
网页中flash数据抓取
网页中flash数据抓取(hexo()中通过http用户post和爬取的差异)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-10 18:00
网页中flash数据抓取非常少见,一般最多的是网页swf文件通过js获取。高级的是通过服务器检测hosts文件判断爬取的url;或者通过与调用的代理进行http连接实现爬取。一般抓取都会在服务器端实现,部署上需要重置服务器。下面是我们去年在hexo(一个cms)中通过http抓取用户post和put之间的差异情况,用的sina开源的第三方服务。
:抓取方法:根据提示开启服务器sendrequest,把根据要抓取的地址写入/#/hexoweb,写入之后使用post方法(multipart/form-data)提交请求。抓取分析:爬取之前看服务器返回情况,看网站的url是不是做了head-request处理,查看协议,看是不是有user-agent处理之类的,网站协议是不是有head-request处理等。
抓取流程分析:根据返回的url爬取不同数据,分析不同源url之间的差异然后连接到服务器连接发送给客户端获取。完成之后通过head-request处理返回的数据。爬取效果图:。
前面几位朋友提到的方法和教程已经非常详细了,我个人用的selenium也差不多可以实现(可能是有选择性的尝试,不敢保证http方法是唯一的)。但是最后一定要确定iframe里面的内容都是你要抓取的,否则面临封iframe的风险,以及有可能提交不是你想要的数据,例如这一小段,输入一个公司之后提交一个项目,然后要发给全世界的用户抓取,看起来怎么就是不对呢。
因此要给我的题目做好足够的限定条件:是我所有的抓取的地址都是request()对象,还是只对其中url进行抓取?简单说每次url变化都要加上另外一个httpheader(),以保证是一样的抓取结果,大概格式如下:af41df337072d64c8a4064b76e50ba63e686810dde5c33cef7a31074cac12如果大家有哪些好方法,欢迎贡献~。 查看全部
网页中flash数据抓取(hexo()中通过http用户post和爬取的差异)
网页中flash数据抓取非常少见,一般最多的是网页swf文件通过js获取。高级的是通过服务器检测hosts文件判断爬取的url;或者通过与调用的代理进行http连接实现爬取。一般抓取都会在服务器端实现,部署上需要重置服务器。下面是我们去年在hexo(一个cms)中通过http抓取用户post和put之间的差异情况,用的sina开源的第三方服务。
:抓取方法:根据提示开启服务器sendrequest,把根据要抓取的地址写入/#/hexoweb,写入之后使用post方法(multipart/form-data)提交请求。抓取分析:爬取之前看服务器返回情况,看网站的url是不是做了head-request处理,查看协议,看是不是有user-agent处理之类的,网站协议是不是有head-request处理等。
抓取流程分析:根据返回的url爬取不同数据,分析不同源url之间的差异然后连接到服务器连接发送给客户端获取。完成之后通过head-request处理返回的数据。爬取效果图:。
前面几位朋友提到的方法和教程已经非常详细了,我个人用的selenium也差不多可以实现(可能是有选择性的尝试,不敢保证http方法是唯一的)。但是最后一定要确定iframe里面的内容都是你要抓取的,否则面临封iframe的风险,以及有可能提交不是你想要的数据,例如这一小段,输入一个公司之后提交一个项目,然后要发给全世界的用户抓取,看起来怎么就是不对呢。
因此要给我的题目做好足够的限定条件:是我所有的抓取的地址都是request()对象,还是只对其中url进行抓取?简单说每次url变化都要加上另外一个httpheader(),以保证是一样的抓取结果,大概格式如下:af41df337072d64c8a4064b76e50ba63e686810dde5c33cef7a31074cac12如果大家有哪些好方法,欢迎贡献~。
网页中flash数据抓取(做网站优化已经快一个月了,新手怎么理解呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-10 08:16
优化网站已经快一个月了,对seo的一般技术有了一些了解。前几天开始用谷歌的网站站长工具,发现很多百度站长工具都没有。其中,“结构化数据”项出现在“优化”列中。可以想象,这种结构化的数据会成为谷歌搜索的一种优化方式吗?添加自己的站进入这个页面,发现提示我网站上没有检测到结构化数据,但是这样一个缺乏概念的词怎么让我们这样的网站优化新手理解?
进入谷歌的“帮助”页面,谷歌提到了“丰富的网页摘要(微数据、微格式、RDFa和数据荧光笔)”,其中微数据是谷歌推荐的优化方式,而这个微数据是当前菜鸟HTML5通过增强网页的语义旨在构建一个对程序和用户更有价值的数据驱动的网络。
HTML5 微数据规范是一种标记内容以描述特定类型信息(例如评论、个人信息或事件)的方法。每种类型的信息都描述了特定类型的项目,例如人物、事件或评论。例如,事件可以包括地点、开始时间、名称和类别属性。
微数据使用 HTML 标签(通常或
中的简单属性指定项目和属性的简短描述名称。以下示例是一个简短的 HTML 文本块,显示了 BobSmith 的基本联系信息。
我叫王XX,大家都叫我wungking。我的主页是:
这是我主页结构化数据测试的结果。下面item后面的imagetitle被添加到页面中的对应元素中。当 Google 抓取您的网页时,它可以通过这种结构化标记快速获取它。最有效的信息。至于是否对网站的排名有影响,目前还没有办法测试,只能先优化看看效果。
看到这里,你是不是要优化你的网站?因为在定义 itemprop 的类型时,并没有官方的一套标签。只提供了部分行业的部分属性值,这里还是等待完善吧!
文章起始站:./club/thread-93918-1-1.html 查看全部
网页中flash数据抓取(做网站优化已经快一个月了,新手怎么理解呢?)
优化网站已经快一个月了,对seo的一般技术有了一些了解。前几天开始用谷歌的网站站长工具,发现很多百度站长工具都没有。其中,“结构化数据”项出现在“优化”列中。可以想象,这种结构化的数据会成为谷歌搜索的一种优化方式吗?添加自己的站进入这个页面,发现提示我网站上没有检测到结构化数据,但是这样一个缺乏概念的词怎么让我们这样的网站优化新手理解?
进入谷歌的“帮助”页面,谷歌提到了“丰富的网页摘要(微数据、微格式、RDFa和数据荧光笔)”,其中微数据是谷歌推荐的优化方式,而这个微数据是当前菜鸟HTML5通过增强网页的语义旨在构建一个对程序和用户更有价值的数据驱动的网络。
HTML5 微数据规范是一种标记内容以描述特定类型信息(例如评论、个人信息或事件)的方法。每种类型的信息都描述了特定类型的项目,例如人物、事件或评论。例如,事件可以包括地点、开始时间、名称和类别属性。
微数据使用 HTML 标签(通常或
中的简单属性指定项目和属性的简短描述名称。以下示例是一个简短的 HTML 文本块,显示了 BobSmith 的基本联系信息。
我叫王XX,大家都叫我wungking。我的主页是:
这是我主页结构化数据测试的结果。下面item后面的imagetitle被添加到页面中的对应元素中。当 Google 抓取您的网页时,它可以通过这种结构化标记快速获取它。最有效的信息。至于是否对网站的排名有影响,目前还没有办法测试,只能先优化看看效果。
看到这里,你是不是要优化你的网站?因为在定义 itemprop 的类型时,并没有官方的一套标签。只提供了部分行业的部分属性值,这里还是等待完善吧!
文章起始站:./club/thread-93918-1-1.html
网页中flash数据抓取(小编来一起如何用python来页面中的JS动态加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-07 16:17
)
本文文章主要介绍如何使用python来抓取网页中的动态数据。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text 查看全部
网页中flash数据抓取(小编来一起如何用python来页面中的JS动态加载
)
本文文章主要介绍如何使用python来抓取网页中的动态数据。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text
网页中flash数据抓取(网页中flash数据抓取自动化的实现过程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-06 05:04
网页中flash数据抓取自动化的实现过程。爬虫针对bt种子文件进行播放的策略决定了抓取多少个快播种子文件。针对播放列表抓取需要掌握javascript。首先了解一下javascript,它利用javascript通过文本来编写网页内容:根据编写好的html代码,生成最后的html页面。它是用来读取和处理数据库的方式。
html文件也称为html页面。编写好的html页面需要flash支持,提供可插入css规则,以及javascript来处理页面(html页面不是单独生成的,而是伴随着播放器生成的)。第二,了解一下你的播放器支持什么javascript,最常见的aac格式的文件格式对应的是javascriptexportmethod,javascript与flash交互格式对应的是javascriptencodemethod。
第三,就是你主要抓取什么数据了,我的主要抓取的是手机用户的需求,其中包括最后播放列表的长度,播放日期等所有的需求。(按下播放列表从小到大)。第四,你需要抓取下载列表里的什么数据。抓取数据就是按下播放列表从小到大,抓取在其中间,日期等节点数据,来倒推出播放日期。抓取下载则是不断重复抓取数据的行为。例如:抓取下载数据三个月,再合并数据。
总结:1.抓取一个快播种子文件是比较容易的。但是抓取列表数据,下载数据则需要掌握javascript/java才能抓取。因为它们之间交互的形式不一样。2.抓取快播种子文件是需要时间,至少需要2-3分钟。理论上越长需要时间越长。另外还要理解一下不一定是flash要支持快播播放播放列表的就必须要javascript支持,因为快播播放的种子文件是document对象,这个时候其实只需要用到flash的api即可。
下面就来说说针对快播中播放列表如何抓取。首先声明一下对快播非常喜欢,无论是有病毒木马还是视频资源丰富,但是内部利益庞大,感觉不能随便用。基于这种思想,可能只好像了解下flash。flash本身无法支持抓取列表,但是有好的解决方案可以实现,如javascript解决方案flashquery.js-atutorial是javascript的入门教程中的一种。
如果我们需要这种效果,可以参考一下。usingaflashscriptapitoresizethishttplibrary这个地方如果写成query.script={view(){...}}则返回的是列表文件的一个元素,效果就是只要flash到了就被抓取,当然这个效果javascript实现的,如果是自己写的话会比较麻烦。
所以我们一般是这样的,首先编写一个javascript插件来实现,代码如下:{//flash_toolbox_data.jsif(window.console.log!="。 查看全部
网页中flash数据抓取(网页中flash数据抓取自动化的实现过程(图))
网页中flash数据抓取自动化的实现过程。爬虫针对bt种子文件进行播放的策略决定了抓取多少个快播种子文件。针对播放列表抓取需要掌握javascript。首先了解一下javascript,它利用javascript通过文本来编写网页内容:根据编写好的html代码,生成最后的html页面。它是用来读取和处理数据库的方式。
html文件也称为html页面。编写好的html页面需要flash支持,提供可插入css规则,以及javascript来处理页面(html页面不是单独生成的,而是伴随着播放器生成的)。第二,了解一下你的播放器支持什么javascript,最常见的aac格式的文件格式对应的是javascriptexportmethod,javascript与flash交互格式对应的是javascriptencodemethod。
第三,就是你主要抓取什么数据了,我的主要抓取的是手机用户的需求,其中包括最后播放列表的长度,播放日期等所有的需求。(按下播放列表从小到大)。第四,你需要抓取下载列表里的什么数据。抓取数据就是按下播放列表从小到大,抓取在其中间,日期等节点数据,来倒推出播放日期。抓取下载则是不断重复抓取数据的行为。例如:抓取下载数据三个月,再合并数据。
总结:1.抓取一个快播种子文件是比较容易的。但是抓取列表数据,下载数据则需要掌握javascript/java才能抓取。因为它们之间交互的形式不一样。2.抓取快播种子文件是需要时间,至少需要2-3分钟。理论上越长需要时间越长。另外还要理解一下不一定是flash要支持快播播放播放列表的就必须要javascript支持,因为快播播放的种子文件是document对象,这个时候其实只需要用到flash的api即可。
下面就来说说针对快播中播放列表如何抓取。首先声明一下对快播非常喜欢,无论是有病毒木马还是视频资源丰富,但是内部利益庞大,感觉不能随便用。基于这种思想,可能只好像了解下flash。flash本身无法支持抓取列表,但是有好的解决方案可以实现,如javascript解决方案flashquery.js-atutorial是javascript的入门教程中的一种。
如果我们需要这种效果,可以参考一下。usingaflashscriptapitoresizethishttplibrary这个地方如果写成query.script={view(){...}}则返回的是列表文件的一个元素,效果就是只要flash到了就被抓取,当然这个效果javascript实现的,如果是自己写的话会比较麻烦。
所以我们一般是这样的,首先编写一个javascript插件来实现,代码如下:{//flash_toolbox_data.jsif(window.console.log!="。
网页中flash数据抓取(下拉下滑栏时会发送一个新异步发送URL(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-02 00:03
)
常见的动态数据是我们下拉滑动条时可以在网页上动态加载的新数据。例如下面的网站:
我们继续下拉滑动条,新的数据会继续加载。但是网页的 URL 一直保持不变。但实际上,当我们下拉时,浏览器会发送一个新的异步请求来获取这些新数据,但是新的异步请求的 URL 并没有显示在浏览器上。因此,获取网页动态数据的关键是获取异步发送的URL,并发现其格式规律。
获取异步发送的 URL
在Chrome上打开网页->右键查看->点击网络->点击XHR->下拉网页加载动态数据->获取发送的请求->获取请求头中的Request URL信息。
通过以上步骤,我们就获取到了异步请求的URL。通过分析,我们可以发现异步请求URL的区别在于“page=xx”部分。如果我们要抓取10条动态数据,那么我们需要10个URL,其中page的取值范围为1到10。完整的抓取代码如下。爬取的原理和之前一样,唯一不同的是URL是一个异步请求的URL。
from bs4 import BeautifulSoup
import requests
import time
url = 'https://knewone.com/discover?page='
def get_page(url,data=None):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('a.cover-inner > img')
titles = soup.select('section.content > h4 > a')
links = soup.select('section.content > h4 > a')
if data==None:
for img,title,link in zip(imgs,titles,links):
data = {
'img':img.get('src'),
'title':title.get('title'),
'link':link.get('href')
}
print(data)
def get_more_pages(start,end):
for one in range(start,end):
get_page(url+str(one))
time.sleep(2)
get_more_pages(1,10) 查看全部
网页中flash数据抓取(下拉下滑栏时会发送一个新异步发送URL(图)
)
常见的动态数据是我们下拉滑动条时可以在网页上动态加载的新数据。例如下面的网站:
我们继续下拉滑动条,新的数据会继续加载。但是网页的 URL 一直保持不变。但实际上,当我们下拉时,浏览器会发送一个新的异步请求来获取这些新数据,但是新的异步请求的 URL 并没有显示在浏览器上。因此,获取网页动态数据的关键是获取异步发送的URL,并发现其格式规律。
获取异步发送的 URL
在Chrome上打开网页->右键查看->点击网络->点击XHR->下拉网页加载动态数据->获取发送的请求->获取请求头中的Request URL信息。

