
从网页抓取数据
从网页抓取数据(从网上抓取数据的方法总结,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-10-10 16:34
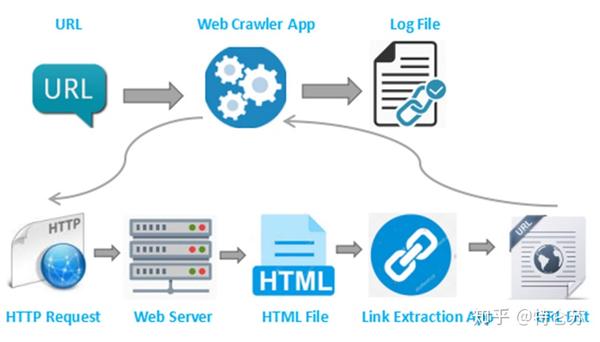
首先要知道的是,有很多方法可以从互联网上抓取数据。抓取的来源主要有两种,一种是html网页,一种是json。
从网上抓取这两个东西的时候,不用全用R,用java、php、python之类的就可以快速完成任务。问题的关键在于文档的解析。至于通过网站获取json接口,这是老手的经验。
文档对象模型
不管你使用任何语言或工具,重要的是你必须了解文档对象模型——这很重要!如果你对文档对象模型有深刻的理解,从网上抓取数据就像回家一样容易。
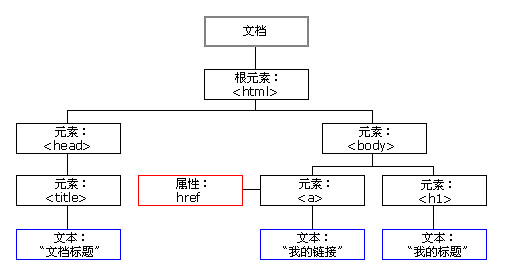
上图是对文档对象模型的直观印象。您打开的任何网页都可以转换为上图。一个文档就是一个页面,然后从根开始,一直向下细分。学过数据结构就好了,没学也没关系,你要知道的是,它是一棵“树”——如果把它倒过来,会更生动,我们总是从根 出发去寻找一些东西。例如,假设我要访问写着"text:"my link"的节点,我们需要从根元素开始,然后找到元素,然后找到元素,然后找到我们要找的节点。这些节点是路径和引导我们可以从根节点中找到我们需要的节点,路径很重要,一旦理解了就可以使用java的jsoup,或者php'
我将引用 W3School 提供的另一个示例
哈利波特
JK罗琳
2005年
29.99
这是一个xml文件,是另一种用图片表示文档的方式,如上图,它们没有什么不同。第一行规定它是一个xml文件。从一开始,它将是根节点,然后是诸如下面的节点。
那么下面,直接引用w3school的原文,里面介绍了节点的分类,类似于人类社会种族的分类,很简单:
上述 XML 文档中的节点示例:
(文档节点)
J K. Rowling(元素节点)(属性节点)
基本值(或原子值,Atomic value)基本值是一个没有父节点或子节点的节点。
基本值示例:
J K.罗琳“en”
物品
项目是基本值或节点。
节点关系
父级(Parent) 每个元素和属性都有一个父级。
在以下示例中, book 元素是 title、author、year 和 price 元素的父元素:
哈利波特 J K. 罗琳 2005
29.99
Children 元素节点可以有零个、一个或多个子节点。
在下面的例子中,title、author、year 和 price 元素都是 book 元素的子元素:
哈利波特 J K. 罗琳 2005
29.99
具有相同父节点的兄弟节点
在以下示例中,title、author、year 和 price 元素都是同级元素:
哈利波特 J K. 罗琳 2005
29.99
祖先(Ancestor)节点的父节点、父节点的父节点等等。
在以下示例中,title 元素的祖先是 book 元素和 bookstore 元素:
哈利波特 J K. 罗琳 2005
29.99
后代节点的子节点、子节点的子节点等。
在以下示例中, bookstore 的后代是 book、title、author、year 和 price 元素:
哈利波特 J K. 罗琳 2005
29.99 查看全部
从网页抓取数据(从网上抓取数据的方法总结,你知道几个?)
首先要知道的是,有很多方法可以从互联网上抓取数据。抓取的来源主要有两种,一种是html网页,一种是json。
从网上抓取这两个东西的时候,不用全用R,用java、php、python之类的就可以快速完成任务。问题的关键在于文档的解析。至于通过网站获取json接口,这是老手的经验。
文档对象模型
不管你使用任何语言或工具,重要的是你必须了解文档对象模型——这很重要!如果你对文档对象模型有深刻的理解,从网上抓取数据就像回家一样容易。
上图是对文档对象模型的直观印象。您打开的任何网页都可以转换为上图。一个文档就是一个页面,然后从根开始,一直向下细分。学过数据结构就好了,没学也没关系,你要知道的是,它是一棵“树”——如果把它倒过来,会更生动,我们总是从根 出发去寻找一些东西。例如,假设我要访问写着"text:"my link"的节点,我们需要从根元素开始,然后找到元素,然后找到元素,然后找到我们要找的节点。这些节点是路径和引导我们可以从根节点中找到我们需要的节点,路径很重要,一旦理解了就可以使用java的jsoup,或者php'
我将引用 W3School 提供的另一个示例
哈利波特
JK罗琳
2005年
29.99
这是一个xml文件,是另一种用图片表示文档的方式,如上图,它们没有什么不同。第一行规定它是一个xml文件。从一开始,它将是根节点,然后是诸如下面的节点。
那么下面,直接引用w3school的原文,里面介绍了节点的分类,类似于人类社会种族的分类,很简单:
上述 XML 文档中的节点示例:
(文档节点)
J K. Rowling(元素节点)(属性节点)
基本值(或原子值,Atomic value)基本值是一个没有父节点或子节点的节点。
基本值示例:
J K.罗琳“en”
物品
项目是基本值或节点。
节点关系
父级(Parent) 每个元素和属性都有一个父级。
在以下示例中, book 元素是 title、author、year 和 price 元素的父元素:
哈利波特 J K. 罗琳 2005
29.99
Children 元素节点可以有零个、一个或多个子节点。
在下面的例子中,title、author、year 和 price 元素都是 book 元素的子元素:
哈利波特 J K. 罗琳 2005
29.99
具有相同父节点的兄弟节点
在以下示例中,title、author、year 和 price 元素都是同级元素:
哈利波特 J K. 罗琳 2005
29.99
祖先(Ancestor)节点的父节点、父节点的父节点等等。
在以下示例中,title 元素的祖先是 book 元素和 bookstore 元素:
哈利波特 J K. 罗琳 2005
29.99
后代节点的子节点、子节点的子节点等。
在以下示例中, bookstore 的后代是 book、title、author、year 和 price 元素:
哈利波特 J K. 罗琳 2005
29.99
从网页抓取数据( 如何用PowerBI批量采集多个网页的数据(一)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-10-09 07:13
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不会再有延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论: 查看全部
从网页抓取数据(
如何用PowerBI批量采集多个网页的数据(一)?)

之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,

向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。

从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,

从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。

这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>

并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。

输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:

然后调用自定义函数,

在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。

点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,

至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不会再有延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
从网页抓取数据( Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2021-10-09 07:13
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
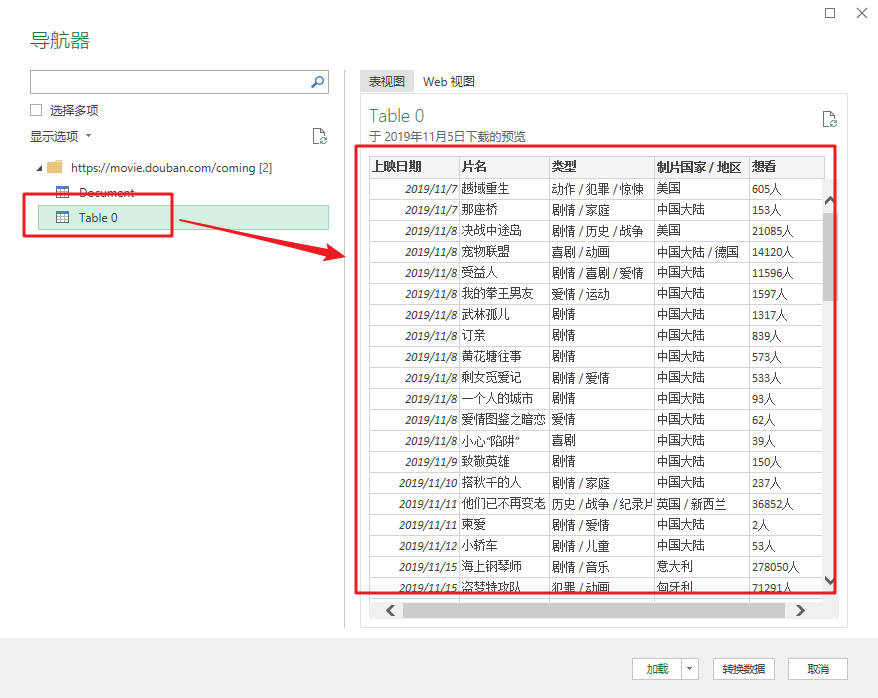
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
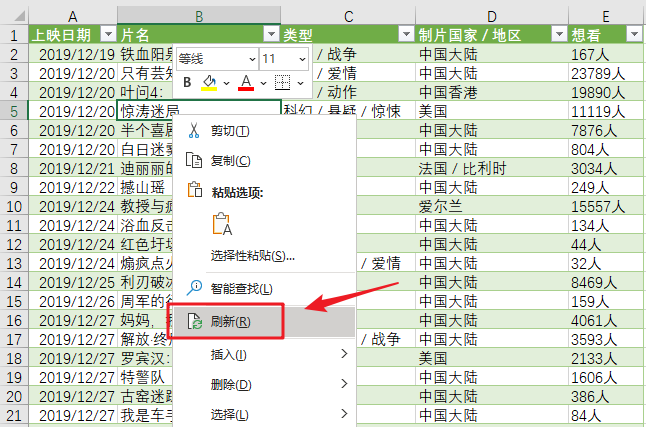
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。
方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?
这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
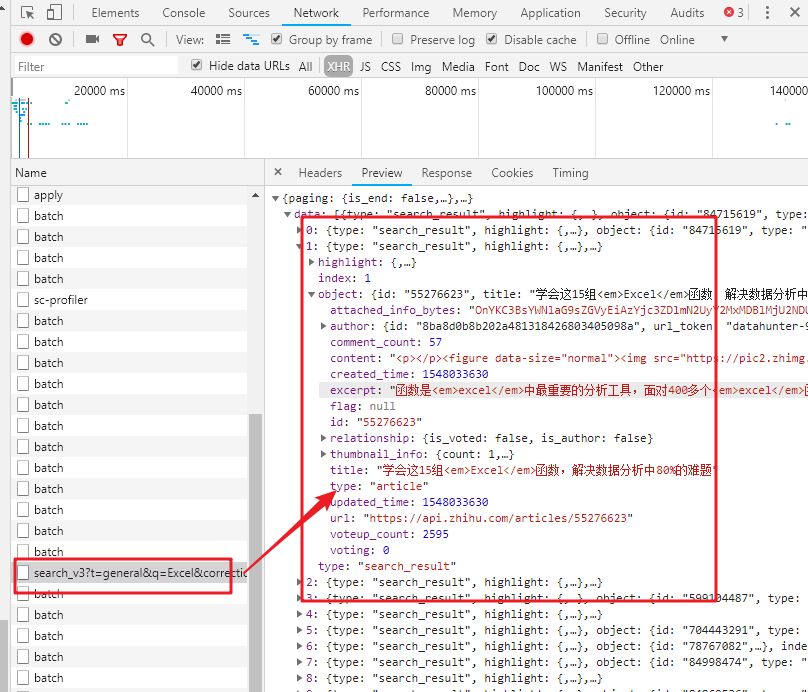
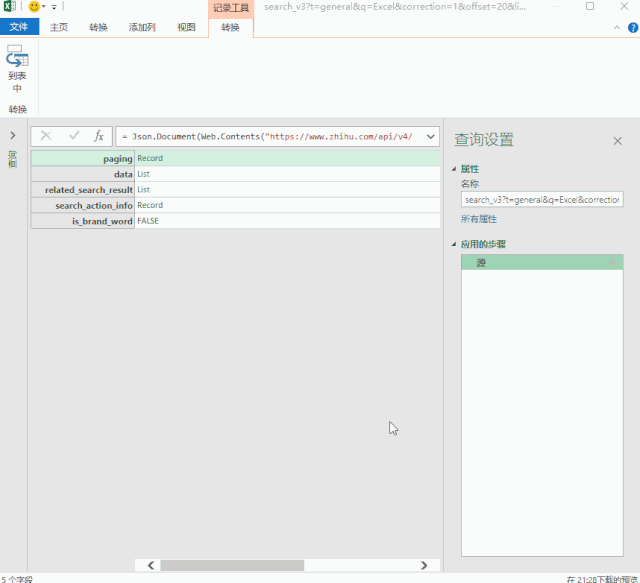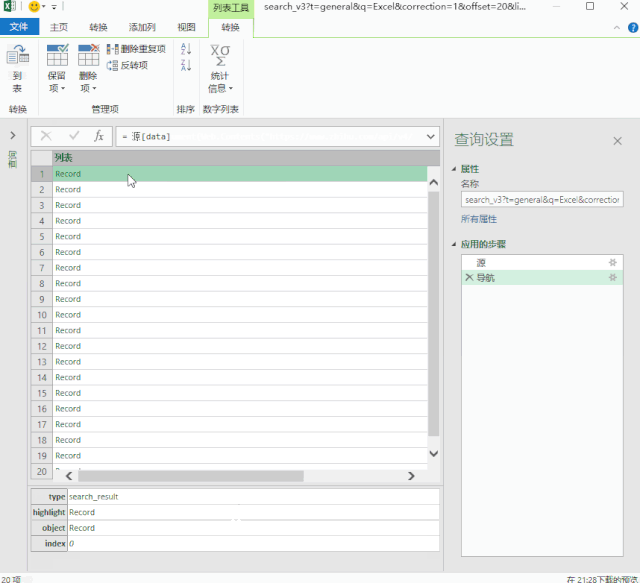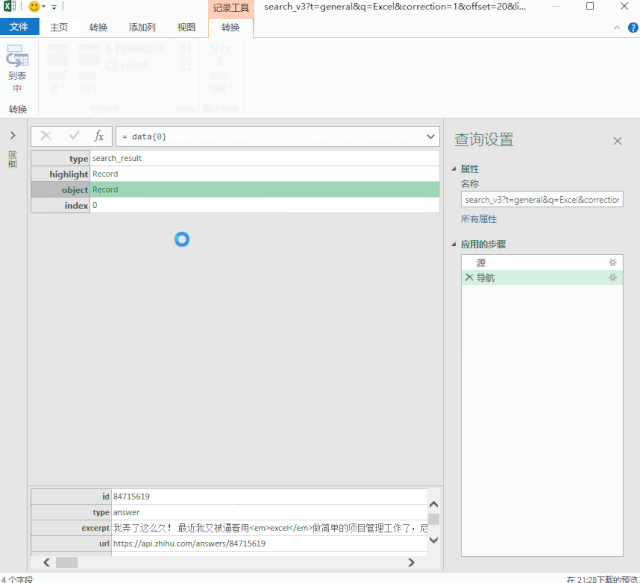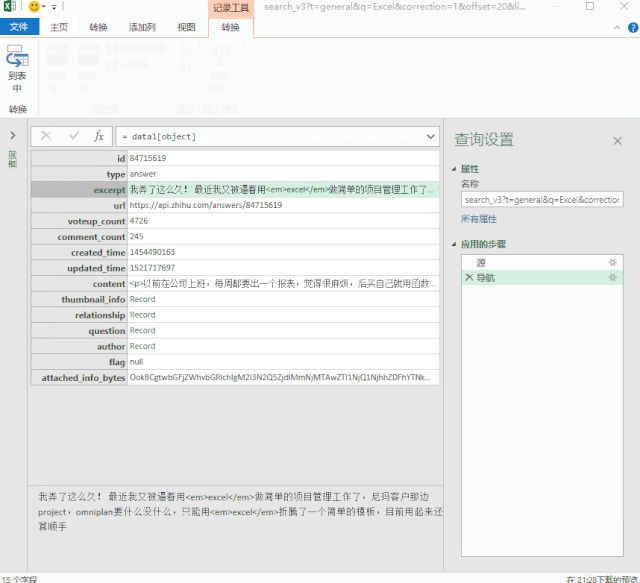
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
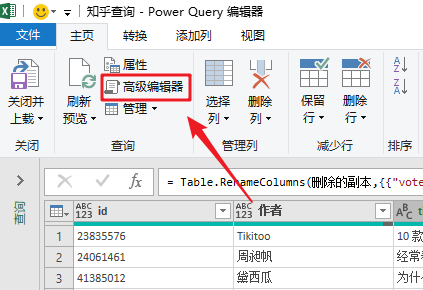
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
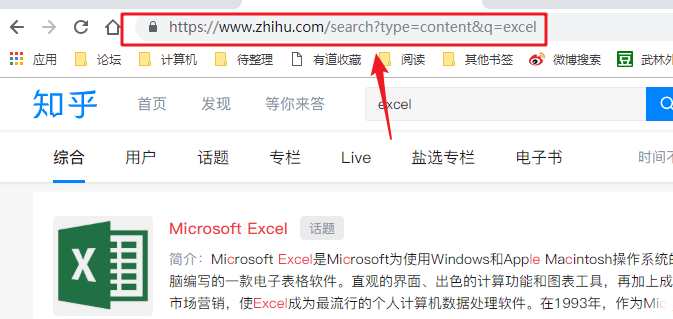
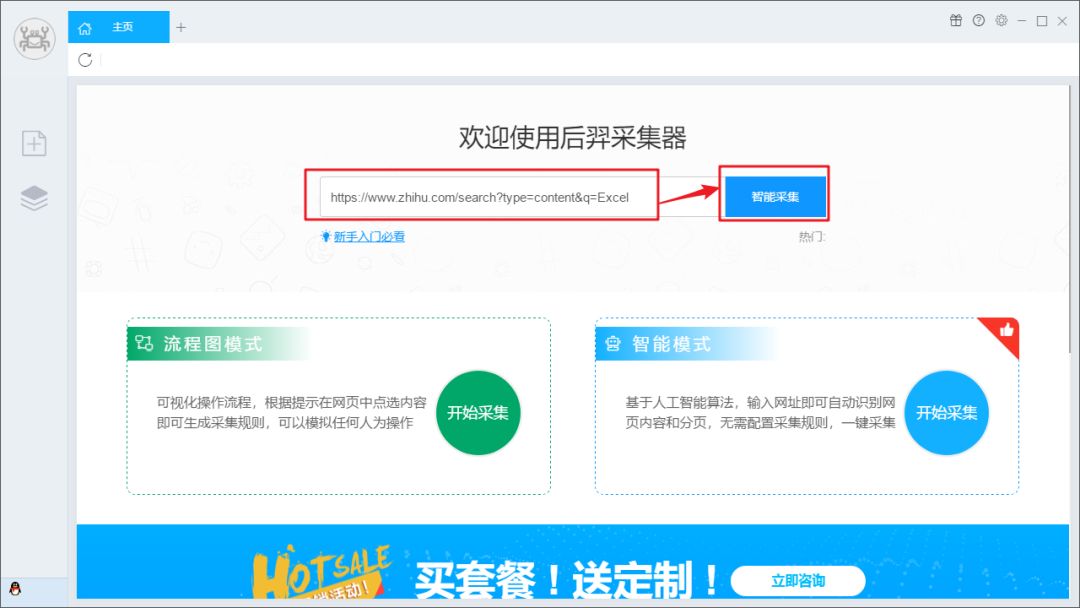
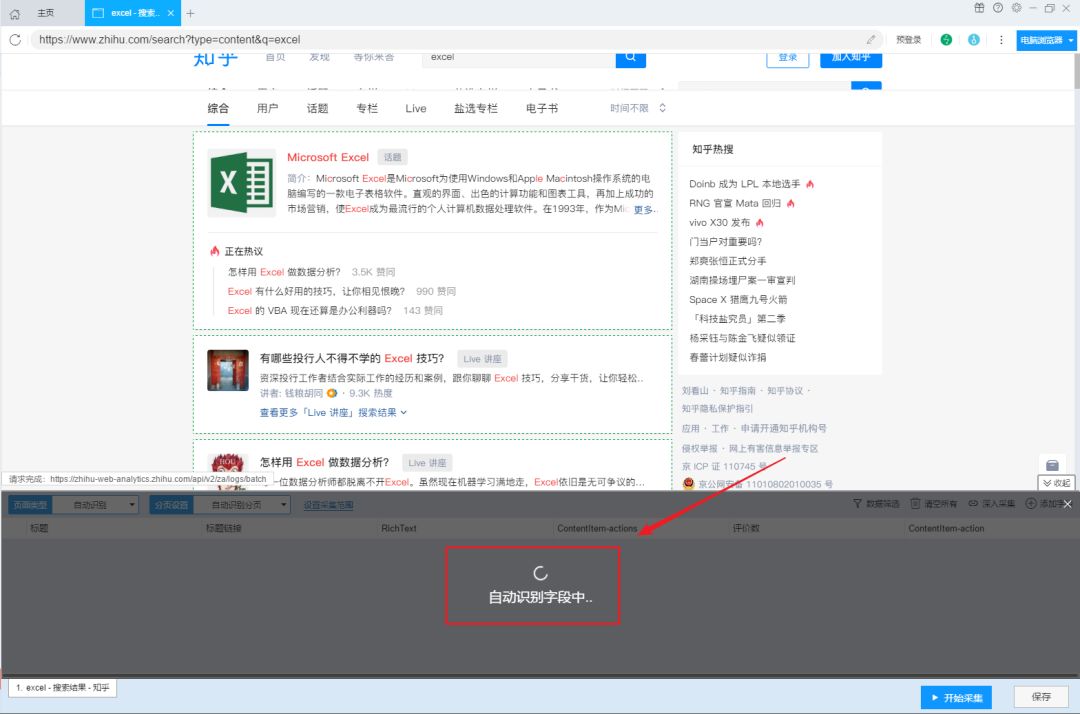
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
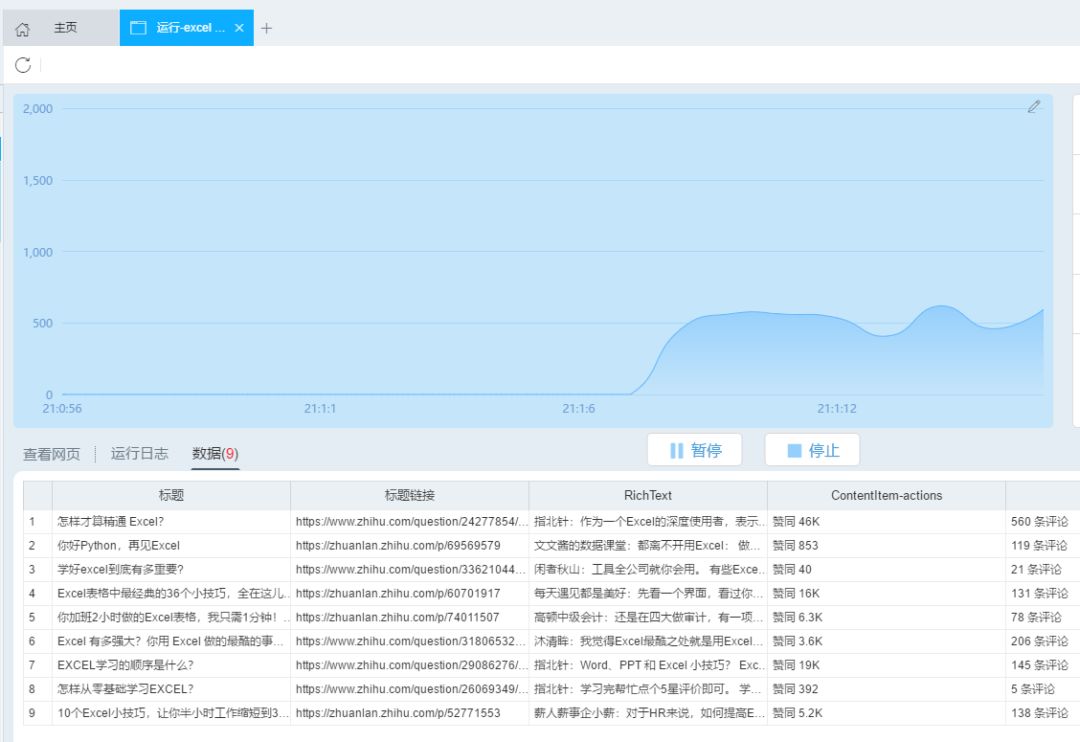
识别完成后,点击“开始采集”,开始爬取数据。
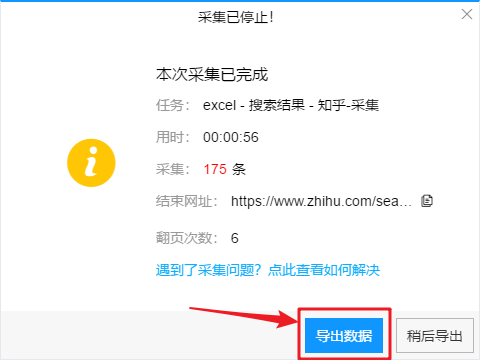
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。 查看全部
从网页抓取数据(
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)

