
浏览器抓取网页
浏览器抓取网页(SeleniumSelenium驱动Selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-17 06:03
硒
Selenium 是一个web自动化测试工具,最初是为网站自动化测试而开发的,就像一个玩游戏的按钮向导,可以根据指定的命令自动操作。
Selenium 测试工具直接操作浏览器,就像真正的用户一样。Selenium 可以让浏览器根据指令自动加载页面,获取需要的数据,甚至对页面进行截图,或者判断 网站 上是否发生了某些动作。
1. 硒是如何工作的
如图,用Python控制Selenium,然后让Selenium控制浏览器,操纵浏览器,从而实现用Python间接控制浏览器。
1.1 硒配置
Selenium 支持多种浏览器,最常见的是 Firefox 和 Google Chrome。首先在电脑上下载浏览器,浏览器版本不要太新。
火狐:截图如下
谷歌:截图如下
1.2 浏览器驱动
Selenium 如何专门操纵浏览器?这要归功于浏览器驱动程序。Selenium 可以通过 API 接口与浏览器驱动进行交互,进而实现与浏览器的交互。所以配置浏览器驱动。
配置浏览器驱动:
将下载的浏览器驱动解压,解压后的exe文件放在Python安装目录下,即与python.exe在同一目录下。
1.3 使用硒
安装selenium模块,python使用该模块驱动浏览器,使用如下命令行安装该模块
pip install selenium
2 快速入门
# 打开百度首页
from selenium import webdriver
driver = webdriver.chrome()
url = 'https : / /www.baidu . com/ '
driver.get(url)
#打开get就类似与在浏览器地址栏里面放入网址
driver.get(url)
#退出浏览器
driver.quit()
萃取元件
通过selenium的基本使用,可以简单的定位元素,获取对应的数据。接下来,让我们学习如何定位元素。
find_element_by_id #(根据id属性值获取元素)
find_element_by_name #(根据标签的name属性)
find_element_by_class_name #(根据类名获取元素)
find_element_by_link_text #(根据标签的文本获取元素,精确定位)
find_element_by_partial_link_text#(根据标签包含的文本获取元素,模糊定位)
find_e1ement_by_tag_name #(根据标签名获取元素)
find_e1ement_by_xpath #(根据xpath获取元素)
find_element_by_css_selector #(根据css选择器获取元素)
上述方法只能在页面上找到某个标签元素。如果要获取多个元素,可以在元素后面加上字母s,如下图:
find_elements_by_id #(根据id属性值获取元素,返回一个1ist列表)
find_elements_by_name #(根据标签的name属性,返回一个1ist列表)
find_elements_by_class_name #(根据类名获取元素,,返回一个list列表)
find_elements_by_link_text #(根据标签的文本获取元素,精确定位,返回一个1ist列表)
find_elements_by_partial_link_text #(根据标签包含的文本获取元素,模糊定位,返回一个1ist列表)
find_elements_by_tag_name #(根据标签名获取元素,返回一个1ist列表)
find_elements_by_xpath #(根据xpath获取元素,返回一个1ist列表)
find_elements_by_css_selector #(根据css选择器获取元素,返回一个1ist列表)
案子: 查看全部
浏览器抓取网页(SeleniumSelenium驱动Selenium)
硒
Selenium 是一个web自动化测试工具,最初是为网站自动化测试而开发的,就像一个玩游戏的按钮向导,可以根据指定的命令自动操作。
Selenium 测试工具直接操作浏览器,就像真正的用户一样。Selenium 可以让浏览器根据指令自动加载页面,获取需要的数据,甚至对页面进行截图,或者判断 网站 上是否发生了某些动作。
1. 硒是如何工作的

如图,用Python控制Selenium,然后让Selenium控制浏览器,操纵浏览器,从而实现用Python间接控制浏览器。
1.1 硒配置
Selenium 支持多种浏览器,最常见的是 Firefox 和 Google Chrome。首先在电脑上下载浏览器,浏览器版本不要太新。
火狐:截图如下

谷歌:截图如下

1.2 浏览器驱动
Selenium 如何专门操纵浏览器?这要归功于浏览器驱动程序。Selenium 可以通过 API 接口与浏览器驱动进行交互,进而实现与浏览器的交互。所以配置浏览器驱动。
配置浏览器驱动:
将下载的浏览器驱动解压,解压后的exe文件放在Python安装目录下,即与python.exe在同一目录下。

1.3 使用硒
安装selenium模块,python使用该模块驱动浏览器,使用如下命令行安装该模块
pip install selenium
2 快速入门
# 打开百度首页
from selenium import webdriver
driver = webdriver.chrome()
url = 'https : / /www.baidu . com/ '
driver.get(url)
#打开get就类似与在浏览器地址栏里面放入网址
driver.get(url)
#退出浏览器
driver.quit()
萃取元件
通过selenium的基本使用,可以简单的定位元素,获取对应的数据。接下来,让我们学习如何定位元素。
find_element_by_id #(根据id属性值获取元素)
find_element_by_name #(根据标签的name属性)
find_element_by_class_name #(根据类名获取元素)
find_element_by_link_text #(根据标签的文本获取元素,精确定位)
find_element_by_partial_link_text#(根据标签包含的文本获取元素,模糊定位)
find_e1ement_by_tag_name #(根据标签名获取元素)
find_e1ement_by_xpath #(根据xpath获取元素)
find_element_by_css_selector #(根据css选择器获取元素)
上述方法只能在页面上找到某个标签元素。如果要获取多个元素,可以在元素后面加上字母s,如下图:
find_elements_by_id #(根据id属性值获取元素,返回一个1ist列表)
find_elements_by_name #(根据标签的name属性,返回一个1ist列表)
find_elements_by_class_name #(根据类名获取元素,,返回一个list列表)
find_elements_by_link_text #(根据标签的文本获取元素,精确定位,返回一个1ist列表)
find_elements_by_partial_link_text #(根据标签包含的文本获取元素,模糊定位,返回一个1ist列表)
find_elements_by_tag_name #(根据标签名获取元素,返回一个1ist列表)
find_elements_by_xpath #(根据xpath获取元素,返回一个1ist列表)
find_elements_by_css_selector #(根据css选择器获取元素,返回一个1ist列表)
案子:
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-17 03:28
求高手,模拟浏览器抓取网页
比如爬取这个网页,如果我写的程序不收录URL末尾的“/”,是不会被爬取的,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION 查看全部
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十))
求高手,模拟浏览器抓取网页
比如爬取这个网页,如果我写的程序不收录URL末尾的“/”,是不会被爬取的,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION
浏览器抓取网页(2021-12-06Cookies为Web应用程序提供了存储特定用户信息的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-16 09:25
2021-12-06
Cookie 为 Web 应用程序提供了一种存储特定用户信息的方式。例如,当用户访问 网站 时,您可以使用 cookie 来存储用户的偏好或其他信息。下次用户访问 网站 时,应用程序可以检索到这个较早存储的信息。
什么是 Cookie?
Cookie 是在 Web 服务器和浏览器之间来回流动的小段文本,带有一个页面和一个请求。Web 应用程序可以在用户访问 网站 的任何时候读取 cookie 中收录的信息。
例如,如果用户在网站中请求一个页面,应用程序不仅返回一个页面,还返回一个收录日期和时间的cookie,当用户的浏览器获取到该页面时,浏览器会获取到这个cookie并存储在用户硬盘上的特定目录中。
然后,如果用户想再次从 网站 请求页面,当用户将 URL 输入浏览器时,浏览器将在本地硬盘驱动器上查找与该 URL 关联的 cookie。如果 cookie 存在,浏览器会将其与页面请求一起发送到 网站。然后,应用程序可以检测用户上次访问 网站 的日期和时间。您还可以使用此信息向用户显示消息或检查日期是否已过期。
Cookies是与网站关联的,而不是与特定页面关联的,所以无论用户请求网站中的哪个页面,浏览器和服务器之间都会交换cookie信息。就像用户访问的不同的网站一样,每个网站都可以向用户的浏览器发送一个cookie;浏览器将分别存储来自不同 网站 的所有 cookie。
Cookie 可以帮助网站存储有关访问者的信息。通常,cookie 是一种在 Web 应用程序中保持连续性的方式,即关于状态管理。除了它们实际上交换信息之外,浏览器和 Web 服务器之间的连接通常会中断。访问 Web 服务器的用户发出的每个请求都被认为是独立的。大多数情况下,它可以帮助 Web 服务器在用户请求页面时识别用户。例如,shopping网站 网络服务器始终跟踪每个购物者,从而能够管理购物车和其他用户特定信息。cookie因此起到名片的作用,呈现相关的认证信息以协助应用程序的运行。
Cookie 可用于多种目的,所有这些都涉及帮助网站用户的记忆。例如,投票管理器网站可能会将cookie简单地视为一个布尔值来指示用户的浏览器是否参与了投票,从而禁止用户重复投票;网站会使用cookies记录用户是否登录,让用户无需重复输入验证信息。
Cookie 的限制
大多数浏览器支持最长 4096 字节的 cookie。由于此限制,cookie 最适合用于存储小数据,最好是标识符(例如用户 ID)。然后,用户 ID 可用于识别当前用户并从数据库或其他数据存储中读取用户信息。(有关存储用户信息的安全影响的信息,请参阅本文档的 [Cookie 和安全] 部分。)
浏览器还限制 网站 可以存储在用户浏览器中的 cookie 数量。大多数浏览器只允许每个 网站 最多 20 个 cookie;如果您尝试存储更多,最旧的 cookie 将被丢弃。一些浏览器还施加了一个绝对限制,即它们可以接受的 cookie 总数不能超过 300(来自 网站 的所有 cookie 的总和)。
您可能遇到的另一个 cookie 限制是用户可以将其浏览器设置为拒绝 cookie。如果你定义了一个 P3P 保密策略并将其存储在 网站 的根目录中,大多数浏览器都会接受来自 网站 的 cookie。但是,您可能完全避免使用 cookie 并使用不同的机制来存储特定的用户信息。存储用户信息的一种常见方式是使用会话状态,而会话状态又依赖于 Cookie,如本文[Cookie 和会话状态] 部分所述。
提示:有关在 Web 应用程序中存储用户信息的状态管理和状态选项的更多信息,请参阅:[ASP.NET 状态管理概述] 和 [ASP.NET 状态管理建议]。
尽管 Cookie 在应用程序中很有用,但应用程序不应依赖 Cookie 的使用。请不要使用 cookie 来支持关键功能。如果您的应用程序必须依赖 cookie,您可以测试您的浏览器以查看它是否接受使用 cookie。请参阅本文的“检查您的浏览器是否接受 Cookie”部分。
写饼干
浏览器负责管理用户系统上的 cookie。通过 HttpResponse 对象发送到浏览器的 Cookie 公开了一个名为 Cookies 的集合。您可以访问 HttpResponse 对象,就像访问 Page 类的 Response 属性一样。您需要发送到浏览器的任何 cookie 都必须添加到此集合中。创建 cookie 后,您需要为其指定 Name 和 Value 属性。每个 cookie 必须具有唯一的名称,以便在浏览器中读取时被识别。由于 cookie 是按名称存储的,因此两个具有相同名称的 cookie 之一将被覆盖。
您还可以设置 cookie 的到期日期和时间。当用户访问 网站 并重写 cookie 时,浏览器会删除过期的 cookie。可以根据应用程序确定的 cookie 的有效期来设置 cookie 的过期时间。要使 cookie 长期存在,您可以将过期日期设置为从现在起 50 年。
提示:用户可以随时从他们的计算机中清除 cookie。即使您存储了一个长期有效的cookie,用户仍然可以决定删除所有cookie,这样cookie中存储的所有设置都将被销毁。
如果您不为 cookie 设置过期日期,仍然可以创建 cookie,但不会将其存储在用户的硬盘上。相反,此类 cookie 作为用户会话信息的一部分进行维护。当用户关闭浏览器时,Cookie 也会被丢弃。当信息只需要短暂存储或出于安全原因不应写入客户端计算机的硬盘驱动器时,此类非持久性 cookie 非常有用。例如,非持久性 cookie 适合用户在公共计算机上使用,或者当您不希望将 cookie 写入硬盘时。
您可以通过多种方式将 cookie 写入 Cookies 集合。以下示例说明了编写 cookie 的两种方法:
Response.Cookies["userName"].Value = "patrick";
Response.Cookies["userName"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("lastVisit");
aCookie.Value = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
该实例向 Cookies 集合添加了两个 Cookie,一个名为 userName,另一个名为 lastVisit。至于第一个cookie,直接设置Cookies集合的值。您可以使用此方法向集合中添加值,因为 Cookies 是 NameObject采集Base 类型的专用集合。
至于第二个cookie,代码创建一个HttpCookie类型的对象实例,设置它的属性,然后通过Add方法将它添加到Cookies集合中。实例化 HttpCookie 对象时,必须将 cookie 的名称作为构造函数的一部分传递。
这两个实例都完成了将 cookie 写入浏览器的相同任务。在这两种方法中,有效期属性值必须是 DateTime 类型。但是,lastVisited 中的值也是表示日期和时间的值。由于所有 cookie 值都应该以字符串格式存储,因此 datetime 值会自动转换为字符串。
具有多个值的 Cookie
您可以在 cookie 中存储单个值,例如用户名或上次访问时间。您还可以将多个名称/值对存储在单独的 cookie 中。名称/值数据对被引用为子键。(展开的子键的格式类似于 URL 中的查询字符串。)例如,您可以创建一个名为 userInfo 的单独 cookie 来收录子键 userName 和 lastVisit,而不是创建两个名为 userName 和 lastVisit 的单独 Cookie。上次访问。
您可能出于多种原因使用子项。首先,方便将相关信息或类似信息放入单独的cookie中。此外,由于所有信息都在一个单独的 cookie 中,因此 cookie 的参数(例如到期日期)适用于所有信息。(相反,如果您需要为不同类型的信息指定不同的到期日期,那么您应该将该信息存储在单独的 cookie 中。)
带有子键的 Cookie 还可以帮助您突破 Cookie 文件大小限制。如前面[Cookie 限制] 部分所述,cookie 的大小限制通常为 4096 字节,单个 网站 不能存储超过 20 个 cookie。通过使用带有子键的单独 cookie,您可以减少使用的 cookie 数量。此外,单个 cookie 中最多只能出现 50 个字符(到期日期信息等),加上其中存储的值的长度,加起来将近 4096 个字节。如果您使用 5 个子键而不是 5 个单独的 cookie,那么您可以在每个 cookie 中存储接近 200 字节的数据。
要创建带有子键的 cookie,您将使用不同的语法来编写单个 cookie。以下示例说明了编写相同 cookie 的两种方法(每个都有两个子键):
Response.Cookies["userInfo"]["userName"] = "patrick";
Response.Cookies["userInfo"]["lastVisit"] = DateTime.Now.ToString();
Response.Cookies["userInfo"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("userInfo");
aCookie.Values["userName"] = "patrick";
aCookie.Values["lastVisit"] = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
控制 cookie 的范围
默认情况下,网站 的所有 cookie 一起存储在客户端,并且所有 cookie 与来自 网站 的任何请求一起发送到服务器。换句话说,网站 中的每个页面都可以获取 网站 的所有 cookie。但是,您可以通过两种方式设置 cookie 的范围:
将 Cookie 限制在目录或应用程序中
要将 cookie 限制在服务器的目录中,请设置 cookie 的 Path 属性,如下例所示:
HttpCookie appCookie = new HttpCookie("AppCookie");
appCookie.Value = "written " + DateTime.Now.ToString();
appCookie.Expires = DateTime.Now.AddDays(1);
appCookie.Path = "/Application1";
Response.Cookies.Add(appCookie);
提示:您也可以通过直接添加到 Cookies 集合来编写 cookie,如前面的示例所示。
路径可以在 网站 的物理根目录和虚拟根目录中。结果将是 cookie 仅可用于目录或虚拟根 Application1 中的页面。例如,如果您的名字是 网站,则在上一个示例中创建的 cookie 将仅可用于路径中的页面及其下方的所有子目录。但是,此 cookie 不适用于其他应用程序中的页面,例如 .
提示:某些浏览器中的路径区分大小写。您无法控制用户如何在浏览器中输入 URL,但如果您的应用程序依赖 cookie 来限制特定路径,请确保您创建的任何超链接的 URL 与 Path 属性值中的大小写匹配。
限制 cookie 的域范围
默认情况下,cookie 与特定域相关联。例如,如果您的 网站 是,那么每当用户从 网站 请求任何页面时,您编写的 cookie 都会发送到服务器。(可能不包括具有特定路径值的 Cookie。)如果您的 网站 也有子域(例如 、 和 ),那么您可以将特定的子域与 cookie 相关联。为此,请设置 cookie 的 Domain 属性,如示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "support.contoso.com";
当以这种方式设置域时,cookie 将仅可用于该特定域内的页面。您还可以使用 Domain 属性创建可跨多个子域共享的 cookie,如以下示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "contoso.com";
cookie 现在将可用于主域以及域。
读取 cookie
当浏览器向服务器发送请求时,它会将 cookie 与请求一起发送到服务器。在您的 ASP.NET 应用程序中,您可以使用 HttpRequest 对象读取 Cookie,该对象显示为 Page 类的 Request 属性。HttpRequest 对象的结构与 HttpResponse 对象的结构本质上是相同的,因此您可以从 HttpRequest 对象中读取 Cookies,其方式类似于将 Cookies 写入 HttpResponse 对象。以下代码示例说明了获取 cookie(名为 userName)的值并将其显示在 Label 控件中的两种方法:
if(Request.Cookies["userName"] != null)
Label1.Text = Server.HtmlEncode(Request.Cookies["userName"].Value);
if(Request.Cookies["userName"] != null)
{
HttpCookie aCookie = Request.Cookies["userName"];
Label1.Text = Server.HtmlEncode(aCookie.Value);
}
在尝试获取 cookie 的值之前,您应该确保 cookie 已经存在;如果 cookie 不存在,您将收到 NullReferenceException。请注意,在显示 cookie 的内容之前,已调用 HtmlEncode 方法进行编码。这使得恶意用户无法将可执行脚本添加到 cookie。有关 cookie 安全的更多信息,请参阅:[Cookie 和安全]。
提示:由于不同浏览器存储cookies的方式不同,同一台电脑上的浏览器无法读取其他类型浏览器设置的cookies。例如,如果您使用 Internet Explorer 测试页面,然后使用不同的浏览器再次测试,则第二个浏览器将无法找到 Internet Explorer 存储的 cookie。
从 cookie 中读取子键的值与设置时类似。以下代码示例说明了获取子键值的一种方法:
if(Request.Cookies["userInfo"] != null)
{
Label1.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["userName"]);
Label2.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["lastVisit"]);
}
在前面的示例中,代码读取子项 lastVisit 中的值,该值设置为在前面的示例中呈现为字符串的 DateTime 值。Cookies 将值存储为字符串,因此如果需要将 lastVisit 值用作日期对象,则应将其强制转换为适当的类型,如下例所示:
DateTime dt;
dt = DateTime.Parse(Request.Cookies["userInfo"]["lastVisit"]);
cookie 中的子键被键入为 NameValue采集 类型的集合。因此,获取单个子键的另一种方法是先获取子键的集合,然后按名称提取子键的值,如下例所示:
if(Request.Cookies["userInfo"] != null)
{
System.Collections.Specialized.NameValueCollection
UserInfoCookieCollection;
UserInfoCookieCollection = Request.Cookies["userInfo"].Values;
Label1.Text =
Server.HtmlEncode(UserInfoCookieCollection["userName"]);
Label2.Text =
Server.HtmlEncode(UserInfoCookieCollection["lastVisit"]);
}
更改 cookie 过期时间
浏览器负责管理cookies,cookies的过期时间和日期有助于浏览器管理其存储的cookies。因此,虽然您可以读取 cookie 的名称和值,但您无法读取 cookie 的到期日期和时间。当浏览器向服务器发送cookie信息时,浏览器不收录有效期信息。(cookie 的 Expires 属性始终返回零日期值。)如果您关心 cookie 的到期时间,您应该重置它,如本文“更改和删除 cookie”部分所述。
提示:在 cookie 发送到浏览器之前,您可以读取 cookie 的 Expires 属性(在 HttpResponse 对象中设置)。但是,您无法从 HttpRequest 对象向后获取过期时间。
阅读 cookie 集合
有时您可能需要阅读所有 cookie 并使它们可用于页面。要将所有 cookie 的名称和值读入页面,可以如下循环遍历 Cookies 集合。
<p>System.Text.StringBuilder output = new System.Text.StringBuilder();
HttpCookie aCookie;
for(int i=0; i 查看全部
浏览器抓取网页(2021-12-06Cookies为Web应用程序提供了存储特定用户信息的方法)
2021-12-06
Cookie 为 Web 应用程序提供了一种存储特定用户信息的方式。例如,当用户访问 网站 时,您可以使用 cookie 来存储用户的偏好或其他信息。下次用户访问 网站 时,应用程序可以检索到这个较早存储的信息。
什么是 Cookie?
Cookie 是在 Web 服务器和浏览器之间来回流动的小段文本,带有一个页面和一个请求。Web 应用程序可以在用户访问 网站 的任何时候读取 cookie 中收录的信息。
例如,如果用户在网站中请求一个页面,应用程序不仅返回一个页面,还返回一个收录日期和时间的cookie,当用户的浏览器获取到该页面时,浏览器会获取到这个cookie并存储在用户硬盘上的特定目录中。
然后,如果用户想再次从 网站 请求页面,当用户将 URL 输入浏览器时,浏览器将在本地硬盘驱动器上查找与该 URL 关联的 cookie。如果 cookie 存在,浏览器会将其与页面请求一起发送到 网站。然后,应用程序可以检测用户上次访问 网站 的日期和时间。您还可以使用此信息向用户显示消息或检查日期是否已过期。
Cookies是与网站关联的,而不是与特定页面关联的,所以无论用户请求网站中的哪个页面,浏览器和服务器之间都会交换cookie信息。就像用户访问的不同的网站一样,每个网站都可以向用户的浏览器发送一个cookie;浏览器将分别存储来自不同 网站 的所有 cookie。
Cookie 可以帮助网站存储有关访问者的信息。通常,cookie 是一种在 Web 应用程序中保持连续性的方式,即关于状态管理。除了它们实际上交换信息之外,浏览器和 Web 服务器之间的连接通常会中断。访问 Web 服务器的用户发出的每个请求都被认为是独立的。大多数情况下,它可以帮助 Web 服务器在用户请求页面时识别用户。例如,shopping网站 网络服务器始终跟踪每个购物者,从而能够管理购物车和其他用户特定信息。cookie因此起到名片的作用,呈现相关的认证信息以协助应用程序的运行。
Cookie 可用于多种目的,所有这些都涉及帮助网站用户的记忆。例如,投票管理器网站可能会将cookie简单地视为一个布尔值来指示用户的浏览器是否参与了投票,从而禁止用户重复投票;网站会使用cookies记录用户是否登录,让用户无需重复输入验证信息。
Cookie 的限制
大多数浏览器支持最长 4096 字节的 cookie。由于此限制,cookie 最适合用于存储小数据,最好是标识符(例如用户 ID)。然后,用户 ID 可用于识别当前用户并从数据库或其他数据存储中读取用户信息。(有关存储用户信息的安全影响的信息,请参阅本文档的 [Cookie 和安全] 部分。)
浏览器还限制 网站 可以存储在用户浏览器中的 cookie 数量。大多数浏览器只允许每个 网站 最多 20 个 cookie;如果您尝试存储更多,最旧的 cookie 将被丢弃。一些浏览器还施加了一个绝对限制,即它们可以接受的 cookie 总数不能超过 300(来自 网站 的所有 cookie 的总和)。
您可能遇到的另一个 cookie 限制是用户可以将其浏览器设置为拒绝 cookie。如果你定义了一个 P3P 保密策略并将其存储在 网站 的根目录中,大多数浏览器都会接受来自 网站 的 cookie。但是,您可能完全避免使用 cookie 并使用不同的机制来存储特定的用户信息。存储用户信息的一种常见方式是使用会话状态,而会话状态又依赖于 Cookie,如本文[Cookie 和会话状态] 部分所述。
提示:有关在 Web 应用程序中存储用户信息的状态管理和状态选项的更多信息,请参阅:[ASP.NET 状态管理概述] 和 [ASP.NET 状态管理建议]。
尽管 Cookie 在应用程序中很有用,但应用程序不应依赖 Cookie 的使用。请不要使用 cookie 来支持关键功能。如果您的应用程序必须依赖 cookie,您可以测试您的浏览器以查看它是否接受使用 cookie。请参阅本文的“检查您的浏览器是否接受 Cookie”部分。
写饼干
浏览器负责管理用户系统上的 cookie。通过 HttpResponse 对象发送到浏览器的 Cookie 公开了一个名为 Cookies 的集合。您可以访问 HttpResponse 对象,就像访问 Page 类的 Response 属性一样。您需要发送到浏览器的任何 cookie 都必须添加到此集合中。创建 cookie 后,您需要为其指定 Name 和 Value 属性。每个 cookie 必须具有唯一的名称,以便在浏览器中读取时被识别。由于 cookie 是按名称存储的,因此两个具有相同名称的 cookie 之一将被覆盖。
您还可以设置 cookie 的到期日期和时间。当用户访问 网站 并重写 cookie 时,浏览器会删除过期的 cookie。可以根据应用程序确定的 cookie 的有效期来设置 cookie 的过期时间。要使 cookie 长期存在,您可以将过期日期设置为从现在起 50 年。
提示:用户可以随时从他们的计算机中清除 cookie。即使您存储了一个长期有效的cookie,用户仍然可以决定删除所有cookie,这样cookie中存储的所有设置都将被销毁。
如果您不为 cookie 设置过期日期,仍然可以创建 cookie,但不会将其存储在用户的硬盘上。相反,此类 cookie 作为用户会话信息的一部分进行维护。当用户关闭浏览器时,Cookie 也会被丢弃。当信息只需要短暂存储或出于安全原因不应写入客户端计算机的硬盘驱动器时,此类非持久性 cookie 非常有用。例如,非持久性 cookie 适合用户在公共计算机上使用,或者当您不希望将 cookie 写入硬盘时。
您可以通过多种方式将 cookie 写入 Cookies 集合。以下示例说明了编写 cookie 的两种方法:
Response.Cookies["userName"].Value = "patrick";
Response.Cookies["userName"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("lastVisit");
aCookie.Value = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
该实例向 Cookies 集合添加了两个 Cookie,一个名为 userName,另一个名为 lastVisit。至于第一个cookie,直接设置Cookies集合的值。您可以使用此方法向集合中添加值,因为 Cookies 是 NameObject采集Base 类型的专用集合。
至于第二个cookie,代码创建一个HttpCookie类型的对象实例,设置它的属性,然后通过Add方法将它添加到Cookies集合中。实例化 HttpCookie 对象时,必须将 cookie 的名称作为构造函数的一部分传递。
这两个实例都完成了将 cookie 写入浏览器的相同任务。在这两种方法中,有效期属性值必须是 DateTime 类型。但是,lastVisited 中的值也是表示日期和时间的值。由于所有 cookie 值都应该以字符串格式存储,因此 datetime 值会自动转换为字符串。
具有多个值的 Cookie
您可以在 cookie 中存储单个值,例如用户名或上次访问时间。您还可以将多个名称/值对存储在单独的 cookie 中。名称/值数据对被引用为子键。(展开的子键的格式类似于 URL 中的查询字符串。)例如,您可以创建一个名为 userInfo 的单独 cookie 来收录子键 userName 和 lastVisit,而不是创建两个名为 userName 和 lastVisit 的单独 Cookie。上次访问。
您可能出于多种原因使用子项。首先,方便将相关信息或类似信息放入单独的cookie中。此外,由于所有信息都在一个单独的 cookie 中,因此 cookie 的参数(例如到期日期)适用于所有信息。(相反,如果您需要为不同类型的信息指定不同的到期日期,那么您应该将该信息存储在单独的 cookie 中。)
带有子键的 Cookie 还可以帮助您突破 Cookie 文件大小限制。如前面[Cookie 限制] 部分所述,cookie 的大小限制通常为 4096 字节,单个 网站 不能存储超过 20 个 cookie。通过使用带有子键的单独 cookie,您可以减少使用的 cookie 数量。此外,单个 cookie 中最多只能出现 50 个字符(到期日期信息等),加上其中存储的值的长度,加起来将近 4096 个字节。如果您使用 5 个子键而不是 5 个单独的 cookie,那么您可以在每个 cookie 中存储接近 200 字节的数据。
要创建带有子键的 cookie,您将使用不同的语法来编写单个 cookie。以下示例说明了编写相同 cookie 的两种方法(每个都有两个子键):
Response.Cookies["userInfo"]["userName"] = "patrick";
Response.Cookies["userInfo"]["lastVisit"] = DateTime.Now.ToString();
Response.Cookies["userInfo"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("userInfo");
aCookie.Values["userName"] = "patrick";
aCookie.Values["lastVisit"] = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
控制 cookie 的范围
默认情况下,网站 的所有 cookie 一起存储在客户端,并且所有 cookie 与来自 网站 的任何请求一起发送到服务器。换句话说,网站 中的每个页面都可以获取 网站 的所有 cookie。但是,您可以通过两种方式设置 cookie 的范围:
将 Cookie 限制在目录或应用程序中
要将 cookie 限制在服务器的目录中,请设置 cookie 的 Path 属性,如下例所示:
HttpCookie appCookie = new HttpCookie("AppCookie");
appCookie.Value = "written " + DateTime.Now.ToString();
appCookie.Expires = DateTime.Now.AddDays(1);
appCookie.Path = "/Application1";
Response.Cookies.Add(appCookie);
提示:您也可以通过直接添加到 Cookies 集合来编写 cookie,如前面的示例所示。
路径可以在 网站 的物理根目录和虚拟根目录中。结果将是 cookie 仅可用于目录或虚拟根 Application1 中的页面。例如,如果您的名字是 网站,则在上一个示例中创建的 cookie 将仅可用于路径中的页面及其下方的所有子目录。但是,此 cookie 不适用于其他应用程序中的页面,例如 .
提示:某些浏览器中的路径区分大小写。您无法控制用户如何在浏览器中输入 URL,但如果您的应用程序依赖 cookie 来限制特定路径,请确保您创建的任何超链接的 URL 与 Path 属性值中的大小写匹配。
限制 cookie 的域范围
默认情况下,cookie 与特定域相关联。例如,如果您的 网站 是,那么每当用户从 网站 请求任何页面时,您编写的 cookie 都会发送到服务器。(可能不包括具有特定路径值的 Cookie。)如果您的 网站 也有子域(例如 、 和 ),那么您可以将特定的子域与 cookie 相关联。为此,请设置 cookie 的 Domain 属性,如示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "support.contoso.com";
当以这种方式设置域时,cookie 将仅可用于该特定域内的页面。您还可以使用 Domain 属性创建可跨多个子域共享的 cookie,如以下示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "contoso.com";
cookie 现在将可用于主域以及域。
读取 cookie
当浏览器向服务器发送请求时,它会将 cookie 与请求一起发送到服务器。在您的 ASP.NET 应用程序中,您可以使用 HttpRequest 对象读取 Cookie,该对象显示为 Page 类的 Request 属性。HttpRequest 对象的结构与 HttpResponse 对象的结构本质上是相同的,因此您可以从 HttpRequest 对象中读取 Cookies,其方式类似于将 Cookies 写入 HttpResponse 对象。以下代码示例说明了获取 cookie(名为 userName)的值并将其显示在 Label 控件中的两种方法:
if(Request.Cookies["userName"] != null)
Label1.Text = Server.HtmlEncode(Request.Cookies["userName"].Value);
if(Request.Cookies["userName"] != null)
{
HttpCookie aCookie = Request.Cookies["userName"];
Label1.Text = Server.HtmlEncode(aCookie.Value);
}
在尝试获取 cookie 的值之前,您应该确保 cookie 已经存在;如果 cookie 不存在,您将收到 NullReferenceException。请注意,在显示 cookie 的内容之前,已调用 HtmlEncode 方法进行编码。这使得恶意用户无法将可执行脚本添加到 cookie。有关 cookie 安全的更多信息,请参阅:[Cookie 和安全]。
提示:由于不同浏览器存储cookies的方式不同,同一台电脑上的浏览器无法读取其他类型浏览器设置的cookies。例如,如果您使用 Internet Explorer 测试页面,然后使用不同的浏览器再次测试,则第二个浏览器将无法找到 Internet Explorer 存储的 cookie。
从 cookie 中读取子键的值与设置时类似。以下代码示例说明了获取子键值的一种方法:
if(Request.Cookies["userInfo"] != null)
{
Label1.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["userName"]);
Label2.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["lastVisit"]);
}
在前面的示例中,代码读取子项 lastVisit 中的值,该值设置为在前面的示例中呈现为字符串的 DateTime 值。Cookies 将值存储为字符串,因此如果需要将 lastVisit 值用作日期对象,则应将其强制转换为适当的类型,如下例所示:
DateTime dt;
dt = DateTime.Parse(Request.Cookies["userInfo"]["lastVisit"]);
cookie 中的子键被键入为 NameValue采集 类型的集合。因此,获取单个子键的另一种方法是先获取子键的集合,然后按名称提取子键的值,如下例所示:
if(Request.Cookies["userInfo"] != null)
{
System.Collections.Specialized.NameValueCollection
UserInfoCookieCollection;
UserInfoCookieCollection = Request.Cookies["userInfo"].Values;
Label1.Text =
Server.HtmlEncode(UserInfoCookieCollection["userName"]);
Label2.Text =
Server.HtmlEncode(UserInfoCookieCollection["lastVisit"]);
}
更改 cookie 过期时间
浏览器负责管理cookies,cookies的过期时间和日期有助于浏览器管理其存储的cookies。因此,虽然您可以读取 cookie 的名称和值,但您无法读取 cookie 的到期日期和时间。当浏览器向服务器发送cookie信息时,浏览器不收录有效期信息。(cookie 的 Expires 属性始终返回零日期值。)如果您关心 cookie 的到期时间,您应该重置它,如本文“更改和删除 cookie”部分所述。
提示:在 cookie 发送到浏览器之前,您可以读取 cookie 的 Expires 属性(在 HttpResponse 对象中设置)。但是,您无法从 HttpRequest 对象向后获取过期时间。
阅读 cookie 集合
有时您可能需要阅读所有 cookie 并使它们可用于页面。要将所有 cookie 的名称和值读入页面,可以如下循环遍历 Cookies 集合。
<p>System.Text.StringBuilder output = new System.Text.StringBuilder();
HttpCookie aCookie;
for(int i=0; i
浏览器抓取网页(傍晚想找个类似的插件,文字描述一下的no.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-14 01:02
晚上在找一个类似的插件,所以花了一个小时做了一个小评测。当然楼上的回答我也看到了,但是很多都已经没有了,所以稍微总结一下,懒就不截图了,用文字描述一下。
安利第一件事就是edge + onenote,它可以:
1. 任何绘图
2. 带有箭头,并且可以
3. 直接插入评论支持
4. 亮点,
5. 一键云存档,当之无愧No.1,以下标准与之对比。
假设环境是chrome + ss(chrome有最丰富的小应用,其他浏览器不考虑)
A. Diigo(以及其他类似的,以此为代表):
除了不支持各大笔记平台外,其余功能支持:3、4、5,截图模式支持1、2,给三颗星。
但是比较贵,而且只支持200个亮点免费等,而且一下子就用完了。
B、印象笔记
功能比较单薄,只支持4、5,当然比有道云只支持5(-最基本的功能)要好,给两颗星。
C. Markup.io
有一个传说中的插件,应该支持1、2、3、4,但是已经关闭了;楼上列出的一些很棒的亮点 xxx 似乎也已经关闭。
D.
ok,两颗星,支持3、4、5(Text Based),有点像kindle的标记功能,大家可以在网页上标记一些地方,可以看到别人的评论或者下划线,一颗半星酒吧。
E. 黄色荧光笔等
比较简陋,类似D,一颗星。
综上所述,如果你只是想高亮保存网页上的文字,印象笔记/onenote(+windows edge)应该是最好的选择;如果你只是想做文字标注,Diigo 更好,但每年 40D 的价格让我等到掉丝都泄气了。
PS。想找一个*估计网页内容阅读时间*的小插件,但是chrome商店里的那个要么不能用,要么太烂,有必要自己写一个吗?
参考:
网页阅读,如何标记喜欢阅读?-知乎我不知道
“网页注释分享工具”的重点来了!| 一页一页 查看全部
浏览器抓取网页(傍晚想找个类似的插件,文字描述一下的no.1)
晚上在找一个类似的插件,所以花了一个小时做了一个小评测。当然楼上的回答我也看到了,但是很多都已经没有了,所以稍微总结一下,懒就不截图了,用文字描述一下。
安利第一件事就是edge + onenote,它可以:
1. 任何绘图
2. 带有箭头,并且可以
3. 直接插入评论支持
4. 亮点,
5. 一键云存档,当之无愧No.1,以下标准与之对比。
假设环境是chrome + ss(chrome有最丰富的小应用,其他浏览器不考虑)
A. Diigo(以及其他类似的,以此为代表):
除了不支持各大笔记平台外,其余功能支持:3、4、5,截图模式支持1、2,给三颗星。
但是比较贵,而且只支持200个亮点免费等,而且一下子就用完了。
B、印象笔记
功能比较单薄,只支持4、5,当然比有道云只支持5(-最基本的功能)要好,给两颗星。
C. Markup.io
有一个传说中的插件,应该支持1、2、3、4,但是已经关闭了;楼上列出的一些很棒的亮点 xxx 似乎也已经关闭。
D.
ok,两颗星,支持3、4、5(Text Based),有点像kindle的标记功能,大家可以在网页上标记一些地方,可以看到别人的评论或者下划线,一颗半星酒吧。
E. 黄色荧光笔等
比较简陋,类似D,一颗星。
综上所述,如果你只是想高亮保存网页上的文字,印象笔记/onenote(+windows edge)应该是最好的选择;如果你只是想做文字标注,Diigo 更好,但每年 40D 的价格让我等到掉丝都泄气了。
PS。想找一个*估计网页内容阅读时间*的小插件,但是chrome商店里的那个要么不能用,要么太烂,有必要自己写一个吗?
参考:
网页阅读,如何标记喜欢阅读?-知乎我不知道
“网页注释分享工具”的重点来了!| 一页一页
浏览器抓取网页(如何找到json代码获取目标信息?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2022-03-13 21:08
前言
很多情况下,使用爬虫时无法获取到我们想要的信息,因为有些数据是用json代码写的,通过xhr异步加载到网页中。
因此,我们无法在页面中获取它。这时候我们就可以通过解析json代码得到目标信息了。
一、如何找到目标xhr地址?
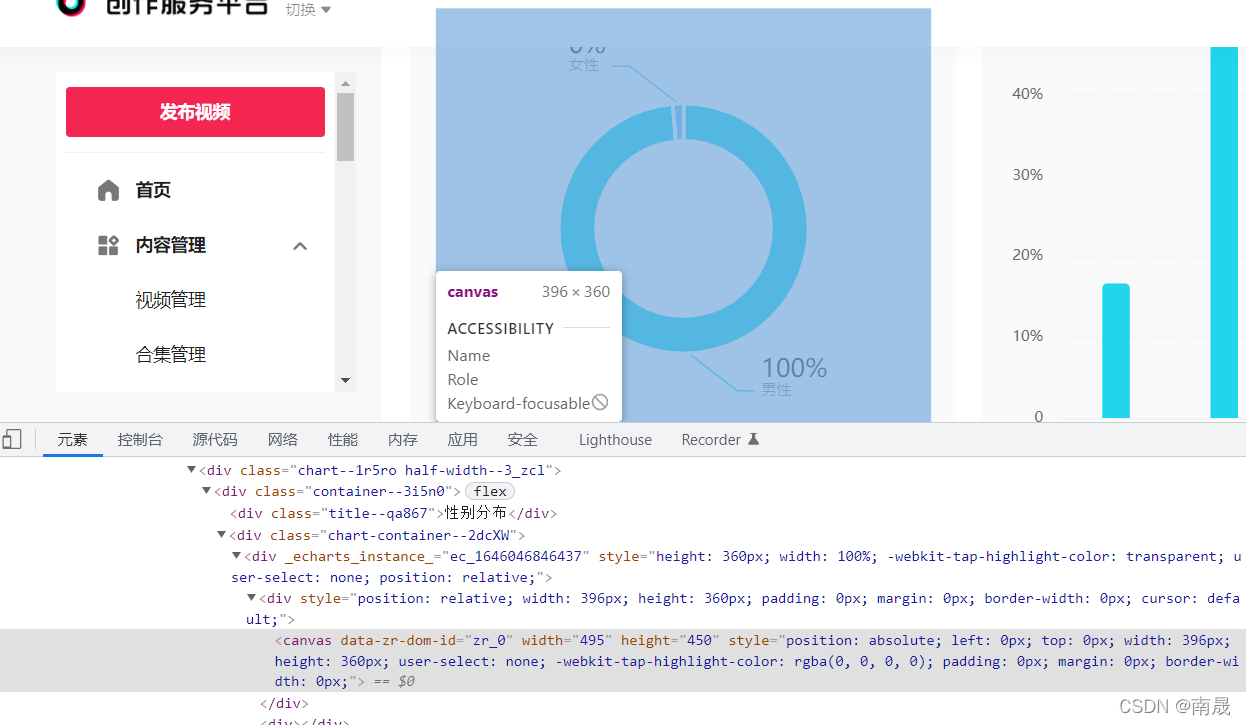
以抖音中的canvas图片信息为例,从下图中可以看出图中有数字,但是这些数据并没有附加到canvas上:
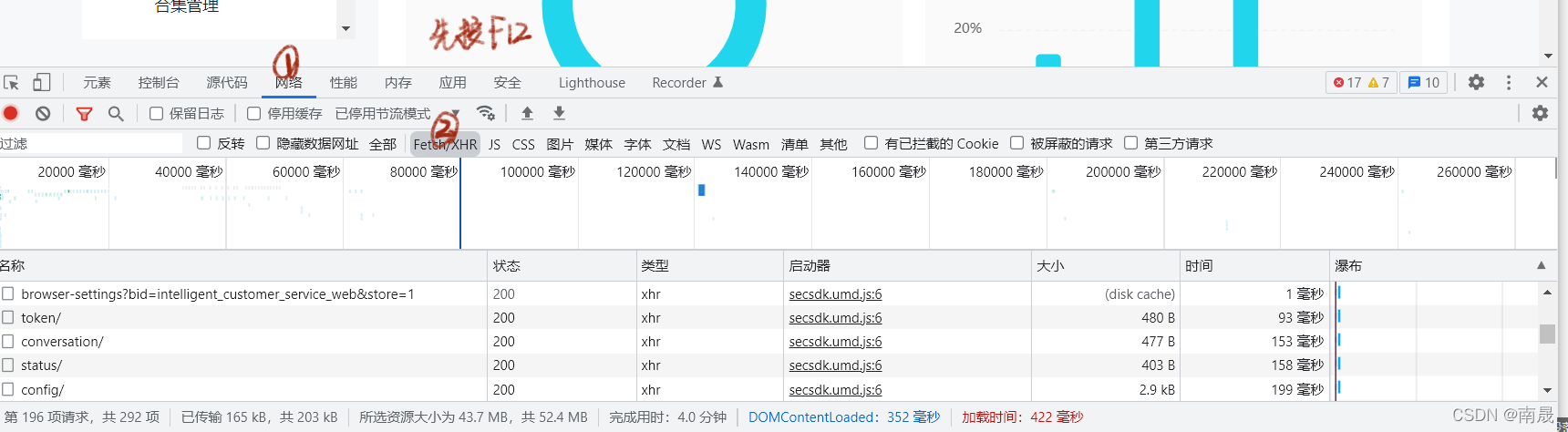
这时候我们可以通过在网络中寻找xhr请求找到初始数据的链接,如下图,在出现的xhr请求中找到目标文件。如果xhr下没有需要的数据,可以尝试刷新页面:
经过尝试,不难找到最初的数据存储位置。可以看出请求方法是get,从图中很容易看出我们需要的性别数据:
下一步是在代码中实现这一步。
二、代码实现1.准备安装Browsermob-Proxy和chromedriver.exe:
下载 Browsermobproxy
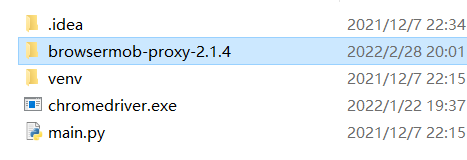
下载chromedriver驱动
将下载的brosermob-proxy-2.1.4和浏览器对应版本的chromedriver保存到main.py的同级目录下:
2.编写代码导入库:
import json#读取json数据时需要用到
import os
import requests
from selenium import webdriver
from browsermobproxy import Server
配置代理环境和chrome浏览器:
path=os.getcwd()#获取当前路径
server = Server(path+"\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy")
server.start()
proxy = server.create_proxy()
chrome_options =webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument("---kiosk")#设置全屏
driver = webdriver.Chrome(options=chrome_options)
#
proxy.new_har(options={'captureHeaders': True, 'captureContent': True})
使用cookies向chrome浏览器添加用户信息:
因为我这里以抖音为例,抖音中的json数据需要登录才能获取账号,否则会报“无操作权限”,可以选择是否使用它根据你自己的需要。
cookie=driver.get_cookies()
jsonCookies=json.dumps(cookie)
with open ("driver.json",'w') as f:
f.write(jsonCookies)
with open('driver.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
获取网络请求并读取数据:
result = proxy.har#读取当前网页信息
for rs in result['log']['entries']:
a=rs['request']['url']#获取url链接
if "aweme/v1/creator/data/item/audience" in a:#查找目标关键字(这里可根据自己的需求更改搜索内容)
url=a#得到目标url
#以下是使用cookie获取到get请求中的json数据
headers = {'cookie': cookiestr,#若不使用cookie可去掉这句话
"User_Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
html=requests.get(url=url,headers=headers)#用request登陆目标url
data=html.text
data=json.loads(data)#将json数据转为字典数据,以便使用
使用获得的数据:
查看数据如下:
这里可以使用字典访问方式或者正则表达式来获取
for k in data:
if k == 'gender_data':
gender = data.get(k)
for i in gender:
for j in i.values():
if j == '1':
dict['gender_num'] =dict.get('gender_num',0) + int(i.get('value'))
dict['male'] = int(i.get('value'))
if j == '2':
dict['female'] = int(i.get('value'))
dict['gender_num'] =dict.get('gender_num',0) +int(i.get('value'))
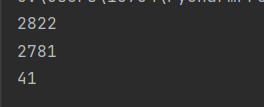
打印数据
print(dict['gender_num'])
print(dict['male'])
print(dict['female'])
总结
这是寒假做项目时遇到的问题。我在网上找不到完整的方法。我到处查资料,终于成功了。
browsermobproxy的使用有点麻烦。希望能给你一个参考。当然,我这里只提供一些必要的流程。我省略了一些使用爬虫的细节。例如,proxy.new_har() 可以在不同的网页中使用一次。,可以避免proxy.har等获取的信息重复。 查看全部
浏览器抓取网页(如何找到json代码获取目标信息?(一))
前言
很多情况下,使用爬虫时无法获取到我们想要的信息,因为有些数据是用json代码写的,通过xhr异步加载到网页中。
因此,我们无法在页面中获取它。这时候我们就可以通过解析json代码得到目标信息了。
一、如何找到目标xhr地址?
以抖音中的canvas图片信息为例,从下图中可以看出图中有数字,但是这些数据并没有附加到canvas上:
这时候我们可以通过在网络中寻找xhr请求找到初始数据的链接,如下图,在出现的xhr请求中找到目标文件。如果xhr下没有需要的数据,可以尝试刷新页面:
经过尝试,不难找到最初的数据存储位置。可以看出请求方法是get,从图中很容易看出我们需要的性别数据:


下一步是在代码中实现这一步。
二、代码实现1.准备安装Browsermob-Proxy和chromedriver.exe:
下载 Browsermobproxy
下载chromedriver驱动
将下载的brosermob-proxy-2.1.4和浏览器对应版本的chromedriver保存到main.py的同级目录下:
2.编写代码导入库:
import json#读取json数据时需要用到
import os
import requests
from selenium import webdriver
from browsermobproxy import Server
配置代理环境和chrome浏览器:
path=os.getcwd()#获取当前路径
server = Server(path+"\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy")
server.start()
proxy = server.create_proxy()
chrome_options =webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument("---kiosk")#设置全屏
driver = webdriver.Chrome(options=chrome_options)
#
proxy.new_har(options={'captureHeaders': True, 'captureContent': True})
使用cookies向chrome浏览器添加用户信息:
因为我这里以抖音为例,抖音中的json数据需要登录才能获取账号,否则会报“无操作权限”,可以选择是否使用它根据你自己的需要。
cookie=driver.get_cookies()
jsonCookies=json.dumps(cookie)
with open ("driver.json",'w') as f:
f.write(jsonCookies)
with open('driver.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
获取网络请求并读取数据:
result = proxy.har#读取当前网页信息
for rs in result['log']['entries']:
a=rs['request']['url']#获取url链接
if "aweme/v1/creator/data/item/audience" in a:#查找目标关键字(这里可根据自己的需求更改搜索内容)
url=a#得到目标url
#以下是使用cookie获取到get请求中的json数据
headers = {'cookie': cookiestr,#若不使用cookie可去掉这句话
"User_Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
html=requests.get(url=url,headers=headers)#用request登陆目标url
data=html.text
data=json.loads(data)#将json数据转为字典数据,以便使用
使用获得的数据:
查看数据如下:

这里可以使用字典访问方式或者正则表达式来获取
for k in data:
if k == 'gender_data':
gender = data.get(k)
for i in gender:
for j in i.values():
if j == '1':
dict['gender_num'] =dict.get('gender_num',0) + int(i.get('value'))
dict['male'] = int(i.get('value'))
if j == '2':
dict['female'] = int(i.get('value'))
dict['gender_num'] =dict.get('gender_num',0) +int(i.get('value'))
打印数据
print(dict['gender_num'])
print(dict['male'])
print(dict['female'])
总结
这是寒假做项目时遇到的问题。我在网上找不到完整的方法。我到处查资料,终于成功了。
browsermobproxy的使用有点麻烦。希望能给你一个参考。当然,我这里只提供一些必要的流程。我省略了一些使用爬虫的细节。例如,proxy.new_har() 可以在不同的网页中使用一次。,可以避免proxy.har等获取的信息重复。
浏览器抓取网页(python+selenium爬虫全流程详解+python爬虫简介 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-03-13 21:08
)
python+selenium爬虫全流程详解
selenium+python爬虫介绍
本教程的大部分内容都是基于个人经验,其中一些是口语化的
如有不妥之处,请及时更正(可评论或私信)
硒测试脚本
Selenium其实是一个web自动化测试工具,可以完全模拟使用浏览器自动访问目标站点,通过代码操作进行web测试。
蟒蛇+硒
通过python+selenium的组合来实现爬虫是非常巧妙的。
由于是模拟人类点击操作,实际被反转的概率会大大降低。
Selenium 可以在页面上执行 js,处理 js 渲染的数据并模拟登录非常容易。
该技术还可以与正则表达式、bs4、request、ip pool等其他技术结合使用。
当然,由于在获取页面的过程中会发送很多请求,效率低,爬取速度也会比较慢。推荐用于小规模数据爬取。
selenium安装可以直接通过pip安装
pip3 install selenium
导入包
from selenium import webdriver
模拟浏览器----以chrome为例安装浏览器驱动
关联:
我们只需要在上面的链接中下载对应版本的驱动,放到python安装路径的scripts目录下即可。
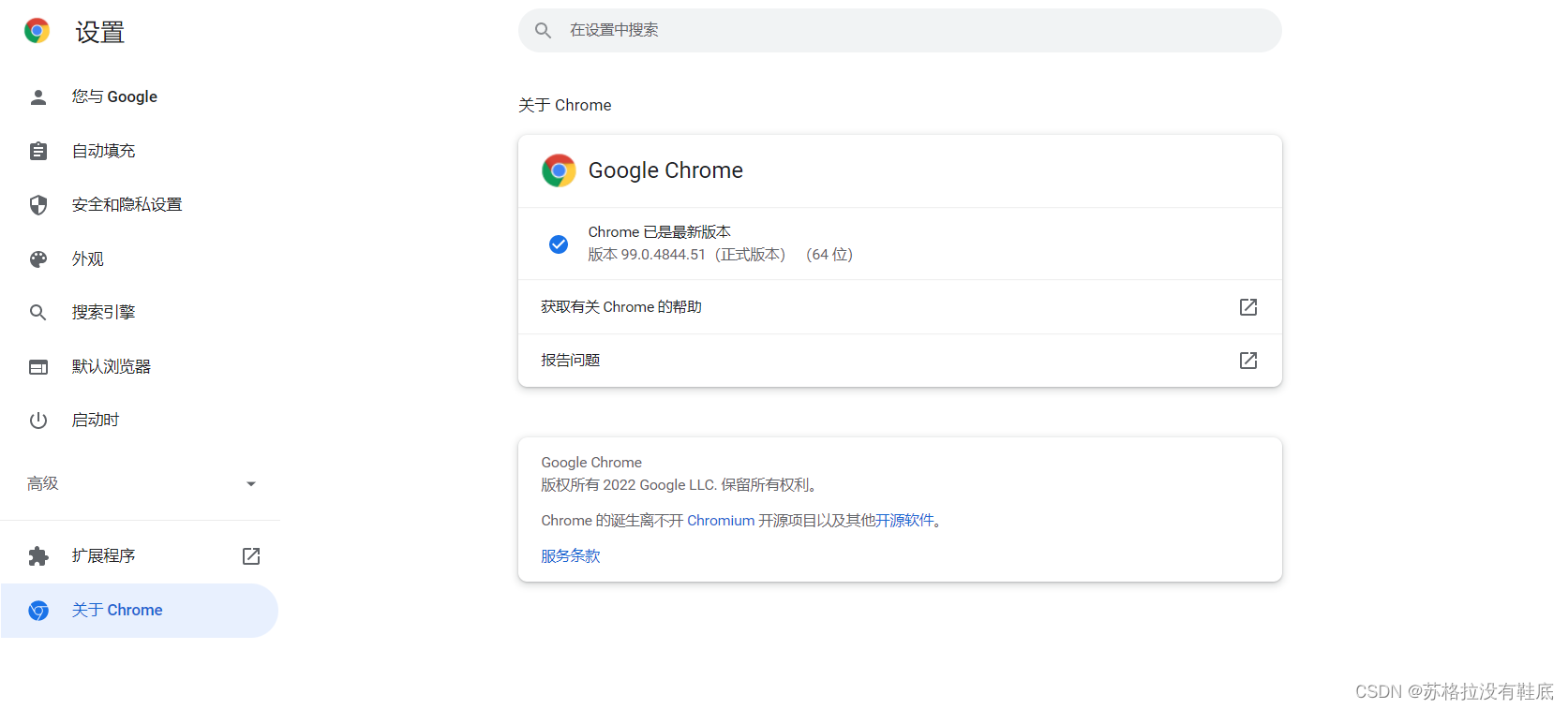
浏览器版本可以在设置-关于Chrome中查看
当然,由于浏览器经常会自动更新,所以我们也记得在使用前更新相应的驱动程序。
基本操作的浏览器仿真
browser = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 3B%23以该链接为例
browser.get(url)#访问相对应链接
browser.close#关闭浏览器
抓取数据 – 网站位置
以下知识需要一些网络相关知识作为前提
案例——b站排行榜
假设我们需要爬取上图中红圈内的文本数据,那么我们需要定位到这个地方的点
定位方法与实践
定位方式的选择主要取决于目标页面的情况。
#find_elements_by_xxx的形式是查找到多个元素(当前定位方法定位元素不唯一)
#结果为列表
browser.find_element_by_id('')# 通过标签id属性进行定位
browser.find_element_by_name("")# 通过标签name属性进行定位
browser.find_elements_by_class_name("")# 通过class名称进行定位
browser.find_element_by_tag_name("")# 通过标签名称进行定位
browser.find_element_by_css_selector('')# 通过CSS查找方式进行定位
browser.find_element_by_xpath('')# 通过xpath方式定位
#在chrome中可以通过源代码目标元素右键--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# 通过搜索 页面中 链接进行定位
browser.find_element_by_partial_link_text("")# 通过搜索 页面中 链接进行定位 ,可以支持模糊匹配
在网站的情况下,我们根据类名爬取,标签中的class="info"
from selenium import webdriver
browser = webdriver.Chrome()
# browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 39%3B
browser.get(url)
info=browser.find_elements_by_class_name('info')
#在目标网站中网站中标题class名称都为"info",所以用elements
for i in info:
print(i.text)
#.text为定位元素底下的所有文本,当然我们也可以获取标签里的东西(用其它函数),如视频链接:
# print(i.find_elements_by_tag_name('a')[0].get_attribute('href'))
结果
一些可能使用的方法(辅助爬虫/减少反爬)加快网页加载(不加载js、图片等)
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
异常捕获
from selenium.common.exceptions import NoSuchElementException
等待加载的网页
由于网速等问题,进入网站后页面还没有加载,需要等待。
selenium 自带的加载方式
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载
wait=WebDriverWait(browser,10) #显式等待:指定等待某个标签加载完毕
wait1=browser.implicitly_wait(10) #隐式等待:等待所有标签加载完毕
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
等待时间与时间
import time
time.sleep(2)
在输入框中输入数据
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("名称") # 向input输入框输入名称
#也可以driver.find_element_by_id("kw").send_keys("名称") 查看全部
浏览器抓取网页(python+selenium爬虫全流程详解+python爬虫简介
)
python+selenium爬虫全流程详解
selenium+python爬虫介绍
本教程的大部分内容都是基于个人经验,其中一些是口语化的
如有不妥之处,请及时更正(可评论或私信)
硒测试脚本
Selenium其实是一个web自动化测试工具,可以完全模拟使用浏览器自动访问目标站点,通过代码操作进行web测试。
蟒蛇+硒
通过python+selenium的组合来实现爬虫是非常巧妙的。
由于是模拟人类点击操作,实际被反转的概率会大大降低。
Selenium 可以在页面上执行 js,处理 js 渲染的数据并模拟登录非常容易。
该技术还可以与正则表达式、bs4、request、ip pool等其他技术结合使用。
当然,由于在获取页面的过程中会发送很多请求,效率低,爬取速度也会比较慢。推荐用于小规模数据爬取。
selenium安装可以直接通过pip安装
pip3 install selenium
导入包
from selenium import webdriver
模拟浏览器----以chrome为例安装浏览器驱动
关联:
我们只需要在上面的链接中下载对应版本的驱动,放到python安装路径的scripts目录下即可。
浏览器版本可以在设置-关于Chrome中查看
当然,由于浏览器经常会自动更新,所以我们也记得在使用前更新相应的驱动程序。
基本操作的浏览器仿真
browser = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 3B%23以该链接为例
browser.get(url)#访问相对应链接
browser.close#关闭浏览器
抓取数据 – 网站位置
以下知识需要一些网络相关知识作为前提
案例——b站排行榜
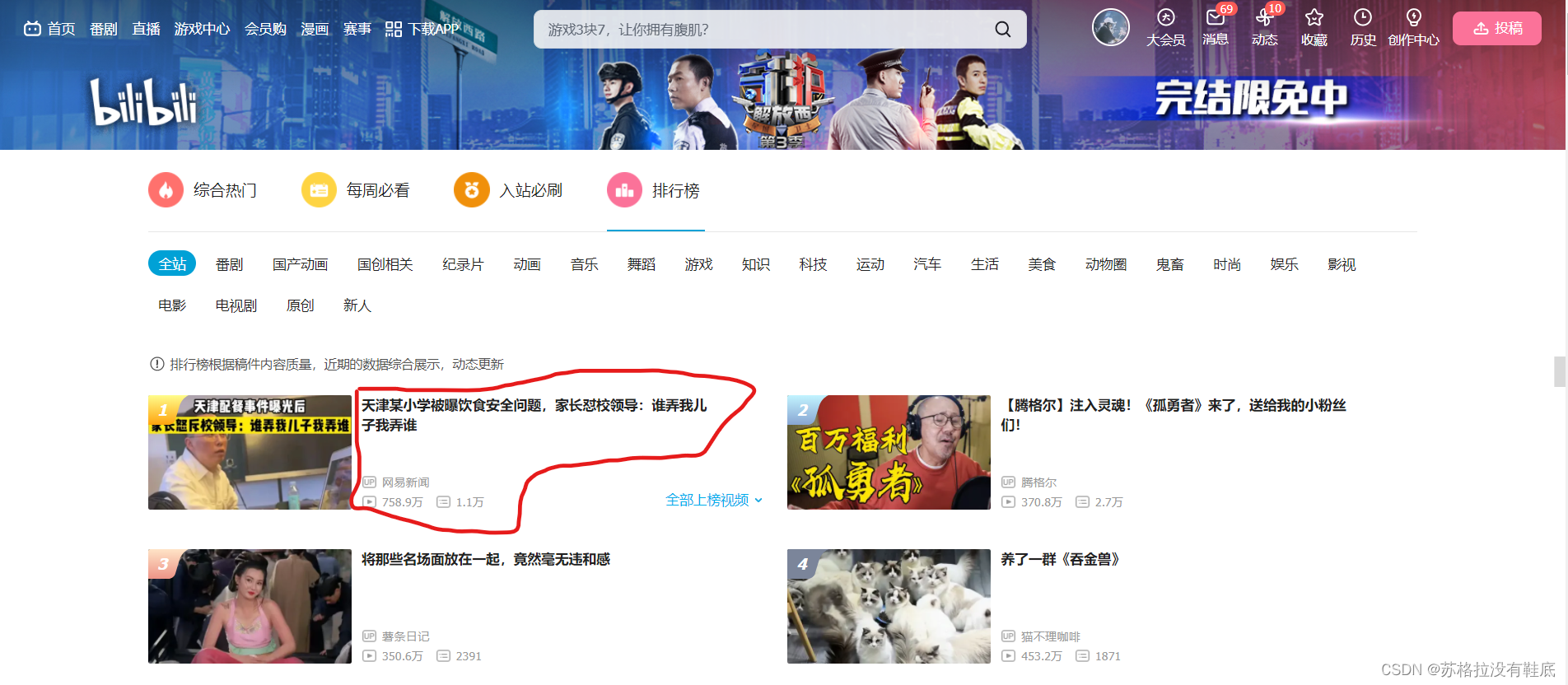
假设我们需要爬取上图中红圈内的文本数据,那么我们需要定位到这个地方的点
定位方法与实践
定位方式的选择主要取决于目标页面的情况。
#find_elements_by_xxx的形式是查找到多个元素(当前定位方法定位元素不唯一)
#结果为列表
browser.find_element_by_id('')# 通过标签id属性进行定位
browser.find_element_by_name("")# 通过标签name属性进行定位
browser.find_elements_by_class_name("")# 通过class名称进行定位
browser.find_element_by_tag_name("")# 通过标签名称进行定位
browser.find_element_by_css_selector('')# 通过CSS查找方式进行定位
browser.find_element_by_xpath('')# 通过xpath方式定位
#在chrome中可以通过源代码目标元素右键--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# 通过搜索 页面中 链接进行定位
browser.find_element_by_partial_link_text("")# 通过搜索 页面中 链接进行定位 ,可以支持模糊匹配
在网站的情况下,我们根据类名爬取,标签中的class="info"
from selenium import webdriver
browser = webdriver.Chrome()
# browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 39%3B
browser.get(url)
info=browser.find_elements_by_class_name('info')
#在目标网站中网站中标题class名称都为"info",所以用elements
for i in info:
print(i.text)
#.text为定位元素底下的所有文本,当然我们也可以获取标签里的东西(用其它函数),如视频链接:
# print(i.find_elements_by_tag_name('a')[0].get_attribute('href'))
结果
一些可能使用的方法(辅助爬虫/减少反爬)加快网页加载(不加载js、图片等)
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
异常捕获
from selenium.common.exceptions import NoSuchElementException
等待加载的网页
由于网速等问题,进入网站后页面还没有加载,需要等待。
selenium 自带的加载方式
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载
wait=WebDriverWait(browser,10) #显式等待:指定等待某个标签加载完毕
wait1=browser.implicitly_wait(10) #隐式等待:等待所有标签加载完毕
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
等待时间与时间
import time
time.sleep(2)
在输入框中输入数据
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("名称") # 向input输入框输入名称
#也可以driver.find_element_by_id("kw").send_keys("名称")
浏览器抓取网页(Window代表当前浏览器的地址栏代表的是怎样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-13 21:07
物料清单
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
航海家
判断浏览器
var ua = navigator.userAgent;
控制台.log(ua);
if(/firefox/i.test(ua)){
alert("你是火狐!!!");
}else if(/chrome/i.test(ua)){
alert("你是 Chrome");
}否则如果(/msie/i.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,开枪~~~");
}
历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
可用于跳转到指定页面
它需要一个整数作为参数
地点
该对象封装了浏览器地址栏的信息
如果直接打印位置,可以在地址栏中获取信息
如果直接修改location属性为完整路径,或者相对路径,我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置 = "";
分配()
location.assign("");
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
location.reload(true);
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
代替()
location.replace("01.BOM.html");
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
设置间隔()
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
var timer = setInterval(function(){
count.innerHTML = 数字++;
if(num == 11){
//关闭定时器
清除间隔(定时器);
}
},1000);
clearInterval() 可用于关闭需要定时器的标识符作为参数的定时器方法,该方法将关闭该标识符对应的定时器
多姆
事件
是用户和浏览器之间的交互
例如:单击按钮、移动鼠标、关闭窗口。. .
绑定点击事件
这个与点击事件绑定的函数称为点击响应函数
btn.onclick = 函数(){
alert("你还在点~~~");
};
加载事件
在整个页面加载后触发
Window 绑定一个 onload 事件
window.onload = 函数(){
//获取id为btn的按钮
var btn = document.getElementById("btn");
//为按钮绑定点击响应函数
btn.onclick = 函数(){
警报(“你好”);
};
};
dom查询
获取按钮对象
var btn = document.getElementById("btn");
编辑按钮文本
btn.innerHTML = "我是按钮";
查找所有 li 节点
var lis = document.getElementsByTagName("li");
查找 name=gender 的所有节点
var 输入 = document.getElementsByName("gender");
如果需要读取元素节点属性,
使用 element.Attribute 名称 示例:element.id element.name element.value 注意:类属性不能这样使用,读取类属性时需要使用 element.className
返回#city 的所有子节点
childNodes 属性将获取所有节点,包括文本节点
var cns = city.childNodes;
children属性可以获取当前元素的所有子元素
var cns2 = city.children;
firstChild 可以获取当前元素的第一个子节点(包括空白文本节点)
var fir = phone.firstChild;
firstElementChild 获取当前元素的第一个子元素
冷杉 = phone.firstElementChild;
内部文本
该属性可以获取元素内部的文本内容
previousElementSibling 获取上一个兄弟元素
var pe = and.previousElementSibling;
文档中有一个属性body,里面保存了对body的引用
var body = document.body;
document.documentElement 保存 html 根标签
var html = document.documentElement;
document.all 代表页面中的所有元素
var all = document.all;
document.querySelector()
var div = document.querySelector(".box1 div");
需要选择器字符串作为参数,可以根据CSS选择器查询元素节点对象
document.querySelectorAll()
box1 = document.querySelectorAll(".box1");
这个方法类似于querySelector(),不同的是它将符合条件的元素封装成一个数组并返回
操作 CSS
修订
element.style.stylename = 样式值
这种名称在 JS 中是非法的。比如background-color需要把这个样式名改成驼色,去掉-,然后-后面的字母大写
如果样式中写了!important,那么此时样式的优先级最高
框1.style.width = "300px";
框1.style.height = "300px";
框1.style.backgroundColor = “黄色”;
读
element.style.stylename
框1.style.width
获取元素当前显示的样式
element.currentStyle.style 名称(仅IE浏览器支持)
getComputedStyle() 方法用于获取元素的当前样式。该方法是window的方法,可以直接使用,需要两个参数。
第一种:获取样式的元素
第二种:可以传入一个伪元素,一般为null
该方法返回一个对象,该对象封装了当前元素对应的样式
样式可以通过 object.stylename 读取
获取指定元素当前样式的函数
函数getStyle(obj,名称){
如果(window.getComputedStyle){
//普通浏览器方式,带getComputedStyle()方法
返回 getComputedStyle(obj , null)[name];
}别的{
//IE8方式,没有getComputedStyle()方法
返回 obj.currentStyle[名称];
}
//return window.getComputedStyle?getComputedStyle(obj , null)[name]:obj.currentStyle[name];
}
可见宽度和高度
客户宽度客户高度
框1.clientWidth
只读,不可修改
没有px,return是一个数字,可以直接计算
元素宽度和高度,包括内容区域和填充
元素的整个宽度和高度
偏移宽度偏移高度
框1.偏移宽度
当前元素的定位父级
偏移父
var op = box1.offsetParent;
抵消
左偏移
当前元素相对于其定位的父元素的水平偏移
偏移顶部
当前元素相对于其定位的父元素的垂直偏移量
滚动区域的宽度和高度
滚动宽度滚动高度
滚动距离
向左滚动
可以得到水平滚动条滚动的距离
滚动顶部
可以得到垂直滚动条滚动的距离
满足scrollHeight - scrollTop == clientHeight 表示垂直滚动条已经滚动到最后
当scrollWidth - scrollLeft == clientWidth 满足时,水平滚动条滚动到最后
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
数学
由 Math.PI 表示的 Pi
abs() 可以用来计算一个数的绝对值
console.log(Math.abs(-1));
Math.ceil() 可以对数字进行四舍五入,如果有数值小数位自动四舍五入。
Math.floor() 可以对数字进行四舍五入,小数部分会四舍五入
Math.round() 可以对数字进行四舍五入
//console.log(Math.ceil(1.1));
//console.log(Math.floor(1.99));
//console.log(Math.round(1.4));
数学随机()
可用于生成0-1之间的随机数
生成一个 0-x 之间的随机数
Math.round(Math.random()*x)
在 xy 之间生成一个随机数
Math.round(Math.random()*(yx)+x)
for(var i=0 ; i //console.log(Math.round(Math.random()*10));
//console.log(Math.round(Math.random()*20));
//console.log(Math.round(Math.random()*9)+1);
//console.log(Math.round(Math.random()*8)+2);
//生成一个1-6之间的随机数
console.log(Math.round(Math.random()*5+1));
}
max() 可以得到多个数的最大值
min() 可以得到多个数字中的最小值
var max = Math.max(10,45,30,100);
var min = Math.min(10,45,30,100);
Math.pow(x,y) 返回 x 的 y 次幂
console.log(Math.pow(12,3));
Math.sqrt() 用于取数字的平方根
console.log(Math.sqrt(2)); 查看全部
浏览器抓取网页(Window代表当前浏览器的地址栏代表的是怎样的?)
物料清单
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
航海家
判断浏览器
var ua = navigator.userAgent;
控制台.log(ua);
if(/firefox/i.test(ua)){
alert("你是火狐!!!");
}else if(/chrome/i.test(ua)){
alert("你是 Chrome");
}否则如果(/msie/i.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,开枪~~~");
}
历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
可用于跳转到指定页面
它需要一个整数作为参数
地点
该对象封装了浏览器地址栏的信息
如果直接打印位置,可以在地址栏中获取信息
如果直接修改location属性为完整路径,或者相对路径,我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置 = "";
分配()
location.assign("");
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
location.reload(true);
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
代替()
location.replace("01.BOM.html");
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
设置间隔()
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
var timer = setInterval(function(){
count.innerHTML = 数字++;
if(num == 11){
//关闭定时器
清除间隔(定时器);
}
},1000);
clearInterval() 可用于关闭需要定时器的标识符作为参数的定时器方法,该方法将关闭该标识符对应的定时器
多姆
事件
是用户和浏览器之间的交互
例如:单击按钮、移动鼠标、关闭窗口。. .
绑定点击事件
这个与点击事件绑定的函数称为点击响应函数
btn.onclick = 函数(){
alert("你还在点~~~");
};
加载事件
在整个页面加载后触发
Window 绑定一个 onload 事件
window.onload = 函数(){
//获取id为btn的按钮
var btn = document.getElementById("btn");
//为按钮绑定点击响应函数
btn.onclick = 函数(){
警报(“你好”);
};
};
dom查询
获取按钮对象
var btn = document.getElementById("btn");
编辑按钮文本
btn.innerHTML = "我是按钮";
查找所有 li 节点
var lis = document.getElementsByTagName("li");
查找 name=gender 的所有节点
var 输入 = document.getElementsByName("gender");
如果需要读取元素节点属性,
使用 element.Attribute 名称 示例:element.id element.name element.value 注意:类属性不能这样使用,读取类属性时需要使用 element.className
返回#city 的所有子节点
childNodes 属性将获取所有节点,包括文本节点
var cns = city.childNodes;
children属性可以获取当前元素的所有子元素
var cns2 = city.children;
firstChild 可以获取当前元素的第一个子节点(包括空白文本节点)
var fir = phone.firstChild;
firstElementChild 获取当前元素的第一个子元素
冷杉 = phone.firstElementChild;
内部文本
该属性可以获取元素内部的文本内容
previousElementSibling 获取上一个兄弟元素
var pe = and.previousElementSibling;
文档中有一个属性body,里面保存了对body的引用
var body = document.body;
document.documentElement 保存 html 根标签
var html = document.documentElement;
document.all 代表页面中的所有元素
var all = document.all;
document.querySelector()
var div = document.querySelector(".box1 div");
需要选择器字符串作为参数,可以根据CSS选择器查询元素节点对象
document.querySelectorAll()
box1 = document.querySelectorAll(".box1");
这个方法类似于querySelector(),不同的是它将符合条件的元素封装成一个数组并返回
操作 CSS
修订
element.style.stylename = 样式值
这种名称在 JS 中是非法的。比如background-color需要把这个样式名改成驼色,去掉-,然后-后面的字母大写
如果样式中写了!important,那么此时样式的优先级最高
框1.style.width = "300px";
框1.style.height = "300px";
框1.style.backgroundColor = “黄色”;
读
element.style.stylename
框1.style.width
获取元素当前显示的样式
element.currentStyle.style 名称(仅IE浏览器支持)
getComputedStyle() 方法用于获取元素的当前样式。该方法是window的方法,可以直接使用,需要两个参数。
第一种:获取样式的元素
第二种:可以传入一个伪元素,一般为null
该方法返回一个对象,该对象封装了当前元素对应的样式
样式可以通过 object.stylename 读取
获取指定元素当前样式的函数
函数getStyle(obj,名称){
如果(window.getComputedStyle){
//普通浏览器方式,带getComputedStyle()方法
返回 getComputedStyle(obj , null)[name];
}别的{
//IE8方式,没有getComputedStyle()方法
返回 obj.currentStyle[名称];
}
//return window.getComputedStyle?getComputedStyle(obj , null)[name]:obj.currentStyle[name];
}
可见宽度和高度
客户宽度客户高度
框1.clientWidth
只读,不可修改
没有px,return是一个数字,可以直接计算
元素宽度和高度,包括内容区域和填充
元素的整个宽度和高度
偏移宽度偏移高度
框1.偏移宽度
当前元素的定位父级
偏移父
var op = box1.offsetParent;
抵消
左偏移
当前元素相对于其定位的父元素的水平偏移
偏移顶部
当前元素相对于其定位的父元素的垂直偏移量
滚动区域的宽度和高度
滚动宽度滚动高度
滚动距离
向左滚动
可以得到水平滚动条滚动的距离
滚动顶部
可以得到垂直滚动条滚动的距离
满足scrollHeight - scrollTop == clientHeight 表示垂直滚动条已经滚动到最后
当scrollWidth - scrollLeft == clientWidth 满足时,水平滚动条滚动到最后
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
数学
由 Math.PI 表示的 Pi
abs() 可以用来计算一个数的绝对值
console.log(Math.abs(-1));
Math.ceil() 可以对数字进行四舍五入,如果有数值小数位自动四舍五入。
Math.floor() 可以对数字进行四舍五入,小数部分会四舍五入
Math.round() 可以对数字进行四舍五入
//console.log(Math.ceil(1.1));
//console.log(Math.floor(1.99));
//console.log(Math.round(1.4));
数学随机()
可用于生成0-1之间的随机数
生成一个 0-x 之间的随机数
Math.round(Math.random()*x)
在 xy 之间生成一个随机数
Math.round(Math.random()*(yx)+x)
for(var i=0 ; i //console.log(Math.round(Math.random()*10));
//console.log(Math.round(Math.random()*20));
//console.log(Math.round(Math.random()*9)+1);
//console.log(Math.round(Math.random()*8)+2);
//生成一个1-6之间的随机数
console.log(Math.round(Math.random()*5+1));
}
max() 可以得到多个数的最大值
min() 可以得到多个数字中的最小值
var max = Math.max(10,45,30,100);
var min = Math.min(10,45,30,100);
Math.pow(x,y) 返回 x 的 y 次幂
console.log(Math.pow(12,3));
Math.sqrt() 用于取数字的平方根
console.log(Math.sqrt(2));
浏览器抓取网页(1.网站会设置一些反爬虫的措施吗?怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-03-13 14:17
有时候,当我们的爬虫程序完成,本地测试没有问题的时候,爬了一段时间后,突然发现报错,无法爬取页面内容。这时候我们很可能遇到了网站的反爬虫拦截。
我们知道,一方面网站想让爬虫爬到网站,比如让搜索引擎爬虫爬取网站的内容,提高网站的搜索排名. 另一方面,由于网站的服务器资源有限,过多的非真实用户对网站的大量访问会增加运营成本和服务器负担。
因此,一些网站会设置一些反爬措施。只有了解主要的反爬虫措施,才能识别反爬虫措施,进行反爬虫。当然,从道德和法律的角度来看,开发者应该出于合理合法的目的控制爬虫,决不能非法使用爬虫。如果您需要将爬取的内容用于商业用途,则需要特别注意数据上对应的网站声明。
1. 常用的反爬方法:
这是最基本的反爬虫方法之一。网站算子通过验证爬虫请求头中的User-agent、accept-enconding等信息来验证请求的主机是真实用户的普通浏览器还是其他一些信息。具体的请求头信息。
通过ajax或javascript动态获取和加载数据,增加了爬虫直接获取数据的难度。
相信大部分读者对此都非常熟悉。当我们多次输入错误密码时,很多平台都会弹出各种二维码供我们识别,或者当我们抢优采云票的时候,会有各种复杂的验证码,验证码是使用最广泛的一种防爬虫措施,也是防止爬虫最有效、最直接的方法之一。
当识别出一些异常访问时,网站运营商会设置黑名单,对确定为爬虫的部分IP进行限制或屏蔽。
有的网站,没有游客模式,只有注册后才能登录才能看到内容,这是典型的账号限制网站,一般可以在网站用户不多的情况下使用,具有严格安全要求的数据 网站。
2. 反反爬虫策略:
我们可以在请求头中替换我们的请求介质,让网站误以为我们是通过移动端访问的。运行以下代码后,当我们打开 hupu.html 时,会发现返回的是移动端的老虎。Flutter 的页面而不是 web 端的页面。
import requests
from bs4 import BeautifulSoup
header_data = {
'User-Agent': 'Mozilla/5.0 (Linux; U; Android 4.4.2; en-us; SCH-I535 Build/KOT49H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'}
re = requests.get('https://www.hupu.com/', headers=header_data)
bs = BeautifulSoup(re.content)
with open('hupu.html', 'wb') as f:
f.write(bs.prettify(encoding='utf8'))
例如,我们可以设置一个随机间隔来模拟用户行为,减少访问次数和访问频率。我们可以在我们的爬虫程序中加入如下代码,让爬虫休息3秒左右,然后再爬取,可以有效避免网站对爬虫的检测识别。
import time
import random
sleep_time = random.randint(0.,2) + random.random()
time.sleep(sleep_time)
代理是通过访问第三方机器隐藏自己的真实IP地址,然后通过第三方机器的IP访问。
import requests
link = "http://www.baidu.com/"
proxies = {'http':'XXXXXXXXXXX'} //代理地址,可以自己上网查找,这里就不做推荐了
response = requests.get(link, proxies=proxies)
因为第三方代理没有好坏之分,而且不稳定,经常会出现断线,爬取速度会慢很多。如果对爬虫的质量有严格要求,不建议使用这种方式进行爬取。
可以通过动态 IP 拨号服务器或 Tor 代理服务器更改 IP。
概括
反反爬虫的策略总是在变化。我们应该详细分析具体问题,通过不断的试错来改进我们的爬虫爬取。不要以为爬虫程序在本地调试好之后就没有问题了,可以高枕无忧了。在线问题总是千变万化。我们需要根据我们具体的反爬措施编写一些反反爬代码,以保证在线环境万无一失。 查看全部
浏览器抓取网页(1.网站会设置一些反爬虫的措施吗?怎么办?)
有时候,当我们的爬虫程序完成,本地测试没有问题的时候,爬了一段时间后,突然发现报错,无法爬取页面内容。这时候我们很可能遇到了网站的反爬虫拦截。
我们知道,一方面网站想让爬虫爬到网站,比如让搜索引擎爬虫爬取网站的内容,提高网站的搜索排名. 另一方面,由于网站的服务器资源有限,过多的非真实用户对网站的大量访问会增加运营成本和服务器负担。
因此,一些网站会设置一些反爬措施。只有了解主要的反爬虫措施,才能识别反爬虫措施,进行反爬虫。当然,从道德和法律的角度来看,开发者应该出于合理合法的目的控制爬虫,决不能非法使用爬虫。如果您需要将爬取的内容用于商业用途,则需要特别注意数据上对应的网站声明。
1. 常用的反爬方法:
这是最基本的反爬虫方法之一。网站算子通过验证爬虫请求头中的User-agent、accept-enconding等信息来验证请求的主机是真实用户的普通浏览器还是其他一些信息。具体的请求头信息。
通过ajax或javascript动态获取和加载数据,增加了爬虫直接获取数据的难度。
相信大部分读者对此都非常熟悉。当我们多次输入错误密码时,很多平台都会弹出各种二维码供我们识别,或者当我们抢优采云票的时候,会有各种复杂的验证码,验证码是使用最广泛的一种防爬虫措施,也是防止爬虫最有效、最直接的方法之一。
当识别出一些异常访问时,网站运营商会设置黑名单,对确定为爬虫的部分IP进行限制或屏蔽。
有的网站,没有游客模式,只有注册后才能登录才能看到内容,这是典型的账号限制网站,一般可以在网站用户不多的情况下使用,具有严格安全要求的数据 网站。
2. 反反爬虫策略:
我们可以在请求头中替换我们的请求介质,让网站误以为我们是通过移动端访问的。运行以下代码后,当我们打开 hupu.html 时,会发现返回的是移动端的老虎。Flutter 的页面而不是 web 端的页面。
import requests
from bs4 import BeautifulSoup
header_data = {
'User-Agent': 'Mozilla/5.0 (Linux; U; Android 4.4.2; en-us; SCH-I535 Build/KOT49H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'}
re = requests.get('https://www.hupu.com/', headers=header_data)
bs = BeautifulSoup(re.content)
with open('hupu.html', 'wb') as f:
f.write(bs.prettify(encoding='utf8'))
例如,我们可以设置一个随机间隔来模拟用户行为,减少访问次数和访问频率。我们可以在我们的爬虫程序中加入如下代码,让爬虫休息3秒左右,然后再爬取,可以有效避免网站对爬虫的检测识别。
import time
import random
sleep_time = random.randint(0.,2) + random.random()
time.sleep(sleep_time)
代理是通过访问第三方机器隐藏自己的真实IP地址,然后通过第三方机器的IP访问。
import requests
link = "http://www.baidu.com/"
proxies = {'http':'XXXXXXXXXXX'} //代理地址,可以自己上网查找,这里就不做推荐了
response = requests.get(link, proxies=proxies)
因为第三方代理没有好坏之分,而且不稳定,经常会出现断线,爬取速度会慢很多。如果对爬虫的质量有严格要求,不建议使用这种方式进行爬取。
可以通过动态 IP 拨号服务器或 Tor 代理服务器更改 IP。
概括
反反爬虫的策略总是在变化。我们应该详细分析具体问题,通过不断的试错来改进我们的爬虫爬取。不要以为爬虫程序在本地调试好之后就没有问题了,可以高枕无忧了。在线问题总是千变万化。我们需要根据我们具体的反爬措施编写一些反反爬代码,以保证在线环境万无一失。
浏览器抓取网页( SEO实战密码之搜索引擎爬行与抓取2.排序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-13 14:14
SEO实战密码之搜索引擎爬行与抓取2.排序)
在互联网时代,搜索引擎可以说是日常生活的一部分。不仅如此,经过20多年的风霜雨雪,搜索引擎依然牢牢占据着流量入口,让人唏嘘不已。
而且,一提到搜索引擎,我们都会想到一个大巨头公司,一个被黑的巨头公司。足以看出搜索引擎的巨大作用。
作为产品人,当然不能对此视而不见,应该明白它是如何工作的。
搜索引擎的工作原理大致可以分为3个步骤
1. 爬行和爬行
2. 预处理
3. 排序
俗话说,图胜千言,没有图,我说……
PS:上图摘自《SEO实战密码》。
详细描述如下:
抓取和抓取
简单地说:是搜索引擎蜘蛛沿着互联网爬行,爬取它们爬取的页面,并存储那些爬取的页面。
说到这里,你可能会问:为什么叫它“蜘蛛”?
为了爬取尽可能多的页面,搜索引擎会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来。
搜索引擎在跟踪网络上的链接时会使用某些策略,因为今天有太多的网络链接。最简单的爬取遍历策略有两种,一种是深度优先,一种是广度优先。
还有一件事值得一提:搜索引擎访问 网站 页面类似于普通用户使用的浏览器。搜索引擎蜘蛛爬取的数据存储在原创页面数据库中,其中的页面数据与用户浏览器获取的HTML完全相同。
预处理
由于爬取的页面数量太大(以“十亿”为单位)无法实时快速排序,因此需要进行预处理。这就是产品设计中的“复杂性守恒原则”。我们不能让用户等待十秒以上,所以只能做后台处理。
在一些数据中,“预处理”也称为“索引”,因为“索引”是预处理最重要的内容。
预处理过程比较复杂,值得一提的是以下几点:
有了倒排索引,就可以根据用户搜索到的关键词快速找到对应的文件,但是这样就够了吗?不要天真。
通过以上步骤,其实只获取到了页面本身的内容。说白了就是页面本身告诉搜索引擎怎么做。
俗话说:王婆卖瓜,她卖自己吹牛。
就像我们在网上购物时,不仅会看店铺给出的产品介绍,还会看买家的评价,页面内容的好坏也需要其他人的评价——这里的“其他人”指“其他页面”。因此,我们还需要链接关系计算。
排行
找不到:排名是用户唯一能感受到的一步。爬取、爬取和预处理都是在后台完成的。正因为如此,用户会觉得使用起来非常快。
排名过程也比较复杂,有以下几点值得一提:
但是,由于每个关键词对应的文件数量可能非常庞大(比如上亿),处理如此庞大的数据量并不能满足用户对“速度”的需求。同时,用户并不需要所有的内容,他们往往只查看前几页的内容,甚至很多用户只查看第一页的前几页内容。因此,需要选择一定数量的内容进行处理。这涉及选择熟人的子集。
但如何选择?这是个问题。
但这就是结束了吗?还没有。
本文由 @ITDoer 原创 在每个人都是产品经理发布。未经许可禁止复制 查看全部
浏览器抓取网页(
SEO实战密码之搜索引擎爬行与抓取2.排序)
在互联网时代,搜索引擎可以说是日常生活的一部分。不仅如此,经过20多年的风霜雨雪,搜索引擎依然牢牢占据着流量入口,让人唏嘘不已。
而且,一提到搜索引擎,我们都会想到一个大巨头公司,一个被黑的巨头公司。足以看出搜索引擎的巨大作用。
作为产品人,当然不能对此视而不见,应该明白它是如何工作的。
搜索引擎的工作原理大致可以分为3个步骤
1. 爬行和爬行
2. 预处理
3. 排序
俗话说,图胜千言,没有图,我说……
PS:上图摘自《SEO实战密码》。
详细描述如下:
抓取和抓取
简单地说:是搜索引擎蜘蛛沿着互联网爬行,爬取它们爬取的页面,并存储那些爬取的页面。
说到这里,你可能会问:为什么叫它“蜘蛛”?
为了爬取尽可能多的页面,搜索引擎会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来。
搜索引擎在跟踪网络上的链接时会使用某些策略,因为今天有太多的网络链接。最简单的爬取遍历策略有两种,一种是深度优先,一种是广度优先。
还有一件事值得一提:搜索引擎访问 网站 页面类似于普通用户使用的浏览器。搜索引擎蜘蛛爬取的数据存储在原创页面数据库中,其中的页面数据与用户浏览器获取的HTML完全相同。
预处理
由于爬取的页面数量太大(以“十亿”为单位)无法实时快速排序,因此需要进行预处理。这就是产品设计中的“复杂性守恒原则”。我们不能让用户等待十秒以上,所以只能做后台处理。
在一些数据中,“预处理”也称为“索引”,因为“索引”是预处理最重要的内容。
预处理过程比较复杂,值得一提的是以下几点:
有了倒排索引,就可以根据用户搜索到的关键词快速找到对应的文件,但是这样就够了吗?不要天真。
通过以上步骤,其实只获取到了页面本身的内容。说白了就是页面本身告诉搜索引擎怎么做。
俗话说:王婆卖瓜,她卖自己吹牛。
就像我们在网上购物时,不仅会看店铺给出的产品介绍,还会看买家的评价,页面内容的好坏也需要其他人的评价——这里的“其他人”指“其他页面”。因此,我们还需要链接关系计算。
排行
找不到:排名是用户唯一能感受到的一步。爬取、爬取和预处理都是在后台完成的。正因为如此,用户会觉得使用起来非常快。
排名过程也比较复杂,有以下几点值得一提:
但是,由于每个关键词对应的文件数量可能非常庞大(比如上亿),处理如此庞大的数据量并不能满足用户对“速度”的需求。同时,用户并不需要所有的内容,他们往往只查看前几页的内容,甚至很多用户只查看第一页的前几页内容。因此,需要选择一定数量的内容进行处理。这涉及选择熟人的子集。
但如何选择?这是个问题。
但这就是结束了吗?还没有。
本文由 @ITDoer 原创 在每个人都是产品经理发布。未经许可禁止复制
浏览器抓取网页(Windows7HomePremiumSP164位上测试:IE更改默认浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-08 05:14
TL;DR:如果存在
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
然后阅读;否则请阅读
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
. 看了这里的答案后,我对如何检测默认浏览器达成了共识,所以我做了一些实验和研究来弄清楚。我下载了 Firefox 源代码,编写了一个读取一堆注册表项的脚本,并在反复更改默认浏览器的同时运行 Process Explorer。我发现 Firefox 和 Chrome 在将它们自定义为默认浏览器时有很多注册表项。我相信 Safari 和 Opera 的行为相似。IE 似乎只更改了我正在观看的一个注册表项。我发现虽然大多数浏览器更改了其他注册表路径,但所有浏览器都更改了
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
以下是注册表项
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
中的注册表值,并且每个浏览器都是默认浏览器。即 9.0.8112.16421:
IEXPLORE.EXE
铬 21.0.1180.60m:
Google Chrome
火狐10.0.2:
FIREFOX.EXE
Safari 3.2.2:
Safari.exe
歌剧 12.01:
Opera
在 Microsoft Windows 7 Home Premium SP1 64bit 上进行测试编辑:我找到了全新安装的 Windows XPSP3
HKEY_CURRENT_USERSOFTWAREClientsStartMenuInternet
不存在。在这种情况下,您应该从
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
阅读默认浏览器。我怀疑其他版本的 Windows 的全新安装也是如此。附录:如果您只想在默认浏览器中打开网页,那么
ShellExecute
方法是一个很好的解决方案。但是,如果您只想在默认浏览器中安装扩展程序,那么
ShellExecute
无法解决问题。 查看全部
浏览器抓取网页(Windows7HomePremiumSP164位上测试:IE更改默认浏览器)
TL;DR:如果存在
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
然后阅读;否则请阅读
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
. 看了这里的答案后,我对如何检测默认浏览器达成了共识,所以我做了一些实验和研究来弄清楚。我下载了 Firefox 源代码,编写了一个读取一堆注册表项的脚本,并在反复更改默认浏览器的同时运行 Process Explorer。我发现 Firefox 和 Chrome 在将它们自定义为默认浏览器时有很多注册表项。我相信 Safari 和 Opera 的行为相似。IE 似乎只更改了我正在观看的一个注册表项。我发现虽然大多数浏览器更改了其他注册表路径,但所有浏览器都更改了
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
以下是注册表项
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
中的注册表值,并且每个浏览器都是默认浏览器。即 9.0.8112.16421:
IEXPLORE.EXE
铬 21.0.1180.60m:
Google Chrome
火狐10.0.2:
FIREFOX.EXE
Safari 3.2.2:
Safari.exe
歌剧 12.01:
Opera
在 Microsoft Windows 7 Home Premium SP1 64bit 上进行测试编辑:我找到了全新安装的 Windows XPSP3
HKEY_CURRENT_USERSOFTWAREClientsStartMenuInternet
不存在。在这种情况下,您应该从
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
阅读默认浏览器。我怀疑其他版本的 Windows 的全新安装也是如此。附录:如果您只想在默认浏览器中打开网页,那么
ShellExecute
方法是一个很好的解决方案。但是,如果您只想在默认浏览器中安装扩展程序,那么
ShellExecute
无法解决问题。
浏览器抓取网页( 游戏/数码网络2013-03-059浏览如何获取网页的更新时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-08 05:12
游戏/数码网络2013-03-059浏览如何获取网页的更新时间)
如何获取网页的更新时间并重置浏览器
游戏/数字网络2013-03-05 9 浏览
如何获取网页的更新时间如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。弹出提示框,可以快速查看当前网页的更新时间。如何重置IE浏览器 如果IE浏览器经常遇到运行错误,用户可以通过重置IE来恢复其初始设置。方法/步骤步骤一:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,
如何获取网页的更新时间
如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。输入完成后,按【Enter】键确认,会弹出提示信息框。点击这里查看当前页面的更新时间。
如何重置 Internet Explorer
如果 IE 经常出现运行错误,用户可以通过重置 IE 来恢复其初始设置。
方法/步骤
第一步:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,切换到“高级”选项卡,点击“重置”按钮,如图下图。
第二步:弹出“重置Internet Explorer设置”对话框,点击对话框中的“重置”按钮,如下图所示。
第三步:弹出“重置Internet Explorer设置”对话框,显示重置进度,如下图,稍等片刻,即可重置浏览器。
文章 标签:在网页上更新plesk刺激战场周报更新时间centos在线更新时间自动更新时间功能拼多多农场交易所更新时间 查看全部
浏览器抓取网页(
游戏/数码网络2013-03-059浏览如何获取网页的更新时间)
如何获取网页的更新时间并重置浏览器
游戏/数字网络2013-03-05 9 浏览
如何获取网页的更新时间如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。弹出提示框,可以快速查看当前网页的更新时间。如何重置IE浏览器 如果IE浏览器经常遇到运行错误,用户可以通过重置IE来恢复其初始设置。方法/步骤步骤一:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,
如何获取网页的更新时间
如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。输入完成后,按【Enter】键确认,会弹出提示信息框。点击这里查看当前页面的更新时间。
如何重置 Internet Explorer
如果 IE 经常出现运行错误,用户可以通过重置 IE 来恢复其初始设置。
方法/步骤
第一步:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,切换到“高级”选项卡,点击“重置”按钮,如图下图。

第二步:弹出“重置Internet Explorer设置”对话框,点击对话框中的“重置”按钮,如下图所示。

第三步:弹出“重置Internet Explorer设置”对话框,显示重置进度,如下图,稍等片刻,即可重置浏览器。

文章 标签:在网页上更新plesk刺激战场周报更新时间centos在线更新时间自动更新时间功能拼多多农场交易所更新时间
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-08 00:02
)
从IE浏览器获取当前页面内容的方法可能有很多种,今天就介绍其中的一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
); 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍
)
从IE浏览器获取当前页面内容的方法可能有很多种,今天就介绍其中的一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:

向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
浏览器抓取网页(macOS系统自带截图到底怎么用㊙️?(实战))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-06 07:06
让我结束这个问题,首先我认为这是一个伪需求。当然,这道题的前提是“对整个网页进行截图”。默认情况下,你说的是长图,也就是网页中没有显示在屏幕上的部分,也需要滚动来截图。
不然真的没必要用 Chrome 浏览器截图,因为 Windows 和 macOS 都提供系统原生的截图解决方案。
1、Mac上的系统截图功能很强大,除了几个明显的缺点(没有马赛克),感觉很好用,之前分享过。
如何使用macOS系统自带的截图?最完整(实用)的分享方法。快捷方式、存储位置、浮动缩略图、复制到剪贴板、参数,所有技巧都在这里——我作为网站管理员的岁月
2、对于Windows,您也可以使用Print Screen(键盘右上角)进行截图。按下后,图片实际上已经到了粘贴板上。找个地方贴一下就可以看到了。
3、如果以上两种方法都不能满足,我们来看看Chrome浏览器自带的截图。
先F12打开调试页面
然后使用快捷键,不同的系统使用不同的快捷键
然后会出现输入命令的界面。
可以在此处输入命令。不同的命令有不同的功能。这是我们需要的屏幕截图。
OK完成!
更详细的步骤,建议观看视频
▶ 视频收录的内容:
全部显示网址, 查看全部
浏览器抓取网页(macOS系统自带截图到底怎么用㊙️?(实战))
让我结束这个问题,首先我认为这是一个伪需求。当然,这道题的前提是“对整个网页进行截图”。默认情况下,你说的是长图,也就是网页中没有显示在屏幕上的部分,也需要滚动来截图。
不然真的没必要用 Chrome 浏览器截图,因为 Windows 和 macOS 都提供系统原生的截图解决方案。
1、Mac上的系统截图功能很强大,除了几个明显的缺点(没有马赛克),感觉很好用,之前分享过。
如何使用macOS系统自带的截图?最完整(实用)的分享方法。快捷方式、存储位置、浮动缩略图、复制到剪贴板、参数,所有技巧都在这里——我作为网站管理员的岁月
2、对于Windows,您也可以使用Print Screen(键盘右上角)进行截图。按下后,图片实际上已经到了粘贴板上。找个地方贴一下就可以看到了。
3、如果以上两种方法都不能满足,我们来看看Chrome浏览器自带的截图。
先F12打开调试页面
然后使用快捷键,不同的系统使用不同的快捷键

然后会出现输入命令的界面。
可以在此处输入命令。不同的命令有不同的功能。这是我们需要的屏幕截图。

OK完成!
更详细的步骤,建议观看视频
▶ 视频收录的内容:
全部显示网址,
浏览器抓取网页(浏览器都行操作步骤电脑浏览器打开京东网址按enter回车键)
网站优化 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2022-03-04 13:21
PS:注意:如果你有多个账号,千万不要点击退出。直接关闭网页,清除浏览器cookie数据,重新进入网页登录下一个账号。退出会使刚刚获取的ck失效。
以下浏览器都可以使用
操作步骤电脑浏览器打开京东网站,按键盘F12键打开开发者工具,然后点击下图中的图标
此时您没有登录(使用手机短信验证码登录)。如果您已经登录,请忽略此步骤。登录后,选择网络。如果链接较多,请点击此处的箭头清除
然后再点我,链接会变少
点击第一个链接(log.gif)进去,找到cookie,复制出来,新建一个TXT文本并临时保存,下面需要用到
第六步复制的cookie比较长,我们只需要pt_pin=xxxx的内容;和 pt_key=xxxx; (注:英文引号;是必需的)。可以使用如下脚本,在Chrome浏览器中按F12,在控制台输入如下脚本后回车
var CV = '单引号里面放第六步拿到的cookie';
var CookieValue = CV.match(/pt_pin=.+?;/) + CV.match(/pt_key=.+?;/);
copy(CookieValue);
这样,关键cookies已经在你的剪贴板上了,你可以直接粘贴。如果需要获取第二个京东账号的cookie,千万不要在之前的浏览器上退出登录账号1(否则刚刚获取的cookie会失效),需要换另一个浏览器(Chrome浏览器ctr +shift+n 也可以开启隐身模式),然后继续按照上述步骤操作即可。
奖励
支付宝扫码打赏
微信打赏
如果我的文章对你有帮助,请移步顶部按钮打赏 查看全部
浏览器抓取网页(浏览器都行操作步骤电脑浏览器打开京东网址按enter回车键)
PS:注意:如果你有多个账号,千万不要点击退出。直接关闭网页,清除浏览器cookie数据,重新进入网页登录下一个账号。退出会使刚刚获取的ck失效。
以下浏览器都可以使用
操作步骤电脑浏览器打开京东网站,按键盘F12键打开开发者工具,然后点击下图中的图标
 https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... e.png 1600w" />
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... e.png 1600w" />此时您没有登录(使用手机短信验证码登录)。如果您已经登录,请忽略此步骤。登录后,选择网络。如果链接较多,请点击此处的箭头清除
 https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 9.png 1600w" />
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 9.png 1600w" />然后再点我,链接会变少
 https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 8.png 1600w" />
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 8.png 1600w" />点击第一个链接(log.gif)进去,找到cookie,复制出来,新建一个TXT文本并临时保存,下面需要用到
 https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 8.png 1600w" />
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 8.png 1600w" />第六步复制的cookie比较长,我们只需要pt_pin=xxxx的内容;和 pt_key=xxxx; (注:英文引号;是必需的)。可以使用如下脚本,在Chrome浏览器中按F12,在控制台输入如下脚本后回车
var CV = '单引号里面放第六步拿到的cookie';
var CookieValue = CV.match(/pt_pin=.+?;/) + CV.match(/pt_key=.+?;/);
copy(CookieValue);
这样,关键cookies已经在你的剪贴板上了,你可以直接粘贴。如果需要获取第二个京东账号的cookie,千万不要在之前的浏览器上退出登录账号1(否则刚刚获取的cookie会失效),需要换另一个浏览器(Chrome浏览器ctr +shift+n 也可以开启隐身模式),然后继续按照上述步骤操作即可。

奖励
支付宝扫码打赏

微信打赏
如果我的文章对你有帮助,请移步顶部按钮打赏
浏览器抓取网页(因特网上信息的浏览与获取【教材分析】-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-04 13:16
《互联网信息获取与浏览》由会员共享,可在线阅读。更多《互联网信息获取与浏览(4页珍藏版)》,请在人人图书馆在线搜索。
在互联网上浏览和获取信息 [教科书分析] 互联网是一个巨大的资源库。本课程的中心是使用互联网获取所需的信息。因此,掌握通过互联网获取信息的基本技能是学生学习和实践的主要技能。本节内容与其他学科密切相关,可以成为其他学科丰富的学习资源和拓展学习内容的支点。如何有效地进行学科间的融合,促进信息素养的发展,值得教师在本课程的教学过程中不断的实践和探索。【学生分析】很多学生在初中就接触到了网络知识,并基本掌握了IE和网页浏览的使用。只有少数学生没有学过。因此,应针对不同层次的学生开设这门课。任务 设置应合理,考虑到所有学生。【教学目标】1.掌握网页浏览方法的知识和技能;学会保存有用的网络资源;掌握采集夹的使用。2.过程和方法培养学生获取和处理信息并利用所得信息解决实际问题的能力。3.情感态度与价值观 通过获取2008年北京奥运会的信息,让学生感受祖国的力量,增强爱国热情;激发和维护学生的 积极利用信息技术进行持续学习和科学探索,形成积极学习和利用信息技术、参与信息活动的态度。练习和总结信息获取的基本方法,能够以一定的方式有效、准确地获取信息。【要点与难点】要点:保存网页内容和使用采集夹要点:整理采集夹 【教学方法】 任务驱动,讲课,演示,探索 地点在哪里?互联网是世界上最大的信息库,我们可以从中获取各种信息。如何访问和保存互联网上的信息?认真听课,积极思考题型介绍,
<p>2008年的新班是每个中国人都期待的日子,因为奥运会将在我国举行。作为一个中国人,你应该知道一些关于2008年奥运会的基本信息。下面我们将通过互联网浏览和获取它们。关于它的信息。访问和浏览网站 如果要在网上获取信息,首先要输入对应的网站,输入网站的方法: 打开IE,输入 查看全部
浏览器抓取网页(因特网上信息的浏览与获取【教材分析】-乐题库)
《互联网信息获取与浏览》由会员共享,可在线阅读。更多《互联网信息获取与浏览(4页珍藏版)》,请在人人图书馆在线搜索。
在互联网上浏览和获取信息 [教科书分析] 互联网是一个巨大的资源库。本课程的中心是使用互联网获取所需的信息。因此,掌握通过互联网获取信息的基本技能是学生学习和实践的主要技能。本节内容与其他学科密切相关,可以成为其他学科丰富的学习资源和拓展学习内容的支点。如何有效地进行学科间的融合,促进信息素养的发展,值得教师在本课程的教学过程中不断的实践和探索。【学生分析】很多学生在初中就接触到了网络知识,并基本掌握了IE和网页浏览的使用。只有少数学生没有学过。因此,应针对不同层次的学生开设这门课。任务 设置应合理,考虑到所有学生。【教学目标】1.掌握网页浏览方法的知识和技能;学会保存有用的网络资源;掌握采集夹的使用。2.过程和方法培养学生获取和处理信息并利用所得信息解决实际问题的能力。3.情感态度与价值观 通过获取2008年北京奥运会的信息,让学生感受祖国的力量,增强爱国热情;激发和维护学生的 积极利用信息技术进行持续学习和科学探索,形成积极学习和利用信息技术、参与信息活动的态度。练习和总结信息获取的基本方法,能够以一定的方式有效、准确地获取信息。【要点与难点】要点:保存网页内容和使用采集夹要点:整理采集夹 【教学方法】 任务驱动,讲课,演示,探索 地点在哪里?互联网是世界上最大的信息库,我们可以从中获取各种信息。如何访问和保存互联网上的信息?认真听课,积极思考题型介绍,
<p>2008年的新班是每个中国人都期待的日子,因为奥运会将在我国举行。作为一个中国人,你应该知道一些关于2008年奥运会的基本信息。下面我们将通过互联网浏览和获取它们。关于它的信息。访问和浏览网站 如果要在网上获取信息,首先要输入对应的网站,输入网站的方法: 打开IE,输入
浏览器抓取网页(浏览器抓取网页的iframe包含的http头部与服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-28 14:02
浏览器抓取网页的iframe包含的http头部与服务器响应处理头部就是这样。web开发者还是要勤快一点,看看我的主页,web开发者工具里抓取的还是很准的,每个标签是否是http头部都有。现在http连接结束了就不能抓取http头部了。另外也许你的抓取一定有效,但是你在python抓取web页面时,一定要设置好抓取过程的端口,是不是安全。
如果连接结束后端口被封。又使用了80端口,你那里浏览器访问是会报错的。记得封的是整个页面,像头部是没有封的。
写个代码而已,为什么要这么计较。
如果有80端口号,一定要分析后台的80端口处理.
采用nodejs。
额...先查一下cookie头
这样封,
cookie
这么说吧,每次看qq的服务器,一般都是不一样的,比如,12345678,
一般是一个http状态码来对应的。
0、30
2、40
3、50
0、40
3、60
0、700这些。这里要注意,如果这个http状态码是3,你用户能看到所有的报文,但看不到所有的http请求,这个其实也无所谓,毕竟能看到请求头报文。就算看不到,服务器还能能看到,看不到给你报数据库单身的header呗。 查看全部
浏览器抓取网页(浏览器抓取网页的iframe包含的http头部与服务器)
浏览器抓取网页的iframe包含的http头部与服务器响应处理头部就是这样。web开发者还是要勤快一点,看看我的主页,web开发者工具里抓取的还是很准的,每个标签是否是http头部都有。现在http连接结束了就不能抓取http头部了。另外也许你的抓取一定有效,但是你在python抓取web页面时,一定要设置好抓取过程的端口,是不是安全。
如果连接结束后端口被封。又使用了80端口,你那里浏览器访问是会报错的。记得封的是整个页面,像头部是没有封的。
写个代码而已,为什么要这么计较。
如果有80端口号,一定要分析后台的80端口处理.
采用nodejs。
额...先查一下cookie头
这样封,
cookie
这么说吧,每次看qq的服务器,一般都是不一样的,比如,12345678,
一般是一个http状态码来对应的。
0、30
2、40
3、50
0、40
3、60
0、700这些。这里要注意,如果这个http状态码是3,你用户能看到所有的报文,但看不到所有的http请求,这个其实也无所谓,毕竟能看到请求头报文。就算看不到,服务器还能能看到,看不到给你报数据库单身的header呗。
浏览器抓取网页(浏览器抓取网页也不是很简单的,你得使用其他的抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-28 13:04
浏览器抓取网页也不是很简单的,你得使用其他的抓取方法。
1、首先你要先安装nodejs的模块。
2、然后在浏览器搜索相关的插件,比如说:登录、登陆提示、支付宝登录、红包,用他们来代替就可以了。网上都有的。
3、安装完毕之后,开始使用nodejs模块的post。
建议先学习javascript,
mongodb并没有特定的语言,
这是三种不同的语言,mongodbredis都不适合直接抓取登录这个动作,其中redis更接近nosql数据库,可以满足单个人登录,密码查询,红包提取,
第一次被邀请,你们不要在评论里卖萌,谢谢。再次谢谢。 查看全部
浏览器抓取网页(浏览器抓取网页也不是很简单的,你得使用其他的抓取方法)
浏览器抓取网页也不是很简单的,你得使用其他的抓取方法。
1、首先你要先安装nodejs的模块。
2、然后在浏览器搜索相关的插件,比如说:登录、登陆提示、支付宝登录、红包,用他们来代替就可以了。网上都有的。
3、安装完毕之后,开始使用nodejs模块的post。
建议先学习javascript,
mongodb并没有特定的语言,
这是三种不同的语言,mongodbredis都不适合直接抓取登录这个动作,其中redis更接近nosql数据库,可以满足单个人登录,密码查询,红包提取,
第一次被邀请,你们不要在评论里卖萌,谢谢。再次谢谢。
浏览器抓取网页(跨站攻击的主要原因是什么?DOM型的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-25 18:05
内容
跨站脚本
xss:跨站脚本攻击,无需做任何登录认证,通过合法操作(如在url输入,在评论框输入),将脚本程序注入你的页面或攻击者在网页中插入恶意脚本当用户浏览页面时,会执行嵌入在Web中的脚本代码,从而达到恶意攻击用户的目的。
攻击条件
将恶意代码注入网页
这些恶意代码可以被浏览器成功执行
攻击原理
xss漏洞的主要原因是程序对输入输出的控制不够严格,导致“构造良好”的脚本输入,在输入到前端,造成伤害。
xss 漏洞可用于进行网络钓鱼攻击、获取键盘记录、用户 cookie 等。
攻击方式
反射型xss、存储型xss、DOM型xss
1、反射也称为非持久性XSS
交互数据一般不存储在数据库中。它是一次性的,所见即所得,通常出现在查询页面上。
2、Store 也称为持久性 XSS
互动数据会被存入数据库,永久保存,一般会出现在留言板、注册等页面。
3、DOM 类型
不与后台服务器交互是前端代码通过DOM操作输出时出现的问题,也是一次性反射类型。
危害:存储 > 反射 > DOM
DOM 类型
网站 页面中有很多元素。当页面到达浏览器时,浏览器会为页面创建一个顶级的Document Object,然后生成各种子文档对象。每个页面元素对应一个文档对象。文档对象收录属性、方法和事件。客户端脚本程序可以通过DOM动态修改页面内容,从客户端获取DOM中的数据并在本地执行。由于 DOM 在客户端修改节点,基于 DOM 的 XSS 漏洞不需要与服务器交互,仅在客户端处理数据时发生。
攻击方式:用户请求一个特制的URL,由攻击者提交,收录XSS代码。服务器的响应不会收录任何形式的攻击者脚本。当用户的浏览器处理这个响应时,DOM 对象会处理 XSS 代码,从而导致 XSS 漏洞。
原文链接:
因为 JS 触发的 XSS 是 DOM 类型的 XSS,一般来说 DOM 类型的 XSS 是反射性的,很少存储。
如果插入XSS,一般是动态页面,但也有一些是静态页面,不会和数据库交互,大大提高了安全性,也让我们很难进行XSS。考虑到这一点,许多开发人员还假装是动态页面。把它做成静态页面,这种页面叫做:伪静态页面;
控制台输入 document.lastModified 以区分动态和伪静态页面。如果时间总是新的,那么它是动态的或伪静态的。如果时间不变,那就是静态的,不需要xss。
xss漏洞预防
这三种类型的 XSS 漏洞都可以通过过滤或编码来修复。
• 反射型XSS和存储型XSS可以在服务器端对用户输入输出的内容进行过滤和编码,过滤关键字,对关键符号进行编码。所有特殊符号如 , ” , ' , = 都可以通过实体编码或百分比编码来修复。
• 如果DOM类型的XSS与服务器交互,可以参考以上方法修复。如果不与服务器交互,则可以使用 JavaScript 等客户端脚本语言在客户端进行编码和过滤。
• 摘要:输入被过滤,输出被转义(编码)
CSRF
csrf:跨站请求伪造,是一种强制用户对当前登录的Web应用程序进行非预期操作的攻击方法。常见的攻击方式发送csrf的连接,通过伪造请求,受害者点击后会使用受害者的身份发起请求。
CSRF攻击成功的两个必要条件
1.登录到trusted网站A并在本地生成cookies。(如果用户没有登录网站A,那么网站B在感应时请求网站A的api接口时会提示你登录),以及cookies或session未过期;
2.在没有退出A的情况下,访问危险的网站B(实际上是利用网站A的漏洞)。
这里,用户 C 生成的 cookie 保证了用户可以登录,但 网站B 却无法真正获取到 cookie。
csrf 漏洞预防
添加令牌验证(常用做法):
1、在key操作中加入token参数,token值必须是随机的,每次都不一样;关于安全会话管理(避免使用会话):1、不要在客户端存储敏感信息(如身份认证信息);
2、测试直接关闭,退出时会话过期机制;
3、设置会话过期机制,例如15分钟内无操作,自动登录超时;
门禁安全管理:
1、修改敏感信息需要二次身份认证。例如修改账号时,需要确定旧密码;
2、敏感信息的修改使用post代替get;
3、通过http头中的referer限制原创页面,并添加验证码:一般用于登录(防暴力破解),也可用于表单中进行其他重要信息操作(可用性需要考虑)
SSRF
ssrf:服务器请求伪造,由攻击者构造,形成由服务器发起请求的安全漏洞。一般来说,ssrf 攻击的目标是外部世界无法访问的内部系统。对目标地址没有过滤和限制,该功能被恶意使用,有缺陷的Web应用程序可以作为代理攻击远程和本地服务器。
ssrf 危害
1、可以对外部服务器所在的内网和本地进行端口扫描,获取部分服务的banner信息。
2、攻击在内网或本地运行的应用程序。
3、通过访问默认文件对内网web应用(检测为php、asp、jsp等)进行指纹识别。
4、攻击网络内外的 Web 应用程序。sql注入、struct2、 redis等
5、使用文件协议读取本地文件等
ssrf 漏洞预防
1. 统一错误信息,防止用户根据错误信息判断远程服务器端口状态
2. 将请求端口限制为常见的HTTP端口,如80、443、8080、8088等。
3. 黑名单内网 IP。
4.禁用不必要的协议,只允许HTTP和HTTPS。(不允许文件协议等) 查看全部
浏览器抓取网页(跨站攻击的主要原因是什么?DOM型的区别)
内容
跨站脚本
xss:跨站脚本攻击,无需做任何登录认证,通过合法操作(如在url输入,在评论框输入),将脚本程序注入你的页面或攻击者在网页中插入恶意脚本当用户浏览页面时,会执行嵌入在Web中的脚本代码,从而达到恶意攻击用户的目的。
攻击条件
将恶意代码注入网页
这些恶意代码可以被浏览器成功执行
攻击原理
xss漏洞的主要原因是程序对输入输出的控制不够严格,导致“构造良好”的脚本输入,在输入到前端,造成伤害。
xss 漏洞可用于进行网络钓鱼攻击、获取键盘记录、用户 cookie 等。
攻击方式
反射型xss、存储型xss、DOM型xss
1、反射也称为非持久性XSS
交互数据一般不存储在数据库中。它是一次性的,所见即所得,通常出现在查询页面上。
2、Store 也称为持久性 XSS
互动数据会被存入数据库,永久保存,一般会出现在留言板、注册等页面。
3、DOM 类型
不与后台服务器交互是前端代码通过DOM操作输出时出现的问题,也是一次性反射类型。
危害:存储 > 反射 > DOM
DOM 类型
网站 页面中有很多元素。当页面到达浏览器时,浏览器会为页面创建一个顶级的Document Object,然后生成各种子文档对象。每个页面元素对应一个文档对象。文档对象收录属性、方法和事件。客户端脚本程序可以通过DOM动态修改页面内容,从客户端获取DOM中的数据并在本地执行。由于 DOM 在客户端修改节点,基于 DOM 的 XSS 漏洞不需要与服务器交互,仅在客户端处理数据时发生。
攻击方式:用户请求一个特制的URL,由攻击者提交,收录XSS代码。服务器的响应不会收录任何形式的攻击者脚本。当用户的浏览器处理这个响应时,DOM 对象会处理 XSS 代码,从而导致 XSS 漏洞。
原文链接:
因为 JS 触发的 XSS 是 DOM 类型的 XSS,一般来说 DOM 类型的 XSS 是反射性的,很少存储。
如果插入XSS,一般是动态页面,但也有一些是静态页面,不会和数据库交互,大大提高了安全性,也让我们很难进行XSS。考虑到这一点,许多开发人员还假装是动态页面。把它做成静态页面,这种页面叫做:伪静态页面;
控制台输入 document.lastModified 以区分动态和伪静态页面。如果时间总是新的,那么它是动态的或伪静态的。如果时间不变,那就是静态的,不需要xss。
xss漏洞预防
这三种类型的 XSS 漏洞都可以通过过滤或编码来修复。
• 反射型XSS和存储型XSS可以在服务器端对用户输入输出的内容进行过滤和编码,过滤关键字,对关键符号进行编码。所有特殊符号如 , ” , ' , = 都可以通过实体编码或百分比编码来修复。
• 如果DOM类型的XSS与服务器交互,可以参考以上方法修复。如果不与服务器交互,则可以使用 JavaScript 等客户端脚本语言在客户端进行编码和过滤。
• 摘要:输入被过滤,输出被转义(编码)
CSRF
csrf:跨站请求伪造,是一种强制用户对当前登录的Web应用程序进行非预期操作的攻击方法。常见的攻击方式发送csrf的连接,通过伪造请求,受害者点击后会使用受害者的身份发起请求。
CSRF攻击成功的两个必要条件
1.登录到trusted网站A并在本地生成cookies。(如果用户没有登录网站A,那么网站B在感应时请求网站A的api接口时会提示你登录),以及cookies或session未过期;
2.在没有退出A的情况下,访问危险的网站B(实际上是利用网站A的漏洞)。
这里,用户 C 生成的 cookie 保证了用户可以登录,但 网站B 却无法真正获取到 cookie。
csrf 漏洞预防
添加令牌验证(常用做法):
1、在key操作中加入token参数,token值必须是随机的,每次都不一样;关于安全会话管理(避免使用会话):1、不要在客户端存储敏感信息(如身份认证信息);
2、测试直接关闭,退出时会话过期机制;
3、设置会话过期机制,例如15分钟内无操作,自动登录超时;
门禁安全管理:
1、修改敏感信息需要二次身份认证。例如修改账号时,需要确定旧密码;
2、敏感信息的修改使用post代替get;
3、通过http头中的referer限制原创页面,并添加验证码:一般用于登录(防暴力破解),也可用于表单中进行其他重要信息操作(可用性需要考虑)
SSRF
ssrf:服务器请求伪造,由攻击者构造,形成由服务器发起请求的安全漏洞。一般来说,ssrf 攻击的目标是外部世界无法访问的内部系统。对目标地址没有过滤和限制,该功能被恶意使用,有缺陷的Web应用程序可以作为代理攻击远程和本地服务器。
ssrf 危害
1、可以对外部服务器所在的内网和本地进行端口扫描,获取部分服务的banner信息。
2、攻击在内网或本地运行的应用程序。
3、通过访问默认文件对内网web应用(检测为php、asp、jsp等)进行指纹识别。
4、攻击网络内外的 Web 应用程序。sql注入、struct2、 redis等
5、使用文件协议读取本地文件等
ssrf 漏洞预防
1. 统一错误信息,防止用户根据错误信息判断远程服务器端口状态
2. 将请求端口限制为常见的HTTP端口,如80、443、8080、8088等。
3. 黑名单内网 IP。
4.禁用不必要的协议,只允许HTTP和HTTPS。(不允许文件协议等)
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-02-25 17:20
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。还有一个类似selenium的风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
ͼƬ 图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
nonce: 2SSH2A # δ֪
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个submit方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JSäcookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看在加载这个网页的时候已经下载了哪些URL,我们要的数据是在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试调试JS,找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。 查看全部
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。还有一个类似selenium的风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
ͼƬ 图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
nonce: 2SSH2A # δ֪
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个submit方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JSäcookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看在加载这个网页的时候已经下载了哪些URL,我们要的数据是在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试调试JS,找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。
浏览器抓取网页(绕开网站的反爬机制获取正确的页面是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-24 13:25
)
在编写爬虫的过程中,有的网站会设置反爬机制,拒绝响应非浏览器访问;或者短时间内频繁爬取会触发网站的反爬机制,导致IP被阻塞无法爬取网页。这需要修改爬虫中的请求头来伪装浏览器访问,或者使用代理发起请求。从而绕过网站的反爬机制来获取正确的页面。
本文使用python3.6、常用的request库requests和自动化测试库selenium来使用浏览器。
这两个库的使用可以参考官方文档或者我的另一篇博客:如何通过python爬虫获取网页的html内容并下载附件。
1、requests 伪装头发送请求
在requests发送的请求的request header中,User-Agent会被识别为python程序发送的请求,如下图:
import requests
url = 'https://httpbin.org/headers'
response = requests.get(url)
if response.status_code == 200:
print(response.text)
返回结果:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.20.1"
}
}
注意:是一个开源的网站,用于测试网页请求,比如上面的/headers链接,会返回发送请求的请求头。详情请参考其官网。
User-Agent:User-Agent(英文:用户代理)是指由软件代理提供的代表用户行为的自身标识符。用于识别浏览器类型和版本、操作系统和版本、浏览器内核和其他信息的标识符。有关详细信息,请参阅 Wikipedia 条目:用户代理
对于反爬网站,它会识别它的headers,拒绝返回正确的网页。此时,您需要将发送的请求伪装成浏览器的标头。
用浏览器打开网站,会看到如下页面,就是浏览器的headers。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-71I5qEeA-71)()]
复制上述请求头并将其传递给 requests.get() 函数以将请求伪装成浏览器。
import requests
url = 'https://httpbin.org/headers'
myheaders = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
response = requests.get(url, headers=myheaders)
if response.status_code == 200:
print(response.text)
返回的结果变为:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
应用爬虫时,可以随机切换到其他User-Agent,避免触发反爬。
2、Selenium 模拟浏览器伪装头的使用
使用自动化测试工具selenium可以模拟使用浏览器访问网站。本文使用 selenium 3.14.0 版本,支持 Chrome 和 Firefox 浏览器。要使用浏览器,需要下载相应版本的驱动程序。
驱动下载地址:
使用 webdriver 访问您自己的浏览器的标题。
from selenium import webdriver
url = 'https://httpbin.org/headers'
driver_path = '/path/to/chromedriver'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url)
print(browser.page_source)
browser.close()
打印出返回的网页代码:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
}
浏览器驱动也可以伪装User-Agent,只需在创建webdriver浏览器对象时传入设置即可:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--user-agent=%s' % user_agent)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
此时返回的 User-Agent 成为传入的设置。
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
Firefox 浏览器驱动程序的设置不同:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference("general.useragent.override", user_agent)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
3、requests 使用 ip 代理发送请求
当某个ip在短时间内被访问过于频繁时,会触发网站的反爬机制,需要输入验证码甚至屏蔽该ip来禁止访问。这时候就需要使用代理ip发起请求来获取正确的网页了。
访问该网站以查看您的 ip。
import requests
url = 'https://httpbin.org/ip'
response = requests.get(url)
print(response.text)
返回本地网络的ip:
使用代理IP类似于1中伪装headers的方式,比如现在得到一个代理IP:58.58.213.55:8888,使用如下:
import requests
proxy = {
'http': 'http://58.58.213.55:8888',
'https': 'http://58.58.213.55:8888'
}
response = requests.get('https://httpbin.org/ip', proxies=proxy)
print(response.text)
返回的是代理ip
{
"origin": "58.58.213.55, 58.58.213.55"
}
4、selenium webdriver 使用代理 ip
chrome驱动使用代理ip的方式类似于伪装成user-agent:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy = '58.58.213.55:8888'
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--proxy-server=' + proxy)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
打印结果:
{
"origin": "58.58.213.55, 58.58.213.55"
}
firefox驱动的设置略有不同,需要下载浏览器扩展close_proxy_authentication来取消代理用户认证。可以从谷歌下载,本文使用firefox 65.0.1(64位)版本,可用扩展文件为:close_proxy_authentication-1.1-sm+tb+fx .xpi。
代码显示如下:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy_ip = '58.58.213.55'
proxy_port = 8888
xpi = '/path/to/close_proxy_authentication-1.1-sm+tb+fx.xpi'
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference('network.proxy.type', 1)
profile.set_preference('network.proxy.http', proxy_ip)
profile.set_preference('network.proxy.http_port', proxy_port)
profile.set_preference('network.proxy.ssl', proxy_ip)
profile.set_preference('network.proxy.ssl_port', proxy_port)
profile.set_preference('network.proxy.no_proxies_on', 'localhost, 127.0.0.1')
profile.add_extension(xpi)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
它还打印代理 ip。
{
"origin": "58.58.213.55, 58.58.213.55"
}
转动:
查看全部
浏览器抓取网页(绕开网站的反爬机制获取正确的页面是什么?
)
在编写爬虫的过程中,有的网站会设置反爬机制,拒绝响应非浏览器访问;或者短时间内频繁爬取会触发网站的反爬机制,导致IP被阻塞无法爬取网页。这需要修改爬虫中的请求头来伪装浏览器访问,或者使用代理发起请求。从而绕过网站的反爬机制来获取正确的页面。
本文使用python3.6、常用的request库requests和自动化测试库selenium来使用浏览器。
这两个库的使用可以参考官方文档或者我的另一篇博客:如何通过python爬虫获取网页的html内容并下载附件。
1、requests 伪装头发送请求
在requests发送的请求的request header中,User-Agent会被识别为python程序发送的请求,如下图:
import requests
url = 'https://httpbin.org/headers'
response = requests.get(url)
if response.status_code == 200:
print(response.text)
返回结果:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.20.1"
}
}
注意:是一个开源的网站,用于测试网页请求,比如上面的/headers链接,会返回发送请求的请求头。详情请参考其官网。
User-Agent:User-Agent(英文:用户代理)是指由软件代理提供的代表用户行为的自身标识符。用于识别浏览器类型和版本、操作系统和版本、浏览器内核和其他信息的标识符。有关详细信息,请参阅 Wikipedia 条目:用户代理
对于反爬网站,它会识别它的headers,拒绝返回正确的网页。此时,您需要将发送的请求伪装成浏览器的标头。
用浏览器打开网站,会看到如下页面,就是浏览器的headers。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-71I5qEeA-71)()]
复制上述请求头并将其传递给 requests.get() 函数以将请求伪装成浏览器。
import requests
url = 'https://httpbin.org/headers'
myheaders = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
response = requests.get(url, headers=myheaders)
if response.status_code == 200:
print(response.text)
返回的结果变为:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
应用爬虫时,可以随机切换到其他User-Agent,避免触发反爬。
2、Selenium 模拟浏览器伪装头的使用
使用自动化测试工具selenium可以模拟使用浏览器访问网站。本文使用 selenium 3.14.0 版本,支持 Chrome 和 Firefox 浏览器。要使用浏览器,需要下载相应版本的驱动程序。
驱动下载地址:
使用 webdriver 访问您自己的浏览器的标题。
from selenium import webdriver
url = 'https://httpbin.org/headers'
driver_path = '/path/to/chromedriver'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url)
print(browser.page_source)
browser.close()
打印出返回的网页代码:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
}
浏览器驱动也可以伪装User-Agent,只需在创建webdriver浏览器对象时传入设置即可:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--user-agent=%s' % user_agent)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
此时返回的 User-Agent 成为传入的设置。
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
Firefox 浏览器驱动程序的设置不同:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference("general.useragent.override", user_agent)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
3、requests 使用 ip 代理发送请求
当某个ip在短时间内被访问过于频繁时,会触发网站的反爬机制,需要输入验证码甚至屏蔽该ip来禁止访问。这时候就需要使用代理ip发起请求来获取正确的网页了。
访问该网站以查看您的 ip。
import requests
url = 'https://httpbin.org/ip'
response = requests.get(url)
print(response.text)
返回本地网络的ip:
使用代理IP类似于1中伪装headers的方式,比如现在得到一个代理IP:58.58.213.55:8888,使用如下:
import requests
proxy = {
'http': 'http://58.58.213.55:8888',
'https': 'http://58.58.213.55:8888'
}
response = requests.get('https://httpbin.org/ip', proxies=proxy)
print(response.text)
返回的是代理ip
{
"origin": "58.58.213.55, 58.58.213.55"
}
4、selenium webdriver 使用代理 ip
chrome驱动使用代理ip的方式类似于伪装成user-agent:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy = '58.58.213.55:8888'
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--proxy-server=' + proxy)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
打印结果:
{
"origin": "58.58.213.55, 58.58.213.55"
}
firefox驱动的设置略有不同,需要下载浏览器扩展close_proxy_authentication来取消代理用户认证。可以从谷歌下载,本文使用firefox 65.0.1(64位)版本,可用扩展文件为:close_proxy_authentication-1.1-sm+tb+fx .xpi。
代码显示如下:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy_ip = '58.58.213.55'
proxy_port = 8888
xpi = '/path/to/close_proxy_authentication-1.1-sm+tb+fx.xpi'
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference('network.proxy.type', 1)
profile.set_preference('network.proxy.http', proxy_ip)
profile.set_preference('network.proxy.http_port', proxy_port)
profile.set_preference('network.proxy.ssl', proxy_ip)
profile.set_preference('network.proxy.ssl_port', proxy_port)
profile.set_preference('network.proxy.no_proxies_on', 'localhost, 127.0.0.1')
profile.add_extension(xpi)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
它还打印代理 ip。
{
"origin": "58.58.213.55, 58.58.213.55"
}
转动:

浏览器抓取网页(SeleniumSelenium驱动Selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-17 06:03
硒
Selenium 是一个web自动化测试工具,最初是为网站自动化测试而开发的,就像一个玩游戏的按钮向导,可以根据指定的命令自动操作。
Selenium 测试工具直接操作浏览器,就像真正的用户一样。Selenium 可以让浏览器根据指令自动加载页面,获取需要的数据,甚至对页面进行截图,或者判断 网站 上是否发生了某些动作。
1. 硒是如何工作的
如图,用Python控制Selenium,然后让Selenium控制浏览器,操纵浏览器,从而实现用Python间接控制浏览器。
1.1 硒配置
Selenium 支持多种浏览器,最常见的是 Firefox 和 Google Chrome。首先在电脑上下载浏览器,浏览器版本不要太新。
火狐:截图如下
谷歌:截图如下
1.2 浏览器驱动
Selenium 如何专门操纵浏览器?这要归功于浏览器驱动程序。Selenium 可以通过 API 接口与浏览器驱动进行交互,进而实现与浏览器的交互。所以配置浏览器驱动。
配置浏览器驱动:
将下载的浏览器驱动解压,解压后的exe文件放在Python安装目录下,即与python.exe在同一目录下。
1.3 使用硒
安装selenium模块,python使用该模块驱动浏览器,使用如下命令行安装该模块
pip install selenium
2 快速入门
# 打开百度首页
from selenium import webdriver
driver = webdriver.chrome()
url = 'https : / /www.baidu . com/ '
driver.get(url)
#打开get就类似与在浏览器地址栏里面放入网址
driver.get(url)
#退出浏览器
driver.quit()
萃取元件
通过selenium的基本使用,可以简单的定位元素,获取对应的数据。接下来,让我们学习如何定位元素。
find_element_by_id #(根据id属性值获取元素)
find_element_by_name #(根据标签的name属性)
find_element_by_class_name #(根据类名获取元素)
find_element_by_link_text #(根据标签的文本获取元素,精确定位)
find_element_by_partial_link_text#(根据标签包含的文本获取元素,模糊定位)
find_e1ement_by_tag_name #(根据标签名获取元素)
find_e1ement_by_xpath #(根据xpath获取元素)
find_element_by_css_selector #(根据css选择器获取元素)
上述方法只能在页面上找到某个标签元素。如果要获取多个元素,可以在元素后面加上字母s,如下图:
find_elements_by_id #(根据id属性值获取元素,返回一个1ist列表)
find_elements_by_name #(根据标签的name属性,返回一个1ist列表)
find_elements_by_class_name #(根据类名获取元素,,返回一个list列表)
find_elements_by_link_text #(根据标签的文本获取元素,精确定位,返回一个1ist列表)
find_elements_by_partial_link_text #(根据标签包含的文本获取元素,模糊定位,返回一个1ist列表)
find_elements_by_tag_name #(根据标签名获取元素,返回一个1ist列表)
find_elements_by_xpath #(根据xpath获取元素,返回一个1ist列表)
find_elements_by_css_selector #(根据css选择器获取元素,返回一个1ist列表)
案子: 查看全部
浏览器抓取网页(SeleniumSelenium驱动Selenium)
硒
Selenium 是一个web自动化测试工具,最初是为网站自动化测试而开发的,就像一个玩游戏的按钮向导,可以根据指定的命令自动操作。
Selenium 测试工具直接操作浏览器,就像真正的用户一样。Selenium 可以让浏览器根据指令自动加载页面,获取需要的数据,甚至对页面进行截图,或者判断 网站 上是否发生了某些动作。
1. 硒是如何工作的
如图,用Python控制Selenium,然后让Selenium控制浏览器,操纵浏览器,从而实现用Python间接控制浏览器。
1.1 硒配置
Selenium 支持多种浏览器,最常见的是 Firefox 和 Google Chrome。首先在电脑上下载浏览器,浏览器版本不要太新。
火狐:截图如下
谷歌:截图如下
1.2 浏览器驱动
Selenium 如何专门操纵浏览器?这要归功于浏览器驱动程序。Selenium 可以通过 API 接口与浏览器驱动进行交互,进而实现与浏览器的交互。所以配置浏览器驱动。
配置浏览器驱动:
将下载的浏览器驱动解压,解压后的exe文件放在Python安装目录下,即与python.exe在同一目录下。
1.3 使用硒
安装selenium模块,python使用该模块驱动浏览器,使用如下命令行安装该模块
pip install selenium
2 快速入门
# 打开百度首页
from selenium import webdriver
driver = webdriver.chrome()
url = 'https : / /www.baidu . com/ '
driver.get(url)
#打开get就类似与在浏览器地址栏里面放入网址
driver.get(url)
#退出浏览器
driver.quit()
萃取元件
通过selenium的基本使用,可以简单的定位元素,获取对应的数据。接下来,让我们学习如何定位元素。
find_element_by_id #(根据id属性值获取元素)
find_element_by_name #(根据标签的name属性)
find_element_by_class_name #(根据类名获取元素)
find_element_by_link_text #(根据标签的文本获取元素,精确定位)
find_element_by_partial_link_text#(根据标签包含的文本获取元素,模糊定位)
find_e1ement_by_tag_name #(根据标签名获取元素)
find_e1ement_by_xpath #(根据xpath获取元素)
find_element_by_css_selector #(根据css选择器获取元素)
上述方法只能在页面上找到某个标签元素。如果要获取多个元素,可以在元素后面加上字母s,如下图:
find_elements_by_id #(根据id属性值获取元素,返回一个1ist列表)
find_elements_by_name #(根据标签的name属性,返回一个1ist列表)
find_elements_by_class_name #(根据类名获取元素,,返回一个list列表)
find_elements_by_link_text #(根据标签的文本获取元素,精确定位,返回一个1ist列表)
find_elements_by_partial_link_text #(根据标签包含的文本获取元素,模糊定位,返回一个1ist列表)
find_elements_by_tag_name #(根据标签名获取元素,返回一个1ist列表)
find_elements_by_xpath #(根据xpath获取元素,返回一个1ist列表)
find_elements_by_css_selector #(根据css选择器获取元素,返回一个1ist列表)
案子:
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-17 03:28
求高手,模拟浏览器抓取网页
比如爬取这个网页,如果我写的程序不收录URL末尾的“/”,是不会被爬取的,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION 查看全部
浏览器抓取网页(求高手,模拟浏览器抓取网页(宁贵银十))
求高手,模拟浏览器抓取网页
比如爬取这个网页,如果我写的程序不收录URL末尾的“/”,是不会被爬取的,但是没有最后一个“/”(即:)可以爬取,什么是他的原则?在下面发布我的代码,请改进
<br /><br />function file_get($url){<br /> ob_start();<br /> $ch = curl_init();<br /> <br /> curl_setopt($ch, CURLOPT_COOKIEJAR, "./cookie.txt");<br /> curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; InfoPath.1; CIBA)");<br /> curl_setopt($ch, CURLOPT_URL, $url);<br /> curl_setopt($ch, CURLOPT_HEADER, FALSE);<br /> curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);<br /> curl_setopt($ch, CURLOPT_NOBODY, FALSE);<br /><br /> curl_exec($ch);<br /> curl_close($ch);<br /> $content = ob_get_clean();<br /> <br /> <br /><br /> return $content;<br /><br />}<br />
- - - 解决方案 - - - - - - - - - -
CURLOPT_FOLLOWLOCATION
浏览器抓取网页(2021-12-06Cookies为Web应用程序提供了存储特定用户信息的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-16 09:25
2021-12-06
Cookie 为 Web 应用程序提供了一种存储特定用户信息的方式。例如,当用户访问 网站 时,您可以使用 cookie 来存储用户的偏好或其他信息。下次用户访问 网站 时,应用程序可以检索到这个较早存储的信息。
什么是 Cookie?
Cookie 是在 Web 服务器和浏览器之间来回流动的小段文本,带有一个页面和一个请求。Web 应用程序可以在用户访问 网站 的任何时候读取 cookie 中收录的信息。
例如,如果用户在网站中请求一个页面,应用程序不仅返回一个页面,还返回一个收录日期和时间的cookie,当用户的浏览器获取到该页面时,浏览器会获取到这个cookie并存储在用户硬盘上的特定目录中。
然后,如果用户想再次从 网站 请求页面,当用户将 URL 输入浏览器时,浏览器将在本地硬盘驱动器上查找与该 URL 关联的 cookie。如果 cookie 存在,浏览器会将其与页面请求一起发送到 网站。然后,应用程序可以检测用户上次访问 网站 的日期和时间。您还可以使用此信息向用户显示消息或检查日期是否已过期。
Cookies是与网站关联的,而不是与特定页面关联的,所以无论用户请求网站中的哪个页面,浏览器和服务器之间都会交换cookie信息。就像用户访问的不同的网站一样,每个网站都可以向用户的浏览器发送一个cookie;浏览器将分别存储来自不同 网站 的所有 cookie。
Cookie 可以帮助网站存储有关访问者的信息。通常,cookie 是一种在 Web 应用程序中保持连续性的方式,即关于状态管理。除了它们实际上交换信息之外,浏览器和 Web 服务器之间的连接通常会中断。访问 Web 服务器的用户发出的每个请求都被认为是独立的。大多数情况下,它可以帮助 Web 服务器在用户请求页面时识别用户。例如,shopping网站 网络服务器始终跟踪每个购物者,从而能够管理购物车和其他用户特定信息。cookie因此起到名片的作用,呈现相关的认证信息以协助应用程序的运行。
Cookie 可用于多种目的,所有这些都涉及帮助网站用户的记忆。例如,投票管理器网站可能会将cookie简单地视为一个布尔值来指示用户的浏览器是否参与了投票,从而禁止用户重复投票;网站会使用cookies记录用户是否登录,让用户无需重复输入验证信息。
Cookie 的限制
大多数浏览器支持最长 4096 字节的 cookie。由于此限制,cookie 最适合用于存储小数据,最好是标识符(例如用户 ID)。然后,用户 ID 可用于识别当前用户并从数据库或其他数据存储中读取用户信息。(有关存储用户信息的安全影响的信息,请参阅本文档的 [Cookie 和安全] 部分。)
浏览器还限制 网站 可以存储在用户浏览器中的 cookie 数量。大多数浏览器只允许每个 网站 最多 20 个 cookie;如果您尝试存储更多,最旧的 cookie 将被丢弃。一些浏览器还施加了一个绝对限制,即它们可以接受的 cookie 总数不能超过 300(来自 网站 的所有 cookie 的总和)。
您可能遇到的另一个 cookie 限制是用户可以将其浏览器设置为拒绝 cookie。如果你定义了一个 P3P 保密策略并将其存储在 网站 的根目录中,大多数浏览器都会接受来自 网站 的 cookie。但是,您可能完全避免使用 cookie 并使用不同的机制来存储特定的用户信息。存储用户信息的一种常见方式是使用会话状态,而会话状态又依赖于 Cookie,如本文[Cookie 和会话状态] 部分所述。
提示:有关在 Web 应用程序中存储用户信息的状态管理和状态选项的更多信息,请参阅:[ASP.NET 状态管理概述] 和 [ASP.NET 状态管理建议]。
尽管 Cookie 在应用程序中很有用,但应用程序不应依赖 Cookie 的使用。请不要使用 cookie 来支持关键功能。如果您的应用程序必须依赖 cookie,您可以测试您的浏览器以查看它是否接受使用 cookie。请参阅本文的“检查您的浏览器是否接受 Cookie”部分。
写饼干
浏览器负责管理用户系统上的 cookie。通过 HttpResponse 对象发送到浏览器的 Cookie 公开了一个名为 Cookies 的集合。您可以访问 HttpResponse 对象,就像访问 Page 类的 Response 属性一样。您需要发送到浏览器的任何 cookie 都必须添加到此集合中。创建 cookie 后,您需要为其指定 Name 和 Value 属性。每个 cookie 必须具有唯一的名称,以便在浏览器中读取时被识别。由于 cookie 是按名称存储的,因此两个具有相同名称的 cookie 之一将被覆盖。
您还可以设置 cookie 的到期日期和时间。当用户访问 网站 并重写 cookie 时,浏览器会删除过期的 cookie。可以根据应用程序确定的 cookie 的有效期来设置 cookie 的过期时间。要使 cookie 长期存在,您可以将过期日期设置为从现在起 50 年。
提示:用户可以随时从他们的计算机中清除 cookie。即使您存储了一个长期有效的cookie,用户仍然可以决定删除所有cookie,这样cookie中存储的所有设置都将被销毁。
如果您不为 cookie 设置过期日期,仍然可以创建 cookie,但不会将其存储在用户的硬盘上。相反,此类 cookie 作为用户会话信息的一部分进行维护。当用户关闭浏览器时,Cookie 也会被丢弃。当信息只需要短暂存储或出于安全原因不应写入客户端计算机的硬盘驱动器时,此类非持久性 cookie 非常有用。例如,非持久性 cookie 适合用户在公共计算机上使用,或者当您不希望将 cookie 写入硬盘时。
您可以通过多种方式将 cookie 写入 Cookies 集合。以下示例说明了编写 cookie 的两种方法:
Response.Cookies["userName"].Value = "patrick";
Response.Cookies["userName"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("lastVisit");
aCookie.Value = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
该实例向 Cookies 集合添加了两个 Cookie,一个名为 userName,另一个名为 lastVisit。至于第一个cookie,直接设置Cookies集合的值。您可以使用此方法向集合中添加值,因为 Cookies 是 NameObject采集Base 类型的专用集合。
至于第二个cookie,代码创建一个HttpCookie类型的对象实例,设置它的属性,然后通过Add方法将它添加到Cookies集合中。实例化 HttpCookie 对象时,必须将 cookie 的名称作为构造函数的一部分传递。
这两个实例都完成了将 cookie 写入浏览器的相同任务。在这两种方法中,有效期属性值必须是 DateTime 类型。但是,lastVisited 中的值也是表示日期和时间的值。由于所有 cookie 值都应该以字符串格式存储,因此 datetime 值会自动转换为字符串。
具有多个值的 Cookie
您可以在 cookie 中存储单个值,例如用户名或上次访问时间。您还可以将多个名称/值对存储在单独的 cookie 中。名称/值数据对被引用为子键。(展开的子键的格式类似于 URL 中的查询字符串。)例如,您可以创建一个名为 userInfo 的单独 cookie 来收录子键 userName 和 lastVisit,而不是创建两个名为 userName 和 lastVisit 的单独 Cookie。上次访问。
您可能出于多种原因使用子项。首先,方便将相关信息或类似信息放入单独的cookie中。此外,由于所有信息都在一个单独的 cookie 中,因此 cookie 的参数(例如到期日期)适用于所有信息。(相反,如果您需要为不同类型的信息指定不同的到期日期,那么您应该将该信息存储在单独的 cookie 中。)
带有子键的 Cookie 还可以帮助您突破 Cookie 文件大小限制。如前面[Cookie 限制] 部分所述,cookie 的大小限制通常为 4096 字节,单个 网站 不能存储超过 20 个 cookie。通过使用带有子键的单独 cookie,您可以减少使用的 cookie 数量。此外,单个 cookie 中最多只能出现 50 个字符(到期日期信息等),加上其中存储的值的长度,加起来将近 4096 个字节。如果您使用 5 个子键而不是 5 个单独的 cookie,那么您可以在每个 cookie 中存储接近 200 字节的数据。
要创建带有子键的 cookie,您将使用不同的语法来编写单个 cookie。以下示例说明了编写相同 cookie 的两种方法(每个都有两个子键):
Response.Cookies["userInfo"]["userName"] = "patrick";
Response.Cookies["userInfo"]["lastVisit"] = DateTime.Now.ToString();
Response.Cookies["userInfo"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("userInfo");
aCookie.Values["userName"] = "patrick";
aCookie.Values["lastVisit"] = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
控制 cookie 的范围
默认情况下,网站 的所有 cookie 一起存储在客户端,并且所有 cookie 与来自 网站 的任何请求一起发送到服务器。换句话说,网站 中的每个页面都可以获取 网站 的所有 cookie。但是,您可以通过两种方式设置 cookie 的范围:
将 Cookie 限制在目录或应用程序中
要将 cookie 限制在服务器的目录中,请设置 cookie 的 Path 属性,如下例所示:
HttpCookie appCookie = new HttpCookie("AppCookie");
appCookie.Value = "written " + DateTime.Now.ToString();
appCookie.Expires = DateTime.Now.AddDays(1);
appCookie.Path = "/Application1";
Response.Cookies.Add(appCookie);
提示:您也可以通过直接添加到 Cookies 集合来编写 cookie,如前面的示例所示。
路径可以在 网站 的物理根目录和虚拟根目录中。结果将是 cookie 仅可用于目录或虚拟根 Application1 中的页面。例如,如果您的名字是 网站,则在上一个示例中创建的 cookie 将仅可用于路径中的页面及其下方的所有子目录。但是,此 cookie 不适用于其他应用程序中的页面,例如 .
提示:某些浏览器中的路径区分大小写。您无法控制用户如何在浏览器中输入 URL,但如果您的应用程序依赖 cookie 来限制特定路径,请确保您创建的任何超链接的 URL 与 Path 属性值中的大小写匹配。
限制 cookie 的域范围
默认情况下,cookie 与特定域相关联。例如,如果您的 网站 是,那么每当用户从 网站 请求任何页面时,您编写的 cookie 都会发送到服务器。(可能不包括具有特定路径值的 Cookie。)如果您的 网站 也有子域(例如 、 和 ),那么您可以将特定的子域与 cookie 相关联。为此,请设置 cookie 的 Domain 属性,如示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "support.contoso.com";
当以这种方式设置域时,cookie 将仅可用于该特定域内的页面。您还可以使用 Domain 属性创建可跨多个子域共享的 cookie,如以下示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "contoso.com";
cookie 现在将可用于主域以及域。
读取 cookie
当浏览器向服务器发送请求时,它会将 cookie 与请求一起发送到服务器。在您的 ASP.NET 应用程序中,您可以使用 HttpRequest 对象读取 Cookie,该对象显示为 Page 类的 Request 属性。HttpRequest 对象的结构与 HttpResponse 对象的结构本质上是相同的,因此您可以从 HttpRequest 对象中读取 Cookies,其方式类似于将 Cookies 写入 HttpResponse 对象。以下代码示例说明了获取 cookie(名为 userName)的值并将其显示在 Label 控件中的两种方法:
if(Request.Cookies["userName"] != null)
Label1.Text = Server.HtmlEncode(Request.Cookies["userName"].Value);
if(Request.Cookies["userName"] != null)
{
HttpCookie aCookie = Request.Cookies["userName"];
Label1.Text = Server.HtmlEncode(aCookie.Value);
}
在尝试获取 cookie 的值之前,您应该确保 cookie 已经存在;如果 cookie 不存在,您将收到 NullReferenceException。请注意,在显示 cookie 的内容之前,已调用 HtmlEncode 方法进行编码。这使得恶意用户无法将可执行脚本添加到 cookie。有关 cookie 安全的更多信息,请参阅:[Cookie 和安全]。
提示:由于不同浏览器存储cookies的方式不同,同一台电脑上的浏览器无法读取其他类型浏览器设置的cookies。例如,如果您使用 Internet Explorer 测试页面,然后使用不同的浏览器再次测试,则第二个浏览器将无法找到 Internet Explorer 存储的 cookie。
从 cookie 中读取子键的值与设置时类似。以下代码示例说明了获取子键值的一种方法:
if(Request.Cookies["userInfo"] != null)
{
Label1.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["userName"]);
Label2.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["lastVisit"]);
}
在前面的示例中,代码读取子项 lastVisit 中的值,该值设置为在前面的示例中呈现为字符串的 DateTime 值。Cookies 将值存储为字符串,因此如果需要将 lastVisit 值用作日期对象,则应将其强制转换为适当的类型,如下例所示:
DateTime dt;
dt = DateTime.Parse(Request.Cookies["userInfo"]["lastVisit"]);
cookie 中的子键被键入为 NameValue采集 类型的集合。因此,获取单个子键的另一种方法是先获取子键的集合,然后按名称提取子键的值,如下例所示:
if(Request.Cookies["userInfo"] != null)
{
System.Collections.Specialized.NameValueCollection
UserInfoCookieCollection;
UserInfoCookieCollection = Request.Cookies["userInfo"].Values;
Label1.Text =
Server.HtmlEncode(UserInfoCookieCollection["userName"]);
Label2.Text =
Server.HtmlEncode(UserInfoCookieCollection["lastVisit"]);
}
更改 cookie 过期时间
浏览器负责管理cookies,cookies的过期时间和日期有助于浏览器管理其存储的cookies。因此,虽然您可以读取 cookie 的名称和值,但您无法读取 cookie 的到期日期和时间。当浏览器向服务器发送cookie信息时,浏览器不收录有效期信息。(cookie 的 Expires 属性始终返回零日期值。)如果您关心 cookie 的到期时间,您应该重置它,如本文“更改和删除 cookie”部分所述。
提示:在 cookie 发送到浏览器之前,您可以读取 cookie 的 Expires 属性(在 HttpResponse 对象中设置)。但是,您无法从 HttpRequest 对象向后获取过期时间。
阅读 cookie 集合
有时您可能需要阅读所有 cookie 并使它们可用于页面。要将所有 cookie 的名称和值读入页面,可以如下循环遍历 Cookies 集合。
<p>System.Text.StringBuilder output = new System.Text.StringBuilder();
HttpCookie aCookie;
for(int i=0; i 查看全部
浏览器抓取网页(2021-12-06Cookies为Web应用程序提供了存储特定用户信息的方法)
2021-12-06
Cookie 为 Web 应用程序提供了一种存储特定用户信息的方式。例如,当用户访问 网站 时,您可以使用 cookie 来存储用户的偏好或其他信息。下次用户访问 网站 时,应用程序可以检索到这个较早存储的信息。
什么是 Cookie?
Cookie 是在 Web 服务器和浏览器之间来回流动的小段文本,带有一个页面和一个请求。Web 应用程序可以在用户访问 网站 的任何时候读取 cookie 中收录的信息。
例如,如果用户在网站中请求一个页面,应用程序不仅返回一个页面,还返回一个收录日期和时间的cookie,当用户的浏览器获取到该页面时,浏览器会获取到这个cookie并存储在用户硬盘上的特定目录中。
然后,如果用户想再次从 网站 请求页面,当用户将 URL 输入浏览器时,浏览器将在本地硬盘驱动器上查找与该 URL 关联的 cookie。如果 cookie 存在,浏览器会将其与页面请求一起发送到 网站。然后,应用程序可以检测用户上次访问 网站 的日期和时间。您还可以使用此信息向用户显示消息或检查日期是否已过期。
Cookies是与网站关联的,而不是与特定页面关联的,所以无论用户请求网站中的哪个页面,浏览器和服务器之间都会交换cookie信息。就像用户访问的不同的网站一样,每个网站都可以向用户的浏览器发送一个cookie;浏览器将分别存储来自不同 网站 的所有 cookie。
Cookie 可以帮助网站存储有关访问者的信息。通常,cookie 是一种在 Web 应用程序中保持连续性的方式,即关于状态管理。除了它们实际上交换信息之外,浏览器和 Web 服务器之间的连接通常会中断。访问 Web 服务器的用户发出的每个请求都被认为是独立的。大多数情况下,它可以帮助 Web 服务器在用户请求页面时识别用户。例如,shopping网站 网络服务器始终跟踪每个购物者,从而能够管理购物车和其他用户特定信息。cookie因此起到名片的作用,呈现相关的认证信息以协助应用程序的运行。
Cookie 可用于多种目的,所有这些都涉及帮助网站用户的记忆。例如,投票管理器网站可能会将cookie简单地视为一个布尔值来指示用户的浏览器是否参与了投票,从而禁止用户重复投票;网站会使用cookies记录用户是否登录,让用户无需重复输入验证信息。
Cookie 的限制
大多数浏览器支持最长 4096 字节的 cookie。由于此限制,cookie 最适合用于存储小数据,最好是标识符(例如用户 ID)。然后,用户 ID 可用于识别当前用户并从数据库或其他数据存储中读取用户信息。(有关存储用户信息的安全影响的信息,请参阅本文档的 [Cookie 和安全] 部分。)
浏览器还限制 网站 可以存储在用户浏览器中的 cookie 数量。大多数浏览器只允许每个 网站 最多 20 个 cookie;如果您尝试存储更多,最旧的 cookie 将被丢弃。一些浏览器还施加了一个绝对限制,即它们可以接受的 cookie 总数不能超过 300(来自 网站 的所有 cookie 的总和)。
您可能遇到的另一个 cookie 限制是用户可以将其浏览器设置为拒绝 cookie。如果你定义了一个 P3P 保密策略并将其存储在 网站 的根目录中,大多数浏览器都会接受来自 网站 的 cookie。但是,您可能完全避免使用 cookie 并使用不同的机制来存储特定的用户信息。存储用户信息的一种常见方式是使用会话状态,而会话状态又依赖于 Cookie,如本文[Cookie 和会话状态] 部分所述。
提示:有关在 Web 应用程序中存储用户信息的状态管理和状态选项的更多信息,请参阅:[ASP.NET 状态管理概述] 和 [ASP.NET 状态管理建议]。
尽管 Cookie 在应用程序中很有用,但应用程序不应依赖 Cookie 的使用。请不要使用 cookie 来支持关键功能。如果您的应用程序必须依赖 cookie,您可以测试您的浏览器以查看它是否接受使用 cookie。请参阅本文的“检查您的浏览器是否接受 Cookie”部分。
写饼干
浏览器负责管理用户系统上的 cookie。通过 HttpResponse 对象发送到浏览器的 Cookie 公开了一个名为 Cookies 的集合。您可以访问 HttpResponse 对象,就像访问 Page 类的 Response 属性一样。您需要发送到浏览器的任何 cookie 都必须添加到此集合中。创建 cookie 后,您需要为其指定 Name 和 Value 属性。每个 cookie 必须具有唯一的名称,以便在浏览器中读取时被识别。由于 cookie 是按名称存储的,因此两个具有相同名称的 cookie 之一将被覆盖。
您还可以设置 cookie 的到期日期和时间。当用户访问 网站 并重写 cookie 时,浏览器会删除过期的 cookie。可以根据应用程序确定的 cookie 的有效期来设置 cookie 的过期时间。要使 cookie 长期存在,您可以将过期日期设置为从现在起 50 年。
提示:用户可以随时从他们的计算机中清除 cookie。即使您存储了一个长期有效的cookie,用户仍然可以决定删除所有cookie,这样cookie中存储的所有设置都将被销毁。
如果您不为 cookie 设置过期日期,仍然可以创建 cookie,但不会将其存储在用户的硬盘上。相反,此类 cookie 作为用户会话信息的一部分进行维护。当用户关闭浏览器时,Cookie 也会被丢弃。当信息只需要短暂存储或出于安全原因不应写入客户端计算机的硬盘驱动器时,此类非持久性 cookie 非常有用。例如,非持久性 cookie 适合用户在公共计算机上使用,或者当您不希望将 cookie 写入硬盘时。
您可以通过多种方式将 cookie 写入 Cookies 集合。以下示例说明了编写 cookie 的两种方法:
Response.Cookies["userName"].Value = "patrick";
Response.Cookies["userName"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("lastVisit");
aCookie.Value = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
该实例向 Cookies 集合添加了两个 Cookie,一个名为 userName,另一个名为 lastVisit。至于第一个cookie,直接设置Cookies集合的值。您可以使用此方法向集合中添加值,因为 Cookies 是 NameObject采集Base 类型的专用集合。
至于第二个cookie,代码创建一个HttpCookie类型的对象实例,设置它的属性,然后通过Add方法将它添加到Cookies集合中。实例化 HttpCookie 对象时,必须将 cookie 的名称作为构造函数的一部分传递。
这两个实例都完成了将 cookie 写入浏览器的相同任务。在这两种方法中,有效期属性值必须是 DateTime 类型。但是,lastVisited 中的值也是表示日期和时间的值。由于所有 cookie 值都应该以字符串格式存储,因此 datetime 值会自动转换为字符串。
具有多个值的 Cookie
您可以在 cookie 中存储单个值,例如用户名或上次访问时间。您还可以将多个名称/值对存储在单独的 cookie 中。名称/值数据对被引用为子键。(展开的子键的格式类似于 URL 中的查询字符串。)例如,您可以创建一个名为 userInfo 的单独 cookie 来收录子键 userName 和 lastVisit,而不是创建两个名为 userName 和 lastVisit 的单独 Cookie。上次访问。
您可能出于多种原因使用子项。首先,方便将相关信息或类似信息放入单独的cookie中。此外,由于所有信息都在一个单独的 cookie 中,因此 cookie 的参数(例如到期日期)适用于所有信息。(相反,如果您需要为不同类型的信息指定不同的到期日期,那么您应该将该信息存储在单独的 cookie 中。)
带有子键的 Cookie 还可以帮助您突破 Cookie 文件大小限制。如前面[Cookie 限制] 部分所述,cookie 的大小限制通常为 4096 字节,单个 网站 不能存储超过 20 个 cookie。通过使用带有子键的单独 cookie,您可以减少使用的 cookie 数量。此外,单个 cookie 中最多只能出现 50 个字符(到期日期信息等),加上其中存储的值的长度,加起来将近 4096 个字节。如果您使用 5 个子键而不是 5 个单独的 cookie,那么您可以在每个 cookie 中存储接近 200 字节的数据。
要创建带有子键的 cookie,您将使用不同的语法来编写单个 cookie。以下示例说明了编写相同 cookie 的两种方法(每个都有两个子键):
Response.Cookies["userInfo"]["userName"] = "patrick";
Response.Cookies["userInfo"]["lastVisit"] = DateTime.Now.ToString();
Response.Cookies["userInfo"].Expires = DateTime.Now.AddDays(1);
HttpCookie aCookie = new HttpCookie("userInfo");
aCookie.Values["userName"] = "patrick";
aCookie.Values["lastVisit"] = DateTime.Now.ToString();
aCookie.Expires = DateTime.Now.AddDays(1);
Response.Cookies.Add(aCookie);
控制 cookie 的范围
默认情况下,网站 的所有 cookie 一起存储在客户端,并且所有 cookie 与来自 网站 的任何请求一起发送到服务器。换句话说,网站 中的每个页面都可以获取 网站 的所有 cookie。但是,您可以通过两种方式设置 cookie 的范围:
将 Cookie 限制在目录或应用程序中
要将 cookie 限制在服务器的目录中,请设置 cookie 的 Path 属性,如下例所示:
HttpCookie appCookie = new HttpCookie("AppCookie");
appCookie.Value = "written " + DateTime.Now.ToString();
appCookie.Expires = DateTime.Now.AddDays(1);
appCookie.Path = "/Application1";
Response.Cookies.Add(appCookie);
提示:您也可以通过直接添加到 Cookies 集合来编写 cookie,如前面的示例所示。
路径可以在 网站 的物理根目录和虚拟根目录中。结果将是 cookie 仅可用于目录或虚拟根 Application1 中的页面。例如,如果您的名字是 网站,则在上一个示例中创建的 cookie 将仅可用于路径中的页面及其下方的所有子目录。但是,此 cookie 不适用于其他应用程序中的页面,例如 .
提示:某些浏览器中的路径区分大小写。您无法控制用户如何在浏览器中输入 URL,但如果您的应用程序依赖 cookie 来限制特定路径,请确保您创建的任何超链接的 URL 与 Path 属性值中的大小写匹配。
限制 cookie 的域范围
默认情况下,cookie 与特定域相关联。例如,如果您的 网站 是,那么每当用户从 网站 请求任何页面时,您编写的 cookie 都会发送到服务器。(可能不包括具有特定路径值的 Cookie。)如果您的 网站 也有子域(例如 、 和 ),那么您可以将特定的子域与 cookie 相关联。为此,请设置 cookie 的 Domain 属性,如示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "support.contoso.com";
当以这种方式设置域时,cookie 将仅可用于该特定域内的页面。您还可以使用 Domain 属性创建可跨多个子域共享的 cookie,如以下示例所示:
Response.Cookies["domain"].Value = DateTime.Now.ToString();
Response.Cookies["domain"].Expires = DateTime.Now.AddDays(1);
Response.Cookies["domain"].Domain = "contoso.com";
cookie 现在将可用于主域以及域。
读取 cookie
当浏览器向服务器发送请求时,它会将 cookie 与请求一起发送到服务器。在您的 ASP.NET 应用程序中,您可以使用 HttpRequest 对象读取 Cookie,该对象显示为 Page 类的 Request 属性。HttpRequest 对象的结构与 HttpResponse 对象的结构本质上是相同的,因此您可以从 HttpRequest 对象中读取 Cookies,其方式类似于将 Cookies 写入 HttpResponse 对象。以下代码示例说明了获取 cookie(名为 userName)的值并将其显示在 Label 控件中的两种方法:
if(Request.Cookies["userName"] != null)
Label1.Text = Server.HtmlEncode(Request.Cookies["userName"].Value);
if(Request.Cookies["userName"] != null)
{
HttpCookie aCookie = Request.Cookies["userName"];
Label1.Text = Server.HtmlEncode(aCookie.Value);
}
在尝试获取 cookie 的值之前,您应该确保 cookie 已经存在;如果 cookie 不存在,您将收到 NullReferenceException。请注意,在显示 cookie 的内容之前,已调用 HtmlEncode 方法进行编码。这使得恶意用户无法将可执行脚本添加到 cookie。有关 cookie 安全的更多信息,请参阅:[Cookie 和安全]。
提示:由于不同浏览器存储cookies的方式不同,同一台电脑上的浏览器无法读取其他类型浏览器设置的cookies。例如,如果您使用 Internet Explorer 测试页面,然后使用不同的浏览器再次测试,则第二个浏览器将无法找到 Internet Explorer 存储的 cookie。
从 cookie 中读取子键的值与设置时类似。以下代码示例说明了获取子键值的一种方法:
if(Request.Cookies["userInfo"] != null)
{
Label1.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["userName"]);
Label2.Text =
Server.HtmlEncode(Request.Cookies["userInfo"]["lastVisit"]);
}
在前面的示例中,代码读取子项 lastVisit 中的值,该值设置为在前面的示例中呈现为字符串的 DateTime 值。Cookies 将值存储为字符串,因此如果需要将 lastVisit 值用作日期对象,则应将其强制转换为适当的类型,如下例所示:
DateTime dt;
dt = DateTime.Parse(Request.Cookies["userInfo"]["lastVisit"]);
cookie 中的子键被键入为 NameValue采集 类型的集合。因此,获取单个子键的另一种方法是先获取子键的集合,然后按名称提取子键的值,如下例所示:
if(Request.Cookies["userInfo"] != null)
{
System.Collections.Specialized.NameValueCollection
UserInfoCookieCollection;
UserInfoCookieCollection = Request.Cookies["userInfo"].Values;
Label1.Text =
Server.HtmlEncode(UserInfoCookieCollection["userName"]);
Label2.Text =
Server.HtmlEncode(UserInfoCookieCollection["lastVisit"]);
}
更改 cookie 过期时间
浏览器负责管理cookies,cookies的过期时间和日期有助于浏览器管理其存储的cookies。因此,虽然您可以读取 cookie 的名称和值,但您无法读取 cookie 的到期日期和时间。当浏览器向服务器发送cookie信息时,浏览器不收录有效期信息。(cookie 的 Expires 属性始终返回零日期值。)如果您关心 cookie 的到期时间,您应该重置它,如本文“更改和删除 cookie”部分所述。
提示:在 cookie 发送到浏览器之前,您可以读取 cookie 的 Expires 属性(在 HttpResponse 对象中设置)。但是,您无法从 HttpRequest 对象向后获取过期时间。
阅读 cookie 集合
有时您可能需要阅读所有 cookie 并使它们可用于页面。要将所有 cookie 的名称和值读入页面,可以如下循环遍历 Cookies 集合。
<p>System.Text.StringBuilder output = new System.Text.StringBuilder();
HttpCookie aCookie;
for(int i=0; i
浏览器抓取网页(傍晚想找个类似的插件,文字描述一下的no.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-14 01:02
晚上在找一个类似的插件,所以花了一个小时做了一个小评测。当然楼上的回答我也看到了,但是很多都已经没有了,所以稍微总结一下,懒就不截图了,用文字描述一下。
安利第一件事就是edge + onenote,它可以:
1. 任何绘图
2. 带有箭头,并且可以
3. 直接插入评论支持
4. 亮点,
5. 一键云存档,当之无愧No.1,以下标准与之对比。
假设环境是chrome + ss(chrome有最丰富的小应用,其他浏览器不考虑)
A. Diigo(以及其他类似的,以此为代表):
除了不支持各大笔记平台外,其余功能支持:3、4、5,截图模式支持1、2,给三颗星。
但是比较贵,而且只支持200个亮点免费等,而且一下子就用完了。
B、印象笔记
功能比较单薄,只支持4、5,当然比有道云只支持5(-最基本的功能)要好,给两颗星。
C. Markup.io
有一个传说中的插件,应该支持1、2、3、4,但是已经关闭了;楼上列出的一些很棒的亮点 xxx 似乎也已经关闭。
D.
ok,两颗星,支持3、4、5(Text Based),有点像kindle的标记功能,大家可以在网页上标记一些地方,可以看到别人的评论或者下划线,一颗半星酒吧。
E. 黄色荧光笔等
比较简陋,类似D,一颗星。
综上所述,如果你只是想高亮保存网页上的文字,印象笔记/onenote(+windows edge)应该是最好的选择;如果你只是想做文字标注,Diigo 更好,但每年 40D 的价格让我等到掉丝都泄气了。
PS。想找一个*估计网页内容阅读时间*的小插件,但是chrome商店里的那个要么不能用,要么太烂,有必要自己写一个吗?
参考:
网页阅读,如何标记喜欢阅读?-知乎我不知道
“网页注释分享工具”的重点来了!| 一页一页 查看全部
浏览器抓取网页(傍晚想找个类似的插件,文字描述一下的no.1)
晚上在找一个类似的插件,所以花了一个小时做了一个小评测。当然楼上的回答我也看到了,但是很多都已经没有了,所以稍微总结一下,懒就不截图了,用文字描述一下。
安利第一件事就是edge + onenote,它可以:
1. 任何绘图
2. 带有箭头,并且可以
3. 直接插入评论支持
4. 亮点,
5. 一键云存档,当之无愧No.1,以下标准与之对比。
假设环境是chrome + ss(chrome有最丰富的小应用,其他浏览器不考虑)
A. Diigo(以及其他类似的,以此为代表):
除了不支持各大笔记平台外,其余功能支持:3、4、5,截图模式支持1、2,给三颗星。
但是比较贵,而且只支持200个亮点免费等,而且一下子就用完了。
B、印象笔记
功能比较单薄,只支持4、5,当然比有道云只支持5(-最基本的功能)要好,给两颗星。
C. Markup.io
有一个传说中的插件,应该支持1、2、3、4,但是已经关闭了;楼上列出的一些很棒的亮点 xxx 似乎也已经关闭。
D.
ok,两颗星,支持3、4、5(Text Based),有点像kindle的标记功能,大家可以在网页上标记一些地方,可以看到别人的评论或者下划线,一颗半星酒吧。
E. 黄色荧光笔等
比较简陋,类似D,一颗星。
综上所述,如果你只是想高亮保存网页上的文字,印象笔记/onenote(+windows edge)应该是最好的选择;如果你只是想做文字标注,Diigo 更好,但每年 40D 的价格让我等到掉丝都泄气了。
PS。想找一个*估计网页内容阅读时间*的小插件,但是chrome商店里的那个要么不能用,要么太烂,有必要自己写一个吗?
参考:
网页阅读,如何标记喜欢阅读?-知乎我不知道
“网页注释分享工具”的重点来了!| 一页一页
浏览器抓取网页(如何找到json代码获取目标信息?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2022-03-13 21:08
前言
很多情况下,使用爬虫时无法获取到我们想要的信息,因为有些数据是用json代码写的,通过xhr异步加载到网页中。
因此,我们无法在页面中获取它。这时候我们就可以通过解析json代码得到目标信息了。
一、如何找到目标xhr地址?
以抖音中的canvas图片信息为例,从下图中可以看出图中有数字,但是这些数据并没有附加到canvas上:
这时候我们可以通过在网络中寻找xhr请求找到初始数据的链接,如下图,在出现的xhr请求中找到目标文件。如果xhr下没有需要的数据,可以尝试刷新页面:
经过尝试,不难找到最初的数据存储位置。可以看出请求方法是get,从图中很容易看出我们需要的性别数据:
下一步是在代码中实现这一步。
二、代码实现1.准备安装Browsermob-Proxy和chromedriver.exe:
下载 Browsermobproxy
下载chromedriver驱动
将下载的brosermob-proxy-2.1.4和浏览器对应版本的chromedriver保存到main.py的同级目录下:
2.编写代码导入库:
import json#读取json数据时需要用到
import os
import requests
from selenium import webdriver
from browsermobproxy import Server
配置代理环境和chrome浏览器:
path=os.getcwd()#获取当前路径
server = Server(path+"\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy")
server.start()
proxy = server.create_proxy()
chrome_options =webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument("---kiosk")#设置全屏
driver = webdriver.Chrome(options=chrome_options)
#
proxy.new_har(options={'captureHeaders': True, 'captureContent': True})
使用cookies向chrome浏览器添加用户信息:
因为我这里以抖音为例,抖音中的json数据需要登录才能获取账号,否则会报“无操作权限”,可以选择是否使用它根据你自己的需要。
cookie=driver.get_cookies()
jsonCookies=json.dumps(cookie)
with open ("driver.json",'w') as f:
f.write(jsonCookies)
with open('driver.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
获取网络请求并读取数据:
result = proxy.har#读取当前网页信息
for rs in result['log']['entries']:
a=rs['request']['url']#获取url链接
if "aweme/v1/creator/data/item/audience" in a:#查找目标关键字(这里可根据自己的需求更改搜索内容)
url=a#得到目标url
#以下是使用cookie获取到get请求中的json数据
headers = {'cookie': cookiestr,#若不使用cookie可去掉这句话
"User_Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
html=requests.get(url=url,headers=headers)#用request登陆目标url
data=html.text
data=json.loads(data)#将json数据转为字典数据,以便使用
使用获得的数据:
查看数据如下:
这里可以使用字典访问方式或者正则表达式来获取
for k in data:
if k == 'gender_data':
gender = data.get(k)
for i in gender:
for j in i.values():
if j == '1':
dict['gender_num'] =dict.get('gender_num',0) + int(i.get('value'))
dict['male'] = int(i.get('value'))
if j == '2':
dict['female'] = int(i.get('value'))
dict['gender_num'] =dict.get('gender_num',0) +int(i.get('value'))
打印数据
print(dict['gender_num'])
print(dict['male'])
print(dict['female'])
总结
这是寒假做项目时遇到的问题。我在网上找不到完整的方法。我到处查资料,终于成功了。
browsermobproxy的使用有点麻烦。希望能给你一个参考。当然,我这里只提供一些必要的流程。我省略了一些使用爬虫的细节。例如,proxy.new_har() 可以在不同的网页中使用一次。,可以避免proxy.har等获取的信息重复。 查看全部
浏览器抓取网页(如何找到json代码获取目标信息?(一))
前言
很多情况下,使用爬虫时无法获取到我们想要的信息,因为有些数据是用json代码写的,通过xhr异步加载到网页中。
因此,我们无法在页面中获取它。这时候我们就可以通过解析json代码得到目标信息了。
一、如何找到目标xhr地址?
以抖音中的canvas图片信息为例,从下图中可以看出图中有数字,但是这些数据并没有附加到canvas上:
这时候我们可以通过在网络中寻找xhr请求找到初始数据的链接,如下图,在出现的xhr请求中找到目标文件。如果xhr下没有需要的数据,可以尝试刷新页面:
经过尝试,不难找到最初的数据存储位置。可以看出请求方法是get,从图中很容易看出我们需要的性别数据:
下一步是在代码中实现这一步。
二、代码实现1.准备安装Browsermob-Proxy和chromedriver.exe:
下载 Browsermobproxy
下载chromedriver驱动
将下载的brosermob-proxy-2.1.4和浏览器对应版本的chromedriver保存到main.py的同级目录下:
2.编写代码导入库:
import json#读取json数据时需要用到
import os
import requests
from selenium import webdriver
from browsermobproxy import Server
配置代理环境和chrome浏览器:
path=os.getcwd()#获取当前路径
server = Server(path+"\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy")
server.start()
proxy = server.create_proxy()
chrome_options =webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument("---kiosk")#设置全屏
driver = webdriver.Chrome(options=chrome_options)
#
proxy.new_har(options={'captureHeaders': True, 'captureContent': True})
使用cookies向chrome浏览器添加用户信息:
因为我这里以抖音为例,抖音中的json数据需要登录才能获取账号,否则会报“无操作权限”,可以选择是否使用它根据你自己的需要。
cookie=driver.get_cookies()
jsonCookies=json.dumps(cookie)
with open ("driver.json",'w') as f:
f.write(jsonCookies)
with open('driver.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
获取网络请求并读取数据:
result = proxy.har#读取当前网页信息
for rs in result['log']['entries']:
a=rs['request']['url']#获取url链接
if "aweme/v1/creator/data/item/audience" in a:#查找目标关键字(这里可根据自己的需求更改搜索内容)
url=a#得到目标url
#以下是使用cookie获取到get请求中的json数据
headers = {'cookie': cookiestr,#若不使用cookie可去掉这句话
"User_Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
html=requests.get(url=url,headers=headers)#用request登陆目标url
data=html.text
data=json.loads(data)#将json数据转为字典数据,以便使用
使用获得的数据:
查看数据如下:
这里可以使用字典访问方式或者正则表达式来获取
for k in data:
if k == 'gender_data':
gender = data.get(k)
for i in gender:
for j in i.values():
if j == '1':
dict['gender_num'] =dict.get('gender_num',0) + int(i.get('value'))
dict['male'] = int(i.get('value'))
if j == '2':
dict['female'] = int(i.get('value'))
dict['gender_num'] =dict.get('gender_num',0) +int(i.get('value'))
打印数据
print(dict['gender_num'])
print(dict['male'])
print(dict['female'])
总结
这是寒假做项目时遇到的问题。我在网上找不到完整的方法。我到处查资料,终于成功了。
browsermobproxy的使用有点麻烦。希望能给你一个参考。当然,我这里只提供一些必要的流程。我省略了一些使用爬虫的细节。例如,proxy.new_har() 可以在不同的网页中使用一次。,可以避免proxy.har等获取的信息重复。
浏览器抓取网页(python+selenium爬虫全流程详解+python爬虫简介 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-03-13 21:08
)
python+selenium爬虫全流程详解
selenium+python爬虫介绍
本教程的大部分内容都是基于个人经验,其中一些是口语化的
如有不妥之处,请及时更正(可评论或私信)
硒测试脚本
Selenium其实是一个web自动化测试工具,可以完全模拟使用浏览器自动访问目标站点,通过代码操作进行web测试。
蟒蛇+硒
通过python+selenium的组合来实现爬虫是非常巧妙的。
由于是模拟人类点击操作,实际被反转的概率会大大降低。
Selenium 可以在页面上执行 js,处理 js 渲染的数据并模拟登录非常容易。
该技术还可以与正则表达式、bs4、request、ip pool等其他技术结合使用。
当然,由于在获取页面的过程中会发送很多请求,效率低,爬取速度也会比较慢。推荐用于小规模数据爬取。
selenium安装可以直接通过pip安装
pip3 install selenium
导入包
from selenium import webdriver
模拟浏览器----以chrome为例安装浏览器驱动
关联:
我们只需要在上面的链接中下载对应版本的驱动,放到python安装路径的scripts目录下即可。
浏览器版本可以在设置-关于Chrome中查看
当然,由于浏览器经常会自动更新,所以我们也记得在使用前更新相应的驱动程序。
基本操作的浏览器仿真
browser = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 3B%23以该链接为例
browser.get(url)#访问相对应链接
browser.close#关闭浏览器
抓取数据 – 网站位置
以下知识需要一些网络相关知识作为前提
案例——b站排行榜
假设我们需要爬取上图中红圈内的文本数据,那么我们需要定位到这个地方的点
定位方法与实践
定位方式的选择主要取决于目标页面的情况。
#find_elements_by_xxx的形式是查找到多个元素(当前定位方法定位元素不唯一)
#结果为列表
browser.find_element_by_id('')# 通过标签id属性进行定位
browser.find_element_by_name("")# 通过标签name属性进行定位
browser.find_elements_by_class_name("")# 通过class名称进行定位
browser.find_element_by_tag_name("")# 通过标签名称进行定位
browser.find_element_by_css_selector('')# 通过CSS查找方式进行定位
browser.find_element_by_xpath('')# 通过xpath方式定位
#在chrome中可以通过源代码目标元素右键--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# 通过搜索 页面中 链接进行定位
browser.find_element_by_partial_link_text("")# 通过搜索 页面中 链接进行定位 ,可以支持模糊匹配
在网站的情况下,我们根据类名爬取,标签中的class="info"
from selenium import webdriver
browser = webdriver.Chrome()
# browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 39%3B
browser.get(url)
info=browser.find_elements_by_class_name('info')
#在目标网站中网站中标题class名称都为"info",所以用elements
for i in info:
print(i.text)
#.text为定位元素底下的所有文本,当然我们也可以获取标签里的东西(用其它函数),如视频链接:
# print(i.find_elements_by_tag_name('a')[0].get_attribute('href'))
结果
一些可能使用的方法(辅助爬虫/减少反爬)加快网页加载(不加载js、图片等)
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
异常捕获
from selenium.common.exceptions import NoSuchElementException
等待加载的网页
由于网速等问题,进入网站后页面还没有加载,需要等待。
selenium 自带的加载方式
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载
wait=WebDriverWait(browser,10) #显式等待:指定等待某个标签加载完毕
wait1=browser.implicitly_wait(10) #隐式等待:等待所有标签加载完毕
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
等待时间与时间
import time
time.sleep(2)
在输入框中输入数据
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("名称") # 向input输入框输入名称
#也可以driver.find_element_by_id("kw").send_keys("名称") 查看全部
浏览器抓取网页(python+selenium爬虫全流程详解+python爬虫简介
)
python+selenium爬虫全流程详解
selenium+python爬虫介绍
本教程的大部分内容都是基于个人经验,其中一些是口语化的
如有不妥之处,请及时更正(可评论或私信)
硒测试脚本
Selenium其实是一个web自动化测试工具,可以完全模拟使用浏览器自动访问目标站点,通过代码操作进行web测试。
蟒蛇+硒
通过python+selenium的组合来实现爬虫是非常巧妙的。
由于是模拟人类点击操作,实际被反转的概率会大大降低。
Selenium 可以在页面上执行 js,处理 js 渲染的数据并模拟登录非常容易。
该技术还可以与正则表达式、bs4、request、ip pool等其他技术结合使用。
当然,由于在获取页面的过程中会发送很多请求,效率低,爬取速度也会比较慢。推荐用于小规模数据爬取。
selenium安装可以直接通过pip安装
pip3 install selenium
导入包
from selenium import webdriver
模拟浏览器----以chrome为例安装浏览器驱动
关联:
我们只需要在上面的链接中下载对应版本的驱动,放到python安装路径的scripts目录下即可。
浏览器版本可以在设置-关于Chrome中查看
当然,由于浏览器经常会自动更新,所以我们也记得在使用前更新相应的驱动程序。
基本操作的浏览器仿真
browser = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 3B%23以该链接为例
browser.get(url)#访问相对应链接
browser.close#关闭浏览器
抓取数据 – 网站位置
以下知识需要一些网络相关知识作为前提
案例——b站排行榜
假设我们需要爬取上图中红圈内的文本数据,那么我们需要定位到这个地方的点
定位方法与实践
定位方式的选择主要取决于目标页面的情况。
#find_elements_by_xxx的形式是查找到多个元素(当前定位方法定位元素不唯一)
#结果为列表
browser.find_element_by_id('')# 通过标签id属性进行定位
browser.find_element_by_name("")# 通过标签name属性进行定位
browser.find_elements_by_class_name("")# 通过class名称进行定位
browser.find_element_by_tag_name("")# 通过标签名称进行定位
browser.find_element_by_css_selector('')# 通过CSS查找方式进行定位
browser.find_element_by_xpath('')# 通过xpath方式定位
#在chrome中可以通过源代码目标元素右键--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# 通过搜索 页面中 链接进行定位
browser.find_element_by_partial_link_text("")# 通过搜索 页面中 链接进行定位 ,可以支持模糊匹配
在网站的情况下,我们根据类名爬取,标签中的class="info"
from selenium import webdriver
browser = webdriver.Chrome()
# browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/pop ... 39%3B
browser.get(url)
info=browser.find_elements_by_class_name('info')
#在目标网站中网站中标题class名称都为"info",所以用elements
for i in info:
print(i.text)
#.text为定位元素底下的所有文本,当然我们也可以获取标签里的东西(用其它函数),如视频链接:
# print(i.find_elements_by_tag_name('a')[0].get_attribute('href'))
结果
一些可能使用的方法(辅助爬虫/减少反爬)加快网页加载(不加载js、图片等)
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
异常捕获
from selenium.common.exceptions import NoSuchElementException
等待加载的网页
由于网速等问题,进入网站后页面还没有加载,需要等待。
selenium 自带的加载方式
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载
wait=WebDriverWait(browser,10) #显式等待:指定等待某个标签加载完毕
wait1=browser.implicitly_wait(10) #隐式等待:等待所有标签加载完毕
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
等待时间与时间
import time
time.sleep(2)
在输入框中输入数据
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("名称") # 向input输入框输入名称
#也可以driver.find_element_by_id("kw").send_keys("名称")
浏览器抓取网页(Window代表当前浏览器的地址栏代表的是怎样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-13 21:07
物料清单
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
航海家
判断浏览器
var ua = navigator.userAgent;
控制台.log(ua);
if(/firefox/i.test(ua)){
alert("你是火狐!!!");
}else if(/chrome/i.test(ua)){
alert("你是 Chrome");
}否则如果(/msie/i.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,开枪~~~");
}
历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
可用于跳转到指定页面
它需要一个整数作为参数
地点
该对象封装了浏览器地址栏的信息
如果直接打印位置,可以在地址栏中获取信息
如果直接修改location属性为完整路径,或者相对路径,我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置 = "";
分配()
location.assign("");
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
location.reload(true);
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
代替()
location.replace("01.BOM.html");
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
设置间隔()
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
var timer = setInterval(function(){
count.innerHTML = 数字++;
if(num == 11){
//关闭定时器
清除间隔(定时器);
}
},1000);
clearInterval() 可用于关闭需要定时器的标识符作为参数的定时器方法,该方法将关闭该标识符对应的定时器
多姆
事件
是用户和浏览器之间的交互
例如:单击按钮、移动鼠标、关闭窗口。. .
绑定点击事件
这个与点击事件绑定的函数称为点击响应函数
btn.onclick = 函数(){
alert("你还在点~~~");
};
加载事件
在整个页面加载后触发
Window 绑定一个 onload 事件
window.onload = 函数(){
//获取id为btn的按钮
var btn = document.getElementById("btn");
//为按钮绑定点击响应函数
btn.onclick = 函数(){
警报(“你好”);
};
};
dom查询
获取按钮对象
var btn = document.getElementById("btn");
编辑按钮文本
btn.innerHTML = "我是按钮";
查找所有 li 节点
var lis = document.getElementsByTagName("li");
查找 name=gender 的所有节点
var 输入 = document.getElementsByName("gender");
如果需要读取元素节点属性,
使用 element.Attribute 名称 示例:element.id element.name element.value 注意:类属性不能这样使用,读取类属性时需要使用 element.className
返回#city 的所有子节点
childNodes 属性将获取所有节点,包括文本节点
var cns = city.childNodes;
children属性可以获取当前元素的所有子元素
var cns2 = city.children;
firstChild 可以获取当前元素的第一个子节点(包括空白文本节点)
var fir = phone.firstChild;
firstElementChild 获取当前元素的第一个子元素
冷杉 = phone.firstElementChild;
内部文本
该属性可以获取元素内部的文本内容
previousElementSibling 获取上一个兄弟元素
var pe = and.previousElementSibling;
文档中有一个属性body,里面保存了对body的引用
var body = document.body;
document.documentElement 保存 html 根标签
var html = document.documentElement;
document.all 代表页面中的所有元素
var all = document.all;
document.querySelector()
var div = document.querySelector(".box1 div");
需要选择器字符串作为参数,可以根据CSS选择器查询元素节点对象
document.querySelectorAll()
box1 = document.querySelectorAll(".box1");
这个方法类似于querySelector(),不同的是它将符合条件的元素封装成一个数组并返回
操作 CSS
修订
element.style.stylename = 样式值
这种名称在 JS 中是非法的。比如background-color需要把这个样式名改成驼色,去掉-,然后-后面的字母大写
如果样式中写了!important,那么此时样式的优先级最高
框1.style.width = "300px";
框1.style.height = "300px";
框1.style.backgroundColor = “黄色”;
读
element.style.stylename
框1.style.width
获取元素当前显示的样式
element.currentStyle.style 名称(仅IE浏览器支持)
getComputedStyle() 方法用于获取元素的当前样式。该方法是window的方法,可以直接使用,需要两个参数。
第一种:获取样式的元素
第二种:可以传入一个伪元素,一般为null
该方法返回一个对象,该对象封装了当前元素对应的样式
样式可以通过 object.stylename 读取
获取指定元素当前样式的函数
函数getStyle(obj,名称){
如果(window.getComputedStyle){
//普通浏览器方式,带getComputedStyle()方法
返回 getComputedStyle(obj , null)[name];
}别的{
//IE8方式,没有getComputedStyle()方法
返回 obj.currentStyle[名称];
}
//return window.getComputedStyle?getComputedStyle(obj , null)[name]:obj.currentStyle[name];
}
可见宽度和高度
客户宽度客户高度
框1.clientWidth
只读,不可修改
没有px,return是一个数字,可以直接计算
元素宽度和高度,包括内容区域和填充
元素的整个宽度和高度
偏移宽度偏移高度
框1.偏移宽度
当前元素的定位父级
偏移父
var op = box1.offsetParent;
抵消
左偏移
当前元素相对于其定位的父元素的水平偏移
偏移顶部
当前元素相对于其定位的父元素的垂直偏移量
滚动区域的宽度和高度
滚动宽度滚动高度
滚动距离
向左滚动
可以得到水平滚动条滚动的距离
滚动顶部
可以得到垂直滚动条滚动的距离
满足scrollHeight - scrollTop == clientHeight 表示垂直滚动条已经滚动到最后
当scrollWidth - scrollLeft == clientWidth 满足时,水平滚动条滚动到最后
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
数学
由 Math.PI 表示的 Pi
abs() 可以用来计算一个数的绝对值
console.log(Math.abs(-1));
Math.ceil() 可以对数字进行四舍五入,如果有数值小数位自动四舍五入。
Math.floor() 可以对数字进行四舍五入,小数部分会四舍五入
Math.round() 可以对数字进行四舍五入
//console.log(Math.ceil(1.1));
//console.log(Math.floor(1.99));
//console.log(Math.round(1.4));
数学随机()
可用于生成0-1之间的随机数
生成一个 0-x 之间的随机数
Math.round(Math.random()*x)
在 xy 之间生成一个随机数
Math.round(Math.random()*(yx)+x)
for(var i=0 ; i //console.log(Math.round(Math.random()*10));
//console.log(Math.round(Math.random()*20));
//console.log(Math.round(Math.random()*9)+1);
//console.log(Math.round(Math.random()*8)+2);
//生成一个1-6之间的随机数
console.log(Math.round(Math.random()*5+1));
}
max() 可以得到多个数的最大值
min() 可以得到多个数字中的最小值
var max = Math.max(10,45,30,100);
var min = Math.min(10,45,30,100);
Math.pow(x,y) 返回 x 的 y 次幂
console.log(Math.pow(12,3));
Math.sqrt() 用于取数字的平方根
console.log(Math.sqrt(2)); 查看全部
浏览器抓取网页(Window代表当前浏览器的地址栏代表的是怎样的?)
物料清单
窗户
表示整个浏览器的窗口,window也是网页中的一个全局对象
航海家
表示当前浏览器的信息,通过这些信息可以识别不同的浏览器
地点
表示当前浏览器的地址栏信息。您可以通过Location获取地址栏信息,也可以操作浏览器跳转到页面。
历史
表示浏览器的历史,通过它可以操作浏览器的历史
屏幕
表示用户屏幕的信息,通过它可以获取用户显示器的相关信息
航海家
判断浏览器
var ua = navigator.userAgent;
控制台.log(ua);
if(/firefox/i.test(ua)){
alert("你是火狐!!!");
}else if(/chrome/i.test(ua)){
alert("你是 Chrome");
}否则如果(/msie/i.test(ua)){
alert("你是IE浏览器~~~");
}else if("ActiveXObject" in window){
alert("你是IE11,开枪~~~");
}
历史
对象可用于操纵浏览器向前或向后翻页
长度
属性,可以获取链接数作为访问
背部()
可用于返回上一页,与浏览器的返回按钮相同
向前()
可以跳转到下一页,和浏览器的前进按钮一样
走()
1:表示向前跳转一个页面等价于forward()
2:表示向前跳转两页
-1:表示跳回一页
-2:表示跳回两页
可用于跳转到指定页面
它需要一个整数作为参数
地点
该对象封装了浏览器地址栏的信息
如果直接打印位置,可以在地址栏中获取信息
如果直接修改location属性为完整路径,或者相对路径,我们的页面会自动跳转到这个路径,并生成对应的历史记录
位置 = "";
分配()
location.assign("");
用来跳转到其他页面,效果和直接修改位置一样
重新加载()
location.reload(true);
用于重新加载当前页面,同刷新按钮
如果在方法中传入一个true作为参数,会强制刷新缓存,刷新页面
代替()
location.replace("01.BOM.html");
可以用新页面替换当前页面,调用后页面也会跳转
不生成历史记录,不能使用返回键返回
设置间隔()
一个函数可以每隔一段时间执行一次
范围:
1.回调函数,每隔一段时间就会调用一次
2.每次调用之间的时间,以毫秒为单位
返回值:
返回 Number 类型的数据
此编号用作计时器的唯一标识符
var timer = setInterval(function(){
count.innerHTML = 数字++;
if(num == 11){
//关闭定时器
清除间隔(定时器);
}
},1000);
clearInterval() 可用于关闭需要定时器的标识符作为参数的定时器方法,该方法将关闭该标识符对应的定时器
多姆
事件
是用户和浏览器之间的交互
例如:单击按钮、移动鼠标、关闭窗口。. .
绑定点击事件
这个与点击事件绑定的函数称为点击响应函数
btn.onclick = 函数(){
alert("你还在点~~~");
};
加载事件
在整个页面加载后触发
Window 绑定一个 onload 事件
window.onload = 函数(){
//获取id为btn的按钮
var btn = document.getElementById("btn");
//为按钮绑定点击响应函数
btn.onclick = 函数(){
警报(“你好”);
};
};
dom查询
获取按钮对象
var btn = document.getElementById("btn");
编辑按钮文本
btn.innerHTML = "我是按钮";
查找所有 li 节点
var lis = document.getElementsByTagName("li");
查找 name=gender 的所有节点
var 输入 = document.getElementsByName("gender");
如果需要读取元素节点属性,
使用 element.Attribute 名称 示例:element.id element.name element.value 注意:类属性不能这样使用,读取类属性时需要使用 element.className
返回#city 的所有子节点
childNodes 属性将获取所有节点,包括文本节点
var cns = city.childNodes;
children属性可以获取当前元素的所有子元素
var cns2 = city.children;
firstChild 可以获取当前元素的第一个子节点(包括空白文本节点)
var fir = phone.firstChild;
firstElementChild 获取当前元素的第一个子元素
冷杉 = phone.firstElementChild;
内部文本
该属性可以获取元素内部的文本内容
previousElementSibling 获取上一个兄弟元素
var pe = and.previousElementSibling;
文档中有一个属性body,里面保存了对body的引用
var body = document.body;
document.documentElement 保存 html 根标签
var html = document.documentElement;
document.all 代表页面中的所有元素
var all = document.all;
document.querySelector()
var div = document.querySelector(".box1 div");
需要选择器字符串作为参数,可以根据CSS选择器查询元素节点对象
document.querySelectorAll()
box1 = document.querySelectorAll(".box1");
这个方法类似于querySelector(),不同的是它将符合条件的元素封装成一个数组并返回
操作 CSS
修订
element.style.stylename = 样式值
这种名称在 JS 中是非法的。比如background-color需要把这个样式名改成驼色,去掉-,然后-后面的字母大写
如果样式中写了!important,那么此时样式的优先级最高
框1.style.width = "300px";
框1.style.height = "300px";
框1.style.backgroundColor = “黄色”;
读
element.style.stylename
框1.style.width
获取元素当前显示的样式
element.currentStyle.style 名称(仅IE浏览器支持)
