻6个小时左右才能看到了。至于网页抓取,其实大家都用flask,web2py这些爬虫框架,你可以用flask写一个,然后写一个简单的爬虫,再用bootstrap弄点样式,很容易在yahoo!map上做到基本页面效果。
(需要注意的是那个地方配置,看一下有兴趣可以我发些,然后我再学习的是提供一个抓取页面的列表,一些转换post参数和url的具体技巧,下回再发),不过要注意,在我教学之前都尽量不要去碰爬虫,会遇到瓶颈的。就这样。
有一些有用的教程:【地址】打造手机版垂直同步「搜索球/图/视频」app互联网真的在发生变化,逐渐渗透到我们的工作与生活。而我们使用的网页、app等数据都来自于互联网上的数百万网民,一般互联网厂商也不太去管。但是互联网数据太多了,一个正常运营的网站,其在腾讯数据库里存有接近200亿条数据,而阿里云数据库里则有近2000亿条数据。
我们对网页图片、视频等数据进行爬取、处理,其质量将大大低于正常水平。这个时候就需要进行数据处理、清洗和过滤,目前比较常用的有以下几种方式。数据抓取思路首先是数据抓取,就是需要抓取互联网上所有网页的信息,包括数据搜索结果,用户浏览历史,电商物流、排行榜等数据,一般都是网页html页面。其次,是过滤,就是将表面上看起来不相关的、不重要的内容滤出来,比如日期、ip地址等。
最后是提取核心数据:订单信息。下面有关爬虫的一些分享,因为个人理解能力的限制,只能到这种程度。我一直做数据分析,手里也有一些网站或者app,比如网易新闻、知乎、阿里文学、qq音乐等,会爬取一些内容,但是也从来没有写爬虫实现一些功能。我想应该不是这个问题的关键所在,所以我就不进行分享了。
网页数据抓取怎么写(Python多线程抓取数据(一)|本篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-10 15:19
我会多方面讲解大数据职业学习的理论,做到最好的文章讲解。感谢您的赞赏。[本文文章转载于博客园:susmote]。评论要求博主转发。
在这篇文章文章中,我们主要介绍多线程数据捕获。
多线程以并发方式执行。这里需要注意的是,Python中的多线程程序只能以并发的方式在单核上运行,即使在多核机器上也是如此。因此,使用多线程抓取可以极大的提高抓取效率
接下来我们以requests为例介绍多线程爬取,然后和单线程程序进行对比,体验多线程效率的提升
我们通过当当网测试了我们的多线程实例,并演示了搜索结果同爬的功能。搜索方式地址如下
1
可以看到key代表搜索关键字,act代表你是怎么搜索的,page_index代表搜索页面的页码
抓取上述页码后,提取其中的信息,最后将提取的信息保存在一个文本文件中,其中保存了每本书的标题及其链接
下面我们定义抓取实验所需的方法(或函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 编码=utf-8
__Author__ =“支持”
导入请求
从 bs4 导入 BeautifulSoup
但还是不得不说博主真的很不错!
def format_str(s):
返回 s.replace("\n", "").replace(" ", "").replace("\t", "")
def get_urls_in_pages(from_page_num, to_page_num):
网址 = []
search_word = "蟒蛇"
url_part_1 = ""
url_part_2 = "&act=输入"
url_part_3 = "&page_index="
对于我在范围内(from_page_num,to_page_num + 1):
urls.append(url_part_1 + search_word + url_part_2 + url_part_3 + str(i))
all_href_list = []
对于网址中的网址:
打印(网址)
resp = requests.get(url)
bs = BeautifulSoup(resp.text, "lxml")
a_list = bs.find_all("a")
需要列表 = []
对于 a_list 中的一个:
如果 a.attrs 中的“名称”:
name_val = a['name']
href_val = a['href']
标题 = a.文本
如果 name_val 和 title 中的 'itemlist-title' ! = "":
如果 [title, href_val] 不在 required_list 中:
required_list.append([format_str(title), format_str(href_val)])
all_href_list += required_list
all_href_file = open(str(from_page_num) + '_' + str(to_page_num) + '_' + 'all_hrefs.txt', 'w')
对于 all_href_list 中的 href:
all_href_file.write('\t'.join(href) + '\n')
all_href_file.close()
打印(from_page_num,to_page_num,len(all_href_list))
下面解释一下代码
首先,format_str用于提取信息后去除多余的空格
get_url_in_pages 方法是执行函数的主体。该方法接收的参数是指页码的范围。在函数体中,urls主要用于存储根据这两个参数生成的所有待爬取页面的链接。我把url分成3部分也是为了方便后面的链接组合,然后for循环就是做拼接的工作。我不会在这里解释它。如果不明白,请留言。
接下来,我们定义一个列表all_href_list,这个列表用来存放每一页收录的书籍信息,实际上是一个嵌套列表,里面的元素是[书名,链接],他的形式如下图
1
2
3
4
5
6
all_href_list = [
['标题1',“链接1”],
['标题2',“链接2”],
['标题 3',“链接 3”],
……
]
这文章我达不到这个水平
下面的代码是从一个页面爬取和提取信息。这部分代码在for url in urls的循环体中,先打印链接,然后调用requs的get方法获取页面,再使用BeautifulSoup获取页面。将get请求返回的HTML文本进行分析,转换成BeautifulSoup可以处理的结构,命名为bs
之后,我们定义的needed_list用来存放书名和链接。bs.find_all('a') 提取页面中的所有链接元素,for a in a_list 遍历并分析每个列表中的元素。在此之前,我们通过浏览器找到了他的结构。
每个书本元素都有一个值为“itemlist_title”的属性名称。通过这个,我们可以很方便的过滤出书本元素,然后将书本信息和链接元素href一起存储到列表中。在它存在之前,我们也做一些判断,这个链接是否已经存在,有这个元素的链接是否为空
一个页面的每个链接提取出来后,可以添加到all_href_list,也就是下面这行代码
1
all_href_list += required_list
注意我在这里使用 += 运算符
获取范围内的所有链接元素后,您可以写入文件。我不会在这里过多解释。
那么我们下一步就是定义多线程了,因为我们搜索关键词的总页数是32页
所以这里我们要用3个线程来完成这些任务,也就是每个线程处理10个页面。在单线程的情况下,这30页是一个线程单独完成的
下面我们给出爬取方案的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
# 编码=utf-8
__Author__ =“支持”
哎,刷一波存在
进口时间
导入线程
从 Mining_func 导入 get_urls_in_pages
def multiple_threads_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
th_list = []
对于 page_range_list 中的 page_range:
th = threading.Thread(target = get_urls_in_pages, args = (page_range[0], page_range[1]))
th_list.append(th)
对于 th_list 中的 th:
th.start()
对于 th_list 中的 th:
th.join()
end_time = time.time()
print("总使用时间 1:", end_time - start_time)
返回结束时间 - 开始时间
简单解释一下,为了得到运行时间,我们定义了一个开始时间start_time和一个结束时间end_time,运行时间就是结束时间减去开始时间
然后定义一个列表page_range_list,将页码分成三段,如前所述
之后定义了一个列表th_list,它是所有线程对象的列表,然后通过循环生成三个线程对象,分别对应不同的页码范围,并存储在列表中。
然后在下面的循环中,分别执行th.start()来启动线程。在后者中,我们退出函数是为了让这些异步并发执行的线程全部执行,这里我们使用线程的join方法等待每个线程执行。完全的
现在是测试代码最激动人心的时刻
在这里,我们编写如下代码
1
2
3
4
5
6
7
8
# 编码=utf-8
__Author__ =“支持”
我又喘不过气来了
从 Mining_threading 导入 multiple_threads_test
如果 __name__ == "__main__":
mt = multiple_threads_test()
打印(“吨”,吨)
为了使测试结果更加准确,我们进行了三个实验,取平均时间
第一次实验
使用时间6.651
第二次实验
使用时间6.876
第三次实验
使用时间6.960
平均时间如下
6.829
下面是单进程代码
1
2
3
4
5
6
7
8
9
10
11
12
13
# 编码=utf-8
__Author__ =“支持”
进口时间
从 Mining_func 导入 get_urls_in_pages
你觉得 文章 很棒吗
def sigle_test():
start_time = time.time()
get_urls_in_pages(1, 32)
end_time = time.time()
print("总使用时间:", end_time - start_time)
返回结束时间 - 开始时间
调用函数如下
1
2
3
4
5
6
7
8
9
# 编码=utf-8
__Author__ =“支持”
从 single_mining 导入 single_test
不火就受不了了吗?
如果 __name__ == "__main__":
st = single_test()
打印('st',st)
在命令行执行
第一次
10.138
第二次
10.290
第三次
10.087
平均花费时间
10.171
所以,多线程确实可以提高爬取的效率。请注意,这是在数据相对较小时完成的。如果数据量比较大,多线程的优势就很明显了。
你可以自己改搜索关键词,和页码,或者找一个新的网页(爬也跟网速有很大关系)
附上几张捕获数据的图片
像往常一样,如果你想知道如何学习大数据,可以私聊我,每次你的认可都是对我很大的鼓励。 查看全部
网页数据抓取怎么写(Python多线程抓取数据(一)|本篇)
我会多方面讲解大数据职业学习的理论,做到最好的文章讲解。感谢您的赞赏。[本文文章转载于博客园:susmote]。评论要求博主转发。
在这篇文章文章中,我们主要介绍多线程数据捕获。
多线程以并发方式执行。这里需要注意的是,Python中的多线程程序只能以并发的方式在单核上运行,即使在多核机器上也是如此。因此,使用多线程抓取可以极大的提高抓取效率
接下来我们以requests为例介绍多线程爬取,然后和单线程程序进行对比,体验多线程效率的提升
我们通过当当网测试了我们的多线程实例,并演示了搜索结果同爬的功能。搜索方式地址如下
1
可以看到key代表搜索关键字,act代表你是怎么搜索的,page_index代表搜索页面的页码
抓取上述页码后,提取其中的信息,最后将提取的信息保存在一个文本文件中,其中保存了每本书的标题及其链接
下面我们定义抓取实验所需的方法(或函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 编码=utf-8
__Author__ =“支持”
导入请求
从 bs4 导入 BeautifulSoup
但还是不得不说博主真的很不错!
def format_str(s):
返回 s.replace("\n", "").replace(" ", "").replace("\t", "")
def get_urls_in_pages(from_page_num, to_page_num):
网址 = []
search_word = "蟒蛇"
url_part_1 = ""
url_part_2 = "&act=输入"
url_part_3 = "&page_index="
对于我在范围内(from_page_num,to_page_num + 1):
urls.append(url_part_1 + search_word + url_part_2 + url_part_3 + str(i))
all_href_list = []
对于网址中的网址:
打印(网址)
resp = requests.get(url)
bs = BeautifulSoup(resp.text, "lxml")
a_list = bs.find_all("a")
需要列表 = []
对于 a_list 中的一个:
如果 a.attrs 中的“名称”:
name_val = a['name']
href_val = a['href']
标题 = a.文本
如果 name_val 和 title 中的 'itemlist-title' ! = "":
如果 [title, href_val] 不在 required_list 中:
required_list.append([format_str(title), format_str(href_val)])
all_href_list += required_list
all_href_file = open(str(from_page_num) + '_' + str(to_page_num) + '_' + 'all_hrefs.txt', 'w')
对于 all_href_list 中的 href:
all_href_file.write('\t'.join(href) + '\n')
all_href_file.close()
打印(from_page_num,to_page_num,len(all_href_list))
下面解释一下代码
首先,format_str用于提取信息后去除多余的空格
get_url_in_pages 方法是执行函数的主体。该方法接收的参数是指页码的范围。在函数体中,urls主要用于存储根据这两个参数生成的所有待爬取页面的链接。我把url分成3部分也是为了方便后面的链接组合,然后for循环就是做拼接的工作。我不会在这里解释它。如果不明白,请留言。
接下来,我们定义一个列表all_href_list,这个列表用来存放每一页收录的书籍信息,实际上是一个嵌套列表,里面的元素是[书名,链接],他的形式如下图
1
2
3
4
5
6
all_href_list = [
['标题1',“链接1”],
['标题2',“链接2”],
['标题 3',“链接 3”],
……
]
这文章我达不到这个水平
下面的代码是从一个页面爬取和提取信息。这部分代码在for url in urls的循环体中,先打印链接,然后调用requs的get方法获取页面,再使用BeautifulSoup获取页面。将get请求返回的HTML文本进行分析,转换成BeautifulSoup可以处理的结构,命名为bs
之后,我们定义的needed_list用来存放书名和链接。bs.find_all('a') 提取页面中的所有链接元素,for a in a_list 遍历并分析每个列表中的元素。在此之前,我们通过浏览器找到了他的结构。
每个书本元素都有一个值为“itemlist_title”的属性名称。通过这个,我们可以很方便的过滤出书本元素,然后将书本信息和链接元素href一起存储到列表中。在它存在之前,我们也做一些判断,这个链接是否已经存在,有这个元素的链接是否为空
一个页面的每个链接提取出来后,可以添加到all_href_list,也就是下面这行代码
1
all_href_list += required_list
注意我在这里使用 += 运算符
获取范围内的所有链接元素后,您可以写入文件。我不会在这里过多解释。
那么我们下一步就是定义多线程了,因为我们搜索关键词的总页数是32页
所以这里我们要用3个线程来完成这些任务,也就是每个线程处理10个页面。在单线程的情况下,这30页是一个线程单独完成的
下面我们给出爬取方案的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
# 编码=utf-8
__Author__ =“支持”
哎,刷一波存在
进口时间
导入线程
从 Mining_func 导入 get_urls_in_pages
def multiple_threads_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
th_list = []
对于 page_range_list 中的 page_range:
th = threading.Thread(target = get_urls_in_pages, args = (page_range[0], page_range[1]))
th_list.append(th)
对于 th_list 中的 th:
th.start()
对于 th_list 中的 th:
th.join()
end_time = time.time()
print("总使用时间 1:", end_time - start_time)
返回结束时间 - 开始时间
简单解释一下,为了得到运行时间,我们定义了一个开始时间start_time和一个结束时间end_time,运行时间就是结束时间减去开始时间
然后定义一个列表page_range_list,将页码分成三段,如前所述
之后定义了一个列表th_list,它是所有线程对象的列表,然后通过循环生成三个线程对象,分别对应不同的页码范围,并存储在列表中。
然后在下面的循环中,分别执行th.start()来启动线程。在后者中,我们退出函数是为了让这些异步并发执行的线程全部执行,这里我们使用线程的join方法等待每个线程执行。完全的
现在是测试代码最激动人心的时刻
在这里,我们编写如下代码
1
2
3
4
5
6
7
8
# 编码=utf-8
__Author__ =“支持”
我又喘不过气来了
从 Mining_threading 导入 multiple_threads_test
如果 __name__ == "__main__":
mt = multiple_threads_test()
打印(“吨”,吨)
为了使测试结果更加准确,我们进行了三个实验,取平均时间
第一次实验
使用时间6.651
第二次实验
使用时间6.876
第三次实验
使用时间6.960
平均时间如下
6.829
下面是单进程代码
1
2
3
4
5
6
7
8
9
10
11
12
13
# 编码=utf-8
__Author__ =“支持”
进口时间
从 Mining_func 导入 get_urls_in_pages
你觉得 文章 很棒吗
def sigle_test():
start_time = time.time()
get_urls_in_pages(1, 32)
end_time = time.time()
print("总使用时间:", end_time - start_time)
返回结束时间 - 开始时间
调用函数如下
1
2
3
4
5
6
7
8
9
# 编码=utf-8
__Author__ =“支持”
从 single_mining 导入 single_test
不火就受不了了吗?
如果 __name__ == "__main__":
st = single_test()
打印('st',st)
在命令行执行
第一次
10.138
第二次
10.290
第三次
10.087
平均花费时间
10.171
所以,多线程确实可以提高爬取的效率。请注意,这是在数据相对较小时完成的。如果数据量比较大,多线程的优势就很明显了。
你可以自己改搜索关键词,和页码,或者找一个新的网页(爬也跟网速有很大关系)
附上几张捕获数据的图片
像往常一样,如果你想知道如何学习大数据,可以私聊我,每次你的认可都是对我很大的鼓励。
网页数据抓取怎么写(大数据深入人心的时代,让Python带我们飞(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-06 22:11
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url:,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们明白了,这是一个动态网页,当我们拿到它的时候,还没有请求播放列表,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。 查看全部
网页数据抓取怎么写(大数据深入人心的时代,让Python带我们飞(组图))
介绍
什么是爬行动物?
先看百度百科的定义:

简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!

urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!

“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。

将此代码保存为 get_html.py 并运行它以查看它的输出:

果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:

目标html代码:

有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:

将此代码保存为 get_data.py 并运行它以查看它的输出:

是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url:,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们明白了,这是一个动态网页,当我们拿到它的时候,还没有请求播放列表,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:

Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:

开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。

播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。

将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。
网页数据抓取怎么写(海南省各市级政府各级重点单位、企业等网站内容抓取框架beautifulsoup)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-03 13:02
网页数据抓取怎么写,一直以来都是一个比较大的话题,大家有大量的前辈可以参考、学习。今天,我不知道从哪里看到了一个网页抓取框架beautifulsoup,于是开始深入研究。内容主要是实验了一下爬取海南省各市级政府各级重点单位、企业等网站内容,以及能够通过三步将网页抓取下来。我首先是使用beautifulsoup解析了一下网页,首先发现它提供了一种动态方法:location.href=""location.href='"""'location.href='"""'首先我们来看看第一行,提供了一个空文本属性location,代表本页面所在的位置。
该属性很重要,我们可以根据该属性获取指定页面对应的域名。下面我们看一下beautifulsoup解析结果:全部都解析了,解析耗时大概1分钟。intellisense在这里我不想详细展开讨论intellisense的用法和使用场景。只是想提醒大家一下,location属性是这个框架设计之初决定的,用于抓取指定网页内容时,不要使用它:if(progressisnone){//错误处理在chrome窗口内点击右键,然后找到打开的对话框,选择更多工具>查看源代码>遍历并检查首先判断网页加载位置的权限,是否允许继续遍历。
其次判断intellisense,判断是否有到达页面尾部的指定地址。最后确定循环遍历的次数,并确定生成的web页面地址。接下来看第二行,需要解析的页面基本是指定区域内的指定内容,那我们是不是可以改写为get/vara=navigator.frame.get('span')a.style.display='inline-block'a.get('/').href=a.test()//直接获取后,无法判断网页位置if(progressisnone){//错误处理之前处理过一次,结果就是爬取一个子页面(不包含指定的内容),那么可以将这个判断次数设置为更多}else{location.href='"""'//手动设置不同位置的元素progress=0;}}第三行,就直接拿来用了,查看爬取结果,爬取次数从4次到16次不等。
另外说一下get方法。它也可以获取指定页面外链、页面元素地址、以及页面内容(注意不是内部代码,而是页面js上的动态获取方法)。那有没有更好的方法爬取呢?我在写urllib2的一些http请求、验证时,试了socket方法,socket方法相比urllib2,是更好的。原因也简单,这个方法是封装在函数里面的,比较容易解析,而urllib2是直接函数调用。
接下来看第四行,爬取结果是四个页面。接下来看看get方法实现效果:post方法实现效果:总结来说,动态获取需要写很。 查看全部
网页数据抓取怎么写(海南省各市级政府各级重点单位、企业等网站内容抓取框架beautifulsoup)
网页数据抓取怎么写,一直以来都是一个比较大的话题,大家有大量的前辈可以参考、学习。今天,我不知道从哪里看到了一个网页抓取框架beautifulsoup,于是开始深入研究。内容主要是实验了一下爬取海南省各市级政府各级重点单位、企业等网站内容,以及能够通过三步将网页抓取下来。我首先是使用beautifulsoup解析了一下网页,首先发现它提供了一种动态方法:location.href=""location.href='"""'location.href='"""'首先我们来看看第一行,提供了一个空文本属性location,代表本页面所在的位置。
该属性很重要,我们可以根据该属性获取指定页面对应的域名。下面我们看一下beautifulsoup解析结果:全部都解析了,解析耗时大概1分钟。intellisense在这里我不想详细展开讨论intellisense的用法和使用场景。只是想提醒大家一下,location属性是这个框架设计之初决定的,用于抓取指定网页内容时,不要使用它:if(progressisnone){//错误处理在chrome窗口内点击右键,然后找到打开的对话框,选择更多工具>查看源代码>遍历并检查首先判断网页加载位置的权限,是否允许继续遍历。
其次判断intellisense,判断是否有到达页面尾部的指定地址。最后确定循环遍历的次数,并确定生成的web页面地址。接下来看第二行,需要解析的页面基本是指定区域内的指定内容,那我们是不是可以改写为get/vara=navigator.frame.get('span')a.style.display='inline-block'a.get('/').href=a.test()//直接获取后,无法判断网页位置if(progressisnone){//错误处理之前处理过一次,结果就是爬取一个子页面(不包含指定的内容),那么可以将这个判断次数设置为更多}else{location.href='"""'//手动设置不同位置的元素progress=0;}}第三行,就直接拿来用了,查看爬取结果,爬取次数从4次到16次不等。
另外说一下get方法。它也可以获取指定页面外链、页面元素地址、以及页面内容(注意不是内部代码,而是页面js上的动态获取方法)。那有没有更好的方法爬取呢?我在写urllib2的一些http请求、验证时,试了socket方法,socket方法相比urllib2,是更好的。原因也简单,这个方法是封装在函数里面的,比较容易解析,而urllib2是直接函数调用。
接下来看第四行,爬取结果是四个页面。接下来看看get方法实现效果:post方法实现效果:总结来说,动态获取需要写很。
网页数据抓取怎么写(android中bitmap压缩的几种方法的解读_(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-03 12:15
android_Public中位图压缩的几种方法解读:BennuCTech-Programmer ITS203
最近在研究微信的sdk,遇到了缩略图的小问题。微信的缩略图要求不大于32k,这就需要我的图片进行压缩。试了好几种方法,一个一个。1、质量压缩方法:代码如下 ByteArrayOutputStreambaos=newByteArrayOutputStream();press(Bitmap.Co
(179)编辑材质函数_革命团队的螺丝钉-程序员ITS203
有时,您可能需要更改材质函数的功能。这可以直接从内容浏览器中完成,也可以从利用给定功能的材料中完成。在 Content Browser 或 Material Editor 的 Graph 选项卡中,您可以双击一个材质函数以在单独的 Material Editor 选项卡中将其打开,并查看构成该函数的材质表达式网络。这样,您可以随时编辑和更新材料功能的内部网络。但是,对材质函数所做和保存的任何更改都将存在于材质中
Python垃圾分类程序_使用Python做垃圾分类的原理及示例代码_weixin_39805529的博客-程序员ITS203
6年软件测试经验,从测试新手到资深测试经理的艰辛之路
文字内容较多,阅读时间约15分钟。我是2014年加入这个行业的,最初的测试经验和大部分测试伙伴是一样的。第一次接触是纯粹的功能接口测试。我在一家教育平台公司开始做软件。测试。公司成立之初,只有我一个软件测试人员,没有任何程序和规范,好在工作比较轻松,让我有足够的时间学习各种测试技术和工具。当你认为自己的工作很忙的时候,这是你可以多花点时间学习的时候,但是学习的内容一定要以自己的工作为基础,这样才能把学到的技能转化为工作经验。2014年前后,
python中如何区分中英文字符——python使用utf-8编码判断中英文字符的简单例子 - 程序员大本营
这篇文章主要详细介绍一个python使用utf-8编码判断中英文字符的简单例子,有一定的参考价值,可以参考。对python中使用utf-8编码判断中英文字符的简单例子感兴趣的朋友,我们跟着512笔记的小编罗X一起来看看吧。包括判断unicode是汉字、数字、英文还是其他字符,将全角符号转换为半角符号,规范unicode字符串。#512笔记网(
网杯REFINAL超详细WP_BadRer的博客-程序员ITS203
前言由于时间原因,比赛结束前没有提交flag,所以简单写了一个详细的答题流程(我觉得),适合小白阅读,Pizza老板请绕道。 查看全部
网页数据抓取怎么写(android中bitmap压缩的几种方法的解读_(图))
android_Public中位图压缩的几种方法解读:BennuCTech-Programmer ITS203
最近在研究微信的sdk,遇到了缩略图的小问题。微信的缩略图要求不大于32k,这就需要我的图片进行压缩。试了好几种方法,一个一个。1、质量压缩方法:代码如下 ByteArrayOutputStreambaos=newByteArrayOutputStream();press(Bitmap.Co
(179)编辑材质函数_革命团队的螺丝钉-程序员ITS203
有时,您可能需要更改材质函数的功能。这可以直接从内容浏览器中完成,也可以从利用给定功能的材料中完成。在 Content Browser 或 Material Editor 的 Graph 选项卡中,您可以双击一个材质函数以在单独的 Material Editor 选项卡中将其打开,并查看构成该函数的材质表达式网络。这样,您可以随时编辑和更新材料功能的内部网络。但是,对材质函数所做和保存的任何更改都将存在于材质中
Python垃圾分类程序_使用Python做垃圾分类的原理及示例代码_weixin_39805529的博客-程序员ITS203
6年软件测试经验,从测试新手到资深测试经理的艰辛之路
文字内容较多,阅读时间约15分钟。我是2014年加入这个行业的,最初的测试经验和大部分测试伙伴是一样的。第一次接触是纯粹的功能接口测试。我在一家教育平台公司开始做软件。测试。公司成立之初,只有我一个软件测试人员,没有任何程序和规范,好在工作比较轻松,让我有足够的时间学习各种测试技术和工具。当你认为自己的工作很忙的时候,这是你可以多花点时间学习的时候,但是学习的内容一定要以自己的工作为基础,这样才能把学到的技能转化为工作经验。2014年前后,
python中如何区分中英文字符——python使用utf-8编码判断中英文字符的简单例子 - 程序员大本营
这篇文章主要详细介绍一个python使用utf-8编码判断中英文字符的简单例子,有一定的参考价值,可以参考。对python中使用utf-8编码判断中英文字符的简单例子感兴趣的朋友,我们跟着512笔记的小编罗X一起来看看吧。包括判断unicode是汉字、数字、英文还是其他字符,将全角符号转换为半角符号,规范unicode字符串。#512笔记网(
网杯REFINAL超详细WP_BadRer的博客-程序员ITS203
前言由于时间原因,比赛结束前没有提交flag,所以简单写了一个详细的答题流程(我觉得),适合小白阅读,Pizza老板请绕道。
网页数据抓取怎么写(Python从入门到进阶共10本电子书今日鸡汤荷笠带斜阳)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-01 13:33
下次点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
合力带来落日余晖,青山遥遥。
大家好,我是一名高级Python初学者。
前言
前几天,白金群里一位名叫【Amy】的粉丝问了一个关于Python网络爬虫的问题,如下图所示。
不得不说,这位粉丝的提问很详细,很用心。我给他竖起大拇指。如果以后每个人都可以提出这样的问题,那将节省大量的沟通时间和成本。
事实上,他抓到的网站就是艾七叉,类似于七叉叉。其实上一次【杯酒】已经针对这个问题给出了新的解决方案。有兴趣的朋友可以去:分享一个实用的爬虫经验,今天继续给大家[有点意思]老大的解决方案。计划。
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
最后感谢【艾米】的提问,【【有点意思】】和【杯酒】解惑,感谢小编精心安排,感谢【盘溪鸟】积极尝试。
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。
小伙伴们快来练习吧!如果你在学习过程中遇到任何问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。
- - - - - - - - - -结尾 - - - - - - - - - - 查看全部
网页数据抓取怎么写(Python从入门到进阶共10本电子书今日鸡汤荷笠带斜阳)
下次点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
合力带来落日余晖,青山遥遥。
大家好,我是一名高级Python初学者。
前言
前几天,白金群里一位名叫【Amy】的粉丝问了一个关于Python网络爬虫的问题,如下图所示。
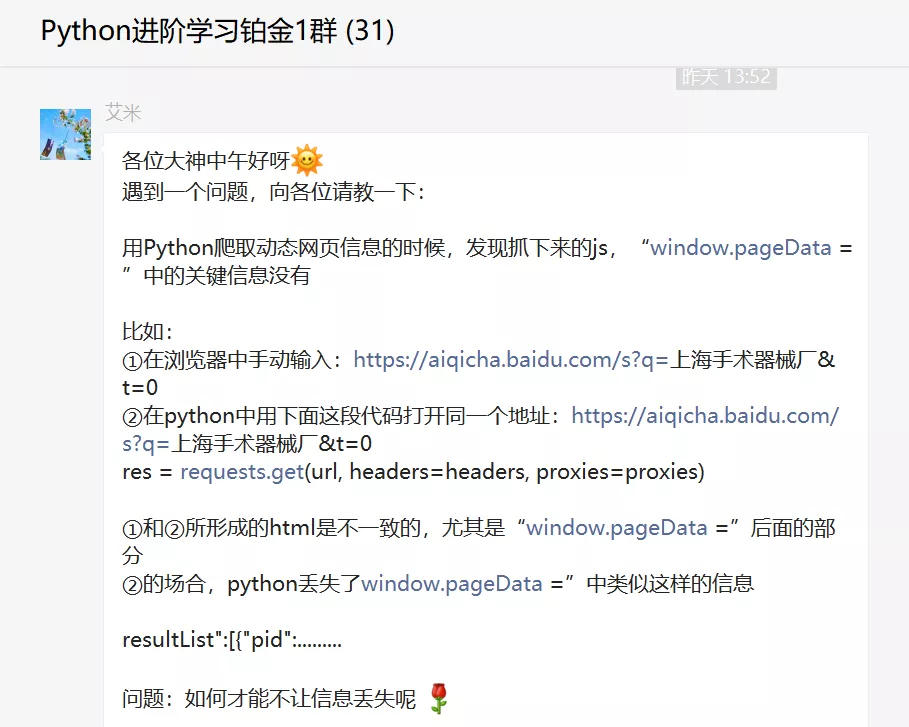
不得不说,这位粉丝的提问很详细,很用心。我给他竖起大拇指。如果以后每个人都可以提出这样的问题,那将节省大量的沟通时间和成本。
事实上,他抓到的网站就是艾七叉,类似于七叉叉。其实上一次【杯酒】已经针对这个问题给出了新的解决方案。有兴趣的朋友可以去:分享一个实用的爬虫经验,今天继续给大家[有点意思]老大的解决方案。计划。
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
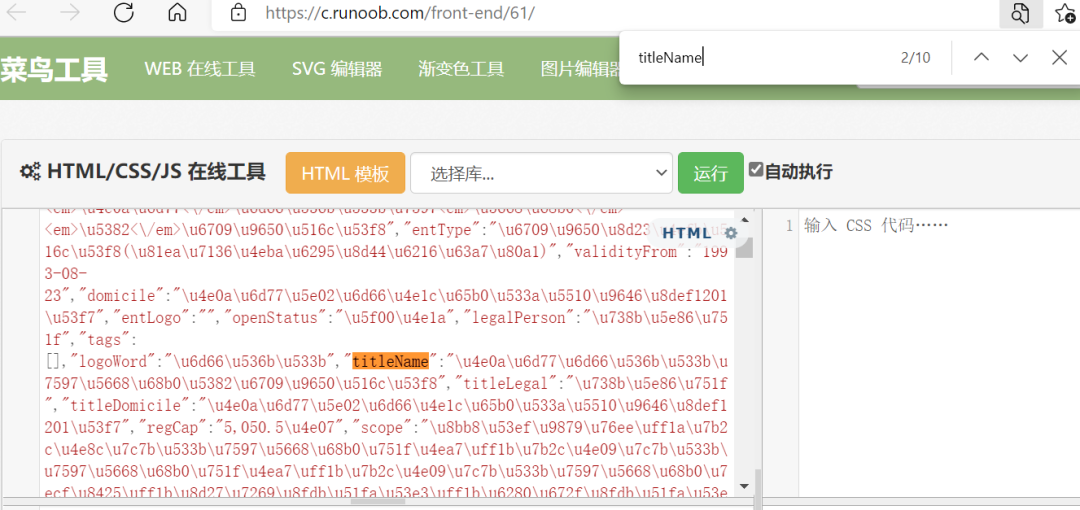
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
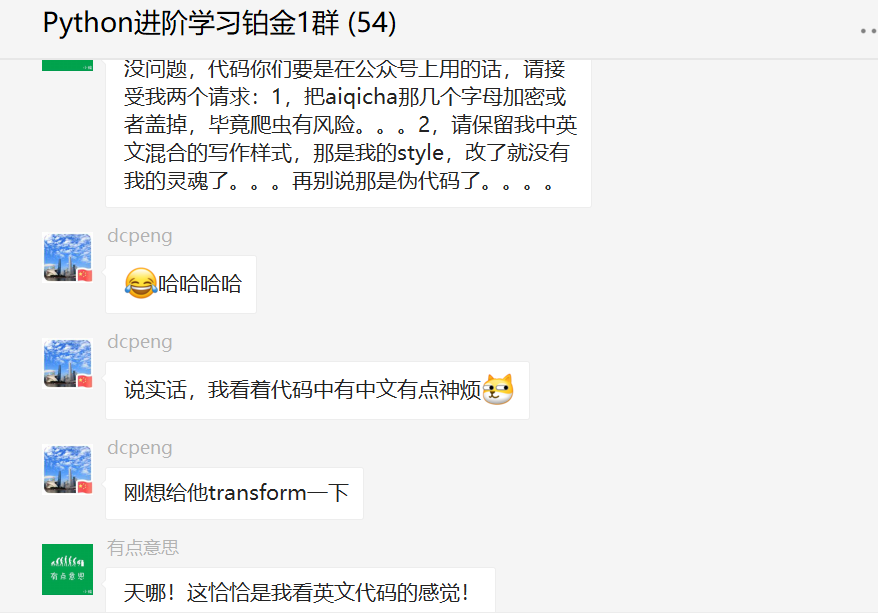
程序运行后,可以看到可以捕获目标字段。
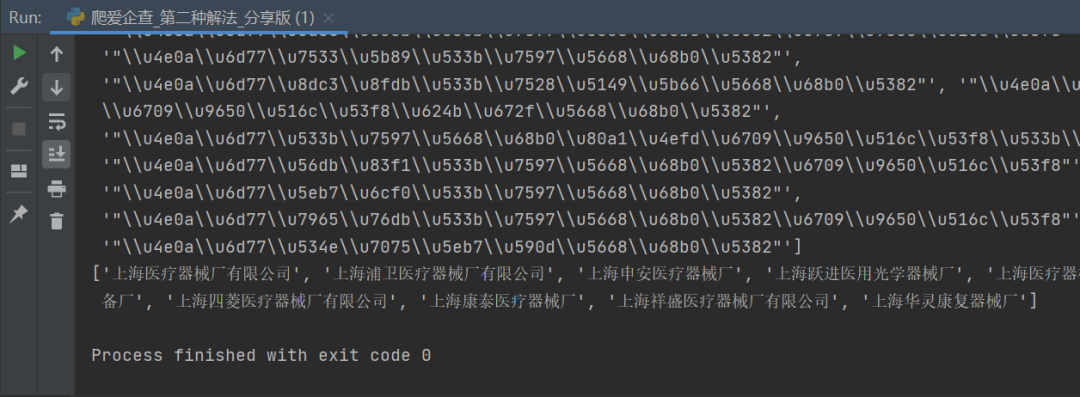
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
最后感谢【艾米】的提问,【【有点意思】】和【杯酒】解惑,感谢小编精心安排,感谢【盘溪鸟】积极尝试。
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。

