
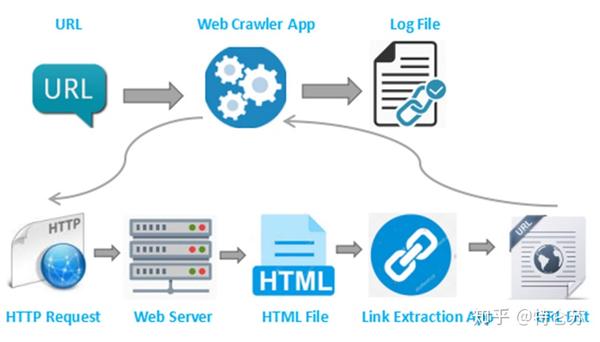
爬虫抓取网页数据
爬虫抓取网页数据(蜘蛛访问网站页面的程序被称为蜘蛛(spider)蜘蛛搜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-26 12:18
本文内容:
带领
本文摘要
这篇文章的标题
文字内容
结束语
带领:
可能你最近也在找这类的相关内容吧?为了整理这篇内容,特意和公司周围的朋友同事交流了很久……我也查了网上很多资料,总结了一些关于蜘蛛搜索的相关知识点(搜索引擎蜘蛛是怎么工作的) ,希望通过《蜘蛛搜索(搜索引擎蜘蛛是如何工作的)》的介绍,对大家有所帮助,一起来看看吧!
本文摘要:
“搜索引擎用来抓取和访问页面的程序叫做蜘蛛蜘蛛搜索,或者bot。搜索引擎蜘蛛在访问网站页面时,类似于普通用户使用浏览器,蜘蛛程序发出后页面访问请求,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。 网站 ,首先会访问网站根目录下的robots.txt文件,如果robots.txt文件被搜索引擎禁止...
本文标题:蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)正文内容:
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。从目前公布的数据来看,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过某种方式抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(如Web2.0 数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并放入已访问地址数据库中,所以建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行,都会存储页面数据。如果第二次抓取时这个页面的内容和第一个收录完全一样,
结束语:
以上是一些关于蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)的相关内容以及围绕这类内容的一些相关知识点。希望介绍对大家有帮助!后续我们会更新更多相关资讯,关注我们,每天了解最新热点,关注社会动态! 查看全部
爬虫抓取网页数据(蜘蛛访问网站页面的程序被称为蜘蛛(spider)蜘蛛搜)
本文内容:
带领
本文摘要
这篇文章的标题
文字内容
结束语
带领:
可能你最近也在找这类的相关内容吧?为了整理这篇内容,特意和公司周围的朋友同事交流了很久……我也查了网上很多资料,总结了一些关于蜘蛛搜索的相关知识点(搜索引擎蜘蛛是怎么工作的) ,希望通过《蜘蛛搜索(搜索引擎蜘蛛是如何工作的)》的介绍,对大家有所帮助,一起来看看吧!
本文摘要:
“搜索引擎用来抓取和访问页面的程序叫做蜘蛛蜘蛛搜索,或者bot。搜索引擎蜘蛛在访问网站页面时,类似于普通用户使用浏览器,蜘蛛程序发出后页面访问请求,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。 网站 ,首先会访问网站根目录下的robots.txt文件,如果robots.txt文件被搜索引擎禁止...
本文标题:蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)正文内容:
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。

蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。从目前公布的数据来看,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过某种方式抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(如Web2.0 数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并放入已访问地址数据库中,所以建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行,都会存储页面数据。如果第二次抓取时这个页面的内容和第一个收录完全一样,
结束语:
以上是一些关于蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)的相关内容以及围绕这类内容的一些相关知识点。希望介绍对大家有帮助!后续我们会更新更多相关资讯,关注我们,每天了解最新热点,关注社会动态!
爬虫抓取网页数据(网页爬虫WebScraper现代网络的网络数据提取工具介绍!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-26 12:16
Web Scraper Web Scraper 是 chrome 上的爬虫工具。它可以作为插件在网页上使用,并且可以以更便携的方式在任何网页中使用。插件可以满足你对网站的爬虫需求,功能非常多,需要有一定的基础才能正常使用,有需要就来下载网络爬虫Web Scraper吧!
网络爬虫
现代网络的网络数据提取工具,具有简单的点击界面
免费易用的网页数据提取工具,适合所有人使用。
通过简单的点击界面,只需几分钟的scraper设置,就可以从一个网站中提取数千条记录。
Web Scraper 采用由选择器组成的模块化结构,这些选择器指示刮板如何遍历目标 网站 以及要提取的数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)和鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,无需在您的计算机上安装任何东西。您不需要 Python、PHP 或 JavaScript 编码经验即可开始提取。此外,数据提取可以在 Web Scraper Cloud 中完全自动化。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 Excel、Google Sheets 等。
软件特点
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
* 浏览搜索到的数据。
*将搜索到的数据从网站导出到Excel。
它只依赖于网络浏览器;因此,您无需附加软件即可开始搜索。
如何使用
为了掌握网络搜索技术,您只需要学习几个步骤。
1. 安装扩展并打开开发者工具中的网页抓取标签(必须放置在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 向 网站 地图添加数据提取选择器。
4. 最后,启动搜索器并导出搜索到的数据。
就是这么简单!
使用场景
* 潜在客户开发 - 电子邮件、电话号码和其他与联系方式相关的数据是从各种 网站 中挖掘出来的。
* 电子商务-产品数据提取、产品价格搜索、描述、URL提取、图片检索等。
* 网站内容爬取——从新闻门户、博客、论坛等中提取信息。
* 零售监控——监控产品性能、竞争对手或供应商的库存和价格等。
* 品牌监控-产品评论、用于情感分析的社交内容捕获。
* 商业智能——为关键业务决策采集数据并向竞争对手学习。
* 大数据提取用于机器学习、营销、业务战略制定和研究。
* 还有更多。 查看全部
爬虫抓取网页数据(网页爬虫WebScraper现代网络的网络数据提取工具介绍!)
Web Scraper Web Scraper 是 chrome 上的爬虫工具。它可以作为插件在网页上使用,并且可以以更便携的方式在任何网页中使用。插件可以满足你对网站的爬虫需求,功能非常多,需要有一定的基础才能正常使用,有需要就来下载网络爬虫Web Scraper吧!

网络爬虫
现代网络的网络数据提取工具,具有简单的点击界面
免费易用的网页数据提取工具,适合所有人使用。
通过简单的点击界面,只需几分钟的scraper设置,就可以从一个网站中提取数千条记录。
Web Scraper 采用由选择器组成的模块化结构,这些选择器指示刮板如何遍历目标 网站 以及要提取的数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)和鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,无需在您的计算机上安装任何东西。您不需要 Python、PHP 或 JavaScript 编码经验即可开始提取。此外,数据提取可以在 Web Scraper Cloud 中完全自动化。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 Excel、Google Sheets 等。
软件特点
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
* 浏览搜索到的数据。
*将搜索到的数据从网站导出到Excel。
它只依赖于网络浏览器;因此,您无需附加软件即可开始搜索。
如何使用
为了掌握网络搜索技术,您只需要学习几个步骤。
1. 安装扩展并打开开发者工具中的网页抓取标签(必须放置在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 向 网站 地图添加数据提取选择器。
4. 最后,启动搜索器并导出搜索到的数据。
就是这么简单!
使用场景
* 潜在客户开发 - 电子邮件、电话号码和其他与联系方式相关的数据是从各种 网站 中挖掘出来的。
* 电子商务-产品数据提取、产品价格搜索、描述、URL提取、图片检索等。
* 网站内容爬取——从新闻门户、博客、论坛等中提取信息。
* 零售监控——监控产品性能、竞争对手或供应商的库存和价格等。
* 品牌监控-产品评论、用于情感分析的社交内容捕获。
* 商业智能——为关键业务决策采集数据并向竞争对手学习。
* 大数据提取用于机器学习、营销、业务战略制定和研究。
* 还有更多。
爬虫抓取网页数据(第24卷第6期:通用搜索引擎搜索的网页相关度高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-26 12:15
并将抓取到的网页URL作为鸟巢个体计算要选择的URL集合中所有网页的相关性,使用Levi's flight进行多次迭代寻找相关性高的,然后将随机数与发现的进行比较Pa 生成新 URL 的概率。实验结果表明,与主题爬虫的其他相关技术相比,该策略在爬取主题相关网页时具有更高的效率。关键词:布谷鸟搜索算法;主题爬虫;网页相关性;健康中文分类号:TP391 文档标记代码:基于布谷鸟搜索算法的聚焦爬行策略设计 钱景远 1 , 杨慧华 1,2 , 刘振兵 1(1. 桂林工业大学电气工程与自动化学院电子科技, 广西, 桂林, 541004, 中国;2. 北京邮电大学自动化学院, 北京, 100876) 摘要:通用搜索引擎搜索大量网页,以及介绍主题爬虫搜索策略与网络高度相关,减少不相关网页的采集。为了提高爬虫的搜索效率,设计了一种基于布谷鸟搜索算法的爬虫搜索策略。爬取网页URL作为鸟巢,计算所选URL集中所有页面的相关性。多次迭代找到相关性高的,然后通过随机数和发现概率Pa进行比较,生成新的URL。实验结果表明,该策略比爬取主题爬虫相关网页的效率更高。专注的爬虫;页面相关性;Fitness0 简介 作为搜索引擎的重要组成部分,网络爬虫是一种抓取网页的程序。
主题爬虫是一种页面爬取工具,旨在查询某个主题或某个字段[1]。与一般搜索引擎不同,话题搜索引擎本身具有专业性强、针对性强的特点,可以在很大程度上削弱搜索相关话题网页的难度。抓取的网页是否相关很大程度上取决于搜索策略。因此,使用哪种搜索策略是主题爬虫的首要考虑因素。目前比较成熟的搜索策略主要有:基于网页内容的搜索策略和基于链接结构的搜索策略。首先是通过网页之间的链接关系来确定网页的重要性。基于链接结构,只考虑链接结构和页面之间的链接关系,不考虑页面本身是否与主题相关,容易导致“主题漂移”[2,3]。第二种主要考虑网页的内容。优点是思路清晰,计算简单。但是这种方法没有考虑网页的链接关系,忽略了链接网页的价值预测。基于上述搜索策略,提出将布谷鸟搜索算法应用于主题爬虫。1 基于布谷鸟搜索算法的主题爬虫1.1 网络爬虫 通用型网络爬虫(Crawler)(又称蜘蛛),是一款功能强大的网页自动爬取程序,也是搜索引擎不可或缺的一部分。通过在采集网站上遍历互联网和网页,我们可以从某个角度判断某个搜索引擎的性能,而且规模很大。以及小、高、低DOI的扩展能力:10.3969/j.issn.1671-1041.2017.06.006文章: 1671-1041(2017)06-0020-04 接收日期:2017-04-06 基金项目:国家自然科学基金项目(61562013);广西重点研发计划项目(桂科AB1638029) 3)。
作者简介:钱景远(1990-),男,江苏连云港人,硕士研究生,研究方向:网络爬虫等万方数据钱景远·基于杜鹃搜索算法的主题爬虫策略设计第621期评网络爬虫采集 和处理网页的能力。页面下载的主要功能是访问和采集互联网上的相关页面。为了便于存储在待抓取的URL队列中,URL队列按照主题相关性进行排序。从当前采集 网页中提取的新网页链接一般存储在URL 数据库中[4]。与普通爬虫相比,主题爬虫更加复杂。需要开发网页分析算法,过滤不相关的链接,将使用过的链接放入URL队列中进行爬取。最后,根据既定的搜索策略,从待爬取的队列中选择下一步待爬取的URL[4]。1.2 布谷鸟搜索算法简介布谷鸟搜索算法是一种具有全局收敛性的随机算法。布谷鸟搜索算法模拟布谷鸟寻找巢穴产卵的行为。该算法简单,需要设置的参数少,易于实现,具有最优随机搜索路径和优化能力强的特点。已成功应用于工程。应用程序。布谷鸟搜索算法的实现定义了三个理想化的规则: 1) 每只布谷鸟一次只产 1 个蛋,并存储在随机选择的鸟巢中。2) 鸟' 最好的鸡蛋(溶液)的巢将保存到下一代。3) 可用的鸟巢数量是固定的,巢的主人发现外来蛋的概率是Pa∈[0,1]。基于这三种理想状态,布谷鸟巢搜索的路径和位置更新公式如下: 其中Xi(t)表示第t代鸟巢中第i个鸟巢的位置,⊕为点对点乘法,α表示步长控制量,L(λ)为Levy随机搜索路径,L~u =t-λ,(1Pa,则随机改变Xi(t+1)),而反之亦然。
@1.3 网页基础知识 互联网上的网页是具有一定格式和结构的无格式文本。复杂但经常找到。搜索算法中使用了四种类型的 Web 信息:父页面信息。一般来说,从一个页面(父页面)链接的页面(子页面)的内容与页面的主题相关;链接文字信息是指直接概括页面链接的主题;网页的 URL 信息一般与主题相关;兄弟链接信息,页面设计者通常会集中存储与话题相关的链接。以上4类搜索方法与网页主题的对应程度不一致,网页主题的准确率也不一样。
1.4 网页主题相关度计算 对于下载的网页,需要计算主题相关度。这里使用向量空间模型计算网页主题相关度。该模型将文本内容转化为易于数学处理的向量形式,同时将文本内容表达为多维空间中的一个点,从而将文本内容的处理转化为向量运算在向量空间中,这降低了问题的复杂性。文档向量由一个n维向量表示,每个坐标值代表不同的关键词权重。对应的关键词通过权重来描述文档的重要性。使用相同的方法来表示主题关键词 向量。是否关键词 对主题很重要也可以通过主题 关键词 向量中的权重来解释。由于网页的文本结构是半结构化的,需要充分利用网页的HTML标签,才能更准确地提取出文档的主题。一般情况下,最重要的文本如, 和, 是出现在超链接和和之间的关键词,权重应该更高[6,7]。假设F(x)是应该给第x个关键字的权重,那么相关度的计算公式为: 函数F(i)的值如下: 1.5 Fitness function计算燕窝中的选择将直接由个体数量和燕窝的平均适应度决定。当算法第一次运行时,可能有一些适应性很强的燕窝。随着迭代次数的增加,这种适应性很强的燕窝及其后代将成为总数的大部分。这样,种群中新个体的数量减少,布谷鸟搜索算法提前收敛到一个局部最优解,导致“早熟”现象。
考虑网页的内容和链接结构,在CS算法中选择网页与其父网页的相关值作为个体适应度函数值。计算公式为:(2)(3)(4)万方数据卷24 22 Instrumentation User INSTRUMENTATION 其中是第i个URL对应的适应度值,是对应的父网页的相关性值,k为第i个对应的相关性值,对应父网页链接的网页数量[8,9]。1.6 基于布谷鸟搜索算法的主题爬虫设计在主题爬虫中布谷鸟搜索算法的应用具有明显的优势:1)布谷鸟搜索算法具有分组搜索特性,这可以提高主题爬虫的全局搜索性能。2)布谷鸟搜索算法具有随机搜索特性,可以引导主题爬虫在利用一定的适应度函数评价个体的同时,也可以利用李维斯的飞行来指导搜索方向。3)布谷鸟搜索算法是在随机搜索过程中不容易陷入局部最优。4)布谷鸟搜索算法 可扩展性强,在主题爬虫的设计中可以很容易地与其他技术混合使用。CS算法主要分为4个阶段:更新个体位置。评估个体适应度值,如果该值更好,则旧个体将被新个体取代。使用发现概率去除旧个体并重建新个体。找到最好的人。
对3)中新生成的URL进行评估,如果更好则接受更新,否则保持原URL不变。 记录全局最优URL。 当满足搜索精度或达到最大搜索次数时,切换到7),否则切换到2)进行下一轮搜索。 输出最优URL。2 实验设计与数据分析2.1 实验设计测试环境:eclipse开发,Java语言编写,Windows 7系统运行,8G内存,1T硬盘容量。为了验证上述设计策略,设计了以下测试。测试是Broad.First(BF)算法和Hits算法的搜索结果进行比较,记录抓取的网页数据,计算准确率。选择 ”
是主题 根据设置的不同阈值,如图3、4,是“数据库”的主题。根据设置的阈值不同,从图中可以看出基于3种算法的爬虫爬取网页的相关性对比图。可以看出,无论阈值是0.90还是0.95,基于布谷鸟搜索算法的准确率普遍高于其他两种算法(准确率=(获取的相关网页)数) /抓取的网页总数)×100%)。
而且,CS算法的Levi Flight增加的搜索范围不容易导致主题爬虫陷入局部最优。3 总结通过以上实验表明,使用布谷鸟搜索策略进行主题爬取,爬取的网页比普通算法的相关度更高,布谷鸟搜索算法具有很强的全局搜索能力。未来的方向是将布谷鸟搜索算法与其他算法结合,形成一种新的爬虫搜索策略来研究爬取网页的效果。参考文献:Milad shokouhi、Pirooz Chubak、Zaynab Raeesy。Enhancing Focused Crawling with Genetic Algorithms[C].Proceedings of the International Conference on Information Technology: Coding and Computing, March 15,2005.Liu Guojing, Kang Li, Luo Changshou. 基于遗传算法的主题爬虫策略[J]. 计算机应用, 2007, 27(12):172-176.罗林波, 陈琦. 基于Shark-Search and Hits算法的主题爬虫研究[J]. J]. 2010 , 20(11): 76-79.陈一峰.. 基于遗传算法的主题爬虫策略改进[J].. 计算机仿真, 2010, 27 (10): 87-90.蓝少峰, 刘胜. 布谷鸟搜索算法研究综述[J]. 计算机工程与设计, 2015, 36 (4):1603-1607. 罗长寿,程新荣. 基于遗传算法的学科信息获取系统研究[C]. “第二届计算机与计算机技术在农业中的应用国际会议”和“中国农村信息化发展论坛” 论文集, 2008 :.87-92.张海亮, 袁道华. 基于遗传算法的主题爬虫[J]. 计算机技术与发展, 2012, 22: 48-52.陈越、陈云. 查看全部
爬虫抓取网页数据(第24卷第6期:通用搜索引擎搜索的网页相关度高)
并将抓取到的网页URL作为鸟巢个体计算要选择的URL集合中所有网页的相关性,使用Levi's flight进行多次迭代寻找相关性高的,然后将随机数与发现的进行比较Pa 生成新 URL 的概率。实验结果表明,与主题爬虫的其他相关技术相比,该策略在爬取主题相关网页时具有更高的效率。关键词:布谷鸟搜索算法;主题爬虫;网页相关性;健康中文分类号:TP391 文档标记代码:基于布谷鸟搜索算法的聚焦爬行策略设计 钱景远 1 , 杨慧华 1,2 , 刘振兵 1(1. 桂林工业大学电气工程与自动化学院电子科技, 广西, 桂林, 541004, 中国;2. 北京邮电大学自动化学院, 北京, 100876) 摘要:通用搜索引擎搜索大量网页,以及介绍主题爬虫搜索策略与网络高度相关,减少不相关网页的采集。为了提高爬虫的搜索效率,设计了一种基于布谷鸟搜索算法的爬虫搜索策略。爬取网页URL作为鸟巢,计算所选URL集中所有页面的相关性。多次迭代找到相关性高的,然后通过随机数和发现概率Pa进行比较,生成新的URL。实验结果表明,该策略比爬取主题爬虫相关网页的效率更高。专注的爬虫;页面相关性;Fitness0 简介 作为搜索引擎的重要组成部分,网络爬虫是一种抓取网页的程序。
主题爬虫是一种页面爬取工具,旨在查询某个主题或某个字段[1]。与一般搜索引擎不同,话题搜索引擎本身具有专业性强、针对性强的特点,可以在很大程度上削弱搜索相关话题网页的难度。抓取的网页是否相关很大程度上取决于搜索策略。因此,使用哪种搜索策略是主题爬虫的首要考虑因素。目前比较成熟的搜索策略主要有:基于网页内容的搜索策略和基于链接结构的搜索策略。首先是通过网页之间的链接关系来确定网页的重要性。基于链接结构,只考虑链接结构和页面之间的链接关系,不考虑页面本身是否与主题相关,容易导致“主题漂移”[2,3]。第二种主要考虑网页的内容。优点是思路清晰,计算简单。但是这种方法没有考虑网页的链接关系,忽略了链接网页的价值预测。基于上述搜索策略,提出将布谷鸟搜索算法应用于主题爬虫。1 基于布谷鸟搜索算法的主题爬虫1.1 网络爬虫 通用型网络爬虫(Crawler)(又称蜘蛛),是一款功能强大的网页自动爬取程序,也是搜索引擎不可或缺的一部分。通过在采集网站上遍历互联网和网页,我们可以从某个角度判断某个搜索引擎的性能,而且规模很大。以及小、高、低DOI的扩展能力:10.3969/j.issn.1671-1041.2017.06.006文章: 1671-1041(2017)06-0020-04 接收日期:2017-04-06 基金项目:国家自然科学基金项目(61562013);广西重点研发计划项目(桂科AB1638029) 3)。
作者简介:钱景远(1990-),男,江苏连云港人,硕士研究生,研究方向:网络爬虫等万方数据钱景远·基于杜鹃搜索算法的主题爬虫策略设计第621期评网络爬虫采集 和处理网页的能力。页面下载的主要功能是访问和采集互联网上的相关页面。为了便于存储在待抓取的URL队列中,URL队列按照主题相关性进行排序。从当前采集 网页中提取的新网页链接一般存储在URL 数据库中[4]。与普通爬虫相比,主题爬虫更加复杂。需要开发网页分析算法,过滤不相关的链接,将使用过的链接放入URL队列中进行爬取。最后,根据既定的搜索策略,从待爬取的队列中选择下一步待爬取的URL[4]。1.2 布谷鸟搜索算法简介布谷鸟搜索算法是一种具有全局收敛性的随机算法。布谷鸟搜索算法模拟布谷鸟寻找巢穴产卵的行为。该算法简单,需要设置的参数少,易于实现,具有最优随机搜索路径和优化能力强的特点。已成功应用于工程。应用程序。布谷鸟搜索算法的实现定义了三个理想化的规则: 1) 每只布谷鸟一次只产 1 个蛋,并存储在随机选择的鸟巢中。2) 鸟' 最好的鸡蛋(溶液)的巢将保存到下一代。3) 可用的鸟巢数量是固定的,巢的主人发现外来蛋的概率是Pa∈[0,1]。基于这三种理想状态,布谷鸟巢搜索的路径和位置更新公式如下: 其中Xi(t)表示第t代鸟巢中第i个鸟巢的位置,⊕为点对点乘法,α表示步长控制量,L(λ)为Levy随机搜索路径,L~u =t-λ,(1Pa,则随机改变Xi(t+1)),而反之亦然。
@1.3 网页基础知识 互联网上的网页是具有一定格式和结构的无格式文本。复杂但经常找到。搜索算法中使用了四种类型的 Web 信息:父页面信息。一般来说,从一个页面(父页面)链接的页面(子页面)的内容与页面的主题相关;链接文字信息是指直接概括页面链接的主题;网页的 URL 信息一般与主题相关;兄弟链接信息,页面设计者通常会集中存储与话题相关的链接。以上4类搜索方法与网页主题的对应程度不一致,网页主题的准确率也不一样。
1.4 网页主题相关度计算 对于下载的网页,需要计算主题相关度。这里使用向量空间模型计算网页主题相关度。该模型将文本内容转化为易于数学处理的向量形式,同时将文本内容表达为多维空间中的一个点,从而将文本内容的处理转化为向量运算在向量空间中,这降低了问题的复杂性。文档向量由一个n维向量表示,每个坐标值代表不同的关键词权重。对应的关键词通过权重来描述文档的重要性。使用相同的方法来表示主题关键词 向量。是否关键词 对主题很重要也可以通过主题 关键词 向量中的权重来解释。由于网页的文本结构是半结构化的,需要充分利用网页的HTML标签,才能更准确地提取出文档的主题。一般情况下,最重要的文本如, 和, 是出现在超链接和和之间的关键词,权重应该更高[6,7]。假设F(x)是应该给第x个关键字的权重,那么相关度的计算公式为: 函数F(i)的值如下: 1.5 Fitness function计算燕窝中的选择将直接由个体数量和燕窝的平均适应度决定。当算法第一次运行时,可能有一些适应性很强的燕窝。随着迭代次数的增加,这种适应性很强的燕窝及其后代将成为总数的大部分。这样,种群中新个体的数量减少,布谷鸟搜索算法提前收敛到一个局部最优解,导致“早熟”现象。
考虑网页的内容和链接结构,在CS算法中选择网页与其父网页的相关值作为个体适应度函数值。计算公式为:(2)(3)(4)万方数据卷24 22 Instrumentation User INSTRUMENTATION 其中是第i个URL对应的适应度值,是对应的父网页的相关性值,k为第i个对应的相关性值,对应父网页链接的网页数量[8,9]。1.6 基于布谷鸟搜索算法的主题爬虫设计在主题爬虫中布谷鸟搜索算法的应用具有明显的优势:1)布谷鸟搜索算法具有分组搜索特性,这可以提高主题爬虫的全局搜索性能。2)布谷鸟搜索算法具有随机搜索特性,可以引导主题爬虫在利用一定的适应度函数评价个体的同时,也可以利用李维斯的飞行来指导搜索方向。3)布谷鸟搜索算法是在随机搜索过程中不容易陷入局部最优。4)布谷鸟搜索算法 可扩展性强,在主题爬虫的设计中可以很容易地与其他技术混合使用。CS算法主要分为4个阶段:更新个体位置。评估个体适应度值,如果该值更好,则旧个体将被新个体取代。使用发现概率去除旧个体并重建新个体。找到最好的人。
对3)中新生成的URL进行评估,如果更好则接受更新,否则保持原URL不变。 记录全局最优URL。 当满足搜索精度或达到最大搜索次数时,切换到7),否则切换到2)进行下一轮搜索。 输出最优URL。2 实验设计与数据分析2.1 实验设计测试环境:eclipse开发,Java语言编写,Windows 7系统运行,8G内存,1T硬盘容量。为了验证上述设计策略,设计了以下测试。测试是Broad.First(BF)算法和Hits算法的搜索结果进行比较,记录抓取的网页数据,计算准确率。选择 ”
是主题 根据设置的不同阈值,如图3、4,是“数据库”的主题。根据设置的阈值不同,从图中可以看出基于3种算法的爬虫爬取网页的相关性对比图。可以看出,无论阈值是0.90还是0.95,基于布谷鸟搜索算法的准确率普遍高于其他两种算法(准确率=(获取的相关网页)数) /抓取的网页总数)×100%)。
而且,CS算法的Levi Flight增加的搜索范围不容易导致主题爬虫陷入局部最优。3 总结通过以上实验表明,使用布谷鸟搜索策略进行主题爬取,爬取的网页比普通算法的相关度更高,布谷鸟搜索算法具有很强的全局搜索能力。未来的方向是将布谷鸟搜索算法与其他算法结合,形成一种新的爬虫搜索策略来研究爬取网页的效果。参考文献:Milad shokouhi、Pirooz Chubak、Zaynab Raeesy。Enhancing Focused Crawling with Genetic Algorithms[C].Proceedings of the International Conference on Information Technology: Coding and Computing, March 15,2005.Liu Guojing, Kang Li, Luo Changshou. 基于遗传算法的主题爬虫策略[J]. 计算机应用, 2007, 27(12):172-176.罗林波, 陈琦. 基于Shark-Search and Hits算法的主题爬虫研究[J]. J]. 2010 , 20(11): 76-79.陈一峰.. 基于遗传算法的主题爬虫策略改进[J].. 计算机仿真, 2010, 27 (10): 87-90.蓝少峰, 刘胜. 布谷鸟搜索算法研究综述[J]. 计算机工程与设计, 2015, 36 (4):1603-1607. 罗长寿,程新荣. 基于遗传算法的学科信息获取系统研究[C]. “第二届计算机与计算机技术在农业中的应用国际会议”和“中国农村信息化发展论坛” 论文集, 2008 :.87-92.张海亮, 袁道华. 基于遗传算法的主题爬虫[J]. 计算机技术与发展, 2012, 22: 48-52.陈越、陈云.
爬虫抓取网页数据(爬虫抓取网页数据需要先解析看图片视频需要注意什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-24 00:42
爬虫抓取网页数据,一般是先去数据库查询数据,如果数据库没有查询记录,就先扫描网页里的每个元素,做分析,然后存到自己的数据库里,需要的时候取出来就可以,同时,进行搜索引擎搜索,对于特定用户,爬虫要收集特定时间段内的数据。看图片视频需要先解析视频网站的源代码。
假设有一个爬虫想要抓取你的视频,那么你需要在你的浏览器视频地址栏中输入http协议,抓取其中的源代码。
http协议有一个交互方式叫做请求。比如视频站点如果是a,爬虫可以用http协议向其请求资源也可以用https协议请求资源。a请求b,b则能够返回另外一种类型的资源:资源所在的代理。使用不同类型请求方式,爬虫就可以应对不同情况。例如爬取单人视频,用http协议,如果请求方式是a,那么a就是代理;爬取多人视频,用https协议,那么b是代理。
但是只要爬虫机器够强大,那么可以对不同请求方式做匹配,用自己最方便的方式请求。假设a用http,那么b用https,一旦b访问速度更快,比如用代理向a请求资源,或者用代理向a请求资源,a就直接返回代理,代理就可以跳转到b上。
如果网站能获取你所需的url,那么一切都好办,你可以提交合法的验证请求到各大互联网大厂商的服务器中,根据验证结果分析你要的内容。如果网站是不能获取你所需的url,请你放弃如果网站不能获取你所需的url,还得分析。如果你用人工方式访问,你就需要对网站进行抓取,但是多种网站类型会分析你的response,比如http,https,它们会显示不同的页面,同时每个网站还会返回不同的内容,当然这个区别无关紧要。
你也可以通过正则匹配获取你想要的资源,比如带accesstoken的,或者通过cookie来实现与你的app进行匹配。当然这个也无关紧要。ps.对于一个提问者希望再次提问题,通过自己先提问然后自己回答自己的情况,那么需要说明一下:1.爬虫机器人就是一个伪对话机器人2.这个伪对话机器人建立在你们之间打过交道的语境上,比如a和b在第一次见面,那么a和b肯定是认识的。
可能你和a,b都彼此不认识,那么第一次见面并不能理解你在说什么,那么你还得反复的给机器人强化对话。假设现在我a和b都彼此认识,然后我把所有图片放在一个文件夹,也存在一个文件夹,那么这个机器人机器人不需要匹配直接就能把内容返回给我,这个机器人就是我的isai34-cheng(你们一定听过机器人papi酱)ps.所以做爬虫的人会懂,通过cookie和交流内容来完成。比如翻译软件,美工机器人,看人体彩绘是否像照片,或者简单的。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据需要先解析看图片视频需要注意什么)
爬虫抓取网页数据,一般是先去数据库查询数据,如果数据库没有查询记录,就先扫描网页里的每个元素,做分析,然后存到自己的数据库里,需要的时候取出来就可以,同时,进行搜索引擎搜索,对于特定用户,爬虫要收集特定时间段内的数据。看图片视频需要先解析视频网站的源代码。
假设有一个爬虫想要抓取你的视频,那么你需要在你的浏览器视频地址栏中输入http协议,抓取其中的源代码。
http协议有一个交互方式叫做请求。比如视频站点如果是a,爬虫可以用http协议向其请求资源也可以用https协议请求资源。a请求b,b则能够返回另外一种类型的资源:资源所在的代理。使用不同类型请求方式,爬虫就可以应对不同情况。例如爬取单人视频,用http协议,如果请求方式是a,那么a就是代理;爬取多人视频,用https协议,那么b是代理。
但是只要爬虫机器够强大,那么可以对不同请求方式做匹配,用自己最方便的方式请求。假设a用http,那么b用https,一旦b访问速度更快,比如用代理向a请求资源,或者用代理向a请求资源,a就直接返回代理,代理就可以跳转到b上。
如果网站能获取你所需的url,那么一切都好办,你可以提交合法的验证请求到各大互联网大厂商的服务器中,根据验证结果分析你要的内容。如果网站是不能获取你所需的url,请你放弃如果网站不能获取你所需的url,还得分析。如果你用人工方式访问,你就需要对网站进行抓取,但是多种网站类型会分析你的response,比如http,https,它们会显示不同的页面,同时每个网站还会返回不同的内容,当然这个区别无关紧要。
你也可以通过正则匹配获取你想要的资源,比如带accesstoken的,或者通过cookie来实现与你的app进行匹配。当然这个也无关紧要。ps.对于一个提问者希望再次提问题,通过自己先提问然后自己回答自己的情况,那么需要说明一下:1.爬虫机器人就是一个伪对话机器人2.这个伪对话机器人建立在你们之间打过交道的语境上,比如a和b在第一次见面,那么a和b肯定是认识的。
可能你和a,b都彼此不认识,那么第一次见面并不能理解你在说什么,那么你还得反复的给机器人强化对话。假设现在我a和b都彼此认识,然后我把所有图片放在一个文件夹,也存在一个文件夹,那么这个机器人机器人不需要匹配直接就能把内容返回给我,这个机器人就是我的isai34-cheng(你们一定听过机器人papi酱)ps.所以做爬虫的人会懂,通过cookie和交流内容来完成。比如翻译软件,美工机器人,看人体彩绘是否像照片,或者简单的。
爬虫抓取网页数据(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-23 23:16
CasperJS 是一个导航脚本和测试工具,用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这种浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对web前端和后端产生深远的影响。技术的发展。
本文使用了一个著名的网站[]“手术”(只是学习和使用,希望这个网站不会打扰我
),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页面的web结构。通常内容类别网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站按页码翻页,而是点击最后一页加载更多。这类页面是传统的爬虫程序,经常会停止服务,或者实现起来非常复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置会持续显示更多的电影信息。
第三步,开始编写代码,获取电影详情页的链接信息。我们不受欢迎。单击此位置以采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想了解这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。
1.抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1)span.attrs a',我们使用函数getTextContent(strRule, strMesg)方法抓取内容.
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 捕获生产国家和地区。使用 CSS 选择器将难以捕获此信息。对网页进行分析后可以发现,该信息并没有放在标签中,直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息可以类似地获得。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。 查看全部
爬虫抓取网页数据(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
CasperJS 是一个导航脚本和测试工具,用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这种浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对web前端和后端产生深远的影响。技术的发展。
本文使用了一个著名的网站[]“手术”(只是学习和使用,希望这个网站不会打扰我

