
网页抓取qq
网页抓取qq(网站抓取是很多SEO小伙伴关注的重点,蜘蛛是否有来我们的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-24 05:08
网站 爬行是很多SEO合作伙伴关注的焦点。我们的 网站 被 SEO 蜘蛛抓取了吗?蜘蛛来我们的网站了吗?其实这些问题的一些信息可以通过网站爬虫看到,由超级排名系统的编辑整理发布。
所谓爬行异常,我们可以从字面上知道这是爬行中的一种异常情况。在这个功能下,还有一个具体的解释:蜘蛛不能正常爬行,是爬行异常。
异常爬取的影响是:网站内容量大,不能正常爬取,会被认为是用户体验有缺陷网站,会降低网站'的影响s评价,影响网站的爬取、索引、权重等,最终影响大家的网站SEO流量。
可以看出,如果我们的网站出现异常爬行情况,频繁出现此类问题会导致被请求的网站被降级,导致我们的网站流量减少。
显然,这需要SEO人员关注他们的网站爬行异常。
关于网站抓取异常的问题,其实我们点击这个函数就可以看到具体的异常,如图:
网站 爬行异常包括:
1、DNS 错误
2、连接错误
3、连接超时
4、 抓取超时
在这些方面,可能有seoer的朋友在这里问。我刚看到这些错误,我不知道是什么导致了爬行错误。下面说一下seo的常见原因。导致爬取异常的情况:
1、 解析不正确。不管是对SEO蜘蛛还是用户来说,我们的网站被他们抓到,才能看到正确的解析是必不可少的。同时,dns的稳定性和速度也是不可或缺的,如果dns不稳定,就会出现爬行错误和爬行异常。为此,您需要选择安全稳定的 dns。
2、空间带宽不足。我们的网站能否提供稳定快速的运行过程,也与我们设置的带宽有关。为此,站长需要根据我们的网站流量情况购买足够的空间和带宽。
注意带宽不足。这就是很多网站 爬取异常的原因。当然,有时候seoer会发现设置的带宽就足够了。为什么查看时满负荷运行?
这时候可能是因为我们的网站被seo蜘蛛抓取,被修改等原因,如果有机器运行我们的网站会占用很大的空间,这会作为结果我们的网站加载太慢,爬行不正常。
3、在SEO中,页面太大,加载过程很长。显然,页面越小越容易打开,页面越大,加载时间越长。如果这个时间过长,很容易出现超时这个原因,大家也要注意我们的网站加载时间,网站页面大小,特别是现在很多网站用的图片很多,一些网站很多js,这些都是会影响速度的。
以上就是《网站爬虫知识》的全部内容。如有其他问题,请咨询超级排位系统编辑。 查看全部
网页抓取qq(网站抓取是很多SEO小伙伴关注的重点,蜘蛛是否有来我们的网站)
网站 爬行是很多SEO合作伙伴关注的焦点。我们的 网站 被 SEO 蜘蛛抓取了吗?蜘蛛来我们的网站了吗?其实这些问题的一些信息可以通过网站爬虫看到,由超级排名系统的编辑整理发布。
所谓爬行异常,我们可以从字面上知道这是爬行中的一种异常情况。在这个功能下,还有一个具体的解释:蜘蛛不能正常爬行,是爬行异常。
异常爬取的影响是:网站内容量大,不能正常爬取,会被认为是用户体验有缺陷网站,会降低网站'的影响s评价,影响网站的爬取、索引、权重等,最终影响大家的网站SEO流量。
可以看出,如果我们的网站出现异常爬行情况,频繁出现此类问题会导致被请求的网站被降级,导致我们的网站流量减少。
显然,这需要SEO人员关注他们的网站爬行异常。
关于网站抓取异常的问题,其实我们点击这个函数就可以看到具体的异常,如图:
网站 爬行异常包括:
1、DNS 错误
2、连接错误
3、连接超时
4、 抓取超时
在这些方面,可能有seoer的朋友在这里问。我刚看到这些错误,我不知道是什么导致了爬行错误。下面说一下seo的常见原因。导致爬取异常的情况:
1、 解析不正确。不管是对SEO蜘蛛还是用户来说,我们的网站被他们抓到,才能看到正确的解析是必不可少的。同时,dns的稳定性和速度也是不可或缺的,如果dns不稳定,就会出现爬行错误和爬行异常。为此,您需要选择安全稳定的 dns。
2、空间带宽不足。我们的网站能否提供稳定快速的运行过程,也与我们设置的带宽有关。为此,站长需要根据我们的网站流量情况购买足够的空间和带宽。
注意带宽不足。这就是很多网站 爬取异常的原因。当然,有时候seoer会发现设置的带宽就足够了。为什么查看时满负荷运行?
这时候可能是因为我们的网站被seo蜘蛛抓取,被修改等原因,如果有机器运行我们的网站会占用很大的空间,这会作为结果我们的网站加载太慢,爬行不正常。
3、在SEO中,页面太大,加载过程很长。显然,页面越小越容易打开,页面越大,加载时间越长。如果这个时间过长,很容易出现超时这个原因,大家也要注意我们的网站加载时间,网站页面大小,特别是现在很多网站用的图片很多,一些网站很多js,这些都是会影响速度的。
以上就是《网站爬虫知识》的全部内容。如有其他问题,请咨询超级排位系统编辑。
网页抓取qq(Scrapyscrapy网络爬虫运行流程及组件:Scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-22 22:21
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(如 Web 服务)或一般网络爬虫返回的数据。
Scrapy还可以帮你实现爬虫过程中的网站认证、内容分析处理、重复爬取、分布式爬取等高级爬虫框架。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
长凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg
|____tutorial
| |______init__.py
| |______init__.pyc
| |____items.py
| |____items.pyc
| |____pipelines.py
| |____settings.py
| |____settings.pyc
| |____spiders
| | |______init__.py
| | |______init__.pyc
| | |____example.py
| | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,你会在这里添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的、必需的属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。 查看全部
网页抓取qq(Scrapyscrapy网络爬虫运行流程及组件:Scrapy)
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(如 Web 服务)或一般网络爬虫返回的数据。
Scrapy还可以帮你实现爬虫过程中的网站认证、内容分析处理、重复爬取、分布式爬取等高级爬虫框架。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
长凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg
|____tutorial
| |______init__.py
| |______init__.pyc
| |____items.py
| |____items.pyc
| |____pipelines.py
| |____settings.py
| |____settings.pyc
| |____spiders
| | |______init__.py
| | |______init__.pyc
| | |____example.py
| | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,你会在这里添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的、必需的属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。
网页抓取qq(微信公众号实现扫码获取微信用户信息(网页授权))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-21 08:15
微信公众号实现扫码获取微信用户信息(网页授权)
刚接触微信的时候,一头雾水。领导想要一个功能,可以扫码获取微信用户信息,也可以扫别人的二维码。我很忙。经过艰苦的努力和实验,终于得到了回报。赶紧记录下来吧。我用thinkphp写的。,真正的目的是扫描带参数的二维码,获取微信用户信息。下面介绍如何生成带参数的二维码。授权需要公众号的几个参数:1是AppID 2是AppSecret,在公众号申请成功后分配(2)使用这两个参数,然后配合获取access_token的值。代码如下(扫描后跳转到getUserInfo方法,传入唯一键值): $tid = 0; 传值参数 $level=3;$size$tid ); 这是设置参数和授权后重定向回调链接地址snsapi_userinfo弹出授权页面,可以通过openid获取昵称、性别、位置snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值
663 查看全部
网页抓取qq(微信公众号实现扫码获取微信用户信息(网页授权))
微信公众号实现扫码获取微信用户信息(网页授权)
刚接触微信的时候,一头雾水。领导想要一个功能,可以扫码获取微信用户信息,也可以扫别人的二维码。我很忙。经过艰苦的努力和实验,终于得到了回报。赶紧记录下来吧。我用thinkphp写的。,真正的目的是扫描带参数的二维码,获取微信用户信息。下面介绍如何生成带参数的二维码。授权需要公众号的几个参数:1是AppID 2是AppSecret,在公众号申请成功后分配(2)使用这两个参数,然后配合获取access_token的值。代码如下(扫描后跳转到getUserInfo方法,传入唯一键值): $tid = 0; 传值参数 $level=3;$size$tid ); 这是设置参数和授权后重定向回调链接地址snsapi_userinfo弹出授权页面,可以通过openid获取昵称、性别、位置snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值
663
网页抓取qq(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-20 04:09
vba网页元素代码抓取小工具【支持win10+】
<p>使用IE提取网页信息的优点是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。 查看全部
网页抓取qq(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
vba网页元素代码抓取小工具【支持win10+】
<p>使用IE提取网页信息的优点是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。
网页抓取qq(1.导入urllib的方式先导入需要的模块两种方法:编码和解码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-18 20:16
)
Python爬虫获取浏览器静态网页html的几种简单方法1.导入urllib的方法
先导入需要的模块
import urllib
from urllib import request
两种方式:带浏览器头和代理IP,不带浏览器头和代理IP
带有浏览器标头和代理IP
url = '需要访问的网址'
#将网页的url网址包装成请求
myrequest=request.Request(url)
#增加浏览器头部
#准备头部,这里有好多 https://blog.csdn.net/m0_37499 ... 03731
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
#增加进去,random.choice(user_agent)随机选择一个
myrequest.add_header('User-Agent',random.choice(user_agent))
#设置代理ip
#这里以进西刺网为例,免费高匿代理可以从西刺网获取
proxies = [
'61.135.217.7:80',
'180.173.199.79:47404',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80',
'115.194.160.162:8118'
]
#固定写法
proxy_support = urllib.request.ProxyHandler({'http':random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
#访问得到结果
result = request.urlopen(myrequest)
没有浏览器头和代理IP,所以很容易访问不到IP被封,这与访问网站的反爬虫功能有关
url = '需要访问的网址'
#变为请求
r=request.Request(url)
#访问得到结果
result = request.urlopen(r)
2.当然每个网页的编码格式都不一样,所以一定要编码解码
#导入获取编码的模块
import chardet
#上面通过request访问得到了网页的请求,下面进行编码和解码
html=result.read()
code=chardet.detect(html)['encoding']
#code即为我们获取的编码格式,输出一下看看
print(code)
html=html.decode('utf-8')
#decode进行解码,这样网页的html就可以看得到了哦
print(html) 查看全部
网页抓取qq(1.导入urllib的方式先导入需要的模块两种方法:编码和解码
)
Python爬虫获取浏览器静态网页html的几种简单方法1.导入urllib的方法
先导入需要的模块
import urllib
from urllib import request
两种方式:带浏览器头和代理IP,不带浏览器头和代理IP
带有浏览器标头和代理IP
url = '需要访问的网址'
#将网页的url网址包装成请求
myrequest=request.Request(url)
#增加浏览器头部
#准备头部,这里有好多 https://blog.csdn.net/m0_37499 ... 03731
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
#增加进去,random.choice(user_agent)随机选择一个
myrequest.add_header('User-Agent',random.choice(user_agent))
#设置代理ip
#这里以进西刺网为例,免费高匿代理可以从西刺网获取
proxies = [
'61.135.217.7:80',
'180.173.199.79:47404',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80',
'115.194.160.162:8118'
]
#固定写法
proxy_support = urllib.request.ProxyHandler({'http':random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
#访问得到结果
result = request.urlopen(myrequest)
没有浏览器头和代理IP,所以很容易访问不到IP被封,这与访问网站的反爬虫功能有关
url = '需要访问的网址'
#变为请求
r=request.Request(url)
#访问得到结果
result = request.urlopen(r)
2.当然每个网页的编码格式都不一样,所以一定要编码解码
#导入获取编码的模块
import chardet
#上面通过request访问得到了网页的请求,下面进行编码和解码
html=result.read()
code=chardet.detect(html)['encoding']
#code即为我们获取的编码格式,输出一下看看
print(code)
html=html.decode('utf-8')
#decode进行解码,这样网页的html就可以看得到了哦
print(html)
网页抓取qq(新手做网站有时候404后带来不必要的收录和流量损失)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-17 00:16
新手做网站 有时候页面还没准备好就上线了,当这些页面被百度抓取时,返回码是404,所以页面被百度抓取后,会直接作为死链接删除. 不过这个页面会在隔天或者几天后建好,会显示在网站中,但是由于之前已经被百度删除为死链接,所以只能等这些链接被删除了再次发现,然后抓到为了显示,这样的操作最终会导致部分页面在百度一段时间内不出现。
例如,某大型门户网站网站爆料了百度不及时收录的大量时间敏感话题。QQ统计,网站统计,经过检查验证,发现是因为页面没有完成,放到网上,返回404状态码,被百度当做死链接删除,导致 收录 和流量丢失。
如果出现这样的问题,建议网站新创建的页面可以使用503合理使用返回码,这样百度的蜘蛛抓取503返回码一段时间后才会访问这个地址。新页面建好后可以再次爬取,保证页面被及时爬取和索引,避免未建内容设置为404后造成不必要的收录和流量损失。
下面详细介绍一下百度支持的几种常见返回码:
1、404:404返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、301:301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
3、503:503返回码的意思是“Service Unavailable”,百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
总结:
1、 如果百度蜘蛛对你的网站抓取压力太大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试抓取这个链接. 如果该站点当时是免费的,它将被成功抓取。
2、 如果网站暂时关闭或页面尚未准备好上线,请不要在网页无法打开或未完成时立即返回404。推荐使用503状态。503可以告诉百度蜘蛛该页面暂时无法访问,请稍后再试
本文转载于:网站访客QQ统计 查看全部
网页抓取qq(新手做网站有时候404后带来不必要的收录和流量损失)
新手做网站 有时候页面还没准备好就上线了,当这些页面被百度抓取时,返回码是404,所以页面被百度抓取后,会直接作为死链接删除. 不过这个页面会在隔天或者几天后建好,会显示在网站中,但是由于之前已经被百度删除为死链接,所以只能等这些链接被删除了再次发现,然后抓到为了显示,这样的操作最终会导致部分页面在百度一段时间内不出现。
例如,某大型门户网站网站爆料了百度不及时收录的大量时间敏感话题。QQ统计,网站统计,经过检查验证,发现是因为页面没有完成,放到网上,返回404状态码,被百度当做死链接删除,导致 收录 和流量丢失。
如果出现这样的问题,建议网站新创建的页面可以使用503合理使用返回码,这样百度的蜘蛛抓取503返回码一段时间后才会访问这个地址。新页面建好后可以再次爬取,保证页面被及时爬取和索引,避免未建内容设置为404后造成不必要的收录和流量损失。
下面详细介绍一下百度支持的几种常见返回码:
1、404:404返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、301:301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
3、503:503返回码的意思是“Service Unavailable”,百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
总结:
1、 如果百度蜘蛛对你的网站抓取压力太大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试抓取这个链接. 如果该站点当时是免费的,它将被成功抓取。
2、 如果网站暂时关闭或页面尚未准备好上线,请不要在网页无法打开或未完成时立即返回404。推荐使用503状态。503可以告诉百度蜘蛛该页面暂时无法访问,请稍后再试
本文转载于:网站访客QQ统计
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-16 14:13
当你浏览网页时,你会看到你喜欢的图片。我只想截图。网络截图的用途非常广泛,尤其是在写一些教程的时候。我经常需要用截图来提高文章的人气,大家不妨看看这篇文章介绍的QQ截图怎么用、用截图软件截图、网页全页截图
当你上网时,你经常会看到各种漂亮的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。网络截图非常有用。,尤其是在写一些教程的时候,经常需要用到截图来提高文章的人气。下面html中文网站将与大家分享如何使用QQ截图、截图软件截图、网页全页面截图。
一:首先介绍一下QQ截图。QQ是大家最常用的聊天工具,几乎每台电脑都有,所以用QQ截图非常方便。目前QQ聊天工具里的截图比怎么截图还多。输入说明文字,画箭头,画一些形状等等,让我们看看如何使用它:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。
请点击小箭头设置截图
具体的使用方法比较简单,这里就不啰嗦了,自己试试就知道了。
-----------------------html中文网友提供的其他截图方法-------------------- ——
1.windows 打印密钥截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴即可保存。.
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度嗨默认截图快捷键是:Shift+Alt+A
3. 浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
菜单栏的工具截图中有全屏截图、区域截图、窗口截图等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图。
在 URL 字段中输入您要拦截的网页的 URL,修改其他设置,然后按 OK 按钮即可获取该网页的屏幕截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,比如单屏截图、滚动截图、缩略图等等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。
使用在线网页截图工具
5.专业软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320K
软件性质:绿色免费
网页滚动截图软件下载
随着网站信息量的不断增加,大部分网页内容都超过了一个屏幕。借助这款软件,我们可以实现滚动截屏,也就是说第一屏的底部也会被截取,让你随心所欲地保存喜欢的页面。
第五种和第四种可以实现滚动截图(即截取空间首页的整个页面)。
截屏完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截屏进行裁剪和修改截屏的大小和大小。
修改完成后,将截图上传到空间相册,获取地址图。(百度贴吧改版后,图片宽度大于570px会自动缩写)
如何滚动和抓取整个网页图像
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、 截取全屏
单击 PrintScreen 按钮,然后启动“绘图(开始-程序-附件)”,按 Ctrl+V 或“编辑-粘贴”来捕获当前屏幕,然后将其另存为 Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键,只截取当前活动窗口,然后如上保存。
3.截取DirectX镜像
Print Screen按钮不能捕捉DirectX图像,没关系,只要我们做一点,就可以让它大展拳脚。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写在输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。(时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
下面介绍一下在线截图工具:
网页截图看起来是一件很简单的事情,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就束手无策了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图!: 专门为网页截图创建的网站。主页非常简单。只需填写您要截图的网址,然后单击“开始”。
炸糖网:以前叫Ask Ask,后来改名为炸糖。它是一个中文截屏服务网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图尺寸,可以自定义所有截图。所需的尺寸。默认为 160*120 和 1024*768。您还可以以秒为单位指定捕获时间。
thumbalizr:可以抓取任意网页的截图,提供150、320、640、800、1024、1280等宽度的截图给你要下载,当然你也可以自定义大小。
webthumb:一个非常简单的在线截图工具,你可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图将根据网站的变化自动更新。
websnapr:非常有名的国外截图网站。但是不建议大家使用这个。默认只提供两种尺寸的小(202×152))和微(90×70))截图。你必须成为他们的付费会员才能享受更大的截图。
以上是html中文网站提供的多种网络截图方法。到目前为止,它是我找到的所有截图方法的总结。应该是网上最详细的截图了。文章,更多电脑技能>>
以上是整理网络截图的方法:QQ截图/网页截图/浏览器截图技巧大全详情请关注其他相关html中文网站文章! 查看全部
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
当你浏览网页时,你会看到你喜欢的图片。我只想截图。网络截图的用途非常广泛,尤其是在写一些教程的时候。我经常需要用截图来提高文章的人气,大家不妨看看这篇文章介绍的QQ截图怎么用、用截图软件截图、网页全页截图
当你上网时,你经常会看到各种漂亮的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。网络截图非常有用。,尤其是在写一些教程的时候,经常需要用到截图来提高文章的人气。下面html中文网站将与大家分享如何使用QQ截图、截图软件截图、网页全页面截图。
一:首先介绍一下QQ截图。QQ是大家最常用的聊天工具,几乎每台电脑都有,所以用QQ截图非常方便。目前QQ聊天工具里的截图比怎么截图还多。输入说明文字,画箭头,画一些形状等等,让我们看看如何使用它:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。

使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。

请点击小箭头设置截图
具体的使用方法比较简单,这里就不啰嗦了,自己试试就知道了。
-----------------------html中文网友提供的其他截图方法-------------------- ——
1.windows 打印密钥截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴即可保存。.
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度嗨默认截图快捷键是:Shift+Alt+A
3. 浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
菜单栏的工具截图中有全屏截图、区域截图、窗口截图等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1

使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图。
在 URL 字段中输入您要拦截的网页的 URL,修改其他设置,然后按 OK 按钮即可获取该网页的屏幕截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,比如单屏截图、滚动截图、缩略图等等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。

使用在线网页截图工具
5.专业软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320K
软件性质:绿色免费
网页滚动截图软件下载
随着网站信息量的不断增加,大部分网页内容都超过了一个屏幕。借助这款软件,我们可以实现滚动截屏,也就是说第一屏的底部也会被截取,让你随心所欲地保存喜欢的页面。

第五种和第四种可以实现滚动截图(即截取空间首页的整个页面)。
截屏完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截屏进行裁剪和修改截屏的大小和大小。
修改完成后,将截图上传到空间相册,获取地址图。(百度贴吧改版后,图片宽度大于570px会自动缩写)
如何滚动和抓取整个网页图像
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、 截取全屏
单击 PrintScreen 按钮,然后启动“绘图(开始-程序-附件)”,按 Ctrl+V 或“编辑-粘贴”来捕获当前屏幕,然后将其另存为 Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键,只截取当前活动窗口,然后如上保存。
3.截取DirectX镜像
Print Screen按钮不能捕捉DirectX图像,没关系,只要我们做一点,就可以让它大展拳脚。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写在输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。(时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
下面介绍一下在线截图工具:
网页截图看起来是一件很简单的事情,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就束手无策了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图!: 专门为网页截图创建的网站。主页非常简单。只需填写您要截图的网址,然后单击“开始”。
炸糖网:以前叫Ask Ask,后来改名为炸糖。它是一个中文截屏服务网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图尺寸,可以自定义所有截图。所需的尺寸。默认为 160*120 和 1024*768。您还可以以秒为单位指定捕获时间。
thumbalizr:可以抓取任意网页的截图,提供150、320、640、800、1024、1280等宽度的截图给你要下载,当然你也可以自定义大小。
webthumb:一个非常简单的在线截图工具,你可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图将根据网站的变化自动更新。
websnapr:非常有名的国外截图网站。但是不建议大家使用这个。默认只提供两种尺寸的小(202×152))和微(90×70))截图。你必须成为他们的付费会员才能享受更大的截图。
以上是html中文网站提供的多种网络截图方法。到目前为止,它是我找到的所有截图方法的总结。应该是网上最详细的截图了。文章,更多电脑技能>>
以上是整理网络截图的方法:QQ截图/网页截图/浏览器截图技巧大全详情请关注其他相关html中文网站文章!
网页抓取qq(搜索引擎蜘蛛抓取份额是由什么决定抓取需求需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-16 14:12
搜索引擎蜘蛛的抓取份额是多少?顾名思义,爬取份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
英文版 Google 抓取共享使用抓取预算。直译是爬行预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多页面而拖拽其他网站服务器。因此,会为某个网站设置一个爬取限速,即爬取限速,即服务器可以容忍的上限,在这个限速内,蜘蛛爬取不会拖慢服务器并影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
抓取份额是同时考虑了抓取需求和抓取速度限制的结果,即搜索引擎“想要”抓取同时“可以”抓取的页面数量。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站往往需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑捕获份额不够的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬一次网站可能需要几个月,甚至一年,这也可能意味着一些重要的页面无法爬取,所以没有排名,或者重要的页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。
当然,前面说过,能抓取百万页是一方面,搜索引擎要不要抓取是另一方面。
大网站 经常需要考虑爬取份额的另一个原因是不要把有限的爬取份额浪费在无意义的页面爬行上。结果,应该被抓取的重要页面没有被抓取的机会。
浪费抓取共享的典型页面是:
大量的过滤器过滤页面。这一点在几年前关于无效的URL爬取索引的帖子中详细讨论过。
复制网站内容
低质量,垃圾邮件
无限页面,如日历
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。小网站,因为爬取份额用不完,加nofollow没有意义。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是带有规范标签的页面通常被抓取的频率较低,因此它会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。
更多免费友情链接交流、流量交流尽在:2898站长资源平台 查看全部
网页抓取qq(搜索引擎蜘蛛抓取份额是由什么决定抓取需求需求)
搜索引擎蜘蛛的抓取份额是多少?顾名思义,爬取份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
英文版 Google 抓取共享使用抓取预算。直译是爬行预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多页面而拖拽其他网站服务器。因此,会为某个网站设置一个爬取限速,即爬取限速,即服务器可以容忍的上限,在这个限速内,蜘蛛爬取不会拖慢服务器并影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
抓取份额是同时考虑了抓取需求和抓取速度限制的结果,即搜索引擎“想要”抓取同时“可以”抓取的页面数量。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站往往需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑捕获份额不够的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬一次网站可能需要几个月,甚至一年,这也可能意味着一些重要的页面无法爬取,所以没有排名,或者重要的页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。
当然,前面说过,能抓取百万页是一方面,搜索引擎要不要抓取是另一方面。
大网站 经常需要考虑爬取份额的另一个原因是不要把有限的爬取份额浪费在无意义的页面爬行上。结果,应该被抓取的重要页面没有被抓取的机会。
浪费抓取共享的典型页面是:
大量的过滤器过滤页面。这一点在几年前关于无效的URL爬取索引的帖子中详细讨论过。
复制网站内容
低质量,垃圾邮件
无限页面,如日历
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。小网站,因为爬取份额用不完,加nofollow没有意义。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是带有规范标签的页面通常被抓取的频率较低,因此它会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。
更多免费友情链接交流、流量交流尽在:2898站长资源平台
网页抓取qq( 魔法猪系统重装大师官网介绍窗口的抓取软件软件,Spy+及AccExplorer32.exe)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-11-16 01:10
魔法猪系统重装大师官网介绍窗口的抓取软件软件,Spy+及AccExplorer32.exe)
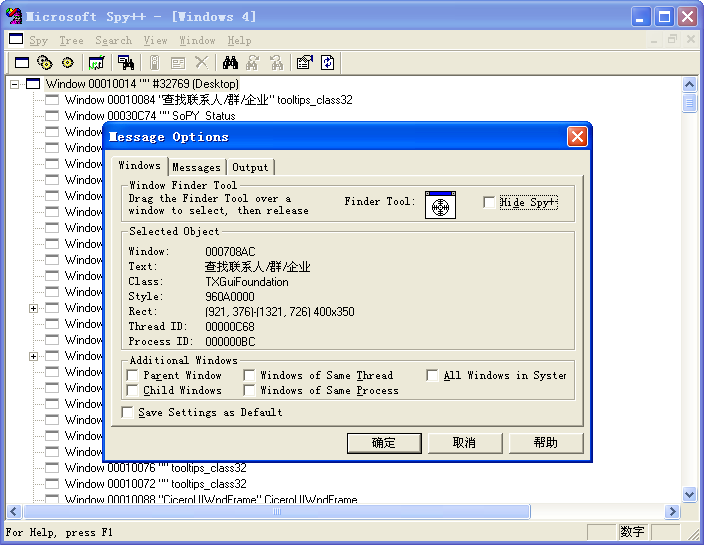
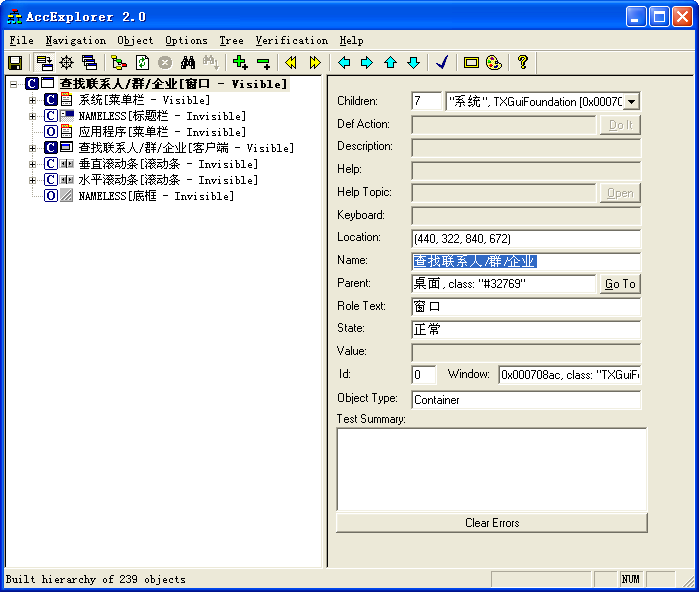
QQ编程的QQ窗口抓取以及如何自动化操作
时间:2015-04-02 15:44:32 来源:魔猪系统重装大师官网 人气:12346
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能可以互补。
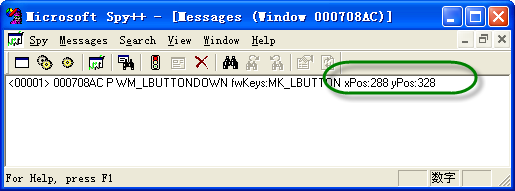
先看两者的界面,抓取QQ的【查找联系人/群组/企业】窗口时的情况:
Sp++接口
AccExplorer32.exe界面
两个接口不同,但基本功能重叠。Spy++ 可能会提供更多功能。这两款软件都可以对列出的窗口进行一系列的操作,比如查找相关的窗口信息、窗口位置,以及各种窗口操作的信息,包括可以模拟鼠标键盘等一系列操作,功能非常强大。
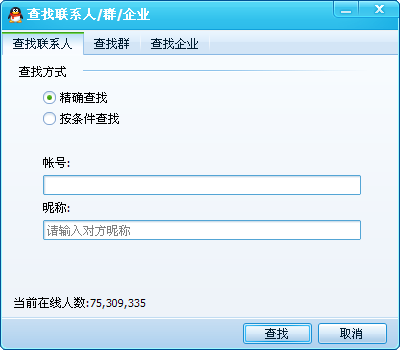
为了模拟窗口捕获和对窗口的各种操作,我们可以处理FindWindow和FindWindowEx、SendMessage、PostMessage等Windows消息,实现基本的窗口和控件操作。除了按钮操作,我们还可以模拟鼠标点击某个坐标点的方式,实现对按钮点击操作的模拟。模拟的QQ界面窗口如下图,是一个搜索窗口。
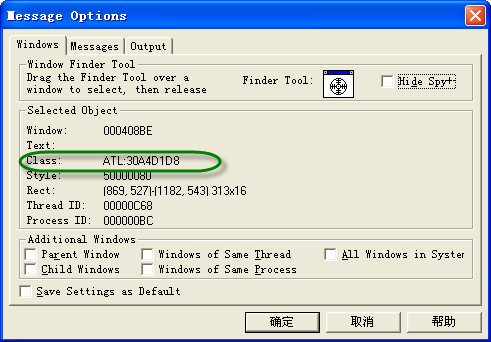
通过抓取窗口信息,我们看到窗口下方只有两个可见的窗口,对应两个输入控件,我们可以在窗口中找到一个输入框的类名(账号和昵称输入框任意一个)如下:
首先我们创建一个界面,如下图,模拟相关操作。
我们在辅助类中定义了几个函数来实现窗口操作
[DllImport("user32.dll")]
privatestaticexternIntPtrFindWindowEx(IntPtrparent,IntPtrchildAfter,stringclassName,stringwindowName);
[DllImport("user32.dll",EntryPoint="FindWindow")]
privatestaticexternIntPtrFindWindowWin32(stringclassName,stringwindowName);
[DllImport("user32.dll")]
publicstaticexternintGetClassName(IntPtrhWnd,[Out]StringBuilderclassName,intmaxCount);
[DllImport("user32.dll")]
privatestaticexternintSendMessage(IntPtrwindow,intmessage,intwparam,intlparam);
[DllImport("user32",CharSet=CharSet.Auto)]
privateexternstaticintSendMessage(IntPtrhWnd,intwMsg,intwParam,stringlpstring);
[DllImport("user32.dll")]
privatestaticexternintPostMessage(IntPtrwindow,intmessage,intwparam,intlparam);
在实际的按钮操作代码中,我们简化了具体操作,只调用了辅助类。
privatevoidbtnSearch_Click(objectsender,EventArgse)
{
Win32Windowwin=Win32Window.FindWindow(null,this.txtWindowName.Text);
如果(赢!=空)
{
ArrayListlist=win.Children;
foreach(Win32Windowsubinlist)
{
if(sub.Visible&&sub.ClassName=="ATL:30A4D1D8")
{
sub.SendMessage(WindowMessage.WM_SETTEXT,0,this.txtInput.Text);
}
}
}
整数=288;
输入=328;
win.ClickWindow("left",x,y,false);
}
位置信息是Spy++监控的信息。
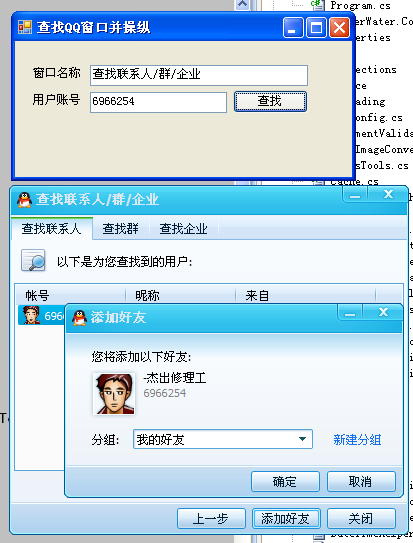
最终结果如下,修改控件内容,执行点击按钮操作,弹出添加好友确认消息。
如果要进行进一步的操作,可以继续分析弹出窗口。其他所有窗口操作原理相同,可以实现多种程序的自动模拟操作。是不是很方便? 查看全部
网页抓取qq(
魔法猪系统重装大师官网介绍窗口的抓取软件软件,Spy+及AccExplorer32.exe)
QQ编程的QQ窗口抓取以及如何自动化操作
时间:2015-04-02 15:44:32 来源:魔猪系统重装大师官网 人气:12346
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能可以互补。
先看两者的界面,抓取QQ的【查找联系人/群组/企业】窗口时的情况:
Sp++接口
AccExplorer32.exe界面
两个接口不同,但基本功能重叠。Spy++ 可能会提供更多功能。这两款软件都可以对列出的窗口进行一系列的操作,比如查找相关的窗口信息、窗口位置,以及各种窗口操作的信息,包括可以模拟鼠标键盘等一系列操作,功能非常强大。
为了模拟窗口捕获和对窗口的各种操作,我们可以处理FindWindow和FindWindowEx、SendMessage、PostMessage等Windows消息,实现基本的窗口和控件操作。除了按钮操作,我们还可以模拟鼠标点击某个坐标点的方式,实现对按钮点击操作的模拟。模拟的QQ界面窗口如下图,是一个搜索窗口。
通过抓取窗口信息,我们看到窗口下方只有两个可见的窗口,对应两个输入控件,我们可以在窗口中找到一个输入框的类名(账号和昵称输入框任意一个)如下:
首先我们创建一个界面,如下图,模拟相关操作。
我们在辅助类中定义了几个函数来实现窗口操作
[DllImport("user32.dll")]
privatestaticexternIntPtrFindWindowEx(IntPtrparent,IntPtrchildAfter,stringclassName,stringwindowName);
[DllImport("user32.dll",EntryPoint="FindWindow")]
privatestaticexternIntPtrFindWindowWin32(stringclassName,stringwindowName);
[DllImport("user32.dll")]
publicstaticexternintGetClassName(IntPtrhWnd,[Out]StringBuilderclassName,intmaxCount);
[DllImport("user32.dll")]
privatestaticexternintSendMessage(IntPtrwindow,intmessage,intwparam,intlparam);
[DllImport("user32",CharSet=CharSet.Auto)]
privateexternstaticintSendMessage(IntPtrhWnd,intwMsg,intwParam,stringlpstring);
[DllImport("user32.dll")]
privatestaticexternintPostMessage(IntPtrwindow,intmessage,intwparam,intlparam);
在实际的按钮操作代码中,我们简化了具体操作,只调用了辅助类。
privatevoidbtnSearch_Click(objectsender,EventArgse)
{
Win32Windowwin=Win32Window.FindWindow(null,this.txtWindowName.Text);
如果(赢!=空)
{
ArrayListlist=win.Children;
foreach(Win32Windowsubinlist)
{
if(sub.Visible&&sub.ClassName=="ATL:30A4D1D8")
{
sub.SendMessage(WindowMessage.WM_SETTEXT,0,this.txtInput.Text);
}
}
}
整数=288;
输入=328;
win.ClickWindow("left",x,y,false);
}
位置信息是Spy++监控的信息。
最终结果如下,修改控件内容,执行点击按钮操作,弹出添加好友确认消息。
如果要进行进一步的操作,可以继续分析弹出窗口。其他所有窗口操作原理相同,可以实现多种程序的自动模拟操作。是不是很方便?
网页抓取qq(模拟登陆和异步爬一下QQ群成员的信息获取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-11-12 16:12
自从开始学爬,就控制不住那颗躁动的心。我总是想每天爬一些东西。我爬过电影、影评、图片(美女)和视频链接。从最初对网页的简单分析到模拟登录再到异步加载,现在看到一个网页首先想到的就是要不要爬。话不多说,今天来到我们的项目,通过模拟登录和异步加载爬取QQ群成员信息。
大概的概念
我们通过网页版的QQ群管理获取相应的群信息,点击QQ群首页的“群管理”进入QQ群页面。分析链接后,我们发现每个QQ群的链接形式都是“#gid=”加上群号,这样就为我们的爬虫减少了一定的工作量。爬腾讯的网站最大的问题是登录,我们不能像刚开始的时候一样简单的发送一个登录请求包,然后在获取cookies后使用cookies访问。腾讯的网站是异步加载的。有的分析监控网络和js请求,找到想要的负载,很麻烦。所以我们使用selenuim,不需要查找请求,直接登录即可,登录后直接获取网页源码,
一、模拟登录
首先,通过 selenuim 定义一个驱动对象。这里我用的是火狐,可以通过下面的命令直接调用
定义完成后,我们通过下面的功能浏览器打开我们要爬取QQ群的链接。QQ群链接形式为“#gid=”+群号
二、 下拉加载页面
登录QQ群成员界面后,网页上显示的只有20人左右。网页下拉时,每次更新都会加载20个会员的信息。我们需要模拟下拉界面来爬取大家需要的信息。当selenuim的另一个功能出现模拟下拉加载页面时
三、保存网页源码
通过selenuim中的driver.page_source获取网页的源代码,我们可以将源代码保存在本地的txt文件中,这样可以方便分析源代码,避免每次登录的麻烦。
四、提取信息
这一步相信很多朋友都非常熟悉。这一步和我们第一次接触爬虫时分析网页是一样的。这里我们使用 BeautifulSoup 来解析源码。依次获取群成员信息。 查看全部
网页抓取qq(模拟登陆和异步爬一下QQ群成员的信息获取方法)
自从开始学爬,就控制不住那颗躁动的心。我总是想每天爬一些东西。我爬过电影、影评、图片(美女)和视频链接。从最初对网页的简单分析到模拟登录再到异步加载,现在看到一个网页首先想到的就是要不要爬。话不多说,今天来到我们的项目,通过模拟登录和异步加载爬取QQ群成员信息。
大概的概念
我们通过网页版的QQ群管理获取相应的群信息,点击QQ群首页的“群管理”进入QQ群页面。分析链接后,我们发现每个QQ群的链接形式都是“#gid=”加上群号,这样就为我们的爬虫减少了一定的工作量。爬腾讯的网站最大的问题是登录,我们不能像刚开始的时候一样简单的发送一个登录请求包,然后在获取cookies后使用cookies访问。腾讯的网站是异步加载的。有的分析监控网络和js请求,找到想要的负载,很麻烦。所以我们使用selenuim,不需要查找请求,直接登录即可,登录后直接获取网页源码,
一、模拟登录
首先,通过 selenuim 定义一个驱动对象。这里我用的是火狐,可以通过下面的命令直接调用
定义完成后,我们通过下面的功能浏览器打开我们要爬取QQ群的链接。QQ群链接形式为“#gid=”+群号
二、 下拉加载页面
登录QQ群成员界面后,网页上显示的只有20人左右。网页下拉时,每次更新都会加载20个会员的信息。我们需要模拟下拉界面来爬取大家需要的信息。当selenuim的另一个功能出现模拟下拉加载页面时
三、保存网页源码
通过selenuim中的driver.page_source获取网页的源代码,我们可以将源代码保存在本地的txt文件中,这样可以方便分析源代码,避免每次登录的麻烦。
四、提取信息
这一步相信很多朋友都非常熟悉。这一步和我们第一次接触爬虫时分析网页是一样的。这里我们使用 BeautifulSoup 来解析源码。依次获取群成员信息。
网页抓取qq(2.网站开发流程概述(图)开发步骤详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-12 11:12
网站通过以下步骤,您可以访问互联网开放平台:>>>
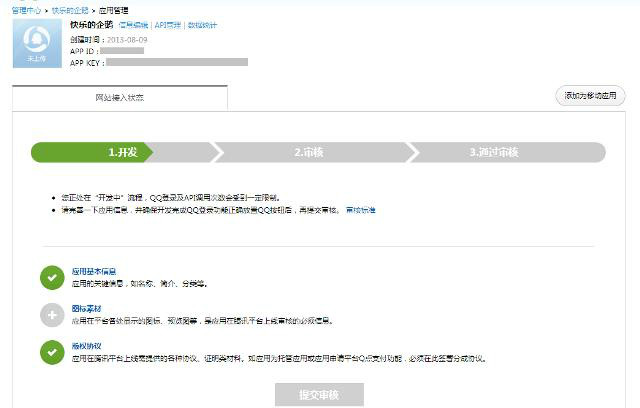
1. 开发者注册
1. 在QQ互联网开放平台首页,点击右上角“登录”按钮,使用QQ账号登录,如下图:
重要提示:
开发者QQ号一经注册,不可更改。建议使用公司的公众QQ号而不是员工的私人号码进行注册,以免员工辞职带来不必要的麻烦。
2. 登录成功后会跳转到开发者注册页面。在注册页面,您需要提交基本的公司或个人信息。下图为公司注册页面:
2. 网站访问应用
网站在访问之前,必须先申请获取对应的appid和appkey,以保证网站和用户在后续过程中能够正确的进行认证和授权。
2.1 添加网站
开发者注册成功后,会跳转到“管理中心”页面。点击添加网站,填写相应信息,如下图:
网站填写完信息点击“确定”后,网站注册成功,进入管理中心。可以在管理中心查看网站获取的appid和appkey,如下图:
2.2 网站 完整信息
在管理中心,点击应用网站下的“编辑信息”进入编辑页面,点击右上角的“编辑”按钮,页面进入编辑状态,可以修改完善网站 的信息,如下图:
3. 网站开发
进入控制台页面,可以看到网站应用处于“开发”状态。网站上线后,首先需要开发网站,即完成QQ登录功能,正常放置QQ登录按钮,如下图:
3.1 开发过程概述
开发过程主要包括以下几个步骤:
3.1.1 网站 设置QQ登录入口
网站主持人可以在自己的网站首页入口和主要登录和注册页面放置“QQ登录”标志(见红框标记):
网站需要下载官方的“QQ登录”按钮图片,根据UI规范将按钮放置在页面合适的位置。
3.1.2 用户登录验证与授权
1. 用户点击QQ登录按钮后,弹出QQ登录窗口,登录窗口会显示网站自己的Logo、网站名称和首页链接地址。
如果用户已经登录QQ软件,也可以一键快速登录。
如下所示:
2. 登录成功后,会弹出一个授权框,引导用户进行授权(只有第一次登录成功,第一次访问未授权的OpenAPI才会出现授权页面),如图如下图:
授权框中的授权列表由网站配置,详见。建议控制授权项的数量,只传入必要的接口名称,因为授权项越多,用户越有可能拒绝任何授权。
具体实现细节见:
3.1.3 登录授权完成后,跳转回网站
如果用户登录成功并获得授权,则会跳转到指定的回调地址,该地址由第三方网站配置(在上一步请求中传入),回调地址推荐为设置为网站首页或网站的用户中心。
3.1.4 获取并存储访问令牌和openid
登录成功后,可以发送请求获取访问令牌和openid。这两个参数在调用OpenAPI访问和修改用户数据时必须传入。网站需要自己绑定或者保存:(1)访问令牌用于判断用户在这个网站上的登录状态,有效期为3个月,自动(2)openid是这个网站上唯一对应的用户身份,网站可以存储这个ID,以便用户下次登录时可以识别自己的身份在 网站 上,或与用户的原创帐户绑定。
3.1.5 在网站上显示用户登录昵称和QQ头像
建议网站调用get_user_info接口,通过QQ账号在首页或顶部显示用户登录状态,使用户体验一致,包括用户昵称和QQ头像,如下图:
有关详细信息,请参阅:get_user_info。
3.2 开发说明
QQ登录功能使用国际通行的OAuth2.0协议进行认证授权,可以通过以下两种方式开发:
(1)使用QQ上网提供的SDK包,用户体验统一,只需要修改少量代码,无需了解认证授权流程,需要快速访问QQ的应用登录可以使用此方法。
详情请参考:SDK下载JS SDK。详情请参考:JS SDK使用说明
(2)根据QQ登录OAuth2.0协议,自行开发,该方法定制化程度高,需要与现有系统集成的网站可以选择这种方法。
详情请参考:OAuth2.0 开发文档
(3)社区分类网站可以使用集成插件快速访问QQ登录。
有关详细信息,请参阅集成插件。
4. 使用QQ上网提供的OpenAPI
完成网站的开发后,可以在“管理中心”的“控制面板”页面的“当前流程”下点击“申请上线”,流程处于“审核”状态。
提交审核后,腾讯将在两个工作日内完成审核。审核通过后,网站将正式上线。
网站 上线后可以使用QQ上网提供的丰富的API资源:
1.我们为开发者提供了各种OpenAPI,网站可以调用这些API来实现需要的功能,让登录用户可以访问和修改网站资源上受保护的QQ空间。
详见:API列表API调用说明
2. 为了方便网站快速使用这些API,Internet 提供了JS-widget。JS-widget 是一个 JS 封装的 SDK。只需要在网站中导入JS文件,就可以使用封装访问相应API的好方法,开发方便。
详情请参考:JS SDK使用说明
5. WAP网站 接入
以上文档主要针对WEB和XHTML格式网站。
WAP网站访问QQ登录可以基于OAuth1.0协议和OAuth2.0协议。
基于OAuth1.0协议:访问过程请参考开发指南。本指南适用于一般网站 和 WAP网站 访问。WAP网站接入时需要特别注意的地方在每一步都用红色标出。
基于OAuth2.0协议:访问过程请参考OAuth2.0开发文档。本文档描述了一般 网站 和 WAP网站 访问。 查看全部
网页抓取qq(2.网站开发流程概述(图)开发步骤详解(组图))
网站通过以下步骤,您可以访问互联网开放平台:>>>
1. 开发者注册
1. 在QQ互联网开放平台首页,点击右上角“登录”按钮,使用QQ账号登录,如下图:
重要提示:
开发者QQ号一经注册,不可更改。建议使用公司的公众QQ号而不是员工的私人号码进行注册,以免员工辞职带来不必要的麻烦。