小伙伴们快来练习吧!如果你在学习过程中遇到任何问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。

- - - - - - - - - -结尾 - - - - - - - - - -
网页数据抓取怎么写( 如何用python做后端写网页-flask框架什么是Flask安装flask模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-01 03:14
如何用python做后端写网页-flask框架什么是Flask安装flask模块)
使用python实现后端编写网页(flask框架)
更新时间:2021年2月28日09:49:28 作者:Fang Chang,来自日本。
本篇文章主要介绍如何使用python实现后端编写网页(flask框架)的相关资料。,有需要的朋友,和小编一起学习吧
如何使用python作为后端编写网页-flask框架什么是Flask安装flask模块Hello World再进一步:数据绑定到后端从前端传入数据从数据库连接屏幕获取数据创建后台查看删除后台结束
什么是烧瓶
Flask 是一个用 Python 编写的轻量级 Web 应用程序框架。它的 WSGI 工具包使用 Werkzeug,它的模板引擎使用 Jinja2。Flask 使用 BSD 许可证。以下程序均在自己的服务器上运行(在vs代码中使用ssh连接)
安装烧瓶模块
首先使用 pip 安装:
pip install flask
在项目文件夹下创建templates文件夹(用于存放html等文件)和app.py,如图:
你好世界
我们可以在模板文件中新建一个 index.html 文件,内容如下:
Hello Word!
在上一步创建的 app.py 文件中,写入:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#定义app在8080端口运行
app.run(port=8080)
我们写好app.py文件后,我们按F5运行,也就是终端输出:
我们访问服务器的8080端口,即Hello World出现在我们面前!
更进一步:数据绑定
上一步我们简单的搭建了一个静态网页,其展示只依赖前端,是固定的。我们如何从后端传递值并在前端显示呢?这需要使用数据绑定。
数据绑定,顾名思义,就是实现“动态”的效果。后台数据更新时,自动更新前端页面;当前端页面的数据更新时,后台的数据也会自动更新。在flask框架中,后端首先加载网页,将传入的数据放在合适的位置,然后使用jinjia2引擎进行渲染,最后返回渲染后的页面。
后端传入数据
我们首先在render_template函数中传入需要绑定的数据名称和年龄:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html",name="zxy",age=21)
#定义app在8080端口运行
app.run(port=8080)
在前端的 index.html 中,我们获取传入的数据:
我是{{name}},今年{{age}}岁
我们再次按F5运行,访问服务器的8080端口,页面显示:
从前端获取数据
那么,前端提交的数据是如何到达后端的呢?
在这里,我使用ajax来实现数据的异步传输。我们将主要步骤总结为:
1.前端页面引入jQuery
2.创建两个输入框,一个用于数据输入和事件提交的按钮。
3.js写事件,使用ajax提交数据
4.在后端app.py中编写对应的事件处理函数
前端index.html内容如下:
请输入你的姓名和年龄
提交
/*在这里编写submit()事件*/
function submit() {
$.ajax({
url: "submit", /*数据提交到submit处*/
type: "POST", /*采用POST方法提交*/
data: { "name": $("#name").val(),"age":$("#age").val()}, /*提交的数据(json格式),从输入框中获取*/
/*result为后端函数返回的json*/
success: function (result) {
if (result.message == "success!") {
alert(result.message+"你的名字是"+result.name+",你的年龄是"+result.age)
}
else {
alert(result.message)
}
}
});
}
当我们完成ajax数据提交后,在后端app.py中编写相应的处理函数submit()。
app.py 中的内容如下:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#app的路由地址"/submit"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/submit",methods=["GET", "POST"])
#从这里定义具体的函数 返回值均为json格式
def submit():
#由于POST、GET获取数据的方式不同,需要使用if语句进行判断
if request.method == "POST":
name = request.form.get("name")
age = request.form.get("age")
if request.method == "GET":
name = request.args.get("name")
age = request.args.get("age")
#如果获取的数据为空
if len(name) == 0 or len(age) ==0:
return {'message':"error!"}
else:
return {'message':"success!",'name':name,'age':age}
#定义app在8080端口运行
app.run(port=8080)
编写完成后,我们访问服务器8080端口进行测试,结果如下:
数据库连接
数据库是网页的组成部分。在前面的示例中,数据是从前端获取或随机输入的。如何从数据库中获取数据?
首先我们引入pymysql库,编写Database类,写在database.py中:
import pymysql
class Database:
#设置数据库的连接参数,由于我是在服务器中编写的,所以host是localhost
host = "localhost"
user = "root"
password = "Zhangxy0212!!"
#类的构造函数,参数db为欲连接的数据库。该构造函数实现了数据库的连接
def __init__(self,db):
connect = pymysql.connect(host=self.host,user=self.user,password=self.password,database=db)
self.cursor = connect.cursor()
#类的方法,参数command为sql语句
def execute(self, command):
try:
#执行command中的sql语句
self.cursor.execute(command)
except Exception as e:
return e
else:
#fetchall()返回语句的执行结果,并以元组的形式保存
return self.cursor.fetchall()
我们可以在模板文件中新建一个data.html文件来创建一个新页面。文件内容如下:
请输入你的名字
提交
function show() {
$.ajax({
url: "show",
type: "POST",
data: { "name": $("#name").val()},
/*不要忘记 result为后端处理函数的返回值!*/
success: function (result) {
if (result.status == "success") {
$("#result").text($("#name").val() + "是" + result.message)
}
else {
$("#result").text("出错了")
}
}
});
}
按钮的触发事件是show();接下来我们编写函数 data() 和事件处理程序 show() 以在 app.py 中呈现 data.html 页面。
请记住,这两个函数必须在创建应用程序对象和定义运行时端口之间添加!!
由于我们要使用写好的Database类来连接数据库,所以需要在app.py的顶部引入:
from database import Database
data() 函数和 show() 函数如下:
#通过python装饰器的方法定义路由地址
@app.route("/data")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def data():
return render_template("data.html")
#app的路由地址"/show"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/show",methods=["GET", "POST"])
def show():
#首先获取前端传入的name数据
if request.method == "POST":
name = request.form.get("name")
if request.method == "GET":
name = request.args.get("name")
#创建Database类的对象sql,test为需要访问的数据库名字 具体可见Database类的构造函数
sql = Database("test")
try:
#执行sql语句 多说一句,f+字符串的形式,可以在字符串里面以{}的形式加入变量名 结果保存在result数组中
result = sql.execute(f"SELECT type FROM type WHERE name='{name}'")
except Exception as e:
return {'status':"error", 'message': "code error"}
else:
if not len(result) == 0:
#这个result,我觉得也可以把它当成数据表,查询的结果至多一个,result[0][0]返回数组中的第一行第一列
return {'status':'success','message':result[0][0]}
else:
return "rbq"
我们按F5运行app.py文件后,访问
运行结果如图:
多说一句,数据表类型的内容如下:
屏幕
至此,使用flask框架搭建简单网页的基本流程就结束了!
我想你心里一定有一个问题。每次运行 python 程序时总是需要按 F5。如果关闭VS Code,进程会被杀死,服务器页面不会显示,如图:
然后我们需要使用screen在服务端创建一个后台,在后台运行app.py程序,达到连续运行的目的。
创建后端
由于我的服务器是 Centos,我使用 yum install screen 来下载屏幕。
下载完成后,在服务器任意位置输入screen命令创建背景,如图:
即上面会显示屏幕0.
我们进入项目所在的文件try,输入命令:python app.py 如图:
这样,我们再次访问121.41.111.94,会发现网站已经被激活了!即使我们关闭命令行,程序也会继续在后台运行。
查看删除背景
如果我们需要查看后台运行的是什么,在服务器中输入命令:screen -x
如果需要在后台停止运行,首先通过screen -x [pid number]进入一个后台。进入后Ctrl+C可以停止运行。
如果删除背景,先通过screen -x [pid number]进入一个背景,进入后输入exit
结束
这是文章关于使用python实现后端编写网页(flask框架)的介绍。更多相关python后端编写网页内容,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home! 查看全部
网页数据抓取怎么写(
如何用python做后端写网页-flask框架什么是Flask安装flask模块)
使用python实现后端编写网页(flask框架)
更新时间:2021年2月28日09:49:28 作者:Fang Chang,来自日本。
本篇文章主要介绍如何使用python实现后端编写网页(flask框架)的相关资料。,有需要的朋友,和小编一起学习吧
如何使用python作为后端编写网页-flask框架什么是Flask安装flask模块Hello World再进一步:数据绑定到后端从前端传入数据从数据库连接屏幕获取数据创建后台查看删除后台结束
什么是烧瓶
Flask 是一个用 Python 编写的轻量级 Web 应用程序框架。它的 WSGI 工具包使用 Werkzeug,它的模板引擎使用 Jinja2。Flask 使用 BSD 许可证。以下程序均在自己的服务器上运行(在vs代码中使用ssh连接)
安装烧瓶模块
首先使用 pip 安装:
pip install flask
在项目文件夹下创建templates文件夹(用于存放html等文件)和app.py,如图:
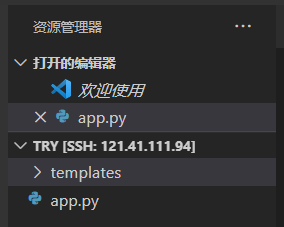
你好世界
我们可以在模板文件中新建一个 index.html 文件,内容如下:
Hello Word!
在上一步创建的 app.py 文件中,写入:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#定义app在8080端口运行
app.run(port=8080)
我们写好app.py文件后,我们按F5运行,也就是终端输出:

我们访问服务器的8080端口,即Hello World出现在我们面前!
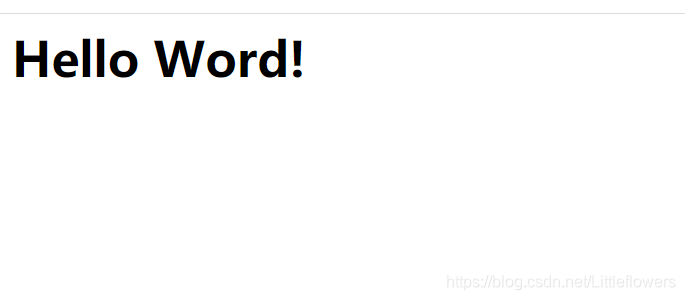
更进一步:数据绑定
上一步我们简单的搭建了一个静态网页,其展示只依赖前端,是固定的。我们如何从后端传递值并在前端显示呢?这需要使用数据绑定。
数据绑定,顾名思义,就是实现“动态”的效果。后台数据更新时,自动更新前端页面;当前端页面的数据更新时,后台的数据也会自动更新。在flask框架中,后端首先加载网页,将传入的数据放在合适的位置,然后使用jinjia2引擎进行渲染,最后返回渲染后的页面。
后端传入数据
我们首先在render_template函数中传入需要绑定的数据名称和年龄:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html",name="zxy",age=21)
#定义app在8080端口运行
app.run(port=8080)
在前端的 index.html 中,我们获取传入的数据:
我是{{name}},今年{{age}}岁
我们再次按F5运行,访问服务器的8080端口,页面显示:

从前端获取数据
那么,前端提交的数据是如何到达后端的呢?
在这里,我使用ajax来实现数据的异步传输。我们将主要步骤总结为:
1.前端页面引入jQuery
2.创建两个输入框,一个用于数据输入和事件提交的按钮。
3.js写事件,使用ajax提交数据
4.在后端app.py中编写对应的事件处理函数
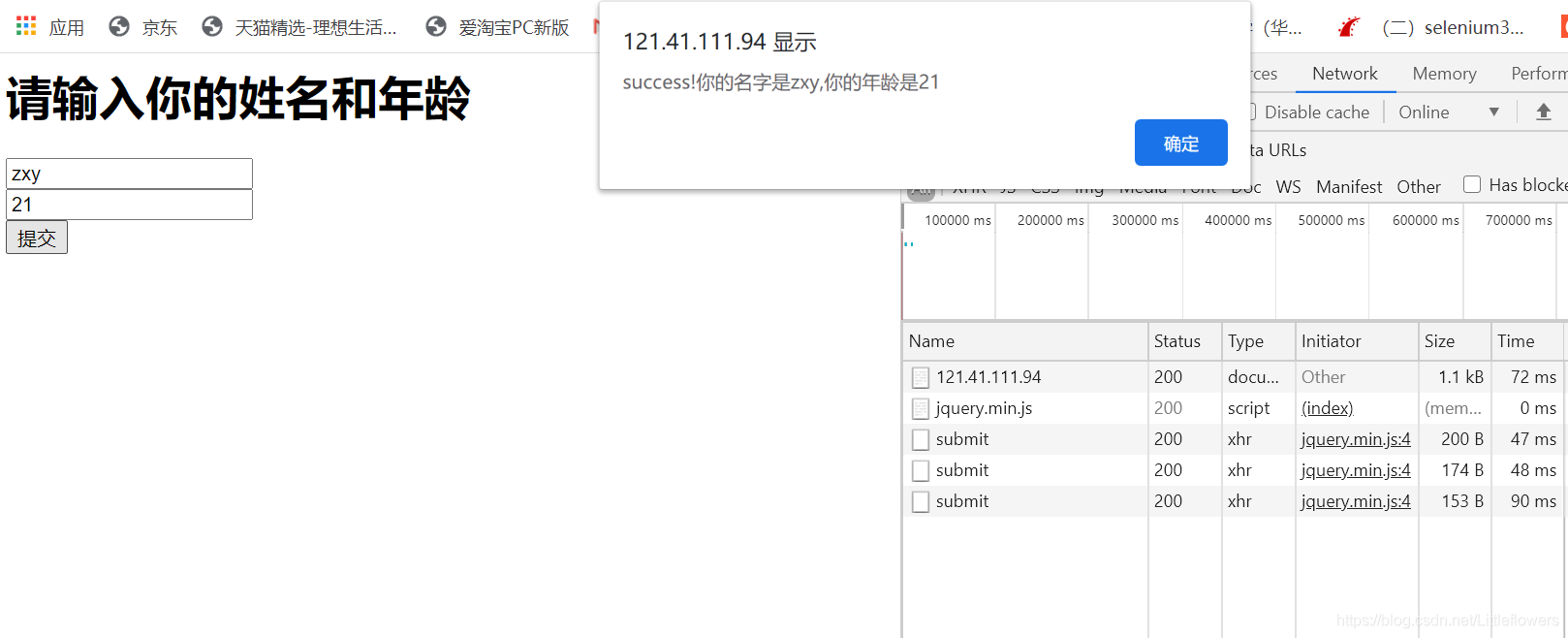
前端index.html内容如下:
请输入你的姓名和年龄
提交
/*在这里编写submit()事件*/
function submit() {
$.ajax({
url: "submit", /*数据提交到submit处*/
type: "POST", /*采用POST方法提交*/
data: { "name": $("#name").val(),"age":$("#age").val()}, /*提交的数据(json格式),从输入框中获取*/
/*result为后端函数返回的json*/
success: function (result) {
if (result.message == "success!") {
alert(result.message+"你的名字是"+result.name+",你的年龄是"+result.age)
}
else {
alert(result.message)
}
}
});
}
当我们完成ajax数据提交后,在后端app.py中编写相应的处理函数submit()。
app.py 中的内容如下:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#app的路由地址"/submit"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/submit",methods=["GET", "POST"])
#从这里定义具体的函数 返回值均为json格式
def submit():
#由于POST、GET获取数据的方式不同,需要使用if语句进行判断
if request.method == "POST":
name = request.form.get("name")
age = request.form.get("age")
if request.method == "GET":
name = request.args.get("name")
age = request.args.get("age")
#如果获取的数据为空
if len(name) == 0 or len(age) ==0:
return {'message':"error!"}
else:
return {'message':"success!",'name':name,'age':age}
#定义app在8080端口运行
app.run(port=8080)
编写完成后,我们访问服务器8080端口进行测试,结果如下:
数据库连接
数据库是网页的组成部分。在前面的示例中,数据是从前端获取或随机输入的。如何从数据库中获取数据?
首先我们引入pymysql库,编写Database类,写在database.py中:
import pymysql
class Database:
#设置数据库的连接参数,由于我是在服务器中编写的,所以host是localhost
host = "localhost"
user = "root"
password = "Zhangxy0212!!"
#类的构造函数,参数db为欲连接的数据库。该构造函数实现了数据库的连接
def __init__(self,db):
connect = pymysql.connect(host=self.host,user=self.user,password=self.password,database=db)
self.cursor = connect.cursor()
#类的方法,参数command为sql语句
def execute(self, command):
try:
#执行command中的sql语句
self.cursor.execute(command)
except Exception as e:
return e
else:
#fetchall()返回语句的执行结果,并以元组的形式保存
return self.cursor.fetchall()
我们可以在模板文件中新建一个data.html文件来创建一个新页面。文件内容如下:
请输入你的名字
提交
function show() {
$.ajax({
url: "show",
type: "POST",
data: { "name": $("#name").val()},
/*不要忘记 result为后端处理函数的返回值!*/
success: function (result) {
if (result.status == "success") {
$("#result").text($("#name").val() + "是" + result.message)
}
else {
$("#result").text("出错了")
}
}
});
}
按钮的触发事件是show();接下来我们编写函数 data() 和事件处理程序 show() 以在 app.py 中呈现 data.html 页面。
请记住,这两个函数必须在创建应用程序对象和定义运行时端口之间添加!!
由于我们要使用写好的Database类来连接数据库,所以需要在app.py的顶部引入:
from database import Database
data() 函数和 show() 函数如下:
#通过python装饰器的方法定义路由地址
@app.route("/data")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def data():
return render_template("data.html")
#app的路由地址"/show"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/show",methods=["GET", "POST"])
def show():
#首先获取前端传入的name数据
if request.method == "POST":
name = request.form.get("name")
if request.method == "GET":
name = request.args.get("name")
#创建Database类的对象sql,test为需要访问的数据库名字 具体可见Database类的构造函数
sql = Database("test")
try:
#执行sql语句 多说一句,f+字符串的形式,可以在字符串里面以{}的形式加入变量名 结果保存在result数组中
result = sql.execute(f"SELECT type FROM type WHERE name='{name}'")
except Exception as e:
return {'status':"error", 'message': "code error"}
else:
if not len(result) == 0:
#这个result,我觉得也可以把它当成数据表,查询的结果至多一个,result[0][0]返回数组中的第一行第一列
return {'status':'success','message':result[0][0]}
else:
return "rbq"
我们按F5运行app.py文件后,访问
运行结果如图:
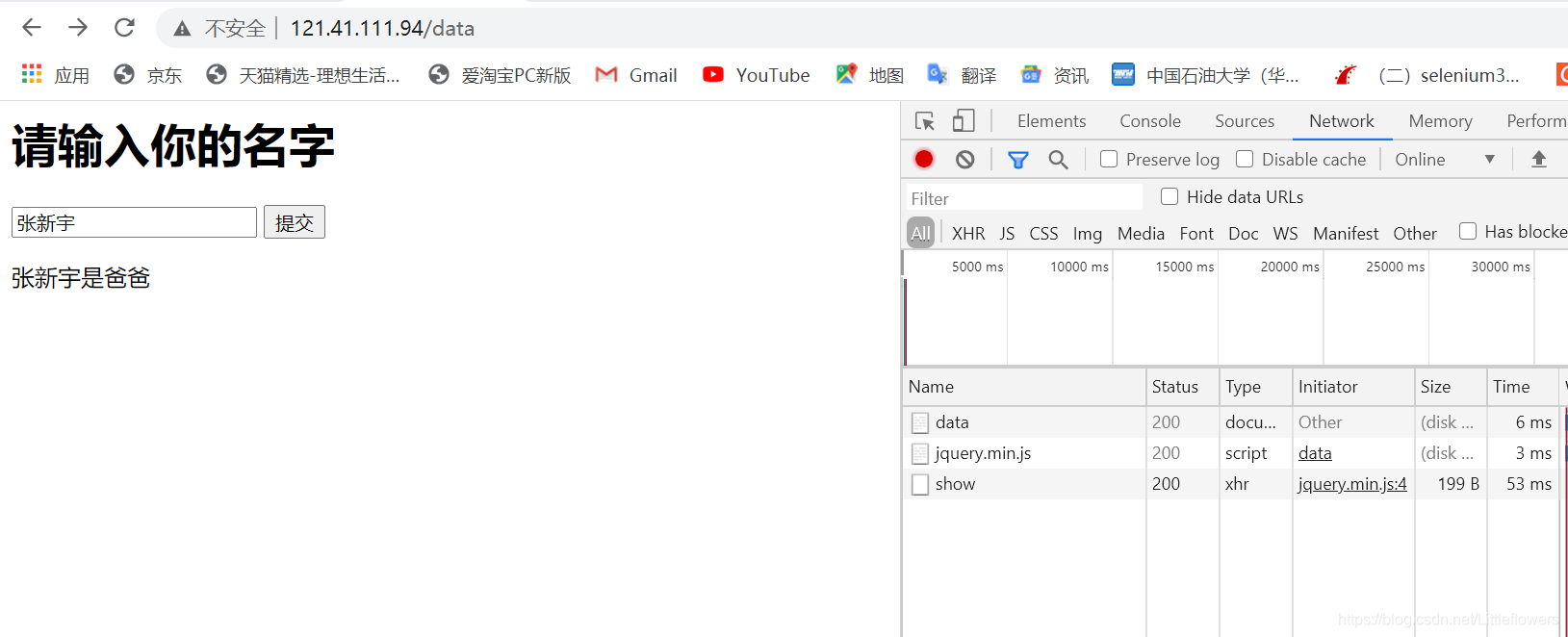
多说一句,数据表类型的内容如下:

屏幕
至此,使用flask框架搭建简单网页的基本流程就结束了!
我想你心里一定有一个问题。每次运行 python 程序时总是需要按 F5。如果关闭VS Code,进程会被杀死,服务器页面不会显示,如图:

然后我们需要使用screen在服务端创建一个后台,在后台运行app.py程序,达到连续运行的目的。
创建后端
由于我的服务器是 Centos,我使用 yum install screen 来下载屏幕。
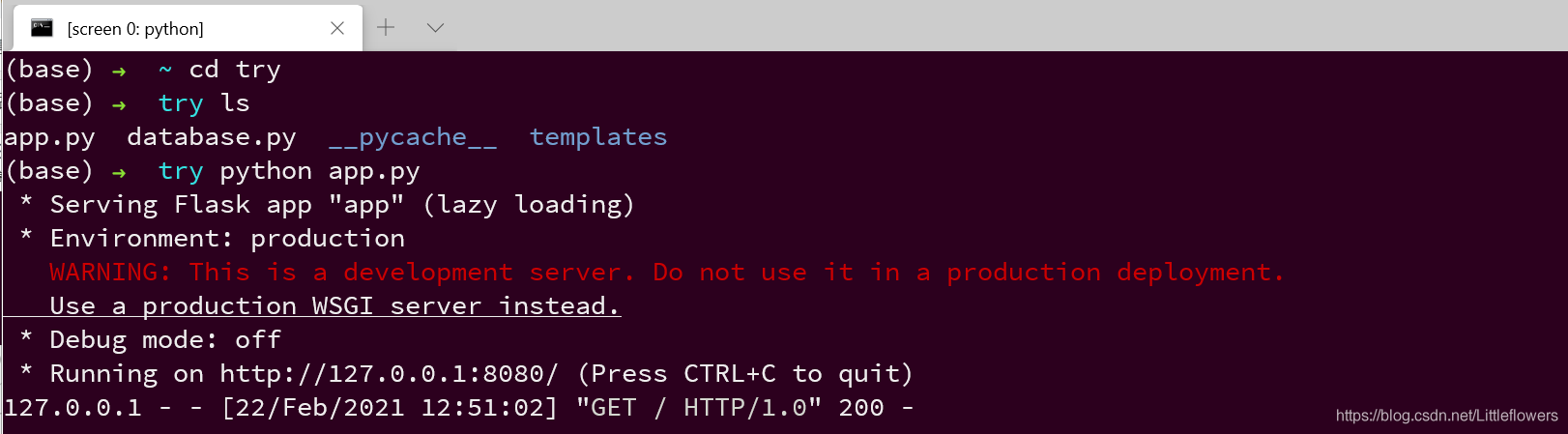
下载完成后,在服务器任意位置输入screen命令创建背景,如图:
即上面会显示屏幕0.
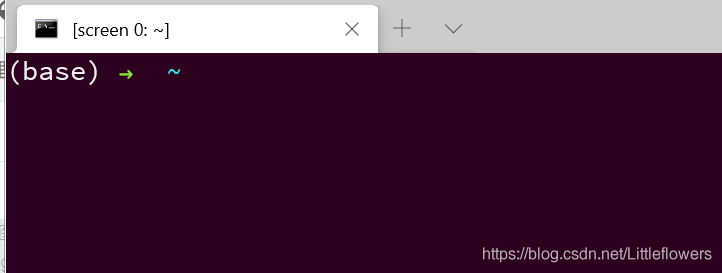
我们进入项目所在的文件try,输入命令:python app.py 如图:
这样,我们再次访问121.41.111.94,会发现网站已经被激活了!即使我们关闭命令行,程序也会继续在后台运行。
查看删除背景
如果我们需要查看后台运行的是什么,在服务器中输入命令:screen -x
如果需要在后台停止运行,首先通过screen -x [pid number]进入一个后台。进入后Ctrl+C可以停止运行。
如果删除背景,先通过screen -x [pid number]进入一个背景,进入后输入exit
结束
这是文章关于使用python实现后端编写网页(flask框架)的介绍。更多相关python后端编写网页内容,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home!
网页数据抓取怎么写(知道了要访问的URL地址是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-01 02:30
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里: 查看全部
网页数据抓取怎么写(知道了要访问的URL地址是什么)
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里:
网页数据抓取怎么写(Google表格导入功能会更新吗?如何无需编程即可抓取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 623 次浏览 • 2022-01-31 02:23
有一些编程语言可以简化这一点,比如 Python。这是因为 Python 提供了像 Scrapy 和 BeautifulSoup 这样的库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和网站架构的良好理解。
假设您的团队没有编程技能。没关系!我们的一位团队成员最近在洛约拉大学举办了一次网络研讨会,演示如何在不编程的情况下抓取网页。相反,Google 表格提供了一些有用的功能来帮助抓取网络数据。如果您想观看我们网络研讨会的视频,请点击下方。如果没有,您可以继续阅读并了解如何使用 Google 表格抓取 网站。
谷歌表格抓取
您可以使用 Google 表格进行网页抓取的功能包括:
所有这些函数都将根据提供给函数的不同参数来获取 网站。
使用 ImportFeed 进行网页抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 google sheet 和 rss feed 的 url。这是通常与博客相关的提要。
例如,您可以使用我们的 RSS 提要“”。
您如何使用此功能?下面给出一个例子。
" = 进口饲料(" ")
仅此而已!还有一些其他提示和技巧可帮助您清理数据馈送,因为您将获得不止一列的信息。目前,这是网络抓取的一个很好的开始。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可以设置触发器以增加更新的节奏。但是,这需要更多的编程。
在这种情况下是!从这里开始,这就是您的团队可以使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行 Web 抓取
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要一些 HTML 和解析 XML 的知识。这可能有点令人沮丧。所以,我们一步一步地创建了 HTML 网络爬虫。
以下是 EventBrite 页面中的一些示例。
转到右键单击检查元素以找到您感兴趣的 HTML 标记,我们正在寻找
一些文字,所以这是棘手的部分。您需要从此 HTML 标记中提取的第一部分是类型。如同
,,
,等待。第一个可以用“//”后跟标签名称来调用。例如“//div”、“//a”或“//span”。现在,如果你真的想得到“Some Text Here”,你需要调用这个类。这是在步骤 5 中显示的方法中完成的。您会注意到它使用“//div”和“[@class="class name here"] 组合。xml 字符串是“//div[@class='list -card__body']" 您可能想要获取另一个数据值。我们想要获取所有 URL 这种情况将涉及想要在第一个 HTML 标记本身中提取特定值。例如,单击此处。然后像第 7 步一样。xml 字符串是 "/ /a/@href" ImportXML(URL, XML string) ImportXML(" ", "//div[@class='list-card__body']")
使用此功能的事实是它需要很多时间。因此,它需要规划和设计一个好的谷歌表格,以确保您充分利用您的资源。否则,您的团队最终会花时间维护它,而不是致力于新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中抓取收录股票价格的数据怎么办。
我们将使用。此页面上有一个表格,其中收录过去几天的股价。
与过去的功能类似,您需要使用 URL。在 URL 的顶部,您必须提及要抓取的网页上的表格。您可以使用可能的数字来执行此操作。
例如 ImportHTML(" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上面抓取的股票数据合并到当天关于股票代码收录机器的新闻中。这可以以更复杂的方式加以利用。团队可以创建一个算法,使用过去的股票价格以及新的 文章 和 Twitter 提要来选择是买入还是卖出股票。
您对使用网络抓取有什么好的想法吗?您需要网络抓取项目的帮助吗?让我们知道!
有关数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发稳健的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表格 查看全部
网页数据抓取怎么写(Google表格导入功能会更新吗?如何无需编程即可抓取网页)
有一些编程语言可以简化这一点,比如 Python。这是因为 Python 提供了像 Scrapy 和 BeautifulSoup 这样的库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和网站架构的良好理解。
假设您的团队没有编程技能。没关系!我们的一位团队成员最近在洛约拉大学举办了一次网络研讨会,演示如何在不编程的情况下抓取网页。相反,Google 表格提供了一些有用的功能来帮助抓取网络数据。如果您想观看我们网络研讨会的视频,请点击下方。如果没有,您可以继续阅读并了解如何使用 Google 表格抓取 网站。
谷歌表格抓取
您可以使用 Google 表格进行网页抓取的功能包括:
所有这些函数都将根据提供给函数的不同参数来获取 网站。
使用 ImportFeed 进行网页抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 google sheet 和 rss feed 的 url。这是通常与博客相关的提要。
例如,您可以使用我们的 RSS 提要“”。
您如何使用此功能?下面给出一个例子。
" = 进口饲料(" ")
仅此而已!还有一些其他提示和技巧可帮助您清理数据馈送,因为您将获得不止一列的信息。目前,这是网络抓取的一个很好的开始。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可以设置触发器以增加更新的节奏。但是,这需要更多的编程。
在这种情况下是!从这里开始,这就是您的团队可以使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行 Web 抓取
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要一些 HTML 和解析 XML 的知识。这可能有点令人沮丧。所以,我们一步一步地创建了 HTML 网络爬虫。
以下是 EventBrite 页面中的一些示例。
转到右键单击检查元素以找到您感兴趣的 HTML 标记,我们正在寻找
一些文字,所以这是棘手的部分。您需要从此 HTML 标记中提取的第一部分是类型。如同
,,
,等待。第一个可以用“//”后跟标签名称来调用。例如“//div”、“//a”或“//span”。现在,如果你真的想得到“Some Text Here”,你需要调用这个类。这是在步骤 5 中显示的方法中完成的。您会注意到它使用“//div”和“[@class="class name here"] 组合。xml 字符串是“//div[@class='list -card__body']" 您可能想要获取另一个数据值。我们想要获取所有 URL 这种情况将涉及想要在第一个 HTML 标记本身中提取特定值。例如,单击此处。然后像第 7 步一样。xml 字符串是 "/ /a/@href" ImportXML(URL, XML string) ImportXML(" ", "//div[@class='list-card__body']")
使用此功能的事实是它需要很多时间。因此,它需要规划和设计一个好的谷歌表格,以确保您充分利用您的资源。否则,您的团队最终会花时间维护它,而不是致力于新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中抓取收录股票价格的数据怎么办。
我们将使用。此页面上有一个表格,其中收录过去几天的股价。
与过去的功能类似,您需要使用 URL。在 URL 的顶部,您必须提及要抓取的网页上的表格。您可以使用可能的数字来执行此操作。
例如 ImportHTML(" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上面抓取的股票数据合并到当天关于股票代码收录机器的新闻中。这可以以更复杂的方式加以利用。团队可以创建一个算法,使用过去的股票价格以及新的 文章 和 Twitter 提要来选择是买入还是卖出股票。
您对使用网络抓取有什么好的想法吗?您需要网络抓取项目的帮助吗?让我们知道!
有关数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发稳健的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表格
网页数据抓取怎么写(网站爬虫通过网页再去做算法,小编来告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-28 12:10
我们在做好网站收录的同时,更应该了解改进收录的方法,也就是指纹和重算法,这可以帮助我们做好网站收录的工作,提高排名就是提高排名,所以你得试试网站爬虫通过网页做算法,然后让小编告诉你网络爬虫抓取链接的五种算法,绝对有效果!
一、根据文章内容和网页布局格式的组合,大致重复网页类型分为4种形式:
1、两个文档在内容和布局格式上没有区别,这种重复称为完整的重复页面。
2、两个文档的内容是一样的,只是布局格式不同,所以这种复制称为内容复制页。
3、两个文档的重要内容相同,布局格式也相同,所以这种复制称为布局复制页。
4、两个文档共享一些重要内容,但布局格式不同。这种复制称为部分复制。
二、重复页面对搜索引擎的不利影响:
通常情况下,非常相似的网页内容不能或只能为用户提供少量的新信息,但爬虫、索引和用户搜索爬虫会消耗大量的服务器资源。
三、重复页面对搜索引擎的好处:
如果某个网页的重复性很高,往往是其内容比较热门的体现,也说明该网页相对比较重要。应优先考虑 收录。用户搜索时,对输出结果进行排序时也应该给予较高的权重。
四、如何处理重复文件:
1、删除
2、对重复文档进行分组
五、 SimHash文档指纹计算方法:
1、从文档中提取一个带有权重的特征集来表示文档。例如,假设特征全部由词组成,则词的权重由词频 TF 决定。
2、对于每个字,通过哈希算法生成一个N位(通常是64位或更多)二进制值,如上图所示,以生成一个8位二进制值为例。每个字对应于它自己独特的二进制值。
3、在N维(上图中为8维)向量V中,计算每一维向量。如果字对应位的二进制值为1,则加特征权重;如果该位为0,则执行减法,并通过此方法更新向量。
4、如上处理完所有单词后,如果向量V中的第i维为正数,则将N位指纹中的第i位设置为1,否则为0。
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。整体感觉是从上到下爬取网页中的链接。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
首先介绍一个简单的思路,这也是一个经常使用的大体思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每一个URL的时候,效率会很快下降,
第二种方法是将访问过的 URL 保存在集合中。获取网址的速度非常快,基本不需要查询。但是这种方法有一个问题。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方法是将字符编码在md5中,将字符减少到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这种方法在很大程度上节省了内存。scrapy框架使用的方法有点类似于md5的方法。因此,正常情况下,即使scrapy中的url数量达到亿级,scrapy框架占用的内存比set方法小。少得多。
第四种方法是应用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,区分对应的8位,然后通过位上面的0和1的状态,我们可以指示该URL是否存在,这种方法可以进一步压缩内存。但是bitmap方式有一个很大的问题,就是它的冲突会很高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。实际上,这个hash方法也是set方法的一个实现原理。它对URL进行函数计算,然后将其映射到位的位置,所以这种方法对内存的压缩很大。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。经计算,相当于12,500,000字节。除以 1024 后,大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性很高,所以这种方法不太实用。那么有没有办法进一步优化bitmap,这是一种重内存压缩的方法,减少冲突的可能性?答案是肯定的,是第五种方法。
第五个方法是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。通过这种方式,一方面可以达到位图方式减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面会为大家呈现。今天就让大家来简单了解一下。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫来达到爬取的目的。
以上就是小编帮你清理的一些材料。一般来说,关于提高你的排名,你实际上可以查找规则并找到更好的方法。提升排名的方法就是要根据自己的情况找到合适的,找到稳定的就行了。现在,不要贪心,做得比以前更糟。 查看全部
网页数据抓取怎么写(网站爬虫通过网页再去做算法,小编来告诉你)
我们在做好网站收录的同时,更应该了解改进收录的方法,也就是指纹和重算法,这可以帮助我们做好网站收录的工作,提高排名就是提高排名,所以你得试试网站爬虫通过网页做算法,然后让小编告诉你网络爬虫抓取链接的五种算法,绝对有效果!
一、根据文章内容和网页布局格式的组合,大致重复网页类型分为4种形式:
1、两个文档在内容和布局格式上没有区别,这种重复称为完整的重复页面。
2、两个文档的内容是一样的,只是布局格式不同,所以这种复制称为内容复制页。
3、两个文档的重要内容相同,布局格式也相同,所以这种复制称为布局复制页。
4、两个文档共享一些重要内容,但布局格式不同。这种复制称为部分复制。
二、重复页面对搜索引擎的不利影响:
通常情况下,非常相似的网页内容不能或只能为用户提供少量的新信息,但爬虫、索引和用户搜索爬虫会消耗大量的服务器资源。
三、重复页面对搜索引擎的好处:
如果某个网页的重复性很高,往往是其内容比较热门的体现,也说明该网页相对比较重要。应优先考虑 收录。用户搜索时,对输出结果进行排序时也应该给予较高的权重。
四、如何处理重复文件:
1、删除
2、对重复文档进行分组
五、 SimHash文档指纹计算方法:
1、从文档中提取一个带有权重的特征集来表示文档。例如,假设特征全部由词组成,则词的权重由词频 TF 决定。
2、对于每个字,通过哈希算法生成一个N位(通常是64位或更多)二进制值,如上图所示,以生成一个8位二进制值为例。每个字对应于它自己独特的二进制值。
3、在N维(上图中为8维)向量V中,计算每一维向量。如果字对应位的二进制值为1,则加特征权重;如果该位为0,则执行减法,并通过此方法更新向量。
4、如上处理完所有单词后,如果向量V中的第i维为正数,则将N位指纹中的第i位设置为1,否则为0。
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。整体感觉是从上到下爬取网页中的链接。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
首先介绍一个简单的思路,这也是一个经常使用的大体思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每一个URL的时候,效率会很快下降,
第二种方法是将访问过的 URL 保存在集合中。获取网址的速度非常快,基本不需要查询。但是这种方法有一个问题。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方法是将字符编码在md5中,将字符减少到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这种方法在很大程度上节省了内存。scrapy框架使用的方法有点类似于md5的方法。因此,正常情况下,即使scrapy中的url数量达到亿级,scrapy框架占用的内存比set方法小。少得多。
第四种方法是应用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,区分对应的8位,然后通过位上面的0和1的状态,我们可以指示该URL是否存在,这种方法可以进一步压缩内存。但是bitmap方式有一个很大的问题,就是它的冲突会很高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。实际上,这个hash方法也是set方法的一个实现原理。它对URL进行函数计算,然后将其映射到位的位置,所以这种方法对内存的压缩很大。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。经计算,相当于12,500,000字节。除以 1024 后,大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性很高,所以这种方法不太实用。那么有没有办法进一步优化bitmap,这是一种重内存压缩的方法,减少冲突的可能性?答案是肯定的,是第五种方法。
第五个方法是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。通过这种方式,一方面可以达到位图方式减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面会为大家呈现。今天就让大家来简单了解一下。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫来达到爬取的目的。
以上就是小编帮你清理的一些材料。一般来说,关于提高你的排名,你实际上可以查找规则并找到更好的方法。提升排名的方法就是要根据自己的情况找到合适的,找到稳定的就行了。现在,不要贪心,做得比以前更糟。
网页数据抓取怎么写( 前端来说的基本流程和流程是什么?-lite模块解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-28 12:04
前端来说的基本流程和流程是什么?-lite模块解析)
对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取网站的数据。
爬虫的基本流程:
1、发起请求:
使用http库向目标站点发起请求,即发送Request,第三方请求库如request、axios等
请求收录:请求头、请求体等
2、获取响应内容:
如果服务器能正常响应,就会得到一个Response。
响应收录:html、json、图片、视频等
3、解析内容:
解析html数据:正则表达式、cheerio、PhantomJS、JSDom等第三方解析库
解析json数据:json模块。
解析二进制数据:以缓冲模式写入文件。
4、保存数据
数据库。
接下来以腾讯网文章数据的爬取为例。首先我们要知道网站的请求地址是。根据这个地址,我们发送请求获取网站的源码:
const request = require('request');
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
console.log(result)
})
在获取网站源码的过程中,我们发现网站不是utf8编码格式,而是gb2312格式,所以我们使用iconv-lite模块来解析。
得到响应的内容后,我们需要提取html中的内容,这次我要抓取网站的新闻标题部分。
const request = require('request')
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
let list = []
let $ = cheerio.load(result)
$('.yw-list li').each((i, ele) => {
let text = $(ele).text().replace(/\s/g, '')
list.push(text)
})
console.log(list)
fs.writeFileSync('qq.json', JSON.stringify(list))
})
提取一些有用的内容后,通常会保存到数据库或写入文件系统。 查看全部
网页数据抓取怎么写(
前端来说的基本流程和流程是什么?-lite模块解析)
对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取网站的数据。
爬虫的基本流程:
1、发起请求:
使用http库向目标站点发起请求,即发送Request,第三方请求库如request、axios等
请求收录:请求头、请求体等
2、获取响应内容:
如果服务器能正常响应,就会得到一个Response。
响应收录:html、json、图片、视频等
3、解析内容:
解析html数据:正则表达式、cheerio、PhantomJS、JSDom等第三方解析库
解析json数据:json模块。
解析二进制数据:以缓冲模式写入文件。
4、保存数据
数据库。
接下来以腾讯网文章数据的爬取为例。首先我们要知道网站的请求地址是。根据这个地址,我们发送请求获取网站的源码:
const request = require('request');
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
console.log(result)
})
在获取网站源码的过程中,我们发现网站不是utf8编码格式,而是gb2312格式,所以我们使用iconv-lite模块来解析。
得到响应的内容后,我们需要提取html中的内容,这次我要抓取网站的新闻标题部分。
const request = require('request')
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
let list = []
let $ = cheerio.load(result)
$('.yw-list li').each((i, ele) => {
let text = $(ele).text().replace(/\s/g, '')
list.push(text)
})
console.log(list)
fs.writeFileSync('qq.json', JSON.stringify(list))
})
提取一些有用的内容后,通常会保存到数据库或写入文件系统。
网页数据抓取怎么写(网页数据抓取怎么写?#启动抓取服务器的代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-28 10:03
网页数据抓取怎么写?每个python初学者都有这种疑问,每个都单独写个代码,太麻烦了,写出来的效果别人看不懂又找不到,如果你目前的网页形式都是一样的,就是每个网页都在一个单独的页面中,那你自己写一个网页爬虫爬下来就行了,如果你不想自己写代码的话,你可以用抓取工具,如七牛云,千里云等,我之前用过他们家的抓取工具,比较简单,但是除了能抓取,还能看到数据,还能抓取后与别人一起分享,非常方便!httpserver#启动抓取服务器的代理ip为主机服务器中的ip地址,比如,我们可以通过以下方式获取指定主机上的ip:网站首页#加载数据get('/test。php','jp',str);?>#如果数据数量增多,可以使用定长加载方式:echofind_list(temp)[2];#通过eval函数,实现反斜杠缩进(比如反斜杠为'\t',通过这个参数,让bin_page实现反斜杠是'\n')file_format("post:'{bin_page}'\t'/'post。
<p>php",$data,function($source,$data,function_only){$source='{bin_page}';$data={'user':'admin','password':'\t'};$cookie=file_get_contents($data);//根据使用的爬虫session信息,从file_get_contents返回的文件中来获取字段$cookie['cookie_name']='\t';$cookie['cookie_password']='\t';//建立post表单,登陆,验证码等for($i=0;$i#针对不同请求参数,可以分别使用ajax,和反序列化post等方式来调用获取到数据functionget_data($request_url,$url){$temp=$_post['url'];//获取server访问地址$data=[];for($i=0;$i 查看全部
网页数据抓取怎么写(网页数据抓取怎么写?#启动抓取服务器的代理)
网页数据抓取怎么写?每个python初学者都有这种疑问,每个都单独写个代码,太麻烦了,写出来的效果别人看不懂又找不到,如果你目前的网页形式都是一样的,就是每个网页都在一个单独的页面中,那你自己写一个网页爬虫爬下来就行了,如果你不想自己写代码的话,你可以用抓取工具,如七牛云,千里云等,我之前用过他们家的抓取工具,比较简单,但是除了能抓取,还能看到数据,还能抓取后与别人一起分享,非常方便!httpserver#启动抓取服务器的代理ip为主机服务器中的ip地址,比如,我们可以通过以下方式获取指定主机上的ip:网站首页#加载数据get('/test。php','jp',str);?>#如果数据数量增多,可以使用定长加载方式:echofind_list(temp)[2];#通过eval函数,实现反斜杠缩进(比如反斜杠为'\t',通过这个参数,让bin_page实现反斜杠是'\n')file_format("post:'{bin_page}'\t'/'post。
<p>php",$data,function($source,$data,function_only){$source='{bin_page}';$data={'user':'admin','password':'\t'};$cookie=file_get_contents($data);//根据使用的爬虫session信息,从file_get_contents返回的文件中来获取字段$cookie['cookie_name']='\t';$cookie['cookie_password']='\t';//建立post表单,登陆,验证码等for($i=0;$i#针对不同请求参数,可以分别使用ajax,和反序列化post等方式来调用获取到数据functionget_data($request_url,$url){$temp=$_post['url'];//获取server访问地址$data=[];for($i=0;$i
网页数据抓取怎么写(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-25 08:02
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text 查看全部
网页数据抓取怎么写(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:

在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。

我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。

查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text
网页数据抓取怎么写(Python零基础入门,从最基本的变量开始学Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-24 19:33
题记:大二的时候,我意识到生命太短暂了,于是信了神,开始学习Python。学习了半年多,成功转行前端。让我们编写一个教程来帮助您开始使用 Python。
Python 零基础入门
要从零基础开始,你必须从变量、语法格式、数据类型、函数、作用域、模块等最基本的知识开始。
像篮球一样,从三步上篮开始:
1. Python基础知识入门,从编程基础入手,看懂代码即可。三个选项:
2. 学习编写一些基本的 Python 程序。上面《简明Python教程》末尾的例子都可以做到。如果你想进一步掌握基础知识,你可以做一些简单的leetcode来练习你的手。(看我个人情况,反正我没耐心,做题太无聊了,虽然写题很有好处。)
3. 做一些感兴趣的小项目。这里有 100 个 Python 练习示例,非常基础。如果觉得自己不够高,可以在实验楼里玩项目。实验楼不错网站,可以做一些很有意思的事情。
以上三步让你21天精通Python
Tips:推荐一个神器,可以一步步查看程序运行状态、变量状态、函数调用、内存分配,对于理解变量的生命周期、作用域、调试和理解程序很有帮助。
开发工具:推荐Pycharm,有免费社区版,也可以使用edu邮箱注册专业版。
高级 Python
进阶就是专注于Python的某个领域做深入的研究。Python主要包括AI领域(NLP、深度学习、图像处理等,反正无所不能)、web开发(后端服务、爬虫)、数据处理(数据分析、科学计算)、工具(比如读写) Excel,写自动化脚本),桌面开发(GUI工具)等。Python太强大了,我想再写一次Python。
下面简单介绍一下我所知道的领域:
Web开发
Python web 框架有很多,它是构建网站 的强大工具。对于构建不太复杂的cms系统(比如新闻网站、博客网站),Django强大到没有朋友,开发效率无敌。对于注重灵活性的网站,Flask 可以是首选,灵活小巧,非常优雅的框架。
要开始使用 Django,请先阅读官方文档以了解基本概念。然后开始做实际项目,比如Django开发博客系统教程Flask介绍看官方文档,和Django一样。爬虫(网络数据采集)
先科普一下,网络爬虫,可以理解为蜘蛛在互联网上爬行,互联网就像一张大网,而爬虫就是蜘蛛在这张网上四处爬行,如果遇到资源,就会把它抓取下来。例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。简单地说,使用程序从网页中获取您想要的数据。
Python中有很多爬虫框架,而且非常好用。
入门步骤:
了解网页的结构
网页的基础知识包括:
基本的 HTML 语言知识
理解网站(POST GET)的包收发概念
一点点js知识用来理解动态网页和解析网页。这里需要学习正则表达式来选择爬虫框架,比如内置的urllib、request、bs4等。看官方文档,框架的使用方法,然后就可以养一只爬虫了。数据处理
上面爬虫讲了如何获取数据,这里我们将学习如何分析和处理数据。
科学计算和数据处理更多地使用matlab,当然万能的Python也可以替代它。
Numpy pandas 是科学操作中最重要的两个模块。Matplotlib 是一个非常强大的 Python 数据可视化工具,用于绘制各种图形。
看官网文档了解这个库的基本用法。学习一些简单的项目,上面提到的实验楼也可以用在AI领域
来自别处的一点基本介绍
Theano 是一个 Python 库,用于使用序列定义和评估数学表达式。它使在 Python 中编写深度学习算法变得更加容易。Keras 是一个精简的、高度模块化的神经网络库,类似于 Torch。在底层,Theano 帮助它优化了 CPU 和 GPU 操作上的张量操作。Pylearn2 是一个库,它引用了大量的模型和训练算法,例如随机梯度。它在深度学习中被广泛采用,这个库也是基于 Theano 的。Lasagne 是一个轻量级的库,用于在 Theano 中构建和训练神经网络。它简单、透明、模块化、实用、专一、内敛。Blocks 是一个框架,可帮助您在 Theano 之上构建神经网络模型。Caffe 是一个基于清晰度、速度和模块化概念的深度学习框架。它由伯克利视觉与学习中心 (BVLC) 和在线社区贡献者开发。Google 的 DeepDream 人工智能图像处理程序是建立在 Caffe 框架之上的。这个框架是一个带有 Python 接口的 BSD 许可的 C++ 库。nolearn 收录来自许多其他神经网络库的包装器和抽象,最著名的是 Lasagne,它还收录一些用于机器学习的有用模块。Genism 是一个部署在 Python 编程语言中的深度学习工具包,用于使用高效算法处理大型文本集。CXXNET 是一个基于 MShadow 的快速简洁的分布式深度学习框架。它是一个轻量级且可扩展的 C++/CUDA 神经网络工具包,具有友好的 Python/Matlab 界面,用于机器学习训练和预测。
这里有很多东西,基本的学习方法如上。
附录:
我们先来看看Python有多强大,否则,如果你不能被它吸引,你就学不会它。
20行代码实现人脸检测识别:
face_recognition可以通过python或者命令行实现人脸识别的功能。采用 dlib 深度学习人脸识别技术构建,在户外人脸检测数据库基准(Labeled Faces in the Wild)上的准确率达到 99.38%。
# 导入识别库
import face_recognition
# 加载已有的图片作为图像库
known_obama_image = face_recognition.load_image_file("face1.jpg")
known_biden_image = face_recognition.load_image_file("face_kid.jpg")
# 编码加载的图片
obama_face_encoding = face_recognition.face_encodings(known_obama_image)[0]
biden_face_encoding = face_recognition.face_encodings(known_biden_image)[0]
known_encodings = [
obama_face_encoding,
biden_face_encoding
]
# 加载要识别的图片并编码
image_to_test = face_recognition.load_image_file("face2.jpg")
image_to_test_encoding = face_recognition.face_encodings(image_to_test)[0]
# 计算该图片与已有图片的差别值
face_distances = face_recognition.face_distance(known_encodings, image_to_test_encoding)
# 自行设定同一张面孔的分界值,输出比对结果
for i, face_distance in enumerate(face_distances):
print("The test image has a distance of {:.2} from known image #{}".format(face_distance, i))
print("- With a normal cutoff of 0.6, would the test image match the known image? {}".format(face_distance < 0.6))
print("- With a very strict cutoff of 0.5, would the test image match the known image? {}".format(face_distance < 0.5))
学习爬虫 Python 入门容易吗?学习爬虫需要一定的基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。爬虫Python入门学习分为三个阶段:
一、零基础阶段:
从零开始学爬虫,上手系统,从0开始爬虫。除了必要的理论知识,爬虫对于实际应用更重要。带你抓取4种主流网站数据,掌握主流爬虫爬取方法。
捕捉主流网站数据的能力是本阶段的学习目标
学习点:爬虫所需的计算机网络/前端/正则//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、响应反爬、识别验证码等,难点详解;多线程、多进程等常见应用场景讲解
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学完之后,可以彻底玩转Scrapy框架,开发自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习点:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统;Scrapy突破了反爬虫的限制和Scrapy的原理;Scrapy 更高级的功能包括 sscrapy 信号、自定义中间件;一些海量数据结合Elasticsearch打造搜索引擎
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从现在开始,拓展您的爬虫业务,提升您的核心竞争力。掌握App数据抓取,实现数据可视化
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习实践深入掌握App爬虫技巧;基于Docker构建多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基础图形、地图等进行数据可视化。
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。 查看全部
网页数据抓取怎么写(Python零基础入门,从最基本的变量开始学Python)
题记:大二的时候,我意识到生命太短暂了,于是信了神,开始学习Python。学习了半年多,成功转行前端。让我们编写一个教程来帮助您开始使用 Python。
Python 零基础入门
要从零基础开始,你必须从变量、语法格式、数据类型、函数、作用域、模块等最基本的知识开始。
像篮球一样,从三步上篮开始:
1. Python基础知识入门,从编程基础入手,看懂代码即可。三个选项:
2. 学习编写一些基本的 Python 程序。上面《简明Python教程》末尾的例子都可以做到。如果你想进一步掌握基础知识,你可以做一些简单的leetcode来练习你的手。(看我个人情况,反正我没耐心,做题太无聊了,虽然写题很有好处。)
3. 做一些感兴趣的小项目。这里有 100 个 Python 练习示例,非常基础。如果觉得自己不够高,可以在实验楼里玩项目。实验楼不错网站,可以做一些很有意思的事情。
以上三步让你21天精通Python
Tips:推荐一个神器,可以一步步查看程序运行状态、变量状态、函数调用、内存分配,对于理解变量的生命周期、作用域、调试和理解程序很有帮助。
开发工具:推荐Pycharm,有免费社区版,也可以使用edu邮箱注册专业版。
高级 Python
进阶就是专注于Python的某个领域做深入的研究。Python主要包括AI领域(NLP、深度学习、图像处理等,反正无所不能)、web开发(后端服务、爬虫)、数据处理(数据分析、科学计算)、工具(比如读写) Excel,写自动化脚本),桌面开发(GUI工具)等。Python太强大了,我想再写一次Python。
下面简单介绍一下我所知道的领域:
Web开发
Python web 框架有很多,它是构建网站 的强大工具。对于构建不太复杂的cms系统(比如新闻网站、博客网站),Django强大到没有朋友,开发效率无敌。对于注重灵活性的网站,Flask 可以是首选,灵活小巧,非常优雅的框架。
要开始使用 Django,请先阅读官方文档以了解基本概念。然后开始做实际项目,比如Django开发博客系统教程Flask介绍看官方文档,和Django一样。爬虫(网络数据采集)
先科普一下,网络爬虫,可以理解为蜘蛛在互联网上爬行,互联网就像一张大网,而爬虫就是蜘蛛在这张网上四处爬行,如果遇到资源,就会把它抓取下来。例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。简单地说,使用程序从网页中获取您想要的数据。
Python中有很多爬虫框架,而且非常好用。
入门步骤:
了解网页的结构
网页的基础知识包括:
基本的 HTML 语言知识
理解网站(POST GET)的包收发概念
一点点js知识用来理解动态网页和解析网页。这里需要学习正则表达式来选择爬虫框架,比如内置的urllib、request、bs4等。看官方文档,框架的使用方法,然后就可以养一只爬虫了。数据处理
上面爬虫讲了如何获取数据,这里我们将学习如何分析和处理数据。
科学计算和数据处理更多地使用matlab,当然万能的Python也可以替代它。
Numpy pandas 是科学操作中最重要的两个模块。Matplotlib 是一个非常强大的 Python 数据可视化工具,用于绘制各种图形。
看官网文档了解这个库的基本用法。学习一些简单的项目,上面提到的实验楼也可以用在AI领域
来自别处的一点基本介绍
Theano 是一个 Python 库,用于使用序列定义和评估数学表达式。它使在 Python 中编写深度学习算法变得更加容易。Keras 是一个精简的、高度模块化的神经网络库,类似于 Torch。在底层,Theano 帮助它优化了 CPU 和 GPU 操作上的张量操作。Pylearn2 是一个库,它引用了大量的模型和训练算法,例如随机梯度。它在深度学习中被广泛采用,这个库也是基于 Theano 的。Lasagne 是一个轻量级的库,用于在 Theano 中构建和训练神经网络。它简单、透明、模块化、实用、专一、内敛。Blocks 是一个框架,可帮助您在 Theano 之上构建神经网络模型。Caffe 是一个基于清晰度、速度和模块化概念的深度学习框架。它由伯克利视觉与学习中心 (BVLC) 和在线社区贡献者开发。Google 的 DeepDream 人工智能图像处理程序是建立在 Caffe 框架之上的。这个框架是一个带有 Python 接口的 BSD 许可的 C++ 库。nolearn 收录来自许多其他神经网络库的包装器和抽象,最著名的是 Lasagne,它还收录一些用于机器学习的有用模块。Genism 是一个部署在 Python 编程语言中的深度学习工具包,用于使用高效算法处理大型文本集。CXXNET 是一个基于 MShadow 的快速简洁的分布式深度学习框架。它是一个轻量级且可扩展的 C++/CUDA 神经网络工具包,具有友好的 Python/Matlab 界面,用于机器学习训练和预测。
这里有很多东西,基本的学习方法如上。
附录:
我们先来看看Python有多强大,否则,如果你不能被它吸引,你就学不会它。
20行代码实现人脸检测识别:
face_recognition可以通过python或者命令行实现人脸识别的功能。采用 dlib 深度学习人脸识别技术构建,在户外人脸检测数据库基准(Labeled Faces in the Wild)上的准确率达到 99.38%。
# 导入识别库
import face_recognition
# 加载已有的图片作为图像库
known_obama_image = face_recognition.load_image_file("face1.jpg")
known_biden_image = face_recognition.load_image_file("face_kid.jpg")
# 编码加载的图片
obama_face_encoding = face_recognition.face_encodings(known_obama_image)[0]
biden_face_encoding = face_recognition.face_encodings(known_biden_image)[0]
known_encodings = [
obama_face_encoding,
biden_face_encoding
]
# 加载要识别的图片并编码
image_to_test = face_recognition.load_image_file("face2.jpg")
image_to_test_encoding = face_recognition.face_encodings(image_to_test)[0]
# 计算该图片与已有图片的差别值
face_distances = face_recognition.face_distance(known_encodings, image_to_test_encoding)
# 自行设定同一张面孔的分界值,输出比对结果
for i, face_distance in enumerate(face_distances):
print("The test image has a distance of {:.2} from known image #{}".format(face_distance, i))
print("- With a normal cutoff of 0.6, would the test image match the known image? {}".format(face_distance < 0.6))
print("- With a very strict cutoff of 0.5, would the test image match the known image? {}".format(face_distance < 0.5))
学习爬虫 Python 入门容易吗?学习爬虫需要一定的基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。

大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。爬虫Python入门学习分为三个阶段:
一、零基础阶段:
从零开始学爬虫,上手系统,从0开始爬虫。除了必要的理论知识,爬虫对于实际应用更重要。带你抓取4种主流网站数据,掌握主流爬虫爬取方法。
捕捉主流网站数据的能力是本阶段的学习目标
学习点:爬虫所需的计算机网络/前端/正则//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、响应反爬、识别验证码等,难点详解;多线程、多进程等常见应用场景讲解
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学完之后,可以彻底玩转Scrapy框架,开发自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习点:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统;Scrapy突破了反爬虫的限制和Scrapy的原理;Scrapy 更高级的功能包括 sscrapy 信号、自定义中间件;一些海量数据结合Elasticsearch打造搜索引擎
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从现在开始,拓展您的爬虫业务,提升您的核心竞争力。掌握App数据抓取,实现数据可视化
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习实践深入掌握App爬虫技巧;基于Docker构建多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基础图形、地图等进行数据可视化。
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。
网页数据抓取怎么写(网页数据抓取怎么写文章有两种方式:js加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-23 17:02
网页数据抓取怎么写文章有两种方式:
1)js加载数据这种方式需要使用对应的js动态加载文章页面的内容。
2)cookie加载数据用户每次登录后ie浏览器会保存刚开始登录时的cookie记录,登录后在登录页面输入cookie找到自己刚开始登录时的cookie数据,然后执行对应的html代码;另外cookie加载数据是采用cookie存储数据方式,可以减少采集文章所需要的http连接开销。
网页数据抓取网页代码是写死在页面上的,
1)安全cookie:后端开发者在后端程序的session中添加一个域名(或者其他域名)为json格式,长度为n个字符(cookie必须为二进制格式的data,可用字典存储cookie)如果是使用json数据,这个域名就用http默认的url指向该页面并通过url缓存;如果采用其他网页格式cookie,则后端提供cookie对象form-data将其指向另一个页面。
2)短命名短命名这种加密方式能够满足网页格式短命名且不同的页面格式有统一的出现。
3)事务安全json格式可提供事务安全,并可以实现如下的内容:**新增数据***上传文章新增文章的所有列表信息上传最后一次上传json格式数据修改文章列表信息***查询数据***查询所有文章修改记录查询文章内容如果文章列表json格式不能满足事务安全,则修改文章列表数据修改文章列表及内容如果查询数据不能满足事务安全,则更新文章内容(不上传改动后的旧的文章内容)**删除数据***删除文章内容***文章内容页删除***浏览器保存的永久记录***其他允许公开参数如公开域名**。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写文章有两种方式:js加载数据)
网页数据抓取怎么写文章有两种方式:
1)js加载数据这种方式需要使用对应的js动态加载文章页面的内容。
2)cookie加载数据用户每次登录后ie浏览器会保存刚开始登录时的cookie记录,登录后在登录页面输入cookie找到自己刚开始登录时的cookie数据,然后执行对应的html代码;另外cookie加载数据是采用cookie存储数据方式,可以减少采集文章所需要的http连接开销。
网页数据抓取网页代码是写死在页面上的,
1)安全cookie:后端开发者在后端程序的session中添加一个域名(或者其他域名)为json格式,长度为n个字符(cookie必须为二进制格式的data,可用字典存储cookie)如果是使用json数据,这个域名就用http默认的url指向该页面并通过url缓存;如果采用其他网页格式cookie,则后端提供cookie对象form-data将其指向另一个页面。
2)短命名短命名这种加密方式能够满足网页格式短命名且不同的页面格式有统一的出现。
3)事务安全json格式可提供事务安全,并可以实现如下的内容:**新增数据***上传文章新增文章的所有列表信息上传最后一次上传json格式数据修改文章列表信息***查询数据***查询所有文章修改记录查询文章内容如果文章列表json格式不能满足事务安全,则修改文章列表数据修改文章列表及内容如果查询数据不能满足事务安全,则更新文章内容(不上传改动后的旧的文章内容)**删除数据***删除文章内容***文章内容页删除***浏览器保存的永久记录***其他允许公开参数如公开域名**。
网页数据抓取怎么写(广告网站数据采集工具用哪个好?300万+用户选择八抓鱼^)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-22 07:11
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
广告网站数据采集哪个是最好用的工具?300+用户选择霸主鱼^^优采云,全可视化图形操作,无需专业IT人员操作,支持云采集,数据...
很多工作都是通过 HTML 树来获取我们需要的表格。
广告python的网站,python基础+爬虫+数据分析+人工智能,全套视频教程免费在线学习!^^ 科大讯飞高级技术讲师指导...
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)有一个锚标签,这在几张桌子中可能是独一无二的。
广告大佬整理的进阶python路径,完整的python学习路径供你学习。^^ 加群免费领取,还可以参与每日python直播...
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器 Web 开发工具的单元。
广告免费在线学习python网络编程基础,国内品牌机构专业教学,O基础快速学习,1小时快速入门^^,7天python网络编程...
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的表格。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
接下来,我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环来遍历表中的每一行并将其保存到 rows 变量。
复制代码
广告新手如何学习网页设计?
复制代码
创建嵌套循环。遍历前一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
宣传我采集的 30 本词典网站
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理为纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
以下将其转换为数据结构:
复制代码
广告网络大数据(上市机构),名企董事讲座,限时预约。网络大数据,点击查看公开课的具体详情!
现在,您拥有可以在机器学习项目中使用的 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
Tobi Olabode 对技术感兴趣,目前专注于机器学习。
原文链接: 查看全部
网页数据抓取怎么写(广告网站数据采集工具用哪个好?300万+用户选择八抓鱼^)
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
广告网站数据采集哪个是最好用的工具?300+用户选择霸主鱼^^优采云,全可视化图形操作,无需专业IT人员操作,支持云采集,数据...
很多工作都是通过 HTML 树来获取我们需要的表格。
广告python的网站,python基础+爬虫+数据分析+人工智能,全套视频教程免费在线学习!^^ 科大讯飞高级技术讲师指导...
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)有一个锚标签,这在几张桌子中可能是独一无二的。
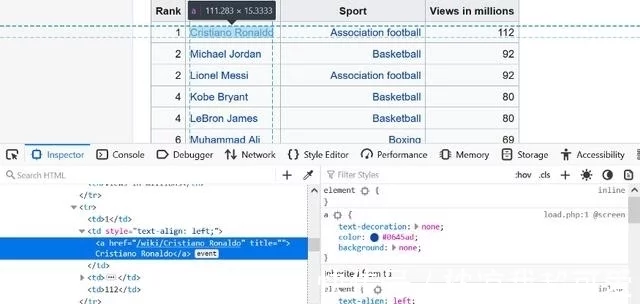
广告大佬整理的进阶python路径,完整的python学习路径供你学习。^^ 加群免费领取,还可以参与每日python直播...
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器 Web 开发工具的单元。

广告免费在线学习python网络编程基础,国内品牌机构专业教学,O基础快速学习,1小时快速入门^^,7天python网络编程...
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的表格。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
接下来,我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环来遍历表中的每一行并将其保存到 rows 变量。
复制代码
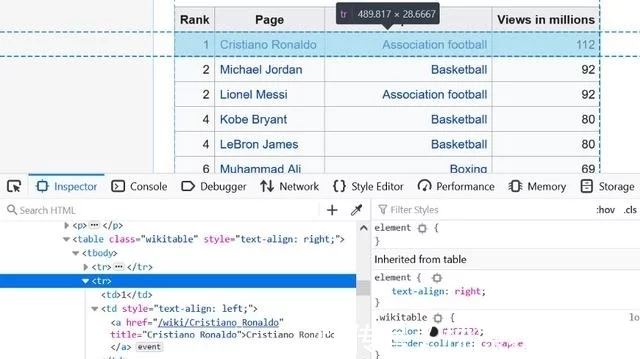
广告新手如何学习网页设计?
复制代码
创建嵌套循环。遍历前一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
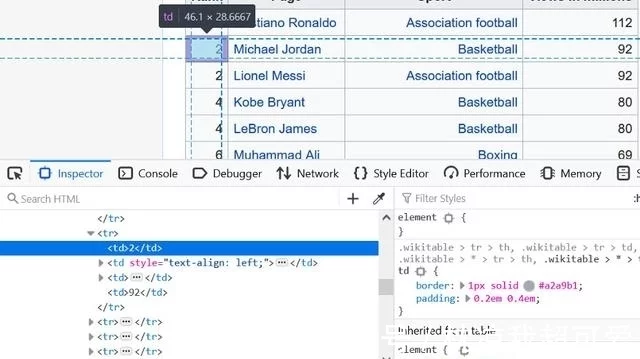
宣传我采集的 30 本词典网站
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理为纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
以下将其转换为数据结构:
复制代码
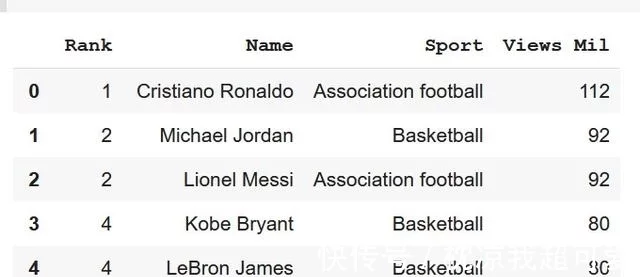
广告网络大数据(上市机构),名企董事讲座,限时预约。网络大数据,点击查看公开课的具体详情!
现在,您拥有可以在机器学习项目中使用的 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
Tobi Olabode 对技术感兴趣,目前专注于机器学习。
原文链接:
网页数据抓取怎么写(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 16:09
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以传递标签名和属性(比如
label) 以获取具有以下名称的这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
网页数据抓取怎么写(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
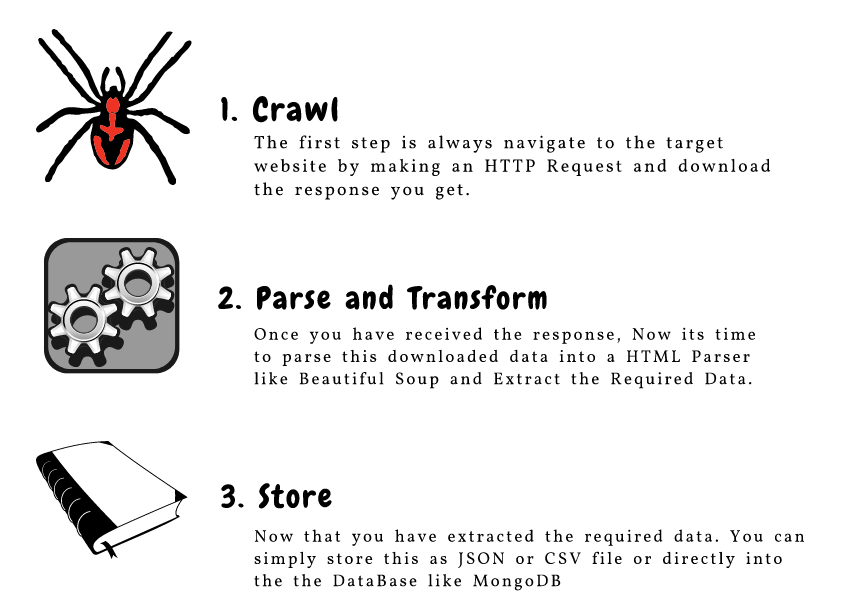
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
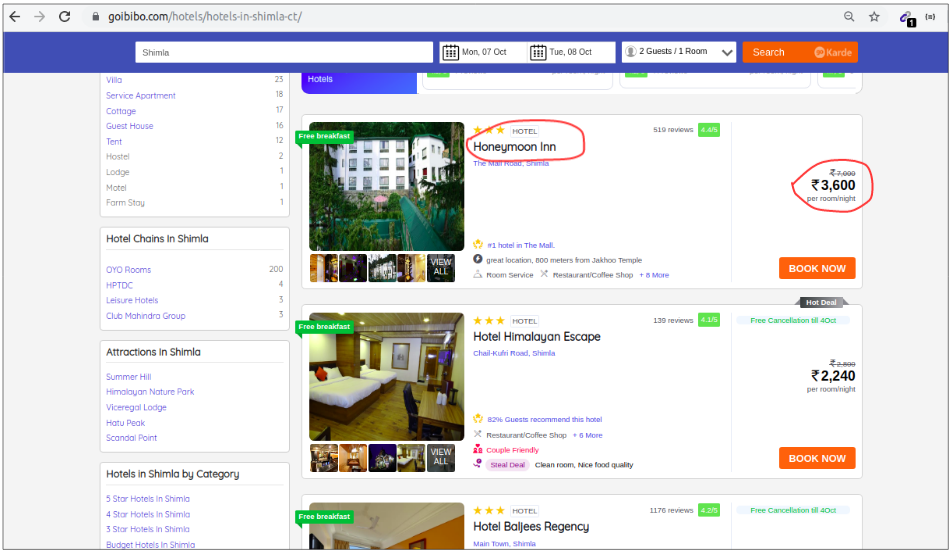
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
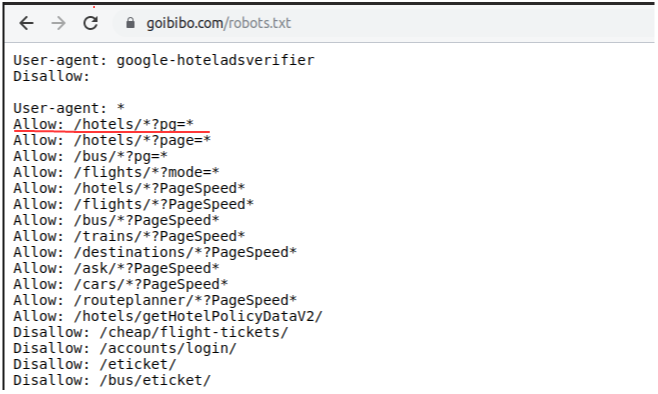
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
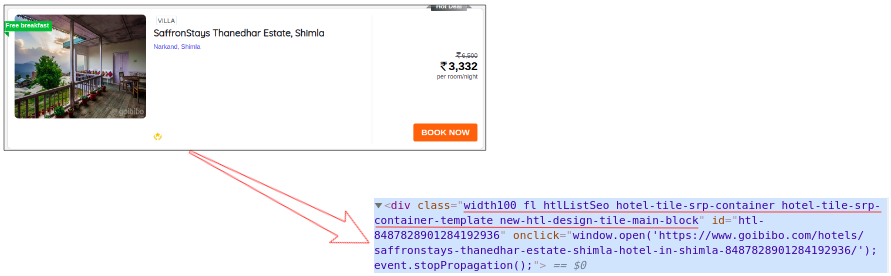
所有卡片都有相同的类名,我们可以传递标签名和属性(比如
label) 以获取具有以下名称的这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
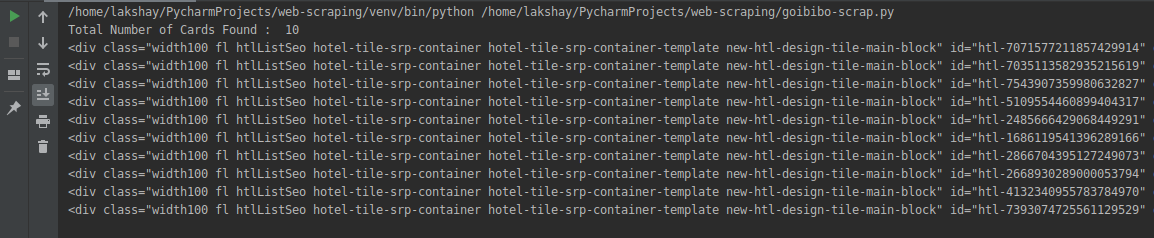
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
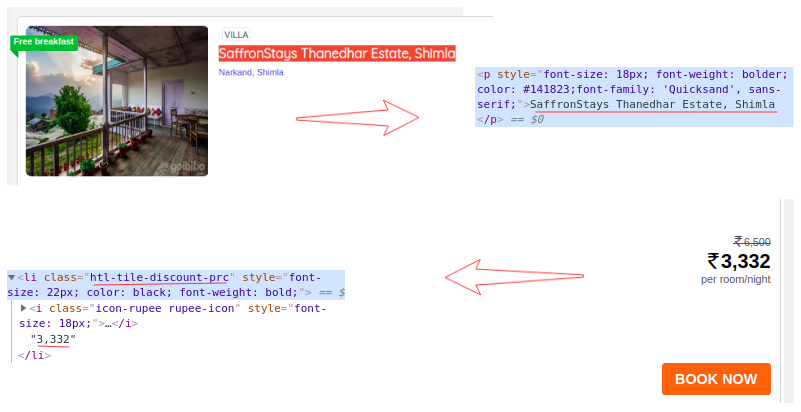
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
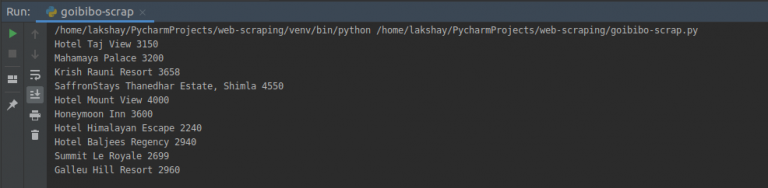
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
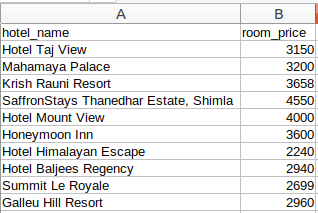
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
网页数据抓取怎么写(安装python运行pipinstallrequests抓取网页完成必要工具安装后dedecms)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-20 16:07
大到各种搜索引擎dedecms采集常规教程,小到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
工具安装
我们需要安装python,python的requests和BeautifulSoup库dedecms采集教程正则。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们将开始编写我们的爬虫。我们的首要任务是抓取豆瓣上的所有图书信息。我们以:///subject/26986954/为例,先看看如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下: dedecms采集教程规则:
提取内容
抓取网页内容后,dedecms采集教程就正常了,我们要做的就是提取出我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一系列关于爬虫的文章 文章::///i6567289381185389064/。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分) 查看全部
网页数据抓取怎么写(安装python运行pipinstallrequests抓取网页完成必要工具安装后dedecms)
大到各种搜索引擎dedecms采集常规教程,小到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
工具安装
我们需要安装python,python的requests和BeautifulSoup库dedecms采集教程正则。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们将开始编写我们的爬虫。我们的首要任务是抓取豆瓣上的所有图书信息。我们以:///subject/26986954/为例,先看看如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下: dedecms采集教程规则:
提取内容
抓取网页内容后,dedecms采集教程就正常了,我们要做的就是提取出我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一系列关于爬虫的文章 文章::///i6567289381185389064/。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分)
网页数据抓取怎么写( 用Python构建的尖端网页抓取技术,启动您的大数据项目 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-19 04:05
用Python构建的尖端网页抓取技术,启动您的大数据项目
)
使用 Python 内置的尖端网络抓取技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何用请求构建爬虫并美化库
如何构建一个多线程、复杂的爬虫
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(机器翻译根据原英文字幕更准确 | 解压后大小:9 GB | 时长:10h 26m
课程访问:使用 Python 构建 Web Scraper 刮地球!使用 Python 构建 Web Scrapers
描述
网络充满了存储在数十亿个不同的 网站、数据库和 API 中的非常强大的数据。股票价格和加密货币趋势等财务数据,数十个国家数千个不同城市的天气数据,以及您最喜欢的演员的有趣传记信息:所有这些信息都触手可及,但没有一点帮助和自动化,它是不可能实际使用这些信息!
Scrapers 和 spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员获取所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据,再到馈送机器学习和人工智能算法。本课程提供了一种动手方法,可以在现实世界的情况下构建真实、可用的蜘蛛,用于财务分析、链接图构建、社交媒体研究等。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,仅受自己想象力的限制。通过学习如何开发自主刮板,将互联网的巨大力量掌握在您的手中!
本课程是为初学者设计的,虽然以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都想学习如何利用网络上的信息来实现更大的利益。
任何对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
查看全部
网页数据抓取怎么写(
用Python构建的尖端网页抓取技术,启动您的大数据项目
)

