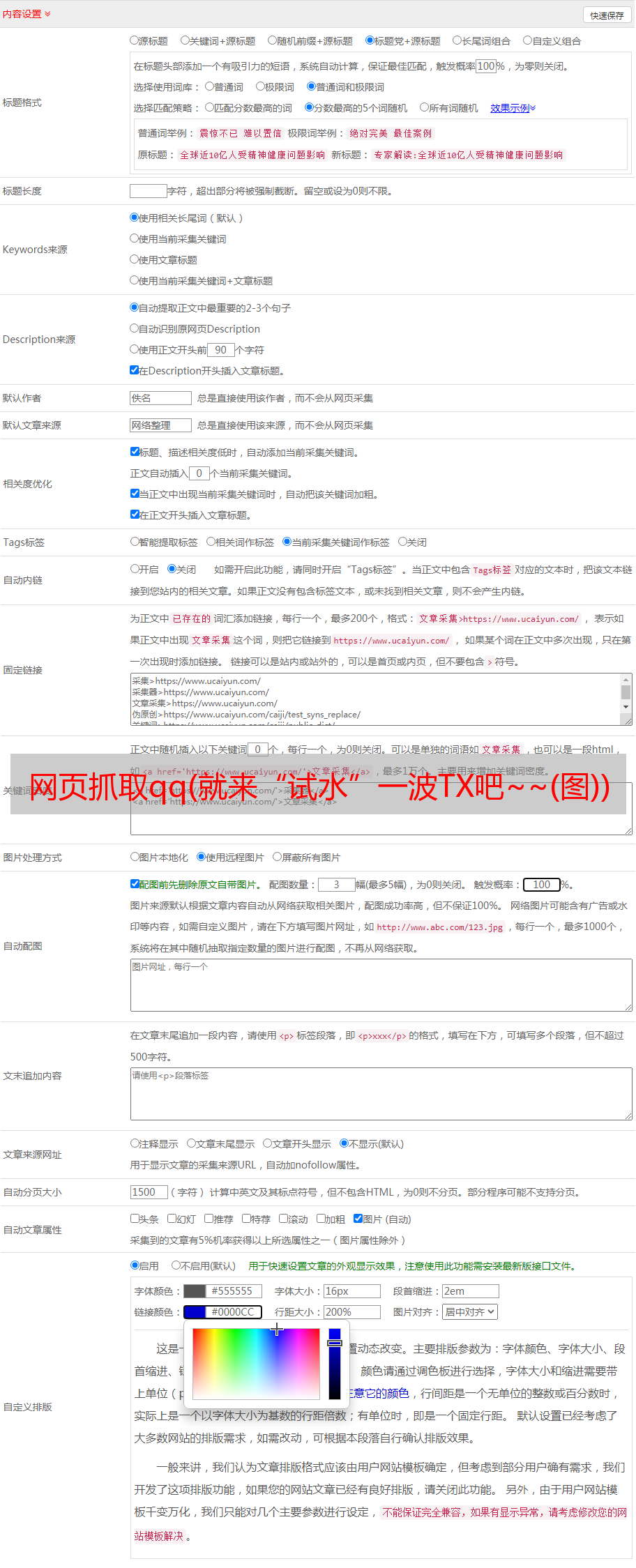
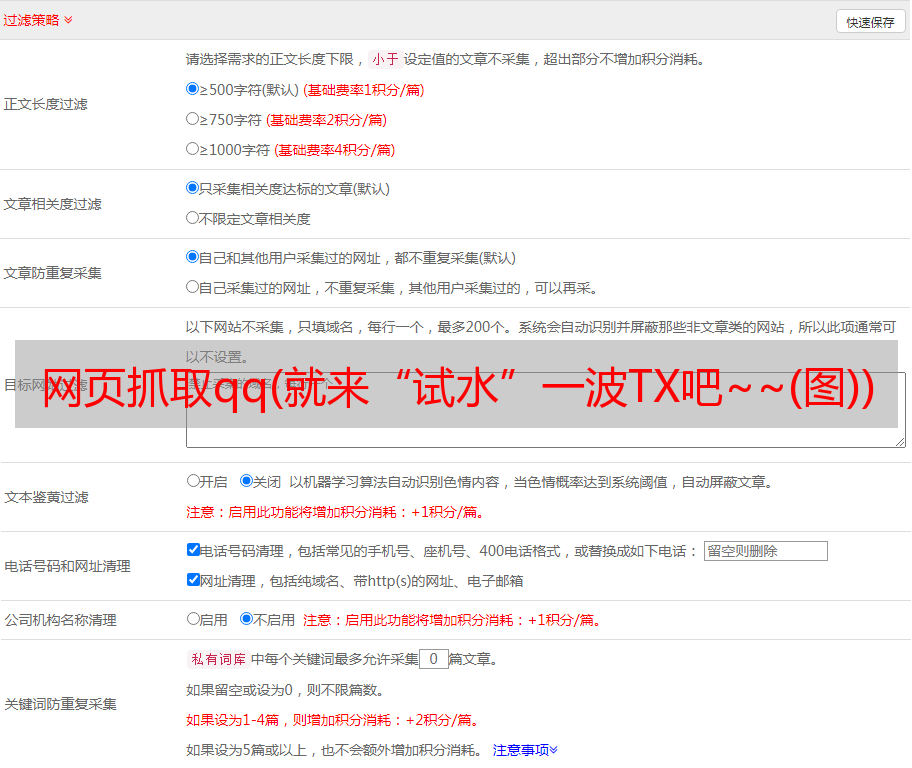
网页抓取qq(就来“试水”一波TX吧~~(图))
优采云 发布时间: 2021-11-25 06:15网页抓取qq(就来“试水”一波TX吧~~(图))
本文转载至知乎ID:查尔斯(白露维希)知乎个人专栏
下载W3Cschool手机app,0基础随时随地学习编程>>戳这里了解
带领
阅读之前关于爬虫的文章。. .
好像一直在欺负肖网站,没什么挑战性。. .
那就来一波TX“试水”吧~~~
本着T_T的原则,我决定把这期文章分成两部分。第一篇主要解决QQ空间的登录问题,尝试抓取一些信息,第二篇专门抓取QQ空间好友的信息,做可视化分析。
让我们愉快的开始吧~~~
相关文件
百度网盘下载链接:
密码:ycc
开发工具
Python版本:3.6.4
相关模块:
请求模块;
