爬虫抓取网页数据(先来说下数据抓取系统的大致工作流程.下背景 )
优采云 发布时间: 2022-03-27 18:05爬虫抓取网页数据(先来说下数据抓取系统的大致工作流程.下背景
)
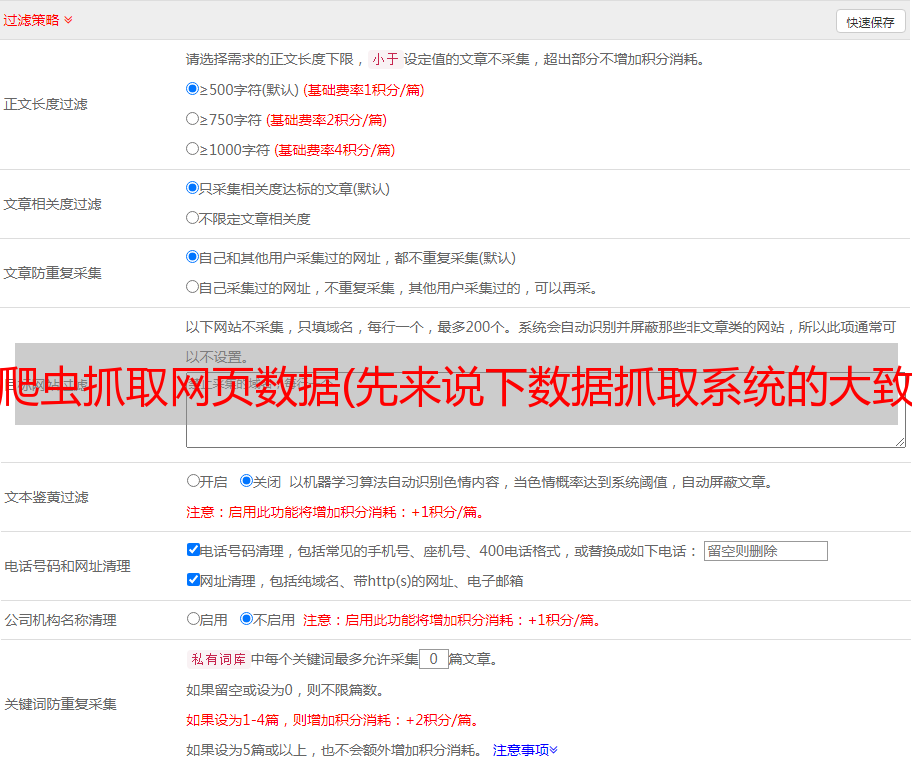
公司的数据采集系统也写了一段时间了,该总结一下了,不然凭我的记忆力,一会就快忘记了。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,让我们谈谈数据捕获的一般工作流程。
先说一下背景,这家公司是做企业征信服务的。整合各个方面的数据以生成商业信用报告。主要数据来源,包括:第三方采购(整体采购数据或接口形式);捕获在 Internet 上发布的数据。那么就需要一个数据采集平台,以便为采集方便快捷的添加新的数据对象。对于数据采集平台的架构设计,本人也是新手,以后在学习的同时总结这方面的经验和教训。本系列从实战开始,然后是第一个*敏*感*词*:数据采集的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人认为这三个步骤是我做的。不过,先听我说。##清除数据采集先分享场景的要求:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张加班后还没有完成任务。是因为产品经理没有把需求解释清楚吗?但产品经理也表示,这个页面上的所有内容都是必需的。问题是:
要分析数据为采集的url和相关参数,我先走一下我抓取数据的流程,看下面四张图:
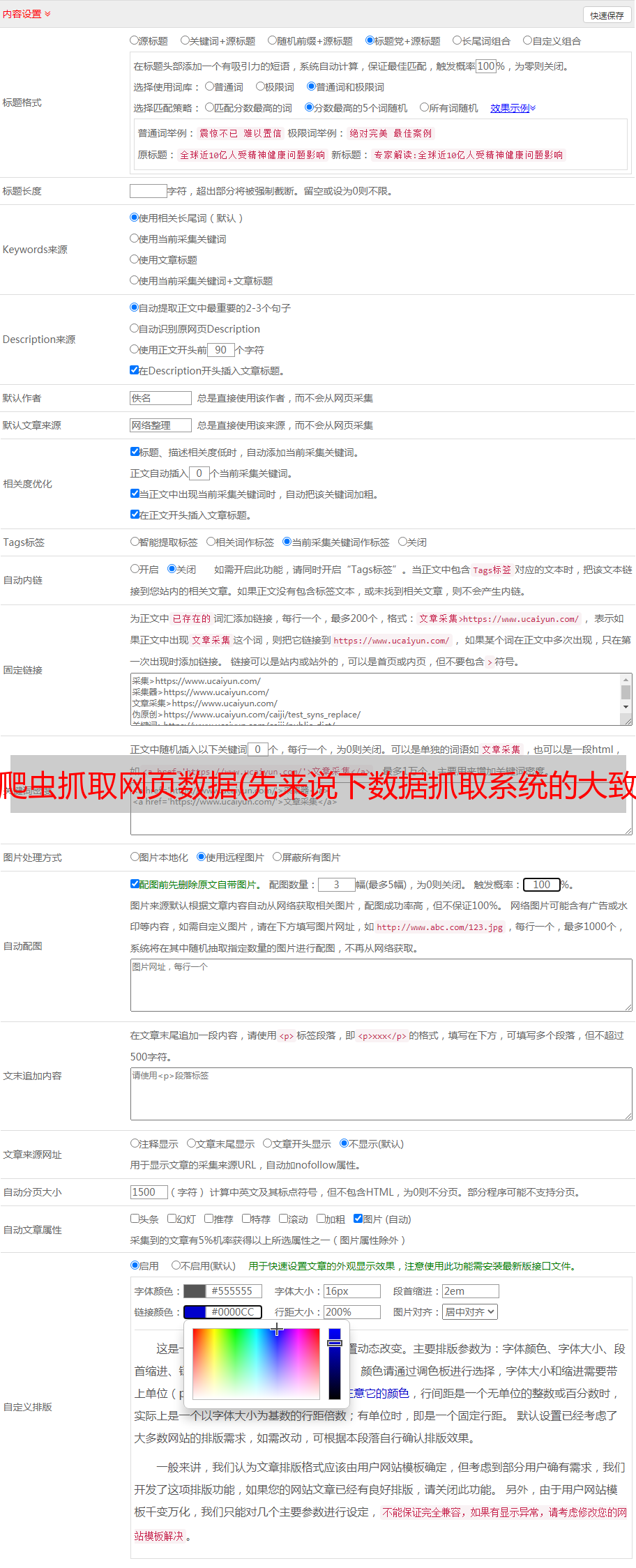
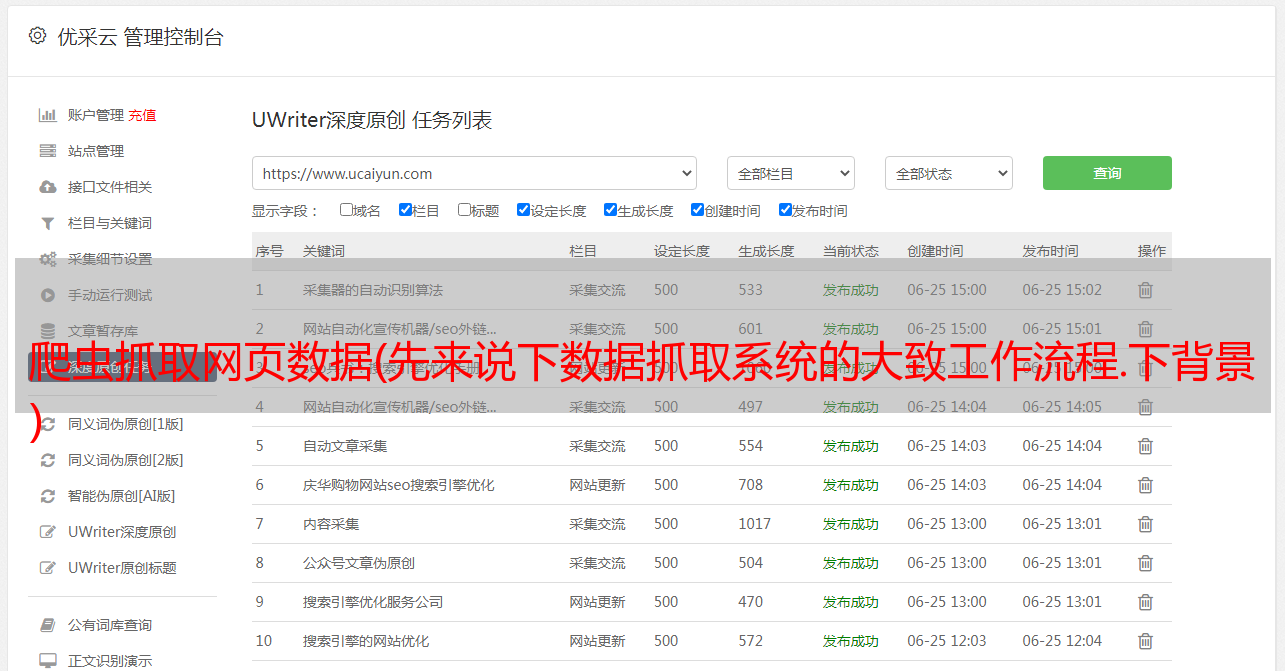
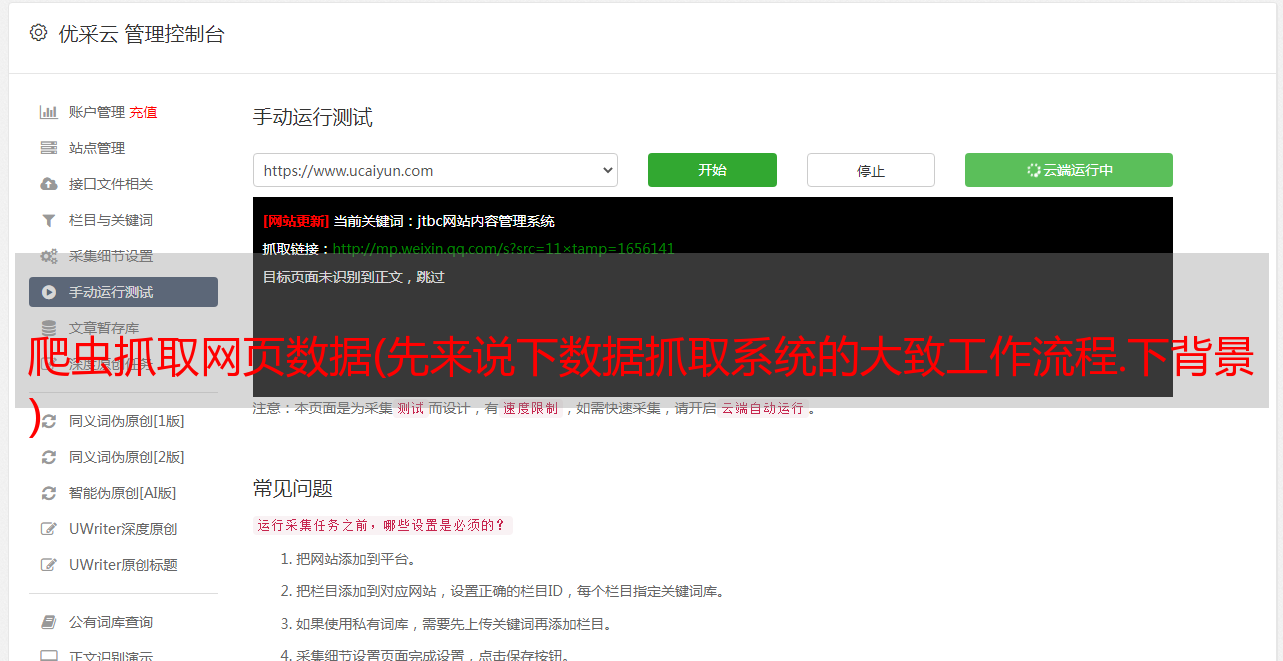
提取url和参数
从以上四张图我们可以确认有以下几个连接需要处理:- 1、获取验证码连接- 2、提交查询- 3、查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用chrome的开发者工具来分析页面。有很多类似的工具。各个浏览器自带的开发者工具基本可以满足需求。也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们提取了企业的基本注册信息为采集,我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。这个文章就不详细介绍代码实现的具体逻辑了,因为本文的重点是讲解:爬取网页的工作流程。后面代码实现过程中用到的关键技术点和踩过的坑都会一一总结。暂列涉及的相关内容:
也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天做个小笔记,每天进步一点:
善待大众:enilu123