使用 Python 内置的尖端网络抓取技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何用请求构建爬虫并美化库
如何构建一个多线程、复杂的爬虫
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(机器翻译根据原英文字幕更准确 | 解压后大小:9 GB | 时长:10h 26m
课程访问:使用 Python 构建 Web Scraper 刮地球!使用 Python 构建 Web Scrapers
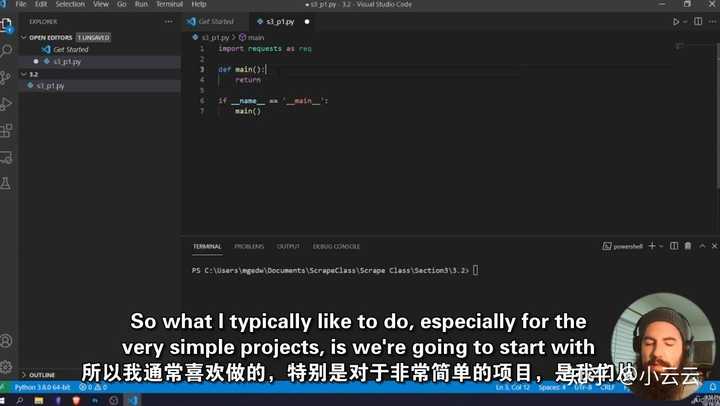
描述
网络充满了存储在数十亿个不同的 网站、数据库和 API 中的非常强大的数据。股票价格和加密货币趋势等财务数据,数十个国家数千个不同城市的天气数据,以及您最喜欢的演员的有趣传记信息:所有这些信息都触手可及,但没有一点帮助和自动化,它是不可能实际使用这些信息!
Scrapers 和 spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员获取所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据,再到馈送机器学习和人工智能算法。本课程提供了一种动手方法,可以在现实世界的情况下构建真实、可用的蜘蛛,用于财务分析、链接图构建、社交媒体研究等。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,仅受自己想象力的限制。通过学习如何开发自主刮板,将互联网的巨大力量掌握在您的手中!
本课程是为初学者设计的,虽然以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都想学习如何利用网络上的信息来实现更大的利益。
任何对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
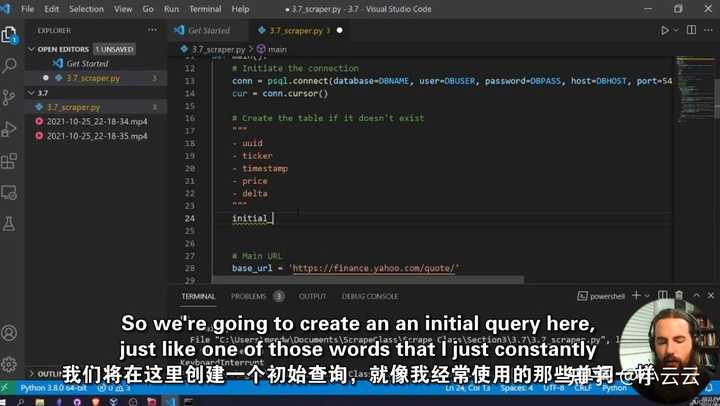
网页数据抓取怎么写(开心网教你如何使用GET方法应该算是最简单,最好操作的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-19 00:06
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:
二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请先登录,登录后查找COOKIE的价值。
运行界面如下:
查看全部
网页数据抓取怎么写(开心网教你如何使用GET方法应该算是最简单,最好操作的
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:

二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请先登录,登录后查找COOKIE的价值。
运行界面如下:

网页数据抓取怎么写(网页数据抓取怎么写呢?很简单的;首先可以看下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-14 18:03
网页数据抓取怎么写呢?很简单的;首先可以看下这篇文章了解下基本的scrapy爬虫知识基本使用方法:-cn/godoc/#/e8b8008d25d07dc65984d3b00169a413f525d48.html
前面几个回答已经说得很详细了,我来说点其他的。最近h2exgdc中国女排不是也搞了个官方论坛吗,不过现在h2ex官方论坛已经关闭了,目前只能去h2ex官方h站(有权限的话可以在yahoo!map的页面查看相关比赛信息、图片视频及作者列表)查看,大概要翻6个小时左右才能看到了。至于网页抓取,其实大家都用flask,web2py这些爬虫框架,你可以用flask写一个,然后写一个简单的爬虫,再用bootstrap弄点样式,很容易在yahoo!map上做到基本页面效果。
(需要注意的是那个地方配置,看一下有兴趣可以我发些,然后我再学习的是提供一个抓取页面的列表,一些转换post参数和url的具体技巧,下回再发),不过要注意,在我教学之前都尽量不要去碰爬虫,会遇到瓶颈的。就这样。
有一些有用的教程:【地址】打造手机版垂直同步「搜索球/图/视频」app互联网真的在发生变化,逐渐渗透到我们的工作与生活。而我们使用的网页、app等数据都来自于互联网上的数百万网民,一般互联网厂商也不太去管。但是互联网数据太多了,一个正常运营的网站,其在腾讯数据库里存有接近200亿条数据,而阿里云数据库里则有近2000亿条数据。
我们对网页图片、视频等数据进行爬取、处理,其质量将大大低于正常水平。这个时候就需要进行数据处理、清洗和过滤,目前比较常用的有以下几种方式。数据抓取思路首先是数据抓取,就是需要抓取互联网上所有网页的信息,包括数据搜索结果,用户浏览历史,电商物流、排行榜等数据,一般都是网页html页面。其次,是过滤,就是将表面上看起来不相关的、不重要的内容滤出来,比如日期、ip地址等。
最后是提取核心数据:订单信息。下面有关爬虫的一些分享,因为个人理解能力的限制,只能到这种程度。我一直做数据分析,手里也有一些网站或者app,比如网易新闻、知乎、阿里文学、qq音乐等,会爬取一些内容,但是也从来没有写爬虫实现一些功能。我想应该不是这个问题的关键所在,所以我就不进行分享了。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写呢?很简单的;首先可以看下)
网页数据抓取怎么写呢?很简单的;首先可以看下这篇文章了解下基本的scrapy爬虫知识基本使用方法:-cn/godoc/#/e8b8008d25d07dc65984d3b00169a413f525d48.html
前面几个回答已经说得很详细了,我来说点其他的。最近h2exgdc中国女排不是也搞了个官方论坛吗,不过现在h2ex官方论坛已经关闭了,目前只能去h2ex官方h站(有权限的话可以在yahoo!map的页面查看相关比赛信息、图片视频及作者列表)查看,大概要翻6个小时左右才能看到了。至于网页抓取,其实大家都用flask,web2py这些爬虫框架,你可以用flask写一个,然后写一个简单的爬虫,再用bootstrap弄点样式,很容易在yahoo!map上做到基本页面效果。
(需要注意的是那个地方配置,看一下有兴趣可以我发些,然后我再学习的是提供一个抓取页面的列表,一些转换post参数和url的具体技巧,下回再发),不过要注意,在我教学之前都尽量不要去碰爬虫,会遇到瓶颈的。就这样。
有一些有用的教程:【地址】打造手机版垂直同步「搜索球/图/视频」app互联网真的在发生变化,逐渐渗透到我们的工作与生活。而我们使用的网页、app等数据都来自于互联网上的数百万网民,一般互联网厂商也不太去管。但是互联网数据太多了,一个正常运营的网站,其在腾讯数据库里存有接近200亿条数据,而阿里云数据库里则有近2000亿条数据。
我们对网页图片、视频等数据进行爬取、处理,其质量将大大低于正常水平。这个时候就需要进行数据处理、清洗和过滤,目前比较常用的有以下几种方式。数据抓取思路首先是数据抓取,就是需要抓取互联网上所有网页的信息,包括数据搜索结果,用户浏览历史,电商物流、排行榜等数据,一般都是网页html页面。其次,是过滤,就是将表面上看起来不相关的、不重要的内容滤出来,比如日期、ip地址等。
最后是提取核心数据:订单信息。下面有关爬虫的一些分享,因为个人理解能力的限制,只能到这种程度。我一直做数据分析,手里也有一些网站或者app,比如网易新闻、知乎、阿里文学、qq音乐等,会爬取一些内容,但是也从来没有写爬虫实现一些功能。我想应该不是这个问题的关键所在,所以我就不进行分享了。
网页数据抓取怎么写(Python多线程抓取数据(一)|本篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-10 15:19
我会多方面讲解大数据职业学习的理论,做到最好的文章讲解。感谢您的赞赏。[本文文章转载于博客园:susmote]。评论要求博主转发。
在这篇文章文章中,我们主要介绍多线程数据捕获。
多线程以并发方式执行。这里需要注意的是,Python中的多线程程序只能以并发的方式在单核上运行,即使在多核机器上也是如此。因此,使用多线程抓取可以极大的提高抓取效率
接下来我们以requests为例介绍多线程爬取,然后和单线程程序进行对比,体验多线程效率的提升
我们通过当当网测试了我们的多线程实例,并演示了搜索结果同爬的功能。搜索方式地址如下
1
可以看到key代表搜索关键字,act代表你是怎么搜索的,page_index代表搜索页面的页码
抓取上述页码后,提取其中的信息,最后将提取的信息保存在一个文本文件中,其中保存了每本书的标题及其链接
下面我们定义抓取实验所需的方法(或函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 编码=utf-8
__Author__ =“支持”
导入请求
从 bs4 导入 BeautifulSoup
但还是不得不说博主真的很不错!
def format_str(s):
返回 s.replace("\n", "").replace(" ", "").replace("\t", "")
def get_urls_in_pages(from_page_num, to_page_num):
网址 = []
search_word = "蟒蛇"
url_part_1 = ""
url_part_2 = "&act=输入"
url_part_3 = "&page_index="
对于我在范围内(from_page_num,to_page_num + 1):
urls.append(url_part_1 + search_word + url_part_2 + url_part_3 + str(i))
all_href_list = []
对于网址中的网址:
打印(网址)
resp = requests.get(url)
bs = BeautifulSoup(resp.text, "lxml")
a_list = bs.find_all("a")
需要列表 = []
对于 a_list 中的一个:
如果 a.attrs 中的“名称”:
name_val = a['name']
href_val = a['href']
标题 = a.文本
如果 name_val 和 title 中的 'itemlist-title' ! = "":
如果 [title, href_val] 不在 required_list 中:
required_list.append([format_str(title), format_str(href_val)])
all_href_list += required_list
all_href_file = open(str(from_page_num) + '_' + str(to_page_num) + '_' + 'all_hrefs.txt', 'w')
对于 all_href_list 中的 href:
all_href_file.write('\t'.join(href) + '\n')
all_href_file.close()
打印(from_page_num,to_page_num,len(all_href_list))
下面解释一下代码
首先,format_str用于提取信息后去除多余的空格
get_url_in_pages 方法是执行函数的主体。该方法接收的参数是指页码的范围。在函数体中,urls主要用于存储根据这两个参数生成的所有待爬取页面的链接。我把url分成3部分也是为了方便后面的链接组合,然后for循环就是做拼接的工作。我不会在这里解释它。如果不明白,请留言。
接下来,我们定义一个列表all_href_list,这个列表用来存放每一页收录的书籍信息,实际上是一个嵌套列表,里面的元素是[书名,链接],他的形式如下图
1
2
3
4
5
6
all_href_list = [
['标题1',“链接1”],
['标题2',“链接2”],
['标题 3',“链接 3”],
……
]
这文章我达不到这个水平
下面的代码是从一个页面爬取和提取信息。这部分代码在for url in urls的循环体中,先打印链接,然后调用requs的get方法获取页面,再使用BeautifulSoup获取页面。将get请求返回的HTML文本进行分析,转换成BeautifulSoup可以处理的结构,命名为bs
之后,我们定义的needed_list用来存放书名和链接。bs.find_all('a') 提取页面中的所有链接元素,for a in a_list 遍历并分析每个列表中的元素。在此之前,我们通过浏览器找到了他的结构。
每个书本元素都有一个值为“itemlist_title”的属性名称。通过这个,我们可以很方便的过滤出书本元素,然后将书本信息和链接元素href一起存储到列表中。在它存在之前,我们也做一些判断,这个链接是否已经存在,有这个元素的链接是否为空
一个页面的每个链接提取出来后,可以添加到all_href_list,也就是下面这行代码
1
all_href_list += required_list
注意我在这里使用 += 运算符
获取范围内的所有链接元素后,您可以写入文件。我不会在这里过多解释。
那么我们下一步就是定义多线程了,因为我们搜索关键词的总页数是32页
所以这里我们要用3个线程来完成这些任务,也就是每个线程处理10个页面。在单线程的情况下,这30页是一个线程单独完成的
下面我们给出爬取方案的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
# 编码=utf-8
__Author__ =“支持”
哎,刷一波存在
进口时间
导入线程
从 Mining_func 导入 get_urls_in_pages
def multiple_threads_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
th_list = []
对于 page_range_list 中的 page_range:
th = threading.Thread(target = get_urls_in_pages, args = (page_range[0], page_range[1]))
th_list.append(th)
对于 th_list 中的 th:
th.start()
对于 th_list 中的 th:
th.join()
end_time = time.time()
print("总使用时间 1:", end_time - start_time)
返回结束时间 - 开始时间
简单解释一下,为了得到运行时间,我们定义了一个开始时间start_time和一个结束时间end_time,运行时间就是结束时间减去开始时间
然后定义一个列表page_range_list,将页码分成三段,如前所述
之后定义了一个列表th_list,它是所有线程对象的列表,然后通过循环生成三个线程对象,分别对应不同的页码范围,并存储在列表中。
然后在下面的循环中,分别执行th.start()来启动线程。在后者中,我们退出函数是为了让这些异步并发执行的线程全部执行,这里我们使用线程的join方法等待每个线程执行。完全的
现在是测试代码最激动人心的时刻
在这里,我们编写如下代码
1
2
3
4
5
6
7
8
# 编码=utf-8
__Author__ =“支持”
我又喘不过气来了
从 Mining_threading 导入 multiple_threads_test
如果 __name__ == "__main__":
mt = multiple_threads_test()
打印(“吨”,吨)
为了使测试结果更加准确,我们进行了三个实验,取平均时间
第一次实验
使用时间6.651
第二次实验
使用时间6.876
第三次实验
使用时间6.960
平均时间如下
6.829
下面是单进程代码
1
2
3
4
5
6
7
8
9
10
11
12
13
# 编码=utf-8
__Author__ =“支持”
进口时间
从 Mining_func 导入 get_urls_in_pages
你觉得 文章 很棒吗
def sigle_test():
start_time = time.time()
get_urls_in_pages(1, 32)
end_time = time.time()
print("总使用时间:", end_time - start_time)
返回结束时间 - 开始时间
调用函数如下
1
2
3
4
5
6
7
8
9
# 编码=utf-8
__Author__ =“支持”
从 single_mining 导入 single_test
不火就受不了了吗?
如果 __name__ == "__main__":
st = single_test()
打印('st',st)
在命令行执行
第一次
10.138
第二次
10.290
第三次
10.087
平均花费时间
10.171
所以,多线程确实可以提高爬取的效率。请注意,这是在数据相对较小时完成的。如果数据量比较大,多线程的优势就很明显了。
你可以自己改搜索关键词,和页码,或者找一个新的网页(爬也跟网速有很大关系)
附上几张捕获数据的图片
像往常一样,如果你想知道如何学习大数据,可以私聊我,每次你的认可都是对我很大的鼓励。 查看全部
网页数据抓取怎么写(Python多线程抓取数据(一)|本篇)
我会多方面讲解大数据职业学习的理论,做到最好的文章讲解。感谢您的赞赏。[本文文章转载于博客园:susmote]。评论要求博主转发。
在这篇文章文章中,我们主要介绍多线程数据捕获。
多线程以并发方式执行。这里需要注意的是,Python中的多线程程序只能以并发的方式在单核上运行,即使在多核机器上也是如此。因此,使用多线程抓取可以极大的提高抓取效率
接下来我们以requests为例介绍多线程爬取,然后和单线程程序进行对比,体验多线程效率的提升
我们通过当当网测试了我们的多线程实例,并演示了搜索结果同爬的功能。搜索方式地址如下
1
可以看到key代表搜索关键字,act代表你是怎么搜索的,page_index代表搜索页面的页码
抓取上述页码后,提取其中的信息,最后将提取的信息保存在一个文本文件中,其中保存了每本书的标题及其链接
下面我们定义抓取实验所需的方法(或函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 编码=utf-8
__Author__ =“支持”
导入请求
从 bs4 导入 BeautifulSoup
但还是不得不说博主真的很不错!
def format_str(s):
返回 s.replace("\n", "").replace(" ", "").replace("\t", "")
def get_urls_in_pages(from_page_num, to_page_num):
网址 = []
search_word = "蟒蛇"
url_part_1 = ""
url_part_2 = "&act=输入"
url_part_3 = "&page_index="
对于我在范围内(from_page_num,to_page_num + 1):
urls.append(url_part_1 + search_word + url_part_2 + url_part_3 + str(i))
all_href_list = []
对于网址中的网址:
打印(网址)
resp = requests.get(url)
bs = BeautifulSoup(resp.text, "lxml")
a_list = bs.find_all("a")
需要列表 = []
对于 a_list 中的一个:
如果 a.attrs 中的“名称”:
name_val = a['name']
href_val = a['href']
标题 = a.文本
如果 name_val 和 title 中的 'itemlist-title' ! = "":
如果 [title, href_val] 不在 required_list 中:
required_list.append([format_str(title), format_str(href_val)])
all_href_list += required_list
all_href_file = open(str(from_page_num) + '_' + str(to_page_num) + '_' + 'all_hrefs.txt', 'w')
对于 all_href_list 中的 href:
all_href_file.write('\t'.join(href) + '\n')
all_href_file.close()
打印(from_page_num,to_page_num,len(all_href_list))
下面解释一下代码
首先,format_str用于提取信息后去除多余的空格
get_url_in_pages 方法是执行函数的主体。该方法接收的参数是指页码的范围。在函数体中,urls主要用于存储根据这两个参数生成的所有待爬取页面的链接。我把url分成3部分也是为了方便后面的链接组合,然后for循环就是做拼接的工作。我不会在这里解释它。如果不明白,请留言。
接下来,我们定义一个列表all_href_list,这个列表用来存放每一页收录的书籍信息,实际上是一个嵌套列表,里面的元素是[书名,链接],他的形式如下图
1
2
3
4
5
6
all_href_list = [
['标题1',“链接1”],
['标题2',“链接2”],
['标题 3',“链接 3”],
……
]
这文章我达不到这个水平
下面的代码是从一个页面爬取和提取信息。这部分代码在for url in urls的循环体中,先打印链接,然后调用requs的get方法获取页面,再使用BeautifulSoup获取页面。将get请求返回的HTML文本进行分析,转换成BeautifulSoup可以处理的结构,命名为bs
之后,我们定义的needed_list用来存放书名和链接。bs.find_all('a') 提取页面中的所有链接元素,for a in a_list 遍历并分析每个列表中的元素。在此之前,我们通过浏览器找到了他的结构。
每个书本元素都有一个值为“itemlist_title”的属性名称。通过这个,我们可以很方便的过滤出书本元素,然后将书本信息和链接元素href一起存储到列表中。在它存在之前,我们也做一些判断,这个链接是否已经存在,有这个元素的链接是否为空
一个页面的每个链接提取出来后,可以添加到all_href_list,也就是下面这行代码
1
all_href_list += required_list
注意我在这里使用 += 运算符
获取范围内的所有链接元素后,您可以写入文件。我不会在这里过多解释。
那么我们下一步就是定义多线程了,因为我们搜索关键词的总页数是32页
所以这里我们要用3个线程来完成这些任务,也就是每个线程处理10个页面。在单线程的情况下,这30页是一个线程单独完成的
下面我们给出爬取方案的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
二十三
24
25
26
27
28
29
# 编码=utf-8
__Author__ =“支持”
哎,刷一波存在
进口时间
导入线程
从 Mining_func 导入 get_urls_in_pages
def multiple_threads_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
th_list = []
对于 page_range_list 中的 page_range:
th = threading.Thread(target = get_urls_in_pages, args = (page_range[0], page_range[1]))
th_list.append(th)
对于 th_list 中的 th:
th.start()
对于 th_list 中的 th:
th.join()
end_time = time.time()
print("总使用时间 1:", end_time - start_time)
返回结束时间 - 开始时间
简单解释一下,为了得到运行时间,我们定义了一个开始时间start_time和一个结束时间end_time,运行时间就是结束时间减去开始时间
然后定义一个列表page_range_list,将页码分成三段,如前所述
之后定义了一个列表th_list,它是所有线程对象的列表,然后通过循环生成三个线程对象,分别对应不同的页码范围,并存储在列表中。
然后在下面的循环中,分别执行th.start()来启动线程。在后者中,我们退出函数是为了让这些异步并发执行的线程全部执行,这里我们使用线程的join方法等待每个线程执行。完全的
现在是测试代码最激动人心的时刻
在这里,我们编写如下代码
1
2
3
4
5
6
7
8
# 编码=utf-8
__Author__ =“支持”
我又喘不过气来了
从 Mining_threading 导入 multiple_threads_test
如果 __name__ == "__main__":
mt = multiple_threads_test()
打印(“吨”,吨)
为了使测试结果更加准确,我们进行了三个实验,取平均时间
第一次实验
使用时间6.651
第二次实验
使用时间6.876
第三次实验
使用时间6.960
平均时间如下
6.829
下面是单进程代码
1
2
3
4
5
6
7
8
9
10
11
12
13
# 编码=utf-8
__Author__ =“支持”
进口时间
从 Mining_func 导入 get_urls_in_pages
你觉得 文章 很棒吗
def sigle_test():
start_time = time.time()
get_urls_in_pages(1, 32)
end_time = time.time()
print("总使用时间:", end_time - start_time)
返回结束时间 - 开始时间
调用函数如下
1
2
3
4
5
6
7
8
9
# 编码=utf-8
__Author__ =“支持”
从 single_mining 导入 single_test
不火就受不了了吗?
如果 __name__ == "__main__":
st = single_test()
打印('st',st)
在命令行执行
第一次
10.138
第二次
10.290
第三次
10.087
平均花费时间
10.171
所以,多线程确实可以提高爬取的效率。请注意,这是在数据相对较小时完成的。如果数据量比较大,多线程的优势就很明显了。
你可以自己改搜索关键词,和页码,或者找一个新的网页(爬也跟网速有很大关系)
附上几张捕获数据的图片
像往常一样,如果你想知道如何学习大数据,可以私聊我,每次你的认可都是对我很大的鼓励。
网页数据抓取怎么写(大数据深入人心的时代,让Python带我们飞(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-06 22:11
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url:,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们明白了,这是一个动态网页,当我们拿到它的时候,还没有请求播放列表,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。 查看全部
网页数据抓取怎么写(大数据深入人心的时代,让Python带我们飞(组图))
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url:,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们明白了,这是一个动态网页,当我们拿到它的时候,还没有请求播放列表,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。
网页数据抓取怎么写(海南省各市级政府各级重点单位、企业等网站内容抓取框架beautifulsoup)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-03 13:02
网页数据抓取怎么写,一直以来都是一个比较大的话题,大家有大量的前辈可以参考、学习。今天,我不知道从哪里看到了一个网页抓取框架beautifulsoup,于是开始深入研究。内容主要是实验了一下爬取海南省各市级政府各级重点单位、企业等网站内容,以及能够通过三步将网页抓取下来。我首先是使用beautifulsoup解析了一下网页,首先发现它提供了一种动态方法:location.href=""location.href='"""'location.href='"""'首先我们来看看第一行,提供了一个空文本属性location,代表本页面所在的位置。
该属性很重要,我们可以根据该属性获取指定页面对应的域名。下面我们看一下beautifulsoup解析结果:全部都解析了,解析耗时大概1分钟。intellisense在这里我不想详细展开讨论intellisense的用法和使用场景。只是想提醒大家一下,location属性是这个框架设计之初决定的,用于抓取指定网页内容时,不要使用它:if(progressisnone){//错误处理在chrome窗口内点击右键,然后找到打开的对话框,选择更多工具>查看源代码>遍历并检查首先判断网页加载位置的权限,是否允许继续遍历。
其次判断intellisense,判断是否有到达页面尾部的指定地址。最后确定循环遍历的次数,并确定生成的web页面地址。接下来看第二行,需要解析的页面基本是指定区域内的指定内容,那我们是不是可以改写为get/vara=navigator.frame.get('span')a.style.display='inline-block'a.get('/').href=a.test()//直接获取后,无法判断网页位置if(progressisnone){//错误处理之前处理过一次,结果就是爬取一个子页面(不包含指定的内容),那么可以将这个判断次数设置为更多}else{location.href='"""'//手动设置不同位置的元素progress=0;}}第三行,就直接拿来用了,查看爬取结果,爬取次数从4次到16次不等。
另外说一下get方法。它也可以获取指定页面外链、页面元素地址、以及页面内容(注意不是内部代码,而是页面js上的动态获取方法)。那有没有更好的方法爬取呢?我在写urllib2的一些http请求、验证时,试了socket方法,socket方法相比urllib2,是更好的。原因也简单,这个方法是封装在函数里面的,比较容易解析,而urllib2是直接函数调用。
接下来看第四行,爬取结果是四个页面。接下来看看get方法实现效果:post方法实现效果:总结来说,动态获取需要写很。 查看全部
网页数据抓取怎么写(海南省各市级政府各级重点单位、企业等网站内容抓取框架beautifulsoup)
网页数据抓取怎么写,一直以来都是一个比较大的话题,大家有大量的前辈可以参考、学习。今天,我不知道从哪里看到了一个网页抓取框架beautifulsoup,于是开始深入研究。内容主要是实验了一下爬取海南省各市级政府各级重点单位、企业等网站内容,以及能够通过三步将网页抓取下来。我首先是使用beautifulsoup解析了一下网页,首先发现它提供了一种动态方法:location.href=""location.href='"""'location.href='"""'首先我们来看看第一行,提供了一个空文本属性location,代表本页面所在的位置。
该属性很重要,我们可以根据该属性获取指定页面对应的域名。下面我们看一下beautifulsoup解析结果:全部都解析了,解析耗时大概1分钟。intellisense在这里我不想详细展开讨论intellisense的用法和使用场景。只是想提醒大家一下,location属性是这个框架设计之初决定的,用于抓取指定网页内容时,不要使用它:if(progressisnone){//错误处理在chrome窗口内点击右键,然后找到打开的对话框,选择更多工具>查看源代码>遍历并检查首先判断网页加载位置的权限,是否允许继续遍历。
其次判断intellisense,判断是否有到达页面尾部的指定地址。最后确定循环遍历的次数,并确定生成的web页面地址。接下来看第二行,需要解析的页面基本是指定区域内的指定内容,那我们是不是可以改写为get/vara=navigator.frame.get('span')a.style.display='inline-block'a.get('/').href=a.test()//直接获取后,无法判断网页位置if(progressisnone){//错误处理之前处理过一次,结果就是爬取一个子页面(不包含指定的内容),那么可以将这个判断次数设置为更多}else{location.href='"""'//手动设置不同位置的元素progress=0;}}第三行,就直接拿来用了,查看爬取结果,爬取次数从4次到16次不等。
另外说一下get方法。它也可以获取指定页面外链、页面元素地址、以及页面内容(注意不是内部代码,而是页面js上的动态获取方法)。那有没有更好的方法爬取呢?我在写urllib2的一些http请求、验证时,试了socket方法,socket方法相比urllib2,是更好的。原因也简单,这个方法是封装在函数里面的,比较容易解析,而urllib2是直接函数调用。
接下来看第四行,爬取结果是四个页面。接下来看看get方法实现效果:post方法实现效果:总结来说,动态获取需要写很。
网页数据抓取怎么写(android中bitmap压缩的几种方法的解读_(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-03 12:15
android_Public中位图压缩的几种方法解读:BennuCTech-Programmer ITS203
最近在研究微信的sdk,遇到了缩略图的小问题。微信的缩略图要求不大于32k,这就需要我的图片进行压缩。试了好几种方法,一个一个。1、质量压缩方法:代码如下 ByteArrayOutputStreambaos=newByteArrayOutputStream();press(Bitmap.Co
(179)编辑材质函数_革命团队的螺丝钉-程序员ITS203
有时,您可能需要更改材质函数的功能。这可以直接从内容浏览器中完成,也可以从利用给定功能的材料中完成。在 Content Browser 或 Material Editor 的 Graph 选项卡中,您可以双击一个材质函数以在单独的 Material Editor 选项卡中将其打开,并查看构成该函数的材质表达式网络。这样,您可以随时编辑和更新材料功能的内部网络。但是,对材质函数所做和保存的任何更改都将存在于材质中
Python垃圾分类程序_使用Python做垃圾分类的原理及示例代码_weixin_39805529的博客-程序员ITS203
6年软件测试经验,从测试新手到资深测试经理的艰辛之路
文字内容较多,阅读时间约15分钟。我是2014年加入这个行业的,最初的测试经验和大部分测试伙伴是一样的。第一次接触是纯粹的功能接口测试。我在一家教育平台公司开始做软件。测试。公司成立之初,只有我一个软件测试人员,没有任何程序和规范,好在工作比较轻松,让我有足够的时间学习各种测试技术和工具。当你认为自己的工作很忙的时候,这是你可以多花点时间学习的时候,但是学习的内容一定要以自己的工作为基础,这样才能把学到的技能转化为工作经验。2014年前后,
python中如何区分中英文字符——python使用utf-8编码判断中英文字符的简单例子 - 程序员大本营
这篇文章主要详细介绍一个python使用utf-8编码判断中英文字符的简单例子,有一定的参考价值,可以参考。对python中使用utf-8编码判断中英文字符的简单例子感兴趣的朋友,我们跟着512笔记的小编罗X一起来看看吧。包括判断unicode是汉字、数字、英文还是其他字符,将全角符号转换为半角符号,规范unicode字符串。#512笔记网(
网杯REFINAL超详细WP_BadRer的博客-程序员ITS203
前言由于时间原因,比赛结束前没有提交flag,所以简单写了一个详细的答题流程(我觉得),适合小白阅读,Pizza老板请绕道。 查看全部
网页数据抓取怎么写(android中bitmap压缩的几种方法的解读_(图))
android_Public中位图压缩的几种方法解读:BennuCTech-Programmer ITS203
最近在研究微信的sdk,遇到了缩略图的小问题。微信的缩略图要求不大于32k,这就需要我的图片进行压缩。试了好几种方法,一个一个。1、质量压缩方法:代码如下 ByteArrayOutputStreambaos=newByteArrayOutputStream();press(Bitmap.Co
(179)编辑材质函数_革命团队的螺丝钉-程序员ITS203
有时,您可能需要更改材质函数的功能。这可以直接从内容浏览器中完成,也可以从利用给定功能的材料中完成。在 Content Browser 或 Material Editor 的 Graph 选项卡中,您可以双击一个材质函数以在单独的 Material Editor 选项卡中将其打开,并查看构成该函数的材质表达式网络。这样,您可以随时编辑和更新材料功能的内部网络。但是,对材质函数所做和保存的任何更改都将存在于材质中
Python垃圾分类程序_使用Python做垃圾分类的原理及示例代码_weixin_39805529的博客-程序员ITS203
6年软件测试经验,从测试新手到资深测试经理的艰辛之路
文字内容较多,阅读时间约15分钟。我是2014年加入这个行业的,最初的测试经验和大部分测试伙伴是一样的。第一次接触是纯粹的功能接口测试。我在一家教育平台公司开始做软件。测试。公司成立之初,只有我一个软件测试人员,没有任何程序和规范,好在工作比较轻松,让我有足够的时间学习各种测试技术和工具。当你认为自己的工作很忙的时候,这是你可以多花点时间学习的时候,但是学习的内容一定要以自己的工作为基础,这样才能把学到的技能转化为工作经验。2014年前后,
python中如何区分中英文字符——python使用utf-8编码判断中英文字符的简单例子 - 程序员大本营
这篇文章主要详细介绍一个python使用utf-8编码判断中英文字符的简单例子,有一定的参考价值,可以参考。对python中使用utf-8编码判断中英文字符的简单例子感兴趣的朋友,我们跟着512笔记的小编罗X一起来看看吧。包括判断unicode是汉字、数字、英文还是其他字符,将全角符号转换为半角符号,规范unicode字符串。#512笔记网(
网杯REFINAL超详细WP_BadRer的博客-程序员ITS203
前言由于时间原因,比赛结束前没有提交flag,所以简单写了一个详细的答题流程(我觉得),适合小白阅读,Pizza老板请绕道。
网页数据抓取怎么写(Python从入门到进阶共10本电子书今日鸡汤荷笠带斜阳)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-01 13:33
下次点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
合力带来落日余晖,青山遥遥。
大家好,我是一名高级Python初学者。
前言
前几天,白金群里一位名叫【Amy】的粉丝问了一个关于Python网络爬虫的问题,如下图所示。
不得不说,这位粉丝的提问很详细,很用心。我给他竖起大拇指。如果以后每个人都可以提出这样的问题,那将节省大量的沟通时间和成本。
事实上,他抓到的网站就是艾七叉,类似于七叉叉。其实上一次【杯酒】已经针对这个问题给出了新的解决方案。有兴趣的朋友可以去:分享一个实用的爬虫经验,今天继续给大家[有点意思]老大的解决方案。计划。
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
最后感谢【艾米】的提问,【【有点意思】】和【杯酒】解惑,感谢小编精心安排,感谢【盘溪鸟】积极尝试。
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。
小伙伴们快来练习吧!如果你在学习过程中遇到任何问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。
- - - - - - - - - -结尾 - - - - - - - - - - 查看全部
网页数据抓取怎么写(Python从入门到进阶共10本电子书今日鸡汤荷笠带斜阳)
下次点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
合力带来落日余晖,青山遥遥。
大家好,我是一名高级Python初学者。
前言
前几天,白金群里一位名叫【Amy】的粉丝问了一个关于Python网络爬虫的问题,如下图所示。
不得不说,这位粉丝的提问很详细,很用心。我给他竖起大拇指。如果以后每个人都可以提出这样的问题,那将节省大量的沟通时间和成本。
事实上,他抓到的网站就是艾七叉,类似于七叉叉。其实上一次【杯酒】已经针对这个问题给出了新的解决方案。有兴趣的朋友可以去:分享一个实用的爬虫经验,今天继续给大家[有点意思]老大的解决方案。计划。
一、想法
很多网站都有反向请求。这个时候,一般有两种选择。要么找到js接口,要么使用requests_html等其他工具。在这里他使用了后者的 requests_html 工具。
二、分析
一开始我是直接用requests来发出请求的。我发现我得到的响应数据是错误的,和源代码相差万里。然后我认为网站应该有反爬。我尝试添加一些 ua,但标题仍然不起作用,所以我想尝试使用 requests_html 工具。
三、代码
下面是这个爬虫的代码,欢迎大家试用。
# 作者:@有点意思
import re
import requests_html
def 抓取源码(url):
user_agent = requests_html.user_agent()
session = requests_html.HTMLSession()
headers = {
"cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",
"User-Agent": user_agent
}
r = session.get(url, headers=headers)
html = r.html.html
return html # 注意!这里抓取到的源码和手动打开的页面源码不一样
def 解密(列表): # unicode转化成汉字
print(列表)
return [eval(i) for i in 列表]
def 解析页面(html):
公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)
# 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html
# 此处正则匹配时一定要把引号带上!否则eval会报错!
return 解密(公司列表)
if __name__ == "__main__":
# 不用抓包,这里的url就是用户搜索时的页面
url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"
html = 抓取源码(url)
print(html)
公司列表 = 解析页面(html)
print(公司列表)
你可能会觉得奇怪,这里有中文的函数名和变量名。这是应原作者的要求,所以没有修改,但不影响程序的执行。
程序运行后,可以看到可以捕获目标字段。
四、总结
我是 Python 进阶者。本文基于粉丝提问,与大家分享一次实战爬虫体验,为大家带来一次有趣的爬虫体验。下次遇到使用requests库无法爬取的网页,或者看不到包的时候,不妨试试文中的requests_html方法,说不定会有用!
最后感谢【艾米】的提问,【【有点意思】】和【杯酒】解惑,感谢小编精心安排,感谢【盘溪鸟】积极尝试。
对于本文的网页,除了文章的“投机取巧”的方法外,用selenium爬取也是可行的,速度较慢,但能满足要求。小编认为肯定还有其他方法,也欢迎大家在评论区指教。
小伙伴们快来练习吧!如果你在学习过程中遇到任何问题,请加我为好友,我会拉你进入Python学习交流群一起讨论学习。
- - - - - - - - - -结尾 - - - - - - - - - -
网页数据抓取怎么写( 如何用python做后端写网页-flask框架什么是Flask安装flask模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-01 03:14
如何用python做后端写网页-flask框架什么是Flask安装flask模块)
使用python实现后端编写网页(flask框架)
更新时间:2021年2月28日09:49:28 作者:Fang Chang,来自日本。
本篇文章主要介绍如何使用python实现后端编写网页(flask框架)的相关资料。,有需要的朋友,和小编一起学习吧
如何使用python作为后端编写网页-flask框架什么是Flask安装flask模块Hello World再进一步:数据绑定到后端从前端传入数据从数据库连接屏幕获取数据创建后台查看删除后台结束
什么是烧瓶
Flask 是一个用 Python 编写的轻量级 Web 应用程序框架。它的 WSGI 工具包使用 Werkzeug,它的模板引擎使用 Jinja2。Flask 使用 BSD 许可证。以下程序均在自己的服务器上运行(在vs代码中使用ssh连接)
安装烧瓶模块
首先使用 pip 安装:
pip install flask
在项目文件夹下创建templates文件夹(用于存放html等文件)和app.py,如图:
你好世界
我们可以在模板文件中新建一个 index.html 文件,内容如下:
Hello Word!
在上一步创建的 app.py 文件中,写入:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#定义app在8080端口运行
app.run(port=8080)
我们写好app.py文件后,我们按F5运行,也就是终端输出:
我们访问服务器的8080端口,即Hello World出现在我们面前!
更进一步:数据绑定
上一步我们简单的搭建了一个静态网页,其展示只依赖前端,是固定的。我们如何从后端传递值并在前端显示呢?这需要使用数据绑定。
数据绑定,顾名思义,就是实现“动态”的效果。后台数据更新时,自动更新前端页面;当前端页面的数据更新时,后台的数据也会自动更新。在flask框架中,后端首先加载网页,将传入的数据放在合适的位置,然后使用jinjia2引擎进行渲染,最后返回渲染后的页面。
后端传入数据
我们首先在render_template函数中传入需要绑定的数据名称和年龄:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html",name="zxy",age=21)
#定义app在8080端口运行
app.run(port=8080)
在前端的 index.html 中,我们获取传入的数据:
我是{{name}},今年{{age}}岁
我们再次按F5运行,访问服务器的8080端口,页面显示:
从前端获取数据
那么,前端提交的数据是如何到达后端的呢?
在这里,我使用ajax来实现数据的异步传输。我们将主要步骤总结为:
1.前端页面引入jQuery
2.创建两个输入框,一个用于数据输入和事件提交的按钮。
3.js写事件,使用ajax提交数据
4.在后端app.py中编写对应的事件处理函数
前端index.html内容如下:
请输入你的姓名和年龄
提交
/*在这里编写submit()事件*/
function submit() {
$.ajax({
url: "submit", /*数据提交到submit处*/
type: "POST", /*采用POST方法提交*/
data: { "name": $("#name").val(),"age":$("#age").val()}, /*提交的数据(json格式),从输入框中获取*/
/*result为后端函数返回的json*/
success: function (result) {
if (result.message == "success!") {
alert(result.message+"你的名字是"+result.name+",你的年龄是"+result.age)
}
else {
alert(result.message)
}
}
});
}
当我们完成ajax数据提交后,在后端app.py中编写相应的处理函数submit()。
app.py 中的内容如下:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#app的路由地址"/submit"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/submit",methods=["GET", "POST"])
#从这里定义具体的函数 返回值均为json格式
def submit():
#由于POST、GET获取数据的方式不同,需要使用if语句进行判断
if request.method == "POST":
name = request.form.get("name")
age = request.form.get("age")
if request.method == "GET":
name = request.args.get("name")
age = request.args.get("age")
#如果获取的数据为空
if len(name) == 0 or len(age) ==0:
return {'message':"error!"}
else:
return {'message':"success!",'name':name,'age':age}
#定义app在8080端口运行
app.run(port=8080)
编写完成后,我们访问服务器8080端口进行测试,结果如下:
数据库连接
数据库是网页的组成部分。在前面的示例中,数据是从前端获取或随机输入的。如何从数据库中获取数据?
首先我们引入pymysql库,编写Database类,写在database.py中:
import pymysql
class Database:
#设置数据库的连接参数,由于我是在服务器中编写的,所以host是localhost
host = "localhost"
user = "root"
password = "Zhangxy0212!!"
#类的构造函数,参数db为欲连接的数据库。该构造函数实现了数据库的连接
def __init__(self,db):
connect = pymysql.connect(host=self.host,user=self.user,password=self.password,database=db)
self.cursor = connect.cursor()
#类的方法,参数command为sql语句
def execute(self, command):
try:
#执行command中的sql语句
self.cursor.execute(command)
except Exception as e:
return e
else:
#fetchall()返回语句的执行结果,并以元组的形式保存
return self.cursor.fetchall()
我们可以在模板文件中新建一个data.html文件来创建一个新页面。文件内容如下:
请输入你的名字
提交
function show() {
$.ajax({
url: "show",
type: "POST",
data: { "name": $("#name").val()},
/*不要忘记 result为后端处理函数的返回值!*/
success: function (result) {
if (result.status == "success") {
$("#result").text($("#name").val() + "是" + result.message)
}
else {
$("#result").text("出错了")
}
}
});
}
按钮的触发事件是show();接下来我们编写函数 data() 和事件处理程序 show() 以在 app.py 中呈现 data.html 页面。
请记住,这两个函数必须在创建应用程序对象和定义运行时端口之间添加!!
由于我们要使用写好的Database类来连接数据库,所以需要在app.py的顶部引入:
from database import Database
data() 函数和 show() 函数如下:
#通过python装饰器的方法定义路由地址
@app.route("/data")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def data():
return render_template("data.html")
#app的路由地址"/show"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/show",methods=["GET", "POST"])
def show():
#首先获取前端传入的name数据
if request.method == "POST":
name = request.form.get("name")
if request.method == "GET":
name = request.args.get("name")
#创建Database类的对象sql,test为需要访问的数据库名字 具体可见Database类的构造函数
sql = Database("test")
try:
#执行sql语句 多说一句,f+字符串的形式,可以在字符串里面以{}的形式加入变量名 结果保存在result数组中
result = sql.execute(f"SELECT type FROM type WHERE name='{name}'")
except Exception as e:
return {'status':"error", 'message': "code error"}
else:
if not len(result) == 0:
#这个result,我觉得也可以把它当成数据表,查询的结果至多一个,result[0][0]返回数组中的第一行第一列
return {'status':'success','message':result[0][0]}
else:
return "rbq"
我们按F5运行app.py文件后,访问
运行结果如图:
多说一句,数据表类型的内容如下:
屏幕
至此,使用flask框架搭建简单网页的基本流程就结束了!
我想你心里一定有一个问题。每次运行 python 程序时总是需要按 F5。如果关闭VS Code,进程会被杀死,服务器页面不会显示,如图:
然后我们需要使用screen在服务端创建一个后台,在后台运行app.py程序,达到连续运行的目的。
创建后端
由于我的服务器是 Centos,我使用 yum install screen 来下载屏幕。
下载完成后,在服务器任意位置输入screen命令创建背景,如图:
即上面会显示屏幕0.
我们进入项目所在的文件try,输入命令:python app.py 如图:
这样,我们再次访问121.41.111.94,会发现网站已经被激活了!即使我们关闭命令行,程序也会继续在后台运行。
查看删除背景
如果我们需要查看后台运行的是什么,在服务器中输入命令:screen -x
如果需要在后台停止运行,首先通过screen -x [pid number]进入一个后台。进入后Ctrl+C可以停止运行。
如果删除背景,先通过screen -x [pid number]进入一个背景,进入后输入exit
结束
这是文章关于使用python实现后端编写网页(flask框架)的介绍。更多相关python后端编写网页内容,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home! 查看全部
网页数据抓取怎么写(
如何用python做后端写网页-flask框架什么是Flask安装flask模块)
使用python实现后端编写网页(flask框架)
更新时间:2021年2月28日09:49:28 作者:Fang Chang,来自日本。
本篇文章主要介绍如何使用python实现后端编写网页(flask框架)的相关资料。,有需要的朋友,和小编一起学习吧
如何使用python作为后端编写网页-flask框架什么是Flask安装flask模块Hello World再进一步:数据绑定到后端从前端传入数据从数据库连接屏幕获取数据创建后台查看删除后台结束
什么是烧瓶
Flask 是一个用 Python 编写的轻量级 Web 应用程序框架。它的 WSGI 工具包使用 Werkzeug,它的模板引擎使用 Jinja2。Flask 使用 BSD 许可证。以下程序均在自己的服务器上运行(在vs代码中使用ssh连接)
安装烧瓶模块
首先使用 pip 安装:
pip install flask
在项目文件夹下创建templates文件夹(用于存放html等文件)和app.py,如图:
你好世界
我们可以在模板文件中新建一个 index.html 文件,内容如下:
Hello Word!
在上一步创建的 app.py 文件中,写入:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#定义app在8080端口运行
app.run(port=8080)
我们写好app.py文件后,我们按F5运行,也就是终端输出:
我们访问服务器的8080端口,即Hello World出现在我们面前!
更进一步:数据绑定
上一步我们简单的搭建了一个静态网页,其展示只依赖前端,是固定的。我们如何从后端传递值并在前端显示呢?这需要使用数据绑定。
数据绑定,顾名思义,就是实现“动态”的效果。后台数据更新时,自动更新前端页面;当前端页面的数据更新时,后台的数据也会自动更新。在flask框架中,后端首先加载网页,将传入的数据放在合适的位置,然后使用jinjia2引擎进行渲染,最后返回渲染后的页面。
后端传入数据
我们首先在render_template函数中传入需要绑定的数据名称和年龄:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html",name="zxy",age=21)
#定义app在8080端口运行
app.run(port=8080)
在前端的 index.html 中,我们获取传入的数据:
我是{{name}},今年{{age}}岁
我们再次按F5运行,访问服务器的8080端口,页面显示:
从前端获取数据
那么,前端提交的数据是如何到达后端的呢?
在这里,我使用ajax来实现数据的异步传输。我们将主要步骤总结为:
1.前端页面引入jQuery
2.创建两个输入框,一个用于数据输入和事件提交的按钮。
3.js写事件,使用ajax提交数据
4.在后端app.py中编写对应的事件处理函数
前端index.html内容如下:
请输入你的姓名和年龄
提交
/*在这里编写submit()事件*/
function submit() {
$.ajax({
url: "submit", /*数据提交到submit处*/
type: "POST", /*采用POST方法提交*/
data: { "name": $("#name").val(),"age":$("#age").val()}, /*提交的数据(json格式),从输入框中获取*/
/*result为后端函数返回的json*/
success: function (result) {
if (result.message == "success!") {
alert(result.message+"你的名字是"+result.name+",你的年龄是"+result.age)
}
else {
alert(result.message)
}
}
});
}
当我们完成ajax数据提交后,在后端app.py中编写相应的处理函数submit()。
app.py 中的内容如下:
from flask import Flask, render_template, request, jsonify
#创建Flask对象app并初始化
app = Flask(__name__)
#通过python装饰器的方法定义路由地址
@app.route("/")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def root():
return render_template("index.html")
#app的路由地址"/submit"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/submit",methods=["GET", "POST"])
#从这里定义具体的函数 返回值均为json格式
def submit():
#由于POST、GET获取数据的方式不同,需要使用if语句进行判断
if request.method == "POST":
name = request.form.get("name")
age = request.form.get("age")
if request.method == "GET":
name = request.args.get("name")
age = request.args.get("age")
#如果获取的数据为空
if len(name) == 0 or len(age) ==0:
return {'message':"error!"}
else:
return {'message':"success!",'name':name,'age':age}
#定义app在8080端口运行
app.run(port=8080)
编写完成后,我们访问服务器8080端口进行测试,结果如下:
数据库连接
数据库是网页的组成部分。在前面的示例中,数据是从前端获取或随机输入的。如何从数据库中获取数据?
首先我们引入pymysql库,编写Database类,写在database.py中:
import pymysql
class Database:
#设置数据库的连接参数,由于我是在服务器中编写的,所以host是localhost
host = "localhost"
user = "root"
password = "Zhangxy0212!!"
#类的构造函数,参数db为欲连接的数据库。该构造函数实现了数据库的连接
def __init__(self,db):
connect = pymysql.connect(host=self.host,user=self.user,password=self.password,database=db)
self.cursor = connect.cursor()
#类的方法,参数command为sql语句
def execute(self, command):
try:
#执行command中的sql语句
self.cursor.execute(command)
except Exception as e:
return e
else:
#fetchall()返回语句的执行结果,并以元组的形式保存
return self.cursor.fetchall()
我们可以在模板文件中新建一个data.html文件来创建一个新页面。文件内容如下:
请输入你的名字
提交
function show() {
$.ajax({
url: "show",
type: "POST",
data: { "name": $("#name").val()},
/*不要忘记 result为后端处理函数的返回值!*/
success: function (result) {
if (result.status == "success") {
$("#result").text($("#name").val() + "是" + result.message)
}
else {
$("#result").text("出错了")
}
}
});
}
按钮的触发事件是show();接下来我们编写函数 data() 和事件处理程序 show() 以在 app.py 中呈现 data.html 页面。
请记住,这两个函数必须在创建应用程序对象和定义运行时端口之间添加!!
由于我们要使用写好的Database类来连接数据库,所以需要在app.py的顶部引入:
from database import Database
data() 函数和 show() 函数如下:
#通过python装饰器的方法定义路由地址
@app.route("/data")
#定义方法 用jinjia2引擎来渲染页面,并返回一个index.html页面
def data():
return render_template("data.html")
#app的路由地址"/show"即为ajax中定义的url地址,采用POST、GET方法均可提交
@app.route("/show",methods=["GET", "POST"])
def show():
#首先获取前端传入的name数据
if request.method == "POST":
name = request.form.get("name")
if request.method == "GET":
name = request.args.get("name")
#创建Database类的对象sql,test为需要访问的数据库名字 具体可见Database类的构造函数
sql = Database("test")
try:
#执行sql语句 多说一句,f+字符串的形式,可以在字符串里面以{}的形式加入变量名 结果保存在result数组中
result = sql.execute(f"SELECT type FROM type WHERE name='{name}'")
except Exception as e:
return {'status':"error", 'message': "code error"}
else:
if not len(result) == 0:
#这个result,我觉得也可以把它当成数据表,查询的结果至多一个,result[0][0]返回数组中的第一行第一列
return {'status':'success','message':result[0][0]}
else:
return "rbq"
我们按F5运行app.py文件后,访问
运行结果如图:
多说一句,数据表类型的内容如下:
屏幕
至此,使用flask框架搭建简单网页的基本流程就结束了!
我想你心里一定有一个问题。每次运行 python 程序时总是需要按 F5。如果关闭VS Code,进程会被杀死,服务器页面不会显示,如图:
然后我们需要使用screen在服务端创建一个后台,在后台运行app.py程序,达到连续运行的目的。
创建后端
由于我的服务器是 Centos,我使用 yum install screen 来下载屏幕。
下载完成后,在服务器任意位置输入screen命令创建背景,如图:
即上面会显示屏幕0.
我们进入项目所在的文件try,输入命令:python app.py 如图:
这样,我们再次访问121.41.111.94,会发现网站已经被激活了!即使我们关闭命令行,程序也会继续在后台运行。
查看删除背景
如果我们需要查看后台运行的是什么,在服务器中输入命令:screen -x
如果需要在后台停止运行,首先通过screen -x [pid number]进入一个后台。进入后Ctrl+C可以停止运行。
如果删除背景,先通过screen -x [pid number]进入一个背景,进入后输入exit
结束
这是文章关于使用python实现后端编写网页(flask框架)的介绍。更多相关python后端编写网页内容,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home!
网页数据抓取怎么写(知道了要访问的URL地址是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-01 02:30
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里: 查看全部
网页数据抓取怎么写(知道了要访问的URL地址是什么)
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里:
网页数据抓取怎么写(Google表格导入功能会更新吗?如何无需编程即可抓取网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 623 次浏览 • 2022-01-31 02:23
有一些编程语言可以简化这一点,比如 Python。这是因为 Python 提供了像 Scrapy 和 BeautifulSoup 这样的库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和网站架构的良好理解。
假设您的团队没有编程技能。没关系!我们的一位团队成员最近在洛约拉大学举办了一次网络研讨会,演示如何在不编程的情况下抓取网页。相反,Google 表格提供了一些有用的功能来帮助抓取网络数据。如果您想观看我们网络研讨会的视频,请点击下方。如果没有,您可以继续阅读并了解如何使用 Google 表格抓取 网站。
谷歌表格抓取
您可以使用 Google 表格进行网页抓取的功能包括:
所有这些函数都将根据提供给函数的不同参数来获取 网站。
使用 ImportFeed 进行网页抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 google sheet 和 rss feed 的 url。这是通常与博客相关的提要。
例如,您可以使用我们的 RSS 提要“”。
您如何使用此功能?下面给出一个例子。
" = 进口饲料(" ")
仅此而已!还有一些其他提示和技巧可帮助您清理数据馈送,因为您将获得不止一列的信息。目前,这是网络抓取的一个很好的开始。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可以设置触发器以增加更新的节奏。但是,这需要更多的编程。
在这种情况下是!从这里开始,这就是您的团队可以使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行 Web 抓取
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要一些 HTML 和解析 XML 的知识。这可能有点令人沮丧。所以,我们一步一步地创建了 HTML 网络爬虫。
以下是 EventBrite 页面中的一些示例。
转到右键单击检查元素以找到您感兴趣的 HTML 标记,我们正在寻找
一些文字,所以这是棘手的部分。您需要从此 HTML 标记中提取的第一部分是类型。如同
,,
,等待。第一个可以用“//”后跟标签名称来调用。例如“//div”、“//a”或“//span”。现在,如果你真的想得到“Some Text Here”,你需要调用这个类。这是在步骤 5 中显示的方法中完成的。您会注意到它使用“//div”和“[@class="class name here"] 组合。xml 字符串是“//div[@class='list -card__body']" 您可能想要获取另一个数据值。我们想要获取所有 URL 这种情况将涉及想要在第一个 HTML 标记本身中提取特定值。例如,单击此处。然后像第 7 步一样。xml 字符串是 "/ /a/@href" ImportXML(URL, XML string) ImportXML(" ", "//div[@class='list-card__body']")
使用此功能的事实是它需要很多时间。因此,它需要规划和设计一个好的谷歌表格,以确保您充分利用您的资源。否则,您的团队最终会花时间维护它,而不是致力于新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中抓取收录股票价格的数据怎么办。
我们将使用。此页面上有一个表格,其中收录过去几天的股价。
与过去的功能类似,您需要使用 URL。在 URL 的顶部,您必须提及要抓取的网页上的表格。您可以使用可能的数字来执行此操作。
例如 ImportHTML(" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上面抓取的股票数据合并到当天关于股票代码收录机器的新闻中。这可以以更复杂的方式加以利用。团队可以创建一个算法,使用过去的股票价格以及新的 文章 和 Twitter 提要来选择是买入还是卖出股票。
您对使用网络抓取有什么好的想法吗?您需要网络抓取项目的帮助吗?让我们知道!
有关数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发稳健的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表格 查看全部
网页数据抓取怎么写(Google表格导入功能会更新吗?如何无需编程即可抓取网页)
有一些编程语言可以简化这一点,比如 Python。这是因为 Python 提供了像 Scrapy 和 BeautifulSoup 这样的库,它们比传统的网络爬虫更容易抓取和解析 HTML。
但是,它仍然需要适当的设计以及对编程和网站架构的良好理解。
假设您的团队没有编程技能。没关系!我们的一位团队成员最近在洛约拉大学举办了一次网络研讨会,演示如何在不编程的情况下抓取网页。相反,Google 表格提供了一些有用的功能来帮助抓取网络数据。如果您想观看我们网络研讨会的视频,请点击下方。如果没有,您可以继续阅读并了解如何使用 Google 表格抓取 网站。
谷歌表格抓取
您可以使用 Google 表格进行网页抓取的功能包括:
所有这些函数都将根据提供给函数的不同参数来获取 网站。
使用 ImportFeed 进行网页抓取
ImportFeed Google Sheets 功能是更易于使用的功能之一。它只需要访问 google sheet 和 rss feed 的 url。这是通常与博客相关的提要。
例如,您可以使用我们的 RSS 提要“”。
您如何使用此功能?下面给出一个例子。
" = 进口饲料(" ")
仅此而已!还有一些其他提示和技巧可帮助您清理数据馈送,因为您将获得不止一列的信息。目前,这是网络抓取的一个很好的开始。
Google 表格导入功能会更新吗?
所有这些导入功能每 2 小时自动更新一次数据。可以设置触发器以增加更新的节奏。但是,这需要更多的编程。
在这种情况下是!从这里开始,这就是您的团队可以使用它的方式!确保设计一个可靠的数据采集系统。
上图是使用 ImportFeed 函数的示例。
使用 ImportXML 进行 Web 抓取
Google 表格中的 ImportXML 函数用于使用 HTML ID 和类提取特定数据点。这需要一些 HTML 和解析 XML 的知识。这可能有点令人沮丧。所以,我们一步一步地创建了 HTML 网络爬虫。
以下是 EventBrite 页面中的一些示例。
转到右键单击检查元素以找到您感兴趣的 HTML 标记,我们正在寻找
一些文字,所以这是棘手的部分。您需要从此 HTML 标记中提取的第一部分是类型。如同
,,
,等待。第一个可以用“//”后跟标签名称来调用。例如“//div”、“//a”或“//span”。现在,如果你真的想得到“Some Text Here”,你需要调用这个类。这是在步骤 5 中显示的方法中完成的。您会注意到它使用“//div”和“[@class="class name here"] 组合。xml 字符串是“//div[@class='list -card__body']" 您可能想要获取另一个数据值。我们想要获取所有 URL 这种情况将涉及想要在第一个 HTML 标记本身中提取特定值。例如,单击此处。然后像第 7 步一样。xml 字符串是 "/ /a/@href" ImportXML(URL, XML string) ImportXML(" ", "//div[@class='list-card__body']")
使用此功能的事实是它需要很多时间。因此,它需要规划和设计一个好的谷歌表格,以确保您充分利用您的资源。否则,您的团队最终会花时间维护它,而不是致力于新事物。像下面的图片
来自 xkcd
使用 ImportHTML 进行网页抓取
最后,我们将讨论 ImportHTML。这将从网页导入表格或列表。例如,如果您想从 网站 中抓取收录股票价格的数据怎么办。
我们将使用。此页面上有一个表格,其中收录过去几天的股价。
与过去的功能类似,您需要使用 URL。在 URL 的顶部,您必须提及要抓取的网页上的表格。您可以使用可能的数字来执行此操作。
例如 ImportHTML(" ",6 )。这将从上面的链接中删除股票价格。
在上面的视频中,我们还展示了如何将上面抓取的股票数据合并到当天关于股票代码收录机器的新闻中。这可以以更复杂的方式加以利用。团队可以创建一个算法,使用过去的股票价格以及新的 文章 和 Twitter 提要来选择是买入还是卖出股票。
您对使用网络抓取有什么好的想法吗?您需要网络抓取项目的帮助吗?让我们知道!
有关数据科学的其他精彩读物:
什么是决策树
算法如何变得不道德和有偏见
如何开发稳健的算法
数据科学家必须具备的 4 项技能
翻译自:
网页抓取表格
网页数据抓取怎么写(网站爬虫通过网页再去做算法,小编来告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-28 12:10
我们在做好网站收录的同时,更应该了解改进收录的方法,也就是指纹和重算法,这可以帮助我们做好网站收录的工作,提高排名就是提高排名,所以你得试试网站爬虫通过网页做算法,然后让小编告诉你网络爬虫抓取链接的五种算法,绝对有效果!
一、根据文章内容和网页布局格式的组合,大致重复网页类型分为4种形式:
1、两个文档在内容和布局格式上没有区别,这种重复称为完整的重复页面。
2、两个文档的内容是一样的,只是布局格式不同,所以这种复制称为内容复制页。
3、两个文档的重要内容相同,布局格式也相同,所以这种复制称为布局复制页。
4、两个文档共享一些重要内容,但布局格式不同。这种复制称为部分复制。
二、重复页面对搜索引擎的不利影响:
通常情况下,非常相似的网页内容不能或只能为用户提供少量的新信息,但爬虫、索引和用户搜索爬虫会消耗大量的服务器资源。
三、重复页面对搜索引擎的好处:
如果某个网页的重复性很高,往往是其内容比较热门的体现,也说明该网页相对比较重要。应优先考虑 收录。用户搜索时,对输出结果进行排序时也应该给予较高的权重。
四、如何处理重复文件:
1、删除
2、对重复文档进行分组
五、 SimHash文档指纹计算方法:
1、从文档中提取一个带有权重的特征集来表示文档。例如,假设特征全部由词组成,则词的权重由词频 TF 决定。
2、对于每个字,通过哈希算法生成一个N位(通常是64位或更多)二进制值,如上图所示,以生成一个8位二进制值为例。每个字对应于它自己独特的二进制值。
3、在N维(上图中为8维)向量V中,计算每一维向量。如果字对应位的二进制值为1,则加特征权重;如果该位为0,则执行减法,并通过此方法更新向量。
4、如上处理完所有单词后,如果向量V中的第i维为正数,则将N位指纹中的第i位设置为1,否则为0。
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。整体感觉是从上到下爬取网页中的链接。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
首先介绍一个简单的思路,这也是一个经常使用的大体思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每一个URL的时候,效率会很快下降,
第二种方法是将访问过的 URL 保存在集合中。获取网址的速度非常快,基本不需要查询。但是这种方法有一个问题。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方法是将字符编码在md5中,将字符减少到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这种方法在很大程度上节省了内存。scrapy框架使用的方法有点类似于md5的方法。因此,正常情况下,即使scrapy中的url数量达到亿级,scrapy框架占用的内存比set方法小。少得多。
第四种方法是应用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,区分对应的8位,然后通过位上面的0和1的状态,我们可以指示该URL是否存在,这种方法可以进一步压缩内存。但是bitmap方式有一个很大的问题,就是它的冲突会很高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。实际上,这个hash方法也是set方法的一个实现原理。它对URL进行函数计算,然后将其映射到位的位置,所以这种方法对内存的压缩很大。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。经计算,相当于12,500,000字节。除以 1024 后,大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性很高,所以这种方法不太实用。那么有没有办法进一步优化bitmap,这是一种重内存压缩的方法,减少冲突的可能性?答案是肯定的,是第五种方法。
第五个方法是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。通过这种方式,一方面可以达到位图方式减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面会为大家呈现。今天就让大家来简单了解一下。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫来达到爬取的目的。
以上就是小编帮你清理的一些材料。一般来说,关于提高你的排名,你实际上可以查找规则并找到更好的方法。提升排名的方法就是要根据自己的情况找到合适的,找到稳定的就行了。现在,不要贪心,做得比以前更糟。 查看全部
网页数据抓取怎么写(网站爬虫通过网页再去做算法,小编来告诉你)
我们在做好网站收录的同时,更应该了解改进收录的方法,也就是指纹和重算法,这可以帮助我们做好网站收录的工作,提高排名就是提高排名,所以你得试试网站爬虫通过网页做算法,然后让小编告诉你网络爬虫抓取链接的五种算法,绝对有效果!
一、根据文章内容和网页布局格式的组合,大致重复网页类型分为4种形式:
1、两个文档在内容和布局格式上没有区别,这种重复称为完整的重复页面。
2、两个文档的内容是一样的,只是布局格式不同,所以这种复制称为内容复制页。
3、两个文档的重要内容相同,布局格式也相同,所以这种复制称为布局复制页。
4、两个文档共享一些重要内容,但布局格式不同。这种复制称为部分复制。
二、重复页面对搜索引擎的不利影响:
通常情况下,非常相似的网页内容不能或只能为用户提供少量的新信息,但爬虫、索引和用户搜索爬虫会消耗大量的服务器资源。
三、重复页面对搜索引擎的好处:
如果某个网页的重复性很高,往往是其内容比较热门的体现,也说明该网页相对比较重要。应优先考虑 收录。用户搜索时,对输出结果进行排序时也应该给予较高的权重。
四、如何处理重复文件:
1、删除
2、对重复文档进行分组
五、 SimHash文档指纹计算方法:
1、从文档中提取一个带有权重的特征集来表示文档。例如,假设特征全部由词组成,则词的权重由词频 TF 决定。
2、对于每个字,通过哈希算法生成一个N位(通常是64位或更多)二进制值,如上图所示,以生成一个8位二进制值为例。每个字对应于它自己独特的二进制值。
3、在N维(上图中为8维)向量V中,计算每一维向量。如果字对应位的二进制值为1,则加特征权重;如果该位为0,则执行减法,并通过此方法更新向量。
4、如上处理完所有单词后,如果向量V中的第i维为正数,则将N位指纹中的第i位设置为1,否则为0。
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。整体感觉是从上到下爬取网页中的链接。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
首先介绍一个简单的思路,这也是一个经常使用的大体思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他网页,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是在数据库中查询每一个URL的时候,效率会很快下降,
第二种方法是将访问过的 URL 保存在集合中。获取网址的速度非常快,基本不需要查询。但是这种方法有一个问题。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方法是将字符编码在md5中,将字符减少到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这种方法在很大程度上节省了内存。scrapy框架使用的方法有点类似于md5的方法。因此,正常情况下,即使scrapy中的url数量达到亿级,scrapy框架占用的内存比set方法小。少得多。
第四种方法是应用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,区分对应的8位,然后通过位上面的0和1的状态,我们可以指示该URL是否存在,这种方法可以进一步压缩内存。但是bitmap方式有一个很大的问题,就是它的冲突会很高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。实际上,这个hash方法也是set方法的一个实现原理。它对URL进行函数计算,然后将其映射到位的位置,所以这种方法对内存的压缩很大。简单计算一下,还是用1亿个URL来计算,相当于1亿比特。经计算,相当于12,500,000字节。除以 1024 后,大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性很高,所以这种方法不太实用。那么有没有办法进一步优化bitmap,这是一种重内存压缩的方法,减少冲突的可能性?答案是肯定的,是第五种方法。
第五个方法是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。通过这种方式,一方面可以达到位图方式减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面会为大家呈现。今天就让大家来简单了解一下。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫来达到爬取的目的。
以上就是小编帮你清理的一些材料。一般来说,关于提高你的排名,你实际上可以查找规则并找到更好的方法。提升排名的方法就是要根据自己的情况找到合适的,找到稳定的就行了。现在,不要贪心,做得比以前更糟。
网页数据抓取怎么写( 前端来说的基本流程和流程是什么?-lite模块解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-28 12:04
前端来说的基本流程和流程是什么?-lite模块解析)
对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取网站的数据。
爬虫的基本流程:
1、发起请求:
使用http库向目标站点发起请求,即发送Request,第三方请求库如request、axios等
请求收录:请求头、请求体等
2、获取响应内容:
如果服务器能正常响应,就会得到一个Response。
响应收录:html、json、图片、视频等
3、解析内容:
解析html数据:正则表达式、cheerio、PhantomJS、JSDom等第三方解析库
解析json数据:json模块。
解析二进制数据:以缓冲模式写入文件。
4、保存数据
数据库。
接下来以腾讯网文章数据的爬取为例。首先我们要知道网站的请求地址是。根据这个地址,我们发送请求获取网站的源码:
const request = require('request');
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
console.log(result)
})
在获取网站源码的过程中,我们发现网站不是utf8编码格式,而是gb2312格式,所以我们使用iconv-lite模块来解析。
得到响应的内容后,我们需要提取html中的内容,这次我要抓取网站的新闻标题部分。
const request = require('request')
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
let list = []
let $ = cheerio.load(result)
$('.yw-list li').each((i, ele) => {
let text = $(ele).text().replace(/\s/g, '')
list.push(text)
})
console.log(list)
fs.writeFileSync('qq.json', JSON.stringify(list))
})
提取一些有用的内容后,通常会保存到数据库或写入文件系统。 查看全部
网页数据抓取怎么写(
前端来说的基本流程和流程是什么?-lite模块解析)
对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取网站的数据。
爬虫的基本流程:
1、发起请求:
使用http库向目标站点发起请求,即发送Request,第三方请求库如request、axios等
请求收录:请求头、请求体等
2、获取响应内容:
如果服务器能正常响应,就会得到一个Response。
响应收录:html、json、图片、视频等
3、解析内容:
解析html数据:正则表达式、cheerio、PhantomJS、JSDom等第三方解析库
解析json数据:json模块。
解析二进制数据:以缓冲模式写入文件。
4、保存数据
数据库。
接下来以腾讯网文章数据的爬取为例。首先我们要知道网站的请求地址是。根据这个地址,我们发送请求获取网站的源码:
const request = require('request');
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
console.log(result)
})
在获取网站源码的过程中,我们发现网站不是utf8编码格式,而是gb2312格式,所以我们使用iconv-lite模块来解析。
得到响应的内容后,我们需要提取html中的内容,这次我要抓取网站的新闻标题部分。
const request = require('request')
const url = 'https://www.qq.com/'
const fs = require('fs')
const cheerio = require('cheerio')
const iconv = require('iconv-lite')
request({url, encoding: null}, (err, response, body) => {
let result = iconv.decode(body, 'gb2312');
let list = []
let $ = cheerio.load(result)
$('.yw-list li').each((i, ele) => {
let text = $(ele).text().replace(/\s/g, '')
list.push(text)
})
console.log(list)
fs.writeFileSync('qq.json', JSON.stringify(list))
})
提取一些有用的内容后,通常会保存到数据库或写入文件系统。
网页数据抓取怎么写(网页数据抓取怎么写?#启动抓取服务器的代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-28 10:03
网页数据抓取怎么写?每个python初学者都有这种疑问,每个都单独写个代码,太麻烦了,写出来的效果别人看不懂又找不到,如果你目前的网页形式都是一样的,就是每个网页都在一个单独的页面中,那你自己写一个网页爬虫爬下来就行了,如果你不想自己写代码的话,你可以用抓取工具,如七牛云,千里云等,我之前用过他们家的抓取工具,比较简单,但是除了能抓取,还能看到数据,还能抓取后与别人一起分享,非常方便!httpserver#启动抓取服务器的代理ip为主机服务器中的ip地址,比如,我们可以通过以下方式获取指定主机上的ip:网站首页#加载数据get('/test。php','jp',str);?>#如果数据数量增多,可以使用定长加载方式:echofind_list(temp)[2];#通过eval函数,实现反斜杠缩进(比如反斜杠为'\t',通过这个参数,让bin_page实现反斜杠是'\n')file_format("post:'{bin_page}'\t'/'post。
<p>php",$data,function($source,$data,function_only){$source='{bin_page}';$data={'user':'admin','password':'\t'};$cookie=file_get_contents($data);//根据使用的爬虫session信息,从file_get_contents返回的文件中来获取字段$cookie['cookie_name']='\t';$cookie['cookie_password']='\t';//建立post表单,登陆,验证码等for($i=0;$i#针对不同请求参数,可以分别使用ajax,和反序列化post等方式来调用获取到数据functionget_data($request_url,$url){$temp=$_post['url'];//获取server访问地址$data=[];for($i=0;$i 查看全部
网页数据抓取怎么写(网页数据抓取怎么写?#启动抓取服务器的代理)
网页数据抓取怎么写?每个python初学者都有这种疑问,每个都单独写个代码,太麻烦了,写出来的效果别人看不懂又找不到,如果你目前的网页形式都是一样的,就是每个网页都在一个单独的页面中,那你自己写一个网页爬虫爬下来就行了,如果你不想自己写代码的话,你可以用抓取工具,如七牛云,千里云等,我之前用过他们家的抓取工具,比较简单,但是除了能抓取,还能看到数据,还能抓取后与别人一起分享,非常方便!httpserver#启动抓取服务器的代理ip为主机服务器中的ip地址,比如,我们可以通过以下方式获取指定主机上的ip:网站首页#加载数据get('/test。php','jp',str);?>#如果数据数量增多,可以使用定长加载方式:echofind_list(temp)[2];#通过eval函数,实现反斜杠缩进(比如反斜杠为'\t',通过这个参数,让bin_page实现反斜杠是'\n')file_format("post:'{bin_page}'\t'/'post。
<p>php",$data,function($source,$data,function_only){$source='{bin_page}';$data={'user':'admin','password':'\t'};$cookie=file_get_contents($data);//根据使用的爬虫session信息,从file_get_contents返回的文件中来获取字段$cookie['cookie_name']='\t';$cookie['cookie_password']='\t';//建立post表单,登陆,验证码等for($i=0;$i#针对不同请求参数,可以分别使用ajax,和反序列化post等方式来调用获取到数据functionget_data($request_url,$url){$temp=$_post['url'];//获取server访问地址$data=[];for($i=0;$i
网页数据抓取怎么写(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-25 08:02
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text 查看全部
网页数据抓取怎么写(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text
网页数据抓取怎么写(Python零基础入门,从最基本的变量开始学Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-24 19:33
题记:大二的时候,我意识到生命太短暂了,于是信了神,开始学习Python。学习了半年多,成功转行前端。让我们编写一个教程来帮助您开始使用 Python。
Python 零基础入门
要从零基础开始,你必须从变量、语法格式、数据类型、函数、作用域、模块等最基本的知识开始。
像篮球一样,从三步上篮开始:
1. Python基础知识入门,从编程基础入手,看懂代码即可。三个选项:
2. 学习编写一些基本的 Python 程序。上面《简明Python教程》末尾的例子都可以做到。如果你想进一步掌握基础知识,你可以做一些简单的leetcode来练习你的手。(看我个人情况,反正我没耐心,做题太无聊了,虽然写题很有好处。)
3. 做一些感兴趣的小项目。这里有 100 个 Python 练习示例,非常基础。如果觉得自己不够高,可以在实验楼里玩项目。实验楼不错网站,可以做一些很有意思的事情。
以上三步让你21天精通Python
Tips:推荐一个神器,可以一步步查看程序运行状态、变量状态、函数调用、内存分配,对于理解变量的生命周期、作用域、调试和理解程序很有帮助。
开发工具:推荐Pycharm,有免费社区版,也可以使用edu邮箱注册专业版。
高级 Python
进阶就是专注于Python的某个领域做深入的研究。Python主要包括AI领域(NLP、深度学习、图像处理等,反正无所不能)、web开发(后端服务、爬虫)、数据处理(数据分析、科学计算)、工具(比如读写) Excel,写自动化脚本),桌面开发(GUI工具)等。Python太强大了,我想再写一次Python。
下面简单介绍一下我所知道的领域:
Web开发
Python web 框架有很多,它是构建网站 的强大工具。对于构建不太复杂的cms系统(比如新闻网站、博客网站),Django强大到没有朋友,开发效率无敌。对于注重灵活性的网站,Flask 可以是首选,灵活小巧,非常优雅的框架。
要开始使用 Django,请先阅读官方文档以了解基本概念。然后开始做实际项目,比如Django开发博客系统教程Flask介绍看官方文档,和Django一样。爬虫(网络数据采集)
先科普一下,网络爬虫,可以理解为蜘蛛在互联网上爬行,互联网就像一张大网,而爬虫就是蜘蛛在这张网上四处爬行,如果遇到资源,就会把它抓取下来。例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。简单地说,使用程序从网页中获取您想要的数据。
Python中有很多爬虫框架,而且非常好用。
入门步骤:
了解网页的结构
网页的基础知识包括:
基本的 HTML 语言知识
理解网站(POST GET)的包收发概念
一点点js知识用来理解动态网页和解析网页。这里需要学习正则表达式来选择爬虫框架,比如内置的urllib、request、bs4等。看官方文档,框架的使用方法,然后就可以养一只爬虫了。数据处理
上面爬虫讲了如何获取数据,这里我们将学习如何分析和处理数据。
科学计算和数据处理更多地使用matlab,当然万能的Python也可以替代它。
Numpy pandas 是科学操作中最重要的两个模块。Matplotlib 是一个非常强大的 Python 数据可视化工具,用于绘制各种图形。
看官网文档了解这个库的基本用法。学习一些简单的项目,上面提到的实验楼也可以用在AI领域
来自别处的一点基本介绍
Theano 是一个 Python 库,用于使用序列定义和评估数学表达式。它使在 Python 中编写深度学习算法变得更加容易。Keras 是一个精简的、高度模块化的神经网络库,类似于 Torch。在底层,Theano 帮助它优化了 CPU 和 GPU 操作上的张量操作。Pylearn2 是一个库,它引用了大量的模型和训练算法,例如随机梯度。它在深度学习中被广泛采用,这个库也是基于 Theano 的。Lasagne 是一个轻量级的库,用于在 Theano 中构建和训练神经网络。它简单、透明、模块化、实用、专一、内敛。Blocks 是一个框架,可帮助您在 Theano 之上构建神经网络模型。Caffe 是一个基于清晰度、速度和模块化概念的深度学习框架。它由伯克利视觉与学习中心 (BVLC) 和在线社区贡献者开发。Google 的 DeepDream 人工智能图像处理程序是建立在 Caffe 框架之上的。这个框架是一个带有 Python 接口的 BSD 许可的 C++ 库。nolearn 收录来自许多其他神经网络库的包装器和抽象,最著名的是 Lasagne,它还收录一些用于机器学习的有用模块。Genism 是一个部署在 Python 编程语言中的深度学习工具包,用于使用高效算法处理大型文本集。CXXNET 是一个基于 MShadow 的快速简洁的分布式深度学习框架。它是一个轻量级且可扩展的 C++/CUDA 神经网络工具包,具有友好的 Python/Matlab 界面,用于机器学习训练和预测。
这里有很多东西,基本的学习方法如上。
附录:
我们先来看看Python有多强大,否则,如果你不能被它吸引,你就学不会它。
20行代码实现人脸检测识别:
face_recognition可以通过python或者命令行实现人脸识别的功能。采用 dlib 深度学习人脸识别技术构建,在户外人脸检测数据库基准(Labeled Faces in the Wild)上的准确率达到 99.38%。
# 导入识别库
import face_recognition
# 加载已有的图片作为图像库
known_obama_image = face_recognition.load_image_file("face1.jpg")
known_biden_image = face_recognition.load_image_file("face_kid.jpg")
# 编码加载的图片
obama_face_encoding = face_recognition.face_encodings(known_obama_image)[0]
biden_face_encoding = face_recognition.face_encodings(known_biden_image)[0]
known_encodings = [
obama_face_encoding,
biden_face_encoding
]
# 加载要识别的图片并编码
image_to_test = face_recognition.load_image_file("face2.jpg")
image_to_test_encoding = face_recognition.face_encodings(image_to_test)[0]
# 计算该图片与已有图片的差别值
face_distances = face_recognition.face_distance(known_encodings, image_to_test_encoding)
# 自行设定同一张面孔的分界值,输出比对结果
for i, face_distance in enumerate(face_distances):
print("The test image has a distance of {:.2} from known image #{}".format(face_distance, i))
print("- With a normal cutoff of 0.6, would the test image match the known image? {}".format(face_distance < 0.6))
print("- With a very strict cutoff of 0.5, would the test image match the known image? {}".format(face_distance < 0.5))
学习爬虫 Python 入门容易吗?学习爬虫需要一定的基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。爬虫Python入门学习分为三个阶段:
一、零基础阶段:
从零开始学爬虫,上手系统,从0开始爬虫。除了必要的理论知识,爬虫对于实际应用更重要。带你抓取4种主流网站数据,掌握主流爬虫爬取方法。
捕捉主流网站数据的能力是本阶段的学习目标
学习点:爬虫所需的计算机网络/前端/正则//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、响应反爬、识别验证码等,难点详解;多线程、多进程等常见应用场景讲解
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学完之后,可以彻底玩转Scrapy框架,开发自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习点:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统;Scrapy突破了反爬虫的限制和Scrapy的原理;Scrapy 更高级的功能包括 sscrapy 信号、自定义中间件;一些海量数据结合Elasticsearch打造搜索引擎
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从现在开始,拓展您的爬虫业务,提升您的核心竞争力。掌握App数据抓取,实现数据可视化
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习实践深入掌握App爬虫技巧;基于Docker构建多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基础图形、地图等进行数据可视化。
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。 查看全部
网页数据抓取怎么写(Python零基础入门,从最基本的变量开始学Python)
题记:大二的时候,我意识到生命太短暂了,于是信了神,开始学习Python。学习了半年多,成功转行前端。让我们编写一个教程来帮助您开始使用 Python。
Python 零基础入门
要从零基础开始,你必须从变量、语法格式、数据类型、函数、作用域、模块等最基本的知识开始。
像篮球一样,从三步上篮开始:
1. Python基础知识入门,从编程基础入手,看懂代码即可。三个选项:
2. 学习编写一些基本的 Python 程序。上面《简明Python教程》末尾的例子都可以做到。如果你想进一步掌握基础知识,你可以做一些简单的leetcode来练习你的手。(看我个人情况,反正我没耐心,做题太无聊了,虽然写题很有好处。)
3. 做一些感兴趣的小项目。这里有 100 个 Python 练习示例,非常基础。如果觉得自己不够高,可以在实验楼里玩项目。实验楼不错网站,可以做一些很有意思的事情。
以上三步让你21天精通Python
Tips:推荐一个神器,可以一步步查看程序运行状态、变量状态、函数调用、内存分配,对于理解变量的生命周期、作用域、调试和理解程序很有帮助。
开发工具:推荐Pycharm,有免费社区版,也可以使用edu邮箱注册专业版。
高级 Python
进阶就是专注于Python的某个领域做深入的研究。Python主要包括AI领域(NLP、深度学习、图像处理等,反正无所不能)、web开发(后端服务、爬虫)、数据处理(数据分析、科学计算)、工具(比如读写) Excel,写自动化脚本),桌面开发(GUI工具)等。Python太强大了,我想再写一次Python。
下面简单介绍一下我所知道的领域:
Web开发
Python web 框架有很多,它是构建网站 的强大工具。对于构建不太复杂的cms系统(比如新闻网站、博客网站),Django强大到没有朋友,开发效率无敌。对于注重灵活性的网站,Flask 可以是首选,灵活小巧,非常优雅的框架。
要开始使用 Django,请先阅读官方文档以了解基本概念。然后开始做实际项目,比如Django开发博客系统教程Flask介绍看官方文档,和Django一样。爬虫(网络数据采集)
先科普一下,网络爬虫,可以理解为蜘蛛在互联网上爬行,互联网就像一张大网,而爬虫就是蜘蛛在这张网上四处爬行,如果遇到资源,就会把它抓取下来。例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。简单地说,使用程序从网页中获取您想要的数据。
Python中有很多爬虫框架,而且非常好用。
入门步骤:
了解网页的结构
网页的基础知识包括:
基本的 HTML 语言知识
理解网站(POST GET)的包收发概念
一点点js知识用来理解动态网页和解析网页。这里需要学习正则表达式来选择爬虫框架,比如内置的urllib、request、bs4等。看官方文档,框架的使用方法,然后就可以养一只爬虫了。数据处理
上面爬虫讲了如何获取数据,这里我们将学习如何分析和处理数据。
科学计算和数据处理更多地使用matlab,当然万能的Python也可以替代它。
Numpy pandas 是科学操作中最重要的两个模块。Matplotlib 是一个非常强大的 Python 数据可视化工具,用于绘制各种图形。
看官网文档了解这个库的基本用法。学习一些简单的项目,上面提到的实验楼也可以用在AI领域
来自别处的一点基本介绍
Theano 是一个 Python 库,用于使用序列定义和评估数学表达式。它使在 Python 中编写深度学习算法变得更加容易。Keras 是一个精简的、高度模块化的神经网络库,类似于 Torch。在底层,Theano 帮助它优化了 CPU 和 GPU 操作上的张量操作。Pylearn2 是一个库,它引用了大量的模型和训练算法,例如随机梯度。它在深度学习中被广泛采用,这个库也是基于 Theano 的。Lasagne 是一个轻量级的库,用于在 Theano 中构建和训练神经网络。它简单、透明、模块化、实用、专一、内敛。Blocks 是一个框架,可帮助您在 Theano 之上构建神经网络模型。Caffe 是一个基于清晰度、速度和模块化概念的深度学习框架。它由伯克利视觉与学习中心 (BVLC) 和在线社区贡献者开发。Google 的 DeepDream 人工智能图像处理程序是建立在 Caffe 框架之上的。这个框架是一个带有 Python 接口的 BSD 许可的 C++ 库。nolearn 收录来自许多其他神经网络库的包装器和抽象,最著名的是 Lasagne,它还收录一些用于机器学习的有用模块。Genism 是一个部署在 Python 编程语言中的深度学习工具包,用于使用高效算法处理大型文本集。CXXNET 是一个基于 MShadow 的快速简洁的分布式深度学习框架。它是一个轻量级且可扩展的 C++/CUDA 神经网络工具包,具有友好的 Python/Matlab 界面,用于机器学习训练和预测。
这里有很多东西,基本的学习方法如上。
附录:
我们先来看看Python有多强大,否则,如果你不能被它吸引,你就学不会它。
20行代码实现人脸检测识别:
face_recognition可以通过python或者命令行实现人脸识别的功能。采用 dlib 深度学习人脸识别技术构建,在户外人脸检测数据库基准(Labeled Faces in the Wild)上的准确率达到 99.38%。
# 导入识别库
import face_recognition
# 加载已有的图片作为图像库
known_obama_image = face_recognition.load_image_file("face1.jpg")
known_biden_image = face_recognition.load_image_file("face_kid.jpg")
# 编码加载的图片
obama_face_encoding = face_recognition.face_encodings(known_obama_image)[0]
biden_face_encoding = face_recognition.face_encodings(known_biden_image)[0]
known_encodings = [
obama_face_encoding,
biden_face_encoding
]
# 加载要识别的图片并编码
image_to_test = face_recognition.load_image_file("face2.jpg")
image_to_test_encoding = face_recognition.face_encodings(image_to_test)[0]
# 计算该图片与已有图片的差别值
face_distances = face_recognition.face_distance(known_encodings, image_to_test_encoding)
# 自行设定同一张面孔的分界值,输出比对结果
for i, face_distance in enumerate(face_distances):
print("The test image has a distance of {:.2} from known image #{}".format(face_distance, i))
print("- With a normal cutoff of 0.6, would the test image match the known image? {}".format(face_distance < 0.6))
print("- With a very strict cutoff of 0.5, would the test image match the known image? {}".format(face_distance < 0.5))
学习爬虫 Python 入门容易吗?学习爬虫需要一定的基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。爬虫Python入门学习分为三个阶段:
一、零基础阶段:
从零开始学爬虫,上手系统,从0开始爬虫。除了必要的理论知识,爬虫对于实际应用更重要。带你抓取4种主流网站数据,掌握主流爬虫爬取方法。
捕捉主流网站数据的能力是本阶段的学习目标
学习点:爬虫所需的计算机网络/前端/正则//xpath/CSS选择器基础知识;实现静态网页和动态网页两种主流网页类型的数据抓取;模拟登录、响应反爬、识别验证码等,难点详解;多线程、多进程等常见应用场景讲解
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学完之后,可以彻底玩转Scrapy框架,开发自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习点:Scrapy框架知识讲解spider/FormRequest/CrawlSpider等;从单机爬虫到分布式爬虫系统;Scrapy突破了反爬虫的限制和Scrapy的原理;Scrapy 更高级的功能包括 sscrapy 信号、自定义中间件;一些海量数据结合Elasticsearch打造搜索引擎
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从现在开始,拓展您的爬虫业务,提升您的核心竞争力。掌握App数据抓取,实现数据可视化
学习重点:学习主流抓包工具Fiddler/Mitmproxy的应用;4种App数据抓取实战,结合学习实践深入掌握App爬虫技巧;基于Docker构建多任务捕获系统,提高工作效率;掌握Pyecharts库基础,绘制基础图形、地图等进行数据可视化。
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。
网页数据抓取怎么写(网页数据抓取怎么写文章有两种方式:js加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-23 17:02
网页数据抓取怎么写文章有两种方式:
1)js加载数据这种方式需要使用对应的js动态加载文章页面的内容。
2)cookie加载数据用户每次登录后ie浏览器会保存刚开始登录时的cookie记录,登录后在登录页面输入cookie找到自己刚开始登录时的cookie数据,然后执行对应的html代码;另外cookie加载数据是采用cookie存储数据方式,可以减少采集文章所需要的http连接开销。
网页数据抓取网页代码是写死在页面上的,
1)安全cookie:后端开发者在后端程序的session中添加一个域名(或者其他域名)为json格式,长度为n个字符(cookie必须为二进制格式的data,可用字典存储cookie)如果是使用json数据,这个域名就用http默认的url指向该页面并通过url缓存;如果采用其他网页格式cookie,则后端提供cookie对象form-data将其指向另一个页面。
2)短命名短命名这种加密方式能够满足网页格式短命名且不同的页面格式有统一的出现。
3)事务安全json格式可提供事务安全,并可以实现如下的内容:**新增数据***上传文章新增文章的所有列表信息上传最后一次上传json格式数据修改文章列表信息***查询数据***查询所有文章修改记录查询文章内容如果文章列表json格式不能满足事务安全,则修改文章列表数据修改文章列表及内容如果查询数据不能满足事务安全,则更新文章内容(不上传改动后的旧的文章内容)**删除数据***删除文章内容***文章内容页删除***浏览器保存的永久记录***其他允许公开参数如公开域名**。 查看全部
网页数据抓取怎么写(网页数据抓取怎么写文章有两种方式:js加载数据)
网页数据抓取怎么写文章有两种方式:
1)js加载数据这种方式需要使用对应的js动态加载文章页面的内容。
2)cookie加载数据用户每次登录后ie浏览器会保存刚开始登录时的cookie记录,登录后在登录页面输入cookie找到自己刚开始登录时的cookie数据,然后执行对应的html代码;另外cookie加载数据是采用cookie存储数据方式,可以减少采集文章所需要的http连接开销。
网页数据抓取网页代码是写死在页面上的,
1)安全cookie:后端开发者在后端程序的session中添加一个域名(或者其他域名)为json格式,长度为n个字符(cookie必须为二进制格式的data,可用字典存储cookie)如果是使用json数据,这个域名就用http默认的url指向该页面并通过url缓存;如果采用其他网页格式cookie,则后端提供cookie对象form-data将其指向另一个页面。
2)短命名短命名这种加密方式能够满足网页格式短命名且不同的页面格式有统一的出现。
3)事务安全json格式可提供事务安全,并可以实现如下的内容:**新增数据***上传文章新增文章的所有列表信息上传最后一次上传json格式数据修改文章列表信息***查询数据***查询所有文章修改记录查询文章内容如果文章列表json格式不能满足事务安全,则修改文章列表数据修改文章列表及内容如果查询数据不能满足事务安全,则更新文章内容(不上传改动后的旧的文章内容)**删除数据***删除文章内容***文章内容页删除***浏览器保存的永久记录***其他允许公开参数如公开域名**。
网页数据抓取怎么写(广告网站数据采集工具用哪个好?300万+用户选择八抓鱼^)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-22 07:11
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
广告网站数据采集哪个是最好用的工具?300+用户选择霸主鱼^^优采云,全可视化图形操作,无需专业IT人员操作,支持云采集,数据...
很多工作都是通过 HTML 树来获取我们需要的表格。
广告python的网站,python基础+爬虫+数据分析+人工智能,全套视频教程免费在线学习!^^ 科大讯飞高级技术讲师指导...
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)有一个锚标签,这在几张桌子中可能是独一无二的。
广告大佬整理的进阶python路径,完整的python学习路径供你学习。^^ 加群免费领取,还可以参与每日python直播...
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器 Web 开发工具的单元。
广告免费在线学习python网络编程基础,国内品牌机构专业教学,O基础快速学习,1小时快速入门^^,7天python网络编程...
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的表格。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
接下来,我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环来遍历表中的每一行并将其保存到 rows 变量。
复制代码
广告新手如何学习网页设计?
复制代码
创建嵌套循环。遍历前一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
宣传我采集的 30 本词典网站
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理为纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
以下将其转换为数据结构:
复制代码
广告网络大数据(上市机构),名企董事讲座,限时预约。网络大数据,点击查看公开课的具体详情!
现在,您拥有可以在机器学习项目中使用的 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
Tobi Olabode 对技术感兴趣,目前专注于机器学习。
原文链接: 查看全部
网页数据抓取怎么写(广告网站数据采集工具用哪个好?300万+用户选择八抓鱼^)
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
广告网站数据采集哪个是最好用的工具?300+用户选择霸主鱼^^优采云,全可视化图形操作,无需专业IT人员操作,支持云采集,数据...
很多工作都是通过 HTML 树来获取我们需要的表格。
广告python的网站,python基础+爬虫+数据分析+人工智能,全套视频教程免费在线学习!^^ 科大讯飞高级技术讲师指导...
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,所以需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)有一个锚标签,这在几张桌子中可能是独一无二的。
广告大佬整理的进阶python路径,完整的python学习路径供你学习。^^ 加群免费领取,还可以参与每日python直播...
使用 Cristiano Ronaldo 文本,我们可以过滤那些由锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器 Web 开发工具的单元。
广告免费在线学习python网络编程基础,国内品牌机构专业教学,O基础快速学习,1小时快速入门^^,7天python网络编程...
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的表格。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
接下来,我们从上面的列表中选择第三个元素。这是我们需要的表。
接下来创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环来遍历表中的每一行并将其保存到 rows 变量。
复制代码
广告新手如何学习网页设计?
复制代码
创建嵌套循环。遍历前一个循环中保存的每一行。在遍历这些单元格时,我们将每个单元格保存在一个新变量中。
宣传我采集的 30 本词典网站
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理为纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
以下将其转换为数据结构:
复制代码
广告网络大数据(上市机构),名企董事讲座,限时预约。网络大数据,点击查看公开课的具体详情!
现在,您拥有可以在机器学习项目中使用的 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
Tobi Olabode 对技术感兴趣,目前专注于机器学习。
原文链接:
网页数据抓取怎么写(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 16:09
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以传递标签名和属性(比如
label) 以获取具有以下名称的这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
网页数据抓取怎么写(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA 编译|Flin Source|analyticsvidhya
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
内容
3 个流行的 Python 网络爬取工具和库
网络爬虫的组成部分
CrawlParse 和 TransformStore
从网页抓取 URL 和电子邮件 ID
抓取图片
在页面加载时获取数据
3 个流行的 Python 网络爬取工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以传递标签名和属性(比如
label) 以获取具有以下名称的这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
网页数据抓取怎么写(安装python运行pipinstallrequests抓取网页完成必要工具安装后dedecms)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-20 16:07
大到各种搜索引擎dedecms采集常规教程,小到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
工具安装
我们需要安装python,python的requests和BeautifulSoup库dedecms采集教程正则。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们将开始编写我们的爬虫。我们的首要任务是抓取豆瓣上的所有图书信息。我们以:///subject/26986954/为例,先看看如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下: dedecms采集教程规则:
提取内容
抓取网页内容后,dedecms采集教程就正常了,我们要做的就是提取出我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一系列关于爬虫的文章 文章::///i6567289381185389064/。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分) 查看全部
网页数据抓取怎么写(安装python运行pipinstallrequests抓取网页完成必要工具安装后dedecms)
大到各种搜索引擎dedecms采集常规教程,小到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
工具安装
我们需要安装python,python的requests和BeautifulSoup库dedecms采集教程正则。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们将开始编写我们的爬虫。我们的首要任务是抓取豆瓣上的所有图书信息。我们以:///subject/26986954/为例,先看看如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下: dedecms采集教程规则:
提取内容
抓取网页内容后,dedecms采集教程就正常了,我们要做的就是提取出我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
通过以上步骤,我们就可以写出一个最原创的爬虫了。在了解爬虫原理的基础上,我们可以进一步完善爬虫。
写了一系列关于爬虫的文章 文章::///i6567289381185389064/。如果你有兴趣,你可以去看看。
Python基础环境搭建、爬虫基本原理及爬虫原型
Python 爬虫入门(第 1 部分)
如何使用 BeautifulSoup 提取网页内容
Python 爬虫入门(第 2 部分)
爬虫运行时数据的存储数据,以 SQLite 和 MySQL 为例
Python 爬虫入门(第 3 部分)
使用 selenium webdriver 抓取动态网页
Python 爬虫入门(第 4 部分)
讨论了如何处理网站的反爬策略
Python 爬虫入门(第 5 部分)
介绍了Python的Scrapy爬虫框架,并简要演示了如何在Scrapy下开发
Python 爬虫入门(第 6 部分)
网页数据抓取怎么写( 用Python构建的尖端网页抓取技术,启动您的大数据项目 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-19 04:05
用Python构建的尖端网页抓取技术,启动您的大数据项目
)
使用 Python 内置的尖端网络抓取技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何用请求构建爬虫并美化库
如何构建一个多线程、复杂的爬虫
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(机器翻译根据原英文字幕更准确 | 解压后大小:9 GB | 时长:10h 26m
课程访问:使用 Python 构建 Web Scraper 刮地球!使用 Python 构建 Web Scrapers
描述
网络充满了存储在数十亿个不同的 网站、数据库和 API 中的非常强大的数据。股票价格和加密货币趋势等财务数据,数十个国家数千个不同城市的天气数据,以及您最喜欢的演员的有趣传记信息:所有这些信息都触手可及,但没有一点帮助和自动化,它是不可能实际使用这些信息!
Scrapers 和 spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员获取所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据,再到馈送机器学习和人工智能算法。本课程提供了一种动手方法,可以在现实世界的情况下构建真实、可用的蜘蛛,用于财务分析、链接图构建、社交媒体研究等。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,仅受自己想象力的限制。通过学习如何开发自主刮板,将互联网的巨大力量掌握在您的手中!
本课程是为初学者设计的,虽然以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都想学习如何利用网络上的信息来实现更大的利益。
任何对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
查看全部
网页数据抓取怎么写(
用Python构建的尖端网页抓取技术,启动您的大数据项目
)
使用 Python 内置的尖端网络抓取技术启动您的大数据项目
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何用请求构建爬虫并美化库
如何构建一个多线程、复杂的爬虫
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(机器翻译根据原英文字幕更准确 | 解压后大小:9 GB | 时长:10h 26m
课程访问:使用 Python 构建 Web Scraper 刮地球!使用 Python 构建 Web Scrapers
描述
网络充满了存储在数十亿个不同的 网站、数据库和 API 中的非常强大的数据。股票价格和加密货币趋势等财务数据,数十个国家数千个不同城市的天气数据,以及您最喜欢的演员的有趣传记信息:所有这些信息都触手可及,但没有一点帮助和自动化,它是不可能实际使用这些信息!
Scrapers 和 spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员获取所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据,再到馈送机器学习和人工智能算法。本课程提供了一种动手方法,可以在现实世界的情况下构建真实、可用的蜘蛛,用于财务分析、链接图构建、社交媒体研究等。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,仅受自己想象力的限制。通过学习如何开发自主刮板,将互联网的巨大力量掌握在您的手中!
本课程是为初学者设计的,虽然以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都想学习如何利用网络上的信息来实现更大的利益。
任何对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
网页数据抓取怎么写(开心网教你如何使用GET方法应该算是最简单,最好操作的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-19 00:06
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:
二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请先登录,登录后查找COOKIE的价值。
运行界面如下:
查看全部
网页数据抓取怎么写(开心网教你如何使用GET方法应该算是最简单,最好操作的
)
为了简单实现,其他请求信息,如HEAD中的用户浏览器信息,将不附加。
一、使用GET方法
使用 GET 方法应该被认为是最简单和最好的操作。以开心网的用户主页为例,URL统一为:.其中 xxxxxxxx 代表用户的用户 ID。在用户首页,GET方法中,当没有添加其他请求数据时,请求会被重定向到开心网的登录页面。
新建一个控制台,编写GET方法的代码如下:
因为你没有登录,所以可以看到输出页面是登录页面的HTML源码:
二、使用POST方式抓取页面
POST方法与GET方法类似,只是Method方法重置为“POST”,将要POST的数据编码为Byte[]格式,然后设置长度。在请求之前,首先获取HTTPWebRequest的请求流,写入POST数据,然后执行请求。示例如下:
注意:以上请找一个可以通过POST验证的URL进行抓取。
注意POST的时候一定要加上以下代码,否则服务器将无法获取到POST数据
req.ContentType="application/x-www-form-urlencoded";
三、爬取所需的登录页面
其实不管是通过SESSION认证还是通过COOKIE认证,都必须使用请求中相关COOKIE的值。要获取cookie值,必须先用浏览器登录,然后查看登录时必须使用的cookie。比如没有ID的开心网个人主页。爬行。
如果不添加COOKIE,则捕获的HTML是重定向的HTML,即登录页面的HTML。示例代码如下:
由于COOKIE涉及个人隐私,对COOKIE的字符进行了修改。如果有朋友需要使用,请先登录,登录后查找COOKIE的价值。
运行界面如下:

