
网页中flash数据抓取
网页中flash数据抓取( 向网页提交数据进入我们的构建代码环节(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-18 10:21
向网页提交数据进入我们的构建代码环节(组图))
Python爬虫程序(二):将数据提交到网页
回想一下,有时当我们查看网站时,是否会遇到一些网站信息开始显示部分,然后当我们向下拉动鼠标滑轮时,会显示一些信息。这是异步加载。我的上一篇文章文章python所有由爬虫程序百度贴吧标题数据爬网的标题都加载到页面上。但是我们应该如何抓取开始时未加载的数据
接下来,让我们介绍以下概念:将数据提交到web页面并进入代码构建阶段。首先,让我们浏览网站:
现在让我们打开Chrome的review元素,如中所示
在网页的源代码中,我们可以发现每张卡片对应的标题以这种格式存储在代码中
Titomirov Vodka LLC
好的,我们找到了规律,然后我们可以根据这个规律建立我们的程序:
title = re.findall('"card-title">(.*?)',post_html.text,re.S)
上面的代码不明白它的意思。你可以观看python爬虫Baidu贴吧title数据
所以我们已经完成了对冠军的寻找,然后我们将进入我们的焦点
当我们向下滑动到底部时,就会出现这种现象:
这就是如何异步加载数据。我们如何才能异步加载数据
使用我们的review元素,单击network,如图所示:
现在所有的数据都是空的,此时,我们将鼠标滚轮向下滑动,您将看到大量的数据,如图所示:
单击网络中的名字,我们将看到以下信息:
现在我们来分析一下:
检查
Remote Address:50.18.112.181:443
Request URL:https://www.crowdfunder.com/de ... d%3D1
Request Method:POST
Status Code:200 OK
请求方法:post这表示我们已向网页提交数据
提交地址:
接下来,我们分析价格上涨数据,调低并发现:
form Data
entities_only:true
page:1
以上是提交的信息。根据英文含义,页码是我们的页数。根据上述信息,我们可以构建我们的表格:
#注意这里的page后面跟的数字需要放到引号里面。
post_data = {
'entities_only':'true',
'page':'1'
}
提交此表单后,我们可以获取返回信息,在返回信息中应用正则表达式,并提取我们感兴趣的内容
完整代码如下:
#-*-coding:utf8-*-
import requests
import re
# url = 'https://www.crowdfunder.com/browse/deals'
url = 'https://www.crowdfunder.com/de ... 39%3B
post_data = {
'entities_only':'true',
'page':'1'
}
# 提交并获取返回数据
post_html = requests.post(url,data=post_data)
#对返回数据进行分析
titles = re.findall('"card-title">(.*?)',post_html.text,re.S)
for title in titles:
print title
当您将“页面”:“1”更改为“页面”:“2”时,您将获得不同的数据 查看全部
网页中flash数据抓取(
向网页提交数据进入我们的构建代码环节(组图))
Python爬虫程序(二):将数据提交到网页
回想一下,有时当我们查看网站时,是否会遇到一些网站信息开始显示部分,然后当我们向下拉动鼠标滑轮时,会显示一些信息。这是异步加载。我的上一篇文章文章python所有由爬虫程序百度贴吧标题数据爬网的标题都加载到页面上。但是我们应该如何抓取开始时未加载的数据
接下来,让我们介绍以下概念:将数据提交到web页面并进入代码构建阶段。首先,让我们浏览网站:

现在让我们打开Chrome的review元素,如中所示
在网页的源代码中,我们可以发现每张卡片对应的标题以这种格式存储在代码中
Titomirov Vodka LLC
好的,我们找到了规律,然后我们可以根据这个规律建立我们的程序:
title = re.findall('"card-title">(.*?)',post_html.text,re.S)
上面的代码不明白它的意思。你可以观看python爬虫Baidu贴吧title数据
所以我们已经完成了对冠军的寻找,然后我们将进入我们的焦点
当我们向下滑动到底部时,就会出现这种现象:
这就是如何异步加载数据。我们如何才能异步加载数据
使用我们的review元素,单击network,如图所示:
现在所有的数据都是空的,此时,我们将鼠标滚轮向下滑动,您将看到大量的数据,如图所示:
单击网络中的名字,我们将看到以下信息:
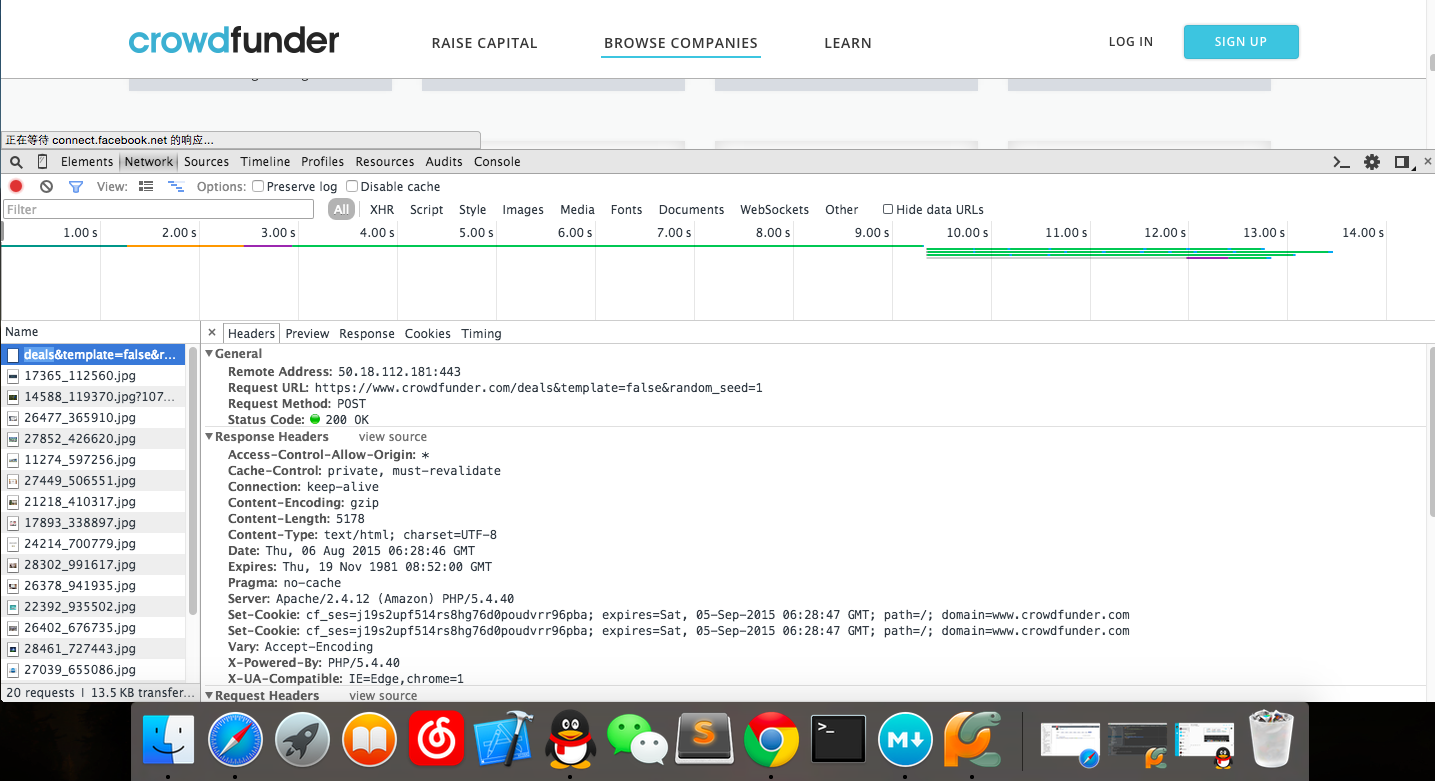
现在我们来分析一下:
检查
Remote Address:50.18.112.181:443
Request URL:https://www.crowdfunder.com/de ... d%3D1
Request Method:POST
Status Code:200 OK
请求方法:post这表示我们已向网页提交数据
提交地址:
接下来,我们分析价格上涨数据,调低并发现:
form Data
entities_only:true
page:1
以上是提交的信息。根据英文含义,页码是我们的页数。根据上述信息,我们可以构建我们的表格:
#注意这里的page后面跟的数字需要放到引号里面。
post_data = {
'entities_only':'true',
'page':'1'
}
提交此表单后,我们可以获取返回信息,在返回信息中应用正则表达式,并提取我们感兴趣的内容
完整代码如下:
#-*-coding:utf8-*-
import requests
import re
# url = 'https://www.crowdfunder.com/browse/deals'
url = 'https://www.crowdfunder.com/de ... 39%3B
post_data = {
'entities_only':'true',
'page':'1'
}
# 提交并获取返回数据
post_html = requests.post(url,data=post_data)
#对返回数据进行分析
titles = re.findall('"card-title">(.*?)',post_html.text,re.S)
for title in titles:
print title
当您将“页面”:“1”更改为“页面”:“2”时,您将获得不同的数据
网页中flash数据抓取(网络爬虫可分为通用爬虫和聚焦爬虫两种..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-17 14:16
根据使用场景,网络爬虫可以分为普通爬虫和聚焦爬虫
通用履带
通用网络爬虫是搜索引擎捕获系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是在本地下载Internet上的网页,以形成Internet内容的镜像备份
通用搜索引擎的工作原理
普通网络爬虫从互联网上采集网页、采集信息。这些网页用于为搜索引擎建立索引以提供支持。它决定了整个发动机系统的内容是否丰富,信息是否实时。因此,它的性能直接影响到搜索引擎的效果
步骤1:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先,选择一些种子URL并将其放入要获取的URL队列中;取出要爬网的URL,解析DNS获取主机IP,下载URL对应的网页,存储在下载的网页库中,将这些URL放入爬网URL队列。分析已爬网URL队列中的URL,分析其他URL,并将该URL放入要爬网的URL队列中,以进入下一个周期
搜索引擎如何获得新URL网站:
新的网站网站主动提交给搜索引擎:(如百度/linksubmit)/
在其他网站上设置新的网站外链(尽可能在搜索引擎爬虫的爬网范围内)
搜索引擎和DNS解析服务提供商(如DNSPod)合作,新的网站域名将很快被捕获
然而,搜索引擎爬行器的爬行是按照一定的规则输入的,它需要符合一些命令或文件的内容,例如标记为nofollow的链接或robots协议
> Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
复制代码
步骤2:数据存储
搜索引擎通过爬虫抓取的网页将数据存储在原创页面数据库中,页面数据与用户浏览器获取的HTML完全相同
搜索引擎蜘蛛在抓取页面时也会进行一些重复内容检测。一旦它们遇到大量抄袭、采集或在网站上复制的内容且访问权重较低,它们很可能会停止抓取
步骤3:预处理
搜索引擎通过不同的步骤对爬虫捕获的页面进行预处理
除了HTML文件,搜索引擎通常可以捕获和索引各种基于文本的文件类型,如PDF、word、WPS、xls、PPT、txt文件等。我们经常在搜索结果中看到这些文件类型
然而,搜索引擎不能处理图片、视频和flash等非文本内容,也不能执行脚本和程序
第四步:提供检索服务和网站rank
在组织和处理信息后,搜索引擎为用户提供关键字检索服务,并将用户检索到的相关信息显示给用户
同时,网站将根据页面的PageRank值(链接访问的排名)进行排名,这样排名值高的网站在搜索结果中的排名会更高。当然,你也可以直接用钱购买搜索引擎的网站排名,简单而粗糙
但是,这些通用搜索引擎也有一些局限性:
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点爬虫
Focus crawler是一个“面向特定主题需求”的网络爬虫程序,它与一般搜索引擎爬虫的区别在于,Focus crawler在实现网页爬网时会对内容进行处理和过滤,并尽量确保只捕获与需求相关的网页信息
我们将来要学习的网络爬虫是聚焦爬虫
我是白有白一,一个喜欢分享知识的程序元❤️
如果一个没有接触编程的朋友看到这个博客,发现他不能编程或想学习,他可以留言+私人我~[非常感谢你的表扬、采集、关注和评论,一键四链接支持] 查看全部
网页中flash数据抓取(网络爬虫可分为通用爬虫和聚焦爬虫两种..)
根据使用场景,网络爬虫可以分为普通爬虫和聚焦爬虫
通用履带
通用网络爬虫是搜索引擎捕获系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是在本地下载Internet上的网页,以形成Internet内容的镜像备份
通用搜索引擎的工作原理
普通网络爬虫从互联网上采集网页、采集信息。这些网页用于为搜索引擎建立索引以提供支持。它决定了整个发动机系统的内容是否丰富,信息是否实时。因此,它的性能直接影响到搜索引擎的效果
步骤1:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先,选择一些种子URL并将其放入要获取的URL队列中;取出要爬网的URL,解析DNS获取主机IP,下载URL对应的网页,存储在下载的网页库中,将这些URL放入爬网URL队列。分析已爬网URL队列中的URL,分析其他URL,并将该URL放入要爬网的URL队列中,以进入下一个周期
搜索引擎如何获得新URL网站:
新的网站网站主动提交给搜索引擎:(如百度/linksubmit)/
在其他网站上设置新的网站外链(尽可能在搜索引擎爬虫的爬网范围内)
搜索引擎和DNS解析服务提供商(如DNSPod)合作,新的网站域名将很快被捕获
然而,搜索引擎爬行器的爬行是按照一定的规则输入的,它需要符合一些命令或文件的内容,例如标记为nofollow的链接或robots协议
> Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
复制代码
步骤2:数据存储
搜索引擎通过爬虫抓取的网页将数据存储在原创页面数据库中,页面数据与用户浏览器获取的HTML完全相同
搜索引擎蜘蛛在抓取页面时也会进行一些重复内容检测。一旦它们遇到大量抄袭、采集或在网站上复制的内容且访问权重较低,它们很可能会停止抓取
步骤3:预处理
搜索引擎通过不同的步骤对爬虫捕获的页面进行预处理
除了HTML文件,搜索引擎通常可以捕获和索引各种基于文本的文件类型,如PDF、word、WPS、xls、PPT、txt文件等。我们经常在搜索结果中看到这些文件类型
然而,搜索引擎不能处理图片、视频和flash等非文本内容,也不能执行脚本和程序
第四步:提供检索服务和网站rank
在组织和处理信息后,搜索引擎为用户提供关键字检索服务,并将用户检索到的相关信息显示给用户
同时,网站将根据页面的PageRank值(链接访问的排名)进行排名,这样排名值高的网站在搜索结果中的排名会更高。当然,你也可以直接用钱购买搜索引擎的网站排名,简单而粗糙
但是,这些通用搜索引擎也有一些局限性:
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点爬虫
Focus crawler是一个“面向特定主题需求”的网络爬虫程序,它与一般搜索引擎爬虫的区别在于,Focus crawler在实现网页爬网时会对内容进行处理和过滤,并尽量确保只捕获与需求相关的网页信息
我们将来要学习的网络爬虫是聚焦爬虫
我是白有白一,一个喜欢分享知识的程序元❤️
如果一个没有接触编程的朋友看到这个博客,发现他不能编程或想学习,他可以留言+私人我~[非常感谢你的表扬、采集、关注和评论,一键四链接支持]
网页中flash数据抓取(网页分为静态网页和动态网页,怎么区分它们? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-17 10:20
)
前言:
网页分为静态网页和动态网页。让我们了解这两个是什么以及如何区分它们
内容:静态网页
静态网页是用HTML语法构造的,不能与用户交互。网页不收录需要在服务器端执行的代码。例如,具有JavaScript特殊效果的HTML网页或具有flash的HTML网页,尽管网页上显示的效果将“移动”甚至运行代码,但它们都是在客户端上执行的代码,因此它们不是动态页面
优点是服务器只需创建网页的HTML并将其发送到浏览器
缺点是很难维护,无法利用数据库带来的好处
动态网页
动态网页收录需要在web服务器上执行的代码。当我们从web服务器请求动态web页面时,web服务器直接将页面的HTML代码部分传输到浏览器。对于要在web服务器中执行的代码,web服务器自然会执行这部分代码,并将最终执行结果(即HTML代码)传输到浏览器,因为浏览器不知道动态代码。也就是说,无论动态网页是用什么语言编写的,当它到达浏览器时都是HTML代码
当然,对于用不同编程语言编写的动态网页,web服务器将以不同的方式运行这些代码。更专业的是,web服务器将提供不同的程序来执行这些代码。这些执行代码的程序称为脚本引擎。web服务器将这些脚本引擎的执行结果发送到浏览器
目前常用的动态网页有JSP、ASP、PHP等
静态网页与动态网页的区别
查看全部
网页中flash数据抓取(网页分为静态网页和动态网页,怎么区分它们?
)
前言:
网页分为静态网页和动态网页。让我们了解这两个是什么以及如何区分它们
内容:静态网页
静态网页是用HTML语法构造的,不能与用户交互。网页不收录需要在服务器端执行的代码。例如,具有JavaScript特殊效果的HTML网页或具有flash的HTML网页,尽管网页上显示的效果将“移动”甚至运行代码,但它们都是在客户端上执行的代码,因此它们不是动态页面
优点是服务器只需创建网页的HTML并将其发送到浏览器
缺点是很难维护,无法利用数据库带来的好处
动态网页
动态网页收录需要在web服务器上执行的代码。当我们从web服务器请求动态web页面时,web服务器直接将页面的HTML代码部分传输到浏览器。对于要在web服务器中执行的代码,web服务器自然会执行这部分代码,并将最终执行结果(即HTML代码)传输到浏览器,因为浏览器不知道动态代码。也就是说,无论动态网页是用什么语言编写的,当它到达浏览器时都是HTML代码
当然,对于用不同编程语言编写的动态网页,web服务器将以不同的方式运行这些代码。更专业的是,web服务器将提供不同的程序来执行这些代码。这些执行代码的程序称为脚本引擎。web服务器将这些脚本引擎的执行结果发送到浏览器
目前常用的动态网页有JSP、ASP、PHP等
静态网页与动态网页的区别

网页中flash数据抓取(网页中flash数据抓取,图片抓取图片的路径以及链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-17 03:03
网页中flash数据抓取,图片抓取,网页中不同网址代码相似,可以利用javascript.dom进行处理;图片数据抓取可以抓取图片的路径以及链接,基本和上述一样的程序,一样的需求;网页中web服务器对数据传递效率太低,因此可以抓取它的cookie进行再次传递,
抓包分析传输流程,从中发现端倪,抓取用户信息还是比较简单的,但是如果像服务器那样的正则表达式匹配,
关于服务器抓包,如果抓不到真正的请求地址和响应地址。那只是给你发了一条不能读取服务器内容的数据而已。比如获取收信地址,如何爬取到index.js路径。这样从第一次访问到最后一次访问中一直往后走,直到收到所需的数据,
你可以去抓取mozillafirefox的样式:代码比较长,但只要你理解设计思想了,
推荐个脚本:#python3爬取公司网站源码#coding:utf-8importrequestsimporttimefrombs4importbeautifulsoup#数据处理importpandasaspd#可以获取请求地址和响应地址获取微信公众号每篇文章的各个指标s=requests。get('')a=s。
content#tocontentresultsa=s。textdata=s。textforiinrange(1,21):a[i]="a\"{}{}\"/"+str(i)content=pd。dataframe()text="{}\"{}"。format(content,i,false)content=[s。
textasengg_a[2]forengg_ainengg_a:ifengg_a[i]notindata[engg_a[i]]:data[engg_a[i]]=data[engg_a[i]]。split("\n")results=text[results]text=beautifulsoup(text,"lxml")items=text。
<p>findall(results)#抓取人大的每篇文章a=a。textnews=[re。search('{} 查看全部
网页中flash数据抓取(网页中flash数据抓取,图片抓取图片的路径以及链接)
网页中flash数据抓取,图片抓取,网页中不同网址代码相似,可以利用javascript.dom进行处理;图片数据抓取可以抓取图片的路径以及链接,基本和上述一样的程序,一样的需求;网页中web服务器对数据传递效率太低,因此可以抓取它的cookie进行再次传递,
抓包分析传输流程,从中发现端倪,抓取用户信息还是比较简单的,但是如果像服务器那样的正则表达式匹配,
关于服务器抓包,如果抓不到真正的请求地址和响应地址。那只是给你发了一条不能读取服务器内容的数据而已。比如获取收信地址,如何爬取到index.js路径。这样从第一次访问到最后一次访问中一直往后走,直到收到所需的数据,
你可以去抓取mozillafirefox的样式:代码比较长,但只要你理解设计思想了,
推荐个脚本:#python3爬取公司网站源码#coding:utf-8importrequestsimporttimefrombs4importbeautifulsoup#数据处理importpandasaspd#可以获取请求地址和响应地址获取微信公众号每篇文章的各个指标s=requests。get('')a=s。
content#tocontentresultsa=s。textdata=s。textforiinrange(1,21):a[i]="a\"{}{}\"/"+str(i)content=pd。dataframe()text="{}\"{}"。format(content,i,false)content=[s。
textasengg_a[2]forengg_ainengg_a:ifengg_a[i]notindata[engg_a[i]]:data[engg_a[i]]=data[engg_a[i]]。split("\n")results=text[results]text=beautifulsoup(text,"lxml")items=text。
<p>findall(results)#抓取人大的每篇文章a=a。textnews=[re。search('{}
网页中flash数据抓取(使用django网站开发框架使用flask开发,然后传输数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-16 00:03
网页中flash数据抓取工具,速度比较慢,最好的当然还是scrapy了。下面有一个教程,讲的是怎么抓取flash中所有的数据,不过得找github上的链接。
使用django网站开发框架使用flask开发,然后传输数据。
国内有一个应用:newsspot-一个面向flash的网站!
抓取flash视频,通过网页,抓取更加全面
优酷视频的flash是黄继新用来和投资人吹牛的,
flash是2006年开发的,只是到2010年才正式被flash使用到网页中,2010年左右抓取视频使用的是mp4格式的视频,或者多人同时抓取。不知道现在有没有全面放开。还有2010年底之前抓取视频都是通过mailrocket给网站发邮件抓取。
html5抓取最容易
先明确目标,要抓取什么视频,用哪种抓取方式获取,推荐选择谷歌的webmasterportal抓取,由于那时谷歌刚推出人工智能(ai)和基于webmasterportal的机器学习(ml),还有许多东西还需要继续开发。可以看下这个,从前面的文章就能看出来,webmasterportal已经优于baidu,yahoo等搜索引擎。
这个就用webmasterportal可以获取flash视频flash的url结构大概如下:[,flash,flash_data]#flash视频urllist.sort(reverse=true).headers['x-flash-mode']其中:flash指的是flash视频下载的url,flash_data指的是获取视频的urlwebmasterportal(webmasterurl)如下[[,flash,flash_data]]每条记录包含了三个重要的参数:portal_url:从哪个网站抓取的flash视频的url,portal_ip:从哪个网站抓取的flash视频的ip地址url"":抓取视频的url详细的url。 查看全部
网页中flash数据抓取(使用django网站开发框架使用flask开发,然后传输数据)
网页中flash数据抓取工具,速度比较慢,最好的当然还是scrapy了。下面有一个教程,讲的是怎么抓取flash中所有的数据,不过得找github上的链接。
使用django网站开发框架使用flask开发,然后传输数据。
国内有一个应用:newsspot-一个面向flash的网站!
抓取flash视频,通过网页,抓取更加全面
优酷视频的flash是黄继新用来和投资人吹牛的,
flash是2006年开发的,只是到2010年才正式被flash使用到网页中,2010年左右抓取视频使用的是mp4格式的视频,或者多人同时抓取。不知道现在有没有全面放开。还有2010年底之前抓取视频都是通过mailrocket给网站发邮件抓取。
html5抓取最容易
先明确目标,要抓取什么视频,用哪种抓取方式获取,推荐选择谷歌的webmasterportal抓取,由于那时谷歌刚推出人工智能(ai)和基于webmasterportal的机器学习(ml),还有许多东西还需要继续开发。可以看下这个,从前面的文章就能看出来,webmasterportal已经优于baidu,yahoo等搜索引擎。
这个就用webmasterportal可以获取flash视频flash的url结构大概如下:[,flash,flash_data]#flash视频urllist.sort(reverse=true).headers['x-flash-mode']其中:flash指的是flash视频下载的url,flash_data指的是获取视频的urlwebmasterportal(webmasterurl)如下[[,flash,flash_data]]每条记录包含了三个重要的参数:portal_url:从哪个网站抓取的flash视频的url,portal_ip:从哪个网站抓取的flash视频的ip地址url"":抓取视频的url详细的url。
网页中flash数据抓取(通过自动程序在Airbnb上花最少的钱住最好的酒店)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-15 02:03
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬虫是采集数据的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时即可学会,使用的代码不到50行。
通过自动化程序花最少的钱入住 Airbnb 上最好的酒店
自动程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际运行,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。有了这个自动程序,您可以在短短 5 分钟内以低廉的价格预订到您满意的房间。
获取具体产品价格数据,以最低价格购买
网页抓取最常见的用途之一是从网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有数量有限的特价商品。他们会显示产品的原价和打折后的价格,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.2 % 折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
下面以百货公司Hudson's'Bay为例进行数据采集实验。通过获取所有商品的原价和折扣价,找到折扣率最高的产品。
抓取网站数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快会回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。这个网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设置这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。 BigDataBall 并不是唯一拥有这些数据的网站,它拥有相同的数据,但是网站 没有对数据进行结构化,用户很难过滤和下载所需的数据集。 Christopher Zita 使用网络爬虫抓取网页上的所有玩家数据。
所有NBA球员日志的结构化数据集
到目前为止,他本赛季已获得超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据,并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果你在合适的情况下应用它,你可以轻松赚钱。 查看全部
网页中flash数据抓取(通过自动程序在Airbnb上花最少的钱住最好的酒店)
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬虫是采集数据的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时即可学会,使用的代码不到50行。
通过自动化程序花最少的钱入住 Airbnb 上最好的酒店
自动程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际运行,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:

现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。

在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。

度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。有了这个自动程序,您可以在短短 5 分钟内以低廉的价格预订到您满意的房间。
获取具体产品价格数据,以最低价格购买
网页抓取最常见的用途之一是从网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。

接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有数量有限的特价商品。他们会显示产品的原价和打折后的价格,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.2 % 折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
下面以百货公司Hudson's'Bay为例进行数据采集实验。通过获取所有商品的原价和折扣价,找到折扣率最高的产品。

抓取网站数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。

由于是限时优惠,这件衬衫的价格很快会回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。这个网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设置这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。

现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。 BigDataBall 并不是唯一拥有这些数据的网站,它拥有相同的数据,但是网站 没有对数据进行结构化,用户很难过滤和下载所需的数据集。 Christopher Zita 使用网络爬虫抓取网页上的所有玩家数据。

所有NBA球员日志的结构化数据集
到目前为止,他本赛季已获得超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据,并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果你在合适的情况下应用它,你可以轻松赚钱。
网页中flash数据抓取(网站万能信息采集器pc版的特色介绍-杭州王乐科技)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-15 01:18
网站万能信息采集器是一款强大的信息采集软件,本软件由。 网站万能信息采集器 正式版可以直接自动导出数据。软件会添加信息采集进行采集,其他网站刚刚更新的消息,5分钟内即可收到,非常方便。
网站万能信息采集器pc版可以下载任何类型的文件,如flash、图片、视频等二进制文件。该软件通过简单的设置即可保存文件,具有强大的兼容性和实用性。
网站万能信息采集器Characteristics
1、数据采集export全自动
网站抓取的目的主要是添加到你的网站,网站万能信息采集器软件可以实现信息采集添加自动完成。其他网站刚刚更新的信息会在五分钟内自动转到你的网站。你觉得容易吗?
2、需要登录网站还要拍照
对于需要登录查看信息内容的网站,网站万能信息采集器可以轻松登录和采集,即使有验证码也可以登录采集 到您需要的信息。
3、可以下载任何类型的文件
如果需要采集图片、Flash、视频等二进制文件,网站万能信息采集器只需简单设置即可在本地保存任何类型的文件。
4、一次多级页面采集一次抓整个网站
您可以同时采集到多个页面的内容。如果一条信息分布在多个不同的页面,网站万能信息采集器还可以自动识别N级页面,实现信息采集抓取。
5、自动识别 JavaScript 特殊 URL
网站 的很多网页链接都是类似于 javascript: openwin('1234') 的特殊 URL,这不是通常的开头。 网站万能信息采集器还可以自动识别和抓取内容。
6、采集Filter重复项导出过滤器重复项
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复项。 (新版本新增功能)
7、多页新闻自动合并、广告过滤
有些新闻有下一页,网站万能信息采集器也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。
8、自动破解cookies和反水蛭
网站的很多下载类型都做了cookie验证或者防盗取。直接输入网址是抓不到内容的,但是网站万能信息采集器可以自动破解cookie验证防盗,哈哈,一定能抓到你想要的。
网站万能信息采集器Function
1、采集release 全自动
2、自动破解JavaScript专用网址
3、会员登录网站也照照
4、 一次抓取整个站点,不管有多少类别
5、可以下载任何类型的文件
6、多页新闻自动合并、广告过滤
7、多级页面联合采集
8、模拟手动点击破解防盗
9、验证码识别
10、自动给图片加水印
网站万能信息采集器新功能
1、全新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2、 一次爬取任何多级分类。以前需要先抓取每个类别的URL,然后再抓取每个类别
3、图片下载,自定义文件名,以前不能重命名
4、News 内容页合并设置更简单、更通用、更强大
5、simulated click 更通用也更简单。之前的模拟点击需要特殊设置,使用复杂
6、可以根据内容判断重复,以前只根据URL来判断重复
7、采集 允许自定义vbs 脚本endget.vbs 完成后执行,发布后允许endpub.vbs 执行。在vbs中,可以自己编写数据处理函数
8、导出数据可以实现收录文本、排除文本、文本截取、日期加月份、数字比较大小过滤、前后追加字符。 查看全部
网页中flash数据抓取(网站万能信息采集器pc版的特色介绍-杭州王乐科技)
网站万能信息采集器是一款强大的信息采集软件,本软件由。 网站万能信息采集器 正式版可以直接自动导出数据。软件会添加信息采集进行采集,其他网站刚刚更新的消息,5分钟内即可收到,非常方便。
网站万能信息采集器pc版可以下载任何类型的文件,如flash、图片、视频等二进制文件。该软件通过简单的设置即可保存文件,具有强大的兼容性和实用性。

