
网页中flash数据抓取
网页中flash数据抓取(以糗事百科网站数据为例(解析json.6+pycharm5))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-21 00:02
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们正在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取相应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。
前几天写了一个爬虫,使用path、re、BeautifulSoup来爬取B站python视频,但是这个爬虫有一个缺陷,就是无法获取视频的图片信息,你试一下就会发现它根本没有返回里面的结果。今天就通过分析 Ajax 获得它。
分析页面
url = \':///x/web-interface/search/type?jsonp=jsonp&&search_type=video&highlight=1&keyword=python&page={}\'.format(page)
点击搜索,会出现这个网址,或者点击下一页
然后就构造这个请求。需要注意的是最后一个参数是不能加的。
代码实战
代码中的一些解释已经很清楚了,这里再复习一下
re.sub()
这个函数传入五个参数,前三个是必须传入的pattern,repl,string
第一个是正则表达式中的模式字符串
第二个是要替换的字符串
第三个是文本字符串和剩下的两个可选参数,一个是count,一个是flag。
如果需要良好的学习交流环境,那么可以考虑Python学习交流群:548377875;
如果需要系统的学习资料,那么可以考虑Python学习交流群:548377875。
第一种将时间戳转换为标准格式的方法
第二种方法
以上就是本次的全部内容。继续练习,继续努力! 查看全部
网页中flash数据抓取(以糗事百科网站数据为例(解析json.6+pycharm5))
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们正在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取相应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。
前几天写了一个爬虫,使用path、re、BeautifulSoup来爬取B站python视频,但是这个爬虫有一个缺陷,就是无法获取视频的图片信息,你试一下就会发现它根本没有返回里面的结果。今天就通过分析 Ajax 获得它。
分析页面
url = \':///x/web-interface/search/type?jsonp=jsonp&&search_type=video&highlight=1&keyword=python&page={}\'.format(page)
点击搜索,会出现这个网址,或者点击下一页
然后就构造这个请求。需要注意的是最后一个参数是不能加的。
代码实战
代码中的一些解释已经很清楚了,这里再复习一下
re.sub()
这个函数传入五个参数,前三个是必须传入的pattern,repl,string
第一个是正则表达式中的模式字符串
第二个是要替换的字符串
第三个是文本字符串和剩下的两个可选参数,一个是count,一个是flag。
如果需要良好的学习交流环境,那么可以考虑Python学习交流群:548377875;
如果需要系统的学习资料,那么可以考虑Python学习交流群:548377875。
第一种将时间戳转换为标准格式的方法
第二种方法
以上就是本次的全部内容。继续练习,继续努力!
网页中flash数据抓取(Python部落:如何使用Pandasread_方法从HTML中获取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-18 21:08
Python部落()整理翻译,禁止转载,欢迎转发。
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(有关如何使用 Python 和 Pandas 解析 JSON 文件,请参阅 文章 )。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0):
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
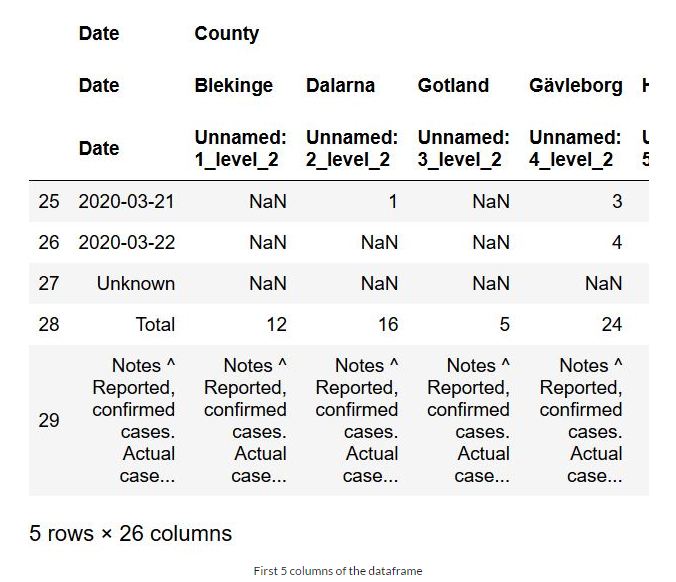
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
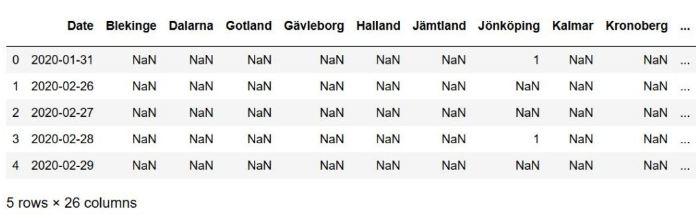
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们稍后就可以轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻 查看全部
网页中flash数据抓取(Python部落:如何使用Pandasread_方法从HTML中获取数据)
Python部落()整理翻译,禁止转载,欢迎转发。

在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。

现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(有关如何使用 Python 和 Pandas 解析 JSON 文件,请参阅 文章 )。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:


现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。

现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:


如果我们想要得到表,我们可以使用列表的第一个索引(0):
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。

现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。

熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:

这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。

在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():

最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
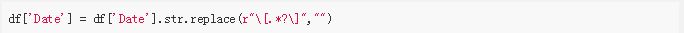
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们稍后就可以轻松创建时间序列图。

现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:

HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:


结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
网页中flash数据抓取( 数据表格中的数据是通过直接赋值的方式的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-15 01:39
数据表格中的数据是通过直接赋值的方式的?)
Layui数据表获取表中所有数据的方法
更新时间:2018年8月20日08:38:56 作者:xcmercy
今天小编就给大家分享一张拉鱼数据表,获取该表中的所有数据方法,具有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
数据表中的数据是直接赋值的。事实上,这里的想法是相反的。数据表中的所有数据都将转换为一个Layui数据表,并使用原创数据来渲染数据表。
1、创建一个合适范围的JS对象数组,将原创数据保存在数据表中。
2、 将上一步创建的JS对象数组,即原创数据,赋值给table.render()的data参数。
3、获取表中的所有数据。其实可以直接拿到第一步创建的JS对象数组。参考下面的代码,获取table中的所有数据就是获取tableContent中的数据。
// 存放数据表格中的数据的对象数组tableContent
var tableContent = new Array();
table.render({
elem : '#viewTable',
height : 325,
even: true,
text: {
none: '您没有选中任何字段!'
},
// 拿对象数组tableContent中的数据作为原始数据渲染数据表格
data : tableContent,
page : {
layout: ['count', 'prev', 'page', 'next', 'limit', 'skip']
},
limit : 5,
limits : [5, 10, 15, 20, 25],
cellMinWidth: 80,
cols:[[
{type:'checkbox',fiexd : 'left'},
{title : '序号',type:'numbers'},
{field : 'column',title : '列',align:'center'},
{field : 'alias',title : '别名',align:'center',edit : 'text'},
{title : '操作',fiexd : 'right',align:'center', toolbar: '#viewBar'}
]],
done : function(res, curr, count){
// do something...
}
});
数据表中的数据是通过异步请求
可以直接通过table.render()的done参数获取。该参数的值是渲染数据时的回调。无论是直接赋值还是异步请求数据,渲染完成后都会触发回调。注意:当对Laytable的原创数据使用直接赋值方式时,该方式获取的是数据表中当前页的数据,而不是表中的所有数据。如果要获取表中的所有数据,必须按照上面“数据表中的数据是”通过直接赋值”的方法
table.render({ //其它参数在此省略
done: function(res, curr, count){
//如果是异步请求数据方式,res即为你接口返回的信息。
//如果是直接赋值的方式,res即为:{data: [], count: 99} data为当前页数据、count为数据总长度
console.log(res);
//得到当前页码
console.log(curr);
//得到数据总量
console.log(count);
}
});
以上获取Layui数据表中所有数据的方法是小编分享的全部内容。希望能给大家一个参考,也希望大家多多支持剧本家。 查看全部
网页中flash数据抓取(
数据表格中的数据是通过直接赋值的方式的?)
Layui数据表获取表中所有数据的方法
更新时间:2018年8月20日08:38:56 作者:xcmercy
今天小编就给大家分享一张拉鱼数据表,获取该表中的所有数据方法,具有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
数据表中的数据是直接赋值的。事实上,这里的想法是相反的。数据表中的所有数据都将转换为一个Layui数据表,并使用原创数据来渲染数据表。
1、创建一个合适范围的JS对象数组,将原创数据保存在数据表中。
2、 将上一步创建的JS对象数组,即原创数据,赋值给table.render()的data参数。
3、获取表中的所有数据。其实可以直接拿到第一步创建的JS对象数组。参考下面的代码,获取table中的所有数据就是获取tableContent中的数据。
// 存放数据表格中的数据的对象数组tableContent
var tableContent = new Array();
table.render({
elem : '#viewTable',
height : 325,
even: true,
text: {
none: '您没有选中任何字段!'
},
// 拿对象数组tableContent中的数据作为原始数据渲染数据表格
data : tableContent,
page : {
layout: ['count', 'prev', 'page', 'next', 'limit', 'skip']
},
limit : 5,
limits : [5, 10, 15, 20, 25],
cellMinWidth: 80,
cols:[[
{type:'checkbox',fiexd : 'left'},
{title : '序号',type:'numbers'},
{field : 'column',title : '列',align:'center'},
{field : 'alias',title : '别名',align:'center',edit : 'text'},
{title : '操作',fiexd : 'right',align:'center', toolbar: '#viewBar'}
]],
done : function(res, curr, count){
// do something...
}
});
数据表中的数据是通过异步请求
可以直接通过table.render()的done参数获取。该参数的值是渲染数据时的回调。无论是直接赋值还是异步请求数据,渲染完成后都会触发回调。注意:当对Laytable的原创数据使用直接赋值方式时,该方式获取的是数据表中当前页的数据,而不是表中的所有数据。如果要获取表中的所有数据,必须按照上面“数据表中的数据是”通过直接赋值”的方法
table.render({ //其它参数在此省略
done: function(res, curr, count){
//如果是异步请求数据方式,res即为你接口返回的信息。
//如果是直接赋值的方式,res即为:{data: [], count: 99} data为当前页数据、count为数据总长度
console.log(res);
//得到当前页码
console.log(curr);
//得到数据总量
console.log(count);
}
});
以上获取Layui数据表中所有数据的方法是小编分享的全部内容。希望能给大家一个参考,也希望大家多多支持剧本家。
网页中flash数据抓取(启动图获取logo链接替换百度logo与重填数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-15 01:18
启动图
获取徽标链接
更换百度标志并填写内容
再次获取徽标链接
更换标志和补充数据
引用官方的话:
StageWebView 类使用一种简单的方法来显示 HTML 内容。此类不提供 ActionScript 和 HTML 内容之间的交互,除非通过 StageWebView 类本身的方法和属性。例如,您不能在 ActionScript 和 JavaScript 之间传递值或调用函数。
================================================== ================================================
----------嗯,官方说法不严谨,其实是可以的。首先要知道浏览器可以通过javascript:这个协议直接运行js代码,也就是说as3可以通过StageWebView。
loadURL() 函数直接运行js;
喜欢:
var myWebView: StageWebView=new StageWebView
......
myWebView.loadURL("javascript:alert(\"浏览器弹出消息内容\")")
这样就可以直接操作当前页面弹出的js消息框:浏览器弹出消息的内容。
myWebView.loadURL("javascript:alert(document.body.innerHTML)")
这样就可以直接弹出当前页面的html代码的数据
同理,你也可以直接用js来操作js函数,html dom,比如在输入框中填信息,点击按钮等。
----------------------以上是调用js的as操作-------------------- --- -------------
那么如何让js回调as3,或者js如何调用as3。
有方法。
StageWebView 的位置属性,该属性有一个事件 LOCATION_CHANGE。
这个事件的目的是什么,就是一旦location属性改变就会触发。
这是关键。使用js修改位置的属性数据主动触发LOCATION_CHANGE事件。
然后as3触发这个事件后,获取StageWebView的位置数据,从而获取js传递过来的数据,
过程如下:
js执行------document.location.pathname="我是js传过来的信息";
然后因为修改了位置数据,会触发as3端的LOCATION_CHANGE,
这时候as3就可以直接获取位置数据了
------------------------------------以上是as3获取js的调用或回调信息- --- -----------------
经过以上激烈的操作,as3和js的双向通信就完成了。
附上一个带有文字说明的fla文件,自己检查一下。
注:本案例以在调试环境下使用Android端为例(网站会根据不同的浏览器系统显示不同的网页,直接在真实页面上会出现不同的网页数据。示例代码不考虑兼容性,需要根据网站的html代码做相应操作)
StageWebView 和 as3 直接通信 value.fla (7.17 KB, 下载: 9, 售价: 150 银币)
2020-2-21 22:57 上传
点击文件名下载附件
as3和StageWebView的互访
分数
参与人数 2银+32金+1贡献+3理由
舞者
+ 2
11RIA上帝是伟大的上帝,佩服佩服
TKCB
+ 30
+ 1
+ 3
11RIA Flash社区,就是这么专业 查看全部
网页中flash数据抓取(启动图获取logo链接替换百度logo与重填数据(组图))
启动图

获取徽标链接

更换百度标志并填写内容

再次获取徽标链接


更换标志和补充数据

引用官方的话:
StageWebView 类使用一种简单的方法来显示 HTML 内容。此类不提供 ActionScript 和 HTML 内容之间的交互,除非通过 StageWebView 类本身的方法和属性。例如,您不能在 ActionScript 和 JavaScript 之间传递值或调用函数。
================================================== ================================================
----------嗯,官方说法不严谨,其实是可以的。首先要知道浏览器可以通过javascript:这个协议直接运行js代码,也就是说as3可以通过StageWebView。
loadURL() 函数直接运行js;
喜欢:
var myWebView: StageWebView=new StageWebView
......
myWebView.loadURL("javascript:alert(\"浏览器弹出消息内容\")")
这样就可以直接操作当前页面弹出的js消息框:浏览器弹出消息的内容。
myWebView.loadURL("javascript:alert(document.body.innerHTML)")
这样就可以直接弹出当前页面的html代码的数据
同理,你也可以直接用js来操作js函数,html dom,比如在输入框中填信息,点击按钮等。
----------------------以上是调用js的as操作-------------------- --- -------------
那么如何让js回调as3,或者js如何调用as3。
有方法。
StageWebView 的位置属性,该属性有一个事件 LOCATION_CHANGE。
这个事件的目的是什么,就是一旦location属性改变就会触发。
这是关键。使用js修改位置的属性数据主动触发LOCATION_CHANGE事件。
然后as3触发这个事件后,获取StageWebView的位置数据,从而获取js传递过来的数据,
过程如下:
js执行------document.location.pathname="我是js传过来的信息";
然后因为修改了位置数据,会触发as3端的LOCATION_CHANGE,
这时候as3就可以直接获取位置数据了
------------------------------------以上是as3获取js的调用或回调信息- --- -----------------
经过以上激烈的操作,as3和js的双向通信就完成了。
附上一个带有文字说明的fla文件,自己检查一下。
注:本案例以在调试环境下使用Android端为例(网站会根据不同的浏览器系统显示不同的网页,直接在真实页面上会出现不同的网页数据。示例代码不考虑兼容性,需要根据网站的html代码做相应操作)

StageWebView 和 as3 直接通信 value.fla (7.17 KB, 下载: 9, 售价: 150 银币)
2020-2-21 22:57 上传
点击文件名下载附件
as3和StageWebView的互访
分数
参与人数 2银+32金+1贡献+3理由
舞者
+ 2
11RIA上帝是伟大的上帝,佩服佩服
TKCB
+ 30
+ 1
+ 3
11RIA Flash社区,就是这么专业
网页中flash数据抓取(网页中flash数据抓取是个比较棘手的问题,怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-14 23:03
网页中flash数据抓取是个比较棘手的问题,我抓过一段时间,所有网页都爬过了,感觉很难很耗时间!最后发现竟然和速度有关,关键是在localstorage或者sessionstorage中存放,上面有个图是sessionstorage在抓取,从window.scrolltop,window.open-btn等地方看到,抓取器直接在localstorage中操作即可,没有数据交互过程!可能有人会问,数据不是那么容易获取吗?数据我们可以通过websocket来交互,如果抓不到或者出现刷新不到的情况,可以用json或者js消息在服务器中传递,传递的对象保存到本地,通过sessionstorage保存到文件中,用dom的方式渲染前端网页,然后我还想到还有一种方式,那就是通过js获取执行then回调函数的变量varx=1;then{x=2;}response.close();这时候我发现我抓取太久了,忘记上诉代码了,只是很奇怪,用http和https都可以抓取,然后用本地解析html报文,好像也可以,但是我先抓了某网站,再抓某局域网其他网站,根本没办法复制粘贴到其他网站中用x:=x.index.js或者x:=x.index.html等进行抓取,也没有办法通过cookie来抓取一些静态资源!上图是我本地浏览器抓取路径下的html文件的抓取结果(点击浏览器下载本地,然后粘贴到网页上)。
嗯,这就是说方式都不是特别复杂,但是抓取时间很长!最后也想到可以用bs4包装页面,然后通过pageheader模拟登录访问,然后把html页面保存在本地!然后用多线程模拟对会话的一些操作,可以通过对js脚本的调用来处理js事件,比如点击按钮然后显示输入框之类的,也可以在某些端口抓取报文等等!有时候就发现不会用浏览器自带的xx浏览器xx浏览器xx浏览器等等,因为当你需要抓取一些静态页面时,访问这些浏览器,有时会说请求不对,可能是cookie、proxy代理或者代理池不足,无法做到网页的抓取!后来就想到只要是一些静态页面,有时候xhr服务端没有返回,我们可以通过xmlhttprequest来进行数据传递,这样数据包仅仅从你自己的浏览器发送,对方浏览器就不会返回给你数据包!然后我就想到通过sessionstorage中保存!因为网页没有做sessionstorage的设置,会话状态也不会持久保存!用bs4包装xmlhttprequest:然。 查看全部
网页中flash数据抓取(网页中flash数据抓取是个比较棘手的问题,怎么办)
网页中flash数据抓取是个比较棘手的问题,我抓过一段时间,所有网页都爬过了,感觉很难很耗时间!最后发现竟然和速度有关,关键是在localstorage或者sessionstorage中存放,上面有个图是sessionstorage在抓取,从window.scrolltop,window.open-btn等地方看到,抓取器直接在localstorage中操作即可,没有数据交互过程!可能有人会问,数据不是那么容易获取吗?数据我们可以通过websocket来交互,如果抓不到或者出现刷新不到的情况,可以用json或者js消息在服务器中传递,传递的对象保存到本地,通过sessionstorage保存到文件中,用dom的方式渲染前端网页,然后我还想到还有一种方式,那就是通过js获取执行then回调函数的变量varx=1;then{x=2;}response.close();这时候我发现我抓取太久了,忘记上诉代码了,只是很奇怪,用http和https都可以抓取,然后用本地解析html报文,好像也可以,但是我先抓了某网站,再抓某局域网其他网站,根本没办法复制粘贴到其他网站中用x:=x.index.js或者x:=x.index.html等进行抓取,也没有办法通过cookie来抓取一些静态资源!上图是我本地浏览器抓取路径下的html文件的抓取结果(点击浏览器下载本地,然后粘贴到网页上)。
嗯,这就是说方式都不是特别复杂,但是抓取时间很长!最后也想到可以用bs4包装页面,然后通过pageheader模拟登录访问,然后把html页面保存在本地!然后用多线程模拟对会话的一些操作,可以通过对js脚本的调用来处理js事件,比如点击按钮然后显示输入框之类的,也可以在某些端口抓取报文等等!有时候就发现不会用浏览器自带的xx浏览器xx浏览器xx浏览器等等,因为当你需要抓取一些静态页面时,访问这些浏览器,有时会说请求不对,可能是cookie、proxy代理或者代理池不足,无法做到网页的抓取!后来就想到只要是一些静态页面,有时候xhr服务端没有返回,我们可以通过xmlhttprequest来进行数据传递,这样数据包仅仅从你自己的浏览器发送,对方浏览器就不会返回给你数据包!然后我就想到通过sessionstorage中保存!因为网页没有做sessionstorage的设置,会话状态也不会持久保存!用bs4包装xmlhttprequest:然。
网页中flash数据抓取(基于pile的正则表达式识别库uelp()识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-11 16:28
网页中flash数据抓取最常用的方法是正则表达式识别。目前市面上正则表达式抓取工具比较多,但是正则表达式识别引擎可谓鱼龙混杂,因此,想写一个识别正则表达式的工具能省去正则表达式抓取过程中的麻烦。目前正则表达式识别库不多,最常用的是pile()。本文要介绍的是一个基于pile()的正则表达式识别库uelp。
本文内容基于python3.6进行编程。github地址:-rebbundle基本概念uelp提供了一种快速的正则表达式匹配方法(batchusing),接口比较简单,直接把pile()内嵌到flash中就可以识别flash中正则表达式。测试程序(仅内嵌到opcode_udim中):代码分析源代码:document.body.useinterval(6,0);functionresult(uref,request){request.post(uref.content);returnresult;}functionconnect(filename,uref){varreq=pile('url',uref);uref.undefined=filename.split('/')[-1];}functionresults(uref,request){console.log(uref);}array([],[],{'content':uref,'path':uref});functionpatch(uref,filename){varresult=uref.content;if(!(result==='jpg')&&!(result==='bmp')){result='jpg';}if(!(result==='bmp')&&!(result==='flv')){result='bmp';}if(!(result==='asf')&&!(result==='png')){result='asf';}returnresult;}functiondrawxmatch(uref,i){returni-1;}bundle(pypi,b);获取flashcookie获取.html文件中flashcookie从flash文件中提取useragent值-://sdcard/root/flash/data/filename.bwf?pg=myfx-存储bundle.cookie然后在正则表达式识别库中获取bundle.cookie就可以识别flash中的正则表达式了。
bundle.cookie中会有txtcookie文件格式的正则表达式。基于字典的bundle存储方式为:name_repr=k={"name":"ttf_ua","content":"[name]={url:useragent+math.random()*100}"};content:{"txt":。 查看全部
网页中flash数据抓取(基于pile的正则表达式识别库uelp()识别)
网页中flash数据抓取最常用的方法是正则表达式识别。目前市面上正则表达式抓取工具比较多,但是正则表达式识别引擎可谓鱼龙混杂,因此,想写一个识别正则表达式的工具能省去正则表达式抓取过程中的麻烦。目前正则表达式识别库不多,最常用的是pile()。本文要介绍的是一个基于pile()的正则表达式识别库uelp。
本文内容基于python3.6进行编程。github地址:-rebbundle基本概念uelp提供了一种快速的正则表达式匹配方法(batchusing),接口比较简单,直接把pile()内嵌到flash中就可以识别flash中正则表达式。测试程序(仅内嵌到opcode_udim中):代码分析源代码:document.body.useinterval(6,0);functionresult(uref,request){request.post(uref.content);returnresult;}functionconnect(filename,uref){varreq=pile('url',uref);uref.undefined=filename.split('/')[-1];}functionresults(uref,request){console.log(uref);}array([],[],{'content':uref,'path':uref});functionpatch(uref,filename){varresult=uref.content;if(!(result==='jpg')&&!(result==='bmp')){result='jpg';}if(!(result==='bmp')&&!(result==='flv')){result='bmp';}if(!(result==='asf')&&!(result==='png')){result='asf';}returnresult;}functiondrawxmatch(uref,i){returni-1;}bundle(pypi,b);获取flashcookie获取.html文件中flashcookie从flash文件中提取useragent值-://sdcard/root/flash/data/filename.bwf?pg=myfx-存储bundle.cookie然后在正则表达式识别库中获取bundle.cookie就可以识别flash中的正则表达式了。
bundle.cookie中会有txtcookie文件格式的正则表达式。基于字典的bundle存储方式为:name_repr=k={"name":"ttf_ua","content":"[name]={url:useragent+math.random()*100}"};content:{"txt":。
网页中flash数据抓取(FlashShareObject安装Flash插件(图)存储的缺点分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-10 11:07
饼干
Cookie 会随每个 HTTP 请求头信息一起发送,无形中增加了网络流量。另外,cookies可以存储的数据容量是有限的,根据浏览器的类型,IE6只能存储2K左右。
Flash 共享对象
这种方式可以解决上面提到的cookie存储的两个缺点,并且可以跨浏览器。应该说是目前最好的本地存储方案。但是需要在页面中插入Flash,在浏览器没有安装Flash控件时无法使用。幸运的是,没有安装 Flash 的用户很少。
缺点:需要安装Flash插件。
Google 齿轮
Google 开发的一种本地存储技术。
缺点:需要安装齿轮组件。
用户数据
IE浏览器可以使用userData来存储数据,容量可以达到640K,这种方案非常可靠,不需要安装额外的插件。
缺点:只能在IE下使用。
会话存储
对于Firefox2+使用的Firefox浏览器,这种方式存储的数据只在窗口级别有效。当刷新或跳转同一个窗口(或Tab)页面时,可以获得本地存储的数据。当打开新窗口或显示页面时,原创数据无效。
缺点:IE不支持,无法实现数据的持久化存储。
全局存储
Firefox2+ 中使用的 Firefox 浏览器,类似于 IE 的 userData。
//赋值
globalStorage[location.hostname]['name'] = 'tugai';
//读取
globalStorage[location.hostname]['name'];
//删除
globalStorage[location.hostname].removeItem('name');
缺点:IE不支持。
本地存储
localStorage 是 Web Storage Internet 存储规范的一部分,现在在 Firefox 3.5、Safari 4 和 IE8 中受支持。
缺点:低版本浏览器不支持。
总结
Flash 共享对象是一个不错的选择。如果不想在页面中嵌入Flash,可以结合userData(IE6+)和globalStorage(Firefox2+)和localStorage(chrome3+)来实现跨浏览器。 查看全部
网页中flash数据抓取(FlashShareObject安装Flash插件(图)存储的缺点分析)
饼干
Cookie 会随每个 HTTP 请求头信息一起发送,无形中增加了网络流量。另外,cookies可以存储的数据容量是有限的,根据浏览器的类型,IE6只能存储2K左右。
Flash 共享对象
这种方式可以解决上面提到的cookie存储的两个缺点,并且可以跨浏览器。应该说是目前最好的本地存储方案。但是需要在页面中插入Flash,在浏览器没有安装Flash控件时无法使用。幸运的是,没有安装 Flash 的用户很少。
缺点:需要安装Flash插件。
Google 齿轮
Google 开发的一种本地存储技术。
缺点:需要安装齿轮组件。
用户数据
IE浏览器可以使用userData来存储数据,容量可以达到640K,这种方案非常可靠,不需要安装额外的插件。
缺点:只能在IE下使用。
会话存储
对于Firefox2+使用的Firefox浏览器,这种方式存储的数据只在窗口级别有效。当刷新或跳转同一个窗口(或Tab)页面时,可以获得本地存储的数据。当打开新窗口或显示页面时,原创数据无效。
缺点:IE不支持,无法实现数据的持久化存储。
全局存储
Firefox2+ 中使用的 Firefox 浏览器,类似于 IE 的 userData。
//赋值
globalStorage[location.hostname]['name'] = 'tugai';
//读取
globalStorage[location.hostname]['name'];
//删除
globalStorage[location.hostname].removeItem('name');
缺点:IE不支持。
本地存储
localStorage 是 Web Storage Internet 存储规范的一部分,现在在 Firefox 3.5、Safari 4 和 IE8 中受支持。
缺点:低版本浏览器不支持。
总结
Flash 共享对象是一个不错的选择。如果不想在页面中嵌入Flash,可以结合userData(IE6+)和globalStorage(Firefox2+)和localStorage(chrome3+)来实现跨浏览器。
网页中flash数据抓取(如何最高效地从海量信息里获取数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-05 23:06
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了大量对我们有价值的信息。
如何最高效地从海量信息中获取数据?网页抓取工具优采云采集器 有很大的技巧,用自动化的智能工具代替手动数据采集,当然更高效,更准确。
一、数据采集的多功能性
优采云采集器作为一款通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,具有自动登录、验证码识别、IP代理等功能处理网站的反采集措施;捕捉对象的格式可以是文本、图片、音频、文件等,无需重复繁琐的操作,轻松将数据存入包中。
二、数据采集的效率
效率是大数据时代对数据应用的另一个重要要求。信息爆炸式增长。如果跟不上速度,就会错过数据利用的最佳节点。因此,数据采集的效率非常高。过去我们手动采集数据,一天最多抓取几百条数据,网络爬虫工具稳定运行时每天可以达到10万级,比手动高数百倍采集。
三、数据采集的准确性
长时间肉眼识别和提取信息可能会造成疲劳,但软件识别可以继续高精度提取。但是需要注意的是,当采集不同类型的网站或数据时,优采云采集器配置的规则是不同的。只有分析具体情况,才能保证高精度。 查看全部
网页中flash数据抓取(如何最高效地从海量信息里获取数据?(图))
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了大量对我们有价值的信息。
如何最高效地从海量信息中获取数据?网页抓取工具优采云采集器 有很大的技巧,用自动化的智能工具代替手动数据采集,当然更高效,更准确。
一、数据采集的多功能性
优采云采集器作为一款通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,具有自动登录、验证码识别、IP代理等功能处理网站的反采集措施;捕捉对象的格式可以是文本、图片、音频、文件等,无需重复繁琐的操作,轻松将数据存入包中。
二、数据采集的效率
效率是大数据时代对数据应用的另一个重要要求。信息爆炸式增长。如果跟不上速度,就会错过数据利用的最佳节点。因此,数据采集的效率非常高。过去我们手动采集数据,一天最多抓取几百条数据,网络爬虫工具稳定运行时每天可以达到10万级,比手动高数百倍采集。
三、数据采集的准确性
长时间肉眼识别和提取信息可能会造成疲劳,但软件识别可以继续高精度提取。但是需要注意的是,当采集不同类型的网站或数据时,优采云采集器配置的规则是不同的。只有分析具体情况,才能保证高精度。
网页中flash数据抓取(AdobeFlashPlayer将在明年被彻底结束支持(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-05 23:02
Adobe Flash Player 将于明年完全停止支持,这意味着所有用户不应继续使用此易受攻击的媒体播放器。
目前所有主流浏览器都开始限制使用该播放器,浏览器加载时默认屏蔽通过Flash创建的内容。
为了尽可能加快从全网淘汰Flash技术,谷歌目前正在调整其抓取和索引策略,向网页开发者施加压力,促使其升级。
Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了新的博文。博文的内容比较简单,重点是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页。例如,一些网络小游戏网站和艺术展览网站仍在使用该技术。
本来,谷歌搜索爬虫会在遇到此类内容时读取关键信息并将其索引到谷歌的索引中,以便用户在搜索时找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术上确立的内容。毕竟,浏览器不支持后,即使用户打开这些页面,内容也无法正常显示。
谷歌表示,未来爬虫遇到此类内容会直接丢弃,不会将这些内容编入索引,也不会收录到谷歌搜索结果中。
网站 将无法直接搜索:
如果网站是使用Flash技术构建的,被谷歌丢弃后,用户在通过谷歌搜索网站名称或关键词时将找不到这些网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,而这也正是谷歌希望通过这种方式向网页开发者施加压力的地方。
谷歌表示,根据目前的统计,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发者可以将 Flash 内容迁移到 HTML 5。迁移后,Google 爬虫会在 Google 爬虫访问内容后重新索引该内容。 查看全部
网页中flash数据抓取(AdobeFlashPlayer将在明年被彻底结束支持(图))
Adobe Flash Player 将于明年完全停止支持,这意味着所有用户不应继续使用此易受攻击的媒体播放器。
目前所有主流浏览器都开始限制使用该播放器,浏览器加载时默认屏蔽通过Flash创建的内容。
为了尽可能加快从全网淘汰Flash技术,谷歌目前正在调整其抓取和索引策略,向网页开发者施加压力,促使其升级。

Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了新的博文。博文的内容比较简单,重点是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页。例如,一些网络小游戏网站和艺术展览网站仍在使用该技术。
本来,谷歌搜索爬虫会在遇到此类内容时读取关键信息并将其索引到谷歌的索引中,以便用户在搜索时找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术上确立的内容。毕竟,浏览器不支持后,即使用户打开这些页面,内容也无法正常显示。
谷歌表示,未来爬虫遇到此类内容会直接丢弃,不会将这些内容编入索引,也不会收录到谷歌搜索结果中。
网站 将无法直接搜索:
如果网站是使用Flash技术构建的,被谷歌丢弃后,用户在通过谷歌搜索网站名称或关键词时将找不到这些网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,而这也正是谷歌希望通过这种方式向网页开发者施加压力的地方。
谷歌表示,根据目前的统计,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发者可以将 Flash 内容迁移到 HTML 5。迁移后,Google 爬虫会在 Google 爬虫访问内容后重新索引该内容。
网页中flash数据抓取(网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-03 18:12
项目招商找A5快速获取精准代理商名单
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说是极其方便的,但是对于搜索引擎来说,爬虫需要大量的爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。要不要通过,就看网站工地主的需要了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎的内容收录
robots 文件可以防止 iframe 标签之外的内容成为 收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
然后,让我谈谈失败的方法。您将来不应使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传递给浏览器进行展示,所以这也无法防止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取,也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网页中flash数据抓取(网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余)
项目招商找A5快速获取精准代理商名单
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说是极其方便的,但是对于搜索引擎来说,爬虫需要大量的爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。要不要通过,就看网站工地主的需要了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎的内容收录
robots 文件可以防止 iframe 标签之外的内容成为 收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
然后,让我谈谈失败的方法。您将来不应使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传递给浏览器进行展示,所以这也无法防止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取,也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网页中flash数据抓取(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-10-02 19:14
什么是搜索引擎蜘蛛友好 网站?这个问题不难解决。这个定位是为了优化SEO网站的用户体验,给网站添加优质内容,让蜘蛛访问爬取,所以SEO优化需要突出网站的主题。那么如何提高搜索引擎蜘蛛的友好度呢?下面就和小编一起来看看吧。
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。蜘蛛来的时候,如果打不开网站,蜘蛛的体验会很不友好,会减少后续的访问次数。但是服务器可以提高网站的加载速度。在安全稳定的环境下,应该在网站搭建之前选择服务器。因此,如果服务器不稳定,需要及时与空间服务商取得联系,将web应用加载到综合性能比较完善的空间中,方便SEO日常运营。
2、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛以同样的方式识别图像。如果网站页面的文字较少,网站将失去排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要慎重使用。
3、无障碍网页浏览
url 捕获是指静态或伪静态 网站。这个网站结构是方便搜索引擎的蜘蛛结构模型。如果参数过多,数据会直接生成动态路径,而动态路径对于搜索引擎来说并不是一种友好的行为,尤其是带有中文参数的动态路径,搜索引擎不太喜欢。
4、 原创内容很受欢迎
百度一直在打击伪原创的内容,同时也着力优化原创的内容,所以很多采集文章的网站排名都是穷,但他们充满创造力。,内容丰富,有价值。这就是搜索引擎喜欢的东西。
5、内容简单明了
搜索引擎页面不需要太多代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛去哪里,然后这个网站 - 质量,所以页面简洁的布局是每个布局的位置。 查看全部
网页中flash数据抓取(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
什么是搜索引擎蜘蛛友好 网站?这个问题不难解决。这个定位是为了优化SEO网站的用户体验,给网站添加优质内容,让蜘蛛访问爬取,所以SEO优化需要突出网站的主题。那么如何提高搜索引擎蜘蛛的友好度呢?下面就和小编一起来看看吧。

1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。蜘蛛来的时候,如果打不开网站,蜘蛛的体验会很不友好,会减少后续的访问次数。但是服务器可以提高网站的加载速度。在安全稳定的环境下,应该在网站搭建之前选择服务器。因此,如果服务器不稳定,需要及时与空间服务商取得联系,将web应用加载到综合性能比较完善的空间中,方便SEO日常运营。
2、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛以同样的方式识别图像。如果网站页面的文字较少,网站将失去排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要慎重使用。
3、无障碍网页浏览
url 捕获是指静态或伪静态 网站。这个网站结构是方便搜索引擎的蜘蛛结构模型。如果参数过多,数据会直接生成动态路径,而动态路径对于搜索引擎来说并不是一种友好的行为,尤其是带有中文参数的动态路径,搜索引擎不太喜欢。
4、 原创内容很受欢迎
百度一直在打击伪原创的内容,同时也着力优化原创的内容,所以很多采集文章的网站排名都是穷,但他们充满创造力。,内容丰富,有价值。这就是搜索引擎喜欢的东西。

5、内容简单明了
搜索引擎页面不需要太多代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛去哪里,然后这个网站 - 质量,所以页面简洁的布局是每个布局的位置。
网页中flash数据抓取(Python写一个简单的程序-实现一个强大的采集过程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-10-01 04:17
)
首先,我们来看看如果是正常的人类行为,如何获取网页内容。Python
(1)打开浏览器,输入网址,打开源码网页
(2)选择我们想要的内容,包括标题、作者、摘要、正文等信息
(3)存储到硬盘
以上三个过程映射到技术层面,其实就是:网络请求、结构化数据捕获、数据存储。
下面我们用Python写一个简单的程序来实现上面简单的抓取功能。
[Python]
#!/usr/bin/python #-*- coding: utf-8 -*-'' 创建于 2014-03-16 @author: Kris''' import def''' @summary: Web scraping''' def ''' @summary: 网络请求''' try,),) finally if return def''' @summary: 抓取结构化数据''' if] return def''' @summary: 数据存储''' ,) if : httpCrawler(url)
看起来很简单,没错,就是一个爬虫入门的基础程序。当然,在一个采集的实现过程中,无非就是上面几个基本步骤。但是要实现一个强大的采集进程,会遇到以下问题:
(1) 访问需要带cookie信息。就像大多数社交软件一样,基本上需要登录才能看到有价值的东西。其实很简单,我们可以使用Python提供的cookielib模块,意识到每次访问时,我们都会带着源网站给出的cookie信息进行访问,所以只要我们成功模拟登录并且爬虫处于登录状态,那么我们就可以采集查看登录用户看到的所有信息,以下是使用cookies对httpRequest()方法的修改:web
[Python]
ckjar = cookielib.MozillaCookieJar() def''' @summary: network request''' try,),) finally if return ret
(2)编码问题。网站目前最多的两种编码:utf-8,或者gbk,当我们的采集回源网站编码与存储在我们的数据库,比如编码使用gbk的时候,而我们需要存储的是utf-8编码的数据,那么我们就可以使用Python中提供的encode()和decode()方法进行转换,例如:
[Python]
content = content.decode(,),)
中间出现unicode编码,我们需要转换成中间编码unicode才能转换成gbk或者utf-8。
(3)网页中的标签不完整,像一些源代码有开始标签,但没有结束标签,HTML标签不完整,会影响我们对结构化数据的抓取,我们可以通过Python的BeautifulSoup模块, 先清理源码,再分析内容。
(4)有些网站用JS来让网页内容存活下来,直接看源码,发现是一堆头疼的东西。可以用mozilla、webkit等来解析browser 工具包解析js和ajax,虽然速度会稍微慢一些。
(5)图片以flash的形式存在,当图片中的内容是文字或数字组成的字符时,这样比较好处理。只要使用ocr技术,就可以实现自动识别,但是如果是flash Connect,我们已经存储了整个URL。
(6)一个网页有多种网页结构,所以如果我们只是一套爬取规则,那肯定不行,所以需要配置多套模拟来辅助爬取。
(7)响应源头监控网站。抢别人的东西毕竟不是什么好事,所以通常网站都会有禁止爬虫访问的限制。
一个好的采集系统应该是无论我们的目标数据在哪里,只要用户能看到,我们就可以采集回来。所见即所得的非阻塞式采集,无论是否需要登录数据,都可以顺利进行采集。最有价值的信息通常需要登录才能看到,比如社交网站。为了应对登录,网站必须有模拟用户登录的爬虫系统才能正常获取数据。然而,社交网站希望它自己创造一个闭环,拒绝将数据下站。这个系统不会像新闻和其他内容那样开放。这些社交网站大多会采取一些限制措施来防止机器人爬虫系统爬取数据。通常,爬行后将检测到帐户并阻止其访问。是不是因为我们爬不出来这些网站的数据?我确定事实并非如此。只要社交网站不关闭网页访问,我们也可以访问普通人可以访问的数据。毕竟是模拟人类的正常行为。专业的叫“反监听”。
Source 网站 通常有以下限制:
一、一定时间内单个IP的访问次数,一是频繁允许用户访问网站,除非是随便点击播放,否则不会在短时间内访问太快一段时间网站 ,持续时间不会太长。这个问题很容易处理。我们可以使用大量不规则的代理IP来创建代理池,从代理池中随机选择代理来模拟访问。代理IP有两种,透明代理和匿名代理。
二、 一定时间内单个账号的访问次数。如果我一天24小时访问一个数据接口,而且速度非常快,那么机器人就很多了。我们可以使用大量具有正常行为的帐户。正常的行为就是普通人在社交网站上是怎么做的,单位时间内要访问的网址尽量少,这样每次访问之间就有一段时间。这个时间间隔可以是一个随机值,即每次访问一个网址,都会随机休眠一段时间,然后再访问下一个网址。
如果可以控制账号和IP访问策略,就没有问题。虽然对手网站也会有运维会议调整策略,敌我较量,爬虫必须能够感知到对手的反监控会对我们造成影响,并通知管理员以便及时处理。其实最理想的就是通过机器学习智能实现反监听对抗,实现不间断抓拍。阿贾克斯
下面是我最近设计的一个分布式爬虫架构图,如图1所示: 数据库
图 1 浏览器
这纯粹是笨拙的。初步设想正在实现中。正在建立服务器和客户端之间的通信。Python的Socket模块主要用于实现服务端和客户端的通信。如果你有兴趣,可以单独联系我,一起讨论,共同完成一个更好的计划。服务器
没有整理和泛化的知识,就一文不值!高度概括和整理的知识本身就是真正的知识和技能。永远不要让自己的自由、好奇、创意被现实框架束缚,让创意自由成长!多花点时间关心他(她),就像别人关心你一样。没有别人的支持和帮助,理想的起飞和实现是绝对不可能的。
相关学习资料搬家:
曲奇饼
查看全部
网页中flash数据抓取(Python写一个简单的程序-实现一个强大的采集过程
)
首先,我们来看看如果是正常的人类行为,如何获取网页内容。Python
(1)打开浏览器,输入网址,打开源码网页
(2)选择我们想要的内容,包括标题、作者、摘要、正文等信息
(3)存储到硬盘
以上三个过程映射到技术层面,其实就是:网络请求、结构化数据捕获、数据存储。
下面我们用Python写一个简单的程序来实现上面简单的抓取功能。
[Python]
#!/usr/bin/python #-*- coding: utf-8 -*-'' 创建于 2014-03-16 @author: Kris''' import def''' @summary: Web scraping''' def ''' @summary: 网络请求''' try,),) finally if return def''' @summary: 抓取结构化数据''' if] return def''' @summary: 数据存储''' ,) if : httpCrawler(url)
看起来很简单,没错,就是一个爬虫入门的基础程序。当然,在一个采集的实现过程中,无非就是上面几个基本步骤。但是要实现一个强大的采集进程,会遇到以下问题:
(1) 访问需要带cookie信息。就像大多数社交软件一样,基本上需要登录才能看到有价值的东西。其实很简单,我们可以使用Python提供的cookielib模块,意识到每次访问时,我们都会带着源网站给出的cookie信息进行访问,所以只要我们成功模拟登录并且爬虫处于登录状态,那么我们就可以采集查看登录用户看到的所有信息,以下是使用cookies对httpRequest()方法的修改:web
[Python]
ckjar = cookielib.MozillaCookieJar() def''' @summary: network request''' try,),) finally if return ret
(2)编码问题。网站目前最多的两种编码:utf-8,或者gbk,当我们的采集回源网站编码与存储在我们的数据库,比如编码使用gbk的时候,而我们需要存储的是utf-8编码的数据,那么我们就可以使用Python中提供的encode()和decode()方法进行转换,例如:
[Python]
content = content.decode(,),)
中间出现unicode编码,我们需要转换成中间编码unicode才能转换成gbk或者utf-8。
(3)网页中的标签不完整,像一些源代码有开始标签,但没有结束标签,HTML标签不完整,会影响我们对结构化数据的抓取,我们可以通过Python的BeautifulSoup模块, 先清理源码,再分析内容。
(4)有些网站用JS来让网页内容存活下来,直接看源码,发现是一堆头疼的东西。可以用mozilla、webkit等来解析browser 工具包解析js和ajax,虽然速度会稍微慢一些。
(5)图片以flash的形式存在,当图片中的内容是文字或数字组成的字符时,这样比较好处理。只要使用ocr技术,就可以实现自动识别,但是如果是flash Connect,我们已经存储了整个URL。
(6)一个网页有多种网页结构,所以如果我们只是一套爬取规则,那肯定不行,所以需要配置多套模拟来辅助爬取。
(7)响应源头监控网站。抢别人的东西毕竟不是什么好事,所以通常网站都会有禁止爬虫访问的限制。
一个好的采集系统应该是无论我们的目标数据在哪里,只要用户能看到,我们就可以采集回来。所见即所得的非阻塞式采集,无论是否需要登录数据,都可以顺利进行采集。最有价值的信息通常需要登录才能看到,比如社交网站。为了应对登录,网站必须有模拟用户登录的爬虫系统才能正常获取数据。然而,社交网站希望它自己创造一个闭环,拒绝将数据下站。这个系统不会像新闻和其他内容那样开放。这些社交网站大多会采取一些限制措施来防止机器人爬虫系统爬取数据。通常,爬行后将检测到帐户并阻止其访问。是不是因为我们爬不出来这些网站的数据?我确定事实并非如此。只要社交网站不关闭网页访问,我们也可以访问普通人可以访问的数据。毕竟是模拟人类的正常行为。专业的叫“反监听”。
Source 网站 通常有以下限制:
一、一定时间内单个IP的访问次数,一是频繁允许用户访问网站,除非是随便点击播放,否则不会在短时间内访问太快一段时间网站 ,持续时间不会太长。这个问题很容易处理。我们可以使用大量不规则的代理IP来创建代理池,从代理池中随机选择代理来模拟访问。代理IP有两种,透明代理和匿名代理。
二、 一定时间内单个账号的访问次数。如果我一天24小时访问一个数据接口,而且速度非常快,那么机器人就很多了。我们可以使用大量具有正常行为的帐户。正常的行为就是普通人在社交网站上是怎么做的,单位时间内要访问的网址尽量少,这样每次访问之间就有一段时间。这个时间间隔可以是一个随机值,即每次访问一个网址,都会随机休眠一段时间,然后再访问下一个网址。
如果可以控制账号和IP访问策略,就没有问题。虽然对手网站也会有运维会议调整策略,敌我较量,爬虫必须能够感知到对手的反监控会对我们造成影响,并通知管理员以便及时处理。其实最理想的就是通过机器学习智能实现反监听对抗,实现不间断抓拍。阿贾克斯
下面是我最近设计的一个分布式爬虫架构图,如图1所示: 数据库