今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
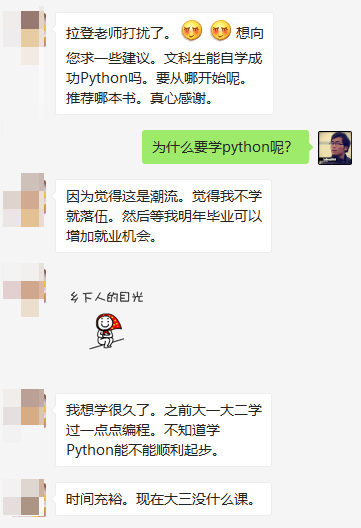
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。

今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?

方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
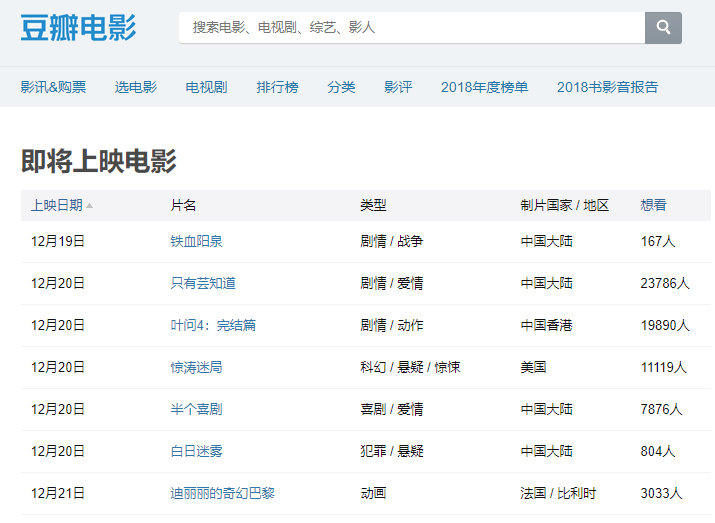
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
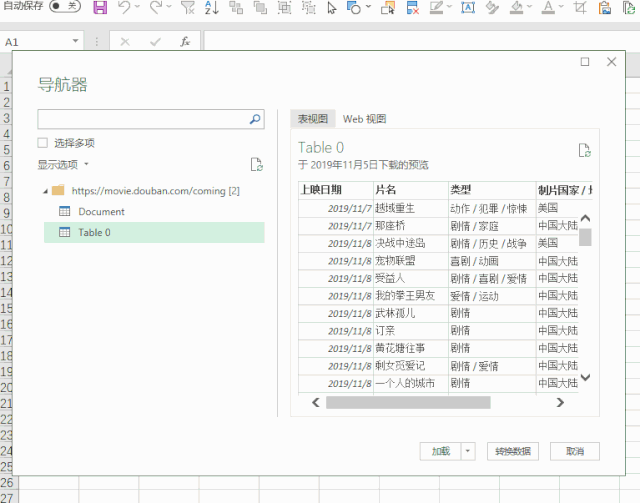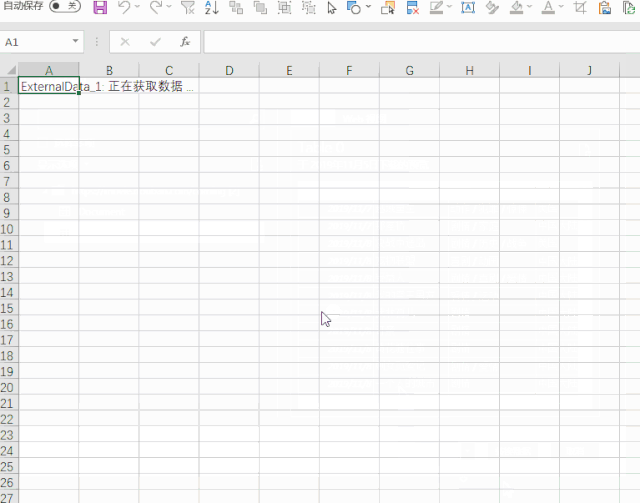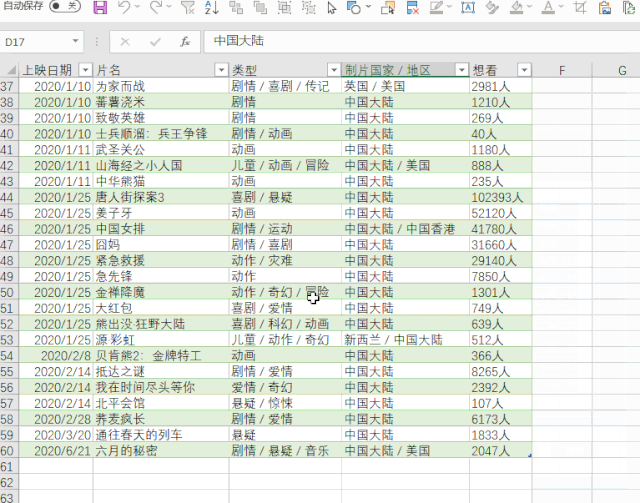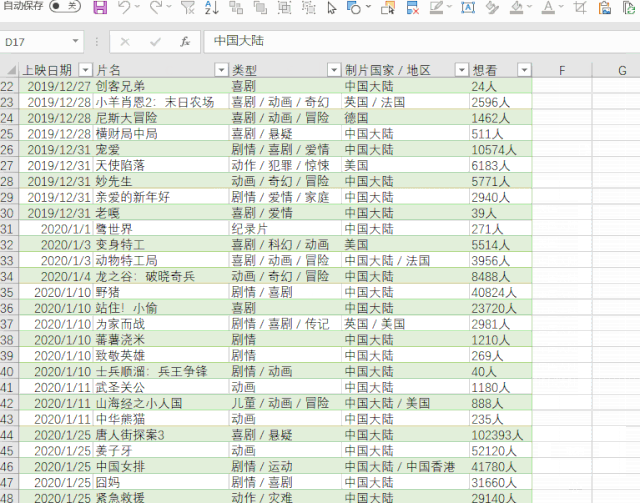
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
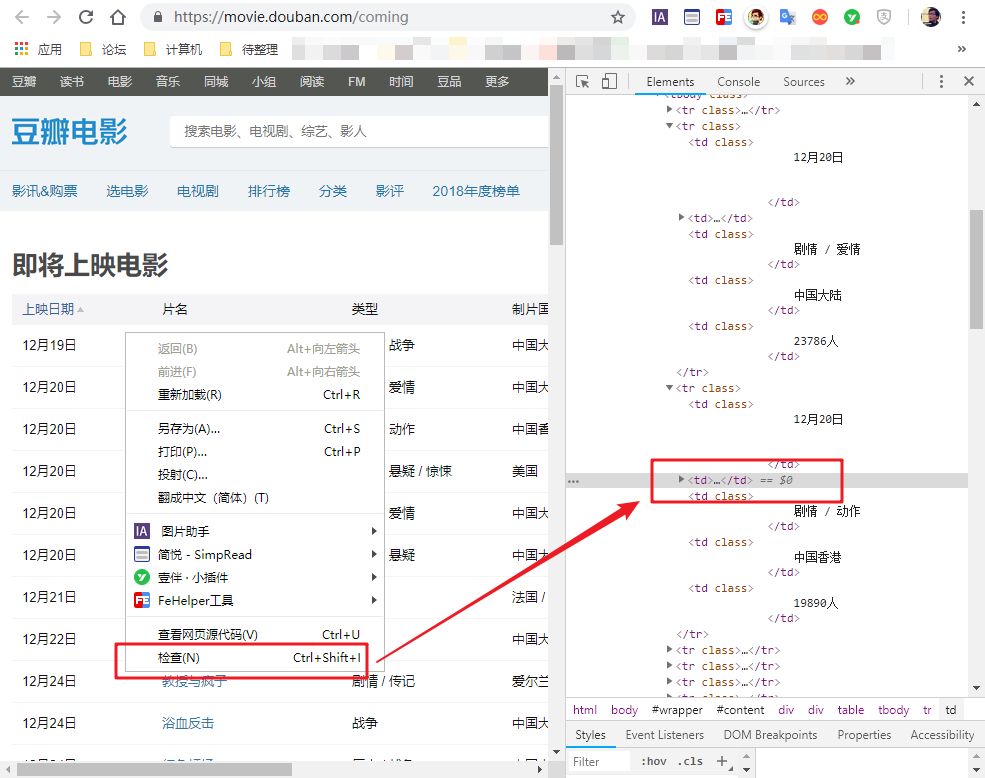
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。

