
浏览器抓取网页
浏览器抓取网页(浏览器抓取网页的逻辑处理是否清晰?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-08 17:04
浏览器抓取网页,一方面是要考虑对于各种各样的页面名称是否敏感,另一方面是对于他的逻辑处理是否清晰。例如一个包含页码的页面,是否用普通方式拦截?某段文字的前景色改变时,是否及时请求返回值?position:absolute;是否请求,
知乎问题页一直是强制ajax加载的,无法进行设置我设置过但是没有用,
爬虫最早做的页面莫过于我博客。
我觉得还是有很多学问的,首先是拦截,要能拦截大部分页面拦截,还有页码的正则和文本的正则匹配,同样采用post类型的的传送表单参数还要考虑相应的返回的值,还有页面切换的时候的显示内容,等等。仅仅针对你说的抓取网页,是可以进行设置的,仅供参考。
现在小网站很少用ajax了。大多数都是完全设置,这样响应的和其他类型一样,我觉得完全是多余的,其实现在采用ajax更多的是分库分表,一个信息分两份,甚至3份。然后用setrequest()从不同服务器抓取数据。多余的那个非必要,
如果抓图,那么就有小网站的规律了。如果抓别的,那就更复杂,并且可能抓本地,也可能抓接受域。而且,你问的是页面那么最起码要有js的相关特征值,传入才有数据抓取。
根据页面要求设置还是完全正常的所以其实关键看需求与技术最后我觉得还是要强调"自己的产品是什么"比如做餐饮,那么页面分类有些用分类表示,比如服务员必须佩戴的口罩和垃圾桶,有些才可以添加厨师, 查看全部
浏览器抓取网页(浏览器抓取网页的逻辑处理是否清晰?(图))
浏览器抓取网页,一方面是要考虑对于各种各样的页面名称是否敏感,另一方面是对于他的逻辑处理是否清晰。例如一个包含页码的页面,是否用普通方式拦截?某段文字的前景色改变时,是否及时请求返回值?position:absolute;是否请求,
知乎问题页一直是强制ajax加载的,无法进行设置我设置过但是没有用,
爬虫最早做的页面莫过于我博客。
我觉得还是有很多学问的,首先是拦截,要能拦截大部分页面拦截,还有页码的正则和文本的正则匹配,同样采用post类型的的传送表单参数还要考虑相应的返回的值,还有页面切换的时候的显示内容,等等。仅仅针对你说的抓取网页,是可以进行设置的,仅供参考。
现在小网站很少用ajax了。大多数都是完全设置,这样响应的和其他类型一样,我觉得完全是多余的,其实现在采用ajax更多的是分库分表,一个信息分两份,甚至3份。然后用setrequest()从不同服务器抓取数据。多余的那个非必要,
如果抓图,那么就有小网站的规律了。如果抓别的,那就更复杂,并且可能抓本地,也可能抓接受域。而且,你问的是页面那么最起码要有js的相关特征值,传入才有数据抓取。
根据页面要求设置还是完全正常的所以其实关键看需求与技术最后我觉得还是要强调"自己的产品是什么"比如做餐饮,那么页面分类有些用分类表示,比如服务员必须佩戴的口罩和垃圾桶,有些才可以添加厨师,
浏览器抓取网页(使用默认浏览器和第三方打开要使用指定的指定浏览器打开 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-07 14:21
)
使用场景、应用与第三方交互时,需要点击按钮,直接跳转到网页。
使用默认浏览器打开
将跳转代码添加到按钮的点击事件中,即可实现,需要使用System.Diagnostics添加。
//使用默认浏览器打开
string url = "http://www.codehello.net";
Process.Start(url);
用指定浏览器打开
要用指定的浏览器打开它,我们首先需要获取浏览器运行程序的路径。我们可以将浏览器地址写入配置文件方便访问,也可以通过读取注册表来获取。一般我们使用后者。
以chrome.exe为例,可以通过HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe获取注册表中的安装位置
//读取注册表
RegistryKey registryKey = Registry.LocalMachine.OpenSubKey(@"SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe");
if (registryKey != null)
{
string exePath = (string)registryKey.GetValue("");
if (!string.IsNullOrEmpty(exePath) && File.Exists(exePath))
{
Process.Start(exePath,url);
}
} 查看全部
浏览器抓取网页(使用默认浏览器和第三方打开要使用指定的指定浏览器打开
)
使用场景、应用与第三方交互时,需要点击按钮,直接跳转到网页。
使用默认浏览器打开
将跳转代码添加到按钮的点击事件中,即可实现,需要使用System.Diagnostics添加。
//使用默认浏览器打开
string url = "http://www.codehello.net";
Process.Start(url);
用指定浏览器打开
要用指定的浏览器打开它,我们首先需要获取浏览器运行程序的路径。我们可以将浏览器地址写入配置文件方便访问,也可以通过读取注册表来获取。一般我们使用后者。
以chrome.exe为例,可以通过HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe获取注册表中的安装位置
//读取注册表
RegistryKey registryKey = Registry.LocalMachine.OpenSubKey(@"SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe");
if (registryKey != null)
{
string exePath = (string)registryKey.GetValue("");
if (!string.IsNullOrEmpty(exePath) && File.Exists(exePath))
{
Process.Start(exePath,url);
}
}
浏览器抓取网页(使用GooSeeker浏览器的谋数台做了的抓取规则和爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-07 11:09
GooSeeker浏览器制定的爬取规则和爬虫路径:
数据规则:
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011"/>
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011">
线索规则:
能源政策 007
HTML
一个
//*[@class='main4_b1 main4_b1_3']//a[.//text()="加载更多"]
线程
能源政策 007
主机名+路径名
未定义
DS电脑抓取数据时,浏览器会按照设置的'load more'页面增长,但下面抓取的数据和第一个一样,没有变化。
请指导我!
谢谢! 查看全部
浏览器抓取网页(使用GooSeeker浏览器的谋数台做了的抓取规则和爬虫)
GooSeeker浏览器制定的爬取规则和爬虫路径:
数据规则:
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011"/>
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011">
线索规则:
能源政策 007
HTML
一个
//*[@class='main4_b1 main4_b1_3']//a[.//text()="加载更多"]
线程
能源政策 007
主机名+路径名
未定义
DS电脑抓取数据时,浏览器会按照设置的'load more'页面增长,但下面抓取的数据和第一个一样,没有变化。
请指导我!
谢谢!
浏览器抓取网页(基于智能预测模型的浏览器网页信息的预获取方法及系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-07 05:14
本发明专利技术涉及一种浏览器网页信息的预获取方法及系统,包括以下步骤:根据抓取的网页和历史网页的集合以及对应的URL特征建立倒排索引。分别抓取的网页和历史网页;用户输入的待访问URL是否在访问记录中,根据倒排索引获取历史网页信息或爬取网页信息,或提取待访问URL的URL特征;根据提取的 URL 特征集构建候选集;计算要访问的URL与特征候选集中每个URL的相似度,根据相似度权重选择历史访问过的URL;将历史访问过的URL对应的URL信息作为预测候选集,计算每个URL信息的概率,选择概率最高的URL作为最终的URL信息,返回预测候选结果。本发明专利技术根据返回的预测结果进行DNS预测分析、TCP预测连接和资源预测加载后,大大提高了网页的加载速度。
下载所有详细的技术数据
【技术实现步骤总结】
一种浏览器网页信息预获取方法及系统
本专利技术涉及一种浏览器网页信息的预获取方法及系统。
技术介绍
网页加载是浏览器的核心和基本功能。网页加载速度的提升有很多工作要做,比如缓存优化、预加载、基于服务器端技术、网络协议改进(比如SPDY)等等。基于智能预测模型的浏览器网页加载方法是一种可以大幅度提高网页加载速度的方法。在这个方法中,我们将智能预测模型命名为PageLoadOracle,主要是因为PageLoadOracle可以提前告诉我们需要解析什么域名,需要连接什么域名,给定URL需要加载哪些资源。但是,现实中并没有万能的预言机,我们只能尽可能地构建一个高效的预测模型。如何提高预测模型的预测准确率和召回率是一个关键问题。准确率是指预测模型返回需要执行的正确预测行为(DNS解析、TCP连接、资源下载),不执行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。
技术实现思路
该专利技术要解决的技术问题是提供一种能够快速冷启动的浏览器网页信息预获取,满足用户个性化长尾需求,提高召回率,无论是否有用户个性化数据或不是。方法和系统。本专利技术解决上述技术问题的技术方案如下: 一种浏览器网页信息的预获取方法,包括以下步骤: 步骤一:针对互联网上预定范围内的所有网站,从每个网站随机抓取预定数量的爬取网页,保存所有爬取网页对应的爬取网页信息;第二步:获取用户在预定时间段内访问的历史网页,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征,根据爬取的网页和历史对应的爬取网页和历史网页分别为网页。建立倒排索引,用于采集用户的 URL 特征;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则根据倒排索引获取与该待访问URL相关的历史网页信息或爬取网页信息,结束进程,如果没有,提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征集并集的特征候选集;步骤6:计算待访问网站与特征候选集中各个网站的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;步骤7:将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中各网站信息的概率,
在没有用户个性化数据的情况下,可以快速冷启动,提高召回率;并且可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。在上述技术方案的基础上,还可以对专利技术进行如下改进。进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步,步骤6中计算待访问网站与特征候选集中各网站的相似度具体为,根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。进一步的,一种浏览器网页信息预获取系统,包括抓取模块、获取模块、提取模块、判断模块、构建模块、计算模块和返回模块。网站中的所有网站,从每个网站中随机抓取预定数量的抓取网页,并保存所有抓取网页对应的抓取网页信息;获取模块用于获取用户在预定时间段内访问网页的历史记录,保存所有历史网页对应的历史网页信息;提取模块,用于根据所有被爬取的网页和历史网页构建访问记录,分别从每个网站抓取的网页和历史网页中提取URL特征,并根据被爬取的集合建立倒排索引网页和历史网页,以及被抓取的网页和历史网页分别对应的URL特征;判断模块用于获取用户输入的待访问网站,判断用户输入的要访问的URL是否在访问记录中,如果是,则获取历史网页信息或爬取相关网页信息根据倒排索引到要访问的URL,结束进程,如果不是,提取要访问的URL的URL特征;模块,用于根据提取的待访问URL的URL特征集合构建候选集,候选集为倒排索引中所有URL特征集并集的特征候选集;根据相似度权重对访问URL与特征候选集中的每个URL的相似度进行排序,选择相似度权重最高的URL特征对应的历史访问URL;
进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,计算模块计算待访问网站与特征候选集中各网站的相似度具体为根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。[附图说明] 图。图1为本专利技术的方法步骤流程图;无花果。图2是专利技术体系结构图。附图中,各个标签所代表的零件清单如下:1、抓取模块、2、获取模块、3、提取模块、4、判断模块、5、@ > 构建模块,6、 计算模块,7、 返回模块。具体实施方式下面结合附图对本专利技术的原理和特点进行说明,举例仅用于说明本专利技术,并不用于限定本专利技术的范围。图1为本专利技术的方法步骤流程图;图2是该专利技术的系统结构图。示例1 从提高智能预测模型的准确率和召回率的角度,我们的预测模型综合考虑了互联网顶级站点和用户个性化的历史数据。一方面,在没有用户个性化历史数据的情况下,基于互联网热门站点网站群体行为数据进行预测;另一方面,预测是基于每个用户自己的个性化历史数据进行的。
前者保证在没有用户个性化数据的情况下,能够快速冷启动,提高召回率;后者可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。两者缺一不可。一种浏览器网页信息的预获取方法,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存并存储所有抓取的网页 抓取网页对应的网页信息;Step 1具体为WWW中Top 500站点(作为Top 50 0)的每个站点,开始随机访问,从站点首页抓取k个网页; Step 2:获取用户在预定时间内访问的历史网页时间,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页建立访问记录,从各个网站抓取网页和历史网页 从 中提取URL特征,根据爬取的网页和历史网页建立倒排索引,分别对应爬取网页和历史网页的URL特征集合;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P)
【技术保护点】
一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存它们对应的所有爬取网页的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:基于所有爬取的网页和历史网页建立访问权限 分别从各个网站爬取的网页和历史网页中记录并提取URL特征,根据抓取的网页和历史网页的集合以及被抓取的网页和历史网页分别对应的URL特征建立倒排排名索引;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则获取与待访问URL相关的历史网页信息或爬取网页信息根据倒排索引访问,结束处理,如果没有,则提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引候选集中所有网站特征的集合并集的特征;第 6 步:计算待访问URL与特征候选集中各个URL的相似度,按照相似度权重排序,选择相似度权重最高的URL特征对应的历史访问URL;将网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回。
【技术特点总结】
1.一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤一:对互联网中预定范围内的所有网站,随机抓取预定数量的Crawl网页,保存所有已爬取网页对应的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征。建立倒排索引;第四步:获取用户输入的要访问的网站,判断用户输入的要访问的网站是否在访问记录中,如果是,则根据倒排索引获取与要访问的网站相关的历史网页信息或者抓取获取网页信息,结束处理,如果不是,提取要访问的网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征的集合并集的特征候选集;步骤6:计算待访问网站中每个网址与特征候选集的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;第 7 步:通过将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回. 2.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述抓取的网页信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源加载。3.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述历史网页信息包括DNS解析的域名,要创建连接的域名和/或要加载的资源。4.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述网址信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源。加载。5.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于: 步骤6中的待访问网站与特征候选集中各网站的相似度计算具体为,根据待访问网站与特征候选集中任意网站的特征向量计算余弦距离。6. 一种浏览器网页信息的预获取系统,
【专利技术性质】
技术研发人员:莫宇、喻言、李洪亮、刘铁峰、
申请人(专利权)持有人:,
类型:发明
国家、省、市:湖北;42
下载所有详细的技术数据 我是该专利的所有者 查看全部
浏览器抓取网页(基于智能预测模型的浏览器网页信息的预获取方法及系统)
本发明专利技术涉及一种浏览器网页信息的预获取方法及系统,包括以下步骤:根据抓取的网页和历史网页的集合以及对应的URL特征建立倒排索引。分别抓取的网页和历史网页;用户输入的待访问URL是否在访问记录中,根据倒排索引获取历史网页信息或爬取网页信息,或提取待访问URL的URL特征;根据提取的 URL 特征集构建候选集;计算要访问的URL与特征候选集中每个URL的相似度,根据相似度权重选择历史访问过的URL;将历史访问过的URL对应的URL信息作为预测候选集,计算每个URL信息的概率,选择概率最高的URL作为最终的URL信息,返回预测候选结果。本发明专利技术根据返回的预测结果进行DNS预测分析、TCP预测连接和资源预测加载后,大大提高了网页的加载速度。
下载所有详细的技术数据
【技术实现步骤总结】
一种浏览器网页信息预获取方法及系统
本专利技术涉及一种浏览器网页信息的预获取方法及系统。
技术介绍
网页加载是浏览器的核心和基本功能。网页加载速度的提升有很多工作要做,比如缓存优化、预加载、基于服务器端技术、网络协议改进(比如SPDY)等等。基于智能预测模型的浏览器网页加载方法是一种可以大幅度提高网页加载速度的方法。在这个方法中,我们将智能预测模型命名为PageLoadOracle,主要是因为PageLoadOracle可以提前告诉我们需要解析什么域名,需要连接什么域名,给定URL需要加载哪些资源。但是,现实中并没有万能的预言机,我们只能尽可能地构建一个高效的预测模型。如何提高预测模型的预测准确率和召回率是一个关键问题。准确率是指预测模型返回需要执行的正确预测行为(DNS解析、TCP连接、资源下载),不执行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。
技术实现思路
该专利技术要解决的技术问题是提供一种能够快速冷启动的浏览器网页信息预获取,满足用户个性化长尾需求,提高召回率,无论是否有用户个性化数据或不是。方法和系统。本专利技术解决上述技术问题的技术方案如下: 一种浏览器网页信息的预获取方法,包括以下步骤: 步骤一:针对互联网上预定范围内的所有网站,从每个网站随机抓取预定数量的爬取网页,保存所有爬取网页对应的爬取网页信息;第二步:获取用户在预定时间段内访问的历史网页,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征,根据爬取的网页和历史对应的爬取网页和历史网页分别为网页。建立倒排索引,用于采集用户的 URL 特征;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则根据倒排索引获取与该待访问URL相关的历史网页信息或爬取网页信息,结束进程,如果没有,提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征集并集的特征候选集;步骤6:计算待访问网站与特征候选集中各个网站的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;步骤7:将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中各网站信息的概率,
在没有用户个性化数据的情况下,可以快速冷启动,提高召回率;并且可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。在上述技术方案的基础上,还可以对专利技术进行如下改进。进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步,步骤6中计算待访问网站与特征候选集中各网站的相似度具体为,根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。进一步的,一种浏览器网页信息预获取系统,包括抓取模块、获取模块、提取模块、判断模块、构建模块、计算模块和返回模块。网站中的所有网站,从每个网站中随机抓取预定数量的抓取网页,并保存所有抓取网页对应的抓取网页信息;获取模块用于获取用户在预定时间段内访问网页的历史记录,保存所有历史网页对应的历史网页信息;提取模块,用于根据所有被爬取的网页和历史网页构建访问记录,分别从每个网站抓取的网页和历史网页中提取URL特征,并根据被爬取的集合建立倒排索引网页和历史网页,以及被抓取的网页和历史网页分别对应的URL特征;判断模块用于获取用户输入的待访问网站,判断用户输入的要访问的URL是否在访问记录中,如果是,则获取历史网页信息或爬取相关网页信息根据倒排索引到要访问的URL,结束进程,如果不是,提取要访问的URL的URL特征;模块,用于根据提取的待访问URL的URL特征集合构建候选集,候选集为倒排索引中所有URL特征集并集的特征候选集;根据相似度权重对访问URL与特征候选集中的每个URL的相似度进行排序,选择相似度权重最高的URL特征对应的历史访问URL;
进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,计算模块计算待访问网站与特征候选集中各网站的相似度具体为根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。[附图说明] 图。图1为本专利技术的方法步骤流程图;无花果。图2是专利技术体系结构图。附图中,各个标签所代表的零件清单如下:1、抓取模块、2、获取模块、3、提取模块、4、判断模块、5、@ > 构建模块,6、 计算模块,7、 返回模块。具体实施方式下面结合附图对本专利技术的原理和特点进行说明,举例仅用于说明本专利技术,并不用于限定本专利技术的范围。图1为本专利技术的方法步骤流程图;图2是该专利技术的系统结构图。示例1 从提高智能预测模型的准确率和召回率的角度,我们的预测模型综合考虑了互联网顶级站点和用户个性化的历史数据。一方面,在没有用户个性化历史数据的情况下,基于互联网热门站点网站群体行为数据进行预测;另一方面,预测是基于每个用户自己的个性化历史数据进行的。
前者保证在没有用户个性化数据的情况下,能够快速冷启动,提高召回率;后者可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。两者缺一不可。一种浏览器网页信息的预获取方法,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存并存储所有抓取的网页 抓取网页对应的网页信息;Step 1具体为WWW中Top 500站点(作为Top 50 0)的每个站点,开始随机访问,从站点首页抓取k个网页; Step 2:获取用户在预定时间内访问的历史网页时间,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页建立访问记录,从各个网站抓取网页和历史网页 从 中提取URL特征,根据爬取的网页和历史网页建立倒排索引,分别对应爬取网页和历史网页的URL特征集合;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P)

【技术保护点】
一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存它们对应的所有爬取网页的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:基于所有爬取的网页和历史网页建立访问权限 分别从各个网站爬取的网页和历史网页中记录并提取URL特征,根据抓取的网页和历史网页的集合以及被抓取的网页和历史网页分别对应的URL特征建立倒排排名索引;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则获取与待访问URL相关的历史网页信息或爬取网页信息根据倒排索引访问,结束处理,如果没有,则提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引候选集中所有网站特征的集合并集的特征;第 6 步:计算待访问URL与特征候选集中各个URL的相似度,按照相似度权重排序,选择相似度权重最高的URL特征对应的历史访问URL;将网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回。
【技术特点总结】
1.一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤一:对互联网中预定范围内的所有网站,随机抓取预定数量的Crawl网页,保存所有已爬取网页对应的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征。建立倒排索引;第四步:获取用户输入的要访问的网站,判断用户输入的要访问的网站是否在访问记录中,如果是,则根据倒排索引获取与要访问的网站相关的历史网页信息或者抓取获取网页信息,结束处理,如果不是,提取要访问的网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征的集合并集的特征候选集;步骤6:计算待访问网站中每个网址与特征候选集的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;第 7 步:通过将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回. 2.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述抓取的网页信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源加载。3.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述历史网页信息包括DNS解析的域名,要创建连接的域名和/或要加载的资源。4.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述网址信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源。加载。5.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于: 步骤6中的待访问网站与特征候选集中各网站的相似度计算具体为,根据待访问网站与特征候选集中任意网站的特征向量计算余弦距离。6. 一种浏览器网页信息的预获取系统,
【专利技术性质】
技术研发人员:莫宇、喻言、李洪亮、刘铁峰、
申请人(专利权)持有人:,
类型:发明
国家、省、市:湖北;42
下载所有详细的技术数据 我是该专利的所有者
浏览器抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-06 15:07
2021-11-26
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页的源代码,直观可见,代码内容与网页内容一致通过浏览器右键—— > 点击查看网页源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient只是在后端返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于Js生成的内容HttpClient无法获取。
对于获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到相应的内容。
我们在这里讨论的模拟方法大致有两种:
我们这次的目标是获取bilibili动态生成的动画列表。左上为抓取的目标列表,左下为浏览器渲染的HTML内容,右为服务器返回的响应正文。通过对比可以看出,目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于自动测试 Web 应用程序的工具,更多的是在 Google 上。这里我们主要用它来模拟页面的操作并返回结果,对于网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。由于是无接口的,所以在速度性能方面会更好。
1.下载
使用PhantomJS需要从官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的一个子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的非界面浏览器。因为没有接口,所以执行速度还是可以的。
1.maven依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都有很好的模拟浏览器页面生成的功能。PhantomJS作为一个无界面的WebKit,渲染页面的功能非常完善,并且有浏览器截图功能,可以模拟登录操作。HtmlUnit使用Rhino引擎解析Js,有时候解析速度很慢,像上面的例子,需要很长的时间,但是HtmlUnit可以获取页面并解析一组元素(当然最好用Jsoup 来解析元素),不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟,可能我不会用QAQ
欢迎补充:)
分类:
技术要点:
相关文章: 查看全部
浏览器抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
2021-11-26
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页的源代码,直观可见,代码内容与网页内容一致通过浏览器右键—— > 点击查看网页源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient只是在后端返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于Js生成的内容HttpClient无法获取。
对于获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到相应的内容。
我们在这里讨论的模拟方法大致有两种:
我们这次的目标是获取bilibili动态生成的动画列表。左上为抓取的目标列表,左下为浏览器渲染的HTML内容,右为服务器返回的响应正文。通过对比可以看出,目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于自动测试 Web 应用程序的工具,更多的是在 Google 上。这里我们主要用它来模拟页面的操作并返回结果,对于网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。由于是无接口的,所以在速度性能方面会更好。
1.下载
使用PhantomJS需要从官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的一个子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的非界面浏览器。因为没有接口,所以执行速度还是可以的。
1.maven依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都有很好的模拟浏览器页面生成的功能。PhantomJS作为一个无界面的WebKit,渲染页面的功能非常完善,并且有浏览器截图功能,可以模拟登录操作。HtmlUnit使用Rhino引擎解析Js,有时候解析速度很慢,像上面的例子,需要很长的时间,但是HtmlUnit可以获取页面并解析一组元素(当然最好用Jsoup 来解析元素),不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟,可能我不会用QAQ
欢迎补充:)
分类:
技术要点:
相关文章:
浏览器抓取网页(存储将数据存储到Cookie会话的技术管理技术技术 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-06 15:04
)
一、会话管理1、概述:
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。(版本1)
一个会话收录多个请求和响应(浏览器第一次向服务器资源发送请求,会话建立,直到一方断开连接。)(版本 2)
例:张三给李四打电话,李四接听电话,通话建立,双方挂断通话结束。
2、特点:
在会话范围内的多个请求之间共享数据
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
3、生命周期
开始:会话在浏览器访问服务器时开始
结束:浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
4、会话技术:
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
二、Cookies 1、概述:
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
功能:跟踪特定对象、统计页面浏览量、简化登录
2、常用方法:
void setMaxAge(int e):设置cookie的有效期,以秒为单位,正数为过了多少秒就会过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge():获取cookie的有效时间,以秒为单位
void setValue(String value):创建cookie后给cookie赋值
String getValue():获取cookie的值
String getName():获取cookie的名称
Cookie[] getCookies():获取cookie中的所有属性名
3、使用方法:
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
Cookie cookie = 新 Cookie(key,value);
(2)写入 Cookie 对象(来自服务器 ---> 客户端)
response.addCookie(cookie)
(3)获取cookie,获取数据
Cookies[] Cookies = request.getCookies()
4、注意事项:
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
新闻详情页面
三、Session内置对象1、概述:session是jsp9内置对象之一(out、request、response、session、applicationconfig、page、pageContext、exception)
(1)服务器端会话技术,一个会话中多个请求之间共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)可以通过Session在应用程序的WEB页面之间跳转时保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。(即用户浏览网站的时间花费。)
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
2、常用方法
(1)public void setAttribute(String name,String value);
设置具有指定名称的属性的值并将其添加到会话会话范围,或者如果该属性存在于会话范围内,则更改该属性的值。
(2)public Object getAttribute(String name);
获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在,则返回null。
(3)public void removeAttribute(String name);
删除具有指定名称的会话属性。如果该属性不存在,则会发生异常。
(4)公共无效无效();
使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
(5)public String getId();
获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
(6)public void setMaxInactiveInterval(int interval);
设置会话的最大持续时间,以秒为单位,负数表示会话永不过期。
(7)public int getMaxInActiveInterval();
获取会话的最大时长,使用时需要进行一些处理
3、session和window的关系
(1)每个会话对象都与浏览器一一对应。重新打开浏览器相当于重新创建会话对象。
(2)通过超链接打开的新窗口,新窗口的会话与其父窗口的会话相同
四、Session和Cookie的区别
(1)session 将数据存储在服务器上,cookies 存储在客户端
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
自动登录
7天内自动登录 查看全部
浏览器抓取网页(存储将数据存储到Cookie会话的技术管理技术技术
)
一、会话管理1、概述:
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。(版本1)
一个会话收录多个请求和响应(浏览器第一次向服务器资源发送请求,会话建立,直到一方断开连接。)(版本 2)
例:张三给李四打电话,李四接听电话,通话建立,双方挂断通话结束。
2、特点:
在会话范围内的多个请求之间共享数据
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
3、生命周期
开始:会话在浏览器访问服务器时开始
结束:浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
4、会话技术:
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
二、Cookies 1、概述:
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
功能:跟踪特定对象、统计页面浏览量、简化登录
2、常用方法:
void setMaxAge(int e):设置cookie的有效期,以秒为单位,正数为过了多少秒就会过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge():获取cookie的有效时间,以秒为单位
void setValue(String value):创建cookie后给cookie赋值
String getValue():获取cookie的值
String getName():获取cookie的名称
Cookie[] getCookies():获取cookie中的所有属性名
3、使用方法:
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
Cookie cookie = 新 Cookie(key,value);
(2)写入 Cookie 对象(来自服务器 ---> 客户端)
response.addCookie(cookie)
(3)获取cookie,获取数据
Cookies[] Cookies = request.getCookies()
4、注意事项:
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
新闻详情页面
三、Session内置对象1、概述:session是jsp9内置对象之一(out、request、response、session、applicationconfig、page、pageContext、exception)
(1)服务器端会话技术,一个会话中多个请求之间共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)可以通过Session在应用程序的WEB页面之间跳转时保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。(即用户浏览网站的时间花费。)
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
2、常用方法
(1)public void setAttribute(String name,String value);
设置具有指定名称的属性的值并将其添加到会话会话范围,或者如果该属性存在于会话范围内,则更改该属性的值。
(2)public Object getAttribute(String name);
获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在,则返回null。
(3)public void removeAttribute(String name);
删除具有指定名称的会话属性。如果该属性不存在,则会发生异常。
(4)公共无效无效();
使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
(5)public String getId();
获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
(6)public void setMaxInactiveInterval(int interval);
设置会话的最大持续时间,以秒为单位,负数表示会话永不过期。
(7)public int getMaxInActiveInterval();
获取会话的最大时长,使用时需要进行一些处理
3、session和window的关系
(1)每个会话对象都与浏览器一一对应。重新打开浏览器相当于重新创建会话对象。
(2)通过超链接打开的新窗口,新窗口的会话与其父窗口的会话相同
四、Session和Cookie的区别
(1)session 将数据存储在服务器上,cookies 存储在客户端
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
自动登录
7天内自动登录
浏览器抓取网页(会话管理技术技术最常见的方案-上海怡健医学 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-06 15:03
)
会话管理
会话概述
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。
一个会话中的多个请求和响应
对话功能
在会话范围内的多个请求之间共享数据
功能:
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
生命周期
开始
会话在浏览器访问服务器的那一刻开始
结尾
当浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
会话技术
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
一、 Cookie
翻译:饼干
概述
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
常用方法
无效 setMaxAge(int e);
** 设置cookie的有效期,以秒为单位,正数为秒数后过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge();
** 获取cookie的有效时间,以秒为单位
无效 setValue(字符串值);
** 创建cookie后,给cookie赋值
字符串 getValue();
** 获取cookie的值
字符串 getName();
** 获取 cookie 的名称
饼干[] getCookies();
** 获取cookie中的所有属性名
如何使用
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
**Cookie cookie = new Cookie(key,value);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
** response.addCookie(cookie)
(3)获取cookies,获取数据
**Cookie[]cookies = request.getCookies()
防范措施
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
使用 Cookie
1.介绍
1.1 案例:张三和李四的会面(从头到尾)====》Client and Server
2.会话
2.1 概述:一个会话中的多个请求和响应
一次会话:浏览器第一次向服务器资源发送请求,会话建立,直到一方断开。
2.2 功能:一个会话范围内的多个请求之间共享数据
2.3 种方式:
(1)客户端会话技术:Cookies
(2)服务器端会话技术:session
3.Cookie
3.1 概述
客户端会话技术,将数据保存到客户端
3.2 快速入门
使用步骤:
(1)创建Cookie对象并绑定数据
新 Cookie(键,值);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
request.addCookie(cookie)
(3)获取cookies,获取数据
request.getCookies()
4.Cookie 详细信息
4.1 可以同时发送多个cookie吗?
** 能
** 可以创建多个 Cookie 对象,并使用响应多次调用 addCookie 方法发送 cookie。
4.2 cookie 在浏览器中保存多长时间?
(1)默认在关闭浏览器时销毁cookie数据
(2)持久存储
** setMaxAge(int 秒); 秒
** 参数:
正数---》将cookie数据写入硬盘文件。持久化存储[cookie生命周期]
** 负数:
默认值
** 零:
删除cookie信息
4.3 cookie 可以存储中文吗?
** 在tomcat8.0之前,中文数据不能直接存入cookies。
** 中文数据需要转码---》一般使用URL编码
** tomcat8.0后,cookies支持中文数据,但仍不支持特殊字符。建议使用 URL 编码存储
使用 URL 解码解析
* 编码 URLEncoder.encode("string","utf-8");
* 解码 URLDecoder.decode("string","utf-8");
5.cookies的特性和功能
特征:
(1)cookies 将数据存储在客户端浏览器中
(2)浏览器有单个cookie大小限制(4KB)和同域名下cookie总数限制(20个)
影响:
(1)cookies 通常用于存储少量不太敏感的数据
(2)无需登录即可完成服务端对客户端的识别
二、 会话
概述
session 是属于 jsp9 的大型内置对象之一
(1)服务器端会话技术,一个会话中多个请求共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)在应用程序的WEB页面之间跳转时可以通过Session保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
常用方法
公共无效setAttribute(字符串名称,字符串值);
** 设置具有指定名称的属性的值并将其添加到会话范围。如果该属性存在于会话范围内,请更改该属性的值。
公共对象getAttribute(字符串名称);
** 获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在则为null。
公共无效removeAttribute(字符串名称);
** 删除指定名称的会话属性。如果该属性不存在,则会发生异常。
公共无效无效();
** 使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
公共字符串 getId();
** 获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
公共无效 setMaxInactiveInterval(int 间隔);
** 以秒为单位设置会话的最大持续时间,负数表示会话永不过期。
公共 int getMaxInActiveInterval();
** 获取会话的最大时长,使用时需要进行一些处理
session和cookie的区别
(1)session在服务器端存储数据,在客户端存储cookies
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
会话的使用
会话->内置对象
1.概览
服务器端会话技术,它在一个会话中的多个请求之间共享数据,并将数据保存在服务器端对象中。jsp:会话小服务程序:HttpSession
2.快速入门
(1)getAttribute(字符串名称);
(2)setAttribute(字符串名称,对象值)
(3)removeAattribute(字符串名称)
3.详情
1.客户端关闭时,服务端没有关闭,两次获取的session是一样的吗?
* 默认情况下,不
* 如果需要的话,可以创建一个cookie,key是JSESSIONID,设置最大存活时间,让cookie持久化。
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
2.客户端没有关闭。服务器关闭后,两次获得的session是一样的吗?
* 不是同一个,但请确保没有数据丢失。tomcat 会自动执行以下操作。
** 会话钝化:
在服务器正常关闭之前将会话对象序列化到磁盘
** 会话激活:
服务器启动后,可以将会话文件转换为内存中的会话对象。
3.会话何时销毁?
(1) 服务器宕机
(2) 会话对象调用 invalidate() 方法
(3)会话默认过期时间为 30 分钟 => web.xml
4.会话功能
Session 用于存储一个会话的多个请求的数据,存储在服务器端
会话可以存储任何类型和大小的数据
session和cookie的区别
1.session 将数据存储在服务端,cookies 存储在客户端
Cookie存储的数据只能是文本,Session---Object
2.session 没有数据大小限制,cookie 有
3.session数据安全,cookies比较不安全
包括指令
查看全部
浏览器抓取网页(会话管理技术技术最常见的方案-上海怡健医学
)
会话管理
会话概述
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。
一个会话中的多个请求和响应
对话功能
在会话范围内的多个请求之间共享数据
功能:
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
生命周期
开始
会话在浏览器访问服务器的那一刻开始
结尾
当浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
会话技术
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
一、 Cookie
翻译:饼干
概述
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
常用方法
无效 setMaxAge(int e);
** 设置cookie的有效期,以秒为单位,正数为秒数后过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge();
** 获取cookie的有效时间,以秒为单位
无效 setValue(字符串值);
** 创建cookie后,给cookie赋值
字符串 getValue();
** 获取cookie的值
字符串 getName();
** 获取 cookie 的名称
饼干[] getCookies();
** 获取cookie中的所有属性名
如何使用
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
**Cookie cookie = new Cookie(key,value);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
** response.addCookie(cookie)
(3)获取cookies,获取数据
**Cookie[]cookies = request.getCookies()
防范措施
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
使用 Cookie
1.介绍
1.1 案例:张三和李四的会面(从头到尾)====》Client and Server
2.会话
2.1 概述:一个会话中的多个请求和响应
一次会话:浏览器第一次向服务器资源发送请求,会话建立,直到一方断开。
2.2 功能:一个会话范围内的多个请求之间共享数据
2.3 种方式:
(1)客户端会话技术:Cookies
(2)服务器端会话技术:session
3.Cookie
3.1 概述
客户端会话技术,将数据保存到客户端
3.2 快速入门
使用步骤:
(1)创建Cookie对象并绑定数据
新 Cookie(键,值);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
request.addCookie(cookie)
(3)获取cookies,获取数据
request.getCookies()
4.Cookie 详细信息
4.1 可以同时发送多个cookie吗?
** 能
** 可以创建多个 Cookie 对象,并使用响应多次调用 addCookie 方法发送 cookie。
4.2 cookie 在浏览器中保存多长时间?
(1)默认在关闭浏览器时销毁cookie数据
(2)持久存储
** setMaxAge(int 秒); 秒
** 参数:
正数---》将cookie数据写入硬盘文件。持久化存储[cookie生命周期]
** 负数:
默认值
** 零:
删除cookie信息
4.3 cookie 可以存储中文吗?
** 在tomcat8.0之前,中文数据不能直接存入cookies。
** 中文数据需要转码---》一般使用URL编码
** tomcat8.0后,cookies支持中文数据,但仍不支持特殊字符。建议使用 URL 编码存储
使用 URL 解码解析
* 编码 URLEncoder.encode("string","utf-8");
* 解码 URLDecoder.decode("string","utf-8");
5.cookies的特性和功能
特征:
(1)cookies 将数据存储在客户端浏览器中
(2)浏览器有单个cookie大小限制(4KB)和同域名下cookie总数限制(20个)
影响:
(1)cookies 通常用于存储少量不太敏感的数据
(2)无需登录即可完成服务端对客户端的识别
二、 会话
概述
session 是属于 jsp9 的大型内置对象之一
(1)服务器端会话技术,一个会话中多个请求共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)在应用程序的WEB页面之间跳转时可以通过Session保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
常用方法
公共无效setAttribute(字符串名称,字符串值);
** 设置具有指定名称的属性的值并将其添加到会话范围。如果该属性存在于会话范围内,请更改该属性的值。
公共对象getAttribute(字符串名称);
** 获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在则为null。
公共无效removeAttribute(字符串名称);
** 删除指定名称的会话属性。如果该属性不存在,则会发生异常。
公共无效无效();
** 使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
公共字符串 getId();
** 获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
公共无效 setMaxInactiveInterval(int 间隔);
** 以秒为单位设置会话的最大持续时间,负数表示会话永不过期。
公共 int getMaxInActiveInterval();
** 获取会话的最大时长,使用时需要进行一些处理
session和cookie的区别
(1)session在服务器端存储数据,在客户端存储cookies
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
会话的使用
会话->内置对象
1.概览
服务器端会话技术,它在一个会话中的多个请求之间共享数据,并将数据保存在服务器端对象中。jsp:会话小服务程序:HttpSession
2.快速入门
(1)getAttribute(字符串名称);
(2)setAttribute(字符串名称,对象值)
(3)removeAattribute(字符串名称)
3.详情
1.客户端关闭时,服务端没有关闭,两次获取的session是一样的吗?
* 默认情况下,不
* 如果需要的话,可以创建一个cookie,key是JSESSIONID,设置最大存活时间,让cookie持久化。
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
2.客户端没有关闭。服务器关闭后,两次获得的session是一样的吗?
* 不是同一个,但请确保没有数据丢失。tomcat 会自动执行以下操作。
** 会话钝化:
在服务器正常关闭之前将会话对象序列化到磁盘
** 会话激活:
服务器启动后,可以将会话文件转换为内存中的会话对象。
3.会话何时销毁?
(1) 服务器宕机
(2) 会话对象调用 invalidate() 方法
(3)会话默认过期时间为 30 分钟 => web.xml
4.会话功能
Session 用于存储一个会话的多个请求的数据,存储在服务器端
会话可以存储任何类型和大小的数据
session和cookie的区别
1.session 将数据存储在服务端,cookies 存储在客户端
Cookie存储的数据只能是文本,Session---Object
2.session 没有数据大小限制,cookie 有
3.session数据安全,cookies比较不安全
包括指令