getComputedStyle() 方法用于获取元素的当前样式。该方法是window的方法,可以直接使用,需要两个参数。
第一种:获取样式的元素
第二种:可以传入一个伪元素,一般为null
该方法返回一个对象,该对象封装了当前元素对应的样式
样式可以通过 object.stylename 读取
获取指定元素当前样式的函数
函数getStyle(obj,名称){
如果(window.getComputedStyle){
//普通浏览器方式,带getComputedStyle()方法
返回 getComputedStyle(obj , null)[name];
}别的{
//IE8方式,没有getComputedStyle()方法
返回 obj.currentStyle[名称];
}
//return window.getComputedStyle?getComputedStyle(obj , null)[name]:obj.currentStyle[name];
}
可见宽度和高度
客户宽度客户高度
框1.clientWidth
只读,不可修改
没有px,return是一个数字,可以直接计算
元素宽度和高度,包括内容区域和填充
元素的整个宽度和高度
偏移宽度偏移高度
框1.偏移宽度
当前元素的定位父级
偏移父
var op = box1.offsetParent;
抵消
左偏移
当前元素相对于其定位的父元素的水平偏移
偏移顶部
当前元素相对于其定位的父元素的垂直偏移量
滚动区域的宽度和高度
滚动宽度滚动高度
滚动距离
向左滚动
可以得到水平滚动条滚动的距离
滚动顶部
可以得到垂直滚动条滚动的距离
满足scrollHeight - scrollTop == clientHeight 表示垂直滚动条已经滚动到最后
当scrollWidth - scrollLeft == clientWidth 满足时,水平滚动条滚动到最后
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
日期对象
JS中使用Date对象表示时间
创建一个日期对象
var d = 新日期();
创建指定时间对象
日期格式 月/日/年 时:分:秒
var d2 = new Date("2/18/2011 11:10:30");
获取日期()
获取当前日期对象是天
var date = d2.getDate();
获取日()
获取当前日期对象是星期几
将返回 0-6 值 0 代表星期日,1 代表星期一
var day = d2.getDay();
获取月份()
获取当前时间对象的月份
将返回值 0-11 0 表示 1 月 1 日表示 2 月 11 日表示 12 月
var 月 = d2.getMonth();
getFullYear()
获取当前日期对象的年份
var year = d2.getFullYear();
获取时间()
获取当前日期对象的时间戳
时间戳,指 1970 年 1 月 1 日 0:00:00 GMT
var time = d2.getTime();
数学
由 Math.PI 表示的 Pi
abs() 可以用来计算一个数的绝对值
console.log(Math.abs(-1));
Math.ceil() 可以对数字进行四舍五入,如果有数值小数位自动四舍五入。
Math.floor() 可以对数字进行四舍五入,小数部分会四舍五入
Math.round() 可以对数字进行四舍五入
//console.log(Math.ceil(1.1));
//console.log(Math.floor(1.99));
//console.log(Math.round(1.4));
数学随机()
可用于生成0-1之间的随机数
生成一个 0-x 之间的随机数
Math.round(Math.random()*x)
在 xy 之间生成一个随机数
Math.round(Math.random()*(yx)+x)
for(var i=0 ; i //console.log(Math.round(Math.random()*10));
//console.log(Math.round(Math.random()*20));
//console.log(Math.round(Math.random()*9)+1);
//console.log(Math.round(Math.random()*8)+2);
//生成一个1-6之间的随机数
console.log(Math.round(Math.random()*5+1));
}
max() 可以得到多个数的最大值
min() 可以得到多个数字中的最小值
var max = Math.max(10,45,30,100);
var min = Math.min(10,45,30,100);
Math.pow(x,y) 返回 x 的 y 次幂
console.log(Math.pow(12,3));
Math.sqrt() 用于取数字的平方根
console.log(Math.sqrt(2));
浏览器抓取网页(1.网站会设置一些反爬虫的措施吗?怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-03-13 14:17
有时候,当我们的爬虫程序完成,本地测试没有问题的时候,爬了一段时间后,突然发现报错,无法爬取页面内容。这时候我们很可能遇到了网站的反爬虫拦截。
我们知道,一方面网站想让爬虫爬到网站,比如让搜索引擎爬虫爬取网站的内容,提高网站的搜索排名. 另一方面,由于网站的服务器资源有限,过多的非真实用户对网站的大量访问会增加运营成本和服务器负担。
因此,一些网站会设置一些反爬措施。只有了解主要的反爬虫措施,才能识别反爬虫措施,进行反爬虫。当然,从道德和法律的角度来看,开发者应该出于合理合法的目的控制爬虫,决不能非法使用爬虫。如果您需要将爬取的内容用于商业用途,则需要特别注意数据上对应的网站声明。
1. 常用的反爬方法:
这是最基本的反爬虫方法之一。网站算子通过验证爬虫请求头中的User-agent、accept-enconding等信息来验证请求的主机是真实用户的普通浏览器还是其他一些信息。具体的请求头信息。
通过ajax或javascript动态获取和加载数据,增加了爬虫直接获取数据的难度。
相信大部分读者对此都非常熟悉。当我们多次输入错误密码时,很多平台都会弹出各种二维码供我们识别,或者当我们抢优采云票的时候,会有各种复杂的验证码,验证码是使用最广泛的一种防爬虫措施,也是防止爬虫最有效、最直接的方法之一。
当识别出一些异常访问时,网站运营商会设置黑名单,对确定为爬虫的部分IP进行限制或屏蔽。
有的网站,没有游客模式,只有注册后才能登录才能看到内容,这是典型的账号限制网站,一般可以在网站用户不多的情况下使用,具有严格安全要求的数据 网站。
2. 反反爬虫策略:
我们可以在请求头中替换我们的请求介质,让网站误以为我们是通过移动端访问的。运行以下代码后,当我们打开 hupu.html 时,会发现返回的是移动端的老虎。Flutter 的页面而不是 web 端的页面。
import requests
from bs4 import BeautifulSoup
header_data = {
'User-Agent': 'Mozilla/5.0 (Linux; U; Android 4.4.2; en-us; SCH-I535 Build/KOT49H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'}
re = requests.get('https://www.hupu.com/', headers=header_data)
bs = BeautifulSoup(re.content)
with open('hupu.html', 'wb') as f:
f.write(bs.prettify(encoding='utf8'))
例如,我们可以设置一个随机间隔来模拟用户行为,减少访问次数和访问频率。我们可以在我们的爬虫程序中加入如下代码,让爬虫休息3秒左右,然后再爬取,可以有效避免网站对爬虫的检测识别。
import time
import random
sleep_time = random.randint(0.,2) + random.random()
time.sleep(sleep_time)
代理是通过访问第三方机器隐藏自己的真实IP地址,然后通过第三方机器的IP访问。
import requests
link = "http://www.baidu.com/"
proxies = {'http':'XXXXXXXXXXX'} //代理地址,可以自己上网查找,这里就不做推荐了
response = requests.get(link, proxies=proxies)
因为第三方代理没有好坏之分,而且不稳定,经常会出现断线,爬取速度会慢很多。如果对爬虫的质量有严格要求,不建议使用这种方式进行爬取。
可以通过动态 IP 拨号服务器或 Tor 代理服务器更改 IP。
概括
反反爬虫的策略总是在变化。我们应该详细分析具体问题,通过不断的试错来改进我们的爬虫爬取。不要以为爬虫程序在本地调试好之后就没有问题了,可以高枕无忧了。在线问题总是千变万化。我们需要根据我们具体的反爬措施编写一些反反爬代码,以保证在线环境万无一失。 查看全部
浏览器抓取网页(1.网站会设置一些反爬虫的措施吗?怎么办?)
有时候,当我们的爬虫程序完成,本地测试没有问题的时候,爬了一段时间后,突然发现报错,无法爬取页面内容。这时候我们很可能遇到了网站的反爬虫拦截。
我们知道,一方面网站想让爬虫爬到网站,比如让搜索引擎爬虫爬取网站的内容,提高网站的搜索排名. 另一方面,由于网站的服务器资源有限,过多的非真实用户对网站的大量访问会增加运营成本和服务器负担。
因此,一些网站会设置一些反爬措施。只有了解主要的反爬虫措施,才能识别反爬虫措施,进行反爬虫。当然,从道德和法律的角度来看,开发者应该出于合理合法的目的控制爬虫,决不能非法使用爬虫。如果您需要将爬取的内容用于商业用途,则需要特别注意数据上对应的网站声明。
1. 常用的反爬方法:
这是最基本的反爬虫方法之一。网站算子通过验证爬虫请求头中的User-agent、accept-enconding等信息来验证请求的主机是真实用户的普通浏览器还是其他一些信息。具体的请求头信息。
通过ajax或javascript动态获取和加载数据,增加了爬虫直接获取数据的难度。
相信大部分读者对此都非常熟悉。当我们多次输入错误密码时,很多平台都会弹出各种二维码供我们识别,或者当我们抢优采云票的时候,会有各种复杂的验证码,验证码是使用最广泛的一种防爬虫措施,也是防止爬虫最有效、最直接的方法之一。
当识别出一些异常访问时,网站运营商会设置黑名单,对确定为爬虫的部分IP进行限制或屏蔽。
有的网站,没有游客模式,只有注册后才能登录才能看到内容,这是典型的账号限制网站,一般可以在网站用户不多的情况下使用,具有严格安全要求的数据 网站。
2. 反反爬虫策略:
我们可以在请求头中替换我们的请求介质,让网站误以为我们是通过移动端访问的。运行以下代码后,当我们打开 hupu.html 时,会发现返回的是移动端的老虎。Flutter 的页面而不是 web 端的页面。
import requests
from bs4 import BeautifulSoup
header_data = {
'User-Agent': 'Mozilla/5.0 (Linux; U; Android 4.4.2; en-us; SCH-I535 Build/KOT49H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'}
re = requests.get('https://www.hupu.com/', headers=header_data)
bs = BeautifulSoup(re.content)
with open('hupu.html', 'wb') as f:
f.write(bs.prettify(encoding='utf8'))
例如,我们可以设置一个随机间隔来模拟用户行为,减少访问次数和访问频率。我们可以在我们的爬虫程序中加入如下代码,让爬虫休息3秒左右,然后再爬取,可以有效避免网站对爬虫的检测识别。
import time
import random
sleep_time = random.randint(0.,2) + random.random()
time.sleep(sleep_time)
代理是通过访问第三方机器隐藏自己的真实IP地址,然后通过第三方机器的IP访问。
import requests
link = "http://www.baidu.com/"
proxies = {'http':'XXXXXXXXXXX'} //代理地址,可以自己上网查找,这里就不做推荐了
response = requests.get(link, proxies=proxies)
因为第三方代理没有好坏之分,而且不稳定,经常会出现断线,爬取速度会慢很多。如果对爬虫的质量有严格要求,不建议使用这种方式进行爬取。
可以通过动态 IP 拨号服务器或 Tor 代理服务器更改 IP。
概括
反反爬虫的策略总是在变化。我们应该详细分析具体问题,通过不断的试错来改进我们的爬虫爬取。不要以为爬虫程序在本地调试好之后就没有问题了,可以高枕无忧了。在线问题总是千变万化。我们需要根据我们具体的反爬措施编写一些反反爬代码,以保证在线环境万无一失。
浏览器抓取网页( SEO实战密码之搜索引擎爬行与抓取2.排序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-13 14:14
SEO实战密码之搜索引擎爬行与抓取2.排序)
在互联网时代,搜索引擎可以说是日常生活的一部分。不仅如此,经过20多年的风霜雨雪,搜索引擎依然牢牢占据着流量入口,让人唏嘘不已。
而且,一提到搜索引擎,我们都会想到一个大巨头公司,一个被黑的巨头公司。足以看出搜索引擎的巨大作用。
作为产品人,当然不能对此视而不见,应该明白它是如何工作的。
搜索引擎的工作原理大致可以分为3个步骤
1. 爬行和爬行
2. 预处理
3. 排序
俗话说,图胜千言,没有图,我说……
PS:上图摘自《SEO实战密码》。
详细描述如下:
抓取和抓取
简单地说:是搜索引擎蜘蛛沿着互联网爬行,爬取它们爬取的页面,并存储那些爬取的页面。
说到这里,你可能会问:为什么叫它“蜘蛛”?
为了爬取尽可能多的页面,搜索引擎会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来。
搜索引擎在跟踪网络上的链接时会使用某些策略,因为今天有太多的网络链接。最简单的爬取遍历策略有两种,一种是深度优先,一种是广度优先。
还有一件事值得一提:搜索引擎访问 网站 页面类似于普通用户使用的浏览器。搜索引擎蜘蛛爬取的数据存储在原创页面数据库中,其中的页面数据与用户浏览器获取的HTML完全相同。
预处理
由于爬取的页面数量太大(以“十亿”为单位)无法实时快速排序,因此需要进行预处理。这就是产品设计中的“复杂性守恒原则”。我们不能让用户等待十秒以上,所以只能做后台处理。
在一些数据中,“预处理”也称为“索引”,因为“索引”是预处理最重要的内容。
预处理过程比较复杂,值得一提的是以下几点:
有了倒排索引,就可以根据用户搜索到的关键词快速找到对应的文件,但是这样就够了吗?不要天真。
通过以上步骤,其实只获取到了页面本身的内容。说白了就是页面本身告诉搜索引擎怎么做。
俗话说:王婆卖瓜,她卖自己吹牛。
就像我们在网上购物时,不仅会看店铺给出的产品介绍,还会看买家的评价,页面内容的好坏也需要其他人的评价——这里的“其他人”指“其他页面”。因此,我们还需要链接关系计算。
排行
找不到:排名是用户唯一能感受到的一步。爬取、爬取和预处理都是在后台完成的。正因为如此,用户会觉得使用起来非常快。
排名过程也比较复杂,有以下几点值得一提:
但是,由于每个关键词对应的文件数量可能非常庞大(比如上亿),处理如此庞大的数据量并不能满足用户对“速度”的需求。同时,用户并不需要所有的内容,他们往往只查看前几页的内容,甚至很多用户只查看第一页的前几页内容。因此,需要选择一定数量的内容进行处理。这涉及选择熟人的子集。
但如何选择?这是个问题。
但这就是结束了吗?还没有。
本文由 @ITDoer 原创 在每个人都是产品经理发布。未经许可禁止复制 查看全部
浏览器抓取网页(
SEO实战密码之搜索引擎爬行与抓取2.排序)
在互联网时代,搜索引擎可以说是日常生活的一部分。不仅如此,经过20多年的风霜雨雪,搜索引擎依然牢牢占据着流量入口,让人唏嘘不已。
而且,一提到搜索引擎,我们都会想到一个大巨头公司,一个被黑的巨头公司。足以看出搜索引擎的巨大作用。
作为产品人,当然不能对此视而不见,应该明白它是如何工作的。
搜索引擎的工作原理大致可以分为3个步骤
1. 爬行和爬行
2. 预处理
3. 排序
俗话说,图胜千言,没有图,我说……
PS:上图摘自《SEO实战密码》。
详细描述如下:
抓取和抓取
简单地说:是搜索引擎蜘蛛沿着互联网爬行,爬取它们爬取的页面,并存储那些爬取的页面。
说到这里,你可能会问:为什么叫它“蜘蛛”?
为了爬取尽可能多的页面,搜索引擎会跟随页面上的链接,从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样,这就是搜索引擎蜘蛛这个名字的由来。
搜索引擎在跟踪网络上的链接时会使用某些策略,因为今天有太多的网络链接。最简单的爬取遍历策略有两种,一种是深度优先,一种是广度优先。
还有一件事值得一提:搜索引擎访问 网站 页面类似于普通用户使用的浏览器。搜索引擎蜘蛛爬取的数据存储在原创页面数据库中,其中的页面数据与用户浏览器获取的HTML完全相同。
预处理
由于爬取的页面数量太大(以“十亿”为单位)无法实时快速排序,因此需要进行预处理。这就是产品设计中的“复杂性守恒原则”。我们不能让用户等待十秒以上,所以只能做后台处理。
在一些数据中,“预处理”也称为“索引”,因为“索引”是预处理最重要的内容。
预处理过程比较复杂,值得一提的是以下几点:
有了倒排索引,就可以根据用户搜索到的关键词快速找到对应的文件,但是这样就够了吗?不要天真。
通过以上步骤,其实只获取到了页面本身的内容。说白了就是页面本身告诉搜索引擎怎么做。
俗话说:王婆卖瓜,她卖自己吹牛。
就像我们在网上购物时,不仅会看店铺给出的产品介绍,还会看买家的评价,页面内容的好坏也需要其他人的评价——这里的“其他人”指“其他页面”。因此,我们还需要链接关系计算。
排行
找不到:排名是用户唯一能感受到的一步。爬取、爬取和预处理都是在后台完成的。正因为如此,用户会觉得使用起来非常快。
排名过程也比较复杂,有以下几点值得一提:
但是,由于每个关键词对应的文件数量可能非常庞大(比如上亿),处理如此庞大的数据量并不能满足用户对“速度”的需求。同时,用户并不需要所有的内容,他们往往只查看前几页的内容,甚至很多用户只查看第一页的前几页内容。因此,需要选择一定数量的内容进行处理。这涉及选择熟人的子集。
但如何选择?这是个问题。
但这就是结束了吗?还没有。
本文由 @ITDoer 原创 在每个人都是产品经理发布。未经许可禁止复制
浏览器抓取网页(Windows7HomePremiumSP164位上测试:IE更改默认浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-08 05:14
TL;DR:如果存在
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
然后阅读;否则请阅读
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
. 看了这里的答案后,我对如何检测默认浏览器达成了共识,所以我做了一些实验和研究来弄清楚。我下载了 Firefox 源代码,编写了一个读取一堆注册表项的脚本,并在反复更改默认浏览器的同时运行 Process Explorer。我发现 Firefox 和 Chrome 在将它们自定义为默认浏览器时有很多注册表项。我相信 Safari 和 Opera 的行为相似。IE 似乎只更改了我正在观看的一个注册表项。我发现虽然大多数浏览器更改了其他注册表路径,但所有浏览器都更改了
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
以下是注册表项
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
中的注册表值,并且每个浏览器都是默认浏览器。即 9.0.8112.16421:
IEXPLORE.EXE
铬 21.0.1180.60m:
Google Chrome
火狐10.0.2:
FIREFOX.EXE
Safari 3.2.2:
Safari.exe
歌剧 12.01:
Opera
在 Microsoft Windows 7 Home Premium SP1 64bit 上进行测试编辑:我找到了全新安装的 Windows XPSP3
HKEY_CURRENT_USERSOFTWAREClientsStartMenuInternet
不存在。在这种情况下,您应该从
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
阅读默认浏览器。我怀疑其他版本的 Windows 的全新安装也是如此。附录:如果您只想在默认浏览器中打开网页,那么
ShellExecute
方法是一个很好的解决方案。但是,如果您只想在默认浏览器中安装扩展程序,那么
ShellExecute
无法解决问题。 查看全部
浏览器抓取网页(Windows7HomePremiumSP164位上测试:IE更改默认浏览器)
TL;DR:如果存在
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
然后阅读;否则请阅读
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
. 看了这里的答案后,我对如何检测默认浏览器达成了共识,所以我做了一些实验和研究来弄清楚。我下载了 Firefox 源代码,编写了一个读取一堆注册表项的脚本,并在反复更改默认浏览器的同时运行 Process Explorer。我发现 Firefox 和 Chrome 在将它们自定义为默认浏览器时有很多注册表项。我相信 Safari 和 Opera 的行为相似。IE 似乎只更改了我正在观看的一个注册表项。我发现虽然大多数浏览器更改了其他注册表路径,但所有浏览器都更改了
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
以下是注册表项
HKEY_CURRENT_USERSoftwareClientsStartMenuInternet
(default)
中的注册表值,并且每个浏览器都是默认浏览器。即 9.0.8112.16421:
IEXPLORE.EXE
铬 21.0.1180.60m:
Google Chrome
火狐10.0.2:
FIREFOX.EXE
Safari 3.2.2:
Safari.exe
歌剧 12.01:
Opera
在 Microsoft Windows 7 Home Premium SP1 64bit 上进行测试编辑:我找到了全新安装的 Windows XPSP3
HKEY_CURRENT_USERSOFTWAREClientsStartMenuInternet
不存在。在这种情况下,您应该从
HKEY_LOCAL_MACHINESOFTWAREClientsStartMenuInternet
阅读默认浏览器。我怀疑其他版本的 Windows 的全新安装也是如此。附录:如果您只想在默认浏览器中打开网页,那么
ShellExecute
方法是一个很好的解决方案。但是,如果您只想在默认浏览器中安装扩展程序,那么
ShellExecute
无法解决问题。
浏览器抓取网页( 游戏/数码网络2013-03-059浏览如何获取网页的更新时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-08 05:12
游戏/数码网络2013-03-059浏览如何获取网页的更新时间)
如何获取网页的更新时间并重置浏览器
游戏/数字网络2013-03-05 9 浏览
如何获取网页的更新时间如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。弹出提示框,可以快速查看当前网页的更新时间。如何重置IE浏览器 如果IE浏览器经常遇到运行错误,用户可以通过重置IE来恢复其初始设置。方法/步骤步骤一:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,
如何获取网页的更新时间
如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。输入完成后,按【Enter】键确认,会弹出提示信息框。点击这里查看当前页面的更新时间。
如何重置 Internet Explorer
如果 IE 经常出现运行错误,用户可以通过重置 IE 来恢复其初始设置。
方法/步骤
第一步:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,切换到“高级”选项卡,点击“重置”按钮,如图下图。
第二步:弹出“重置Internet Explorer设置”对话框,点击对话框中的“重置”按钮,如下图所示。
第三步:弹出“重置Internet Explorer设置”对话框,显示重置进度,如下图,稍等片刻,即可重置浏览器。
文章 标签:在网页上更新plesk刺激战场周报更新时间centos在线更新时间自动更新时间功能拼多多农场交易所更新时间 查看全部
浏览器抓取网页(
游戏/数码网络2013-03-059浏览如何获取网页的更新时间)
如何获取网页的更新时间并重置浏览器
游戏/数字网络2013-03-05 9 浏览
如何获取网页的更新时间如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。弹出提示框,可以快速查看当前网页的更新时间。如何重置IE浏览器 如果IE浏览器经常遇到运行错误,用户可以通过重置IE来恢复其初始设置。方法/步骤步骤一:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,
如何获取网页的更新时间
如果用户想知道一个网页的更新时间,可以在打开网页后在IE地址栏中输入pt:alert(document.lastModified)。输入完成后,按【Enter】键确认,会弹出提示信息框。点击这里查看当前页面的更新时间。
如何重置 Internet Explorer
如果 IE 经常出现运行错误,用户可以通过重置 IE 来恢复其初始设置。
方法/步骤
第一步:启动IE浏览器,点击“工具”“Internet选项”命令,弹出“Internet选项”对话框,切换到“高级”选项卡,点击“重置”按钮,如图下图。
第二步:弹出“重置Internet Explorer设置”对话框,点击对话框中的“重置”按钮,如下图所示。
第三步:弹出“重置Internet Explorer设置”对话框,显示重置进度,如下图,稍等片刻,即可重置浏览器。
文章 标签:在网页上更新plesk刺激战场周报更新时间centos在线更新时间自动更新时间功能拼多多农场交易所更新时间
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-08 00:02
)
从IE浏览器获取当前页面内容的方法可能有很多种,今天就介绍其中的一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
); 查看全部
浏览器抓取网页(从IE浏览器获取当前页面内容可能有多种方式的介绍
)
从IE浏览器获取当前页面内容的方法可能有很多种,今天就介绍其中的一种。基本原理:鼠标点击当前IE页面时,获取鼠标的坐标位置,根据鼠标位置获取当前页面的句柄,然后根据句柄调用win32的东西获取页面内容。具体代码:
1 private void timer1_Tick(object sender, EventArgs e)
2 {
3 lock (currentLock)
4 {
5 System.Drawing.Point MousePoint = System.Windows.Forms.Form.MousePosition;
6 if (_leftClick)
7 {
8 timer1.Stop();
9 _leftClick = false;
10
11 _lastDocument = GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false));
12 if (_lastDocument != null)
13 {
14 if (_getDocument)
15 {
16 _getDocument = true;
17 try
18 {
19 string url = _lastDocument.url;
20 string html = _lastDocument.documentElement.outerHTML;
21 string cookie = _lastDocument.cookie;
22 string domain = _lastDocument.domain;
23
24 var resolveParams = new ResolveParam
25 {
26 Url = new Uri(url),
27 Html = html,
28 PageCookie = cookie,
29 Domain = domain
30 };
31
32 RequetResove(resolveParams);
33 }
34 catch (Exception ex)
35 {
36 System.Windows.MessageBox.Show(ex.Message);
37 Console.WriteLine(ex.Message);
38 Console.WriteLine(ex.StackTrace);
39 }
40 }
41 }
42 else
43 {
44 new MessageTip().Show("xx", "当前页面不是IE浏览器页面,或使用了非IE内核浏览器,如火狐,搜狗等。请使用IE浏览器打开网页");
45 }
46
47 _getDocument = false;
48 }
49 else
50 {
51 _pointFrm.Left = MousePoint.X + 10;
52 _pointFrm.Top = MousePoint.Y + 10;
53 }
54 }
55
56 }
在第11行GetHTMLDocumentFormHwnd(GetPointControl(MousePoint, false))的分解下,首先从鼠标坐标获取页面句柄:
1 public static IntPtr GetPointControl(System.Drawing.Point p, bool allControl)
2 {
3 IntPtr handle = Win32APIsFull.WindowFromPoint(p);
4 if (handle != IntPtr.Zero)
5 {
6 System.Drawing.Rectangle rect = default(System.Drawing.Rectangle);
7 if (Win32APIsFull.GetWindowRect(handle, out rect))
8 {
9 return Win32APIsFull.ChildWindowFromPointEx(handle, new System.Drawing.Point(p.X - rect.X, p.Y - rect.Y), allControl ? Win32APIsFull.CWP.ALL : Win32APIsFull.CWP.SKIPINVISIBLE);
10 }
11 }
12 return IntPtr.Zero;
13
14 }
接下来根据句柄获取页面内容:
1 public static HTMLDocument GetHTMLDocumentFormHwnd(IntPtr hwnd)
2 {
3 IntPtr result = Marshal.AllocHGlobal(4);
4 Object obj = null;
5
6 Console.WriteLine(Win32APIsFull.SendMessageTimeoutA(hwnd, HTML_GETOBJECT_mid, 0, 0, 2, 1000, result));
7 if (Marshal.ReadInt32(result) != 0)
8 {
9 Console.WriteLine(Win32APIsFull.ObjectFromLresult(Marshal.ReadInt32(result), ref IID_IHTMLDocument, 0, out obj));
10 }
11
12 Marshal.FreeHGlobal(result);
13
14 return obj as HTMLDocument;
15 }
一般原则:
向IE窗体发送消息,获取指向IE浏览器内存块的指针(非托管),然后根据该指针获取HTMLDocument对象。
该方法涉及win32的两个功能:
[System.Runtime.InteropServices.DllImportAttribute("user32.dll", EntryPoint = "SendMessageTimeoutA")]
public static extern int SendMessageTimeoutA(
[InAttribute()] System.IntPtr hWnd,
uint Msg, uint wParam, int lParam,
uint fuFlags,
uint uTimeout,
System.IntPtr lpdwResult);
[System.Runtime.InteropServices.DllImportAttribute("oleacc.dll", EntryPoint = "ObjectFromLresult")]
public static extern int ObjectFromLresult(
int lResult,
ref Guid riid,
int wParam,
[MarshalAs(UnmanagedType.IDispatch), Out]
out Object pObject
);
浏览器抓取网页(macOS系统自带截图到底怎么用㊙️?(实战))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-06 07:06
让我结束这个问题,首先我认为这是一个伪需求。当然,这道题的前提是“对整个网页进行截图”。默认情况下,你说的是长图,也就是网页中没有显示在屏幕上的部分,也需要滚动来截图。
不然真的没必要用 Chrome 浏览器截图,因为 Windows 和 macOS 都提供系统原生的截图解决方案。
1、Mac上的系统截图功能很强大,除了几个明显的缺点(没有马赛克),感觉很好用,之前分享过。
如何使用macOS系统自带的截图?最完整(实用)的分享方法。快捷方式、存储位置、浮动缩略图、复制到剪贴板、参数,所有技巧都在这里——我作为网站管理员的岁月
2、对于Windows,您也可以使用Print Screen(键盘右上角)进行截图。按下后,图片实际上已经到了粘贴板上。找个地方贴一下就可以看到了。
3、如果以上两种方法都不能满足,我们来看看Chrome浏览器自带的截图。
先F12打开调试页面
然后使用快捷键,不同的系统使用不同的快捷键
然后会出现输入命令的界面。
可以在此处输入命令。不同的命令有不同的功能。这是我们需要的屏幕截图。
OK完成!
更详细的步骤,建议观看视频
▶ 视频收录的内容:
全部显示网址, 查看全部
浏览器抓取网页(macOS系统自带截图到底怎么用㊙️?(实战))
让我结束这个问题,首先我认为这是一个伪需求。当然,这道题的前提是“对整个网页进行截图”。默认情况下,你说的是长图,也就是网页中没有显示在屏幕上的部分,也需要滚动来截图。
不然真的没必要用 Chrome 浏览器截图,因为 Windows 和 macOS 都提供系统原生的截图解决方案。
1、Mac上的系统截图功能很强大,除了几个明显的缺点(没有马赛克),感觉很好用,之前分享过。
如何使用macOS系统自带的截图?最完整(实用)的分享方法。快捷方式、存储位置、浮动缩略图、复制到剪贴板、参数,所有技巧都在这里——我作为网站管理员的岁月
2、对于Windows,您也可以使用Print Screen(键盘右上角)进行截图。按下后,图片实际上已经到了粘贴板上。找个地方贴一下就可以看到了。
3、如果以上两种方法都不能满足,我们来看看Chrome浏览器自带的截图。
先F12打开调试页面
然后使用快捷键,不同的系统使用不同的快捷键
然后会出现输入命令的界面。
可以在此处输入命令。不同的命令有不同的功能。这是我们需要的屏幕截图。
OK完成!
更详细的步骤,建议观看视频
▶ 视频收录的内容:
全部显示网址,
浏览器抓取网页(浏览器都行操作步骤电脑浏览器打开京东网址按enter回车键)
网站优化 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2022-03-04 13:21
PS:注意:如果你有多个账号,千万不要点击退出。直接关闭网页,清除浏览器cookie数据,重新进入网页登录下一个账号。退出会使刚刚获取的ck失效。
以下浏览器都可以使用
操作步骤电脑浏览器打开京东网站,按键盘F12键打开开发者工具,然后点击下图中的图标
此时您没有登录(使用手机短信验证码登录)。如果您已经登录,请忽略此步骤。登录后,选择网络。如果链接较多,请点击此处的箭头清除
然后再点我,链接会变少
点击第一个链接(log.gif)进去,找到cookie,复制出来,新建一个TXT文本并临时保存,下面需要用到
第六步复制的cookie比较长,我们只需要pt_pin=xxxx的内容;和 pt_key=xxxx; (注:英文引号;是必需的)。可以使用如下脚本,在Chrome浏览器中按F12,在控制台输入如下脚本后回车
var CV = '单引号里面放第六步拿到的cookie';
var CookieValue = CV.match(/pt_pin=.+?;/) + CV.match(/pt_key=.+?;/);
copy(CookieValue);
这样,关键cookies已经在你的剪贴板上了,你可以直接粘贴。如果需要获取第二个京东账号的cookie,千万不要在之前的浏览器上退出登录账号1(否则刚刚获取的cookie会失效),需要换另一个浏览器(Chrome浏览器ctr +shift+n 也可以开启隐身模式),然后继续按照上述步骤操作即可。
奖励
支付宝扫码打赏
微信打赏
如果我的文章对你有帮助,请移步顶部按钮打赏 查看全部
浏览器抓取网页(浏览器都行操作步骤电脑浏览器打开京东网址按enter回车键)
PS:注意:如果你有多个账号,千万不要点击退出。直接关闭网页,清除浏览器cookie数据,重新进入网页登录下一个账号。退出会使刚刚获取的ck失效。
以下浏览器都可以使用
操作步骤电脑浏览器打开京东网站,按键盘F12键打开开发者工具,然后点击下图中的图标
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... e.png 1600w" />此时您没有登录(使用手机短信验证码登录)。如果您已经登录,请忽略此步骤。登录后,选择网络。如果链接较多,请点击此处的箭头清除
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 9.png 1600w" />然后再点我,链接会变少
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 8.png 1600w" />点击第一个链接(log.gif)进去,找到cookie,复制出来,新建一个TXT文本并临时保存,下面需要用到
https://www.juan920.com/wp-con ... 2.png 300w, https://www.juan920.com/wp-con ... 3.png 768w, https://www.juan920.com/wp-con ... 7.png 1536w, https://www.juan920.com/wp-con ... 8.png 1600w" />第六步复制的cookie比较长,我们只需要pt_pin=xxxx的内容;和 pt_key=xxxx; (注:英文引号;是必需的)。可以使用如下脚本,在Chrome浏览器中按F12,在控制台输入如下脚本后回车
var CV = '单引号里面放第六步拿到的cookie';
var CookieValue = CV.match(/pt_pin=.+?;/) + CV.match(/pt_key=.+?;/);
copy(CookieValue);
这样,关键cookies已经在你的剪贴板上了,你可以直接粘贴。如果需要获取第二个京东账号的cookie,千万不要在之前的浏览器上退出登录账号1(否则刚刚获取的cookie会失效),需要换另一个浏览器(Chrome浏览器ctr +shift+n 也可以开启隐身模式),然后继续按照上述步骤操作即可。
奖励
支付宝扫码打赏
微信打赏
如果我的文章对你有帮助,请移步顶部按钮打赏
浏览器抓取网页(因特网上信息的浏览与获取【教材分析】-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-04 13:16
《互联网信息获取与浏览》由会员共享,可在线阅读。更多《互联网信息获取与浏览(4页珍藏版)》,请在人人图书馆在线搜索。
在互联网上浏览和获取信息 [教科书分析] 互联网是一个巨大的资源库。本课程的中心是使用互联网获取所需的信息。因此,掌握通过互联网获取信息的基本技能是学生学习和实践的主要技能。本节内容与其他学科密切相关,可以成为其他学科丰富的学习资源和拓展学习内容的支点。如何有效地进行学科间的融合,促进信息素养的发展,值得教师在本课程的教学过程中不断的实践和探索。【学生分析】很多学生在初中就接触到了网络知识,并基本掌握了IE和网页浏览的使用。只有少数学生没有学过。因此,应针对不同层次的学生开设这门课。任务 设置应合理,考虑到所有学生。【教学目标】1.掌握网页浏览方法的知识和技能;学会保存有用的网络资源;掌握采集夹的使用。2.过程和方法培养学生获取和处理信息并利用所得信息解决实际问题的能力。3.情感态度与价值观 通过获取2008年北京奥运会的信息,让学生感受祖国的力量,增强爱国热情;激发和维护学生的 积极利用信息技术进行持续学习和科学探索,形成积极学习和利用信息技术、参与信息活动的态度。练习和总结信息获取的基本方法,能够以一定的方式有效、准确地获取信息。【要点与难点】要点:保存网页内容和使用采集夹要点:整理采集夹 【教学方法】 任务驱动,讲课,演示,探索 地点在哪里?互联网是世界上最大的信息库,我们可以从中获取各种信息。如何访问和保存互联网上的信息?认真听课,积极思考题型介绍,
<p>2008年的新班是每个中国人都期待的日子,因为奥运会将在我国举行。作为一个中国人,你应该知道一些关于2008年奥运会的基本信息。下面我们将通过互联网浏览和获取它们。关于它的信息。访问和浏览网站 如果要在网上获取信息,首先要输入对应的网站,输入网站的方法: 打开IE,输入 查看全部
浏览器抓取网页(因特网上信息的浏览与获取【教材分析】-乐题库)
《互联网信息获取与浏览》由会员共享,可在线阅读。更多《互联网信息获取与浏览(4页珍藏版)》,请在人人图书馆在线搜索。