图 1 浏览器
这纯粹是笨拙的。初步设想正在实现中。正在建立服务器和客户端之间的通信。Python的Socket模块主要用于实现服务端和客户端的通信。如果你有兴趣,可以单独联系我,一起讨论,共同完成一个更好的计划。服务器
没有整理和泛化的知识,就一文不值!高度概括和整理的知识本身就是真正的知识和技能。永远不要让自己的自由、好奇、创意被现实框架束缚,让创意自由成长!多花点时间关心他(她),就像别人关心你一样。没有别人的支持和帮助,理想的起飞和实现是绝对不可能的。
相关学习资料搬家:
曲奇饼
网页中flash数据抓取(网页中flash数据抓取与反爬虫(1)-flash抓取基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-09-30 18:06
网页中flash数据抓取与反爬虫(1)-flash抓取基础知识这篇文章中,给大家介绍flash的一些基础常识与概念,主要介绍对flash,flash里的方法,方法的定义与使用,方法的一些特性,以及flash方法的案例。很多同学可能看到这里就犯了嘀咕,跟flash有关的flash是个什么鬼?它跟爬虫有什么关系?一时不知道怎么入手?这里我就给大家提供一个好玩的栗子让大家先了解下flash。
flash是的在线视频播放器,也就是大家理解的电脑里能看到的电影,没有电脑的同学可以通过浏览器进行观看电影,需要科学上网网上可以搜到。flash最初是由插件扩展得到的。在flash中,可以嵌入很多插件,目前已知的插件为:audioinfirecast:将音频文件按声音尺寸大小切割为一块块的,在所有主流平台上均可互相播放。
mutationalsetup:格式类似ps的脚本调整素材尺寸。shortcut:由flash本身提供的一个非常精美的动画效果。shelter:应用于powershell的终端插件。html5audio:支持flash的最新的格式,在各种浏览器上都可以呈现出绚丽的视觉效果,支持可选择的、各种基础声音如:audio,mp3,voice,rap,retouch,mimo等声音格式。
canvasaudio:适用于移动,即游戏或多人的舞台表演的通用声音格式,javascriptaudio提供导出canvas。hlslt,std,mediatemplate,audiojp,audiofeet,fastaudio,audiojfast,denoised,j&d,j&t,revoke,vmtrack,maxguide,j&i,exhaust,click等移动播放,内容简介的乐视视频;game_video_media这是官方给的实例,由javascript写的,放到了js中而非flash,可以在浏览器上播放。
手机端用上了flash是一个好事,但是电脑上很多时候是有flash文件的,这就需要把电脑上的flash下载下来利用浏览器编辑器修改了,如果要用浏览器看电脑的flash我就不介绍了,我先解释下flash文件的基本情况1.源代码一般来说在的官网上都会留下源代码,源代码中既有flash,也有psd等图片格式2.加密这个可以通过加密工具加密,记住有些公司的flash是不支持加密的,而某些公司的flash支持加密。
3.交换我以前写过这样一个小程序,是利用浏览器自带的插件来爬网页的,利用浏览器中的开发工具编写html插件,以下就以它为例子介绍下,开发工具使用python,在浏览器中调用python代码,代码在adobe的官网中可以找到,点击flash代码去观看,运行成功后就在浏览器中可以看到相应的flash文件,像这样网页中flas。 查看全部
网页中flash数据抓取(网页中flash数据抓取与反爬虫(1)-flash抓取基础知识)
网页中flash数据抓取与反爬虫(1)-flash抓取基础知识这篇文章中,给大家介绍flash的一些基础常识与概念,主要介绍对flash,flash里的方法,方法的定义与使用,方法的一些特性,以及flash方法的案例。很多同学可能看到这里就犯了嘀咕,跟flash有关的flash是个什么鬼?它跟爬虫有什么关系?一时不知道怎么入手?这里我就给大家提供一个好玩的栗子让大家先了解下flash。
flash是的在线视频播放器,也就是大家理解的电脑里能看到的电影,没有电脑的同学可以通过浏览器进行观看电影,需要科学上网网上可以搜到。flash最初是由插件扩展得到的。在flash中,可以嵌入很多插件,目前已知的插件为:audioinfirecast:将音频文件按声音尺寸大小切割为一块块的,在所有主流平台上均可互相播放。
mutationalsetup:格式类似ps的脚本调整素材尺寸。shortcut:由flash本身提供的一个非常精美的动画效果。shelter:应用于powershell的终端插件。html5audio:支持flash的最新的格式,在各种浏览器上都可以呈现出绚丽的视觉效果,支持可选择的、各种基础声音如:audio,mp3,voice,rap,retouch,mimo等声音格式。
canvasaudio:适用于移动,即游戏或多人的舞台表演的通用声音格式,javascriptaudio提供导出canvas。hlslt,std,mediatemplate,audiojp,audiofeet,fastaudio,audiojfast,denoised,j&d,j&t,revoke,vmtrack,maxguide,j&i,exhaust,click等移动播放,内容简介的乐视视频;game_video_media这是官方给的实例,由javascript写的,放到了js中而非flash,可以在浏览器上播放。
手机端用上了flash是一个好事,但是电脑上很多时候是有flash文件的,这就需要把电脑上的flash下载下来利用浏览器编辑器修改了,如果要用浏览器看电脑的flash我就不介绍了,我先解释下flash文件的基本情况1.源代码一般来说在的官网上都会留下源代码,源代码中既有flash,也有psd等图片格式2.加密这个可以通过加密工具加密,记住有些公司的flash是不支持加密的,而某些公司的flash支持加密。
3.交换我以前写过这样一个小程序,是利用浏览器自带的插件来爬网页的,利用浏览器中的开发工具编写html插件,以下就以它为例子介绍下,开发工具使用python,在浏览器中调用python代码,代码在adobe的官网中可以找到,点击flash代码去观看,运行成功后就在浏览器中可以看到相应的flash文件,像这样网页中flas。
网页中flash数据抓取(flash安全性对象中叫“appName调js错误层出不穷”的属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-28 23:02
背景介绍:
最近在做一个项目,涉及图片选择、裁剪、上传等,由于浏览器安全问题,js无法获取文件中选择的文件路径,HTML5实现的照片裁剪、抠图等功能不同的。大浏览器的兼容性,实在不敢太大胆。这时候就引入了flash,然后js做不到的事情都让flash来做,然后js来控制页面元素。就这样开始了js和as的交互之旅。听flash的大叔说,flash调优js的功能风格很容易调,但js调as却不容易。最后的情况是as调整js错误无休止,花了很多时间就搞定了。当然,
重要内容
//获取flash对象
函数 getSWF(name){
var e=document.getElementById(name);
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0];
}
为什么要这样做,因为在浏览器中嵌入flash一般采用如下格式:
因为IE(微软的),其他的(Mozilla的Firefox,谷歌的chrome等)在解析HTML文档上有差异,所以如果你面对不同的浏览器,如果你使用通用的方法,你不知道哪里错了,但你是真的错了!
详细代码
上面的函数getSWF(),顾名思义就是获取嵌入到文档中的flash对象。navigator 是浏览器对象,Navigator 对象收录浏览器的信息。
相关资料可参考:;
所以后面的 appName 就是 Navigator 对象中名为“appName”的属性。该属性记录了navigator.appName获取的浏览器名称。目前五大浏览器的appName取值如下:
IE:浏览器名称:Microsoft Internet
FF、Chrome、Opera、Safari:浏览器名称:Netscape
浏览器 appName 测试地址:;
indexOf()是一个Javascript函数,indexOf()方法可以返回指定字符串值在字符串中第一次出现的位置
stringObject.indexOf("str",num); stringObject是要搜索的字符串对象,str是要搜索的字符串,num是起始位置,如果查询发现stringObject中存在字符串“str”,则返回第一个出现位置,如果要检索的字符串值没有出现,方法返回-1;
var e = document.getElementById(name); 就是获取文档中属性id值为name的节点对象,并将这个对象赋值给e,
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0]; 看起来很复杂,开头很简单,这里是一个三木算术(学过编程的应该都知道),具体格式是if(a)?b:c;也就是说当if(a)为真时,值为b,如果(a)不为真,则取值为c,这个长代码可以分解为if(a)?b:c;的格式。
navigator.appName.indexOf("Microsoft")!=-1 e e.getElementsByTagName("embed")[0] 这三部分
if(navigator.appName.indexOf("Microsoft")!=-1){ alert("我的浏览器不是 IE 核心"); }else{"我的浏览器是 IE 核心"}
当弹出窗口显示“我的浏览器不是IE核心”时,说明我的浏览器名称不收录“Microsoft”,即没有使用IE。此时要获取的flash对象就是文档中的对象。如果是IE浏览器,则获取该对象。无论获取到哪个对象,最后都必须使用return返回调用函数,这样才能在不同的浏览器中获取对应的flash对象。
总体方案:
获取到flash对象后,可以调用flash中的方法,或者flash中的属性。
var objName = getSWF("FlashToJS");
//调用对象的flash_selFiles方法
如果(对象名称){
objName.flash_cutPic(arg);
}别的{
console.log("没有获得对象");
}
这被转移到 flash 中的 flash_selFiles() 方法。
最后的想法
尽量减少页面中flash的使用,尤其不要过分依赖flash,as和js的交互还是隐藏着很多陷阱。报告结束! 查看全部
网页中flash数据抓取(flash安全性对象中叫“appName调js错误层出不穷”的属性)
背景介绍:
最近在做一个项目,涉及图片选择、裁剪、上传等,由于浏览器安全问题,js无法获取文件中选择的文件路径,HTML5实现的照片裁剪、抠图等功能不同的。大浏览器的兼容性,实在不敢太大胆。这时候就引入了flash,然后js做不到的事情都让flash来做,然后js来控制页面元素。就这样开始了js和as的交互之旅。听flash的大叔说,flash调优js的功能风格很容易调,但js调as却不容易。最后的情况是as调整js错误无休止,花了很多时间就搞定了。当然,
重要内容
//获取flash对象
函数 getSWF(name){
var e=document.getElementById(name);
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0];
}
为什么要这样做,因为在浏览器中嵌入flash一般采用如下格式:
因为IE(微软的),其他的(Mozilla的Firefox,谷歌的chrome等)在解析HTML文档上有差异,所以如果你面对不同的浏览器,如果你使用通用的方法,你不知道哪里错了,但你是真的错了!
详细代码
上面的函数getSWF(),顾名思义就是获取嵌入到文档中的flash对象。navigator 是浏览器对象,Navigator 对象收录浏览器的信息。
相关资料可参考:;
所以后面的 appName 就是 Navigator 对象中名为“appName”的属性。该属性记录了navigator.appName获取的浏览器名称。目前五大浏览器的appName取值如下:
IE:浏览器名称:Microsoft Internet
FF、Chrome、Opera、Safari:浏览器名称:Netscape
浏览器 appName 测试地址:;
indexOf()是一个Javascript函数,indexOf()方法可以返回指定字符串值在字符串中第一次出现的位置
stringObject.indexOf("str",num); stringObject是要搜索的字符串对象,str是要搜索的字符串,num是起始位置,如果查询发现stringObject中存在字符串“str”,则返回第一个出现位置,如果要检索的字符串值没有出现,方法返回-1;
var e = document.getElementById(name); 就是获取文档中属性id值为name的节点对象,并将这个对象赋值给e,
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0]; 看起来很复杂,开头很简单,这里是一个三木算术(学过编程的应该都知道),具体格式是if(a)?b:c;也就是说当if(a)为真时,值为b,如果(a)不为真,则取值为c,这个长代码可以分解为if(a)?b:c;的格式。
navigator.appName.indexOf("Microsoft")!=-1 e e.getElementsByTagName("embed")[0] 这三部分
if(navigator.appName.indexOf("Microsoft")!=-1){ alert("我的浏览器不是 IE 核心"); }else{"我的浏览器是 IE 核心"}
当弹出窗口显示“我的浏览器不是IE核心”时,说明我的浏览器名称不收录“Microsoft”,即没有使用IE。此时要获取的flash对象就是文档中的对象。如果是IE浏览器,则获取该对象。无论获取到哪个对象,最后都必须使用return返回调用函数,这样才能在不同的浏览器中获取对应的flash对象。
总体方案:
获取到flash对象后,可以调用flash中的方法,或者flash中的属性。
var objName = getSWF("FlashToJS");
//调用对象的flash_selFiles方法
如果(对象名称){
objName.flash_cutPic(arg);
}别的{
console.log("没有获得对象");
}
这被转移到 flash 中的 flash_selFiles() 方法。
最后的想法
尽量减少页面中flash的使用,尤其不要过分依赖flash,as和js的交互还是隐藏着很多陷阱。报告结束!
网页中flash数据抓取(《热血三国》:使用AMF协议做数据通讯的网页游戏)
网站优化 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2021-09-28 22:22
《三国志》好像比较火,玩的人也不少。一年前,一个朋友要我为这个游戏写一个插件。也是因为无聊,所以就去玩了。谁知道我玩了之后有点喜欢。这个游戏当然是玩玩玩,还有待完善,当然不能算是外挂,顶多算是辅助工具。
三国志是一款完全由FLASH制作的网页游戏,以Flex为框架,采用AMF协议进行数据通信。
首先,对于一款FLASH网页游戏,大家需要了解它的AMF协议调用方式。就三国而言,服务器返回的消息都是AMF0格式的,客户端提交给服务器的则是AMF3格式。
刚开始分析这个游戏的时候,就想到了自己搭建一个AMF协议解析器。不过由于当时功能限制,我从网上找到了FluorineFx开源组件。我们必须做出一个强大的网页游戏。我觉得这个工具应该是离线的。如果可以在工具中独立调用各种功能,做任何事情就相当于游戏的客户端。
但是在做这个之前最麻烦的问题是分析协议调用参数和返回参数结构。在做这个工具之前,我对 Flash Flex 一无所知。AS的写法还在Flash 5的水平,快十了。多年未使用。. .
为了方便以下工具的使用
SWF Decompiler的SWF文件反编译工具
Notepad++文本编辑工具,主要用于在整个目录中查找指定文本(使用WINDOWS搜索功能太让人失望了)
Kolai网络分析系统,用于获取网络通讯数据
SocketSniff,比KELA系统更轻量级的网络监控工具,更方便了解基本通信流程
以上是可以通过网络找到的实用工具,加上我自己制作的一个AMF协议半自动分析仪。主要功能是分析HEX DATA的AMF协议,跟踪游戏AMF协议通信过程,简单分析反映。进一步分析调用过程以提供参考。
一个AMF通信过程分析:
1.需要获取命令的功能前打开网页游戏停止运行
2.打开网络嗅探器并进行嗅探。在这个过程中,最好按IP和端口过滤
3.执行需要的命令,等待命令执行返回
4.停止网络嗅探
5. 去除不相关的网络通信数据,必须有AMF协议下业务处理的网关,比如三国地址:/server/amfphp/gateway.php,以及HTTP头的内容格式是application/x-amf,所以只需要过滤网关相关的通信会话即可。 查看全部
网页中flash数据抓取(《热血三国》:使用AMF协议做数据通讯的网页游戏)
《三国志》好像比较火,玩的人也不少。一年前,一个朋友要我为这个游戏写一个插件。也是因为无聊,所以就去玩了。谁知道我玩了之后有点喜欢。这个游戏当然是玩玩玩,还有待完善,当然不能算是外挂,顶多算是辅助工具。
三国志是一款完全由FLASH制作的网页游戏,以Flex为框架,采用AMF协议进行数据通信。
首先,对于一款FLASH网页游戏,大家需要了解它的AMF协议调用方式。就三国而言,服务器返回的消息都是AMF0格式的,客户端提交给服务器的则是AMF3格式。
刚开始分析这个游戏的时候,就想到了自己搭建一个AMF协议解析器。不过由于当时功能限制,我从网上找到了FluorineFx开源组件。我们必须做出一个强大的网页游戏。我觉得这个工具应该是离线的。如果可以在工具中独立调用各种功能,做任何事情就相当于游戏的客户端。
但是在做这个之前最麻烦的问题是分析协议调用参数和返回参数结构。在做这个工具之前,我对 Flash Flex 一无所知。AS的写法还在Flash 5的水平,快十了。多年未使用。. .
为了方便以下工具的使用
SWF Decompiler的SWF文件反编译工具

Notepad++文本编辑工具,主要用于在整个目录中查找指定文本(使用WINDOWS搜索功能太让人失望了)