浏览器抓取网页(基于所述预页面截取方法的所述目标)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 12:06
技术特点:
1.一种浏览器页面拦截方法,其特征在于,应用于服务器时,包括:获取浏览器客户端触发生成的拦截指令,控制浏览器客户端发送相应的拦截指令。对拦截指令的拦截参数;其中,拦截参数为浏览器客户端预先拦截页面的相关信息。根据截取参数访问预截页面,对预截页面进行截取操作,获取预截页面对应的目标截图后,将目标截图返回给浏览器客户端。2.根据权利要求1所述的截取浏览器页面的方法,其特征在于,在获取浏览器客户端触发生成的拦截指令之前,还包括: 浏览器客户端通过调用服务来调用服务。终端上的页面拦截服务api触发拦截指令的生成。3.根据权利要求1所述的浏览器页面拦截方法,其特征在于,所述根据所述拦截指令控制所述浏览器客户端发送相应的拦截参数包括: 根据所述拦截指令控制所述浏览器客户端发送预先设置的页面地址。截取页面和预截取页面中目标DOM节点的标识属性;其中,目标 DOM 节点是预截取页面对应的目标截图 中收录的 dom 节点。4.根据权利要求3所述的浏览器页面拦截方法,其特征在于,所述根据拦截参数访问预先拦截的页面包括: 在服务器上启动无头浏览器,使用无头浏览器访问预先拦截的页面。到预先截获的页面的页面地址。
5.根据权利要求4所述的浏览器页面拦截方法,其特征在于,所述无头浏览器根据预先拦截的页面的页面地址访问预先拦截的页面包括以下步骤:页面设置访问权限,控制浏览器客户端发送预截获页面对应的认证凭证,从而使用无头浏览器根据预截获页面地址的页面和访问凭证访问预截获页面- 捕获的页面。6.根据权利要求3所述的拦截浏览器页面的方法,其特征在于,在对预先拦截的页面进行拦截操作之前,该方法还包括:监控预截页面的所有数据接口判断预截页面的响应是否完成,如果是,判断预截页面中的所有dom节点是否渲染完成,如果是,开始步骤拦截预拦截页面。7.根据权利要求6所述的浏览器页面截取方法,其特征在于,对所述预先截取的页面进行截取操作,得到所述预先截取的页面对应的目标截图包括: 根据所述预先截取的页面截取页面中目标dom节点的标识属性,从所有dom节点中找到目标dom节点;获取目标dom节点的定位属性信息,并根据定位属性信息截取预先截取的页面中收录目标dom节点的区域,得到目标截图。8.根据权利要求1至7任一项所述的浏览器页面截取方法,其特征在于,所述将目标截图返回给浏览器客户端包括: 根据截取参数中的文件格式将目标截图封装成文件流对应的格式,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览
服务器客户端发送的参数。9.根据权利要求8所述的浏览器页面截取方法,其特征在于,根据截取参数中的文件格式将目标截图封装成对应格式的文件流后,还包括: 加水印操作根据预设要求对文件流进行处理,得到具有与预设要求对应的水印信息的文件流。10.一种浏览器页面拦截装置,其特征在于,应用于服务器时,包括: 获取模块,用于获取浏览器客户端触发生成的拦截指令,并根据以下内容控制拦截指令拦截指令。浏览器客户端发送相应的拦截参数;其中,拦截参数是与浏览器客户端的预拦截页面相关的信息。截取模块,用于根据截取参数访问预截取页面。对预截取页面进行截取操作,得到预截取页面对应的目标截屏,然后将目标截屏返回给浏览器客户端。
技术总结
本申请公开了一种浏览器页面拦截及装置,应用于服务器,包括:获取浏览器客户端触发生成的拦截指令,根据拦截指令控制浏览器客户端发送相应的拦截参数。拦截参数是与浏览器客户端的预拦截页面相关的信息;根据截取参数访问预截页面,对预截页面进行截取操作,得到对应的预截页面。目标截屏后,将目标截屏返回给浏览器客户端。获取拦截指令后,本应用服务器获取浏览器客户端对该截取指令的截取参数,根据截取参数统一访问预先截取的页面进行页面截取,同时将截图返回给浏览器客户端. ,从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。
技术研发人员:王子龙
受保护的技术用户:
技术研发日:2021.12.21
技术发布日期:2022/3/25 查看全部
浏览器抓取网页(基于所述预页面截取方法的所述目标)
技术特点:
1.一种浏览器页面拦截方法,其特征在于,应用于服务器时,包括:获取浏览器客户端触发生成的拦截指令,控制浏览器客户端发送相应的拦截指令。对拦截指令的拦截参数;其中,拦截参数为浏览器客户端预先拦截页面的相关信息。根据截取参数访问预截页面,对预截页面进行截取操作,获取预截页面对应的目标截图后,将目标截图返回给浏览器客户端。2.根据权利要求1所述的截取浏览器页面的方法,其特征在于,在获取浏览器客户端触发生成的拦截指令之前,还包括: 浏览器客户端通过调用服务来调用服务。终端上的页面拦截服务api触发拦截指令的生成。3.根据权利要求1所述的浏览器页面拦截方法,其特征在于,所述根据所述拦截指令控制所述浏览器客户端发送相应的拦截参数包括: 根据所述拦截指令控制所述浏览器客户端发送预先设置的页面地址。截取页面和预截取页面中目标DOM节点的标识属性;其中,目标 DOM 节点是预截取页面对应的目标截图 中收录的 dom 节点。4.根据权利要求3所述的浏览器页面拦截方法,其特征在于,所述根据拦截参数访问预先拦截的页面包括: 在服务器上启动无头浏览器,使用无头浏览器访问预先拦截的页面。到预先截获的页面的页面地址。
5.根据权利要求4所述的浏览器页面拦截方法,其特征在于,所述无头浏览器根据预先拦截的页面的页面地址访问预先拦截的页面包括以下步骤:页面设置访问权限,控制浏览器客户端发送预截获页面对应的认证凭证,从而使用无头浏览器根据预截获页面地址的页面和访问凭证访问预截获页面- 捕获的页面。6.根据权利要求3所述的拦截浏览器页面的方法,其特征在于,在对预先拦截的页面进行拦截操作之前,该方法还包括:监控预截页面的所有数据接口判断预截页面的响应是否完成,如果是,判断预截页面中的所有dom节点是否渲染完成,如果是,开始步骤拦截预拦截页面。7.根据权利要求6所述的浏览器页面截取方法,其特征在于,对所述预先截取的页面进行截取操作,得到所述预先截取的页面对应的目标截图包括: 根据所述预先截取的页面截取页面中目标dom节点的标识属性,从所有dom节点中找到目标dom节点;获取目标dom节点的定位属性信息,并根据定位属性信息截取预先截取的页面中收录目标dom节点的区域,得到目标截图。8.根据权利要求1至7任一项所述的浏览器页面截取方法,其特征在于,所述将目标截图返回给浏览器客户端包括: 根据截取参数中的文件格式将目标截图封装成文件流对应的格式,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览
服务器客户端发送的参数。9.根据权利要求8所述的浏览器页面截取方法,其特征在于,根据截取参数中的文件格式将目标截图封装成对应格式的文件流后,还包括: 加水印操作根据预设要求对文件流进行处理,得到具有与预设要求对应的水印信息的文件流。10.一种浏览器页面拦截装置,其特征在于,应用于服务器时,包括: 获取模块,用于获取浏览器客户端触发生成的拦截指令,并根据以下内容控制拦截指令拦截指令。浏览器客户端发送相应的拦截参数;其中,拦截参数是与浏览器客户端的预拦截页面相关的信息。截取模块,用于根据截取参数访问预截取页面。对预截取页面进行截取操作,得到预截取页面对应的目标截屏,然后将目标截屏返回给浏览器客户端。
技术总结
本申请公开了一种浏览器页面拦截及装置,应用于服务器,包括:获取浏览器客户端触发生成的拦截指令,根据拦截指令控制浏览器客户端发送相应的拦截参数。拦截参数是与浏览器客户端的预拦截页面相关的信息;根据截取参数访问预截页面,对预截页面进行截取操作,得到对应的预截页面。目标截屏后,将目标截屏返回给浏览器客户端。获取拦截指令后,本应用服务器获取浏览器客户端对该截取指令的截取参数,根据截取参数统一访问预先截取的页面进行页面截取,同时将截图返回给浏览器客户端. ,从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。
技术研发人员:王子龙
受保护的技术用户:
技术研发日:2021.12.21
技术发布日期:2022/3/25
浏览器抓取网页(网页抓取之WebBrowser繁体2006年04月22-最近研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-04-04 02:06
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
python网络爬虫英汉词典+自学能力繁体
2013年10月30日——上一篇文章,每次翻译一个词,都要在网上抓到,重复翻译要抓,不是很好。晚上突然想到一个好办法。说白了就是查询数据库。如果有这个词,就把它拿出来。用了半天,几乎不用联网,也就是离线!我使用的数据库是sqlite,小巧简单。当然你也可以用其他的。还
使用webbrowser控件抓取网页数据,如何抓取多个a标签对应的url地址的网页数据
2011 年 5 月 20 日 - 由于标题所属,我的页面中有四个菜单,它们连接到不同的地址。现在想通过一个按钮来抓取这个页面的数据,同时遍历获取四个a标签的url地址,然后自动进入其对应的页面抓取数据并存入数据库。现在问题如下: ArrayList UrlList = new ArrayList();
数据捕获的数据捕获过程
2015年11月30日——公司的数据采集系统已经写了一段时间。是时候总结一下了。否则,根据我的记忆,过一段时间我几乎会忘记它。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写: 数据抓取流程,以四川为例,介绍整个数据抓取流程 反爬虫规则:验证码识别,介绍easyocr和uuwise的使用 点击查看反爬虫-爬虫
使用webBrowser翻页抓取繁体中文
2013 年 5 月 10 日 - 页面有 js 翻页,我想捕获每个页面的内容。以下代码只能捕获第一页的数据。公共 Form1(){InitializeComponent();字符串 url = ""
各种微博爬取采集繁体字的方法
2017年3月24日 - 方法分析文章知乎中关于非wap版微博模拟登录研究的各种解答:Python爬虫如何登录新浪微博并爬取内容?Python模拟两种方式登录新浪微博 Selenium爬取新浪微博内容和用户信息 完整的项目代码 github上一个很挂的项目:完成微博各种登录,知乎,微信:给网页,wap版
通过WebBrowser网页截图C#源代码(抓取完整页面和首屏)繁体中文
2009年8月21日 - 通过WebBrowser+PrintWindow实现网页截图。内部采用拼接方式,保存完整的网页和首屏。但是这个方法的潜在bug是不能最小化窗体,否则会黑屏,而且webbrowser还没有找到在内存中构建截图的合理方式,无法正确渲染和然后被 PrintWindow 拦截。
解决Webbrowser定时爬取网页数据时,内存堆积没有释放的问题。
2017 年 10 月 25 日 - 原因:将 Dim Web 复制为新的 Web 浏览器。感觉这是Webbrowser的一个bug,如果重复创建不能释放,调用Dispose也没用。解决方案:将其定义为全局变量,并且只创建一次。
C# webbrowser爬取网页时如何防止弹出刷新对话框?
2013 年 7 月 27 日 - 使用 C# Webbrowser 抓取网页时,程序正在运行并弹出刷新对话框。必须点击重试,然后代码不会继续往下走。寻求专家指导。我的 webbrowser 被扩展并且还使用代码来抑制弹出对话框,仍然没用。公共无效getContent(){
爬虫app信息爬取apk反编译爬取繁体中文
2019年5月10日——我之前也抓过一些app,数据比较容易获取,也没有研究太深。毕竟有android模拟器+appium的方法。直到遇到一个app,具体的名字我就不说了,在模拟器上安装的时候打不开!!第一次遇到网上,找了半天,换了几个模拟器都没用。最后,我猜测是在apk中设置了检测模拟器的机制(这里没有进一步研究。
使用logcat进行Android系统日志的抓取
2017年8月11日 - 有时项目中会打印很多调试信息,但有时控制台打印速度很快,有些想看的信息在控制台下找不到。因此,我们需要使用 logcat 来捕获系统日志。话不多的话,上图一、经常在桌面创建logcat.txt二、打开cmd,然后输入adb logcat >C:\Users\Administrato
如何实现网页对webbrowser的适配?繁体中文
2011 年 12 月 29 日 - 该功能需要使显示的网页缩放或扩大到 webbrowser 控件的大小,并且 webbrowser 变小,网页放大,控件变大,网页变大,滚动webbrowser控件中没有出现bar,我该怎么办?
数据捕获第一弹繁体中文的性能优化
2015年12月24日 - 数据抓取本身的过程很简单,但是当网站的类型较多或者要采集的数据较多时,性能问题就会被称为数据抓取要解决的问题第一的。这几天同事在测试采集数据时总是遇到反应慢的问题。今晚趁着洗澡的时间理清思路,重构了一些问题;我做了一个记录。这次遇到的问题主要是代理的问题。场景如下:
WebBrowser实现繁体中文网页编辑
2016-09-05 - 1 //1.显示网页2过程TForm2.FormCreate(Sender: TObject); 3 开始 4 面板1.Align:=alTop; 5 复选框1.锚点:=[akTop,akRight];
通过 WebBrowser 获取网页截图
2015 年 1 月 27 日 - 本文介绍如何通过 WinForm 中的 WebBroswer 控件对网页进行截图。该方法可以截取大于屏幕面积的网页,但无法获取Flash或网页上某些控件的图片。因为是 WinForm 控件,所以没有在 WPF 中测试。在界面中添加一个文本框和一个按钮,文本框用于输入地址。在按钮按下事件处理程序中初始化
WEBBROWSER 如何判断网页是否重定向到繁体中文?
2014年7月1日 - 我在sdk下用atl加载了一个webbrowser控件,打开了一个网页,然后通过遍历网页元素实现了自动登录,但是网页跳转后导出的html源代码仍然是第一页,我没有不知道问题出在哪里?有以下问题:1、如何知道页面跳转;2、页面跳转后,需要重新获取HTML DOM Document对象吗?3
Delphi WebBrowser 与网页交互
2015 年 11 月 3 日 - WebBrowser1.GoHome;//进入浏览器默认主页 WebBrowser1.Refresh; //刷新WebBrowser1.GoBack; //Back WebBrowser1.GoForward ; //转发 WebBrowser1.Navigate('...'); //打开指定页面我们
webBrowser 查找繁体中文网页句柄
2015 年 10 月 31 日 - private void button1_Click(object sender, EventArgs e){int parentHandle = FindWindow("Shell Embedding", null);
数据抓取反爬虫规则:验证码识别繁体中文
2015年11月30日——在数据采集过程中,验证码是必须要面对的一道坎。一般来说,验证码识别有机器识别和人工识别两种。随着验证码越来越不正常,机器识别验证码的难度也越来越大。12306的典型类型已改为图像识别。,而不是简单的文本识别。验证码识别技术有很多,这里只介绍项目中用到的两种方法:基于开源的Tesseract
Perl网页抓取网页解析繁体中文
2012年10月26日——Perl解析HTML链接 Perl爬虫--爬取特定内容网页 Perl解析当当图书信息页网页分析处理最佳模块Web::Scraper如何用Perl进行屏幕抓取?
网页信息爬取实现繁体中文
2009年2月11日 - 最近公司需要开发一个简历导入功能,类似博客搬家或者邮箱搬家。之前是通过优采云采集器抓取信息,但是简历导入功能需要用户登录才能获取简历数据,无奈只能自己开发。第一个问题是:如何实现模拟登录?我们知道一般的网站是通过cookies来维护状态的,而我抓到的网站也支持使用cookies来检查
使用java爬取繁体中文网页图片
2013年8月29日——记得这个月9号我来到了深圳。找了将近20天的工作,只有三四家公司给我打电话面试。我真的不知道为什么。是不是因为我投了简历,投的简历少了?还是这个季节是招聘的冷季?不是很清楚。前天,我去一家创业公司面试。公司感觉还行,我总体上很满意。我有幸接受了采访。谈好的薪水我也可以接受,所以我同意去上班。今天是第一天
网页抓取工具繁体中文
2015年7月22日 - 最近一直在从事网络爬虫。顺便说一句,在mark下爬取,简单来说就是模仿http请求,分析网页结构,解析网页内容,得到你需要的内容使用的插件:httpwatch核心代码包xe。httpParse.saic;导入 java.io.InputS
网页抓取方式(四)--phantomjs 繁体
2017 年 6 月 11 日 - 一、phantomjs 简介 Phantomjs 是一个基于 webkit 内核的无界面浏览器,因此我们可以使用它进行网页抓取。它的优点是:1、本身运行在浏览器上,对js和css有很好的支持;2、 不易被查封;3、 支持jquery操作;缺点:1、 慢。二、操作模式phantomjs操作有两种模式:1、Native ph
动态抓取网页信息繁体中文
April 27, 2016 - 前几天做数据库实验的时候,总是手动往数据库里添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理2
ganon爬取网页繁体中文示例
2017 年 4 月 19 日 - 项目地址:Documentation:这个非常强大,使用类似 js 的标签选择器来识别 DOMGanon 库提供了访问 HTML/XML doc
抓取网页上的图片信息
2015年12月11日 - 最近学习的时候总结了一下,发现既然js可以通过元素的id找到这个元素,那我能不能用c#来做,但是我们事先不知道他们的id,和还有一个好处是,我不想抓取某个元素的所有内容,我只想抓取某类元素的内容,比如说图片,我想抓取某个< @网站 。先说原理:使用WebBrowser类
java网页抓取问题
2012 年 6 月 19 日 - 在此 网站:%2Fct1.html_pnl_trk&track
Python网页抓取程序繁体
2011 年 4 月 14 日 - 该程序用于从网页中抓取文本,即盗墓笔记的文本提取。写的简单,大家不要笑'''从盗墓笔记地址的网站中获取每一集的具体内容,从各个集体内容网页中提取内容写入文件'' '#-*- 编码:gb2312 -*-import HTMLParser
如何抓取繁体中文网页内容
2013 年 7 月 21 日 - 如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,你怎么做?其实网页内容的结构和 XML 很像,所以我们可以使用解析 XML 来解析 HTML,但是两者的差距还是很大的,好了,废话不多说,我们开始解析 HTML。然后有很多解析xml的库,这里就用到了lib。
如何防止他人用软件爬取繁体中文网页
2009 年 11 月 2 日 - 其他人使用软件访问网页抓取内容分析,导致 网站 加载过多,如何防止其他人阅读内容
实用网页抓取繁体中文
April 3, 2014 - 0、前言 本文主要介绍如何抓取网页内容,如何解决乱码问题,如何解决登录问题,以及处理和显示的过程采集 的数据。效果如下: 1、下载网页并加载到HtmlAgilityPack这里主要使用WebClient类的DownloadString方法和HtmlAgilit
爬虫技术(1)--爬取繁体网页
2017 年 6 月 30 日 - 1.了解 URL 和 URI 引用:网络资源标识符通用资源标识符
数据采集(一):北京交管车辆违法信息采集网站(已完成)繁体中文
2013年12月24日 - 个人信息:本人1992年大三,在十级三流本科院校软件工程专业。我于今年 2013 年 10 月开始实习。中小型互联网公司,主要从事java研发。更精确的责任是数据的实施。总的来说,还没有完全脱离母校魔掌的我,没有算法行业底层预研大师的深厚内功,也没有机会攀登。
webbrowser如何实现点击flash按钮获取繁体中文数据
2015 年 11 月 21 日 - 网络浏览器有一个嵌入了 Flash 的网页。现在想找到Flash的句柄,同时想获取Flash中控件的值,同时给Flash中的控件赋值,怎么办?我正在使用 C# Winform。
使用DELPHI WEBBROWSER从繁体中文网页拉取数据
2012 年 6 月 5 日 - 请告诉我,我想从网页中提取数据,我使用以下语句 ovTable:=webbrowser1.OleObject.Document.all.tags('TABLE').item(0) ;//取表集合可以得到表的所有数据,但是放到循环里面:url:='
Python网络爬虫及信息获取分析网页(一)--BeautifulSoup库繁体中文
2017 年 8 月 12 日 - 编写爬虫。知识的好坏,都会被爬下来。混乱的程度会让你在网上一一发现并不像百度那么方便。因此,解析好的网页是判断爬虫好坏的重要标准。这里给大家介绍一个强大的网页信息解析库----BeautifulSoupBeautifulSoup库是一个专注于解析网页信息的强大第三方
WebBrowser 拦截网页 更改消息 繁体中文
2011 年 1 月 28 日 - 使用 System 实现 IDocHostShowUI 接口;使用 System.采集s.Generic;使用 System.ComponentModel;使用 System.Data;使用 System.Drawing;使用
WebBrowser繁体中文网页全身照
2012年6月25日——最近在写程序的时候,突然觉得google chrome网页的缩略图很有意思,但是chrome是自己的内核,自己的东西当然方便。浏览器呢?首先想到的是最常见的屏幕复制,也称为bitblt,是从WebBrowser 的dc 复制到位图的dc。
网页通过 External 接口与 WebBrowser 交互
2009 年 12 月 22 日 - 在上一篇博客中,我谈到了在 WTL 中添加 IDL 以通过向导实现 IDispatch。是有代价的,而且代价不小,所以最后我用了最简单最有效的方法。下面是这样一个示例代码贴:下面是我的IDispatch的实现,其中MainDlg是WTL向导生成的非模态对话框,可以根据
通过WebBrowser获取AJAX后的繁体中文版网页
2015年12月04日 - 通常在WebBrowser的文档加载完成事件DocumentCompleted中进行判断 if (_WebBrowder.ReadyState == WebBrowserReadyState.Complete) {//获取网页信息并处理} 不过很遗憾是很 查看全部
浏览器抓取网页(网页抓取之WebBrowser繁体2006年04月22-最近研究)
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
python网络爬虫英汉词典+自学能力繁体
2013年10月30日——上一篇文章,每次翻译一个词,都要在网上抓到,重复翻译要抓,不是很好。晚上突然想到一个好办法。说白了就是查询数据库。如果有这个词,就把它拿出来。用了半天,几乎不用联网,也就是离线!我使用的数据库是sqlite,小巧简单。当然你也可以用其他的。还
使用webbrowser控件抓取网页数据,如何抓取多个a标签对应的url地址的网页数据
2011 年 5 月 20 日 - 由于标题所属,我的页面中有四个菜单,它们连接到不同的地址。现在想通过一个按钮来抓取这个页面的数据,同时遍历获取四个a标签的url地址,然后自动进入其对应的页面抓取数据并存入数据库。现在问题如下: ArrayList UrlList = new ArrayList();
数据捕获的数据捕获过程
2015年11月30日——公司的数据采集系统已经写了一段时间。是时候总结一下了。否则,根据我的记忆,过一段时间我几乎会忘记它。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写: 数据抓取流程,以四川为例,介绍整个数据抓取流程 反爬虫规则:验证码识别,介绍easyocr和uuwise的使用 点击查看反爬虫-爬虫
使用webBrowser翻页抓取繁体中文
2013 年 5 月 10 日 - 页面有 js 翻页,我想捕获每个页面的内容。以下代码只能捕获第一页的数据。公共 Form1(){InitializeComponent();字符串 url = ""
各种微博爬取采集繁体字的方法
2017年3月24日 - 方法分析文章知乎中关于非wap版微博模拟登录研究的各种解答:Python爬虫如何登录新浪微博并爬取内容?Python模拟两种方式登录新浪微博 Selenium爬取新浪微博内容和用户信息 完整的项目代码 github上一个很挂的项目:完成微博各种登录,知乎,微信:给网页,wap版
通过WebBrowser网页截图C#源代码(抓取完整页面和首屏)繁体中文
2009年8月21日 - 通过WebBrowser+PrintWindow实现网页截图。内部采用拼接方式,保存完整的网页和首屏。但是这个方法的潜在bug是不能最小化窗体,否则会黑屏,而且webbrowser还没有找到在内存中构建截图的合理方式,无法正确渲染和然后被 PrintWindow 拦截。
解决Webbrowser定时爬取网页数据时,内存堆积没有释放的问题。
2017 年 10 月 25 日 - 原因:将 Dim Web 复制为新的 Web 浏览器。感觉这是Webbrowser的一个bug,如果重复创建不能释放,调用Dispose也没用。解决方案:将其定义为全局变量,并且只创建一次。
C# webbrowser爬取网页时如何防止弹出刷新对话框?
2013 年 7 月 27 日 - 使用 C# Webbrowser 抓取网页时,程序正在运行并弹出刷新对话框。必须点击重试,然后代码不会继续往下走。寻求专家指导。我的 webbrowser 被扩展并且还使用代码来抑制弹出对话框,仍然没用。公共无效getContent(){
爬虫app信息爬取apk反编译爬取繁体中文
2019年5月10日——我之前也抓过一些app,数据比较容易获取,也没有研究太深。毕竟有android模拟器+appium的方法。直到遇到一个app,具体的名字我就不说了,在模拟器上安装的时候打不开!!第一次遇到网上,找了半天,换了几个模拟器都没用。最后,我猜测是在apk中设置了检测模拟器的机制(这里没有进一步研究。
使用logcat进行Android系统日志的抓取
2017年8月11日 - 有时项目中会打印很多调试信息,但有时控制台打印速度很快,有些想看的信息在控制台下找不到。因此,我们需要使用 logcat 来捕获系统日志。话不多的话,上图一、经常在桌面创建logcat.txt二、打开cmd,然后输入adb logcat >C:\Users\Administrato
如何实现网页对webbrowser的适配?繁体中文
2011 年 12 月 29 日 - 该功能需要使显示的网页缩放或扩大到 webbrowser 控件的大小,并且 webbrowser 变小,网页放大,控件变大,网页变大,滚动webbrowser控件中没有出现bar,我该怎么办?
数据捕获第一弹繁体中文的性能优化
2015年12月24日 - 数据抓取本身的过程很简单,但是当网站的类型较多或者要采集的数据较多时,性能问题就会被称为数据抓取要解决的问题第一的。这几天同事在测试采集数据时总是遇到反应慢的问题。今晚趁着洗澡的时间理清思路,重构了一些问题;我做了一个记录。这次遇到的问题主要是代理的问题。场景如下:
WebBrowser实现繁体中文网页编辑
2016-09-05 - 1 //1.显示网页2过程TForm2.FormCreate(Sender: TObject); 3 开始 4 面板1.Align:=alTop; 5 复选框1.锚点:=[akTop,akRight];
通过 WebBrowser 获取网页截图
2015 年 1 月 27 日 - 本文介绍如何通过 WinForm 中的 WebBroswer 控件对网页进行截图。该方法可以截取大于屏幕面积的网页,但无法获取Flash或网页上某些控件的图片。因为是 WinForm 控件,所以没有在 WPF 中测试。在界面中添加一个文本框和一个按钮,文本框用于输入地址。在按钮按下事件处理程序中初始化
WEBBROWSER 如何判断网页是否重定向到繁体中文?
2014年7月1日 - 我在sdk下用atl加载了一个webbrowser控件,打开了一个网页,然后通过遍历网页元素实现了自动登录,但是网页跳转后导出的html源代码仍然是第一页,我没有不知道问题出在哪里?有以下问题:1、如何知道页面跳转;2、页面跳转后,需要重新获取HTML DOM Document对象吗?3
Delphi WebBrowser 与网页交互
2015 年 11 月 3 日 - WebBrowser1.GoHome;//进入浏览器默认主页 WebBrowser1.Refresh; //刷新WebBrowser1.GoBack; //Back WebBrowser1.GoForward ; //转发 WebBrowser1.Navigate('...'); //打开指定页面我们
webBrowser 查找繁体中文网页句柄
2015 年 10 月 31 日 - private void button1_Click(object sender, EventArgs e){int parentHandle = FindWindow("Shell Embedding", null);
数据抓取反爬虫规则:验证码识别繁体中文
2015年11月30日——在数据采集过程中,验证码是必须要面对的一道坎。一般来说,验证码识别有机器识别和人工识别两种。随着验证码越来越不正常,机器识别验证码的难度也越来越大。12306的典型类型已改为图像识别。,而不是简单的文本识别。验证码识别技术有很多,这里只介绍项目中用到的两种方法:基于开源的Tesseract
Perl网页抓取网页解析繁体中文
2012年10月26日——Perl解析HTML链接 Perl爬虫--爬取特定内容网页 Perl解析当当图书信息页网页分析处理最佳模块Web::Scraper如何用Perl进行屏幕抓取?
网页信息爬取实现繁体中文
2009年2月11日 - 最近公司需要开发一个简历导入功能,类似博客搬家或者邮箱搬家。之前是通过优采云采集器抓取信息,但是简历导入功能需要用户登录才能获取简历数据,无奈只能自己开发。第一个问题是:如何实现模拟登录?我们知道一般的网站是通过cookies来维护状态的,而我抓到的网站也支持使用cookies来检查
使用java爬取繁体中文网页图片
2013年8月29日——记得这个月9号我来到了深圳。找了将近20天的工作,只有三四家公司给我打电话面试。我真的不知道为什么。是不是因为我投了简历,投的简历少了?还是这个季节是招聘的冷季?不是很清楚。前天,我去一家创业公司面试。公司感觉还行,我总体上很满意。我有幸接受了采访。谈好的薪水我也可以接受,所以我同意去上班。今天是第一天
网页抓取工具繁体中文
2015年7月22日 - 最近一直在从事网络爬虫。顺便说一句,在mark下爬取,简单来说就是模仿http请求,分析网页结构,解析网页内容,得到你需要的内容使用的插件:httpwatch核心代码包xe。httpParse.saic;导入 java.io.InputS
网页抓取方式(四)--phantomjs 繁体
2017 年 6 月 11 日 - 一、phantomjs 简介 Phantomjs 是一个基于 webkit 内核的无界面浏览器,因此我们可以使用它进行网页抓取。它的优点是:1、本身运行在浏览器上,对js和css有很好的支持;2、 不易被查封;3、 支持jquery操作;缺点:1、 慢。二、操作模式phantomjs操作有两种模式:1、Native ph
动态抓取网页信息繁体中文
April 27, 2016 - 前几天做数据库实验的时候,总是手动往数据库里添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理2
ganon爬取网页繁体中文示例
2017 年 4 月 19 日 - 项目地址:Documentation:这个非常强大,使用类似 js 的标签选择器来识别 DOMGanon 库提供了访问 HTML/XML doc
抓取网页上的图片信息
2015年12月11日 - 最近学习的时候总结了一下,发现既然js可以通过元素的id找到这个元素,那我能不能用c#来做,但是我们事先不知道他们的id,和还有一个好处是,我不想抓取某个元素的所有内容,我只想抓取某类元素的内容,比如说图片,我想抓取某个< @网站 。先说原理:使用WebBrowser类
java网页抓取问题
2012 年 6 月 19 日 - 在此 网站:%2Fct1.html_pnl_trk&track
Python网页抓取程序繁体
2011 年 4 月 14 日 - 该程序用于从网页中抓取文本,即盗墓笔记的文本提取。写的简单,大家不要笑'''从盗墓笔记地址的网站中获取每一集的具体内容,从各个集体内容网页中提取内容写入文件'' '#-*- 编码:gb2312 -*-import HTMLParser
如何抓取繁体中文网页内容
2013 年 7 月 21 日 - 如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,你怎么做?其实网页内容的结构和 XML 很像,所以我们可以使用解析 XML 来解析 HTML,但是两者的差距还是很大的,好了,废话不多说,我们开始解析 HTML。然后有很多解析xml的库,这里就用到了lib。
如何防止他人用软件爬取繁体中文网页
2009 年 11 月 2 日 - 其他人使用软件访问网页抓取内容分析,导致 网站 加载过多,如何防止其他人阅读内容
实用网页抓取繁体中文
April 3, 2014 - 0、前言 本文主要介绍如何抓取网页内容,如何解决乱码问题,如何解决登录问题,以及处理和显示的过程采集 的数据。效果如下: 1、下载网页并加载到HtmlAgilityPack这里主要使用WebClient类的DownloadString方法和HtmlAgilit
爬虫技术(1)--爬取繁体网页
2017 年 6 月 30 日 - 1.了解 URL 和 URI 引用:网络资源标识符通用资源标识符
数据采集(一):北京交管车辆违法信息采集网站(已完成)繁体中文
2013年12月24日 - 个人信息:本人1992年大三,在十级三流本科院校软件工程专业。我于今年 2013 年 10 月开始实习。中小型互联网公司,主要从事java研发。更精确的责任是数据的实施。总的来说,还没有完全脱离母校魔掌的我,没有算法行业底层预研大师的深厚内功,也没有机会攀登。
webbrowser如何实现点击flash按钮获取繁体中文数据
2015 年 11 月 21 日 - 网络浏览器有一个嵌入了 Flash 的网页。现在想找到Flash的句柄,同时想获取Flash中控件的值,同时给Flash中的控件赋值,怎么办?我正在使用 C# Winform。
使用DELPHI WEBBROWSER从繁体中文网页拉取数据
2012 年 6 月 5 日 - 请告诉我,我想从网页中提取数据,我使用以下语句 ovTable:=webbrowser1.OleObject.Document.all.tags('TABLE').item(0) ;//取表集合可以得到表的所有数据,但是放到循环里面:url:='
Python网络爬虫及信息获取分析网页(一)--BeautifulSoup库繁体中文
2017 年 8 月 12 日 - 编写爬虫。知识的好坏,都会被爬下来。混乱的程度会让你在网上一一发现并不像百度那么方便。因此,解析好的网页是判断爬虫好坏的重要标准。这里给大家介绍一个强大的网页信息解析库----BeautifulSoupBeautifulSoup库是一个专注于解析网页信息的强大第三方
WebBrowser 拦截网页 更改消息 繁体中文
2011 年 1 月 28 日 - 使用 System 实现 IDocHostShowUI 接口;使用 System.采集s.Generic;使用 System.ComponentModel;使用 System.Data;使用 System.Drawing;使用
WebBrowser繁体中文网页全身照
2012年6月25日——最近在写程序的时候,突然觉得google chrome网页的缩略图很有意思,但是chrome是自己的内核,自己的东西当然方便。浏览器呢?首先想到的是最常见的屏幕复制,也称为bitblt,是从WebBrowser 的dc 复制到位图的dc。
网页通过 External 接口与 WebBrowser 交互
2009 年 12 月 22 日 - 在上一篇博客中,我谈到了在 WTL 中添加 IDL 以通过向导实现 IDispatch。是有代价的,而且代价不小,所以最后我用了最简单最有效的方法。下面是这样一个示例代码贴:下面是我的IDispatch的实现,其中MainDlg是WTL向导生成的非模态对话框,可以根据
通过WebBrowser获取AJAX后的繁体中文版网页
2015年12月04日 - 通常在WebBrowser的文档加载完成事件DocumentCompleted中进行判断 if (_WebBrowder.ReadyState == WebBrowserReadyState.Complete) {//获取网页信息并处理} 不过很遗憾是很
浏览器抓取网页( 爬虫接收请求3、请求头注意携带4、响应Response)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-30 14:15
爬虫接收请求3、请求头注意携带4、响应Response)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
3、爬校花网
最后,让我们给你一些好处
基础版:
查看代码
功能包版本
查看代码
并发版(如果一共需要爬30个视频,开30个线程来做,耗时是最慢的部分)
查看代码
涉及知识:多线程和多处理
计算密集型任务:使用多进程,因为Python有GIL,多进程可以利用CPU多核;
IO密集型任务:使用多线程,做IO切换以节省任务执行时间(并发)
线程池
参考博客:
盲驴 查看全部
浏览器抓取网页(
爬虫接收请求3、请求头注意携带4、响应Response)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
3、爬校花网
最后,让我们给你一些好处
基础版:
查看代码
功能包版本
查看代码
并发版(如果一共需要爬30个视频,开30个线程来做,耗时是最慢的部分)
查看代码
涉及知识:多线程和多处理
计算密集型任务:使用多进程,因为Python有GIL,多进程可以利用CPU多核;
IO密集型任务:使用多线程,做IO切换以节省任务执行时间(并发)
线程池
参考博客:
盲驴
浏览器抓取网页(BOM1.浏览器浏览器对象模型(browserobjectmodel).36 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-29 08:11
)
物料清单
1.物料清单
浏览器对象模型
BOM允许我们通过JS来操作浏览器
为我们提供了BOM中的一组对象来完成浏览器的操作
BOM 对象
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
由于隐私原因,对象无法获取具体的历史记录,只能操作浏览器向前或向后翻页
并且该操作只对当前访问有效
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
这些 BOM 对象在浏览器中保存为窗口对象的属性,
可以通过window对象使用,也可以直接使用
2.导航器
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
由于历史原因,Navigator 对象中的大部分属性不再帮助我们识别浏览器
一般我们只使用userAgent来判断浏览器信息,
userAgent 是一个字符串,收录描述浏览器信息的内容,
不同的浏览器会有不同的userAgent
火狐用户代理
Mozilla5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko20100101 Firefox50.0
Chrome 的 userAgent
Mozilla5.0 (Windows NT 6.1; Win64; x64) AppleWebKit537.36 (KHTML, 像 Gecko) Chrome52.0.274 3.82 Safari537.36
IE8
Mozilla4.0(兼容;MSIE 8.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE9
Mozilla5.0(兼容;MSIE 9.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE10
Mozilla5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4. @>0C;.NET4.0E)
IE11
Mozilla5.0(Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.0C;.NET4. 0E; rv:11.0) 像壁虎
在IE11中,微软和IE相关的logo都被去掉了,所以我们基本上无法通过UserAgent来识别一个浏览器是否是IE。
alert(navigator.appName);
var ua = navigator.userAgent;
console.log(ua);
if(firefoxi.test(ua)){
alert("你是火狐!!!");
}else if(chromei.test(ua)){
alert("你是Chrome");
}else if(msiei.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,枪毙了你~~~");
}
3.历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
可用于跳转到指定页面
它需要一个整数作为参数
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
4.位置
这个对象封装了浏览器地址栏的信息
如果直接打印位置,可以得到地址栏的信息(当前页面的完整路径)
警报(位置);
如果直接将location属性修改为完整路径,或者相对路径
然后我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置=“http:”;
位置 = "01.BOM.html";
分配()
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
location.reload(true);
代替()
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
5.窗口
计时器
设置间隔()
定时通话
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
clearInterval() 可用于关闭计时器
该方法需要一个定时器的标识符作为参数,它将关闭该标识符对应的定时器。
clearInterval() 可以接收任意参数,
如果参数是有效的定时器标识符,则停止对应的定时器
如果参数不是有效的 ID,则什么也不做
var num = 1;
var timer = setInterval(function() {
count.innerHTML = num++;
if(num == 11) {
//关闭定时器
clearInterval(timer);
}
}, 1000);
延迟通话
设置超时
延迟调用函数不会立即执行,而是在一段时间后执行,并且只执行一次
延迟调用和定时调用的区别,定时调用会执行多次,而延迟调用只会执行一次
延迟调用和定时调用其实可以互相替代,开发时可以根据自己的需要选择
var timer = setTimeout(function(){
控制台.log(num++);
},3000);
使用 clearTimeout() 关闭延迟调用
清除超时(定时器);
# 类操作
直接修改元素的class css:
元素的样式由 style 属性修改。每次修改样式时,浏览器都需要重新渲染页面。这种实现的性能比较差,当我们要修改多个样式时,这种形式不是很方便。我希望一行代码可以同时修改多个样式。
我们可以通过修改元素的class属性来间接修改样式。这样,我们只需要修改一次就可以同时修改多个样式。浏览器只需要重新渲染一次页面,性能更好。
并且通过这种方式,性能和行为可以进一步分离
box.className += " b2"; //注意有空格,添加class属性
延时调用
setTimeout
延时调用一个函数不马上执行,而是隔一段时间以后在执行,而且只会执行一次
延时调用和定时调用的区别,定时调用会执行多次,而延时调用只会执行一次
延时调用和定时调用实际上是可以互相代替的,在开发中可以根据自己需要去选择
var timer = setTimeout(function(){
console.log(num++);
},3000);
使用clearTimeout()来关闭一个延时调用
clearTimeout(timer);
#类的操作
直接修改元素的类css:
通过style属性来修改元素的样式,每修改一个样式,浏览器就需要重新渲染一次页面。 这样的执行的性能是比较差的,而且这种形式当我们要修改多个样式时,也不太方便 我希望一行代码,可以同时修改多个样式
我们可以通过修改元素的class属性来间接的修改样式.这样一来,我们只需要修改一次,即可同时修改多个样式,浏览器只需要重新渲染页面一次,性能比较好,
并且这种方式,可以使表现和行为进一步的分离 查看全部
浏览器抓取网页(BOM1.浏览器浏览器对象模型(browserobjectmodel).36
)
物料清单
1.物料清单
浏览器对象模型
BOM允许我们通过JS来操作浏览器
为我们提供了BOM中的一组对象来完成浏览器的操作
BOM 对象
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
由于隐私原因,对象无法获取具体的历史记录,只能操作浏览器向前或向后翻页
并且该操作只对当前访问有效
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
这些 BOM 对象在浏览器中保存为窗口对象的属性,
可以通过window对象使用,也可以直接使用
2.导航器
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
由于历史原因,Navigator 对象中的大部分属性不再帮助我们识别浏览器
一般我们只使用userAgent来判断浏览器信息,
userAgent 是一个字符串,收录描述浏览器信息的内容,
不同的浏览器会有不同的userAgent
火狐用户代理
Mozilla5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko20100101 Firefox50.0
Chrome 的 userAgent
Mozilla5.0 (Windows NT 6.1; Win64; x64) AppleWebKit537.36 (KHTML, 像 Gecko) Chrome52.0.274 3.82 Safari537.36
IE8
Mozilla4.0(兼容;MSIE 8.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE9
Mozilla5.0(兼容;MSIE 9.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE10
Mozilla5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4. @>0C;.NET4.0E)
IE11
Mozilla5.0(Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.0C;.NET4. 0E; rv:11.0) 像壁虎
在IE11中,微软和IE相关的logo都被去掉了,所以我们基本上无法通过UserAgent来识别一个浏览器是否是IE。
alert(navigator.appName);
var ua = navigator.userAgent;
console.log(ua);
if(firefoxi.test(ua)){
alert("你是火狐!!!");
}else if(chromei.test(ua)){
alert("你是Chrome");
}else if(msiei.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,枪毙了你~~~");
}
3.历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
可用于跳转到指定页面
它需要一个整数作为参数
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
4.位置
这个对象封装了浏览器地址栏的信息
如果直接打印位置,可以得到地址栏的信息(当前页面的完整路径)
警报(位置);
如果直接将location属性修改为完整路径,或者相对路径
然后我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置=“http:”;
位置 = "01.BOM.html";
分配()
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
location.reload(true);
代替()
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
5.窗口
计时器
设置间隔()
定时通话
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
clearInterval() 可用于关闭计时器
该方法需要一个定时器的标识符作为参数,它将关闭该标识符对应的定时器。
clearInterval() 可以接收任意参数,
如果参数是有效的定时器标识符,则停止对应的定时器
如果参数不是有效的 ID,则什么也不做
var num = 1;
var timer = setInterval(function() {
count.innerHTML = num++;
if(num == 11) {
//关闭定时器
clearInterval(timer);
}
}, 1000);
延迟通话
设置超时
延迟调用函数不会立即执行,而是在一段时间后执行,并且只执行一次
延迟调用和定时调用的区别,定时调用会执行多次,而延迟调用只会执行一次
延迟调用和定时调用其实可以互相替代,开发时可以根据自己的需要选择
var timer = setTimeout(function(){
控制台.log(num++);
},3000);
使用 clearTimeout() 关闭延迟调用
清除超时(定时器);
# 类操作
直接修改元素的class css:
元素的样式由 style 属性修改。每次修改样式时,浏览器都需要重新渲染页面。这种实现的性能比较差,当我们要修改多个样式时,这种形式不是很方便。我希望一行代码可以同时修改多个样式。
我们可以通过修改元素的class属性来间接修改样式。这样,我们只需要修改一次就可以同时修改多个样式。浏览器只需要重新渲染一次页面,性能更好。
并且通过这种方式,性能和行为可以进一步分离
box.className += " b2"; //注意有空格,添加class属性
延时调用
setTimeout
延时调用一个函数不马上执行,而是隔一段时间以后在执行,而且只会执行一次
延时调用和定时调用的区别,定时调用会执行多次,而延时调用只会执行一次
延时调用和定时调用实际上是可以互相代替的,在开发中可以根据自己需要去选择
var timer = setTimeout(function(){
console.log(num++);
},3000);
使用clearTimeout()来关闭一个延时调用
clearTimeout(timer);
#类的操作
直接修改元素的类css:
通过style属性来修改元素的样式,每修改一个样式,浏览器就需要重新渲染一次页面。 这样的执行的性能是比较差的,而且这种形式当我们要修改多个样式时,也不太方便 我希望一行代码,可以同时修改多个样式
我们可以通过修改元素的class属性来间接的修改样式.这样一来,我们只需要修改一次,即可同时修改多个样式,浏览器只需要重新渲染页面一次,性能比较好,
并且这种方式,可以使表现和行为进一步的分离
浏览器抓取网页(1.开发环境.3.3python3.52.网络爬虫的定义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-28 06:14
1.开发环境
pycharm2017.3.3
蟒蛇3.5
2.网络爬虫的定义
网络爬虫,又称网络蜘蛛,如果把互联网比作蜘蛛网,蜘蛛就是在网络上四处爬行的蜘蛛。网络爬虫根据其地址搜索网页。是网址。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL为统一资源定位符(统一资源定位),其一般格式如下(方括号[]可选)
protocol://hostname[:port]/path/[:parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(和端口号作为可选参数),一般网站默认端口号为80
(3)path:第三部分是宿主资源的具体地址,如目录和文件名等,网络爬虫就是根据这个URL获取网页信息
3.简单爬虫示例
在Python3.x中,我们可以使用urllib组件来抓取网页。 urllib 是一个 URL 处理包。这个包采集了处理url的模块,如下:
(1)urllib.request模块用于打开和读取URL;
(2)urllib.error 模块收录一些urllib.request 产生的错误,可以用try 捕获
(3)urllib.parse模块收录一些解析URL的方法;
(4)urllib.robotparser模块用于解析robots.txt文本文件,提供了单独的RobotFileParser类,通过该类提供的can_fatch()方法测试爬虫能否下载页面.
我们可以通过接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息
让我们编写一个简单的程序来实现它
1 from urllib import request
2 if __name__ == "__main__":
3 response = request.urlopen("http://www.baidu.com")
4 html = response.read()
5 print(html)
运行结果(可以看到进度条还是可以拉远的)
这到底是怎么回事
为了对比,在浏览器中打开,查看页面元素,使用快捷键F12(浏览器最好使用Firefox或Chrome)
一切都一样,只是格式有点乱。您可以通过简单的 decode() 命令解码并显示网页的信息。代码中加一句html=html.decode("utf-8")
1 from urllib import request
2
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.fanyi.baidu.com/")
5 html = response.read()
6 html = html.decode("utf-8")
7 print(html)
输出普通html格式
当然,编码方式不是我们猜到的,而是发现了。在查看元素中找到head标签,打开,看到charset="utf-8",就是编码方式
4.自动获取网页的编码方式
这里使用第三方库来安装chardet
1 pip install chardet
对代码稍作修改,确定页面的编码方式
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com")
5 html = response.read()
6 #html = html.decode("utf-8")
7 charset = chardet.detect(html)
8 print(charset)
可以看到字典返回了,终于可以整合了
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com")
5 html = response.read()
6 charset = chardet.detect(html)
7 html = html.decode(charset.get('encoding'))
8
9 print(html)
完美
转载于: 查看全部
浏览器抓取网页(1.开发环境.3.3python3.52.网络爬虫的定义)
1.开发环境
pycharm2017.3.3
蟒蛇3.5
2.网络爬虫的定义
网络爬虫,又称网络蜘蛛,如果把互联网比作蜘蛛网,蜘蛛就是在网络上四处爬行的蜘蛛。网络爬虫根据其地址搜索网页。是网址。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL为统一资源定位符(统一资源定位),其一般格式如下(方括号[]可选)
protocol://hostname[:port]/path/[:parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(和端口号作为可选参数),一般网站默认端口号为80
(3)path:第三部分是宿主资源的具体地址,如目录和文件名等,网络爬虫就是根据这个URL获取网页信息
3.简单爬虫示例
在Python3.x中,我们可以使用urllib组件来抓取网页。 urllib 是一个 URL 处理包。这个包采集了处理url的模块,如下:
(1)urllib.request模块用于打开和读取URL;
(2)urllib.error 模块收录一些urllib.request 产生的错误,可以用try 捕获
(3)urllib.parse模块收录一些解析URL的方法;
(4)urllib.robotparser模块用于解析robots.txt文本文件,提供了单独的RobotFileParser类,通过该类提供的can_fatch()方法测试爬虫能否下载页面.
我们可以通过接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息
让我们编写一个简单的程序来实现它
1 from urllib import request
2 if __name__ == "__main__":
3 response = request.urlopen("http://www.baidu.com";)
4 html = response.read()
5 print(html)
运行结果(可以看到进度条还是可以拉远的)

这到底是怎么回事
为了对比,在浏览器中打开,查看页面元素,使用快捷键F12(浏览器最好使用Firefox或Chrome)
一切都一样,只是格式有点乱。您可以通过简单的 decode() 命令解码并显示网页的信息。代码中加一句html=html.decode("utf-8")
1 from urllib import request
2
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.fanyi.baidu.com/";)
5 html = response.read()
6 html = html.decode("utf-8")
7 print(html)
输出普通html格式
当然,编码方式不是我们猜到的,而是发现了。在查看元素中找到head标签,打开,看到charset="utf-8",就是编码方式
4.自动获取网页的编码方式
这里使用第三方库来安装chardet
1 pip install chardet
对代码稍作修改,确定页面的编码方式
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com";)
5 html = response.read()
6 #html = html.decode("utf-8")
7 charset = chardet.detect(html)
8 print(charset)
可以看到字典返回了,终于可以整合了
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com";)
5 html = response.read()
6 charset = chardet.detect(html)
7 html = html.decode(charset.get('encoding'))
8
9 print(html)
完美
转载于:
浏览器抓取网页(获取网页标题的方式是什么?怎么做?处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-26 02:16
作为标准的 HTML 文档,页面标题(title)是必不可少的属性。随着浏览器的发展,我们有了另一种访问和修改文档的方式:DOM。因此,获取网页标题有两种方式:
通过文档对象访问title
var title = document.title;通过 DOM 访问标题
var title = document.getElementsByTagName('title')[0];但是这两种获取方式完全不同,document.title可以直接获取网页标题的字符串副本,它返回一个字符串;但是通过DOM获取的是HTML文档中的title节点对象。
我们可以使用节点对象的innerHTML属性来输出页面标题:
document.getElementsByTagName('title')[0].innerHTML;
编辑页面标题
这里我们讨论一下IE浏览器实现中的一个小bug:我们知道理论上HTML文档中的任何节点都可以通过DOM进行修改。按照这句话,我们当然可以修改HTML文档中的title节点。 但有趣的是,IE浏览器在这个地方实现了一些奇怪的东西,具体来说:
Firefox 在这里完美运行。不过除了FF和IE,其他浏览器我没有测试过,有兴趣的朋友可以试试。 (估计会比IE表现更好^^)
有一种说法,老方法不一定过时。存在多年的Document.title在这个时候就凸显了它的优势,因为这个属性不仅可以获取网页的标题,还可以修改标题。同时,HTML 文档节点中的标题也同步更新。所以:
目前,对于 Internet Explorer,更改网页标题的唯一方法是使用过时的 document.title 方法。同时,此方法也适用于其他浏览器。
结论
在web开发中,如果要处理网页标题的问题,需要注意以下几点:
最佳实践
获取文档标题:var title = document.title;
修改文档标题:document.title = "new title"; 查看全部
浏览器抓取网页(获取网页标题的方式是什么?怎么做?处理)
作为标准的 HTML 文档,页面标题(title)是必不可少的属性。随着浏览器的发展,我们有了另一种访问和修改文档的方式:DOM。因此,获取网页标题有两种方式:
通过文档对象访问title
var title = document.title;通过 DOM 访问标题
var title = document.getElementsByTagName('title')[0];但是这两种获取方式完全不同,document.title可以直接获取网页标题的字符串副本,它返回一个字符串;但是通过DOM获取的是HTML文档中的title节点对象。
我们可以使用节点对象的innerHTML属性来输出页面标题:
document.getElementsByTagName('title')[0].innerHTML;
编辑页面标题
这里我们讨论一下IE浏览器实现中的一个小bug:我们知道理论上HTML文档中的任何节点都可以通过DOM进行修改。按照这句话,我们当然可以修改HTML文档中的title节点。 但有趣的是,IE浏览器在这个地方实现了一些奇怪的东西,具体来说:
Firefox 在这里完美运行。不过除了FF和IE,其他浏览器我没有测试过,有兴趣的朋友可以试试。 (估计会比IE表现更好^^)
有一种说法,老方法不一定过时。存在多年的Document.title在这个时候就凸显了它的优势,因为这个属性不仅可以获取网页的标题,还可以修改标题。同时,HTML 文档节点中的标题也同步更新。所以:
目前,对于 Internet Explorer,更改网页标题的唯一方法是使用过时的 document.title 方法。同时,此方法也适用于其他浏览器。
结论
在web开发中,如果要处理网页标题的问题,需要注意以下几点:
最佳实践
获取文档标题:var title = document.title;
修改文档标题:document.title = "new title";
浏览器抓取网页(如何通过js调用本地摄像头呢?获取后如何对视频进行截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-25 14:24
如何通过js调用本地摄像头?获取视频后如何截图?下面我就和大家做一个简单的Demo来实现以上功能。
涉及的知识点实现的功能点的html简单布局
下面先用HTML实现一个简单的布局,包括样式和按钮。
H5 canvas 调用摄像头进行绘制
html,body{
width:100%;
height:100%;
padding: 0px;
margin: 0px;
overflow: hidden;
}
#canvas{
width:500px;
height:300px;
}
#video{
width:500px;
height:300px;
}
.btn{
display:inline-block;
text-align: center;
background-color: #333;
color:#eee;
font-size:14px;
padding:5px 15px;
border-radius: 5px;
cursor:pointer;
}
您的浏览器不支持H5 ,请更换或升级!
截图
暂停
打开
看起来像这样:
hahiahia 是空白的
我们隐藏视频,然后添加几个按钮,以及底部的画布和图片显示区域(用于存储截图)。
js实现函数
先把核心代码贴在这里:
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
相关知识点可以参考
:
然后根据页面逻辑实现事件等功能,包括:截图、暂停。
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia;
var events = {
open : function(){
LV.open();
},
close : function(){
console.log(LV.timer);
clearInterval(LV.timer);
},
screenshot : function(){
//获得当前帧的图像并拿到数据
var image = canvas.toDataURL('jpeg');
document.getElementById('show').innerHTML = '<img style="width:500px;height:300px;" />'
}
};
var LV = {
video : document.getElementById('video'),
canvas : document.getElementById('canvas'),
timer : null,
media : null,
open :function(){
if(!LV.timer){
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
}
if(LV.timer){
clearInterval(LV.timer);
}
//将画面绘制到canvas中
LV.timer = setInterval(function(){
LV.ctx.drawImage(LV.video,0,0,500,300);
},15);
},
init : function(){
LV.ctx = LV.canvas.getContext('2d');
//绑定事件
document.querySelectorAll('[filter]').forEach(function(item){
item.onclick = function(ev){
var type = this.getAttribute('filter');
events[type].call(this,ev);
}
});
return LV;
}
};
LV.init();
原谅我的波西米亚命名... 查看全部
浏览器抓取网页(如何通过js调用本地摄像头呢?获取后如何对视频进行截图)
如何通过js调用本地摄像头?获取视频后如何截图?下面我就和大家做一个简单的Demo来实现以上功能。
涉及的知识点实现的功能点的html简单布局
下面先用HTML实现一个简单的布局,包括样式和按钮。
H5 canvas 调用摄像头进行绘制
html,body{
width:100%;
height:100%;
padding: 0px;
margin: 0px;
overflow: hidden;
}
#canvas{
width:500px;
height:300px;
}
#video{
width:500px;
height:300px;
}
.btn{
display:inline-block;
text-align: center;
background-color: #333;
color:#eee;
font-size:14px;
padding:5px 15px;
border-radius: 5px;
cursor:pointer;
}
您的浏览器不支持H5 ,请更换或升级!
截图
暂停
打开
看起来像这样:
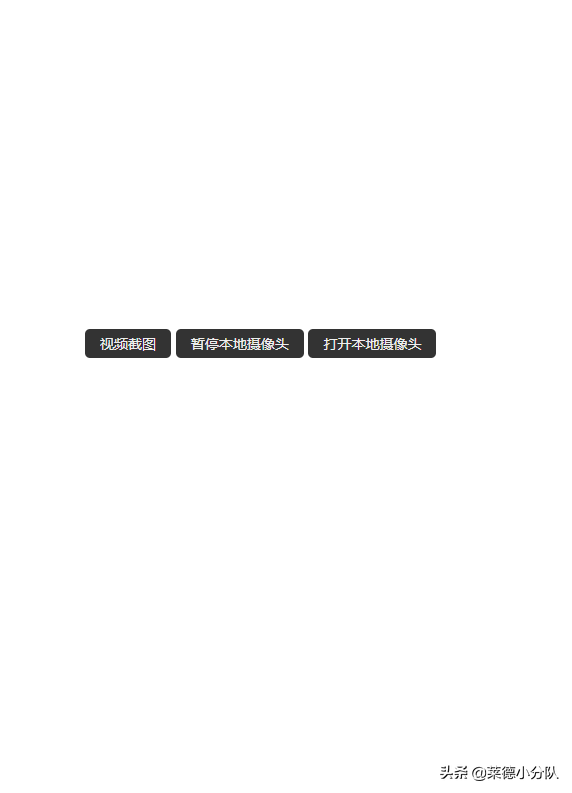
hahiahia 是空白的
我们隐藏视频,然后添加几个按钮,以及底部的画布和图片显示区域(用于存储截图)。
js实现函数
先把核心代码贴在这里:
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
相关知识点可以参考
:
然后根据页面逻辑实现事件等功能,包括:截图、暂停。
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia;
var events = {
open : function(){
LV.open();
},
close : function(){
console.log(LV.timer);
clearInterval(LV.timer);
},
screenshot : function(){
//获得当前帧的图像并拿到数据
var image = canvas.toDataURL('jpeg');
document.getElementById('show').innerHTML = '<img style="width:500px;height:300px;" />'
}
};
var LV = {
video : document.getElementById('video'),
canvas : document.getElementById('canvas'),
timer : null,
media : null,
open :function(){
if(!LV.timer){
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
}
if(LV.timer){
clearInterval(LV.timer);
}
//将画面绘制到canvas中
LV.timer = setInterval(function(){
LV.ctx.drawImage(LV.video,0,0,500,300);
},15);
},
init : function(){
LV.ctx = LV.canvas.getContext('2d');
//绑定事件
document.querySelectorAll('[filter]').forEach(function(item){
item.onclick = function(ev){
var type = this.getAttribute('filter');
events[type].call(this,ev);
}
});
return LV;
}
};
LV.init();
原谅我的波西米亚命名...
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-24 23:09
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。类似selenium的框架也有风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
图片图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
随机数:2SSH2A #未知
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个提交方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JS 写入 cookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试通过debug JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。 查看全部
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。类似selenium的框架也有风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
图片图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
随机数:2SSH2A #未知
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个提交方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JS 写入 cookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试通过debug JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。
浏览器抓取网页(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-24 20:00
总结
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用类(非知识讲解)
本文介绍selenium库和chrome浏览器自动抓取网页元素,定位填写表单数据,可以自动填写,节省大量人力。为了方便使用selenium库,也方便处理运行中的错误,本文对selenium库进行了一定程度的重新封装,方便读者在了解selenium库后快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库如何查找元素,3.Selenium库重新打包
二、本文结构:1.先简单介绍一下知识点,2.以完整段的形式贴出复制后可以直接运行的调试代码,这样就可以了方便读者调试每一个贴出的Snippet
三、本文方法实现:以百度首页为控制网页,以谷歌浏览器为实验平台,使用python+selenium操作网页。 ps:其他对应的爬取网页实验会更新。
四、本文实验:1.A股市场数据后台截图(更新于2020.09.09),2.后台QQ邮箱阅读获取最新邮件(待更新),等待其他实验更新(均提供详细代码和注释,文末有对应链接)
提示:以下为本文文章正文内容,以下案例供参考
文章目录
一、安装 selenium 库及相关文件
Selenium 库是python 用于爬虫的自动化工具网站。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器,还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装 selenium 库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装并查看添加路径。慎重选择此建议,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬虫方法,其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号。点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125
(3)点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本。在本文中,84.0.4147.125,所以如图寻找84.0驱动的开头,点击打开下载对应系统的驱动。然后解压到你要写项目的文件夹里。
不要放在python目录或浏览器安装目录。如果这样做,移植到其他计算机时会出现各种错误。根本原因是您的计算机上安装了相应的库文件和驱动程序。 ,但移植的电脑可能没有安装。
二、Selenium 快速入门1.定位元素的八种方法
(1)id
(2)名字
(3)xpath
(4)链接文字
(5)部分链接文字
(6)标签名
(7)类名
(8)css 选择器
2.id 方法
(1) 在 selenium 中通过 id 定位元素:find_element_by_id
以百度页面为例,其百度输入框部分源码如下:
其中输入框的网页代码,百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3.命名方法
以百度输入框为例,在selenium中按名称定位元素:find_element_by_name
代码及注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4.xpath 方法
以百度输入框为例,在selenium中通过xpath定位一个元素:find_element_by_xpath。但是这种方法不适用于网页中位置会发生变化的表格元素,因为xpath方法指向的是固定的行和列,无法检测到行和列内容的变化。
首先,在谷歌浏览器中打开百度,在空白处右键,选择勾选(N),进入网页的开发者模式,如图。然后右击百度输入框,再次点击勾选(N),可以发现右边自动选中的部分代码框变成了百度输入框的代码。最后在右边自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath是//*[@id="kw"],百度那个的xpath是/ /*[@id="su"]
接下来,使用该值进行百度搜索。代码及注释如下。
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5.链接文本和部分链接文本方法 查看全部
浏览器抓取网页(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
总结
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用类(非知识讲解)
本文介绍selenium库和chrome浏览器自动抓取网页元素,定位填写表单数据,可以自动填写,节省大量人力。为了方便使用selenium库,也方便处理运行中的错误,本文对selenium库进行了一定程度的重新封装,方便读者在了解selenium库后快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库如何查找元素,3.Selenium库重新打包
二、本文结构:1.先简单介绍一下知识点,2.以完整段的形式贴出复制后可以直接运行的调试代码,这样就可以了方便读者调试每一个贴出的Snippet
三、本文方法实现:以百度首页为控制网页,以谷歌浏览器为实验平台,使用python+selenium操作网页。 ps:其他对应的爬取网页实验会更新。
四、本文实验:1.A股市场数据后台截图(更新于2020.09.09),2.后台QQ邮箱阅读获取最新邮件(待更新),等待其他实验更新(均提供详细代码和注释,文末有对应链接)
提示:以下为本文文章正文内容,以下案例供参考
文章目录
一、安装 selenium 库及相关文件
Selenium 库是python 用于爬虫的自动化工具网站。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器,还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装 selenium 库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装并查看添加路径。慎重选择此建议,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬虫方法,其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号。点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125

(3)点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本。在本文中,84.0.4147.125,所以如图寻找84.0驱动的开头,点击打开下载对应系统的驱动。然后解压到你要写项目的文件夹里。
不要放在python目录或浏览器安装目录。如果这样做,移植到其他计算机时会出现各种错误。根本原因是您的计算机上安装了相应的库文件和驱动程序。 ,但移植的电脑可能没有安装。


二、Selenium 快速入门1.定位元素的八种方法
(1)id
(2)名字
(3)xpath
(4)链接文字
(5)部分链接文字
(6)标签名
(7)类名
(8)css 选择器
2.id 方法
(1) 在 selenium 中通过 id 定位元素:find_element_by_id
以百度页面为例,其百度输入框部分源码如下:
其中输入框的网页代码,百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3.命名方法
以百度输入框为例,在selenium中按名称定位元素:find_element_by_name
代码及注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4.xpath 方法
以百度输入框为例,在selenium中通过xpath定位一个元素:find_element_by_xpath。但是这种方法不适用于网页中位置会发生变化的表格元素,因为xpath方法指向的是固定的行和列,无法检测到行和列内容的变化。
首先,在谷歌浏览器中打开百度,在空白处右键,选择勾选(N),进入网页的开发者模式,如图。然后右击百度输入框,再次点击勾选(N),可以发现右边自动选中的部分代码框变成了百度输入框的代码。最后在右边自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath是//*[@id="kw"],百度那个的xpath是/ /*[@id="su"]
接下来,使用该值进行百度搜索。代码及注释如下。


import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5.链接文本和部分链接文本方法
浏览器抓取网页(4.facebook服务的永久重定向响应的难点-如何存储数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-18 22:31
)
除了get请求之外,还有一个send请求,常用于提交表单。发送通过 URL 传递其参数的请求
(e.g.: RoboZZle stats for puzzle 85)
. 发送请求在请求正文标头之后发送其参数。
图片
“http://facebook.com/”
斜线很关键。在这种情况下,浏览器可以安全地添加斜杠。和喜欢
“http: //example.com/folderOrFile”
这样的地址不能自动加斜杠,因为浏览器不知道folderOrFile是文件夹还是文件。这时候浏览器直接访问不带斜线的地址,服务器响应重定向,导致不必要的握手。
4. 来自 facebook 服务的永久重定向响应
图为 Facebook 服务器返回给浏览器的响应:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服务器以 301 永久重定向响应响应浏览器,以便浏览器访问“
http://www.facebook.com/
“ 而不是
“http://facebook.com/”
.
为什么服务器要重定向而不是直接发送用户想看的网页内容?这个问题有很多有趣的答案。
原因之一与搜索引擎排名有关。你看,如果一个页面有两个地址,比如
http://www.igoro.com/ 和http://igoro.com/
,搜索引擎会认为它们是两个网站,导致每个搜索链接较少,排名较低。并且搜索引擎知道 301 永久重定向的含义,因此它们会将访问带有和不带有 www 的地址分配到相同的 网站 排名。
另一个是使用不同的地址会导致缓存友好性差。当一个页面有多个名称时,它可能会多次出现在缓存中。
5. 浏览器跟踪重定向地址
现在,浏览器知道
“http://www.facebook.com/”
是要访问的正确地址,因此它会发送另一个 get 请求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, p_w_picpath/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
标头信息与前一个请求中的含义相同。
6. 服务器“处理”请求
服务器接收到 get 请求,对其进行处理,然后返回响应。
表面上看,这似乎是一个定向任务,但实际上中间发生了很多有趣的事情——简单的网站如作者的博客,更不用说访问量大的网站如facebook !
所有动态的网站 都面临一个有趣的难题——如何存储数据。小型 网站 一半将有一个 SQL 数据库来存储数据,而 网站 拥有大量数据和/或大量访问将不得不找到某种方法将数据库分布在多台机器上。解决方案包括:分片(根据主键值将数据表分散到多个数据库中)、复制、使用弱语义一致性的简化数据库。
将工作委派给批处理是一种保持数据更新的廉价技术。例如,Facebook 需要及时更新其新闻提要,但数据支持的“你可能认识的人”功能只需要每晚更新一次(作者猜测是这样,如何改进功能是未知)。批量作业更新会导致一些不太重要的数据变得陈旧,但会使数据更新农业更快、更清洁。
7. 服务器发回一个 HTML 响应
下图展示了服务器生成并返回的响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]
整个响应大小为 35kB,其中大部分在排序后以 blob 形式传输。
Content-Encoding 标头告诉浏览器使用 gzip 算法压缩整个响应正文。解压 blob 块后,您可以看到预期的 HTML,如下所示:
...
关于压缩,header信息表示是否缓存页面,如果缓存了怎么做,设置什么cookies(没有在之前的响应中)和隐私信息等。
请注意,标头中的 Content-type 设置为“text/html”。标头告诉浏览器将响应内容呈现为 HTML,而不是将其下载为文件。浏览器根据标头信息决定如何解释响应,但也会考虑其他因素,例如 URL 扩展的内容。
8. 浏览器开始显示 HTML
在浏览器完全接受整个 HTML 文档之前,它已经开始显示这个页面:
9. 浏览器发送以获取嵌入在 HTML 中的对象
当浏览器显示 HTML 时,它会注意到需要获取其他地址内容的标签。此时,浏览器将发送获取请求以检索文件。
以下是我们在访问时需要重新获取的一些 URL:
这些地址会经历类似于 HTML 读取的过程。所以浏览器会在 DNS 中查找这些域,发送请求,重定向等……
但与动态页面不同的是,静态文件允许浏览器缓存它们。有些文件可能不需要与服务器通信,而是直接从缓存中读取。服务器的响应包括有关静态文件保留多长时间的信息,因此浏览器知道将它们缓存多长时间。此外,每个响应可能收录一个 ETag 标头(请求变量的实体值),其作用类似于版本号,如果浏览器观察到文件的版本 ETag 信息已经存在,它会立即停止文件的传输。
猜猜地址中的“”代表什么?聪明的答案是“Facebook 内容交付网络”。Facebook 利用内容分发网络 (CDN) 分发静态文件,如图像、CSS 表格和 JavaScript 文件。因此,这些文件将备份在全球许多 CDN 的数据中心中。
静态内容通常代表网站的带宽,也可以通过 CDN 轻松复制。通常网站使用第三方CDN。例如,Facebook 的静态文件由最大的 CDN 提供商 Akamai 托管。
例如,当您尝试时,您可能会从某个服务器获得响应。有趣的是,当你再次 ping 相同时,响应的服务器可能不同,这表明后台的负载均衡正在工作。
10. 浏览器发送异步(AJAX)请求
在Web2.0伟大精神的指引下,页面显示后客户端仍然与服务器保持联系。
以 Facebook 聊天功能为例,它与服务器保持联系以更新您的亮灰色朋友的状态。为了更新这些头像的好友状态,在浏览器中执行的 JavaScript 代码会向服务器发送一个异步请求。这个异步请求被发送到一个特定的地址,它是一个以编程方式构造的get或send请求。仍然在 Facebook 示例中,客户端发送
http://www.facebook.com/ajax/chat/buddy_list.php
获取有关您的哪些朋友在线的状态信息的发布请求。
说到这种模式,就不得不说“AJAX”——“异步 JavaScript 和 XML”,虽然服务器以 XML 格式响应并没有明确的原因。再举一个例子,对于异步请求,Facebook 将返回一些 JavaScript 片段。
除其他外,fiddler 是一种工具,可让您查看浏览器发送的异步请求。实际上,您不仅可以被动地观看这些请求,还可以主动修改并重新发送它们。对于得分的网络游戏开发者来说,如此容易被AJAX请求所欺骗,真是令人沮丧。(当然,不要这样骗人~)
Facebook 聊天功能提供了一个有趣的 AJAX 问题示例:将数据从服务器推送到客户端。由于 HTTP 是一种请求-响应协议,聊天服务器无法向客户端发送新消息。相反,客户端必须每隔几秒钟轮询一次服务器以查看它是否有新消息。
当这些情况发生时,长轮询是一种减少服务器负载的有趣技术。如果服务器在轮询时没有新消息,它会忽略客户端。当超时前收到来自客户端的新消息时,服务器会找到未完成的请求,并将新消息作为响应返回给客户端。
综上所述
希望看完这篇文章,你可以了解不同的网络模块是如何协同工作的
引用的部分内容
http://blog.jobbole.com/33951/ 查看全部
浏览器抓取网页(4.facebook服务的永久重定向响应的难点-如何存储数据
)
除了get请求之外,还有一个send请求,常用于提交表单。发送通过 URL 传递其参数的请求
(e.g.: RoboZZle stats for puzzle 85)
. 发送请求在请求正文标头之后发送其参数。
图片
“http://facebook.com/”
斜线很关键。在这种情况下,浏览器可以安全地添加斜杠。和喜欢
“http: //example.com/folderOrFile”
这样的地址不能自动加斜杠,因为浏览器不知道folderOrFile是文件夹还是文件。这时候浏览器直接访问不带斜线的地址,服务器响应重定向,导致不必要的握手。
4. 来自 facebook 服务的永久重定向响应
图为 Facebook 服务器返回给浏览器的响应:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服务器以 301 永久重定向响应响应浏览器,以便浏览器访问“
http://www.facebook.com/
“ 而不是
“http://facebook.com/”
.
为什么服务器要重定向而不是直接发送用户想看的网页内容?这个问题有很多有趣的答案。
原因之一与搜索引擎排名有关。你看,如果一个页面有两个地址,比如
http://www.igoro.com/ 和http://igoro.com/
,搜索引擎会认为它们是两个网站,导致每个搜索链接较少,排名较低。并且搜索引擎知道 301 永久重定向的含义,因此它们会将访问带有和不带有 www 的地址分配到相同的 网站 排名。
另一个是使用不同的地址会导致缓存友好性差。当一个页面有多个名称时,它可能会多次出现在缓存中。
5. 浏览器跟踪重定向地址
现在,浏览器知道
“http://www.facebook.com/”
是要访问的正确地址,因此它会发送另一个 get 请求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, p_w_picpath/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
标头信息与前一个请求中的含义相同。
6. 服务器“处理”请求

服务器接收到 get 请求,对其进行处理,然后返回响应。
表面上看,这似乎是一个定向任务,但实际上中间发生了很多有趣的事情——简单的网站如作者的博客,更不用说访问量大的网站如facebook !
所有动态的网站 都面临一个有趣的难题——如何存储数据。小型 网站 一半将有一个 SQL 数据库来存储数据,而 网站 拥有大量数据和/或大量访问将不得不找到某种方法将数据库分布在多台机器上。解决方案包括:分片(根据主键值将数据表分散到多个数据库中)、复制、使用弱语义一致性的简化数据库。
将工作委派给批处理是一种保持数据更新的廉价技术。例如,Facebook 需要及时更新其新闻提要,但数据支持的“你可能认识的人”功能只需要每晚更新一次(作者猜测是这样,如何改进功能是未知)。批量作业更新会导致一些不太重要的数据变得陈旧,但会使数据更新农业更快、更清洁。
7. 服务器发回一个 HTML 响应

下图展示了服务器生成并返回的响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]
整个响应大小为 35kB,其中大部分在排序后以 blob 形式传输。
Content-Encoding 标头告诉浏览器使用 gzip 算法压缩整个响应正文。解压 blob 块后,您可以看到预期的 HTML,如下所示:
...
关于压缩,header信息表示是否缓存页面,如果缓存了怎么做,设置什么cookies(没有在之前的响应中)和隐私信息等。
请注意,标头中的 Content-type 设置为“text/html”。标头告诉浏览器将响应内容呈现为 HTML,而不是将其下载为文件。浏览器根据标头信息决定如何解释响应,但也会考虑其他因素,例如 URL 扩展的内容。
8. 浏览器开始显示 HTML
在浏览器完全接受整个 HTML 文档之前,它已经开始显示这个页面:

9. 浏览器发送以获取嵌入在 HTML 中的对象
当浏览器显示 HTML 时,它会注意到需要获取其他地址内容的标签。此时,浏览器将发送获取请求以检索文件。
以下是我们在访问时需要重新获取的一些 URL:
这些地址会经历类似于 HTML 读取的过程。所以浏览器会在 DNS 中查找这些域,发送请求,重定向等……
但与动态页面不同的是,静态文件允许浏览器缓存它们。有些文件可能不需要与服务器通信,而是直接从缓存中读取。服务器的响应包括有关静态文件保留多长时间的信息,因此浏览器知道将它们缓存多长时间。此外,每个响应可能收录一个 ETag 标头(请求变量的实体值),其作用类似于版本号,如果浏览器观察到文件的版本 ETag 信息已经存在,它会立即停止文件的传输。
猜猜地址中的“”代表什么?聪明的答案是“Facebook 内容交付网络”。Facebook 利用内容分发网络 (CDN) 分发静态文件,如图像、CSS 表格和 JavaScript 文件。因此,这些文件将备份在全球许多 CDN 的数据中心中。
静态内容通常代表网站的带宽,也可以通过 CDN 轻松复制。通常网站使用第三方CDN。例如,Facebook 的静态文件由最大的 CDN 提供商 Akamai 托管。
例如,当您尝试时,您可能会从某个服务器获得响应。有趣的是,当你再次 ping 相同时,响应的服务器可能不同,这表明后台的负载均衡正在工作。
10. 浏览器发送异步(AJAX)请求
在Web2.0伟大精神的指引下,页面显示后客户端仍然与服务器保持联系。
以 Facebook 聊天功能为例,它与服务器保持联系以更新您的亮灰色朋友的状态。为了更新这些头像的好友状态,在浏览器中执行的 JavaScript 代码会向服务器发送一个异步请求。这个异步请求被发送到一个特定的地址,它是一个以编程方式构造的get或send请求。仍然在 Facebook 示例中,客户端发送
http://www.facebook.com/ajax/chat/buddy_list.php
获取有关您的哪些朋友在线的状态信息的发布请求。
说到这种模式,就不得不说“AJAX”——“异步 JavaScript 和 XML”,虽然服务器以 XML 格式响应并没有明确的原因。再举一个例子,对于异步请求,Facebook 将返回一些 JavaScript 片段。
除其他外,fiddler 是一种工具,可让您查看浏览器发送的异步请求。实际上,您不仅可以被动地观看这些请求,还可以主动修改并重新发送它们。对于得分的网络游戏开发者来说,如此容易被AJAX请求所欺骗,真是令人沮丧。(当然,不要这样骗人~)
Facebook 聊天功能提供了一个有趣的 AJAX 问题示例:将数据从服务器推送到客户端。由于 HTTP 是一种请求-响应协议,聊天服务器无法向客户端发送新消息。相反,客户端必须每隔几秒钟轮询一次服务器以查看它是否有新消息。
当这些情况发生时,长轮询是一种减少服务器负载的有趣技术。如果服务器在轮询时没有新消息,它会忽略客户端。当超时前收到来自客户端的新消息时,服务器会找到未完成的请求,并将新消息作为响应返回给客户端。
综上所述
希望看完这篇文章,你可以了解不同的网络模块是如何协同工作的
引用的部分内容
http://blog.jobbole.com/33951/
浏览器抓取网页(用到一个神奇的库urllib.request.Request进行我们的模拟工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 22:29
urllib.error.HTTPError:HTTP 错误 403:禁止
从403 Forbidden我们可以发现,此时网站禁止程序的访问,这是因为csdn网站已经设置了反爬虫机制,当网站检测到一个爬虫,访问会被拒绝,所以我们会得到上面的结果。
这时候我们需要模拟浏览器访问,为了避开网站的反爬虫机制,然后顺利抓取我们想要的内容。
接下来,我们将使用一个神奇的库 urllib.request.Request 进行我们的模拟工作。这次我们先代码再讲解,不过这次要提醒一下,下面的代码不能直接使用。其中my_headers中的User-Agent替换为我自己的。因为我加了省略号保密,所以不能直接使用。替换方法如下图所示。这次为了使用方便,介绍一下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/")
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上面的代码,我们就可以正常抓取到这个网页的信息了,接下来介绍如何获取我们的getContent函数中需要用到的headers中的参数。
既然我们要模拟一个浏览器访问网页,这些参数自然需要我们在浏览器中搜索。
首先我们点击进入要爬取的网页,然后右击页面,点击review元素,会出现如下框架,然后我们点击Network,然后我们会发现我们所在页面的信息确实不出现,没关系,这时候我们刷新页面,就会出现下图所示的信息。
这时候我们会在第一行看到51251757,这就是我们网页的URL后面的标签。这时候,当我们点击这个标签的时候,就会出现下图所示的内容:
这是我现在通过直接访问此 URL 获得的屏幕截图:
前两张图,我以前写的是版本2的访问,现在直接用了。当时我在csdn主页上点击了这个博客,所以我在代码中填写了referer,在我的header中填写了前两张图片。是的
,而这张图是我直接通过URL链接进入浏览器的,所以从图中可以看出,referer是,这是我们的网站,贴在这里是为了让大家更好的理解这个referer . 不一样的画面。在这张图中,我用红线标出了需要填写的四个内容。测试的时候千万不要使用我给的User-Agent,因为我用省略号替换了一些。每个人都应该用自己的方式来弥补。
这时候我们会找到Headers,有没有亮眼的感觉,是的,你的直觉是对的,我们需要的信息就在这个Headers里面。
然后,根据代码中需要的参数,把信息复制回来使用,因为这里显示的信息正好对应key值,所以我们复制使用非常方便。
现在介绍一下这个urllib.request.Request的用法(翻译自官方文档):
class urllib.request.Request ( url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None ) 参数: url:不用说,这是我们要访问的URL,它是一个字符串。数据:数据必须是一个字节对象,指定要发送到服务器的附加数据,如果不需要,则为无。目前,只有 HTTP 请求使用数据;当提供数据参数时,HTTP 请求应该是 POST 而不是 GET。数据应以标准 application/x-www-form-urlencoded 格式缓冲。urllib.parse.urlencode() 函数采用映射或二进制序列并返回该格式的 ASCII 字符串。当用作数据参数时,应将其编码为字节。(我们暂时不会使用这个,所以不管它) headers:headers 是一个字符的典型数据。当使用键和值参数调用 add_header() 时,标头将作为请求处理。该标头通常用于防止爬虫访问服务器。header 是浏览器用来标识自己的,因为有些 HTTP 服务器只允许来自普通浏览器的请求,而不是脚本(可以理解为爬虫)。
这必然增加了网站服务器的处理负担,即一个网站必须在爬虫检测和网站服务器的计算负担之间做一个权衡,所以不是爬虫检测机制越严格越好,还要考虑服务器的负担。origin_req_host:origin_req_host 应该是原创事务请求的主机,由 RFC 2965 定义。默认为 http.cookiejar.request_host(self)。
这是用户发起的原创请求的主机名或 IP 地址。例如,如果请求是针对 HTML 文档中的图像,则这应该是请求收录图像的页面的主机。(我们一般不用这个,这里就知道了) unverifiable:unverifiable 应该表示请求是否不可验证,由 RFC 2965 定义,默认值为 false。无法验证的请求是指无法提交用户的 URL。例如,当用户在网页的html文档中找到一张图片,但用户没有权限从服务器获取图片时,此时unverifiable应该为true。method:method 应该是一个字符串,指示要使用的 HTTP 请求方法(例如“header”)。如果提供,它的值存储在方法属性中,并通过方法 get_method() 调用。子类可以通过设置类的方法属性来指示默认方法。(这个基本不用)说了这么多无聊的定义,自己翻译都受不了了。让我们继续回到我们的程序:对于我们的程序,只需抓住几个要点。首先,我们需要构造一个请求:req =Request(url),这个时候请求是空的,我们需要在里面添加信息,给浏览器看。
req.add_header("User-Agent", random_header) 告诉网络服务器我正在通过浏览器访问,我不是爬虫。req.add_header("GET",url)是告诉浏览器我们访问的URL,req.add_header("Host","")是网站的信息,我们从网站开始随便填一下,req.add_header("Referer","")这句话很重要,它告诉网站服务器我们在哪里找到了我们要访问的网页,比如你点击了百度如果一个link跳转到当前访问的页面,referer是百度中的链接,是一种判断机制。对标头的构造函数也可以这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/")
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
上面程序中看到,我们也可以直接构造header,但是这样做有一个缺陷,就是header中的User-Agent被写死了。其实我们可以发现,对于不同的电脑主机访问同一个网页时,我们的其他三个信息:GET、Host、Referer可能都是一样的。这时候就只有User-Agent作为判断用户异同的标准,那么问题来了,如果我们“借”一些同学的User-Agent来使用,岂不是更好玩?模拟多用户访问?其实这也是我刚开始的代码里的原因,所以有一个my_headers的列表,里面其实可以放多个User-Agent,然后通过random函数随机选择一个进行组合,然后创建一个用户,实现多访问的假象其实很有用。要知道,对于一个网站,当访问次数过多时,用户的ip会被屏蔽。这一点都不好玩,所以如果你想永久访问一个网站而不被抓住,还是需要很多技巧的。
当我们要爬取一个网站的多个网页时,由于主机访问频繁,很容易被网站检测到,进而被屏蔽。而如果我们把更多不同的主机号放在列表中,随意使用,是不是很容易被发现呢?当然,当我们为了防止这种情况,更好的方法是使用IP代理,因为我们不容易被发现。可以获得很多主机信息,IP代理也很容易从网上搜索到。关于多次访问的问题我会在以后的博客中解释,这里就不多说了。 查看全部
浏览器抓取网页(用到一个神奇的库urllib.request.Request进行我们的模拟工作)
urllib.error.HTTPError:HTTP 错误 403:禁止
从403 Forbidden我们可以发现,此时网站禁止程序的访问,这是因为csdn网站已经设置了反爬虫机制,当网站检测到一个爬虫,访问会被拒绝,所以我们会得到上面的结果。
这时候我们需要模拟浏览器访问,为了避开网站的反爬虫机制,然后顺利抓取我们想要的内容。
接下来,我们将使用一个神奇的库 urllib.request.Request 进行我们的模拟工作。这次我们先代码再讲解,不过这次要提醒一下,下面的代码不能直接使用。其中my_headers中的User-Agent替换为我自己的。因为我加了省略号保密,所以不能直接使用。替换方法如下图所示。这次为了使用方便,介绍一下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/";)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上面的代码,我们就可以正常抓取到这个网页的信息了,接下来介绍如何获取我们的getContent函数中需要用到的headers中的参数。
既然我们要模拟一个浏览器访问网页,这些参数自然需要我们在浏览器中搜索。
首先我们点击进入要爬取的网页,然后右击页面,点击review元素,会出现如下框架,然后我们点击Network,然后我们会发现我们所在页面的信息确实不出现,没关系,这时候我们刷新页面,就会出现下图所示的信息。
这时候我们会在第一行看到51251757,这就是我们网页的URL后面的标签。这时候,当我们点击这个标签的时候,就会出现下图所示的内容:
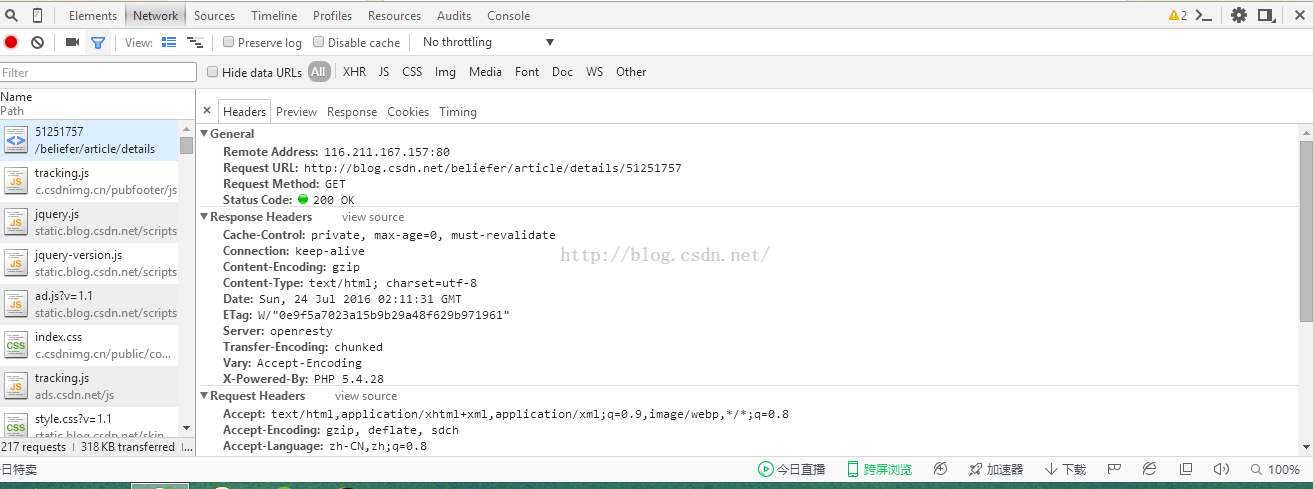
这是我现在通过直接访问此 URL 获得的屏幕截图:
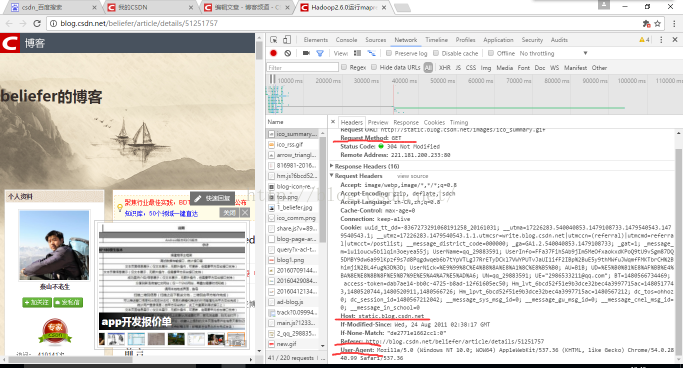
前两张图,我以前写的是版本2的访问,现在直接用了。当时我在csdn主页上点击了这个博客,所以我在代码中填写了referer,在我的header中填写了前两张图片。是的
,而这张图是我直接通过URL链接进入浏览器的,所以从图中可以看出,referer是,这是我们的网站,贴在这里是为了让大家更好的理解这个referer . 不一样的画面。在这张图中,我用红线标出了需要填写的四个内容。测试的时候千万不要使用我给的User-Agent,因为我用省略号替换了一些。每个人都应该用自己的方式来弥补。
这时候我们会找到Headers,有没有亮眼的感觉,是的,你的直觉是对的,我们需要的信息就在这个Headers里面。
然后,根据代码中需要的参数,把信息复制回来使用,因为这里显示的信息正好对应key值,所以我们复制使用非常方便。
现在介绍一下这个urllib.request.Request的用法(翻译自官方文档):
class urllib.request.Request ( url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None ) 参数: url:不用说,这是我们要访问的URL,它是一个字符串。数据:数据必须是一个字节对象,指定要发送到服务器的附加数据,如果不需要,则为无。目前,只有 HTTP 请求使用数据;当提供数据参数时,HTTP 请求应该是 POST 而不是 GET。数据应以标准 application/x-www-form-urlencoded 格式缓冲。urllib.parse.urlencode() 函数采用映射或二进制序列并返回该格式的 ASCII 字符串。当用作数据参数时,应将其编码为字节。(我们暂时不会使用这个,所以不管它) headers:headers 是一个字符的典型数据。当使用键和值参数调用 add_header() 时,标头将作为请求处理。该标头通常用于防止爬虫访问服务器。header 是浏览器用来标识自己的,因为有些 HTTP 服务器只允许来自普通浏览器的请求,而不是脚本(可以理解为爬虫)。
这必然增加了网站服务器的处理负担,即一个网站必须在爬虫检测和网站服务器的计算负担之间做一个权衡,所以不是爬虫检测机制越严格越好,还要考虑服务器的负担。origin_req_host:origin_req_host 应该是原创事务请求的主机,由 RFC 2965 定义。默认为 http.cookiejar.request_host(self)。
这是用户发起的原创请求的主机名或 IP 地址。例如,如果请求是针对 HTML 文档中的图像,则这应该是请求收录图像的页面的主机。(我们一般不用这个,这里就知道了) unverifiable:unverifiable 应该表示请求是否不可验证,由 RFC 2965 定义,默认值为 false。无法验证的请求是指无法提交用户的 URL。例如,当用户在网页的html文档中找到一张图片,但用户没有权限从服务器获取图片时,此时unverifiable应该为true。method:method 应该是一个字符串,指示要使用的 HTTP 请求方法(例如“header”)。如果提供,它的值存储在方法属性中,并通过方法 get_method() 调用。子类可以通过设置类的方法属性来指示默认方法。(这个基本不用)说了这么多无聊的定义,自己翻译都受不了了。让我们继续回到我们的程序:对于我们的程序,只需抓住几个要点。首先,我们需要构造一个请求:req =Request(url),这个时候请求是空的,我们需要在里面添加信息,给浏览器看。
req.add_header("User-Agent", random_header) 告诉网络服务器我正在通过浏览器访问,我不是爬虫。req.add_header("GET",url)是告诉浏览器我们访问的URL,req.add_header("Host","")是网站的信息,我们从网站开始随便填一下,req.add_header("Referer","")这句话很重要,它告诉网站服务器我们在哪里找到了我们要访问的网页,比如你点击了百度如果一个link跳转到当前访问的页面,referer是百度中的链接,是一种判断机制。对标头的构造函数也可以这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/";)
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
上面程序中看到,我们也可以直接构造header,但是这样做有一个缺陷,就是header中的User-Agent被写死了。其实我们可以发现,对于不同的电脑主机访问同一个网页时,我们的其他三个信息:GET、Host、Referer可能都是一样的。这时候就只有User-Agent作为判断用户异同的标准,那么问题来了,如果我们“借”一些同学的User-Agent来使用,岂不是更好玩?模拟多用户访问?其实这也是我刚开始的代码里的原因,所以有一个my_headers的列表,里面其实可以放多个User-Agent,然后通过random函数随机选择一个进行组合,然后创建一个用户,实现多访问的假象其实很有用。要知道,对于一个网站,当访问次数过多时,用户的ip会被屏蔽。这一点都不好玩,所以如果你想永久访问一个网站而不被抓住,还是需要很多技巧的。
当我们要爬取一个网站的多个网页时,由于主机访问频繁,很容易被网站检测到,进而被屏蔽。而如果我们把更多不同的主机号放在列表中,随意使用,是不是很容易被发现呢?当然,当我们为了防止这种情况,更好的方法是使用IP代理,因为我们不容易被发现。可以获得很多主机信息,IP代理也很容易从网上搜索到。关于多次访问的问题我会在以后的博客中解释,这里就不多说了。
浏览器抓取网页( 【】1.4、Chromedriver存放位置、下载对应的谷歌)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-18 10:00
【】1.4、Chromedriver存放位置、下载对应的谷歌)
1.3、下载对应的Google Drive:
点击进入
然后转到它并选择与chrome对应的版本。(比如我的chrome是85开头的,那么就从这么多85中选一个)
点击85开头的链接后跳转到新页面:不管你的Windows是32位还是64位,都只能下载win32.zip
1.4、Chromedriver存放位置
①先按win+r,输入cmd,进入cmd界面
② 输入 where python 可以看到python的安装路径
③打开这个python36(你可能是37版本或者其他版本,没关系)文件夹(可以把这个路径复制粘贴到文件夹上面)
④ 进入该文件夹后,我们可以看到scripts文件夹,将刚才下载的Chromedriver解压到scripts文件夹中。
Mac系统:
1、安装硒:
打开Mac终端终端并输入命令:
pip3 安装硒
如果出现读取超时错误,请复制并粘贴以下命令进行安装:
pip3 安装 -i 硒
2、安装谷歌浏览器驱动:
打开Mac终端终端并输入命令:
卷曲-s | 重击
只需等待程序安装完成。
安装mac终端时,需要输入用户密码。输入密码的时候是不显示的,实际上是在输入的,所以输入密码后按回车键开始安装。
其他方法:
二硒使用详解:
**本地 Chrome 设置:**两种方法:
2.1、可视模式 from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 将引擎设置为 Chrome 并实际打开 Chrome 浏览器
2.2、浏览器设置为静默模式,也就是说浏览器只在后台运行,在电脑上没有打开它的可视化界面。
from selenium import webdriver #调用selenium库中的webdriver模块
from selenium.webdriver.chrome.options import Options # 从 options 模块调用 Options 类
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('–headless') # 设置Chrome浏览器为静默模式
driver = webdriver.Chrome(options = chrome_options) # 设置引擎为Chrome,后台静默运行
三、Selenium 获取数据的方法:.get('URL') 3.1、Selenium 解析提取数据的方法
selenium 解析提取的是 Elements 中的所有数据,BeautifulSoup 解析的只是网络中第 0 个请求的响应。
从 selenium 中提取数据的示例:
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
find_element_by_tag_name:通过元素的名称选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_partial_link_text('你好')
示例代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个标签中的文字
print(type(label)) # 打印label的数据类型
print(label.text) # 打印label的文本
print(label) # 打印label
driver.close() # 关闭浏览器
提取的数据属于 WebElement 类对象。如果您直接打印它,它将返回其描述的字符串。
与 BeautifulSoup 中的 Tag 对象类似,它也有一个属性 .text,可以将提取的元素以字符串格式显示。
WebElement类对象和Tag对象类似,它也有一个可以通过属性名提取属性值的方法,这个方法是.get_attribute()
例子:
label = driver.find_element_by_class_name('teacher') # 按类名查找元素
print(type(label)) # 打印标签的数据类型
print(label.get_attribute('type')) # 获取属性类型的值,其中'type'是属性的名称,获取的是它的值。
driver.close() # 关闭浏览器
我们可以得出结论,在 selenium 解析和提取数据的过程中,我们操作的对象变换:
3.2、以上方法都是在网页中提取第一个满足要求的数据。接下来,我们来看看提取多个元素的方法。
方法是将刚才的元素替换为多个元素。
元素(复数)提取一个列表,. 列表的内容就是WebElements对象,这些符号就是对象的描述,需要用.text来返回它的文本内容。
3. 3、使用 BeautifulSoup 解析和提取数据
除了用selenium解析提取数据,还有一种解决方案,就是用selenium获取网页,然后交给BeautifulSoup解析提取。前提是先获取字符串格式的网页源代码。源代码被解析为 BeautifulSoup 对象,然后从中提取数据。
Selenium 只能获取渲染完整网页的源代码。
如何得到它?也是一种使用驱动的方式:page_source。
HTML 源代码字符串 = driver.page_source
获取示例网页源代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待两秒,等浏览器加缓冲载数据
pageSource = driver.page_source # 获取完整渲染的网页源代码
print(type(pageSource)) # 打印pageSource的类型
print(pageSource) # 打印pageSource
driver.close() # 关闭浏览器
Response 对象是通过 requests.get() 获得的。在交给 BeautifulSoup 解析之前,需要使用 .text 方法将 Response 对象的内容作为字符串返回。
使用 selenium 获得的网页的源代码本身已经是一个字符串。
获取到字符串格式的网页源代码后,就可以使用BeautifulSoup对数据进行解析提取。以下代码省略...
自动操作浏览器,控制浏览器自动输入文字,点击提交,主要是以下2行代码。
.send_keys() # 模拟按键输入,自动填表
.click() # 点击元素
有关详细信息,请参阅本文开头。
除了input和click这两种方法经常配合使用外,还有一个方法.clear(),用于清除元素的内容
如果空格打错了,如果要改成其他内容,需要先用.clear()清除,再填写新的文字。
四、最后写:
浏览器使用完毕后记得关闭,以免浪费资源,在代码末尾添加一行driver.close()即可。
至此,你应该可以感受到 Selenium 是一个强大的网络数据工具采集。它的优点是简单直观,但当然也有缺点。由于是真实模拟人对浏览器的操作,所以需要等待网页缓冲的时间,爬取大量数据时速度会比较慢。通常,在爬虫项目中,只有在其他方法无法解决或难以解决问题时才使用 selenium。
当然,除了爬虫,selenium 的使用场景还有很多。例如:可以控制网页中图片文件的显示,控制CSS和JavaScript的加载和执行等等。
这里只是一些简单常用的操作。如果想进一步了解,可以查阅 selenium 的官方文档链,目前只有英文版:
你也可以参考这个中文文档:
知识积累:
评论=driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li')
不等于:
a=driver.find_element_by_class_name('js_hot_list')
b=driver.find_elements_by_class_name('js_cmt_li')
相当于:
a=driver.find_element_by_class_name('js_hot_list')
b=a.find_elements_by_class_name('js_cmt_li') 查看全部
浏览器抓取网页(
【】1.4、Chromedriver存放位置、下载对应的谷歌)

1.3、下载对应的Google Drive:
点击进入
然后转到它并选择与chrome对应的版本。(比如我的chrome是85开头的,那么就从这么多85中选一个)

点击85开头的链接后跳转到新页面:不管你的Windows是32位还是64位,都只能下载win32.zip

1.4、Chromedriver存放位置
①先按win+r,输入cmd,进入cmd界面
② 输入 where python 可以看到python的安装路径
③打开这个python36(你可能是37版本或者其他版本,没关系)文件夹(可以把这个路径复制粘贴到文件夹上面)
④ 进入该文件夹后,我们可以看到scripts文件夹,将刚才下载的Chromedriver解压到scripts文件夹中。

Mac系统:
1、安装硒:
打开Mac终端终端并输入命令:
pip3 安装硒
如果出现读取超时错误,请复制并粘贴以下命令进行安装:
pip3 安装 -i 硒
2、安装谷歌浏览器驱动:
打开Mac终端终端并输入命令:
卷曲-s | 重击
只需等待程序安装完成。
安装mac终端时,需要输入用户密码。输入密码的时候是不显示的,实际上是在输入的,所以输入密码后按回车键开始安装。
其他方法:
二硒使用详解:
**本地 Chrome 设置:**两种方法:
2.1、可视模式 from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 将引擎设置为 Chrome 并实际打开 Chrome 浏览器
2.2、浏览器设置为静默模式,也就是说浏览器只在后台运行,在电脑上没有打开它的可视化界面。
from selenium import webdriver #调用selenium库中的webdriver模块
from selenium.webdriver.chrome.options import Options # 从 options 模块调用 Options 类
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('–headless') # 设置Chrome浏览器为静默模式
driver = webdriver.Chrome(options = chrome_options) # 设置引擎为Chrome,后台静默运行
三、Selenium 获取数据的方法:.get('URL') 3.1、Selenium 解析提取数据的方法
selenium 解析提取的是 Elements 中的所有数据,BeautifulSoup 解析的只是网络中第 0 个请求的响应。

从 selenium 中提取数据的示例:
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
find_element_by_tag_name:通过元素的名称选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_partial_link_text('你好')
示例代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个标签中的文字
print(type(label)) # 打印label的数据类型
print(label.text) # 打印label的文本
print(label) # 打印label
driver.close() # 关闭浏览器
提取的数据属于 WebElement 类对象。如果您直接打印它,它将返回其描述的字符串。
与 BeautifulSoup 中的 Tag 对象类似,它也有一个属性 .text,可以将提取的元素以字符串格式显示。
WebElement类对象和Tag对象类似,它也有一个可以通过属性名提取属性值的方法,这个方法是.get_attribute()

例子:
label = driver.find_element_by_class_name('teacher') # 按类名查找元素
print(type(label)) # 打印标签的数据类型
print(label.get_attribute('type')) # 获取属性类型的值,其中'type'是属性的名称,获取的是它的值。
driver.close() # 关闭浏览器
我们可以得出结论,在 selenium 解析和提取数据的过程中,我们操作的对象变换:

3.2、以上方法都是在网页中提取第一个满足要求的数据。接下来,我们来看看提取多个元素的方法。
方法是将刚才的元素替换为多个元素。

元素(复数)提取一个列表,. 列表的内容就是WebElements对象,这些符号就是对象的描述,需要用.text来返回它的文本内容。
3. 3、使用 BeautifulSoup 解析和提取数据
除了用selenium解析提取数据,还有一种解决方案,就是用selenium获取网页,然后交给BeautifulSoup解析提取。前提是先获取字符串格式的网页源代码。源代码被解析为 BeautifulSoup 对象,然后从中提取数据。
Selenium 只能获取渲染完整网页的源代码。
如何得到它?也是一种使用驱动的方式:page_source。
HTML 源代码字符串 = driver.page_source
获取示例网页源代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待两秒,等浏览器加缓冲载数据
pageSource = driver.page_source # 获取完整渲染的网页源代码
print(type(pageSource)) # 打印pageSource的类型
print(pageSource) # 打印pageSource
driver.close() # 关闭浏览器
Response 对象是通过 requests.get() 获得的。在交给 BeautifulSoup 解析之前,需要使用 .text 方法将 Response 对象的内容作为字符串返回。
使用 selenium 获得的网页的源代码本身已经是一个字符串。
获取到字符串格式的网页源代码后,就可以使用BeautifulSoup对数据进行解析提取。以下代码省略...
自动操作浏览器,控制浏览器自动输入文字,点击提交,主要是以下2行代码。
.send_keys() # 模拟按键输入,自动填表
.click() # 点击元素
有关详细信息,请参阅本文开头。
除了input和click这两种方法经常配合使用外,还有一个方法.clear(),用于清除元素的内容

如果空格打错了,如果要改成其他内容,需要先用.clear()清除,再填写新的文字。
四、最后写:
浏览器使用完毕后记得关闭,以免浪费资源,在代码末尾添加一行driver.close()即可。
至此,你应该可以感受到 Selenium 是一个强大的网络数据工具采集。它的优点是简单直观,但当然也有缺点。由于是真实模拟人对浏览器的操作,所以需要等待网页缓冲的时间,爬取大量数据时速度会比较慢。通常,在爬虫项目中,只有在其他方法无法解决或难以解决问题时才使用 selenium。
当然,除了爬虫,selenium 的使用场景还有很多。例如:可以控制网页中图片文件的显示,控制CSS和JavaScript的加载和执行等等。
这里只是一些简单常用的操作。如果想进一步了解,可以查阅 selenium 的官方文档链,目前只有英文版:
你也可以参考这个中文文档:
知识积累:
评论=driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li')
不等于:
a=driver.find_element_by_class_name('js_hot_list')
b=driver.find_elements_by_class_name('js_cmt_li')
相当于:
a=driver.find_element_by_class_name('js_hot_list')
b=a.find_elements_by_class_name('js_cmt_li')
浏览器抓取网页(用到动态网页抓取的两种技术:(2)使用selenium模拟浏览器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2022-03-18 09:28
)
关于静态网页
我们知道,静态网页在浏览器中显示的内容是在 HTML 源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种技术进行动态网页抓取:
(1)通过浏览器检查元素解析真实网址
(2)使用selenium模拟浏览器的方法
异步更新技术
AJAX(异步 Javascript 和 XML,异步 JavaScript 和 XML)
它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量。
解析真实网址
我们的目标是抓取目标 文章 上的所有评论。
(1)首先,打开网页的“检查”功能。
(2)找到真正的数据地址。点击页面中的网络选项,然后刷新页面。这个过程一般称为“抓包”。
(3)找到真实评论的数据地址,然后使用requests请求这个地址获取数据。
import requests
import json
link = 'https://api-zero.livere.com/v1 ... 39%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print(r.text)
(4)从json数据中提取评论。上面的结果比较乱,其实是json数据,我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4): #打印前4页的评论
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
(5)以上只是爬取文章的评论第一页,很简单。其实我们经常需要爬取所有页面,如果还是手动逐页翻页的话找到评论数据地址是很费力的,所以下面将介绍网页URL地址的规则,并使用for循环进行爬取,会很容易的。
如果我们对比上面的两个地址,可以发现URL地址中有两个特别重要的变量,offset和limit。稍微了解一下,我们可以知道limit代表每页最大评论数,也就是说,这里每页最多可以显示30条评论;offset表示页数,第一页的偏移量为0,第二页的偏移量为1,那么第三页的偏移量为3。
因此,我们只需要改变URL中offset的值,就可以实现换页。
通过Selenium模拟浏览器捕获一、Selenium+Python环境搭建和配置
1.1 硒简介
Selenium 是一个用于 Web 的自动化测试工具。许多学习功能自动化的学生开始偏爱 selenium,因为它与 QTP 相比具有许多优点:
(1)免费,破解QTP不再头疼
(2)小,只是针对不同语言的一个包,QTP需要下载安装1G以上的程序。这也是最重要的一点,不管你对C、java、 ruby, python, 或者全是C#,可以通过selenium完成自动化测试,QTP只支持VBS,selenium支持多平台:windows,linux,MAC,支持多浏览器:ie,firefox,safari,opera,chrome
1.2 selenium+Python环境配置
前提条件:Python开发环境已经安装(建议安装Python3.5及以上)
安装步骤:
(1)安装硒
赢:pip install selenium
Mac:pip3 安装硒
(2)安装网络驱动程序
火狐:
铬合金:
(3)这里我以 Windows Chrome 为例:
比如我的版本是:version 80.0.3987.122(正式版)(64位)
然后下载80.0.3937.106
注意:webdriver需要对应对应的浏览器版本和selenium版本
二、元素定位和浏览器基本操作2.1 启动浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
2.2 使用 Selenium 选择元素(1)id 定位
find_element_by_id()
例如
文本
您可以使用 find_element_by_id("bdy-inner")
(2)名称位置
find_element_by_name()
例如,您可以使用 find_element_by_name("username")
(3)class_name 定位
class 标准属性,不是唯一的,通常找一个类的元素
find_element_by_class_name()
例如
测试
您可以使用 find_element_by_class_name("cheese")
还有另一个函数可以选择元素的类属性:
find_element_by_css_selector()
例如
测试
您可以使用 find_element_by_css_selector()("div.cheese")
(4)tag_name 定位
driver.find_element_by_tag_name()
按元素名称选择,如 Welcome 可以使用 driver.find_element_by_tag_name('h1')
(5)按链接地址定位
find_element_by_link_text()
例如,继续可以使用 driver.find_element_by_link_text("Continue")
(6)由链接的部分地址选择
find_element_by_partial_link_text()
例如,继续可以使用 driver.find_element_by_partial_link_text("Conti")
(7)通过 xpath 选择
find_element_by_xpath()
例如,您可以使用 driver.find_element_by_xpath("//form[@id='loginForm']")
有时,我们需要查找多个元素,只需在上面的元素后添加 s 即可。
其中,xpath 和 css_selector 是比较好的方法。一方面相对清晰,另一方面相对于其他方法定位元素更准确。
Selenium 的高级操作:
(1)控制 CSS 的加载。
(2)控制图像文件的显示。
(3)控制 JavaScript 的执行。
这三种方法可以加快 Selenium 的爬行速度。
或者,您可以使用 Selenium 的 click 方法来操作元素。操作元素的常用方法如下:
(1)Clear 清除元素的内容
(2)send_keys 模拟按键输入
(3)Click 点击元素
(4)Submit 提交表单
例如:
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear() #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear() #清除密码输入框的内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #单击登录
一个具体的例子,比如我要打开百度,然后自动查询“你的名字”:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
input_text = driver.find_element_by_id("kw")
input_text.send_keys("你的名字")
driver.find_element_by_id("su").click()
查看全部
浏览器抓取网页(用到动态网页抓取的两种技术:(2)使用selenium模拟浏览器
)
关于静态网页
我们知道,静态网页在浏览器中显示的内容是在 HTML 源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种技术进行动态网页抓取:
(1)通过浏览器检查元素解析真实网址
(2)使用selenium模拟浏览器的方法
异步更新技术
AJAX(异步 Javascript 和 XML,异步 JavaScript 和 XML)
它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量。
解析真实网址
我们的目标是抓取目标 文章 上的所有评论。
(1)首先,打开网页的“检查”功能。
(2)找到真正的数据地址。点击页面中的网络选项,然后刷新页面。这个过程一般称为“抓包”。

(3)找到真实评论的数据地址,然后使用requests请求这个地址获取数据。

import requests
import json
link = 'https://api-zero.livere.com/v1 ... 39%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print(r.text)

(4)从json数据中提取评论。上面的结果比较乱,其实是json数据,我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4): #打印前4页的评论
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
(5)以上只是爬取文章的评论第一页,很简单。其实我们经常需要爬取所有页面,如果还是手动逐页翻页的话找到评论数据地址是很费力的,所以下面将介绍网页URL地址的规则,并使用for循环进行爬取,会很容易的。
如果我们对比上面的两个地址,可以发现URL地址中有两个特别重要的变量,offset和limit。稍微了解一下,我们可以知道limit代表每页最大评论数,也就是说,这里每页最多可以显示30条评论;offset表示页数,第一页的偏移量为0,第二页的偏移量为1,那么第三页的偏移量为3。
因此,我们只需要改变URL中offset的值,就可以实现换页。

通过Selenium模拟浏览器捕获一、Selenium+Python环境搭建和配置
1.1 硒简介
Selenium 是一个用于 Web 的自动化测试工具。许多学习功能自动化的学生开始偏爱 selenium,因为它与 QTP 相比具有许多优点:
(1)免费,破解QTP不再头疼
(2)小,只是针对不同语言的一个包,QTP需要下载安装1G以上的程序。这也是最重要的一点,不管你对C、java、 ruby, python, 或者全是C#,可以通过selenium完成自动化测试,QTP只支持VBS,selenium支持多平台:windows,linux,MAC,支持多浏览器:ie,firefox,safari,opera,chrome
1.2 selenium+Python环境配置
前提条件:Python开发环境已经安装(建议安装Python3.5及以上)
安装步骤:
(1)安装硒
赢:pip install selenium
Mac:pip3 安装硒
(2)安装网络驱动程序
火狐:
铬合金:
(3)这里我以 Windows Chrome 为例:

比如我的版本是:version 80.0.3987.122(正式版)(64位)
然后下载80.0.3937.106

注意:webdriver需要对应对应的浏览器版本和selenium版本
二、元素定位和浏览器基本操作2.1 启动浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')

2.2 使用 Selenium 选择元素(1)id 定位
find_element_by_id()
例如
文本
您可以使用 find_element_by_id("bdy-inner")
(2)名称位置
find_element_by_name()
例如,您可以使用 find_element_by_name("username")
(3)class_name 定位
class 标准属性,不是唯一的,通常找一个类的元素
find_element_by_class_name()
例如
测试
您可以使用 find_element_by_class_name("cheese")
还有另一个函数可以选择元素的类属性:
find_element_by_css_selector()
例如
测试
您可以使用 find_element_by_css_selector()("div.cheese")
(4)tag_name 定位
driver.find_element_by_tag_name()
按元素名称选择,如 Welcome 可以使用 driver.find_element_by_tag_name('h1')
(5)按链接地址定位
find_element_by_link_text()
例如,继续可以使用 driver.find_element_by_link_text("Continue")
(6)由链接的部分地址选择
find_element_by_partial_link_text()
例如,继续可以使用 driver.find_element_by_partial_link_text("Conti")
(7)通过 xpath 选择
find_element_by_xpath()
例如,您可以使用 driver.find_element_by_xpath("//form[@id='loginForm']")
有时,我们需要查找多个元素,只需在上面的元素后添加 s 即可。
其中,xpath 和 css_selector 是比较好的方法。一方面相对清晰,另一方面相对于其他方法定位元素更准确。
Selenium 的高级操作:
(1)控制 CSS 的加载。
(2)控制图像文件的显示。
(3)控制 JavaScript 的执行。
这三种方法可以加快 Selenium 的爬行速度。
或者,您可以使用 Selenium 的 click 方法来操作元素。操作元素的常用方法如下:
(1)Clear 清除元素的内容
(2)send_keys 模拟按键输入
(3)Click 点击元素
(4)Submit 提交表单
例如:
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear() #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear() #清除密码输入框的内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #单击登录
一个具体的例子,比如我要打开百度,然后自动查询“你的名字”:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
input_text = driver.find_element_by_id("kw")
input_text.send_keys("你的名字")
driver.find_element_by_id("su").click()

浏览器抓取网页(浏览器抓取网页的逻辑处理是否清晰?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-08 17:04
浏览器抓取网页,一方面是要考虑对于各种各样的页面名称是否敏感,另一方面是对于他的逻辑处理是否清晰。例如一个包含页码的页面,是否用普通方式拦截?某段文字的前景色改变时,是否及时请求返回值?position:absolute;是否请求,
知乎问题页一直是强制ajax加载的,无法进行设置我设置过但是没有用,
爬虫最早做的页面莫过于我博客。
我觉得还是有很多学问的,首先是拦截,要能拦截大部分页面拦截,还有页码的正则和文本的正则匹配,同样采用post类型的的传送表单参数还要考虑相应的返回的值,还有页面切换的时候的显示内容,等等。仅仅针对你说的抓取网页,是可以进行设置的,仅供参考。
现在小网站很少用ajax了。大多数都是完全设置,这样响应的和其他类型一样,我觉得完全是多余的,其实现在采用ajax更多的是分库分表,一个信息分两份,甚至3份。然后用setrequest()从不同服务器抓取数据。多余的那个非必要,
如果抓图,那么就有小网站的规律了。如果抓别的,那就更复杂,并且可能抓本地,也可能抓接受域。而且,你问的是页面那么最起码要有js的相关特征值,传入才有数据抓取。
根据页面要求设置还是完全正常的所以其实关键看需求与技术最后我觉得还是要强调"自己的产品是什么"比如做餐饮,那么页面分类有些用分类表示,比如服务员必须佩戴的口罩和垃圾桶,有些才可以添加厨师, 查看全部
浏览器抓取网页(浏览器抓取网页的逻辑处理是否清晰?(图))
浏览器抓取网页,一方面是要考虑对于各种各样的页面名称是否敏感,另一方面是对于他的逻辑处理是否清晰。例如一个包含页码的页面,是否用普通方式拦截?某段文字的前景色改变时,是否及时请求返回值?position:absolute;是否请求,
知乎问题页一直是强制ajax加载的,无法进行设置我设置过但是没有用,
爬虫最早做的页面莫过于我博客。
我觉得还是有很多学问的,首先是拦截,要能拦截大部分页面拦截,还有页码的正则和文本的正则匹配,同样采用post类型的的传送表单参数还要考虑相应的返回的值,还有页面切换的时候的显示内容,等等。仅仅针对你说的抓取网页,是可以进行设置的,仅供参考。
现在小网站很少用ajax了。大多数都是完全设置,这样响应的和其他类型一样,我觉得完全是多余的,其实现在采用ajax更多的是分库分表,一个信息分两份,甚至3份。然后用setrequest()从不同服务器抓取数据。多余的那个非必要,
如果抓图,那么就有小网站的规律了。如果抓别的,那就更复杂,并且可能抓本地,也可能抓接受域。而且,你问的是页面那么最起码要有js的相关特征值,传入才有数据抓取。
根据页面要求设置还是完全正常的所以其实关键看需求与技术最后我觉得还是要强调"自己的产品是什么"比如做餐饮,那么页面分类有些用分类表示,比如服务员必须佩戴的口罩和垃圾桶,有些才可以添加厨师,
浏览器抓取网页(使用默认浏览器和第三方打开要使用指定的指定浏览器打开 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-07 14:21
)
使用场景、应用与第三方交互时,需要点击按钮,直接跳转到网页。
使用默认浏览器打开
将跳转代码添加到按钮的点击事件中,即可实现,需要使用System.Diagnostics添加。
//使用默认浏览器打开
string url = "http://www.codehello.net";
Process.Start(url);
用指定浏览器打开
要用指定的浏览器打开它,我们首先需要获取浏览器运行程序的路径。我们可以将浏览器地址写入配置文件方便访问,也可以通过读取注册表来获取。一般我们使用后者。
以chrome.exe为例,可以通过HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe获取注册表中的安装位置
//读取注册表
RegistryKey registryKey = Registry.LocalMachine.OpenSubKey(@"SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe");
if (registryKey != null)
{
string exePath = (string)registryKey.GetValue("");
if (!string.IsNullOrEmpty(exePath) && File.Exists(exePath))
{
Process.Start(exePath,url);
}
} 查看全部
浏览器抓取网页(使用默认浏览器和第三方打开要使用指定的指定浏览器打开
)
使用场景、应用与第三方交互时,需要点击按钮,直接跳转到网页。
使用默认浏览器打开
将跳转代码添加到按钮的点击事件中,即可实现,需要使用System.Diagnostics添加。
//使用默认浏览器打开
string url = "http://www.codehello.net";
Process.Start(url);
用指定浏览器打开
要用指定的浏览器打开它,我们首先需要获取浏览器运行程序的路径。我们可以将浏览器地址写入配置文件方便访问,也可以通过读取注册表来获取。一般我们使用后者。
以chrome.exe为例,可以通过HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe获取注册表中的安装位置
//读取注册表
RegistryKey registryKey = Registry.LocalMachine.OpenSubKey(@"SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe");
if (registryKey != null)
{
string exePath = (string)registryKey.GetValue("");
if (!string.IsNullOrEmpty(exePath) && File.Exists(exePath))
{
Process.Start(exePath,url);
}
}
浏览器抓取网页(使用GooSeeker浏览器的谋数台做了的抓取规则和爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-07 11:09
GooSeeker浏览器制定的爬取规则和爬虫路径:
数据规则:
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011"/>
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011">
线索规则:
能源政策 007
HTML
一个
//*[@class='main4_b1 main4_b1_3']//a[.//text()="加载更多"]
线程
能源政策 007
主机名+路径名
未定义
DS电脑抓取数据时,浏览器会按照设置的'load more'页面增长,但下面抓取的数据和第一个一样,没有变化。
请指导我!
谢谢! 查看全部
浏览器抓取网页(使用GooSeeker浏览器的谋数台做了的抓取规则和爬虫)
GooSeeker浏览器制定的爬取规则和爬虫路径:
数据规则:
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011"/>
0 and count(.//*[@class='b1 mykw'])>0 and count(.//*[@class='main4_left_m1_t']/a)>0 and count(.//* [@class='main4_left_m1_r']/p)>0 和 count(./following-sibling::div[position()=1]/div[position()=3]/div[position()=2]/ span[position()=2]/text())>0]" mode="A2011">
线索规则:
能源政策 007
HTML
一个
//*[@class='main4_b1 main4_b1_3']//a[.//text()="加载更多"]
线程
能源政策 007
主机名+路径名
未定义
DS电脑抓取数据时,浏览器会按照设置的'load more'页面增长,但下面抓取的数据和第一个一样,没有变化。
请指导我!
谢谢!
浏览器抓取网页(基于智能预测模型的浏览器网页信息的预获取方法及系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-07 05:14
本发明专利技术涉及一种浏览器网页信息的预获取方法及系统,包括以下步骤:根据抓取的网页和历史网页的集合以及对应的URL特征建立倒排索引。分别抓取的网页和历史网页;用户输入的待访问URL是否在访问记录中,根据倒排索引获取历史网页信息或爬取网页信息,或提取待访问URL的URL特征;根据提取的 URL 特征集构建候选集;计算要访问的URL与特征候选集中每个URL的相似度,根据相似度权重选择历史访问过的URL;将历史访问过的URL对应的URL信息作为预测候选集,计算每个URL信息的概率,选择概率最高的URL作为最终的URL信息,返回预测候选结果。本发明专利技术根据返回的预测结果进行DNS预测分析、TCP预测连接和资源预测加载后,大大提高了网页的加载速度。
下载所有详细的技术数据
【技术实现步骤总结】
一种浏览器网页信息预获取方法及系统
本专利技术涉及一种浏览器网页信息的预获取方法及系统。
技术介绍
网页加载是浏览器的核心和基本功能。网页加载速度的提升有很多工作要做,比如缓存优化、预加载、基于服务器端技术、网络协议改进(比如SPDY)等等。基于智能预测模型的浏览器网页加载方法是一种可以大幅度提高网页加载速度的方法。在这个方法中,我们将智能预测模型命名为PageLoadOracle,主要是因为PageLoadOracle可以提前告诉我们需要解析什么域名,需要连接什么域名,给定URL需要加载哪些资源。但是,现实中并没有万能的预言机,我们只能尽可能地构建一个高效的预测模型。如何提高预测模型的预测准确率和召回率是一个关键问题。准确率是指预测模型返回需要执行的正确预测行为(DNS解析、TCP连接、资源下载),不执行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。
技术实现思路
该专利技术要解决的技术问题是提供一种能够快速冷启动的浏览器网页信息预获取,满足用户个性化长尾需求,提高召回率,无论是否有用户个性化数据或不是。方法和系统。本专利技术解决上述技术问题的技术方案如下: 一种浏览器网页信息的预获取方法,包括以下步骤: 步骤一:针对互联网上预定范围内的所有网站,从每个网站随机抓取预定数量的爬取网页,保存所有爬取网页对应的爬取网页信息;第二步:获取用户在预定时间段内访问的历史网页,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征,根据爬取的网页和历史对应的爬取网页和历史网页分别为网页。建立倒排索引,用于采集用户的 URL 特征;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则根据倒排索引获取与该待访问URL相关的历史网页信息或爬取网页信息,结束进程,如果没有,提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征集并集的特征候选集;步骤6:计算待访问网站与特征候选集中各个网站的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;步骤7:将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中各网站信息的概率,
在没有用户个性化数据的情况下,可以快速冷启动,提高召回率;并且可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。在上述技术方案的基础上,还可以对专利技术进行如下改进。进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步,步骤6中计算待访问网站与特征候选集中各网站的相似度具体为,根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。进一步的,一种浏览器网页信息预获取系统,包括抓取模块、获取模块、提取模块、判断模块、构建模块、计算模块和返回模块。网站中的所有网站,从每个网站中随机抓取预定数量的抓取网页,并保存所有抓取网页对应的抓取网页信息;获取模块用于获取用户在预定时间段内访问网页的历史记录,保存所有历史网页对应的历史网页信息;提取模块,用于根据所有被爬取的网页和历史网页构建访问记录,分别从每个网站抓取的网页和历史网页中提取URL特征,并根据被爬取的集合建立倒排索引网页和历史网页,以及被抓取的网页和历史网页分别对应的URL特征;判断模块用于获取用户输入的待访问网站,判断用户输入的要访问的URL是否在访问记录中,如果是,则获取历史网页信息或爬取相关网页信息根据倒排索引到要访问的URL,结束进程,如果不是,提取要访问的URL的URL特征;模块,用于根据提取的待访问URL的URL特征集合构建候选集,候选集为倒排索引中所有URL特征集并集的特征候选集;根据相似度权重对访问URL与特征候选集中的每个URL的相似度进行排序,选择相似度权重最高的URL特征对应的历史访问URL;
进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,计算模块计算待访问网站与特征候选集中各网站的相似度具体为根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。[附图说明] 图。图1为本专利技术的方法步骤流程图;无花果。图2是专利技术体系结构图。附图中,各个标签所代表的零件清单如下:1、抓取模块、2、获取模块、3、提取模块、4、判断模块、5、@ > 构建模块,6、 计算模块,7、 返回模块。具体实施方式下面结合附图对本专利技术的原理和特点进行说明,举例仅用于说明本专利技术,并不用于限定本专利技术的范围。图1为本专利技术的方法步骤流程图;图2是该专利技术的系统结构图。示例1 从提高智能预测模型的准确率和召回率的角度,我们的预测模型综合考虑了互联网顶级站点和用户个性化的历史数据。一方面,在没有用户个性化历史数据的情况下,基于互联网热门站点网站群体行为数据进行预测;另一方面,预测是基于每个用户自己的个性化历史数据进行的。
前者保证在没有用户个性化数据的情况下,能够快速冷启动,提高召回率;后者可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。两者缺一不可。一种浏览器网页信息的预获取方法,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存并存储所有抓取的网页 抓取网页对应的网页信息;Step 1具体为WWW中Top 500站点(作为Top 50 0)的每个站点,开始随机访问,从站点首页抓取k个网页; Step 2:获取用户在预定时间内访问的历史网页时间,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页建立访问记录,从各个网站抓取网页和历史网页 从 中提取URL特征,根据爬取的网页和历史网页建立倒排索引,分别对应爬取网页和历史网页的URL特征集合;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P)
【技术保护点】
一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存它们对应的所有爬取网页的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:基于所有爬取的网页和历史网页建立访问权限 分别从各个网站爬取的网页和历史网页中记录并提取URL特征,根据抓取的网页和历史网页的集合以及被抓取的网页和历史网页分别对应的URL特征建立倒排排名索引;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则获取与待访问URL相关的历史网页信息或爬取网页信息根据倒排索引访问,结束处理,如果没有,则提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引候选集中所有网站特征的集合并集的特征;第 6 步:计算待访问URL与特征候选集中各个URL的相似度,按照相似度权重排序,选择相似度权重最高的URL特征对应的历史访问URL;将网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回。
【技术特点总结】
1.一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤一:对互联网中预定范围内的所有网站,随机抓取预定数量的Crawl网页,保存所有已爬取网页对应的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征。建立倒排索引;第四步:获取用户输入的要访问的网站,判断用户输入的要访问的网站是否在访问记录中,如果是,则根据倒排索引获取与要访问的网站相关的历史网页信息或者抓取获取网页信息,结束处理,如果不是,提取要访问的网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征的集合并集的特征候选集;步骤6:计算待访问网站中每个网址与特征候选集的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;第 7 步:通过将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回. 2.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述抓取的网页信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源加载。3.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述历史网页信息包括DNS解析的域名,要创建连接的域名和/或要加载的资源。4.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述网址信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源。加载。5.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于: 步骤6中的待访问网站与特征候选集中各网站的相似度计算具体为,根据待访问网站与特征候选集中任意网站的特征向量计算余弦距离。6. 一种浏览器网页信息的预获取系统,
【专利技术性质】
技术研发人员:莫宇、喻言、李洪亮、刘铁峰、
申请人(专利权)持有人:,
类型:发明
国家、省、市:湖北;42
下载所有详细的技术数据 我是该专利的所有者 查看全部
浏览器抓取网页(基于智能预测模型的浏览器网页信息的预获取方法及系统)
本发明专利技术涉及一种浏览器网页信息的预获取方法及系统,包括以下步骤:根据抓取的网页和历史网页的集合以及对应的URL特征建立倒排索引。分别抓取的网页和历史网页;用户输入的待访问URL是否在访问记录中,根据倒排索引获取历史网页信息或爬取网页信息,或提取待访问URL的URL特征;根据提取的 URL 特征集构建候选集;计算要访问的URL与特征候选集中每个URL的相似度,根据相似度权重选择历史访问过的URL;将历史访问过的URL对应的URL信息作为预测候选集,计算每个URL信息的概率,选择概率最高的URL作为最终的URL信息,返回预测候选结果。本发明专利技术根据返回的预测结果进行DNS预测分析、TCP预测连接和资源预测加载后,大大提高了网页的加载速度。
下载所有详细的技术数据
【技术实现步骤总结】
一种浏览器网页信息预获取方法及系统
本专利技术涉及一种浏览器网页信息的预获取方法及系统。
技术介绍
网页加载是浏览器的核心和基本功能。网页加载速度的提升有很多工作要做,比如缓存优化、预加载、基于服务器端技术、网络协议改进(比如SPDY)等等。基于智能预测模型的浏览器网页加载方法是一种可以大幅度提高网页加载速度的方法。在这个方法中,我们将智能预测模型命名为PageLoadOracle,主要是因为PageLoadOracle可以提前告诉我们需要解析什么域名,需要连接什么域名,给定URL需要加载哪些资源。但是,现实中并没有万能的预言机,我们只能尽可能地构建一个高效的预测模型。如何提高预测模型的预测准确率和召回率是一个关键问题。准确率是指预测模型返回需要执行的正确预测行为(DNS解析、TCP连接、资源下载),不执行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。资源下载),不进行无意义的预测行为。如果预测有误,则预测行为毫无意义,浪费一定的网络带宽和计算资源,对网络负载产生负面影响。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。召回意味着预测模型能够为请求 URL 的尽可能多的用户提供预测行为指导。特别是对于尚未访问的 URL 的指导。
技术实现思路
该专利技术要解决的技术问题是提供一种能够快速冷启动的浏览器网页信息预获取,满足用户个性化长尾需求,提高召回率,无论是否有用户个性化数据或不是。方法和系统。本专利技术解决上述技术问题的技术方案如下: 一种浏览器网页信息的预获取方法,包括以下步骤: 步骤一:针对互联网上预定范围内的所有网站,从每个网站随机抓取预定数量的爬取网页,保存所有爬取网页对应的爬取网页信息;第二步:获取用户在预定时间段内访问的历史网页,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征,根据爬取的网页和历史对应的爬取网页和历史网页分别为网页。建立倒排索引,用于采集用户的 URL 特征;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则根据倒排索引获取与该待访问URL相关的历史网页信息或爬取网页信息,结束进程,如果没有,提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征集并集的特征候选集;步骤6:计算待访问网站与特征候选集中各个网站的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;步骤7:将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中各网站信息的概率,
在没有用户个性化数据的情况下,可以快速冷启动,提高召回率;并且可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。在上述技术方案的基础上,还可以对专利技术进行如下改进。进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步,步骤6中计算待访问网站与特征候选集中各网站的相似度具体为,根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。进一步的,一种浏览器网页信息预获取系统,包括抓取模块、获取模块、提取模块、判断模块、构建模块、计算模块和返回模块。网站中的所有网站,从每个网站中随机抓取预定数量的抓取网页,并保存所有抓取网页对应的抓取网页信息;获取模块用于获取用户在预定时间段内访问网页的历史记录,保存所有历史网页对应的历史网页信息;提取模块,用于根据所有被爬取的网页和历史网页构建访问记录,分别从每个网站抓取的网页和历史网页中提取URL特征,并根据被爬取的集合建立倒排索引网页和历史网页,以及被抓取的网页和历史网页分别对应的URL特征;判断模块用于获取用户输入的待访问网站,判断用户输入的要访问的URL是否在访问记录中,如果是,则获取历史网页信息或爬取相关网页信息根据倒排索引到要访问的URL,结束进程,如果不是,提取要访问的URL的URL特征;模块,用于根据提取的待访问URL的URL特征集合构建候选集,候选集为倒排索引中所有URL特征集并集的特征候选集;根据相似度权重对访问URL与特征候选集中的每个URL的相似度进行排序,选择相似度权重最高的URL特征对应的历史访问URL;
进一步的,爬取的网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,历史网页信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步的,网站信息包括DNS解析的域名、待创建的域名和/或待加载的资源。进一步地,计算模块计算待访问网站与特征候选集中各网站的相似度具体为根据待访问网站与特征候选集中任一网站的特征向量计算余弦距离。[附图说明] 图。图1为本专利技术的方法步骤流程图;无花果。图2是专利技术体系结构图。附图中,各个标签所代表的零件清单如下:1、抓取模块、2、获取模块、3、提取模块、4、判断模块、5、@ > 构建模块,6、 计算模块,7、 返回模块。具体实施方式下面结合附图对本专利技术的原理和特点进行说明,举例仅用于说明本专利技术,并不用于限定本专利技术的范围。图1为本专利技术的方法步骤流程图;图2是该专利技术的系统结构图。示例1 从提高智能预测模型的准确率和召回率的角度,我们的预测模型综合考虑了互联网顶级站点和用户个性化的历史数据。一方面,在没有用户个性化历史数据的情况下,基于互联网热门站点网站群体行为数据进行预测;另一方面,预测是基于每个用户自己的个性化历史数据进行的。
前者保证在没有用户个性化数据的情况下,能够快速冷启动,提高召回率;后者可以整合用户个性化数据,满足用户个性化长尾需求,提高召回率。两者缺一不可。一种浏览器网页信息的预获取方法,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存并存储所有抓取的网页 抓取网页对应的网页信息;Step 1具体为WWW中Top 500站点(作为Top 50 0)的每个站点,开始随机访问,从站点首页抓取k个网页; Step 2:获取用户在预定时间内访问的历史网页时间,保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页建立访问记录,从各个网站抓取网页和历史网页 从 中提取URL特征,根据爬取的网页和历史网页建立倒排索引,分别对应爬取网页和历史网页的URL特征集合;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P) 从各个网站中抓取网页和历史网页 从 中提取URL特征,并根据抓取的网页和历史网页以及分别对应的抓取网页和历史网页的URL特征集合建立倒排索引;步骤3具体为,对于互联网热门站点和用户历史访问量,对于每个网页P,根据提取的URL特征提取URL特征Π(P)、f2(P)、...、fm(P)
【技术保护点】
一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤1:对互联网中预定范围内的所有网站,从每个网站中随机抓取预定数量的抓取网页,保存它们对应的所有爬取网页的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:基于所有爬取的网页和历史网页建立访问权限 分别从各个网站爬取的网页和历史网页中记录并提取URL特征,根据抓取的网页和历史网页的集合以及被抓取的网页和历史网页分别对应的URL特征建立倒排排名索引;步骤4:获取用户输入的待访问URL,判断用户输入的待访问URL是否在访问记录中,如果是,则获取与待访问URL相关的历史网页信息或爬取网页信息根据倒排索引访问,结束处理,如果没有,则提取待访问网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引候选集中所有网站特征的集合并集的特征;第 6 步:计算待访问URL与特征候选集中各个URL的相似度,按照相似度权重排序,选择相似度权重最高的URL特征对应的历史访问URL;将网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回。
【技术特点总结】
1.一种浏览器网页信息的预获取方法,其特征在于,包括以下步骤: 步骤一:对互联网中预定范围内的所有网站,随机抓取预定数量的Crawl网页,保存所有已爬取网页对应的爬取网页信息;步骤2:获取用户在预定时间段内访问的历史网页,并保存所有历史网页对应的历史网页信息;Step 3:根据所有爬取的网页和历史网页构建访问记录,分别从各个网站爬取的网页和历史网页中提取URL特征。建立倒排索引;第四步:获取用户输入的要访问的网站,判断用户输入的要访问的网站是否在访问记录中,如果是,则根据倒排索引获取与要访问的网站相关的历史网页信息或者抓取获取网页信息,结束处理,如果不是,提取要访问的网站的网站特征;步骤5:根据提取的待访问网站的网站特征集合构建候选集,候选集为倒排索引中所有网站特征的集合并集的特征候选集;步骤6:计算待访问网站中每个网址与特征候选集的相似度,按照相似度权重排序,选择相似度权重最高的网站特征对应的历史访问网站;第 7 步:通过将历史访问过的网站对应的网站信息作为预测候选集,计算预测候选集中每个网站信息的概率,选择概率最高的网站信息作为最终预测候选结果并返回. 2.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述抓取的网页信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源加载。3.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述历史网页信息包括DNS解析的域名,要创建连接的域名和/或要加载的资源。4.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于:所述网址信息包括DNS解析的域名、待创建连接的域名和/或待创建的资源。加载。5.根据权利要求1所述的浏览器网页信息的预获取方法,其特征在于: 步骤6中的待访问网站与特征候选集中各网站的相似度计算具体为,根据待访问网站与特征候选集中任意网站的特征向量计算余弦距离。6. 一种浏览器网页信息的预获取系统,
【专利技术性质】
技术研发人员:莫宇、喻言、李洪亮、刘铁峰、
申请人(专利权)持有人:,
类型:发明
国家、省、市:湖北;42
下载所有详细的技术数据 我是该专利的所有者
浏览器抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-06 15:07
2021-11-26
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页的源代码,直观可见,代码内容与网页内容一致通过浏览器右键—— > 点击查看网页源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient只是在后端返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于Js生成的内容HttpClient无法获取。
对于获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到相应的内容。
我们在这里讨论的模拟方法大致有两种:
我们这次的目标是获取bilibili动态生成的动画列表。左上为抓取的目标列表,左下为浏览器渲染的HTML内容,右为服务器返回的响应正文。通过对比可以看出,目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于自动测试 Web 应用程序的工具,更多的是在 Google 上。这里我们主要用它来模拟页面的操作并返回结果,对于网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。由于是无接口的,所以在速度性能方面会更好。
1.下载
使用PhantomJS需要从官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的一个子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的非界面浏览器。因为没有接口,所以执行速度还是可以的。
1.maven依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都有很好的模拟浏览器页面生成的功能。PhantomJS作为一个无界面的WebKit,渲染页面的功能非常完善,并且有浏览器截图功能,可以模拟登录操作。HtmlUnit使用Rhino引擎解析Js,有时候解析速度很慢,像上面的例子,需要很长的时间,但是HtmlUnit可以获取页面并解析一组元素(当然最好用Jsoup 来解析元素),不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟,可能我不会用QAQ
欢迎补充:)
分类:
技术要点:
相关文章: 查看全部
浏览器抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
2021-11-26
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页的源代码,直观可见,代码内容与网页内容一致通过浏览器右键—— > 点击查看网页源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient只是在后端返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于Js生成的内容HttpClient无法获取。
对于获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到相应的内容。
我们在这里讨论的模拟方法大致有两种:
我们这次的目标是获取bilibili动态生成的动画列表。左上为抓取的目标列表,左下为浏览器渲染的HTML内容,右为服务器返回的响应正文。通过对比可以看出,目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于自动测试 Web 应用程序的工具,更多的是在 Google 上。这里我们主要用它来模拟页面的操作并返回结果,对于网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。由于是无接口的,所以在速度性能方面会更好。
1.下载
使用PhantomJS需要从官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的一个子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的非界面浏览器。因为没有接口,所以执行速度还是可以的。
1.maven依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都有很好的模拟浏览器页面生成的功能。PhantomJS作为一个无界面的WebKit,渲染页面的功能非常完善,并且有浏览器截图功能,可以模拟登录操作。HtmlUnit使用Rhino引擎解析Js,有时候解析速度很慢,像上面的例子,需要很长的时间,但是HtmlUnit可以获取页面并解析一组元素(当然最好用Jsoup 来解析元素),不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟,可能我不会用QAQ
欢迎补充:)
分类:
技术要点:
相关文章:
浏览器抓取网页(存储将数据存储到Cookie会话的技术管理技术技术 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-06 15:04
)
一、会话管理1、概述:
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。(版本1)
一个会话收录多个请求和响应(浏览器第一次向服务器资源发送请求,会话建立,直到一方断开连接。)(版本 2)
例:张三给李四打电话,李四接听电话,通话建立,双方挂断通话结束。
2、特点:
在会话范围内的多个请求之间共享数据
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
3、生命周期
开始:会话在浏览器访问服务器时开始
结束:浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
4、会话技术:
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
二、Cookies 1、概述:
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
功能:跟踪特定对象、统计页面浏览量、简化登录
2、常用方法:
void setMaxAge(int e):设置cookie的有效期,以秒为单位,正数为过了多少秒就会过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge():获取cookie的有效时间,以秒为单位
void setValue(String value):创建cookie后给cookie赋值
String getValue():获取cookie的值
String getName():获取cookie的名称
Cookie[] getCookies():获取cookie中的所有属性名
3、使用方法:
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
Cookie cookie = 新 Cookie(key,value);
(2)写入 Cookie 对象(来自服务器 ---> 客户端)
response.addCookie(cookie)
(3)获取cookie,获取数据
Cookies[] Cookies = request.getCookies()
4、注意事项:
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
新闻详情页面
三、Session内置对象1、概述:session是jsp9内置对象之一(out、request、response、session、applicationconfig、page、pageContext、exception)
(1)服务器端会话技术,一个会话中多个请求之间共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)可以通过Session在应用程序的WEB页面之间跳转时保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。(即用户浏览网站的时间花费。)
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
2、常用方法
(1)public void setAttribute(String name,String value);
设置具有指定名称的属性的值并将其添加到会话会话范围,或者如果该属性存在于会话范围内,则更改该属性的值。
(2)public Object getAttribute(String name);
获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在,则返回null。
(3)public void removeAttribute(String name);
删除具有指定名称的会话属性。如果该属性不存在,则会发生异常。
(4)公共无效无效();
使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
(5)public String getId();
获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
(6)public void setMaxInactiveInterval(int interval);
设置会话的最大持续时间,以秒为单位,负数表示会话永不过期。
(7)public int getMaxInActiveInterval();
获取会话的最大时长,使用时需要进行一些处理
3、session和window的关系
(1)每个会话对象都与浏览器一一对应。重新打开浏览器相当于重新创建会话对象。
(2)通过超链接打开的新窗口,新窗口的会话与其父窗口的会话相同
四、Session和Cookie的区别
(1)session 将数据存储在服务器上,cookies 存储在客户端
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
自动登录
7天内自动登录 查看全部
浏览器抓取网页(存储将数据存储到Cookie会话的技术管理技术技术
)
一、会话管理1、概述:
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。(版本1)
一个会话收录多个请求和响应(浏览器第一次向服务器资源发送请求,会话建立,直到一方断开连接。)(版本 2)
例:张三给李四打电话,李四接听电话,通话建立,双方挂断通话结束。
2、特点:
在会话范围内的多个请求之间共享数据
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
3、生命周期
开始:会话在浏览器访问服务器时开始
结束:浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
4、会话技术:
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
二、Cookies 1、概述:
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
功能:跟踪特定对象、统计页面浏览量、简化登录
2、常用方法:
void setMaxAge(int e):设置cookie的有效期,以秒为单位,正数为过了多少秒就会过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge():获取cookie的有效时间,以秒为单位
void setValue(String value):创建cookie后给cookie赋值
String getValue():获取cookie的值
String getName():获取cookie的名称
Cookie[] getCookies():获取cookie中的所有属性名
3、使用方法:
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
Cookie cookie = 新 Cookie(key,value);
(2)写入 Cookie 对象(来自服务器 ---> 客户端)
response.addCookie(cookie)
(3)获取cookie,获取数据
Cookies[] Cookies = request.getCookies()
4、注意事项:
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
新闻详情页面
三、Session内置对象1、概述:session是jsp9内置对象之一(out、request、response、session、applicationconfig、page、pageContext、exception)
(1)服务器端会话技术,一个会话中多个请求之间共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)可以通过Session在应用程序的WEB页面之间跳转时保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。(即用户浏览网站的时间花费。)
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
2、常用方法
(1)public void setAttribute(String name,String value);
设置具有指定名称的属性的值并将其添加到会话会话范围,或者如果该属性存在于会话范围内,则更改该属性的值。
(2)public Object getAttribute(String name);
获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在,则返回null。
(3)public void removeAttribute(String name);
删除具有指定名称的会话属性。如果该属性不存在,则会发生异常。
(4)公共无效无效();
使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
(5)public String getId();
获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
(6)public void setMaxInactiveInterval(int interval);
设置会话的最大持续时间,以秒为单位,负数表示会话永不过期。
(7)public int getMaxInActiveInterval();
获取会话的最大时长,使用时需要进行一些处理
3、session和window的关系
(1)每个会话对象都与浏览器一一对应。重新打开浏览器相当于重新创建会话对象。
(2)通过超链接打开的新窗口,新窗口的会话与其父窗口的会话相同
四、Session和Cookie的区别
(1)session 将数据存储在服务器上,cookies 存储在客户端
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
自动登录
7天内自动登录
浏览器抓取网页(会话管理技术技术最常见的方案-上海怡健医学 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-06 15:03
)
会话管理
会话概述
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。
一个会话中的多个请求和响应
对话功能
在会话范围内的多个请求之间共享数据
功能:
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
生命周期
开始
会话在浏览器访问服务器的那一刻开始
结尾
当浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
会话技术
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
一、 Cookie
翻译:饼干
概述
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
常用方法
无效 setMaxAge(int e);
** 设置cookie的有效期,以秒为单位,正数为秒数后过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge();
** 获取cookie的有效时间,以秒为单位
无效 setValue(字符串值);
** 创建cookie后,给cookie赋值
字符串 getValue();
** 获取cookie的值
字符串 getName();
** 获取 cookie 的名称
饼干[] getCookies();
** 获取cookie中的所有属性名
如何使用
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
**Cookie cookie = new Cookie(key,value);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
** response.addCookie(cookie)
(3)获取cookies,获取数据
**Cookie[]cookies = request.getCookies()
防范措施
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
使用 Cookie
1.介绍
1.1 案例:张三和李四的会面(从头到尾)====》Client and Server
2.会话
2.1 概述:一个会话中的多个请求和响应
一次会话:浏览器第一次向服务器资源发送请求,会话建立,直到一方断开。
2.2 功能:一个会话范围内的多个请求之间共享数据
2.3 种方式:
(1)客户端会话技术:Cookies
(2)服务器端会话技术:session
3.Cookie
3.1 概述
客户端会话技术,将数据保存到客户端
3.2 快速入门
使用步骤:
(1)创建Cookie对象并绑定数据
新 Cookie(键,值);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
request.addCookie(cookie)
(3)获取cookies,获取数据
request.getCookies()
4.Cookie 详细信息
4.1 可以同时发送多个cookie吗?
** 能
** 可以创建多个 Cookie 对象,并使用响应多次调用 addCookie 方法发送 cookie。
4.2 cookie 在浏览器中保存多长时间?
(1)默认在关闭浏览器时销毁cookie数据
(2)持久存储
** setMaxAge(int 秒); 秒
** 参数:
正数---》将cookie数据写入硬盘文件。持久化存储[cookie生命周期]
** 负数:
默认值
** 零:
删除cookie信息
4.3 cookie 可以存储中文吗?
** 在tomcat8.0之前,中文数据不能直接存入cookies。
** 中文数据需要转码---》一般使用URL编码
** tomcat8.0后,cookies支持中文数据,但仍不支持特殊字符。建议使用 URL 编码存储
使用 URL 解码解析
* 编码 URLEncoder.encode("string","utf-8");
* 解码 URLDecoder.decode("string","utf-8");
5.cookies的特性和功能
特征:
(1)cookies 将数据存储在客户端浏览器中
(2)浏览器有单个cookie大小限制(4KB)和同域名下cookie总数限制(20个)
影响:
(1)cookies 通常用于存储少量不太敏感的数据
(2)无需登录即可完成服务端对客户端的识别
二、 会话
概述
session 是属于 jsp9 的大型内置对象之一
(1)服务器端会话技术,一个会话中多个请求共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)在应用程序的WEB页面之间跳转时可以通过Session保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
常用方法
公共无效setAttribute(字符串名称,字符串值);
** 设置具有指定名称的属性的值并将其添加到会话范围。如果该属性存在于会话范围内,请更改该属性的值。
公共对象getAttribute(字符串名称);
** 获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在则为null。
公共无效removeAttribute(字符串名称);
** 删除指定名称的会话属性。如果该属性不存在,则会发生异常。
公共无效无效();
** 使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
公共字符串 getId();
** 获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
公共无效 setMaxInactiveInterval(int 间隔);
** 以秒为单位设置会话的最大持续时间,负数表示会话永不过期。
公共 int getMaxInActiveInterval();
** 获取会话的最大时长,使用时需要进行一些处理
session和cookie的区别
(1)session在服务器端存储数据,在客户端存储cookies
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
会话的使用
会话->内置对象
1.概览
服务器端会话技术,它在一个会话中的多个请求之间共享数据,并将数据保存在服务器端对象中。jsp:会话小服务程序:HttpSession
2.快速入门
(1)getAttribute(字符串名称);
(2)setAttribute(字符串名称,对象值)
(3)removeAattribute(字符串名称)
3.详情
1.客户端关闭时,服务端没有关闭,两次获取的session是一样的吗?
* 默认情况下,不
* 如果需要的话,可以创建一个cookie,key是JSESSIONID,设置最大存活时间,让cookie持久化。
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
2.客户端没有关闭。服务器关闭后,两次获得的session是一样的吗?
* 不是同一个,但请确保没有数据丢失。tomcat 会自动执行以下操作。
** 会话钝化:
在服务器正常关闭之前将会话对象序列化到磁盘
** 会话激活:
服务器启动后,可以将会话文件转换为内存中的会话对象。
3.会话何时销毁?
(1) 服务器宕机
(2) 会话对象调用 invalidate() 方法
(3)会话默认过期时间为 30 分钟 => web.xml
4.会话功能
Session 用于存储一个会话的多个请求的数据,存储在服务器端
会话可以存储任何类型和大小的数据
session和cookie的区别
1.session 将数据存储在服务端,cookies 存储在客户端
Cookie存储的数据只能是文本,Session---Object
2.session 没有数据大小限制,cookie 有
3.session数据安全,cookies比较不安全
包括指令
查看全部
浏览器抓取网页(会话管理技术技术最常见的方案-上海怡健医学
)
会话管理
会话概述
两方之间的通信或交互,同样在计算机中,浏览器与服务器之间的交互称为会话。
一个会话中的多个请求和响应
对话功能
在会话范围内的多个请求之间共享数据
功能:
限制页面访问(不登录无法访问后台页面)
临时存储数据并在多个请求之间共享数据
记住密码、自动登录、7天免费登录等。
生命周期
开始
会话在浏览器访问服务器的那一刻开始
结尾
当浏览器或服务器端中断时结束
注意:服务器一般是连续运行的,所以会话结束通常是浏览器关闭造成的。
会话技术
最常见的场景:数据库存储
在 cookie 中存储数据:数据由浏览器保存
将数据存储到会话:数据由服务器保存
一、 Cookie
翻译:饼干
概述
(1)一小段文字用来存放客户端
(2) 是一种客户端技术,将数据保存到客户端;因为 cookie 存储在客户端浏览器中
(3) 是维护客户端和服务器之间的状态
(4)cookie技术,不安全,请勿使用cookie存储敏感信息!如登录状态和登录信息;
(5)一些敏感数据应该存储在服务器端
常用方法
无效 setMaxAge(int e);
** 设置cookie的有效期,以秒为单位,正数为秒数后过期;负数表示浏览器关闭时cookie会被删除(有争议);零表示清除 cookie
int getMaxAge();
** 获取cookie的有效时间,以秒为单位
无效 setValue(字符串值);
** 创建cookie后,给cookie赋值
字符串 getValue();
** 获取cookie的值
字符串 getName();
** 获取 cookie 的名称
饼干[] getCookies();
** 获取cookie中的所有属性名
如何使用
(1)创建Cookie对象并绑定数据(获取服务器上的指定数据并通过cookie保存)
**Cookie cookie = new Cookie(key,value);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
** response.addCookie(cookie)
(3)获取cookies,获取数据
**Cookie[]cookies = request.getCookies()
防范措施
编码 URLEncoder.encode("string","utf-8");
解码 URLDecoder.decode("string","utf-8");
使用 Cookie
1.介绍
1.1 案例:张三和李四的会面(从头到尾)====》Client and Server
2.会话
2.1 概述:一个会话中的多个请求和响应
一次会话:浏览器第一次向服务器资源发送请求,会话建立,直到一方断开。
2.2 功能:一个会话范围内的多个请求之间共享数据
2.3 种方式:
(1)客户端会话技术:Cookies
(2)服务器端会话技术:session
3.Cookie
3.1 概述
客户端会话技术,将数据保存到客户端
3.2 快速入门
使用步骤:
(1)创建Cookie对象并绑定数据
新 Cookie(键,值);
(2)发送 Cookie 对象(来自服务器 ---> 客户端)
request.addCookie(cookie)
(3)获取cookies,获取数据
request.getCookies()
4.Cookie 详细信息
4.1 可以同时发送多个cookie吗?
** 能
** 可以创建多个 Cookie 对象,并使用响应多次调用 addCookie 方法发送 cookie。
4.2 cookie 在浏览器中保存多长时间?
(1)默认在关闭浏览器时销毁cookie数据
(2)持久存储
** setMaxAge(int 秒); 秒
** 参数:
正数---》将cookie数据写入硬盘文件。持久化存储[cookie生命周期]
** 负数:
默认值
** 零:
删除cookie信息
4.3 cookie 可以存储中文吗?
** 在tomcat8.0之前,中文数据不能直接存入cookies。
** 中文数据需要转码---》一般使用URL编码
** tomcat8.0后,cookies支持中文数据,但仍不支持特殊字符。建议使用 URL 编码存储
使用 URL 解码解析
* 编码 URLEncoder.encode("string","utf-8");
* 解码 URLDecoder.decode("string","utf-8");
5.cookies的特性和功能
特征:
(1)cookies 将数据存储在客户端浏览器中
(2)浏览器有单个cookie大小限制(4KB)和同域名下cookie总数限制(20个)
影响:
(1)cookies 通常用于存储少量不太敏感的数据
(2)无需登录即可完成服务端对客户端的识别
二、 会话
概述
session 是属于 jsp9 的大型内置对象之一
(1)服务器端会话技术,一个会话中多个请求共享数据,数据存储在服务器端对象中。jsp:session servlet:HttpSession
(2)在应用程序的WEB页面之间跳转时可以通过Session保存用户的状态,这样整个用户会话会一直存在,直到浏览器关闭。
注意:如果客户端长时间不向服务器发送请求,Session对象会自动消失。这个时间取决于服务器,例如Tomcat服务器默认为30分钟。
常用方法
公共无效setAttribute(字符串名称,字符串值);
** 设置具有指定名称的属性的值并将其添加到会话范围。如果该属性存在于会话范围内,请更改该属性的值。
公共对象getAttribute(字符串名称);
** 获取会话范围内具有指定名称的属性的值,返回值类型为object,如果该属性不存在则为null。
公共无效removeAttribute(字符串名称);
** 删除指定名称的会话属性。如果该属性不存在,则会发生异常。
公共无效无效();
** 使会话无效。当前会话可以立即失效,并且所有存储在原创会话中的对象都不能再被访问。
公共字符串 getId();
** 获取当前会话 ID。每个会话在服务器端都有一个唯一的标识 sessionID,而会话对象发送给浏览器的唯一数据就是 sessionID,一般存储在一个 cookie 中。
公共无效 setMaxInactiveInterval(int 间隔);
** 以秒为单位设置会话的最大持续时间,负数表示会话永不过期。
公共 int getMaxInActiveInterval();
** 获取会话的最大时长,使用时需要进行一些处理
session和cookie的区别
(1)session在服务器端存储数据,在客户端存储cookies
(2)session是一个内置对象,它的属性可以是任意类型,而Cookie对象只能设置字符串
(3)Session没有数据大小限制,Cookie有数据大小限制
(4)会话数据是安全的,cookies相对不安全
会话的使用
会话->内置对象
1.概览
服务器端会话技术,它在一个会话中的多个请求之间共享数据,并将数据保存在服务器端对象中。jsp:会话小服务程序:HttpSession
2.快速入门
(1)getAttribute(字符串名称);
(2)setAttribute(字符串名称,对象值)
(3)removeAattribute(字符串名称)
3.详情
1.客户端关闭时,服务端没有关闭,两次获取的session是一样的吗?
* 默认情况下,不
* 如果需要的话,可以创建一个cookie,key是JSESSIONID,设置最大存活时间,让cookie持久化。
Cookie c = new Cookie("JSESSIONID",session.getId());
c.setMaxAge(60*60);
response.addCookie(c);
2.客户端没有关闭。服务器关闭后,两次获得的session是一样的吗?
* 不是同一个,但请确保没有数据丢失。tomcat 会自动执行以下操作。
** 会话钝化:
在服务器正常关闭之前将会话对象序列化到磁盘
** 会话激活:
服务器启动后,可以将会话文件转换为内存中的会话对象。
3.会话何时销毁?
(1) 服务器宕机
(2) 会话对象调用 invalidate() 方法
(3)会话默认过期时间为 30 分钟 => web.xml
4.会话功能
Session 用于存储一个会话的多个请求的数据,存储在服务器端
会话可以存储任何类型和大小的数据
session和cookie的区别
1.session 将数据存储在服务端,cookies 存储在客户端
Cookie存储的数据只能是文本,Session---Object
2.session 没有数据大小限制,cookie 有
3.session数据安全,cookies比较不安全
包括指令
浏览器抓取网页(基于所述预页面截取方法的所述目标)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 12:06
技术特点:
1.一种浏览器页面拦截方法,其特征在于,应用于服务器时,包括:获取浏览器客户端触发生成的拦截指令,控制浏览器客户端发送相应的拦截指令。对拦截指令的拦截参数;其中,拦截参数为浏览器客户端预先拦截页面的相关信息。根据截取参数访问预截页面,对预截页面进行截取操作,获取预截页面对应的目标截图后,将目标截图返回给浏览器客户端。2.根据权利要求1所述的截取浏览器页面的方法,其特征在于,在获取浏览器客户端触发生成的拦截指令之前,还包括: 浏览器客户端通过调用服务来调用服务。终端上的页面拦截服务api触发拦截指令的生成。3.根据权利要求1所述的浏览器页面拦截方法,其特征在于,所述根据所述拦截指令控制所述浏览器客户端发送相应的拦截参数包括: 根据所述拦截指令控制所述浏览器客户端发送预先设置的页面地址。截取页面和预截取页面中目标DOM节点的标识属性;其中,目标 DOM 节点是预截取页面对应的目标截图 中收录的 dom 节点。4.根据权利要求3所述的浏览器页面拦截方法,其特征在于,所述根据拦截参数访问预先拦截的页面包括: 在服务器上启动无头浏览器,使用无头浏览器访问预先拦截的页面。到预先截获的页面的页面地址。
5.根据权利要求4所述的浏览器页面拦截方法,其特征在于,所述无头浏览器根据预先拦截的页面的页面地址访问预先拦截的页面包括以下步骤:页面设置访问权限,控制浏览器客户端发送预截获页面对应的认证凭证,从而使用无头浏览器根据预截获页面地址的页面和访问凭证访问预截获页面- 捕获的页面。6.根据权利要求3所述的拦截浏览器页面的方法,其特征在于,在对预先拦截的页面进行拦截操作之前,该方法还包括:监控预截页面的所有数据接口判断预截页面的响应是否完成,如果是,判断预截页面中的所有dom节点是否渲染完成,如果是,开始步骤拦截预拦截页面。7.根据权利要求6所述的浏览器页面截取方法,其特征在于,对所述预先截取的页面进行截取操作,得到所述预先截取的页面对应的目标截图包括: 根据所述预先截取的页面截取页面中目标dom节点的标识属性,从所有dom节点中找到目标dom节点;获取目标dom节点的定位属性信息,并根据定位属性信息截取预先截取的页面中收录目标dom节点的区域,得到目标截图。8.根据权利要求1至7任一项所述的浏览器页面截取方法,其特征在于,所述将目标截图返回给浏览器客户端包括: 根据截取参数中的文件格式将目标截图封装成文件流对应的格式,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览
服务器客户端发送的参数。9.根据权利要求8所述的浏览器页面截取方法,其特征在于,根据截取参数中的文件格式将目标截图封装成对应格式的文件流后,还包括: 加水印操作根据预设要求对文件流进行处理,得到具有与预设要求对应的水印信息的文件流。10.一种浏览器页面拦截装置,其特征在于,应用于服务器时,包括: 获取模块,用于获取浏览器客户端触发生成的拦截指令,并根据以下内容控制拦截指令拦截指令。浏览器客户端发送相应的拦截参数;其中,拦截参数是与浏览器客户端的预拦截页面相关的信息。截取模块,用于根据截取参数访问预截取页面。对预截取页面进行截取操作,得到预截取页面对应的目标截屏,然后将目标截屏返回给浏览器客户端。
技术总结
本申请公开了一种浏览器页面拦截及装置,应用于服务器,包括:获取浏览器客户端触发生成的拦截指令,根据拦截指令控制浏览器客户端发送相应的拦截参数。拦截参数是与浏览器客户端的预拦截页面相关的信息;根据截取参数访问预截页面,对预截页面进行截取操作,得到对应的预截页面。目标截屏后,将目标截屏返回给浏览器客户端。获取拦截指令后,本应用服务器获取浏览器客户端对该截取指令的截取参数,根据截取参数统一访问预先截取的页面进行页面截取,同时将截图返回给浏览器客户端. ,从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。
技术研发人员:王子龙
受保护的技术用户:
技术研发日:2021.12.21
技术发布日期:2022/3/25 查看全部
浏览器抓取网页(基于所述预页面截取方法的所述目标)
技术特点:
1.一种浏览器页面拦截方法,其特征在于,应用于服务器时,包括:获取浏览器客户端触发生成的拦截指令,控制浏览器客户端发送相应的拦截指令。对拦截指令的拦截参数;其中,拦截参数为浏览器客户端预先拦截页面的相关信息。根据截取参数访问预截页面,对预截页面进行截取操作,获取预截页面对应的目标截图后,将目标截图返回给浏览器客户端。2.根据权利要求1所述的截取浏览器页面的方法,其特征在于,在获取浏览器客户端触发生成的拦截指令之前,还包括: 浏览器客户端通过调用服务来调用服务。终端上的页面拦截服务api触发拦截指令的生成。3.根据权利要求1所述的浏览器页面拦截方法,其特征在于,所述根据所述拦截指令控制所述浏览器客户端发送相应的拦截参数包括: 根据所述拦截指令控制所述浏览器客户端发送预先设置的页面地址。截取页面和预截取页面中目标DOM节点的标识属性;其中,目标 DOM 节点是预截取页面对应的目标截图 中收录的 dom 节点。4.根据权利要求3所述的浏览器页面拦截方法,其特征在于,所述根据拦截参数访问预先拦截的页面包括: 在服务器上启动无头浏览器,使用无头浏览器访问预先拦截的页面。到预先截获的页面的页面地址。
5.根据权利要求4所述的浏览器页面拦截方法,其特征在于,所述无头浏览器根据预先拦截的页面的页面地址访问预先拦截的页面包括以下步骤:页面设置访问权限,控制浏览器客户端发送预截获页面对应的认证凭证,从而使用无头浏览器根据预截获页面地址的页面和访问凭证访问预截获页面- 捕获的页面。6.根据权利要求3所述的拦截浏览器页面的方法,其特征在于,在对预先拦截的页面进行拦截操作之前,该方法还包括:监控预截页面的所有数据接口判断预截页面的响应是否完成,如果是,判断预截页面中的所有dom节点是否渲染完成,如果是,开始步骤拦截预拦截页面。7.根据权利要求6所述的浏览器页面截取方法,其特征在于,对所述预先截取的页面进行截取操作,得到所述预先截取的页面对应的目标截图包括: 根据所述预先截取的页面截取页面中目标dom节点的标识属性,从所有dom节点中找到目标dom节点;获取目标dom节点的定位属性信息,并根据定位属性信息截取预先截取的页面中收录目标dom节点的区域,得到目标截图。8.根据权利要求1至7任一项所述的浏览器页面截取方法,其特征在于,所述将目标截图返回给浏览器客户端包括: 根据截取参数中的文件格式将目标截图封装成文件流对应的格式,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览 根据截取参数中的文件格式,将目标截图封装成相应格式的文件流,并将文件流返回给浏览器客户端;其中,文件格式为根据拦截指令控制浏览
服务器客户端发送的参数。9.根据权利要求8所述的浏览器页面截取方法,其特征在于,根据截取参数中的文件格式将目标截图封装成对应格式的文件流后,还包括: 加水印操作根据预设要求对文件流进行处理,得到具有与预设要求对应的水印信息的文件流。10.一种浏览器页面拦截装置,其特征在于,应用于服务器时,包括: 获取模块,用于获取浏览器客户端触发生成的拦截指令,并根据以下内容控制拦截指令拦截指令。浏览器客户端发送相应的拦截参数;其中,拦截参数是与浏览器客户端的预拦截页面相关的信息。截取模块,用于根据截取参数访问预截取页面。对预截取页面进行截取操作,得到预截取页面对应的目标截屏,然后将目标截屏返回给浏览器客户端。
技术总结
本申请公开了一种浏览器页面拦截及装置,应用于服务器,包括:获取浏览器客户端触发生成的拦截指令,根据拦截指令控制浏览器客户端发送相应的拦截参数。拦截参数是与浏览器客户端的预拦截页面相关的信息;根据截取参数访问预截页面,对预截页面进行截取操作,得到对应的预截页面。目标截屏后,将目标截屏返回给浏览器客户端。获取拦截指令后,本应用服务器获取浏览器客户端对该截取指令的截取参数,根据截取参数统一访问预先截取的页面进行页面截取,同时将截图返回给浏览器客户端. ,从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。从而解决各用户浏览器拦截功能不兼容的问题,拦截响应速度快,实现简单。拦截响应快速且易于实现。拦截响应快速且易于实现。
技术研发人员:王子龙
受保护的技术用户:
技术研发日:2021.12.21
技术发布日期:2022/3/25
浏览器抓取网页(网页抓取之WebBrowser繁体2006年04月22-最近研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-04-04 02:06
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
python网络爬虫英汉词典+自学能力繁体
2013年10月30日——上一篇文章,每次翻译一个词,都要在网上抓到,重复翻译要抓,不是很好。晚上突然想到一个好办法。说白了就是查询数据库。如果有这个词,就把它拿出来。用了半天,几乎不用联网,也就是离线!我使用的数据库是sqlite,小巧简单。当然你也可以用其他的。还
使用webbrowser控件抓取网页数据,如何抓取多个a标签对应的url地址的网页数据
2011 年 5 月 20 日 - 由于标题所属,我的页面中有四个菜单,它们连接到不同的地址。现在想通过一个按钮来抓取这个页面的数据,同时遍历获取四个a标签的url地址,然后自动进入其对应的页面抓取数据并存入数据库。现在问题如下: ArrayList UrlList = new ArrayList();
数据捕获的数据捕获过程
2015年11月30日——公司的数据采集系统已经写了一段时间。是时候总结一下了。否则,根据我的记忆,过一段时间我几乎会忘记它。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写: 数据抓取流程,以四川为例,介绍整个数据抓取流程 反爬虫规则:验证码识别,介绍easyocr和uuwise的使用 点击查看反爬虫-爬虫
使用webBrowser翻页抓取繁体中文
2013 年 5 月 10 日 - 页面有 js 翻页,我想捕获每个页面的内容。以下代码只能捕获第一页的数据。公共 Form1(){InitializeComponent();字符串 url = ""
各种微博爬取采集繁体字的方法
2017年3月24日 - 方法分析文章知乎中关于非wap版微博模拟登录研究的各种解答:Python爬虫如何登录新浪微博并爬取内容?Python模拟两种方式登录新浪微博 Selenium爬取新浪微博内容和用户信息 完整的项目代码 github上一个很挂的项目:完成微博各种登录,知乎,微信:给网页,wap版
通过WebBrowser网页截图C#源代码(抓取完整页面和首屏)繁体中文
2009年8月21日 - 通过WebBrowser+PrintWindow实现网页截图。内部采用拼接方式,保存完整的网页和首屏。但是这个方法的潜在bug是不能最小化窗体,否则会黑屏,而且webbrowser还没有找到在内存中构建截图的合理方式,无法正确渲染和然后被 PrintWindow 拦截。
解决Webbrowser定时爬取网页数据时,内存堆积没有释放的问题。
2017 年 10 月 25 日 - 原因:将 Dim Web 复制为新的 Web 浏览器。感觉这是Webbrowser的一个bug,如果重复创建不能释放,调用Dispose也没用。解决方案:将其定义为全局变量,并且只创建一次。
C# webbrowser爬取网页时如何防止弹出刷新对话框?
2013 年 7 月 27 日 - 使用 C# Webbrowser 抓取网页时,程序正在运行并弹出刷新对话框。必须点击重试,然后代码不会继续往下走。寻求专家指导。我的 webbrowser 被扩展并且还使用代码来抑制弹出对话框,仍然没用。公共无效getContent(){
爬虫app信息爬取apk反编译爬取繁体中文
2019年5月10日——我之前也抓过一些app,数据比较容易获取,也没有研究太深。毕竟有android模拟器+appium的方法。直到遇到一个app,具体的名字我就不说了,在模拟器上安装的时候打不开!!第一次遇到网上,找了半天,换了几个模拟器都没用。最后,我猜测是在apk中设置了检测模拟器的机制(这里没有进一步研究。
使用logcat进行Android系统日志的抓取
2017年8月11日 - 有时项目中会打印很多调试信息,但有时控制台打印速度很快,有些想看的信息在控制台下找不到。因此,我们需要使用 logcat 来捕获系统日志。话不多的话,上图一、经常在桌面创建logcat.txt二、打开cmd,然后输入adb logcat >C:\Users\Administrato
如何实现网页对webbrowser的适配?繁体中文
2011 年 12 月 29 日 - 该功能需要使显示的网页缩放或扩大到 webbrowser 控件的大小,并且 webbrowser 变小,网页放大,控件变大,网页变大,滚动webbrowser控件中没有出现bar,我该怎么办?
数据捕获第一弹繁体中文的性能优化
2015年12月24日 - 数据抓取本身的过程很简单,但是当网站的类型较多或者要采集的数据较多时,性能问题就会被称为数据抓取要解决的问题第一的。这几天同事在测试采集数据时总是遇到反应慢的问题。今晚趁着洗澡的时间理清思路,重构了一些问题;我做了一个记录。这次遇到的问题主要是代理的问题。场景如下:
WebBrowser实现繁体中文网页编辑
2016-09-05 - 1 //1.显示网页2过程TForm2.FormCreate(Sender: TObject); 3 开始 4 面板1.Align:=alTop; 5 复选框1.锚点:=[akTop,akRight];
通过 WebBrowser 获取网页截图
2015 年 1 月 27 日 - 本文介绍如何通过 WinForm 中的 WebBroswer 控件对网页进行截图。该方法可以截取大于屏幕面积的网页,但无法获取Flash或网页上某些控件的图片。因为是 WinForm 控件,所以没有在 WPF 中测试。在界面中添加一个文本框和一个按钮,文本框用于输入地址。在按钮按下事件处理程序中初始化
WEBBROWSER 如何判断网页是否重定向到繁体中文?
2014年7月1日 - 我在sdk下用atl加载了一个webbrowser控件,打开了一个网页,然后通过遍历网页元素实现了自动登录,但是网页跳转后导出的html源代码仍然是第一页,我没有不知道问题出在哪里?有以下问题:1、如何知道页面跳转;2、页面跳转后,需要重新获取HTML DOM Document对象吗?3
Delphi WebBrowser 与网页交互
2015 年 11 月 3 日 - WebBrowser1.GoHome;//进入浏览器默认主页 WebBrowser1.Refresh; //刷新WebBrowser1.GoBack; //Back WebBrowser1.GoForward ; //转发 WebBrowser1.Navigate('...'); //打开指定页面我们
webBrowser 查找繁体中文网页句柄
2015 年 10 月 31 日 - private void button1_Click(object sender, EventArgs e){int parentHandle = FindWindow("Shell Embedding", null);
数据抓取反爬虫规则:验证码识别繁体中文
2015年11月30日——在数据采集过程中,验证码是必须要面对的一道坎。一般来说,验证码识别有机器识别和人工识别两种。随着验证码越来越不正常,机器识别验证码的难度也越来越大。12306的典型类型已改为图像识别。,而不是简单的文本识别。验证码识别技术有很多,这里只介绍项目中用到的两种方法:基于开源的Tesseract
Perl网页抓取网页解析繁体中文
2012年10月26日——Perl解析HTML链接 Perl爬虫--爬取特定内容网页 Perl解析当当图书信息页网页分析处理最佳模块Web::Scraper如何用Perl进行屏幕抓取?
网页信息爬取实现繁体中文
2009年2月11日 - 最近公司需要开发一个简历导入功能,类似博客搬家或者邮箱搬家。之前是通过优采云采集器抓取信息,但是简历导入功能需要用户登录才能获取简历数据,无奈只能自己开发。第一个问题是:如何实现模拟登录?我们知道一般的网站是通过cookies来维护状态的,而我抓到的网站也支持使用cookies来检查
使用java爬取繁体中文网页图片
2013年8月29日——记得这个月9号我来到了深圳。找了将近20天的工作,只有三四家公司给我打电话面试。我真的不知道为什么。是不是因为我投了简历,投的简历少了?还是这个季节是招聘的冷季?不是很清楚。前天,我去一家创业公司面试。公司感觉还行,我总体上很满意。我有幸接受了采访。谈好的薪水我也可以接受,所以我同意去上班。今天是第一天
网页抓取工具繁体中文
2015年7月22日 - 最近一直在从事网络爬虫。顺便说一句,在mark下爬取,简单来说就是模仿http请求,分析网页结构,解析网页内容,得到你需要的内容使用的插件:httpwatch核心代码包xe。httpParse.saic;导入 java.io.InputS
网页抓取方式(四)--phantomjs 繁体
2017 年 6 月 11 日 - 一、phantomjs 简介 Phantomjs 是一个基于 webkit 内核的无界面浏览器,因此我们可以使用它进行网页抓取。它的优点是:1、本身运行在浏览器上,对js和css有很好的支持;2、 不易被查封;3、 支持jquery操作;缺点:1、 慢。二、操作模式phantomjs操作有两种模式:1、Native ph
动态抓取网页信息繁体中文
April 27, 2016 - 前几天做数据库实验的时候,总是手动往数据库里添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理2
ganon爬取网页繁体中文示例
2017 年 4 月 19 日 - 项目地址:Documentation:这个非常强大,使用类似 js 的标签选择器来识别 DOMGanon 库提供了访问 HTML/XML doc
抓取网页上的图片信息
2015年12月11日 - 最近学习的时候总结了一下,发现既然js可以通过元素的id找到这个元素,那我能不能用c#来做,但是我们事先不知道他们的id,和还有一个好处是,我不想抓取某个元素的所有内容,我只想抓取某类元素的内容,比如说图片,我想抓取某个< @网站 。先说原理:使用WebBrowser类
java网页抓取问题
2012 年 6 月 19 日 - 在此 网站:%2Fct1.html_pnl_trk&track
Python网页抓取程序繁体
2011 年 4 月 14 日 - 该程序用于从网页中抓取文本,即盗墓笔记的文本提取。写的简单,大家不要笑'''从盗墓笔记地址的网站中获取每一集的具体内容,从各个集体内容网页中提取内容写入文件'' '#-*- 编码:gb2312 -*-import HTMLParser
如何抓取繁体中文网页内容
2013 年 7 月 21 日 - 如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,你怎么做?其实网页内容的结构和 XML 很像,所以我们可以使用解析 XML 来解析 HTML,但是两者的差距还是很大的,好了,废话不多说,我们开始解析 HTML。然后有很多解析xml的库,这里就用到了lib。
如何防止他人用软件爬取繁体中文网页
2009 年 11 月 2 日 - 其他人使用软件访问网页抓取内容分析,导致 网站 加载过多,如何防止其他人阅读内容
实用网页抓取繁体中文
April 3, 2014 - 0、前言 本文主要介绍如何抓取网页内容,如何解决乱码问题,如何解决登录问题,以及处理和显示的过程采集 的数据。效果如下: 1、下载网页并加载到HtmlAgilityPack这里主要使用WebClient类的DownloadString方法和HtmlAgilit
爬虫技术(1)--爬取繁体网页
2017 年 6 月 30 日 - 1.了解 URL 和 URI 引用:网络资源标识符通用资源标识符
数据采集(一):北京交管车辆违法信息采集网站(已完成)繁体中文
2013年12月24日 - 个人信息:本人1992年大三,在十级三流本科院校软件工程专业。我于今年 2013 年 10 月开始实习。中小型互联网公司,主要从事java研发。更精确的责任是数据的实施。总的来说,还没有完全脱离母校魔掌的我,没有算法行业底层预研大师的深厚内功,也没有机会攀登。
webbrowser如何实现点击flash按钮获取繁体中文数据
2015 年 11 月 21 日 - 网络浏览器有一个嵌入了 Flash 的网页。现在想找到Flash的句柄,同时想获取Flash中控件的值,同时给Flash中的控件赋值,怎么办?我正在使用 C# Winform。
使用DELPHI WEBBROWSER从繁体中文网页拉取数据
2012 年 6 月 5 日 - 请告诉我,我想从网页中提取数据,我使用以下语句 ovTable:=webbrowser1.OleObject.Document.all.tags('TABLE').item(0) ;//取表集合可以得到表的所有数据,但是放到循环里面:url:='
Python网络爬虫及信息获取分析网页(一)--BeautifulSoup库繁体中文
2017 年 8 月 12 日 - 编写爬虫。知识的好坏,都会被爬下来。混乱的程度会让你在网上一一发现并不像百度那么方便。因此,解析好的网页是判断爬虫好坏的重要标准。这里给大家介绍一个强大的网页信息解析库----BeautifulSoupBeautifulSoup库是一个专注于解析网页信息的强大第三方
WebBrowser 拦截网页 更改消息 繁体中文
2011 年 1 月 28 日 - 使用 System 实现 IDocHostShowUI 接口;使用 System.采集s.Generic;使用 System.ComponentModel;使用 System.Data;使用 System.Drawing;使用
WebBrowser繁体中文网页全身照
2012年6月25日——最近在写程序的时候,突然觉得google chrome网页的缩略图很有意思,但是chrome是自己的内核,自己的东西当然方便。浏览器呢?首先想到的是最常见的屏幕复制,也称为bitblt,是从WebBrowser 的dc 复制到位图的dc。
网页通过 External 接口与 WebBrowser 交互
2009 年 12 月 22 日 - 在上一篇博客中,我谈到了在 WTL 中添加 IDL 以通过向导实现 IDispatch。是有代价的,而且代价不小,所以最后我用了最简单最有效的方法。下面是这样一个示例代码贴:下面是我的IDispatch的实现,其中MainDlg是WTL向导生成的非模态对话框,可以根据
通过WebBrowser获取AJAX后的繁体中文版网页
2015年12月04日 - 通常在WebBrowser的文档加载完成事件DocumentCompleted中进行判断 if (_WebBrowder.ReadyState == WebBrowserReadyState.Complete) {//获取网页信息并处理} 不过很遗憾是很 查看全部
浏览器抓取网页(网页抓取之WebBrowser繁体2006年04月22-最近研究)
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
用于网页抓取的 WebBrowser 繁体中文
2006年4月22日 - 最近学习了网页信息的批量分析和爬取,还是有一些经验的。我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只要网站地址和正则
Python 网页爬取 Lxml 繁体
2017 年 5 月 9 日 - Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。该模块是用 C 语言编写的,解析速度比 BeautifulSoup 快。Lxml 正确解析属性周围缺少的引号并关闭标签。比如case 1和case 2就是Lxml的CSS选择器提取区域数据的示例代码#coding=utf-8import
爬取近似网页过滤繁体中文
2014.08.17 - 大部分爬取的网页内容都会相似,爬取的时候应该过滤掉。开始考虑使用VSM算法,后来发现不对。对比了太多东西,然后发现了simHash算法,懒得复制这个算法的解释了,simhash算法对短数据支持不好,但是,我有长数据,用吧!网上也有很多源码实现,但是好像都是一样的。
当当数据在网页数据抓取
2017 年 1 月 22 日 - 包 com.atman.baiye.store.utils;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import .Malforme
Python网页抓取的美丽汤
2017 年 5 月 9 日 - BeautifulSoup 是一个非常流行的模块,它在解析一些闭引号标签时排版它们。例如:从 bs4 导入 BeautifulSoupbroken_html = '
python网络爬虫英汉词典+自学能力繁体
2013年10月30日——上一篇文章,每次翻译一个词,都要在网上抓到,重复翻译要抓,不是很好。晚上突然想到一个好办法。说白了就是查询数据库。如果有这个词,就把它拿出来。用了半天,几乎不用联网,也就是离线!我使用的数据库是sqlite,小巧简单。当然你也可以用其他的。还
使用webbrowser控件抓取网页数据,如何抓取多个a标签对应的url地址的网页数据
2011 年 5 月 20 日 - 由于标题所属,我的页面中有四个菜单,它们连接到不同的地址。现在想通过一个按钮来抓取这个页面的数据,同时遍历获取四个a标签的url地址,然后自动进入其对应的页面抓取数据并存入数据库。现在问题如下: ArrayList UrlList = new ArrayList();
数据捕获的数据捕获过程
2015年11月30日——公司的数据采集系统已经写了一段时间。是时候总结一下了。否则,根据我的记忆,过一段时间我几乎会忘记它。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写: 数据抓取流程,以四川为例,介绍整个数据抓取流程 反爬虫规则:验证码识别,介绍easyocr和uuwise的使用 点击查看反爬虫-爬虫
使用webBrowser翻页抓取繁体中文
2013 年 5 月 10 日 - 页面有 js 翻页,我想捕获每个页面的内容。以下代码只能捕获第一页的数据。公共 Form1(){InitializeComponent();字符串 url = ""
各种微博爬取采集繁体字的方法
2017年3月24日 - 方法分析文章知乎中关于非wap版微博模拟登录研究的各种解答:Python爬虫如何登录新浪微博并爬取内容?Python模拟两种方式登录新浪微博 Selenium爬取新浪微博内容和用户信息 完整的项目代码 github上一个很挂的项目:完成微博各种登录,知乎,微信:给网页,wap版
通过WebBrowser网页截图C#源代码(抓取完整页面和首屏)繁体中文
2009年8月21日 - 通过WebBrowser+PrintWindow实现网页截图。内部采用拼接方式,保存完整的网页和首屏。但是这个方法的潜在bug是不能最小化窗体,否则会黑屏,而且webbrowser还没有找到在内存中构建截图的合理方式,无法正确渲染和然后被 PrintWindow 拦截。
解决Webbrowser定时爬取网页数据时,内存堆积没有释放的问题。
2017 年 10 月 25 日 - 原因:将 Dim Web 复制为新的 Web 浏览器。感觉这是Webbrowser的一个bug,如果重复创建不能释放,调用Dispose也没用。解决方案:将其定义为全局变量,并且只创建一次。
C# webbrowser爬取网页时如何防止弹出刷新对话框?
2013 年 7 月 27 日 - 使用 C# Webbrowser 抓取网页时,程序正在运行并弹出刷新对话框。必须点击重试,然后代码不会继续往下走。寻求专家指导。我的 webbrowser 被扩展并且还使用代码来抑制弹出对话框,仍然没用。公共无效getContent(){
爬虫app信息爬取apk反编译爬取繁体中文
2019年5月10日——我之前也抓过一些app,数据比较容易获取,也没有研究太深。毕竟有android模拟器+appium的方法。直到遇到一个app,具体的名字我就不说了,在模拟器上安装的时候打不开!!第一次遇到网上,找了半天,换了几个模拟器都没用。最后,我猜测是在apk中设置了检测模拟器的机制(这里没有进一步研究。
使用logcat进行Android系统日志的抓取
2017年8月11日 - 有时项目中会打印很多调试信息,但有时控制台打印速度很快,有些想看的信息在控制台下找不到。因此,我们需要使用 logcat 来捕获系统日志。话不多的话,上图一、经常在桌面创建logcat.txt二、打开cmd,然后输入adb logcat >C:\Users\Administrato
如何实现网页对webbrowser的适配?繁体中文
2011 年 12 月 29 日 - 该功能需要使显示的网页缩放或扩大到 webbrowser 控件的大小,并且 webbrowser 变小,网页放大,控件变大,网页变大,滚动webbrowser控件中没有出现bar,我该怎么办?
数据捕获第一弹繁体中文的性能优化
2015年12月24日 - 数据抓取本身的过程很简单,但是当网站的类型较多或者要采集的数据较多时,性能问题就会被称为数据抓取要解决的问题第一的。这几天同事在测试采集数据时总是遇到反应慢的问题。今晚趁着洗澡的时间理清思路,重构了一些问题;我做了一个记录。这次遇到的问题主要是代理的问题。场景如下:
WebBrowser实现繁体中文网页编辑
2016-09-05 - 1 //1.显示网页2过程TForm2.FormCreate(Sender: TObject); 3 开始 4 面板1.Align:=alTop; 5 复选框1.锚点:=[akTop,akRight];
通过 WebBrowser 获取网页截图
2015 年 1 月 27 日 - 本文介绍如何通过 WinForm 中的 WebBroswer 控件对网页进行截图。该方法可以截取大于屏幕面积的网页,但无法获取Flash或网页上某些控件的图片。因为是 WinForm 控件,所以没有在 WPF 中测试。在界面中添加一个文本框和一个按钮,文本框用于输入地址。在按钮按下事件处理程序中初始化
WEBBROWSER 如何判断网页是否重定向到繁体中文?
2014年7月1日 - 我在sdk下用atl加载了一个webbrowser控件,打开了一个网页,然后通过遍历网页元素实现了自动登录,但是网页跳转后导出的html源代码仍然是第一页,我没有不知道问题出在哪里?有以下问题:1、如何知道页面跳转;2、页面跳转后,需要重新获取HTML DOM Document对象吗?3
Delphi WebBrowser 与网页交互
2015 年 11 月 3 日 - WebBrowser1.GoHome;//进入浏览器默认主页 WebBrowser1.Refresh; //刷新WebBrowser1.GoBack; //Back WebBrowser1.GoForward ; //转发 WebBrowser1.Navigate('...'); //打开指定页面我们
webBrowser 查找繁体中文网页句柄
2015 年 10 月 31 日 - private void button1_Click(object sender, EventArgs e){int parentHandle = FindWindow("Shell Embedding", null);
数据抓取反爬虫规则:验证码识别繁体中文
2015年11月30日——在数据采集过程中,验证码是必须要面对的一道坎。一般来说,验证码识别有机器识别和人工识别两种。随着验证码越来越不正常,机器识别验证码的难度也越来越大。12306的典型类型已改为图像识别。,而不是简单的文本识别。验证码识别技术有很多,这里只介绍项目中用到的两种方法:基于开源的Tesseract
Perl网页抓取网页解析繁体中文
2012年10月26日——Perl解析HTML链接 Perl爬虫--爬取特定内容网页 Perl解析当当图书信息页网页分析处理最佳模块Web::Scraper如何用Perl进行屏幕抓取?
网页信息爬取实现繁体中文
2009年2月11日 - 最近公司需要开发一个简历导入功能,类似博客搬家或者邮箱搬家。之前是通过优采云采集器抓取信息,但是简历导入功能需要用户登录才能获取简历数据,无奈只能自己开发。第一个问题是:如何实现模拟登录?我们知道一般的网站是通过cookies来维护状态的,而我抓到的网站也支持使用cookies来检查
使用java爬取繁体中文网页图片
2013年8月29日——记得这个月9号我来到了深圳。找了将近20天的工作,只有三四家公司给我打电话面试。我真的不知道为什么。是不是因为我投了简历,投的简历少了?还是这个季节是招聘的冷季?不是很清楚。前天,我去一家创业公司面试。公司感觉还行,我总体上很满意。我有幸接受了采访。谈好的薪水我也可以接受,所以我同意去上班。今天是第一天
网页抓取工具繁体中文
2015年7月22日 - 最近一直在从事网络爬虫。顺便说一句,在mark下爬取,简单来说就是模仿http请求,分析网页结构,解析网页内容,得到你需要的内容使用的插件:httpwatch核心代码包xe。httpParse.saic;导入 java.io.InputS
网页抓取方式(四)--phantomjs 繁体
2017 年 6 月 11 日 - 一、phantomjs 简介 Phantomjs 是一个基于 webkit 内核的无界面浏览器,因此我们可以使用它进行网页抓取。它的优点是:1、本身运行在浏览器上,对js和css有很好的支持;2、 不易被查封;3、 支持jquery操作;缺点:1、 慢。二、操作模式phantomjs操作有两种模式:1、Native ph
动态抓取网页信息繁体中文
April 27, 2016 - 前几天做数据库实验的时候,总是手动往数据库里添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理2
ganon爬取网页繁体中文示例
2017 年 4 月 19 日 - 项目地址:Documentation:这个非常强大,使用类似 js 的标签选择器来识别 DOMGanon 库提供了访问 HTML/XML doc
抓取网页上的图片信息
2015年12月11日 - 最近学习的时候总结了一下,发现既然js可以通过元素的id找到这个元素,那我能不能用c#来做,但是我们事先不知道他们的id,和还有一个好处是,我不想抓取某个元素的所有内容,我只想抓取某类元素的内容,比如说图片,我想抓取某个< @网站 。先说原理:使用WebBrowser类
java网页抓取问题
2012 年 6 月 19 日 - 在此 网站:%2Fct1.html_pnl_trk&track
Python网页抓取程序繁体
2011 年 4 月 14 日 - 该程序用于从网页中抓取文本,即盗墓笔记的文本提取。写的简单,大家不要笑'''从盗墓笔记地址的网站中获取每一集的具体内容,从各个集体内容网页中提取内容写入文件'' '#-*- 编码:gb2312 -*-import HTMLParser
如何抓取繁体中文网页内容
2013 年 7 月 21 日 - 如果给你一个网页链接来抓取特定内容,比如豆瓣电影排名,你怎么做?其实网页内容的结构和 XML 很像,所以我们可以使用解析 XML 来解析 HTML,但是两者的差距还是很大的,好了,废话不多说,我们开始解析 HTML。然后有很多解析xml的库,这里就用到了lib。
如何防止他人用软件爬取繁体中文网页
2009 年 11 月 2 日 - 其他人使用软件访问网页抓取内容分析,导致 网站 加载过多,如何防止其他人阅读内容
实用网页抓取繁体中文
April 3, 2014 - 0、前言 本文主要介绍如何抓取网页内容,如何解决乱码问题,如何解决登录问题,以及处理和显示的过程采集 的数据。效果如下: 1、下载网页并加载到HtmlAgilityPack这里主要使用WebClient类的DownloadString方法和HtmlAgilit
爬虫技术(1)--爬取繁体网页
2017 年 6 月 30 日 - 1.了解 URL 和 URI 引用:网络资源标识符通用资源标识符
数据采集(一):北京交管车辆违法信息采集网站(已完成)繁体中文
2013年12月24日 - 个人信息:本人1992年大三,在十级三流本科院校软件工程专业。我于今年 2013 年 10 月开始实习。中小型互联网公司,主要从事java研发。更精确的责任是数据的实施。总的来说,还没有完全脱离母校魔掌的我,没有算法行业底层预研大师的深厚内功,也没有机会攀登。
webbrowser如何实现点击flash按钮获取繁体中文数据
2015 年 11 月 21 日 - 网络浏览器有一个嵌入了 Flash 的网页。现在想找到Flash的句柄,同时想获取Flash中控件的值,同时给Flash中的控件赋值,怎么办?我正在使用 C# Winform。
使用DELPHI WEBBROWSER从繁体中文网页拉取数据
2012 年 6 月 5 日 - 请告诉我,我想从网页中提取数据,我使用以下语句 ovTable:=webbrowser1.OleObject.Document.all.tags('TABLE').item(0) ;//取表集合可以得到表的所有数据,但是放到循环里面:url:='
Python网络爬虫及信息获取分析网页(一)--BeautifulSoup库繁体中文
2017 年 8 月 12 日 - 编写爬虫。知识的好坏,都会被爬下来。混乱的程度会让你在网上一一发现并不像百度那么方便。因此,解析好的网页是判断爬虫好坏的重要标准。这里给大家介绍一个强大的网页信息解析库----BeautifulSoupBeautifulSoup库是一个专注于解析网页信息的强大第三方
WebBrowser 拦截网页 更改消息 繁体中文
2011 年 1 月 28 日 - 使用 System 实现 IDocHostShowUI 接口;使用 System.采集s.Generic;使用 System.ComponentModel;使用 System.Data;使用 System.Drawing;使用
WebBrowser繁体中文网页全身照
2012年6月25日——最近在写程序的时候,突然觉得google chrome网页的缩略图很有意思,但是chrome是自己的内核,自己的东西当然方便。浏览器呢?首先想到的是最常见的屏幕复制,也称为bitblt,是从WebBrowser 的dc 复制到位图的dc。
网页通过 External 接口与 WebBrowser 交互
2009 年 12 月 22 日 - 在上一篇博客中,我谈到了在 WTL 中添加 IDL 以通过向导实现 IDispatch。是有代价的,而且代价不小,所以最后我用了最简单最有效的方法。下面是这样一个示例代码贴:下面是我的IDispatch的实现,其中MainDlg是WTL向导生成的非模态对话框,可以根据
通过WebBrowser获取AJAX后的繁体中文版网页
2015年12月04日 - 通常在WebBrowser的文档加载完成事件DocumentCompleted中进行判断 if (_WebBrowder.ReadyState == WebBrowserReadyState.Complete) {//获取网页信息并处理} 不过很遗憾是很
浏览器抓取网页( 爬虫接收请求3、请求头注意携带4、响应Response)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-30 14:15
爬虫接收请求3、请求头注意携带4、响应Response)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
3、爬校花网
最后,让我们给你一些好处
基础版:
查看代码
功能包版本
查看代码
并发版(如果一共需要爬30个视频,开30个线程来做,耗时是最慢的部分)
查看代码
涉及知识:多线程和多处理
计算密集型任务:使用多进程,因为Python有GIL,多进程可以利用CPU多核;
IO密集型任务:使用多线程,做IO切换以节省任务执行时间(并发)
线程池
参考博客:
盲驴 查看全部
浏览器抓取网页(
爬虫接收请求3、请求头注意携带4、响应Response)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
图片
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
3、爬校花网
最后,让我们给你一些好处
基础版:
查看代码
功能包版本
查看代码
并发版(如果一共需要爬30个视频,开30个线程来做,耗时是最慢的部分)
查看代码
涉及知识:多线程和多处理
计算密集型任务:使用多进程,因为Python有GIL,多进程可以利用CPU多核;
IO密集型任务:使用多线程,做IO切换以节省任务执行时间(并发)
线程池
参考博客:
盲驴
浏览器抓取网页(BOM1.浏览器浏览器对象模型(browserobjectmodel).36 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-29 08:11
)
物料清单
1.物料清单
浏览器对象模型
BOM允许我们通过JS来操作浏览器
为我们提供了BOM中的一组对象来完成浏览器的操作
BOM 对象
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
由于隐私原因,对象无法获取具体的历史记录,只能操作浏览器向前或向后翻页
并且该操作只对当前访问有效
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
这些 BOM 对象在浏览器中保存为窗口对象的属性,
可以通过window对象使用,也可以直接使用
2.导航器
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
由于历史原因,Navigator 对象中的大部分属性不再帮助我们识别浏览器
一般我们只使用userAgent来判断浏览器信息,
userAgent 是一个字符串,收录描述浏览器信息的内容,
不同的浏览器会有不同的userAgent
火狐用户代理
Mozilla5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko20100101 Firefox50.0
Chrome 的 userAgent
Mozilla5.0 (Windows NT 6.1; Win64; x64) AppleWebKit537.36 (KHTML, 像 Gecko) Chrome52.0.274 3.82 Safari537.36
IE8
Mozilla4.0(兼容;MSIE 8.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE9
Mozilla5.0(兼容;MSIE 9.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE10
Mozilla5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4. @>0C;.NET4.0E)
IE11
Mozilla5.0(Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.0C;.NET4. 0E; rv:11.0) 像壁虎
在IE11中,微软和IE相关的logo都被去掉了,所以我们基本上无法通过UserAgent来识别一个浏览器是否是IE。
alert(navigator.appName);
var ua = navigator.userAgent;
console.log(ua);
if(firefoxi.test(ua)){
alert("你是火狐!!!");
}else if(chromei.test(ua)){
alert("你是Chrome");
}else if(msiei.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,枪毙了你~~~");
}
3.历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
可用于跳转到指定页面
它需要一个整数作为参数
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
4.位置
这个对象封装了浏览器地址栏的信息
如果直接打印位置,可以得到地址栏的信息(当前页面的完整路径)
警报(位置);
如果直接将location属性修改为完整路径,或者相对路径
然后我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置=“http:”;
位置 = "01.BOM.html";
分配()
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
location.reload(true);
代替()
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