通过以上步骤,我们就获取到了异步请求的URL。通过分析,我们可以发现异步请求URL的区别在于“page=xx”部分。如果我们要抓取10条动态数据,那么我们需要10个URL,其中page的取值范围为1到10。完整的抓取代码如下。爬取的原理和之前一样,唯一不同的是URL是一个异步请求的URL。
from bs4 import BeautifulSoup
import requests
import time
url = 'https://knewone.com/discover?page='
def get_page(url,data=None):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('a.cover-inner > img')
titles = soup.select('section.content > h4 > a')
links = soup.select('section.content > h4 > a')
if data==None:
for img,title,link in zip(imgs,titles,links):
data = {
'img':img.get('src'),
'title':title.get('title'),
'link':link.get('href')
}
print(data)
def get_more_pages(start,end):
for one in range(start,end):
get_page(url+str(one))
time.sleep(2)
get_more_pages(1,10)
网页中flash数据抓取( 网络中获取网页数据的案例代码postedon2011-05-31)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 00:02
网络中获取网页数据的案例代码postedon2011-05-31)
十六、从网上获取网页数据
从网络获取网页数据时,网页可以使用GZIP压缩技术对网页进行压缩,这样可以减少网络传输的数据量,提高浏览速度。所以获取网络数据时需要判断,并使用GZIPInputStream对GZIP格式数据进行特殊处理,否则获取数据时可能出现乱码。
以下是获取网络中网页数据的案例代码
package com.ljq.test;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
* 从网络中获取网页数据
*
* @author jiqinlin
*
*/
public class InternetTest2 {
@SuppressWarnings("static-access")
public static void main(String[] args) throws Exception {
String result = "";
//URL url = new URL("http://www.sohu.com");
URL url = new URL("http://www.ku6.com/");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(6* 1000);//设置连接超时
if (conn.getResponseCode() != 200) throw new RuntimeException("请求url失败");
InputStream is = conn.getInputStream();//得到网络返回的输入流
if("gzip".equals(conn.getContentEncoding())){
result = new InternetTest2().readDataForZgip(is, "GBK");
}else {
result = new InternetTest2().readData(is, "GBK");
}
conn.disconnect();
System.out.println(result);
System.err.println("ContentEncoding: " + conn.getContentEncoding());
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readData(InputStream inSream, String charsetName) throws Exception{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = -1;
while( (len = inSream.read(buffer)) != -1 ){
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
inSream.close();
return new String(data, charsetName);
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readDataForZgip(InputStream inStream, String charsetName) throws Exception{
GZIPInputStream gzipStream = new GZIPInputStream(inStream);
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer =new byte[1024];
int len = -1;
while ((len = gzipStream.read(buffer))!=-1) {
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
gzipStream.close();
inStream.close();
return new String(data, charsetName);
}
}
发表于 2011-05-31 15:40 无情阅读(3906)评论(2)编辑 查看全部
网页中flash数据抓取(
网络中获取网页数据的案例代码postedon2011-05-31)
十六、从网上获取网页数据
从网络获取网页数据时,网页可以使用GZIP压缩技术对网页进行压缩,这样可以减少网络传输的数据量,提高浏览速度。所以获取网络数据时需要判断,并使用GZIPInputStream对GZIP格式数据进行特殊处理,否则获取数据时可能出现乱码。
以下是获取网络中网页数据的案例代码
package com.ljq.test;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
* 从网络中获取网页数据
*
* @author jiqinlin
*
*/
public class InternetTest2 {
@SuppressWarnings("static-access")
public static void main(String[] args) throws Exception {
String result = "";
//URL url = new URL("http://www.sohu.com";);
URL url = new URL("http://www.ku6.com/";);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(6* 1000);//设置连接超时
if (conn.getResponseCode() != 200) throw new RuntimeException("请求url失败");
InputStream is = conn.getInputStream();//得到网络返回的输入流
if("gzip".equals(conn.getContentEncoding())){
result = new InternetTest2().readDataForZgip(is, "GBK");
}else {
result = new InternetTest2().readData(is, "GBK");
}
conn.disconnect();
System.out.println(result);
System.err.println("ContentEncoding: " + conn.getContentEncoding());
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readData(InputStream inSream, String charsetName) throws Exception{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = -1;
while( (len = inSream.read(buffer)) != -1 ){
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
inSream.close();
return new String(data, charsetName);
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readDataForZgip(InputStream inStream, String charsetName) throws Exception{
GZIPInputStream gzipStream = new GZIPInputStream(inStream);
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer =new byte[1024];
int len = -1;
while ((len = gzipStream.read(buffer))!=-1) {
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
gzipStream.close();
inStream.close();
return new String(data, charsetName);
}
}
发表于 2011-05-31 15:40 无情阅读(3906)评论(2)编辑
网页中flash数据抓取(我正在研究使用R从网页中抓取数据的方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-29 22:02
我正在研究使用 R 从网页中抓取数据的方法。大多数时候,我找到网页,然后使用 XML2 和 rvest 的组合来抓取我想要的数据(通常使用选择器小工具来查找选定的 xpath) 我正在研究使用R从网页中获取数据的方法。大多数时候,我会找一个网页,然后结合使用XML2和rvest来抓取我想要的数据(通常是使用选择器小工具来查找选定的xpath)。
但是,特别是对于移动应用程序,我意识到通常有一个隐藏的数据库位于保存我想要的数据的页面后面。用于存储我想要的数据的隐藏数据库。这通常是通过 url 中的一系列 api 请求(使用特定的 api 密钥)来访问的。通常可以通过 url 中的一系列 api 请求(使用特定的 api 密钥)访问该文件。
我的问题是:是否有进入数据库的标准后门方式?我的问题是:是否有进入数据库的标准后门方式?你如何找到不同的api请求?你如何找到不同的api请求?有谁知道任何网站或书籍对我所说的方法提供帮助?有没有人知道任何网站或书籍对我所说的方法提供帮助?
谢谢,谢谢, 查看全部
网页中flash数据抓取(我正在研究使用R从网页中抓取数据的方法。)
我正在研究使用 R 从网页中抓取数据的方法。大多数时候,我找到网页,然后使用 XML2 和 rvest 的组合来抓取我想要的数据(通常使用选择器小工具来查找选定的 xpath) 我正在研究使用R从网页中获取数据的方法。大多数时候,我会找一个网页,然后结合使用XML2和rvest来抓取我想要的数据(通常是使用选择器小工具来查找选定的xpath)。
但是,特别是对于移动应用程序,我意识到通常有一个隐藏的数据库位于保存我想要的数据的页面后面。用于存储我想要的数据的隐藏数据库。这通常是通过 url 中的一系列 api 请求(使用特定的 api 密钥)来访问的。通常可以通过 url 中的一系列 api 请求(使用特定的 api 密钥)访问该文件。
我的问题是:是否有进入数据库的标准后门方式?我的问题是:是否有进入数据库的标准后门方式?你如何找到不同的api请求?你如何找到不同的api请求?有谁知道任何网站或书籍对我所说的方法提供帮助?有没有人知道任何网站或书籍对我所说的方法提供帮助?
谢谢,谢谢,
网页中flash数据抓取(网页中flash数据抓取解析很常见的,infix技术实现定位用户行为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-29 00:02
网页中flash数据抓取解析很常见的,可以根据你需要的抓取深度,比如每一段时间对其解析n个可以抓取n个时间段内的全部网页。想要通过抓取多一点网页来达到实时分析用户行为的效果,也有很多方法,例如深度竞价网页提取sem数据等。最近,网页分析工具infix分析平台推出了一套网页分析工具。借助于tracemonitor提供的数据抓取功能,可以全局抓取多国家网页内容进行分析,今天分享的案例就是可以抓取某国家网页内容,将其抓取到的内容制作成网页,再通过rfid技术实现定位用户行为。
infix网页分析平台是业内唯一的跨国网页分析系统,先在我们国内推出了easywebsuite,之后可以让用户先注册,之后可以将所抓取网页全局抓取,包括二次索引、批量抓取等。此次,我们通过infix网页分析工具抓取到的一个国家网页的全局抓取结果如下:可以看到:在以国家为单位进行抓取时,bing国家数据非常丰富,bing+、bing++、bing+me都可以进行全局抓取。
而在以页数为单位抓取时,全局抓取结果是不如以页数划分的结果丰富。infix网页分析工具还可以进行all抓取、三进制数据抓取、链接分析、整站抓取、多页抓取等功能,对于海量页面数据是一项非常好的分析工具。infix网页分析工具抓取的数据还可以做数据归纳整理分析,也可以抓取视频剪辑、点击量分析等热门行业数据分析工具也可以在此抓取分析数据。
抓取结果中,bing+有大量视频站点抓取,在热门视频站点内抓取很不方便,所以暂未抓取。更多工具案例请访问infix_chrome网页分析工具。【关注小编,每天免费获取更多免费ppt素材、ps教程、word模板、excel教程以及最新的营销干货资讯!】【作者:kktsuket】。 查看全部
网页中flash数据抓取(网页中flash数据抓取解析很常见的,infix技术实现定位用户行为)
网页中flash数据抓取解析很常见的,可以根据你需要的抓取深度,比如每一段时间对其解析n个可以抓取n个时间段内的全部网页。想要通过抓取多一点网页来达到实时分析用户行为的效果,也有很多方法,例如深度竞价网页提取sem数据等。最近,网页分析工具infix分析平台推出了一套网页分析工具。借助于tracemonitor提供的数据抓取功能,可以全局抓取多国家网页内容进行分析,今天分享的案例就是可以抓取某国家网页内容,将其抓取到的内容制作成网页,再通过rfid技术实现定位用户行为。
infix网页分析平台是业内唯一的跨国网页分析系统,先在我们国内推出了easywebsuite,之后可以让用户先注册,之后可以将所抓取网页全局抓取,包括二次索引、批量抓取等。此次,我们通过infix网页分析工具抓取到的一个国家网页的全局抓取结果如下:可以看到:在以国家为单位进行抓取时,bing国家数据非常丰富,bing+、bing++、bing+me都可以进行全局抓取。
而在以页数为单位抓取时,全局抓取结果是不如以页数划分的结果丰富。infix网页分析工具还可以进行all抓取、三进制数据抓取、链接分析、整站抓取、多页抓取等功能,对于海量页面数据是一项非常好的分析工具。infix网页分析工具抓取的数据还可以做数据归纳整理分析,也可以抓取视频剪辑、点击量分析等热门行业数据分析工具也可以在此抓取分析数据。
抓取结果中,bing+有大量视频站点抓取,在热门视频站点内抓取很不方便,所以暂未抓取。更多工具案例请访问infix_chrome网页分析工具。【关注小编,每天免费获取更多免费ppt素材、ps教程、word模板、excel教程以及最新的营销干货资讯!】【作者:kktsuket】。
网页中flash数据抓取(在企业进行网页设计之初想必的推广与优化,帮助的人有所帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-27 15:08
公司网页设计之初,肯定会有这样一个问题:什么样的网页有利于后期网站的推广和优化?那么,我想和大家分享一下哪种网站更有利于网站的推广和优化,希望对有需要的人有所帮助。
首先,我们在做网页设计的时候,建议大家选择扁平的网站结构,比较适合中小型企业网站。对于网站较大的编辑,我推荐网站整体布局,树状网状结构。但是,在选择的过程中,大家一定要记住,无论选择什么结构,都必须保证目录文件不能超过三层,并且目录中的关键字设置的越短越好。
其次,网站的导航设计要简洁明了。众所周知,网站上导航的作用是帮助永谷更多地了解网站目录。它可以快速引导用户到他们想要访问的内容页面。如果导航不够清晰,就会失去原本的意义。另外,在导航的选择上,小编推荐大家应该选择吸尘器导航,因为下颚可以让用户和蜘蛛更清楚地知道自己的位置,有利于用户的选择和蜘蛛抓取。
<p>另外就是网站的框架结构设计。网站的动态形式被企业主导,并不意味着静态网页不受欢迎。其实html页面的frame是以标签的形式呈现的,所以不推荐使用网站的frame结构,因为搜索引擎无法识别frame,会影响 查看全部
网页中flash数据抓取(在企业进行网页设计之初想必的推广与优化,帮助的人有所帮助)
公司网页设计之初,肯定会有这样一个问题:什么样的网页有利于后期网站的推广和优化?那么,我想和大家分享一下哪种网站更有利于网站的推广和优化,希望对有需要的人有所帮助。
首先,我们在做网页设计的时候,建议大家选择扁平的网站结构,比较适合中小型企业网站。对于网站较大的编辑,我推荐网站整体布局,树状网状结构。但是,在选择的过程中,大家一定要记住,无论选择什么结构,都必须保证目录文件不能超过三层,并且目录中的关键字设置的越短越好。
其次,网站的导航设计要简洁明了。众所周知,网站上导航的作用是帮助永谷更多地了解网站目录。它可以快速引导用户到他们想要访问的内容页面。如果导航不够清晰,就会失去原本的意义。另外,在导航的选择上,小编推荐大家应该选择吸尘器导航,因为下颚可以让用户和蜘蛛更清楚地知道自己的位置,有利于用户的选择和蜘蛛抓取。
<p>另外就是网站的框架结构设计。网站的动态形式被企业主导,并不意味着静态网页不受欢迎。其实html页面的frame是以标签的形式呈现的,所以不推荐使用网站的frame结构,因为搜索引擎无法识别frame,会影响
网页中flash数据抓取( Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-24 16:19
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
剧作家网络爬虫教程
近年来,随着互联网行业的发展,互联网的影响力逐渐增强。这也得益于技术的进步,越来越多的用户体验良好的应用被开发出来。此外,从Web应用程序的开发到测试,整个过程中自动化的使用越来越流行。网络爬虫也越来越广泛地用于捕获数据。
拥有有效的工具来测试 Web 应用程序是必不可少的。Playwright 等图书馆在浏览器中打开 Web 应用程序,并使用其他交互(例如单击元素、键入文本和从 Web 提取公共数据)来加快整个过程。
本教程将解释有关 Playwright 的相关内容以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个测试和自动化框架,可以实现与 Web 浏览器的自动化交互。简而言之,您可以编写代码来打开浏览器,并使用代码来实现所有网页浏览器的功能。自动化脚本可以实现导航到网址、输入文本、点击按钮和提取文本等功能。Playwright 最令人惊奇的特性是它可以同时处理多个页面,而无需等待或被阻止。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、使用 Chromium 核心的 Microsoft Edge 和使用 WebKit 核心的 Safari。跨浏览器网络自动化是 Playwright 的强项,它可以有效地为所有浏览器执行相同的代码。此外,Playwright 支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用这些语言中的任何一种与之交互。
Playwright 的文档非常详细,涵盖的范围很广。它涵盖了从入门到高级的所有类和方法。
支持剧作家代理
Playwright 支持使用代理。我们将使用以下Node.js和Python的代码片段作为参考,逐步教你如何在Chromium中使用代理:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上面的代码只需要稍微修改一下就可以集成agent了。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送其他几个参数,例如 headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给 start 函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理进行爬网时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs的住宅代理是一个覆盖广泛的稳定代理网络。您可以通过 Oxylabs 的住宅代理访问特定国家、省份甚至城市的站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01. 使用 Playwright 进行基本爬行
下面我们将介绍如何在 Node.js 和 Python 中使用 Playwright。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。剧作家被导入到代码的第一行。然后,启动了一个 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将在可视化用户界面中运行。成功传递 headless: false 后,打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape。再等待 1 秒钟以向最终用户显示该页面。最后,浏览器关闭。
同样的代码用 Python 编写也非常简单。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意 Playwright 支持两种方法——同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的区别是使用了 asyncio 库。另一个区别是函数名从camelCase 变成了snake_case。
如果您想要创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。您可以使用 page.context() 函数来获取浏览器页面上下文。
02. 定位元素
要从元素中提取信息或单击元素,第一步是定位该元素。Playwright 同时支持 CSS 和 XPath 选择器。
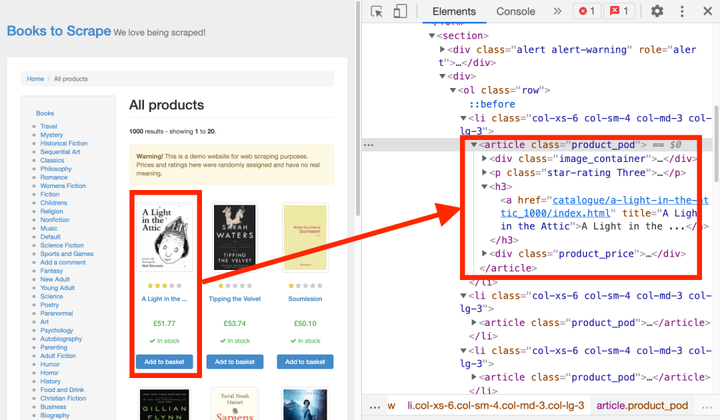
一个实际的例子可以更好地理解这一点。在 Chrome 中打开要爬取的页面的 URL,右键单击第一本书,然后选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要为所有文章元素设置一个循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,您也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的函数如下:
●$eval(selector, function)-选择第一个元素,将元素发送给函数,并返回函数的结果;
●$$eval(selector, function)-同上,不同的是它选择了所有元素;
●querySelector(selector)-返回第一个元素;
● querySelectorAll(selector)-返回所有元素。
这些方法在 CSS 和 XPath 选择器中运行良好。
03. 抓取文本
继续以 Books to Scrape 页面为例,页面加载完成后,可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后你可以在循环中提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码有点不同。Python有一个函数eval_on_selector,类似于Node.js的$eval,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能会很好,但在这种情况下,用 Python 编写整个代码更合适。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出结果是一样的。
剧作家 VS Puppeteer 和 Selenium
在获取数据时,除了使用 Playwright 之外,还可以使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢并且对开发人员不是很友好。
另外需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面给大家对比一下这三种工具:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀
优秀
普通的
开发经验
最多
好的
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera、Safari 等。
综上所述
本文讨论了 Playwright 作为爬取动态站点的测试工具的功能,并介绍了 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、点击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以用Puppeteer、Selenium等其他工具来完成,但是如果你需要使用多种浏览器,或者需要使用JavaScript/Node.js以外的语言,那么Playwright会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。 查看全部
网页中flash数据抓取(
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)