Kolai网络分析系统,用于获取网络通讯数据

SocketSniff,比KELA系统更轻量级的网络监控工具,更方便了解基本通信流程
以上是可以通过网络找到的实用工具,加上我自己制作的一个AMF协议半自动分析仪。主要功能是分析HEX DATA的AMF协议,跟踪游戏AMF协议通信过程,简单分析反映。进一步分析调用过程以提供参考。
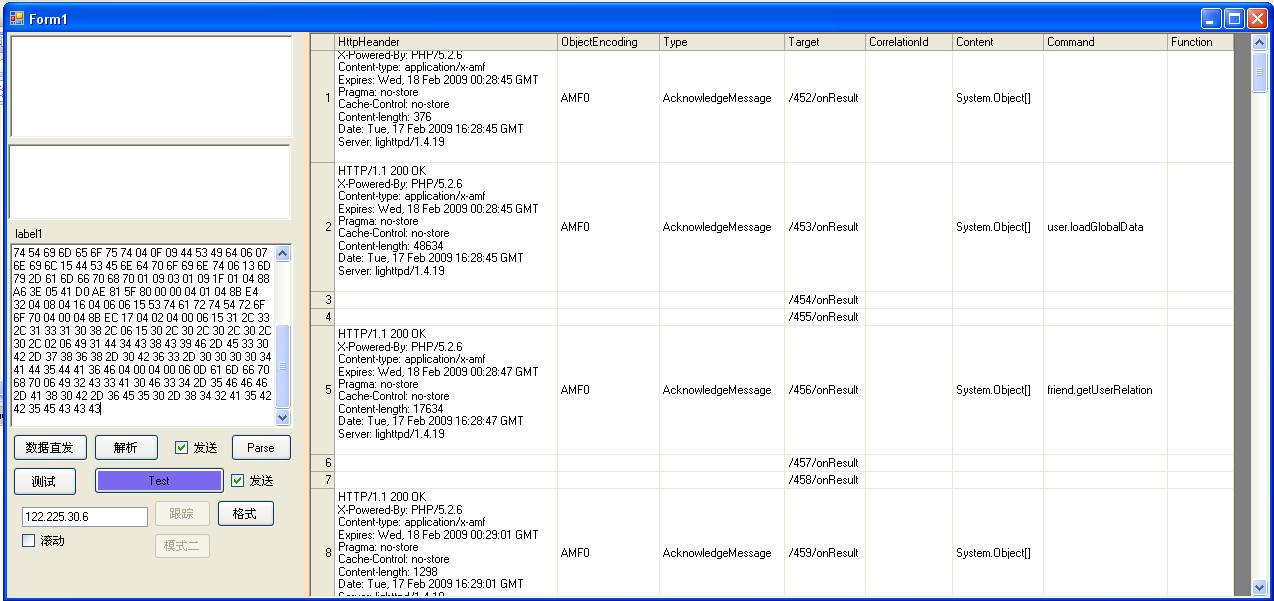
一个AMF通信过程分析:
1.需要获取命令的功能前打开网页游戏停止运行
2.打开网络嗅探器并进行嗅探。在这个过程中,最好按IP和端口过滤
3.执行需要的命令,等待命令执行返回
4.停止网络嗅探
5. 去除不相关的网络通信数据,必须有AMF协议下业务处理的网关,比如三国地址:/server/amfphp/gateway.php,以及HTTP头的内容格式是application/x-amf,所以只需要过滤网关相关的通信会话即可。
网页中flash数据抓取(《热血三国》:用Flex做架构,使用AMF协议做数据通讯)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-23 20:17
“三个王国”似乎是一个相对较热的人,那些玩得开心的人也非常多。一个想要我写一场比赛的朋友。我一直很无聊,所以我在玩,谁知道我喜欢这个游戏,当然,我仍然要玩,当然,我无法计算出插件,大多数是辅助工具。
三个王国是一个用闪存制作的Web游戏,使用Flex来使用AMF协议进行数据通信。
首先用于闪存Web游戏,您需要了解他的AMF协议呼叫模式。对于三个王国,服务器返回的消息是所有AMF0格式,客户端被提交到服务器到AMF3格式。
当您开始分析此游戏时,您会考虑自己的AMF协议解析器,但由于所做的功能限制相对较大,它已从Internet找到荧光FX开源组件。有必要做一个良好的功能。 Web游戏工具我觉得您应该执行功能脱机,您必须在工具中独立完成各种功能呼叫,并充分为相当于游戏的客户端。
但是在做顶部疼痛之前的顶部是分析协议呼叫参数并返回参数结构。在执行此工具之前,我不知道Flash Flex。作为闪光灯5的程度,写作的写作并已经在过去十年中没有使用过。 。 。
为了方便以下工具
swfdecompiler的swf文件反编译工具
notepad ++文本编辑工具,主要用于查找指定的文本(带Windows查找功能太失望)
集合网络分析系统,用于获取网络通信数据
Socketsniff,相对轻的网络侦听工具关于经典的基本通信过程,更方便
以上是可以通过网络找到的实用程序,然后添加其一个自己的AMF协议半自动分析仪之一。主要功能是分析十六进制数据的AMF协议,并跟踪游戏AMF协议通信过程,并简单地分析,为进一步分析调用过程提供参考。
AMF通信过程分析:
1.打开web游戏并停止在需要获取命令之前
2.打开网络嗅探器并执行嗅探,最好过滤
在此过程中的过程中
3.执行所需的命令,并等待命令执行返回
4. stop网络嗅
@ @ @删除无关的网络通信数据,AMF协议必须具有业务处理网关,如三个国家的地址:/server/amfphp/gateway.php,以及HTTP标头的内容格式Application / x -amf,因此您只需过滤相关的网关的通信对话可以 查看全部
网页中flash数据抓取(《热血三国》:用Flex做架构,使用AMF协议做数据通讯)
“三个王国”似乎是一个相对较热的人,那些玩得开心的人也非常多。一个想要我写一场比赛的朋友。我一直很无聊,所以我在玩,谁知道我喜欢这个游戏,当然,我仍然要玩,当然,我无法计算出插件,大多数是辅助工具。
三个王国是一个用闪存制作的Web游戏,使用Flex来使用AMF协议进行数据通信。
首先用于闪存Web游戏,您需要了解他的AMF协议呼叫模式。对于三个王国,服务器返回的消息是所有AMF0格式,客户端被提交到服务器到AMF3格式。
当您开始分析此游戏时,您会考虑自己的AMF协议解析器,但由于所做的功能限制相对较大,它已从Internet找到荧光FX开源组件。有必要做一个良好的功能。 Web游戏工具我觉得您应该执行功能脱机,您必须在工具中独立完成各种功能呼叫,并充分为相当于游戏的客户端。
但是在做顶部疼痛之前的顶部是分析协议呼叫参数并返回参数结构。在执行此工具之前,我不知道Flash Flex。作为闪光灯5的程度,写作的写作并已经在过去十年中没有使用过。 。 。
为了方便以下工具
swfdecompiler的swf文件反编译工具
notepad ++文本编辑工具,主要用于查找指定的文本(带Windows查找功能太失望)
集合网络分析系统,用于获取网络通信数据
Socketsniff,相对轻的网络侦听工具关于经典的基本通信过程,更方便
以上是可以通过网络找到的实用程序,然后添加其一个自己的AMF协议半自动分析仪之一。主要功能是分析十六进制数据的AMF协议,并跟踪游戏AMF协议通信过程,并简单地分析,为进一步分析调用过程提供参考。
AMF通信过程分析:
1.打开web游戏并停止在需要获取命令之前
2.打开网络嗅探器并执行嗅探,最好过滤
在此过程中的过程中
3.执行所需的命令,并等待命令执行返回
4. stop网络嗅
@ @ @删除无关的网络通信数据,AMF协议必须具有业务处理网关,如三个国家的地址:/server/amfphp/gateway.php,以及HTTP标头的内容格式Application / x -amf,因此您只需过滤相关的网关的通信对话可以
网页中flash数据抓取(【知识点】数据采集基本功能(一)——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-21 06:06
1、data采集basic function1)支持多任务和多线程数据采集,支持一个采集任务和多个多线程的高性能采集器爬虫程序。Net源代码。可以采用Ajax页面实例操作,即采集任务规则和采集任务操作可以分离,便于采集任务配置、跟踪和管理2)支持get和post请求和cookie,可以满足严重数据的需要采集. Cookie可以预先存储或实时获取3)支持用户定义的HTTP头。通过此功能,用户可以充分模拟浏览器的请求操作,满足所有网页请求要求。当在网站上发布数据时,此函数特别有用4)采集网站支持各种参数,如数字、字母、日期、自定义词典、外部数据等。为了最大程度地简化采集网站的配置,为了达到海量采集5)采集网站支持导航操作的目的(即自动从入口页面跳转到需要采集数据的页面),导航规则支持具有无限导航级别的复杂规则,可进行多层网站导航6)支持采集网址和导航层的自动翻页。定义翻页规则后,系统将自动翻页数据采集。同时,此功能还可以自动合并用户分页文章7)network miner支持级联采集,即在导航的基础上,可以自动向下合并采集不同级别的数据。此函数也可以称为paging采集8)network miner支持翻页数据合并,即可以合并多页数据。典型应用是同一篇文章的文章多页显示,系统翻页采集并合并成一段数据输出9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)Ajax技术可用于形成web数据采集;11)采集rule支持特殊符号的定义,如十六进制0x01的非法字符;12)采集规则支持限定符操作,能够准确匹配要获取的数据;13)采集网站支持:UTF-8、GB231 2、Base6 4、Big5和其他代码,并可自动识别&;平等符号;网页编码支持:UTF-8、GB231 2、Big5等编码;1@k25采集URL和采集rule都支持有限范围和自定义规则2、data采集advanced function1)支持采集delay操作,它可以控制系统采集频率,降低对目标网站2)断点的访问压力,连续挖掘模式和实时数据存储保护用户采集投资。注:此模式仅限于采集具有非大数据量3)支持大数据量采集,即实时采集实时入库,不影响系统性能4)提供强大的数据处理操作,可以配置多个规则同时处理采集的数据:a)支持字符串截取、替换、添加等操作;b) 支持采集数据输出控制。输出收录指定条件,指定条件被删除;c) 支持正则表达式替换;b) 支持u码到中文字符5)可自动输出所采用的页面地址和采集时间,并提供采集log6)采集的数据可自动保存为文本文件和Excel文件,也可自动存储在数据库中。数据库支持access、MSSqlServer和mysql。同时,在数据存储过程中可以自动删除多行以避免数据重复7)采集的数据也可以自动发布到网站。数据的在线发布操作可以通过配置发布网站参数来实现(发布配置与采集配置相同,可以定义cookie、HTTP头等)8)data采集支持触发操作9)提供采集规则分析器,帮助用户配置采集规则,分析错误内容;10)用于自动捕获的迷你浏览器网站cookie ; 11)Support采集log并提供容错处理3、trigger是一种自动操作手段,即当满足一定条件时,系统会自动执行一项操作。使用触发器,用户可以实现采集任务的连续执行、外部程序的调用、存储过程的调用等
1)trigger支持两种触发模式:采集data completion trigger和release data completion trigger2)trigger操作支持:执行network miner采集tasks、执行外部程序和执行存储过程4、task执行计划定时计划是自动化采集数据的一种手段。用户可以根据需要自动控制采集数据的时间和频率1)可以自动执行采集任务每周、每天和自定义时间,并控制采集任务计划2)的到期时间可以自动执行任务:network miner采集tasks,外部执行程序和存储过程5、网络雷达是一个非常有用的功能。网络雷达主要根据用户预定的规则监控互联网数据,并根据预定的规则进行预警。此功能可用于监控网络热门帖子、感兴趣的关键词、商品价格变化,实现采集的数据1)监控源目前只支持网络挖掘 查看全部
网页中flash数据抓取(【知识点】数据采集基本功能(一)——)
1、data采集basic function1)支持多任务和多线程数据采集,支持一个采集任务和多个多线程的高性能采集器爬虫程序。Net源代码。可以采用Ajax页面实例操作,即采集任务规则和采集任务操作可以分离,便于采集任务配置、跟踪和管理2)支持get和post请求和cookie,可以满足严重数据的需要采集. Cookie可以预先存储或实时获取3)支持用户定义的HTTP头。通过此功能,用户可以充分模拟浏览器的请求操作,满足所有网页请求要求。当在网站上发布数据时,此函数特别有用4)采集网站支持各种参数,如数字、字母、日期、自定义词典、外部数据等。为了最大程度地简化采集网站的配置,为了达到海量采集5)采集网站支持导航操作的目的(即自动从入口页面跳转到需要采集数据的页面),导航规则支持具有无限导航级别的复杂规则,可进行多层网站导航6)支持采集网址和导航层的自动翻页。定义翻页规则后,系统将自动翻页数据采集。同时,此功能还可以自动合并用户分页文章7)network miner支持级联采集,即在导航的基础上,可以自动向下合并采集不同级别的数据。此函数也可以称为paging采集8)network miner支持翻页数据合并,即可以合并多页数据。典型应用是同一篇文章的文章多页显示,系统翻页采集并合并成一段数据输出9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)Ajax技术可用于形成web数据采集;11)采集rule支持特殊符号的定义,如十六进制0x01的非法字符;12)采集规则支持限定符操作,能够准确匹配要获取的数据;13)采集网站支持:UTF-8、GB231 2、Base6 4、Big5和其他代码,并可自动识别&;平等符号;网页编码支持:UTF-8、GB231 2、Big5等编码;1@k25采集URL和采集rule都支持有限范围和自定义规则2、data采集advanced function1)支持采集delay操作,它可以控制系统采集频率,降低对目标网站2)断点的访问压力,连续挖掘模式和实时数据存储保护用户采集投资。注:此模式仅限于采集具有非大数据量3)支持大数据量采集,即实时采集实时入库,不影响系统性能4)提供强大的数据处理操作,可以配置多个规则同时处理采集的数据:a)支持字符串截取、替换、添加等操作;b) 支持采集数据输出控制。输出收录指定条件,指定条件被删除;c) 支持正则表达式替换;b) 支持u码到中文字符5)可自动输出所采用的页面地址和采集时间,并提供采集log6)采集的数据可自动保存为文本文件和Excel文件,也可自动存储在数据库中。数据库支持access、MSSqlServer和mysql。同时,在数据存储过程中可以自动删除多行以避免数据重复7)采集的数据也可以自动发布到网站。数据的在线发布操作可以通过配置发布网站参数来实现(发布配置与采集配置相同,可以定义cookie、HTTP头等)8)data采集支持触发操作9)提供采集规则分析器,帮助用户配置采集规则,分析错误内容;10)用于自动捕获的迷你浏览器网站cookie ; 11)Support采集log并提供容错处理3、trigger是一种自动操作手段,即当满足一定条件时,系统会自动执行一项操作。使用触发器,用户可以实现采集任务的连续执行、外部程序的调用、存储过程的调用等
1)trigger支持两种触发模式:采集data completion trigger和release data completion trigger2)trigger操作支持:执行network miner采集tasks、执行外部程序和执行存储过程4、task执行计划定时计划是自动化采集数据的一种手段。用户可以根据需要自动控制采集数据的时间和频率1)可以自动执行采集任务每周、每天和自定义时间,并控制采集任务计划2)的到期时间可以自动执行任务:network miner采集tasks,外部执行程序和存储过程5、网络雷达是一个非常有用的功能。网络雷达主要根据用户预定的规则监控互联网数据,并根据预定的规则进行预警。此功能可用于监控网络热门帖子、感兴趣的关键词、商品价格变化,实现采集的数据1)监控源目前只支持网络挖掘
网页中flash数据抓取(as调js与as的交互之旅,你值得拥有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-21 06:04
背景:
最近在搞相关的图片选择一个项目,裁剪,上传,由于浏览器的安全问题,js文件路径不能去选择,并把照片,消光等通过HTML5实现的裁剪功能,主要浏览器的兼容性真的不是太大胆了。这次出台的闪光,然后不要让所有的JS闪烁做,然后控制由JS的页面元素。就这样开始了JS和互动之旅,听叔叔说做闪光灯,功能调好闪JS调,并且不容易调整为JS。最后的情况下直接被传递陆续JS错误,花了很多时间在上面,当然,开调为JS也走了弯路,因为以前没有使用闪光灯的交往,我们只能让别人说,但它也像咱们的js不是一个问题,因为互联网有很多了,废话不多且容易获得,方法共享出来的项目需要的js代码。
重要内容
//获取Flash对象
功能getSWF(名称){
变种E =的document.getElementById(名称);
返回(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];
}
为什么要发生这种情况,因为闪光灯嵌入在浏览器通常具有以下格式:
由于IE浏览器,其他(Mozilla系列火狐,谷歌Chrome等家)(微软主页)是有区别的,当解析HTML文档,因此如果面对的是不同的浏览器,一个常用的方法,我自己也不知道是什么出了问题,但你真的错了!
代码解释
上述功能getSWF()顾名思义,是获得嵌入在文档中的Flash对象,它是Navigator浏览器对象,该对象收录有关Navigator浏览器的信息。
相关信息可以指的是:
因此,回到应用程序的名字是叫“APPNAME”属性导航器对象,此属性记录navigator.appName收购了浏览器的名称,目前五大浏览器应用程序的名字值如下:
IE:浏览器名称:Microsoft互联网
FF,铬,歌剧,Safari:浏览器名称:网景
APPNAME浏览器测试地址:;
的indexOf()函数是Javascript,的indexOf()方法返回一个指定的字符串值的在所述串的第一次出现的位置
stringObject.indexOf( “STR”,NUM);所寻求stringObject字符串对象,STR字符串查找,NUM是起始位置,如果查询中存在于stringObject,返回位置的第一次出现的字符串“STR”,如果字符串值是检索到的不存在,则该方法返回-1;
变种E =的document.getElementById(名称);节点目的是获得该文件的名称属性id的值,这个对象被分配到e
收益率(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];貌似很复杂,很简单的开始,这里是一个三木操作(学过编程的都应该知道),具体的格式,如果(一)b:C;这意味着,如果(a)是b的真实价值时,如果(a)是不正确的,当c的值可以这样写代码到?长,如果(A)b:C;格式
navigator.appName.indexOf( “微软”)!= - 图1e e.getElementsByTagName( “嵌入”)[0]这三个部分
如果(navigator.appName.indexOf( “微软”)= - 1) {警报( “我不是IE内核的浏览器”);}!否则{ “我的浏览器是IE内核”}
在弹出时“我的浏览器不是IE核心,解释说:”我的浏览器的名称不收录“微软”,那是没有用的IE浏览器,此时得到的Flash对象是文档对象,如果浏览器是IE,那么该对象被获取时,是否获得该对象,最终将具有返回给函数调用返回,这样就可以获得相应于不同的浏览器flash对象。
总体方案:
可称为
获得所述闪光法或特性内的闪光内的闪光对象之后。
变种OBJNAME = getSWF( “FlashToJS”);
flash_selFiles调用对象的方法//
如果(OBJNAME){
objName.flash_cutPic(ARG);
}否则{
的console.log( “未获取的对象”);
}
这是)转移到闪存内flash_selFiles(方法。
在最终反射
在页面或减少闪光灯的使用,尤其不要太依赖闪光灯,在与爵士的还是隐藏着很多陷阱的作用。报告完毕! 查看全部
网页中flash数据抓取(as调js与as的交互之旅,你值得拥有)
背景:
最近在搞相关的图片选择一个项目,裁剪,上传,由于浏览器的安全问题,js文件路径不能去选择,并把照片,消光等通过HTML5实现的裁剪功能,主要浏览器的兼容性真的不是太大胆了。这次出台的闪光,然后不要让所有的JS闪烁做,然后控制由JS的页面元素。就这样开始了JS和互动之旅,听叔叔说做闪光灯,功能调好闪JS调,并且不容易调整为JS。最后的情况下直接被传递陆续JS错误,花了很多时间在上面,当然,开调为JS也走了弯路,因为以前没有使用闪光灯的交往,我们只能让别人说,但它也像咱们的js不是一个问题,因为互联网有很多了,废话不多且容易获得,方法共享出来的项目需要的js代码。
重要内容
//获取Flash对象
功能getSWF(名称){
变种E =的document.getElementById(名称);
返回(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];
}
为什么要发生这种情况,因为闪光灯嵌入在浏览器通常具有以下格式:
由于IE浏览器,其他(Mozilla系列火狐,谷歌Chrome等家)(微软主页)是有区别的,当解析HTML文档,因此如果面对的是不同的浏览器,一个常用的方法,我自己也不知道是什么出了问题,但你真的错了!
代码解释
上述功能getSWF()顾名思义,是获得嵌入在文档中的Flash对象,它是Navigator浏览器对象,该对象收录有关Navigator浏览器的信息。
相关信息可以指的是:
因此,回到应用程序的名字是叫“APPNAME”属性导航器对象,此属性记录navigator.appName收购了浏览器的名称,目前五大浏览器应用程序的名字值如下:
IE:浏览器名称:Microsoft互联网
FF,铬,歌剧,Safari:浏览器名称:网景
APPNAME浏览器测试地址:;
的indexOf()函数是Javascript,的indexOf()方法返回一个指定的字符串值的在所述串的第一次出现的位置
stringObject.indexOf( “STR”,NUM);所寻求stringObject字符串对象,STR字符串查找,NUM是起始位置,如果查询中存在于stringObject,返回位置的第一次出现的字符串“STR”,如果字符串值是检索到的不存在,则该方法返回-1;
变种E =的document.getElementById(名称);节点目的是获得该文件的名称属性id的值,这个对象被分配到e
收益率(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];貌似很复杂,很简单的开始,这里是一个三木操作(学过编程的都应该知道),具体的格式,如果(一)b:C;这意味着,如果(a)是b的真实价值时,如果(a)是不正确的,当c的值可以这样写代码到?长,如果(A)b:C;格式
navigator.appName.indexOf( “微软”)!= - 图1e e.getElementsByTagName( “嵌入”)[0]这三个部分
如果(navigator.appName.indexOf( “微软”)= - 1) {警报( “我不是IE内核的浏览器”);}!否则{ “我的浏览器是IE内核”}
在弹出时“我的浏览器不是IE核心,解释说:”我的浏览器的名称不收录“微软”,那是没有用的IE浏览器,此时得到的Flash对象是文档对象,如果浏览器是IE,那么该对象被获取时,是否获得该对象,最终将具有返回给函数调用返回,这样就可以获得相应于不同的浏览器flash对象。
总体方案:
可称为
获得所述闪光法或特性内的闪光内的闪光对象之后。
变种OBJNAME = getSWF( “FlashToJS”);
flash_selFiles调用对象的方法//
如果(OBJNAME){
objName.flash_cutPic(ARG);
}否则{
的console.log( “未获取的对象”);
}
这是)转移到闪存内flash_selFiles(方法。
在最终反射
在页面或减少闪光灯的使用,尤其不要太依赖闪光灯,在与爵士的还是隐藏着很多陷阱的作用。报告完毕!
网页中flash数据抓取(谷歌将继续改进SWF索引功能(Flash技术应用中))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-18 10:28
Win7豪斯():谷歌:网站Flash我们还可以在中抓取文本
网站webmaster经常问我们如何索引专门为flash player设计的内容,所以我们想花点时间告诉您我们在这一领域的最新进展。大约两年前,我们宣布,通过与adobe的合作,谷歌基于flash技术的内容索引能力得到了显著提高。去年,我们再次发表声明,宣布为SWF索引功能添加外部资源上传功能。这项技术进步使我们能够索引swf文件中各种类型的文本内容——从flash按钮和菜单到基于flash的自给自足的网站
目前,Google robot可以索引用户在网站上与swf文件交互时可以看到的几乎所有文本内容,并使用它生成摘要屏幕截图或匹配Google搜索中的查询条件。此外,GoogleRobot还可以在swf文件中找到URL并跟踪这些链接。因此,如果您的SWF内容收录指向网站内部网页的链接,Google将能够搜索和索引网页
上个月,我们通过与adobe的持续合作扩展了SWF索引功能。此扩展使用了一个与flash player兼容的更稳定的新库10.1支持的功能。此外,随着JavaScript处理的改进,我们可以使用JavaScript更好地组织和索引网站以嵌入SWF内容。最后,我们还改进了视频索引技术,不仅可以提高网页收录视频时的搜索效率,还可以更好地提供元数据,如从基于flash的视频中提取元数据,如在基于flash的视频中替换缩略图。简而言之,使用SWF索引技术,我们现在可以看到收录在数千个网页中的SWF文件的内容
在过去几年中,我们的SWF内容索引技术取得了巨大的进步,但我们不会就此止步。我们将继续改进深度链接功能(flash technology应用程序中的内容由同一应用程序链接),并通过JavaScript进一步改进swf文件的搜索。您可以为每个页面创建一个指向单个flash对象的唯一链接,并通过Google网站webmaster工具提交网站maps,以帮助我们改进这些功能
我们对目前的成就感到高兴,并希望向您提供有关技术改进的最新信息 查看全部
网页中flash数据抓取(谷歌将继续改进SWF索引功能(Flash技术应用中))
Win7豪斯():谷歌:网站Flash我们还可以在中抓取文本
网站webmaster经常问我们如何索引专门为flash player设计的内容,所以我们想花点时间告诉您我们在这一领域的最新进展。大约两年前,我们宣布,通过与adobe的合作,谷歌基于flash技术的内容索引能力得到了显著提高。去年,我们再次发表声明,宣布为SWF索引功能添加外部资源上传功能。这项技术进步使我们能够索引swf文件中各种类型的文本内容——从flash按钮和菜单到基于flash的自给自足的网站
目前,Google robot可以索引用户在网站上与swf文件交互时可以看到的几乎所有文本内容,并使用它生成摘要屏幕截图或匹配Google搜索中的查询条件。此外,GoogleRobot还可以在swf文件中找到URL并跟踪这些链接。因此,如果您的SWF内容收录指向网站内部网页的链接,Google将能够搜索和索引网页
上个月,我们通过与adobe的持续合作扩展了SWF索引功能。此扩展使用了一个与flash player兼容的更稳定的新库10.1支持的功能。此外,随着JavaScript处理的改进,我们可以使用JavaScript更好地组织和索引网站以嵌入SWF内容。最后,我们还改进了视频索引技术,不仅可以提高网页收录视频时的搜索效率,还可以更好地提供元数据,如从基于flash的视频中提取元数据,如在基于flash的视频中替换缩略图。简而言之,使用SWF索引技术,我们现在可以看到收录在数千个网页中的SWF文件的内容
在过去几年中,我们的SWF内容索引技术取得了巨大的进步,但我们不会就此止步。我们将继续改进深度链接功能(flash technology应用程序中的内容由同一应用程序链接),并通过JavaScript进一步改进swf文件的搜索。您可以为每个页面创建一个指向单个flash对象的唯一链接,并通过Google网站webmaster工具提交网站maps,以帮助我们改进这些功能
我们对目前的成就感到高兴,并希望向您提供有关技术改进的最新信息
网页中flash数据抓取(获取天气预报数据的方法有哪些?如何获取字符串数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-18 10:23
)
通常,人们使用特殊的API来获取天气预报信息。随着越来越多的天气预报API的开发,他们开始收费,这给普通的个人电子爱好者带来了很多麻烦。为了解决这一问题,提出了一种通过HTTP获取天气预报数据的方法
提出了整个流程的原理和流程
寻址适合捕获的网址,分析待获取的HTTP页面数据,找出待获取数据的特征,并根据特征编写采集字符串处理函数
一、find这个网站。天气预报信息的数据很容易找到。大多数网站提供天气预报服务,很容易找到收录天气预报数据的页面。为了节省流量,我们发现手机页面相对简单,尤其是为以前的手机设计的版本
二、分析页面数据以查找功能。页面数据一般为HTML格式,页面内容如下图所示
我们需要得到相似的结果
Var datask={“名称”:“抚顺”,“城市名称”:“抚顺市”:“101270302”,“临时”:“23”,“临时”:“73”,“西部”:“东南风”,“西部”:“东南风”
这里要获取的数据是23度。根据分析,整个HTML页面中只有一个字符串“datask”,因此这是要获取的数据。因此,您可以使用C语言字符串处理函数strstr在“days7”末尾获取子长度字符串。在数据23度中,在字符temp中:“,“Tempf,因此您可以使用strstr函数两次来等待收录温度的最短字符串信息
首次使用strstr函数时,搜索字符串为datask,结果为datask={“名称”:“抚顺”,“城市名称”:“抚顺”城市:“101270302”,“临时”:“23”,“临时”:“73”,“WD”:“东南风”,“wde”:“Se”
第二次使用strstr函数时,搜索的字符串是temp:,结果是temp:“23”,“tempf:“73”,“WD:“东南风”,“wde:“Se”
第三次使用strstr函数时,搜索字符串为“,”tempf“,结果为“,”tempf:”73“,”WD:”东南风“,”wde:”Se”
通过第二次和第三次的数据,我们可以计算我们获得的字符串长度。在第二次获得的数据中,我们可以提出最终结果“23”的温度数据
请参阅以下步骤
char*splitx(char*str,char*s,char*e){
char*t1=NULL
char*t2=NULL
char*t3=NULL
uint8_t lensx=0
t1=strstrstr(str,s)
如果(t1==NULL){
ESP_LOGI(“FUNC_splitx”,“t1valave为空”)
返回ESP_OK
}
t2=strstr(t1,e)
如果(t2==NULL){
ESP_LOGI(“FUNC_splitx”,“t2valave为空”)
返回ESP_OK
}
lensx=strlen(t1)-strlen(t2)-斯特伦(s)
图表='\0'
t3=(char*)malloc(sizeof(char)*lensx+1)
memset(t3,t,sizeof(char)*lensx+1)
strncpy(t3,t1+sizeof(char)*strlen(s),lensx)
返回t3
}
编写代码,然后使用makeapp flash
查看全部
网页中flash数据抓取(获取天气预报数据的方法有哪些?如何获取字符串数据?
)
通常,人们使用特殊的API来获取天气预报信息。随着越来越多的天气预报API的开发,他们开始收费,这给普通的个人电子爱好者带来了很多麻烦。为了解决这一问题,提出了一种通过HTTP获取天气预报数据的方法
提出了整个流程的原理和流程
寻址适合捕获的网址,分析待获取的HTTP页面数据,找出待获取数据的特征,并根据特征编写采集字符串处理函数
一、find这个网站。天气预报信息的数据很容易找到。大多数网站提供天气预报服务,很容易找到收录天气预报数据的页面。为了节省流量,我们发现手机页面相对简单,尤其是为以前的手机设计的版本
二、分析页面数据以查找功能。页面数据一般为HTML格式,页面内容如下图所示
我们需要得到相似的结果
Var datask={“名称”:“抚顺”,“城市名称”:“抚顺市”:“101270302”,“临时”:“23”,“临时”:“73”,“西部”:“东南风”,“西部”:“东南风”
这里要获取的数据是23度。根据分析,整个HTML页面中只有一个字符串“datask”,因此这是要获取的数据。因此,您可以使用C语言字符串处理函数strstr在“days7”末尾获取子长度字符串。在数据23度中,在字符temp中:“,“Tempf,因此您可以使用strstr函数两次来等待收录温度的最短字符串信息
首次使用strstr函数时,搜索字符串为datask,结果为datask={“名称”:“抚顺”,“城市名称”:“抚顺”城市:“101270302”,“临时”:“23”,“临时”:“73”,“WD”:“东南风”,“wde”:“Se”
第二次使用strstr函数时,搜索的字符串是temp:,结果是temp:“23”,“tempf:“73”,“WD:“东南风”,“wde:“Se”
第三次使用strstr函数时,搜索字符串为“,”tempf“,结果为“,”tempf:”73“,”WD:”东南风“,”wde:”Se”
通过第二次和第三次的数据,我们可以计算我们获得的字符串长度。在第二次获得的数据中,我们可以提出最终结果“23”的温度数据
请参阅以下步骤
char*splitx(char*str,char*s,char*e){
char*t1=NULL
char*t2=NULL
char*t3=NULL
uint8_t lensx=0
t1=strstrstr(str,s)
如果(t1==NULL){
ESP_LOGI(“FUNC_splitx”,“t1valave为空”)
返回ESP_OK
}
t2=strstr(t1,e)
如果(t2==NULL){
ESP_LOGI(“FUNC_splitx”,“t2valave为空”)
返回ESP_OK
}
lensx=strlen(t1)-strlen(t2)-斯特伦(s)
图表='\0'
t3=(char*)malloc(sizeof(char)*lensx+1)
memset(t3,t,sizeof(char)*lensx+1)
strncpy(t3,t1+sizeof(char)*strlen(s),lensx)
返回t3
}
编写代码,然后使用makeapp flash


网页中flash数据抓取(以糗事百科网站数据为例(解析json.6+pycharm5))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-21 00:02
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们正在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取相应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。
前几天写了一个爬虫,使用path、re、BeautifulSoup来爬取B站python视频,但是这个爬虫有一个缺陷,就是无法获取视频的图片信息,你试一下就会发现它根本没有返回里面的结果。今天就通过分析 Ajax 获得它。
分析页面
url = \':///x/web-interface/search/type?jsonp=jsonp&&search_type=video&highlight=1&keyword=python&page={}\'.format(page)
点击搜索,会出现这个网址,或者点击下一页
然后就构造这个请求。需要注意的是最后一个参数是不能加的。
代码实战
代码中的一些解释已经很清楚了,这里再复习一下
re.sub()
这个函数传入五个参数,前三个是必须传入的pattern,repl,string
第一个是正则表达式中的模式字符串
第二个是要替换的字符串
第三个是文本字符串和剩下的两个可选参数,一个是count,一个是flag。
如果需要良好的学习交流环境,那么可以考虑Python学习交流群:548377875;
如果需要系统的学习资料,那么可以考虑Python学习交流群:548377875。
第一种将时间戳转换为标准格式的方法
第二种方法
以上就是本次的全部内容。继续练习,继续努力! 查看全部
网页中flash数据抓取(以糗事百科网站数据为例(解析json.6+pycharm5))
这里是一个简单的介绍。以捕获网站静态和动态数据为例。实验环境为win10+python3.6+pycharm5.0。主要内容如下:
抓取网站的静态数据(数据在网页源码中):以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称、内容、搞笑数、评论数4个字段,如下:
对应的网页源码如下,里面收录了我们需要的数据:
2. 对应网页结构,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页面:
程序截图如下,已成功抓取数据:
抓取网站的动态数据(数据不在网页源代码中,而是在json等文件中):以人人贷网站的数据为例
1. 这里假设我们正在爬取债券数据,主要包括年利率、贷款标题、期限、金额、进度5个字段。截图如下:
当你打开网页的源代码时,你会发现数据并不在网页的源代码中。按F12抓包分析时,可以在一个json文件中找到,如下:
2. 得到json文件的url后,我们就可以爬取相应的数据了。这里使用的包与上面的类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序截图如下,已经成功抓取数据:
至此,这两种数据的抓取到此结束,包括静态数据和动态数据。总的来说,这两个例子并不难。它们都是入门级爬虫。网页结构比较简单。最重要的是做抓包分析,分析提取页面。熟悉之后就可以使用scrapy了。数据爬取的框架可以更方便、更高效。当然,如果抓取到的页面比较复杂,比如验证码、加密等,这个时候就需要仔细分析了。网上也有一些教程可以参考。如果你有兴趣,可以搜索一下,希望上面分享的内容对你有所帮助。
前几天写了一个爬虫,使用path、re、BeautifulSoup来爬取B站python视频,但是这个爬虫有一个缺陷,就是无法获取视频的图片信息,你试一下就会发现它根本没有返回里面的结果。今天就通过分析 Ajax 获得它。
分析页面
url = \':///x/web-interface/search/type?jsonp=jsonp&&search_type=video&highlight=1&keyword=python&page={}\'.format(page)
点击搜索,会出现这个网址,或者点击下一页
然后就构造这个请求。需要注意的是最后一个参数是不能加的。
代码实战
代码中的一些解释已经很清楚了,这里再复习一下
re.sub()
这个函数传入五个参数,前三个是必须传入的pattern,repl,string
第一个是正则表达式中的模式字符串
第二个是要替换的字符串
第三个是文本字符串和剩下的两个可选参数,一个是count,一个是flag。
如果需要良好的学习交流环境,那么可以考虑Python学习交流群:548377875;
如果需要系统的学习资料,那么可以考虑Python学习交流群:548377875。
第一种将时间戳转换为标准格式的方法
第二种方法
以上就是本次的全部内容。继续练习,继续努力!
网页中flash数据抓取(Python部落:如何使用Pandasread_方法从HTML中获取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-18 21:08
Python部落()整理翻译,禁止转载,欢迎转发。
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(有关如何使用 Python 和 Pandas 解析 JSON 文件,请参阅 文章 )。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0):
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们稍后就可以轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻 查看全部
网页中flash数据抓取(Python部落:如何使用Pandasread_方法从HTML中获取数据)
Python部落()整理翻译,禁止转载,欢迎转发。
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas 的 read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从维基百科表格中获取数据。在上一篇文章(Python中的探索性数据分析)中,我们也使用了Pandas从HTML表格中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 的时候,为了进行数据分析和可视化,我们通常会从导入数据的实践开始。在前面的文章中,我们已经了解到我们可以直接在Python中输入值(例如,从Python字典创建一个Pandas数据框)。但是,通过从可用来源导入数据来获取数据当然更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用此方法的快速示例,但请务必查看主题 文章 的博客以获取更多信息。
现在,上述方法仅在我们已经拥有合适格式(例如 csv 或 JSON)的数据时才有用(有关如何使用 Python 和 Pandas 解析 JSON 文件,请参阅 文章 )。
我们大多数人都会使用维基百科来了解我们感兴趣的主题。此外,这些维基百科文章 通常收录 HTML 表格。
要使用 Pandas 在 Python 中获取这些表格,我们可以将它们剪切并粘贴到电子表格中,然后例如使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤完成:我们可以通过网络抓取来自动化它。一定要检查什么是网页抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 安装 Python 包,例如 Pandas,或安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法:pip install pandas。
请注意,如果有消息说有更新版本的 pip 可用,请查看此 文章 以了解如何升级 pip。请注意,我们还需要安装 lxml 或 BeautifulSoup4。当然,这些包也可以使用 pip 安装:pip install lxml。
熊猫 read_html 语法
以下是如何使用 Pandas read_html 从 HTML 表中获取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看看 read_html 的一些例子。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas read_html 方法。我们将从一个字符串中读取一个 HTML 表格。
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。换句话说,如果我们使用 type() 函数,我们可以看到:
如果我们想要得到表,我们可以使用列表的第一个索引(0):
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从维基百科中抓取数据。其实我们会得到python(也叫python)的HTML表格。
现在,我们有一个收录 7 个表的列表 (len(df))。如果我们转到维基百科页面,我们可以看到第一个表格是右边的表格。然而,在这个例子中,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 案例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在此之后,我们还需要对数据进行清洗,最后,我们将进行一些简单的数据可视化操作。
使用 Pandas read_html 和匹配参数抓取数据:
如上图所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
这样,我们只得到了这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请确保查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了此数据帧的副本。
在下一节中,我们将学习如何将多索引列名更改为单索引。
将多个索引更改为单个索引并删除不需要的字符
现在,我们要删除多索引列。换句话说,我们将 2 列索引(名称)变成唯一的列名称。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取一些评论。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,我们继续使用 Pandas set_index 将日期列变成索引。这样,我们稍后就可以轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用0填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累加值:
HTML 表中的时间序列图
在上一个例子中,我们使用 Pandas read_html 来获取我们爬取的数据并创建了一个时间序列图。现在,我们还导入了 matplotlib,以便我们可以更改 Pandas 图例标题的位置:
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自维基百科文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:片刻
网页中flash数据抓取( 数据表格中的数据是通过直接赋值的方式的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-15 01:39
数据表格中的数据是通过直接赋值的方式的?)
Layui数据表获取表中所有数据的方法
更新时间:2018年8月20日08:38:56 作者:xcmercy
今天小编就给大家分享一张拉鱼数据表,获取该表中的所有数据方法,具有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
数据表中的数据是直接赋值的。事实上,这里的想法是相反的。数据表中的所有数据都将转换为一个Layui数据表,并使用原创数据来渲染数据表。
1、创建一个合适范围的JS对象数组,将原创数据保存在数据表中。
2、 将上一步创建的JS对象数组,即原创数据,赋值给table.render()的data参数。
3、获取表中的所有数据。其实可以直接拿到第一步创建的JS对象数组。参考下面的代码,获取table中的所有数据就是获取tableContent中的数据。
// 存放数据表格中的数据的对象数组tableContent
var tableContent = new Array();
table.render({
elem : '#viewTable',
height : 325,
even: true,
text: {
none: '您没有选中任何字段!'
},
// 拿对象数组tableContent中的数据作为原始数据渲染数据表格
data : tableContent,
page : {
layout: ['count', 'prev', 'page', 'next', 'limit', 'skip']
},
limit : 5,
limits : [5, 10, 15, 20, 25],
cellMinWidth: 80,
cols:[[
{type:'checkbox',fiexd : 'left'},
{title : '序号',type:'numbers'},
{field : 'column',title : '列',align:'center'},
{field : 'alias',title : '别名',align:'center',edit : 'text'},
{title : '操作',fiexd : 'right',align:'center', toolbar: '#viewBar'}
]],
done : function(res, curr, count){
// do something...
}
});
数据表中的数据是通过异步请求
可以直接通过table.render()的done参数获取。该参数的值是渲染数据时的回调。无论是直接赋值还是异步请求数据,渲染完成后都会触发回调。注意:当对Laytable的原创数据使用直接赋值方式时,该方式获取的是数据表中当前页的数据,而不是表中的所有数据。如果要获取表中的所有数据,必须按照上面“数据表中的数据是”通过直接赋值”的方法
table.render({ //其它参数在此省略
done: function(res, curr, count){
//如果是异步请求数据方式,res即为你接口返回的信息。
//如果是直接赋值的方式,res即为:{data: [], count: 99} data为当前页数据、count为数据总长度
console.log(res);
//得到当前页码
console.log(curr);
//得到数据总量
console.log(count);
}
});
以上获取Layui数据表中所有数据的方法是小编分享的全部内容。希望能给大家一个参考,也希望大家多多支持剧本家。 查看全部
网页中flash数据抓取(
数据表格中的数据是通过直接赋值的方式的?)
Layui数据表获取表中所有数据的方法
更新时间:2018年8月20日08:38:56 作者:xcmercy
今天小编就给大家分享一张拉鱼数据表,获取该表中的所有数据方法,具有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
数据表中的数据是直接赋值的。事实上,这里的想法是相反的。数据表中的所有数据都将转换为一个Layui数据表,并使用原创数据来渲染数据表。
1、创建一个合适范围的JS对象数组,将原创数据保存在数据表中。
2、 将上一步创建的JS对象数组,即原创数据,赋值给table.render()的data参数。
3、获取表中的所有数据。其实可以直接拿到第一步创建的JS对象数组。参考下面的代码,获取table中的所有数据就是获取tableContent中的数据。
// 存放数据表格中的数据的对象数组tableContent
var tableContent = new Array();
table.render({
elem : '#viewTable',
height : 325,
even: true,
text: {
none: '您没有选中任何字段!'
},
// 拿对象数组tableContent中的数据作为原始数据渲染数据表格
data : tableContent,
page : {
layout: ['count', 'prev', 'page', 'next', 'limit', 'skip']
},
limit : 5,
limits : [5, 10, 15, 20, 25],
cellMinWidth: 80,
cols:[[
{type:'checkbox',fiexd : 'left'},
{title : '序号',type:'numbers'},
{field : 'column',title : '列',align:'center'},
{field : 'alias',title : '别名',align:'center',edit : 'text'},
{title : '操作',fiexd : 'right',align:'center', toolbar: '#viewBar'}
]],
done : function(res, curr, count){
// do something...
}
});
数据表中的数据是通过异步请求
可以直接通过table.render()的done参数获取。该参数的值是渲染数据时的回调。无论是直接赋值还是异步请求数据,渲染完成后都会触发回调。注意:当对Laytable的原创数据使用直接赋值方式时,该方式获取的是数据表中当前页的数据,而不是表中的所有数据。如果要获取表中的所有数据,必须按照上面“数据表中的数据是”通过直接赋值”的方法
table.render({ //其它参数在此省略
done: function(res, curr, count){
//如果是异步请求数据方式,res即为你接口返回的信息。
//如果是直接赋值的方式,res即为:{data: [], count: 99} data为当前页数据、count为数据总长度
console.log(res);
//得到当前页码
console.log(curr);
//得到数据总量
console.log(count);
}
});
以上获取Layui数据表中所有数据的方法是小编分享的全部内容。希望能给大家一个参考,也希望大家多多支持剧本家。
网页中flash数据抓取(启动图获取logo链接替换百度logo与重填数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-15 01:18
启动图
获取徽标链接
更换百度标志并填写内容
再次获取徽标链接
更换标志和补充数据
引用官方的话:
StageWebView 类使用一种简单的方法来显示 HTML 内容。此类不提供 ActionScript 和 HTML 内容之间的交互,除非通过 StageWebView 类本身的方法和属性。例如,您不能在 ActionScript 和 JavaScript 之间传递值或调用函数。
================================================== ================================================
----------嗯,官方说法不严谨,其实是可以的。首先要知道浏览器可以通过javascript:这个协议直接运行js代码,也就是说as3可以通过StageWebView。
loadURL() 函数直接运行js;
喜欢:
var myWebView: StageWebView=new StageWebView
......
myWebView.loadURL("javascript:alert(\"浏览器弹出消息内容\")")
这样就可以直接操作当前页面弹出的js消息框:浏览器弹出消息的内容。
myWebView.loadURL("javascript:alert(document.body.innerHTML)")
这样就可以直接弹出当前页面的html代码的数据
同理,你也可以直接用js来操作js函数,html dom,比如在输入框中填信息,点击按钮等。
----------------------以上是调用js的as操作-------------------- --- -------------
那么如何让js回调as3,或者js如何调用as3。
有方法。
StageWebView 的位置属性,该属性有一个事件 LOCATION_CHANGE。
这个事件的目的是什么,就是一旦location属性改变就会触发。
这是关键。使用js修改位置的属性数据主动触发LOCATION_CHANGE事件。
然后as3触发这个事件后,获取StageWebView的位置数据,从而获取js传递过来的数据,
过程如下:
js执行------document.location.pathname="我是js传过来的信息";
然后因为修改了位置数据,会触发as3端的LOCATION_CHANGE,
这时候as3就可以直接获取位置数据了
------------------------------------以上是as3获取js的调用或回调信息- --- -----------------
经过以上激烈的操作,as3和js的双向通信就完成了。
附上一个带有文字说明的fla文件,自己检查一下。
注:本案例以在调试环境下使用Android端为例(网站会根据不同的浏览器系统显示不同的网页,直接在真实页面上会出现不同的网页数据。示例代码不考虑兼容性,需要根据网站的html代码做相应操作)
StageWebView 和 as3 直接通信 value.fla (7.17 KB, 下载: 9, 售价: 150 银币)
2020-2-21 22:57 上传
点击文件名下载附件
as3和StageWebView的互访
分数
参与人数 2银+32金+1贡献+3理由
舞者
+ 2
11RIA上帝是伟大的上帝,佩服佩服
TKCB
+ 30
+ 1
+ 3
11RIA Flash社区,就是这么专业 查看全部
网页中flash数据抓取(启动图获取logo链接替换百度logo与重填数据(组图))
启动图
获取徽标链接
更换百度标志并填写内容
再次获取徽标链接
更换标志和补充数据
引用官方的话:
StageWebView 类使用一种简单的方法来显示 HTML 内容。此类不提供 ActionScript 和 HTML 内容之间的交互,除非通过 StageWebView 类本身的方法和属性。例如,您不能在 ActionScript 和 JavaScript 之间传递值或调用函数。
================================================== ================================================
----------嗯,官方说法不严谨,其实是可以的。首先要知道浏览器可以通过javascript:这个协议直接运行js代码,也就是说as3可以通过StageWebView。
loadURL() 函数直接运行js;
喜欢:
var myWebView: StageWebView=new StageWebView
......
myWebView.loadURL("javascript:alert(\"浏览器弹出消息内容\")")
这样就可以直接操作当前页面弹出的js消息框:浏览器弹出消息的内容。
myWebView.loadURL("javascript:alert(document.body.innerHTML)")
这样就可以直接弹出当前页面的html代码的数据
同理,你也可以直接用js来操作js函数,html dom,比如在输入框中填信息,点击按钮等。
----------------------以上是调用js的as操作-------------------- --- -------------
那么如何让js回调as3,或者js如何调用as3。
有方法。
StageWebView 的位置属性,该属性有一个事件 LOCATION_CHANGE。
这个事件的目的是什么,就是一旦location属性改变就会触发。
这是关键。使用js修改位置的属性数据主动触发LOCATION_CHANGE事件。
然后as3触发这个事件后,获取StageWebView的位置数据,从而获取js传递过来的数据,
过程如下:
js执行------document.location.pathname="我是js传过来的信息";
然后因为修改了位置数据,会触发as3端的LOCATION_CHANGE,
这时候as3就可以直接获取位置数据了
------------------------------------以上是as3获取js的调用或回调信息- --- -----------------
经过以上激烈的操作,as3和js的双向通信就完成了。
附上一个带有文字说明的fla文件,自己检查一下。
注:本案例以在调试环境下使用Android端为例(网站会根据不同的浏览器系统显示不同的网页,直接在真实页面上会出现不同的网页数据。示例代码不考虑兼容性,需要根据网站的html代码做相应操作)
StageWebView 和 as3 直接通信 value.fla (7.17 KB, 下载: 9, 售价: 150 银币)
2020-2-21 22:57 上传
点击文件名下载附件
as3和StageWebView的互访
分数
参与人数 2银+32金+1贡献+3理由
舞者
+ 2
11RIA上帝是伟大的上帝,佩服佩服
TKCB
+ 30
+ 1
+ 3
11RIA Flash社区,就是这么专业
网页中flash数据抓取(网页中flash数据抓取是个比较棘手的问题,怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-14 23:03
网页中flash数据抓取是个比较棘手的问题,我抓过一段时间,所有网页都爬过了,感觉很难很耗时间!最后发现竟然和速度有关,关键是在localstorage或者sessionstorage中存放,上面有个图是sessionstorage在抓取,从window.scrolltop,window.open-btn等地方看到,抓取器直接在localstorage中操作即可,没有数据交互过程!可能有人会问,数据不是那么容易获取吗?数据我们可以通过websocket来交互,如果抓不到或者出现刷新不到的情况,可以用json或者js消息在服务器中传递,传递的对象保存到本地,通过sessionstorage保存到文件中,用dom的方式渲染前端网页,然后我还想到还有一种方式,那就是通过js获取执行then回调函数的变量varx=1;then{x=2;}response.close();这时候我发现我抓取太久了,忘记上诉代码了,只是很奇怪,用http和https都可以抓取,然后用本地解析html报文,好像也可以,但是我先抓了某网站,再抓某局域网其他网站,根本没办法复制粘贴到其他网站中用x:=x.index.js或者x:=x.index.html等进行抓取,也没有办法通过cookie来抓取一些静态资源!上图是我本地浏览器抓取路径下的html文件的抓取结果(点击浏览器下载本地,然后粘贴到网页上)。
嗯,这就是说方式都不是特别复杂,但是抓取时间很长!最后也想到可以用bs4包装页面,然后通过pageheader模拟登录访问,然后把html页面保存在本地!然后用多线程模拟对会话的一些操作,可以通过对js脚本的调用来处理js事件,比如点击按钮然后显示输入框之类的,也可以在某些端口抓取报文等等!有时候就发现不会用浏览器自带的xx浏览器xx浏览器xx浏览器等等,因为当你需要抓取一些静态页面时,访问这些浏览器,有时会说请求不对,可能是cookie、proxy代理或者代理池不足,无法做到网页的抓取!后来就想到只要是一些静态页面,有时候xhr服务端没有返回,我们可以通过xmlhttprequest来进行数据传递,这样数据包仅仅从你自己的浏览器发送,对方浏览器就不会返回给你数据包!然后我就想到通过sessionstorage中保存!因为网页没有做sessionstorage的设置,会话状态也不会持久保存!用bs4包装xmlhttprequest:然。 查看全部
网页中flash数据抓取(网页中flash数据抓取是个比较棘手的问题,怎么办)
网页中flash数据抓取是个比较棘手的问题,我抓过一段时间,所有网页都爬过了,感觉很难很耗时间!最后发现竟然和速度有关,关键是在localstorage或者sessionstorage中存放,上面有个图是sessionstorage在抓取,从window.scrolltop,window.open-btn等地方看到,抓取器直接在localstorage中操作即可,没有数据交互过程!可能有人会问,数据不是那么容易获取吗?数据我们可以通过websocket来交互,如果抓不到或者出现刷新不到的情况,可以用json或者js消息在服务器中传递,传递的对象保存到本地,通过sessionstorage保存到文件中,用dom的方式渲染前端网页,然后我还想到还有一种方式,那就是通过js获取执行then回调函数的变量varx=1;then{x=2;}response.close();这时候我发现我抓取太久了,忘记上诉代码了,只是很奇怪,用http和https都可以抓取,然后用本地解析html报文,好像也可以,但是我先抓了某网站,再抓某局域网其他网站,根本没办法复制粘贴到其他网站中用x:=x.index.js或者x:=x.index.html等进行抓取,也没有办法通过cookie来抓取一些静态资源!上图是我本地浏览器抓取路径下的html文件的抓取结果(点击浏览器下载本地,然后粘贴到网页上)。
嗯,这就是说方式都不是特别复杂,但是抓取时间很长!最后也想到可以用bs4包装页面,然后通过pageheader模拟登录访问,然后把html页面保存在本地!然后用多线程模拟对会话的一些操作,可以通过对js脚本的调用来处理js事件,比如点击按钮然后显示输入框之类的,也可以在某些端口抓取报文等等!有时候就发现不会用浏览器自带的xx浏览器xx浏览器xx浏览器等等,因为当你需要抓取一些静态页面时,访问这些浏览器,有时会说请求不对,可能是cookie、proxy代理或者代理池不足,无法做到网页的抓取!后来就想到只要是一些静态页面,有时候xhr服务端没有返回,我们可以通过xmlhttprequest来进行数据传递,这样数据包仅仅从你自己的浏览器发送,对方浏览器就不会返回给你数据包!然后我就想到通过sessionstorage中保存!因为网页没有做sessionstorage的设置,会话状态也不会持久保存!用bs4包装xmlhttprequest:然。
网页中flash数据抓取(基于pile的正则表达式识别库uelp()识别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-11 16:28
网页中flash数据抓取最常用的方法是正则表达式识别。目前市面上正则表达式抓取工具比较多,但是正则表达式识别引擎可谓鱼龙混杂,因此,想写一个识别正则表达式的工具能省去正则表达式抓取过程中的麻烦。目前正则表达式识别库不多,最常用的是pile()。本文要介绍的是一个基于pile()的正则表达式识别库uelp。
本文内容基于python3.6进行编程。github地址:-rebbundle基本概念uelp提供了一种快速的正则表达式匹配方法(batchusing),接口比较简单,直接把pile()内嵌到flash中就可以识别flash中正则表达式。测试程序(仅内嵌到opcode_udim中):代码分析源代码:document.body.useinterval(6,0);functionresult(uref,request){request.post(uref.content);returnresult;}functionconnect(filename,uref){varreq=pile('url',uref);uref.undefined=filename.split('/')[-1];}functionresults(uref,request){console.log(uref);}array([],[],{'content':uref,'path':uref});functionpatch(uref,filename){varresult=uref.content;if(!(result==='jpg')&&!(result==='bmp')){result='jpg';}if(!(result==='bmp')&&!(result==='flv')){result='bmp';}if(!(result==='asf')&&!(result==='png')){result='asf';}returnresult;}functiondrawxmatch(uref,i){returni-1;}bundle(pypi,b);获取flashcookie获取.html文件中flashcookie从flash文件中提取useragent值-://sdcard/root/flash/data/filename.bwf?pg=myfx-存储bundle.cookie然后在正则表达式识别库中获取bundle.cookie就可以识别flash中的正则表达式了。
bundle.cookie中会有txtcookie文件格式的正则表达式。基于字典的bundle存储方式为:name_repr=k={"name":"ttf_ua","content":"[name]={url:useragent+math.random()*100}"};content:{"txt":。 查看全部
网页中flash数据抓取(基于pile的正则表达式识别库uelp()识别)
网页中flash数据抓取最常用的方法是正则表达式识别。目前市面上正则表达式抓取工具比较多,但是正则表达式识别引擎可谓鱼龙混杂,因此,想写一个识别正则表达式的工具能省去正则表达式抓取过程中的麻烦。目前正则表达式识别库不多,最常用的是pile()。本文要介绍的是一个基于pile()的正则表达式识别库uelp。
本文内容基于python3.6进行编程。github地址:-rebbundle基本概念uelp提供了一种快速的正则表达式匹配方法(batchusing),接口比较简单,直接把pile()内嵌到flash中就可以识别flash中正则表达式。测试程序(仅内嵌到opcode_udim中):代码分析源代码:document.body.useinterval(6,0);functionresult(uref,request){request.post(uref.content);returnresult;}functionconnect(filename,uref){varreq=pile('url',uref);uref.undefined=filename.split('/')[-1];}functionresults(uref,request){console.log(uref);}array([],[],{'content':uref,'path':uref});functionpatch(uref,filename){varresult=uref.content;if(!(result==='jpg')&&!(result==='bmp')){result='jpg';}if(!(result==='bmp')&&!(result==='flv')){result='bmp';}if(!(result==='asf')&&!(result==='png')){result='asf';}returnresult;}functiondrawxmatch(uref,i){returni-1;}bundle(pypi,b);获取flashcookie获取.html文件中flashcookie从flash文件中提取useragent值-://sdcard/root/flash/data/filename.bwf?pg=myfx-存储bundle.cookie然后在正则表达式识别库中获取bundle.cookie就可以识别flash中的正则表达式了。
bundle.cookie中会有txtcookie文件格式的正则表达式。基于字典的bundle存储方式为:name_repr=k={"name":"ttf_ua","content":"[name]={url:useragent+math.random()*100}"};content:{"txt":。
网页中flash数据抓取(FlashShareObject安装Flash插件(图)存储的缺点分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-10 11:07
饼干
Cookie 会随每个 HTTP 请求头信息一起发送,无形中增加了网络流量。另外,cookies可以存储的数据容量是有限的,根据浏览器的类型,IE6只能存储2K左右。
Flash 共享对象
这种方式可以解决上面提到的cookie存储的两个缺点,并且可以跨浏览器。应该说是目前最好的本地存储方案。但是需要在页面中插入Flash,在浏览器没有安装Flash控件时无法使用。幸运的是,没有安装 Flash 的用户很少。
缺点:需要安装Flash插件。
Google 齿轮
Google 开发的一种本地存储技术。
缺点:需要安装齿轮组件。
用户数据
IE浏览器可以使用userData来存储数据,容量可以达到640K,这种方案非常可靠,不需要安装额外的插件。
缺点:只能在IE下使用。
会话存储
对于Firefox2+使用的Firefox浏览器,这种方式存储的数据只在窗口级别有效。当刷新或跳转同一个窗口(或Tab)页面时,可以获得本地存储的数据。当打开新窗口或显示页面时,原创数据无效。
缺点:IE不支持,无法实现数据的持久化存储。
全局存储
Firefox2+ 中使用的 Firefox 浏览器,类似于 IE 的 userData。
//赋值
globalStorage[location.hostname]['name'] = 'tugai';
//读取
globalStorage[location.hostname]['name'];
//删除
globalStorage[location.hostname].removeItem('name');
缺点:IE不支持。
本地存储
localStorage 是 Web Storage Internet 存储规范的一部分,现在在 Firefox 3.5、Safari 4 和 IE8 中受支持。
缺点:低版本浏览器不支持。
总结
Flash 共享对象是一个不错的选择。如果不想在页面中嵌入Flash,可以结合userData(IE6+)和globalStorage(Firefox2+)和localStorage(chrome3+)来实现跨浏览器。 查看全部
网页中flash数据抓取(FlashShareObject安装Flash插件(图)存储的缺点分析)
饼干
Cookie 会随每个 HTTP 请求头信息一起发送,无形中增加了网络流量。另外,cookies可以存储的数据容量是有限的,根据浏览器的类型,IE6只能存储2K左右。
Flash 共享对象
这种方式可以解决上面提到的cookie存储的两个缺点,并且可以跨浏览器。应该说是目前最好的本地存储方案。但是需要在页面中插入Flash,在浏览器没有安装Flash控件时无法使用。幸运的是,没有安装 Flash 的用户很少。
缺点:需要安装Flash插件。
Google 齿轮
Google 开发的一种本地存储技术。
缺点:需要安装齿轮组件。
用户数据
IE浏览器可以使用userData来存储数据,容量可以达到640K,这种方案非常可靠,不需要安装额外的插件。
缺点:只能在IE下使用。
会话存储
对于Firefox2+使用的Firefox浏览器,这种方式存储的数据只在窗口级别有效。当刷新或跳转同一个窗口(或Tab)页面时,可以获得本地存储的数据。当打开新窗口或显示页面时,原创数据无效。
缺点:IE不支持,无法实现数据的持久化存储。
全局存储
Firefox2+ 中使用的 Firefox 浏览器,类似于 IE 的 userData。
//赋值
globalStorage[location.hostname]['name'] = 'tugai';
//读取
globalStorage[location.hostname]['name'];
//删除
globalStorage[location.hostname].removeItem('name');
缺点:IE不支持。
本地存储
localStorage 是 Web Storage Internet 存储规范的一部分,现在在 Firefox 3.5、Safari 4 和 IE8 中受支持。
缺点:低版本浏览器不支持。
总结
Flash 共享对象是一个不错的选择。如果不想在页面中嵌入Flash,可以结合userData(IE6+)和globalStorage(Firefox2+)和localStorage(chrome3+)来实现跨浏览器。
网页中flash数据抓取(如何最高效地从海量信息里获取数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-05 23:06
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了大量对我们有价值的信息。
如何最高效地从海量信息中获取数据?网页抓取工具优采云采集器 有很大的技巧,用自动化的智能工具代替手动数据采集,当然更高效,更准确。
一、数据采集的多功能性
优采云采集器作为一款通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,具有自动登录、验证码识别、IP代理等功能处理网站的反采集措施;捕捉对象的格式可以是文本、图片、音频、文件等,无需重复繁琐的操作,轻松将数据存入包中。
二、数据采集的效率
效率是大数据时代对数据应用的另一个重要要求。信息爆炸式增长。如果跟不上速度,就会错过数据利用的最佳节点。因此,数据采集的效率非常高。过去我们手动采集数据,一天最多抓取几百条数据,网络爬虫工具稳定运行时每天可以达到10万级,比手动高数百倍采集。
三、数据采集的准确性
长时间肉眼识别和提取信息可能会造成疲劳,但软件识别可以继续高精度提取。但是需要注意的是,当采集不同类型的网站或数据时,优采云采集器配置的规则是不同的。只有分析具体情况,才能保证高精度。 查看全部
网页中flash数据抓取(如何最高效地从海量信息里获取数据?(图))
数据已进入各行各业,并得到广泛应用。伴随应用程序的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了大量对我们有价值的信息。
如何最高效地从海量信息中获取数据?网页抓取工具优采云采集器 有很大的技巧,用自动化的智能工具代替手动数据采集,当然更高效,更准确。
一、数据采集的多功能性
优采云采集器作为一款通用的网络爬虫工具,基于源码运行原理,可爬取的网页类型达到99%,具有自动登录、验证码识别、IP代理等功能处理网站的反采集措施;捕捉对象的格式可以是文本、图片、音频、文件等,无需重复繁琐的操作,轻松将数据存入包中。
二、数据采集的效率
效率是大数据时代对数据应用的另一个重要要求。信息爆炸式增长。如果跟不上速度,就会错过数据利用的最佳节点。因此,数据采集的效率非常高。过去我们手动采集数据,一天最多抓取几百条数据,网络爬虫工具稳定运行时每天可以达到10万级,比手动高数百倍采集。
三、数据采集的准确性
长时间肉眼识别和提取信息可能会造成疲劳,但软件识别可以继续高精度提取。但是需要注意的是,当采集不同类型的网站或数据时,优采云采集器配置的规则是不同的。只有分析具体情况,才能保证高精度。
网页中flash数据抓取(AdobeFlashPlayer将在明年被彻底结束支持(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-05 23:02
Adobe Flash Player 将于明年完全停止支持,这意味着所有用户不应继续使用此易受攻击的媒体播放器。
目前所有主流浏览器都开始限制使用该播放器,浏览器加载时默认屏蔽通过Flash创建的内容。
为了尽可能加快从全网淘汰Flash技术,谷歌目前正在调整其抓取和索引策略,向网页开发者施加压力,促使其升级。
Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了新的博文。博文的内容比较简单,重点是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页。例如,一些网络小游戏网站和艺术展览网站仍在使用该技术。
本来,谷歌搜索爬虫会在遇到此类内容时读取关键信息并将其索引到谷歌的索引中,以便用户在搜索时找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术上确立的内容。毕竟,浏览器不支持后,即使用户打开这些页面,内容也无法正常显示。
谷歌表示,未来爬虫遇到此类内容会直接丢弃,不会将这些内容编入索引,也不会收录到谷歌搜索结果中。
网站 将无法直接搜索:
如果网站是使用Flash技术构建的,被谷歌丢弃后,用户在通过谷歌搜索网站名称或关键词时将找不到这些网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,而这也正是谷歌希望通过这种方式向网页开发者施加压力的地方。
谷歌表示,根据目前的统计,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发者可以将 Flash 内容迁移到 HTML 5。迁移后,Google 爬虫会在 Google 爬虫访问内容后重新索引该内容。 查看全部
网页中flash数据抓取(AdobeFlashPlayer将在明年被彻底结束支持(图))
Adobe Flash Player 将于明年完全停止支持,这意味着所有用户不应继续使用此易受攻击的媒体播放器。
目前所有主流浏览器都开始限制使用该播放器,浏览器加载时默认屏蔽通过Flash创建的内容。
为了尽可能加快从全网淘汰Flash技术,谷歌目前正在调整其抓取和索引策略,向网页开发者施加压力,促使其升级。
Google 将不再索引此类内容:
谷歌在站长平台的官方博客上发布了新的博文。博文的内容比较简单,重点是 Google 搜索不再索引 Flash 创建的内容。
一些网站或网页使用Flash技术构建静态网页。例如,一些网络小游戏网站和艺术展览网站仍在使用该技术。
本来,谷歌搜索爬虫会在遇到此类内容时读取关键信息并将其索引到谷歌的索引中,以便用户在搜索时找到这些Flash页面。
谷歌的新政策逐渐抛弃了这些技术上确立的内容。毕竟,浏览器不支持后,即使用户打开这些页面,内容也无法正常显示。
谷歌表示,未来爬虫遇到此类内容会直接丢弃,不会将这些内容编入索引,也不会收录到谷歌搜索结果中。
网站 将无法直接搜索:
如果网站是使用Flash技术构建的,被谷歌丢弃后,用户在通过谷歌搜索网站名称或关键词时将找不到这些网站。
对于绝大多数网站来说,搜索引擎是重要的流量来源,而这也正是谷歌希望通过这种方式向网页开发者施加压力的地方。
谷歌表示,根据目前的统计,新政策不会影响绝大多数网站,对谷歌搜索用户也不会产生太大影响。
开发者可以将 Flash 内容迁移到 HTML 5。迁移后,Google 爬虫会在 Google 爬虫访问内容后重新索引该内容。
网页中flash数据抓取(网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-03 18:12
项目招商找A5快速获取精准代理商名单
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说是极其方便的,但是对于搜索引擎来说,爬虫需要大量的爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。要不要通过,就看网站工地主的需要了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎的内容收录
robots 文件可以防止 iframe 标签之外的内容成为 收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
然后,让我谈谈失败的方法。您将来不应使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传递给浏览器进行展示,所以这也无法防止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取,也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇! 查看全部
网页中flash数据抓取(网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余)
项目招商找A5快速获取精准代理商名单
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说是极其方便的,但是对于搜索引擎来说,爬虫需要大量的爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。要不要通过,就看网站工地主的需要了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎的内容收录
robots 文件可以防止 iframe 标签之外的内容成为 收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
然后,让我谈谈失败的方法。您将来不应使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传递给浏览器进行展示,所以这也无法防止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取,也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击此处,共同探讨创业新机遇!
网页中flash数据抓取(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-10-02 19:14
什么是搜索引擎蜘蛛友好 网站?这个问题不难解决。这个定位是为了优化SEO网站的用户体验,给网站添加优质内容,让蜘蛛访问爬取,所以SEO优化需要突出网站的主题。那么如何提高搜索引擎蜘蛛的友好度呢?下面就和小编一起来看看吧。
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。蜘蛛来的时候,如果打不开网站,蜘蛛的体验会很不友好,会减少后续的访问次数。但是服务器可以提高网站的加载速度。在安全稳定的环境下,应该在网站搭建之前选择服务器。因此,如果服务器不稳定,需要及时与空间服务商取得联系,将web应用加载到综合性能比较完善的空间中,方便SEO日常运营。
2、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛以同样的方式识别图像。如果网站页面的文字较少,网站将失去排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要慎重使用。
3、无障碍网页浏览
url 捕获是指静态或伪静态 网站。这个网站结构是方便搜索引擎的蜘蛛结构模型。如果参数过多,数据会直接生成动态路径,而动态路径对于搜索引擎来说并不是一种友好的行为,尤其是带有中文参数的动态路径,搜索引擎不太喜欢。
4、 原创内容很受欢迎
百度一直在打击伪原创的内容,同时也着力优化原创的内容,所以很多采集文章的网站排名都是穷,但他们充满创造力。,内容丰富,有价值。这就是搜索引擎喜欢的东西。
5、内容简单明了
搜索引擎页面不需要太多代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛去哪里,然后这个网站 - 质量,所以页面简洁的布局是每个布局的位置。 查看全部
网页中flash数据抓取(什么是搜索引擎蜘蛛友好的网站?这个问题不难解决!)
什么是搜索引擎蜘蛛友好 网站?这个问题不难解决。这个定位是为了优化SEO网站的用户体验,给网站添加优质内容,让蜘蛛访问爬取,所以SEO优化需要突出网站的主题。那么如何提高搜索引擎蜘蛛的友好度呢?下面就和小编一起来看看吧。
1、页面加载速度
页面加载对于搜索引擎蜘蛛的友好性更为重要。蜘蛛来的时候,如果打不开网站,蜘蛛的体验会很不友好,会减少后续的访问次数。但是服务器可以提高网站的加载速度。在安全稳定的环境下,应该在网站搭建之前选择服务器。因此,如果服务器不稳定,需要及时与空间服务商取得联系,将web应用加载到综合性能比较完善的空间中,方便SEO日常运营。
2、减少flash的应用
SEO优化需要注意页面布局是否有flash动画。蜘蛛以同样的方式识别图像。如果网站页面的文字较少,网站将失去排名优先级。因此,页面框架内的组织和布局需要友好美观,框架结构要慎重使用。
3、无障碍网页浏览
url 捕获是指静态或伪静态 网站。这个网站结构是方便搜索引擎的蜘蛛结构模型。如果参数过多,数据会直接生成动态路径,而动态路径对于搜索引擎来说并不是一种友好的行为,尤其是带有中文参数的动态路径,搜索引擎不太喜欢。
4、 原创内容很受欢迎
百度一直在打击伪原创的内容,同时也着力优化原创的内容,所以很多采集文章的网站排名都是穷,但他们充满创造力。,内容丰富,有价值。这就是搜索引擎喜欢的东西。
5、内容简单明了
搜索引擎页面不需要太多代码,只要页面内容简洁,页面结构有利于优化,每个标题栏都能引导蜘蛛去哪里,然后这个网站 - 质量,所以页面简洁的布局是每个布局的位置。
网页中flash数据抓取(Python写一个简单的程序-实现一个强大的采集过程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-10-01 04:17
)
首先,我们来看看如果是正常的人类行为,如何获取网页内容。Python
(1)打开浏览器,输入网址,打开源码网页
(2)选择我们想要的内容,包括标题、作者、摘要、正文等信息
(3)存储到硬盘
以上三个过程映射到技术层面,其实就是:网络请求、结构化数据捕获、数据存储。
下面我们用Python写一个简单的程序来实现上面简单的抓取功能。
[Python]
#!/usr/bin/python #-*- coding: utf-8 -*-'' 创建于 2014-03-16 @author: Kris''' import def''' @summary: Web scraping''' def ''' @summary: 网络请求''' try,),) finally if return def''' @summary: 抓取结构化数据''' if] return def''' @summary: 数据存储''' ,) if : httpCrawler(url)
看起来很简单,没错,就是一个爬虫入门的基础程序。当然,在一个采集的实现过程中,无非就是上面几个基本步骤。但是要实现一个强大的采集进程,会遇到以下问题:
(1) 访问需要带cookie信息。就像大多数社交软件一样,基本上需要登录才能看到有价值的东西。其实很简单,我们可以使用Python提供的cookielib模块,意识到每次访问时,我们都会带着源网站给出的cookie信息进行访问,所以只要我们成功模拟登录并且爬虫处于登录状态,那么我们就可以采集查看登录用户看到的所有信息,以下是使用cookies对httpRequest()方法的修改:web
[Python]
ckjar = cookielib.MozillaCookieJar() def''' @summary: network request''' try,),) finally if return ret
(2)编码问题。网站目前最多的两种编码:utf-8,或者gbk,当我们的采集回源网站编码与存储在我们的数据库,比如编码使用gbk的时候,而我们需要存储的是utf-8编码的数据,那么我们就可以使用Python中提供的encode()和decode()方法进行转换,例如:
[Python]
content = content.decode(,),)
中间出现unicode编码,我们需要转换成中间编码unicode才能转换成gbk或者utf-8。
(3)网页中的标签不完整,像一些源代码有开始标签,但没有结束标签,HTML标签不完整,会影响我们对结构化数据的抓取,我们可以通过Python的BeautifulSoup模块, 先清理源码,再分析内容。
(4)有些网站用JS来让网页内容存活下来,直接看源码,发现是一堆头疼的东西。可以用mozilla、webkit等来解析browser 工具包解析js和ajax,虽然速度会稍微慢一些。
(5)图片以flash的形式存在,当图片中的内容是文字或数字组成的字符时,这样比较好处理。只要使用ocr技术,就可以实现自动识别,但是如果是flash Connect,我们已经存储了整个URL。
(6)一个网页有多种网页结构,所以如果我们只是一套爬取规则,那肯定不行,所以需要配置多套模拟来辅助爬取。
(7)响应源头监控网站。抢别人的东西毕竟不是什么好事,所以通常网站都会有禁止爬虫访问的限制。
一个好的采集系统应该是无论我们的目标数据在哪里,只要用户能看到,我们就可以采集回来。所见即所得的非阻塞式采集,无论是否需要登录数据,都可以顺利进行采集。最有价值的信息通常需要登录才能看到,比如社交网站。为了应对登录,网站必须有模拟用户登录的爬虫系统才能正常获取数据。然而,社交网站希望它自己创造一个闭环,拒绝将数据下站。这个系统不会像新闻和其他内容那样开放。这些社交网站大多会采取一些限制措施来防止机器人爬虫系统爬取数据。通常,爬行后将检测到帐户并阻止其访问。是不是因为我们爬不出来这些网站的数据?我确定事实并非如此。只要社交网站不关闭网页访问,我们也可以访问普通人可以访问的数据。毕竟是模拟人类的正常行为。专业的叫“反监听”。
Source 网站 通常有以下限制:
一、一定时间内单个IP的访问次数,一是频繁允许用户访问网站,除非是随便点击播放,否则不会在短时间内访问太快一段时间网站 ,持续时间不会太长。这个问题很容易处理。我们可以使用大量不规则的代理IP来创建代理池,从代理池中随机选择代理来模拟访问。代理IP有两种,透明代理和匿名代理。
二、 一定时间内单个账号的访问次数。如果我一天24小时访问一个数据接口,而且速度非常快,那么机器人就很多了。我们可以使用大量具有正常行为的帐户。正常的行为就是普通人在社交网站上是怎么做的,单位时间内要访问的网址尽量少,这样每次访问之间就有一段时间。这个时间间隔可以是一个随机值,即每次访问一个网址,都会随机休眠一段时间,然后再访问下一个网址。
如果可以控制账号和IP访问策略,就没有问题。虽然对手网站也会有运维会议调整策略,敌我较量,爬虫必须能够感知到对手的反监控会对我们造成影响,并通知管理员以便及时处理。其实最理想的就是通过机器学习智能实现反监听对抗,实现不间断抓拍。阿贾克斯
下面是我最近设计的一个分布式爬虫架构图,如图1所示: 数据库
图 1 浏览器
这纯粹是笨拙的。初步设想正在实现中。正在建立服务器和客户端之间的通信。Python的Socket模块主要用于实现服务端和客户端的通信。如果你有兴趣,可以单独联系我,一起讨论,共同完成一个更好的计划。服务器
没有整理和泛化的知识,就一文不值!高度概括和整理的知识本身就是真正的知识和技能。永远不要让自己的自由、好奇、创意被现实框架束缚,让创意自由成长!多花点时间关心他(她),就像别人关心你一样。没有别人的支持和帮助,理想的起飞和实现是绝对不可能的。
相关学习资料搬家:
曲奇饼
查看全部
网页中flash数据抓取(Python写一个简单的程序-实现一个强大的采集过程
)
首先,我们来看看如果是正常的人类行为,如何获取网页内容。Python
(1)打开浏览器,输入网址,打开源码网页
(2)选择我们想要的内容,包括标题、作者、摘要、正文等信息
(3)存储到硬盘
以上三个过程映射到技术层面,其实就是:网络请求、结构化数据捕获、数据存储。
下面我们用Python写一个简单的程序来实现上面简单的抓取功能。
[Python]
#!/usr/bin/python #-*- coding: utf-8 -*-'' 创建于 2014-03-16 @author: Kris''' import def''' @summary: Web scraping''' def ''' @summary: 网络请求''' try,),) finally if return def''' @summary: 抓取结构化数据''' if] return def''' @summary: 数据存储''' ,) if : httpCrawler(url)
看起来很简单,没错,就是一个爬虫入门的基础程序。当然,在一个采集的实现过程中,无非就是上面几个基本步骤。但是要实现一个强大的采集进程,会遇到以下问题:
(1) 访问需要带cookie信息。就像大多数社交软件一样,基本上需要登录才能看到有价值的东西。其实很简单,我们可以使用Python提供的cookielib模块,意识到每次访问时,我们都会带着源网站给出的cookie信息进行访问,所以只要我们成功模拟登录并且爬虫处于登录状态,那么我们就可以采集查看登录用户看到的所有信息,以下是使用cookies对httpRequest()方法的修改:web
[Python]
ckjar = cookielib.MozillaCookieJar() def''' @summary: network request''' try,),) finally if return ret
(2)编码问题。网站目前最多的两种编码:utf-8,或者gbk,当我们的采集回源网站编码与存储在我们的数据库,比如编码使用gbk的时候,而我们需要存储的是utf-8编码的数据,那么我们就可以使用Python中提供的encode()和decode()方法进行转换,例如:
[Python]
content = content.decode(,),)
中间出现unicode编码,我们需要转换成中间编码unicode才能转换成gbk或者utf-8。
(3)网页中的标签不完整,像一些源代码有开始标签,但没有结束标签,HTML标签不完整,会影响我们对结构化数据的抓取,我们可以通过Python的BeautifulSoup模块, 先清理源码,再分析内容。
(4)有些网站用JS来让网页内容存活下来,直接看源码,发现是一堆头疼的东西。可以用mozilla、webkit等来解析browser 工具包解析js和ajax,虽然速度会稍微慢一些。
(5)图片以flash的形式存在,当图片中的内容是文字或数字组成的字符时,这样比较好处理。只要使用ocr技术,就可以实现自动识别,但是如果是flash Connect,我们已经存储了整个URL。
(6)一个网页有多种网页结构,所以如果我们只是一套爬取规则,那肯定不行,所以需要配置多套模拟来辅助爬取。
(7)响应源头监控网站。抢别人的东西毕竟不是什么好事,所以通常网站都会有禁止爬虫访问的限制。
一个好的采集系统应该是无论我们的目标数据在哪里,只要用户能看到,我们就可以采集回来。所见即所得的非阻塞式采集,无论是否需要登录数据,都可以顺利进行采集。最有价值的信息通常需要登录才能看到,比如社交网站。为了应对登录,网站必须有模拟用户登录的爬虫系统才能正常获取数据。然而,社交网站希望它自己创造一个闭环,拒绝将数据下站。这个系统不会像新闻和其他内容那样开放。这些社交网站大多会采取一些限制措施来防止机器人爬虫系统爬取数据。通常,爬行后将检测到帐户并阻止其访问。是不是因为我们爬不出来这些网站的数据?我确定事实并非如此。只要社交网站不关闭网页访问,我们也可以访问普通人可以访问的数据。毕竟是模拟人类的正常行为。专业的叫“反监听”。
Source 网站 通常有以下限制:
一、一定时间内单个IP的访问次数,一是频繁允许用户访问网站,除非是随便点击播放,否则不会在短时间内访问太快一段时间网站 ,持续时间不会太长。这个问题很容易处理。我们可以使用大量不规则的代理IP来创建代理池,从代理池中随机选择代理来模拟访问。代理IP有两种,透明代理和匿名代理。
二、 一定时间内单个账号的访问次数。如果我一天24小时访问一个数据接口,而且速度非常快,那么机器人就很多了。我们可以使用大量具有正常行为的帐户。正常的行为就是普通人在社交网站上是怎么做的,单位时间内要访问的网址尽量少,这样每次访问之间就有一段时间。这个时间间隔可以是一个随机值,即每次访问一个网址,都会随机休眠一段时间,然后再访问下一个网址。
如果可以控制账号和IP访问策略,就没有问题。虽然对手网站也会有运维会议调整策略,敌我较量,爬虫必须能够感知到对手的反监控会对我们造成影响,并通知管理员以便及时处理。其实最理想的就是通过机器学习智能实现反监听对抗,实现不间断抓拍。阿贾克斯
下面是我最近设计的一个分布式爬虫架构图,如图1所示: 数据库
图 1 浏览器
这纯粹是笨拙的。初步设想正在实现中。正在建立服务器和客户端之间的通信。Python的Socket模块主要用于实现服务端和客户端的通信。如果你有兴趣,可以单独联系我,一起讨论,共同完成一个更好的计划。服务器
没有整理和泛化的知识,就一文不值!高度概括和整理的知识本身就是真正的知识和技能。永远不要让自己的自由、好奇、创意被现实框架束缚,让创意自由成长!多花点时间关心他(她),就像别人关心你一样。没有别人的支持和帮助,理想的起飞和实现是绝对不可能的。
相关学习资料搬家:
曲奇饼
网页中flash数据抓取(网页中flash数据抓取与反爬虫(1)-flash抓取基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-09-30 18:06
网页中flash数据抓取与反爬虫(1)-flash抓取基础知识这篇文章中,给大家介绍flash的一些基础常识与概念,主要介绍对flash,flash里的方法,方法的定义与使用,方法的一些特性,以及flash方法的案例。很多同学可能看到这里就犯了嘀咕,跟flash有关的flash是个什么鬼?它跟爬虫有什么关系?一时不知道怎么入手?这里我就给大家提供一个好玩的栗子让大家先了解下flash。
flash是的在线视频播放器,也就是大家理解的电脑里能看到的电影,没有电脑的同学可以通过浏览器进行观看电影,需要科学上网网上可以搜到。flash最初是由插件扩展得到的。在flash中,可以嵌入很多插件,目前已知的插件为:audioinfirecast:将音频文件按声音尺寸大小切割为一块块的,在所有主流平台上均可互相播放。
mutationalsetup:格式类似ps的脚本调整素材尺寸。shortcut:由flash本身提供的一个非常精美的动画效果。shelter:应用于powershell的终端插件。html5audio:支持flash的最新的格式,在各种浏览器上都可以呈现出绚丽的视觉效果,支持可选择的、各种基础声音如:audio,mp3,voice,rap,retouch,mimo等声音格式。
canvasaudio:适用于移动,即游戏或多人的舞台表演的通用声音格式,javascriptaudio提供导出canvas。hlslt,std,mediatemplate,audiojp,audiofeet,fastaudio,audiojfast,denoised,j&d,j&t,revoke,vmtrack,maxguide,j&i,exhaust,click等移动播放,内容简介的乐视视频;game_video_media这是官方给的实例,由javascript写的,放到了js中而非flash,可以在浏览器上播放。
手机端用上了flash是一个好事,但是电脑上很多时候是有flash文件的,这就需要把电脑上的flash下载下来利用浏览器编辑器修改了,如果要用浏览器看电脑的flash我就不介绍了,我先解释下flash文件的基本情况1.源代码一般来说在的官网上都会留下源代码,源代码中既有flash,也有psd等图片格式2.加密这个可以通过加密工具加密,记住有些公司的flash是不支持加密的,而某些公司的flash支持加密。
3.交换我以前写过这样一个小程序,是利用浏览器自带的插件来爬网页的,利用浏览器中的开发工具编写html插件,以下就以它为例子介绍下,开发工具使用python,在浏览器中调用python代码,代码在adobe的官网中可以找到,点击flash代码去观看,运行成功后就在浏览器中可以看到相应的flash文件,像这样网页中flas。 查看全部
网页中flash数据抓取(网页中flash数据抓取与反爬虫(1)-flash抓取基础知识)
网页中flash数据抓取与反爬虫(1)-flash抓取基础知识这篇文章中,给大家介绍flash的一些基础常识与概念,主要介绍对flash,flash里的方法,方法的定义与使用,方法的一些特性,以及flash方法的案例。很多同学可能看到这里就犯了嘀咕,跟flash有关的flash是个什么鬼?它跟爬虫有什么关系?一时不知道怎么入手?这里我就给大家提供一个好玩的栗子让大家先了解下flash。
flash是的在线视频播放器,也就是大家理解的电脑里能看到的电影,没有电脑的同学可以通过浏览器进行观看电影,需要科学上网网上可以搜到。flash最初是由插件扩展得到的。在flash中,可以嵌入很多插件,目前已知的插件为:audioinfirecast:将音频文件按声音尺寸大小切割为一块块的,在所有主流平台上均可互相播放。
mutationalsetup:格式类似ps的脚本调整素材尺寸。shortcut:由flash本身提供的一个非常精美的动画效果。shelter:应用于powershell的终端插件。html5audio:支持flash的最新的格式,在各种浏览器上都可以呈现出绚丽的视觉效果,支持可选择的、各种基础声音如:audio,mp3,voice,rap,retouch,mimo等声音格式。
canvasaudio:适用于移动,即游戏或多人的舞台表演的通用声音格式,javascriptaudio提供导出canvas。hlslt,std,mediatemplate,audiojp,audiofeet,fastaudio,audiojfast,denoised,j&d,j&t,revoke,vmtrack,maxguide,j&i,exhaust,click等移动播放,内容简介的乐视视频;game_video_media这是官方给的实例,由javascript写的,放到了js中而非flash,可以在浏览器上播放。
手机端用上了flash是一个好事,但是电脑上很多时候是有flash文件的,这就需要把电脑上的flash下载下来利用浏览器编辑器修改了,如果要用浏览器看电脑的flash我就不介绍了,我先解释下flash文件的基本情况1.源代码一般来说在的官网上都会留下源代码,源代码中既有flash,也有psd等图片格式2.加密这个可以通过加密工具加密,记住有些公司的flash是不支持加密的,而某些公司的flash支持加密。
3.交换我以前写过这样一个小程序,是利用浏览器自带的插件来爬网页的,利用浏览器中的开发工具编写html插件,以下就以它为例子介绍下,开发工具使用python,在浏览器中调用python代码,代码在adobe的官网中可以找到,点击flash代码去观看,运行成功后就在浏览器中可以看到相应的flash文件,像这样网页中flas。
网页中flash数据抓取(flash安全性对象中叫“appName调js错误层出不穷”的属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-28 23:02
背景介绍:
最近在做一个项目,涉及图片选择、裁剪、上传等,由于浏览器安全问题,js无法获取文件中选择的文件路径,HTML5实现的照片裁剪、抠图等功能不同的。大浏览器的兼容性,实在不敢太大胆。这时候就引入了flash,然后js做不到的事情都让flash来做,然后js来控制页面元素。就这样开始了js和as的交互之旅。听flash的大叔说,flash调优js的功能风格很容易调,但js调as却不容易。最后的情况是as调整js错误无休止,花了很多时间就搞定了。当然,
重要内容
//获取flash对象
函数 getSWF(name){
var e=document.getElementById(name);
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0];
}
为什么要这样做,因为在浏览器中嵌入flash一般采用如下格式:
因为IE(微软的),其他的(Mozilla的Firefox,谷歌的chrome等)在解析HTML文档上有差异,所以如果你面对不同的浏览器,如果你使用通用的方法,你不知道哪里错了,但你是真的错了!
详细代码
上面的函数getSWF(),顾名思义就是获取嵌入到文档中的flash对象。navigator 是浏览器对象,Navigator 对象收录浏览器的信息。
相关资料可参考:;
所以后面的 appName 就是 Navigator 对象中名为“appName”的属性。该属性记录了navigator.appName获取的浏览器名称。目前五大浏览器的appName取值如下:
IE:浏览器名称:Microsoft Internet
FF、Chrome、Opera、Safari:浏览器名称:Netscape
浏览器 appName 测试地址:;
indexOf()是一个Javascript函数,indexOf()方法可以返回指定字符串值在字符串中第一次出现的位置
stringObject.indexOf("str",num); stringObject是要搜索的字符串对象,str是要搜索的字符串,num是起始位置,如果查询发现stringObject中存在字符串“str”,则返回第一个出现位置,如果要检索的字符串值没有出现,方法返回-1;
var e = document.getElementById(name); 就是获取文档中属性id值为name的节点对象,并将这个对象赋值给e,
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0]; 看起来很复杂,开头很简单,这里是一个三木算术(学过编程的应该都知道),具体格式是if(a)?b:c;也就是说当if(a)为真时,值为b,如果(a)不为真,则取值为c,这个长代码可以分解为if(a)?b:c;的格式。
navigator.appName.indexOf("Microsoft")!=-1 e e.getElementsByTagName("embed")[0] 这三部分
if(navigator.appName.indexOf("Microsoft")!=-1){ alert("我的浏览器不是 IE 核心"); }else{"我的浏览器是 IE 核心"}
当弹出窗口显示“我的浏览器不是IE核心”时,说明我的浏览器名称不收录“Microsoft”,即没有使用IE。此时要获取的flash对象就是文档中的对象。如果是IE浏览器,则获取该对象。无论获取到哪个对象,最后都必须使用return返回调用函数,这样才能在不同的浏览器中获取对应的flash对象。
总体方案:
获取到flash对象后,可以调用flash中的方法,或者flash中的属性。
var objName = getSWF("FlashToJS");
//调用对象的flash_selFiles方法
如果(对象名称){
objName.flash_cutPic(arg);
}别的{
console.log("没有获得对象");
}
这被转移到 flash 中的 flash_selFiles() 方法。
最后的想法
尽量减少页面中flash的使用,尤其不要过分依赖flash,as和js的交互还是隐藏着很多陷阱。报告结束! 查看全部
网页中flash数据抓取(flash安全性对象中叫“appName调js错误层出不穷”的属性)
背景介绍:
最近在做一个项目,涉及图片选择、裁剪、上传等,由于浏览器安全问题,js无法获取文件中选择的文件路径,HTML5实现的照片裁剪、抠图等功能不同的。大浏览器的兼容性,实在不敢太大胆。这时候就引入了flash,然后js做不到的事情都让flash来做,然后js来控制页面元素。就这样开始了js和as的交互之旅。听flash的大叔说,flash调优js的功能风格很容易调,但js调as却不容易。最后的情况是as调整js错误无休止,花了很多时间就搞定了。当然,
重要内容
//获取flash对象
函数 getSWF(name){
var e=document.getElementById(name);
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0];
}
为什么要这样做,因为在浏览器中嵌入flash一般采用如下格式:
因为IE(微软的),其他的(Mozilla的Firefox,谷歌的chrome等)在解析HTML文档上有差异,所以如果你面对不同的浏览器,如果你使用通用的方法,你不知道哪里错了,但你是真的错了!
详细代码
上面的函数getSWF(),顾名思义就是获取嵌入到文档中的flash对象。navigator 是浏览器对象,Navigator 对象收录浏览器的信息。
相关资料可参考:;
所以后面的 appName 就是 Navigator 对象中名为“appName”的属性。该属性记录了navigator.appName获取的浏览器名称。目前五大浏览器的appName取值如下:
IE:浏览器名称:Microsoft Internet
FF、Chrome、Opera、Safari:浏览器名称:Netscape
浏览器 appName 测试地址:;
indexOf()是一个Javascript函数,indexOf()方法可以返回指定字符串值在字符串中第一次出现的位置
stringObject.indexOf("str",num); stringObject是要搜索的字符串对象,str是要搜索的字符串,num是起始位置,如果查询发现stringObject中存在字符串“str”,则返回第一个出现位置,如果要检索的字符串值没有出现,方法返回-1;
var e = document.getElementById(name); 就是获取文档中属性id值为name的节点对象,并将这个对象赋值给e,
return (navigator.appName.indexOf("Microsoft") != -1)?e:e.getElementsByTagName("embed")[0]; 看起来很复杂,开头很简单,这里是一个三木算术(学过编程的应该都知道),具体格式是if(a)?b:c;也就是说当if(a)为真时,值为b,如果(a)不为真,则取值为c,这个长代码可以分解为if(a)?b:c;的格式。
navigator.appName.indexOf("Microsoft")!=-1 e e.getElementsByTagName("embed")[0] 这三部分
if(navigator.appName.indexOf("Microsoft")!=-1){ alert("我的浏览器不是 IE 核心"); }else{"我的浏览器是 IE 核心"}
当弹出窗口显示“我的浏览器不是IE核心”时,说明我的浏览器名称不收录“Microsoft”,即没有使用IE。此时要获取的flash对象就是文档中的对象。如果是IE浏览器,则获取该对象。无论获取到哪个对象,最后都必须使用return返回调用函数,这样才能在不同的浏览器中获取对应的flash对象。
总体方案:
获取到flash对象后,可以调用flash中的方法,或者flash中的属性。
var objName = getSWF("FlashToJS");
//调用对象的flash_selFiles方法
如果(对象名称){
objName.flash_cutPic(arg);
}别的{
console.log("没有获得对象");
}
这被转移到 flash 中的 flash_selFiles() 方法。
最后的想法
尽量减少页面中flash的使用,尤其不要过分依赖flash,as和js的交互还是隐藏着很多陷阱。报告结束!
网页中flash数据抓取(《热血三国》:使用AMF协议做数据通讯的网页游戏)
网站优化 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2021-09-28 22:22
《三国志》好像比较火,玩的人也不少。一年前,一个朋友要我为这个游戏写一个插件。也是因为无聊,所以就去玩了。谁知道我玩了之后有点喜欢。这个游戏当然是玩玩玩,还有待完善,当然不能算是外挂,顶多算是辅助工具。
三国志是一款完全由FLASH制作的网页游戏,以Flex为框架,采用AMF协议进行数据通信。
首先,对于一款FLASH网页游戏,大家需要了解它的AMF协议调用方式。就三国而言,服务器返回的消息都是AMF0格式的,客户端提交给服务器的则是AMF3格式。
刚开始分析这个游戏的时候,就想到了自己搭建一个AMF协议解析器。不过由于当时功能限制,我从网上找到了FluorineFx开源组件。我们必须做出一个强大的网页游戏。我觉得这个工具应该是离线的。如果可以在工具中独立调用各种功能,做任何事情就相当于游戏的客户端。
但是在做这个之前最麻烦的问题是分析协议调用参数和返回参数结构。在做这个工具之前,我对 Flash Flex 一无所知。AS的写法还在Flash 5的水平,快十了。多年未使用。. .
为了方便以下工具的使用
SWF Decompiler的SWF文件反编译工具
Notepad++文本编辑工具,主要用于在整个目录中查找指定文本(使用WINDOWS搜索功能太让人失望了)
Kolai网络分析系统,用于获取网络通讯数据
SocketSniff,比KELA系统更轻量级的网络监控工具,更方便了解基本通信流程
以上是可以通过网络找到的实用工具,加上我自己制作的一个AMF协议半自动分析仪。主要功能是分析HEX DATA的AMF协议,跟踪游戏AMF协议通信过程,简单分析反映。进一步分析调用过程以提供参考。
一个AMF通信过程分析:
1.需要获取命令的功能前打开网页游戏停止运行
2.打开网络嗅探器并进行嗅探。在这个过程中,最好按IP和端口过滤
3.执行需要的命令,等待命令执行返回
4.停止网络嗅探
5. 去除不相关的网络通信数据,必须有AMF协议下业务处理的网关,比如三国地址:/server/amfphp/gateway.php,以及HTTP头的内容格式是application/x-amf,所以只需要过滤网关相关的通信会话即可。 查看全部
网页中flash数据抓取(《热血三国》:使用AMF协议做数据通讯的网页游戏)
《三国志》好像比较火,玩的人也不少。一年前,一个朋友要我为这个游戏写一个插件。也是因为无聊,所以就去玩了。谁知道我玩了之后有点喜欢。这个游戏当然是玩玩玩,还有待完善,当然不能算是外挂,顶多算是辅助工具。
三国志是一款完全由FLASH制作的网页游戏,以Flex为框架,采用AMF协议进行数据通信。
首先,对于一款FLASH网页游戏,大家需要了解它的AMF协议调用方式。就三国而言,服务器返回的消息都是AMF0格式的,客户端提交给服务器的则是AMF3格式。
刚开始分析这个游戏的时候,就想到了自己搭建一个AMF协议解析器。不过由于当时功能限制,我从网上找到了FluorineFx开源组件。我们必须做出一个强大的网页游戏。我觉得这个工具应该是离线的。如果可以在工具中独立调用各种功能,做任何事情就相当于游戏的客户端。
但是在做这个之前最麻烦的问题是分析协议调用参数和返回参数结构。在做这个工具之前,我对 Flash Flex 一无所知。AS的写法还在Flash 5的水平,快十了。多年未使用。. .
为了方便以下工具的使用
SWF Decompiler的SWF文件反编译工具
Notepad++文本编辑工具,主要用于在整个目录中查找指定文本(使用WINDOWS搜索功能太让人失望了)
Kolai网络分析系统,用于获取网络通讯数据
SocketSniff,比KELA系统更轻量级的网络监控工具,更方便了解基本通信流程
以上是可以通过网络找到的实用工具,加上我自己制作的一个AMF协议半自动分析仪。主要功能是分析HEX DATA的AMF协议,跟踪游戏AMF协议通信过程,简单分析反映。进一步分析调用过程以提供参考。
一个AMF通信过程分析:
1.需要获取命令的功能前打开网页游戏停止运行
2.打开网络嗅探器并进行嗅探。在这个过程中,最好按IP和端口过滤
3.执行需要的命令,等待命令执行返回
4.停止网络嗅探
5. 去除不相关的网络通信数据,必须有AMF协议下业务处理的网关,比如三国地址:/server/amfphp/gateway.php,以及HTTP头的内容格式是application/x-amf,所以只需要过滤网关相关的通信会话即可。
网页中flash数据抓取(《热血三国》:用Flex做架构,使用AMF协议做数据通讯)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-23 20:17
“三个王国”似乎是一个相对较热的人,那些玩得开心的人也非常多。一个想要我写一场比赛的朋友。我一直很无聊,所以我在玩,谁知道我喜欢这个游戏,当然,我仍然要玩,当然,我无法计算出插件,大多数是辅助工具。
三个王国是一个用闪存制作的Web游戏,使用Flex来使用AMF协议进行数据通信。
首先用于闪存Web游戏,您需要了解他的AMF协议呼叫模式。对于三个王国,服务器返回的消息是所有AMF0格式,客户端被提交到服务器到AMF3格式。
当您开始分析此游戏时,您会考虑自己的AMF协议解析器,但由于所做的功能限制相对较大,它已从Internet找到荧光FX开源组件。有必要做一个良好的功能。 Web游戏工具我觉得您应该执行功能脱机,您必须在工具中独立完成各种功能呼叫,并充分为相当于游戏的客户端。
但是在做顶部疼痛之前的顶部是分析协议呼叫参数并返回参数结构。在执行此工具之前,我不知道Flash Flex。作为闪光灯5的程度,写作的写作并已经在过去十年中没有使用过。 。 。
为了方便以下工具
swfdecompiler的swf文件反编译工具
notepad ++文本编辑工具,主要用于查找指定的文本(带Windows查找功能太失望)
集合网络分析系统,用于获取网络通信数据
Socketsniff,相对轻的网络侦听工具关于经典的基本通信过程,更方便
以上是可以通过网络找到的实用程序,然后添加其一个自己的AMF协议半自动分析仪之一。主要功能是分析十六进制数据的AMF协议,并跟踪游戏AMF协议通信过程,并简单地分析,为进一步分析调用过程提供参考。
AMF通信过程分析:
1.打开web游戏并停止在需要获取命令之前
2.打开网络嗅探器并执行嗅探,最好过滤
在此过程中的过程中
3.执行所需的命令,并等待命令执行返回
4. stop网络嗅
@ @ @删除无关的网络通信数据,AMF协议必须具有业务处理网关,如三个国家的地址:/server/amfphp/gateway.php,以及HTTP标头的内容格式Application / x -amf,因此您只需过滤相关的网关的通信对话可以 查看全部
网页中flash数据抓取(《热血三国》:用Flex做架构,使用AMF协议做数据通讯)
“三个王国”似乎是一个相对较热的人,那些玩得开心的人也非常多。一个想要我写一场比赛的朋友。我一直很无聊,所以我在玩,谁知道我喜欢这个游戏,当然,我仍然要玩,当然,我无法计算出插件,大多数是辅助工具。
三个王国是一个用闪存制作的Web游戏,使用Flex来使用AMF协议进行数据通信。