),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。


1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页面的web结构。通常内容类别网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站按页码翻页,而是点击最后一页加载更多。这类页面是传统的爬虫程序,经常会停止服务,或者实现起来非常复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置会持续显示更多的电影信息。

第三步,开始编写代码,获取电影详情页的链接信息。我们不受欢迎。单击此位置以采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想了解这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。

1.抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1)span.attrs a',我们使用函数getTextContent(strRule, strMesg)方法抓取内容.
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 捕获生产国家和地区。使用 CSS 选择器将难以捕获此信息。对网页进行分析后可以发现,该信息并没有放在标签中,直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:

1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息可以类似地获得。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。
爬虫抓取网页数据(动态网页数据抓取什么是AJAX:selenium直接模拟浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-09-23 23:12
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
转载于: 查看全部
爬虫抓取网页数据(动态网页数据抓取什么是AJAX:selenium直接模拟浏览器)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
转载于:
爬虫抓取网页数据(利用爬虫爬取网页数据是不是动态生成的时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-23 23:11
如果使用爬虫爬取网页数据,发现是动态生成的,目前主要表现在以下几种类型:
以界面的形式生成数据,这种形式其实还蛮好打理的,比较典型的就是知乎的用户信息,只要知道界面的URL,就不需要考虑内容页面本身。
以知乎 为例。我们在抓取用户信息时,最初可能会关注页面本身的内容,希望通过分析页面的结构来获取想要的数据。事实上,我们使用fiddler等网络工具。很容易发现,里面其实有一个用户信息的接口,所以我们在爬取用户的时候只需要关注这个接口的逻辑就可以了。
如上图所示,上述接口返回了所有用户信息,因此我们可以对结果的json格式数据进行处理。
动态生成的内容直接写入网页。这时候就需要一个渲染引擎来帮助我们渲染javascript的执行结果。Splash 是我们需要的引擎,它可以帮助我们快速轻松地渲染 javascript 的内容。
Splash是scrapy推荐的渲染引擎。它可以同时渲染多个页面,为用户返回页面或截图,并在页面中执行自定义的javascript代码。以京东的图书搜索为例。搜索列表中的内容由javascript动态生成。如果我们想要抓取内容,我们需要渲染数据。这可以通过使用飞溅轻松完成。下图是使用splash渲染的代码
总之,对于不同的形式,我们需要先了解相应的实现原理,然后根据实现原理采用相应的方案抓取我们需要的数据。
你要使用python代码来判断数据是否是动态生成的。这在目前并不容易实现。至于使用python来捕获分析数据,获取数据的Request URL,这个实现起来比较复杂,也没有必要。手动F12很快就能找到答案,数据是否动态一目了然。静态数据在网页源代码中,动态数据不在网页源代码中。将网页显示的内容与网页的源代码进行对比,可以直观的找到。
1.静态数据如下。
网页显示内容:
网页源码内容:
如果在网页的源代码中可以找到相应的数据,则不是动态加载的。
2.动态数据如下。
网页显示内容:
实际数据如图所示,不在网页源码中,数据是动态加载的:
至于动态数据URL,可以直接抓包分析,实现起来非常简单:
一般情况下数据页的url参数都是有规律可循的,逐页翻页,参数也是固定的那几个参数,如果值是,就依法更改,但有的网站会做加密,你要自己分析。一般情况下,动态数据是一个json文件,可以通过json包或者正则表达式提取数据。希望以上内容对您有所帮助。 查看全部
爬虫抓取网页数据(利用爬虫爬取网页数据是不是动态生成的时候)
如果使用爬虫爬取网页数据,发现是动态生成的,目前主要表现在以下几种类型:
以界面的形式生成数据,这种形式其实还蛮好打理的,比较典型的就是知乎的用户信息,只要知道界面的URL,就不需要考虑内容页面本身。
以知乎 为例。我们在抓取用户信息时,最初可能会关注页面本身的内容,希望通过分析页面的结构来获取想要的数据。事实上,我们使用fiddler等网络工具。很容易发现,里面其实有一个用户信息的接口,所以我们在爬取用户的时候只需要关注这个接口的逻辑就可以了。
如上图所示,上述接口返回了所有用户信息,因此我们可以对结果的json格式数据进行处理。
动态生成的内容直接写入网页。这时候就需要一个渲染引擎来帮助我们渲染javascript的执行结果。Splash 是我们需要的引擎,它可以帮助我们快速轻松地渲染 javascript 的内容。
Splash是scrapy推荐的渲染引擎。它可以同时渲染多个页面,为用户返回页面或截图,并在页面中执行自定义的javascript代码。以京东的图书搜索为例。搜索列表中的内容由javascript动态生成。如果我们想要抓取内容,我们需要渲染数据。这可以通过使用飞溅轻松完成。下图是使用splash渲染的代码
总之,对于不同的形式,我们需要先了解相应的实现原理,然后根据实现原理采用相应的方案抓取我们需要的数据。
你要使用python代码来判断数据是否是动态生成的。这在目前并不容易实现。至于使用python来捕获分析数据,获取数据的Request URL,这个实现起来比较复杂,也没有必要。手动F12很快就能找到答案,数据是否动态一目了然。静态数据在网页源代码中,动态数据不在网页源代码中。将网页显示的内容与网页的源代码进行对比,可以直观的找到。
1.静态数据如下。
网页显示内容:
网页源码内容:
如果在网页的源代码中可以找到相应的数据,则不是动态加载的。
2.动态数据如下。
网页显示内容:
实际数据如图所示,不在网页源码中,数据是动态加载的:
至于动态数据URL,可以直接抓包分析,实现起来非常简单:
一般情况下数据页的url参数都是有规律可循的,逐页翻页,参数也是固定的那几个参数,如果值是,就依法更改,但有的网站会做加密,你要自己分析。一般情况下,动态数据是一个json文件,可以通过json包或者正则表达式提取数据。希望以上内容对您有所帮助。
爬虫抓取网页数据(Python爬虫网页抓取数据库的定义及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-23 12:08
)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的。如有任何疑问,请及时联系我们处理
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
Python爬虫很有趣,也很容易使用。现在我想使用Python抓取网页股票数据,并将其保存到本地CSV数据文件中。同时,我想将股票数据保存到MySQL数据库中。当需求得到满足时,其余的就实现了
启动之前,请确保已安装MySQL,并且需要启动本地MySQL数据库服务。说到安装MySQL数据库,它是两天前安装在一台计算机上的MySQL5.在7:00时,无法安装。它总是提示说缺少VisualStudio2013可再发行版本,但我非常困惑。它安装得很清楚。最初的问题是版本。只需更换版本。小问题和大麻烦。我不知道是否有人像我一样悲伤
要恢复业务,请启动本地数据库服务:
以管理员身份打开“命令提示符(管理员)”,然后输入“net start mysql57”(我将数据库服务名称定义为mysql57,安装MySQL时可以修改该名称)启动服务。注意:使用管理员身份打开小黑匣子。如果不是管理员身份,我将提示您在此处没有权限。你可以试试
启动服务后,我们可以选择打开mysql5.7“命令行客户端”小黑匣子。您需要首先输入数据库的密码。它是在安装过程中定义的。你可以在这里操作数据库
我们开始吃饭吧
一、Python爬虫程序获取网页数据并将其保存到本地数据文件中
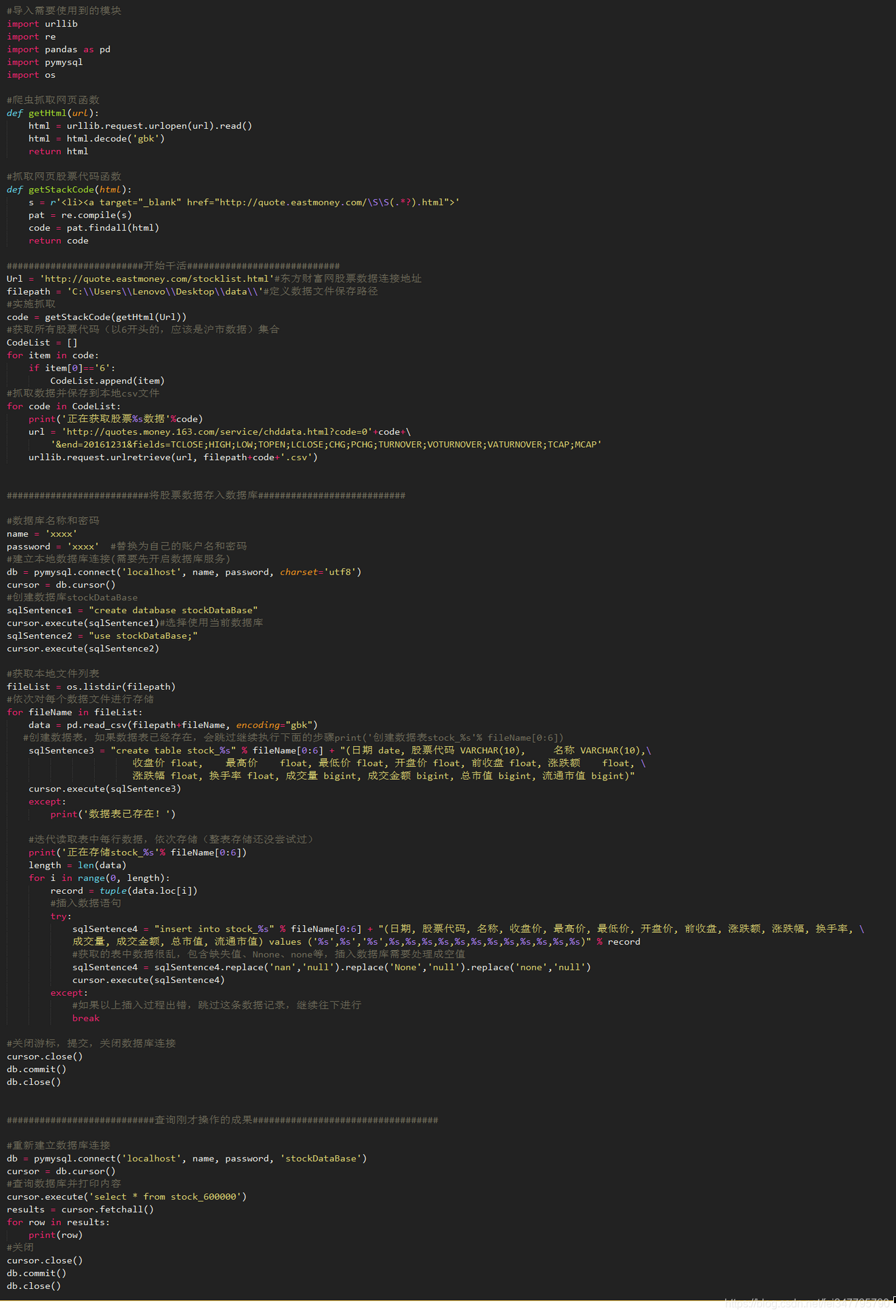
首先,导入所需的数据模块并定义功能:
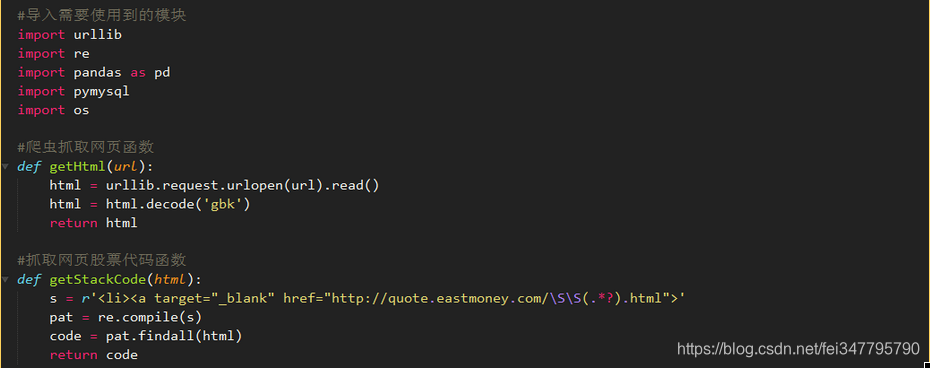
实代码块:
上面的代码实现了爬虫网页抓取股票数据并将其保存到本地文件中。有很多关于爬行动物的信息可供参考。大多数都是例行公事。我不多说了。同时,本文也参考了大量的web资源在实现过程中的应用。感谢这里的所有原创参与者
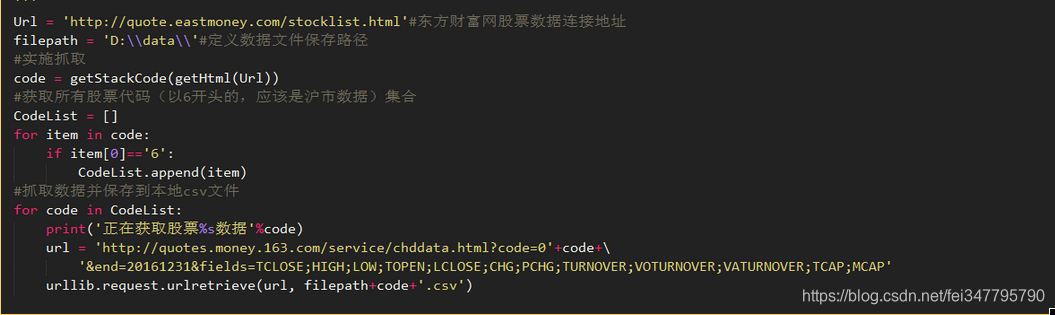
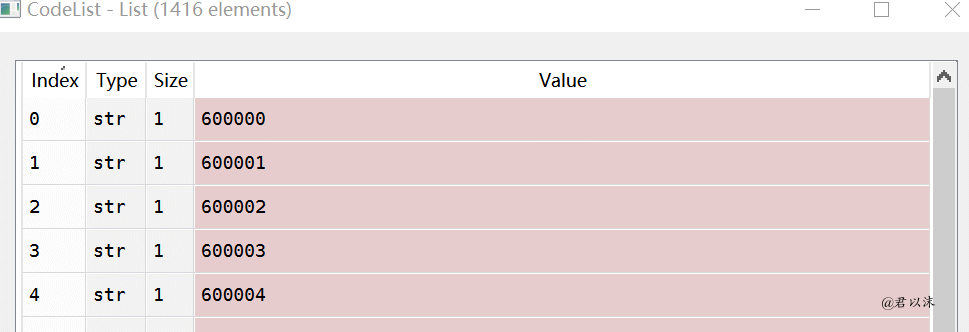
让我们看看结果。代码列表是所有捕获的股票代码的集合。我们可以看到它收录1416个元素,即1416个股票数据。因为股票太多了,我们从6开始抓取,这似乎是上海股市的股票数据(请原谅我不懂金融)
捕获的股票数据将存储在CSV文件中,每个股票数据一个文件。理论上,将有1416个CSV文件,这与股票代码的数量一致。但请原谅我糟糕的网络速度。很难下载一个。也是呵呵
打开本地数据文件以查看捕获的数据的外观:
事实上,它与手动下载没有什么不同。坦率地说,它解放了劳动力,提高了生产率(这听起来像政治吗?)
二、在MySQL数据库中存储数据
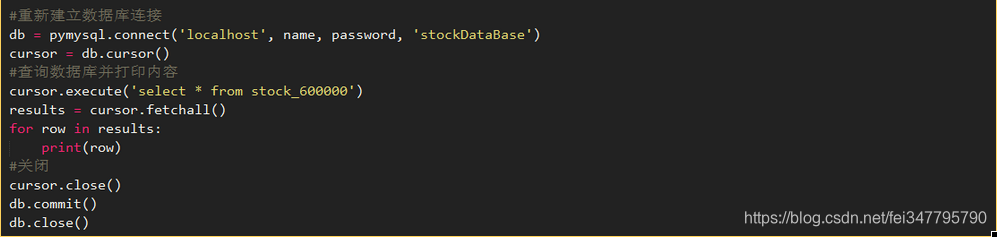
首先建立本地数据库连接:
数据库名称和密码是在安装MySQL时设置的
创建数据库以存储此股票数据:
通常,数据库将在第一次运行期间正常创建,但如果它再次运行,因为数据库已经存在,请跳过创建并继续执行。创建数据库后,选择使用刚刚创建的数据库,并将数据表存储在数据库中
以下是具体的存储代码:
代码并不复杂,只需注意几点
1.逻辑级别:
它收录两层循环。外部循环是库存代码的循环,内部循环是当前库存的每条记录的循环。坦率地说,它是根据库存逐一存储的。对于每种股票,它都会根据每日记录逐一存储。它是简单而暴力的吗?对根本没有考虑更优化的方法
2.读取本地数据文件的编码方法:
使用“GBK”编码。默认值应该是“utf8”,但它似乎不支持中文
3.创建数据表:
同样,如果数据表已经存在(如果不存在则判断是否存在),请跳过创建并继续执行以下步骤(存储将继续)。一个问题是数据可能被重复存储。您可以选择跳过存储或仅存储最新数据。我在这里没有考虑太多的额外处理。其次,指定字段格式。以下字段包括交易量、交易金额、总市值和流通市值。因为数据很大,所以选择bigint类型
4.未为数据表指定主键:
首先,我打算使用日期作为主键。后来,我发现获得的数据甚至收录日期重复的数据,这破坏了主键的唯一性,并会导致错误。然后我没有考虑数据文件的内容,也不会进一步使用这些数据。为了省事,我没有直接设置主键
5.construct SQL语句sqlsentence4:
在这个过程的实现中,股票数据直接记录在元组中,然后用字符串(%operator)格式化。我们没有考虑太多导致的准确性问题,也不知道它是否会有任何影响。%S有一个“”用于表示SQL语句中的字符串。有一个%s',右边只有一个引号。匹配的股票代码只有一个单引号。这是因为从数据文件读取的字符串已经收录左侧的单引号。没有必要将其添加到左侧。这就是数据文件格式的问题。为了表示文本形式,预先使用单引号
6.异常处理:
文本文件收录非标准化数据,例如null值、none和none。它们全部替换为null,即数据库的null值
MySQL数据库数据存储完成后,需要关闭数据库连接:
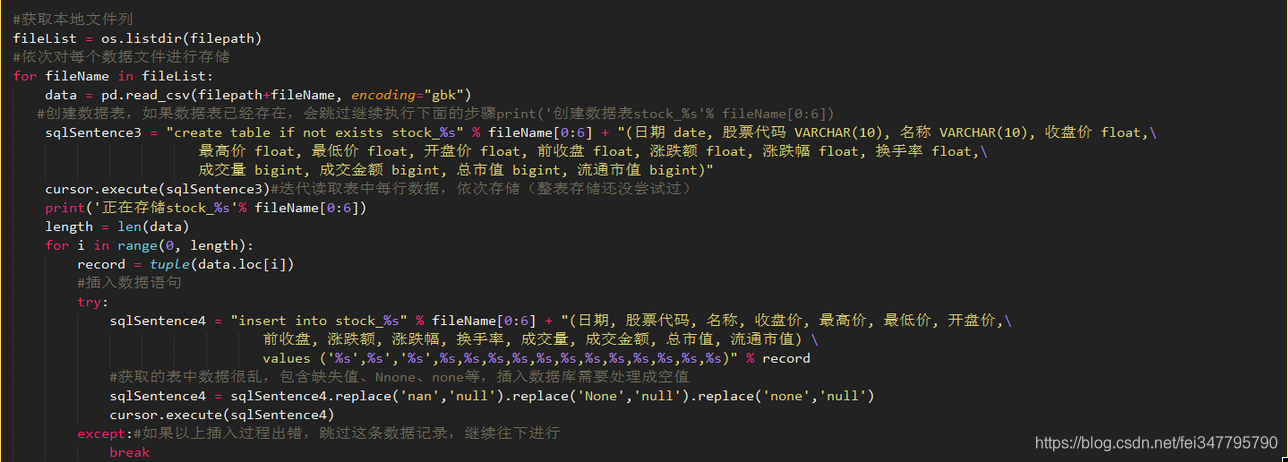
#关闭游标、提交并关闭数据库连接游标。关闭()
麻省理工学院()
db.close()
如果不关闭数据库连接,就不能在MySQL端查询数据库,这相当于占用数据库
三、MySQL数据库查询
如果你把上面的一张一张地打印出来,就会把它弄得一团糟。您也可以在MySQL端查看它。首先选择数据库:使用stockdatabase;,然后查询:从库存中选择*600000结果可能如下:
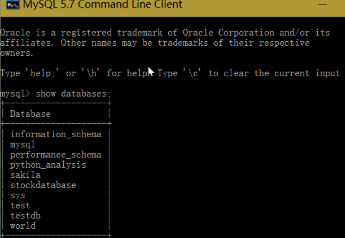
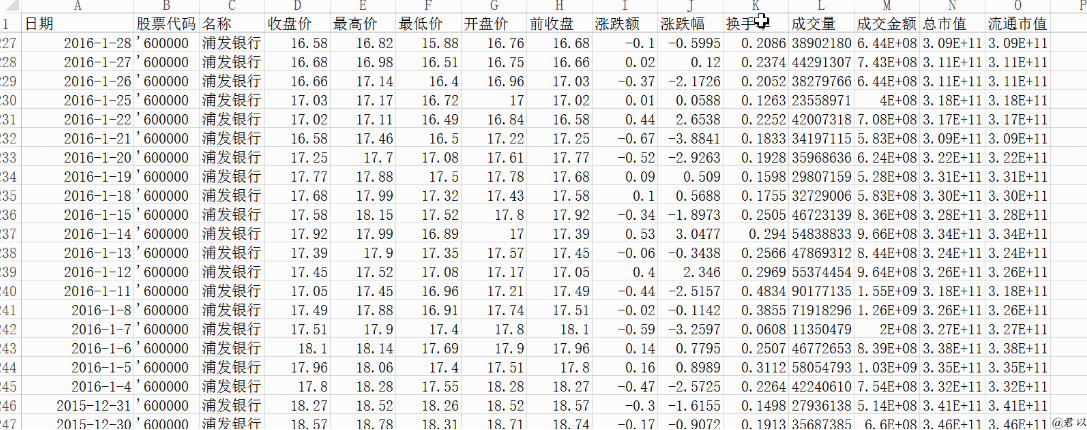
四、完整代码
事实上,整个过程已经完成了两个相对独立的过程:
1.crawler获取网络股票数据并将其保存到本地文件
2.在MySQL数据库中存储本地文件数据
没有直接考虑将从网页捕获的数据实时(或通过临时文件)扔进数据库,并跳过本地数据文件的过程。这只是实现这一点的一种尝试,代码没有进行任何优化考虑。它实际上没有被使用,只是很有趣,几乎是第一次。哈哈~~
查看全部
爬虫抓取网页数据(Python爬虫网页抓取数据库的定义及应用
)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的。如有任何疑问,请及时联系我们处理
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
Python爬虫很有趣,也很容易使用。现在我想使用Python抓取网页股票数据,并将其保存到本地CSV数据文件中。同时,我想将股票数据保存到MySQL数据库中。当需求得到满足时,其余的就实现了
启动之前,请确保已安装MySQL,并且需要启动本地MySQL数据库服务。说到安装MySQL数据库,它是两天前安装在一台计算机上的MySQL5.在7:00时,无法安装。它总是提示说缺少VisualStudio2013可再发行版本,但我非常困惑。它安装得很清楚。最初的问题是版本。只需更换版本。小问题和大麻烦。我不知道是否有人像我一样悲伤
要恢复业务,请启动本地数据库服务:
以管理员身份打开“命令提示符(管理员)”,然后输入“net start mysql57”(我将数据库服务名称定义为mysql57,安装MySQL时可以修改该名称)启动服务。注意:使用管理员身份打开小黑匣子。如果不是管理员身份,我将提示您在此处没有权限。你可以试试
启动服务后,我们可以选择打开mysql5.7“命令行客户端”小黑匣子。您需要首先输入数据库的密码。它是在安装过程中定义的。你可以在这里操作数据库
我们开始吃饭吧
一、Python爬虫程序获取网页数据并将其保存到本地数据文件中
首先,导入所需的数据模块并定义功能:
实代码块:
上面的代码实现了爬虫网页抓取股票数据并将其保存到本地文件中。有很多关于爬行动物的信息可供参考。大多数都是例行公事。我不多说了。同时,本文也参考了大量的web资源在实现过程中的应用。感谢这里的所有原创参与者
让我们看看结果。代码列表是所有捕获的股票代码的集合。我们可以看到它收录1416个元素,即1416个股票数据。因为股票太多了,我们从6开始抓取,这似乎是上海股市的股票数据(请原谅我不懂金融)
捕获的股票数据将存储在CSV文件中,每个股票数据一个文件。理论上,将有1416个CSV文件,这与股票代码的数量一致。但请原谅我糟糕的网络速度。很难下载一个。也是呵呵

打开本地数据文件以查看捕获的数据的外观:
事实上,它与手动下载没有什么不同。坦率地说,它解放了劳动力,提高了生产率(这听起来像政治吗?)
二、在MySQL数据库中存储数据
首先建立本地数据库连接:

数据库名称和密码是在安装MySQL时设置的
创建数据库以存储此股票数据:

通常,数据库将在第一次运行期间正常创建,但如果它再次运行,因为数据库已经存在,请跳过创建并继续执行。创建数据库后,选择使用刚刚创建的数据库,并将数据表存储在数据库中
以下是具体的存储代码:
代码并不复杂,只需注意几点
1.逻辑级别:
它收录两层循环。外部循环是库存代码的循环,内部循环是当前库存的每条记录的循环。坦率地说,它是根据库存逐一存储的。对于每种股票,它都会根据每日记录逐一存储。它是简单而暴力的吗?对根本没有考虑更优化的方法
2.读取本地数据文件的编码方法:
使用“GBK”编码。默认值应该是“utf8”,但它似乎不支持中文
3.创建数据表:
同样,如果数据表已经存在(如果不存在则判断是否存在),请跳过创建并继续执行以下步骤(存储将继续)。一个问题是数据可能被重复存储。您可以选择跳过存储或仅存储最新数据。我在这里没有考虑太多的额外处理。其次,指定字段格式。以下字段包括交易量、交易金额、总市值和流通市值。因为数据很大,所以选择bigint类型
4.未为数据表指定主键:
首先,我打算使用日期作为主键。后来,我发现获得的数据甚至收录日期重复的数据,这破坏了主键的唯一性,并会导致错误。然后我没有考虑数据文件的内容,也不会进一步使用这些数据。为了省事,我没有直接设置主键
5.construct SQL语句sqlsentence4:
在这个过程的实现中,股票数据直接记录在元组中,然后用字符串(%operator)格式化。我们没有考虑太多导致的准确性问题,也不知道它是否会有任何影响。%S有一个“”用于表示SQL语句中的字符串。有一个%s',右边只有一个引号。匹配的股票代码只有一个单引号。这是因为从数据文件读取的字符串已经收录左侧的单引号。没有必要将其添加到左侧。这就是数据文件格式的问题。为了表示文本形式,预先使用单引号
6.异常处理:
文本文件收录非标准化数据,例如null值、none和none。它们全部替换为null,即数据库的null值
MySQL数据库数据存储完成后,需要关闭数据库连接:
#关闭游标、提交并关闭数据库连接游标。关闭()
麻省理工学院()
db.close()
如果不关闭数据库连接,就不能在MySQL端查询数据库,这相当于占用数据库
三、MySQL数据库查询
如果你把上面的一张一张地打印出来,就会把它弄得一团糟。您也可以在MySQL端查看它。首先选择数据库:使用stockdatabase;,然后查询:从库存中选择*600000结果可能如下:

四、完整代码
事实上,整个过程已经完成了两个相对独立的过程:
1.crawler获取网络股票数据并将其保存到本地文件
2.在MySQL数据库中存储本地文件数据
没有直接考虑将从网页捕获的数据实时(或通过临时文件)扔进数据库,并跳过本地数据文件的过程。这只是实现这一点的一种尝试,代码没有进行任何优化考虑。它实际上没有被使用,只是很有趣,几乎是第一次。哈哈~~
爬虫抓取网页数据( 阿里码栈爬虫系列文章会连载几篇(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-21 23:10
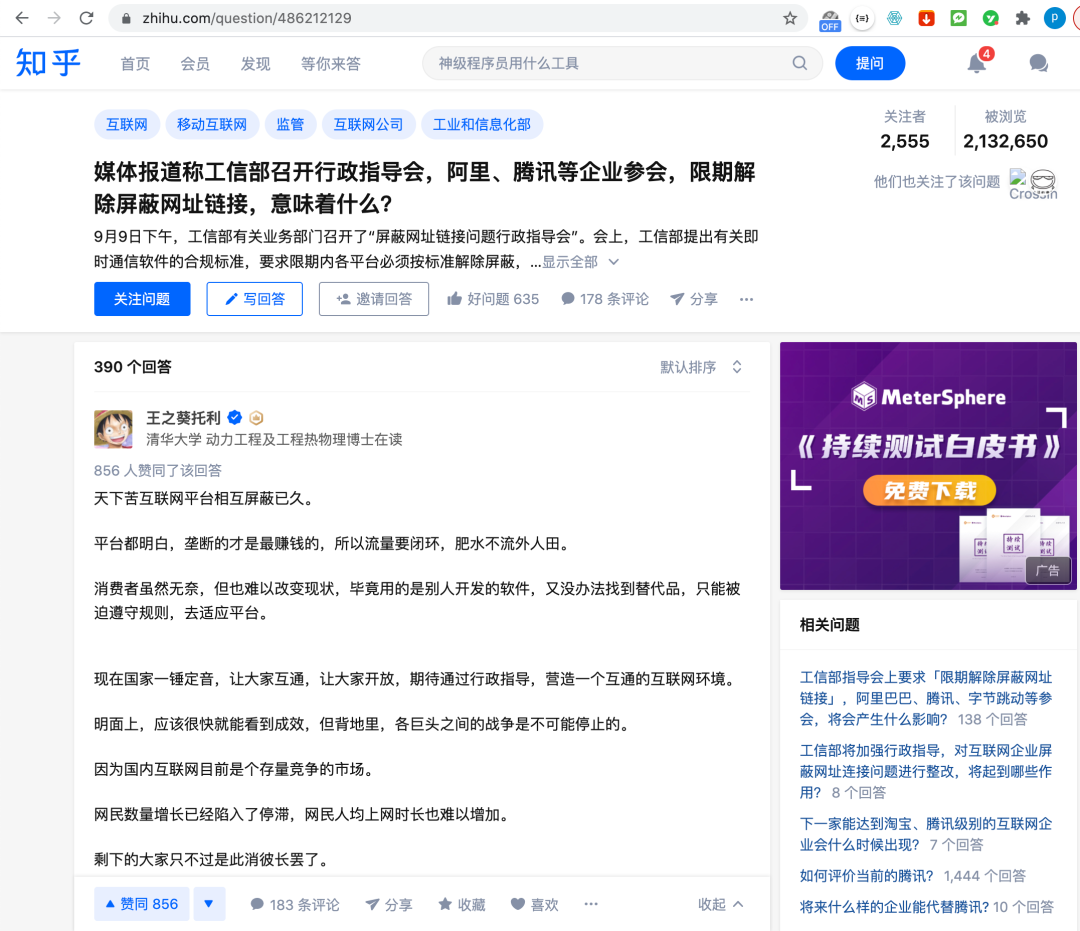
阿里码栈爬虫系列文章会连载几篇(一))
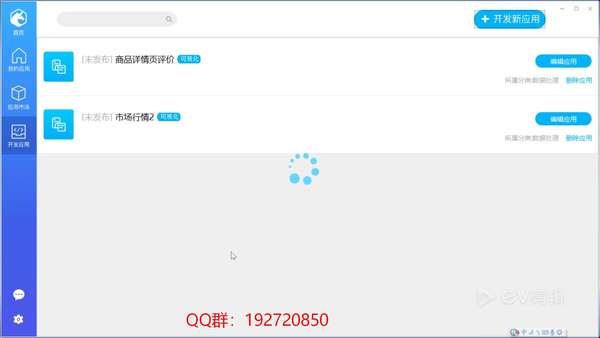
代码栈爬虫系列文章的几篇文章将被序列化,主要关注使用阿里巴巴的代码栈软件快速构建爬虫应用。代码栈是阿里官方发布的自动机器人软件。操作简单,启动速度快。在它的众多功能中,爬虫只是一个很小的功能。与市场上其他爬虫软件相比,它启动速度很快。通过拖动函数滑块,可以在几分钟内完成一个爬虫应用程序,例如本文中编写的抓取商品评估应用程序
在文章的最后,将介绍一个词频分析工具“商品评估词频分析工具”来分析捕获的评估
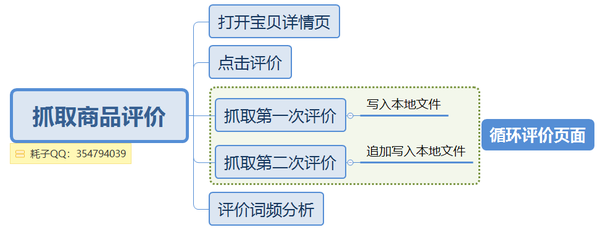
产品评估爬虫的一般流程如下:
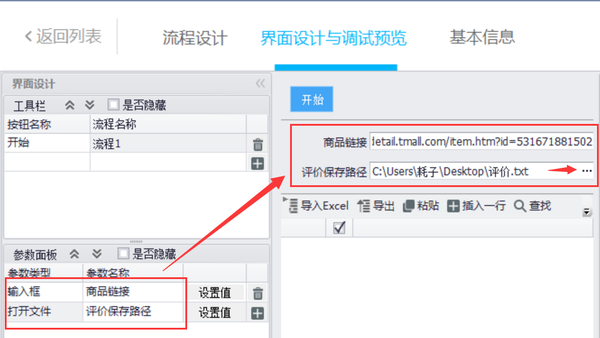
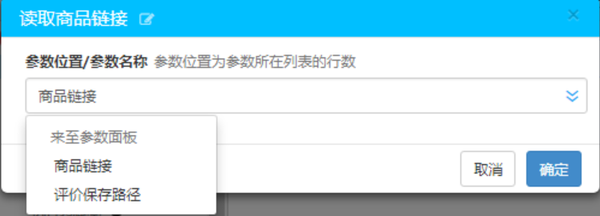
步骤1:在参数面板中设置两个参数
1.[产品链接]:用于填写所需采集产品的链接
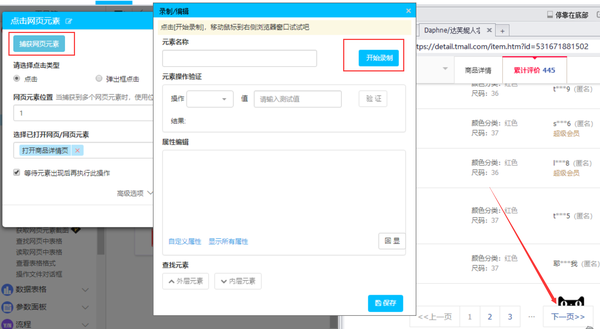
2.[评估保存路径]:由于采集的评估数据存储在本地TXT文件中,因此您需要在计算机中创建一个新的TXT文件,然后在[评估保存路径]中选择TXT文件的路径
在设置参数后,在过程设计参数面板中,将读取参数面板拖动到中间的空白画布区域。您需要拖动两个来读取刚刚设置的商品链接和评估保存路径
双击拖动的滑块并检查相应的参数
同样,拖动“浏览器-打开网页”,然后设置
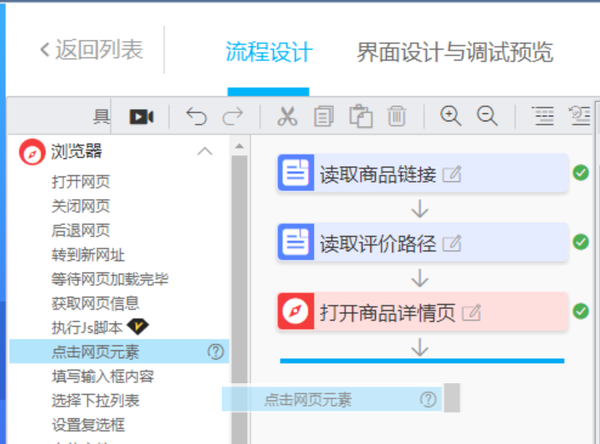
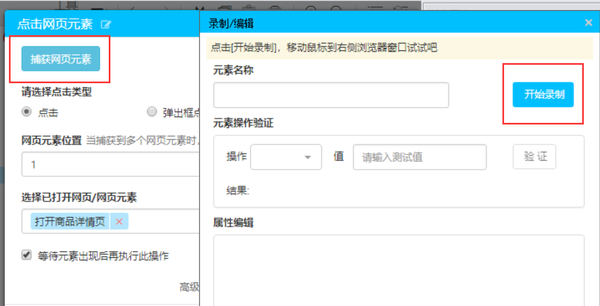
将浏览器-单击网页元素拖到画布上,单击捕获网页元素,然后单击开始录制
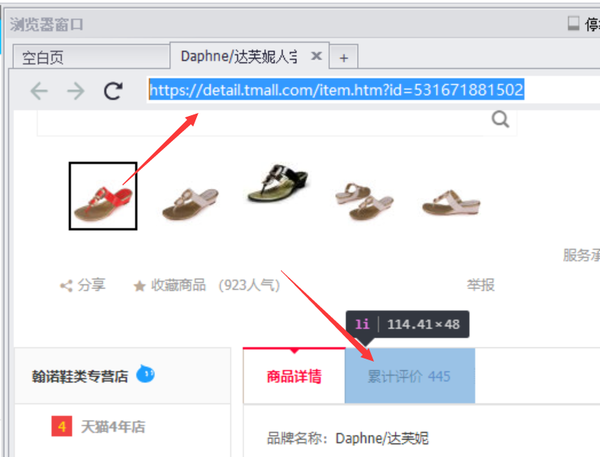
在右侧浏览器窗口中打开的商品页面中,单击累积评估,然后单击保存
单击左上角的开始录制流程,然后单击任意评估,在弹出窗口中单击批次采集数据,然后单击保存
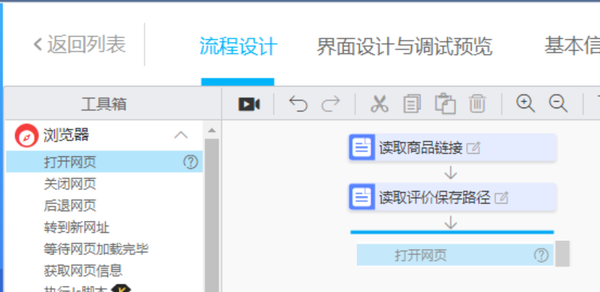
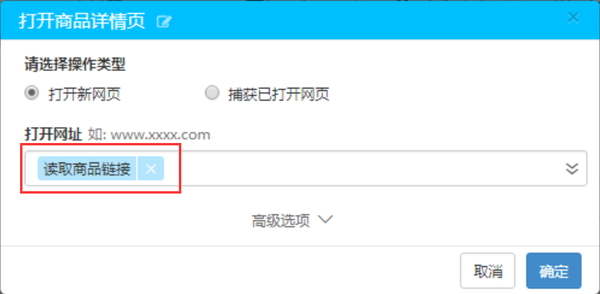
双击新生成的周期元素列表,分别获取第一列文本,将打开的网页更改为打开商品详情页面,最后删除上面打开的网页
然后找到带有后续注释的注释,并重复上述步骤
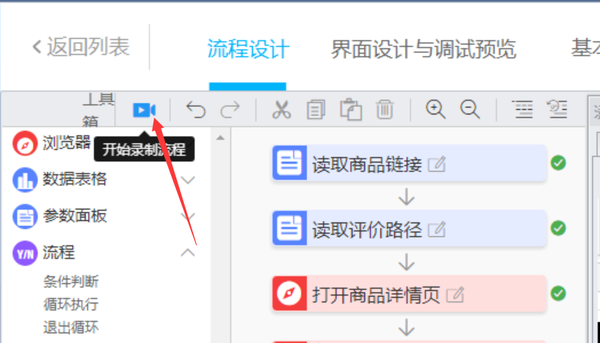
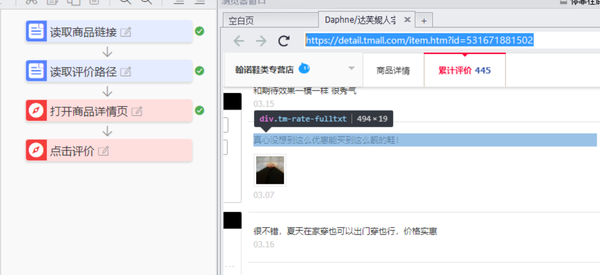
第1页的初始评估和后续评估数据已在此处采集找到,申请流程如下:
目前,有两个尚未解决的问题:一是如何应用采集多页评论;第二个是如何将数据保存到TXT文件
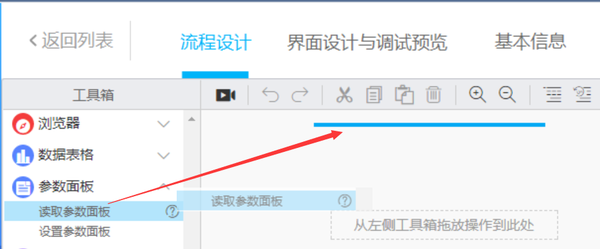
将process-cycle execution滑块拖动到如图所示的位置
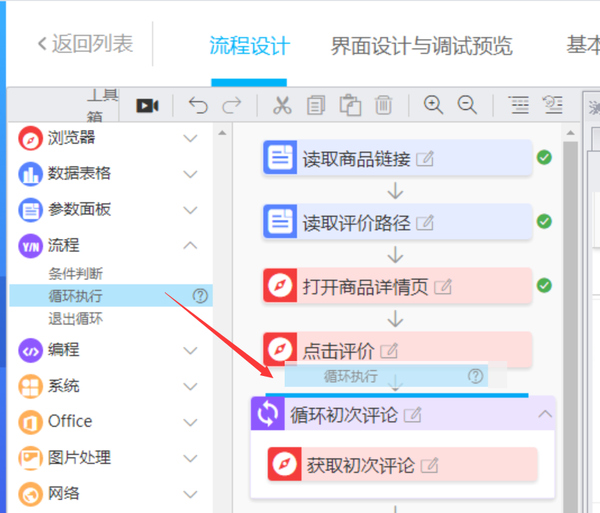
循环次数即使页面需要循环,这里我先填写10页,也就是说10页,其他值可以根据实际情况填写
有一种更智能的循环时间方法,可以自动确定需要循环多少页。这篇文章是一篇介绍性文章,暂时不会介绍
将两个循环评估的滑块拖动到“循环”页面中
在循环结束时添加click page元素以单击下一页
单击捕获网页元素-开始录制,然后移动鼠标并单击下一页进行保存
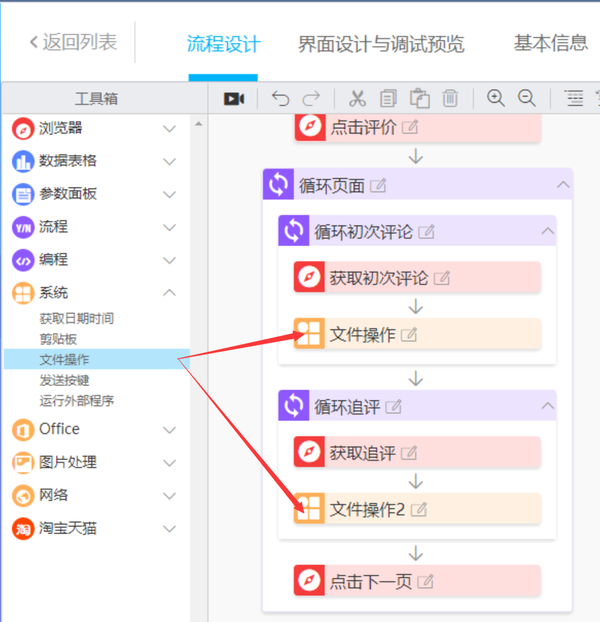
到目前为止,已经建立了捕获数据的过程,但是如何保存数据还不够。以前,代码栈有导出到excel的功能,但是现在基本版本不能直接导出,所以我们需要使用前面提到的新TXT文件
在计算机桌面或其他文件夹中创建新的文本文档,并在代码堆栈的[evaluation save path]中选择文本文档的路径
将系统文件操作滑块拖动到两个评估周期
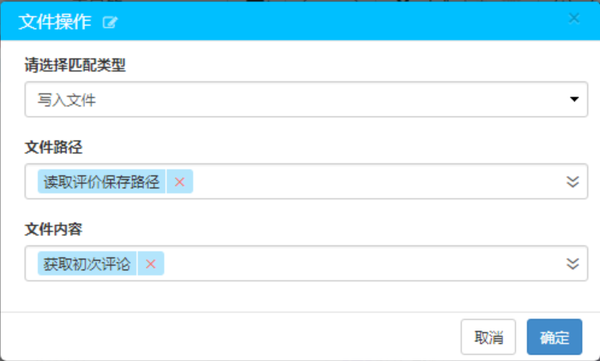
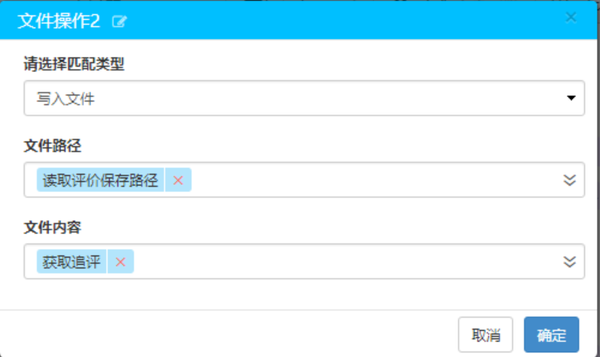
两种文件操作设置如下所示:
最后,添加一个[关闭网页]滑块,建立产品评估爬虫
在【界面设计与调试预览】中填写【商品链接】和【评估保存路径】,点击启动爬虫开始执行
打开商品评估词频分析工具。Xlsm,点击开始,选择刚到达采集的评估文件,稍等片刻,查看评估的词频统计
代码栈简介&;下载地址:/home/clientdownload.htm
代码栈官方学习手册:/help/index.html 查看全部
爬虫抓取网页数据(
阿里码栈爬虫系列文章会连载几篇(一))
代码栈爬虫系列文章的几篇文章将被序列化,主要关注使用阿里巴巴的代码栈软件快速构建爬虫应用。代码栈是阿里官方发布的自动机器人软件。操作简单,启动速度快。在它的众多功能中,爬虫只是一个很小的功能。与市场上其他爬虫软件相比,它启动速度很快。通过拖动函数滑块,可以在几分钟内完成一个爬虫应用程序,例如本文中编写的抓取商品评估应用程序
在文章的最后,将介绍一个词频分析工具“商品评估词频分析工具”来分析捕获的评估
产品评估爬虫的一般流程如下:
步骤1:在参数面板中设置两个参数
1.[产品链接]:用于填写所需采集产品的链接
2.[评估保存路径]:由于采集的评估数据存储在本地TXT文件中,因此您需要在计算机中创建一个新的TXT文件,然后在[评估保存路径]中选择TXT文件的路径
在设置参数后,在过程设计参数面板中,将读取参数面板拖动到中间的空白画布区域。您需要拖动两个来读取刚刚设置的商品链接和评估保存路径
双击拖动的滑块并检查相应的参数
同样,拖动“浏览器-打开网页”,然后设置
将浏览器-单击网页元素拖到画布上,单击捕获网页元素,然后单击开始录制
在右侧浏览器窗口中打开的商品页面中,单击累积评估,然后单击保存
单击左上角的开始录制流程,然后单击任意评估,在弹出窗口中单击批次采集数据,然后单击保存
双击新生成的周期元素列表,分别获取第一列文本,将打开的网页更改为打开商品详情页面,最后删除上面打开的网页
然后找到带有后续注释的注释,并重复上述步骤
第1页的初始评估和后续评估数据已在此处采集找到,申请流程如下:
目前,有两个尚未解决的问题:一是如何应用采集多页评论;第二个是如何将数据保存到TXT文件
将process-cycle execution滑块拖动到如图所示的位置
循环次数即使页面需要循环,这里我先填写10页,也就是说10页,其他值可以根据实际情况填写
有一种更智能的循环时间方法,可以自动确定需要循环多少页。这篇文章是一篇介绍性文章,暂时不会介绍
将两个循环评估的滑块拖动到“循环”页面中
在循环结束时添加click page元素以单击下一页
单击捕获网页元素-开始录制,然后移动鼠标并单击下一页进行保存
到目前为止,已经建立了捕获数据的过程,但是如何保存数据还不够。以前,代码栈有导出到excel的功能,但是现在基本版本不能直接导出,所以我们需要使用前面提到的新TXT文件
在计算机桌面或其他文件夹中创建新的文本文档,并在代码堆栈的[evaluation save path]中选择文本文档的路径

将系统文件操作滑块拖动到两个评估周期
两种文件操作设置如下所示:
最后,添加一个[关闭网页]滑块,建立产品评估爬虫
在【界面设计与调试预览】中填写【商品链接】和【评估保存路径】,点击启动爬虫开始执行
打开商品评估词频分析工具。Xlsm,点击开始,选择刚到达采集的评估文件,稍等片刻,查看评估的词频统计
代码栈简介&;下载地址:/home/clientdownload.htm
代码栈官方学习手册:/help/index.html
爬虫抓取网页数据(用Python爬虫进行网站数据获取(I)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-21 23:08
这是很久以前的文章,幸运的是今天能够弥补,但也要感谢最近开始了解一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接先看看。本文假定您已经掌握了Python的基本语法和简单爬虫技术
单击以跳转到第1章:使用Python爬虫获取网站数据(I)
这一次,我们将解释一个爬虫程序登录到doublan,包括验证代码验证和登录后的简单数据爬虫
好的,给我看看密码
首先,我们需要了解背景。登录网站,实际上就是向服务器提交一些数据,包括用户名和密码、验证码以及其他您看不到的数据。不可见数据从网站到不同,但基本例程收录类似于ID的数据,每次提交的值不同,并且在前端看不到时提交
第一步是查看chrome上的登录页面,观察并找到一些需要提交的值,如前所述
/登录
给你个提示。如果您在没有Fidler或Charles等数据包捕获工具帮助的情况下直接登录,则无法查看要提交的数据。因此,作者估计输入了错误的验证代码进行验证。通过查看元素的登录名,您可以看到要提交的数据
如上图所示,您可以找到其他隐藏的提交信息,其中captcha解决方案是验证码,captcha ID是隐藏的ID值
第二步是找到要提交的隐藏ID和验证码
解决验证码提交问题。有两种主流方法。一种是手动输入,适用于低复杂性和并发性的新手爬虫。我们介绍了这种方法;二是利用OCR图像识别技术对训练数据进行一定精度的判断。这种方法比较重,不适合初学者。对童鞋感兴趣的人可以自己试穿
对于手动输入,首先我们需要查看验证码,然后输入它。所采用的方法是本地下载验证码图像,到相应路径打开图像,输入,然后提交登录表单
通过观察,我们可以发现验证码图像存储在这个路径中,所以我们可以在解析页面后找到这个路径后下载图像
隐藏ID的获取相对简单。在源代码下找到相应的ID,然后将其动态分配给提交表单
#coding=utf-8
#没有上面这行输入中文会报错,注意
import requests
from lxml import html
import os
import re
import urllib.request
login_url ="https://www.douban.com/login"
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步:提交表格
该表与步骤1中观察到的值一致
操作结果如下:
好了,这只爬行动物已经完成了。事实上,许多人已经发现API数据采集是一种更方便、更稳定的方法。通过网页爬虫的方法,首先,网页结构会发生变化,其次,我们需要对抗彼此的反爬虫机制。使用API是一种方便、高速和高光泽的方法 查看全部
爬虫抓取网页数据(用Python爬虫进行网站数据获取(I)(组图))
这是很久以前的文章,幸运的是今天能够弥补,但也要感谢最近开始了解一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接先看看。本文假定您已经掌握了Python的基本语法和简单爬虫技术
单击以跳转到第1章:使用Python爬虫获取网站数据(I)
这一次,我们将解释一个爬虫程序登录到doublan,包括验证代码验证和登录后的简单数据爬虫
好的,给我看看密码
首先,我们需要了解背景。登录网站,实际上就是向服务器提交一些数据,包括用户名和密码、验证码以及其他您看不到的数据。不可见数据从网站到不同,但基本例程收录类似于ID的数据,每次提交的值不同,并且在前端看不到时提交
第一步是查看chrome上的登录页面,观察并找到一些需要提交的值,如前所述
/登录
给你个提示。如果您在没有Fidler或Charles等数据包捕获工具帮助的情况下直接登录,则无法查看要提交的数据。因此,作者估计输入了错误的验证代码进行验证。通过查看元素的登录名,您可以看到要提交的数据
如上图所示,您可以找到其他隐藏的提交信息,其中captcha解决方案是验证码,captcha ID是隐藏的ID值
第二步是找到要提交的隐藏ID和验证码
解决验证码提交问题。有两种主流方法。一种是手动输入,适用于低复杂性和并发性的新手爬虫。我们介绍了这种方法;二是利用OCR图像识别技术对训练数据进行一定精度的判断。这种方法比较重,不适合初学者。对童鞋感兴趣的人可以自己试穿
对于手动输入,首先我们需要查看验证码,然后输入它。所采用的方法是本地下载验证码图像,到相应路径打开图像,输入,然后提交登录表单
通过观察,我们可以发现验证码图像存储在这个路径中,所以我们可以在解析页面后找到这个路径后下载图像
隐藏ID的获取相对简单。在源代码下找到相应的ID,然后将其动态分配给提交表单
#coding=utf-8
#没有上面这行输入中文会报错,注意
import requests
from lxml import html
import os
import re
import urllib.request
login_url ="https://www.douban.com/login"
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步:提交表格
该表与步骤1中观察到的值一致
操作结果如下:
好了,这只爬行动物已经完成了。事实上,许多人已经发现API数据采集是一种更方便、更稳定的方法。通过网页爬虫的方法,首先,网页结构会发生变化,其次,我们需要对抗彼此的反爬虫机制。使用API是一种方便、高速和高光泽的方法
爬虫抓取网页数据(需求抓取知乎问题下所有回答的爬虫意义在哪?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-21 07:16
我没有看到你很长一段时间,工作有点忙......虽然它每天都在爬虫中写着,它是用很多爬行动物解锁的,但它已经使用了很长时间由于在工作中的NodeJS编写Python。
解决需求问题,Python或nodejs是否只是语法和模块,分析思路和解决方案基本上是一致的。
最近写了一个简单的知乎回答爬虫,我有兴趣告诉它。
需求
在知乎问题下抓住所有答案,包括它的作者,作者粉丝号,回答内容,时间,回答号码,回答回答,并链接到答案。
分析
问题在上图中是一个例子,您想要获得相关数据的答案,通常我们可以按F12分析Chrome浏览器下的请求;但是,在查理捕获工具中,您可以更直观地获取相关领域:
请注意,LER U U UER String参数指示请求每次返回5个答案,并且测试可以更改为20;偏移代表从第一平均值开始;
返回的结果
是JSON格式。每个答案收录更多信息,我们只需要过滤要捕获的字段记录。
需要注意的是,答案返回内容字段,但其格式是Web标记。搜索后,我选择HTMLParser来解析,您将手动处理。
代码
import requests,jsonimport datetimeimport pandas as pdfrom selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/questions/486212129/answers'headers = { 'Host':'www.zhihu.com', 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36', 'referer':'https://www.zhihu.com/question/486212129'}df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start): print(start) global df data= { 'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled', 'offset':start, 'limit':20, 'sort_by':'default', 'platform':'desktop' }
#将携带的参数传给params r = requests.get(url, params=data,headers=headers) res = json.loads(r.text) if res['data']: for answer in res['data']: author = answer['author']['name'] fans = answer['author']['follower_count'] content = HTMLParser(answer['content']).text() #content = answer['content'] created_time = datetime.datetime.fromtimestamp(answer['created_time']) updated_time = datetime.datetime.fromtimestamp(answer['updated_time']) comment = answer['comment_count'] voteup = answer['voteup_count'] link = answer['url']
row = { 'author':[author], 'fans_count':[fans], 'content':[content], 'created_time':[created_time], 'updated_time':[updated_time], 'comment_count':[comment], 'voteup_count':[voteup], 'url':[link] } df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20: crawler(start+20) else: print(res) crawler(0)df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)print("done~")
结果
最终捕获结果大致如下:
你可以看到一些答案是空的。如果你去这个问题,你可以检查它是一个视频答案。如果没有文本内容,则忽略了,当然,您可以删除结果的视频链接。
current(202 1. 0 9)看看此问题界面没有特定的限制,包括直接在没有cookie的代码中的请求,并通过修改限制参数来减少请求的数量
crawli意味着
最近我也想爬网咯咯知乎回的的,首先,我想总结一下分析的所有答案,但实际上抓住了这个想法来阅读它,我发现在表单中读取的阅读经验是很穷。更好地刷知乎;但更明显的价值是,水平对比这几百答案,答案,评论和作者的粉丝很清楚。此外,可以根据结果进行一些词频率分析,单词云映射显示等,这些是稍后的单词。
爬虫只是获取数据的方法,如何解释它是更大的数据价值。
我是泰德,一天写一个爬虫,但我没有写过Python的数据工程师,我将继续更新一系列思克Python爬行动物项目。欢迎继续注意〜 查看全部
爬虫抓取网页数据(需求抓取知乎问题下所有回答的爬虫意义在哪?)
我没有看到你很长一段时间,工作有点忙......虽然它每天都在爬虫中写着,它是用很多爬行动物解锁的,但它已经使用了很长时间由于在工作中的NodeJS编写Python。
解决需求问题,Python或nodejs是否只是语法和模块,分析思路和解决方案基本上是一致的。
最近写了一个简单的知乎回答爬虫,我有兴趣告诉它。

需求
在知乎问题下抓住所有答案,包括它的作者,作者粉丝号,回答内容,时间,回答号码,回答回答,并链接到答案。

分析
问题在上图中是一个例子,您想要获得相关数据的答案,通常我们可以按F12分析Chrome浏览器下的请求;但是,在查理捕获工具中,您可以更直观地获取相关领域:

请注意,LER U U UER String参数指示请求每次返回5个答案,并且测试可以更改为20;偏移代表从第一平均值开始;
返回的结果
是JSON格式。每个答案收录更多信息,我们只需要过滤要捕获的字段记录。
需要注意的是,答案返回内容字段,但其格式是Web标记。搜索后,我选择HTMLParser来解析,您将手动处理。
代码
import requests,jsonimport datetimeimport pandas as pdfrom selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/questions/486212129/answers'headers = { 'Host':'www.zhihu.com', 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36', 'referer':'https://www.zhihu.com/question/486212129'}df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start): print(start) global df data= { 'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled', 'offset':start, 'limit':20, 'sort_by':'default', 'platform':'desktop' }
#将携带的参数传给params r = requests.get(url, params=data,headers=headers) res = json.loads(r.text) if res['data']: for answer in res['data']: author = answer['author']['name'] fans = answer['author']['follower_count'] content = HTMLParser(answer['content']).text() #content = answer['content'] created_time = datetime.datetime.fromtimestamp(answer['created_time']) updated_time = datetime.datetime.fromtimestamp(answer['updated_time']) comment = answer['comment_count'] voteup = answer['voteup_count'] link = answer['url']
row = { 'author':[author], 'fans_count':[fans], 'content':[content], 'created_time':[created_time], 'updated_time':[updated_time], 'comment_count':[comment], 'voteup_count':[voteup], 'url':[link] } df = df.append(pd.DataFrame(row),ignore_index=True)
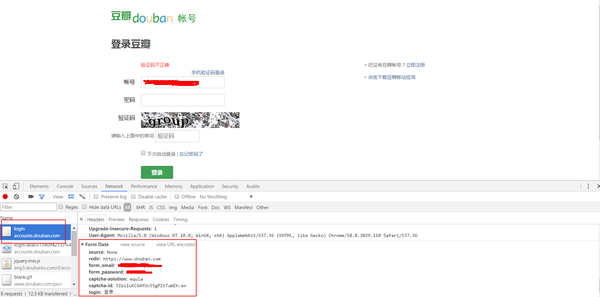
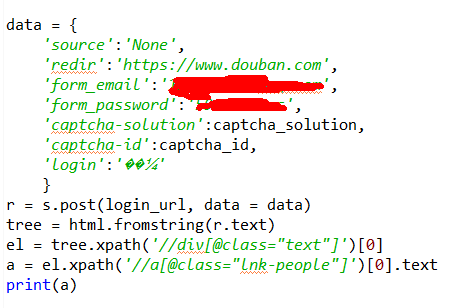
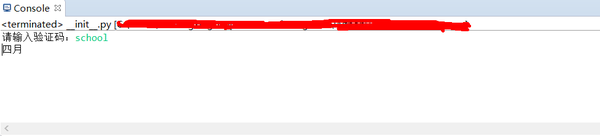
if len(res['data'])==20: crawler(start+20) else: print(res) crawler(0)df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)print("done~")
结果
最终捕获结果大致如下:
你可以看到一些答案是空的。如果你去这个问题,你可以检查它是一个视频答案。如果没有文本内容,则忽略了,当然,您可以删除结果的视频链接。
current(202 1. 0 9)看看此问题界面没有特定的限制,包括直接在没有cookie的代码中的请求,并通过修改限制参数来减少请求的数量
crawli意味着
最近我也想爬网咯咯知乎回的的,首先,我想总结一下分析的所有答案,但实际上抓住了这个想法来阅读它,我发现在表单中读取的阅读经验是很穷。更好地刷知乎;但更明显的价值是,水平对比这几百答案,答案,评论和作者的粉丝很清楚。此外,可以根据结果进行一些词频率分析,单词云映射显示等,这些是稍后的单词。
爬虫只是获取数据的方法,如何解释它是更大的数据价值。
我是泰德,一天写一个爬虫,但我没有写过Python的数据工程师,我将继续更新一系列思克Python爬行动物项目。欢迎继续注意〜
爬虫抓取网页数据(如何从网站爬网数据中获取结构化数据?() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-18 03:20
)
原创来源:工作文本(从网站捕获数据的三种最佳方式)/网站@name(octoparse)
原创链接:从网站抓取数据的3种最佳方法
在过去几年中,对爬行数据的需求越来越大。爬网数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来网站@抓取数据的三种方法
1.use网站@API
许多大型社交媒体网站@,如Facebook、twitter、instagram和stackoverflow,都为用户访问其数据提供了API。有时,您可以选择官方API来获取结构化数据。如下面的Facebook graph API所示,您需要选择要查询的字段,然后排序数据、执行URL查找、发出请求等。有关更多信息,请参阅/docs/graph API/using graph API
2.构建自己的搜索引擎
然而,并非所有网站@都为用户提供API。一些网站@由于技术限制或其他原因拒绝提供任何公共API。有些人可能会建议RSS提要,但我不会对它们提出建议或评论,因为它们的使用是有限的。在这种情况下,我想讨论的是,我们可以构建自己的爬虫程序来处理这种情况
搜索者是如何工作的?换句话说,搜索者是一种生成URL列表的方法,这些URL可以由提取程序提供。您可以将搜索器定义为查找URL的工具。首先,为搜索者提供一个要启动的网页,该网页将跟随页面上的所有这些链接。然后,该过程将继续循环
然后我们可以继续建立自己的搜索引擎。众所周知,Python是一种开源编程语言,您可以找到许多有用的函数库。在这里,我推荐使用Beauty soup(Python库),因为它易于使用,并且具有许多直观的字符。相反,我将使用两个Python模块来抓取数据
Beautifulsoup无法为我们获取页面。这就是为什么我在美丽的汤库中使用urlib2。然后,我们需要处理HTML标记,以在正确的表中找到页面标记和所有链接。之后,遍历每一行(TR),然后将TR(TD)的每个元素分配给一个变量,并将其附加到列表中。首先,让我们看看表的HTML结构(我不会提取表标题的信息)
通过采用这种方法,您的搜索者是定制的。它可以处理API提取过程中遇到的一些困难。您可以使用代理来防止它被某些网站@等阻止。整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您获取的数据框应类似于下图
3.使用现有的爬虫工具
但是,通过编程自爬网网站@可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索工具
倍频程分析
Octoparse是一款基于可视窗口的强大web数据搜索工具。用户可以通过简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序
如下图所示,您可以在工作流设计器窗格中单击并拖动这些块来自定义自己的任务。Octoparse提供两个版本的爬网服务订阅计划-免费和付费。两者都可以满足用户的基本爬行或爬行需求。使用免费版本,您可以在本地运行任务
如果您将免费版本切换到付费版本,您可以通过将任务上载到云平台来使用基于云的服务。6到14台ECS将以更高的速度运行您的任务,并在更宽的范围内爬行。此外,您可以使用octoparse的匿名代理函数自动提取数据,而不留下任何痕迹。此功能可以依次使用大量IP,这可以防止您被网站@阻止。这是一个关于云提取的视频
Octoparse还提供API来实时将系统连接到爬网数据。您可以将octoparse数据导入自己的数据库,也可以使用API}请求访问您帐户的数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、txt和数据库(mysql、SQL server和Oracle)
进口
Import.io也称为web searcher,涵盖所有不同级别的搜索要求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果您需要获取更复杂的网站@,建议用户下载其桌面应用程序。构建API后,它们将提供许多简单的集成选项,如Google sheets、plot.ly、Excel以及get和post请求。当您认为所有这些都有终身免费的价格标签和强大的支持团队时,import.io无疑是寻找结构化数据的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项
本山达
Mozenda是另一个用户友好的web数据提取器。它为用户提供了一个点击式用户界面,无需任何编码技巧即可使用。Mozenda还消除了自动化和发布提取数据的麻烦。告诉mozenda您需要的数据一次,然后无论您需要多少次都可以得到它。此外,它允许使用RESTAPI进行高级编程,用户可以直接连接到mozenda帐户。它还提供基于云的服务和IP轮换
刮板架
SEO专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉scrapebox,它有一个非常友好的用户界面。用户可以轻松地从网站@采集数据,以获取电子邮件、检查页面排名、验证工作代理和RSS提交。通过使用数千个轮换代理,您将能够隐藏竞争对手的网站@关键字gov网站@进行研究、采集数据和评论,不被阻止或发现
GoogleWebScraper插件
如果人们只是想以简单的方式获取数据,建议您选择GoogleWebScraper插件。它是一个基于浏览器的网络爬虫,工作原理类似于Firefox的outwit hub。您可以将其作为扩展下载并安装到浏览器中。您需要突出显示要爬网的数据字段,右键单击并选择“类似刮擦…”。任何与突出显示的内容类似的内容都将呈现在准备导出的表中,并与Google文档兼容。最新版本的电子表格上仍有一些错误。虽然操作简单,但应该引起所有用户的注意,但它不能抓取图像和大量数据
查看全部
爬虫抓取网页数据(如何从网站爬网数据中获取结构化数据?()
)
原创来源:工作文本(从网站捕获数据的三种最佳方式)/网站@name(octoparse)
原创链接:从网站抓取数据的3种最佳方法
在过去几年中,对爬行数据的需求越来越大。爬网数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来网站@抓取数据的三种方法
1.use网站@API
许多大型社交媒体网站@,如Facebook、twitter、instagram和stackoverflow,都为用户访问其数据提供了API。有时,您可以选择官方API来获取结构化数据。如下面的Facebook graph API所示,您需要选择要查询的字段,然后排序数据、执行URL查找、发出请求等。有关更多信息,请参阅/docs/graph API/using graph API
2.构建自己的搜索引擎
然而,并非所有网站@都为用户提供API。一些网站@由于技术限制或其他原因拒绝提供任何公共API。有些人可能会建议RSS提要,但我不会对它们提出建议或评论,因为它们的使用是有限的。在这种情况下,我想讨论的是,我们可以构建自己的爬虫程序来处理这种情况
搜索者是如何工作的?换句话说,搜索者是一种生成URL列表的方法,这些URL可以由提取程序提供。您可以将搜索器定义为查找URL的工具。首先,为搜索者提供一个要启动的网页,该网页将跟随页面上的所有这些链接。然后,该过程将继续循环
然后我们可以继续建立自己的搜索引擎。众所周知,Python是一种开源编程语言,您可以找到许多有用的函数库。在这里,我推荐使用Beauty soup(Python库),因为它易于使用,并且具有许多直观的字符。相反,我将使用两个Python模块来抓取数据
Beautifulsoup无法为我们获取页面。这就是为什么我在美丽的汤库中使用urlib2。然后,我们需要处理HTML标记,以在正确的表中找到页面标记和所有链接。之后,遍历每一行(TR),然后将TR(TD)的每个元素分配给一个变量,并将其附加到列表中。首先,让我们看看表的HTML结构(我不会提取表标题的信息)
通过采用这种方法,您的搜索者是定制的。它可以处理API提取过程中遇到的一些困难。您可以使用代理来防止它被某些网站@等阻止。整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您获取的数据框应类似于下图
3.使用现有的爬虫工具
但是,通过编程自爬网网站@可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索工具
倍频程分析
Octoparse是一款基于可视窗口的强大web数据搜索工具。用户可以通过简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序
如下图所示,您可以在工作流设计器窗格中单击并拖动这些块来自定义自己的任务。Octoparse提供两个版本的爬网服务订阅计划-免费和付费。两者都可以满足用户的基本爬行或爬行需求。使用免费版本,您可以在本地运行任务
如果您将免费版本切换到付费版本,您可以通过将任务上载到云平台来使用基于云的服务。6到14台ECS将以更高的速度运行您的任务,并在更宽的范围内爬行。此外,您可以使用octoparse的匿名代理函数自动提取数据,而不留下任何痕迹。此功能可以依次使用大量IP,这可以防止您被网站@阻止。这是一个关于云提取的视频
Octoparse还提供API来实时将系统连接到爬网数据。您可以将octoparse数据导入自己的数据库,也可以使用API}请求访问您帐户的数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、txt和数据库(mysql、SQL server和Oracle)
进口
Import.io也称为web searcher,涵盖所有不同级别的搜索要求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果您需要获取更复杂的网站@,建议用户下载其桌面应用程序。构建API后,它们将提供许多简单的集成选项,如Google sheets、plot.ly、Excel以及get和post请求。当您认为所有这些都有终身免费的价格标签和强大的支持团队时,import.io无疑是寻找结构化数据的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项
本山达
Mozenda是另一个用户友好的web数据提取器。它为用户提供了一个点击式用户界面,无需任何编码技巧即可使用。Mozenda还消除了自动化和发布提取数据的麻烦。告诉mozenda您需要的数据一次,然后无论您需要多少次都可以得到它。此外,它允许使用RESTAPI进行高级编程,用户可以直接连接到mozenda帐户。它还提供基于云的服务和IP轮换
刮板架
SEO专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉scrapebox,它有一个非常友好的用户界面。用户可以轻松地从网站@采集数据,以获取电子邮件、检查页面排名、验证工作代理和RSS提交。通过使用数千个轮换代理,您将能够隐藏竞争对手的网站@关键字gov网站@进行研究、采集数据和评论,不被阻止或发现
GoogleWebScraper插件
如果人们只是想以简单的方式获取数据,建议您选择GoogleWebScraper插件。它是一个基于浏览器的网络爬虫,工作原理类似于Firefox的outwit hub。您可以将其作为扩展下载并安装到浏览器中。您需要突出显示要爬网的数据字段,右键单击并选择“类似刮擦…”。任何与突出显示的内容类似的内容都将呈现在准备导出的表中,并与Google文档兼容。最新版本的电子表格上仍有一些错误。虽然操作简单,但应该引起所有用户的注意,但它不能抓取图像和大量数据

爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 532 次浏览 • 2021-09-17 18:04
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下
抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):
本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:
马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它
捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行
观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行
生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]
切割和更换
继续切割、更换和固定
最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:
查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文
标准->;经典 查看全部
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下

抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):

本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:

马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它

捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行

观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行

生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]

切割和更换

继续切割、更换和固定

最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:

查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文

标准->;经典
爬虫抓取网页数据(一下爬虫如何获取网页数据?IP代理精灵为您介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-17 14:14
使用爬虫可以获取大量的Web信息,从而节省时间。如果只靠手动操作,时间会大大增加。现在,随着互联网用户数量的增加和大量的网络信息,如何抓取收录如此大量信息的数据?以下IP代理向导介绍爬虫程序如何获取网页数据
一、crawler如何获取web数据
1.输入网站,选择所需网页的一部分,并使用这些网页的链接地址作为种子URL
2.URL将其放入要爬网的URL队列中,爬网器依次从要爬网的URL队列中读取URL,通过DNS解析URL,并将链接地址转换为网站服务器对应的IP地址
3.将与网页相关的路径名提供给网页下载程序,该程序负责下载网页内容
4.将下载的网页存储在页面库中,等待后续处理,如索引;另一方面,将下载网页的URL放入爬网URL队列,该队列记录爬网器系统下载的网页URL,以避免网页重复爬网
5.对于新下载的网页,从中提取所有链接信息,并在已爬网的URL队列中进行检查。如果发现该链接尚未爬网,则将该URL放在要爬网的URL队列的末尾,在后续爬网调度中将下载该URL对应的网页
这样,就形成了一个循环,直到要获取的URL队列为空,这意味着爬虫系统已经获取了所有可以获取的网页。此时,完成了一轮完整的获取过程
二、爬行动物的常见类型是什么
大多数爬行动物都遵循这个过程,但这并不意味着所有的爬行动物都是如此一致。根据不同的应用,爬虫系统在许多方面有所不同。一般来说,爬虫可分为以下三种类型:
1.垂直爬行动物
垂直爬虫关注特定行业的特定主题内容或网页。例如,对于health网站,他们只需要从互联网页面中查找与健康相关的页面内容,而不考虑其他行业的内容。垂直爬虫最大的特点和困难之一是如何识别web内容是否属于特定的行业或主题。从节省系统资源的角度来看,下载后不太可能对所有互联网页面进行筛选。这种资源浪费太多了。为了节省资源,爬虫通常需要在捕获阶段动态识别网站是否与主题相关,并尽量不捕获不相关的页面。垂直搜索网站或垂直行业网站通常需要这种类型的爬虫程序
2.batch crawler
批处理爬虫具有相对清晰的捕获范围和目标。当爬虫到达设置的目标时,它将停止捕获过程。至于具体的目标,它们可能会有所不同,可能设置为爬网一定数量的网页,或者设置爬网所消耗的时间,等等
3.incremental crawler
与批处理爬虫不同,增量爬虫保持连续爬虫。捕获的网页应定期更新,因为Internet网页不断变化,新网页、网页被删除或网页内容更改很常见,而增量爬虫需要及时反映这些变化,因此它们处于不断爬网的过程中,要么抓取新网页,要么更新现有网页。一般的商业搜索引擎爬虫基本上属于这一类
上面描述了抓取数据的过程,可以清楚地了解爬虫是如何获取网页数据的。爬虫也分为不同的类型。不同的类型使用不同的方法,但需要注意的是,有些网络爬虫无法爬行,而且比例也很高。这部分网页构成了一个不可知的网页集合 查看全部
爬虫抓取网页数据(一下爬虫如何获取网页数据?IP代理精灵为您介绍)
使用爬虫可以获取大量的Web信息,从而节省时间。如果只靠手动操作,时间会大大增加。现在,随着互联网用户数量的增加和大量的网络信息,如何抓取收录如此大量信息的数据?以下IP代理向导介绍爬虫程序如何获取网页数据

一、crawler如何获取web数据
1.输入网站,选择所需网页的一部分,并使用这些网页的链接地址作为种子URL
2.URL将其放入要爬网的URL队列中,爬网器依次从要爬网的URL队列中读取URL,通过DNS解析URL,并将链接地址转换为网站服务器对应的IP地址
3.将与网页相关的路径名提供给网页下载程序,该程序负责下载网页内容
4.将下载的网页存储在页面库中,等待后续处理,如索引;另一方面,将下载网页的URL放入爬网URL队列,该队列记录爬网器系统下载的网页URL,以避免网页重复爬网
5.对于新下载的网页,从中提取所有链接信息,并在已爬网的URL队列中进行检查。如果发现该链接尚未爬网,则将该URL放在要爬网的URL队列的末尾,在后续爬网调度中将下载该URL对应的网页
这样,就形成了一个循环,直到要获取的URL队列为空,这意味着爬虫系统已经获取了所有可以获取的网页。此时,完成了一轮完整的获取过程
二、爬行动物的常见类型是什么
大多数爬行动物都遵循这个过程,但这并不意味着所有的爬行动物都是如此一致。根据不同的应用,爬虫系统在许多方面有所不同。一般来说,爬虫可分为以下三种类型:
1.垂直爬行动物
垂直爬虫关注特定行业的特定主题内容或网页。例如,对于health网站,他们只需要从互联网页面中查找与健康相关的页面内容,而不考虑其他行业的内容。垂直爬虫最大的特点和困难之一是如何识别web内容是否属于特定的行业或主题。从节省系统资源的角度来看,下载后不太可能对所有互联网页面进行筛选。这种资源浪费太多了。为了节省资源,爬虫通常需要在捕获阶段动态识别网站是否与主题相关,并尽量不捕获不相关的页面。垂直搜索网站或垂直行业网站通常需要这种类型的爬虫程序
2.batch crawler
批处理爬虫具有相对清晰的捕获范围和目标。当爬虫到达设置的目标时,它将停止捕获过程。至于具体的目标,它们可能会有所不同,可能设置为爬网一定数量的网页,或者设置爬网所消耗的时间,等等
3.incremental crawler
与批处理爬虫不同,增量爬虫保持连续爬虫。捕获的网页应定期更新,因为Internet网页不断变化,新网页、网页被删除或网页内容更改很常见,而增量爬虫需要及时反映这些变化,因此它们处于不断爬网的过程中,要么抓取新网页,要么更新现有网页。一般的商业搜索引擎爬虫基本上属于这一类
上面描述了抓取数据的过程,可以清楚地了解爬虫是如何获取网页数据的。爬虫也分为不同的类型。不同的类型使用不同的方法,但需要注意的是,有些网络爬虫无法爬行,而且比例也很高。这部分网页构成了一个不可知的网页集合
爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-17 09:22
引用别人的答案,希望对你有用
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。以下是爬虫和爬虫系统的简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子URL
2.将这些URL放入要获取的URL队列
3.从要获取的URL队列中获取要获取的URL,解析DNS,获取主机IP,下载URL对应的网页并存储在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4.分析已爬网URL队列中的URL,分析其他URL,将URL放入待爬网的URL队列中,进入下一个循环
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
1.下载的未过期页面
2.下载和过期网页:捕获的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。互联网上的一些内容发生了变化。此时,捕获的网页已过期
3.待下载网页:即URL队列中待抓取的网页
4.known web page:尚未捕获且不在要捕获的URL队列中,但可以通过分析捕获的页面或与要捕获的URL对应的页面来获得的URL被视为已知网页
5.还有一些网页不能被爬虫直接抓取和下载。它被称为不可知网页
三、grab策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
4.PartialPageRank策略
部分PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与要获取的URL队列中的URL一起,形成一个网页集合,计算每个页面的PageRank值,计算后根据PageRank值的大小排列要获取的URL队列中的URL,然后按这个顺序抓取页面
如果一次抓取一页,请重新计算PageRank值。折衷方案是每k页重新计算PageRank值。但是,在这种情况下会有一个问题:对于下载页面中分析的链接,即前面提到的未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面提供一个临时的PageRank值:汇总该页面链中传递的所有PageRank值,从而形成未知页面的PageRank值,从而参与排序。以下是一个例子:
5.OPIC战略战略
事实上,该算法还对页面的重要性进行评分。在算法开始之前,为所有页面提供相同的初始现金(cash)。下载页面P后,将P的现金分配给从P分析的所有链接,并清空P的现金。URL队列中要提取的所有页面都按现金金额排序
6.大站优先战略
要获取的URL队列中的所有网页都根据它们所属的网站进行分类。对于需要下载大量页面的网站而言,应优先考虑下载。这种策略也称为大站优先策略 查看全部
爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
引用别人的答案,希望对你有用
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。以下是爬虫和爬虫系统的简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子URL
2.将这些URL放入要获取的URL队列
3.从要获取的URL队列中获取要获取的URL,解析DNS,获取主机IP,下载URL对应的网页并存储在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4.分析已爬网URL队列中的URL,分析其他URL,将URL放入待爬网的URL队列中,进入下一个循环
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
1.下载的未过期页面
2.下载和过期网页:捕获的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。互联网上的一些内容发生了变化。此时,捕获的网页已过期
3.待下载网页:即URL队列中待抓取的网页
4.known web page:尚未捕获且不在要捕获的URL队列中,但可以通过分析捕获的页面或与要捕获的URL对应的页面来获得的URL被视为已知网页
5.还有一些网页不能被爬虫直接抓取和下载。它被称为不可知网页
三、grab策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
4.PartialPageRank策略
部分PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与要获取的URL队列中的URL一起,形成一个网页集合,计算每个页面的PageRank值,计算后根据PageRank值的大小排列要获取的URL队列中的URL,然后按这个顺序抓取页面
如果一次抓取一页,请重新计算PageRank值。折衷方案是每k页重新计算PageRank值。但是,在这种情况下会有一个问题:对于下载页面中分析的链接,即前面提到的未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面提供一个临时的PageRank值:汇总该页面链中传递的所有PageRank值,从而形成未知页面的PageRank值,从而参与排序。以下是一个例子:
5.OPIC战略战略
事实上,该算法还对页面的重要性进行评分。在算法开始之前,为所有页面提供相同的初始现金(cash)。下载页面P后,将P的现金分配给从P分析的所有链接,并清空P的现金。URL队列中要提取的所有页面都按现金金额排序
6.大站优先战略
要获取的URL队列中的所有网页都根据它们所属的网站进行分类。对于需要下载大量页面的网站而言,应优先考虑下载。这种策略也称为大站优先策略
爬虫抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-17 09:19
我们可以把互联网比作一个大网络,而爬虫(即网络爬虫)就是在互联网上爬行的蜘蛛。通过比较web节点和web页面,爬虫会爬到该页面,这相当于访问该页面并获取其信息。节点之间的连接可以比作网页之间的链接关系。这样,爬行器通过一个节点后,可以继续沿着节点连接爬行到下一个节点,也就是说,可以继续通过一个网页获取后续的网页,这样爬行器就可以对整个网络的节点进行爬行,并捕获网站数据
1.爬行动物概述
简而言之,crawler是一个自动获取网页、提取和保存信息的程序。以下是概述
(1)get网页)
爬虫应该做的第一件事是获取网页。以下是该网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息
我们在前面讨论了请求和响应的概念。当您向网站server发送请求时,返回的响应主体是网页源代码。因此,最关键的部分是构造一个请求并将其发送到服务器,然后接收响应并解析它。如何实施这一过程?您无法手动截取网页源代码
不用担心,python提供了许多库来帮助我们实现此操作,例如urllib、请求等。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。得到响应后,只需解析数据结构的主体部分即可得到网页的源代码,这样就可以用程序实现获取网页的过程
(2)提取信息)
获得网页源代码后,下一步是分析网页源代码并提取所需的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但在构造正则表达式时非常复杂且容易出错
此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如beautiful soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、,文本值等
信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
(3)save data)
在提取信息之后,我们通常将提取的数据保存在某个地方以供后续使用。有很多方法可以保存它,例如简单地将其保存为TXT文本或JSON文本,将其保存到数据库(如MySQL和mongodb),或将其保存到远程服务器(如使用SFTP操作)
(4)automated program)
说到自动化程序,这意味着爬虫程序可以代替人来完成这些操作。首先,我们可以手动提取这些信息,但如果等价物非常大,或者您想要快速获取大量数据,则必须使用程序。爬虫程序是代替我们完成爬虫工作的自动化程序,它可以执行爬虫过程处理、错误重试等操作中的各种异常,以确保爬虫的持续高效运行
2.可以捕获什么样的数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码
此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便
此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中
此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
事实上,上述内容对应于各自的URL,并且基于HTTP或HTTPS协议。只要是这样的数据,爬虫就可以抓取它
3.JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同
这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
This is a Demo
body节点中只有一个ID为container的节点,但需要注意的是app.js是在body节点之后引入的,它负责整个网站的渲染@
在浏览器中打开此页面时,将首先加载HTML内容,然后浏览器将发现其中引入了app.js文件,然后它将请求此文件。获取文件后,将执行JavaScript代码,JavaScript将更改HTML中的节点,向其中添加内容,最后获得完整的页面
但是,当使用库(如urllib或requests)请求当前页面时,我们得到的只是HTML代码,这不会帮助我们继续加载JavaScript文件,因此我们无法在浏览器中看到内容
这也解释了为什么有时我们会从浏览器中看到不同的源代码
因此,使用基本HTTP请求库获得的源代码可能与浏览器中的页面源代码不同。在本例中,我们可以分析其背景Ajax接口,或者使用selenium和splash等库来模拟JavaScript呈现
稍后,我们将介绍如何采集JavaScript呈现网页
本节介绍了爬虫的一些基本原理,这些原理可以帮助我们以后更轻松地编写爬虫
本资源来源于崔庆才的个人博客《精米:Python 3网络爬虫开发实用教程》|精米 查看全部
爬虫抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
我们可以把互联网比作一个大网络,而爬虫(即网络爬虫)就是在互联网上爬行的蜘蛛。通过比较web节点和web页面,爬虫会爬到该页面,这相当于访问该页面并获取其信息。节点之间的连接可以比作网页之间的链接关系。这样,爬行器通过一个节点后,可以继续沿着节点连接爬行到下一个节点,也就是说,可以继续通过一个网页获取后续的网页,这样爬行器就可以对整个网络的节点进行爬行,并捕获网站数据
1.爬行动物概述
简而言之,crawler是一个自动获取网页、提取和保存信息的程序。以下是概述
(1)get网页)
爬虫应该做的第一件事是获取网页。以下是该网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息
我们在前面讨论了请求和响应的概念。当您向网站server发送请求时,返回的响应主体是网页源代码。因此,最关键的部分是构造一个请求并将其发送到服务器,然后接收响应并解析它。如何实施这一过程?您无法手动截取网页源代码
不用担心,python提供了许多库来帮助我们实现此操作,例如urllib、请求等。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。得到响应后,只需解析数据结构的主体部分即可得到网页的源代码,这样就可以用程序实现获取网页的过程
(2)提取信息)
获得网页源代码后,下一步是分析网页源代码并提取所需的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但在构造正则表达式时非常复杂且容易出错
此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如beautiful soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、,文本值等
信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
(3)save data)
在提取信息之后,我们通常将提取的数据保存在某个地方以供后续使用。有很多方法可以保存它,例如简单地将其保存为TXT文本或JSON文本,将其保存到数据库(如MySQL和mongodb),或将其保存到远程服务器(如使用SFTP操作)
(4)automated program)
说到自动化程序,这意味着爬虫程序可以代替人来完成这些操作。首先,我们可以手动提取这些信息,但如果等价物非常大,或者您想要快速获取大量数据,则必须使用程序。爬虫程序是代替我们完成爬虫工作的自动化程序,它可以执行爬虫过程处理、错误重试等操作中的各种异常,以确保爬虫的持续高效运行
2.可以捕获什么样的数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码
此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便
此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中
此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
事实上,上述内容对应于各自的URL,并且基于HTTP或HTTPS协议。只要是这样的数据,爬虫就可以抓取它
3.JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同
这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
This is a Demo
body节点中只有一个ID为container的节点,但需要注意的是app.js是在body节点之后引入的,它负责整个网站的渲染@
在浏览器中打开此页面时,将首先加载HTML内容,然后浏览器将发现其中引入了app.js文件,然后它将请求此文件。获取文件后,将执行JavaScript代码,JavaScript将更改HTML中的节点,向其中添加内容,最后获得完整的页面
但是,当使用库(如urllib或requests)请求当前页面时,我们得到的只是HTML代码,这不会帮助我们继续加载JavaScript文件,因此我们无法在浏览器中看到内容
这也解释了为什么有时我们会从浏览器中看到不同的源代码
因此,使用基本HTTP请求库获得的源代码可能与浏览器中的页面源代码不同。在本例中,我们可以分析其背景Ajax接口,或者使用selenium和splash等库来模拟JavaScript呈现
稍后,我们将介绍如何采集JavaScript呈现网页
本节介绍了爬虫的一些基本原理,这些原理可以帮助我们以后更轻松地编写爬虫
本资源来源于崔庆才的个人博客《精米:Python 3网络爬虫开发实用教程》|精米
爬虫抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-17 09:17
网络爬虫与网络爬虫
在当今时代,基于数据做出业务决策是许多公司的头等大事。为了推动这些决策,该公司24小时跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量公共数据,这有助于企业在竞争激烈的市场中保持领先地位
许多公司出于商业目的从各种网站中提取数据是很常见的。但是,在获取数据后,手动提取操作无法轻松快速地将数据应用到日常工作中。因此,在本文中,little oxy将向您介绍网络数据提取的方法和需要面对的困难,并向您介绍几种可以帮助您更好地抓取数据的解决方案
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂和难以理解的事情。然而,理解整个过程并不那么复杂
网站提取数据的过程称为网络爬网,有时称为网络采集。该术语通常指使用机器人或网络爬虫自动提取数据的过程。有时,网络爬行的概念很容易与网络爬行的概念混淆。因此,在上一篇文章文章中,我们介绍了web爬行和web爬行之间的主要区别
今天,让我们讨论数据提取的整个过程,以充分了解数据提取的工作原理
数据提取的工作原理
今天,我们获取的数据主要由HTML表示,HTML是一种基于文本的标记语言。它通过各种组件定义网站内容结构,包括
,等等。开发人员可以使用脚本从任何形式的数据结构中提取数据
构建数据提取脚本
这一切都是从构建数据提取脚本开始的。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的刮板机器人。Python的优势,如多样的库、简单性和活跃的社区,使其成为编写web爬网脚本的最流行编程语言。这些脚本支持完全自动化的数据提取。它们向服务器发送请求,访问选定的URL,并遍历每个先前定义的页面、HTML标记和组件。然后,从这些地方提取数据
开发各种数据爬行模式
可以个性化开发数据提取脚本,并且只能从特定的HTML组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这还将减轻服务器的负担,减少存储空间需求,并使数据处理更容易
设置服务器环境
要连续运行网络爬虫,您需要一台服务器。因此,下一步是投资于服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周7天、每天24小时运行数据提取脚本,并简化数据记录和存储
确保有足够的存储空间
数据提取脚本的交付是数据。大规模数据需要大的存储容量。从多个网站页面提取的数据可以转换成数千个网页。由于过程是连续的,最终会获得大量的数据。确保有足够的存储空间来维护爬网操作非常重要
数据处理
采集数据以其原创形式出现,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分
数据提取工具
有很多方法可以从网页中提取公共数据—构建内部工具或使用现成的web捕获解决方案,如Oxylab real-time crawler
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源团队,那么构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎都不想公开他们的数据,并且已经建立了检测机器人行为的算法,这使得爬行更具挑战性
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型
2.找到数据的显示位置并构建抓取路径
3.导入并安装所需的必备环境
4.编写一个数据提取脚本并实现它
为了避免IP阻塞,模仿普通互联网用户的行为非常重要。这是代理需要干预的地方,这使得所有数据采集任务都更容易。我们将在以下内容中继续讨论
实时爬虫
实时爬虫等工具的主要优点之一是,它可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间
内部解决方案必须通过试错来创造解决方案,这意味着不可避免的效率降低、IP地址阻塞和不可靠的定价数据流。使用实时抓取工具,整个过程完全自动化。您的员工可以专注于更紧急的事项,直接进行数据分析,而不是无休止地复制和粘贴
网络数据提取的好处
大数据是商界的一个新词。它涵盖了许多面向目标的数据采集过程——获得有意义的见解、确定趋势和模式以及预测经济状况。例如,在线获取房地产数据有助于分析哪些因素会影响该行业。同样,从汽车行业获取数据也很有用。公司采集有关汽车行业的数据,如用户和汽车零部件评论
各行各业的公司从网站提取数据,以更新数据的相关性和实时性。其他网站也将这样做,以确保数据集的完整性。数据越多越好,可以提供更多的参考,使整个数据集更加有效
企业想要提取哪些数据
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素
您可能会对许多数据目标感兴趣。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等。您还可以自定义数据提取脚本以查找新产品和服务。只需确保在执行任何爬网活动之前,爬网公共数据不会侵犯任何第三方的权利
常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:
数据捕获的最佳实践
为了解决上述问题,我们可以通过由经验丰富的专业人员开发的复杂数据提取脚本来解决这些问题。然而,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案——代理。更具体地说,IP代理
IP轮换代理将允许您访问大量IP地址。从位于不同地理区域的IP发送请求将欺骗服务器并防止阻塞。或者,可以使用代理旋转。代理旋转器将使用代理数据中心池中的IP,并自动分配它们,而不是手动分配IP
如果你没有足够的资源和经验丰富的开发团队来进行网络爬行,现在是考虑使用现成的解决方案的时候了,比如实时爬虫。它确保了搜索引擎和电子商务的访问网站100%完成捕获任务,简化数据管理并汇总数据,以便您能够轻松理解
从网站提取数据合法吗@
许多企业依赖大数据,其需求显著增加。根据statista的研究统计,大数据市场每年都在快速增长,预计到2027年将达到1030亿美元。这使得越来越多的企业将网络爬网作为最常用的数据采集方法之一。这种流行引发了一个广泛讨论的问题,即网络爬网是否合法
由于这个复杂的问题没有明确的答案,因此有必要确保要执行的任何网络捕获操作都不会违反相关法律。更重要的是,在获取任何数据之前,我们强烈建议根据具体情况寻求专业法律意见
此外,我们强烈建议您不要捕获任何非公共数据,除非您获得目标网站的明确许可@
Little oxy提醒您,本文中的任何内容都不应被解释为捕获任何非公开数据的建议
结论
总之,您需要一个数据提取脚本来从中提取数据网站. 正如您所看到的,由于操作范围、复杂性和网站结构的变化,构建这些脚本可能具有挑战性。然而,即使有一个好的脚本,如果您想在长时间内实时捕获数据而不被阻止,您仍然需要使用旋转代理来更改您的IP
如果您认为您的企业需要一个多功能的解决方案来简化数据提取,那么现在就可以注册并开始使用Oxylab的实时爬虫
如果您有任何问题,请随时与我们联系 查看全部
爬虫抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网络爬虫与网络爬虫

在当今时代,基于数据做出业务决策是许多公司的头等大事。为了推动这些决策,该公司24小时跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量公共数据,这有助于企业在竞争激烈的市场中保持领先地位
许多公司出于商业目的从各种网站中提取数据是很常见的。但是,在获取数据后,手动提取操作无法轻松快速地将数据应用到日常工作中。因此,在本文中,little oxy将向您介绍网络数据提取的方法和需要面对的困难,并向您介绍几种可以帮助您更好地抓取数据的解决方案
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂和难以理解的事情。然而,理解整个过程并不那么复杂
网站提取数据的过程称为网络爬网,有时称为网络采集。该术语通常指使用机器人或网络爬虫自动提取数据的过程。有时,网络爬行的概念很容易与网络爬行的概念混淆。因此,在上一篇文章文章中,我们介绍了web爬行和web爬行之间的主要区别
今天,让我们讨论数据提取的整个过程,以充分了解数据提取的工作原理
数据提取的工作原理
今天,我们获取的数据主要由HTML表示,HTML是一种基于文本的标记语言。它通过各种组件定义网站内容结构,包括
,等等。开发人员可以使用脚本从任何形式的数据结构中提取数据

构建数据提取脚本
这一切都是从构建数据提取脚本开始的。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的刮板机器人。Python的优势,如多样的库、简单性和活跃的社区,使其成为编写web爬网脚本的最流行编程语言。这些脚本支持完全自动化的数据提取。它们向服务器发送请求,访问选定的URL,并遍历每个先前定义的页面、HTML标记和组件。然后,从这些地方提取数据
开发各种数据爬行模式
可以个性化开发数据提取脚本,并且只能从特定的HTML组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这还将减轻服务器的负担,减少存储空间需求,并使数据处理更容易
设置服务器环境
要连续运行网络爬虫,您需要一台服务器。因此,下一步是投资于服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周7天、每天24小时运行数据提取脚本,并简化数据记录和存储
确保有足够的存储空间
数据提取脚本的交付是数据。大规模数据需要大的存储容量。从多个网站页面提取的数据可以转换成数千个网页。由于过程是连续的,最终会获得大量的数据。确保有足够的存储空间来维护爬网操作非常重要
数据处理
采集数据以其原创形式出现,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分
数据提取工具
有很多方法可以从网页中提取公共数据—构建内部工具或使用现成的web捕获解决方案,如Oxylab real-time crawler
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源团队,那么构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎都不想公开他们的数据,并且已经建立了检测机器人行为的算法,这使得爬行更具挑战性
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型
2.找到数据的显示位置并构建抓取路径
3.导入并安装所需的必备环境
4.编写一个数据提取脚本并实现它
为了避免IP阻塞,模仿普通互联网用户的行为非常重要。这是代理需要干预的地方,这使得所有数据采集任务都更容易。我们将在以下内容中继续讨论
实时爬虫
实时爬虫等工具的主要优点之一是,它可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间
内部解决方案必须通过试错来创造解决方案,这意味着不可避免的效率降低、IP地址阻塞和不可靠的定价数据流。使用实时抓取工具,整个过程完全自动化。您的员工可以专注于更紧急的事项,直接进行数据分析,而不是无休止地复制和粘贴
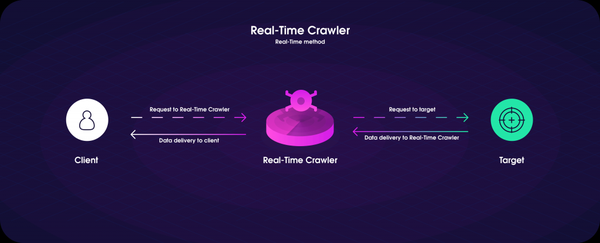
网络数据提取的好处
大数据是商界的一个新词。它涵盖了许多面向目标的数据采集过程——获得有意义的见解、确定趋势和模式以及预测经济状况。例如,在线获取房地产数据有助于分析哪些因素会影响该行业。同样,从汽车行业获取数据也很有用。公司采集有关汽车行业的数据,如用户和汽车零部件评论
各行各业的公司从网站提取数据,以更新数据的相关性和实时性。其他网站也将这样做,以确保数据集的完整性。数据越多越好,可以提供更多的参考,使整个数据集更加有效
企业想要提取哪些数据
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素
您可能会对许多数据目标感兴趣。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等。您还可以自定义数据提取脚本以查找新产品和服务。只需确保在执行任何爬网活动之前,爬网公共数据不会侵犯任何第三方的权利

常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:

数据捕获的最佳实践
为了解决上述问题,我们可以通过由经验丰富的专业人员开发的复杂数据提取脚本来解决这些问题。然而,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案——代理。更具体地说,IP代理
IP轮换代理将允许您访问大量IP地址。从位于不同地理区域的IP发送请求将欺骗服务器并防止阻塞。或者,可以使用代理旋转。代理旋转器将使用代理数据中心池中的IP,并自动分配它们,而不是手动分配IP
如果你没有足够的资源和经验丰富的开发团队来进行网络爬行,现在是考虑使用现成的解决方案的时候了,比如实时爬虫。它确保了搜索引擎和电子商务的访问网站100%完成捕获任务,简化数据管理并汇总数据,以便您能够轻松理解
从网站提取数据合法吗@
许多企业依赖大数据,其需求显著增加。根据statista的研究统计,大数据市场每年都在快速增长,预计到2027年将达到1030亿美元。这使得越来越多的企业将网络爬网作为最常用的数据采集方法之一。这种流行引发了一个广泛讨论的问题,即网络爬网是否合法
由于这个复杂的问题没有明确的答案,因此有必要确保要执行的任何网络捕获操作都不会违反相关法律。更重要的是,在获取任何数据之前,我们强烈建议根据具体情况寻求专业法律意见
此外,我们强烈建议您不要捕获任何非公共数据,除非您获得目标网站的明确许可@
Little oxy提醒您,本文中的任何内容都不应被解释为捕获任何非公开数据的建议
结论
总之,您需要一个数据提取脚本来从中提取数据网站. 正如您所看到的,由于操作范围、复杂性和网站结构的变化,构建这些脚本可能具有挑战性。然而,即使有一个好的脚本,如果您想在长时间内实时捕获数据而不被阻止,您仍然需要使用旋转代理来更改您的IP
如果您认为您的企业需要一个多功能的解决方案来简化数据提取,那么现在就可以注册并开始使用Oxylab的实时爬虫
如果您有任何问题,请随时与我们联系
爬虫抓取网页数据(爬虫抓取网页数据的三个文件,你可以只需要一台python3.5)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-16 13:07
爬虫抓取网页数据,是不是必须有合适的机器才能抓取呢?是的,抓取网页数据基本上需要用到服务器。不过,使用本篇文章的环境搭建方法,你可以只需要一台python3.5,就可以实现抓取网页。以上图为例,我们以动态网页的抓取为例,演示安装和配置所需要的一些系统环境。首先,打开python的文件夹,你可以看到动态网页抓取的三个文件:loadserver.pyps:loadserver.py是静态网页抓取用的,支持python3和python2.7。
爬虫服务器方法:global=""配置文件,cp=5001/python37750/3.5/scrapy10.cmd需要global=""设置的是scrapy默认爬取下来的内容的global变量。我们可以调用这个global变量,来控制scrapy需要抓取的单元内容。配置http_url_txt="-"配置http_url_txt文件,需要在一个文件内增加两行,content="phantomjs"app_urls=["/","="]app_url_txt=content+"/".format(app_urls.format())withscrapy.session()assession:scrapy.session.save(url_txt,http_url_txt)scrapy.session.reload(session)defspeed(item):item.set_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/51.0.3039.121safari/537.36")scrapy.session.connect("",process_scrapy_on_message="connectto",url_txt,http_url_txt)scrapy.session.autoscroll("",item.page_bytes())scrapy.session.use_random()defurl(item):url_txt="",and"path_by"=item.paths["index.php"]["index"]["full_page"]["show_rel"]["content"]["title"]["category"]scrapy.session.save(url_txt,url_txt,http_url_txt)returnurl_txt将#url_txt配置为本地,可直接调用!#loadserver.py配置为局域网环境,防止主机名被封。如果您要做的是全局爬取网页而不是爬取独立服务器上的某个网页,请使用局域网环境。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据的三个文件,你可以只需要一台python3.5)
爬虫抓取网页数据,是不是必须有合适的机器才能抓取呢?是的,抓取网页数据基本上需要用到服务器。不过,使用本篇文章的环境搭建方法,你可以只需要一台python3.5,就可以实现抓取网页。以上图为例,我们以动态网页的抓取为例,演示安装和配置所需要的一些系统环境。首先,打开python的文件夹,你可以看到动态网页抓取的三个文件:loadserver.pyps:loadserver.py是静态网页抓取用的,支持python3和python2.7。
爬虫服务器方法:global=""配置文件,cp=5001/python37750/3.5/scrapy10.cmd需要global=""设置的是scrapy默认爬取下来的内容的global变量。我们可以调用这个global变量,来控制scrapy需要抓取的单元内容。配置http_url_txt="-"配置http_url_txt文件,需要在一个文件内增加两行,content="phantomjs"app_urls=["/","="]app_url_txt=content+"/".format(app_urls.format())withscrapy.session()assession:scrapy.session.save(url_txt,http_url_txt)scrapy.session.reload(session)defspeed(item):item.set_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/51.0.3039.121safari/537.36")scrapy.session.connect("",process_scrapy_on_message="connectto",url_txt,http_url_txt)scrapy.session.autoscroll("",item.page_bytes())scrapy.session.use_random()defurl(item):url_txt="",and"path_by"=item.paths["index.php"]["index"]["full_page"]["show_rel"]["content"]["title"]["category"]scrapy.session.save(url_txt,url_txt,http_url_txt)returnurl_txt将#url_txt配置为本地,可直接调用!#loadserver.py配置为局域网环境,防止主机名被封。如果您要做的是全局爬取网页而不是爬取独立服务器上的某个网页,请使用局域网环境。
爬虫抓取网页数据(文中介绍的非常详细,具有一定的参考价值们一定要看完!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-16 09:01
本文文章主要介绍如何在Python crawler中捕获著名的引号网站。它非常详细,具有一定的参考价值。有兴趣的朋友一定要读
1、输入网址
/,转到网站主页,观察网页的结构。我们发现网页的内容非常清晰
它主要分为名人名言、作者和标签三个主要字段,三个字段的内容都是提取的内容
2、确定需求并分析网页结构
打开开发者工具并单击networ进行网络数据包捕获分析,网站是一个不带参数的get请求。然后我们可以使用请求库中的get()方法来模拟请求。我们需要引入headers请求来模拟浏览器信息验证,以防止网站服务器将其检测为爬虫请求
您还可以单击开发人员工具的左箭头,帮助我们在“元素”选项卡上快速找到网页数据的位置
3、分析网页结构并提取数据
请求成功后,可以开始提取数据~。我使用XPath的解析方法。因此,首先解析XPath页面并单击左侧的小箭头以帮助我们快速定位数据。网页数据位于“元素”选项卡上。因为网页的请求数据在列表中逐项排序,所以我们可以首先找到整个列表的数据。在LXM中,HTML解析器将字段逐个抓取并保存到列表中,这便于下一步的数据清理
4、保存到CSV文件 查看全部
爬虫抓取网页数据(文中介绍的非常详细,具有一定的参考价值们一定要看完!)
本文文章主要介绍如何在Python crawler中捕获著名的引号网站。它非常详细,具有一定的参考价值。有兴趣的朋友一定要读
1、输入网址
/,转到网站主页,观察网页的结构。我们发现网页的内容非常清晰
它主要分为名人名言、作者和标签三个主要字段,三个字段的内容都是提取的内容
2、确定需求并分析网页结构
打开开发者工具并单击networ进行网络数据包捕获分析,网站是一个不带参数的get请求。然后我们可以使用请求库中的get()方法来模拟请求。我们需要引入headers请求来模拟浏览器信息验证,以防止网站服务器将其检测为爬虫请求
您还可以单击开发人员工具的左箭头,帮助我们在“元素”选项卡上快速找到网页数据的位置
3、分析网页结构并提取数据
请求成功后,可以开始提取数据~。我使用XPath的解析方法。因此,首先解析XPath页面并单击左侧的小箭头以帮助我们快速定位数据。网页数据位于“元素”选项卡上。因为网页的请求数据在列表中逐项排序,所以我们可以首先找到整个列表的数据。在LXM中,HTML解析器将字段逐个抓取并保存到列表中,这便于下一步的数据清理
4、保存到CSV文件
爬虫抓取网页数据(大数据从业工作者Import.io网页数据抽取工具一览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-09-14 15:02
作为大数据从业者和研究人员,很多时候需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网页数据提取工具来实现这个目的。接下来小编就为大家盘点七种常用的网络数据提取工具。
1.Import.io
这个工具是一个不需要客户端的爬虫工具。一切都可以在浏览器中完成。操作方便简单。抓取数据后,可以在可视化界面进行过滤。
2.Parsehub
此工具需要下载客户端才能运行。该工具打开后,类似于浏览器。输入网址后,就可以提取数据了。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
本工具是一款基于Chrome浏览器的插件,可直接通过谷歌应用商店免费获取安装。可以轻松抓取静态网页,用js动态加载网页。
想进一步了解这个工具的使用方法,可以参考下面的教程:对于爬虫问题,这个就够了
4. 80legs
该工具的背后是一个由 50,000 台计算机组成的 Plura 网格。它功能强大,但更适合企业级客户。商业用途明显,监控能力强,价格相对较贵。
5.优采云采集器
该工具是目前国内最成熟的网页数据采集工具。需要下载客户端,可以在客户端抓取可视化数据。该工具还有国际版的 Octoparse 软件。根据采集能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。价格从每年0元到69800元不等。虽然免费版可以免费采集,但数据导出需要额外收费。
6.早熟
这是一款面向起步较晚但爬取效率高的企业的基于网络的云爬取工具。无需额外下载客户端。
7.优采云采集器
这是中国老牌的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。收费方式为软件收费,旗舰版售价1000元左右,付款后不限。 查看全部
爬虫抓取网页数据(大数据从业工作者Import.io网页数据抽取工具一览)
作为大数据从业者和研究人员,很多时候需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网页数据提取工具来实现这个目的。接下来小编就为大家盘点七种常用的网络数据提取工具。
1.Import.io
这个工具是一个不需要客户端的爬虫工具。一切都可以在浏览器中完成。操作方便简单。抓取数据后,可以在可视化界面进行过滤。
2.Parsehub
此工具需要下载客户端才能运行。该工具打开后,类似于浏览器。输入网址后,就可以提取数据了。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
本工具是一款基于Chrome浏览器的插件,可直接通过谷歌应用商店免费获取安装。可以轻松抓取静态网页,用js动态加载网页。
想进一步了解这个工具的使用方法,可以参考下面的教程:对于爬虫问题,这个就够了
4. 80legs
该工具的背后是一个由 50,000 台计算机组成的 Plura 网格。它功能强大,但更适合企业级客户。商业用途明显,监控能力强,价格相对较贵。
5.优采云采集器

该工具是目前国内最成熟的网页数据采集工具。需要下载客户端,可以在客户端抓取可视化数据。该工具还有国际版的 Octoparse 软件。根据采集能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。价格从每年0元到69800元不等。虽然免费版可以免费采集,但数据导出需要额外收费。
6.早熟