方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?

这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。

然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
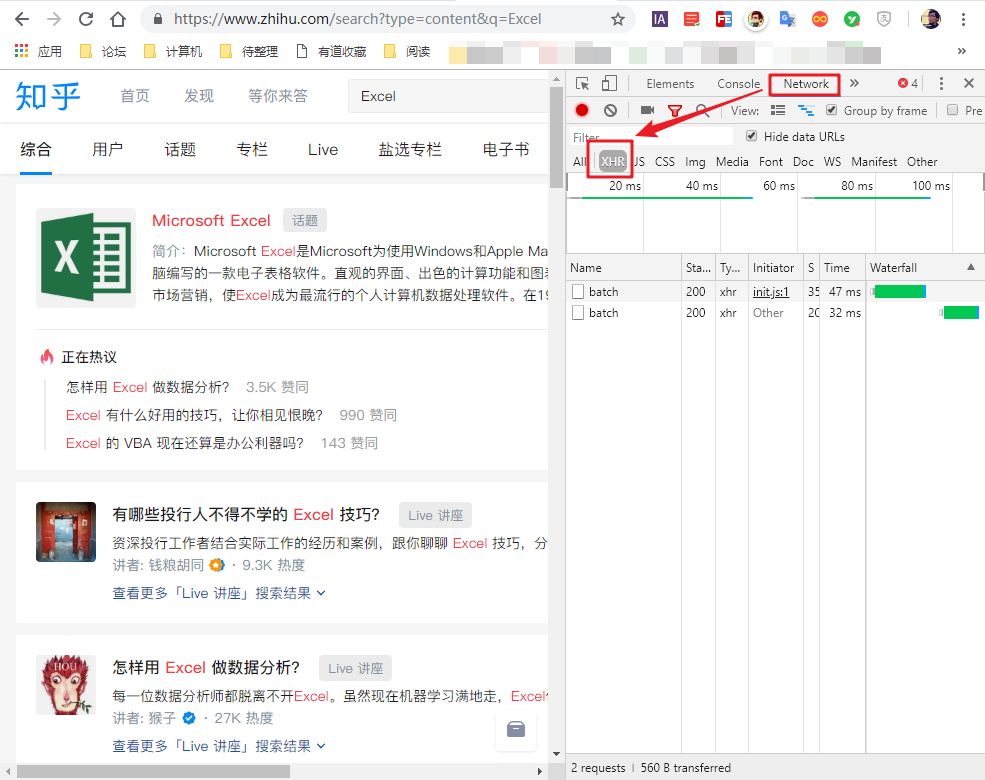
尝试在知乎中搜索“Excel”,可以看到数据传输。
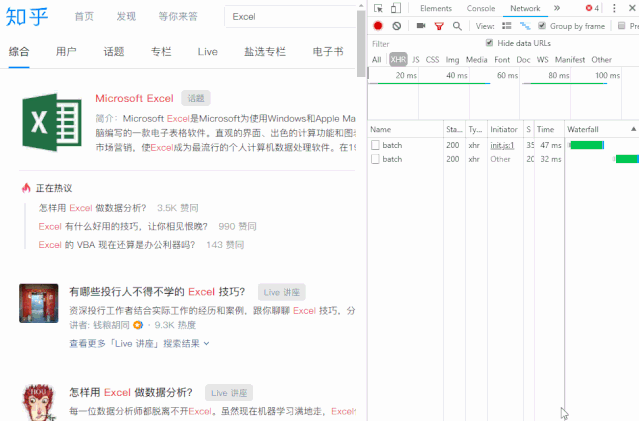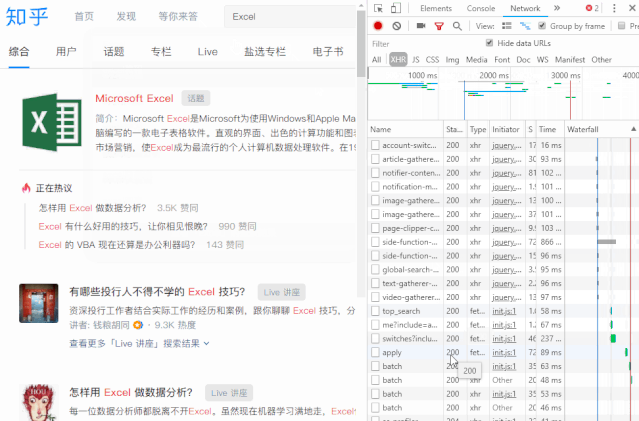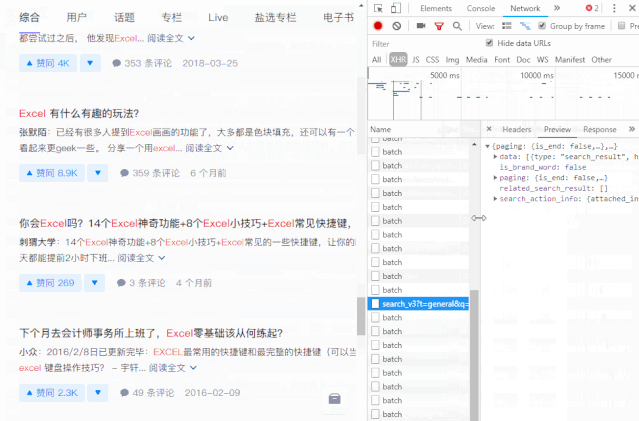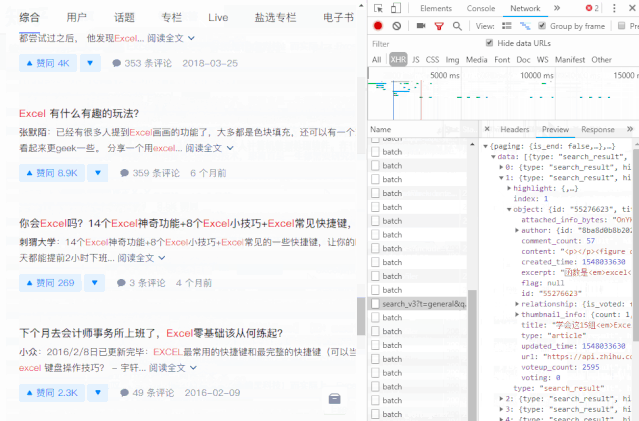
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
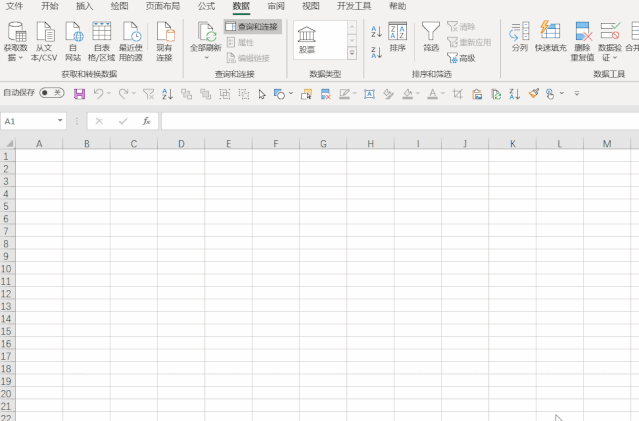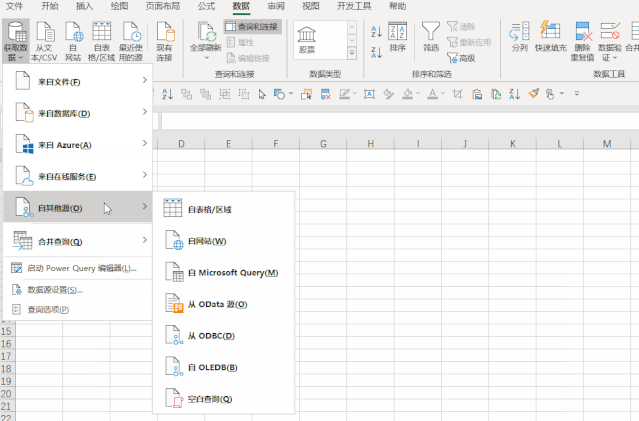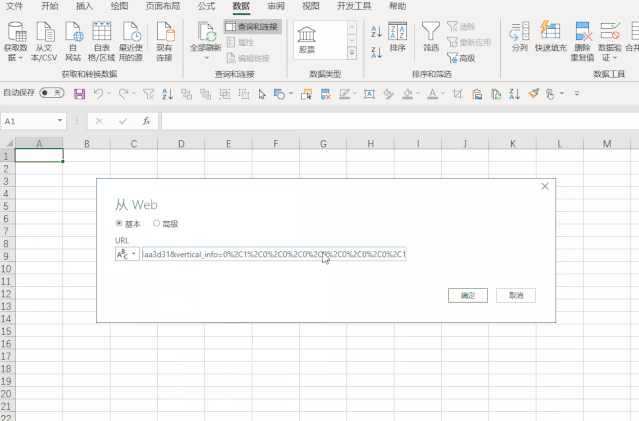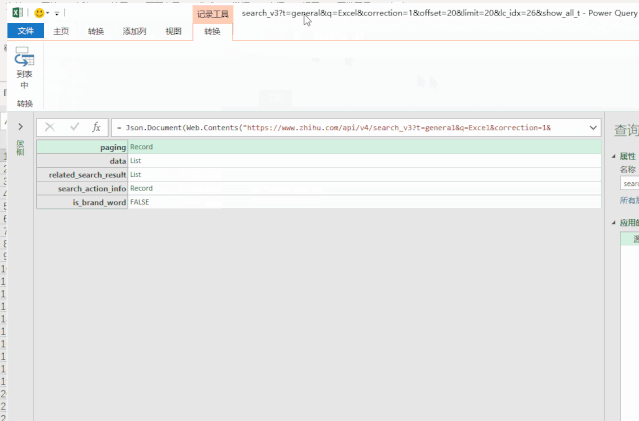
单击确定后,您将进入 Power Query 界面。
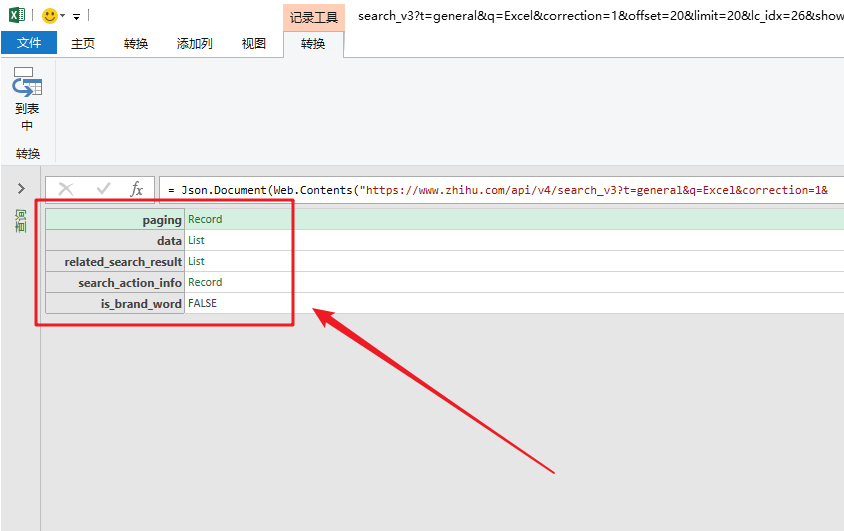
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
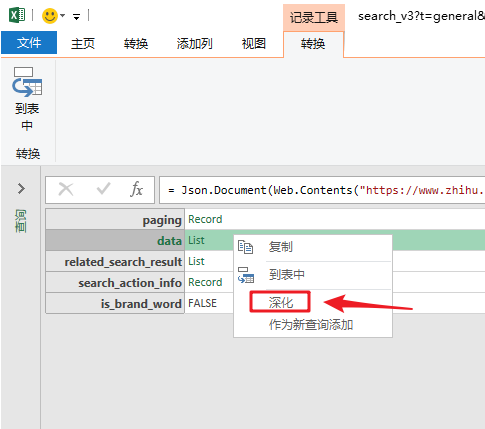
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
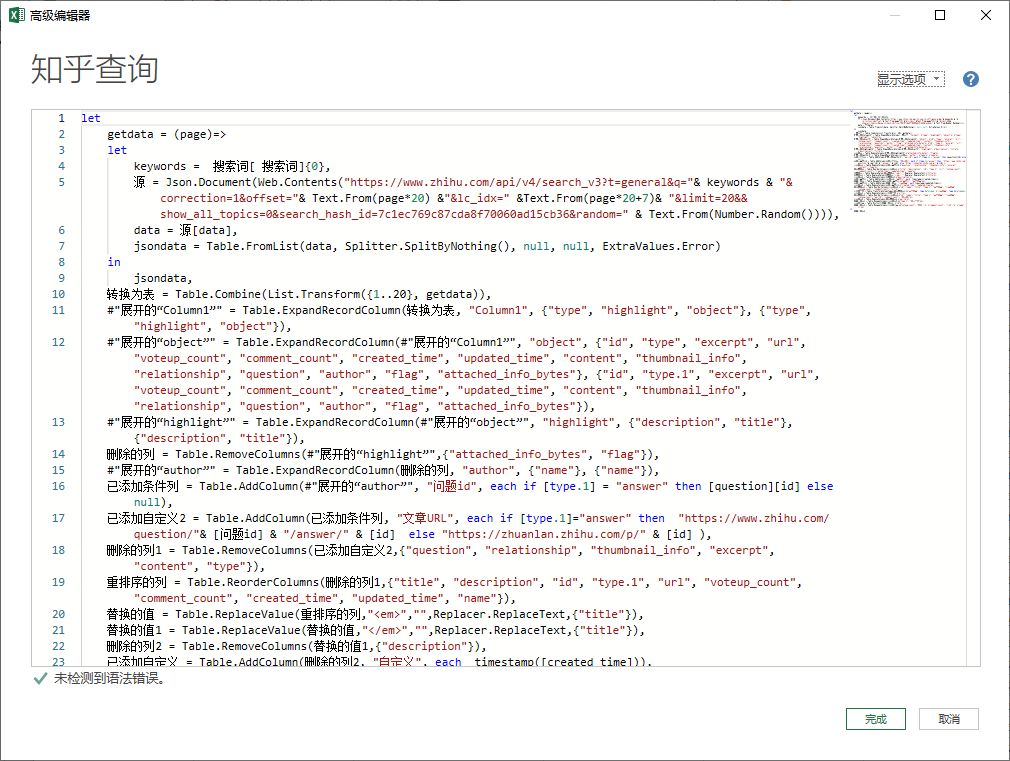
