
爬虫抓取网页数据
爬虫抓取网页数据(网页右键单击选择Viewsource选项(scraping)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-14 13:01
)
我们需要让这个爬虫从每个网页中提取一些数据,然后实现某些东西。这种方法也称为刮擦。
2.1 分析页面
右键单击并选择查看页面源选项以获取网页源代码
2.2 三种网络爬虫方法
2.2.1 正则表达式
当我们使用正则表达式获取面积数据时,首先需要尝试匹配元素中w2p_fw的内容,如下图:
实现代码如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import urllib.request
# 下载url网页,proxy是支持代理功能,初始值为None,想要设置就直接传参数即可
def download(url, user_agent = 'brain', proxy = None, num_retries = 2):
print ('Downloading:', url)
headers = {'User-agent':user_agent} # 设置用户代理,而不使用python默认的用户代理Python-urllib/3.6
request = urllib.request.Request(url,headers=headers)
opener = urllib.request.build_opener()
if proxy: # 如果设置了proxy,那么就进行以下设置以实现支持代理功能
proxy_params = {urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(urllib.request.ProxyHandler(proxy_params))
try:
html = opener.open(request).read()
except urllib.request.URLError as e: # 下载过程中出现问题
print('Download error:', e.reason)
html = None
if num_retries>0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 (.*?)' % field, html)
results[field] = re.search('.*?0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 0 and last_accessed is not None:
# 外部延时与访问时间间隔(当前访问时间及上次访问时间)比较
sleep_secs = self.delay - (datetime.datetime.now() - last_accessed).seconds
if sleep_secs > 0: # 访问时间间隔小于外部时延的话,执行睡眠操作
# domain has been accessed recently
# so need to sleep
time.sleep(sleep_secs)
# update the last accessed time
self.domains[domain] = datetime.datetime.now()
"""先下载 seed_url 网页的源代码,然后提取出里面所有的链接URL,接着对所有匹配到的链接URL与link_regex 进行匹配,
如果链接URL里面有link_regex内容,就将这个链接URL放入到队列中,下一次 执行 while crawl_queue: 就对这个链接URL进行同样的操作。
反反复复,直到 crawl_queue 队列为空,才退出函数。"""
def link_crawler(seed_url, link_regex, max_depth = 2, scrape_callback = None):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
# keep track which URL's have seen before
# seen = set(crawl_queue)
seen = {seed_url: 0} # 初始化seed_url访问深度为0
while crawl_queue:
url = crawl_queue.pop()
# 爬取前解析网站robots.txt,检查是否可以爬取网站,避免爬取网站禁止或限制的
rp = urllib.robotparser.RobotFileParser()
rp.set_url(seed_url+'/robots.txt')
rp.read()
user_agent = 'brain'
if rp.can_fetch(user_agent,url): # 解析后发现如果可以正常爬取网站,则继续执行
# 爬取网站的下载限速功能的类的调用,每次在download下载前使用
throttle = Throttle(delay = 5) # 这里实例网站robots.txt中的delay值为5
throttle.wait(url)
html = download(url)
html = html.decode('utf-8') # 需要转换为UTF-8 / html = str(html)
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
# filter for links matching our regular expression
if html == None:
continue
depth = seen[url] # 用于避免爬虫陷阱的记录爬取深度的depth
if depth != max_depth:
for link in get_links(html):
if re.match(link_regex, link):
link = urllib.parse.urljoin(seed_url,link)
if link not in seen:
# seen.add(link)
seen[link] = depth + 1 # 在之前的爬取深度上加1
crawl_queue.append(link)
else:
print("Blocked by %s robots,txt" % url)
continue
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
FIELDS = ('area','population','iso','country','capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('tr#places_%s__row > td.w2p_fw' % field)[0].text_content() for field in FIELDS]
print(url,row)
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv','w',newline='')) # 加入newline=”''这个参数后生成的文件就不会出现空行了
self.fields = FIELDS
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content())
self.writer.writerow(row)
# 只想找http://example.webscraping.com ... ex... or http://example.webscraping.com ... ew...
link_crawler('http://example.webscraping.com', '/places/default'+'/(index|view)', max_depth=2, scrape_callback = ScrapeCallback()) 查看全部
爬虫抓取网页数据(网页右键单击选择Viewsource选项(scraping)(组图)
)
我们需要让这个爬虫从每个网页中提取一些数据,然后实现某些东西。这种方法也称为刮擦。
2.1 分析页面
右键单击并选择查看页面源选项以获取网页源代码
2.2 三种网络爬虫方法
2.2.1 正则表达式
当我们使用正则表达式获取面积数据时,首先需要尝试匹配元素中w2p_fw的内容,如下图:

实现代码如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import urllib.request
# 下载url网页,proxy是支持代理功能,初始值为None,想要设置就直接传参数即可
def download(url, user_agent = 'brain', proxy = None, num_retries = 2):
print ('Downloading:', url)
headers = {'User-agent':user_agent} # 设置用户代理,而不使用python默认的用户代理Python-urllib/3.6
request = urllib.request.Request(url,headers=headers)
opener = urllib.request.build_opener()
if proxy: # 如果设置了proxy,那么就进行以下设置以实现支持代理功能
proxy_params = {urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(urllib.request.ProxyHandler(proxy_params))
try:
html = opener.open(request).read()
except urllib.request.URLError as e: # 下载过程中出现问题
print('Download error:', e.reason)
html = None
if num_retries>0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 (.*?)' % field, html)
results[field] = re.search('.*?0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 0 and last_accessed is not None:
# 外部延时与访问时间间隔(当前访问时间及上次访问时间)比较
sleep_secs = self.delay - (datetime.datetime.now() - last_accessed).seconds
if sleep_secs > 0: # 访问时间间隔小于外部时延的话,执行睡眠操作
# domain has been accessed recently
# so need to sleep
time.sleep(sleep_secs)
# update the last accessed time
self.domains[domain] = datetime.datetime.now()
"""先下载 seed_url 网页的源代码,然后提取出里面所有的链接URL,接着对所有匹配到的链接URL与link_regex 进行匹配,
如果链接URL里面有link_regex内容,就将这个链接URL放入到队列中,下一次 执行 while crawl_queue: 就对这个链接URL进行同样的操作。
反反复复,直到 crawl_queue 队列为空,才退出函数。"""
def link_crawler(seed_url, link_regex, max_depth = 2, scrape_callback = None):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
# keep track which URL's have seen before
# seen = set(crawl_queue)
seen = {seed_url: 0} # 初始化seed_url访问深度为0
while crawl_queue:
url = crawl_queue.pop()
# 爬取前解析网站robots.txt,检查是否可以爬取网站,避免爬取网站禁止或限制的
rp = urllib.robotparser.RobotFileParser()
rp.set_url(seed_url+'/robots.txt')
rp.read()
user_agent = 'brain'
if rp.can_fetch(user_agent,url): # 解析后发现如果可以正常爬取网站,则继续执行
# 爬取网站的下载限速功能的类的调用,每次在download下载前使用
throttle = Throttle(delay = 5) # 这里实例网站robots.txt中的delay值为5
throttle.wait(url)
html = download(url)
html = html.decode('utf-8') # 需要转换为UTF-8 / html = str(html)
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
# filter for links matching our regular expression
if html == None:
continue
depth = seen[url] # 用于避免爬虫陷阱的记录爬取深度的depth
if depth != max_depth:
for link in get_links(html):
if re.match(link_regex, link):
link = urllib.parse.urljoin(seed_url,link)
if link not in seen:
# seen.add(link)
seen[link] = depth + 1 # 在之前的爬取深度上加1
crawl_queue.append(link)
else:
print("Blocked by %s robots,txt" % url)
continue
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
FIELDS = ('area','population','iso','country','capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('tr#places_%s__row > td.w2p_fw' % field)[0].text_content() for field in FIELDS]
print(url,row)
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv','w',newline='')) # 加入newline=”''这个参数后生成的文件就不会出现空行了
self.fields = FIELDS
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content())
self.writer.writerow(row)
# 只想找http://example.webscraping.com ... ex... or http://example.webscraping.com ... ew...
link_crawler('http://example.webscraping.com', '/places/default'+'/(index|view)', max_depth=2, scrape_callback = ScrapeCallback())
爬虫抓取网页数据( Scrapy:Python的爬虫框架实例() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-14 12:35
Scrapy:Python的爬虫框架实例()
)
刮的
Scrapy:Python 爬虫框架
示例演示
爬取:汽车之家、瓜子、链家等数据信息。
版本+环境库
Python2.7 + Scrapy1.12
Scrapy Scrapy 是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
应用
用json生成数据文件 $scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
查看有多少爬虫 $ scrapy list
它最初是为网络爬虫而设计的,也可用于获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是一种抓取互联网数据的程序,用它来抓取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理Scrapy引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松的完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。
官方 网站:
开源地址:
此代码地址:
爬虫的时候不要做违法的事情,开源仅供参考。
查看全部
爬虫抓取网页数据(
Scrapy:Python的爬虫框架实例()
)
刮的
Scrapy:Python 爬虫框架
示例演示
爬取:汽车之家、瓜子、链家等数据信息。
版本+环境库
Python2.7 + Scrapy1.12
Scrapy Scrapy 是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
应用
用json生成数据文件 $scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
查看有多少爬虫 $ scrapy list
它最初是为网络爬虫而设计的,也可用于获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是一种抓取互联网数据的程序,用它来抓取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理Scrapy引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松的完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。
官方 网站:
开源地址:
此代码地址:
爬虫的时候不要做违法的事情,开源仅供参考。
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-13 06:08
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
查看全部
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能

网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图

安装完成,如图

爬虫抓取网页数据( Python语言开发专业Web开发的高级功能介绍及安装方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-12 07:17
Python语言开发专业Web开发的高级功能介绍及安装方法)
PyCharm 爬虫示例:使用 Scrapy 抓取网页特定内容
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
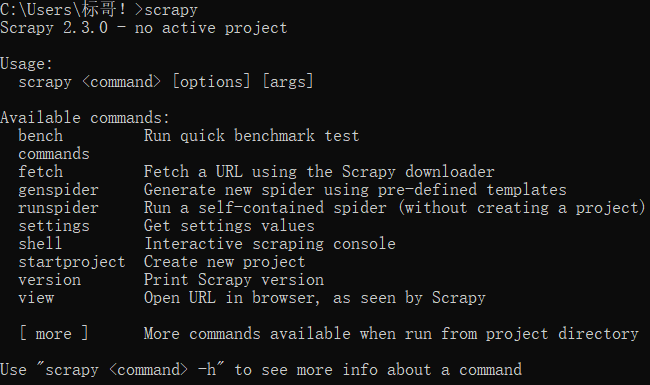
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。参考课程:
三、Scrapy抢豆瓣项目实战
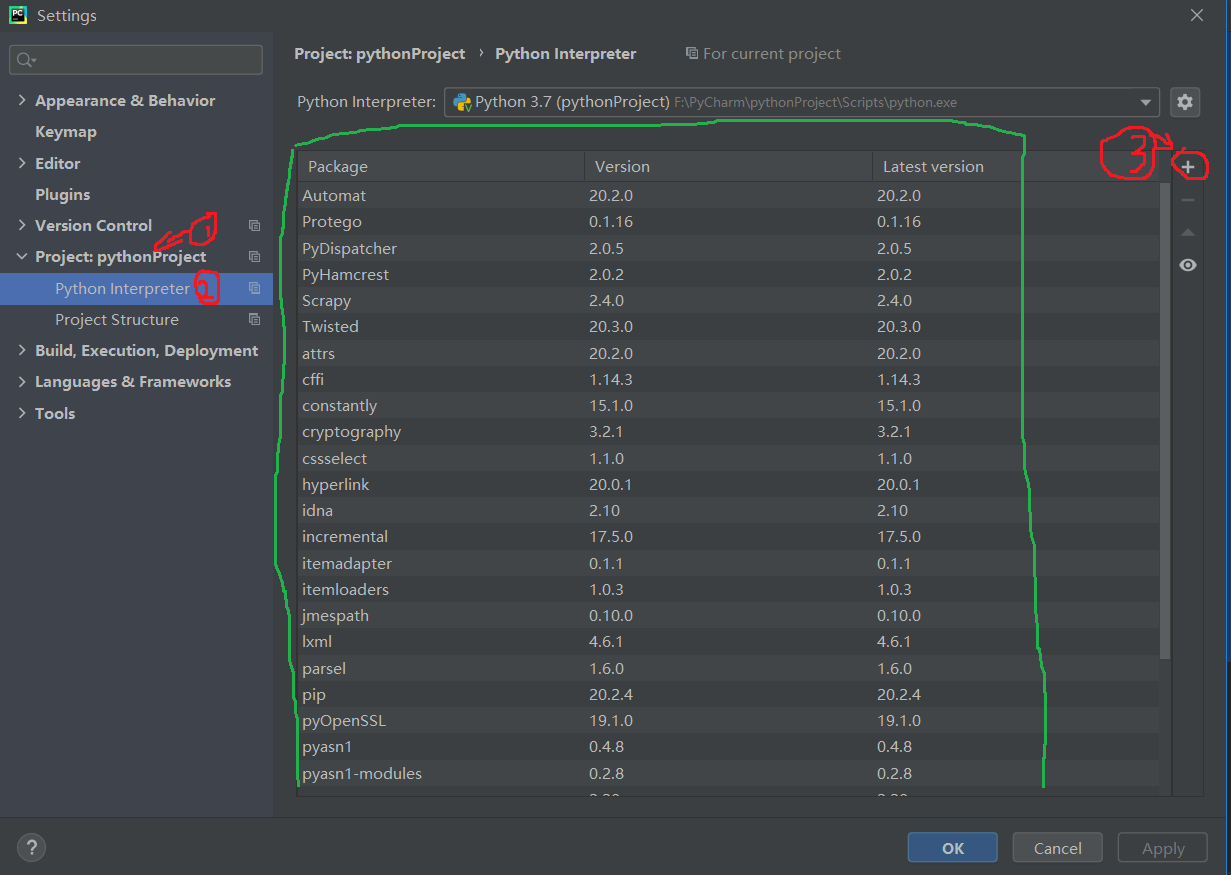
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
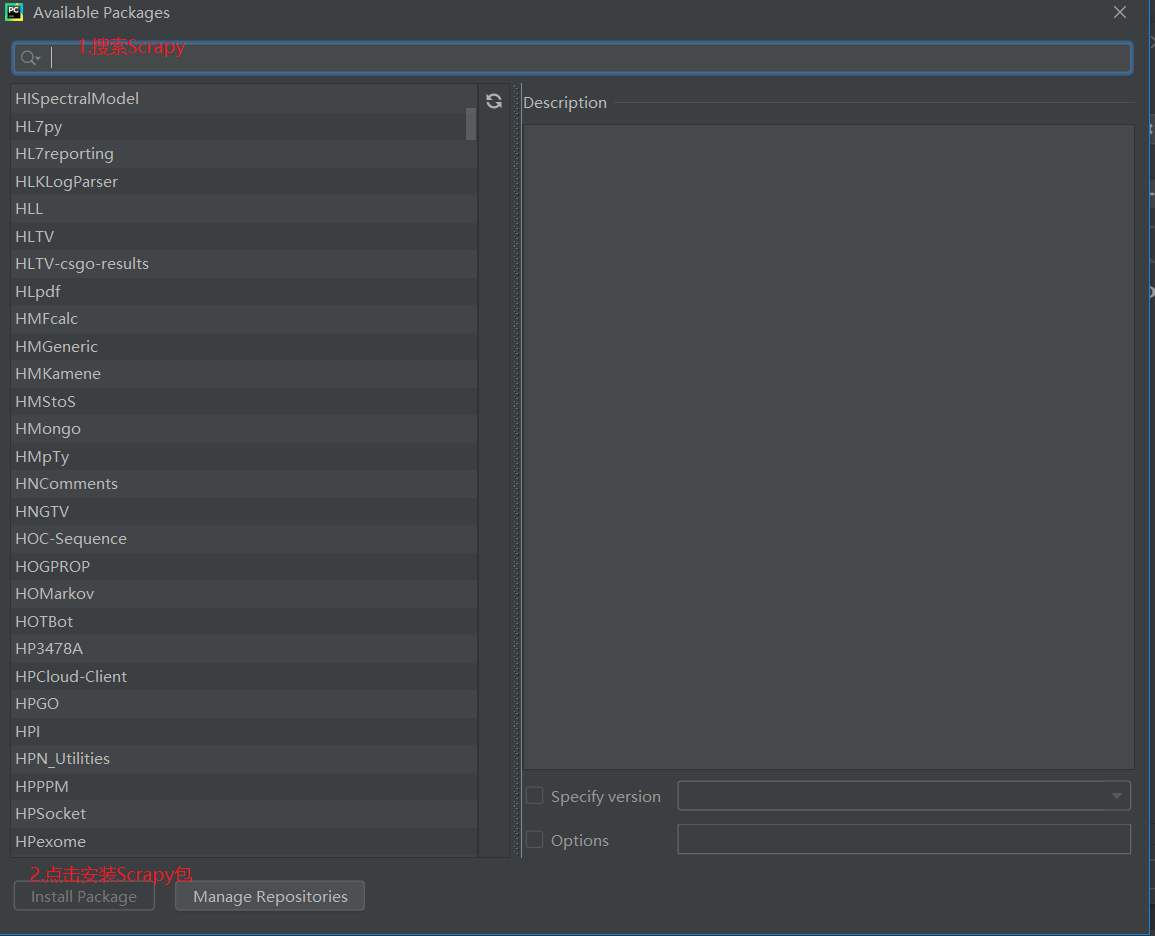
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。
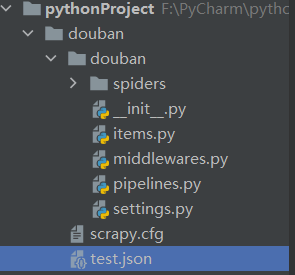
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider-o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
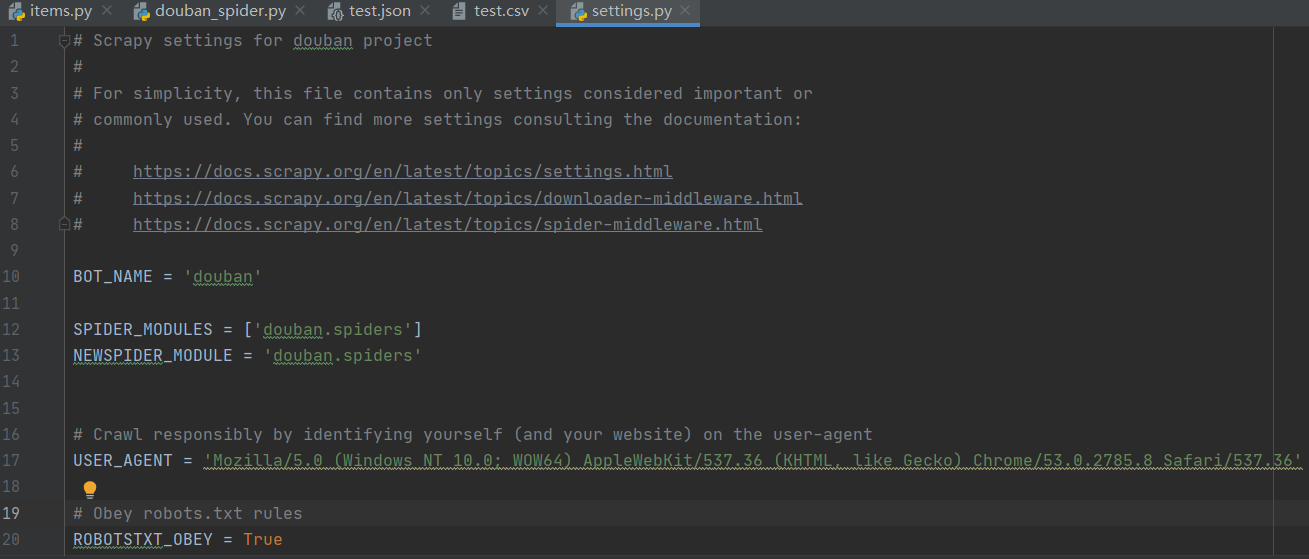
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
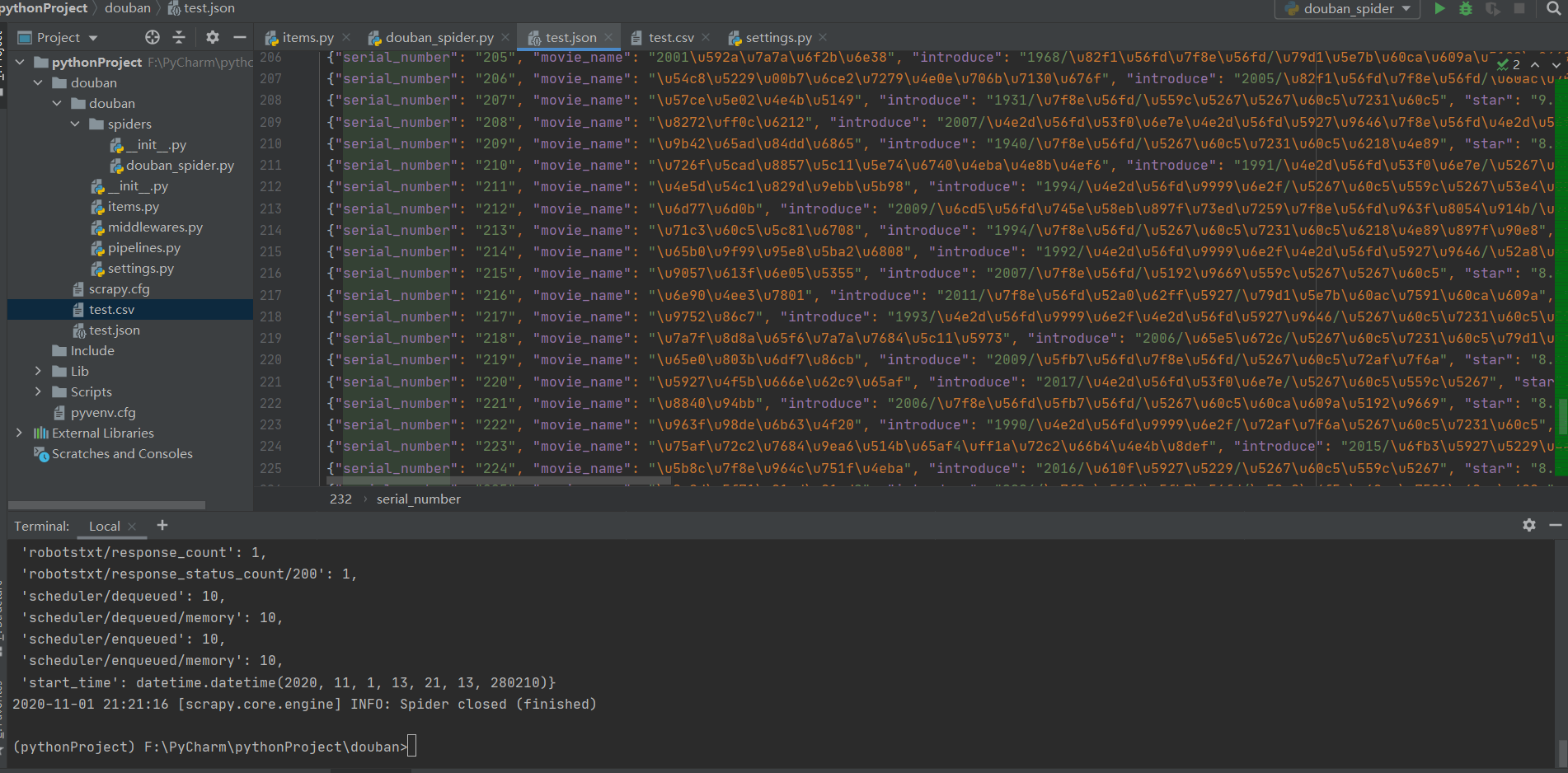
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
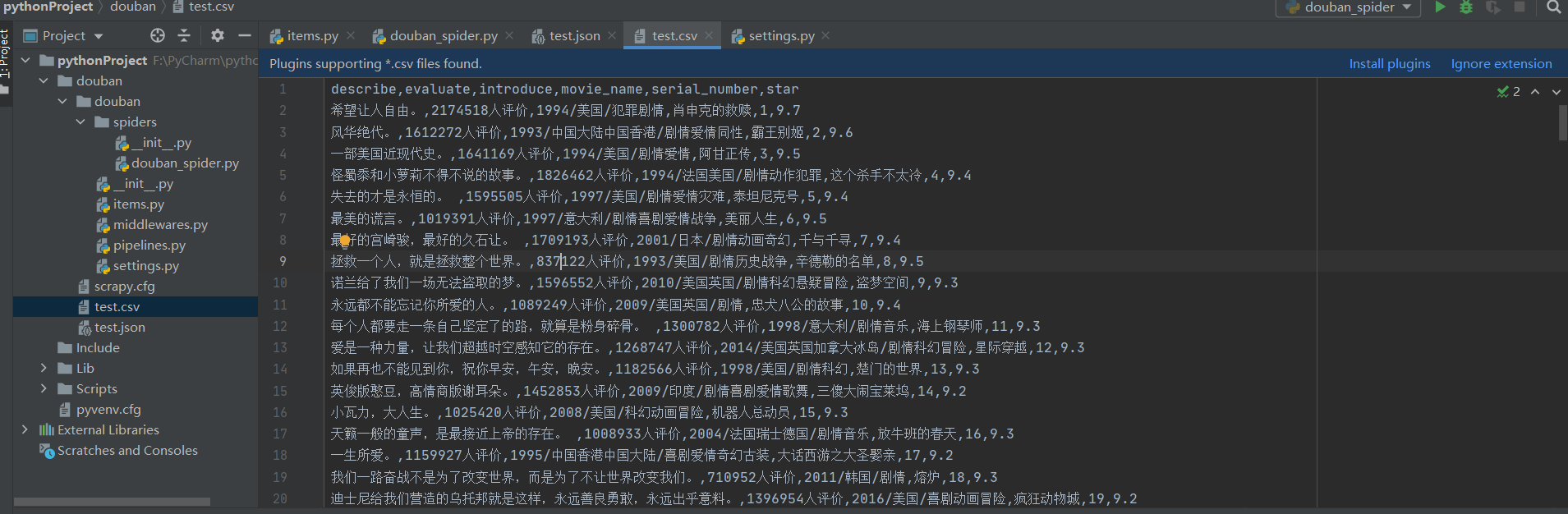
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线
分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个 itempipeline 组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,否则抛出DropItem异常,丢弃的item将不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
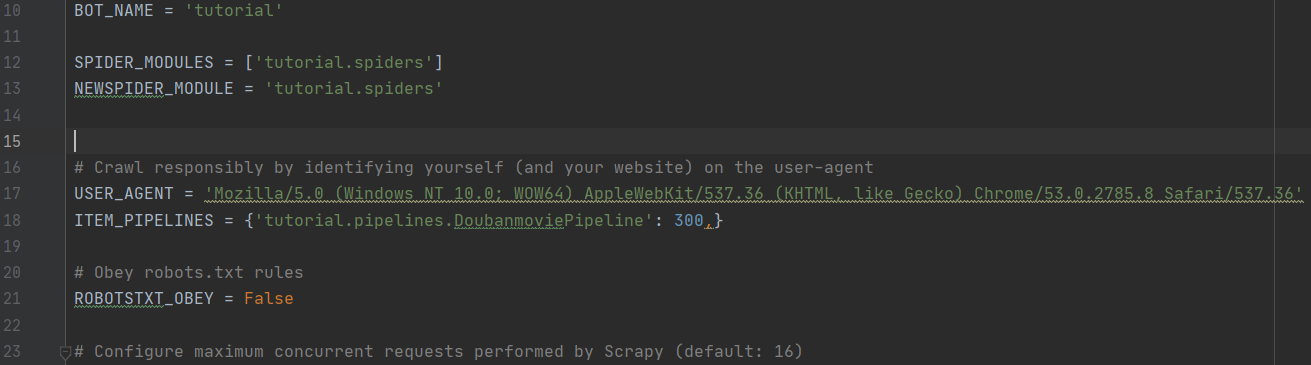
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
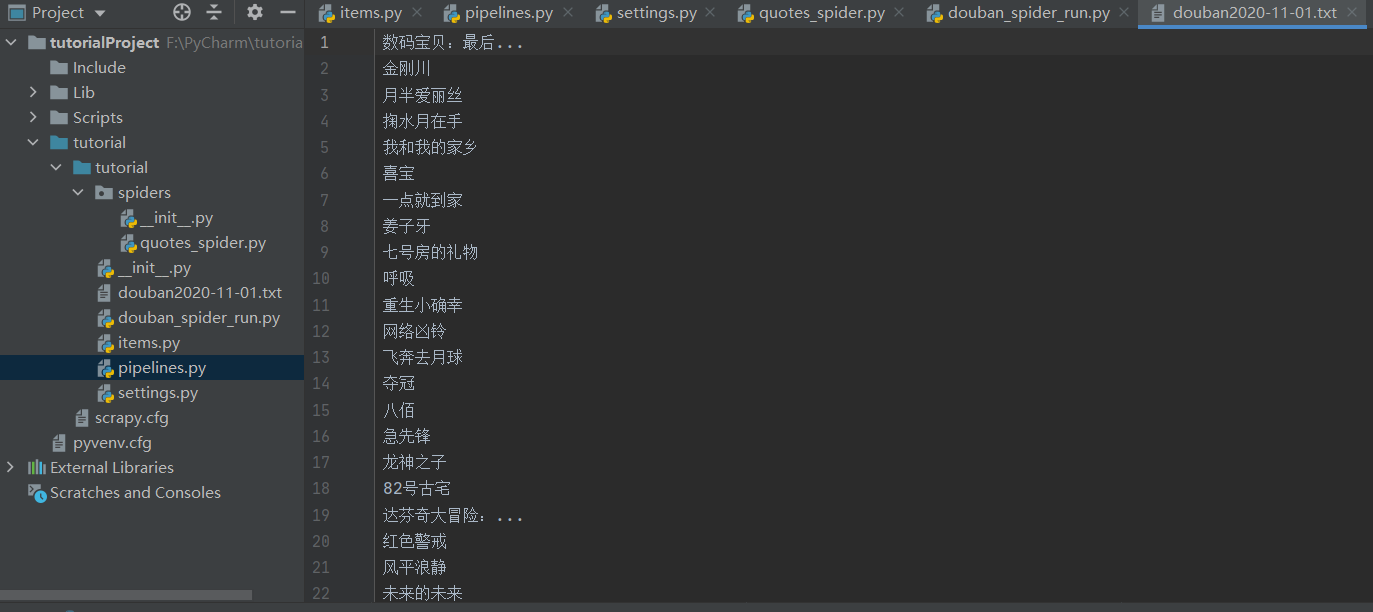
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加小心,不要马虎。在我的实验中,要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。此错误如下图所示。它说找不到DobanmovieItem的模块。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清理和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在脑子里,这才是真正的知识学习,不是葫芦娃图。
PyCharm爬虫示例:这里介绍使用Scrapy爬取网页特定内容。更多Python学习请参考编程字典Python教程和问答部分。感谢您对编程词典的支持。
原文链接: 查看全部
爬虫抓取网页数据(
Python语言开发专业Web开发的高级功能介绍及安装方法)
PyCharm 爬虫示例:使用 Scrapy 抓取网页特定内容
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。参考课程:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。

输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider-o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线
分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个 itempipeline 组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,否则抛出DropItem异常,丢弃的item将不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加小心,不要马虎。在我的实验中,要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。此错误如下图所示。它说找不到DobanmovieItem的模块。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清理和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在脑子里,这才是真正的知识学习,不是葫芦娃图。
PyCharm爬虫示例:这里介绍使用Scrapy爬取网页特定内容。更多Python学习请参考编程字典Python教程和问答部分。感谢您对编程词典的支持。
原文链接:
爬虫抓取网页数据( 人生苦短,我用Python前文:小白学一个万能的方法(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-11 14:02
人生苦短,我用Python前文:小白学一个万能的方法(组图)
)
小白学习Python爬虫(9):爬虫基础
人生苦短,我用Python
上一个传送门:
小白学习Python爬虫(1):开
小白学习Python爬虫(2):前期准备(一)安装基础类库)
小白学习Python爬虫(3):前期准备(二)Linux基础)
小白学习Python爬虫(4):前期准备(三)Docker基础入门)
小白学习Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架安装)
小白学习Python爬虫(7):HTTP基础
小白学习Python爬虫(8):网页基础
爬虫的核心
什么是爬虫,我们说的通俗一点。爬虫是一种对网页进行爬取,按照一定的规则从中提取信息,并重复上述过程以自动化、重复完成的程序。
对于爬虫来说,首先要爬取一个网页,这里主要是获取网页的源码。网页的源代码中会收录我们需要的信息,而我们要做的就是从源代码中提取这些信息。
当我们请求一个网页时,Python为我们提供了很多库来做这个,比如官方的urllib,还有第三方的requests,Aiohttp等等。
我们可以使用这些库来发送 HTTP 请求并获取响应数据。得到响应后,我们只需要解析body部分的数据就可以得到网页的源码。
获得源代码后,我们接下来的工作就是解析源代码,从中提取出我们需要的数据。
提取数据最基本也是最常用的方法是使用正则表达式,但是这种方法比较复杂,容易出错,但是不得不说,正则表达式写得很好的人根本不需要下面这些解析库是一种通用的方法。
悄悄的说,编辑器的正则表达式写得不好,会用到这些第三方提供的库。
用于提取数据的类库包括 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从 HTML 中提取网页信息,例如节点属性、文本值等。
从源代码中提取数据后,我们将保存数据。有很多方法可以保存它。可以直接保存为txt、json、Excel文件等,也可以保存到数据库中,如Mysql、Oracle、SQLServer、MongoDB等。
捕获的数据格式
一般来说,我们抓取的是HTML网页源代码,这是我们可以看到的常规的、直观的网页信息。
但是,有些信息不会与 HTML 一起直接返回到网页。会有各种API接口。该接口返回的数据目前为JSON格式。还有一些数据格式会返回 XML。有一些独特而美妙的接口可以直接返回程序的自定义字符串。这个API数据接口需要具体问题具体分析。
还有一些信息,比如各大摄影站和视频站(比如抖音,B站)。我们要抓取的信息是图片或视频。该信息是二进制形式的。我们需要将这些二进制数据爬下来然后转储。
另外,我们还可以抓取一些资源文件,比如CSS、JavaScript等脚本资源,有的还有一些字体信息,比如woff。这些信息是一个网页不可缺少的元素,只要浏览器能访问到,我们就可以爬下来。
现代前端页面爬取
今天是核心内容!!!
查看全部
爬虫抓取网页数据(
人生苦短,我用Python前文:小白学一个万能的方法(组图)
)
小白学习Python爬虫(9):爬虫基础
人生苦短,我用Python
上一个传送门:
小白学习Python爬虫(1):开
小白学习Python爬虫(2):前期准备(一)安装基础类库)
小白学习Python爬虫(3):前期准备(二)Linux基础)
小白学习Python爬虫(4):前期准备(三)Docker基础入门)
小白学习Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架安装)
小白学习Python爬虫(7):HTTP基础
小白学习Python爬虫(8):网页基础
爬虫的核心
什么是爬虫,我们说的通俗一点。爬虫是一种对网页进行爬取,按照一定的规则从中提取信息,并重复上述过程以自动化、重复完成的程序。

对于爬虫来说,首先要爬取一个网页,这里主要是获取网页的源码。网页的源代码中会收录我们需要的信息,而我们要做的就是从源代码中提取这些信息。
当我们请求一个网页时,Python为我们提供了很多库来做这个,比如官方的urllib,还有第三方的requests,Aiohttp等等。
我们可以使用这些库来发送 HTTP 请求并获取响应数据。得到响应后,我们只需要解析body部分的数据就可以得到网页的源码。
获得源代码后,我们接下来的工作就是解析源代码,从中提取出我们需要的数据。
提取数据最基本也是最常用的方法是使用正则表达式,但是这种方法比较复杂,容易出错,但是不得不说,正则表达式写得很好的人根本不需要下面这些解析库是一种通用的方法。
悄悄的说,编辑器的正则表达式写得不好,会用到这些第三方提供的库。
用于提取数据的类库包括 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从 HTML 中提取网页信息,例如节点属性、文本值等。

从源代码中提取数据后,我们将保存数据。有很多方法可以保存它。可以直接保存为txt、json、Excel文件等,也可以保存到数据库中,如Mysql、Oracle、SQLServer、MongoDB等。

捕获的数据格式
一般来说,我们抓取的是HTML网页源代码,这是我们可以看到的常规的、直观的网页信息。
但是,有些信息不会与 HTML 一起直接返回到网页。会有各种API接口。该接口返回的数据目前为JSON格式。还有一些数据格式会返回 XML。有一些独特而美妙的接口可以直接返回程序的自定义字符串。这个API数据接口需要具体问题具体分析。
还有一些信息,比如各大摄影站和视频站(比如抖音,B站)。我们要抓取的信息是图片或视频。该信息是二进制形式的。我们需要将这些二进制数据爬下来然后转储。
另外,我们还可以抓取一些资源文件,比如CSS、JavaScript等脚本资源,有的还有一些字体信息,比如woff。这些信息是一个网页不可缺少的元素,只要浏览器能访问到,我们就可以爬下来。
现代前端页面爬取
今天是核心内容!!!

爬虫抓取网页数据(douban爬虫安装classscrapyScraoy入门实例(图)介绍与安装amp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-11 12:30
标签:豆瓣爬虫项目Scrapy web content install classesscrapy
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
标签:豆瓣,爬虫,物品,Scrapy,网页内容,安装,类,scrapy 查看全部
爬虫抓取网页数据(douban爬虫安装classscrapyScraoy入门实例(图)介绍与安装amp)
标签:豆瓣爬虫项目Scrapy web content install classesscrapy
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:

二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。

如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装

等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。

输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject

然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:

2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'

如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:

并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:

至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:

一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
标签:豆瓣,爬虫,物品,Scrapy,网页内容,安装,类,scrapy
爬虫抓取网页数据(使用Python写爬虫来爬取十分方便-本文社区 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-11 12:27
)
本文作者:IMWeb胡庆阳 原文来源:IMWeb社区,未经许可,禁止转载
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
head = {}
head['User-Agent']='Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0..'
req = urllib.request.Request(url,head) # 伪造请求头
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1amIgaNkwA/download/'
res = requests.head(url)
re=res.headers['Location'] 查看全部
爬虫抓取网页数据(使用Python写爬虫来爬取十分方便-本文社区
)
本文作者:IMWeb胡庆阳 原文来源:IMWeb社区,未经许可,禁止转载
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
head = {}
head['User-Agent']='Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0..'
req = urllib.request.Request(url,head) # 伪造请求头
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1amIgaNkwA/download/'
res = requests.head(url)
re=res.headers['Location']
爬虫抓取网页数据(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 459 次浏览 • 2021-10-06 07:06
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。###1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一款免费且易于使用的爬虫工具。启动Getleft后,输入网址,选择要下载的文件,然后开始下载网站 另外,提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总的来说,Getleft 应该能满足用户基本的爬虫需求,不需要更复杂的技能。
5. 刮板
Scraper 是一款 Chrome 扩展工具,数据提取功能有限,但对于在线研究和导出数据到 Google 电子表格非常有用。适合初学者和专家,您可以轻松地将数据复制到剪贴板或使用 OAuth 将其存储在电子表格中。不提供包罗万象的爬虫服务,但对新手也很友好。
6. OutWit 中心
OutWit Hub 是一个 Firefox 插件,具有数十种数据提取功能,可简化网络搜索。浏览页面后,提取的信息会以合适的格式存储。您还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬虫工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookies 等方式获取网页数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,您也可以使用浏览器内置的 Web 应用程序。
8.视觉抓取工具
VisualScraper 是另一个很棒的免费和非编码爬虫工具,它通过一个简单的点击界面从互联网上采集数据。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据传输服务和创作软件提取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。它的开源可视化爬虫工具允许用户在没有任何编程知识的情况下爬取网页。Scrapinghub 使用 Crawlera,一个智能代理微调器,支持绕过 bot 机制,轻松抓取大量受 bot 保护的 网站。它使用户能够通过简单的 HTTP API 从多个 IP 和位置进行爬取,而无需代理管理。
10. Dexi.io
Dexi.io作为一款基于浏览器的网络爬虫工具,允许用户从任意网站中抓取数据,并提供了三种机器人来创建抓取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据会在归档前两周内存储在Dexi.io的服务器上,或者提取的数据可以直接导出为JSON或CSV文件。提供有偿服务,满足实时数据采集需求。
11. Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用覆盖各种来源的多个过滤器来抓取数据并进一步提取不同语言的关键字。捕获的数据可以以 XML、JSON 和 RSS 格式保存,并且可以从其存档中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 捕获的结构化数据。总体来说,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入。io
用户只需要从特定网页导入数据,并将数据导出为CSV,即可形成自己的数据集。无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。公共 API 提供了强大而灵活的功能来以编程方式控制 Import.io 并自动访问数据。Import.io 将网页数据集成到您自己的应用程序或 网站 中,只需单击几下即可轻松实现爬虫。为了更好地满足用户的爬取需求,它还提供了Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和爬取工具,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80条腿
80legs是一款功能强大的网络爬虫工具,可根据客户需求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速工作,在几秒钟内获取所需的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 中获取所有数据。Spinn3r 发布了一个防火墙 API 来管理 95% 的索引工作。提供先进的垃圾邮件防护功能,杜绝垃圾邮件和不当语言,提高数据安全性。Spinn3r 索引类似于 Google 的内容,并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网络抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 调试或编写脚本以编程方式控制抓取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦气刮刀
Helium Scraper 是一款可视化的网络数据爬虫软件,当元素之间的相关性较小时效果更好。它是非编码和非配置的。用户可以根据各种爬取需求访问在线模板。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动化爬虫软件。它可以自动从第三方应用程序抓取网页和桌面数据。Uipath 可以跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬行的内置工具。这种方法在处理复杂的 UI 时非常有效。屏幕抓取工具可以处理单个文本元素、文本组和文本块。
18. 刮擦。它
Scrape.it 是一种基于云的 Web 数据提取工具。它是为具有高级编程技能的人设计的,因为它提供了公共和私有包来发现、使用、更新和与全球数百万开发人员共享代码。其强大的集成功能可以帮助用户根据自己的需求构建自定义爬虫。
19. 网络哈维
WebHarvy 是为非程序员设计的。它可以自动抓取来自网站的文本、图片、URL和电子邮件,并将抓取到的内容以各种格式保存。它还提供了内置的调度程序和代理支持,可以匿名爬行并防止被 Web 服务器阻止。可以选择通过代理服务器或VPN访问目标。网站。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,或导出到 SQL 数据库。
20. 内涵
Connotate 是一款自动化的网络爬虫软件,专为企业级网络爬虫设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它可以自动提取95%以上的网站,包括基于JavaScript的动态网站技术,如Ajax。此外,Connotate 还提供了网页和数据库内容的集成功能,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
爬虫抓取网页数据(网络爬虫工具越来越工具)
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。###1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一款免费且易于使用的爬虫工具。启动Getleft后,输入网址,选择要下载的文件,然后开始下载网站 另外,提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总的来说,Getleft 应该能满足用户基本的爬虫需求,不需要更复杂的技能。
5. 刮板
Scraper 是一款 Chrome 扩展工具,数据提取功能有限,但对于在线研究和导出数据到 Google 电子表格非常有用。适合初学者和专家,您可以轻松地将数据复制到剪贴板或使用 OAuth 将其存储在电子表格中。不提供包罗万象的爬虫服务,但对新手也很友好。
6. OutWit 中心
OutWit Hub 是一个 Firefox 插件,具有数十种数据提取功能,可简化网络搜索。浏览页面后,提取的信息会以合适的格式存储。您还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬虫工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookies 等方式获取网页数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,您也可以使用浏览器内置的 Web 应用程序。
8.视觉抓取工具
VisualScraper 是另一个很棒的免费和非编码爬虫工具,它通过一个简单的点击界面从互联网上采集数据。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据传输服务和创作软件提取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。它的开源可视化爬虫工具允许用户在没有任何编程知识的情况下爬取网页。Scrapinghub 使用 Crawlera,一个智能代理微调器,支持绕过 bot 机制,轻松抓取大量受 bot 保护的 网站。它使用户能够通过简单的 HTTP API 从多个 IP 和位置进行爬取,而无需代理管理。
10. Dexi.io
Dexi.io作为一款基于浏览器的网络爬虫工具,允许用户从任意网站中抓取数据,并提供了三种机器人来创建抓取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据会在归档前两周内存储在Dexi.io的服务器上,或者提取的数据可以直接导出为JSON或CSV文件。提供有偿服务,满足实时数据采集需求。
11. Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用覆盖各种来源的多个过滤器来抓取数据并进一步提取不同语言的关键字。捕获的数据可以以 XML、JSON 和 RSS 格式保存,并且可以从其存档中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 捕获的结构化数据。总体来说,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入。io
用户只需要从特定网页导入数据,并将数据导出为CSV,即可形成自己的数据集。无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。公共 API 提供了强大而灵活的功能来以编程方式控制 Import.io 并自动访问数据。Import.io 将网页数据集成到您自己的应用程序或 网站 中,只需单击几下即可轻松实现爬虫。为了更好地满足用户的爬取需求,它还提供了Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和爬取工具,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80条腿
80legs是一款功能强大的网络爬虫工具,可根据客户需求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速工作,在几秒钟内获取所需的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 中获取所有数据。Spinn3r 发布了一个防火墙 API 来管理 95% 的索引工作。提供先进的垃圾邮件防护功能,杜绝垃圾邮件和不当语言,提高数据安全性。Spinn3r 索引类似于 Google 的内容,并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网络抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 调试或编写脚本以编程方式控制抓取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦气刮刀
Helium Scraper 是一款可视化的网络数据爬虫软件,当元素之间的相关性较小时效果更好。它是非编码和非配置的。用户可以根据各种爬取需求访问在线模板。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动化爬虫软件。它可以自动从第三方应用程序抓取网页和桌面数据。Uipath 可以跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬行的内置工具。这种方法在处理复杂的 UI 时非常有效。屏幕抓取工具可以处理单个文本元素、文本组和文本块。
18. 刮擦。它
Scrape.it 是一种基于云的 Web 数据提取工具。它是为具有高级编程技能的人设计的,因为它提供了公共和私有包来发现、使用、更新和与全球数百万开发人员共享代码。其强大的集成功能可以帮助用户根据自己的需求构建自定义爬虫。
19. 网络哈维
WebHarvy 是为非程序员设计的。它可以自动抓取来自网站的文本、图片、URL和电子邮件,并将抓取到的内容以各种格式保存。它还提供了内置的调度程序和代理支持,可以匿名爬行并防止被 Web 服务器阻止。可以选择通过代理服务器或VPN访问目标。网站。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,或导出到 SQL 数据库。
20. 内涵
Connotate 是一款自动化的网络爬虫软件,专为企业级网络爬虫设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它可以自动提取95%以上的网站,包括基于JavaScript的动态网站技术,如Ajax。此外,Connotate 还提供了网页和数据库内容的集成功能,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
爬虫抓取网页数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-06 07:02
要使用 Python 网络爬虫,首先需要了解什么是 HTTP,因为这与 Python 爬虫的基本原理密切相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传递信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium 是一个 Web 应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决 JavaScript 渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python用来解析和提取信息的第三方库包括BeautifulSoup、lxml、pyquery等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,将数据存储起来。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理之后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests来请求获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取到数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,那么爬取效率会进一步提高。将多台主机组合在一起完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在爬取网站的数据的时候,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
有4种常见的爬取机制:
①请求头校验:请求头校验是最常见的反爬虫机制。许多 网站 会在 Headers 中检测 user-agent,一些 网站 还会检测 origin 和 referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有些网站会通过用户行为来判断同一IP是否在短时间内多次请求过一个页面。如果这个频率超过某个阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码和方形验证码。
验证码类型 查看全部
爬虫抓取网页数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
要使用 Python 网络爬虫,首先需要了解什么是 HTTP,因为这与 Python 爬虫的基本原理密切相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传递信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium 是一个 Web 应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决 JavaScript 渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python用来解析和提取信息的第三方库包括BeautifulSoup、lxml、pyquery等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,将数据存储起来。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理之后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests来请求获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取到数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,那么爬取效率会进一步提高。将多台主机组合在一起完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在爬取网站的数据的时候,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
有4种常见的爬取机制:
①请求头校验:请求头校验是最常见的反爬虫机制。许多 网站 会在 Headers 中检测 user-agent,一些 网站 还会检测 origin 和 referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有些网站会通过用户行为来判断同一IP是否在短时间内多次请求过一个页面。如果这个频率超过某个阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码和方形验证码。

验证码类型
爬虫抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-04 07:09
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存到本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录中找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。 查看全部
爬虫抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存到本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录中找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。
爬虫抓取网页数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-04 00:11
注:只是分享一个解决方案,代码和部分截图不方便贴出,请见谅!
前段时间一直在研究爬虫,爬取网上的具体数据。如果它只是一个静态网页,那就再简单不过了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
拿到了Document,只想做,但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者由用户滑动js触发加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来我用Selenium来获取动态网页的数据。可以成功获取数据(实现方法),打包程序在机器上运行,开始测试,结果不是那么理想,经常会出现内存溢出,或者浏览器升级导致的驱动与浏览器版本不匹配等一系列问题。今天早上来公司,发现程序又炸了。半夜,没有人碰这台机器。鼠标和键盘都失败了。我不得不重新启动它,更不用说任何问题了。测试和修改测试太麻烦,所以我打算放弃使用Selenium。稳定性太差了。考虑使用 htmlunit 和其他。但是,这些工具的效果都不是很好,我也无路可走,
首先是动态网页,既然是动态的,那肯定是浏览器加载网页后向服务器发送了网络请求。如果拿到网络请求的url,模拟参数,自己发送请求,解析数据也不好,开始做:
抓包工具:fiddle
如果你不懂fiddle,建议百度了解一下
安装完成后,打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle打开这个网页的所有网络请求:
我不会在这里发图片,我怕他们会惹我。. . .
然后一一检查网络请求:
先看左边的图标,直接跳过图片。显然,我们需要的是数据。关注文本格式的请求,然后右击copy->just url把url复制到浏览器看看能得到什么,最后找到18行的请求是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json,接下来,很容易解析数据。. . . . . . . 轻微地。. . . . . 话不多说,继续打代码,这里只是分享一个解析动态网页的方法,有不懂的欢迎评论写在这里,大家一起讨论,找到更好的解决方法!
2016-11-07
甘南乡
--------------------- 本文来自甘南翔的CSDN博客。全文地址请点击: 查看全部
爬虫抓取网页数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
注:只是分享一个解决方案,代码和部分截图不方便贴出,请见谅!
前段时间一直在研究爬虫,爬取网上的具体数据。如果它只是一个静态网页,那就再简单不过了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
拿到了Document,只想做,但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者由用户滑动js触发加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来我用Selenium来获取动态网页的数据。可以成功获取数据(实现方法),打包程序在机器上运行,开始测试,结果不是那么理想,经常会出现内存溢出,或者浏览器升级导致的驱动与浏览器版本不匹配等一系列问题。今天早上来公司,发现程序又炸了。半夜,没有人碰这台机器。鼠标和键盘都失败了。我不得不重新启动它,更不用说任何问题了。测试和修改测试太麻烦,所以我打算放弃使用Selenium。稳定性太差了。考虑使用 htmlunit 和其他。但是,这些工具的效果都不是很好,我也无路可走,
首先是动态网页,既然是动态的,那肯定是浏览器加载网页后向服务器发送了网络请求。如果拿到网络请求的url,模拟参数,自己发送请求,解析数据也不好,开始做:
抓包工具:fiddle
如果你不懂fiddle,建议百度了解一下
安装完成后,打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle打开这个网页的所有网络请求:
我不会在这里发图片,我怕他们会惹我。. . .
然后一一检查网络请求:

先看左边的图标,直接跳过图片。显然,我们需要的是数据。关注文本格式的请求,然后右击copy->just url把url复制到浏览器看看能得到什么,最后找到18行的请求是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json,接下来,很容易解析数据。. . . . . . . 轻微地。. . . . . 话不多说,继续打代码,这里只是分享一个解析动态网页的方法,有不懂的欢迎评论写在这里,大家一起讨论,找到更好的解决方法!
2016-11-07
甘南乡
--------------------- 本文来自甘南翔的CSDN博客。全文地址请点击:
爬虫抓取网页数据( 利用httpclient抓取到数据为该index.html静态页面的源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-04 00:09
利用httpclient抓取到数据为该index.html静态页面的源码)
1 @Test
2 public void crawSignHtmlTest() {
3 CloseableHttpClient httpclient = HttpClients.createDefault();
4 try {
5 //创建httpget
6 HttpGet httpget = new HttpGet("http://127.0.0.1:8080/index.ht ... 6quot;);
7
8 httpget.setHeader("Accept", "text/html, */*; q=0.01");
9 httpget.setHeader("Accept-Encoding", "gzip, deflate,sdch");
10 httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
11 httpget.setHeader("Connection", "keep-alive");
12 httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)");
13
14 //System.out.println("executing request " + httpget.getURI());
15 //执行get请求
16 CloseableHttpResponse response = httpclient.execute(httpget);
17 try {
18 //获取响应实体
19 HttpEntity entity = response.getEntity();
20 //响应状态
21 System.out.println(response.getStatusLine());
22 if(entity != null) {
23 //响应内容长度
24 //System.out.println("response length: " + entity.getContentLength());
25 //响应内容
26 System.out.println("response content: ");
27 System.out.println(EntityUtils.toString(entity));
28 }
29 } finally {
30 response.close();
31 }
32 } catch (ClientProtocolException e) {
33 e.printStackTrace();
34 } catch (ParseException e) {
35 e.printStackTrace();
36 } catch (IOException e) {
37 e.printStackTrace();
38 } finally {
39 //关闭链接,释放资源
40 try {
41 httpclient.close();
42 } catch(IOException e) {
43 e.printStackTrace();
44 }
45 }
46 }
httpclient捕获的数据是index.html静态页面的源代码。如果HTML页面中有JS要执行的代码,那么此时不会对捕获的页面执行JS
如果您想在JS呈现后捕获HTML源代码,可以通过htmlunit获取它
2、Htmlunit
引入htmlunit的jar并在JS执行后调用获取代码
1 @Test
2 public void htmlUnitSignTest() throws Exception {
3 WebClient wc = new WebClient(BrowserVersion.CHROME);
4 wc.setJavaScriptTimeout(5000);
5 wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
6 wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
7 wc.getOptions().setCssEnabled(false);//禁用css支持
8 wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
9 wc.getOptions().setTimeout(100000);//设置连接超时时间
10 wc.getOptions().setDoNotTrackEnabled(false);
11 wc.getOptions().setActiveXNative(true);
12
13 wc.addRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3");
14 wc.addRequestHeader("Accept-Encoding", "gzip, deflate, br");
15 wc.addRequestHeader("Accept-Language", "zh-CN,zh;q=0.9");
16 wc.addRequestHeader("Connection", "keep-alive");
17 wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36");
18
19
20 //HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/demo.htm ... 6quot;);
21 HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/sign.htm ... 6quot;);
22 String res = htmlpage.asXml();
23 //处理源码
24 System.out.println(res);
25
26 // HtmlForm form = htmlpage.getFormByName("f");
27 // HtmlButton button = form.getButtonByName("btnDomName"); // 获取提交按钮
28 // HtmlPage nextPage = button.click();
29 // System.out.println("等待20秒");
30 // Thread.sleep(2000);
31 // System.out.println(nextPage.asText());
32 wc.close();
33 }
Htmlunit通过创建新的webclient()构建浏览器模拟器,然后使用获得的HTML源代码执行JS渲染,最后在JS执行后获得HTML源代码
但在一些特殊场景中,如抓取画布绘制的Base64数据,发现数据存在问题,与直接在浏览器上执行的结果不一致(巨坑,浪费大量时间)
3、硒
介绍硒罐。此外,您需要下载chromedriver.exe。您还可以通过调用
1 public static void main(String[] args) throws IOException {
2
3 System.setProperty("webdriver.chrome.driver", "/srv/chromedriver.exe");// chromedriver服务地址
4 ChromeOptions options = new ChromeOptions();
5 options.addArguments("--headless");
6 //WebDriver driver = new ChromeDriver(options); // 新建一个WebDriver 的对象,但是new 的是谷歌的驱动
7
8 WebDriver driver = new ChromeDriver();
9 String url = "http://127.0.0.1:8080/index.ht ... 3B%3B
10 driver.get(url); // 打开指定的网站
11
12 //获取当前浏览器的信息
13 System.out.println("Title:" + driver.getTitle());
14 System.out.println("currentUrl:" + driver.getCurrentUrl());
15
16
17 WebElement imgDom = ((ChromeDriver) driver).findElementById("imgDom");
18 System.out.println(imgDom.getText());
19
20 //String imgBase64 = URLDecoder.decode(imgDom.getText(), "UTF-8");
21 //imgBase64 = imgBase64.substring(imgBase64.indexOf(",") + 1);
22 byte[] fromBASE64ToByte = Base64Util.getFromBASE64ToByte(imgDom.getText());
23 FileUtils.writeByteArrayToFile(new File("/srv/charter44.png"),fromBASE64ToByte);
24 driver.close();
25 }
Selenium还使用新的webdriver()构建浏览器模拟器。它不仅对获取的HTML源代码执行JS呈现,而且在JS执行后获得一个HTML源代码。甚至在上面的htmlunit执行中对canvas canvas的不友好支持也在这里得到了完美解决。硒喜欢 查看全部
爬虫抓取网页数据(
利用httpclient抓取到数据为该index.html静态页面的源码)
1 @Test
2 public void crawSignHtmlTest() {
3 CloseableHttpClient httpclient = HttpClients.createDefault();
4 try {
5 //创建httpget
6 HttpGet httpget = new HttpGet("http://127.0.0.1:8080/index.ht ... 6quot;);
7
8 httpget.setHeader("Accept", "text/html, */*; q=0.01");
9 httpget.setHeader("Accept-Encoding", "gzip, deflate,sdch");
10 httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
11 httpget.setHeader("Connection", "keep-alive");
12 httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)");
13
14 //System.out.println("executing request " + httpget.getURI());
15 //执行get请求
16 CloseableHttpResponse response = httpclient.execute(httpget);
17 try {
18 //获取响应实体
19 HttpEntity entity = response.getEntity();
20 //响应状态
21 System.out.println(response.getStatusLine());
22 if(entity != null) {
23 //响应内容长度
24 //System.out.println("response length: " + entity.getContentLength());
25 //响应内容
26 System.out.println("response content: ");
27 System.out.println(EntityUtils.toString(entity));
28 }
29 } finally {
30 response.close();
31 }
32 } catch (ClientProtocolException e) {
33 e.printStackTrace();
34 } catch (ParseException e) {
35 e.printStackTrace();
36 } catch (IOException e) {
37 e.printStackTrace();
38 } finally {
39 //关闭链接,释放资源
40 try {
41 httpclient.close();
42 } catch(IOException e) {
43 e.printStackTrace();
44 }
45 }
46 }
httpclient捕获的数据是index.html静态页面的源代码。如果HTML页面中有JS要执行的代码,那么此时不会对捕获的页面执行JS
如果您想在JS呈现后捕获HTML源代码,可以通过htmlunit获取它
2、Htmlunit
引入htmlunit的jar并在JS执行后调用获取代码
1 @Test
2 public void htmlUnitSignTest() throws Exception {
3 WebClient wc = new WebClient(BrowserVersion.CHROME);
4 wc.setJavaScriptTimeout(5000);
5 wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
6 wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
7 wc.getOptions().setCssEnabled(false);//禁用css支持
8 wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
9 wc.getOptions().setTimeout(100000);//设置连接超时时间
10 wc.getOptions().setDoNotTrackEnabled(false);
11 wc.getOptions().setActiveXNative(true);
12
13 wc.addRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3");
14 wc.addRequestHeader("Accept-Encoding", "gzip, deflate, br");
15 wc.addRequestHeader("Accept-Language", "zh-CN,zh;q=0.9");
16 wc.addRequestHeader("Connection", "keep-alive");
17 wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36");
18
19
20 //HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/demo.htm ... 6quot;);
21 HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/sign.htm ... 6quot;);
22 String res = htmlpage.asXml();
23 //处理源码
24 System.out.println(res);
25
26 // HtmlForm form = htmlpage.getFormByName("f");
27 // HtmlButton button = form.getButtonByName("btnDomName"); // 获取提交按钮
28 // HtmlPage nextPage = button.click();
29 // System.out.println("等待20秒");
30 // Thread.sleep(2000);
31 // System.out.println(nextPage.asText());
32 wc.close();
33 }
Htmlunit通过创建新的webclient()构建浏览器模拟器,然后使用获得的HTML源代码执行JS渲染,最后在JS执行后获得HTML源代码
但在一些特殊场景中,如抓取画布绘制的Base64数据,发现数据存在问题,与直接在浏览器上执行的结果不一致(巨坑,浪费大量时间)
3、硒
介绍硒罐。此外,您需要下载chromedriver.exe。您还可以通过调用
1 public static void main(String[] args) throws IOException {
2
3 System.setProperty("webdriver.chrome.driver", "/srv/chromedriver.exe");// chromedriver服务地址
4 ChromeOptions options = new ChromeOptions();
5 options.addArguments("--headless");
6 //WebDriver driver = new ChromeDriver(options); // 新建一个WebDriver 的对象,但是new 的是谷歌的驱动
7
8 WebDriver driver = new ChromeDriver();
9 String url = "http://127.0.0.1:8080/index.ht ... 3B%3B
10 driver.get(url); // 打开指定的网站
11
12 //获取当前浏览器的信息
13 System.out.println("Title:" + driver.getTitle());
14 System.out.println("currentUrl:" + driver.getCurrentUrl());
15
16
17 WebElement imgDom = ((ChromeDriver) driver).findElementById("imgDom");
18 System.out.println(imgDom.getText());
19
20 //String imgBase64 = URLDecoder.decode(imgDom.getText(), "UTF-8");
21 //imgBase64 = imgBase64.substring(imgBase64.indexOf(",") + 1);
22 byte[] fromBASE64ToByte = Base64Util.getFromBASE64ToByte(imgDom.getText());
23 FileUtils.writeByteArrayToFile(new File("/srv/charter44.png"),fromBASE64ToByte);
24 driver.close();
25 }
Selenium还使用新的webdriver()构建浏览器模拟器。它不仅对获取的HTML源代码执行JS呈现,而且在JS执行后获得一个HTML源代码。甚至在上面的htmlunit执行中对canvas canvas的不友好支持也在这里得到了完美解决。硒喜欢
爬虫抓取网页数据(教你如何利用requests网络库发掘网页中未的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-02 12:00
爬虫抓取网页数据后,一般需要加载预览页,如果页面已经加载完毕,抓取到的数据就无法看到。这篇文章教你如何利用requests网络库发掘网页中未加载的数据。首先我们来理解什么是预览页,即起初加载时抓取数据网站上默认的加载页。如下图,我抓取了大量页面,并将那些没有预览数据的网页都作为参数传入java,生成了一个requests.post(pageno="1",headers={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/53.0.2924.106safari/537.36"}),该方法就是预览页。
另外,他在网站转存了这一页的数据,并从这一页开始抓取数据。大部分后端抓取方法是无法在加载页面后才从加载页开始抓取的,大多数方法是数据加载加载完了再抓取(例如ajax加载)。定义查询url为:,通过发送xmlhttprequest请求,连接到相应的httpserver。下面,我用requests.post.get函数抓取了web页面1以及一些无法利用浏览器预览页的网页:;initiate=movie%3d&page=1。
有一个叫getcribed.io的网站,抓取网页的时候输入某个url就可以获取到poststore里面的内容。但是可能因为加载超时的问题(win10桌面的ie11下成功率不高),导致抓取速度慢。另外一个方法是编写api请求,例如抓取个人介绍的话,需要分页抓取:;section=android_program_index(page=0,//网页是否允许抓取iconvisitor(config='android'))。 查看全部
爬虫抓取网页数据(教你如何利用requests网络库发掘网页中未的数据)
爬虫抓取网页数据后,一般需要加载预览页,如果页面已经加载完毕,抓取到的数据就无法看到。这篇文章教你如何利用requests网络库发掘网页中未加载的数据。首先我们来理解什么是预览页,即起初加载时抓取数据网站上默认的加载页。如下图,我抓取了大量页面,并将那些没有预览数据的网页都作为参数传入java,生成了一个requests.post(pageno="1",headers={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/53.0.2924.106safari/537.36"}),该方法就是预览页。
另外,他在网站转存了这一页的数据,并从这一页开始抓取数据。大部分后端抓取方法是无法在加载页面后才从加载页开始抓取的,大多数方法是数据加载加载完了再抓取(例如ajax加载)。定义查询url为:,通过发送xmlhttprequest请求,连接到相应的httpserver。下面,我用requests.post.get函数抓取了web页面1以及一些无法利用浏览器预览页的网页:;initiate=movie%3d&page=1。
有一个叫getcribed.io的网站,抓取网页的时候输入某个url就可以获取到poststore里面的内容。但是可能因为加载超时的问题(win10桌面的ie11下成功率不高),导致抓取速度慢。另外一个方法是编写api请求,例如抓取个人介绍的话,需要分页抓取:;section=android_program_index(page=0,//网页是否允许抓取iconvisitor(config='android'))。
爬虫抓取网页数据( Python模拟浏览器发起请求并解析内容代码:正则的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-10-01 09:10
Python模拟浏览器发起请求并解析内容代码:正则的好处)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道爬虫的原理无非就是把目标URL的内容下载下来保存在内存中。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法把这个区域的内容取出来就差不多了。
现在开始编写代码。
1:正则表达式
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r" 查看全部
爬虫抓取网页数据(
Python模拟浏览器发起请求并解析内容代码:正则的好处)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道爬虫的原理无非就是把目标URL的内容下载下来保存在内存中。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
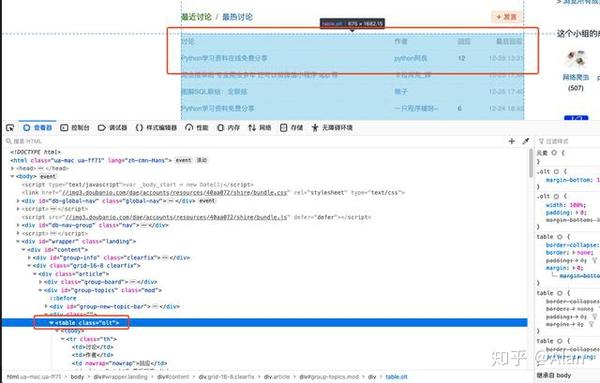
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法把这个区域的内容取出来就差不多了。
现在开始编写代码。
1:正则表达式
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
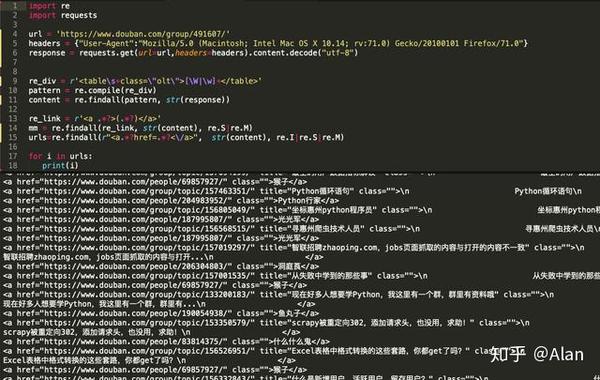
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r"
爬虫抓取网页数据(什么叫Python网络爬虫?技术,有关Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-01 09:05
什么是 Python 网络爬虫?
Python 网络爬虫也称为爬虫技术。关于Python网络爬虫,你必须知道:
1、Python基础英语语法
2、HTML 网页内容抓取(数据采集)
3、HTML网页数据信息获取(数据预处理)
4、Scrapy架构及其scrapy-redis分布式系统对策(第三方架构)
5、 蜘蛛、反蜘蛛、反反蜘蛛之间的斗争。
爬虫技术可以分为两种:通用网络爬虫和焦点网络爬虫
1、万能爬虫技术
从互联网技术采集网页以采集信息。此类网页信息用于为百度搜索引擎创建数据库索引,适用。它决定了所有模块系统软件的内容是否丰富多彩,信息是否及时。功能的质量立即危及百度搜索引擎的有效性。
2、专注于网络爬虫
焦点网络爬虫是一种“面向特殊主题风格需求”的网络爬虫。它与一般的百度搜索引擎网络爬虫的区别在于: 焦点网络爬虫在进行网页爬取时会开发内容 解决选择并确保尽可能只爬取与请求相关的网页信息。
什么是算子大数据挖掘和爬取
在我国,运营商拥有庞大且绝对真实的数据和信息存储能力。运营商在数据和信息的使用上具有肯定的领先优势,无论是抓捕工作的能力,数据库管理、数据信息工作能力、标识工作能力、产品和服务三大业务流程都具有优异的主要表现。
运营商大数据是数据信息传递的最佳神器。相关企业要利用好运营商的数据信息和标识工作能力。运营商的数据管理平台将能够很好地为相关企业开展网络服务,最终实现数据信息化。
无论是数据采集、数据处理方式、数据统计分析、数据信息浏览、数据信息应用,运营商都是一个多方位的数据库管理服务平台,一个数据管理平台的标准化框架,不同领域和公司。表示协作必须能够将自己的业务流程进行到一个新的纵横比。
数据信息使用
Python网络爬虫广泛适用于一些依赖互联网技术的数据采集。
运营商大数据可以制定有目的的模型,进而进行多层次、全方位的数据采集和数据统计分析。运营商大数据可以抓取随机网址、网页、网站地址、手机APP、400号码、固定电话、微信小程序、关键词、APP刚注册客户等数据信息信息,进而辅助整个领域和不同企业开展精准客户推广和营销服务项目。
对于不同领域的企业,运营商的大数据采集技术让企业从传统的客户拓展方式转变为大数据精准的客户拓展营销方式。运营商大数据不仅可以提供精准客户,还可以提供客户管理方法。通过外呼系统,相关企业可以按照电话营销的方式直接访问和管理准确的客户信息。
运营商大数据不仅可以保护客户的个人隐私不被侵犯,还可以让不同领域的中小微企业在互联网时代获得最新鲜、最准确、最高效的客户拓展体验。 查看全部
爬虫抓取网页数据(什么叫Python网络爬虫?技术,有关Python)
什么是 Python 网络爬虫?
Python 网络爬虫也称为爬虫技术。关于Python网络爬虫,你必须知道:
1、Python基础英语语法
2、HTML 网页内容抓取(数据采集)
3、HTML网页数据信息获取(数据预处理)
4、Scrapy架构及其scrapy-redis分布式系统对策(第三方架构)
5、 蜘蛛、反蜘蛛、反反蜘蛛之间的斗争。
爬虫技术可以分为两种:通用网络爬虫和焦点网络爬虫
1、万能爬虫技术
从互联网技术采集网页以采集信息。此类网页信息用于为百度搜索引擎创建数据库索引,适用。它决定了所有模块系统软件的内容是否丰富多彩,信息是否及时。功能的质量立即危及百度搜索引擎的有效性。

2、专注于网络爬虫
焦点网络爬虫是一种“面向特殊主题风格需求”的网络爬虫。它与一般的百度搜索引擎网络爬虫的区别在于: 焦点网络爬虫在进行网页爬取时会开发内容 解决选择并确保尽可能只爬取与请求相关的网页信息。
什么是算子大数据挖掘和爬取
在我国,运营商拥有庞大且绝对真实的数据和信息存储能力。运营商在数据和信息的使用上具有肯定的领先优势,无论是抓捕工作的能力,数据库管理、数据信息工作能力、标识工作能力、产品和服务三大业务流程都具有优异的主要表现。
运营商大数据是数据信息传递的最佳神器。相关企业要利用好运营商的数据信息和标识工作能力。运营商的数据管理平台将能够很好地为相关企业开展网络服务,最终实现数据信息化。
无论是数据采集、数据处理方式、数据统计分析、数据信息浏览、数据信息应用,运营商都是一个多方位的数据库管理服务平台,一个数据管理平台的标准化框架,不同领域和公司。表示协作必须能够将自己的业务流程进行到一个新的纵横比。

数据信息使用
Python网络爬虫广泛适用于一些依赖互联网技术的数据采集。
运营商大数据可以制定有目的的模型,进而进行多层次、全方位的数据采集和数据统计分析。运营商大数据可以抓取随机网址、网页、网站地址、手机APP、400号码、固定电话、微信小程序、关键词、APP刚注册客户等数据信息信息,进而辅助整个领域和不同企业开展精准客户推广和营销服务项目。
对于不同领域的企业,运营商的大数据采集技术让企业从传统的客户拓展方式转变为大数据精准的客户拓展营销方式。运营商大数据不仅可以提供精准客户,还可以提供客户管理方法。通过外呼系统,相关企业可以按照电话营销的方式直接访问和管理准确的客户信息。
运营商大数据不仅可以保护客户的个人隐私不被侵犯,还可以让不同领域的中小微企业在互联网时代获得最新鲜、最准确、最高效的客户拓展体验。
爬虫抓取网页数据(【每日一题】python爬虫专题(一):用最简单的代码抓取最基础的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-01 09:04
本专栏从这里开始python爬虫的话题。
专题定位:目标是抓取固定数量的数据进行分析,不设计工程爬虫(实时大规模爬取展示,设计存储等),所以不会涉及真正难的部分爬虫,但只能算是介绍。
题目的整体思路是这样设计的
文章 目录如下,这是一个初步的想法,在写的过程中可能会有所改动
入门
爬虫基本原理:用最简单的代码爬取最基本的网页,展示爬虫最基本的思想,让读者知道爬虫其实是一个很简单的东西。
爬虫代码改进:这部分是一系列文章,从程序设计的角度来说,是爬虫需要掌握的基本代码设计思想。主要从两个方面对之前的代码进行改进:一是代码设计的角度,让读者习惯于定义函数、使用生成器等;二是展示多页面爬取和爬取二级页面的代码逻辑。
爬虫相关库的安装:讲述了本主题将用到的所有库的安装方法,有的简单,有的有点复杂。这个文章主要是帮助读者排除学习过程中不必要的障碍。
学完这三部分,读者可以在数据量小、没有反爬机制的情况下自由抓取网站(其实这样的网站还是很多的)。
网页分析和数据存储
Python提供了很多网页解析方法;同时,根据不同的需要,它可能会存储在不同的文件格式或数据库中,所以这部分将两者放在一起说。每个部分都有理论和实战;每个部分使用一个解析库并以文件格式存储。
注意:这些分析方法是相互替代的(尽管每种方法都有自己的优点和缺点)。基本上只需要掌握一个,最好掌握所有的文件存储。
beautifulsoup详解:这篇文章全面讲解了beautifulsoup解析库的使用
bs4+json捕捉实战:json介绍,在stackoverflow中捕捉最新的python题数据并存入json文件
Xpath详解:这篇文章全面讲解了xpath解析语法的使用
Xpath+mongodb爬虫实战:爬取伯乐在线python爬虫页面数据并存入mongodb数据库
pyquery详解:这篇文章全面讲解了CSS解析语法的使用
pyquery+mysql抓捕实战:抓捕赶集的狗数据存入mysql
正则表达式+csv/txt爬取实战:正则表达式网上教程很多,这里不再赘述,只提供网络爬取的正则方法。下面是豆瓣top250中比较难整理的数据。
Selenium详解:这篇文章全面讲解了beautifulsoup解析库的使用
Selenium爬虫实战:爬取新浪微博数据
各种网页解析库的比较
到目前为止,我已经讲了流行的网页解析库和数据存储方法。掌握了这些,网页解析和数据存储对你来说就不难了。您可以集中精力攻克各种反爬虫机制。
友情提示:对于没有时间的同学,这部分其实可以系统学习。先略过,看一些防爬措施。遇到问题可以把文章当成文档查看。但是如果你事先学会了,写代码会非常得心应手。
获得经验
在实际操作过程中,我们会遇到一些障碍,比如限制header、登录验证、限制IP、动态加载等反爬方法,以及爬取app、get/post请求等等。
这些都是一一的小问题。有了之前的基础,解决这些问题应该不难。这个过程中最重要的就是积累。爬的越多,落的洞越多,体验自然就会丰富。
这部分以每篇文章文章的形式解决一个问题。考虑到本人水平有限,肯定不能把坑全部说完,请尽量多填!
一些简单的反爬虫技巧:包括UA设置和技巧、cookies设置、延迟等基本反爬虫方法
使用代理:当抓取很多页面时,我们的ip地址会被屏蔽,所以你可以使用代理来不断地改变ip
动态加载网页的Ajax爬取
看完以上三个文章,大部分网页都可以自由抓取了。你可以先在这里看到反爬虫的技巧。一、学习scrapy框架,让日常爬行更方便。如果还有其他网页,说到其他防爬方法,赶紧查一下。
抓包介绍
网页状态码分析
发布请求
抓取应用数据
深入介绍请求
Scrapy爬虫框架系列:本系列将从scrapy的安装、基本概念开始,逐步深入讲解。
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明 查看全部
爬虫抓取网页数据(【每日一题】python爬虫专题(一):用最简单的代码抓取最基础的网页)
本专栏从这里开始python爬虫的话题。
专题定位:目标是抓取固定数量的数据进行分析,不设计工程爬虫(实时大规模爬取展示,设计存储等),所以不会涉及真正难的部分爬虫,但只能算是介绍。
题目的整体思路是这样设计的
文章 目录如下,这是一个初步的想法,在写的过程中可能会有所改动
入门
爬虫基本原理:用最简单的代码爬取最基本的网页,展示爬虫最基本的思想,让读者知道爬虫其实是一个很简单的东西。
爬虫代码改进:这部分是一系列文章,从程序设计的角度来说,是爬虫需要掌握的基本代码设计思想。主要从两个方面对之前的代码进行改进:一是代码设计的角度,让读者习惯于定义函数、使用生成器等;二是展示多页面爬取和爬取二级页面的代码逻辑。
爬虫相关库的安装:讲述了本主题将用到的所有库的安装方法,有的简单,有的有点复杂。这个文章主要是帮助读者排除学习过程中不必要的障碍。
学完这三部分,读者可以在数据量小、没有反爬机制的情况下自由抓取网站(其实这样的网站还是很多的)。
网页分析和数据存储
Python提供了很多网页解析方法;同时,根据不同的需要,它可能会存储在不同的文件格式或数据库中,所以这部分将两者放在一起说。每个部分都有理论和实战;每个部分使用一个解析库并以文件格式存储。
注意:这些分析方法是相互替代的(尽管每种方法都有自己的优点和缺点)。基本上只需要掌握一个,最好掌握所有的文件存储。
beautifulsoup详解:这篇文章全面讲解了beautifulsoup解析库的使用
bs4+json捕捉实战:json介绍,在stackoverflow中捕捉最新的python题数据并存入json文件
Xpath详解:这篇文章全面讲解了xpath解析语法的使用
Xpath+mongodb爬虫实战:爬取伯乐在线python爬虫页面数据并存入mongodb数据库
pyquery详解:这篇文章全面讲解了CSS解析语法的使用
pyquery+mysql抓捕实战:抓捕赶集的狗数据存入mysql
正则表达式+csv/txt爬取实战:正则表达式网上教程很多,这里不再赘述,只提供网络爬取的正则方法。下面是豆瓣top250中比较难整理的数据。
Selenium详解:这篇文章全面讲解了beautifulsoup解析库的使用
Selenium爬虫实战:爬取新浪微博数据
各种网页解析库的比较
到目前为止,我已经讲了流行的网页解析库和数据存储方法。掌握了这些,网页解析和数据存储对你来说就不难了。您可以集中精力攻克各种反爬虫机制。
友情提示:对于没有时间的同学,这部分其实可以系统学习。先略过,看一些防爬措施。遇到问题可以把文章当成文档查看。但是如果你事先学会了,写代码会非常得心应手。
获得经验
在实际操作过程中,我们会遇到一些障碍,比如限制header、登录验证、限制IP、动态加载等反爬方法,以及爬取app、get/post请求等等。
这些都是一一的小问题。有了之前的基础,解决这些问题应该不难。这个过程中最重要的就是积累。爬的越多,落的洞越多,体验自然就会丰富。
这部分以每篇文章文章的形式解决一个问题。考虑到本人水平有限,肯定不能把坑全部说完,请尽量多填!
一些简单的反爬虫技巧:包括UA设置和技巧、cookies设置、延迟等基本反爬虫方法
使用代理:当抓取很多页面时,我们的ip地址会被屏蔽,所以你可以使用代理来不断地改变ip
动态加载网页的Ajax爬取
看完以上三个文章,大部分网页都可以自由抓取了。你可以先在这里看到反爬虫的技巧。一、学习scrapy框架,让日常爬行更方便。如果还有其他网页,说到其他防爬方法,赶紧查一下。
抓包介绍
网页状态码分析
发布请求
抓取应用数据
深入介绍请求
Scrapy爬虫框架系列:本系列将从scrapy的安装、基本概念开始,逐步深入讲解。
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明
爬虫抓取网页数据( 实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-01 09:03
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
url = r'/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉勾网招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市是北京
tag = ['companyName','companyShortName','positionName','education','salary','financeStage','companySize',
'industryField','companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、薪资等。
tag_name = ['公司名称','公司简称','职位名称','学历要求','薪资','公司资质','公司规模','类别','公司介绍']
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['content']['result'] #通过分析得到的json信息,可以看到返回的结果中收录招聘信息,其中收录很多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的列表占位符来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num> 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ =='__main__':
print('**************************************** 即将被抓取******** * *****************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将各个页面的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num (1, max_page_num):
print('************************************ 正在下载页面 %s ********* 的内容************************'% page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('抓包完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间-开始时间).秒
print('使用的总时间:%ss'% time)
可以添加的功能很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请别人 查看全部
爬虫抓取网页数据(
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。

可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。

我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:

我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
url = r'/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉勾网招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市是北京
tag = ['companyName','companyShortName','positionName','education','salary','financeStage','companySize',
'industryField','companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、薪资等。
tag_name = ['公司名称','公司简称','职位名称','学历要求','薪资','公司资质','公司规模','类别','公司介绍']
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['content']['result'] #通过分析得到的json信息,可以看到返回的结果中收录招聘信息,其中收录很多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的列表占位符来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num> 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ =='__main__':
print('**************************************** 即将被抓取******** * *****************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将各个页面的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num (1, max_page_num):
print('************************************ 正在下载页面 %s ********* 的内容************************'% page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('抓包完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间-开始时间).秒
print('使用的总时间:%ss'% time)
可以添加的功能很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请别人
爬虫抓取网页数据( 本发明公开了一种,流程及专利说明(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-30 03:08
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索 查看全部
爬虫抓取网页数据(
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索
爬虫抓取网页数据(网址被降权惩罚的首要因素是什么?怎么破?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-30 02:24
在管理方法站点的过程中,我们会遇到K站或者被降级处罚的情况。一旦网站被K或降级处罚,则表示该网址已被robots文件处罚。一般的原因是垃圾信息的内容太多。百度搜索引擎的计算方式升级了,是K站造成的。还有其他因素。所有因素都导致URL受到惩罚。
1、被降职处罚
降级处罚的关键是该网站采用了百度搜索引擎的标准增加权重值,最终被百度搜索引擎发现并采取了预警对策。导致降级处罚的主要因素有:网络服务器不稳定、同一网络服务器介入、网站改版升级、隐藏友情链接、过度推广、隐藏外部链接、采集多。这些QQ空间是完全免费的关注和点赞。
网站被降权处罚的情况比起K站来说不是很严重。如果您看到该网站被降权处罚,您可以按照上述方法进行盘点。通常,您必须在整个推广过程中注意这些情况的发生。您不需要应用一些过度的促销方法。如果网站被不稳定的网络服务器降级处罚,应尽快响应网络服务器,做好企业网站的备份数据。
2、K站
降级处罚只是对网站的警告,K站意味着搜索引擎网站对平台的相应处罚。执行网站降级处罚后,如果网站长期没有进行检查和调整,一旦受到处罚,网站将难以修复。出现K站的原因是:网站更新了大量非正式内容,站群系统惯例,网站被撤销备案。
大量垃圾信息内容被推送,造成不良影响。大量应用二级域名,建立网站群以营利。域名注册根据可靠结果批准后,采取取消注册的对策,后续操作违反指定的URL。这种情况的发生会立即导致网站被K站。
3、差异
K站的因素可能是降权惩罚造成的,但降权惩罚不一定是K站造成的。被降权处罚的网址并不代表该网址失效。当您发现网站被降权处罚时,一定要慎重调整。不要故意违反百度搜索引擎的标准,造成很大的损失。一旦网站被K站封杀,就相当于百度搜索引擎封禁该网站,无望。因此,在做seo的过程中,大家一定要使用一些可靠、合理、合法的seo技术来进行搜索引擎优化。
如何喂养百度爬虫?
理论上,爬行是指逐渐前进,但这不是互联网术语的意思。爬行一词来源于百度爬虫,指的是百度爬虫根据网址并留下标记的全过程。百度爬虫可以保证快速收录并展示实际效果,但不会急于展示出来。它只会根据审查期限出现在百度搜索引擎上。
那么,百度爬虫爬取的形式是什么?
1、显式爬取
显式抓取是指当网址升级时,百度爬虫会第一时间抓取该网址,并明确该网址是准确定位的。但是,无法立即显示百度收录的网页。
2、平滑爬行
平滑爬行一般是指网站上线后的一段时间,顺利度过沙盒游戏期。百度爬虫每天都会进入网站进行抓取,并尽快呈现网站收录的网页。
3、井喷爬行
这种方法一般出现在百度彻底改变优化算法,对所有网页进行大改动时。百度搜索去除了非标准网址,并为一些优质网站提供了更强的排名。
4、 爬行爬行
根据词汇,可以理解为先爬后爬。百度爬虫在对平台进行爬取时,通常会选择先区分robots文件中的内容,再区分哪些文件是禁止爬取的。对这个机器人文件的理解是基于国际规范和标准。俗话说,无规则无规则,百度搜索也不例外。
5、爬行运动轨迹
百度爬虫抓取到的轨迹是逐步以网站首页为基础,根据首页链接获取的。根据 W3C 规范,所有 URL 分为三个部分,即顶部部分、文章 正文部分和底部部分。首页顶部导航图会正确引导百度爬虫抓取频道页,首页文章列表会正确引导百度爬虫抓取文章内容页。
为了更好的保证平台的畅通,百度搜索达到了网站内链和内链的定义。 查看全部
爬虫抓取网页数据(网址被降权惩罚的首要因素是什么?怎么破?)
在管理方法站点的过程中,我们会遇到K站或者被降级处罚的情况。一旦网站被K或降级处罚,则表示该网址已被robots文件处罚。一般的原因是垃圾信息的内容太多。百度搜索引擎的计算方式升级了,是K站造成的。还有其他因素。所有因素都导致URL受到惩罚。

1、被降职处罚
降级处罚的关键是该网站采用了百度搜索引擎的标准增加权重值,最终被百度搜索引擎发现并采取了预警对策。导致降级处罚的主要因素有:网络服务器不稳定、同一网络服务器介入、网站改版升级、隐藏友情链接、过度推广、隐藏外部链接、采集多。这些QQ空间是完全免费的关注和点赞。
网站被降权处罚的情况比起K站来说不是很严重。如果您看到该网站被降权处罚,您可以按照上述方法进行盘点。通常,您必须在整个推广过程中注意这些情况的发生。您不需要应用一些过度的促销方法。如果网站被不稳定的网络服务器降级处罚,应尽快响应网络服务器,做好企业网站的备份数据。
2、K站
降级处罚只是对网站的警告,K站意味着搜索引擎网站对平台的相应处罚。执行网站降级处罚后,如果网站长期没有进行检查和调整,一旦受到处罚,网站将难以修复。出现K站的原因是:网站更新了大量非正式内容,站群系统惯例,网站被撤销备案。
大量垃圾信息内容被推送,造成不良影响。大量应用二级域名,建立网站群以营利。域名注册根据可靠结果批准后,采取取消注册的对策,后续操作违反指定的URL。这种情况的发生会立即导致网站被K站。
3、差异
K站的因素可能是降权惩罚造成的,但降权惩罚不一定是K站造成的。被降权处罚的网址并不代表该网址失效。当您发现网站被降权处罚时,一定要慎重调整。不要故意违反百度搜索引擎的标准,造成很大的损失。一旦网站被K站封杀,就相当于百度搜索引擎封禁该网站,无望。因此,在做seo的过程中,大家一定要使用一些可靠、合理、合法的seo技术来进行搜索引擎优化。
如何喂养百度爬虫?
理论上,爬行是指逐渐前进,但这不是互联网术语的意思。爬行一词来源于百度爬虫,指的是百度爬虫根据网址并留下标记的全过程。百度爬虫可以保证快速收录并展示实际效果,但不会急于展示出来。它只会根据审查期限出现在百度搜索引擎上。

那么,百度爬虫爬取的形式是什么?
1、显式爬取
显式抓取是指当网址升级时,百度爬虫会第一时间抓取该网址,并明确该网址是准确定位的。但是,无法立即显示百度收录的网页。
2、平滑爬行
平滑爬行一般是指网站上线后的一段时间,顺利度过沙盒游戏期。百度爬虫每天都会进入网站进行抓取,并尽快呈现网站收录的网页。
3、井喷爬行
这种方法一般出现在百度彻底改变优化算法,对所有网页进行大改动时。百度搜索去除了非标准网址,并为一些优质网站提供了更强的排名。
4、 爬行爬行
根据词汇,可以理解为先爬后爬。百度爬虫在对平台进行爬取时,通常会选择先区分robots文件中的内容,再区分哪些文件是禁止爬取的。对这个机器人文件的理解是基于国际规范和标准。俗话说,无规则无规则,百度搜索也不例外。
5、爬行运动轨迹
百度爬虫抓取到的轨迹是逐步以网站首页为基础,根据首页链接获取的。根据 W3C 规范,所有 URL 分为三个部分,即顶部部分、文章 正文部分和底部部分。首页顶部导航图会正确引导百度爬虫抓取频道页,首页文章列表会正确引导百度爬虫抓取文章内容页。
为了更好的保证平台的畅通,百度搜索达到了网站内链和内链的定义。
爬虫抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-29 19:25
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频 查看全部
爬虫抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?