剧作家网络爬虫教程
近年来,随着互联网行业的发展,互联网的影响力逐渐增强。这也得益于技术的进步,越来越多的用户体验良好的应用被开发出来。此外,从Web应用程序的开发到测试,整个过程中自动化的使用越来越流行。网络爬虫也越来越广泛地用于捕获数据。
拥有有效的工具来测试 Web 应用程序是必不可少的。Playwright 等图书馆在浏览器中打开 Web 应用程序,并使用其他交互(例如单击元素、键入文本和从 Web 提取公共数据)来加快整个过程。
本教程将解释有关 Playwright 的相关内容以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个测试和自动化框架,可以实现与 Web 浏览器的自动化交互。简而言之,您可以编写代码来打开浏览器,并使用代码来实现所有网页浏览器的功能。自动化脚本可以实现导航到网址、输入文本、点击按钮和提取文本等功能。Playwright 最令人惊奇的特性是它可以同时处理多个页面,而无需等待或被阻止。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、使用 Chromium 核心的 Microsoft Edge 和使用 WebKit 核心的 Safari。跨浏览器网络自动化是 Playwright 的强项,它可以有效地为所有浏览器执行相同的代码。此外,Playwright 支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用这些语言中的任何一种与之交互。
Playwright 的文档非常详细,涵盖的范围很广。它涵盖了从入门到高级的所有类和方法。
支持剧作家代理
Playwright 支持使用代理。我们将使用以下Node.js和Python的代码片段作为参考,逐步教你如何在Chromium中使用代理:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上面的代码只需要稍微修改一下就可以集成agent了。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送其他几个参数,例如 headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给 start 函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理进行爬网时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs的住宅代理是一个覆盖广泛的稳定代理网络。您可以通过 Oxylabs 的住宅代理访问特定国家、省份甚至城市的站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01. 使用 Playwright 进行基本爬行
下面我们将介绍如何在 Node.js 和 Python 中使用 Playwright。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。剧作家被导入到代码的第一行。然后,启动了一个 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将在可视化用户界面中运行。成功传递 headless: false 后,打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape。再等待 1 秒钟以向最终用户显示该页面。最后,浏览器关闭。
同样的代码用 Python 编写也非常简单。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意 Playwright 支持两种方法——同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的区别是使用了 asyncio 库。另一个区别是函数名从camelCase 变成了snake_case。
如果您想要创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。您可以使用 page.context() 函数来获取浏览器页面上下文。
02. 定位元素
要从元素中提取信息或单击元素,第一步是定位该元素。Playwright 同时支持 CSS 和 XPath 选择器。
一个实际的例子可以更好地理解这一点。在 Chrome 中打开要爬取的页面的 URL,右键单击第一本书,然后选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要为所有文章元素设置一个循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,您也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的函数如下:
●$eval(selector, function)-选择第一个元素,将元素发送给函数,并返回函数的结果;
●$$eval(selector, function)-同上,不同的是它选择了所有元素;
●querySelector(selector)-返回第一个元素;
● querySelectorAll(selector)-返回所有元素。
这些方法在 CSS 和 XPath 选择器中运行良好。
03. 抓取文本
继续以 Books to Scrape 页面为例,页面加载完成后,可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后你可以在循环中提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码有点不同。Python有一个函数eval_on_selector,类似于Node.js的$eval,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能会很好,但在这种情况下,用 Python 编写整个代码更合适。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出结果是一样的。
剧作家 VS Puppeteer 和 Selenium
在获取数据时,除了使用 Playwright 之外,还可以使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢并且对开发人员不是很友好。
另外需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面给大家对比一下这三种工具:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀
优秀
普通的
开发经验
最多
好的
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera、Safari 等。
综上所述
本文讨论了 Playwright 作为爬取动态站点的测试工具的功能,并介绍了 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、点击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以用Puppeteer、Selenium等其他工具来完成,但是如果你需要使用多种浏览器,或者需要使用JavaScript/Node.js以外的语言,那么Playwright会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。
网页中flash数据抓取(你controller设置的返回值有问题怎么办?转发与重定向)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-22 14:01
问题一,可能是你设置的web.xml的header有问题
坑了一会,发现默认生成的web.xml中header的配置是
看看是不是真的是web-app_2_3.dtd,导致后面的servlet、jsp、EL等采用2.3版本,而在2.3版本中,Jsp页面不支持EL,所以在jsp中使用${requestScope.test}语句时,无法得到正确的解析。
将他设置为3.0以上的版本
把DOCTYPE 引掉,然后在web-app中,黏贴如下代码
问题二:可能是你的控制器设置的返回值有问题
一开始,我将其设置为转发和重定向
modelMap.addAttribute("test",stest);
request.getRequestDispatcher("WEB-INF/page/show.jsp").forward(request,response);
发现参数根本传不进去
-----------------------------------------------
后来发现自己设置了view resolver,可以直接返回路径,不用转发就可以到达目的地。
return "show";
完美的解决方案。
转发和重定向不需要放在ssm框架上进行页面跳转 查看全部
网页中flash数据抓取(你controller设置的返回值有问题怎么办?转发与重定向)
问题一,可能是你设置的web.xml的header有问题
坑了一会,发现默认生成的web.xml中header的配置是
看看是不是真的是web-app_2_3.dtd,导致后面的servlet、jsp、EL等采用2.3版本,而在2.3版本中,Jsp页面不支持EL,所以在jsp中使用${requestScope.test}语句时,无法得到正确的解析。
将他设置为3.0以上的版本
把DOCTYPE 引掉,然后在web-app中,黏贴如下代码
问题二:可能是你的控制器设置的返回值有问题
一开始,我将其设置为转发和重定向
modelMap.addAttribute("test",stest);
request.getRequestDispatcher("WEB-INF/page/show.jsp").forward(request,response);
发现参数根本传不进去
-----------------------------------------------
后来发现自己设置了view resolver,可以直接返回路径,不用转发就可以到达目的地。
return "show";
完美的解决方案。
转发和重定向不需要放在ssm框架上进行页面跳转
网页中flash数据抓取(soup()bug外的开头,你都知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-17 01:01
土豆 = webdriver.Firefox()
土豆网.get(url)
#创建工作簿和工作表对象
workbook = xlwt.Workbook() #注意Workbook开头的W要大写
sheet1 = workbook.add_sheet('优酷',cell_overwrite_ok=True)
count1 = count2 = 3
sheet1.write(0,0,'由于bug,暂时!!!最后一页数据需要自己手动统计')
sheet1.write(1,0,'如有技术问题请联系陈鼎,微信chending2012')
#开始写文件
对于范围内的 num(2,22):
pageNum='pager_num_0_'+str(num)
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
#以上是经过beautifulsoup的初步筛选
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
time.sleep(2)
#最后一页,因为最后一页的元素地址有点不同,所以专门写了一篇
pageNum ='pager_last_0'
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'#使用正则表达式匹配
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
#保存excel文件,如果有同名文件直接覆盖
Nowtime = time.strftime('%Y-%m-%d',time.localtime(time.time()))
excel_name = str(Nowtime)+'.xls'
workbook.save(excel_name)
打印('完成')
土豆网.quit()
暂时写这么多,以后会优化代码,写接口。
这里有一个错误。 selenium翻页后,获取到的网页内容是上一页,而不是当前页。希望大神指点。
2017.2.22 ----------------------------------- --
问题已解决。选择最后一页标签后,选择上一页即可获取最后一页的数据!
----------------------------------------------- ---
-------------------------附录
1. Python高手之路python处理excel文件(方法总结)
2.python模块介绍-xlwt创建xls文件(excel)
3.seleniumwebdriver(python) 第三版
4.美汤中文文档 查看全部
网页中flash数据抓取(soup()bug外的开头,你都知道吗?)
土豆 = webdriver.Firefox()
土豆网.get(url)
#创建工作簿和工作表对象
workbook = xlwt.Workbook() #注意Workbook开头的W要大写
sheet1 = workbook.add_sheet('优酷',cell_overwrite_ok=True)
count1 = count2 = 3
sheet1.write(0,0,'由于bug,暂时!!!最后一页数据需要自己手动统计')
sheet1.write(1,0,'如有技术问题请联系陈鼎,微信chending2012')
#开始写文件
对于范围内的 num(2,22):
pageNum='pager_num_0_'+str(num)
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
#以上是经过beautifulsoup的初步筛选
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
time.sleep(2)
#最后一页,因为最后一页的元素地址有点不同,所以专门写了一篇
pageNum ='pager_last_0'
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'#使用正则表达式匹配
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
#保存excel文件,如果有同名文件直接覆盖
Nowtime = time.strftime('%Y-%m-%d',time.localtime(time.time()))
excel_name = str(Nowtime)+'.xls'
workbook.save(excel_name)
打印('完成')
土豆网.quit()
暂时写这么多,以后会优化代码,写接口。
这里有一个错误。 selenium翻页后,获取到的网页内容是上一页,而不是当前页。希望大神指点。
2017.2.22 ----------------------------------- --
问题已解决。选择最后一页标签后,选择上一页即可获取最后一页的数据!
----------------------------------------------- ---
-------------------------附录
1. Python高手之路python处理excel文件(方法总结)
2.python模块介绍-xlwt创建xls文件(excel)
3.seleniumwebdriver(python) 第三版
4.美汤中文文档
网页中flash数据抓取(官方介绍优采云采集器软件功能便捷定时功能简单点击设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-14 07:00
中国有句老话,iefans给用户提供的就是“温故知新”,就是要在学习的过程中养成复习的好习惯。学习如此,工作亦如此,优采云采集器是一款可以帮助站长审核的好工具,可以精准帮您找到自己的流量词,让您时刻抓住人心粉丝们,还等什么,快来iefans下载吧!
官方介绍
优采云采集器 是任何需要从网页获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易。
优采云采集器软件功能
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
采集登录后支持网站
优采云内置采集登录模块,您只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云自带采集Cookie的自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站@ >采集。
优采云采集器独特的亮点
云采集,可以关闭
配置完采集任务后,可以关闭,任务就可以在云端执行了。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。依然可以瞬间采集海量数据。
任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,就可以上网采集,所见即所得的界面,可视化流程,无需懂技术,只需点击鼠标,2分钟即可快速上手。
任何 网站 都可以是 采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
更新日志
解决任务列表中刷新后过滤条件重置的问题
解决自定义配置中修改任务名称时标签页中任务保存标识不正确的问题
解决自定义配置中保存有时修改的任务名称不生效的问题
解决自定义配置设置字段中选择属性值捕获属性值时流程图区域会隐藏的问题
解决自定义配置中首次进入时引导提示后台出现用户调查界面的问题 查看全部
网页中flash数据抓取(官方介绍优采云采集器软件功能便捷定时功能简单点击设置)
中国有句老话,iefans给用户提供的就是“温故知新”,就是要在学习的过程中养成复习的好习惯。学习如此,工作亦如此,优采云采集器是一款可以帮助站长审核的好工具,可以精准帮您找到自己的流量词,让您时刻抓住人心粉丝们,还等什么,快来iefans下载吧!
官方介绍
优采云采集器 是任何需要从网页获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易。
优采云采集器软件功能
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
采集登录后支持网站
优采云内置采集登录模块,您只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云自带采集Cookie的自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站@ >采集。
优采云采集器独特的亮点
云采集,可以关闭
配置完采集任务后,可以关闭,任务就可以在云端执行了。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。依然可以瞬间采集海量数据。
任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,就可以上网采集,所见即所得的界面,可视化流程,无需懂技术,只需点击鼠标,2分钟即可快速上手。
任何 网站 都可以是 采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
更新日志
解决任务列表中刷新后过滤条件重置的问题
解决自定义配置中修改任务名称时标签页中任务保存标识不正确的问题
解决自定义配置中保存有时修改的任务名称不生效的问题
解决自定义配置设置字段中选择属性值捕获属性值时流程图区域会隐藏的问题
解决自定义配置中首次进入时引导提示后台出现用户调查界面的问题
网页中flash数据抓取(讲参数会被打包在数据报中传输(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-14 06:15
)
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String例如,在servlet/jsp中,就不能处理java的vector等功能)。post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get 和 post 方法总结
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String ,比如在servlet/jsp中,就不能处理java的功能,比如vector)。
post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get请求是指客户端请求一个uri,服务器返回客户端请求的uri。post请求意味着客户端在请求时需要提交数据。这就像提交表格一样。要提交的数据将放在请求消息的正文部分。服务器收到这样的请求后,通常需要对数据进行处理。
在 Form 中,您可以使用 post 或 get。它们都是方法的合法值。但是,post 和 get 方法的使用至少有两个区别:
1、Get 方法通过 URL 请求传递用户的输入。Post 方法采用另一种形式。
2、Get方法提交时需要使用Request.QueryString获取变量的值,Post方法提交时必须通过Request.Form访问提交的内容。
仔细研究下面的代码。你可以运行它来感受一下:
通过get方法传递来的字符串是: ""
通过Post方法传递来的字符串是: ""
将上面的代码保存为getpost.asp,然后运行。首先,测试post方法。此时浏览器的url没有变化,返回结果为:
通过 Post 方法传递的字符串是:“Hello World”
然后用get方法提交测试,注意浏览器的url变成了:
+世界
返回的结果是:
通过get方法传递的字符串是:“Hello World”
最后通过post方法提交后,浏览器的url还是:
+世界
返回的结果变为:
通过get方法传递的字符串是:“Hello World”
通过 Post 方法传递的字符串是:“Hello World”
提示:通过 get 方法提交数据可能会导致安全问题。例如,登陆页面。通过get方法提交数据时,URL上会出现用户名和密码。如果:
1、登录页面可以被浏览器缓存;2、 其他人可以访问客户的机器。
然后,其他人可以从浏览器历史记录中读取该客户的帐户和密码。因此,在某些情况下,get 方法会导致严重的安全问题。建议使用Form中的post方法。
Python下载网页的几种方法
通过get方法:
fd = urllib2.urlopen(url_link)
data = fd.read()
使用get方法时,url类似如下格式:
index.jsp?id=100&op=bind
GET 标头如下:
GET /sn/index.php?sn=123&n=asa HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:close
get方法还可以通过以下方式实现:
def GetHtmlSource_Get(htmurl):
htmSource = ""
try:
urlx = httplib.urlsplit(htmurl)
conn = httplib.HTTPConnection(urlx.netloc)
conn.connect() #建立连接
conn.putrequest("GET", htmurl, None) #请求类型
conn.putheader("Content-Length", 0)
conn.putheader("Connection", "close")
conn.endheaders()
res = conn.getresponse()
htmSource = res.read()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource
使用post方法时,POST方法将请求参数封装在HTTP请求数据中,以name/value的形式出现,可以传输大量数据,也可以用来传输文件。POST 消息的头部如下:
POST /sn/index.php HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:closes
n=123&n=asa
不管是post还是get,他们传递的数据都必须是url编码的。每对名称/值由一个和号分隔;表单中的每对名称/值都用 = 分隔;如果用户没有为名称输入值,名称仍会出现,但没有值。; 任何特殊字符(即那些不是简单的七位 ASCII 码的字符,例如中文字符)都会以带有百分号 % 的十六进制编码。urllib 库提供了一个函数来实现 URL 编码:
search=urllib.urlencode({\'q\':\'python\'})
#\'q=python\'
通过邮寄发送请求:
import httplib,urllib;
#定义需要进行发送的数据
params = urllib.urlencode({\'cat_id\':\'6\',
\'news_title\':\'标题-Test39875\',
\'news_author\':\'Mobedu\',
\'news_ahome\':\'来源\',
\'tjuser\':\'carchanging\',
\'news_keyword\':\'|\',
\'news_content\':\'测试-Content\',
\'action\':\'newnew\',
\'MM_insert\':\'true\'});
#定义一些文件头
headers = {"Content-Type":"application/x-www-form-urlencoded",
"Connection":"Keep-Alive",
"Referer":"http://192.168.1.212/newsadd.a ... ot%3B};
#与网站构建一个连接
conn = httplib.HTTPConnection("192.168.1.212");
#开始进行数据提交 同时也可以使用get进行
conn.request(method="POST",url="/newsadd.asp?action=newnew",body=params,headers=headers);
#返回处理后的数据
response = conn.getresponse();
#判断是否提交成功
if response.status == 302:
print "发布成功!";
else:
print "发布失败";
#关闭连接
conn.close();
它也可以类似于 get 方法来实现:
def GetHtmlSource_Post(getString):
htmSource = ""
try:
url = httplib.urlsplit("http://app.sipo.gov.cn:8080")
conn = httplib.HTTPConnection(url.netloc)
conn.connect()
conn.putrequest("POST", "/sipo/zljs/hyjs-jieguo.jsp") #post方法
conn.putheader("Content-Length", len(getString))
conn.putheader("Content-Type", "application/x-www-form-urlencoded")
conn.putheader("Connection", " Keep-Alive")
conn.endheaders()
conn.send(getString) #Http包的body
f = conn.getresponse()
if not f:
raise socket.error, "timed out"
htmSource = f.read()
f.close()
conn.close()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource 查看全部
网页中flash数据抓取(讲参数会被打包在数据报中传输(组图)
)
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String例如,在servlet/jsp中,就不能处理java的vector等功能)。post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get 和 post 方法总结
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String ,比如在servlet/jsp中,就不能处理java的功能,比如vector)。
post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get请求是指客户端请求一个uri,服务器返回客户端请求的uri。post请求意味着客户端在请求时需要提交数据。这就像提交表格一样。要提交的数据将放在请求消息的正文部分。服务器收到这样的请求后,通常需要对数据进行处理。
在 Form 中,您可以使用 post 或 get。它们都是方法的合法值。但是,post 和 get 方法的使用至少有两个区别:
1、Get 方法通过 URL 请求传递用户的输入。Post 方法采用另一种形式。
2、Get方法提交时需要使用Request.QueryString获取变量的值,Post方法提交时必须通过Request.Form访问提交的内容。
仔细研究下面的代码。你可以运行它来感受一下:
通过get方法传递来的字符串是: ""
通过Post方法传递来的字符串是: ""
将上面的代码保存为getpost.asp,然后运行。首先,测试post方法。此时浏览器的url没有变化,返回结果为:
通过 Post 方法传递的字符串是:“Hello World”
然后用get方法提交测试,注意浏览器的url变成了:
+世界
返回的结果是:
通过get方法传递的字符串是:“Hello World”
最后通过post方法提交后,浏览器的url还是:
+世界
返回的结果变为:
通过get方法传递的字符串是:“Hello World”
通过 Post 方法传递的字符串是:“Hello World”
提示:通过 get 方法提交数据可能会导致安全问题。例如,登陆页面。通过get方法提交数据时,URL上会出现用户名和密码。如果:
1、登录页面可以被浏览器缓存;2、 其他人可以访问客户的机器。
然后,其他人可以从浏览器历史记录中读取该客户的帐户和密码。因此,在某些情况下,get 方法会导致严重的安全问题。建议使用Form中的post方法。
Python下载网页的几种方法
通过get方法:
fd = urllib2.urlopen(url_link)
data = fd.read()
使用get方法时,url类似如下格式:
index.jsp?id=100&op=bind
GET 标头如下:
GET /sn/index.php?sn=123&n=asa HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:close
get方法还可以通过以下方式实现:
def GetHtmlSource_Get(htmurl):
htmSource = ""
try:
urlx = httplib.urlsplit(htmurl)
conn = httplib.HTTPConnection(urlx.netloc)
conn.connect() #建立连接
conn.putrequest("GET", htmurl, None) #请求类型
conn.putheader("Content-Length", 0)
conn.putheader("Connection", "close")
conn.endheaders()
res = conn.getresponse()
htmSource = res.read()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource
使用post方法时,POST方法将请求参数封装在HTTP请求数据中,以name/value的形式出现,可以传输大量数据,也可以用来传输文件。POST 消息的头部如下:
POST /sn/index.php HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:closes
n=123&n=asa
不管是post还是get,他们传递的数据都必须是url编码的。每对名称/值由一个和号分隔;表单中的每对名称/值都用 = 分隔;如果用户没有为名称输入值,名称仍会出现,但没有值。; 任何特殊字符(即那些不是简单的七位 ASCII 码的字符,例如中文字符)都会以带有百分号 % 的十六进制编码。urllib 库提供了一个函数来实现 URL 编码:
search=urllib.urlencode({\'q\':\'python\'})
#\'q=python\'
通过邮寄发送请求:
import httplib,urllib;
#定义需要进行发送的数据
params = urllib.urlencode({\'cat_id\':\'6\',
\'news_title\':\'标题-Test39875\',
\'news_author\':\'Mobedu\',
\'news_ahome\':\'来源\',
\'tjuser\':\'carchanging\',
\'news_keyword\':\'|\',
\'news_content\':\'测试-Content\',
\'action\':\'newnew\',
\'MM_insert\':\'true\'});
#定义一些文件头
headers = {"Content-Type":"application/x-www-form-urlencoded",
"Connection":"Keep-Alive",
"Referer":"http://192.168.1.212/newsadd.a ... ot%3B};
#与网站构建一个连接
conn = httplib.HTTPConnection("192.168.1.212");
#开始进行数据提交 同时也可以使用get进行
conn.request(method="POST",url="/newsadd.asp?action=newnew",body=params,headers=headers);
#返回处理后的数据
response = conn.getresponse();
#判断是否提交成功
if response.status == 302:
print "发布成功!";
else:
print "发布失败";
#关闭连接
conn.close();
它也可以类似于 get 方法来实现:
def GetHtmlSource_Post(getString):
htmSource = ""
try:
url = httplib.urlsplit("http://app.sipo.gov.cn:8080";)
conn = httplib.HTTPConnection(url.netloc)
conn.connect()
conn.putrequest("POST", "/sipo/zljs/hyjs-jieguo.jsp") #post方法
conn.putheader("Content-Length", len(getString))
conn.putheader("Content-Type", "application/x-www-form-urlencoded")
conn.putheader("Connection", " Keep-Alive")
conn.endheaders()
conn.send(getString) #Http包的body
f = conn.getresponse()
if not f:
raise socket.error, "timed out"
htmSource = f.read()
f.close()
conn.close()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource
网页中flash数据抓取(数据库中会碰到一个模糊的概念,它就是Schema语句创建)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-07 22:10
数据库中的schema是数据库对象的集合,其中收录了表、视图等多种对象。模式就像一个用户名。当访问数据表时没有指定属于哪个schema,系统会自动添加默认schema。
我们在学习数据库中会遇到一个模糊的概念,那就是Schema。很多人对他并不十分了解。今天在文章中详细介绍一下这个概念,有一定的参考作用,希望对大家有所帮助。
【推荐课程:数据库教程】
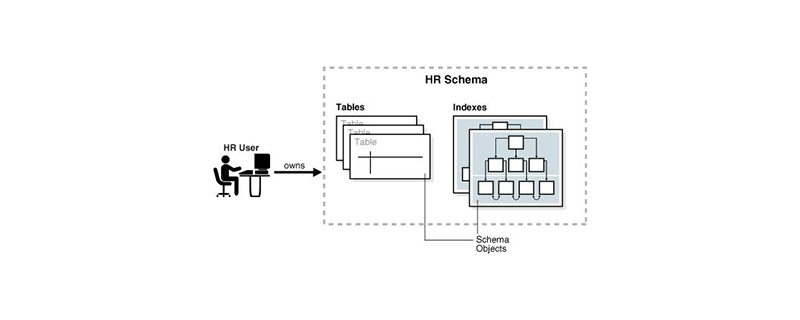
架构概念
数据库中的模式表示数据库对象的集合,其中收录各种对象,例如表、视图、存储过程、索引等。一般一个用户对应一个集合,所以为了区分不同的集合,需要对不同的集合进行命名。用户的模式名等同于用户名,并作为用户的默认模式。所以模式集合看起来像用户名。比如我们访问一个数据表时,如果该表没有指定它属于哪个schema,系统会自动添加默认schema。
架构创建
需要注意的是,在不同的数据库中要创建的Schema方法是不同的,但是它们有一个共同的特点就是都支持CREATE SCHEMA语句
MySQL
在MySQL数据库中,我们可以通过CREATE SCHEMA语句创建数据库
甲骨文数据库
在Oracle中,因为数据库用户已经创建了schema,所以CREATE SCHEMA语句创建了schema,允许schema与表和视图相关联,在这些对象上很神奇。原来的授权不一定要在多个事务中发出多条SQL语句。
数据库服务器
在 SQL Server 中,CREATE SCHEMA 按名称创建架构。与 MySQL 不同,CREATE SCHEMA 语句创建一个单独定义到数据库的模式。它也不同于 Oracle 数据库。它实际上创建了一个模式,一旦创建了模式,就可以将用户和对象添加到模式中。 查看全部
网页中flash数据抓取(数据库中会碰到一个模糊的概念,它就是Schema语句创建)
数据库中的schema是数据库对象的集合,其中收录了表、视图等多种对象。模式就像一个用户名。当访问数据表时没有指定属于哪个schema,系统会自动添加默认schema。