硒模块;
lxml 模块;
以及一些 Python 自带的模块。
环境设置
安装Python并添加到环境变量中,pip安装需要的相关模块,进入:
下载您使用的Chrome浏览器版本对应的驱动文件,下载完成后将chromedriver.exe所在的文件夹添加到环境变量中。
原理介绍
本文主要解决QQ空间的登录问题。
主要思想是:
使用selenium模拟登录QQ空间,获取登录QQ空间所需的cookie值,从而可以使用requests模块抓取QQ空间的数据。
为什么这么绕?
selenium 好久没用了,写的太慢了。而且,自身的速度、资源消耗等问题也一直被大家诟病。
并且省略了无数的理由。
一些细节:
(1)第一次获取后保存cookie,下次登录前尝试看看保存的cookie是否有用,如果有用就直接使用,这样可以进一步节省时间。
(2)在抓包分析过程中,可以发现抓QQ空间数据所需的所有链接都收录了g_tk参数,这个参数其实是利用cookie中的skey参数计算出来的,所以我也是懒得打公式了,贴一小段代码:
最后:
如果你不抓取一些数据,似乎并不能证明这个 文章 真的有用。
好的,然后输入:

脱掉~~~
具体实现过程详见相关文件中的源码。
使用演示
QQ号(用户名)和密码(密码):
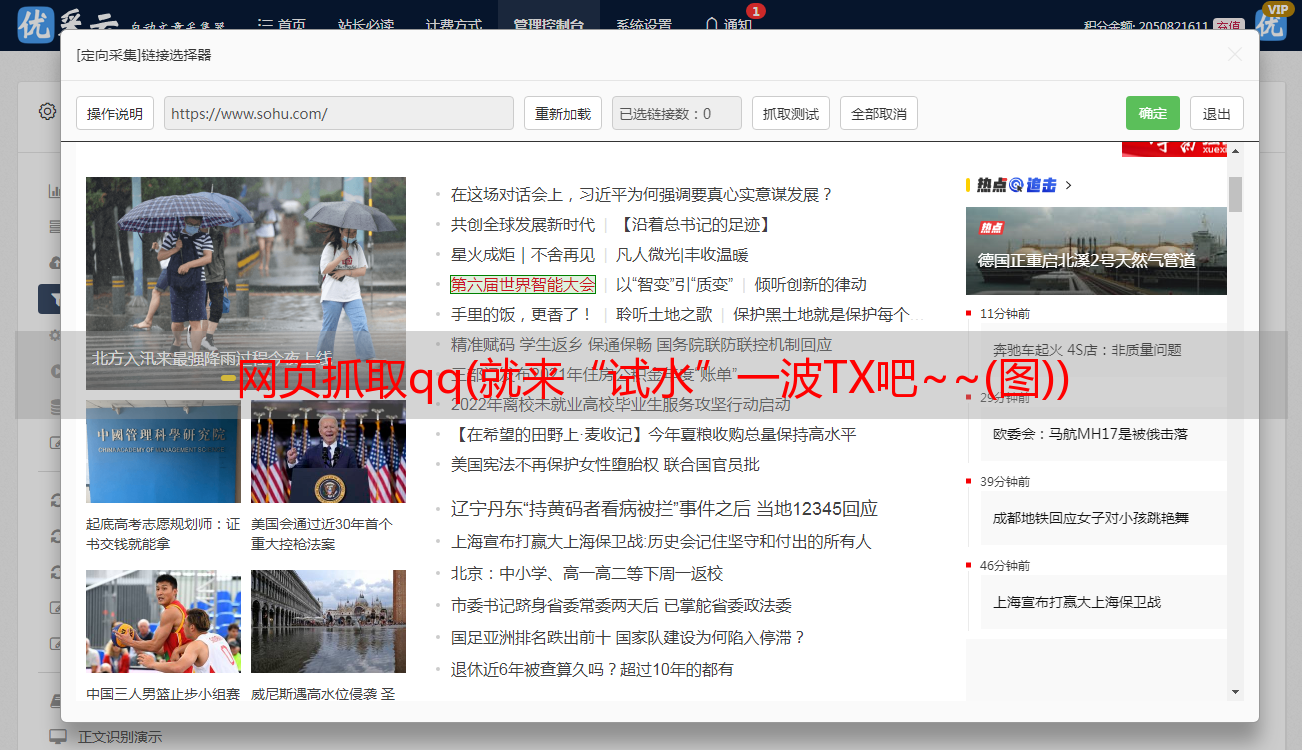
填写QQ_Spider.py文件,位置如下图:
跑:
只需在 cmd 窗口中运行 QQ_Spider.py 文件即可。
结果:
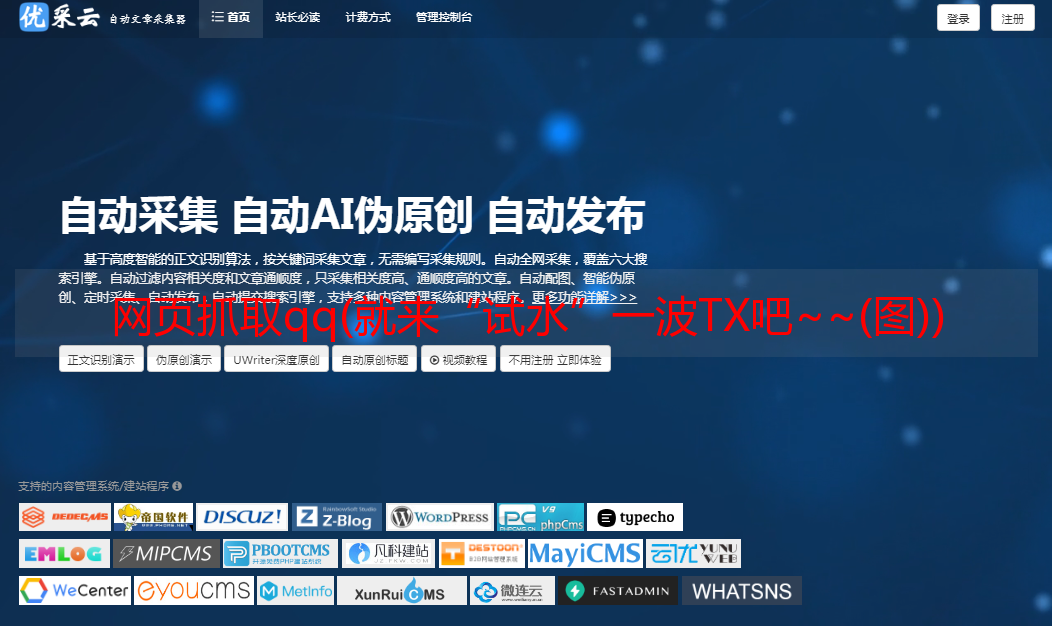
就这样。
下一个预览
在此问题的基础上,抓取好友的个人信息,并直观地分析抓取的结果。有兴趣的朋友可以提前试试~~~
其实,微调本文提供的代码,理论上可以捕获QQ所有用户的信息。当然,这只是理论上的,并且做了很多有趣的事情。
T_T,作为一个不乱不爱喝茶的男孩子,以上理论的实现我概不负责。