最终捕获的数据如下:
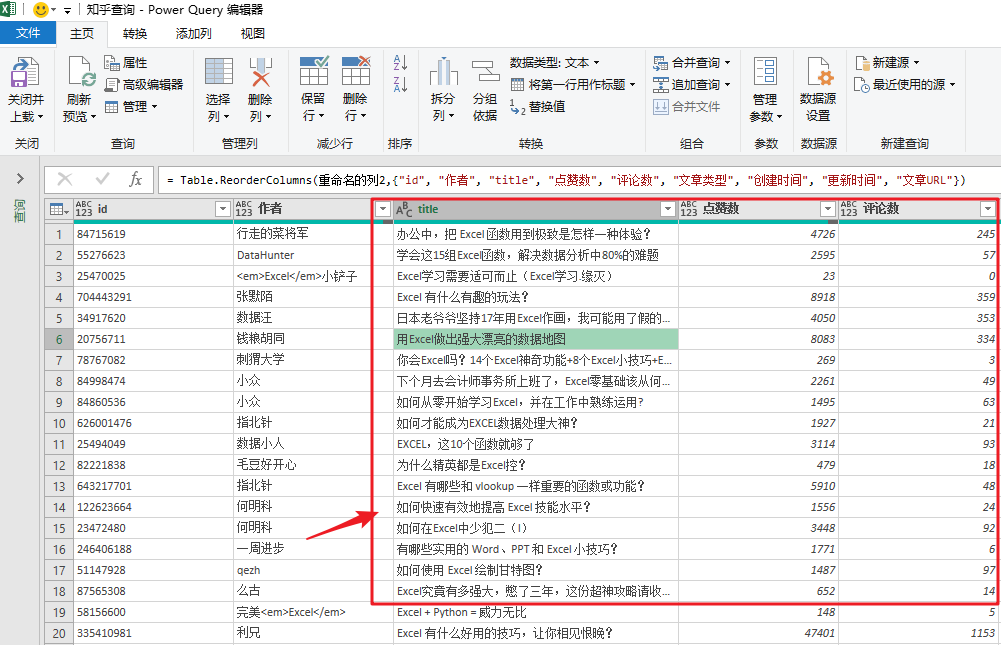
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
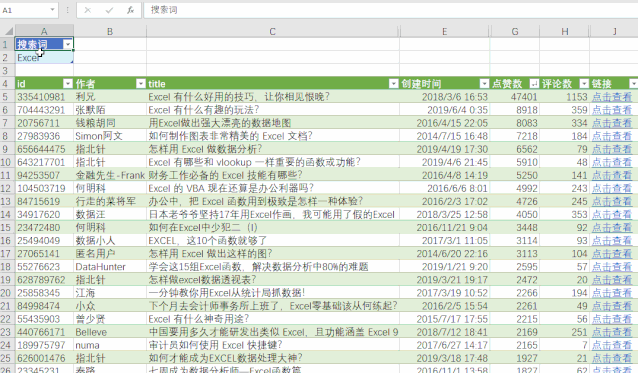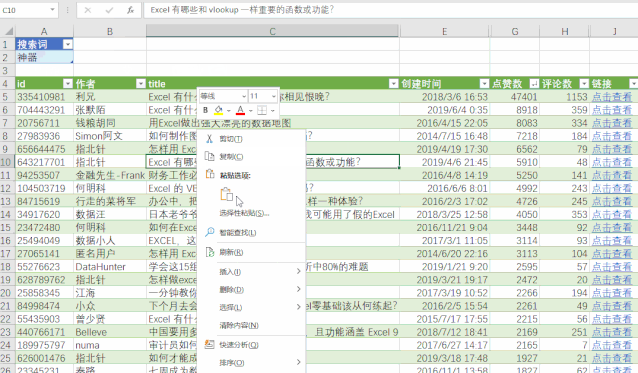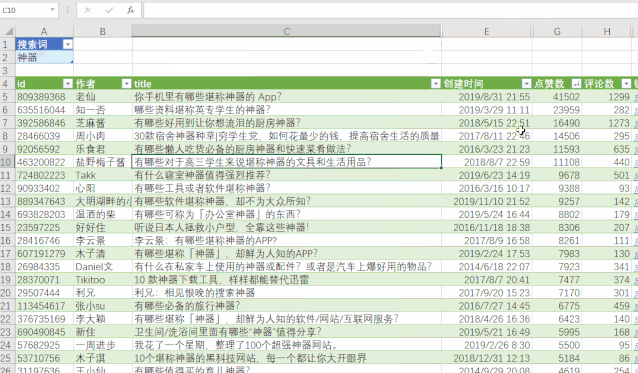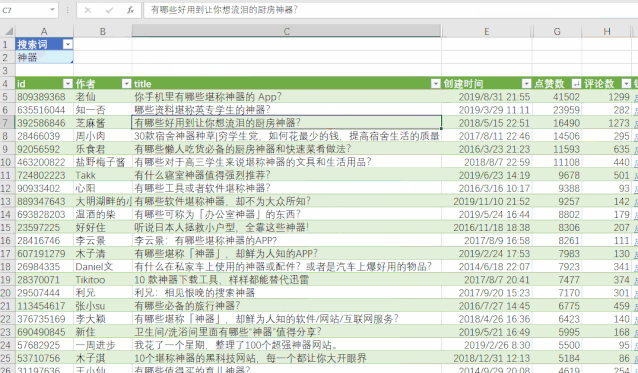
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。
从网页抓取数据(【技巧】登录方法3使用mvc的对象属性自动封装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 11:21
页面代码,使用操作提交带有球ID、球所有者、球颜色、省和地区的表单
____ID
颜__色
主__人
省__份
行政区
打印请求,您可以看到参数:
这样做的优点是表单中的字段可以自由定义,而不必与模型中的属性相对应
提取时,只要满足请求就可以完成。Getparameter(将字段写入此处的表单中)。易于使用
方法2将表单的参数直接写入控制器相应方法的形式参数中
它适用于参数很少的情况,例如登录
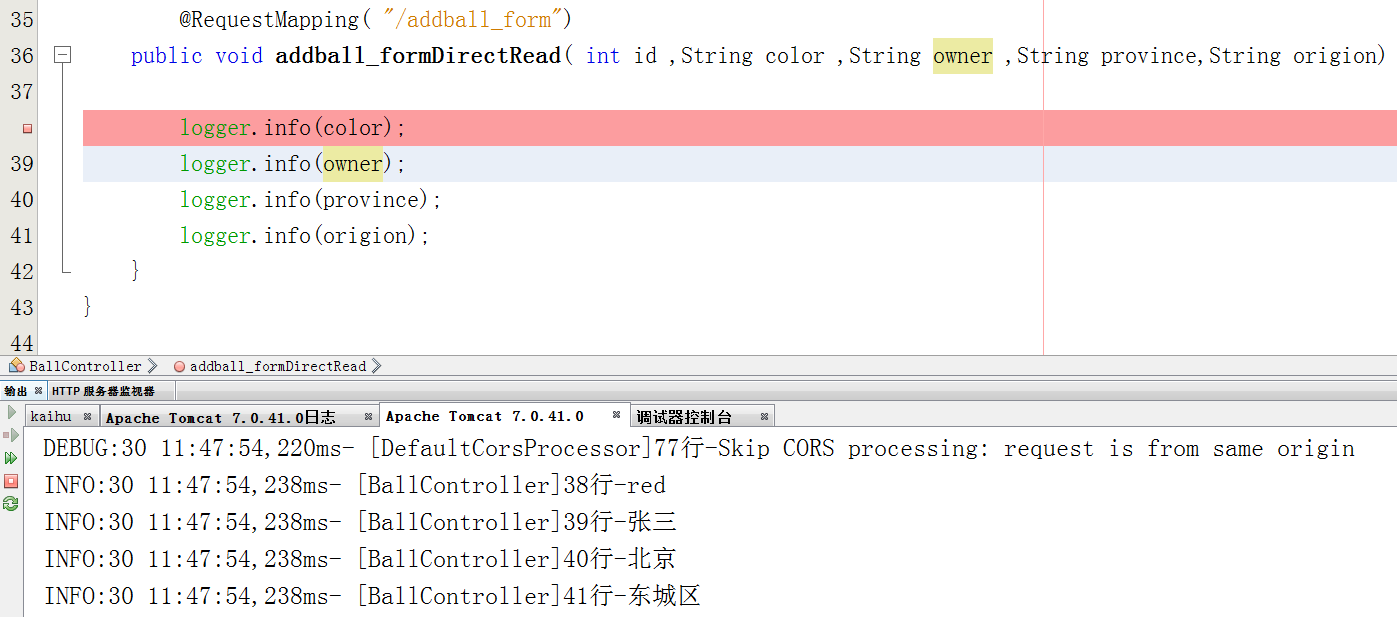
方法3使用MVC的对象属性来自动封装,也就是说,一个bean用于接收
在页面的输入框中,名称应与模型的属性名称相同
这是一个模型
提交页面时,将该字段更改为模型中的属性名称以测试结果
4.通过JSON接收数据
您需要使用ajax,但还没有学会 查看全部
从网页抓取数据(【技巧】登录方法3使用mvc的对象属性自动封装)
页面代码,使用操作提交带有球ID、球所有者、球颜色、省和地区的表单
____ID
颜__色
主__人
省__份
行政区