我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
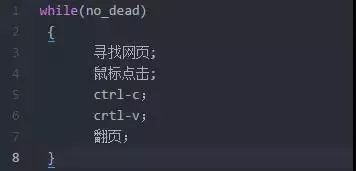
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频
爬虫抓取网页数据(网页右键单击选择Viewsource选项(scraping)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-14 13:01
)
我们需要让这个爬虫从每个网页中提取一些数据,然后实现某些东西。这种方法也称为刮擦。
2.1 分析页面
右键单击并选择查看页面源选项以获取网页源代码
2.2 三种网络爬虫方法
2.2.1 正则表达式
当我们使用正则表达式获取面积数据时,首先需要尝试匹配元素中w2p_fw的内容,如下图:
实现代码如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import urllib.request
# 下载url网页,proxy是支持代理功能,初始值为None,想要设置就直接传参数即可
def download(url, user_agent = 'brain', proxy = None, num_retries = 2):
print ('Downloading:', url)
headers = {'User-agent':user_agent} # 设置用户代理,而不使用python默认的用户代理Python-urllib/3.6
request = urllib.request.Request(url,headers=headers)
opener = urllib.request.build_opener()
if proxy: # 如果设置了proxy,那么就进行以下设置以实现支持代理功能
proxy_params = {urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(urllib.request.ProxyHandler(proxy_params))
try:
html = opener.open(request).read()
except urllib.request.URLError as e: # 下载过程中出现问题
print('Download error:', e.reason)
html = None
if num_retries>0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 (.*?)' % field, html)
results[field] = re.search('.*?0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 0 and last_accessed is not None:
# 外部延时与访问时间间隔(当前访问时间及上次访问时间)比较
sleep_secs = self.delay - (datetime.datetime.now() - last_accessed).seconds
if sleep_secs > 0: # 访问时间间隔小于外部时延的话,执行睡眠操作
# domain has been accessed recently
# so need to sleep
time.sleep(sleep_secs)
# update the last accessed time
self.domains[domain] = datetime.datetime.now()
"""先下载 seed_url 网页的源代码,然后提取出里面所有的链接URL,接着对所有匹配到的链接URL与link_regex 进行匹配,
如果链接URL里面有link_regex内容,就将这个链接URL放入到队列中,下一次 执行 while crawl_queue: 就对这个链接URL进行同样的操作。
反反复复,直到 crawl_queue 队列为空,才退出函数。"""
def link_crawler(seed_url, link_regex, max_depth = 2, scrape_callback = None):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
# keep track which URL's have seen before
# seen = set(crawl_queue)
seen = {seed_url: 0} # 初始化seed_url访问深度为0
while crawl_queue:
url = crawl_queue.pop()
# 爬取前解析网站robots.txt,检查是否可以爬取网站,避免爬取网站禁止或限制的
rp = urllib.robotparser.RobotFileParser()
rp.set_url(seed_url+'/robots.txt')
rp.read()
user_agent = 'brain'
if rp.can_fetch(user_agent,url): # 解析后发现如果可以正常爬取网站,则继续执行
# 爬取网站的下载限速功能的类的调用,每次在download下载前使用
throttle = Throttle(delay = 5) # 这里实例网站robots.txt中的delay值为5
throttle.wait(url)
html = download(url)
html = html.decode('utf-8') # 需要转换为UTF-8 / html = str(html)
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
# filter for links matching our regular expression
if html == None:
continue
depth = seen[url] # 用于避免爬虫陷阱的记录爬取深度的depth
if depth != max_depth:
for link in get_links(html):
if re.match(link_regex, link):
link = urllib.parse.urljoin(seed_url,link)
if link not in seen:
# seen.add(link)
seen[link] = depth + 1 # 在之前的爬取深度上加1
crawl_queue.append(link)
else:
print("Blocked by %s robots,txt" % url)
continue
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
FIELDS = ('area','population','iso','country','capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('tr#places_%s__row > td.w2p_fw' % field)[0].text_content() for field in FIELDS]
print(url,row)
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv','w',newline='')) # 加入newline=”''这个参数后生成的文件就不会出现空行了
self.fields = FIELDS
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content())
self.writer.writerow(row)
# 只想找http://example.webscraping.com ... ex... or http://example.webscraping.com ... ew...
link_crawler('http://example.webscraping.com', '/places/default'+'/(index|view)', max_depth=2, scrape_callback = ScrapeCallback()) 查看全部
爬虫抓取网页数据(网页右键单击选择Viewsource选项(scraping)(组图)
)
我们需要让这个爬虫从每个网页中提取一些数据,然后实现某些东西。这种方法也称为刮擦。
2.1 分析页面
右键单击并选择查看页面源选项以获取网页源代码
2.2 三种网络爬虫方法
2.2.1 正则表达式
当我们使用正则表达式获取面积数据时,首先需要尝试匹配元素中w2p_fw的内容,如下图:
实现代码如下:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import urllib.request
# 下载url网页,proxy是支持代理功能,初始值为None,想要设置就直接传参数即可
def download(url, user_agent = 'brain', proxy = None, num_retries = 2):
print ('Downloading:', url)
headers = {'User-agent':user_agent} # 设置用户代理,而不使用python默认的用户代理Python-urllib/3.6
request = urllib.request.Request(url,headers=headers)
opener = urllib.request.build_opener()
if proxy: # 如果设置了proxy,那么就进行以下设置以实现支持代理功能
proxy_params = {urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(urllib.request.ProxyHandler(proxy_params))
try:
html = opener.open(request).read()
except urllib.request.URLError as e: # 下载过程中出现问题
print('Download error:', e.reason)
html = None
if num_retries>0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 (.*?)' % field, html)
results[field] = re.search('.*?0: # 错误4XX发生在请求存在问题,而5XX错误则发生在服务端存在问题,所以在发生5XX错误时重试下载
if hasattr(e,'code') and 500 0 and last_accessed is not None:
# 外部延时与访问时间间隔(当前访问时间及上次访问时间)比较
sleep_secs = self.delay - (datetime.datetime.now() - last_accessed).seconds
if sleep_secs > 0: # 访问时间间隔小于外部时延的话,执行睡眠操作
# domain has been accessed recently
# so need to sleep
time.sleep(sleep_secs)
# update the last accessed time
self.domains[domain] = datetime.datetime.now()
"""先下载 seed_url 网页的源代码,然后提取出里面所有的链接URL,接着对所有匹配到的链接URL与link_regex 进行匹配,
如果链接URL里面有link_regex内容,就将这个链接URL放入到队列中,下一次 执行 while crawl_queue: 就对这个链接URL进行同样的操作。
反反复复,直到 crawl_queue 队列为空,才退出函数。"""
def link_crawler(seed_url, link_regex, max_depth = 2, scrape_callback = None):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
# keep track which URL's have seen before
# seen = set(crawl_queue)
seen = {seed_url: 0} # 初始化seed_url访问深度为0
while crawl_queue:
url = crawl_queue.pop()
# 爬取前解析网站robots.txt,检查是否可以爬取网站,避免爬取网站禁止或限制的
rp = urllib.robotparser.RobotFileParser()
rp.set_url(seed_url+'/robots.txt')
rp.read()
user_agent = 'brain'
if rp.can_fetch(user_agent,url): # 解析后发现如果可以正常爬取网站,则继续执行
# 爬取网站的下载限速功能的类的调用,每次在download下载前使用
throttle = Throttle(delay = 5) # 这里实例网站robots.txt中的delay值为5
throttle.wait(url)
html = download(url)
html = html.decode('utf-8') # 需要转换为UTF-8 / html = str(html)
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
# filter for links matching our regular expression
if html == None:
continue
depth = seen[url] # 用于避免爬虫陷阱的记录爬取深度的depth
if depth != max_depth:
for link in get_links(html):
if re.match(link_regex, link):
link = urllib.parse.urljoin(seed_url,link)
if link not in seen:
# seen.add(link)
seen[link] = depth + 1 # 在之前的爬取深度上加1
crawl_queue.append(link)
else:
print("Blocked by %s robots,txt" % url)
continue
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
FIELDS = ('area','population','iso','country','capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('tr#places_%s__row > td.w2p_fw' % field)[0].text_content() for field in FIELDS]
print(url,row)
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv','w',newline='')) # 加入newline=”''这个参数后生成的文件就不会出现空行了
self.fields = FIELDS
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content())
self.writer.writerow(row)
# 只想找http://example.webscraping.com ... ex... or http://example.webscraping.com ... ew...
link_crawler('http://example.webscraping.com', '/places/default'+'/(index|view)', max_depth=2, scrape_callback = ScrapeCallback())
爬虫抓取网页数据( Scrapy:Python的爬虫框架实例() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-14 12:35
Scrapy:Python的爬虫框架实例()
)
刮的
Scrapy:Python 爬虫框架
示例演示
爬取:汽车之家、瓜子、链家等数据信息。
版本+环境库
Python2.7 + Scrapy1.12
Scrapy Scrapy 是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
应用
用json生成数据文件 $scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
查看有多少爬虫 $ scrapy list
它最初是为网络爬虫而设计的,也可用于获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是一种抓取互联网数据的程序,用它来抓取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理Scrapy引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松的完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。
官方 网站:
开源地址:
此代码地址:
爬虫的时候不要做违法的事情,开源仅供参考。
查看全部
爬虫抓取网页数据(
Scrapy:Python的爬虫框架实例()
)
刮的
Scrapy:Python 爬虫框架
示例演示
爬取:汽车之家、瓜子、链家等数据信息。
版本+环境库
Python2.7 + Scrapy1.12
Scrapy Scrapy 是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。
应用
用json生成数据文件 $scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
查看有多少爬虫 $ scrapy list
它最初是为网络爬虫而设计的,也可用于获取 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是一种抓取互联网数据的程序,用它来抓取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理Scrapy引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松的完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。是从 Scrapy 引擎发送到调度的请求和响应。使用Scrapy可以轻松完成在线数据采集的工作,它已经为我们做了很多工作,不需要花大力气去开发。
官方 网站:
开源地址:
此代码地址:
爬虫的时候不要做违法的事情,开源仅供参考。
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-13 06:08
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
查看全部
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
爬虫抓取网页数据( Python语言开发专业Web开发的高级功能介绍及安装方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-12 07:17
Python语言开发专业Web开发的高级功能介绍及安装方法)
PyCharm 爬虫示例:使用 Scrapy 抓取网页特定内容
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。参考课程:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider-o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线
分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个 itempipeline 组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,否则抛出DropItem异常,丢弃的item将不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加小心,不要马虎。在我的实验中,要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。此错误如下图所示。它说找不到DobanmovieItem的模块。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清理和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在脑子里,这才是真正的知识学习,不是葫芦娃图。
PyCharm爬虫示例:这里介绍使用Scrapy爬取网页特定内容。更多Python学习请参考编程字典Python教程和问答部分。感谢您对编程词典的支持。
原文链接: 查看全部
爬虫抓取网页数据(
Python语言开发专业Web开发的高级功能介绍及安装方法)
PyCharm 爬虫示例:使用 Scrapy 抓取网页特定内容
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序中。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。参考课程:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider-o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线
分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
每个item管道组件都是一个独立的pyhton类,必须通过process_item(self, item, spider)方法实现。每个 itempipeline 组件都需要调用这个方法。该方法必须返回一个带有数据的dict,或者一个item对象,否则抛出DropItem异常,丢弃的item将不会被后续的管道组件处理。定义的 pipelines.py 代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/lat ... .html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class TutorialPipeline(object):
def process_item(self, item, spider):
return item
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0]+"\n")
return item
四、配置setting.py
由于这次用到了管道,我们需要在settings.py中打开管道通道注释,在管道中添加一条新的记录,如下图所示:
五、写爬虫文件
在tutorial/spiders目录下创建quotes_spider.py文件,目录结构如下,编写初步代码:
quotes_spider.py 的代码如下:
import scrapy
from items import DoubanmovieItem
class QuotesSpider(scrapy.Spider):
name = "doubanSpider"
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/cinema/nowplaying',
'http://movie.douban.com/cinema/nowplaying/beijing/']
def parse(self, response):
print("--" * 20 )
#print(response.body)
print("==" * 20 )
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
#print(sub.xpath('normalize-space(./a/text())').extract())
print(sub)
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('normalize-space(./a/text())').extract()
items.append(item)
print(items)
return items
六、通过启动文件运行
在豆瓣文件目录下新建一个启动文件douban_spider_run.py(文件名可取),运行该文件查看结果。编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanSpider".split())
最后,处理后的爬取数据如下图(部分):
最后,希望大家在写代码的时候能更加小心,不要马虎。在我的实验中,要引入的方法DoubanmovieItem写成DobanmovieItem,导致整个程序失败,PyCharm没有告诉我在哪里。我错了。我到处搜索,但找不到解决问题的方法。最后查了很多次,才发现方法是什么时候生成的,所以一定要小心。此错误如下图所示。它说找不到DobanmovieItem的模块。它可能已经告诉我错误的地方,因为我太傻了没有找到,所以花了很长时间。希望大家多多指教!
至此,使用Scrapy对网页内容进行爬取,并对爬取的内容进行清理和处理的实验已经完成。要求熟悉和使用这个过程中的代码和操作,不会在网上找内容消化。吸收,记在脑子里,这才是真正的知识学习,不是葫芦娃图。
PyCharm爬虫示例:这里介绍使用Scrapy爬取网页特定内容。更多Python学习请参考编程字典Python教程和问答部分。感谢您对编程词典的支持。
原文链接:
爬虫抓取网页数据( 人生苦短,我用Python前文:小白学一个万能的方法(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-11 14:02
人生苦短,我用Python前文:小白学一个万能的方法(组图)
)
小白学习Python爬虫(9):爬虫基础
人生苦短,我用Python
上一个传送门:
小白学习Python爬虫(1):开
小白学习Python爬虫(2):前期准备(一)安装基础类库)
小白学习Python爬虫(3):前期准备(二)Linux基础)
小白学习Python爬虫(4):前期准备(三)Docker基础入门)
小白学习Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架安装)
小白学习Python爬虫(7):HTTP基础
小白学习Python爬虫(8):网页基础
爬虫的核心
什么是爬虫,我们说的通俗一点。爬虫是一种对网页进行爬取,按照一定的规则从中提取信息,并重复上述过程以自动化、重复完成的程序。
对于爬虫来说,首先要爬取一个网页,这里主要是获取网页的源码。网页的源代码中会收录我们需要的信息,而我们要做的就是从源代码中提取这些信息。
当我们请求一个网页时,Python为我们提供了很多库来做这个,比如官方的urllib,还有第三方的requests,Aiohttp等等。
我们可以使用这些库来发送 HTTP 请求并获取响应数据。得到响应后,我们只需要解析body部分的数据就可以得到网页的源码。
获得源代码后,我们接下来的工作就是解析源代码,从中提取出我们需要的数据。
提取数据最基本也是最常用的方法是使用正则表达式,但是这种方法比较复杂,容易出错,但是不得不说,正则表达式写得很好的人根本不需要下面这些解析库是一种通用的方法。
悄悄的说,编辑器的正则表达式写得不好,会用到这些第三方提供的库。
用于提取数据的类库包括 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从 HTML 中提取网页信息,例如节点属性、文本值等。
从源代码中提取数据后,我们将保存数据。有很多方法可以保存它。可以直接保存为txt、json、Excel文件等,也可以保存到数据库中,如Mysql、Oracle、SQLServer、MongoDB等。
捕获的数据格式
一般来说,我们抓取的是HTML网页源代码,这是我们可以看到的常规的、直观的网页信息。
但是,有些信息不会与 HTML 一起直接返回到网页。会有各种API接口。该接口返回的数据目前为JSON格式。还有一些数据格式会返回 XML。有一些独特而美妙的接口可以直接返回程序的自定义字符串。这个API数据接口需要具体问题具体分析。
还有一些信息,比如各大摄影站和视频站(比如抖音,B站)。我们要抓取的信息是图片或视频。该信息是二进制形式的。我们需要将这些二进制数据爬下来然后转储。
另外,我们还可以抓取一些资源文件,比如CSS、JavaScript等脚本资源,有的还有一些字体信息,比如woff。这些信息是一个网页不可缺少的元素,只要浏览器能访问到,我们就可以爬下来。
现代前端页面爬取
今天是核心内容!!!
查看全部
爬虫抓取网页数据(
人生苦短,我用Python前文:小白学一个万能的方法(组图)
)
小白学习Python爬虫(9):爬虫基础
人生苦短,我用Python
上一个传送门:
小白学习Python爬虫(1):开
小白学习Python爬虫(2):前期准备(一)安装基础类库)
小白学习Python爬虫(3):前期准备(二)Linux基础)
小白学习Python爬虫(4):前期准备(三)Docker基础入门)
小白学习Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架安装)
小白学习Python爬虫(7):HTTP基础
小白学习Python爬虫(8):网页基础
爬虫的核心
什么是爬虫,我们说的通俗一点。爬虫是一种对网页进行爬取,按照一定的规则从中提取信息,并重复上述过程以自动化、重复完成的程序。
对于爬虫来说,首先要爬取一个网页,这里主要是获取网页的源码。网页的源代码中会收录我们需要的信息,而我们要做的就是从源代码中提取这些信息。
当我们请求一个网页时,Python为我们提供了很多库来做这个,比如官方的urllib,还有第三方的requests,Aiohttp等等。
我们可以使用这些库来发送 HTTP 请求并获取响应数据。得到响应后,我们只需要解析body部分的数据就可以得到网页的源码。
获得源代码后,我们接下来的工作就是解析源代码,从中提取出我们需要的数据。
提取数据最基本也是最常用的方法是使用正则表达式,但是这种方法比较复杂,容易出错,但是不得不说,正则表达式写得很好的人根本不需要下面这些解析库是一种通用的方法。
悄悄的说,编辑器的正则表达式写得不好,会用到这些第三方提供的库。
用于提取数据的类库包括 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从 HTML 中提取网页信息,例如节点属性、文本值等。
从源代码中提取数据后,我们将保存数据。有很多方法可以保存它。可以直接保存为txt、json、Excel文件等,也可以保存到数据库中,如Mysql、Oracle、SQLServer、MongoDB等。
捕获的数据格式
一般来说,我们抓取的是HTML网页源代码,这是我们可以看到的常规的、直观的网页信息。
但是,有些信息不会与 HTML 一起直接返回到网页。会有各种API接口。该接口返回的数据目前为JSON格式。还有一些数据格式会返回 XML。有一些独特而美妙的接口可以直接返回程序的自定义字符串。这个API数据接口需要具体问题具体分析。
还有一些信息,比如各大摄影站和视频站(比如抖音,B站)。我们要抓取的信息是图片或视频。该信息是二进制形式的。我们需要将这些二进制数据爬下来然后转储。
另外,我们还可以抓取一些资源文件,比如CSS、JavaScript等脚本资源,有的还有一些字体信息,比如woff。这些信息是一个网页不可缺少的元素,只要浏览器能访问到,我们就可以爬下来。
现代前端页面爬取
今天是核心内容!!!
爬虫抓取网页数据(douban爬虫安装classscrapyScraoy入门实例(图)介绍与安装amp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-11 12:30
标签:豆瓣爬虫项目Scrapy web content install classesscrapy
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
标签:豆瓣,爬虫,物品,Scrapy,网页内容,安装,类,scrapy 查看全部
爬虫抓取网页数据(douban爬虫安装classscrapyScraoy入门实例(图)介绍与安装amp)
标签:豆瓣爬虫项目Scrapy web content install classesscrapy
Scraoy入门实例一---Scrapy介绍与安装&PyCharm安装&项目实战
一、Scrapy 安装
1.Scrapy 介绍
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
2.Scrapy 安装
推荐使用Anaconda安装Scrapy
Anaconda 是一个开源包和环境管理工件。Anaconda 收录 180 多个科学包及其依赖项,包括 conda 和 Python。从官网下载安装Anaconda(个人版),根据自己的系统选择下载,安装,选择next继续安装,Install for选项选择Just for me。选择安装位置后,等待安装完成。
安装完成后,打开命令行,输入conda install scrapy,根据提示按Y,就会下载Scrapy及其依赖的所有包,从而完成安装。
注意:使用命令行安装scrapy包时,会出现下载超时问题,即下载失败。我们可以通过修改其镜像文件来提高scrapy包的下载速度。可以参考博客:
这时测试Scrapy是否安装成功:在命令行窗口输入scrapy,回车。如果出现如下界面,则说明安装成功:
二、PyCharm 安装
1.PyCharm 介绍
PyCharm 是一个 PythonIDE,带有一组工具,可以帮助用户在使用 Python 语言进行开发时提高效率,例如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试和版本控制。此外,IDE 提供了一些高级功能,以支持 Django 框架下的专业 Web 开发。
2.PyCharm 安装
进入PyCharm官网,点击DownLoad下载。专业版在左边,社区版在右边。社区版免费,专业版免费试用。
如果之前没有下载过Python解释器,可以在等待安装的同时下载Python解释器,进入Python官网,根据系统和版本下载对应的压缩包。安装完成后,在环境变量 Path 中配置 Python 解释器的安装路径。可以参考博客:
三、Scrapy抢豆瓣项目实战
前提条件:如果想在PyCharm中使用Scrapy,必须先在PyCharm中安装支持的Scrapy包。流程如下,点击File>>Settings...,步骤如下图,我安装Scrapy之前的绿框只有两个Package。如果点击后看到一个Scrapy包,则无需安装,直接进行下一步操作即可。
如果没有Scrapy包,点击“+”,搜索Scrapy包,点击Install Package进行安装
等待安装完成。
1.新项目
打开新安装的PyCharm,使用软件终端中的pycharm工具,如果找不到PyCharm终端,点击左下角的终端即可。
输入命令:scrapy startproject douban 这是使用命令行新建一个爬虫项目,如下图,图中项目名称为pythonProject
然后在命令行输入命令:cd douban进入生成项目的根目录
然后在终端继续输入命令:scrapy genspider douban_spider,生成douban_spider爬虫文件。
此时的项目结构如下图所示:
2.明确的目标
我们要练习的网站是:
假设,我们抓取top250电影的序列号、电影名称、介绍、星级、评分数量、电影描述选项
此时,我们在items.py文件中定义捕获的数据项,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 序列号
serial_number = scrapy.Field();
# 电影名
movie_name = scrapy.Field();
# 介绍
introduce = scrapy.Field();
# 星级
star = scrapy.Field();
# 评价数
evaluate = scrapy.Field();
# 描述
describe = scrapy.Field();
pass
3.接下来需要制作爬虫并存储爬取的内容
在douban_spider.py爬虫文件中编写具体逻辑代码,如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
#循环电影的条目
for i_item in movie_list:
#导入item,进行数据解析
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']/a/span[1]/text()").extract_first()
#如果文件有多行进行解析
content = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract()
for i_content in content:
content_s ="".join( i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
yield douban_item
#解析下一页,取后一页的XPATH
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
这个时候不需要运行这个python文件,因为我们不是单独使用它,所以不需要运行它。允许报错。关于import引入的问题,关于home目录的绝对路径和相对路径的问题,原因是我们使用了相对路径。“..Items”,对相关内容感兴趣的同学可以上网查找对此类问题的解释。
4.存储内容
将抓取到的内容存入json或csv格式的文件中
在命令行输入:scrapy crawl douban_spider -o test.json 或者scrapy crawl douban_spider -o test.csv
将抓取到的数据存储在 json 文件或 csv 文件中。
执行 crawl 命令后,将鼠标焦点放在项目面板上时,将显示生成的 json 文件或 csv 文件。打开json或者csv文件后,如果里面什么都没有,那么我们需要进一步修改,修改代理USER_AGENT的内容,
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.8 Safari/537.36'
如果存储在一个json文件中,所有的内容都会以16进制的形式显示,可以通过相应的方法进行转码。这里就不多解释了,如下图所示:
并且保存在csv文件中,会直接显示我们要抓取的所有内容,如下图:
至此,我们已经完成了对网站具体内容的抓取。接下来,我们需要处理爬取的数据。
分割线------------------------------------------------ -------------------------------------------------- --------------------分割线
Scraoy 介绍示例二——使用Pipeline来实现
在这次实战中,需要重新创建一个项目,或者需要安装scrapy包。参考以上内容,新建项目的方法也参考以上内容,这里不再赘述。
项目目录结构如下图所示:
一、管道介绍
当我们通过Spider爬取数据,通过Item采集数据时,需要对数据进行处理,因为我们爬取的数据不一定是我们想要的最终数据,可能还需要进行数据清洗和校验。数据的有效性。Scripy 中的 Pipeline 组件用于数据处理。Pipeline 组件是一个收录特定接口的类。它通常只负责一个功能的数据处理。可以在一个项目中同时启用多个管道。
二、在items.py中定义要捕获的数据
首先打开一个新的pycharm项目,通过终端新建一个项目教程,在item中定义要抓取的数据,比如电影的名字,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/lat ... .html
import scrapy
class TutorialItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
pass
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
三、定义pipeline.py文件
标签:豆瓣,爬虫,物品,Scrapy,网页内容,安装,类,scrapy
爬虫抓取网页数据(使用Python写爬虫来爬取十分方便-本文社区 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-11 12:27
)
本文作者:IMWeb胡庆阳 原文来源:IMWeb社区,未经许可,禁止转载
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
head = {}
head['User-Agent']='Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0..'
req = urllib.request.Request(url,head) # 伪造请求头
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1amIgaNkwA/download/'
res = requests.head(url)
re=res.headers['Location'] 查看全部
爬虫抓取网页数据(使用Python写爬虫来爬取十分方便-本文社区
)
本文作者:IMWeb胡庆阳 原文来源:IMWeb社区,未经许可,禁止转载
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
head = {}
head['User-Agent']='Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0..'
req = urllib.request.Request(url,head) # 伪造请求头
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null'
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1amIgaNkwA/download/'
res = requests.head(url)
re=res.headers['Location']
爬虫抓取网页数据(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 459 次浏览 • 2021-10-06 07:06
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。###1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一款免费且易于使用的爬虫工具。启动Getleft后,输入网址,选择要下载的文件,然后开始下载网站 另外,提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总的来说,Getleft 应该能满足用户基本的爬虫需求,不需要更复杂的技能。
5. 刮板
Scraper 是一款 Chrome 扩展工具,数据提取功能有限,但对于在线研究和导出数据到 Google 电子表格非常有用。适合初学者和专家,您可以轻松地将数据复制到剪贴板或使用 OAuth 将其存储在电子表格中。不提供包罗万象的爬虫服务,但对新手也很友好。
6. OutWit 中心
OutWit Hub 是一个 Firefox 插件,具有数十种数据提取功能,可简化网络搜索。浏览页面后,提取的信息会以合适的格式存储。您还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬虫工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookies 等方式获取网页数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,您也可以使用浏览器内置的 Web 应用程序。
8.视觉抓取工具
VisualScraper 是另一个很棒的免费和非编码爬虫工具,它通过一个简单的点击界面从互联网上采集数据。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据传输服务和创作软件提取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。它的开源可视化爬虫工具允许用户在没有任何编程知识的情况下爬取网页。Scrapinghub 使用 Crawlera,一个智能代理微调器,支持绕过 bot 机制,轻松抓取大量受 bot 保护的 网站。它使用户能够通过简单的 HTTP API 从多个 IP 和位置进行爬取,而无需代理管理。
10. Dexi.io
Dexi.io作为一款基于浏览器的网络爬虫工具,允许用户从任意网站中抓取数据,并提供了三种机器人来创建抓取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据会在归档前两周内存储在Dexi.io的服务器上,或者提取的数据可以直接导出为JSON或CSV文件。提供有偿服务,满足实时数据采集需求。
11. Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用覆盖各种来源的多个过滤器来抓取数据并进一步提取不同语言的关键字。捕获的数据可以以 XML、JSON 和 RSS 格式保存,并且可以从其存档中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 捕获的结构化数据。总体来说,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入。io
用户只需要从特定网页导入数据,并将数据导出为CSV,即可形成自己的数据集。无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。公共 API 提供了强大而灵活的功能来以编程方式控制 Import.io 并自动访问数据。Import.io 将网页数据集成到您自己的应用程序或 网站 中,只需单击几下即可轻松实现爬虫。为了更好地满足用户的爬取需求,它还提供了Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和爬取工具,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80条腿
80legs是一款功能强大的网络爬虫工具,可根据客户需求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速工作,在几秒钟内获取所需的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 中获取所有数据。Spinn3r 发布了一个防火墙 API 来管理 95% 的索引工作。提供先进的垃圾邮件防护功能,杜绝垃圾邮件和不当语言,提高数据安全性。Spinn3r 索引类似于 Google 的内容,并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网络抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 调试或编写脚本以编程方式控制抓取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦气刮刀
Helium Scraper 是一款可视化的网络数据爬虫软件,当元素之间的相关性较小时效果更好。它是非编码和非配置的。用户可以根据各种爬取需求访问在线模板。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动化爬虫软件。它可以自动从第三方应用程序抓取网页和桌面数据。Uipath 可以跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬行的内置工具。这种方法在处理复杂的 UI 时非常有效。屏幕抓取工具可以处理单个文本元素、文本组和文本块。
18. 刮擦。它
Scrape.it 是一种基于云的 Web 数据提取工具。它是为具有高级编程技能的人设计的,因为它提供了公共和私有包来发现、使用、更新和与全球数百万开发人员共享代码。其强大的集成功能可以帮助用户根据自己的需求构建自定义爬虫。
19. 网络哈维
WebHarvy 是为非程序员设计的。它可以自动抓取来自网站的文本、图片、URL和电子邮件,并将抓取到的内容以各种格式保存。它还提供了内置的调度程序和代理支持,可以匿名爬行并防止被 Web 服务器阻止。可以选择通过代理服务器或VPN访问目标。网站。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,或导出到 SQL 数据库。
20. 内涵
Connotate 是一款自动化的网络爬虫软件,专为企业级网络爬虫设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它可以自动提取95%以上的网站,包括基于JavaScript的动态网站技术,如Ajax。此外,Connotate 还提供了网页和数据库内容的集成功能,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
爬虫抓取网页数据(网络爬虫工具越来越工具)
网络爬虫广泛应用于许多领域。它的目标是从 网站 获取新数据并将其存储以便于访问。网络爬虫工具越来越广为人知,因为它可以简化和自动化整个爬虫过程,让每个人都可以轻松访问网络数据资源。###1. Octoparse
Octoparse 是一款免费且功能强大的 网站 爬虫工具,用于从 网站 中提取所需的各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。您可以下载网站的几乎所有内容,并以EXCEL、TXT、HTML或数据库等结构化格式保存。通过定时云抽取功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性的网站检测到。总之,Octoparse 应该可以满足用户最基本或者高端的爬虫需求,不需要任何编码技能。
2. Cyotek WebCopy
WebCopy 是一款免费的爬虫工具,允许将部分或完整的网站 内容本地复制到硬盘上以供离线阅读。在将网站的内容下载到硬盘之前,它会扫描指定的网站,并自动重新映射网站中的图像和其他网络资源的链接以匹配它们的本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它。您还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为一款网站免费爬虫软件,HTTrack提供的功能非常适合将整个网站从网上下载到您的PC上。它提供了适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置”下决定下载网页时同时打开的连接数。您可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一款免费且易于使用的爬虫工具。启动Getleft后,输入网址,选择要下载的文件,然后开始下载网站 另外,提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总的来说,Getleft 应该能满足用户基本的爬虫需求,不需要更复杂的技能。
5. 刮板
Scraper 是一款 Chrome 扩展工具,数据提取功能有限,但对于在线研究和导出数据到 Google 电子表格非常有用。适合初学者和专家,您可以轻松地将数据复制到剪贴板或使用 OAuth 将其存储在电子表格中。不提供包罗万象的爬虫服务,但对新手也很友好。
6. OutWit 中心
OutWit Hub 是一个 Firefox 插件,具有数十种数据提取功能,可简化网络搜索。浏览页面后,提取的信息会以合适的格式存储。您还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬虫工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub 是一款优秀的爬虫工具,支持使用 AJAX 技术、JavaScript、cookies 等方式获取网页数据。其机器学习技术可以读取、分析网络文档并将其转换为相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,您也可以使用浏览器内置的 Web 应用程序。
8.视觉抓取工具
VisualScraper 是另一个很棒的免费和非编码爬虫工具,它通过一个简单的点击界面从互联网上采集数据。您可以从多个网页获取实时数据,并将提取的数据导出为 CSV、XML、JSON 或 SQL 文件。除了SaaS,VisualScraper还提供网页抓取服务,例如数据传输服务和创作软件提取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一种基于云的数据提取工具,可以帮助成千上万的开发人员获取有价值的数据。它的开源可视化爬虫工具允许用户在没有任何编程知识的情况下爬取网页。Scrapinghub 使用 Crawlera,一个智能代理微调器,支持绕过 bot 机制,轻松抓取大量受 bot 保护的 网站。它使用户能够通过简单的 HTTP API 从多个 IP 和位置进行爬取,而无需代理管理。
10. Dexi.io
Dexi.io作为一款基于浏览器的网络爬虫工具,允许用户从任意网站中抓取数据,并提供了三种机器人来创建抓取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据会在归档前两周内存储在Dexi.io的服务器上,或者提取的数据可以直接导出为JSON或CSV文件。提供有偿服务,满足实时数据采集需求。
11. Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用覆盖各种来源的多个过滤器来抓取数据并进一步提取不同语言的关键字。捕获的数据可以以 XML、JSON 和 RSS 格式保存,并且可以从其存档中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 捕获的结构化数据。总体来说,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入。io
用户只需要从特定网页导入数据,并将数据导出为CSV,即可形成自己的数据集。无需编写任何代码,您可以在几分钟内轻松抓取数千个网页,并根据您的需求构建 1,000 多个 API。公共 API 提供了强大而灵活的功能来以编程方式控制 Import.io 并自动访问数据。Import.io 将网页数据集成到您自己的应用程序或 网站 中,只需单击几下即可轻松实现爬虫。为了更好地满足用户的爬取需求,它还提供了Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和爬取工具,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80条腿
80legs是一款功能强大的网络爬虫工具,可根据客户需求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速工作,在几秒钟内获取所需的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 中获取所有数据。Spinn3r 发布了一个防火墙 API 来管理 95% 的索引工作。提供先进的垃圾邮件防护功能,杜绝垃圾邮件和不当语言,提高数据安全性。Spinn3r 索引类似于 Google 的内容,并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网络抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合具有高级编程技能的人,因为它为有需要的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 调试或编写脚本以编程方式控制抓取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16. 氦气刮刀
Helium Scraper 是一款可视化的网络数据爬虫软件,当元素之间的相关性较小时效果更好。它是非编码和非配置的。用户可以根据各种爬取需求访问在线模板。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动化爬虫软件。它可以自动从第三方应用程序抓取网页和桌面数据。Uipath 可以跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬行的内置工具。这种方法在处理复杂的 UI 时非常有效。屏幕抓取工具可以处理单个文本元素、文本组和文本块。
18. 刮擦。它
Scrape.it 是一种基于云的 Web 数据提取工具。它是为具有高级编程技能的人设计的,因为它提供了公共和私有包来发现、使用、更新和与全球数百万开发人员共享代码。其强大的集成功能可以帮助用户根据自己的需求构建自定义爬虫。
19. 网络哈维
WebHarvy 是为非程序员设计的。它可以自动抓取来自网站的文本、图片、URL和电子邮件,并将抓取到的内容以各种格式保存。它还提供了内置的调度程序和代理支持,可以匿名爬行并防止被 Web 服务器阻止。可以选择通过代理服务器或VPN访问目标。网站。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,或导出到 SQL 数据库。
20. 内涵
Connotate 是一款自动化的网络爬虫软件,专为企业级网络爬虫设计,需要企业级解决方案。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它可以自动提取95%以上的网站,包括基于JavaScript的动态网站技术,如Ajax。此外,Connotate 还提供了网页和数据库内容的集成功能,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
爬虫抓取网页数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-06 07:02
要使用 Python 网络爬虫,首先需要了解什么是 HTTP,因为这与 Python 爬虫的基本原理密切相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传递信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium 是一个 Web 应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决 JavaScript 渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python用来解析和提取信息的第三方库包括BeautifulSoup、lxml、pyquery等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,将数据存储起来。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理之后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests来请求获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取到数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,那么爬取效率会进一步提高。将多台主机组合在一起完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在爬取网站的数据的时候,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
有4种常见的爬取机制:
①请求头校验:请求头校验是最常见的反爬虫机制。许多 网站 会在 Headers 中检测 user-agent,一些 网站 还会检测 origin 和 referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有些网站会通过用户行为来判断同一IP是否在短时间内多次请求过一个页面。如果这个频率超过某个阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码和方形验证码。
验证码类型 查看全部
爬虫抓取网页数据(使用Python网络爬虫首先需要了解一下什么是HTTP的请求)
要使用 Python 网络爬虫,首先需要了解什么是 HTTP,因为这与 Python 爬虫的基本原理密切相关。正是围绕着这些底层逻辑,Python爬虫才能一步步进行。
HTTP的全称是Hyper Text Transfer Protocol,中文称为Hyper Text Transfer Protocol。它用于将超文本数据从网络传输到本地浏览器。它也是 Internet 上使用最广泛的网络传输协议。
请求和响应
当我们在浏览器中输入 URL 并按 Enter 键时,浏览器会向 网站 所在的服务器发送请求。服务器收到请求后,会解析处理,然后返回浏览器对应的响应。收录页面源代码等内容,我们在浏览器上看到的内容经过浏览器解析后呈现出来。这整个过程就是 HTTP 请求和响应。
请求方法 有两种常见的请求方法:GET 和 POST。两者的主要区别在于GET请求的内容会反映在URL中,POST请求的内容会反映在表单中。因此,当涉及到一些敏感或私密的信息时,例如用户名和密码,我们使用POST请求来传递信息。.
响应状态码 请求完成后,客户端会收到服务器返回的响应状态。常见的响应状态码有 200(来自服务器的正常响应)、404(未找到页面)、500(服务器内部发生错误)等。
2.网页
爬取的时候,我们通过网页源代码和响应中得到的JSON数据提取需要的信息和数据,所以需要了解网页的基本结构。一个网页基本上由以下三部分组成:
HTML,全称Hyper Text Marked Language,中文称为Hypertext Marked Language,用于表达网页呈现的内容,如文字、图片、视频等,相当于一个网页的骨架。
JavaScript,简称JS,是一种可以为页面添加实时、动态、交互功能的脚本语言,相当于一个网页的肌肉。
CSS,全称Cascading Style Sheets,中文叫Cascading Style Sheets。它对网页进行布局和装饰,使网页美观大方,相当于网页的皮肤。
3.基本原则
Python爬虫的基本原理其实是围绕HTTP和网页结构展开的:首先请求网页,然后解析提取信息,最后存储信息。
1) 请求
Python经常用来请求的第三方库有requests和selenium,内置库也可以使用urllib。
requests 是用 Python 编写的,基于 urllib,使用 Apache2 许可的开源协议的 HTTP 库。与urllib库相比,requests库更方便,可以为我们节省很多工作,所以我们倾向于使用requests来请求网页。
Selenium 是一个 Web 应用的自动化测试工具,它可以驱动浏览器执行特定的动作,比如输入、点击、下拉等,就像真实用户在操作一样,常用于爬虫解决 JavaScript 渲染问题。Selenium 可以支持多种浏览器,如 Chrome、Firefox、Edge 等,在通过 selenium 使用这些浏览器之前,需要配置相关的浏览器驱动:
2)解析和提取
Python用来解析和提取信息的第三方库包括BeautifulSoup、lxml、pyquery等。
每个库可以使用不同的方法来提取数据:
此外,您还可以使用正则表达式来提取您想要的信息。有了它,字符串检索、替换和匹配就是一切。
3)存储
提取数据后,将数据存储起来。最简单的数据可以保存为文本文件,如TXT文本、CSV文件、Excel文件、JSON文件等,也可以保存为二进制数据,如图片、音频、视频等,也可以保存到数据库中,如关系型数据库MySQL、非关系型数据库MongoDB、Redis等。
如果要将数据存储为 CSV 文件、Excel 文件和 JSON 文件,则需要使用 csv 库、openpyxl 库和 json 库。
4.静态网页抓取
了解了爬虫的基本原理之后,就可以抓取网页了,其中静态网页是最容易操作的。
抓取静态网页,我们可以选择requests来请求获取网页的源代码,然后使用BeautifulSoup进行解析提取,最后选择合适的存储方式。
5.动态网页抓取
有时在使用请求爬取网页时,会发现爬取的内容和浏览器显示的不一样。在浏览器中可以看到要爬取的内容,但是爬取后的结果却不是。它与网页是静态的还是动态的有关。
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。动态网页是基本的html语法规范与Java、VB、VC等高级编程语言、数据库编程等技术的融合,以实现网站托管网页的高效、动态、交互的内容和风格。页。
两者的区别在于:
1)阿贾克斯
Ajax 不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页内容而无需重新加载整个页面的技术。
由于使用Ajax技术的网页中的信息是通过JavaScript脚本语言动态生成的,使用requests-BeautifulSoup的静态页面爬取方法无法抓取到数据。我们可以通过以下两种方式抓取Ajax数据:
2)Cookie 和会话
Cookie 是存储在用户本地终端上的数据(通常是加密的),用于识别用户身份以进行 Session 跟踪,由用户的客户端计算机临时或永久存储。
会话称为“会话”,存储特定用户会话所需的属性和配置信息。
在很多情况下,您需要登录才能在页面上查看更多信息。因此,面对此类网页时,需要先模拟登录,才能进一步抓取网页。当我们模拟登录时,客户端会生成一个cookie并发送给服务器。因为Cookie中存储了SessionID信息,服务器可以根据Cookie确定对应的SessionID,进而找到会话。如果当前会话有效,服务器会判断用户已经登录并返回请求的页面信息,以便进一步抓取网页。
6.APP抓取
除了web端,Python也可以抓取APP数据,但这需要一个抓包工具,比如Fiddler。
与网页端相比,APP数据爬取其实更容易,反爬虫也没有那么强。大多数返回的数据类型是json。
7.多协程
我们在做爬虫项目的时候,如果要爬取的数据很多,因为程序是一行一行的执行,爬取的速度会很慢。多协程可以解决这个问题。
使用多协程,我们可以同时执行多个任务。其实在使用多协程的时候,如果一个任务在执行过程中遇到等待,它会先执行其他任务,等待结束后又回来继续执行之前的任务。因为这个进程切换的非常快,看起来就像是同时执行了多个任务。如果用计算机的概念来解释,这其实是异步的。
我们可以使用gevent库实现多协程,使用Queue()创建队列,spawn()创建任务,最后joinall()执行任务。
8.爬虫框架
当遇到比较大的需求时,为了方便管理和扩展,我们可以使用爬虫框架来实现数据爬取。
有了爬虫框架,我们就不用一一组织整个爬虫流程,只需要关心爬虫的核心逻辑,大大提高了开发效率,节省了大量时间。爬虫框架有很多,比如Scrapy、PySpider等。
9.分布式爬虫
爬虫框架的使用大大提高了开发效率,但这些框架都是运行在同一台主机上的。如果多台主机可以一起爬取,那么爬取效率会进一步提高。将多台主机组合在一起完成一个爬虫任务,就是分布式爬虫。
10.反爬虫机制及对策
为了防止爬虫开发者过度爬取造成网站的负担或恶意爬取数据,很多网站都会设置反爬虫机制。所以我们在爬取网站的数据的时候,可以通过查看网站的robots.txt,了解哪些网站是允许爬取的,哪些是不允许爬取的。
有4种常见的爬取机制:
①请求头校验:请求头校验是最常见的反爬虫机制。许多 网站 会在 Headers 中检测 user-agent,一些 网站 还会检测 origin 和 referer。对付这种反爬虫机制,可以给爬虫添加请求头,在浏览器中以字典的形式添加相应的值。
②Cookie限制:部分网站会使用cookies来跟踪您的访问过程,如果发现爬虫的异常行为,会中断爬虫的访问。对于处理cookie限制的反爬虫,一般可以先获取网站 cookie,然后将cookie发送到服务器。您可以手动添加它或使用 Session 机制。但是对于一些网站需要用户浏览页面生成cookie的情况,比如点击按钮,可以使用selenium-PhantomJS请求网页并获取cookie。
③IP访问频率限制:有些网站会通过用户行为来判断同一IP是否在短时间内多次请求过一个页面。如果这个频率超过某个阈值,网站通常会提示爬虫并要求输入验证码,或者直接屏蔽IP拒绝服务。针对这种情况,可以使用IP代理方式绕过反爬虫,如代理池维护、付费代理、ADSL拨号代理等。
④验证码限制:很多网站需要在登录时输入验证码,常见的有:图文验证码、捷喜滑动验证码、tap验证码和方形验证码。
验证码类型
爬虫抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-04 07:09
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存到本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录中找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。 查看全部
爬虫抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存到本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录中找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。
爬虫抓取网页数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-04 00:11
注:只是分享一个解决方案,代码和部分截图不方便贴出,请见谅!
前段时间一直在研究爬虫,爬取网上的具体数据。如果它只是一个静态网页,那就再简单不过了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
拿到了Document,只想做,但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者由用户滑动js触发加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来我用Selenium来获取动态网页的数据。可以成功获取数据(实现方法),打包程序在机器上运行,开始测试,结果不是那么理想,经常会出现内存溢出,或者浏览器升级导致的驱动与浏览器版本不匹配等一系列问题。今天早上来公司,发现程序又炸了。半夜,没有人碰这台机器。鼠标和键盘都失败了。我不得不重新启动它,更不用说任何问题了。测试和修改测试太麻烦,所以我打算放弃使用Selenium。稳定性太差了。考虑使用 htmlunit 和其他。但是,这些工具的效果都不是很好,我也无路可走,
首先是动态网页,既然是动态的,那肯定是浏览器加载网页后向服务器发送了网络请求。如果拿到网络请求的url,模拟参数,自己发送请求,解析数据也不好,开始做:
抓包工具:fiddle
如果你不懂fiddle,建议百度了解一下
安装完成后,打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle打开这个网页的所有网络请求:
我不会在这里发图片,我怕他们会惹我。. . .
然后一一检查网络请求:
先看左边的图标,直接跳过图片。显然,我们需要的是数据。关注文本格式的请求,然后右击copy->just url把url复制到浏览器看看能得到什么,最后找到18行的请求是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json,接下来,很容易解析数据。. . . . . . . 轻微地。. . . . . 话不多说,继续打代码,这里只是分享一个解析动态网页的方法,有不懂的欢迎评论写在这里,大家一起讨论,找到更好的解决方法!
2016-11-07
甘南乡
--------------------- 本文来自甘南翔的CSDN博客。全文地址请点击: 查看全部
爬虫抓取网页数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
注:只是分享一个解决方案,代码和部分截图不方便贴出,请见谅!
前段时间一直在研究爬虫,爬取网上的具体数据。如果它只是一个静态网页,那就再简单不过了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
拿到了Document,只想做,但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者由用户滑动js触发加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来我用Selenium来获取动态网页的数据。可以成功获取数据(实现方法),打包程序在机器上运行,开始测试,结果不是那么理想,经常会出现内存溢出,或者浏览器升级导致的驱动与浏览器版本不匹配等一系列问题。今天早上来公司,发现程序又炸了。半夜,没有人碰这台机器。鼠标和键盘都失败了。我不得不重新启动它,更不用说任何问题了。测试和修改测试太麻烦,所以我打算放弃使用Selenium。稳定性太差了。考虑使用 htmlunit 和其他。但是,这些工具的效果都不是很好,我也无路可走,
首先是动态网页,既然是动态的,那肯定是浏览器加载网页后向服务器发送了网络请求。如果拿到网络请求的url,模拟参数,自己发送请求,解析数据也不好,开始做:
抓包工具:fiddle
如果你不懂fiddle,建议百度了解一下
安装完成后,打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle打开这个网页的所有网络请求:
我不会在这里发图片,我怕他们会惹我。. . .
然后一一检查网络请求:
先看左边的图标,直接跳过图片。显然,我们需要的是数据。关注文本格式的请求,然后右击copy->just url把url复制到浏览器看看能得到什么,最后找到18行的请求是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json,接下来,很容易解析数据。. . . . . . . 轻微地。. . . . . 话不多说,继续打代码,这里只是分享一个解析动态网页的方法,有不懂的欢迎评论写在这里,大家一起讨论,找到更好的解决方法!
2016-11-07
甘南乡
--------------------- 本文来自甘南翔的CSDN博客。全文地址请点击:
爬虫抓取网页数据( 利用httpclient抓取到数据为该index.html静态页面的源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-04 00:09
利用httpclient抓取到数据为该index.html静态页面的源码)
1 @Test
2 public void crawSignHtmlTest() {
3 CloseableHttpClient httpclient = HttpClients.createDefault();
4 try {
5 //创建httpget
6 HttpGet httpget = new HttpGet("http://127.0.0.1:8080/index.ht ... 6quot;);
7
8 httpget.setHeader("Accept", "text/html, */*; q=0.01");
9 httpget.setHeader("Accept-Encoding", "gzip, deflate,sdch");
10 httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
11 httpget.setHeader("Connection", "keep-alive");
12 httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)");
13
14 //System.out.println("executing request " + httpget.getURI());
15 //执行get请求
16 CloseableHttpResponse response = httpclient.execute(httpget);
17 try {
18 //获取响应实体
19 HttpEntity entity = response.getEntity();
20 //响应状态
21 System.out.println(response.getStatusLine());
22 if(entity != null) {
23 //响应内容长度
24 //System.out.println("response length: " + entity.getContentLength());
25 //响应内容
26 System.out.println("response content: ");
27 System.out.println(EntityUtils.toString(entity));
28 }
29 } finally {
30 response.close();
31 }
32 } catch (ClientProtocolException e) {
33 e.printStackTrace();
34 } catch (ParseException e) {
35 e.printStackTrace();
36 } catch (IOException e) {
37 e.printStackTrace();
38 } finally {
39 //关闭链接,释放资源
40 try {
41 httpclient.close();
42 } catch(IOException e) {
43 e.printStackTrace();
44 }
45 }
46 }
httpclient捕获的数据是index.html静态页面的源代码。如果HTML页面中有JS要执行的代码,那么此时不会对捕获的页面执行JS
如果您想在JS呈现后捕获HTML源代码,可以通过htmlunit获取它
2、Htmlunit
引入htmlunit的jar并在JS执行后调用获取代码
1 @Test
2 public void htmlUnitSignTest() throws Exception {
3 WebClient wc = new WebClient(BrowserVersion.CHROME);
4 wc.setJavaScriptTimeout(5000);
5 wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
6 wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
7 wc.getOptions().setCssEnabled(false);//禁用css支持
8 wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
9 wc.getOptions().setTimeout(100000);//设置连接超时时间
10 wc.getOptions().setDoNotTrackEnabled(false);
11 wc.getOptions().setActiveXNative(true);
12
13 wc.addRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3");
14 wc.addRequestHeader("Accept-Encoding", "gzip, deflate, br");
15 wc.addRequestHeader("Accept-Language", "zh-CN,zh;q=0.9");
16 wc.addRequestHeader("Connection", "keep-alive");
17 wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36");
18
19
20 //HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/demo.htm ... 6quot;);
21 HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/sign.htm ... 6quot;);
22 String res = htmlpage.asXml();
23 //处理源码
24 System.out.println(res);
25
26 // HtmlForm form = htmlpage.getFormByName("f");
27 // HtmlButton button = form.getButtonByName("btnDomName"); // 获取提交按钮
28 // HtmlPage nextPage = button.click();
29 // System.out.println("等待20秒");
30 // Thread.sleep(2000);
31 // System.out.println(nextPage.asText());
32 wc.close();
33 }
Htmlunit通过创建新的webclient()构建浏览器模拟器,然后使用获得的HTML源代码执行JS渲染,最后在JS执行后获得HTML源代码
但在一些特殊场景中,如抓取画布绘制的Base64数据,发现数据存在问题,与直接在浏览器上执行的结果不一致(巨坑,浪费大量时间)
3、硒
介绍硒罐。此外,您需要下载chromedriver.exe。您还可以通过调用
1 public static void main(String[] args) throws IOException {
2
3 System.setProperty("webdriver.chrome.driver", "/srv/chromedriver.exe");// chromedriver服务地址
4 ChromeOptions options = new ChromeOptions();
5 options.addArguments("--headless");
6 //WebDriver driver = new ChromeDriver(options); // 新建一个WebDriver 的对象,但是new 的是谷歌的驱动
7
8 WebDriver driver = new ChromeDriver();
9 String url = "http://127.0.0.1:8080/index.ht ... 3B%3B
10 driver.get(url); // 打开指定的网站
11
12 //获取当前浏览器的信息
13 System.out.println("Title:" + driver.getTitle());
14 System.out.println("currentUrl:" + driver.getCurrentUrl());
15
16
17 WebElement imgDom = ((ChromeDriver) driver).findElementById("imgDom");
18 System.out.println(imgDom.getText());
19
20 //String imgBase64 = URLDecoder.decode(imgDom.getText(), "UTF-8");
21 //imgBase64 = imgBase64.substring(imgBase64.indexOf(",") + 1);
22 byte[] fromBASE64ToByte = Base64Util.getFromBASE64ToByte(imgDom.getText());
23 FileUtils.writeByteArrayToFile(new File("/srv/charter44.png"),fromBASE64ToByte);
24 driver.close();
25 }
Selenium还使用新的webdriver()构建浏览器模拟器。它不仅对获取的HTML源代码执行JS呈现,而且在JS执行后获得一个HTML源代码。甚至在上面的htmlunit执行中对canvas canvas的不友好支持也在这里得到了完美解决。硒喜欢 查看全部
爬虫抓取网页数据(
利用httpclient抓取到数据为该index.html静态页面的源码)
1 @Test
2 public void crawSignHtmlTest() {
3 CloseableHttpClient httpclient = HttpClients.createDefault();
4 try {
5 //创建httpget
6 HttpGet httpget = new HttpGet("http://127.0.0.1:8080/index.ht ... 6quot;);
7
8 httpget.setHeader("Accept", "text/html, */*; q=0.01");
9 httpget.setHeader("Accept-Encoding", "gzip, deflate,sdch");
10 httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
11 httpget.setHeader("Connection", "keep-alive");
12 httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)");
13
14 //System.out.println("executing request " + httpget.getURI());
15 //执行get请求
16 CloseableHttpResponse response = httpclient.execute(httpget);
17 try {
18 //获取响应实体
19 HttpEntity entity = response.getEntity();
20 //响应状态
21 System.out.println(response.getStatusLine());
22 if(entity != null) {
23 //响应内容长度
24 //System.out.println("response length: " + entity.getContentLength());
25 //响应内容
26 System.out.println("response content: ");
27 System.out.println(EntityUtils.toString(entity));
28 }
29 } finally {
30 response.close();
31 }
32 } catch (ClientProtocolException e) {
33 e.printStackTrace();
34 } catch (ParseException e) {
35 e.printStackTrace();
36 } catch (IOException e) {
37 e.printStackTrace();
38 } finally {
39 //关闭链接,释放资源
40 try {
41 httpclient.close();
42 } catch(IOException e) {
43 e.printStackTrace();
44 }
45 }
46 }
httpclient捕获的数据是index.html静态页面的源代码。如果HTML页面中有JS要执行的代码,那么此时不会对捕获的页面执行JS
如果您想在JS呈现后捕获HTML源代码,可以通过htmlunit获取它
2、Htmlunit
引入htmlunit的jar并在JS执行后调用获取代码
1 @Test
2 public void htmlUnitSignTest() throws Exception {
3 WebClient wc = new WebClient(BrowserVersion.CHROME);
4 wc.setJavaScriptTimeout(5000);
5 wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
6 wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
7 wc.getOptions().setCssEnabled(false);//禁用css支持
8 wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
9 wc.getOptions().setTimeout(100000);//设置连接超时时间
10 wc.getOptions().setDoNotTrackEnabled(false);
11 wc.getOptions().setActiveXNative(true);
12
13 wc.addRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3");
14 wc.addRequestHeader("Accept-Encoding", "gzip, deflate, br");
15 wc.addRequestHeader("Accept-Language", "zh-CN,zh;q=0.9");
16 wc.addRequestHeader("Connection", "keep-alive");
17 wc.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36");
18
19
20 //HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/demo.htm ... 6quot;);
21 HtmlPage htmlpage = wc.getPage("http://127.0.0.1:8081/sign.htm ... 6quot;);
22 String res = htmlpage.asXml();
23 //处理源码
24 System.out.println(res);
25
26 // HtmlForm form = htmlpage.getFormByName("f");
27 // HtmlButton button = form.getButtonByName("btnDomName"); // 获取提交按钮
28 // HtmlPage nextPage = button.click();
29 // System.out.println("等待20秒");
30 // Thread.sleep(2000);
31 // System.out.println(nextPage.asText());
32 wc.close();
33 }
Htmlunit通过创建新的webclient()构建浏览器模拟器,然后使用获得的HTML源代码执行JS渲染,最后在JS执行后获得HTML源代码
但在一些特殊场景中,如抓取画布绘制的Base64数据,发现数据存在问题,与直接在浏览器上执行的结果不一致(巨坑,浪费大量时间)
3、硒
介绍硒罐。此外,您需要下载chromedriver.exe。您还可以通过调用
1 public static void main(String[] args) throws IOException {
2
3 System.setProperty("webdriver.chrome.driver", "/srv/chromedriver.exe");// chromedriver服务地址
4 ChromeOptions options = new ChromeOptions();
5 options.addArguments("--headless");
6 //WebDriver driver = new ChromeDriver(options); // 新建一个WebDriver 的对象,但是new 的是谷歌的驱动
7
8 WebDriver driver = new ChromeDriver();
9 String url = "http://127.0.0.1:8080/index.ht ... 3B%3B
10 driver.get(url); // 打开指定的网站
11
12 //获取当前浏览器的信息
13 System.out.println("Title:" + driver.getTitle());
14 System.out.println("currentUrl:" + driver.getCurrentUrl());
15
16
17 WebElement imgDom = ((ChromeDriver) driver).findElementById("imgDom");
18 System.out.println(imgDom.getText());
19
20 //String imgBase64 = URLDecoder.decode(imgDom.getText(), "UTF-8");
21 //imgBase64 = imgBase64.substring(imgBase64.indexOf(",") + 1);
22 byte[] fromBASE64ToByte = Base64Util.getFromBASE64ToByte(imgDom.getText());
23 FileUtils.writeByteArrayToFile(new File("/srv/charter44.png"),fromBASE64ToByte);
24 driver.close();
25 }
Selenium还使用新的webdriver()构建浏览器模拟器。它不仅对获取的HTML源代码执行JS呈现,而且在JS执行后获得一个HTML源代码。甚至在上面的htmlunit执行中对canvas canvas的不友好支持也在这里得到了完美解决。硒喜欢
爬虫抓取网页数据(教你如何利用requests网络库发掘网页中未的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-02 12:00
爬虫抓取网页数据后,一般需要加载预览页,如果页面已经加载完毕,抓取到的数据就无法看到。这篇文章教你如何利用requests网络库发掘网页中未加载的数据。首先我们来理解什么是预览页,即起初加载时抓取数据网站上默认的加载页。如下图,我抓取了大量页面,并将那些没有预览数据的网页都作为参数传入java,生成了一个requests.post(pageno="1",headers={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/53.0.2924.106safari/537.36"}),该方法就是预览页。
