
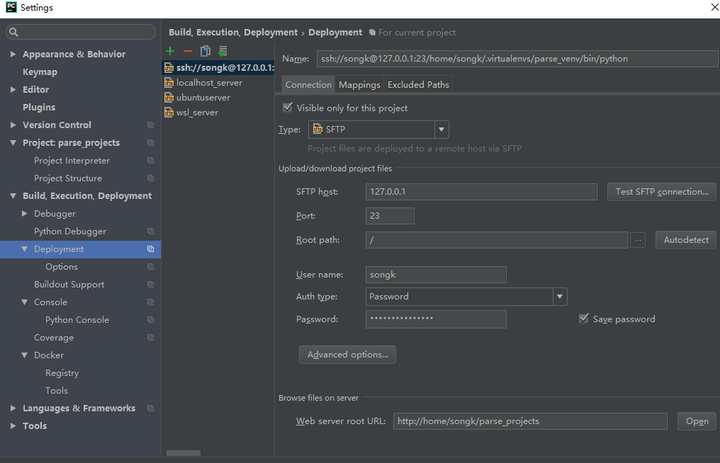
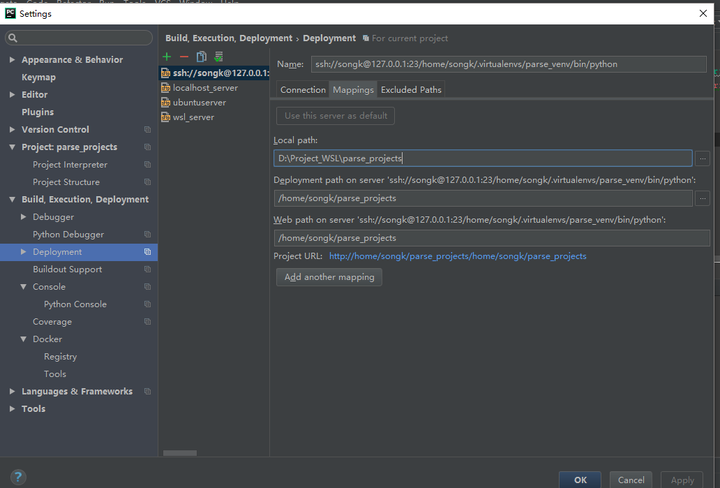
浏览器抓取网页
浏览器抓取网页(一个HTTP请求报文的Content-Type网络进程会影响后续流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-24 13:16
HTTP 请求消息由四部分组成:请求行、请求头、空行和请求实体。浏览器端开始构造请求行、请求头和请求体等信息,将浏览器的一些基本信息和cookie等信息添加到请求头中,然后将构造好的请求消息发送给服务器。
(5)服务器处理请求并返回数据
服务器收到请求消息后,会根据消息信息生成响应头、响应行、响应体等数据。网络进程收到响应头和响应行后,就可以解析响应头的内容了。网络进程解析响应头信息后,会转发给浏览器进程进行处理。
影响后续流程的两条信息:
响应行中的 301/302 状态代码执行重定向
在解析响应头的时候,还需要注意一个重定向操作:如果响应行信息是301/302,则表示需要重定向到另一个URL地址。这时,网络进程会从响应头中读取位置字段。值并重新发起 http/https 请求。
响应标头中的 Content-Type
网络进程会首先根据响应头中的 Content-Type 字段判断服务器返回什么类型的资源文件,因为不同的资源类型对浏览器的处理方式不同:
(6)断开连接:TCP 挥手四次
核心思想:TCP为什么需要四次挥手?原因是:释放连接是释放客户端到服务器和服务器到客户端的双向连接。具体来说就是确认客户端和服务端的发送和接收功能都关闭了;
3. 准备渲染进程4. 提交文档 当浏览器进程收到网络进程的响应头数据时,向渲染进程发送“提交文档”消息;渲染进程收到“提交文档”消息后,会与网络进程建立“管道”传输数据;文档数据传输完成后,渲染进程会向浏览器进程返回“确认提交”消息;浏览器进程收到消息后,开始更新页面状态,包括安全状态、地址栏URL、前进后退历史状态、更新网页等。
5. 浏览器解析并渲染页面
一旦文档被确认提交,渲染过程就开始解析资源并渲染页面。注意浏览器的渲染页面并不是等所有资源加载完毕才开始渲染,而是边解析边渲染,这也是为什么有些页面会先将文本呈现给用户,然后再加载图片等资源之后。
详细渲染过程见第4点
四、浏览器是如何工作的?
以chrome浏览器为例
浏览器的结构大致可以分为:用户界面、浏览器引擎、渲染引擎
4.1 不同的浏览器内核
IE:三叉戟
火狐:壁虎
Safari:Webkit
Chrome/Opera/Edge:基于 Webkit 改造的 Blink
4.2 浏览器的多进程结构
今天的浏览器是多进程结构,而早期的浏览器是单进程结构
早期浏览器单进程结构:
单进程结构提出了许多问题:
不稳定:其中一个线程卡住可能会导致整个进程出现问题。例如,如果您打开多个选项卡,其中一个卡住的选项卡可能会导致浏览器无法运行。不安全:数据可以在浏览器之间共享,那么js可以自由访问浏览器中的所有数据进程不流畅:一个进程需要负责的事情太多,导致效率低下
因此,当今的浏览器选择了多进程结构。根据不同的进程功能,浏览器可以分为:
4.3 chrome的4个进程模型
Chrome 共有 4 种进程模型,不同的进程模式对 tab 进程的处理方式不同。
4.4 在浏览器地址栏中输入内容时,浏览器内部会发生什么?(详细请看三) 1.用户输入URL阶段+DNS+请求数据+处理返回数据
当我在地址栏中输入内容时,浏览器进程的UI线程会捕获我输入的内容,如果输入了URL,UI线程会启动一个网络线程(这是在浏览器进程中,而不是网络进程,网络过程 当你发起http请求请求DNS进行域名解析,然后开始连接服务器获取数据,如果输入关键词,浏览器就知道你要使用搜索功能,所以它将使用默认配置的搜索引擎进行查询;
网络线程获取到数据后,会通过Safe Browsing(Google内部的一个站点安全系统,通过检测站点数据来判断是否安全)检查该站点是否为恶意站点,如果是,则发出警告页面会提示。告诉我这个站点存在安全问题,浏览器会阻止我访问,但我可以强制它继续。当返回的数据准备好并且安全检查通过时,网络线程会通知UI线程我准备好了,轮到你了。
2. 渲染页面阶段
然后UI线程会创建一个渲染器进程来渲染页面,浏览器进程将数据通过IPC管道传递给渲染器进程,进入渲染进程。渲染器进程接收数据(html(通常收录 css、js 和图像资源))。
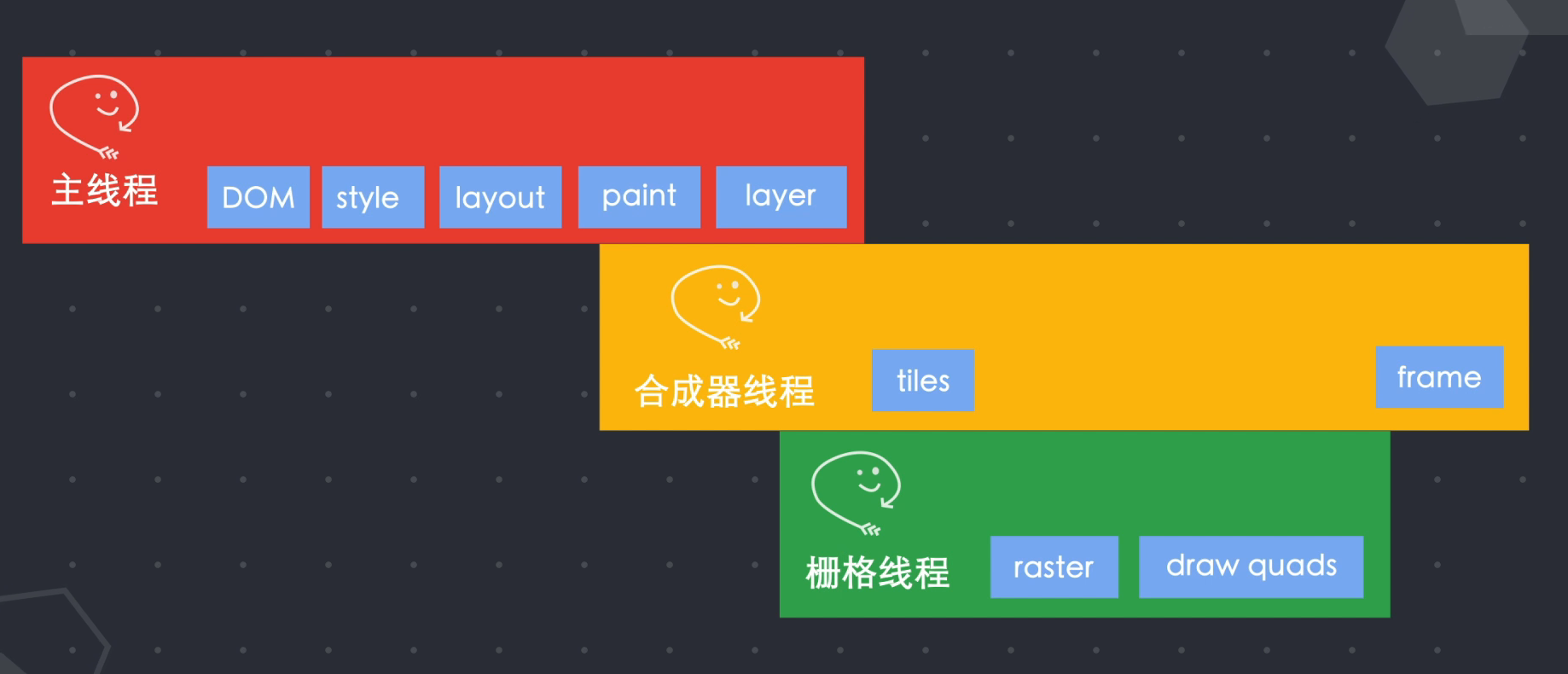
渲染器进程的核心任务:将html、js、css、image等资源渲染成用户可以交互的网页。渲染器进程的主线程解析html并构造DOM结构。
HTML首先通过Tokeniser进行token化,输入的html内容通过词法分析解析成多个标签,根据识别出的标签进行DOM树的构建。在DOM树的创建过程中,会创建一个document对象,然后会创建一个以document为根节点的文档。DOM 树。
需要注意的是,html代码中经常会引入一些额外的资源,比如js、css、图片等。图片、CSS等资源需要从网络下载或者直接从缓存中加载。这些资源不会阻塞 html 的解析,因为它们不会影响 DOM 的生成。当解析过程中遇到脚本标签时,会停止对html的解析。,然后加载、解析并执行js,因为js可能会改变当前页面的html结构,有可能在js中添加或删除节点等操作会影响html的结构,所以script标签必须放在合适的位置,或者使用async或者defer属性异步加载js。
html解析完成后,我们会得到一个DOM Tree,但是此时我们并不知道DOM树上的每个节点是什么样子的。这是主线程需要解析 CSS 并确定每个 DOM 节点的计算样式。
在了解了每个节点的 DOM 结构和样式之后,就需要知道每个节点在页面上的位置,即节点的坐标以及节点需要占用多少区域。这个阶段称为布局布局。线程通过遍历 dom 和计算出来的样式生成 Layout 树。布局树上的每个节点都记录了 x、y 坐标和边框大小。
需要注意的是,DOM树和Layout树并不是一一对应的。如果设置了 display: none,则不会出现在布局树上。如果在 before 伪类中添加了一个带有 content 值的元素,就会出现 content 中的内容。不会出现在Layout树上的DOM树上,因为DOM是通过html解析得到的,不关心样式,而Layout树是DOM树结合CSSOM树生成的。
只知道元素的大小、形状和位置是不够的。我们还需要知道绘制节点的顺序。毕竟像z-index这样的属性会影响节点绘制的层次关系。如果我们按照 DOM 层次绘制,就会导致渲染不正确。所以为了保证屏幕上显示正确的层级,主线程遍历Layout树创建了一个绘制记录表(Paint Record),记录了绘制的顺序。这个阶段称为绘画。
知道了节点的绘制顺序,是时候将这些信息转换成像素并在屏幕上显示了。这种行为称为光栅化。
Chrome 早期的光栅化方案只是对用户可见区域的内容进行了光栅化。当用户滚动页面时,更多的内容被光栅化以填补缺失的部分。这种方案会导致显示延迟。现在chrome的光栅化过程称为堆肥。Composting是一种将页面的每一部分分成多个层,分别进行光栅化,在合成器线程技术中分别合成页面的技术。简单来说,就是将页面的所有元素按照一定的规则划分成图层,对图层进行光栅化处理,然后只将可视区域的内容组合成一帧显示给用户。
主线程遍历布局树生成层树。当层树生成并确定了绘制顺序时,主线程将此信息传递给合成器线程。
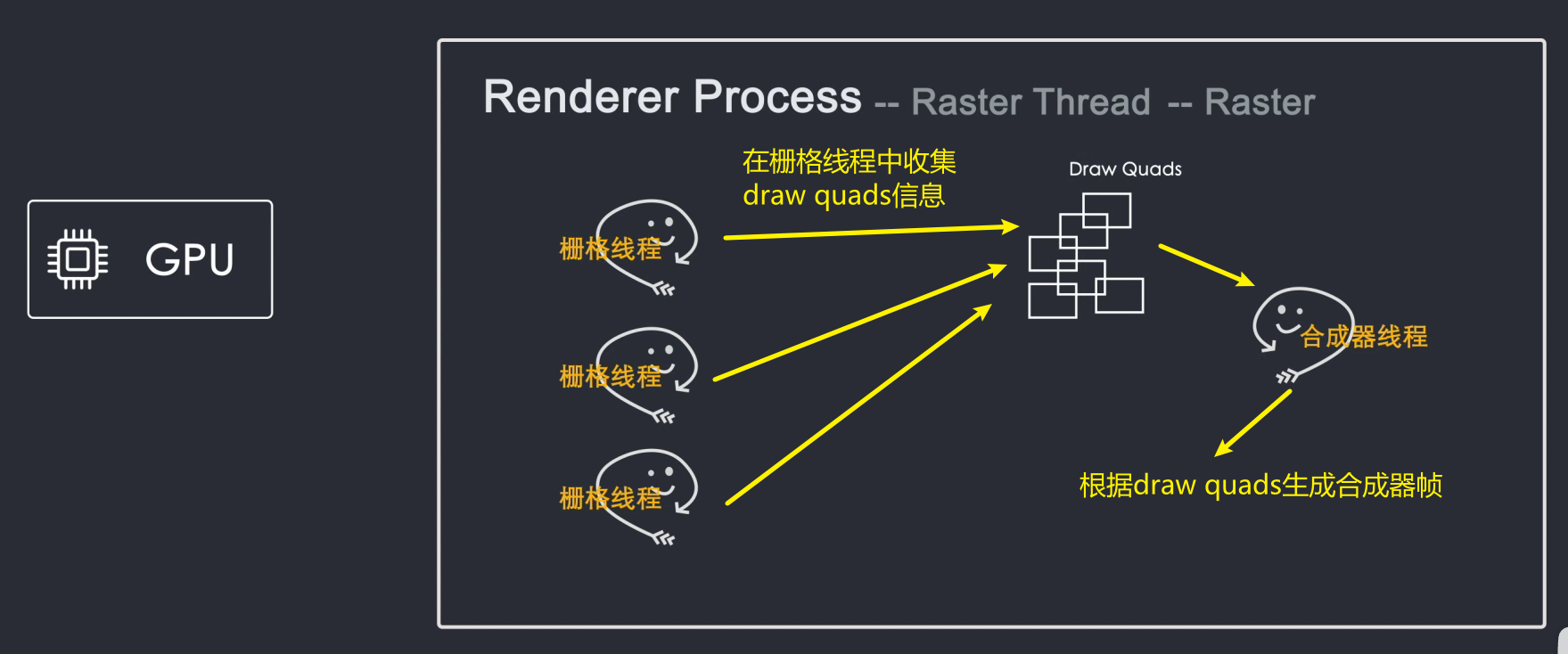
合成器线程对每一层进行光栅化,并且由于层可以与页面的整个长度一样大,因此合成器线程将它们切成许多块并将每个块发送到光栅化器线程。
光栅化线程光栅化每个图块并将它们存储到 GPU 内存中
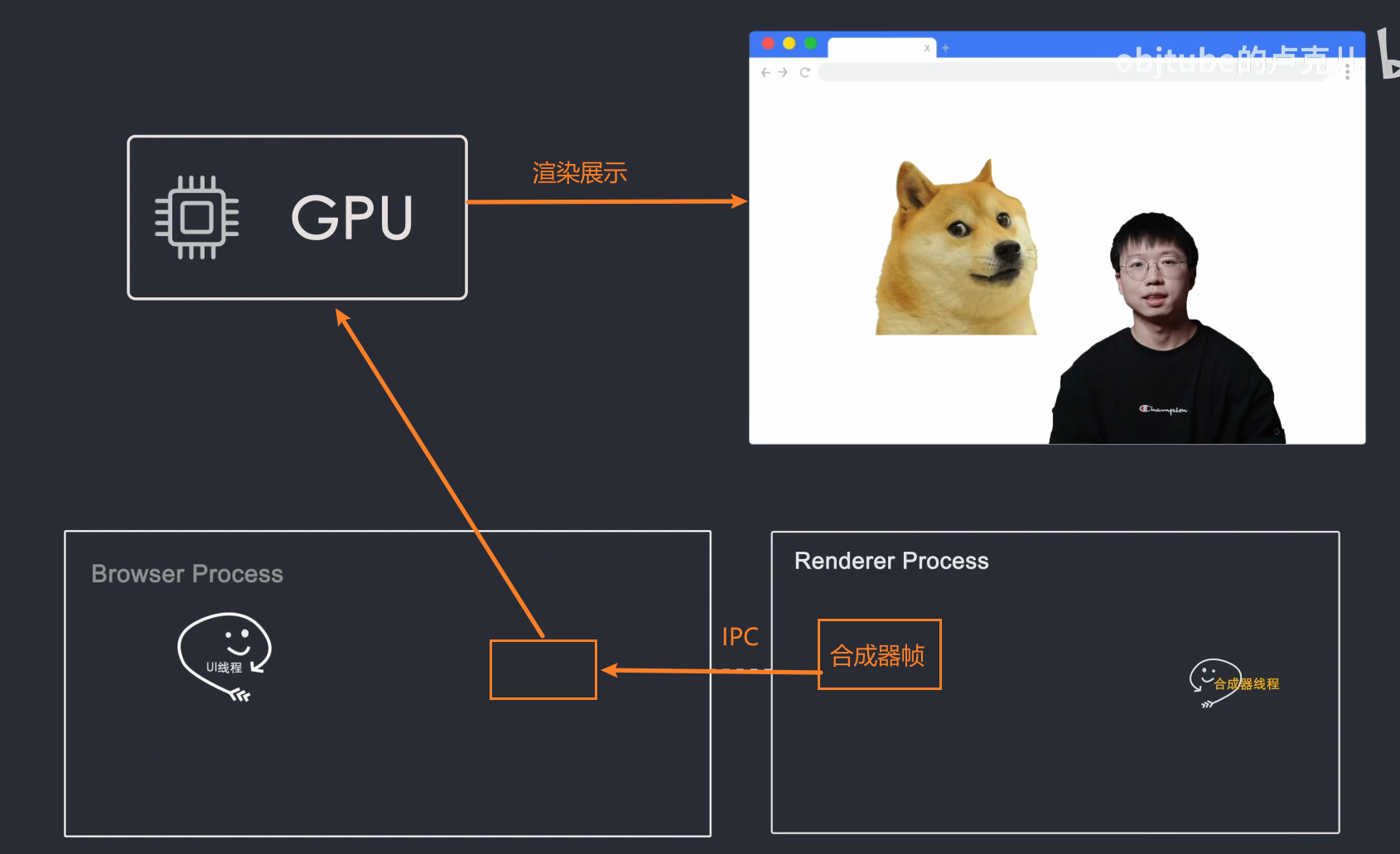
当瓦片被光栅化时,合成器线程将采集称为“绘制四边形”(来自网格线程)的瓦片信息,这些信息记录瓦片在内存中的位置以及它们在页面上的绘制位置。瓦片的信息,合成器线程根据该信息生成合成器帧(Compositor Frame)
然后这个合成器帧通过IPC传给浏览器进程,然后浏览器进程把合成器帧传给GPU,然后GPU渲染到屏幕上,然后就可以看到页面的内容了。
但是当页面发生变化时,会生成一个新的合成器框架,并重复上述动作
3. 回流和重绘
重排重绘会占用主线程,而js也在主线程上运行,所以会出现抢占执行时间的问题。在一帧内完成布局绘制后还有时间时,js会获得使用主线程的权利。如果js的执行时间过长,js会在下一帧开始时没有及时返回到主线程,导致下面的一帧动画没有按时渲染,页面动画就会卡住。
有什么优化方法吗?? ?
当然有!!
4. 优化回流和重绘导致页面动画卡顿的问题
第一个是通过 requestAnimationFrame() API。每一帧都会调用这个方法。通过API回调,我们可以将JS运行的任务分成更小的任务块(划分为每一帧),并在每一帧时间用完前暂停js执行并返回主线程,这样主线程就可以布局和下一帧开始时准时绘制
第二种光栅化不占用主线程,只运行在合成器线程和网格线程中,也就是说不会用js抢占主线程。CSS有一个动画属性transform,这个属性实现的动画是不会通过的。布局和绘图直接运行在合成器线程和网格线程上,因此不会受主线程中的 JS 影响。更重要的是,由于transform实现的动画不需要经过布局绘制样式计算等操作,因此节省了大量的计算时间
5. 渲染管道
当网络进程向渲染进程提交资源时,渲染进程就会开始渲染页面。浏览器的渲染机制非常复杂,所以渲染会分为很多子阶段。输入的 HTML、CSS、JS 以及图片等资源都会经过这些阶段,最终输出的像素会显示在页面上。处理流程称为渲染管道。
根据渲染的时间顺序,我们将浏览器的渲染时间段划分为以下几个子阶段。需要注意的是,每个子阶段的输出都会作为下一个子阶段的输入,这也符合实际工厂流水线场景。
6. 渲染过程总结
1、渲染过程将HTML内容转化为可读的DOM树结构
2、渲染引擎将CSS样式表转换成浏览器可以理解的样式表,并计算出DOM节点的样式
3、创建布局树并计算元素的布局信息。
4、对布局树进行分层并生成分层树。
5、为每一层生成绘制列表并将它们提交到合成线程。
6、合成线程将图层划分为瓦片,并将瓦片转换为光栅化线程池中的位图。
7、合成线程向浏览器进程发送绘图平铺命令DrawQuads
8、浏览器进程根据 DrawQuads 消息生成页面并显示在监视器上。
五、JS的运行原理(重点:JS引擎)5.1 js继承了以下四种语言的特点
5.2个奇怪的js
5.3 JIT
js是动态类型语言,但这也导致我们在运行前无法知道变量的类型。只有在运行过程中才能确定每个变量的类型,这使得js无法在运行前编译更快、更底层。语言代码(机器代码)。尽管如此,js 执行起来还是很快的,这是为什么呢?? ? 这是因为当前的 JavaScript 引擎使用了一种技术:Just-In-Time Compilation,简称 JIT,就是在运行阶段生成机器码,而不是提前生成。JIT 在运行代码的同时生成机器码。
5.4 JS 引擎
js 是一种高级语言。在被计算机CPU执行之前,需要将JS转换为低级机器语言,通过程序执行。该程序称为 JavaScript 引擎。JavaScript 有很多引擎:
js引擎执行的一般流程(new V8)首先通过解析器将JS源码解析成抽象语法树AST;然后通过解释器将AST编译成字节码btyecode,字节码是一个中间表示跨平台的,不同于最终的机器码。字节码是平台无关的,可以运行在不同的操作系统上;字节码最终通过编译器(compiler)生成机器码,由于不同的处理编译平台所使用的机器码会是不同,所以编译器会根据当前平台编译对应的机器码
5.5 以V8为例了解JS引擎编译和JS优化
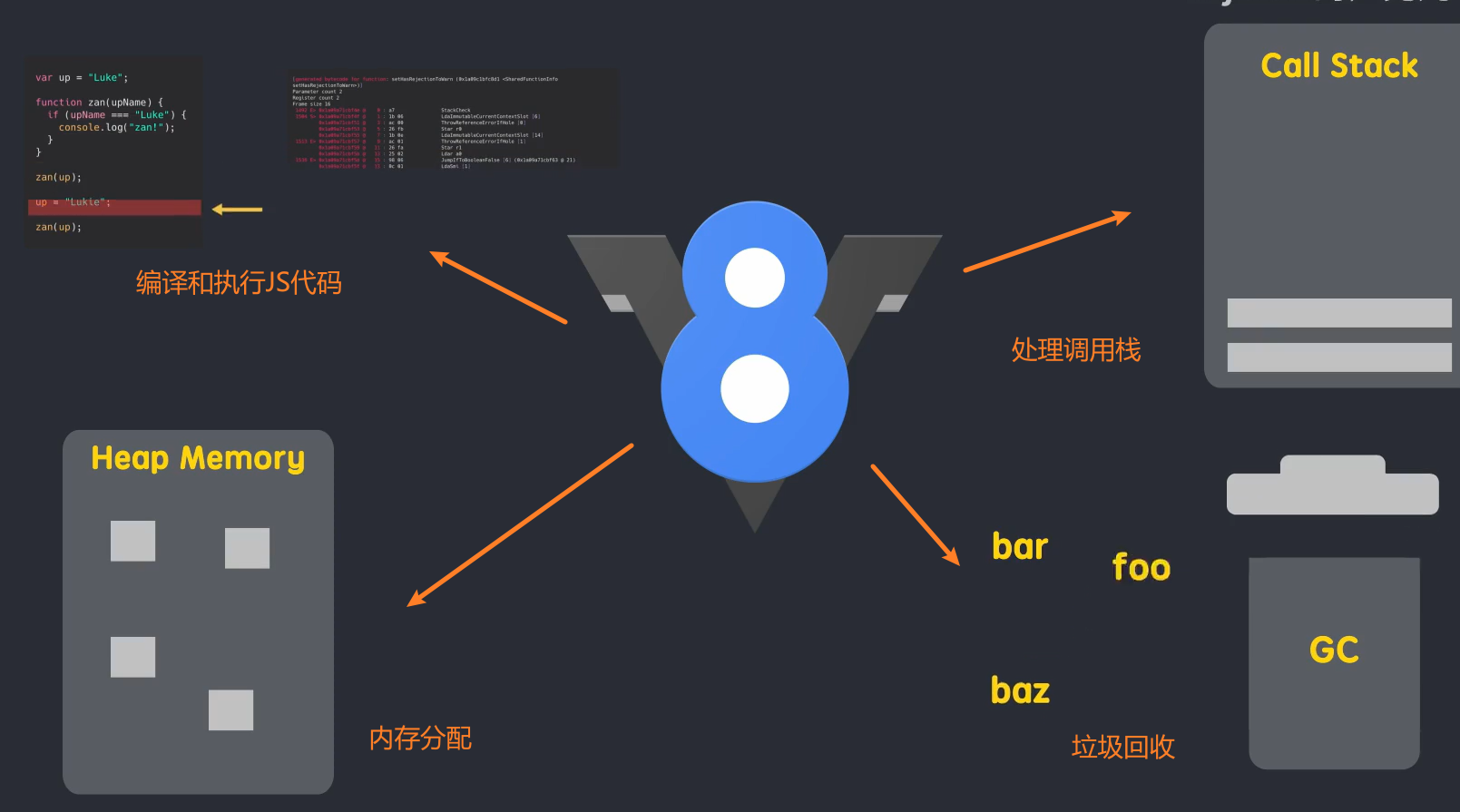
JS的引擎是V8,node.js的运行环境也是V8引擎,electron的底层引擎也是V8.
简单地说,V8 是一个 C++ 程序,它接收 JavaScript 代码,编译代码然后执行。编译后的代码可以在多个操作系统和多个处理器上运行。
V8主要负责工作:
1. 早期的 V8 引擎
JS 引擎在编译和执行 JS 代码时使用了三个重要的组件:
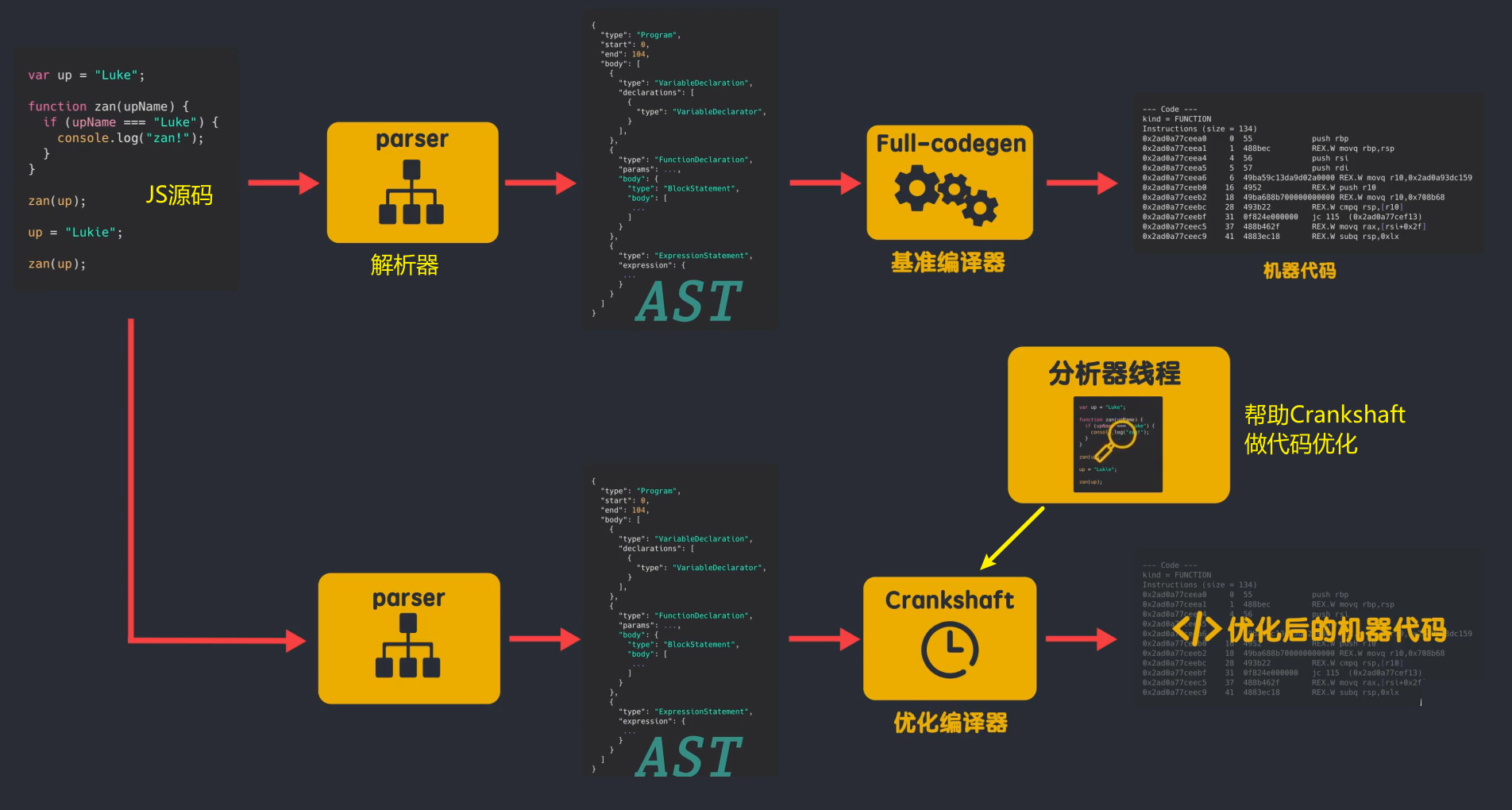
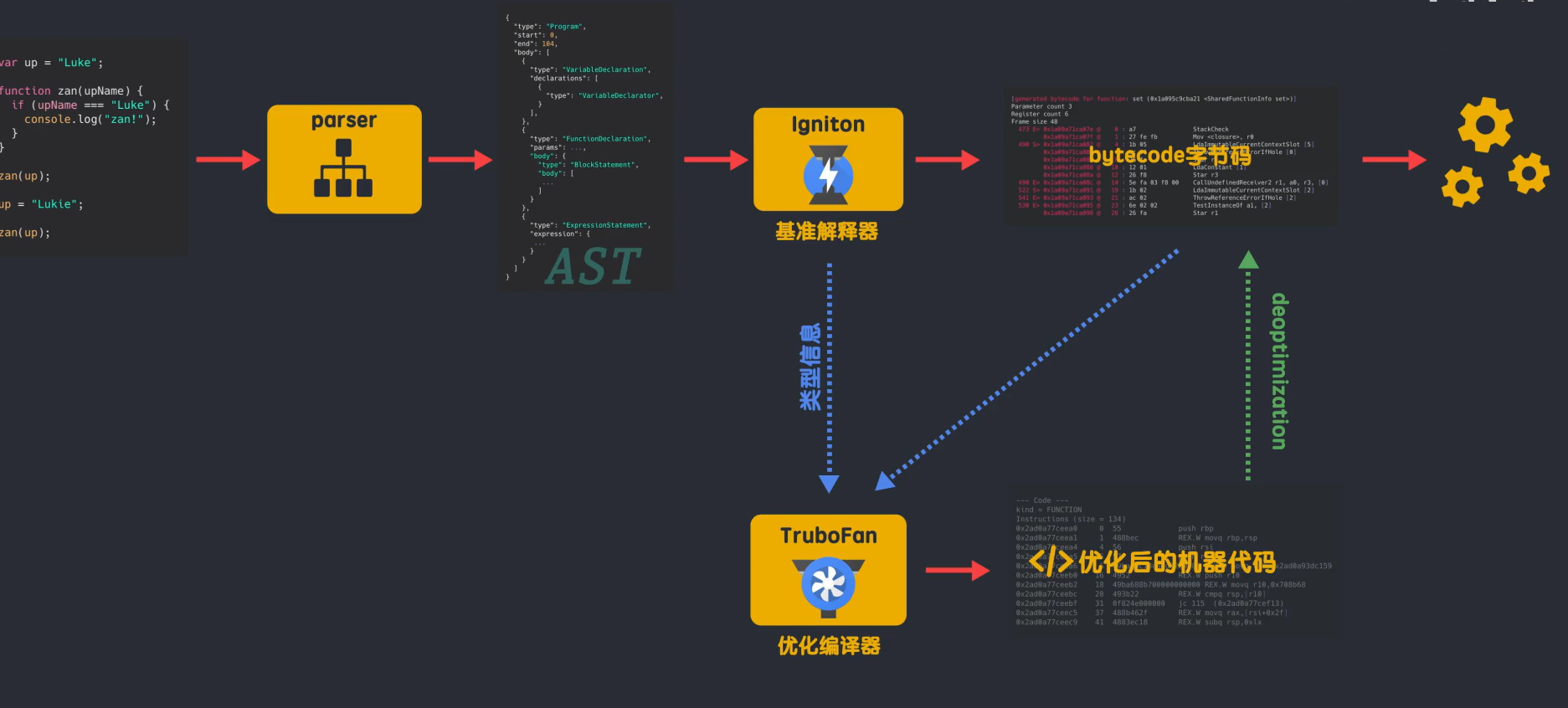
但在 V8 版本之前,V8 引擎没有解释器,而是有两个编译器。编译过程如下:
JS源码由解析器解析生成抽象语法树AST;那么 Full-codegen 编译器直接使用 AST 编译机器码,无需任何中间转换。Full-codegen 编译器也称为基准编译器,因为它生成基准未优化的机器代码。这样做的好处是我第一次执行JS时,直接使用高效的机器码,因为没有生成中间字节码,所以不需要解释器;代码运行一段时间后,V8 中的分析器线程已经采集到足够的数据来帮助另一个编译器 Crankshaft 进行代码优化,然后重新启动需要优化的代码解析并生成 AST,
这个设计的初衷是好的,减少了AST到字节码的转换时间,提高了JS在外部浏览器中的执行性能,但是也存在很多问题:(文章地址:)
所有提议的新 V8 架构
2. 在新的V8架构中,JS源代码首先被解析器解析,生成抽象语法树AST;但是在获得AST之后,添加了解释器Ignition,AST通过Ignition生成字节码bytecode,此时AST被清空。如果被丢弃,则释放内存空间;生成的字节码由解释器直接执行,生成的字节码将作为基准执行模型。字节码更简洁,生成的字节码大小相当于等效基准机器码的25%~50%左右;在代码的持续运行过程中,解释器采集可用于优化代码的信息,例如:变量的类型,哪些函数执行效率更高,
3. 新V8引擎在处理JS过程中的一些优化策略。如果不调用函数知识声明,则不会解析函数生成AST,也不会生成字节码;如果该函数只被调用一次,Ignition生成字节码后会直接被解释执行。Turbofan不会优化和编译,因为函数执行时需要ignition来采集类型信息,这就要求函数至少执行一次,Turbofan才能优化;如果该函数被多次调用,可能会被识别为热点函数。当 Ignition 采集的类型信息确定后,Turbofan 会将字节码编译成优化的机器码,以提高代码的执行性能。
4. 去优化
必须注意的是:
在某些情况下,优化的机器码可能会被反转为字节码。这个过程称为去优化。这是因为 JS 是一种动态类型的语言,这会导致 Ignition 采集到的信息不正确。
举个例子:比如有个sum(x,y)函数,JS引擎不知道x和y是什么类型的参数,但是在后面的多次调用中,传入的x和y都是整数,而sum 函数 当函数被识别为非热点时,解释器将采集到的类型信息和字节码发送给编译器,因此编译器生成的优化机器码假设 sum 函数的参数是整数,然后遇到函数调用直接使用速度更快的机器码,但是如果在使用sum函数的时候传入一个字符串,就会出现问题。机器码不知道如何处理字符串的参数,所以需要对字节码进行反优化回退,由解释器解释执行。
5. 新 V8 架构的好处
除了解决旧架构的问题,新架构还带来了好处:
由于一开始不需要编译成机器码,而是生成中间层的字节码,而且生成字节码的速度比机器码快很多,所以初始化、解析和执行JS的时间网页的长度被缩短,网页可以更新。快速加载;在生成优化的机器码时,不需要从源代码重新编译,而是使用字节码,当需要反优化时,只需要返回字节码的解释和执行。
新模块的性能得到了更好的提升,功能模块的功能页面更加清晰,为以后JS的新功能和优化页面铺路
六、跨域问题6.1 跨域问题的原因
由于浏览器同源策略限制。同源策略(Sameorigin Policy)是一种约定。它是浏览器的核心和最基本的安全策略。如果缺少同源策略,可能会影响浏览器的正常功能。可以说,Web是建立在同源策略的基础上的,而浏览器只是同源策略的一个实现。同源策略防止来自一个域的 JavaScript 脚本与来自另一个域的内容进行交互。所谓同源(意思是在同一个域中)是指两个页面具有相同的协议、主机和端口。
6.2 跨域的概念
当请求url的协议、域名和端口中的任何一项与当前页面url不同时,即为跨域
当前页面url是否被请求页面url是否跨域
不
同源(同一个协议、同一个域名、同一个端口号)
跨域 查看全部
浏览器抓取网页(一个HTTP请求报文的Content-Type网络进程会影响后续流程)
HTTP 请求消息由四部分组成:请求行、请求头、空行和请求实体。浏览器端开始构造请求行、请求头和请求体等信息,将浏览器的一些基本信息和cookie等信息添加到请求头中,然后将构造好的请求消息发送给服务器。
(5)服务器处理请求并返回数据
服务器收到请求消息后,会根据消息信息生成响应头、响应行、响应体等数据。网络进程收到响应头和响应行后,就可以解析响应头的内容了。网络进程解析响应头信息后,会转发给浏览器进程进行处理。
影响后续流程的两条信息:
响应行中的 301/302 状态代码执行重定向
在解析响应头的时候,还需要注意一个重定向操作:如果响应行信息是301/302,则表示需要重定向到另一个URL地址。这时,网络进程会从响应头中读取位置字段。值并重新发起 http/https 请求。
响应标头中的 Content-Type
网络进程会首先根据响应头中的 Content-Type 字段判断服务器返回什么类型的资源文件,因为不同的资源类型对浏览器的处理方式不同:
(6)断开连接:TCP 挥手四次
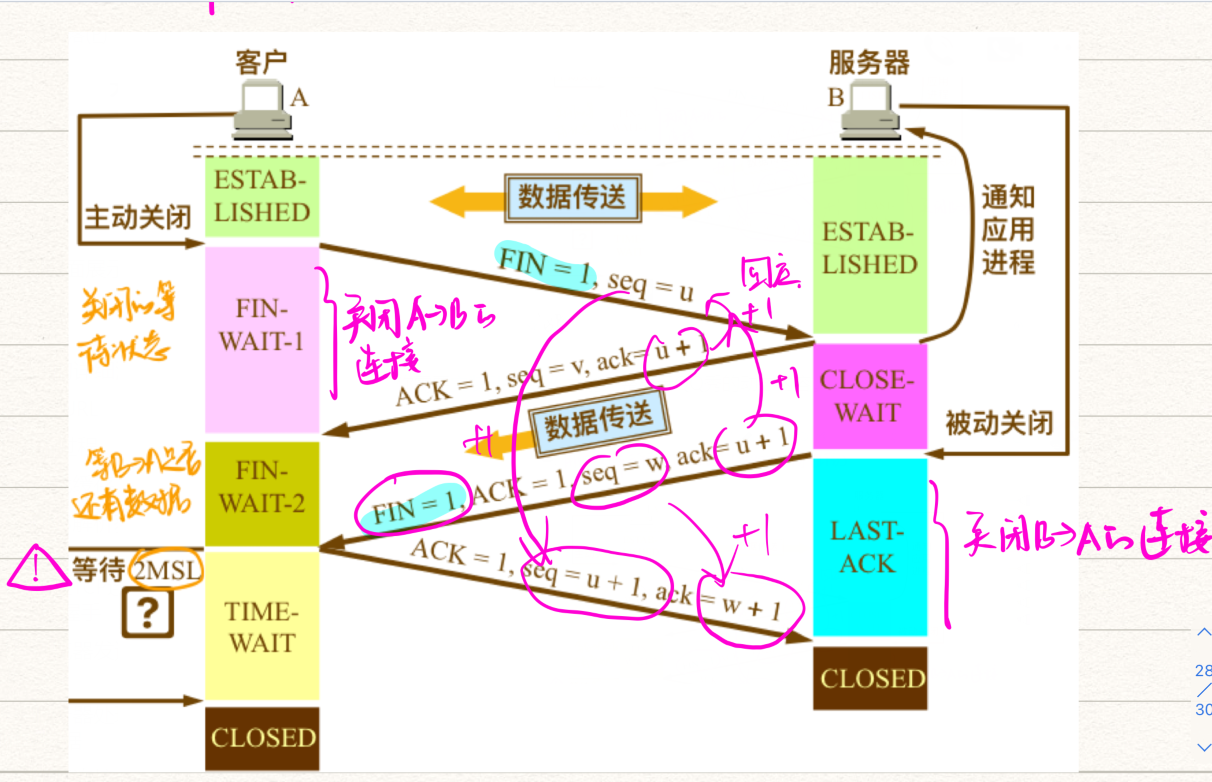

核心思想:TCP为什么需要四次挥手?原因是:释放连接是释放客户端到服务器和服务器到客户端的双向连接。具体来说就是确认客户端和服务端的发送和接收功能都关闭了;
3. 准备渲染进程4. 提交文档 当浏览器进程收到网络进程的响应头数据时,向渲染进程发送“提交文档”消息;渲染进程收到“提交文档”消息后,会与网络进程建立“管道”传输数据;文档数据传输完成后,渲染进程会向浏览器进程返回“确认提交”消息;浏览器进程收到消息后,开始更新页面状态,包括安全状态、地址栏URL、前进后退历史状态、更新网页等。
5. 浏览器解析并渲染页面
一旦文档被确认提交,渲染过程就开始解析资源并渲染页面。注意浏览器的渲染页面并不是等所有资源加载完毕才开始渲染,而是边解析边渲染,这也是为什么有些页面会先将文本呈现给用户,然后再加载图片等资源之后。
详细渲染过程见第4点
四、浏览器是如何工作的?
以chrome浏览器为例
浏览器的结构大致可以分为:用户界面、浏览器引擎、渲染引擎
4.1 不同的浏览器内核
IE:三叉戟
火狐:壁虎
Safari:Webkit
Chrome/Opera/Edge:基于 Webkit 改造的 Blink

4.2 浏览器的多进程结构
今天的浏览器是多进程结构,而早期的浏览器是单进程结构
早期浏览器单进程结构:
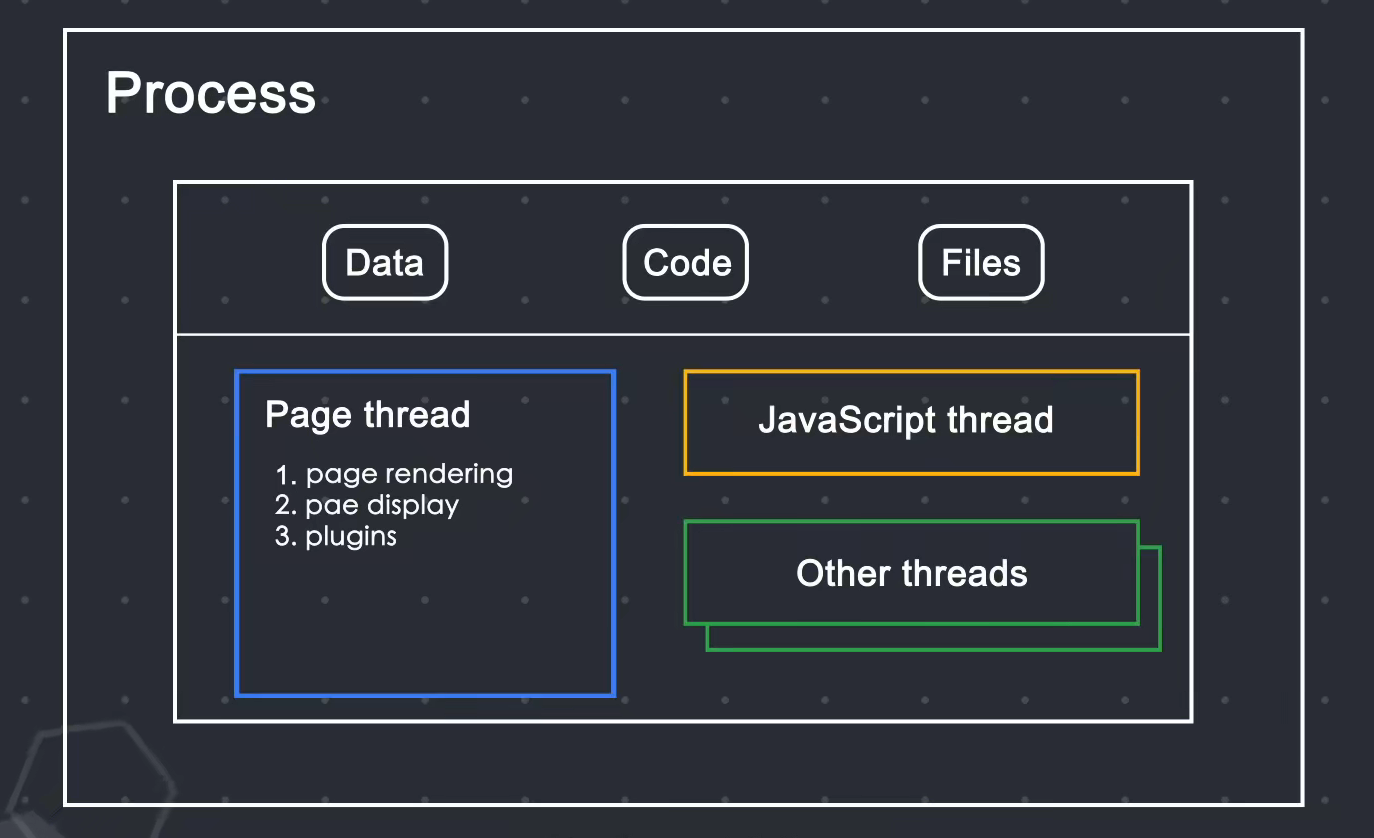
单进程结构提出了许多问题:
不稳定:其中一个线程卡住可能会导致整个进程出现问题。例如,如果您打开多个选项卡,其中一个卡住的选项卡可能会导致浏览器无法运行。不安全:数据可以在浏览器之间共享,那么js可以自由访问浏览器中的所有数据进程不流畅:一个进程需要负责的事情太多,导致效率低下
因此,当今的浏览器选择了多进程结构。根据不同的进程功能,浏览器可以分为:
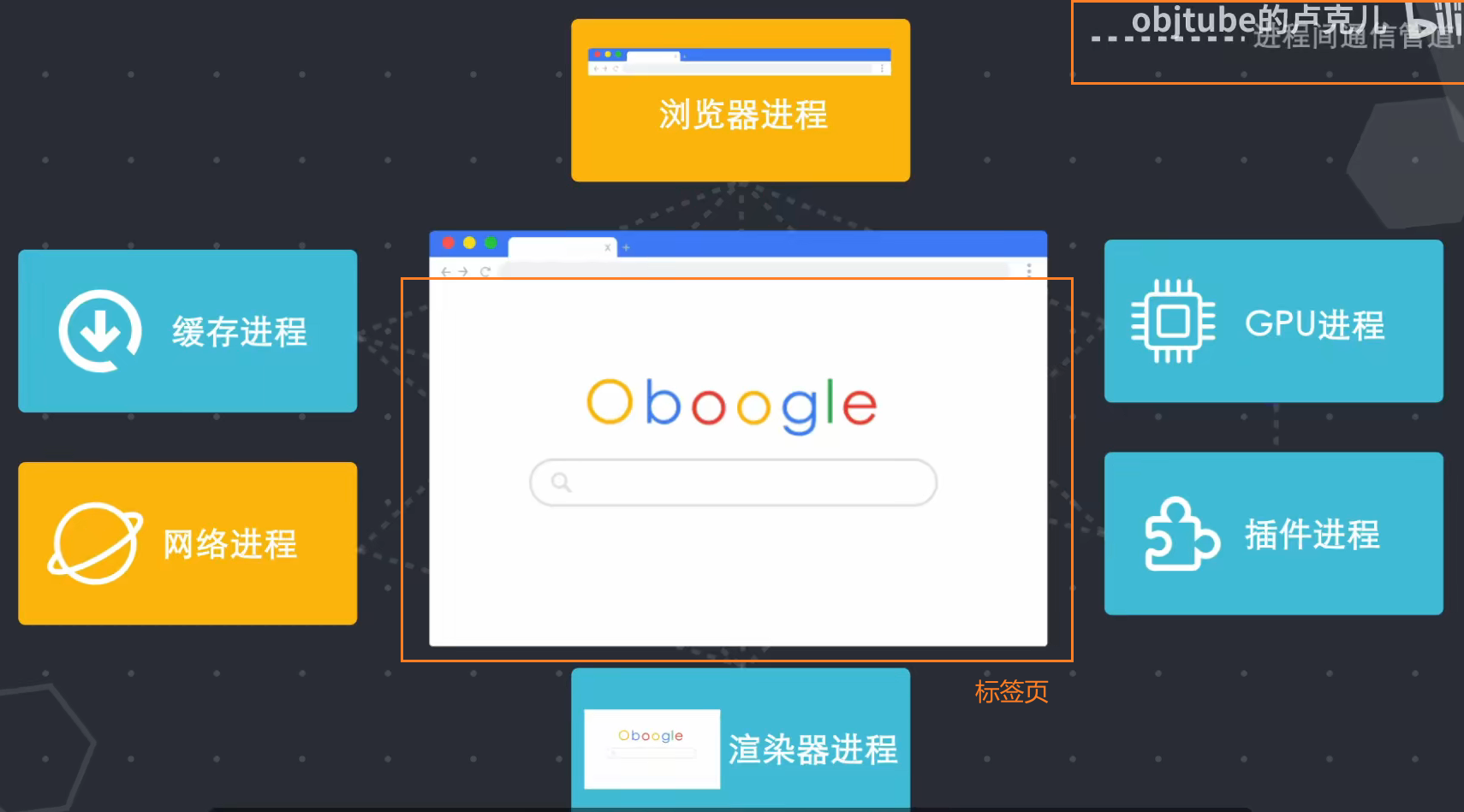
4.3 chrome的4个进程模型
Chrome 共有 4 种进程模型,不同的进程模式对 tab 进程的处理方式不同。
4.4 在浏览器地址栏中输入内容时,浏览器内部会发生什么?(详细请看三) 1.用户输入URL阶段+DNS+请求数据+处理返回数据
当我在地址栏中输入内容时,浏览器进程的UI线程会捕获我输入的内容,如果输入了URL,UI线程会启动一个网络线程(这是在浏览器进程中,而不是网络进程,网络过程 当你发起http请求请求DNS进行域名解析,然后开始连接服务器获取数据,如果输入关键词,浏览器就知道你要使用搜索功能,所以它将使用默认配置的搜索引擎进行查询;
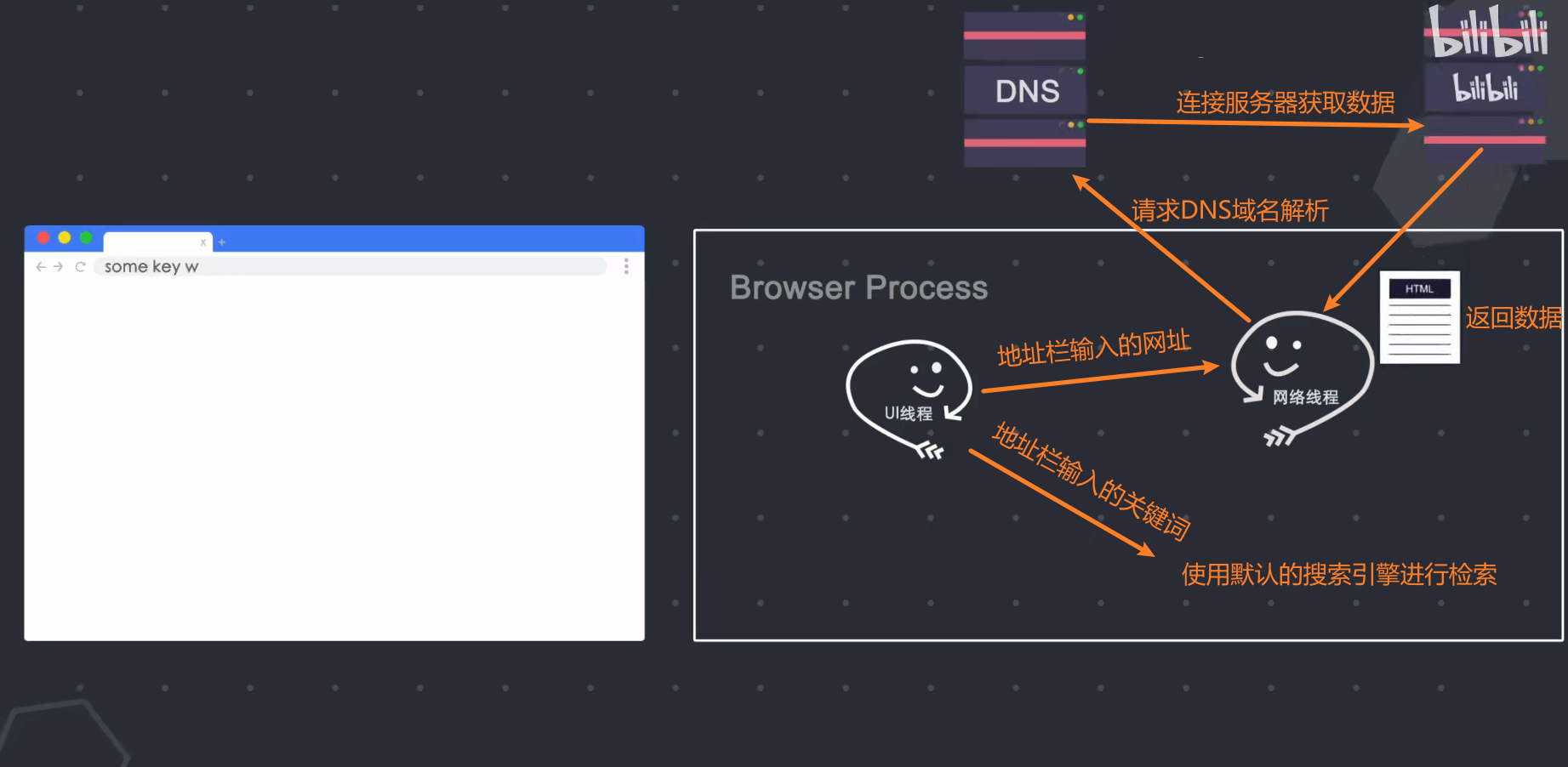
网络线程获取到数据后,会通过Safe Browsing(Google内部的一个站点安全系统,通过检测站点数据来判断是否安全)检查该站点是否为恶意站点,如果是,则发出警告页面会提示。告诉我这个站点存在安全问题,浏览器会阻止我访问,但我可以强制它继续。当返回的数据准备好并且安全检查通过时,网络线程会通知UI线程我准备好了,轮到你了。
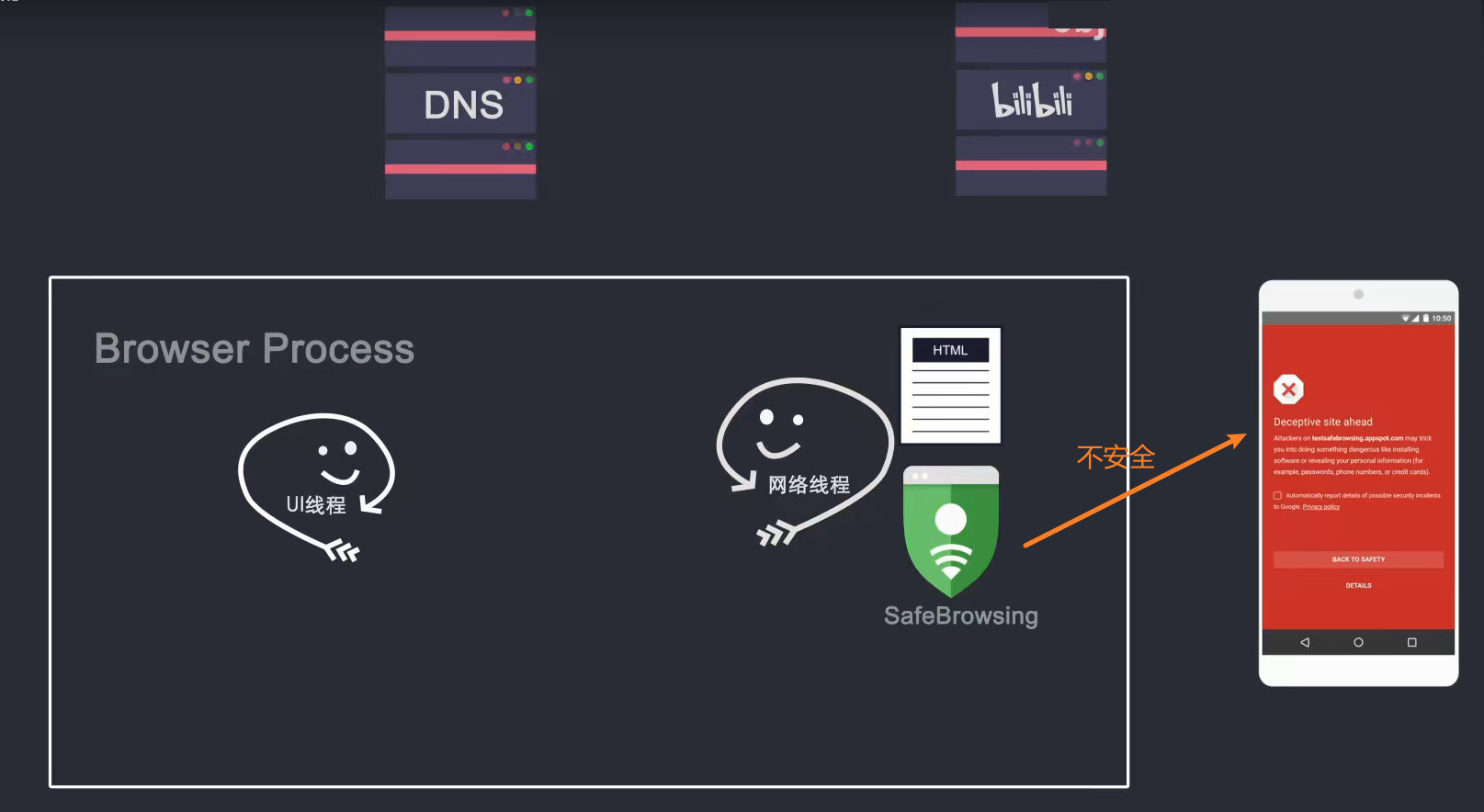
2. 渲染页面阶段
然后UI线程会创建一个渲染器进程来渲染页面,浏览器进程将数据通过IPC管道传递给渲染器进程,进入渲染进程。渲染器进程接收数据(html(通常收录 css、js 和图像资源))。
渲染器进程的核心任务:将html、js、css、image等资源渲染成用户可以交互的网页。渲染器进程的主线程解析html并构造DOM结构。
HTML首先通过Tokeniser进行token化,输入的html内容通过词法分析解析成多个标签,根据识别出的标签进行DOM树的构建。在DOM树的创建过程中,会创建一个document对象,然后会创建一个以document为根节点的文档。DOM 树。
需要注意的是,html代码中经常会引入一些额外的资源,比如js、css、图片等。图片、CSS等资源需要从网络下载或者直接从缓存中加载。这些资源不会阻塞 html 的解析,因为它们不会影响 DOM 的生成。当解析过程中遇到脚本标签时,会停止对html的解析。,然后加载、解析并执行js,因为js可能会改变当前页面的html结构,有可能在js中添加或删除节点等操作会影响html的结构,所以script标签必须放在合适的位置,或者使用async或者defer属性异步加载js。
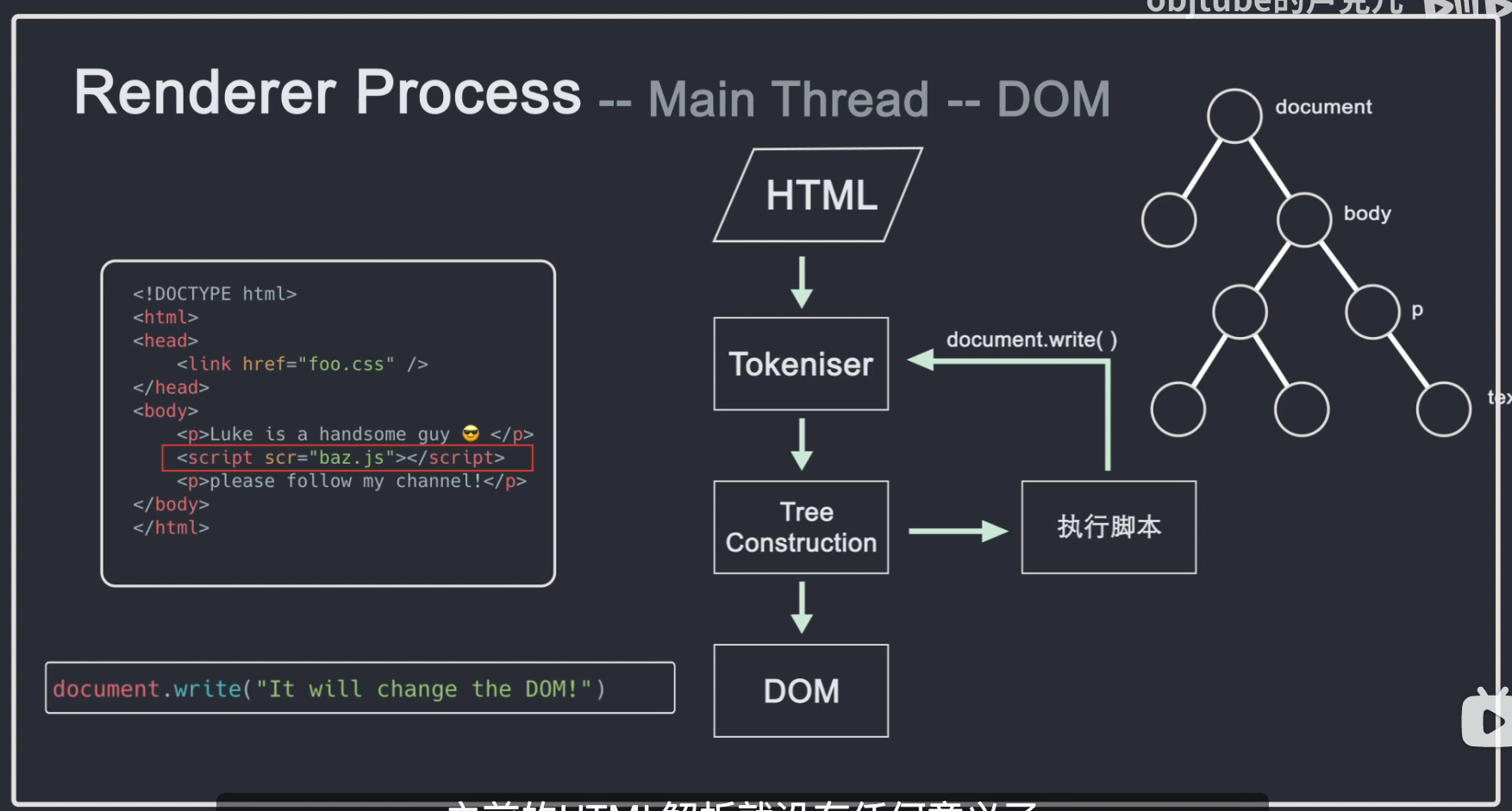
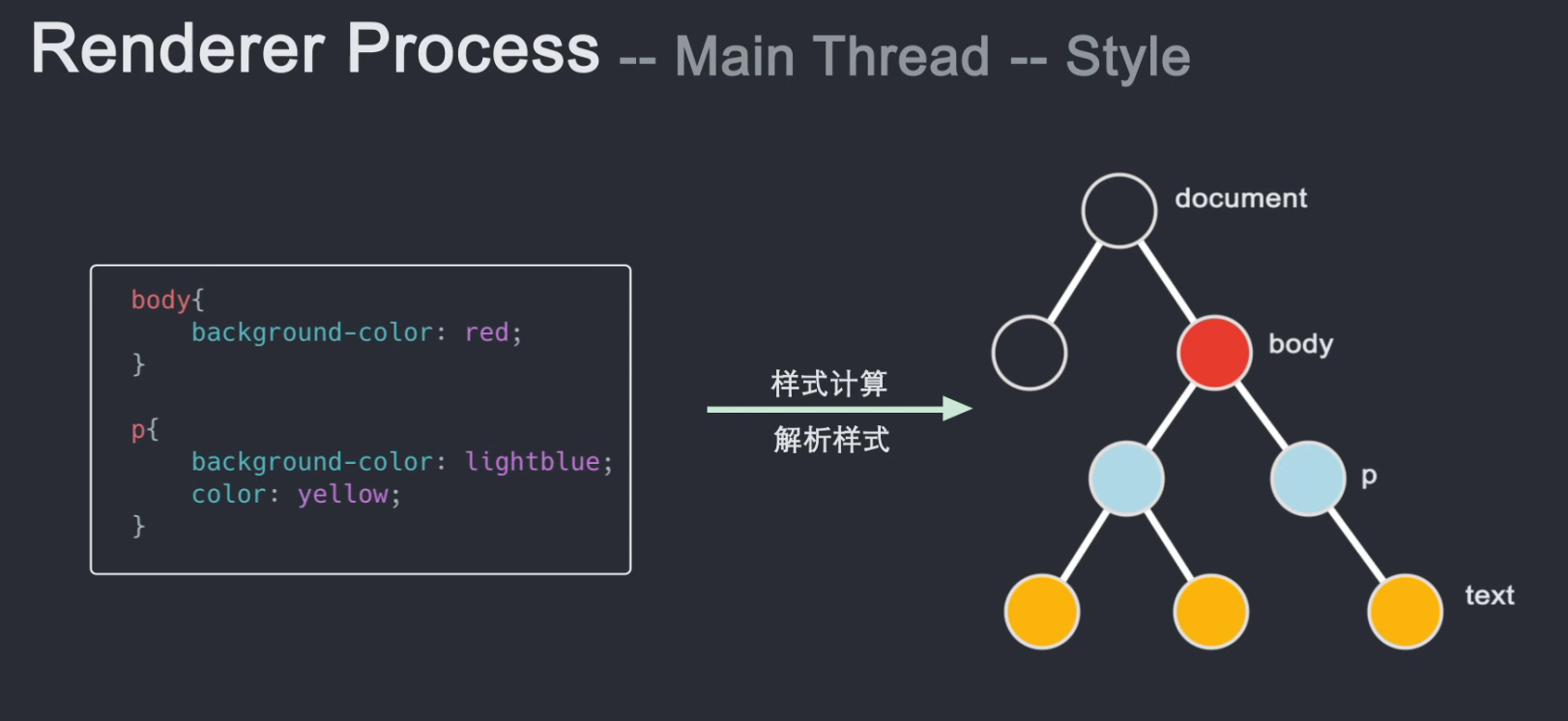
html解析完成后,我们会得到一个DOM Tree,但是此时我们并不知道DOM树上的每个节点是什么样子的。这是主线程需要解析 CSS 并确定每个 DOM 节点的计算样式。
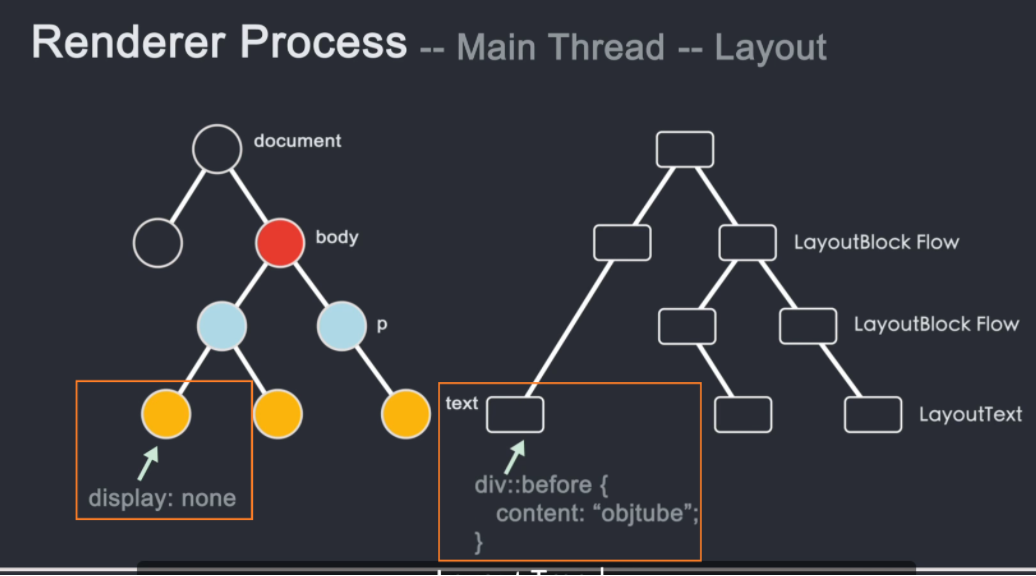
在了解了每个节点的 DOM 结构和样式之后,就需要知道每个节点在页面上的位置,即节点的坐标以及节点需要占用多少区域。这个阶段称为布局布局。线程通过遍历 dom 和计算出来的样式生成 Layout 树。布局树上的每个节点都记录了 x、y 坐标和边框大小。
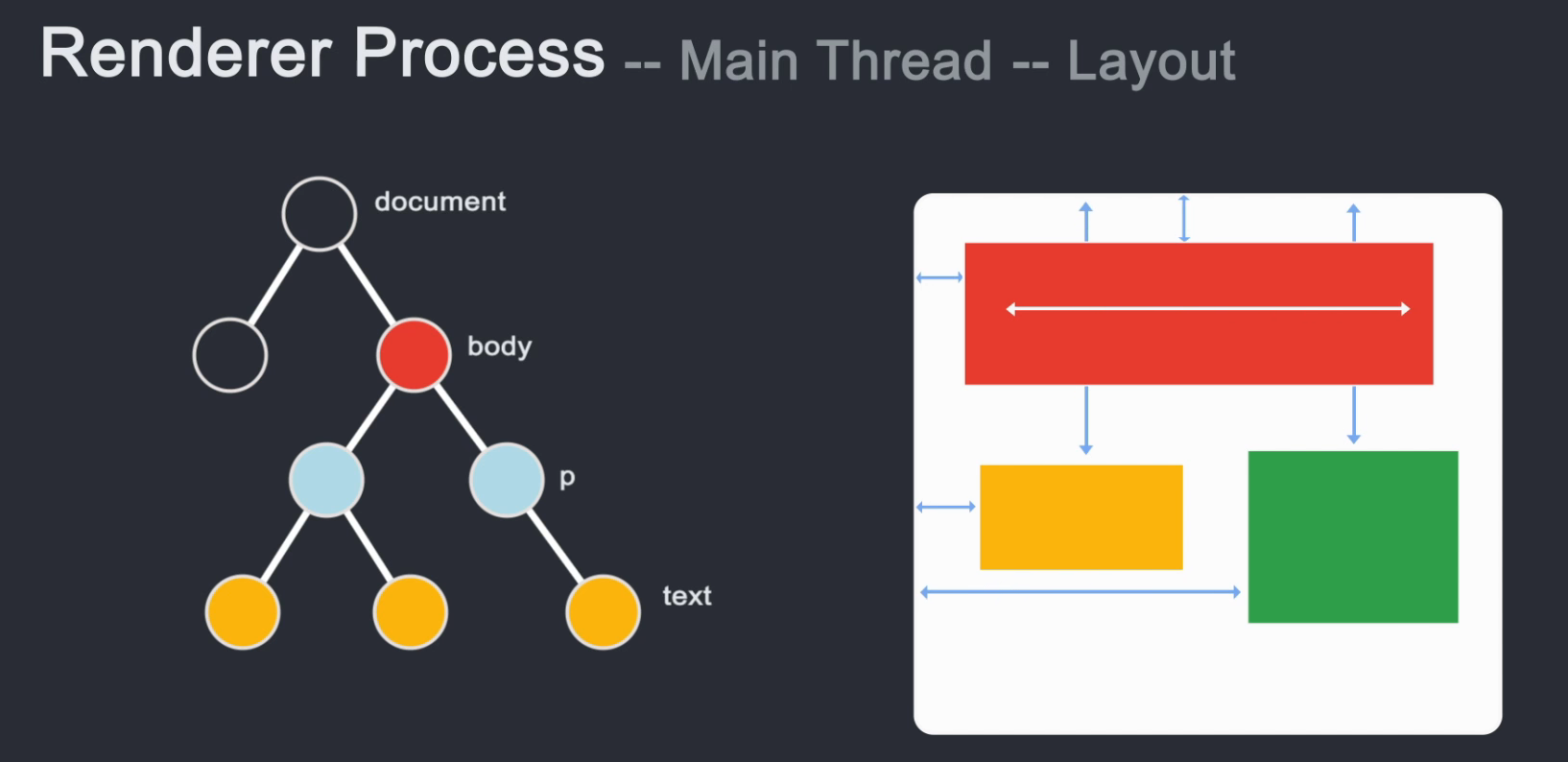
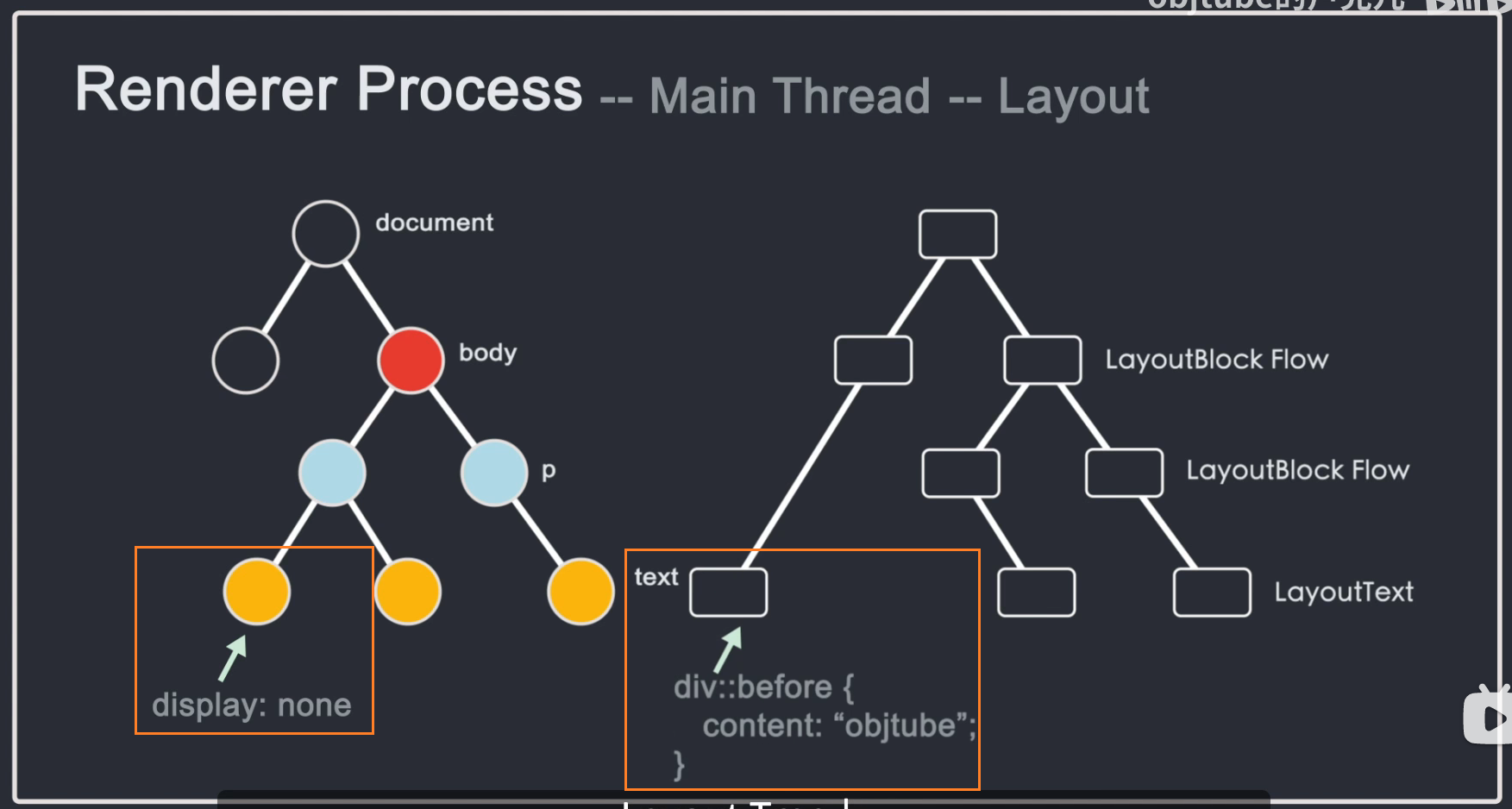
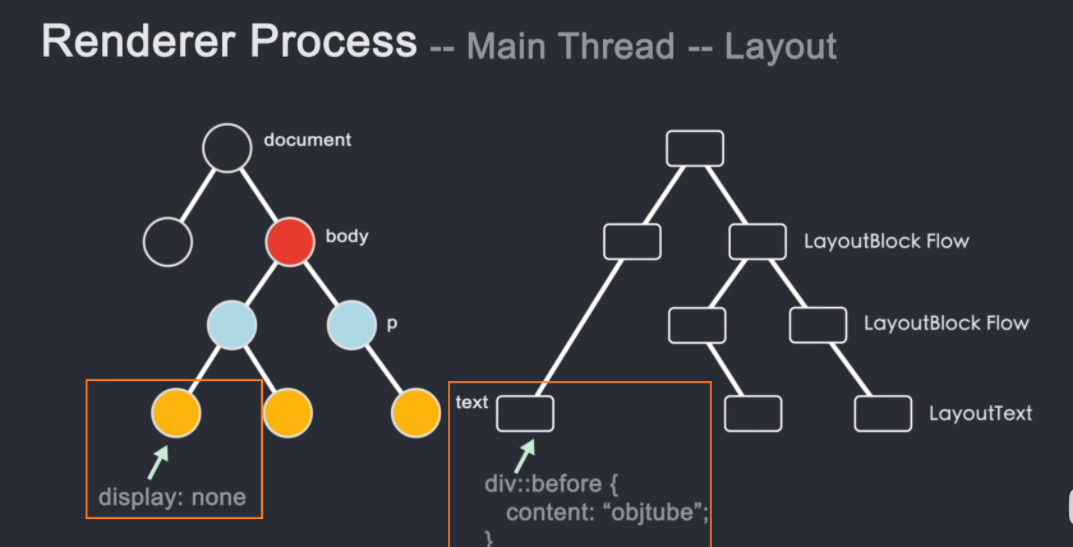
需要注意的是,DOM树和Layout树并不是一一对应的。如果设置了 display: none,则不会出现在布局树上。如果在 before 伪类中添加了一个带有 content 值的元素,就会出现 content 中的内容。不会出现在Layout树上的DOM树上,因为DOM是通过html解析得到的,不关心样式,而Layout树是DOM树结合CSSOM树生成的。
只知道元素的大小、形状和位置是不够的。我们还需要知道绘制节点的顺序。毕竟像z-index这样的属性会影响节点绘制的层次关系。如果我们按照 DOM 层次绘制,就会导致渲染不正确。所以为了保证屏幕上显示正确的层级,主线程遍历Layout树创建了一个绘制记录表(Paint Record),记录了绘制的顺序。这个阶段称为绘画。
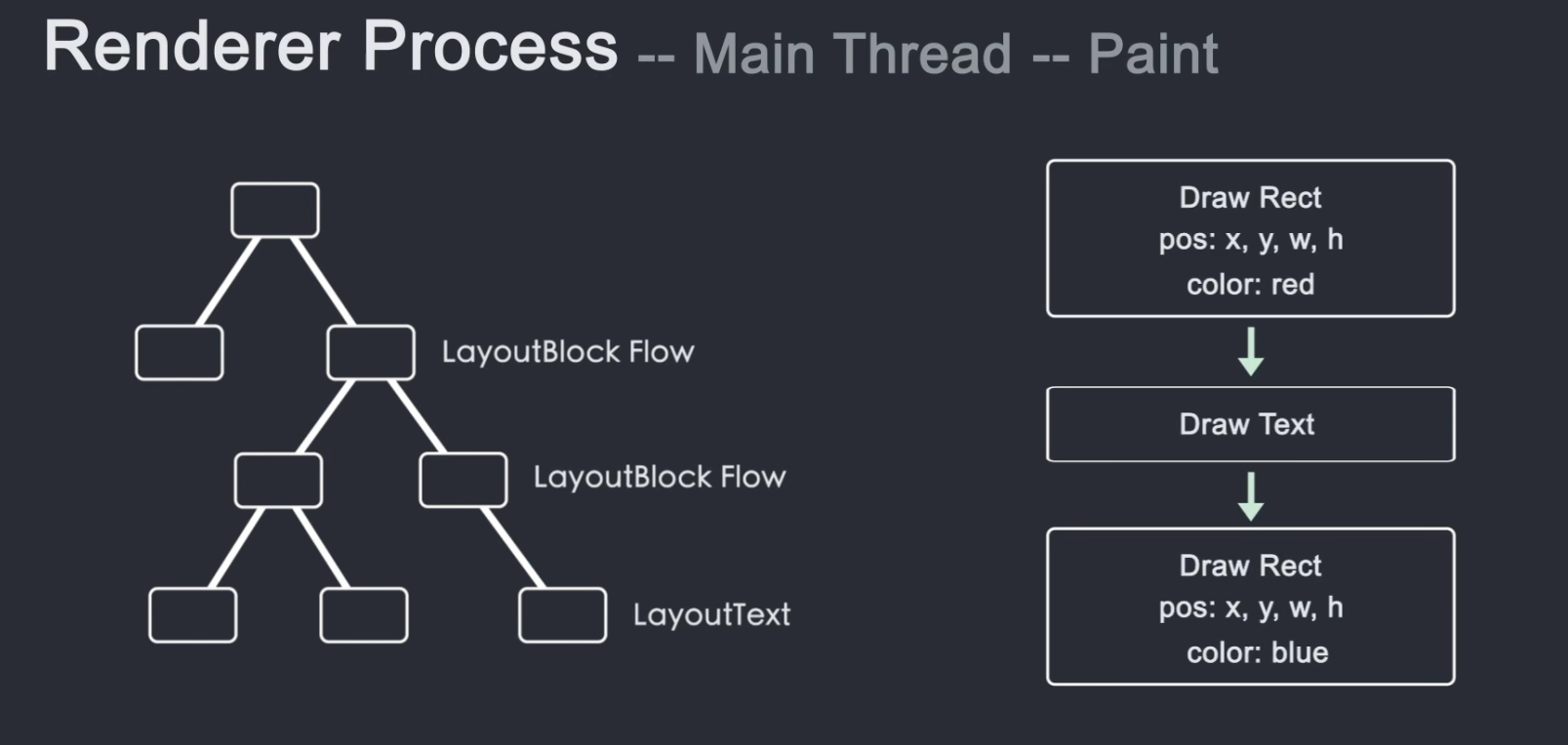
知道了节点的绘制顺序,是时候将这些信息转换成像素并在屏幕上显示了。这种行为称为光栅化。
Chrome 早期的光栅化方案只是对用户可见区域的内容进行了光栅化。当用户滚动页面时,更多的内容被光栅化以填补缺失的部分。这种方案会导致显示延迟。现在chrome的光栅化过程称为堆肥。Composting是一种将页面的每一部分分成多个层,分别进行光栅化,在合成器线程技术中分别合成页面的技术。简单来说,就是将页面的所有元素按照一定的规则划分成图层,对图层进行光栅化处理,然后只将可视区域的内容组合成一帧显示给用户。

