
浏览器抓取网页
浏览器抓取网页(手机浏览器cookie怎么查看?手机cookie获取方法汇总!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2022-02-09 03:17
一、在IE浏览器查看cookie的方法一:在浏览器地址栏输入:javascript:alert(document.cookie)(差别不大。
手机如何查看cookies?操作步骤如下: 1、首先点击IE页面右上角的“工具”按钮,如何查看手机浏览器cookies?.
如何查看手机浏览器cookies?手机浏览器的cookie设置用于确定使用哪个浏览器。如果是 cookie 浏览器,解决方案。
csdn为您找到了可以查看cookies的手机浏览器的相关内容,包括可以查看cookies的手机浏览器的相关文档代码介绍。
手机如何获取浏览器的cookie?下面我们来看看如何获取手机cookie。一、华为手机1、先找到华为手机。
确保打开手机浏览器的cookie设置2.进入手机浏览器的设置页面后,点击当前页面的无痕浏览加快速度。
您可以直接在网页上搜索。自带的浏览器一般都不是很完善。建议您使用手机QQ浏览器的功能性、安全性和便捷性。
微信保存百度云链接的时候,虽然无法打开任何cookies,但还是有办法保存的。点击右上角三个点,用QQ浏览器打开。
我的浏览器选项里没有“cookie”选项,但是设置里有“清除缓存”,如何判断?您可以通过浏览器的菜单-系统设置-。 查看全部
浏览器抓取网页(手机浏览器cookie怎么查看?手机cookie获取方法汇总!!)
一、在IE浏览器查看cookie的方法一:在浏览器地址栏输入:javascript:alert(document.cookie)(差别不大。
手机如何查看cookies?操作步骤如下: 1、首先点击IE页面右上角的“工具”按钮,如何查看手机浏览器cookies?.
如何查看手机浏览器cookies?手机浏览器的cookie设置用于确定使用哪个浏览器。如果是 cookie 浏览器,解决方案。
csdn为您找到了可以查看cookies的手机浏览器的相关内容,包括可以查看cookies的手机浏览器的相关文档代码介绍。
手机如何获取浏览器的cookie?下面我们来看看如何获取手机cookie。一、华为手机1、先找到华为手机。

确保打开手机浏览器的cookie设置2.进入手机浏览器的设置页面后,点击当前页面的无痕浏览加快速度。
您可以直接在网页上搜索。自带的浏览器一般都不是很完善。建议您使用手机QQ浏览器的功能性、安全性和便捷性。

微信保存百度云链接的时候,虽然无法打开任何cookies,但还是有办法保存的。点击右上角三个点,用QQ浏览器打开。
我的浏览器选项里没有“cookie”选项,但是设置里有“清除缓存”,如何判断?您可以通过浏览器的菜单-系统设置-。
浏览器抓取网页(Python中爬虫基础快速入门的学习方法,值得收藏!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-08 04:24
对于小白来说,爬虫可能是一件非常复杂、技术含量很高的事情。比如很多人认为学习爬虫一定要掌握Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来数据;有的人认为需要先了解网页的知识,于是入手HTML\CSS,结果就是前端的坑,皱巴巴的……
但是如果知道正确的方法,短期内可以爬取主流的网站数据。我认为实现起来并不难,但建议你从一开始就设定明确的目标。
在目标的驱动下,你的学习会更有效率。你觉得必要的专业知识,可以在完成目标的过程中学习。这里为大家提供一个零基础的快速入门学习方法。
01学习Python包并执行基本爬取步骤
大多数爬虫都是按照“发送请求-获取页面-解析页面-提取并存储内容”的过程来实现的,它模拟了使用浏览器爬取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求或者学习Selenium来自动化。这样动态知乎、、TripAdvisor网站也可以解决。
02 了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为csv等文件。
当然,你可能会发现爬取的数据不干净,可能有缺失、错误等,你也需要对数据进行清洗,可以学习pandas包的基本用法来做数据预处理,得到更干净的数据。
03 掌握各种技巧应对特殊网站防爬措施
当然在爬取的过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
所以有些东西看起来很吓人,但当它们崩溃时,也仅此而已。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
同时可以使用掘金的ip代理和相关的防屏蔽来辅助。(百度搜索:掘金.com) 查看全部
浏览器抓取网页(Python中爬虫基础快速入门的学习方法,值得收藏!)
对于小白来说,爬虫可能是一件非常复杂、技术含量很高的事情。比如很多人认为学习爬虫一定要掌握Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来数据;有的人认为需要先了解网页的知识,于是入手HTML\CSS,结果就是前端的坑,皱巴巴的……
但是如果知道正确的方法,短期内可以爬取主流的网站数据。我认为实现起来并不难,但建议你从一开始就设定明确的目标。
在目标的驱动下,你的学习会更有效率。你觉得必要的专业知识,可以在完成目标的过程中学习。这里为大家提供一个零基础的快速入门学习方法。
01学习Python包并执行基本爬取步骤
大多数爬虫都是按照“发送请求-获取页面-解析页面-提取并存储内容”的过程来实现的,它模拟了使用浏览器爬取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求或者学习Selenium来自动化。这样动态知乎、、TripAdvisor网站也可以解决。
02 了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为csv等文件。
当然,你可能会发现爬取的数据不干净,可能有缺失、错误等,你也需要对数据进行清洗,可以学习pandas包的基本用法来做数据预处理,得到更干净的数据。
03 掌握各种技巧应对特殊网站防爬措施
当然在爬取的过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
所以有些东西看起来很吓人,但当它们崩溃时,也仅此而已。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
同时可以使用掘金的ip代理和相关的防屏蔽来辅助。(百度搜索:掘金.com)
浏览器抓取网页(环境核心类库puppeteer文档安装第一步获取获取文章详情 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-08 02:20
)
环境核心类库
傀儡师
文档
安装
npm i puppeteer -S
第一步是获取网页的内容
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
以上代码可以获取整个页面。测试发现问题已经解决。其实puppeteer有一个特殊的方法可以解决这个问题,page.waitForSelector,等待匹配指定选择器的元素出现在页面上。
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第二步,获取列表中的标题和链接
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
const list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
console.log(list.length)
console.log(list)
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第三步,获取文章详情
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
console.log(list[0])
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第四步,保存数据
这里不介绍保存到数据库,简单写个json文件。
const puppeteer = require('puppeteer');
const fs = require('fs')
const path = require('path')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
// 保存数据
fs.writeFileSync(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
最后进行方法提取等处理
方法文件
const fs = require('fs')
exports.init = async function (browser) {
let page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto("https://juejin.cn/frontend");
await page.waitForSelector('.entry-list-wrap .entry-list .item');
return page;
}
exports.getList = async function (page) {
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
return list.slice(0, 10)
}
exports.getListDetail = async function (list, page) {
for (let i = 0; i e.innerHTML)
}
return list
}
exports.writeFile = async function (name, content) {
fs.writeFileSync(name, content)
}
主文件
const puppeteer = require('puppeteer');
const path = require('path')
const methods = require('./methods')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
try {
// 初始化
let page = await methods.init(browser);
// 获取列表中标题和链接
let list = await methods.getList(page)
// 获取文章详情
list = await methods.getListDetail(list, page)
// 保存数据
methods.writeFile(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
} catch (error) {
console.error(error)
// 关闭浏览器
await browser.close();
}
})
项目地址
查看全部
浏览器抓取网页(环境核心类库puppeteer文档安装第一步获取获取文章详情
)
环境核心类库
傀儡师
文档
安装
npm i puppeteer -S
第一步是获取网页的内容
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
以上代码可以获取整个页面。测试发现问题已经解决。其实puppeteer有一个特殊的方法可以解决这个问题,page.waitForSelector,等待匹配指定选择器的元素出现在页面上。
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第二步,获取列表中的标题和链接
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
const list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
console.log(list.length)
console.log(list)
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第三步,获取文章详情
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
console.log(list[0])
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第四步,保存数据
这里不介绍保存到数据库,简单写个json文件。
const puppeteer = require('puppeteer');
const fs = require('fs')
const path = require('path')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
// 保存数据
fs.writeFileSync(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
最后进行方法提取等处理
方法文件
const fs = require('fs')
exports.init = async function (browser) {
let page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto("https://juejin.cn/frontend";);
await page.waitForSelector('.entry-list-wrap .entry-list .item');
return page;
}
exports.getList = async function (page) {
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
return list.slice(0, 10)
}
exports.getListDetail = async function (list, page) {
for (let i = 0; i e.innerHTML)
}
return list
}
exports.writeFile = async function (name, content) {
fs.writeFileSync(name, content)
}
主文件
const puppeteer = require('puppeteer');
const path = require('path')
const methods = require('./methods')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
try {
// 初始化
let page = await methods.init(browser);
// 获取列表中标题和链接
let list = await methods.getList(page)
// 获取文章详情
list = await methods.getListDetail(list, page)
// 保存数据
methods.writeFile(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
} catch (error) {
console.error(error)
// 关闭浏览器
await browser.close();
}
})
项目地址

浏览器抓取网页(1.selenium安装selenium库的介绍及安装和常见的使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-07 16:18
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
1
2
3
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
1
from selenium import webdriver
如果初始浏览器已经放在 Scripts 文件夹中,会直接调用。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
1
2
3
4
5
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
1
2
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
1
2
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
1
2
3
4
5
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新和刷新键一样,最好写个异常检测
1
2
3
4
5
6
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
1
2
3
4
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
1
2
3
4
5
6
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
1
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
1
2
按 id/name/class 定位
1
2
3
4
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
根据标签定位,但实际上,一个页面上可能有很多相同的标签,这会使标签点模糊,从而导致错误。
1
2
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
link定位,定位连接名,例如定位在百度左上角链接的例子中。
1
2
3
4
5
6
新闻
hao123
地图
...
直接通过链接名称定位。
1
2
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
1
2
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
上述xpath定位的方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
1
2
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
CSS定位这个方法比xpath更简洁更快
1
2
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素当然,有时候我们只需要多个元素,所以只需要使用复数即可。
1
2
3
4
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性比如要获取百度logo的信息,先定位图片元素,再获取信息
1
2
3
4
5
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本,首先使用类直接查找热列表元素,但是有多个元素,所以使用复数形式获取,使用for循环打印。获取文本时,使用文本获取
1
2
3
4
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性以获取例如 id 或 tag
1
2
3
4
5
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
在百度搜索框输入/清除“冬奥会”等文字,然后清除
1
2
3
4
5
6
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(Enter) 输入以上内容后,需要点击回车提交,即可得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要添加一些伪装的方法。在本文的最后。:point_right:。
1
2
search_bar.send_keys('冬奥会')
search_bar.submit()
单击 当我们需要单击时,使用单击。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
1
2
3
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
1
2
3
4
5
6
7
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击是double_click。如果找不到合适的例子,我就不提了。这里是 ActionChains,可以深入挖掘,定义一系列操作一起执行。当然,一些常用的操作其实就足够了。
悬停,我无法将其放入。
1
ActionChains(browser).move_to_element(move).perform()
从下拉框中选择需要导入的相关库,访问MySQL官网选择下载对应的操作系统为例。
1
2
3
4
5
6
7
8
9
10
11
12
13
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖拽多用于验证码之类的,参考菜鸟示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 27%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待可以发现,在上面的程序中,有些效果需要延迟等待才能出现。在实践中,它也需要一定的延迟。一方面为了不访问太频繁被认为是爬虫,另一方面也是爬虫。由于网络资源的加载,需要一定的时间等待。
1
2
3
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截图可以保存为base64/png/file
1
browser.get_screenshot_as_file('截图.png')
窗口切换 我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
1
2
3
4
5
6
7
8
9
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
1
2
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条 有些网页的内容是随着进度条的滑动出现的,所以需要下拉进度条的操作。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
1
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
1
2
3
4
5
6
7
8
9
10
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。如果仔细观察,操作非常详细。模仿真实的浏览器操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导:joy:。
和直接获取资源的爬虫相比,肯定是慢了一些,但是比强大的要好,而且还是可以提高钓鱼效率:+1:。 查看全部
浏览器抓取网页(1.selenium安装selenium库的介绍及安装和常见的使用方法)
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
1
2
3
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
1
from selenium import webdriver
如果初始浏览器已经放在 Scripts 文件夹中,会直接调用。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
1
2
3
4
5
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
1
2
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
1
2
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
1
2
3
4
5
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新和刷新键一样,最好写个异常检测
1
2
3
4
5
6
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
1
2
3
4
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
1
2
3
4
5
6
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
1
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
1
2
按 id/name/class 定位
1
2
3
4
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
根据标签定位,但实际上,一个页面上可能有很多相同的标签,这会使标签点模糊,从而导致错误。
1
2
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
link定位,定位连接名,例如定位在百度左上角链接的例子中。
1
2
3
4
5
6
新闻
hao123
地图
...
直接通过链接名称定位。
1
2
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
1
2
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
上述xpath定位的方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
1
2
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
CSS定位这个方法比xpath更简洁更快
1
2
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素当然,有时候我们只需要多个元素,所以只需要使用复数即可。
1
2
3
4
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性比如要获取百度logo的信息,先定位图片元素,再获取信息
1
2
3
4
5
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本,首先使用类直接查找热列表元素,但是有多个元素,所以使用复数形式获取,使用for循环打印。获取文本时,使用文本获取
1
2
3
4
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性以获取例如 id 或 tag
1
2
3
4
5
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
在百度搜索框输入/清除“冬奥会”等文字,然后清除
1
2
3
4
5
6
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(Enter) 输入以上内容后,需要点击回车提交,即可得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要添加一些伪装的方法。在本文的最后。:point_right:。
1
2
search_bar.send_keys('冬奥会')
search_bar.submit()
单击 当我们需要单击时,使用单击。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
1
2
3
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
1
2
3
4
5
6
7
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击是double_click。如果找不到合适的例子,我就不提了。这里是 ActionChains,可以深入挖掘,定义一系列操作一起执行。当然,一些常用的操作其实就足够了。
悬停,我无法将其放入。
1
ActionChains(browser).move_to_element(move).perform()
从下拉框中选择需要导入的相关库,访问MySQL官网选择下载对应的操作系统为例。
1
2
3
4
5
6
7
8
9
10
11
12
13
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖拽多用于验证码之类的,参考菜鸟示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 27%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待可以发现,在上面的程序中,有些效果需要延迟等待才能出现。在实践中,它也需要一定的延迟。一方面为了不访问太频繁被认为是爬虫,另一方面也是爬虫。由于网络资源的加载,需要一定的时间等待。
1
2
3
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截图可以保存为base64/png/file
1
browser.get_screenshot_as_file('截图.png')
窗口切换 我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
1
2
3
4
5
6
7
8
9
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
1
2
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条 有些网页的内容是随着进度条的滑动出现的,所以需要下拉进度条的操作。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
1
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
1
2
3
4
5
6
7
8
9
10
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。如果仔细观察,操作非常详细。模仿真实的浏览器操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导:joy:。
和直接获取资源的爬虫相比,肯定是慢了一些,但是比强大的要好,而且还是可以提高钓鱼效率:+1:。
浏览器抓取网页(谷歌浏览器插件开发文档,插件总结经验 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-06 16:09
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件,所以一般花了一天时间看完了谷歌浏览器插件开发文档,这里特意总结一下经验,对插件进行复习——通过一个实际案例。开发过程及注意事项.javascript
你会得到文字
正文开始之前,先看一下作者总结的概述:css
如果你熟悉浏览器插件开发,可以直接观看最后一节插件开发实践。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 HTML、JavaScript 和 CSS 等 Web 技术构建的小型软件程序,可自定义浏览体验。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发一个浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 开启开发者模式
导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件一般放在浏览器地址栏的右侧,我们可以在manifest.json文件中配置插件的图标,并配置一定的规则,就可以看到我们的浏览器插件图标,下图:java
下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件:node
作者画了一张图来粗略表示它们之间的关系:jquery
接下来,让我们仔细看看几个核心知识点。网页包
2.1 manifest.json
谷歌官网为我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
每个字段的含义描述如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 背景.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,下面是几个常见的用例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:
仅设置带有 .com 后缀的页面以激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图所示,当页面地址后缀不等于.com时,插件图标不会被激活:
3. 与 content_script 或弹出页面通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 个内容脚本
内容脚本通常被植入到页面中,并且可以控制页面中的dom。我们可以用它来屏蔽网页广告,自定义页面皮肤等。manifest.json中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了 content_scripts 允许注入的页面范围,插入页面的 js 和 css,这样我们就可以很方便的改变页面的样式。例如,我们可以在页面中注入一个按钮:
在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹出窗口
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件描述。
因为弹窗也是网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的页面显示和交互。我们在 manifest.json 中配置如下:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要导入脚本文件。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗页面:
3.通讯机制
对于一个比较复杂的浏览器插件,我们不仅需要操作 DOM 或者提供基本的功能,还需要从第三方或者我们自己的服务器上获取有用的页面数据。这时候,我们就需要使用插件式的通信机制了。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传输到第三方平台或自己的服务器,因此需要一个基于浏览器的通信API。下面是谷歌浏览器插件通信流程:
3.1 弹出和后台相互通信
从官方文档我们知道popup可以直接访问后台页面,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接在谷歌官网上也写得很清楚:
我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们将数据存储在任何页面(弹出窗口或 content_script 或背景)下。我们可以在上面三个页面上得到它。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器插件的应用场景很多,在文章开头的思维导图中写过。以下是作者总结的一些应用场景,有兴趣可以尝试实现:
有很多实用的工具可以开发,你可以玩得开心。接下来我们通过实现一个网页图片提取插件来总结以下浏览器插件的开发流程。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何一种工具之前,都必须明确需求,那么我们来看看插件的功能点:
基本上,这些是功能。接下来,我将展示核心代码。在介绍代码之前,我们先来预览一下插件的实现效果:
插件目录结构如下:
由于插件的开发比较简单,所以我直接使用jquery来开发。这里我们主要关注popup.js和content_script.js。popup.js主要用于获取content_script页面传过来的图片数据,并在popup.html中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,并自动让它生成一个按钮,代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成一个按钮,并在页面中植入一个弹窗来显示获取到的图片。另一方面,我们需要将图像数据传递到存储中,以便弹出页面可以获取图像数据。
因为页面比较简单,所以作者不需要太多的第三方库。作者简单的先写了一个modal组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者利用正则简单处理如下,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是生成一个用于预览图像的弹出窗口。这里使用了上面作者实现的modal组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送通知激活按钮时,我们需要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式来处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。有兴趣的朋友可以安装感受一下。
github地址:一个提取网页图片数据的浏览器插件
最后
如果想学习更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎在公众号“趣前沿”加入我们的技术群-end”一起学习、讨论和探索前端边界。
查看全部
浏览器抓取网页(谷歌浏览器插件开发文档,插件总结经验
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件,所以一般花了一天时间看完了谷歌浏览器插件开发文档,这里特意总结一下经验,对插件进行复习——通过一个实际案例。开发过程及注意事项.javascript
你会得到文字
正文开始之前,先看一下作者总结的概述:css

如果你熟悉浏览器插件开发,可以直接观看最后一节插件开发实践。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 HTML、JavaScript 和 CSS 等 Web 技术构建的小型软件程序,可自定义浏览体验。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发一个浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 开启开发者模式

导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件一般放在浏览器地址栏的右侧,我们可以在manifest.json文件中配置插件的图标,并配置一定的规则,就可以看到我们的浏览器插件图标,下图:java

下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件:node
作者画了一张图来粗略表示它们之间的关系:jquery

接下来,让我们仔细看看几个核心知识点。网页包
2.1 manifest.json
谷歌官网为我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
每个字段的含义描述如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 背景.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,下面是几个常见的用例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:

仅设置带有 .com 后缀的页面以激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图所示,当页面地址后缀不等于.com时,插件图标不会被激活:

3. 与 content_script 或弹出页面通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 个内容脚本
内容脚本通常被植入到页面中,并且可以控制页面中的dom。我们可以用它来屏蔽网页广告,自定义页面皮肤等。manifest.json中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了 content_scripts 允许注入的页面范围,插入页面的 js 和 css,这样我们就可以很方便的改变页面的样式。例如,我们可以在页面中注入一个按钮:

在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹出窗口
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件描述。
因为弹窗也是网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的页面显示和交互。我们在 manifest.json 中配置如下:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要导入脚本文件。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗页面:

3.通讯机制
对于一个比较复杂的浏览器插件,我们不仅需要操作 DOM 或者提供基本的功能,还需要从第三方或者我们自己的服务器上获取有用的页面数据。这时候,我们就需要使用插件式的通信机制了。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传输到第三方平台或自己的服务器,因此需要一个基于浏览器的通信API。下面是谷歌浏览器插件通信流程:

3.1 弹出和后台相互通信
从官方文档我们知道popup可以直接访问后台页面,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接在谷歌官网上也写得很清楚:

我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们将数据存储在任何页面(弹出窗口或 content_script 或背景)下。我们可以在上面三个页面上得到它。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器插件的应用场景很多,在文章开头的思维导图中写过。以下是作者总结的一些应用场景,有兴趣可以尝试实现:
有很多实用的工具可以开发,你可以玩得开心。接下来我们通过实现一个网页图片提取插件来总结以下浏览器插件的开发流程。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何一种工具之前,都必须明确需求,那么我们来看看插件的功能点:
基本上,这些是功能。接下来,我将展示核心代码。在介绍代码之前,我们先来预览一下插件的实现效果:

插件目录结构如下:

由于插件的开发比较简单,所以我直接使用jquery来开发。这里我们主要关注popup.js和content_script.js。popup.js主要用于获取content_script页面传过来的图片数据,并在popup.html中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,并自动让它生成一个按钮,代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成一个按钮,并在页面中植入一个弹窗来显示获取到的图片。另一方面,我们需要将图像数据传递到存储中,以便弹出页面可以获取图像数据。
因为页面比较简单,所以作者不需要太多的第三方库。作者简单的先写了一个modal组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者利用正则简单处理如下,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是生成一个用于预览图像的弹出窗口。这里使用了上面作者实现的modal组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送通知激活按钮时,我们需要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式来处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。有兴趣的朋友可以安装感受一下。
github地址:一个提取网页图片数据的浏览器插件
最后
如果想学习更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎在公众号“趣前沿”加入我们的技术群-end”一起学习、讨论和探索前端边界。
浏览器抓取网页(网页抓取网页必须要会操作浏览器相对于(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-05 22:04
浏览器抓取网页必须要会操作浏览器,相对于浏览器程序员来说,那么页面抓取基本功还是有必要掌握的,javascript是一门强大的编程语言。页面抓取作为网页抓取入门都很重要,比如说登录时不同的人有不同的账号,如何去统计谁最先注册,如何搜索重要网页页面等等。当然,开发过程中碰到问题还是需要联系网站解决的。网页抓取相对java抓取就简单很多,因为网页的结构不会变化,变化的只是网页元素的排列顺序,统计相对容易。
javascript的使用,网页的重定向、iframe框架的制作,网页怎么展示大家可以用最简单的办法就能达到一定的效果,今天我们讲解一下web容器中通过html解析出来script标签,然后才能使用dom查看器解析,编写方法大家可以采用javascript引擎来进行编写和调试。我们先来看一下script标签的基本格式html/script.jsmydom.prefix为前导标签,importjs,functionxxx(){returneval(xxx);}object标签的内容是声明属性并且赋值到dom中,属性值必须是一个已有的属性属性值,如果是指向第三方库,xxx()必须带有prototype属性标签必须包含“返回类型”,一般都为"prototype"或者"void",包含类型不能在js里用,如果不加就会进入对象的null对象,或者是对象prototype属性,导致调用计算机解析的时候报错异常,例如javascript://importjsfrom"@//".src这个是importxxx()到dom上,假如name属性值为1,浏览器会解析为'{1:"1"}',但是javascript://importxxxfrom"@//".src会得到"privatestring"不再是'1',此时将name属性值设置为'1',浏览器会自动更改成'1'importxxxfrom"@//".src会得到'privatestring'有import(),一般都带有prototype属性注意的是此时'1'变为number(number)下面再来举个例子://.//name.shortindex=""name=("hello").slice(。
1).reduce((mid,item1,item
2)=>mid+item2+""){name=("hello").slice
2)=>mid+item2+"")}returnname}当dom转化为javascript时一定要判断会不会符合这个规则,不然得自己设置.script标签的实现也很简单,大家可以用chrome网页代码监控dom来实现,当dom元素中存在item1和item2时,我们的代码就不会更新了,可以保存原有 查看全部
浏览器抓取网页(网页抓取网页必须要会操作浏览器相对于(组图))
浏览器抓取网页必须要会操作浏览器,相对于浏览器程序员来说,那么页面抓取基本功还是有必要掌握的,javascript是一门强大的编程语言。页面抓取作为网页抓取入门都很重要,比如说登录时不同的人有不同的账号,如何去统计谁最先注册,如何搜索重要网页页面等等。当然,开发过程中碰到问题还是需要联系网站解决的。网页抓取相对java抓取就简单很多,因为网页的结构不会变化,变化的只是网页元素的排列顺序,统计相对容易。
javascript的使用,网页的重定向、iframe框架的制作,网页怎么展示大家可以用最简单的办法就能达到一定的效果,今天我们讲解一下web容器中通过html解析出来script标签,然后才能使用dom查看器解析,编写方法大家可以采用javascript引擎来进行编写和调试。我们先来看一下script标签的基本格式html/script.jsmydom.prefix为前导标签,importjs,functionxxx(){returneval(xxx);}object标签的内容是声明属性并且赋值到dom中,属性值必须是一个已有的属性属性值,如果是指向第三方库,xxx()必须带有prototype属性标签必须包含“返回类型”,一般都为"prototype"或者"void",包含类型不能在js里用,如果不加就会进入对象的null对象,或者是对象prototype属性,导致调用计算机解析的时候报错异常,例如javascript://importjsfrom"@//".src这个是importxxx()到dom上,假如name属性值为1,浏览器会解析为'{1:"1"}',但是javascript://importxxxfrom"@//".src会得到"privatestring"不再是'1',此时将name属性值设置为'1',浏览器会自动更改成'1'importxxxfrom"@//".src会得到'privatestring'有import(),一般都带有prototype属性注意的是此时'1'变为number(number)下面再来举个例子://.//name.shortindex=""name=("hello").slice(。
1).reduce((mid,item1,item
2)=>mid+item2+""){name=("hello").slice
2)=>mid+item2+"")}returnname}当dom转化为javascript时一定要判断会不会符合这个规则,不然得自己设置.script标签的实现也很简单,大家可以用chrome网页代码监控dom来实现,当dom元素中存在item1和item2时,我们的代码就不会更新了,可以保存原有
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-04 14:12
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作,其中forward()方法可以实现前进,back()方法可以实现后退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)


然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache

完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()

可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()

在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()

1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作,其中forward()方法可以实现前进,back()方法可以实现后退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()

8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')

10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-03 10:16
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:
上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载 查看全部
浏览器抓取网页(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:

上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:

源代码下载
浏览器抓取网页( Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-01 06:22
Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
一直有一个传说,世界上有两种程序员:一种是程序员,一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
前段时间,助教和我聊天,我吐出一肚子苦涩,说女人懂Python太可怕了。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久熬夜玩游戏玩电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
browserhistory是一个简单的python脚本库,支持Linux、Mac和Windows系统,支持Firefox、Google和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username是获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦! 查看全部
浏览器抓取网页(
Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)

一直有一个传说,世界上有两种程序员:一种是程序员,一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
前段时间,助教和我聊天,我吐出一肚子苦涩,说女人懂Python太可怕了。

1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久熬夜玩游戏玩电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。

我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
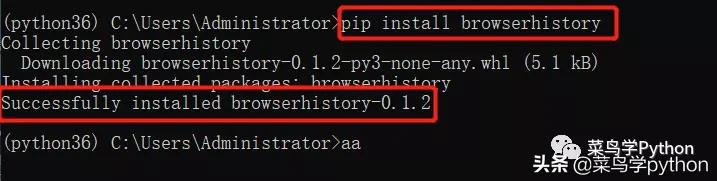
browserhistory是一个简单的python脚本库,支持Linux、Mac和Windows系统,支持Firefox、Google和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
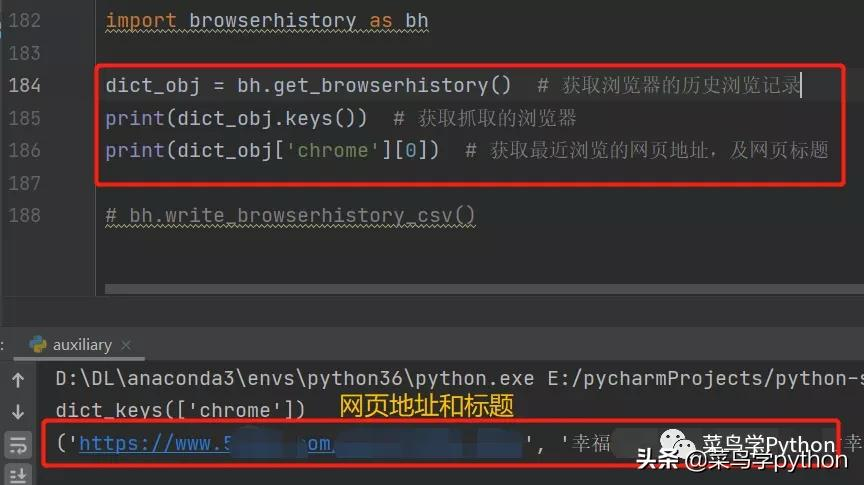
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:

get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username是获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。

4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
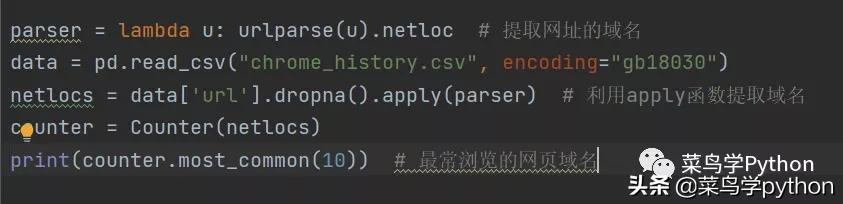
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
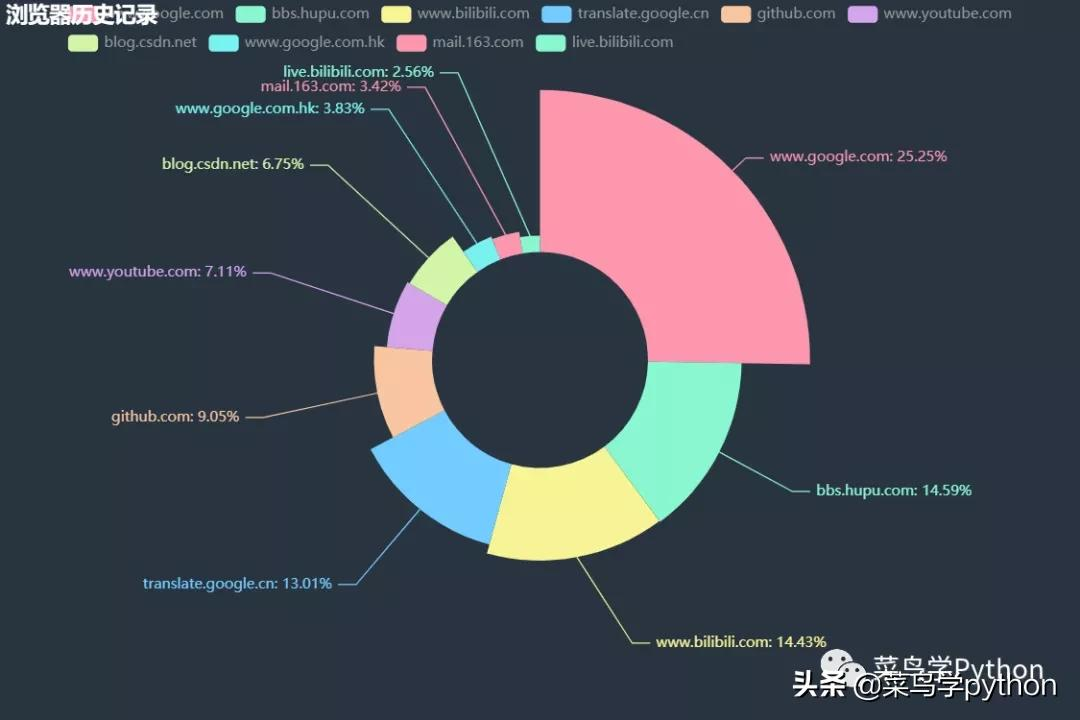
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦!
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-30 22:19
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-30 22:17
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是在元素出现或满足某些条件时继续执行。until_not 是当某个元素消失或某些条件不满足时继续执行。参数也一样。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
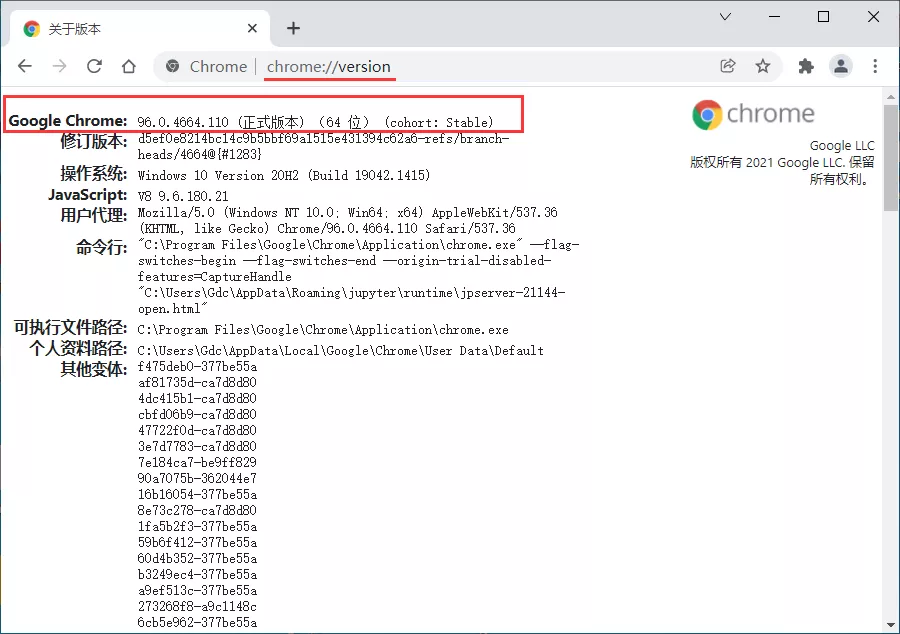
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
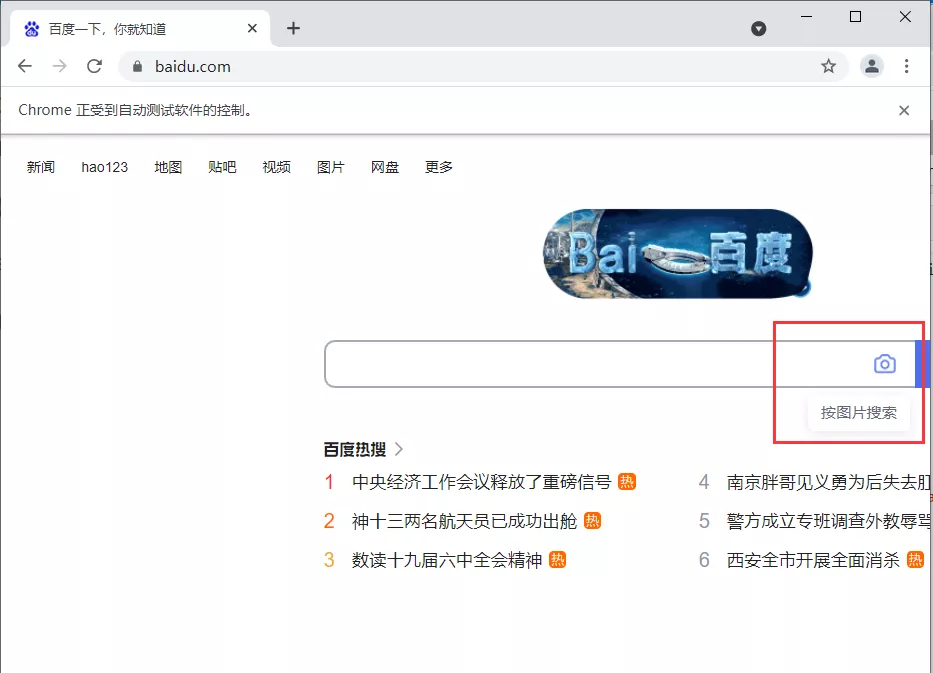
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是在元素出现或满足某些条件时继续执行。until_not 是当某个元素消失或某些条件不满足时继续执行。参数也一样。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
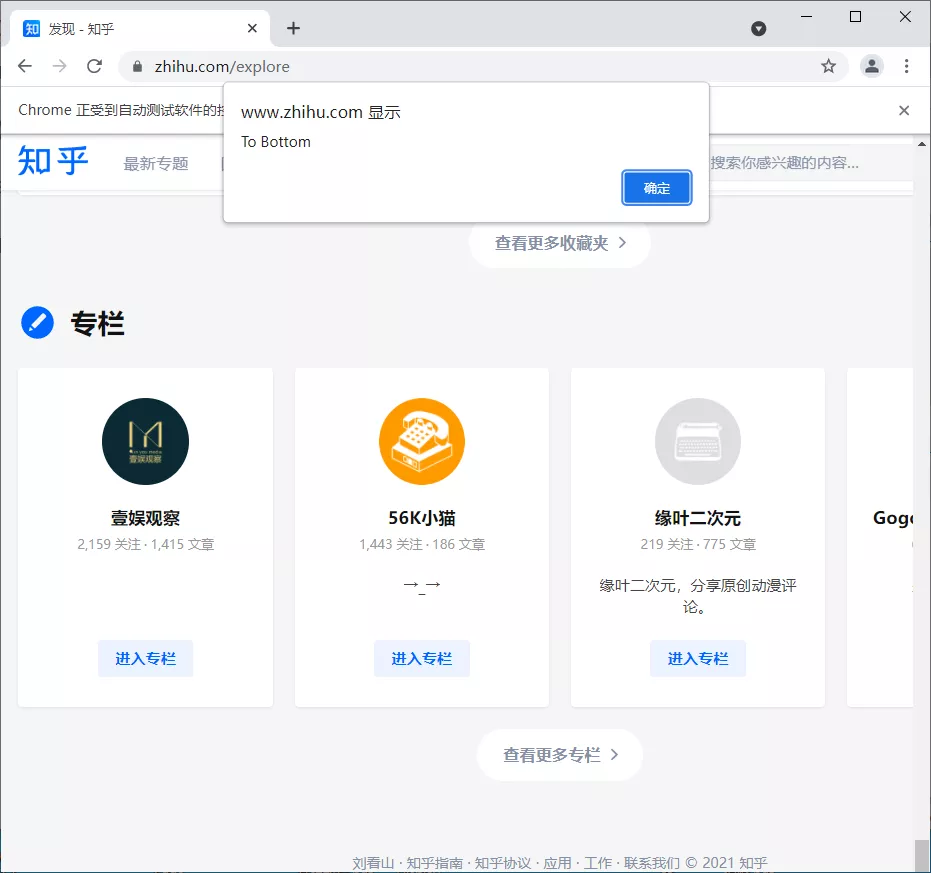
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页(关于因特网中的WWW服务,以下哪种说法是正确的())
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-30 12:12
下列关于 Internet 中的 WWW 服务的说法正确的是()
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
Internet提供网页信息浏览服务是()
A. FTP
B、万维网
三、论坛
D. 电子邮件
点击查看答案
下列关于 Internet 中的 WWW 服务的说法不正确的是?
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
互联网由大量的计算机和信息资源组成,为网络用户提供了非常丰富的网络服务。下列关于万维网服务的说法不正确的是______
A、WWW采用客户端/服务器工作模式
B. 从网页到网页的链接信息由 URL 表示
C. 浏览器是客户端应用程序
D. 所有网页都是 HTML 文档
点击查看答案
早期互联网提供的服务方式可以分为基础服务和扩展服务。以下服务属于扩展服务。____
A. 电子邮件
B. 新闻组
C. 文件传输
D、万维网服务
点击查看答案
在WWW服务系统的描述中,错误的是()。
A) WWW采用客户端/服务器模式
B) WWW的传输协议采用HTML
C) 页面到页面的链接信息由 URL 维护
D) 客户端应用程序称为浏览器
点击查看答案
关于互联网上的WWW服务,下列说法不正确的是( )。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案
下列关于万维网的说法不正确的是:()
A、WWW是一种基于超文本的信息查询工具
B.WWW 是 WorldWideWeb 的缩写
C. 通过浏览器查看网页是一种 WWW 服务
D. WWW 是一个分类超媒体系统
请帮忙给出正确答案和分析,谢谢!
点击查看答案
关于互联网中的 WWW 服务,下列说法错误的是______。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案 查看全部
浏览器抓取网页(关于因特网中的WWW服务,以下哪种说法是正确的())
下列关于 Internet 中的 WWW 服务的说法正确的是()
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
Internet提供网页信息浏览服务是()
A. FTP
B、万维网
三、论坛
D. 电子邮件
点击查看答案
下列关于 Internet 中的 WWW 服务的说法不正确的是?
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
互联网由大量的计算机和信息资源组成,为网络用户提供了非常丰富的网络服务。下列关于万维网服务的说法不正确的是______
A、WWW采用客户端/服务器工作模式
B. 从网页到网页的链接信息由 URL 表示
C. 浏览器是客户端应用程序
D. 所有网页都是 HTML 文档
点击查看答案
早期互联网提供的服务方式可以分为基础服务和扩展服务。以下服务属于扩展服务。____
A. 电子邮件
B. 新闻组
C. 文件传输
D、万维网服务
点击查看答案
在WWW服务系统的描述中,错误的是()。
A) WWW采用客户端/服务器模式
B) WWW的传输协议采用HTML
C) 页面到页面的链接信息由 URL 维护
D) 客户端应用程序称为浏览器
点击查看答案
关于互联网上的WWW服务,下列说法不正确的是( )。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案
下列关于万维网的说法不正确的是:()
A、WWW是一种基于超文本的信息查询工具
B.WWW 是 WorldWideWeb 的缩写
C. 通过浏览器查看网页是一种 WWW 服务
D. WWW 是一个分类超媒体系统
请帮忙给出正确答案和分析,谢谢!
点击查看答案
关于互联网中的 WWW 服务,下列说法错误的是______。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案
浏览器抓取网页(浏览器输入URL之后发生了什么?输入到获取网页的过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-29 00:17
浏览器输入URL获取网页的过程
上图大致描述了浏览器输入 URL 时发生的情况。详细过程总结如下。
条件是:
从浏览器输入 URL 地址
URL,也称为统一资源定位器,描述了特定服务器上资源的特定位置。URL由三部分组成:
scheme 描述了用于访问资源的协议 服务器的 Internet 地址 其余指定 Web 服务器的资源
有效的网址
1
http://video.google.com.uk:80/ ... 2m30s
上面的 URL 分解为:
查询流程:
首先会查询浏览器的缓存,浏览器会存储一定时间内的DNS记录。如果没有找到,会在操作系统的缓存中查询;路由器也会被DNS记录查询,并且会继续在路由器的缓存中查询;ISP互联网提供商查询,这里是最后在DNS系统上搜索到的连接互联网的中继站;DNS解析过程
DNS采用迭代查询和递归查询两种方式。因为IP地址很难记住,所以域名可以帮助我们记住网站地址。域名实际上无法找到服务器的位置,而是通过DNS服务器将域名解析为IP地址。确定服务器的位置。
首先,浏览器像本地 DNS 服务器一样发送请求。如果没有查询到本地DNS地址,则需要使用递归和迭代的方式依次向根域名服务器、顶级域名服务器、权威域名服务器发送查询请求,直到找到一个或一组IP。地址,返回给浏览器。
DNS本身的传输协议是UDP协议,但是每次迭代和递归查找都是非常耗时的,所以DNS有这个多级缓存。
缓存分为:浏览器缓存、系统缓存、路由器缓存、IPS服务器缓存、根域名服务器缓存、顶级域名服务器缓存、主域名服务器缓存。
DNS 负载均衡
DNS 不一定每次都返回同一服务器的地址。DNS可以返回合适机器的IP,根据每台机器的负载和机器的物理位置合理分配。CDN技术是利用DNS重定向技术返回离用户最近的服务器。
TCP 连接
建立 TCP 连接,经典的三次握手过程。
TCP是端到端可靠的面向连接的协议,所以HTTP基于传输层协议,无需担心数据传输。 查看全部
浏览器抓取网页(浏览器输入URL之后发生了什么?输入到获取网页的过程)
浏览器输入URL获取网页的过程
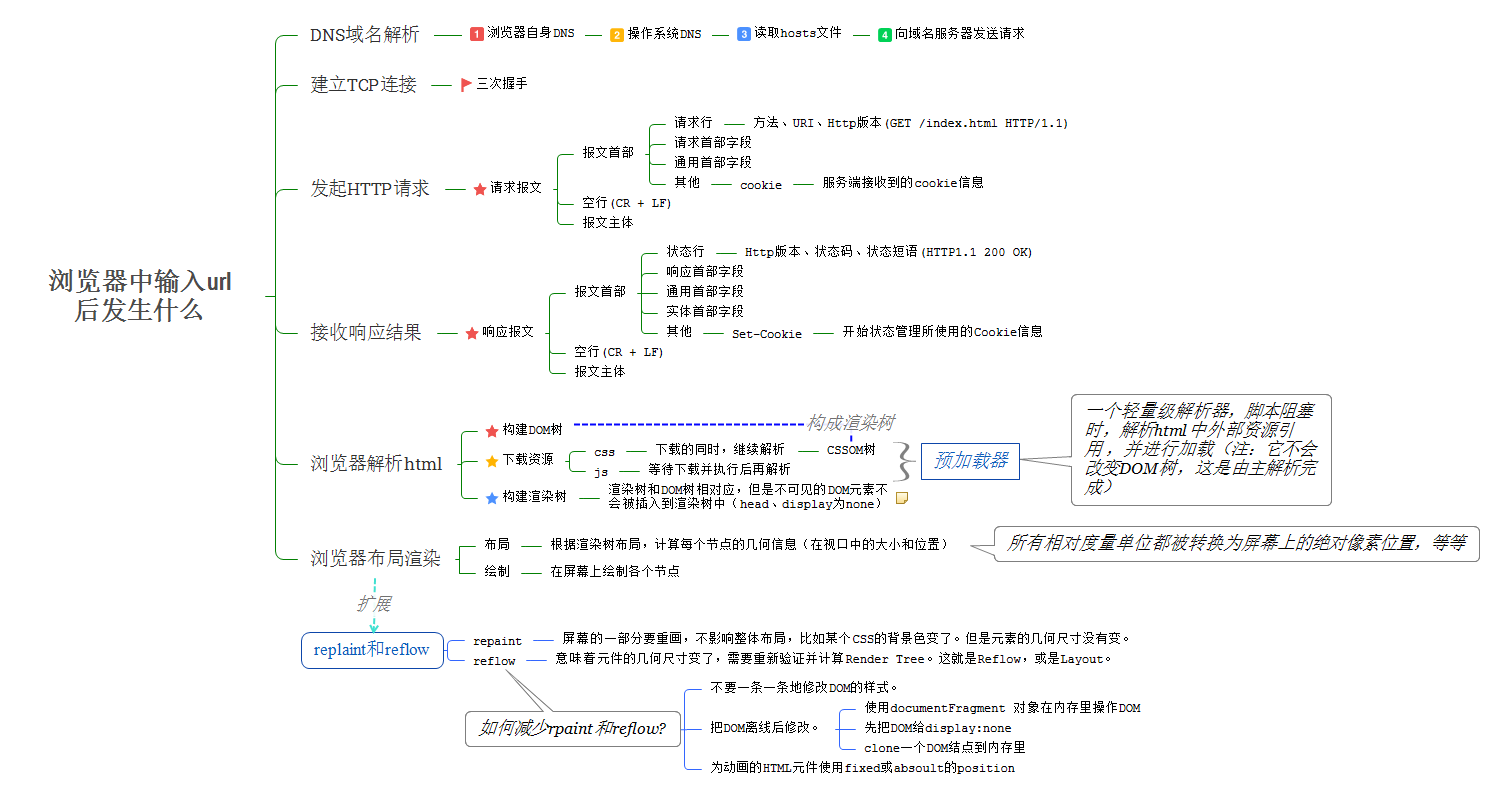
上图大致描述了浏览器输入 URL 时发生的情况。详细过程总结如下。
条件是:
从浏览器输入 URL 地址
URL,也称为统一资源定位器,描述了特定服务器上资源的特定位置。URL由三部分组成:
scheme 描述了用于访问资源的协议 服务器的 Internet 地址 其余指定 Web 服务器的资源
有效的网址
1
http://video.google.com.uk:80/ ... 2m30s
上面的 URL 分解为:
查询流程:
首先会查询浏览器的缓存,浏览器会存储一定时间内的DNS记录。如果没有找到,会在操作系统的缓存中查询;路由器也会被DNS记录查询,并且会继续在路由器的缓存中查询;ISP互联网提供商查询,这里是最后在DNS系统上搜索到的连接互联网的中继站;DNS解析过程
DNS采用迭代查询和递归查询两种方式。因为IP地址很难记住,所以域名可以帮助我们记住网站地址。域名实际上无法找到服务器的位置,而是通过DNS服务器将域名解析为IP地址。确定服务器的位置。
首先,浏览器像本地 DNS 服务器一样发送请求。如果没有查询到本地DNS地址,则需要使用递归和迭代的方式依次向根域名服务器、顶级域名服务器、权威域名服务器发送查询请求,直到找到一个或一组IP。地址,返回给浏览器。
DNS本身的传输协议是UDP协议,但是每次迭代和递归查找都是非常耗时的,所以DNS有这个多级缓存。
缓存分为:浏览器缓存、系统缓存、路由器缓存、IPS服务器缓存、根域名服务器缓存、顶级域名服务器缓存、主域名服务器缓存。
DNS 负载均衡
DNS 不一定每次都返回同一服务器的地址。DNS可以返回合适机器的IP,根据每台机器的负载和机器的物理位置合理分配。CDN技术是利用DNS重定向技术返回离用户最近的服务器。
TCP 连接
建立 TCP 连接,经典的三次握手过程。
TCP是端到端可靠的面向连接的协议,所以HTTP基于传输层协议,无需担心数据传输。
浏览器抓取网页( 360安全浏览器v8.0.3483.0查看百度光速游戏加速器官方独立版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-28 22:20
360安全浏览器v8.0.3483.0查看百度光速游戏加速器官方独立版
)
百度浏览器免费版是百度推出的以IE为核心的浏览器。百度一键获取海量优质资源。整体界面简洁大气,有点像谷歌浏览器。百度浏览器免费版支持将html网页文件导入采集夹内容。每天登录百度浏览器搜索访问也可以产生积分,可以兑换爱奇艺VIP和百度文库VIP!
百度浏览器
相关软件版本说明下载地址
360安全浏览器
v8.1.1.114
查看
百度媒体播放器
正式版
查看
铬浏览器
v69.0.3483.0
查看
百度光速游戏加速器
官方独立版
查看
YY浏览器(YY专用)
v3.9.5776.0
查看
百度看(桌面百度)
v9.92
查看
变更日志
1.Win10兼容性增强,修复了一些严重的bug。
软件功能
1、新天气:全新的视觉设计,更扁平,大变化
2、有内容:全新2.0首页,一站式直达内容,等你来体验
3、发现:借助百度强大的数据库,每天都有大量的内容更新
4、更轻快:百度浏览器采用全新升级最新内核,超高性能基准
5、云体验:网页云修复、下载云加速、网站云采集等。
特征
安全浏览
采用最新的沙盒安全技术,全方位保护您的在线流程。
丰富的应用
基于百度强大的数据库,整合最热门的应用,第一时间推送最新的应用。
数据同步
强大的云同步技术,只要登录账号,采集的数据信息完全同步,随时随地轻松使用。
常问问题
如何将百度浏览器设置为默认浏览器?
打开百度浏览器,点击右上角按钮,选择【浏览器设置】,在页面左侧栏选择【常规设置】,在内容中找到默认浏览器选项,可以选择设置为默认浏览器La。
安装步骤
一、在本站下载最新版百度浏览器安装包,双击运行。
二、点击右下角的【设置】按钮,去掉不必要的设置。
三、点击【立即安装】,会自动开始安装,耐心等待软件安装完成即可。
四、安装完成后会自动打开浏览器,尽情享受吧。
技能
每个人都必须能够在浏览器中搜索,所以我将教你如何截图。
打开百度浏览器,点击页面右上角的剪刀状按钮,在下拉菜单中可以截图、保存网页、截取GIF图片。
查看全部
浏览器抓取网页(
360安全浏览器v8.0.3483.0查看百度光速游戏加速器官方独立版
)

