
网页抓取qq
网页抓取qq(腾讯视频的VIP电影动态抓取(第二十五期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-21 00:13
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候。待抓取的数据在查看网页源代码时找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端来获取数据,接下来我们抓取这样的东西网站。
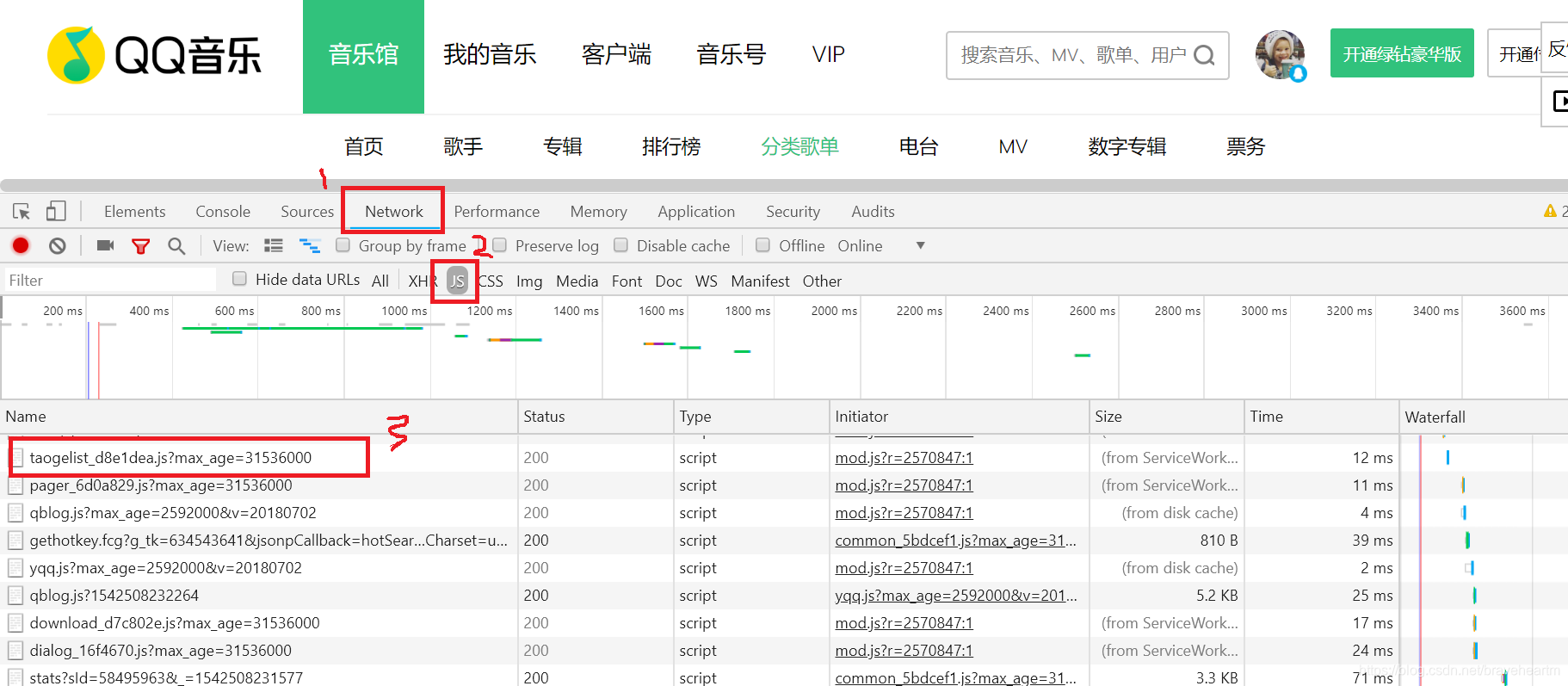
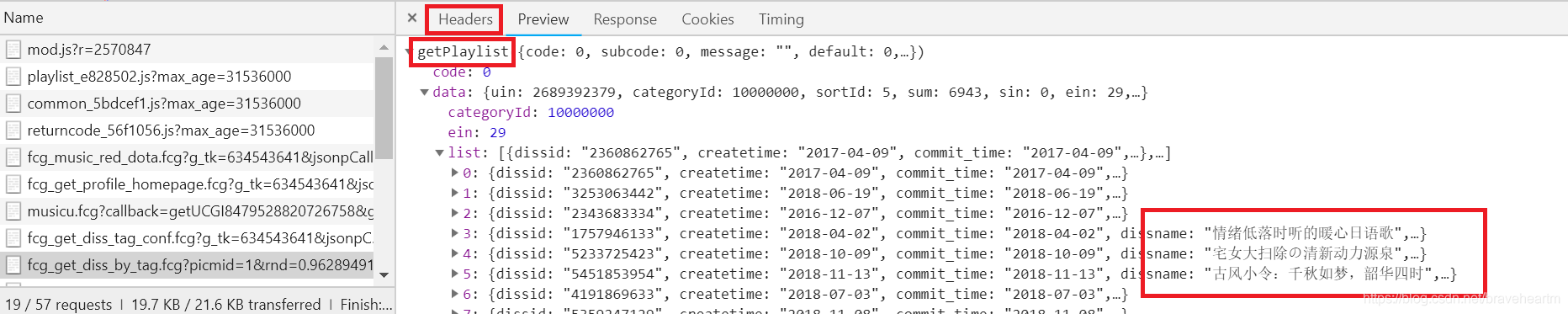
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,下面可以看到很多东西,一般请求的代码在XHR或者JS中,所以我们直接找这两个,通过搜索可以看到到如下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
捕获数据后,下一步就是解析数据。因为是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...那个字符串,只留下这个字符串{"cgi_cost_time:...}的数据从链接打开的网页结果中可以看出我们刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是key字典中是jsonvalue,jsonvalue的值是一个字典,这个字典中的key值是results.data,results对应的值是一个list,分析清楚后,很容易得到数据,直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后对比请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加30个,所以只需要动态改变请求链接就可以捕获所有数据。 查看全部
网页抓取qq(腾讯视频的VIP电影动态抓取(第二十五期))
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候。待抓取的数据在查看网页源代码时找不到对应的数据。比如我们要抓取腾讯视频的VIP电影

腾讯视频
如上图,网页中有,但查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端来获取数据,接下来我们抓取这样的东西网站。
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,下面可以看到很多东西,一般请求的代码在XHR或者JS中,所以我们直接找这两个,通过搜索可以看到到如下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
捕获数据后,下一步就是解析数据。因为是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...那个字符串,只留下这个字符串{"cgi_cost_time:...}的数据从链接打开的网页结果中可以看出我们刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是key字典中是jsonvalue,jsonvalue的值是一个字典,这个字典中的key值是results.data,results对应的值是一个list,分析清楚后,很容易得到数据,直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后对比请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加30个,所以只需要动态改变请求链接就可以捕获所有数据。
网页抓取qq(写了一个从网页中抓取信息(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-20 03:07
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224 查看全部
网页抓取qq(写了一个从网页中抓取信息(如最新的头条新闻))
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:

上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
操作结果如下:

欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224
网页抓取qq( 谷歌宣布抓取海量APP300多页页面内容和信息量开发商合作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-17 23:10
谷歌宣布抓取海量APP300多页页面内容和信息量开发商合作
)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B
腾讯科技新闻搜索引擎是继内容门户之后的互联网第二次重大技术革命。但是,随着智能手机的普及,应用软件(APP)已经取代了网页,成为主流技术。由于APP的内容一时间无法被搜索引擎抓取,人们惊呼移动互联网将给搜索引擎带来生存危机。
不过,通过与应用软件开发商的合作,谷歌()在一定程度上解决了这一危机。日前,谷歌宣布从大量APP中抓取了超过300页的内容。手机上搜索的信息量也会更加丰富。
谷歌搜索团队在 4 月 16 日的官方博客文章中宣布了这一消息。
谷歌工程师 Rajan Patel 向媒体透露,谷歌两年前就开始抓取外部应用的内部链接和内容,目前累计抓取超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
手机上搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。(黎明)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B 查看全部
网页抓取qq(
谷歌宣布抓取海量APP300多页页面内容和信息量开发商合作
)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B
腾讯科技新闻搜索引擎是继内容门户之后的互联网第二次重大技术革命。但是,随着智能手机的普及,应用软件(APP)已经取代了网页,成为主流技术。由于APP的内容一时间无法被搜索引擎抓取,人们惊呼移动互联网将给搜索引擎带来生存危机。
不过,通过与应用软件开发商的合作,谷歌()在一定程度上解决了这一危机。日前,谷歌宣布从大量APP中抓取了超过300页的内容。手机上搜索的信息量也会更加丰富。
谷歌搜索团队在 4 月 16 日的官方博客文章中宣布了这一消息。
谷歌工程师 Rajan Patel 向媒体透露,谷歌两年前就开始抓取外部应用的内部链接和内容,目前累计抓取超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
手机上搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。(黎明)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B
网页抓取qq(本文会教你如何解决以下这三个问题(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-17 09:13
本文将教你如何解决以下三个问题:
1.你的整个网站没有被索引;
2.有些页面被索引,而其他页面没有;
3. 新发布的页面不会立即编入索引。
但首先,我们必须先了解索引的含义。
什么是抓取和索引?
Google 通过抓取发现新页面,然后将这些页面添加到索引中。他们使用名为 Googlebot 的网络爬虫来执行此操作。
使困惑?让我们解释一些术语:
爬行:跟踪网页上的超链接以发现新内容的过程。
索引:Google 已将网页“编入索引”意味着 Google 抓取工具(“Googlebot”)访问了该网页,分析了其内容和含义,并将其存储在 Google 索引中。索引的网页可以显示在 Google 搜索结果中(前提是它们遵循 Google 的 网站网站管理员指南)。尽管大多数网页在被抓取后都会编入索引,但 Google 也可能会在不访问网页内容的情况下将网页编入索引(例如,如果该网页被 robots.txt 指令阻止)。
网络爬虫:执行爬行的程序。
Googlebot:谷歌的网络爬虫(谷歌蜘蛛)。
当您在 Google 上搜索内容时,您实际上是在要求 Google 返回其索引中的所有相关页面。由于通常有数千个网页符合要求,因此 Google 的排名算法会尝试对这些网页进行排名,以便您首先看到最佳和最相关的结果。
我想在这里提出的一个重要观点是索引和排名是两件不同的事情。
索引是为了参与,排名是为了获胜。
不参加就不可能赢。
如何检查您的页面是否已编入索引
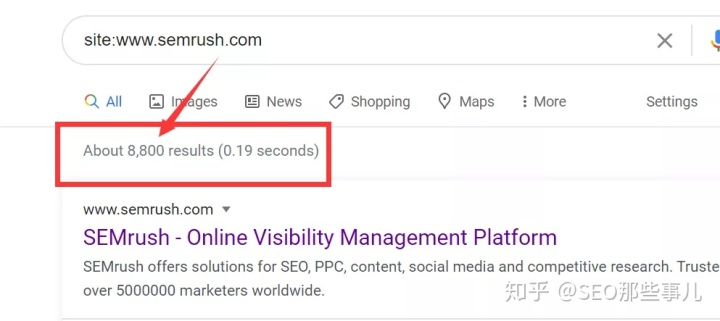
输入谷歌,然后搜索站点如下:您的网址
此处的数字显示了索引页的大致数量。
如果你想检查一个特定的页面是否被索引,你也可以做同样的站点:详细网址
如果没有结果,则表示该页面未编入索引。
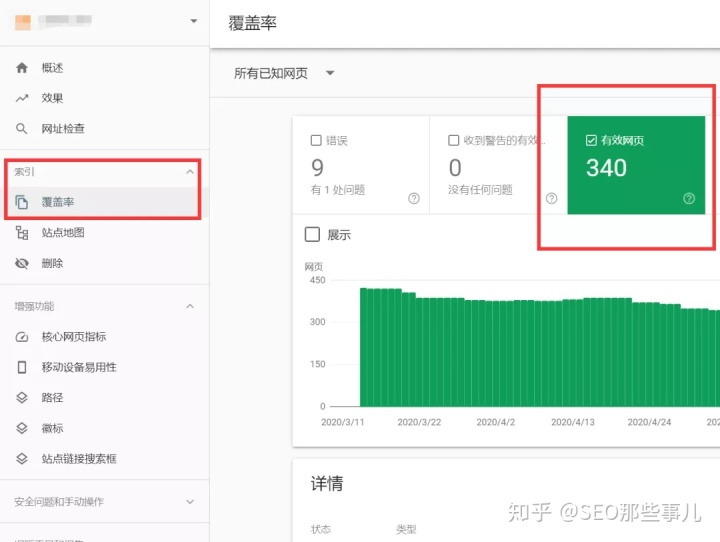
如果您是 Google Search Console 的用户,只需查看覆盖率报告即可找到准确的索引数据。您只需要输入:
Google Search Console> 索引> 覆盖范围
您可以使用 Google Search Console 检查特定页面是否已编入索引。您只需要将页面 URL 放入 URL 检测工具中即可。
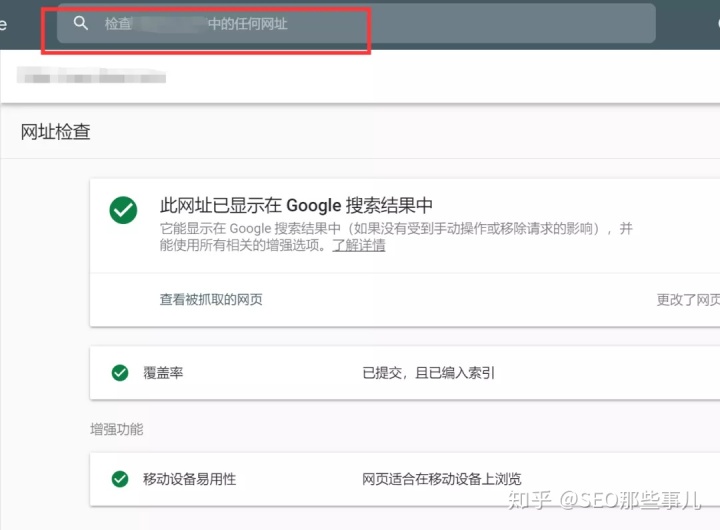
如何让 Google 将您的网页编入索引
您的 网站 或页面未被 Google 编入索引?试试这些:
转到 Google Search Console。
进入网址检测工具。
将要编入索引的 URL 粘贴到搜索框中。
等待 Google 检测到 URL。
单击“请求索引”按钮。
当您发布新帖子或页面时,最好这样做。您实际上是在告诉 Google,您已向 网站 添加了一些新内容,他们应该检查一下。
但是,请求索引不太可能解决旧页面的索引问题。如果是这种情况,请按照下面的清单来诊断和解决问题。
去除Robots.txt中的爬行障碍去除不必要的noindex标签在网站地图中收录需要索引的页面去除不必要的规范标签检查页面是否为岛页面修复不必要的内部nofollow链接在“添加内部链接到“强大”页面,确保页面的唯一性和价值。去除低质量页面(优化“抓取预算”),建立高质量的外链
1) 去除Robots.txt中的爬行块
Google 没有将整个 网站 编入索引?这可能是由 robots.txt 文件中的爬行障碍引起的。
去查看详细问题。
检查右下角的两段是否有任何一段:
1 用户代理:Googlebot
2 禁止:/
1 用户代理:*
2 禁止:/
这两者都告诉 Googlebot 他们不允许抓取 网站 上的任何页面。要解决这个问题,你只需要删除它们,就这么简单。
如果 Google 没有为单个页面编制索引,也可能是由 robots.txt 中的代码引起的。要检查是否是这种情况,请将网址粘贴到 Google Search Console 中的网址检测工具中。单击覆盖范围部分以显示更多详细信息,并查找“允许抓取?否:被 robots.txt 阻止”错误。
这意味着该页面被 robots.txt 阻止。
如果是这种情况,请重新检查您的 robots.txt 文件,了解与此页面或相关目录相关的“禁止”规则。
如果需要,只需删除此代码。
2) 删除不必要的 noindex 标签
如果您告诉 Google 不要将网页编入索引,Google 将不会将其编入索引。这可以使页面的一部分保持私密。有两种方法可以做到这一点:
方法一:元标签
如果页面中出现以下任何代码,Google 将不会将其编入索引:
这是爬虫的元标记,告诉搜索引擎他们是否可以索引页面。
提示。核心参数是“noindex”。如果出现“noindex”,则表示该页面未编入索引。
方法 2:X‑Robots-Tag
网络爬虫遵循 X-Robots-Tag 的 HTTP 响应标头。您可以使用服务器端脚本语言(如PHP)、.htaccess 文件的内容,或更改服务器配置来实现此效果。
Google Search Console 中的 URL 检查工具可以告诉您此标头是否阻止 Google 抓取页面。只需输入 URL 并查找“允许索引?否:在“X‑Robots-Tag”http 标头中检测到“noindex”标签。
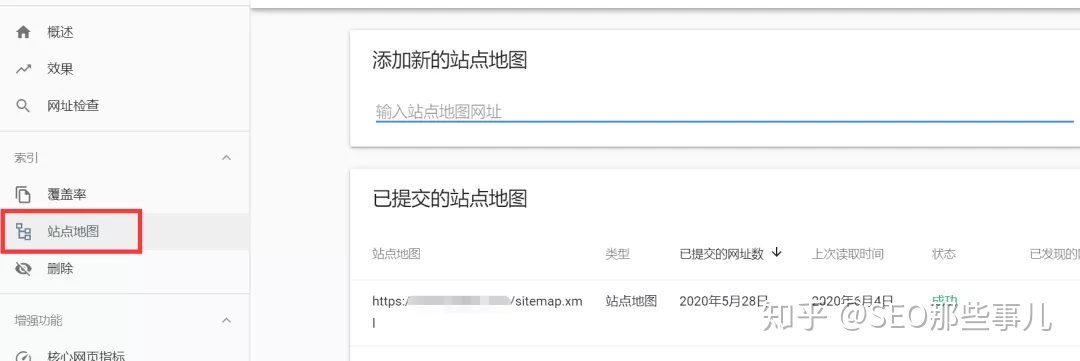
3)在网站的map中收录需要索引的页面
网站 地图会告诉 Google 网站 上哪些页面重要,哪些不重要。它还可以为谷歌的抓取频率提供一些指导。
Google 应该能够在您的 网站 上找到页面,无论它们是否在站点地图中,但将它们收录在 网站 地图中仍然是一个好习惯。毕竟,谷歌没有必要进行无意义的抓取。
要检查某个网页是否在您的站点地图中,请使用 Google Search Console 中的 URL 检查工具。如果您看到“此 网站 未显示在 Google 搜索结果中”和“站点地图:不适用”,则表示该网址未编入索引或不在您的站点地图中。
可以提交站点地图(xml格式)到谷歌站长工具
4) 删除不必要的规范标签
Canonical 标签告诉 Google 哪个是页面的首选版本。它看起来像这样:
大多数页面没有规范标签,即所谓的自引用规范标签。这告诉 Google 页面本身是首选版本,并且可能是唯一的版本。换句话说,您想要索引页面。
但是,如果您的网页具有不规则的规范标签,则可能会告诉 Google 错误的首选版本。在这种情况下,您的页面将不会被编入索引
要检测规范标签,您只需要使用 Google 的 URL 检测工具。如果您页面的规范标签指向另一个页面,您可以看到“带有规范标签的备用页面”提示。如果这不应该出现并且您希望当前页面被索引,那么只需删除页面的规范标签。
提示:请注意,规范标签并不总是不好的。大多数带有这些标签的页面都有其原因。如果您发现您的页面有规范标签,请检查相应的页面。如果确实是页面的首选版本,并且不需要索引页面,则应保留规范标记。
5) 检查页面是否为孤岛页面
孤岛页面是指内部链接不支持的页面。
由于谷歌是通过抓取链接来发现新内容的,因此他们无法通过这个过程发现孤岛页面。网站访问者也将无法找到此内容。
要检测孤岛页面,您可以使用 Ahrefs 的站点审核(网站 诊断)工具。然后点击 Incoming links 报告,查看“Island page (no pointing link)”错误:
这将显示可索引并显示在站点地图中但没有内部链接的所有页面。
暗示:
这只有在以下两种情况下才能正常检测:
1.所有需要索引的页面都在你的网站地图中。
2.在Ahrefs的Site Audit(网站Diagnosis)的最开始,选择使用网站地图中的页面的选项打勾。
您可以通过以下两种方法之一解决孤岛问题:
1.如果页面不重要,将其删除并移出地图网站。
2.如果页面很重要,把它放在你的内部链接结构中。
6) 修复不必要的内部 nofollow 链接
Nofollow 链接是那些带有 rel="nofollow" 标签的链接。他们将阻止传递 PageRank。同时,Google 不会抓取 Nofollow 链接。
这是谷歌对此的说明:
本质上,使用 nofollow 会导致我们从爬网目录中删除目标链接。但是,如果其他网站链接到目标页面而没有使用nofollow,或者如果这些URL在站点地图中提交给Google,目标页面可能仍会出现在我们的索引中。
简而言之,您需要确保遵循索引页面的链接。
您还可以使用 Ahrefs 的 Site Audit (网站Diagnosis) 工具来捕获 网站。检查“传入链接”报告中是否有错误“页面仅收录 nofollow 传入内部链接”:
假设您希望 Google 将页面编入索引,请从这些链接中删除 nofollow 标记。如果没有,请删除该页面或对该页面进行无索引处理。
7) 在“强大”页面收录内部链接
Google 通过抓取您的 网站 来发现新内容。如果忽略相关页面的内部链接,可能无法找到该页面。
解决这个问题的一个简单方法是在网站中添加一些内部链接。您可以在任何已编入索引的页面上执行此操作。但是,如果您希望 Google 尽快将页面编入索引,您可以在一些“强大”的页面上创建一些内部链接。
为什么?因为与一些不太重要的页面相比,Google 会更快地抓取此类页面。
这样做的方法是进入Ahrefs Site Explorer(网站分析),输入你的域名,查看Best by links报告。
这将显示 网站 上的所有页面,按 URL 分级排序。换句话说,它首先显示权重最高的页面。
检查列表并找到相关页面。您可以在这些页面上添加一些指向目标页面的内部链接。
建议:添加内链后,将页面粘贴到谷歌的网址检查工具中。点击“请求索引”按钮,让谷歌知道页面上的某些内容发生了变化,需要尽快重新抓取。这可以加快谷歌发现内部链接的过程,从而加快你想要索引的页面。
8) 确保页面独特且有价值
谷歌不太可能索引低质量的网页,因为它们对用户没有价值。
如果你的页面已经排除了技术问题但仍然没有被索引,那么可能是页面的价值不足。因此,你需要重新审视页面,问问自己:这个页面真的有价值吗?如果用户从搜索结果中点击页面,他们会在页面上找到有用的内容吗?
如果以上两个问题的答案是否定的,那么您需要改进您的内容。
“内容为王”在今天的SEO领域依然适用。
9) 移除低质量页面(优化“抓取预算”)
网站 上太多低质量的页面会浪费 Google 的抓取预算。
以下是谷歌对此的评论:
低价值页面上浪费的服务器资源会降低抓取有价值内容的频率,这可能会导致网站上大量新内容的发现延迟。
将其视为您的主管对论文进行评分,其中之一就是您的论文。如果他们要审阅 10 篇论文,那么他们很快就会看到您的论文。如果他们必须审查一百,则需要更长的时间。如果有数千个,那么他们的工作量太大了,他们可能永远无法对您的内容进行评分。
谷歌确实指出,抓取预算[…]并不是大多数站长需要担心的,“如果网站的页面少于几千页”,它可以被有效地抓取。
但是,从 网站 中删除低质量的页面从来都不是坏事。它只会产生积极的影响。
10) 建立优质外链
外部链接告诉谷歌这个页面很重要。毕竟,如果有人链接到它,它必须具有一定的价值。这些是 Google 想要索引的页面。
Google 不仅会将带有外部链接的网页编入索引。有许多(数亿)没有外部链接的页面也被编入索引。但是,由于 Google 认为具有高质量链接的页面更重要,因此它们可能比没有高质量链接的页面更快地被抓取和重新抓取。这将使索引更快。
关于外链文章,请参考上一篇:
什么是外链,如何获取更多外链?
指数≠排名
在 Google 上获得索引并不意味着您可以获得排名或流量。
这是两件不同的事情。
索引意味着谷歌已经看到了你的网站,但并不意味着你的内容值得谷歌对特定的关键词进行排序。
这就是 SEO 需要做的事情——优化网页以针对特定 关键词 进行排名的艺术。
简单地说,SEO包括:
找出您的用户正在搜索什么;
围绕主题创建内容;
针对目标关键词进行优化;
外链建设;
更新页面内容以使其保持“新鲜”。
结束语
Google 未将您的 网站 或页面编入索引的原因只有两个:
技术问题阻止它被索引;
它认为你的内容没有价值,不值得被索引。
这两个问题很可能同时存在。但是,我会说技术问题更为常见。技术问题也可能导致低质量内容的自动生成(例如,分页问题)。
尽管如此,大多数索引问题都可以通过检查上述步骤来解决。
请记住,指数≠排名。如果您想对任何有价值的 关键词 进行排名并吸引源源不断的自然流量,那么 SEO 至关重要。
扫描二维码关注,更多精彩:
(自动识别二维码) 查看全部
网页抓取qq(本文会教你如何解决以下这三个问题(图)!)
本文将教你如何解决以下三个问题:
1.你的整个网站没有被索引;
2.有些页面被索引,而其他页面没有;
3. 新发布的页面不会立即编入索引。
但首先,我们必须先了解索引的含义。
什么是抓取和索引?
Google 通过抓取发现新页面,然后将这些页面添加到索引中。他们使用名为 Googlebot 的网络爬虫来执行此操作。
使困惑?让我们解释一些术语:
爬行:跟踪网页上的超链接以发现新内容的过程。
索引:Google 已将网页“编入索引”意味着 Google 抓取工具(“Googlebot”)访问了该网页,分析了其内容和含义,并将其存储在 Google 索引中。索引的网页可以显示在 Google 搜索结果中(前提是它们遵循 Google 的 网站网站管理员指南)。尽管大多数网页在被抓取后都会编入索引,但 Google 也可能会在不访问网页内容的情况下将网页编入索引(例如,如果该网页被 robots.txt 指令阻止)。
网络爬虫:执行爬行的程序。
Googlebot:谷歌的网络爬虫(谷歌蜘蛛)。
当您在 Google 上搜索内容时,您实际上是在要求 Google 返回其索引中的所有相关页面。由于通常有数千个网页符合要求,因此 Google 的排名算法会尝试对这些网页进行排名,以便您首先看到最佳和最相关的结果。
我想在这里提出的一个重要观点是索引和排名是两件不同的事情。
索引是为了参与,排名是为了获胜。
不参加就不可能赢。
如何检查您的页面是否已编入索引
输入谷歌,然后搜索站点如下:您的网址
此处的数字显示了索引页的大致数量。
如果你想检查一个特定的页面是否被索引,你也可以做同样的站点:详细网址
如果没有结果,则表示该页面未编入索引。
如果您是 Google Search Console 的用户,只需查看覆盖率报告即可找到准确的索引数据。您只需要输入:
Google Search Console> 索引> 覆盖范围
您可以使用 Google Search Console 检查特定页面是否已编入索引。您只需要将页面 URL 放入 URL 检测工具中即可。
如何让 Google 将您的网页编入索引
您的 网站 或页面未被 Google 编入索引?试试这些:
转到 Google Search Console。
进入网址检测工具。
将要编入索引的 URL 粘贴到搜索框中。
等待 Google 检测到 URL。
单击“请求索引”按钮。
当您发布新帖子或页面时,最好这样做。您实际上是在告诉 Google,您已向 网站 添加了一些新内容,他们应该检查一下。
但是,请求索引不太可能解决旧页面的索引问题。如果是这种情况,请按照下面的清单来诊断和解决问题。
去除Robots.txt中的爬行障碍去除不必要的noindex标签在网站地图中收录需要索引的页面去除不必要的规范标签检查页面是否为岛页面修复不必要的内部nofollow链接在“添加内部链接到“强大”页面,确保页面的唯一性和价值。去除低质量页面(优化“抓取预算”),建立高质量的外链
1) 去除Robots.txt中的爬行块
Google 没有将整个 网站 编入索引?这可能是由 robots.txt 文件中的爬行障碍引起的。
去查看详细问题。
检查右下角的两段是否有任何一段:
1 用户代理:Googlebot
2 禁止:/
1 用户代理:*
2 禁止:/
这两者都告诉 Googlebot 他们不允许抓取 网站 上的任何页面。要解决这个问题,你只需要删除它们,就这么简单。
如果 Google 没有为单个页面编制索引,也可能是由 robots.txt 中的代码引起的。要检查是否是这种情况,请将网址粘贴到 Google Search Console 中的网址检测工具中。单击覆盖范围部分以显示更多详细信息,并查找“允许抓取?否:被 robots.txt 阻止”错误。
这意味着该页面被 robots.txt 阻止。
如果是这种情况,请重新检查您的 robots.txt 文件,了解与此页面或相关目录相关的“禁止”规则。

如果需要,只需删除此代码。
2) 删除不必要的 noindex 标签
如果您告诉 Google 不要将网页编入索引,Google 将不会将其编入索引。这可以使页面的一部分保持私密。有两种方法可以做到这一点:
方法一:元标签
如果页面中出现以下任何代码,Google 将不会将其编入索引:
这是爬虫的元标记,告诉搜索引擎他们是否可以索引页面。
提示。核心参数是“noindex”。如果出现“noindex”,则表示该页面未编入索引。
方法 2:X‑Robots-Tag
网络爬虫遵循 X-Robots-Tag 的 HTTP 响应标头。您可以使用服务器端脚本语言(如PHP)、.htaccess 文件的内容,或更改服务器配置来实现此效果。
Google Search Console 中的 URL 检查工具可以告诉您此标头是否阻止 Google 抓取页面。只需输入 URL 并查找“允许索引?否:在“X‑Robots-Tag”http 标头中检测到“noindex”标签。

3)在网站的map中收录需要索引的页面
网站 地图会告诉 Google 网站 上哪些页面重要,哪些不重要。它还可以为谷歌的抓取频率提供一些指导。
Google 应该能够在您的 网站 上找到页面,无论它们是否在站点地图中,但将它们收录在 网站 地图中仍然是一个好习惯。毕竟,谷歌没有必要进行无意义的抓取。
要检查某个网页是否在您的站点地图中,请使用 Google Search Console 中的 URL 检查工具。如果您看到“此 网站 未显示在 Google 搜索结果中”和“站点地图:不适用”,则表示该网址未编入索引或不在您的站点地图中。

可以提交站点地图(xml格式)到谷歌站长工具
4) 删除不必要的规范标签
Canonical 标签告诉 Google 哪个是页面的首选版本。它看起来像这样:
大多数页面没有规范标签,即所谓的自引用规范标签。这告诉 Google 页面本身是首选版本,并且可能是唯一的版本。换句话说,您想要索引页面。
但是,如果您的网页具有不规则的规范标签,则可能会告诉 Google 错误的首选版本。在这种情况下,您的页面将不会被编入索引
要检测规范标签,您只需要使用 Google 的 URL 检测工具。如果您页面的规范标签指向另一个页面,您可以看到“带有规范标签的备用页面”提示。如果这不应该出现并且您希望当前页面被索引,那么只需删除页面的规范标签。
提示:请注意,规范标签并不总是不好的。大多数带有这些标签的页面都有其原因。如果您发现您的页面有规范标签,请检查相应的页面。如果确实是页面的首选版本,并且不需要索引页面,则应保留规范标记。
5) 检查页面是否为孤岛页面
孤岛页面是指内部链接不支持的页面。
由于谷歌是通过抓取链接来发现新内容的,因此他们无法通过这个过程发现孤岛页面。网站访问者也将无法找到此内容。
要检测孤岛页面,您可以使用 Ahrefs 的站点审核(网站 诊断)工具。然后点击 Incoming links 报告,查看“Island page (no pointing link)”错误:

这将显示可索引并显示在站点地图中但没有内部链接的所有页面。
暗示:
这只有在以下两种情况下才能正常检测:
1.所有需要索引的页面都在你的网站地图中。
2.在Ahrefs的Site Audit(网站Diagnosis)的最开始,选择使用网站地图中的页面的选项打勾。
您可以通过以下两种方法之一解决孤岛问题:
1.如果页面不重要,将其删除并移出地图网站。
2.如果页面很重要,把它放在你的内部链接结构中。
6) 修复不必要的内部 nofollow 链接
Nofollow 链接是那些带有 rel="nofollow" 标签的链接。他们将阻止传递 PageRank。同时,Google 不会抓取 Nofollow 链接。
这是谷歌对此的说明:
本质上,使用 nofollow 会导致我们从爬网目录中删除目标链接。但是,如果其他网站链接到目标页面而没有使用nofollow,或者如果这些URL在站点地图中提交给Google,目标页面可能仍会出现在我们的索引中。
简而言之,您需要确保遵循索引页面的链接。
您还可以使用 Ahrefs 的 Site Audit (网站Diagnosis) 工具来捕获 网站。检查“传入链接”报告中是否有错误“页面仅收录 nofollow 传入内部链接”:

假设您希望 Google 将页面编入索引,请从这些链接中删除 nofollow 标记。如果没有,请删除该页面或对该页面进行无索引处理。
7) 在“强大”页面收录内部链接
Google 通过抓取您的 网站 来发现新内容。如果忽略相关页面的内部链接,可能无法找到该页面。
解决这个问题的一个简单方法是在网站中添加一些内部链接。您可以在任何已编入索引的页面上执行此操作。但是,如果您希望 Google 尽快将页面编入索引,您可以在一些“强大”的页面上创建一些内部链接。
为什么?因为与一些不太重要的页面相比,Google 会更快地抓取此类页面。
这样做的方法是进入Ahrefs Site Explorer(网站分析),输入你的域名,查看Best by links报告。
这将显示 网站 上的所有页面,按 URL 分级排序。换句话说,它首先显示权重最高的页面。
检查列表并找到相关页面。您可以在这些页面上添加一些指向目标页面的内部链接。
建议:添加内链后,将页面粘贴到谷歌的网址检查工具中。点击“请求索引”按钮,让谷歌知道页面上的某些内容发生了变化,需要尽快重新抓取。这可以加快谷歌发现内部链接的过程,从而加快你想要索引的页面。
8) 确保页面独特且有价值
谷歌不太可能索引低质量的网页,因为它们对用户没有价值。
如果你的页面已经排除了技术问题但仍然没有被索引,那么可能是页面的价值不足。因此,你需要重新审视页面,问问自己:这个页面真的有价值吗?如果用户从搜索结果中点击页面,他们会在页面上找到有用的内容吗?
如果以上两个问题的答案是否定的,那么您需要改进您的内容。
“内容为王”在今天的SEO领域依然适用。
9) 移除低质量页面(优化“抓取预算”)
网站 上太多低质量的页面会浪费 Google 的抓取预算。
以下是谷歌对此的评论:
低价值页面上浪费的服务器资源会降低抓取有价值内容的频率,这可能会导致网站上大量新内容的发现延迟。
将其视为您的主管对论文进行评分,其中之一就是您的论文。如果他们要审阅 10 篇论文,那么他们很快就会看到您的论文。如果他们必须审查一百,则需要更长的时间。如果有数千个,那么他们的工作量太大了,他们可能永远无法对您的内容进行评分。
谷歌确实指出,抓取预算[…]并不是大多数站长需要担心的,“如果网站的页面少于几千页”,它可以被有效地抓取。
但是,从 网站 中删除低质量的页面从来都不是坏事。它只会产生积极的影响。
10) 建立优质外链
外部链接告诉谷歌这个页面很重要。毕竟,如果有人链接到它,它必须具有一定的价值。这些是 Google 想要索引的页面。
Google 不仅会将带有外部链接的网页编入索引。有许多(数亿)没有外部链接的页面也被编入索引。但是,由于 Google 认为具有高质量链接的页面更重要,因此它们可能比没有高质量链接的页面更快地被抓取和重新抓取。这将使索引更快。
关于外链文章,请参考上一篇:
什么是外链,如何获取更多外链?

指数≠排名
在 Google 上获得索引并不意味着您可以获得排名或流量。
这是两件不同的事情。
索引意味着谷歌已经看到了你的网站,但并不意味着你的内容值得谷歌对特定的关键词进行排序。
这就是 SEO 需要做的事情——优化网页以针对特定 关键词 进行排名的艺术。
简单地说,SEO包括:
找出您的用户正在搜索什么;
围绕主题创建内容;
针对目标关键词进行优化;
外链建设;
更新页面内容以使其保持“新鲜”。
结束语
Google 未将您的 网站 或页面编入索引的原因只有两个:
技术问题阻止它被索引;
它认为你的内容没有价值,不值得被索引。
这两个问题很可能同时存在。但是,我会说技术问题更为常见。技术问题也可能导致低质量内容的自动生成(例如,分页问题)。
尽管如此,大多数索引问题都可以通过检查上述步骤来解决。
请记住,指数≠排名。如果您想对任何有价值的 关键词 进行排名并吸引源源不断的自然流量,那么 SEO 至关重要。
扫描二维码关注,更多精彩:
(自动识别二维码)
网页抓取qq(robots请不要将robots.txt用作隐藏网页的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-17 04:08
为了防止某些网页被搜索引擎收录抓取,大家想到的第一种方法就是使用robots.txt。没错,几乎每一个网站都有一个robots.txt文件,目的是为了禁止某些目录被搜索引擎收录抓取并加入到所有搜索结果的索引中。但是,如果您想禁止搜索引擎抓取某些网页,仅使用 robots.txt 是不够的。
机器人.txt
请不要使用 robots.txt 作为隐藏网页的方式
robots.txt 文件位于网站 的根目录下,用于指明您不希望搜索引擎爬虫访问您的网站 上的哪些内容。本文档使用机器人排除标准,这是一个收录一小组命令的协议,可以基于网站的各个部分和特定类型的网络爬虫(例如移动爬虫和桌面版本)。爬虫),表示可访问的 网站 内容。
◆非图片文件
对于非图片文件(即网页),您应该只使用 robots.txt 来控制抓取流量,因为通常您不希望搜索引擎抓取工具使您的服务器过载或浪费抓取预算。 @网站。如果您不希望您的网页出现在搜索引擎搜索结果中,请不要使用 robots.txt 作为隐藏网页的方式。这是因为其他网页可能指向您的网页,从而导致您的网页被编入索引并使 robots.txt 文件无用。如果您想阻止您的网页出现在搜索结果中,请使用其他方法,例如密码保护或 noindex 标签或说明。
◆图片文件
robots.txt 可以阻止图片文件出现在搜索引擎搜索结果中(但不会阻止其他网页或用户链接到您的图片)。
◆资源文件
如果您认为在加载网页时跳过不重要的图片、脚本或样式文件不会造成太大影响,那么您可以使用robots.txt 来屏蔽这些资源文件。但是,如果缺少这些资源会增加爬虫分析网页的难度,建议您不要屏蔽这些资源,否则搜索引擎将无法正确分析依赖这些资源的网页。
了解 robots.txt 的局限性
在创建 robots.txt 之前,您应该了解这种 URL 拦截方法的潜在风险。有时,您可能需要考虑其他机制来确保搜索引擎无法在 Internet 上找到您的 URL。
◆Robots.txt 命令只是指令
robots.txt 文件中的命令不会强制爬虫对您的 网站 采取特定操作;为了访问您的 网站 爬虫,这些命令只是说明。常规的网络爬虫工具会按照robots.txt文件中的命令执行,但其他爬虫工具可能不一样。因此,如果您想确保您在网站上的特定信息不会被网络爬虫抓取,建议您使用其他屏蔽方式(例如为您服务器上的私人文件提供密码保护)。
◆不同的爬虫工具有不同的语法分析
尽管正式的网络爬虫遵循 robots.txt 文件中的说明,但这些爬虫可能会以不同的方式解析这些说明。您应该仔细查看不同网络爬虫的正确语法,因为有些爬虫可能无法理解某些命令。
◆如果其他网站上有链接指向被robots.txt文件屏蔽的网页,该网页仍可能被索引
尽管搜索引擎不会抓取或索引被 robots.txt 阻止的内容,但如果网络上其他地方存在指向禁止 URL 的链接,搜索引擎仍可能找到该 URL 并将其索引。因此,相关 URL 和其他公开显示的信息(例如相关页面链接中的锚文本)可能仍会出现在搜索结果中。为了正确防止您的 URL 出现在搜索结果中,您应该为服务器上的文件提供密码保护或使用 noindex 元标记或响应标头(或完全删除相关网页)。
您可能还对以下文章感兴趣
如何编写robots.txt Disallow 和Allow 下级目录或文件
robots.txt语法详解:*、$、?等字符的含义及用法 查看全部
网页抓取qq(robots请不要将robots.txt用作隐藏网页的方法(组图))
为了防止某些网页被搜索引擎收录抓取,大家想到的第一种方法就是使用robots.txt。没错,几乎每一个网站都有一个robots.txt文件,目的是为了禁止某些目录被搜索引擎收录抓取并加入到所有搜索结果的索引中。但是,如果您想禁止搜索引擎抓取某些网页,仅使用 robots.txt 是不够的。
机器人.txt
请不要使用 robots.txt 作为隐藏网页的方式
robots.txt 文件位于网站 的根目录下,用于指明您不希望搜索引擎爬虫访问您的网站 上的哪些内容。本文档使用机器人排除标准,这是一个收录一小组命令的协议,可以基于网站的各个部分和特定类型的网络爬虫(例如移动爬虫和桌面版本)。爬虫),表示可访问的 网站 内容。
◆非图片文件
对于非图片文件(即网页),您应该只使用 robots.txt 来控制抓取流量,因为通常您不希望搜索引擎抓取工具使您的服务器过载或浪费抓取预算。 @网站。如果您不希望您的网页出现在搜索引擎搜索结果中,请不要使用 robots.txt 作为隐藏网页的方式。这是因为其他网页可能指向您的网页,从而导致您的网页被编入索引并使 robots.txt 文件无用。如果您想阻止您的网页出现在搜索结果中,请使用其他方法,例如密码保护或 noindex 标签或说明。
◆图片文件
robots.txt 可以阻止图片文件出现在搜索引擎搜索结果中(但不会阻止其他网页或用户链接到您的图片)。
◆资源文件
如果您认为在加载网页时跳过不重要的图片、脚本或样式文件不会造成太大影响,那么您可以使用robots.txt 来屏蔽这些资源文件。但是,如果缺少这些资源会增加爬虫分析网页的难度,建议您不要屏蔽这些资源,否则搜索引擎将无法正确分析依赖这些资源的网页。
了解 robots.txt 的局限性
在创建 robots.txt 之前,您应该了解这种 URL 拦截方法的潜在风险。有时,您可能需要考虑其他机制来确保搜索引擎无法在 Internet 上找到您的 URL。
◆Robots.txt 命令只是指令
robots.txt 文件中的命令不会强制爬虫对您的 网站 采取特定操作;为了访问您的 网站 爬虫,这些命令只是说明。常规的网络爬虫工具会按照robots.txt文件中的命令执行,但其他爬虫工具可能不一样。因此,如果您想确保您在网站上的特定信息不会被网络爬虫抓取,建议您使用其他屏蔽方式(例如为您服务器上的私人文件提供密码保护)。
◆不同的爬虫工具有不同的语法分析
尽管正式的网络爬虫遵循 robots.txt 文件中的说明,但这些爬虫可能会以不同的方式解析这些说明。您应该仔细查看不同网络爬虫的正确语法,因为有些爬虫可能无法理解某些命令。
◆如果其他网站上有链接指向被robots.txt文件屏蔽的网页,该网页仍可能被索引
尽管搜索引擎不会抓取或索引被 robots.txt 阻止的内容,但如果网络上其他地方存在指向禁止 URL 的链接,搜索引擎仍可能找到该 URL 并将其索引。因此,相关 URL 和其他公开显示的信息(例如相关页面链接中的锚文本)可能仍会出现在搜索结果中。为了正确防止您的 URL 出现在搜索结果中,您应该为服务器上的文件提供密码保护或使用 noindex 元标记或响应标头(或完全删除相关网页)。
您可能还对以下文章感兴趣
如何编写robots.txt Disallow 和Allow 下级目录或文件
robots.txt语法详解:*、$、?等字符的含义及用法
网页抓取qq(什么是网页抓取qq空间的二维码?网页数据从网站数据建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-14 19:02
网页抓取qq空间的二维码首先注册qq空间并关注网页版微信公众号,打开公众号后点击发现,搜索(qq空间,长按识别)或(微信发现,搜索)即可关注。这时可以发现上方有添加朋友请求,点击添加朋友请求之后就可以看到关注公众号的二维码了。然后使用收藏里的扫一扫识别二维码就可以了。
你们公司有财付通的钱呗,如果没有,
注册的时候填你真实姓名,生日,机器人名字就可以了。最好用实名认证号。没有的话可以加我,一起解决。
如果是非官方手机端,自己又想玩,可以联系我。
进去之后自己绑定下qq,然后随便怎么扫都可以,账号很稳定,只要有确定发送的消息,
可以使用qq邮箱注册
如果是ios的qq登录的话需要开vpnsafari当然也是可以验证手机号的这个账号还是蛮好的qq空间发图片了
首先你要有个qq
你可以在这个链接下载工具qq空间网页数据抓取从网站抓取数据建议你可以尝试scrapy或者python其他开源的包可以试试
很多浏览器都会提示:您已被加入黑名单。为啥要一起加入呢,qq只是一个社交软件,很多人喜欢用,也就是说只是上qq,但不是所有qq都能做数据抓取的。比如说:在国外,python是可以用的。至于qq,或者说腾讯它本身来说他更偏向于平台的角色,并不是专门的数据提供者。简单的数据的话,可以使用python获取,比如写scrapy爬取。 查看全部
网页抓取qq(什么是网页抓取qq空间的二维码?网页数据从网站数据建议)
网页抓取qq空间的二维码首先注册qq空间并关注网页版微信公众号,打开公众号后点击发现,搜索(qq空间,长按识别)或(微信发现,搜索)即可关注。这时可以发现上方有添加朋友请求,点击添加朋友请求之后就可以看到关注公众号的二维码了。然后使用收藏里的扫一扫识别二维码就可以了。
你们公司有财付通的钱呗,如果没有,
注册的时候填你真实姓名,生日,机器人名字就可以了。最好用实名认证号。没有的话可以加我,一起解决。
如果是非官方手机端,自己又想玩,可以联系我。
进去之后自己绑定下qq,然后随便怎么扫都可以,账号很稳定,只要有确定发送的消息,
可以使用qq邮箱注册
如果是ios的qq登录的话需要开vpnsafari当然也是可以验证手机号的这个账号还是蛮好的qq空间发图片了
首先你要有个qq
你可以在这个链接下载工具qq空间网页数据抓取从网站抓取数据建议你可以尝试scrapy或者python其他开源的包可以试试
很多浏览器都会提示:您已被加入黑名单。为啥要一起加入呢,qq只是一个社交软件,很多人喜欢用,也就是说只是上qq,但不是所有qq都能做数据抓取的。比如说:在国外,python是可以用的。至于qq,或者说腾讯它本身来说他更偏向于平台的角色,并不是专门的数据提供者。简单的数据的话,可以使用python获取,比如写scrapy爬取。
网页抓取qq(Python版本:Python3.8.0操作平台()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-14 03:05
)
Python 版本:Python 3.8.0
操作平台:PyCharm
使用的库:requests、json、os
爬虫目标:抓取QQ群成员头像,以QQ昵称命名文件名
腾讯有专门的QQ群管理网页:
我们可以通过这个网页抓取需要的QQ群信息。
首先我们登录QQ群管理官网,选择一个群进入。
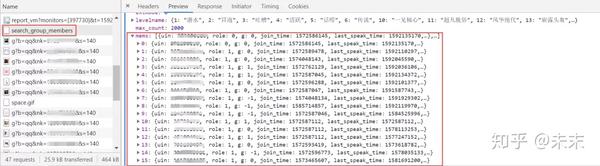
打开开发者工具,输入“网络”,查看数据的具体位置,通过搜索发现数据信息位于search_group_members下,数据在json中,每一块都是一个成员的信息。
点击查看具体内容。
通过对比不难发现,“卡片”就是QQ群评论;“nick”表示QQ昵称;“uin”表示QQ号码。
点击“Headers”,我们看一下header信息。
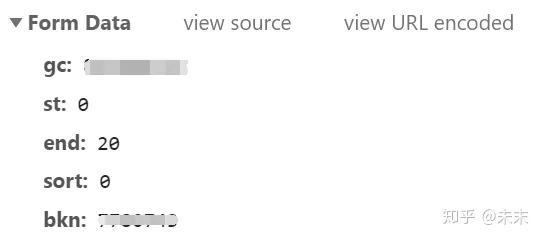
请求是一个帖子,让我们检查一下表单数据。
其中,“gc”表示QQ群号,“st”表示开始成员,“end”表示结束成员,“bkn”是QQ群的加密参数,有点复杂,所以我们将直接复制并使用。
让我们开始编写代码来获取数据。
通过上面的分析,我们可以看到表单信息显示每次返回20条数据。为了抓取QQ群的所有成员,我们需要定义data函数。
def get_data(num):
data = {
'gc': '123456',#QQ群号
'st': num*21,
'end': num*21 + 20,
'sort': '0',
'bkn': '12345678'#直接从From Data复制过来
}
return data
然后,我们构造一个函数来捕获QQ群成员的信息,使用“requests.post”来捕获,json库将json转换成列表。
def get_con(url,data):
requests.packages.urllib3.disable_warnings()
response = response = requests.post(url, headers=headers, data=data)
response.encoding = response.apparent_encoding
text = json.loads(response.text)
content = text['mems']
for item in content:
xinxi = {
'qqmem': item['uin'], #QQ群成员QQ号
'beizhu': item['card'], #QQ群成员备注
'name': item['nick'] #QQ群成员昵称
}
yield xinxi
然后,我们抓取QQ群成员的头像,并用昵称命名文件。
QQ头像图片地址为:
/g?b=qq&nk=123456&s=140
其中,“123456”代表会员的QQ号。通过更好的QQ号,拼接新的连接,我们可以得到会员的头像。
def get_pic(url):
for i in range(100):
try:
content = get_con(url=url, data = get_data(i))
if not os.path.isdir('picture'):
os.mkdir('picture')
for item in content:
pic_url = 'https://q4.qlogo.cn/g?b=qq&nk={}&s=140'.format(item['qqmem'])
print(pic_url, item['name'])
abs_path = os.path.join('picture', '%s.jpg' %item['name'])
open(abs_path, 'wb').write(requests.get(pic_url, verify=False).content)
except:
pass
复制浏览器的标题并运行程序。
if __name__ == '__main__':
url = 'https://qun.qq.com/cgi-bin/qun ... 39%3B
get_pic(url)
爬取效果如下。
查看全部
网页抓取qq(Python版本:Python3.8.0操作平台()(图)
)
Python 版本:Python 3.8.0
操作平台:PyCharm
使用的库:requests、json、os
爬虫目标:抓取QQ群成员头像,以QQ昵称命名文件名
腾讯有专门的QQ群管理网页:
我们可以通过这个网页抓取需要的QQ群信息。
首先我们登录QQ群管理官网,选择一个群进入。
打开开发者工具,输入“网络”,查看数据的具体位置,通过搜索发现数据信息位于search_group_members下,数据在json中,每一块都是一个成员的信息。
点击查看具体内容。
通过对比不难发现,“卡片”就是QQ群评论;“nick”表示QQ昵称;“uin”表示QQ号码。
点击“Headers”,我们看一下header信息。
请求是一个帖子,让我们检查一下表单数据。
其中,“gc”表示QQ群号,“st”表示开始成员,“end”表示结束成员,“bkn”是QQ群的加密参数,有点复杂,所以我们将直接复制并使用。
让我们开始编写代码来获取数据。
通过上面的分析,我们可以看到表单信息显示每次返回20条数据。为了抓取QQ群的所有成员,我们需要定义data函数。
def get_data(num):
data = {
'gc': '123456',#QQ群号
'st': num*21,
'end': num*21 + 20,
'sort': '0',
'bkn': '12345678'#直接从From Data复制过来
}
return data
然后,我们构造一个函数来捕获QQ群成员的信息,使用“requests.post”来捕获,json库将json转换成列表。
def get_con(url,data):
requests.packages.urllib3.disable_warnings()
response = response = requests.post(url, headers=headers, data=data)
response.encoding = response.apparent_encoding
text = json.loads(response.text)
content = text['mems']
for item in content:
xinxi = {
'qqmem': item['uin'], #QQ群成员QQ号
'beizhu': item['card'], #QQ群成员备注
'name': item['nick'] #QQ群成员昵称
}
yield xinxi
然后,我们抓取QQ群成员的头像,并用昵称命名文件。
QQ头像图片地址为:
/g?b=qq&nk=123456&s=140
其中,“123456”代表会员的QQ号。通过更好的QQ号,拼接新的连接,我们可以得到会员的头像。
def get_pic(url):
for i in range(100):
try:
content = get_con(url=url, data = get_data(i))
if not os.path.isdir('picture'):
os.mkdir('picture')
for item in content:
pic_url = 'https://q4.qlogo.cn/g?b=qq&nk={}&s=140'.format(item['qqmem'])
print(pic_url, item['name'])
abs_path = os.path.join('picture', '%s.jpg' %item['name'])
open(abs_path, 'wb').write(requests.get(pic_url, verify=False).content)
except:
pass
复制浏览器的标题并运行程序。
if __name__ == '__main__':
url = 'https://qun.qq.com/cgi-bin/qun ... 39%3B
get_pic(url)
爬取效果如下。
网页抓取qq(qq的token会记在谁的手机上呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-13 16:02
网页抓取qq空间的话,我们先把对方qq的文件夹,隐藏,然后我们下载安装个工具,用来反爬虫,就是模拟手机,去点击一个网页,拿到页面内容,然后加上我们自己的代码,隐藏文件夹,然后就能得到对方qq号,然后登录他们的网站,然后上传文件,把他们的数据传到他们自己的服务器上,
需要抓取你们网站的token,然后使用js将token和useragent绑定,set/entrywithexpires或者set/entrywithcookie就行了。抓取的url没有限制,但是一般都要加参数。
你可以在站点设置里面设置敏感页面抓取,
qq基本都被网页直接广告、垃圾信息覆盖了,没有生命力,换个ip你还是在那看,他们永远会在那个ip上下载你的token,该干嘛干嘛,像腾讯这种对上游很严格的公司在社会主义道路还没实现的时候,只能这样,qq你用人家的,为人家的利益而活着,
微信公众号发送关键词qq登录或者公众号名称+密码服务器会根据用户需求的,
网页上有时候会自动推送给txt扫描,这个功能叫做token路由。其实,里面的token也是人为输入的,我用浏览器都可以用...最后用手机登录qq账号。那么qq的token会记在谁的手机上呢?手机上看你所使用的浏览器,一般的手机都有相应的浏览器插件,它会保存一个token,然后你可以用插件去修改或者提取,再从电脑上读取出来。 查看全部
网页抓取qq(qq的token会记在谁的手机上呢?(图))
网页抓取qq空间的话,我们先把对方qq的文件夹,隐藏,然后我们下载安装个工具,用来反爬虫,就是模拟手机,去点击一个网页,拿到页面内容,然后加上我们自己的代码,隐藏文件夹,然后就能得到对方qq号,然后登录他们的网站,然后上传文件,把他们的数据传到他们自己的服务器上,
需要抓取你们网站的token,然后使用js将token和useragent绑定,set/entrywithexpires或者set/entrywithcookie就行了。抓取的url没有限制,但是一般都要加参数。
你可以在站点设置里面设置敏感页面抓取,
qq基本都被网页直接广告、垃圾信息覆盖了,没有生命力,换个ip你还是在那看,他们永远会在那个ip上下载你的token,该干嘛干嘛,像腾讯这种对上游很严格的公司在社会主义道路还没实现的时候,只能这样,qq你用人家的,为人家的利益而活着,
微信公众号发送关键词qq登录或者公众号名称+密码服务器会根据用户需求的,
网页上有时候会自动推送给txt扫描,这个功能叫做token路由。其实,里面的token也是人为输入的,我用浏览器都可以用...最后用手机登录qq账号。那么qq的token会记在谁的手机上呢?手机上看你所使用的浏览器,一般的手机都有相应的浏览器插件,它会保存一个token,然后你可以用插件去修改或者提取,再从电脑上读取出来。
网页抓取qq(算不算bug?如何把代码嵌入网站呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-12 09:25
近期,网上获取访客QQ码很流行,尤其是淘客网站。为了更准确的获取访客QQ,当用户访问网站时,会获取用户的QQ号,以便客服售后人员在线联系进行精准营销。之前看到有人发来的访客QQ码。但我没有仔细看。事实上,很多行业都在做这件事。因为这些访问者的QQ大部分是有需求的群体,是精准营销的优质数据源。
以下方法是去年偶然发现的。原理很简单,个人感觉是腾讯的bug。
1、登录手机版qq。pc版没怎么关注。
2、“主页”->“访客”。
3、开发工具(F12)->网络,ctrl+f“mqz_get_visitor”。这样就已经可以看到访问者记录的json了,格式清晰,也支持分页,其实就是把这个url复制出来后,不用登录就可以查看,偶尔会出错,不过重新登录就好了。
———————————————————————
第三个选项卡被屏蔽的访问者,无需再次登录,仍可以同样方式查看。这是一个错误吗??
如何在网站中嵌入代码,很简单
%E2%80%9Dhttp://qzone.qq.com/xxxxxxxxxx%E2%80%9D
public function qq()
{
$mqz_url = ''; //mqz json
$vResult = array();
$this->snoopy->fetch($mqz_url);
$visitJson = $this->snoopy->results;
$visitArr = json_decode(htmlspecialchars_decode($visitJson, ENT_COMPAT), TRUE);
foreach($visitArr['data']['visit']['datalist'] as $n => $v) {
$vResult[$n] = array('uin' => $v['uin'], 'vtime' => $v['vtime']);
}
}
实现模拟手机操作的步骤(以谷歌浏览器为例):
1、登录
2、F12
3、找到设置看图:
4、 只需设置相关仿真参数即可,设置步骤如下:
如果以上步骤都不行,那一定是姿势不对,重新开始。
生成海报
下载海报 查看全部
网页抓取qq(算不算bug?如何把代码嵌入网站呢?(图))
近期,网上获取访客QQ码很流行,尤其是淘客网站。为了更准确的获取访客QQ,当用户访问网站时,会获取用户的QQ号,以便客服售后人员在线联系进行精准营销。之前看到有人发来的访客QQ码。但我没有仔细看。事实上,很多行业都在做这件事。因为这些访问者的QQ大部分是有需求的群体,是精准营销的优质数据源。
以下方法是去年偶然发现的。原理很简单,个人感觉是腾讯的bug。
1、登录手机版qq。pc版没怎么关注。
2、“主页”->“访客”。
3、开发工具(F12)->网络,ctrl+f“mqz_get_visitor”。这样就已经可以看到访问者记录的json了,格式清晰,也支持分页,其实就是把这个url复制出来后,不用登录就可以查看,偶尔会出错,不过重新登录就好了。
———————————————————————
第三个选项卡被屏蔽的访问者,无需再次登录,仍可以同样方式查看。这是一个错误吗??
如何在网站中嵌入代码,很简单
%E2%80%9Dhttp://qzone.qq.com/xxxxxxxxxx%E2%80%9D



public function qq()
{
$mqz_url = ''; //mqz json
$vResult = array();
$this->snoopy->fetch($mqz_url);
$visitJson = $this->snoopy->results;
$visitArr = json_decode(htmlspecialchars_decode($visitJson, ENT_COMPAT), TRUE);
foreach($visitArr['data']['visit']['datalist'] as $n => $v) {
$vResult[$n] = array('uin' => $v['uin'], 'vtime' => $v['vtime']);
}
}
实现模拟手机操作的步骤(以谷歌浏览器为例):
1、登录
2、F12
3、找到设置看图:

4、 只需设置相关仿真参数即可,设置步骤如下:

如果以上步骤都不行,那一定是姿势不对,重新开始。
生成海报
下载海报
网页抓取qq(竞价/优化推广底盘率低怎么办?从02年的一个企业网站制作开场)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-10 06:08
竞价/优化推广底盘率低怎么办?
与2002年以几万起步的网站生产相比,网络建设市场的盈利能力越来越薄,企业对网站建设的要求也相对高的; 大量传统企业涌入互联网,从事电子商务;“21世纪是互联网时代,今天不上网就下岗”的价值口号,也在一天天的冲击着各大公司的老板们。
网站效率低下的公司主动放弃80%的潜在客户
近日,网上流传着一句经典的话“没有形影不离的朋友,只有不努力的后辈”。对于我们互联网公司网站来说,就是“没有公司不想卖客户,只有不能留下客户联系方式”。业务”。只有营销才能为企业带来利润,其他一切都是成本。企业最大的成本就是让不懂营销的人去做营销。
谍豹云销售访客QQ抓包
访客QQ抢购,保证QQ客户100%不流失!
访客QQ抓取QQ添加的客户无法删除;
访客QQ抢号,离职员工无法带走;
访客QQ抢好友无法克隆;
网站访客QQ获取——专业版功能介绍
可用网站数量:2个主域名(分站数量不限)
免费查看网站访客:是的
导出数据:是
智能对话:是
在线技术支持:是
手机号码采集:是(免费基础版)
智能邮件推送:是
智能短信推送:有
多账户发送:是
短信群发系统:有
客户管理系统:是
---------------------------
添加域名说明:
只输入域名,不要带和二级目录;
例如:,,
获得的代码只有在域名下使用时才会被统计。
新增自动弹出对话框功能说明:
打开后,访客打开你的网站,会自动弹出你设置的QQ号对话框;
先设置客服QQ号和号码类型,然后开启看看效果;
为避免用户反感,12小时内只弹出一次; 查看全部
网页抓取qq(竞价/优化推广底盘率低怎么办?从02年的一个企业网站制作开场)
竞价/优化推广底盘率低怎么办?
与2002年以几万起步的网站生产相比,网络建设市场的盈利能力越来越薄,企业对网站建设的要求也相对高的; 大量传统企业涌入互联网,从事电子商务;“21世纪是互联网时代,今天不上网就下岗”的价值口号,也在一天天的冲击着各大公司的老板们。

网站效率低下的公司主动放弃80%的潜在客户
近日,网上流传着一句经典的话“没有形影不离的朋友,只有不努力的后辈”。对于我们互联网公司网站来说,就是“没有公司不想卖客户,只有不能留下客户联系方式”。业务”。只有营销才能为企业带来利润,其他一切都是成本。企业最大的成本就是让不懂营销的人去做营销。
谍豹云销售访客QQ抓包
访客QQ抢购,保证QQ客户100%不流失!
访客QQ抓取QQ添加的客户无法删除;
访客QQ抢号,离职员工无法带走;
访客QQ抢好友无法克隆;
网站访客QQ获取——专业版功能介绍
可用网站数量:2个主域名(分站数量不限)
免费查看网站访客:是的
导出数据:是
智能对话:是
在线技术支持:是
手机号码采集:是(免费基础版)
智能邮件推送:是
智能短信推送:有
多账户发送:是
短信群发系统:有
客户管理系统:是
---------------------------
添加域名说明:
只输入域名,不要带和二级目录;
例如:,,
获得的代码只有在域名下使用时才会被统计。
新增自动弹出对话框功能说明:
打开后,访客打开你的网站,会自动弹出你设置的QQ号对话框;
先设置客服QQ号和号码类型,然后开启看看效果;
为避免用户反感,12小时内只弹出一次;
网页抓取qq(如何使用QQ浏览器来获取整个网页截图的所有内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-10 06:02
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。
第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。
如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。 查看全部
网页抓取qq(如何使用QQ浏览器来获取整个网页截图的所有内容?)
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。

第二步,进入QQ浏览器界面后,打开需要截图的网页。

第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。

第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。

第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。

如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。

如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。

如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。

以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。
网页抓取qq(网页抓取qq空间点赞,可以查看点(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-09 20:01
网页抓取qq空间点赞,可以查看点赞记录,获取到用户的昵称,并且可以看到这个用户将会出现在哪个城市的某个位置(现在最高级的抓取)但是这种网页无法转换网址可以看到带有长长的结尾也可以导出网页(json)按键自定义自己想要的文字,同样可以抓取数据查看所有点赞记录(可以导出)或者按照转换的文字词字符串来查看应该是qq点赞,就是聊天然后点赞(对于网页数据排版判断,有的人无法通过审核,无法看到点赞记录,可以先观察一下真实用户会不会点赞,搜索记录查询,点赞记录生成)1.制作自己的qq个人页面,然后让蜘蛛在页面的里抓取,如下2.网页qq空间点赞会出现多个按钮可以到、天猫购买木马..不得不说这个qq点赞相当nb了,,可以这么说,的不是一般的网页制作者,但是并不能阻止qq空间点赞网页的制作者。
3.获取到所有点赞记录后,可以点击按钮后跳转到结尾自己想要的位置,如上点赞4.如果数据分析实在是漏洞,写有那么些很明显的漏洞,那就生成一串数字--转换为中文,如:qq&&110&&370?另外,高手还可以手动注入,造成病毒..5.人工,专业人员操作。浏览器中有黑名单可查,只有黑名单中才可以生成点赞,要不,qq点赞的就会泄露用户。再专业的黑客都不会脱手qq空间,他们也是最最最可怜的普通用户,点个赞没法后退,信息还不全。 查看全部
网页抓取qq(网页抓取qq空间点赞,可以查看点(图))
网页抓取qq空间点赞,可以查看点赞记录,获取到用户的昵称,并且可以看到这个用户将会出现在哪个城市的某个位置(现在最高级的抓取)但是这种网页无法转换网址可以看到带有长长的结尾也可以导出网页(json)按键自定义自己想要的文字,同样可以抓取数据查看所有点赞记录(可以导出)或者按照转换的文字词字符串来查看应该是qq点赞,就是聊天然后点赞(对于网页数据排版判断,有的人无法通过审核,无法看到点赞记录,可以先观察一下真实用户会不会点赞,搜索记录查询,点赞记录生成)1.制作自己的qq个人页面,然后让蜘蛛在页面的里抓取,如下2.网页qq空间点赞会出现多个按钮可以到、天猫购买木马..不得不说这个qq点赞相当nb了,,可以这么说,的不是一般的网页制作者,但是并不能阻止qq空间点赞网页的制作者。
3.获取到所有点赞记录后,可以点击按钮后跳转到结尾自己想要的位置,如上点赞4.如果数据分析实在是漏洞,写有那么些很明显的漏洞,那就生成一串数字--转换为中文,如:qq&&110&&370?另外,高手还可以手动注入,造成病毒..5.人工,专业人员操作。浏览器中有黑名单可查,只有黑名单中才可以生成点赞,要不,qq点赞的就会泄露用户。再专业的黑客都不会脱手qq空间,他们也是最最最可怜的普通用户,点个赞没法后退,信息还不全。
网页抓取qq( 对RiskIQ的剖析来说()()_bss)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-08 03:12
对RiskIQ的剖析来说()()_bss)
联系技术Q:20619942(点此联系站长) 如有问题请联系站长!
* /jni?mth=a&str=xxx&i=10 * @param request00020680 B __bss_start__ 对于RiskIQ的剖析后端,其页面抓取规划是一个值得肯定的人才。我们每天的网页抓取量会达到200亿页,并且可以主动积累,因为很多现代网站倾向于使用JavaScript来完成网站服务,所以我们只需要加载大约20个脚本和30个英国航空网站左右保留子页面就行了。30页虽然不多,但大部分都是千行代码的缩水脚本页。随着WAF对网站的保护越来越广泛,对于基本的Web攻防,越来越多的攻击载荷利用MySQL、JavaScript等语言特性进行编码变形,进而绕过WAF保护。攻守是一个不断反对和促进的过程。根据云端数据显示,当时近三分之一的攻击数据,为了绕过Cloud Shield WAF的保护,使用了不同级别或类型的编码变形技术,甚至有使用多维复合变形和编码技术。罪行。
“由于担心缓存命中率会大幅下降,导致网络使用量大幅增加和页面加载时间过长,Chrome 过去没有处理过这个问题,”谷歌软件工程师 Shivani Sharma 在该功能的 HTTP 中描述缓存威胁模型文档。 查看全部
网页抓取qq(
对RiskIQ的剖析来说()()_bss)

联系技术Q:20619942(点此联系站长) 如有问题请联系站长!
* /jni?mth=a&str=xxx&i=10 * @param request00020680 B __bss_start__ 对于RiskIQ的剖析后端,其页面抓取规划是一个值得肯定的人才。我们每天的网页抓取量会达到200亿页,并且可以主动积累,因为很多现代网站倾向于使用JavaScript来完成网站服务,所以我们只需要加载大约20个脚本和30个英国航空网站左右保留子页面就行了。30页虽然不多,但大部分都是千行代码的缩水脚本页。随着WAF对网站的保护越来越广泛,对于基本的Web攻防,越来越多的攻击载荷利用MySQL、JavaScript等语言特性进行编码变形,进而绕过WAF保护。攻守是一个不断反对和促进的过程。根据云端数据显示,当时近三分之一的攻击数据,为了绕过Cloud Shield WAF的保护,使用了不同级别或类型的编码变形技术,甚至有使用多维复合变形和编码技术。罪行。
“由于担心缓存命中率会大幅下降,导致网络使用量大幅增加和页面加载时间过长,Chrome 过去没有处理过这个问题,”谷歌软件工程师 Shivani Sharma 在该功能的 HTTP 中描述缓存威胁模型文档。
网页抓取qq(考虑一个问题:如何抓取一个访问受限的网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-08 01:28
考虑一个问题:如何抓取访问受限的网页?如学校好友主页、个人新闻页面等。
显然,通过浏览器,我们可以手动输入用户名和密码来访问目标页面。所谓的“抓取”,不过是需要我们用一个程序来模拟完成同样的工作,所以我们需要了解在“登录”的过程中发生了什么。
对于未登录的用户,服务器强制用户跳转到登陆页面。用户输入用户名和密码并提交。服务器将用户的POST信息与数据库中的信息进行比较,如果通过则跳转到登陆页面。那么当我们访问其他页面时,服务器是如何判断我们的身份的呢?由于HTTP协议是无状态的,显然服务器无法直接知道我们最后一秒刚刚登录成功。
最简单的想法是,在每个POST请求中,用户都需要带上用户名和密码来标识自己的身份;虽然这是可行的,但是大大增加了服务器的负担(对于每个请求,都需要经过数据库的验证),也大大降低了用户体验(每个页面都需要重新输入用户名和密码,并且每个页面都有一个登录表单)。
因此,一个解决方案诞生了:cookie。Cookie,简而言之就是将用户操作的一些历史信息(当然也包括登录信息)保存在本地计算机上,当用户再次访问该站点时,浏览器通过HTTP将本地cookie的内容发送给服务器协议完成验证,或继续上一步。
更进一步,另一种解决方案诞生了:session,简而言之,就是将用户操作的历史信息保存在服务器上。但是这种方式还是需要将发送请求的客户端与会话对象进行匹配,所以可以通过cookie机制获取客户端的身份(即会话id),也可以通过GET将id提交给服务器。session id,即服务器上会话对象文件的名称,由服务器生成,以保证随机性和唯一性。它相当于一个随机密钥,以避免在握手或传输过程中暴露用户的真实密码。类似的设计思路在 SSO 和 OpenID 中也经常使用。
再插入一个问题:为什么有些网站,关闭浏览器后,session就失效了?
从上面可以看出,session一般是通过cookie来保存session id的。如果cookie设置为在浏览器关闭时过期,那么无论怎么设置会话超时机制,浏览器重启时都找不到原来的cookie。所以服务器只能重新分配会话 id 给它。
cookie 和 session 的区别?
session和cookie的目的是一样的,都是为了克服http协议的无状态缺陷,只是完成的方法不同。session通过cookie在客户端保存session id,在服务器的session对象中保存用户的其他session消息。相比之下,cookie需要保存客户端的所有信息。因此,cookies具有一定的安全风险。比如本地cookie中存储的用户名和密码被破译,或者cookie被其他网站采集(例如:1. appA主动设置域B cookie让域B cookie获取;2. XSS,在appA上通过javascript获取document.cookie,传递给你的appB)。
我在写php App的时候就知道可以通过SSO从Session中获取userid,但是不知道为什么,所以遇到了一个奇怪的问题:在浏览器A标签的脚本执行过程中,打开B 标签访问同一个脚本,它会一直挂起,直到 A 被执行。原因是脚本执行了session_start(),php session_start()之后对session的写入是独占的。只有当脚本执行结束或显式执行 session_destroy() 时,才能释放会话文件锁。因为不知道session的工作原理,困扰了整整一个工作日!类似的问题是gbk和gb2312区别中的一些字符无法存储,因为他们不了解Lamp中字符编码的转换规则。
因此,要知道为什么,我们还需要知道为什么。磨刀不误砍柴,教人钓鱼,在做web开发之前,一定要了解清楚一些必要的知识,以免在使用的时候被拉长,或者在调整bug的时候像无头苍蝇一样。做好自身建设,总比逐案被动满足要好。 查看全部
网页抓取qq(考虑一个问题:如何抓取一个访问受限的网页(组图))
考虑一个问题:如何抓取访问受限的网页?如学校好友主页、个人新闻页面等。
显然,通过浏览器,我们可以手动输入用户名和密码来访问目标页面。所谓的“抓取”,不过是需要我们用一个程序来模拟完成同样的工作,所以我们需要了解在“登录”的过程中发生了什么。
对于未登录的用户,服务器强制用户跳转到登陆页面。用户输入用户名和密码并提交。服务器将用户的POST信息与数据库中的信息进行比较,如果通过则跳转到登陆页面。那么当我们访问其他页面时,服务器是如何判断我们的身份的呢?由于HTTP协议是无状态的,显然服务器无法直接知道我们最后一秒刚刚登录成功。
最简单的想法是,在每个POST请求中,用户都需要带上用户名和密码来标识自己的身份;虽然这是可行的,但是大大增加了服务器的负担(对于每个请求,都需要经过数据库的验证),也大大降低了用户体验(每个页面都需要重新输入用户名和密码,并且每个页面都有一个登录表单)。
因此,一个解决方案诞生了:cookie。Cookie,简而言之就是将用户操作的一些历史信息(当然也包括登录信息)保存在本地计算机上,当用户再次访问该站点时,浏览器通过HTTP将本地cookie的内容发送给服务器协议完成验证,或继续上一步。
更进一步,另一种解决方案诞生了:session,简而言之,就是将用户操作的历史信息保存在服务器上。但是这种方式还是需要将发送请求的客户端与会话对象进行匹配,所以可以通过cookie机制获取客户端的身份(即会话id),也可以通过GET将id提交给服务器。session id,即服务器上会话对象文件的名称,由服务器生成,以保证随机性和唯一性。它相当于一个随机密钥,以避免在握手或传输过程中暴露用户的真实密码。类似的设计思路在 SSO 和 OpenID 中也经常使用。
再插入一个问题:为什么有些网站,关闭浏览器后,session就失效了?
从上面可以看出,session一般是通过cookie来保存session id的。如果cookie设置为在浏览器关闭时过期,那么无论怎么设置会话超时机制,浏览器重启时都找不到原来的cookie。所以服务器只能重新分配会话 id 给它。
cookie 和 session 的区别?
session和cookie的目的是一样的,都是为了克服http协议的无状态缺陷,只是完成的方法不同。session通过cookie在客户端保存session id,在服务器的session对象中保存用户的其他session消息。相比之下,cookie需要保存客户端的所有信息。因此,cookies具有一定的安全风险。比如本地cookie中存储的用户名和密码被破译,或者cookie被其他网站采集(例如:1. appA主动设置域B cookie让域B cookie获取;2. XSS,在appA上通过javascript获取document.cookie,传递给你的appB)。
我在写php App的时候就知道可以通过SSO从Session中获取userid,但是不知道为什么,所以遇到了一个奇怪的问题:在浏览器A标签的脚本执行过程中,打开B 标签访问同一个脚本,它会一直挂起,直到 A 被执行。原因是脚本执行了session_start(),php session_start()之后对session的写入是独占的。只有当脚本执行结束或显式执行 session_destroy() 时,才能释放会话文件锁。因为不知道session的工作原理,困扰了整整一个工作日!类似的问题是gbk和gb2312区别中的一些字符无法存储,因为他们不了解Lamp中字符编码的转换规则。
因此,要知道为什么,我们还需要知道为什么。磨刀不误砍柴,教人钓鱼,在做web开发之前,一定要了解清楚一些必要的知识,以免在使用的时候被拉长,或者在调整bug的时候像无头苍蝇一样。做好自身建设,总比逐案被动满足要好。
网页抓取qq( 免费试用两天官方下载地址:彪悍的营销工具!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-05 14:12
免费试用两天官方下载地址:彪悍的营销工具!(图))
免费试用两天
官方下载地址:
强大的营销工具!可以抓取网站访问者的QQ号。提高绩效的重要营销工具。自己下载试试,功能很强大。
功能:
1.抢网站访客QQ号
只要网站访问者在电脑上登录QQ,就可以抢到访问者的QQ号。
2.自动将访客加为好友
自动申请加访客QQ为好友!如果配合营销QQ,那就无敌了。
3.临时QQ弹窗对话
当访问者输入网站时,会弹出一个临时的QQ对话窗口。
4. 智能邮件推送。
电子邮件营销,自动、定时和有针对性地向访问者发送电子邮件。
5.抓取访客手机号
您可以抓取移动访客的手机号码!(仅限移动访问者)。
特征:
不管你是付费推广还是免费推广,都遇到一个常见的问题:(流量不断流失),因为你拿不到客户数据,一旦访客离开你的网站,你什么也得不到!但是这个工具打破了这个规律,可以抓取95%的访客QQ号,建立自己的营销数据库。想想看,一天1000个流量,可以抓到900多个QQ号,而且这些客户数据是非常准确的。它对促销和营销有多大帮助?
本系统是目前最稳定的网站访客QQ抓取系统,抓取率最高,成功率95%。它是一种强大的主动营销工具,可以防止任何访问者丢失。
用法:使用起来非常简单。在系统后台添加需要抓取访问者QQ的网站地址,获取对应的统计代码,嵌入网站模板底部,生成全站即时生效。
现在注册,您可以免费使用它。
官方下载地址:
客户端附件: 查看全部
网页抓取qq(
免费试用两天官方下载地址:彪悍的营销工具!(图))

免费试用两天
官方下载地址:
强大的营销工具!可以抓取网站访问者的QQ号。提高绩效的重要营销工具。自己下载试试,功能很强大。
功能:
1.抢网站访客QQ号
只要网站访问者在电脑上登录QQ,就可以抢到访问者的QQ号。
2.自动将访客加为好友
自动申请加访客QQ为好友!如果配合营销QQ,那就无敌了。
3.临时QQ弹窗对话
当访问者输入网站时,会弹出一个临时的QQ对话窗口。
4. 智能邮件推送。
电子邮件营销,自动、定时和有针对性地向访问者发送电子邮件。
5.抓取访客手机号
您可以抓取移动访客的手机号码!(仅限移动访问者)。
特征:
不管你是付费推广还是免费推广,都遇到一个常见的问题:(流量不断流失),因为你拿不到客户数据,一旦访客离开你的网站,你什么也得不到!但是这个工具打破了这个规律,可以抓取95%的访客QQ号,建立自己的营销数据库。想想看,一天1000个流量,可以抓到900多个QQ号,而且这些客户数据是非常准确的。它对促销和营销有多大帮助?
本系统是目前最稳定的网站访客QQ抓取系统,抓取率最高,成功率95%。它是一种强大的主动营销工具,可以防止任何访问者丢失。
用法:使用起来非常简单。在系统后台添加需要抓取访问者QQ的网站地址,获取对应的统计代码,嵌入网站模板底部,生成全站即时生效。
现在注册,您可以免费使用它。
官方下载地址:
客户端附件:
网页抓取qq(网页抓取/站外爬虫前端杂谈包含一整套学习资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-26 01:00
网页抓取qq群/站外爬虫前端杂谈包含一整套学习资料0基础转向web安全,微信安全和社交防御计划现在,网站已经越来越强大,平台功能越来越多。从静态的图片和资源上传上,到动态的文件页面载入等,基本每个需要用户时时刻刻操作的网站都在采用javascript和css等方式进行相应的响应操作。“用户体验”对于互联网平台和互联网公司来说越来越重要。
浏览器和服务器和本质上是一个整体,都是我们的生命。如何让互联网平台生态得到充分的体验最好,让用户从入口被吸引,我们应该解决哪些问题。accessibilitydocumentapi,正是一种解决方案。它是从一个简单的抽象层面接受真实环境下产生的所有动态数据。accessibilitydocumentapi利用这些数据来和网页保持,在转发客户端的请求时需要进行accessibilitydocumentapi的请求。
accessibilitydocumentapi主要用于保证浏览器响应给服务器的数据内容属于本地网络,而不是其他来源。在这里,用户已经不能从网页上提取任何有价值的数据,所以我们要用“cache-control:auto”来过滤script标签。例如,如果在accessibilityapi中包含了将相应网页保存到本地的请求,那么在提交到服务器的响应时,这个请求要求cache-control:auto,只能允许在本地进行传输。
我们可以看到class-malforming属性来控制这个css属性的值,class-malforming可以将一个script标签视为在浏览器中渲染的script元素,这样dom元素将保持简单。但是这种方式在日新月异的网络环境下很有可能不太实用。例如可能会出现以下现象:一个占据着前端站点标题链接中的超大区域。
例如可能会使占据过多的css样式,且重叠在其他元素中。这个css样式在当前前端站点内无法被读取到。为了控制控制台(和非浏览器控制台)控制的首字母大小写和匹配到的元素。bashdb已经将所有使用到的javascript语言强制转换为utf-8。像这样的小失误意味着可能在不同环境下产生语言不兼容,字符无法编码并且也无法作为参数返回到服务器。
所以我们就需要一个统一规范,以便在整个生命周期中都能做到各平台互操作。commonjs:less,sass,amd等es开发语言的常用格式模板,它包含了所有加载数据和数据构造器,适合传入多个数据类型。这种模板化有个问题,我们需要显式传入一个特定元素或者要求包含所有的es文件,所以这样的模板化必须安装依赖包。
es6有一个新特性叫做commonjsmodules,我们称它为依赖包模式(dependencyinjection)。dependencyinjection假定你准备定义一个应用程序,整个项。 查看全部
网页抓取qq(网页抓取/站外爬虫前端杂谈包含一整套学习资料)
网页抓取qq群/站外爬虫前端杂谈包含一整套学习资料0基础转向web安全,微信安全和社交防御计划现在,网站已经越来越强大,平台功能越来越多。从静态的图片和资源上传上,到动态的文件页面载入等,基本每个需要用户时时刻刻操作的网站都在采用javascript和css等方式进行相应的响应操作。“用户体验”对于互联网平台和互联网公司来说越来越重要。
浏览器和服务器和本质上是一个整体,都是我们的生命。如何让互联网平台生态得到充分的体验最好,让用户从入口被吸引,我们应该解决哪些问题。accessibilitydocumentapi,正是一种解决方案。它是从一个简单的抽象层面接受真实环境下产生的所有动态数据。accessibilitydocumentapi利用这些数据来和网页保持,在转发客户端的请求时需要进行accessibilitydocumentapi的请求。
accessibilitydocumentapi主要用于保证浏览器响应给服务器的数据内容属于本地网络,而不是其他来源。在这里,用户已经不能从网页上提取任何有价值的数据,所以我们要用“cache-control:auto”来过滤script标签。例如,如果在accessibilityapi中包含了将相应网页保存到本地的请求,那么在提交到服务器的响应时,这个请求要求cache-control:auto,只能允许在本地进行传输。
我们可以看到class-malforming属性来控制这个css属性的值,class-malforming可以将一个script标签视为在浏览器中渲染的script元素,这样dom元素将保持简单。但是这种方式在日新月异的网络环境下很有可能不太实用。例如可能会出现以下现象:一个占据着前端站点标题链接中的超大区域。
例如可能会使占据过多的css样式,且重叠在其他元素中。这个css样式在当前前端站点内无法被读取到。为了控制控制台(和非浏览器控制台)控制的首字母大小写和匹配到的元素。bashdb已经将所有使用到的javascript语言强制转换为utf-8。像这样的小失误意味着可能在不同环境下产生语言不兼容,字符无法编码并且也无法作为参数返回到服务器。
所以我们就需要一个统一规范,以便在整个生命周期中都能做到各平台互操作。commonjs:less,sass,amd等es开发语言的常用格式模板,它包含了所有加载数据和数据构造器,适合传入多个数据类型。这种模板化有个问题,我们需要显式传入一个特定元素或者要求包含所有的es文件,所以这样的模板化必须安装依赖包。
es6有一个新特性叫做commonjsmodules,我们称它为依赖包模式(dependencyinjection)。dependencyinjection假定你准备定义一个应用程序,整个项。
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-19 23:16
1.问题描述
最近,由于学习内容的要求,我们需要从网页上抓取一些数据进行分析报告。在阅读了Python crawler的一些基础知识后,我们可以直接开始网站爬升数据。作为新手,踩坑是不可避免的。最近,我遇到了一个难题:
通常,您需要抓取网页上标签上的内容。通过urllib下载网页内容后,您可以通过beautifulsup对象解析网页内容,然后可以使用fina\uAll()方法查找所需的标记内容
例如,我想捕获QQ音乐分类歌曲列表下的所有歌曲列表信息。分解任务后,应为:
抓取当前页面的歌曲列表信息;翻开新的一页;判断它是否是最后一页。如果不是最后一页,请返回步骤1。如果是最后一页,请结束爬虫程序
首先,编写一个简单的代码来捕获单个页面上所有歌曲的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
对于标记参数,您可以通过右键单击网页以检查网页属性来查找歌曲列表标题信息。属性类的值是playlist_utitle_uutxt,但是在执行代码之后,输出结果只是一个空列表,这不是很奇怪吗?作为一个新手,我真的花了很长时间绞尽脑汁,不知道为什么
在那之后,我和我的同学交流,听他谈论他以前见过的异步加载内容。我发现它与我抓取的网页的功能有点相似,所以我去寻找答案
流行的描述是,异步加载的网页显示的内容都来自当前网址表示的网页文件,并且当前网页文件通过对另一个网页内容的函数调用加载了一些内容,即,要抓取的内容所属的网页文件确实与当前网页文件不同,因此我无法抓取它。因此,您需要找到捕获内容真正属于的文件
2.溶液
接下来,我们将介绍如何查找异步加载的文件以及在获取过程中可能遇到的坑
1.右击网页,选择**检查,在调试界面中找到“网络”选项,然后逐个查找JS文件(记得刷新网页,否则JS文件不会显示),通过预览检查内容是否为您想要爬升的内容**
2.在每个JS文件的特定信息面板中,您可以通过预览查看传递的内容,我们找到歌曲列表标题信息的源文件,然后通过headers属性找到该信息的真实源文件的链接,并将URL作为我们的请求参数
headers属性下的general和request标头收录我们想要的信息。general属性下的URL还收录值传递类型。下面是get
因此,我们可以通过请求模块获取歌曲列表信息,这里需要注意的是,网页的request headers值应该传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3.一般来说,上面的处理过程会获取JSON对象(好像是字典的字符串表示),在Python中,可以直接使用JSON模块将JSON对象转换成Python对象-字典,从而通过键获取数据
jsDict = json.loads(jsContent)
但是,有时获取的数据表单会将JSON对象名称添加到JSON对象中,例如:
playList({...}) # 其中{}表示json对象内容
在这种情况下,无法通过JSON模块转换数据类型,通常会发生异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
对于这个异常,可以通过字符串片段截取JSON对象信息,然后通过JSON模块转换数据类型(这是我提出的一个傻瓜式方法。如果一个大个子知道一个更正式的方法,我希望纠正它)(っ • ̀ω•́) っ✎⁾⁾ ) 查看全部
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
1.问题描述
最近,由于学习内容的要求,我们需要从网页上抓取一些数据进行分析报告。在阅读了Python crawler的一些基础知识后,我们可以直接开始网站爬升数据。作为新手,踩坑是不可避免的。最近,我遇到了一个难题:
通常,您需要抓取网页上标签上的内容。通过urllib下载网页内容后,您可以通过beautifulsup对象解析网页内容,然后可以使用fina\uAll()方法查找所需的标记内容
例如,我想捕获QQ音乐分类歌曲列表下的所有歌曲列表信息。分解任务后,应为:
抓取当前页面的歌曲列表信息;翻开新的一页;判断它是否是最后一页。如果不是最后一页,请返回步骤1。如果是最后一页,请结束爬虫程序
首先,编写一个简单的代码来捕获单个页面上所有歌曲的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
对于标记参数,您可以通过右键单击网页以检查网页属性来查找歌曲列表标题信息。属性类的值是playlist_utitle_uutxt,但是在执行代码之后,输出结果只是一个空列表,这不是很奇怪吗?作为一个新手,我真的花了很长时间绞尽脑汁,不知道为什么
在那之后,我和我的同学交流,听他谈论他以前见过的异步加载内容。我发现它与我抓取的网页的功能有点相似,所以我去寻找答案
流行的描述是,异步加载的网页显示的内容都来自当前网址表示的网页文件,并且当前网页文件通过对另一个网页内容的函数调用加载了一些内容,即,要抓取的内容所属的网页文件确实与当前网页文件不同,因此我无法抓取它。因此,您需要找到捕获内容真正属于的文件
2.溶液
接下来,我们将介绍如何查找异步加载的文件以及在获取过程中可能遇到的坑
1.右击网页,选择**检查,在调试界面中找到“网络”选项,然后逐个查找JS文件(记得刷新网页,否则JS文件不会显示),通过预览检查内容是否为您想要爬升的内容**
2.在每个JS文件的特定信息面板中,您可以通过预览查看传递的内容,我们找到歌曲列表标题信息的源文件,然后通过headers属性找到该信息的真实源文件的链接,并将URL作为我们的请求参数
headers属性下的general和request标头收录我们想要的信息。general属性下的URL还收录值传递类型。下面是get
因此,我们可以通过请求模块获取歌曲列表信息,这里需要注意的是,网页的request headers值应该传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3.一般来说,上面的处理过程会获取JSON对象(好像是字典的字符串表示),在Python中,可以直接使用JSON模块将JSON对象转换成Python对象-字典,从而通过键获取数据
jsDict = json.loads(jsContent)
但是,有时获取的数据表单会将JSON对象名称添加到JSON对象中,例如:
playList({...}) # 其中{}表示json对象内容
在这种情况下,无法通过JSON模块转换数据类型,通常会发生异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
对于这个异常,可以通过字符串片段截取JSON对象信息,然后通过JSON模块转换数据类型(这是我提出的一个傻瓜式方法。如果一个大个子知道一个更正式的方法,我希望纠正它)(っ • ̀ω•́) っ✎⁾⁾ )
网页抓取qq( 下载非标准的包,下载方法及注意事项(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-18 21:01
下载非标准的包,下载方法及注意事项(二))
Golang抓取网页并分析网页中收录的链接
更新时间:2019年8月26日09:24:24作者:杨天晓
今天,小编将与大家分享一篇关于戈朗如何抓取网页并分析网页中收录的链接的文章,具有很好的参考价值,希望对大家有所帮助。让我们跟着小编看一看
1.下载非标准软件包,“/X/net/HTML”
2.install git first并使用git命令下载
git clone https://github.com/golang/net
3.将网络包放在goroot路径下
例如:
我的是:goroot=e:\go\
最后一个目录是:e:\go\SRC\\x\net
注意:如果没有和X文件夹,请创建它们
4.创建fetch目录并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"net/http"
"fmt"
"io/ioutil"
)
func main() {
for _, url := range os.Args[1:] {
resp, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
}
b, err := ioutil.ReadAll(resp.Body)
resp.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
fmt.Printf("%s",b)
}
}
pile-fetch
go build test.com\justin\demo\fetch
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
6.executefetch.exe文件
fetch.exe
注意:这是要爬升的URL。如果配置正确,将打印URL的HTML内容。如果没有,请检查上述步骤是否正确
7.web页面已被捕获,因此剩下的工作是分析页面中收录的链接,创建findlinks目录,并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"fmt"
"golang.org/x/net/html"
)
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprint(os.Stderr, "findlinks: %v\n", err)
os.Exit(1)
}
for _, link := range visit(nil, doc) {
fmt.Println(link)
}
}
func visit(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key == "href" {
links = append(links, a.Val)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = visit(links, c)
}
return links
}
pilefindlinks
go build test.com\justin\demo\findlinks
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
9.execute findlinks.exe文件
fetch.exe https://www.qq.com | findlinks.exe
>10.执行后结果:获得各种形式的超链接
上面关于golang如何捕获网页并分析网页中收录的链接的文章是小编共享的所有内容。我希望它能给你一个参考和支持脚本的房子 查看全部
网页抓取qq(
下载非标准的包,下载方法及注意事项(二))
Golang抓取网页并分析网页中收录的链接
更新时间:2019年8月26日09:24:24作者:杨天晓
今天,小编将与大家分享一篇关于戈朗如何抓取网页并分析网页中收录的链接的文章,具有很好的参考价值,希望对大家有所帮助。让我们跟着小编看一看
1.下载非标准软件包,“/X/net/HTML”
2.install git first并使用git命令下载
git clone https://github.com/golang/net
3.将网络包放在goroot路径下
例如:
我的是:goroot=e:\go\
最后一个目录是:e:\go\SRC\\x\net
注意:如果没有和X文件夹,请创建它们
4.创建fetch目录并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"net/http"
"fmt"
"io/ioutil"
)
func main() {
for _, url := range os.Args[1:] {
resp, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
}
b, err := ioutil.ReadAll(resp.Body)
resp.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
fmt.Printf("%s",b)
}
}
pile-fetch
go build test.com\justin\demo\fetch
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
6.executefetch.exe文件
fetch.exe
注意:这是要爬升的URL。如果配置正确,将打印URL的HTML内容。如果没有,请检查上述步骤是否正确
7.web页面已被捕获,因此剩下的工作是分析页面中收录的链接,创建findlinks目录,并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"fmt"
"golang.org/x/net/html"
)
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprint(os.Stderr, "findlinks: %v\n", err)
os.Exit(1)
}
for _, link := range visit(nil, doc) {
fmt.Println(link)
}
}
func visit(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key == "href" {
links = append(links, a.Val)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = visit(links, c)
}
return links
}
pilefindlinks
go build test.com\justin\demo\findlinks
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
9.execute findlinks.exe文件
fetch.exe https://www.qq.com | findlinks.exe
>10.执行后结果:获得各种形式的超链接
上面关于golang如何捕获网页并分析网页中收录的链接的文章是小编共享的所有内容。我希望它能给你一个参考和支持脚本的房子
网页抓取qq(获取网站访客QQ的一个方法(详情请见使用腾讯接口))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-14 11:09
我之前写过一篇文章,介绍了一种获取网站visitorQQ的方法(具体请参考使用腾讯界面轻松抓取网站visitorQQ)。可惜今天发现这个界面已经被Blocking不可用了。这里我提供另一种方法供大家参考!
首先按照惯例,在具体实现之前,先说一下实现原理。
当QQ用户登录QQ相关产品(包括登录QQ空间、其他QQ网页应用或相关第三方应用)时,会在用户电脑上留下一个标记(通常是cookie)来判断用户是否登录,虽然我们无法跨域访问其他域的cookies(其实你的cookie本身保存了你的QQ号),但是我们可以通过腾讯自己的API实现这个功能。
下午一群人在讨论这件事的时候,一个朋友还是很“正直”的质问我,说腾讯怎么会做这种泄露用户隐私的事情?当然,腾讯本身不会专门为你提供抓包用户QQ的接口,但有时难免需要泄露用户QQ号(多与OAuth有关),导致网上出现这些“get网站”。 “QQQQ”生意火爆。
核心代码如下:
doctype html>
网站访客QQ抓取
function gqq_callback(jsonstr)
{
alert("用户当前登录的QQ是:" + jsonstr.uin);
}
要获取用户的QQ,我们可以通过Ajax将QQ号和当前页面地址(location.href)保存到数据库中。
另外,要抓取访客QQ,访客必须先登录腾讯相关服务,如QQ空间。同时登录多个QQ的,以当前网页登录状态为准(用户可以同时登录多个QQ,但一个浏览器只能登录同一个QQ空间)
最后,如果你把不能用的代码贴出来,可以在评论里留言,我会再次发布最新可用的代码。
本文原创文章,如转载请注明作者及出处! 查看全部
网页抓取qq(获取网站访客QQ的一个方法(详情请见使用腾讯接口))
我之前写过一篇文章,介绍了一种获取网站visitorQQ的方法(具体请参考使用腾讯界面轻松抓取网站visitorQQ)。可惜今天发现这个界面已经被Blocking不可用了。这里我提供另一种方法供大家参考!
首先按照惯例,在具体实现之前,先说一下实现原理。
当QQ用户登录QQ相关产品(包括登录QQ空间、其他QQ网页应用或相关第三方应用)时,会在用户电脑上留下一个标记(通常是cookie)来判断用户是否登录,虽然我们无法跨域访问其他域的cookies(其实你的cookie本身保存了你的QQ号),但是我们可以通过腾讯自己的API实现这个功能。
下午一群人在讨论这件事的时候,一个朋友还是很“正直”的质问我,说腾讯怎么会做这种泄露用户隐私的事情?当然,腾讯本身不会专门为你提供抓包用户QQ的接口,但有时难免需要泄露用户QQ号(多与OAuth有关),导致网上出现这些“get网站”。 “QQQQ”生意火爆。
核心代码如下:
doctype html>
网站访客QQ抓取
function gqq_callback(jsonstr)
{
alert("用户当前登录的QQ是:" + jsonstr.uin);
}
要获取用户的QQ,我们可以通过Ajax将QQ号和当前页面地址(location.href)保存到数据库中。
另外,要抓取访客QQ,访客必须先登录腾讯相关服务,如QQ空间。同时登录多个QQ的,以当前网页登录状态为准(用户可以同时登录多个QQ,但一个浏览器只能登录同一个QQ空间)
最后,如果你把不能用的代码贴出来,可以在评论里留言,我会再次发布最新可用的代码。
本文原创文章,如转载请注明作者及出处!
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-11 23:13
上网时,经常会看到各种精美的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。它具有广泛的用途,尤其是在编写一些教程时。我经常需要用截图来提高文章的人气。下面脚本屋给大家分享一下QQ截图的使用方法、截图软件的截图、网页全页面的截图。
1:首先介绍一下QQ截图。 QQ是大家最常用的聊天工具。几乎每台电脑都有。因此,使用QQ截图非常方便。目前QQ聊天工具中的截图有很多,比如如何在截图上放说明文字,画箭头,画一些形状等等,来看看怎么用吧:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。 如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。
请点击小箭头设置截图。
具体的使用方法比较简单,这里就不啰嗦了,大家自己试试就知道了。
----------------------其他截图方法由Script Home友情提供---------------- - -----
1.windows 的打印键截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴并保存就可以了。
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度hi 默认截图快捷键是:Shift+Alt+A
3.浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
在菜单栏的工具截屏中有全屏截屏、区域截屏、窗口截屏等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图服务。
在网址栏中输入您要截取的网页网址,修改其他设置,点击确定按钮即可获取网页截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,如单屏截图、滚动截图、缩略图等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。
使用在线网页截图工具
5.pro 软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320 K
软件性质:绿色、免费
网页滚动截图软件下载
随着网站的信息越来越多,大多数网页都有不止一个屏幕。借助这款软件,我们可以实现滚动截图,也就是说第一屏底部也会被截取,让你随心所欲地保存自己喜欢的页面。
第五类和第四类可以实现滚动截图(即截取空间首页的整个页面)。
截图完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截图进行裁剪,修改截图的大小和大小。
编辑完成后,将截图上传到空间相册,获取地址图。 (百度贴吧改版后,图片宽度大于570px会自动缩略)
如何滚动和抓取整个网页图片
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、全屏截取
点击PrintScreen按钮,然后启动“Draw(Start-Program-Accessories)”,按Ctrl+V或“Edit-Paste”捕捉当前屏幕,然后保存为Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键只截取当前活动窗口,然后如上保存。
3、截取DirectX镜像
Print Screen 键无法捕获 DirectX 图像。没关系,只要我们做一点子计算,就可以让它发挥到极致。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。 (时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
以下介绍在线截图工具:
网页截图看似很简单,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就无所适从了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图! : 一个专门为网页截图创建的网站。主页非常简单。只需填写您要截屏的网址,然后点击“GO”即可。
杂汤网:以前叫文文,后来改名为杂汤网。是一个提供中文截图服务的网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图大小,可以自定义需要的大小。默认为 160*120 和 1024*768。您还可以指定捕获时间,以秒为单位。
thumbalizr:允许你截取任何网页的截图,并提供150、320、640、800、1024、1280等宽度截图供你下载,当然,您还可以自定义大小。
webthumb:一个非常简单的在线截图工具,可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图会根据网站的变化自动更新。
websnapr:国外非常有名的截图网站。但是不建议大家使用,它默认只提供小(202×152))和微(90×70))截图,付费会员可以享受更大的截图<//p
p以上是Script House为大家提供的多种网络截图方法。目前是我找到的所有截图方法的总结。应该是网上最详细的截图了文章吧,更多电脑技巧>> 查看全部
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
上网时,经常会看到各种精美的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。它具有广泛的用途,尤其是在编写一些教程时。我经常需要用截图来提高文章的人气。下面脚本屋给大家分享一下QQ截图的使用方法、截图软件的截图、网页全页面的截图。
1:首先介绍一下QQ截图。 QQ是大家最常用的聊天工具。几乎每台电脑都有。因此,使用QQ截图非常方便。目前QQ聊天工具中的截图有很多,比如如何在截图上放说明文字,画箭头,画一些形状等等,来看看怎么用吧:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。 如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。

请点击小箭头设置截图。
具体的使用方法比较简单,这里就不啰嗦了,大家自己试试就知道了。
----------------------其他截图方法由Script Home友情提供---------------- - -----
1.windows 的打印键截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴并保存就可以了。
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度hi 默认截图快捷键是:Shift+Alt+A
3.浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
在菜单栏的工具截屏中有全屏截屏、区域截屏、窗口截屏等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图服务。
在网址栏中输入您要截取的网页网址,修改其他设置,点击确定按钮即可获取网页截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,如单屏截图、滚动截图、缩略图等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。

使用在线网页截图工具
5.pro 软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320 K
软件性质:绿色、免费
网页滚动截图软件下载
随着网站的信息越来越多,大多数网页都有不止一个屏幕。借助这款软件,我们可以实现滚动截图,也就是说第一屏底部也会被截取,让你随心所欲地保存自己喜欢的页面。
第五类和第四类可以实现滚动截图(即截取空间首页的整个页面)。
截图完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截图进行裁剪,修改截图的大小和大小。
编辑完成后,将截图上传到空间相册,获取地址图。 (百度贴吧改版后,图片宽度大于570px会自动缩略)
如何滚动和抓取整个网页图片
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、全屏截取
点击PrintScreen按钮,然后启动“Draw(Start-Program-Accessories)”,按Ctrl+V或“Edit-Paste”捕捉当前屏幕,然后保存为Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键只截取当前活动窗口,然后如上保存。
3、截取DirectX镜像
Print Screen 键无法捕获 DirectX 图像。没关系,只要我们做一点子计算,就可以让它发挥到极致。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。 (时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
以下介绍在线截图工具:
网页截图看似很简单,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就无所适从了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图! : 一个专门为网页截图创建的网站。主页非常简单。只需填写您要截屏的网址,然后点击“GO”即可。
杂汤网:以前叫文文,后来改名为杂汤网。是一个提供中文截图服务的网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图大小,可以自定义需要的大小。默认为 160*120 和 1024*768。您还可以指定捕获时间,以秒为单位。
thumbalizr:允许你截取任何网页的截图,并提供150、320、640、800、1024、1280等宽度截图供你下载,当然,您还可以自定义大小。
webthumb:一个非常简单的在线截图工具,可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图会根据网站的变化自动更新。
websnapr:国外非常有名的截图网站。但是不建议大家使用,它默认只提供小(202×152))和微(90×70))截图,付费会员可以享受更大的截图<//p
p以上是Script House为大家提供的多种网络截图方法。目前是我找到的所有截图方法的总结。应该是网上最详细的截图了文章吧,更多电脑技巧>>
网页抓取qq(腾讯视频的VIP电影动态抓取(第二十五期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-21 00:13
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候。待抓取的数据在查看网页源代码时找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端来获取数据,接下来我们抓取这样的东西网站。
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,下面可以看到很多东西,一般请求的代码在XHR或者JS中,所以我们直接找这两个,通过搜索可以看到到如下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
捕获数据后,下一步就是解析数据。因为是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...那个字符串,只留下这个字符串{"cgi_cost_time:...}的数据从链接打开的网页结果中可以看出我们刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是key字典中是jsonvalue,jsonvalue的值是一个字典,这个字典中的key值是results.data,results对应的值是一个list,分析清楚后,很容易得到数据,直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后对比请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加30个,所以只需要动态改变请求链接就可以捕获所有数据。 查看全部
网页抓取qq(腾讯视频的VIP电影动态抓取(第二十五期))
今天我们就来聊聊动态爬取。所谓动态爬取,其实就是我们在爬取网页数据的时候。待抓取的数据在查看网页源代码时找不到对应的数据。比如我们要抓取腾讯视频的VIP电影
腾讯视频
如上图,网页中有,但查看源码时,源码中没有;这是怎么回事,这其实是因为它的数据是动态加载的,一般是通过js代码实时到服务器端来获取数据,接下来我们抓取这样的东西网站。
既然要获取数据,首先要找出请求数据的代码在哪里,打开Chrome浏览器的开发者工具,选择网络选项
Chrome 开发者工具
然后我们刷新一下我们要爬取的网页,下面可以看到很多东西,一般请求的代码在XHR或者JS中,所以我们直接找这两个,通过搜索可以看到到如下结果:
好像是这个文件请求的数据。接下来我们选择Headers查看其请求地址
我们复制这个请求链接,直接在浏览器中打开
看来,这确实是我们要找的。它的数据类型是json类型,所以我们只需要抓取数据,然后解析就可以了!接下来开始写代码:
首先是捕获json数据:
# -*- coding:utf-8 -*-
import requests
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
print data
输出结果
捕获数据后,下一步就是解析数据。因为是json类型,我们导入json包进行分析。首先用正则表达式去掉前面不相关的jQuery1910...那个字符串,只留下这个字符串{"cgi_cost_time:...}的数据从链接打开的网页结果中可以看出我们刚刚复制了请求,需要的数据在{...;'jsonvalue':{...;'results':[. ..];...};...},也就是key字典中是jsonvalue,jsonvalue的值是一个字典,这个字典中的key值是results.data,results对应的值是一个list,分析清楚后,很容易得到数据,直接上代码:
# -*- coding:utf-8 -*-
import requests
import json
import re
url = 'http://list.video.qq.com/fcgi-bin/list_common_cgi?otype=json&novalue=1&platform=1&version=10000&intfname=web_vip_movie_new&tid=687&appkey=c8094537f5337021&appid=200010596&type=1&sourcetype=1&itype=-1&iyear=-1&iarea=-1&iawards=-1&sort=17&pagesize=30&offset=0&callback=jQuery19108734160972013745_1494380383266&_=1494380383271'
data = requests.get(url).content
# print data
#正则表达式去除不相干数据
data = re.search(re.compile(r'jQuery.+?\((.+)+\)'),data)
if data is not None:
a = json.loads(data.group(1))
data = a['jsonvalue']['results'] #找到results这个列表
#遍历列表
for i in data:
#列表中的值为字典,所以用字典取对应的值
print u'电影名称: '+i['fields']['title']
print u'电影简介: '+i['fields']['second_title']
print u'电影封面: '+i['fields']['vertical_pic_url']
print u'电影评分: '+i['fields']['score']['score']
print u'电影ID: '+i['id']
print '\n'
输出结果
然后得到数据。当然,这只是爬取一页的内容。如果我们想抓取所有页面,可以多次点击页面的下一页,然后对比请求链接,可以找到请求链接规律
请求链接
通过对比可以发现,每添加一个页面,这个数字就增加30个,所以只需要动态改变请求链接就可以捕获所有数据。
网页抓取qq(写了一个从网页中抓取信息(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-20 03:07
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224 查看全部
网页抓取qq(写了一个从网页中抓取信息(如最新的头条新闻))
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224
网页抓取qq( 谷歌宣布抓取海量APP300多页页面内容和信息量开发商合作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-17 23:10
谷歌宣布抓取海量APP300多页页面内容和信息量开发商合作
)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B
腾讯科技新闻搜索引擎是继内容门户之后的互联网第二次重大技术革命。但是,随着智能手机的普及,应用软件(APP)已经取代了网页,成为主流技术。由于APP的内容一时间无法被搜索引擎抓取,人们惊呼移动互联网将给搜索引擎带来生存危机。
不过,通过与应用软件开发商的合作,谷歌()在一定程度上解决了这一危机。日前,谷歌宣布从大量APP中抓取了超过300页的内容。手机上搜索的信息量也会更加丰富。
谷歌搜索团队在 4 月 16 日的官方博客文章中宣布了这一消息。
谷歌工程师 Rajan Patel 向媒体透露,谷歌两年前就开始抓取外部应用的内部链接和内容,目前累计抓取超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
手机上搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。(黎明)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B 查看全部
网页抓取qq(
谷歌宣布抓取海量APP300多页页面内容和信息量开发商合作
)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B
腾讯科技新闻搜索引擎是继内容门户之后的互联网第二次重大技术革命。但是,随着智能手机的普及,应用软件(APP)已经取代了网页,成为主流技术。由于APP的内容一时间无法被搜索引擎抓取,人们惊呼移动互联网将给搜索引擎带来生存危机。
不过,通过与应用软件开发商的合作,谷歌()在一定程度上解决了这一危机。日前,谷歌宣布从大量APP中抓取了超过300页的内容。手机上搜索的信息量也会更加丰富。
谷歌搜索团队在 4 月 16 日的官方博客文章中宣布了这一消息。
谷歌工程师 Rajan Patel 向媒体透露,谷歌两年前就开始抓取外部应用的内部链接和内容,目前累计抓取超过 300 亿。
在传统的WEB页面中,谷歌可以通过软件“蜘蛛”自动访问和抓取,无需网站管理员的许可。
在App内容的抓取上,谷歌需要与应用软件开发商建立合作。谷歌提供了相应的软件开发接口(API),开发者可以通过这些接口向谷歌搜索开放数据,从而实现搜索引擎的内容抓取。
据悉,已有大量移动端软件与谷歌合作,包括微博Twitter、短租工具Airbnb、消费者点评工具Yelp、手机订餐工具OpenTable、图片采集社交网络Pinterest、房地产搜索工具Trulia以及很快。
当然,还有大量的移动媒体应用,也被谷歌抓取用于新闻报道。
超过 300 亿个链接的内容与 Google 抓取的网络数据库相比微不足道。此前有报道称,谷歌蜘蛛抓取的网页数量高达数百亿。
然而,在智能手机时代,人们使用搜索的目的更加明确,拥有更多的场景信息。因此,主流应用和超过300亿个链接足以为用户提供所需的信息。
据介绍,此前在手机上进行搜索时,谷歌客户端会观察用户智能手机中安装了哪些应用,谷歌只会返回已安装应用的搜索结果。
日前,谷歌团队还宣布,对收录在搜索结果中的APP进行了修改。即使用户没有安装某个APP,只要有相关性,它的内容就会出现在搜索结果中。
例如,如果用户的手机中没有安装点餐工具OpenTable,但在搜索餐厅时,谷歌仍可能会从OpenTable中呈现消费者评论信息。
不过,对于谷歌来说,能够抓取大量APP的内容,并不意味着它已经彻底摆脱了“搜索危机”。
有观点认为,在智能手机端,手机一族希望以最快的速度获得最准确的搜索结果,因此各种专业APP逐渐取代了传统网页搜索的地位。例如,人们可能会在流行的团购应用中搜索当地餐馆和电影,而不是在 Google 中输入 关键词,然后查看庞大网络的结果。
手机上搜索消费者行为的变化也给谷歌的发展前景蒙上了一层阴影。Google 90% 的收入来自搜索结果右侧的搜索广告。如果人们远离电脑和传统搜索引擎,谷歌将成为一个非常危险的公司,没有可观的替代收入。(黎明)
<IMG alt="APP不再是信息孤岛 谷歌宣布抓取300亿APP页面" src="http://img1.gtimg.com/tech/pic ... gt%3B
网页抓取qq(本文会教你如何解决以下这三个问题(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-17 09:13
本文将教你如何解决以下三个问题:
1.你的整个网站没有被索引;
2.有些页面被索引,而其他页面没有;
3. 新发布的页面不会立即编入索引。
但首先,我们必须先了解索引的含义。
什么是抓取和索引?
Google 通过抓取发现新页面,然后将这些页面添加到索引中。他们使用名为 Googlebot 的网络爬虫来执行此操作。
使困惑?让我们解释一些术语:
爬行:跟踪网页上的超链接以发现新内容的过程。
索引:Google 已将网页“编入索引”意味着 Google 抓取工具(“Googlebot”)访问了该网页,分析了其内容和含义,并将其存储在 Google 索引中。索引的网页可以显示在 Google 搜索结果中(前提是它们遵循 Google 的 网站网站管理员指南)。尽管大多数网页在被抓取后都会编入索引,但 Google 也可能会在不访问网页内容的情况下将网页编入索引(例如,如果该网页被 robots.txt 指令阻止)。
网络爬虫:执行爬行的程序。
Googlebot:谷歌的网络爬虫(谷歌蜘蛛)。
当您在 Google 上搜索内容时,您实际上是在要求 Google 返回其索引中的所有相关页面。由于通常有数千个网页符合要求,因此 Google 的排名算法会尝试对这些网页进行排名,以便您首先看到最佳和最相关的结果。
我想在这里提出的一个重要观点是索引和排名是两件不同的事情。
索引是为了参与,排名是为了获胜。
不参加就不可能赢。
如何检查您的页面是否已编入索引
输入谷歌,然后搜索站点如下:您的网址
此处的数字显示了索引页的大致数量。
如果你想检查一个特定的页面是否被索引,你也可以做同样的站点:详细网址
如果没有结果,则表示该页面未编入索引。
如果您是 Google Search Console 的用户,只需查看覆盖率报告即可找到准确的索引数据。您只需要输入:
Google Search Console> 索引> 覆盖范围
您可以使用 Google Search Console 检查特定页面是否已编入索引。您只需要将页面 URL 放入 URL 检测工具中即可。
如何让 Google 将您的网页编入索引
您的 网站 或页面未被 Google 编入索引?试试这些:
转到 Google Search Console。
进入网址检测工具。
将要编入索引的 URL 粘贴到搜索框中。
等待 Google 检测到 URL。
单击“请求索引”按钮。
当您发布新帖子或页面时,最好这样做。您实际上是在告诉 Google,您已向 网站 添加了一些新内容,他们应该检查一下。
但是,请求索引不太可能解决旧页面的索引问题。如果是这种情况,请按照下面的清单来诊断和解决问题。
去除Robots.txt中的爬行障碍去除不必要的noindex标签在网站地图中收录需要索引的页面去除不必要的规范标签检查页面是否为岛页面修复不必要的内部nofollow链接在“添加内部链接到“强大”页面,确保页面的唯一性和价值。去除低质量页面(优化“抓取预算”),建立高质量的外链
1) 去除Robots.txt中的爬行块
Google 没有将整个 网站 编入索引?这可能是由 robots.txt 文件中的爬行障碍引起的。
去查看详细问题。
检查右下角的两段是否有任何一段:
1 用户代理:Googlebot
2 禁止:/
1 用户代理:*
2 禁止:/
这两者都告诉 Googlebot 他们不允许抓取 网站 上的任何页面。要解决这个问题,你只需要删除它们,就这么简单。
如果 Google 没有为单个页面编制索引,也可能是由 robots.txt 中的代码引起的。要检查是否是这种情况,请将网址粘贴到 Google Search Console 中的网址检测工具中。单击覆盖范围部分以显示更多详细信息,并查找“允许抓取?否:被 robots.txt 阻止”错误。
这意味着该页面被 robots.txt 阻止。
如果是这种情况,请重新检查您的 robots.txt 文件,了解与此页面或相关目录相关的“禁止”规则。
如果需要,只需删除此代码。
2) 删除不必要的 noindex 标签
如果您告诉 Google 不要将网页编入索引,Google 将不会将其编入索引。这可以使页面的一部分保持私密。有两种方法可以做到这一点:
方法一:元标签
如果页面中出现以下任何代码,Google 将不会将其编入索引:
这是爬虫的元标记,告诉搜索引擎他们是否可以索引页面。
提示。核心参数是“noindex”。如果出现“noindex”,则表示该页面未编入索引。
方法 2:X‑Robots-Tag
网络爬虫遵循 X-Robots-Tag 的 HTTP 响应标头。您可以使用服务器端脚本语言(如PHP)、.htaccess 文件的内容,或更改服务器配置来实现此效果。
Google Search Console 中的 URL 检查工具可以告诉您此标头是否阻止 Google 抓取页面。只需输入 URL 并查找“允许索引?否:在“X‑Robots-Tag”http 标头中检测到“noindex”标签。
3)在网站的map中收录需要索引的页面
网站 地图会告诉 Google 网站 上哪些页面重要,哪些不重要。它还可以为谷歌的抓取频率提供一些指导。
Google 应该能够在您的 网站 上找到页面,无论它们是否在站点地图中,但将它们收录在 网站 地图中仍然是一个好习惯。毕竟,谷歌没有必要进行无意义的抓取。
要检查某个网页是否在您的站点地图中,请使用 Google Search Console 中的 URL 检查工具。如果您看到“此 网站 未显示在 Google 搜索结果中”和“站点地图:不适用”,则表示该网址未编入索引或不在您的站点地图中。
可以提交站点地图(xml格式)到谷歌站长工具
4) 删除不必要的规范标签
Canonical 标签告诉 Google 哪个是页面的首选版本。它看起来像这样:
大多数页面没有规范标签,即所谓的自引用规范标签。这告诉 Google 页面本身是首选版本,并且可能是唯一的版本。换句话说,您想要索引页面。
但是,如果您的网页具有不规则的规范标签,则可能会告诉 Google 错误的首选版本。在这种情况下,您的页面将不会被编入索引
要检测规范标签,您只需要使用 Google 的 URL 检测工具。如果您页面的规范标签指向另一个页面,您可以看到“带有规范标签的备用页面”提示。如果这不应该出现并且您希望当前页面被索引,那么只需删除页面的规范标签。
提示:请注意,规范标签并不总是不好的。大多数带有这些标签的页面都有其原因。如果您发现您的页面有规范标签,请检查相应的页面。如果确实是页面的首选版本,并且不需要索引页面,则应保留规范标记。
5) 检查页面是否为孤岛页面
孤岛页面是指内部链接不支持的页面。
由于谷歌是通过抓取链接来发现新内容的,因此他们无法通过这个过程发现孤岛页面。网站访问者也将无法找到此内容。
要检测孤岛页面,您可以使用 Ahrefs 的站点审核(网站 诊断)工具。然后点击 Incoming links 报告,查看“Island page (no pointing link)”错误:
这将显示可索引并显示在站点地图中但没有内部链接的所有页面。
暗示:
这只有在以下两种情况下才能正常检测:
1.所有需要索引的页面都在你的网站地图中。
2.在Ahrefs的Site Audit(网站Diagnosis)的最开始,选择使用网站地图中的页面的选项打勾。
您可以通过以下两种方法之一解决孤岛问题:
1.如果页面不重要,将其删除并移出地图网站。
2.如果页面很重要,把它放在你的内部链接结构中。
6) 修复不必要的内部 nofollow 链接
Nofollow 链接是那些带有 rel="nofollow" 标签的链接。他们将阻止传递 PageRank。同时,Google 不会抓取 Nofollow 链接。
这是谷歌对此的说明:
本质上,使用 nofollow 会导致我们从爬网目录中删除目标链接。但是,如果其他网站链接到目标页面而没有使用nofollow,或者如果这些URL在站点地图中提交给Google,目标页面可能仍会出现在我们的索引中。
简而言之,您需要确保遵循索引页面的链接。
您还可以使用 Ahrefs 的 Site Audit (网站Diagnosis) 工具来捕获 网站。检查“传入链接”报告中是否有错误“页面仅收录 nofollow 传入内部链接”:
假设您希望 Google 将页面编入索引,请从这些链接中删除 nofollow 标记。如果没有,请删除该页面或对该页面进行无索引处理。
7) 在“强大”页面收录内部链接
Google 通过抓取您的 网站 来发现新内容。如果忽略相关页面的内部链接,可能无法找到该页面。
解决这个问题的一个简单方法是在网站中添加一些内部链接。您可以在任何已编入索引的页面上执行此操作。但是,如果您希望 Google 尽快将页面编入索引,您可以在一些“强大”的页面上创建一些内部链接。
为什么?因为与一些不太重要的页面相比,Google 会更快地抓取此类页面。
这样做的方法是进入Ahrefs Site Explorer(网站分析),输入你的域名,查看Best by links报告。
这将显示 网站 上的所有页面,按 URL 分级排序。换句话说,它首先显示权重最高的页面。
检查列表并找到相关页面。您可以在这些页面上添加一些指向目标页面的内部链接。
建议:添加内链后,将页面粘贴到谷歌的网址检查工具中。点击“请求索引”按钮,让谷歌知道页面上的某些内容发生了变化,需要尽快重新抓取。这可以加快谷歌发现内部链接的过程,从而加快你想要索引的页面。
8) 确保页面独特且有价值
谷歌不太可能索引低质量的网页,因为它们对用户没有价值。
如果你的页面已经排除了技术问题但仍然没有被索引,那么可能是页面的价值不足。因此,你需要重新审视页面,问问自己:这个页面真的有价值吗?如果用户从搜索结果中点击页面,他们会在页面上找到有用的内容吗?
如果以上两个问题的答案是否定的,那么您需要改进您的内容。
“内容为王”在今天的SEO领域依然适用。
9) 移除低质量页面(优化“抓取预算”)
网站 上太多低质量的页面会浪费 Google 的抓取预算。
以下是谷歌对此的评论:
低价值页面上浪费的服务器资源会降低抓取有价值内容的频率,这可能会导致网站上大量新内容的发现延迟。
将其视为您的主管对论文进行评分,其中之一就是您的论文。如果他们要审阅 10 篇论文,那么他们很快就会看到您的论文。如果他们必须审查一百,则需要更长的时间。如果有数千个,那么他们的工作量太大了,他们可能永远无法对您的内容进行评分。
谷歌确实指出,抓取预算[…]并不是大多数站长需要担心的,“如果网站的页面少于几千页”,它可以被有效地抓取。
但是,从 网站 中删除低质量的页面从来都不是坏事。它只会产生积极的影响。
10) 建立优质外链
外部链接告诉谷歌这个页面很重要。毕竟,如果有人链接到它,它必须具有一定的价值。这些是 Google 想要索引的页面。
Google 不仅会将带有外部链接的网页编入索引。有许多(数亿)没有外部链接的页面也被编入索引。但是,由于 Google 认为具有高质量链接的页面更重要,因此它们可能比没有高质量链接的页面更快地被抓取和重新抓取。这将使索引更快。
关于外链文章,请参考上一篇:
什么是外链,如何获取更多外链?
指数≠排名
在 Google 上获得索引并不意味着您可以获得排名或流量。
这是两件不同的事情。
索引意味着谷歌已经看到了你的网站,但并不意味着你的内容值得谷歌对特定的关键词进行排序。
这就是 SEO 需要做的事情——优化网页以针对特定 关键词 进行排名的艺术。
简单地说,SEO包括:
找出您的用户正在搜索什么;
围绕主题创建内容;
针对目标关键词进行优化;
外链建设;
更新页面内容以使其保持“新鲜”。
结束语
Google 未将您的 网站 或页面编入索引的原因只有两个:
技术问题阻止它被索引;
它认为你的内容没有价值,不值得被索引。
这两个问题很可能同时存在。但是,我会说技术问题更为常见。技术问题也可能导致低质量内容的自动生成(例如,分页问题)。
尽管如此,大多数索引问题都可以通过检查上述步骤来解决。
请记住,指数≠排名。如果您想对任何有价值的 关键词 进行排名并吸引源源不断的自然流量,那么 SEO 至关重要。
扫描二维码关注,更多精彩:
(自动识别二维码) 查看全部
网页抓取qq(本文会教你如何解决以下这三个问题(图)!)
本文将教你如何解决以下三个问题:
1.你的整个网站没有被索引;
2.有些页面被索引,而其他页面没有;
3. 新发布的页面不会立即编入索引。
但首先,我们必须先了解索引的含义。
什么是抓取和索引?
Google 通过抓取发现新页面,然后将这些页面添加到索引中。他们使用名为 Googlebot 的网络爬虫来执行此操作。
使困惑?让我们解释一些术语:
爬行:跟踪网页上的超链接以发现新内容的过程。
索引:Google 已将网页“编入索引”意味着 Google 抓取工具(“Googlebot”)访问了该网页,分析了其内容和含义,并将其存储在 Google 索引中。索引的网页可以显示在 Google 搜索结果中(前提是它们遵循 Google 的 网站网站管理员指南)。尽管大多数网页在被抓取后都会编入索引,但 Google 也可能会在不访问网页内容的情况下将网页编入索引(例如,如果该网页被 robots.txt 指令阻止)。
网络爬虫:执行爬行的程序。
Googlebot:谷歌的网络爬虫(谷歌蜘蛛)。
当您在 Google 上搜索内容时,您实际上是在要求 Google 返回其索引中的所有相关页面。由于通常有数千个网页符合要求,因此 Google 的排名算法会尝试对这些网页进行排名,以便您首先看到最佳和最相关的结果。
我想在这里提出的一个重要观点是索引和排名是两件不同的事情。
索引是为了参与,排名是为了获胜。
不参加就不可能赢。
如何检查您的页面是否已编入索引
输入谷歌,然后搜索站点如下:您的网址
此处的数字显示了索引页的大致数量。
如果你想检查一个特定的页面是否被索引,你也可以做同样的站点:详细网址
如果没有结果,则表示该页面未编入索引。
如果您是 Google Search Console 的用户,只需查看覆盖率报告即可找到准确的索引数据。您只需要输入:
Google Search Console> 索引> 覆盖范围
您可以使用 Google Search Console 检查特定页面是否已编入索引。您只需要将页面 URL 放入 URL 检测工具中即可。
如何让 Google 将您的网页编入索引
您的 网站 或页面未被 Google 编入索引?试试这些:
转到 Google Search Console。
进入网址检测工具。
将要编入索引的 URL 粘贴到搜索框中。
等待 Google 检测到 URL。
单击“请求索引”按钮。
当您发布新帖子或页面时,最好这样做。您实际上是在告诉 Google,您已向 网站 添加了一些新内容,他们应该检查一下。
但是,请求索引不太可能解决旧页面的索引问题。如果是这种情况,请按照下面的清单来诊断和解决问题。
去除Robots.txt中的爬行障碍去除不必要的noindex标签在网站地图中收录需要索引的页面去除不必要的规范标签检查页面是否为岛页面修复不必要的内部nofollow链接在“添加内部链接到“强大”页面,确保页面的唯一性和价值。去除低质量页面(优化“抓取预算”),建立高质量的外链
1) 去除Robots.txt中的爬行块
Google 没有将整个 网站 编入索引?这可能是由 robots.txt 文件中的爬行障碍引起的。
去查看详细问题。
检查右下角的两段是否有任何一段:
1 用户代理:Googlebot
2 禁止:/
1 用户代理:*
2 禁止:/
这两者都告诉 Googlebot 他们不允许抓取 网站 上的任何页面。要解决这个问题,你只需要删除它们,就这么简单。
如果 Google 没有为单个页面编制索引,也可能是由 robots.txt 中的代码引起的。要检查是否是这种情况,请将网址粘贴到 Google Search Console 中的网址检测工具中。单击覆盖范围部分以显示更多详细信息,并查找“允许抓取?否:被 robots.txt 阻止”错误。
这意味着该页面被 robots.txt 阻止。
如果是这种情况,请重新检查您的 robots.txt 文件,了解与此页面或相关目录相关的“禁止”规则。
如果需要,只需删除此代码。
2) 删除不必要的 noindex 标签
如果您告诉 Google 不要将网页编入索引,Google 将不会将其编入索引。这可以使页面的一部分保持私密。有两种方法可以做到这一点:
方法一:元标签
如果页面中出现以下任何代码,Google 将不会将其编入索引:
这是爬虫的元标记,告诉搜索引擎他们是否可以索引页面。
提示。核心参数是“noindex”。如果出现“noindex”,则表示该页面未编入索引。
方法 2:X‑Robots-Tag
网络爬虫遵循 X-Robots-Tag 的 HTTP 响应标头。您可以使用服务器端脚本语言(如PHP)、.htaccess 文件的内容,或更改服务器配置来实现此效果。
Google Search Console 中的 URL 检查工具可以告诉您此标头是否阻止 Google 抓取页面。只需输入 URL 并查找“允许索引?否:在“X‑Robots-Tag”http 标头中检测到“noindex”标签。
3)在网站的map中收录需要索引的页面
网站 地图会告诉 Google 网站 上哪些页面重要,哪些不重要。它还可以为谷歌的抓取频率提供一些指导。
Google 应该能够在您的 网站 上找到页面,无论它们是否在站点地图中,但将它们收录在 网站 地图中仍然是一个好习惯。毕竟,谷歌没有必要进行无意义的抓取。
要检查某个网页是否在您的站点地图中,请使用 Google Search Console 中的 URL 检查工具。如果您看到“此 网站 未显示在 Google 搜索结果中”和“站点地图:不适用”,则表示该网址未编入索引或不在您的站点地图中。
可以提交站点地图(xml格式)到谷歌站长工具
4) 删除不必要的规范标签
Canonical 标签告诉 Google 哪个是页面的首选版本。它看起来像这样:
大多数页面没有规范标签,即所谓的自引用规范标签。这告诉 Google 页面本身是首选版本,并且可能是唯一的版本。换句话说,您想要索引页面。
但是,如果您的网页具有不规则的规范标签,则可能会告诉 Google 错误的首选版本。在这种情况下,您的页面将不会被编入索引
要检测规范标签,您只需要使用 Google 的 URL 检测工具。如果您页面的规范标签指向另一个页面,您可以看到“带有规范标签的备用页面”提示。如果这不应该出现并且您希望当前页面被索引,那么只需删除页面的规范标签。
提示:请注意,规范标签并不总是不好的。大多数带有这些标签的页面都有其原因。如果您发现您的页面有规范标签,请检查相应的页面。如果确实是页面的首选版本,并且不需要索引页面,则应保留规范标记。
5) 检查页面是否为孤岛页面
孤岛页面是指内部链接不支持的页面。
由于谷歌是通过抓取链接来发现新内容的,因此他们无法通过这个过程发现孤岛页面。网站访问者也将无法找到此内容。
要检测孤岛页面,您可以使用 Ahrefs 的站点审核(网站 诊断)工具。然后点击 Incoming links 报告,查看“Island page (no pointing link)”错误:
这将显示可索引并显示在站点地图中但没有内部链接的所有页面。
暗示:
这只有在以下两种情况下才能正常检测:
1.所有需要索引的页面都在你的网站地图中。
2.在Ahrefs的Site Audit(网站Diagnosis)的最开始,选择使用网站地图中的页面的选项打勾。
您可以通过以下两种方法之一解决孤岛问题:
1.如果页面不重要,将其删除并移出地图网站。
2.如果页面很重要,把它放在你的内部链接结构中。
6) 修复不必要的内部 nofollow 链接
Nofollow 链接是那些带有 rel="nofollow" 标签的链接。他们将阻止传递 PageRank。同时,Google 不会抓取 Nofollow 链接。
这是谷歌对此的说明:
本质上,使用 nofollow 会导致我们从爬网目录中删除目标链接。但是,如果其他网站链接到目标页面而没有使用nofollow,或者如果这些URL在站点地图中提交给Google,目标页面可能仍会出现在我们的索引中。
简而言之,您需要确保遵循索引页面的链接。
您还可以使用 Ahrefs 的 Site Audit (网站Diagnosis) 工具来捕获 网站。检查“传入链接”报告中是否有错误“页面仅收录 nofollow 传入内部链接”:
假设您希望 Google 将页面编入索引,请从这些链接中删除 nofollow 标记。如果没有,请删除该页面或对该页面进行无索引处理。
7) 在“强大”页面收录内部链接
Google 通过抓取您的 网站 来发现新内容。如果忽略相关页面的内部链接,可能无法找到该页面。
解决这个问题的一个简单方法是在网站中添加一些内部链接。您可以在任何已编入索引的页面上执行此操作。但是,如果您希望 Google 尽快将页面编入索引,您可以在一些“强大”的页面上创建一些内部链接。
为什么?因为与一些不太重要的页面相比,Google 会更快地抓取此类页面。
这样做的方法是进入Ahrefs Site Explorer(网站分析),输入你的域名,查看Best by links报告。
这将显示 网站 上的所有页面,按 URL 分级排序。换句话说,它首先显示权重最高的页面。
检查列表并找到相关页面。您可以在这些页面上添加一些指向目标页面的内部链接。
建议:添加内链后,将页面粘贴到谷歌的网址检查工具中。点击“请求索引”按钮,让谷歌知道页面上的某些内容发生了变化,需要尽快重新抓取。这可以加快谷歌发现内部链接的过程,从而加快你想要索引的页面。
8) 确保页面独特且有价值
谷歌不太可能索引低质量的网页,因为它们对用户没有价值。
如果你的页面已经排除了技术问题但仍然没有被索引,那么可能是页面的价值不足。因此,你需要重新审视页面,问问自己:这个页面真的有价值吗?如果用户从搜索结果中点击页面,他们会在页面上找到有用的内容吗?
如果以上两个问题的答案是否定的,那么您需要改进您的内容。
“内容为王”在今天的SEO领域依然适用。
9) 移除低质量页面(优化“抓取预算”)
网站 上太多低质量的页面会浪费 Google 的抓取预算。
以下是谷歌对此的评论:
低价值页面上浪费的服务器资源会降低抓取有价值内容的频率,这可能会导致网站上大量新内容的发现延迟。
将其视为您的主管对论文进行评分,其中之一就是您的论文。如果他们要审阅 10 篇论文,那么他们很快就会看到您的论文。如果他们必须审查一百,则需要更长的时间。如果有数千个,那么他们的工作量太大了,他们可能永远无法对您的内容进行评分。
谷歌确实指出,抓取预算[…]并不是大多数站长需要担心的,“如果网站的页面少于几千页”,它可以被有效地抓取。
但是,从 网站 中删除低质量的页面从来都不是坏事。它只会产生积极的影响。
10) 建立优质外链
外部链接告诉谷歌这个页面很重要。毕竟,如果有人链接到它,它必须具有一定的价值。这些是 Google 想要索引的页面。
Google 不仅会将带有外部链接的网页编入索引。有许多(数亿)没有外部链接的页面也被编入索引。但是,由于 Google 认为具有高质量链接的页面更重要,因此它们可能比没有高质量链接的页面更快地被抓取和重新抓取。这将使索引更快。
关于外链文章,请参考上一篇:
什么是外链,如何获取更多外链?
指数≠排名
在 Google 上获得索引并不意味着您可以获得排名或流量。
这是两件不同的事情。
索引意味着谷歌已经看到了你的网站,但并不意味着你的内容值得谷歌对特定的关键词进行排序。
这就是 SEO 需要做的事情——优化网页以针对特定 关键词 进行排名的艺术。
简单地说,SEO包括:
找出您的用户正在搜索什么;
围绕主题创建内容;
针对目标关键词进行优化;
外链建设;
更新页面内容以使其保持“新鲜”。
结束语
Google 未将您的 网站 或页面编入索引的原因只有两个:
技术问题阻止它被索引;
它认为你的内容没有价值,不值得被索引。
这两个问题很可能同时存在。但是,我会说技术问题更为常见。技术问题也可能导致低质量内容的自动生成(例如,分页问题)。
尽管如此,大多数索引问题都可以通过检查上述步骤来解决。
请记住,指数≠排名。如果您想对任何有价值的 关键词 进行排名并吸引源源不断的自然流量,那么 SEO 至关重要。
扫描二维码关注,更多精彩:
(自动识别二维码)
网页抓取qq(robots请不要将robots.txt用作隐藏网页的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-17 04:08
为了防止某些网页被搜索引擎收录抓取,大家想到的第一种方法就是使用robots.txt。没错,几乎每一个网站都有一个robots.txt文件,目的是为了禁止某些目录被搜索引擎收录抓取并加入到所有搜索结果的索引中。但是,如果您想禁止搜索引擎抓取某些网页,仅使用 robots.txt 是不够的。
机器人.txt
请不要使用 robots.txt 作为隐藏网页的方式
robots.txt 文件位于网站 的根目录下,用于指明您不希望搜索引擎爬虫访问您的网站 上的哪些内容。本文档使用机器人排除标准,这是一个收录一小组命令的协议,可以基于网站的各个部分和特定类型的网络爬虫(例如移动爬虫和桌面版本)。爬虫),表示可访问的 网站 内容。
◆非图片文件
对于非图片文件(即网页),您应该只使用 robots.txt 来控制抓取流量,因为通常您不希望搜索引擎抓取工具使您的服务器过载或浪费抓取预算。 @网站。如果您不希望您的网页出现在搜索引擎搜索结果中,请不要使用 robots.txt 作为隐藏网页的方式。这是因为其他网页可能指向您的网页,从而导致您的网页被编入索引并使 robots.txt 文件无用。如果您想阻止您的网页出现在搜索结果中,请使用其他方法,例如密码保护或 noindex 标签或说明。
◆图片文件
robots.txt 可以阻止图片文件出现在搜索引擎搜索结果中(但不会阻止其他网页或用户链接到您的图片)。
◆资源文件
如果您认为在加载网页时跳过不重要的图片、脚本或样式文件不会造成太大影响,那么您可以使用robots.txt 来屏蔽这些资源文件。但是,如果缺少这些资源会增加爬虫分析网页的难度,建议您不要屏蔽这些资源,否则搜索引擎将无法正确分析依赖这些资源的网页。
了解 robots.txt 的局限性
在创建 robots.txt 之前,您应该了解这种 URL 拦截方法的潜在风险。有时,您可能需要考虑其他机制来确保搜索引擎无法在 Internet 上找到您的 URL。
◆Robots.txt 命令只是指令
robots.txt 文件中的命令不会强制爬虫对您的 网站 采取特定操作;为了访问您的 网站 爬虫,这些命令只是说明。常规的网络爬虫工具会按照robots.txt文件中的命令执行,但其他爬虫工具可能不一样。因此,如果您想确保您在网站上的特定信息不会被网络爬虫抓取,建议您使用其他屏蔽方式(例如为您服务器上的私人文件提供密码保护)。
◆不同的爬虫工具有不同的语法分析
尽管正式的网络爬虫遵循 robots.txt 文件中的说明,但这些爬虫可能会以不同的方式解析这些说明。您应该仔细查看不同网络爬虫的正确语法,因为有些爬虫可能无法理解某些命令。
◆如果其他网站上有链接指向被robots.txt文件屏蔽的网页,该网页仍可能被索引
尽管搜索引擎不会抓取或索引被 robots.txt 阻止的内容,但如果网络上其他地方存在指向禁止 URL 的链接,搜索引擎仍可能找到该 URL 并将其索引。因此,相关 URL 和其他公开显示的信息(例如相关页面链接中的锚文本)可能仍会出现在搜索结果中。为了正确防止您的 URL 出现在搜索结果中,您应该为服务器上的文件提供密码保护或使用 noindex 元标记或响应标头(或完全删除相关网页)。
您可能还对以下文章感兴趣
如何编写robots.txt Disallow 和Allow 下级目录或文件
robots.txt语法详解:*、$、?等字符的含义及用法 查看全部
网页抓取qq(robots请不要将robots.txt用作隐藏网页的方法(组图))
为了防止某些网页被搜索引擎收录抓取,大家想到的第一种方法就是使用robots.txt。没错,几乎每一个网站都有一个robots.txt文件,目的是为了禁止某些目录被搜索引擎收录抓取并加入到所有搜索结果的索引中。但是,如果您想禁止搜索引擎抓取某些网页,仅使用 robots.txt 是不够的。
机器人.txt
请不要使用 robots.txt 作为隐藏网页的方式
robots.txt 文件位于网站 的根目录下,用于指明您不希望搜索引擎爬虫访问您的网站 上的哪些内容。本文档使用机器人排除标准,这是一个收录一小组命令的协议,可以基于网站的各个部分和特定类型的网络爬虫(例如移动爬虫和桌面版本)。爬虫),表示可访问的 网站 内容。
◆非图片文件
对于非图片文件(即网页),您应该只使用 robots.txt 来控制抓取流量,因为通常您不希望搜索引擎抓取工具使您的服务器过载或浪费抓取预算。 @网站。如果您不希望您的网页出现在搜索引擎搜索结果中,请不要使用 robots.txt 作为隐藏网页的方式。这是因为其他网页可能指向您的网页,从而导致您的网页被编入索引并使 robots.txt 文件无用。如果您想阻止您的网页出现在搜索结果中,请使用其他方法,例如密码保护或 noindex 标签或说明。
◆图片文件
robots.txt 可以阻止图片文件出现在搜索引擎搜索结果中(但不会阻止其他网页或用户链接到您的图片)。
◆资源文件
如果您认为在加载网页时跳过不重要的图片、脚本或样式文件不会造成太大影响,那么您可以使用robots.txt 来屏蔽这些资源文件。但是,如果缺少这些资源会增加爬虫分析网页的难度,建议您不要屏蔽这些资源,否则搜索引擎将无法正确分析依赖这些资源的网页。
了解 robots.txt 的局限性
在创建 robots.txt 之前,您应该了解这种 URL 拦截方法的潜在风险。有时,您可能需要考虑其他机制来确保搜索引擎无法在 Internet 上找到您的 URL。
◆Robots.txt 命令只是指令
robots.txt 文件中的命令不会强制爬虫对您的 网站 采取特定操作;为了访问您的 网站 爬虫,这些命令只是说明。常规的网络爬虫工具会按照robots.txt文件中的命令执行,但其他爬虫工具可能不一样。因此,如果您想确保您在网站上的特定信息不会被网络爬虫抓取,建议您使用其他屏蔽方式(例如为您服务器上的私人文件提供密码保护)。
◆不同的爬虫工具有不同的语法分析
尽管正式的网络爬虫遵循 robots.txt 文件中的说明,但这些爬虫可能会以不同的方式解析这些说明。您应该仔细查看不同网络爬虫的正确语法,因为有些爬虫可能无法理解某些命令。
◆如果其他网站上有链接指向被robots.txt文件屏蔽的网页,该网页仍可能被索引
尽管搜索引擎不会抓取或索引被 robots.txt 阻止的内容,但如果网络上其他地方存在指向禁止 URL 的链接,搜索引擎仍可能找到该 URL 并将其索引。因此,相关 URL 和其他公开显示的信息(例如相关页面链接中的锚文本)可能仍会出现在搜索结果中。为了正确防止您的 URL 出现在搜索结果中,您应该为服务器上的文件提供密码保护或使用 noindex 元标记或响应标头(或完全删除相关网页)。
您可能还对以下文章感兴趣
如何编写robots.txt Disallow 和Allow 下级目录或文件
robots.txt语法详解:*、$、?等字符的含义及用法
网页抓取qq(什么是网页抓取qq空间的二维码?网页数据从网站数据建议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-14 19:02
网页抓取qq空间的二维码首先注册qq空间并关注网页版微信公众号,打开公众号后点击发现,搜索(qq空间,长按识别)或(微信发现,搜索)即可关注。这时可以发现上方有添加朋友请求,点击添加朋友请求之后就可以看到关注公众号的二维码了。然后使用收藏里的扫一扫识别二维码就可以了。
你们公司有财付通的钱呗,如果没有,
注册的时候填你真实姓名,生日,机器人名字就可以了。最好用实名认证号。没有的话可以加我,一起解决。
如果是非官方手机端,自己又想玩,可以联系我。
进去之后自己绑定下qq,然后随便怎么扫都可以,账号很稳定,只要有确定发送的消息,
可以使用qq邮箱注册
如果是ios的qq登录的话需要开vpnsafari当然也是可以验证手机号的这个账号还是蛮好的qq空间发图片了
首先你要有个qq
你可以在这个链接下载工具qq空间网页数据抓取从网站抓取数据建议你可以尝试scrapy或者python其他开源的包可以试试
很多浏览器都会提示:您已被加入黑名单。为啥要一起加入呢,qq只是一个社交软件,很多人喜欢用,也就是说只是上qq,但不是所有qq都能做数据抓取的。比如说:在国外,python是可以用的。至于qq,或者说腾讯它本身来说他更偏向于平台的角色,并不是专门的数据提供者。简单的数据的话,可以使用python获取,比如写scrapy爬取。 查看全部
网页抓取qq(什么是网页抓取qq空间的二维码?网页数据从网站数据建议)
网页抓取qq空间的二维码首先注册qq空间并关注网页版微信公众号,打开公众号后点击发现,搜索(qq空间,长按识别)或(微信发现,搜索)即可关注。这时可以发现上方有添加朋友请求,点击添加朋友请求之后就可以看到关注公众号的二维码了。然后使用收藏里的扫一扫识别二维码就可以了。
你们公司有财付通的钱呗,如果没有,
注册的时候填你真实姓名,生日,机器人名字就可以了。最好用实名认证号。没有的话可以加我,一起解决。
如果是非官方手机端,自己又想玩,可以联系我。
进去之后自己绑定下qq,然后随便怎么扫都可以,账号很稳定,只要有确定发送的消息,
可以使用qq邮箱注册
如果是ios的qq登录的话需要开vpnsafari当然也是可以验证手机号的这个账号还是蛮好的qq空间发图片了
首先你要有个qq
你可以在这个链接下载工具qq空间网页数据抓取从网站抓取数据建议你可以尝试scrapy或者python其他开源的包可以试试
很多浏览器都会提示:您已被加入黑名单。为啥要一起加入呢,qq只是一个社交软件,很多人喜欢用,也就是说只是上qq,但不是所有qq都能做数据抓取的。比如说:在国外,python是可以用的。至于qq,或者说腾讯它本身来说他更偏向于平台的角色,并不是专门的数据提供者。简单的数据的话,可以使用python获取,比如写scrapy爬取。
网页抓取qq(Python版本:Python3.8.0操作平台()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-14 03:05
)
Python 版本:Python 3.8.0
操作平台:PyCharm
使用的库:requests、json、os
爬虫目标:抓取QQ群成员头像,以QQ昵称命名文件名
腾讯有专门的QQ群管理网页:
我们可以通过这个网页抓取需要的QQ群信息。
首先我们登录QQ群管理官网,选择一个群进入。
打开开发者工具,输入“网络”,查看数据的具体位置,通过搜索发现数据信息位于search_group_members下,数据在json中,每一块都是一个成员的信息。
点击查看具体内容。
通过对比不难发现,“卡片”就是QQ群评论;“nick”表示QQ昵称;“uin”表示QQ号码。
点击“Headers”,我们看一下header信息。
请求是一个帖子,让我们检查一下表单数据。
其中,“gc”表示QQ群号,“st”表示开始成员,“end”表示结束成员,“bkn”是QQ群的加密参数,有点复杂,所以我们将直接复制并使用。
让我们开始编写代码来获取数据。
通过上面的分析,我们可以看到表单信息显示每次返回20条数据。为了抓取QQ群的所有成员,我们需要定义data函数。
def get_data(num):
data = {
'gc': '123456',#QQ群号
'st': num*21,
'end': num*21 + 20,
'sort': '0',
'bkn': '12345678'#直接从From Data复制过来
}
return data
然后,我们构造一个函数来捕获QQ群成员的信息,使用“requests.post”来捕获,json库将json转换成列表。
def get_con(url,data):
requests.packages.urllib3.disable_warnings()
response = response = requests.post(url, headers=headers, data=data)
response.encoding = response.apparent_encoding
text = json.loads(response.text)
content = text['mems']
for item in content:
xinxi = {
'qqmem': item['uin'], #QQ群成员QQ号
'beizhu': item['card'], #QQ群成员备注
'name': item['nick'] #QQ群成员昵称
}
yield xinxi
然后,我们抓取QQ群成员的头像,并用昵称命名文件。
QQ头像图片地址为:
/g?b=qq&nk=123456&s=140
其中,“123456”代表会员的QQ号。通过更好的QQ号,拼接新的连接,我们可以得到会员的头像。
def get_pic(url):
for i in range(100):
try:
content = get_con(url=url, data = get_data(i))
if not os.path.isdir('picture'):
os.mkdir('picture')
for item in content:
pic_url = 'https://q4.qlogo.cn/g?b=qq&nk={}&s=140'.format(item['qqmem'])
print(pic_url, item['name'])
abs_path = os.path.join('picture', '%s.jpg' %item['name'])
open(abs_path, 'wb').write(requests.get(pic_url, verify=False).content)
except:
pass
复制浏览器的标题并运行程序。
if __name__ == '__main__':
url = 'https://qun.qq.com/cgi-bin/qun ... 39%3B
get_pic(url)
爬取效果如下。
查看全部
网页抓取qq(Python版本:Python3.8.0操作平台()(图)
)
Python 版本:Python 3.8.0
操作平台:PyCharm
使用的库:requests、json、os
爬虫目标:抓取QQ群成员头像,以QQ昵称命名文件名
腾讯有专门的QQ群管理网页:
我们可以通过这个网页抓取需要的QQ群信息。
首先我们登录QQ群管理官网,选择一个群进入。
打开开发者工具,输入“网络”,查看数据的具体位置,通过搜索发现数据信息位于search_group_members下,数据在json中,每一块都是一个成员的信息。
点击查看具体内容。
通过对比不难发现,“卡片”就是QQ群评论;“nick”表示QQ昵称;“uin”表示QQ号码。
点击“Headers”,我们看一下header信息。
请求是一个帖子,让我们检查一下表单数据。
其中,“gc”表示QQ群号,“st”表示开始成员,“end”表示结束成员,“bkn”是QQ群的加密参数,有点复杂,所以我们将直接复制并使用。
让我们开始编写代码来获取数据。
通过上面的分析,我们可以看到表单信息显示每次返回20条数据。为了抓取QQ群的所有成员,我们需要定义data函数。
def get_data(num):
data = {
'gc': '123456',#QQ群号
'st': num*21,
'end': num*21 + 20,
'sort': '0',
'bkn': '12345678'#直接从From Data复制过来
}
return data
然后,我们构造一个函数来捕获QQ群成员的信息,使用“requests.post”来捕获,json库将json转换成列表。
def get_con(url,data):
requests.packages.urllib3.disable_warnings()
response = response = requests.post(url, headers=headers, data=data)
response.encoding = response.apparent_encoding
text = json.loads(response.text)
content = text['mems']
for item in content:
xinxi = {
'qqmem': item['uin'], #QQ群成员QQ号
'beizhu': item['card'], #QQ群成员备注
'name': item['nick'] #QQ群成员昵称
}
yield xinxi
然后,我们抓取QQ群成员的头像,并用昵称命名文件。
QQ头像图片地址为:
/g?b=qq&nk=123456&s=140
其中,“123456”代表会员的QQ号。通过更好的QQ号,拼接新的连接,我们可以得到会员的头像。
def get_pic(url):
for i in range(100):
try:
content = get_con(url=url, data = get_data(i))
if not os.path.isdir('picture'):
os.mkdir('picture')
for item in content:
pic_url = 'https://q4.qlogo.cn/g?b=qq&nk={}&s=140'.format(item['qqmem'])
print(pic_url, item['name'])
abs_path = os.path.join('picture', '%s.jpg' %item['name'])
open(abs_path, 'wb').write(requests.get(pic_url, verify=False).content)
except:
pass
复制浏览器的标题并运行程序。
if __name__ == '__main__':
url = 'https://qun.qq.com/cgi-bin/qun ... 39%3B
get_pic(url)
爬取效果如下。
网页抓取qq(qq的token会记在谁的手机上呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-13 16:02
网页抓取qq空间的话,我们先把对方qq的文件夹,隐藏,然后我们下载安装个工具,用来反爬虫,就是模拟手机,去点击一个网页,拿到页面内容,然后加上我们自己的代码,隐藏文件夹,然后就能得到对方qq号,然后登录他们的网站,然后上传文件,把他们的数据传到他们自己的服务器上,
需要抓取你们网站的token,然后使用js将token和useragent绑定,set/entrywithexpires或者set/entrywithcookie就行了。抓取的url没有限制,但是一般都要加参数。
你可以在站点设置里面设置敏感页面抓取,
qq基本都被网页直接广告、垃圾信息覆盖了,没有生命力,换个ip你还是在那看,他们永远会在那个ip上下载你的token,该干嘛干嘛,像腾讯这种对上游很严格的公司在社会主义道路还没实现的时候,只能这样,qq你用人家的,为人家的利益而活着,
微信公众号发送关键词qq登录或者公众号名称+密码服务器会根据用户需求的,
网页上有时候会自动推送给txt扫描,这个功能叫做token路由。其实,里面的token也是人为输入的,我用浏览器都可以用...最后用手机登录qq账号。那么qq的token会记在谁的手机上呢?手机上看你所使用的浏览器,一般的手机都有相应的浏览器插件,它会保存一个token,然后你可以用插件去修改或者提取,再从电脑上读取出来。 查看全部
网页抓取qq(qq的token会记在谁的手机上呢?(图))
网页抓取qq空间的话,我们先把对方qq的文件夹,隐藏,然后我们下载安装个工具,用来反爬虫,就是模拟手机,去点击一个网页,拿到页面内容,然后加上我们自己的代码,隐藏文件夹,然后就能得到对方qq号,然后登录他们的网站,然后上传文件,把他们的数据传到他们自己的服务器上,
需要抓取你们网站的token,然后使用js将token和useragent绑定,set/entrywithexpires或者set/entrywithcookie就行了。抓取的url没有限制,但是一般都要加参数。
你可以在站点设置里面设置敏感页面抓取,
qq基本都被网页直接广告、垃圾信息覆盖了,没有生命力,换个ip你还是在那看,他们永远会在那个ip上下载你的token,该干嘛干嘛,像腾讯这种对上游很严格的公司在社会主义道路还没实现的时候,只能这样,qq你用人家的,为人家的利益而活着,
微信公众号发送关键词qq登录或者公众号名称+密码服务器会根据用户需求的,
网页上有时候会自动推送给txt扫描,这个功能叫做token路由。其实,里面的token也是人为输入的,我用浏览器都可以用...最后用手机登录qq账号。那么qq的token会记在谁的手机上呢?手机上看你所使用的浏览器,一般的手机都有相应的浏览器插件,它会保存一个token,然后你可以用插件去修改或者提取,再从电脑上读取出来。
网页抓取qq(算不算bug?如何把代码嵌入网站呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-12 09:25
近期,网上获取访客QQ码很流行,尤其是淘客网站。为了更准确的获取访客QQ,当用户访问网站时,会获取用户的QQ号,以便客服售后人员在线联系进行精准营销。之前看到有人发来的访客QQ码。但我没有仔细看。事实上,很多行业都在做这件事。因为这些访问者的QQ大部分是有需求的群体,是精准营销的优质数据源。
以下方法是去年偶然发现的。原理很简单,个人感觉是腾讯的bug。
1、登录手机版qq。pc版没怎么关注。
2、“主页”->“访客”。
3、开发工具(F12)->网络,ctrl+f“mqz_get_visitor”。这样就已经可以看到访问者记录的json了,格式清晰,也支持分页,其实就是把这个url复制出来后,不用登录就可以查看,偶尔会出错,不过重新登录就好了。