另外,他在网站转存了这一页的数据,并从这一页开始抓取数据。大部分后端抓取方法是无法在加载页面后才从加载页开始抓取的,大多数方法是数据加载加载完了再抓取(例如ajax加载)。定义查询url为:,通过发送xmlhttprequest请求,连接到相应的httpserver。下面,我用requests.post.get函数抓取了web页面1以及一些无法利用浏览器预览页的网页:;initiate=movie%3d&page=1。
有一个叫getcribed.io的网站,抓取网页的时候输入某个url就可以获取到poststore里面的内容。但是可能因为加载超时的问题(win10桌面的ie11下成功率不高),导致抓取速度慢。另外一个方法是编写api请求,例如抓取个人介绍的话,需要分页抓取:;section=android_program_index(page=0,//网页是否允许抓取iconvisitor(config='android'))。 查看全部
爬虫抓取网页数据(教你如何利用requests网络库发掘网页中未的数据)
爬虫抓取网页数据后,一般需要加载预览页,如果页面已经加载完毕,抓取到的数据就无法看到。这篇文章教你如何利用requests网络库发掘网页中未加载的数据。首先我们来理解什么是预览页,即起初加载时抓取数据网站上默认的加载页。如下图,我抓取了大量页面,并将那些没有预览数据的网页都作为参数传入java,生成了一个requests.post(pageno="1",headers={"user-agent":"mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/53.0.2924.106safari/537.36"}),该方法就是预览页。
另外,他在网站转存了这一页的数据,并从这一页开始抓取数据。大部分后端抓取方法是无法在加载页面后才从加载页开始抓取的,大多数方法是数据加载加载完了再抓取(例如ajax加载)。定义查询url为:,通过发送xmlhttprequest请求,连接到相应的httpserver。下面,我用requests.post.get函数抓取了web页面1以及一些无法利用浏览器预览页的网页:;initiate=movie%3d&page=1。
有一个叫getcribed.io的网站,抓取网页的时候输入某个url就可以获取到poststore里面的内容。但是可能因为加载超时的问题(win10桌面的ie11下成功率不高),导致抓取速度慢。另外一个方法是编写api请求,例如抓取个人介绍的话,需要分页抓取:;section=android_program_index(page=0,//网页是否允许抓取iconvisitor(config='android'))。
爬虫抓取网页数据( Python模拟浏览器发起请求并解析内容代码:正则的好处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2021-10-01 09:10
Python模拟浏览器发起请求并解析内容代码:正则的好处)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道爬虫的原理无非就是把目标URL的内容下载下来保存在内存中。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法把这个区域的内容取出来就差不多了。
现在开始编写代码。
1:正则表达式
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r" 查看全部
爬虫抓取网页数据(
Python模拟浏览器发起请求并解析内容代码:正则的好处)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道爬虫的原理无非就是把目标URL的内容下载下来保存在内存中。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法把这个区域的内容取出来就差不多了。
现在开始编写代码。
1:正则表达式
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r"
爬虫抓取网页数据(什么叫Python网络爬虫?技术,有关Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-01 09:05
什么是 Python 网络爬虫?
Python 网络爬虫也称为爬虫技术。关于Python网络爬虫,你必须知道:
1、Python基础英语语法
2、HTML 网页内容抓取(数据采集)
3、HTML网页数据信息获取(数据预处理)
4、Scrapy架构及其scrapy-redis分布式系统对策(第三方架构)
5、 蜘蛛、反蜘蛛、反反蜘蛛之间的斗争。
爬虫技术可以分为两种:通用网络爬虫和焦点网络爬虫
1、万能爬虫技术
从互联网技术采集网页以采集信息。此类网页信息用于为百度搜索引擎创建数据库索引,适用。它决定了所有模块系统软件的内容是否丰富多彩,信息是否及时。功能的质量立即危及百度搜索引擎的有效性。
2、专注于网络爬虫
焦点网络爬虫是一种“面向特殊主题风格需求”的网络爬虫。它与一般的百度搜索引擎网络爬虫的区别在于: 焦点网络爬虫在进行网页爬取时会开发内容 解决选择并确保尽可能只爬取与请求相关的网页信息。
什么是算子大数据挖掘和爬取
在我国,运营商拥有庞大且绝对真实的数据和信息存储能力。运营商在数据和信息的使用上具有肯定的领先优势,无论是抓捕工作的能力,数据库管理、数据信息工作能力、标识工作能力、产品和服务三大业务流程都具有优异的主要表现。
运营商大数据是数据信息传递的最佳神器。相关企业要利用好运营商的数据信息和标识工作能力。运营商的数据管理平台将能够很好地为相关企业开展网络服务,最终实现数据信息化。
无论是数据采集、数据处理方式、数据统计分析、数据信息浏览、数据信息应用,运营商都是一个多方位的数据库管理服务平台,一个数据管理平台的标准化框架,不同领域和公司。表示协作必须能够将自己的业务流程进行到一个新的纵横比。
数据信息使用
Python网络爬虫广泛适用于一些依赖互联网技术的数据采集。
运营商大数据可以制定有目的的模型,进而进行多层次、全方位的数据采集和数据统计分析。运营商大数据可以抓取随机网址、网页、网站地址、手机APP、400号码、固定电话、微信小程序、关键词、APP刚注册客户等数据信息信息,进而辅助整个领域和不同企业开展精准客户推广和营销服务项目。
对于不同领域的企业,运营商的大数据采集技术让企业从传统的客户拓展方式转变为大数据精准的客户拓展营销方式。运营商大数据不仅可以提供精准客户,还可以提供客户管理方法。通过外呼系统,相关企业可以按照电话营销的方式直接访问和管理准确的客户信息。
运营商大数据不仅可以保护客户的个人隐私不被侵犯,还可以让不同领域的中小微企业在互联网时代获得最新鲜、最准确、最高效的客户拓展体验。 查看全部
爬虫抓取网页数据(什么叫Python网络爬虫?技术,有关Python)
什么是 Python 网络爬虫?
Python 网络爬虫也称为爬虫技术。关于Python网络爬虫,你必须知道:
1、Python基础英语语法
2、HTML 网页内容抓取(数据采集)
3、HTML网页数据信息获取(数据预处理)
4、Scrapy架构及其scrapy-redis分布式系统对策(第三方架构)
5、 蜘蛛、反蜘蛛、反反蜘蛛之间的斗争。
爬虫技术可以分为两种:通用网络爬虫和焦点网络爬虫
1、万能爬虫技术
从互联网技术采集网页以采集信息。此类网页信息用于为百度搜索引擎创建数据库索引,适用。它决定了所有模块系统软件的内容是否丰富多彩,信息是否及时。功能的质量立即危及百度搜索引擎的有效性。
2、专注于网络爬虫
焦点网络爬虫是一种“面向特殊主题风格需求”的网络爬虫。它与一般的百度搜索引擎网络爬虫的区别在于: 焦点网络爬虫在进行网页爬取时会开发内容 解决选择并确保尽可能只爬取与请求相关的网页信息。
什么是算子大数据挖掘和爬取
在我国,运营商拥有庞大且绝对真实的数据和信息存储能力。运营商在数据和信息的使用上具有肯定的领先优势,无论是抓捕工作的能力,数据库管理、数据信息工作能力、标识工作能力、产品和服务三大业务流程都具有优异的主要表现。
运营商大数据是数据信息传递的最佳神器。相关企业要利用好运营商的数据信息和标识工作能力。运营商的数据管理平台将能够很好地为相关企业开展网络服务,最终实现数据信息化。
无论是数据采集、数据处理方式、数据统计分析、数据信息浏览、数据信息应用,运营商都是一个多方位的数据库管理服务平台,一个数据管理平台的标准化框架,不同领域和公司。表示协作必须能够将自己的业务流程进行到一个新的纵横比。
数据信息使用
Python网络爬虫广泛适用于一些依赖互联网技术的数据采集。
运营商大数据可以制定有目的的模型,进而进行多层次、全方位的数据采集和数据统计分析。运营商大数据可以抓取随机网址、网页、网站地址、手机APP、400号码、固定电话、微信小程序、关键词、APP刚注册客户等数据信息信息,进而辅助整个领域和不同企业开展精准客户推广和营销服务项目。
对于不同领域的企业,运营商的大数据采集技术让企业从传统的客户拓展方式转变为大数据精准的客户拓展营销方式。运营商大数据不仅可以提供精准客户,还可以提供客户管理方法。通过外呼系统,相关企业可以按照电话营销的方式直接访问和管理准确的客户信息。
运营商大数据不仅可以保护客户的个人隐私不被侵犯,还可以让不同领域的中小微企业在互联网时代获得最新鲜、最准确、最高效的客户拓展体验。
爬虫抓取网页数据(【每日一题】python爬虫专题(一):用最简单的代码抓取最基础的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-01 09:04
本专栏从这里开始python爬虫的话题。
专题定位:目标是抓取固定数量的数据进行分析,不设计工程爬虫(实时大规模爬取展示,设计存储等),所以不会涉及真正难的部分爬虫,但只能算是介绍。
题目的整体思路是这样设计的
文章 目录如下,这是一个初步的想法,在写的过程中可能会有所改动
入门
爬虫基本原理:用最简单的代码爬取最基本的网页,展示爬虫最基本的思想,让读者知道爬虫其实是一个很简单的东西。
爬虫代码改进:这部分是一系列文章,从程序设计的角度来说,是爬虫需要掌握的基本代码设计思想。主要从两个方面对之前的代码进行改进:一是代码设计的角度,让读者习惯于定义函数、使用生成器等;二是展示多页面爬取和爬取二级页面的代码逻辑。
爬虫相关库的安装:讲述了本主题将用到的所有库的安装方法,有的简单,有的有点复杂。这个文章主要是帮助读者排除学习过程中不必要的障碍。
学完这三部分,读者可以在数据量小、没有反爬机制的情况下自由抓取网站(其实这样的网站还是很多的)。
网页分析和数据存储
Python提供了很多网页解析方法;同时,根据不同的需要,它可能会存储在不同的文件格式或数据库中,所以这部分将两者放在一起说。每个部分都有理论和实战;每个部分使用一个解析库并以文件格式存储。
注意:这些分析方法是相互替代的(尽管每种方法都有自己的优点和缺点)。基本上只需要掌握一个,最好掌握所有的文件存储。
beautifulsoup详解:这篇文章全面讲解了beautifulsoup解析库的使用
bs4+json捕捉实战:json介绍,在stackoverflow中捕捉最新的python题数据并存入json文件
Xpath详解:这篇文章全面讲解了xpath解析语法的使用
Xpath+mongodb爬虫实战:爬取伯乐在线python爬虫页面数据并存入mongodb数据库
pyquery详解:这篇文章全面讲解了CSS解析语法的使用
pyquery+mysql抓捕实战:抓捕赶集的狗数据存入mysql
正则表达式+csv/txt爬取实战:正则表达式网上教程很多,这里不再赘述,只提供网络爬取的正则方法。下面是豆瓣top250中比较难整理的数据。
Selenium详解:这篇文章全面讲解了beautifulsoup解析库的使用
Selenium爬虫实战:爬取新浪微博数据
各种网页解析库的比较
到目前为止,我已经讲了流行的网页解析库和数据存储方法。掌握了这些,网页解析和数据存储对你来说就不难了。您可以集中精力攻克各种反爬虫机制。
友情提示:对于没有时间的同学,这部分其实可以系统学习。先略过,看一些防爬措施。遇到问题可以把文章当成文档查看。但是如果你事先学会了,写代码会非常得心应手。
获得经验
在实际操作过程中,我们会遇到一些障碍,比如限制header、登录验证、限制IP、动态加载等反爬方法,以及爬取app、get/post请求等等。
这些都是一一的小问题。有了之前的基础,解决这些问题应该不难。这个过程中最重要的就是积累。爬的越多,落的洞越多,体验自然就会丰富。
这部分以每篇文章文章的形式解决一个问题。考虑到本人水平有限,肯定不能把坑全部说完,请尽量多填!
一些简单的反爬虫技巧:包括UA设置和技巧、cookies设置、延迟等基本反爬虫方法
使用代理:当抓取很多页面时,我们的ip地址会被屏蔽,所以你可以使用代理来不断地改变ip
动态加载网页的Ajax爬取
看完以上三个文章,大部分网页都可以自由抓取了。你可以先在这里看到反爬虫的技巧。一、学习scrapy框架,让日常爬行更方便。如果还有其他网页,说到其他防爬方法,赶紧查一下。
抓包介绍
网页状态码分析
发布请求
抓取应用数据
深入介绍请求
Scrapy爬虫框架系列:本系列将从scrapy的安装、基本概念开始,逐步深入讲解。
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明 查看全部
爬虫抓取网页数据(【每日一题】python爬虫专题(一):用最简单的代码抓取最基础的网页)
本专栏从这里开始python爬虫的话题。
专题定位:目标是抓取固定数量的数据进行分析,不设计工程爬虫(实时大规模爬取展示,设计存储等),所以不会涉及真正难的部分爬虫,但只能算是介绍。
题目的整体思路是这样设计的
文章 目录如下,这是一个初步的想法,在写的过程中可能会有所改动
入门
爬虫基本原理:用最简单的代码爬取最基本的网页,展示爬虫最基本的思想,让读者知道爬虫其实是一个很简单的东西。
爬虫代码改进:这部分是一系列文章,从程序设计的角度来说,是爬虫需要掌握的基本代码设计思想。主要从两个方面对之前的代码进行改进:一是代码设计的角度,让读者习惯于定义函数、使用生成器等;二是展示多页面爬取和爬取二级页面的代码逻辑。
爬虫相关库的安装:讲述了本主题将用到的所有库的安装方法,有的简单,有的有点复杂。这个文章主要是帮助读者排除学习过程中不必要的障碍。
学完这三部分,读者可以在数据量小、没有反爬机制的情况下自由抓取网站(其实这样的网站还是很多的)。
网页分析和数据存储
Python提供了很多网页解析方法;同时,根据不同的需要,它可能会存储在不同的文件格式或数据库中,所以这部分将两者放在一起说。每个部分都有理论和实战;每个部分使用一个解析库并以文件格式存储。
注意:这些分析方法是相互替代的(尽管每种方法都有自己的优点和缺点)。基本上只需要掌握一个,最好掌握所有的文件存储。
beautifulsoup详解:这篇文章全面讲解了beautifulsoup解析库的使用
bs4+json捕捉实战:json介绍,在stackoverflow中捕捉最新的python题数据并存入json文件
Xpath详解:这篇文章全面讲解了xpath解析语法的使用
Xpath+mongodb爬虫实战:爬取伯乐在线python爬虫页面数据并存入mongodb数据库
pyquery详解:这篇文章全面讲解了CSS解析语法的使用
pyquery+mysql抓捕实战:抓捕赶集的狗数据存入mysql
正则表达式+csv/txt爬取实战:正则表达式网上教程很多,这里不再赘述,只提供网络爬取的正则方法。下面是豆瓣top250中比较难整理的数据。
Selenium详解:这篇文章全面讲解了beautifulsoup解析库的使用
Selenium爬虫实战:爬取新浪微博数据
各种网页解析库的比较
到目前为止,我已经讲了流行的网页解析库和数据存储方法。掌握了这些,网页解析和数据存储对你来说就不难了。您可以集中精力攻克各种反爬虫机制。
友情提示:对于没有时间的同学,这部分其实可以系统学习。先略过,看一些防爬措施。遇到问题可以把文章当成文档查看。但是如果你事先学会了,写代码会非常得心应手。
获得经验
在实际操作过程中,我们会遇到一些障碍,比如限制header、登录验证、限制IP、动态加载等反爬方法,以及爬取app、get/post请求等等。
这些都是一一的小问题。有了之前的基础,解决这些问题应该不难。这个过程中最重要的就是积累。爬的越多,落的洞越多,体验自然就会丰富。
这部分以每篇文章文章的形式解决一个问题。考虑到本人水平有限,肯定不能把坑全部说完,请尽量多填!
一些简单的反爬虫技巧:包括UA设置和技巧、cookies设置、延迟等基本反爬虫方法
使用代理:当抓取很多页面时,我们的ip地址会被屏蔽,所以你可以使用代理来不断地改变ip
动态加载网页的Ajax爬取
看完以上三个文章,大部分网页都可以自由抓取了。你可以先在这里看到反爬虫的技巧。一、学习scrapy框架,让日常爬行更方便。如果还有其他网页,说到其他防爬方法,赶紧查一下。
抓包介绍
网页状态码分析
发布请求
抓取应用数据
深入介绍请求
Scrapy爬虫框架系列:本系列将从scrapy的安装、基本概念开始,逐步深入讲解。
栏目信息
专栏首页:python编程
栏目目录:目录
履带目录:履带系列目录
版本说明:软件和软件包版本说明
爬虫抓取网页数据( 实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-01 09:03
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
url = r'/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉勾网招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市是北京
tag = ['companyName','companyShortName','positionName','education','salary','financeStage','companySize',
'industryField','companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、薪资等。
tag_name = ['公司名称','公司简称','职位名称','学历要求','薪资','公司资质','公司规模','类别','公司介绍']
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['content']['result'] #通过分析得到的json信息,可以看到返回的结果中收录招聘信息,其中收录很多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的列表占位符来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num> 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ =='__main__':
print('**************************************** 即将被抓取******** * *****************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将各个页面的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num (1, max_page_num):
print('************************************ 正在下载页面 %s ********* 的内容************************'% page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('抓包完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间-开始时间).秒
print('使用的总时间:%ss'% time)
可以添加的功能很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请别人 查看全部
爬虫抓取网页数据(
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
url = r'/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉勾网招聘信息是动态获取的,所以需要通过post方式提交json信息。默认城市是北京
tag = ['companyName','companyShortName','positionName','education','salary','financeStage','companySize',
'industryField','companyLabelList'] # 这是需要抓取的标签信息,包括公司名称、学历要求、薪资等。
tag_name = ['公司名称','公司简称','职位名称','学历要求','薪资','公司资质','公司规模','类别','公司介绍']
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主机':'#39;,
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['content']['result'] #通过分析得到的json信息,可以看到返回的结果中收录招聘信息,其中收录很多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的列表占位符来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
def read_max_page(page): # 获取当前招聘的最大页数关键词,大于30的会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
如果 max_page_num> 30:
max_page_num = 30
返回 max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
如果 __name__ =='__main__':
print('**************************************** 即将被抓取******** * *****************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将各个页面的招聘信息汇总成最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, 关键字))
对于范围内的 page_num (1, max_page_num):
print('************************************ 正在下载页面 %s ********* 的内容************************'% page_num)
page = read_page(url, page_num, 关键字)
page_result = read_tag(页面,标签)
fin_result.extend(page_result)
file_name = input('抓包完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
结束时间 = datetime.datetime.now()
时间 = (结束时间-开始时间).秒
print('使用的总时间:%ss'% time)
可以添加的功能很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请别人
爬虫抓取网页数据( 本发明公开了一种,流程及专利说明(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-30 03:08
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索 查看全部
爬虫抓取网页数据(
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索
爬虫抓取网页数据(网址被降权惩罚的首要因素是什么?怎么破?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-30 02:24
在管理方法站点的过程中,我们会遇到K站或者被降级处罚的情况。一旦网站被K或降级处罚,则表示该网址已被robots文件处罚。一般的原因是垃圾信息的内容太多。百度搜索引擎的计算方式升级了,是K站造成的。还有其他因素。所有因素都导致URL受到惩罚。
1、被降职处罚
降级处罚的关键是该网站采用了百度搜索引擎的标准增加权重值,最终被百度搜索引擎发现并采取了预警对策。导致降级处罚的主要因素有:网络服务器不稳定、同一网络服务器介入、网站改版升级、隐藏友情链接、过度推广、隐藏外部链接、采集多。这些QQ空间是完全免费的关注和点赞。
网站被降权处罚的情况比起K站来说不是很严重。如果您看到该网站被降权处罚,您可以按照上述方法进行盘点。通常,您必须在整个推广过程中注意这些情况的发生。您不需要应用一些过度的促销方法。如果网站被不稳定的网络服务器降级处罚,应尽快响应网络服务器,做好企业网站的备份数据。
2、K站
降级处罚只是对网站的警告,K站意味着搜索引擎网站对平台的相应处罚。执行网站降级处罚后,如果网站长期没有进行检查和调整,一旦受到处罚,网站将难以修复。出现K站的原因是:网站更新了大量非正式内容,站群系统惯例,网站被撤销备案。
大量垃圾信息内容被推送,造成不良影响。大量应用二级域名,建立网站群以营利。域名注册根据可靠结果批准后,采取取消注册的对策,后续操作违反指定的URL。这种情况的发生会立即导致网站被K站。
3、差异
K站的因素可能是降权惩罚造成的,但降权惩罚不一定是K站造成的。被降权处罚的网址并不代表该网址失效。当您发现网站被降权处罚时,一定要慎重调整。不要故意违反百度搜索引擎的标准,造成很大的损失。一旦网站被K站封杀,就相当于百度搜索引擎封禁该网站,无望。因此,在做seo的过程中,大家一定要使用一些可靠、合理、合法的seo技术来进行搜索引擎优化。
如何喂养百度爬虫?
理论上,爬行是指逐渐前进,但这不是互联网术语的意思。爬行一词来源于百度爬虫,指的是百度爬虫根据网址并留下标记的全过程。百度爬虫可以保证快速收录并展示实际效果,但不会急于展示出来。它只会根据审查期限出现在百度搜索引擎上。
那么,百度爬虫爬取的形式是什么?
1、显式爬取
显式抓取是指当网址升级时,百度爬虫会第一时间抓取该网址,并明确该网址是准确定位的。但是,无法立即显示百度收录的网页。
2、平滑爬行
平滑爬行一般是指网站上线后的一段时间,顺利度过沙盒游戏期。百度爬虫每天都会进入网站进行抓取,并尽快呈现网站收录的网页。
3、井喷爬行
这种方法一般出现在百度彻底改变优化算法,对所有网页进行大改动时。百度搜索去除了非标准网址,并为一些优质网站提供了更强的排名。
4、 爬行爬行
根据词汇,可以理解为先爬后爬。百度爬虫在对平台进行爬取时,通常会选择先区分robots文件中的内容,再区分哪些文件是禁止爬取的。对这个机器人文件的理解是基于国际规范和标准。俗话说,无规则无规则,百度搜索也不例外。
5、爬行运动轨迹
百度爬虫抓取到的轨迹是逐步以网站首页为基础,根据首页链接获取的。根据 W3C 规范,所有 URL 分为三个部分,即顶部部分、文章 正文部分和底部部分。首页顶部导航图会正确引导百度爬虫抓取频道页,首页文章列表会正确引导百度爬虫抓取文章内容页。
为了更好的保证平台的畅通,百度搜索达到了网站内链和内链的定义。 查看全部
爬虫抓取网页数据(网址被降权惩罚的首要因素是什么?怎么破?)
在管理方法站点的过程中,我们会遇到K站或者被降级处罚的情况。一旦网站被K或降级处罚,则表示该网址已被robots文件处罚。一般的原因是垃圾信息的内容太多。百度搜索引擎的计算方式升级了,是K站造成的。还有其他因素。所有因素都导致URL受到惩罚。
1、被降职处罚
降级处罚的关键是该网站采用了百度搜索引擎的标准增加权重值,最终被百度搜索引擎发现并采取了预警对策。导致降级处罚的主要因素有:网络服务器不稳定、同一网络服务器介入、网站改版升级、隐藏友情链接、过度推广、隐藏外部链接、采集多。这些QQ空间是完全免费的关注和点赞。
网站被降权处罚的情况比起K站来说不是很严重。如果您看到该网站被降权处罚,您可以按照上述方法进行盘点。通常,您必须在整个推广过程中注意这些情况的发生。您不需要应用一些过度的促销方法。如果网站被不稳定的网络服务器降级处罚,应尽快响应网络服务器,做好企业网站的备份数据。
2、K站
降级处罚只是对网站的警告,K站意味着搜索引擎网站对平台的相应处罚。执行网站降级处罚后,如果网站长期没有进行检查和调整,一旦受到处罚,网站将难以修复。出现K站的原因是:网站更新了大量非正式内容,站群系统惯例,网站被撤销备案。
大量垃圾信息内容被推送,造成不良影响。大量应用二级域名,建立网站群以营利。域名注册根据可靠结果批准后,采取取消注册的对策,后续操作违反指定的URL。这种情况的发生会立即导致网站被K站。
3、差异
K站的因素可能是降权惩罚造成的,但降权惩罚不一定是K站造成的。被降权处罚的网址并不代表该网址失效。当您发现网站被降权处罚时,一定要慎重调整。不要故意违反百度搜索引擎的标准,造成很大的损失。一旦网站被K站封杀,就相当于百度搜索引擎封禁该网站,无望。因此,在做seo的过程中,大家一定要使用一些可靠、合理、合法的seo技术来进行搜索引擎优化。
如何喂养百度爬虫?
理论上,爬行是指逐渐前进,但这不是互联网术语的意思。爬行一词来源于百度爬虫,指的是百度爬虫根据网址并留下标记的全过程。百度爬虫可以保证快速收录并展示实际效果,但不会急于展示出来。它只会根据审查期限出现在百度搜索引擎上。
那么,百度爬虫爬取的形式是什么?
1、显式爬取
显式抓取是指当网址升级时,百度爬虫会第一时间抓取该网址,并明确该网址是准确定位的。但是,无法立即显示百度收录的网页。
2、平滑爬行
平滑爬行一般是指网站上线后的一段时间,顺利度过沙盒游戏期。百度爬虫每天都会进入网站进行抓取,并尽快呈现网站收录的网页。
3、井喷爬行
这种方法一般出现在百度彻底改变优化算法,对所有网页进行大改动时。百度搜索去除了非标准网址,并为一些优质网站提供了更强的排名。
4、 爬行爬行
根据词汇,可以理解为先爬后爬。百度爬虫在对平台进行爬取时,通常会选择先区分robots文件中的内容,再区分哪些文件是禁止爬取的。对这个机器人文件的理解是基于国际规范和标准。俗话说,无规则无规则,百度搜索也不例外。
5、爬行运动轨迹
百度爬虫抓取到的轨迹是逐步以网站首页为基础,根据首页链接获取的。根据 W3C 规范,所有 URL 分为三个部分,即顶部部分、文章 正文部分和底部部分。首页顶部导航图会正确引导百度爬虫抓取频道页,首页文章列表会正确引导百度爬虫抓取文章内容页。
为了更好的保证平台的畅通,百度搜索达到了网站内链和内链的定义。
爬虫抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-29 19:25
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频 查看全部
爬虫抓取网页数据(福利时刻网络爬虫学习资源统统送给你获取方式即可领取)
当我们浏览网页时,我们经常会看到像下面这样的漂亮图片。您要保存和下载这些图片吗?
我们最常用的方法是使用鼠标右键并选择另存为。但是有些图片没有鼠标右键另存为的选项,也可以用截图工具截图,但是这样会降低图片的清晰度,效率很低。
如果我肿了怎么办?
我们可以通过python实现这样一个简单的爬虫功能,将我们想要的代码爬到本地。
说到网络爬虫(也叫网络蜘蛛、网络机器人等),其实不是爬虫~而是可以在网上任意搜索的脚本程序。
如果一定要说明网络爬虫是用来干发的?尝试了很多解释,最后总结成一句话:“你再也不用鼠标一一复制网页上的信息了!”
一个爬虫程序会高效准确地从互联网上获取您想要的所有信息,从而为您节省以下操作:
当然,网络爬虫的真正含义还不止这些,因为它可以自动提取网页信息,成为从万维网上爬取数据的重要工具。
下面我们来看看如何使用python来实现这样的功能。
蜘蛛获取数据的主要路径:获取整个页面数据→过滤页面中想要的数据→将页面过滤后的数据保存到本地→最终获取所有想要的数据。
它简单有效吗?来吧,让我们自己实现一个666飞的功能。
今天的福利时刻
网络爬虫学习资源全给你
获得方法
您可以收到爬虫视频