百度浏览器免费版是百度推出的以IE为核心的浏览器。百度一键获取海量优质资源。整体界面简洁大气,有点像谷歌浏览器。百度浏览器免费版支持将html网页文件导入采集夹内容。每天登录百度浏览器搜索访问也可以产生积分,可以兑换爱奇艺VIP和百度文库VIP!

百度浏览器
相关软件版本说明下载地址
360安全浏览器
v8.1.1.114
查看
百度媒体播放器
正式版
查看
铬浏览器
v69.0.3483.0
查看
百度光速游戏加速器
官方独立版
查看
YY浏览器(YY专用)
v3.9.5776.0
查看
百度看(桌面百度)
v9.92
查看
变更日志
1.Win10兼容性增强,修复了一些严重的bug。
软件功能
1、新天气:全新的视觉设计,更扁平,大变化
2、有内容:全新2.0首页,一站式直达内容,等你来体验
3、发现:借助百度强大的数据库,每天都有大量的内容更新
4、更轻快:百度浏览器采用全新升级最新内核,超高性能基准
5、云体验:网页云修复、下载云加速、网站云采集等。
特征
安全浏览
采用最新的沙盒安全技术,全方位保护您的在线流程。
丰富的应用
基于百度强大的数据库,整合最热门的应用,第一时间推送最新的应用。
数据同步
强大的云同步技术,只要登录账号,采集的数据信息完全同步,随时随地轻松使用。
常问问题
如何将百度浏览器设置为默认浏览器?
打开百度浏览器,点击右上角按钮,选择【浏览器设置】,在页面左侧栏选择【常规设置】,在内容中找到默认浏览器选项,可以选择设置为默认浏览器La。
安装步骤
一、在本站下载最新版百度浏览器安装包,双击运行。

二、点击右下角的【设置】按钮,去掉不必要的设置。
三、点击【立即安装】,会自动开始安装,耐心等待软件安装完成即可。

四、安装完成后会自动打开浏览器,尽情享受吧。
技能
每个人都必须能够在浏览器中搜索,所以我将教你如何截图。
打开百度浏览器,点击页面右上角的剪刀状按钮,在下拉菜单中可以截图、保存网页、截取GIF图片。
浏览器抓取网页( 这个是想要跳过这个,直接把你最终打开的页面里的cookie拷贝出来回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-28 22:17
这个是想要跳过这个,直接把你最终打开的页面里的cookie拷贝出来回答)
这就是我要抢的网站
答案:
在你最终直接打开的页面中复制cookie
import requests
headers = {
'Cookie': '__cfduid=d1e0cc7faadf90af5d64ff45aa2aba92c1503910637; cf_clearance=37fa4932d1e2dde34e9074b0f03aabb0d5f7e8ab-1503910642-31536000',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
}
url = 'http://www.agronet.com.cn/'
r = requests.get('http://www.agronet.com.cn/', headers=headers)
r.encoding = 'utf'
print r.text
答案:
访问域名时,做了302重定向,
Request URL:http://www.agronet.com.cn/cdn- ... 84273
Request Method:GET
Status Code:302 Moved Temporarily
Remote Address:119.147.134.219:80
Referrer Policy:no-referrer-when-downgrade
Response Headers
view source
CF-RAY:395c1714639389e9-SZX
Connection:keep-alive
Content-Length:165
Content-Type:text/html
Date:Tue, 29 Aug 2017 02:30:45 GMT
Location:http://www.agronet.com.cn/
Server:yunjiasu-nginx
Set-Cookie:cf_clearance=df2e88c103783c5b5a9524bbd4105fbd74b4b4cd-1503973845-31536000; path=/; expires=Wed, 29-Aug-18 03:30:45 GMT; domain=.agronet.com.cn; HttpOnly
X-Frame-Options:SAMEORIGIN
因为处理302的参数未知,所以使用request.Session来处理请求
答案:
对于python,有一个很好的库:requests
可以解决301、302跳转、UA、cookie等问题,
文档地址:...
答案:
如果你要爬取的数据不是js执行生成的,可以使用以下方法
import requests
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0","Connection":"close","Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1"}
cookies = {"safedog-flow-item":"A7C62592B3B3C821E8940811D417910B","__utmz":"63149887.1503977571.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)","ctrl_time":"1","Hm_lvt_8f396c620ee16c3d331cf84fd54feafe":"1503977516","__utmt":"1","__cfduid":"d61cc443d7df1327ad4ee0c17da83adcf1503977565","Hm_lpvt_8f396c620ee16c3d331cf84fd54feafe":"1503977628","cf_clearance":"6c62a4b3214679cbbf0e76f7feb17fcbe1e9955a-1503977569-31536000","agronetCookie":"D98233C159EF3AEA333D883B971C1FCA9B6F08A7476FD809","__utmb":"63149887.2.10.1503977571","bdshare_firstime":"1503977570334","__utmc":"63149887","yjs_id":"Mozilla%2F5.0%20(Macintosh%3B%20Intel%20Mac%20OS%20X%2010.12%3B%20rv%3A52.0)%20Gecko%2F20100101%20Firefox%2F52.0%7Cwww.agronet.com.cn%7C1503977570020%7Chttp%3A%2F%2Fwww.agronet.com.cn%2F","__utma":"63149887.720670875.1503977571.1503977571.1503977571.1"}
response = session.get("http://www.agronet.com.cn/", headers=headers, cookies=cookies)
print("Status code: %i" % response.status_code)
print("Response body: %s" % response.content)
如果数据是js生成的,建议使用webdriver
答案:
如果 cookie 是动态变化的呢?
本文地址:H5W3 » 爬虫爬取网页,返回的页面是,请打开浏览器的javascript,然后刷新浏览器。如何解决这个问题。要跳过这个,请抓住 网站 查看全部
浏览器抓取网页(
这个是想要跳过这个,直接把你最终打开的页面里的cookie拷贝出来回答)