这是一款面向起步较晚但爬取效率高的企业的基于网络的云爬取工具。无需额外下载客户端。
7.优采云采集器

这是中国老牌的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。收费方式为软件收费,旗舰版售价1000元左右,付款后不限。
爬虫抓取网页数据(蜘蛛访问网站页面的程序被称为蜘蛛(spider)蜘蛛搜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-26 12:18
本文内容:
带领
本文摘要
这篇文章的标题
文字内容
结束语
带领:
可能你最近也在找这类的相关内容吧?为了整理这篇内容,特意和公司周围的朋友同事交流了很久……我也查了网上很多资料,总结了一些关于蜘蛛搜索的相关知识点(搜索引擎蜘蛛是怎么工作的) ,希望通过《蜘蛛搜索(搜索引擎蜘蛛是如何工作的)》的介绍,对大家有所帮助,一起来看看吧!
本文摘要:
“搜索引擎用来抓取和访问页面的程序叫做蜘蛛蜘蛛搜索,或者bot。搜索引擎蜘蛛在访问网站页面时,类似于普通用户使用浏览器,蜘蛛程序发出后页面访问请求,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。 网站 ,首先会访问网站根目录下的robots.txt文件,如果robots.txt文件被搜索引擎禁止...
本文标题:蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)正文内容:
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。从目前公布的数据来看,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过某种方式抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(如Web2.0 数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并放入已访问地址数据库中,所以建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行,都会存储页面数据。如果第二次抓取时这个页面的内容和第一个收录完全一样,
结束语:
以上是一些关于蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)的相关内容以及围绕这类内容的一些相关知识点。希望介绍对大家有帮助!后续我们会更新更多相关资讯,关注我们,每天了解最新热点,关注社会动态! 查看全部
爬虫抓取网页数据(蜘蛛访问网站页面的程序被称为蜘蛛(spider)蜘蛛搜)
本文内容:
带领
本文摘要
这篇文章的标题
文字内容
结束语
带领:
可能你最近也在找这类的相关内容吧?为了整理这篇内容,特意和公司周围的朋友同事交流了很久……我也查了网上很多资料,总结了一些关于蜘蛛搜索的相关知识点(搜索引擎蜘蛛是怎么工作的) ,希望通过《蜘蛛搜索(搜索引擎蜘蛛是如何工作的)》的介绍,对大家有所帮助,一起来看看吧!
本文摘要:
“搜索引擎用来抓取和访问页面的程序叫做蜘蛛蜘蛛搜索,或者bot。搜索引擎蜘蛛在访问网站页面时,类似于普通用户使用浏览器,蜘蛛程序发出后页面访问请求,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。 网站 ,首先会访问网站根目录下的robots.txt文件,如果robots.txt文件被搜索引擎禁止...
本文标题:蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)正文内容:
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。从目前公布的数据来看,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过某种方式抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(如Web2.0 数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并放入已访问地址数据库中,所以建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行,都会存储页面数据。如果第二次抓取时这个页面的内容和第一个收录完全一样,
结束语:
以上是一些关于蜘蛛搜索(搜索引擎爬虫蜘蛛是如何工作的)的相关内容以及围绕这类内容的一些相关知识点。希望介绍对大家有帮助!后续我们会更新更多相关资讯,关注我们,每天了解最新热点,关注社会动态!
爬虫抓取网页数据(网页爬虫WebScraper现代网络的网络数据提取工具介绍!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-26 12:16
Web Scraper Web Scraper 是 chrome 上的爬虫工具。它可以作为插件在网页上使用,并且可以以更便携的方式在任何网页中使用。插件可以满足你对网站的爬虫需求,功能非常多,需要有一定的基础才能正常使用,有需要就来下载网络爬虫Web Scraper吧!
网络爬虫
现代网络的网络数据提取工具,具有简单的点击界面
免费易用的网页数据提取工具,适合所有人使用。
通过简单的点击界面,只需几分钟的scraper设置,就可以从一个网站中提取数千条记录。
Web Scraper 采用由选择器组成的模块化结构,这些选择器指示刮板如何遍历目标 网站 以及要提取的数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)和鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,无需在您的计算机上安装任何东西。您不需要 Python、PHP 或 JavaScript 编码经验即可开始提取。此外,数据提取可以在 Web Scraper Cloud 中完全自动化。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 Excel、Google Sheets 等。
软件特点
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
* 浏览搜索到的数据。
*将搜索到的数据从网站导出到Excel。
它只依赖于网络浏览器;因此,您无需附加软件即可开始搜索。
如何使用
为了掌握网络搜索技术,您只需要学习几个步骤。
1. 安装扩展并打开开发者工具中的网页抓取标签(必须放置在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 向 网站 地图添加数据提取选择器。
4. 最后,启动搜索器并导出搜索到的数据。
就是这么简单!
使用场景
* 潜在客户开发 - 电子邮件、电话号码和其他与联系方式相关的数据是从各种 网站 中挖掘出来的。
* 电子商务-产品数据提取、产品价格搜索、描述、URL提取、图片检索等。
* 网站内容爬取——从新闻门户、博客、论坛等中提取信息。
* 零售监控——监控产品性能、竞争对手或供应商的库存和价格等。
* 品牌监控-产品评论、用于情感分析的社交内容捕获。
* 商业智能——为关键业务决策采集数据并向竞争对手学习。
* 大数据提取用于机器学习、营销、业务战略制定和研究。
* 还有更多。 查看全部
爬虫抓取网页数据(网页爬虫WebScraper现代网络的网络数据提取工具介绍!)
Web Scraper Web Scraper 是 chrome 上的爬虫工具。它可以作为插件在网页上使用,并且可以以更便携的方式在任何网页中使用。插件可以满足你对网站的爬虫需求,功能非常多,需要有一定的基础才能正常使用,有需要就来下载网络爬虫Web Scraper吧!
网络爬虫
现代网络的网络数据提取工具,具有简单的点击界面
免费易用的网页数据提取工具,适合所有人使用。
通过简单的点击界面,只需几分钟的scraper设置,就可以从一个网站中提取数千条记录。
Web Scraper 采用由选择器组成的模块化结构,这些选择器指示刮板如何遍历目标 网站 以及要提取的数据。由于这种结构,从现代和动态的 网站(例如 Amazon、Tripadvisor、eBay)和鲜为人知的 网站 中提取数据是毫不费力的。
数据提取在您的浏览器上运行,无需在您的计算机上安装任何东西。您不需要 Python、PHP 或 JavaScript 编码经验即可开始提取。此外,数据提取可以在 Web Scraper Cloud 中完全自动化。
提取数据后,可以将其下载为 CSV 文件,该文件可以进一步导入 Excel、Google Sheets 等。
软件特点
Web Scraper 是一个简单的网络抓取工具,它允许您使用许多高级功能来获取您正在寻找的确切信息。它提供的功能包括。
* 从多个网页中抓取数据。
* 多种数据提取类型(文本、图像、URL 等)。
* 从动态页面中抓取数据(JavaScript+AJAX,无限滚动)。
* 浏览搜索到的数据。
*将搜索到的数据从网站导出到Excel。
它只依赖于网络浏览器;因此,您无需附加软件即可开始搜索。
如何使用
为了掌握网络搜索技术,您只需要学习几个步骤。
1. 安装扩展并打开开发者工具中的网页抓取标签(必须放置在屏幕底部)。
2. 创建一个新的 网站 地图。
3. 向 网站 地图添加数据提取选择器。
4. 最后,启动搜索器并导出搜索到的数据。
就是这么简单!
使用场景
* 潜在客户开发 - 电子邮件、电话号码和其他与联系方式相关的数据是从各种 网站 中挖掘出来的。
* 电子商务-产品数据提取、产品价格搜索、描述、URL提取、图片检索等。
* 网站内容爬取——从新闻门户、博客、论坛等中提取信息。
* 零售监控——监控产品性能、竞争对手或供应商的库存和价格等。
* 品牌监控-产品评论、用于情感分析的社交内容捕获。
* 商业智能——为关键业务决策采集数据并向竞争对手学习。
* 大数据提取用于机器学习、营销、业务战略制定和研究。
* 还有更多。
爬虫抓取网页数据(第24卷第6期:通用搜索引擎搜索的网页相关度高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-26 12:15
并将抓取到的网页URL作为鸟巢个体计算要选择的URL集合中所有网页的相关性,使用Levi's flight进行多次迭代寻找相关性高的,然后将随机数与发现的进行比较Pa 生成新 URL 的概率。实验结果表明,与主题爬虫的其他相关技术相比,该策略在爬取主题相关网页时具有更高的效率。关键词:布谷鸟搜索算法;主题爬虫;网页相关性;健康中文分类号:TP391 文档标记代码:基于布谷鸟搜索算法的聚焦爬行策略设计 钱景远 1 , 杨慧华 1,2 , 刘振兵 1(1. 桂林工业大学电气工程与自动化学院电子科技, 广西, 桂林, 541004, 中国;2. 北京邮电大学自动化学院, 北京, 100876) 摘要:通用搜索引擎搜索大量网页,以及介绍主题爬虫搜索策略与网络高度相关,减少不相关网页的采集。为了提高爬虫的搜索效率,设计了一种基于布谷鸟搜索算法的爬虫搜索策略。爬取网页URL作为鸟巢,计算所选URL集中所有页面的相关性。多次迭代找到相关性高的,然后通过随机数和发现概率Pa进行比较,生成新的URL。实验结果表明,该策略比爬取主题爬虫相关网页的效率更高。专注的爬虫;页面相关性;Fitness0 简介 作为搜索引擎的重要组成部分,网络爬虫是一种抓取网页的程序。
主题爬虫是一种页面爬取工具,旨在查询某个主题或某个字段[1]。与一般搜索引擎不同,话题搜索引擎本身具有专业性强、针对性强的特点,可以在很大程度上削弱搜索相关话题网页的难度。抓取的网页是否相关很大程度上取决于搜索策略。因此,使用哪种搜索策略是主题爬虫的首要考虑因素。目前比较成熟的搜索策略主要有:基于网页内容的搜索策略和基于链接结构的搜索策略。首先是通过网页之间的链接关系来确定网页的重要性。基于链接结构,只考虑链接结构和页面之间的链接关系,不考虑页面本身是否与主题相关,容易导致“主题漂移”[2,3]。第二种主要考虑网页的内容。优点是思路清晰,计算简单。但是这种方法没有考虑网页的链接关系,忽略了链接网页的价值预测。基于上述搜索策略,提出将布谷鸟搜索算法应用于主题爬虫。1 基于布谷鸟搜索算法的主题爬虫1.1 网络爬虫 通用型网络爬虫(Crawler)(又称蜘蛛),是一款功能强大的网页自动爬取程序,也是搜索引擎不可或缺的一部分。通过在采集网站上遍历互联网和网页,我们可以从某个角度判断某个搜索引擎的性能,而且规模很大。以及小、高、低DOI的扩展能力:10.3969/j.issn.1671-1041.2017.06.006文章: 1671-1041(2017)06-0020-04 接收日期:2017-04-06 基金项目:国家自然科学基金项目(61562013);广西重点研发计划项目(桂科AB1638029) 3)。
作者简介:钱景远(1990-),男,江苏连云港人,硕士研究生,研究方向:网络爬虫等万方数据钱景远·基于杜鹃搜索算法的主题爬虫策略设计第621期评网络爬虫采集 和处理网页的能力。页面下载的主要功能是访问和采集互联网上的相关页面。为了便于存储在待抓取的URL队列中,URL队列按照主题相关性进行排序。从当前采集 网页中提取的新网页链接一般存储在URL 数据库中[4]。与普通爬虫相比,主题爬虫更加复杂。需要开发网页分析算法,过滤不相关的链接,将使用过的链接放入URL队列中进行爬取。最后,根据既定的搜索策略,从待爬取的队列中选择下一步待爬取的URL[4]。1.2 布谷鸟搜索算法简介布谷鸟搜索算法是一种具有全局收敛性的随机算法。布谷鸟搜索算法模拟布谷鸟寻找巢穴产卵的行为。该算法简单,需要设置的参数少,易于实现,具有最优随机搜索路径和优化能力强的特点。已成功应用于工程。应用程序。布谷鸟搜索算法的实现定义了三个理想化的规则: 1) 每只布谷鸟一次只产 1 个蛋,并存储在随机选择的鸟巢中。2) 鸟' 最好的鸡蛋(溶液)的巢将保存到下一代。3) 可用的鸟巢数量是固定的,巢的主人发现外来蛋的概率是Pa∈[0,1]。基于这三种理想状态,布谷鸟巢搜索的路径和位置更新公式如下: 其中Xi(t)表示第t代鸟巢中第i个鸟巢的位置,⊕为点对点乘法,α表示步长控制量,L(λ)为Levy随机搜索路径,L~u =t-λ,(1Pa,则随机改变Xi(t+1)),而反之亦然。
@1.3 网页基础知识 互联网上的网页是具有一定格式和结构的无格式文本。复杂但经常找到。搜索算法中使用了四种类型的 Web 信息:父页面信息。一般来说,从一个页面(父页面)链接的页面(子页面)的内容与页面的主题相关;链接文字信息是指直接概括页面链接的主题;网页的 URL 信息一般与主题相关;兄弟链接信息,页面设计者通常会集中存储与话题相关的链接。以上4类搜索方法与网页主题的对应程度不一致,网页主题的准确率也不一样。
1.4 网页主题相关度计算 对于下载的网页,需要计算主题相关度。这里使用向量空间模型计算网页主题相关度。该模型将文本内容转化为易于数学处理的向量形式,同时将文本内容表达为多维空间中的一个点,从而将文本内容的处理转化为向量运算在向量空间中,这降低了问题的复杂性。文档向量由一个n维向量表示,每个坐标值代表不同的关键词权重。对应的关键词通过权重来描述文档的重要性。使用相同的方法来表示主题关键词 向量。是否关键词 对主题很重要也可以通过主题 关键词 向量中的权重来解释。由于网页的文本结构是半结构化的,需要充分利用网页的HTML标签,才能更准确地提取出文档的主题。一般情况下,最重要的文本如, 和, 是出现在超链接和和之间的关键词,权重应该更高[6,7]。假设F(x)是应该给第x个关键字的权重,那么相关度的计算公式为: 函数F(i)的值如下: 1.5 Fitness function计算燕窝中的选择将直接由个体数量和燕窝的平均适应度决定。当算法第一次运行时,可能有一些适应性很强的燕窝。随着迭代次数的增加,这种适应性很强的燕窝及其后代将成为总数的大部分。这样,种群中新个体的数量减少,布谷鸟搜索算法提前收敛到一个局部最优解,导致“早熟”现象。
考虑网页的内容和链接结构,在CS算法中选择网页与其父网页的相关值作为个体适应度函数值。计算公式为:(2)(3)(4)万方数据卷24 22 Instrumentation User INSTRUMENTATION 其中是第i个URL对应的适应度值,是对应的父网页的相关性值,k为第i个对应的相关性值,对应父网页链接的网页数量[8,9]。1.6 基于布谷鸟搜索算法的主题爬虫设计在主题爬虫中布谷鸟搜索算法的应用具有明显的优势:1)布谷鸟搜索算法具有分组搜索特性,这可以提高主题爬虫的全局搜索性能。2)布谷鸟搜索算法具有随机搜索特性,可以引导主题爬虫在利用一定的适应度函数评价个体的同时,也可以利用李维斯的飞行来指导搜索方向。3)布谷鸟搜索算法是在随机搜索过程中不容易陷入局部最优。4)布谷鸟搜索算法 可扩展性强,在主题爬虫的设计中可以很容易地与其他技术混合使用。CS算法主要分为4个阶段:更新个体位置。评估个体适应度值,如果该值更好,则旧个体将被新个体取代。使用发现概率去除旧个体并重建新个体。找到最好的人。
对3)中新生成的URL进行评估,如果更好则接受更新,否则保持原URL不变。 记录全局最优URL。 当满足搜索精度或达到最大搜索次数时,切换到7),否则切换到2)进行下一轮搜索。 输出最优URL。2 实验设计与数据分析2.1 实验设计测试环境:eclipse开发,Java语言编写,Windows 7系统运行,8G内存,1T硬盘容量。为了验证上述设计策略,设计了以下测试。测试是Broad.First(BF)算法和Hits算法的搜索结果进行比较,记录抓取的网页数据,计算准确率。选择 ”
是主题 根据设置的不同阈值,如图3、4,是“数据库”的主题。根据设置的阈值不同,从图中可以看出基于3种算法的爬虫爬取网页的相关性对比图。可以看出,无论阈值是0.90还是0.95,基于布谷鸟搜索算法的准确率普遍高于其他两种算法(准确率=(获取的相关网页)数) /抓取的网页总数)×100%)。
而且,CS算法的Levi Flight增加的搜索范围不容易导致主题爬虫陷入局部最优。3 总结通过以上实验表明,使用布谷鸟搜索策略进行主题爬取,爬取的网页比普通算法的相关度更高,布谷鸟搜索算法具有很强的全局搜索能力。未来的方向是将布谷鸟搜索算法与其他算法结合,形成一种新的爬虫搜索策略来研究爬取网页的效果。参考文献:Milad shokouhi、Pirooz Chubak、Zaynab Raeesy。Enhancing Focused Crawling with Genetic Algorithms[C].Proceedings of the International Conference on Information Technology: Coding and Computing, March 15,2005.Liu Guojing, Kang Li, Luo Changshou. 基于遗传算法的主题爬虫策略[J]. 计算机应用, 2007, 27(12):172-176.罗林波, 陈琦. 基于Shark-Search and Hits算法的主题爬虫研究[J]. J]. 2010 , 20(11): 76-79.陈一峰.. 基于遗传算法的主题爬虫策略改进[J].. 计算机仿真, 2010, 27 (10): 87-90.蓝少峰, 刘胜. 布谷鸟搜索算法研究综述[J]. 计算机工程与设计, 2015, 36 (4):1603-1607. 罗长寿,程新荣. 基于遗传算法的学科信息获取系统研究[C]. “第二届计算机与计算机技术在农业中的应用国际会议”和“中国农村信息化发展论坛” 论文集, 2008 :.87-92.张海亮, 袁道华. 基于遗传算法的主题爬虫[J]. 计算机技术与发展, 2012, 22: 48-52.陈越、陈云. 查看全部
爬虫抓取网页数据(第24卷第6期:通用搜索引擎搜索的网页相关度高)
并将抓取到的网页URL作为鸟巢个体计算要选择的URL集合中所有网页的相关性,使用Levi's flight进行多次迭代寻找相关性高的,然后将随机数与发现的进行比较Pa 生成新 URL 的概率。实验结果表明,与主题爬虫的其他相关技术相比,该策略在爬取主题相关网页时具有更高的效率。关键词:布谷鸟搜索算法;主题爬虫;网页相关性;健康中文分类号:TP391 文档标记代码:基于布谷鸟搜索算法的聚焦爬行策略设计 钱景远 1 , 杨慧华 1,2 , 刘振兵 1(1. 桂林工业大学电气工程与自动化学院电子科技, 广西, 桂林, 541004, 中国;2. 北京邮电大学自动化学院, 北京, 100876) 摘要:通用搜索引擎搜索大量网页,以及介绍主题爬虫搜索策略与网络高度相关,减少不相关网页的采集。为了提高爬虫的搜索效率,设计了一种基于布谷鸟搜索算法的爬虫搜索策略。爬取网页URL作为鸟巢,计算所选URL集中所有页面的相关性。多次迭代找到相关性高的,然后通过随机数和发现概率Pa进行比较,生成新的URL。实验结果表明,该策略比爬取主题爬虫相关网页的效率更高。专注的爬虫;页面相关性;Fitness0 简介 作为搜索引擎的重要组成部分,网络爬虫是一种抓取网页的程序。
主题爬虫是一种页面爬取工具,旨在查询某个主题或某个字段[1]。与一般搜索引擎不同,话题搜索引擎本身具有专业性强、针对性强的特点,可以在很大程度上削弱搜索相关话题网页的难度。抓取的网页是否相关很大程度上取决于搜索策略。因此,使用哪种搜索策略是主题爬虫的首要考虑因素。目前比较成熟的搜索策略主要有:基于网页内容的搜索策略和基于链接结构的搜索策略。首先是通过网页之间的链接关系来确定网页的重要性。基于链接结构,只考虑链接结构和页面之间的链接关系,不考虑页面本身是否与主题相关,容易导致“主题漂移”[2,3]。第二种主要考虑网页的内容。优点是思路清晰,计算简单。但是这种方法没有考虑网页的链接关系,忽略了链接网页的价值预测。基于上述搜索策略,提出将布谷鸟搜索算法应用于主题爬虫。1 基于布谷鸟搜索算法的主题爬虫1.1 网络爬虫 通用型网络爬虫(Crawler)(又称蜘蛛),是一款功能强大的网页自动爬取程序,也是搜索引擎不可或缺的一部分。通过在采集网站上遍历互联网和网页,我们可以从某个角度判断某个搜索引擎的性能,而且规模很大。以及小、高、低DOI的扩展能力:10.3969/j.issn.1671-1041.2017.06.006文章: 1671-1041(2017)06-0020-04 接收日期:2017-04-06 基金项目:国家自然科学基金项目(61562013);广西重点研发计划项目(桂科AB1638029) 3)。
作者简介:钱景远(1990-),男,江苏连云港人,硕士研究生,研究方向:网络爬虫等万方数据钱景远·基于杜鹃搜索算法的主题爬虫策略设计第621期评网络爬虫采集 和处理网页的能力。页面下载的主要功能是访问和采集互联网上的相关页面。为了便于存储在待抓取的URL队列中,URL队列按照主题相关性进行排序。从当前采集 网页中提取的新网页链接一般存储在URL 数据库中[4]。与普通爬虫相比,主题爬虫更加复杂。需要开发网页分析算法,过滤不相关的链接,将使用过的链接放入URL队列中进行爬取。最后,根据既定的搜索策略,从待爬取的队列中选择下一步待爬取的URL[4]。1.2 布谷鸟搜索算法简介布谷鸟搜索算法是一种具有全局收敛性的随机算法。布谷鸟搜索算法模拟布谷鸟寻找巢穴产卵的行为。该算法简单,需要设置的参数少,易于实现,具有最优随机搜索路径和优化能力强的特点。已成功应用于工程。应用程序。布谷鸟搜索算法的实现定义了三个理想化的规则: 1) 每只布谷鸟一次只产 1 个蛋,并存储在随机选择的鸟巢中。2) 鸟' 最好的鸡蛋(溶液)的巢将保存到下一代。3) 可用的鸟巢数量是固定的,巢的主人发现外来蛋的概率是Pa∈[0,1]。基于这三种理想状态,布谷鸟巢搜索的路径和位置更新公式如下: 其中Xi(t)表示第t代鸟巢中第i个鸟巢的位置,⊕为点对点乘法,α表示步长控制量,L(λ)为Levy随机搜索路径,L~u =t-λ,(1Pa,则随机改变Xi(t+1)),而反之亦然。
@1.3 网页基础知识 互联网上的网页是具有一定格式和结构的无格式文本。复杂但经常找到。搜索算法中使用了四种类型的 Web 信息:父页面信息。一般来说,从一个页面(父页面)链接的页面(子页面)的内容与页面的主题相关;链接文字信息是指直接概括页面链接的主题;网页的 URL 信息一般与主题相关;兄弟链接信息,页面设计者通常会集中存储与话题相关的链接。以上4类搜索方法与网页主题的对应程度不一致,网页主题的准确率也不一样。
1.4 网页主题相关度计算 对于下载的网页,需要计算主题相关度。这里使用向量空间模型计算网页主题相关度。该模型将文本内容转化为易于数学处理的向量形式,同时将文本内容表达为多维空间中的一个点,从而将文本内容的处理转化为向量运算在向量空间中,这降低了问题的复杂性。文档向量由一个n维向量表示,每个坐标值代表不同的关键词权重。对应的关键词通过权重来描述文档的重要性。使用相同的方法来表示主题关键词 向量。是否关键词 对主题很重要也可以通过主题 关键词 向量中的权重来解释。由于网页的文本结构是半结构化的,需要充分利用网页的HTML标签,才能更准确地提取出文档的主题。一般情况下,最重要的文本如, 和, 是出现在超链接和和之间的关键词,权重应该更高[6,7]。假设F(x)是应该给第x个关键字的权重,那么相关度的计算公式为: 函数F(i)的值如下: 1.5 Fitness function计算燕窝中的选择将直接由个体数量和燕窝的平均适应度决定。当算法第一次运行时,可能有一些适应性很强的燕窝。随着迭代次数的增加,这种适应性很强的燕窝及其后代将成为总数的大部分。这样,种群中新个体的数量减少,布谷鸟搜索算法提前收敛到一个局部最优解,导致“早熟”现象。
考虑网页的内容和链接结构,在CS算法中选择网页与其父网页的相关值作为个体适应度函数值。计算公式为:(2)(3)(4)万方数据卷24 22 Instrumentation User INSTRUMENTATION 其中是第i个URL对应的适应度值,是对应的父网页的相关性值,k为第i个对应的相关性值,对应父网页链接的网页数量[8,9]。1.6 基于布谷鸟搜索算法的主题爬虫设计在主题爬虫中布谷鸟搜索算法的应用具有明显的优势:1)布谷鸟搜索算法具有分组搜索特性,这可以提高主题爬虫的全局搜索性能。2)布谷鸟搜索算法具有随机搜索特性,可以引导主题爬虫在利用一定的适应度函数评价个体的同时,也可以利用李维斯的飞行来指导搜索方向。3)布谷鸟搜索算法是在随机搜索过程中不容易陷入局部最优。4)布谷鸟搜索算法 可扩展性强,在主题爬虫的设计中可以很容易地与其他技术混合使用。CS算法主要分为4个阶段:更新个体位置。评估个体适应度值,如果该值更好,则旧个体将被新个体取代。使用发现概率去除旧个体并重建新个体。找到最好的人。
对3)中新生成的URL进行评估,如果更好则接受更新,否则保持原URL不变。 记录全局最优URL。 当满足搜索精度或达到最大搜索次数时,切换到7),否则切换到2)进行下一轮搜索。 输出最优URL。2 实验设计与数据分析2.1 实验设计测试环境:eclipse开发,Java语言编写,Windows 7系统运行,8G内存,1T硬盘容量。为了验证上述设计策略,设计了以下测试。测试是Broad.First(BF)算法和Hits算法的搜索结果进行比较,记录抓取的网页数据,计算准确率。选择 ”
是主题 根据设置的不同阈值,如图3、4,是“数据库”的主题。根据设置的阈值不同,从图中可以看出基于3种算法的爬虫爬取网页的相关性对比图。可以看出,无论阈值是0.90还是0.95,基于布谷鸟搜索算法的准确率普遍高于其他两种算法(准确率=(获取的相关网页)数) /抓取的网页总数)×100%)。
而且,CS算法的Levi Flight增加的搜索范围不容易导致主题爬虫陷入局部最优。3 总结通过以上实验表明,使用布谷鸟搜索策略进行主题爬取,爬取的网页比普通算法的相关度更高,布谷鸟搜索算法具有很强的全局搜索能力。未来的方向是将布谷鸟搜索算法与其他算法结合,形成一种新的爬虫搜索策略来研究爬取网页的效果。参考文献:Milad shokouhi、Pirooz Chubak、Zaynab Raeesy。Enhancing Focused Crawling with Genetic Algorithms[C].Proceedings of the International Conference on Information Technology: Coding and Computing, March 15,2005.Liu Guojing, Kang Li, Luo Changshou. 基于遗传算法的主题爬虫策略[J]. 计算机应用, 2007, 27(12):172-176.罗林波, 陈琦. 基于Shark-Search and Hits算法的主题爬虫研究[J]. J]. 2010 , 20(11): 76-79.陈一峰.. 基于遗传算法的主题爬虫策略改进[J].. 计算机仿真, 2010, 27 (10): 87-90.蓝少峰, 刘胜. 布谷鸟搜索算法研究综述[J]. 计算机工程与设计, 2015, 36 (4):1603-1607. 罗长寿,程新荣. 基于遗传算法的学科信息获取系统研究[C]. “第二届计算机与计算机技术在农业中的应用国际会议”和“中国农村信息化发展论坛” 论文集, 2008 :.87-92.张海亮, 袁道华. 基于遗传算法的主题爬虫[J]. 计算机技术与发展, 2012, 22: 48-52.陈越、陈云.
爬虫抓取网页数据(爬虫抓取网页数据需要先解析看图片视频需要注意什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-24 00:42
爬虫抓取网页数据,一般是先去数据库查询数据,如果数据库没有查询记录,就先扫描网页里的每个元素,做分析,然后存到自己的数据库里,需要的时候取出来就可以,同时,进行搜索引擎搜索,对于特定用户,爬虫要收集特定时间段内的数据。看图片视频需要先解析视频网站的源代码。
假设有一个爬虫想要抓取你的视频,那么你需要在你的浏览器视频地址栏中输入http协议,抓取其中的源代码。
http协议有一个交互方式叫做请求。比如视频站点如果是a,爬虫可以用http协议向其请求资源也可以用https协议请求资源。a请求b,b则能够返回另外一种类型的资源:资源所在的代理。使用不同类型请求方式,爬虫就可以应对不同情况。例如爬取单人视频,用http协议,如果请求方式是a,那么a就是代理;爬取多人视频,用https协议,那么b是代理。
但是只要爬虫机器够强大,那么可以对不同请求方式做匹配,用自己最方便的方式请求。假设a用http,那么b用https,一旦b访问速度更快,比如用代理向a请求资源,或者用代理向a请求资源,a就直接返回代理,代理就可以跳转到b上。
如果网站能获取你所需的url,那么一切都好办,你可以提交合法的验证请求到各大互联网大厂商的服务器中,根据验证结果分析你要的内容。如果网站是不能获取你所需的url,请你放弃如果网站不能获取你所需的url,还得分析。如果你用人工方式访问,你就需要对网站进行抓取,但是多种网站类型会分析你的response,比如http,https,它们会显示不同的页面,同时每个网站还会返回不同的内容,当然这个区别无关紧要。
你也可以通过正则匹配获取你想要的资源,比如带accesstoken的,或者通过cookie来实现与你的app进行匹配。当然这个也无关紧要。ps.对于一个提问者希望再次提问题,通过自己先提问然后自己回答自己的情况,那么需要说明一下:1.爬虫机器人就是一个伪对话机器人2.这个伪对话机器人建立在你们之间打过交道的语境上,比如a和b在第一次见面,那么a和b肯定是认识的。
可能你和a,b都彼此不认识,那么第一次见面并不能理解你在说什么,那么你还得反复的给机器人强化对话。假设现在我a和b都彼此认识,然后我把所有图片放在一个文件夹,也存在一个文件夹,那么这个机器人机器人不需要匹配直接就能把内容返回给我,这个机器人就是我的isai34-cheng(你们一定听过机器人papi酱)ps.所以做爬虫的人会懂,通过cookie和交流内容来完成。比如翻译软件,美工机器人,看人体彩绘是否像照片,或者简单的。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据需要先解析看图片视频需要注意什么)
爬虫抓取网页数据,一般是先去数据库查询数据,如果数据库没有查询记录,就先扫描网页里的每个元素,做分析,然后存到自己的数据库里,需要的时候取出来就可以,同时,进行搜索引擎搜索,对于特定用户,爬虫要收集特定时间段内的数据。看图片视频需要先解析视频网站的源代码。
假设有一个爬虫想要抓取你的视频,那么你需要在你的浏览器视频地址栏中输入http协议,抓取其中的源代码。
http协议有一个交互方式叫做请求。比如视频站点如果是a,爬虫可以用http协议向其请求资源也可以用https协议请求资源。a请求b,b则能够返回另外一种类型的资源:资源所在的代理。使用不同类型请求方式,爬虫就可以应对不同情况。例如爬取单人视频,用http协议,如果请求方式是a,那么a就是代理;爬取多人视频,用https协议,那么b是代理。
但是只要爬虫机器够强大,那么可以对不同请求方式做匹配,用自己最方便的方式请求。假设a用http,那么b用https,一旦b访问速度更快,比如用代理向a请求资源,或者用代理向a请求资源,a就直接返回代理,代理就可以跳转到b上。
如果网站能获取你所需的url,那么一切都好办,你可以提交合法的验证请求到各大互联网大厂商的服务器中,根据验证结果分析你要的内容。如果网站是不能获取你所需的url,请你放弃如果网站不能获取你所需的url,还得分析。如果你用人工方式访问,你就需要对网站进行抓取,但是多种网站类型会分析你的response,比如http,https,它们会显示不同的页面,同时每个网站还会返回不同的内容,当然这个区别无关紧要。
你也可以通过正则匹配获取你想要的资源,比如带accesstoken的,或者通过cookie来实现与你的app进行匹配。当然这个也无关紧要。ps.对于一个提问者希望再次提问题,通过自己先提问然后自己回答自己的情况,那么需要说明一下:1.爬虫机器人就是一个伪对话机器人2.这个伪对话机器人建立在你们之间打过交道的语境上,比如a和b在第一次见面,那么a和b肯定是认识的。
可能你和a,b都彼此不认识,那么第一次见面并不能理解你在说什么,那么你还得反复的给机器人强化对话。假设现在我a和b都彼此认识,然后我把所有图片放在一个文件夹,也存在一个文件夹,那么这个机器人机器人不需要匹配直接就能把内容返回给我,这个机器人就是我的isai34-cheng(你们一定听过机器人papi酱)ps.所以做爬虫的人会懂,通过cookie和交流内容来完成。比如翻译软件,美工机器人,看人体彩绘是否像照片,或者简单的。
爬虫抓取网页数据(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-23 23:16
CasperJS 是一个导航脚本和测试工具,用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这种浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对web前端和后端产生深远的影响。技术的发展。
本文使用了一个著名的网站[]“手术”(只是学习和使用,希望这个网站不会打扰我
),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页面的web结构。通常内容类别网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站按页码翻页,而是点击最后一页加载更多。这类页面是传统的爬虫程序,经常会停止服务,或者实现起来非常复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置会持续显示更多的电影信息。
第三步,开始编写代码,获取电影详情页的链接信息。我们不受欢迎。单击此位置以采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想了解这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。
1.抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1)span.attrs a',我们使用函数getTextContent(strRule, strMesg)方法抓取内容.
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 捕获生产国家和地区。使用 CSS 选择器将难以捕获此信息。对网页进行分析后可以发现,该信息并没有放在标签中,直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息可以类似地获得。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。 查看全部
爬虫抓取网页数据(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
CasperJS 是一个导航脚本和测试工具,用于 PhantomJS (WebKit) 和 SlimerJS (Gecko) 无头浏览器,用 Javascript 编写。
PhantomJS 是一个基于 WebKit 核心的无头浏览器
SlimerJS 是一个基于 Gecko 内核的无头浏览器
Headless browser:无界面显示的浏览器,可用于自动化测试、网页截图、JS注入、DOM操作等,是一种非常新型的Web应用工具。这种浏览器虽然没有任何界面输出,但是可以在很多方面得到广泛的应用。整篇文章文章将介绍使用Casperjs进行网络爬虫(web crawler)的应用。这篇文章只是一个介绍。事实上,无头浏览器技术的应用将会非常广泛,甚至可能对web前端和后端产生深远的影响。技术的发展。
本文使用了一个著名的网站[]“手术”(只是学习和使用,希望这个网站不会打扰我
),来测试强大的 Headless Browser 网络爬虫技术。
第一步是安装Casperjs。打开CasperJS官网,下载最新稳定版CasperJS并安装。官网有非常详细的文档,是学习CasperJS最好的第一手资料。当然,如果安装npm,也可以直接通过npm安装。同时,这也是官方推荐的安装方式。关于安装的介绍不多,官方文档很详细。
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
查看代码
第二步,分析目标网站的列表页面的web结构。通常内容类别网站分为列表页和详细内容页。豆瓣也不例外。我们来看看豆瓣的listing页面是什么样子的。经过分析,发现豆瓣电影网的列表页面是这样的。首先,您可以单击排序规则。翻页不像传统的网站按页码翻页,而是点击最后一页加载更多。这类页面是传统的爬虫程序,经常会停止服务,或者实现起来非常复杂。但对于无头浏览器技术来说,这些都是小case。通过对网页的分析,可以看到点击这个【加载更多】位置会持续显示更多的电影信息。
第三步,开始编写代码,获取电影详情页的链接信息。我们不受欢迎。单击此位置以采集超链接列表。以下代码是获取链接的代码。引用并创建一个 casperJS 对象。如果网页需要插入脚本,可以在生成casper对象时在ClientScript部分引用要注入网页的脚本。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
查看代码
)
获取详情页链接的完整代码,这里是点击【加载更多】,循环50次的模拟。其实循环可以改进一下,【判断while(没有“加载更多”)then(停止)】,得到后,使用require('utils').dump(...)输出链表。将以下代码保存为getDoubanList.js,然后运行casperjs getDoubanList.js,获取并输出该分类下的所有详情页链接。
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
获取所有网址
引用的RecordUrl模块,存储在MongoDB中的部分就不写了,可以自己完成。
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录网址
第四步,分析详情页,编写详情页爬取程序
至此,大家已经拿到了要爬取的详情页列表。现在我们打开一个电影详细信息页面来查看它的结构并分析如何捕获每个信息。对于信息的抓取,需要用到DOM、文本处理和JS脚本等技术。想了解这部分的信息,包括导演、编剧、评分等,本文不再赘述。这里仅举几个用于演示的信息项示例。
1.抓取导演列表:导演列表的DOM CSS选择器'div#info span:nth-child(1)span.attrs a',我们使用函数getTextContent(strRule, strMesg)方法抓取内容.
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获取导演
2. 捕获生产国家和地区。使用 CSS 选择器将难以捕获此信息。对网页进行分析后可以发现,该信息并没有放在标签中,直接在
在这个高级元素中。对于这类信息,我们采用另一种方法,文本分析截取,首先映射String模块 var S = require("string"); 该模块也需要单独安装。然后抓取整个信息块,再用文字截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
获取国家
其他信息可以类似地获得。
第五步是将捕获的信息存储为分析源。推荐使用MongoDB等NoSql数据库存储,更适合存储此类非结构化数据,性能更好。
爬虫抓取网页数据(动态网页数据抓取什么是AJAX:selenium直接模拟浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-09-23 23:12
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
转载于: 查看全部
爬虫抓取网页数据(动态网页数据抓取什么是AJAX:selenium直接模拟浏览器)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
转载于:
爬虫抓取网页数据(利用爬虫爬取网页数据是不是动态生成的时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-23 23:11
如果使用爬虫爬取网页数据,发现是动态生成的,目前主要表现在以下几种类型:
以界面的形式生成数据,这种形式其实还蛮好打理的,比较典型的就是知乎的用户信息,只要知道界面的URL,就不需要考虑内容页面本身。
以知乎 为例。我们在抓取用户信息时,最初可能会关注页面本身的内容,希望通过分析页面的结构来获取想要的数据。事实上,我们使用fiddler等网络工具。很容易发现,里面其实有一个用户信息的接口,所以我们在爬取用户的时候只需要关注这个接口的逻辑就可以了。
如上图所示,上述接口返回了所有用户信息,因此我们可以对结果的json格式数据进行处理。
动态生成的内容直接写入网页。这时候就需要一个渲染引擎来帮助我们渲染javascript的执行结果。Splash 是我们需要的引擎,它可以帮助我们快速轻松地渲染 javascript 的内容。
Splash是scrapy推荐的渲染引擎。它可以同时渲染多个页面,为用户返回页面或截图,并在页面中执行自定义的javascript代码。以京东的图书搜索为例。搜索列表中的内容由javascript动态生成。如果我们想要抓取内容,我们需要渲染数据。这可以通过使用飞溅轻松完成。下图是使用splash渲染的代码
总之,对于不同的形式,我们需要先了解相应的实现原理,然后根据实现原理采用相应的方案抓取我们需要的数据。
你要使用python代码来判断数据是否是动态生成的。这在目前并不容易实现。至于使用python来捕获分析数据,获取数据的Request URL,这个实现起来比较复杂,也没有必要。手动F12很快就能找到答案,数据是否动态一目了然。静态数据在网页源代码中,动态数据不在网页源代码中。将网页显示的内容与网页的源代码进行对比,可以直观的找到。
1.静态数据如下。
网页显示内容:
网页源码内容:
如果在网页的源代码中可以找到相应的数据,则不是动态加载的。
2.动态数据如下。
网页显示内容:
实际数据如图所示,不在网页源码中,数据是动态加载的:
至于动态数据URL,可以直接抓包分析,实现起来非常简单:
一般情况下数据页的url参数都是有规律可循的,逐页翻页,参数也是固定的那几个参数,如果值是,就依法更改,但有的网站会做加密,你要自己分析。一般情况下,动态数据是一个json文件,可以通过json包或者正则表达式提取数据。希望以上内容对您有所帮助。 查看全部
爬虫抓取网页数据(利用爬虫爬取网页数据是不是动态生成的时候)
如果使用爬虫爬取网页数据,发现是动态生成的,目前主要表现在以下几种类型:
以界面的形式生成数据,这种形式其实还蛮好打理的,比较典型的就是知乎的用户信息,只要知道界面的URL,就不需要考虑内容页面本身。
以知乎 为例。我们在抓取用户信息时,最初可能会关注页面本身的内容,希望通过分析页面的结构来获取想要的数据。事实上,我们使用fiddler等网络工具。很容易发现,里面其实有一个用户信息的接口,所以我们在爬取用户的时候只需要关注这个接口的逻辑就可以了。
如上图所示,上述接口返回了所有用户信息,因此我们可以对结果的json格式数据进行处理。
动态生成的内容直接写入网页。这时候就需要一个渲染引擎来帮助我们渲染javascript的执行结果。Splash 是我们需要的引擎,它可以帮助我们快速轻松地渲染 javascript 的内容。
Splash是scrapy推荐的渲染引擎。它可以同时渲染多个页面,为用户返回页面或截图,并在页面中执行自定义的javascript代码。以京东的图书搜索为例。搜索列表中的内容由javascript动态生成。如果我们想要抓取内容,我们需要渲染数据。这可以通过使用飞溅轻松完成。下图是使用splash渲染的代码
总之,对于不同的形式,我们需要先了解相应的实现原理,然后根据实现原理采用相应的方案抓取我们需要的数据。
你要使用python代码来判断数据是否是动态生成的。这在目前并不容易实现。至于使用python来捕获分析数据,获取数据的Request URL,这个实现起来比较复杂,也没有必要。手动F12很快就能找到答案,数据是否动态一目了然。静态数据在网页源代码中,动态数据不在网页源代码中。将网页显示的内容与网页的源代码进行对比,可以直观的找到。
1.静态数据如下。
网页显示内容:
网页源码内容:
如果在网页的源代码中可以找到相应的数据,则不是动态加载的。
2.动态数据如下。
网页显示内容:
实际数据如图所示,不在网页源码中,数据是动态加载的:
至于动态数据URL,可以直接抓包分析,实现起来非常简单:
一般情况下数据页的url参数都是有规律可循的,逐页翻页,参数也是固定的那几个参数,如果值是,就依法更改,但有的网站会做加密,你要自己分析。一般情况下,动态数据是一个json文件,可以通过json包或者正则表达式提取数据。希望以上内容对您有所帮助。
爬虫抓取网页数据(Python爬虫网页抓取数据库的定义及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-23 12:08
)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的。如有任何疑问,请及时联系我们处理
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
Python爬虫很有趣,也很容易使用。现在我想使用Python抓取网页股票数据,并将其保存到本地CSV数据文件中。同时,我想将股票数据保存到MySQL数据库中。当需求得到满足时,其余的就实现了
启动之前,请确保已安装MySQL,并且需要启动本地MySQL数据库服务。说到安装MySQL数据库,它是两天前安装在一台计算机上的MySQL5.在7:00时,无法安装。它总是提示说缺少VisualStudio2013可再发行版本,但我非常困惑。它安装得很清楚。最初的问题是版本。只需更换版本。小问题和大麻烦。我不知道是否有人像我一样悲伤
要恢复业务,请启动本地数据库服务:
以管理员身份打开“命令提示符(管理员)”,然后输入“net start mysql57”(我将数据库服务名称定义为mysql57,安装MySQL时可以修改该名称)启动服务。注意:使用管理员身份打开小黑匣子。如果不是管理员身份,我将提示您在此处没有权限。你可以试试
启动服务后,我们可以选择打开mysql5.7“命令行客户端”小黑匣子。您需要首先输入数据库的密码。它是在安装过程中定义的。你可以在这里操作数据库
我们开始吃饭吧
一、Python爬虫程序获取网页数据并将其保存到本地数据文件中
首先,导入所需的数据模块并定义功能:
实代码块:
上面的代码实现了爬虫网页抓取股票数据并将其保存到本地文件中。有很多关于爬行动物的信息可供参考。大多数都是例行公事。我不多说了。同时,本文也参考了大量的web资源在实现过程中的应用。感谢这里的所有原创参与者
让我们看看结果。代码列表是所有捕获的股票代码的集合。我们可以看到它收录1416个元素,即1416个股票数据。因为股票太多了,我们从6开始抓取,这似乎是上海股市的股票数据(请原谅我不懂金融)
捕获的股票数据将存储在CSV文件中,每个股票数据一个文件。理论上,将有1416个CSV文件,这与股票代码的数量一致。但请原谅我糟糕的网络速度。很难下载一个。也是呵呵
打开本地数据文件以查看捕获的数据的外观:
事实上,它与手动下载没有什么不同。坦率地说,它解放了劳动力,提高了生产率(这听起来像政治吗?)