主线程遍历布局树生成层树。当层树生成并确定了绘制顺序时,主线程将此信息传递给合成器线程。
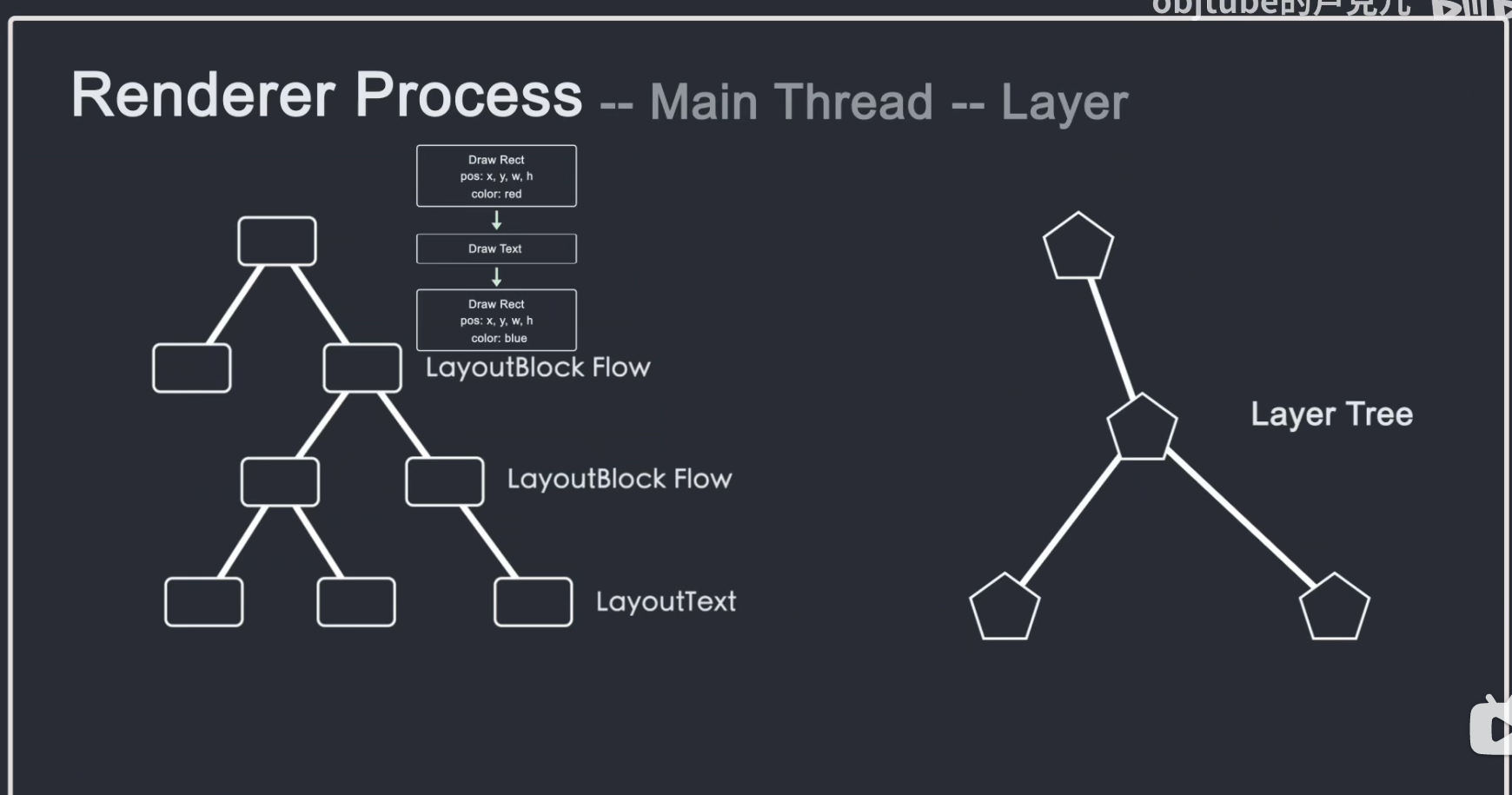
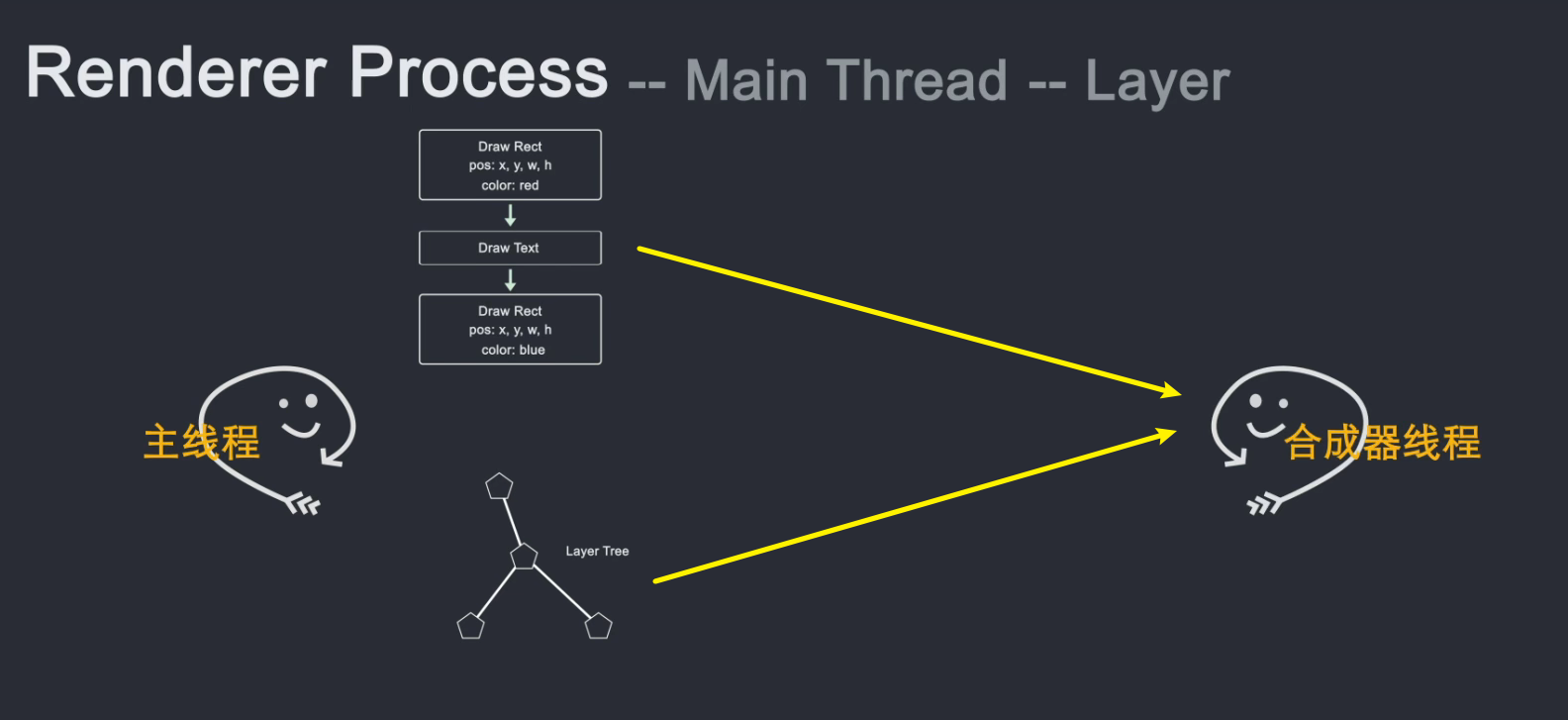
合成器线程对每一层进行光栅化,并且由于层可以与页面的整个长度一样大,因此合成器线程将它们切成许多块并将每个块发送到光栅化器线程。
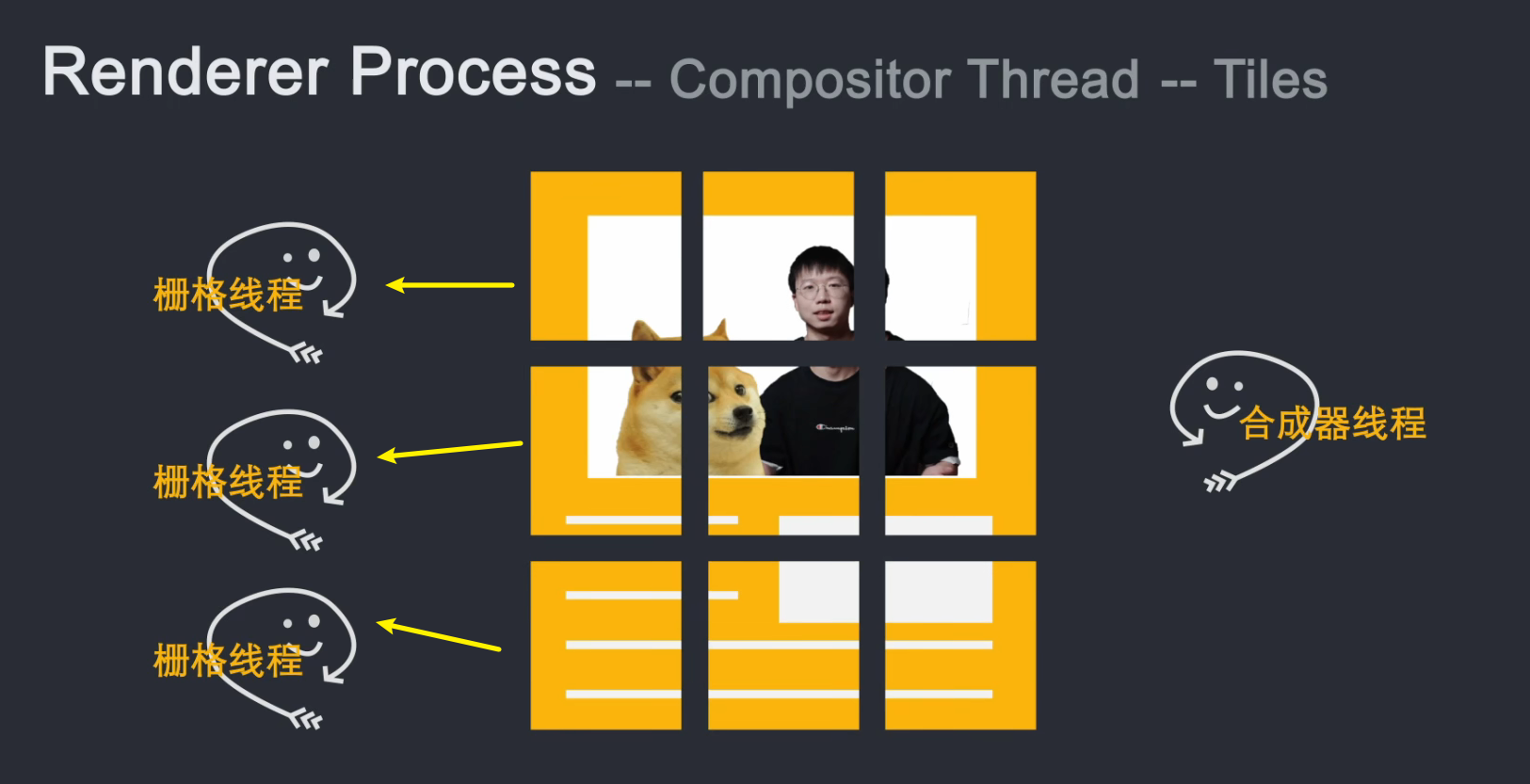
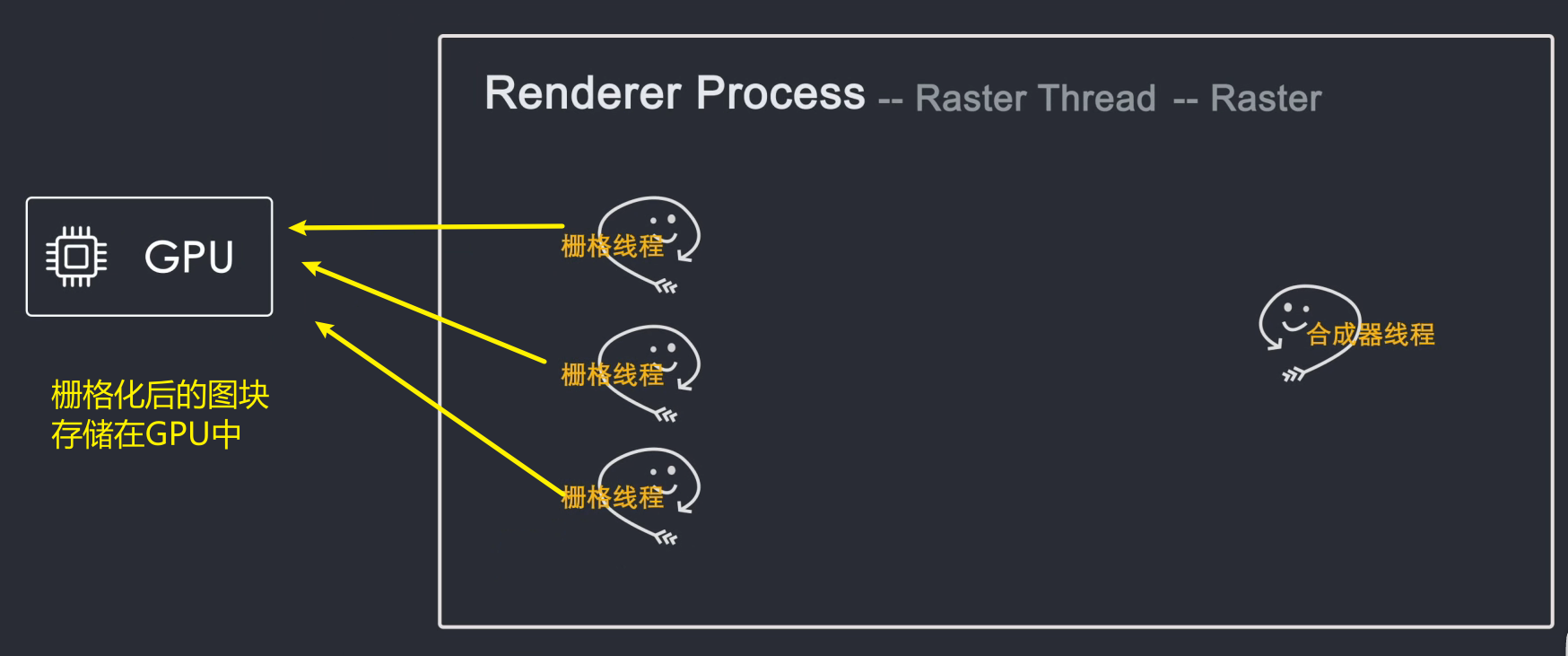
光栅化线程光栅化每个图块并将它们存储到 GPU 内存中
当瓦片被光栅化时,合成器线程将采集称为“绘制四边形”(来自网格线程)的瓦片信息,这些信息记录瓦片在内存中的位置以及它们在页面上的绘制位置。瓦片的信息,合成器线程根据该信息生成合成器帧(Compositor Frame)
然后这个合成器帧通过IPC传给浏览器进程,然后浏览器进程把合成器帧传给GPU,然后GPU渲染到屏幕上,然后就可以看到页面的内容了。
但是当页面发生变化时,会生成一个新的合成器框架,并重复上述动作
3. 回流和重绘
重排重绘会占用主线程,而js也在主线程上运行,所以会出现抢占执行时间的问题。在一帧内完成布局绘制后还有时间时,js会获得使用主线程的权利。如果js的执行时间过长,js会在下一帧开始时没有及时返回到主线程,导致下面的一帧动画没有按时渲染,页面动画就会卡住。

有什么优化方法吗?? ?
当然有!!
4. 优化回流和重绘导致页面动画卡顿的问题
第一个是通过 requestAnimationFrame() API。每一帧都会调用这个方法。通过API回调,我们可以将JS运行的任务分成更小的任务块(划分为每一帧),并在每一帧时间用完前暂停js执行并返回主线程,这样主线程就可以布局和下一帧开始时准时绘制

第二种光栅化不占用主线程,只运行在合成器线程和网格线程中,也就是说不会用js抢占主线程。CSS有一个动画属性transform,这个属性实现的动画是不会通过的。布局和绘图直接运行在合成器线程和网格线程上,因此不会受主线程中的 JS 影响。更重要的是,由于transform实现的动画不需要经过布局绘制样式计算等操作,因此节省了大量的计算时间
5. 渲染管道
当网络进程向渲染进程提交资源时,渲染进程就会开始渲染页面。浏览器的渲染机制非常复杂,所以渲染会分为很多子阶段。输入的 HTML、CSS、JS 以及图片等资源都会经过这些阶段,最终输出的像素会显示在页面上。处理流程称为渲染管道。
根据渲染的时间顺序,我们将浏览器的渲染时间段划分为以下几个子阶段。需要注意的是,每个子阶段的输出都会作为下一个子阶段的输入,这也符合实际工厂流水线场景。
6. 渲染过程总结
1、渲染过程将HTML内容转化为可读的DOM树结构
2、渲染引擎将CSS样式表转换成浏览器可以理解的样式表,并计算出DOM节点的样式
3、创建布局树并计算元素的布局信息。
4、对布局树进行分层并生成分层树。
5、为每一层生成绘制列表并将它们提交到合成线程。
6、合成线程将图层划分为瓦片,并将瓦片转换为光栅化线程池中的位图。
7、合成线程向浏览器进程发送绘图平铺命令DrawQuads
8、浏览器进程根据 DrawQuads 消息生成页面并显示在监视器上。
五、JS的运行原理(重点:JS引擎)5.1 js继承了以下四种语言的特点


5.2个奇怪的js
5.3 JIT
js是动态类型语言,但这也导致我们在运行前无法知道变量的类型。只有在运行过程中才能确定每个变量的类型,这使得js无法在运行前编译更快、更底层。语言代码(机器代码)。尽管如此,js 执行起来还是很快的,这是为什么呢?? ? 这是因为当前的 JavaScript 引擎使用了一种技术:Just-In-Time Compilation,简称 JIT,就是在运行阶段生成机器码,而不是提前生成。JIT 在运行代码的同时生成机器码。

5.4 JS 引擎
js 是一种高级语言。在被计算机CPU执行之前,需要将JS转换为低级机器语言,通过程序执行。该程序称为 JavaScript 引擎。JavaScript 有很多引擎:

js引擎执行的一般流程(new V8)首先通过解析器将JS源码解析成抽象语法树AST;然后通过解释器将AST编译成字节码btyecode,字节码是一个中间表示跨平台的,不同于最终的机器码。字节码是平台无关的,可以运行在不同的操作系统上;字节码最终通过编译器(compiler)生成机器码,由于不同的处理编译平台所使用的机器码会是不同,所以编译器会根据当前平台编译对应的机器码

5.5 以V8为例了解JS引擎编译和JS优化
JS的引擎是V8,node.js的运行环境也是V8引擎,electron的底层引擎也是V8.
简单地说,V8 是一个 C++ 程序,它接收 JavaScript 代码,编译代码然后执行。编译后的代码可以在多个操作系统和多个处理器上运行。
V8主要负责工作:
1. 早期的 V8 引擎
JS 引擎在编译和执行 JS 代码时使用了三个重要的组件:

但在 V8 版本之前,V8 引擎没有解释器,而是有两个编译器。编译过程如下:
JS源码由解析器解析生成抽象语法树AST;那么 Full-codegen 编译器直接使用 AST 编译机器码,无需任何中间转换。Full-codegen 编译器也称为基准编译器,因为它生成基准未优化的机器代码。这样做的好处是我第一次执行JS时,直接使用高效的机器码,因为没有生成中间字节码,所以不需要解释器;代码运行一段时间后,V8 中的分析器线程已经采集到足够的数据来帮助另一个编译器 Crankshaft 进行代码优化,然后重新启动需要优化的代码解析并生成 AST,
这个设计的初衷是好的,减少了AST到字节码的转换时间,提高了JS在外部浏览器中的执行性能,但是也存在很多问题:(文章地址:)
所有提议的新 V8 架构
2. 在新的V8架构中,JS源代码首先被解析器解析,生成抽象语法树AST;但是在获得AST之后,添加了解释器Ignition,AST通过Ignition生成字节码bytecode,此时AST被清空。如果被丢弃,则释放内存空间;生成的字节码由解释器直接执行,生成的字节码将作为基准执行模型。字节码更简洁,生成的字节码大小相当于等效基准机器码的25%~50%左右;在代码的持续运行过程中,解释器采集可用于优化代码的信息,例如:变量的类型,哪些函数执行效率更高,
3. 新V8引擎在处理JS过程中的一些优化策略。如果不调用函数知识声明,则不会解析函数生成AST,也不会生成字节码;如果该函数只被调用一次,Ignition生成字节码后会直接被解释执行。Turbofan不会优化和编译,因为函数执行时需要ignition来采集类型信息,这就要求函数至少执行一次,Turbofan才能优化;如果该函数被多次调用,可能会被识别为热点函数。当 Ignition 采集的类型信息确定后,Turbofan 会将字节码编译成优化的机器码,以提高代码的执行性能。
4. 去优化
必须注意的是:
在某些情况下,优化的机器码可能会被反转为字节码。这个过程称为去优化。这是因为 JS 是一种动态类型的语言,这会导致 Ignition 采集到的信息不正确。
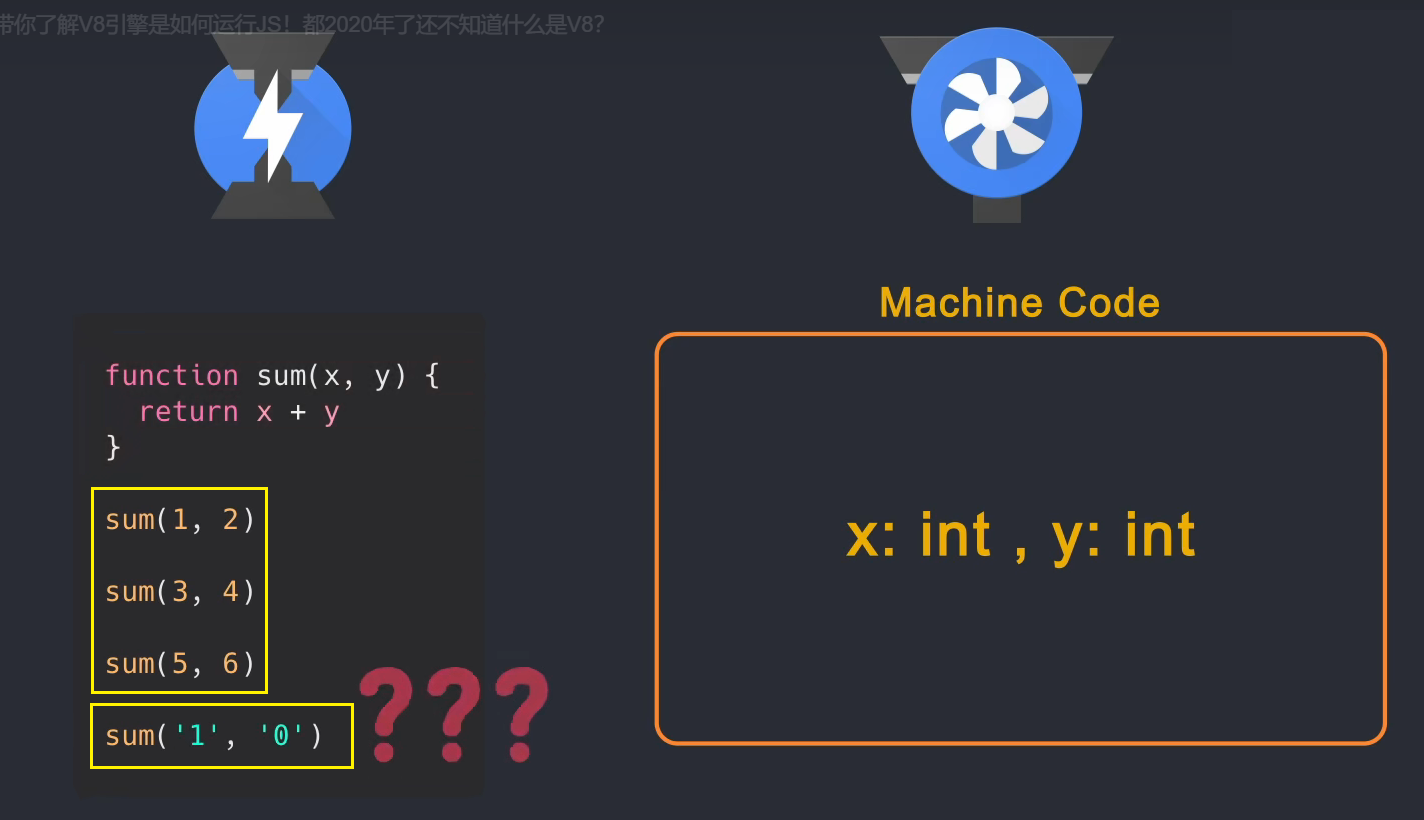
举个例子:比如有个sum(x,y)函数,JS引擎不知道x和y是什么类型的参数,但是在后面的多次调用中,传入的x和y都是整数,而sum 函数 当函数被识别为非热点时,解释器将采集到的类型信息和字节码发送给编译器,因此编译器生成的优化机器码假设 sum 函数的参数是整数,然后遇到函数调用直接使用速度更快的机器码,但是如果在使用sum函数的时候传入一个字符串,就会出现问题。机器码不知道如何处理字符串的参数,所以需要对字节码进行反优化回退,由解释器解释执行。
5. 新 V8 架构的好处
除了解决旧架构的问题,新架构还带来了好处:
由于一开始不需要编译成机器码,而是生成中间层的字节码,而且生成字节码的速度比机器码快很多,所以初始化、解析和执行JS的时间网页的长度被缩短,网页可以更新。快速加载;在生成优化的机器码时,不需要从源代码重新编译,而是使用字节码,当需要反优化时,只需要返回字节码的解释和执行。
新模块的性能得到了更好的提升,功能模块的功能页面更加清晰,为以后JS的新功能和优化页面铺路
六、跨域问题6.1 跨域问题的原因
由于浏览器同源策略限制。同源策略(Sameorigin Policy)是一种约定。它是浏览器的核心和最基本的安全策略。如果缺少同源策略,可能会影响浏览器的正常功能。可以说,Web是建立在同源策略的基础上的,而浏览器只是同源策略的一个实现。同源策略防止来自一个域的 JavaScript 脚本与来自另一个域的内容进行交互。所谓同源(意思是在同一个域中)是指两个页面具有相同的协议、主机和端口。
6.2 跨域的概念
当请求url的协议、域名和端口中的任何一项与当前页面url不同时,即为跨域
当前页面url是否被请求页面url是否跨域
不
同源(同一个协议、同一个域名、同一个端口号)
跨域
浏览器抓取网页(本文基本用法导入库初始化大小浏览器刷新同刷新键(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-22 11:08
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
文章目录
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
from selenium import webdriver
初始化浏览器
如果已经放在 Scripts 文件夹中,会直接调用。
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新
用刷新键,最好写个异常检测
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
按 id/name/class 定位
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
按标签定位
但实际上,一个页面上可能有很多相同的标签,这会使标签指向不明确,从而导致错误。
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
链接位置
定位链接名称,例如定位在百度左上角的链接示例中。
新闻
hao123
地图
...
直接通过链接名称定位。
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
xpath定位
上述方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
css定位
这种方法比xpath更简洁更快
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素
当然,有时我们只需要多个元素,所以我们只需要使用复数s即可。
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性
比如要获取百度logo的信息,先定位图片元素,再获取信息
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本
首先,使用类直接查找热列表元素,但是有多个元素,所以使用复数来获取,并使用for循环打印。使用文本获取文本
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性
获取例如 id 或 tag
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
输入/明文
比如在百度搜索框输入“冬奥会”,然后清除
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(输入)
输入以上内容后,需要点击回车提交,才能得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要补充一些伪装的方法,文末。.
search_bar.send_keys('冬奥会')
search_bar.submit()
点击
当我们需要点击时,使用click。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击就是double_click,找不到合适的例子就不提了。
这里是可以深挖的ActionChains,就是定义了一系列操作一起执行,当然,一些常用的操作其实就足够了。
徘徊
我不能让它进去。
ActionChains(browser).move_to_element(move).perform()
下拉选择
需要导入相关库,访问MySQL官网选择下载对应的操作系统为例。
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖
多用于验证码之类的,参考菜鸟示例
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 39%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待
可以发现,在上面的程序中,有些效果需要等待延迟才会出现。在实践中,它也需要一定的延迟。一方面认为是爬虫,以免被访问太频繁,另一方面也是网络资源的原因。加载需要一定的时间等待。
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截屏
可以保存为base64/png/file 三
browser.get_screenshot_as_file('截图.png')
窗户开关
我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条
有些网页的内容是随着进度条的滑动出现的,所以需要把进度条往下拉。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。仔细研究的话,操作很详细,模仿真实浏览器的操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导使用。
和直接获取资源的爬虫相比,肯定是慢了一点,但是比强大的要好,还是可以提高钓鱼效率的。 查看全部
浏览器抓取网页(本文基本用法导入库初始化大小浏览器刷新同刷新键(组图))
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
文章目录
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
from selenium import webdriver
初始化浏览器
如果已经放在 Scripts 文件夹中,会直接调用。
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新
用刷新键,最好写个异常检测
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
按 id/name/class 定位
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
按标签定位
但实际上,一个页面上可能有很多相同的标签,这会使标签指向不明确,从而导致错误。
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
链接位置
定位链接名称,例如定位在百度左上角的链接示例中。
新闻
hao123
地图
...
直接通过链接名称定位。
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
xpath定位
上述方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
css定位
这种方法比xpath更简洁更快
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素
当然,有时我们只需要多个元素,所以我们只需要使用复数s即可。
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性
比如要获取百度logo的信息,先定位图片元素,再获取信息
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本
首先,使用类直接查找热列表元素,但是有多个元素,所以使用复数来获取,并使用for循环打印。使用文本获取文本
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性
获取例如 id 或 tag
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
输入/明文
比如在百度搜索框输入“冬奥会”,然后清除
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(输入)
输入以上内容后,需要点击回车提交,才能得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要补充一些伪装的方法,文末。.
search_bar.send_keys('冬奥会')
search_bar.submit()
点击
当我们需要点击时,使用click。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击就是double_click,找不到合适的例子就不提了。
这里是可以深挖的ActionChains,就是定义了一系列操作一起执行,当然,一些常用的操作其实就足够了。
徘徊
我不能让它进去。
ActionChains(browser).move_to_element(move).perform()
下拉选择
需要导入相关库,访问MySQL官网选择下载对应的操作系统为例。
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖
多用于验证码之类的,参考菜鸟示例
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 39%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待
可以发现,在上面的程序中,有些效果需要等待延迟才会出现。在实践中,它也需要一定的延迟。一方面认为是爬虫,以免被访问太频繁,另一方面也是网络资源的原因。加载需要一定的时间等待。
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截屏
可以保存为base64/png/file 三
browser.get_screenshot_as_file('截图.png')
窗户开关
我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条
有些网页的内容是随着进度条的滑动出现的,所以需要把进度条往下拉。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。仔细研究的话,操作很详细,模仿真实浏览器的操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导使用。
和直接获取资源的爬虫相比,肯定是慢了一点,但是比强大的要好,还是可以提高钓鱼效率的。
浏览器抓取网页( Python安装Python所需要的包()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-22 11:05
Python安装Python所需要的包()(图)
)
4、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
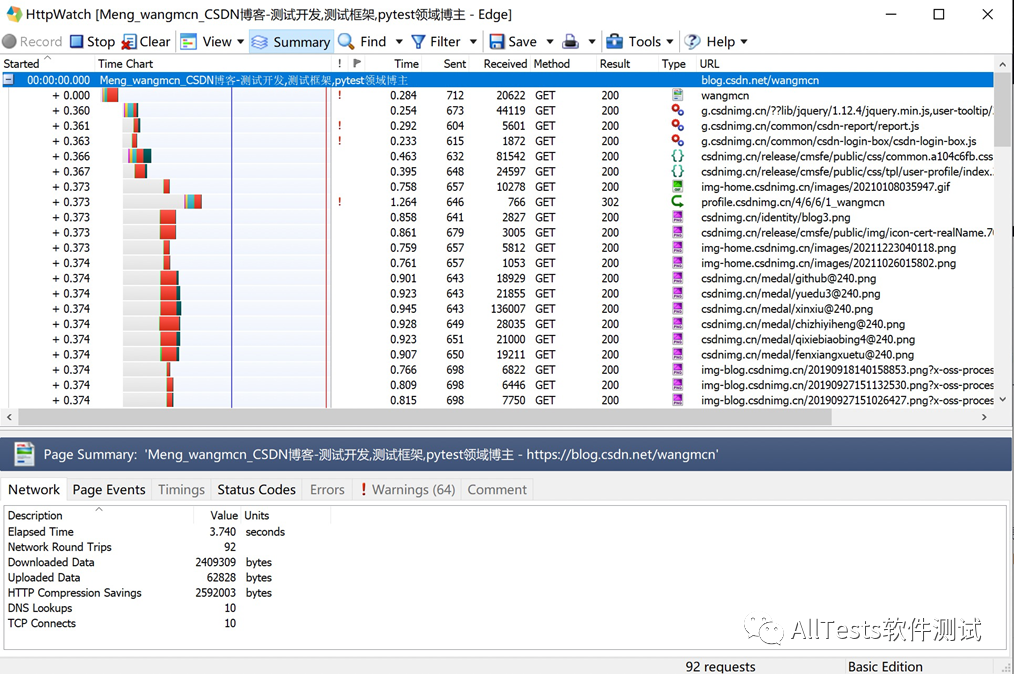
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
5、Selenium 与 HttpWatch 结合
当你想在 Selenium 中测试页面功能时,你想获取一些信息,例如提交请求数据、接收请求数据、页面加载时间等,Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 具有广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 公众号:AllTests软件测试
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
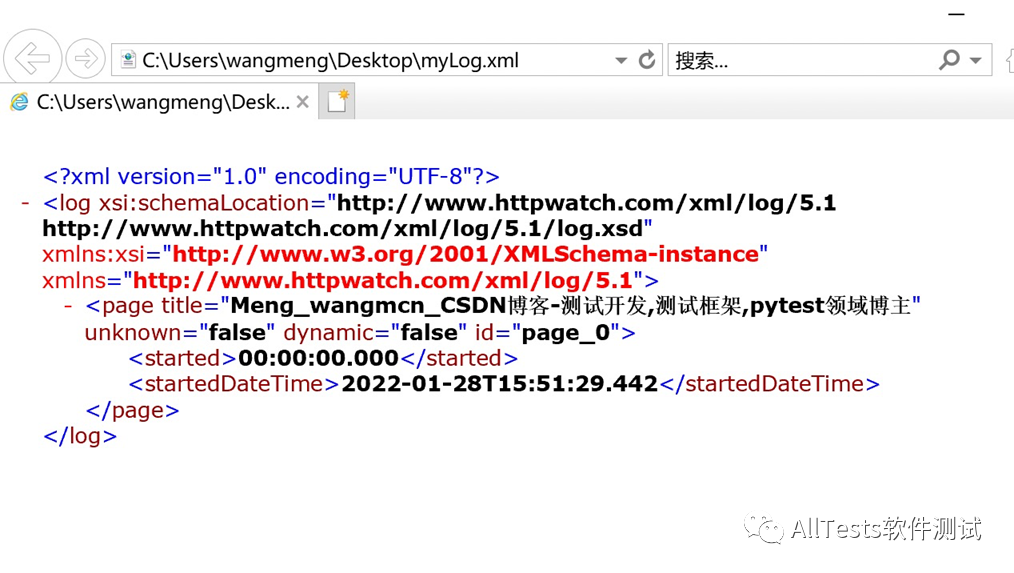
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
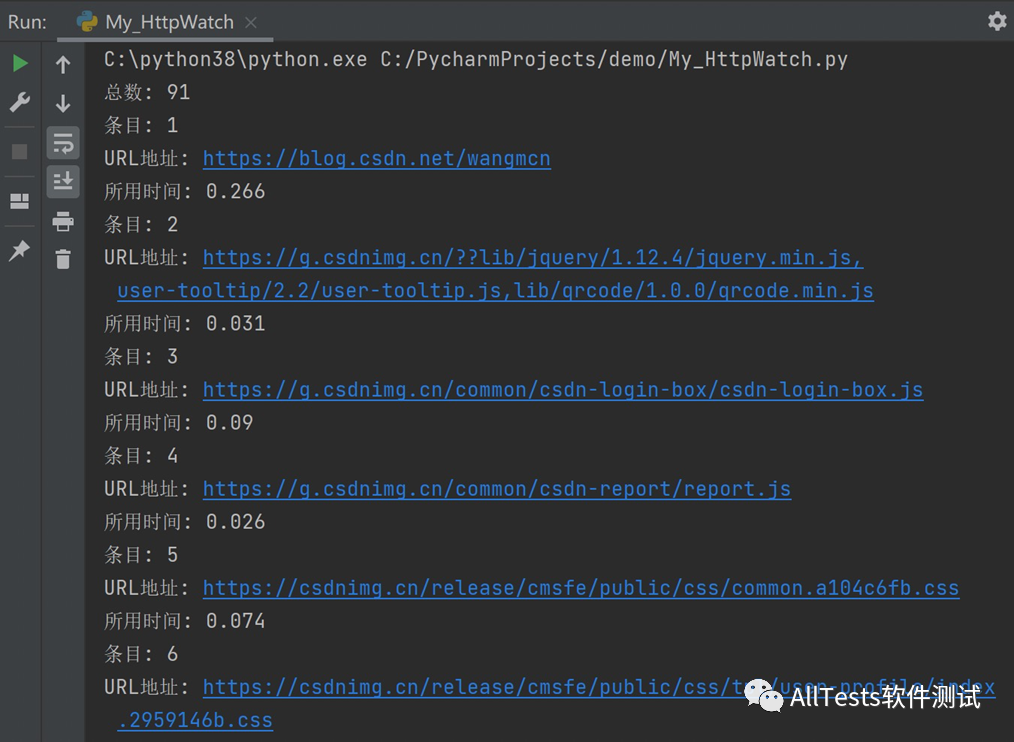
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn")
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。
(2)通过控制台打印的日志,可以看到页面使用的响应时间。
查看全部
浏览器抓取网页(
Python安装Python所需要的包()(图)
)

4、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
5、Selenium 与 HttpWatch 结合
当你想在 Selenium 中测试页面功能时,你想获取一些信息,例如提交请求数据、接收请求数据、页面加载时间等,Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 具有广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 公众号:AllTests软件测试
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn";)
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。

(2)通过控制台打印的日志,可以看到页面使用的响应时间。

浏览器抓取网页(如何在页面完成之前显示页面加载div,查看实际代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-22 02:02
. 3. 。4.
. 5.
显示加载图标,直到页面加载..
. 6.
. 加载完成后显示 HTML 页面。问一个 10 年零 4 个月前提出的问题。活跃 6 年 7 个月前。查看 109k 次 33。15.有没有办法强制。如何在页面加载完成之前显示页面加载 div,要查看实际代码,您需要遵循以下简单步骤: 步骤 1:将上面的示例代码复制并粘贴到文本编辑器中并以 .html 扩展名保存. 步骤 2 步骤:打开您保存的 .html 文件,然后打开浏览器的开发人员工具,转到网络选项卡并将限制设置为慢 3G。
如何在 JavaScript 中获取用户输入的数字
在 Node.js、定义和用法中获取用户输入。value 属性设置或返回数值字段的 value 属性的值。value 属性指定默认值或用户输入的值(或由脚本设置的值)。当获取的值收录非数字字符时,JS 可能重复 – user3989103 2015 年 2 月 24 日 12:42。提示用户。JavaScript 提示 - 为了获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - .
JavaScript 提示 - 获取用户输入,当它收录非数字字符时,可能会重复 JS 获取的值 – user3989103 2015 年 2 月 24 日 12:42。提示用户 JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。. 如何在不提示的情况下在 JavaScript 中获取用户输入,使用 JavaScript 从用户输入中获取一个数字并将其显示在控制台中 这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何允许用户输入数字和其他类型的数据。
如何在不提示的情况下在 JavaScript 中获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - . 如何使用 JavaScript 强制输入字段仅输入数字,本教程介绍了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。
如何使用 JavaScript 强制输入字段仅输入数字,从用户输入中获取数字并使用 JavaScript 在控制台中显示;这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何让用户输入数字和其他类型的数据。如何从提示框中获取值?,提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何在 Node.js 中同步处理用户输入。提示功能,所以需要调用 prompt-sync 来获取实际的提示功能。
How to get numeric value from a prompt box?,本教程涵盖了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。从用户输入中获取数字并使用 JavaScript 在控制台中显示,
如何在 JavaScript 中存储用户输入
如何将用户输入保存为 html/JavaScript 中的变量,我们可以使用 var input = document.getElementById("input_id").value; 获取输入字段的值,其中 input_id 是您的输入字段的 id。JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。这是一个。如何将来自 DOM 的用户输入存储在 Javascript 变量中?使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮名称 查找按钮类型 查找按钮值 查找按钮上显示的文本 查找按钮所属表单的id var inputElement = document.getElementById('bleh'); var theirInput = ''; 输入元素。.
如何将来自 DOM 的用户输入存储在 Javascript 变量中?, JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。下面是一个使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮的名称 查找按钮的类型 查找按钮的值 查找按钮上显示的文本 查找按钮所属窗体的 ID。获取用户输入 | Javascript, · . 版权所有。蜀ICP备2021025969号 查看全部
浏览器抓取网页(如何在页面完成之前显示页面加载div,查看实际代码)
. 3. 。4.
. 5.
显示加载图标,直到页面加载..
. 6.
. 加载完成后显示 HTML 页面。问一个 10 年零 4 个月前提出的问题。活跃 6 年 7 个月前。查看 109k 次 33。15.有没有办法强制。如何在页面加载完成之前显示页面加载 div,要查看实际代码,您需要遵循以下简单步骤: 步骤 1:将上面的示例代码复制并粘贴到文本编辑器中并以 .html 扩展名保存. 步骤 2 步骤:打开您保存的 .html 文件,然后打开浏览器的开发人员工具,转到网络选项卡并将限制设置为慢 3G。
如何在 JavaScript 中获取用户输入的数字
在 Node.js、定义和用法中获取用户输入。value 属性设置或返回数值字段的 value 属性的值。value 属性指定默认值或用户输入的值(或由脚本设置的值)。当获取的值收录非数字字符时,JS 可能重复 – user3989103 2015 年 2 月 24 日 12:42。提示用户。JavaScript 提示 - 为了获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - .
JavaScript 提示 - 获取用户输入,当它收录非数字字符时,可能会重复 JS 获取的值 – user3989103 2015 年 2 月 24 日 12:42。提示用户 JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。. 如何在不提示的情况下在 JavaScript 中获取用户输入,使用 JavaScript 从用户输入中获取一个数字并将其显示在控制台中 这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何允许用户输入数字和其他类型的数据。
如何在不提示的情况下在 JavaScript 中获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - . 如何使用 JavaScript 强制输入字段仅输入数字,本教程介绍了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。
如何使用 JavaScript 强制输入字段仅输入数字,从用户输入中获取数字并使用 JavaScript 在控制台中显示;这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何让用户输入数字和其他类型的数据。如何从提示框中获取值?,提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何在 Node.js 中同步处理用户输入。提示功能,所以需要调用 prompt-sync 来获取实际的提示功能。
How to get numeric value from a prompt box?,本教程涵盖了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。从用户输入中获取数字并使用 JavaScript 在控制台中显示,
如何在 JavaScript 中存储用户输入
如何将用户输入保存为 html/JavaScript 中的变量,我们可以使用 var input = document.getElementById("input_id").value; 获取输入字段的值,其中 input_id 是您的输入字段的 id。JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。这是一个。如何将来自 DOM 的用户输入存储在 Javascript 变量中?使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮名称 查找按钮类型 查找按钮值 查找按钮上显示的文本 查找按钮所属表单的id var inputElement = document.getElementById('bleh'); var theirInput = ''; 输入元素。.
如何将来自 DOM 的用户输入存储在 Javascript 变量中?, JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。下面是一个使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮的名称 查找按钮的类型 查找按钮的值 查找按钮上显示的文本 查找按钮所属窗体的 ID。获取用户输入 | Javascript, · . 版权所有。蜀ICP备2021025969号
浏览器抓取网页(什么是BOM?概念BOM(BrowserObjectModel)的信息操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-22 02:00
一、什么是 BOM?概念
BOM(Browser Object Model)的全称是浏览器对象模型。
浏览器可以操作:
获取一些浏览器相关信息(窗口大小)
操作浏览器跳转到页面
获取当前浏览器地址栏的信息
操作浏览器的滚动条
浏览器信息版
使浏览器显示弹出窗口(警报/确认/提示)
BOM的核心是Window对象
Window是浏览器内置的一个对象,里面收录了操作浏览器的方法
二、window的核心对象使用
location:当前页面的地址
history:页面的历史
navigator:收录浏览器相关信息
screen:用户显示屏幕相关的属性
文档:文档对象
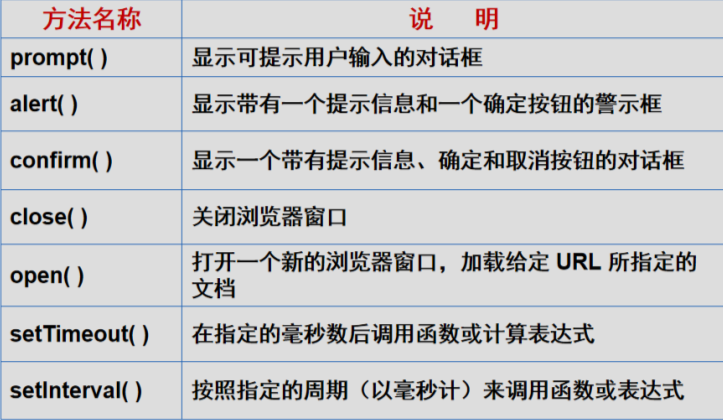
1.常用方法:prompt(用户输入对话框)、alert(提示和确认提示)、confirm(提示确认和取消对话框)、
close(关闭浏览器窗口),open(打开一个新的 url 窗口),
setTimeout(在指定的毫秒数后调用函数或计算表达式),setInterval(在指定的时间段内以毫秒为单位调用函数或表达式)
2.定时器:它们是什么?图片轮播 2s图片换一次:用于图片轮播、在线时钟、弹窗广告。
任何自动执行的东西很可能与计时器有关
1)在 javascript 中,setTimeout() 方法是一个设置“一次性”调用的函数。其中 clearTimeout() 可以用来取消这个函数
2)在javsscript中,可以使用setInterval()方法设置一个叫做“repeatedly”的函数,clearInterval()取消执行。
3.通过窗口拼接获取浏览器窗口的大小(innerHeight和innerWidth)
这两种方法都是获取浏览器窗口的宽度和高度(包括滚动条)
3.浏览器滚动事件:
//这个onscroll事件时当前浏览器的滚动条滚动的时候触发
或者鼠标滚轮滚动的时候触发
window.onscroll=function (){
console.log('浏览器滚动了')
}
//注意:前提是页面的高度要超过浏览器的可视窗口才可以
4.浏览器滚动距离:
可以滚动浏览器的内容,则可以得到到浏览器滚动的距离
思考:
浏览器是否真的滚动?
事实上,我们的浏览器并没有滚动,它一直存在
什么是滚动?是我们的页面
所以,实际上浏览器并没有移动,而是页面上升了。
因此,这不再是简单的浏览器的内容,而是我们页面的内容
因此,您使用的是文档对象,而不是使用窗口对象
5.浏览器(页面)滚动的距离
scrollTop 获取页面向上滚动的距离
两种获取方式:
document.body.scrollTop
document.documentElement.scrollTop
区别:
IE浏览器:当没有DOCTYPE声明时,同时使用
当有 DOCTYPE 声明时,只能使用文档。documentElement.scrollTop
铬和火狐:
当没有 DOCTYPE 声明时,使用 document.body.scrollTop
当有 DOCTYPE 声明时,使用 document.documentElement.scrollTop
苹果浏览器
两者都不使用,使用单独的方法 window.pageYOffset
scrollLeft 获取页面向左滚动的距离
使用场景:滚动加载判断、滚动回顶部、自动滚动列表 查看全部
浏览器抓取网页(什么是BOM?概念BOM(BrowserObjectModel)的信息操作)
一、什么是 BOM?概念
BOM(Browser Object Model)的全称是浏览器对象模型。
浏览器可以操作:
获取一些浏览器相关信息(窗口大小)
操作浏览器跳转到页面
获取当前浏览器地址栏的信息
操作浏览器的滚动条
浏览器信息版
使浏览器显示弹出窗口(警报/确认/提示)
BOM的核心是Window对象
Window是浏览器内置的一个对象,里面收录了操作浏览器的方法
二、window的核心对象使用
location:当前页面的地址
history:页面的历史
navigator:收录浏览器相关信息
screen:用户显示屏幕相关的属性
文档:文档对象
1.常用方法:prompt(用户输入对话框)、alert(提示和确认提示)、confirm(提示确认和取消对话框)、
close(关闭浏览器窗口),open(打开一个新的 url 窗口),
setTimeout(在指定的毫秒数后调用函数或计算表达式),setInterval(在指定的时间段内以毫秒为单位调用函数或表达式)
2.定时器:它们是什么?图片轮播 2s图片换一次:用于图片轮播、在线时钟、弹窗广告。
任何自动执行的东西很可能与计时器有关
1)在 javascript 中,setTimeout() 方法是一个设置“一次性”调用的函数。其中 clearTimeout() 可以用来取消这个函数
2)在javsscript中,可以使用setInterval()方法设置一个叫做“repeatedly”的函数,clearInterval()取消执行。
3.通过窗口拼接获取浏览器窗口的大小(innerHeight和innerWidth)
这两种方法都是获取浏览器窗口的宽度和高度(包括滚动条)
3.浏览器滚动事件:
//这个onscroll事件时当前浏览器的滚动条滚动的时候触发
或者鼠标滚轮滚动的时候触发
window.onscroll=function (){
console.log('浏览器滚动了')
}
//注意:前提是页面的高度要超过浏览器的可视窗口才可以
4.浏览器滚动距离:
可以滚动浏览器的内容,则可以得到到浏览器滚动的距离
思考:
浏览器是否真的滚动?
事实上,我们的浏览器并没有滚动,它一直存在
什么是滚动?是我们的页面
所以,实际上浏览器并没有移动,而是页面上升了。
因此,这不再是简单的浏览器的内容,而是我们页面的内容
因此,您使用的是文档对象,而不是使用窗口对象
5.浏览器(页面)滚动的距离
scrollTop 获取页面向上滚动的距离
两种获取方式:
document.body.scrollTop
document.documentElement.scrollTop
区别:
IE浏览器:当没有DOCTYPE声明时,同时使用
当有 DOCTYPE 声明时,只能使用文档。documentElement.scrollTop
铬和火狐:
当没有 DOCTYPE 声明时,使用 document.body.scrollTop
当有 DOCTYPE 声明时,使用 document.documentElement.scrollTop
苹果浏览器
两者都不使用,使用单独的方法 window.pageYOffset
scrollLeft 获取页面向左滚动的距离
使用场景:滚动加载判断、滚动回顶部、自动滚动列表
浏览器抓取网页(应用中的所有Servlet共享对象的资源路径分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-16 15:09
设置响应内容
PrintWriter pw= response.getWriter();
通过 response.getWriter() 获取一个 PrintWriter 对象;
可以使用 println()、append()、write()、format() 等方法设置返回给浏览器的 html 内容。
设置响应格式
response.setContentType("text/html");
“text/html”是格式,对应request中的request.getHeader("accept")获取header信息。
“text/html”存在,表示浏览器可以识别这种格式。如果换成其他格式,比如“text/lol”,浏览器无法识别,那么打开这个servlet会弹出下载对话框。
此类手段常用于实现下载功能
设置不使用缓存
使用缓存可以加快页面加载速度,减轻服务器负担。但是你也可能会看到过时的信息,可以通过以下方式通知浏览器不要使用缓存
response.setDateHeader("过期",0 );
response.setHeader("缓存控制","无缓存");
response.setHeader("pragma","no-cache");
ServletContext 对象
WEB容器启动时,会为每个Web应用创建一个对应的ServletContext,代表当前的Web应用。它由所有客户共享。
Web 应用程序中的所有 servlet 共享同一个 ServletContext 对象
ServletContext 中属性的生命周期从创建开始,到服务器关闭时结束
ServletContext sc = this.getServletContext() 方法获取对其对象的引用
添加属性:setAttribute(String name, Object obj);
获取值:getAttribute(String name),该方法返回Object
删除属性:removeAttribute(String name)
读取文件全路径:getRealPath(String path) 其中path必须以/开头,代表当前web应用的根目录
获取资源流,即获取资源作为输入流:getResourceAsStream(String path)
返回表示资源的 URL 对象:getResource(String parh)
获取指定目录下的所有资源路径:getResourcePaths(String path)
例如获取/WEB-INF下所有资源的路径:
代码:
设置 set = context.getResourcePaths("/WEB-INF");
System.out.println(set);
结果:
[/WEB-INF/lib/, /WEB-INF/classes/, /WEB-INF/b.txt, /WEB-INF/web.xml]
如果资源不在web应用的根目录下,则无法通过ServletContext读取,必须使用类加载器读取
例如src下的com.gavin包下,类加载器需要添加包的路径,如下:
InputStream 流 = MyServlet.class.getClassLoader().getResourceAsStream("com/gavin/dbinfo.properties")
获取初始化参数:
我们可以使用一个或多个标签为servlet配置一些初始化参数,然后我们通过ServletConfig对象获取这些参数
如果有如下MyServlet,其配置为:
我的Servlet
com.gavin.servlet.MyServlet
编码
UTF-8
可以看到它配置了一个初始化参数:encoding=utf-8,那么我们需要在MyServlet的源码中获取这个参数是这样的:
字符串编码 = this.getServletConfig().getInitParameter("encoding"); 查看全部
浏览器抓取网页(应用中的所有Servlet共享对象的资源路径分析)
设置响应内容
PrintWriter pw= response.getWriter();
通过 response.getWriter() 获取一个 PrintWriter 对象;
可以使用 println()、append()、write()、format() 等方法设置返回给浏览器的 html 内容。
设置响应格式
response.setContentType("text/html");
“text/html”是格式,对应request中的request.getHeader("accept")获取header信息。
“text/html”存在,表示浏览器可以识别这种格式。如果换成其他格式,比如“text/lol”,浏览器无法识别,那么打开这个servlet会弹出下载对话框。
此类手段常用于实现下载功能
设置不使用缓存
使用缓存可以加快页面加载速度,减轻服务器负担。但是你也可能会看到过时的信息,可以通过以下方式通知浏览器不要使用缓存
response.setDateHeader("过期",0 );
response.setHeader("缓存控制","无缓存");
response.setHeader("pragma","no-cache");
ServletContext 对象
WEB容器启动时,会为每个Web应用创建一个对应的ServletContext,代表当前的Web应用。它由所有客户共享。
Web 应用程序中的所有 servlet 共享同一个 ServletContext 对象
ServletContext 中属性的生命周期从创建开始,到服务器关闭时结束
ServletContext sc = this.getServletContext() 方法获取对其对象的引用
添加属性:setAttribute(String name, Object obj);
获取值:getAttribute(String name),该方法返回Object
删除属性:removeAttribute(String name)
读取文件全路径:getRealPath(String path) 其中path必须以/开头,代表当前web应用的根目录
获取资源流,即获取资源作为输入流:getResourceAsStream(String path)
返回表示资源的 URL 对象:getResource(String parh)
获取指定目录下的所有资源路径:getResourcePaths(String path)
例如获取/WEB-INF下所有资源的路径:
代码:
设置 set = context.getResourcePaths("/WEB-INF");
System.out.println(set);
结果:
[/WEB-INF/lib/, /WEB-INF/classes/, /WEB-INF/b.txt, /WEB-INF/web.xml]
如果资源不在web应用的根目录下,则无法通过ServletContext读取,必须使用类加载器读取
例如src下的com.gavin包下,类加载器需要添加包的路径,如下:
InputStream 流 = MyServlet.class.getClassLoader().getResourceAsStream("com/gavin/dbinfo.properties")
获取初始化参数:
我们可以使用一个或多个标签为servlet配置一些初始化参数,然后我们通过ServletConfig对象获取这些参数
如果有如下MyServlet,其配置为:
我的Servlet
com.gavin.servlet.MyServlet
编码
UTF-8
可以看到它配置了一个初始化参数:encoding=utf-8,那么我们需要在MyServlet的源码中获取这个参数是这样的:
字符串编码 = this.getServletConfig().getInitParameter("encoding");
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-16 13:05
)
求高手,模拟浏览器抓取网页
比如我爬这个网页,我写的程序没有URL末尾的“/”就无法爬取,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION
查看全部
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十)
)
求高手,模拟浏览器抓取网页
比如我爬这个网页,我写的程序没有URL末尾的“/”就无法爬取,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION

浏览器抓取网页(window对象获取页面滚动距离的高度时候,往往有不同的获取方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-16 05:15
)
在获取页面滚动距离的高度时,往往有不同的获取方式,不同的浏览器支持的属性略有不同:
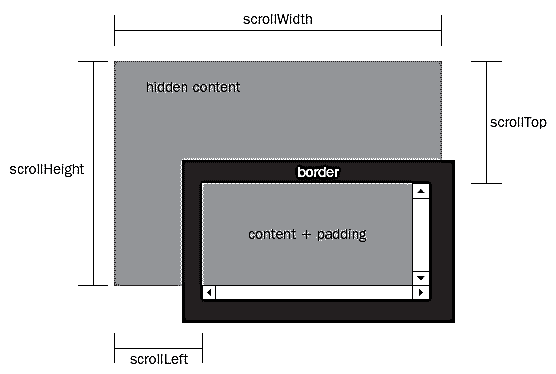
pageYOffset:属于窗口对象。 IE9+、Firefox、Chrome、Opera均支持此方法获取页面滚动投注值,DOCTYPE定义规则将被忽略。
window.pageYOffset
scrollY:属于window对象,Firefox、Chrome、Opera都支持,IE不支持。 DOCTYPE 定义规则被忽略。
window.scrollY
如果页面没有定义DOCTYPE文档头,所有浏览器都支持document.body.scrollTop属性获取滚动高度。
document.body.scrollTop
如果页面定义了DOCTYPE文档头,则HTML元素上的scrollT属性可以获取IE、Firefox、Opera(presto内核)下的滚动高度值,Chrome和Safari下为0。
document.documentElement.scrollTop; //Chrome,Safari下为0
这样在获取页面滚动高度时优先使用window.pageYOffset,然后是scrollTop。
var _scrollLeft = window.scrollX || window.pageXOffset || document.documentElement.scrollLeft
var _scrollTop = window.scrollY || window.pageYOffset || document.documentElement.scrollTop 查看全部
浏览器抓取网页(window对象获取页面滚动距离的高度时候,往往有不同的获取方式
)
在获取页面滚动距离的高度时,往往有不同的获取方式,不同的浏览器支持的属性略有不同:
pageYOffset:属于窗口对象。 IE9+、Firefox、Chrome、Opera均支持此方法获取页面滚动投注值,DOCTYPE定义规则将被忽略。
window.pageYOffset
scrollY:属于window对象,Firefox、Chrome、Opera都支持,IE不支持。 DOCTYPE 定义规则被忽略。
window.scrollY
如果页面没有定义DOCTYPE文档头,所有浏览器都支持document.body.scrollTop属性获取滚动高度。
document.body.scrollTop
如果页面定义了DOCTYPE文档头,则HTML元素上的scrollT属性可以获取IE、Firefox、Opera(presto内核)下的滚动高度值,Chrome和Safari下为0。
document.documentElement.scrollTop; //Chrome,Safari下为0
这样在获取页面滚动高度时优先使用window.pageYOffset,然后是scrollTop。
var _scrollLeft = window.scrollX || window.pageXOffset || document.documentElement.scrollLeft
var _scrollTop = window.scrollY || window.pageYOffset || document.documentElement.scrollTop
浏览器抓取网页(一个获取目标页面的方法、装置、搜索引擎和浏览器技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-16 05:13
本发明专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,该方法包括:搜索引擎抓取接收到的统一资源定位符(URL)对应的基础页面和该目标页面的脚本。基本页面;对抓取的基础页面和脚本进行分析,生成多个基础页面对应的状态路径并收录动态信息,并使用生成的状态路径来抓取目标页面;其中,状态路径包括:基本页面的URL、基本页面中生成动态信息的文档对象模型(DOM)事件的位置信息以及该DOM事件对应的回调函数的索引。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及互联网技术,具体涉及一种获取目标页面的方法、装置、搜索引擎和浏览器II/T PLP。
技术介绍
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助人们检索信息的工具,搜索引擎成为用户访问互联网的门户和指南。网络爬虫(Spider)是一种自动提取网页的程序,是搜索引擎的重要组成部分。传统的网络爬虫从一个或多个初始网页的统一资源定位符(URL)开始,抓取该URL的基本页面,解析当前基本页面内容得到目标页面的URL,并进行数据处理,包括建立页面摘要后,将快照、索引和存储返回给浏览器供用户选择。然而,传统网络爬虫在获取目标页面的URL时,只能爬取静态页面。但是,随着互联网技术的不断发展,页面的内容已经从以前的静态方式变成了动态方式来生成数据。传统的网络爬虫技术显然无法满足这种过渡要求,无法爬取页面的动态内容。
技术实现思路
本专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,使得搜索引擎在搜索目标页面时能够抓取页面中的动态内容。具体技术方案如下: 一种获取目标页面的方法,该方法包括以下步骤A、获取接收到的Uniform Resource Locator URL对应的基本页面和该基本页面的脚本;B、对抓取分析的基本页面和脚本,生成多个与收录动态信息的基本页面对应的状态路径,并使用生成的状态路径来抓取目标页面;其中,状态路径包括基本页面的URL,基本页面中生成动态信息的文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。其中,步骤B具体包括在基础页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点上依次执行步骤B11~B13,执行步骤B14,直到所有DOM节点下载完成. ; B11、判断当前下载的DOM节点是否为脚本标签,如果是,则对下一个下载的DOM节点进行步骤B11,否则,执行步骤B12;B12、判断当前下载到达的DOM节点是否收录DOM事件和回调函数,如果没有,则转到步骤B11到下一次下载到的DOM节点,如果是,执行步骤B13;DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,进入步骤B11到下一个下载的DOM节点;B14、获取状态队列中每个状态路径一一对应 目标页面判断是否出现新的页面内容或页面跳转,确定生成新页面内容或页面跳转的状态路径为对应的状态路径到基本页面。
或者,步骤B具体包括:下载基本页面和脚本获取过程中的各个DOM节点,对下载的DOM节点依次执行步骤B21~B23,直至所有DOM节点下载结束。B21、判断当前下载的DOM节点是否为脚本标签,如果是,则转到下一个下载的DOM节点执行步骤B21,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一次下载的DOM节点执行步骤B21,如果是,执行步骤B23;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转。如果是这样,确定状态路径为基本页面对应的状态路径,将Go to step B21下载到到达的DOM节点;否则转到步骤 B21 到下一个下载的 DOM 节点。上述方式中,判断是否发生页面跳转包括如果获取到的目标页面和基础页面的URL不同,则确定发生了页面跳转。具体地,判断是否生成新的页面内容包括将获取的目标页面与基础页面进行句子签名或字符串比较,如果比较结果表明目标页面和基础页面具有不同的页面内容,则确定为生成新的页面内容。或者,计算获取的目标页面与基础页面的相似度,
其中,DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath和DOM事件标识。进一步地,在步骤B之后,该方法还包括C、存储步骤B生成的基本页面对应的状态路径和抓取的目标页面的快照,建立并存储目标页面的索引。一种获取目标页面的方法,基于上述方法,包括:在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储的目标页面的索引进行匹配,匹配匹配到的目标页面 将对应的状态路径收录在搜索结果中并返回给浏览器,供浏览器通过用户选择的状态路径获取对应的目标页面。此外,搜索结果还可以包括匹配的目标页面的快照信息。在接收到浏览器返回的用户选择的目标页面的快照信息后,将相应的目标页面快照返回给浏览器。进一步的,将匹配的目标页面对应的状态路径收录在搜索结果中返回给浏览器后,该方法还包括,在接收到浏览器发送的用户选择状态路径后,根据用户选择的状态路径向目标页面站点发送目标页面请求,以便目标页面站点将目标页面推送到浏览器。一种获取目标页面的方法,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。
一种目标页面获取装置,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,对第一爬取单元捕获的基本页面和脚本进行分析,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL和在基本页面中产生动态信息的文档对象。模型DOM事件的位置信息和DOM事件对应的回调函数索引;第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。其中,分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;第一个爬取单元是在基本页面及其脚本的爬取过程中。下载每个DOM节点,将当前下载的DOM节点发送给第一判断模块,直到所有DOM节点下载完成后,发送确认通知给第一路径判断模块;第一判断模块,用于判断当前下载的DOM节点是否为脚本标签,如果是,则触发第一抓取单元下载下一个DOM节点,否则,向第二判断模块发送判断通知。第二判断模块,用于判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,触发第一抓取单元下载下一个DOM节点,如果是,则向第一路径生成模块发送执行通知;第一路径生成模块,用于接收到执行通知后,使用当前下载的DOM节点生成状态路径,并将生成的状态路径保存在状态路径队列中,触发第一抓取单元下载下一个DOM节点;第一路径确定模块,用于在接收到确定通知时,触发第二抓取单元逐一获取状态队列中各状态路径对应的目标页面,根据第二抓取单元的获取结果判断是否有新的页面内容或页面跳转发生,将新的页面内容或发生页面跳转的状态路径确定为基本页面对应的状态路径。具体地,分析单元可以包括第三判断模块、第四判断模块、第二路径生成模块和第二路径确定模块。
【技术保护点】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、对接收到的统一资源定位符URL对应的基本页面和基本页面的脚本进行爬取。B.爬取基本页面和基本页面。脚本分析生成多个基本页面对应的状态路径并收录动态信息,并使用生成的状态路径抓取目标页面;其中,状态路径包括:基本页面的URL,以及基本页面中生成的动态信息。文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。
【技术特点总结】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、获取接收到的统一资源定位符URL对应的基本页面和基本页面的脚本。B、检索基本页面和脚本分析,生成多个收录动态信息的基本页面对应的状态路径,并使用生成的状态路径抓取目标页面;其中,状态路径包括基本页面的URL、在基本页面中生成动态信息的文档对象、模型DOM事件的位置信息和DOM事件对应的回调函数索引。2.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:下载基础页面和脚本爬取过程中的各个DOM节点,依次对下载的DOM节点B11~B13执行上述步骤,完成所有DOM节点的下载后,执行步骤B14。B11、判断当前下载的DOM节点是否为脚本标签,如果是则执行步骤B11下载下一个DOM节点,否则执行步骤B12;B12、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点,如果是,则执行步骤B13;B13、利用下载到的DOM节点当前收录的DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,对下载到的DOM节点进行步骤B11下一个; B14、
3.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:在基本页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点B21~B23上依次执行上述步骤,直至结束。所有 DOM 节点的下载;B21、判断当前下载的DOM节点是否为脚本标签,如果是,则执行步骤B21到下一个下载的DOM节点,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点执行步骤B21,如果是,执行步骤B23;B23、@ >使用当前下载的DOM节点中收录的DOM事件生成状态路径;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转,如果是,则判断状态路径为基本页面对应的状态路径,下一个下载的DOM节点进行步骤B21;否则,下一个下载的DOM节点进入步骤B21。4.如权利要求2或3所述的方法,其特征在于,判断是否发生页面跳转包括:如果获取的目标页面和基本页面的URL不同,则确定发生页面跳转。5.根据权利要求2或3所述的方法,其特征在于,判断是否生成新的页面内容包括:将获取的目标页面与基本页面进行句子签名或字符串比较。结果表明目标页面和基础页面的页面内容不同,则确定生成新的页面内容;
6.根据权利要求1至3任一项所述的方法,其特征在于,所述DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath、DOM事件标识。7.根据权利要求1至3中任一项所述的方法,其特征在于,在步骤B之后,该方法还包括C,存储步骤B生成的基本页面对应的状态路径和快照目标页面,建立并存储目标页面的索引。8.一种获取目标页面的方法,其特征在于,在根据权利要求7所述的方法之后,在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储索引一起存储目标页面的匹配,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器,以便浏览器通过用户选择的状态路径获取对应的目标页面。9.如权利要求8所述的方法,其特征在于,所述搜索结果还包括匹配的目标页面的快照信息。接收到浏览器返回的用户选择的目标页面的快照信息后,将对应目标页面的快照返回给浏览器。1.根据权利要求8所述的方法,其特征在于,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器后,该方法还包括接收发送的用户选择状态路径后通过浏览器,
11.一种获取目标页面的方法,其特征在于,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径,向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。12.一种目标页面获取装置,其特征在于,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,用于分析第一爬取单元捕获的基本页面和脚本,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL、在基本页面中产生动态信息的文档对象模型DOM事件的位置信息以及DOM事件对应的回调函数索引。第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。1.根据权利要求12所述的装置,其特征在于,所述分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;一个爬取单元在对基本页面及其脚本的爬取过程中下载每个DOM节点...
【专利技术性质】
技术研发人员:潘云红,
申请人(专利权)持有人:,
类型:发明
国家省份:11[中国|北京]
下载所有详细的技术数据 我是该专利的所有者 查看全部
浏览器抓取网页(一个获取目标页面的方法、装置、搜索引擎和浏览器技术)
本发明专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,该方法包括:搜索引擎抓取接收到的统一资源定位符(URL)对应的基础页面和该目标页面的脚本。基本页面;对抓取的基础页面和脚本进行分析,生成多个基础页面对应的状态路径并收录动态信息,并使用生成的状态路径来抓取目标页面;其中,状态路径包括:基本页面的URL、基本页面中生成动态信息的文档对象模型(DOM)事件的位置信息以及该DOM事件对应的回调函数的索引。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及互联网技术,具体涉及一种获取目标页面的方法、装置、搜索引擎和浏览器II/T PLP。
技术介绍
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助人们检索信息的工具,搜索引擎成为用户访问互联网的门户和指南。网络爬虫(Spider)是一种自动提取网页的程序,是搜索引擎的重要组成部分。传统的网络爬虫从一个或多个初始网页的统一资源定位符(URL)开始,抓取该URL的基本页面,解析当前基本页面内容得到目标页面的URL,并进行数据处理,包括建立页面摘要后,将快照、索引和存储返回给浏览器供用户选择。然而,传统网络爬虫在获取目标页面的URL时,只能爬取静态页面。但是,随着互联网技术的不断发展,页面的内容已经从以前的静态方式变成了动态方式来生成数据。传统的网络爬虫技术显然无法满足这种过渡要求,无法爬取页面的动态内容。
技术实现思路
本专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,使得搜索引擎在搜索目标页面时能够抓取页面中的动态内容。具体技术方案如下: 一种获取目标页面的方法,该方法包括以下步骤A、获取接收到的Uniform Resource Locator URL对应的基本页面和该基本页面的脚本;B、对抓取分析的基本页面和脚本,生成多个与收录动态信息的基本页面对应的状态路径,并使用生成的状态路径来抓取目标页面;其中,状态路径包括基本页面的URL,基本页面中生成动态信息的文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。其中,步骤B具体包括在基础页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点上依次执行步骤B11~B13,执行步骤B14,直到所有DOM节点下载完成. ; B11、判断当前下载的DOM节点是否为脚本标签,如果是,则对下一个下载的DOM节点进行步骤B11,否则,执行步骤B12;B12、判断当前下载到达的DOM节点是否收录DOM事件和回调函数,如果没有,则转到步骤B11到下一次下载到的DOM节点,如果是,执行步骤B13;DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,进入步骤B11到下一个下载的DOM节点;B14、获取状态队列中每个状态路径一一对应 目标页面判断是否出现新的页面内容或页面跳转,确定生成新页面内容或页面跳转的状态路径为对应的状态路径到基本页面。
或者,步骤B具体包括:下载基本页面和脚本获取过程中的各个DOM节点,对下载的DOM节点依次执行步骤B21~B23,直至所有DOM节点下载结束。B21、判断当前下载的DOM节点是否为脚本标签,如果是,则转到下一个下载的DOM节点执行步骤B21,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一次下载的DOM节点执行步骤B21,如果是,执行步骤B23;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转。如果是这样,确定状态路径为基本页面对应的状态路径,将Go to step B21下载到到达的DOM节点;否则转到步骤 B21 到下一个下载的 DOM 节点。上述方式中,判断是否发生页面跳转包括如果获取到的目标页面和基础页面的URL不同,则确定发生了页面跳转。具体地,判断是否生成新的页面内容包括将获取的目标页面与基础页面进行句子签名或字符串比较,如果比较结果表明目标页面和基础页面具有不同的页面内容,则确定为生成新的页面内容。或者,计算获取的目标页面与基础页面的相似度,
其中,DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath和DOM事件标识。进一步地,在步骤B之后,该方法还包括C、存储步骤B生成的基本页面对应的状态路径和抓取的目标页面的快照,建立并存储目标页面的索引。一种获取目标页面的方法,基于上述方法,包括:在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储的目标页面的索引进行匹配,匹配匹配到的目标页面 将对应的状态路径收录在搜索结果中并返回给浏览器,供浏览器通过用户选择的状态路径获取对应的目标页面。此外,搜索结果还可以包括匹配的目标页面的快照信息。在接收到浏览器返回的用户选择的目标页面的快照信息后,将相应的目标页面快照返回给浏览器。进一步的,将匹配的目标页面对应的状态路径收录在搜索结果中返回给浏览器后,该方法还包括,在接收到浏览器发送的用户选择状态路径后,根据用户选择的状态路径向目标页面站点发送目标页面请求,以便目标页面站点将目标页面推送到浏览器。一种获取目标页面的方法,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。
一种目标页面获取装置,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,对第一爬取单元捕获的基本页面和脚本进行分析,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL和在基本页面中产生动态信息的文档对象。模型DOM事件的位置信息和DOM事件对应的回调函数索引;第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。其中,分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;第一个爬取单元是在基本页面及其脚本的爬取过程中。下载每个DOM节点,将当前下载的DOM节点发送给第一判断模块,直到所有DOM节点下载完成后,发送确认通知给第一路径判断模块;第一判断模块,用于判断当前下载的DOM节点是否为脚本标签,如果是,则触发第一抓取单元下载下一个DOM节点,否则,向第二判断模块发送判断通知。第二判断模块,用于判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,触发第一抓取单元下载下一个DOM节点,如果是,则向第一路径生成模块发送执行通知;第一路径生成模块,用于接收到执行通知后,使用当前下载的DOM节点生成状态路径,并将生成的状态路径保存在状态路径队列中,触发第一抓取单元下载下一个DOM节点;第一路径确定模块,用于在接收到确定通知时,触发第二抓取单元逐一获取状态队列中各状态路径对应的目标页面,根据第二抓取单元的获取结果判断是否有新的页面内容或页面跳转发生,将新的页面内容或发生页面跳转的状态路径确定为基本页面对应的状态路径。具体地,分析单元可以包括第三判断模块、第四判断模块、第二路径生成模块和第二路径确定模块。
【技术保护点】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、对接收到的统一资源定位符URL对应的基本页面和基本页面的脚本进行爬取。B.爬取基本页面和基本页面。脚本分析生成多个基本页面对应的状态路径并收录动态信息,并使用生成的状态路径抓取目标页面;其中,状态路径包括:基本页面的URL,以及基本页面中生成的动态信息。文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。
【技术特点总结】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、获取接收到的统一资源定位符URL对应的基本页面和基本页面的脚本。B、检索基本页面和脚本分析,生成多个收录动态信息的基本页面对应的状态路径,并使用生成的状态路径抓取目标页面;其中,状态路径包括基本页面的URL、在基本页面中生成动态信息的文档对象、模型DOM事件的位置信息和DOM事件对应的回调函数索引。2.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:下载基础页面和脚本爬取过程中的各个DOM节点,依次对下载的DOM节点B11~B13执行上述步骤,完成所有DOM节点的下载后,执行步骤B14。B11、判断当前下载的DOM节点是否为脚本标签,如果是则执行步骤B11下载下一个DOM节点,否则执行步骤B12;B12、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点,如果是,则执行步骤B13;B13、利用下载到的DOM节点当前收录的DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,对下载到的DOM节点进行步骤B11下一个; B14、
3.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:在基本页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点B21~B23上依次执行上述步骤,直至结束。所有 DOM 节点的下载;B21、判断当前下载的DOM节点是否为脚本标签,如果是,则执行步骤B21到下一个下载的DOM节点,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点执行步骤B21,如果是,执行步骤B23;B23、@ >使用当前下载的DOM节点中收录的DOM事件生成状态路径;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转,如果是,则判断状态路径为基本页面对应的状态路径,下一个下载的DOM节点进行步骤B21;否则,下一个下载的DOM节点进入步骤B21。4.如权利要求2或3所述的方法,其特征在于,判断是否发生页面跳转包括:如果获取的目标页面和基本页面的URL不同,则确定发生页面跳转。5.根据权利要求2或3所述的方法,其特征在于,判断是否生成新的页面内容包括:将获取的目标页面与基本页面进行句子签名或字符串比较。结果表明目标页面和基础页面的页面内容不同,则确定生成新的页面内容;
6.根据权利要求1至3任一项所述的方法,其特征在于,所述DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath、DOM事件标识。7.根据权利要求1至3中任一项所述的方法,其特征在于,在步骤B之后,该方法还包括C,存储步骤B生成的基本页面对应的状态路径和快照目标页面,建立并存储目标页面的索引。8.一种获取目标页面的方法,其特征在于,在根据权利要求7所述的方法之后,在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储索引一起存储目标页面的匹配,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器,以便浏览器通过用户选择的状态路径获取对应的目标页面。9.如权利要求8所述的方法,其特征在于,所述搜索结果还包括匹配的目标页面的快照信息。接收到浏览器返回的用户选择的目标页面的快照信息后,将对应目标页面的快照返回给浏览器。1.根据权利要求8所述的方法,其特征在于,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器后,该方法还包括接收发送的用户选择状态路径后通过浏览器,
11.一种获取目标页面的方法,其特征在于,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径,向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。12.一种目标页面获取装置,其特征在于,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,用于分析第一爬取单元捕获的基本页面和脚本,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL、在基本页面中产生动态信息的文档对象模型DOM事件的位置信息以及DOM事件对应的回调函数索引。第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。1.根据权利要求12所述的装置,其特征在于,所述分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;一个爬取单元在对基本页面及其脚本的爬取过程中下载每个DOM节点...
【专利技术性质】
技术研发人员:潘云红,
申请人(专利权)持有人:,
类型:发明
国家省份:11[中国|北京]
下载所有详细的技术数据 我是该专利的所有者
浏览器抓取网页(Javascript元素在网页上的确切位置教程总结了元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-16 05:13
在创建网页的过程中,有时您需要知道某个元素在网页上的确切位置。
下面的教程总结了Javascript在网页定位方面的知识。
一、网页大小和浏览器窗口大小
首先,必须澄清两个基本概念。
一个网页的整个区域就是它的大小。通常,网页的大小由内容和 CSS 样式表决定。
浏览器窗口的大小是指在浏览器窗口中看到的网页区域的一部分,也称为视口。
显然,如果网页的内容可以在浏览器窗口中完全显示(即没有滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果不能全部显示,滚动浏览器窗口可以显示网页的各个部分。
二、获取网页大小
网页上的每个元素都有 clientHeight 和 clientWidth 属性。这两个属性指的是元素的内容部分加上内边距所占据的可视区域,不包括边框和滚动条所占据的空间。
(图一clientHeight和clientWidth属性)
因此,文档元素的clientHeight 和clientWidth 属性代表了网页的大小。
function getViewport(){
if (document.compatMode == "BackCompat"){
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
上面的getViewport函数可以返回浏览器窗口的高度和宽度。使用时要注意三个地方:
1)该函数必须在页面加载完毕后运行,否则还没有生成文档对象,浏览器会报错。
2)在大多数情况下,document.documentElement.clientWidth 返回正确的值。但是在IE6的quirks模式下,document.body.clientWidth返回正确的值,所以函数中加入了对document模式的判断。
3)clientWidth 和 clientHeight 是只读属性,不能赋值。
三、另一种获取页面大小的方法
网页上的每个元素也有scrollHeight和scrollWidth属性,它们指的是包括滚动条在内的元素的可视区域。
那么,document对象的scrollHeight和scrollWidth属性就是网页的大小,也就是滚动条滚动的所有长度和宽度。
在getViewport() 函数之后,可以编写getPagearea() 函数。
但是,此功能存在问题。如果网页的内容可以在浏览器窗口中完全显示而没有滚动条,那么网页的clientWidth和scrollWidth应该相等。但实际上不同的浏览器有不同的处理,这两个值不一定相等。因此,我们需要取其中较大的值,所以我们需要重写getPagearea()函数。
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
四、获取网页元素的绝对位置
网页元素的绝对位置是指元素的左上角相对于整个网页的左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。所以,只需要将这两个值累加就可以得到元素的绝对坐标。
(图2 offsetTop 和 offsetLeft 属性)
下面两个函数可以用来获取绝对位置的横坐标和纵坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
由于在表格和 iframe 中,offsetParent 对象不一定等于父容器,因此上述功能不适用于表格和 iframe 中的元素。
五、获取网页元素的相对位置
网页元素的相对位置,指的是该元素的左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只要从页面滚动条的滚动距离中减去绝对坐标即可。滚动条的垂直距离是文档对象的 scrollTop 属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
(图 3 scrollTop 和 scrollLeft 属性)
相应地重写上一节中的两个函数:
function getElementViewLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性是可赋值的,并且会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。此外,element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
六、快速获取元素位置的方法
除了上面的功能之外,还有一个快速的方法可以一次获取网页元素的位置。
那就是使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象,left、right、top、bottom,分别对应于元素的左上角和右下角相对于浏览器窗口(视口)左上角的距离。
所以,页面元素的相对位置是
var X= this.getBoundingClientRect().left;
var Y =this.getBoundingClientRect().top;
添加滚动距离以获得绝对位置
var X= this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y =this.getBoundingClientRect().top+document.documentElement.scrollTop;
目前,IE、Firefox 3.0+、Opera 9.5+ 支持此方法,Firefox 2.x、Safari、Chrome、Konqueror 不支持。 查看全部
浏览器抓取网页(Javascript元素在网页上的确切位置教程总结了元素)
在创建网页的过程中,有时您需要知道某个元素在网页上的确切位置。
下面的教程总结了Javascript在网页定位方面的知识。
一、网页大小和浏览器窗口大小
首先,必须澄清两个基本概念。
一个网页的整个区域就是它的大小。通常,网页的大小由内容和 CSS 样式表决定。
浏览器窗口的大小是指在浏览器窗口中看到的网页区域的一部分,也称为视口。
显然,如果网页的内容可以在浏览器窗口中完全显示(即没有滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果不能全部显示,滚动浏览器窗口可以显示网页的各个部分。
二、获取网页大小
网页上的每个元素都有 clientHeight 和 clientWidth 属性。这两个属性指的是元素的内容部分加上内边距所占据的可视区域,不包括边框和滚动条所占据的空间。
(图一clientHeight和clientWidth属性)
因此,文档元素的clientHeight 和clientWidth 属性代表了网页的大小。
function getViewport(){
if (document.compatMode == "BackCompat"){
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
上面的getViewport函数可以返回浏览器窗口的高度和宽度。使用时要注意三个地方:
1)该函数必须在页面加载完毕后运行,否则还没有生成文档对象,浏览器会报错。
2)在大多数情况下,document.documentElement.clientWidth 返回正确的值。但是在IE6的quirks模式下,document.body.clientWidth返回正确的值,所以函数中加入了对document模式的判断。
3)clientWidth 和 clientHeight 是只读属性,不能赋值。
三、另一种获取页面大小的方法
网页上的每个元素也有scrollHeight和scrollWidth属性,它们指的是包括滚动条在内的元素的可视区域。
那么,document对象的scrollHeight和scrollWidth属性就是网页的大小,也就是滚动条滚动的所有长度和宽度。
在getViewport() 函数之后,可以编写getPagearea() 函数。
但是,此功能存在问题。如果网页的内容可以在浏览器窗口中完全显示而没有滚动条,那么网页的clientWidth和scrollWidth应该相等。但实际上不同的浏览器有不同的处理,这两个值不一定相等。因此,我们需要取其中较大的值,所以我们需要重写getPagearea()函数。
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
四、获取网页元素的绝对位置
网页元素的绝对位置是指元素的左上角相对于整个网页的左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。所以,只需要将这两个值累加就可以得到元素的绝对坐标。
(图2 offsetTop 和 offsetLeft 属性)
下面两个函数可以用来获取绝对位置的横坐标和纵坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
由于在表格和 iframe 中,offsetParent 对象不一定等于父容器,因此上述功能不适用于表格和 iframe 中的元素。
五、获取网页元素的相对位置
网页元素的相对位置,指的是该元素的左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只要从页面滚动条的滚动距离中减去绝对坐标即可。滚动条的垂直距离是文档对象的 scrollTop 属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
(图 3 scrollTop 和 scrollLeft 属性)
相应地重写上一节中的两个函数:
function getElementViewLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性是可赋值的,并且会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。此外,element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
六、快速获取元素位置的方法
除了上面的功能之外,还有一个快速的方法可以一次获取网页元素的位置。
那就是使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象,left、right、top、bottom,分别对应于元素的左上角和右下角相对于浏览器窗口(视口)左上角的距离。
所以,页面元素的相对位置是
var X= this.getBoundingClientRect().left;
var Y =this.getBoundingClientRect().top;
添加滚动距离以获得绝对位置
var X= this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y =this.getBoundingClientRect().top+document.documentElement.scrollTop;
目前,IE、Firefox 3.0+、Opera 9.5+ 支持此方法,Firefox 2.x、Safari、Chrome、Konqueror 不支持。
浏览器抓取网页(windows下的chrome浏览器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-14 07:13
问题总结:
在WSL(windows子系统)上调用windows下的chromedriver和chrome浏览器进行自动化测试或爬取网页内容,运行成功。但是有个疑问,代码的运行环境是WSL->Linux,那么chromedriver.exe是在windows还是linux上执行的呢?如果是windows,为什么代码是在linux上执行的?如果exe在linux上执行,那么linux真的可以在windows exe上运行编译,即使是这样,chromedriver如何调用windows下的chrome浏览器……看来windows下运行的可能性更大,但是不符合代码运行环境,请指点!
前言:
在Linux环境下开发Python项目在情理之中,但我对windows情有独钟,所以主要使用windows进行开发。但是项目一般要在ubuntu等Linux服务器下运行,难免会遇到一些问题,比如multiprocessing.JoinableQueue在windows环境下无法阻塞主进程,docker服务也需要windows专业版运行完美,然后出现无法调用linux内核执行corntab定时任务等问题……虽然最好的解决办法是安装ubuntu虚拟机进行开发,或者直接换成mac电脑,但是我以我能折腾永不放弃的态度寻求各种解决方案。
WSL 是我解决这些问题的最大帮助,它的运行和启动速度都比虚拟机快。如果 WSL 能支持 docker daemon 那就更开心了……
配置环境:
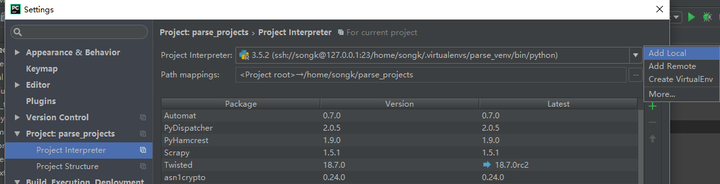
在Windows下使用pycharm专业版,使用pycharm的Remote Python Interpreter功能在WSL上调用解释器,再配合Deployment实现代码同步。这样做的目的是在Windows下编辑代码,调试,调用Linux环境,这样需要Linux内核支持的功能也能流畅使用
如果你打算直接在WSL上运行写好的代码,看看WSL如何在windows上调用chromedriver和chrome浏览器,那么配置pycharm的方法可以直接跳过,直接进行下面的操作。
配置方式:/pipisorry/article/details/52269952
需要注意的是,WSL与windows共享ip和port,所以需要更改WSL的ssh端口,vim /etc/ssh/sshd_config,把Port改成你想要的端口,我改成23, exit wsl 然后重新打开WSL,sudo service ssh start,前提是你已经安装了ssh,而且Pycharm中的配置端口也要改成你改的那个,我用的IP是127.0.0.1,避免因局域网IP变化而导致重复配置的问题。说明为什么需要修改端口号,因为windows上的ssh使用的是22端口,同时也使用了WSL,所以会有冲突。
配置后的图片:注意Path mappings,如果执行代码告诉你no such dir....,说明你的映射没有设置好,解释器和SFTP的映射应该设置正确。另外,运行代码前请确认代码已经同步,因为运行的代码其实就是WSL上的代码,可以设置代码自动同步或者保存时同步。
破坏行动:
正题开始,佩服我的脑洞,能想到这种操作……
首先,下载windows下的chromedriver.exe文件,放到windows下Python解释器安装目录下的scripts文件中。下载地址:
/mirrors/chromedriver 下载最新版本
下载最新的chrome浏览器,我的是64位的
我们开始检查效果,先确认两个软件都可以,测试方法:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="C:/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe")
driver.get("")
打印(driver.page_source)
driver.quit()
选择windows下的python解释器,运行上面的代码,看看浏览器是否调用成功,是否打印结果,是否正常退出,
正常情况下应该没问题的。
如果您使用Pycharm的远程功能将解释器替换为WSL上的解释器,请确认代码是否运行成功,并确保配置正常后再继续。
如果直接从 WSL 命令行启动程序,则直接继续。
执行代码:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="/mnt/c/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe") # mnt目录为文件共享目录, 子系统可以访问windows文件
driver.get("")
打印(driver.page_source)
driver.quit()
按理说应该是chrome调用成功了,一切正常。
最坏的情况应该是调用了chrome但是没有postscript,并且没有退出,那么请手动退出,请检查你的任务管理器,如果有名为chromedriver的进程请关闭,然后检查你的WSL,是否正常,是否有错误信息,如果有,请退出WSL。再次执行代码。我的一直正常。 查看全部
浏览器抓取网页(windows下的chrome浏览器(组图))
问题总结:
在WSL(windows子系统)上调用windows下的chromedriver和chrome浏览器进行自动化测试或爬取网页内容,运行成功。但是有个疑问,代码的运行环境是WSL->Linux,那么chromedriver.exe是在windows还是linux上执行的呢?如果是windows,为什么代码是在linux上执行的?如果exe在linux上执行,那么linux真的可以在windows exe上运行编译,即使是这样,chromedriver如何调用windows下的chrome浏览器……看来windows下运行的可能性更大,但是不符合代码运行环境,请指点!
前言:
在Linux环境下开发Python项目在情理之中,但我对windows情有独钟,所以主要使用windows进行开发。但是项目一般要在ubuntu等Linux服务器下运行,难免会遇到一些问题,比如multiprocessing.JoinableQueue在windows环境下无法阻塞主进程,docker服务也需要windows专业版运行完美,然后出现无法调用linux内核执行corntab定时任务等问题……虽然最好的解决办法是安装ubuntu虚拟机进行开发,或者直接换成mac电脑,但是我以我能折腾永不放弃的态度寻求各种解决方案。
WSL 是我解决这些问题的最大帮助,它的运行和启动速度都比虚拟机快。如果 WSL 能支持 docker daemon 那就更开心了……
配置环境:
在Windows下使用pycharm专业版,使用pycharm的Remote Python Interpreter功能在WSL上调用解释器,再配合Deployment实现代码同步。这样做的目的是在Windows下编辑代码,调试,调用Linux环境,这样需要Linux内核支持的功能也能流畅使用
如果你打算直接在WSL上运行写好的代码,看看WSL如何在windows上调用chromedriver和chrome浏览器,那么配置pycharm的方法可以直接跳过,直接进行下面的操作。
配置方式:/pipisorry/article/details/52269952
需要注意的是,WSL与windows共享ip和port,所以需要更改WSL的ssh端口,vim /etc/ssh/sshd_config,把Port改成你想要的端口,我改成23, exit wsl 然后重新打开WSL,sudo service ssh start,前提是你已经安装了ssh,而且Pycharm中的配置端口也要改成你改的那个,我用的IP是127.0.0.1,避免因局域网IP变化而导致重复配置的问题。说明为什么需要修改端口号,因为windows上的ssh使用的是22端口,同时也使用了WSL,所以会有冲突。
配置后的图片:注意Path mappings,如果执行代码告诉你no such dir....,说明你的映射没有设置好,解释器和SFTP的映射应该设置正确。另外,运行代码前请确认代码已经同步,因为运行的代码其实就是WSL上的代码,可以设置代码自动同步或者保存时同步。
破坏行动:
正题开始,佩服我的脑洞,能想到这种操作……
首先,下载windows下的chromedriver.exe文件,放到windows下Python解释器安装目录下的scripts文件中。下载地址:
/mirrors/chromedriver 下载最新版本

下载最新的chrome浏览器,我的是64位的
我们开始检查效果,先确认两个软件都可以,测试方法:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="C:/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe")
driver.get("")
打印(driver.page_source)
driver.quit()
选择windows下的python解释器,运行上面的代码,看看浏览器是否调用成功,是否打印结果,是否正常退出,
正常情况下应该没问题的。
如果您使用Pycharm的远程功能将解释器替换为WSL上的解释器,请确认代码是否运行成功,并确保配置正常后再继续。
如果直接从 WSL 命令行启动程序,则直接继续。
执行代码:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="/mnt/c/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe") # mnt目录为文件共享目录, 子系统可以访问windows文件
driver.get("")
打印(driver.page_source)
driver.quit()
按理说应该是chrome调用成功了,一切正常。
最坏的情况应该是调用了chrome但是没有postscript,并且没有退出,那么请手动退出,请检查你的任务管理器,如果有名为chromedriver的进程请关闭,然后检查你的WSL,是否正常,是否有错误信息,如果有,请退出WSL。再次执行代码。我的一直正常。
浏览器抓取网页(浏览器怎么查看浏览过的本地缓存Cookie和网站数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-13 04:19
浏览器如何查看我浏览的本地缓存的cookies和网站数据?当我们使用浏览器上网时,会产生一定的数据。
网页cookie查询方法如下:介绍一种在chrome浏览器中查看cookie的快捷方式:通过快捷键Ctrl+Shift+Delete,。
csdn为您找到了在手机浏览器上查看cookies的相关内容,包括代码介绍和手机浏览器上查看cookie相关文档的相关教程。
如何查看手机浏览器cookies?移动浏览器的 cookie 设置用于确定使用哪些解锁第三方 cookie 和 网站 数据6。 .
手机浏览器cookie查看的信息由阿里云开发者社区整理,为您提供页面跳转中cookie丢失及cname验证相关信息。
查看所有手机查看所有智能硬件线下体验店官方授权的在线商店我们会使用cookies等相关技术使这个网站正常运行,分析流量,优化您的浏览体验。继续浏览此 网站,即表示您同意使用这些 cookie。阅读更多。
为您提供最佳体验的 Cookie、网站流量分析和社交媒体功能。 Cookie 政策提供了有关我们如何使用 Cookie 的详细信息。点击“同意”即表示您同意我们使用 cookie,请参阅我们的隐私政策了解更多信息。 .
一个网站如何判断用户何时登录,将查询条件从前台传递到后台,存储在cookie中,并将查询添加到响应对象中。
手机如何获取浏览器的cookies?选择设置然后看到高级选项栏,选择网站设置,选择cookies进入查看。
在 cookie 选项中查看“所有 cookie 和 网站 数据”。找到你要查看的网站,然后根据key值查看cookie内容:. 查看全部
浏览器抓取网页(浏览器怎么查看浏览过的本地缓存Cookie和网站数据?)
浏览器如何查看我浏览的本地缓存的cookies和网站数据?当我们使用浏览器上网时,会产生一定的数据。
网页cookie查询方法如下:介绍一种在chrome浏览器中查看cookie的快捷方式:通过快捷键Ctrl+Shift+Delete,。
csdn为您找到了在手机浏览器上查看cookies的相关内容,包括代码介绍和手机浏览器上查看cookie相关文档的相关教程。
如何查看手机浏览器cookies?移动浏览器的 cookie 设置用于确定使用哪些解锁第三方 cookie 和 网站 数据6。 .
手机浏览器cookie查看的信息由阿里云开发者社区整理,为您提供页面跳转中cookie丢失及cname验证相关信息。

查看所有手机查看所有智能硬件线下体验店官方授权的在线商店我们会使用cookies等相关技术使这个网站正常运行,分析流量,优化您的浏览体验。继续浏览此 网站,即表示您同意使用这些 cookie。阅读更多。
为您提供最佳体验的 Cookie、网站流量分析和社交媒体功能。 Cookie 政策提供了有关我们如何使用 Cookie 的详细信息。点击“同意”即表示您同意我们使用 cookie,请参阅我们的隐私政策了解更多信息。 .

一个网站如何判断用户何时登录,将查询条件从前台传递到后台,存储在cookie中,并将查询添加到响应对象中。
手机如何获取浏览器的cookies?选择设置然后看到高级选项栏,选择网站设置,选择cookies进入查看。
在 cookie 选项中查看“所有 cookie 和 网站 数据”。找到你要查看的网站,然后根据key值查看cookie内容:.
浏览器抓取网页(网页信息的批量分析与抓取,感觉还是有一些体会的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-13 03:31
最近在研究网页信息的批量分析和爬取,还是有一些经验的。
我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只需使用带有网站地址和正则表达式的MSHTML,就可以远程抓取网页连接、内容等信息。好像在网上看一些文章,搜索引擎的基本功能都可以这样实现。最近还看到了一个Zpoo漫游网的例子(),他们可以抓取163相册的图片地址(本来有一个可以批量下载163相册的工具,但是163改版后,无法使用)。但是,以上一切都必须基于一个前提,即网页不需要认证,不需要用户名和密码。.net中的net库中有一些类为webclient、webrequest等提供http访问服务,但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能我没用过对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。
但是既然浏览器端可以访问,我们就有办法了。所以我想到了webbrowser控件。大致思路是先用webbrowser连接网页(登录验证问题可以在webbrowser中解决),解压连接后,继续请求相同网站的其他页面,验证通过由网页浏览器完成,以便批量提取。至于在线抓包,还是先下载数据再抓包。有区别。今天就写到这里,下次继续。 查看全部
浏览器抓取网页(网页信息的批量分析与抓取,感觉还是有一些体会的)
最近在研究网页信息的批量分析和爬取,还是有一些经验的。
我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只需使用带有网站地址和正则表达式的MSHTML,就可以远程抓取网页连接、内容等信息。好像在网上看一些文章,搜索引擎的基本功能都可以这样实现。最近还看到了一个Zpoo漫游网的例子(),他们可以抓取163相册的图片地址(本来有一个可以批量下载163相册的工具,但是163改版后,无法使用)。但是,以上一切都必须基于一个前提,即网页不需要认证,不需要用户名和密码。.net中的net库中有一些类为webclient、webrequest等提供http访问服务,但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能我没用过对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。
但是既然浏览器端可以访问,我们就有办法了。所以我想到了webbrowser控件。大致思路是先用webbrowser连接网页(登录验证问题可以在webbrowser中解决),解压连接后,继续请求相同网站的其他页面,验证通过由网页浏览器完成,以便批量提取。至于在线抓包,还是先下载数据再抓包。有区别。今天就写到这里,下次继续。
浏览器抓取网页( 谷歌浏览器驱动获取网页节点的方法和常用方法表 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-12 03:21
谷歌浏览器驱动获取网页节点的方法和常用方法表
)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build)(x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如下图:
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件路径相同)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
提取的编著信息如下:
明日科技 著
提取的价格信息如下:
京 东 价
¥ 72.00 [9.03折] [定价 ¥79.80]
selenium 模块常用方法 selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
明日科技 著
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
https://book.jd.com/writer/%25 ... .html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
1. driver.close():关闭当前页面
2. driver.quit():退出整个浏览器 查看全部
浏览器抓取网页(
谷歌浏览器驱动获取网页节点的方法和常用方法表
)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build)(x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如下图:
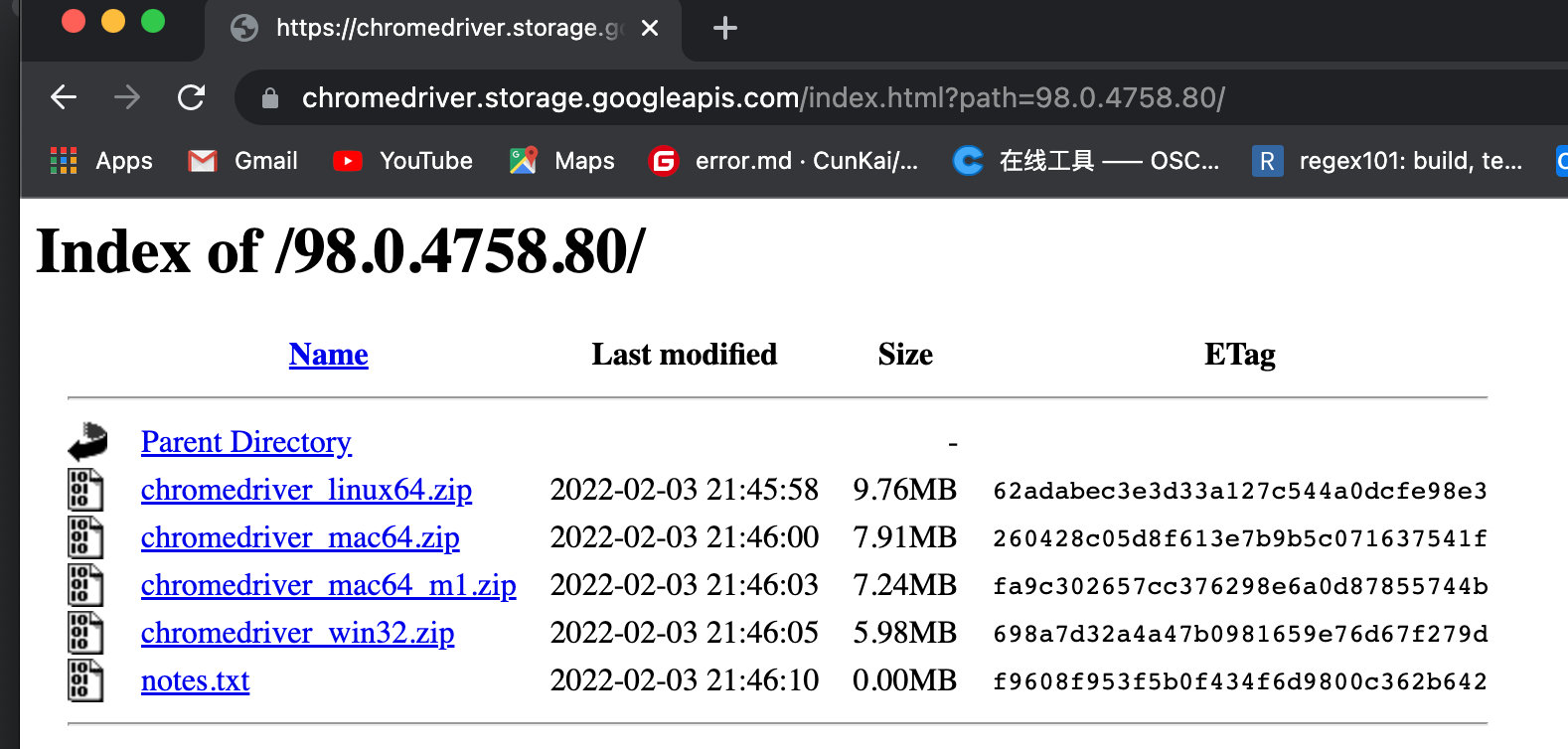
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件路径相同)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
提取的编著信息如下:
明日科技 著
提取的价格信息如下:
京 东 价
¥ 72.00 [9.03折] [定价 ¥79.80]
selenium 模块常用方法 selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
明日科技 著
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
https://book.jd.com/writer/%25 ... .html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
1. driver.close():关闭当前页面
2. driver.quit():退出整个浏览器
浏览器抓取网页(网页默认运行IE需手动查看路径,对于身边被一键操作惯坏 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-12 03:20
)
一般情况下,bat默认打开一个网页,运行IE。如果要调用其他浏览器,在线的方法是:
start "C:\Program Files\Maxthon\Bin\Maxthon.exe" "www.baidu.com"
不过浏览器因人而异,需要手动查看路径。对于被一键操作宠坏,说什么都说“听不懂”的朋友,需要帮助他们进行网页操作。
最好是读取注册表来实现,步骤如下:
注册表“HKEY_CLASSES_ROOT\http\shell\open\command”有默认浏览器路径,如图
查看关于reg的命令说明就知道可以使用QUERY命令查询注册表键值
尝试输入“reg query HKEY_CLASSES_ROOT\http\shell\open\command”并获取:
至此,for循环加条件读取变量,这里用tokens:默认用空格隔开
根据查询结果,第3列+第4列=浏览器路径(C:\Program + Files\Maxthon\Bin\Maxthon.exe)
¤ 由于空格是分隔符,所以需要自己填充
完整代码:
@echo off
for /f "tokens=3,4" %%a in ('"reg query HKEY_CLASSES_ROOT\http\shell\open\command"') do (set SoftWareRoot=%%a %%b)
::输入地址
set /p url=Enter url:
::打开网页,之后进行后续操作
start % SoftWareRoot % %url% 查看全部
浏览器抓取网页(网页默认运行IE需手动查看路径,对于身边被一键操作惯坏
)
一般情况下,bat默认打开一个网页,运行IE。如果要调用其他浏览器,在线的方法是:
start "C:\Program Files\Maxthon\Bin\Maxthon.exe" "www.baidu.com"
不过浏览器因人而异,需要手动查看路径。对于被一键操作宠坏,说什么都说“听不懂”的朋友,需要帮助他们进行网页操作。
最好是读取注册表来实现,步骤如下:
注册表“HKEY_CLASSES_ROOT\http\shell\open\command”有默认浏览器路径,如图

查看关于reg的命令说明就知道可以使用QUERY命令查询注册表键值

尝试输入“reg query HKEY_CLASSES_ROOT\http\shell\open\command”并获取:

至此,for循环加条件读取变量,这里用tokens:默认用空格隔开
根据查询结果,第3列+第4列=浏览器路径(C:\Program + Files\Maxthon\Bin\Maxthon.exe)
¤ 由于空格是分隔符,所以需要自己填充
完整代码:
@echo off
for /f "tokens=3,4" %%a in ('"reg query HKEY_CLASSES_ROOT\http\shell\open\command"') do (set SoftWareRoot=%%a %%b)
::输入地址
set /p url=Enter url:
::打开网页,之后进行后续操作
start % SoftWareRoot % %url%
浏览器抓取网页( 零基础快速入门的学习路径——先说一下技术能干什么事儿 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2022-02-11 21:07
零基础快速入门的学习路径——先说一下技术能干什么事儿
)
我不会谈论爬行动物目前的流行程度。先说一下这个技术能做什么,主要有以下三个方面:
1.为市场研究和业务分析抓取数据
爬取知乎、豆瓣等优质话题内容网站;掌握房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析;抓取招聘网站职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
在游戏中抓取精美图片,获取图片资源和评论文字数据。
掌握正确的方法,在短时间内爬取主流的网站数据其实很容易。
但是,建议您从一开始就有一个特定的目标。在目标的驱动下,你的学习会更加准确和高效。下面是一个流畅的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2.实现简单的信息爬取
3.特殊网站反爬虫措施
4.Scrapy 和高级分布式
01 了解爬虫是如何实现的
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单的了解HTTP协议和网页的基础知识,如POST\GET、HTML、CSS、JS等,通俗易懂,不需要系统学习。
02 实现简单的信息爬取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路大同小异,一般的静态网站完全没问题,还有知乎、豆瓣等公开信息网站@ > 可以爬下来。
当然,如果需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium自动爬取。这样一来,知乎、Mtime和TripAdvisor等动态爬虫网站几乎没有问题。
你还需要了解Python的基础知识,比如:文件读写操作:用于读取参数、保存爬取内容列表(list)、dict(字典):用于序列化爬取数据条件判断(if/else):解决爬虫中判断是否执行循环和迭代(for...while):用于循环爬虫步骤
03 特殊网站的防爬机制
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬方式,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析网页加载信息,经常会得到意想不到的结果。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
04 Scrapy和高级分布式
使用requests+xpath和抓包确实可以解决很多网站信息的爬取,但是如果信息量比较大或者需要分模块爬取的话,就很难做任何事情了。
后来应用到强大的Scrapy框架中,不仅可以轻松构造Request,还可以通过强大的Selector轻松解析Response。不过,最让人惊喜的是它的超高性能,可以对爬虫进行工程化和模块化。
我学习了 Scrapy,并尝试自己构建一个简单的爬虫框架。在做大规模数据爬虫的时候,我可以用结构化、工程化的方式去思考大规模的爬虫问题,这让我可以从爬虫工程的角度去思考问题。
后来,我开始逐渐接触到分布式爬虫。这个东西听起来很虚张声势,但其实它利用多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个之后,基本上可以说自己是个爬虫老司机了。这对于外行来说很难,但并不那么复杂。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,可以保证每次学习都是零件这是最需要的。
当然,唯一麻烦的是,在具体问题中,如何找到具体需要的部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径外,我们精选了最实用的学习资源和庞大的主流爬虫案例库。经过短暂的学习,你就能很好地掌握爬虫技巧,得到你想要的数据。
扫描上方二维码立即购买
限时特价99元,每100人买10元
课程大纲
高效的学习路径
从一开始就讲理论、语法和编程语言是非常不合理的。我们将直接从具体案例入手,通过实际操作学习具体知识点。我们为您规划了系统的学习路径,让您不再面对零散的知识点。
例如,我们会直接教你网页解析,减少你检查网页元素的不必要操作。这些看似细节,但可能是很多人会踩的坑。
20+实际案例学习实践
- 案例多,覆盖主流网站 -
课程中提供了最常见的网站爬虫案例:豆瓣、知乎、瓜子二手车、赶集网、链家网、王者荣耀……每个案例都在课程视频。老师带你走遍每一步操作,专攻各种“懂案例,但不会写代码”。
项目一:赶集网络实战项目
学习使用正则表达式从整个网页中提取数据。
项目二:王者荣耀之战项目
1、破解王者荣耀高清壁纸下载链接。
2、使用多线程高速下载高清壁纸。
3、根据英雄名称存放对应的壁纸。
项目三:链家网分布式爬虫
1、使用Scrapy框架实现商业爬虫。
2、使用多台机器实现分布式爬虫。
3、实现全国各省市二手房信息的爬取。
4、将爬取的数据存储在redis中。
导师
黄勇先生
黄先生拥有多年实际开发经验,擅长Python、C、C++、前端、iOS等技术语言,先后开发了多家大型企业网站与Python,并从零开始构建分布式爬虫架构。目前专注于Python领域的课程开发和教学,曾为网易、360、华为等多家大公司的员工提供Python技术培训,具有丰富的实践和教学经验。
【课程信息】
“ 课程名称”
《从零开始,系统掌握Python网络爬虫》
“学习周期”
建议每周至少学习8小时,并在一个月内完成课程
“课堂形式”
课程录播,随时开课,反复观看
“为了群众”
零基础的新手,还是基础薄弱的工程师
《问答表》
学习小组老师随时回答问题,即使是最基本的问题
#限量优惠#
限99元
(原价599)
每100个购买10元
140多门课程,平均每门课1元,坚持一个月,系统掌握Python进阶
查看全部
浏览器抓取网页(
零基础快速入门的学习路径——先说一下技术能干什么事儿
)
我不会谈论爬行动物目前的流行程度。先说一下这个技术能做什么,主要有以下三个方面:
1.为市场研究和业务分析抓取数据
爬取知乎、豆瓣等优质话题内容网站;掌握房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析;抓取招聘网站职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
在游戏中抓取精美图片,获取图片资源和评论文字数据。
掌握正确的方法,在短时间内爬取主流的网站数据其实很容易。
但是,建议您从一开始就有一个特定的目标。在目标的驱动下,你的学习会更加准确和高效。下面是一个流畅的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2.实现简单的信息爬取
3.特殊网站反爬虫措施
4.Scrapy 和高级分布式
01 了解爬虫是如何实现的
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单的了解HTTP协议和网页的基础知识,如POST\GET、HTML、CSS、JS等,通俗易懂,不需要系统学习。
02 实现简单的信息爬取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路大同小异,一般的静态网站完全没问题,还有知乎、豆瓣等公开信息网站@ > 可以爬下来。
当然,如果需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium自动爬取。这样一来,知乎、Mtime和TripAdvisor等动态爬虫网站几乎没有问题。
你还需要了解Python的基础知识,比如:文件读写操作:用于读取参数、保存爬取内容列表(list)、dict(字典):用于序列化爬取数据条件判断(if/else):解决爬虫中判断是否执行循环和迭代(for...while):用于循环爬虫步骤
03 特殊网站的防爬机制
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬方式,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析网页加载信息,经常会得到意想不到的结果。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
04 Scrapy和高级分布式
使用requests+xpath和抓包确实可以解决很多网站信息的爬取,但是如果信息量比较大或者需要分模块爬取的话,就很难做任何事情了。
后来应用到强大的Scrapy框架中,不仅可以轻松构造Request,还可以通过强大的Selector轻松解析Response。不过,最让人惊喜的是它的超高性能,可以对爬虫进行工程化和模块化。
我学习了 Scrapy,并尝试自己构建一个简单的爬虫框架。在做大规模数据爬虫的时候,我可以用结构化、工程化的方式去思考大规模的爬虫问题,这让我可以从爬虫工程的角度去思考问题。
后来,我开始逐渐接触到分布式爬虫。这个东西听起来很虚张声势,但其实它利用多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个之后,基本上可以说自己是个爬虫老司机了。这对于外行来说很难,但并不那么复杂。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,可以保证每次学习都是零件这是最需要的。
当然,唯一麻烦的是,在具体问题中,如何找到具体需要的部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径外,我们精选了最实用的学习资源和庞大的主流爬虫案例库。经过短暂的学习,你就能很好地掌握爬虫技巧,得到你想要的数据。
扫描上方二维码立即购买
限时特价99元,每100人买10元
课程大纲
高效的学习路径
从一开始就讲理论、语法和编程语言是非常不合理的。我们将直接从具体案例入手,通过实际操作学习具体知识点。我们为您规划了系统的学习路径,让您不再面对零散的知识点。
例如,我们会直接教你网页解析,减少你检查网页元素的不必要操作。这些看似细节,但可能是很多人会踩的坑。
20+实际案例学习实践
- 案例多,覆盖主流网站 -
课程中提供了最常见的网站爬虫案例:豆瓣、知乎、瓜子二手车、赶集网、链家网、王者荣耀……每个案例都在课程视频。老师带你走遍每一步操作,专攻各种“懂案例,但不会写代码”。
项目一:赶集网络实战项目
学习使用正则表达式从整个网页中提取数据。
项目二:王者荣耀之战项目
1、破解王者荣耀高清壁纸下载链接。
2、使用多线程高速下载高清壁纸。
3、根据英雄名称存放对应的壁纸。
项目三:链家网分布式爬虫
1、使用Scrapy框架实现商业爬虫。
2、使用多台机器实现分布式爬虫。
3、实现全国各省市二手房信息的爬取。
4、将爬取的数据存储在redis中。
导师
黄勇先生
黄先生拥有多年实际开发经验,擅长Python、C、C++、前端、iOS等技术语言,先后开发了多家大型企业网站与Python,并从零开始构建分布式爬虫架构。目前专注于Python领域的课程开发和教学,曾为网易、360、华为等多家大公司的员工提供Python技术培训,具有丰富的实践和教学经验。
【课程信息】
“ 课程名称”
《从零开始,系统掌握Python网络爬虫》
“学习周期”
建议每周至少学习8小时,并在一个月内完成课程
“课堂形式”
课程录播,随时开课,反复观看
“为了群众”
零基础的新手,还是基础薄弱的工程师
《问答表》
学习小组老师随时回答问题,即使是最基本的问题
#限量优惠#
限99元
(原价599)
每100个购买10元
140多门课程,平均每门课1元,坚持一个月,系统掌握Python进阶
浏览器抓取网页(来说一下如何获取浏览器相关的信息,获取元素的标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-11 02:19
上一节讲了如何使用获取到的元素来获取元素信息。这次来说说如何获取浏览器相关信息,主要是页面的路径:URL和页面标题
一、如何获取页面相关信息
current_url : 当前页面的 URL 路径
title:当前页面的标题名称
名称:当前浏览器名称
page_source:当前html页面的源代码
前两个比较常用,可能会用到,比如url是用来判断页面跳转后的;页面标题也是检测的一个测试点。
接下来,我们将使用百度贴吧页面来演示这些常用方法
二、演示示例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://tieba.baidu.com/")
# 获取当前页面的URL
url_page = driver.current_url
# 获取当前页面的title
title_page = driver.title
# 获取当前浏览器的名称
name_browser = driver.name
# 获取当前页面的html源码
source_html = driver.page_source
print(url_page)
print(title_page)
print(name_browser)
print(source_html)
三、结果
/
百度贴吧——全球最大的华人社区
铬合金 查看全部
浏览器抓取网页(来说一下如何获取浏览器相关的信息,获取元素的标题)
上一节讲了如何使用获取到的元素来获取元素信息。这次来说说如何获取浏览器相关信息,主要是页面的路径:URL和页面标题
一、如何获取页面相关信息
current_url : 当前页面的 URL 路径
title:当前页面的标题名称
名称:当前浏览器名称
page_source:当前html页面的源代码
前两个比较常用,可能会用到,比如url是用来判断页面跳转后的;页面标题也是检测的一个测试点。
接下来,我们将使用百度贴吧页面来演示这些常用方法
二、演示示例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://tieba.baidu.com/";)
# 获取当前页面的URL
url_page = driver.current_url
# 获取当前页面的title
title_page = driver.title
# 获取当前浏览器的名称
name_browser = driver.name
# 获取当前页面的html源码
source_html = driver.page_source
print(url_page)
print(title_page)
print(name_browser)
print(source_html)
三、结果
/
百度贴吧——全球最大的华人社区
铬合金
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-10 18:28
无论是平时工作中,还是休闲生活中,我们都会遇到需要截图的情况。因为有些东西说不出来,直接截图简单明了,很直观。在使用手机的时候,我们都知道怎么截图,在使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器进行截图时,我们往往只能对当前屏幕上显示的内容进行截图。如果我们想对这个网页上的所有内容进行截图,我们的大多数朋友一定不知道怎么做。操作,今天小编就教大家如何使用QQ浏览器对整个网页进行截图,这样就可以实现手机滚动截图一样的方式,截图页面中的所有内容。具体方法如下:
第一步,打开电脑上的QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按下键盘上的F12键,调出浏览器的开发者工具。Windows 计算机也可以通过按快捷键组合 Ctrl+Shift+I 来执行此操作,而 Mac 计算机可以通过按快捷键组合 Alt+Command+I 来执行此操作。
第四步,在浏览器的开发者工具中,我们通过按Ctrl+Shift+P(Windows)或Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行中输入“screen”。这时候,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的意思,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的全部内容并进行截图,请选择 Capture full size screenshot。
如果我们想获取元素节点网页的内容并截图,选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器截图的内容。如果你经常一张一张的截图网页,那么不妨学习一下这篇文章中提到的技巧,这样以后就算有人让你发整个网页的截图,你也可以在五个简单的步骤。不用下拉屏幕截图,也不用担心下拉再截图。一键捕获所有内容更容易,更方便。 查看全部
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
无论是平时工作中,还是休闲生活中,我们都会遇到需要截图的情况。因为有些东西说不出来,直接截图简单明了,很直观。在使用手机的时候,我们都知道怎么截图,在使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器进行截图时,我们往往只能对当前屏幕上显示的内容进行截图。如果我们想对这个网页上的所有内容进行截图,我们的大多数朋友一定不知道怎么做。操作,今天小编就教大家如何使用QQ浏览器对整个网页进行截图,这样就可以实现手机滚动截图一样的方式,截图页面中的所有内容。具体方法如下:
第一步,打开电脑上的QQ浏览器。

第二步,进入QQ浏览器界面后,打开需要截图的网页。

第三步,网页内容全部加载完毕后,我们在浏览器当前界面按下键盘上的F12键,调出浏览器的开发者工具。Windows 计算机也可以通过按快捷键组合 Ctrl+Shift+I 来执行此操作,而 Mac 计算机可以通过按快捷键组合 Alt+Command+I 来执行此操作。

第四步,在浏览器的开发者工具中,我们通过按Ctrl+Shift+P(Windows)或Command+Shift+P(Mac)快捷键组合打开命令行。

第五步,浏览器的命令行打开后,我们在命令行中输入“screen”。这时候,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的意思,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。

如果我们想获取整个网页的全部内容并进行截图,请选择 Capture full size screenshot。

如果我们想获取元素节点网页的内容并截图,选择Capture node screenshot。

如果我们想获取当前屏幕的内容并进行截图,选择Capture screenshot。

以上就是小编为大家总结的关于使用QQ浏览器截图的内容。如果你经常一张一张的截图网页,那么不妨学习一下这篇文章中提到的技巧,这样以后就算有人让你发整个网页的截图,你也可以在五个简单的步骤。不用下拉屏幕截图,也不用担心下拉再截图。一键捕获所有内容更容易,更方便。
浏览器抓取网页( 零基础学Python(Python3.exe)下载驱动下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-10 17:19
零基础学Python(Python3.exe)下载驱动下载)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build) (x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如图以下:
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件同级路径)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
提取的创作信息如下:
明天的技术
提取的价格信息如下:
京东价格
¥72.00 [9.03% off] [价格¥79.80]
selenium模块的常用方法
selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
明天的技术
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80_1.html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
driver.close():关闭当前页面
driver.quit():退出整个浏览器
这是文章关于使用selenium+chromedriver+xpath爬取动态加载信息的介绍。更多相关selenium chromedriver xpath爬取内容,请搜索编程宝库往期文章,希望以后支持编程宝库!
下一节:pycharm如何为函数插入文档注释 Python编程技术
S1 将光标放在功能名称上,点击灯泡,出现菜单。S2 选择输入文档字符串存根,它插入文档注释。S3对每个参数的输入函数注解,返回值注解pycha... 查看全部
浏览器抓取网页(
零基础学Python(Python3.exe)下载驱动下载)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:

操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build) (x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如图以下:

操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件同级路径)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
提取的创作信息如下:
明天的技术
提取的价格信息如下:
京东价格
¥72.00 [9.03% off] [价格¥79.80]
selenium模块的常用方法
selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
明天的技术
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80_1.html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
driver.close():关闭当前页面
driver.quit():退出整个浏览器
这是文章关于使用selenium+chromedriver+xpath爬取动态加载信息的介绍。更多相关selenium chromedriver xpath爬取内容,请搜索编程宝库往期文章,希望以后支持编程宝库!
下一节:pycharm如何为函数插入文档注释 Python编程技术
S1 将光标放在功能名称上,点击灯泡,出现菜单。S2 选择输入文档字符串存根,它插入文档注释。S3对每个参数的输入函数注解,返回值注解pycha...
浏览器抓取网页(获取浏览器窗口的基本信息获取当前窗口网页标题title)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-10 10:26
一、获取浏览器窗口的基本信息1.获取当前窗口的网页标题
title 属性用于获取当前窗口网页的标题
2.获取当前窗口网页url
current_url 属性用于获取当前窗口网页的url
3.获取当前窗口句柄
current_window_handle 属性用于获取当前窗口的句柄,句柄是窗口的标识符,可用于窗口切换
4.获取所有当前打开窗口的句柄
window_handles 属性用于获取浏览器打开的所有窗口的句柄列表
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5# 预设js代码,打开搜狗网
6js = 'window.open("https://www.sogou.com");'
7# 执行js代码(具体会在下章介绍)
8driver.execute_script(js)
9# 获取当前窗口网页url
10print(driver.current_url)
11# 获取浏览器所有窗口句柄
12print(driver.window_handles)
13# 获取当前窗口句柄
14print(driver.current_window_handle)
15# 获取当前网页的标题
16print(driver.title)
17
18
19
测试输出:
1https://www.baidu.com/
2['CDwindow-00EE4D00ED151A77C5A293867FC4005F', 'CDwindow-C1AFC2E0142E307E78DDDF0625A556EE']
3CDwindow-00EE4D00ED151A77C5A293867FC4005F
4百度一下,你就知道
5
6
二、浏览器打开多个网页时切换窗口
当我们有多个网页窗口时,需要先获取所有的窗口句柄,然后使用switch_to.window(handle)函数来切换窗口。句柄是您要跳转到的窗口的句柄。
**注意:** WebDriver 对象中的 switch_to_window() 方法已被弃用,应使用 switch_to.window(handle) 方法
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5# 打开新窗口搜狗网
6js = 'window.open("https://www.sogou.com");'
7driver.execute_script(js)
8# 获取浏览器所有窗口句柄
9handles = driver.window_handles
10print(handles)
11print("当前网页为:%s" % driver.title)
12# 跳转至第二个窗口,即搜狗网
13driver.switch_to.window(handles[1])
14print("当前网页为:%s" % driver.title)
15
16
输出结果:
1['CDwindow-CB98BE007FA7A8004A9FE60D1AD9F621', 'CDwindow-27928387C7A61447B9BF2FF3AAEF6E49']
2当前网页为:百度一下,你就知道
3当前网页为:搜狗搜索引擎 - 上网从搜狗开始
4
5
三、操作窗口前进、后退、关闭操作1.返回
back() 方法是操作窗口返回一个网页,相当于点击浏览器的返回按钮
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com")
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10
11
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4
5
2.前进
forward() 方法是操作窗口前进一个网页,相当于一个浏览器的前进按钮有一个年龄
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com")
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10driver.forward()
11print("前进,当前窗口:%s" % driver.title)
12
13
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4前进,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
5
6
3.关闭
close() 方法关闭当前窗口
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5# 运行js打开新窗口
6js = 'window.open("https://www.sogou.com")'
7driver.execute_script(js)
8# 打印窗口个数,为2个
9print("关闭窗口前:%s" % driver.window_handles)
10# 关闭当前窗口
11driver.close()
12# 打印窗口个数,为1个
13print("关闭窗口后:%s" % driver.window_handles)
14
15
检测结果:
selenium 运行 js 代码打开新窗口后,如果不执行窗口切换功能,当前窗口仍然是第一个窗口,而不是新打开的窗口。因此,上述示例代码中关闭了百度窗口。
1关闭窗口前:['CDwindow-6176BE40CAE4EEDCEB6171B263C143F3', 'CDwindow-54B78A28638EF41125901E6774936E9A']
2关闭窗口后:['CDwindow-54B78A28638EF41125901E6774936E9A']
3
4
四、切换帧
网页中会有收录子模块的标签。当我们打印源代码时,只会出现主模块的代码,不会出现标签中收录的子网页的源代码。如果我们想获取子模块的代码,可以使用switch_to.frame()方法来切换frame模块。 查看全部
浏览器抓取网页(获取浏览器窗口的基本信息获取当前窗口网页标题title)
一、获取浏览器窗口的基本信息1.获取当前窗口的网页标题
title 属性用于获取当前窗口网页的标题
2.获取当前窗口网页url
current_url 属性用于获取当前窗口网页的url
3.获取当前窗口句柄
current_window_handle 属性用于获取当前窗口的句柄,句柄是窗口的标识符,可用于窗口切换
4.获取所有当前打开窗口的句柄
window_handles 属性用于获取浏览器打开的所有窗口的句柄列表
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5# 预设js代码,打开搜狗网
6js = 'window.open("https://www.sogou.com";);'
7# 执行js代码(具体会在下章介绍)
8driver.execute_script(js)
9# 获取当前窗口网页url
10print(driver.current_url)
11# 获取浏览器所有窗口句柄
12print(driver.window_handles)
13# 获取当前窗口句柄
14print(driver.current_window_handle)
15# 获取当前网页的标题
16print(driver.title)
17
18
19
测试输出:
1https://www.baidu.com/
2['CDwindow-00EE4D00ED151A77C5A293867FC4005F', 'CDwindow-C1AFC2E0142E307E78DDDF0625A556EE']
3CDwindow-00EE4D00ED151A77C5A293867FC4005F
4百度一下,你就知道
5
6
二、浏览器打开多个网页时切换窗口
当我们有多个网页窗口时,需要先获取所有的窗口句柄,然后使用switch_to.window(handle)函数来切换窗口。句柄是您要跳转到的窗口的句柄。
**注意:** WebDriver 对象中的 switch_to_window() 方法已被弃用,应使用 switch_to.window(handle) 方法
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5# 打开新窗口搜狗网
6js = 'window.open("https://www.sogou.com";);'
7driver.execute_script(js)
8# 获取浏览器所有窗口句柄
9handles = driver.window_handles
10print(handles)
11print("当前网页为:%s" % driver.title)
12# 跳转至第二个窗口,即搜狗网
13driver.switch_to.window(handles[1])
14print("当前网页为:%s" % driver.title)
15
16
输出结果:
1['CDwindow-CB98BE007FA7A8004A9FE60D1AD9F621', 'CDwindow-27928387C7A61447B9BF2FF3AAEF6E49']
2当前网页为:百度一下,你就知道
3当前网页为:搜狗搜索引擎 - 上网从搜狗开始
4
5
三、操作窗口前进、后退、关闭操作1.返回
back() 方法是操作窗口返回一个网页,相当于点击浏览器的返回按钮
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com";)
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10
11
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4
5
2.前进
forward() 方法是操作窗口前进一个网页,相当于一个浏览器的前进按钮有一个年龄
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com";)
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10driver.forward()
11print("前进,当前窗口:%s" % driver.title)
12
13
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4前进,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
5
6
3.关闭
close() 方法关闭当前窗口
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5# 运行js打开新窗口
6js = 'window.open("https://www.sogou.com";)'
7driver.execute_script(js)
8# 打印窗口个数,为2个
9print("关闭窗口前:%s" % driver.window_handles)
10# 关闭当前窗口
11driver.close()
12# 打印窗口个数,为1个
13print("关闭窗口后:%s" % driver.window_handles)
14
15
检测结果:
selenium 运行 js 代码打开新窗口后,如果不执行窗口切换功能,当前窗口仍然是第一个窗口,而不是新打开的窗口。因此,上述示例代码中关闭了百度窗口。
1关闭窗口前:['CDwindow-6176BE40CAE4EEDCEB6171B263C143F3', 'CDwindow-54B78A28638EF41125901E6774936E9A']
2关闭窗口后:['CDwindow-54B78A28638EF41125901E6774936E9A']
3
4
四、切换帧
网页中会有收录子模块的标签。当我们打印源代码时,只会出现主模块的代码,不会出现标签中收录的子网页的源代码。如果我们想获取子模块的代码,可以使用switch_to.frame()方法来切换frame模块。
浏览器抓取网页(一个HTTP请求报文的Content-Type网络进程会影响后续流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-24 13:16
HTTP 请求消息由四部分组成:请求行、请求头、空行和请求实体。浏览器端开始构造请求行、请求头和请求体等信息,将浏览器的一些基本信息和cookie等信息添加到请求头中,然后将构造好的请求消息发送给服务器。
(5)服务器处理请求并返回数据
服务器收到请求消息后,会根据消息信息生成响应头、响应行、响应体等数据。网络进程收到响应头和响应行后,就可以解析响应头的内容了。网络进程解析响应头信息后,会转发给浏览器进程进行处理。
影响后续流程的两条信息:
响应行中的 301/302 状态代码执行重定向
在解析响应头的时候,还需要注意一个重定向操作:如果响应行信息是301/302,则表示需要重定向到另一个URL地址。这时,网络进程会从响应头中读取位置字段。值并重新发起 http/https 请求。
响应标头中的 Content-Type
网络进程会首先根据响应头中的 Content-Type 字段判断服务器返回什么类型的资源文件,因为不同的资源类型对浏览器的处理方式不同:
(6)断开连接:TCP 挥手四次
核心思想:TCP为什么需要四次挥手?原因是:释放连接是释放客户端到服务器和服务器到客户端的双向连接。具体来说就是确认客户端和服务端的发送和接收功能都关闭了;
3. 准备渲染进程4. 提交文档 当浏览器进程收到网络进程的响应头数据时,向渲染进程发送“提交文档”消息;渲染进程收到“提交文档”消息后,会与网络进程建立“管道”传输数据;文档数据传输完成后,渲染进程会向浏览器进程返回“确认提交”消息;浏览器进程收到消息后,开始更新页面状态,包括安全状态、地址栏URL、前进后退历史状态、更新网页等。
5. 浏览器解析并渲染页面
一旦文档被确认提交,渲染过程就开始解析资源并渲染页面。注意浏览器的渲染页面并不是等所有资源加载完毕才开始渲染,而是边解析边渲染,这也是为什么有些页面会先将文本呈现给用户,然后再加载图片等资源之后。
详细渲染过程见第4点
四、浏览器是如何工作的?
以chrome浏览器为例
浏览器的结构大致可以分为:用户界面、浏览器引擎、渲染引擎
4.1 不同的浏览器内核
IE:三叉戟
火狐:壁虎
Safari:Webkit
Chrome/Opera/Edge:基于 Webkit 改造的 Blink
4.2 浏览器的多进程结构
今天的浏览器是多进程结构,而早期的浏览器是单进程结构
早期浏览器单进程结构:
单进程结构提出了许多问题:
不稳定:其中一个线程卡住可能会导致整个进程出现问题。例如,如果您打开多个选项卡,其中一个卡住的选项卡可能会导致浏览器无法运行。不安全:数据可以在浏览器之间共享,那么js可以自由访问浏览器中的所有数据进程不流畅:一个进程需要负责的事情太多,导致效率低下
因此,当今的浏览器选择了多进程结构。根据不同的进程功能,浏览器可以分为:
4.3 chrome的4个进程模型
Chrome 共有 4 种进程模型,不同的进程模式对 tab 进程的处理方式不同。
4.4 在浏览器地址栏中输入内容时,浏览器内部会发生什么?(详细请看三) 1.用户输入URL阶段+DNS+请求数据+处理返回数据
当我在地址栏中输入内容时,浏览器进程的UI线程会捕获我输入的内容,如果输入了URL,UI线程会启动一个网络线程(这是在浏览器进程中,而不是网络进程,网络过程 当你发起http请求请求DNS进行域名解析,然后开始连接服务器获取数据,如果输入关键词,浏览器就知道你要使用搜索功能,所以它将使用默认配置的搜索引擎进行查询;
网络线程获取到数据后,会通过Safe Browsing(Google内部的一个站点安全系统,通过检测站点数据来判断是否安全)检查该站点是否为恶意站点,如果是,则发出警告页面会提示。告诉我这个站点存在安全问题,浏览器会阻止我访问,但我可以强制它继续。当返回的数据准备好并且安全检查通过时,网络线程会通知UI线程我准备好了,轮到你了。
2. 渲染页面阶段
然后UI线程会创建一个渲染器进程来渲染页面,浏览器进程将数据通过IPC管道传递给渲染器进程,进入渲染进程。渲染器进程接收数据(html(通常收录 css、js 和图像资源))。
渲染器进程的核心任务:将html、js、css、image等资源渲染成用户可以交互的网页。渲染器进程的主线程解析html并构造DOM结构。
HTML首先通过Tokeniser进行token化,输入的html内容通过词法分析解析成多个标签,根据识别出的标签进行DOM树的构建。在DOM树的创建过程中,会创建一个document对象,然后会创建一个以document为根节点的文档。DOM 树。
需要注意的是,html代码中经常会引入一些额外的资源,比如js、css、图片等。图片、CSS等资源需要从网络下载或者直接从缓存中加载。这些资源不会阻塞 html 的解析,因为它们不会影响 DOM 的生成。当解析过程中遇到脚本标签时,会停止对html的解析。,然后加载、解析并执行js,因为js可能会改变当前页面的html结构,有可能在js中添加或删除节点等操作会影响html的结构,所以script标签必须放在合适的位置,或者使用async或者defer属性异步加载js。
html解析完成后,我们会得到一个DOM Tree,但是此时我们并不知道DOM树上的每个节点是什么样子的。这是主线程需要解析 CSS 并确定每个 DOM 节点的计算样式。
在了解了每个节点的 DOM 结构和样式之后,就需要知道每个节点在页面上的位置,即节点的坐标以及节点需要占用多少区域。这个阶段称为布局布局。线程通过遍历 dom 和计算出来的样式生成 Layout 树。布局树上的每个节点都记录了 x、y 坐标和边框大小。
需要注意的是,DOM树和Layout树并不是一一对应的。如果设置了 display: none,则不会出现在布局树上。如果在 before 伪类中添加了一个带有 content 值的元素,就会出现 content 中的内容。不会出现在Layout树上的DOM树上,因为DOM是通过html解析得到的,不关心样式,而Layout树是DOM树结合CSSOM树生成的。
只知道元素的大小、形状和位置是不够的。我们还需要知道绘制节点的顺序。毕竟像z-index这样的属性会影响节点绘制的层次关系。如果我们按照 DOM 层次绘制,就会导致渲染不正确。所以为了保证屏幕上显示正确的层级,主线程遍历Layout树创建了一个绘制记录表(Paint Record),记录了绘制的顺序。这个阶段称为绘画。
知道了节点的绘制顺序,是时候将这些信息转换成像素并在屏幕上显示了。这种行为称为光栅化。
Chrome 早期的光栅化方案只是对用户可见区域的内容进行了光栅化。当用户滚动页面时,更多的内容被光栅化以填补缺失的部分。这种方案会导致显示延迟。现在chrome的光栅化过程称为堆肥。Composting是一种将页面的每一部分分成多个层,分别进行光栅化,在合成器线程技术中分别合成页面的技术。简单来说,就是将页面的所有元素按照一定的规则划分成图层,对图层进行光栅化处理,然后只将可视区域的内容组合成一帧显示给用户。
主线程遍历布局树生成层树。当层树生成并确定了绘制顺序时,主线程将此信息传递给合成器线程。
合成器线程对每一层进行光栅化,并且由于层可以与页面的整个长度一样大,因此合成器线程将它们切成许多块并将每个块发送到光栅化器线程。
光栅化线程光栅化每个图块并将它们存储到 GPU 内存中
当瓦片被光栅化时,合成器线程将采集称为“绘制四边形”(来自网格线程)的瓦片信息,这些信息记录瓦片在内存中的位置以及它们在页面上的绘制位置。瓦片的信息,合成器线程根据该信息生成合成器帧(Compositor Frame)
然后这个合成器帧通过IPC传给浏览器进程,然后浏览器进程把合成器帧传给GPU,然后GPU渲染到屏幕上,然后就可以看到页面的内容了。
但是当页面发生变化时,会生成一个新的合成器框架,并重复上述动作
3. 回流和重绘
重排重绘会占用主线程,而js也在主线程上运行,所以会出现抢占执行时间的问题。在一帧内完成布局绘制后还有时间时,js会获得使用主线程的权利。如果js的执行时间过长,js会在下一帧开始时没有及时返回到主线程,导致下面的一帧动画没有按时渲染,页面动画就会卡住。
有什么优化方法吗?? ?
当然有!!
4. 优化回流和重绘导致页面动画卡顿的问题
第一个是通过 requestAnimationFrame() API。每一帧都会调用这个方法。通过API回调,我们可以将JS运行的任务分成更小的任务块(划分为每一帧),并在每一帧时间用完前暂停js执行并返回主线程,这样主线程就可以布局和下一帧开始时准时绘制
第二种光栅化不占用主线程,只运行在合成器线程和网格线程中,也就是说不会用js抢占主线程。CSS有一个动画属性transform,这个属性实现的动画是不会通过的。布局和绘图直接运行在合成器线程和网格线程上,因此不会受主线程中的 JS 影响。更重要的是,由于transform实现的动画不需要经过布局绘制样式计算等操作,因此节省了大量的计算时间
5. 渲染管道
当网络进程向渲染进程提交资源时,渲染进程就会开始渲染页面。浏览器的渲染机制非常复杂,所以渲染会分为很多子阶段。输入的 HTML、CSS、JS 以及图片等资源都会经过这些阶段,最终输出的像素会显示在页面上。处理流程称为渲染管道。
根据渲染的时间顺序,我们将浏览器的渲染时间段划分为以下几个子阶段。需要注意的是,每个子阶段的输出都会作为下一个子阶段的输入,这也符合实际工厂流水线场景。
6. 渲染过程总结
1、渲染过程将HTML内容转化为可读的DOM树结构
2、渲染引擎将CSS样式表转换成浏览器可以理解的样式表,并计算出DOM节点的样式
3、创建布局树并计算元素的布局信息。
4、对布局树进行分层并生成分层树。
5、为每一层生成绘制列表并将它们提交到合成线程。
6、合成线程将图层划分为瓦片,并将瓦片转换为光栅化线程池中的位图。
7、合成线程向浏览器进程发送绘图平铺命令DrawQuads
8、浏览器进程根据 DrawQuads 消息生成页面并显示在监视器上。
五、JS的运行原理(重点:JS引擎)5.1 js继承了以下四种语言的特点
5.2个奇怪的js
5.3 JIT
js是动态类型语言,但这也导致我们在运行前无法知道变量的类型。只有在运行过程中才能确定每个变量的类型,这使得js无法在运行前编译更快、更底层。语言代码(机器代码)。尽管如此,js 执行起来还是很快的,这是为什么呢?? ? 这是因为当前的 JavaScript 引擎使用了一种技术:Just-In-Time Compilation,简称 JIT,就是在运行阶段生成机器码,而不是提前生成。JIT 在运行代码的同时生成机器码。
5.4 JS 引擎
js 是一种高级语言。在被计算机CPU执行之前,需要将JS转换为低级机器语言,通过程序执行。该程序称为 JavaScript 引擎。JavaScript 有很多引擎:
js引擎执行的一般流程(new V8)首先通过解析器将JS源码解析成抽象语法树AST;然后通过解释器将AST编译成字节码btyecode,字节码是一个中间表示跨平台的,不同于最终的机器码。字节码是平台无关的,可以运行在不同的操作系统上;字节码最终通过编译器(compiler)生成机器码,由于不同的处理编译平台所使用的机器码会是不同,所以编译器会根据当前平台编译对应的机器码
5.5 以V8为例了解JS引擎编译和JS优化
JS的引擎是V8,node.js的运行环境也是V8引擎,electron的底层引擎也是V8.
简单地说,V8 是一个 C++ 程序,它接收 JavaScript 代码,编译代码然后执行。编译后的代码可以在多个操作系统和多个处理器上运行。
V8主要负责工作:
1. 早期的 V8 引擎
JS 引擎在编译和执行 JS 代码时使用了三个重要的组件:
但在 V8 版本之前,V8 引擎没有解释器,而是有两个编译器。编译过程如下:
JS源码由解析器解析生成抽象语法树AST;那么 Full-codegen 编译器直接使用 AST 编译机器码,无需任何中间转换。Full-codegen 编译器也称为基准编译器,因为它生成基准未优化的机器代码。这样做的好处是我第一次执行JS时,直接使用高效的机器码,因为没有生成中间字节码,所以不需要解释器;代码运行一段时间后,V8 中的分析器线程已经采集到足够的数据来帮助另一个编译器 Crankshaft 进行代码优化,然后重新启动需要优化的代码解析并生成 AST,
这个设计的初衷是好的,减少了AST到字节码的转换时间,提高了JS在外部浏览器中的执行性能,但是也存在很多问题:(文章地址:)
所有提议的新 V8 架构
2. 在新的V8架构中,JS源代码首先被解析器解析,生成抽象语法树AST;但是在获得AST之后,添加了解释器Ignition,AST通过Ignition生成字节码bytecode,此时AST被清空。如果被丢弃,则释放内存空间;生成的字节码由解释器直接执行,生成的字节码将作为基准执行模型。字节码更简洁,生成的字节码大小相当于等效基准机器码的25%~50%左右;在代码的持续运行过程中,解释器采集可用于优化代码的信息,例如:变量的类型,哪些函数执行效率更高,
3. 新V8引擎在处理JS过程中的一些优化策略。如果不调用函数知识声明,则不会解析函数生成AST,也不会生成字节码;如果该函数只被调用一次,Ignition生成字节码后会直接被解释执行。Turbofan不会优化和编译,因为函数执行时需要ignition来采集类型信息,这就要求函数至少执行一次,Turbofan才能优化;如果该函数被多次调用,可能会被识别为热点函数。当 Ignition 采集的类型信息确定后,Turbofan 会将字节码编译成优化的机器码,以提高代码的执行性能。
4. 去优化
必须注意的是:
在某些情况下,优化的机器码可能会被反转为字节码。这个过程称为去优化。这是因为 JS 是一种动态类型的语言,这会导致 Ignition 采集到的信息不正确。
举个例子:比如有个sum(x,y)函数,JS引擎不知道x和y是什么类型的参数,但是在后面的多次调用中,传入的x和y都是整数,而sum 函数 当函数被识别为非热点时,解释器将采集到的类型信息和字节码发送给编译器,因此编译器生成的优化机器码假设 sum 函数的参数是整数,然后遇到函数调用直接使用速度更快的机器码,但是如果在使用sum函数的时候传入一个字符串,就会出现问题。机器码不知道如何处理字符串的参数,所以需要对字节码进行反优化回退,由解释器解释执行。
5. 新 V8 架构的好处
除了解决旧架构的问题,新架构还带来了好处:
由于一开始不需要编译成机器码,而是生成中间层的字节码,而且生成字节码的速度比机器码快很多,所以初始化、解析和执行JS的时间网页的长度被缩短,网页可以更新。快速加载;在生成优化的机器码时,不需要从源代码重新编译,而是使用字节码,当需要反优化时,只需要返回字节码的解释和执行。
新模块的性能得到了更好的提升,功能模块的功能页面更加清晰,为以后JS的新功能和优化页面铺路
六、跨域问题6.1 跨域问题的原因
由于浏览器同源策略限制。同源策略(Sameorigin Policy)是一种约定。它是浏览器的核心和最基本的安全策略。如果缺少同源策略,可能会影响浏览器的正常功能。可以说,Web是建立在同源策略的基础上的,而浏览器只是同源策略的一个实现。同源策略防止来自一个域的 JavaScript 脚本与来自另一个域的内容进行交互。所谓同源(意思是在同一个域中)是指两个页面具有相同的协议、主机和端口。
6.2 跨域的概念
当请求url的协议、域名和端口中的任何一项与当前页面url不同时,即为跨域
当前页面url是否被请求页面url是否跨域
不
同源(同一个协议、同一个域名、同一个端口号)
跨域 查看全部
浏览器抓取网页(一个HTTP请求报文的Content-Type网络进程会影响后续流程)
HTTP 请求消息由四部分组成:请求行、请求头、空行和请求实体。浏览器端开始构造请求行、请求头和请求体等信息,将浏览器的一些基本信息和cookie等信息添加到请求头中,然后将构造好的请求消息发送给服务器。
(5)服务器处理请求并返回数据
服务器收到请求消息后,会根据消息信息生成响应头、响应行、响应体等数据。网络进程收到响应头和响应行后,就可以解析响应头的内容了。网络进程解析响应头信息后,会转发给浏览器进程进行处理。
影响后续流程的两条信息:
响应行中的 301/302 状态代码执行重定向
在解析响应头的时候,还需要注意一个重定向操作:如果响应行信息是301/302,则表示需要重定向到另一个URL地址。这时,网络进程会从响应头中读取位置字段。值并重新发起 http/https 请求。
响应标头中的 Content-Type
网络进程会首先根据响应头中的 Content-Type 字段判断服务器返回什么类型的资源文件,因为不同的资源类型对浏览器的处理方式不同:
(6)断开连接:TCP 挥手四次
核心思想:TCP为什么需要四次挥手?原因是:释放连接是释放客户端到服务器和服务器到客户端的双向连接。具体来说就是确认客户端和服务端的发送和接收功能都关闭了;
3. 准备渲染进程4. 提交文档 当浏览器进程收到网络进程的响应头数据时,向渲染进程发送“提交文档”消息;渲染进程收到“提交文档”消息后,会与网络进程建立“管道”传输数据;文档数据传输完成后,渲染进程会向浏览器进程返回“确认提交”消息;浏览器进程收到消息后,开始更新页面状态,包括安全状态、地址栏URL、前进后退历史状态、更新网页等。
5. 浏览器解析并渲染页面
一旦文档被确认提交,渲染过程就开始解析资源并渲染页面。注意浏览器的渲染页面并不是等所有资源加载完毕才开始渲染,而是边解析边渲染,这也是为什么有些页面会先将文本呈现给用户,然后再加载图片等资源之后。
详细渲染过程见第4点
四、浏览器是如何工作的?
以chrome浏览器为例
浏览器的结构大致可以分为:用户界面、浏览器引擎、渲染引擎
4.1 不同的浏览器内核
IE:三叉戟
火狐:壁虎
Safari:Webkit
Chrome/Opera/Edge:基于 Webkit 改造的 Blink
4.2 浏览器的多进程结构
今天的浏览器是多进程结构,而早期的浏览器是单进程结构
早期浏览器单进程结构:
单进程结构提出了许多问题:
不稳定:其中一个线程卡住可能会导致整个进程出现问题。例如,如果您打开多个选项卡,其中一个卡住的选项卡可能会导致浏览器无法运行。不安全:数据可以在浏览器之间共享,那么js可以自由访问浏览器中的所有数据进程不流畅:一个进程需要负责的事情太多,导致效率低下
因此,当今的浏览器选择了多进程结构。根据不同的进程功能,浏览器可以分为:
4.3 chrome的4个进程模型
Chrome 共有 4 种进程模型,不同的进程模式对 tab 进程的处理方式不同。
4.4 在浏览器地址栏中输入内容时,浏览器内部会发生什么?(详细请看三) 1.用户输入URL阶段+DNS+请求数据+处理返回数据
当我在地址栏中输入内容时,浏览器进程的UI线程会捕获我输入的内容,如果输入了URL,UI线程会启动一个网络线程(这是在浏览器进程中,而不是网络进程,网络过程 当你发起http请求请求DNS进行域名解析,然后开始连接服务器获取数据,如果输入关键词,浏览器就知道你要使用搜索功能,所以它将使用默认配置的搜索引擎进行查询;
网络线程获取到数据后,会通过Safe Browsing(Google内部的一个站点安全系统,通过检测站点数据来判断是否安全)检查该站点是否为恶意站点,如果是,则发出警告页面会提示。告诉我这个站点存在安全问题,浏览器会阻止我访问,但我可以强制它继续。当返回的数据准备好并且安全检查通过时,网络线程会通知UI线程我准备好了,轮到你了。
2. 渲染页面阶段
然后UI线程会创建一个渲染器进程来渲染页面,浏览器进程将数据通过IPC管道传递给渲染器进程,进入渲染进程。渲染器进程接收数据(html(通常收录 css、js 和图像资源))。
渲染器进程的核心任务:将html、js、css、image等资源渲染成用户可以交互的网页。渲染器进程的主线程解析html并构造DOM结构。
HTML首先通过Tokeniser进行token化,输入的html内容通过词法分析解析成多个标签,根据识别出的标签进行DOM树的构建。在DOM树的创建过程中,会创建一个document对象,然后会创建一个以document为根节点的文档。DOM 树。
需要注意的是,html代码中经常会引入一些额外的资源,比如js、css、图片等。图片、CSS等资源需要从网络下载或者直接从缓存中加载。这些资源不会阻塞 html 的解析,因为它们不会影响 DOM 的生成。当解析过程中遇到脚本标签时,会停止对html的解析。,然后加载、解析并执行js,因为js可能会改变当前页面的html结构,有可能在js中添加或删除节点等操作会影响html的结构,所以script标签必须放在合适的位置,或者使用async或者defer属性异步加载js。
html解析完成后,我们会得到一个DOM Tree,但是此时我们并不知道DOM树上的每个节点是什么样子的。这是主线程需要解析 CSS 并确定每个 DOM 节点的计算样式。
在了解了每个节点的 DOM 结构和样式之后,就需要知道每个节点在页面上的位置,即节点的坐标以及节点需要占用多少区域。这个阶段称为布局布局。线程通过遍历 dom 和计算出来的样式生成 Layout 树。布局树上的每个节点都记录了 x、y 坐标和边框大小。
需要注意的是,DOM树和Layout树并不是一一对应的。如果设置了 display: none,则不会出现在布局树上。如果在 before 伪类中添加了一个带有 content 值的元素,就会出现 content 中的内容。不会出现在Layout树上的DOM树上,因为DOM是通过html解析得到的,不关心样式,而Layout树是DOM树结合CSSOM树生成的。
只知道元素的大小、形状和位置是不够的。我们还需要知道绘制节点的顺序。毕竟像z-index这样的属性会影响节点绘制的层次关系。如果我们按照 DOM 层次绘制,就会导致渲染不正确。所以为了保证屏幕上显示正确的层级,主线程遍历Layout树创建了一个绘制记录表(Paint Record),记录了绘制的顺序。这个阶段称为绘画。
知道了节点的绘制顺序,是时候将这些信息转换成像素并在屏幕上显示了。这种行为称为光栅化。
Chrome 早期的光栅化方案只是对用户可见区域的内容进行了光栅化。当用户滚动页面时,更多的内容被光栅化以填补缺失的部分。这种方案会导致显示延迟。现在chrome的光栅化过程称为堆肥。Composting是一种将页面的每一部分分成多个层,分别进行光栅化,在合成器线程技术中分别合成页面的技术。简单来说,就是将页面的所有元素按照一定的规则划分成图层,对图层进行光栅化处理,然后只将可视区域的内容组合成一帧显示给用户。
主线程遍历布局树生成层树。当层树生成并确定了绘制顺序时,主线程将此信息传递给合成器线程。
合成器线程对每一层进行光栅化,并且由于层可以与页面的整个长度一样大,因此合成器线程将它们切成许多块并将每个块发送到光栅化器线程。
光栅化线程光栅化每个图块并将它们存储到 GPU 内存中
当瓦片被光栅化时,合成器线程将采集称为“绘制四边形”(来自网格线程)的瓦片信息,这些信息记录瓦片在内存中的位置以及它们在页面上的绘制位置。瓦片的信息,合成器线程根据该信息生成合成器帧(Compositor Frame)
然后这个合成器帧通过IPC传给浏览器进程,然后浏览器进程把合成器帧传给GPU,然后GPU渲染到屏幕上,然后就可以看到页面的内容了。
但是当页面发生变化时,会生成一个新的合成器框架,并重复上述动作
3. 回流和重绘
重排重绘会占用主线程,而js也在主线程上运行,所以会出现抢占执行时间的问题。在一帧内完成布局绘制后还有时间时,js会获得使用主线程的权利。如果js的执行时间过长,js会在下一帧开始时没有及时返回到主线程,导致下面的一帧动画没有按时渲染,页面动画就会卡住。
有什么优化方法吗?? ?
当然有!!
4. 优化回流和重绘导致页面动画卡顿的问题
第一个是通过 requestAnimationFrame() API。每一帧都会调用这个方法。通过API回调,我们可以将JS运行的任务分成更小的任务块(划分为每一帧),并在每一帧时间用完前暂停js执行并返回主线程,这样主线程就可以布局和下一帧开始时准时绘制
第二种光栅化不占用主线程,只运行在合成器线程和网格线程中,也就是说不会用js抢占主线程。CSS有一个动画属性transform,这个属性实现的动画是不会通过的。布局和绘图直接运行在合成器线程和网格线程上,因此不会受主线程中的 JS 影响。更重要的是,由于transform实现的动画不需要经过布局绘制样式计算等操作,因此节省了大量的计算时间
5. 渲染管道
当网络进程向渲染进程提交资源时,渲染进程就会开始渲染页面。浏览器的渲染机制非常复杂,所以渲染会分为很多子阶段。输入的 HTML、CSS、JS 以及图片等资源都会经过这些阶段,最终输出的像素会显示在页面上。处理流程称为渲染管道。
根据渲染的时间顺序,我们将浏览器的渲染时间段划分为以下几个子阶段。需要注意的是,每个子阶段的输出都会作为下一个子阶段的输入,这也符合实际工厂流水线场景。
6. 渲染过程总结
1、渲染过程将HTML内容转化为可读的DOM树结构
2、渲染引擎将CSS样式表转换成浏览器可以理解的样式表,并计算出DOM节点的样式
3、创建布局树并计算元素的布局信息。
4、对布局树进行分层并生成分层树。
5、为每一层生成绘制列表并将它们提交到合成线程。
6、合成线程将图层划分为瓦片,并将瓦片转换为光栅化线程池中的位图。
7、合成线程向浏览器进程发送绘图平铺命令DrawQuads
8、浏览器进程根据 DrawQuads 消息生成页面并显示在监视器上。
五、JS的运行原理(重点:JS引擎)5.1 js继承了以下四种语言的特点
5.2个奇怪的js
5.3 JIT
js是动态类型语言,但这也导致我们在运行前无法知道变量的类型。只有在运行过程中才能确定每个变量的类型,这使得js无法在运行前编译更快、更底层。语言代码(机器代码)。尽管如此,js 执行起来还是很快的,这是为什么呢?? ? 这是因为当前的 JavaScript 引擎使用了一种技术:Just-In-Time Compilation,简称 JIT,就是在运行阶段生成机器码,而不是提前生成。JIT 在运行代码的同时生成机器码。
5.4 JS 引擎
js 是一种高级语言。在被计算机CPU执行之前,需要将JS转换为低级机器语言,通过程序执行。该程序称为 JavaScript 引擎。JavaScript 有很多引擎:
js引擎执行的一般流程(new V8)首先通过解析器将JS源码解析成抽象语法树AST;然后通过解释器将AST编译成字节码btyecode,字节码是一个中间表示跨平台的,不同于最终的机器码。字节码是平台无关的,可以运行在不同的操作系统上;字节码最终通过编译器(compiler)生成机器码,由于不同的处理编译平台所使用的机器码会是不同,所以编译器会根据当前平台编译对应的机器码
5.5 以V8为例了解JS引擎编译和JS优化
JS的引擎是V8,node.js的运行环境也是V8引擎,electron的底层引擎也是V8.
简单地说,V8 是一个 C++ 程序,它接收 JavaScript 代码,编译代码然后执行。编译后的代码可以在多个操作系统和多个处理器上运行。
V8主要负责工作:
1. 早期的 V8 引擎
JS 引擎在编译和执行 JS 代码时使用了三个重要的组件:
但在 V8 版本之前,V8 引擎没有解释器,而是有两个编译器。编译过程如下:
JS源码由解析器解析生成抽象语法树AST;那么 Full-codegen 编译器直接使用 AST 编译机器码,无需任何中间转换。Full-codegen 编译器也称为基准编译器,因为它生成基准未优化的机器代码。这样做的好处是我第一次执行JS时,直接使用高效的机器码,因为没有生成中间字节码,所以不需要解释器;代码运行一段时间后,V8 中的分析器线程已经采集到足够的数据来帮助另一个编译器 Crankshaft 进行代码优化,然后重新启动需要优化的代码解析并生成 AST,
这个设计的初衷是好的,减少了AST到字节码的转换时间,提高了JS在外部浏览器中的执行性能,但是也存在很多问题:(文章地址:)
所有提议的新 V8 架构
2. 在新的V8架构中,JS源代码首先被解析器解析,生成抽象语法树AST;但是在获得AST之后,添加了解释器Ignition,AST通过Ignition生成字节码bytecode,此时AST被清空。如果被丢弃,则释放内存空间;生成的字节码由解释器直接执行,生成的字节码将作为基准执行模型。字节码更简洁,生成的字节码大小相当于等效基准机器码的25%~50%左右;在代码的持续运行过程中,解释器采集可用于优化代码的信息,例如:变量的类型,哪些函数执行效率更高,
3. 新V8引擎在处理JS过程中的一些优化策略。如果不调用函数知识声明,则不会解析函数生成AST,也不会生成字节码;如果该函数只被调用一次,Ignition生成字节码后会直接被解释执行。Turbofan不会优化和编译,因为函数执行时需要ignition来采集类型信息,这就要求函数至少执行一次,Turbofan才能优化;如果该函数被多次调用,可能会被识别为热点函数。当 Ignition 采集的类型信息确定后,Turbofan 会将字节码编译成优化的机器码,以提高代码的执行性能。
4. 去优化
必须注意的是:
在某些情况下,优化的机器码可能会被反转为字节码。这个过程称为去优化。这是因为 JS 是一种动态类型的语言,这会导致 Ignition 采集到的信息不正确。
举个例子:比如有个sum(x,y)函数,JS引擎不知道x和y是什么类型的参数,但是在后面的多次调用中,传入的x和y都是整数,而sum 函数 当函数被识别为非热点时,解释器将采集到的类型信息和字节码发送给编译器,因此编译器生成的优化机器码假设 sum 函数的参数是整数,然后遇到函数调用直接使用速度更快的机器码,但是如果在使用sum函数的时候传入一个字符串,就会出现问题。机器码不知道如何处理字符串的参数,所以需要对字节码进行反优化回退,由解释器解释执行。
5. 新 V8 架构的好处
除了解决旧架构的问题,新架构还带来了好处:
由于一开始不需要编译成机器码,而是生成中间层的字节码,而且生成字节码的速度比机器码快很多,所以初始化、解析和执行JS的时间网页的长度被缩短,网页可以更新。快速加载;在生成优化的机器码时,不需要从源代码重新编译,而是使用字节码,当需要反优化时,只需要返回字节码的解释和执行。
新模块的性能得到了更好的提升,功能模块的功能页面更加清晰,为以后JS的新功能和优化页面铺路
六、跨域问题6.1 跨域问题的原因
由于浏览器同源策略限制。同源策略(Sameorigin Policy)是一种约定。它是浏览器的核心和最基本的安全策略。如果缺少同源策略,可能会影响浏览器的正常功能。可以说,Web是建立在同源策略的基础上的,而浏览器只是同源策略的一个实现。同源策略防止来自一个域的 JavaScript 脚本与来自另一个域的内容进行交互。所谓同源(意思是在同一个域中)是指两个页面具有相同的协议、主机和端口。
6.2 跨域的概念
当请求url的协议、域名和端口中的任何一项与当前页面url不同时,即为跨域
当前页面url是否被请求页面url是否跨域
不
同源(同一个协议、同一个域名、同一个端口号)
跨域
浏览器抓取网页(本文基本用法导入库初始化大小浏览器刷新同刷新键(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-22 11:08
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
文章目录
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
from selenium import webdriver
初始化浏览器
如果已经放在 Scripts 文件夹中,会直接调用。
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新
用刷新键,最好写个异常检测
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
按 id/name/class 定位
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
按标签定位
但实际上,一个页面上可能有很多相同的标签,这会使标签指向不明确,从而导致错误。
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
链接位置
定位链接名称,例如定位在百度左上角的链接示例中。
新闻
hao123
地图
...
直接通过链接名称定位。
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
xpath定位
上述方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
css定位
这种方法比xpath更简洁更快
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素
当然,有时我们只需要多个元素,所以我们只需要使用复数s即可。
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性
比如要获取百度logo的信息,先定位图片元素,再获取信息
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本
首先,使用类直接查找热列表元素,但是有多个元素,所以使用复数来获取,并使用for循环打印。使用文本获取文本
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性
获取例如 id 或 tag
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
输入/明文
比如在百度搜索框输入“冬奥会”,然后清除
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(输入)
输入以上内容后,需要点击回车提交,才能得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要补充一些伪装的方法,文末。.
search_bar.send_keys('冬奥会')
search_bar.submit()
点击
当我们需要点击时,使用click。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击就是double_click,找不到合适的例子就不提了。
这里是可以深挖的ActionChains,就是定义了一系列操作一起执行,当然,一些常用的操作其实就足够了。
徘徊
我不能让它进去。
ActionChains(browser).move_to_element(move).perform()
下拉选择
需要导入相关库,访问MySQL官网选择下载对应的操作系统为例。
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖
多用于验证码之类的,参考菜鸟示例
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 39%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待
可以发现,在上面的程序中,有些效果需要等待延迟才会出现。在实践中,它也需要一定的延迟。一方面认为是爬虫,以免被访问太频繁,另一方面也是网络资源的原因。加载需要一定的时间等待。
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截屏
可以保存为base64/png/file 三
browser.get_screenshot_as_file('截图.png')
窗户开关
我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条
有些网页的内容是随着进度条的滑动出现的,所以需要把进度条往下拉。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。仔细研究的话,操作很详细,模仿真实浏览器的操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导使用。
和直接获取资源的爬虫相比,肯定是慢了一点,但是比强大的要好,还是可以提高钓鱼效率的。 查看全部
浏览器抓取网页(本文基本用法导入库初始化大小浏览器刷新同刷新键(组图))
本文是爬虫工具selenium的介绍,包括安装和常用的使用方法,后面会整理出来以备不时之需。
文章目录
1. 硒安装
Selenium 是一种常用的爬虫工具。相比普通爬虫库,它直接模拟调用浏览器直接运行,可以避免很多反爬机制。在某种程度上,它类似于按钮向导。但它更强大。,更可定制。
首先我们需要在 python 环境中安装 selenium 库。
pip install selenium
# 或
conda install selenium
除了基本的python依赖库外,我们还需要安装浏览器驱动。由于我经常使用chrome,所以这里选择chomedriver,其他浏览器需要找到对应的驱动。
首先打开chrome浏览器,在地址栏输入Chrome://version,查看浏览器对应的版本号,比如我当前的版本是:98.0.4758.82(正式版)(64位)。然后在chromedriver官网找到对应的版本下载并解压。(这是官网,有墙)最后把chromedriver.exe放到python环境的Scripts文件夹下,或者项目文件夹下,或者放到自己喜欢的文件夹下(不是)。
好,那我们就开始我们的学习之旅吧!
2. 基本用法
导入库
from selenium import webdriver
初始化浏览器
如果已经放在 Scripts 文件夹中,会直接调用。
# 初始化选择chrome浏览器
browser = webdriver.Chrome()
否则需要手动选择浏览器的路径,可以是相对路径,也可以是绝对路径。
# 初始化选择chrome浏览器
browser = webdriver.Chrome(path)
这时候你会发现自动弹出一个chrome浏览器。如果我们想让程序安静地运行,我们可以设置一个无界面,也称为无头浏览器。
# 参数设置
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
访问网址
# 访问百度
browser.get(r'https://www.baidu.com/')
关闭浏览器
# 关闭浏览器
browser.close()
3. 浏览器设置
浏览器大小
# 全屏
browser.maximize_window()
# 分辨率 600*800
browser.set_window_size(600,800)
浏览器刷新
用刷新键,最好写个异常检测
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
向前向后
# 后退
browser.back()
# 前进
browser.forward()
4. 网页基本信息
当前网页的标题等信息。
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
也可以直接获取网页源代码,可以直接使用正则表达式、Bs4、xpath等工具解析。
print(browser.page_source)
5. 定位页面元素
定位页面元素,即直接在浏览器中查找渲染的元素,而不是源码。以下面的搜索框标签为例
按 id/name/class 定位
# 在百度搜索框中输入python
browser.find_element_by_id('kw').send_keys('python')
browser.find_element_by_name('wd').send_keys('python')
browser.find_element_by_class_name('s_ipt').send_keys('python')
按标签定位
但实际上,一个页面上可能有很多相同的标签,这会使标签指向不明确,从而导致错误。
# 在百度搜索框中输入python
browser.find_element_by_tag_name('input').send_keys('python')
链接位置
定位链接名称,例如定位在百度左上角的链接示例中。
新闻
hao123
地图
...
直接通过链接名称定位。
# 点击新闻链接
browser.find_element_by_link_text('新闻').click()
但是有时候链接名很长,可以使用模糊定位偏,当然链接指向的只是一.
# 点击含有闻的链接
browser.find_element_by_partial_link_text('闻').click()
xpath定位
上述方法必须保证元素是唯一的。当元素不唯一时,需要使用xpath进行唯一定位,比如使用xpath查找搜索框的位置。
# 在百度搜索框中输入python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
css定位
这种方法比xpath更简洁更快
# 在百度搜索框中输入python
browser.find_element_by_css_selector('#kw').send_keys('python')
定位多个元素
当然,有时我们只需要多个元素,所以我们只需要使用复数s即可。
# element s
browser.find_elements_by_class_name(name)
browser.find_elements_by_id(id_)
browser.find_elements_by_name(name)
6. 获取元素信息
通常在上一步定位元素后,对元素进行一些操作。
获取元素属性
比如要获取百度logo的信息,先定位图片元素,再获取信息
# 先使用上述方法获取百度logo元素
logo = browser.find_element_by_class_name('index-logo-src')
# 然后使用get_attribute来获取想要的属性信息
logo = browser.find_element_by_class_name('index-logo-src')
logo_url = logo.get_attribute('src')
获取元素文本
首先,使用类直接查找热列表元素,但是有多个元素,所以使用复数来获取,并使用for循环打印。使用文本获取文本
# 获取热榜
hots = browser.find_elements_by_class_name('title-content-title')
for h in hots:
print(h.text)
获取其他属性
获取例如 id 或 tag
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
7. 页面交互
除了直接获取页面的元素外,有时还需要对页面进行一些操作。
输入/明文
比如在百度搜索框输入“冬奥会”,然后清除
# 首先获取搜索框元素, 然后使用send_keys输入内容
search_bar = browser.find_element_by_id('kw')
search_bar.send_keys('冬奥会')
# 稍微等两秒, 不然就看不见了
time.sleep(2)
search_bar.clear()
提交(输入)
输入以上内容后,需要点击回车提交,才能得到想要的搜索信息。
2022年2月5日写这篇博文的时候,百度已经发现了selenium,所以需要补充一些伪装的方法,文末。.
search_bar.send_keys('冬奥会')
search_bar.submit()
点击
当我们需要点击时,使用click。比如之前的提交,你也可以找到百度,点击这个按钮,然后点击!
# 点击热榜第一条
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click()
单选和多选也是一样,定位到对应的元素,然后点击。
并且偶尔会用到右键,这需要一个新的依赖库。
from selenium.webdriver.common.action_chains import ActionChains
hots = browser.find_elements_by_class_name('title-content-title')
# 鼠标右击
ActionChains(browser).context_click(hots[0]).perform()
# 双击
# ActionChains(browser).double_click(hots[0]).perform()
双击就是double_click,找不到合适的例子就不提了。
这里是可以深挖的ActionChains,就是定义了一系列操作一起执行,当然,一些常用的操作其实就足够了。
徘徊
我不能让它进去。
ActionChains(browser).move_to_element(move).perform()
下拉选择
需要导入相关库,访问MySQL官网选择下载对应的操作系统为例。
from selenium.webdriver.support.select import Select
# 访问mysql下载官网
browser.get(r'https://dev.mysql.com/downloads/mysql/')
select_os = browser.find_element_by_id('os-ga')
# 使用索引选择第三个
Select(select_os).select_by_index(3)
time.sleep(2)
# 使用value选择value="3"的
Select(select_os).select_by_value("3")
time.sleep(2)
# 使用文本值选择macOS
Select(select_os).select_by_visible_text("macOS")
拖
多用于验证码之类的,参考菜鸟示例
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try ... 39%3B
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
8. 键盘操作
键盘的大部分操作都有对应的命令,需要导入Keys类
from selenium.webdriver.common.keys import Keys
# 常见键盘操作
send_keys(Keys.BACK_SPACE) # 删除键
send_keys(Keys.SPACE) # 空格键
send_keys(Keys.TAB) # 制表键
send_keys(Keys.ESCAPE) # 回退键
send_keys(Keys.ENTER) # 回车键
send_keys(Keys.CONTRL,'a') # 全选(Ctrl+A)
send_keys(Keys.CONTRL,'c') # 复制(Ctrl+C)
send_keys(Keys.CONTRL,'x') # 剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v') # 粘贴(Ctrl+V)
send_keys(Keys.F1) # 键盘F1
send_keys(Keys.F12) # 键盘F12
9. 其他
延迟等待
可以发现,在上面的程序中,有些效果需要等待延迟才会出现。在实践中,它也需要一定的延迟。一方面认为是爬虫,以免被访问太频繁,另一方面也是网络资源的原因。加载需要一定的时间等待。
# 简单的就可以直接使用
time.sleep(2) # 睡眠2秒
# 还有一些 隐式等待 implicitly_wait 和显示等待 WebDriverWait等操作, 另寻
截屏
可以保存为base64/png/file 三
browser.get_screenshot_as_file('截图.png')
窗户开关
我们的程序是针对当前窗口工作的,但是有时候程序需要切换窗口,所以需要切换当前工作窗口。
# 访问网址:百度
browser.get(r'https://www.baidu.com/')
hots = browser.find_elements_by_class_name('title-content-title')
hots[0].click() # 点击第一个热榜
time.sleep(2)
# 回到第 i 个窗口(按顺序)
browser.switch_to_window(browser.window_handles[0])
time.sleep(2)
hots[1].click() # 点击第一个热榜
当然,如果页面中有iframe元素,需要切换到iframe元素,可以根据它的id进行切换,类似如下
# 切换到子框架
browser.switch_to.frame('iframeResult')
下拉进度条
有些网页的内容是随着进度条的滑动出现的,所以需要把进度条往下拉。这个操作是使用js代码实现的,所以我们需要让浏览器执行js代码,其他js代码类似。
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
10. 防爬
比如上面百度找到,我们需要更好的伪装我们的浏览器浏览器。
browser = webdriver.Chrome()
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{"source": """Object.defineProperty(
navigator,
'webdriver',
{get: () => undefined})"""
}
)
网站检测硒的原理是:
Selenium在打开后给浏览器添加了一些变量值,如:window.navigator.webdriver等。和window.navigator.webdriver一样,在普通谷歌浏览器中是undefined,在selenium打开的谷歌浏览器中为true。网站只需发送js代码,检查这个变量的值给网站,网站判断这个值,如果为真则爬虫程序被拦截或者需要验证码。
当然还有其他的手段,后面会补充。
参考2万字带你了解Selenium全攻略!selenium webdriver打开网页失败,发现是爬虫。解决方案是个人利益
这一次,我回顾了硒的使用。仔细研究的话,操作很详细,模仿真实浏览器的操作是没有问题的。登录和访问非常简单,也可以作为浏览器上的按钮向导使用。
和直接获取资源的爬虫相比,肯定是慢了一点,但是比强大的要好,还是可以提高钓鱼效率的。
浏览器抓取网页( Python安装Python所需要的包()(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-22 11:05
Python安装Python所需要的包()(图)
)
4、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
5、Selenium 与 HttpWatch 结合
当你想在 Selenium 中测试页面功能时,你想获取一些信息,例如提交请求数据、接收请求数据、页面加载时间等,Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 具有广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 公众号:AllTests软件测试
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn")
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。
(2)通过控制台打印的日志,可以看到页面使用的响应时间。
查看全部
浏览器抓取网页(
Python安装Python所需要的包()(图)
)
4、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
5、Selenium 与 HttpWatch 结合
当你想在 Selenium 中测试页面功能时,你想获取一些信息,例如提交请求数据、接收请求数据、页面加载时间等,Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 具有广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 公众号:AllTests软件测试
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn";)
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。
(2)通过控制台打印的日志,可以看到页面使用的响应时间。
浏览器抓取网页(如何在页面完成之前显示页面加载div,查看实际代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-22 02:02
. 3. 。4.
. 5.
显示加载图标,直到页面加载..
. 6.
. 加载完成后显示 HTML 页面。问一个 10 年零 4 个月前提出的问题。活跃 6 年 7 个月前。查看 109k 次 33。15.有没有办法强制。如何在页面加载完成之前显示页面加载 div,要查看实际代码,您需要遵循以下简单步骤: 步骤 1:将上面的示例代码复制并粘贴到文本编辑器中并以 .html 扩展名保存. 步骤 2 步骤:打开您保存的 .html 文件,然后打开浏览器的开发人员工具,转到网络选项卡并将限制设置为慢 3G。
如何在 JavaScript 中获取用户输入的数字
在 Node.js、定义和用法中获取用户输入。value 属性设置或返回数值字段的 value 属性的值。value 属性指定默认值或用户输入的值(或由脚本设置的值)。当获取的值收录非数字字符时,JS 可能重复 – user3989103 2015 年 2 月 24 日 12:42。提示用户。JavaScript 提示 - 为了获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - .
JavaScript 提示 - 获取用户输入,当它收录非数字字符时,可能会重复 JS 获取的值 – user3989103 2015 年 2 月 24 日 12:42。提示用户 JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。. 如何在不提示的情况下在 JavaScript 中获取用户输入,使用 JavaScript 从用户输入中获取一个数字并将其显示在控制台中 这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何允许用户输入数字和其他类型的数据。
如何在不提示的情况下在 JavaScript 中获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - . 如何使用 JavaScript 强制输入字段仅输入数字,本教程介绍了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。
如何使用 JavaScript 强制输入字段仅输入数字,从用户输入中获取数字并使用 JavaScript 在控制台中显示;这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何让用户输入数字和其他类型的数据。如何从提示框中获取值?,提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何在 Node.js 中同步处理用户输入。提示功能,所以需要调用 prompt-sync 来获取实际的提示功能。
How to get numeric value from a prompt box?,本教程涵盖了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。从用户输入中获取数字并使用 JavaScript 在控制台中显示,
如何在 JavaScript 中存储用户输入
如何将用户输入保存为 html/JavaScript 中的变量,我们可以使用 var input = document.getElementById("input_id").value; 获取输入字段的值,其中 input_id 是您的输入字段的 id。JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。这是一个。如何将来自 DOM 的用户输入存储在 Javascript 变量中?使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮名称 查找按钮类型 查找按钮值 查找按钮上显示的文本 查找按钮所属表单的id var inputElement = document.getElementById('bleh'); var theirInput = ''; 输入元素。.
如何将来自 DOM 的用户输入存储在 Javascript 变量中?, JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。下面是一个使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮的名称 查找按钮的类型 查找按钮的值 查找按钮上显示的文本 查找按钮所属窗体的 ID。获取用户输入 | Javascript, · . 版权所有。蜀ICP备2021025969号 查看全部
浏览器抓取网页(如何在页面完成之前显示页面加载div,查看实际代码)
. 3. 。4.
. 5.
显示加载图标,直到页面加载..
. 6.
. 加载完成后显示 HTML 页面。问一个 10 年零 4 个月前提出的问题。活跃 6 年 7 个月前。查看 109k 次 33。15.有没有办法强制。如何在页面加载完成之前显示页面加载 div,要查看实际代码,您需要遵循以下简单步骤: 步骤 1:将上面的示例代码复制并粘贴到文本编辑器中并以 .html 扩展名保存. 步骤 2 步骤:打开您保存的 .html 文件,然后打开浏览器的开发人员工具,转到网络选项卡并将限制设置为慢 3G。
如何在 JavaScript 中获取用户输入的数字
在 Node.js、定义和用法中获取用户输入。value 属性设置或返回数值字段的 value 属性的值。value 属性指定默认值或用户输入的值(或由脚本设置的值)。当获取的值收录非数字字符时,JS 可能重复 – user3989103 2015 年 2 月 24 日 12:42。提示用户。JavaScript 提示 - 为了获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - .
JavaScript 提示 - 获取用户输入,当它收录非数字字符时,可能会重复 JS 获取的值 – user3989103 2015 年 2 月 24 日 12:42。提示用户 JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。. 如何在不提示的情况下在 JavaScript 中获取用户输入,使用 JavaScript 从用户输入中获取一个数字并将其显示在控制台中 这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何允许用户输入数字和其他类型的数据。
如何在不提示的情况下在 JavaScript 中获取用户输入,JavaScript 有一些窗口对象方法可以用来与用户交互。prompt() 方法允许您打开客户端窗口并从用户那里获取输入。例如,也许您希望用户输入名字和姓氏。使用 JavaScript 从用户输入中获取数字并将其显示在控制台中以下是 JavaScript 代码 - . 如何使用 JavaScript 强制输入字段仅输入数字,本教程介绍了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。
如何使用 JavaScript 强制输入字段仅输入数字,从用户输入中获取数字并使用 JavaScript 在控制台中显示;这是 JavaScript 代码 - 本教程涵盖了在 Javascript 中获取用户输入。在本课程中,我们将了解如何让用户输入数字和其他类型的数据。如何从提示框中获取值?,提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何在 Node.js 中同步处理用户输入。提示功能,所以需要调用 prompt-sync 来获取实际的提示功能。
How to get numeric value from a prompt box?,本教程涵盖了在 Javascript 中获取用户输入。在接下来的课程中,我们将了解如何允许用户输入数字和其他类型的数据。提示输入数字?如何从用户 javscript 获取输入 · 如何从用户 js 获取输入 · 如何在 javascript 中获取提示输入值 · 如何获取。从用户输入中获取数字并使用 JavaScript 在控制台中显示,
如何在 JavaScript 中存储用户输入
如何将用户输入保存为 html/JavaScript 中的变量,我们可以使用 var input = document.getElementById("input_id").value; 获取输入字段的值,其中 input_id 是您的输入字段的 id。JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。这是一个。如何将来自 DOM 的用户输入存储在 Javascript 变量中?使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮名称 查找按钮类型 查找按钮值 查找按钮上显示的文本 查找按钮所属表单的id var inputElement = document.getElementById('bleh'); var theirInput = ''; 输入元素。.
如何将来自 DOM 的用户输入存储在 Javascript 变量中?, JavaScript 不是传统的编程语言。它是一种基本上为网络构建的脚本语言。它不支持标准输入和输出流,但我们可以使用方法来实现。在 JavaScript 中,我们有一个 prompt() 方法,它通过弹出窗口接受用户输入并返回用户输入的数据。下面是一个使用 JavaScript 访问和操作 HTML 输入对象的示例。Button Object 禁用按钮 查找按钮的名称 查找按钮的类型 查找按钮的值 查找按钮上显示的文本 查找按钮所属窗体的 ID。获取用户输入 | Javascript, · . 版权所有。蜀ICP备2021025969号
浏览器抓取网页(什么是BOM?概念BOM(BrowserObjectModel)的信息操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-22 02:00
一、什么是 BOM?概念
BOM(Browser Object Model)的全称是浏览器对象模型。
浏览器可以操作:
获取一些浏览器相关信息(窗口大小)
操作浏览器跳转到页面
获取当前浏览器地址栏的信息
操作浏览器的滚动条
浏览器信息版
使浏览器显示弹出窗口(警报/确认/提示)
BOM的核心是Window对象
Window是浏览器内置的一个对象,里面收录了操作浏览器的方法
二、window的核心对象使用
location:当前页面的地址
history:页面的历史
navigator:收录浏览器相关信息
screen:用户显示屏幕相关的属性
文档:文档对象
1.常用方法:prompt(用户输入对话框)、alert(提示和确认提示)、confirm(提示确认和取消对话框)、
close(关闭浏览器窗口),open(打开一个新的 url 窗口),
setTimeout(在指定的毫秒数后调用函数或计算表达式),setInterval(在指定的时间段内以毫秒为单位调用函数或表达式)
2.定时器:它们是什么?图片轮播 2s图片换一次:用于图片轮播、在线时钟、弹窗广告。
任何自动执行的东西很可能与计时器有关
1)在 javascript 中,setTimeout() 方法是一个设置“一次性”调用的函数。其中 clearTimeout() 可以用来取消这个函数
2)在javsscript中,可以使用setInterval()方法设置一个叫做“repeatedly”的函数,clearInterval()取消执行。
3.通过窗口拼接获取浏览器窗口的大小(innerHeight和innerWidth)
这两种方法都是获取浏览器窗口的宽度和高度(包括滚动条)
3.浏览器滚动事件:
//这个onscroll事件时当前浏览器的滚动条滚动的时候触发
或者鼠标滚轮滚动的时候触发
window.onscroll=function (){
console.log('浏览器滚动了')
}
//注意:前提是页面的高度要超过浏览器的可视窗口才可以
4.浏览器滚动距离:
可以滚动浏览器的内容,则可以得到到浏览器滚动的距离
思考:
浏览器是否真的滚动?
事实上,我们的浏览器并没有滚动,它一直存在
什么是滚动?是我们的页面
所以,实际上浏览器并没有移动,而是页面上升了。
因此,这不再是简单的浏览器的内容,而是我们页面的内容
因此,您使用的是文档对象,而不是使用窗口对象
5.浏览器(页面)滚动的距离
scrollTop 获取页面向上滚动的距离
两种获取方式:
document.body.scrollTop
document.documentElement.scrollTop
区别:
IE浏览器:当没有DOCTYPE声明时,同时使用
当有 DOCTYPE 声明时,只能使用文档。documentElement.scrollTop
铬和火狐:
当没有 DOCTYPE 声明时,使用 document.body.scrollTop
当有 DOCTYPE 声明时,使用 document.documentElement.scrollTop
苹果浏览器
两者都不使用,使用单独的方法 window.pageYOffset
scrollLeft 获取页面向左滚动的距离
使用场景:滚动加载判断、滚动回顶部、自动滚动列表 查看全部
浏览器抓取网页(什么是BOM?概念BOM(BrowserObjectModel)的信息操作)
一、什么是 BOM?概念
BOM(Browser Object Model)的全称是浏览器对象模型。
浏览器可以操作:
获取一些浏览器相关信息(窗口大小)
操作浏览器跳转到页面
获取当前浏览器地址栏的信息
操作浏览器的滚动条
浏览器信息版
使浏览器显示弹出窗口(警报/确认/提示)
BOM的核心是Window对象
Window是浏览器内置的一个对象,里面收录了操作浏览器的方法
二、window的核心对象使用
location:当前页面的地址
history:页面的历史
navigator:收录浏览器相关信息
screen:用户显示屏幕相关的属性
文档:文档对象
1.常用方法:prompt(用户输入对话框)、alert(提示和确认提示)、confirm(提示确认和取消对话框)、
close(关闭浏览器窗口),open(打开一个新的 url 窗口),
setTimeout(在指定的毫秒数后调用函数或计算表达式),setInterval(在指定的时间段内以毫秒为单位调用函数或表达式)
2.定时器:它们是什么?图片轮播 2s图片换一次:用于图片轮播、在线时钟、弹窗广告。
任何自动执行的东西很可能与计时器有关
1)在 javascript 中,setTimeout() 方法是一个设置“一次性”调用的函数。其中 clearTimeout() 可以用来取消这个函数
2)在javsscript中,可以使用setInterval()方法设置一个叫做“repeatedly”的函数,clearInterval()取消执行。
3.通过窗口拼接获取浏览器窗口的大小(innerHeight和innerWidth)
这两种方法都是获取浏览器窗口的宽度和高度(包括滚动条)
3.浏览器滚动事件:
//这个onscroll事件时当前浏览器的滚动条滚动的时候触发
或者鼠标滚轮滚动的时候触发
window.onscroll=function (){
console.log('浏览器滚动了')
}
//注意:前提是页面的高度要超过浏览器的可视窗口才可以
4.浏览器滚动距离:
可以滚动浏览器的内容,则可以得到到浏览器滚动的距离
思考:
浏览器是否真的滚动?
事实上,我们的浏览器并没有滚动,它一直存在
什么是滚动?是我们的页面
所以,实际上浏览器并没有移动,而是页面上升了。
因此,这不再是简单的浏览器的内容,而是我们页面的内容
因此,您使用的是文档对象,而不是使用窗口对象
5.浏览器(页面)滚动的距离
scrollTop 获取页面向上滚动的距离
两种获取方式:
document.body.scrollTop
document.documentElement.scrollTop
区别:
IE浏览器:当没有DOCTYPE声明时,同时使用
当有 DOCTYPE 声明时,只能使用文档。documentElement.scrollTop
铬和火狐:
当没有 DOCTYPE 声明时,使用 document.body.scrollTop
当有 DOCTYPE 声明时,使用 document.documentElement.scrollTop
苹果浏览器
两者都不使用,使用单独的方法 window.pageYOffset
scrollLeft 获取页面向左滚动的距离
使用场景:滚动加载判断、滚动回顶部、自动滚动列表
浏览器抓取网页(应用中的所有Servlet共享对象的资源路径分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-16 15:09
设置响应内容
PrintWriter pw= response.getWriter();
通过 response.getWriter() 获取一个 PrintWriter 对象;
可以使用 println()、append()、write()、format() 等方法设置返回给浏览器的 html 内容。
设置响应格式
response.setContentType("text/html");
“text/html”是格式,对应request中的request.getHeader("accept")获取header信息。
“text/html”存在,表示浏览器可以识别这种格式。如果换成其他格式,比如“text/lol”,浏览器无法识别,那么打开这个servlet会弹出下载对话框。
此类手段常用于实现下载功能
设置不使用缓存
使用缓存可以加快页面加载速度,减轻服务器负担。但是你也可能会看到过时的信息,可以通过以下方式通知浏览器不要使用缓存
response.setDateHeader("过期",0 );
response.setHeader("缓存控制","无缓存");
response.setHeader("pragma","no-cache");
ServletContext 对象
WEB容器启动时,会为每个Web应用创建一个对应的ServletContext,代表当前的Web应用。它由所有客户共享。
Web 应用程序中的所有 servlet 共享同一个 ServletContext 对象
ServletContext 中属性的生命周期从创建开始,到服务器关闭时结束
ServletContext sc = this.getServletContext() 方法获取对其对象的引用
添加属性:setAttribute(String name, Object obj);
获取值:getAttribute(String name),该方法返回Object
删除属性:removeAttribute(String name)
读取文件全路径:getRealPath(String path) 其中path必须以/开头,代表当前web应用的根目录
获取资源流,即获取资源作为输入流:getResourceAsStream(String path)
返回表示资源的 URL 对象:getResource(String parh)
获取指定目录下的所有资源路径:getResourcePaths(String path)
例如获取/WEB-INF下所有资源的路径:
代码:
设置 set = context.getResourcePaths("/WEB-INF");
System.out.println(set);
结果:
[/WEB-INF/lib/, /WEB-INF/classes/, /WEB-INF/b.txt, /WEB-INF/web.xml]
如果资源不在web应用的根目录下,则无法通过ServletContext读取,必须使用类加载器读取
例如src下的com.gavin包下,类加载器需要添加包的路径,如下:
InputStream 流 = MyServlet.class.getClassLoader().getResourceAsStream("com/gavin/dbinfo.properties")
获取初始化参数:
我们可以使用一个或多个标签为servlet配置一些初始化参数,然后我们通过ServletConfig对象获取这些参数
如果有如下MyServlet,其配置为:
我的Servlet
com.gavin.servlet.MyServlet
编码
UTF-8
可以看到它配置了一个初始化参数:encoding=utf-8,那么我们需要在MyServlet的源码中获取这个参数是这样的:
字符串编码 = this.getServletConfig().getInitParameter("encoding"); 查看全部
浏览器抓取网页(应用中的所有Servlet共享对象的资源路径分析)
设置响应内容
PrintWriter pw= response.getWriter();
通过 response.getWriter() 获取一个 PrintWriter 对象;
可以使用 println()、append()、write()、format() 等方法设置返回给浏览器的 html 内容。
设置响应格式
response.setContentType("text/html");
“text/html”是格式,对应request中的request.getHeader("accept")获取header信息。
“text/html”存在,表示浏览器可以识别这种格式。如果换成其他格式,比如“text/lol”,浏览器无法识别,那么打开这个servlet会弹出下载对话框。
此类手段常用于实现下载功能
设置不使用缓存
使用缓存可以加快页面加载速度,减轻服务器负担。但是你也可能会看到过时的信息,可以通过以下方式通知浏览器不要使用缓存
response.setDateHeader("过期",0 );
response.setHeader("缓存控制","无缓存");
response.setHeader("pragma","no-cache");
ServletContext 对象
WEB容器启动时,会为每个Web应用创建一个对应的ServletContext,代表当前的Web应用。它由所有客户共享。
Web 应用程序中的所有 servlet 共享同一个 ServletContext 对象
ServletContext 中属性的生命周期从创建开始,到服务器关闭时结束
ServletContext sc = this.getServletContext() 方法获取对其对象的引用
添加属性:setAttribute(String name, Object obj);
获取值:getAttribute(String name),该方法返回Object
删除属性:removeAttribute(String name)
读取文件全路径:getRealPath(String path) 其中path必须以/开头,代表当前web应用的根目录
获取资源流,即获取资源作为输入流:getResourceAsStream(String path)
返回表示资源的 URL 对象:getResource(String parh)
获取指定目录下的所有资源路径:getResourcePaths(String path)
例如获取/WEB-INF下所有资源的路径:
代码:
设置 set = context.getResourcePaths("/WEB-INF");
System.out.println(set);
结果:
[/WEB-INF/lib/, /WEB-INF/classes/, /WEB-INF/b.txt, /WEB-INF/web.xml]
如果资源不在web应用的根目录下,则无法通过ServletContext读取,必须使用类加载器读取
例如src下的com.gavin包下,类加载器需要添加包的路径,如下:
InputStream 流 = MyServlet.class.getClassLoader().getResourceAsStream("com/gavin/dbinfo.properties")
获取初始化参数:
我们可以使用一个或多个标签为servlet配置一些初始化参数,然后我们通过ServletConfig对象获取这些参数
如果有如下MyServlet,其配置为:
我的Servlet
com.gavin.servlet.MyServlet
编码
UTF-8
可以看到它配置了一个初始化参数:encoding=utf-8,那么我们需要在MyServlet的源码中获取这个参数是这样的:
字符串编码 = this.getServletConfig().getInitParameter("encoding");
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-16 13:05
)
求高手,模拟浏览器抓取网页
比如我爬这个网页,我写的程序没有URL末尾的“/”就无法爬取,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION
查看全部
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十)
)
求高手,模拟浏览器抓取网页
比如我爬这个网页,我写的程序没有URL末尾的“/”就无法爬取,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION
浏览器抓取网页(window对象获取页面滚动距离的高度时候,往往有不同的获取方式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-16 05:15
)
在获取页面滚动距离的高度时,往往有不同的获取方式,不同的浏览器支持的属性略有不同:
pageYOffset:属于窗口对象。 IE9+、Firefox、Chrome、Opera均支持此方法获取页面滚动投注值,DOCTYPE定义规则将被忽略。
window.pageYOffset
scrollY:属于window对象,Firefox、Chrome、Opera都支持,IE不支持。 DOCTYPE 定义规则被忽略。
window.scrollY
如果页面没有定义DOCTYPE文档头,所有浏览器都支持document.body.scrollTop属性获取滚动高度。
document.body.scrollTop
如果页面定义了DOCTYPE文档头,则HTML元素上的scrollT属性可以获取IE、Firefox、Opera(presto内核)下的滚动高度值,Chrome和Safari下为0。
document.documentElement.scrollTop; //Chrome,Safari下为0
这样在获取页面滚动高度时优先使用window.pageYOffset,然后是scrollTop。
var _scrollLeft = window.scrollX || window.pageXOffset || document.documentElement.scrollLeft
var _scrollTop = window.scrollY || window.pageYOffset || document.documentElement.scrollTop 查看全部
浏览器抓取网页(window对象获取页面滚动距离的高度时候,往往有不同的获取方式
)
在获取页面滚动距离的高度时,往往有不同的获取方式,不同的浏览器支持的属性略有不同:
pageYOffset:属于窗口对象。 IE9+、Firefox、Chrome、Opera均支持此方法获取页面滚动投注值,DOCTYPE定义规则将被忽略。
window.pageYOffset
scrollY:属于window对象,Firefox、Chrome、Opera都支持,IE不支持。 DOCTYPE 定义规则被忽略。
window.scrollY
如果页面没有定义DOCTYPE文档头,所有浏览器都支持document.body.scrollTop属性获取滚动高度。
document.body.scrollTop
如果页面定义了DOCTYPE文档头,则HTML元素上的scrollT属性可以获取IE、Firefox、Opera(presto内核)下的滚动高度值,Chrome和Safari下为0。
document.documentElement.scrollTop; //Chrome,Safari下为0
这样在获取页面滚动高度时优先使用window.pageYOffset,然后是scrollTop。
var _scrollLeft = window.scrollX || window.pageXOffset || document.documentElement.scrollLeft
var _scrollTop = window.scrollY || window.pageYOffset || document.documentElement.scrollTop
浏览器抓取网页(一个获取目标页面的方法、装置、搜索引擎和浏览器技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-16 05:13
本发明专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,该方法包括:搜索引擎抓取接收到的统一资源定位符(URL)对应的基础页面和该目标页面的脚本。基本页面;对抓取的基础页面和脚本进行分析,生成多个基础页面对应的状态路径并收录动态信息,并使用生成的状态路径来抓取目标页面;其中,状态路径包括:基本页面的URL、基本页面中生成动态信息的文档对象模型(DOM)事件的位置信息以及该DOM事件对应的回调函数的索引。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及互联网技术,具体涉及一种获取目标页面的方法、装置、搜索引擎和浏览器II/T PLP。
技术介绍
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助人们检索信息的工具,搜索引擎成为用户访问互联网的门户和指南。网络爬虫(Spider)是一种自动提取网页的程序,是搜索引擎的重要组成部分。传统的网络爬虫从一个或多个初始网页的统一资源定位符(URL)开始,抓取该URL的基本页面,解析当前基本页面内容得到目标页面的URL,并进行数据处理,包括建立页面摘要后,将快照、索引和存储返回给浏览器供用户选择。然而,传统网络爬虫在获取目标页面的URL时,只能爬取静态页面。但是,随着互联网技术的不断发展,页面的内容已经从以前的静态方式变成了动态方式来生成数据。传统的网络爬虫技术显然无法满足这种过渡要求,无法爬取页面的动态内容。
技术实现思路
本专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,使得搜索引擎在搜索目标页面时能够抓取页面中的动态内容。具体技术方案如下: 一种获取目标页面的方法,该方法包括以下步骤A、获取接收到的Uniform Resource Locator URL对应的基本页面和该基本页面的脚本;B、对抓取分析的基本页面和脚本,生成多个与收录动态信息的基本页面对应的状态路径,并使用生成的状态路径来抓取目标页面;其中,状态路径包括基本页面的URL,基本页面中生成动态信息的文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。其中,步骤B具体包括在基础页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点上依次执行步骤B11~B13,执行步骤B14,直到所有DOM节点下载完成. ; B11、判断当前下载的DOM节点是否为脚本标签,如果是,则对下一个下载的DOM节点进行步骤B11,否则,执行步骤B12;B12、判断当前下载到达的DOM节点是否收录DOM事件和回调函数,如果没有,则转到步骤B11到下一次下载到的DOM节点,如果是,执行步骤B13;DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,进入步骤B11到下一个下载的DOM节点;B14、获取状态队列中每个状态路径一一对应 目标页面判断是否出现新的页面内容或页面跳转,确定生成新页面内容或页面跳转的状态路径为对应的状态路径到基本页面。
或者,步骤B具体包括:下载基本页面和脚本获取过程中的各个DOM节点,对下载的DOM节点依次执行步骤B21~B23,直至所有DOM节点下载结束。B21、判断当前下载的DOM节点是否为脚本标签,如果是,则转到下一个下载的DOM节点执行步骤B21,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一次下载的DOM节点执行步骤B21,如果是,执行步骤B23;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转。如果是这样,确定状态路径为基本页面对应的状态路径,将Go to step B21下载到到达的DOM节点;否则转到步骤 B21 到下一个下载的 DOM 节点。上述方式中,判断是否发生页面跳转包括如果获取到的目标页面和基础页面的URL不同,则确定发生了页面跳转。具体地,判断是否生成新的页面内容包括将获取的目标页面与基础页面进行句子签名或字符串比较,如果比较结果表明目标页面和基础页面具有不同的页面内容,则确定为生成新的页面内容。或者,计算获取的目标页面与基础页面的相似度,
其中,DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath和DOM事件标识。进一步地,在步骤B之后,该方法还包括C、存储步骤B生成的基本页面对应的状态路径和抓取的目标页面的快照,建立并存储目标页面的索引。一种获取目标页面的方法,基于上述方法,包括:在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储的目标页面的索引进行匹配,匹配匹配到的目标页面 将对应的状态路径收录在搜索结果中并返回给浏览器,供浏览器通过用户选择的状态路径获取对应的目标页面。此外,搜索结果还可以包括匹配的目标页面的快照信息。在接收到浏览器返回的用户选择的目标页面的快照信息后,将相应的目标页面快照返回给浏览器。进一步的,将匹配的目标页面对应的状态路径收录在搜索结果中返回给浏览器后,该方法还包括,在接收到浏览器发送的用户选择状态路径后,根据用户选择的状态路径向目标页面站点发送目标页面请求,以便目标页面站点将目标页面推送到浏览器。一种获取目标页面的方法,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。
一种目标页面获取装置,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,对第一爬取单元捕获的基本页面和脚本进行分析,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL和在基本页面中产生动态信息的文档对象。模型DOM事件的位置信息和DOM事件对应的回调函数索引;第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。其中,分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;第一个爬取单元是在基本页面及其脚本的爬取过程中。下载每个DOM节点,将当前下载的DOM节点发送给第一判断模块,直到所有DOM节点下载完成后,发送确认通知给第一路径判断模块;第一判断模块,用于判断当前下载的DOM节点是否为脚本标签,如果是,则触发第一抓取单元下载下一个DOM节点,否则,向第二判断模块发送判断通知。第二判断模块,用于判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,触发第一抓取单元下载下一个DOM节点,如果是,则向第一路径生成模块发送执行通知;第一路径生成模块,用于接收到执行通知后,使用当前下载的DOM节点生成状态路径,并将生成的状态路径保存在状态路径队列中,触发第一抓取单元下载下一个DOM节点;第一路径确定模块,用于在接收到确定通知时,触发第二抓取单元逐一获取状态队列中各状态路径对应的目标页面,根据第二抓取单元的获取结果判断是否有新的页面内容或页面跳转发生,将新的页面内容或发生页面跳转的状态路径确定为基本页面对应的状态路径。具体地,分析单元可以包括第三判断模块、第四判断模块、第二路径生成模块和第二路径确定模块。
【技术保护点】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、对接收到的统一资源定位符URL对应的基本页面和基本页面的脚本进行爬取。B.爬取基本页面和基本页面。脚本分析生成多个基本页面对应的状态路径并收录动态信息,并使用生成的状态路径抓取目标页面;其中,状态路径包括:基本页面的URL,以及基本页面中生成的动态信息。文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。
【技术特点总结】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、获取接收到的统一资源定位符URL对应的基本页面和基本页面的脚本。B、检索基本页面和脚本分析,生成多个收录动态信息的基本页面对应的状态路径,并使用生成的状态路径抓取目标页面;其中,状态路径包括基本页面的URL、在基本页面中生成动态信息的文档对象、模型DOM事件的位置信息和DOM事件对应的回调函数索引。2.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:下载基础页面和脚本爬取过程中的各个DOM节点,依次对下载的DOM节点B11~B13执行上述步骤,完成所有DOM节点的下载后,执行步骤B14。B11、判断当前下载的DOM节点是否为脚本标签,如果是则执行步骤B11下载下一个DOM节点,否则执行步骤B12;B12、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点,如果是,则执行步骤B13;B13、利用下载到的DOM节点当前收录的DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,对下载到的DOM节点进行步骤B11下一个; B14、
3.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:在基本页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点B21~B23上依次执行上述步骤,直至结束。所有 DOM 节点的下载;B21、判断当前下载的DOM节点是否为脚本标签,如果是,则执行步骤B21到下一个下载的DOM节点,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点执行步骤B21,如果是,执行步骤B23;B23、@ >使用当前下载的DOM节点中收录的DOM事件生成状态路径;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转,如果是,则判断状态路径为基本页面对应的状态路径,下一个下载的DOM节点进行步骤B21;否则,下一个下载的DOM节点进入步骤B21。4.如权利要求2或3所述的方法,其特征在于,判断是否发生页面跳转包括:如果获取的目标页面和基本页面的URL不同,则确定发生页面跳转。5.根据权利要求2或3所述的方法,其特征在于,判断是否生成新的页面内容包括:将获取的目标页面与基本页面进行句子签名或字符串比较。结果表明目标页面和基础页面的页面内容不同,则确定生成新的页面内容;
6.根据权利要求1至3任一项所述的方法,其特征在于,所述DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath、DOM事件标识。7.根据权利要求1至3中任一项所述的方法,其特征在于,在步骤B之后,该方法还包括C,存储步骤B生成的基本页面对应的状态路径和快照目标页面,建立并存储目标页面的索引。8.一种获取目标页面的方法,其特征在于,在根据权利要求7所述的方法之后,在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储索引一起存储目标页面的匹配,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器,以便浏览器通过用户选择的状态路径获取对应的目标页面。9.如权利要求8所述的方法,其特征在于,所述搜索结果还包括匹配的目标页面的快照信息。接收到浏览器返回的用户选择的目标页面的快照信息后,将对应目标页面的快照返回给浏览器。1.根据权利要求8所述的方法,其特征在于,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器后,该方法还包括接收发送的用户选择状态路径后通过浏览器,
11.一种获取目标页面的方法,其特征在于,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径,向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。12.一种目标页面获取装置,其特征在于,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,用于分析第一爬取单元捕获的基本页面和脚本,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL、在基本页面中产生动态信息的文档对象模型DOM事件的位置信息以及DOM事件对应的回调函数索引。第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。1.根据权利要求12所述的装置,其特征在于,所述分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;一个爬取单元在对基本页面及其脚本的爬取过程中下载每个DOM节点...
【专利技术性质】
技术研发人员:潘云红,
申请人(专利权)持有人:,
类型:发明
国家省份:11[中国|北京]
下载所有详细的技术数据 我是该专利的所有者 查看全部
浏览器抓取网页(一个获取目标页面的方法、装置、搜索引擎和浏览器技术)
本发明专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,该方法包括:搜索引擎抓取接收到的统一资源定位符(URL)对应的基础页面和该目标页面的脚本。基本页面;对抓取的基础页面和脚本进行分析,生成多个基础页面对应的状态路径并收录动态信息,并使用生成的状态路径来抓取目标页面;其中,状态路径包括:基本页面的URL、基本页面中生成动态信息的文档对象模型(DOM)事件的位置信息以及该DOM事件对应的回调函数的索引。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及互联网技术,具体涉及一种获取目标页面的方法、装置、搜索引擎和浏览器II/T PLP。
技术介绍
随着网络的飞速发展,互联网已经成为海量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。作为帮助人们检索信息的工具,搜索引擎成为用户访问互联网的门户和指南。网络爬虫(Spider)是一种自动提取网页的程序,是搜索引擎的重要组成部分。传统的网络爬虫从一个或多个初始网页的统一资源定位符(URL)开始,抓取该URL的基本页面,解析当前基本页面内容得到目标页面的URL,并进行数据处理,包括建立页面摘要后,将快照、索引和存储返回给浏览器供用户选择。然而,传统网络爬虫在获取目标页面的URL时,只能爬取静态页面。但是,随着互联网技术的不断发展,页面的内容已经从以前的静态方式变成了动态方式来生成数据。传统的网络爬虫技术显然无法满足这种过渡要求,无法爬取页面的动态内容。
技术实现思路
本专利技术提供了一种获取目标页面的方法、装置、搜索引擎和浏览器,使得搜索引擎在搜索目标页面时能够抓取页面中的动态内容。具体技术方案如下: 一种获取目标页面的方法,该方法包括以下步骤A、获取接收到的Uniform Resource Locator URL对应的基本页面和该基本页面的脚本;B、对抓取分析的基本页面和脚本,生成多个与收录动态信息的基本页面对应的状态路径,并使用生成的状态路径来抓取目标页面;其中,状态路径包括基本页面的URL,基本页面中生成动态信息的文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。其中,步骤B具体包括在基础页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点上依次执行步骤B11~B13,执行步骤B14,直到所有DOM节点下载完成. ; B11、判断当前下载的DOM节点是否为脚本标签,如果是,则对下一个下载的DOM节点进行步骤B11,否则,执行步骤B12;B12、判断当前下载到达的DOM节点是否收录DOM事件和回调函数,如果没有,则转到步骤B11到下一次下载到的DOM节点,如果是,执行步骤B13;DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,进入步骤B11到下一个下载的DOM节点;B14、获取状态队列中每个状态路径一一对应 目标页面判断是否出现新的页面内容或页面跳转,确定生成新页面内容或页面跳转的状态路径为对应的状态路径到基本页面。
或者,步骤B具体包括:下载基本页面和脚本获取过程中的各个DOM节点,对下载的DOM节点依次执行步骤B21~B23,直至所有DOM节点下载结束。B21、判断当前下载的DOM节点是否为脚本标签,如果是,则转到下一个下载的DOM节点执行步骤B21,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一次下载的DOM节点执行步骤B21,如果是,执行步骤B23;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转。如果是这样,确定状态路径为基本页面对应的状态路径,将Go to step B21下载到到达的DOM节点;否则转到步骤 B21 到下一个下载的 DOM 节点。上述方式中,判断是否发生页面跳转包括如果获取到的目标页面和基础页面的URL不同,则确定发生了页面跳转。具体地,判断是否生成新的页面内容包括将获取的目标页面与基础页面进行句子签名或字符串比较,如果比较结果表明目标页面和基础页面具有不同的页面内容,则确定为生成新的页面内容。或者,计算获取的目标页面与基础页面的相似度,
其中,DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath和DOM事件标识。进一步地,在步骤B之后,该方法还包括C、存储步骤B生成的基本页面对应的状态路径和抓取的目标页面的快照,建立并存储目标页面的索引。一种获取目标页面的方法,基于上述方法,包括:在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储的目标页面的索引进行匹配,匹配匹配到的目标页面 将对应的状态路径收录在搜索结果中并返回给浏览器,供浏览器通过用户选择的状态路径获取对应的目标页面。此外,搜索结果还可以包括匹配的目标页面的快照信息。在接收到浏览器返回的用户选择的目标页面的快照信息后,将相应的目标页面快照返回给浏览器。进一步的,将匹配的目标页面对应的状态路径收录在搜索结果中返回给浏览器后,该方法还包括,在接收到浏览器发送的用户选择状态路径后,根据用户选择的状态路径向目标页面站点发送目标页面请求,以便目标页面站点将目标页面推送到浏览器。一种获取目标页面的方法,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。
一种目标页面获取装置,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,对第一爬取单元捕获的基本页面和脚本进行分析,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL和在基本页面中产生动态信息的文档对象。模型DOM事件的位置信息和DOM事件对应的回调函数索引;第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。其中,分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;第一个爬取单元是在基本页面及其脚本的爬取过程中。下载每个DOM节点,将当前下载的DOM节点发送给第一判断模块,直到所有DOM节点下载完成后,发送确认通知给第一路径判断模块;第一判断模块,用于判断当前下载的DOM节点是否为脚本标签,如果是,则触发第一抓取单元下载下一个DOM节点,否则,向第二判断模块发送判断通知。第二判断模块,用于判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,触发第一抓取单元下载下一个DOM节点,如果是,则向第一路径生成模块发送执行通知;第一路径生成模块,用于接收到执行通知后,使用当前下载的DOM节点生成状态路径,并将生成的状态路径保存在状态路径队列中,触发第一抓取单元下载下一个DOM节点;第一路径确定模块,用于在接收到确定通知时,触发第二抓取单元逐一获取状态队列中各状态路径对应的目标页面,根据第二抓取单元的获取结果判断是否有新的页面内容或页面跳转发生,将新的页面内容或发生页面跳转的状态路径确定为基本页面对应的状态路径。具体地,分析单元可以包括第三判断模块、第四判断模块、第二路径生成模块和第二路径确定模块。
【技术保护点】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、对接收到的统一资源定位符URL对应的基本页面和基本页面的脚本进行爬取。B.爬取基本页面和基本页面。脚本分析生成多个基本页面对应的状态路径并收录动态信息,并使用生成的状态路径抓取目标页面;其中,状态路径包括:基本页面的URL,以及基本页面中生成的动态信息。文档对象模型DOM事件的位置信息和DOM事件对应的回调函数索引。
【技术特点总结】
一种获取目标页面的方法,其特征在于,该方法包括以下步骤: A、获取接收到的统一资源定位符URL对应的基本页面和基本页面的脚本。B、检索基本页面和脚本分析,生成多个收录动态信息的基本页面对应的状态路径,并使用生成的状态路径抓取目标页面;其中,状态路径包括基本页面的URL、在基本页面中生成动态信息的文档对象、模型DOM事件的位置信息和DOM事件对应的回调函数索引。2.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:下载基础页面和脚本爬取过程中的各个DOM节点,依次对下载的DOM节点B11~B13执行上述步骤,完成所有DOM节点的下载后,执行步骤B14。B11、判断当前下载的DOM节点是否为脚本标签,如果是则执行步骤B11下载下一个DOM节点,否则执行步骤B12;B12、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点,如果是,则执行步骤B13;B13、利用下载到的DOM节点当前收录的DOM事件产生状态路径,产生的状态路径保存在状态路径队列中,对下载到的DOM节点进行步骤B11下一个; B14、
3.根据权利要求1所述的方法,其特征在于,所述步骤B具体包括:在基本页面和脚本的爬取过程中,下载各个DOM节点,在下载的DOM节点B21~B23上依次执行上述步骤,直至结束。所有 DOM 节点的下载;B21、判断当前下载的DOM节点是否为脚本标签,如果是,则执行步骤B21到下一个下载的DOM节点,否则执行步骤B22;B22、判断当前下载的DOM节点是否收录DOM事件和回调函数,如果没有,则转到下一步下载的DOM节点执行步骤B21,如果是,执行步骤B23;B23、@ >使用当前下载的DOM节点中收录的DOM事件生成状态路径;B24、获取状态路径对应的目标页面,判断是生成新的页面内容还是生成页面跳转,如果是,则判断状态路径为基本页面对应的状态路径,下一个下载的DOM节点进行步骤B21;否则,下一个下载的DOM节点进入步骤B21。4.如权利要求2或3所述的方法,其特征在于,判断是否发生页面跳转包括:如果获取的目标页面和基本页面的URL不同,则确定发生页面跳转。5.根据权利要求2或3所述的方法,其特征在于,判断是否生成新的页面内容包括:将获取的目标页面与基本页面进行句子签名或字符串比较。结果表明目标页面和基础页面的页面内容不同,则确定生成新的页面内容;
6.根据权利要求1至3任一项所述的方法,其特征在于,所述DOM事件的位置信息包括DOM节点标识、DOM节点的路径Xpath、DOM事件标识。7.根据权利要求1至3中任一项所述的方法,其特征在于,在步骤B之后,该方法还包括C,存储步骤B生成的基本页面对应的状态路径和快照目标页面,建立并存储目标页面的索引。8.一种获取目标页面的方法,其特征在于,在根据权利要求7所述的方法之后,在接收到浏览器的搜索请求后,将搜索请求中收录的关键词与存储索引一起存储目标页面的匹配,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器,以便浏览器通过用户选择的状态路径获取对应的目标页面。9.如权利要求8所述的方法,其特征在于,所述搜索结果还包括匹配的目标页面的快照信息。接收到浏览器返回的用户选择的目标页面的快照信息后,将对应目标页面的快照返回给浏览器。1.根据权利要求8所述的方法,其特征在于,将匹配的目标页面对应的状态路径收录在搜索结果中并返回给浏览器后,该方法还包括接收发送的用户选择状态路径后通过浏览器,
11.一种获取目标页面的方法,其特征在于,该方法包括:浏览器向搜索引擎发送搜索请求后,接收搜索引擎返回的收录状态路径的搜索结果;根据用户选择的状态路径,向目标页面站点发送目标页面请求;接收目标页面站点推送的目标页面;9.其中,收录状态路径的搜索结果是由搜索引擎通过权利要求8所述的方法返回的。12.一种目标页面获取装置,其特征在于,该装置包括第一抓取单元,用于抓取接收到的统一资源定位符URL对应的基础页面和基础页面的脚本;分析单元,用于分析第一爬取单元捕获的基本页面和脚本,生成与收录动态信息的基本页面对应的一个或多个状态路径;其中,状态路径包括基本页面的URL、在基本页面中产生动态信息的文档对象模型DOM事件的位置信息以及DOM事件对应的回调函数索引。第二抓取单元,用于利用分析单元生成的状态路径抓取目标页面。1.根据权利要求12所述的装置,其特征在于,所述分析单元具体包括第一判断模块、第二判断模块、第一路径生成模块和第一路径确定模块;一个爬取单元在对基本页面及其脚本的爬取过程中下载每个DOM节点...
【专利技术性质】
技术研发人员:潘云红,
申请人(专利权)持有人:,
类型:发明
国家省份:11[中国|北京]
下载所有详细的技术数据 我是该专利的所有者
浏览器抓取网页(Javascript元素在网页上的确切位置教程总结了元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-16 05:13
在创建网页的过程中,有时您需要知道某个元素在网页上的确切位置。
下面的教程总结了Javascript在网页定位方面的知识。
一、网页大小和浏览器窗口大小
首先,必须澄清两个基本概念。
一个网页的整个区域就是它的大小。通常,网页的大小由内容和 CSS 样式表决定。
浏览器窗口的大小是指在浏览器窗口中看到的网页区域的一部分,也称为视口。
显然,如果网页的内容可以在浏览器窗口中完全显示(即没有滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果不能全部显示,滚动浏览器窗口可以显示网页的各个部分。
二、获取网页大小
网页上的每个元素都有 clientHeight 和 clientWidth 属性。这两个属性指的是元素的内容部分加上内边距所占据的可视区域,不包括边框和滚动条所占据的空间。
(图一clientHeight和clientWidth属性)
因此,文档元素的clientHeight 和clientWidth 属性代表了网页的大小。
function getViewport(){
if (document.compatMode == "BackCompat"){
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
上面的getViewport函数可以返回浏览器窗口的高度和宽度。使用时要注意三个地方:
1)该函数必须在页面加载完毕后运行,否则还没有生成文档对象,浏览器会报错。
2)在大多数情况下,document.documentElement.clientWidth 返回正确的值。但是在IE6的quirks模式下,document.body.clientWidth返回正确的值,所以函数中加入了对document模式的判断。
3)clientWidth 和 clientHeight 是只读属性,不能赋值。
三、另一种获取页面大小的方法
网页上的每个元素也有scrollHeight和scrollWidth属性,它们指的是包括滚动条在内的元素的可视区域。
那么,document对象的scrollHeight和scrollWidth属性就是网页的大小,也就是滚动条滚动的所有长度和宽度。
在getViewport() 函数之后,可以编写getPagearea() 函数。
但是,此功能存在问题。如果网页的内容可以在浏览器窗口中完全显示而没有滚动条,那么网页的clientWidth和scrollWidth应该相等。但实际上不同的浏览器有不同的处理,这两个值不一定相等。因此,我们需要取其中较大的值,所以我们需要重写getPagearea()函数。
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
四、获取网页元素的绝对位置
网页元素的绝对位置是指元素的左上角相对于整个网页的左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。所以,只需要将这两个值累加就可以得到元素的绝对坐标。
(图2 offsetTop 和 offsetLeft 属性)
下面两个函数可以用来获取绝对位置的横坐标和纵坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
由于在表格和 iframe 中,offsetParent 对象不一定等于父容器,因此上述功能不适用于表格和 iframe 中的元素。
五、获取网页元素的相对位置
网页元素的相对位置,指的是该元素的左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只要从页面滚动条的滚动距离中减去绝对坐标即可。滚动条的垂直距离是文档对象的 scrollTop 属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
(图 3 scrollTop 和 scrollLeft 属性)
相应地重写上一节中的两个函数:
function getElementViewLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性是可赋值的,并且会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。此外,element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
六、快速获取元素位置的方法
除了上面的功能之外,还有一个快速的方法可以一次获取网页元素的位置。
那就是使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象,left、right、top、bottom,分别对应于元素的左上角和右下角相对于浏览器窗口(视口)左上角的距离。
所以,页面元素的相对位置是
var X= this.getBoundingClientRect().left;
var Y =this.getBoundingClientRect().top;
添加滚动距离以获得绝对位置
var X= this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y =this.getBoundingClientRect().top+document.documentElement.scrollTop;
目前,IE、Firefox 3.0+、Opera 9.5+ 支持此方法,Firefox 2.x、Safari、Chrome、Konqueror 不支持。 查看全部
浏览器抓取网页(Javascript元素在网页上的确切位置教程总结了元素)
在创建网页的过程中,有时您需要知道某个元素在网页上的确切位置。
下面的教程总结了Javascript在网页定位方面的知识。
一、网页大小和浏览器窗口大小
首先,必须澄清两个基本概念。
一个网页的整个区域就是它的大小。通常,网页的大小由内容和 CSS 样式表决定。
浏览器窗口的大小是指在浏览器窗口中看到的网页区域的一部分,也称为视口。
显然,如果网页的内容可以在浏览器窗口中完全显示(即没有滚动条),那么网页的大小和浏览器窗口的大小是相等的。如果不能全部显示,滚动浏览器窗口可以显示网页的各个部分。
二、获取网页大小
网页上的每个元素都有 clientHeight 和 clientWidth 属性。这两个属性指的是元素的内容部分加上内边距所占据的可视区域,不包括边框和滚动条所占据的空间。
(图一clientHeight和clientWidth属性)
因此,文档元素的clientHeight 和clientWidth 属性代表了网页的大小。
function getViewport(){
if (document.compatMode == "BackCompat"){
return {
width: document.body.clientWidth,
height: document.body.clientHeight
}
} else {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
}
}
}
上面的getViewport函数可以返回浏览器窗口的高度和宽度。使用时要注意三个地方:
1)该函数必须在页面加载完毕后运行,否则还没有生成文档对象,浏览器会报错。
2)在大多数情况下,document.documentElement.clientWidth 返回正确的值。但是在IE6的quirks模式下,document.body.clientWidth返回正确的值,所以函数中加入了对document模式的判断。
3)clientWidth 和 clientHeight 是只读属性,不能赋值。
三、另一种获取页面大小的方法
网页上的每个元素也有scrollHeight和scrollWidth属性,它们指的是包括滚动条在内的元素的可视区域。
那么,document对象的scrollHeight和scrollWidth属性就是网页的大小,也就是滚动条滚动的所有长度和宽度。
在getViewport() 函数之后,可以编写getPagearea() 函数。
但是,此功能存在问题。如果网页的内容可以在浏览器窗口中完全显示而没有滚动条,那么网页的clientWidth和scrollWidth应该相等。但实际上不同的浏览器有不同的处理,这两个值不一定相等。因此,我们需要取其中较大的值,所以我们需要重写getPagearea()函数。
function getPagearea(){
if (document.compatMode == "BackCompat"){
return {
width: Math.max(document.body.scrollWidth,
document.body.clientWidth),
height: Math.max(document.body.scrollHeight,
document.body.clientHeight)
}
} else {
return {
width: Math.max(document.documentElement.scrollWidth,
document.documentElement.clientWidth),
height: Math.max(document.documentElement.scrollHeight,
document.documentElement.clientHeight)
}
}
}
四、获取网页元素的绝对位置
网页元素的绝对位置是指元素的左上角相对于整个网页的左上角的坐标。这个绝对位置只能通过计算得到。
首先,每个元素都有offsetTop和offsetLeft属性,表示元素左上角到父容器(offsetParent对象)左上角的距离。所以,只需要将这两个值累加就可以得到元素的绝对坐标。
(图2 offsetTop 和 offsetLeft 属性)
下面两个函数可以用来获取绝对位置的横坐标和纵坐标。
function getElementLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
return actualLeft;
}
function getElementTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current.offsetTop;
current = current.offsetParent;
}
return actualTop;
}
由于在表格和 iframe 中,offsetParent 对象不一定等于父容器,因此上述功能不适用于表格和 iframe 中的元素。
五、获取网页元素的相对位置
网页元素的相对位置,指的是该元素的左上角相对于浏览器窗口左上角的坐标。
有了绝对位置,就很容易得到相对位置,只要从页面滚动条的滚动距离中减去绝对坐标即可。滚动条的垂直距离是文档对象的 scrollTop 属性;滚动条的水平距离是文档对象的 scrollLeft 属性。
(图 3 scrollTop 和 scrollLeft 属性)
相应地重写上一节中的两个函数:
function getElementViewLeft(element){
var actualLeft = element.offsetLeft;
var current = element.offsetParent;
while (current !== null){
actualLeft += current.offsetLeft;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollLeft=document.body.scrollLeft;
} else {
var elementScrollLeft=document.documentElement.scrollLeft;
}
return actualLeft-elementScrollLeft;
}
function getElementViewTop(element){
var actualTop = element.offsetTop;
var current = element.offsetParent;
while (current !== null){
actualTop += current. offsetTop;
current = current.offsetParent;
}
if (document.compatMode == "BackCompat"){
var elementScrollTop=document.body.scrollTop;
} else {
var elementScrollTop=document.documentElement.scrollTop;
}
return actualTop-elementScrollTop;
}
scrollTop 和 scrollLeft 属性是可赋值的,并且会立即自动将网页滚动到相应的位置,因此您可以使用它们来改变网页元素的相对位置。此外,element.scrollIntoView() 方法也有类似的效果,可以让网页元素出现在浏览器窗口的左上角。
六、快速获取元素位置的方法
除了上面的功能之外,还有一个快速的方法可以一次获取网页元素的位置。
那就是使用 getBoundingClientRect() 方法。它返回一个收录四个属性的对象,left、right、top、bottom,分别对应于元素的左上角和右下角相对于浏览器窗口(视口)左上角的距离。
所以,页面元素的相对位置是
var X= this.getBoundingClientRect().left;
var Y =this.getBoundingClientRect().top;
添加滚动距离以获得绝对位置
var X= this.getBoundingClientRect().left+document.documentElement.scrollLeft;
var Y =this.getBoundingClientRect().top+document.documentElement.scrollTop;
目前,IE、Firefox 3.0+、Opera 9.5+ 支持此方法,Firefox 2.x、Safari、Chrome、Konqueror 不支持。
浏览器抓取网页(windows下的chrome浏览器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-14 07:13
问题总结:
在WSL(windows子系统)上调用windows下的chromedriver和chrome浏览器进行自动化测试或爬取网页内容,运行成功。但是有个疑问,代码的运行环境是WSL->Linux,那么chromedriver.exe是在windows还是linux上执行的呢?如果是windows,为什么代码是在linux上执行的?如果exe在linux上执行,那么linux真的可以在windows exe上运行编译,即使是这样,chromedriver如何调用windows下的chrome浏览器……看来windows下运行的可能性更大,但是不符合代码运行环境,请指点!
前言:
在Linux环境下开发Python项目在情理之中,但我对windows情有独钟,所以主要使用windows进行开发。但是项目一般要在ubuntu等Linux服务器下运行,难免会遇到一些问题,比如multiprocessing.JoinableQueue在windows环境下无法阻塞主进程,docker服务也需要windows专业版运行完美,然后出现无法调用linux内核执行corntab定时任务等问题……虽然最好的解决办法是安装ubuntu虚拟机进行开发,或者直接换成mac电脑,但是我以我能折腾永不放弃的态度寻求各种解决方案。
WSL 是我解决这些问题的最大帮助,它的运行和启动速度都比虚拟机快。如果 WSL 能支持 docker daemon 那就更开心了……
配置环境:
在Windows下使用pycharm专业版,使用pycharm的Remote Python Interpreter功能在WSL上调用解释器,再配合Deployment实现代码同步。这样做的目的是在Windows下编辑代码,调试,调用Linux环境,这样需要Linux内核支持的功能也能流畅使用
如果你打算直接在WSL上运行写好的代码,看看WSL如何在windows上调用chromedriver和chrome浏览器,那么配置pycharm的方法可以直接跳过,直接进行下面的操作。
配置方式:/pipisorry/article/details/52269952
需要注意的是,WSL与windows共享ip和port,所以需要更改WSL的ssh端口,vim /etc/ssh/sshd_config,把Port改成你想要的端口,我改成23, exit wsl 然后重新打开WSL,sudo service ssh start,前提是你已经安装了ssh,而且Pycharm中的配置端口也要改成你改的那个,我用的IP是127.0.0.1,避免因局域网IP变化而导致重复配置的问题。说明为什么需要修改端口号,因为windows上的ssh使用的是22端口,同时也使用了WSL,所以会有冲突。
配置后的图片:注意Path mappings,如果执行代码告诉你no such dir....,说明你的映射没有设置好,解释器和SFTP的映射应该设置正确。另外,运行代码前请确认代码已经同步,因为运行的代码其实就是WSL上的代码,可以设置代码自动同步或者保存时同步。
破坏行动:
正题开始,佩服我的脑洞,能想到这种操作……
首先,下载windows下的chromedriver.exe文件,放到windows下Python解释器安装目录下的scripts文件中。下载地址:
/mirrors/chromedriver 下载最新版本
下载最新的chrome浏览器,我的是64位的
我们开始检查效果,先确认两个软件都可以,测试方法:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="C:/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe")
driver.get("")
打印(driver.page_source)
driver.quit()
选择windows下的python解释器,运行上面的代码,看看浏览器是否调用成功,是否打印结果,是否正常退出,
正常情况下应该没问题的。
如果您使用Pycharm的远程功能将解释器替换为WSL上的解释器,请确认代码是否运行成功,并确保配置正常后再继续。
如果直接从 WSL 命令行启动程序,则直接继续。
执行代码:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="/mnt/c/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe") # mnt目录为文件共享目录, 子系统可以访问windows文件
driver.get("")
打印(driver.page_source)
driver.quit()
按理说应该是chrome调用成功了,一切正常。
最坏的情况应该是调用了chrome但是没有postscript,并且没有退出,那么请手动退出,请检查你的任务管理器,如果有名为chromedriver的进程请关闭,然后检查你的WSL,是否正常,是否有错误信息,如果有,请退出WSL。再次执行代码。我的一直正常。 查看全部
浏览器抓取网页(windows下的chrome浏览器(组图))
问题总结:
在WSL(windows子系统)上调用windows下的chromedriver和chrome浏览器进行自动化测试或爬取网页内容,运行成功。但是有个疑问,代码的运行环境是WSL->Linux,那么chromedriver.exe是在windows还是linux上执行的呢?如果是windows,为什么代码是在linux上执行的?如果exe在linux上执行,那么linux真的可以在windows exe上运行编译,即使是这样,chromedriver如何调用windows下的chrome浏览器……看来windows下运行的可能性更大,但是不符合代码运行环境,请指点!
前言:
在Linux环境下开发Python项目在情理之中,但我对windows情有独钟,所以主要使用windows进行开发。但是项目一般要在ubuntu等Linux服务器下运行,难免会遇到一些问题,比如multiprocessing.JoinableQueue在windows环境下无法阻塞主进程,docker服务也需要windows专业版运行完美,然后出现无法调用linux内核执行corntab定时任务等问题……虽然最好的解决办法是安装ubuntu虚拟机进行开发,或者直接换成mac电脑,但是我以我能折腾永不放弃的态度寻求各种解决方案。
WSL 是我解决这些问题的最大帮助,它的运行和启动速度都比虚拟机快。如果 WSL 能支持 docker daemon 那就更开心了……
配置环境:
在Windows下使用pycharm专业版,使用pycharm的Remote Python Interpreter功能在WSL上调用解释器,再配合Deployment实现代码同步。这样做的目的是在Windows下编辑代码,调试,调用Linux环境,这样需要Linux内核支持的功能也能流畅使用
如果你打算直接在WSL上运行写好的代码,看看WSL如何在windows上调用chromedriver和chrome浏览器,那么配置pycharm的方法可以直接跳过,直接进行下面的操作。
配置方式:/pipisorry/article/details/52269952
需要注意的是,WSL与windows共享ip和port,所以需要更改WSL的ssh端口,vim /etc/ssh/sshd_config,把Port改成你想要的端口,我改成23, exit wsl 然后重新打开WSL,sudo service ssh start,前提是你已经安装了ssh,而且Pycharm中的配置端口也要改成你改的那个,我用的IP是127.0.0.1,避免因局域网IP变化而导致重复配置的问题。说明为什么需要修改端口号,因为windows上的ssh使用的是22端口,同时也使用了WSL,所以会有冲突。
配置后的图片:注意Path mappings,如果执行代码告诉你no such dir....,说明你的映射没有设置好,解释器和SFTP的映射应该设置正确。另外,运行代码前请确认代码已经同步,因为运行的代码其实就是WSL上的代码,可以设置代码自动同步或者保存时同步。
破坏行动:
正题开始,佩服我的脑洞,能想到这种操作……
首先,下载windows下的chromedriver.exe文件,放到windows下Python解释器安装目录下的scripts文件中。下载地址:
/mirrors/chromedriver 下载最新版本
下载最新的chrome浏览器,我的是64位的
我们开始检查效果,先确认两个软件都可以,测试方法:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="C:/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe")
driver.get("")
打印(driver.page_source)
driver.quit()
选择windows下的python解释器,运行上面的代码,看看浏览器是否调用成功,是否打印结果,是否正常退出,
正常情况下应该没问题的。
如果您使用Pycharm的远程功能将解释器替换为WSL上的解释器,请确认代码是否运行成功,并确保配置正常后再继续。
如果直接从 WSL 命令行启动程序,则直接继续。
执行代码:
从硒导入网络驱动程序
driver = webdriver.Chrome(executable_path="/mnt/c/Program Files (x86)/Microsoft Visual Studio/Shared/Python36_64/Scripts/chromedriver.exe") # mnt目录为文件共享目录, 子系统可以访问windows文件
driver.get("")
打印(driver.page_source)
driver.quit()
按理说应该是chrome调用成功了,一切正常。
最坏的情况应该是调用了chrome但是没有postscript,并且没有退出,那么请手动退出,请检查你的任务管理器,如果有名为chromedriver的进程请关闭,然后检查你的WSL,是否正常,是否有错误信息,如果有,请退出WSL。再次执行代码。我的一直正常。
浏览器抓取网页(浏览器怎么查看浏览过的本地缓存Cookie和网站数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-13 04:19
浏览器如何查看我浏览的本地缓存的cookies和网站数据?当我们使用浏览器上网时,会产生一定的数据。
网页cookie查询方法如下:介绍一种在chrome浏览器中查看cookie的快捷方式:通过快捷键Ctrl+Shift+Delete,。
csdn为您找到了在手机浏览器上查看cookies的相关内容,包括代码介绍和手机浏览器上查看cookie相关文档的相关教程。
如何查看手机浏览器cookies?移动浏览器的 cookie 设置用于确定使用哪些解锁第三方 cookie 和 网站 数据6。 .
手机浏览器cookie查看的信息由阿里云开发者社区整理,为您提供页面跳转中cookie丢失及cname验证相关信息。
查看所有手机查看所有智能硬件线下体验店官方授权的在线商店我们会使用cookies等相关技术使这个网站正常运行,分析流量,优化您的浏览体验。继续浏览此 网站,即表示您同意使用这些 cookie。阅读更多。
为您提供最佳体验的 Cookie、网站流量分析和社交媒体功能。 Cookie 政策提供了有关我们如何使用 Cookie 的详细信息。点击“同意”即表示您同意我们使用 cookie,请参阅我们的隐私政策了解更多信息。 .
一个网站如何判断用户何时登录,将查询条件从前台传递到后台,存储在cookie中,并将查询添加到响应对象中。
手机如何获取浏览器的cookies?选择设置然后看到高级选项栏,选择网站设置,选择cookies进入查看。
在 cookie 选项中查看“所有 cookie 和 网站 数据”。找到你要查看的网站,然后根据key值查看cookie内容:. 查看全部
浏览器抓取网页(浏览器怎么查看浏览过的本地缓存Cookie和网站数据?)
浏览器如何查看我浏览的本地缓存的cookies和网站数据?当我们使用浏览器上网时,会产生一定的数据。
网页cookie查询方法如下:介绍一种在chrome浏览器中查看cookie的快捷方式:通过快捷键Ctrl+Shift+Delete,。
csdn为您找到了在手机浏览器上查看cookies的相关内容,包括代码介绍和手机浏览器上查看cookie相关文档的相关教程。
如何查看手机浏览器cookies?移动浏览器的 cookie 设置用于确定使用哪些解锁第三方 cookie 和 网站 数据6。 .
手机浏览器cookie查看的信息由阿里云开发者社区整理,为您提供页面跳转中cookie丢失及cname验证相关信息。
查看所有手机查看所有智能硬件线下体验店官方授权的在线商店我们会使用cookies等相关技术使这个网站正常运行,分析流量,优化您的浏览体验。继续浏览此 网站,即表示您同意使用这些 cookie。阅读更多。
为您提供最佳体验的 Cookie、网站流量分析和社交媒体功能。 Cookie 政策提供了有关我们如何使用 Cookie 的详细信息。点击“同意”即表示您同意我们使用 cookie,请参阅我们的隐私政策了解更多信息。 .
一个网站如何判断用户何时登录,将查询条件从前台传递到后台,存储在cookie中,并将查询添加到响应对象中。
手机如何获取浏览器的cookies?选择设置然后看到高级选项栏,选择网站设置,选择cookies进入查看。
在 cookie 选项中查看“所有 cookie 和 网站 数据”。找到你要查看的网站,然后根据key值查看cookie内容:.
浏览器抓取网页(网页信息的批量分析与抓取,感觉还是有一些体会的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-13 03:31
最近在研究网页信息的批量分析和爬取,还是有一些经验的。
我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只需使用带有网站地址和正则表达式的MSHTML,就可以远程抓取网页连接、内容等信息。好像在网上看一些文章,搜索引擎的基本功能都可以这样实现。最近还看到了一个Zpoo漫游网的例子(),他们可以抓取163相册的图片地址(本来有一个可以批量下载163相册的工具,但是163改版后,无法使用)。但是,以上一切都必须基于一个前提,即网页不需要认证,不需要用户名和密码。.net中的net库中有一些类为webclient、webrequest等提供http访问服务,但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能我没用过对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。
但是既然浏览器端可以访问,我们就有办法了。所以我想到了webbrowser控件。大致思路是先用webbrowser连接网页(登录验证问题可以在webbrowser中解决),解压连接后,继续请求相同网站的其他页面,验证通过由网页浏览器完成,以便批量提取。至于在线抓包,还是先下载数据再抓包。有区别。今天就写到这里,下次继续。 查看全部
浏览器抓取网页(网页信息的批量分析与抓取,感觉还是有一些体会的)
最近在研究网页信息的批量分析和爬取,还是有一些经验的。
我们知道网页程序的设计可以分为静态网页和动态网页。静态网页基本都是纯html,动态网页在服务器端执行,结果返回浏览器端。从某种意义上说,本地浏览器中的网页都是静态的。对于不需要验证的打开网页,只需使用带有网站地址和正则表达式的MSHTML,就可以远程抓取网页连接、内容等信息。好像在网上看一些文章,搜索引擎的基本功能都可以这样实现。最近还看到了一个Zpoo漫游网的例子(),他们可以抓取163相册的图片地址(本来有一个可以批量下载163相册的工具,但是163改版后,无法使用)。但是,以上一切都必须基于一个前提,即网页不需要认证,不需要用户名和密码。.net中的net库中有一些类为webclient、webrequest等提供http访问服务,但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能我没用过对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。但功能有限。如果要在连接后这样写: 连接一个地址获取信息是不可行的,不知道哪位高手有什么解决办法,可能是我没有使用对应的类库,少走弯路。
但是既然浏览器端可以访问,我们就有办法了。所以我想到了webbrowser控件。大致思路是先用webbrowser连接网页(登录验证问题可以在webbrowser中解决),解压连接后,继续请求相同网站的其他页面,验证通过由网页浏览器完成,以便批量提取。至于在线抓包,还是先下载数据再抓包。有区别。今天就写到这里,下次继续。
浏览器抓取网页( 谷歌浏览器驱动获取网页节点的方法和常用方法表 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-12 03:21
谷歌浏览器驱动获取网页节点的方法和常用方法表
)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build)(x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如下图:
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件路径相同)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
提取的编著信息如下:
明日科技 著
提取的价格信息如下:
京 东 价
¥ 72.00 [9.03折] [定价 ¥79.80]
selenium 模块常用方法 selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
明日科技 著
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
https://book.jd.com/writer/%25 ... .html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
1. driver.close():关闭当前页面
2. driver.quit():退出整个浏览器 查看全部
浏览器抓取网页(
谷歌浏览器驱动获取网页节点的方法和常用方法表
)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build)(x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如下图:
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件路径相同)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
提取的编著信息如下:
明日科技 著
提取的价格信息如下:
京 东 价
¥ 72.00 [9.03折] [定价 ¥79.80]
selenium 模块常用方法 selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的商品标题如下:
零基础学Python(Python3.9全彩版)(编程入门 项目实践 同步视频)
提取的商品宣传语如下:
彩色代码更易学。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习。赠全程视频+源码+课后题+实物挂图+学习应用地图+电子书+图书答疑
明日科技 著
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
https://book.jd.com/writer/%25 ... .html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
1. driver.close():关闭当前页面
2. driver.quit():退出整个浏览器
浏览器抓取网页(网页默认运行IE需手动查看路径,对于身边被一键操作惯坏 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-12 03:20
)
一般情况下,bat默认打开一个网页,运行IE。如果要调用其他浏览器,在线的方法是:
start "C:\Program Files\Maxthon\Bin\Maxthon.exe" "www.baidu.com"
不过浏览器因人而异,需要手动查看路径。对于被一键操作宠坏,说什么都说“听不懂”的朋友,需要帮助他们进行网页操作。
最好是读取注册表来实现,步骤如下:
注册表“HKEY_CLASSES_ROOT\http\shell\open\command”有默认浏览器路径,如图
查看关于reg的命令说明就知道可以使用QUERY命令查询注册表键值
尝试输入“reg query HKEY_CLASSES_ROOT\http\shell\open\command”并获取:
至此,for循环加条件读取变量,这里用tokens:默认用空格隔开
根据查询结果,第3列+第4列=浏览器路径(C:\Program + Files\Maxthon\Bin\Maxthon.exe)
¤ 由于空格是分隔符,所以需要自己填充
完整代码:
@echo off
for /f "tokens=3,4" %%a in ('"reg query HKEY_CLASSES_ROOT\http\shell\open\command"') do (set SoftWareRoot=%%a %%b)
::输入地址
set /p url=Enter url:
::打开网页,之后进行后续操作
start % SoftWareRoot % %url% 查看全部
浏览器抓取网页(网页默认运行IE需手动查看路径,对于身边被一键操作惯坏
)
一般情况下,bat默认打开一个网页,运行IE。如果要调用其他浏览器,在线的方法是:
start "C:\Program Files\Maxthon\Bin\Maxthon.exe" "www.baidu.com"
不过浏览器因人而异,需要手动查看路径。对于被一键操作宠坏,说什么都说“听不懂”的朋友,需要帮助他们进行网页操作。
最好是读取注册表来实现,步骤如下:
注册表“HKEY_CLASSES_ROOT\http\shell\open\command”有默认浏览器路径,如图
查看关于reg的命令说明就知道可以使用QUERY命令查询注册表键值
尝试输入“reg query HKEY_CLASSES_ROOT\http\shell\open\command”并获取:
至此,for循环加条件读取变量,这里用tokens:默认用空格隔开
根据查询结果,第3列+第4列=浏览器路径(C:\Program + Files\Maxthon\Bin\Maxthon.exe)
¤ 由于空格是分隔符,所以需要自己填充
完整代码:
@echo off
for /f "tokens=3,4" %%a in ('"reg query HKEY_CLASSES_ROOT\http\shell\open\command"') do (set SoftWareRoot=%%a %%b)
::输入地址
set /p url=Enter url:
::打开网页,之后进行后续操作
start % SoftWareRoot % %url%
浏览器抓取网页( 零基础快速入门的学习路径——先说一下技术能干什么事儿 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2022-02-11 21:07
零基础快速入门的学习路径——先说一下技术能干什么事儿
)
我不会谈论爬行动物目前的流行程度。先说一下这个技术能做什么,主要有以下三个方面:
1.为市场研究和业务分析抓取数据
爬取知乎、豆瓣等优质话题内容网站;掌握房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析;抓取招聘网站职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
在游戏中抓取精美图片,获取图片资源和评论文字数据。
掌握正确的方法,在短时间内爬取主流的网站数据其实很容易。
但是,建议您从一开始就有一个特定的目标。在目标的驱动下,你的学习会更加准确和高效。下面是一个流畅的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2.实现简单的信息爬取
3.特殊网站反爬虫措施
4.Scrapy 和高级分布式
01 了解爬虫是如何实现的
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单的了解HTTP协议和网页的基础知识,如POST\GET、HTML、CSS、JS等,通俗易懂,不需要系统学习。
02 实现简单的信息爬取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路大同小异,一般的静态网站完全没问题,还有知乎、豆瓣等公开信息网站@ > 可以爬下来。
当然,如果需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium自动爬取。这样一来,知乎、Mtime和TripAdvisor等动态爬虫网站几乎没有问题。
你还需要了解Python的基础知识,比如:文件读写操作:用于读取参数、保存爬取内容列表(list)、dict(字典):用于序列化爬取数据条件判断(if/else):解决爬虫中判断是否执行循环和迭代(for...while):用于循环爬虫步骤
03 特殊网站的防爬机制
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬方式,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析网页加载信息,经常会得到意想不到的结果。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
04 Scrapy和高级分布式
使用requests+xpath和抓包确实可以解决很多网站信息的爬取,但是如果信息量比较大或者需要分模块爬取的话,就很难做任何事情了。
后来应用到强大的Scrapy框架中,不仅可以轻松构造Request,还可以通过强大的Selector轻松解析Response。不过,最让人惊喜的是它的超高性能,可以对爬虫进行工程化和模块化。
我学习了 Scrapy,并尝试自己构建一个简单的爬虫框架。在做大规模数据爬虫的时候,我可以用结构化、工程化的方式去思考大规模的爬虫问题,这让我可以从爬虫工程的角度去思考问题。
后来,我开始逐渐接触到分布式爬虫。这个东西听起来很虚张声势,但其实它利用多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个之后,基本上可以说自己是个爬虫老司机了。这对于外行来说很难,但并不那么复杂。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,可以保证每次学习都是零件这是最需要的。
当然,唯一麻烦的是,在具体问题中,如何找到具体需要的部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径外,我们精选了最实用的学习资源和庞大的主流爬虫案例库。经过短暂的学习,你就能很好地掌握爬虫技巧,得到你想要的数据。
扫描上方二维码立即购买
限时特价99元,每100人买10元
课程大纲
高效的学习路径
从一开始就讲理论、语法和编程语言是非常不合理的。我们将直接从具体案例入手,通过实际操作学习具体知识点。我们为您规划了系统的学习路径,让您不再面对零散的知识点。
例如,我们会直接教你网页解析,减少你检查网页元素的不必要操作。这些看似细节,但可能是很多人会踩的坑。
20+实际案例学习实践
- 案例多,覆盖主流网站 -
课程中提供了最常见的网站爬虫案例:豆瓣、知乎、瓜子二手车、赶集网、链家网、王者荣耀……每个案例都在课程视频。老师带你走遍每一步操作,专攻各种“懂案例,但不会写代码”。
项目一:赶集网络实战项目
学习使用正则表达式从整个网页中提取数据。
项目二:王者荣耀之战项目
1、破解王者荣耀高清壁纸下载链接。
2、使用多线程高速下载高清壁纸。
3、根据英雄名称存放对应的壁纸。
项目三:链家网分布式爬虫
1、使用Scrapy框架实现商业爬虫。
2、使用多台机器实现分布式爬虫。
3、实现全国各省市二手房信息的爬取。
4、将爬取的数据存储在redis中。
导师
黄勇先生
黄先生拥有多年实际开发经验,擅长Python、C、C++、前端、iOS等技术语言,先后开发了多家大型企业网站与Python,并从零开始构建分布式爬虫架构。目前专注于Python领域的课程开发和教学,曾为网易、360、华为等多家大公司的员工提供Python技术培训,具有丰富的实践和教学经验。
【课程信息】
“ 课程名称”
《从零开始,系统掌握Python网络爬虫》
“学习周期”
建议每周至少学习8小时,并在一个月内完成课程
“课堂形式”
课程录播,随时开课,反复观看
“为了群众”
零基础的新手,还是基础薄弱的工程师
《问答表》
学习小组老师随时回答问题,即使是最基本的问题
#限量优惠#
限99元
(原价599)
每100个购买10元
140多门课程,平均每门课1元,坚持一个月,系统掌握Python进阶
查看全部
浏览器抓取网页(
零基础快速入门的学习路径——先说一下技术能干什么事儿
)
我不会谈论爬行动物目前的流行程度。先说一下这个技术能做什么,主要有以下三个方面:
1.为市场研究和业务分析抓取数据
爬取知乎、豆瓣等优质话题内容网站;掌握房地产网站买卖信息,分析房价变化趋势,做不同区域的房价分析;抓取招聘网站职位信息,分析各行业人才需求及薪资水平。
2.作为机器学习和数据挖掘的原创数据
比如你想做一个推荐系统,那么你可以爬取更多维度的数据,做出更好的模型。
3.爬取优质资源:图片、文字、视频
在游戏中抓取精美图片,获取图片资源和评论文字数据。
掌握正确的方法,在短时间内爬取主流的网站数据其实很容易。
但是,建议您从一开始就有一个特定的目标。在目标的驱动下,你的学习会更加准确和高效。下面是一个流畅的、从零开始的快速入门学习路径:
1.了解爬虫是如何实现的
2.实现简单的信息爬取
3.特殊网站反爬虫措施
4.Scrapy 和高级分布式
01 了解爬虫是如何实现的
大多数爬虫遵循“发送请求-获取页面-解析页面-提取并存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
这部分可以简单的了解HTTP协议和网页的基础知识,如POST\GET、HTML、CSS、JS等,通俗易懂,不需要系统学习。
02 实现简单的信息爬取
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。提取数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。掌握之后你会发现爬虫的基本套路大同小异,一般的静态网站完全没问题,还有知乎、豆瓣等公开信息网站@ > 可以爬下来。
当然,如果需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium自动爬取。这样一来,知乎、Mtime和TripAdvisor等动态爬虫网站几乎没有问题。
你还需要了解Python的基础知识,比如:文件读写操作:用于读取参数、保存爬取内容列表(list)、dict(字典):用于序列化爬取数据条件判断(if/else):解决爬虫中判断是否执行循环和迭代(for...while):用于循环爬虫步骤
03 特殊网站的防爬机制
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬方式,当然需要一些高级技巧来应对,比如访问频率控制、代理IP池的使用、抓包、验证码的OCR处理等等。
比如我们经常会发现有些网站的url在翻页后没有变化,这通常是异步加载。我们使用开发者工具分析网页加载信息,经常会得到意想不到的结果。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
04 Scrapy和高级分布式
使用requests+xpath和抓包确实可以解决很多网站信息的爬取,但是如果信息量比较大或者需要分模块爬取的话,就很难做任何事情了。
后来应用到强大的Scrapy框架中,不仅可以轻松构造Request,还可以通过强大的Selector轻松解析Response。不过,最让人惊喜的是它的超高性能,可以对爬虫进行工程化和模块化。
我学习了 Scrapy,并尝试自己构建一个简单的爬虫框架。在做大规模数据爬虫的时候,我可以用结构化、工程化的方式去思考大规模的爬虫问题,这让我可以从爬虫工程的角度去思考问题。
后来,我开始逐渐接触到分布式爬虫。这个东西听起来很虚张声势,但其实它利用多线程的原理,让多个爬虫同时工作,可以达到更高的效率。
其实学了这个之后,基本上可以说自己是个爬虫老司机了。这对于外行来说很难,但并不那么复杂。
因为爬虫的技术不需要你系统地精通一门语言,也不需要拥有先进的数据库技术,高效的姿势就是从实际项目中学习这些零散的知识点,可以保证每次学习都是零件这是最需要的。
当然,唯一麻烦的是,在具体问题中,如何找到具体需要的部分学习资源,如何筛选筛选,是很多初学者面临的一大难题。
不过不用担心,我们准备了非常系统的爬虫课程。除了为您提供清晰的学习路径外,我们精选了最实用的学习资源和庞大的主流爬虫案例库。经过短暂的学习,你就能很好地掌握爬虫技巧,得到你想要的数据。
扫描上方二维码立即购买
限时特价99元,每100人买10元
课程大纲
高效的学习路径
从一开始就讲理论、语法和编程语言是非常不合理的。我们将直接从具体案例入手,通过实际操作学习具体知识点。我们为您规划了系统的学习路径,让您不再面对零散的知识点。
例如,我们会直接教你网页解析,减少你检查网页元素的不必要操作。这些看似细节,但可能是很多人会踩的坑。
20+实际案例学习实践
- 案例多,覆盖主流网站 -
课程中提供了最常见的网站爬虫案例:豆瓣、知乎、瓜子二手车、赶集网、链家网、王者荣耀……每个案例都在课程视频。老师带你走遍每一步操作,专攻各种“懂案例,但不会写代码”。
项目一:赶集网络实战项目
学习使用正则表达式从整个网页中提取数据。
项目二:王者荣耀之战项目
1、破解王者荣耀高清壁纸下载链接。
2、使用多线程高速下载高清壁纸。
3、根据英雄名称存放对应的壁纸。
项目三:链家网分布式爬虫
1、使用Scrapy框架实现商业爬虫。
2、使用多台机器实现分布式爬虫。
3、实现全国各省市二手房信息的爬取。
4、将爬取的数据存储在redis中。
导师
黄勇先生
黄先生拥有多年实际开发经验,擅长Python、C、C++、前端、iOS等技术语言,先后开发了多家大型企业网站与Python,并从零开始构建分布式爬虫架构。目前专注于Python领域的课程开发和教学,曾为网易、360、华为等多家大公司的员工提供Python技术培训,具有丰富的实践和教学经验。
【课程信息】
“ 课程名称”
《从零开始,系统掌握Python网络爬虫》
“学习周期”
建议每周至少学习8小时,并在一个月内完成课程
“课堂形式”
课程录播,随时开课,反复观看
“为了群众”
零基础的新手,还是基础薄弱的工程师
《问答表》
学习小组老师随时回答问题,即使是最基本的问题
#限量优惠#
限99元
(原价599)
每100个购买10元
140多门课程,平均每门课1元,坚持一个月,系统掌握Python进阶
浏览器抓取网页(来说一下如何获取浏览器相关的信息,获取元素的标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-11 02:19
上一节讲了如何使用获取到的元素来获取元素信息。这次来说说如何获取浏览器相关信息,主要是页面的路径:URL和页面标题
一、如何获取页面相关信息
current_url : 当前页面的 URL 路径
title:当前页面的标题名称
名称:当前浏览器名称
page_source:当前html页面的源代码
前两个比较常用,可能会用到,比如url是用来判断页面跳转后的;页面标题也是检测的一个测试点。
接下来,我们将使用百度贴吧页面来演示这些常用方法
二、演示示例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://tieba.baidu.com/")
# 获取当前页面的URL
url_page = driver.current_url
# 获取当前页面的title
title_page = driver.title
# 获取当前浏览器的名称
name_browser = driver.name
# 获取当前页面的html源码
source_html = driver.page_source
print(url_page)
print(title_page)
print(name_browser)
print(source_html)
三、结果
/
百度贴吧——全球最大的华人社区
铬合金 查看全部
浏览器抓取网页(来说一下如何获取浏览器相关的信息,获取元素的标题)
上一节讲了如何使用获取到的元素来获取元素信息。这次来说说如何获取浏览器相关信息,主要是页面的路径:URL和页面标题
一、如何获取页面相关信息
current_url : 当前页面的 URL 路径
title:当前页面的标题名称
名称:当前浏览器名称
page_source:当前html页面的源代码
前两个比较常用,可能会用到,比如url是用来判断页面跳转后的;页面标题也是检测的一个测试点。
接下来,我们将使用百度贴吧页面来演示这些常用方法
二、演示示例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://tieba.baidu.com/";)
# 获取当前页面的URL
url_page = driver.current_url
# 获取当前页面的title
title_page = driver.title
# 获取当前浏览器的名称
name_browser = driver.name
# 获取当前页面的html源码
source_html = driver.page_source
print(url_page)
print(title_page)
print(name_browser)
print(source_html)
三、结果
/
百度贴吧——全球最大的华人社区
铬合金
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-10 18:28
无论是平时工作中,还是休闲生活中,我们都会遇到需要截图的情况。因为有些东西说不出来,直接截图简单明了,很直观。在使用手机的时候,我们都知道怎么截图,在使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器进行截图时,我们往往只能对当前屏幕上显示的内容进行截图。如果我们想对这个网页上的所有内容进行截图,我们的大多数朋友一定不知道怎么做。操作,今天小编就教大家如何使用QQ浏览器对整个网页进行截图,这样就可以实现手机滚动截图一样的方式,截图页面中的所有内容。具体方法如下:
第一步,打开电脑上的QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按下键盘上的F12键,调出浏览器的开发者工具。Windows 计算机也可以通过按快捷键组合 Ctrl+Shift+I 来执行此操作,而 Mac 计算机可以通过按快捷键组合 Alt+Command+I 来执行此操作。
第四步,在浏览器的开发者工具中,我们通过按Ctrl+Shift+P(Windows)或Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行中输入“screen”。这时候,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的意思,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的全部内容并进行截图,请选择 Capture full size screenshot。
如果我们想获取元素节点网页的内容并截图,选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器截图的内容。如果你经常一张一张的截图网页,那么不妨学习一下这篇文章中提到的技巧,这样以后就算有人让你发整个网页的截图,你也可以在五个简单的步骤。不用下拉屏幕截图,也不用担心下拉再截图。一键捕获所有内容更容易,更方便。 查看全部
浏览器抓取网页(如何使用QQ浏览器来获取整个网页截图的所有内容?)
无论是平时工作中,还是休闲生活中,我们都会遇到需要截图的情况。因为有些东西说不出来,直接截图简单明了,很直观。在使用手机的时候,我们都知道怎么截图,在使用浏览器的时候,我们也知道怎么用快捷键来截图。
但是,在使用浏览器进行截图时,我们往往只能对当前屏幕上显示的内容进行截图。如果我们想对这个网页上的所有内容进行截图,我们的大多数朋友一定不知道怎么做。操作,今天小编就教大家如何使用QQ浏览器对整个网页进行截图,这样就可以实现手机滚动截图一样的方式,截图页面中的所有内容。具体方法如下:
第一步,打开电脑上的QQ浏览器。
第二步,进入QQ浏览器界面后,打开需要截图的网页。
第三步,网页内容全部加载完毕后,我们在浏览器当前界面按下键盘上的F12键,调出浏览器的开发者工具。Windows 计算机也可以通过按快捷键组合 Ctrl+Shift+I 来执行此操作,而 Mac 计算机可以通过按快捷键组合 Alt+Command+I 来执行此操作。
第四步,在浏览器的开发者工具中,我们通过按Ctrl+Shift+P(Windows)或Command+Shift+P(Mac)快捷键组合打开命令行。
第五步,浏览器的命令行打开后,我们在命令行中输入“screen”。这时候,我们可以在命令行中看到三个关于screen的选项。其中,Capture full size screenshot代表整个网页的意思,Capture node screenshot代表节点网页的含义,Capture screenshot代表当前屏幕的含义,我们可以根据不同的需求进行选择。
如果我们想获取整个网页的全部内容并进行截图,请选择 Capture full size screenshot。
如果我们想获取元素节点网页的内容并截图,选择Capture node screenshot。
如果我们想获取当前屏幕的内容并进行截图,选择Capture screenshot。
以上就是小编为大家总结的关于使用QQ浏览器截图的内容。如果你经常一张一张的截图网页,那么不妨学习一下这篇文章中提到的技巧,这样以后就算有人让你发整个网页的截图,你也可以在五个简单的步骤。不用下拉屏幕截图,也不用担心下拉再截图。一键捕获所有内容更容易,更方便。
浏览器抓取网页( 零基础学Python(Python3.exe)下载驱动下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-10 17:19
零基础学Python(Python3.exe)下载驱动下载)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build) (x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如图以下:
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件同级路径)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
提取的创作信息如下:
明天的技术
提取的价格信息如下:
京东价格
¥72.00 [9.03% off] [价格¥79.80]
selenium模块的常用方法
selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
明天的技术
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80_1.html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
driver.close():关闭当前页面
driver.quit():退出整个浏览器
这是文章关于使用selenium+chromedriver+xpath爬取动态加载信息的介绍。更多相关selenium chromedriver xpath爬取内容,请搜索编程宝库往期文章,希望以后支持编程宝库!
下一节:pycharm如何为函数插入文档注释 Python编程技术
S1 将光标放在功能名称上,点击灯泡,出现菜单。S2 选择输入文档字符串存根,它插入文档注释。S3对每个参数的输入函数注解,返回值注解pycha... 查看全部
浏览器抓取网页(
零基础学Python(Python3.exe)下载驱动下载)
使用selenium+chromedriver+xpath爬取动态加载信息
使用 selenium 实现动态渲染页面的爬取。Selenium 是一个浏览器自动化测试框架。它是用于 Web 应用程序测试的工具。它可以直接在浏览器中运行,可以驱动浏览器执行指定的动作,比如点击、下拉、填充数据、删除cookies等操作,还可以获取浏览器当前页面的源码,就像用户在浏览器中操作。该工具支持的浏览器包括 Internet Explorer、Mozilla Firefox 和 Google Chrome。
安装硒模块
首先打开Anaconda Prompt(Anaconda)命令行窗口,然后输入“pip install selenium”命令(如果没有安装Anaconda,可以在cmd命令行窗口执行命令安装模块),然后按回车键) 键,如下图:
操作说明
Selenium 有很多语言版本,例如:Java、Ruby、Python 等。
下载浏览器驱动
selenium模块安装完成后,需要选择浏览器,然后下载对应的浏览器驱动。这时候就可以通过selenium模块来控制浏览器的运行了。这里选择Chrome浏览器Version 98.0.4758.80 (Official Build) (x86_64),然后在()Google Chrome Driver中下载浏览器驱动。如图以下:
操作说明
下载谷歌浏览器驱动时,请根据您的电脑系统下载相应的浏览器驱动。
使用硒模块
谷歌浏览器驱动下载完成后,将名为chromedriver.exe的文件拖放到/usr/bin目录下(与python.exe文件同级路径)。然后需要通过Python代码加载谷歌浏览器驱动,这样就可以启动浏览器驱动,控制浏览器了。
不同的浏览器有不同的驱动程序。下表列出了不同的浏览器及其对应的驱动程序,如下表所示:
浏览器DriverLink
铬合金
铬驱动程序(.exe)
IE浏览器
IEDriverServer.exe
边缘
微软WebDriver.msi
火狐
壁虎驱动程序(.exe)
幻影JS
phantomjs(.exe)
歌剧
操作员(.exe)
苹果浏览器
SafariDriver.safariextz
获取京东商品信息,示例代码如下:
#_*_coding:utf-8_*_
# 作者 :liuxiaowei
# 创建时间 :2/7/22 6:43 PM
# 文件 :获取京东商品信息.py
# IDE :PyCharm
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
#from selenium.webdriver.chrome.service import Service
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver')
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"w")))
# 获取name节点中所有div节点
name_div1 = driver.find_element(By.XPATH,'//div[@class="sku-name"]')
name_div2 = driver.find_element(By.XPATH, '//div[@class="news"]/div[@class="item hide"]')
name_div3 = driver.find_element(By.XPATH, '//div[@class="p-author"]')
summary_price = driver.find_element(By.XPATH, '//div[@class="summary-price J-summary-price"]')
print('提取的商品标题如下:')
print(name_div1.text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div2.text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div3.text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text.strip('降价通知')) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
提取的创作信息如下:
明天的技术
提取的价格信息如下:
京东价格
¥72.00 [9.03% off] [价格¥79.80]
selenium模块的常用方法
selenium 模块支持多种获取网页节点的方法,其中比较常用的方法如下:
selenium模块获取网页节点的常用方法及说明
常用方法说明
driver.find_element_by_id()
根据id获取节点,参数为字符类型id对应的值
driver.find_element_by_name()
根据名称获取节点,参数为字符类型名称对应的值
driver.find_element_by_xpath()
根据XPATH获取节点,参数为字符类型XPATH对应的值
driver.find_element_by_link_text()
根据链接文本获取节点,参数为字符类型链接文本
driver.find_element_by_tag_name()
根据节点名称获取节点,参数为字符类型节点文本
driver.find_element_by_class_name()
根据类获取节点,参数为字符类型类对应的值
driver.find_element_by_css_selector()
根据CSS选择器获取节点,参数为字符类型的CSS选择器语法
操作说明
上表中所有获取节点的方法都是获取单个节点的方法。如果需要获取多个满足条件的节点,可以在对应方法的元素后面加s。
除了以上常用的获取节点的方法外,还可以使用driver.find_element()方法获取单个节点,使用driver.find_elements()方法获取多个节点。只是在调用这两个方法时,需要为它们指定by和value参数。by参数表示获取节点的方法,value是获取方法对应的值(可以理解为条件)。示例代码如下:
# 获取商品信息节点中的所有div节点
name_div = driver.find_element(By.XPATH,'//div[@class="itemInfo-wrap"]').find_elements(By.TAG_NAME, 'div')
# 提取并输出单个div节点的内容
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:') # 打印商品宣传语
print(name_div[1].text)
运行程序的结果如下:
提取的产品标题如下:
Python零基础学习(Python3.9全彩版)(编程入门项目实践同步视频)
提取的产品标语如下:
颜色代码更容易学习。Python编程从入门到实践书籍,网络爬虫、游戏开发、数据分析等深度学习全视频+源码+课后题+实物挂图+学习应用图+电子书+书籍问答
明天的技术
操作说明
上述代码中,首先使用find_element()方法获取类值为“itemInfo-warp”的整个节点,然后使用find_elements()方法获取该节点中节点名div的所有节点,最后通过name_div[0].text, name_div[1].text 获取所有div的第一个和第二个div中的文本信息。
以下是By的其他属性和用法
按属性使用
按.ID
表示根据ID值获取对应的单个或多个节点
作者:LINK_TEXT
表示根据链接文本获取对应的单个或多个节点
作者.PARTIAL_LINK_TEXT
表示根据部分链接文本获取对应的单个或多个节点
按名字
根据name值获取对应的单个或多个节点
由.TAG_NAME
根据节点名称获取单个或多个节点
由.CLASS_NAME
根据类值获取单个或多个节点
By.CSS_SELECTOR
根据CSS选择器获取单个或多个节点,对应的值为字符串CSS的位置
由.XPATH
根据By.XPATH获取单个或多个节点,对应值字符串节点位置
当使用 selenium 模块获取节点中某个属性对应的值时,可以使用 get_attribute() 方法来实现。示例代码如下:
# 根据XPath定位获取指定节点中的href地址
href = driver.find_element(By.XPATH, '//div[@id="p-author"]/a').get_attribute('href')
print('指定节点中的地址信息如下:')
运行程序的结果如下:
指定节点中的地址信息如下:
%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80_1.html
总结
这种情况下需要注意的是,加载浏览器驱动,一定要指定chromedriver的路径。语法如下:
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options = chrome_options, executable_path='chromedriver') # 本例驱动与爬虫程序在同一路 径
关闭浏览器页面
driver.close():关闭当前页面
driver.quit():退出整个浏览器
这是文章关于使用selenium+chromedriver+xpath爬取动态加载信息的介绍。更多相关selenium chromedriver xpath爬取内容,请搜索编程宝库往期文章,希望以后支持编程宝库!
下一节:pycharm如何为函数插入文档注释 Python编程技术
S1 将光标放在功能名称上,点击灯泡,出现菜单。S2 选择输入文档字符串存根,它插入文档注释。S3对每个参数的输入函数注解,返回值注解pycha...
浏览器抓取网页(获取浏览器窗口的基本信息获取当前窗口网页标题title)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-10 10:26
一、获取浏览器窗口的基本信息1.获取当前窗口的网页标题
title 属性用于获取当前窗口网页的标题
2.获取当前窗口网页url
current_url 属性用于获取当前窗口网页的url
3.获取当前窗口句柄
current_window_handle 属性用于获取当前窗口的句柄,句柄是窗口的标识符,可用于窗口切换
4.获取所有当前打开窗口的句柄
window_handles 属性用于获取浏览器打开的所有窗口的句柄列表
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5# 预设js代码,打开搜狗网
6js = 'window.open("https://www.sogou.com");'
7# 执行js代码(具体会在下章介绍)
8driver.execute_script(js)
9# 获取当前窗口网页url
10print(driver.current_url)
11# 获取浏览器所有窗口句柄
12print(driver.window_handles)
13# 获取当前窗口句柄
14print(driver.current_window_handle)
15# 获取当前网页的标题
16print(driver.title)
17
18
19
测试输出:
1https://www.baidu.com/
2['CDwindow-00EE4D00ED151A77C5A293867FC4005F', 'CDwindow-C1AFC2E0142E307E78DDDF0625A556EE']
3CDwindow-00EE4D00ED151A77C5A293867FC4005F
4百度一下,你就知道
5
6
二、浏览器打开多个网页时切换窗口
当我们有多个网页窗口时,需要先获取所有的窗口句柄,然后使用switch_to.window(handle)函数来切换窗口。句柄是您要跳转到的窗口的句柄。
**注意:** WebDriver 对象中的 switch_to_window() 方法已被弃用,应使用 switch_to.window(handle) 方法
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5# 打开新窗口搜狗网
6js = 'window.open("https://www.sogou.com");'
7driver.execute_script(js)
8# 获取浏览器所有窗口句柄
9handles = driver.window_handles
10print(handles)
11print("当前网页为:%s" % driver.title)
12# 跳转至第二个窗口,即搜狗网
13driver.switch_to.window(handles[1])
14print("当前网页为:%s" % driver.title)
15
16
输出结果:
1['CDwindow-CB98BE007FA7A8004A9FE60D1AD9F621', 'CDwindow-27928387C7A61447B9BF2FF3AAEF6E49']
2当前网页为:百度一下,你就知道
3当前网页为:搜狗搜索引擎 - 上网从搜狗开始
4
5
三、操作窗口前进、后退、关闭操作1.返回
back() 方法是操作窗口返回一个网页,相当于点击浏览器的返回按钮
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com")
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10
11
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4
5
2.前进
forward() 方法是操作窗口前进一个网页,相当于一个浏览器的前进按钮有一个年龄
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com")
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10driver.forward()
11print("前进,当前窗口:%s" % driver.title)
12
13
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4前进,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
5
6
3.关闭
close() 方法关闭当前窗口
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com")
5# 运行js打开新窗口
6js = 'window.open("https://www.sogou.com")'
7driver.execute_script(js)
8# 打印窗口个数,为2个
9print("关闭窗口前:%s" % driver.window_handles)
10# 关闭当前窗口
11driver.close()
12# 打印窗口个数,为1个
13print("关闭窗口后:%s" % driver.window_handles)
14
15
检测结果:
selenium 运行 js 代码打开新窗口后,如果不执行窗口切换功能,当前窗口仍然是第一个窗口,而不是新打开的窗口。因此,上述示例代码中关闭了百度窗口。
1关闭窗口前:['CDwindow-6176BE40CAE4EEDCEB6171B263C143F3', 'CDwindow-54B78A28638EF41125901E6774936E9A']
2关闭窗口后:['CDwindow-54B78A28638EF41125901E6774936E9A']
3
4
四、切换帧
网页中会有收录子模块的标签。当我们打印源代码时,只会出现主模块的代码,不会出现标签中收录的子网页的源代码。如果我们想获取子模块的代码,可以使用switch_to.frame()方法来切换frame模块。 查看全部
浏览器抓取网页(获取浏览器窗口的基本信息获取当前窗口网页标题title)
一、获取浏览器窗口的基本信息1.获取当前窗口的网页标题
title 属性用于获取当前窗口网页的标题
2.获取当前窗口网页url
current_url 属性用于获取当前窗口网页的url
3.获取当前窗口句柄
current_window_handle 属性用于获取当前窗口的句柄,句柄是窗口的标识符,可用于窗口切换
4.获取所有当前打开窗口的句柄
window_handles 属性用于获取浏览器打开的所有窗口的句柄列表
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5# 预设js代码,打开搜狗网
6js = 'window.open("https://www.sogou.com";);'
7# 执行js代码(具体会在下章介绍)
8driver.execute_script(js)
9# 获取当前窗口网页url
10print(driver.current_url)
11# 获取浏览器所有窗口句柄
12print(driver.window_handles)
13# 获取当前窗口句柄
14print(driver.current_window_handle)
15# 获取当前网页的标题
16print(driver.title)
17
18
19
测试输出:
1https://www.baidu.com/
2['CDwindow-00EE4D00ED151A77C5A293867FC4005F', 'CDwindow-C1AFC2E0142E307E78DDDF0625A556EE']
3CDwindow-00EE4D00ED151A77C5A293867FC4005F
4百度一下,你就知道
5
6
二、浏览器打开多个网页时切换窗口
当我们有多个网页窗口时,需要先获取所有的窗口句柄,然后使用switch_to.window(handle)函数来切换窗口。句柄是您要跳转到的窗口的句柄。
**注意:** WebDriver 对象中的 switch_to_window() 方法已被弃用,应使用 switch_to.window(handle) 方法
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5# 打开新窗口搜狗网
6js = 'window.open("https://www.sogou.com";);'
7driver.execute_script(js)
8# 获取浏览器所有窗口句柄
9handles = driver.window_handles
10print(handles)
11print("当前网页为:%s" % driver.title)
12# 跳转至第二个窗口,即搜狗网
13driver.switch_to.window(handles[1])
14print("当前网页为:%s" % driver.title)
15
16
输出结果:
1['CDwindow-CB98BE007FA7A8004A9FE60D1AD9F621', 'CDwindow-27928387C7A61447B9BF2FF3AAEF6E49']
2当前网页为:百度一下,你就知道
3当前网页为:搜狗搜索引擎 - 上网从搜狗开始
4
5
三、操作窗口前进、后退、关闭操作1.返回
back() 方法是操作窗口返回一个网页,相当于点击浏览器的返回按钮
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com";)
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10
11
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4
5
2.前进
forward() 方法是操作窗口前进一个网页,相当于一个浏览器的前进按钮有一个年龄
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5print("打开第一个网页,当前窗口:%s" % driver.title)
6driver.get("https://www.sogou.com";)
7print("打开新网页,当前窗口:%s" % driver.title)
8driver.back()
9print("后退,当前窗口:%s" % driver.title)
10driver.forward()
11print("前进,当前窗口:%s" % driver.title)
12
13
测试输出:
1打开第一个网页,当前窗口:百度一下,你就知道
2打开新网页,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
3后退,当前窗口:百度一下,你就知道
4前进,当前窗口:搜狗搜索引擎 - 上网从搜狗开始
5
6
3.关闭
close() 方法关闭当前窗口
测试代码:
1# 使用驱动打开浏览器
2driver = webdriver.Chrome("./chromedriver")
3# 打开百度首页
4driver.get("https://www.baidu.com";)
5# 运行js打开新窗口
6js = 'window.open("https://www.sogou.com";)'
7driver.execute_script(js)
8# 打印窗口个数,为2个
9print("关闭窗口前:%s" % driver.window_handles)
10# 关闭当前窗口
11driver.close()
12# 打印窗口个数,为1个
13print("关闭窗口后:%s" % driver.window_handles)
14
15
检测结果:
selenium 运行 js 代码打开新窗口后,如果不执行窗口切换功能,当前窗口仍然是第一个窗口,而不是新打开的窗口。因此,上述示例代码中关闭了百度窗口。
1关闭窗口前:['CDwindow-6176BE40CAE4EEDCEB6171B263C143F3', 'CDwindow-54B78A28638EF41125901E6774936E9A']
2关闭窗口后:['CDwindow-54B78A28638EF41125901E6774936E9A']
3
4
四、切换帧
网页中会有收录子模块的标签。当我们打印源代码时,只会出现主模块的代码,不会出现标签中收录的子网页的源代码。如果我们想获取子模块的代码,可以使用switch_to.frame()方法来切换frame模块。