这就是我要抢的网站
答案:
在你最终直接打开的页面中复制cookie
import requests
headers = {
'Cookie': '__cfduid=d1e0cc7faadf90af5d64ff45aa2aba92c1503910637; cf_clearance=37fa4932d1e2dde34e9074b0f03aabb0d5f7e8ab-1503910642-31536000',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
}
url = 'http://www.agronet.com.cn/'
r = requests.get('http://www.agronet.com.cn/', headers=headers)
r.encoding = 'utf'
print r.text
答案:
访问域名时,做了302重定向,
Request URL:http://www.agronet.com.cn/cdn- ... 84273
Request Method:GET
Status Code:302 Moved Temporarily
Remote Address:119.147.134.219:80
Referrer Policy:no-referrer-when-downgrade
Response Headers
view source
CF-RAY:395c1714639389e9-SZX
Connection:keep-alive
Content-Length:165
Content-Type:text/html
Date:Tue, 29 Aug 2017 02:30:45 GMT
Location:http://www.agronet.com.cn/
Server:yunjiasu-nginx
Set-Cookie:cf_clearance=df2e88c103783c5b5a9524bbd4105fbd74b4b4cd-1503973845-31536000; path=/; expires=Wed, 29-Aug-18 03:30:45 GMT; domain=.agronet.com.cn; HttpOnly
X-Frame-Options:SAMEORIGIN
因为处理302的参数未知,所以使用request.Session来处理请求
答案:
对于python,有一个很好的库:requests
可以解决301、302跳转、UA、cookie等问题,
文档地址:...
答案:
如果你要爬取的数据不是js执行生成的,可以使用以下方法
import requests
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0","Connection":"close","Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1"}
cookies = {"safedog-flow-item":"A7C62592B3B3C821E8940811D417910B","__utmz":"63149887.1503977571.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)","ctrl_time":"1","Hm_lvt_8f396c620ee16c3d331cf84fd54feafe":"1503977516","__utmt":"1","__cfduid":"d61cc443d7df1327ad4ee0c17da83adcf1503977565","Hm_lpvt_8f396c620ee16c3d331cf84fd54feafe":"1503977628","cf_clearance":"6c62a4b3214679cbbf0e76f7feb17fcbe1e9955a-1503977569-31536000","agronetCookie":"D98233C159EF3AEA333D883B971C1FCA9B6F08A7476FD809","__utmb":"63149887.2.10.1503977571","bdshare_firstime":"1503977570334","__utmc":"63149887","yjs_id":"Mozilla%2F5.0%20(Macintosh%3B%20Intel%20Mac%20OS%20X%2010.12%3B%20rv%3A52.0)%20Gecko%2F20100101%20Firefox%2F52.0%7Cwww.agronet.com.cn%7C1503977570020%7Chttp%3A%2F%2Fwww.agronet.com.cn%2F","__utma":"63149887.720670875.1503977571.1503977571.1503977571.1"}
response = session.get("http://www.agronet.com.cn/", headers=headers, cookies=cookies)
print("Status code: %i" % response.status_code)
print("Response body: %s" % response.content)
如果数据是js生成的,建议使用webdriver
答案:
如果 cookie 是动态变化的呢?
本文地址:H5W3 » 爬虫爬取网页,返回的页面是,请打开浏览器的javascript,然后刷新浏览器。如何解决这个问题。要跳过这个,请抓住 网站
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-28 00:02
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间检查条件是否成立,如果成立,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间检查条件是否成立,如果成立,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页( Web应用程序更为迅捷地回应用户动作并避免了没有改变的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-25 08:09
Web应用程序更为迅捷地回应用户动作并避免了没有改变的信息)
Ajax技术(属于前端技术)
那就是“异步 JavaScript 和 XML”,它与服务器交互而不刷新页面。
特点:异步请求,部分刷新
同步:发送方发送数据后,等待接收方发回响应,然后再发送下一个数据包;
异步:发送方发送数据后,不等待接收方回传响应,然后发送下一个数据包。
**好处:** Web 应用程序对用户操作的响应速度更快,避免通过网络发送未更改的信息,从而减少服务器压力。
**缺点:**浏览器实现的差异,需要处理兼容性问题;不利于SEO(SEO只能识别页面首次呈现的数据,不能异步);不能前后左右;默认不支持跨域访问。
**注意:**ajax 技术只能在网络协议环境中使用。不能直接将页面拖入浏览器执行。它必须以 Web 服务器模式访问。
AJAX编写步骤:
1.创建一个AJAX对象;
2.设置请求路径、请求方式等;
3.绑定监听状态变化的处理函数,可以在处理函数中获取响应数据(回调函数);
4.发送请求;
创建 ajax 对象时的浏览器兼容性处理
function createAjax() {
var ajax;
try { //非IE
ajax = new XMLHttpRequest(); //IE浏览器下没有XMLHttpRquest这个对象就会报错
} catch(e) {
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
return ajax;
}
响应处理和响应流
响应处理,即根据状态码和AJAX对象的状态信息,对服务响应浏览器的数据进行不同的处理,可以在绑定状态的处理函数中编写相应的逻辑代码改变。
AJAX 对象有 4 个属性:
readyState 一共有5个状态值,0-4,每个值代表不同的含义:onreadystatechange,一旦状态不标准,就会被执行,多次改变,多次执行
0:初始化,AJAX对象还没有初始化,new XMLHttpRequest();
1:加载,AJAX对象开始发送请求,ajax.open(请求方法,请求路径);
2:加载完成,发送AJAX对象的请求,ajax.send();
3:分析:AJAX对象开始读取服务器的响应,ajax.onreadystatechange;
4:完成,AJAX对象读取服务器响应并结束。
status 表示响应的 HTTP 状态码。常见的状态码如下:
200:成功;
302:重定向;
404:找不到资源;
500:服务器错误;
responseText 获取字符串形式的响应数据(常用)
responseXML 获取 XML 格式的响应数据
综上所述,状态变化的处理函数一般只针对ajax.readyState4和ajax.status200这两种情况进行处理(这也意味着我们什么时候可以开始渲染数据?服务器响应并成功获取数据后),然后根据后台返回的数据类型决定从responseText或responseXML中获取服务器响应返回的数据。
ajax 获取请求
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
console.log("点击了按钮");
//发送ajax请求
//1.创建ajax对象
let ajax = new XMLHttpRequest();
//2.设置请求方式、请求路径url
ajax.open("GET", "/get_data");
//3.绑定监听状态的改变的处理函数,在这个函数里面可以获取响应数据(回调函数)
ajax.onreadystatechange = () => {
//这个函数里面的代码什么时候执行?状态发生改变的时候就执行
//获取响应的数据
//什么时候页面开始渲染数据?服务器响应完毕之后ajax.readyState为4,并且成功获取数据之后ajax.status为200
if(ajax.readyState === 4 && ajax.status === 200) {
//服务器传来的数据用什么表示?ajax.readyState
console.log(ajax.readyState);
//渲染数据到页面上
oDiv.innerHTML = ajax.responseText;
}
}
//发送请求
ajax.send();
}
服务器代码(在 nodejs 文档中解释)
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
const server = http.createServer((request, response) => {
//每来一个请求就执行一次这里的代码
//判断浏览器需要哪个资源文件,把下面这些代码进行封装的话就是路由
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "index.html");
let content = fs.readFileSync(filePath);
response.end(content);
} else if(reqUrl === '/detail.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "detail.html");
let content = fs.readFileSync(filePath);
response.end(content); //这句不能放在外面,因为使用let定义的content有块级作用域
} else if(reqUrl === '/get_data') { //或者正则:/get_data.*/.test(reqUrl)
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
} else if(reqUrl.endsWith(".css")) {
//如果读取的是一个css文件,也是一个请求,也会执行一次代码
//哪些标签会造成请求?就有href(link)和src(src img)属性的标签,浏览器是自发的请求;还有像按钮、a标签的话需要在表单里而且需要点击过后才会请求
//如果用a标签实现跳转的话,index.html中跳转到详情页
//这里的跳转地址不是看前端的路径,而是看后端的路由是怎么配的,和这里的if else里的判断内容一致,点击之后也是一次请求
let filePath = path.join(__dirname, "assets", "css", "index.css");
let content = fs.readFileSync(filePath);
response.end(content);
} else {
response.setHeader("Content-type", "text/html; charset=utf-8"); //不加这句下面的语句会出现乱码
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
ajax 发布请求
附:根本没有提交行为,但是在某些浏览器中有提交行为
用户名:
密&emsp码:
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
//post提交
//获取用户填写的数据
let username = document.getElementById("username").value;
let password = document.getElementById("password").value;
let params = { //这样的形式是将获取的值看着方便且容易处理,下面处理时还需要转换为服务器需要的JSON格式
username,
password
}
//Ajax提交(四个步骤)
let ajax = new XMLHttpRequest();
ajax.open("POST", "/login_post");
ajax.onreadystatechange = () => {
if(ajax.readyState === 4 && ajax.status === 200) {
//相当于成功后的回调函数,这里可以封装为一个函数,写在最外面,通过调用使用
//ajax.responseText是服务器传过来的字符串
oDiv.innerHTML = ajax.responseText;
}
}
ajax.send(JSON.stringify(params)); //服务器需要的是JSON格式的数据,所以需要转换一下
}
服务器代码
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
let uname = "laozhuang";
let pwd = "123456";
//包装为函数
function responseEnd(response, dirName, fileName) { //dirName文件路径,fileName文件名称
let filePath = path.join(__dirname, "assets", "dirName", "fileName");
let content = fs.readFileSync(filePath);
response.end(content);
}
const server = http.createServer((request, response) => {
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
responseEnd(response, "html", "index.html");
} else if(reqUrl === '/detail.html') {
responseEnd(response, "html", "detail.html");
} else if(reqUrl === '/login.html') {
responseEnd(response, "html", "login.html");
} else if(reqUrl === '/get_data') {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
} else if(reqUrl === '/login_post') {
//处理post请求
//一旦post请求过来就会触发data事件
request.on("data", (postData) => {
//postData就是post请求传递过来的参数,是Buffer对象,需要toString()一下
//还需要把JSON格式的字符串转换为对象,因为转为对象才能通过.的方式拿到属性值
//获取到浏览器传过来的数据,就是post请求传递过来的参数
let {username, password} = JSON.parse(postData.toString()); //解构
//需要查询数据库看有没有用户名,没有的话就需要注册,如果有还需对比密码是否正确,或者其他逻辑操作
if(username === uname && password === pwd) {
//还可以跳转之类的操作
response.end("登录成功!");
} else {
response.end("用户名或者密码错误,登录失败")
}
})
} else if(reqUrl.endsWith(".css")) {
responseEnd(response, "css", "index.css");
} else if(reqUrl.endsWith(".js")) {
responseEnd(response, "js", "index.js");
} else {
response.setHeader("Content-type", "text/html; charset=utf-8");
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
避免缓存问题:
AJAX 减少了重复数据的加载,提高了页面加载速度,因为数据会一直缓存在内存中,当提交的 URL 与历史 URL 一致时,就不需要提交给服务器了。虽然减轻了服务器的负载,提升了用户体验,但无法获取最新的数据。为了保证数据是最新的,需要禁用其缓存功能,主要有以下几种方式:
1.在 URL 中添加一个随机数:Math.random()
//客户端代码
ajax.open("GET", "/get_data" + Math.random());
//服务端代码
else if(reqUrl.startsWith('/get_data')) {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
}
2.给 URL 添加时间戳:new Date().getTime(),从 197 开始的毫秒数0.01.01
3.在使用 AJAX 发送请求之前添加 ajax.setRequestHeader("Cache-Control", "no-cache");
ajax.open(...);
ajax.setRequestHeader('Cache-Control', 'no-cache'); //请求头设置,在ajax.open()后面
ajax.send();
4. 在开发者工具下手动勾选 Network 的 Disable cache
超时处理:
有时网络有问题或者服务器有问题,导致请求时间过长。一般会提示网络请求稍后重试,以增加用户体验。代码可以通过定时器和请求中断来达到超时处理的效果。
var timer = setTimeout(() => {
//取消请求,终端请求
ajax.abort();
alert("请稍后重试")
}, time)
方法提取(不是最终形式,工作中不会这样写,懂的)
一个ajax请求、请求方法、请求路径、请求参数、获取服务器内容后的回调函数、时间等都可以封装成函数,这样get和post请求就可以写在一起了
function ajax(method, url, param, success, time) {
var ajax;
//处理ajax获取时候的兼容性问题
try { //非IE
ajax = new XMLHttpRequest();
} catch(e) { //IE
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
if(method === 'get') {
param = encodeURL(param); //针对get请求的查询参数出现中文的编码处理
url = url + '?' + param;
param = null;
}
ajax.open(method, url);
if(method === 'post') {
//请求体格式,例如name=nodejs&age=11
ajax.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
//也可以在标签中设设置
//...
}
ajax.onreadystatechange = function() {
if(ajax.readyState === 4 && ajax.status === 200) {
success(ajax.responseText); //在外面设置的获取服务端数据后处理数据的回调函数
}
}
ajax.send(param);
var time = setTimeout(() => {
ajax.abort();
}, time)
}
jQuery的ajax方法,get请求,post请求(没看过视频),指jQuery,指jQuery,指jQuery,.ajax就是jQuery.ajax 查看全部
浏览器抓取网页(
Web应用程序更为迅捷地回应用户动作并避免了没有改变的信息)
Ajax技术(属于前端技术)
那就是“异步 JavaScript 和 XML”,它与服务器交互而不刷新页面。
特点:异步请求,部分刷新
同步:发送方发送数据后,等待接收方发回响应,然后再发送下一个数据包;
异步:发送方发送数据后,不等待接收方回传响应,然后发送下一个数据包。
**好处:** Web 应用程序对用户操作的响应速度更快,避免通过网络发送未更改的信息,从而减少服务器压力。
**缺点:**浏览器实现的差异,需要处理兼容性问题;不利于SEO(SEO只能识别页面首次呈现的数据,不能异步);不能前后左右;默认不支持跨域访问。
**注意:**ajax 技术只能在网络协议环境中使用。不能直接将页面拖入浏览器执行。它必须以 Web 服务器模式访问。
AJAX编写步骤:
1.创建一个AJAX对象;
2.设置请求路径、请求方式等;
3.绑定监听状态变化的处理函数,可以在处理函数中获取响应数据(回调函数);
4.发送请求;
创建 ajax 对象时的浏览器兼容性处理
function createAjax() {
var ajax;
try { //非IE
ajax = new XMLHttpRequest(); //IE浏览器下没有XMLHttpRquest这个对象就会报错
} catch(e) {
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
return ajax;
}
响应处理和响应流
响应处理,即根据状态码和AJAX对象的状态信息,对服务响应浏览器的数据进行不同的处理,可以在绑定状态的处理函数中编写相应的逻辑代码改变。
AJAX 对象有 4 个属性:
readyState 一共有5个状态值,0-4,每个值代表不同的含义:onreadystatechange,一旦状态不标准,就会被执行,多次改变,多次执行
0:初始化,AJAX对象还没有初始化,new XMLHttpRequest();
1:加载,AJAX对象开始发送请求,ajax.open(请求方法,请求路径);
2:加载完成,发送AJAX对象的请求,ajax.send();
3:分析:AJAX对象开始读取服务器的响应,ajax.onreadystatechange;
4:完成,AJAX对象读取服务器响应并结束。
status 表示响应的 HTTP 状态码。常见的状态码如下:
200:成功;
302:重定向;
404:找不到资源;
500:服务器错误;
responseText 获取字符串形式的响应数据(常用)
responseXML 获取 XML 格式的响应数据
综上所述,状态变化的处理函数一般只针对ajax.readyState4和ajax.status200这两种情况进行处理(这也意味着我们什么时候可以开始渲染数据?服务器响应并成功获取数据后),然后根据后台返回的数据类型决定从responseText或responseXML中获取服务器响应返回的数据。
ajax 获取请求
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
console.log("点击了按钮");
//发送ajax请求
//1.创建ajax对象
let ajax = new XMLHttpRequest();
//2.设置请求方式、请求路径url
ajax.open("GET", "/get_data");
//3.绑定监听状态的改变的处理函数,在这个函数里面可以获取响应数据(回调函数)
ajax.onreadystatechange = () => {
//这个函数里面的代码什么时候执行?状态发生改变的时候就执行
//获取响应的数据
//什么时候页面开始渲染数据?服务器响应完毕之后ajax.readyState为4,并且成功获取数据之后ajax.status为200
if(ajax.readyState === 4 && ajax.status === 200) {
//服务器传来的数据用什么表示?ajax.readyState
console.log(ajax.readyState);
//渲染数据到页面上
oDiv.innerHTML = ajax.responseText;
}
}
//发送请求
ajax.send();
}
服务器代码(在 nodejs 文档中解释)
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
const server = http.createServer((request, response) => {
//每来一个请求就执行一次这里的代码
//判断浏览器需要哪个资源文件,把下面这些代码进行封装的话就是路由
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "index.html");
let content = fs.readFileSync(filePath);
response.end(content);
} else if(reqUrl === '/detail.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "detail.html");
let content = fs.readFileSync(filePath);
response.end(content); //这句不能放在外面,因为使用let定义的content有块级作用域
} else if(reqUrl === '/get_data') { //或者正则:/get_data.*/.test(reqUrl)
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
} else if(reqUrl.endsWith(".css")) {
//如果读取的是一个css文件,也是一个请求,也会执行一次代码
//哪些标签会造成请求?就有href(link)和src(src img)属性的标签,浏览器是自发的请求;还有像按钮、a标签的话需要在表单里而且需要点击过后才会请求
//如果用a标签实现跳转的话,index.html中跳转到详情页
//这里的跳转地址不是看前端的路径,而是看后端的路由是怎么配的,和这里的if else里的判断内容一致,点击之后也是一次请求
let filePath = path.join(__dirname, "assets", "css", "index.css");
let content = fs.readFileSync(filePath);
response.end(content);
} else {
response.setHeader("Content-type", "text/html; charset=utf-8"); //不加这句下面的语句会出现乱码
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
ajax 发布请求
附:根本没有提交行为,但是在某些浏览器中有提交行为
用户名:
密&emsp码:
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
//post提交
//获取用户填写的数据
let username = document.getElementById("username").value;
let password = document.getElementById("password").value;
let params = { //这样的形式是将获取的值看着方便且容易处理,下面处理时还需要转换为服务器需要的JSON格式
username,
password
}
//Ajax提交(四个步骤)
let ajax = new XMLHttpRequest();
ajax.open("POST", "/login_post");
ajax.onreadystatechange = () => {
if(ajax.readyState === 4 && ajax.status === 200) {
//相当于成功后的回调函数,这里可以封装为一个函数,写在最外面,通过调用使用
//ajax.responseText是服务器传过来的字符串
oDiv.innerHTML = ajax.responseText;
}
}
ajax.send(JSON.stringify(params)); //服务器需要的是JSON格式的数据,所以需要转换一下
}
服务器代码
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
let uname = "laozhuang";
let pwd = "123456";
//包装为函数
function responseEnd(response, dirName, fileName) { //dirName文件路径,fileName文件名称
let filePath = path.join(__dirname, "assets", "dirName", "fileName");
let content = fs.readFileSync(filePath);
response.end(content);
}
const server = http.createServer((request, response) => {
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
responseEnd(response, "html", "index.html");
} else if(reqUrl === '/detail.html') {
responseEnd(response, "html", "detail.html");
} else if(reqUrl === '/login.html') {
responseEnd(response, "html", "login.html");
} else if(reqUrl === '/get_data') {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
} else if(reqUrl === '/login_post') {
//处理post请求
//一旦post请求过来就会触发data事件
request.on("data", (postData) => {
//postData就是post请求传递过来的参数,是Buffer对象,需要toString()一下
//还需要把JSON格式的字符串转换为对象,因为转为对象才能通过.的方式拿到属性值
//获取到浏览器传过来的数据,就是post请求传递过来的参数
let {username, password} = JSON.parse(postData.toString()); //解构
//需要查询数据库看有没有用户名,没有的话就需要注册,如果有还需对比密码是否正确,或者其他逻辑操作
if(username === uname && password === pwd) {
//还可以跳转之类的操作
response.end("登录成功!");
} else {
response.end("用户名或者密码错误,登录失败")
}
})
} else if(reqUrl.endsWith(".css")) {
responseEnd(response, "css", "index.css");
} else if(reqUrl.endsWith(".js")) {
responseEnd(response, "js", "index.js");
} else {
response.setHeader("Content-type", "text/html; charset=utf-8");
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
避免缓存问题:
AJAX 减少了重复数据的加载,提高了页面加载速度,因为数据会一直缓存在内存中,当提交的 URL 与历史 URL 一致时,就不需要提交给服务器了。虽然减轻了服务器的负载,提升了用户体验,但无法获取最新的数据。为了保证数据是最新的,需要禁用其缓存功能,主要有以下几种方式:
1.在 URL 中添加一个随机数:Math.random()
//客户端代码
ajax.open("GET", "/get_data" + Math.random());
//服务端代码
else if(reqUrl.startsWith('/get_data')) {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
}
2.给 URL 添加时间戳:new Date().getTime(),从 197 开始的毫秒数0.01.01
3.在使用 AJAX 发送请求之前添加 ajax.setRequestHeader("Cache-Control", "no-cache");
ajax.open(...);
ajax.setRequestHeader('Cache-Control', 'no-cache'); //请求头设置,在ajax.open()后面
ajax.send();
4. 在开发者工具下手动勾选 Network 的 Disable cache
超时处理:
有时网络有问题或者服务器有问题,导致请求时间过长。一般会提示网络请求稍后重试,以增加用户体验。代码可以通过定时器和请求中断来达到超时处理的效果。
var timer = setTimeout(() => {
//取消请求,终端请求
ajax.abort();
alert("请稍后重试")
}, time)
方法提取(不是最终形式,工作中不会这样写,懂的)
一个ajax请求、请求方法、请求路径、请求参数、获取服务器内容后的回调函数、时间等都可以封装成函数,这样get和post请求就可以写在一起了
function ajax(method, url, param, success, time) {
var ajax;
//处理ajax获取时候的兼容性问题
try { //非IE
ajax = new XMLHttpRequest();
} catch(e) { //IE
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
if(method === 'get') {
param = encodeURL(param); //针对get请求的查询参数出现中文的编码处理
url = url + '?' + param;
param = null;
}
ajax.open(method, url);
if(method === 'post') {
//请求体格式,例如name=nodejs&age=11
ajax.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