二、在MySQL数据库中存储数据
首先建立本地数据库连接:
数据库名称和密码是在安装MySQL时设置的
创建数据库以存储此股票数据:
通常,数据库将在第一次运行期间正常创建,但如果它再次运行,因为数据库已经存在,请跳过创建并继续执行。创建数据库后,选择使用刚刚创建的数据库,并将数据表存储在数据库中
以下是具体的存储代码:
代码并不复杂,只需注意几点
1.逻辑级别:
它收录两层循环。外部循环是库存代码的循环,内部循环是当前库存的每条记录的循环。坦率地说,它是根据库存逐一存储的。对于每种股票,它都会根据每日记录逐一存储。它是简单而暴力的吗?对根本没有考虑更优化的方法
2.读取本地数据文件的编码方法:
使用“GBK”编码。默认值应该是“utf8”,但它似乎不支持中文
3.创建数据表:
同样,如果数据表已经存在(如果不存在则判断是否存在),请跳过创建并继续执行以下步骤(存储将继续)。一个问题是数据可能被重复存储。您可以选择跳过存储或仅存储最新数据。我在这里没有考虑太多的额外处理。其次,指定字段格式。以下字段包括交易量、交易金额、总市值和流通市值。因为数据很大,所以选择bigint类型
4.未为数据表指定主键:
首先,我打算使用日期作为主键。后来,我发现获得的数据甚至收录日期重复的数据,这破坏了主键的唯一性,并会导致错误。然后我没有考虑数据文件的内容,也不会进一步使用这些数据。为了省事,我没有直接设置主键
5.construct SQL语句sqlsentence4:
在这个过程的实现中,股票数据直接记录在元组中,然后用字符串(%operator)格式化。我们没有考虑太多导致的准确性问题,也不知道它是否会有任何影响。%S有一个“”用于表示SQL语句中的字符串。有一个%s',右边只有一个引号。匹配的股票代码只有一个单引号。这是因为从数据文件读取的字符串已经收录左侧的单引号。没有必要将其添加到左侧。这就是数据文件格式的问题。为了表示文本形式,预先使用单引号
6.异常处理:
文本文件收录非标准化数据,例如null值、none和none。它们全部替换为null,即数据库的null值
MySQL数据库数据存储完成后,需要关闭数据库连接:
#关闭游标、提交并关闭数据库连接游标。关闭()
麻省理工学院()
db.close()
如果不关闭数据库连接,就不能在MySQL端查询数据库,这相当于占用数据库
三、MySQL数据库查询
如果你把上面的一张一张地打印出来,就会把它弄得一团糟。您也可以在MySQL端查看它。首先选择数据库:使用stockdatabase;,然后查询:从库存中选择*600000结果可能如下:
四、完整代码
事实上,整个过程已经完成了两个相对独立的过程:
1.crawler获取网络股票数据并将其保存到本地文件
2.在MySQL数据库中存储本地文件数据
没有直接考虑将从网页捕获的数据实时(或通过临时文件)扔进数据库,并跳过本地数据文件的过程。这只是实现这一点的一种尝试,代码没有进行任何优化考虑。它实际上没有被使用,只是很有趣,几乎是第一次。哈哈~~
查看全部
爬虫抓取网页数据(Python爬虫网页抓取数据库的定义及应用
)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的。如有任何疑问,请及时联系我们处理
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
Python免费学习资料和组通信解决方案。点击加入
Python爬虫很有趣,也很容易使用。现在我想使用Python抓取网页股票数据,并将其保存到本地CSV数据文件中。同时,我想将股票数据保存到MySQL数据库中。当需求得到满足时,其余的就实现了
启动之前,请确保已安装MySQL,并且需要启动本地MySQL数据库服务。说到安装MySQL数据库,它是两天前安装在一台计算机上的MySQL5.在7:00时,无法安装。它总是提示说缺少VisualStudio2013可再发行版本,但我非常困惑。它安装得很清楚。最初的问题是版本。只需更换版本。小问题和大麻烦。我不知道是否有人像我一样悲伤
要恢复业务,请启动本地数据库服务:
以管理员身份打开“命令提示符(管理员)”,然后输入“net start mysql57”(我将数据库服务名称定义为mysql57,安装MySQL时可以修改该名称)启动服务。注意:使用管理员身份打开小黑匣子。如果不是管理员身份,我将提示您在此处没有权限。你可以试试
启动服务后,我们可以选择打开mysql5.7“命令行客户端”小黑匣子。您需要首先输入数据库的密码。它是在安装过程中定义的。你可以在这里操作数据库
我们开始吃饭吧
一、Python爬虫程序获取网页数据并将其保存到本地数据文件中
首先,导入所需的数据模块并定义功能:
实代码块:
上面的代码实现了爬虫网页抓取股票数据并将其保存到本地文件中。有很多关于爬行动物的信息可供参考。大多数都是例行公事。我不多说了。同时,本文也参考了大量的web资源在实现过程中的应用。感谢这里的所有原创参与者
让我们看看结果。代码列表是所有捕获的股票代码的集合。我们可以看到它收录1416个元素,即1416个股票数据。因为股票太多了,我们从6开始抓取,这似乎是上海股市的股票数据(请原谅我不懂金融)
捕获的股票数据将存储在CSV文件中,每个股票数据一个文件。理论上,将有1416个CSV文件,这与股票代码的数量一致。但请原谅我糟糕的网络速度。很难下载一个。也是呵呵
打开本地数据文件以查看捕获的数据的外观:
事实上,它与手动下载没有什么不同。坦率地说,它解放了劳动力,提高了生产率(这听起来像政治吗?)
二、在MySQL数据库中存储数据
首先建立本地数据库连接:
数据库名称和密码是在安装MySQL时设置的
创建数据库以存储此股票数据:
通常,数据库将在第一次运行期间正常创建,但如果它再次运行,因为数据库已经存在,请跳过创建并继续执行。创建数据库后,选择使用刚刚创建的数据库,并将数据表存储在数据库中
以下是具体的存储代码:
代码并不复杂,只需注意几点
1.逻辑级别:
它收录两层循环。外部循环是库存代码的循环,内部循环是当前库存的每条记录的循环。坦率地说,它是根据库存逐一存储的。对于每种股票,它都会根据每日记录逐一存储。它是简单而暴力的吗?对根本没有考虑更优化的方法
2.读取本地数据文件的编码方法:
使用“GBK”编码。默认值应该是“utf8”,但它似乎不支持中文
3.创建数据表:
同样,如果数据表已经存在(如果不存在则判断是否存在),请跳过创建并继续执行以下步骤(存储将继续)。一个问题是数据可能被重复存储。您可以选择跳过存储或仅存储最新数据。我在这里没有考虑太多的额外处理。其次,指定字段格式。以下字段包括交易量、交易金额、总市值和流通市值。因为数据很大,所以选择bigint类型
4.未为数据表指定主键:
首先,我打算使用日期作为主键。后来,我发现获得的数据甚至收录日期重复的数据,这破坏了主键的唯一性,并会导致错误。然后我没有考虑数据文件的内容,也不会进一步使用这些数据。为了省事,我没有直接设置主键
5.construct SQL语句sqlsentence4:
在这个过程的实现中,股票数据直接记录在元组中,然后用字符串(%operator)格式化。我们没有考虑太多导致的准确性问题,也不知道它是否会有任何影响。%S有一个“”用于表示SQL语句中的字符串。有一个%s',右边只有一个引号。匹配的股票代码只有一个单引号。这是因为从数据文件读取的字符串已经收录左侧的单引号。没有必要将其添加到左侧。这就是数据文件格式的问题。为了表示文本形式,预先使用单引号
6.异常处理:
文本文件收录非标准化数据,例如null值、none和none。它们全部替换为null,即数据库的null值
MySQL数据库数据存储完成后,需要关闭数据库连接:
#关闭游标、提交并关闭数据库连接游标。关闭()
麻省理工学院()
db.close()
如果不关闭数据库连接,就不能在MySQL端查询数据库,这相当于占用数据库
三、MySQL数据库查询
如果你把上面的一张一张地打印出来,就会把它弄得一团糟。您也可以在MySQL端查看它。首先选择数据库:使用stockdatabase;,然后查询:从库存中选择*600000结果可能如下:
四、完整代码
事实上,整个过程已经完成了两个相对独立的过程:
1.crawler获取网络股票数据并将其保存到本地文件
2.在MySQL数据库中存储本地文件数据
没有直接考虑将从网页捕获的数据实时(或通过临时文件)扔进数据库,并跳过本地数据文件的过程。这只是实现这一点的一种尝试,代码没有进行任何优化考虑。它实际上没有被使用,只是很有趣,几乎是第一次。哈哈~~
爬虫抓取网页数据( 阿里码栈爬虫系列文章会连载几篇(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-21 23:10
阿里码栈爬虫系列文章会连载几篇(一))
代码栈爬虫系列文章的几篇文章将被序列化,主要关注使用阿里巴巴的代码栈软件快速构建爬虫应用。代码栈是阿里官方发布的自动机器人软件。操作简单,启动速度快。在它的众多功能中,爬虫只是一个很小的功能。与市场上其他爬虫软件相比,它启动速度很快。通过拖动函数滑块,可以在几分钟内完成一个爬虫应用程序,例如本文中编写的抓取商品评估应用程序
在文章的最后,将介绍一个词频分析工具“商品评估词频分析工具”来分析捕获的评估
产品评估爬虫的一般流程如下:
步骤1:在参数面板中设置两个参数
1.[产品链接]:用于填写所需采集产品的链接
2.[评估保存路径]:由于采集的评估数据存储在本地TXT文件中,因此您需要在计算机中创建一个新的TXT文件,然后在[评估保存路径]中选择TXT文件的路径
在设置参数后,在过程设计参数面板中,将读取参数面板拖动到中间的空白画布区域。您需要拖动两个来读取刚刚设置的商品链接和评估保存路径
双击拖动的滑块并检查相应的参数
同样,拖动“浏览器-打开网页”,然后设置
将浏览器-单击网页元素拖到画布上,单击捕获网页元素,然后单击开始录制
在右侧浏览器窗口中打开的商品页面中,单击累积评估,然后单击保存
单击左上角的开始录制流程,然后单击任意评估,在弹出窗口中单击批次采集数据,然后单击保存
双击新生成的周期元素列表,分别获取第一列文本,将打开的网页更改为打开商品详情页面,最后删除上面打开的网页
然后找到带有后续注释的注释,并重复上述步骤
第1页的初始评估和后续评估数据已在此处采集找到,申请流程如下:
目前,有两个尚未解决的问题:一是如何应用采集多页评论;第二个是如何将数据保存到TXT文件
将process-cycle execution滑块拖动到如图所示的位置
循环次数即使页面需要循环,这里我先填写10页,也就是说10页,其他值可以根据实际情况填写
有一种更智能的循环时间方法,可以自动确定需要循环多少页。这篇文章是一篇介绍性文章,暂时不会介绍
将两个循环评估的滑块拖动到“循环”页面中
在循环结束时添加click page元素以单击下一页
单击捕获网页元素-开始录制,然后移动鼠标并单击下一页进行保存
到目前为止,已经建立了捕获数据的过程,但是如何保存数据还不够。以前,代码栈有导出到excel的功能,但是现在基本版本不能直接导出,所以我们需要使用前面提到的新TXT文件
在计算机桌面或其他文件夹中创建新的文本文档,并在代码堆栈的[evaluation save path]中选择文本文档的路径
将系统文件操作滑块拖动到两个评估周期
两种文件操作设置如下所示:
最后,添加一个[关闭网页]滑块,建立产品评估爬虫
在【界面设计与调试预览】中填写【商品链接】和【评估保存路径】,点击启动爬虫开始执行
打开商品评估词频分析工具。Xlsm,点击开始,选择刚到达采集的评估文件,稍等片刻,查看评估的词频统计
代码栈简介&;下载地址:/home/clientdownload.htm
代码栈官方学习手册:/help/index.html 查看全部
爬虫抓取网页数据(
阿里码栈爬虫系列文章会连载几篇(一))
代码栈爬虫系列文章的几篇文章将被序列化,主要关注使用阿里巴巴的代码栈软件快速构建爬虫应用。代码栈是阿里官方发布的自动机器人软件。操作简单,启动速度快。在它的众多功能中,爬虫只是一个很小的功能。与市场上其他爬虫软件相比,它启动速度很快。通过拖动函数滑块,可以在几分钟内完成一个爬虫应用程序,例如本文中编写的抓取商品评估应用程序
在文章的最后,将介绍一个词频分析工具“商品评估词频分析工具”来分析捕获的评估
产品评估爬虫的一般流程如下:
步骤1:在参数面板中设置两个参数
1.[产品链接]:用于填写所需采集产品的链接
2.[评估保存路径]:由于采集的评估数据存储在本地TXT文件中,因此您需要在计算机中创建一个新的TXT文件,然后在[评估保存路径]中选择TXT文件的路径
在设置参数后,在过程设计参数面板中,将读取参数面板拖动到中间的空白画布区域。您需要拖动两个来读取刚刚设置的商品链接和评估保存路径
双击拖动的滑块并检查相应的参数
同样,拖动“浏览器-打开网页”,然后设置
将浏览器-单击网页元素拖到画布上,单击捕获网页元素,然后单击开始录制
在右侧浏览器窗口中打开的商品页面中,单击累积评估,然后单击保存
单击左上角的开始录制流程,然后单击任意评估,在弹出窗口中单击批次采集数据,然后单击保存
双击新生成的周期元素列表,分别获取第一列文本,将打开的网页更改为打开商品详情页面,最后删除上面打开的网页
然后找到带有后续注释的注释,并重复上述步骤
第1页的初始评估和后续评估数据已在此处采集找到,申请流程如下:
目前,有两个尚未解决的问题:一是如何应用采集多页评论;第二个是如何将数据保存到TXT文件
将process-cycle execution滑块拖动到如图所示的位置
循环次数即使页面需要循环,这里我先填写10页,也就是说10页,其他值可以根据实际情况填写
有一种更智能的循环时间方法,可以自动确定需要循环多少页。这篇文章是一篇介绍性文章,暂时不会介绍
将两个循环评估的滑块拖动到“循环”页面中
在循环结束时添加click page元素以单击下一页
单击捕获网页元素-开始录制,然后移动鼠标并单击下一页进行保存
到目前为止,已经建立了捕获数据的过程,但是如何保存数据还不够。以前,代码栈有导出到excel的功能,但是现在基本版本不能直接导出,所以我们需要使用前面提到的新TXT文件
在计算机桌面或其他文件夹中创建新的文本文档,并在代码堆栈的[evaluation save path]中选择文本文档的路径
将系统文件操作滑块拖动到两个评估周期
两种文件操作设置如下所示:
最后,添加一个[关闭网页]滑块,建立产品评估爬虫
在【界面设计与调试预览】中填写【商品链接】和【评估保存路径】,点击启动爬虫开始执行
打开商品评估词频分析工具。Xlsm,点击开始,选择刚到达采集的评估文件,稍等片刻,查看评估的词频统计
代码栈简介&;下载地址:/home/clientdownload.htm
代码栈官方学习手册:/help/index.html
爬虫抓取网页数据(用Python爬虫进行网站数据获取(I)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-21 23:08
这是很久以前的文章,幸运的是今天能够弥补,但也要感谢最近开始了解一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接先看看。本文假定您已经掌握了Python的基本语法和简单爬虫技术
单击以跳转到第1章:使用Python爬虫获取网站数据(I)
这一次,我们将解释一个爬虫程序登录到doublan,包括验证代码验证和登录后的简单数据爬虫
好的,给我看看密码
首先,我们需要了解背景。登录网站,实际上就是向服务器提交一些数据,包括用户名和密码、验证码以及其他您看不到的数据。不可见数据从网站到不同,但基本例程收录类似于ID的数据,每次提交的值不同,并且在前端看不到时提交
第一步是查看chrome上的登录页面,观察并找到一些需要提交的值,如前所述
/登录
给你个提示。如果您在没有Fidler或Charles等数据包捕获工具帮助的情况下直接登录,则无法查看要提交的数据。因此,作者估计输入了错误的验证代码进行验证。通过查看元素的登录名,您可以看到要提交的数据
如上图所示,您可以找到其他隐藏的提交信息,其中captcha解决方案是验证码,captcha ID是隐藏的ID值
第二步是找到要提交的隐藏ID和验证码
解决验证码提交问题。有两种主流方法。一种是手动输入,适用于低复杂性和并发性的新手爬虫。我们介绍了这种方法;二是利用OCR图像识别技术对训练数据进行一定精度的判断。这种方法比较重,不适合初学者。对童鞋感兴趣的人可以自己试穿
对于手动输入,首先我们需要查看验证码,然后输入它。所采用的方法是本地下载验证码图像,到相应路径打开图像,输入,然后提交登录表单
通过观察,我们可以发现验证码图像存储在这个路径中,所以我们可以在解析页面后找到这个路径后下载图像
隐藏ID的获取相对简单。在源代码下找到相应的ID,然后将其动态分配给提交表单
#coding=utf-8
#没有上面这行输入中文会报错,注意
import requests
from lxml import html
import os
import re
import urllib.request
login_url ="https://www.douban.com/login"
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步:提交表格
该表与步骤1中观察到的值一致
操作结果如下:
好了,这只爬行动物已经完成了。事实上,许多人已经发现API数据采集是一种更方便、更稳定的方法。通过网页爬虫的方法,首先,网页结构会发生变化,其次,我们需要对抗彼此的反爬虫机制。使用API是一种方便、高速和高光泽的方法 查看全部
爬虫抓取网页数据(用Python爬虫进行网站数据获取(I)(组图))
这是很久以前的文章,幸运的是今天能够弥补,但也要感谢最近开始了解一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接先看看。本文假定您已经掌握了Python的基本语法和简单爬虫技术
单击以跳转到第1章:使用Python爬虫获取网站数据(I)
这一次,我们将解释一个爬虫程序登录到doublan,包括验证代码验证和登录后的简单数据爬虫
好的,给我看看密码
首先,我们需要了解背景。登录网站,实际上就是向服务器提交一些数据,包括用户名和密码、验证码以及其他您看不到的数据。不可见数据从网站到不同,但基本例程收录类似于ID的数据,每次提交的值不同,并且在前端看不到时提交
第一步是查看chrome上的登录页面,观察并找到一些需要提交的值,如前所述
/登录
给你个提示。如果您在没有Fidler或Charles等数据包捕获工具帮助的情况下直接登录,则无法查看要提交的数据。因此,作者估计输入了错误的验证代码进行验证。通过查看元素的登录名,您可以看到要提交的数据
如上图所示,您可以找到其他隐藏的提交信息,其中captcha解决方案是验证码,captcha ID是隐藏的ID值
第二步是找到要提交的隐藏ID和验证码
解决验证码提交问题。有两种主流方法。一种是手动输入,适用于低复杂性和并发性的新手爬虫。我们介绍了这种方法;二是利用OCR图像识别技术对训练数据进行一定精度的判断。这种方法比较重,不适合初学者。对童鞋感兴趣的人可以自己试穿
对于手动输入,首先我们需要查看验证码,然后输入它。所采用的方法是本地下载验证码图像,到相应路径打开图像,输入,然后提交登录表单
通过观察,我们可以发现验证码图像存储在这个路径中,所以我们可以在解析页面后找到这个路径后下载图像
隐藏ID的获取相对简单。在源代码下找到相应的ID,然后将其动态分配给提交表单
#coding=utf-8
#没有上面这行输入中文会报错,注意
import requests
from lxml import html
import os
import re
import urllib.request
login_url ="https://www.douban.com/login"
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步:提交表格
该表与步骤1中观察到的值一致
操作结果如下:
好了,这只爬行动物已经完成了。事实上,许多人已经发现API数据采集是一种更方便、更稳定的方法。通过网页爬虫的方法,首先,网页结构会发生变化,其次,我们需要对抗彼此的反爬虫机制。使用API是一种方便、高速和高光泽的方法
爬虫抓取网页数据(需求抓取知乎问题下所有回答的爬虫意义在哪?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-21 07:16
我没有看到你很长一段时间,工作有点忙......虽然它每天都在爬虫中写着,它是用很多爬行动物解锁的,但它已经使用了很长时间由于在工作中的NodeJS编写Python。
解决需求问题,Python或nodejs是否只是语法和模块,分析思路和解决方案基本上是一致的。
最近写了一个简单的知乎回答爬虫,我有兴趣告诉它。
需求
在知乎问题下抓住所有答案,包括它的作者,作者粉丝号,回答内容,时间,回答号码,回答回答,并链接到答案。
分析
问题在上图中是一个例子,您想要获得相关数据的答案,通常我们可以按F12分析Chrome浏览器下的请求;但是,在查理捕获工具中,您可以更直观地获取相关领域:
请注意,LER U U UER String参数指示请求每次返回5个答案,并且测试可以更改为20;偏移代表从第一平均值开始;
返回的结果
是JSON格式。每个答案收录更多信息,我们只需要过滤要捕获的字段记录。
需要注意的是,答案返回内容字段,但其格式是Web标记。搜索后,我选择HTMLParser来解析,您将手动处理。
代码
import requests,jsonimport datetimeimport pandas as pdfrom selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/questions/486212129/answers'headers = { 'Host':'www.zhihu.com', 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36', 'referer':'https://www.zhihu.com/question/486212129'}df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start): print(start) global df data= { 'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled', 'offset':start, 'limit':20, 'sort_by':'default', 'platform':'desktop' }
#将携带的参数传给params r = requests.get(url, params=data,headers=headers) res = json.loads(r.text) if res['data']: for answer in res['data']: author = answer['author']['name'] fans = answer['author']['follower_count'] content = HTMLParser(answer['content']).text() #content = answer['content'] created_time = datetime.datetime.fromtimestamp(answer['created_time']) updated_time = datetime.datetime.fromtimestamp(answer['updated_time']) comment = answer['comment_count'] voteup = answer['voteup_count'] link = answer['url']
row = { 'author':[author], 'fans_count':[fans], 'content':[content], 'created_time':[created_time], 'updated_time':[updated_time], 'comment_count':[comment], 'voteup_count':[voteup], 'url':[link] } df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20: crawler(start+20) else: print(res) crawler(0)df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)print("done~")
结果
最终捕获结果大致如下:
你可以看到一些答案是空的。如果你去这个问题,你可以检查它是一个视频答案。如果没有文本内容,则忽略了,当然,您可以删除结果的视频链接。
current(202 1. 0 9)看看此问题界面没有特定的限制,包括直接在没有cookie的代码中的请求,并通过修改限制参数来减少请求的数量
crawli意味着
最近我也想爬网咯咯知乎回的的,首先,我想总结一下分析的所有答案,但实际上抓住了这个想法来阅读它,我发现在表单中读取的阅读经验是很穷。更好地刷知乎;但更明显的价值是,水平对比这几百答案,答案,评论和作者的粉丝很清楚。此外,可以根据结果进行一些词频率分析,单词云映射显示等,这些是稍后的单词。
爬虫只是获取数据的方法,如何解释它是更大的数据价值。
我是泰德,一天写一个爬虫,但我没有写过Python的数据工程师,我将继续更新一系列思克Python爬行动物项目。欢迎继续注意〜 查看全部
爬虫抓取网页数据(需求抓取知乎问题下所有回答的爬虫意义在哪?)
我没有看到你很长一段时间,工作有点忙......虽然它每天都在爬虫中写着,它是用很多爬行动物解锁的,但它已经使用了很长时间由于在工作中的NodeJS编写Python。
解决需求问题,Python或nodejs是否只是语法和模块,分析思路和解决方案基本上是一致的。
最近写了一个简单的知乎回答爬虫,我有兴趣告诉它。
需求
在知乎问题下抓住所有答案,包括它的作者,作者粉丝号,回答内容,时间,回答号码,回答回答,并链接到答案。
分析
问题在上图中是一个例子,您想要获得相关数据的答案,通常我们可以按F12分析Chrome浏览器下的请求;但是,在查理捕获工具中,您可以更直观地获取相关领域:
请注意,LER U U UER String参数指示请求每次返回5个答案,并且测试可以更改为20;偏移代表从第一平均值开始;
返回的结果
是JSON格式。每个答案收录更多信息,我们只需要过滤要捕获的字段记录。
需要注意的是,答案返回内容字段,但其格式是Web标记。搜索后,我选择HTMLParser来解析,您将手动处理。
代码
import requests,jsonimport datetimeimport pandas as pdfrom selectolax.parser import HTMLParser
url = 'https://www.zhihu.com/api/v4/questions/486212129/answers'headers = { 'Host':'www.zhihu.com', 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36', 'referer':'https://www.zhihu.com/question/486212129'}df = pd.DataFrame(columns=('author','fans_count','content','created_time','updated_time','comment_count','voteup_count','url'))
def crawler(start): print(start) global df data= { 'include':'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_recognized;data[*].mark_infos[*].url;data[*].author.follower_count,vip_info,badge[*].topics;data[*].settings.table_of_content.enabled', 'offset':start, 'limit':20, 'sort_by':'default', 'platform':'desktop' }
#将携带的参数传给params r = requests.get(url, params=data,headers=headers) res = json.loads(r.text) if res['data']: for answer in res['data']: author = answer['author']['name'] fans = answer['author']['follower_count'] content = HTMLParser(answer['content']).text() #content = answer['content'] created_time = datetime.datetime.fromtimestamp(answer['created_time']) updated_time = datetime.datetime.fromtimestamp(answer['updated_time']) comment = answer['comment_count'] voteup = answer['voteup_count'] link = answer['url']
row = { 'author':[author], 'fans_count':[fans], 'content':[content], 'created_time':[created_time], 'updated_time':[updated_time], 'comment_count':[comment], 'voteup_count':[voteup], 'url':[link] } df = df.append(pd.DataFrame(row),ignore_index=True)
if len(res['data'])==20: crawler(start+20) else: print(res) crawler(0)df.to_csv(f'result_{datetime.datetime.now().strftime("%Y-%m-%d")}.csv',index=False)print("done~")
结果
最终捕获结果大致如下:
你可以看到一些答案是空的。如果你去这个问题,你可以检查它是一个视频答案。如果没有文本内容,则忽略了,当然,您可以删除结果的视频链接。
current(202 1. 0 9)看看此问题界面没有特定的限制,包括直接在没有cookie的代码中的请求,并通过修改限制参数来减少请求的数量
crawli意味着
最近我也想爬网咯咯知乎回的的,首先,我想总结一下分析的所有答案,但实际上抓住了这个想法来阅读它,我发现在表单中读取的阅读经验是很穷。更好地刷知乎;但更明显的价值是,水平对比这几百答案,答案,评论和作者的粉丝很清楚。此外,可以根据结果进行一些词频率分析,单词云映射显示等,这些是稍后的单词。
爬虫只是获取数据的方法,如何解释它是更大的数据价值。
我是泰德,一天写一个爬虫,但我没有写过Python的数据工程师,我将继续更新一系列思克Python爬行动物项目。欢迎继续注意〜
爬虫抓取网页数据(如何从网站爬网数据中获取结构化数据?() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-18 03:20
)
原创来源:工作文本(从网站捕获数据的三种最佳方式)/网站@name(octoparse)
原创链接:从网站抓取数据的3种最佳方法
在过去几年中,对爬行数据的需求越来越大。爬网数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来网站@抓取数据的三种方法
1.use网站@API
许多大型社交媒体网站@,如Facebook、twitter、instagram和stackoverflow,都为用户访问其数据提供了API。有时,您可以选择官方API来获取结构化数据。如下面的Facebook graph API所示,您需要选择要查询的字段,然后排序数据、执行URL查找、发出请求等。有关更多信息,请参阅/docs/graph API/using graph API
2.构建自己的搜索引擎
然而,并非所有网站@都为用户提供API。一些网站@由于技术限制或其他原因拒绝提供任何公共API。有些人可能会建议RSS提要,但我不会对它们提出建议或评论,因为它们的使用是有限的。在这种情况下,我想讨论的是,我们可以构建自己的爬虫程序来处理这种情况
搜索者是如何工作的?换句话说,搜索者是一种生成URL列表的方法,这些URL可以由提取程序提供。您可以将搜索器定义为查找URL的工具。首先,为搜索者提供一个要启动的网页,该网页将跟随页面上的所有这些链接。然后,该过程将继续循环
然后我们可以继续建立自己的搜索引擎。众所周知,Python是一种开源编程语言,您可以找到许多有用的函数库。在这里,我推荐使用Beauty soup(Python库),因为它易于使用,并且具有许多直观的字符。相反,我将使用两个Python模块来抓取数据
Beautifulsoup无法为我们获取页面。这就是为什么我在美丽的汤库中使用urlib2。然后,我们需要处理HTML标记,以在正确的表中找到页面标记和所有链接。之后,遍历每一行(TR),然后将TR(TD)的每个元素分配给一个变量,并将其附加到列表中。首先,让我们看看表的HTML结构(我不会提取表标题的信息)
通过采用这种方法,您的搜索者是定制的。它可以处理API提取过程中遇到的一些困难。您可以使用代理来防止它被某些网站@等阻止。整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您获取的数据框应类似于下图
3.使用现有的爬虫工具
但是,通过编程自爬网网站@可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索工具
倍频程分析
Octoparse是一款基于可视窗口的强大web数据搜索工具。用户可以通过简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序
如下图所示,您可以在工作流设计器窗格中单击并拖动这些块来自定义自己的任务。Octoparse提供两个版本的爬网服务订阅计划-免费和付费。两者都可以满足用户的基本爬行或爬行需求。使用免费版本,您可以在本地运行任务
如果您将免费版本切换到付费版本,您可以通过将任务上载到云平台来使用基于云的服务。6到14台ECS将以更高的速度运行您的任务,并在更宽的范围内爬行。此外,您可以使用octoparse的匿名代理函数自动提取数据,而不留下任何痕迹。此功能可以依次使用大量IP,这可以防止您被网站@阻止。这是一个关于云提取的视频
Octoparse还提供API来实时将系统连接到爬网数据。您可以将octoparse数据导入自己的数据库,也可以使用API}请求访问您帐户的数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、txt和数据库(mysql、SQL server和Oracle)
进口
Import.io也称为web searcher,涵盖所有不同级别的搜索要求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果您需要获取更复杂的网站@,建议用户下载其桌面应用程序。构建API后,它们将提供许多简单的集成选项,如Google sheets、plot.ly、Excel以及get和post请求。当您认为所有这些都有终身免费的价格标签和强大的支持团队时,import.io无疑是寻找结构化数据的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项
本山达
Mozenda是另一个用户友好的web数据提取器。它为用户提供了一个点击式用户界面,无需任何编码技巧即可使用。Mozenda还消除了自动化和发布提取数据的麻烦。告诉mozenda您需要的数据一次,然后无论您需要多少次都可以得到它。此外,它允许使用RESTAPI进行高级编程,用户可以直接连接到mozenda帐户。它还提供基于云的服务和IP轮换
刮板架
SEO专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉scrapebox,它有一个非常友好的用户界面。用户可以轻松地从网站@采集数据,以获取电子邮件、检查页面排名、验证工作代理和RSS提交。通过使用数千个轮换代理,您将能够隐藏竞争对手的网站@关键字gov网站@进行研究、采集数据和评论,不被阻止或发现
GoogleWebScraper插件
如果人们只是想以简单的方式获取数据,建议您选择GoogleWebScraper插件。它是一个基于浏览器的网络爬虫,工作原理类似于Firefox的outwit hub。您可以将其作为扩展下载并安装到浏览器中。您需要突出显示要爬网的数据字段,右键单击并选择“类似刮擦…”。任何与突出显示的内容类似的内容都将呈现在准备导出的表中,并与Google文档兼容。最新版本的电子表格上仍有一些错误。虽然操作简单,但应该引起所有用户的注意,但它不能抓取图像和大量数据
查看全部
爬虫抓取网页数据(如何从网站爬网数据中获取结构化数据?()
)
原创来源:工作文本(从网站捕获数据的三种最佳方式)/网站@name(octoparse)
原创链接:从网站抓取数据的3种最佳方法
在过去几年中,对爬行数据的需求越来越大。爬网数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来网站@抓取数据的三种方法
1.use网站@API
许多大型社交媒体网站@,如Facebook、twitter、instagram和stackoverflow,都为用户访问其数据提供了API。有时,您可以选择官方API来获取结构化数据。如下面的Facebook graph API所示,您需要选择要查询的字段,然后排序数据、执行URL查找、发出请求等。有关更多信息,请参阅/docs/graph API/using graph API
2.构建自己的搜索引擎
然而,并非所有网站@都为用户提供API。一些网站@由于技术限制或其他原因拒绝提供任何公共API。有些人可能会建议RSS提要,但我不会对它们提出建议或评论,因为它们的使用是有限的。在这种情况下,我想讨论的是,我们可以构建自己的爬虫程序来处理这种情况
搜索者是如何工作的?换句话说,搜索者是一种生成URL列表的方法,这些URL可以由提取程序提供。您可以将搜索器定义为查找URL的工具。首先,为搜索者提供一个要启动的网页,该网页将跟随页面上的所有这些链接。然后,该过程将继续循环
然后我们可以继续建立自己的搜索引擎。众所周知,Python是一种开源编程语言,您可以找到许多有用的函数库。在这里,我推荐使用Beauty soup(Python库),因为它易于使用,并且具有许多直观的字符。相反,我将使用两个Python模块来抓取数据
Beautifulsoup无法为我们获取页面。这就是为什么我在美丽的汤库中使用urlib2。然后,我们需要处理HTML标记,以在正确的表中找到页面标记和所有链接。之后,遍历每一行(TR),然后将TR(TD)的每个元素分配给一个变量,并将其附加到列表中。首先,让我们看看表的HTML结构(我不会提取表标题的信息)
通过采用这种方法,您的搜索者是定制的。它可以处理API提取过程中遇到的一些困难。您可以使用代理来防止它被某些网站@等阻止。整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您获取的数据框应类似于下图
3.使用现有的爬虫工具
但是,通过编程自爬网网站@可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索工具
倍频程分析
Octoparse是一款基于可视窗口的强大web数据搜索工具。用户可以通过简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序
如下图所示,您可以在工作流设计器窗格中单击并拖动这些块来自定义自己的任务。Octoparse提供两个版本的爬网服务订阅计划-免费和付费。两者都可以满足用户的基本爬行或爬行需求。使用免费版本,您可以在本地运行任务
如果您将免费版本切换到付费版本,您可以通过将任务上载到云平台来使用基于云的服务。6到14台ECS将以更高的速度运行您的任务,并在更宽的范围内爬行。此外,您可以使用octoparse的匿名代理函数自动提取数据,而不留下任何痕迹。此功能可以依次使用大量IP,这可以防止您被网站@阻止。这是一个关于云提取的视频
Octoparse还提供API来实时将系统连接到爬网数据。您可以将octoparse数据导入自己的数据库,也可以使用API}请求访问您帐户的数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、txt和数据库(mysql、SQL server和Oracle)
进口
Import.io也称为web searcher,涵盖所有不同级别的搜索要求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果您需要获取更复杂的网站@,建议用户下载其桌面应用程序。构建API后,它们将提供许多简单的集成选项,如Google sheets、plot.ly、Excel以及get和post请求。当您认为所有这些都有终身免费的价格标签和强大的支持团队时,import.io无疑是寻找结构化数据的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项
本山达
Mozenda是另一个用户友好的web数据提取器。它为用户提供了一个点击式用户界面,无需任何编码技巧即可使用。Mozenda还消除了自动化和发布提取数据的麻烦。告诉mozenda您需要的数据一次,然后无论您需要多少次都可以得到它。此外,它允许使用RESTAPI进行高级编程,用户可以直接连接到mozenda帐户。它还提供基于云的服务和IP轮换
刮板架
SEO专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉scrapebox,它有一个非常友好的用户界面。用户可以轻松地从网站@采集数据,以获取电子邮件、检查页面排名、验证工作代理和RSS提交。通过使用数千个轮换代理,您将能够隐藏竞争对手的网站@关键字gov网站@进行研究、采集数据和评论,不被阻止或发现
GoogleWebScraper插件
如果人们只是想以简单的方式获取数据,建议您选择GoogleWebScraper插件。它是一个基于浏览器的网络爬虫,工作原理类似于Firefox的outwit hub。您可以将其作为扩展下载并安装到浏览器中。您需要突出显示要爬网的数据字段,右键单击并选择“类似刮擦…”。任何与突出显示的内容类似的内容都将呈现在准备导出的表中,并与Google文档兼容。最新版本的电子表格上仍有一些错误。虽然操作简单,但应该引起所有用户的注意,但它不能抓取图像和大量数据
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 532 次浏览 • 2021-09-17 18:04
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下
抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):
本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:
马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它
捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行
观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行
生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]
切割和更换
继续切割、更换和固定
最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:
查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文
标准->;经典 查看全部
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
续自第1部分:Stata crawler在网页上捕获数据的详细说明第1部分
Do文件和相关文件链接:密码:40uq
如果链接失败,请发送一封私人信件,您将回复。多谢各位
让我们开始捕获1000个网页的源代码,它们是temp1.txt-temp1000.Txt保存在e盘的2文件夹中,再次使用“merge.Bat”将1000个Txt文件合并成一个文件all.Txt。首先将命令放在这里,并在下面逐一解释:
注意:第一行上的本地命令必须与以下两个循环一起运行,否则将提示错误。原因解释如下
抓取1000个网页源代码并合并它们
使用local命令生成一个临时变量n=\un(注意:在Stata中,nand是具有固定含义的默认变量,它表示观察值的数量,这里当然等于1000,表示从1到1000。要理解这两种情况,可以使用Gen n=\n,Gen n=\n,然后浏览查看n和n之间的差异),但本地命令生成的变量n不会显示在变量窗口中,它临时存储在Stata的内存中,必要时可以调用。下面是一个小示例,演示本地命令的作用(请注意,必须同时运行本地命令行和调用本地生成的变量的下一行,否则将提示错误,因为本地宏命令生成的变量只是临时的。一旦遇到do文件结尾[观察Stata主界面,每个命令运行后都会提示do文件结束]生成的临时变量将被删除,不能再次调用,见下图官方英文解释,图中已用蓝色标记,特别是最后一句):
本地命令演示和比较\un和\un差异
有关Marco宏的进一步说明,请参阅官方帮助文件中的相关说明,如下所示:
马可·麦克罗的官方解释
在理解了local之后,接下来的两个循环就容易多了。第二个循环对应并存储URL变量和purl变量(purl变量是前1000个链接)一个接一个,但不显示在变量窗口中。第三个循环调用URL变量中存储的1000个网址,并复制1000个网页的源代码,它存储在磁盘E的2文件夹中,并命名为temp1.txt-temp1000.Txt,这个过程取决于网络速度,大约需要30分钟。请看数字变化如下图所示,最后temp1000.Txt已完成。之所以提示未找到,是因为我们在grab命令后附加了replace选项,即如果在e盘的文件夹2中找到同名文件,则通知Stata替换该文件,但Stata发现没有同名文件,因此不会提示f如果Stata发现一个同名的文件,它将不会被提示,而是直接替换它
捕获1000个网页源代码的过程
经过长时间的等待,我们最终使用第1部分中使用的bat batch命令调用DOS,将1000个TXT合并到all.TXT中(这次在文件夹2中处理,这与之前的all.TXT不同).到目前为止,我们已经获得了1000个网页的源代码,这非常重要,因为我们需要的所有GDP信息都收录在其中。类似地,我们使用中缀命令将其读入Stata进行处理。该命令显示在文本开头的图中。由于文本较大,因此最好在阅读之前将其清除文本,否则Stata可能会崩溃。如果写了半天的dofile没有保存,它就坏了(我不知道具体原因,我想可能是内存不足?)
阅读文本后,它是一个变量V,然后开始过滤和净化。这也是最复杂的工作,因为从总共735748行代码中只需要提取两个信息,一个是“某个地区的多少年”,另一个是“GDP”.根据我们需要的信息,我们寻找收录这两个信息的关键行,并观察这些行的共同特征。通过观察,我们可以看到带有区域名称的行收录这些字符,带有GDP或GDP的行收录“GDP”等字符(如下图所示)因此,我们只需要保留收录这两个字符的代码行
观察代码行的特征并找出规则
步骤1:设置两个指标变量(虚拟变量形式的虚拟变量)a和B。对于一个变量,如果V变量(即所有代码行所在的变量)收录,则让Stata返回值1,表示“是”,否则返回0,表示“否”。同样,B变量与“国内生产总值”一起生成作为指示符。那么,如果a==1,则keep | B==1意味着保留收录或收录“GDP”的行。此步骤快速过滤代码行数,使其仅为4570行
生成两个指标变量
第2步-第n步:都是切割、保留、切割、保留、切割、保留…因为处理方法可能不同。My不一定是最好的,但原理是一样的。因此,只解释了使用的一些命令和功能。请参阅do文件中的相关注释[strpos,duplicates drop]
切割和更换
继续切割、更换和固定
最终数据
可以看出,有些数据前面有一些乱七八糟的字符,这是由于每个公告的书写格式不一致造成的,需要继续处理,方法同上,拆分、替换、保留,这里没有进一步的演示,有兴趣的可以继续
随机查找多个数据进行网站查询,查看对应数据是否准确,比如我在上图左右随机选择了2015年合肥、2013年九江进行验证,查询结果如下,验证准确:
查询验证结果
最后,对于空缺部分,您可以网站单独查找数据进行填充。此外,本次到期的数据为1000行,但最终获得的数据为1015行。原因可能是公告的格式不完全统一,部分数据为本省GDP(较少),有些是城市的GDP,因此存在重复部分。这些错误必须根据研究人员的需要进行处理
好了,这一章的详细讲解到此结束。洒些花吧!(0.0))@
最后提示:Stata12、13白色主界面默认不支持中文,中文显示为乱码,您可以在主界面的任意位置右键点击>;首选项,然后将配色方案模式由标准改为经典,正常显示中文
标准->;经典
爬虫抓取网页数据(一下爬虫如何获取网页数据?IP代理精灵为您介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-17 14:14
使用爬虫可以获取大量的Web信息,从而节省时间。如果只靠手动操作,时间会大大增加。现在,随着互联网用户数量的增加和大量的网络信息,如何抓取收录如此大量信息的数据?以下IP代理向导介绍爬虫程序如何获取网页数据
一、crawler如何获取web数据
1.输入网站,选择所需网页的一部分,并使用这些网页的链接地址作为种子URL
2.URL将其放入要爬网的URL队列中,爬网器依次从要爬网的URL队列中读取URL,通过DNS解析URL,并将链接地址转换为网站服务器对应的IP地址
3.将与网页相关的路径名提供给网页下载程序,该程序负责下载网页内容
4.将下载的网页存储在页面库中,等待后续处理,如索引;另一方面,将下载网页的URL放入爬网URL队列,该队列记录爬网器系统下载的网页URL,以避免网页重复爬网
5.对于新下载的网页,从中提取所有链接信息,并在已爬网的URL队列中进行检查。如果发现该链接尚未爬网,则将该URL放在要爬网的URL队列的末尾,在后续爬网调度中将下载该URL对应的网页
这样,就形成了一个循环,直到要获取的URL队列为空,这意味着爬虫系统已经获取了所有可以获取的网页。此时,完成了一轮完整的获取过程
二、爬行动物的常见类型是什么
大多数爬行动物都遵循这个过程,但这并不意味着所有的爬行动物都是如此一致。根据不同的应用,爬虫系统在许多方面有所不同。一般来说,爬虫可分为以下三种类型:
1.垂直爬行动物
垂直爬虫关注特定行业的特定主题内容或网页。例如,对于health网站,他们只需要从互联网页面中查找与健康相关的页面内容,而不考虑其他行业的内容。垂直爬虫最大的特点和困难之一是如何识别web内容是否属于特定的行业或主题。从节省系统资源的角度来看,下载后不太可能对所有互联网页面进行筛选。这种资源浪费太多了。为了节省资源,爬虫通常需要在捕获阶段动态识别网站是否与主题相关,并尽量不捕获不相关的页面。垂直搜索网站或垂直行业网站通常需要这种类型的爬虫程序
2.batch crawler
批处理爬虫具有相对清晰的捕获范围和目标。当爬虫到达设置的目标时,它将停止捕获过程。至于具体的目标,它们可能会有所不同,可能设置为爬网一定数量的网页,或者设置爬网所消耗的时间,等等
3.incremental crawler
与批处理爬虫不同,增量爬虫保持连续爬虫。捕获的网页应定期更新,因为Internet网页不断变化,新网页、网页被删除或网页内容更改很常见,而增量爬虫需要及时反映这些变化,因此它们处于不断爬网的过程中,要么抓取新网页,要么更新现有网页。一般的商业搜索引擎爬虫基本上属于这一类
上面描述了抓取数据的过程,可以清楚地了解爬虫是如何获取网页数据的。爬虫也分为不同的类型。不同的类型使用不同的方法,但需要注意的是,有些网络爬虫无法爬行,而且比例也很高。这部分网页构成了一个不可知的网页集合 查看全部
爬虫抓取网页数据(一下爬虫如何获取网页数据?IP代理精灵为您介绍)
使用爬虫可以获取大量的Web信息,从而节省时间。如果只靠手动操作,时间会大大增加。现在,随着互联网用户数量的增加和大量的网络信息,如何抓取收录如此大量信息的数据?以下IP代理向导介绍爬虫程序如何获取网页数据
一、crawler如何获取web数据
1.输入网站,选择所需网页的一部分,并使用这些网页的链接地址作为种子URL
2.URL将其放入要爬网的URL队列中,爬网器依次从要爬网的URL队列中读取URL,通过DNS解析URL,并将链接地址转换为网站服务器对应的IP地址
3.将与网页相关的路径名提供给网页下载程序,该程序负责下载网页内容
4.将下载的网页存储在页面库中,等待后续处理,如索引;另一方面,将下载网页的URL放入爬网URL队列,该队列记录爬网器系统下载的网页URL,以避免网页重复爬网
5.对于新下载的网页,从中提取所有链接信息,并在已爬网的URL队列中进行检查。如果发现该链接尚未爬网,则将该URL放在要爬网的URL队列的末尾,在后续爬网调度中将下载该URL对应的网页
这样,就形成了一个循环,直到要获取的URL队列为空,这意味着爬虫系统已经获取了所有可以获取的网页。此时,完成了一轮完整的获取过程
二、爬行动物的常见类型是什么
大多数爬行动物都遵循这个过程,但这并不意味着所有的爬行动物都是如此一致。根据不同的应用,爬虫系统在许多方面有所不同。一般来说,爬虫可分为以下三种类型:
1.垂直爬行动物
垂直爬虫关注特定行业的特定主题内容或网页。例如,对于health网站,他们只需要从互联网页面中查找与健康相关的页面内容,而不考虑其他行业的内容。垂直爬虫最大的特点和困难之一是如何识别web内容是否属于特定的行业或主题。从节省系统资源的角度来看,下载后不太可能对所有互联网页面进行筛选。这种资源浪费太多了。为了节省资源,爬虫通常需要在捕获阶段动态识别网站是否与主题相关,并尽量不捕获不相关的页面。垂直搜索网站或垂直行业网站通常需要这种类型的爬虫程序
2.batch crawler
批处理爬虫具有相对清晰的捕获范围和目标。当爬虫到达设置的目标时,它将停止捕获过程。至于具体的目标,它们可能会有所不同,可能设置为爬网一定数量的网页,或者设置爬网所消耗的时间,等等
3.incremental crawler
与批处理爬虫不同,增量爬虫保持连续爬虫。捕获的网页应定期更新,因为Internet网页不断变化,新网页、网页被删除或网页内容更改很常见,而增量爬虫需要及时反映这些变化,因此它们处于不断爬网的过程中,要么抓取新网页,要么更新现有网页。一般的商业搜索引擎爬虫基本上属于这一类
上面描述了抓取数据的过程,可以清楚地了解爬虫是如何获取网页数据的。爬虫也分为不同的类型。不同的类型使用不同的方法,但需要注意的是,有些网络爬虫无法爬行,而且比例也很高。这部分网页构成了一个不可知的网页集合
爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-17 09:22
引用别人的答案,希望对你有用
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。以下是爬虫和爬虫系统的简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子URL
2.将这些URL放入要获取的URL队列
3.从要获取的URL队列中获取要获取的URL,解析DNS,获取主机IP,下载URL对应的网页并存储在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4.分析已爬网URL队列中的URL,分析其他URL,将URL放入待爬网的URL队列中,进入下一个循环
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
1.下载的未过期页面
2.下载和过期网页:捕获的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。互联网上的一些内容发生了变化。此时,捕获的网页已过期
3.待下载网页:即URL队列中待抓取的网页
4.known web page:尚未捕获且不在要捕获的URL队列中,但可以通过分析捕获的页面或与要捕获的URL对应的页面来获得的URL被视为已知网页
5.还有一些网页不能被爬虫直接抓取和下载。它被称为不可知网页
三、grab策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
4.PartialPageRank策略
部分PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与要获取的URL队列中的URL一起,形成一个网页集合,计算每个页面的PageRank值,计算后根据PageRank值的大小排列要获取的URL队列中的URL,然后按这个顺序抓取页面
如果一次抓取一页,请重新计算PageRank值。折衷方案是每k页重新计算PageRank值。但是,在这种情况下会有一个问题:对于下载页面中分析的链接,即前面提到的未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面提供一个临时的PageRank值:汇总该页面链中传递的所有PageRank值,从而形成未知页面的PageRank值,从而参与排序。以下是一个例子:
5.OPIC战略战略
事实上,该算法还对页面的重要性进行评分。在算法开始之前,为所有页面提供相同的初始现金(cash)。下载页面P后,将P的现金分配给从P分析的所有链接,并清空P的现金。URL队列中要提取的所有页面都按现金金额排序
6.大站优先战略
要获取的URL队列中的所有网页都根据它们所属的网站进行分类。对于需要下载大量页面的网站而言,应优先考虑下载。这种策略也称为大站优先策略 查看全部
爬虫抓取网页数据(一个通用的网络爬虫的基本结构及工作流程(组图))
引用别人的答案,希望对你有用
网络爬虫是搜索引擎捕获系统的重要组成部分。爬虫的主要目的是将Internet上的网页下载到本地,以形成网络内容的镜像或备份。以下是爬虫和爬虫系统的简要概述
一、web爬虫的基本结构和工作流程
网络爬虫的总体框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子URL
2.将这些URL放入要获取的URL队列
3.从要获取的URL队列中获取要获取的URL,解析DNS,获取主机IP,下载URL对应的网页并存储在下载的网页库中。此外,将这些URL放入已爬网的URL队列
4.分析已爬网URL队列中的URL,分析其他URL,将URL放入待爬网的URL队列中,进入下一个循环
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可分为五个部分:
1.下载的未过期页面
2.下载和过期网页:捕获的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。互联网上的一些内容发生了变化。此时,捕获的网页已过期
3.待下载网页:即URL队列中待抓取的网页
4.known web page:尚未捕获且不在要捕获的URL队列中,但可以通过分析捕获的页面或与要捕获的URL对应的页面来获得的URL被视为已知网页
5.还有一些网页不能被爬虫直接抓取和下载。它被称为不可知网页
三、grab策略
在爬虫系统中,要获取的URL队列是一个非常重要的部分。URL队列中要获取的URL的排列顺序也是一个非常重要的问题,因为它涉及先获取页面,然后获取哪个页面。确定这些URL顺序的方法称为爬网策略。以下重点介绍几种常见的捕获策略:
1.深度优先遍历策略
深度优先遍历策略意味着网络爬虫将从起始页开始,逐个跟踪链接。处理完这一行后,它将转到下一个起始页并继续跟踪链接。以下图为例:
遍历路径:a-f-g e-h-i B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思想是将新下载的网页中的链接直接插入要爬网的URL队列的末尾。也就是说,网络爬虫将首先抓取起始页面中的所有链接页面,然后选择其中一个链接页面以继续抓取此页面中的所有链接页面。以上图为例:
遍历路径:a-b-c-d-e-f g h I
3.反向链路计数策略
反向链接数是指其他网页指向某个网页的链接数。反向链接的数量表示其他人推荐网页内容的程度。因此,大多数情况下,搜索引擎的爬行系统都会利用这个指标来评价网页的重要性,从而确定不同网页的爬行顺序
在现实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全等着他或我。因此,搜索引擎经常考虑可靠的反向链接数量
4.PartialPageRank策略
部分PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与要获取的URL队列中的URL一起,形成一个网页集合,计算每个页面的PageRank值,计算后根据PageRank值的大小排列要获取的URL队列中的URL,然后按这个顺序抓取页面
如果一次抓取一页,请重新计算PageRank值。折衷方案是每k页重新计算PageRank值。但是,在这种情况下会有一个问题:对于下载页面中分析的链接,即前面提到的未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面提供一个临时的PageRank值:汇总该页面链中传递的所有PageRank值,从而形成未知页面的PageRank值,从而参与排序。以下是一个例子:
5.OPIC战略战略
事实上,该算法还对页面的重要性进行评分。在算法开始之前,为所有页面提供相同的初始现金(cash)。下载页面P后,将P的现金分配给从P分析的所有链接,并清空P的现金。URL队列中要提取的所有页面都按现金金额排序
6.大站优先战略
要获取的URL队列中的所有网页都根据它们所属的网站进行分类。对于需要下载大量页面的网站而言,应优先考虑下载。这种策略也称为大站优先策略
爬虫抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-17 09:19
我们可以把互联网比作一个大网络,而爬虫(即网络爬虫)就是在互联网上爬行的蜘蛛。通过比较web节点和web页面,爬虫会爬到该页面,这相当于访问该页面并获取其信息。节点之间的连接可以比作网页之间的链接关系。这样,爬行器通过一个节点后,可以继续沿着节点连接爬行到下一个节点,也就是说,可以继续通过一个网页获取后续的网页,这样爬行器就可以对整个网络的节点进行爬行,并捕获网站数据
1.爬行动物概述
简而言之,crawler是一个自动获取网页、提取和保存信息的程序。以下是概述
(1)get网页)
爬虫应该做的第一件事是获取网页。以下是该网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息
我们在前面讨论了请求和响应的概念。当您向网站server发送请求时,返回的响应主体是网页源代码。因此,最关键的部分是构造一个请求并将其发送到服务器,然后接收响应并解析它。如何实施这一过程?您无法手动截取网页源代码
不用担心,python提供了许多库来帮助我们实现此操作,例如urllib、请求等。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。得到响应后,只需解析数据结构的主体部分即可得到网页的源代码,这样就可以用程序实现获取网页的过程
(2)提取信息)
获得网页源代码后,下一步是分析网页源代码并提取所需的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但在构造正则表达式时非常复杂且容易出错
此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如beautiful soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、,文本值等
信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
(3)save data)
在提取信息之后,我们通常将提取的数据保存在某个地方以供后续使用。有很多方法可以保存它,例如简单地将其保存为TXT文本或JSON文本,将其保存到数据库(如MySQL和mongodb),或将其保存到远程服务器(如使用SFTP操作)
(4)automated program)
说到自动化程序,这意味着爬虫程序可以代替人来完成这些操作。首先,我们可以手动提取这些信息,但如果等价物非常大,或者您想要快速获取大量数据,则必须使用程序。爬虫程序是代替我们完成爬虫工作的自动化程序,它可以执行爬虫过程处理、错误重试等操作中的各种异常,以确保爬虫的持续高效运行
2.可以捕获什么样的数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码
此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便
此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中
此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
事实上,上述内容对应于各自的URL,并且基于HTTP或HTTPS协议。只要是这样的数据,爬虫就可以抓取它
3.JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同
这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
This is a Demo
body节点中只有一个ID为container的节点,但需要注意的是app.js是在body节点之后引入的,它负责整个网站的渲染@
在浏览器中打开此页面时,将首先加载HTML内容,然后浏览器将发现其中引入了app.js文件,然后它将请求此文件。获取文件后,将执行JavaScript代码,JavaScript将更改HTML中的节点,向其中添加内容,最后获得完整的页面
但是,当使用库(如urllib或requests)请求当前页面时,我们得到的只是HTML代码,这不会帮助我们继续加载JavaScript文件,因此我们无法在浏览器中看到内容
这也解释了为什么有时我们会从浏览器中看到不同的源代码
因此,使用基本HTTP请求库获得的源代码可能与浏览器中的页面源代码不同。在本例中,我们可以分析其背景Ajax接口,或者使用selenium和splash等库来模拟JavaScript呈现
稍后,我们将介绍如何采集JavaScript呈现网页
本节介绍了爬虫的一些基本原理,这些原理可以帮助我们以后更轻松地编写爬虫
本资源来源于崔庆才的个人博客《精米:Python 3网络爬虫开发实用教程》|精米 查看全部
爬虫抓取网页数据(总不能手工去网页源码吧(1)_光明网(组图))
我们可以把互联网比作一个大网络,而爬虫(即网络爬虫)就是在互联网上爬行的蜘蛛。通过比较web节点和web页面,爬虫会爬到该页面,这相当于访问该页面并获取其信息。节点之间的连接可以比作网页之间的链接关系。这样,爬行器通过一个节点后,可以继续沿着节点连接爬行到下一个节点,也就是说,可以继续通过一个网页获取后续的网页,这样爬行器就可以对整个网络的节点进行爬行,并捕获网站数据
1.爬行动物概述
简而言之,crawler是一个自动获取网页、提取和保存信息的程序。以下是概述
(1)get网页)
爬虫应该做的第一件事是获取网页。以下是该网页的源代码。源代码收录一些有用的网页信息,因此只要您获得源代码,就可以从中提取所需的信息
我们在前面讨论了请求和响应的概念。当您向网站server发送请求时,返回的响应主体是网页源代码。因此,最关键的部分是构造一个请求并将其发送到服务器,然后接收响应并解析它。如何实施这一过程?您无法手动截取网页源代码
不用担心,python提供了许多库来帮助我们实现此操作,例如urllib、请求等。我们可以使用这些库来帮助我们实现HTTP请求操作。请求和响应可以由类库提供的数据结构表示。得到响应后,只需解析数据结构的主体部分即可得到网页的源代码,这样就可以用程序实现获取网页的过程
(2)提取信息)
获得网页源代码后,下一步是分析网页源代码并提取所需的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但在构造正则表达式时非常复杂且容易出错
此外,由于网页的结构有一定的规则,因此有一些库可以根据网页节点属性、CSS选择器或XPath提取网页信息,如beautiful soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、,文本值等
信息提取是爬虫的重要组成部分。它可以使杂乱的数据组织和清晰,以便我们以后可以处理和分析数据
(3)save data)
在提取信息之后,我们通常将提取的数据保存在某个地方以供后续使用。有很多方法可以保存它,例如简单地将其保存为TXT文本或JSON文本,将其保存到数据库(如MySQL和mongodb),或将其保存到远程服务器(如使用SFTP操作)
(4)automated program)
说到自动化程序,这意味着爬虫程序可以代替人来完成这些操作。首先,我们可以手动提取这些信息,但如果等价物非常大,或者您想要快速获取大量数据,则必须使用程序。爬虫程序是代替我们完成爬虫工作的自动化程序,它可以执行爬虫过程处理、错误重试等操作中的各种异常,以确保爬虫的持续高效运行
2.可以捕获什么样的数据
我们可以在网页上看到各种各样的信息。最常见的是与HTML代码相对应的常规网页,最常见的捕获是HTML源代码
此外,一些网页可能会返回JSON字符串而不是HTML代码(大多数API接口都采用这种形式)。这种格式的数据便于传输和解析。它们也可以被抓取,数据提取更方便
此外,我们还可以看到各种二进制数据,如图片、视频和音频。使用爬虫,我们可以抓取这些二进制数据并将它们保存到相应的文件名中
此外,您还可以看到具有各种扩展名的文件,例如CSS、JavaScript和配置文件。事实上,这些也是最常见的文件。只要您可以在浏览器中访问它们,就可以抓取它们
事实上,上述内容对应于各自的URL,并且基于HTTP或HTTPS协议。只要是这样的数据,爬虫就可以抓取它
3.JavaScript呈现页面
有时候,当我们抓取一个收录urllib或请求的网页时,我们得到的源代码实际上与我们在浏览器中看到的不同
这是一个非常普遍的问题。如今,越来越多的web页面是通过Ajax和前端模块工具构建的。整个网页可能由JavaScript呈现,也就是说,原创HTML代码是一个空壳,例如:
This is a Demo
body节点中只有一个ID为container的节点,但需要注意的是app.js是在body节点之后引入的,它负责整个网站的渲染@
在浏览器中打开此页面时,将首先加载HTML内容,然后浏览器将发现其中引入了app.js文件,然后它将请求此文件。获取文件后,将执行JavaScript代码,JavaScript将更改HTML中的节点,向其中添加内容,最后获得完整的页面
但是,当使用库(如urllib或requests)请求当前页面时,我们得到的只是HTML代码,这不会帮助我们继续加载JavaScript文件,因此我们无法在浏览器中看到内容
这也解释了为什么有时我们会从浏览器中看到不同的源代码
因此,使用基本HTTP请求库获得的源代码可能与浏览器中的页面源代码不同。在本例中,我们可以分析其背景Ajax接口,或者使用selenium和splash等库来模拟JavaScript呈现
稍后,我们将介绍如何采集JavaScript呈现网页
本节介绍了爬虫的一些基本原理,这些原理可以帮助我们以后更轻松地编写爬虫
本资源来源于崔庆才的个人博客《精米:Python 3网络爬虫开发实用教程》|精米
爬虫抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-17 09:17
网络爬虫与网络爬虫
在当今时代,基于数据做出业务决策是许多公司的头等大事。为了推动这些决策,该公司24小时跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量公共数据,这有助于企业在竞争激烈的市场中保持领先地位
许多公司出于商业目的从各种网站中提取数据是很常见的。但是,在获取数据后,手动提取操作无法轻松快速地将数据应用到日常工作中。因此,在本文中,little oxy将向您介绍网络数据提取的方法和需要面对的困难,并向您介绍几种可以帮助您更好地抓取数据的解决方案
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂和难以理解的事情。然而,理解整个过程并不那么复杂
网站提取数据的过程称为网络爬网,有时称为网络采集。该术语通常指使用机器人或网络爬虫自动提取数据的过程。有时,网络爬行的概念很容易与网络爬行的概念混淆。因此,在上一篇文章文章中,我们介绍了web爬行和web爬行之间的主要区别
今天,让我们讨论数据提取的整个过程,以充分了解数据提取的工作原理
数据提取的工作原理
今天,我们获取的数据主要由HTML表示,HTML是一种基于文本的标记语言。它通过各种组件定义网站内容结构,包括
,等等。开发人员可以使用脚本从任何形式的数据结构中提取数据
构建数据提取脚本
这一切都是从构建数据提取脚本开始的。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的刮板机器人。Python的优势,如多样的库、简单性和活跃的社区,使其成为编写web爬网脚本的最流行编程语言。这些脚本支持完全自动化的数据提取。它们向服务器发送请求,访问选定的URL,并遍历每个先前定义的页面、HTML标记和组件。然后,从这些地方提取数据
开发各种数据爬行模式
可以个性化开发数据提取脚本,并且只能从特定的HTML组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这还将减轻服务器的负担,减少存储空间需求,并使数据处理更容易
设置服务器环境
要连续运行网络爬虫,您需要一台服务器。因此,下一步是投资于服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周7天、每天24小时运行数据提取脚本,并简化数据记录和存储
确保有足够的存储空间
数据提取脚本的交付是数据。大规模数据需要大的存储容量。从多个网站页面提取的数据可以转换成数千个网页。由于过程是连续的,最终会获得大量的数据。确保有足够的存储空间来维护爬网操作非常重要
数据处理
采集数据以其原创形式出现,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分
数据提取工具
有很多方法可以从网页中提取公共数据—构建内部工具或使用现成的web捕获解决方案,如Oxylab real-time crawler
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源团队,那么构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎都不想公开他们的数据,并且已经建立了检测机器人行为的算法,这使得爬行更具挑战性
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型
2.找到数据的显示位置并构建抓取路径
3.导入并安装所需的必备环境
4.编写一个数据提取脚本并实现它
为了避免IP阻塞,模仿普通互联网用户的行为非常重要。这是代理需要干预的地方,这使得所有数据采集任务都更容易。我们将在以下内容中继续讨论
实时爬虫
实时爬虫等工具的主要优点之一是,它可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间
内部解决方案必须通过试错来创造解决方案,这意味着不可避免的效率降低、IP地址阻塞和不可靠的定价数据流。使用实时抓取工具,整个过程完全自动化。您的员工可以专注于更紧急的事项,直接进行数据分析,而不是无休止地复制和粘贴
网络数据提取的好处
大数据是商界的一个新词。它涵盖了许多面向目标的数据采集过程——获得有意义的见解、确定趋势和模式以及预测经济状况。例如,在线获取房地产数据有助于分析哪些因素会影响该行业。同样,从汽车行业获取数据也很有用。公司采集有关汽车行业的数据,如用户和汽车零部件评论
各行各业的公司从网站提取数据,以更新数据的相关性和实时性。其他网站也将这样做,以确保数据集的完整性。数据越多越好,可以提供更多的参考,使整个数据集更加有效
企业想要提取哪些数据
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素
您可能会对许多数据目标感兴趣。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等。您还可以自定义数据提取脚本以查找新产品和服务。只需确保在执行任何爬网活动之前,爬网公共数据不会侵犯任何第三方的权利
常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:
数据捕获的最佳实践
为了解决上述问题,我们可以通过由经验丰富的专业人员开发的复杂数据提取脚本来解决这些问题。然而,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案——代理。更具体地说,IP代理
IP轮换代理将允许您访问大量IP地址。从位于不同地理区域的IP发送请求将欺骗服务器并防止阻塞。或者,可以使用代理旋转。代理旋转器将使用代理数据中心池中的IP,并自动分配它们,而不是手动分配IP
如果你没有足够的资源和经验丰富的开发团队来进行网络爬行,现在是考虑使用现成的解决方案的时候了,比如实时爬虫。它确保了搜索引擎和电子商务的访问网站100%完成捕获任务,简化数据管理并汇总数据,以便您能够轻松理解
从网站提取数据合法吗@
许多企业依赖大数据,其需求显著增加。根据statista的研究统计,大数据市场每年都在快速增长,预计到2027年将达到1030亿美元。这使得越来越多的企业将网络爬网作为最常用的数据采集方法之一。这种流行引发了一个广泛讨论的问题,即网络爬网是否合法
由于这个复杂的问题没有明确的答案,因此有必要确保要执行的任何网络捕获操作都不会违反相关法律。更重要的是,在获取任何数据之前,我们强烈建议根据具体情况寻求专业法律意见
此外,我们强烈建议您不要捕获任何非公共数据,除非您获得目标网站的明确许可@
Little oxy提醒您,本文中的任何内容都不应被解释为捕获任何非公开数据的建议
结论
总之,您需要一个数据提取脚本来从中提取数据网站. 正如您所看到的,由于操作范围、复杂性和网站结构的变化,构建这些脚本可能具有挑战性。然而,即使有一个好的脚本,如果您想在长时间内实时捕获数据而不被阻止,您仍然需要使用旋转代理来更改您的IP
如果您认为您的企业需要一个多功能的解决方案来简化数据提取,那么现在就可以注册并开始使用Oxylab的实时爬虫
如果您有任何问题,请随时与我们联系 查看全部
爬虫抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网络爬虫与网络爬虫
在当今时代,基于数据做出业务决策是许多公司的头等大事。为了推动这些决策,该公司24小时跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量公共数据,这有助于企业在竞争激烈的市场中保持领先地位
许多公司出于商业目的从各种网站中提取数据是很常见的。但是,在获取数据后,手动提取操作无法轻松快速地将数据应用到日常工作中。因此,在本文中,little oxy将向您介绍网络数据提取的方法和需要面对的困难,并向您介绍几种可以帮助您更好地抓取数据的解决方案
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂和难以理解的事情。然而,理解整个过程并不那么复杂
网站提取数据的过程称为网络爬网,有时称为网络采集。该术语通常指使用机器人或网络爬虫自动提取数据的过程。有时,网络爬行的概念很容易与网络爬行的概念混淆。因此,在上一篇文章文章中,我们介绍了web爬行和web爬行之间的主要区别
今天,让我们讨论数据提取的整个过程,以充分了解数据提取的工作原理
数据提取的工作原理
今天,我们获取的数据主要由HTML表示,HTML是一种基于文本的标记语言。它通过各种组件定义网站内容结构,包括
,等等。开发人员可以使用脚本从任何形式的数据结构中提取数据
构建数据提取脚本
这一切都是从构建数据提取脚本开始的。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的刮板机器人。Python的优势,如多样的库、简单性和活跃的社区,使其成为编写web爬网脚本的最流行编程语言。这些脚本支持完全自动化的数据提取。它们向服务器发送请求,访问选定的URL,并遍历每个先前定义的页面、HTML标记和组件。然后,从这些地方提取数据
开发各种数据爬行模式
可以个性化开发数据提取脚本,并且只能从特定的HTML组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这还将减轻服务器的负担,减少存储空间需求,并使数据处理更容易
设置服务器环境
要连续运行网络爬虫,您需要一台服务器。因此,下一步是投资于服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周7天、每天24小时运行数据提取脚本,并简化数据记录和存储
确保有足够的存储空间
数据提取脚本的交付是数据。大规模数据需要大的存储容量。从多个网站页面提取的数据可以转换成数千个网页。由于过程是连续的,最终会获得大量的数据。确保有足够的存储空间来维护爬网操作非常重要
数据处理
采集数据以其原创形式出现,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分
数据提取工具
有很多方法可以从网页中提取公共数据—构建内部工具或使用现成的web捕获解决方案,如Oxylab real-time crawler
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源团队,那么构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎都不想公开他们的数据,并且已经建立了检测机器人行为的算法,这使得爬行更具挑战性
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型
2.找到数据的显示位置并构建抓取路径
3.导入并安装所需的必备环境
4.编写一个数据提取脚本并实现它
为了避免IP阻塞,模仿普通互联网用户的行为非常重要。这是代理需要干预的地方,这使得所有数据采集任务都更容易。我们将在以下内容中继续讨论
实时爬虫
实时爬虫等工具的主要优点之一是,它可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间
内部解决方案必须通过试错来创造解决方案,这意味着不可避免的效率降低、IP地址阻塞和不可靠的定价数据流。使用实时抓取工具,整个过程完全自动化。您的员工可以专注于更紧急的事项,直接进行数据分析,而不是无休止地复制和粘贴
网络数据提取的好处
大数据是商界的一个新词。它涵盖了许多面向目标的数据采集过程——获得有意义的见解、确定趋势和模式以及预测经济状况。例如,在线获取房地产数据有助于分析哪些因素会影响该行业。同样,从汽车行业获取数据也很有用。公司采集有关汽车行业的数据,如用户和汽车零部件评论
各行各业的公司从网站提取数据,以更新数据的相关性和实时性。其他网站也将这样做,以确保数据集的完整性。数据越多越好,可以提供更多的参考,使整个数据集更加有效
企业想要提取哪些数据
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素
您可能会对许多数据目标感兴趣。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等。您还可以自定义数据提取脚本以查找新产品和服务。只需确保在执行任何爬网活动之前,爬网公共数据不会侵犯任何第三方的权利
常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:
数据捕获的最佳实践
为了解决上述问题,我们可以通过由经验丰富的专业人员开发的复杂数据提取脚本来解决这些问题。然而,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案——代理。更具体地说,IP代理
IP轮换代理将允许您访问大量IP地址。从位于不同地理区域的IP发送请求将欺骗服务器并防止阻塞。或者,可以使用代理旋转。代理旋转器将使用代理数据中心池中的IP,并自动分配它们,而不是手动分配IP
如果你没有足够的资源和经验丰富的开发团队来进行网络爬行,现在是考虑使用现成的解决方案的时候了,比如实时爬虫。它确保了搜索引擎和电子商务的访问网站100%完成捕获任务,简化数据管理并汇总数据,以便您能够轻松理解
从网站提取数据合法吗@
许多企业依赖大数据,其需求显著增加。根据statista的研究统计,大数据市场每年都在快速增长,预计到2027年将达到1030亿美元。这使得越来越多的企业将网络爬网作为最常用的数据采集方法之一。这种流行引发了一个广泛讨论的问题,即网络爬网是否合法
由于这个复杂的问题没有明确的答案,因此有必要确保要执行的任何网络捕获操作都不会违反相关法律。更重要的是,在获取任何数据之前,我们强烈建议根据具体情况寻求专业法律意见
此外,我们强烈建议您不要捕获任何非公共数据,除非您获得目标网站的明确许可@
Little oxy提醒您,本文中的任何内容都不应被解释为捕获任何非公开数据的建议
结论
总之,您需要一个数据提取脚本来从中提取数据网站. 正如您所看到的,由于操作范围、复杂性和网站结构的变化,构建这些脚本可能具有挑战性。然而,即使有一个好的脚本,如果您想在长时间内实时捕获数据而不被阻止,您仍然需要使用旋转代理来更改您的IP
如果您认为您的企业需要一个多功能的解决方案来简化数据提取,那么现在就可以注册并开始使用Oxylab的实时爬虫
如果您有任何问题,请随时与我们联系
爬虫抓取网页数据(爬虫抓取网页数据的三个文件,你可以只需要一台python3.5)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-16 13:07
爬虫抓取网页数据,是不是必须有合适的机器才能抓取呢?是的,抓取网页数据基本上需要用到服务器。不过,使用本篇文章的环境搭建方法,你可以只需要一台python3.5,就可以实现抓取网页。以上图为例,我们以动态网页的抓取为例,演示安装和配置所需要的一些系统环境。首先,打开python的文件夹,你可以看到动态网页抓取的三个文件:loadserver.pyps:loadserver.py是静态网页抓取用的,支持python3和python2.7。
爬虫服务器方法:global=""配置文件,cp=5001/python37750/3.5/scrapy10.cmd需要global=""设置的是scrapy默认爬取下来的内容的global变量。我们可以调用这个global变量,来控制scrapy需要抓取的单元内容。配置http_url_txt="-"配置http_url_txt文件,需要在一个文件内增加两行,content="phantomjs"app_urls=["/","="]app_url_txt=content+"/".format(app_urls.format())withscrapy.session()assession:scrapy.session.save(url_txt,http_url_txt)scrapy.session.reload(session)defspeed(item):item.set_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/51.0.3039.121safari/537.36")scrapy.session.connect("",process_scrapy_on_message="connectto",url_txt,http_url_txt)scrapy.session.autoscroll("",item.page_bytes())scrapy.session.use_random()defurl(item):url_txt="",and"path_by"=item.paths["index.php"]["index"]["full_page"]["show_rel"]["content"]["title"]["category"]scrapy.session.save(url_txt,url_txt,http_url_txt)returnurl_txt将#url_txt配置为本地,可直接调用!#loadserver.py配置为局域网环境,防止主机名被封。如果您要做的是全局爬取网页而不是爬取独立服务器上的某个网页,请使用局域网环境。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据的三个文件,你可以只需要一台python3.5)
爬虫抓取网页数据,是不是必须有合适的机器才能抓取呢?是的,抓取网页数据基本上需要用到服务器。不过,使用本篇文章的环境搭建方法,你可以只需要一台python3.5,就可以实现抓取网页。以上图为例,我们以动态网页的抓取为例,演示安装和配置所需要的一些系统环境。首先,打开python的文件夹,你可以看到动态网页抓取的三个文件:loadserver.pyps:loadserver.py是静态网页抓取用的,支持python3和python2.7。
爬虫服务器方法:global=""配置文件,cp=5001/python37750/3.5/scrapy10.cmd需要global=""设置的是scrapy默认爬取下来的内容的global变量。我们可以调用这个global变量,来控制scrapy需要抓取的单元内容。配置http_url_txt="-"配置http_url_txt文件,需要在一个文件内增加两行,content="phantomjs"app_urls=["/","="]app_url_txt=content+"/".format(app_urls.format())withscrapy.session()assession:scrapy.session.save(url_txt,http_url_txt)scrapy.session.reload(session)defspeed(item):item.set_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/51.0.3039.121safari/537.36")scrapy.session.connect("",process_scrapy_on_message="connectto",url_txt,http_url_txt)scrapy.session.autoscroll("",item.page_bytes())scrapy.session.use_random()defurl(item):url_txt="",and"path_by"=item.paths["index.php"]["index"]["full_page"]["show_rel"]["content"]["title"]["category"]scrapy.session.save(url_txt,url_txt,http_url_txt)returnurl_txt将#url_txt配置为本地,可直接调用!#loadserver.py配置为局域网环境,防止主机名被封。如果您要做的是全局爬取网页而不是爬取独立服务器上的某个网页,请使用局域网环境。
爬虫抓取网页数据(文中介绍的非常详细,具有一定的参考价值们一定要看完!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-16 09:01
本文文章主要介绍如何在Python crawler中捕获著名的引号网站。它非常详细,具有一定的参考价值。有兴趣的朋友一定要读
1、输入网址
/,转到网站主页,观察网页的结构。我们发现网页的内容非常清晰
它主要分为名人名言、作者和标签三个主要字段,三个字段的内容都是提取的内容
2、确定需求并分析网页结构
打开开发者工具并单击networ进行网络数据包捕获分析,网站是一个不带参数的get请求。然后我们可以使用请求库中的get()方法来模拟请求。我们需要引入headers请求来模拟浏览器信息验证,以防止网站服务器将其检测为爬虫请求
您还可以单击开发人员工具的左箭头,帮助我们在“元素”选项卡上快速找到网页数据的位置
3、分析网页结构并提取数据
请求成功后,可以开始提取数据~。我使用XPath的解析方法。因此,首先解析XPath页面并单击左侧的小箭头以帮助我们快速定位数据。网页数据位于“元素”选项卡上。因为网页的请求数据在列表中逐项排序,所以我们可以首先找到整个列表的数据。在LXM中,HTML解析器将字段逐个抓取并保存到列表中,这便于下一步的数据清理
4、保存到CSV文件 查看全部
爬虫抓取网页数据(文中介绍的非常详细,具有一定的参考价值们一定要看完!)
本文文章主要介绍如何在Python crawler中捕获著名的引号网站。它非常详细,具有一定的参考价值。有兴趣的朋友一定要读
1、输入网址
/,转到网站主页,观察网页的结构。我们发现网页的内容非常清晰
它主要分为名人名言、作者和标签三个主要字段,三个字段的内容都是提取的内容
2、确定需求并分析网页结构
打开开发者工具并单击networ进行网络数据包捕获分析,网站是一个不带参数的get请求。然后我们可以使用请求库中的get()方法来模拟请求。我们需要引入headers请求来模拟浏览器信息验证,以防止网站服务器将其检测为爬虫请求
您还可以单击开发人员工具的左箭头,帮助我们在“元素”选项卡上快速找到网页数据的位置
3、分析网页结构并提取数据
请求成功后,可以开始提取数据~。我使用XPath的解析方法。因此,首先解析XPath页面并单击左侧的小箭头以帮助我们快速定位数据。网页数据位于“元素”选项卡上。因为网页的请求数据在列表中逐项排序,所以我们可以首先找到整个列表的数据。在LXM中,HTML解析器将字段逐个抓取并保存到列表中,这便于下一步的数据清理
4、保存到CSV文件
爬虫抓取网页数据(大数据从业工作者Import.io网页数据抽取工具一览)
网站优化 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-09-14 15:02
作为大数据从业者和研究人员,很多时候需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网页数据提取工具来实现这个目的。接下来小编就为大家盘点七种常用的网络数据提取工具。
1.Import.io
这个工具是一个不需要客户端的爬虫工具。一切都可以在浏览器中完成。操作方便简单。抓取数据后,可以在可视化界面进行过滤。
2.Parsehub
此工具需要下载客户端才能运行。该工具打开后,类似于浏览器。输入网址后,就可以提取数据了。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
本工具是一款基于Chrome浏览器的插件,可直接通过谷歌应用商店免费获取安装。可以轻松抓取静态网页,用js动态加载网页。
想进一步了解这个工具的使用方法,可以参考下面的教程:对于爬虫问题,这个就够了
4. 80legs
该工具的背后是一个由 50,000 台计算机组成的 Plura 网格。它功能强大,但更适合企业级客户。商业用途明显,监控能力强,价格相对较贵。
5.优采云采集器
该工具是目前国内最成熟的网页数据采集工具。需要下载客户端,可以在客户端抓取可视化数据。该工具还有国际版的 Octoparse 软件。根据采集能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。价格从每年0元到69800元不等。虽然免费版可以免费采集,但数据导出需要额外收费。
6.早熟
这是一款面向起步较晚但爬取效率高的企业的基于网络的云爬取工具。无需额外下载客户端。
7.优采云采集器
这是中国老牌的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。收费方式为软件收费,旗舰版售价1000元左右,付款后不限。 查看全部
爬虫抓取网页数据(大数据从业工作者Import.io网页数据抽取工具一览)
作为大数据从业者和研究人员,很多时候需要从网页中获取数据。如果不想自己写爬虫程序,可以使用一些专业的网页数据提取工具来实现这个目的。接下来小编就为大家盘点七种常用的网络数据提取工具。
1.Import.io
这个工具是一个不需要客户端的爬虫工具。一切都可以在浏览器中完成。操作方便简单。抓取数据后,可以在可视化界面进行过滤。
2.Parsehub
此工具需要下载客户端才能运行。该工具打开后,类似于浏览器。输入网址后,就可以提取数据了。它支持 Windows、MacOS 和 Linux 操作系统。
3. 网络爬虫
本工具是一款基于Chrome浏览器的插件,可直接通过谷歌应用商店免费获取安装。可以轻松抓取静态网页,用js动态加载网页。
想进一步了解这个工具的使用方法,可以参考下面的教程:对于爬虫问题,这个就够了
4. 80legs
该工具的背后是一个由 50,000 台计算机组成的 Plura 网格。它功能强大,但更适合企业级客户。商业用途明显,监控能力强,价格相对较贵。
5.优采云采集器
该工具是目前国内最成熟的网页数据采集工具。需要下载客户端,可以在客户端抓取可视化数据。该工具还有国际版的 Octoparse 软件。根据采集能力,该工具分为免费版、专业版、旗舰版、私有云、企业定制版五个版本。价格从每年0元到69800元不等。虽然免费版可以免费采集,但数据导出需要额外收费。
6.早熟
这是一款面向起步较晚但爬取效率高的企业的基于网络的云爬取工具。无需额外下载客户端。
7.优采云采集器
这是中国老牌的采集器公司。很早就商业化了,但是学习成本高,规则制定也比较复杂。收费方式为软件收费,旗舰版售价1000元左右,付款后不限。

