
网页抓取qq
网页抓取qq(存储1.安装Selenium分析网页结构说说的时间代码实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-25 05:08
代码参考 /p/a6769dccd34d
只需联系 Selenium,点击这里 Selenium 和 PhantomJS
PS:代码的缺点是只能抓取第一页的内容。代码的改进是增加了与数据库的交互和存储。1.安装硒
pip install Selenium
2.Python中使用Selenium获取QQ空间小伙伴们的说说
分析网页结构
谈内容
说话的时间
3.代码实现(基于Python3)
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pymongo
# #使用Selenium的webdriver实例化一个浏览器对象,在这里使用Phantomjs
# driver = webdriver.PhantomJS(executable_path=r"D:\phantomjs-2.1.1-windows\bin\phantomjs.exe")
# #设置Phantomjs窗口最大化
# driver.maximize_window()
# 登录QQ空间
def get_shuoshuo(qq):
#建立与MongoClient的链接
client = pymongo.MongoClient('localhost', 27017)
#得到数据库
db = client['shuoshuo']
#得到一个数据集合
sheet_tab = db['sheet_tab']
chromedriver = r"E:\mycode\chromedriver.exe"
driver = webdriver.Chrome(chromedriver)
#使用get()方法打开待抓取的URL
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
#等待5秒后,判断页面是否需要登录,通过查找页面是否有相应的DIV的id来判断
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
#如果页面存在登录的DIV,则模拟登录
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear() # 选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
#判断好友空间是否设置了权限,通过判断是否存在元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
#如果有权限能够访问到说说页面,那么定位元素和数据,并解析
if b == True:
driver.switch_to.frame('app_canvas_frame')
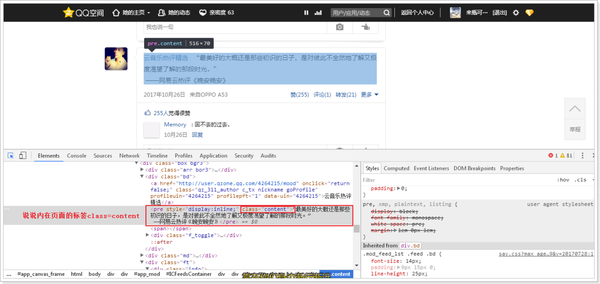
content = driver.find_elements_by_css_selector('.content')
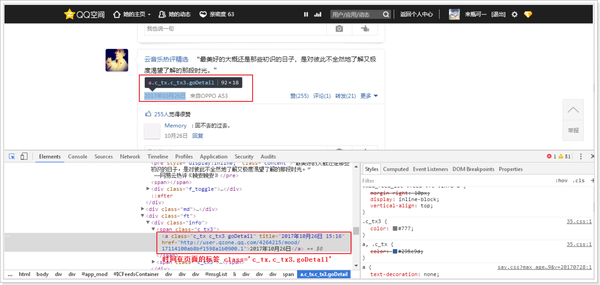
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con, sti in zip(content, stime):
data = {
'time': sti.text,
'shuos': con.text
}
print(data)
sheet_tab.insert_one(data)
pages = driver.page_source
soup = BeautifulSoup(pages, 'lxml')
#尝试一下获取Cookie,使用get_cookies()
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'], c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:', i)
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('好友的QQ号')
注意:使用前记得安装chromedriver插件,使用过程中会调用谷歌浏览器。如果写了绝对路径还是报错,请添加环境变量。
通过 Robo 3T(强大的数据库 MongoDB 数据库管理工具),我们可以看到我们已经将数据库存储在了数据库中。
接下来,我们应该用我们得到的数据做一些数据分析相关的事情……但我不会!!!
正在努力学习数据分析... 查看全部
网页抓取qq(存储1.安装Selenium分析网页结构说说的时间代码实现)
代码参考 /p/a6769dccd34d
只需联系 Selenium,点击这里 Selenium 和 PhantomJS
PS:代码的缺点是只能抓取第一页的内容。代码的改进是增加了与数据库的交互和存储。1.安装硒
pip install Selenium
2.Python中使用Selenium获取QQ空间小伙伴们的说说
分析网页结构
谈内容
说话的时间

3.代码实现(基于Python3)
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pymongo
# #使用Selenium的webdriver实例化一个浏览器对象,在这里使用Phantomjs
# driver = webdriver.PhantomJS(executable_path=r"D:\phantomjs-2.1.1-windows\bin\phantomjs.exe")
# #设置Phantomjs窗口最大化
# driver.maximize_window()
# 登录QQ空间
def get_shuoshuo(qq):
#建立与MongoClient的链接
client = pymongo.MongoClient('localhost', 27017)
#得到数据库
db = client['shuoshuo']
#得到一个数据集合
sheet_tab = db['sheet_tab']
chromedriver = r"E:\mycode\chromedriver.exe"
driver = webdriver.Chrome(chromedriver)
#使用get()方法打开待抓取的URL
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
#等待5秒后,判断页面是否需要登录,通过查找页面是否有相应的DIV的id来判断
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
#如果页面存在登录的DIV,则模拟登录
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear() # 选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
#判断好友空间是否设置了权限,通过判断是否存在元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
#如果有权限能够访问到说说页面,那么定位元素和数据,并解析
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con, sti in zip(content, stime):
data = {
'time': sti.text,
'shuos': con.text
}
print(data)
sheet_tab.insert_one(data)
pages = driver.page_source
soup = BeautifulSoup(pages, 'lxml')
#尝试一下获取Cookie,使用get_cookies()
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'], c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:', i)
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('好友的QQ号')
注意:使用前记得安装chromedriver插件,使用过程中会调用谷歌浏览器。如果写了绝对路径还是报错,请添加环境变量。

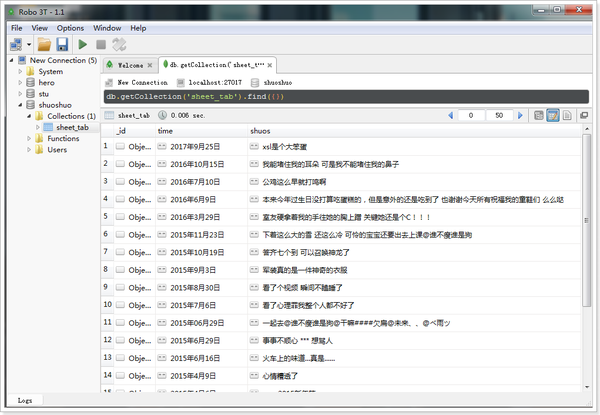
通过 Robo 3T(强大的数据库 MongoDB 数据库管理工具),我们可以看到我们已经将数据库存储在了数据库中。
接下来,我们应该用我们得到的数据做一些数据分析相关的事情……但我不会!!!
正在努力学习数据分析...
网页抓取qq(SEO优化:常用的指令指令整合、禁止搜索引擎的精确控制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-24 12:03
介绍
在做SEO的时候,很多时候我们都希望对页面进行准确的控制。Robots.txt 不能完全满足我们的需求。这时候我们就可以利用html的meta标签来精准的控制搜索引擎了。下面文章比较长,锐叔为大家综合了常用命令!
命令集成:禁止搜索引擎创建快照
百度不缓存快照(禁止百度快照):
所有搜索引擎,抓取本页,抓取链接,禁止快照:
所有搜索引擎,没有快照
上面的一段代码限制所有搜索引擎创建您的网页快照。需要注意的是,这样的标记只是禁止搜索引擎为你的网站创建快照。如果您想禁止搜索引擎将您的页面编入索引 对于该页面,请参考以下方法。
禁止搜索引擎抓取此页面
为了防止搜索引擎抓取这个页面,我们一般的做法是在页面的meta标签中添加如下代码:
这里的meta name="robots"泛指所有搜索引擎,这里也可以指特定的搜索引擎。
例如,元名称="Googlebot"、元名称="Baiduspide"等。
内容部分有四个命令:index、noindex、follow和nofollow。命令用英文“,”分隔。
根据上面的命令,我们有以下四种组合
:可以抓取本页,而且可以顺着本页继续索引别的链接
:不许抓取本页,但是可以顺着本页抓取索引别的链接
:可以抓取本页,但是不许顺着本页抓取索引别的链接
:不许抓取本页,也不许顺着本页抓取索引别的链接
这里需要注意的是,两个对立的反义词不能写在一起,例如
或者同时写两个句子
这是一个简单的写法,如果是
的形式,可以写成:
如果
的形式,可以写成:
当然,我们也可以将禁止创建快照和搜索引擎的命令写入命令元标记中。从上面文章,我们知道禁止创建网页快照的命令是noarchive,那么我们可以写成如下形式:
如果是针对单个不允许创建快照的搜索引擎,比如百度,我们可以这样写:
如果没有在meta标签中写关于蜘蛛的命令,那么默认命令如下
因此,如果我们对这部分不确定,我们可以直接写上面这行命令,或者留空。
在SEO中,对蜘蛛的控制是内容中非常重要的一部分,希望大家能够准确把握这部分内容。
原文链接:未经许可禁止转载。 查看全部
网页抓取qq(SEO优化:常用的指令指令整合、禁止搜索引擎的精确控制)
介绍
在做SEO的时候,很多时候我们都希望对页面进行准确的控制。Robots.txt 不能完全满足我们的需求。这时候我们就可以利用html的meta标签来精准的控制搜索引擎了。下面文章比较长,锐叔为大家综合了常用命令!

命令集成:禁止搜索引擎创建快照
百度不缓存快照(禁止百度快照):
所有搜索引擎,抓取本页,抓取链接,禁止快照:
所有搜索引擎,没有快照
上面的一段代码限制所有搜索引擎创建您的网页快照。需要注意的是,这样的标记只是禁止搜索引擎为你的网站创建快照。如果您想禁止搜索引擎将您的页面编入索引 对于该页面,请参考以下方法。
禁止搜索引擎抓取此页面
为了防止搜索引擎抓取这个页面,我们一般的做法是在页面的meta标签中添加如下代码:
这里的meta name="robots"泛指所有搜索引擎,这里也可以指特定的搜索引擎。
例如,元名称="Googlebot"、元名称="Baiduspide"等。
内容部分有四个命令:index、noindex、follow和nofollow。命令用英文“,”分隔。
根据上面的命令,我们有以下四种组合
:可以抓取本页,而且可以顺着本页继续索引别的链接
:不许抓取本页,但是可以顺着本页抓取索引别的链接
:可以抓取本页,但是不许顺着本页抓取索引别的链接
:不许抓取本页,也不许顺着本页抓取索引别的链接
这里需要注意的是,两个对立的反义词不能写在一起,例如
或者同时写两个句子
这是一个简单的写法,如果是
的形式,可以写成:
如果
的形式,可以写成:
当然,我们也可以将禁止创建快照和搜索引擎的命令写入命令元标记中。从上面文章,我们知道禁止创建网页快照的命令是noarchive,那么我们可以写成如下形式:
如果是针对单个不允许创建快照的搜索引擎,比如百度,我们可以这样写:
如果没有在meta标签中写关于蜘蛛的命令,那么默认命令如下
因此,如果我们对这部分不确定,我们可以直接写上面这行命令,或者留空。
在SEO中,对蜘蛛的控制是内容中非常重要的一部分,希望大家能够准确把握这部分内容。
原文链接:未经许可禁止转载。
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-24 12:00
1.问题描述
最近由于学习内容的要求,需要从网页抓取一些数据做分析报告。看了一些python爬虫的基础知识,直接去网站爬取数据。作为新手,踩坑在所难免。最近遇到了一个比较难的问题:
一般情况下,我们需要抓取网页上某个标签上的内容,通过urllib下载网页内容后,通过BeautifulSoup对象解析网页内容,然后通过fina_all()方法找到我们想要的标签内容。
比如我想抓取QQ音乐类播放列表下的所有播放列表信息。分解任务后,应该是:
抓取当前页面的播放列表信息;翻页;判断是否是最后一页,如果不是最后一页,则返回步骤1,如果是最后一页,则结束爬虫程序。
首先,编写一个简单的代码来获取单个页面上所有播放列表的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
可以通过右键单击网页并检查网页属性来找到标签参数。播放列表的标题信息可以通过属性类为playlist_title_txt的span标签找到,但是执行代码后,输出的结果只是一个空列表。是不是很奇怪?作为一个菜鸟,我真是绞尽脑汁想了半天也想不出原因。
然后和同学交流,听他讲了他之前看到的异步加载内容,发现我爬的网页的特征有点相似,于是去了解了一下。
一个流行的描述是,这个异步加载的网页显示的内容全部来自当前URL所代表的网页文件。部分内容是从当前网页文件中通过对另一个网页内容的函数调用来加载的,也就是说要获取的内容所属的网页文件确实与当前网页文件不是同一个文件当前网页文件,因此无法获取。因此,需要找到获取的内容真正所属的文件。
2.解决方案
接下来,我们将介绍如何查找异步加载的文件以及在爬取过程中可能遇到的坑。
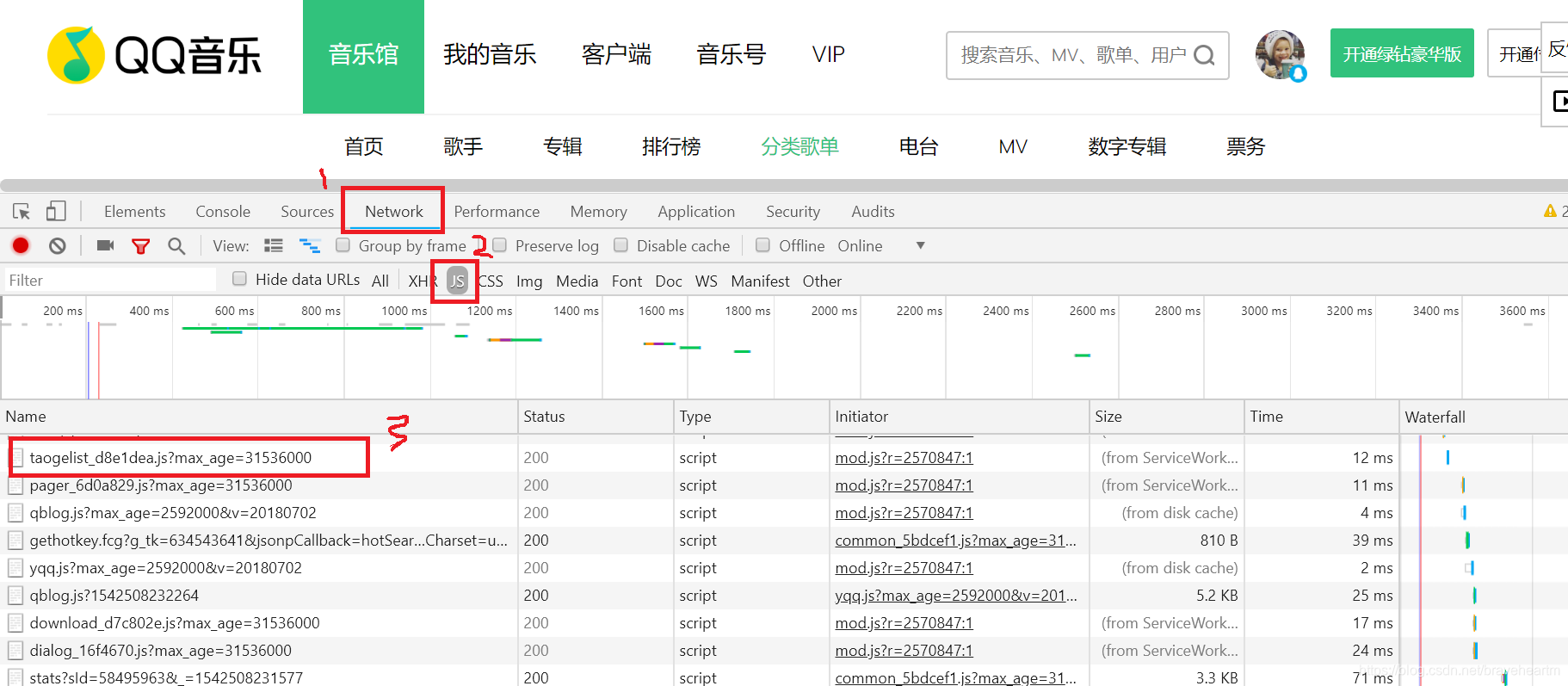
1.网页右键选择**“检查”,在调试界面找到“网络”选项,然后一一找到js文件(记得刷新网页否则js文件不会被显示),通过预览**来查看内容是否是你要爬取的
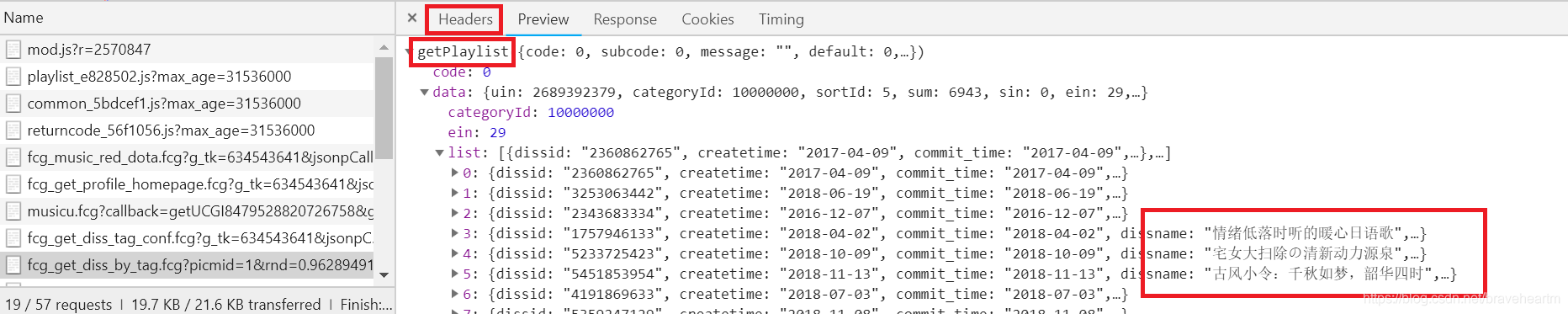
2. 在各个js文件的具体信息面板中,可以通过预览查看传入的内容。我们找到了播放列表的标题信息的源文件,然后通过Headers属性可以找到该信息的真实源文件的链接,并使用url作为我们的requests参数。
Headers 属性下的通用和请求头收录了我们想要的信息。通用属性下的URL还包括值类型,这里是get。
所以我们可以通过请求模块获取播放列表信息。这里需要注意:网页的request headers值要传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3. 一般情况下,上面的处理过程会得到一个json对象(看起来像字典的字符串表示)。可以直接使用python中的json模块将json对象转成python对象—字典,方便通过key获取数据
jsDict = json.loads(jsContent)
但有时获取的数据形式除了json对象外还会加上json对象名,比如:
playList({...}) # 其中{}表示json对象内容
这种情况下无法通过json模块转换数据类型,通常会出现异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
在这种异常情况下,可以通过字符串的切片截取json对象信息,然后通过json模块转换数据类型(这是我想出来的一个笨方法。如果有人知道更正式的方法,希望能指正。点击(っ•̀ω•́)っ✎⁾⁾) 查看全部
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
1.问题描述
最近由于学习内容的要求,需要从网页抓取一些数据做分析报告。看了一些python爬虫的基础知识,直接去网站爬取数据。作为新手,踩坑在所难免。最近遇到了一个比较难的问题:
一般情况下,我们需要抓取网页上某个标签上的内容,通过urllib下载网页内容后,通过BeautifulSoup对象解析网页内容,然后通过fina_all()方法找到我们想要的标签内容。
比如我想抓取QQ音乐类播放列表下的所有播放列表信息。分解任务后,应该是:
抓取当前页面的播放列表信息;翻页;判断是否是最后一页,如果不是最后一页,则返回步骤1,如果是最后一页,则结束爬虫程序。
首先,编写一个简单的代码来获取单个页面上所有播放列表的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
可以通过右键单击网页并检查网页属性来找到标签参数。播放列表的标题信息可以通过属性类为playlist_title_txt的span标签找到,但是执行代码后,输出的结果只是一个空列表。是不是很奇怪?作为一个菜鸟,我真是绞尽脑汁想了半天也想不出原因。
然后和同学交流,听他讲了他之前看到的异步加载内容,发现我爬的网页的特征有点相似,于是去了解了一下。
一个流行的描述是,这个异步加载的网页显示的内容全部来自当前URL所代表的网页文件。部分内容是从当前网页文件中通过对另一个网页内容的函数调用来加载的,也就是说要获取的内容所属的网页文件确实与当前网页文件不是同一个文件当前网页文件,因此无法获取。因此,需要找到获取的内容真正所属的文件。
2.解决方案
接下来,我们将介绍如何查找异步加载的文件以及在爬取过程中可能遇到的坑。
1.网页右键选择**“检查”,在调试界面找到“网络”选项,然后一一找到js文件(记得刷新网页否则js文件不会被显示),通过预览**来查看内容是否是你要爬取的
2. 在各个js文件的具体信息面板中,可以通过预览查看传入的内容。我们找到了播放列表的标题信息的源文件,然后通过Headers属性可以找到该信息的真实源文件的链接,并使用url作为我们的requests参数。
Headers 属性下的通用和请求头收录了我们想要的信息。通用属性下的URL还包括值类型,这里是get。
所以我们可以通过请求模块获取播放列表信息。这里需要注意:网页的request headers值要传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3. 一般情况下,上面的处理过程会得到一个json对象(看起来像字典的字符串表示)。可以直接使用python中的json模块将json对象转成python对象—字典,方便通过key获取数据
jsDict = json.loads(jsContent)
但有时获取的数据形式除了json对象外还会加上json对象名,比如:
playList({...}) # 其中{}表示json对象内容
这种情况下无法通过json模块转换数据类型,通常会出现异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
在这种异常情况下,可以通过字符串的切片截取json对象信息,然后通过json模块转换数据类型(这是我想出来的一个笨方法。如果有人知道更正式的方法,希望能指正。点击(っ•̀ω•́)っ✎⁾⁾)
网页抓取qq(2020年7月29日2.JS型网页(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-24 09:00
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage之后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页没有采用嵌入网页的方式,而是选择了JS加载
这里我举一个北京请愿页面的例子()
我们会发现,当您选择不同的页面时,URL 不会改变,这与上面提到的嵌入页面相同。
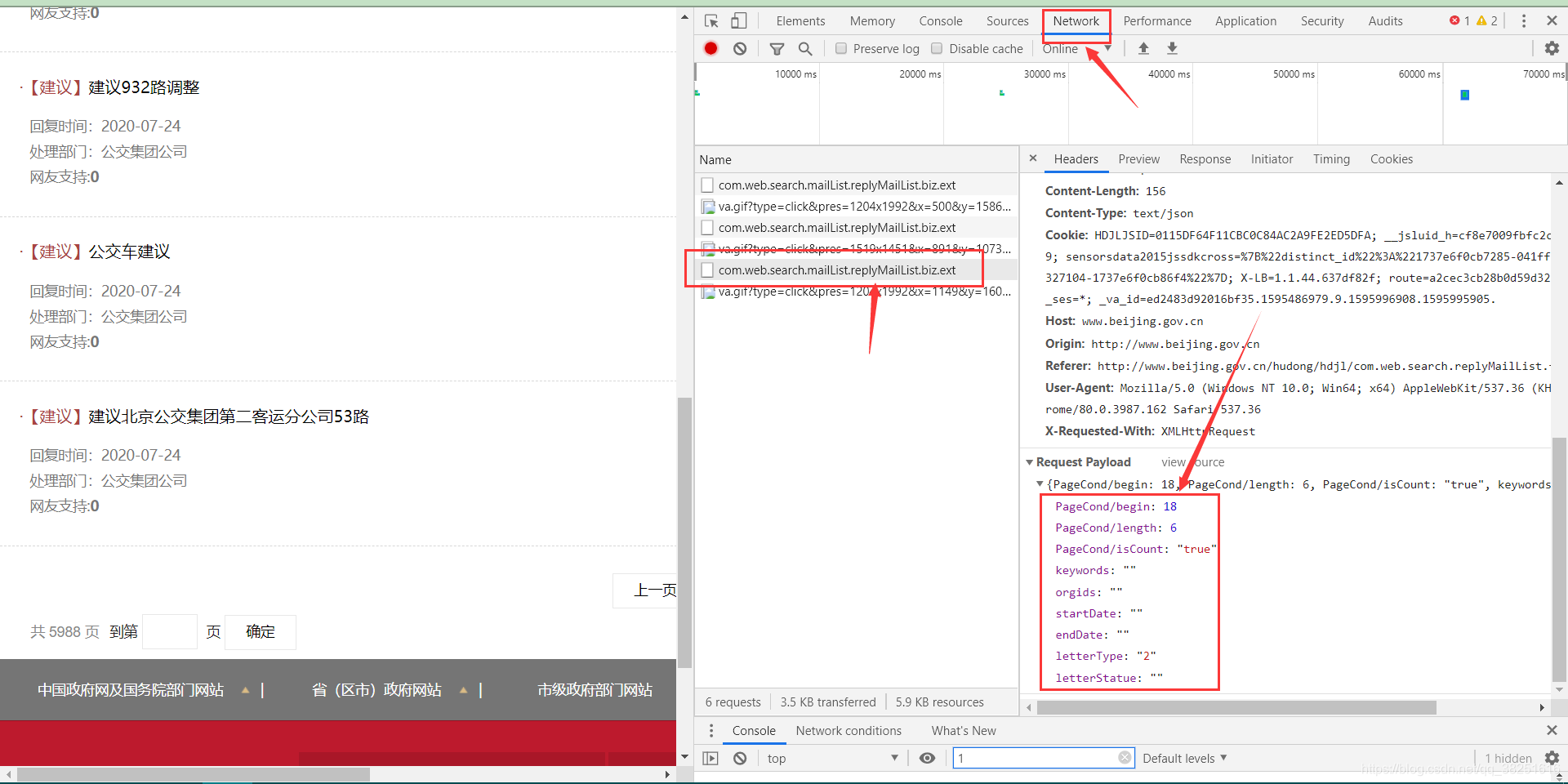
右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载过程的一个明显标志。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载了新数据的JS文件,打开会发现PageCond/begin: 1< @8、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,和post请求一起发送给网站,我们就可以拿到数据了我们想要。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
网页抓取qq(2020年7月29日2.JS型网页(组图)
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址

在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。

进入第二个页面,我们可以找到页面中的规则,只需要改变curpage之后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页没有采用嵌入网页的方式,而是选择了JS加载
这里我举一个北京请愿页面的例子()
我们会发现,当您选择不同的页面时,URL 不会改变,这与上面提到的嵌入页面相同。

右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载过程的一个明显标志。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载了新数据的JS文件,打开会发现PageCond/begin: 1< @8、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,和post请求一起发送给网站,我们就可以拿到数据了我们想要。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
网页抓取qq(一下代理如何使用步骤和步骤?代理IP的试用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-22 16:02
不知道大家在访问网站时有没有遇到过这样的情况。被采访的网站会给出提示。提示显示“访问频率太高”。如果要继续,则必须稍等片刻,否则对方会给出验证码,使用验证码解锁访问的网站。出现这个提示的原因是我们要爬取或访问的网站有反爬虫机制。例如,当使用同一个IP频繁请求一个网页的次数过多时,服务器是由于反爬虫机制的指示。因此,我们选择拒绝服务。这种情况单靠解封比较难处理,所以一种解决办法是伪装机器的IP地址来访问或抓取网页,
目前网上有很多代理ip,有的免费,有的收费。比如West Spur代理等,免费的不花钱,但有效的代理少且不稳定。付费的可能会更好。比如下面介绍的犀牛在线代理。试用一下代理IP,将可用IP保存到MongoDB中,方便下次检索。
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他:Chrome浏览器
该过程的简要说明是:
第 1 步:了解如何使用请求代理
第二步:从代理网页爬取到ip和端口
第三步:检查爬取的ip是否可用
第四步:将爬取到的可用代理存入MongoDB
第五步:从可用ip的数据库中随机抽取一个ip,测试成功后返回
对于请求,代理设置比较简单,只需要传入代理参数即可。
不过需要注意的是,这里我在机器上安装了抓包工具Fiddler,并用它在本地8888端口创建了一个HTTP代理服务(使用Chrome插件SwitchyOmega),即代理服务为: 127.0.0.1:8888,只要我们设置好这个代理,就可以成功地将本地IP切换到代理软件连接的服务器IP。
这里我用它作为测试网站,我们可以访问网页获取请求的相关信息,其中origin字段为客户端ip,根据返回的信息判断代理是否成功结果。返回结果如下:
接下来,我们开始爬取代理IP。首先,我们打开Chrome浏览器查看网页,找到ip和port元素的信息。
可以看到,代理IP将IP地址和相关信息存储在一个表中,所以我们在用BeautifulSoup提取的时候可以很方便的提取出相关信息,但是需要注意的是,爬取到的IP很可能是重复的。特别是当我们同时抓取多个代理网页并将它们存储在同一个数组中时,我们可以使用集合来去除重复的IP。
爬取到要爬取的页面数的ip后,存入数组,然后一一测试ip。
这里就是上面提到的请求设置代理的方法,我们用它作为测试网站,它可以直接返回我们的ip地址,测试通过后会存入MomgoDB数据库中。
连接数据库然后指定数据库和集合,然后插入数据就OK了。
最后运行查看结果
运行一段时间后,很少看到连续三个测试通过,所以我赶紧保存截图。事实上,它毕竟是一个自由球员。有效的很少,存活时间真的很短。但是,爬取量很大。, 还是可以找到的,如果只是作为练习,勉强够用。现在看看数据库中存储了什么。
因为爬取的页面不多,加上有效IP也很少,我也没有做太多爬取,所以现在数据库里的IP并不多,但是这些IP还是保存了下来。现在让我们看看如何随机取出它。
因为担心ip放入数据库一段时间后会失效,所以重新测试了一下才取出来。如果成功,我将返回该ip。如果不成功,我会把它移出数据库。
这样,当我们需要使用代理时,就可以随时通过数据库进行检索。
总代码如下:
/人/hdmi博客
本文转载于:,由犀牛社主办 查看全部
网页抓取qq(一下代理如何使用步骤和步骤?代理IP的试用)
不知道大家在访问网站时有没有遇到过这样的情况。被采访的网站会给出提示。提示显示“访问频率太高”。如果要继续,则必须稍等片刻,否则对方会给出验证码,使用验证码解锁访问的网站。出现这个提示的原因是我们要爬取或访问的网站有反爬虫机制。例如,当使用同一个IP频繁请求一个网页的次数过多时,服务器是由于反爬虫机制的指示。因此,我们选择拒绝服务。这种情况单靠解封比较难处理,所以一种解决办法是伪装机器的IP地址来访问或抓取网页,
目前网上有很多代理ip,有的免费,有的收费。比如West Spur代理等,免费的不花钱,但有效的代理少且不稳定。付费的可能会更好。比如下面介绍的犀牛在线代理。试用一下代理IP,将可用IP保存到MongoDB中,方便下次检索。
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他:Chrome浏览器
该过程的简要说明是:
第 1 步:了解如何使用请求代理
第二步:从代理网页爬取到ip和端口
第三步:检查爬取的ip是否可用
第四步:将爬取到的可用代理存入MongoDB
第五步:从可用ip的数据库中随机抽取一个ip,测试成功后返回
对于请求,代理设置比较简单,只需要传入代理参数即可。
不过需要注意的是,这里我在机器上安装了抓包工具Fiddler,并用它在本地8888端口创建了一个HTTP代理服务(使用Chrome插件SwitchyOmega),即代理服务为: 127.0.0.1:8888,只要我们设置好这个代理,就可以成功地将本地IP切换到代理软件连接的服务器IP。
这里我用它作为测试网站,我们可以访问网页获取请求的相关信息,其中origin字段为客户端ip,根据返回的信息判断代理是否成功结果。返回结果如下:
接下来,我们开始爬取代理IP。首先,我们打开Chrome浏览器查看网页,找到ip和port元素的信息。
可以看到,代理IP将IP地址和相关信息存储在一个表中,所以我们在用BeautifulSoup提取的时候可以很方便的提取出相关信息,但是需要注意的是,爬取到的IP很可能是重复的。特别是当我们同时抓取多个代理网页并将它们存储在同一个数组中时,我们可以使用集合来去除重复的IP。
爬取到要爬取的页面数的ip后,存入数组,然后一一测试ip。
这里就是上面提到的请求设置代理的方法,我们用它作为测试网站,它可以直接返回我们的ip地址,测试通过后会存入MomgoDB数据库中。
连接数据库然后指定数据库和集合,然后插入数据就OK了。
最后运行查看结果
运行一段时间后,很少看到连续三个测试通过,所以我赶紧保存截图。事实上,它毕竟是一个自由球员。有效的很少,存活时间真的很短。但是,爬取量很大。, 还是可以找到的,如果只是作为练习,勉强够用。现在看看数据库中存储了什么。
因为爬取的页面不多,加上有效IP也很少,我也没有做太多爬取,所以现在数据库里的IP并不多,但是这些IP还是保存了下来。现在让我们看看如何随机取出它。
因为担心ip放入数据库一段时间后会失效,所以重新测试了一下才取出来。如果成功,我将返回该ip。如果不成功,我会把它移出数据库。
这样,当我们需要使用代理时,就可以随时通过数据库进行检索。
总代码如下:
/人/hdmi博客
本文转载于:,由犀牛社主办
网页抓取qq(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-17 23:17
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:
您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系! 查看全部
网页抓取qq(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:

您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系!
网页抓取qq(想要轻松获取网站的内链,那就赶紧来使用网页链接提取工具绿色版软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-12-17 11:13
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大、实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!
功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、 并且可以自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先进入个人网站 网站地图:个人网站域名/sitemap.xml
二、 输入后点击Extract and Save即可获取最近更新的域名信息
三、网页链接提取自动保存到软件所在文件夹 查看全部
网页抓取qq(想要轻松获取网站的内链,那就赶紧来使用网页链接提取工具绿色版软件)
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大、实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!

功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、 并且可以自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先进入个人网站 网站地图:个人网站域名/sitemap.xml

二、 输入后点击Extract and Save即可获取最近更新的域名信息

三、网页链接提取自动保存到软件所在文件夹
网页抓取qq(网页文字版权是归刘小月文艺创作编码标签(Content-Type))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-16 03:29
网页文字版权归刘晓月艺术创作工作室所有
编码标签(Content-Type)
网页文件格式编码国标gb2312
使用这些标签可以使搜索引擎更容易理解您的网页内容。
综合应用如下:
二。头部区域标签注意事项
(1)标题长度
标题是对网页内容的总结和提炼。在标题标签中过多重复 关键词 通常会适得其反。搜索引擎一般只分析前20个汉字。超过20个汉字将被丢弃。如果是英文,应该控制在60个字母以内,超出的部分也不计入排名计算。
(2)描述和关键词
Description和关键词是头部区域权重仅次于title的标签。Description 和 关键词 都是标识 关键词 的标签。然而,描述也承担着在自然列表中展示网页内容的重要任务。其内容的好坏关系到它能否吸引到网站的访问者。
(图5-1)说明了国美网上商城的实力,吸引搜索者浏览。
(3)title的重要性
标题标签是搜索引擎计算网页排名的主要依据。可以说,标题标签是整个网页中最重要的标签。
(4)如何写出好的描述
描述奇奇在在线推广和营销中将搜索者拉入自我网站 的作用。写描述时,要诚恳,不要夸大其词,不要过分夸大个性,给搜索者一个友好的印象。
(5)关键词标签的禁忌
关键字标签一直是搜索引擎优化中作弊的重灾区。在这里重复堆砌相同的关键词,已经成为一种让排名高的手段,也是搜索引擎惩罚网站的一个原因。
三体区的组成
标题标题标签
Hx 标签是身体区域中最重要的标签。它负责网页内容的分割和归属。H1、H2、H3、H4、H5、H6 分别代表段落标题的递减权重。例如,H1 是网页的标题。H2 是小节级别的标题。H3 是每个部分的标题。那么H6没用吗?当然不是。H6只是权重意义的弱化,代表意义依然存在。
比如一篇关于亚洲旅游的文章,网页上的安排如下
(图5-2)HX标签从最重要到最小的顺序递减
亚洲旅游
中国旅游
上海旅游
四川旅游
日本旅游
东京旅游
京都旅游
二、 标签的理解
标签的使用在于两个方面:熟练度和排列。使用计算机理解来模拟人类思考和分析问题的方式。把你想表达的意思准确地传达给电脑才是最重要的。
三、 网页命名
网页的命名与域名的选择非常相似。例如,对于链接和拼音计算中不需要的具有特定含义的字母,拼音的url地址更有优势。对比/list253和/xiamennews,同一个介绍厦门新闻的网页,显然厦门新闻有更多的含义,而这个含义本身就是对搜索引擎的描述。 查看全部
网页抓取qq(网页文字版权是归刘小月文艺创作编码标签(Content-Type))
网页文字版权归刘晓月艺术创作工作室所有
编码标签(Content-Type)
网页文件格式编码国标gb2312
使用这些标签可以使搜索引擎更容易理解您的网页内容。
综合应用如下:
二。头部区域标签注意事项
(1)标题长度
标题是对网页内容的总结和提炼。在标题标签中过多重复 关键词 通常会适得其反。搜索引擎一般只分析前20个汉字。超过20个汉字将被丢弃。如果是英文,应该控制在60个字母以内,超出的部分也不计入排名计算。
(2)描述和关键词
Description和关键词是头部区域权重仅次于title的标签。Description 和 关键词 都是标识 关键词 的标签。然而,描述也承担着在自然列表中展示网页内容的重要任务。其内容的好坏关系到它能否吸引到网站的访问者。
(图5-1)说明了国美网上商城的实力,吸引搜索者浏览。
(3)title的重要性
标题标签是搜索引擎计算网页排名的主要依据。可以说,标题标签是整个网页中最重要的标签。
(4)如何写出好的描述
描述奇奇在在线推广和营销中将搜索者拉入自我网站 的作用。写描述时,要诚恳,不要夸大其词,不要过分夸大个性,给搜索者一个友好的印象。
(5)关键词标签的禁忌
关键字标签一直是搜索引擎优化中作弊的重灾区。在这里重复堆砌相同的关键词,已经成为一种让排名高的手段,也是搜索引擎惩罚网站的一个原因。
三体区的组成
标题标题标签
Hx 标签是身体区域中最重要的标签。它负责网页内容的分割和归属。H1、H2、H3、H4、H5、H6 分别代表段落标题的递减权重。例如,H1 是网页的标题。H2 是小节级别的标题。H3 是每个部分的标题。那么H6没用吗?当然不是。H6只是权重意义的弱化,代表意义依然存在。
比如一篇关于亚洲旅游的文章,网页上的安排如下
(图5-2)HX标签从最重要到最小的顺序递减
亚洲旅游
中国旅游
上海旅游
四川旅游
日本旅游
东京旅游
京都旅游
二、 标签的理解
标签的使用在于两个方面:熟练度和排列。使用计算机理解来模拟人类思考和分析问题的方式。把你想表达的意思准确地传达给电脑才是最重要的。
三、 网页命名
网页的命名与域名的选择非常相似。例如,对于链接和拼音计算中不需要的具有特定含义的字母,拼音的url地址更有优势。对比/list253和/xiamennews,同一个介绍厦门新闻的网页,显然厦门新闻有更多的含义,而这个含义本身就是对搜索引擎的描述。
网页抓取qq(Java抓取前端渲染的页面如何处理-pageapplication? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-10 09:24
)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容,往往无法获取有效信息。那么如何处理这种页面呢?一般来说有两种方法:html
在爬取阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬取。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。由于js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且相对于页面样式,这种界面变化的可能性较小。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我个人的看法是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种还是比较可靠的。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。前端
对于第一种方法,webmagic-selenium 就是这样的一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,跟平台和版本有关。没有稳定的解决方案。我们先介绍一下这个尝试。爪哇
由于无论怎么动态加载,初始页面总是收录基本信息,我们可以用爬虫代码模拟js代码,js读取页面元素值,我们也读取页面元素值;js发送ajax,我们只是拼凑参数,发送ajax,解析返回的json。这总是可以的,但是比较麻烦。有没有更省力的方法?更好的方法可能是嵌入浏览器。Python
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。Selenium 是跨语言的,有Java、C#、python 等版本,支持多种浏览器、chrome、firefox 和IE。angularjs
在Java项目中使用Selenium,需要做两件事:web
在项目中引入Selenium Java模块,以Maven为例:
org.seleniumhq.selenium
selenium-java
2.33.0
下载对应的驱动,以chrome为例:
下载后需要将驱动的位置写入Java环境变量中。比如mac下下载到/Users/yihua/Downloads/chromedriver,需要在程序中加入如下代码(虽然在JVM参数中写-Dxxx=xxx也是可以的):
System.getProperties().setProperty("webdriver.chrome.driver","/Users/yihua/Downloads/chromedriver");
Selenium的API很简单,核心是WebDriver,下面是动态渲染页面并获取最终html的代码:ajax
@Test
public void testSelenium() {
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/yihua/Downloads/chromedriver");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://huaban.com/");
WebElement webElement = webDriver.findElement(By.xpath("/html"));
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
值得注意的是,每次 new ChromeDriver() 时,Selenium 都会创建一个 Chrome 进程,并使用一个随机端口与 Java 中的 chrome 进程进行通信进行交互。所以有两个问题:chrome
最后说一下效率问题。嵌入浏览器后,不仅需要更多的CPU来渲染页面,还要下载页面附带的资源。似乎缓存了单个 webDriver 中的静态资源。初始化后,访问速度会加快。尝试ChromeDriver加载花瓣首页100次,总共耗时263秒,平均每页2.6秒。苹果系统
/**
* 花瓣网抽取器。
* 使用Selenium作页面动态渲染。
*/
public class HuabanProcessor implements PageProcessor {
private Site site;
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("http://huaban\\.com/.*").all());
if (page.getUrl().toString().contains("pins")) {
page.putField("img", page.getHtml().xpath("//div[@id='pin_img']/img/@src").toString());
} else {
page.getResultItems().setSkip(true);
}
}
@Override
public Site getSite() {
if (site == null) {
site = Site.me().setDomain("huaban.com").addStartUrl("http://huaban.com/").setSleepTime(1000);
}
return site;
}
public static void main(String[] args) {
Spider.create(new HuabanProcessor()).thread(5)
.scheduler(new RedisScheduler("localhost"))
.pipeline(new FilePipeline("/data/webmagic/test/"))
.downloader(new SeleniumDownloader("/Users/yihua/Downloads/chromedriver"))
.run();
}
}
public class SeleniumDownloader implements Downloader, Closeable {
private volatile WebDriverPool webDriverPool;
private Logger logger = Logger.getLogger(getClass());
private int sleepTime = 0;
private int poolSize = 1;
private static final String DRIVER_PHANTOMJS = "phantomjs";
/**
* 新建
*
* @param chromeDriverPath chromeDriverPath
*/
public SeleniumDownloader(String chromeDriverPath) {
System.getProperties().setProperty("webdriver.chrome.driver",
chromeDriverPath);
}
/**
* Constructor without any filed. Construct PhantomJS browser
*
* @author bob.li.0718@gmail.com
*/
public SeleniumDownloader() {
// System.setProperty("phantomjs.binary.path",
// "/Users/Bingo/Downloads/phantomjs-1.9.7-macosx/bin/phantomjs");
}
/**
* set sleep time to wait until load success
*
* @param sleepTime sleepTime
* @return this
*/
public SeleniumDownloader setSleepTime(int sleepTime) {
this.sleepTime = sleepTime;
return this;
}
@Override
public Page download(Request request, Task task) {
checkInit();
WebDriver webDriver;
try {
webDriver = webDriverPool.get();
} catch (InterruptedException e) {
logger.warn("interrupted", e);
return null;
}
logger.info("downloading page " + request.getUrl());
webDriver.get(request.getUrl());
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebDriver.Options manage = webDriver.manage();
Site site = task.getSite();
if (site.getCookies() != null) {
for (Map.Entry cookieEntry : site.getCookies()
.entrySet()) {
Cookie cookie = new Cookie(cookieEntry.getKey(),
cookieEntry.getValue());
manage.addCookie(cookie);
}
}
/*
* TODO You can add mouse event or other processes
*
* @author: bob.li.0718@gmail.com
*/
WebElement webElement = webDriver.findElement(By.xpath("/html"));
String content = webElement.getAttribute("outerHTML");
Page page = new Page();
page.setRawText(content);
page.setHtml(new Html(content, request.getUrl()));
page.setUrl(new PlainText(request.getUrl()));
page.setRequest(request);
webDriverPool.returnToPool(webDriver);
return page;
}
private void checkInit() {
if (webDriverPool == null) {
synchronized (this) {
webDriverPool = new WebDriverPool(poolSize);
}
}
}
@Override
public void setThread(int thread) {
this.poolSize = thread;
}
@Override
public void close() throws IOException {
webDriverPool.closeAll();
}
}
这里我们以AngularJS中文社区为例。
json
(1) 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息(Ctrl+F),基本可以确定是js渲染。
在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,则可以确定是js渲染,这个数据是通过AJAX获取的。
(2)分析请求
现在让我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例。我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(而且大部分都是下拉页面,总之所有你认为可能会触发新数据的操作)做),然后记得保持现场,一一分析请求。
这一步需要一点耐心,但也不是没有规律可循。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会在XHR选项卡下显示,JSONP请求会在Scripts选项卡下。这是两种常见的数据类型。
然后可以根据数据的大小来判断,通常结果越大返回数据的接口。剩下的基本就是凭经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,您现在可以查看响应正文是什么。这在开发人员工具中并不清楚。让我们将 URL 复制到地址栏并再次请求它。看结果,好像找到了自己想要的。
有时,返回的类型不是json格式,而是html格式。我们稍后会解释这一点。
(3) 编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只不过我们替换了AJAX方法-AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
1)数据列表:
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情的请求由一些固定的URL加上这个id组成。因此,在这一步中,我们自己手动构建了URL,并将其添加到待抓取的队列中。这里我们使用JsonPath,一种选择数据的语言(webmagic-extension包提供了JsonPathSelector来支持)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里咱们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
2)目标数据
有了URL,解析目标数据其实很简单。由于JSON数据完全结构化,因此省略了分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
最终代码如下:
public class AngularJSProcessor implements PageProcessor {
private Site site = Site.me();
private static final String ARITICALE_URL = "http://angularjs\\.cn/api/article/\\w+";
private static final String LIST_URL = "http://angularjs\\.cn/api/article/latest.*";
@Override
public void process(Page page) {
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/" + id);
}
}
} else {
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new AngularJSProcessor()).addUrl("http://angularjs.cn/api/articl ... 6quot;).run();
}
}
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现连接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建连接 => 下载并分析目标 AJAX
对于不同的站点,这种辅助数据大部分是在页面的HTML中预先输出的,大部分是通过AJAX请求的,大部分是重复数据请求的过程,但是这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点。因此,如前所述,如果js请求的结果也是Html,其实只需要再构造一个http请求,将请求的Url添加到要查询的Url中即可。
那么对于前面的例子,如果公告不可用,我该怎么办?
查看源代码后是这样的:
断言:是通过ajax获取的。
然后我们检查请求的Url:
返回的是html。这很简单。将请求的连接放入并再次处理。我们来看看url是什么:
触及知识盲区。
一世?? ? ? ? ? ? ?
这个id是哪里来的??
一世?? ? ?
我现在迷失在风和沙中。. . .
算了,等我弄明白再说。它很难。
public void process(Page page) {
//判断连接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
page.putField("name",page.getHtml().xpath("//*[@id=\"author_profile_detail\"]/a[1]/text()"));
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor2()).addUrl("https://www.cnblogs.com/mvc/bl ... 6quot;).addPipeline(new MyPipeline()).thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
} 查看全部
网页抓取qq(Java抓取前端渲染的页面如何处理-pageapplication?
)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容,往往无法获取有效信息。那么如何处理这种页面呢?一般来说有两种方法:html
在爬取阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬取。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。由于js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且相对于页面样式,这种界面变化的可能性较小。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我个人的看法是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种还是比较可靠的。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。前端
对于第一种方法,webmagic-selenium 就是这样的一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,跟平台和版本有关。没有稳定的解决方案。我们先介绍一下这个尝试。爪哇
由于无论怎么动态加载,初始页面总是收录基本信息,我们可以用爬虫代码模拟js代码,js读取页面元素值,我们也读取页面元素值;js发送ajax,我们只是拼凑参数,发送ajax,解析返回的json。这总是可以的,但是比较麻烦。有没有更省力的方法?更好的方法可能是嵌入浏览器。Python
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。Selenium 是跨语言的,有Java、C#、python 等版本,支持多种浏览器、chrome、firefox 和IE。angularjs
在Java项目中使用Selenium,需要做两件事:web
在项目中引入Selenium Java模块,以Maven为例:
org.seleniumhq.selenium
selenium-java
2.33.0
下载对应的驱动,以chrome为例:
下载后需要将驱动的位置写入Java环境变量中。比如mac下下载到/Users/yihua/Downloads/chromedriver,需要在程序中加入如下代码(虽然在JVM参数中写-Dxxx=xxx也是可以的):
System.getProperties().setProperty("webdriver.chrome.driver","/Users/yihua/Downloads/chromedriver");
Selenium的API很简单,核心是WebDriver,下面是动态渲染页面并获取最终html的代码:ajax
@Test
public void testSelenium() {
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/yihua/Downloads/chromedriver");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://huaban.com/";);
WebElement webElement = webDriver.findElement(By.xpath("/html"));
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
值得注意的是,每次 new ChromeDriver() 时,Selenium 都会创建一个 Chrome 进程,并使用一个随机端口与 Java 中的 chrome 进程进行通信进行交互。所以有两个问题:chrome
最后说一下效率问题。嵌入浏览器后,不仅需要更多的CPU来渲染页面,还要下载页面附带的资源。似乎缓存了单个 webDriver 中的静态资源。初始化后,访问速度会加快。尝试ChromeDriver加载花瓣首页100次,总共耗时263秒,平均每页2.6秒。苹果系统
/**
* 花瓣网抽取器。
* 使用Selenium作页面动态渲染。
*/
public class HuabanProcessor implements PageProcessor {
private Site site;
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("http://huaban\\.com/.*").all());
if (page.getUrl().toString().contains("pins")) {
page.putField("img", page.getHtml().xpath("//div[@id='pin_img']/img/@src").toString());
} else {
page.getResultItems().setSkip(true);
}
}
@Override
public Site getSite() {
if (site == null) {
site = Site.me().setDomain("huaban.com").addStartUrl("http://huaban.com/";).setSleepTime(1000);
}
return site;
}
public static void main(String[] args) {
Spider.create(new HuabanProcessor()).thread(5)
.scheduler(new RedisScheduler("localhost"))
.pipeline(new FilePipeline("/data/webmagic/test/"))
.downloader(new SeleniumDownloader("/Users/yihua/Downloads/chromedriver"))
.run();
}
}
public class SeleniumDownloader implements Downloader, Closeable {
private volatile WebDriverPool webDriverPool;
private Logger logger = Logger.getLogger(getClass());
private int sleepTime = 0;
private int poolSize = 1;
private static final String DRIVER_PHANTOMJS = "phantomjs";
/**
* 新建
*
* @param chromeDriverPath chromeDriverPath
*/
public SeleniumDownloader(String chromeDriverPath) {
System.getProperties().setProperty("webdriver.chrome.driver",
chromeDriverPath);
}
/**
* Constructor without any filed. Construct PhantomJS browser
*
* @author bob.li.0718@gmail.com
*/
public SeleniumDownloader() {
// System.setProperty("phantomjs.binary.path",
// "/Users/Bingo/Downloads/phantomjs-1.9.7-macosx/bin/phantomjs");
}
/**
* set sleep time to wait until load success
*
* @param sleepTime sleepTime
* @return this
*/
public SeleniumDownloader setSleepTime(int sleepTime) {
this.sleepTime = sleepTime;
return this;
}
@Override
public Page download(Request request, Task task) {
checkInit();
WebDriver webDriver;
try {
webDriver = webDriverPool.get();
} catch (InterruptedException e) {
logger.warn("interrupted", e);
return null;
}
logger.info("downloading page " + request.getUrl());
webDriver.get(request.getUrl());
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebDriver.Options manage = webDriver.manage();
Site site = task.getSite();
if (site.getCookies() != null) {
for (Map.Entry cookieEntry : site.getCookies()
.entrySet()) {
Cookie cookie = new Cookie(cookieEntry.getKey(),
cookieEntry.getValue());
manage.addCookie(cookie);
}
}
/*
* TODO You can add mouse event or other processes
*
* @author: bob.li.0718@gmail.com
*/
WebElement webElement = webDriver.findElement(By.xpath("/html"));
String content = webElement.getAttribute("outerHTML");
Page page = new Page();
page.setRawText(content);
page.setHtml(new Html(content, request.getUrl()));
page.setUrl(new PlainText(request.getUrl()));
page.setRequest(request);
webDriverPool.returnToPool(webDriver);
return page;
}
private void checkInit() {
if (webDriverPool == null) {
synchronized (this) {
webDriverPool = new WebDriverPool(poolSize);
}
}
}
@Override
public void setThread(int thread) {
this.poolSize = thread;
}
@Override
public void close() throws IOException {
webDriverPool.closeAll();
}
}
这里我们以AngularJS中文社区为例。

json
(1) 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息(Ctrl+F),基本可以确定是js渲染。

在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,则可以确定是js渲染,这个数据是通过AJAX获取的。
(2)分析请求
现在让我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例。我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(而且大部分都是下拉页面,总之所有你认为可能会触发新数据的操作)做),然后记得保持现场,一一分析请求。
这一步需要一点耐心,但也不是没有规律可循。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会在XHR选项卡下显示,JSONP请求会在Scripts选项卡下。这是两种常见的数据类型。
然后可以根据数据的大小来判断,通常结果越大返回数据的接口。剩下的基本就是凭经验了。比如这里的“latest?p=1&s=20”一看就可疑……

对于可疑地址,您现在可以查看响应正文是什么。这在开发人员工具中并不清楚。让我们将 URL 复制到地址栏并再次请求它。看结果,好像找到了自己想要的。

有时,返回的类型不是json格式,而是html格式。我们稍后会解释这一点。
(3) 编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只不过我们替换了AJAX方法-AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
1)数据列表:
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情的请求由一些固定的URL加上这个id组成。因此,在这一步中,我们自己手动构建了URL,并将其添加到待抓取的队列中。这里我们使用JsonPath,一种选择数据的语言(webmagic-extension包提供了JsonPathSelector来支持)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里咱们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
2)目标数据
有了URL,解析目标数据其实很简单。由于JSON数据完全结构化,因此省略了分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
最终代码如下:
public class AngularJSProcessor implements PageProcessor {
private Site site = Site.me();
private static final String ARITICALE_URL = "http://angularjs\\.cn/api/article/\\w+";
private static final String LIST_URL = "http://angularjs\\.cn/api/article/latest.*";
@Override
public void process(Page page) {
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/" + id);
}
}
} else {
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new AngularJSProcessor()).addUrl("http://angularjs.cn/api/articl ... 6quot;).run();
}
}
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现连接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建连接 => 下载并分析目标 AJAX
对于不同的站点,这种辅助数据大部分是在页面的HTML中预先输出的,大部分是通过AJAX请求的,大部分是重复数据请求的过程,但是这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点。因此,如前所述,如果js请求的结果也是Html,其实只需要再构造一个http请求,将请求的Url添加到要查询的Url中即可。
那么对于前面的例子,如果公告不可用,我该怎么办?

查看源代码后是这样的:

断言:是通过ajax获取的。
然后我们检查请求的Url:


返回的是html。这很简单。将请求的连接放入并再次处理。我们来看看url是什么:
触及知识盲区。
一世?? ? ? ? ? ? ?
这个id是哪里来的??
一世?? ? ?
我现在迷失在风和沙中。. . .

算了,等我弄明白再说。它很难。
public void process(Page page) {
//判断连接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
page.putField("name",page.getHtml().xpath("//*[@id=\"author_profile_detail\"]/a[1]/text()"));
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor2()).addUrl("https://www.cnblogs.com/mvc/bl ... 6quot;).addPipeline(new MyPipeline()).thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
网页抓取qq(登陆页面二维码图片登陆校验需要哪些参数(上)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2021-12-09 09:09
一、背景:前几天收到一个请求:获取QQ好友、QQ群、QQ群好友的账号。可惜抓不到QQ程序的包。我觉得应该是QQ程序之间的通讯协议大部分不是HTTP或HTTPS,我用的Fillder所以找不到包,但不影响我完成需求。找了大部分QQ的相关应用,终于在QQ空间找到了可以满足这个需求的数据。于是我改变了思路和方法去Qzone抓数据。
二、分析:QQ空间一般采用两种登录方式:一种是账号密码登录,一种是扫码登录。领导要求扫码登录,所以我来做扫码登录。
反复抓包查资料,发现相关登录接口如下(注意后面文中用接口名代替连接):
登录页面
二维码图片
登录验证
首先我们分析一下登录验证需要哪些参数(因为它最容易找到,而且我们一进入就一直在等待验证):
经过反复抓包测试,发现需要的参数不定:ptqrtoken、action、login_sig。一看就知道action是一个时间戳拼接字段,另外两个字段应该是页面请求时设置的cookie值。通过全局搜索字段发现login_sig就是登录页面的pt_login_sig。
然后,到登录页面获取cookie中pt_login_sig对应的值。经过几次抓包,发现接口参数是固定的:
至于ptqrtoken全局搜索,会找到c_login_2.js的js文件。进入预览视图格式化js代码,搜索ptqrtoken,会发现如下一段代码:
很明显,他的意思是获取某个cookie中的qrsig字段,然后进行hash33加密,首先全局查找qrsig,发现二维码图片的cookie中有这个字段,同时保存二维码获得领域。这个接口是固定的,除了一个参数是0-1之间的随机数。
然后全局查找hash33加密过程,结果还是c_login_2.js文件中找到的如下代码片段:
将js代码转换为python代码:
<p> def __decrypt_qrsig(self, qrsig):
e = 0
for c in qrsig:
e += (e 查看全部
网页抓取qq(登陆页面二维码图片登陆校验需要哪些参数(上)?)
一、背景:前几天收到一个请求:获取QQ好友、QQ群、QQ群好友的账号。可惜抓不到QQ程序的包。我觉得应该是QQ程序之间的通讯协议大部分不是HTTP或HTTPS,我用的Fillder所以找不到包,但不影响我完成需求。找了大部分QQ的相关应用,终于在QQ空间找到了可以满足这个需求的数据。于是我改变了思路和方法去Qzone抓数据。
二、分析:QQ空间一般采用两种登录方式:一种是账号密码登录,一种是扫码登录。领导要求扫码登录,所以我来做扫码登录。
反复抓包查资料,发现相关登录接口如下(注意后面文中用接口名代替连接):
登录页面
二维码图片
登录验证
首先我们分析一下登录验证需要哪些参数(因为它最容易找到,而且我们一进入就一直在等待验证):
经过反复抓包测试,发现需要的参数不定:ptqrtoken、action、login_sig。一看就知道action是一个时间戳拼接字段,另外两个字段应该是页面请求时设置的cookie值。通过全局搜索字段发现login_sig就是登录页面的pt_login_sig。
然后,到登录页面获取cookie中pt_login_sig对应的值。经过几次抓包,发现接口参数是固定的:
至于ptqrtoken全局搜索,会找到c_login_2.js的js文件。进入预览视图格式化js代码,搜索ptqrtoken,会发现如下一段代码:
很明显,他的意思是获取某个cookie中的qrsig字段,然后进行hash33加密,首先全局查找qrsig,发现二维码图片的cookie中有这个字段,同时保存二维码获得领域。这个接口是固定的,除了一个参数是0-1之间的随机数。
然后全局查找hash33加密过程,结果还是c_login_2.js文件中找到的如下代码片段:
将js代码转换为python代码:
<p> def __decrypt_qrsig(self, qrsig):
e = 0
for c in qrsig:
e += (e
网页抓取qq(竞价必备神器,页面访客QQ提取工具(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-08 16:06
竞价必备神器,页面访客QQ提取工具 首先欢迎大家观看本教程,本教程是竞价必备神器,做竞价的朋友会发现有些网站每次点击一天,但没有咨询,没有咨询也意味着没有秩序。为了解决这个问题,济南大神向出价用户的朋友们强烈推荐一款神器页面客户QQ提取软件。这个软件的神奇之处在于,即使不咨询你,你也会得到客户的QQ号,主动联系客户,最终拿到订单。为减少客户流失,下面详细介绍本软件的优点。7. 可以给客户发邮件(需要企业QQ邮箱)。我们先来看看软件的实际操作。您将看到以下文件。首先点击生成js文件。输入你的黄钻QQ号,先运行页面访客提取工具.exe。运行后会看到界面,点击Generate,js文本就升级了。例如,命名为1.js,上传1.js到你的网站根目录,在你的网站主页前加人“/body”,把我的网站替换为你的。然后单击导入帐户。把你的QQ账号和密码放在记事本里。格式如 657235615----12345678 密码在哪里。导入成功后,会看到如下界面,然后点击批量登录。登录后,点击开始采集。效果图是这样的。那么如果你去找你< @网站 见。右侧列表中会出现客户的QQ号码,可以实现在线QQ对话。也可以给客户发邮件(需要QQ企业邮箱)。视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 查看全部
网页抓取qq(竞价必备神器,页面访客QQ提取工具(图)!)
竞价必备神器,页面访客QQ提取工具 首先欢迎大家观看本教程,本教程是竞价必备神器,做竞价的朋友会发现有些网站每次点击一天,但没有咨询,没有咨询也意味着没有秩序。为了解决这个问题,济南大神向出价用户的朋友们强烈推荐一款神器页面客户QQ提取软件。这个软件的神奇之处在于,即使不咨询你,你也会得到客户的QQ号,主动联系客户,最终拿到订单。为减少客户流失,下面详细介绍本软件的优点。7. 可以给客户发邮件(需要企业QQ邮箱)。我们先来看看软件的实际操作。您将看到以下文件。首先点击生成js文件。输入你的黄钻QQ号,先运行页面访客提取工具.exe。运行后会看到界面,点击Generate,js文本就升级了。例如,命名为1.js,上传1.js到你的网站根目录,在你的网站主页前加人“/body”,把我的网站替换为你的。然后单击导入帐户。把你的QQ账号和密码放在记事本里。格式如 657235615----12345678 密码在哪里。导入成功后,会看到如下界面,然后点击批量登录。登录后,点击开始采集。效果图是这样的。那么如果你去找你< @网站 见。右侧列表中会出现客户的QQ号码,可以实现在线QQ对话。也可以给客户发邮件(需要QQ企业邮箱)。视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系
网页抓取qq(无良商家就是利用那么简单的原理卖几千块一套源码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-07 22:20
最近经常在网上看到很多卖网站获取访客QQ号的程序。没有统一的价格。最高的是6000,最低的是一两百元。出于好奇,我测试了他们的系统,看到了获取访客QQ号码的神奇原理。当我添加一段 JS 脚本代码时,他们将我发送到我们的主页 html。我访问了自己的网页,却一直没有得到 号码。然后我咨询了卖家。他说,在访问自己的网站之前,需要先登录自己的QQ空间或QQ邮箱等腾讯相关产品。不,那么它不能被抓取。此时,我先登录QQ空间访问我的网站,结果果然是卖家说的。
那么我有一个问题,为什么我需要登录QQ空间才能抓取访客QQ号?我大胆地想象,当我的朋友访问我的QQ空间时,他们可以查看我最近访问者中朋友的QQ号码。我只需要通过IFRAME把QQ空间的首页放到网站,然后就可以得到访问者的QQ号,得到来人的方式。但是有一个缺点,就是访问者必须登录过QQ空间或其他QQ产品,所以无法获取所有QQ号。我想这应该是他们说的为什么我在访问网站之前需要登录Qzone等相关产品的原因。这就是网站获取访客QQ号统计的原理。
想到这里,我立马写了一个DEMO放到网站上。我发现成功率这么高。访问了50多个IP,抢到了30多个QQ号。真没想到如果你网站访问者是年轻用户,成功率会更高。原理很简单。发布这个的原则是希望大家可以自己写程序,不用把别人的代码放在自己的网站上,数据也不怕被泄露。这只是其中的一种方法,以后公开的方法还有好几种。鄙视那些无良商家,就是用这么简单的道理,卖上千条源代码。因为不公,我也写了一个统计程序供大家免费使用。318 个统计数据***。
文章转载自318 stats***.com请带此链接,谢谢 查看全部
网页抓取qq(无良商家就是利用那么简单的原理卖几千块一套源码。)
最近经常在网上看到很多卖网站获取访客QQ号的程序。没有统一的价格。最高的是6000,最低的是一两百元。出于好奇,我测试了他们的系统,看到了获取访客QQ号码的神奇原理。当我添加一段 JS 脚本代码时,他们将我发送到我们的主页 html。我访问了自己的网页,却一直没有得到 号码。然后我咨询了卖家。他说,在访问自己的网站之前,需要先登录自己的QQ空间或QQ邮箱等腾讯相关产品。不,那么它不能被抓取。此时,我先登录QQ空间访问我的网站,结果果然是卖家说的。
那么我有一个问题,为什么我需要登录QQ空间才能抓取访客QQ号?我大胆地想象,当我的朋友访问我的QQ空间时,他们可以查看我最近访问者中朋友的QQ号码。我只需要通过IFRAME把QQ空间的首页放到网站,然后就可以得到访问者的QQ号,得到来人的方式。但是有一个缺点,就是访问者必须登录过QQ空间或其他QQ产品,所以无法获取所有QQ号。我想这应该是他们说的为什么我在访问网站之前需要登录Qzone等相关产品的原因。这就是网站获取访客QQ号统计的原理。
想到这里,我立马写了一个DEMO放到网站上。我发现成功率这么高。访问了50多个IP,抢到了30多个QQ号。真没想到如果你网站访问者是年轻用户,成功率会更高。原理很简单。发布这个的原则是希望大家可以自己写程序,不用把别人的代码放在自己的网站上,数据也不怕被泄露。这只是其中的一种方法,以后公开的方法还有好几种。鄙视那些无良商家,就是用这么简单的道理,卖上千条源代码。因为不公,我也写了一个统计程序供大家免费使用。318 个统计数据***。
文章转载自318 stats***.com请带此链接,谢谢
网页抓取qq(【新三板】一下+beautifulsoup实现抓取中财网数据引擎的公司档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-07 14:17
记录一个python爬虫的快速实现,想抓取中国财经网数据引擎新三板板块下所有股票的公司文件。网站在这里。html
更简单的网站不同的页码有不同的联系。可以通过观察连接的变化找出规律,然后生成所有与页码对应的连接然后分别抓取,但是这个网站改变页面的时候连接没有变化,所以我计划在第二页被点击时观察请求python
发现使用了get的请求方法,并且请求中有一个curpage参数,好像控制不同的页数,所以在请求连接中改变了这个参数的值,其他的值发现没有变化,所以我决定改变它。就是利用我们标题中提到的selenium+beautifulsoup来模拟点击网页中的下一页按钮进行翻页,分别抓取网页的内容。混帐
首先我们做一些准备工作,安装必要的包,打开命令行,直接pip install selenium和pip installbeautifulsoup4github
然后就是下载安装chromedriver驱动了,网址下面,记得配置环境变量或者直接安装在工作目录下。(也可以使用IE、phantomJS等) web
这里我们先抓取每只股票对应的首页链接,代码如下(使用python2):chrome
1 # -*- coding: utf-8 -*-
2 from selenium import webdriver
3 from bs4 import BeautifulSoup
4 import sys
5 reload(sys)
6 sys.setdefaultencoding('utf-8')
7
8 def crawl(url):
9 driver = webdriver.Chrome()
10 driver.get(url)
11 page = 0
12 lst=[]
13 with open('./url.txt','a') as f:
14 while page < 234:
15 soup = BeautifulSoup(driver.page_source, "html.parser")
16 print(soup)
17 urls_tag = soup.find_all('a',target='_blank')
18 print(urls_tag)
19 for i in urls_tag:
20 if i['href'] not in lst:
21 f.write(i['href']+'\n')
22 lst.append(i['href'])
23 driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
24 time.sleep(2)
25 return 'Finished'
26 def main():
27 url = 'http://data.cfi.cn/cfidata.aspx?sortfd=&sortway=&curpage=2&fr=content&ndk=A0A1934A1935A1986A1995&xztj=&mystock='
28 crawl(url)
29 if __name__ == '__main__':
30 main()
运行代码,发现老是报错:app
这里的错误意味着找不到您要查找的按钮。蟒蛇爬虫
那么我们查看一下网页的源码:网站
发现网页被分成了不同的frame,所以我们猜测需要跳转到frame。我们需要抓取的连接所在的frame名称是“content”,所以我们添加一行代码:driver.switch_to.frame('content') google
def crawl(url):
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame('content')
page = 0
lst=[]
with open('./url.txt','a') as f:
while page < 234:
soup = BeautifulSoup(driver.page_source, "html.parser")
print(soup)
urls_tag = soup.find_all('a',target='_blank')
print(urls_tag)
for i in urls_tag:
if i['href'] not in lst:
f.write(i['href']+'\n')
lst.append(i['href'])
driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
time.sleep(2)
return 'Finished'
到目前为止,它运行到:
参考博文链接:%E5%88%A9%E7%94%A8beautifulsoup+selenium%E8%87%AA%E5%8A%A8%E7%BF%BB%E9%A1%B5%E6%8A%93% E5 %8F%96%E7%BD%91%E9%A1%B5%E5%86%85%E5%AE%B9/ 查看全部
网页抓取qq(【新三板】一下+beautifulsoup实现抓取中财网数据引擎的公司档案)
记录一个python爬虫的快速实现,想抓取中国财经网数据引擎新三板板块下所有股票的公司文件。网站在这里。html
更简单的网站不同的页码有不同的联系。可以通过观察连接的变化找出规律,然后生成所有与页码对应的连接然后分别抓取,但是这个网站改变页面的时候连接没有变化,所以我计划在第二页被点击时观察请求python

发现使用了get的请求方法,并且请求中有一个curpage参数,好像控制不同的页数,所以在请求连接中改变了这个参数的值,其他的值发现没有变化,所以我决定改变它。就是利用我们标题中提到的selenium+beautifulsoup来模拟点击网页中的下一页按钮进行翻页,分别抓取网页的内容。混帐
首先我们做一些准备工作,安装必要的包,打开命令行,直接pip install selenium和pip installbeautifulsoup4github
然后就是下载安装chromedriver驱动了,网址下面,记得配置环境变量或者直接安装在工作目录下。(也可以使用IE、phantomJS等) web
这里我们先抓取每只股票对应的首页链接,代码如下(使用python2):chrome
1 # -*- coding: utf-8 -*-
2 from selenium import webdriver
3 from bs4 import BeautifulSoup
4 import sys
5 reload(sys)
6 sys.setdefaultencoding('utf-8')
7
8 def crawl(url):
9 driver = webdriver.Chrome()
10 driver.get(url)
11 page = 0
12 lst=[]
13 with open('./url.txt','a') as f:
14 while page < 234:
15 soup = BeautifulSoup(driver.page_source, "html.parser")
16 print(soup)
17 urls_tag = soup.find_all('a',target='_blank')
18 print(urls_tag)
19 for i in urls_tag:
20 if i['href'] not in lst:
21 f.write(i['href']+'\n')
22 lst.append(i['href'])
23 driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
24 time.sleep(2)
25 return 'Finished'
26 def main():
27 url = 'http://data.cfi.cn/cfidata.aspx?sortfd=&sortway=&curpage=2&fr=content&ndk=A0A1934A1935A1986A1995&xztj=&mystock='
28 crawl(url)
29 if __name__ == '__main__':
30 main()
运行代码,发现老是报错:app
这里的错误意味着找不到您要查找的按钮。蟒蛇爬虫
那么我们查看一下网页的源码:网站
发现网页被分成了不同的frame,所以我们猜测需要跳转到frame。我们需要抓取的连接所在的frame名称是“content”,所以我们添加一行代码:driver.switch_to.frame('content') google
def crawl(url):
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame('content')
page = 0
lst=[]
with open('./url.txt','a') as f:
while page < 234:
soup = BeautifulSoup(driver.page_source, "html.parser")
print(soup)
urls_tag = soup.find_all('a',target='_blank')
print(urls_tag)
for i in urls_tag:
if i['href'] not in lst:
f.write(i['href']+'\n')
lst.append(i['href'])
driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
time.sleep(2)
return 'Finished'
到目前为止,它运行到:
参考博文链接:%E5%88%A9%E7%94%A8beautifulsoup+selenium%E8%87%AA%E5%8A%A8%E7%BF%BB%E9%A1%B5%E6%8A%93% E5 %8F%96%E7%BD%91%E9%A1%B5%E5%86%85%E5%AE%B9/
网页抓取qq(场景有时候想使用某些网页上的数据,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-02 15:13
1、场景
有时我想使用某些网页上的数据,但这些数据不是通过简单的get/post请求获得的,但是即使没有现成的界面,只要显示在网页上,就可以爬下来使用,就是用代码为我们进行选择→复制→粘贴操作
2、原理
只要加载的网页是html文档,在这个网页上爬取文本数据就可以理解为从一串很长的字符串中截取我们想要的部分。理论上,根据一定的匹配/拦截规则,即使只是使用 if Else 也可以从html文档中得到你想要的数据,因为html本身有一套完整的语法/标签,所以有第三方可以直接根据这些规则使用,快速抓取数据。
3、使用的第三方
Java可以使用Jsoup
swift可以使用ji(注意使用的版本,swift的很多方法名这几年都更新了,老版本的库也有改动)
OC 可以使用一个框架
本文主要记录One框架下载链接的使用,包括demo
手动集成需要在Header Search Paths中添加/usr/include/libxml2、/usr/include/libresolv
4、代码
1、下载网页数据
NSData * data = [NSData dataWithContentsOfURL:[NSURL URLWithString:[urlStr stringByAddingPercentEncodingWithAllowedCharacters:[NSCharacterSet URLQueryAllowedCharacterSet]]]];
2、获取网页文档对象
NSError *错误;
ONOXMLDocument *doc=[ONOXMLDocument HTMLDocumentWithData:data error:&error];
3、根据条件查询节点对象
[doc firstChildWithXPath:@"///*[@id='test'] // 获取第一个id为test的节点
[doc firstChildWithXPath:@"///*[.class='test'] // 获取第一个类为 test 的节点
[doc firstChildWithTag:@"span"]// 获取第一个span
4、获取节点对象文本
元素.stringValue 查看全部
网页抓取qq(场景有时候想使用某些网页上的数据,怎么办?)
1、场景
有时我想使用某些网页上的数据,但这些数据不是通过简单的get/post请求获得的,但是即使没有现成的界面,只要显示在网页上,就可以爬下来使用,就是用代码为我们进行选择→复制→粘贴操作
2、原理
只要加载的网页是html文档,在这个网页上爬取文本数据就可以理解为从一串很长的字符串中截取我们想要的部分。理论上,根据一定的匹配/拦截规则,即使只是使用 if Else 也可以从html文档中得到你想要的数据,因为html本身有一套完整的语法/标签,所以有第三方可以直接根据这些规则使用,快速抓取数据。
3、使用的第三方
Java可以使用Jsoup
swift可以使用ji(注意使用的版本,swift的很多方法名这几年都更新了,老版本的库也有改动)
OC 可以使用一个框架
本文主要记录One框架下载链接的使用,包括demo
手动集成需要在Header Search Paths中添加/usr/include/libxml2、/usr/include/libresolv
4、代码
1、下载网页数据
NSData * data = [NSData dataWithContentsOfURL:[NSURL URLWithString:[urlStr stringByAddingPercentEncodingWithAllowedCharacters:[NSCharacterSet URLQueryAllowedCharacterSet]]]];
2、获取网页文档对象
NSError *错误;
ONOXMLDocument *doc=[ONOXMLDocument HTMLDocumentWithData:data error:&error];
3、根据条件查询节点对象
[doc firstChildWithXPath:@"///*[@id='test'] // 获取第一个id为test的节点
[doc firstChildWithXPath:@"///*[.class='test'] // 获取第一个类为 test 的节点
[doc firstChildWithTag:@"span"]// 获取第一个span
4、获取节点对象文本
元素.stringValue
网页抓取qq(如何使用访客统计助手联系本站客服开通账号,请注意区分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-02 11:13
1、什么是访客统计助手
访客统计助手通过一段JS代码连接本站独有的分析系统,获取您的网站实时访客QQ信息,
通过这种有意的QQ访客,进行二次营销,尽可能挽回你流失的客户,让你的流量和竞价成本不再浪费!
2、使用访客统计助手有什么好处
只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确地分析来访的目标客户,
更多网站一个用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户的QQ号码后,
您可以在系统后台直接与客户发起临时QQ对话,主动询问客户需求。
了解客户的需求,并持续跟进,最终产生销售。此外,本站还推出了全网独有的基于网络的在线邮件群发功能。
您还可以访问关键词 分析潜在客户以发送个人广告电子邮件。快捷方便!
3、如何使用访客统计助手
联系我们客服开户,登录网站后台,然后获取访客QQ统计码,
插入你的 网站 底部或头部开始计数!
1、如何插入访客QQ统计代码
登录后台,点击左侧导航的Get Code按钮,复制你得到的code,插入你的网站,
在这里你会看到两段代码。第一段是html代码,可以插入html、php、asp等文件,第二段是js代码。
只能插入到你的网站 js文件中,请注意区分!
百度网盘下载地址: 查看全部
网页抓取qq(如何使用访客统计助手联系本站客服开通账号,请注意区分)
1、什么是访客统计助手
访客统计助手通过一段JS代码连接本站独有的分析系统,获取您的网站实时访客QQ信息,
通过这种有意的QQ访客,进行二次营销,尽可能挽回你流失的客户,让你的流量和竞价成本不再浪费!
2、使用访客统计助手有什么好处
只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确地分析来访的目标客户,
更多网站一个用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户的QQ号码后,
您可以在系统后台直接与客户发起临时QQ对话,主动询问客户需求。
了解客户的需求,并持续跟进,最终产生销售。此外,本站还推出了全网独有的基于网络的在线邮件群发功能。
您还可以访问关键词 分析潜在客户以发送个人广告电子邮件。快捷方便!
3、如何使用访客统计助手
联系我们客服开户,登录网站后台,然后获取访客QQ统计码,
插入你的 网站 底部或头部开始计数!
1、如何插入访客QQ统计代码
登录后台,点击左侧导航的Get Code按钮,复制你得到的code,插入你的网站,
在这里你会看到两段代码。第一段是html代码,可以插入html、php、asp等文件,第二段是js代码。
只能插入到你的网站 js文件中,请注意区分!
百度网盘下载地址:
网页抓取qq(网站总是频繁出现“异常提示”怎么办?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2021-12-02 05:15
自从百度进行了“抓取异常”检查后,很多站长发现网站总是频繁出现“异常提示”。那么百度网页抓取的要点有哪些呢?一起来奇帆网了解更多吧!
一:爬取时出现DNS错误
很多新手发现网页无法访问,会找服务商,但忽略了一点:网站域名DNS web服务器也会有问题!当网站出现问题时,应该一会就清楚了。问题。如果是DNS问题,建议立即更换DSN。温馨提示:DNSPOD应用广泛,作者最近监测了空闲节点的一些超时情况,也提醒DSNPOD开始解决。
另外,很多网站站长现阶段喜欢使用“一些云加速”,但小编也应该说,现阶段很多直言云加速并不完善,尤其是这些完全免费的时候而且前期做的很好,到了中后期有客户的时候,就惨了。
提醒:当您的网站没有受到强烈攻击时,请不要使用纯云加速,追求完美的花式,很容易伤害到自己。网站域名DSN级别目前在万网(阿里巴巴)稳定。
二:存在爬取超时问题
在A5营销推广的SEO诊断中,人们非常重视客户体验。有一点非常重要:客户打开网页的速度。如果网页不能一次打开,它们就会丢失。浏览资格,并跳转到其他网站。搜索引擎蜘蛛呢?也是如此。如果暂时不能爬取,就会出现爬取超时问题。
这个爬取请求的超时通常是网络带宽不足和大网页造成的。网页级别的人建议: A:在不影响照片质量的情况下,尽可能缩小和提交照片。在这种情况下,进行了减持。B:减少JS脚本等应用做扩展,或者进行合并。 查看全部
网页抓取qq(网站总是频繁出现“异常提示”怎么办?(图))
自从百度进行了“抓取异常”检查后,很多站长发现网站总是频繁出现“异常提示”。那么百度网页抓取的要点有哪些呢?一起来奇帆网了解更多吧!
一:爬取时出现DNS错误
很多新手发现网页无法访问,会找服务商,但忽略了一点:网站域名DNS web服务器也会有问题!当网站出现问题时,应该一会就清楚了。问题。如果是DNS问题,建议立即更换DSN。温馨提示:DNSPOD应用广泛,作者最近监测了空闲节点的一些超时情况,也提醒DSNPOD开始解决。

另外,很多网站站长现阶段喜欢使用“一些云加速”,但小编也应该说,现阶段很多直言云加速并不完善,尤其是这些完全免费的时候而且前期做的很好,到了中后期有客户的时候,就惨了。
提醒:当您的网站没有受到强烈攻击时,请不要使用纯云加速,追求完美的花式,很容易伤害到自己。网站域名DSN级别目前在万网(阿里巴巴)稳定。
二:存在爬取超时问题
在A5营销推广的SEO诊断中,人们非常重视客户体验。有一点非常重要:客户打开网页的速度。如果网页不能一次打开,它们就会丢失。浏览资格,并跳转到其他网站。搜索引擎蜘蛛呢?也是如此。如果暂时不能爬取,就会出现爬取超时问题。
这个爬取请求的超时通常是网络带宽不足和大网页造成的。网页级别的人建议: A:在不影响照片质量的情况下,尽可能缩小和提交照片。在这种情况下,进行了减持。B:减少JS脚本等应用做扩展,或者进行合并。
网页抓取qq(第二代V2全面升级支持:定时循环监控采集访客、自动保存访客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-30 16:02
QQ空间访客采集专家v0831免费版.zip
QQ空间访客采集专家是一款可以批量批量处理采集QQ空间访客的工具。只需输入一个或多个源QQ,即可采集一键访问QQ空间访客信息(访客QQ、访客昵称、访问时间),支持多层采集(如如采集123456 访问者84302438,程序可以继续采集84302438 子访问者,自定义层计数等,无限循环采集)!此功能用于采集捕捉准确的QQ客户,可以是采集竞争对手空间的访客,方便营销!支持导出为表格或文本!二代V2全面升级支持:采集访客定时循环监控,指定日期访客过滤,访客自动保存。还支持QQ空间动态浏览访客采集(一般朋友刷新空间时会在动态浏览中留下痕迹,类似抢竞争对手的朋友,超强大功能)请注意:需要相同权限采集 未经许可不能做。注意,软件目前支持采集最新访问者、相册访问者、动态浏览3个频道的访问者。采集采集之前请确保您有权限(您可以手动检查。)该软件无法突破任何限制。空间有限或无相册访问者不能采集,敬请谅解。目前第一代和第二代都开放使用,第一代不再更新。QQ空间访客采集
现在就下载 查看全部
网页抓取qq(第二代V2全面升级支持:定时循环监控采集访客、自动保存访客)
QQ空间访客采集专家v0831免费版.zip
QQ空间访客采集专家是一款可以批量批量处理采集QQ空间访客的工具。只需输入一个或多个源QQ,即可采集一键访问QQ空间访客信息(访客QQ、访客昵称、访问时间),支持多层采集(如如采集123456 访问者84302438,程序可以继续采集84302438 子访问者,自定义层计数等,无限循环采集)!此功能用于采集捕捉准确的QQ客户,可以是采集竞争对手空间的访客,方便营销!支持导出为表格或文本!二代V2全面升级支持:采集访客定时循环监控,指定日期访客过滤,访客自动保存。还支持QQ空间动态浏览访客采集(一般朋友刷新空间时会在动态浏览中留下痕迹,类似抢竞争对手的朋友,超强大功能)请注意:需要相同权限采集 未经许可不能做。注意,软件目前支持采集最新访问者、相册访问者、动态浏览3个频道的访问者。采集采集之前请确保您有权限(您可以手动检查。)该软件无法突破任何限制。空间有限或无相册访问者不能采集,敬请谅解。目前第一代和第二代都开放使用,第一代不再更新。QQ空间访客采集
现在就下载
网页抓取qq(如何判断是否是有序翻页式网页的抓住机制看法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 01:15
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下,保持系统和实际环境中页面的一致性,这意味着蜘蛛不会抓取网站 的所有页面。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这也是我们要做好网站的链接结构的原因。接下来,笔者将只关注蜘蛛对翻页网页的抓取机制。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率不同,而文章链接很有可能是Push到翻页栏,这样蜘蛛就不能每天从第一个翻页栏爬到第80个,然后爬一个文章和一个文章比较用数据库,太浪费蜘蛛的时间也浪费你网站的收录时间,所以蜘蛛需要额外的爬取机制来针对这种特殊类型的翻页网页,保证网站的完整性
如何判断是否是有序翻页?
判断文章是否按照发布时间有序排列,是这类页面的必要条件,下面会讲到。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使不写发布时间,Spider Writer也可以根据文章本身的实际发布时间来判断。
爬取机制是如何工作的?
对于这种翻页页面,蜘蛛主要记录每次抓取网页时找到的文章链接,然后将本次找到的文章链接与历史上找到的链接进行比较。如果有Intersection,说明这次爬取已经找到了所有新的文章,可以停止下一页翻页栏的爬取;否则,说明这次爬取没有找到所有新的文章,需要继续爬下一页甚至后面几页才能找到所有新的文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比起手机网站Building as在网站页面目录,新增了29篇文章,据说上次最新的文章是第30篇,并且蜘蛛一次抓取了10篇文章链接,这样蜘蛛第一次抓取了10篇文章,与上次没有重叠,所以继续抓取我第二次抓取了10篇文章时间,也就是我一共抓了20篇文章。还是和上次没有重叠,再继续抢。这次抢了第30篇,也就是和上次有重叠。这意味着蜘蛛从上次爬取到这次网站更新的29篇文章文章已经全部爬取了。
建议
目前百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据实际情况,但蜘蛛毕竟不能做100。%识别准确率,所以如果站长在做翻页栏的时候不使用JS,就不要使用FALSH,同时经常更新文章,配合蜘蛛爬行,可以大大提高准确率蜘蛛识别,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛正在考虑为公司构建爬行机制。实际上,许多机制是同时进行的。 查看全部
网页抓取qq(如何判断是否是有序翻页式网页的抓住机制看法?)
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下,保持系统和实际环境中页面的一致性,这意味着蜘蛛不会抓取网站 的所有页面。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这也是我们要做好网站的链接结构的原因。接下来,笔者将只关注蜘蛛对翻页网页的抓取机制。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率不同,而文章链接很有可能是Push到翻页栏,这样蜘蛛就不能每天从第一个翻页栏爬到第80个,然后爬一个文章和一个文章比较用数据库,太浪费蜘蛛的时间也浪费你网站的收录时间,所以蜘蛛需要额外的爬取机制来针对这种特殊类型的翻页网页,保证网站的完整性
如何判断是否是有序翻页?
判断文章是否按照发布时间有序排列,是这类页面的必要条件,下面会讲到。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使不写发布时间,Spider Writer也可以根据文章本身的实际发布时间来判断。
爬取机制是如何工作的?
对于这种翻页页面,蜘蛛主要记录每次抓取网页时找到的文章链接,然后将本次找到的文章链接与历史上找到的链接进行比较。如果有Intersection,说明这次爬取已经找到了所有新的文章,可以停止下一页翻页栏的爬取;否则,说明这次爬取没有找到所有新的文章,需要继续爬下一页甚至后面几页才能找到所有新的文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比起手机网站Building as在网站页面目录,新增了29篇文章,据说上次最新的文章是第30篇,并且蜘蛛一次抓取了10篇文章链接,这样蜘蛛第一次抓取了10篇文章,与上次没有重叠,所以继续抓取我第二次抓取了10篇文章时间,也就是我一共抓了20篇文章。还是和上次没有重叠,再继续抢。这次抢了第30篇,也就是和上次有重叠。这意味着蜘蛛从上次爬取到这次网站更新的29篇文章文章已经全部爬取了。
建议
目前百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据实际情况,但蜘蛛毕竟不能做100。%识别准确率,所以如果站长在做翻页栏的时候不使用JS,就不要使用FALSH,同时经常更新文章,配合蜘蛛爬行,可以大大提高准确率蜘蛛识别,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛正在考虑为公司构建爬行机制。实际上,许多机制是同时进行的。
网页抓取qq(Google的MattCutts确认了AdSense的Mediabot的确是会帮助Googlebot网页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-29 01:13
Google 的 Matt Cutts 证实 AdSense 的 Mediabot 确实会帮助 Googlebot 抓取网页,但有些人不相信 Matt Cutts,或者不相信他可以代表 Google 官员。作为 Matt Cutts 博客的忠实读者,我认为没有必要在 Matt Cutts 的权威上花任何篇幅。我想说的是,Matt Cutts 是谷歌质量管理部门的高级软件工程师。外界所知道的是,他负责研发防止垃圾邮件和控制排名的技术。所以,信不信由你,当然这取决于你。
镇江网站建筑公司
事实上,马特上次透露的只是内容的一个方面。今天Matt再次写了一篇很详细的文章,讲解了谷歌的各种bot是如何爬取网页的,以及谷歌最新的BigDaddy在爬取网页方面有哪些新的变化等等。非常精彩,分享给大家。
首先要介绍的是谷歌的爬取缓存代理。Matt 举了一个 ISP 和一个用户的例子来说明它。用户上网时,总是先通过ISP获取网页内容,再由ISP缓存用户访问过的网页,以备后用。例如,当用户A访问时,中国电信(或网通等)会将80后创业基地发送给用户A,然后缓存80后创业基地。当用户B下一秒再次访问时,中国电信会将缓存中幻灭的麦克风发送给用户B,从而节省带宽。
正如本站此前报道的那样,谷歌最新的软件升级(转移到BigDaddy)已经基本完成,所以升级后谷歌的各方面能力都会得到加强。这些增强功能包括更智能的 googlebot 抓取、改进的标准化以及更好的 收录 网页功能。在Googlebot抓取和抓取网页方面,谷歌也采用了节省带宽的方法。Googlebot 也随着 BigDaddy 的升级而升级。新的Googlebot已经正式支持gzip编码,所以如果你的网站开启了gzip编码,可以节省Googlebot在抓取你的网页时占用的带宽。
除了改进后的Googlebot,升级后的Google还会使用上面提到的抓取缓存代理来抓取网页,进一步节省带宽。
创业基地SEO频道了解到:谷歌蜘蛛主要在Googlebot上爬行,A服务器指的是AdSense,N服务器可以是Google的blogsearch或其他。我们可以看到同样的网站,Googlebot,AdSense的Mediabot,blogsearch的bots都爬过了,重复爬取的次数很多。升级后的谷歌使用的抓取缓存代理呢?
很明显,因为爬虫缓存代理缓存了各种爬虫的爬取,当Googlebot已经爬取了一些网页,而Mediabot或者其他爬虫又爬取了重复的网页时,爬取缓存代理就会发挥作用。缓存中的网页直接返回给Mediabot等,减少了实际爬取次数,节省了带宽。
从马特的分析可以看出,谷歌确实可以为自己和网站节省带宽。好处是谷歌的各种大庆网站建筑公司bots可以在一定时间内爬取更多。网页方便收录。我的理解是,虽然好处很明显,但也有坏处。例如,当 网站 以 AdSense 的广告费为生时,它需要 AdSense 的 Mediabot 不断访问以分析其更新网页的内容并投放更多相关广告。但是当这个网站是一个具有良好PR值的网站时,那么Googlebot很可能每天都在抓取它。这样,抓取缓存代理就会缓存Googlebot的抓取,等待Mediabot再次来。爬行时,它直接将缓存的内容返回给 Mediabot。这减少了 Mediabot 抓取此 网站 的次数。由于这两个机器人使用的工作机制并不完全相同,因此这个 网站 可能会因为 Mediabot 抓取次数的减少而降低所展示的 AdSense 广告的相关性。 查看全部
网页抓取qq(Google的MattCutts确认了AdSense的Mediabot的确是会帮助Googlebot网页的)
Google 的 Matt Cutts 证实 AdSense 的 Mediabot 确实会帮助 Googlebot 抓取网页,但有些人不相信 Matt Cutts,或者不相信他可以代表 Google 官员。作为 Matt Cutts 博客的忠实读者,我认为没有必要在 Matt Cutts 的权威上花任何篇幅。我想说的是,Matt Cutts 是谷歌质量管理部门的高级软件工程师。外界所知道的是,他负责研发防止垃圾邮件和控制排名的技术。所以,信不信由你,当然这取决于你。
镇江网站建筑公司
事实上,马特上次透露的只是内容的一个方面。今天Matt再次写了一篇很详细的文章,讲解了谷歌的各种bot是如何爬取网页的,以及谷歌最新的BigDaddy在爬取网页方面有哪些新的变化等等。非常精彩,分享给大家。
首先要介绍的是谷歌的爬取缓存代理。Matt 举了一个 ISP 和一个用户的例子来说明它。用户上网时,总是先通过ISP获取网页内容,再由ISP缓存用户访问过的网页,以备后用。例如,当用户A访问时,中国电信(或网通等)会将80后创业基地发送给用户A,然后缓存80后创业基地。当用户B下一秒再次访问时,中国电信会将缓存中幻灭的麦克风发送给用户B,从而节省带宽。
正如本站此前报道的那样,谷歌最新的软件升级(转移到BigDaddy)已经基本完成,所以升级后谷歌的各方面能力都会得到加强。这些增强功能包括更智能的 googlebot 抓取、改进的标准化以及更好的 收录 网页功能。在Googlebot抓取和抓取网页方面,谷歌也采用了节省带宽的方法。Googlebot 也随着 BigDaddy 的升级而升级。新的Googlebot已经正式支持gzip编码,所以如果你的网站开启了gzip编码,可以节省Googlebot在抓取你的网页时占用的带宽。
除了改进后的Googlebot,升级后的Google还会使用上面提到的抓取缓存代理来抓取网页,进一步节省带宽。
创业基地SEO频道了解到:谷歌蜘蛛主要在Googlebot上爬行,A服务器指的是AdSense,N服务器可以是Google的blogsearch或其他。我们可以看到同样的网站,Googlebot,AdSense的Mediabot,blogsearch的bots都爬过了,重复爬取的次数很多。升级后的谷歌使用的抓取缓存代理呢?
很明显,因为爬虫缓存代理缓存了各种爬虫的爬取,当Googlebot已经爬取了一些网页,而Mediabot或者其他爬虫又爬取了重复的网页时,爬取缓存代理就会发挥作用。缓存中的网页直接返回给Mediabot等,减少了实际爬取次数,节省了带宽。
从马特的分析可以看出,谷歌确实可以为自己和网站节省带宽。好处是谷歌的各种大庆网站建筑公司bots可以在一定时间内爬取更多。网页方便收录。我的理解是,虽然好处很明显,但也有坏处。例如,当 网站 以 AdSense 的广告费为生时,它需要 AdSense 的 Mediabot 不断访问以分析其更新网页的内容并投放更多相关广告。但是当这个网站是一个具有良好PR值的网站时,那么Googlebot很可能每天都在抓取它。这样,抓取缓存代理就会缓存Googlebot的抓取,等待Mediabot再次来。爬行时,它直接将缓存的内容返回给 Mediabot。这减少了 Mediabot 抓取此 网站 的次数。由于这两个机器人使用的工作机制并不完全相同,因此这个 网站 可能会因为 Mediabot 抓取次数的减少而降低所展示的 AdSense 广告的相关性。
网页抓取qq(就来“试水”一波TX吧~~(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-25 06:15
本文转载至知乎ID:查尔斯(白露维希)知乎个人专栏
下载W3Cschool手机app,0基础随时随地学习编程>>戳这里了解
带领
阅读之前关于爬虫的文章。. .
好像一直在欺负肖网站,没什么挑战性。. .
那就来一波TX“试水”吧~~~
本着T_T的原则,我决定把这期文章分成两部分。第一篇主要解决QQ空间的登录问题,尝试抓取一些信息,第二篇专门抓取QQ空间好友的信息,做可视化分析。
让我们愉快的开始吧~~~
相关文件
百度网盘下载链接:
密码:ycc
开发工具
Python版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
以及一些 Python 自带的模块。
环境设置
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载您使用的Chrome浏览器版本对应的驱动文件,下载完成后将chromedriver.exe所在的文件夹添加到环境变量中。
原理介绍
本文主要解决QQ空间的登录问题。
主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么这么绕?
selenium 好久没用了,写的太慢了。而且,自身的速度、资源消耗等问题也一直被大家诟病。
并且省略了无数的理由。
一些细节:
(1)第一次获取后保存cookie,下次登录前尝试看看保存的cookie是否有用,如果有用就直接使用,这样可以进一步节省时间。
(2)在抓包分析过程中,可以发现抓QQ空间数据所需的所有链接都收录了g_tk参数,这个参数其实是利用cookie中的skey参数计算出来的,所以我也是懒得打公式了,贴一小段代码:
最后:
如果你不抓取一些数据,似乎并不能证明这个 文章 真的有用。
好的,然后输入:
脱掉~~~
具体实现过程详见相关文件中的源码。
使用演示
QQ号(用户名)和密码(密码):
填写QQ_Spider.py文件,位置如下图:
跑:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
就这样。
下一个预览
在此问题的基础上,抓取好友的个人信息,并直观地分析抓取的结果。有兴趣的朋友可以提前试试~~~
其实,微调本文提供的代码,理论上可以捕获QQ所有用户的信息。当然,这只是理论上的,并且做了很多有趣的事情。
T_T,作为一个不乱不爱喝茶的男孩子,以上理论的实现我概不负责。 查看全部
网页抓取qq(就来“试水”一波TX吧~~(图))
本文转载至知乎ID:查尔斯(白露维希)知乎个人专栏
下载W3Cschool手机app,0基础随时随地学习编程>>戳这里了解
带领
阅读之前关于爬虫的文章。. .
好像一直在欺负肖网站,没什么挑战性。. .
那就来一波TX“试水”吧~~~
本着T_T的原则,我决定把这期文章分成两部分。第一篇主要解决QQ空间的登录问题,尝试抓取一些信息,第二篇专门抓取QQ空间好友的信息,做可视化分析。
让我们愉快的开始吧~~~
相关文件
百度网盘下载链接:
密码:ycc
开发工具
Python版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
以及一些 Python 自带的模块。
环境设置
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载您使用的Chrome浏览器版本对应的驱动文件,下载完成后将chromedriver.exe所在的文件夹添加到环境变量中。
原理介绍
本文主要解决QQ空间的登录问题。
主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么这么绕?
selenium 好久没用了,写的太慢了。而且,自身的速度、资源消耗等问题也一直被大家诟病。
并且省略了无数的理由。
一些细节:
(1)第一次获取后保存cookie,下次登录前尝试看看保存的cookie是否有用,如果有用就直接使用,这样可以进一步节省时间。
(2)在抓包分析过程中,可以发现抓QQ空间数据所需的所有链接都收录了g_tk参数,这个参数其实是利用cookie中的skey参数计算出来的,所以我也是懒得打公式了,贴一小段代码:
最后:
如果你不抓取一些数据,似乎并不能证明这个 文章 真的有用。
好的,然后输入:
脱掉~~~
具体实现过程详见相关文件中的源码。
使用演示
QQ号(用户名)和密码(密码):
填写QQ_Spider.py文件,位置如下图:

跑:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:


就这样。
下一个预览
在此问题的基础上,抓取好友的个人信息,并直观地分析抓取的结果。有兴趣的朋友可以提前试试~~~
其实,微调本文提供的代码,理论上可以捕获QQ所有用户的信息。当然,这只是理论上的,并且做了很多有趣的事情。
T_T,作为一个不乱不爱喝茶的男孩子,以上理论的实现我概不负责。
网页抓取qq(存储1.安装Selenium分析网页结构说说的时间代码实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-25 05:08
代码参考 /p/a6769dccd34d
只需联系 Selenium,点击这里 Selenium 和 PhantomJS
PS:代码的缺点是只能抓取第一页的内容。代码的改进是增加了与数据库的交互和存储。1.安装硒
pip install Selenium
2.Python中使用Selenium获取QQ空间小伙伴们的说说
分析网页结构
谈内容
说话的时间
3.代码实现(基于Python3)
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pymongo
# #使用Selenium的webdriver实例化一个浏览器对象,在这里使用Phantomjs
# driver = webdriver.PhantomJS(executable_path=r"D:\phantomjs-2.1.1-windows\bin\phantomjs.exe")
# #设置Phantomjs窗口最大化
# driver.maximize_window()
# 登录QQ空间
def get_shuoshuo(qq):
#建立与MongoClient的链接
client = pymongo.MongoClient('localhost', 27017)
#得到数据库
db = client['shuoshuo']
#得到一个数据集合
sheet_tab = db['sheet_tab']
chromedriver = r"E:\mycode\chromedriver.exe"
driver = webdriver.Chrome(chromedriver)
#使用get()方法打开待抓取的URL
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
#等待5秒后,判断页面是否需要登录,通过查找页面是否有相应的DIV的id来判断
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
#如果页面存在登录的DIV,则模拟登录
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear() # 选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
#判断好友空间是否设置了权限,通过判断是否存在元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
#如果有权限能够访问到说说页面,那么定位元素和数据,并解析
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con, sti in zip(content, stime):
data = {
'time': sti.text,
'shuos': con.text
}
print(data)
sheet_tab.insert_one(data)
pages = driver.page_source
soup = BeautifulSoup(pages, 'lxml')
#尝试一下获取Cookie,使用get_cookies()
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'], c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:', i)
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('好友的QQ号')
注意:使用前记得安装chromedriver插件,使用过程中会调用谷歌浏览器。如果写了绝对路径还是报错,请添加环境变量。
通过 Robo 3T(强大的数据库 MongoDB 数据库管理工具),我们可以看到我们已经将数据库存储在了数据库中。
接下来,我们应该用我们得到的数据做一些数据分析相关的事情……但我不会!!!
正在努力学习数据分析... 查看全部
网页抓取qq(存储1.安装Selenium分析网页结构说说的时间代码实现)
代码参考 /p/a6769dccd34d
只需联系 Selenium,点击这里 Selenium 和 PhantomJS
PS:代码的缺点是只能抓取第一页的内容。代码的改进是增加了与数据库的交互和存储。1.安装硒
pip install Selenium
2.Python中使用Selenium获取QQ空间小伙伴们的说说
分析网页结构
谈内容
说话的时间
3.代码实现(基于Python3)
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pymongo
# #使用Selenium的webdriver实例化一个浏览器对象,在这里使用Phantomjs
# driver = webdriver.PhantomJS(executable_path=r"D:\phantomjs-2.1.1-windows\bin\phantomjs.exe")
# #设置Phantomjs窗口最大化
# driver.maximize_window()
# 登录QQ空间
def get_shuoshuo(qq):
#建立与MongoClient的链接
client = pymongo.MongoClient('localhost', 27017)
#得到数据库
db = client['shuoshuo']
#得到一个数据集合
sheet_tab = db['sheet_tab']
chromedriver = r"E:\mycode\chromedriver.exe"
driver = webdriver.Chrome(chromedriver)
#使用get()方法打开待抓取的URL
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
#等待5秒后,判断页面是否需要登录,通过查找页面是否有相应的DIV的id来判断
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
#如果页面存在登录的DIV,则模拟登录
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear() # 选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
#判断好友空间是否设置了权限,通过判断是否存在元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
#如果有权限能够访问到说说页面,那么定位元素和数据,并解析
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con, sti in zip(content, stime):
data = {
'time': sti.text,
'shuos': con.text
}
print(data)
sheet_tab.insert_one(data)
pages = driver.page_source
soup = BeautifulSoup(pages, 'lxml')
#尝试一下获取Cookie,使用get_cookies()
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'], c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:', i)
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('好友的QQ号')
注意:使用前记得安装chromedriver插件,使用过程中会调用谷歌浏览器。如果写了绝对路径还是报错,请添加环境变量。
通过 Robo 3T(强大的数据库 MongoDB 数据库管理工具),我们可以看到我们已经将数据库存储在了数据库中。
接下来,我们应该用我们得到的数据做一些数据分析相关的事情……但我不会!!!
正在努力学习数据分析...
网页抓取qq(SEO优化:常用的指令指令整合、禁止搜索引擎的精确控制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-24 12:03
介绍
在做SEO的时候,很多时候我们都希望对页面进行准确的控制。Robots.txt 不能完全满足我们的需求。这时候我们就可以利用html的meta标签来精准的控制搜索引擎了。下面文章比较长,锐叔为大家综合了常用命令!
命令集成:禁止搜索引擎创建快照
百度不缓存快照(禁止百度快照):
所有搜索引擎,抓取本页,抓取链接,禁止快照:
所有搜索引擎,没有快照
上面的一段代码限制所有搜索引擎创建您的网页快照。需要注意的是,这样的标记只是禁止搜索引擎为你的网站创建快照。如果您想禁止搜索引擎将您的页面编入索引 对于该页面,请参考以下方法。
禁止搜索引擎抓取此页面
为了防止搜索引擎抓取这个页面,我们一般的做法是在页面的meta标签中添加如下代码:
这里的meta name="robots"泛指所有搜索引擎,这里也可以指特定的搜索引擎。
例如,元名称="Googlebot"、元名称="Baiduspide"等。
内容部分有四个命令:index、noindex、follow和nofollow。命令用英文“,”分隔。
根据上面的命令,我们有以下四种组合
:可以抓取本页,而且可以顺着本页继续索引别的链接
:不许抓取本页,但是可以顺着本页抓取索引别的链接
:可以抓取本页,但是不许顺着本页抓取索引别的链接
:不许抓取本页,也不许顺着本页抓取索引别的链接
这里需要注意的是,两个对立的反义词不能写在一起,例如
或者同时写两个句子
这是一个简单的写法,如果是
的形式,可以写成:
如果
的形式,可以写成:
当然,我们也可以将禁止创建快照和搜索引擎的命令写入命令元标记中。从上面文章,我们知道禁止创建网页快照的命令是noarchive,那么我们可以写成如下形式:
如果是针对单个不允许创建快照的搜索引擎,比如百度,我们可以这样写:
如果没有在meta标签中写关于蜘蛛的命令,那么默认命令如下
因此,如果我们对这部分不确定,我们可以直接写上面这行命令,或者留空。
在SEO中,对蜘蛛的控制是内容中非常重要的一部分,希望大家能够准确把握这部分内容。
原文链接:未经许可禁止转载。 查看全部
网页抓取qq(SEO优化:常用的指令指令整合、禁止搜索引擎的精确控制)
介绍
在做SEO的时候,很多时候我们都希望对页面进行准确的控制。Robots.txt 不能完全满足我们的需求。这时候我们就可以利用html的meta标签来精准的控制搜索引擎了。下面文章比较长,锐叔为大家综合了常用命令!
命令集成:禁止搜索引擎创建快照
百度不缓存快照(禁止百度快照):
所有搜索引擎,抓取本页,抓取链接,禁止快照:
所有搜索引擎,没有快照
上面的一段代码限制所有搜索引擎创建您的网页快照。需要注意的是,这样的标记只是禁止搜索引擎为你的网站创建快照。如果您想禁止搜索引擎将您的页面编入索引 对于该页面,请参考以下方法。
禁止搜索引擎抓取此页面
为了防止搜索引擎抓取这个页面,我们一般的做法是在页面的meta标签中添加如下代码:
这里的meta name="robots"泛指所有搜索引擎,这里也可以指特定的搜索引擎。
例如,元名称="Googlebot"、元名称="Baiduspide"等。
内容部分有四个命令:index、noindex、follow和nofollow。命令用英文“,”分隔。
根据上面的命令,我们有以下四种组合
:可以抓取本页,而且可以顺着本页继续索引别的链接
:不许抓取本页,但是可以顺着本页抓取索引别的链接
:可以抓取本页,但是不许顺着本页抓取索引别的链接
:不许抓取本页,也不许顺着本页抓取索引别的链接
这里需要注意的是,两个对立的反义词不能写在一起,例如
或者同时写两个句子
这是一个简单的写法,如果是
的形式,可以写成:
如果
的形式,可以写成:
当然,我们也可以将禁止创建快照和搜索引擎的命令写入命令元标记中。从上面文章,我们知道禁止创建网页快照的命令是noarchive,那么我们可以写成如下形式:
如果是针对单个不允许创建快照的搜索引擎,比如百度,我们可以这样写:
如果没有在meta标签中写关于蜘蛛的命令,那么默认命令如下
因此,如果我们对这部分不确定,我们可以直接写上面这行命令,或者留空。
在SEO中,对蜘蛛的控制是内容中非常重要的一部分,希望大家能够准确把握这部分内容。
原文链接:未经许可禁止转载。
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-24 12:00
1.问题描述
最近由于学习内容的要求,需要从网页抓取一些数据做分析报告。看了一些python爬虫的基础知识,直接去网站爬取数据。作为新手,踩坑在所难免。最近遇到了一个比较难的问题:
一般情况下,我们需要抓取网页上某个标签上的内容,通过urllib下载网页内容后,通过BeautifulSoup对象解析网页内容,然后通过fina_all()方法找到我们想要的标签内容。
比如我想抓取QQ音乐类播放列表下的所有播放列表信息。分解任务后,应该是:
抓取当前页面的播放列表信息;翻页;判断是否是最后一页,如果不是最后一页,则返回步骤1,如果是最后一页,则结束爬虫程序。
首先,编写一个简单的代码来获取单个页面上所有播放列表的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
可以通过右键单击网页并检查网页属性来找到标签参数。播放列表的标题信息可以通过属性类为playlist_title_txt的span标签找到,但是执行代码后,输出的结果只是一个空列表。是不是很奇怪?作为一个菜鸟,我真是绞尽脑汁想了半天也想不出原因。
然后和同学交流,听他讲了他之前看到的异步加载内容,发现我爬的网页的特征有点相似,于是去了解了一下。
一个流行的描述是,这个异步加载的网页显示的内容全部来自当前URL所代表的网页文件。部分内容是从当前网页文件中通过对另一个网页内容的函数调用来加载的,也就是说要获取的内容所属的网页文件确实与当前网页文件不是同一个文件当前网页文件,因此无法获取。因此,需要找到获取的内容真正所属的文件。
2.解决方案
接下来,我们将介绍如何查找异步加载的文件以及在爬取过程中可能遇到的坑。
1.网页右键选择**“检查”,在调试界面找到“网络”选项,然后一一找到js文件(记得刷新网页否则js文件不会被显示),通过预览**来查看内容是否是你要爬取的
2. 在各个js文件的具体信息面板中,可以通过预览查看传入的内容。我们找到了播放列表的标题信息的源文件,然后通过Headers属性可以找到该信息的真实源文件的链接,并使用url作为我们的requests参数。
Headers 属性下的通用和请求头收录了我们想要的信息。通用属性下的URL还包括值类型,这里是get。
所以我们可以通过请求模块获取播放列表信息。这里需要注意:网页的request headers值要传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3. 一般情况下,上面的处理过程会得到一个json对象(看起来像字典的字符串表示)。可以直接使用python中的json模块将json对象转成python对象—字典,方便通过key获取数据
jsDict = json.loads(jsContent)
但有时获取的数据形式除了json对象外还会加上json对象名,比如:
playList({...}) # 其中{}表示json对象内容
这种情况下无法通过json模块转换数据类型,通常会出现异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
在这种异常情况下,可以通过字符串的切片截取json对象信息,然后通过json模块转换数据类型(这是我想出来的一个笨方法。如果有人知道更正式的方法,希望能指正。点击(っ•̀ω•́)っ✎⁾⁾) 查看全部
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
1.问题描述
最近由于学习内容的要求,需要从网页抓取一些数据做分析报告。看了一些python爬虫的基础知识,直接去网站爬取数据。作为新手,踩坑在所难免。最近遇到了一个比较难的问题:
一般情况下,我们需要抓取网页上某个标签上的内容,通过urllib下载网页内容后,通过BeautifulSoup对象解析网页内容,然后通过fina_all()方法找到我们想要的标签内容。
比如我想抓取QQ音乐类播放列表下的所有播放列表信息。分解任务后,应该是:
抓取当前页面的播放列表信息;翻页;判断是否是最后一页,如果不是最后一页,则返回步骤1,如果是最后一页,则结束爬虫程序。
首先,编写一个简单的代码来获取单个页面上所有播放列表的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
可以通过右键单击网页并检查网页属性来找到标签参数。播放列表的标题信息可以通过属性类为playlist_title_txt的span标签找到,但是执行代码后,输出的结果只是一个空列表。是不是很奇怪?作为一个菜鸟,我真是绞尽脑汁想了半天也想不出原因。
然后和同学交流,听他讲了他之前看到的异步加载内容,发现我爬的网页的特征有点相似,于是去了解了一下。
一个流行的描述是,这个异步加载的网页显示的内容全部来自当前URL所代表的网页文件。部分内容是从当前网页文件中通过对另一个网页内容的函数调用来加载的,也就是说要获取的内容所属的网页文件确实与当前网页文件不是同一个文件当前网页文件,因此无法获取。因此,需要找到获取的内容真正所属的文件。
2.解决方案
接下来,我们将介绍如何查找异步加载的文件以及在爬取过程中可能遇到的坑。
1.网页右键选择**“检查”,在调试界面找到“网络”选项,然后一一找到js文件(记得刷新网页否则js文件不会被显示),通过预览**来查看内容是否是你要爬取的
2. 在各个js文件的具体信息面板中,可以通过预览查看传入的内容。我们找到了播放列表的标题信息的源文件,然后通过Headers属性可以找到该信息的真实源文件的链接,并使用url作为我们的requests参数。
Headers 属性下的通用和请求头收录了我们想要的信息。通用属性下的URL还包括值类型,这里是get。
所以我们可以通过请求模块获取播放列表信息。这里需要注意:网页的request headers值要传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3. 一般情况下,上面的处理过程会得到一个json对象(看起来像字典的字符串表示)。可以直接使用python中的json模块将json对象转成python对象—字典,方便通过key获取数据
jsDict = json.loads(jsContent)
但有时获取的数据形式除了json对象外还会加上json对象名,比如:
playList({...}) # 其中{}表示json对象内容
这种情况下无法通过json模块转换数据类型,通常会出现异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
在这种异常情况下,可以通过字符串的切片截取json对象信息,然后通过json模块转换数据类型(这是我想出来的一个笨方法。如果有人知道更正式的方法,希望能指正。点击(っ•̀ω•́)っ✎⁾⁾)
网页抓取qq(2020年7月29日2.JS型网页(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-24 09:00
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage之后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页没有采用嵌入网页的方式,而是选择了JS加载
这里我举一个北京请愿页面的例子()
我们会发现,当您选择不同的页面时,URL 不会改变,这与上面提到的嵌入页面相同。
右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载过程的一个明显标志。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载了新数据的JS文件,打开会发现PageCond/begin: 1< @8、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,和post请求一起发送给网站,我们就可以拿到数据了我们想要。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
网页抓取qq(2020年7月29日2.JS型网页(组图)
)
时间:2020年7月29日
联系电子邮件:
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage之后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS 可加载网页抓取
示例:一些动态网页没有采用嵌入网页的方式,而是选择了JS加载
这里我举一个北京请愿页面的例子()
我们会发现,当您选择不同的页面时,URL 不会改变,这与上面提到的嵌入页面相同。
右键打开源码,并没有找到iframe、html等内嵌页面的标志性标签,但是不难发现放置数据的div中有一个id,就是JS加载过程的一个明显标志。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,找到里面加载了新数据的JS文件,打开会发现PageCond/begin: 1< @8、 PageCond/length: 6个类似的参数,很明显网站根据这个参数加载了相关数据,和post请求一起发送给网站,我们就可以拿到数据了我们想要。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
网页抓取qq(一下代理如何使用步骤和步骤?代理IP的试用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-22 16:02
不知道大家在访问网站时有没有遇到过这样的情况。被采访的网站会给出提示。提示显示“访问频率太高”。如果要继续,则必须稍等片刻,否则对方会给出验证码,使用验证码解锁访问的网站。出现这个提示的原因是我们要爬取或访问的网站有反爬虫机制。例如,当使用同一个IP频繁请求一个网页的次数过多时,服务器是由于反爬虫机制的指示。因此,我们选择拒绝服务。这种情况单靠解封比较难处理,所以一种解决办法是伪装机器的IP地址来访问或抓取网页,
目前网上有很多代理ip,有的免费,有的收费。比如West Spur代理等,免费的不花钱,但有效的代理少且不稳定。付费的可能会更好。比如下面介绍的犀牛在线代理。试用一下代理IP,将可用IP保存到MongoDB中,方便下次检索。
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他:Chrome浏览器
该过程的简要说明是:
第 1 步:了解如何使用请求代理
第二步:从代理网页爬取到ip和端口
第三步:检查爬取的ip是否可用
第四步:将爬取到的可用代理存入MongoDB
第五步:从可用ip的数据库中随机抽取一个ip,测试成功后返回
对于请求,代理设置比较简单,只需要传入代理参数即可。
不过需要注意的是,这里我在机器上安装了抓包工具Fiddler,并用它在本地8888端口创建了一个HTTP代理服务(使用Chrome插件SwitchyOmega),即代理服务为: 127.0.0.1:8888,只要我们设置好这个代理,就可以成功地将本地IP切换到代理软件连接的服务器IP。
这里我用它作为测试网站,我们可以访问网页获取请求的相关信息,其中origin字段为客户端ip,根据返回的信息判断代理是否成功结果。返回结果如下:
接下来,我们开始爬取代理IP。首先,我们打开Chrome浏览器查看网页,找到ip和port元素的信息。
可以看到,代理IP将IP地址和相关信息存储在一个表中,所以我们在用BeautifulSoup提取的时候可以很方便的提取出相关信息,但是需要注意的是,爬取到的IP很可能是重复的。特别是当我们同时抓取多个代理网页并将它们存储在同一个数组中时,我们可以使用集合来去除重复的IP。
爬取到要爬取的页面数的ip后,存入数组,然后一一测试ip。
这里就是上面提到的请求设置代理的方法,我们用它作为测试网站,它可以直接返回我们的ip地址,测试通过后会存入MomgoDB数据库中。
连接数据库然后指定数据库和集合,然后插入数据就OK了。
最后运行查看结果
运行一段时间后,很少看到连续三个测试通过,所以我赶紧保存截图。事实上,它毕竟是一个自由球员。有效的很少,存活时间真的很短。但是,爬取量很大。, 还是可以找到的,如果只是作为练习,勉强够用。现在看看数据库中存储了什么。
因为爬取的页面不多,加上有效IP也很少,我也没有做太多爬取,所以现在数据库里的IP并不多,但是这些IP还是保存了下来。现在让我们看看如何随机取出它。
因为担心ip放入数据库一段时间后会失效,所以重新测试了一下才取出来。如果成功,我将返回该ip。如果不成功,我会把它移出数据库。
这样,当我们需要使用代理时,就可以随时通过数据库进行检索。
总代码如下:
/人/hdmi博客
本文转载于:,由犀牛社主办 查看全部
网页抓取qq(一下代理如何使用步骤和步骤?代理IP的试用)
不知道大家在访问网站时有没有遇到过这样的情况。被采访的网站会给出提示。提示显示“访问频率太高”。如果要继续,则必须稍等片刻,否则对方会给出验证码,使用验证码解锁访问的网站。出现这个提示的原因是我们要爬取或访问的网站有反爬虫机制。例如,当使用同一个IP频繁请求一个网页的次数过多时,服务器是由于反爬虫机制的指示。因此,我们选择拒绝服务。这种情况单靠解封比较难处理,所以一种解决办法是伪装机器的IP地址来访问或抓取网页,
目前网上有很多代理ip,有的免费,有的收费。比如West Spur代理等,免费的不花钱,但有效的代理少且不稳定。付费的可能会更好。比如下面介绍的犀牛在线代理。试用一下代理IP,将可用IP保存到MongoDB中,方便下次检索。
操作平台:Windows
Python版本:Python3.6
IDE:崇高的文本
其他:Chrome浏览器
该过程的简要说明是:
第 1 步:了解如何使用请求代理
第二步:从代理网页爬取到ip和端口
第三步:检查爬取的ip是否可用
第四步:将爬取到的可用代理存入MongoDB
第五步:从可用ip的数据库中随机抽取一个ip,测试成功后返回
对于请求,代理设置比较简单,只需要传入代理参数即可。
不过需要注意的是,这里我在机器上安装了抓包工具Fiddler,并用它在本地8888端口创建了一个HTTP代理服务(使用Chrome插件SwitchyOmega),即代理服务为: 127.0.0.1:8888,只要我们设置好这个代理,就可以成功地将本地IP切换到代理软件连接的服务器IP。
这里我用它作为测试网站,我们可以访问网页获取请求的相关信息,其中origin字段为客户端ip,根据返回的信息判断代理是否成功结果。返回结果如下:
接下来,我们开始爬取代理IP。首先,我们打开Chrome浏览器查看网页,找到ip和port元素的信息。
可以看到,代理IP将IP地址和相关信息存储在一个表中,所以我们在用BeautifulSoup提取的时候可以很方便的提取出相关信息,但是需要注意的是,爬取到的IP很可能是重复的。特别是当我们同时抓取多个代理网页并将它们存储在同一个数组中时,我们可以使用集合来去除重复的IP。
爬取到要爬取的页面数的ip后,存入数组,然后一一测试ip。
这里就是上面提到的请求设置代理的方法,我们用它作为测试网站,它可以直接返回我们的ip地址,测试通过后会存入MomgoDB数据库中。
连接数据库然后指定数据库和集合,然后插入数据就OK了。
最后运行查看结果
运行一段时间后,很少看到连续三个测试通过,所以我赶紧保存截图。事实上,它毕竟是一个自由球员。有效的很少,存活时间真的很短。但是,爬取量很大。, 还是可以找到的,如果只是作为练习,勉强够用。现在看看数据库中存储了什么。
因为爬取的页面不多,加上有效IP也很少,我也没有做太多爬取,所以现在数据库里的IP并不多,但是这些IP还是保存了下来。现在让我们看看如何随机取出它。
因为担心ip放入数据库一段时间后会失效,所以重新测试了一下才取出来。如果成功,我将返回该ip。如果不成功,我会把它移出数据库。
这样,当我们需要使用代理时,就可以随时通过数据库进行检索。
总代码如下:
/人/hdmi博客
本文转载于:,由犀牛社主办
网页抓取qq(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-17 23:17
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:
您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系! 查看全部
网页抓取qq(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
我们来看看 Steam 社区 Grant Theft Auto V 评论的网页。您会注意到网页的完整内容不会一次性加载。
我们需要向下滚动以在页面上加载更多内容。这是网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但对我们来说,问题是当我们试图从这个页面抓取数据时,我们只能得到那个页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容受限的问题依然存在。那么让我们看看如何抓取这些页面。
导航到目标 URL 并打开“检查元素网络”窗口。接下来点击reload按钮,它会为你记录网络的加载顺序,比如图片加载、API请求、POST请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送对更多数据的请求:
进一步滚动,您将看到 网站 如何发出请求。看下面的网址——只有部分参数值在变化,你可以用简单的Python代码轻松生成这些网址:
您需要按照相同的步骤通过将请求逐页发送到每个页面来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网页抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要有关现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将教授 Web 抓取 BeatifulSoup。您可以在此处查看-使用 Python 进行 Web 爬网简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听你最喜欢的图书馆想法(即使你使用 R!),以及你在这个主题上的经验。在下面的评论部分告诉我,我们会与您联系!
网页抓取qq(想要轻松获取网站的内链,那就赶紧来使用网页链接提取工具绿色版软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-12-17 11:13
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大、实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!
功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、 并且可以自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先进入个人网站 网站地图:个人网站域名/sitemap.xml
二、 输入后点击Extract and Save即可获取最近更新的域名信息
三、网页链接提取自动保存到软件所在文件夹 查看全部
网页抓取qq(想要轻松获取网站的内链,那就赶紧来使用网页链接提取工具绿色版软件)
如果你想轻松获取网站的内链,那就赶紧使用绿色版的网页链接提取工具吧。本软件是一款功能强大、实用的网站内链采集软件,功能强大。@网站内链获取工具,使用后即可获取所有内链网站,大大提高工作效率,操作简单,使用方便。绿色版网页链接提取工具可以帮助用户一键获取网站中的链接,非常适合来做SEO优化排名的用户。本工具自动获取网站的所有内部链接,节省大量人工完成时间,方便快捷;如果您是从事seo优化的用户,而且工作流程没有相关的排名优化来帮你,会浪费你很多时间。如果您目前急需提高排名优化的效率。网页链接提取工具绿色版可以帮你解决。感兴趣的小伙伴快来下载体验吧!
功能介绍1、批量获取网站链接、图片链接
2、批量获取脚本链接
3、批量获取CSS链接
4、支持快速复制源码
5、支持快速复制链接软件功能1、网页链接提取工具绿色版,非常适合做seo优化的排名人员
2、使用这个软件可以节省很多时间
3、 并且可以自动完成网站的所有内链选择
4、还可以有计划地将提取的内链提交给各种收录工具
5、这样就可以完成收录数量的增加。如何使用绿色版网页链接提取工具一、 下载并打开绿色版网页链接提取工具,首先进入个人网站 网站地图:个人网站域名/sitemap.xml
二、 输入后点击Extract and Save即可获取最近更新的域名信息
三、网页链接提取自动保存到软件所在文件夹
网页抓取qq(网页文字版权是归刘小月文艺创作编码标签(Content-Type))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-16 03:29
网页文字版权归刘晓月艺术创作工作室所有
编码标签(Content-Type)
网页文件格式编码国标gb2312
使用这些标签可以使搜索引擎更容易理解您的网页内容。
综合应用如下:
二。头部区域标签注意事项
(1)标题长度
标题是对网页内容的总结和提炼。在标题标签中过多重复 关键词 通常会适得其反。搜索引擎一般只分析前20个汉字。超过20个汉字将被丢弃。如果是英文,应该控制在60个字母以内,超出的部分也不计入排名计算。
(2)描述和关键词
Description和关键词是头部区域权重仅次于title的标签。Description 和 关键词 都是标识 关键词 的标签。然而,描述也承担着在自然列表中展示网页内容的重要任务。其内容的好坏关系到它能否吸引到网站的访问者。
(图5-1)说明了国美网上商城的实力,吸引搜索者浏览。
(3)title的重要性
标题标签是搜索引擎计算网页排名的主要依据。可以说,标题标签是整个网页中最重要的标签。
(4)如何写出好的描述
描述奇奇在在线推广和营销中将搜索者拉入自我网站 的作用。写描述时,要诚恳,不要夸大其词,不要过分夸大个性,给搜索者一个友好的印象。
(5)关键词标签的禁忌
关键字标签一直是搜索引擎优化中作弊的重灾区。在这里重复堆砌相同的关键词,已经成为一种让排名高的手段,也是搜索引擎惩罚网站的一个原因。
三体区的组成
标题标题标签
Hx 标签是身体区域中最重要的标签。它负责网页内容的分割和归属。H1、H2、H3、H4、H5、H6 分别代表段落标题的递减权重。例如,H1 是网页的标题。H2 是小节级别的标题。H3 是每个部分的标题。那么H6没用吗?当然不是。H6只是权重意义的弱化,代表意义依然存在。
比如一篇关于亚洲旅游的文章,网页上的安排如下
(图5-2)HX标签从最重要到最小的顺序递减
亚洲旅游
中国旅游
上海旅游
四川旅游
日本旅游
东京旅游
京都旅游
二、 标签的理解
标签的使用在于两个方面:熟练度和排列。使用计算机理解来模拟人类思考和分析问题的方式。把你想表达的意思准确地传达给电脑才是最重要的。
三、 网页命名
网页的命名与域名的选择非常相似。例如,对于链接和拼音计算中不需要的具有特定含义的字母,拼音的url地址更有优势。对比/list253和/xiamennews,同一个介绍厦门新闻的网页,显然厦门新闻有更多的含义,而这个含义本身就是对搜索引擎的描述。 查看全部
网页抓取qq(网页文字版权是归刘小月文艺创作编码标签(Content-Type))
网页文字版权归刘晓月艺术创作工作室所有
编码标签(Content-Type)
网页文件格式编码国标gb2312
使用这些标签可以使搜索引擎更容易理解您的网页内容。
综合应用如下:
二。头部区域标签注意事项
(1)标题长度
标题是对网页内容的总结和提炼。在标题标签中过多重复 关键词 通常会适得其反。搜索引擎一般只分析前20个汉字。超过20个汉字将被丢弃。如果是英文,应该控制在60个字母以内,超出的部分也不计入排名计算。
(2)描述和关键词
Description和关键词是头部区域权重仅次于title的标签。Description 和 关键词 都是标识 关键词 的标签。然而,描述也承担着在自然列表中展示网页内容的重要任务。其内容的好坏关系到它能否吸引到网站的访问者。
(图5-1)说明了国美网上商城的实力,吸引搜索者浏览。
(3)title的重要性
标题标签是搜索引擎计算网页排名的主要依据。可以说,标题标签是整个网页中最重要的标签。
(4)如何写出好的描述
描述奇奇在在线推广和营销中将搜索者拉入自我网站 的作用。写描述时,要诚恳,不要夸大其词,不要过分夸大个性,给搜索者一个友好的印象。
(5)关键词标签的禁忌
关键字标签一直是搜索引擎优化中作弊的重灾区。在这里重复堆砌相同的关键词,已经成为一种让排名高的手段,也是搜索引擎惩罚网站的一个原因。
三体区的组成
标题标题标签
Hx 标签是身体区域中最重要的标签。它负责网页内容的分割和归属。H1、H2、H3、H4、H5、H6 分别代表段落标题的递减权重。例如,H1 是网页的标题。H2 是小节级别的标题。H3 是每个部分的标题。那么H6没用吗?当然不是。H6只是权重意义的弱化,代表意义依然存在。
比如一篇关于亚洲旅游的文章,网页上的安排如下
(图5-2)HX标签从最重要到最小的顺序递减
亚洲旅游
中国旅游
上海旅游
四川旅游
日本旅游
东京旅游
京都旅游
二、 标签的理解
标签的使用在于两个方面:熟练度和排列。使用计算机理解来模拟人类思考和分析问题的方式。把你想表达的意思准确地传达给电脑才是最重要的。
三、 网页命名
网页的命名与域名的选择非常相似。例如,对于链接和拼音计算中不需要的具有特定含义的字母,拼音的url地址更有优势。对比/list253和/xiamennews,同一个介绍厦门新闻的网页,显然厦门新闻有更多的含义,而这个含义本身就是对搜索引擎的描述。
网页抓取qq(Java抓取前端渲染的页面如何处理-pageapplication? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-10 09:24
)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容,往往无法获取有效信息。那么如何处理这种页面呢?一般来说有两种方法:html
在爬取阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬取。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。由于js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且相对于页面样式,这种界面变化的可能性较小。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我个人的看法是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种还是比较可靠的。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。前端
对于第一种方法,webmagic-selenium 就是这样的一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,跟平台和版本有关。没有稳定的解决方案。我们先介绍一下这个尝试。爪哇
由于无论怎么动态加载,初始页面总是收录基本信息,我们可以用爬虫代码模拟js代码,js读取页面元素值,我们也读取页面元素值;js发送ajax,我们只是拼凑参数,发送ajax,解析返回的json。这总是可以的,但是比较麻烦。有没有更省力的方法?更好的方法可能是嵌入浏览器。Python
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。Selenium 是跨语言的,有Java、C#、python 等版本,支持多种浏览器、chrome、firefox 和IE。angularjs
在Java项目中使用Selenium,需要做两件事:web
在项目中引入Selenium Java模块,以Maven为例:
org.seleniumhq.selenium
selenium-java
2.33.0
下载对应的驱动,以chrome为例:
下载后需要将驱动的位置写入Java环境变量中。比如mac下下载到/Users/yihua/Downloads/chromedriver,需要在程序中加入如下代码(虽然在JVM参数中写-Dxxx=xxx也是可以的):
System.getProperties().setProperty("webdriver.chrome.driver","/Users/yihua/Downloads/chromedriver");
Selenium的API很简单,核心是WebDriver,下面是动态渲染页面并获取最终html的代码:ajax
@Test
public void testSelenium() {
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/yihua/Downloads/chromedriver");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://huaban.com/");
WebElement webElement = webDriver.findElement(By.xpath("/html"));
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
值得注意的是,每次 new ChromeDriver() 时,Selenium 都会创建一个 Chrome 进程,并使用一个随机端口与 Java 中的 chrome 进程进行通信进行交互。所以有两个问题:chrome
最后说一下效率问题。嵌入浏览器后,不仅需要更多的CPU来渲染页面,还要下载页面附带的资源。似乎缓存了单个 webDriver 中的静态资源。初始化后,访问速度会加快。尝试ChromeDriver加载花瓣首页100次,总共耗时263秒,平均每页2.6秒。苹果系统
/**
* 花瓣网抽取器。
* 使用Selenium作页面动态渲染。
*/
public class HuabanProcessor implements PageProcessor {
private Site site;
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("http://huaban\\.com/.*").all());
if (page.getUrl().toString().contains("pins")) {
page.putField("img", page.getHtml().xpath("//div[@id='pin_img']/img/@src").toString());
} else {
page.getResultItems().setSkip(true);
}
}
@Override
public Site getSite() {
if (site == null) {
site = Site.me().setDomain("huaban.com").addStartUrl("http://huaban.com/").setSleepTime(1000);
}
return site;
}
public static void main(String[] args) {
Spider.create(new HuabanProcessor()).thread(5)
.scheduler(new RedisScheduler("localhost"))
.pipeline(new FilePipeline("/data/webmagic/test/"))
.downloader(new SeleniumDownloader("/Users/yihua/Downloads/chromedriver"))
.run();
}
}
public class SeleniumDownloader implements Downloader, Closeable {
private volatile WebDriverPool webDriverPool;
private Logger logger = Logger.getLogger(getClass());
private int sleepTime = 0;
private int poolSize = 1;
private static final String DRIVER_PHANTOMJS = "phantomjs";
/**
* 新建
*
* @param chromeDriverPath chromeDriverPath
*/
public SeleniumDownloader(String chromeDriverPath) {
System.getProperties().setProperty("webdriver.chrome.driver",
chromeDriverPath);
}
/**
* Constructor without any filed. Construct PhantomJS browser
*
* @author bob.li.0718@gmail.com
*/
public SeleniumDownloader() {
// System.setProperty("phantomjs.binary.path",
// "/Users/Bingo/Downloads/phantomjs-1.9.7-macosx/bin/phantomjs");
}
/**
* set sleep time to wait until load success
*
* @param sleepTime sleepTime
* @return this
*/
public SeleniumDownloader setSleepTime(int sleepTime) {
this.sleepTime = sleepTime;
return this;
}
@Override
public Page download(Request request, Task task) {
checkInit();
WebDriver webDriver;
try {
webDriver = webDriverPool.get();
} catch (InterruptedException e) {
logger.warn("interrupted", e);
return null;
}
logger.info("downloading page " + request.getUrl());
webDriver.get(request.getUrl());
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebDriver.Options manage = webDriver.manage();
Site site = task.getSite();
if (site.getCookies() != null) {
for (Map.Entry cookieEntry : site.getCookies()
.entrySet()) {
Cookie cookie = new Cookie(cookieEntry.getKey(),
cookieEntry.getValue());
manage.addCookie(cookie);
}
}
/*
* TODO You can add mouse event or other processes
*
* @author: bob.li.0718@gmail.com
*/
WebElement webElement = webDriver.findElement(By.xpath("/html"));
String content = webElement.getAttribute("outerHTML");
Page page = new Page();
page.setRawText(content);
page.setHtml(new Html(content, request.getUrl()));
page.setUrl(new PlainText(request.getUrl()));
page.setRequest(request);
webDriverPool.returnToPool(webDriver);
return page;
}
private void checkInit() {
if (webDriverPool == null) {
synchronized (this) {
webDriverPool = new WebDriverPool(poolSize);
}
}
}
@Override
public void setThread(int thread) {
this.poolSize = thread;
}
@Override
public void close() throws IOException {
webDriverPool.closeAll();
}
}
这里我们以AngularJS中文社区为例。
json
(1) 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息(Ctrl+F),基本可以确定是js渲染。
在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,则可以确定是js渲染,这个数据是通过AJAX获取的。
(2)分析请求
现在让我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例。我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(而且大部分都是下拉页面,总之所有你认为可能会触发新数据的操作)做),然后记得保持现场,一一分析请求。
这一步需要一点耐心,但也不是没有规律可循。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会在XHR选项卡下显示,JSONP请求会在Scripts选项卡下。这是两种常见的数据类型。
然后可以根据数据的大小来判断,通常结果越大返回数据的接口。剩下的基本就是凭经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,您现在可以查看响应正文是什么。这在开发人员工具中并不清楚。让我们将 URL 复制到地址栏并再次请求它。看结果,好像找到了自己想要的。
有时,返回的类型不是json格式,而是html格式。我们稍后会解释这一点。
(3) 编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只不过我们替换了AJAX方法-AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
1)数据列表:
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情的请求由一些固定的URL加上这个id组成。因此,在这一步中,我们自己手动构建了URL,并将其添加到待抓取的队列中。这里我们使用JsonPath,一种选择数据的语言(webmagic-extension包提供了JsonPathSelector来支持)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里咱们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
2)目标数据
有了URL,解析目标数据其实很简单。由于JSON数据完全结构化,因此省略了分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
最终代码如下:
public class AngularJSProcessor implements PageProcessor {
private Site site = Site.me();
private static final String ARITICALE_URL = "http://angularjs\\.cn/api/article/\\w+";
private static final String LIST_URL = "http://angularjs\\.cn/api/article/latest.*";
@Override
public void process(Page page) {
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/" + id);
}
}
} else {
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new AngularJSProcessor()).addUrl("http://angularjs.cn/api/articl ... 6quot;).run();
}
}
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现连接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建连接 => 下载并分析目标 AJAX
对于不同的站点,这种辅助数据大部分是在页面的HTML中预先输出的,大部分是通过AJAX请求的,大部分是重复数据请求的过程,但是这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点。因此,如前所述,如果js请求的结果也是Html,其实只需要再构造一个http请求,将请求的Url添加到要查询的Url中即可。
那么对于前面的例子,如果公告不可用,我该怎么办?
查看源代码后是这样的:
断言:是通过ajax获取的。
然后我们检查请求的Url:
返回的是html。这很简单。将请求的连接放入并再次处理。我们来看看url是什么:
触及知识盲区。
一世?? ? ? ? ? ? ?
这个id是哪里来的??
一世?? ? ?
我现在迷失在风和沙中。. . .
算了,等我弄明白再说。它很难。
public void process(Page page) {
//判断连接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
page.putField("name",page.getHtml().xpath("//*[@id=\"author_profile_detail\"]/a[1]/text()"));
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor2()).addUrl("https://www.cnblogs.com/mvc/bl ... 6quot;).addPipeline(new MyPipeline()).thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
} 查看全部
网页抓取qq(Java抓取前端渲染的页面如何处理-pageapplication?
)
抓取前端渲染的页面
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容,往往无法获取有效信息。那么如何处理这种页面呢?一般来说有两种方法:html
在爬取阶段,爬虫内置浏览器内核,执行js渲染页面后,进行爬取。这方面对应的工具有Selenium、HtmlUnit或PhantomJs。但是,这些工具存在一定的效率问题,同时也不太稳定。优点是写入规则与静态页面相同。由于js渲染页面的数据也是从后端获取的,而且基本都是通过AJAX获取的,所以分析AJAX请求,找到对应数据的请求也是一种可行的方式。并且相对于页面样式,这种界面变化的可能性较小。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较多的分析经验。
比较两种方法,我个人的看法是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种还是比较可靠的。对于某些站点,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,第二种方法会很复杂。前端
对于第一种方法,webmagic-selenium 就是这样的一种尝试。它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,跟平台和版本有关。没有稳定的解决方案。我们先介绍一下这个尝试。爪哇
由于无论怎么动态加载,初始页面总是收录基本信息,我们可以用爬虫代码模拟js代码,js读取页面元素值,我们也读取页面元素值;js发送ajax,我们只是拼凑参数,发送ajax,解析返回的json。这总是可以的,但是比较麻烦。有没有更省力的方法?更好的方法可能是嵌入浏览器。Python
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。Selenium 是跨语言的,有Java、C#、python 等版本,支持多种浏览器、chrome、firefox 和IE。angularjs
在Java项目中使用Selenium,需要做两件事:web
在项目中引入Selenium Java模块,以Maven为例:
org.seleniumhq.selenium
selenium-java
2.33.0
下载对应的驱动,以chrome为例:
下载后需要将驱动的位置写入Java环境变量中。比如mac下下载到/Users/yihua/Downloads/chromedriver,需要在程序中加入如下代码(虽然在JVM参数中写-Dxxx=xxx也是可以的):
System.getProperties().setProperty("webdriver.chrome.driver","/Users/yihua/Downloads/chromedriver");
Selenium的API很简单,核心是WebDriver,下面是动态渲染页面并获取最终html的代码:ajax
@Test
public void testSelenium() {
System.getProperties().setProperty("webdriver.chrome.driver", "/Users/yihua/Downloads/chromedriver");
WebDriver webDriver = new ChromeDriver();
webDriver.get("http://huaban.com/";);
WebElement webElement = webDriver.findElement(By.xpath("/html"));
System.out.println(webElement.getAttribute("outerHTML"));
webDriver.close();
}
值得注意的是,每次 new ChromeDriver() 时,Selenium 都会创建一个 Chrome 进程,并使用一个随机端口与 Java 中的 chrome 进程进行通信进行交互。所以有两个问题:chrome
最后说一下效率问题。嵌入浏览器后,不仅需要更多的CPU来渲染页面,还要下载页面附带的资源。似乎缓存了单个 webDriver 中的静态资源。初始化后,访问速度会加快。尝试ChromeDriver加载花瓣首页100次,总共耗时263秒,平均每页2.6秒。苹果系统
/**
* 花瓣网抽取器。
* 使用Selenium作页面动态渲染。
*/
public class HuabanProcessor implements PageProcessor {
private Site site;
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("http://huaban\\.com/.*").all());
if (page.getUrl().toString().contains("pins")) {
page.putField("img", page.getHtml().xpath("//div[@id='pin_img']/img/@src").toString());
} else {
page.getResultItems().setSkip(true);
}
}
@Override
public Site getSite() {
if (site == null) {
site = Site.me().setDomain("huaban.com").addStartUrl("http://huaban.com/";).setSleepTime(1000);
}
return site;
}
public static void main(String[] args) {
Spider.create(new HuabanProcessor()).thread(5)
.scheduler(new RedisScheduler("localhost"))
.pipeline(new FilePipeline("/data/webmagic/test/"))
.downloader(new SeleniumDownloader("/Users/yihua/Downloads/chromedriver"))
.run();
}
}
public class SeleniumDownloader implements Downloader, Closeable {
private volatile WebDriverPool webDriverPool;
private Logger logger = Logger.getLogger(getClass());
private int sleepTime = 0;
private int poolSize = 1;
private static final String DRIVER_PHANTOMJS = "phantomjs";
/**
* 新建
*
* @param chromeDriverPath chromeDriverPath
*/
public SeleniumDownloader(String chromeDriverPath) {
System.getProperties().setProperty("webdriver.chrome.driver",
chromeDriverPath);
}
/**
* Constructor without any filed. Construct PhantomJS browser
*
* @author bob.li.0718@gmail.com
*/
public SeleniumDownloader() {
// System.setProperty("phantomjs.binary.path",
// "/Users/Bingo/Downloads/phantomjs-1.9.7-macosx/bin/phantomjs");
}
/**
* set sleep time to wait until load success
*
* @param sleepTime sleepTime
* @return this
*/
public SeleniumDownloader setSleepTime(int sleepTime) {
this.sleepTime = sleepTime;
return this;
}
@Override
public Page download(Request request, Task task) {
checkInit();
WebDriver webDriver;
try {
webDriver = webDriverPool.get();
} catch (InterruptedException e) {
logger.warn("interrupted", e);
return null;
}
logger.info("downloading page " + request.getUrl());
webDriver.get(request.getUrl());
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebDriver.Options manage = webDriver.manage();
Site site = task.getSite();
if (site.getCookies() != null) {
for (Map.Entry cookieEntry : site.getCookies()
.entrySet()) {
Cookie cookie = new Cookie(cookieEntry.getKey(),
cookieEntry.getValue());
manage.addCookie(cookie);
}
}
/*
* TODO You can add mouse event or other processes
*
* @author: bob.li.0718@gmail.com
*/
WebElement webElement = webDriver.findElement(By.xpath("/html"));
String content = webElement.getAttribute("outerHTML");
Page page = new Page();
page.setRawText(content);
page.setHtml(new Html(content, request.getUrl()));
page.setUrl(new PlainText(request.getUrl()));
page.setRequest(request);
webDriverPool.returnToPool(webDriver);
return page;
}
private void checkInit() {
if (webDriverPool == null) {
synchronized (this) {
webDriverPool = new WebDriverPool(poolSize);
}
}
}
@Override
public void setThread(int thread) {
this.poolSize = thread;
}
@Override
public void close() throws IOException {
webDriverPool.closeAll();
}
}
这里我们以AngularJS中文社区为例。
json
(1) 如何判断前端渲染
判断页面是否被js渲染的方法比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果找不到有效信息(Ctrl+F),基本可以确定是js渲染。
在这个例子中,如果源代码中找不到页面上的标题“有福计算机网络-前端攻城引擎”,则可以确定是js渲染,这个数据是通过AJAX获取的。
(2)分析请求
现在让我们进入最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是在浏览器中查看网络请求的开发者工具。
以Chome为例。我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(而且大部分都是下拉页面,总之所有你认为可能会触发新数据的操作)做),然后记得保持现场,一一分析请求。
这一步需要一点耐心,但也不是没有规律可循。首先可以帮助我们的是上面的分类过滤器(All、Document 等选项)。如果是普通的AJAX,会在XHR选项卡下显示,JSONP请求会在Scripts选项卡下。这是两种常见的数据类型。
然后可以根据数据的大小来判断,通常结果越大返回数据的接口。剩下的基本就是凭经验了。比如这里的“latest?p=1&s=20”一看就可疑……
对于可疑地址,您现在可以查看响应正文是什么。这在开发人员工具中并不清楚。让我们将 URL 复制到地址栏并再次请求它。看结果,好像找到了自己想要的。
有时,返回的类型不是json格式,而是html格式。我们稍后会解释这一点。
(3) 编程
回顾之前的列表+目标页面的例子,我们会发现我们这次的需求和之前的差不多,只不过我们替换了AJAX方法-AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们还是可以用最后一种方法,分成两页来写:
1)数据列表:
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情的请求由一些固定的URL加上这个id组成。因此,在这一步中,我们自己手动构建了URL,并将其添加到待抓取的队列中。这里我们使用JsonPath,一种选择数据的语言(webmagic-extension包提供了JsonPathSelector来支持)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里咱们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
2)目标数据
有了URL,解析目标数据其实很简单。由于JSON数据完全结构化,因此省略了分析页面和编写XPath的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
最终代码如下:
public class AngularJSProcessor implements PageProcessor {
private Site site = Site.me();
private static final String ARITICALE_URL = "http://angularjs\\.cn/api/article/\\w+";
private static final String LIST_URL = "http://angularjs\\.cn/api/article/latest.*";
@Override
public void process(Page page) {
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/" + id);
}
}
} else {
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new AngularJSProcessor()).addUrl("http://angularjs.cn/api/articl ... 6quot;).run();
}
}
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。其实动态页面爬取最大的区别就是增加了链接发现的难度。让我们比较一下两种开发模式:
后台渲染页面
下载辅助页面 => 发现连接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建连接 => 下载并分析目标 AJAX
对于不同的站点,这种辅助数据大部分是在页面的HTML中预先输出的,大部分是通过AJAX请求的,大部分是重复数据请求的过程,但是这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点。因此,如前所述,如果js请求的结果也是Html,其实只需要再构造一个http请求,将请求的Url添加到要查询的Url中即可。
那么对于前面的例子,如果公告不可用,我该怎么办?
查看源代码后是这样的:
断言:是通过ajax获取的。
然后我们检查请求的Url:
返回的是html。这很简单。将请求的连接放入并再次处理。我们来看看url是什么:
触及知识盲区。
一世?? ? ? ? ? ? ?
这个id是哪里来的??
一世?? ? ?
我现在迷失在风和沙中。. . .
算了,等我弄明白再说。它很难。
public void process(Page page) {
//判断连接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
page.putField("name",page.getHtml().xpath("//*[@id=\"author_profile_detail\"]/a[1]/text()"));
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor2()).addUrl("https://www.cnblogs.com/mvc/bl ... 6quot;).addPipeline(new MyPipeline()).thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
网页抓取qq(登陆页面二维码图片登陆校验需要哪些参数(上)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 419 次浏览 • 2021-12-09 09:09
一、背景:前几天收到一个请求:获取QQ好友、QQ群、QQ群好友的账号。可惜抓不到QQ程序的包。我觉得应该是QQ程序之间的通讯协议大部分不是HTTP或HTTPS,我用的Fillder所以找不到包,但不影响我完成需求。找了大部分QQ的相关应用,终于在QQ空间找到了可以满足这个需求的数据。于是我改变了思路和方法去Qzone抓数据。
二、分析:QQ空间一般采用两种登录方式:一种是账号密码登录,一种是扫码登录。领导要求扫码登录,所以我来做扫码登录。
反复抓包查资料,发现相关登录接口如下(注意后面文中用接口名代替连接):
登录页面
二维码图片
登录验证
首先我们分析一下登录验证需要哪些参数(因为它最容易找到,而且我们一进入就一直在等待验证):
经过反复抓包测试,发现需要的参数不定:ptqrtoken、action、login_sig。一看就知道action是一个时间戳拼接字段,另外两个字段应该是页面请求时设置的cookie值。通过全局搜索字段发现login_sig就是登录页面的pt_login_sig。
然后,到登录页面获取cookie中pt_login_sig对应的值。经过几次抓包,发现接口参数是固定的:
至于ptqrtoken全局搜索,会找到c_login_2.js的js文件。进入预览视图格式化js代码,搜索ptqrtoken,会发现如下一段代码:
很明显,他的意思是获取某个cookie中的qrsig字段,然后进行hash33加密,首先全局查找qrsig,发现二维码图片的cookie中有这个字段,同时保存二维码获得领域。这个接口是固定的,除了一个参数是0-1之间的随机数。
然后全局查找hash33加密过程,结果还是c_login_2.js文件中找到的如下代码片段:
将js代码转换为python代码:
<p> def __decrypt_qrsig(self, qrsig):
e = 0
for c in qrsig:
e += (e 查看全部
网页抓取qq(登陆页面二维码图片登陆校验需要哪些参数(上)?)
一、背景:前几天收到一个请求:获取QQ好友、QQ群、QQ群好友的账号。可惜抓不到QQ程序的包。我觉得应该是QQ程序之间的通讯协议大部分不是HTTP或HTTPS,我用的Fillder所以找不到包,但不影响我完成需求。找了大部分QQ的相关应用,终于在QQ空间找到了可以满足这个需求的数据。于是我改变了思路和方法去Qzone抓数据。
二、分析:QQ空间一般采用两种登录方式:一种是账号密码登录,一种是扫码登录。领导要求扫码登录,所以我来做扫码登录。
反复抓包查资料,发现相关登录接口如下(注意后面文中用接口名代替连接):
登录页面
二维码图片
登录验证
首先我们分析一下登录验证需要哪些参数(因为它最容易找到,而且我们一进入就一直在等待验证):
经过反复抓包测试,发现需要的参数不定:ptqrtoken、action、login_sig。一看就知道action是一个时间戳拼接字段,另外两个字段应该是页面请求时设置的cookie值。通过全局搜索字段发现login_sig就是登录页面的pt_login_sig。
然后,到登录页面获取cookie中pt_login_sig对应的值。经过几次抓包,发现接口参数是固定的:
至于ptqrtoken全局搜索,会找到c_login_2.js的js文件。进入预览视图格式化js代码,搜索ptqrtoken,会发现如下一段代码:
很明显,他的意思是获取某个cookie中的qrsig字段,然后进行hash33加密,首先全局查找qrsig,发现二维码图片的cookie中有这个字段,同时保存二维码获得领域。这个接口是固定的,除了一个参数是0-1之间的随机数。
然后全局查找hash33加密过程,结果还是c_login_2.js文件中找到的如下代码片段:
将js代码转换为python代码:
<p> def __decrypt_qrsig(self, qrsig):
e = 0
for c in qrsig:
e += (e
网页抓取qq(竞价必备神器,页面访客QQ提取工具(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-08 16:06
竞价必备神器,页面访客QQ提取工具 首先欢迎大家观看本教程,本教程是竞价必备神器,做竞价的朋友会发现有些网站每次点击一天,但没有咨询,没有咨询也意味着没有秩序。为了解决这个问题,济南大神向出价用户的朋友们强烈推荐一款神器页面客户QQ提取软件。这个软件的神奇之处在于,即使不咨询你,你也会得到客户的QQ号,主动联系客户,最终拿到订单。为减少客户流失,下面详细介绍本软件的优点。7. 可以给客户发邮件(需要企业QQ邮箱)。我们先来看看软件的实际操作。您将看到以下文件。首先点击生成js文件。输入你的黄钻QQ号,先运行页面访客提取工具.exe。运行后会看到界面,点击Generate,js文本就升级了。例如,命名为1.js,上传1.js到你的网站根目录,在你的网站主页前加人“/body”,把我的网站替换为你的。然后单击导入帐户。把你的QQ账号和密码放在记事本里。格式如 657235615----12345678 密码在哪里。导入成功后,会看到如下界面,然后点击批量登录。登录后,点击开始采集。效果图是这样的。那么如果你去找你< @网站 见。右侧列表中会出现客户的QQ号码,可以实现在线QQ对话。也可以给客户发邮件(需要QQ企业邮箱)。视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 查看全部
网页抓取qq(竞价必备神器,页面访客QQ提取工具(图)!)
竞价必备神器,页面访客QQ提取工具 首先欢迎大家观看本教程,本教程是竞价必备神器,做竞价的朋友会发现有些网站每次点击一天,但没有咨询,没有咨询也意味着没有秩序。为了解决这个问题,济南大神向出价用户的朋友们强烈推荐一款神器页面客户QQ提取软件。这个软件的神奇之处在于,即使不咨询你,你也会得到客户的QQ号,主动联系客户,最终拿到订单。为减少客户流失,下面详细介绍本软件的优点。7. 可以给客户发邮件(需要企业QQ邮箱)。我们先来看看软件的实际操作。您将看到以下文件。首先点击生成js文件。输入你的黄钻QQ号,先运行页面访客提取工具.exe。运行后会看到界面,点击Generate,js文本就升级了。例如,命名为1.js,上传1.js到你的网站根目录,在你的网站主页前加人“/body”,把我的网站替换为你的。然后单击导入帐户。把你的QQ账号和密码放在记事本里。格式如 657235615----12345678 密码在哪里。导入成功后,会看到如下界面,然后点击批量登录。登录后,点击开始采集。效果图是这样的。那么如果你去找你< @网站 见。右侧列表中会出现客户的QQ号码,可以实现在线QQ对话。也可以给客户发邮件(需要QQ企业邮箱)。视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系 视频教程是全网最低价。这款神器软件只要500元,软件+注册机只要2000元。不能亏本2000块买。你买不到。购买后可以卖给别人。朋友们,还等什么,行动起来,有了这个神器,你就有了你客户的联系方式。买家请联系
网页抓取qq(无良商家就是利用那么简单的原理卖几千块一套源码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-07 22:20
最近经常在网上看到很多卖网站获取访客QQ号的程序。没有统一的价格。最高的是6000,最低的是一两百元。出于好奇,我测试了他们的系统,看到了获取访客QQ号码的神奇原理。当我添加一段 JS 脚本代码时,他们将我发送到我们的主页 html。我访问了自己的网页,却一直没有得到 号码。然后我咨询了卖家。他说,在访问自己的网站之前,需要先登录自己的QQ空间或QQ邮箱等腾讯相关产品。不,那么它不能被抓取。此时,我先登录QQ空间访问我的网站,结果果然是卖家说的。
那么我有一个问题,为什么我需要登录QQ空间才能抓取访客QQ号?我大胆地想象,当我的朋友访问我的QQ空间时,他们可以查看我最近访问者中朋友的QQ号码。我只需要通过IFRAME把QQ空间的首页放到网站,然后就可以得到访问者的QQ号,得到来人的方式。但是有一个缺点,就是访问者必须登录过QQ空间或其他QQ产品,所以无法获取所有QQ号。我想这应该是他们说的为什么我在访问网站之前需要登录Qzone等相关产品的原因。这就是网站获取访客QQ号统计的原理。
想到这里,我立马写了一个DEMO放到网站上。我发现成功率这么高。访问了50多个IP,抢到了30多个QQ号。真没想到如果你网站访问者是年轻用户,成功率会更高。原理很简单。发布这个的原则是希望大家可以自己写程序,不用把别人的代码放在自己的网站上,数据也不怕被泄露。这只是其中的一种方法,以后公开的方法还有好几种。鄙视那些无良商家,就是用这么简单的道理,卖上千条源代码。因为不公,我也写了一个统计程序供大家免费使用。318 个统计数据***。
文章转载自318 stats***.com请带此链接,谢谢 查看全部
网页抓取qq(无良商家就是利用那么简单的原理卖几千块一套源码。)
最近经常在网上看到很多卖网站获取访客QQ号的程序。没有统一的价格。最高的是6000,最低的是一两百元。出于好奇,我测试了他们的系统,看到了获取访客QQ号码的神奇原理。当我添加一段 JS 脚本代码时,他们将我发送到我们的主页 html。我访问了自己的网页,却一直没有得到 号码。然后我咨询了卖家。他说,在访问自己的网站之前,需要先登录自己的QQ空间或QQ邮箱等腾讯相关产品。不,那么它不能被抓取。此时,我先登录QQ空间访问我的网站,结果果然是卖家说的。
那么我有一个问题,为什么我需要登录QQ空间才能抓取访客QQ号?我大胆地想象,当我的朋友访问我的QQ空间时,他们可以查看我最近访问者中朋友的QQ号码。我只需要通过IFRAME把QQ空间的首页放到网站,然后就可以得到访问者的QQ号,得到来人的方式。但是有一个缺点,就是访问者必须登录过QQ空间或其他QQ产品,所以无法获取所有QQ号。我想这应该是他们说的为什么我在访问网站之前需要登录Qzone等相关产品的原因。这就是网站获取访客QQ号统计的原理。
想到这里,我立马写了一个DEMO放到网站上。我发现成功率这么高。访问了50多个IP,抢到了30多个QQ号。真没想到如果你网站访问者是年轻用户,成功率会更高。原理很简单。发布这个的原则是希望大家可以自己写程序,不用把别人的代码放在自己的网站上,数据也不怕被泄露。这只是其中的一种方法,以后公开的方法还有好几种。鄙视那些无良商家,就是用这么简单的道理,卖上千条源代码。因为不公,我也写了一个统计程序供大家免费使用。318 个统计数据***。
文章转载自318 stats***.com请带此链接,谢谢
网页抓取qq(【新三板】一下+beautifulsoup实现抓取中财网数据引擎的公司档案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-07 14:17
记录一个python爬虫的快速实现,想抓取中国财经网数据引擎新三板板块下所有股票的公司文件。网站在这里。html
更简单的网站不同的页码有不同的联系。可以通过观察连接的变化找出规律,然后生成所有与页码对应的连接然后分别抓取,但是这个网站改变页面的时候连接没有变化,所以我计划在第二页被点击时观察请求python
发现使用了get的请求方法,并且请求中有一个curpage参数,好像控制不同的页数,所以在请求连接中改变了这个参数的值,其他的值发现没有变化,所以我决定改变它。就是利用我们标题中提到的selenium+beautifulsoup来模拟点击网页中的下一页按钮进行翻页,分别抓取网页的内容。混帐
首先我们做一些准备工作,安装必要的包,打开命令行,直接pip install selenium和pip installbeautifulsoup4github
然后就是下载安装chromedriver驱动了,网址下面,记得配置环境变量或者直接安装在工作目录下。(也可以使用IE、phantomJS等) web
这里我们先抓取每只股票对应的首页链接,代码如下(使用python2):chrome
1 # -*- coding: utf-8 -*-
2 from selenium import webdriver
3 from bs4 import BeautifulSoup
4 import sys
5 reload(sys)
6 sys.setdefaultencoding('utf-8')
7
8 def crawl(url):
9 driver = webdriver.Chrome()
10 driver.get(url)
11 page = 0
12 lst=[]
13 with open('./url.txt','a') as f:
14 while page < 234:
15 soup = BeautifulSoup(driver.page_source, "html.parser")
16 print(soup)
17 urls_tag = soup.find_all('a',target='_blank')
18 print(urls_tag)
19 for i in urls_tag:
20 if i['href'] not in lst:
21 f.write(i['href']+'\n')
22 lst.append(i['href'])
23 driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
24 time.sleep(2)
25 return 'Finished'
26 def main():
27 url = 'http://data.cfi.cn/cfidata.aspx?sortfd=&sortway=&curpage=2&fr=content&ndk=A0A1934A1935A1986A1995&xztj=&mystock='
28 crawl(url)
29 if __name__ == '__main__':
30 main()
运行代码,发现老是报错:app
这里的错误意味着找不到您要查找的按钮。蟒蛇爬虫
那么我们查看一下网页的源码:网站
发现网页被分成了不同的frame,所以我们猜测需要跳转到frame。我们需要抓取的连接所在的frame名称是“content”,所以我们添加一行代码:driver.switch_to.frame('content') google
def crawl(url):
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame('content')
page = 0
lst=[]
with open('./url.txt','a') as f:
while page < 234:
soup = BeautifulSoup(driver.page_source, "html.parser")
print(soup)
urls_tag = soup.find_all('a',target='_blank')
print(urls_tag)
for i in urls_tag:
if i['href'] not in lst:
f.write(i['href']+'\n')
lst.append(i['href'])
driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
time.sleep(2)
return 'Finished'
到目前为止,它运行到:
参考博文链接:%E5%88%A9%E7%94%A8beautifulsoup+selenium%E8%87%AA%E5%8A%A8%E7%BF%BB%E9%A1%B5%E6%8A%93% E5 %8F%96%E7%BD%91%E9%A1%B5%E5%86%85%E5%AE%B9/ 查看全部
网页抓取qq(【新三板】一下+beautifulsoup实现抓取中财网数据引擎的公司档案)
记录一个python爬虫的快速实现,想抓取中国财经网数据引擎新三板板块下所有股票的公司文件。网站在这里。html
更简单的网站不同的页码有不同的联系。可以通过观察连接的变化找出规律,然后生成所有与页码对应的连接然后分别抓取,但是这个网站改变页面的时候连接没有变化,所以我计划在第二页被点击时观察请求python
发现使用了get的请求方法,并且请求中有一个curpage参数,好像控制不同的页数,所以在请求连接中改变了这个参数的值,其他的值发现没有变化,所以我决定改变它。就是利用我们标题中提到的selenium+beautifulsoup来模拟点击网页中的下一页按钮进行翻页,分别抓取网页的内容。混帐
首先我们做一些准备工作,安装必要的包,打开命令行,直接pip install selenium和pip installbeautifulsoup4github
然后就是下载安装chromedriver驱动了,网址下面,记得配置环境变量或者直接安装在工作目录下。(也可以使用IE、phantomJS等) web
这里我们先抓取每只股票对应的首页链接,代码如下(使用python2):chrome
1 # -*- coding: utf-8 -*-
2 from selenium import webdriver
3 from bs4 import BeautifulSoup
4 import sys
5 reload(sys)
6 sys.setdefaultencoding('utf-8')
7
8 def crawl(url):
9 driver = webdriver.Chrome()
10 driver.get(url)
11 page = 0
12 lst=[]
13 with open('./url.txt','a') as f:
14 while page < 234:
15 soup = BeautifulSoup(driver.page_source, "html.parser")
16 print(soup)
17 urls_tag = soup.find_all('a',target='_blank')
18 print(urls_tag)
19 for i in urls_tag:
20 if i['href'] not in lst:
21 f.write(i['href']+'\n')
22 lst.append(i['href'])
23 driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
24 time.sleep(2)
25 return 'Finished'
26 def main():
27 url = 'http://data.cfi.cn/cfidata.aspx?sortfd=&sortway=&curpage=2&fr=content&ndk=A0A1934A1935A1986A1995&xztj=&mystock='
28 crawl(url)
29 if __name__ == '__main__':
30 main()
运行代码,发现老是报错:app
这里的错误意味着找不到您要查找的按钮。蟒蛇爬虫
那么我们查看一下网页的源码:网站
发现网页被分成了不同的frame,所以我们猜测需要跳转到frame。我们需要抓取的连接所在的frame名称是“content”,所以我们添加一行代码:driver.switch_to.frame('content') google
def crawl(url):
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame('content')
page = 0
lst=[]
with open('./url.txt','a') as f:
while page < 234:
soup = BeautifulSoup(driver.page_source, "html.parser")
print(soup)
urls_tag = soup.find_all('a',target='_blank')
print(urls_tag)
for i in urls_tag:
if i['href'] not in lst:
f.write(i['href']+'\n')
lst.append(i['href'])
driver.find_element_by_xpath("//a[contains(text(),'下一页')]").click()
time.sleep(2)
return 'Finished'
到目前为止,它运行到:
参考博文链接:%E5%88%A9%E7%94%A8beautifulsoup+selenium%E8%87%AA%E5%8A%A8%E7%BF%BB%E9%A1%B5%E6%8A%93% E5 %8F%96%E7%BD%91%E9%A1%B5%E5%86%85%E5%AE%B9/
网页抓取qq(场景有时候想使用某些网页上的数据,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-02 15:13
1、场景
有时我想使用某些网页上的数据,但这些数据不是通过简单的get/post请求获得的,但是即使没有现成的界面,只要显示在网页上,就可以爬下来使用,就是用代码为我们进行选择→复制→粘贴操作
2、原理
只要加载的网页是html文档,在这个网页上爬取文本数据就可以理解为从一串很长的字符串中截取我们想要的部分。理论上,根据一定的匹配/拦截规则,即使只是使用 if Else 也可以从html文档中得到你想要的数据,因为html本身有一套完整的语法/标签,所以有第三方可以直接根据这些规则使用,快速抓取数据。
3、使用的第三方
Java可以使用Jsoup
swift可以使用ji(注意使用的版本,swift的很多方法名这几年都更新了,老版本的库也有改动)
OC 可以使用一个框架
本文主要记录One框架下载链接的使用,包括demo
手动集成需要在Header Search Paths中添加/usr/include/libxml2、/usr/include/libresolv
4、代码
1、下载网页数据
NSData * data = [NSData dataWithContentsOfURL:[NSURL URLWithString:[urlStr stringByAddingPercentEncodingWithAllowedCharacters:[NSCharacterSet URLQueryAllowedCharacterSet]]]];
2、获取网页文档对象
NSError *错误;
ONOXMLDocument *doc=[ONOXMLDocument HTMLDocumentWithData:data error:&error];
3、根据条件查询节点对象
[doc firstChildWithXPath:@"///*[@id='test'] // 获取第一个id为test的节点
[doc firstChildWithXPath:@"///*[.class='test'] // 获取第一个类为 test 的节点
[doc firstChildWithTag:@"span"]// 获取第一个span
4、获取节点对象文本
元素.stringValue 查看全部
网页抓取qq(场景有时候想使用某些网页上的数据,怎么办?)
1、场景
有时我想使用某些网页上的数据,但这些数据不是通过简单的get/post请求获得的,但是即使没有现成的界面,只要显示在网页上,就可以爬下来使用,就是用代码为我们进行选择→复制→粘贴操作
2、原理
只要加载的网页是html文档,在这个网页上爬取文本数据就可以理解为从一串很长的字符串中截取我们想要的部分。理论上,根据一定的匹配/拦截规则,即使只是使用 if Else 也可以从html文档中得到你想要的数据,因为html本身有一套完整的语法/标签,所以有第三方可以直接根据这些规则使用,快速抓取数据。
3、使用的第三方
Java可以使用Jsoup
swift可以使用ji(注意使用的版本,swift的很多方法名这几年都更新了,老版本的库也有改动)
OC 可以使用一个框架
本文主要记录One框架下载链接的使用,包括demo
手动集成需要在Header Search Paths中添加/usr/include/libxml2、/usr/include/libresolv
4、代码
1、下载网页数据
NSData * data = [NSData dataWithContentsOfURL:[NSURL URLWithString:[urlStr stringByAddingPercentEncodingWithAllowedCharacters:[NSCharacterSet URLQueryAllowedCharacterSet]]]];
2、获取网页文档对象
NSError *错误;
ONOXMLDocument *doc=[ONOXMLDocument HTMLDocumentWithData:data error:&error];
3、根据条件查询节点对象
[doc firstChildWithXPath:@"///*[@id='test'] // 获取第一个id为test的节点
[doc firstChildWithXPath:@"///*[.class='test'] // 获取第一个类为 test 的节点
[doc firstChildWithTag:@"span"]// 获取第一个span
4、获取节点对象文本
元素.stringValue
网页抓取qq(如何使用访客统计助手联系本站客服开通账号,请注意区分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-02 11:13
1、什么是访客统计助手
访客统计助手通过一段JS代码连接本站独有的分析系统,获取您的网站实时访客QQ信息,
通过这种有意的QQ访客,进行二次营销,尽可能挽回你流失的客户,让你的流量和竞价成本不再浪费!
2、使用访客统计助手有什么好处
只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确地分析来访的目标客户,
更多网站一个用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户的QQ号码后,
您可以在系统后台直接与客户发起临时QQ对话,主动询问客户需求。
了解客户的需求,并持续跟进,最终产生销售。此外,本站还推出了全网独有的基于网络的在线邮件群发功能。
您还可以访问关键词 分析潜在客户以发送个人广告电子邮件。快捷方便!
3、如何使用访客统计助手
联系我们客服开户,登录网站后台,然后获取访客QQ统计码,
插入你的 网站 底部或头部开始计数!
1、如何插入访客QQ统计代码
登录后台,点击左侧导航的Get Code按钮,复制你得到的code,插入你的网站,
在这里你会看到两段代码。第一段是html代码,可以插入html、php、asp等文件,第二段是js代码。
只能插入到你的网站 js文件中,请注意区分!
百度网盘下载地址: 查看全部
网页抓取qq(如何使用访客统计助手联系本站客服开通账号,请注意区分)
1、什么是访客统计助手
访客统计助手通过一段JS代码连接本站独有的分析系统,获取您的网站实时访客QQ信息,
通过这种有意的QQ访客,进行二次营销,尽可能挽回你流失的客户,让你的流量和竞价成本不再浪费!
2、使用访客统计助手有什么好处
只需在您的网页中添加一段代码,即可准确获取客户QQ号。配置超级简单。快速准确地分析来访的目标客户,
更多网站一个用户后台可管理,节省人力物力,最大化广告效果。使用我们的系统获取潜在客户的QQ号码后,
您可以在系统后台直接与客户发起临时QQ对话,主动询问客户需求。
了解客户的需求,并持续跟进,最终产生销售。此外,本站还推出了全网独有的基于网络的在线邮件群发功能。
您还可以访问关键词 分析潜在客户以发送个人广告电子邮件。快捷方便!
3、如何使用访客统计助手
联系我们客服开户,登录网站后台,然后获取访客QQ统计码,
插入你的 网站 底部或头部开始计数!
1、如何插入访客QQ统计代码
登录后台,点击左侧导航的Get Code按钮,复制你得到的code,插入你的网站,
在这里你会看到两段代码。第一段是html代码,可以插入html、php、asp等文件,第二段是js代码。
只能插入到你的网站 js文件中,请注意区分!
百度网盘下载地址:
网页抓取qq(网站总是频繁出现“异常提示”怎么办?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2021-12-02 05:15
自从百度进行了“抓取异常”检查后,很多站长发现网站总是频繁出现“异常提示”。那么百度网页抓取的要点有哪些呢?一起来奇帆网了解更多吧!
一:爬取时出现DNS错误
很多新手发现网页无法访问,会找服务商,但忽略了一点:网站域名DNS web服务器也会有问题!当网站出现问题时,应该一会就清楚了。问题。如果是DNS问题,建议立即更换DSN。温馨提示:DNSPOD应用广泛,作者最近监测了空闲节点的一些超时情况,也提醒DSNPOD开始解决。
另外,很多网站站长现阶段喜欢使用“一些云加速”,但小编也应该说,现阶段很多直言云加速并不完善,尤其是这些完全免费的时候而且前期做的很好,到了中后期有客户的时候,就惨了。
提醒:当您的网站没有受到强烈攻击时,请不要使用纯云加速,追求完美的花式,很容易伤害到自己。网站域名DSN级别目前在万网(阿里巴巴)稳定。
二:存在爬取超时问题
在A5营销推广的SEO诊断中,人们非常重视客户体验。有一点非常重要:客户打开网页的速度。如果网页不能一次打开,它们就会丢失。浏览资格,并跳转到其他网站。搜索引擎蜘蛛呢?也是如此。如果暂时不能爬取,就会出现爬取超时问题。
这个爬取请求的超时通常是网络带宽不足和大网页造成的。网页级别的人建议: A:在不影响照片质量的情况下,尽可能缩小和提交照片。在这种情况下,进行了减持。B:减少JS脚本等应用做扩展,或者进行合并。 查看全部
网页抓取qq(网站总是频繁出现“异常提示”怎么办?(图))
自从百度进行了“抓取异常”检查后,很多站长发现网站总是频繁出现“异常提示”。那么百度网页抓取的要点有哪些呢?一起来奇帆网了解更多吧!
一:爬取时出现DNS错误
很多新手发现网页无法访问,会找服务商,但忽略了一点:网站域名DNS web服务器也会有问题!当网站出现问题时,应该一会就清楚了。问题。如果是DNS问题,建议立即更换DSN。温馨提示:DNSPOD应用广泛,作者最近监测了空闲节点的一些超时情况,也提醒DSNPOD开始解决。
另外,很多网站站长现阶段喜欢使用“一些云加速”,但小编也应该说,现阶段很多直言云加速并不完善,尤其是这些完全免费的时候而且前期做的很好,到了中后期有客户的时候,就惨了。
提醒:当您的网站没有受到强烈攻击时,请不要使用纯云加速,追求完美的花式,很容易伤害到自己。网站域名DSN级别目前在万网(阿里巴巴)稳定。
二:存在爬取超时问题
在A5营销推广的SEO诊断中,人们非常重视客户体验。有一点非常重要:客户打开网页的速度。如果网页不能一次打开,它们就会丢失。浏览资格,并跳转到其他网站。搜索引擎蜘蛛呢?也是如此。如果暂时不能爬取,就会出现爬取超时问题。
这个爬取请求的超时通常是网络带宽不足和大网页造成的。网页级别的人建议: A:在不影响照片质量的情况下,尽可能缩小和提交照片。在这种情况下,进行了减持。B:减少JS脚本等应用做扩展,或者进行合并。
网页抓取qq(第二代V2全面升级支持:定时循环监控采集访客、自动保存访客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-30 16:02
QQ空间访客采集专家v0831免费版.zip
QQ空间访客采集专家是一款可以批量批量处理采集QQ空间访客的工具。只需输入一个或多个源QQ,即可采集一键访问QQ空间访客信息(访客QQ、访客昵称、访问时间),支持多层采集(如如采集123456 访问者84302438,程序可以继续采集84302438 子访问者,自定义层计数等,无限循环采集)!此功能用于采集捕捉准确的QQ客户,可以是采集竞争对手空间的访客,方便营销!支持导出为表格或文本!二代V2全面升级支持:采集访客定时循环监控,指定日期访客过滤,访客自动保存。还支持QQ空间动态浏览访客采集(一般朋友刷新空间时会在动态浏览中留下痕迹,类似抢竞争对手的朋友,超强大功能)请注意:需要相同权限采集 未经许可不能做。注意,软件目前支持采集最新访问者、相册访问者、动态浏览3个频道的访问者。采集采集之前请确保您有权限(您可以手动检查。)该软件无法突破任何限制。空间有限或无相册访问者不能采集,敬请谅解。目前第一代和第二代都开放使用,第一代不再更新。QQ空间访客采集
现在就下载 查看全部
网页抓取qq(第二代V2全面升级支持:定时循环监控采集访客、自动保存访客)
QQ空间访客采集专家v0831免费版.zip
QQ空间访客采集专家是一款可以批量批量处理采集QQ空间访客的工具。只需输入一个或多个源QQ,即可采集一键访问QQ空间访客信息(访客QQ、访客昵称、访问时间),支持多层采集(如如采集123456 访问者84302438,程序可以继续采集84302438 子访问者,自定义层计数等,无限循环采集)!此功能用于采集捕捉准确的QQ客户,可以是采集竞争对手空间的访客,方便营销!支持导出为表格或文本!二代V2全面升级支持:采集访客定时循环监控,指定日期访客过滤,访客自动保存。还支持QQ空间动态浏览访客采集(一般朋友刷新空间时会在动态浏览中留下痕迹,类似抢竞争对手的朋友,超强大功能)请注意:需要相同权限采集 未经许可不能做。注意,软件目前支持采集最新访问者、相册访问者、动态浏览3个频道的访问者。采集采集之前请确保您有权限(您可以手动检查。)该软件无法突破任何限制。空间有限或无相册访问者不能采集,敬请谅解。目前第一代和第二代都开放使用,第一代不再更新。QQ空间访客采集
现在就下载
网页抓取qq(如何判断是否是有序翻页式网页的抓住机制看法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 01:15
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下,保持系统和实际环境中页面的一致性,这意味着蜘蛛不会抓取网站 的所有页面。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这也是我们要做好网站的链接结构的原因。接下来,笔者将只关注蜘蛛对翻页网页的抓取机制。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率不同,而文章链接很有可能是Push到翻页栏,这样蜘蛛就不能每天从第一个翻页栏爬到第80个,然后爬一个文章和一个文章比较用数据库,太浪费蜘蛛的时间也浪费你网站的收录时间,所以蜘蛛需要额外的爬取机制来针对这种特殊类型的翻页网页,保证网站的完整性
如何判断是否是有序翻页?
判断文章是否按照发布时间有序排列,是这类页面的必要条件,下面会讲到。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使不写发布时间,Spider Writer也可以根据文章本身的实际发布时间来判断。
爬取机制是如何工作的?
对于这种翻页页面,蜘蛛主要记录每次抓取网页时找到的文章链接,然后将本次找到的文章链接与历史上找到的链接进行比较。如果有Intersection,说明这次爬取已经找到了所有新的文章,可以停止下一页翻页栏的爬取;否则,说明这次爬取没有找到所有新的文章,需要继续爬下一页甚至后面几页才能找到所有新的文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比起手机网站Building as在网站页面目录,新增了29篇文章,据说上次最新的文章是第30篇,并且蜘蛛一次抓取了10篇文章链接,这样蜘蛛第一次抓取了10篇文章,与上次没有重叠,所以继续抓取我第二次抓取了10篇文章时间,也就是我一共抓了20篇文章。还是和上次没有重叠,再继续抢。这次抢了第30篇,也就是和上次有重叠。这意味着蜘蛛从上次爬取到这次网站更新的29篇文章文章已经全部爬取了。
建议
目前百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据实际情况,但蜘蛛毕竟不能做100。%识别准确率,所以如果站长在做翻页栏的时候不使用JS,就不要使用FALSH,同时经常更新文章,配合蜘蛛爬行,可以大大提高准确率蜘蛛识别,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛正在考虑为公司构建爬行机制。实际上,许多机制是同时进行的。 查看全部
网页抓取qq(如何判断是否是有序翻页式网页的抓住机制看法?)
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下,保持系统和实际环境中页面的一致性,这意味着蜘蛛不会抓取网站 的所有页面。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这也是我们要做好网站的链接结构的原因。接下来,笔者将只关注蜘蛛对翻页网页的抓取机制。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率不同,而文章链接很有可能是Push到翻页栏,这样蜘蛛就不能每天从第一个翻页栏爬到第80个,然后爬一个文章和一个文章比较用数据库,太浪费蜘蛛的时间也浪费你网站的收录时间,所以蜘蛛需要额外的爬取机制来针对这种特殊类型的翻页网页,保证网站的完整性
如何判断是否是有序翻页?
判断文章是否按照发布时间有序排列,是这类页面的必要条件,下面会讲到。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使不写发布时间,Spider Writer也可以根据文章本身的实际发布时间来判断。
爬取机制是如何工作的?
对于这种翻页页面,蜘蛛主要记录每次抓取网页时找到的文章链接,然后将本次找到的文章链接与历史上找到的链接进行比较。如果有Intersection,说明这次爬取已经找到了所有新的文章,可以停止下一页翻页栏的爬取;否则,说明这次爬取没有找到所有新的文章,需要继续爬下一页甚至后面几页才能找到所有新的文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比起手机网站Building as在网站页面目录,新增了29篇文章,据说上次最新的文章是第30篇,并且蜘蛛一次抓取了10篇文章链接,这样蜘蛛第一次抓取了10篇文章,与上次没有重叠,所以继续抓取我第二次抓取了10篇文章时间,也就是我一共抓了20篇文章。还是和上次没有重叠,再继续抢。这次抢了第30篇,也就是和上次有重叠。这意味着蜘蛛从上次爬取到这次网站更新的29篇文章文章已经全部爬取了。
建议
目前百度蜘蛛会对网页的类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并根据实际情况,但蜘蛛毕竟不能做100。%识别准确率,所以如果站长在做翻页栏的时候不使用JS,就不要使用FALSH,同时经常更新文章,配合蜘蛛爬行,可以大大提高准确率蜘蛛识别,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛正在考虑为公司构建爬行机制。实际上,许多机制是同时进行的。
网页抓取qq(Google的MattCutts确认了AdSense的Mediabot的确是会帮助Googlebot网页的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-29 01:13
Google 的 Matt Cutts 证实 AdSense 的 Mediabot 确实会帮助 Googlebot 抓取网页,但有些人不相信 Matt Cutts,或者不相信他可以代表 Google 官员。作为 Matt Cutts 博客的忠实读者,我认为没有必要在 Matt Cutts 的权威上花任何篇幅。我想说的是,Matt Cutts 是谷歌质量管理部门的高级软件工程师。外界所知道的是,他负责研发防止垃圾邮件和控制排名的技术。所以,信不信由你,当然这取决于你。
镇江网站建筑公司
事实上,马特上次透露的只是内容的一个方面。今天Matt再次写了一篇很详细的文章,讲解了谷歌的各种bot是如何爬取网页的,以及谷歌最新的BigDaddy在爬取网页方面有哪些新的变化等等。非常精彩,分享给大家。
首先要介绍的是谷歌的爬取缓存代理。Matt 举了一个 ISP 和一个用户的例子来说明它。用户上网时,总是先通过ISP获取网页内容,再由ISP缓存用户访问过的网页,以备后用。例如,当用户A访问时,中国电信(或网通等)会将80后创业基地发送给用户A,然后缓存80后创业基地。当用户B下一秒再次访问时,中国电信会将缓存中幻灭的麦克风发送给用户B,从而节省带宽。
正如本站此前报道的那样,谷歌最新的软件升级(转移到BigDaddy)已经基本完成,所以升级后谷歌的各方面能力都会得到加强。这些增强功能包括更智能的 googlebot 抓取、改进的标准化以及更好的 收录 网页功能。在Googlebot抓取和抓取网页方面,谷歌也采用了节省带宽的方法。Googlebot 也随着 BigDaddy 的升级而升级。新的Googlebot已经正式支持gzip编码,所以如果你的网站开启了gzip编码,可以节省Googlebot在抓取你的网页时占用的带宽。
除了改进后的Googlebot,升级后的Google还会使用上面提到的抓取缓存代理来抓取网页,进一步节省带宽。
创业基地SEO频道了解到:谷歌蜘蛛主要在Googlebot上爬行,A服务器指的是AdSense,N服务器可以是Google的blogsearch或其他。我们可以看到同样的网站,Googlebot,AdSense的Mediabot,blogsearch的bots都爬过了,重复爬取的次数很多。升级后的谷歌使用的抓取缓存代理呢?
很明显,因为爬虫缓存代理缓存了各种爬虫的爬取,当Googlebot已经爬取了一些网页,而Mediabot或者其他爬虫又爬取了重复的网页时,爬取缓存代理就会发挥作用。缓存中的网页直接返回给Mediabot等,减少了实际爬取次数,节省了带宽。
从马特的分析可以看出,谷歌确实可以为自己和网站节省带宽。好处是谷歌的各种大庆网站建筑公司bots可以在一定时间内爬取更多。网页方便收录。我的理解是,虽然好处很明显,但也有坏处。例如,当 网站 以 AdSense 的广告费为生时,它需要 AdSense 的 Mediabot 不断访问以分析其更新网页的内容并投放更多相关广告。但是当这个网站是一个具有良好PR值的网站时,那么Googlebot很可能每天都在抓取它。这样,抓取缓存代理就会缓存Googlebot的抓取,等待Mediabot再次来。爬行时,它直接将缓存的内容返回给 Mediabot。这减少了 Mediabot 抓取此 网站 的次数。由于这两个机器人使用的工作机制并不完全相同,因此这个 网站 可能会因为 Mediabot 抓取次数的减少而降低所展示的 AdSense 广告的相关性。 查看全部
网页抓取qq(Google的MattCutts确认了AdSense的Mediabot的确是会帮助Googlebot网页的)
Google 的 Matt Cutts 证实 AdSense 的 Mediabot 确实会帮助 Googlebot 抓取网页,但有些人不相信 Matt Cutts,或者不相信他可以代表 Google 官员。作为 Matt Cutts 博客的忠实读者,我认为没有必要在 Matt Cutts 的权威上花任何篇幅。我想说的是,Matt Cutts 是谷歌质量管理部门的高级软件工程师。外界所知道的是,他负责研发防止垃圾邮件和控制排名的技术。所以,信不信由你,当然这取决于你。
镇江网站建筑公司
事实上,马特上次透露的只是内容的一个方面。今天Matt再次写了一篇很详细的文章,讲解了谷歌的各种bot是如何爬取网页的,以及谷歌最新的BigDaddy在爬取网页方面有哪些新的变化等等。非常精彩,分享给大家。
首先要介绍的是谷歌的爬取缓存代理。Matt 举了一个 ISP 和一个用户的例子来说明它。用户上网时,总是先通过ISP获取网页内容,再由ISP缓存用户访问过的网页,以备后用。例如,当用户A访问时,中国电信(或网通等)会将80后创业基地发送给用户A,然后缓存80后创业基地。当用户B下一秒再次访问时,中国电信会将缓存中幻灭的麦克风发送给用户B,从而节省带宽。
正如本站此前报道的那样,谷歌最新的软件升级(转移到BigDaddy)已经基本完成,所以升级后谷歌的各方面能力都会得到加强。这些增强功能包括更智能的 googlebot 抓取、改进的标准化以及更好的 收录 网页功能。在Googlebot抓取和抓取网页方面,谷歌也采用了节省带宽的方法。Googlebot 也随着 BigDaddy 的升级而升级。新的Googlebot已经正式支持gzip编码,所以如果你的网站开启了gzip编码,可以节省Googlebot在抓取你的网页时占用的带宽。
除了改进后的Googlebot,升级后的Google还会使用上面提到的抓取缓存代理来抓取网页,进一步节省带宽。
创业基地SEO频道了解到:谷歌蜘蛛主要在Googlebot上爬行,A服务器指的是AdSense,N服务器可以是Google的blogsearch或其他。我们可以看到同样的网站,Googlebot,AdSense的Mediabot,blogsearch的bots都爬过了,重复爬取的次数很多。升级后的谷歌使用的抓取缓存代理呢?
很明显,因为爬虫缓存代理缓存了各种爬虫的爬取,当Googlebot已经爬取了一些网页,而Mediabot或者其他爬虫又爬取了重复的网页时,爬取缓存代理就会发挥作用。缓存中的网页直接返回给Mediabot等,减少了实际爬取次数,节省了带宽。
从马特的分析可以看出,谷歌确实可以为自己和网站节省带宽。好处是谷歌的各种大庆网站建筑公司bots可以在一定时间内爬取更多。网页方便收录。我的理解是,虽然好处很明显,但也有坏处。例如,当 网站 以 AdSense 的广告费为生时,它需要 AdSense 的 Mediabot 不断访问以分析其更新网页的内容并投放更多相关广告。但是当这个网站是一个具有良好PR值的网站时,那么Googlebot很可能每天都在抓取它。这样,抓取缓存代理就会缓存Googlebot的抓取,等待Mediabot再次来。爬行时,它直接将缓存的内容返回给 Mediabot。这减少了 Mediabot 抓取此 网站 的次数。由于这两个机器人使用的工作机制并不完全相同,因此这个 网站 可能会因为 Mediabot 抓取次数的减少而降低所展示的 AdSense 广告的相关性。
网页抓取qq(就来“试水”一波TX吧~~(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-25 06:15
本文转载至知乎ID:查尔斯(白露维希)知乎个人专栏
下载W3Cschool手机app,0基础随时随地学习编程>>戳这里了解
带领
阅读之前关于爬虫的文章。. .
好像一直在欺负肖网站,没什么挑战性。. .
那就来一波TX“试水”吧~~~
本着T_T的原则,我决定把这期文章分成两部分。第一篇主要解决QQ空间的登录问题,尝试抓取一些信息,第二篇专门抓取QQ空间好友的信息,做可视化分析。
让我们愉快的开始吧~~~
相关文件
百度网盘下载链接:
密码:ycc
开发工具
Python版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
以及一些 Python 自带的模块。
环境设置
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载您使用的Chrome浏览器版本对应的驱动文件,下载完成后将chromedriver.exe所在的文件夹添加到环境变量中。
原理介绍
本文主要解决QQ空间的登录问题。
主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么这么绕?
selenium 好久没用了,写的太慢了。而且,自身的速度、资源消耗等问题也一直被大家诟病。
并且省略了无数的理由。
一些细节:
(1)第一次获取后保存cookie,下次登录前尝试看看保存的cookie是否有用,如果有用就直接使用,这样可以进一步节省时间。
(2)在抓包分析过程中,可以发现抓QQ空间数据所需的所有链接都收录了g_tk参数,这个参数其实是利用cookie中的skey参数计算出来的,所以我也是懒得打公式了,贴一小段代码:
最后:
如果你不抓取一些数据,似乎并不能证明这个 文章 真的有用。
好的,然后输入:
脱掉~~~
具体实现过程详见相关文件中的源码。
使用演示
QQ号(用户名)和密码(密码):
填写QQ_Spider.py文件,位置如下图:
跑:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
就这样。
下一个预览
在此问题的基础上,抓取好友的个人信息,并直观地分析抓取的结果。有兴趣的朋友可以提前试试~~~
其实,微调本文提供的代码,理论上可以捕获QQ所有用户的信息。当然,这只是理论上的,并且做了很多有趣的事情。
T_T,作为一个不乱不爱喝茶的男孩子,以上理论的实现我概不负责。 查看全部
网页抓取qq(就来“试水”一波TX吧~~(图))
本文转载至知乎ID:查尔斯(白露维希)知乎个人专栏
下载W3Cschool手机app,0基础随时随地学习编程>>戳这里了解
带领
阅读之前关于爬虫的文章。. .
好像一直在欺负肖网站,没什么挑战性。. .
那就来一波TX“试水”吧~~~
本着T_T的原则,我决定把这期文章分成两部分。第一篇主要解决QQ空间的登录问题,尝试抓取一些信息,第二篇专门抓取QQ空间好友的信息,做可视化分析。
让我们愉快的开始吧~~~
相关文件
百度网盘下载链接:
密码:ycc
开发工具
Python版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
以及一些 Python 自带的模块。
环境设置
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载您使用的Chrome浏览器版本对应的驱动文件,下载完成后将chromedriver.exe所在的文件夹添加到环境变量中。
原理介绍
本文主要解决QQ空间的登录问题。
主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么这么绕?
selenium 好久没用了,写的太慢了。而且,自身的速度、资源消耗等问题也一直被大家诟病。
并且省略了无数的理由。
一些细节:
(1)第一次获取后保存cookie,下次登录前尝试看看保存的cookie是否有用,如果有用就直接使用,这样可以进一步节省时间。
(2)在抓包分析过程中,可以发现抓QQ空间数据所需的所有链接都收录了g_tk参数,这个参数其实是利用cookie中的skey参数计算出来的,所以我也是懒得打公式了,贴一小段代码:
最后:
如果你不抓取一些数据,似乎并不能证明这个 文章 真的有用。
好的,然后输入:
脱掉~~~
具体实现过程详见相关文件中的源码。
使用演示
QQ号(用户名)和密码(密码):
填写QQ_Spider.py文件,位置如下图:
跑:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
就这样。
下一个预览
在此问题的基础上,抓取好友的个人信息,并直观地分析抓取的结果。有兴趣的朋友可以提前试试~~~
其实,微调本文提供的代码,理论上可以捕获QQ所有用户的信息。当然,这只是理论上的,并且做了很多有趣的事情。
T_T,作为一个不乱不爱喝茶的男孩子,以上理论的实现我概不负责。