//也可以在标签中设设置
//...
}
ajax.onreadystatechange = function() {
if(ajax.readyState === 4 && ajax.status === 200) {
success(ajax.responseText); //在外面设置的获取服务端数据后处理数据的回调函数
}
}
ajax.send(param);
var time = setTimeout(() => {
ajax.abort();
}, time)
}
jQuery的ajax方法,get请求,post请求(没看过视频),指jQuery,指jQuery,指jQuery,.ajax就是jQuery.ajax
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-24 16:17
前言
Selenium 是一个模拟浏览器的自动化执行框架,但是如果每次执行任务都需要打开浏览器来处理任务,效率不高。最重要的是,如果是安装在Centos7服务器环境下,更不适合打开浏览器模拟操作,尤其是涉及到需要抓取网页图片的时候。
这时候,就该考虑使用 Chrome 的无头浏览器模式了。所谓无头浏览器模式,就是不需要打开浏览器,但可以模拟打开浏览器的执行效果,一切都在没有界面的情况下执行。
让我们看看安装是否部署执行。
1.安装chrome1.1 添加google的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome的版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
如果selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般是访问国内的镜像地址,如下:
您可以看到有相当多的版本可供下载。从上面可以看出刚刚安装的chrome的版本号Google Chrome79.0.3945.79,所以大致根据版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为我要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后,编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver说明环境配置已经生效。
3. 安装硒
selenium 可以简单地在项目的虚拟环境中使用 pip 安装
pip3 install selenium
4. 脚本测试
编写 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下命令:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
下载图片看看,
可以看出已经能够正常模拟浏览器登录,并抓取网页的图片。从图中可以看出,所有中文的地方都以方框符号显示。这是因为Centos7默认没有安装中文字体,所以chrom浏览器打开时无法正常显示中文。
解决办法是为Centos7安装中文字体,这里就不介绍了。 查看全部
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
前言
Selenium 是一个模拟浏览器的自动化执行框架,但是如果每次执行任务都需要打开浏览器来处理任务,效率不高。最重要的是,如果是安装在Centos7服务器环境下,更不适合打开浏览器模拟操作,尤其是涉及到需要抓取网页图片的时候。
这时候,就该考虑使用 Chrome 的无头浏览器模式了。所谓无头浏览器模式,就是不需要打开浏览器,但可以模拟打开浏览器的执行效果,一切都在没有界面的情况下执行。
让我们看看安装是否部署执行。
1.安装chrome1.1 添加google的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome的版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
如果selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般是访问国内的镜像地址,如下:
您可以看到有相当多的版本可供下载。从上面可以看出刚刚安装的chrome的版本号Google Chrome79.0.3945.79,所以大致根据版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为我要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后,编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver说明环境配置已经生效。
3. 安装硒
selenium 可以简单地在项目的虚拟环境中使用 pip 安装
pip3 install selenium
4. 脚本测试
编写 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下命令:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
下载图片看看,
可以看出已经能够正常模拟浏览器登录,并抓取网页的图片。从图中可以看出,所有中文的地方都以方框符号显示。这是因为Centos7默认没有安装中文字体,所以chrom浏览器打开时无法正常显示中文。
解决办法是为Centos7安装中文字体,这里就不介绍了。
浏览器抓取网页(客户端浏览器获取到一个页面的响应内容是html的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-24 08:08
有些网站使用 ssr 方法,或者类似 java 的 jsp,通过服务器渲染页面。然后后端可以在渲染时将自定义信息添加到响应头中。
那么当客户端浏览器获取一个页面(响应内容为html)并加载时,后端通过javascript响应页面内容时,能否获取加载的响应页面的响应头信息呢?
例如。
客户端向后端请求一个名为 /user/info 的动作,该动作返回一个 html,后端也在响应头中设置自定义数据。
大致分为5个流程:
(1)客户端请求一个名为/user/info的动作。(比如在浏览器上输入网址,回车确认)
(2)后端接收客户端的请求,后端在响应头中设置自定义信息
(3)后端将html内容响应给客户端
(4)客户端浏览器接收到后端的响应,包括响应头和页面信息(html字符串)
(5)客户端浏览器会从后端响应中获取html内容进行页面渲染。
那么问题来了,客户端请求/user/info这个动作,响应之后,浏览器渲染页面的时候,也就是第五步流程,能否调用js获取流程中的第二个流程,即,后者在请求处理的过程中,响应头中的数据集呢?
这可以用js完成吗? 查看全部
浏览器抓取网页(客户端浏览器获取到一个页面的响应内容是html的?)
有些网站使用 ssr 方法,或者类似 java 的 jsp,通过服务器渲染页面。然后后端可以在渲染时将自定义信息添加到响应头中。
那么当客户端浏览器获取一个页面(响应内容为html)并加载时,后端通过javascript响应页面内容时,能否获取加载的响应页面的响应头信息呢?
例如。
客户端向后端请求一个名为 /user/info 的动作,该动作返回一个 html,后端也在响应头中设置自定义数据。
大致分为5个流程:
(1)客户端请求一个名为/user/info的动作。(比如在浏览器上输入网址,回车确认)
(2)后端接收客户端的请求,后端在响应头中设置自定义信息
(3)后端将html内容响应给客户端
(4)客户端浏览器接收到后端的响应,包括响应头和页面信息(html字符串)
(5)客户端浏览器会从后端响应中获取html内容进行页面渲染。
那么问题来了,客户端请求/user/info这个动作,响应之后,浏览器渲染页面的时候,也就是第五步流程,能否调用js获取流程中的第二个流程,即,后者在请求处理的过程中,响应头中的数据集呢?
这可以用js完成吗?
浏览器抓取网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-23 23:19
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思想是从一个起始网页开始爬取,然后根据链接逐个爬取,直到不能再进一步爬取,然后返回上一页继续跟踪关联。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。 查看全部
浏览器抓取网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思想是从一个起始网页开始爬取,然后根据链接逐个爬取,直到不能再进一步爬取,然后返回上一页继续跟踪关联。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
浏览器抓取网页(手机浏览器cookie怎么查看?手机cookie获取方法汇总!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2022-02-09 03:17
一、在IE浏览器查看cookie的方法一:在浏览器地址栏输入:javascript:alert(document.cookie)(差别不大。
手机如何查看cookies?操作步骤如下: 1、首先点击IE页面右上角的“工具”按钮,如何查看手机浏览器cookies?.
如何查看手机浏览器cookies?手机浏览器的cookie设置用于确定使用哪个浏览器。如果是 cookie 浏览器,解决方案。
csdn为您找到了可以查看cookies的手机浏览器的相关内容,包括可以查看cookies的手机浏览器的相关文档代码介绍。
手机如何获取浏览器的cookie?下面我们来看看如何获取手机cookie。一、华为手机1、先找到华为手机。
确保打开手机浏览器的cookie设置2.进入手机浏览器的设置页面后,点击当前页面的无痕浏览加快速度。
您可以直接在网页上搜索。自带的浏览器一般都不是很完善。建议您使用手机QQ浏览器的功能性、安全性和便捷性。
微信保存百度云链接的时候,虽然无法打开任何cookies,但还是有办法保存的。点击右上角三个点,用QQ浏览器打开。
我的浏览器选项里没有“cookie”选项,但是设置里有“清除缓存”,如何判断?您可以通过浏览器的菜单-系统设置-。 查看全部
浏览器抓取网页(手机浏览器cookie怎么查看?手机cookie获取方法汇总!!)
一、在IE浏览器查看cookie的方法一:在浏览器地址栏输入:javascript:alert(document.cookie)(差别不大。
手机如何查看cookies?操作步骤如下: 1、首先点击IE页面右上角的“工具”按钮,如何查看手机浏览器cookies?.
如何查看手机浏览器cookies?手机浏览器的cookie设置用于确定使用哪个浏览器。如果是 cookie 浏览器,解决方案。
csdn为您找到了可以查看cookies的手机浏览器的相关内容,包括可以查看cookies的手机浏览器的相关文档代码介绍。
手机如何获取浏览器的cookie?下面我们来看看如何获取手机cookie。一、华为手机1、先找到华为手机。
确保打开手机浏览器的cookie设置2.进入手机浏览器的设置页面后,点击当前页面的无痕浏览加快速度。
您可以直接在网页上搜索。自带的浏览器一般都不是很完善。建议您使用手机QQ浏览器的功能性、安全性和便捷性。
微信保存百度云链接的时候,虽然无法打开任何cookies,但还是有办法保存的。点击右上角三个点,用QQ浏览器打开。
我的浏览器选项里没有“cookie”选项,但是设置里有“清除缓存”,如何判断?您可以通过浏览器的菜单-系统设置-。
浏览器抓取网页(Python中爬虫基础快速入门的学习方法,值得收藏!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-08 04:24
对于小白来说,爬虫可能是一件非常复杂、技术含量很高的事情。比如很多人认为学习爬虫一定要掌握Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来数据;有的人认为需要先了解网页的知识,于是入手HTML\CSS,结果就是前端的坑,皱巴巴的……
但是如果知道正确的方法,短期内可以爬取主流的网站数据。我认为实现起来并不难,但建议你从一开始就设定明确的目标。
在目标的驱动下,你的学习会更有效率。你觉得必要的专业知识,可以在完成目标的过程中学习。这里为大家提供一个零基础的快速入门学习方法。
01学习Python包并执行基本爬取步骤
大多数爬虫都是按照“发送请求-获取页面-解析页面-提取并存储内容”的过程来实现的,它模拟了使用浏览器爬取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求或者学习Selenium来自动化。这样动态知乎、、TripAdvisor网站也可以解决。
02 了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为csv等文件。
当然,你可能会发现爬取的数据不干净,可能有缺失、错误等,你也需要对数据进行清洗,可以学习pandas包的基本用法来做数据预处理,得到更干净的数据。
03 掌握各种技巧应对特殊网站防爬措施
当然在爬取的过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
所以有些东西看起来很吓人,但当它们崩溃时,也仅此而已。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
同时可以使用掘金的ip代理和相关的防屏蔽来辅助。(百度搜索:掘金.com) 查看全部
浏览器抓取网页(Python中爬虫基础快速入门的学习方法,值得收藏!)
对于小白来说,爬虫可能是一件非常复杂、技术含量很高的事情。比如很多人认为学习爬虫一定要掌握Python,然后系统地学习Python的每一个知识点,但是时间长了发现还是爬不出来数据;有的人认为需要先了解网页的知识,于是入手HTML\CSS,结果就是前端的坑,皱巴巴的……
但是如果知道正确的方法,短期内可以爬取主流的网站数据。我认为实现起来并不难,但建议你从一开始就设定明确的目标。
在目标的驱动下,你的学习会更有效率。你觉得必要的专业知识,可以在完成目标的过程中学习。这里为大家提供一个零基础的快速入门学习方法。
01学习Python包并执行基本爬取步骤
大多数爬虫都是按照“发送请求-获取页面-解析页面-提取并存储内容”的过程来实现的,它模拟了使用浏览器爬取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求或者学习Selenium来自动化。这样动态知乎、、TripAdvisor网站也可以解决。
02 了解非结构化数据的存储
爬取的数据可以以文档的形式存储在本地,也可以存储在数据库中。
刚开始数据量不大的时候,可以直接通过Python语法或者pandas方法将数据保存为csv等文件。
当然,你可能会发现爬取的数据不干净,可能有缺失、错误等,你也需要对数据进行清洗,可以学习pandas包的基本用法来做数据预处理,得到更干净的数据。
03 掌握各种技巧应对特殊网站防爬措施
当然在爬取的过程中也会有一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
遇到这些反爬的方法,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
所以有些东西看起来很吓人,但当它们崩溃时,也仅此而已。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
同时可以使用掘金的ip代理和相关的防屏蔽来辅助。(百度搜索:掘金.com)
浏览器抓取网页(环境核心类库puppeteer文档安装第一步获取获取文章详情 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-08 02:20
)
环境核心类库
傀儡师
文档
安装
npm i puppeteer -S
第一步是获取网页的内容
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
以上代码可以获取整个页面。测试发现问题已经解决。其实puppeteer有一个特殊的方法可以解决这个问题,page.waitForSelector,等待匹配指定选择器的元素出现在页面上。
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第二步,获取列表中的标题和链接
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
const list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
console.log(list.length)
console.log(list)
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第三步,获取文章详情
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
console.log(list[0])
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第四步,保存数据
这里不介绍保存到数据库,简单写个json文件。
const puppeteer = require('puppeteer');
const fs = require('fs')
const path = require('path')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend");
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
// 保存数据
fs.writeFileSync(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
最后进行方法提取等处理
方法文件
const fs = require('fs')
exports.init = async function (browser) {
let page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto("https://juejin.cn/frontend");
await page.waitForSelector('.entry-list-wrap .entry-list .item');
return page;
}
exports.getList = async function (page) {
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
return list.slice(0, 10)
}
exports.getListDetail = async function (list, page) {
for (let i = 0; i e.innerHTML)
}
return list
}
exports.writeFile = async function (name, content) {
fs.writeFileSync(name, content)
}
主文件
const puppeteer = require('puppeteer');
const path = require('path')
const methods = require('./methods')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
try {
// 初始化
let page = await methods.init(browser);
// 获取列表中标题和链接
let list = await methods.getList(page)
// 获取文章详情
list = await methods.getListDetail(list, page)
// 保存数据
methods.writeFile(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
} catch (error) {
console.error(error)
// 关闭浏览器
await browser.close();
}
})
项目地址
查看全部
浏览器抓取网页(环境核心类库puppeteer文档安装第一步获取获取文章详情
)
环境核心类库
傀儡师
文档
安装
npm i puppeteer -S
第一步是获取网页的内容
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
以上代码可以获取整个页面。测试发现问题已经解决。其实puppeteer有一个特殊的方法可以解决这个问题,page.waitForSelector,等待匹配指定选择器的元素出现在页面上。
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
console.log(await page.content())
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第二步,获取列表中的标题和链接
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
const list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
console.log(list.length)
console.log(list)
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第三步,获取文章详情
const puppeteer = require('puppeteer');
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
console.log(list[0])
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
第四步,保存数据
这里不介绍保存到数据库,简单写个json文件。
const puppeteer = require('puppeteer');
const fs = require('fs')
const path = require('path')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
// 一个新的 Page 对象
let page = await browser.newPage();
// 启用js
await page.setJavaScriptEnabled(true);
// 打开URL
await page.goto("https://juejin.cn/frontend";);
// 等待列表出现
await page.waitForSelector('.entry-list-wrap .entry-list .item');
// 获取列表中标题和链接
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
list = list.slice(0, 10)
// 获取文章详情
for (let i = 0; i e.innerHTML)
}
// 保存数据
fs.writeFileSync(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
})
最后进行方法提取等处理
方法文件
const fs = require('fs')
exports.init = async function (browser) {
let page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto("https://juejin.cn/frontend";);
await page.waitForSelector('.entry-list-wrap .entry-list .item');
return page;
}
exports.getList = async function (page) {
let list = await page.$$eval('.entry-list-wrap .entry-list .title-row a', list => {
return list.map(item => {
return {
title: item.innerText,
href: item.href,
}
});
});
return list.slice(0, 10)
}
exports.getListDetail = async function (list, page) {
for (let i = 0; i e.innerHTML)
}
return list
}
exports.writeFile = async function (name, content) {
fs.writeFileSync(name, content)
}
主文件
const puppeteer = require('puppeteer');
const path = require('path')
const methods = require('./methods')
puppeteer.launch({
// 在导航期间忽略 HTTPS 错误
ignoreHTTPSErrors: true,
// 不在 无头模式 下运行浏览器
headless: false,
// 将 Puppeteer 操作减少指定的毫秒数
slowMo: 250,
// 等待浏览器实例启动的最长时间,0禁用超时
timeout: 0
}).then(async browser => {
try {
// 初始化
let page = await methods.init(browser);
// 获取列表中标题和链接
let list = await methods.getList(page)
// 获取文章详情
list = await methods.getListDetail(list, page)
// 保存数据
methods.writeFile(path.resolve(__dirname, '../out/articles.json'), JSON.stringify(list, null, 2))
// 关闭页面
await page.close();
// 关闭浏览器
await browser.close();
} catch (error) {
console.error(error)
// 关闭浏览器
await browser.close();
}
})
项目地址
浏览器抓取网页(1.selenium安装selenium库的介绍及安装和常见的使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-07 16:18
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
1
2
3
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
1
from selenium import webdriver
如果初始浏览器已经放在 Scripts 文件夹中,会直接调用。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
1
2
3
4
5
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
1
2
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
1
2
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
1
2
3
4
5
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新和刷新键一样,最好写个异常检测
1
2
3
4
5
6
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
1
2
3
4
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
1
2
3
4
5
6
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
1
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
1
2
按 id/name/class 定位
1
2
3
4
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
根据标签定位,但实际上,一个页面上可能有很多相同的标签,这会使标签点模糊,从而导致错误。
1
2
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
link定位,定位连接名,例如定位在百度左上角链接的例子中。
1
2
3
4
5
6
新闻
hao123
地图
...
直接通过链接名称定位。
1
2
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
1
2
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
上述xpath定位的方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
1
2
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
CSS定位这个方法比xpath更简洁更快
1
2
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素当然,有时候我们只需要多个元素,所以只需要使用复数即可。
1
2
3
4
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性比如要获取百度logo的信息,先定位图片元素,再获取信息
1
2
3
4
5
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本,首先使用类直接查找热列表元素,但是有多个元素,所以使用复数形式获取,使用for循环打印。获取文本时,使用文本获取
1
2
3
4
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性以获取例如 id 或 tag
1
2
3
4
5
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
在百度搜索框输入/清除“冬奥会”等文字,然后清除
1
2
3
4
5
6
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(Enter) 输入以上内容后,需要点击回车提交,即可得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要添加一些伪装的方法。在本文的最后。:point_right:。
1
2
search_bar.send_keys('冬奥会')
search_bar.submit()
单击 当我们需要单击时,使用单击。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
1
2
3
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
1
2
3
4
5
6
7
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击是double_click。如果找不到合适的例子,我就不提了。这里是 ActionChains,可以深入挖掘,定义一系列操作一起执行。当然,一些常用的操作其实就足够了。
悬停,我无法将其放入。
1
ActionChains(browser).move_to_element(move).perform()
从下拉框中选择需要导入的相关库,访问MySQL官网选择下载对应的操作系统为例。
1
2
3
4
5
6
7
8
9
10
11
12
13
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖拽多用于验证码之类的,参考菜鸟示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 27%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待可以发现,在上面的程序中,有些效果需要延迟等待才能出现。在实践中,它也需要一定的延迟。一方面为了不访问太频繁被认为是爬虫,另一方面也是爬虫。由于网络资源的加载,需要一定的时间等待。
1
2
3
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截图可以保存为base64/png/file
1
browser.get_screenshot_as_file('截图.png')
窗口切换 我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
1
2
3
4
5
6
7
8
9
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
1
2
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条 有些网页的内容是随着进度条的滑动出现的,所以需要下拉进度条的操作。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
1
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
1
2
3
4
5
6
7
8
9
10
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。如果仔细观察,操作非常详细。模仿真实的浏览器操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导:joy:。
和直接获取资源的爬虫相比,肯定是慢了一些,但是比强大的要好,而且还是可以提高钓鱼效率:+1:。 查看全部
浏览器抓取网页(1.selenium安装selenium库的介绍及安装和常见的使用方法)
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
1
2
3
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
1
from selenium import webdriver
如果初始浏览器已经放在 Scripts 文件夹中,会直接调用。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
1
2
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
1
2
3
4
5
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
1
2
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
1
2
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
1
2
3
4
5
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新和刷新键一样,最好写个异常检测
1
2
3
4
5
6
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
1
2
3
4
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
1
2
3
4
5
6
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
1
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
1
2
按 id/name/class 定位
1
2
3
4
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
根据标签定位,但实际上,一个页面上可能有很多相同的标签,这会使标签点模糊,从而导致错误。
1
2
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
link定位,定位连接名,例如定位在百度左上角链接的例子中。
1
2
3
4
5
6
新闻
hao123
地图
...
直接通过链接名称定位。
1
2
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
1
2
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
上述xpath定位的方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
1
2
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
CSS定位这个方法比xpath更简洁更快
1
2
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素当然,有时候我们只需要多个元素,所以只需要使用复数即可。
1
2
3
4
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性比如要获取百度logo的信息,先定位图片元素,再获取信息
1
2
3
4
5
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本,首先使用类直接查找热列表元素,但是有多个元素,所以使用复数形式获取,使用for循环打印。获取文本时,使用文本获取
1
2
3
4
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性以获取例如 id 或 tag
1
2
3
4
5
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
在百度搜索框输入/清除“冬奥会”等文字,然后清除
1
2
3
4
5
6
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(Enter) 输入以上内容后,需要点击回车提交,即可得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要添加一些伪装的方法。在本文的最后。:point_right:。
1
2
search_bar.send_keys('冬奥会')
search_bar.submit()
单击 当我们需要单击时,使用单击。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
1
2
3
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
1
2
3
4
5
6
7
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击是double_click。如果找不到合适的例子,我就不提了。这里是 ActionChains,可以深入挖掘,定义一系列操作一起执行。当然,一些常用的操作其实就足够了。
悬停,我无法将其放入。
1
ActionChains(browser).move_to_element(move).perform()
从下拉框中选择需要导入的相关库,访问MySQL官网选择下载对应的操作系统为例。
1
2
3
4
5
6
7
8
9
10
11
12
13
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖拽多用于验证码之类的,参考菜鸟示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 27%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待可以发现,在上面的程序中,有些效果需要延迟等待才能出现。在实践中,它也需要一定的延迟。一方面为了不访问太频繁被认为是爬虫,另一方面也是爬虫。由于网络资源的加载,需要一定的时间等待。
1
2
3
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截图可以保存为base64/png/file
1
browser.get_screenshot_as_file('截图.png')
窗口切换 我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
1
2
3
4
5
6
7
8
9
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
1
2
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条 有些网页的内容是随着进度条的滑动出现的,所以需要下拉进度条的操作。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
1
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
1
2
3
4
5
6
7
8
9
10
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。如果仔细观察,操作非常详细。模仿真实的浏览器操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导:joy:。
和直接获取资源的爬虫相比,肯定是慢了一些,但是比强大的要好,而且还是可以提高钓鱼效率:+1:。
浏览器抓取网页(谷歌浏览器插件开发文档,插件总结经验 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-06 16:09
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件,所以一般花了一天时间看完了谷歌浏览器插件开发文档,这里特意总结一下经验,对插件进行复习——通过一个实际案例。开发过程及注意事项.javascript
你会得到文字
正文开始之前,先看一下作者总结的概述:css
如果你熟悉浏览器插件开发,可以直接观看最后一节插件开发实践。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 HTML、JavaScript 和 CSS 等 Web 技术构建的小型软件程序,可自定义浏览体验。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发一个浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 开启开发者模式
导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件一般放在浏览器地址栏的右侧,我们可以在manifest.json文件中配置插件的图标,并配置一定的规则,就可以看到我们的浏览器插件图标,下图:java
下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件:node
作者画了一张图来粗略表示它们之间的关系:jquery
接下来,让我们仔细看看几个核心知识点。网页包
2.1 manifest.json
谷歌官网为我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
每个字段的含义描述如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 背景.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,下面是几个常见的用例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:
仅设置带有 .com 后缀的页面以激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图所示,当页面地址后缀不等于.com时,插件图标不会被激活:
3. 与 content_script 或弹出页面通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 个内容脚本
内容脚本通常被植入到页面中,并且可以控制页面中的dom。我们可以用它来屏蔽网页广告,自定义页面皮肤等。manifest.json中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了 content_scripts 允许注入的页面范围,插入页面的 js 和 css,这样我们就可以很方便的改变页面的样式。例如,我们可以在页面中注入一个按钮:
在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹出窗口
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件描述。
因为弹窗也是网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的页面显示和交互。我们在 manifest.json 中配置如下:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要导入脚本文件。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗页面:
3.通讯机制
对于一个比较复杂的浏览器插件,我们不仅需要操作 DOM 或者提供基本的功能,还需要从第三方或者我们自己的服务器上获取有用的页面数据。这时候,我们就需要使用插件式的通信机制了。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传输到第三方平台或自己的服务器,因此需要一个基于浏览器的通信API。下面是谷歌浏览器插件通信流程:
3.1 弹出和后台相互通信
从官方文档我们知道popup可以直接访问后台页面,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接在谷歌官网上也写得很清楚:
我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们将数据存储在任何页面(弹出窗口或 content_script 或背景)下。我们可以在上面三个页面上得到它。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器插件的应用场景很多,在文章开头的思维导图中写过。以下是作者总结的一些应用场景,有兴趣可以尝试实现:
有很多实用的工具可以开发,你可以玩得开心。接下来我们通过实现一个网页图片提取插件来总结以下浏览器插件的开发流程。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何一种工具之前,都必须明确需求,那么我们来看看插件的功能点:
基本上,这些是功能。接下来,我将展示核心代码。在介绍代码之前,我们先来预览一下插件的实现效果:
插件目录结构如下:
由于插件的开发比较简单,所以我直接使用jquery来开发。这里我们主要关注popup.js和content_script.js。popup.js主要用于获取content_script页面传过来的图片数据,并在popup.html中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,并自动让它生成一个按钮,代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成一个按钮,并在页面中植入一个弹窗来显示获取到的图片。另一方面,我们需要将图像数据传递到存储中,以便弹出页面可以获取图像数据。
因为页面比较简单,所以作者不需要太多的第三方库。作者简单的先写了一个modal组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者利用正则简单处理如下,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是生成一个用于预览图像的弹出窗口。这里使用了上面作者实现的modal组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送通知激活按钮时,我们需要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式来处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。有兴趣的朋友可以安装感受一下。
github地址:一个提取网页图片数据的浏览器插件
最后
如果想学习更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎在公众号“趣前沿”加入我们的技术群-end”一起学习、讨论和探索前端边界。
查看全部
浏览器抓取网页(谷歌浏览器插件开发文档,插件总结经验
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件,所以一般花了一天时间看完了谷歌浏览器插件开发文档,这里特意总结一下经验,对插件进行复习——通过一个实际案例。开发过程及注意事项.javascript
你会得到文字
正文开始之前,先看一下作者总结的概述:css
如果你熟悉浏览器插件开发,可以直接观看最后一节插件开发实践。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 HTML、JavaScript 和 CSS 等 Web 技术构建的小型软件程序,可自定义浏览体验。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发一个浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 开启开发者模式
导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件一般放在浏览器地址栏的右侧,我们可以在manifest.json文件中配置插件的图标,并配置一定的规则,就可以看到我们的浏览器插件图标,下图:java
下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件:node
作者画了一张图来粗略表示它们之间的关系:jquery
接下来,让我们仔细看看几个核心知识点。网页包
2.1 manifest.json
谷歌官网为我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
每个字段的含义描述如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 背景.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,下面是几个常见的用例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:
仅设置带有 .com 后缀的页面以激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图所示,当页面地址后缀不等于.com时,插件图标不会被激活:
3. 与 content_script 或弹出页面通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 个内容脚本
内容脚本通常被植入到页面中,并且可以控制页面中的dom。我们可以用它来屏蔽网页广告,自定义页面皮肤等。manifest.json中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了 content_scripts 允许注入的页面范围,插入页面的 js 和 css,这样我们就可以很方便的改变页面的样式。例如,我们可以在页面中注入一个按钮:
在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹出窗口
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件描述。
因为弹窗也是网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的页面显示和交互。我们在 manifest.json 中配置如下:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要导入脚本文件。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗页面:
3.通讯机制
对于一个比较复杂的浏览器插件,我们不仅需要操作 DOM 或者提供基本的功能,还需要从第三方或者我们自己的服务器上获取有用的页面数据。这时候,我们就需要使用插件式的通信机制了。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传输到第三方平台或自己的服务器,因此需要一个基于浏览器的通信API。下面是谷歌浏览器插件通信流程:
3.1 弹出和后台相互通信
从官方文档我们知道popup可以直接访问后台页面,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接在谷歌官网上也写得很清楚:
我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们将数据存储在任何页面(弹出窗口或 content_script 或背景)下。我们可以在上面三个页面上得到它。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器插件的应用场景很多,在文章开头的思维导图中写过。以下是作者总结的一些应用场景,有兴趣可以尝试实现:
有很多实用的工具可以开发,你可以玩得开心。接下来我们通过实现一个网页图片提取插件来总结以下浏览器插件的开发流程。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何一种工具之前,都必须明确需求,那么我们来看看插件的功能点:
基本上,这些是功能。接下来,我将展示核心代码。在介绍代码之前,我们先来预览一下插件的实现效果:
插件目录结构如下:
由于插件的开发比较简单,所以我直接使用jquery来开发。这里我们主要关注popup.js和content_script.js。popup.js主要用于获取content_script页面传过来的图片数据,并在popup.html中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,并自动让它生成一个按钮,代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成一个按钮,并在页面中植入一个弹窗来显示获取到的图片。另一方面,我们需要将图像数据传递到存储中,以便弹出页面可以获取图像数据。
因为页面比较简单,所以作者不需要太多的第三方库。作者简单的先写了一个modal组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者利用正则简单处理如下,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是生成一个用于预览图像的弹出窗口。这里使用了上面作者实现的modal组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送通知激活按钮时,我们需要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式来处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。有兴趣的朋友可以安装感受一下。
github地址:一个提取网页图片数据的浏览器插件
最后
如果想学习更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎在公众号“趣前沿”加入我们的技术群-end”一起学习、讨论和探索前端边界。
浏览器抓取网页(网页抓取网页必须要会操作浏览器相对于(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-05 22:04
浏览器抓取网页必须要会操作浏览器,相对于浏览器程序员来说,那么页面抓取基本功还是有必要掌握的,javascript是一门强大的编程语言。页面抓取作为网页抓取入门都很重要,比如说登录时不同的人有不同的账号,如何去统计谁最先注册,如何搜索重要网页页面等等。当然,开发过程中碰到问题还是需要联系网站解决的。网页抓取相对java抓取就简单很多,因为网页的结构不会变化,变化的只是网页元素的排列顺序,统计相对容易。
javascript的使用,网页的重定向、iframe框架的制作,网页怎么展示大家可以用最简单的办法就能达到一定的效果,今天我们讲解一下web容器中通过html解析出来script标签,然后才能使用dom查看器解析,编写方法大家可以采用javascript引擎来进行编写和调试。我们先来看一下script标签的基本格式html/script.jsmydom.prefix为前导标签,importjs,functionxxx(){returneval(xxx);}object标签的内容是声明属性并且赋值到dom中,属性值必须是一个已有的属性属性值,如果是指向第三方库,xxx()必须带有prototype属性标签必须包含“返回类型”,一般都为"prototype"或者"void",包含类型不能在js里用,如果不加就会进入对象的null对象,或者是对象prototype属性,导致调用计算机解析的时候报错异常,例如javascript://importjsfrom"@//".src这个是importxxx()到dom上,假如name属性值为1,浏览器会解析为'{1:"1"}',但是javascript://importxxxfrom"@//".src会得到"privatestring"不再是'1',此时将name属性值设置为'1',浏览器会自动更改成'1'importxxxfrom"@//".src会得到'privatestring'有import(),一般都带有prototype属性注意的是此时'1'变为number(number)下面再来举个例子://.//name.shortindex=""name=("hello").slice(。
1).reduce((mid,item1,item
2)=>mid+item2+""){name=("hello").slice
2)=>mid+item2+"")}returnname}当dom转化为javascript时一定要判断会不会符合这个规则,不然得自己设置.script标签的实现也很简单,大家可以用chrome网页代码监控dom来实现,当dom元素中存在item1和item2时,我们的代码就不会更新了,可以保存原有 查看全部
浏览器抓取网页(网页抓取网页必须要会操作浏览器相对于(组图))
浏览器抓取网页必须要会操作浏览器,相对于浏览器程序员来说,那么页面抓取基本功还是有必要掌握的,javascript是一门强大的编程语言。页面抓取作为网页抓取入门都很重要,比如说登录时不同的人有不同的账号,如何去统计谁最先注册,如何搜索重要网页页面等等。当然,开发过程中碰到问题还是需要联系网站解决的。网页抓取相对java抓取就简单很多,因为网页的结构不会变化,变化的只是网页元素的排列顺序,统计相对容易。
javascript的使用,网页的重定向、iframe框架的制作,网页怎么展示大家可以用最简单的办法就能达到一定的效果,今天我们讲解一下web容器中通过html解析出来script标签,然后才能使用dom查看器解析,编写方法大家可以采用javascript引擎来进行编写和调试。我们先来看一下script标签的基本格式html/script.jsmydom.prefix为前导标签,importjs,functionxxx(){returneval(xxx);}object标签的内容是声明属性并且赋值到dom中,属性值必须是一个已有的属性属性值,如果是指向第三方库,xxx()必须带有prototype属性标签必须包含“返回类型”,一般都为"prototype"或者"void",包含类型不能在js里用,如果不加就会进入对象的null对象,或者是对象prototype属性,导致调用计算机解析的时候报错异常,例如javascript://importjsfrom"@//".src这个是importxxx()到dom上,假如name属性值为1,浏览器会解析为'{1:"1"}',但是javascript://importxxxfrom"@//".src会得到"privatestring"不再是'1',此时将name属性值设置为'1',浏览器会自动更改成'1'importxxxfrom"@//".src会得到'privatestring'有import(),一般都带有prototype属性注意的是此时'1'变为number(number)下面再来举个例子://.//name.shortindex=""name=("hello").slice(。
1).reduce((mid,item1,item
2)=>mid+item2+""){name=("hello").slice
2)=>mid+item2+"")}returnname}当dom转化为javascript时一定要判断会不会符合这个规则,不然得自己设置.script标签的实现也很简单,大家可以用chrome网页代码监控dom来实现,当dom元素中存在item1和item2时,我们的代码就不会更新了,可以保存原有
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-04 14:12
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作,其中forward()方法可以实现前进,back()方法可以实现后退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作,其中forward()方法可以实现前进,back()方法可以实现后退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-03 10:16
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:
上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载 查看全部
浏览器抓取网页(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
之前做聊天室的时候,因为聊天室提供的新闻阅读功能,写了一个类,从网页中抓取信息(如最新的头条新闻、新闻来源、标题、内容等)。本文将介绍如何使用该类从网页中抓取您需要的信息。本文将以博客园首页的博客标题和链接为例:
上图是博客园首页的 DOM 树。显然,你只需要提取带有类 post_item 的 div,然后提取带有类 titlelnk 的 a 标志。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的函数:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博园首页抓取文章的标题和链接为例介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载
浏览器抓取网页( Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-01 06:22
Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
一直有一个传说,世界上有两种程序员:一种是程序员,一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
前段时间,助教和我聊天,我吐出一肚子苦涩,说女人懂Python太可怕了。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久熬夜玩游戏玩电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
browserhistory是一个简单的python脚本库,支持Linux、Mac和Windows系统,支持Firefox、Google和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username是获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦! 查看全部
浏览器抓取网页(
Python公众号学的值得收藏|菜鸟学Python【入门文章大全】)
一直有一个传说,世界上有两种程序员:一种是程序员,一种是女程序员。如果你的女票是程序员,那么恭喜你好运!请多加小心,否则,我分分钟教你怎么做人。
前段时间,助教和我聊天,我吐出一肚子苦涩,说女人懂Python太可怕了。
1.事件起因
小马哥的女朋友也是懂Python的程序员(据说刚开始看我的菜鸟学Python公众号也值得采集|菜鸟学Python【简介文章大全】),相处后时间长了,生活中难免会有一点小摩擦。前不久熬夜玩游戏玩电脑,没精力陪女朋友逛街看电视剧,让她不开心,情绪激动。
我去洗了个澡,偷偷打开他的电脑看看他整天在看什么。你为什么不考虑妇女的选票?没想到女票只用了一行Python代码就获取了浏览器历史,让小马的上网记录一目了然。事发后,一切安好,没有危险。今天给大家介绍一下这款神器。
1.神库浏览器历史库介绍
browserhistory 是 Python 的第三方库 browserhistory。获取浏览器的历史记录非常方便。Python真是无所不能,现成的轮子太多了,你只需要学会组装。
对于 browserhistory 的安装,可以使用命令 pip install browserhistory 来安装。
browserhistory是一个简单的python脚本库,支持Linux、Mac和Windows系统,支持Firefox、Google和Safari浏览器的历史记录。使用的方法非常简单。
2.如何使用
我们先来看看 browserhistory 的简单用法。需要注意的是,在使用浏览器历史库之前需要关闭浏览器。一个简单的应用程序如下所示:
程序首先导入 browserhistory 库,然后使用 get_browserhistory 函数获取浏览器的历史记录。dict_obj.keys() 返回要抓取的浏览器类型。爬取的浏览器历史记录收录网页地址和网页标题。
3.抓取浏览记录并写入本地文件
browserhistory库有四个函数,我们主要用到两个:
get_browserhistory 函数是获取浏览器的历史记录;write_browserhistory_csv函数是将获取的历史浏览记录写入本地csv文件。
get_database_paths函数用于输出浏览器的历史存储路径,get_username是获取用户名。
我们可以直接使用browserhistory.write_browserhistory_csv,一行代码就可以将浏览器的历史写入本地。
4.窥探历史
获得上述浏览器历史记录后,可以通过简单的数据分析进一步窥探秘密。
1)。用五行代码统计你经常浏览的网址的域名:
程序使用urlparse解析网页地址,输入网页地址的域名(netloc)。接下来,您可以进行统计并获取浏览时间最长的网页的域名。
2)。使用 Pyecharts 进行可视化分析
为了更好的展示,可以使用pyecharts库进行可视化展示。结果如下所示:
可以看出,访问量最大的网页域名是虎扑域名。当他的女朋友检查并分析了他的浏览器历史时,她终于满意地笑了,一个潜在的危机解决了。
所以,一个友好的提醒,不要继续一些奇怪的网站。另外,记得及时清理你的历史!友情提示,没事的话,回去看看浏览器记录吧!
好了,今天的分享就到这里了,欢迎大家在评论区吆喝~记得给个三连哦!
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-30 22:19
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-30 22:17
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是在元素出现或满足某些条件时继续执行。until_not 是当某个元素消失或某些条件不满足时继续执行。参数也一样。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它将自动获取当前浏览器版本并在本地下载相应的驱动程序。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置等待时间和条件,在规定时间内,每隔一段时间检查条件是否成立。如果是,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是在元素出现或满足某些条件时继续执行。until_not 是当某个元素消失或某些条件不满足时继续执行。参数也一样。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页(关于因特网中的WWW服务,以下哪种说法是正确的())
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-30 12:12
下列关于 Internet 中的 WWW 服务的说法正确的是()
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
Internet提供网页信息浏览服务是()
A. FTP
B、万维网
三、论坛
D. 电子邮件
点击查看答案
下列关于 Internet 中的 WWW 服务的说法不正确的是?
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
互联网由大量的计算机和信息资源组成,为网络用户提供了非常丰富的网络服务。下列关于万维网服务的说法不正确的是______
A、WWW采用客户端/服务器工作模式
B. 从网页到网页的链接信息由 URL 表示
C. 浏览器是客户端应用程序
D. 所有网页都是 HTML 文档
点击查看答案
早期互联网提供的服务方式可以分为基础服务和扩展服务。以下服务属于扩展服务。____
A. 电子邮件
B. 新闻组
C. 文件传输
D、万维网服务
点击查看答案
在WWW服务系统的描述中,错误的是()。
A) WWW采用客户端/服务器模式
B) WWW的传输协议采用HTML
C) 页面到页面的链接信息由 URL 维护
D) 客户端应用程序称为浏览器
点击查看答案
关于互联网上的WWW服务,下列说法不正确的是( )。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案
下列关于万维网的说法不正确的是:()
A、WWW是一种基于超文本的信息查询工具
B.WWW 是 WorldWideWeb 的缩写
C. 通过浏览器查看网页是一种 WWW 服务
D. WWW 是一个分类超媒体系统
请帮忙给出正确答案和分析,谢谢!
点击查看答案
关于互联网中的 WWW 服务,下列说法错误的是______。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案 查看全部
浏览器抓取网页(关于因特网中的WWW服务,以下哪种说法是正确的())
下列关于 Internet 中的 WWW 服务的说法正确的是()
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
Internet提供网页信息浏览服务是()
A. FTP
B、万维网
三、论坛
D. 电子邮件
点击查看答案
下列关于 Internet 中的 WWW 服务的说法不正确的是?
A. WWW服务器通常是符合HTML规范的结构化文档
B、WWW服务器必须具备网页创建和编辑功能
C. WWW 客户端程序也称为 WWW 浏览器
D. WWW服务器也称为Web站点
点击查看答案
互联网由大量的计算机和信息资源组成,为网络用户提供了非常丰富的网络服务。下列关于万维网服务的说法不正确的是______
A、WWW采用客户端/服务器工作模式
B. 从网页到网页的链接信息由 URL 表示
C. 浏览器是客户端应用程序
D. 所有网页都是 HTML 文档
点击查看答案
早期互联网提供的服务方式可以分为基础服务和扩展服务。以下服务属于扩展服务。____
A. 电子邮件
B. 新闻组
C. 文件传输
D、万维网服务
点击查看答案
在WWW服务系统的描述中,错误的是()。
A) WWW采用客户端/服务器模式
B) WWW的传输协议采用HTML
C) 页面到页面的链接信息由 URL 维护
D) 客户端应用程序称为浏览器
点击查看答案
关于互联网上的WWW服务,下列说法不正确的是( )。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案
下列关于万维网的说法不正确的是:()
A、WWW是一种基于超文本的信息查询工具
B.WWW 是 WorldWideWeb 的缩写
C. 通过浏览器查看网页是一种 WWW 服务
D. WWW 是一个分类超媒体系统
请帮忙给出正确答案和分析,谢谢!
点击查看答案
关于互联网中的 WWW 服务,下列说法错误的是______。
A. WWW 服务器通常存储符合 HTML 规范的结构化文档
湾。WWW服务器必须具有创建和编辑网页的能力
C。WWW 客户端程序也称为 WWW 浏览器
D. WWW 服务器也称为网站
请帮忙给出正确答案和分析,谢谢!
点击查看答案
浏览器抓取网页(浏览器输入URL之后发生了什么?输入到获取网页的过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-29 00:17
浏览器输入URL获取网页的过程
上图大致描述了浏览器输入 URL 时发生的情况。详细过程总结如下。
条件是:
从浏览器输入 URL 地址
URL,也称为统一资源定位器,描述了特定服务器上资源的特定位置。URL由三部分组成:
scheme 描述了用于访问资源的协议 服务器的 Internet 地址 其余指定 Web 服务器的资源
有效的网址
1
http://video.google.com.uk:80/ ... 2m30s
上面的 URL 分解为:
查询流程:
首先会查询浏览器的缓存,浏览器会存储一定时间内的DNS记录。如果没有找到,会在操作系统的缓存中查询;路由器也会被DNS记录查询,并且会继续在路由器的缓存中查询;ISP互联网提供商查询,这里是最后在DNS系统上搜索到的连接互联网的中继站;DNS解析过程
DNS采用迭代查询和递归查询两种方式。因为IP地址很难记住,所以域名可以帮助我们记住网站地址。域名实际上无法找到服务器的位置,而是通过DNS服务器将域名解析为IP地址。确定服务器的位置。
首先,浏览器像本地 DNS 服务器一样发送请求。如果没有查询到本地DNS地址,则需要使用递归和迭代的方式依次向根域名服务器、顶级域名服务器、权威域名服务器发送查询请求,直到找到一个或一组IP。地址,返回给浏览器。
DNS本身的传输协议是UDP协议,但是每次迭代和递归查找都是非常耗时的,所以DNS有这个多级缓存。
缓存分为:浏览器缓存、系统缓存、路由器缓存、IPS服务器缓存、根域名服务器缓存、顶级域名服务器缓存、主域名服务器缓存。
DNS 负载均衡
DNS 不一定每次都返回同一服务器的地址。DNS可以返回合适机器的IP,根据每台机器的负载和机器的物理位置合理分配。CDN技术是利用DNS重定向技术返回离用户最近的服务器。
TCP 连接
建立 TCP 连接,经典的三次握手过程。
TCP是端到端可靠的面向连接的协议,所以HTTP基于传输层协议,无需担心数据传输。 查看全部
浏览器抓取网页(浏览器输入URL之后发生了什么?输入到获取网页的过程)
浏览器输入URL获取网页的过程
上图大致描述了浏览器输入 URL 时发生的情况。详细过程总结如下。
条件是:
从浏览器输入 URL 地址
URL,也称为统一资源定位器,描述了特定服务器上资源的特定位置。URL由三部分组成:
scheme 描述了用于访问资源的协议 服务器的 Internet 地址 其余指定 Web 服务器的资源
有效的网址
1
http://video.google.com.uk:80/ ... 2m30s
上面的 URL 分解为:
查询流程:
首先会查询浏览器的缓存,浏览器会存储一定时间内的DNS记录。如果没有找到,会在操作系统的缓存中查询;路由器也会被DNS记录查询,并且会继续在路由器的缓存中查询;ISP互联网提供商查询,这里是最后在DNS系统上搜索到的连接互联网的中继站;DNS解析过程
DNS采用迭代查询和递归查询两种方式。因为IP地址很难记住,所以域名可以帮助我们记住网站地址。域名实际上无法找到服务器的位置,而是通过DNS服务器将域名解析为IP地址。确定服务器的位置。
首先,浏览器像本地 DNS 服务器一样发送请求。如果没有查询到本地DNS地址,则需要使用递归和迭代的方式依次向根域名服务器、顶级域名服务器、权威域名服务器发送查询请求,直到找到一个或一组IP。地址,返回给浏览器。
DNS本身的传输协议是UDP协议,但是每次迭代和递归查找都是非常耗时的,所以DNS有这个多级缓存。
缓存分为:浏览器缓存、系统缓存、路由器缓存、IPS服务器缓存、根域名服务器缓存、顶级域名服务器缓存、主域名服务器缓存。
DNS 负载均衡
DNS 不一定每次都返回同一服务器的地址。DNS可以返回合适机器的IP,根据每台机器的负载和机器的物理位置合理分配。CDN技术是利用DNS重定向技术返回离用户最近的服务器。
TCP 连接
建立 TCP 连接,经典的三次握手过程。
TCP是端到端可靠的面向连接的协议,所以HTTP基于传输层协议,无需担心数据传输。
浏览器抓取网页( 360安全浏览器v8.0.3483.0查看百度光速游戏加速器官方独立版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-28 22:20
360安全浏览器v8.0.3483.0查看百度光速游戏加速器官方独立版
)
百度浏览器免费版是百度推出的以IE为核心的浏览器。百度一键获取海量优质资源。整体界面简洁大气,有点像谷歌浏览器。百度浏览器免费版支持将html网页文件导入采集夹内容。每天登录百度浏览器搜索访问也可以产生积分,可以兑换爱奇艺VIP和百度文库VIP!
百度浏览器
相关软件版本说明下载地址
360安全浏览器
v8.1.1.114
查看
百度媒体播放器
正式版
查看
铬浏览器
v69.0.3483.0
查看
百度光速游戏加速器
官方独立版
查看
YY浏览器(YY专用)
v3.9.5776.0
查看
百度看(桌面百度)
v9.92
查看
变更日志
1.Win10兼容性增强,修复了一些严重的bug。
软件功能
1、新天气:全新的视觉设计,更扁平,大变化
2、有内容:全新2.0首页,一站式直达内容,等你来体验
3、发现:借助百度强大的数据库,每天都有大量的内容更新
4、更轻快:百度浏览器采用全新升级最新内核,超高性能基准
5、云体验:网页云修复、下载云加速、网站云采集等。
特征
安全浏览
采用最新的沙盒安全技术,全方位保护您的在线流程。
丰富的应用
基于百度强大的数据库,整合最热门的应用,第一时间推送最新的应用。
数据同步
强大的云同步技术,只要登录账号,采集的数据信息完全同步,随时随地轻松使用。
常问问题
如何将百度浏览器设置为默认浏览器?
打开百度浏览器,点击右上角按钮,选择【浏览器设置】,在页面左侧栏选择【常规设置】,在内容中找到默认浏览器选项,可以选择设置为默认浏览器La。
安装步骤
一、在本站下载最新版百度浏览器安装包,双击运行。
二、点击右下角的【设置】按钮,去掉不必要的设置。
三、点击【立即安装】,会自动开始安装,耐心等待软件安装完成即可。
四、安装完成后会自动打开浏览器,尽情享受吧。
技能
每个人都必须能够在浏览器中搜索,所以我将教你如何截图。
打开百度浏览器,点击页面右上角的剪刀状按钮,在下拉菜单中可以截图、保存网页、截取GIF图片。
查看全部
浏览器抓取网页(
360安全浏览器v8.0.3483.0查看百度光速游戏加速器官方独立版
)
百度浏览器免费版是百度推出的以IE为核心的浏览器。百度一键获取海量优质资源。整体界面简洁大气,有点像谷歌浏览器。百度浏览器免费版支持将html网页文件导入采集夹内容。每天登录百度浏览器搜索访问也可以产生积分,可以兑换爱奇艺VIP和百度文库VIP!
百度浏览器
相关软件版本说明下载地址
360安全浏览器
v8.1.1.114
查看
百度媒体播放器
正式版
查看
铬浏览器
v69.0.3483.0
查看
百度光速游戏加速器
官方独立版
查看
YY浏览器(YY专用)
v3.9.5776.0
查看
百度看(桌面百度)
v9.92
查看
变更日志
1.Win10兼容性增强,修复了一些严重的bug。
软件功能
1、新天气:全新的视觉设计,更扁平,大变化
2、有内容:全新2.0首页,一站式直达内容,等你来体验
3、发现:借助百度强大的数据库,每天都有大量的内容更新
4、更轻快:百度浏览器采用全新升级最新内核,超高性能基准
5、云体验:网页云修复、下载云加速、网站云采集等。
特征
安全浏览
采用最新的沙盒安全技术,全方位保护您的在线流程。
丰富的应用
基于百度强大的数据库,整合最热门的应用,第一时间推送最新的应用。
数据同步
强大的云同步技术,只要登录账号,采集的数据信息完全同步,随时随地轻松使用。
常问问题
如何将百度浏览器设置为默认浏览器?
打开百度浏览器,点击右上角按钮,选择【浏览器设置】,在页面左侧栏选择【常规设置】,在内容中找到默认浏览器选项,可以选择设置为默认浏览器La。
安装步骤
一、在本站下载最新版百度浏览器安装包,双击运行。
二、点击右下角的【设置】按钮,去掉不必要的设置。
三、点击【立即安装】,会自动开始安装,耐心等待软件安装完成即可。
四、安装完成后会自动打开浏览器,尽情享受吧。
技能
每个人都必须能够在浏览器中搜索,所以我将教你如何截图。
打开百度浏览器,点击页面右上角的剪刀状按钮,在下拉菜单中可以截图、保存网页、截取GIF图片。
浏览器抓取网页( 这个是想要跳过这个,直接把你最终打开的页面里的cookie拷贝出来回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-28 22:17
这个是想要跳过这个,直接把你最终打开的页面里的cookie拷贝出来回答)
这就是我要抢的网站
答案:
在你最终直接打开的页面中复制cookie
import requests
headers = {
'Cookie': '__cfduid=d1e0cc7faadf90af5d64ff45aa2aba92c1503910637; cf_clearance=37fa4932d1e2dde34e9074b0f03aabb0d5f7e8ab-1503910642-31536000',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
}
url = 'http://www.agronet.com.cn/'
r = requests.get('http://www.agronet.com.cn/', headers=headers)
r.encoding = 'utf'
print r.text
答案:
访问域名时,做了302重定向,
Request URL:http://www.agronet.com.cn/cdn- ... 84273
Request Method:GET
Status Code:302 Moved Temporarily
Remote Address:119.147.134.219:80
Referrer Policy:no-referrer-when-downgrade
Response Headers
view source
CF-RAY:395c1714639389e9-SZX
Connection:keep-alive
Content-Length:165
Content-Type:text/html
Date:Tue, 29 Aug 2017 02:30:45 GMT
Location:http://www.agronet.com.cn/
Server:yunjiasu-nginx
Set-Cookie:cf_clearance=df2e88c103783c5b5a9524bbd4105fbd74b4b4cd-1503973845-31536000; path=/; expires=Wed, 29-Aug-18 03:30:45 GMT; domain=.agronet.com.cn; HttpOnly
X-Frame-Options:SAMEORIGIN
因为处理302的参数未知,所以使用request.Session来处理请求
答案:
对于python,有一个很好的库:requests
可以解决301、302跳转、UA、cookie等问题,
文档地址:...
答案:
如果你要爬取的数据不是js执行生成的,可以使用以下方法
import requests
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0","Connection":"close","Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1"}
cookies = {"safedog-flow-item":"A7C62592B3B3C821E8940811D417910B","__utmz":"63149887.1503977571.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)","ctrl_time":"1","Hm_lvt_8f396c620ee16c3d331cf84fd54feafe":"1503977516","__utmt":"1","__cfduid":"d61cc443d7df1327ad4ee0c17da83adcf1503977565","Hm_lpvt_8f396c620ee16c3d331cf84fd54feafe":"1503977628","cf_clearance":"6c62a4b3214679cbbf0e76f7feb17fcbe1e9955a-1503977569-31536000","agronetCookie":"D98233C159EF3AEA333D883B971C1FCA9B6F08A7476FD809","__utmb":"63149887.2.10.1503977571","bdshare_firstime":"1503977570334","__utmc":"63149887","yjs_id":"Mozilla%2F5.0%20(Macintosh%3B%20Intel%20Mac%20OS%20X%2010.12%3B%20rv%3A52.0)%20Gecko%2F20100101%20Firefox%2F52.0%7Cwww.agronet.com.cn%7C1503977570020%7Chttp%3A%2F%2Fwww.agronet.com.cn%2F","__utma":"63149887.720670875.1503977571.1503977571.1503977571.1"}
response = session.get("http://www.agronet.com.cn/", headers=headers, cookies=cookies)
print("Status code: %i" % response.status_code)
print("Response body: %s" % response.content)
如果数据是js生成的,建议使用webdriver
答案:
如果 cookie 是动态变化的呢?
本文地址:H5W3 » 爬虫爬取网页,返回的页面是,请打开浏览器的javascript,然后刷新浏览器。如何解决这个问题。要跳过这个,请抓住 网站 查看全部
浏览器抓取网页(
这个是想要跳过这个,直接把你最终打开的页面里的cookie拷贝出来回答)
这就是我要抢的网站
答案:
在你最终直接打开的页面中复制cookie
import requests
headers = {
'Cookie': '__cfduid=d1e0cc7faadf90af5d64ff45aa2aba92c1503910637; cf_clearance=37fa4932d1e2dde34e9074b0f03aabb0d5f7e8ab-1503910642-31536000',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'
}
url = 'http://www.agronet.com.cn/'
r = requests.get('http://www.agronet.com.cn/', headers=headers)
r.encoding = 'utf'
print r.text
答案:
访问域名时,做了302重定向,
Request URL:http://www.agronet.com.cn/cdn- ... 84273
Request Method:GET
Status Code:302 Moved Temporarily
Remote Address:119.147.134.219:80
Referrer Policy:no-referrer-when-downgrade
Response Headers
view source
CF-RAY:395c1714639389e9-SZX
Connection:keep-alive
Content-Length:165
Content-Type:text/html
Date:Tue, 29 Aug 2017 02:30:45 GMT
Location:http://www.agronet.com.cn/
Server:yunjiasu-nginx
Set-Cookie:cf_clearance=df2e88c103783c5b5a9524bbd4105fbd74b4b4cd-1503973845-31536000; path=/; expires=Wed, 29-Aug-18 03:30:45 GMT; domain=.agronet.com.cn; HttpOnly
X-Frame-Options:SAMEORIGIN
因为处理302的参数未知,所以使用request.Session来处理请求
答案:
对于python,有一个很好的库:requests
可以解决301、302跳转、UA、cookie等问题,
文档地址:...
答案:
如果你要爬取的数据不是js执行生成的,可以使用以下方法
import requests
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:52.0) Gecko/20100101 Firefox/52.0","Connection":"close","Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1"}
cookies = {"safedog-flow-item":"A7C62592B3B3C821E8940811D417910B","__utmz":"63149887.1503977571.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)","ctrl_time":"1","Hm_lvt_8f396c620ee16c3d331cf84fd54feafe":"1503977516","__utmt":"1","__cfduid":"d61cc443d7df1327ad4ee0c17da83adcf1503977565","Hm_lpvt_8f396c620ee16c3d331cf84fd54feafe":"1503977628","cf_clearance":"6c62a4b3214679cbbf0e76f7feb17fcbe1e9955a-1503977569-31536000","agronetCookie":"D98233C159EF3AEA333D883B971C1FCA9B6F08A7476FD809","__utmb":"63149887.2.10.1503977571","bdshare_firstime":"1503977570334","__utmc":"63149887","yjs_id":"Mozilla%2F5.0%20(Macintosh%3B%20Intel%20Mac%20OS%20X%2010.12%3B%20rv%3A52.0)%20Gecko%2F20100101%20Firefox%2F52.0%7Cwww.agronet.com.cn%7C1503977570020%7Chttp%3A%2F%2Fwww.agronet.com.cn%2F","__utma":"63149887.720670875.1503977571.1503977571.1503977571.1"}
response = session.get("http://www.agronet.com.cn/", headers=headers, cookies=cookies)
print("Status code: %i" % response.status_code)
print("Response body: %s" % response.content)
如果数据是js生成的,建议使用webdriver
答案:
如果 cookie 是动态变化的呢?
本文地址:H5W3 » 爬虫爬取网页,返回的页面是,请打开浏览器的javascript,然后刷新浏览器。如何解决这个问题。要跳过这个,请抓住 网站
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-28 00:02
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间检查条件是否成立,如果成立,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!! 查看全部
浏览器抓取网页(一起学(复)习模拟浏览器运行的库Selenium运行)
以下文章来自你可以叫我菜哥,作者刀菜
今天带大家学习(复习)模拟浏览器运行的库Selenium。它是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera and Edge等。
这里我以 Chrome 为例来演示 Selenium 的功能~
0. 准备工作
在开始后续功能演示之前,我们需要安装Chrome浏览器并配置ChromeDriver,当然还要安装selenium库!
0.1. 安装 selenium 库
pip install selenium
0.2. 安装浏览器驱动
其实浏览器驱动的安装方式有两种:一种是常见的手动安装,另一种是使用第三方库自动安装。
以下前提:每个人都安装了Chrome浏览器。
手动安装
先查看本地Chrome浏览器版本:(两种方式都可以)
然后选择版本号对应的驱动版本
下载链接:
最后配置环境变量,即将对应的ChromeDriver可执行chromedriver.exe文件拖到Python Scripts目录下。
注意:当然,你可以不这样做,但你也可以在调用时指定chromedriver.exe的绝对路径。
自动安装
自动安装需要使用第三方库 webdriver_manager。先安装这个库,然后调用对应的方法。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
上面代码中,ChromeDriverManager().install()方法是自动安装驱动。它会自动获取当前浏览器版本,并将相应的驱动下载到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
Trying to download new driver from https://chromedriver.storage.g ... 2.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果浏览器通道在本地已经存在,会提示已经存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
完成以上准备后,我们就可以开始学习本文的官方内容啦~
1. 基本用法
在本节中,我们从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面以及前进和后退等基本操作开始。
1.1. 初始化浏览器对象
在准备部分,我们提到需要将浏览器通道添加到环境变量或指定绝对路径。前者可以直接初始化,后者需要指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
可以看到上面是有界面的浏览器,我们也可以将浏览器初始化为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
在完成浏览器对象的初始化并赋值给浏览器对象之后,我们就可以调用浏览器执行各种方法来模拟浏览器的操作了。
1.2. 访问页面
get方法用于页面访问,传入的参数是要访问的页面的URL地址。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
1.3. 设置浏览器大小
set_window_size()方法可以用来设置浏览器的大小(也就是分辨率),maximize_window就是设置浏览器全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自己演示一下效果吧~
1.4. 刷新页面
刷新页面是我们在操作浏览器时很常见的操作,这里可以使用refresh()方法来刷新浏览器页面。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
效果大家也自己演示一下,和F5快捷键一样。
1.5. 前进后退
前进和后退也是我们在使用浏览器时很常见的操作。这里可以用forward()方法实现forward,用back()方法实现backward。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面的基本属性
当我们用 selenium 打开一个页面时,会有一些基本的属性,例如页面标题、URL、浏览器名称、页面源代码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
8. 模拟键盘操作
selenium 中的 Keys() 类提供了大部分的键盘操作方法,通过 send_keys() 方法模拟键盘上的按键。
引入 Keys 类
from selenium.webdriver.common.keys import Keys
常用键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):Tab键(TAB)
send_keys(Keys.ESCAPE):后备键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'): 全选 (Ctrl+A)
send_keys(Keys.CONTRL,'c'): 复制 (Ctrl+C)
send_keys(Keys.CONTRL,'x'): 剪切 (Ctrl+X)
send_keys(Keys.CONTRL,'v'): 粘贴 (Ctrl+V)
send_keys(Keys.F1): 键盘 F1
......
send_keys(Keys.F12): 键盘 F12
示例操作演示:
找到需要操纵的元素,然后操纵它!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延迟等待
如果遇到使用 ajax 加载的网页,页面元素可能不会同时加载。此时,在执行get方法时尝试获取网页的源代码,可能不是浏览器完全加载的页面。因此,在这种情况下,需要设置一个延迟并等待一定的时间,以确保所有节点都加载完毕。
三种玩法:强制等待、隐式等待和显式等待
9.1. 强制等待
很简单,直接time.sleep(n)强制等待n秒,执行get方法后执行。
9.2. 隐式等待
Implicitly_wait() 设置等待时间。如果有一个元素节点到时候没有加载,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
9.3. 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间检查条件是否成立,如果成立,程序会继续执行,否则会抛出超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
驱动:浏览器驱动
timeout:超时,等待的最长时间(还要考虑隐式等待时间)
poll_frequency:每次检测的时间间隔,默认为0.5秒
ignore_exceptions:超时后的异常信息,默认抛出NoSuchElementException
直到(方法,消息='')
method:在等待期间,每隔一段时间调用这个传入的方法,直到返回值不为False
message:如果超时,抛出 TimeoutException 并将消息传递给异常
直到_not(方法,消息='')
until_not 与直到相反。until 是当元素出现或满足某些条件时继续执行, until_not 是当元素消失或某些条件不满足时继续执行,参数相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
添加一些
10.1. 运行 JavaScript
还有一些操作,比如下拉进度条,模拟javascript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
10.2. Cookie
在 selenium 的使用过程中,获取、添加和删除 cookie 也非常方便。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
10.3. 反掩码
发现美团直接屏蔽了Selenium,不知道怎么办!!
浏览器抓取网页( Web应用程序更为迅捷地回应用户动作并避免了没有改变的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-25 08:09
Web应用程序更为迅捷地回应用户动作并避免了没有改变的信息)
Ajax技术(属于前端技术)
那就是“异步 JavaScript 和 XML”,它与服务器交互而不刷新页面。
特点:异步请求,部分刷新
同步:发送方发送数据后,等待接收方发回响应,然后再发送下一个数据包;
异步:发送方发送数据后,不等待接收方回传响应,然后发送下一个数据包。
**好处:** Web 应用程序对用户操作的响应速度更快,避免通过网络发送未更改的信息,从而减少服务器压力。
**缺点:**浏览器实现的差异,需要处理兼容性问题;不利于SEO(SEO只能识别页面首次呈现的数据,不能异步);不能前后左右;默认不支持跨域访问。
**注意:**ajax 技术只能在网络协议环境中使用。不能直接将页面拖入浏览器执行。它必须以 Web 服务器模式访问。
AJAX编写步骤:
1.创建一个AJAX对象;
2.设置请求路径、请求方式等;
3.绑定监听状态变化的处理函数,可以在处理函数中获取响应数据(回调函数);
4.发送请求;
创建 ajax 对象时的浏览器兼容性处理
function createAjax() {
var ajax;
try { //非IE
ajax = new XMLHttpRequest(); //IE浏览器下没有XMLHttpRquest这个对象就会报错
} catch(e) {
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
return ajax;
}
响应处理和响应流
响应处理,即根据状态码和AJAX对象的状态信息,对服务响应浏览器的数据进行不同的处理,可以在绑定状态的处理函数中编写相应的逻辑代码改变。
AJAX 对象有 4 个属性:
readyState 一共有5个状态值,0-4,每个值代表不同的含义:onreadystatechange,一旦状态不标准,就会被执行,多次改变,多次执行
0:初始化,AJAX对象还没有初始化,new XMLHttpRequest();
1:加载,AJAX对象开始发送请求,ajax.open(请求方法,请求路径);
2:加载完成,发送AJAX对象的请求,ajax.send();
3:分析:AJAX对象开始读取服务器的响应,ajax.onreadystatechange;
4:完成,AJAX对象读取服务器响应并结束。
status 表示响应的 HTTP 状态码。常见的状态码如下:
200:成功;
302:重定向;
404:找不到资源;
500:服务器错误;
responseText 获取字符串形式的响应数据(常用)
responseXML 获取 XML 格式的响应数据
综上所述,状态变化的处理函数一般只针对ajax.readyState4和ajax.status200这两种情况进行处理(这也意味着我们什么时候可以开始渲染数据?服务器响应并成功获取数据后),然后根据后台返回的数据类型决定从responseText或responseXML中获取服务器响应返回的数据。
ajax 获取请求
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
console.log("点击了按钮");
//发送ajax请求
//1.创建ajax对象
let ajax = new XMLHttpRequest();
//2.设置请求方式、请求路径url
ajax.open("GET", "/get_data");
//3.绑定监听状态的改变的处理函数,在这个函数里面可以获取响应数据(回调函数)
ajax.onreadystatechange = () => {
//这个函数里面的代码什么时候执行?状态发生改变的时候就执行
//获取响应的数据
//什么时候页面开始渲染数据?服务器响应完毕之后ajax.readyState为4,并且成功获取数据之后ajax.status为200
if(ajax.readyState === 4 && ajax.status === 200) {
//服务器传来的数据用什么表示?ajax.readyState
console.log(ajax.readyState);
//渲染数据到页面上
oDiv.innerHTML = ajax.responseText;
}
}
//发送请求
ajax.send();
}
服务器代码(在 nodejs 文档中解释)
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
const server = http.createServer((request, response) => {
//每来一个请求就执行一次这里的代码
//判断浏览器需要哪个资源文件,把下面这些代码进行封装的话就是路由
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "index.html");
let content = fs.readFileSync(filePath);
response.end(content);
} else if(reqUrl === '/detail.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "detail.html");
let content = fs.readFileSync(filePath);
response.end(content); //这句不能放在外面,因为使用let定义的content有块级作用域
} else if(reqUrl === '/get_data') { //或者正则:/get_data.*/.test(reqUrl)
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
} else if(reqUrl.endsWith(".css")) {
//如果读取的是一个css文件,也是一个请求,也会执行一次代码
//哪些标签会造成请求?就有href(link)和src(src img)属性的标签,浏览器是自发的请求;还有像按钮、a标签的话需要在表单里而且需要点击过后才会请求