在互联网上浏览和获取信息 [教科书分析] 互联网是一个巨大的资源库。本课程的中心是使用互联网获取所需的信息。因此,掌握通过互联网获取信息的基本技能是学生学习和实践的主要技能。本节内容与其他学科密切相关,可以成为其他学科丰富的学习资源和拓展学习内容的支点。如何有效地进行学科间的融合,促进信息素养的发展,值得教师在本课程的教学过程中不断的实践和探索。【学生分析】很多学生在初中就接触到了网络知识,并基本掌握了IE和网页浏览的使用。只有少数学生没有学过。因此,应针对不同层次的学生开设这门课。任务 设置应合理,考虑到所有学生。【教学目标】1.掌握网页浏览方法的知识和技能;学会保存有用的网络资源;掌握采集夹的使用。2.过程和方法培养学生获取和处理信息并利用所得信息解决实际问题的能力。3.情感态度与价值观 通过获取2008年北京奥运会的信息,让学生感受祖国的力量,增强爱国热情;激发和维护学生的 积极利用信息技术进行持续学习和科学探索,形成积极学习和利用信息技术、参与信息活动的态度。练习和总结信息获取的基本方法,能够以一定的方式有效、准确地获取信息。【要点与难点】要点:保存网页内容和使用采集夹要点:整理采集夹 【教学方法】 任务驱动,讲课,演示,探索 地点在哪里?互联网是世界上最大的信息库,我们可以从中获取各种信息。如何访问和保存互联网上的信息?认真听课,积极思考题型介绍,
<p>2008年的新班是每个中国人都期待的日子,因为奥运会将在我国举行。作为一个中国人,你应该知道一些关于2008年奥运会的基本信息。下面我们将通过互联网浏览和获取它们。关于它的信息。访问和浏览网站 如果要在网上获取信息,首先要输入对应的网站,输入网站的方法: 打开IE,输入
浏览器抓取网页(浏览器抓取网页的iframe包含的http头部与服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-28 14:02
浏览器抓取网页的iframe包含的http头部与服务器响应处理头部就是这样。web开发者还是要勤快一点,看看我的主页,web开发者工具里抓取的还是很准的,每个标签是否是http头部都有。现在http连接结束了就不能抓取http头部了。另外也许你的抓取一定有效,但是你在python抓取web页面时,一定要设置好抓取过程的端口,是不是安全。
如果连接结束后端口被封。又使用了80端口,你那里浏览器访问是会报错的。记得封的是整个页面,像头部是没有封的。
写个代码而已,为什么要这么计较。
如果有80端口号,一定要分析后台的80端口处理.
采用nodejs。
额...先查一下cookie头
这样封,
cookie
这么说吧,每次看qq的服务器,一般都是不一样的,比如,12345678,
一般是一个http状态码来对应的。
0、30
2、40
3、50
0、40
3、60
0、700这些。这里要注意,如果这个http状态码是3,你用户能看到所有的报文,但看不到所有的http请求,这个其实也无所谓,毕竟能看到请求头报文。就算看不到,服务器还能能看到,看不到给你报数据库单身的header呗。 查看全部
浏览器抓取网页(浏览器抓取网页的iframe包含的http头部与服务器)
浏览器抓取网页的iframe包含的http头部与服务器响应处理头部就是这样。web开发者还是要勤快一点,看看我的主页,web开发者工具里抓取的还是很准的,每个标签是否是http头部都有。现在http连接结束了就不能抓取http头部了。另外也许你的抓取一定有效,但是你在python抓取web页面时,一定要设置好抓取过程的端口,是不是安全。
如果连接结束后端口被封。又使用了80端口,你那里浏览器访问是会报错的。记得封的是整个页面,像头部是没有封的。
写个代码而已,为什么要这么计较。
如果有80端口号,一定要分析后台的80端口处理.
采用nodejs。
额...先查一下cookie头
这样封,
cookie
这么说吧,每次看qq的服务器,一般都是不一样的,比如,12345678,
一般是一个http状态码来对应的。
0、30
2、40
3、50
0、40
3、60
0、700这些。这里要注意,如果这个http状态码是3,你用户能看到所有的报文,但看不到所有的http请求,这个其实也无所谓,毕竟能看到请求头报文。就算看不到,服务器还能能看到,看不到给你报数据库单身的header呗。
浏览器抓取网页(浏览器抓取网页也不是很简单的,你得使用其他的抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-28 13:04
浏览器抓取网页也不是很简单的,你得使用其他的抓取方法。
1、首先你要先安装nodejs的模块。
2、然后在浏览器搜索相关的插件,比如说:登录、登陆提示、支付宝登录、红包,用他们来代替就可以了。网上都有的。
3、安装完毕之后,开始使用nodejs模块的post。
建议先学习javascript,
mongodb并没有特定的语言,
这是三种不同的语言,mongodbredis都不适合直接抓取登录这个动作,其中redis更接近nosql数据库,可以满足单个人登录,密码查询,红包提取,
第一次被邀请,你们不要在评论里卖萌,谢谢。再次谢谢。 查看全部
浏览器抓取网页(浏览器抓取网页也不是很简单的,你得使用其他的抓取方法)
浏览器抓取网页也不是很简单的,你得使用其他的抓取方法。
1、首先你要先安装nodejs的模块。
2、然后在浏览器搜索相关的插件,比如说:登录、登陆提示、支付宝登录、红包,用他们来代替就可以了。网上都有的。
3、安装完毕之后,开始使用nodejs模块的post。
建议先学习javascript,
mongodb并没有特定的语言,
这是三种不同的语言,mongodbredis都不适合直接抓取登录这个动作,其中redis更接近nosql数据库,可以满足单个人登录,密码查询,红包提取,
第一次被邀请,你们不要在评论里卖萌,谢谢。再次谢谢。
浏览器抓取网页(跨站攻击的主要原因是什么?DOM型的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-25 18:05
内容
跨站脚本
xss:跨站脚本攻击,无需做任何登录认证,通过合法操作(如在url输入,在评论框输入),将脚本程序注入你的页面或攻击者在网页中插入恶意脚本当用户浏览页面时,会执行嵌入在Web中的脚本代码,从而达到恶意攻击用户的目的。
攻击条件
将恶意代码注入网页
这些恶意代码可以被浏览器成功执行
攻击原理
xss漏洞的主要原因是程序对输入输出的控制不够严格,导致“构造良好”的脚本输入,在输入到前端,造成伤害。
xss 漏洞可用于进行网络钓鱼攻击、获取键盘记录、用户 cookie 等。
攻击方式
反射型xss、存储型xss、DOM型xss
1、反射也称为非持久性XSS
交互数据一般不存储在数据库中。它是一次性的,所见即所得,通常出现在查询页面上。
2、Store 也称为持久性 XSS
互动数据会被存入数据库,永久保存,一般会出现在留言板、注册等页面。
3、DOM 类型
不与后台服务器交互是前端代码通过DOM操作输出时出现的问题,也是一次性反射类型。
危害:存储 > 反射 > DOM
DOM 类型
网站 页面中有很多元素。当页面到达浏览器时,浏览器会为页面创建一个顶级的Document Object,然后生成各种子文档对象。每个页面元素对应一个文档对象。文档对象收录属性、方法和事件。客户端脚本程序可以通过DOM动态修改页面内容,从客户端获取DOM中的数据并在本地执行。由于 DOM 在客户端修改节点,基于 DOM 的 XSS 漏洞不需要与服务器交互,仅在客户端处理数据时发生。
攻击方式:用户请求一个特制的URL,由攻击者提交,收录XSS代码。服务器的响应不会收录任何形式的攻击者脚本。当用户的浏览器处理这个响应时,DOM 对象会处理 XSS 代码,从而导致 XSS 漏洞。
原文链接:
因为 JS 触发的 XSS 是 DOM 类型的 XSS,一般来说 DOM 类型的 XSS 是反射性的,很少存储。
如果插入XSS,一般是动态页面,但也有一些是静态页面,不会和数据库交互,大大提高了安全性,也让我们很难进行XSS。考虑到这一点,许多开发人员还假装是动态页面。把它做成静态页面,这种页面叫做:伪静态页面;
控制台输入 document.lastModified 以区分动态和伪静态页面。如果时间总是新的,那么它是动态的或伪静态的。如果时间不变,那就是静态的,不需要xss。
xss漏洞预防
这三种类型的 XSS 漏洞都可以通过过滤或编码来修复。
• 反射型XSS和存储型XSS可以在服务器端对用户输入输出的内容进行过滤和编码,过滤关键字,对关键符号进行编码。所有特殊符号如 , ” , ' , = 都可以通过实体编码或百分比编码来修复。
• 如果DOM类型的XSS与服务器交互,可以参考以上方法修复。如果不与服务器交互,则可以使用 JavaScript 等客户端脚本语言在客户端进行编码和过滤。
• 摘要:输入被过滤,输出被转义(编码)
CSRF
csrf:跨站请求伪造,是一种强制用户对当前登录的Web应用程序进行非预期操作的攻击方法。常见的攻击方式发送csrf的连接,通过伪造请求,受害者点击后会使用受害者的身份发起请求。
CSRF攻击成功的两个必要条件
1.登录到trusted网站A并在本地生成cookies。(如果用户没有登录网站A,那么网站B在感应时请求网站A的api接口时会提示你登录),以及cookies或session未过期;
2.在没有退出A的情况下,访问危险的网站B(实际上是利用网站A的漏洞)。
这里,用户 C 生成的 cookie 保证了用户可以登录,但 网站B 却无法真正获取到 cookie。
csrf 漏洞预防
添加令牌验证(常用做法):
1、在key操作中加入token参数,token值必须是随机的,每次都不一样;关于安全会话管理(避免使用会话):1、不要在客户端存储敏感信息(如身份认证信息);
2、测试直接关闭,退出时会话过期机制;
3、设置会话过期机制,例如15分钟内无操作,自动登录超时;
门禁安全管理:
1、修改敏感信息需要二次身份认证。例如修改账号时,需要确定旧密码;
2、敏感信息的修改使用post代替get;
3、通过http头中的referer限制原创页面,并添加验证码:一般用于登录(防暴力破解),也可用于表单中进行其他重要信息操作(可用性需要考虑)
SSRF
ssrf:服务器请求伪造,由攻击者构造,形成由服务器发起请求的安全漏洞。一般来说,ssrf 攻击的目标是外部世界无法访问的内部系统。对目标地址没有过滤和限制,该功能被恶意使用,有缺陷的Web应用程序可以作为代理攻击远程和本地服务器。
ssrf 危害
1、可以对外部服务器所在的内网和本地进行端口扫描,获取部分服务的banner信息。
2、攻击在内网或本地运行的应用程序。
3、通过访问默认文件对内网web应用(检测为php、asp、jsp等)进行指纹识别。
4、攻击网络内外的 Web 应用程序。sql注入、struct2、 redis等
5、使用文件协议读取本地文件等
ssrf 漏洞预防
1. 统一错误信息,防止用户根据错误信息判断远程服务器端口状态
2. 将请求端口限制为常见的HTTP端口,如80、443、8080、8088等。
3. 黑名单内网 IP。
4.禁用不必要的协议,只允许HTTP和HTTPS。(不允许文件协议等) 查看全部
浏览器抓取网页(跨站攻击的主要原因是什么?DOM型的区别)
内容
跨站脚本
xss:跨站脚本攻击,无需做任何登录认证,通过合法操作(如在url输入,在评论框输入),将脚本程序注入你的页面或攻击者在网页中插入恶意脚本当用户浏览页面时,会执行嵌入在Web中的脚本代码,从而达到恶意攻击用户的目的。
攻击条件
将恶意代码注入网页
这些恶意代码可以被浏览器成功执行
攻击原理
xss漏洞的主要原因是程序对输入输出的控制不够严格,导致“构造良好”的脚本输入,在输入到前端,造成伤害。
xss 漏洞可用于进行网络钓鱼攻击、获取键盘记录、用户 cookie 等。
攻击方式
反射型xss、存储型xss、DOM型xss
1、反射也称为非持久性XSS
交互数据一般不存储在数据库中。它是一次性的,所见即所得,通常出现在查询页面上。
2、Store 也称为持久性 XSS
互动数据会被存入数据库,永久保存,一般会出现在留言板、注册等页面。
3、DOM 类型
不与后台服务器交互是前端代码通过DOM操作输出时出现的问题,也是一次性反射类型。
危害:存储 > 反射 > DOM
DOM 类型
网站 页面中有很多元素。当页面到达浏览器时,浏览器会为页面创建一个顶级的Document Object,然后生成各种子文档对象。每个页面元素对应一个文档对象。文档对象收录属性、方法和事件。客户端脚本程序可以通过DOM动态修改页面内容,从客户端获取DOM中的数据并在本地执行。由于 DOM 在客户端修改节点,基于 DOM 的 XSS 漏洞不需要与服务器交互,仅在客户端处理数据时发生。
攻击方式:用户请求一个特制的URL,由攻击者提交,收录XSS代码。服务器的响应不会收录任何形式的攻击者脚本。当用户的浏览器处理这个响应时,DOM 对象会处理 XSS 代码,从而导致 XSS 漏洞。
原文链接:
因为 JS 触发的 XSS 是 DOM 类型的 XSS,一般来说 DOM 类型的 XSS 是反射性的,很少存储。
如果插入XSS,一般是动态页面,但也有一些是静态页面,不会和数据库交互,大大提高了安全性,也让我们很难进行XSS。考虑到这一点,许多开发人员还假装是动态页面。把它做成静态页面,这种页面叫做:伪静态页面;
控制台输入 document.lastModified 以区分动态和伪静态页面。如果时间总是新的,那么它是动态的或伪静态的。如果时间不变,那就是静态的,不需要xss。
xss漏洞预防
这三种类型的 XSS 漏洞都可以通过过滤或编码来修复。
• 反射型XSS和存储型XSS可以在服务器端对用户输入输出的内容进行过滤和编码,过滤关键字,对关键符号进行编码。所有特殊符号如 , ” , ' , = 都可以通过实体编码或百分比编码来修复。
• 如果DOM类型的XSS与服务器交互,可以参考以上方法修复。如果不与服务器交互,则可以使用 JavaScript 等客户端脚本语言在客户端进行编码和过滤。
• 摘要:输入被过滤,输出被转义(编码)
CSRF
csrf:跨站请求伪造,是一种强制用户对当前登录的Web应用程序进行非预期操作的攻击方法。常见的攻击方式发送csrf的连接,通过伪造请求,受害者点击后会使用受害者的身份发起请求。
CSRF攻击成功的两个必要条件
1.登录到trusted网站A并在本地生成cookies。(如果用户没有登录网站A,那么网站B在感应时请求网站A的api接口时会提示你登录),以及cookies或session未过期;
2.在没有退出A的情况下,访问危险的网站B(实际上是利用网站A的漏洞)。
这里,用户 C 生成的 cookie 保证了用户可以登录,但 网站B 却无法真正获取到 cookie。
csrf 漏洞预防
添加令牌验证(常用做法):
1、在key操作中加入token参数,token值必须是随机的,每次都不一样;关于安全会话管理(避免使用会话):1、不要在客户端存储敏感信息(如身份认证信息);
2、测试直接关闭,退出时会话过期机制;
3、设置会话过期机制,例如15分钟内无操作,自动登录超时;
门禁安全管理:
1、修改敏感信息需要二次身份认证。例如修改账号时,需要确定旧密码;
2、敏感信息的修改使用post代替get;
3、通过http头中的referer限制原创页面,并添加验证码:一般用于登录(防暴力破解),也可用于表单中进行其他重要信息操作(可用性需要考虑)
SSRF
ssrf:服务器请求伪造,由攻击者构造,形成由服务器发起请求的安全漏洞。一般来说,ssrf 攻击的目标是外部世界无法访问的内部系统。对目标地址没有过滤和限制,该功能被恶意使用,有缺陷的Web应用程序可以作为代理攻击远程和本地服务器。
ssrf 危害
1、可以对外部服务器所在的内网和本地进行端口扫描,获取部分服务的banner信息。
2、攻击在内网或本地运行的应用程序。
3、通过访问默认文件对内网web应用(检测为php、asp、jsp等)进行指纹识别。
4、攻击网络内外的 Web 应用程序。sql注入、struct2、 redis等
5、使用文件协议读取本地文件等
ssrf 漏洞预防
1. 统一错误信息,防止用户根据错误信息判断远程服务器端口状态
2. 将请求端口限制为常见的HTTP端口,如80、443、8080、8088等。
3. 黑名单内网 IP。
4.禁用不必要的协议,只允许HTTP和HTTPS。(不允许文件协议等)
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-02-25 17:20
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。还有一个类似selenium的风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
ͼƬ 图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
nonce: 2SSH2A # δ֪
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个submit方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JSäcookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看在加载这个网页的时候已经下载了哪些URL,我们要的数据是在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试调试JS,找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。 查看全部
浏览器抓取网页(python爬取js动态网页抓取方式(重点)(重点))
3、js动态网页爬取方法(重点)
很多情况下,爬虫检索到的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。
一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面两种方案可以用于python爬取js执行后输出的信息。
① 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。
WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js等的网页。
进口干刮
使用 dryscrape 库动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url)) # 将输出一个文本
这也适用于其他收录js的网页。虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!
但想想也是有道理的。Python调用webkit请求页面,页面加载完毕,加载js文件,让js执行,返回执行的页面,速度有点慢。
除此之外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现爬取页面的需求。
使用 selenium webdriver 可以工作,但会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url) #请求一个页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#打印html_text
返回 html_text
get_text_line(get_url_dynamic2(url)) # 将输出一个文本
可以看作是治标不治本。还有一个类似selenium的风车,感觉稍微复杂一些,这里就不赘述了。
4、解析js(强调)
我们的爬虫每次只有一个请求,但实际上很多请求是和js一起发送的,所以我们需要使用爬虫解析js来实现这些请求的发送。
网页中的参数主要有四种来源:
固定值,html写的参数
用户给定的参数
服务器返回的参数(通过ajax),例如时间戳、token等。
js生成参数
这里主要介绍解析js、破解加密方式或者生成参数值的方法。python代码模拟这个方法来获取我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们所需要的。通过比较多个请求中的参数,再加上一些经验和猜测,我们可以过滤掉固定参数或者服务器自带的参数和用户输入的参数。
这是js生成的剩余值或加密值;
得到的最终值:
ͼƬ 图片编号:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
用户名:
苏:cXdlcnRxd3Jl
nonce: 2SSH2A # δ֪
密码:
SP:e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28ee897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果需要模拟登录,就需要找到这种加密方式,用它来加密我们的数据。
1)找到需要的js
要找到加密方法,首先我们需要找到登录所需的js代码,我们可以使用以下3种方法:
① 查找事件;在页面中查看目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;在Network中的列表界面点击对应的Initiator,跳转到对应的js界面;
③ 通过搜索参数名称定位;
2)登录js代码
3)在这个submit方法上断点,然后输入用户名和密码,先不要登录,回到开发工具点击这个按钮开启调试。
4)然后点击登录按钮,就可以开始调试了;
5)一边一步步执行代码,一边观察我们输入的参数。变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
导入base64
a = “aaaaaaaaaaaa” # 输入用户名
print(base64.b64encode(a.encode())) #得到的加密结果:b'YWFhYWFhYWFhYWFh'
如果用户名中收录@等特殊符号,需要先用parse.quote()进行转义
得到的加密结果与网页上js的执行结果一致;
5、爬虫遇到的JS反爬技术(重点)
1)JSäcookie
requests请求的网页是一对JS,和浏览器查看的网页源代码完全不同。在这种情况下,浏览器经常会运行这个 JS 来生成一个(或多个)cookie,然后拿这个 cookie 来做第二次请求。
这个过程可以在浏览器(chrome和Firefox)中看到,先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox是“Persist logs"),刷新网页,可以看到历史网络请求记录。
第一次打开“index.html”页面时,返回521,内容为一段JS代码;
第二次请求此页面时,您将获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实它是由JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密ajax请求参数
抓取某个网页中的数据,发现该网页的源码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开Network窗口,刷新网页看看在加载这个网页的时候已经下载了哪些URL,我们要的数据是在一个URL请求的结果中。
Chrome 的 Network 中的这些 URL 大部分都是 XHR,我们可以通过观察它们的“Response”来找到我们想要的数据。
我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于这样的加密参数,可以尝试调试JS,找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
3)JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站增加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。
无论我们点击多少次继续运行,它总是在这个“调试器”中,每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用.
这个“调试器”让我们无法调试JS,但是当F12窗口关闭时,网页正常加载。
解决方法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
4)JS 发送鼠标点击事件
有的网站它的反爬不是上面的方法,可以从浏览器打开正常的页面,但是requests中会要求你输入验证码或者重定向其他网页。
您可以尝试从“网络”中查看,例如以下网络流中的信息:
仔细一看,你会发现每次点击页面上的链接,都会发出一个“cl.gif”请求,看起来是下载gif图片,其实不是。
它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先按照它的逻辑:
JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
很容易理解其中的逻辑!
解决方案:在访问链接之前访问 cl.gif。关键是研究cl.gif后的参数。带上这些参数问题不大,这样就可以绕过这个反爬策略了。
浏览器抓取网页(绕开网站的反爬机制获取正确的页面是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-24 13:25
)
在编写爬虫的过程中,有的网站会设置反爬机制,拒绝响应非浏览器访问;或者短时间内频繁爬取会触发网站的反爬机制,导致IP被阻塞无法爬取网页。这需要修改爬虫中的请求头来伪装浏览器访问,或者使用代理发起请求。从而绕过网站的反爬机制来获取正确的页面。
本文使用python3.6、常用的request库requests和自动化测试库selenium来使用浏览器。
这两个库的使用可以参考官方文档或者我的另一篇博客:如何通过python爬虫获取网页的html内容并下载附件。
1、requests 伪装头发送请求
在requests发送的请求的request header中,User-Agent会被识别为python程序发送的请求,如下图:
import requests
url = 'https://httpbin.org/headers'
response = requests.get(url)
if response.status_code == 200:
print(response.text)
返回结果:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.20.1"
}
}
注意:是一个开源的网站,用于测试网页请求,比如上面的/headers链接,会返回发送请求的请求头。详情请参考其官网。
User-Agent:User-Agent(英文:用户代理)是指由软件代理提供的代表用户行为的自身标识符。用于识别浏览器类型和版本、操作系统和版本、浏览器内核和其他信息的标识符。有关详细信息,请参阅 Wikipedia 条目:用户代理
对于反爬网站,它会识别它的headers,拒绝返回正确的网页。此时,您需要将发送的请求伪装成浏览器的标头。
用浏览器打开网站,会看到如下页面,就是浏览器的headers。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-71I5qEeA-71)()]
复制上述请求头并将其传递给 requests.get() 函数以将请求伪装成浏览器。
import requests
url = 'https://httpbin.org/headers'
myheaders = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
response = requests.get(url, headers=myheaders)
if response.status_code == 200:
print(response.text)
返回的结果变为:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
应用爬虫时,可以随机切换到其他User-Agent,避免触发反爬。
2、Selenium 模拟浏览器伪装头的使用
使用自动化测试工具selenium可以模拟使用浏览器访问网站。本文使用 selenium 3.14.0 版本,支持 Chrome 和 Firefox 浏览器。要使用浏览器,需要下载相应版本的驱动程序。
驱动下载地址:
使用 webdriver 访问您自己的浏览器的标题。
from selenium import webdriver
url = 'https://httpbin.org/headers'
driver_path = '/path/to/chromedriver'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url)
print(browser.page_source)
browser.close()
打印出返回的网页代码:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
}
浏览器驱动也可以伪装User-Agent,只需在创建webdriver浏览器对象时传入设置即可:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--user-agent=%s' % user_agent)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
此时返回的 User-Agent 成为传入的设置。
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
Firefox 浏览器驱动程序的设置不同:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference("general.useragent.override", user_agent)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
3、requests 使用 ip 代理发送请求
当某个ip在短时间内被访问过于频繁时,会触发网站的反爬机制,需要输入验证码甚至屏蔽该ip来禁止访问。这时候就需要使用代理ip发起请求来获取正确的网页了。
访问该网站以查看您的 ip。
import requests
url = 'https://httpbin.org/ip'
response = requests.get(url)
print(response.text)
返回本地网络的ip:
使用代理IP类似于1中伪装headers的方式,比如现在得到一个代理IP:58.58.213.55:8888,使用如下:
import requests
proxy = {
'http': 'http://58.58.213.55:8888',
'https': 'http://58.58.213.55:8888'
}
response = requests.get('https://httpbin.org/ip', proxies=proxy)
print(response.text)
返回的是代理ip
{
"origin": "58.58.213.55, 58.58.213.55"
}
4、selenium webdriver 使用代理 ip
chrome驱动使用代理ip的方式类似于伪装成user-agent:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy = '58.58.213.55:8888'
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--proxy-server=' + proxy)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
打印结果:
{
"origin": "58.58.213.55, 58.58.213.55"
}
firefox驱动的设置略有不同,需要下载浏览器扩展close_proxy_authentication来取消代理用户认证。可以从谷歌下载,本文使用firefox 65.0.1(64位)版本,可用扩展文件为:close_proxy_authentication-1.1-sm+tb+fx .xpi。
代码显示如下:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy_ip = '58.58.213.55'
proxy_port = 8888
xpi = '/path/to/close_proxy_authentication-1.1-sm+tb+fx.xpi'
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference('network.proxy.type', 1)
profile.set_preference('network.proxy.http', proxy_ip)
profile.set_preference('network.proxy.http_port', proxy_port)
profile.set_preference('network.proxy.ssl', proxy_ip)
profile.set_preference('network.proxy.ssl_port', proxy_port)
profile.set_preference('network.proxy.no_proxies_on', 'localhost, 127.0.0.1')
profile.add_extension(xpi)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
它还打印代理 ip。
{
"origin": "58.58.213.55, 58.58.213.55"
}
转动:
查看全部
浏览器抓取网页(绕开网站的反爬机制获取正确的页面是什么?
)
在编写爬虫的过程中,有的网站会设置反爬机制,拒绝响应非浏览器访问;或者短时间内频繁爬取会触发网站的反爬机制,导致IP被阻塞无法爬取网页。这需要修改爬虫中的请求头来伪装浏览器访问,或者使用代理发起请求。从而绕过网站的反爬机制来获取正确的页面。
本文使用python3.6、常用的request库requests和自动化测试库selenium来使用浏览器。
这两个库的使用可以参考官方文档或者我的另一篇博客:如何通过python爬虫获取网页的html内容并下载附件。
1、requests 伪装头发送请求
在requests发送的请求的request header中,User-Agent会被识别为python程序发送的请求,如下图:
import requests
url = 'https://httpbin.org/headers'
response = requests.get(url)
if response.status_code == 200:
print(response.text)
返回结果:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.20.1"
}
}
注意:是一个开源的网站,用于测试网页请求,比如上面的/headers链接,会返回发送请求的请求头。详情请参考其官网。
User-Agent:User-Agent(英文:用户代理)是指由软件代理提供的代表用户行为的自身标识符。用于识别浏览器类型和版本、操作系统和版本、浏览器内核和其他信息的标识符。有关详细信息,请参阅 Wikipedia 条目:用户代理
对于反爬网站,它会识别它的headers,拒绝返回正确的网页。此时,您需要将发送的请求伪装成浏览器的标头。
用浏览器打开网站,会看到如下页面,就是浏览器的headers。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-71I5qEeA-71)()]
复制上述请求头并将其传递给 requests.get() 函数以将请求伪装成浏览器。
import requests
url = 'https://httpbin.org/headers'
myheaders = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
response = requests.get(url, headers=myheaders)
if response.status_code == 200:
print(response.text)
返回的结果变为:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "br, gzip, deflate",
"Accept-Language": "zh-cn",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
应用爬虫时,可以随机切换到其他User-Agent,避免触发反爬。
2、Selenium 模拟浏览器伪装头的使用
使用自动化测试工具selenium可以模拟使用浏览器访问网站。本文使用 selenium 3.14.0 版本,支持 Chrome 和 Firefox 浏览器。要使用浏览器,需要下载相应版本的驱动程序。
驱动下载地址:
使用 webdriver 访问您自己的浏览器的标题。
from selenium import webdriver
url = 'https://httpbin.org/headers'
driver_path = '/path/to/chromedriver'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url)
print(browser.page_source)
browser.close()
打印出返回的网页代码:
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
}
浏览器驱动也可以伪装User-Agent,只需在创建webdriver浏览器对象时传入设置即可:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--user-agent=%s' % user_agent)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
此时返回的 User-Agent 成为传入的设置。
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
}
}
Firefox 浏览器驱动程序的设置不同:
from selenium import webdriver
url = 'https://httpbin.org/headers'
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference("general.useragent.override", user_agent)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
3、requests 使用 ip 代理发送请求
当某个ip在短时间内被访问过于频繁时,会触发网站的反爬机制,需要输入验证码甚至屏蔽该ip来禁止访问。这时候就需要使用代理ip发起请求来获取正确的网页了。
访问该网站以查看您的 ip。
import requests
url = 'https://httpbin.org/ip'
response = requests.get(url)
print(response.text)
返回本地网络的ip:
使用代理IP类似于1中伪装headers的方式,比如现在得到一个代理IP:58.58.213.55:8888,使用如下:
import requests
proxy = {
'http': 'http://58.58.213.55:8888',
'https': 'http://58.58.213.55:8888'
}
response = requests.get('https://httpbin.org/ip', proxies=proxy)
print(response.text)
返回的是代理ip
{
"origin": "58.58.213.55, 58.58.213.55"
}
4、selenium webdriver 使用代理 ip
chrome驱动使用代理ip的方式类似于伪装成user-agent:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy = '58.58.213.55:8888'
driver_path = '/path/to/chromedriver'
opt = webdriver.ChromeOptions()
opt.add_argument('--proxy-server=' + proxy)
browser = webdriver.Chrome(executable_path=driver_path, options=opt)
browser.get(url)
print(browser.page_source)
browser.close()
打印结果:
{
"origin": "58.58.213.55, 58.58.213.55"
}
firefox驱动的设置略有不同,需要下载浏览器扩展close_proxy_authentication来取消代理用户认证。可以从谷歌下载,本文使用firefox 65.0.1(64位)版本,可用扩展文件为:close_proxy_authentication-1.1-sm+tb+fx .xpi。
代码显示如下:
from selenium import webdriver
url = 'https://httpbin.org/ip'
proxy_ip = '58.58.213.55'
proxy_port = 8888
xpi = '/path/to/close_proxy_authentication-1.1-sm+tb+fx.xpi'
driver_path = '/path/to/geckodriver'
profile = webdriver.FirefoxProfile()
profile.set_preference('network.proxy.type', 1)
profile.set_preference('network.proxy.http', proxy_ip)
profile.set_preference('network.proxy.http_port', proxy_port)
profile.set_preference('network.proxy.ssl', proxy_ip)
profile.set_preference('network.proxy.ssl_port', proxy_port)
profile.set_preference('network.proxy.no_proxies_on', 'localhost, 127.0.0.1')
profile.add_extension(xpi)
browser = webdriver.Firefox(executable_path=driver_path, firefox_profile=profile)
browser.get(url)
print(browser.page_source)
browser.close()
它还打印代理 ip。
{
"origin": "58.58.213.55, 58.58.213.55"
}
转动:

