
浏览器抓取网页
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-21 23:14
前言
Selenium是一个模拟浏览器的自动化执行框架,但是如果每次执行都要打开浏览器处理任务,效率不高。最重要的是,如果安装在Centos7服务器环境下,打开浏览器模拟操作比较不合适,尤其是需要截取网页图片的时候。
这时候可以考虑使用Chrome的无头浏览器模式。所谓无头浏览器模式,不需要打开浏览器,但是可以模拟打开浏览器的执行效果,一切都是无界面执行的。
下面我们来看看如何安装部署到执行。
1.安装chrome1.1 添加谷歌的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般都是访问国内的镜像地址,如下:
可以看到有很多版本可供下载。从上面可以看到chrome版本号Google Chrome79.0.3945.79,所以大致按照版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver,说明环境配置已经生效。
3. 安装硒
Selenium 可以简单地用 pip 安装在你项目的虚拟环境中
pip3 install selenium
4. 脚本测试
编写一个 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下操作:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
只需下载并检查图片,
可以看到已经可以正常模拟浏览器登录了,并且截取了网页的图片。从图中可以看出,只要有中文,就会显示方框符号。这是因为Centos7默认没有安装中文字体,所以在打开Chrom浏览器时无法正常显示中文。
解决办法是安装Centos7的中文字体,这里就不介绍了。 查看全部
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
前言
Selenium是一个模拟浏览器的自动化执行框架,但是如果每次执行都要打开浏览器处理任务,效率不高。最重要的是,如果安装在Centos7服务器环境下,打开浏览器模拟操作比较不合适,尤其是需要截取网页图片的时候。
这时候可以考虑使用Chrome的无头浏览器模式。所谓无头浏览器模式,不需要打开浏览器,但是可以模拟打开浏览器的执行效果,一切都是无界面执行的。
下面我们来看看如何安装部署到执行。
1.安装chrome1.1 添加谷歌的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般都是访问国内的镜像地址,如下:
可以看到有很多版本可供下载。从上面可以看到chrome版本号Google Chrome79.0.3945.79,所以大致按照版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver,说明环境配置已经生效。
3. 安装硒
Selenium 可以简单地用 pip 安装在你项目的虚拟环境中
pip3 install selenium
4. 脚本测试
编写一个 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下操作:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
只需下载并检查图片,
可以看到已经可以正常模拟浏览器登录了,并且截取了网页的图片。从图中可以看出,只要有中文,就会显示方框符号。这是因为Centos7默认没有安装中文字体,所以在打开Chrom浏览器时无法正常显示中文。
解决办法是安装Centos7的中文字体,这里就不介绍了。
浏览器抓取网页(R语言利用RSelenium包或者Rwebdriver模拟浏览器异步加载等难爬取的网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-21 00:21
Python使用selenium模拟浏览器抓取异步加载等难抓取页面信息背景
在我之前的文章《R语言使用RSelenium包或者Rwebdriver模拟浏览器爬取异步加载等难爬的网页信息》中提到过
这次我将添加上一篇博客中提到的python实现。其他背景和一些包的介绍将不再解释。
程序说明
从中文起点抓取信息后,存储到本地MySQL数据库中。有一些处理的细节,我在这里提一下:
1、 部分数据不计分,使用try...except...pass语句处理,避免出错和数据格式不一致;
2、不知道为什么,Firefox总是爬500多本书(不超过1000)而且总是提示crash,所以我设置在这里,每次爬300本书)本书重启浏览器,虽然会延迟时间,但是避免了浏览器崩溃。另外,使用谷歌浏览器抓取时总是出现启动问题,换几个版本也不好。它不像 Firefox 那样容易使用。
3、因为一一写入数据库太慢,全部不适合。我也用和上面第二个一样的设置,用300条记录批量写入一次。
代码
所有代码都贴在下面供您参考。基本学会了模拟浏览器,大部分网页都可以爬取。另一个是速度问题,当然最好不要使用浏览器。
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 28 11:32:42 2017
@author: tiger
"""
from selenium import webdriver
from bs4 import BeautifulSoup
import datetime
import random
import requests
import MySQLdb
######获取所有的入选书籍页面链接
# 获得进入每部书籍相应的页面链接
def get_link(soup_page):
soup = soup_page
items = soup('div','book-mid-info')
## 提取链接
links = []
for item in items:
links.append('https:'+item.h4.a.get('href'))
return links
### 进入每个链接,提取需要的信息
def get_book_info(link):
driver.get(link)
#soup = BeautifulSoup(driver.page_source)
#根据日期随机分配的id
book_id=datetime.datetime.now().strftime("%Y%m%d%H%M%S")+str(random.randint(1000,9999))
### 名称
title = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/em").text
### 作者
author = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/span/a").text
###类型
types = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/a").text
###状态
status = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/span[1]").text
###字数
words = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[1]").text
###点击
cliks = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[2]").text
###推荐
recoms = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[3]").text
### 评论数
try :
votes = driver.find_element_by_xpath("//p[@id='j_userCount']/span").text
except (ZeroDivisionError,Exception) as e:
votes=0
print e
pass
#### 评分
score = driver.find_element_by_id("j_bookScore").text
##其他信息
info = driver.find_element_by_xpath("//div[@class='book-intro']").text.replace('\n','')
return (book_id,title,author,types,status,words,cliks,recoms,votes,score,info)
#############保持数据到mysql
def to_sql(data):
conn=MySQLdb.connect("localhost","root","tiger","test",charset="utf8" )
cursor = conn.cursor()
sql_create_database = 'create database if not exists test'
cursor.execute(sql_create_database)
# try :
# cursor.select_db('test')
# except (ZeroDivisionError,Exception) as e:
# print e
#cursor.execute("set names gb2312")
cursor.execute('''create table if not exists test.tiger_book2(book_id bigint(80),
title varchar(50),
author varchar(50),
types varchar(30),
status varchar(20),
words numeric(8,2),
cliks numeric(10,2),
recoms numeric(8,2),
votes varchar(20),
score varchar(20),
info varchar(3000),
primary key (book_id));''')
cursor.executemany('insert ignore into test.tiger_book2 values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);',data)
cursor.execute('select * from test.tiger_book2 limit 5;')
conn.commit()
cursor.close()
conn.close()
#####进入每部影片的介绍页面提取信息
base_url = "http://a.qidian.com/%3Fsize%3D ... ot%3B
links = []
Max_Page = 30090
rank = 0
for page in range(1,Max_Page+1):
print "Processing Page ",page,".Please wait..."
CurrentUrl = base_url +unicode(page)+u'&month=-1&style=1&action=-1&vip=-1'
CurrentSoup = BeautifulSoup(requests.get(CurrentUrl).text,"lxml")
links.append(get_link(CurrentSoup))
#sleep(1)
print links[9][19]
### 获得所有书籍信息
books = []
rate = 1
driver = webdriver.Firefox()
for i in range(0,Max_Page):
for j in range(0,20):
try:
print "Getting information of the",rate,"-th book."
books.append(get_book_info(links[i][j]))
#sleep(0.8)
except Exception,e:
print e
rate+=1
if i % 15 ==0 :
driver.quit()
#写入数据库
to_sql(books)
books=[]
driver = webdriver.Firefox()
driver.quit()
to_sql(books)
###添加id
#n=len(books)
#books=zip(*books)
#books.insert(0,range(1,n+1))
#books=zip(*books)
##print books[198]
4、 比较
Python比R更容易安装Selenium,不需要在命令提示符下启动selenium。然而,在没有性能优化的情况下,R 速度更快,编码问题也相对较少。 查看全部
浏览器抓取网页(R语言利用RSelenium包或者Rwebdriver模拟浏览器异步加载等难爬取的网页信息)
Python使用selenium模拟浏览器抓取异步加载等难抓取页面信息背景
在我之前的文章《R语言使用RSelenium包或者Rwebdriver模拟浏览器爬取异步加载等难爬的网页信息》中提到过
这次我将添加上一篇博客中提到的python实现。其他背景和一些包的介绍将不再解释。
程序说明
从中文起点抓取信息后,存储到本地MySQL数据库中。有一些处理的细节,我在这里提一下:
1、 部分数据不计分,使用try...except...pass语句处理,避免出错和数据格式不一致;
2、不知道为什么,Firefox总是爬500多本书(不超过1000)而且总是提示crash,所以我设置在这里,每次爬300本书)本书重启浏览器,虽然会延迟时间,但是避免了浏览器崩溃。另外,使用谷歌浏览器抓取时总是出现启动问题,换几个版本也不好。它不像 Firefox 那样容易使用。
3、因为一一写入数据库太慢,全部不适合。我也用和上面第二个一样的设置,用300条记录批量写入一次。
代码
所有代码都贴在下面供您参考。基本学会了模拟浏览器,大部分网页都可以爬取。另一个是速度问题,当然最好不要使用浏览器。
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 28 11:32:42 2017
@author: tiger
"""
from selenium import webdriver
from bs4 import BeautifulSoup
import datetime
import random
import requests
import MySQLdb
######获取所有的入选书籍页面链接
# 获得进入每部书籍相应的页面链接
def get_link(soup_page):
soup = soup_page
items = soup('div','book-mid-info')
## 提取链接
links = []
for item in items:
links.append('https:'+item.h4.a.get('href'))
return links
### 进入每个链接,提取需要的信息
def get_book_info(link):
driver.get(link)
#soup = BeautifulSoup(driver.page_source)
#根据日期随机分配的id
book_id=datetime.datetime.now().strftime("%Y%m%d%H%M%S")+str(random.randint(1000,9999))
### 名称
title = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/em").text
### 作者
author = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/span/a").text
###类型
types = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/a").text
###状态
status = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/span[1]").text
###字数
words = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[1]").text
###点击
cliks = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[2]").text
###推荐
recoms = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[3]").text
### 评论数
try :
votes = driver.find_element_by_xpath("//p[@id='j_userCount']/span").text
except (ZeroDivisionError,Exception) as e:
votes=0
print e
pass
#### 评分
score = driver.find_element_by_id("j_bookScore").text
##其他信息
info = driver.find_element_by_xpath("//div[@class='book-intro']").text.replace('\n','')
return (book_id,title,author,types,status,words,cliks,recoms,votes,score,info)
#############保持数据到mysql
def to_sql(data):
conn=MySQLdb.connect("localhost","root","tiger","test",charset="utf8" )
cursor = conn.cursor()
sql_create_database = 'create database if not exists test'
cursor.execute(sql_create_database)
# try :
# cursor.select_db('test')
# except (ZeroDivisionError,Exception) as e:
# print e
#cursor.execute("set names gb2312")
cursor.execute('''create table if not exists test.tiger_book2(book_id bigint(80),
title varchar(50),
author varchar(50),
types varchar(30),
status varchar(20),
words numeric(8,2),
cliks numeric(10,2),
recoms numeric(8,2),
votes varchar(20),
score varchar(20),
info varchar(3000),
primary key (book_id));''')
cursor.executemany('insert ignore into test.tiger_book2 values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);',data)
cursor.execute('select * from test.tiger_book2 limit 5;')
conn.commit()
cursor.close()
conn.close()
#####进入每部影片的介绍页面提取信息
base_url = "http://a.qidian.com/%3Fsize%3D ... ot%3B
links = []
Max_Page = 30090
rank = 0
for page in range(1,Max_Page+1):
print "Processing Page ",page,".Please wait..."
CurrentUrl = base_url +unicode(page)+u'&month=-1&style=1&action=-1&vip=-1'
CurrentSoup = BeautifulSoup(requests.get(CurrentUrl).text,"lxml")
links.append(get_link(CurrentSoup))
#sleep(1)
print links[9][19]
### 获得所有书籍信息
books = []
rate = 1
driver = webdriver.Firefox()
for i in range(0,Max_Page):
for j in range(0,20):
try:
print "Getting information of the",rate,"-th book."
books.append(get_book_info(links[i][j]))
#sleep(0.8)
except Exception,e:
print e
rate+=1
if i % 15 ==0 :
driver.quit()
#写入数据库
to_sql(books)
books=[]
driver = webdriver.Firefox()
driver.quit()
to_sql(books)
###添加id
#n=len(books)
#books=zip(*books)
#books.insert(0,range(1,n+1))
#books=zip(*books)
##print books[198]
4、 比较
Python比R更容易安装Selenium,不需要在命令提示符下启动selenium。然而,在没有性能优化的情况下,R 速度更快,编码问题也相对较少。
浏览器抓取网页(示例2.右击word参数就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-20 04:15
1.先打开要爬取的网页,这里我觉得是个例子
2.在网页的属性上右击,直接点击check或者F12进入调试,效果如下
3.然后在搜索框中输入教父
搜索后,我们可以看到数据发生了变化。我们打开上图中Name栏中红线标注的部分。请求 URL 就是我们需要的 API。此 API 用于搜索歌曲。我们可以分析 URL 中的参数。知道它的参数。这个API返回的是json数据类型,word参数就是我们刚才查询的关键字。只是将你刚才搜索到的内容转换成URL编码格式而已。所以我们在调用这个API的时候,需要把关键字转换成URl代码,然后传入。
3.测试API
这里做一个简单的测试,代码如下
package weather;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Scanner;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class SearcheWeather {
public static void main(String[] args) {
StringBuffer buffer=new StringBuffer();
try {
Scanner input=new Scanner(System.in);
System.out.print("请输入要查询的音乐:");
String iput=input.next();
//转换为url编码
String urlStr = URLEncoder.encode(iput, "utf-8");
System.out.println(urlStr);
//1.建立url
URL url=new URL("http://sug.qianqian.com/info/s ... 6quot;);
//2.打开http连接
HttpURLConnection httpUrlConn=(HttpURLConnection)url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
httpUrlConn.connect();
//获得输入
InputStream inputStream=httpUrlConn.getInputStream();
InputStreamReader inputStreamReader=new InputStreamReader(inputStream,"utf-8");
BufferedReader bufferReader=new BufferedReader(inputStreamReader);
//将bufferReader放入到Buff里面
String str=null;
while ((str=bufferReader.readLine())!=null) {
buffer.append(str);
}
bufferReader.close();
inputStreamReader.close();
inputStream.close();
inputStream=null;
//断开连接
httpUrlConn.disconnect();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(buffer.toString());
}
}
运行结果如下:
在 web 应用中,需要将缓冲区转换为 JSON 数据类型。
不同的API参数类型也不同,需要观察数据的变化进行分析,仅供参考。
---------结束 查看全部
浏览器抓取网页(示例2.右击word参数就是)
1.先打开要爬取的网页,这里我觉得是个例子

2.在网页的属性上右击,直接点击check或者F12进入调试,效果如下

3.然后在搜索框中输入教父

搜索后,我们可以看到数据发生了变化。我们打开上图中Name栏中红线标注的部分。请求 URL 就是我们需要的 API。此 API 用于搜索歌曲。我们可以分析 URL 中的参数。知道它的参数。这个API返回的是json数据类型,word参数就是我们刚才查询的关键字。只是将你刚才搜索到的内容转换成URL编码格式而已。所以我们在调用这个API的时候,需要把关键字转换成URl代码,然后传入。
3.测试API
这里做一个简单的测试,代码如下
package weather;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Scanner;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class SearcheWeather {
public static void main(String[] args) {
StringBuffer buffer=new StringBuffer();
try {
Scanner input=new Scanner(System.in);
System.out.print("请输入要查询的音乐:");
String iput=input.next();
//转换为url编码
String urlStr = URLEncoder.encode(iput, "utf-8");
System.out.println(urlStr);
//1.建立url
URL url=new URL("http://sug.qianqian.com/info/s ... 6quot;);
//2.打开http连接
HttpURLConnection httpUrlConn=(HttpURLConnection)url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
httpUrlConn.connect();
//获得输入
InputStream inputStream=httpUrlConn.getInputStream();
InputStreamReader inputStreamReader=new InputStreamReader(inputStream,"utf-8");
BufferedReader bufferReader=new BufferedReader(inputStreamReader);
//将bufferReader放入到Buff里面
String str=null;
while ((str=bufferReader.readLine())!=null) {
buffer.append(str);
}
bufferReader.close();
inputStreamReader.close();
inputStream.close();
inputStream=null;
//断开连接
httpUrlConn.disconnect();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(buffer.toString());
}
}
运行结果如下:

在 web 应用中,需要将缓冲区转换为 JSON 数据类型。
不同的API参数类型也不同,需要观察数据的变化进行分析,仅供参考。
---------结束
浏览器抓取网页(Python中urllib库Python2系列使用的步骤和访问步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 15:18
)
一:获取一个简单的页面:
用Python做爬虫爬取网站 这个功能很强大。今天尝试爬取百度主页。它成功了。让我们来看看步骤。
首先,你需要准备工具:
1.python:比较喜欢用新东西,所以用Python3.6,python下载地址:
2.开发工具:可以使用Python编译器(小),但是因为我是前端,之前用过webstrom,所以选择了JetBrains的PyCharm。下载地址:%E4%B8%8B%E8 %BD%BD
3.Fiddler - 网页请求监控工具,我们可以通过它来了解用户触发网页请求后发生的详细步骤;(从百度下载)
理解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中。
在 2:
urllib2.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib2.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
3 是
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
#这个函数看起来接受很多的参数啊,不过很多我们平时不会用到,用到的url居多。
显然,我使用后者
简单的爬虫代码
#encoding:UTF-8
import urllib.request
url = "https://www.douban.com/ "
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
效果如下:
二:捕获需要伪装浏览器的网站
但是一个小小的百度主页怎么能满足我,于是想到了一些网站,需要伪装浏览器才能爬取,比如豆瓣,
1.伪装浏览器:
对于一些需要登录的网站,如果请求不是从浏览器发出的,将得不到响应。因此,我们需要将爬虫程序发送的请求伪装成普通浏览器。
具体实现:自定义网页请求头。
2.,使用Fiddler查看请求和响应头
打开工具 Fiddler,然后在浏览器中访问“”。在Fiddler左侧的访问记录中,找到条目“200 HTTPS”,点击查看对应请求和响应头的具体内容:
3. 访问:
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context
# 定义保存函数
def saveFile(data):
path = "F:\\pachong\\02_douban.out"
f = open(path, 'wb')
f.write(data)
f.close()
# 网址
url = "https://www.douban.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
# 也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
# 打印抓取的内容
print(data)
# 打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
让我们看看这段代码:
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context 查看全部
浏览器抓取网页(Python中urllib库Python2系列使用的步骤和访问步骤
)
一:获取一个简单的页面:
用Python做爬虫爬取网站 这个功能很强大。今天尝试爬取百度主页。它成功了。让我们来看看步骤。
首先,你需要准备工具:
1.python:比较喜欢用新东西,所以用Python3.6,python下载地址:
2.开发工具:可以使用Python编译器(小),但是因为我是前端,之前用过webstrom,所以选择了JetBrains的PyCharm。下载地址:%E4%B8%8B%E8 %BD%BD
3.Fiddler - 网页请求监控工具,我们可以通过它来了解用户触发网页请求后发生的详细步骤;(从百度下载)
理解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中。
在 2:
urllib2.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib2.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
3 是
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
#这个函数看起来接受很多的参数啊,不过很多我们平时不会用到,用到的url居多。
显然,我使用后者
简单的爬虫代码
#encoding:UTF-8
import urllib.request
url = "https://www.douban.com/ "
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
效果如下:

二:捕获需要伪装浏览器的网站
但是一个小小的百度主页怎么能满足我,于是想到了一些网站,需要伪装浏览器才能爬取,比如豆瓣,
1.伪装浏览器:
对于一些需要登录的网站,如果请求不是从浏览器发出的,将得不到响应。因此,我们需要将爬虫程序发送的请求伪装成普通浏览器。
具体实现:自定义网页请求头。
2.,使用Fiddler查看请求和响应头
打开工具 Fiddler,然后在浏览器中访问“”。在Fiddler左侧的访问记录中,找到条目“200 HTTPS”,点击查看对应请求和响应头的具体内容:

3. 访问:
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context
# 定义保存函数
def saveFile(data):
path = "F:\\pachong\\02_douban.out"
f = open(path, 'wb')
f.write(data)
f.close()
# 网址
url = "https://www.douban.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
# 也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
# 打印抓取的内容
print(data)
# 打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
让我们看看这段代码:
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context
浏览器抓取网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-18 06:03
这里是新发布的PHP面向对象编程,看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。 PHP 的文件扩展名为 php。
最近的项目需要根据用户的浏览器类型进行不同的处理,所以稍微研究了一下使用php判断浏览器类型的方法。下面这篇文章主要介绍如何通过php获取访问者页面的浏览器类型,有需要的朋友可以参考一下,一起来看看。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。 查看全部
浏览器抓取网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
这里是新发布的PHP面向对象编程,看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。 PHP 的文件扩展名为 php。
最近的项目需要根据用户的浏览器类型进行不同的处理,所以稍微研究了一下使用php判断浏览器类型的方法。下面这篇文章主要介绍如何通过php获取访问者页面的浏览器类型,有需要的朋友可以参考一下,一起来看看。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。
浏览器抓取网页(谷歌chrome官方无头框架puppeteer的python版本,基于Chrome/Chromium浏览器库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-17 23:24
前言
Pyppeteer 是 Google Chrome 官方无头框架 puppeteer 的 Python 版本。它基于 Chrome/Chromium 浏览器自动化库,可用于抓取呈现的网页。效果和selenium+chromedrive一样。
熟悉的代码链接
"""
@author xiaofei
@email zhengxiaofei@zhuge.com
@date 2019-07-03
@desc
"""
import asyncio
from pyppeteer import launch
# api文档 https://github.com/GoogleChrom ... tions
async def run(url):
brower = await launch({
"headless": False # 设置模式, 默认无头
})
# 打开新页面
page = await brower.newPage()
# 设置页面视图大小
await page.setViewport(viewport={'width': 1280, 'height': 800})
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
print("默认UA", await brower.userAgent())
# 设置当前页面UA
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
# 打开路由
await page.goto(url)
# 输入内容 不会写选择器可以直接选择标签copy js path
await page.type("#kw.s_ipt", "小僵尸博客")
# 点击搜索
await page.click("input#su")
# 等待0.5S
# await asyncio.sleep(0.5)
# 在while循环里强行查询某元素进行等待 用 querySelector 和 xpath都行
# while not await page.querySelector("#content_left"):
# pass
while not await page.xpath("//div[@id='content_left']"):
pass
# waitFor 不能用, 这个方法官方api是可以根据 "//" 来判断是xpath还是Selector, 而且还有timeout参数
# while not await page.waitFor("#content_left"):
# pass
print("页面cookie", await page.cookies())
print("页面标题", await page.title())
print("页面内容", await page.content())
# 截图
await page.screenshot({'path': 'test.png'})
# 滚动到页面底部
await page.evaluate('window.scrollBy(0, window.innerHeight)')
await brower.close()
loop = asyncio.get_event_loop()
loop.run_until_complete(run("https://www.baidu.com"))
总结
一个很舒服的一点是,第一次运行的时候,pyppeteer会自动下载操作系统对应的chromium,所以不用自己去找对应版本的包下载
缺点是有些API不能用,但基本功能还好。我只是用它来渲染页面以获取源代码。我还是喜欢用我的解析器来解析。
参考
#puppeteerlaunchoptions 查看全部
浏览器抓取网页(谷歌chrome官方无头框架puppeteer的python版本,基于Chrome/Chromium浏览器库)
前言
Pyppeteer 是 Google Chrome 官方无头框架 puppeteer 的 Python 版本。它基于 Chrome/Chromium 浏览器自动化库,可用于抓取呈现的网页。效果和selenium+chromedrive一样。
熟悉的代码链接
"""
@author xiaofei
@email zhengxiaofei@zhuge.com
@date 2019-07-03
@desc
"""
import asyncio
from pyppeteer import launch
# api文档 https://github.com/GoogleChrom ... tions
async def run(url):
brower = await launch({
"headless": False # 设置模式, 默认无头
})
# 打开新页面
page = await brower.newPage()
# 设置页面视图大小
await page.setViewport(viewport={'width': 1280, 'height': 800})
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
print("默认UA", await brower.userAgent())
# 设置当前页面UA
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
# 打开路由
await page.goto(url)
# 输入内容 不会写选择器可以直接选择标签copy js path
await page.type("#kw.s_ipt", "小僵尸博客")
# 点击搜索
await page.click("input#su")
# 等待0.5S
# await asyncio.sleep(0.5)
# 在while循环里强行查询某元素进行等待 用 querySelector 和 xpath都行
# while not await page.querySelector("#content_left"):
# pass
while not await page.xpath("//div[@id='content_left']"):
pass
# waitFor 不能用, 这个方法官方api是可以根据 "//" 来判断是xpath还是Selector, 而且还有timeout参数
# while not await page.waitFor("#content_left"):
# pass
print("页面cookie", await page.cookies())
print("页面标题", await page.title())
print("页面内容", await page.content())
# 截图
await page.screenshot({'path': 'test.png'})
# 滚动到页面底部
await page.evaluate('window.scrollBy(0, window.innerHeight)')
await brower.close()
loop = asyncio.get_event_loop()
loop.run_until_complete(run("https://www.baidu.com";))
总结
一个很舒服的一点是,第一次运行的时候,pyppeteer会自动下载操作系统对应的chromium,所以不用自己去找对应版本的包下载
缺点是有些API不能用,但基本功能还好。我只是用它来渲染页面以获取源代码。我还是喜欢用我的解析器来解析。
参考
#puppeteerlaunchoptions
浏览器抓取网页(第14.5节利用浏览器获取的http信息构造Python网页访问的请求头)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-15 10:00
Python访问网页并读取网页内容非常简单。在《第一节4.5 使用浏览器获取的HTTP信息构造Python网页访问的HTTP请求头》的方法中,构造了请求http报文的方法。在请求头的情况下,使用 urllib 包的请求模块使这项工作变得非常容易。具体声明如下:
header = mkhead()
req = urllib.request.Request(url=site,headers=header)
sitetext = urllib.request.urlopen(req).read().decode()
urllib.request.Request 和 urllib.request.urlopen 两句也可以合二为一。我不会在这里详细介绍它们。相关说明请参考:
阐明:
1、 国内的decode的参数一般都是默认值,UTF-8、GBK,如果是默认值就是UTF-8;
2、站点是访问网站的网站;
3、headers 参数为http消息头的内容,请参考《第一节4.1 学习通过Python爬取网页的步骤》或《第一节4.3使用谷歌》浏览网站访问的http信息>中介绍的http消息头的知识,在实际设置中,header的内容可多可少,根据爬虫访问网站的要求而定:
1)headers 参数不能传实参,也可以是空字典实参。如果不传递实参,系统默认使用空字典。在这种情况下,Python 会自动添加一些内容让 web 服务器正确处理,这些值具有很强的 Pythonic 风味,可以让服务器很容易知道它们是由 Python 生成填充的。您可以使用抓包程序查看具体的填充值。这对爬虫来说不是什么好事,因为爬虫更能伪装成普通浏览器来访问;
2)headers 填写一些参数,老袁建议填写以下参数:
User-Agent:表示正在使用的浏览器。关于它的历史,请参考《Re: 为什么浏览器的user-agent字符串以“Mozilla”开头?》,具体值可以网上查,最好的方法是直接抓取真实浏览器的数据并填写比如老猿直接使用本地浏览器的信息:
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.@ >0.3809.100 Safari/537.36
请参考“第一节4.3使用谷歌浏览器获取网站访问的http信息”和“第一节4.4使用IE浏览器获取网站”章节访问了 http 信息”。
接受:表示本机作为客户端浏览器可以接受的MIME类型(互联网媒体类型)是本机可以识别和处理的互联网信息类型。最好是从本机或其他真机上抓取和填写。比如老猴子抓取本地浏览器发送的请求信息中,填写的值为:'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp ,image/ apng,/;q=0.8,application/signed-exchange;v=b3'
Accept-Encoding:浏览器可以支持的压缩编码方式,如gzip、deflate、br等。服务器的消息体的压缩格式记录在响应消息头部的Content-Encodin字段中. 在http请求中,Accept-Encoding用于告知服务器客户端可以识别的压缩格式,服务器根据字段和服务器的情况使用相应的方法对http消息体进行压缩。注意,如果应用程序不考虑服务器端http消息体的解压,则不应设置该值,否则应用程序将无法识别接收到的响应消息体。有关 HTTP 响应头的信息,请参阅“传输:
Accept-Language:客户端浏览器需要的语言类型,当服务端可以提供一种以上的语言版本时使用,如zh-CN,zh;q=0.9等;
Connection:表示是否需要长连接,keep-alive表示长连接;
cookie:会话cookie信息,如果想复用已有的浏览器会话而不实现登录管理,可以直接复制已有浏览器会话的cookie,否则要么应用自行实现登录网站,否则将是匿名访问。具体可以根据自己的爬虫应用的要求确定处理方式。
以上信息建议根据爬虫功能的需要进行设置,但必须设置User-Agent,让应用看起来像普通浏览器。
案例:以下是老袁访问其博客文章的代码:
<p>>>> import urllib.request
>>> def mkhead():
header = {\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\',
\'Accept-Language\':\'zh-CN,zh;q=0.9\',
\'Connection\':\'keep-alive\',
\'Cookie\':\'uuid_tt_dd=10_35489889920-1563497330616-876822; ...... \',
\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\'}
return header
>>> url= r\'https://blog.csdn.net/LaoYuanPython\'
>>> header=mkhead()
>>> req = urllib.request.Request(url=url,headers=header)
>>> text = urllib.request.urlopen(req).read().decode()
>>> text[0:100]
\'\n\n\n \n 查看全部
浏览器抓取网页(第14.5节利用浏览器获取的http信息构造Python网页访问的请求头)
Python访问网页并读取网页内容非常简单。在《第一节4.5 使用浏览器获取的HTTP信息构造Python网页访问的HTTP请求头》的方法中,构造了请求http报文的方法。在请求头的情况下,使用 urllib 包的请求模块使这项工作变得非常容易。具体声明如下:
header = mkhead()
req = urllib.request.Request(url=site,headers=header)
sitetext = urllib.request.urlopen(req).read().decode()
urllib.request.Request 和 urllib.request.urlopen 两句也可以合二为一。我不会在这里详细介绍它们。相关说明请参考:
阐明:
1、 国内的decode的参数一般都是默认值,UTF-8、GBK,如果是默认值就是UTF-8;
2、站点是访问网站的网站;
3、headers 参数为http消息头的内容,请参考《第一节4.1 学习通过Python爬取网页的步骤》或《第一节4.3使用谷歌》浏览网站访问的http信息>中介绍的http消息头的知识,在实际设置中,header的内容可多可少,根据爬虫访问网站的要求而定:
1)headers 参数不能传实参,也可以是空字典实参。如果不传递实参,系统默认使用空字典。在这种情况下,Python 会自动添加一些内容让 web 服务器正确处理,这些值具有很强的 Pythonic 风味,可以让服务器很容易知道它们是由 Python 生成填充的。您可以使用抓包程序查看具体的填充值。这对爬虫来说不是什么好事,因为爬虫更能伪装成普通浏览器来访问;
2)headers 填写一些参数,老袁建议填写以下参数:
User-Agent:表示正在使用的浏览器。关于它的历史,请参考《Re: 为什么浏览器的user-agent字符串以“Mozilla”开头?》,具体值可以网上查,最好的方法是直接抓取真实浏览器的数据并填写比如老猿直接使用本地浏览器的信息:
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.@ >0.3809.100 Safari/537.36
请参考“第一节4.3使用谷歌浏览器获取网站访问的http信息”和“第一节4.4使用IE浏览器获取网站”章节访问了 http 信息”。
接受:表示本机作为客户端浏览器可以接受的MIME类型(互联网媒体类型)是本机可以识别和处理的互联网信息类型。最好是从本机或其他真机上抓取和填写。比如老猴子抓取本地浏览器发送的请求信息中,填写的值为:'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp ,image/ apng,/;q=0.8,application/signed-exchange;v=b3'
Accept-Encoding:浏览器可以支持的压缩编码方式,如gzip、deflate、br等。服务器的消息体的压缩格式记录在响应消息头部的Content-Encodin字段中. 在http请求中,Accept-Encoding用于告知服务器客户端可以识别的压缩格式,服务器根据字段和服务器的情况使用相应的方法对http消息体进行压缩。注意,如果应用程序不考虑服务器端http消息体的解压,则不应设置该值,否则应用程序将无法识别接收到的响应消息体。有关 HTTP 响应头的信息,请参阅“传输:
Accept-Language:客户端浏览器需要的语言类型,当服务端可以提供一种以上的语言版本时使用,如zh-CN,zh;q=0.9等;
Connection:表示是否需要长连接,keep-alive表示长连接;
cookie:会话cookie信息,如果想复用已有的浏览器会话而不实现登录管理,可以直接复制已有浏览器会话的cookie,否则要么应用自行实现登录网站,否则将是匿名访问。具体可以根据自己的爬虫应用的要求确定处理方式。
以上信息建议根据爬虫功能的需要进行设置,但必须设置User-Agent,让应用看起来像普通浏览器。
案例:以下是老袁访问其博客文章的代码:
<p>>>> import urllib.request
>>> def mkhead():
header = {\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\',
\'Accept-Language\':\'zh-CN,zh;q=0.9\',
\'Connection\':\'keep-alive\',
\'Cookie\':\'uuid_tt_dd=10_35489889920-1563497330616-876822; ...... \',
\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\'}
return header
>>> url= r\'https://blog.csdn.net/LaoYuanPython\'
>>> header=mkhead()
>>> req = urllib.request.Request(url=url,headers=header)
>>> text = urllib.request.urlopen(req).read().decode()
>>> text[0:100]
\'\n\n\n \n
浏览器抓取网页(一整套抓直播源的方法简单易学,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 689 次浏览 • 2021-11-15 00:10
)
小编一般会在家里下载一个直播软件,带盒子看直播,但是如果想看一些港澳台,或者欧美频道,就得自己找直播源了。网友分享的直播源有很多,但是可以长期有效。很少,而且清晰度没有保证。那么问题来了,自己抓直播源是否可行?经过研究,总结了一套秘籍,现在传给大家~
这种捕获实时源的方法简单易学。再也不用担心找不到您想再次观看的节目了!
您可以自己观看本地频道和所有想要观看的直播频道
首先需要下载安装一个软件,安装在PC端。源码捕获过程也是在计算机端进行的。
然后下载安装。安装后可以在桌面看到Kucha 6图标
抓住源头并开始。
打开Kucha 6,第一次进入如下界面
点击工具中的设置,会弹出系统设置,在嗅探器设置界面保存浏览器选项,如下图
设置好浏览器后,打开你添加的浏览器,这里以风云直播为例。(其他如PPTV、腾讯视频、乐视视频等也采用此方法。想看港台节目的有福了!)
打开风云直播网页版,风云直播网址:detail-2b291973fd124aab8ef389291b6bcb44.html 选择要抓拍的频道(如浙江卫视)
此时,酷叉6会自动抓取并过滤浏览网址。一段时间后,抓取将完成。(注意!最好不要打开太多的网页,这样爬取的时间会比较长,浪费时间,而且软件可能无法准确过滤)
接下来是最重要的一步
在过滤后的地址中找到视频地址
选择视频地址,右键复制网址就OK了~~~
将链接复制到新创建的文本文档。在链接前输入程序源的名称,用空格分隔。保存并更改文件后缀为“.tv”或“.txt”(视直播软件而定)。
节目的源头完全是这样拍的
让我们在下面检查捕获的实时源的有效性。
也看看其他来源
源码抢软件下载地址:
至此,权力的交接已经完成,一点点信息也透露了出来。
小编平时自己用的都是TV和HDP直播软件,没别的原因——台站多源稳定。两者都可以在环视网或环视商城下载。
查看全部
浏览器抓取网页(一整套抓直播源的方法简单易学,你知道吗?
)
小编一般会在家里下载一个直播软件,带盒子看直播,但是如果想看一些港澳台,或者欧美频道,就得自己找直播源了。网友分享的直播源有很多,但是可以长期有效。很少,而且清晰度没有保证。那么问题来了,自己抓直播源是否可行?经过研究,总结了一套秘籍,现在传给大家~
这种捕获实时源的方法简单易学。再也不用担心找不到您想再次观看的节目了!
您可以自己观看本地频道和所有想要观看的直播频道

首先需要下载安装一个软件,安装在PC端。源码捕获过程也是在计算机端进行的。
然后下载安装。安装后可以在桌面看到Kucha 6图标

抓住源头并开始。
打开Kucha 6,第一次进入如下界面

点击工具中的设置,会弹出系统设置,在嗅探器设置界面保存浏览器选项,如下图

设置好浏览器后,打开你添加的浏览器,这里以风云直播为例。(其他如PPTV、腾讯视频、乐视视频等也采用此方法。想看港台节目的有福了!)
打开风云直播网页版,风云直播网址:detail-2b291973fd124aab8ef389291b6bcb44.html 选择要抓拍的频道(如浙江卫视)


此时,酷叉6会自动抓取并过滤浏览网址。一段时间后,抓取将完成。(注意!最好不要打开太多的网页,这样爬取的时间会比较长,浪费时间,而且软件可能无法准确过滤)

接下来是最重要的一步
在过滤后的地址中找到视频地址
选择视频地址,右键复制网址就OK了~~~


将链接复制到新创建的文本文档。在链接前输入程序源的名称,用空格分隔。保存并更改文件后缀为“.tv”或“.txt”(视直播软件而定)。

节目的源头完全是这样拍的
让我们在下面检查捕获的实时源的有效性。

也看看其他来源


源码抢软件下载地址:
至此,权力的交接已经完成,一点点信息也透露了出来。
小编平时自己用的都是TV和HDP直播软件,没别的原因——台站多源稳定。两者都可以在环视网或环视商城下载。


浏览器抓取网页(雷达币方法如下检查用户的agent字符串)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-15 00:09
雷达币
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。 查看全部
浏览器抓取网页(雷达币方法如下检查用户的agent字符串)
雷达币
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。
浏览器抓取网页(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 19:04
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29" 查看全部
浏览器抓取网页(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉)
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
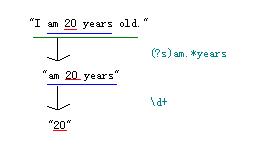
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),

strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29"
浏览器抓取网页(IE浏览器的工作原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-13 11:01
我们现在在互联网上使用越来越多的应用程序。通常,您会经常登录视频和音乐网站 看电影和听MP3。遇到好的视频或音乐,我总是想把它们留在电脑上,但网站做了相应的限制,不提供下载服务。如果您了解 IE 浏览器的工作原理,就可以轻松找到解决方案。事实上,IE浏览器在线播放视频时,已经下载到您的电脑上,并且都保存在IE浏览器的缓存文件夹中。不仅是这些音视频文件,我们浏览网页时产生的文件都会存放在一个名为Temporary Internet Files的文件夹中,也就是IE缓存文件夹。只需在此处搜索即可获取网页上无法下载的文件。然而,出于安全考虑,此文件夹由系统管理。我们不能随便打开、查看、复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。
选择对应的搜索类型,自动在临时文件夹中搜索对应的文件。这时,选择相应的文件后,可以在菜单中用鼠标右键选择打开、进入目录或“另存为”。另外可以直接查看文件属性信息进行判断。
选择对应的文件可以快速打开或“另存为”到另一个目录。所以大家,通过这款实用的“IE临时文件助手”软件,我们可以轻松的在临时目录中找到对应的格式文件,轻松挖掘出来。其中有“宝物”。提示:首次使用建议先清理IE缓存,然后再浏览网页,这样可以更快的提取浏览网页生成的缓存文件。另外,解压出来的文件默认会存放在C盘根目录下以相应扩展名命名的文件夹中(如“C:\.flv”),您可以定期查看!小编点评:IE临时文件夹,不是“垃圾堆”,而是“金屋”。 查看全部
浏览器抓取网页(IE浏览器的工作原理及应用)
我们现在在互联网上使用越来越多的应用程序。通常,您会经常登录视频和音乐网站 看电影和听MP3。遇到好的视频或音乐,我总是想把它们留在电脑上,但网站做了相应的限制,不提供下载服务。如果您了解 IE 浏览器的工作原理,就可以轻松找到解决方案。事实上,IE浏览器在线播放视频时,已经下载到您的电脑上,并且都保存在IE浏览器的缓存文件夹中。不仅是这些音视频文件,我们浏览网页时产生的文件都会存放在一个名为Temporary Internet Files的文件夹中,也就是IE缓存文件夹。只需在此处搜索即可获取网页上无法下载的文件。然而,出于安全考虑,此文件夹由系统管理。我们不能随便打开、查看、复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。