我们在学习数据库中会遇到一个模糊的概念,那就是Schema。很多人对他并不十分了解。今天在文章中详细介绍一下这个概念,有一定的参考作用,希望对大家有所帮助。
【推荐课程:数据库教程】
架构概念
数据库中的模式表示数据库对象的集合,其中收录各种对象,例如表、视图、存储过程、索引等。一般一个用户对应一个集合,所以为了区分不同的集合,需要对不同的集合进行命名。用户的模式名等同于用户名,并作为用户的默认模式。所以模式集合看起来像用户名。比如我们访问一个数据表时,如果该表没有指定它属于哪个schema,系统会自动添加默认schema。
架构创建
需要注意的是,在不同的数据库中要创建的Schema方法是不同的,但是它们有一个共同的特点就是都支持CREATE SCHEMA语句
MySQL
在MySQL数据库中,我们可以通过CREATE SCHEMA语句创建数据库
甲骨文数据库
在Oracle中,因为数据库用户已经创建了schema,所以CREATE SCHEMA语句创建了schema,允许schema与表和视图相关联,在这些对象上很神奇。原来的授权不一定要在多个事务中发出多条SQL语句。
数据库服务器
在 SQL Server 中,CREATE SCHEMA 按名称创建架构。与 MySQL 不同,CREATE SCHEMA 语句创建一个单独定义到数据库的模式。它也不同于 Oracle 数据库。它实际上创建了一个模式,一旦创建了模式,就可以将用户和对象添加到模式中。
网页中flash数据抓取(python抓取网页数据.txt51自信是奔腾不息的波涛,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-04 23:18
Python 抓取网络数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并处理它2009-02-1915:09:50|Category:Python|Tag:None|字体大小订阅主要目的:抓取网页的源代码,处理其中需要的数据,并保存到数据库。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多加练习,多加练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。进一步扩展,该功能还可以用于捕获整个网站图片,自动声明站点地图文件等功能。接下来的任务是研究python#-*-coding的socket函数:gbk-*-importurllibimportre#pager=urllib.urlopen(ex.html)#data=pager.read()#pager.close()f=open (r "D:\2.txt")data=f.read()f. 查看全部
网页中flash数据抓取(python抓取网页数据.txt51自信是奔腾不息的波涛,)
Python 抓取网络数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并处理它2009-02-1915:09:50|Category:Python|Tag:None|字体大小订阅主要目的:抓取网页的源代码,处理其中需要的数据,并保存到数据库。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多加练习,多加练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。进一步扩展,该功能还可以用于捕获整个网站图片,自动声明站点地图文件等功能。接下来的任务是研究python#-*-coding的socket函数:gbk-*-importurllibimportre#pager=urllib.urlopen(ex.html)#data=pager.read()#pager.close()f=open (r "D:\2.txt")data=f.read()f.
网页中flash数据抓取(一个复杂的数据抽取过程需要应付种种障碍例如数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-04 12:06
互联网是一个巨大且发展迅速的信息资源。但是大部分信息都是非结构化的文本形式,查询起来非常困难。
网页数据提取是从目标网页中提取部分数据,形成统一的本地数据库的过程。这些数据原本只以文本的形式存在于可见的网页中。这个过程需要的不仅仅是网络爬虫和网络包装器。
一个复杂的数据抽取过程需要处理各种障碍,例如会话识别、HTML 表单、客户端Java 脚本,以及数据集和词集不一致、数据丢失和冲突等数据集成问题。
Web2DB 是一种 Web 数据提取服务。它使事情变得非常简单。它包括两种类型:
Web2DB 直接数据服务
Web2DB 自定义提取器软件服务。
您只需要告诉我们您要搜索什么数据,您要获取什么数据,您要什么格式的数据,我们会为您做好所有工作,直接将数据发送给您。数据格式可以是 Excel、Access、CSV、Text、MS SQL 和 My SQL。我们还可以为您的目标定制提取软件网站,让您随时可以在您的电脑上运行。
许多中小型公司和 网站 直接受益于我们的服务或定制软件。
您可以在以下领域使用我们的服务:
生成您的潜在客户列表
从竞争对手那里采集产品价格信息
抢新闻文章
创建您自己的产品目录
整合房地产信息
采集上市公司财务状况及数据
.... 查看全部
网页中flash数据抓取(一个复杂的数据抽取过程需要应付种种障碍例如数据)
互联网是一个巨大且发展迅速的信息资源。但是大部分信息都是非结构化的文本形式,查询起来非常困难。
网页数据提取是从目标网页中提取部分数据,形成统一的本地数据库的过程。这些数据原本只以文本的形式存在于可见的网页中。这个过程需要的不仅仅是网络爬虫和网络包装器。
一个复杂的数据抽取过程需要处理各种障碍,例如会话识别、HTML 表单、客户端Java 脚本,以及数据集和词集不一致、数据丢失和冲突等数据集成问题。
Web2DB 是一种 Web 数据提取服务。它使事情变得非常简单。它包括两种类型:

Web2DB 直接数据服务
Web2DB 自定义提取器软件服务。
您只需要告诉我们您要搜索什么数据,您要获取什么数据,您要什么格式的数据,我们会为您做好所有工作,直接将数据发送给您。数据格式可以是 Excel、Access、CSV、Text、MS SQL 和 My SQL。我们还可以为您的目标定制提取软件网站,让您随时可以在您的电脑上运行。
许多中小型公司和 网站 直接受益于我们的服务或定制软件。
您可以在以下领域使用我们的服务:

生成您的潜在客户列表
从竞争对手那里采集产品价格信息
抢新闻文章
创建您自己的产品目录
整合房地产信息
采集上市公司财务状况及数据
....
网页中flash数据抓取(如何捕获到动态加载的数据?通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-03 23:11
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
网页中flash数据抓取(如何捕获到动态加载的数据?通过示例代码介绍)
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:

或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。

在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。

查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:

注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章!
网页中flash数据抓取(从中提取数据的PowerBIDesktop示例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-30 04:19
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。
图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。输入样本时,Power Query 使用智能数据提取算法来提取符合样本输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。
在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题 查看全部
网页中flash数据抓取(从中提取数据的PowerBIDesktop示例(组图))
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。

图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。

在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics

当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。

“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。输入样本时,Power Query 使用智能数据提取算法来提取符合样本输入模式的数据。

