抓取网页新闻(新浪搜索主页面中的输入关键词链接和计算相似度)
优采云 发布时间: 2022-02-28 01:02抓取网页新闻(新浪搜索主页面中的输入关键词链接和计算相似度)
前段时间写了一个爬虫,在新浪搜索主页面实现了输入关键词,爬取了与关键词相关的新闻的标题、发布时间、url、关键词和内容. 并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕获
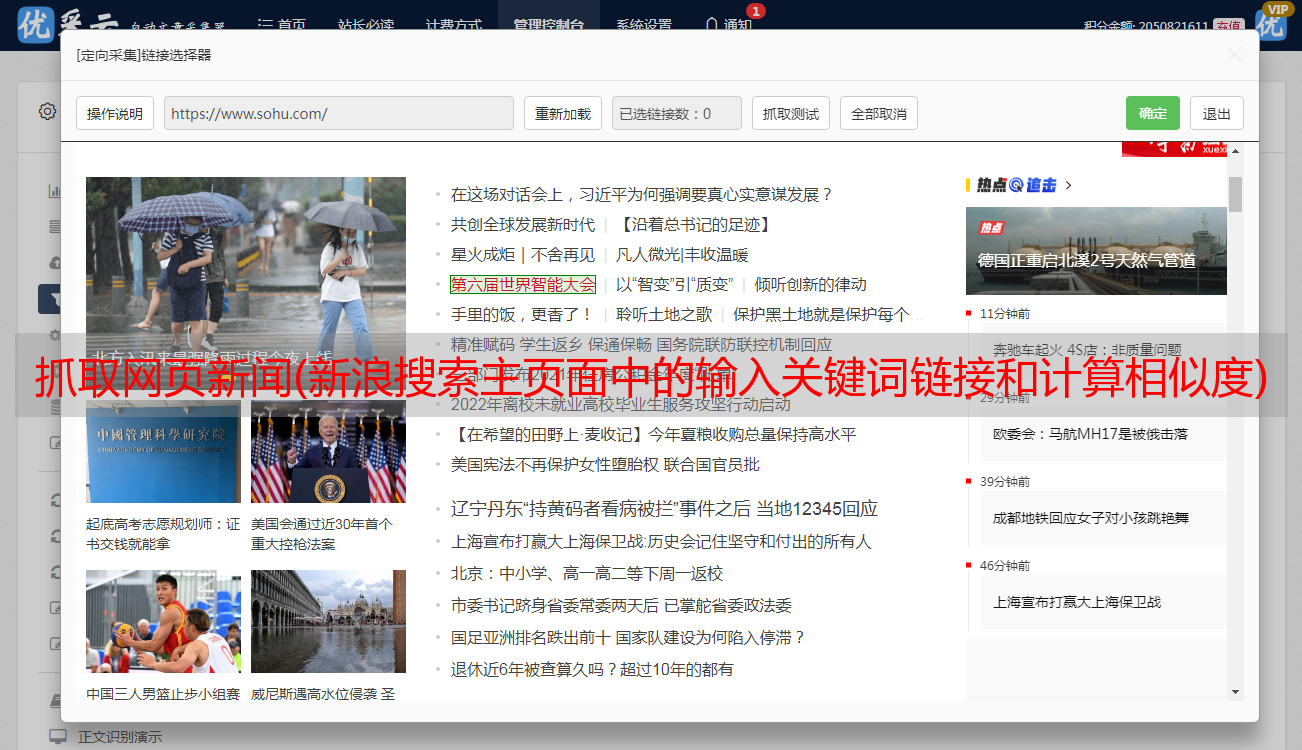
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是在没有界面的情况下使用程序来模拟浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)查找搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻有多少页。找出不同页面之间的url联系,生成翻页的url。
如上图所示,新闻界面出现“查找7651篇相关新闻文章”。使用正则匹配等方法,得到'7651',根据新浪新闻搜索页面的一页出现的新闻m个数,计算出相关新闻页数。: int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url,如上图所示,当新闻url出现时,同样的规则是“”,所以可以根据这个规则提取页面源码中的所有url .
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值为kT_W=0.8;只有标题收录输入词,相关词权重 kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码