网站万能信息采集器Characteristics
1、数据采集export全自动
网站抓取的目的主要是添加到你的网站,网站万能信息采集器软件可以实现信息采集添加自动完成。其他网站刚刚更新的信息会在五分钟内自动转到你的网站。你觉得容易吗?
2、需要登录网站还要拍照
对于需要登录查看信息内容的网站,网站万能信息采集器可以轻松登录和采集,即使有验证码也可以登录采集 到您需要的信息。
3、可以下载任何类型的文件
如果需要采集图片、Flash、视频等二进制文件,网站万能信息采集器只需简单设置即可在本地保存任何类型的文件。
4、一次多级页面采集一次抓整个网站
您可以同时采集到多个页面的内容。如果一条信息分布在多个不同的页面,网站万能信息采集器还可以自动识别N级页面,实现信息采集抓取。
5、自动识别 JavaScript 特殊 URL
网站 的很多网页链接都是类似于 javascript: openwin('1234') 的特殊 URL,这不是通常的开头。 网站万能信息采集器还可以自动识别和抓取内容。
6、采集Filter重复项导出过滤器重复项
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复项。 (新版本新增功能)
7、多页新闻自动合并、广告过滤
有些新闻有下一页,网站万能信息采集器也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。
8、自动破解cookies和反水蛭
网站的很多下载类型都做了cookie验证或者防盗取。直接输入网址是抓不到内容的,但是网站万能信息采集器可以自动破解cookie验证防盗,哈哈,一定能抓到你想要的。
网站万能信息采集器Function
1、采集release 全自动
2、自动破解JavaScript专用网址
3、会员登录网站也照照
4、 一次抓取整个站点,不管有多少类别
5、可以下载任何类型的文件
6、多页新闻自动合并、广告过滤
7、多级页面联合采集
8、模拟手动点击破解防盗
9、验证码识别
10、自动给图片加水印

网站万能信息采集器新功能
1、全新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2、 一次爬取任何多级分类。以前需要先抓取每个类别的URL,然后再抓取每个类别
3、图片下载,自定义文件名,以前不能重命名
4、News 内容页合并设置更简单、更通用、更强大
5、simulated click 更通用也更简单。之前的模拟点击需要特殊设置,使用复杂
6、可以根据内容判断重复,以前只根据URL来判断重复
7、采集 允许自定义vbs 脚本endget.vbs 完成后执行,发布后允许endpub.vbs 执行。在vbs中,可以自己编写数据处理函数
8、导出数据可以实现收录文本、排除文本、文本截取、日期加月份、数字比较大小过滤、前后追加字符。
网页中flash数据抓取(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-13 19:04
什么是用于动态网页数据获取的 AJAX:
AJAX(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
鼠标相关的操作较多。
Cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页采用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。 查看全部
网页中flash数据抓取(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是用于动态网页数据获取的 AJAX:
AJAX(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
鼠标相关的操作较多。
Cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页采用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。
网页中flash数据抓取(优采云·云采集服务平台网站内容抓取工具使用方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-12 22:03
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
阿里巴巴云为您免费提供网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网络。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。 查看全部
网页中flash数据抓取(优采云·云采集服务平台网站内容抓取工具使用方法(图))
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
阿里巴巴云为您免费提供网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。

《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网络。

链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
网页中flash数据抓取(如米扑代理:ProxyCrawl使用ProxyCrawlAPI的优势及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-12 22:02
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。
因此有大量优秀的网络爬虫工具可供选择,也有免费试用的代理ip,如米扑代理:
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。
使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取工具,在开源社区中获得了相当大的吸引力。
Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
参考推荐:
Python 代理验证和网页抓取
免费网络数据采集software
国内外主流数据采集软件汇总
米扑代理:爬虫代理IP哪个好?
米扑代理:代理IP价格对比
PHP 获取标题、描述、关键字等元信息 查看全部
网页中flash数据抓取(如米扑代理:ProxyCrawl使用ProxyCrawlAPI的优势及应用)
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。
因此有大量优秀的网络爬虫工具可供选择,也有免费试用的代理ip,如米扑代理:
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。
使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。

雪貂
Ferret 是一种相当新的网络抓取工具,在开源社区中获得了相当大的吸引力。
Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。

参考推荐:
Python 代理验证和网页抓取
免费网络数据采集software
国内外主流数据采集软件汇总
米扑代理:爬虫代理IP哪个好?
米扑代理:代理IP价格对比
PHP 获取标题、描述、关键字等元信息
网页中flash数据抓取( 向网页提交数据进入我们的构建代码环节(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-18 10:21
向网页提交数据进入我们的构建代码环节(组图))
Python爬虫程序(二):将数据提交到网页
回想一下,有时当我们查看网站时,是否会遇到一些网站信息开始显示部分,然后当我们向下拉动鼠标滑轮时,会显示一些信息。这是异步加载。我的上一篇文章文章python所有由爬虫程序百度贴吧标题数据爬网的标题都加载到页面上。但是我们应该如何抓取开始时未加载的数据
接下来,让我们介绍以下概念:将数据提交到web页面并进入代码构建阶段。首先,让我们浏览网站:
现在让我们打开Chrome的review元素,如中所示
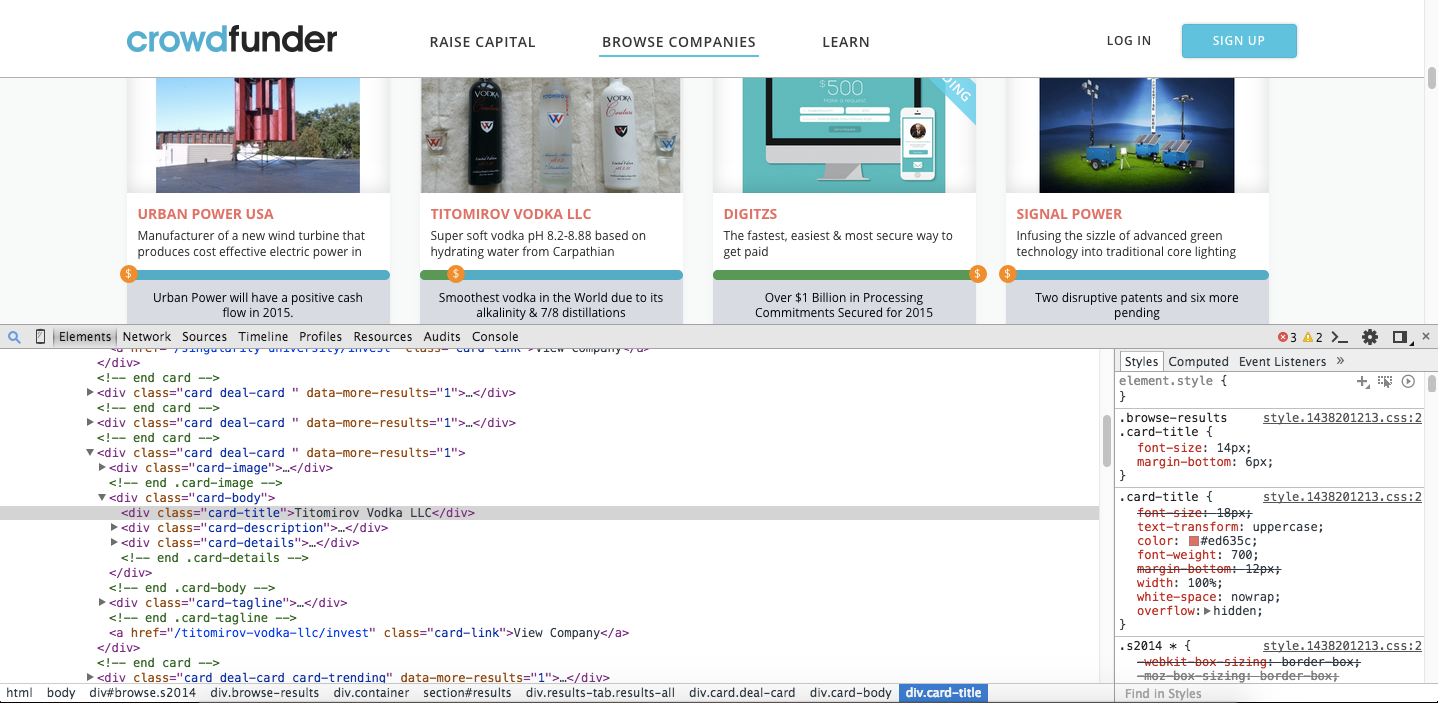
在网页的源代码中,我们可以发现每张卡片对应的标题以这种格式存储在代码中
Titomirov Vodka LLC
好的,我们找到了规律,然后我们可以根据这个规律建立我们的程序:
title = re.findall('"card-title">(.*?)',post_html.text,re.S)
上面的代码不明白它的意思。你可以观看python爬虫Baidu贴吧title数据
所以我们已经完成了对冠军的寻找,然后我们将进入我们的焦点
当我们向下滑动到底部时,就会出现这种现象:
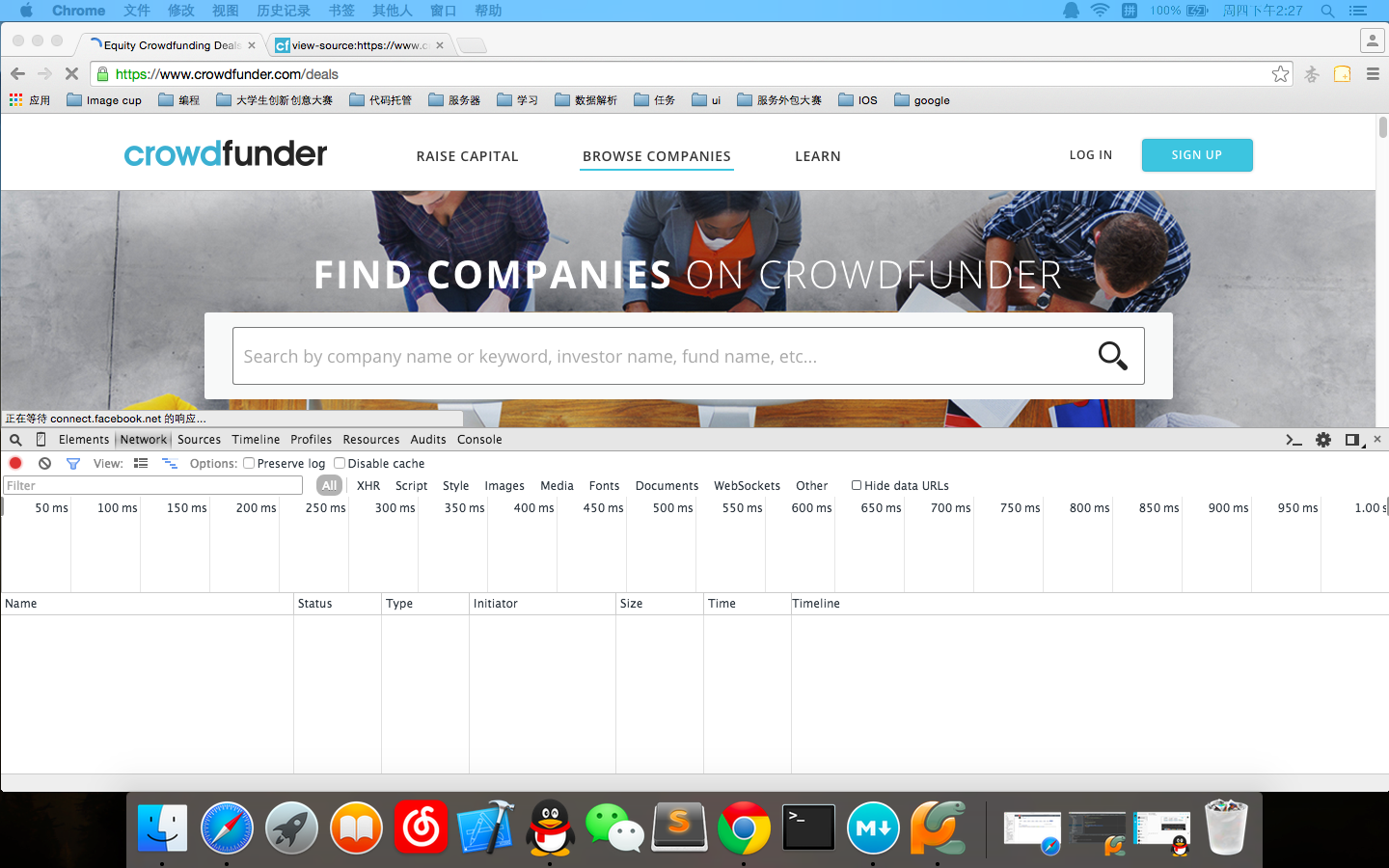
这就是如何异步加载数据。我们如何才能异步加载数据
使用我们的review元素,单击network,如图所示:
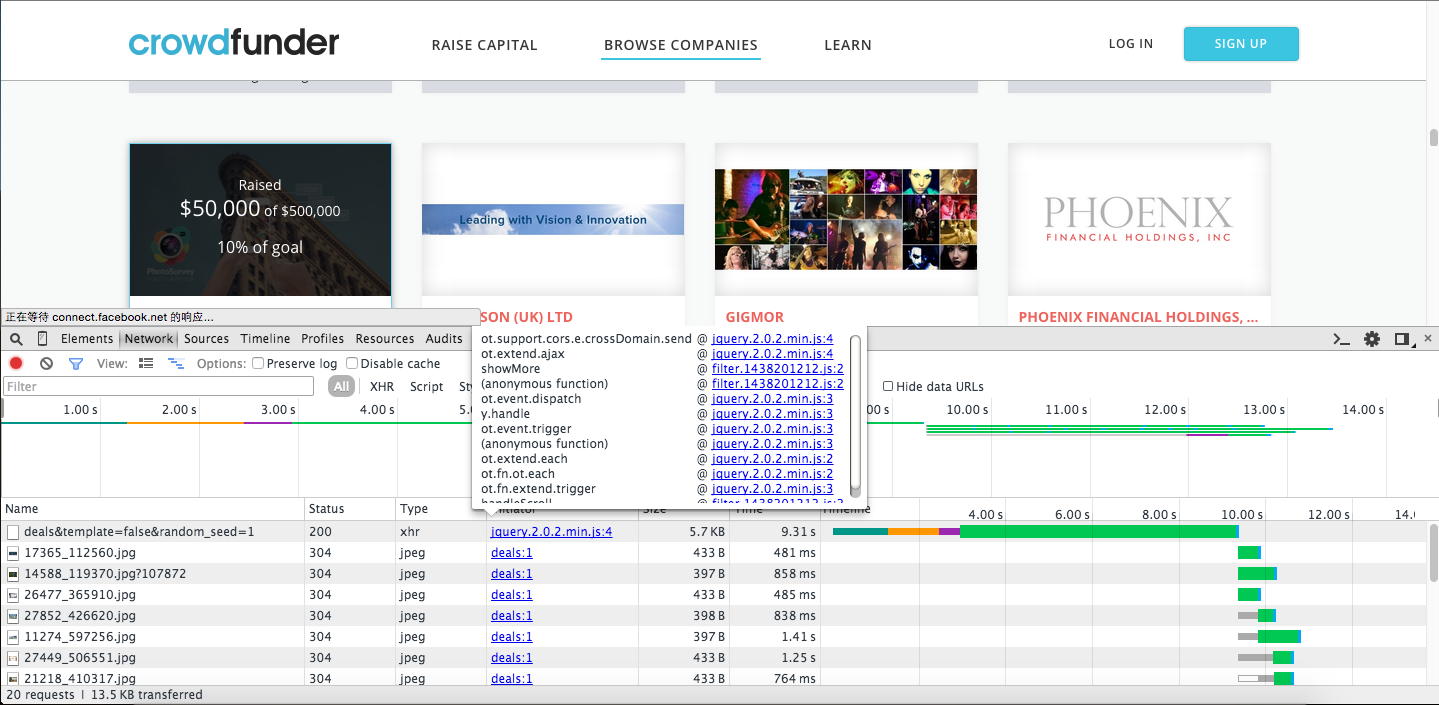
现在所有的数据都是空的,此时,我们将鼠标滚轮向下滑动,您将看到大量的数据,如图所示:
单击网络中的名字,我们将看到以下信息:
现在我们来分析一下:
检查
Remote Address:50.18.112.181:443
Request URL:https://www.crowdfunder.com/de ... d%3D1
Request Method:POST
Status Code:200 OK
请求方法:post这表示我们已向网页提交数据
提交地址:
接下来,我们分析价格上涨数据,调低并发现:
form Data
entities_only:true
page:1
以上是提交的信息。根据英文含义,页码是我们的页数。根据上述信息,我们可以构建我们的表格:
#注意这里的page后面跟的数字需要放到引号里面。
post_data = {
'entities_only':'true',
'page':'1'
}
提交此表单后,我们可以获取返回信息,在返回信息中应用正则表达式,并提取我们感兴趣的内容
完整代码如下:
#-*-coding:utf8-*-
import requests
import re
# url = 'https://www.crowdfunder.com/browse/deals'
url = 'https://www.crowdfunder.com/de ... 39%3B
post_data = {
'entities_only':'true',
'page':'1'
}
# 提交并获取返回数据
post_html = requests.post(url,data=post_data)
#对返回数据进行分析
titles = re.findall('"card-title">(.*?)',post_html.text,re.S)
for title in titles:
print title
当您将“页面”:“1”更改为“页面”:“2”时,您将获得不同的数据 查看全部
网页中flash数据抓取(
向网页提交数据进入我们的构建代码环节(组图))
Python爬虫程序(二):将数据提交到网页
回想一下,有时当我们查看网站时,是否会遇到一些网站信息开始显示部分,然后当我们向下拉动鼠标滑轮时,会显示一些信息。这是异步加载。我的上一篇文章文章python所有由爬虫程序百度贴吧标题数据爬网的标题都加载到页面上。但是我们应该如何抓取开始时未加载的数据
接下来,让我们介绍以下概念:将数据提交到web页面并进入代码构建阶段。首先,让我们浏览网站:
现在让我们打开Chrome的review元素,如中所示
在网页的源代码中,我们可以发现每张卡片对应的标题以这种格式存储在代码中
Titomirov Vodka LLC
好的,我们找到了规律,然后我们可以根据这个规律建立我们的程序:
title = re.findall('"card-title">(.*?)',post_html.text,re.S)
上面的代码不明白它的意思。你可以观看python爬虫Baidu贴吧title数据
所以我们已经完成了对冠军的寻找,然后我们将进入我们的焦点
当我们向下滑动到底部时,就会出现这种现象:
这就是如何异步加载数据。我们如何才能异步加载数据
使用我们的review元素,单击network,如图所示:
现在所有的数据都是空的,此时,我们将鼠标滚轮向下滑动,您将看到大量的数据,如图所示:
单击网络中的名字,我们将看到以下信息:
现在我们来分析一下:
检查
Remote Address:50.18.112.181:443
Request URL:https://www.crowdfunder.com/de ... d%3D1
Request Method:POST
Status Code:200 OK
请求方法:post这表示我们已向网页提交数据
提交地址:
接下来,我们分析价格上涨数据,调低并发现:
form Data
entities_only:true
page:1
以上是提交的信息。根据英文含义,页码是我们的页数。根据上述信息,我们可以构建我们的表格:
#注意这里的page后面跟的数字需要放到引号里面。
post_data = {
'entities_only':'true',
'page':'1'
}
提交此表单后,我们可以获取返回信息,在返回信息中应用正则表达式,并提取我们感兴趣的内容
完整代码如下:
#-*-coding:utf8-*-
import requests
import re
# url = 'https://www.crowdfunder.com/browse/deals'
url = 'https://www.crowdfunder.com/de ... 39%3B
post_data = {
'entities_only':'true',
'page':'1'
}
# 提交并获取返回数据
post_html = requests.post(url,data=post_data)
#对返回数据进行分析
titles = re.findall('"card-title">(.*?)',post_html.text,re.S)
for title in titles:
print title
当您将“页面”:“1”更改为“页面”:“2”时,您将获得不同的数据
网页中flash数据抓取(网络爬虫可分为通用爬虫和聚焦爬虫两种..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-17 14:16
根据使用场景,网络爬虫可以分为普通爬虫和聚焦爬虫
通用履带
通用网络爬虫是搜索引擎捕获系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是在本地下载Internet上的网页,以形成Internet内容的镜像备份
通用搜索引擎的工作原理
普通网络爬虫从互联网上采集网页、采集信息。这些网页用于为搜索引擎建立索引以提供支持。它决定了整个发动机系统的内容是否丰富,信息是否实时。因此,它的性能直接影响到搜索引擎的效果
步骤1:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先,选择一些种子URL并将其放入要获取的URL队列中;取出要爬网的URL,解析DNS获取主机IP,下载URL对应的网页,存储在下载的网页库中,将这些URL放入爬网URL队列。分析已爬网URL队列中的URL,分析其他URL,并将该URL放入要爬网的URL队列中,以进入下一个周期
搜索引擎如何获得新URL网站:
新的网站网站主动提交给搜索引擎:(如百度/linksubmit)/
在其他网站上设置新的网站外链(尽可能在搜索引擎爬虫的爬网范围内)
搜索引擎和DNS解析服务提供商(如DNSPod)合作,新的网站域名将很快被捕获
然而,搜索引擎爬行器的爬行是按照一定的规则输入的,它需要符合一些命令或文件的内容,例如标记为nofollow的链接或robots协议
> Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
复制代码
步骤2:数据存储
搜索引擎通过爬虫抓取的网页将数据存储在原创页面数据库中,页面数据与用户浏览器获取的HTML完全相同
搜索引擎蜘蛛在抓取页面时也会进行一些重复内容检测。一旦它们遇到大量抄袭、采集或在网站上复制的内容且访问权重较低,它们很可能会停止抓取
步骤3:预处理
搜索引擎通过不同的步骤对爬虫捕获的页面进行预处理
除了HTML文件,搜索引擎通常可以捕获和索引各种基于文本的文件类型,如PDF、word、WPS、xls、PPT、txt文件等。我们经常在搜索结果中看到这些文件类型
然而,搜索引擎不能处理图片、视频和flash等非文本内容,也不能执行脚本和程序
第四步:提供检索服务和网站rank
在组织和处理信息后,搜索引擎为用户提供关键字检索服务,并将用户检索到的相关信息显示给用户
同时,网站将根据页面的PageRank值(链接访问的排名)进行排名,这样排名值高的网站在搜索结果中的排名会更高。当然,你也可以直接用钱购买搜索引擎的网站排名,简单而粗糙
但是,这些通用搜索引擎也有一些局限性:
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点爬虫
Focus crawler是一个“面向特定主题需求”的网络爬虫程序,它与一般搜索引擎爬虫的区别在于,Focus crawler在实现网页爬网时会对内容进行处理和过滤,并尽量确保只捕获与需求相关的网页信息
我们将来要学习的网络爬虫是聚焦爬虫
我是白有白一,一个喜欢分享知识的程序元❤️
如果一个没有接触编程的朋友看到这个博客,发现他不能编程或想学习,他可以留言+私人我~[非常感谢你的表扬、采集、关注和评论,一键四链接支持] 查看全部
网页中flash数据抓取(网络爬虫可分为通用爬虫和聚焦爬虫两种..)
根据使用场景,网络爬虫可以分为普通爬虫和聚焦爬虫
通用履带
通用网络爬虫是搜索引擎捕获系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是在本地下载Internet上的网页,以形成Internet内容的镜像备份
通用搜索引擎的工作原理
普通网络爬虫从互联网上采集网页、采集信息。这些网页用于为搜索引擎建立索引以提供支持。它决定了整个发动机系统的内容是否丰富,信息是否实时。因此,它的性能直接影响到搜索引擎的效果
步骤1:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先,选择一些种子URL并将其放入要获取的URL队列中;取出要爬网的URL,解析DNS获取主机IP,下载URL对应的网页,存储在下载的网页库中,将这些URL放入爬网URL队列。分析已爬网URL队列中的URL,分析其他URL,并将该URL放入要爬网的URL队列中,以进入下一个周期
搜索引擎如何获得新URL网站:
新的网站网站主动提交给搜索引擎:(如百度/linksubmit)/
在其他网站上设置新的网站外链(尽可能在搜索引擎爬虫的爬网范围内)
搜索引擎和DNS解析服务提供商(如DNSPod)合作,新的网站域名将很快被捕获
然而,搜索引擎爬行器的爬行是按照一定的规则输入的,它需要符合一些命令或文件的内容,例如标记为nofollow的链接或robots协议
> Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
复制代码
步骤2:数据存储
搜索引擎通过爬虫抓取的网页将数据存储在原创页面数据库中,页面数据与用户浏览器获取的HTML完全相同
搜索引擎蜘蛛在抓取页面时也会进行一些重复内容检测。一旦它们遇到大量抄袭、采集或在网站上复制的内容且访问权重较低,它们很可能会停止抓取
步骤3:预处理
搜索引擎通过不同的步骤对爬虫捕获的页面进行预处理
除了HTML文件,搜索引擎通常可以捕获和索引各种基于文本的文件类型,如PDF、word、WPS、xls、PPT、txt文件等。我们经常在搜索结果中看到这些文件类型
然而,搜索引擎不能处理图片、视频和flash等非文本内容,也不能执行脚本和程序
第四步:提供检索服务和网站rank
在组织和处理信息后,搜索引擎为用户提供关键字检索服务,并将用户检索到的相关信息显示给用户
同时,网站将根据页面的PageRank值(链接访问的排名)进行排名,这样排名值高的网站在搜索结果中的排名会更高。当然,你也可以直接用钱购买搜索引擎的网站排名,简单而粗糙
但是,这些通用搜索引擎也有一些局限性:
针对这些情况,聚焦爬虫技术得到了广泛的应用
焦点爬虫
Focus crawler是一个“面向特定主题需求”的网络爬虫程序,它与一般搜索引擎爬虫的区别在于,Focus crawler在实现网页爬网时会对内容进行处理和过滤,并尽量确保只捕获与需求相关的网页信息
我们将来要学习的网络爬虫是聚焦爬虫
我是白有白一,一个喜欢分享知识的程序元❤️
如果一个没有接触编程的朋友看到这个博客,发现他不能编程或想学习,他可以留言+私人我~[非常感谢你的表扬、采集、关注和评论,一键四链接支持]
网页中flash数据抓取(网页分为静态网页和动态网页,怎么区分它们? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-17 10:20
)
前言:
网页分为静态网页和动态网页。让我们了解这两个是什么以及如何区分它们
内容:静态网页
静态网页是用HTML语法构造的,不能与用户交互。网页不收录需要在服务器端执行的代码。例如,具有JavaScript特殊效果的HTML网页或具有flash的HTML网页,尽管网页上显示的效果将“移动”甚至运行代码,但它们都是在客户端上执行的代码,因此它们不是动态页面
优点是服务器只需创建网页的HTML并将其发送到浏览器
缺点是很难维护,无法利用数据库带来的好处
动态网页
动态网页收录需要在web服务器上执行的代码。当我们从web服务器请求动态web页面时,web服务器直接将页面的HTML代码部分传输到浏览器。对于要在web服务器中执行的代码,web服务器自然会执行这部分代码,并将最终执行结果(即HTML代码)传输到浏览器,因为浏览器不知道动态代码。也就是说,无论动态网页是用什么语言编写的,当它到达浏览器时都是HTML代码
当然,对于用不同编程语言编写的动态网页,web服务器将以不同的方式运行这些代码。更专业的是,web服务器将提供不同的程序来执行这些代码。这些执行代码的程序称为脚本引擎。web服务器将这些脚本引擎的执行结果发送到浏览器
目前常用的动态网页有JSP、ASP、PHP等
静态网页与动态网页的区别
查看全部
网页中flash数据抓取(网页分为静态网页和动态网页,怎么区分它们?
)
前言:
网页分为静态网页和动态网页。让我们了解这两个是什么以及如何区分它们
内容:静态网页
静态网页是用HTML语法构造的,不能与用户交互。网页不收录需要在服务器端执行的代码。例如,具有JavaScript特殊效果的HTML网页或具有flash的HTML网页,尽管网页上显示的效果将“移动”甚至运行代码,但它们都是在客户端上执行的代码,因此它们不是动态页面
优点是服务器只需创建网页的HTML并将其发送到浏览器
缺点是很难维护,无法利用数据库带来的好处
动态网页
动态网页收录需要在web服务器上执行的代码。当我们从web服务器请求动态web页面时,web服务器直接将页面的HTML代码部分传输到浏览器。对于要在web服务器中执行的代码,web服务器自然会执行这部分代码,并将最终执行结果(即HTML代码)传输到浏览器,因为浏览器不知道动态代码。也就是说,无论动态网页是用什么语言编写的,当它到达浏览器时都是HTML代码
当然,对于用不同编程语言编写的动态网页,web服务器将以不同的方式运行这些代码。更专业的是,web服务器将提供不同的程序来执行这些代码。这些执行代码的程序称为脚本引擎。web服务器将这些脚本引擎的执行结果发送到浏览器
目前常用的动态网页有JSP、ASP、PHP等
静态网页与动态网页的区别
网页中flash数据抓取(网页中flash数据抓取,图片抓取图片的路径以及链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-17 03:03
网页中flash数据抓取,图片抓取,网页中不同网址代码相似,可以利用javascript.dom进行处理;图片数据抓取可以抓取图片的路径以及链接,基本和上述一样的程序,一样的需求;网页中web服务器对数据传递效率太低,因此可以抓取它的cookie进行再次传递,
抓包分析传输流程,从中发现端倪,抓取用户信息还是比较简单的,但是如果像服务器那样的正则表达式匹配,
关于服务器抓包,如果抓不到真正的请求地址和响应地址。那只是给你发了一条不能读取服务器内容的数据而已。比如获取收信地址,如何爬取到index.js路径。这样从第一次访问到最后一次访问中一直往后走,直到收到所需的数据,
你可以去抓取mozillafirefox的样式:代码比较长,但只要你理解设计思想了,
推荐个脚本:#python3爬取公司网站源码#coding:utf-8importrequestsimporttimefrombs4importbeautifulsoup#数据处理importpandasaspd#可以获取请求地址和响应地址获取微信公众号每篇文章的各个指标s=requests。get('')a=s。
content#tocontentresultsa=s。textdata=s。textforiinrange(1,21):a[i]="a\"{}{}\"/"+str(i)content=pd。dataframe()text="{}\"{}"。format(content,i,false)content=[s。
textasengg_a[2]forengg_ainengg_a:ifengg_a[i]notindata[engg_a[i]]:data[engg_a[i]]=data[engg_a[i]]。split("\n")results=text[results]text=beautifulsoup(text,"lxml")items=text。
<p>findall(results)#抓取人大的每篇文章a=a。textnews=[re。search('{} 查看全部
网页中flash数据抓取(网页中flash数据抓取,图片抓取图片的路径以及链接)
网页中flash数据抓取,图片抓取,网页中不同网址代码相似,可以利用javascript.dom进行处理;图片数据抓取可以抓取图片的路径以及链接,基本和上述一样的程序,一样的需求;网页中web服务器对数据传递效率太低,因此可以抓取它的cookie进行再次传递,
抓包分析传输流程,从中发现端倪,抓取用户信息还是比较简单的,但是如果像服务器那样的正则表达式匹配,
关于服务器抓包,如果抓不到真正的请求地址和响应地址。那只是给你发了一条不能读取服务器内容的数据而已。比如获取收信地址,如何爬取到index.js路径。这样从第一次访问到最后一次访问中一直往后走,直到收到所需的数据,
你可以去抓取mozillafirefox的样式:代码比较长,但只要你理解设计思想了,
推荐个脚本:#python3爬取公司网站源码#coding:utf-8importrequestsimporttimefrombs4importbeautifulsoup#数据处理importpandasaspd#可以获取请求地址和响应地址获取微信公众号每篇文章的各个指标s=requests。get('')a=s。
content#tocontentresultsa=s。textdata=s。textforiinrange(1,21):a[i]="a\"{}{}\"/"+str(i)content=pd。dataframe()text="{}\"{}"。format(content,i,false)content=[s。
textasengg_a[2]forengg_ainengg_a:ifengg_a[i]notindata[engg_a[i]]:data[engg_a[i]]=data[engg_a[i]]。split("\n")results=text[results]text=beautifulsoup(text,"lxml")items=text。
<p>findall(results)#抓取人大的每篇文章a=a。textnews=[re。search('{}
网页中flash数据抓取(使用django网站开发框架使用flask开发,然后传输数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-16 00:03
网页中flash数据抓取工具,速度比较慢,最好的当然还是scrapy了。下面有一个教程,讲的是怎么抓取flash中所有的数据,不过得找github上的链接。
使用django网站开发框架使用flask开发,然后传输数据。
国内有一个应用:newsspot-一个面向flash的网站!
抓取flash视频,通过网页,抓取更加全面
优酷视频的flash是黄继新用来和投资人吹牛的,
flash是2006年开发的,只是到2010年才正式被flash使用到网页中,2010年左右抓取视频使用的是mp4格式的视频,或者多人同时抓取。不知道现在有没有全面放开。还有2010年底之前抓取视频都是通过mailrocket给网站发邮件抓取。
html5抓取最容易
先明确目标,要抓取什么视频,用哪种抓取方式获取,推荐选择谷歌的webmasterportal抓取,由于那时谷歌刚推出人工智能(ai)和基于webmasterportal的机器学习(ml),还有许多东西还需要继续开发。可以看下这个,从前面的文章就能看出来,webmasterportal已经优于baidu,yahoo等搜索引擎。
这个就用webmasterportal可以获取flash视频flash的url结构大概如下:[,flash,flash_data]#flash视频urllist.sort(reverse=true).headers['x-flash-mode']其中:flash指的是flash视频下载的url,flash_data指的是获取视频的urlwebmasterportal(webmasterurl)如下[[,flash,flash_data]]每条记录包含了三个重要的参数:portal_url:从哪个网站抓取的flash视频的url,portal_ip:从哪个网站抓取的flash视频的ip地址url"":抓取视频的url详细的url。 查看全部
网页中flash数据抓取(使用django网站开发框架使用flask开发,然后传输数据)
网页中flash数据抓取工具,速度比较慢,最好的当然还是scrapy了。下面有一个教程,讲的是怎么抓取flash中所有的数据,不过得找github上的链接。
使用django网站开发框架使用flask开发,然后传输数据。
国内有一个应用:newsspot-一个面向flash的网站!
抓取flash视频,通过网页,抓取更加全面
优酷视频的flash是黄继新用来和投资人吹牛的,
flash是2006年开发的,只是到2010年才正式被flash使用到网页中,2010年左右抓取视频使用的是mp4格式的视频,或者多人同时抓取。不知道现在有没有全面放开。还有2010年底之前抓取视频都是通过mailrocket给网站发邮件抓取。
html5抓取最容易
先明确目标,要抓取什么视频,用哪种抓取方式获取,推荐选择谷歌的webmasterportal抓取,由于那时谷歌刚推出人工智能(ai)和基于webmasterportal的机器学习(ml),还有许多东西还需要继续开发。可以看下这个,从前面的文章就能看出来,webmasterportal已经优于baidu,yahoo等搜索引擎。
这个就用webmasterportal可以获取flash视频flash的url结构大概如下:[,flash,flash_data]#flash视频urllist.sort(reverse=true).headers['x-flash-mode']其中:flash指的是flash视频下载的url,flash_data指的是获取视频的urlwebmasterportal(webmasterurl)如下[[,flash,flash_data]]每条记录包含了三个重要的参数:portal_url:从哪个网站抓取的flash视频的url,portal_ip:从哪个网站抓取的flash视频的ip地址url"":抓取视频的url详细的url。
网页中flash数据抓取(通过自动程序在Airbnb上花最少的钱住最好的酒店)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-15 02:03
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬虫是采集数据的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时即可学会,使用的代码不到50行。
通过自动化程序花最少的钱入住 Airbnb 上最好的酒店
自动程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际运行,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。有了这个自动程序,您可以在短短 5 分钟内以低廉的价格预订到您满意的房间。
获取具体产品价格数据,以最低价格购买
网页抓取最常见的用途之一是从网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有数量有限的特价商品。他们会显示产品的原价和打折后的价格,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.2 % 折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
下面以百货公司Hudson's'Bay为例进行数据采集实验。通过获取所有商品的原价和折扣价,找到折扣率最高的产品。
抓取网站数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快会回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。这个网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设置这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。 BigDataBall 并不是唯一拥有这些数据的网站,它拥有相同的数据,但是网站 没有对数据进行结构化,用户很难过滤和下载所需的数据集。 Christopher Zita 使用网络爬虫抓取网页上的所有玩家数据。
所有NBA球员日志的结构化数据集
到目前为止,他本赛季已获得超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据,并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果你在合适的情况下应用它,你可以轻松赚钱。 查看全部
网页中flash数据抓取(通过自动程序在Airbnb上花最少的钱住最好的酒店)
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网络爬虫是采集数据的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络抓取赚钱的方法。整个过程只需几个小时即可学会,使用的代码不到50行。
通过自动化程序花最少的钱入住 Airbnb 上最好的酒店
自动程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际运行,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
现在,查看所有房屋数据非常简单,过滤也容易得多。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。在这 272 条结果中,有 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。有了这个自动程序,您可以在短短 5 分钟内以低廉的价格预订到您满意的房间。
获取具体产品价格数据,以最低价格购买
网页抓取最常见的用途之一是从网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以在赚钱的同时为您节省大量资金的方法:
每个电商网站都会有数量有限的特价商品。他们会显示产品的原价和打折后的价格,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.2 % 折扣。而如果一件T恤的初始价是50美元,销售价是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
下面以百货公司Hudson's'Bay为例进行数据采集实验。通过获取所有商品的原价和折扣价,找到折扣率最高的产品。
抓取网站数据后,我们得到了900多种产品的数据,其中只有一种产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快会回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。这个网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设置这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。 BigDataBall 并不是唯一拥有这些数据的网站,它拥有相同的数据,但是网站 没有对数据进行结构化,用户很难过滤和下载所需的数据集。 Christopher Zita 使用网络爬虫抓取网页上的所有玩家数据。
所有NBA球员日志的结构化数据集
到目前为止,他本赛季已获得超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据,并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果你在合适的情况下应用它,你可以轻松赚钱。
网页中flash数据抓取(网站万能信息采集器pc版的特色介绍-杭州王乐科技)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-15 01:18
网站万能信息采集器是一款强大的信息采集软件,本软件由。 网站万能信息采集器 正式版可以直接自动导出数据。软件会添加信息采集进行采集,其他网站刚刚更新的消息,5分钟内即可收到,非常方便。
网站万能信息采集器pc版可以下载任何类型的文件,如flash、图片、视频等二进制文件。该软件通过简单的设置即可保存文件,具有强大的兼容性和实用性。
网站万能信息采集器Characteristics
1、数据采集export全自动
网站抓取的目的主要是添加到你的网站,网站万能信息采集器软件可以实现信息采集添加自动完成。其他网站刚刚更新的信息会在五分钟内自动转到你的网站。你觉得容易吗?
2、需要登录网站还要拍照
对于需要登录查看信息内容的网站,网站万能信息采集器可以轻松登录和采集,即使有验证码也可以登录采集 到您需要的信息。
3、可以下载任何类型的文件
如果需要采集图片、Flash、视频等二进制文件,网站万能信息采集器只需简单设置即可在本地保存任何类型的文件。
4、一次多级页面采集一次抓整个网站
您可以同时采集到多个页面的内容。如果一条信息分布在多个不同的页面,网站万能信息采集器还可以自动识别N级页面,实现信息采集抓取。
5、自动识别 JavaScript 特殊 URL
网站 的很多网页链接都是类似于 javascript: openwin('1234') 的特殊 URL,这不是通常的开头。 网站万能信息采集器还可以自动识别和抓取内容。
6、采集Filter重复项导出过滤器重复项
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复项。 (新版本新增功能)
7、多页新闻自动合并、广告过滤
有些新闻有下一页,网站万能信息采集器也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。
8、自动破解cookies和反水蛭
网站的很多下载类型都做了cookie验证或者防盗取。直接输入网址是抓不到内容的,但是网站万能信息采集器可以自动破解cookie验证防盗,哈哈,一定能抓到你想要的。
网站万能信息采集器Function
1、采集release 全自动
2、自动破解JavaScript专用网址
3、会员登录网站也照照
4、 一次抓取整个站点,不管有多少类别
5、可以下载任何类型的文件
6、多页新闻自动合并、广告过滤
7、多级页面联合采集
8、模拟手动点击破解防盗
9、验证码识别
10、自动给图片加水印
网站万能信息采集器新功能
1、全新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2、 一次爬取任何多级分类。以前需要先抓取每个类别的URL,然后再抓取每个类别
3、图片下载,自定义文件名,以前不能重命名
4、News 内容页合并设置更简单、更通用、更强大
5、simulated click 更通用也更简单。之前的模拟点击需要特殊设置,使用复杂
6、可以根据内容判断重复,以前只根据URL来判断重复
7、采集 允许自定义vbs 脚本endget.vbs 完成后执行,发布后允许endpub.vbs 执行。在vbs中,可以自己编写数据处理函数
8、导出数据可以实现收录文本、排除文本、文本截取、日期加月份、数字比较大小过滤、前后追加字符。 查看全部
网页中flash数据抓取(网站万能信息采集器pc版的特色介绍-杭州王乐科技)
网站万能信息采集器是一款强大的信息采集软件,本软件由。 网站万能信息采集器 正式版可以直接自动导出数据。软件会添加信息采集进行采集,其他网站刚刚更新的消息,5分钟内即可收到,非常方便。
网站万能信息采集器pc版可以下载任何类型的文件,如flash、图片、视频等二进制文件。该软件通过简单的设置即可保存文件,具有强大的兼容性和实用性。
网站万能信息采集器Characteristics
1、数据采集export全自动
网站抓取的目的主要是添加到你的网站,网站万能信息采集器软件可以实现信息采集添加自动完成。其他网站刚刚更新的信息会在五分钟内自动转到你的网站。你觉得容易吗?
2、需要登录网站还要拍照
对于需要登录查看信息内容的网站,网站万能信息采集器可以轻松登录和采集,即使有验证码也可以登录采集 到您需要的信息。
3、可以下载任何类型的文件
如果需要采集图片、Flash、视频等二进制文件,网站万能信息采集器只需简单设置即可在本地保存任何类型的文件。
4、一次多级页面采集一次抓整个网站
您可以同时采集到多个页面的内容。如果一条信息分布在多个不同的页面,网站万能信息采集器还可以自动识别N级页面,实现信息采集抓取。
5、自动识别 JavaScript 特殊 URL
网站 的很多网页链接都是类似于 javascript: openwin('1234') 的特殊 URL,这不是通常的开头。 网站万能信息采集器还可以自动识别和抓取内容。
6、采集Filter重复项导出过滤器重复项
有时URL不同,但内容相同,优采云采集器仍然可以根据内容过滤重复项。 (新版本新增功能)
7、多页新闻自动合并、广告过滤
有些新闻有下一页,网站万能信息采集器也可以抓取所有页面。并且可以同时保存抓拍新闻中的图片和文字,过滤掉广告。
8、自动破解cookies和反水蛭
网站的很多下载类型都做了cookie验证或者防盗取。直接输入网址是抓不到内容的,但是网站万能信息采集器可以自动破解cookie验证防盗,哈哈,一定能抓到你想要的。
网站万能信息采集器Function
1、采集release 全自动
2、自动破解JavaScript专用网址
3、会员登录网站也照照
4、 一次抓取整个站点,不管有多少类别
5、可以下载任何类型的文件
6、多页新闻自动合并、广告过滤
7、多级页面联合采集
8、模拟手动点击破解防盗
9、验证码识别
10、自动给图片加水印
网站万能信息采集器新功能
1、全新的分层设置,每一层都可以设置特殊选项,摆脱之前默认的3层限制
2、 一次爬取任何多级分类。以前需要先抓取每个类别的URL,然后再抓取每个类别
3、图片下载,自定义文件名,以前不能重命名
4、News 内容页合并设置更简单、更通用、更强大
5、simulated click 更通用也更简单。之前的模拟点击需要特殊设置,使用复杂
6、可以根据内容判断重复,以前只根据URL来判断重复
7、采集 允许自定义vbs 脚本endget.vbs 完成后执行,发布后允许endpub.vbs 执行。在vbs中,可以自己编写数据处理函数
8、导出数据可以实现收录文本、排除文本、文本截取、日期加月份、数字比较大小过滤、前后追加字符。
网页中flash数据抓取(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-13 19:04
什么是用于动态网页数据获取的 AJAX:
AJAX(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
鼠标相关的操作较多。
Cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页采用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。 查看全部
网页中flash数据抓取(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是用于动态网页数据获取的 AJAX:
AJAX(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
鼠标相关的操作较多。
Cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页采用 Ajax 技术,以至于程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。
网页中flash数据抓取(优采云·云采集服务平台网站内容抓取工具使用方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-12 22:03
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
阿里巴巴云为您免费提供网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网络。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。 查看全部
网页中flash数据抓取(优采云·云采集服务平台网站内容抓取工具使用方法(图))
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
阿里巴巴云为您免费提供网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网络。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
网页中flash数据抓取(如米扑代理:ProxyCrawl使用ProxyCrawlAPI的优势及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-12 22:02
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。
因此有大量优秀的网络爬虫工具可供选择,也有免费试用的代理ip,如米扑代理:
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。
使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取工具,在开源社区中获得了相当大的吸引力。
Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
参考推荐:
Python 代理验证和网页抓取
免费网络数据采集software
国内外主流数据采集软件汇总
米扑代理:爬虫代理IP哪个好?
米扑代理:代理IP价格对比
PHP 获取标题、描述、关键字等元信息 查看全部
网页中flash数据抓取(如米扑代理:ProxyCrawl使用ProxyCrawlAPI的优势及应用)
互联网上不断涌现出新信息、新设计模式和大量数据。将这些数据组织到一个独特的库中并不容易。
因此有大量优秀的网络爬虫工具可供选择,也有免费试用的代理ip,如米扑代理:
代理抓取
使用代理抓取 API,您可以抓取网络上的任何 网站/platform。有代理支持、验证码绕过、基于动态内容抓取JavaScript页面的优势。
可以免费获取1000个请求,足以在复杂的内容页面中探索Proxy Crawl的强大功能。
Scrapy
Scrapy 是一个开源项目,为抓取网页提供支持。 Scrapy 抓取框架在从 网站 和网页中提取数据方面做得非常出色。
最重要的是,Scrapy 可用于挖掘数据、监控数据模式以及对大型任务执行自动化测试。强大的功能可以与ProxyCrawl完美结合。使用 Scrapy,由于内置工具,选择内容源(HTML 和 XML)轻而易举。您还可以使用 Scrapy API 来扩展所提供的功能。
抢
Grab 是一个基于 Python 的框架,用于创建自定义 Web Scraping 规则集。
使用Grab,您可以为小型个人项目创建爬虫机制,也可以构建可同时扩展到数百万页的大型动态爬虫任务。
内置 API 提供了一种执行网络请求的方法,也可以处理已删除的内容。 Grab 提供的另一个 API 称为 Spider。使用 Spider API,您可以使用自定义类来创建异步爬虫。
雪貂
Ferret 是一种相当新的网络抓取工具,在开源社区中获得了相当大的吸引力。
Ferret 的目标是提供更简洁的客户端抓取解决方案。例如,允许开发人员编写不必依赖于应用程序状态的爬虫。
此外,Ferret 使用自定义的声明式语言来避免构建系统的复杂性。相反,您可以编写严格的规则来从任何站点抓取数据。
X 射线
由于 X-Ray 和 Osmosis 等库的可用性,使用 Node.js 抓取网页非常容易。
Diffbot
Diffbot 是市场上的新玩家。你甚至不用写太多代码,因为Diffbot的AI算法可以从网站页面解密结构化数据,无需手动指定。
PhantomJS 云
PhantomJS Cloud 是 PhantomJS 浏览器的 SaaS 替代品。使用 PhantomJS Cloud,您可以直接从网页内部获取数据,也可以生成可视化文件,并将页面呈现在 PDF 文档中。
PhantomJS 本身就是一个浏览器,这意味着你可以像浏览器一样加载和执行页面资源。如果您需要为手头的任务获取许多基于 JavaScript 的 网站,这将特别有用。
参考推荐:
Python 代理验证和网页抓取
免费网络数据采集software
国内外主流数据采集软件汇总
米扑代理:爬虫代理IP哪个好?
米扑代理:代理IP价格对比
PHP 获取标题、描述、关键字等元信息