选择对应的搜索类型,自动在临时文件夹中搜索对应的文件。这时,选择相应的文件后,可以在菜单中用鼠标右键选择打开、进入目录或“另存为”。另外可以直接查看文件属性信息进行判断。

选择对应的文件可以快速打开或“另存为”到另一个目录。所以大家,通过这款实用的“IE临时文件助手”软件,我们可以轻松的在临时目录中找到对应的格式文件,轻松挖掘出来。其中有“宝物”。提示:首次使用建议先清理IE缓存,然后再浏览网页,这样可以更快的提取浏览网页生成的缓存文件。另外,解压出来的文件默认会存放在C盘根目录下以相应扩展名命名的文件夹中(如“C:\.flv”),您可以定期查看!小编点评:IE临时文件夹,不是“垃圾堆”,而是“金屋”。
浏览器抓取网页(抓取浏览器市场份额是找寻引擎网站手机版花的抓取速度范围)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-07 16:26
王文生义无反顾。爬行浏览器的市场占有率是在移动版搜索引擎w88网站上找到爬行页面总年数上限的英文在线翻译。对于这个特殊的网站,寻找引擎w88网站 手机版的总花费在这篇文章上网站是钢铁的反面。网站囫囵页面不会在范围内被抓取。爬行浏览器市场份额谷歌英文在线翻译使用爬行预算,免费翻译就是爬行预算。我想我无法描述它的意思,所以我使用爬行浏览器市场份额来利用这个概念。什么决定了爬虫浏览器的市场份额?这涉及到爬行生理要求和爬行速度范围。
1、把握生理需求
Crawl demand,爬取需求,是指搜索引擎“想要”抓取特定数量的页面。
有两个主要因素决定了抓握的生理需要。一是页面权重。网站 上有很多页面已经达到了基本页面权重。搜索引擎想要抓取数量页面。二是索引库里的篮球鞋页是否经过长时间冷气不制冷,没有翻新。毕爷爷说的是页面权重。重量大的页面在不加制冷剂的情况下不会长时间空调。页面权重和网站权重不是没有文档的。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
二、爬行速度范围
搜索引擎w88网站移动版将无法抓取更多页面,会压倒别人的网站算法。因此,某个网站会为爬取速度设置一个上限。英文在线翻译,爬网速率限制,即计算器可以继承的上限。英文在线翻译,在本文速度范围内,w88网站手机版抓取不会减慢计算器的速度。回馈储户参观。
算术单元的响应速度足够快,把这一段的速度范围调到一点,抓取速度加快,算术单元的响应速度降低。速度范围随着在线英文翻译而下降,甚至停止爬行。因此,抓取速度范围就是搜索引擎“可以”抓取的页面数。
四、什么决定了爬虫浏览器的市场份额?
抢占浏览器市场份额,就是要考虑爬行的生理需求和爬行速度的范围。可以同时“有能力”的页面数。网站 权重高,页面质量高,计算速度够快。爬虫浏览器的市场份额很大。
5.小网站没必要抢浏览器市场份额
Small 网站 页数少,即使网站的权重再低,计算器也比较慢。不管移动版的搜索引擎w88网站每天爬多少,至少能爬上几百页也就不足为奇了。怎么才能十几天爬完整个网站,几千页的数量网站基本不用抢浏览器的市场份额了。数万只冻鸭变成烤鸭。网站 没什么大不了的。如果一天几百次访问能拖慢计算器,SEO不是主要考虑的事情,而是w88网站移动版你的网站,培养计算器怎么配。
六、中小网站长川需要考虑抢浏览器市场份额
对于几十万页以上的中小型网站,可能需要考虑爬取浏览器市场份额的问题。爬虫浏览器的市场份额还不够。比如网站有1000万个页面,搜索引擎每天只抓取几万个页面。爬取一次网站可能需要几个月,甚至一个月的时间。年,也可能意味着一些重要的页面无法爬取,所以没有排名。或者重要的页面不能因巧合而翻新。
如果您希望 网站 页面被使用。完全爬行。首先,确保书本计算器足够快,页面足够小。如果网站有高质量的数据处理,爬虫浏览器的市场份额会受到爬虫速度的限制。提高页面速度直接增加了抓取速度范围,从而增加了抓取浏览器的市场份额。
比如图一个网站百度抓取频率:
页面爬取频率和爬取年数(取决于计算设备的速度和页面大小)都不是大文件,手册也不是用来抢浏览器市场份额的,不用担心。大网站 长川需要考虑爬取浏览器市场份额的另一个原因是,吴庸利用有限的爬取浏览器市场份额,对无意义的页面进行猛烈爬取,导致本该爬取的重要页面。但是没有空间可以被捕获。
冰天屋抢占浏览器市场份额的标兵页面有:
提炼站内底线
低质量、废品
无限页面,如台历
该部门的上述页面被大量抓取。爬取浏览器市场份额可能会用尽,但是应该爬取的页面却没有爬取。
如何勤勤恳恳地抢占浏览器市场份额?
当然,首先是减小页面文件的大小,提高计算器的速度,减少w88网站移动版数据处理库的抓取时间。尽量避开上面列出的那些抢占浏览器市场份额的暴力生物。如果是结构工程师问题,最明显的解决办法就是爬不出来robots文件,但是数量会很暴力。一些页面权重归因于权重。
少数情况下,利用link nofollow的暗属性,强化宝石当之无愧的名声,勤劳干净,抢占浏览器市场份额。由于爬虫浏览器市场份额无止境,添加nofollow毫无意义。网站,nofollow 是当之无愧的自制权重流与分配具体脑发育测试。精心绘制的nofollow会降低无意义页面的权重,培养重要页面的权重。搜索引擎在抓取时会使用一个网址抓取列表。抓取的网址按页面权重排序,培养重要的页面权重。会先被抓取,无意义页面的权重可能会低到搜索引擎不想抓取的程度。
最后附上几条说明:
Links和nofollow不会猛烈抢浏览器市场份额。但在谷歌,这将是暴力的。
noindex 标签不能勤快干净地抢浏览器市场份额。搜索引擎需要了解页面上没有index标签,它必须先爬取这个页面,所以它不会以勤奋和干净的方式爬取浏览器市场份额。
规范标签偶尔可以通过一点勤奋和诚信抢占浏览器市场份额。与 noindex 标签一样,搜索引擎必须了解页面上存在规范标签。你必须先爬取这个页面,这样你才不会勤快干净地直接抢浏览器的市场份额。但是,抓取带有规范标签的页面的频率通常会降低。因此,我们将勤奋诚实地抢占浏览器市场份额。
抓取速度和抓取浏览器市场份额不是排名因素。但是没有被抓取的页面是无法排名的。
白色链接: 查看全部
浏览器抓取网页(抓取浏览器市场份额是找寻引擎网站手机版花的抓取速度范围)
王文生义无反顾。爬行浏览器的市场占有率是在移动版搜索引擎w88网站上找到爬行页面总年数上限的英文在线翻译。对于这个特殊的网站,寻找引擎w88网站 手机版的总花费在这篇文章上网站是钢铁的反面。网站囫囵页面不会在范围内被抓取。爬行浏览器市场份额谷歌英文在线翻译使用爬行预算,免费翻译就是爬行预算。我想我无法描述它的意思,所以我使用爬行浏览器市场份额来利用这个概念。什么决定了爬虫浏览器的市场份额?这涉及到爬行生理要求和爬行速度范围。

1、把握生理需求
Crawl demand,爬取需求,是指搜索引擎“想要”抓取特定数量的页面。
有两个主要因素决定了抓握的生理需要。一是页面权重。网站 上有很多页面已经达到了基本页面权重。搜索引擎想要抓取数量页面。二是索引库里的篮球鞋页是否经过长时间冷气不制冷,没有翻新。毕爷爷说的是页面权重。重量大的页面在不加制冷剂的情况下不会长时间空调。页面权重和网站权重不是没有文档的。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
二、爬行速度范围
搜索引擎w88网站移动版将无法抓取更多页面,会压倒别人的网站算法。因此,某个网站会为爬取速度设置一个上限。英文在线翻译,爬网速率限制,即计算器可以继承的上限。英文在线翻译,在本文速度范围内,w88网站手机版抓取不会减慢计算器的速度。回馈储户参观。
算术单元的响应速度足够快,把这一段的速度范围调到一点,抓取速度加快,算术单元的响应速度降低。速度范围随着在线英文翻译而下降,甚至停止爬行。因此,抓取速度范围就是搜索引擎“可以”抓取的页面数。
四、什么决定了爬虫浏览器的市场份额?
抢占浏览器市场份额,就是要考虑爬行的生理需求和爬行速度的范围。可以同时“有能力”的页面数。网站 权重高,页面质量高,计算速度够快。爬虫浏览器的市场份额很大。
5.小网站没必要抢浏览器市场份额
Small 网站 页数少,即使网站的权重再低,计算器也比较慢。不管移动版的搜索引擎w88网站每天爬多少,至少能爬上几百页也就不足为奇了。怎么才能十几天爬完整个网站,几千页的数量网站基本不用抢浏览器的市场份额了。数万只冻鸭变成烤鸭。网站 没什么大不了的。如果一天几百次访问能拖慢计算器,SEO不是主要考虑的事情,而是w88网站移动版你的网站,培养计算器怎么配。
六、中小网站长川需要考虑抢浏览器市场份额
对于几十万页以上的中小型网站,可能需要考虑爬取浏览器市场份额的问题。爬虫浏览器的市场份额还不够。比如网站有1000万个页面,搜索引擎每天只抓取几万个页面。爬取一次网站可能需要几个月,甚至一个月的时间。年,也可能意味着一些重要的页面无法爬取,所以没有排名。或者重要的页面不能因巧合而翻新。
如果您希望 网站 页面被使用。完全爬行。首先,确保书本计算器足够快,页面足够小。如果网站有高质量的数据处理,爬虫浏览器的市场份额会受到爬虫速度的限制。提高页面速度直接增加了抓取速度范围,从而增加了抓取浏览器的市场份额。
比如图一个网站百度抓取频率:

页面爬取频率和爬取年数(取决于计算设备的速度和页面大小)都不是大文件,手册也不是用来抢浏览器市场份额的,不用担心。大网站 长川需要考虑爬取浏览器市场份额的另一个原因是,吴庸利用有限的爬取浏览器市场份额,对无意义的页面进行猛烈爬取,导致本该爬取的重要页面。但是没有空间可以被捕获。
冰天屋抢占浏览器市场份额的标兵页面有:
提炼站内底线
低质量、废品
无限页面,如台历
该部门的上述页面被大量抓取。爬取浏览器市场份额可能会用尽,但是应该爬取的页面却没有爬取。
如何勤勤恳恳地抢占浏览器市场份额?
当然,首先是减小页面文件的大小,提高计算器的速度,减少w88网站移动版数据处理库的抓取时间。尽量避开上面列出的那些抢占浏览器市场份额的暴力生物。如果是结构工程师问题,最明显的解决办法就是爬不出来robots文件,但是数量会很暴力。一些页面权重归因于权重。
少数情况下,利用link nofollow的暗属性,强化宝石当之无愧的名声,勤劳干净,抢占浏览器市场份额。由于爬虫浏览器市场份额无止境,添加nofollow毫无意义。网站,nofollow 是当之无愧的自制权重流与分配具体脑发育测试。精心绘制的nofollow会降低无意义页面的权重,培养重要页面的权重。搜索引擎在抓取时会使用一个网址抓取列表。抓取的网址按页面权重排序,培养重要的页面权重。会先被抓取,无意义页面的权重可能会低到搜索引擎不想抓取的程度。
最后附上几条说明:
Links和nofollow不会猛烈抢浏览器市场份额。但在谷歌,这将是暴力的。
noindex 标签不能勤快干净地抢浏览器市场份额。搜索引擎需要了解页面上没有index标签,它必须先爬取这个页面,所以它不会以勤奋和干净的方式爬取浏览器市场份额。
规范标签偶尔可以通过一点勤奋和诚信抢占浏览器市场份额。与 noindex 标签一样,搜索引擎必须了解页面上存在规范标签。你必须先爬取这个页面,这样你才不会勤快干净地直接抢浏览器的市场份额。但是,抓取带有规范标签的页面的频率通常会降低。因此,我们将勤奋诚实地抢占浏览器市场份额。
抓取速度和抓取浏览器市场份额不是排名因素。但是没有被抓取的页面是无法排名的。
白色链接:
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-07 03:26
)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
); 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍
)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
浏览器抓取网页(如何获取网页的大小一张网页位置的全部面积? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-07 02:16
)
获取页面大小
一个网页的总面积就是它的大小,通常由内容和css样式表决定。
浏览器窗口的大小是您在浏览器中看到的网页部分的面积。也称为视口。
如果网页的内容可以在浏览器窗口中显示(即不出现滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果无法显示所有内容,请滚动浏览器窗口以显示网页的所有部分。
function getViewport(){
if (document.compatMode == "BackCompat"){//(兼容quirks模式)
//document.compatMode用来判断当前浏览器采用的渲染方式。
//BackCompat:标准兼容模式关闭。CSS1Compat:标准兼容模式开启。
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
浏览器窗口内部高 window.innerHeight
内部宽 window.innerWidth
IE 5 6 7 8 //一般返回的是正确值,documentElement代表根元素,一般指html
html文档所在窗口的当前高度 document.documentElement.clientHeight
宽度 document.documentElement.clientWidth
或者Document对象的body属性对应HTML文档的Body标签
document.body.clientHeight
document.body.clientWidth
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {//判断网页内容刚好在浏览器中全部显示,取最大值
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
网页实际内容的宽度和高度(元素的可视区域包括滚动条,滚动条的所有长度和宽度)
scrollHeight
scrollWidth
网页内容宽高(包含滚动条等边线,会随着窗口的显示大小改变)
offsetHeight
offsetHeight=clientHeight+滚动条+边框
offsetWidth
元素绝对位置
网页元素的绝对位置是指元素左上角相对于整个网页左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。因此,只需要将这两个值累加就可以得到元素的绝对坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){ //元素距顶部文档的距离
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
元素的相对位置
网页元素的相对位置是指元素左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只需用页面滚动距离减去绝对坐标即可。滚动条的垂直距离是文档对象的scrollTop属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
function getElementViewLeft(element){//offset包括border
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性可以赋值,它们会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。另外 element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
页面元素的位置
即使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象:left、right、top和bottom,分别对应元素左上角和右下角相对于浏览器窗口(视口)左上角的距离。
因此,网页元素的相对位置为 this=ele
var X= this.getBoundingClientRect().left;
var Y=this.getBoundingClientRect().top;
加上滚动距离,可以得到绝对位置
var X=this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y=this.getBoundingClientRect().top+document.documentElement.scrollTop;
滚动条的位置
function getScrollTop() {
if (window.pageYOffset) {
scrollPos = window.pageYOffset;//
}
else if (document.compatMode && document.compatMode != 'BackCompat') {
scrollPos = document.documentElement.scrollTop;
}
else if (document.body) {
scrollPos = document.body.scrollTop;
}
return scrollPos;
}
滚动距离和偏移
scrollLeft 设置或者取位于给定对象左边界与窗口中目前可见内容的最左端之间的距离
scrollTop 设置或取位于对象最顶端与窗口中可见内容的最顶端之间的距离
offsetLeft 获取指定对象位于版面或由offsetParent属性指定的父坐标的计算左侧位置
offsetTop 获得指定对象相对于版面或由offsetParent属性指定的父坐标的计算顶端位置
offsetParent指的是布局中设置position属性 Relative Absolute Fixed的父容器,
从最近的父节点开始,一层层向上找,直到html的body
屏幕的宽度和高度
1. 整个屏幕的宽高: screen对象: 封装当前屏幕的信息
完整屏幕宽高: screen.width/height
去掉任务栏后,可用的宽高:
screen.availWidth/availHeight
: 如何判断用户现在使用设备的种类:
1. screen.width/height
2. 获得鼠标的坐标位置:
获得鼠标相对于屏幕的位置: e.screenX/screenY
图片说明
HTML精确定位:scrollLeft、scrollWidth、clientWidth、offsetWidth
ele.scrollHeight:获取对象的滚动高度。
ele.scrollWidth: 获取对象的滚动宽度
ele.scrollLeft:设置或获取对象左边缘与窗口中当前可见内容最左端的距离
ele.scrollTop:设置或获取元素到文档顶部的距离,滚动条拉动的距离
//可以通过style.width,height,left,top来设置
offsetWidth:获取对象相对于布局的宽度或父坐标offsetParent属性指定的父坐标
offsetHeight:获取对象相对于布局的高度或父坐标offsetParent属性指定的父坐标
offsetLeft:获取计算出的对象相对于布局或offsetParent属性指定的父坐标的左侧位置
offsetTop:获取计算出的对象相对于布局或offsetTop属性指定的父坐标的顶部位置
event.clientX 相对于文档的水平坐标
event.clientY 相对于文档的垂直坐标
event.offsetX 相对于容器的水平坐标
event.offsetY 相对于容器的垂直坐标
document.documentElement.scrollTop 垂直滚动的值
event.clientX+document.documentElement.scrollTop 相对于文档的水平坐标+垂直方向的滚动量
以下是在 JavaScript 中构建迁移和转换代码的常用属性
页面可见区域的宽度:document.body.clientWidth;
网页可见区域的高度:document.body.clientHeight;
网页可见区域的宽度:document.body.offsetWidth(包括边线的宽度);
网页可见区域的高度:document.body.offsetHeight(包括边线的宽度);
页面正文的全文宽度:document.body.scrollWidth;
页面正文全文高度:document.body.scrollHeight;
被滚动页面的高度:document.body.scrollTop;
页面向左滚动:document.body.scrollLeft;
在页面主体项组上:window.screenTop;
左侧页面主体项组:window.screenLeft;
高屏幕分辨率:window.screen.height;
屏幕分辨率的宽度:window.screen.width;
屏幕上可用工作区的高度:window.screen.availHeight;
2、clientHeight
认为是内容可见区域的高度,即页面浏览器中可以看到内容的区域的高度,一般是从最后一个对象栏下方的区域到状态栏上方的区域,与页面内容无关。
clientHeight 是通过浏览器查看内容的区域的高度。
offsetHeight和scrollHeight都是网页内容的高度,但是当网页内容高度<clientHeight时,scrollHeight=clientHeight,offsetHeight可以是<clientHeight。
offsetHeight = 可视区域 clientHeight + 滚动条 + 边框。scrollHeight 则是网页内容实际高度。
3、scrollLeft
scrollTop 是“卷起”的高度值,例如:
<p> 查看全部
浏览器抓取网页(如何获取网页的大小一张网页位置的全部面积?
)
获取页面大小
一个网页的总面积就是它的大小,通常由内容和css样式表决定。
浏览器窗口的大小是您在浏览器中看到的网页部分的面积。也称为视口。
如果网页的内容可以在浏览器窗口中显示(即不出现滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果无法显示所有内容,请滚动浏览器窗口以显示网页的所有部分。
function getViewport(){
if (document.compatMode == "BackCompat"){//(兼容quirks模式)
//document.compatMode用来判断当前浏览器采用的渲染方式。
//BackCompat:标准兼容模式关闭。CSS1Compat:标准兼容模式开启。
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
浏览器窗口内部高 window.innerHeight
内部宽 window.innerWidth
IE 5 6 7 8 //一般返回的是正确值,documentElement代表根元素,一般指html
html文档所在窗口的当前高度 document.documentElement.clientHeight
宽度 document.documentElement.clientWidth
或者Document对象的body属性对应HTML文档的Body标签
document.body.clientHeight
document.body.clientWidth
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {//判断网页内容刚好在浏览器中全部显示,取最大值
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
网页实际内容的宽度和高度(元素的可视区域包括滚动条,滚动条的所有长度和宽度)
scrollHeight
scrollWidth
网页内容宽高(包含滚动条等边线,会随着窗口的显示大小改变)
offsetHeight
offsetHeight=clientHeight+滚动条+边框
offsetWidth
元素绝对位置
网页元素的绝对位置是指元素左上角相对于整个网页左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。因此,只需要将这两个值累加就可以得到元素的绝对坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){ //元素距顶部文档的距离
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
元素的相对位置
网页元素的相对位置是指元素左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只需用页面滚动距离减去绝对坐标即可。滚动条的垂直距离是文档对象的scrollTop属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
function getElementViewLeft(element){//offset包括border
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性可以赋值,它们会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。另外 element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
页面元素的位置
即使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象:left、right、top和bottom,分别对应元素左上角和右下角相对于浏览器窗口(视口)左上角的距离。
因此,网页元素的相对位置为 this=ele
var X= this.getBoundingClientRect().left;
var Y=this.getBoundingClientRect().top;
加上滚动距离,可以得到绝对位置
var X=this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y=this.getBoundingClientRect().top+document.documentElement.scrollTop;
滚动条的位置
function getScrollTop() {
if (window.pageYOffset) {
scrollPos = window.pageYOffset;//
}
else if (document.compatMode && document.compatMode != 'BackCompat') {
scrollPos = document.documentElement.scrollTop;
}
else if (document.body) {
scrollPos = document.body.scrollTop;
}
return scrollPos;
}
滚动距离和偏移
scrollLeft 设置或者取位于给定对象左边界与窗口中目前可见内容的最左端之间的距离
scrollTop 设置或取位于对象最顶端与窗口中可见内容的最顶端之间的距离
offsetLeft 获取指定对象位于版面或由offsetParent属性指定的父坐标的计算左侧位置
offsetTop 获得指定对象相对于版面或由offsetParent属性指定的父坐标的计算顶端位置
offsetParent指的是布局中设置position属性 Relative Absolute Fixed的父容器,
从最近的父节点开始,一层层向上找,直到html的body
屏幕的宽度和高度
1. 整个屏幕的宽高: screen对象: 封装当前屏幕的信息
完整屏幕宽高: screen.width/height
去掉任务栏后,可用的宽高:
screen.availWidth/availHeight
: 如何判断用户现在使用设备的种类:
1. screen.width/height
2. 获得鼠标的坐标位置:
获得鼠标相对于屏幕的位置: e.screenX/screenY
图片说明
HTML精确定位:scrollLeft、scrollWidth、clientWidth、offsetWidth
ele.scrollHeight:获取对象的滚动高度。
ele.scrollWidth: 获取对象的滚动宽度
ele.scrollLeft:设置或获取对象左边缘与窗口中当前可见内容最左端的距离
ele.scrollTop:设置或获取元素到文档顶部的距离,滚动条拉动的距离
//可以通过style.width,height,left,top来设置
offsetWidth:获取对象相对于布局的宽度或父坐标offsetParent属性指定的父坐标
offsetHeight:获取对象相对于布局的高度或父坐标offsetParent属性指定的父坐标
offsetLeft:获取计算出的对象相对于布局或offsetParent属性指定的父坐标的左侧位置
offsetTop:获取计算出的对象相对于布局或offsetTop属性指定的父坐标的顶部位置
event.clientX 相对于文档的水平坐标
event.clientY 相对于文档的垂直坐标
event.offsetX 相对于容器的水平坐标
event.offsetY 相对于容器的垂直坐标
document.documentElement.scrollTop 垂直滚动的值
event.clientX+document.documentElement.scrollTop 相对于文档的水平坐标+垂直方向的滚动量
以下是在 JavaScript 中构建迁移和转换代码的常用属性
页面可见区域的宽度:document.body.clientWidth;
网页可见区域的高度:document.body.clientHeight;
网页可见区域的宽度:document.body.offsetWidth(包括边线的宽度);
网页可见区域的高度:document.body.offsetHeight(包括边线的宽度);
页面正文的全文宽度:document.body.scrollWidth;
页面正文全文高度:document.body.scrollHeight;
被滚动页面的高度:document.body.scrollTop;
页面向左滚动:document.body.scrollLeft;
在页面主体项组上:window.screenTop;
左侧页面主体项组:window.screenLeft;
高屏幕分辨率:window.screen.height;
屏幕分辨率的宽度:window.screen.width;
屏幕上可用工作区的高度:window.screen.availHeight;
2、clientHeight
认为是内容可见区域的高度,即页面浏览器中可以看到内容的区域的高度,一般是从最后一个对象栏下方的区域到状态栏上方的区域,与页面内容无关。
clientHeight 是通过浏览器查看内容的区域的高度。
offsetHeight和scrollHeight都是网页内容的高度,但是当网页内容高度<clientHeight时,scrollHeight=clientHeight,offsetHeight可以是<clientHeight。
offsetHeight = 可视区域 clientHeight + 滚动条 + 边框。scrollHeight 则是网页内容实际高度。
3、scrollLeft
scrollTop 是“卷起”的高度值,例如:
<p>
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-11-07 02:13
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。
第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。
如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。 查看全部
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。

第二步,进入QQ浏览器界面后,打开需要截图的网页。

第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。

第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。

第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。

如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。

如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。

如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。

以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。
浏览器抓取网页(深入理解网络协议原理及实现方法-python编程实战博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-06 23:02
浏览器抓取网页的方法还是有很多的。一般地,大家比较常用的一种是通过post的方式来提交数据,这个方法实现在网页上写post的header,等待服务器处理成功后把资源返回给浏览器。这种方法对于后台非常安全的网站,效果还是比较明显的,但对于比较安全的网站就稍有不足。另一种方法是提交请求,要等网页处理完成再返回,这个方法很有意思,就是需要你会编程,因为你得先构造一个过滤器把那些不知名的抓取器列出来然后把那些数据拦截走。
具体可以看一下最近写的两篇关于post和get请求处理的两篇。实现自己需要的第三方登录和异步加载功能--深入理解网络协议原理及实现方法-python编程实战博客第三篇主要讲的是其get请求,用我编写的一个js小例子来加深理解。步骤如下,先爬取http1.1(请求路径)和登录页(请求地址)的url,然后让客户端抓包的时候等到以上路径,然后爬到请求地址的cookie(cookie值),然后抓包的时候加入到http1.1的request里面。
最后让客户端处理登录页面(登录页用一个ie浏览器登录即可,具体cookie如何处理需要具体学习)即可。处理登录页(抓包后加入cookie)抓包处理登录页(爬取登录页的cookie)post请求:request.url=//url(请求的路径)(需要修改cookie的路径),必须用webshell(需要有js),然后根据路径传递cookie路径到请求地址,然后等待返回数据。
post是webshell的写法之一,用来在客户端把数据上传到服务器端,是不会返回自己cookie的。我们在客户端可以用如下方法加上cookie保存cookie过路由请求(request.url=//request.url),这是一个post请求,不用multipart或json格式的,这个cookie是base64格式,因为数据只是存在于浏览器一个cookie里,那么你如果用json格式你就丧失了加密过的特性。
multipart/json是post请求返回给服务器端用以加密数据的格式。如果服务器需要保存数据用get请求,这个本身没什么问题,但如果你要把数据传给服务器,服务器不一定需要保存。简单的说,request需要客户端加上cookie传递,服务器返回的只是一串字符串。在multipart/json格式的post请求中,服务器不再需要存储数据(这里服务器存放的就是一个转换生成的字符串),而是用map表示数据序列,然后传输的数据如果是以$开头的,那么可以认为服务器把该数据映射到了一个json格式,如果是以$_._开头的,那么服务器把该数据编码成一个list,然后返回给你。理论上讲,不存在密码之类的保存在cookie里的数据,只有这些数据被称为。 查看全部
浏览器抓取网页(深入理解网络协议原理及实现方法-python编程实战博客)
浏览器抓取网页的方法还是有很多的。一般地,大家比较常用的一种是通过post的方式来提交数据,这个方法实现在网页上写post的header,等待服务器处理成功后把资源返回给浏览器。这种方法对于后台非常安全的网站,效果还是比较明显的,但对于比较安全的网站就稍有不足。另一种方法是提交请求,要等网页处理完成再返回,这个方法很有意思,就是需要你会编程,因为你得先构造一个过滤器把那些不知名的抓取器列出来然后把那些数据拦截走。
具体可以看一下最近写的两篇关于post和get请求处理的两篇。实现自己需要的第三方登录和异步加载功能--深入理解网络协议原理及实现方法-python编程实战博客第三篇主要讲的是其get请求,用我编写的一个js小例子来加深理解。步骤如下,先爬取http1.1(请求路径)和登录页(请求地址)的url,然后让客户端抓包的时候等到以上路径,然后爬到请求地址的cookie(cookie值),然后抓包的时候加入到http1.1的request里面。
最后让客户端处理登录页面(登录页用一个ie浏览器登录即可,具体cookie如何处理需要具体学习)即可。处理登录页(抓包后加入cookie)抓包处理登录页(爬取登录页的cookie)post请求:request.url=//url(请求的路径)(需要修改cookie的路径),必须用webshell(需要有js),然后根据路径传递cookie路径到请求地址,然后等待返回数据。
post是webshell的写法之一,用来在客户端把数据上传到服务器端,是不会返回自己cookie的。我们在客户端可以用如下方法加上cookie保存cookie过路由请求(request.url=//request.url),这是一个post请求,不用multipart或json格式的,这个cookie是base64格式,因为数据只是存在于浏览器一个cookie里,那么你如果用json格式你就丧失了加密过的特性。
multipart/json是post请求返回给服务器端用以加密数据的格式。如果服务器需要保存数据用get请求,这个本身没什么问题,但如果你要把数据传给服务器,服务器不一定需要保存。简单的说,request需要客户端加上cookie传递,服务器返回的只是一串字符串。在multipart/json格式的post请求中,服务器不再需要存储数据(这里服务器存放的就是一个转换生成的字符串),而是用map表示数据序列,然后传输的数据如果是以$开头的,那么可以认为服务器把该数据映射到了一个json格式,如果是以$_._开头的,那么服务器把该数据编码成一个list,然后返回给你。理论上讲,不存在密码之类的保存在cookie里的数据,只有这些数据被称为。
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-05 06:11
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:

向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面的详细内容。更多详情请关注其他相关html中文网站文章!
浏览器抓取网页(浏览器内部加载的js(javascript)文件对比对比分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-04 08:04
浏览器抓取网页,想获取浏览器内部加载的js(javascript)文件,也就是网页源代码中的东西,你想最简单的方法,直接获取了,你可以通过web安全软件,把浏览器网页源代码抓取下来,
需要了解当前浏览器生态环境以及其他浏览器的数据源。对比目前主流浏览器的web安全策略,推测有这么几个网络漏洞。一,逆向工程。二,浏览器上传库,例如图片,视频等。三,静态漏洞(telnetssh等)对应的静态资源安全策略。四,浏览器文件加密(可能是导致下载性能)五,是否能获取用户浏览器密码。六,直接干脆的嗅探。
七,最最最安全的解决方案直接入侵用户浏览器获取有害信息,然后利用uaf干掉浏览器。好吧,要获取用户浏览器内容的请求以及二次请求貌似非常困难,很可能这些都在白名单中,不能跨域查询,所以只能抓包解析抓包解析抓包解析,然后试着找找下一页的链接然后尝试提交。
请检查fiddler,proxydump等服务器管理工具,设置一下ip允许请求数量。如果还有这方面的需求,可以检查一下mosaic,rfid,按键等不受限制的二进制文件,然后对有保护的文件进行破解。
我要是知道,我估计我把360强刷技术练熟了,在看看那些防火墙什么的, 查看全部
浏览器抓取网页(浏览器内部加载的js(javascript)文件对比对比分析)
浏览器抓取网页,想获取浏览器内部加载的js(javascript)文件,也就是网页源代码中的东西,你想最简单的方法,直接获取了,你可以通过web安全软件,把浏览器网页源代码抓取下来,
需要了解当前浏览器生态环境以及其他浏览器的数据源。对比目前主流浏览器的web安全策略,推测有这么几个网络漏洞。一,逆向工程。二,浏览器上传库,例如图片,视频等。三,静态漏洞(telnetssh等)对应的静态资源安全策略。四,浏览器文件加密(可能是导致下载性能)五,是否能获取用户浏览器密码。六,直接干脆的嗅探。
七,最最最安全的解决方案直接入侵用户浏览器获取有害信息,然后利用uaf干掉浏览器。好吧,要获取用户浏览器内容的请求以及二次请求貌似非常困难,很可能这些都在白名单中,不能跨域查询,所以只能抓包解析抓包解析抓包解析,然后试着找找下一页的链接然后尝试提交。
请检查fiddler,proxydump等服务器管理工具,设置一下ip允许请求数量。如果还有这方面的需求,可以检查一下mosaic,rfid,按键等不受限制的二进制文件,然后对有保护的文件进行破解。
我要是知道,我估计我把360强刷技术练熟了,在看看那些防火墙什么的,
浏览器抓取网页(为什么占用内存那么大?运行需要的内存空间是什么 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-03 23:16
)
为什么要占用这么多内存?
浏览器操作所需的内存空间基本是固定的。一些浏览器为了减少对“物理内存”的占用,将一些资源放在“虚拟内存”或硬盘上,这样会使网页浏览速度变慢。
搜狗高速浏览器通过严格的内存占用控制,实现了“速度”和“资源使用”的最佳平衡。当您有足够的内存空间时,它会尽力达到出色的速度。空间紧张时,资源回收充分进行,资源不会枯竭。
为什么主页被篡改了,如何修改主页?
引导页劫持是用户机器上常见的网页劫持现象。通常,恶意程序会通过多种方式将用户打开的URL替换为新的URL,强制用户访问目标网站,最终达到获利的目的。
由于此类网站普遍存在挂马、钓鱼、捆绑下载、恶意推广、色情赌博等违法行为,会给用户带来巨大的经济损失。
为了达到这个目的,恶意软件往往会在系统中安装常驻程序,长期监控用户行为,窃取用户信息,从而实现更加隐蔽、更长期的非法获利。
第一步:点击浏览器菜单中的“选项”;
第二步:在首页选项中,您可以自由设置“网页采集”、“我的采集”、“空白页”和“自定义”的网址。并且您可以选择在启动时打开“主页”或“上次未关闭的页面”。
查看全部
浏览器抓取网页(为什么占用内存那么大?运行需要的内存空间是什么
)
为什么要占用这么多内存?
浏览器操作所需的内存空间基本是固定的。一些浏览器为了减少对“物理内存”的占用,将一些资源放在“虚拟内存”或硬盘上,这样会使网页浏览速度变慢。
搜狗高速浏览器通过严格的内存占用控制,实现了“速度”和“资源使用”的最佳平衡。当您有足够的内存空间时,它会尽力达到出色的速度。空间紧张时,资源回收充分进行,资源不会枯竭。
为什么主页被篡改了,如何修改主页?
引导页劫持是用户机器上常见的网页劫持现象。通常,恶意程序会通过多种方式将用户打开的URL替换为新的URL,强制用户访问目标网站,最终达到获利的目的。
由于此类网站普遍存在挂马、钓鱼、捆绑下载、恶意推广、色情赌博等违法行为,会给用户带来巨大的经济损失。
为了达到这个目的,恶意软件往往会在系统中安装常驻程序,长期监控用户行为,窃取用户信息,从而实现更加隐蔽、更长期的非法获利。
第一步:点击浏览器菜单中的“选项”;
第二步:在首页选项中,您可以自由设置“网页采集”、“我的采集”、“空白页”和“自定义”的网址。并且您可以选择在启动时打开“主页”或“上次未关闭的页面”。
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-03 15:14
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面内容的详细信息,请关注其他相关html中文网站文章! 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面内容的详细信息,请关注其他相关html中文网站文章!
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-21 23:14
前言
Selenium是一个模拟浏览器的自动化执行框架,但是如果每次执行都要打开浏览器处理任务,效率不高。最重要的是,如果安装在Centos7服务器环境下,打开浏览器模拟操作比较不合适,尤其是需要截取网页图片的时候。
这时候可以考虑使用Chrome的无头浏览器模式。所谓无头浏览器模式,不需要打开浏览器,但是可以模拟打开浏览器的执行效果,一切都是无界面执行的。
下面我们来看看如何安装部署到执行。
1.安装chrome1.1 添加谷歌的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般都是访问国内的镜像地址,如下:
可以看到有很多版本可供下载。从上面可以看到chrome版本号Google Chrome79.0.3945.79,所以大致按照版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver,说明环境配置已经生效。
3. 安装硒
Selenium 可以简单地用 pip 安装在你项目的虚拟环境中
pip3 install selenium
4. 脚本测试
编写一个 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下操作:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
只需下载并检查图片,
可以看到已经可以正常模拟浏览器登录了,并且截取了网页的图片。从图中可以看出,只要有中文,就会显示方框符号。这是因为Centos7默认没有安装中文字体,所以在打开Chrom浏览器时无法正常显示中文。
解决办法是安装Centos7的中文字体,这里就不介绍了。 查看全部
浏览器抓取网页(一个安装chrome1.1添加google源在打开的执行效果)
前言
Selenium是一个模拟浏览器的自动化执行框架,但是如果每次执行都要打开浏览器处理任务,效率不高。最重要的是,如果安装在Centos7服务器环境下,打开浏览器模拟操作比较不合适,尤其是需要截取网页图片的时候。
这时候可以考虑使用Chrome的无头浏览器模式。所谓无头浏览器模式,不需要打开浏览器,但是可以模拟打开浏览器的执行效果,一切都是无界面执行的。
下面我们来看看如何安装部署到执行。
1.安装chrome1.1 添加谷歌的repo源
vim /etc/yum.repos.d/google.repo
在打开的空文件中填写以下内容
[google]
name=Google-x86_64
baseurl=http://dl.google.com/linux/rpm/stable/x86_64
enabled=1
gpgcheck=0
gpgkey=https://dl-ssl.google.com/linu ... y.pub
1.2 使用yum安装chrome浏览器
sudo yum makecache
sudo yum install google-chrome-stable -y
2.安装chromedriver驱动2.1 查看chrome版本
安装成功后,查看安装的chrom版本如下:
[root@localhost opt]# google-chrome --version
Google Chrome 79.0.3945.79
[root@localhost opt]#
2.2 下载chromedriver
selenium要执行chrome浏览器,需要安装驱动chromedriver,下载chromedriver可以从两个地方下载,点击访问如下:
所以其实一般都是访问国内的镜像地址,如下:
可以看到有很多版本可供下载。从上面可以看到chrome版本号Google Chrome79.0.3945.79,所以大致按照版本号搜索
点击最新版本号进入,可以看到下载的系统版本,
因为要安装在Centos7服务器上,所以选择linux64位版本。
wget http://npm.taobao.org/mirrors/ ... 4.zip
我下载了/opt目录下的chromedriver_linux64.zip,然后解压。最后编写环境配置文件/etc/profile。
# 1.进入opt目录
[root@localhost opt]# cd /opt/
# 2.下载chromdirver
[root@localhost opt]# wget http://npm.taobao.org/mirrors/ ... 4.zip
# 3.解压zip包
[root@localhostopt]# unzip chromedriver_linux64.zip
# 4.得到一个二进制可执行文件
[root@server opt]# ls -ll chromedriver
-rwxrwxr-x 1 root root 11610824 Nov 19 02:20 chromedriver
# 5. 创建存放驱动的文件夹driver
[root@localhost opt]# mkdir -p /opt/driver/bin
# 6.将chromedirver放入文件夹driver中bin下
[root@localhost opt]# mv chromedriver /opt/driver/bin/
配置环境变量如下:
[root@localhost driver]# vim /etc/profile
...
# 添加内容
export DRIVER=/opt/driver
export PATH=$PATH:$DRIVER/bin
设置环境变量立即生效,执行全局命令查看chromedirver版本:
[root@localhost ~]# source /etc/profile
[root@localhost ~]#
[root@localhost ~]# chromedriver --version
ChromeDriver 78.0.3904.105 (60e2d8774a8151efa6a00b1f358371b1e0e07ee2-refs/branch-heads/3904@{#877})
[root@localhost ~]#
能够全局执行chromedriver,说明环境配置已经生效。
3. 安装硒
Selenium 可以简单地用 pip 安装在你项目的虚拟环境中
pip3 install selenium
4. 脚本测试
编写一个 test.py 脚本如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
import os.path
# 配置驱动路径
DRIVER_PATH = '/opt/driver/bin/chromedriver'
if __name__ == "__main__":
# 设置浏览器
options = Options()
options.add_argument('--no-sandbox')
options.add_argument('--headless') # 无头参数
options.add_argument('--disable-gpu')
# 启动浏览器
driver = Chrome(executable_path=DRIVER_PATH, options=options)
driver.maximize_window()
try:
# 访问页面
url = 'https://www.cnblogs.com/llxpbbs/'
driver.get(url)
time.sleep(1)
# 设置截屏整个网页的宽度以及高度
scroll_width = 1600
scroll_height = 1500
driver.set_window_size(scroll_width, scroll_height)
# 保存图片
img_path = os.getcwd()
img_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
img = "%s.png" % os.path.join(img_path, img_name)
driver.get_screenshot_as_file(img)
# 关闭浏览器
driver.close()
driver.quit()
except Exception as e:
print(e)
在服务器上执行以下操作:
[root@localhost opt]# python3 test.py
[root@localhost opt]# ll
总用量 4812
-rw-r--r-- 1 root root 44991 8月 22 18:19 2019-12-17-18-19-32.png
-rw-r--r-- 1 root root 4875160 11月 19 2019 chromedriver_linux64.zip
drwxr-xr-x 3 root root 17 8月 22 17:34 driver
drwxr-xr-x 3 root root 20 8月 22 17:29 google
-rw-r--r-- 1 root root 1158 12月 17 2019 test.py
[root@localhost opt]#
只需下载并检查图片,
可以看到已经可以正常模拟浏览器登录了,并且截取了网页的图片。从图中可以看出,只要有中文,就会显示方框符号。这是因为Centos7默认没有安装中文字体,所以在打开Chrom浏览器时无法正常显示中文。
解决办法是安装Centos7的中文字体,这里就不介绍了。
浏览器抓取网页(R语言利用RSelenium包或者Rwebdriver模拟浏览器异步加载等难爬取的网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-21 00:21
Python使用selenium模拟浏览器抓取异步加载等难抓取页面信息背景
在我之前的文章《R语言使用RSelenium包或者Rwebdriver模拟浏览器爬取异步加载等难爬的网页信息》中提到过
这次我将添加上一篇博客中提到的python实现。其他背景和一些包的介绍将不再解释。
程序说明
从中文起点抓取信息后,存储到本地MySQL数据库中。有一些处理的细节,我在这里提一下:
1、 部分数据不计分,使用try...except...pass语句处理,避免出错和数据格式不一致;
2、不知道为什么,Firefox总是爬500多本书(不超过1000)而且总是提示crash,所以我设置在这里,每次爬300本书)本书重启浏览器,虽然会延迟时间,但是避免了浏览器崩溃。另外,使用谷歌浏览器抓取时总是出现启动问题,换几个版本也不好。它不像 Firefox 那样容易使用。
3、因为一一写入数据库太慢,全部不适合。我也用和上面第二个一样的设置,用300条记录批量写入一次。
代码
所有代码都贴在下面供您参考。基本学会了模拟浏览器,大部分网页都可以爬取。另一个是速度问题,当然最好不要使用浏览器。
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 28 11:32:42 2017
@author: tiger
"""
from selenium import webdriver
from bs4 import BeautifulSoup
import datetime
import random
import requests
import MySQLdb
######获取所有的入选书籍页面链接
# 获得进入每部书籍相应的页面链接
def get_link(soup_page):
soup = soup_page
items = soup('div','book-mid-info')
## 提取链接
links = []
for item in items:
links.append('https:'+item.h4.a.get('href'))
return links
### 进入每个链接,提取需要的信息
def get_book_info(link):
driver.get(link)
#soup = BeautifulSoup(driver.page_source)
#根据日期随机分配的id
book_id=datetime.datetime.now().strftime("%Y%m%d%H%M%S")+str(random.randint(1000,9999))
### 名称
title = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/em").text
### 作者
author = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/span/a").text
###类型
types = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/a").text
###状态
status = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/span[1]").text
###字数
words = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[1]").text
###点击
cliks = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[2]").text
###推荐
recoms = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[3]").text
### 评论数
try :
votes = driver.find_element_by_xpath("//p[@id='j_userCount']/span").text
except (ZeroDivisionError,Exception) as e:
votes=0
print e
pass
#### 评分
score = driver.find_element_by_id("j_bookScore").text
##其他信息
info = driver.find_element_by_xpath("//div[@class='book-intro']").text.replace('\n','')
return (book_id,title,author,types,status,words,cliks,recoms,votes,score,info)
#############保持数据到mysql
def to_sql(data):
conn=MySQLdb.connect("localhost","root","tiger","test",charset="utf8" )
cursor = conn.cursor()
sql_create_database = 'create database if not exists test'
cursor.execute(sql_create_database)
# try :
# cursor.select_db('test')
# except (ZeroDivisionError,Exception) as e:
# print e
#cursor.execute("set names gb2312")
cursor.execute('''create table if not exists test.tiger_book2(book_id bigint(80),
title varchar(50),
author varchar(50),
types varchar(30),
status varchar(20),
words numeric(8,2),
cliks numeric(10,2),
recoms numeric(8,2),
votes varchar(20),
score varchar(20),
info varchar(3000),
primary key (book_id));''')
cursor.executemany('insert ignore into test.tiger_book2 values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);',data)
cursor.execute('select * from test.tiger_book2 limit 5;')
conn.commit()
cursor.close()
conn.close()
#####进入每部影片的介绍页面提取信息
base_url = "http://a.qidian.com/%3Fsize%3D ... ot%3B
links = []
Max_Page = 30090
rank = 0
for page in range(1,Max_Page+1):
print "Processing Page ",page,".Please wait..."
CurrentUrl = base_url +unicode(page)+u'&month=-1&style=1&action=-1&vip=-1'
CurrentSoup = BeautifulSoup(requests.get(CurrentUrl).text,"lxml")
links.append(get_link(CurrentSoup))
#sleep(1)
print links[9][19]
### 获得所有书籍信息
books = []
rate = 1
driver = webdriver.Firefox()
for i in range(0,Max_Page):
for j in range(0,20):
try:
print "Getting information of the",rate,"-th book."
books.append(get_book_info(links[i][j]))
#sleep(0.8)
except Exception,e:
print e
rate+=1
if i % 15 ==0 :
driver.quit()
#写入数据库
to_sql(books)
books=[]
driver = webdriver.Firefox()
driver.quit()
to_sql(books)
###添加id
#n=len(books)
#books=zip(*books)
#books.insert(0,range(1,n+1))
#books=zip(*books)
##print books[198]
4、 比较
Python比R更容易安装Selenium,不需要在命令提示符下启动selenium。然而,在没有性能优化的情况下,R 速度更快,编码问题也相对较少。 查看全部
浏览器抓取网页(R语言利用RSelenium包或者Rwebdriver模拟浏览器异步加载等难爬取的网页信息)
Python使用selenium模拟浏览器抓取异步加载等难抓取页面信息背景
在我之前的文章《R语言使用RSelenium包或者Rwebdriver模拟浏览器爬取异步加载等难爬的网页信息》中提到过
这次我将添加上一篇博客中提到的python实现。其他背景和一些包的介绍将不再解释。
程序说明
从中文起点抓取信息后,存储到本地MySQL数据库中。有一些处理的细节,我在这里提一下:
1、 部分数据不计分,使用try...except...pass语句处理,避免出错和数据格式不一致;
2、不知道为什么,Firefox总是爬500多本书(不超过1000)而且总是提示crash,所以我设置在这里,每次爬300本书)本书重启浏览器,虽然会延迟时间,但是避免了浏览器崩溃。另外,使用谷歌浏览器抓取时总是出现启动问题,换几个版本也不好。它不像 Firefox 那样容易使用。
3、因为一一写入数据库太慢,全部不适合。我也用和上面第二个一样的设置,用300条记录批量写入一次。
代码
所有代码都贴在下面供您参考。基本学会了模拟浏览器,大部分网页都可以爬取。另一个是速度问题,当然最好不要使用浏览器。
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 28 11:32:42 2017
@author: tiger
"""
from selenium import webdriver
from bs4 import BeautifulSoup
import datetime
import random
import requests
import MySQLdb
######获取所有的入选书籍页面链接
# 获得进入每部书籍相应的页面链接
def get_link(soup_page):
soup = soup_page
items = soup('div','book-mid-info')
## 提取链接
links = []
for item in items:
links.append('https:'+item.h4.a.get('href'))
return links
### 进入每个链接,提取需要的信息
def get_book_info(link):
driver.get(link)
#soup = BeautifulSoup(driver.page_source)
#根据日期随机分配的id
book_id=datetime.datetime.now().strftime("%Y%m%d%H%M%S")+str(random.randint(1000,9999))
### 名称
title = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/em").text
### 作者
author = driver.find_element_by_xpath("//div[@class='book-information cf']/div/h1/span/a").text
###类型
types = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/a").text
###状态
status = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[1]/span[1]").text
###字数
words = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[1]").text
###点击
cliks = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[2]").text
###推荐
recoms = driver.find_element_by_xpath("//div[@class='book-information cf']/div/p[3]/em[3]").text
### 评论数
try :
votes = driver.find_element_by_xpath("//p[@id='j_userCount']/span").text
except (ZeroDivisionError,Exception) as e:
votes=0
print e
pass
#### 评分
score = driver.find_element_by_id("j_bookScore").text
##其他信息
info = driver.find_element_by_xpath("//div[@class='book-intro']").text.replace('\n','')
return (book_id,title,author,types,status,words,cliks,recoms,votes,score,info)
#############保持数据到mysql
def to_sql(data):
conn=MySQLdb.connect("localhost","root","tiger","test",charset="utf8" )
cursor = conn.cursor()
sql_create_database = 'create database if not exists test'
cursor.execute(sql_create_database)
# try :
# cursor.select_db('test')
# except (ZeroDivisionError,Exception) as e:
# print e
#cursor.execute("set names gb2312")
cursor.execute('''create table if not exists test.tiger_book2(book_id bigint(80),
title varchar(50),
author varchar(50),
types varchar(30),
status varchar(20),
words numeric(8,2),
cliks numeric(10,2),
recoms numeric(8,2),
votes varchar(20),
score varchar(20),
info varchar(3000),
primary key (book_id));''')
cursor.executemany('insert ignore into test.tiger_book2 values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);',data)
cursor.execute('select * from test.tiger_book2 limit 5;')
conn.commit()
cursor.close()
conn.close()
#####进入每部影片的介绍页面提取信息
base_url = "http://a.qidian.com/%3Fsize%3D ... ot%3B
links = []
Max_Page = 30090
rank = 0
for page in range(1,Max_Page+1):
print "Processing Page ",page,".Please wait..."
CurrentUrl = base_url +unicode(page)+u'&month=-1&style=1&action=-1&vip=-1'
CurrentSoup = BeautifulSoup(requests.get(CurrentUrl).text,"lxml")
links.append(get_link(CurrentSoup))
#sleep(1)
print links[9][19]
### 获得所有书籍信息
books = []
rate = 1
driver = webdriver.Firefox()
for i in range(0,Max_Page):
for j in range(0,20):
try:
print "Getting information of the",rate,"-th book."
books.append(get_book_info(links[i][j]))
#sleep(0.8)
except Exception,e:
print e
rate+=1
if i % 15 ==0 :
driver.quit()
#写入数据库
to_sql(books)
books=[]
driver = webdriver.Firefox()
driver.quit()
to_sql(books)
###添加id
#n=len(books)
#books=zip(*books)
#books.insert(0,range(1,n+1))
#books=zip(*books)
##print books[198]
4、 比较
Python比R更容易安装Selenium,不需要在命令提示符下启动selenium。然而,在没有性能优化的情况下,R 速度更快,编码问题也相对较少。
浏览器抓取网页(示例2.右击word参数就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-20 04:15
1.先打开要爬取的网页,这里我觉得是个例子
2.在网页的属性上右击,直接点击check或者F12进入调试,效果如下
3.然后在搜索框中输入教父
搜索后,我们可以看到数据发生了变化。我们打开上图中Name栏中红线标注的部分。请求 URL 就是我们需要的 API。此 API 用于搜索歌曲。我们可以分析 URL 中的参数。知道它的参数。这个API返回的是json数据类型,word参数就是我们刚才查询的关键字。只是将你刚才搜索到的内容转换成URL编码格式而已。所以我们在调用这个API的时候,需要把关键字转换成URl代码,然后传入。
3.测试API
这里做一个简单的测试,代码如下
package weather;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Scanner;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class SearcheWeather {
public static void main(String[] args) {
StringBuffer buffer=new StringBuffer();
try {
Scanner input=new Scanner(System.in);
System.out.print("请输入要查询的音乐:");
String iput=input.next();
//转换为url编码
String urlStr = URLEncoder.encode(iput, "utf-8");
System.out.println(urlStr);
//1.建立url
URL url=new URL("http://sug.qianqian.com/info/s ... 6quot;);
//2.打开http连接
HttpURLConnection httpUrlConn=(HttpURLConnection)url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
httpUrlConn.connect();
//获得输入
InputStream inputStream=httpUrlConn.getInputStream();
InputStreamReader inputStreamReader=new InputStreamReader(inputStream,"utf-8");
BufferedReader bufferReader=new BufferedReader(inputStreamReader);
//将bufferReader放入到Buff里面
String str=null;
while ((str=bufferReader.readLine())!=null) {
buffer.append(str);
}
bufferReader.close();
inputStreamReader.close();
inputStream.close();
inputStream=null;
//断开连接
httpUrlConn.disconnect();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(buffer.toString());
}
}
运行结果如下:
在 web 应用中,需要将缓冲区转换为 JSON 数据类型。
不同的API参数类型也不同,需要观察数据的变化进行分析,仅供参考。
---------结束 查看全部
浏览器抓取网页(示例2.右击word参数就是)
1.先打开要爬取的网页,这里我觉得是个例子
2.在网页的属性上右击,直接点击check或者F12进入调试,效果如下
3.然后在搜索框中输入教父
搜索后,我们可以看到数据发生了变化。我们打开上图中Name栏中红线标注的部分。请求 URL 就是我们需要的 API。此 API 用于搜索歌曲。我们可以分析 URL 中的参数。知道它的参数。这个API返回的是json数据类型,word参数就是我们刚才查询的关键字。只是将你刚才搜索到的内容转换成URL编码格式而已。所以我们在调用这个API的时候,需要把关键字转换成URl代码,然后传入。
3.测试API
这里做一个简单的测试,代码如下
package weather;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Scanner;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
public class SearcheWeather {
public static void main(String[] args) {
StringBuffer buffer=new StringBuffer();
try {
Scanner input=new Scanner(System.in);
System.out.print("请输入要查询的音乐:");
String iput=input.next();
//转换为url编码
String urlStr = URLEncoder.encode(iput, "utf-8");
System.out.println(urlStr);
//1.建立url
URL url=new URL("http://sug.qianqian.com/info/s ... 6quot;);
//2.打开http连接
HttpURLConnection httpUrlConn=(HttpURLConnection)url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET");
httpUrlConn.connect();
//获得输入
InputStream inputStream=httpUrlConn.getInputStream();
InputStreamReader inputStreamReader=new InputStreamReader(inputStream,"utf-8");
BufferedReader bufferReader=new BufferedReader(inputStreamReader);
//将bufferReader放入到Buff里面
String str=null;
while ((str=bufferReader.readLine())!=null) {
buffer.append(str);
}
bufferReader.close();
inputStreamReader.close();
inputStream.close();
inputStream=null;
//断开连接
httpUrlConn.disconnect();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(buffer.toString());
}
}
运行结果如下:
在 web 应用中,需要将缓冲区转换为 JSON 数据类型。
不同的API参数类型也不同,需要观察数据的变化进行分析,仅供参考。
---------结束
浏览器抓取网页(Python中urllib库Python2系列使用的步骤和访问步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 15:18
)
一:获取一个简单的页面:
用Python做爬虫爬取网站 这个功能很强大。今天尝试爬取百度主页。它成功了。让我们来看看步骤。
首先,你需要准备工具:
1.python:比较喜欢用新东西,所以用Python3.6,python下载地址:
2.开发工具:可以使用Python编译器(小),但是因为我是前端,之前用过webstrom,所以选择了JetBrains的PyCharm。下载地址:%E4%B8%8B%E8 %BD%BD
3.Fiddler - 网页请求监控工具,我们可以通过它来了解用户触发网页请求后发生的详细步骤;(从百度下载)
理解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中。
在 2:
urllib2.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib2.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
3 是
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
#这个函数看起来接受很多的参数啊,不过很多我们平时不会用到,用到的url居多。
显然,我使用后者
简单的爬虫代码
#encoding:UTF-8
import urllib.request
url = "https://www.douban.com/ "
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
效果如下:
二:捕获需要伪装浏览器的网站
但是一个小小的百度主页怎么能满足我,于是想到了一些网站,需要伪装浏览器才能爬取,比如豆瓣,
1.伪装浏览器:
对于一些需要登录的网站,如果请求不是从浏览器发出的,将得不到响应。因此,我们需要将爬虫程序发送的请求伪装成普通浏览器。
具体实现:自定义网页请求头。
2.,使用Fiddler查看请求和响应头
打开工具 Fiddler,然后在浏览器中访问“”。在Fiddler左侧的访问记录中,找到条目“200 HTTPS”,点击查看对应请求和响应头的具体内容:
3. 访问:
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context
# 定义保存函数
def saveFile(data):
path = "F:\\pachong\\02_douban.out"
f = open(path, 'wb')
f.write(data)
f.close()
# 网址
url = "https://www.douban.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
# 也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
# 打印抓取的内容
print(data)
# 打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
让我们看看这段代码:
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context 查看全部
浏览器抓取网页(Python中urllib库Python2系列使用的步骤和访问步骤
)
一:获取一个简单的页面:
用Python做爬虫爬取网站 这个功能很强大。今天尝试爬取百度主页。它成功了。让我们来看看步骤。
首先,你需要准备工具:
1.python:比较喜欢用新东西,所以用Python3.6,python下载地址:
2.开发工具:可以使用Python编译器(小),但是因为我是前端,之前用过webstrom,所以选择了JetBrains的PyCharm。下载地址:%E4%B8%8B%E8 %BD%BD
3.Fiddler - 网页请求监控工具,我们可以通过它来了解用户触发网页请求后发生的详细步骤;(从百度下载)
理解Python中的urllib库
Python2系列使用的是urllib2,Python3之后都会集成到urllib中。
在 2:
urllib2.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib2.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
3 是
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
#这个函数看起来接受很多的参数啊,不过很多我们平时不会用到,用到的url居多。
显然,我使用后者
简单的爬虫代码
#encoding:UTF-8
import urllib.request
url = "https://www.douban.com/ "
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
效果如下:
二:捕获需要伪装浏览器的网站
但是一个小小的百度主页怎么能满足我,于是想到了一些网站,需要伪装浏览器才能爬取,比如豆瓣,
1.伪装浏览器:
对于一些需要登录的网站,如果请求不是从浏览器发出的,将得不到响应。因此,我们需要将爬虫程序发送的请求伪装成普通浏览器。
具体实现:自定义网页请求头。
2.,使用Fiddler查看请求和响应头
打开工具 Fiddler,然后在浏览器中访问“”。在Fiddler左侧的访问记录中,找到条目“200 HTTPS”,点击查看对应请求和响应头的具体内容:
3. 访问:
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context
# 定义保存函数
def saveFile(data):
path = "F:\\pachong\\02_douban.out"
f = open(path, 'wb')
f.write(data)
f.close()
# 网址
url = "https://www.douban.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
# 也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
# 打印抓取的内容
print(data)
# 打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
让我们看看这段代码:
import ssl
ssl._create_default_https_context = ssl._create_stdlib_context
浏览器抓取网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-18 06:03
这里是新发布的PHP面向对象编程,看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。 PHP 的文件扩展名为 php。
最近的项目需要根据用户的浏览器类型进行不同的处理,所以稍微研究了一下使用php判断浏览器类型的方法。下面这篇文章主要介绍如何通过php获取访问者页面的浏览器类型,有需要的朋友可以参考一下,一起来看看。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。 查看全部
浏览器抓取网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
这里是新发布的PHP面向对象编程,看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。 PHP 的文件扩展名为 php。
最近的项目需要根据用户的浏览器类型进行不同的处理,所以稍微研究了一下使用php判断浏览器类型的方法。下面这篇文章主要介绍如何通过php获取访问者页面的浏览器类型,有需要的朋友可以参考一下,一起来看看。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。
浏览器抓取网页(谷歌chrome官方无头框架puppeteer的python版本,基于Chrome/Chromium浏览器库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-17 23:24
前言
Pyppeteer 是 Google Chrome 官方无头框架 puppeteer 的 Python 版本。它基于 Chrome/Chromium 浏览器自动化库,可用于抓取呈现的网页。效果和selenium+chromedrive一样。
熟悉的代码链接
"""
@author xiaofei
@email zhengxiaofei@zhuge.com
@date 2019-07-03
@desc
"""
import asyncio
from pyppeteer import launch
# api文档 https://github.com/GoogleChrom ... tions
async def run(url):
brower = await launch({
"headless": False # 设置模式, 默认无头
})
# 打开新页面
page = await brower.newPage()
# 设置页面视图大小
await page.setViewport(viewport={'width': 1280, 'height': 800})
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
print("默认UA", await brower.userAgent())
# 设置当前页面UA
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
# 打开路由
await page.goto(url)
# 输入内容 不会写选择器可以直接选择标签copy js path
await page.type("#kw.s_ipt", "小僵尸博客")
# 点击搜索
await page.click("input#su")
# 等待0.5S
# await asyncio.sleep(0.5)
# 在while循环里强行查询某元素进行等待 用 querySelector 和 xpath都行
# while not await page.querySelector("#content_left"):
# pass
while not await page.xpath("//div[@id='content_left']"):
pass
# waitFor 不能用, 这个方法官方api是可以根据 "//" 来判断是xpath还是Selector, 而且还有timeout参数
# while not await page.waitFor("#content_left"):
# pass
print("页面cookie", await page.cookies())
print("页面标题", await page.title())
print("页面内容", await page.content())
# 截图
await page.screenshot({'path': 'test.png'})
# 滚动到页面底部
await page.evaluate('window.scrollBy(0, window.innerHeight)')
await brower.close()
loop = asyncio.get_event_loop()
loop.run_until_complete(run("https://www.baidu.com"))
总结
一个很舒服的一点是,第一次运行的时候,pyppeteer会自动下载操作系统对应的chromium,所以不用自己去找对应版本的包下载
缺点是有些API不能用,但基本功能还好。我只是用它来渲染页面以获取源代码。我还是喜欢用我的解析器来解析。
参考
#puppeteerlaunchoptions 查看全部
浏览器抓取网页(谷歌chrome官方无头框架puppeteer的python版本,基于Chrome/Chromium浏览器库)
前言
Pyppeteer 是 Google Chrome 官方无头框架 puppeteer 的 Python 版本。它基于 Chrome/Chromium 浏览器自动化库,可用于抓取呈现的网页。效果和selenium+chromedrive一样。
熟悉的代码链接
"""
@author xiaofei
@email zhengxiaofei@zhuge.com
@date 2019-07-03
@desc
"""
import asyncio
from pyppeteer import launch
# api文档 https://github.com/GoogleChrom ... tions
async def run(url):
brower = await launch({
"headless": False # 设置模式, 默认无头
})
# 打开新页面
page = await brower.newPage()
# 设置页面视图大小
await page.setViewport(viewport={'width': 1280, 'height': 800})
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
print("默认UA", await brower.userAgent())
# 设置当前页面UA
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
# 打开路由
await page.goto(url)
# 输入内容 不会写选择器可以直接选择标签copy js path
await page.type("#kw.s_ipt", "小僵尸博客")
# 点击搜索
await page.click("input#su")
# 等待0.5S
# await asyncio.sleep(0.5)
# 在while循环里强行查询某元素进行等待 用 querySelector 和 xpath都行
# while not await page.querySelector("#content_left"):
# pass
while not await page.xpath("//div[@id='content_left']"):
pass
# waitFor 不能用, 这个方法官方api是可以根据 "//" 来判断是xpath还是Selector, 而且还有timeout参数
# while not await page.waitFor("#content_left"):
# pass
print("页面cookie", await page.cookies())
print("页面标题", await page.title())
print("页面内容", await page.content())
# 截图
await page.screenshot({'path': 'test.png'})
# 滚动到页面底部
await page.evaluate('window.scrollBy(0, window.innerHeight)')
await brower.close()
loop = asyncio.get_event_loop()
loop.run_until_complete(run("https://www.baidu.com";))
总结
一个很舒服的一点是,第一次运行的时候,pyppeteer会自动下载操作系统对应的chromium,所以不用自己去找对应版本的包下载
缺点是有些API不能用,但基本功能还好。我只是用它来渲染页面以获取源代码。我还是喜欢用我的解析器来解析。
参考
#puppeteerlaunchoptions
浏览器抓取网页(第14.5节利用浏览器获取的http信息构造Python网页访问的请求头)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-15 10:00
Python访问网页并读取网页内容非常简单。在《第一节4.5 使用浏览器获取的HTTP信息构造Python网页访问的HTTP请求头》的方法中,构造了请求http报文的方法。在请求头的情况下,使用 urllib 包的请求模块使这项工作变得非常容易。具体声明如下:
header = mkhead()
req = urllib.request.Request(url=site,headers=header)
sitetext = urllib.request.urlopen(req).read().decode()
urllib.request.Request 和 urllib.request.urlopen 两句也可以合二为一。我不会在这里详细介绍它们。相关说明请参考:
阐明:
1、 国内的decode的参数一般都是默认值,UTF-8、GBK,如果是默认值就是UTF-8;
2、站点是访问网站的网站;
3、headers 参数为http消息头的内容,请参考《第一节4.1 学习通过Python爬取网页的步骤》或《第一节4.3使用谷歌》浏览网站访问的http信息>中介绍的http消息头的知识,在实际设置中,header的内容可多可少,根据爬虫访问网站的要求而定:
1)headers 参数不能传实参,也可以是空字典实参。如果不传递实参,系统默认使用空字典。在这种情况下,Python 会自动添加一些内容让 web 服务器正确处理,这些值具有很强的 Pythonic 风味,可以让服务器很容易知道它们是由 Python 生成填充的。您可以使用抓包程序查看具体的填充值。这对爬虫来说不是什么好事,因为爬虫更能伪装成普通浏览器来访问;
2)headers 填写一些参数,老袁建议填写以下参数:
User-Agent:表示正在使用的浏览器。关于它的历史,请参考《Re: 为什么浏览器的user-agent字符串以“Mozilla”开头?》,具体值可以网上查,最好的方法是直接抓取真实浏览器的数据并填写比如老猿直接使用本地浏览器的信息:
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.@ >0.3809.100 Safari/537.36
请参考“第一节4.3使用谷歌浏览器获取网站访问的http信息”和“第一节4.4使用IE浏览器获取网站”章节访问了 http 信息”。
接受:表示本机作为客户端浏览器可以接受的MIME类型(互联网媒体类型)是本机可以识别和处理的互联网信息类型。最好是从本机或其他真机上抓取和填写。比如老猴子抓取本地浏览器发送的请求信息中,填写的值为:'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp ,image/ apng,/;q=0.8,application/signed-exchange;v=b3'
Accept-Encoding:浏览器可以支持的压缩编码方式,如gzip、deflate、br等。服务器的消息体的压缩格式记录在响应消息头部的Content-Encodin字段中. 在http请求中,Accept-Encoding用于告知服务器客户端可以识别的压缩格式,服务器根据字段和服务器的情况使用相应的方法对http消息体进行压缩。注意,如果应用程序不考虑服务器端http消息体的解压,则不应设置该值,否则应用程序将无法识别接收到的响应消息体。有关 HTTP 响应头的信息,请参阅“传输:
Accept-Language:客户端浏览器需要的语言类型,当服务端可以提供一种以上的语言版本时使用,如zh-CN,zh;q=0.9等;
Connection:表示是否需要长连接,keep-alive表示长连接;
cookie:会话cookie信息,如果想复用已有的浏览器会话而不实现登录管理,可以直接复制已有浏览器会话的cookie,否则要么应用自行实现登录网站,否则将是匿名访问。具体可以根据自己的爬虫应用的要求确定处理方式。
以上信息建议根据爬虫功能的需要进行设置,但必须设置User-Agent,让应用看起来像普通浏览器。
案例:以下是老袁访问其博客文章的代码:
<p>>>> import urllib.request
>>> def mkhead():
header = {\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\',
\'Accept-Language\':\'zh-CN,zh;q=0.9\',
\'Connection\':\'keep-alive\',
\'Cookie\':\'uuid_tt_dd=10_35489889920-1563497330616-876822; ...... \',
\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\'}
return header
>>> url= r\'https://blog.csdn.net/LaoYuanPython\'
>>> header=mkhead()
>>> req = urllib.request.Request(url=url,headers=header)
>>> text = urllib.request.urlopen(req).read().decode()
>>> text[0:100]
\'\n\n\n \n 查看全部
浏览器抓取网页(第14.5节利用浏览器获取的http信息构造Python网页访问的请求头)
Python访问网页并读取网页内容非常简单。在《第一节4.5 使用浏览器获取的HTTP信息构造Python网页访问的HTTP请求头》的方法中,构造了请求http报文的方法。在请求头的情况下,使用 urllib 包的请求模块使这项工作变得非常容易。具体声明如下:
header = mkhead()
req = urllib.request.Request(url=site,headers=header)
sitetext = urllib.request.urlopen(req).read().decode()
urllib.request.Request 和 urllib.request.urlopen 两句也可以合二为一。我不会在这里详细介绍它们。相关说明请参考:
阐明:
1、 国内的decode的参数一般都是默认值,UTF-8、GBK,如果是默认值就是UTF-8;
2、站点是访问网站的网站;
3、headers 参数为http消息头的内容,请参考《第一节4.1 学习通过Python爬取网页的步骤》或《第一节4.3使用谷歌》浏览网站访问的http信息>中介绍的http消息头的知识,在实际设置中,header的内容可多可少,根据爬虫访问网站的要求而定:
1)headers 参数不能传实参,也可以是空字典实参。如果不传递实参,系统默认使用空字典。在这种情况下,Python 会自动添加一些内容让 web 服务器正确处理,这些值具有很强的 Pythonic 风味,可以让服务器很容易知道它们是由 Python 生成填充的。您可以使用抓包程序查看具体的填充值。这对爬虫来说不是什么好事,因为爬虫更能伪装成普通浏览器来访问;
2)headers 填写一些参数,老袁建议填写以下参数:
User-Agent:表示正在使用的浏览器。关于它的历史,请参考《Re: 为什么浏览器的user-agent字符串以“Mozilla”开头?》,具体值可以网上查,最好的方法是直接抓取真实浏览器的数据并填写比如老猿直接使用本地浏览器的信息:
用户代理:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.@ >0.3809.100 Safari/537.36
请参考“第一节4.3使用谷歌浏览器获取网站访问的http信息”和“第一节4.4使用IE浏览器获取网站”章节访问了 http 信息”。
接受:表示本机作为客户端浏览器可以接受的MIME类型(互联网媒体类型)是本机可以识别和处理的互联网信息类型。最好是从本机或其他真机上抓取和填写。比如老猴子抓取本地浏览器发送的请求信息中,填写的值为:'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp ,image/ apng,/;q=0.8,application/signed-exchange;v=b3'
Accept-Encoding:浏览器可以支持的压缩编码方式,如gzip、deflate、br等。服务器的消息体的压缩格式记录在响应消息头部的Content-Encodin字段中. 在http请求中,Accept-Encoding用于告知服务器客户端可以识别的压缩格式,服务器根据字段和服务器的情况使用相应的方法对http消息体进行压缩。注意,如果应用程序不考虑服务器端http消息体的解压,则不应设置该值,否则应用程序将无法识别接收到的响应消息体。有关 HTTP 响应头的信息,请参阅“传输:
Accept-Language:客户端浏览器需要的语言类型,当服务端可以提供一种以上的语言版本时使用,如zh-CN,zh;q=0.9等;
Connection:表示是否需要长连接,keep-alive表示长连接;
cookie:会话cookie信息,如果想复用已有的浏览器会话而不实现登录管理,可以直接复制已有浏览器会话的cookie,否则要么应用自行实现登录网站,否则将是匿名访问。具体可以根据自己的爬虫应用的要求确定处理方式。
以上信息建议根据爬虫功能的需要进行设置,但必须设置User-Agent,让应用看起来像普通浏览器。
案例:以下是老袁访问其博客文章的代码:
<p>>>> import urllib.request
>>> def mkhead():
header = {\'Accept\':\'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\',
\'Accept-Language\':\'zh-CN,zh;q=0.9\',
\'Connection\':\'keep-alive\',
\'Cookie\':\'uuid_tt_dd=10_35489889920-1563497330616-876822; ...... \',
\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\'}
return header
>>> url= r\'https://blog.csdn.net/LaoYuanPython\'
>>> header=mkhead()
>>> req = urllib.request.Request(url=url,headers=header)
>>> text = urllib.request.urlopen(req).read().decode()
>>> text[0:100]
\'\n\n\n \n
浏览器抓取网页(一整套抓直播源的方法简单易学,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 689 次浏览 • 2021-11-15 00:10
)
小编一般会在家里下载一个直播软件,带盒子看直播,但是如果想看一些港澳台,或者欧美频道,就得自己找直播源了。网友分享的直播源有很多,但是可以长期有效。很少,而且清晰度没有保证。那么问题来了,自己抓直播源是否可行?经过研究,总结了一套秘籍,现在传给大家~
这种捕获实时源的方法简单易学。再也不用担心找不到您想再次观看的节目了!
您可以自己观看本地频道和所有想要观看的直播频道
首先需要下载安装一个软件,安装在PC端。源码捕获过程也是在计算机端进行的。
然后下载安装。安装后可以在桌面看到Kucha 6图标
抓住源头并开始。
打开Kucha 6,第一次进入如下界面
点击工具中的设置,会弹出系统设置,在嗅探器设置界面保存浏览器选项,如下图
设置好浏览器后,打开你添加的浏览器,这里以风云直播为例。(其他如PPTV、腾讯视频、乐视视频等也采用此方法。想看港台节目的有福了!)
打开风云直播网页版,风云直播网址:detail-2b291973fd124aab8ef389291b6bcb44.html 选择要抓拍的频道(如浙江卫视)
此时,酷叉6会自动抓取并过滤浏览网址。一段时间后,抓取将完成。(注意!最好不要打开太多的网页,这样爬取的时间会比较长,浪费时间,而且软件可能无法准确过滤)
接下来是最重要的一步
在过滤后的地址中找到视频地址
选择视频地址,右键复制网址就OK了~~~
将链接复制到新创建的文本文档。在链接前输入程序源的名称,用空格分隔。保存并更改文件后缀为“.tv”或“.txt”(视直播软件而定)。
节目的源头完全是这样拍的
让我们在下面检查捕获的实时源的有效性。
也看看其他来源
源码抢软件下载地址:
至此,权力的交接已经完成,一点点信息也透露了出来。
小编平时自己用的都是TV和HDP直播软件,没别的原因——台站多源稳定。两者都可以在环视网或环视商城下载。
查看全部
浏览器抓取网页(一整套抓直播源的方法简单易学,你知道吗?
)
小编一般会在家里下载一个直播软件,带盒子看直播,但是如果想看一些港澳台,或者欧美频道,就得自己找直播源了。网友分享的直播源有很多,但是可以长期有效。很少,而且清晰度没有保证。那么问题来了,自己抓直播源是否可行?经过研究,总结了一套秘籍,现在传给大家~
这种捕获实时源的方法简单易学。再也不用担心找不到您想再次观看的节目了!
您可以自己观看本地频道和所有想要观看的直播频道
首先需要下载安装一个软件,安装在PC端。源码捕获过程也是在计算机端进行的。
然后下载安装。安装后可以在桌面看到Kucha 6图标
抓住源头并开始。
打开Kucha 6,第一次进入如下界面
点击工具中的设置,会弹出系统设置,在嗅探器设置界面保存浏览器选项,如下图
设置好浏览器后,打开你添加的浏览器,这里以风云直播为例。(其他如PPTV、腾讯视频、乐视视频等也采用此方法。想看港台节目的有福了!)
打开风云直播网页版,风云直播网址:detail-2b291973fd124aab8ef389291b6bcb44.html 选择要抓拍的频道(如浙江卫视)
此时,酷叉6会自动抓取并过滤浏览网址。一段时间后,抓取将完成。(注意!最好不要打开太多的网页,这样爬取的时间会比较长,浪费时间,而且软件可能无法准确过滤)
接下来是最重要的一步
在过滤后的地址中找到视频地址
选择视频地址,右键复制网址就OK了~~~
将链接复制到新创建的文本文档。在链接前输入程序源的名称,用空格分隔。保存并更改文件后缀为“.tv”或“.txt”(视直播软件而定)。
节目的源头完全是这样拍的
让我们在下面检查捕获的实时源的有效性。
也看看其他来源
源码抢软件下载地址:
至此,权力的交接已经完成,一点点信息也透露了出来。
小编平时自己用的都是TV和HDP直播软件,没别的原因——台站多源稳定。两者都可以在环视网或环视商城下载。
浏览器抓取网页(雷达币方法如下检查用户的agent字符串)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-15 00:09
雷达币
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。 查看全部
浏览器抓取网页(雷达币方法如下检查用户的agent字符串)
雷达币
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
它可能是这样打印的:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是本次文章的全部内容。希望本文的内容对大家的学习或工作有所帮助。有什么问题可以留言交流。
浏览器抓取网页(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 19:04
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29" 查看全部
浏览器抓取网页(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉)
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
想要获取年龄数据,即“20”,如何使用常规抓包?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @"(?is)");
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“.” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一起见,我推荐使用 XML 来保存内容。首先,网页中的数据基本可以转换为XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29"
浏览器抓取网页(IE浏览器的工作原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-13 11:01
我们现在在互联网上使用越来越多的应用程序。通常,您会经常登录视频和音乐网站 看电影和听MP3。遇到好的视频或音乐,我总是想把它们留在电脑上,但网站做了相应的限制,不提供下载服务。如果您了解 IE 浏览器的工作原理,就可以轻松找到解决方案。事实上,IE浏览器在线播放视频时,已经下载到您的电脑上,并且都保存在IE浏览器的缓存文件夹中。不仅是这些音视频文件,我们浏览网页时产生的文件都会存放在一个名为Temporary Internet Files的文件夹中,也就是IE缓存文件夹。只需在此处搜索即可获取网页上无法下载的文件。然而,出于安全考虑,此文件夹由系统管理。我们不能随便打开、查看、复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。
选择对应的搜索类型,自动在临时文件夹中搜索对应的文件。这时,选择相应的文件后,可以在菜单中用鼠标右键选择打开、进入目录或“另存为”。另外可以直接查看文件属性信息进行判断。
选择对应的文件可以快速打开或“另存为”到另一个目录。所以大家,通过这款实用的“IE临时文件助手”软件,我们可以轻松的在临时目录中找到对应的格式文件,轻松挖掘出来。其中有“宝物”。提示:首次使用建议先清理IE缓存,然后再浏览网页,这样可以更快的提取浏览网页生成的缓存文件。另外,解压出来的文件默认会存放在C盘根目录下以相应扩展名命名的文件夹中(如“C:\.flv”),您可以定期查看!小编点评:IE临时文件夹,不是“垃圾堆”,而是“金屋”。 查看全部
浏览器抓取网页(IE浏览器的工作原理及应用)
我们现在在互联网上使用越来越多的应用程序。通常,您会经常登录视频和音乐网站 看电影和听MP3。遇到好的视频或音乐,我总是想把它们留在电脑上,但网站做了相应的限制,不提供下载服务。如果您了解 IE 浏览器的工作原理,就可以轻松找到解决方案。事实上,IE浏览器在线播放视频时,已经下载到您的电脑上,并且都保存在IE浏览器的缓存文件夹中。不仅是这些音视频文件,我们浏览网页时产生的文件都会存放在一个名为Temporary Internet Files的文件夹中,也就是IE缓存文件夹。只需在此处搜索即可获取网页上无法下载的文件。然而,出于安全考虑,此文件夹由系统管理。我们不能随便打开、查看、复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。随意复制和移动文件。这里有一个适合大家的工具——IE临时文件助手,用来解除这些限制,现在你可以随心所欲的获取网页中使用的各种文件,轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。并轻松实现分类搜索。运行软件后,会自动定位到IE浏览器的临时文件目录。根据搜索文件类型,我们可以选择相应的搜索文件格式,如FLV视频、SWF文件、MP4、MP3文件等,当然也支持自定义后缀类型,选择格式并选择“开始查找”,会自动列出临时文件夹中对应的格式文件。
选择对应的搜索类型,自动在临时文件夹中搜索对应的文件。这时,选择相应的文件后,可以在菜单中用鼠标右键选择打开、进入目录或“另存为”。另外可以直接查看文件属性信息进行判断。
选择对应的文件可以快速打开或“另存为”到另一个目录。所以大家,通过这款实用的“IE临时文件助手”软件,我们可以轻松的在临时目录中找到对应的格式文件,轻松挖掘出来。其中有“宝物”。提示:首次使用建议先清理IE缓存,然后再浏览网页,这样可以更快的提取浏览网页生成的缓存文件。另外,解压出来的文件默认会存放在C盘根目录下以相应扩展名命名的文件夹中(如“C:\.flv”),您可以定期查看!小编点评:IE临时文件夹,不是“垃圾堆”,而是“金屋”。
浏览器抓取网页(抓取浏览器市场份额是找寻引擎网站手机版花的抓取速度范围)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-07 16:26
王文生义无反顾。爬行浏览器的市场占有率是在移动版搜索引擎w88网站上找到爬行页面总年数上限的英文在线翻译。对于这个特殊的网站,寻找引擎w88网站 手机版的总花费在这篇文章上网站是钢铁的反面。网站囫囵页面不会在范围内被抓取。爬行浏览器市场份额谷歌英文在线翻译使用爬行预算,免费翻译就是爬行预算。我想我无法描述它的意思,所以我使用爬行浏览器市场份额来利用这个概念。什么决定了爬虫浏览器的市场份额?这涉及到爬行生理要求和爬行速度范围。
1、把握生理需求
Crawl demand,爬取需求,是指搜索引擎“想要”抓取特定数量的页面。
有两个主要因素决定了抓握的生理需要。一是页面权重。网站 上有很多页面已经达到了基本页面权重。搜索引擎想要抓取数量页面。二是索引库里的篮球鞋页是否经过长时间冷气不制冷,没有翻新。毕爷爷说的是页面权重。重量大的页面在不加制冷剂的情况下不会长时间空调。页面权重和网站权重不是没有文档的。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
二、爬行速度范围
搜索引擎w88网站移动版将无法抓取更多页面,会压倒别人的网站算法。因此,某个网站会为爬取速度设置一个上限。英文在线翻译,爬网速率限制,即计算器可以继承的上限。英文在线翻译,在本文速度范围内,w88网站手机版抓取不会减慢计算器的速度。回馈储户参观。
算术单元的响应速度足够快,把这一段的速度范围调到一点,抓取速度加快,算术单元的响应速度降低。速度范围随着在线英文翻译而下降,甚至停止爬行。因此,抓取速度范围就是搜索引擎“可以”抓取的页面数。
四、什么决定了爬虫浏览器的市场份额?
抢占浏览器市场份额,就是要考虑爬行的生理需求和爬行速度的范围。可以同时“有能力”的页面数。网站 权重高,页面质量高,计算速度够快。爬虫浏览器的市场份额很大。
5.小网站没必要抢浏览器市场份额
Small 网站 页数少,即使网站的权重再低,计算器也比较慢。不管移动版的搜索引擎w88网站每天爬多少,至少能爬上几百页也就不足为奇了。怎么才能十几天爬完整个网站,几千页的数量网站基本不用抢浏览器的市场份额了。数万只冻鸭变成烤鸭。网站 没什么大不了的。如果一天几百次访问能拖慢计算器,SEO不是主要考虑的事情,而是w88网站移动版你的网站,培养计算器怎么配。
六、中小网站长川需要考虑抢浏览器市场份额
对于几十万页以上的中小型网站,可能需要考虑爬取浏览器市场份额的问题。爬虫浏览器的市场份额还不够。比如网站有1000万个页面,搜索引擎每天只抓取几万个页面。爬取一次网站可能需要几个月,甚至一个月的时间。年,也可能意味着一些重要的页面无法爬取,所以没有排名。或者重要的页面不能因巧合而翻新。
如果您希望 网站 页面被使用。完全爬行。首先,确保书本计算器足够快,页面足够小。如果网站有高质量的数据处理,爬虫浏览器的市场份额会受到爬虫速度的限制。提高页面速度直接增加了抓取速度范围,从而增加了抓取浏览器的市场份额。
比如图一个网站百度抓取频率:
页面爬取频率和爬取年数(取决于计算设备的速度和页面大小)都不是大文件,手册也不是用来抢浏览器市场份额的,不用担心。大网站 长川需要考虑爬取浏览器市场份额的另一个原因是,吴庸利用有限的爬取浏览器市场份额,对无意义的页面进行猛烈爬取,导致本该爬取的重要页面。但是没有空间可以被捕获。
冰天屋抢占浏览器市场份额的标兵页面有:
提炼站内底线
低质量、废品
无限页面,如台历
该部门的上述页面被大量抓取。爬取浏览器市场份额可能会用尽,但是应该爬取的页面却没有爬取。
如何勤勤恳恳地抢占浏览器市场份额?
当然,首先是减小页面文件的大小,提高计算器的速度,减少w88网站移动版数据处理库的抓取时间。尽量避开上面列出的那些抢占浏览器市场份额的暴力生物。如果是结构工程师问题,最明显的解决办法就是爬不出来robots文件,但是数量会很暴力。一些页面权重归因于权重。
少数情况下,利用link nofollow的暗属性,强化宝石当之无愧的名声,勤劳干净,抢占浏览器市场份额。由于爬虫浏览器市场份额无止境,添加nofollow毫无意义。网站,nofollow 是当之无愧的自制权重流与分配具体脑发育测试。精心绘制的nofollow会降低无意义页面的权重,培养重要页面的权重。搜索引擎在抓取时会使用一个网址抓取列表。抓取的网址按页面权重排序,培养重要的页面权重。会先被抓取,无意义页面的权重可能会低到搜索引擎不想抓取的程度。
最后附上几条说明:
Links和nofollow不会猛烈抢浏览器市场份额。但在谷歌,这将是暴力的。
noindex 标签不能勤快干净地抢浏览器市场份额。搜索引擎需要了解页面上没有index标签,它必须先爬取这个页面,所以它不会以勤奋和干净的方式爬取浏览器市场份额。
规范标签偶尔可以通过一点勤奋和诚信抢占浏览器市场份额。与 noindex 标签一样,搜索引擎必须了解页面上存在规范标签。你必须先爬取这个页面,这样你才不会勤快干净地直接抢浏览器的市场份额。但是,抓取带有规范标签的页面的频率通常会降低。因此,我们将勤奋诚实地抢占浏览器市场份额。
抓取速度和抓取浏览器市场份额不是排名因素。但是没有被抓取的页面是无法排名的。
白色链接: 查看全部
浏览器抓取网页(抓取浏览器市场份额是找寻引擎网站手机版花的抓取速度范围)
王文生义无反顾。爬行浏览器的市场占有率是在移动版搜索引擎w88网站上找到爬行页面总年数上限的英文在线翻译。对于这个特殊的网站,寻找引擎w88网站 手机版的总花费在这篇文章上网站是钢铁的反面。网站囫囵页面不会在范围内被抓取。爬行浏览器市场份额谷歌英文在线翻译使用爬行预算,免费翻译就是爬行预算。我想我无法描述它的意思,所以我使用爬行浏览器市场份额来利用这个概念。什么决定了爬虫浏览器的市场份额?这涉及到爬行生理要求和爬行速度范围。
1、把握生理需求
Crawl demand,爬取需求,是指搜索引擎“想要”抓取特定数量的页面。
有两个主要因素决定了抓握的生理需要。一是页面权重。网站 上有很多页面已经达到了基本页面权重。搜索引擎想要抓取数量页面。二是索引库里的篮球鞋页是否经过长时间冷气不制冷,没有翻新。毕爷爷说的是页面权重。重量大的页面在不加制冷剂的情况下不会长时间空调。页面权重和网站权重不是没有文档的。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
二、爬行速度范围
搜索引擎w88网站移动版将无法抓取更多页面,会压倒别人的网站算法。因此,某个网站会为爬取速度设置一个上限。英文在线翻译,爬网速率限制,即计算器可以继承的上限。英文在线翻译,在本文速度范围内,w88网站手机版抓取不会减慢计算器的速度。回馈储户参观。
算术单元的响应速度足够快,把这一段的速度范围调到一点,抓取速度加快,算术单元的响应速度降低。速度范围随着在线英文翻译而下降,甚至停止爬行。因此,抓取速度范围就是搜索引擎“可以”抓取的页面数。
四、什么决定了爬虫浏览器的市场份额?
抢占浏览器市场份额,就是要考虑爬行的生理需求和爬行速度的范围。可以同时“有能力”的页面数。网站 权重高,页面质量高,计算速度够快。爬虫浏览器的市场份额很大。
5.小网站没必要抢浏览器市场份额
Small 网站 页数少,即使网站的权重再低,计算器也比较慢。不管移动版的搜索引擎w88网站每天爬多少,至少能爬上几百页也就不足为奇了。怎么才能十几天爬完整个网站,几千页的数量网站基本不用抢浏览器的市场份额了。数万只冻鸭变成烤鸭。网站 没什么大不了的。如果一天几百次访问能拖慢计算器,SEO不是主要考虑的事情,而是w88网站移动版你的网站,培养计算器怎么配。
六、中小网站长川需要考虑抢浏览器市场份额
对于几十万页以上的中小型网站,可能需要考虑爬取浏览器市场份额的问题。爬虫浏览器的市场份额还不够。比如网站有1000万个页面,搜索引擎每天只抓取几万个页面。爬取一次网站可能需要几个月,甚至一个月的时间。年,也可能意味着一些重要的页面无法爬取,所以没有排名。或者重要的页面不能因巧合而翻新。
如果您希望 网站 页面被使用。完全爬行。首先,确保书本计算器足够快,页面足够小。如果网站有高质量的数据处理,爬虫浏览器的市场份额会受到爬虫速度的限制。提高页面速度直接增加了抓取速度范围,从而增加了抓取浏览器的市场份额。
比如图一个网站百度抓取频率:
页面爬取频率和爬取年数(取决于计算设备的速度和页面大小)都不是大文件,手册也不是用来抢浏览器市场份额的,不用担心。大网站 长川需要考虑爬取浏览器市场份额的另一个原因是,吴庸利用有限的爬取浏览器市场份额,对无意义的页面进行猛烈爬取,导致本该爬取的重要页面。但是没有空间可以被捕获。
冰天屋抢占浏览器市场份额的标兵页面有:
提炼站内底线
低质量、废品
无限页面,如台历
该部门的上述页面被大量抓取。爬取浏览器市场份额可能会用尽,但是应该爬取的页面却没有爬取。
如何勤勤恳恳地抢占浏览器市场份额?
当然,首先是减小页面文件的大小,提高计算器的速度,减少w88网站移动版数据处理库的抓取时间。尽量避开上面列出的那些抢占浏览器市场份额的暴力生物。如果是结构工程师问题,最明显的解决办法就是爬不出来robots文件,但是数量会很暴力。一些页面权重归因于权重。
少数情况下,利用link nofollow的暗属性,强化宝石当之无愧的名声,勤劳干净,抢占浏览器市场份额。由于爬虫浏览器市场份额无止境,添加nofollow毫无意义。网站,nofollow 是当之无愧的自制权重流与分配具体脑发育测试。精心绘制的nofollow会降低无意义页面的权重,培养重要页面的权重。搜索引擎在抓取时会使用一个网址抓取列表。抓取的网址按页面权重排序,培养重要的页面权重。会先被抓取,无意义页面的权重可能会低到搜索引擎不想抓取的程度。
最后附上几条说明:
Links和nofollow不会猛烈抢浏览器市场份额。但在谷歌,这将是暴力的。
noindex 标签不能勤快干净地抢浏览器市场份额。搜索引擎需要了解页面上没有index标签,它必须先爬取这个页面,所以它不会以勤奋和干净的方式爬取浏览器市场份额。
规范标签偶尔可以通过一点勤奋和诚信抢占浏览器市场份额。与 noindex 标签一样,搜索引擎必须了解页面上存在规范标签。你必须先爬取这个页面,这样你才不会勤快干净地直接抢浏览器的市场份额。但是,抓取带有规范标签的页面的频率通常会降低。因此,我们将勤奋诚实地抢占浏览器市场份额。
抓取速度和抓取浏览器市场份额不是排名因素。但是没有被抓取的页面是无法排名的。
白色链接:
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-07 03:26
)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
); 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍
)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
浏览器抓取网页(如何获取网页的大小一张网页位置的全部面积? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-07 02:16
)
获取页面大小
一个网页的总面积就是它的大小,通常由内容和css样式表决定。
浏览器窗口的大小是您在浏览器中看到的网页部分的面积。也称为视口。
如果网页的内容可以在浏览器窗口中显示(即不出现滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果无法显示所有内容,请滚动浏览器窗口以显示网页的所有部分。
function getViewport(){
if (document.compatMode == "BackCompat"){//(兼容quirks模式)
//document.compatMode用来判断当前浏览器采用的渲染方式。
//BackCompat:标准兼容模式关闭。CSS1Compat:标准兼容模式开启。
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
浏览器窗口内部高 window.innerHeight
内部宽 window.innerWidth
IE 5 6 7 8 //一般返回的是正确值,documentElement代表根元素,一般指html
html文档所在窗口的当前高度 document.documentElement.clientHeight
宽度 document.documentElement.clientWidth
或者Document对象的body属性对应HTML文档的Body标签
document.body.clientHeight
document.body.clientWidth
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {//判断网页内容刚好在浏览器中全部显示,取最大值
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
网页实际内容的宽度和高度(元素的可视区域包括滚动条,滚动条的所有长度和宽度)
scrollHeight
scrollWidth
网页内容宽高(包含滚动条等边线,会随着窗口的显示大小改变)
offsetHeight
offsetHeight=clientHeight+滚动条+边框
offsetWidth
元素绝对位置
网页元素的绝对位置是指元素左上角相对于整个网页左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。因此,只需要将这两个值累加就可以得到元素的绝对坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){ //元素距顶部文档的距离
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
元素的相对位置
网页元素的相对位置是指元素左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只需用页面滚动距离减去绝对坐标即可。滚动条的垂直距离是文档对象的scrollTop属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
function getElementViewLeft(element){//offset包括border
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性可以赋值,它们会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。另外 element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
页面元素的位置
即使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象:left、right、top和bottom,分别对应元素左上角和右下角相对于浏览器窗口(视口)左上角的距离。
因此,网页元素的相对位置为 this=ele
var X= this.getBoundingClientRect().left;
var Y=this.getBoundingClientRect().top;
加上滚动距离,可以得到绝对位置
var X=this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y=this.getBoundingClientRect().top+document.documentElement.scrollTop;
滚动条的位置
function getScrollTop() {
if (window.pageYOffset) {
scrollPos = window.pageYOffset;//
}
else if (document.compatMode && document.compatMode != 'BackCompat') {
scrollPos = document.documentElement.scrollTop;
}
else if (document.body) {
scrollPos = document.body.scrollTop;
}
return scrollPos;
}
滚动距离和偏移
scrollLeft 设置或者取位于给定对象左边界与窗口中目前可见内容的最左端之间的距离
scrollTop 设置或取位于对象最顶端与窗口中可见内容的最顶端之间的距离
offsetLeft 获取指定对象位于版面或由offsetParent属性指定的父坐标的计算左侧位置
offsetTop 获得指定对象相对于版面或由offsetParent属性指定的父坐标的计算顶端位置
offsetParent指的是布局中设置position属性 Relative Absolute Fixed的父容器,
从最近的父节点开始,一层层向上找,直到html的body
屏幕的宽度和高度
1. 整个屏幕的宽高: screen对象: 封装当前屏幕的信息
完整屏幕宽高: screen.width/height
去掉任务栏后,可用的宽高:
screen.availWidth/availHeight
: 如何判断用户现在使用设备的种类:
1. screen.width/height
2. 获得鼠标的坐标位置:
获得鼠标相对于屏幕的位置: e.screenX/screenY
图片说明
HTML精确定位:scrollLeft、scrollWidth、clientWidth、offsetWidth
ele.scrollHeight:获取对象的滚动高度。
ele.scrollWidth: 获取对象的滚动宽度
ele.scrollLeft:设置或获取对象左边缘与窗口中当前可见内容最左端的距离
ele.scrollTop:设置或获取元素到文档顶部的距离,滚动条拉动的距离
//可以通过style.width,height,left,top来设置
offsetWidth:获取对象相对于布局的宽度或父坐标offsetParent属性指定的父坐标
offsetHeight:获取对象相对于布局的高度或父坐标offsetParent属性指定的父坐标
offsetLeft:获取计算出的对象相对于布局或offsetParent属性指定的父坐标的左侧位置
offsetTop:获取计算出的对象相对于布局或offsetTop属性指定的父坐标的顶部位置
event.clientX 相对于文档的水平坐标
event.clientY 相对于文档的垂直坐标
event.offsetX 相对于容器的水平坐标
event.offsetY 相对于容器的垂直坐标
document.documentElement.scrollTop 垂直滚动的值
event.clientX+document.documentElement.scrollTop 相对于文档的水平坐标+垂直方向的滚动量
以下是在 JavaScript 中构建迁移和转换代码的常用属性
页面可见区域的宽度:document.body.clientWidth;
网页可见区域的高度:document.body.clientHeight;
网页可见区域的宽度:document.body.offsetWidth(包括边线的宽度);
网页可见区域的高度:document.body.offsetHeight(包括边线的宽度);
页面正文的全文宽度:document.body.scrollWidth;
页面正文全文高度:document.body.scrollHeight;
被滚动页面的高度:document.body.scrollTop;
页面向左滚动:document.body.scrollLeft;
在页面主体项组上:window.screenTop;
左侧页面主体项组:window.screenLeft;
高屏幕分辨率:window.screen.height;
屏幕分辨率的宽度:window.screen.width;
屏幕上可用工作区的高度:window.screen.availHeight;
2、clientHeight
认为是内容可见区域的高度,即页面浏览器中可以看到内容的区域的高度,一般是从最后一个对象栏下方的区域到状态栏上方的区域,与页面内容无关。
clientHeight 是通过浏览器查看内容的区域的高度。
offsetHeight和scrollHeight都是网页内容的高度,但是当网页内容高度<clientHeight时,scrollHeight=clientHeight,offsetHeight可以是<clientHeight。
offsetHeight = 可视区域 clientHeight + 滚动条 + 边框。scrollHeight 则是网页内容实际高度。
3、scrollLeft
scrollTop 是“卷起”的高度值,例如:
<p> 查看全部
浏览器抓取网页(如何获取网页的大小一张网页位置的全部面积?
)
获取页面大小
一个网页的总面积就是它的大小,通常由内容和css样式表决定。
浏览器窗口的大小是您在浏览器中看到的网页部分的面积。也称为视口。
如果网页的内容可以在浏览器窗口中显示(即不出现滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果无法显示所有内容,请滚动浏览器窗口以显示网页的所有部分。
function getViewport(){
if (document.compatMode == "BackCompat"){//(兼容quirks模式)
//document.compatMode用来判断当前浏览器采用的渲染方式。
//BackCompat:标准兼容模式关闭。CSS1Compat:标准兼容模式开启。
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
浏览器窗口内部高 window.innerHeight
内部宽 window.innerWidth
IE 5 6 7 8 //一般返回的是正确值,documentElement代表根元素,一般指html
html文档所在窗口的当前高度 document.documentElement.clientHeight
宽度 document.documentElement.clientWidth
或者Document对象的body属性对应HTML文档的Body标签
document.body.clientHeight
document.body.clientWidth
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {//判断网页内容刚好在浏览器中全部显示,取最大值
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
网页实际内容的宽度和高度(元素的可视区域包括滚动条,滚动条的所有长度和宽度)
scrollHeight
scrollWidth
网页内容宽高(包含滚动条等边线,会随着窗口的显示大小改变)
offsetHeight
offsetHeight=clientHeight+滚动条+边框
offsetWidth
元素绝对位置
网页元素的绝对位置是指元素左上角相对于整个网页左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。因此,只需要将这两个值累加就可以得到元素的绝对坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){ //元素距顶部文档的距离
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
元素的相对位置
网页元素的相对位置是指元素左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只需用页面滚动距离减去绝对坐标即可。滚动条的垂直距离是文档对象的scrollTop属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
function getElementViewLeft(element){//offset包括border
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性可以赋值,它们会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。另外 element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
页面元素的位置
即使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象:left、right、top和bottom,分别对应元素左上角和右下角相对于浏览器窗口(视口)左上角的距离。
因此,网页元素的相对位置为 this=ele
var X= this.getBoundingClientRect().left;
var Y=this.getBoundingClientRect().top;
加上滚动距离,可以得到绝对位置
var X=this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y=this.getBoundingClientRect().top+document.documentElement.scrollTop;
滚动条的位置
function getScrollTop() {
if (window.pageYOffset) {
scrollPos = window.pageYOffset;//
}
else if (document.compatMode && document.compatMode != 'BackCompat') {
scrollPos = document.documentElement.scrollTop;
}
else if (document.body) {
scrollPos = document.body.scrollTop;
}
return scrollPos;
}
滚动距离和偏移
scrollLeft 设置或者取位于给定对象左边界与窗口中目前可见内容的最左端之间的距离
scrollTop 设置或取位于对象最顶端与窗口中可见内容的最顶端之间的距离
offsetLeft 获取指定对象位于版面或由offsetParent属性指定的父坐标的计算左侧位置
offsetTop 获得指定对象相对于版面或由offsetParent属性指定的父坐标的计算顶端位置
offsetParent指的是布局中设置position属性 Relative Absolute Fixed的父容器,
从最近的父节点开始,一层层向上找,直到html的body
屏幕的宽度和高度
1. 整个屏幕的宽高: screen对象: 封装当前屏幕的信息
完整屏幕宽高: screen.width/height
去掉任务栏后,可用的宽高:
screen.availWidth/availHeight
: 如何判断用户现在使用设备的种类:
1. screen.width/height
2. 获得鼠标的坐标位置:
获得鼠标相对于屏幕的位置: e.screenX/screenY
图片说明
HTML精确定位:scrollLeft、scrollWidth、clientWidth、offsetWidth
ele.scrollHeight:获取对象的滚动高度。
ele.scrollWidth: 获取对象的滚动宽度
ele.scrollLeft:设置或获取对象左边缘与窗口中当前可见内容最左端的距离
ele.scrollTop:设置或获取元素到文档顶部的距离,滚动条拉动的距离
//可以通过style.width,height,left,top来设置
offsetWidth:获取对象相对于布局的宽度或父坐标offsetParent属性指定的父坐标
offsetHeight:获取对象相对于布局的高度或父坐标offsetParent属性指定的父坐标
offsetLeft:获取计算出的对象相对于布局或offsetParent属性指定的父坐标的左侧位置
offsetTop:获取计算出的对象相对于布局或offsetTop属性指定的父坐标的顶部位置
event.clientX 相对于文档的水平坐标
event.clientY 相对于文档的垂直坐标
event.offsetX 相对于容器的水平坐标
event.offsetY 相对于容器的垂直坐标
document.documentElement.scrollTop 垂直滚动的值
event.clientX+document.documentElement.scrollTop 相对于文档的水平坐标+垂直方向的滚动量
以下是在 JavaScript 中构建迁移和转换代码的常用属性
页面可见区域的宽度:document.body.clientWidth;
网页可见区域的高度:document.body.clientHeight;
网页可见区域的宽度:document.body.offsetWidth(包括边线的宽度);
网页可见区域的高度:document.body.offsetHeight(包括边线的宽度);
页面正文的全文宽度:document.body.scrollWidth;
页面正文全文高度:document.body.scrollHeight;
被滚动页面的高度:document.body.scrollTop;
页面向左滚动:document.body.scrollLeft;
在页面主体项组上:window.screenTop;
左侧页面主体项组:window.screenLeft;
高屏幕分辨率:window.screen.height;
屏幕分辨率的宽度:window.screen.width;
屏幕上可用工作区的高度:window.screen.availHeight;
2、clientHeight
认为是内容可见区域的高度,即页面浏览器中可以看到内容的区域的高度,一般是从最后一个对象栏下方的区域到状态栏上方的区域,与页面内容无关。
clientHeight 是通过浏览器查看内容的区域的高度。
offsetHeight和scrollHeight都是网页内容的高度,但是当网页内容高度<clientHeight时,scrollHeight=clientHeight,offsetHeight可以是<clientHeight。
offsetHeight = 可视区域 clientHeight + 滚动条 + 边框。scrollHeight 则是网页内容实际高度。
3、scrollLeft
scrollTop 是“卷起”的高度值,例如:
<p>
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-11-07 02:13
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。
第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。
如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。 查看全部
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
无论是在日常工作中,还是在休闲生活中,都会遇到需要截图的情况。因为有些东西不是说出来的,直接截图就简单明了,非常直观。使用手机的时候,大家都知道怎么截图,使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器截屏时,我们往往只能截取当前屏幕显示的内容。如果你想对这个网页的所有内容进行截图,大部分朋友可能不知道怎么做。大功告成,今天小编就教大家如何使用QQ浏览器对整个网页进行截图。这样我们就可以像手机滚动截图一样对页面上的所有内容进行截图。具体方法如下:
第一步,在电脑上打开QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按键盘上的F12键,调出浏览器的开发者工具。Windows电脑也可以通过Ctrl+Shift+I的快捷键组合来实现这个功能,而Mac电脑可以通过Alt+Command+I的快捷键组合来实现这个功能。
第四步,在浏览器的开发者工具中,我们通过Ctrl+Shift+P(Windows)或者Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行输入“screen”。这时,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的含义,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的所有内容并进行截图,我们选择Capture full size screenshot。
如果我们想要获取元素节点网页的内容并进行截图,我们选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,我们选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器进行各种截图的内容。如果你经常一张一张的截图,那你不妨学习一下这篇文章中提到的技巧,这样以后就算有人要你发整个网页的截图,你也能轻松搞定五个脚步。再也不用下拉去截图,下拉再截图再发愁了。一键截取所有内容,更加轻松便捷。
浏览器抓取网页(深入理解网络协议原理及实现方法-python编程实战博客)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-06 23:02
浏览器抓取网页的方法还是有很多的。一般地,大家比较常用的一种是通过post的方式来提交数据,这个方法实现在网页上写post的header,等待服务器处理成功后把资源返回给浏览器。这种方法对于后台非常安全的网站,效果还是比较明显的,但对于比较安全的网站就稍有不足。另一种方法是提交请求,要等网页处理完成再返回,这个方法很有意思,就是需要你会编程,因为你得先构造一个过滤器把那些不知名的抓取器列出来然后把那些数据拦截走。
具体可以看一下最近写的两篇关于post和get请求处理的两篇。实现自己需要的第三方登录和异步加载功能--深入理解网络协议原理及实现方法-python编程实战博客第三篇主要讲的是其get请求,用我编写的一个js小例子来加深理解。步骤如下,先爬取http1.1(请求路径)和登录页(请求地址)的url,然后让客户端抓包的时候等到以上路径,然后爬到请求地址的cookie(cookie值),然后抓包的时候加入到http1.1的request里面。
最后让客户端处理登录页面(登录页用一个ie浏览器登录即可,具体cookie如何处理需要具体学习)即可。处理登录页(抓包后加入cookie)抓包处理登录页(爬取登录页的cookie)post请求:request.url=//url(请求的路径)(需要修改cookie的路径),必须用webshell(需要有js),然后根据路径传递cookie路径到请求地址,然后等待返回数据。
post是webshell的写法之一,用来在客户端把数据上传到服务器端,是不会返回自己cookie的。我们在客户端可以用如下方法加上cookie保存cookie过路由请求(request.url=//request.url),这是一个post请求,不用multipart或json格式的,这个cookie是base64格式,因为数据只是存在于浏览器一个cookie里,那么你如果用json格式你就丧失了加密过的特性。
multipart/json是post请求返回给服务器端用以加密数据的格式。如果服务器需要保存数据用get请求,这个本身没什么问题,但如果你要把数据传给服务器,服务器不一定需要保存。简单的说,request需要客户端加上cookie传递,服务器返回的只是一串字符串。在multipart/json格式的post请求中,服务器不再需要存储数据(这里服务器存放的就是一个转换生成的字符串),而是用map表示数据序列,然后传输的数据如果是以$开头的,那么可以认为服务器把该数据映射到了一个json格式,如果是以$_._开头的,那么服务器把该数据编码成一个list,然后返回给你。理论上讲,不存在密码之类的保存在cookie里的数据,只有这些数据被称为。 查看全部
浏览器抓取网页(深入理解网络协议原理及实现方法-python编程实战博客)
浏览器抓取网页的方法还是有很多的。一般地,大家比较常用的一种是通过post的方式来提交数据,这个方法实现在网页上写post的header,等待服务器处理成功后把资源返回给浏览器。这种方法对于后台非常安全的网站,效果还是比较明显的,但对于比较安全的网站就稍有不足。另一种方法是提交请求,要等网页处理完成再返回,这个方法很有意思,就是需要你会编程,因为你得先构造一个过滤器把那些不知名的抓取器列出来然后把那些数据拦截走。
具体可以看一下最近写的两篇关于post和get请求处理的两篇。实现自己需要的第三方登录和异步加载功能--深入理解网络协议原理及实现方法-python编程实战博客第三篇主要讲的是其get请求,用我编写的一个js小例子来加深理解。步骤如下,先爬取http1.1(请求路径)和登录页(请求地址)的url,然后让客户端抓包的时候等到以上路径,然后爬到请求地址的cookie(cookie值),然后抓包的时候加入到http1.1的request里面。
最后让客户端处理登录页面(登录页用一个ie浏览器登录即可,具体cookie如何处理需要具体学习)即可。处理登录页(抓包后加入cookie)抓包处理登录页(爬取登录页的cookie)post请求:request.url=//url(请求的路径)(需要修改cookie的路径),必须用webshell(需要有js),然后根据路径传递cookie路径到请求地址,然后等待返回数据。
post是webshell的写法之一,用来在客户端把数据上传到服务器端,是不会返回自己cookie的。我们在客户端可以用如下方法加上cookie保存cookie过路由请求(request.url=//request.url),这是一个post请求,不用multipart或json格式的,这个cookie是base64格式,因为数据只是存在于浏览器一个cookie里,那么你如果用json格式你就丧失了加密过的特性。
multipart/json是post请求返回给服务器端用以加密数据的格式。如果服务器需要保存数据用get请求,这个本身没什么问题,但如果你要把数据传给服务器,服务器不一定需要保存。简单的说,request需要客户端加上cookie传递,服务器返回的只是一串字符串。在multipart/json格式的post请求中,服务器不再需要存储数据(这里服务器存放的就是一个转换生成的字符串),而是用map表示数据序列,然后传输的数据如果是以$开头的,那么可以认为服务器把该数据映射到了一个json格式,如果是以$_._开头的,那么服务器把该数据编码成一个list,然后返回给你。理论上讲,不存在密码之类的保存在cookie里的数据,只有这些数据被称为。
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-05 06:11
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面的详细内容。更多详情请关注其他相关html中文网站文章!
浏览器抓取网页(浏览器内部加载的js(javascript)文件对比对比分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-04 08:04
浏览器抓取网页,想获取浏览器内部加载的js(javascript)文件,也就是网页源代码中的东西,你想最简单的方法,直接获取了,你可以通过web安全软件,把浏览器网页源代码抓取下来,
需要了解当前浏览器生态环境以及其他浏览器的数据源。对比目前主流浏览器的web安全策略,推测有这么几个网络漏洞。一,逆向工程。二,浏览器上传库,例如图片,视频等。三,静态漏洞(telnetssh等)对应的静态资源安全策略。四,浏览器文件加密(可能是导致下载性能)五,是否能获取用户浏览器密码。六,直接干脆的嗅探。
七,最最最安全的解决方案直接入侵用户浏览器获取有害信息,然后利用uaf干掉浏览器。好吧,要获取用户浏览器内容的请求以及二次请求貌似非常困难,很可能这些都在白名单中,不能跨域查询,所以只能抓包解析抓包解析抓包解析,然后试着找找下一页的链接然后尝试提交。
请检查fiddler,proxydump等服务器管理工具,设置一下ip允许请求数量。如果还有这方面的需求,可以检查一下mosaic,rfid,按键等不受限制的二进制文件,然后对有保护的文件进行破解。
我要是知道,我估计我把360强刷技术练熟了,在看看那些防火墙什么的, 查看全部
浏览器抓取网页(浏览器内部加载的js(javascript)文件对比对比分析)
浏览器抓取网页,想获取浏览器内部加载的js(javascript)文件,也就是网页源代码中的东西,你想最简单的方法,直接获取了,你可以通过web安全软件,把浏览器网页源代码抓取下来,
需要了解当前浏览器生态环境以及其他浏览器的数据源。对比目前主流浏览器的web安全策略,推测有这么几个网络漏洞。一,逆向工程。二,浏览器上传库,例如图片,视频等。三,静态漏洞(telnetssh等)对应的静态资源安全策略。四,浏览器文件加密(可能是导致下载性能)五,是否能获取用户浏览器密码。六,直接干脆的嗅探。
七,最最最安全的解决方案直接入侵用户浏览器获取有害信息,然后利用uaf干掉浏览器。好吧,要获取用户浏览器内容的请求以及二次请求貌似非常困难,很可能这些都在白名单中,不能跨域查询,所以只能抓包解析抓包解析抓包解析,然后试着找找下一页的链接然后尝试提交。
请检查fiddler,proxydump等服务器管理工具,设置一下ip允许请求数量。如果还有这方面的需求,可以检查一下mosaic,rfid,按键等不受限制的二进制文件,然后对有保护的文件进行破解。
我要是知道,我估计我把360强刷技术练熟了,在看看那些防火墙什么的,
浏览器抓取网页(为什么占用内存那么大?运行需要的内存空间是什么 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-03 23:16
)
为什么要占用这么多内存?
浏览器操作所需的内存空间基本是固定的。一些浏览器为了减少对“物理内存”的占用,将一些资源放在“虚拟内存”或硬盘上,这样会使网页浏览速度变慢。
搜狗高速浏览器通过严格的内存占用控制,实现了“速度”和“资源使用”的最佳平衡。当您有足够的内存空间时,它会尽力达到出色的速度。空间紧张时,资源回收充分进行,资源不会枯竭。
为什么主页被篡改了,如何修改主页?
引导页劫持是用户机器上常见的网页劫持现象。通常,恶意程序会通过多种方式将用户打开的URL替换为新的URL,强制用户访问目标网站,最终达到获利的目的。
由于此类网站普遍存在挂马、钓鱼、捆绑下载、恶意推广、色情赌博等违法行为,会给用户带来巨大的经济损失。
为了达到这个目的,恶意软件往往会在系统中安装常驻程序,长期监控用户行为,窃取用户信息,从而实现更加隐蔽、更长期的非法获利。
第一步:点击浏览器菜单中的“选项”;
第二步:在首页选项中,您可以自由设置“网页采集”、“我的采集”、“空白页”和“自定义”的网址。并且您可以选择在启动时打开“主页”或“上次未关闭的页面”。
查看全部
浏览器抓取网页(为什么占用内存那么大?运行需要的内存空间是什么
)
为什么要占用这么多内存?
浏览器操作所需的内存空间基本是固定的。一些浏览器为了减少对“物理内存”的占用,将一些资源放在“虚拟内存”或硬盘上,这样会使网页浏览速度变慢。
搜狗高速浏览器通过严格的内存占用控制,实现了“速度”和“资源使用”的最佳平衡。当您有足够的内存空间时,它会尽力达到出色的速度。空间紧张时,资源回收充分进行,资源不会枯竭。
为什么主页被篡改了,如何修改主页?
引导页劫持是用户机器上常见的网页劫持现象。通常,恶意程序会通过多种方式将用户打开的URL替换为新的URL,强制用户访问目标网站,最终达到获利的目的。
由于此类网站普遍存在挂马、钓鱼、捆绑下载、恶意推广、色情赌博等违法行为,会给用户带来巨大的经济损失。
为了达到这个目的,恶意软件往往会在系统中安装常驻程序,长期监控用户行为,窃取用户信息,从而实现更加隐蔽、更长期的非法获利。
第一步:点击浏览器菜单中的“选项”;
第二步:在首页选项中,您可以自由设置“网页采集”、“我的采集”、“空白页”和“自定义”的网址。并且您可以选择在启动时打开“主页”或“上次未关闭的页面”。
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-03 15:14
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面内容的详细信息,请关注其他相关html中文网站文章! 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容的多种方法)
IE浏览器获取当前页面内容的方法可能有很多种,今天介绍的就是其中一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西来获取页面内容。有兴趣的朋友可以参考这篇文章
private void timer1_Tick(object sender, EventArgs e) { lock (currentLock) { System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition; if (_leftClick) { timer1.Stop(); _leftClick = false; _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false)); if (_lastDocument != null) { if (_getDocument) { _getDocument = true; try { string url = _lastDocument.url; string html = _lastDocument.documentElement.outerHTML; string cookie = _lastDocument.cookie; string domain = _lastDocument.domain; var resolveParams = new ResolveParam { Url = new Uri(url), Html = html, PageCookie = cookie, Domain = domain }; RequetResove(resolveParams); } catch (Exception ex) { System.Windows.MessageBox.Show(ex.Message); Console.WriteLine(ex.Message); Console.WriteLine(ex.StackTrace); } } } else { new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页"); } _getDocument = false; } else { _pointFrm.Left = MousePoint.X + 10; _pointFrm.Top = MousePoint.Y + 10; } } }
在第11行的GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))分解下,首先从鼠标坐标获取页面的句柄:
public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl) { IntPtr handle = Win32APIsFull.WindowFromPoint(p); if (handle != IntPtr.Zero) { System.Drawing.Rectangle rect = default(System.Drawing.Rectangle); if (Win32APIsFull.GetWindowRect(handle, out rect)) { return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE); } } return IntPtr.Zero; }
接下来根据句柄获取页面内容:
public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd) { IntPtr result = Marshal.AllocHGlobal(4); Object obj = null; Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result)); if (Marshal.ReadInt32(result) != 0) { Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj)); } Marshal.FreeHGlobal(result); return obj as HTMLDocument; }
一般原则:
向IE表单发送消息,获取一个指向IE浏览器内存块的指针(非托管),然后根据这个指针获取HTMLDocument对象。
这个方法涉及到win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeoutA( [InAttribute()] System.IntPtr hWnd, uint Msg, uint wParam, int lParam, uint fuFlags, uint uTimeout, System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")] public static extern int ObjectFromLresult( int lResult, ref Guid riid, int wParam, [MarshalAs(UnmanagedType.IDispatch), Out] out Object pObject );
以上是c#从IE浏览器获取当前页面内容的详细信息,请关注其他相关html中文网站文章!