———————————————————————
第三个选项卡被屏蔽的访问者,无需再次登录,仍可以同样方式查看。这是一个错误吗??
如何在网站中嵌入代码,很简单
%E2%80%9Dhttp://qzone.qq.com/xxxxxxxxxx%E2%80%9D
public function qq()
{
$mqz_url = ''; //mqz json
$vResult = array();
$this->snoopy->fetch($mqz_url);
$visitJson = $this->snoopy->results;
$visitArr = json_decode(htmlspecialchars_decode($visitJson, ENT_COMPAT), TRUE);
foreach($visitArr['data']['visit']['datalist'] as $n => $v) {
$vResult[$n] = array('uin' => $v['uin'], 'vtime' => $v['vtime']);
}
}
实现模拟手机操作的步骤(以谷歌浏览器为例):
1、登录
2、F12
3、找到设置看图:
4、 只需设置相关仿真参数即可,设置步骤如下:
如果以上步骤都不行,那一定是姿势不对,重新开始。
生成海报
下载海报 查看全部
网页抓取qq(算不算bug?如何把代码嵌入网站呢?(图))
近期,网上获取访客QQ码很流行,尤其是淘客网站。为了更准确的获取访客QQ,当用户访问网站时,会获取用户的QQ号,以便客服售后人员在线联系进行精准营销。之前看到有人发来的访客QQ码。但我没有仔细看。事实上,很多行业都在做这件事。因为这些访问者的QQ大部分是有需求的群体,是精准营销的优质数据源。
以下方法是去年偶然发现的。原理很简单,个人感觉是腾讯的bug。
1、登录手机版qq。pc版没怎么关注。
2、“主页”->“访客”。
3、开发工具(F12)->网络,ctrl+f“mqz_get_visitor”。这样就已经可以看到访问者记录的json了,格式清晰,也支持分页,其实就是把这个url复制出来后,不用登录就可以查看,偶尔会出错,不过重新登录就好了。
———————————————————————
第三个选项卡被屏蔽的访问者,无需再次登录,仍可以同样方式查看。这是一个错误吗??
如何在网站中嵌入代码,很简单
%E2%80%9Dhttp://qzone.qq.com/xxxxxxxxxx%E2%80%9D
public function qq()
{
$mqz_url = ''; //mqz json
$vResult = array();
$this->snoopy->fetch($mqz_url);
$visitJson = $this->snoopy->results;
$visitArr = json_decode(htmlspecialchars_decode($visitJson, ENT_COMPAT), TRUE);
foreach($visitArr['data']['visit']['datalist'] as $n => $v) {
$vResult[$n] = array('uin' => $v['uin'], 'vtime' => $v['vtime']);
}
}
实现模拟手机操作的步骤(以谷歌浏览器为例):
1、登录
2、F12
3、找到设置看图:
4、 只需设置相关仿真参数即可,设置步骤如下:
如果以上步骤都不行,那一定是姿势不对,重新开始。
生成海报
下载海报
网页抓取qq(竞价/优化推广底盘率低怎么办?从02年的一个企业网站制作开场)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-10 06:08
竞价/优化推广底盘率低怎么办?
与2002年以几万起步的网站生产相比,网络建设市场的盈利能力越来越薄,企业对网站建设的要求也相对高的; 大量传统企业涌入互联网,从事电子商务;“21世纪是互联网时代,今天不上网就下岗”的价值口号,也在一天天的冲击着各大公司的老板们。
网站效率低下的公司主动放弃80%的潜在客户
近日,网上流传着一句经典的话“没有形影不离的朋友,只有不努力的后辈”。对于我们互联网公司网站来说,就是“没有公司不想卖客户,只有不能留下客户联系方式”。业务”。只有营销才能为企业带来利润,其他一切都是成本。企业最大的成本就是让不懂营销的人去做营销。
谍豹云销售访客QQ抓包
访客QQ抢购,保证QQ客户100%不流失!
访客QQ抓取QQ添加的客户无法删除;
访客QQ抢号,离职员工无法带走;
访客QQ抢好友无法克隆;
网站访客QQ获取——专业版功能介绍
可用网站数量:2个主域名(分站数量不限)
免费查看网站访客:是的
导出数据:是
智能对话:是
在线技术支持:是
手机号码采集:是(免费基础版)
智能邮件推送:是
智能短信推送:有
多账户发送:是
短信群发系统:有
客户管理系统:是
---------------------------
添加域名说明:
只输入域名,不要带和二级目录;
例如:,,
获得的代码只有在域名下使用时才会被统计。
新增自动弹出对话框功能说明:
打开后,访客打开你的网站,会自动弹出你设置的QQ号对话框;
先设置客服QQ号和号码类型,然后开启看看效果;
为避免用户反感,12小时内只弹出一次; 查看全部
网页抓取qq(竞价/优化推广底盘率低怎么办?从02年的一个企业网站制作开场)
竞价/优化推广底盘率低怎么办?
与2002年以几万起步的网站生产相比,网络建设市场的盈利能力越来越薄,企业对网站建设的要求也相对高的; 大量传统企业涌入互联网,从事电子商务;“21世纪是互联网时代,今天不上网就下岗”的价值口号,也在一天天的冲击着各大公司的老板们。
网站效率低下的公司主动放弃80%的潜在客户
近日,网上流传着一句经典的话“没有形影不离的朋友,只有不努力的后辈”。对于我们互联网公司网站来说,就是“没有公司不想卖客户,只有不能留下客户联系方式”。业务”。只有营销才能为企业带来利润,其他一切都是成本。企业最大的成本就是让不懂营销的人去做营销。
谍豹云销售访客QQ抓包
访客QQ抢购,保证QQ客户100%不流失!
访客QQ抓取QQ添加的客户无法删除;
访客QQ抢号,离职员工无法带走;
访客QQ抢好友无法克隆;
网站访客QQ获取——专业版功能介绍
可用网站数量:2个主域名(分站数量不限)
免费查看网站访客:是的
导出数据:是
智能对话:是
在线技术支持:是
手机号码采集:是(免费基础版)
智能邮件推送:是
智能短信推送:有
多账户发送:是
短信群发系统:有
客户管理系统:是
---------------------------
添加域名说明:
只输入域名,不要带和二级目录;
例如:,,
获得的代码只有在域名下使用时才会被统计。
新增自动弹出对话框功能说明:
打开后,访客打开你的网站,会自动弹出你设置的QQ号对话框;
先设置客服QQ号和号码类型,然后开启看看效果;
为避免用户反感,12小时内只弹出一次;
网页抓取qq(如何使用QQ浏览器来获取整个网页截图的所有内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-10 06:02
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。
第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。
如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。 查看全部
网页抓取qq(如何使用QQ浏览器来获取整个网页截图的所有内容?)
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。
第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。
如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。
网页抓取qq(网页抓取qq空间点赞,可以查看点(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-09 20:01
网页抓取qq空间点赞,可以查看点赞记录,获取到用户的昵称,并且可以看到这个用户将会出现在哪个城市的某个位置(现在最高级的抓取)但是这种网页无法转换网址可以看到带有长长的结尾也可以导出网页(json)按键自定义自己想要的文字,同样可以抓取数据查看所有点赞记录(可以导出)或者按照转换的文字词字符串来查看应该是qq点赞,就是聊天然后点赞(对于网页数据排版判断,有的人无法通过审核,无法看到点赞记录,可以先观察一下真实用户会不会点赞,搜索记录查询,点赞记录生成)1.制作自己的qq个人页面,然后让蜘蛛在页面的里抓取,如下2.网页qq空间点赞会出现多个按钮可以到、天猫购买木马..不得不说这个qq点赞相当nb了,,可以这么说,的不是一般的网页制作者,但是并不能阻止qq空间点赞网页的制作者。
3.获取到所有点赞记录后,可以点击按钮后跳转到结尾自己想要的位置,如上点赞4.如果数据分析实在是漏洞,写有那么些很明显的漏洞,那就生成一串数字--转换为中文,如:qq&&110&&370?另外,高手还可以手动注入,造成病毒..5.人工,专业人员操作。浏览器中有黑名单可查,只有黑名单中才可以生成点赞,要不,qq点赞的就会泄露用户。再专业的黑客都不会脱手qq空间,他们也是最最最可怜的普通用户,点个赞没法后退,信息还不全。 查看全部
网页抓取qq(网页抓取qq空间点赞,可以查看点(图))
网页抓取qq空间点赞,可以查看点赞记录,获取到用户的昵称,并且可以看到这个用户将会出现在哪个城市的某个位置(现在最高级的抓取)但是这种网页无法转换网址可以看到带有长长的结尾也可以导出网页(json)按键自定义自己想要的文字,同样可以抓取数据查看所有点赞记录(可以导出)或者按照转换的文字词字符串来查看应该是qq点赞,就是聊天然后点赞(对于网页数据排版判断,有的人无法通过审核,无法看到点赞记录,可以先观察一下真实用户会不会点赞,搜索记录查询,点赞记录生成)1.制作自己的qq个人页面,然后让蜘蛛在页面的里抓取,如下2.网页qq空间点赞会出现多个按钮可以到、天猫购买木马..不得不说这个qq点赞相当nb了,,可以这么说,的不是一般的网页制作者,但是并不能阻止qq空间点赞网页的制作者。
3.获取到所有点赞记录后,可以点击按钮后跳转到结尾自己想要的位置,如上点赞4.如果数据分析实在是漏洞,写有那么些很明显的漏洞,那就生成一串数字--转换为中文,如:qq&&110&&370?另外,高手还可以手动注入,造成病毒..5.人工,专业人员操作。浏览器中有黑名单可查,只有黑名单中才可以生成点赞,要不,qq点赞的就会泄露用户。再专业的黑客都不会脱手qq空间,他们也是最最最可怜的普通用户,点个赞没法后退,信息还不全。
网页抓取qq( 对RiskIQ的剖析来说()()_bss)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-08 03:12
对RiskIQ的剖析来说()()_bss)
联系技术Q:20619942(点此联系站长) 如有问题请联系站长!
* /jni?mth=a&str=xxx&i=10 * @param request00020680 B __bss_start__ 对于RiskIQ的剖析后端,其页面抓取规划是一个值得肯定的人才。我们每天的网页抓取量会达到200亿页,并且可以主动积累,因为很多现代网站倾向于使用JavaScript来完成网站服务,所以我们只需要加载大约20个脚本和30个英国航空网站左右保留子页面就行了。30页虽然不多,但大部分都是千行代码的缩水脚本页。随着WAF对网站的保护越来越广泛,对于基本的Web攻防,越来越多的攻击载荷利用MySQL、JavaScript等语言特性进行编码变形,进而绕过WAF保护。攻守是一个不断反对和促进的过程。根据云端数据显示,当时近三分之一的攻击数据,为了绕过Cloud Shield WAF的保护,使用了不同级别或类型的编码变形技术,甚至有使用多维复合变形和编码技术。罪行。
“由于担心缓存命中率会大幅下降,导致网络使用量大幅增加和页面加载时间过长,Chrome 过去没有处理过这个问题,”谷歌软件工程师 Shivani Sharma 在该功能的 HTTP 中描述缓存威胁模型文档。 查看全部
网页抓取qq(
对RiskIQ的剖析来说()()_bss)
联系技术Q:20619942(点此联系站长) 如有问题请联系站长!
* /jni?mth=a&str=xxx&i=10 * @param request00020680 B __bss_start__ 对于RiskIQ的剖析后端,其页面抓取规划是一个值得肯定的人才。我们每天的网页抓取量会达到200亿页,并且可以主动积累,因为很多现代网站倾向于使用JavaScript来完成网站服务,所以我们只需要加载大约20个脚本和30个英国航空网站左右保留子页面就行了。30页虽然不多,但大部分都是千行代码的缩水脚本页。随着WAF对网站的保护越来越广泛,对于基本的Web攻防,越来越多的攻击载荷利用MySQL、JavaScript等语言特性进行编码变形,进而绕过WAF保护。攻守是一个不断反对和促进的过程。根据云端数据显示,当时近三分之一的攻击数据,为了绕过Cloud Shield WAF的保护,使用了不同级别或类型的编码变形技术,甚至有使用多维复合变形和编码技术。罪行。
“由于担心缓存命中率会大幅下降,导致网络使用量大幅增加和页面加载时间过长,Chrome 过去没有处理过这个问题,”谷歌软件工程师 Shivani Sharma 在该功能的 HTTP 中描述缓存威胁模型文档。
网页抓取qq(考虑一个问题:如何抓取一个访问受限的网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-08 01:28
考虑一个问题:如何抓取访问受限的网页?如学校好友主页、个人新闻页面等。
显然,通过浏览器,我们可以手动输入用户名和密码来访问目标页面。所谓的“抓取”,不过是需要我们用一个程序来模拟完成同样的工作,所以我们需要了解在“登录”的过程中发生了什么。
对于未登录的用户,服务器强制用户跳转到登陆页面。用户输入用户名和密码并提交。服务器将用户的POST信息与数据库中的信息进行比较,如果通过则跳转到登陆页面。那么当我们访问其他页面时,服务器是如何判断我们的身份的呢?由于HTTP协议是无状态的,显然服务器无法直接知道我们最后一秒刚刚登录成功。
最简单的想法是,在每个POST请求中,用户都需要带上用户名和密码来标识自己的身份;虽然这是可行的,但是大大增加了服务器的负担(对于每个请求,都需要经过数据库的验证),也大大降低了用户体验(每个页面都需要重新输入用户名和密码,并且每个页面都有一个登录表单)。
因此,一个解决方案诞生了:cookie。Cookie,简而言之就是将用户操作的一些历史信息(当然也包括登录信息)保存在本地计算机上,当用户再次访问该站点时,浏览器通过HTTP将本地cookie的内容发送给服务器协议完成验证,或继续上一步。
更进一步,另一种解决方案诞生了:session,简而言之,就是将用户操作的历史信息保存在服务器上。但是这种方式还是需要将发送请求的客户端与会话对象进行匹配,所以可以通过cookie机制获取客户端的身份(即会话id),也可以通过GET将id提交给服务器。session id,即服务器上会话对象文件的名称,由服务器生成,以保证随机性和唯一性。它相当于一个随机密钥,以避免在握手或传输过程中暴露用户的真实密码。类似的设计思路在 SSO 和 OpenID 中也经常使用。
再插入一个问题:为什么有些网站,关闭浏览器后,session就失效了?
从上面可以看出,session一般是通过cookie来保存session id的。如果cookie设置为在浏览器关闭时过期,那么无论怎么设置会话超时机制,浏览器重启时都找不到原来的cookie。所以服务器只能重新分配会话 id 给它。
cookie 和 session 的区别?
session和cookie的目的是一样的,都是为了克服http协议的无状态缺陷,只是完成的方法不同。session通过cookie在客户端保存session id,在服务器的session对象中保存用户的其他session消息。相比之下,cookie需要保存客户端的所有信息。因此,cookies具有一定的安全风险。比如本地cookie中存储的用户名和密码被破译,或者cookie被其他网站采集(例如:1. appA主动设置域B cookie让域B cookie获取;2. XSS,在appA上通过javascript获取document.cookie,传递给你的appB)。
我在写php App的时候就知道可以通过SSO从Session中获取userid,但是不知道为什么,所以遇到了一个奇怪的问题:在浏览器A标签的脚本执行过程中,打开B 标签访问同一个脚本,它会一直挂起,直到 A 被执行。原因是脚本执行了session_start(),php session_start()之后对session的写入是独占的。只有当脚本执行结束或显式执行 session_destroy() 时,才能释放会话文件锁。因为不知道session的工作原理,困扰了整整一个工作日!类似的问题是gbk和gb2312区别中的一些字符无法存储,因为他们不了解Lamp中字符编码的转换规则。
因此,要知道为什么,我们还需要知道为什么。磨刀不误砍柴,教人钓鱼,在做web开发之前,一定要了解清楚一些必要的知识,以免在使用的时候被拉长,或者在调整bug的时候像无头苍蝇一样。做好自身建设,总比逐案被动满足要好。 查看全部
网页抓取qq(考虑一个问题:如何抓取一个访问受限的网页(组图))
考虑一个问题:如何抓取访问受限的网页?如学校好友主页、个人新闻页面等。
显然,通过浏览器,我们可以手动输入用户名和密码来访问目标页面。所谓的“抓取”,不过是需要我们用一个程序来模拟完成同样的工作,所以我们需要了解在“登录”的过程中发生了什么。
对于未登录的用户,服务器强制用户跳转到登陆页面。用户输入用户名和密码并提交。服务器将用户的POST信息与数据库中的信息进行比较,如果通过则跳转到登陆页面。那么当我们访问其他页面时,服务器是如何判断我们的身份的呢?由于HTTP协议是无状态的,显然服务器无法直接知道我们最后一秒刚刚登录成功。
最简单的想法是,在每个POST请求中,用户都需要带上用户名和密码来标识自己的身份;虽然这是可行的,但是大大增加了服务器的负担(对于每个请求,都需要经过数据库的验证),也大大降低了用户体验(每个页面都需要重新输入用户名和密码,并且每个页面都有一个登录表单)。
因此,一个解决方案诞生了:cookie。Cookie,简而言之就是将用户操作的一些历史信息(当然也包括登录信息)保存在本地计算机上,当用户再次访问该站点时,浏览器通过HTTP将本地cookie的内容发送给服务器协议完成验证,或继续上一步。
更进一步,另一种解决方案诞生了:session,简而言之,就是将用户操作的历史信息保存在服务器上。但是这种方式还是需要将发送请求的客户端与会话对象进行匹配,所以可以通过cookie机制获取客户端的身份(即会话id),也可以通过GET将id提交给服务器。session id,即服务器上会话对象文件的名称,由服务器生成,以保证随机性和唯一性。它相当于一个随机密钥,以避免在握手或传输过程中暴露用户的真实密码。类似的设计思路在 SSO 和 OpenID 中也经常使用。
再插入一个问题:为什么有些网站,关闭浏览器后,session就失效了?
从上面可以看出,session一般是通过cookie来保存session id的。如果cookie设置为在浏览器关闭时过期,那么无论怎么设置会话超时机制,浏览器重启时都找不到原来的cookie。所以服务器只能重新分配会话 id 给它。
cookie 和 session 的区别?
session和cookie的目的是一样的,都是为了克服http协议的无状态缺陷,只是完成的方法不同。session通过cookie在客户端保存session id,在服务器的session对象中保存用户的其他session消息。相比之下,cookie需要保存客户端的所有信息。因此,cookies具有一定的安全风险。比如本地cookie中存储的用户名和密码被破译,或者cookie被其他网站采集(例如:1. appA主动设置域B cookie让域B cookie获取;2. XSS,在appA上通过javascript获取document.cookie,传递给你的appB)。
我在写php App的时候就知道可以通过SSO从Session中获取userid,但是不知道为什么,所以遇到了一个奇怪的问题:在浏览器A标签的脚本执行过程中,打开B 标签访问同一个脚本,它会一直挂起,直到 A 被执行。原因是脚本执行了session_start(),php session_start()之后对session的写入是独占的。只有当脚本执行结束或显式执行 session_destroy() 时,才能释放会话文件锁。因为不知道session的工作原理,困扰了整整一个工作日!类似的问题是gbk和gb2312区别中的一些字符无法存储,因为他们不了解Lamp中字符编码的转换规则。
因此,要知道为什么,我们还需要知道为什么。磨刀不误砍柴,教人钓鱼,在做web开发之前,一定要了解清楚一些必要的知识,以免在使用的时候被拉长,或者在调整bug的时候像无头苍蝇一样。做好自身建设,总比逐案被动满足要好。
网页抓取qq( 免费试用两天官方下载地址:彪悍的营销工具!(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-05 14:12
免费试用两天官方下载地址:彪悍的营销工具!(图))
免费试用两天
官方下载地址:
强大的营销工具!可以抓取网站访问者的QQ号。提高绩效的重要营销工具。自己下载试试,功能很强大。
功能:
1.抢网站访客QQ号
只要网站访问者在电脑上登录QQ,就可以抢到访问者的QQ号。
2.自动将访客加为好友
自动申请加访客QQ为好友!如果配合营销QQ,那就无敌了。
3.临时QQ弹窗对话
当访问者输入网站时,会弹出一个临时的QQ对话窗口。
4. 智能邮件推送。
电子邮件营销,自动、定时和有针对性地向访问者发送电子邮件。
5.抓取访客手机号
您可以抓取移动访客的手机号码!(仅限移动访问者)。
特征:
不管你是付费推广还是免费推广,都遇到一个常见的问题:(流量不断流失),因为你拿不到客户数据,一旦访客离开你的网站,你什么也得不到!但是这个工具打破了这个规律,可以抓取95%的访客QQ号,建立自己的营销数据库。想想看,一天1000个流量,可以抓到900多个QQ号,而且这些客户数据是非常准确的。它对促销和营销有多大帮助?
本系统是目前最稳定的网站访客QQ抓取系统,抓取率最高,成功率95%。它是一种强大的主动营销工具,可以防止任何访问者丢失。
用法:使用起来非常简单。在系统后台添加需要抓取访问者QQ的网站地址,获取对应的统计代码,嵌入网站模板底部,生成全站即时生效。
现在注册,您可以免费使用它。
官方下载地址:
客户端附件: 查看全部
网页抓取qq(
免费试用两天官方下载地址:彪悍的营销工具!(图))
免费试用两天
官方下载地址:
强大的营销工具!可以抓取网站访问者的QQ号。提高绩效的重要营销工具。自己下载试试,功能很强大。
功能:
1.抢网站访客QQ号
只要网站访问者在电脑上登录QQ,就可以抢到访问者的QQ号。
2.自动将访客加为好友
自动申请加访客QQ为好友!如果配合营销QQ,那就无敌了。
3.临时QQ弹窗对话
当访问者输入网站时,会弹出一个临时的QQ对话窗口。
4. 智能邮件推送。
电子邮件营销,自动、定时和有针对性地向访问者发送电子邮件。
5.抓取访客手机号
您可以抓取移动访客的手机号码!(仅限移动访问者)。
特征:
不管你是付费推广还是免费推广,都遇到一个常见的问题:(流量不断流失),因为你拿不到客户数据,一旦访客离开你的网站,你什么也得不到!但是这个工具打破了这个规律,可以抓取95%的访客QQ号,建立自己的营销数据库。想想看,一天1000个流量,可以抓到900多个QQ号,而且这些客户数据是非常准确的。它对促销和营销有多大帮助?
本系统是目前最稳定的网站访客QQ抓取系统,抓取率最高,成功率95%。它是一种强大的主动营销工具,可以防止任何访问者丢失。
用法:使用起来非常简单。在系统后台添加需要抓取访问者QQ的网站地址,获取对应的统计代码,嵌入网站模板底部,生成全站即时生效。
现在注册,您可以免费使用它。
官方下载地址:
客户端附件:
网页抓取qq(网页抓取/站外爬虫前端杂谈包含一整套学习资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-26 01:00
网页抓取qq群/站外爬虫前端杂谈包含一整套学习资料0基础转向web安全,微信安全和社交防御计划现在,网站已经越来越强大,平台功能越来越多。从静态的图片和资源上传上,到动态的文件页面载入等,基本每个需要用户时时刻刻操作的网站都在采用javascript和css等方式进行相应的响应操作。“用户体验”对于互联网平台和互联网公司来说越来越重要。
浏览器和服务器和本质上是一个整体,都是我们的生命。如何让互联网平台生态得到充分的体验最好,让用户从入口被吸引,我们应该解决哪些问题。accessibilitydocumentapi,正是一种解决方案。它是从一个简单的抽象层面接受真实环境下产生的所有动态数据。accessibilitydocumentapi利用这些数据来和网页保持,在转发客户端的请求时需要进行accessibilitydocumentapi的请求。
accessibilitydocumentapi主要用于保证浏览器响应给服务器的数据内容属于本地网络,而不是其他来源。在这里,用户已经不能从网页上提取任何有价值的数据,所以我们要用“cache-control:auto”来过滤script标签。例如,如果在accessibilityapi中包含了将相应网页保存到本地的请求,那么在提交到服务器的响应时,这个请求要求cache-control:auto,只能允许在本地进行传输。
我们可以看到class-malforming属性来控制这个css属性的值,class-malforming可以将一个script标签视为在浏览器中渲染的script元素,这样dom元素将保持简单。但是这种方式在日新月异的网络环境下很有可能不太实用。例如可能会出现以下现象:一个占据着前端站点标题链接中的超大区域。
例如可能会使占据过多的css样式,且重叠在其他元素中。这个css样式在当前前端站点内无法被读取到。为了控制控制台(和非浏览器控制台)控制的首字母大小写和匹配到的元素。bashdb已经将所有使用到的javascript语言强制转换为utf-8。像这样的小失误意味着可能在不同环境下产生语言不兼容,字符无法编码并且也无法作为参数返回到服务器。
所以我们就需要一个统一规范,以便在整个生命周期中都能做到各平台互操作。commonjs:less,sass,amd等es开发语言的常用格式模板,它包含了所有加载数据和数据构造器,适合传入多个数据类型。这种模板化有个问题,我们需要显式传入一个特定元素或者要求包含所有的es文件,所以这样的模板化必须安装依赖包。
es6有一个新特性叫做commonjsmodules,我们称它为依赖包模式(dependencyinjection)。dependencyinjection假定你准备定义一个应用程序,整个项。 查看全部
网页抓取qq(网页抓取/站外爬虫前端杂谈包含一整套学习资料)
网页抓取qq群/站外爬虫前端杂谈包含一整套学习资料0基础转向web安全,微信安全和社交防御计划现在,网站已经越来越强大,平台功能越来越多。从静态的图片和资源上传上,到动态的文件页面载入等,基本每个需要用户时时刻刻操作的网站都在采用javascript和css等方式进行相应的响应操作。“用户体验”对于互联网平台和互联网公司来说越来越重要。
浏览器和服务器和本质上是一个整体,都是我们的生命。如何让互联网平台生态得到充分的体验最好,让用户从入口被吸引,我们应该解决哪些问题。accessibilitydocumentapi,正是一种解决方案。它是从一个简单的抽象层面接受真实环境下产生的所有动态数据。accessibilitydocumentapi利用这些数据来和网页保持,在转发客户端的请求时需要进行accessibilitydocumentapi的请求。
accessibilitydocumentapi主要用于保证浏览器响应给服务器的数据内容属于本地网络,而不是其他来源。在这里,用户已经不能从网页上提取任何有价值的数据,所以我们要用“cache-control:auto”来过滤script标签。例如,如果在accessibilityapi中包含了将相应网页保存到本地的请求,那么在提交到服务器的响应时,这个请求要求cache-control:auto,只能允许在本地进行传输。
我们可以看到class-malforming属性来控制这个css属性的值,class-malforming可以将一个script标签视为在浏览器中渲染的script元素,这样dom元素将保持简单。但是这种方式在日新月异的网络环境下很有可能不太实用。例如可能会出现以下现象:一个占据着前端站点标题链接中的超大区域。
例如可能会使占据过多的css样式,且重叠在其他元素中。这个css样式在当前前端站点内无法被读取到。为了控制控制台(和非浏览器控制台)控制的首字母大小写和匹配到的元素。bashdb已经将所有使用到的javascript语言强制转换为utf-8。像这样的小失误意味着可能在不同环境下产生语言不兼容,字符无法编码并且也无法作为参数返回到服务器。
所以我们就需要一个统一规范,以便在整个生命周期中都能做到各平台互操作。commonjs:less,sass,amd等es开发语言的常用格式模板,它包含了所有加载数据和数据构造器,适合传入多个数据类型。这种模板化有个问题,我们需要显式传入一个特定元素或者要求包含所有的es文件,所以这样的模板化必须安装依赖包。
es6有一个新特性叫做commonjsmodules,我们称它为依赖包模式(dependencyinjection)。dependencyinjection假定你准备定义一个应用程序,整个项。
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-19 23:16
1.问题描述
最近,由于学习内容的要求,我们需要从网页上抓取一些数据进行分析报告。在阅读了Python crawler的一些基础知识后,我们可以直接开始网站爬升数据。作为新手,踩坑是不可避免的。最近,我遇到了一个难题:
通常,您需要抓取网页上标签上的内容。通过urllib下载网页内容后,您可以通过beautifulsup对象解析网页内容,然后可以使用fina\uAll()方法查找所需的标记内容
例如,我想捕获QQ音乐分类歌曲列表下的所有歌曲列表信息。分解任务后,应为:
抓取当前页面的歌曲列表信息;翻开新的一页;判断它是否是最后一页。如果不是最后一页,请返回步骤1。如果是最后一页,请结束爬虫程序
首先,编写一个简单的代码来捕获单个页面上所有歌曲的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
对于标记参数,您可以通过右键单击网页以检查网页属性来查找歌曲列表标题信息。属性类的值是playlist_utitle_uutxt,但是在执行代码之后,输出结果只是一个空列表,这不是很奇怪吗?作为一个新手,我真的花了很长时间绞尽脑汁,不知道为什么
在那之后,我和我的同学交流,听他谈论他以前见过的异步加载内容。我发现它与我抓取的网页的功能有点相似,所以我去寻找答案
流行的描述是,异步加载的网页显示的内容都来自当前网址表示的网页文件,并且当前网页文件通过对另一个网页内容的函数调用加载了一些内容,即,要抓取的内容所属的网页文件确实与当前网页文件不同,因此我无法抓取它。因此,您需要找到捕获内容真正属于的文件
2.溶液
接下来,我们将介绍如何查找异步加载的文件以及在获取过程中可能遇到的坑
1.右击网页,选择**检查,在调试界面中找到“网络”选项,然后逐个查找JS文件(记得刷新网页,否则JS文件不会显示),通过预览检查内容是否为您想要爬升的内容**
2.在每个JS文件的特定信息面板中,您可以通过预览查看传递的内容,我们找到歌曲列表标题信息的源文件,然后通过headers属性找到该信息的真实源文件的链接,并将URL作为我们的请求参数
headers属性下的general和request标头收录我们想要的信息。general属性下的URL还收录值传递类型。下面是get
因此,我们可以通过请求模块获取歌曲列表信息,这里需要注意的是,网页的request headers值应该传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3.一般来说,上面的处理过程会获取JSON对象(好像是字典的字符串表示),在Python中,可以直接使用JSON模块将JSON对象转换成Python对象-字典,从而通过键获取数据
jsDict = json.loads(jsContent)
但是,有时获取的数据表单会将JSON对象名称添加到JSON对象中,例如:
playList({...}) # 其中{}表示json对象内容
在这种情况下,无法通过JSON模块转换数据类型,通常会发生异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
对于这个异常,可以通过字符串片段截取JSON对象信息,然后通过JSON模块转换数据类型(这是我提出的一个傻瓜式方法。如果一个大个子知道一个更正式的方法,我希望纠正它)(っ • ̀ω•́) っ✎⁾⁾ ) 查看全部
网页抓取qq(如何寻找异步文件以及抓取内容的坑网页的文件)
1.问题描述
最近,由于学习内容的要求,我们需要从网页上抓取一些数据进行分析报告。在阅读了Python crawler的一些基础知识后,我们可以直接开始网站爬升数据。作为新手,踩坑是不可避免的。最近,我遇到了一个难题:
通常,您需要抓取网页上标签上的内容。通过urllib下载网页内容后,您可以通过beautifulsup对象解析网页内容,然后可以使用fina\uAll()方法查找所需的标记内容
例如,我想捕获QQ音乐分类歌曲列表下的所有歌曲列表信息。分解任务后,应为:
抓取当前页面的歌曲列表信息;翻开新的一页;判断它是否是最后一页。如果不是最后一页,请返回步骤1。如果是最后一页,请结束爬虫程序
首先,编写一个简单的代码来捕获单个页面上所有歌曲的标题:
import urllib
from bs4 import BeautifulSoup
url = https://y.qq.com/portal/playlist.html
html = urllib.urlopen(url)
bsObj = BeautifulSoup(html)
playTitle_list = bsObj.find_all("span", {"class": "playlist__title_txt"}) # 抓取该页面歌单标题并保存在列表中
print(playTitle_list)
for playTitle in playTitle_list: # 输出所有标题
print(i.get_text())
对于标记参数,您可以通过右键单击网页以检查网页属性来查找歌曲列表标题信息。属性类的值是playlist_utitle_uutxt,但是在执行代码之后,输出结果只是一个空列表,这不是很奇怪吗?作为一个新手,我真的花了很长时间绞尽脑汁,不知道为什么
在那之后,我和我的同学交流,听他谈论他以前见过的异步加载内容。我发现它与我抓取的网页的功能有点相似,所以我去寻找答案
流行的描述是,异步加载的网页显示的内容都来自当前网址表示的网页文件,并且当前网页文件通过对另一个网页内容的函数调用加载了一些内容,即,要抓取的内容所属的网页文件确实与当前网页文件不同,因此我无法抓取它。因此,您需要找到捕获内容真正属于的文件
2.溶液
接下来,我们将介绍如何查找异步加载的文件以及在获取过程中可能遇到的坑
1.右击网页,选择**检查,在调试界面中找到“网络”选项,然后逐个查找JS文件(记得刷新网页,否则JS文件不会显示),通过预览检查内容是否为您想要爬升的内容**
2.在每个JS文件的特定信息面板中,您可以通过预览查看传递的内容,我们找到歌曲列表标题信息的源文件,然后通过headers属性找到该信息的真实源文件的链接,并将URL作为我们的请求参数
headers属性下的general和request标头收录我们想要的信息。general属性下的URL还收录值传递类型。下面是get
因此,我们可以通过请求模块获取歌曲列表信息,这里需要注意的是,网页的request headers值应该传递给requests模块的get方法,否则无法获取网页
import requests
url = ...
headers ={...} # headers信息要以字典的形式保存
jsContent = requests.get(url).text
3.一般来说,上面的处理过程会获取JSON对象(好像是字典的字符串表示),在Python中,可以直接使用JSON模块将JSON对象转换成Python对象-字典,从而通过键获取数据
jsDict = json.loads(jsContent)
但是,有时获取的数据表单会将JSON对象名称添加到JSON对象中,例如:
playList({...}) # 其中{}表示json对象内容
在这种情况下,无法通过JSON模块转换数据类型,通常会发生异常
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
对于这个异常,可以通过字符串片段截取JSON对象信息,然后通过JSON模块转换数据类型(这是我提出的一个傻瓜式方法。如果一个大个子知道一个更正式的方法,我希望纠正它)(っ • ̀ω•́) っ✎⁾⁾ )
网页抓取qq( 下载非标准的包,下载方法及注意事项(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-18 21:01
下载非标准的包,下载方法及注意事项(二))
Golang抓取网页并分析网页中收录的链接
更新时间:2019年8月26日09:24:24作者:杨天晓
今天,小编将与大家分享一篇关于戈朗如何抓取网页并分析网页中收录的链接的文章,具有很好的参考价值,希望对大家有所帮助。让我们跟着小编看一看
1.下载非标准软件包,“/X/net/HTML”
2.install git first并使用git命令下载
git clone https://github.com/golang/net
3.将网络包放在goroot路径下
例如:
我的是:goroot=e:\go\
最后一个目录是:e:\go\SRC\\x\net
注意:如果没有和X文件夹,请创建它们
4.创建fetch目录并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"net/http"
"fmt"
"io/ioutil"
)
func main() {
for _, url := range os.Args[1:] {
resp, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
}
b, err := ioutil.ReadAll(resp.Body)
resp.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
fmt.Printf("%s",b)
}
}
pile-fetch
go build test.com\justin\demo\fetch
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
6.executefetch.exe文件
fetch.exe
注意:这是要爬升的URL。如果配置正确,将打印URL的HTML内容。如果没有,请检查上述步骤是否正确
7.web页面已被捕获,因此剩下的工作是分析页面中收录的链接,创建findlinks目录,并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"fmt"
"golang.org/x/net/html"
)
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprint(os.Stderr, "findlinks: %v\n", err)
os.Exit(1)
}
for _, link := range visit(nil, doc) {
fmt.Println(link)
}
}
func visit(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key == "href" {
links = append(links, a.Val)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = visit(links, c)
}
return links
}
pilefindlinks
go build test.com\justin\demo\findlinks
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
9.execute findlinks.exe文件
fetch.exe https://www.qq.com | findlinks.exe
>10.执行后结果:获得各种形式的超链接
上面关于golang如何捕获网页并分析网页中收录的链接的文章是小编共享的所有内容。我希望它能给你一个参考和支持脚本的房子 查看全部
网页抓取qq(
下载非标准的包,下载方法及注意事项(二))
Golang抓取网页并分析网页中收录的链接
更新时间:2019年8月26日09:24:24作者:杨天晓
今天,小编将与大家分享一篇关于戈朗如何抓取网页并分析网页中收录的链接的文章,具有很好的参考价值,希望对大家有所帮助。让我们跟着小编看一看
1.下载非标准软件包,“/X/net/HTML”
2.install git first并使用git命令下载
git clone https://github.com/golang/net
3.将网络包放在goroot路径下
例如:
我的是:goroot=e:\go\
最后一个目录是:e:\go\SRC\\x\net
注意:如果没有和X文件夹,请创建它们
4.创建fetch目录并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"net/http"
"fmt"
"io/ioutil"
)
func main() {
for _, url := range os.Args[1:] {
resp, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
}
b, err := ioutil.ReadAll(resp.Body)
resp.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
fmt.Printf("%s",b)
}
}
pile-fetch
go build test.com\justin\demo\fetch
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
6.executefetch.exe文件
fetch.exe
注意:这是要爬升的URL。如果配置正确,将打印URL的HTML内容。如果没有,请检查上述步骤是否正确
7.web页面已被捕获,因此剩下的工作是分析页面中收录的链接,创建findlinks目录,并在其下创建main.go文件。main.go文件的代码内容如下:
package main
import (
"os"
"fmt"
"golang.org/x/net/html"
)
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprint(os.Stderr, "findlinks: %v\n", err)
os.Exit(1)
}
for _, link := range visit(nil, doc) {
fmt.Println(link)
}
}
func visit(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key == "href" {
links = append(links, a.Val)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = visit(links, c)
}
return links
}
pilefindlinks
go build test.com\justin\demo\findlinks
注意:\Justin\demo\是我的项目路径。具体编译基于您自己的项目路径
9.execute findlinks.exe文件
fetch.exe https://www.qq.com | findlinks.exe
>10.执行后结果:获得各种形式的超链接
上面关于golang如何捕获网页并分析网页中收录的链接的文章是小编共享的所有内容。我希望它能给你一个参考和支持脚本的房子
网页抓取qq(获取网站访客QQ的一个方法(详情请见使用腾讯接口))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-14 11:09
我之前写过一篇文章,介绍了一种获取网站visitorQQ的方法(具体请参考使用腾讯界面轻松抓取网站visitorQQ)。可惜今天发现这个界面已经被Blocking不可用了。这里我提供另一种方法供大家参考!
首先按照惯例,在具体实现之前,先说一下实现原理。
当QQ用户登录QQ相关产品(包括登录QQ空间、其他QQ网页应用或相关第三方应用)时,会在用户电脑上留下一个标记(通常是cookie)来判断用户是否登录,虽然我们无法跨域访问其他域的cookies(其实你的cookie本身保存了你的QQ号),但是我们可以通过腾讯自己的API实现这个功能。
下午一群人在讨论这件事的时候,一个朋友还是很“正直”的质问我,说腾讯怎么会做这种泄露用户隐私的事情?当然,腾讯本身不会专门为你提供抓包用户QQ的接口,但有时难免需要泄露用户QQ号(多与OAuth有关),导致网上出现这些“get网站”。 “QQQQ”生意火爆。
核心代码如下:
doctype html>
网站访客QQ抓取
function gqq_callback(jsonstr)
{
alert("用户当前登录的QQ是:" + jsonstr.uin);
}
要获取用户的QQ,我们可以通过Ajax将QQ号和当前页面地址(location.href)保存到数据库中。
另外,要抓取访客QQ,访客必须先登录腾讯相关服务,如QQ空间。同时登录多个QQ的,以当前网页登录状态为准(用户可以同时登录多个QQ,但一个浏览器只能登录同一个QQ空间)
最后,如果你把不能用的代码贴出来,可以在评论里留言,我会再次发布最新可用的代码。
本文原创文章,如转载请注明作者及出处! 查看全部
网页抓取qq(获取网站访客QQ的一个方法(详情请见使用腾讯接口))
我之前写过一篇文章,介绍了一种获取网站visitorQQ的方法(具体请参考使用腾讯界面轻松抓取网站visitorQQ)。可惜今天发现这个界面已经被Blocking不可用了。这里我提供另一种方法供大家参考!
首先按照惯例,在具体实现之前,先说一下实现原理。
当QQ用户登录QQ相关产品(包括登录QQ空间、其他QQ网页应用或相关第三方应用)时,会在用户电脑上留下一个标记(通常是cookie)来判断用户是否登录,虽然我们无法跨域访问其他域的cookies(其实你的cookie本身保存了你的QQ号),但是我们可以通过腾讯自己的API实现这个功能。
下午一群人在讨论这件事的时候,一个朋友还是很“正直”的质问我,说腾讯怎么会做这种泄露用户隐私的事情?当然,腾讯本身不会专门为你提供抓包用户QQ的接口,但有时难免需要泄露用户QQ号(多与OAuth有关),导致网上出现这些“get网站”。 “QQQQ”生意火爆。
核心代码如下:
doctype html>
网站访客QQ抓取
function gqq_callback(jsonstr)
{
alert("用户当前登录的QQ是:" + jsonstr.uin);
}
要获取用户的QQ,我们可以通过Ajax将QQ号和当前页面地址(location.href)保存到数据库中。
另外,要抓取访客QQ,访客必须先登录腾讯相关服务,如QQ空间。同时登录多个QQ的,以当前网页登录状态为准(用户可以同时登录多个QQ,但一个浏览器只能登录同一个QQ空间)
最后,如果你把不能用的代码贴出来,可以在评论里留言,我会再次发布最新可用的代码。
本文原创文章,如转载请注明作者及出处!
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-11 23:13
上网时,经常会看到各种精美的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。它具有广泛的用途,尤其是在编写一些教程时。我经常需要用截图来提高文章的人气。下面脚本屋给大家分享一下QQ截图的使用方法、截图软件的截图、网页全页面的截图。
1:首先介绍一下QQ截图。 QQ是大家最常用的聊天工具。几乎每台电脑都有。因此,使用QQ截图非常方便。目前QQ聊天工具中的截图有很多,比如如何在截图上放说明文字,画箭头,画一些形状等等,来看看怎么用吧:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。 如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。
请点击小箭头设置截图。
具体的使用方法比较简单,这里就不啰嗦了,大家自己试试就知道了。
----------------------其他截图方法由Script Home友情提供---------------- - -----
1.windows 的打印键截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴并保存就可以了。
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度hi 默认截图快捷键是:Shift+Alt+A
3.浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
在菜单栏的工具截屏中有全屏截屏、区域截屏、窗口截屏等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图服务。
在网址栏中输入您要截取的网页网址,修改其他设置,点击确定按钮即可获取网页截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,如单屏截图、滚动截图、缩略图等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。
使用在线网页截图工具
5.pro 软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320 K
软件性质:绿色、免费
网页滚动截图软件下载
随着网站的信息越来越多,大多数网页都有不止一个屏幕。借助这款软件,我们可以实现滚动截图,也就是说第一屏底部也会被截取,让你随心所欲地保存自己喜欢的页面。
第五类和第四类可以实现滚动截图(即截取空间首页的整个页面)。
截图完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截图进行裁剪,修改截图的大小和大小。
编辑完成后,将截图上传到空间相册,获取地址图。 (百度贴吧改版后,图片宽度大于570px会自动缩略)
如何滚动和抓取整个网页图片
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、全屏截取
点击PrintScreen按钮,然后启动“Draw(Start-Program-Accessories)”,按Ctrl+V或“Edit-Paste”捕捉当前屏幕,然后保存为Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键只截取当前活动窗口,然后如上保存。
3、截取DirectX镜像
Print Screen 键无法捕获 DirectX 图像。没关系,只要我们做一点子计算,就可以让它发挥到极致。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。 (时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
以下介绍在线截图工具:
网页截图看似很简单,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就无所适从了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图! : 一个专门为网页截图创建的网站。主页非常简单。只需填写您要截屏的网址,然后点击“GO”即可。
杂汤网:以前叫文文,后来改名为杂汤网。是一个提供中文截图服务的网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图大小,可以自定义需要的大小。默认为 160*120 和 1024*768。您还可以指定捕获时间,以秒为单位。
thumbalizr:允许你截取任何网页的截图,并提供150、320、640、800、1024、1280等宽度截图供你下载,当然,您还可以自定义大小。
webthumb:一个非常简单的在线截图工具,可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图会根据网站的变化自动更新。
websnapr:国外非常有名的截图网站。但是不建议大家使用,它默认只提供小(202×152))和微(90×70))截图,付费会员可以享受更大的截图<//p
p以上是Script House为大家提供的多种网络截图方法。目前是我找到的所有截图方法的总结。应该是网上最详细的截图了文章吧,更多电脑技巧>> 查看全部
网页抓取qq(如何使用QQ截图、使用截图软件截图以及网页全页面截图)
上网时,经常会看到各种精美的图片。有些人只是喜欢图片的一小部分。这时候我们就可以使用截图工具来保存我们喜欢的图片了。它具有广泛的用途,尤其是在编写一些教程时。我经常需要用截图来提高文章的人气。下面脚本屋给大家分享一下QQ截图的使用方法、截图软件的截图、网页全页面的截图。
1:首先介绍一下QQ截图。 QQ是大家最常用的聊天工具。几乎每台电脑都有。因此,使用QQ截图非常方便。目前QQ聊天工具中的截图有很多,比如如何在截图上放说明文字,画箭头,画一些形状等等,来看看怎么用吧:
1、先登录QQ,随机打开一个好友进入聊天界面,然后点击截图工具按钮。
使用QQ截图工具的第一步
点击截图按钮后,鼠标颜色变为彩色。这时候我们就可以用鼠标将需要截屏的区域拖出来,然后点击截屏就完成了。
同时,在完成之前,完成前有很多图标。其中,A为正文。点击A,然后在截图需要的位置拖出一个文本区域输入图片。效果如上图所示。 如果需要设置,比如截屏时隐藏这个聊天窗口,可以在设置中截屏时隐藏当前窗口。
请点击小箭头设置截图。
具体的使用方法比较简单,这里就不啰嗦了,大家自己试试就知道了。
----------------------其他截图方法由Script Home友情提供---------------- - -----
1.windows 的打印键截图
打开需要截图的窗口,按alt+print screen(或prtsc),这个窗口的截图会保存到剪贴板,然后打开绘图或photoshop等软件,新建一个图片文件,粘贴并保存就可以了。
注意:alt+print screen(或prtsc)是截取当前窗口,print screen(或prtsc)是截取全屏。
2.百度hi 默认截图快捷键是:Shift+Alt+A
3.浏览器截图
如果您使用的是傲游浏览器,那么您可以使用其内置的截图功能进行截图。
在菜单栏的工具截屏中有全屏截屏、区域截屏、窗口截屏等几个选项。您可以根据需要截取屏幕截图。区域截图默认快捷键为:Ctrl+F1
使用傲游浏览器工具截图很方便
4.在线网页截图
抓糖网提供免费的网页在线截图服务。
在网址栏中输入您要截取的网页网址,修改其他设置,点击确定按钮即可获取网页截图。值得一提的是,Seacat Snapshot 可以提供多种截图效果,如单屏截图、滚动截图、缩略图等。
网站会不定时清理截图,所以需要将截图保存到本地或者上传到相册。
使用在线网页截图工具
5.pro 软件截图
软件名称:奇峰网页滚动截图软件
软件大小:320 K
软件性质:绿色、免费
网页滚动截图软件下载
随着网站的信息越来越多,大多数网页都有不止一个屏幕。借助这款软件,我们可以实现滚动截图,也就是说第一屏底部也会被截取,让你随心所欲地保存自己喜欢的页面。
第五类和第四类可以实现滚动截图(即截取空间首页的整个页面)。
截图完成后,您可以使用photoshop、光影魔手、绘图等图像处理软件对截图进行裁剪,修改截图的大小和大小。
编辑完成后,将截图上传到空间相册,获取地址图。 (百度贴吧改版后,图片宽度大于570px会自动缩略)
如何滚动和抓取整个网页图片
操作方法:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
HyperSnap-DX 截屏工具下载
具体步骤:
1、全屏截取
点击PrintScreen按钮,然后启动“Draw(Start-Program-Accessories)”,按Ctrl+V或“Edit-Paste”捕捉当前屏幕,然后保存为Bmp/Jpeg。
2.抓取当前活动窗口(最常用)
使用 Print Screen 截屏时,同时按下 Alt 键只截取当前活动窗口,然后如上保存。
3、截取DirectX镜像
Print Screen 键无法捕获 DirectX 图像。没关系,只要我们做一点子计算,就可以让它发挥到极致。在“开始”菜单的“运行”中输入Regedit,打开注册表编辑器,然后展开注册表HKEY_LOCAL_MACHINE\Software\Microsoft\DirectDraw分支,新建“DWORD”值,重命名为“EnablePrintScreen”,填写输入键值“1”,使Print Screen键具有截取DirectX图像的功能。
二、方法其实很简单:
打开 HyperSnap-DX
1、 点击“捕捉”-“捕捉设置”。
2、在打开的对话框中选择“捕获窗口时自动滚动窗口”,并使用默认时间20毫秒。 (时间随着抓取网页内容的多少而增加)
3、确定后会出现警告对话框窗口,忽略,然后确认。
4、 然后打开一个网页,按“ctrl+shift+S”组合键。
好的,试试。
以下介绍在线截图工具:
网页截图看似很简单,但实际上并没有那么简单。普通朋友可以用QQ截图。但是一旦网页比较长(有滚动条),或者周围没有QQ,那我们就无所适从了。有没有办法截取较长网页的屏幕截图?今天给大家带来几个网页版的网页截图工具,那就是网页版网络摄像头。不!不!别担心,它不是工具,只是几个网站。
超级截图! : 一个专门为网页截图创建的网站。主页非常简单。只需填写您要截屏的网址,然后点击“GO”即可。
杂汤网:以前叫文文,后来改名为杂汤网。是一个提供中文截图服务的网站。输入网址可以看到网页截图(全站屏幕截图和网页截图),缩略图、全屏等截图大小,可以自定义需要的大小。默认为 160*120 和 1024*768。您还可以指定捕获时间,以秒为单位。
thumbalizr:允许你截取任何网页的截图,并提供150、320、640、800、1024、1280等宽度截图供你下载,当然,您还可以自定义大小。
webthumb:一个非常简单的在线截图工具,可以选择截图或者页面,并提供合适的大小下载。注册后我们可为您提供250张截图,每张截图会根据网站的变化自动更新。
websnapr:国外非常有名的截图网站。但是不建议大家使用,它默认只提供小(202×152))和微(90×70))截图,付费会员可以享受更大的截图<//p
p以上是Script House为大家提供的多种网络截图方法。目前是我找到的所有截图方法的总结。应该是网上最详细的截图了文章吧,更多电脑技巧>>