首先用于闪存Web游戏,您需要了解他的AMF协议呼叫模式。对于三个王国,服务器返回的消息是所有AMF0格式,客户端被提交到服务器到AMF3格式。
当您开始分析此游戏时,您会考虑自己的AMF协议解析器,但由于所做的功能限制相对较大,它已从Internet找到荧光FX开源组件。有必要做一个良好的功能。 Web游戏工具我觉得您应该执行功能脱机,您必须在工具中独立完成各种功能呼叫,并充分为相当于游戏的客户端。
但是在做顶部疼痛之前的顶部是分析协议呼叫参数并返回参数结构。在执行此工具之前,我不知道Flash Flex。作为闪光灯5的程度,写作的写作并已经在过去十年中没有使用过。 。 。
为了方便以下工具
swfdecompiler的swf文件反编译工具
notepad ++文本编辑工具,主要用于查找指定的文本(带Windows查找功能太失望)
集合网络分析系统,用于获取网络通信数据
Socketsniff,相对轻的网络侦听工具关于经典的基本通信过程,更方便
以上是可以通过网络找到的实用程序,然后添加其一个自己的AMF协议半自动分析仪之一。主要功能是分析十六进制数据的AMF协议,并跟踪游戏AMF协议通信过程,并简单地分析,为进一步分析调用过程提供参考。
AMF通信过程分析:
1.打开web游戏并停止在需要获取命令之前
2.打开网络嗅探器并执行嗅探,最好过滤
在此过程中的过程中
3.执行所需的命令,并等待命令执行返回
4. stop网络嗅
@ @ @删除无关的网络通信数据,AMF协议必须具有业务处理网关,如三个国家的地址:/server/amfphp/gateway.php,以及HTTP标头的内容格式Application / x -amf,因此您只需过滤相关的网关的通信对话可以
网页中flash数据抓取(【知识点】数据采集基本功能(一)——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-21 06:06
1、data采集basic function1)支持多任务和多线程数据采集,支持一个采集任务和多个多线程的高性能采集器爬虫程序。Net源代码。可以采用Ajax页面实例操作,即采集任务规则和采集任务操作可以分离,便于采集任务配置、跟踪和管理2)支持get和post请求和cookie,可以满足严重数据的需要采集. Cookie可以预先存储或实时获取3)支持用户定义的HTTP头。通过此功能,用户可以充分模拟浏览器的请求操作,满足所有网页请求要求。当在网站上发布数据时,此函数特别有用4)采集网站支持各种参数,如数字、字母、日期、自定义词典、外部数据等。为了最大程度地简化采集网站的配置,为了达到海量采集5)采集网站支持导航操作的目的(即自动从入口页面跳转到需要采集数据的页面),导航规则支持具有无限导航级别的复杂规则,可进行多层网站导航6)支持采集网址和导航层的自动翻页。定义翻页规则后,系统将自动翻页数据采集。同时,此功能还可以自动合并用户分页文章7)network miner支持级联采集,即在导航的基础上,可以自动向下合并采集不同级别的数据。此函数也可以称为paging采集8)network miner支持翻页数据合并,即可以合并多页数据。典型应用是同一篇文章的文章多页显示,系统翻页采集并合并成一段数据输出9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)Ajax技术可用于形成web数据采集;11)采集rule支持特殊符号的定义,如十六进制0x01的非法字符;12)采集规则支持限定符操作,能够准确匹配要获取的数据;13)采集网站支持:UTF-8、GB231 2、Base6 4、Big5和其他代码,并可自动识别&;平等符号;网页编码支持:UTF-8、GB231 2、Big5等编码;1@k25采集URL和采集rule都支持有限范围和自定义规则2、data采集advanced function1)支持采集delay操作,它可以控制系统采集频率,降低对目标网站2)断点的访问压力,连续挖掘模式和实时数据存储保护用户采集投资。注:此模式仅限于采集具有非大数据量3)支持大数据量采集,即实时采集实时入库,不影响系统性能4)提供强大的数据处理操作,可以配置多个规则同时处理采集的数据:a)支持字符串截取、替换、添加等操作;b) 支持采集数据输出控制。输出收录指定条件,指定条件被删除;c) 支持正则表达式替换;b) 支持u码到中文字符5)可自动输出所采用的页面地址和采集时间,并提供采集log6)采集的数据可自动保存为文本文件和Excel文件,也可自动存储在数据库中。数据库支持access、MSSqlServer和mysql。同时,在数据存储过程中可以自动删除多行以避免数据重复7)采集的数据也可以自动发布到网站。数据的在线发布操作可以通过配置发布网站参数来实现(发布配置与采集配置相同,可以定义cookie、HTTP头等)8)data采集支持触发操作9)提供采集规则分析器,帮助用户配置采集规则,分析错误内容;10)用于自动捕获的迷你浏览器网站cookie ; 11)Support采集log并提供容错处理3、trigger是一种自动操作手段,即当满足一定条件时,系统会自动执行一项操作。使用触发器,用户可以实现采集任务的连续执行、外部程序的调用、存储过程的调用等
1)trigger支持两种触发模式:采集data completion trigger和release data completion trigger2)trigger操作支持:执行network miner采集tasks、执行外部程序和执行存储过程4、task执行计划定时计划是自动化采集数据的一种手段。用户可以根据需要自动控制采集数据的时间和频率1)可以自动执行采集任务每周、每天和自定义时间,并控制采集任务计划2)的到期时间可以自动执行任务:network miner采集tasks,外部执行程序和存储过程5、网络雷达是一个非常有用的功能。网络雷达主要根据用户预定的规则监控互联网数据,并根据预定的规则进行预警。此功能可用于监控网络热门帖子、感兴趣的关键词、商品价格变化,实现采集的数据1)监控源目前只支持网络挖掘 查看全部
网页中flash数据抓取(【知识点】数据采集基本功能(一)——)
1、data采集basic function1)支持多任务和多线程数据采集,支持一个采集任务和多个多线程的高性能采集器爬虫程序。Net源代码。可以采用Ajax页面实例操作,即采集任务规则和采集任务操作可以分离,便于采集任务配置、跟踪和管理2)支持get和post请求和cookie,可以满足严重数据的需要采集. Cookie可以预先存储或实时获取3)支持用户定义的HTTP头。通过此功能,用户可以充分模拟浏览器的请求操作,满足所有网页请求要求。当在网站上发布数据时,此函数特别有用4)采集网站支持各种参数,如数字、字母、日期、自定义词典、外部数据等。为了最大程度地简化采集网站的配置,为了达到海量采集5)采集网站支持导航操作的目的(即自动从入口页面跳转到需要采集数据的页面),导航规则支持具有无限导航级别的复杂规则,可进行多层网站导航6)支持采集网址和导航层的自动翻页。定义翻页规则后,系统将自动翻页数据采集。同时,此功能还可以自动合并用户分页文章7)network miner支持级联采集,即在导航的基础上,可以自动向下合并采集不同级别的数据。此函数也可以称为paging采集8)network miner支持翻页数据合并,即可以合并多页数据。典型应用是同一篇文章的文章多页显示,系统翻页采集并合并成一段数据输出9)data采集支持文件下载操作,可以下载文件、图片、flash等内容;10)Ajax技术可用于形成web数据采集;11)采集rule支持特殊符号的定义,如十六进制0x01的非法字符;12)采集规则支持限定符操作,能够准确匹配要获取的数据;13)采集网站支持:UTF-8、GB231 2、Base6 4、Big5和其他代码,并可自动识别&;平等符号;网页编码支持:UTF-8、GB231 2、Big5等编码;1@k25采集URL和采集rule都支持有限范围和自定义规则2、data采集advanced function1)支持采集delay操作,它可以控制系统采集频率,降低对目标网站2)断点的访问压力,连续挖掘模式和实时数据存储保护用户采集投资。注:此模式仅限于采集具有非大数据量3)支持大数据量采集,即实时采集实时入库,不影响系统性能4)提供强大的数据处理操作,可以配置多个规则同时处理采集的数据:a)支持字符串截取、替换、添加等操作;b) 支持采集数据输出控制。输出收录指定条件,指定条件被删除;c) 支持正则表达式替换;b) 支持u码到中文字符5)可自动输出所采用的页面地址和采集时间,并提供采集log6)采集的数据可自动保存为文本文件和Excel文件,也可自动存储在数据库中。数据库支持access、MSSqlServer和mysql。同时,在数据存储过程中可以自动删除多行以避免数据重复7)采集的数据也可以自动发布到网站。数据的在线发布操作可以通过配置发布网站参数来实现(发布配置与采集配置相同,可以定义cookie、HTTP头等)8)data采集支持触发操作9)提供采集规则分析器,帮助用户配置采集规则,分析错误内容;10)用于自动捕获的迷你浏览器网站cookie ; 11)Support采集log并提供容错处理3、trigger是一种自动操作手段,即当满足一定条件时,系统会自动执行一项操作。使用触发器,用户可以实现采集任务的连续执行、外部程序的调用、存储过程的调用等
1)trigger支持两种触发模式:采集data completion trigger和release data completion trigger2)trigger操作支持:执行network miner采集tasks、执行外部程序和执行存储过程4、task执行计划定时计划是自动化采集数据的一种手段。用户可以根据需要自动控制采集数据的时间和频率1)可以自动执行采集任务每周、每天和自定义时间,并控制采集任务计划2)的到期时间可以自动执行任务:network miner采集tasks,外部执行程序和存储过程5、网络雷达是一个非常有用的功能。网络雷达主要根据用户预定的规则监控互联网数据,并根据预定的规则进行预警。此功能可用于监控网络热门帖子、感兴趣的关键词、商品价格变化,实现采集的数据1)监控源目前只支持网络挖掘
网页中flash数据抓取(as调js与as的交互之旅,你值得拥有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-21 06:04
背景:
最近在搞相关的图片选择一个项目,裁剪,上传,由于浏览器的安全问题,js文件路径不能去选择,并把照片,消光等通过HTML5实现的裁剪功能,主要浏览器的兼容性真的不是太大胆了。这次出台的闪光,然后不要让所有的JS闪烁做,然后控制由JS的页面元素。就这样开始了JS和互动之旅,听叔叔说做闪光灯,功能调好闪JS调,并且不容易调整为JS。最后的情况下直接被传递陆续JS错误,花了很多时间在上面,当然,开调为JS也走了弯路,因为以前没有使用闪光灯的交往,我们只能让别人说,但它也像咱们的js不是一个问题,因为互联网有很多了,废话不多且容易获得,方法共享出来的项目需要的js代码。
重要内容
//获取Flash对象
功能getSWF(名称){
变种E =的document.getElementById(名称);
返回(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];
}
为什么要发生这种情况,因为闪光灯嵌入在浏览器通常具有以下格式:
由于IE浏览器,其他(Mozilla系列火狐,谷歌Chrome等家)(微软主页)是有区别的,当解析HTML文档,因此如果面对的是不同的浏览器,一个常用的方法,我自己也不知道是什么出了问题,但你真的错了!
代码解释
上述功能getSWF()顾名思义,是获得嵌入在文档中的Flash对象,它是Navigator浏览器对象,该对象收录有关Navigator浏览器的信息。
相关信息可以指的是:
因此,回到应用程序的名字是叫“APPNAME”属性导航器对象,此属性记录navigator.appName收购了浏览器的名称,目前五大浏览器应用程序的名字值如下:
IE:浏览器名称:Microsoft互联网
FF,铬,歌剧,Safari:浏览器名称:网景
APPNAME浏览器测试地址:;
的indexOf()函数是Javascript,的indexOf()方法返回一个指定的字符串值的在所述串的第一次出现的位置
stringObject.indexOf( “STR”,NUM);所寻求stringObject字符串对象,STR字符串查找,NUM是起始位置,如果查询中存在于stringObject,返回位置的第一次出现的字符串“STR”,如果字符串值是检索到的不存在,则该方法返回-1;
变种E =的document.getElementById(名称);节点目的是获得该文件的名称属性id的值,这个对象被分配到e
收益率(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];貌似很复杂,很简单的开始,这里是一个三木操作(学过编程的都应该知道),具体的格式,如果(一)b:C;这意味着,如果(a)是b的真实价值时,如果(a)是不正确的,当c的值可以这样写代码到?长,如果(A)b:C;格式
navigator.appName.indexOf( “微软”)!= - 图1e e.getElementsByTagName( “嵌入”)[0]这三个部分
如果(navigator.appName.indexOf( “微软”)= - 1) {警报( “我不是IE内核的浏览器”);}!否则{ “我的浏览器是IE内核”}
在弹出时“我的浏览器不是IE核心,解释说:”我的浏览器的名称不收录“微软”,那是没有用的IE浏览器,此时得到的Flash对象是文档对象,如果浏览器是IE,那么该对象被获取时,是否获得该对象,最终将具有返回给函数调用返回,这样就可以获得相应于不同的浏览器flash对象。
总体方案:
可称为
获得所述闪光法或特性内的闪光内的闪光对象之后。
变种OBJNAME = getSWF( “FlashToJS”);
flash_selFiles调用对象的方法//
如果(OBJNAME){
objName.flash_cutPic(ARG);
}否则{
的console.log( “未获取的对象”);
}
这是)转移到闪存内flash_selFiles(方法。
在最终反射
在页面或减少闪光灯的使用,尤其不要太依赖闪光灯,在与爵士的还是隐藏着很多陷阱的作用。报告完毕! 查看全部
网页中flash数据抓取(as调js与as的交互之旅,你值得拥有)
背景:
最近在搞相关的图片选择一个项目,裁剪,上传,由于浏览器的安全问题,js文件路径不能去选择,并把照片,消光等通过HTML5实现的裁剪功能,主要浏览器的兼容性真的不是太大胆了。这次出台的闪光,然后不要让所有的JS闪烁做,然后控制由JS的页面元素。就这样开始了JS和互动之旅,听叔叔说做闪光灯,功能调好闪JS调,并且不容易调整为JS。最后的情况下直接被传递陆续JS错误,花了很多时间在上面,当然,开调为JS也走了弯路,因为以前没有使用闪光灯的交往,我们只能让别人说,但它也像咱们的js不是一个问题,因为互联网有很多了,废话不多且容易获得,方法共享出来的项目需要的js代码。
重要内容
//获取Flash对象
功能getSWF(名称){
变种E =的document.getElementById(名称);
返回(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];
}
为什么要发生这种情况,因为闪光灯嵌入在浏览器通常具有以下格式:
由于IE浏览器,其他(Mozilla系列火狐,谷歌Chrome等家)(微软主页)是有区别的,当解析HTML文档,因此如果面对的是不同的浏览器,一个常用的方法,我自己也不知道是什么出了问题,但你真的错了!
代码解释
上述功能getSWF()顾名思义,是获得嵌入在文档中的Flash对象,它是Navigator浏览器对象,该对象收录有关Navigator浏览器的信息。
相关信息可以指的是:
因此,回到应用程序的名字是叫“APPNAME”属性导航器对象,此属性记录navigator.appName收购了浏览器的名称,目前五大浏览器应用程序的名字值如下:
IE:浏览器名称:Microsoft互联网
FF,铬,歌剧,Safari:浏览器名称:网景
APPNAME浏览器测试地址:;
的indexOf()函数是Javascript,的indexOf()方法返回一个指定的字符串值的在所述串的第一次出现的位置
stringObject.indexOf( “STR”,NUM);所寻求stringObject字符串对象,STR字符串查找,NUM是起始位置,如果查询中存在于stringObject,返回位置的第一次出现的字符串“STR”,如果字符串值是检索到的不存在,则该方法返回-1;
变种E =的document.getElementById(名称);节点目的是获得该文件的名称属性id的值,这个对象被分配到e
收益率(navigator.appName.indexOf( “微软”)= - 1) E:!?E.getElementsByTagName( “嵌入”)[0];貌似很复杂,很简单的开始,这里是一个三木操作(学过编程的都应该知道),具体的格式,如果(一)b:C;这意味着,如果(a)是b的真实价值时,如果(a)是不正确的,当c的值可以这样写代码到?长,如果(A)b:C;格式
navigator.appName.indexOf( “微软”)!= - 图1e e.getElementsByTagName( “嵌入”)[0]这三个部分
如果(navigator.appName.indexOf( “微软”)= - 1) {警报( “我不是IE内核的浏览器”);}!否则{ “我的浏览器是IE内核”}
在弹出时“我的浏览器不是IE核心,解释说:”我的浏览器的名称不收录“微软”,那是没有用的IE浏览器,此时得到的Flash对象是文档对象,如果浏览器是IE,那么该对象被获取时,是否获得该对象,最终将具有返回给函数调用返回,这样就可以获得相应于不同的浏览器flash对象。
总体方案:
可称为
获得所述闪光法或特性内的闪光内的闪光对象之后。
变种OBJNAME = getSWF( “FlashToJS”);
flash_selFiles调用对象的方法//
如果(OBJNAME){
objName.flash_cutPic(ARG);
}否则{
的console.log( “未获取的对象”);
}
这是)转移到闪存内flash_selFiles(方法。
在最终反射
在页面或减少闪光灯的使用,尤其不要太依赖闪光灯,在与爵士的还是隐藏着很多陷阱的作用。报告完毕!
网页中flash数据抓取(谷歌将继续改进SWF索引功能(Flash技术应用中))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-18 10:28
Win7豪斯():谷歌:网站Flash我们还可以在中抓取文本
网站webmaster经常问我们如何索引专门为flash player设计的内容,所以我们想花点时间告诉您我们在这一领域的最新进展。大约两年前,我们宣布,通过与adobe的合作,谷歌基于flash技术的内容索引能力得到了显著提高。去年,我们再次发表声明,宣布为SWF索引功能添加外部资源上传功能。这项技术进步使我们能够索引swf文件中各种类型的文本内容——从flash按钮和菜单到基于flash的自给自足的网站
目前,Google robot可以索引用户在网站上与swf文件交互时可以看到的几乎所有文本内容,并使用它生成摘要屏幕截图或匹配Google搜索中的查询条件。此外,GoogleRobot还可以在swf文件中找到URL并跟踪这些链接。因此,如果您的SWF内容收录指向网站内部网页的链接,Google将能够搜索和索引网页
上个月,我们通过与adobe的持续合作扩展了SWF索引功能。此扩展使用了一个与flash player兼容的更稳定的新库10.1支持的功能。此外,随着JavaScript处理的改进,我们可以使用JavaScript更好地组织和索引网站以嵌入SWF内容。最后,我们还改进了视频索引技术,不仅可以提高网页收录视频时的搜索效率,还可以更好地提供元数据,如从基于flash的视频中提取元数据,如在基于flash的视频中替换缩略图。简而言之,使用SWF索引技术,我们现在可以看到收录在数千个网页中的SWF文件的内容
在过去几年中,我们的SWF内容索引技术取得了巨大的进步,但我们不会就此止步。我们将继续改进深度链接功能(flash technology应用程序中的内容由同一应用程序链接),并通过JavaScript进一步改进swf文件的搜索。您可以为每个页面创建一个指向单个flash对象的唯一链接,并通过Google网站webmaster工具提交网站maps,以帮助我们改进这些功能
我们对目前的成就感到高兴,并希望向您提供有关技术改进的最新信息 查看全部
网页中flash数据抓取(谷歌将继续改进SWF索引功能(Flash技术应用中))
Win7豪斯():谷歌:网站Flash我们还可以在中抓取文本
网站webmaster经常问我们如何索引专门为flash player设计的内容,所以我们想花点时间告诉您我们在这一领域的最新进展。大约两年前,我们宣布,通过与adobe的合作,谷歌基于flash技术的内容索引能力得到了显著提高。去年,我们再次发表声明,宣布为SWF索引功能添加外部资源上传功能。这项技术进步使我们能够索引swf文件中各种类型的文本内容——从flash按钮和菜单到基于flash的自给自足的网站
目前,Google robot可以索引用户在网站上与swf文件交互时可以看到的几乎所有文本内容,并使用它生成摘要屏幕截图或匹配Google搜索中的查询条件。此外,GoogleRobot还可以在swf文件中找到URL并跟踪这些链接。因此,如果您的SWF内容收录指向网站内部网页的链接,Google将能够搜索和索引网页
上个月,我们通过与adobe的持续合作扩展了SWF索引功能。此扩展使用了一个与flash player兼容的更稳定的新库10.1支持的功能。此外,随着JavaScript处理的改进,我们可以使用JavaScript更好地组织和索引网站以嵌入SWF内容。最后,我们还改进了视频索引技术,不仅可以提高网页收录视频时的搜索效率,还可以更好地提供元数据,如从基于flash的视频中提取元数据,如在基于flash的视频中替换缩略图。简而言之,使用SWF索引技术,我们现在可以看到收录在数千个网页中的SWF文件的内容
在过去几年中,我们的SWF内容索引技术取得了巨大的进步,但我们不会就此止步。我们将继续改进深度链接功能(flash technology应用程序中的内容由同一应用程序链接),并通过JavaScript进一步改进swf文件的搜索。您可以为每个页面创建一个指向单个flash对象的唯一链接,并通过Google网站webmaster工具提交网站maps,以帮助我们改进这些功能
我们对目前的成就感到高兴,并希望向您提供有关技术改进的最新信息
网页中flash数据抓取(获取天气预报数据的方法有哪些?如何获取字符串数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-18 10:23
)
通常,人们使用特殊的API来获取天气预报信息。随着越来越多的天气预报API的开发,他们开始收费,这给普通的个人电子爱好者带来了很多麻烦。为了解决这一问题,提出了一种通过HTTP获取天气预报数据的方法
提出了整个流程的原理和流程
寻址适合捕获的网址,分析待获取的HTTP页面数据,找出待获取数据的特征,并根据特征编写采集字符串处理函数
一、find这个网站。天气预报信息的数据很容易找到。大多数网站提供天气预报服务,很容易找到收录天气预报数据的页面。为了节省流量,我们发现手机页面相对简单,尤其是为以前的手机设计的版本
二、分析页面数据以查找功能。页面数据一般为HTML格式,页面内容如下图所示
我们需要得到相似的结果
Var datask={“名称”:“抚顺”,“城市名称”:“抚顺市”:“101270302”,“临时”:“23”,“临时”:“73”,“西部”:“东南风”,“西部”:“东南风”
这里要获取的数据是23度。根据分析,整个HTML页面中只有一个字符串“datask”,因此这是要获取的数据。因此,您可以使用C语言字符串处理函数strstr在“days7”末尾获取子长度字符串。在数据23度中,在字符temp中:“,“Tempf,因此您可以使用strstr函数两次来等待收录温度的最短字符串信息
首次使用strstr函数时,搜索字符串为datask,结果为datask={“名称”:“抚顺”,“城市名称”:“抚顺”城市:“101270302”,“临时”:“23”,“临时”:“73”,“WD”:“东南风”,“wde”:“Se”
第二次使用strstr函数时,搜索的字符串是temp:,结果是temp:“23”,“tempf:“73”,“WD:“东南风”,“wde:“Se”
第三次使用strstr函数时,搜索字符串为“,”tempf“,结果为“,”tempf:”73“,”WD:”东南风“,”wde:”Se”
通过第二次和第三次的数据,我们可以计算我们获得的字符串长度。在第二次获得的数据中,我们可以提出最终结果“23”的温度数据
请参阅以下步骤
char*splitx(char*str,char*s,char*e){
char*t1=NULL
char*t2=NULL
char*t3=NULL
uint8_t lensx=0
t1=strstrstr(str,s)
如果(t1==NULL){
ESP_LOGI(“FUNC_splitx”,“t1valave为空”)
返回ESP_OK
}
t2=strstr(t1,e)
如果(t2==NULL){
ESP_LOGI(“FUNC_splitx”,“t2valave为空”)
返回ESP_OK
}
lensx=strlen(t1)-strlen(t2)-斯特伦(s)
图表='\0'
t3=(char*)malloc(sizeof(char)*lensx+1)
memset(t3,t,sizeof(char)*lensx+1)
strncpy(t3,t1+sizeof(char)*strlen(s),lensx)
返回t3
}
编写代码,然后使用makeapp flash
查看全部
网页中flash数据抓取(获取天气预报数据的方法有哪些?如何获取字符串数据?
)
通常,人们使用特殊的API来获取天气预报信息。随着越来越多的天气预报API的开发,他们开始收费,这给普通的个人电子爱好者带来了很多麻烦。为了解决这一问题,提出了一种通过HTTP获取天气预报数据的方法
提出了整个流程的原理和流程
寻址适合捕获的网址,分析待获取的HTTP页面数据,找出待获取数据的特征,并根据特征编写采集字符串处理函数
一、find这个网站。天气预报信息的数据很容易找到。大多数网站提供天气预报服务,很容易找到收录天气预报数据的页面。为了节省流量,我们发现手机页面相对简单,尤其是为以前的手机设计的版本
二、分析页面数据以查找功能。页面数据一般为HTML格式,页面内容如下图所示
我们需要得到相似的结果
Var datask={“名称”:“抚顺”,“城市名称”:“抚顺市”:“101270302”,“临时”:“23”,“临时”:“73”,“西部”:“东南风”,“西部”:“东南风”
这里要获取的数据是23度。根据分析,整个HTML页面中只有一个字符串“datask”,因此这是要获取的数据。因此,您可以使用C语言字符串处理函数strstr在“days7”末尾获取子长度字符串。在数据23度中,在字符temp中:“,“Tempf,因此您可以使用strstr函数两次来等待收录温度的最短字符串信息
首次使用strstr函数时,搜索字符串为datask,结果为datask={“名称”:“抚顺”,“城市名称”:“抚顺”城市:“101270302”,“临时”:“23”,“临时”:“73”,“WD”:“东南风”,“wde”:“Se”
第二次使用strstr函数时,搜索的字符串是temp:,结果是temp:“23”,“tempf:“73”,“WD:“东南风”,“wde:“Se”
第三次使用strstr函数时,搜索字符串为“,”tempf“,结果为“,”tempf:”73“,”WD:”东南风“,”wde:”Se”
通过第二次和第三次的数据,我们可以计算我们获得的字符串长度。在第二次获得的数据中,我们可以提出最终结果“23”的温度数据
请参阅以下步骤
char*splitx(char*str,char*s,char*e){
char*t1=NULL
char*t2=NULL
char*t3=NULL
uint8_t lensx=0
t1=strstrstr(str,s)
如果(t1==NULL){
ESP_LOGI(“FUNC_splitx”,“t1valave为空”)
返回ESP_OK
}
t2=strstr(t1,e)
如果(t2==NULL){
ESP_LOGI(“FUNC_splitx”,“t2valave为空”)
返回ESP_OK
}
lensx=strlen(t1)-strlen(t2)-斯特伦(s)
图表='\0'
t3=(char*)malloc(sizeof(char)*lensx+1)
memset(t3,t,sizeof(char)*lensx+1)
strncpy(t3,t1+sizeof(char)*strlen(s),lensx)
返回t3
}
编写代码,然后使用makeapp flash