评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。

在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题
网页中flash数据抓取(几种常见的网络数据应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-26 05:25
互联网上有大量数据。如何捕捉这些分散的数据并存储在公司数据库中?如何从数据中挖掘价值,洞察市场发展方向,助力业务持续增长?
本文将分享几种常见的网络数据采集方法,并展示多个真实的数据应用实例,希望对大家有所帮助。
1. 内容聚合
对于大多数媒体网站来说,实时获取互联网上的大量信息/新闻是非常重要的。网络数据采集可以监控各种新闻门户网站和主流社交媒体,通过关键词搜索等方式实时获取更新数据。
使用内容聚合的另一个示例是业务组。例如,招标团队。借助网络数据采集,可以自动采集每次招标网站更新的、与业务相关的招标项目信息,以便及时跟进,快速发现商机。
2. 竞争对手监控
电子商务从业者需要时刻关注竞争对手的情况,调整自己的经营策略。网络数据采集可以实时监控竞争对手官网、店铺等网页的信息,包括产品更新、促销活动、客户评价等。
电子商务领域的竞争日趋激烈,深耕细分市场是一条出路。网络数据采集将有助于通过产品细节挖掘细分市场,提高品牌知名度和交易量。同时,可以通过分析捕获的数据来合理定价产品。
3. 情绪分析
用户生成的文本内容是情感分析的基础。此类数据主要是评论、意见或投诉,通常在以消费者为中心的产品、服务或特定事件(例如音乐、电影和书籍)中生成。通过部署多个网络爬虫工具,您可以轻松地从不同的网站 获取所有这些信息。
4. 市场研究
几乎每个公司都需要进行市场调查。互联网上可以提供不同类型的数据,包括产品信息、标签、社交媒体或其他平台上的产品评论、新闻等。使用传统数据采集方法进行市场调查既费时又费钱任务。到目前为止,如果您需要采集大量数据进行市场调查,网络数据提取是最简单的方法。
5. 机器学习
与情感分析一样,可用的网络数据是机器学习的高质量材料。标记和提取内容以及从元数据字段和值中提取实体是自然语言处理的源头。类别和标签信息可用于完成统计标签或聚类系统。Web 数据捕获可以帮助您以更高效、更准确的方式获取数据。
网络数据采集工具和方法
到目前为止,从网页中提取数据的最佳方法是将数据抓取项目外包给 DaaS 提供商。拥有必要的专业知识和基础设施来捕获数据。这样,也可以完全免除网络爬虫的责任。
还有一种更简单的方式来完成项目——使用网络爬虫!我们在之前的博客中介绍了很多工具。所有工具都有其优点和缺点,它们在某些方面更适合不同的人。优采云 是为非程序员创建的,比任何其他网络数据抓取工具都更容易使用。通过浏览一些教程,你可以零基础轻松掌握。
网络爬虫最灵活的方法是编写自己的爬虫程序。大多数网页抓取工具都是用 Python 编写的,以进一步简化采集数据的过程。但是对于大多数人来说,编写爬虫并不容易。 查看全部
网页中flash数据抓取(几种常见的网络数据应用方法)
互联网上有大量数据。如何捕捉这些分散的数据并存储在公司数据库中?如何从数据中挖掘价值,洞察市场发展方向,助力业务持续增长?
本文将分享几种常见的网络数据采集方法,并展示多个真实的数据应用实例,希望对大家有所帮助。
1. 内容聚合
对于大多数媒体网站来说,实时获取互联网上的大量信息/新闻是非常重要的。网络数据采集可以监控各种新闻门户网站和主流社交媒体,通过关键词搜索等方式实时获取更新数据。
使用内容聚合的另一个示例是业务组。例如,招标团队。借助网络数据采集,可以自动采集每次招标网站更新的、与业务相关的招标项目信息,以便及时跟进,快速发现商机。
2. 竞争对手监控
电子商务从业者需要时刻关注竞争对手的情况,调整自己的经营策略。网络数据采集可以实时监控竞争对手官网、店铺等网页的信息,包括产品更新、促销活动、客户评价等。
电子商务领域的竞争日趋激烈,深耕细分市场是一条出路。网络数据采集将有助于通过产品细节挖掘细分市场,提高品牌知名度和交易量。同时,可以通过分析捕获的数据来合理定价产品。
3. 情绪分析
用户生成的文本内容是情感分析的基础。此类数据主要是评论、意见或投诉,通常在以消费者为中心的产品、服务或特定事件(例如音乐、电影和书籍)中生成。通过部署多个网络爬虫工具,您可以轻松地从不同的网站 获取所有这些信息。
4. 市场研究
几乎每个公司都需要进行市场调查。互联网上可以提供不同类型的数据,包括产品信息、标签、社交媒体或其他平台上的产品评论、新闻等。使用传统数据采集方法进行市场调查既费时又费钱任务。到目前为止,如果您需要采集大量数据进行市场调查,网络数据提取是最简单的方法。
5. 机器学习
与情感分析一样,可用的网络数据是机器学习的高质量材料。标记和提取内容以及从元数据字段和值中提取实体是自然语言处理的源头。类别和标签信息可用于完成统计标签或聚类系统。Web 数据捕获可以帮助您以更高效、更准确的方式获取数据。
网络数据采集工具和方法
到目前为止,从网页中提取数据的最佳方法是将数据抓取项目外包给 DaaS 提供商。拥有必要的专业知识和基础设施来捕获数据。这样,也可以完全免除网络爬虫的责任。
还有一种更简单的方式来完成项目——使用网络爬虫!我们在之前的博客中介绍了很多工具。所有工具都有其优点和缺点,它们在某些方面更适合不同的人。优采云 是为非程序员创建的,比任何其他网络数据抓取工具都更容易使用。通过浏览一些教程,你可以零基础轻松掌握。
网络爬虫最灵活的方法是编写自己的爬虫程序。大多数网页抓取工具都是用 Python 编写的,以进一步简化采集数据的过程。但是对于大多数人来说,编写爬虫并不容易。
网页中flash数据抓取(hexo()中通过http用户post和爬取的差异)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-10 18:00
网页中flash数据抓取非常少见,一般最多的是网页swf文件通过js获取。高级的是通过服务器检测hosts文件判断爬取的url;或者通过与调用的代理进行http连接实现爬取。一般抓取都会在服务器端实现,部署上需要重置服务器。下面是我们去年在hexo(一个cms)中通过http抓取用户post和put之间的差异情况,用的sina开源的第三方服务。
:抓取方法:根据提示开启服务器sendrequest,把根据要抓取的地址写入/#/hexoweb,写入之后使用post方法(multipart/form-data)提交请求。抓取分析:爬取之前看服务器返回情况,看网站的url是不是做了head-request处理,查看协议,看是不是有user-agent处理之类的,网站协议是不是有head-request处理等。
抓取流程分析:根据返回的url爬取不同数据,分析不同源url之间的差异然后连接到服务器连接发送给客户端获取。完成之后通过head-request处理返回的数据。爬取效果图:。
前面几位朋友提到的方法和教程已经非常详细了,我个人用的selenium也差不多可以实现(可能是有选择性的尝试,不敢保证http方法是唯一的)。但是最后一定要确定iframe里面的内容都是你要抓取的,否则面临封iframe的风险,以及有可能提交不是你想要的数据,例如这一小段,输入一个公司之后提交一个项目,然后要发给全世界的用户抓取,看起来怎么就是不对呢。
因此要给我的题目做好足够的限定条件:是我所有的抓取的地址都是request()对象,还是只对其中url进行抓取?简单说每次url变化都要加上另外一个httpheader(),以保证是一样的抓取结果,大概格式如下:af41df337072d64c8a4064b76e50ba63e686810dde5c33cef7a31074cac12如果大家有哪些好方法,欢迎贡献~。 查看全部
网页中flash数据抓取(hexo()中通过http用户post和爬取的差异)
网页中flash数据抓取非常少见,一般最多的是网页swf文件通过js获取。高级的是通过服务器检测hosts文件判断爬取的url;或者通过与调用的代理进行http连接实现爬取。一般抓取都会在服务器端实现,部署上需要重置服务器。下面是我们去年在hexo(一个cms)中通过http抓取用户post和put之间的差异情况,用的sina开源的第三方服务。
:抓取方法:根据提示开启服务器sendrequest,把根据要抓取的地址写入/#/hexoweb,写入之后使用post方法(multipart/form-data)提交请求。抓取分析:爬取之前看服务器返回情况,看网站的url是不是做了head-request处理,查看协议,看是不是有user-agent处理之类的,网站协议是不是有head-request处理等。
抓取流程分析:根据返回的url爬取不同数据,分析不同源url之间的差异然后连接到服务器连接发送给客户端获取。完成之后通过head-request处理返回的数据。爬取效果图:。
前面几位朋友提到的方法和教程已经非常详细了,我个人用的selenium也差不多可以实现(可能是有选择性的尝试,不敢保证http方法是唯一的)。但是最后一定要确定iframe里面的内容都是你要抓取的,否则面临封iframe的风险,以及有可能提交不是你想要的数据,例如这一小段,输入一个公司之后提交一个项目,然后要发给全世界的用户抓取,看起来怎么就是不对呢。
因此要给我的题目做好足够的限定条件:是我所有的抓取的地址都是request()对象,还是只对其中url进行抓取?简单说每次url变化都要加上另外一个httpheader(),以保证是一样的抓取结果,大概格式如下:af41df337072d64c8a4064b76e50ba63e686810dde5c33cef7a31074cac12如果大家有哪些好方法,欢迎贡献~。
网页中flash数据抓取(做网站优化已经快一个月了,新手怎么理解呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-10 08:16
优化网站已经快一个月了,对seo的一般技术有了一些了解。前几天开始用谷歌的网站站长工具,发现很多百度站长工具都没有。其中,“结构化数据”项出现在“优化”列中。可以想象,这种结构化的数据会成为谷歌搜索的一种优化方式吗?添加自己的站进入这个页面,发现提示我网站上没有检测到结构化数据,但是这样一个缺乏概念的词怎么让我们这样的网站优化新手理解?
进入谷歌的“帮助”页面,谷歌提到了“丰富的网页摘要(微数据、微格式、RDFa和数据荧光笔)”,其中微数据是谷歌推荐的优化方式,而这个微数据是当前菜鸟HTML5通过增强网页的语义旨在构建一个对程序和用户更有价值的数据驱动的网络。
HTML5 微数据规范是一种标记内容以描述特定类型信息(例如评论、个人信息或事件)的方法。每种类型的信息都描述了特定类型的项目,例如人物、事件或评论。例如,事件可以包括地点、开始时间、名称和类别属性。
微数据使用 HTML 标签(通常或
中的简单属性指定项目和属性的简短描述名称。以下示例是一个简短的 HTML 文本块,显示了 BobSmith 的基本联系信息。
我叫王XX,大家都叫我wungking。我的主页是:
这是我主页结构化数据测试的结果。下面item后面的imagetitle被添加到页面中的对应元素中。当 Google 抓取您的网页时,它可以通过这种结构化标记快速获取它。最有效的信息。至于是否对网站的排名有影响,目前还没有办法测试,只能先优化看看效果。
看到这里,你是不是要优化你的网站?因为在定义 itemprop 的类型时,并没有官方的一套标签。只提供了部分行业的部分属性值,这里还是等待完善吧!
文章起始站:./club/thread-93918-1-1.html 查看全部
网页中flash数据抓取(做网站优化已经快一个月了,新手怎么理解呢?)
优化网站已经快一个月了,对seo的一般技术有了一些了解。前几天开始用谷歌的网站站长工具,发现很多百度站长工具都没有。其中,“结构化数据”项出现在“优化”列中。可以想象,这种结构化的数据会成为谷歌搜索的一种优化方式吗?添加自己的站进入这个页面,发现提示我网站上没有检测到结构化数据,但是这样一个缺乏概念的词怎么让我们这样的网站优化新手理解?
进入谷歌的“帮助”页面,谷歌提到了“丰富的网页摘要(微数据、微格式、RDFa和数据荧光笔)”,其中微数据是谷歌推荐的优化方式,而这个微数据是当前菜鸟HTML5通过增强网页的语义旨在构建一个对程序和用户更有价值的数据驱动的网络。
HTML5 微数据规范是一种标记内容以描述特定类型信息(例如评论、个人信息或事件)的方法。每种类型的信息都描述了特定类型的项目,例如人物、事件或评论。例如,事件可以包括地点、开始时间、名称和类别属性。
微数据使用 HTML 标签(通常或
中的简单属性指定项目和属性的简短描述名称。以下示例是一个简短的 HTML 文本块,显示了 BobSmith 的基本联系信息。
我叫王XX,大家都叫我wungking。我的主页是:
这是我主页结构化数据测试的结果。下面item后面的imagetitle被添加到页面中的对应元素中。当 Google 抓取您的网页时,它可以通过这种结构化标记快速获取它。最有效的信息。至于是否对网站的排名有影响,目前还没有办法测试,只能先优化看看效果。
看到这里,你是不是要优化你的网站?因为在定义 itemprop 的类型时,并没有官方的一套标签。只提供了部分行业的部分属性值,这里还是等待完善吧!
文章起始站:./club/thread-93918-1-1.html
网页中flash数据抓取(小编来一起如何用python来页面中的JS动态加载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-07 16:17
)
本文文章主要介绍如何使用python来抓取网页中的动态数据。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text 查看全部
网页中flash数据抓取(小编来一起如何用python来页面中的JS动态加载
)
本文文章主要介绍如何使用python来抓取网页中的动态数据。文章通过示例代码详细介绍,对大家的学习或工作有一定的参考学习价值,有需要的朋友和小编一起学习吧
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8 import urllib import requests post_param = {'action':'','start':'0','limit':'1'} return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False) print return_data.text
网页中flash数据抓取(网页中flash数据抓取自动化的实现过程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-06 05:04
网页中flash数据抓取自动化的实现过程。爬虫针对bt种子文件进行播放的策略决定了抓取多少个快播种子文件。针对播放列表抓取需要掌握javascript。首先了解一下javascript,它利用javascript通过文本来编写网页内容:根据编写好的html代码,生成最后的html页面。它是用来读取和处理数据库的方式。
html文件也称为html页面。编写好的html页面需要flash支持,提供可插入css规则,以及javascript来处理页面(html页面不是单独生成的,而是伴随着播放器生成的)。第二,了解一下你的播放器支持什么javascript,最常见的aac格式的文件格式对应的是javascriptexportmethod,javascript与flash交互格式对应的是javascriptencodemethod。
第三,就是你主要抓取什么数据了,我的主要抓取的是手机用户的需求,其中包括最后播放列表的长度,播放日期等所有的需求。(按下播放列表从小到大)。第四,你需要抓取下载列表里的什么数据。抓取数据就是按下播放列表从小到大,抓取在其中间,日期等节点数据,来倒推出播放日期。抓取下载则是不断重复抓取数据的行为。例如:抓取下载数据三个月,再合并数据。
总结:1.抓取一个快播种子文件是比较容易的。但是抓取列表数据,下载数据则需要掌握javascript/java才能抓取。因为它们之间交互的形式不一样。2.抓取快播种子文件是需要时间,至少需要2-3分钟。理论上越长需要时间越长。另外还要理解一下不一定是flash要支持快播播放播放列表的就必须要javascript支持,因为快播播放的种子文件是document对象,这个时候其实只需要用到flash的api即可。
下面就来说说针对快播中播放列表如何抓取。首先声明一下对快播非常喜欢,无论是有病毒木马还是视频资源丰富,但是内部利益庞大,感觉不能随便用。基于这种思想,可能只好像了解下flash。flash本身无法支持抓取列表,但是有好的解决方案可以实现,如javascript解决方案flashquery.js-atutorial是javascript的入门教程中的一种。
如果我们需要这种效果,可以参考一下。usingaflashscriptapitoresizethishttplibrary这个地方如果写成query.script={view(){...}}则返回的是列表文件的一个元素,效果就是只要flash到了就被抓取,当然这个效果javascript实现的,如果是自己写的话会比较麻烦。
所以我们一般是这样的,首先编写一个javascript插件来实现,代码如下:{//flash_toolbox_data.jsif(window.console.log!="。 查看全部
网页中flash数据抓取(网页中flash数据抓取自动化的实现过程(图))
网页中flash数据抓取自动化的实现过程。爬虫针对bt种子文件进行播放的策略决定了抓取多少个快播种子文件。针对播放列表抓取需要掌握javascript。首先了解一下javascript,它利用javascript通过文本来编写网页内容:根据编写好的html代码,生成最后的html页面。它是用来读取和处理数据库的方式。
html文件也称为html页面。编写好的html页面需要flash支持,提供可插入css规则,以及javascript来处理页面(html页面不是单独生成的,而是伴随着播放器生成的)。第二,了解一下你的播放器支持什么javascript,最常见的aac格式的文件格式对应的是javascriptexportmethod,javascript与flash交互格式对应的是javascriptencodemethod。
第三,就是你主要抓取什么数据了,我的主要抓取的是手机用户的需求,其中包括最后播放列表的长度,播放日期等所有的需求。(按下播放列表从小到大)。第四,你需要抓取下载列表里的什么数据。抓取数据就是按下播放列表从小到大,抓取在其中间,日期等节点数据,来倒推出播放日期。抓取下载则是不断重复抓取数据的行为。例如:抓取下载数据三个月,再合并数据。
总结:1.抓取一个快播种子文件是比较容易的。但是抓取列表数据,下载数据则需要掌握javascript/java才能抓取。因为它们之间交互的形式不一样。2.抓取快播种子文件是需要时间,至少需要2-3分钟。理论上越长需要时间越长。另外还要理解一下不一定是flash要支持快播播放播放列表的就必须要javascript支持,因为快播播放的种子文件是document对象,这个时候其实只需要用到flash的api即可。
下面就来说说针对快播中播放列表如何抓取。首先声明一下对快播非常喜欢,无论是有病毒木马还是视频资源丰富,但是内部利益庞大,感觉不能随便用。基于这种思想,可能只好像了解下flash。flash本身无法支持抓取列表,但是有好的解决方案可以实现,如javascript解决方案flashquery.js-atutorial是javascript的入门教程中的一种。
如果我们需要这种效果,可以参考一下。usingaflashscriptapitoresizethishttplibrary这个地方如果写成query.script={view(){...}}则返回的是列表文件的一个元素,效果就是只要flash到了就被抓取,当然这个效果javascript实现的,如果是自己写的话会比较麻烦。
所以我们一般是这样的,首先编写一个javascript插件来实现,代码如下:{//flash_toolbox_data.jsif(window.console.log!="。
网页中flash数据抓取(下拉下滑栏时会发送一个新异步发送URL(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-02 00:03
)
常见的动态数据是我们下拉滑动条时可以在网页上动态加载的新数据。例如下面的网站:
我们继续下拉滑动条,新的数据会继续加载。但是网页的 URL 一直保持不变。但实际上,当我们下拉时,浏览器会发送一个新的异步请求来获取这些新数据,但是新的异步请求的 URL 并没有显示在浏览器上。因此,获取网页动态数据的关键是获取异步发送的URL,并发现其格式规律。
获取异步发送的 URL
在Chrome上打开网页->右键查看->点击网络->点击XHR->下拉网页加载动态数据->获取发送的请求->获取请求头中的Request URL信息。
通过以上步骤,我们就获取到了异步请求的URL。通过分析,我们可以发现异步请求URL的区别在于“page=xx”部分。如果我们要抓取10条动态数据,那么我们需要10个URL,其中page的取值范围为1到10。完整的抓取代码如下。爬取的原理和之前一样,唯一不同的是URL是一个异步请求的URL。
from bs4 import BeautifulSoup
import requests
import time
url = 'https://knewone.com/discover?page='
def get_page(url,data=None):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('a.cover-inner > img')
titles = soup.select('section.content > h4 > a')
links = soup.select('section.content > h4 > a')
if data==None:
for img,title,link in zip(imgs,titles,links):
data = {
'img':img.get('src'),
'title':title.get('title'),
'link':link.get('href')
}
print(data)
def get_more_pages(start,end):
for one in range(start,end):
get_page(url+str(one))
time.sleep(2)
get_more_pages(1,10) 查看全部
网页中flash数据抓取(下拉下滑栏时会发送一个新异步发送URL(图)
)
常见的动态数据是我们下拉滑动条时可以在网页上动态加载的新数据。例如下面的网站:
我们继续下拉滑动条,新的数据会继续加载。但是网页的 URL 一直保持不变。但实际上,当我们下拉时,浏览器会发送一个新的异步请求来获取这些新数据,但是新的异步请求的 URL 并没有显示在浏览器上。因此,获取网页动态数据的关键是获取异步发送的URL,并发现其格式规律。
获取异步发送的 URL
在Chrome上打开网页->右键查看->点击网络->点击XHR->下拉网页加载动态数据->获取发送的请求->获取请求头中的Request URL信息。
通过以上步骤,我们就获取到了异步请求的URL。通过分析,我们可以发现异步请求URL的区别在于“page=xx”部分。如果我们要抓取10条动态数据,那么我们需要10个URL,其中page的取值范围为1到10。完整的抓取代码如下。爬取的原理和之前一样,唯一不同的是URL是一个异步请求的URL。
from bs4 import BeautifulSoup
import requests
import time
url = 'https://knewone.com/discover?page='
def get_page(url,data=None):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('a.cover-inner > img')
titles = soup.select('section.content > h4 > a')
links = soup.select('section.content > h4 > a')
if data==None:
for img,title,link in zip(imgs,titles,links):
data = {
'img':img.get('src'),
'title':title.get('title'),
'link':link.get('href')
}
print(data)
def get_more_pages(start,end):
for one in range(start,end):
get_page(url+str(one))
time.sleep(2)
get_more_pages(1,10)
网页中flash数据抓取( 网络中获取网页数据的案例代码postedon2011-05-31)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-02 00:02
网络中获取网页数据的案例代码postedon2011-05-31)
十六、从网上获取网页数据
从网络获取网页数据时,网页可以使用GZIP压缩技术对网页进行压缩,这样可以减少网络传输的数据量,提高浏览速度。所以获取网络数据时需要判断,并使用GZIPInputStream对GZIP格式数据进行特殊处理,否则获取数据时可能出现乱码。
以下是获取网络中网页数据的案例代码
package com.ljq.test;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
* 从网络中获取网页数据
*
* @author jiqinlin
*
*/
public class InternetTest2 {
@SuppressWarnings("static-access")
public static void main(String[] args) throws Exception {
String result = "";
//URL url = new URL("http://www.sohu.com");
URL url = new URL("http://www.ku6.com/");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(6* 1000);//设置连接超时
if (conn.getResponseCode() != 200) throw new RuntimeException("请求url失败");
InputStream is = conn.getInputStream();//得到网络返回的输入流
if("gzip".equals(conn.getContentEncoding())){
result = new InternetTest2().readDataForZgip(is, "GBK");
}else {
result = new InternetTest2().readData(is, "GBK");
}
conn.disconnect();
System.out.println(result);
System.err.println("ContentEncoding: " + conn.getContentEncoding());
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readData(InputStream inSream, String charsetName) throws Exception{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = -1;
while( (len = inSream.read(buffer)) != -1 ){
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
inSream.close();
return new String(data, charsetName);
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readDataForZgip(InputStream inStream, String charsetName) throws Exception{
GZIPInputStream gzipStream = new GZIPInputStream(inStream);
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer =new byte[1024];
int len = -1;
while ((len = gzipStream.read(buffer))!=-1) {
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
gzipStream.close();
inStream.close();
return new String(data, charsetName);
}
}
发表于 2011-05-31 15:40 无情阅读(3906)评论(2)编辑 查看全部
网页中flash数据抓取(
网络中获取网页数据的案例代码postedon2011-05-31)
十六、从网上获取网页数据
从网络获取网页数据时,网页可以使用GZIP压缩技术对网页进行压缩,这样可以减少网络传输的数据量,提高浏览速度。所以获取网络数据时需要判断,并使用GZIPInputStream对GZIP格式数据进行特殊处理,否则获取数据时可能出现乱码。
以下是获取网络中网页数据的案例代码
package com.ljq.test;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
* 从网络中获取网页数据
*
* @author jiqinlin
*
*/
public class InternetTest2 {
@SuppressWarnings("static-access")
public static void main(String[] args) throws Exception {
String result = "";
//URL url = new URL("http://www.sohu.com";);
URL url = new URL("http://www.ku6.com/";);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(6* 1000);//设置连接超时
if (conn.getResponseCode() != 200) throw new RuntimeException("请求url失败");
InputStream is = conn.getInputStream();//得到网络返回的输入流
if("gzip".equals(conn.getContentEncoding())){
result = new InternetTest2().readDataForZgip(is, "GBK");
}else {
result = new InternetTest2().readData(is, "GBK");
}
conn.disconnect();
System.out.println(result);
System.err.println("ContentEncoding: " + conn.getContentEncoding());
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readData(InputStream inSream, String charsetName) throws Exception{
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = -1;
while( (len = inSream.read(buffer)) != -1 ){
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
inSream.close();
return new String(data, charsetName);
}
//第一个参数为输入流,第二个参数为字符集编码
public static String readDataForZgip(InputStream inStream, String charsetName) throws Exception{
GZIPInputStream gzipStream = new GZIPInputStream(inStream);
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer =new byte[1024];
int len = -1;
while ((len = gzipStream.read(buffer))!=-1) {
outStream.write(buffer, 0, len);
}
byte[] data = outStream.toByteArray();
outStream.close();
gzipStream.close();
inStream.close();
return new String(data, charsetName);
}
}
发表于 2011-05-31 15:40 无情阅读(3906)评论(2)编辑
网页中flash数据抓取(我正在研究使用R从网页中抓取数据的方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-29 22:02
我正在研究使用 R 从网页中抓取数据的方法。大多数时候,我找到网页,然后使用 XML2 和 rvest 的组合来抓取我想要的数据(通常使用选择器小工具来查找选定的 xpath) 我正在研究使用R从网页中获取数据的方法。大多数时候,我会找一个网页,然后结合使用XML2和rvest来抓取我想要的数据(通常是使用选择器小工具来查找选定的xpath)。
但是,特别是对于移动应用程序,我意识到通常有一个隐藏的数据库位于保存我想要的数据的页面后面。用于存储我想要的数据的隐藏数据库。这通常是通过 url 中的一系列 api 请求(使用特定的 api 密钥)来访问的。通常可以通过 url 中的一系列 api 请求(使用特定的 api 密钥)访问该文件。
我的问题是:是否有进入数据库的标准后门方式?我的问题是:是否有进入数据库的标准后门方式?你如何找到不同的api请求?你如何找到不同的api请求?有谁知道任何网站或书籍对我所说的方法提供帮助?有没有人知道任何网站或书籍对我所说的方法提供帮助?
谢谢,谢谢, 查看全部
网页中flash数据抓取(我正在研究使用R从网页中抓取数据的方法。)
我正在研究使用 R 从网页中抓取数据的方法。大多数时候,我找到网页,然后使用 XML2 和 rvest 的组合来抓取我想要的数据(通常使用选择器小工具来查找选定的 xpath) 我正在研究使用R从网页中获取数据的方法。大多数时候,我会找一个网页,然后结合使用XML2和rvest来抓取我想要的数据(通常是使用选择器小工具来查找选定的xpath)。
但是,特别是对于移动应用程序,我意识到通常有一个隐藏的数据库位于保存我想要的数据的页面后面。用于存储我想要的数据的隐藏数据库。这通常是通过 url 中的一系列 api 请求(使用特定的 api 密钥)来访问的。通常可以通过 url 中的一系列 api 请求(使用特定的 api 密钥)访问该文件。
我的问题是:是否有进入数据库的标准后门方式?我的问题是:是否有进入数据库的标准后门方式?你如何找到不同的api请求?你如何找到不同的api请求?有谁知道任何网站或书籍对我所说的方法提供帮助?有没有人知道任何网站或书籍对我所说的方法提供帮助?
谢谢,谢谢,
网页中flash数据抓取(网页中flash数据抓取解析很常见的,infix技术实现定位用户行为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-29 00:02
网页中flash数据抓取解析很常见的,可以根据你需要的抓取深度,比如每一段时间对其解析n个可以抓取n个时间段内的全部网页。想要通过抓取多一点网页来达到实时分析用户行为的效果,也有很多方法,例如深度竞价网页提取sem数据等。最近,网页分析工具infix分析平台推出了一套网页分析工具。借助于tracemonitor提供的数据抓取功能,可以全局抓取多国家网页内容进行分析,今天分享的案例就是可以抓取某国家网页内容,将其抓取到的内容制作成网页,再通过rfid技术实现定位用户行为。
infix网页分析平台是业内唯一的跨国网页分析系统,先在我们国内推出了easywebsuite,之后可以让用户先注册,之后可以将所抓取网页全局抓取,包括二次索引、批量抓取等。此次,我们通过infix网页分析工具抓取到的一个国家网页的全局抓取结果如下:可以看到:在以国家为单位进行抓取时,bing国家数据非常丰富,bing+、bing++、bing+me都可以进行全局抓取。
而在以页数为单位抓取时,全局抓取结果是不如以页数划分的结果丰富。infix网页分析工具还可以进行all抓取、三进制数据抓取、链接分析、整站抓取、多页抓取等功能,对于海量页面数据是一项非常好的分析工具。infix网页分析工具抓取的数据还可以做数据归纳整理分析,也可以抓取视频剪辑、点击量分析等热门行业数据分析工具也可以在此抓取分析数据。
抓取结果中,bing+有大量视频站点抓取,在热门视频站点内抓取很不方便,所以暂未抓取。更多工具案例请访问infix_chrome网页分析工具。【关注小编,每天免费获取更多免费ppt素材、ps教程、word模板、excel教程以及最新的营销干货资讯!】【作者:kktsuket】。 查看全部
网页中flash数据抓取(网页中flash数据抓取解析很常见的,infix技术实现定位用户行为)
网页中flash数据抓取解析很常见的,可以根据你需要的抓取深度,比如每一段时间对其解析n个可以抓取n个时间段内的全部网页。想要通过抓取多一点网页来达到实时分析用户行为的效果,也有很多方法,例如深度竞价网页提取sem数据等。最近,网页分析工具infix分析平台推出了一套网页分析工具。借助于tracemonitor提供的数据抓取功能,可以全局抓取多国家网页内容进行分析,今天分享的案例就是可以抓取某国家网页内容,将其抓取到的内容制作成网页,再通过rfid技术实现定位用户行为。
infix网页分析平台是业内唯一的跨国网页分析系统,先在我们国内推出了easywebsuite,之后可以让用户先注册,之后可以将所抓取网页全局抓取,包括二次索引、批量抓取等。此次,我们通过infix网页分析工具抓取到的一个国家网页的全局抓取结果如下:可以看到:在以国家为单位进行抓取时,bing国家数据非常丰富,bing+、bing++、bing+me都可以进行全局抓取。
而在以页数为单位抓取时,全局抓取结果是不如以页数划分的结果丰富。infix网页分析工具还可以进行all抓取、三进制数据抓取、链接分析、整站抓取、多页抓取等功能,对于海量页面数据是一项非常好的分析工具。infix网页分析工具抓取的数据还可以做数据归纳整理分析,也可以抓取视频剪辑、点击量分析等热门行业数据分析工具也可以在此抓取分析数据。
抓取结果中,bing+有大量视频站点抓取,在热门视频站点内抓取很不方便,所以暂未抓取。更多工具案例请访问infix_chrome网页分析工具。【关注小编,每天免费获取更多免费ppt素材、ps教程、word模板、excel教程以及最新的营销干货资讯!】【作者:kktsuket】。
网页中flash数据抓取(在企业进行网页设计之初想必的推广与优化,帮助的人有所帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-27 15:08
公司网页设计之初,肯定会有这样一个问题:什么样的网页有利于后期网站的推广和优化?那么,我想和大家分享一下哪种网站更有利于网站的推广和优化,希望对有需要的人有所帮助。
首先,我们在做网页设计的时候,建议大家选择扁平的网站结构,比较适合中小型企业网站。对于网站较大的编辑,我推荐网站整体布局,树状网状结构。但是,在选择的过程中,大家一定要记住,无论选择什么结构,都必须保证目录文件不能超过三层,并且目录中的关键字设置的越短越好。
其次,网站的导航设计要简洁明了。众所周知,网站上导航的作用是帮助永谷更多地了解网站目录。它可以快速引导用户到他们想要访问的内容页面。如果导航不够清晰,就会失去原本的意义。另外,在导航的选择上,小编推荐大家应该选择吸尘器导航,因为下颚可以让用户和蜘蛛更清楚地知道自己的位置,有利于用户的选择和蜘蛛抓取。
<p>另外就是网站的框架结构设计。网站的动态形式被企业主导,并不意味着静态网页不受欢迎。其实html页面的frame是以标签的形式呈现的,所以不推荐使用网站的frame结构,因为搜索引擎无法识别frame,会影响 查看全部
网页中flash数据抓取(在企业进行网页设计之初想必的推广与优化,帮助的人有所帮助)
公司网页设计之初,肯定会有这样一个问题:什么样的网页有利于后期网站的推广和优化?那么,我想和大家分享一下哪种网站更有利于网站的推广和优化,希望对有需要的人有所帮助。
首先,我们在做网页设计的时候,建议大家选择扁平的网站结构,比较适合中小型企业网站。对于网站较大的编辑,我推荐网站整体布局,树状网状结构。但是,在选择的过程中,大家一定要记住,无论选择什么结构,都必须保证目录文件不能超过三层,并且目录中的关键字设置的越短越好。
其次,网站的导航设计要简洁明了。众所周知,网站上导航的作用是帮助永谷更多地了解网站目录。它可以快速引导用户到他们想要访问的内容页面。如果导航不够清晰,就会失去原本的意义。另外,在导航的选择上,小编推荐大家应该选择吸尘器导航,因为下颚可以让用户和蜘蛛更清楚地知道自己的位置,有利于用户的选择和蜘蛛抓取。
<p>另外就是网站的框架结构设计。网站的动态形式被企业主导,并不意味着静态网页不受欢迎。其实html页面的frame是以标签的形式呈现的,所以不推荐使用网站的frame结构,因为搜索引擎无法识别frame,会影响
网页中flash数据抓取( Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-24 16:19
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
剧作家网络爬虫教程
近年来,随着互联网行业的发展,互联网的影响力逐渐增强。这也得益于技术的进步,越来越多的用户体验良好的应用被开发出来。此外,从Web应用程序的开发到测试,整个过程中自动化的使用越来越流行。网络爬虫也越来越广泛地用于捕获数据。
拥有有效的工具来测试 Web 应用程序是必不可少的。Playwright 等图书馆在浏览器中打开 Web 应用程序,并使用其他交互(例如单击元素、键入文本和从 Web 提取公共数据)来加快整个过程。
本教程将解释有关 Playwright 的相关内容以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个测试和自动化框架,可以实现与 Web 浏览器的自动化交互。简而言之,您可以编写代码来打开浏览器,并使用代码来实现所有网页浏览器的功能。自动化脚本可以实现导航到网址、输入文本、点击按钮和提取文本等功能。Playwright 最令人惊奇的特性是它可以同时处理多个页面,而无需等待或被阻止。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、使用 Chromium 核心的 Microsoft Edge 和使用 WebKit 核心的 Safari。跨浏览器网络自动化是 Playwright 的强项,它可以有效地为所有浏览器执行相同的代码。此外,Playwright 支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用这些语言中的任何一种与之交互。
Playwright 的文档非常详细,涵盖的范围很广。它涵盖了从入门到高级的所有类和方法。
支持剧作家代理
Playwright 支持使用代理。我们将使用以下Node.js和Python的代码片段作为参考,逐步教你如何在Chromium中使用代理:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上面的代码只需要稍微修改一下就可以集成agent了。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送其他几个参数,例如 headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给 start 函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理进行爬网时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs的住宅代理是一个覆盖广泛的稳定代理网络。您可以通过 Oxylabs 的住宅代理访问特定国家、省份甚至城市的站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01. 使用 Playwright 进行基本爬行
下面我们将介绍如何在 Node.js 和 Python 中使用 Playwright。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。剧作家被导入到代码的第一行。然后,启动了一个 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将在可视化用户界面中运行。成功传递 headless: false 后,打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape。再等待 1 秒钟以向最终用户显示该页面。最后,浏览器关闭。
同样的代码用 Python 编写也非常简单。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意 Playwright 支持两种方法——同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的区别是使用了 asyncio 库。另一个区别是函数名从camelCase 变成了snake_case。
如果您想要创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。您可以使用 page.context() 函数来获取浏览器页面上下文。
02. 定位元素
要从元素中提取信息或单击元素,第一步是定位该元素。Playwright 同时支持 CSS 和 XPath 选择器。
一个实际的例子可以更好地理解这一点。在 Chrome 中打开要爬取的页面的 URL,右键单击第一本书,然后选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要为所有文章元素设置一个循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,您也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的函数如下:
●$eval(selector, function)-选择第一个元素,将元素发送给函数,并返回函数的结果;
●$$eval(selector, function)-同上,不同的是它选择了所有元素;
●querySelector(selector)-返回第一个元素;
● querySelectorAll(selector)-返回所有元素。
这些方法在 CSS 和 XPath 选择器中运行良好。
03. 抓取文本
继续以 Books to Scrape 页面为例,页面加载完成后,可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后你可以在循环中提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码有点不同。Python有一个函数eval_on_selector,类似于Node.js的$eval,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能会很好,但在这种情况下,用 Python 编写整个代码更合适。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出结果是一样的。
剧作家 VS Puppeteer 和 Selenium
在获取数据时,除了使用 Playwright 之外,还可以使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢并且对开发人员不是很友好。
另外需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面给大家对比一下这三种工具:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀
优秀
普通的
开发经验
最多
好的
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera、Safari 等。
综上所述
本文讨论了 Playwright 作为爬取动态站点的测试工具的功能,并介绍了 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、点击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以用Puppeteer、Selenium等其他工具来完成,但是如果你需要使用多种浏览器,或者需要使用JavaScript/Node.js以外的语言,那么Playwright会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。 查看全部
网页中flash数据抓取(
Node.js和Python的代码片段作引教您如何在Chromium中使用代理)
剧作家网络爬虫教程
近年来,随着互联网行业的发展,互联网的影响力逐渐增强。这也得益于技术的进步,越来越多的用户体验良好的应用被开发出来。此外,从Web应用程序的开发到测试,整个过程中自动化的使用越来越流行。网络爬虫也越来越广泛地用于捕获数据。
拥有有效的工具来测试 Web 应用程序是必不可少的。Playwright 等图书馆在浏览器中打开 Web 应用程序,并使用其他交互(例如单击元素、键入文本和从 Web 提取公共数据)来加快整个过程。
本教程将解释有关 Playwright 的相关内容以及如何将其用于自动化甚至网络抓取。
什么是剧作家?
Playwright 是一个测试和自动化框架,可以实现与 Web 浏览器的自动化交互。简而言之,您可以编写代码来打开浏览器,并使用代码来实现所有网页浏览器的功能。自动化脚本可以实现导航到网址、输入文本、点击按钮和提取文本等功能。Playwright 最令人惊奇的特性是它可以同时处理多个页面,而无需等待或被阻止。
Playwright 支持大多数浏览器,例如 Google Chrome、Firefox、使用 Chromium 核心的 Microsoft Edge 和使用 WebKit 核心的 Safari。跨浏览器网络自动化是 Playwright 的强项,它可以有效地为所有浏览器执行相同的代码。此外,Playwright 支持 Node.js、Python、Java 和 .NET 等多种编程语言。您可以编写代码来打开 网站 并使用这些语言中的任何一种与之交互。
Playwright 的文档非常详细,涵盖的范围很广。它涵盖了从入门到高级的所有类和方法。
支持剧作家代理
Playwright 支持使用代理。我们将使用以下Node.js和Python的代码片段作为参考,逐步教你如何在Chromium中使用代理:
节点.js:
const { chromium } = require('playwright'); "
const browser = await chromium.launch();
Python:
from playwright.async_api import async_playwright
import asyncio
with async_playwright() as p:
browser = await p.chromium.launch()
上面的代码只需要稍微修改一下就可以集成agent了。使用 Node.js 时,启动函数可以接受 LauchOptions 类型的可选参数。这个 LaunchOption 对象可以发送其他几个参数,例如 headless。另一个需要的参数是代理。这个代理是另一个具有这些属性的对象:服务器、用户名、密码等。第一步是创建一个可以指定这些参数的对象。
// Node.js
const launchOptions = {
proxy: {
server: 123.123.123.123:80'
},
headless: false
}
第二步是将此对象传递给 start 函数:
const browser = await chromium.launch(launchOptions);
就 Python 而言,情况略有不同。无需创建 LaunchOptions。相反,所有值都可以作为单独的参数发送。以下是代理字典的发送方式:
# Python
proxy_to_use = {
'server': '123.123.123.123:80'
}
browser = await pw.chromium.launch(proxy=proxy_to_use, headless=False)
在决定使用哪个代理进行爬网时,最好使用住宅代理,因为它们不会留下任何痕迹,也不会触发任何安全警报。Oxylabs的住宅代理是一个覆盖广泛的稳定代理网络。您可以通过 Oxylabs 的住宅代理访问特定国家、省份甚至城市的站点。最重要的是,您还可以轻松地将 Oxylabs 的代理与 Playwright 集成。
01. 使用 Playwright 进行基本爬行
下面我们将介绍如何在 Node.js 和 Python 中使用 Playwright。
如果您使用的是 Node.js,则需要创建一个新项目并安装 Playwright 库。可以通过这两个简单的命令来完成:
npm init -y
npm install playwright
打开动态页面的基本脚本如下:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch({
headless: false // Show the browser.
});
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
await page.waitForTimeout(1000); // wait for 1 seconds
await browser.close();
})();
我们来看看上面的代码。剧作家被导入到代码的第一行。然后,启动了一个 Chromium 实例。它允许脚本自动化 Chromium。请注意,此脚本将在可视化用户界面中运行。成功传递 headless: false 后,打开一个新的浏览器页面,page.goto 函数将导航到 Books to Scrape。再等待 1 秒钟以向最终用户显示该页面。最后,浏览器关闭。
同样的代码用 Python 编写也非常简单。首先,使用 pip 命令安装 Playwright:
pip install playwright
请注意 Playwright 支持两种方法——同步和异步。以下示例使用异步 API:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False # Show the browser
)
page = await browser.new_page()
await page.goto('https://books.toscrape.com/')
# Data Extraction Code Here
await page.wait_for_timeout(1000) # Wait for 1 second
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
此代码类似于 Node.js 代码。最大的区别是使用了 asyncio 库。另一个区别是函数名从camelCase 变成了snake_case。
如果您想要创建多个浏览器环境,或者想要更精确的控制,您可以创建一个环境对象并在该环境中创建多个页面。此代码将在新选项卡中打开页面:
const context = await browser.newContext();
const page1 = await context.newPage();
const page2 = await context.newPage();
如果您还想在代码中处理页面上下文。您可以使用 page.context() 函数来获取浏览器页面上下文。
02. 定位元素
要从元素中提取信息或单击元素,第一步是定位该元素。Playwright 同时支持 CSS 和 XPath 选择器。
一个实际的例子可以更好地理解这一点。在 Chrome 中打开要爬取的页面的 URL,右键单击第一本书,然后选择查看源代码。
你可以看到所有的书都在 article 元素下,它有一个类 product_prod。
要选择所有书籍,您需要为所有文章元素设置一个循环。可以使用 CSS 选择器选择文章元素:
.product_pod
同样,您也可以使用 XPath 选择器:
//*[@class="product_pod"]
要使用这些选择器,最常用的函数如下:
●$eval(selector, function)-选择第一个元素,将元素发送给函数,并返回函数的结果;
●$$eval(selector, function)-同上,不同的是它选择了所有元素;
●querySelector(selector)-返回第一个元素;
● querySelectorAll(selector)-返回所有元素。
这些方法在 CSS 和 XPath 选择器中运行良好。
03. 抓取文本
继续以 Books to Scrape 页面为例,页面加载完成后,可以使用选择器和 $$eval 函数提取所有书籍容器。
const books = await page.$$eval('.product_pod', all_items
=> {
// run a loop here
})
然后你可以在循环中提取收录书籍数据的所有元素:
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
})
最后,innerText 属性可用于从每个数据点提取数据。以下是 Node.js 中的完整代码:
const playwright = require('playwright');
(async () => {
const browser = await playwright.chromium.launch();
const page = await browser.newPage();
await page.goto('https://books.toscrape.com/');
const books = await page.$$eval('.product_pod', all_items
=> {
const data = [];
all_items.forEach(book => {
const name = book.querySelector('h3').innerText;
const price = book.querySelector('.price_color').
innerText;
const stock = book.querySelector('.availability').
innerText;
data.push({ name, price, stock});
});
return data;
});
console.log(books);
await browser.close();
})();
Python 中的代码有点不同。Python有一个函数eval_on_selector,类似于Node.js的$eval,但不适合这种场景。原因是第二个参数仍然需要是 JavaScript。在某些情况下使用 JavaScript 可能会很好,但在这种情况下,用 Python 编写整个代码更合适。
最好使用 query_selector 和 query_selector_all 分别返回一个元素和一个元素列表。
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as pw:
browser = await pw.chromium.
page = await browser.new_page()
await page.goto('https://books.toscrape.com')
all_items = await page.query_selector_all('.product_pod')
books = []
for item in all_items:
book = {}
name_el = await item.query_selector('h3')
book['name'] = await name_el.inner_text()
price_el = await item.query_selector('.price_color')
book['price'] = await price_el.inner_text()
stock_el = await item.query_selector('.availability')
book['stock'] = await stock_el.inner_text()
books.append(book)
print(books)
await browser.close()
if __name__ == '__main__':
asyncio.run(main())
最后,Node.js 和 Python 代码的输出结果是一样的。
剧作家 VS Puppeteer 和 Selenium
在获取数据时,除了使用 Playwright 之外,还可以使用 Selenium 和 Puppeteer。
使用 Puppeteer,您可以使用的浏览器和编程语言非常有限。目前唯一可用的语言是 JavaScript,唯一兼容的浏览器是 Chromium。
对于Selenium,虽然与浏览器语言的兼容性很好。但是,它很慢并且对开发人员不是很友好。
另外需要注意的是,Playwright 可以拦截网络请求。查看有关网络请求的更多详细信息。
下面给大家对比一下这三种工具:
_
剧作家
傀儡师
硒
速度
快的
快的
慢点
归档能力
优秀
优秀
普通的
开发经验
最多
好的
普通的
编程语言
JavaScript、Python、C# 和 Java
JavaScript
Java、Python、C#、Ruby、JavaScript 和 Kotlin
支持者
微软
谷歌
社区和赞助商
社区
小而活跃
大而活跃
大而活跃
可用的浏览器
Chromium、Firefox 和 WebKit
铬
Chrome、Firefox、IE、Edge、Opera、Safari 等。
综上所述
本文讨论了 Playwright 作为爬取动态站点的测试工具的功能,并介绍了 Node.js 和 Python 中的代码示例。由于其异步特性和跨浏览器支持,Playwright 是其他工具的流行替代品。
Playwright 可以实现导航到 URL、输入文本、点击按钮和提取文本等功能。它可以提取动态呈现的文本。这些事情也可以用Puppeteer、Selenium等其他工具来完成,但是如果你需要使用多种浏览器,或者需要使用JavaScript/Node.js以外的语言,那么Playwright会是更好的选择。
如果您对其他类似主题感兴趣,请查看我们的 文章 使用 Selenium 进行网络抓取或查看 Puppeteer 教程。您也可以随时访问我们的网站与客服沟通。
网页中flash数据抓取(你controller设置的返回值有问题怎么办?转发与重定向)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-22 14:01
问题一,可能是你设置的web.xml的header有问题
坑了一会,发现默认生成的web.xml中header的配置是
看看是不是真的是web-app_2_3.dtd,导致后面的servlet、jsp、EL等采用2.3版本,而在2.3版本中,Jsp页面不支持EL,所以在jsp中使用${requestScope.test}语句时,无法得到正确的解析。
将他设置为3.0以上的版本
把DOCTYPE 引掉,然后在web-app中,黏贴如下代码
问题二:可能是你的控制器设置的返回值有问题
一开始,我将其设置为转发和重定向
modelMap.addAttribute("test",stest);
request.getRequestDispatcher("WEB-INF/page/show.jsp").forward(request,response);
发现参数根本传不进去
-----------------------------------------------
后来发现自己设置了view resolver,可以直接返回路径,不用转发就可以到达目的地。
return "show";
完美的解决方案。
转发和重定向不需要放在ssm框架上进行页面跳转 查看全部
网页中flash数据抓取(你controller设置的返回值有问题怎么办?转发与重定向)
问题一,可能是你设置的web.xml的header有问题
坑了一会,发现默认生成的web.xml中header的配置是
看看是不是真的是web-app_2_3.dtd,导致后面的servlet、jsp、EL等采用2.3版本,而在2.3版本中,Jsp页面不支持EL,所以在jsp中使用${requestScope.test}语句时,无法得到正确的解析。
将他设置为3.0以上的版本
把DOCTYPE 引掉,然后在web-app中,黏贴如下代码
问题二:可能是你的控制器设置的返回值有问题
一开始,我将其设置为转发和重定向
modelMap.addAttribute("test",stest);
request.getRequestDispatcher("WEB-INF/page/show.jsp").forward(request,response);
发现参数根本传不进去
-----------------------------------------------
后来发现自己设置了view resolver,可以直接返回路径,不用转发就可以到达目的地。
return "show";
完美的解决方案。
转发和重定向不需要放在ssm框架上进行页面跳转
网页中flash数据抓取(soup()bug外的开头,你都知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-17 01:01
土豆 = webdriver.Firefox()
土豆网.get(url)
#创建工作簿和工作表对象
workbook = xlwt.Workbook() #注意Workbook开头的W要大写
sheet1 = workbook.add_sheet('优酷',cell_overwrite_ok=True)
count1 = count2 = 3
sheet1.write(0,0,'由于bug,暂时!!!最后一页数据需要自己手动统计')
sheet1.write(1,0,'如有技术问题请联系陈鼎,微信chending2012')
#开始写文件
对于范围内的 num(2,22):
pageNum='pager_num_0_'+str(num)
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
#以上是经过beautifulsoup的初步筛选
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
time.sleep(2)
#最后一页,因为最后一页的元素地址有点不同,所以专门写了一篇
pageNum ='pager_last_0'
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'#使用正则表达式匹配
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
#保存excel文件,如果有同名文件直接覆盖
Nowtime = time.strftime('%Y-%m-%d',time.localtime(time.time()))
excel_name = str(Nowtime)+'.xls'
workbook.save(excel_name)
打印('完成')
土豆网.quit()
暂时写这么多,以后会优化代码,写接口。
这里有一个错误。 selenium翻页后,获取到的网页内容是上一页,而不是当前页。希望大神指点。
2017.2.22 ----------------------------------- --
问题已解决。选择最后一页标签后,选择上一页即可获取最后一页的数据!
----------------------------------------------- ---
-------------------------附录
1. Python高手之路python处理excel文件(方法总结)
2.python模块介绍-xlwt创建xls文件(excel)
3.seleniumwebdriver(python) 第三版
4.美汤中文文档 查看全部
网页中flash数据抓取(soup()bug外的开头,你都知道吗?)
土豆 = webdriver.Firefox()
土豆网.get(url)
#创建工作簿和工作表对象
workbook = xlwt.Workbook() #注意Workbook开头的W要大写
sheet1 = workbook.add_sheet('优酷',cell_overwrite_ok=True)
count1 = count2 = 3
sheet1.write(0,0,'由于bug,暂时!!!最后一页数据需要自己手动统计')
sheet1.write(1,0,'如有技术问题请联系陈鼎,微信chending2012')
#开始写文件
对于范围内的 num(2,22):
pageNum='pager_num_0_'+str(num)
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
#以上是经过beautifulsoup的初步筛选
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
time.sleep(2)
#最后一页,因为最后一页的元素地址有点不同,所以专门写了一篇
pageNum ='pager_last_0'
tudou.find_element_by_id(pageNum).click()
i = tudou.page_source#获取阅读的网络资源
soup = BeautifulSoup(i,"html.parser")
i1 = soup.find_all("strong",class_="figure_title figure_title_two_row")
i2 = soup.find_all("span",class_="info_inner")
对于 i1 中的每个:
p =r'(target="_blank">)(.+)()'#使用正则表达式匹配
play_name =re.search(p,str(each)).group(2)
sheet1.write(count1,0,play_name)
count1 += 1
对于 i2 中的每个:
play_num =''
p = 桩(r'\d+\.?万?')
play_num0 = p.findall(str(each))
对于 play_num0 中的 each1:
play_num +=str(each1)
sheet1.write(count2,1,play_num)
count2 += 1
#保存excel文件,如果有同名文件直接覆盖
Nowtime = time.strftime('%Y-%m-%d',time.localtime(time.time()))
excel_name = str(Nowtime)+'.xls'
workbook.save(excel_name)
打印('完成')
土豆网.quit()
暂时写这么多,以后会优化代码,写接口。
这里有一个错误。 selenium翻页后,获取到的网页内容是上一页,而不是当前页。希望大神指点。
2017.2.22 ----------------------------------- --
问题已解决。选择最后一页标签后,选择上一页即可获取最后一页的数据!
----------------------------------------------- ---
-------------------------附录
1. Python高手之路python处理excel文件(方法总结)
2.python模块介绍-xlwt创建xls文件(excel)
3.seleniumwebdriver(python) 第三版
4.美汤中文文档
网页中flash数据抓取(官方介绍优采云采集器软件功能便捷定时功能简单点击设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-14 07:00
中国有句老话,iefans给用户提供的就是“温故知新”,就是要在学习的过程中养成复习的好习惯。学习如此,工作亦如此,优采云采集器是一款可以帮助站长审核的好工具,可以精准帮您找到自己的流量词,让您时刻抓住人心粉丝们,还等什么,快来iefans下载吧!
官方介绍
优采云采集器 是任何需要从网页获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易。
优采云采集器软件功能
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
采集登录后支持网站
优采云内置采集登录模块,您只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云自带采集Cookie的自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站@ >采集。
优采云采集器独特的亮点
云采集,可以关闭
配置完采集任务后,可以关闭,任务就可以在云端执行了。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。依然可以瞬间采集海量数据。
任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,就可以上网采集,所见即所得的界面,可视化流程,无需懂技术,只需点击鼠标,2分钟即可快速上手。
任何 网站 都可以是 采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
更新日志
解决任务列表中刷新后过滤条件重置的问题
解决自定义配置中修改任务名称时标签页中任务保存标识不正确的问题
解决自定义配置中保存有时修改的任务名称不生效的问题
解决自定义配置设置字段中选择属性值捕获属性值时流程图区域会隐藏的问题
解决自定义配置中首次进入时引导提示后台出现用户调查界面的问题 查看全部
网页中flash数据抓取(官方介绍优采云采集器软件功能便捷定时功能简单点击设置)
中国有句老话,iefans给用户提供的就是“温故知新”,就是要在学习的过程中养成复习的好习惯。学习如此,工作亦如此,优采云采集器是一款可以帮助站长审核的好工具,可以精准帮您找到自己的流量词,让您时刻抓住人心粉丝们,还等什么,快来iefans下载吧!
官方介绍
优采云采集器 是任何需要从网页获取信息的孩子的必备神器。这是一个可以让你的信息采集变得非常简单的工具。优采云改变了互联网上传统的数据思维方式,让用户在互联网上抓取和编译数据变得越来越容易。
优采云采集器软件功能
方便的定时功能
简单几步,即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集,你可以同时自由设置多个任务,根据自己的需要进行多种选择时间组合,灵活部署自己的采集任务。
全自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集全自动处理过程中,无需人工干预,即可得到所需格式的数据。
多级采集
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以拥有无限层的采集数据,满足各种业务采集的需求。
API接口
通过优采云 API,您可以轻松获取优采云任务信息和采集接收到的数据,灵活调度任务,如远程控制任务启停,高效实现数据< @采集 和存档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax 、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
采集登录后支持网站
优采云内置采集登录模块,您只需要配置目标网站的账号和密码,即可使用该模块对采集进行数据登录;同时优采云自带采集Cookie的自定义功能,首次登录后可自动记住cookie,免去多次输入密码的繁琐,支持更多网站@ >采集。
优采云采集器独特的亮点
云采集,可以关闭
配置完采集任务后,可以关闭,任务就可以在云端执行了。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。依然可以瞬间采集海量数据。
任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,就可以上网采集,所见即所得的界面,可视化流程,无需懂技术,只需点击鼠标,2分钟即可快速上手。
任何 网站 都可以是 采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
更新日志
解决任务列表中刷新后过滤条件重置的问题
解决自定义配置中修改任务名称时标签页中任务保存标识不正确的问题
解决自定义配置中保存有时修改的任务名称不生效的问题
解决自定义配置设置字段中选择属性值捕获属性值时流程图区域会隐藏的问题
解决自定义配置中首次进入时引导提示后台出现用户调查界面的问题
网页中flash数据抓取(讲参数会被打包在数据报中传输(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-14 06:15
)
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String例如,在servlet/jsp中,就不能处理java的vector等功能)。post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get 和 post 方法总结
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String ,比如在servlet/jsp中,就不能处理java的功能,比如vector)。
post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get请求是指客户端请求一个uri,服务器返回客户端请求的uri。post请求意味着客户端在请求时需要提交数据。这就像提交表格一样。要提交的数据将放在请求消息的正文部分。服务器收到这样的请求后,通常需要对数据进行处理。
在 Form 中,您可以使用 post 或 get。它们都是方法的合法值。但是,post 和 get 方法的使用至少有两个区别:
1、Get 方法通过 URL 请求传递用户的输入。Post 方法采用另一种形式。
2、Get方法提交时需要使用Request.QueryString获取变量的值,Post方法提交时必须通过Request.Form访问提交的内容。
仔细研究下面的代码。你可以运行它来感受一下:
通过get方法传递来的字符串是: ""
通过Post方法传递来的字符串是: ""
将上面的代码保存为getpost.asp,然后运行。首先,测试post方法。此时浏览器的url没有变化,返回结果为:
通过 Post 方法传递的字符串是:“Hello World”
然后用get方法提交测试,注意浏览器的url变成了:
+世界
返回的结果是:
通过get方法传递的字符串是:“Hello World”
最后通过post方法提交后,浏览器的url还是:
+世界
返回的结果变为:
通过get方法传递的字符串是:“Hello World”
通过 Post 方法传递的字符串是:“Hello World”
提示:通过 get 方法提交数据可能会导致安全问题。例如,登陆页面。通过get方法提交数据时,URL上会出现用户名和密码。如果:
1、登录页面可以被浏览器缓存;2、 其他人可以访问客户的机器。
然后,其他人可以从浏览器历史记录中读取该客户的帐户和密码。因此,在某些情况下,get 方法会导致严重的安全问题。建议使用Form中的post方法。
Python下载网页的几种方法
通过get方法:
fd = urllib2.urlopen(url_link)
data = fd.read()
使用get方法时,url类似如下格式:
index.jsp?id=100&op=bind
GET 标头如下:
GET /sn/index.php?sn=123&n=asa HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:close
get方法还可以通过以下方式实现:
def GetHtmlSource_Get(htmurl):
htmSource = ""
try:
urlx = httplib.urlsplit(htmurl)
conn = httplib.HTTPConnection(urlx.netloc)
conn.connect() #建立连接
conn.putrequest("GET", htmurl, None) #请求类型
conn.putheader("Content-Length", 0)
conn.putheader("Connection", "close")
conn.endheaders()
res = conn.getresponse()
htmSource = res.read()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource
使用post方法时,POST方法将请求参数封装在HTTP请求数据中,以name/value的形式出现,可以传输大量数据,也可以用来传输文件。POST 消息的头部如下:
POST /sn/index.php HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:closes
n=123&n=asa
不管是post还是get,他们传递的数据都必须是url编码的。每对名称/值由一个和号分隔;表单中的每对名称/值都用 = 分隔;如果用户没有为名称输入值,名称仍会出现,但没有值。; 任何特殊字符(即那些不是简单的七位 ASCII 码的字符,例如中文字符)都会以带有百分号 % 的十六进制编码。urllib 库提供了一个函数来实现 URL 编码:
search=urllib.urlencode({\'q\':\'python\'})
#\'q=python\'
通过邮寄发送请求:
import httplib,urllib;
#定义需要进行发送的数据
params = urllib.urlencode({\'cat_id\':\'6\',
\'news_title\':\'标题-Test39875\',
\'news_author\':\'Mobedu\',
\'news_ahome\':\'来源\',
\'tjuser\':\'carchanging\',
\'news_keyword\':\'|\',
\'news_content\':\'测试-Content\',
\'action\':\'newnew\',
\'MM_insert\':\'true\'});
#定义一些文件头
headers = {"Content-Type":"application/x-www-form-urlencoded",
"Connection":"Keep-Alive",
"Referer":"http://192.168.1.212/newsadd.a ... ot%3B};
#与网站构建一个连接
conn = httplib.HTTPConnection("192.168.1.212");
#开始进行数据提交 同时也可以使用get进行
conn.request(method="POST",url="/newsadd.asp?action=newnew",body=params,headers=headers);