5.窗口
计时器
设置间隔()
定时通话
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
clearInterval() 可用于关闭计时器
该方法需要一个定时器的标识符作为参数,它将关闭该标识符对应的定时器。
clearInterval() 可以接收任意参数,
如果参数是有效的定时器标识符,则停止对应的定时器
如果参数不是有效的 ID,则什么也不做
var num = 1;
var timer = setInterval(function() {
count.innerHTML = num++;
if(num == 11) {
//关闭定时器
clearInterval(timer);
}
}, 1000);
延迟通话
设置超时
延迟调用函数不会立即执行,而是在一段时间后执行,并且只执行一次
延迟调用和定时调用的区别,定时调用会执行多次,而延迟调用只会执行一次
延迟调用和定时调用其实可以互相替代,开发时可以根据自己的需要选择
var timer = setTimeout(function(){
控制台.log(num++);
},3000);
使用 clearTimeout() 关闭延迟调用
清除超时(定时器);
# 类操作
直接修改元素的class css:
元素的样式由 style 属性修改。每次修改样式时,浏览器都需要重新渲染页面。这种实现的性能比较差,当我们要修改多个样式时,这种形式不是很方便。我希望一行代码可以同时修改多个样式。
我们可以通过修改元素的class属性来间接修改样式。这样,我们只需要修改一次就可以同时修改多个样式。浏览器只需要重新渲染一次页面,性能更好。
并且通过这种方式,性能和行为可以进一步分离
box.className += " b2"; //注意有空格,添加class属性
延时调用
setTimeout
延时调用一个函数不马上执行,而是隔一段时间以后在执行,而且只会执行一次
延时调用和定时调用的区别,定时调用会执行多次,而延时调用只会执行一次
延时调用和定时调用实际上是可以互相代替的,在开发中可以根据自己需要去选择
var timer = setTimeout(function(){
console.log(num++);
},3000);
使用clearTimeout()来关闭一个延时调用
clearTimeout(timer);
#类的操作
直接修改元素的类css:
通过style属性来修改元素的样式,每修改一个样式,浏览器就需要重新渲染一次页面。 这样的执行的性能是比较差的,而且这种形式当我们要修改多个样式时,也不太方便 我希望一行代码,可以同时修改多个样式
我们可以通过修改元素的class属性来间接的修改样式.这样一来,我们只需要修改一次,即可同时修改多个样式,浏览器只需要重新渲染页面一次,性能比较好,
并且这种方式,可以使表现和行为进一步的分离 查看全部
浏览器抓取网页(BOM1.浏览器浏览器对象模型(browserobjectmodel).36
)
物料清单
1.物料清单
浏览器对象模型
BOM允许我们通过JS来操作浏览器
为我们提供了BOM中的一组对象来完成浏览器的操作
BOM 对象
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
由于隐私原因,对象无法获取具体的历史记录,只能操作浏览器向前或向后翻页
并且该操作只对当前访问有效
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
这些 BOM 对象在浏览器中保存为窗口对象的属性,
可以通过window对象使用,也可以直接使用
2.导航器
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
由于历史原因,Navigator 对象中的大部分属性不再帮助我们识别浏览器
一般我们只使用userAgent来判断浏览器信息,
userAgent 是一个字符串,收录描述浏览器信息的内容,
不同的浏览器会有不同的userAgent
火狐用户代理
Mozilla5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko20100101 Firefox50.0
Chrome 的 userAgent
Mozilla5.0 (Windows NT 6.1; Win64; x64) AppleWebKit537.36 (KHTML, 像 Gecko) Chrome52.0.274 3.82 Safari537.36
IE8
Mozilla4.0(兼容;MSIE 8.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE9
Mozilla5.0(兼容;MSIE 9.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.@ >0C;.NET4.0E)
IE10
Mozilla5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4. @>0C;.NET4.0E)
IE11
Mozilla5.0(Windows NT 6.1;WOW64;三叉戟7.0;SLCC2;.NET CLR 2.0.50727;.NET CLR 3.5.30729;.NET CLR 3.0.30729;媒体中心 PC 6.0;.NET4.0C;.NET4. 0E; rv:11.0) 像壁虎
在IE11中,微软和IE相关的logo都被去掉了,所以我们基本上无法通过UserAgent来识别一个浏览器是否是IE。
alert(navigator.appName);
var ua = navigator.userAgent;
console.log(ua);
if(firefoxi.test(ua)){
alert("你是火狐!!!");
}else if(chromei.test(ua)){
alert("你是Chrome");
}else if(msiei.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,枪毙了你~~~");
}
3.历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
可用于跳转到指定页面
它需要一个整数作为参数
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
4.位置
这个对象封装了浏览器地址栏的信息
如果直接打印位置,可以得到地址栏的信息(当前页面的完整路径)
警报(位置);
如果直接将location属性修改为完整路径,或者相对路径
然后我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置=“http:”;
位置 = "01.BOM.html";
分配()
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
location.reload(true);
代替()
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
5.窗口
计时器
设置间隔()
定时通话
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
clearInterval() 可用于关闭计时器
该方法需要一个定时器的标识符作为参数,它将关闭该标识符对应的定时器。
clearInterval() 可以接收任意参数,
如果参数是有效的定时器标识符,则停止对应的定时器
如果参数不是有效的 ID,则什么也不做
var num = 1;
var timer = setInterval(function() {
count.innerHTML = num++;
if(num == 11) {
//关闭定时器
clearInterval(timer);
}
}, 1000);
延迟通话
设置超时
延迟调用函数不会立即执行,而是在一段时间后执行,并且只执行一次
延迟调用和定时调用的区别,定时调用会执行多次,而延迟调用只会执行一次
延迟调用和定时调用其实可以互相替代,开发时可以根据自己的需要选择
var timer = setTimeout(function(){
控制台.log(num++);
},3000);
使用 clearTimeout() 关闭延迟调用
清除超时(定时器);
# 类操作
直接修改元素的class css:
元素的样式由 style 属性修改。每次修改样式时,浏览器都需要重新渲染页面。这种实现的性能比较差,当我们要修改多个样式时,这种形式不是很方便。我希望一行代码可以同时修改多个样式。
我们可以通过修改元素的class属性来间接修改样式。这样,我们只需要修改一次就可以同时修改多个样式。浏览器只需要重新渲染一次页面,性能更好。
并且通过这种方式,性能和行为可以进一步分离
box.className += " b2"; //注意有空格,添加class属性
延时调用
setTimeout
延时调用一个函数不马上执行,而是隔一段时间以后在执行,而且只会执行一次
延时调用和定时调用的区别,定时调用会执行多次,而延时调用只会执行一次
延时调用和定时调用实际上是可以互相代替的,在开发中可以根据自己需要去选择
var timer = setTimeout(function(){
console.log(num++);
},3000);
使用clearTimeout()来关闭一个延时调用
clearTimeout(timer);
#类的操作
直接修改元素的类css:
通过style属性来修改元素的样式,每修改一个样式,浏览器就需要重新渲染一次页面。 这样的执行的性能是比较差的,而且这种形式当我们要修改多个样式时,也不太方便 我希望一行代码,可以同时修改多个样式
我们可以通过修改元素的class属性来间接的修改样式.这样一来,我们只需要修改一次,即可同时修改多个样式,浏览器只需要重新渲染页面一次,性能比较好,
并且这种方式,可以使表现和行为进一步的分离
浏览器抓取网页(1.开发环境.3.3python3.52.网络爬虫的定义)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-28 06:14
1.开发环境
pycharm2017.3.3
蟒蛇3.5
2.网络爬虫的定义
网络爬虫,又称网络蜘蛛,如果把互联网比作蜘蛛网,蜘蛛就是在网络上四处爬行的蜘蛛。网络爬虫根据其地址搜索网页。是网址。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL为统一资源定位符(统一资源定位),其一般格式如下(方括号[]可选)
protocol://hostname[:port]/path/[:parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(和端口号作为可选参数),一般网站默认端口号为80
(3)path:第三部分是宿主资源的具体地址,如目录和文件名等,网络爬虫就是根据这个URL获取网页信息
3.简单爬虫示例
在Python3.x中,我们可以使用urllib组件来抓取网页。 urllib 是一个 URL 处理包。这个包采集了处理url的模块,如下:
(1)urllib.request模块用于打开和读取URL;
(2)urllib.error 模块收录一些urllib.request 产生的错误,可以用try 捕获
(3)urllib.parse模块收录一些解析URL的方法;
(4)urllib.robotparser模块用于解析robots.txt文本文件,提供了单独的RobotFileParser类,通过该类提供的can_fatch()方法测试爬虫能否下载页面.
我们可以通过接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息
让我们编写一个简单的程序来实现它
1 from urllib import request
2 if __name__ == "__main__":
3 response = request.urlopen("http://www.baidu.com")
4 html = response.read()
5 print(html)
运行结果(可以看到进度条还是可以拉远的)
这到底是怎么回事
为了对比,在浏览器中打开,查看页面元素,使用快捷键F12(浏览器最好使用Firefox或Chrome)
一切都一样,只是格式有点乱。您可以通过简单的 decode() 命令解码并显示网页的信息。代码中加一句html=html.decode("utf-8")
1 from urllib import request
2
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.fanyi.baidu.com/")
5 html = response.read()
6 html = html.decode("utf-8")
7 print(html)
输出普通html格式
当然,编码方式不是我们猜到的,而是发现了。在查看元素中找到head标签,打开,看到charset="utf-8",就是编码方式
4.自动获取网页的编码方式
这里使用第三方库来安装chardet
1 pip install chardet
对代码稍作修改,确定页面的编码方式
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com")
5 html = response.read()
6 #html = html.decode("utf-8")
7 charset = chardet.detect(html)
8 print(charset)
可以看到字典返回了,终于可以整合了
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com")
5 html = response.read()
6 charset = chardet.detect(html)
7 html = html.decode(charset.get('encoding'))
8
9 print(html)
完美
转载于: 查看全部
浏览器抓取网页(1.开发环境.3.3python3.52.网络爬虫的定义)
1.开发环境
pycharm2017.3.3
蟒蛇3.5
2.网络爬虫的定义
网络爬虫,又称网络蜘蛛,如果把互联网比作蜘蛛网,蜘蛛就是在网络上四处爬行的蜘蛛。网络爬虫根据其地址搜索网页。是网址。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL为统一资源定位符(统一资源定位),其一般格式如下(方括号[]可选)
protocol://hostname[:port]/path/[:parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(和端口号作为可选参数),一般网站默认端口号为80
(3)path:第三部分是宿主资源的具体地址,如目录和文件名等,网络爬虫就是根据这个URL获取网页信息
3.简单爬虫示例
在Python3.x中,我们可以使用urllib组件来抓取网页。 urllib 是一个 URL 处理包。这个包采集了处理url的模块,如下:
(1)urllib.request模块用于打开和读取URL;
(2)urllib.error 模块收录一些urllib.request 产生的错误,可以用try 捕获
(3)urllib.parse模块收录一些解析URL的方法;
(4)urllib.robotparser模块用于解析robots.txt文本文件,提供了单独的RobotFileParser类,通过该类提供的can_fatch()方法测试爬虫能否下载页面.
我们可以通过接口函数urllib.request.urlopen()轻松打开一个网站,读取和打印信息
让我们编写一个简单的程序来实现它
1 from urllib import request
2 if __name__ == "__main__":
3 response = request.urlopen("http://www.baidu.com";)
4 html = response.read()
5 print(html)
运行结果(可以看到进度条还是可以拉远的)
这到底是怎么回事
为了对比,在浏览器中打开,查看页面元素,使用快捷键F12(浏览器最好使用Firefox或Chrome)
一切都一样,只是格式有点乱。您可以通过简单的 decode() 命令解码并显示网页的信息。代码中加一句html=html.decode("utf-8")
1 from urllib import request
2
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.fanyi.baidu.com/";)
5 html = response.read()
6 html = html.decode("utf-8")
7 print(html)
输出普通html格式
当然,编码方式不是我们猜到的,而是发现了。在查看元素中找到head标签,打开,看到charset="utf-8",就是编码方式
4.自动获取网页的编码方式
这里使用第三方库来安装chardet
1 pip install chardet
对代码稍作修改,确定页面的编码方式
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com";)
5 html = response.read()
6 #html = html.decode("utf-8")
7 charset = chardet.detect(html)
8 print(charset)
可以看到字典返回了,终于可以整合了
1 from urllib import request
2 import chardet
3 if __name__ == "__main__":
4 response = request.urlopen("http://www.baidu.com";)
5 html = response.read()
6 charset = chardet.detect(html)
7 html = html.decode(charset.get('encoding'))
8
9 print(html)
完美
转载于:
浏览器抓取网页(获取网页标题的方式是什么?怎么做?处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-26 02:16
作为标准的 HTML 文档,页面标题(title)是必不可少的属性。随着浏览器的发展,我们有了另一种访问和修改文档的方式:DOM。因此,获取网页标题有两种方式:
通过文档对象访问title
var title = document.title;通过 DOM 访问标题
var title = document.getElementsByTagName('title')[0];但是这两种获取方式完全不同,document.title可以直接获取网页标题的字符串副本,它返回一个字符串;但是通过DOM获取的是HTML文档中的title节点对象。
我们可以使用节点对象的innerHTML属性来输出页面标题:
document.getElementsByTagName('title')[0].innerHTML;
编辑页面标题
这里我们讨论一下IE浏览器实现中的一个小bug:我们知道理论上HTML文档中的任何节点都可以通过DOM进行修改。按照这句话,我们当然可以修改HTML文档中的title节点。 但有趣的是,IE浏览器在这个地方实现了一些奇怪的东西,具体来说:
Firefox 在这里完美运行。不过除了FF和IE,其他浏览器我没有测试过,有兴趣的朋友可以试试。 (估计会比IE表现更好^^)
有一种说法,老方法不一定过时。存在多年的Document.title在这个时候就凸显了它的优势,因为这个属性不仅可以获取网页的标题,还可以修改标题。同时,HTML 文档节点中的标题也同步更新。所以:
目前,对于 Internet Explorer,更改网页标题的唯一方法是使用过时的 document.title 方法。同时,此方法也适用于其他浏览器。
结论
在web开发中,如果要处理网页标题的问题,需要注意以下几点:
最佳实践
获取文档标题:var title = document.title;
修改文档标题:document.title = "new title"; 查看全部
浏览器抓取网页(获取网页标题的方式是什么?怎么做?处理)
作为标准的 HTML 文档,页面标题(title)是必不可少的属性。随着浏览器的发展,我们有了另一种访问和修改文档的方式:DOM。因此,获取网页标题有两种方式:
通过文档对象访问title
var title = document.title;通过 DOM 访问标题
var title = document.getElementsByTagName('title')[0];但是这两种获取方式完全不同,document.title可以直接获取网页标题的字符串副本,它返回一个字符串;但是通过DOM获取的是HTML文档中的title节点对象。
我们可以使用节点对象的innerHTML属性来输出页面标题:
document.getElementsByTagName('title')[0].innerHTML;
编辑页面标题
这里我们讨论一下IE浏览器实现中的一个小bug:我们知道理论上HTML文档中的任何节点都可以通过DOM进行修改。按照这句话,我们当然可以修改HTML文档中的title节点。 但有趣的是,IE浏览器在这个地方实现了一些奇怪的东西,具体来说:
Firefox 在这里完美运行。不过除了FF和IE,其他浏览器我没有测试过,有兴趣的朋友可以试试。 (估计会比IE表现更好^^)
有一种说法,老方法不一定过时。存在多年的Document.title在这个时候就凸显了它的优势,因为这个属性不仅可以获取网页的标题,还可以修改标题。同时,HTML 文档节点中的标题也同步更新。所以:
目前,对于 Internet Explorer,更改网页标题的唯一方法是使用过时的 document.title 方法。同时,此方法也适用于其他浏览器。
结论
在web开发中,如果要处理网页标题的问题,需要注意以下几点:
最佳实践
获取文档标题:var title = document.title;
修改文档标题:document.title = "new title";
浏览器抓取网页(如何通过js调用本地摄像头呢?获取后如何对视频进行截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-25 14:24
如何通过js调用本地摄像头?获取视频后如何截图?下面我就和大家做一个简单的Demo来实现以上功能。
涉及的知识点实现的功能点的html简单布局
下面先用HTML实现一个简单的布局,包括样式和按钮。
H5 canvas 调用摄像头进行绘制
html,body{
width:100%;
height:100%;
padding: 0px;
margin: 0px;
overflow: hidden;
}
#canvas{
width:500px;
height:300px;
}
#video{
width:500px;
height:300px;
}
.btn{
display:inline-block;
text-align: center;
background-color: #333;
color:#eee;
font-size:14px;
padding:5px 15px;
border-radius: 5px;
cursor:pointer;
}
您的浏览器不支持H5 ,请更换或升级!
截图
暂停
打开
看起来像这样:
hahiahia 是空白的
我们隐藏视频,然后添加几个按钮,以及底部的画布和图片显示区域(用于存储截图)。
js实现函数
先把核心代码贴在这里:
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
相关知识点可以参考
:
然后根据页面逻辑实现事件等功能,包括:截图、暂停。
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia;
var events = {
open : function(){
LV.open();
},
close : function(){
console.log(LV.timer);
clearInterval(LV.timer);
},
screenshot : function(){
//获得当前帧的图像并拿到数据
var image = canvas.toDataURL('jpeg');
document.getElementById('show').innerHTML = '<img style="width:500px;height:300px;" />'
}
};
var LV = {
video : document.getElementById('video'),
canvas : document.getElementById('canvas'),
timer : null,
media : null,
open :function(){
if(!LV.timer){
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
}
if(LV.timer){
clearInterval(LV.timer);
}
//将画面绘制到canvas中
LV.timer = setInterval(function(){
LV.ctx.drawImage(LV.video,0,0,500,300);
},15);
},
init : function(){
LV.ctx = LV.canvas.getContext('2d');
//绑定事件
document.querySelectorAll('[filter]').forEach(function(item){
item.onclick = function(ev){
var type = this.getAttribute('filter');
events[type].call(this,ev);
}
});
return LV;
}
};
LV.init();
原谅我的波西米亚命名... 查看全部
浏览器抓取网页(如何通过js调用本地摄像头呢?获取后如何对视频进行截图)
如何通过js调用本地摄像头?获取视频后如何截图?下面我就和大家做一个简单的Demo来实现以上功能。
涉及的知识点实现的功能点的html简单布局
下面先用HTML实现一个简单的布局,包括样式和按钮。
H5 canvas 调用摄像头进行绘制
html,body{
width:100%;
height:100%;
padding: 0px;
margin: 0px;
overflow: hidden;
}
#canvas{
width:500px;
height:300px;
}
#video{
width:500px;
height:300px;
}
.btn{
display:inline-block;
text-align: center;
background-color: #333;
color:#eee;
font-size:14px;
padding:5px 15px;
border-radius: 5px;
cursor:pointer;
}
您的浏览器不支持H5 ,请更换或升级!
截图
暂停
打开
看起来像这样:
hahiahia 是空白的
我们隐藏视频,然后添加几个按钮,以及底部的画布和图片显示区域(用于存储截图)。
js实现函数
先把核心代码贴在这里:
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
相关知识点可以参考
:
然后根据页面逻辑实现事件等功能,包括:截图、暂停。
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia;
var events = {
open : function(){
LV.open();
},
close : function(){
console.log(LV.timer);
clearInterval(LV.timer);
},
screenshot : function(){
//获得当前帧的图像并拿到数据
var image = canvas.toDataURL('jpeg');
document.getElementById('show').innerHTML = '<img style="width:500px;height:300px;" />'
}
};
var LV = {
video : document.getElementById('video'),
canvas : document.getElementById('canvas'),
timer : null,
media : null,
open :function(){
if(!LV.timer){
navigator.getUserMedia({
video : {width:500,height:300}
},function(stream){
LV.video.srcObject = stream;
LV.video.onloadedmetadata = function(e) {
LV.video.play();
};
},function(err){
alert(err);//弹窗报错
})
}
if(LV.timer){
clearInterval(LV.timer);
}
//将画面绘制到canvas中
LV.timer = setInterval(function(){
LV.ctx.drawImage(LV.video,0,0,500,300);
},15);
},
init : function(){
LV.ctx = LV.canvas.getContext('2d');
//绑定事件
document.querySelectorAll('[filter]').forEach(function(item){
item.onclick = function(ev){
var type = this.getAttribute('filter');
events[type].call(this,ev);
}
});
return LV;
}
};
LV.init();
原谅我的波西米亚命名...
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-24 23:09
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。类似selenium的框架也有风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
图片图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
随机数:2SSH2A #未知
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个提交方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JS 写入 cookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试通过debug JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。 查看全部
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。类似selenium的框架也有风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
图片图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
随机数:2SSH2A #未知
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个提交方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JS 写入 cookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试通过debug JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。
浏览器抓取网页(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-24 20:00
总结
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用类(非知识讲解)
本文介绍selenium库和chrome浏览器自动抓取网页元素,定位填写表单数据,可以自动填写,节省大量人力。为了方便使用selenium库,也方便处理运行中的错误,本文对selenium库进行了一定程度的重新封装,方便读者在了解selenium库后快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库如何查找元素,3.Selenium库重新打包
二、本文结构:1.先简单介绍一下知识点,2.以完整段的形式贴出复制后可以直接运行的调试代码,这样就可以了方便读者调试每一个贴出的Snippet
三、本文方法实现:以百度首页为控制网页,以谷歌浏览器为实验平台,使用python+selenium操作网页。 ps:其他对应的爬取网页实验会更新。
四、本文实验:1.A股市场数据后台截图(更新于2020.09.09),2.后台QQ邮箱阅读获取最新邮件(待更新),等待其他实验更新(均提供详细代码和注释,文末有对应链接)
提示:以下为本文文章正文内容,以下案例供参考
文章目录
一、安装 selenium 库及相关文件
Selenium 库是python 用于爬虫的自动化工具网站。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器,还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装 selenium 库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装并查看添加路径。慎重选择此建议,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬虫方法,其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号。点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125
(3)点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本。在本文中,84.0.4147.125,所以如图寻找84.0驱动的开头,点击打开下载对应系统的驱动。然后解压到你要写项目的文件夹里。
不要放在python目录或浏览器安装目录。如果这样做,移植到其他计算机时会出现各种错误。根本原因是您的计算机上安装了相应的库文件和驱动程序。 ,但移植的电脑可能没有安装。
二、Selenium 快速入门1.定位元素的八种方法
(1)id
(2)名字
(3)xpath
(4)链接文字
(5)部分链接文字
(6)标签名
(7)类名
(8)css 选择器
2.id 方法
(1) 在 selenium 中通过 id 定位元素:find_element_by_id
以百度页面为例,其百度输入框部分源码如下:
其中输入框的网页代码,百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3.命名方法
以百度输入框为例,在selenium中按名称定位元素:find_element_by_name
代码及注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4.xpath 方法
以百度输入框为例,在selenium中通过xpath定位一个元素:find_element_by_xpath。但是这种方法不适用于网页中位置会发生变化的表格元素,因为xpath方法指向的是固定的行和列,无法检测到行和列内容的变化。
首先,在谷歌浏览器中打开百度,在空白处右键,选择勾选(N),进入网页的开发者模式,如图。然后右击百度输入框,再次点击勾选(N),可以发现右边自动选中的部分代码框变成了百度输入框的代码。最后在右边自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath是//*[@id="kw"],百度那个的xpath是/ /*[@id="su"]
接下来,使用该值进行百度搜索。代码及注释如下。
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com")
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5.链接文本和部分链接文本方法 查看全部
浏览器抓取网页(实践应用类(非知识讲解)本文介绍库和chrome浏览器)
总结
最后更新时间:2020.08.20(实验部分待更新)
本文类型:实际应用类(非知识讲解)
本文介绍selenium库和chrome浏览器自动抓取网页元素,定位填写表单数据,可以自动填写,节省大量人力。为了方便使用selenium库,也方便处理运行中的错误,本文对selenium库进行了一定程度的重新封装,方便读者在了解selenium库后快速上手编程。
一、本文知识点:1.安装selenium库,2.selenium库如何查找元素,3.Selenium库重新打包
二、本文结构:1.先简单介绍一下知识点,2.以完整段的形式贴出复制后可以直接运行的调试代码,这样就可以了方便读者调试每一个贴出的Snippet
三、本文方法实现:以百度首页为控制网页,以谷歌浏览器为实验平台,使用python+selenium操作网页。 ps:其他对应的爬取网页实验会更新。
四、本文实验:1.A股市场数据后台截图(更新于2020.09.09),2.后台QQ邮箱阅读获取最新邮件(待更新),等待其他实验更新(均提供详细代码和注释,文末有对应链接)
提示:以下为本文文章正文内容,以下案例供参考
文章目录
一、安装 selenium 库及相关文件
Selenium 库是python 用于爬虫的自动化工具网站。支持的浏览器包括Chrome、Firefox、Safari等主流界面浏览器,还支持Windows、Linux、IOS、Android等多种操作系统。
1.安装 selenium 库
(1)点击win10的开始菜单,直接输入cmd右键以管理员身份运行
(2)如果安装python时勾选了添加路径选项,可以直接输入命令
pip 安装硒
(如果没有添加,建议卸载python,重新安装并查看添加路径。慎重选择此建议,因为需要重新安装之前下载的库)
(3)网络连接下等待完成。如果提示超时,可以尝试以下命令切换下载源重新安装:pip install selenium -i
2.下载谷歌浏览器相关文件
本文使用的浏览器是谷歌浏览器,所以只介绍谷歌浏览器的爬虫方法,其他浏览器的方法类似。
(1)点击下载谷歌浏览器
(2)安装谷歌浏览器后,查看谷歌浏览器的版本号。点击谷歌浏览器右上角的三个点,选择-帮助-关于谷歌浏览器-查看版本号。
如图,本文版本号为84.0.4147.125
(3)点击下载谷歌浏览器驱动
打开驱动下载页面,找到版本号对应的驱动版本。在本文中,84.0.4147.125,所以如图寻找84.0驱动的开头,点击打开下载对应系统的驱动。然后解压到你要写项目的文件夹里。
不要放在python目录或浏览器安装目录。如果这样做,移植到其他计算机时会出现各种错误。根本原因是您的计算机上安装了相应的库文件和驱动程序。 ,但移植的电脑可能没有安装。
二、Selenium 快速入门1.定位元素的八种方法
(1)id
(2)名字
(3)xpath
(4)链接文字
(5)部分链接文字
(6)标签名
(7)类名
(8)css 选择器
2.id 方法
(1) 在 selenium 中通过 id 定位元素:find_element_by_id
以百度页面为例,其百度输入框部分源码如下:
其中输入框的网页代码,百度的网页代码
通过id查找元素的代码和注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过id搜索清除搜索框内容##
浏览器驱动.find_element_by_id("kw").clear()
##通过id搜索输入搜索框内容##
浏览器驱动.find_element_by_id("kw").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
3.命名方法
以百度输入框为例,在selenium中按名称定位元素:find_element_by_name
代码及注释如下:
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过name搜索清除搜索框内容##
浏览器驱动.find_element_by_name("wd").clear()
##通过name搜索输入搜索框内容##
浏览器驱动.find_element_by_name("wd").send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过id搜索点击百度一下进行搜索##
浏览器驱动.find_element_by_id("su").click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
4.xpath 方法
以百度输入框为例,在selenium中通过xpath定位一个元素:find_element_by_xpath。但是这种方法不适用于网页中位置会发生变化的表格元素,因为xpath方法指向的是固定的行和列,无法检测到行和列内容的变化。
首先,在谷歌浏览器中打开百度,在空白处右键,选择勾选(N),进入网页的开发者模式,如图。然后右击百度输入框,再次点击勾选(N),可以发现右边自动选中的部分代码框变成了百度输入框的代码。最后在右边自动选中的代码段右键-选择复制-选择复制Xpath,百度输入框的xpath是//*[@id="kw"],百度那个的xpath是/ /*[@id="su"]
接下来,使用该值进行百度搜索。代码及注释如下。
import os
import sys
import time
from selenium import webdriver
##此方法获取的工作文件夹路径在py文件下或封装exe后运行都有效##
当前工作主路径 = os.path.dirname(os.path.realpath(sys.argv[0]))
##配置谷歌浏览器驱动路径##
谷歌驱动器驱动 = 当前工作主路径+"/"+"chromedriver.exe"
##初始化selenium控件##
浏览器驱动 = webdriver.Chrome(executable_path=谷歌驱动器驱动)
##打开链接,更换其他网址,请注意开头要带上http://##
浏览器驱动.get("http://www.baidu.com";)
##通过xpath搜索清除搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').clear()
##通过xpath搜索输入搜索框内容,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="kw"]').send_keys("python+selenium库 实现爬虫抓取网页数据内容并自动填表的解决方法并附已交付甲方实际稳定运行的代码")
##通过xpath搜索点击百度一下进行搜索,注意单引号与双引号的混合使用##
浏览器驱动.find_element_by_xpath('//*[@id="su"]').click()
##保持5s时间
time.sleep(5)
###关闭退出浏览器
浏览器驱动.quit()
5.链接文本和部分链接文本方法
浏览器抓取网页(4.facebook服务的永久重定向响应的难点-如何存储数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-18 22:31
)
除了get请求之外,还有一个send请求,常用于提交表单。发送通过 URL 传递其参数的请求
(e.g.: RoboZZle stats for puzzle 85)
. 发送请求在请求正文标头之后发送其参数。
图片
“http://facebook.com/”
斜线很关键。在这种情况下,浏览器可以安全地添加斜杠。和喜欢
“http: //example.com/folderOrFile”
这样的地址不能自动加斜杠,因为浏览器不知道folderOrFile是文件夹还是文件。这时候浏览器直接访问不带斜线的地址,服务器响应重定向,导致不必要的握手。
4. 来自 facebook 服务的永久重定向响应
图为 Facebook 服务器返回给浏览器的响应:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服务器以 301 永久重定向响应响应浏览器,以便浏览器访问“
http://www.facebook.com/
“ 而不是
“http://facebook.com/”
.
为什么服务器要重定向而不是直接发送用户想看的网页内容?这个问题有很多有趣的答案。
原因之一与搜索引擎排名有关。你看,如果一个页面有两个地址,比如
http://www.igoro.com/ 和http://igoro.com/
,搜索引擎会认为它们是两个网站,导致每个搜索链接较少,排名较低。并且搜索引擎知道 301 永久重定向的含义,因此它们会将访问带有和不带有 www 的地址分配到相同的 网站 排名。
另一个是使用不同的地址会导致缓存友好性差。当一个页面有多个名称时,它可能会多次出现在缓存中。
5. 浏览器跟踪重定向地址
现在,浏览器知道
“http://www.facebook.com/”
是要访问的正确地址,因此它会发送另一个 get 请求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, p_w_picpath/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
标头信息与前一个请求中的含义相同。
6. 服务器“处理”请求
服务器接收到 get 请求,对其进行处理,然后返回响应。
表面上看,这似乎是一个定向任务,但实际上中间发生了很多有趣的事情——简单的网站如作者的博客,更不用说访问量大的网站如facebook !
所有动态的网站 都面临一个有趣的难题——如何存储数据。小型 网站 一半将有一个 SQL 数据库来存储数据,而 网站 拥有大量数据和/或大量访问将不得不找到某种方法将数据库分布在多台机器上。解决方案包括:分片(根据主键值将数据表分散到多个数据库中)、复制、使用弱语义一致性的简化数据库。
将工作委派给批处理是一种保持数据更新的廉价技术。例如,Facebook 需要及时更新其新闻提要,但数据支持的“你可能认识的人”功能只需要每晚更新一次(作者猜测是这样,如何改进功能是未知)。批量作业更新会导致一些不太重要的数据变得陈旧,但会使数据更新农业更快、更清洁。
7. 服务器发回一个 HTML 响应
下图展示了服务器生成并返回的响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]
整个响应大小为 35kB,其中大部分在排序后以 blob 形式传输。
Content-Encoding 标头告诉浏览器使用 gzip 算法压缩整个响应正文。解压 blob 块后,您可以看到预期的 HTML,如下所示:
...
关于压缩,header信息表示是否缓存页面,如果缓存了怎么做,设置什么cookies(没有在之前的响应中)和隐私信息等。
请注意,标头中的 Content-type 设置为“text/html”。标头告诉浏览器将响应内容呈现为 HTML,而不是将其下载为文件。浏览器根据标头信息决定如何解释响应,但也会考虑其他因素,例如 URL 扩展的内容。
8. 浏览器开始显示 HTML
在浏览器完全接受整个 HTML 文档之前,它已经开始显示这个页面:
9. 浏览器发送以获取嵌入在 HTML 中的对象
当浏览器显示 HTML 时,它会注意到需要获取其他地址内容的标签。此时,浏览器将发送获取请求以检索文件。
以下是我们在访问时需要重新获取的一些 URL:
这些地址会经历类似于 HTML 读取的过程。所以浏览器会在 DNS 中查找这些域,发送请求,重定向等……
但与动态页面不同的是,静态文件允许浏览器缓存它们。有些文件可能不需要与服务器通信,而是直接从缓存中读取。服务器的响应包括有关静态文件保留多长时间的信息,因此浏览器知道将它们缓存多长时间。此外,每个响应可能收录一个 ETag 标头(请求变量的实体值),其作用类似于版本号,如果浏览器观察到文件的版本 ETag 信息已经存在,它会立即停止文件的传输。
猜猜地址中的“”代表什么?聪明的答案是“Facebook 内容交付网络”。Facebook 利用内容分发网络 (CDN) 分发静态文件,如图像、CSS 表格和 JavaScript 文件。因此,这些文件将备份在全球许多 CDN 的数据中心中。
静态内容通常代表网站的带宽,也可以通过 CDN 轻松复制。通常网站使用第三方CDN。例如,Facebook 的静态文件由最大的 CDN 提供商 Akamai 托管。
例如,当您尝试时,您可能会从某个服务器获得响应。有趣的是,当你再次 ping 相同时,响应的服务器可能不同,这表明后台的负载均衡正在工作。
10. 浏览器发送异步(AJAX)请求
在Web2.0伟大精神的指引下,页面显示后客户端仍然与服务器保持联系。
以 Facebook 聊天功能为例,它与服务器保持联系以更新您的亮灰色朋友的状态。为了更新这些头像的好友状态,在浏览器中执行的 JavaScript 代码会向服务器发送一个异步请求。这个异步请求被发送到一个特定的地址,它是一个以编程方式构造的get或send请求。仍然在 Facebook 示例中,客户端发送
http://www.facebook.com/ajax/chat/buddy_list.php
获取有关您的哪些朋友在线的状态信息的发布请求。
说到这种模式,就不得不说“AJAX”——“异步 JavaScript 和 XML”,虽然服务器以 XML 格式响应并没有明确的原因。再举一个例子,对于异步请求,Facebook 将返回一些 JavaScript 片段。
除其他外,fiddler 是一种工具,可让您查看浏览器发送的异步请求。实际上,您不仅可以被动地观看这些请求,还可以主动修改并重新发送它们。对于得分的网络游戏开发者来说,如此容易被AJAX请求所欺骗,真是令人沮丧。(当然,不要这样骗人~)
Facebook 聊天功能提供了一个有趣的 AJAX 问题示例:将数据从服务器推送到客户端。由于 HTTP 是一种请求-响应协议,聊天服务器无法向客户端发送新消息。相反,客户端必须每隔几秒钟轮询一次服务器以查看它是否有新消息。
当这些情况发生时,长轮询是一种减少服务器负载的有趣技术。如果服务器在轮询时没有新消息,它会忽略客户端。当超时前收到来自客户端的新消息时,服务器会找到未完成的请求,并将新消息作为响应返回给客户端。
综上所述
希望看完这篇文章,你可以了解不同的网络模块是如何协同工作的
引用的部分内容
http://blog.jobbole.com/33951/ 查看全部
浏览器抓取网页(4.facebook服务的永久重定向响应的难点-如何存储数据
)
除了get请求之外,还有一个send请求,常用于提交表单。发送通过 URL 传递其参数的请求
(e.g.: RoboZZle stats for puzzle 85)
. 发送请求在请求正文标头之后发送其参数。
图片
“http://facebook.com/”
斜线很关键。在这种情况下,浏览器可以安全地添加斜杠。和喜欢
“http: //example.com/folderOrFile”
这样的地址不能自动加斜杠,因为浏览器不知道folderOrFile是文件夹还是文件。这时候浏览器直接访问不带斜线的地址,服务器响应重定向,导致不必要的握手。
4. 来自 facebook 服务的永久重定向响应
图为 Facebook 服务器返回给浏览器的响应:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服务器以 301 永久重定向响应响应浏览器,以便浏览器访问“
http://www.facebook.com/
“ 而不是
“http://facebook.com/”
.
为什么服务器要重定向而不是直接发送用户想看的网页内容?这个问题有很多有趣的答案。
原因之一与搜索引擎排名有关。你看,如果一个页面有两个地址,比如
http://www.igoro.com/ 和http://igoro.com/
,搜索引擎会认为它们是两个网站,导致每个搜索链接较少,排名较低。并且搜索引擎知道 301 永久重定向的含义,因此它们会将访问带有和不带有 www 的地址分配到相同的 网站 排名。
另一个是使用不同的地址会导致缓存友好性差。当一个页面有多个名称时,它可能会多次出现在缓存中。
5. 浏览器跟踪重定向地址
现在,浏览器知道
“http://www.facebook.com/”
是要访问的正确地址,因此它会发送另一个 get 请求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, p_w_picpath/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
标头信息与前一个请求中的含义相同。
6. 服务器“处理”请求
服务器接收到 get 请求,对其进行处理,然后返回响应。
表面上看,这似乎是一个定向任务,但实际上中间发生了很多有趣的事情——简单的网站如作者的博客,更不用说访问量大的网站如facebook !
所有动态的网站 都面临一个有趣的难题——如何存储数据。小型 网站 一半将有一个 SQL 数据库来存储数据,而 网站 拥有大量数据和/或大量访问将不得不找到某种方法将数据库分布在多台机器上。解决方案包括:分片(根据主键值将数据表分散到多个数据库中)、复制、使用弱语义一致性的简化数据库。
将工作委派给批处理是一种保持数据更新的廉价技术。例如,Facebook 需要及时更新其新闻提要,但数据支持的“你可能认识的人”功能只需要每晚更新一次(作者猜测是这样,如何改进功能是未知)。批量作业更新会导致一些不太重要的数据变得陈旧,但会使数据更新农业更快、更清洁。
7. 服务器发回一个 HTML 响应
下图展示了服务器生成并返回的响应:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3Tn@[...]
整个响应大小为 35kB,其中大部分在排序后以 blob 形式传输。
Content-Encoding 标头告诉浏览器使用 gzip 算法压缩整个响应正文。解压 blob 块后,您可以看到预期的 HTML,如下所示:
...
关于压缩,header信息表示是否缓存页面,如果缓存了怎么做,设置什么cookies(没有在之前的响应中)和隐私信息等。
请注意,标头中的 Content-type 设置为“text/html”。标头告诉浏览器将响应内容呈现为 HTML,而不是将其下载为文件。浏览器根据标头信息决定如何解释响应,但也会考虑其他因素,例如 URL 扩展的内容。
8. 浏览器开始显示 HTML
在浏览器完全接受整个 HTML 文档之前,它已经开始显示这个页面:
9. 浏览器发送以获取嵌入在 HTML 中的对象
当浏览器显示 HTML 时,它会注意到需要获取其他地址内容的标签。此时,浏览器将发送获取请求以检索文件。
以下是我们在访问时需要重新获取的一些 URL:
这些地址会经历类似于 HTML 读取的过程。所以浏览器会在 DNS 中查找这些域,发送请求,重定向等……
但与动态页面不同的是,静态文件允许浏览器缓存它们。有些文件可能不需要与服务器通信,而是直接从缓存中读取。服务器的响应包括有关静态文件保留多长时间的信息,因此浏览器知道将它们缓存多长时间。此外,每个响应可能收录一个 ETag 标头(请求变量的实体值),其作用类似于版本号,如果浏览器观察到文件的版本 ETag 信息已经存在,它会立即停止文件的传输。
猜猜地址中的“”代表什么?聪明的答案是“Facebook 内容交付网络”。Facebook 利用内容分发网络 (CDN) 分发静态文件,如图像、CSS 表格和 JavaScript 文件。因此,这些文件将备份在全球许多 CDN 的数据中心中。
静态内容通常代表网站的带宽,也可以通过 CDN 轻松复制。通常网站使用第三方CDN。例如,Facebook 的静态文件由最大的 CDN 提供商 Akamai 托管。
例如,当您尝试时,您可能会从某个服务器获得响应。有趣的是,当你再次 ping 相同时,响应的服务器可能不同,这表明后台的负载均衡正在工作。
10. 浏览器发送异步(AJAX)请求
在Web2.0伟大精神的指引下,页面显示后客户端仍然与服务器保持联系。
以 Facebook 聊天功能为例,它与服务器保持联系以更新您的亮灰色朋友的状态。为了更新这些头像的好友状态,在浏览器中执行的 JavaScript 代码会向服务器发送一个异步请求。这个异步请求被发送到一个特定的地址,它是一个以编程方式构造的get或send请求。仍然在 Facebook 示例中,客户端发送
http://www.facebook.com/ajax/chat/buddy_list.php
获取有关您的哪些朋友在线的状态信息的发布请求。
说到这种模式,就不得不说“AJAX”——“异步 JavaScript 和 XML”,虽然服务器以 XML 格式响应并没有明确的原因。再举一个例子,对于异步请求,Facebook 将返回一些 JavaScript 片段。
除其他外,fiddler 是一种工具,可让您查看浏览器发送的异步请求。实际上,您不仅可以被动地观看这些请求,还可以主动修改并重新发送它们。对于得分的网络游戏开发者来说,如此容易被AJAX请求所欺骗,真是令人沮丧。(当然,不要这样骗人~)
Facebook 聊天功能提供了一个有趣的 AJAX 问题示例:将数据从服务器推送到客户端。由于 HTTP 是一种请求-响应协议,聊天服务器无法向客户端发送新消息。相反,客户端必须每隔几秒钟轮询一次服务器以查看它是否有新消息。
当这些情况发生时,长轮询是一种减少服务器负载的有趣技术。如果服务器在轮询时没有新消息,它会忽略客户端。当超时前收到来自客户端的新消息时,服务器会找到未完成的请求,并将新消息作为响应返回给客户端。
综上所述
希望看完这篇文章,你可以了解不同的网络模块是如何协同工作的
引用的部分内容
http://blog.jobbole.com/33951/
浏览器抓取网页(用到一个神奇的库urllib.request.Request进行我们的模拟工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-18 22:29
urllib.error.HTTPError:HTTP 错误 403:禁止
从403 Forbidden我们可以发现,此时网站禁止程序的访问,这是因为csdn网站已经设置了反爬虫机制,当网站检测到一个爬虫,访问会被拒绝,所以我们会得到上面的结果。
这时候我们需要模拟浏览器访问,为了避开网站的反爬虫机制,然后顺利抓取我们想要的内容。
接下来,我们将使用一个神奇的库 urllib.request.Request 进行我们的模拟工作。这次我们先代码再讲解,不过这次要提醒一下,下面的代码不能直接使用。其中my_headers中的User-Agent替换为我自己的。因为我加了省略号保密,所以不能直接使用。替换方法如下图所示。这次为了使用方便,介绍一下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/")
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上面的代码,我们就可以正常抓取到这个网页的信息了,接下来介绍如何获取我们的getContent函数中需要用到的headers中的参数。
既然我们要模拟一个浏览器访问网页,这些参数自然需要我们在浏览器中搜索。
首先我们点击进入要爬取的网页,然后右击页面,点击review元素,会出现如下框架,然后我们点击Network,然后我们会发现我们所在页面的信息确实不出现,没关系,这时候我们刷新页面,就会出现下图所示的信息。
这时候我们会在第一行看到51251757,这就是我们网页的URL后面的标签。这时候,当我们点击这个标签的时候,就会出现下图所示的内容:
这是我现在通过直接访问此 URL 获得的屏幕截图:
前两张图,我以前写的是版本2的访问,现在直接用了。当时我在csdn主页上点击了这个博客,所以我在代码中填写了referer,在我的header中填写了前两张图片。是的
,而这张图是我直接通过URL链接进入浏览器的,所以从图中可以看出,referer是,这是我们的网站,贴在这里是为了让大家更好的理解这个referer . 不一样的画面。在这张图中,我用红线标出了需要填写的四个内容。测试的时候千万不要使用我给的User-Agent,因为我用省略号替换了一些。每个人都应该用自己的方式来弥补。
这时候我们会找到Headers,有没有亮眼的感觉,是的,你的直觉是对的,我们需要的信息就在这个Headers里面。
然后,根据代码中需要的参数,把信息复制回来使用,因为这里显示的信息正好对应key值,所以我们复制使用非常方便。
现在介绍一下这个urllib.request.Request的用法(翻译自官方文档):
class urllib.request.Request ( url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None ) 参数: url:不用说,这是我们要访问的URL,它是一个字符串。数据:数据必须是一个字节对象,指定要发送到服务器的附加数据,如果不需要,则为无。目前,只有 HTTP 请求使用数据;当提供数据参数时,HTTP 请求应该是 POST 而不是 GET。数据应以标准 application/x-www-form-urlencoded 格式缓冲。urllib.parse.urlencode() 函数采用映射或二进制序列并返回该格式的 ASCII 字符串。当用作数据参数时,应将其编码为字节。(我们暂时不会使用这个,所以不管它) headers:headers 是一个字符的典型数据。当使用键和值参数调用 add_header() 时,标头将作为请求处理。该标头通常用于防止爬虫访问服务器。header 是浏览器用来标识自己的,因为有些 HTTP 服务器只允许来自普通浏览器的请求,而不是脚本(可以理解为爬虫)。
这必然增加了网站服务器的处理负担,即一个网站必须在爬虫检测和网站服务器的计算负担之间做一个权衡,所以不是爬虫检测机制越严格越好,还要考虑服务器的负担。origin_req_host:origin_req_host 应该是原创事务请求的主机,由 RFC 2965 定义。默认为 http.cookiejar.request_host(self)。
这是用户发起的原创请求的主机名或 IP 地址。例如,如果请求是针对 HTML 文档中的图像,则这应该是请求收录图像的页面的主机。(我们一般不用这个,这里就知道了) unverifiable:unverifiable 应该表示请求是否不可验证,由 RFC 2965 定义,默认值为 false。无法验证的请求是指无法提交用户的 URL。例如,当用户在网页的html文档中找到一张图片,但用户没有权限从服务器获取图片时,此时unverifiable应该为true。method:method 应该是一个字符串,指示要使用的 HTTP 请求方法(例如“header”)。如果提供,它的值存储在方法属性中,并通过方法 get_method() 调用。子类可以通过设置类的方法属性来指示默认方法。(这个基本不用)说了这么多无聊的定义,自己翻译都受不了了。让我们继续回到我们的程序:对于我们的程序,只需抓住几个要点。首先,我们需要构造一个请求:req =Request(url),这个时候请求是空的,我们需要在里面添加信息,给浏览器看。
req.add_header("User-Agent", random_header) 告诉网络服务器我正在通过浏览器访问,我不是爬虫。req.add_header("GET",url)是告诉浏览器我们访问的URL,req.add_header("Host","")是网站的信息,我们从网站开始随便填一下,req.add_header("Referer","")这句话很重要,它告诉网站服务器我们在哪里找到了我们要访问的网页,比如你点击了百度如果一个link跳转到当前访问的页面,referer是百度中的链接,是一种判断机制。对标头的构造函数也可以这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/")
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
上面程序中看到,我们也可以直接构造header,但是这样做有一个缺陷,就是header中的User-Agent被写死了。其实我们可以发现,对于不同的电脑主机访问同一个网页时,我们的其他三个信息:GET、Host、Referer可能都是一样的。这时候就只有User-Agent作为判断用户异同的标准,那么问题来了,如果我们“借”一些同学的User-Agent来使用,岂不是更好玩?模拟多用户访问?其实这也是我刚开始的代码里的原因,所以有一个my_headers的列表,里面其实可以放多个User-Agent,然后通过random函数随机选择一个进行组合,然后创建一个用户,实现多访问的假象其实很有用。要知道,对于一个网站,当访问次数过多时,用户的ip会被屏蔽。这一点都不好玩,所以如果你想永久访问一个网站而不被抓住,还是需要很多技巧的。
当我们要爬取一个网站的多个网页时,由于主机访问频繁,很容易被网站检测到,进而被屏蔽。而如果我们把更多不同的主机号放在列表中,随意使用,是不是很容易被发现呢?当然,当我们为了防止这种情况,更好的方法是使用IP代理,因为我们不容易被发现。可以获得很多主机信息,IP代理也很容易从网上搜索到。关于多次访问的问题我会在以后的博客中解释,这里就不多说了。 查看全部
浏览器抓取网页(用到一个神奇的库urllib.request.Request进行我们的模拟工作)
urllib.error.HTTPError:HTTP 错误 403:禁止
从403 Forbidden我们可以发现,此时网站禁止程序的访问,这是因为csdn网站已经设置了反爬虫机制,当网站检测到一个爬虫,访问会被拒绝,所以我们会得到上面的结果。
这时候我们需要模拟浏览器访问,为了避开网站的反爬虫机制,然后顺利抓取我们想要的内容。
接下来,我们将使用一个神奇的库 urllib.request.Request 进行我们的模拟工作。这次我们先代码再讲解,不过这次要提醒一下,下面的代码不能直接使用。其中my_headers中的User-Agent替换为我自己的。因为我加了省略号保密,所以不能直接使用。替换方法如下图所示。这次为了使用方便,介绍一下功能:
#coding:utf - 8
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
req =Request(url)
req.add_header("User-Agent", random_header)
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://www.csdn.net/";)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53 。。。Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
使用上面的代码,我们就可以正常抓取到这个网页的信息了,接下来介绍如何获取我们的getContent函数中需要用到的headers中的参数。
既然我们要模拟一个浏览器访问网页,这些参数自然需要我们在浏览器中搜索。
首先我们点击进入要爬取的网页,然后右击页面,点击review元素,会出现如下框架,然后我们点击Network,然后我们会发现我们所在页面的信息确实不出现,没关系,这时候我们刷新页面,就会出现下图所示的信息。
这时候我们会在第一行看到51251757,这就是我们网页的URL后面的标签。这时候,当我们点击这个标签的时候,就会出现下图所示的内容:
这是我现在通过直接访问此 URL 获得的屏幕截图:
前两张图,我以前写的是版本2的访问,现在直接用了。当时我在csdn主页上点击了这个博客,所以我在代码中填写了referer,在我的header中填写了前两张图片。是的
,而这张图是我直接通过URL链接进入浏览器的,所以从图中可以看出,referer是,这是我们的网站,贴在这里是为了让大家更好的理解这个referer . 不一样的画面。在这张图中,我用红线标出了需要填写的四个内容。测试的时候千万不要使用我给的User-Agent,因为我用省略号替换了一些。每个人都应该用自己的方式来弥补。
这时候我们会找到Headers,有没有亮眼的感觉,是的,你的直觉是对的,我们需要的信息就在这个Headers里面。
然后,根据代码中需要的参数,把信息复制回来使用,因为这里显示的信息正好对应key值,所以我们复制使用非常方便。
现在介绍一下这个urllib.request.Request的用法(翻译自官方文档):
class urllib.request.Request ( url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None ) 参数: url:不用说,这是我们要访问的URL,它是一个字符串。数据:数据必须是一个字节对象,指定要发送到服务器的附加数据,如果不需要,则为无。目前,只有 HTTP 请求使用数据;当提供数据参数时,HTTP 请求应该是 POST 而不是 GET。数据应以标准 application/x-www-form-urlencoded 格式缓冲。urllib.parse.urlencode() 函数采用映射或二进制序列并返回该格式的 ASCII 字符串。当用作数据参数时,应将其编码为字节。(我们暂时不会使用这个,所以不管它) headers:headers 是一个字符的典型数据。当使用键和值参数调用 add_header() 时,标头将作为请求处理。该标头通常用于防止爬虫访问服务器。header 是浏览器用来标识自己的,因为有些 HTTP 服务器只允许来自普通浏览器的请求,而不是脚本(可以理解为爬虫)。
这必然增加了网站服务器的处理负担,即一个网站必须在爬虫检测和网站服务器的计算负担之间做一个权衡,所以不是爬虫检测机制越严格越好,还要考虑服务器的负担。origin_req_host:origin_req_host 应该是原创事务请求的主机,由 RFC 2965 定义。默认为 http.cookiejar.request_host(self)。
这是用户发起的原创请求的主机名或 IP 地址。例如,如果请求是针对 HTML 文档中的图像,则这应该是请求收录图像的页面的主机。(我们一般不用这个,这里就知道了) unverifiable:unverifiable 应该表示请求是否不可验证,由 RFC 2965 定义,默认值为 false。无法验证的请求是指无法提交用户的 URL。例如,当用户在网页的html文档中找到一张图片,但用户没有权限从服务器获取图片时,此时unverifiable应该为true。method:method 应该是一个字符串,指示要使用的 HTTP 请求方法(例如“header”)。如果提供,它的值存储在方法属性中,并通过方法 get_method() 调用。子类可以通过设置类的方法属性来指示默认方法。(这个基本不用)说了这么多无聊的定义,自己翻译都受不了了。让我们继续回到我们的程序:对于我们的程序,只需抓住几个要点。首先,我们需要构造一个请求:req =Request(url),这个时候请求是空的,我们需要在里面添加信息,给浏览器看。
req.add_header("User-Agent", random_header) 告诉网络服务器我正在通过浏览器访问,我不是爬虫。req.add_header("GET",url)是告诉浏览器我们访问的URL,req.add_header("Host","")是网站的信息,我们从网站开始随便填一下,req.add_header("Referer","")这句话很重要,它告诉网站服务器我们在哪里找到了我们要访问的网页,比如你点击了百度如果一个link跳转到当前访问的页面,referer是百度中的链接,是一种判断机制。对标头的构造函数也可以这样做:
#coding:utf - 8
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import random
import re
def getContent(url,headers):
"""
此函数用于抓取返回403禁止访问的网页
"""
random_header = random.choice(headers)
"""
对于Request中的第二个参数headers,它是字典型参数,所以在传入时
也可以直接将个字典传入,字典中就是下面元组的键值对应
"""
# req =Request(url)
# req.add_header("User-Agent", random_header)
# req.add_header("GET",url)
# req.add_header("Host","blog.csdn.net")
# req.add_header("Referer","http://www.csdn.net/";)
header = {"User-Agent": random_header, "GET": url, "Host": "blog.csdn.net", "Referer": "http://www.csdn.net/"}
req=Request(url,None,header)
content=urlopen(req).read().decode("utf-8")
return content
url="http://blog.csdn.net/beliefer/ ... ot%3B
#这里面的my_headers中的内容由于是个人主机的信息,所以我就用句号省略了一些,在使用时可以将自己主机的User-Agent放进去
my_headers = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/53。。。(KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"]
print(getContent(url,my_headers))
上面程序中看到,我们也可以直接构造header,但是这样做有一个缺陷,就是header中的User-Agent被写死了。其实我们可以发现,对于不同的电脑主机访问同一个网页时,我们的其他三个信息:GET、Host、Referer可能都是一样的。这时候就只有User-Agent作为判断用户异同的标准,那么问题来了,如果我们“借”一些同学的User-Agent来使用,岂不是更好玩?模拟多用户访问?其实这也是我刚开始的代码里的原因,所以有一个my_headers的列表,里面其实可以放多个User-Agent,然后通过random函数随机选择一个进行组合,然后创建一个用户,实现多访问的假象其实很有用。要知道,对于一个网站,当访问次数过多时,用户的ip会被屏蔽。这一点都不好玩,所以如果你想永久访问一个网站而不被抓住,还是需要很多技巧的。
当我们要爬取一个网站的多个网页时,由于主机访问频繁,很容易被网站检测到,进而被屏蔽。而如果我们把更多不同的主机号放在列表中,随意使用,是不是很容易被发现呢?当然,当我们为了防止这种情况,更好的方法是使用IP代理,因为我们不容易被发现。可以获得很多主机信息,IP代理也很容易从网上搜索到。关于多次访问的问题我会在以后的博客中解释,这里就不多说了。
浏览器抓取网页( 【】1.4、Chromedriver存放位置、下载对应的谷歌)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-18 10:00
【】1.4、Chromedriver存放位置、下载对应的谷歌)
1.3、下载对应的Google Drive:
点击进入
然后转到它并选择与chrome对应的版本。(比如我的chrome是85开头的,那么就从这么多85中选一个)
点击85开头的链接后跳转到新页面:不管你的Windows是32位还是64位,都只能下载win32.zip
1.4、Chromedriver存放位置
①先按win+r,输入cmd,进入cmd界面
② 输入 where python 可以看到python的安装路径
③打开这个python36(你可能是37版本或者其他版本,没关系)文件夹(可以把这个路径复制粘贴到文件夹上面)
④ 进入该文件夹后,我们可以看到scripts文件夹,将刚才下载的Chromedriver解压到scripts文件夹中。
Mac系统:
1、安装硒:
打开Mac终端终端并输入命令:
pip3 安装硒
如果出现读取超时错误,请复制并粘贴以下命令进行安装:
pip3 安装 -i 硒
2、安装谷歌浏览器驱动:
打开Mac终端终端并输入命令:
卷曲-s | 重击
只需等待程序安装完成。
安装mac终端时,需要输入用户密码。输入密码的时候是不显示的,实际上是在输入的,所以输入密码后按回车键开始安装。
其他方法:
二硒使用详解:
**本地 Chrome 设置:**两种方法:
2.1、可视模式 from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 将引擎设置为 Chrome 并实际打开 Chrome 浏览器
2.2、浏览器设置为静默模式,也就是说浏览器只在后台运行,在电脑上没有打开它的可视化界面。
from selenium import webdriver #调用selenium库中的webdriver模块
from selenium.webdriver.chrome.options import Options # 从 options 模块调用 Options 类
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('–headless') # 设置Chrome浏览器为静默模式
driver = webdriver.Chrome(options = chrome_options) # 设置引擎为Chrome,后台静默运行
三、Selenium 获取数据的方法:.get('URL') 3.1、Selenium 解析提取数据的方法
selenium 解析提取的是 Elements 中的所有数据,BeautifulSoup 解析的只是网络中第 0 个请求的响应。
从 selenium 中提取数据的示例:
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
find_element_by_tag_name:通过元素的名称选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_partial_link_text('你好')
示例代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个标签中的文字
print(type(label)) # 打印label的数据类型
print(label.text) # 打印label的文本
print(label) # 打印label
driver.close() # 关闭浏览器
提取的数据属于 WebElement 类对象。如果您直接打印它,它将返回其描述的字符串。
与 BeautifulSoup 中的 Tag 对象类似,它也有一个属性 .text,可以将提取的元素以字符串格式显示。
WebElement类对象和Tag对象类似,它也有一个可以通过属性名提取属性值的方法,这个方法是.get_attribute()
例子:
label = driver.find_element_by_class_name('teacher') # 按类名查找元素
print(type(label)) # 打印标签的数据类型
print(label.get_attribute('type')) # 获取属性类型的值,其中'type'是属性的名称,获取的是它的值。
driver.close() # 关闭浏览器
我们可以得出结论,在 selenium 解析和提取数据的过程中,我们操作的对象变换:
3.2、以上方法都是在网页中提取第一个满足要求的数据。接下来,我们来看看提取多个元素的方法。
方法是将刚才的元素替换为多个元素。
元素(复数)提取一个列表,. 列表的内容就是WebElements对象,这些符号就是对象的描述,需要用.text来返回它的文本内容。
3. 3、使用 BeautifulSoup 解析和提取数据
除了用selenium解析提取数据,还有一种解决方案,就是用selenium获取网页,然后交给BeautifulSoup解析提取。前提是先获取字符串格式的网页源代码。源代码被解析为 BeautifulSoup 对象,然后从中提取数据。
Selenium 只能获取渲染完整网页的源代码。
如何得到它?也是一种使用驱动的方式:page_source。
HTML 源代码字符串 = driver.page_source
获取示例网页源代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待两秒,等浏览器加缓冲载数据
pageSource = driver.page_source # 获取完整渲染的网页源代码
print(type(pageSource)) # 打印pageSource的类型
print(pageSource) # 打印pageSource
driver.close() # 关闭浏览器
Response 对象是通过 requests.get() 获得的。在交给 BeautifulSoup 解析之前,需要使用 .text 方法将 Response 对象的内容作为字符串返回。
使用 selenium 获得的网页的源代码本身已经是一个字符串。
获取到字符串格式的网页源代码后,就可以使用BeautifulSoup对数据进行解析提取。以下代码省略...
自动操作浏览器,控制浏览器自动输入文字,点击提交,主要是以下2行代码。
.send_keys() # 模拟按键输入,自动填表
.click() # 点击元素
有关详细信息,请参阅本文开头。
除了input和click这两种方法经常配合使用外,还有一个方法.clear(),用于清除元素的内容
如果空格打错了,如果要改成其他内容,需要先用.clear()清除,再填写新的文字。
四、最后写:
浏览器使用完毕后记得关闭,以免浪费资源,在代码末尾添加一行driver.close()即可。
至此,你应该可以感受到 Selenium 是一个强大的网络数据工具采集。它的优点是简单直观,但当然也有缺点。由于是真实模拟人对浏览器的操作,所以需要等待网页缓冲的时间,爬取大量数据时速度会比较慢。通常,在爬虫项目中,只有在其他方法无法解决或难以解决问题时才使用 selenium。
当然,除了爬虫,selenium 的使用场景还有很多。例如:可以控制网页中图片文件的显示,控制CSS和JavaScript的加载和执行等等。
这里只是一些简单常用的操作。如果想进一步了解,可以查阅 selenium 的官方文档链,目前只有英文版:
你也可以参考这个中文文档:
知识积累:
评论=driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li')
不等于:
a=driver.find_element_by_class_name('js_hot_list')
b=driver.find_elements_by_class_name('js_cmt_li')
相当于:
a=driver.find_element_by_class_name('js_hot_list')
b=a.find_elements_by_class_name('js_cmt_li') 查看全部
浏览器抓取网页(
【】1.4、Chromedriver存放位置、下载对应的谷歌)
1.3、下载对应的Google Drive:
点击进入
然后转到它并选择与chrome对应的版本。(比如我的chrome是85开头的,那么就从这么多85中选一个)
点击85开头的链接后跳转到新页面:不管你的Windows是32位还是64位,都只能下载win32.zip
1.4、Chromedriver存放位置
①先按win+r,输入cmd,进入cmd界面
② 输入 where python 可以看到python的安装路径
③打开这个python36(你可能是37版本或者其他版本,没关系)文件夹(可以把这个路径复制粘贴到文件夹上面)
④ 进入该文件夹后,我们可以看到scripts文件夹,将刚才下载的Chromedriver解压到scripts文件夹中。
Mac系统:
1、安装硒:
打开Mac终端终端并输入命令:
pip3 安装硒
如果出现读取超时错误,请复制并粘贴以下命令进行安装:
pip3 安装 -i 硒
2、安装谷歌浏览器驱动:
打开Mac终端终端并输入命令:
卷曲-s | 重击
只需等待程序安装完成。
安装mac终端时,需要输入用户密码。输入密码的时候是不显示的,实际上是在输入的,所以输入密码后按回车键开始安装。
其他方法:
二硒使用详解:
**本地 Chrome 设置:**两种方法:
2.1、可视模式 from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 将引擎设置为 Chrome 并实际打开 Chrome 浏览器
2.2、浏览器设置为静默模式,也就是说浏览器只在后台运行,在电脑上没有打开它的可视化界面。
from selenium import webdriver #调用selenium库中的webdriver模块
from selenium.webdriver.chrome.options import Options # 从 options 模块调用 Options 类
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('–headless') # 设置Chrome浏览器为静默模式
driver = webdriver.Chrome(options = chrome_options) # 设置引擎为Chrome,后台静默运行
三、Selenium 获取数据的方法:.get('URL') 3.1、Selenium 解析提取数据的方法
selenium 解析提取的是 Elements 中的所有数据,BeautifulSoup 解析的只是网络中第 0 个请求的响应。
从 selenium 中提取数据的示例:
# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
find_element_by_tag_name:通过元素的名称选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如你好,蜘蛛侠!
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如你好,蜘蛛侠!
# 可以使用find_element_by_partial_link_text('你好')
示例代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个标签中的文字
print(type(label)) # 打印label的数据类型
print(label.text) # 打印label的文本
print(label) # 打印label
driver.close() # 关闭浏览器
提取的数据属于 WebElement 类对象。如果您直接打印它,它将返回其描述的字符串。
与 BeautifulSoup 中的 Tag 对象类似,它也有一个属性 .text,可以将提取的元素以字符串格式显示。
WebElement类对象和Tag对象类似,它也有一个可以通过属性名提取属性值的方法,这个方法是.get_attribute()
例子:
label = driver.find_element_by_class_name('teacher') # 按类名查找元素
print(type(label)) # 打印标签的数据类型
print(label.get_attribute('type')) # 获取属性类型的值,其中'type'是属性的名称,获取的是它的值。
driver.close() # 关闭浏览器
我们可以得出结论,在 selenium 解析和提取数据的过程中,我们操作的对象变换:
3.2、以上方法都是在网页中提取第一个满足要求的数据。接下来,我们来看看提取多个元素的方法。
方法是将刚才的元素替换为多个元素。
元素(复数)提取一个列表,. 列表的内容就是WebElements对象,这些符号就是对象的描述,需要用.text来返回它的文本内容。
3. 3、使用 BeautifulSoup 解析和提取数据
除了用selenium解析提取数据,还有一种解决方案,就是用selenium获取网页,然后交给BeautifulSoup解析提取。前提是先获取字符串格式的网页源代码。源代码被解析为 BeautifulSoup 对象,然后从中提取数据。
Selenium 只能获取渲染完整网页的源代码。
如何得到它?也是一种使用驱动的方式:page_source。
HTML 源代码字符串 = driver.page_source
获取示例网页源代码:
# 教学系统的浏览器设置方法
from selenium.webdriver.chrome.webdriver import RemoteWebDriver # 从selenium库中调用RemoteWebDriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
import time
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-cla ... ot%3B, chrome_options.to_capabilities()) # 声明浏览器对象
driver.get('https://localprod.pandateacher ... %2339;) # 访问页面
time.sleep(2) # 等待两秒,等浏览器加缓冲载数据
pageSource = driver.page_source # 获取完整渲染的网页源代码
print(type(pageSource)) # 打印pageSource的类型
print(pageSource) # 打印pageSource
driver.close() # 关闭浏览器
Response 对象是通过 requests.get() 获得的。在交给 BeautifulSoup 解析之前,需要使用 .text 方法将 Response 对象的内容作为字符串返回。
使用 selenium 获得的网页的源代码本身已经是一个字符串。
获取到字符串格式的网页源代码后,就可以使用BeautifulSoup对数据进行解析提取。以下代码省略...
自动操作浏览器,控制浏览器自动输入文字,点击提交,主要是以下2行代码。
.send_keys() # 模拟按键输入,自动填表
.click() # 点击元素
有关详细信息,请参阅本文开头。
除了input和click这两种方法经常配合使用外,还有一个方法.clear(),用于清除元素的内容
如果空格打错了,如果要改成其他内容,需要先用.clear()清除,再填写新的文字。
四、最后写:
浏览器使用完毕后记得关闭,以免浪费资源,在代码末尾添加一行driver.close()即可。
至此,你应该可以感受到 Selenium 是一个强大的网络数据工具采集。它的优点是简单直观,但当然也有缺点。由于是真实模拟人对浏览器的操作,所以需要等待网页缓冲的时间,爬取大量数据时速度会比较慢。通常,在爬虫项目中,只有在其他方法无法解决或难以解决问题时才使用 selenium。
当然,除了爬虫,selenium 的使用场景还有很多。例如:可以控制网页中图片文件的显示,控制CSS和JavaScript的加载和执行等等。
这里只是一些简单常用的操作。如果想进一步了解,可以查阅 selenium 的官方文档链,目前只有英文版:
你也可以参考这个中文文档:
知识积累:
评论=driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li')
不等于:
a=driver.find_element_by_class_name('js_hot_list')
b=driver.find_elements_by_class_name('js_cmt_li')
相当于:
a=driver.find_element_by_class_name('js_hot_list')
b=a.find_elements_by_class_name('js_cmt_li')
浏览器抓取网页(用到动态网页抓取的两种技术:(2)使用selenium模拟浏览器 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2022-03-18 09:28
)
关于静态网页
我们知道,静态网页在浏览器中显示的内容是在 HTML 源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种技术进行动态网页抓取:
(1)通过浏览器检查元素解析真实网址
(2)使用selenium模拟浏览器的方法
异步更新技术
AJAX(异步 Javascript 和 XML,异步 JavaScript 和 XML)
它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量。
解析真实网址
我们的目标是抓取目标 文章 上的所有评论。
(1)首先,打开网页的“检查”功能。
(2)找到真正的数据地址。点击页面中的网络选项,然后刷新页面。这个过程一般称为“抓包”。
(3)找到真实评论的数据地址,然后使用requests请求这个地址获取数据。
import requests
import json
link = 'https://api-zero.livere.com/v1 ... 39%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print(r.text)
(4)从json数据中提取评论。上面的结果比较乱,其实是json数据,我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4): #打印前4页的评论
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
(5)以上只是爬取文章的评论第一页,很简单。其实我们经常需要爬取所有页面,如果还是手动逐页翻页的话找到评论数据地址是很费力的,所以下面将介绍网页URL地址的规则,并使用for循环进行爬取,会很容易的。
如果我们对比上面的两个地址,可以发现URL地址中有两个特别重要的变量,offset和limit。稍微了解一下,我们可以知道limit代表每页最大评论数,也就是说,这里每页最多可以显示30条评论;offset表示页数,第一页的偏移量为0,第二页的偏移量为1,那么第三页的偏移量为3。
因此,我们只需要改变URL中offset的值,就可以实现换页。
通过Selenium模拟浏览器捕获一、Selenium+Python环境搭建和配置
1.1 硒简介
Selenium 是一个用于 Web 的自动化测试工具。许多学习功能自动化的学生开始偏爱 selenium,因为它与 QTP 相比具有许多优点:
(1)免费,破解QTP不再头疼
(2)小,只是针对不同语言的一个包,QTP需要下载安装1G以上的程序。这也是最重要的一点,不管你对C、java、 ruby, python, 或者全是C#,可以通过selenium完成自动化测试,QTP只支持VBS,selenium支持多平台:windows,linux,MAC,支持多浏览器:ie,firefox,safari,opera,chrome
1.2 selenium+Python环境配置
前提条件:Python开发环境已经安装(建议安装Python3.5及以上)
安装步骤:
(1)安装硒
赢:pip install selenium
Mac:pip3 安装硒
(2)安装网络驱动程序
火狐:
铬合金:
(3)这里我以 Windows Chrome 为例:
比如我的版本是:version 80.0.3987.122(正式版)(64位)
然后下载80.0.3937.106
注意:webdriver需要对应对应的浏览器版本和selenium版本
二、元素定位和浏览器基本操作2.1 启动浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
2.2 使用 Selenium 选择元素(1)id 定位
find_element_by_id()
例如
文本
您可以使用 find_element_by_id("bdy-inner")
(2)名称位置
find_element_by_name()
例如,您可以使用 find_element_by_name("username")
(3)class_name 定位
class 标准属性,不是唯一的,通常找一个类的元素
find_element_by_class_name()
例如
测试
您可以使用 find_element_by_class_name("cheese")
还有另一个函数可以选择元素的类属性:
find_element_by_css_selector()
例如
测试
您可以使用 find_element_by_css_selector()("div.cheese")
(4)tag_name 定位
driver.find_element_by_tag_name()
按元素名称选择,如 Welcome 可以使用 driver.find_element_by_tag_name('h1')
(5)按链接地址定位
find_element_by_link_text()
例如,继续可以使用 driver.find_element_by_link_text("Continue")
(6)由链接的部分地址选择
find_element_by_partial_link_text()
例如,继续可以使用 driver.find_element_by_partial_link_text("Conti")
(7)通过 xpath 选择
find_element_by_xpath()
例如,您可以使用 driver.find_element_by_xpath("//form[@id='loginForm']")
有时,我们需要查找多个元素,只需在上面的元素后添加 s 即可。
其中,xpath 和 css_selector 是比较好的方法。一方面相对清晰,另一方面相对于其他方法定位元素更准确。
Selenium 的高级操作:
(1)控制 CSS 的加载。
(2)控制图像文件的显示。
(3)控制 JavaScript 的执行。
这三种方法可以加快 Selenium 的爬行速度。
或者,您可以使用 Selenium 的 click 方法来操作元素。操作元素的常用方法如下:
(1)Clear 清除元素的内容
(2)send_keys 模拟按键输入
(3)Click 点击元素
(4)Submit 提交表单
例如:
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear() #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear() #清除密码输入框的内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #单击登录
一个具体的例子,比如我要打开百度,然后自动查询“你的名字”:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
input_text = driver.find_element_by_id("kw")
input_text.send_keys("你的名字")
driver.find_element_by_id("su").click()
查看全部
浏览器抓取网页(用到动态网页抓取的两种技术:(2)使用selenium模拟浏览器
)
关于静态网页
我们知道,静态网页在浏览器中显示的内容是在 HTML 源代码中的。但是由于主流的网站都使用JavaScript来展示网页内容,不像静态网页,在使用JavaScript的时候,很多内容不会出现在HTML源代码中,所以爬取静态网页的技术可能不会工作正常使用。因此,我们需要使用两种技术进行动态网页抓取:
(1)通过浏览器检查元素解析真实网址
(2)使用selenium模拟浏览器的方法
异步更新技术
AJAX(异步 Javascript 和 XML,异步 JavaScript 和 XML)
它的价值在于可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量。
解析真实网址
我们的目标是抓取目标 文章 上的所有评论。
(1)首先,打开网页的“检查”功能。
(2)找到真正的数据地址。点击页面中的网络选项,然后刷新页面。这个过程一般称为“抓包”。
(3)找到真实评论的数据地址,然后使用requests请求这个地址获取数据。
import requests
import json
link = 'https://api-zero.livere.com/v1 ... 39%3B
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
print(r.text)
(4)从json数据中提取评论。上面的结果比较乱,其实是json数据,我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4): #打印前4页的评论
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
(5)以上只是爬取文章的评论第一页,很简单。其实我们经常需要爬取所有页面,如果还是手动逐页翻页的话找到评论数据地址是很费力的,所以下面将介绍网页URL地址的规则,并使用for循环进行爬取,会很容易的。
如果我们对比上面的两个地址,可以发现URL地址中有两个特别重要的变量,offset和limit。稍微了解一下,我们可以知道limit代表每页最大评论数,也就是说,这里每页最多可以显示30条评论;offset表示页数,第一页的偏移量为0,第二页的偏移量为1,那么第三页的偏移量为3。
因此,我们只需要改变URL中offset的值,就可以实现换页。
通过Selenium模拟浏览器捕获一、Selenium+Python环境搭建和配置
1.1 硒简介
Selenium 是一个用于 Web 的自动化测试工具。许多学习功能自动化的学生开始偏爱 selenium,因为它与 QTP 相比具有许多优点:
(1)免费,破解QTP不再头疼
(2)小,只是针对不同语言的一个包,QTP需要下载安装1G以上的程序。这也是最重要的一点,不管你对C、java、 ruby, python, 或者全是C#,可以通过selenium完成自动化测试,QTP只支持VBS,selenium支持多平台:windows,linux,MAC,支持多浏览器:ie,firefox,safari,opera,chrome
1.2 selenium+Python环境配置
前提条件:Python开发环境已经安装(建议安装Python3.5及以上)
安装步骤:
(1)安装硒
赢:pip install selenium
Mac:pip3 安装硒
(2)安装网络驱动程序
火狐:
铬合金:
(3)这里我以 Windows Chrome 为例:
比如我的版本是:version 80.0.3987.122(正式版)(64位)
然后下载80.0.3937.106
注意:webdriver需要对应对应的浏览器版本和selenium版本
二、元素定位和浏览器基本操作2.1 启动浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
2.2 使用 Selenium 选择元素(1)id 定位
find_element_by_id()
例如
文本
您可以使用 find_element_by_id("bdy-inner")
(2)名称位置
find_element_by_name()
例如,您可以使用 find_element_by_name("username")
(3)class_name 定位
class 标准属性,不是唯一的,通常找一个类的元素
find_element_by_class_name()
例如
测试
您可以使用 find_element_by_class_name("cheese")
还有另一个函数可以选择元素的类属性:
find_element_by_css_selector()
例如
测试
您可以使用 find_element_by_css_selector()("div.cheese")
(4)tag_name 定位
driver.find_element_by_tag_name()
按元素名称选择,如 Welcome 可以使用 driver.find_element_by_tag_name('h1')
(5)按链接地址定位
find_element_by_link_text()
例如,继续可以使用 driver.find_element_by_link_text("Continue")
(6)由链接的部分地址选择
find_element_by_partial_link_text()
例如,继续可以使用 driver.find_element_by_partial_link_text("Conti")
(7)通过 xpath 选择
find_element_by_xpath()
例如,您可以使用 driver.find_element_by_xpath("//form[@id='loginForm']")
有时,我们需要查找多个元素,只需在上面的元素后添加 s 即可。
其中,xpath 和 css_selector 是比较好的方法。一方面相对清晰,另一方面相对于其他方法定位元素更准确。
Selenium 的高级操作:
(1)控制 CSS 的加载。
(2)控制图像文件的显示。
(3)控制 JavaScript 的执行。
这三种方法可以加快 Selenium 的爬行速度。
或者,您可以使用 Selenium 的 click 方法来操作元素。操作元素的常用方法如下:
(1)Clear 清除元素的内容
(2)send_keys 模拟按键输入
(3)Click 点击元素
(4)Submit 提交表单
例如:
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear() #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear() #清除密码输入框的内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #单击登录
一个具体的例子,比如我要打开百度,然后自动查询“你的名字”:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
input_text = driver.find_element_by_id("kw")
input_text.send_keys("你的名字")
driver.find_element_by_id("su").click()