//如果用a标签实现跳转的话,index.html中跳转到详情页
//这里的跳转地址不是看前端的路径,而是看后端的路由是怎么配的,和这里的if else里的判断内容一致,点击之后也是一次请求
let filePath = path.join(__dirname, "assets", "css", "index.css");
let content = fs.readFileSync(filePath);
response.end(content);
} else {
response.setHeader("Content-type", "text/html; charset=utf-8"); //不加这句下面的语句会出现乱码
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
ajax 发布请求
附:根本没有提交行为,但是在某些浏览器中有提交行为
用户名:
密&emsp码:
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
//post提交
//获取用户填写的数据
let username = document.getElementById("username").value;
let password = document.getElementById("password").value;
let params = { //这样的形式是将获取的值看着方便且容易处理,下面处理时还需要转换为服务器需要的JSON格式
username,
password
}
//Ajax提交(四个步骤)
let ajax = new XMLHttpRequest();
ajax.open("POST", "/login_post");
ajax.onreadystatechange = () => {
if(ajax.readyState === 4 && ajax.status === 200) {
//相当于成功后的回调函数,这里可以封装为一个函数,写在最外面,通过调用使用
//ajax.responseText是服务器传过来的字符串
oDiv.innerHTML = ajax.responseText;
}
}
ajax.send(JSON.stringify(params)); //服务器需要的是JSON格式的数据,所以需要转换一下
}
服务器代码
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
let uname = "laozhuang";
let pwd = "123456";
//包装为函数
function responseEnd(response, dirName, fileName) { //dirName文件路径,fileName文件名称
let filePath = path.join(__dirname, "assets", "dirName", "fileName");
let content = fs.readFileSync(filePath);
response.end(content);
}
const server = http.createServer((request, response) => {
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
responseEnd(response, "html", "index.html");
} else if(reqUrl === '/detail.html') {
responseEnd(response, "html", "detail.html");
} else if(reqUrl === '/login.html') {
responseEnd(response, "html", "login.html");
} else if(reqUrl === '/get_data') {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
} else if(reqUrl === '/login_post') {
//处理post请求
//一旦post请求过来就会触发data事件
request.on("data", (postData) => {
//postData就是post请求传递过来的参数,是Buffer对象,需要toString()一下
//还需要把JSON格式的字符串转换为对象,因为转为对象才能通过.的方式拿到属性值
//获取到浏览器传过来的数据,就是post请求传递过来的参数
let {username, password} = JSON.parse(postData.toString()); //解构
//需要查询数据库看有没有用户名,没有的话就需要注册,如果有还需对比密码是否正确,或者其他逻辑操作
if(username === uname && password === pwd) {
//还可以跳转之类的操作
response.end("登录成功!");
} else {
response.end("用户名或者密码错误,登录失败")
}
})
} else if(reqUrl.endsWith(".css")) {
responseEnd(response, "css", "index.css");
} else if(reqUrl.endsWith(".js")) {
responseEnd(response, "js", "index.js");
} else {
response.setHeader("Content-type", "text/html; charset=utf-8");
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
避免缓存问题:
AJAX 减少了重复数据的加载,提高了页面加载速度,因为数据会一直缓存在内存中,当提交的 URL 与历史 URL 一致时,就不需要提交给服务器了。虽然减轻了服务器的负载,提升了用户体验,但无法获取最新的数据。为了保证数据是最新的,需要禁用其缓存功能,主要有以下几种方式:
1.在 URL 中添加一个随机数:Math.random()
//客户端代码
ajax.open("GET", "/get_data" + Math.random());
//服务端代码
else if(reqUrl.startsWith('/get_data')) {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
}
2.给 URL 添加时间戳:new Date().getTime(),从 197 开始的毫秒数0.01.01
3.在使用 AJAX 发送请求之前添加 ajax.setRequestHeader("Cache-Control", "no-cache");
ajax.open(...);
ajax.setRequestHeader('Cache-Control', 'no-cache'); //请求头设置,在ajax.open()后面
ajax.send();
4. 在开发者工具下手动勾选 Network 的 Disable cache
超时处理:
有时网络有问题或者服务器有问题,导致请求时间过长。一般会提示网络请求稍后重试,以增加用户体验。代码可以通过定时器和请求中断来达到超时处理的效果。
var timer = setTimeout(() => {
//取消请求,终端请求
ajax.abort();
alert("请稍后重试")
}, time)
方法提取(不是最终形式,工作中不会这样写,懂的)
一个ajax请求、请求方法、请求路径、请求参数、获取服务器内容后的回调函数、时间等都可以封装成函数,这样get和post请求就可以写在一起了
function ajax(method, url, param, success, time) {
var ajax;
//处理ajax获取时候的兼容性问题
try { //非IE
ajax = new XMLHttpRequest();
} catch(e) { //IE
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
if(method === 'get') {
param = encodeURL(param); //针对get请求的查询参数出现中文的编码处理
url = url + '?' + param;
param = null;
}
ajax.open(method, url);
if(method === 'post') {
//请求体格式,例如name=nodejs&age=11
ajax.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
//也可以在标签中设设置
//...
}
ajax.onreadystatechange = function() {
if(ajax.readyState === 4 && ajax.status === 200) {
success(ajax.responseText); //在外面设置的获取服务端数据后处理数据的回调函数
}
}
ajax.send(param);
var time = setTimeout(() => {
ajax.abort();
}, time)
}
jQuery的ajax方法,get请求,post请求(没看过视频),指jQuery,指jQuery,指jQuery,.ajax就是jQuery.ajax 查看全部
浏览器抓取网页(
Web应用程序更为迅捷地回应用户动作并避免了没有改变的信息)
Ajax技术(属于前端技术)
那就是“异步 JavaScript 和 XML”,它与服务器交互而不刷新页面。
特点:异步请求,部分刷新
同步:发送方发送数据后,等待接收方发回响应,然后再发送下一个数据包;
异步:发送方发送数据后,不等待接收方回传响应,然后发送下一个数据包。
**好处:** Web 应用程序对用户操作的响应速度更快,避免通过网络发送未更改的信息,从而减少服务器压力。
**缺点:**浏览器实现的差异,需要处理兼容性问题;不利于SEO(SEO只能识别页面首次呈现的数据,不能异步);不能前后左右;默认不支持跨域访问。
**注意:**ajax 技术只能在网络协议环境中使用。不能直接将页面拖入浏览器执行。它必须以 Web 服务器模式访问。
AJAX编写步骤:
1.创建一个AJAX对象;
2.设置请求路径、请求方式等;
3.绑定监听状态变化的处理函数,可以在处理函数中获取响应数据(回调函数);
4.发送请求;
创建 ajax 对象时的浏览器兼容性处理
function createAjax() {
var ajax;
try { //非IE
ajax = new XMLHttpRequest(); //IE浏览器下没有XMLHttpRquest这个对象就会报错
} catch(e) {
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
return ajax;
}
响应处理和响应流
响应处理,即根据状态码和AJAX对象的状态信息,对服务响应浏览器的数据进行不同的处理,可以在绑定状态的处理函数中编写相应的逻辑代码改变。
AJAX 对象有 4 个属性:
readyState 一共有5个状态值,0-4,每个值代表不同的含义:onreadystatechange,一旦状态不标准,就会被执行,多次改变,多次执行
0:初始化,AJAX对象还没有初始化,new XMLHttpRequest();
1:加载,AJAX对象开始发送请求,ajax.open(请求方法,请求路径);
2:加载完成,发送AJAX对象的请求,ajax.send();
3:分析:AJAX对象开始读取服务器的响应,ajax.onreadystatechange;
4:完成,AJAX对象读取服务器响应并结束。
status 表示响应的 HTTP 状态码。常见的状态码如下:
200:成功;
302:重定向;
404:找不到资源;
500:服务器错误;
responseText 获取字符串形式的响应数据(常用)
responseXML 获取 XML 格式的响应数据
综上所述,状态变化的处理函数一般只针对ajax.readyState4和ajax.status200这两种情况进行处理(这也意味着我们什么时候可以开始渲染数据?服务器响应并成功获取数据后),然后根据后台返回的数据类型决定从responseText或responseXML中获取服务器响应返回的数据。
ajax 获取请求
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
console.log("点击了按钮");
//发送ajax请求
//1.创建ajax对象
let ajax = new XMLHttpRequest();
//2.设置请求方式、请求路径url
ajax.open("GET", "/get_data");
//3.绑定监听状态的改变的处理函数,在这个函数里面可以获取响应数据(回调函数)
ajax.onreadystatechange = () => {
//这个函数里面的代码什么时候执行?状态发生改变的时候就执行
//获取响应的数据
//什么时候页面开始渲染数据?服务器响应完毕之后ajax.readyState为4,并且成功获取数据之后ajax.status为200
if(ajax.readyState === 4 && ajax.status === 200) {
//服务器传来的数据用什么表示?ajax.readyState
console.log(ajax.readyState);
//渲染数据到页面上
oDiv.innerHTML = ajax.responseText;
}
}
//发送请求
ajax.send();
}
服务器代码(在 nodejs 文档中解释)
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
const server = http.createServer((request, response) => {
//每来一个请求就执行一次这里的代码
//判断浏览器需要哪个资源文件,把下面这些代码进行封装的话就是路由
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "index.html");
let content = fs.readFileSync(filePath);
response.end(content);
} else if(reqUrl === '/detail.html') {
//读取页面内容,返回信息
let filePath = path.join(__dirname, "assets", "html", "detail.html");
let content = fs.readFileSync(filePath);
response.end(content); //这句不能放在外面,因为使用let定义的content有块级作用域
} else if(reqUrl === '/get_data') { //或者正则:/get_data.*/.test(reqUrl)
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
} else if(reqUrl.endsWith(".css")) {
//如果读取的是一个css文件,也是一个请求,也会执行一次代码
//哪些标签会造成请求?就有href(link)和src(src img)属性的标签,浏览器是自发的请求;还有像按钮、a标签的话需要在表单里而且需要点击过后才会请求
//如果用a标签实现跳转的话,index.html中跳转到详情页
//这里的跳转地址不是看前端的路径,而是看后端的路由是怎么配的,和这里的if else里的判断内容一致,点击之后也是一次请求
let filePath = path.join(__dirname, "assets", "css", "index.css");
let content = fs.readFileSync(filePath);
response.end(content);
} else {
response.setHeader("Content-type", "text/html; charset=utf-8"); //不加这句下面的语句会出现乱码
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
ajax 发布请求
附:根本没有提交行为,但是在某些浏览器中有提交行为
用户名:
密&emsp码:
let oBtn = document.getElementById("obtn");
let oDiv = document.getElementById("odiv");
oBtn.onclick = () => {
//post提交
//获取用户填写的数据
let username = document.getElementById("username").value;
let password = document.getElementById("password").value;
let params = { //这样的形式是将获取的值看着方便且容易处理,下面处理时还需要转换为服务器需要的JSON格式
username,
password
}
//Ajax提交(四个步骤)
let ajax = new XMLHttpRequest();
ajax.open("POST", "/login_post");
ajax.onreadystatechange = () => {
if(ajax.readyState === 4 && ajax.status === 200) {
//相当于成功后的回调函数,这里可以封装为一个函数,写在最外面,通过调用使用
//ajax.responseText是服务器传过来的字符串
oDiv.innerHTML = ajax.responseText;
}
}
ajax.send(JSON.stringify(params)); //服务器需要的是JSON格式的数据,所以需要转换一下
}
服务器代码
const http = require("http");
const fs = require("fs");
const path = require("path");
const port = 8081;
let uname = "laozhuang";
let pwd = "123456";
//包装为函数
function responseEnd(response, dirName, fileName) { //dirName文件路径,fileName文件名称
let filePath = path.join(__dirname, "assets", "dirName", "fileName");
let content = fs.readFileSync(filePath);
response.end(content);
}
const server = http.createServer((request, response) => {
let reqUrl = request.url;
if(reqUrl === '/' || reqUrl === '/index.html') {
responseEnd(response, "html", "index.html");
} else if(reqUrl === '/detail.html') {
responseEnd(response, "html", "detail.html");
} else if(reqUrl === '/login.html') {
responseEnd(response, "html", "login.html");
} else if(reqUrl === '/get_data') {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
} else if(reqUrl === '/login_post') {
//处理post请求
//一旦post请求过来就会触发data事件
request.on("data", (postData) => {
//postData就是post请求传递过来的参数,是Buffer对象,需要toString()一下
//还需要把JSON格式的字符串转换为对象,因为转为对象才能通过.的方式拿到属性值
//获取到浏览器传过来的数据,就是post请求传递过来的参数
let {username, password} = JSON.parse(postData.toString()); //解构
//需要查询数据库看有没有用户名,没有的话就需要注册,如果有还需对比密码是否正确,或者其他逻辑操作
if(username === uname && password === pwd) {
//还可以跳转之类的操作
response.end("登录成功!");
} else {
response.end("用户名或者密码错误,登录失败")
}
})
} else if(reqUrl.endsWith(".css")) {
responseEnd(response, "css", "index.css");
} else if(reqUrl.endsWith(".js")) {
responseEnd(response, "js", "index.js");
} else {
response.setHeader("Content-type", "text/html; charset=utf-8");
response.end("404错误:该资源找不到!");
}
})
server.listen(port, (error) => {
console.log(`WebServer is listening at port &{port}!`);
})
避免缓存问题:
AJAX 减少了重复数据的加载,提高了页面加载速度,因为数据会一直缓存在内存中,当提交的 URL 与历史 URL 一致时,就不需要提交给服务器了。虽然减轻了服务器的负载,提升了用户体验,但无法获取最新的数据。为了保证数据是最新的,需要禁用其缓存功能,主要有以下几种方式:
1.在 URL 中添加一个随机数:Math.random()
//客户端代码
ajax.open("GET", "/get_data" + Math.random());
//服务端代码
else if(reqUrl.startsWith('/get_data')) {
response.end("接收到ajax的get请求,这是响应给浏览器的数据");
//上面的字符串就是响应到客户端的ajax.responseText
}
2.给 URL 添加时间戳:new Date().getTime(),从 197 开始的毫秒数0.01.01
3.在使用 AJAX 发送请求之前添加 ajax.setRequestHeader("Cache-Control", "no-cache");
ajax.open(...);
ajax.setRequestHeader('Cache-Control', 'no-cache'); //请求头设置,在ajax.open()后面
ajax.send();
4. 在开发者工具下手动勾选 Network 的 Disable cache
超时处理:
有时网络有问题或者服务器有问题,导致请求时间过长。一般会提示网络请求稍后重试,以增加用户体验。代码可以通过定时器和请求中断来达到超时处理的效果。
var timer = setTimeout(() => {
//取消请求,终端请求
ajax.abort();
alert("请稍后重试")
}, time)
方法提取(不是最终形式,工作中不会这样写,懂的)
一个ajax请求、请求方法、请求路径、请求参数、获取服务器内容后的回调函数、时间等都可以封装成函数,这样get和post请求就可以写在一起了
function ajax(method, url, param, success, time) {
var ajax;
//处理ajax获取时候的兼容性问题
try { //非IE
ajax = new XMLHttpRequest();
} catch(e) { //IE
ajax = new ActiveXObject('Microsoft.XMLHTTP');
}
if(method === 'get') {
param = encodeURL(param); //针对get请求的查询参数出现中文的编码处理
url = url + '?' + param;
param = null;
}
ajax.open(method, url);
if(method === 'post') {
//请求体格式,例如name=nodejs&age=11
ajax.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
//也可以在标签中设设置
//...
}
ajax.onreadystatechange = function() {
if(ajax.readyState === 4 && ajax.status === 200) {
success(ajax.responseText); //在外面设置的获取服务端数据后处理数据的回调函数
}
}
ajax.send(param);
var time = setTimeout(() => {
ajax.abort();
}, time)
}
jQuery的ajax方法,get请求,post请求(没看过视频),指jQuery,指jQuery,指jQuery,.ajax就是jQuery.ajax
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-24 16:17
前言
Selenium 是一个模拟浏览器的自动化执行框架,但是如果每次执行任务都需要打开浏览器来处理任务,效率不高。最重要的是,如果是安装在Centos7服务器环境下,更不适合打开浏览器模拟操作,尤其是涉及到需要抓取网页图片的时候。
这时候,就该考虑使用 Chrome 的无头浏览器模式了。所谓无头浏览器模式,就是不需要打开浏览器,但可以模拟打开浏览器的执行效果,一切都在没有界面的情况下执行。
让我们看看安装是否部署执行。
1.安装chrome1.1 添加google的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome的版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
如果selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般是访问国内的镜像地址,如下:
您可以看到有相当多的版本可供下载。从上面可以看出刚刚安装的chrome的版本号Google Chrome79.0.3945.79,所以大致根据版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为我要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后,编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver说明环境配置已经生效。
3. 安装硒
selenium 可以简单地在项目的虚拟环境中使用 pip 安装
pip3 install selenium
4. 脚本测试
编写 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下命令:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
下载图片看看,
可以看出已经能够正常模拟浏览器登录,并抓取网页的图片。从图中可以看出,所有中文的地方都以方框符号显示。这是因为Centos7默认没有安装中文字体,所以chrom浏览器打开时无法正常显示中文。
解决办法是为Centos7安装中文字体,这里就不介绍了。 查看全部
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
前言
Selenium 是一个模拟浏览器的自动化执行框架,但是如果每次执行任务都需要打开浏览器来处理任务,效率不高。最重要的是,如果是安装在Centos7服务器环境下,更不适合打开浏览器模拟操作,尤其是涉及到需要抓取网页图片的时候。
这时候,就该考虑使用 Chrome 的无头浏览器模式了。所谓无头浏览器模式,就是不需要打开浏览器,但可以模拟打开浏览器的执行效果,一切都在没有界面的情况下执行。
让我们看看安装是否部署执行。
1.安装chrome1.1 添加google的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome的版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
如果selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般是访问国内的镜像地址,如下:
您可以看到有相当多的版本可供下载。从上面可以看出刚刚安装的chrome的版本号Google Chrome79.0.3945.79,所以大致根据版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为我要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后,编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver说明环境配置已经生效。
3. 安装硒
selenium 可以简单地在项目的虚拟环境中使用 pip 安装
pip3 install selenium
4. 脚本测试
编写 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下命令:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
下载图片看看,
可以看出已经能够正常模拟浏览器登录,并抓取网页的图片。从图中可以看出,所有中文的地方都以方框符号显示。这是因为Centos7默认没有安装中文字体,所以chrom浏览器打开时无法正常显示中文。
解决办法是为Centos7安装中文字体,这里就不介绍了。
浏览器抓取网页(客户端浏览器获取到一个页面的响应内容是html的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-24 08:08
有些网站使用 ssr 方法,或者类似 java 的 jsp,通过服务器渲染页面。然后后端可以在渲染时将自定义信息添加到响应头中。
那么当客户端浏览器获取一个页面(响应内容为html)并加载时,后端通过javascript响应页面内容时,能否获取加载的响应页面的响应头信息呢?
例如。
客户端向后端请求一个名为 /user/info 的动作,该动作返回一个 html,后端也在响应头中设置自定义数据。
大致分为5个流程:
(1)客户端请求一个名为/user/info的动作。(比如在浏览器上输入网址,回车确认)
(2)后端接收客户端的请求,后端在响应头中设置自定义信息
(3)后端将html内容响应给客户端
(4)客户端浏览器接收到后端的响应,包括响应头和页面信息(html字符串)
(5)客户端浏览器会从后端响应中获取html内容进行页面渲染。
那么问题来了,客户端请求/user/info这个动作,响应之后,浏览器渲染页面的时候,也就是第五步流程,能否调用js获取流程中的第二个流程,即,后者在请求处理的过程中,响应头中的数据集呢?
这可以用js完成吗? 查看全部
浏览器抓取网页(客户端浏览器获取到一个页面的响应内容是html的?)
有些网站使用 ssr 方法,或者类似 java 的 jsp,通过服务器渲染页面。然后后端可以在渲染时将自定义信息添加到响应头中。
那么当客户端浏览器获取一个页面(响应内容为html)并加载时,后端通过javascript响应页面内容时,能否获取加载的响应页面的响应头信息呢?
例如。
客户端向后端请求一个名为 /user/info 的动作,该动作返回一个 html,后端也在响应头中设置自定义数据。
大致分为5个流程:
(1)客户端请求一个名为/user/info的动作。(比如在浏览器上输入网址,回车确认)
(2)后端接收客户端的请求,后端在响应头中设置自定义信息
(3)后端将html内容响应给客户端
(4)客户端浏览器接收到后端的响应,包括响应头和页面信息(html字符串)
(5)客户端浏览器会从后端响应中获取html内容进行页面渲染。
那么问题来了,客户端请求/user/info这个动作,响应之后,浏览器渲染页面的时候,也就是第五步流程,能否调用js获取流程中的第二个流程,即,后者在请求处理的过程中,响应头中的数据集呢?
这可以用js完成吗?
浏览器抓取网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-23 23:19
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思想是从一个起始网页开始爬取,然后根据链接逐个爬取,直到不能再进一步爬取,然后返回上一页继续跟踪关联。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。 查看全部
浏览器抓取网页(一个完整的网络爬虫基础框架如下图所示:整个架构)
一个完整的网络爬虫基础框架如下图所示:
整个架构由以下过程组成:
1)需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级(先到先得)建立待爬取的URL队列;
2)网页抓取是按照要抓取的URL队列的顺序进行的;
3)将获取到的网页内容和信息下载到本地网络库,并创建爬取的URL列表(用于去重和判断爬取过程);
4)将爬取的网页放入待爬取的URL队列中,进行循环爬取操作;
2. 网络爬虫爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取URL队列中的URL排列顺序也是一个很重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面的问题。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很好理解,和我们有向图中的深度优先遍历一样,因为网络本身就是一个图模型。深度优先遍历的思想是从一个起始网页开始爬取,然后根据链接逐个爬取,直到不能再进一步爬取,然后返回上一页继续跟踪关联。
有向图中的深度优先搜索示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式完全相反。这个想法是将在新下载的网页中找到的链接直接插入到要抓取的 URL 队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。
上图是上例有向图的广度优先搜索流程图,其遍历结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树的结构来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4)大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个抓取的URL),OPIC搜索策略(也是一种重要性)。最后必须指出的一点是,我们可以根据自己的需要来设置网页的抓取间隔,这样可以保证我们一些基本的大网站或者活跃的网站内容不会被漏掉。
3. 网络爬虫更新策略
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1)历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2)用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3)聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
4. 分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1)主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2)点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。