#返回处理后的数据
response = conn.getresponse();
#判断是否提交成功
if response.status == 302:
print "发布成功!";
else:
print "发布失败";
#关闭连接
conn.close();
它也可以类似于 get 方法来实现:
def GetHtmlSource_Post(getString):
htmSource = ""
try:
url = httplib.urlsplit("http://app.sipo.gov.cn:8080")
conn = httplib.HTTPConnection(url.netloc)
conn.connect()
conn.putrequest("POST", "/sipo/zljs/hyjs-jieguo.jsp") #post方法
conn.putheader("Content-Length", len(getString))
conn.putheader("Content-Type", "application/x-www-form-urlencoded")
conn.putheader("Connection", " Keep-Alive")
conn.endheaders()
conn.send(getString) #Http包的body
f = conn.getresponse()
if not f:
raise socket.error, "timed out"
htmSource = f.read()
f.close()
conn.close()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource 查看全部
网页中flash数据抓取(讲参数会被打包在数据报中传输(组图)
)
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String例如,在servlet/jsp中,就不能处理java的vector等功能)。post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get 和 post 方法总结
get方法:data参数通过URL字符串本身传递,可以直接从服务端的变量\'QUERY_STRING\'中读取,效率更高,但缺乏安全性,不能处理复杂的数据(只有字符String ,比如在servlet/jsp中,就不能处理java的功能,比如vector)。
post方式:在传输方式上,将参数打包在数据报中进行传输,从环境变量CONTENT_LENGTH中读取,方便传输较大的数据。同时,由于浏览器地址栏中的数据没有暴露,安全性相对较高,但这样的处理效率会受到影响。
get请求是指客户端请求一个uri,服务器返回客户端请求的uri。post请求意味着客户端在请求时需要提交数据。这就像提交表格一样。要提交的数据将放在请求消息的正文部分。服务器收到这样的请求后,通常需要对数据进行处理。
在 Form 中,您可以使用 post 或 get。它们都是方法的合法值。但是,post 和 get 方法的使用至少有两个区别:
1、Get 方法通过 URL 请求传递用户的输入。Post 方法采用另一种形式。
2、Get方法提交时需要使用Request.QueryString获取变量的值,Post方法提交时必须通过Request.Form访问提交的内容。
仔细研究下面的代码。你可以运行它来感受一下:
通过get方法传递来的字符串是: ""
通过Post方法传递来的字符串是: ""
将上面的代码保存为getpost.asp,然后运行。首先,测试post方法。此时浏览器的url没有变化,返回结果为:
通过 Post 方法传递的字符串是:“Hello World”
然后用get方法提交测试,注意浏览器的url变成了:
+世界
返回的结果是:
通过get方法传递的字符串是:“Hello World”
最后通过post方法提交后,浏览器的url还是:
+世界
返回的结果变为:
通过get方法传递的字符串是:“Hello World”
通过 Post 方法传递的字符串是:“Hello World”
提示:通过 get 方法提交数据可能会导致安全问题。例如,登陆页面。通过get方法提交数据时,URL上会出现用户名和密码。如果:
1、登录页面可以被浏览器缓存;2、 其他人可以访问客户的机器。
然后,其他人可以从浏览器历史记录中读取该客户的帐户和密码。因此,在某些情况下,get 方法会导致严重的安全问题。建议使用Form中的post方法。
Python下载网页的几种方法
通过get方法:
fd = urllib2.urlopen(url_link)
data = fd.read()
使用get方法时,url类似如下格式:
index.jsp?id=100&op=bind
GET 标头如下:
GET /sn/index.php?sn=123&n=asa HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:close
get方法还可以通过以下方式实现:
def GetHtmlSource_Get(htmurl):
htmSource = ""
try:
urlx = httplib.urlsplit(htmurl)
conn = httplib.HTTPConnection(urlx.netloc)
conn.connect() #建立连接
conn.putrequest("GET", htmurl, None) #请求类型
conn.putheader("Content-Length", 0)
conn.putheader("Connection", "close")
conn.endheaders()
res = conn.getresponse()
htmSource = res.read()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource
使用post方法时,POST方法将请求参数封装在HTTP请求数据中,以name/value的形式出现,可以传输大量数据,也可以用来传输文件。POST 消息的头部如下:
POST /sn/index.php HTTP/1.1
Accept: */*
Accept-Language: zh-cn
host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 12
Connection:closes
n=123&n=asa
不管是post还是get,他们传递的数据都必须是url编码的。每对名称/值由一个和号分隔;表单中的每对名称/值都用 = 分隔;如果用户没有为名称输入值,名称仍会出现,但没有值。; 任何特殊字符(即那些不是简单的七位 ASCII 码的字符,例如中文字符)都会以带有百分号 % 的十六进制编码。urllib 库提供了一个函数来实现 URL 编码:
search=urllib.urlencode({\'q\':\'python\'})
#\'q=python\'
通过邮寄发送请求:
import httplib,urllib;
#定义需要进行发送的数据
params = urllib.urlencode({\'cat_id\':\'6\',
\'news_title\':\'标题-Test39875\',
\'news_author\':\'Mobedu\',
\'news_ahome\':\'来源\',
\'tjuser\':\'carchanging\',
\'news_keyword\':\'|\',
\'news_content\':\'测试-Content\',
\'action\':\'newnew\',
\'MM_insert\':\'true\'});
#定义一些文件头
headers = {"Content-Type":"application/x-www-form-urlencoded",
"Connection":"Keep-Alive",
"Referer":"http://192.168.1.212/newsadd.a ... ot%3B};
#与网站构建一个连接
conn = httplib.HTTPConnection("192.168.1.212");
#开始进行数据提交 同时也可以使用get进行
conn.request(method="POST",url="/newsadd.asp?action=newnew",body=params,headers=headers);
#返回处理后的数据
response = conn.getresponse();
#判断是否提交成功
if response.status == 302:
print "发布成功!";
else:
print "发布失败";
#关闭连接
conn.close();
它也可以类似于 get 方法来实现:
def GetHtmlSource_Post(getString):
htmSource = ""
try:
url = httplib.urlsplit("http://app.sipo.gov.cn:8080";)
conn = httplib.HTTPConnection(url.netloc)
conn.connect()
conn.putrequest("POST", "/sipo/zljs/hyjs-jieguo.jsp") #post方法
conn.putheader("Content-Length", len(getString))
conn.putheader("Content-Type", "application/x-www-form-urlencoded")
conn.putheader("Connection", " Keep-Alive")
conn.endheaders()
conn.send(getString) #Http包的body
f = conn.getresponse()
if not f:
raise socket.error, "timed out"
htmSource = f.read()
f.close()
conn.close()
except Exception(), err:
trackback.print_exec()
conn.close()
return htmSource
网页中flash数据抓取(数据库中会碰到一个模糊的概念,它就是Schema语句创建)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-07 22:10
数据库中的schema是数据库对象的集合,其中收录了表、视图等多种对象。模式就像一个用户名。当访问数据表时没有指定属于哪个schema,系统会自动添加默认schema。
我们在学习数据库中会遇到一个模糊的概念,那就是Schema。很多人对他并不十分了解。今天在文章中详细介绍一下这个概念,有一定的参考作用,希望对大家有所帮助。
【推荐课程:数据库教程】
架构概念
数据库中的模式表示数据库对象的集合,其中收录各种对象,例如表、视图、存储过程、索引等。一般一个用户对应一个集合,所以为了区分不同的集合,需要对不同的集合进行命名。用户的模式名等同于用户名,并作为用户的默认模式。所以模式集合看起来像用户名。比如我们访问一个数据表时,如果该表没有指定它属于哪个schema,系统会自动添加默认schema。
架构创建
需要注意的是,在不同的数据库中要创建的Schema方法是不同的,但是它们有一个共同的特点就是都支持CREATE SCHEMA语句
MySQL
在MySQL数据库中,我们可以通过CREATE SCHEMA语句创建数据库
甲骨文数据库
在Oracle中,因为数据库用户已经创建了schema,所以CREATE SCHEMA语句创建了schema,允许schema与表和视图相关联,在这些对象上很神奇。原来的授权不一定要在多个事务中发出多条SQL语句。
数据库服务器
在 SQL Server 中,CREATE SCHEMA 按名称创建架构。与 MySQL 不同,CREATE SCHEMA 语句创建一个单独定义到数据库的模式。它也不同于 Oracle 数据库。它实际上创建了一个模式,一旦创建了模式,就可以将用户和对象添加到模式中。 查看全部
网页中flash数据抓取(数据库中会碰到一个模糊的概念,它就是Schema语句创建)
数据库中的schema是数据库对象的集合,其中收录了表、视图等多种对象。模式就像一个用户名。当访问数据表时没有指定属于哪个schema,系统会自动添加默认schema。
我们在学习数据库中会遇到一个模糊的概念,那就是Schema。很多人对他并不十分了解。今天在文章中详细介绍一下这个概念,有一定的参考作用,希望对大家有所帮助。
【推荐课程:数据库教程】
架构概念
数据库中的模式表示数据库对象的集合,其中收录各种对象,例如表、视图、存储过程、索引等。一般一个用户对应一个集合,所以为了区分不同的集合,需要对不同的集合进行命名。用户的模式名等同于用户名,并作为用户的默认模式。所以模式集合看起来像用户名。比如我们访问一个数据表时,如果该表没有指定它属于哪个schema,系统会自动添加默认schema。
架构创建
需要注意的是,在不同的数据库中要创建的Schema方法是不同的,但是它们有一个共同的特点就是都支持CREATE SCHEMA语句
MySQL
在MySQL数据库中,我们可以通过CREATE SCHEMA语句创建数据库
甲骨文数据库
在Oracle中,因为数据库用户已经创建了schema,所以CREATE SCHEMA语句创建了schema,允许schema与表和视图相关联,在这些对象上很神奇。原来的授权不一定要在多个事务中发出多条SQL语句。
数据库服务器
在 SQL Server 中,CREATE SCHEMA 按名称创建架构。与 MySQL 不同,CREATE SCHEMA 语句创建一个单独定义到数据库的模式。它也不同于 Oracle 数据库。它实际上创建了一个模式,一旦创建了模式,就可以将用户和对象添加到模式中。
网页中flash数据抓取(python抓取网页数据.txt51自信是奔腾不息的波涛,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-04 23:18
Python 抓取网络数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并处理它2009-02-1915:09:50|Category:Python|Tag:None|字体大小订阅主要目的:抓取网页的源代码,处理其中需要的数据,并保存到数据库。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多加练习,多加练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。进一步扩展,该功能还可以用于捕获整个网站图片,自动声明站点地图文件等功能。接下来的任务是研究python#-*-coding的socket函数:gbk-*-importurllibimportre#pager=urllib.urlopen(ex.html)#data=pager.read()#pager.close()f=open (r "D:\2.txt")data=f.read()f. 查看全部
网页中flash数据抓取(python抓取网页数据.txt51自信是奔腾不息的波涛,)
Python 抓取网络数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并处理它2009-02-1915:09:50|Category:Python|Tag:None|字体大小订阅主要目的:抓取网页的源代码,处理其中需要的数据,并保存到数据库。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多加练习,多加练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。进一步扩展,该功能还可以用于捕获整个网站图片,自动声明站点地图文件等功能。接下来的任务是研究python#-*-coding的socket函数:gbk-*-importurllibimportre#pager=urllib.urlopen(ex.html)#data=pager.read()#pager.close()f=open (r "D:\2.txt")data=f.read()f.
网页中flash数据抓取(一个复杂的数据抽取过程需要应付种种障碍例如数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-04 12:06
互联网是一个巨大且发展迅速的信息资源。但是大部分信息都是非结构化的文本形式,查询起来非常困难。
网页数据提取是从目标网页中提取部分数据,形成统一的本地数据库的过程。这些数据原本只以文本的形式存在于可见的网页中。这个过程需要的不仅仅是网络爬虫和网络包装器。
一个复杂的数据抽取过程需要处理各种障碍,例如会话识别、HTML 表单、客户端Java 脚本,以及数据集和词集不一致、数据丢失和冲突等数据集成问题。
Web2DB 是一种 Web 数据提取服务。它使事情变得非常简单。它包括两种类型:
Web2DB 直接数据服务
Web2DB 自定义提取器软件服务。
您只需要告诉我们您要搜索什么数据,您要获取什么数据,您要什么格式的数据,我们会为您做好所有工作,直接将数据发送给您。数据格式可以是 Excel、Access、CSV、Text、MS SQL 和 My SQL。我们还可以为您的目标定制提取软件网站,让您随时可以在您的电脑上运行。
许多中小型公司和 网站 直接受益于我们的服务或定制软件。
您可以在以下领域使用我们的服务:
生成您的潜在客户列表
从竞争对手那里采集产品价格信息
抢新闻文章
创建您自己的产品目录
整合房地产信息
采集上市公司财务状况及数据
.... 查看全部
网页中flash数据抓取(一个复杂的数据抽取过程需要应付种种障碍例如数据)
互联网是一个巨大且发展迅速的信息资源。但是大部分信息都是非结构化的文本形式,查询起来非常困难。
网页数据提取是从目标网页中提取部分数据,形成统一的本地数据库的过程。这些数据原本只以文本的形式存在于可见的网页中。这个过程需要的不仅仅是网络爬虫和网络包装器。
一个复杂的数据抽取过程需要处理各种障碍,例如会话识别、HTML 表单、客户端Java 脚本,以及数据集和词集不一致、数据丢失和冲突等数据集成问题。
Web2DB 是一种 Web 数据提取服务。它使事情变得非常简单。它包括两种类型:
Web2DB 直接数据服务
Web2DB 自定义提取器软件服务。
您只需要告诉我们您要搜索什么数据,您要获取什么数据,您要什么格式的数据,我们会为您做好所有工作,直接将数据发送给您。数据格式可以是 Excel、Access、CSV、Text、MS SQL 和 My SQL。我们还可以为您的目标定制提取软件网站,让您随时可以在您的电脑上运行。
许多中小型公司和 网站 直接受益于我们的服务或定制软件。
您可以在以下领域使用我们的服务:
生成您的潜在客户列表
从竞争对手那里采集产品价格信息
抢新闻文章
创建您自己的产品目录
整合房地产信息
采集上市公司财务状况及数据
....
网页中flash数据抓取(如何捕获到动态加载的数据?通过示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-03 23:11
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
网页中flash数据抓取(如何捕获到动态加载的数据?通过示例代码介绍)
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击了解json序列化和反序列化。代码如下:
import requests import json # 获取商品价格的请求地址 url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \ "=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \ "pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921" jQuery_id = url.split("=")[-1] + "(" # 头部信息 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36" } # 发送网络请求 response = requests.get(url, headers=headers) if response.status_code == 200: goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化 print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}") print(f"定价为: {goods_dict['stock']['jdPrice']['m']}") print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}") else: print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
以上就是Python实现的爬取网页中动态加载数据的详细内容。更多详情请关注其他相关html中文网站文章!
网页中flash数据抓取(从中提取数据的PowerBIDesktop示例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-30 04:19
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。
图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。输入样本时,Power Query 使用智能数据提取算法来提取符合样本输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。
在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题 查看全部
网页中flash数据抓取(从中提取数据的PowerBIDesktop示例(组图))
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。
图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示从网页中自动检测到的所有表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。输入样本时,Power Query 使用智能数据提取算法来提取符合样本输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。
在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题
网页中flash数据抓取(几种常见的网络数据应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-26 05:25
互联网上有大量数据。如何捕捉这些分散的数据并存储在公司数据库中?如何从数据中挖掘价值,洞察市场发展方向,助力业务持续增长?
本文将分享几种常见的网络数据采集方法,并展示多个真实的数据应用实例,希望对大家有所帮助。
1. 内容聚合
对于大多数媒体网站来说,实时获取互联网上的大量信息/新闻是非常重要的。网络数据采集可以监控各种新闻门户网站和主流社交媒体,通过关键词搜索等方式实时获取更新数据。
使用内容聚合的另一个示例是业务组。例如,招标团队。借助网络数据采集,可以自动采集每次招标网站更新的、与业务相关的招标项目信息,以便及时跟进,快速发现商机。
2. 竞争对手监控
电子商务从业者需要时刻关注竞争对手的情况,调整自己的经营策略。网络数据采集可以实时监控竞争对手官网、店铺等网页的信息,包括产品更新、促销活动、客户评价等。
电子商务领域的竞争日趋激烈,深耕细分市场是一条出路。网络数据采集将有助于通过产品细节挖掘细分市场,提高品牌知名度和交易量。同时,可以通过分析捕获的数据来合理定价产品。
3. 情绪分析
用户生成的文本内容是情感分析的基础。此类数据主要是评论、意见或投诉,通常在以消费者为中心的产品、服务或特定事件(例如音乐、电影和书籍)中生成。通过部署多个网络爬虫工具,您可以轻松地从不同的网站 获取所有这些信息。
4. 市场研究
几乎每个公司都需要进行市场调查。互联网上可以提供不同类型的数据,包括产品信息、标签、社交媒体或其他平台上的产品评论、新闻等。使用传统数据采集方法进行市场调查既费时又费钱任务。到目前为止,如果您需要采集大量数据进行市场调查,网络数据提取是最简单的方法。
5. 机器学习
与情感分析一样,可用的网络数据是机器学习的高质量材料。标记和提取内容以及从元数据字段和值中提取实体是自然语言处理的源头。类别和标签信息可用于完成统计标签或聚类系统。Web 数据捕获可以帮助您以更高效、更准确的方式获取数据。
网络数据采集工具和方法
到目前为止,从网页中提取数据的最佳方法是将数据抓取项目外包给 DaaS 提供商。拥有必要的专业知识和基础设施来捕获数据。这样,也可以完全免除网络爬虫的责任。
还有一种更简单的方式来完成项目——使用网络爬虫!我们在之前的博客中介绍了很多工具。所有工具都有其优点和缺点,它们在某些方面更适合不同的人。优采云 是为非程序员创建的,比任何其他网络数据抓取工具都更容易使用。通过浏览一些教程,你可以零基础轻松掌握。
网络爬虫最灵活的方法是编写自己的爬虫程序。大多数网页抓取工具都是用 Python 编写的,以进一步简化采集数据的过程。但是对于大多数人来说,编写爬虫并不容易。 查看全部
网页中flash数据抓取(几种常见的网络数据应用方法)
互联网上有大量数据。如何捕捉这些分散的数据并存储在公司数据库中?如何从数据中挖掘价值,洞察市场发展方向,助力业务持续增长?
本文将分享几种常见的网络数据采集方法,并展示多个真实的数据应用实例,希望对大家有所帮助。
1. 内容聚合
对于大多数媒体网站来说,实时获取互联网上的大量信息/新闻是非常重要的。网络数据采集可以监控各种新闻门户网站和主流社交媒体,通过关键词搜索等方式实时获取更新数据。
使用内容聚合的另一个示例是业务组。例如,招标团队。借助网络数据采集,可以自动采集每次招标网站更新的、与业务相关的招标项目信息,以便及时跟进,快速发现商机。
2. 竞争对手监控
电子商务从业者需要时刻关注竞争对手的情况,调整自己的经营策略。网络数据采集可以实时监控竞争对手官网、店铺等网页的信息,包括产品更新、促销活动、客户评价等。
电子商务领域的竞争日趋激烈,深耕细分市场是一条出路。网络数据采集将有助于通过产品细节挖掘细分市场,提高品牌知名度和交易量。同时,可以通过分析捕获的数据来合理定价产品。
3. 情绪分析
用户生成的文本内容是情感分析的基础。此类数据主要是评论、意见或投诉,通常在以消费者为中心的产品、服务或特定事件(例如音乐、电影和书籍)中生成。通过部署多个网络爬虫工具,您可以轻松地从不同的网站 获取所有这些信息。
4. 市场研究
几乎每个公司都需要进行市场调查。互联网上可以提供不同类型的数据,包括产品信息、标签、社交媒体或其他平台上的产品评论、新闻等。使用传统数据采集方法进行市场调查既费时又费钱任务。到目前为止,如果您需要采集大量数据进行市场调查,网络数据提取是最简单的方法。
5. 机器学习
与情感分析一样,可用的网络数据是机器学习的高质量材料。标记和提取内容以及从元数据字段和值中提取实体是自然语言处理的源头。类别和标签信息可用于完成统计标签或聚类系统。Web 数据捕获可以帮助您以更高效、更准确的方式获取数据。
网络数据采集工具和方法
到目前为止,从网页中提取数据的最佳方法是将数据抓取项目外包给 DaaS 提供商。拥有必要的专业知识和基础设施来捕获数据。这样,也可以完全免除网络爬虫的责任。
还有一种更简单的方式来完成项目——使用网络爬虫!我们在之前的博客中介绍了很多工具。所有工具都有其优点和缺点,它们在某些方面更适合不同的人。优采云 是为非程序员创建的,比任何其他网络数据抓取工具都更容易使用。通过浏览一些教程,你可以零基础轻松掌握。
网络爬虫最灵活的方法是编写自己的爬虫程序。大多数网页抓取工具都是用 Python 编写的,以进一步简化采集数据的过程。但是对于大多数人来说,编写爬虫并不容易。