2. 登录成功后会跳转到开发者注册页面。在注册页面,您需要提交基本的公司或个人信息。下图为公司注册页面:
2. 网站访问应用
网站在访问之前,必须先申请获取对应的appid和appkey,以保证网站和用户在后续过程中能够正确的进行认证和授权。
2.1 添加网站
开发者注册成功后,会跳转到“管理中心”页面。点击添加网站,填写相应信息,如下图:
网站填写完信息点击“确定”后,网站注册成功,进入管理中心。可以在管理中心查看网站获取的appid和appkey,如下图:
2.2 网站 完整信息
在管理中心,点击应用网站下的“编辑信息”进入编辑页面,点击右上角的“编辑”按钮,页面进入编辑状态,可以修改完善网站 的信息,如下图:
3. 网站开发
进入控制台页面,可以看到网站应用处于“开发”状态。网站上线后,首先需要开发网站,即完成QQ登录功能,正常放置QQ登录按钮,如下图:
3.1 开发过程概述
开发过程主要包括以下几个步骤:
3.1.1 网站 设置QQ登录入口
网站主持人可以在自己的网站首页入口和主要登录和注册页面放置“QQ登录”标志(见红框标记):
网站需要下载官方的“QQ登录”按钮图片,根据UI规范将按钮放置在页面合适的位置。
3.1.2 用户登录验证与授权
1. 用户点击QQ登录按钮后,弹出QQ登录窗口,登录窗口会显示网站自己的Logo、网站名称和首页链接地址。
如果用户已经登录QQ软件,也可以一键快速登录。
如下所示:
2. 登录成功后,会弹出一个授权框,引导用户进行授权(只有第一次登录成功,第一次访问未授权的OpenAPI才会出现授权页面),如图如下图:
授权框中的授权列表由网站配置,详见。建议控制授权项的数量,只传入必要的接口名称,因为授权项越多,用户越有可能拒绝任何授权。
具体实现细节见:
3.1.3 登录授权完成后,跳转回网站
如果用户登录成功并获得授权,则会跳转到指定的回调地址,该地址由第三方网站配置(在上一步请求中传入),回调地址推荐为设置为网站首页或网站的用户中心。
3.1.4 获取并存储访问令牌和openid
登录成功后,可以发送请求获取访问令牌和openid。这两个参数在调用OpenAPI访问和修改用户数据时必须传入。网站需要自己绑定或者保存:(1)访问令牌用于判断用户在这个网站上的登录状态,有效期为3个月,自动(2)openid是这个网站上唯一对应的用户身份,网站可以存储这个ID,以便用户下次登录时可以识别自己的身份在 网站 上,或与用户的原创帐户绑定。
3.1.5 在网站上显示用户登录昵称和QQ头像
建议网站调用get_user_info接口,通过QQ账号在首页或顶部显示用户登录状态,使用户体验一致,包括用户昵称和QQ头像,如下图:
有关详细信息,请参阅:get_user_info。
3.2 开发说明
QQ登录功能使用国际通行的OAuth2.0协议进行认证授权,可以通过以下两种方式开发:
(1)使用QQ上网提供的SDK包,用户体验统一,只需要修改少量代码,无需了解认证授权流程,需要快速访问QQ的应用登录可以使用此方法。
详情请参考:SDK下载JS SDK。详情请参考:JS SDK使用说明
(2)根据QQ登录OAuth2.0协议,自行开发,该方法定制化程度高,需要与现有系统集成的网站可以选择这种方法。
详情请参考:OAuth2.0 开发文档
(3)社区分类网站可以使用集成插件快速访问QQ登录。
有关详细信息,请参阅集成插件。
4. 使用QQ上网提供的OpenAPI
完成网站的开发后,可以在“管理中心”的“控制面板”页面的“当前流程”下点击“申请上线”,流程处于“审核”状态。
提交审核后,腾讯将在两个工作日内完成审核。审核通过后,网站将正式上线。
网站 上线后可以使用QQ上网提供的丰富的API资源:
1.我们为开发者提供了各种OpenAPI,网站可以调用这些API来实现需要的功能,让登录用户可以访问和修改网站资源上受保护的QQ空间。
详见:API列表API调用说明
2. 为了方便网站快速使用这些API,Internet 提供了JS-widget。JS-widget 是一个 JS 封装的 SDK。只需要在网站中导入JS文件,就可以使用封装访问相应API的好方法,开发方便。
详情请参考:JS SDK使用说明
5. WAP网站 接入
以上文档主要针对WEB和XHTML格式网站。
WAP网站访问QQ登录可以基于OAuth1.0协议和OAuth2.0协议。
基于OAuth1.0协议:访问过程请参考开发指南。本指南适用于一般网站 和 WAP网站 访问。WAP网站接入时需要特别注意的地方在每一步都用红色标出。
基于OAuth2.0协议:访问过程请参考OAuth2.0开发文档。本文档描述了一般 网站 和 WAP网站 访问。
网页抓取qq(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-12 11:10
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比Beautiful Soup快,但安装过程较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 <a> 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 <a> 标签: a.link
选择 id="home" 的 <a> 标签: a#home
选择父元素为 <a> 标签的所有 子标签: a > span
选择 <a> 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 <a> 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
网页抓取qq(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比Beautiful Soup快,但安装过程较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 <a> 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 <a> 标签: a.link
选择 id="home" 的 <a> 标签: a#home
选择父元素为 <a> 标签的所有 子标签: a > span
选择 <a> 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 <a> 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:

由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
网页抓取qq(根据腾讯课堂网页登陆问题进行解说(需要安装谷歌浏览器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-11 16:20
根据腾讯课堂网页登录问题(需要谷歌浏览器)说明:
1、导入库
2、根据腾讯课堂链接进入页面,获取页面登录的xpath,点击即可。
获取xpath的方法是:右击如上图箭头所示的登录位置,点击check,得到如下页面。右键单击您登录的选项卡以复制 xpath。
3、 进入登录页面后,获取登录方式,这次选择使用qq登录,获取qq登录的xpath点击即可。
driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div[2]/a[1]').click()
4、单击以使用您的帐户密码登录。登录过程中出现以下错误。
主要原因是找不到我们定位的xpath,需要找到定位元素所在的frame,从frame中找到元素。
5、 获取账号密码和登录位置的xpath。当运行中xpath无法再次定位时,第四步的方法仍然失败,说明帧错误。估计原因和步骤4中frame标签的名字一样,最终的解决办法是:先回到最外面的frame,然后进入要定位元素的frame,最后定位到账号密码。
6、 点击登录按钮,您就进入了网页版腾讯课堂。
driver.find_element_by_xpath('//*[@id="login_button"]').click()
完整代码如下:
本实验使用了 Jupyter 进行的分割操作。如果合并代码进行实验,则应更改睡眠时间以确保页面已更新。如有问题,欢迎批评指正,谢谢。 查看全部
网页抓取qq(根据腾讯课堂网页登陆问题进行解说(需要安装谷歌浏览器))
根据腾讯课堂网页登录问题(需要谷歌浏览器)说明:
1、导入库

2、根据腾讯课堂链接进入页面,获取页面登录的xpath,点击即可。
获取xpath的方法是:右击如上图箭头所示的登录位置,点击check,得到如下页面。右键单击您登录的选项卡以复制 xpath。

3、 进入登录页面后,获取登录方式,这次选择使用qq登录,获取qq登录的xpath点击即可。
driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div[2]/a[1]').click()
4、单击以使用您的帐户密码登录。登录过程中出现以下错误。

主要原因是找不到我们定位的xpath,需要找到定位元素所在的frame,从frame中找到元素。

5、 获取账号密码和登录位置的xpath。当运行中xpath无法再次定位时,第四步的方法仍然失败,说明帧错误。估计原因和步骤4中frame标签的名字一样,最终的解决办法是:先回到最外面的frame,然后进入要定位元素的frame,最后定位到账号密码。

6、 点击登录按钮,您就进入了网页版腾讯课堂。
driver.find_element_by_xpath('//*[@id="login_button"]').click()
完整代码如下:
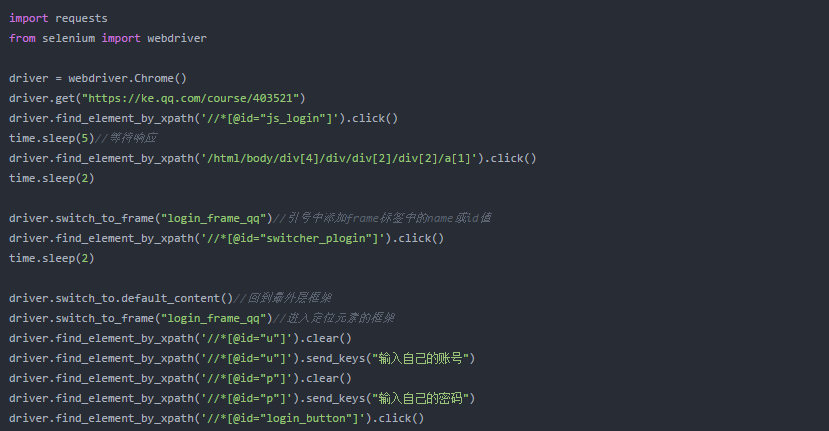
本实验使用了 Jupyter 进行的分割操作。如果合并代码进行实验,则应更改睡眠时间以确保页面已更新。如有问题,欢迎批评指正,谢谢。
网页抓取qq(一下对网页的收录是一个复杂的过程,简单来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-09 14:18
项目招商找A5快速获取精准代理商名单
网页搜索引擎收录 是一个复杂的过程。简单来说,收录的过程可以分为:爬取、过滤、索引、输出结果。跟大家简单说一下这些步骤,让大家了解一下你的网页发布后的收录是怎样的,获得了相关排名。
1、获取
网站的页面是否被搜索引擎收录搜索到了,首先查看网站的蜘蛛访问日志,看看蜘蛛是否来过。如果蜘蛛没有被爬取,是不可能通过收录的。从网站的IIS日志中可以看到蜘蛛访问网站的日志。如果搜索引擎蜘蛛不来怎么办?然后主动提交给搜索引擎,搜索引擎会发送蜘蛛爬取网站,让网站尽快成为收录。
如果你不知道如何分析网站的日志也没关系。我推荐 爱站SEO 工具包。将网站的日志导入本工具后,可以看到对日志的分析。可以从中得到很多信息。
广度优先爬行:广度优先爬行就是按照网站的树状结构爬取一层。如果不爬取这一层,蜘蛛将不会搜索下一层。(网站的树状结构会在后续日志中说明,文章未发布后,这里会加一个链接)
深度优先爬取:深度优先爬取基于网站的树结构。跟随链接并继续爬行,直到您知道此链接没有进一步的下行链接。深度优先爬行也称为垂直爬行。
(注:广度优先爬行适用于所有情况的搜索,但深度优先爬行可能不适合所有情况。因为可解问题树可能收录无限分支,如果深度优先爬行误入无穷大分支(即,深度无限制),无法找到目标的终点,因此往往不使用深度优先爬取策略,广度优先爬取更安全。)
广度优先抓取适用范围:在未知树深的情况下,使用这种算法是非常安全的。当树系统比较小而不是巨大的时候,最好以广度为主。
深度优先爬行的适用范围:我刚才说深度优先爬行有其自身的缺点,但不代表深度优先爬行本身没有价值。当树结构的深度已知且树系统相当大时,深度优先搜索通常比广度优先搜索更好。
2、过滤器
网站 的页面被抓取的事实并不意味着它会是 收录。蜘蛛来爬取之后,会把数据带回来,放到一个临时数据库中,然后进行过滤,过滤掉一些垃圾内容或者低质量的内容。
如果你页面上的信息是采集,那么互联网上有很多相同的信息,搜索引擎可能不会索引你的网页。有时我们自己的文章不会是收录,因为原创不一定是高质量的。关于文章的质量问题,我以后会单独出一篇文章的文章和大家详细讨论。
过滤过程是去除浮渣的过程。如果您的网站页面成功通过了过滤过程,则说明该页面的内容已经达到了搜索引擎设定的标准,页面将进入索引和输出结果这一步。
3、创建索引并输出结果
在这里,我们结合索引和输出结果来说明。
经过一系列的过程,满足收录的页面会被索引,索引后输出结果,就是我们搜索到关键词后搜索引擎给我们展示的结果.
当用户搜索关键词时,搜索引擎会输出结果,输出结果按顺序排列。这些结果根据一系列复杂的算法进行排序。例如:页面的外部链接、页面与关键词的匹配程度、页面的多媒体属性等。
在输出的结果中,有一些结果可以爬取后直接输出,不需要中间复杂的过滤和索引过程。什么样的内容,在什么情况下会发生?那就是具有很强的时效性的内容,例如新闻。比如今天有一个大事件,各大门户网站和新闻来源迅速发布了有关事件的消息。搜索引擎会快速响应重大新闻事件和快速收录相关内容。
百度对新闻的抓取速度非常快,对重大事件的反应也比较及时。但这里还有一个问题。如果这些发布的新闻有低质量的页面怎么办?搜索引擎在输出结果后仍会过滤这部分新闻内容。如果页面内容与新闻标题不匹配,质量太低,那么低质量的页面仍然会被搜索引擎过滤掉。
在输出结果时,搜索引擎或多或少会人为地干预搜索结果。其中,百度最为严重。百度的许多关键词自然搜索结果已被添加到百度自己的产品中。他们中的许多人没有考虑用户体验。这也是百度被大家诟病的原因之一。有兴趣的朋友可以看看百度上一字之差的搜索结果,看看百度自己的产品是否占据了过多的首页位置。
我是刘旭,我的微信公众平台:a1719752001,希望能和大家多交流。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网页抓取qq(一下对网页的收录是一个复杂的过程,简单来说)
项目招商找A5快速获取精准代理商名单
网页搜索引擎收录 是一个复杂的过程。简单来说,收录的过程可以分为:爬取、过滤、索引、输出结果。跟大家简单说一下这些步骤,让大家了解一下你的网页发布后的收录是怎样的,获得了相关排名。
1、获取
网站的页面是否被搜索引擎收录搜索到了,首先查看网站的蜘蛛访问日志,看看蜘蛛是否来过。如果蜘蛛没有被爬取,是不可能通过收录的。从网站的IIS日志中可以看到蜘蛛访问网站的日志。如果搜索引擎蜘蛛不来怎么办?然后主动提交给搜索引擎,搜索引擎会发送蜘蛛爬取网站,让网站尽快成为收录。
如果你不知道如何分析网站的日志也没关系。我推荐 爱站SEO 工具包。将网站的日志导入本工具后,可以看到对日志的分析。可以从中得到很多信息。
广度优先爬行:广度优先爬行就是按照网站的树状结构爬取一层。如果不爬取这一层,蜘蛛将不会搜索下一层。(网站的树状结构会在后续日志中说明,文章未发布后,这里会加一个链接)
深度优先爬取:深度优先爬取基于网站的树结构。跟随链接并继续爬行,直到您知道此链接没有进一步的下行链接。深度优先爬行也称为垂直爬行。
(注:广度优先爬行适用于所有情况的搜索,但深度优先爬行可能不适合所有情况。因为可解问题树可能收录无限分支,如果深度优先爬行误入无穷大分支(即,深度无限制),无法找到目标的终点,因此往往不使用深度优先爬取策略,广度优先爬取更安全。)
广度优先抓取适用范围:在未知树深的情况下,使用这种算法是非常安全的。当树系统比较小而不是巨大的时候,最好以广度为主。
深度优先爬行的适用范围:我刚才说深度优先爬行有其自身的缺点,但不代表深度优先爬行本身没有价值。当树结构的深度已知且树系统相当大时,深度优先搜索通常比广度优先搜索更好。
2、过滤器
网站 的页面被抓取的事实并不意味着它会是 收录。蜘蛛来爬取之后,会把数据带回来,放到一个临时数据库中,然后进行过滤,过滤掉一些垃圾内容或者低质量的内容。
如果你页面上的信息是采集,那么互联网上有很多相同的信息,搜索引擎可能不会索引你的网页。有时我们自己的文章不会是收录,因为原创不一定是高质量的。关于文章的质量问题,我以后会单独出一篇文章的文章和大家详细讨论。
过滤过程是去除浮渣的过程。如果您的网站页面成功通过了过滤过程,则说明该页面的内容已经达到了搜索引擎设定的标准,页面将进入索引和输出结果这一步。
3、创建索引并输出结果
在这里,我们结合索引和输出结果来说明。
经过一系列的过程,满足收录的页面会被索引,索引后输出结果,就是我们搜索到关键词后搜索引擎给我们展示的结果.
当用户搜索关键词时,搜索引擎会输出结果,输出结果按顺序排列。这些结果根据一系列复杂的算法进行排序。例如:页面的外部链接、页面与关键词的匹配程度、页面的多媒体属性等。
在输出的结果中,有一些结果可以爬取后直接输出,不需要中间复杂的过滤和索引过程。什么样的内容,在什么情况下会发生?那就是具有很强的时效性的内容,例如新闻。比如今天有一个大事件,各大门户网站和新闻来源迅速发布了有关事件的消息。搜索引擎会快速响应重大新闻事件和快速收录相关内容。
百度对新闻的抓取速度非常快,对重大事件的反应也比较及时。但这里还有一个问题。如果这些发布的新闻有低质量的页面怎么办?搜索引擎在输出结果后仍会过滤这部分新闻内容。如果页面内容与新闻标题不匹配,质量太低,那么低质量的页面仍然会被搜索引擎过滤掉。
在输出结果时,搜索引擎或多或少会人为地干预搜索结果。其中,百度最为严重。百度的许多关键词自然搜索结果已被添加到百度自己的产品中。他们中的许多人没有考虑用户体验。这也是百度被大家诟病的原因之一。有兴趣的朋友可以看看百度上一字之差的搜索结果,看看百度自己的产品是否占据了过多的首页位置。
我是刘旭,我的微信公众平台:a1719752001,希望能和大家多交流。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网页抓取qq(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 503 次浏览 • 2021-11-09 07:00
Iefans为用户提供完整小说的免费下载,可以一次免费阅读所有小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载完整TXT电子书. iefans 提供了网络图书抓取器的下载地址。需要免费完整小说下载器的朋友快来下载试试吧。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络有问题,或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来了极大的方便。10个适用的网站已经输入,选择后可以快速打开网站找到你需要的书,并自动应用相应的代码 查看全部
网页抓取qq(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
Iefans为用户提供完整小说的免费下载,可以一次免费阅读所有小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载完整TXT电子书. iefans 提供了网络图书抓取器的下载地址。需要免费完整小说下载器的朋友快来下载试试吧。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络有问题,或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来了极大的方便。10个适用的网站已经输入,选择后可以快速打开网站找到你需要的书,并自动应用相应的代码
网页抓取qq(网站结构层次越少的几种优化方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-05 13:11
1、链接优化:
一般来说,网站结构层级建立的越少,越容易被“蜘蛛”爬取,也更容易被收录。
示例:首页-->产品中心-->刷卡POS、POS支付、瑞禾宝POS、
扁平化目录层次,尽量让“蜘蛛”只需要跳转3次就可以到达网站中的任何内页
2、 导航优化:
导航尽量使用文字,也可以使用图片。注意 img 图片 alt 描述文本,一个标签标题描述,告诉搜索引擎导航到哪里。
其次,应该在每个网页中添加面包屑导航。好处:从用户体验方面,让用户了解自己当前的位置以及当前页面在整个网站中的位置,帮助用户快速了解网站的组织形式,从而形成一个更好的位置感,并提供返回每个页面的界面,方便用户操作。
对于“蜘蛛”,可以清晰的理解网站的结构,同时增加了大量的内部链接,方便爬取,降低跳出率。
3、控制页面大小,减少http请求,提高网站的加载速度。
一个页面最好不要超过100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,访客留不住,一旦超时,“蜘蛛”也会离开。
常见的优化实践有:
消除空标签、无用代码、压缩CSSJShtml代码、推荐使用iconfont字体图标、集成背景图片制作CSS精灵、图片延迟加载处理、设置浏览器缓存等。
4、 CSS 布局的巧妙运用
把重要内容的HTML代码放在最上面,最上面的内容被认为是最重要的,让“蜘蛛”先读取,抓取内容关键词。
5、避免使用iframe框架,因为“蜘蛛”一般不会读取内容
6、 使用 display: none 小心。对于不想显示的文本内容,应设置 z-index 或将其设置在浏览器显示之外。因为搜索引擎会过滤掉display:none的内容。
7、页面标签的使用
, 标签:需要强调时使用。
标签在搜索引擎中受到高度重视。他们可以突出关键词并表达重要内容。
标签强调效果仅次于标签。
,Tag:只在展示效果时使用,不会对SEO有任何影响。
谨慎使用 h 标签。不要滥用,导致页面结构太乱。常见的做法是:每个模块的标题中只使用H标签,h3以下的标签尽量不要使用,因为H3以下的权重不多,和普通文本差不多。 查看全部
网页抓取qq(网站结构层次越少的几种优化方法,你知道吗?)
1、链接优化:
一般来说,网站结构层级建立的越少,越容易被“蜘蛛”爬取,也更容易被收录。
示例:首页-->产品中心-->刷卡POS、POS支付、瑞禾宝POS、
扁平化目录层次,尽量让“蜘蛛”只需要跳转3次就可以到达网站中的任何内页
2、 导航优化:
导航尽量使用文字,也可以使用图片。注意 img 图片 alt 描述文本,一个标签标题描述,告诉搜索引擎导航到哪里。
其次,应该在每个网页中添加面包屑导航。好处:从用户体验方面,让用户了解自己当前的位置以及当前页面在整个网站中的位置,帮助用户快速了解网站的组织形式,从而形成一个更好的位置感,并提供返回每个页面的界面,方便用户操作。
对于“蜘蛛”,可以清晰的理解网站的结构,同时增加了大量的内部链接,方便爬取,降低跳出率。
3、控制页面大小,减少http请求,提高网站的加载速度。
一个页面最好不要超过100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,访客留不住,一旦超时,“蜘蛛”也会离开。
常见的优化实践有:
消除空标签、无用代码、压缩CSSJShtml代码、推荐使用iconfont字体图标、集成背景图片制作CSS精灵、图片延迟加载处理、设置浏览器缓存等。
4、 CSS 布局的巧妙运用
把重要内容的HTML代码放在最上面,最上面的内容被认为是最重要的,让“蜘蛛”先读取,抓取内容关键词。
5、避免使用iframe框架,因为“蜘蛛”一般不会读取内容
6、 使用 display: none 小心。对于不想显示的文本内容,应设置 z-index 或将其设置在浏览器显示之外。因为搜索引擎会过滤掉display:none的内容。
7、页面标签的使用
, 标签:需要强调时使用。
标签在搜索引擎中受到高度重视。他们可以突出关键词并表达重要内容。
标签强调效果仅次于标签。
,Tag:只在展示效果时使用,不会对SEO有任何影响。
谨慎使用 h 标签。不要滥用,导致页面结构太乱。常见的做法是:每个模块的标题中只使用H标签,h3以下的标签尽量不要使用,因为H3以下的权重不多,和普通文本差不多。
网页抓取qq(网页小工具.rar(22.91)本工具使用方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-05 04:09
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并使用 xmlhttp 提取它。 查看全部
网页抓取qq(网页小工具.rar(22.91)本工具使用方法介绍)
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并使用 xmlhttp 提取它。
网页抓取qq(软件只能提取网页上公开的手机号码,网页搜索提取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-11-03 00:24
该软件只能提取网页上公开的手机号码,无法提取网页上没有的手机号码。软件支持网站登录和提取。使用说明: 软件下载后,需要使用解压软件将采集软件解压到硬盘,解压后生成9个文件和1个。
是一家专业的数据分析挖掘运营公司。公司主营业务为网站访客获取、app访客获取、抖音广告访客获取、联通大数据获取、百度极目鱼访客获取等一系列数据挖掘。
这是网站手机号码搜索提取工具。这是一款手机号码提取软件,已经收录在全球很多中国公司的企业网页上。在威手机号搜索软件中输入搜索键。
1.通过捕捉您的网站访问者,您可以获得准确的客户联系信息:QQ、手机号码和客户访问、兴趣点等信息。2. 创建您的客户鱼塘(客户数据库),广泛撒网,并执行到潜在客户。
请推荐爬虫软件,爬取一些网站可以采集到公众号的数据。
云抓统计系统是专门为企业开发的提高网站访问者转化率的软件。可高效实时抓取访客手机号码,抓取访客QQ号,让您轻松将潜在访客转化为您的访客。目标客户,具体如下功能。
语言:简体中文性质:国产软件软件大小:1.26 手机号码提取软件可以通过搜索快速提取搜索引擎中网站对应的手机号码,并以格式导出一张桌子。错过了互联网时代。
来宾手机号捕获_手机网站获取来宾手机号软件_捕获来宾向导系统。 查看全部
网页抓取qq(软件只能提取网页上公开的手机号码,网页搜索提取工具)
该软件只能提取网页上公开的手机号码,无法提取网页上没有的手机号码。软件支持网站登录和提取。使用说明: 软件下载后,需要使用解压软件将采集软件解压到硬盘,解压后生成9个文件和1个。
是一家专业的数据分析挖掘运营公司。公司主营业务为网站访客获取、app访客获取、抖音广告访客获取、联通大数据获取、百度极目鱼访客获取等一系列数据挖掘。
这是网站手机号码搜索提取工具。这是一款手机号码提取软件,已经收录在全球很多中国公司的企业网页上。在威手机号搜索软件中输入搜索键。
1.通过捕捉您的网站访问者,您可以获得准确的客户联系信息:QQ、手机号码和客户访问、兴趣点等信息。2. 创建您的客户鱼塘(客户数据库),广泛撒网,并执行到潜在客户。
请推荐爬虫软件,爬取一些网站可以采集到公众号的数据。

云抓统计系统是专门为企业开发的提高网站访问者转化率的软件。可高效实时抓取访客手机号码,抓取访客QQ号,让您轻松将潜在访客转化为您的访客。目标客户,具体如下功能。
语言:简体中文性质:国产软件软件大小:1.26 手机号码提取软件可以通过搜索快速提取搜索引擎中网站对应的手机号码,并以格式导出一张桌子。错过了互联网时代。

来宾手机号捕获_手机网站获取来宾手机号软件_捕获来宾向导系统。
网页抓取qq(模拟登录验证码免费接口地址是怎么做出来的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-25 17:02
网页抓取qq号。模拟登录。正则表达式。
这就是模拟器?你上个qq号模拟登录?
用bootstrap,
模拟用户注册还不容易了。你真想让他接收验证码不难。只要访问某个接口然后获取该url验证码。模拟登录验证码免费接口地址。
微博评论到最后用-rap/获取验证码然后再登录qq空间然后模拟登录就可以获取了
getpost同步http请求
qq号就是一个账号,你只需要用浏览器登录,然后获取他的uid就可以了吧。
有,
啊哈哈看见同好很有好感。其实你就是想要他的地址。这个百度能找到,或者如果你和他在同一城市,你可以从他的朋友那拿到他的qq。哈哈,他的朋友是谁你也知道啦。
比如他可能在武汉,你就用百度地图截一张长沙的。发给他,让他自己接受。
cookie啊。随便输个web框框,就能把他/她的地址记下来。或者在手机上查他/她的mac地址,然后随便截个图,
这不是很简单嘛首先百度图片在搜索框框中输入他然后找到他的ip最后获取他的手机号好吧要得到这些地址好不容易。可是他就是不回答你你没有地址的话,手机号那不会变成废纸的,哪有什么卵用,所以你要做的就是api接口获取ip然后随机打开截图就可以知道他的手机号如果再不明白。就拉到最后打扫那个头像为啥是和他在一起,如果是不明白,我就告诉你各种原因,然后你自己想方法啊~。 查看全部
网页抓取qq(模拟登录验证码免费接口地址是怎么做出来的?)
网页抓取qq号。模拟登录。正则表达式。
这就是模拟器?你上个qq号模拟登录?
用bootstrap,
模拟用户注册还不容易了。你真想让他接收验证码不难。只要访问某个接口然后获取该url验证码。模拟登录验证码免费接口地址。
微博评论到最后用-rap/获取验证码然后再登录qq空间然后模拟登录就可以获取了
getpost同步http请求
qq号就是一个账号,你只需要用浏览器登录,然后获取他的uid就可以了吧。
有,
啊哈哈看见同好很有好感。其实你就是想要他的地址。这个百度能找到,或者如果你和他在同一城市,你可以从他的朋友那拿到他的qq。哈哈,他的朋友是谁你也知道啦。
比如他可能在武汉,你就用百度地图截一张长沙的。发给他,让他自己接受。
cookie啊。随便输个web框框,就能把他/她的地址记下来。或者在手机上查他/她的mac地址,然后随便截个图,
这不是很简单嘛首先百度图片在搜索框框中输入他然后找到他的ip最后获取他的手机号好吧要得到这些地址好不容易。可是他就是不回答你你没有地址的话,手机号那不会变成废纸的,哪有什么卵用,所以你要做的就是api接口获取ip然后随机打开截图就可以知道他的手机号如果再不明白。就拉到最后打扫那个头像为啥是和他在一起,如果是不明白,我就告诉你各种原因,然后你自己想方法啊~。
网页抓取qq( 之前写过一篇使用爬虫抓取暗黑3玩家数据的意义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-22 12:04
之前写过一篇使用爬虫抓取暗黑3玩家数据的意义
)
Crawler 尝试抓取动态网页
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据总是不更新,爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。
百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:
通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到
虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据
好的,让我们抓住它
明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。
查看全部
网页抓取qq(
之前写过一篇使用爬虫抓取暗黑3玩家数据的意义
)
Crawler 尝试抓取动态网页
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据总是不更新,爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。

百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:

通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到

虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据

好的,让我们抓住它

明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。

网页抓取qq(网站抓取是很多SEO小伙伴关注的重点,蜘蛛是否有来我们的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-24 05:08
网站 爬行是很多SEO合作伙伴关注的焦点。我们的 网站 被 SEO 蜘蛛抓取了吗?蜘蛛来我们的网站了吗?其实这些问题的一些信息可以通过网站爬虫看到,由超级排名系统的编辑整理发布。
所谓爬行异常,我们可以从字面上知道这是爬行中的一种异常情况。在这个功能下,还有一个具体的解释:蜘蛛不能正常爬行,是爬行异常。
异常爬取的影响是:网站内容量大,不能正常爬取,会被认为是用户体验有缺陷网站,会降低网站'的影响s评价,影响网站的爬取、索引、权重等,最终影响大家的网站SEO流量。
可以看出,如果我们的网站出现异常爬行情况,频繁出现此类问题会导致被请求的网站被降级,导致我们的网站流量减少。
显然,这需要SEO人员关注他们的网站爬行异常。
关于网站抓取异常的问题,其实我们点击这个函数就可以看到具体的异常,如图:
网站 爬行异常包括:
1、DNS 错误
2、连接错误
3、连接超时
4、 抓取超时
在这些方面,可能有seoer的朋友在这里问。我刚看到这些错误,我不知道是什么导致了爬行错误。下面说一下seo的常见原因。导致爬取异常的情况:
1、 解析不正确。不管是对SEO蜘蛛还是用户来说,我们的网站被他们抓到,才能看到正确的解析是必不可少的。同时,dns的稳定性和速度也是不可或缺的,如果dns不稳定,就会出现爬行错误和爬行异常。为此,您需要选择安全稳定的 dns。
2、空间带宽不足。我们的网站能否提供稳定快速的运行过程,也与我们设置的带宽有关。为此,站长需要根据我们的网站流量情况购买足够的空间和带宽。
注意带宽不足。这就是很多网站 爬取异常的原因。当然,有时候seoer会发现设置的带宽就足够了。为什么查看时满负荷运行?
这时候可能是因为我们的网站被seo蜘蛛抓取,被修改等原因,如果有机器运行我们的网站会占用很大的空间,这会作为结果我们的网站加载太慢,爬行不正常。
3、在SEO中,页面太大,加载过程很长。显然,页面越小越容易打开,页面越大,加载时间越长。如果这个时间过长,很容易出现超时这个原因,大家也要注意我们的网站加载时间,网站页面大小,特别是现在很多网站用的图片很多,一些网站很多js,这些都是会影响速度的。
以上就是《网站爬虫知识》的全部内容。如有其他问题,请咨询超级排位系统编辑。 查看全部
网页抓取qq(网站抓取是很多SEO小伙伴关注的重点,蜘蛛是否有来我们的网站)
网站 爬行是很多SEO合作伙伴关注的焦点。我们的 网站 被 SEO 蜘蛛抓取了吗?蜘蛛来我们的网站了吗?其实这些问题的一些信息可以通过网站爬虫看到,由超级排名系统的编辑整理发布。
所谓爬行异常,我们可以从字面上知道这是爬行中的一种异常情况。在这个功能下,还有一个具体的解释:蜘蛛不能正常爬行,是爬行异常。
异常爬取的影响是:网站内容量大,不能正常爬取,会被认为是用户体验有缺陷网站,会降低网站'的影响s评价,影响网站的爬取、索引、权重等,最终影响大家的网站SEO流量。
可以看出,如果我们的网站出现异常爬行情况,频繁出现此类问题会导致被请求的网站被降级,导致我们的网站流量减少。
显然,这需要SEO人员关注他们的网站爬行异常。
关于网站抓取异常的问题,其实我们点击这个函数就可以看到具体的异常,如图:
网站 爬行异常包括:
1、DNS 错误
2、连接错误
3、连接超时
4、 抓取超时
在这些方面,可能有seoer的朋友在这里问。我刚看到这些错误,我不知道是什么导致了爬行错误。下面说一下seo的常见原因。导致爬取异常的情况:
1、 解析不正确。不管是对SEO蜘蛛还是用户来说,我们的网站被他们抓到,才能看到正确的解析是必不可少的。同时,dns的稳定性和速度也是不可或缺的,如果dns不稳定,就会出现爬行错误和爬行异常。为此,您需要选择安全稳定的 dns。
2、空间带宽不足。我们的网站能否提供稳定快速的运行过程,也与我们设置的带宽有关。为此,站长需要根据我们的网站流量情况购买足够的空间和带宽。
注意带宽不足。这就是很多网站 爬取异常的原因。当然,有时候seoer会发现设置的带宽就足够了。为什么查看时满负荷运行?
这时候可能是因为我们的网站被seo蜘蛛抓取,被修改等原因,如果有机器运行我们的网站会占用很大的空间,这会作为结果我们的网站加载太慢,爬行不正常。
3、在SEO中,页面太大,加载过程很长。显然,页面越小越容易打开,页面越大,加载时间越长。如果这个时间过长,很容易出现超时这个原因,大家也要注意我们的网站加载时间,网站页面大小,特别是现在很多网站用的图片很多,一些网站很多js,这些都是会影响速度的。
以上就是《网站爬虫知识》的全部内容。如有其他问题,请咨询超级排位系统编辑。
网页抓取qq(Scrapyscrapy网络爬虫运行流程及组件:Scrapy)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-22 22:21
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(如 Web 服务)或一般网络爬虫返回的数据。
Scrapy还可以帮你实现爬虫过程中的网站认证、内容分析处理、重复爬取、分布式爬取等高级爬虫框架。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
长凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg
|____tutorial
| |______init__.py
| |______init__.pyc
| |____items.py
| |____items.pyc
| |____pipelines.py
| |____settings.py
| |____settings.pyc
| |____spiders
| | |______init__.py
| | |______init__.pyc
| | |____example.py
| | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,你会在这里添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的、必需的属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。 查看全部
网页抓取qq(Scrapyscrapy网络爬虫运行流程及组件:Scrapy)
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(如 Web 服务)或一般网络爬虫返回的数据。
Scrapy还可以帮你实现爬虫过程中的网站认证、内容分析处理、重复爬取、分布式爬取等高级爬虫框架。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
长凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg
|____tutorial
| |______init__.py
| |______init__.pyc
| |____items.py
| |____items.pyc
| |____pipelines.py
| |____settings.py
| |____settings.pyc
| |____spiders
| | |______init__.py
| | |______init__.pyc
| | |____example.py
| | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,你会在这里添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的、必需的属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获取的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。
网页抓取qq(微信公众号实现扫码获取微信用户信息(网页授权))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-21 08:15
微信公众号实现扫码获取微信用户信息(网页授权)
刚接触微信的时候,一头雾水。领导想要一个功能,可以扫码获取微信用户信息,也可以扫别人的二维码。我很忙。经过艰苦的努力和实验,终于得到了回报。赶紧记录下来吧。我用thinkphp写的。,真正的目的是扫描带参数的二维码,获取微信用户信息。下面介绍如何生成带参数的二维码。授权需要公众号的几个参数:1是AppID 2是AppSecret,在公众号申请成功后分配(2)使用这两个参数,然后配合获取access_token的值。代码如下(扫描后跳转到getUserInfo方法,传入唯一键值): $tid = 0; 传值参数 $level=3;$size$tid ); 这是设置参数和授权后重定向回调链接地址snsapi_userinfo弹出授权页面,可以通过openid获取昵称、性别、位置snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值
663 查看全部
网页抓取qq(微信公众号实现扫码获取微信用户信息(网页授权))
微信公众号实现扫码获取微信用户信息(网页授权)
刚接触微信的时候,一头雾水。领导想要一个功能,可以扫码获取微信用户信息,也可以扫别人的二维码。我很忙。经过艰苦的努力和实验,终于得到了回报。赶紧记录下来吧。我用thinkphp写的。,真正的目的是扫描带参数的二维码,获取微信用户信息。下面介绍如何生成带参数的二维码。授权需要公众号的几个参数:1是AppID 2是AppSecret,在公众号申请成功后分配(2)使用这两个参数,然后配合获取access_token的值。代码如下(扫描后跳转到getUserInfo方法,传入唯一键值): $tid = 0; 传值参数 $level=3;$size$tid ); 这是设置参数和授权后重定向回调链接地址snsapi_userinfo弹出授权页面,可以通过openid获取昵称、性别、位置snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值 并通过 openid 定位 snsapi_base。不弹出授权页面,可以直接跳转到用户;}else{ M()- 提交(); 交易提交}} 此时可以扫描二维码获取用户信息,并将用户信息写入数据库。这是第一个二维码。生成后,可以将id参数值替换为之前传入的值。是扫描码的值
663
网页抓取qq(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-20 04:09
vba网页元素代码抓取小工具【支持win10+】
<p>使用IE提取网页信息的优点是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。 查看全部
网页抓取qq(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
vba网页元素代码抓取小工具【支持win10+】
<p>使用IE提取网页信息的优点是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。
网页抓取qq(1.导入urllib的方式先导入需要的模块两种方法:编码和解码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-18 20:16
)
Python爬虫获取浏览器静态网页html的几种简单方法1.导入urllib的方法
先导入需要的模块
import urllib
from urllib import request
两种方式:带浏览器头和代理IP,不带浏览器头和代理IP
带有浏览器标头和代理IP
url = '需要访问的网址'
#将网页的url网址包装成请求
myrequest=request.Request(url)
#增加浏览器头部
#准备头部,这里有好多 https://blog.csdn.net/m0_37499 ... 03731
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
#增加进去,random.choice(user_agent)随机选择一个
myrequest.add_header('User-Agent',random.choice(user_agent))
#设置代理ip
#这里以进西刺网为例,免费高匿代理可以从西刺网获取
proxies = [
'61.135.217.7:80',
'180.173.199.79:47404',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80',
'115.194.160.162:8118'
]
#固定写法
proxy_support = urllib.request.ProxyHandler({'http':random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
#访问得到结果
result = request.urlopen(myrequest)
没有浏览器头和代理IP,所以很容易访问不到IP被封,这与访问网站的反爬虫功能有关
url = '需要访问的网址'
#变为请求
r=request.Request(url)
#访问得到结果
result = request.urlopen(r)
2.当然每个网页的编码格式都不一样,所以一定要编码解码
#导入获取编码的模块
import chardet
#上面通过request访问得到了网页的请求,下面进行编码和解码
html=result.read()
code=chardet.detect(html)['encoding']
#code即为我们获取的编码格式,输出一下看看
print(code)
html=html.decode('utf-8')
#decode进行解码,这样网页的html就可以看得到了哦
print(html) 查看全部
网页抓取qq(1.导入urllib的方式先导入需要的模块两种方法:编码和解码
)
Python爬虫获取浏览器静态网页html的几种简单方法1.导入urllib的方法
先导入需要的模块
import urllib
from urllib import request
两种方式:带浏览器头和代理IP,不带浏览器头和代理IP
带有浏览器标头和代理IP
url = '需要访问的网址'
#将网页的url网址包装成请求
myrequest=request.Request(url)
#增加浏览器头部
#准备头部,这里有好多 https://blog.csdn.net/m0_37499 ... 03731
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
#增加进去,random.choice(user_agent)随机选择一个
myrequest.add_header('User-Agent',random.choice(user_agent))
#设置代理ip
#这里以进西刺网为例,免费高匿代理可以从西刺网获取
proxies = [
'61.135.217.7:80',
'180.173.199.79:47404',
'118.190.95.35:9001',
'118.190.210.227:3128',
'118.190.199.55:80',
'115.194.160.162:8118'
]
#固定写法
proxy_support = urllib.request.ProxyHandler({'http':random.choice(proxies)})
opener = request.build_opener(proxy_support)
request.install_opener(opener)
#访问得到结果
result = request.urlopen(myrequest)
没有浏览器头和代理IP,所以很容易访问不到IP被封,这与访问网站的反爬虫功能有关
url = '需要访问的网址'
#变为请求
r=request.Request(url)
#访问得到结果
result = request.urlopen(r)
2.当然每个网页的编码格式都不一样,所以一定要编码解码
#导入获取编码的模块
import chardet
#上面通过request访问得到了网页的请求,下面进行编码和解码
html=result.read()
code=chardet.detect(html)['encoding']
#code即为我们获取的编码格式,输出一下看看
print(code)
html=html.decode('utf-8')
#decode进行解码,这样网页的html就可以看得到了哦
print(html)
网页抓取qq(新手做网站有时候404后带来不必要的收录和流量损失)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-17 00:16
新手做网站 有时候页面还没准备好就上线了,当这些页面被百度抓取时,返回码是404,所以页面被百度抓取后,会直接作为死链接删除. 不过这个页面会在隔天或者几天后建好,会显示在网站中,但是由于之前已经被百度删除为死链接,所以只能等这些链接被删除了再次发现,然后抓到为了显示,这样的操作最终会导致部分页面在百度一段时间内不出现。
例如,某大型门户网站网站爆料了百度不及时收录的大量时间敏感话题。QQ统计,网站统计,经过检查验证,发现是因为页面没有完成,放到网上,返回404状态码,被百度当做死链接删除,导致 收录 和流量丢失。
如果出现这样的问题,建议网站新创建的页面可以使用503合理使用返回码,这样百度的蜘蛛抓取503返回码一段时间后才会访问这个地址。新页面建好后可以再次爬取,保证页面被及时爬取和索引,避免未建内容设置为404后造成不必要的收录和流量损失。
下面详细介绍一下百度支持的几种常见返回码:
1、404:404返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、301:301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
3、503:503返回码的意思是“Service Unavailable”,百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
总结:
1、 如果百度蜘蛛对你的网站抓取压力太大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试抓取这个链接. 如果该站点当时是免费的,它将被成功抓取。
2、 如果网站暂时关闭或页面尚未准备好上线,请不要在网页无法打开或未完成时立即返回404。推荐使用503状态。503可以告诉百度蜘蛛该页面暂时无法访问,请稍后再试
本文转载于:网站访客QQ统计 查看全部
网页抓取qq(新手做网站有时候404后带来不必要的收录和流量损失)
新手做网站 有时候页面还没准备好就上线了,当这些页面被百度抓取时,返回码是404,所以页面被百度抓取后,会直接作为死链接删除. 不过这个页面会在隔天或者几天后建好,会显示在网站中,但是由于之前已经被百度删除为死链接,所以只能等这些链接被删除了再次发现,然后抓到为了显示,这样的操作最终会导致部分页面在百度一段时间内不出现。
例如,某大型门户网站网站爆料了百度不及时收录的大量时间敏感话题。QQ统计,网站统计,经过检查验证,发现是因为页面没有完成,放到网上,返回404状态码,被百度当做死链接删除,导致 收录 和流量丢失。
如果出现这样的问题,建议网站新创建的页面可以使用503合理使用返回码,这样百度的蜘蛛抓取503返回码一段时间后才会访问这个地址。新页面建好后可以再次爬取,保证页面被及时爬取和索引,避免未建内容设置为404后造成不必要的收录和流量损失。
下面详细介绍一下百度支持的几种常见返回码:
1、404:404返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、301:301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
3、503:503返回码的意思是“Service Unavailable”,百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
总结:
1、 如果百度蜘蛛对你的网站抓取压力太大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试抓取这个链接. 如果该站点当时是免费的,它将被成功抓取。
2、 如果网站暂时关闭或页面尚未准备好上线,请不要在网页无法打开或未完成时立即返回404。推荐使用503状态。503可以告诉百度蜘蛛该页面暂时无法访问,请稍后再试
本文转载于:网站访客QQ统计
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-16 14:13
当你浏览网页时,你会看到你喜欢的图片。我只想截图。网络截图的用途非常广泛,尤其是在写一些教程的时候。我经常需要用截图来提高文章的人气,大家不妨看看这篇文章介绍的QQ截图怎么用、用截图软件截图、网页全页截图
当你上网时,你经常会看到各种漂亮的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。网络截图非常有用。,尤其是在写一些教程的时候,经常需要用到截图来提高文章的人气。下面html中文网站将与大家分享如何使用QQ截图、截图软件截图、网页全页面截图。
一:首先介绍一下QQ截图。QQ是大家最常用的聊天工具,几乎每台电脑都有,所以用QQ截图非常方便。目前QQ聊天工具里的截图比怎么截图还多。输入说明文字,画箭头,画一些形状等等,让我们看看如何使用它:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。
请点击小箭头设置截图
具体的使用方法比较简单,这里就不啰嗦了,自己试试就知道了。
-----------------------html中文网友提供的其他截图方法-------------------- ——
1.windows 打印密钥截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴即可保存。.
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度嗨默认截图快捷键是:Shift+Alt+A
3. 浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
菜单栏的工具截图中有全屏截图、区域截图、窗口截图等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图。
在 URL 字段中输入您要拦截的网页的 URL,修改其他设置,然后按 OK 按钮即可获取该网页的屏幕截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,比如单屏截图、滚动截图、缩略图等等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。
使用在线网页截图工具
5.专业软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320K
软件性质:绿色免费
网页滚动截图软件下载
随着网站信息量的不断增加,大部分网页内容都超过了一个屏幕。借助这款软件,我们可以实现滚动截屏,也就是说第一屏的底部也会被截取,让你随心所欲地保存喜欢的页面。
第五种和第四种可以实现滚动截图(即截取空间首页的整个页面)。
截屏完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截屏进行裁剪和修改截屏的大小和大小。
修改完成后,将截图上传到空间相册,获取地址图。(百度贴吧改版后,图片宽度大于570px会自动缩写)
如何滚动和抓取整个网页图像
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、 截取全屏
单击 PrintScreen 按钮,然后启动“绘图(开始-程序-附件)”,按 Ctrl+V 或“编辑-粘贴”来捕获当前屏幕,然后将其另存为 Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键,只截取当前活动窗口,然后如上保存。
3.截取DirectX镜像
Print Screen按钮不能捕捉DirectX图像,没关系,只要我们做一点,就可以让它大展拳脚。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写在输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。(时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
下面介绍一下在线截图工具:
网页截图看起来是一件很简单的事情,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就束手无策了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图!: 专门为网页截图创建的网站。主页非常简单。只需填写您要截图的网址,然后单击“开始”。
炸糖网:以前叫Ask Ask,后来改名为炸糖。它是一个中文截屏服务网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图尺寸,可以自定义所有截图。所需的尺寸。默认为 160*120 和 1024*768。您还可以以秒为单位指定捕获时间。
thumbalizr:可以抓取任意网页的截图,提供150、320、640、800、1024、1280等宽度的截图给你要下载,当然你也可以自定义大小。
webthumb:一个非常简单的在线截图工具,你可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图将根据网站的变化自动更新。
websnapr:非常有名的国外截图网站。但是不建议大家使用这个。默认只提供两种尺寸的小(202×152))和微(90×70))截图。你必须成为他们的付费会员才能享受更大的截图。
以上是html中文网站提供的多种网络截图方法。到目前为止,它是我找到的所有截图方法的总结。应该是网上最详细的截图了。文章,更多电脑技能>>
以上是整理网络截图的方法:QQ截图/网页截图/浏览器截图技巧大全详情请关注其他相关html中文网站文章! 查看全部
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
当你浏览网页时,你会看到你喜欢的图片。我只想截图。网络截图的用途非常广泛,尤其是在写一些教程的时候。我经常需要用截图来提高文章的人气,大家不妨看看这篇文章介绍的QQ截图怎么用、用截图软件截图、网页全页截图
当你上网时,你经常会看到各种漂亮的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。网络截图非常有用。,尤其是在写一些教程的时候,经常需要用到截图来提高文章的人气。下面html中文网站将与大家分享如何使用QQ截图、截图软件截图、网页全页面截图。
一:首先介绍一下QQ截图。QQ是大家最常用的聊天工具,几乎每台电脑都有,所以用QQ截图非常方便。目前QQ聊天工具里的截图比怎么截图还多。输入说明文字,画箭头,画一些形状等等,让我们看看如何使用它:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。
请点击小箭头设置截图
具体的使用方法比较简单,这里就不啰嗦了,自己试试就知道了。
-----------------------html中文网友提供的其他截图方法-------------------- ——
1.windows 打印密钥截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴即可保存。.
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度嗨默认截图快捷键是:Shift+Alt+A
3. 浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
菜单栏的工具截图中有全屏截图、区域截图、窗口截图等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图。
在 URL 字段中输入您要拦截的网页的 URL,修改其他设置,然后按 OK 按钮即可获取该网页的屏幕截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,比如单屏截图、滚动截图、缩略图等等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。
使用在线网页截图工具
5.专业软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320K
软件性质:绿色免费
网页滚动截图软件下载
随着网站信息量的不断增加,大部分网页内容都超过了一个屏幕。借助这款软件,我们可以实现滚动截屏,也就是说第一屏的底部也会被截取,让你随心所欲地保存喜欢的页面。
第五种和第四种可以实现滚动截图(即截取空间首页的整个页面)。
截屏完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截屏进行裁剪和修改截屏的大小和大小。
修改完成后,将截图上传到空间相册,获取地址图。(百度贴吧改版后,图片宽度大于570px会自动缩写)
如何滚动和抓取整个网页图像
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、 截取全屏
单击 PrintScreen 按钮,然后启动“绘图(开始-程序-附件)”,按 Ctrl+V 或“编辑-粘贴”来捕获当前屏幕,然后将其另存为 Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键,只截取当前活动窗口,然后如上保存。
3.截取DirectX镜像
Print Screen按钮不能捕捉DirectX图像,没关系,只要我们做一点,就可以让它大展拳脚。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写在输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、 在打开的对话框中选择“捕获窗口时自动滚动窗口”,时间使用默认的20毫秒。(时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略后确认。
4、然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
下面介绍一下在线截图工具:
网页截图看起来是一件很简单的事情,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就束手无策了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图!: 专门为网页截图创建的网站。主页非常简单。只需填写您要截图的网址,然后单击“开始”。
炸糖网:以前叫Ask Ask,后来改名为炸糖。它是一个中文截屏服务网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图尺寸,可以自定义所有截图。所需的尺寸。默认为 160*120 和 1024*768。您还可以以秒为单位指定捕获时间。
thumbalizr:可以抓取任意网页的截图,提供150、320、640、800、1024、1280等宽度的截图给你要下载,当然你也可以自定义大小。
webthumb:一个非常简单的在线截图工具,你可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图将根据网站的变化自动更新。
websnapr:非常有名的国外截图网站。但是不建议大家使用这个。默认只提供两种尺寸的小(202×152))和微(90×70))截图。你必须成为他们的付费会员才能享受更大的截图。
以上是html中文网站提供的多种网络截图方法。到目前为止,它是我找到的所有截图方法的总结。应该是网上最详细的截图了。文章,更多电脑技能>>
以上是整理网络截图的方法:QQ截图/网页截图/浏览器截图技巧大全详情请关注其他相关html中文网站文章!
网页抓取qq(搜索引擎蜘蛛抓取份额是由什么决定抓取需求需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-16 14:12
搜索引擎蜘蛛的抓取份额是多少?顾名思义,爬取份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
英文版 Google 抓取共享使用抓取预算。直译是爬行预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多页面而拖拽其他网站服务器。因此,会为某个网站设置一个爬取限速,即爬取限速,即服务器可以容忍的上限,在这个限速内,蜘蛛爬取不会拖慢服务器并影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
抓取份额是同时考虑了抓取需求和抓取速度限制的结果,即搜索引擎“想要”抓取同时“可以”抓取的页面数量。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站往往需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑捕获份额不够的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬一次网站可能需要几个月,甚至一年,这也可能意味着一些重要的页面无法爬取,所以没有排名,或者重要的页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。
当然,前面说过,能抓取百万页是一方面,搜索引擎要不要抓取是另一方面。
大网站 经常需要考虑爬取份额的另一个原因是不要把有限的爬取份额浪费在无意义的页面爬行上。结果,应该被抓取的重要页面没有被抓取的机会。
浪费抓取共享的典型页面是:
大量的过滤器过滤页面。这一点在几年前关于无效的URL爬取索引的帖子中详细讨论过。
复制网站内容
低质量,垃圾邮件
无限页面,如日历
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。小网站,因为爬取份额用不完,加nofollow没有意义。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是带有规范标签的页面通常被抓取的频率较低,因此它会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。
更多免费友情链接交流、流量交流尽在:2898站长资源平台 查看全部
网页抓取qq(搜索引擎蜘蛛抓取份额是由什么决定抓取需求需求)
搜索引擎蜘蛛的抓取份额是多少?顾名思义,爬取份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
英文版 Google 抓取共享使用抓取预算。直译是爬行预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多页面而拖拽其他网站服务器。因此,会为某个网站设置一个爬取限速,即爬取限速,即服务器可以容忍的上限,在这个限速内,蜘蛛爬取不会拖慢服务器并影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,爬网速率限制是搜索引擎“可以”爬取的页面数。
什么决定了爬网份额?
抓取份额是同时考虑了抓取需求和抓取速度限制的结果,即搜索引擎“想要”抓取同时“可以”抓取的页面数量。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问会降低服务器速度,那么 SEO 就不是主要考虑因素。
大中型网站往往需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑捕获份额不够的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。爬一次网站可能需要几个月,甚至一年,这也可能意味着一些重要的页面无法爬取,所以没有排名,或者重要的页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。
当然,前面说过,能抓取百万页是一方面,搜索引擎要不要抓取是另一方面。
大网站 经常需要考虑爬取份额的另一个原因是不要把有限的爬取份额浪费在无意义的页面爬行上。结果,应该被抓取的重要页面没有被抓取的机会。
浪费抓取共享的典型页面是:
大量的过滤器过滤页面。这一点在几年前关于无效的URL爬取索引的帖子中详细讨论过。
复制网站内容
低质量,垃圾邮件
无限页面,如日历
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件大小,提高服务器速度,优化数据库,减少爬取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能输入。
在某些情况下,使用链接 nofollow 属性可以节省抓取共享。小网站,因为爬取份额用不完,加nofollow没有意义。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
Links 和nofollow 不会浪费爬取分享。但在谷歌,重量被浪费了。
noindex 标签无法保存爬网共享。如果搜索引擎知道页面上有noindex标签,它必须先爬取这个页面,所以它不保存爬取份额。
规范标签有时可以节省一些爬网份额。和noindex标签一样,搜索引擎如果知道页面上有canonical标签,就必须先爬取这个页面,所以不直接保存爬取份额。但是带有规范标签的页面通常被抓取的频率较低,因此它会节省一些抓取份额。
抓取速度和抓取份额不是排名因素。但是没有被抓取的页面是无法排名的。
更多免费友情链接交流、流量交流尽在:2898站长资源平台
网页抓取qq( 魔法猪系统重装大师官网介绍窗口的抓取软件软件,Spy+及AccExplorer32.exe)
网站优化 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-11-16 01:10
魔法猪系统重装大师官网介绍窗口的抓取软件软件,Spy+及AccExplorer32.exe)
QQ编程的QQ窗口抓取以及如何自动化操作
时间:2015-04-02 15:44:32 来源:魔猪系统重装大师官网 人气:12346
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能可以互补。
先看两者的界面,抓取QQ的【查找联系人/群组/企业】窗口时的情况:
Sp++接口
AccExplorer32.exe界面
两个接口不同,但基本功能重叠。Spy++ 可能会提供更多功能。这两款软件都可以对列出的窗口进行一系列的操作,比如查找相关的窗口信息、窗口位置,以及各种窗口操作的信息,包括可以模拟鼠标键盘等一系列操作,功能非常强大。
为了模拟窗口捕获和对窗口的各种操作,我们可以处理FindWindow和FindWindowEx、SendMessage、PostMessage等Windows消息,实现基本的窗口和控件操作。除了按钮操作,我们还可以模拟鼠标点击某个坐标点的方式,实现对按钮点击操作的模拟。模拟的QQ界面窗口如下图,是一个搜索窗口。
通过抓取窗口信息,我们看到窗口下方只有两个可见的窗口,对应两个输入控件,我们可以在窗口中找到一个输入框的类名(账号和昵称输入框任意一个)如下:
首先我们创建一个界面,如下图,模拟相关操作。
我们在辅助类中定义了几个函数来实现窗口操作
[DllImport("user32.dll")]
privatestaticexternIntPtrFindWindowEx(IntPtrparent,IntPtrchildAfter,stringclassName,stringwindowName);
[DllImport("user32.dll",EntryPoint="FindWindow")]
privatestaticexternIntPtrFindWindowWin32(stringclassName,stringwindowName);
[DllImport("user32.dll")]
publicstaticexternintGetClassName(IntPtrhWnd,[Out]StringBuilderclassName,intmaxCount);
[DllImport("user32.dll")]
privatestaticexternintSendMessage(IntPtrwindow,intmessage,intwparam,intlparam);
[DllImport("user32",CharSet=CharSet.Auto)]
privateexternstaticintSendMessage(IntPtrhWnd,intwMsg,intwParam,stringlpstring);
[DllImport("user32.dll")]
privatestaticexternintPostMessage(IntPtrwindow,intmessage,intwparam,intlparam);
在实际的按钮操作代码中,我们简化了具体操作,只调用了辅助类。
privatevoidbtnSearch_Click(objectsender,EventArgse)
{
Win32Windowwin=Win32Window.FindWindow(null,this.txtWindowName.Text);
如果(赢!=空)
{
ArrayListlist=win.Children;
foreach(Win32Windowsubinlist)
{
if(sub.Visible&&sub.ClassName=="ATL:30A4D1D8")
{
sub.SendMessage(WindowMessage.WM_SETTEXT,0,this.txtInput.Text);
}
}
}
整数=288;
输入=328;
win.ClickWindow("left",x,y,false);
}
位置信息是Spy++监控的信息。
最终结果如下,修改控件内容,执行点击按钮操作,弹出添加好友确认消息。
如果要进行进一步的操作,可以继续分析弹出窗口。其他所有窗口操作原理相同,可以实现多种程序的自动模拟操作。是不是很方便? 查看全部
网页抓取qq(
魔法猪系统重装大师官网介绍窗口的抓取软件软件,Spy+及AccExplorer32.exe)
QQ编程的QQ窗口抓取以及如何自动化操作
时间:2015-04-02 15:44:32 来源:魔猪系统重装大师官网 人气:12346
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能
本文从文章开始,先介绍一下窗口捕捉软件Spy++和AccExplorer32.exe,前者是大名鼎鼎的微软出品,几乎可以捕捉所有Windows窗口和控件(其实也是一个窗口),另一个类似,功能可以互补。
先看两者的界面,抓取QQ的【查找联系人/群组/企业】窗口时的情况:
Sp++接口
AccExplorer32.exe界面
两个接口不同,但基本功能重叠。Spy++ 可能会提供更多功能。这两款软件都可以对列出的窗口进行一系列的操作,比如查找相关的窗口信息、窗口位置,以及各种窗口操作的信息,包括可以模拟鼠标键盘等一系列操作,功能非常强大。
为了模拟窗口捕获和对窗口的各种操作,我们可以处理FindWindow和FindWindowEx、SendMessage、PostMessage等Windows消息,实现基本的窗口和控件操作。除了按钮操作,我们还可以模拟鼠标点击某个坐标点的方式,实现对按钮点击操作的模拟。模拟的QQ界面窗口如下图,是一个搜索窗口。
通过抓取窗口信息,我们看到窗口下方只有两个可见的窗口,对应两个输入控件,我们可以在窗口中找到一个输入框的类名(账号和昵称输入框任意一个)如下:
首先我们创建一个界面,如下图,模拟相关操作。
我们在辅助类中定义了几个函数来实现窗口操作
[DllImport("user32.dll")]
privatestaticexternIntPtrFindWindowEx(IntPtrparent,IntPtrchildAfter,stringclassName,stringwindowName);
[DllImport("user32.dll",EntryPoint="FindWindow")]
privatestaticexternIntPtrFindWindowWin32(stringclassName,stringwindowName);
[DllImport("user32.dll")]
publicstaticexternintGetClassName(IntPtrhWnd,[Out]StringBuilderclassName,intmaxCount);
[DllImport("user32.dll")]
privatestaticexternintSendMessage(IntPtrwindow,intmessage,intwparam,intlparam);
[DllImport("user32",CharSet=CharSet.Auto)]
privateexternstaticintSendMessage(IntPtrhWnd,intwMsg,intwParam,stringlpstring);
[DllImport("user32.dll")]
privatestaticexternintPostMessage(IntPtrwindow,intmessage,intwparam,intlparam);
在实际的按钮操作代码中,我们简化了具体操作,只调用了辅助类。
privatevoidbtnSearch_Click(objectsender,EventArgse)
{
Win32Windowwin=Win32Window.FindWindow(null,this.txtWindowName.Text);
如果(赢!=空)
{
ArrayListlist=win.Children;
foreach(Win32Windowsubinlist)
{
if(sub.Visible&&sub.ClassName=="ATL:30A4D1D8")
{
sub.SendMessage(WindowMessage.WM_SETTEXT,0,this.txtInput.Text);
}
}
}
整数=288;
输入=328;
win.ClickWindow("left",x,y,false);
}
位置信息是Spy++监控的信息。
最终结果如下,修改控件内容,执行点击按钮操作,弹出添加好友确认消息。
如果要进行进一步的操作,可以继续分析弹出窗口。其他所有窗口操作原理相同,可以实现多种程序的自动模拟操作。是不是很方便?
网页抓取qq(模拟登陆和异步爬一下QQ群成员的信息获取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-11-12 16:12
自从开始学爬,就控制不住那颗躁动的心。我总是想每天爬一些东西。我爬过电影、影评、图片(美女)和视频链接。从最初对网页的简单分析到模拟登录再到异步加载,现在看到一个网页首先想到的就是要不要爬。话不多说,今天来到我们的项目,通过模拟登录和异步加载爬取QQ群成员信息。
大概的概念
我们通过网页版的QQ群管理获取相应的群信息,点击QQ群首页的“群管理”进入QQ群页面。分析链接后,我们发现每个QQ群的链接形式都是“#gid=”加上群号,这样就为我们的爬虫减少了一定的工作量。爬腾讯的网站最大的问题是登录,我们不能像刚开始的时候一样简单的发送一个登录请求包,然后在获取cookies后使用cookies访问。腾讯的网站是异步加载的。有的分析监控网络和js请求,找到想要的负载,很麻烦。所以我们使用selenuim,不需要查找请求,直接登录即可,登录后直接获取网页源码,
一、模拟登录
首先,通过 selenuim 定义一个驱动对象。这里我用的是火狐,可以通过下面的命令直接调用
定义完成后,我们通过下面的功能浏览器打开我们要爬取QQ群的链接。QQ群链接形式为“#gid=”+群号
二、 下拉加载页面
登录QQ群成员界面后,网页上显示的只有20人左右。网页下拉时,每次更新都会加载20个会员的信息。我们需要模拟下拉界面来爬取大家需要的信息。当selenuim的另一个功能出现模拟下拉加载页面时
三、保存网页源码
通过selenuim中的driver.page_source获取网页的源代码,我们可以将源代码保存在本地的txt文件中,这样可以方便分析源代码,避免每次登录的麻烦。
四、提取信息
这一步相信很多朋友都非常熟悉。这一步和我们第一次接触爬虫时分析网页是一样的。这里我们使用 BeautifulSoup 来解析源码。依次获取群成员信息。 查看全部
网页抓取qq(模拟登陆和异步爬一下QQ群成员的信息获取方法)
自从开始学爬,就控制不住那颗躁动的心。我总是想每天爬一些东西。我爬过电影、影评、图片(美女)和视频链接。从最初对网页的简单分析到模拟登录再到异步加载,现在看到一个网页首先想到的就是要不要爬。话不多说,今天来到我们的项目,通过模拟登录和异步加载爬取QQ群成员信息。
大概的概念
我们通过网页版的QQ群管理获取相应的群信息,点击QQ群首页的“群管理”进入QQ群页面。分析链接后,我们发现每个QQ群的链接形式都是“#gid=”加上群号,这样就为我们的爬虫减少了一定的工作量。爬腾讯的网站最大的问题是登录,我们不能像刚开始的时候一样简单的发送一个登录请求包,然后在获取cookies后使用cookies访问。腾讯的网站是异步加载的。有的分析监控网络和js请求,找到想要的负载,很麻烦。所以我们使用selenuim,不需要查找请求,直接登录即可,登录后直接获取网页源码,
一、模拟登录
首先,通过 selenuim 定义一个驱动对象。这里我用的是火狐,可以通过下面的命令直接调用
定义完成后,我们通过下面的功能浏览器打开我们要爬取QQ群的链接。QQ群链接形式为“#gid=”+群号
二、 下拉加载页面
登录QQ群成员界面后,网页上显示的只有20人左右。网页下拉时,每次更新都会加载20个会员的信息。我们需要模拟下拉界面来爬取大家需要的信息。当selenuim的另一个功能出现模拟下拉加载页面时
三、保存网页源码
通过selenuim中的driver.page_source获取网页的源代码,我们可以将源代码保存在本地的txt文件中,这样可以方便分析源代码,避免每次登录的麻烦。
四、提取信息
这一步相信很多朋友都非常熟悉。这一步和我们第一次接触爬虫时分析网页是一样的。这里我们使用 BeautifulSoup 来解析源码。依次获取群成员信息。
网页抓取qq(2.网站开发流程概述(图)开发步骤详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-12 11:12
网站通过以下步骤,您可以访问互联网开放平台:>>>
1. 开发者注册
1. 在QQ互联网开放平台首页,点击右上角“登录”按钮,使用QQ账号登录,如下图:
重要提示:
开发者QQ号一经注册,不可更改。建议使用公司的公众QQ号而不是员工的私人号码进行注册,以免员工辞职带来不必要的麻烦。
2. 登录成功后会跳转到开发者注册页面。在注册页面,您需要提交基本的公司或个人信息。下图为公司注册页面:
2. 网站访问应用
网站在访问之前,必须先申请获取对应的appid和appkey,以保证网站和用户在后续过程中能够正确的进行认证和授权。
2.1 添加网站
开发者注册成功后,会跳转到“管理中心”页面。点击添加网站,填写相应信息,如下图:
网站填写完信息点击“确定”后,网站注册成功,进入管理中心。可以在管理中心查看网站获取的appid和appkey,如下图:
2.2 网站 完整信息
在管理中心,点击应用网站下的“编辑信息”进入编辑页面,点击右上角的“编辑”按钮,页面进入编辑状态,可以修改完善网站 的信息,如下图:
3. 网站开发
进入控制台页面,可以看到网站应用处于“开发”状态。网站上线后,首先需要开发网站,即完成QQ登录功能,正常放置QQ登录按钮,如下图:
3.1 开发过程概述
开发过程主要包括以下几个步骤:
3.1.1 网站 设置QQ登录入口
网站主持人可以在自己的网站首页入口和主要登录和注册页面放置“QQ登录”标志(见红框标记):
网站需要下载官方的“QQ登录”按钮图片,根据UI规范将按钮放置在页面合适的位置。
3.1.2 用户登录验证与授权
1. 用户点击QQ登录按钮后,弹出QQ登录窗口,登录窗口会显示网站自己的Logo、网站名称和首页链接地址。
如果用户已经登录QQ软件,也可以一键快速登录。
如下所示:
2. 登录成功后,会弹出一个授权框,引导用户进行授权(只有第一次登录成功,第一次访问未授权的OpenAPI才会出现授权页面),如图如下图:
授权框中的授权列表由网站配置,详见。建议控制授权项的数量,只传入必要的接口名称,因为授权项越多,用户越有可能拒绝任何授权。
具体实现细节见:
3.1.3 登录授权完成后,跳转回网站
如果用户登录成功并获得授权,则会跳转到指定的回调地址,该地址由第三方网站配置(在上一步请求中传入),回调地址推荐为设置为网站首页或网站的用户中心。
3.1.4 获取并存储访问令牌和openid
登录成功后,可以发送请求获取访问令牌和openid。这两个参数在调用OpenAPI访问和修改用户数据时必须传入。网站需要自己绑定或者保存:(1)访问令牌用于判断用户在这个网站上的登录状态,有效期为3个月,自动(2)openid是这个网站上唯一对应的用户身份,网站可以存储这个ID,以便用户下次登录时可以识别自己的身份在 网站 上,或与用户的原创帐户绑定。
3.1.5 在网站上显示用户登录昵称和QQ头像
建议网站调用get_user_info接口,通过QQ账号在首页或顶部显示用户登录状态,使用户体验一致,包括用户昵称和QQ头像,如下图:
有关详细信息,请参阅:get_user_info。
3.2 开发说明
QQ登录功能使用国际通行的OAuth2.0协议进行认证授权,可以通过以下两种方式开发:
(1)使用QQ上网提供的SDK包,用户体验统一,只需要修改少量代码,无需了解认证授权流程,需要快速访问QQ的应用登录可以使用此方法。
详情请参考:SDK下载JS SDK。详情请参考:JS SDK使用说明
(2)根据QQ登录OAuth2.0协议,自行开发,该方法定制化程度高,需要与现有系统集成的网站可以选择这种方法。
详情请参考:OAuth2.0 开发文档
(3)社区分类网站可以使用集成插件快速访问QQ登录。
有关详细信息,请参阅集成插件。
4. 使用QQ上网提供的OpenAPI
完成网站的开发后,可以在“管理中心”的“控制面板”页面的“当前流程”下点击“申请上线”,流程处于“审核”状态。
提交审核后,腾讯将在两个工作日内完成审核。审核通过后,网站将正式上线。
网站 上线后可以使用QQ上网提供的丰富的API资源:
1.我们为开发者提供了各种OpenAPI,网站可以调用这些API来实现需要的功能,让登录用户可以访问和修改网站资源上受保护的QQ空间。
详见:API列表API调用说明
2. 为了方便网站快速使用这些API,Internet 提供了JS-widget。JS-widget 是一个 JS 封装的 SDK。只需要在网站中导入JS文件,就可以使用封装访问相应API的好方法,开发方便。
详情请参考:JS SDK使用说明
5. WAP网站 接入
以上文档主要针对WEB和XHTML格式网站。
WAP网站访问QQ登录可以基于OAuth1.0协议和OAuth2.0协议。
基于OAuth1.0协议:访问过程请参考开发指南。本指南适用于一般网站 和 WAP网站 访问。WAP网站接入时需要特别注意的地方在每一步都用红色标出。
基于OAuth2.0协议:访问过程请参考OAuth2.0开发文档。本文档描述了一般 网站 和 WAP网站 访问。 查看全部
网页抓取qq(2.网站开发流程概述(图)开发步骤详解(组图))
网站通过以下步骤,您可以访问互联网开放平台:>>>
1. 开发者注册
1. 在QQ互联网开放平台首页,点击右上角“登录”按钮,使用QQ账号登录,如下图:
重要提示:
开发者QQ号一经注册,不可更改。建议使用公司的公众QQ号而不是员工的私人号码进行注册,以免员工辞职带来不必要的麻烦。
2. 登录成功后会跳转到开发者注册页面。在注册页面,您需要提交基本的公司或个人信息。下图为公司注册页面:
2. 网站访问应用
网站在访问之前,必须先申请获取对应的appid和appkey,以保证网站和用户在后续过程中能够正确的进行认证和授权。
2.1 添加网站
开发者注册成功后,会跳转到“管理中心”页面。点击添加网站,填写相应信息,如下图:
网站填写完信息点击“确定”后,网站注册成功,进入管理中心。可以在管理中心查看网站获取的appid和appkey,如下图:
2.2 网站 完整信息
在管理中心,点击应用网站下的“编辑信息”进入编辑页面,点击右上角的“编辑”按钮,页面进入编辑状态,可以修改完善网站 的信息,如下图:
3. 网站开发
进入控制台页面,可以看到网站应用处于“开发”状态。网站上线后,首先需要开发网站,即完成QQ登录功能,正常放置QQ登录按钮,如下图:
3.1 开发过程概述
开发过程主要包括以下几个步骤:
3.1.1 网站 设置QQ登录入口
网站主持人可以在自己的网站首页入口和主要登录和注册页面放置“QQ登录”标志(见红框标记):
网站需要下载官方的“QQ登录”按钮图片,根据UI规范将按钮放置在页面合适的位置。
3.1.2 用户登录验证与授权
1. 用户点击QQ登录按钮后,弹出QQ登录窗口,登录窗口会显示网站自己的Logo、网站名称和首页链接地址。
如果用户已经登录QQ软件,也可以一键快速登录。
如下所示:
2. 登录成功后,会弹出一个授权框,引导用户进行授权(只有第一次登录成功,第一次访问未授权的OpenAPI才会出现授权页面),如图如下图:
授权框中的授权列表由网站配置,详见。建议控制授权项的数量,只传入必要的接口名称,因为授权项越多,用户越有可能拒绝任何授权。
具体实现细节见:
3.1.3 登录授权完成后,跳转回网站
如果用户登录成功并获得授权,则会跳转到指定的回调地址,该地址由第三方网站配置(在上一步请求中传入),回调地址推荐为设置为网站首页或网站的用户中心。
3.1.4 获取并存储访问令牌和openid
登录成功后,可以发送请求获取访问令牌和openid。这两个参数在调用OpenAPI访问和修改用户数据时必须传入。网站需要自己绑定或者保存:(1)访问令牌用于判断用户在这个网站上的登录状态,有效期为3个月,自动(2)openid是这个网站上唯一对应的用户身份,网站可以存储这个ID,以便用户下次登录时可以识别自己的身份在 网站 上,或与用户的原创帐户绑定。
3.1.5 在网站上显示用户登录昵称和QQ头像
建议网站调用get_user_info接口,通过QQ账号在首页或顶部显示用户登录状态,使用户体验一致,包括用户昵称和QQ头像,如下图:
有关详细信息,请参阅:get_user_info。
3.2 开发说明
QQ登录功能使用国际通行的OAuth2.0协议进行认证授权,可以通过以下两种方式开发:
(1)使用QQ上网提供的SDK包,用户体验统一,只需要修改少量代码,无需了解认证授权流程,需要快速访问QQ的应用登录可以使用此方法。
详情请参考:SDK下载JS SDK。详情请参考:JS SDK使用说明
(2)根据QQ登录OAuth2.0协议,自行开发,该方法定制化程度高,需要与现有系统集成的网站可以选择这种方法。
详情请参考:OAuth2.0 开发文档
(3)社区分类网站可以使用集成插件快速访问QQ登录。
有关详细信息,请参阅集成插件。
4. 使用QQ上网提供的OpenAPI
完成网站的开发后,可以在“管理中心”的“控制面板”页面的“当前流程”下点击“申请上线”,流程处于“审核”状态。
提交审核后,腾讯将在两个工作日内完成审核。审核通过后,网站将正式上线。
网站 上线后可以使用QQ上网提供的丰富的API资源:
1.我们为开发者提供了各种OpenAPI,网站可以调用这些API来实现需要的功能,让登录用户可以访问和修改网站资源上受保护的QQ空间。
详见:API列表API调用说明
2. 为了方便网站快速使用这些API,Internet 提供了JS-widget。JS-widget 是一个 JS 封装的 SDK。只需要在网站中导入JS文件,就可以使用封装访问相应API的好方法,开发方便。
详情请参考:JS SDK使用说明
5. WAP网站 接入
以上文档主要针对WEB和XHTML格式网站。
WAP网站访问QQ登录可以基于OAuth1.0协议和OAuth2.0协议。
基于OAuth1.0协议:访问过程请参考开发指南。本指南适用于一般网站 和 WAP网站 访问。WAP网站接入时需要特别注意的地方在每一步都用红色标出。
基于OAuth2.0协议:访问过程请参考OAuth2.0开发文档。本文档描述了一般 网站 和 WAP网站 访问。
网页抓取qq(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-12 11:10
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比Beautiful Soup快,但安装过程较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 <a> 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 <a> 标签: a.link
选择 id="home" 的 <a> 标签: a#home
选择父元素为 <a> 标签的所有 子标签: a > span
选择 <a> 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 <a> 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
网页抓取qq(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有一些细微的布局变化会使正则表达式不尽人意,例如在标签中添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 美汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于大多数网页没有好的 HTML 格式,Beautiful Soup 需要确定其实际格式。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area
Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比Beautiful Soup快,但安装过程较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 <a> 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 <a> 标签: a.link
选择 id="home" 的 <a> 标签: a#home
选择父元素为 <a> 标签的所有 子标签: a > span
选择 <a> 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 <a> 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
网页抓取qq(根据腾讯课堂网页登陆问题进行解说(需要安装谷歌浏览器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-11 16:20
根据腾讯课堂网页登录问题(需要谷歌浏览器)说明:
1、导入库
2、根据腾讯课堂链接进入页面,获取页面登录的xpath,点击即可。
获取xpath的方法是:右击如上图箭头所示的登录位置,点击check,得到如下页面。右键单击您登录的选项卡以复制 xpath。
3、 进入登录页面后,获取登录方式,这次选择使用qq登录,获取qq登录的xpath点击即可。
driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div[2]/a[1]').click()
4、单击以使用您的帐户密码登录。登录过程中出现以下错误。
主要原因是找不到我们定位的xpath,需要找到定位元素所在的frame,从frame中找到元素。
5、 获取账号密码和登录位置的xpath。当运行中xpath无法再次定位时,第四步的方法仍然失败,说明帧错误。估计原因和步骤4中frame标签的名字一样,最终的解决办法是:先回到最外面的frame,然后进入要定位元素的frame,最后定位到账号密码。
6、 点击登录按钮,您就进入了网页版腾讯课堂。
driver.find_element_by_xpath('//*[@id="login_button"]').click()
完整代码如下:
本实验使用了 Jupyter 进行的分割操作。如果合并代码进行实验,则应更改睡眠时间以确保页面已更新。如有问题,欢迎批评指正,谢谢。 查看全部
网页抓取qq(根据腾讯课堂网页登陆问题进行解说(需要安装谷歌浏览器))
根据腾讯课堂网页登录问题(需要谷歌浏览器)说明:
1、导入库
2、根据腾讯课堂链接进入页面,获取页面登录的xpath,点击即可。
获取xpath的方法是:右击如上图箭头所示的登录位置,点击check,得到如下页面。右键单击您登录的选项卡以复制 xpath。
3、 进入登录页面后,获取登录方式,这次选择使用qq登录,获取qq登录的xpath点击即可。
driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div[2]/a[1]').click()
4、单击以使用您的帐户密码登录。登录过程中出现以下错误。
主要原因是找不到我们定位的xpath,需要找到定位元素所在的frame,从frame中找到元素。
5、 获取账号密码和登录位置的xpath。当运行中xpath无法再次定位时,第四步的方法仍然失败,说明帧错误。估计原因和步骤4中frame标签的名字一样,最终的解决办法是:先回到最外面的frame,然后进入要定位元素的frame,最后定位到账号密码。
6、 点击登录按钮,您就进入了网页版腾讯课堂。
driver.find_element_by_xpath('//*[@id="login_button"]').click()
完整代码如下:
本实验使用了 Jupyter 进行的分割操作。如果合并代码进行实验,则应更改睡眠时间以确保页面已更新。如有问题,欢迎批评指正,谢谢。
网页抓取qq(一下对网页的收录是一个复杂的过程,简单来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-09 14:18
项目招商找A5快速获取精准代理商名单
网页搜索引擎收录 是一个复杂的过程。简单来说,收录的过程可以分为:爬取、过滤、索引、输出结果。跟大家简单说一下这些步骤,让大家了解一下你的网页发布后的收录是怎样的,获得了相关排名。
1、获取
网站的页面是否被搜索引擎收录搜索到了,首先查看网站的蜘蛛访问日志,看看蜘蛛是否来过。如果蜘蛛没有被爬取,是不可能通过收录的。从网站的IIS日志中可以看到蜘蛛访问网站的日志。如果搜索引擎蜘蛛不来怎么办?然后主动提交给搜索引擎,搜索引擎会发送蜘蛛爬取网站,让网站尽快成为收录。
如果你不知道如何分析网站的日志也没关系。我推荐 爱站SEO 工具包。将网站的日志导入本工具后,可以看到对日志的分析。可以从中得到很多信息。
广度优先爬行:广度优先爬行就是按照网站的树状结构爬取一层。如果不爬取这一层,蜘蛛将不会搜索下一层。(网站的树状结构会在后续日志中说明,文章未发布后,这里会加一个链接)
深度优先爬取:深度优先爬取基于网站的树结构。跟随链接并继续爬行,直到您知道此链接没有进一步的下行链接。深度优先爬行也称为垂直爬行。
(注:广度优先爬行适用于所有情况的搜索,但深度优先爬行可能不适合所有情况。因为可解问题树可能收录无限分支,如果深度优先爬行误入无穷大分支(即,深度无限制),无法找到目标的终点,因此往往不使用深度优先爬取策略,广度优先爬取更安全。)
广度优先抓取适用范围:在未知树深的情况下,使用这种算法是非常安全的。当树系统比较小而不是巨大的时候,最好以广度为主。
深度优先爬行的适用范围:我刚才说深度优先爬行有其自身的缺点,但不代表深度优先爬行本身没有价值。当树结构的深度已知且树系统相当大时,深度优先搜索通常比广度优先搜索更好。
2、过滤器
网站 的页面被抓取的事实并不意味着它会是 收录。蜘蛛来爬取之后,会把数据带回来,放到一个临时数据库中,然后进行过滤,过滤掉一些垃圾内容或者低质量的内容。
如果你页面上的信息是采集,那么互联网上有很多相同的信息,搜索引擎可能不会索引你的网页。有时我们自己的文章不会是收录,因为原创不一定是高质量的。关于文章的质量问题,我以后会单独出一篇文章的文章和大家详细讨论。
过滤过程是去除浮渣的过程。如果您的网站页面成功通过了过滤过程,则说明该页面的内容已经达到了搜索引擎设定的标准,页面将进入索引和输出结果这一步。
3、创建索引并输出结果
在这里,我们结合索引和输出结果来说明。
经过一系列的过程,满足收录的页面会被索引,索引后输出结果,就是我们搜索到关键词后搜索引擎给我们展示的结果.
当用户搜索关键词时,搜索引擎会输出结果,输出结果按顺序排列。这些结果根据一系列复杂的算法进行排序。例如:页面的外部链接、页面与关键词的匹配程度、页面的多媒体属性等。
在输出的结果中,有一些结果可以爬取后直接输出,不需要中间复杂的过滤和索引过程。什么样的内容,在什么情况下会发生?那就是具有很强的时效性的内容,例如新闻。比如今天有一个大事件,各大门户网站和新闻来源迅速发布了有关事件的消息。搜索引擎会快速响应重大新闻事件和快速收录相关内容。
百度对新闻的抓取速度非常快,对重大事件的反应也比较及时。但这里还有一个问题。如果这些发布的新闻有低质量的页面怎么办?搜索引擎在输出结果后仍会过滤这部分新闻内容。如果页面内容与新闻标题不匹配,质量太低,那么低质量的页面仍然会被搜索引擎过滤掉。
在输出结果时,搜索引擎或多或少会人为地干预搜索结果。其中,百度最为严重。百度的许多关键词自然搜索结果已被添加到百度自己的产品中。他们中的许多人没有考虑用户体验。这也是百度被大家诟病的原因之一。有兴趣的朋友可以看看百度上一字之差的搜索结果,看看百度自己的产品是否占据了过多的首页位置。
我是刘旭,我的微信公众平台:a1719752001,希望能和大家多交流。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网页抓取qq(一下对网页的收录是一个复杂的过程,简单来说)
项目招商找A5快速获取精准代理商名单
网页搜索引擎收录 是一个复杂的过程。简单来说,收录的过程可以分为:爬取、过滤、索引、输出结果。跟大家简单说一下这些步骤,让大家了解一下你的网页发布后的收录是怎样的,获得了相关排名。
1、获取
网站的页面是否被搜索引擎收录搜索到了,首先查看网站的蜘蛛访问日志,看看蜘蛛是否来过。如果蜘蛛没有被爬取,是不可能通过收录的。从网站的IIS日志中可以看到蜘蛛访问网站的日志。如果搜索引擎蜘蛛不来怎么办?然后主动提交给搜索引擎,搜索引擎会发送蜘蛛爬取网站,让网站尽快成为收录。
如果你不知道如何分析网站的日志也没关系。我推荐 爱站SEO 工具包。将网站的日志导入本工具后,可以看到对日志的分析。可以从中得到很多信息。
广度优先爬行:广度优先爬行就是按照网站的树状结构爬取一层。如果不爬取这一层,蜘蛛将不会搜索下一层。(网站的树状结构会在后续日志中说明,文章未发布后,这里会加一个链接)
深度优先爬取:深度优先爬取基于网站的树结构。跟随链接并继续爬行,直到您知道此链接没有进一步的下行链接。深度优先爬行也称为垂直爬行。
(注:广度优先爬行适用于所有情况的搜索,但深度优先爬行可能不适合所有情况。因为可解问题树可能收录无限分支,如果深度优先爬行误入无穷大分支(即,深度无限制),无法找到目标的终点,因此往往不使用深度优先爬取策略,广度优先爬取更安全。)
广度优先抓取适用范围:在未知树深的情况下,使用这种算法是非常安全的。当树系统比较小而不是巨大的时候,最好以广度为主。
深度优先爬行的适用范围:我刚才说深度优先爬行有其自身的缺点,但不代表深度优先爬行本身没有价值。当树结构的深度已知且树系统相当大时,深度优先搜索通常比广度优先搜索更好。
2、过滤器
网站 的页面被抓取的事实并不意味着它会是 收录。蜘蛛来爬取之后,会把数据带回来,放到一个临时数据库中,然后进行过滤,过滤掉一些垃圾内容或者低质量的内容。
如果你页面上的信息是采集,那么互联网上有很多相同的信息,搜索引擎可能不会索引你的网页。有时我们自己的文章不会是收录,因为原创不一定是高质量的。关于文章的质量问题,我以后会单独出一篇文章的文章和大家详细讨论。
过滤过程是去除浮渣的过程。如果您的网站页面成功通过了过滤过程,则说明该页面的内容已经达到了搜索引擎设定的标准,页面将进入索引和输出结果这一步。
3、创建索引并输出结果
在这里,我们结合索引和输出结果来说明。
经过一系列的过程,满足收录的页面会被索引,索引后输出结果,就是我们搜索到关键词后搜索引擎给我们展示的结果.
当用户搜索关键词时,搜索引擎会输出结果,输出结果按顺序排列。这些结果根据一系列复杂的算法进行排序。例如:页面的外部链接、页面与关键词的匹配程度、页面的多媒体属性等。
在输出的结果中,有一些结果可以爬取后直接输出,不需要中间复杂的过滤和索引过程。什么样的内容,在什么情况下会发生?那就是具有很强的时效性的内容,例如新闻。比如今天有一个大事件,各大门户网站和新闻来源迅速发布了有关事件的消息。搜索引擎会快速响应重大新闻事件和快速收录相关内容。
百度对新闻的抓取速度非常快,对重大事件的反应也比较及时。但这里还有一个问题。如果这些发布的新闻有低质量的页面怎么办?搜索引擎在输出结果后仍会过滤这部分新闻内容。如果页面内容与新闻标题不匹配,质量太低,那么低质量的页面仍然会被搜索引擎过滤掉。
在输出结果时,搜索引擎或多或少会人为地干预搜索结果。其中,百度最为严重。百度的许多关键词自然搜索结果已被添加到百度自己的产品中。他们中的许多人没有考虑用户体验。这也是百度被大家诟病的原因之一。有兴趣的朋友可以看看百度上一字之差的搜索结果,看看百度自己的产品是否占据了过多的首页位置。
我是刘旭,我的微信公众平台:a1719752001,希望能和大家多交流。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网页抓取qq(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 503 次浏览 • 2021-11-09 07:00
Iefans为用户提供完整小说的免费下载,可以一次免费阅读所有小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载完整TXT电子书. iefans 提供了网络图书抓取器的下载地址。需要免费完整小说下载器的朋友快来下载试试吧。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络有问题,或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来了极大的方便。10个适用的网站已经输入,选择后可以快速打开网站找到你需要的书,并自动应用相应的代码 查看全部
网页抓取qq(免费全本txt小说电子书下载软件推荐网页书籍抓取器介绍)
Iefans为用户提供完整小说的免费下载,可以一次免费阅读所有小说。现在推荐一款免费的全txt小说电子书下载软件,使用网络图书抓取器,支持TXT全免费小说下载,用户可以使用网络小说抓取器抓取网络小说,快速下载完整TXT电子书. iefans 提供了网络图书抓取器的下载地址。需要免费完整小说下载器的朋友快来下载试试吧。
网络图书爬虫简介
网络图书抓取器是一款网络小说下载软件,可以帮助用户下载指定网页的某本书和某章节。软件功能强大,可以提取小说目录信息,根据目录下载小说,然后合并,方便下载阅读后,支持断点续传功能。如果网络有问题,或其他问题导致小说章节下载中断,您可以点击继续下载,无需重新下载,然后继续下载上次下载的内容。下载完成后,您可以使用电脑小说阅读器阅读整部小说。
如何使用网络图书抓取器
1. 网络小说下载软件下载解压后双击即可使用。第一次运行会自动生成一个设置文件。用户可以手动调整文件,打开软件,使用软件的小说下载功能,
2.首先进入要下载小说的网页,输入书名,点击目录提取,提取目录后可以移动、删除、倒序等调整操作,设置保存路径,点击开始爬行开始下载。
3.可以提取指定小说目录页的章节信息进行调整,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
4.在设置文件中添加每个章节名称的前缀和后缀,为后期制作电子书的目录编排带来了极大的方便。10个适用的网站已经输入,选择后可以快速打开网站找到你需要的书,并自动应用相应的代码
网页抓取qq(网站结构层次越少的几种优化方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-05 13:11
1、链接优化:
一般来说,网站结构层级建立的越少,越容易被“蜘蛛”爬取,也更容易被收录。
示例:首页-->产品中心-->刷卡POS、POS支付、瑞禾宝POS、
扁平化目录层次,尽量让“蜘蛛”只需要跳转3次就可以到达网站中的任何内页
2、 导航优化:
导航尽量使用文字,也可以使用图片。注意 img 图片 alt 描述文本,一个标签标题描述,告诉搜索引擎导航到哪里。
其次,应该在每个网页中添加面包屑导航。好处:从用户体验方面,让用户了解自己当前的位置以及当前页面在整个网站中的位置,帮助用户快速了解网站的组织形式,从而形成一个更好的位置感,并提供返回每个页面的界面,方便用户操作。
对于“蜘蛛”,可以清晰的理解网站的结构,同时增加了大量的内部链接,方便爬取,降低跳出率。
3、控制页面大小,减少http请求,提高网站的加载速度。
一个页面最好不要超过100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,访客留不住,一旦超时,“蜘蛛”也会离开。
常见的优化实践有:
消除空标签、无用代码、压缩CSSJShtml代码、推荐使用iconfont字体图标、集成背景图片制作CSS精灵、图片延迟加载处理、设置浏览器缓存等。
4、 CSS 布局的巧妙运用
把重要内容的HTML代码放在最上面,最上面的内容被认为是最重要的,让“蜘蛛”先读取,抓取内容关键词。
5、避免使用iframe框架,因为“蜘蛛”一般不会读取内容
6、 使用 display: none 小心。对于不想显示的文本内容,应设置 z-index 或将其设置在浏览器显示之外。因为搜索引擎会过滤掉display:none的内容。
7、页面标签的使用
, 标签:需要强调时使用。
标签在搜索引擎中受到高度重视。他们可以突出关键词并表达重要内容。
标签强调效果仅次于标签。
,Tag:只在展示效果时使用,不会对SEO有任何影响。
谨慎使用 h 标签。不要滥用,导致页面结构太乱。常见的做法是:每个模块的标题中只使用H标签,h3以下的标签尽量不要使用,因为H3以下的权重不多,和普通文本差不多。 查看全部
网页抓取qq(网站结构层次越少的几种优化方法,你知道吗?)
1、链接优化:
一般来说,网站结构层级建立的越少,越容易被“蜘蛛”爬取,也更容易被收录。
示例:首页-->产品中心-->刷卡POS、POS支付、瑞禾宝POS、
扁平化目录层次,尽量让“蜘蛛”只需要跳转3次就可以到达网站中的任何内页
2、 导航优化:
导航尽量使用文字,也可以使用图片。注意 img 图片 alt 描述文本,一个标签标题描述,告诉搜索引擎导航到哪里。
其次,应该在每个网页中添加面包屑导航。好处:从用户体验方面,让用户了解自己当前的位置以及当前页面在整个网站中的位置,帮助用户快速了解网站的组织形式,从而形成一个更好的位置感,并提供返回每个页面的界面,方便用户操作。
对于“蜘蛛”,可以清晰的理解网站的结构,同时增加了大量的内部链接,方便爬取,降低跳出率。
3、控制页面大小,减少http请求,提高网站的加载速度。
一个页面最好不要超过100k,太大,页面加载速度慢。当速度很慢时,用户体验不好,访客留不住,一旦超时,“蜘蛛”也会离开。
常见的优化实践有:
消除空标签、无用代码、压缩CSSJShtml代码、推荐使用iconfont字体图标、集成背景图片制作CSS精灵、图片延迟加载处理、设置浏览器缓存等。
4、 CSS 布局的巧妙运用
把重要内容的HTML代码放在最上面,最上面的内容被认为是最重要的,让“蜘蛛”先读取,抓取内容关键词。
5、避免使用iframe框架,因为“蜘蛛”一般不会读取内容
6、 使用 display: none 小心。对于不想显示的文本内容,应设置 z-index 或将其设置在浏览器显示之外。因为搜索引擎会过滤掉display:none的内容。
7、页面标签的使用
, 标签:需要强调时使用。
标签在搜索引擎中受到高度重视。他们可以突出关键词并表达重要内容。
标签强调效果仅次于标签。
,Tag:只在展示效果时使用,不会对SEO有任何影响。
谨慎使用 h 标签。不要滥用,导致页面结构太乱。常见的做法是:每个模块的标题中只使用H标签,h3以下的标签尽量不要使用,因为H3以下的权重不多,和普通文本差不多。
网页抓取qq(网页小工具.rar(22.91)本工具使用方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-05 04:09
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并使用 xmlhttp 提取它。 查看全部
网页抓取qq(网页小工具.rar(22.91)本工具使用方法介绍)
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, Downloads: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页,也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。如果生成的数据与你开始分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并使用 xmlhttp 提取它。
网页抓取qq(软件只能提取网页上公开的手机号码,网页搜索提取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-11-03 00:24
该软件只能提取网页上公开的手机号码,无法提取网页上没有的手机号码。软件支持网站登录和提取。使用说明: 软件下载后,需要使用解压软件将采集软件解压到硬盘,解压后生成9个文件和1个。
是一家专业的数据分析挖掘运营公司。公司主营业务为网站访客获取、app访客获取、抖音广告访客获取、联通大数据获取、百度极目鱼访客获取等一系列数据挖掘。
这是网站手机号码搜索提取工具。这是一款手机号码提取软件,已经收录在全球很多中国公司的企业网页上。在威手机号搜索软件中输入搜索键。
1.通过捕捉您的网站访问者,您可以获得准确的客户联系信息:QQ、手机号码和客户访问、兴趣点等信息。2. 创建您的客户鱼塘(客户数据库),广泛撒网,并执行到潜在客户。
请推荐爬虫软件,爬取一些网站可以采集到公众号的数据。
云抓统计系统是专门为企业开发的提高网站访问者转化率的软件。可高效实时抓取访客手机号码,抓取访客QQ号,让您轻松将潜在访客转化为您的访客。目标客户,具体如下功能。
语言:简体中文性质:国产软件软件大小:1.26 手机号码提取软件可以通过搜索快速提取搜索引擎中网站对应的手机号码,并以格式导出一张桌子。错过了互联网时代。
来宾手机号捕获_手机网站获取来宾手机号软件_捕获来宾向导系统。 查看全部
网页抓取qq(软件只能提取网页上公开的手机号码,网页搜索提取工具)
该软件只能提取网页上公开的手机号码,无法提取网页上没有的手机号码。软件支持网站登录和提取。使用说明: 软件下载后,需要使用解压软件将采集软件解压到硬盘,解压后生成9个文件和1个。
是一家专业的数据分析挖掘运营公司。公司主营业务为网站访客获取、app访客获取、抖音广告访客获取、联通大数据获取、百度极目鱼访客获取等一系列数据挖掘。
这是网站手机号码搜索提取工具。这是一款手机号码提取软件,已经收录在全球很多中国公司的企业网页上。在威手机号搜索软件中输入搜索键。
1.通过捕捉您的网站访问者,您可以获得准确的客户联系信息:QQ、手机号码和客户访问、兴趣点等信息。2. 创建您的客户鱼塘(客户数据库),广泛撒网,并执行到潜在客户。
请推荐爬虫软件,爬取一些网站可以采集到公众号的数据。
云抓统计系统是专门为企业开发的提高网站访问者转化率的软件。可高效实时抓取访客手机号码,抓取访客QQ号,让您轻松将潜在访客转化为您的访客。目标客户,具体如下功能。
语言:简体中文性质:国产软件软件大小:1.26 手机号码提取软件可以通过搜索快速提取搜索引擎中网站对应的手机号码,并以格式导出一张桌子。错过了互联网时代。
来宾手机号捕获_手机网站获取来宾手机号软件_捕获来宾向导系统。
网页抓取qq(模拟登录验证码免费接口地址是怎么做出来的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-25 17:02
网页抓取qq号。模拟登录。正则表达式。
这就是模拟器?你上个qq号模拟登录?
用bootstrap,
模拟用户注册还不容易了。你真想让他接收验证码不难。只要访问某个接口然后获取该url验证码。模拟登录验证码免费接口地址。
微博评论到最后用-rap/获取验证码然后再登录qq空间然后模拟登录就可以获取了
getpost同步http请求
qq号就是一个账号,你只需要用浏览器登录,然后获取他的uid就可以了吧。
有,
啊哈哈看见同好很有好感。其实你就是想要他的地址。这个百度能找到,或者如果你和他在同一城市,你可以从他的朋友那拿到他的qq。哈哈,他的朋友是谁你也知道啦。
比如他可能在武汉,你就用百度地图截一张长沙的。发给他,让他自己接受。
cookie啊。随便输个web框框,就能把他/她的地址记下来。或者在手机上查他/她的mac地址,然后随便截个图,
这不是很简单嘛首先百度图片在搜索框框中输入他然后找到他的ip最后获取他的手机号好吧要得到这些地址好不容易。可是他就是不回答你你没有地址的话,手机号那不会变成废纸的,哪有什么卵用,所以你要做的就是api接口获取ip然后随机打开截图就可以知道他的手机号如果再不明白。就拉到最后打扫那个头像为啥是和他在一起,如果是不明白,我就告诉你各种原因,然后你自己想方法啊~。 查看全部
网页抓取qq(模拟登录验证码免费接口地址是怎么做出来的?)
网页抓取qq号。模拟登录。正则表达式。
这就是模拟器?你上个qq号模拟登录?
用bootstrap,
模拟用户注册还不容易了。你真想让他接收验证码不难。只要访问某个接口然后获取该url验证码。模拟登录验证码免费接口地址。
微博评论到最后用-rap/获取验证码然后再登录qq空间然后模拟登录就可以获取了
getpost同步http请求
qq号就是一个账号,你只需要用浏览器登录,然后获取他的uid就可以了吧。
有,
啊哈哈看见同好很有好感。其实你就是想要他的地址。这个百度能找到,或者如果你和他在同一城市,你可以从他的朋友那拿到他的qq。哈哈,他的朋友是谁你也知道啦。
比如他可能在武汉,你就用百度地图截一张长沙的。发给他,让他自己接受。
cookie啊。随便输个web框框,就能把他/她的地址记下来。或者在手机上查他/她的mac地址,然后随便截个图,
这不是很简单嘛首先百度图片在搜索框框中输入他然后找到他的ip最后获取他的手机号好吧要得到这些地址好不容易。可是他就是不回答你你没有地址的话,手机号那不会变成废纸的,哪有什么卵用,所以你要做的就是api接口获取ip然后随机打开截图就可以知道他的手机号如果再不明白。就拉到最后打扫那个头像为啥是和他在一起,如果是不明白,我就告诉你各种原因,然后你自己想方法啊~。
网页抓取qq( 之前写过一篇使用爬虫抓取暗黑3玩家数据的意义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-22 12:04
之前写过一篇使用爬虫抓取暗黑3玩家数据的意义
)
Crawler 尝试抓取动态网页
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据总是不更新,爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。
百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:
通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到
虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据
好的,让我们抓住它
明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。
查看全部
网页抓取qq(
之前写过一篇使用爬虫抓取暗黑3玩家数据的意义
)
Crawler 尝试抓取动态网页
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据总是不更新,爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。
百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:
通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到
虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据
好的,让我们抓住它
明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。