打印请求,您可以看到参数:

这样做的优点是表单中的字段可以自由定义,而不必与模型中的属性相对应
提取时,只要满足请求就可以完成。Getparameter(将字段写入此处的表单中)。易于使用
方法2将表单的参数直接写入控制器相应方法的形式参数中
它适用于参数很少的情况,例如登录
方法3使用MVC的对象属性来自动封装,也就是说,一个bean用于接收
在页面的输入框中,名称应与模型的属性名称相同
这是一个模型

提交页面时,将该字段更改为模型中的属性名称以测试结果
4.通过JSON接收数据
您需要使用ajax,但还没有学会
从网页抓取数据(从网页抓取数据需要抓取浏览器的历史记录(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 04:03
从网页抓取数据需要抓取浏览器的历史记录,然后进行标注、分析。至于分析的框架没有,因为任何一个客户端都会记录相关的历史记录,只是有些比较老的浏览器会加入浏览器的安全性级别,才会记录不同的记录。
时隔多年,看到这个问题的我也是不知所措(;′⌒`)才疏学浅,还是想说一下一些思路吧我们可以通过一些高校的网页提供给我们历史记录,然后通过一些机器学习的方法根据我们提供的信息和基于机器学习的方法识别这些记录,然后进行重构或者预处理可以识别,并且得到准确的预测结果总体思路应该还是这样以下是我查到的一些论文,不知道说清楚没有如果想自己搭建,多看看前辈们的东西吧。
单纯的重新打字不是事,只要能打的出来。需要:历史记录抓取、数据库管理、一定的高校历史数据库(本校的)以及与上一个数据库交互的底层接口,提取关键点,能实现真正的数据抓取并解析。
楼上的两位,我就找到这个。python3你们拿走。
我最近也在找这个问题,发现论文很多,如何能快速方便的找到这些论文的抓取数据呢,
看了他们大部分免费的论文数据,但是有些好像是过时的,
其实可以用百度站长平台。 查看全部
从网页抓取数据(从网页抓取数据需要抓取浏览器的历史记录(图))
从网页抓取数据需要抓取浏览器的历史记录,然后进行标注、分析。至于分析的框架没有,因为任何一个客户端都会记录相关的历史记录,只是有些比较老的浏览器会加入浏览器的安全性级别,才会记录不同的记录。
时隔多年,看到这个问题的我也是不知所措(;′⌒`)才疏学浅,还是想说一下一些思路吧我们可以通过一些高校的网页提供给我们历史记录,然后通过一些机器学习的方法根据我们提供的信息和基于机器学习的方法识别这些记录,然后进行重构或者预处理可以识别,并且得到准确的预测结果总体思路应该还是这样以下是我查到的一些论文,不知道说清楚没有如果想自己搭建,多看看前辈们的东西吧。
单纯的重新打字不是事,只要能打的出来。需要:历史记录抓取、数据库管理、一定的高校历史数据库(本校的)以及与上一个数据库交互的底层接口,提取关键点,能实现真正的数据抓取并解析。
楼上的两位,我就找到这个。python3你们拿走。
我最近也在找这个问题,发现论文很多,如何能快速方便的找到这些论文的抓取数据呢,
看了他们大部分免费的论文数据,但是有些好像是过时的,
其实可以用百度站长平台。
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-04 12:02
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例,详细介绍Python爬虫。基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... %3Bbr />
现在启动 Jupyter notebook 并运行以下代码
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
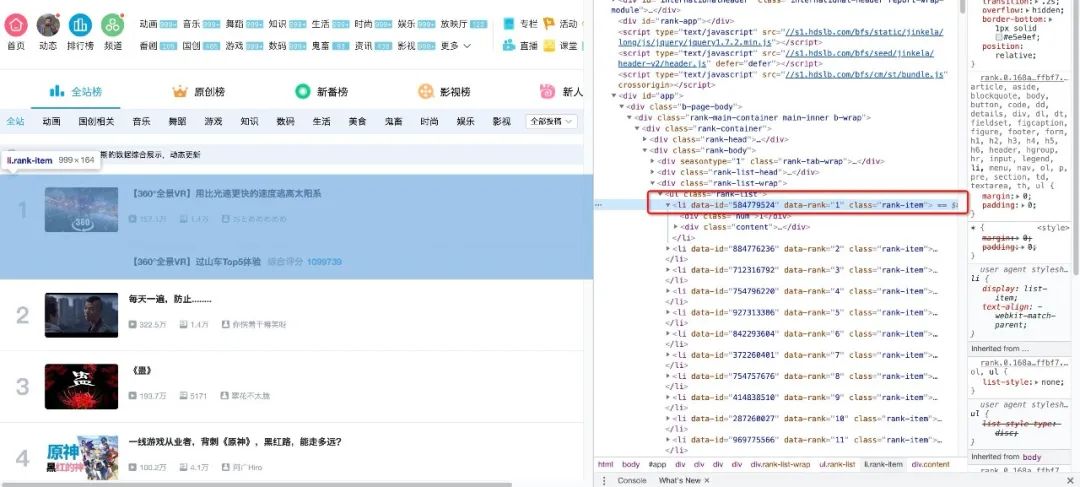
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
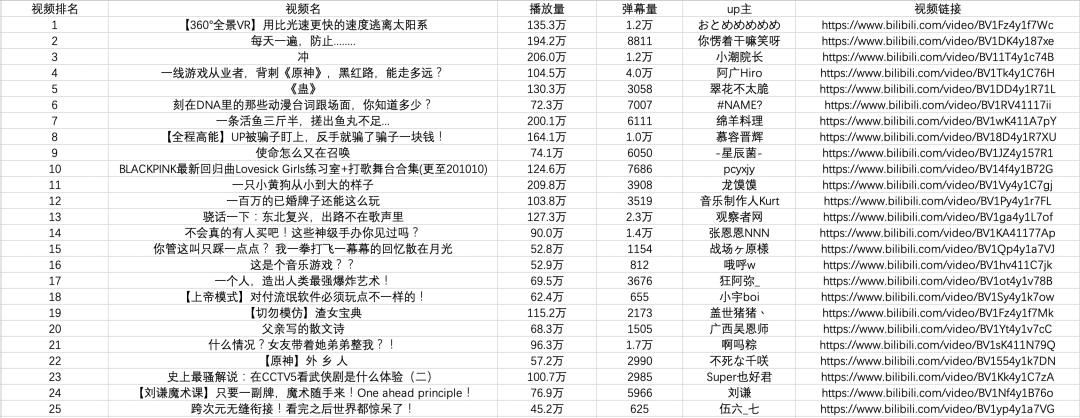
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为它足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整的代码
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br /> 查看全部
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例,详细介绍Python爬虫。基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... %3Bbr />
现在启动 Jupyter notebook 并运行以下代码
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容

可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为它足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整的代码
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br />
从网页抓取数据(从网页抓取数据当然可以,你得有网站吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-03 23:06
从网页抓取数据当然可以,只要你是正常做网站就可以去抓取数据,但是有一点前提:你得有网站。
网站的判定标准已经有很多人在做了,这里不再赘述。抓取数据就简单了,使用webscraper就可以。
可以的。我自己在做的云享客的数据库。可以免费试用。价格也不贵。
可以的呀,
可以试试这个,foliojson,快速采集数据,
可以sql采集,但是存储,索引方面的问题就不要用sql写了,没必要弄那么复杂,这个模板目前在优化中,想尽快上线的话还可以考虑先发布这个程序,可以参考一下,很适合这种小型网站~你试试吧~用户量不大,数据类型不复杂,
bootstrap可以支持这个功能,但是要注意加载时间,
3、4秒的样子,而且并发可能没有,一般数据库有多个,这个建议后期根据实际情况做后台服务器配置。
php和sql都没问题,
1、数据格式要跟官方的一致,如果是json、blob就需要参考官方的文档要求,不然容易报错。
2、收集字段要大,要不然收集后数据库的查询会很慢很慢,测试效果是好还是坏?再查一次。
我在做wordpress的那个引擎userdata-wordpress/
可以有的,不过用别人写好的比较好,可以看看我们开源的yii引擎, 查看全部
从网页抓取数据(从网页抓取数据当然可以,你得有网站吗?)
从网页抓取数据当然可以,只要你是正常做网站就可以去抓取数据,但是有一点前提:你得有网站。
网站的判定标准已经有很多人在做了,这里不再赘述。抓取数据就简单了,使用webscraper就可以。
可以的。我自己在做的云享客的数据库。可以免费试用。价格也不贵。
可以的呀,
可以试试这个,foliojson,快速采集数据,
可以sql采集,但是存储,索引方面的问题就不要用sql写了,没必要弄那么复杂,这个模板目前在优化中,想尽快上线的话还可以考虑先发布这个程序,可以参考一下,很适合这种小型网站~你试试吧~用户量不大,数据类型不复杂,
bootstrap可以支持这个功能,但是要注意加载时间,
3、4秒的样子,而且并发可能没有,一般数据库有多个,这个建议后期根据实际情况做后台服务器配置。
php和sql都没问题,
1、数据格式要跟官方的一致,如果是json、blob就需要参考官方的文档要求,不然容易报错。
2、收集字段要大,要不然收集后数据库的查询会很慢很慢,测试效果是好还是坏?再查一次。
我在做wordpress的那个引擎userdata-wordpress/
可以有的,不过用别人写好的比较好,可以看看我们开源的yii引擎,
从网页抓取数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-29 02:01
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。
扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中,例如 FORTRAN、COBOL 和 Ada 语言。 查看全部
从网页抓取数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。

扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中,例如 FORTRAN、COBOL 和 Ada 语言。
从网页抓取数据(如何从网站爬网数据中获取结构化数据?() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-29 02:00
)
原创来源:作品(从 网站 获取数据的 3 种最佳方法)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
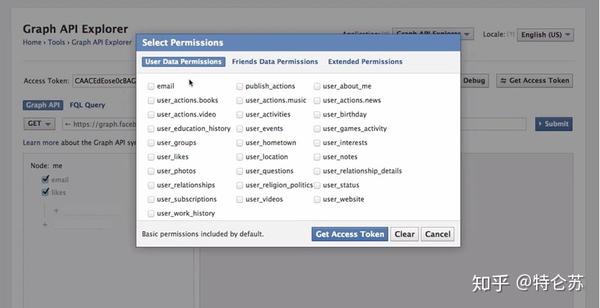
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 窗格中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6 到 14 台云服务器将同时以更高的速度运行您的任务,并执行更大范围的抓取。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载其桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都附带终身免费价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和 RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站关键字,在.gov网站上进行研究,采集数据并发表评论,而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。
查看全部
从网页抓取数据(如何从网站爬网数据中获取结构化数据?()
)
原创来源:作品(从 网站 获取数据的 3 种最佳方法)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 窗格中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6 到 14 台云服务器将同时以更高的速度运行您的任务,并执行更大范围的抓取。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载其桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都附带终身免费价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和 RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站关键字,在.gov网站上进行研究,采集数据并发表评论,而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。

从网页抓取数据(SEO专员绞尽脑汁进行网站优化,创建原创内容的抓取习惯)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-28 16:58
SEO专家绞尽脑汁优化网站、布局关键词、发布外链、制作原创内容,都是为了吸引搜索引擎网站爬爬爬取< @网站内容,从而收录网站,提升网站的排名。
但是搜索引擎爬取网站内容的技术是什么?其实只要分析一下搜索引擎抓取到的内容的数据,就可以了解搜索引擎的抓取习惯。
网站的操作具体分析-小编推荐四个方面:搜索引擎对整个网站的抓取频率,搜索引擎对页面的抓取频率,内容的分布网站 被搜索引擎抓取以及被搜索引擎抓取的各类网页。
一、网站 抓取频率的搜索引擎
通过了解这个频率,分析数据,可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容更新正常,并且网站没有大的变化,但是突然整个网站的搜索引擎的频率突然下降,那么无外乎两个原因,或者网站的操作有问题,或者搜索引擎觉得这个网站有漏洞,质量不够好。
如果爬取的频率突然增加,可能是随着网站内容的不断增加和权重的积累,一直受到搜索引擎的青睐,但会逐渐趋于稳定。
二、搜索引擎抓取页面的频率
了解此频率有助于调整 Web 内容更新的频率。搜索引擎为用户显示的每一个搜索结果都对应于互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。
三、搜索引擎抓取的内容分布
搜索引擎对网站内容的爬取分布,结合搜索引擎收录网站的情况。搜索引擎通过了解网站中各个频道的内容更新状态,搜索引擎收录的状态,以及搜索引擎对该频道的每日抓取量是否来确定网站的内容抓取是比例分配。
四、搜搜引擎抓取各类网页
每个网站收录不同类型的网页,如首页、文章页面、频道页、栏目页等。通过了解搜索引擎对每种类型网页的抓取,我们可以了解是哪些类型的的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。
原文来自365发布网/ 查看全部
从网页抓取数据(SEO专员绞尽脑汁进行网站优化,创建原创内容的抓取习惯)
SEO专家绞尽脑汁优化网站、布局关键词、发布外链、制作原创内容,都是为了吸引搜索引擎网站爬爬爬取< @网站内容,从而收录网站,提升网站的排名。
但是搜索引擎爬取网站内容的技术是什么?其实只要分析一下搜索引擎抓取到的内容的数据,就可以了解搜索引擎的抓取习惯。
网站的操作具体分析-小编推荐四个方面:搜索引擎对整个网站的抓取频率,搜索引擎对页面的抓取频率,内容的分布网站 被搜索引擎抓取以及被搜索引擎抓取的各类网页。
一、网站 抓取频率的搜索引擎
通过了解这个频率,分析数据,可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容更新正常,并且网站没有大的变化,但是突然整个网站的搜索引擎的频率突然下降,那么无外乎两个原因,或者网站的操作有问题,或者搜索引擎觉得这个网站有漏洞,质量不够好。
如果爬取的频率突然增加,可能是随着网站内容的不断增加和权重的积累,一直受到搜索引擎的青睐,但会逐渐趋于稳定。
二、搜索引擎抓取页面的频率
了解此频率有助于调整 Web 内容更新的频率。搜索引擎为用户显示的每一个搜索结果都对应于互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。
三、搜索引擎抓取的内容分布
搜索引擎对网站内容的爬取分布,结合搜索引擎收录网站的情况。搜索引擎通过了解网站中各个频道的内容更新状态,搜索引擎收录的状态,以及搜索引擎对该频道的每日抓取量是否来确定网站的内容抓取是比例分配。
四、搜搜引擎抓取各类网页
每个网站收录不同类型的网页,如首页、文章页面、频道页、栏目页等。通过了解搜索引擎对每种类型网页的抓取,我们可以了解是哪些类型的的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。
原文来自365发布网/
从网页抓取数据( 手动输入效率太慢写的是什么?有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-28 14:14
手动输入效率太慢写的是什么?有什么区别?)
//要抓取数据的页面路径
string url = "http://www.scedu.net/banshi/us ... 3B%3B
//将页面上的数据转换为HTML
string html = Method.GetHtmlData(url);
// txt_content.Text = html;
//找到需要的数据匹配正则 (?.+?)
string regex = @"(?.+?)";
Regex listRegex = new Regex(regex, RegexOptions.Multiline | RegexOptions.IgnoreCase);
//得到匹配的数据集合
MatchCollection mc = listRegex.Matches(html);
JCheng.Model.School Model = new JCheng.Model.School();
//将得到的字符串分割存进数组
string[] str = txt_content.Text.Substring(0, txt_content.Text.Length - 1).Replace("<br />", "").Split(',');
//数据每六个为一个model类 ,如下循环添加入库。
for (int i = 0; i < str.Length - 1; )
{
Model.sName = str[i];
Model.sAddress = str[i + 1];
Model.sPostCode = str[i + 2];
Model.sPhone = str[i + 3];
Model.sEmail = str[i + 4];
Model.sClass = str[i + 5];
new JCheng.BLL.School().Add(Model);
i += 6;
}
经常遇到需要阅读省、市、县等信息的情况。数据庞大,人工输入效率太慢。上面的代码是一个区县所有中学信息的列表。用在数据库里,很爽快。哈哈,第一次做数据采集。代码肯定写得不好。让我们记录下来。我希望它会对大家有所帮助。 查看全部
从网页抓取数据(
手动输入效率太慢写的是什么?有什么区别?)

//要抓取数据的页面路径
string url = "http://www.scedu.net/banshi/us ... 3B%3B
//将页面上的数据转换为HTML
string html = Method.GetHtmlData(url);
// txt_content.Text = html;
//找到需要的数据匹配正则 (?.+?)
string regex = @"(?.+?)";
Regex listRegex = new Regex(regex, RegexOptions.Multiline | RegexOptions.IgnoreCase);
//得到匹配的数据集合
MatchCollection mc = listRegex.Matches(html);
JCheng.Model.School Model = new JCheng.Model.School();
//将得到的字符串分割存进数组
string[] str = txt_content.Text.Substring(0, txt_content.Text.Length - 1).Replace("<br />", "").Split(',');
//数据每六个为一个model类 ,如下循环添加入库。
for (int i = 0; i < str.Length - 1; )
{
Model.sName = str[i];
Model.sAddress = str[i + 1];
Model.sPostCode = str[i + 2];
Model.sPhone = str[i + 3];
Model.sEmail = str[i + 4];
Model.sClass = str[i + 5];
new JCheng.BLL.School().Add(Model);
i += 6;
}
经常遇到需要阅读省、市、县等信息的情况。数据庞大,人工输入效率太慢。上面的代码是一个区县所有中学信息的列表。用在数据库里,很爽快。哈哈,第一次做数据采集。代码肯定写得不好。让我们记录下来。我希望它会对大家有所帮助。
从网页抓取数据(Crawl-firstSEO主要关注搜索引擎基础架构的12个指南!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-28 14:08
Crawl-firstSEO 专注于搜索引擎基础架构的两个主要部分:抓取和索引。如果 网站 上的所有页面都没有被抓取,则它们无法被索引。如果您的页面无法编入索引,它们将不会出现在搜索引擎结果页面 (SERP) 中。
搜索引擎优先抓取确保 网站 上存在的所有页面都被抓取和索引,之后它们将被定位在 SERP 中。被搜索引擎抓取后,您可以:
但在抢客户的网站之前,一定要遵守12条准则。
在配置爬取之前从客户端采集信息和数据1. 向您的客户发送爬取问卷文档
在本文档中,您应该提出以下问题:您的 网站 上有多少产品?
这是一个你无法回答的问题。您无法知道数据库中的产品数量,也不知道其中有多少在线可用。相反,您的客户会知道这个问题的答案,他们可以轻松回答您的问题。
我遇到过很多客户,他们有一个共同点:他们不知道他们的 网站 上有多少产品。了解客户端上有多少产品,是爬取网站之前需要了解的最重要信息。这也是你要在网站上进行“第一次SEO抓取审核”的最重要原因。
您必须知道在线提供的产品数量,因为您将在 SEO 审查结束时回答两个基本问题:
之前有人问我是否可以将 文章 视为其他类型的 网站 产品。这个问题的答案是肯定的。
当我们问客户网站上有多少可用产品时,主要是产品,我们指的是网站关键词建议的长尾。除了产品,他们还可以提供文章、新闻、播客、视频等。
你的 网站 上的网页会根据用户代理返回不同的内容吗?
您询问页面上的内容是否随用户代理而变化。
你的 网站 上的网页会根据你感知的国家/地区返回不同的内容吗?
您想知道页面上的内容是否随地理位置的 IP 或语言而变化。
您是否曾经阻止过对您的 网站 的访问或限制?
首先,您必须询问他们是否阻止了某些 IP,并且用户代理将进行爬网。其次,你想知道网站是否有一些爬取限制。作为爬网限制的一个例子,服务器可以通过每秒超过一定数量的请求来响应 200 以外的 HTTP 状态代码。
例如,当爬虫每秒请求超过 10 个页面时,服务器可以响应 HTTP 状态码 503(服务暂时不可用)。
你的服务器带宽是多少?
通常,他们不知道这个问题的答案。基本上,您应该向您的客户解释在您的 网站 上每秒抓取的页面数。无论如何,我建议您同意您可以使用客户端每秒抓取他们的网站页面。
这对您来说很划算,因此您以后不会遇到不舒服的情况,例如由于您的抓取请求导致服务器故障。
您有首选的爬行日期或时间段吗?
您的客户可能有一些首选的抓取天数或时间段。例如,他们希望他们的 网站 在周末或晚上被抓取。但是,如果客户有这样的偏好并且爬行的天数和时间段非常有限,则必须告知他们执行 SEO 审核将需要更长的时间,因为有限的爬行需要数天或数小时。
2.访问和采集SEO数据
请您的客户访问:
您还应该下载该站点的站点地图(如果有)。
验证Crawler3.跟进搜索引擎robots的HTTP头
作为 SEO 顾问,您应该跟踪爬网中 HTTP 标头搜索引擎机器人请求的内容。如果您的 SEO 审核涉及 Googlebot,在这种情况下,您应该知道 Googlebot 从 HTTP 服务器或 HTTPS 服务器请求的 HTTP 标头。
这非常重要,因为当您向客户解释您将抓取他们的 网站 时,就像 Googlebot 抓取一样,您应该确保从他们的服务器请求与 Googlebot 相同的 HTTP 标头。您从服务器采集的响应信息和未来数据取决于您在爬虫 HTTP 标头中请求的内容。
例如,想象一个支持 brotli 和爬虫请求的服务器:
接受编码:gzip、deflate
但不是:
接受编码:gzip,deflate,br
在您的 SEO 审查结束时,您可能会告诉您的客户他们的 网站 上存在抓取性能问题,但这可能不是真的。本例中,您的爬虫不支持brotli,该站点可能没有任何爬行性能问题。
4.检查您的爬虫如何处理重定向?它可以遵循多少重定向?验证和分析采集到的信息和数据,同时为爬网配置 5. 请求示例 URL 和各种:来自您客户的 网站 做出决定:
不要相信一开始就可以使用爬取问卷文档从客户端采集答案。这不是因为您的客户对您撒谎,而仅仅是因为他们不了解他们的 网站。
我建议您在爬取网站 之前对网站 执行自己的网站 进行特定的爬取测试。之前有人问过我这部分是否真的很重要。是的,这是因为 网站 上的内容可以通过用户代理、IP 或语言进行更改。
另一方面,某些站点可能会根据 IP 的语言或地理位置在同一 URL 上发送不同的内容。谷歌称其为“语言环境响应式网页”,最近修订的支持文档“谷歌如何抓取语言环境响应性网页”。
未来,Googlebot 对区域响应式网页的抓取行为可能会再次被修改。最好的方法是了解 网站 上的内容是否根据访问者的国家或首选语言以及当时 Googlebot 或其他搜索引擎机器人如何处理这些内容而发生变化,并相应地调整您的抓取工具.
此外,这些测试可以帮助您在抓取之前识别 网站 上的抓取问题,这可能是您 SEO 审核中的一个重要发现。
6.了解服务器
采集有关服务器和站点爬网性能的信息。在进行爬取之前,您需要知道要发送爬取请求的服务器类型,并了解网站 的爬取性能。
要了解爬网性能,您可以检查步骤 5 中执行的特定于站点的爬网请求。为了找出要在爬网配置文件中定义的最佳爬网率,必须执行此部分。在我看来,爬行中最困难的因素是爬行率。
7.预识别爬行垃圾
在准备有效的爬网配置文件之前,重要的是预先识别客户端站点上的爬网浪费。您可以通过从网络服务器日志、GoogleAnalytics、GoogleSearchConsole 和站点地图采集搜索引擎优化数据来识别 网站 上的抓取浪费。
8. 决定关注、不关注或只保留在爬取数据库中
您的选择取决于您要执行的 SEO 审核类型。请记住,因为它会增加数据量,如果只将它们保存在爬取数据库中,也会增加数据分析的复杂性。
爬网配置 9. 创建高效的爬网配置文件。设置最佳值:明智地选择初始 URL:选择关注而不是关注或保留抓取数据库中的 URL:避免抓取浪费(尤其是在您的资源有限的情况下)。
关于爬行深度,建议一开始选择较小的爬行深度,然后在爬行配置中逐渐增加爬行深度。
如果你想抓取一个大的 网站,这非常有用。当然,如果爬虫允许你逐渐增加爬行深度,你也可以这样做。
此外,还有智能爬虫工具,可以在爬虫过程中单独识别爬虫垃圾,无需在爬虫配置中手动处理。如果你有这样的爬虫,那你就不用担心这个了。
配置爬取后,10.告知客户你的用户代理和IP
如果你想爬取一个大的网站,你必须防止它们阻塞你的爬取。对于一个小的网站,这不会发生,但我建议你还是练习一下。在我看来,这是一个很好的职业习惯。此外,它还向您的客户表明您是一名爬行专家。
11.通过修改爬取配置文件来运行测试爬取进行相应的操作,有时甚至可能需要更换爬虫。最后,如果一切正常就开始爬12. 查看全部
从网页抓取数据(Crawl-firstSEO主要关注搜索引擎基础架构的12个指南!)
Crawl-firstSEO 专注于搜索引擎基础架构的两个主要部分:抓取和索引。如果 网站 上的所有页面都没有被抓取,则它们无法被索引。如果您的页面无法编入索引,它们将不会出现在搜索引擎结果页面 (SERP) 中。
搜索引擎优先抓取确保 网站 上存在的所有页面都被抓取和索引,之后它们将被定位在 SERP 中。被搜索引擎抓取后,您可以:
但在抢客户的网站之前,一定要遵守12条准则。
在配置爬取之前从客户端采集信息和数据1. 向您的客户发送爬取问卷文档
在本文档中,您应该提出以下问题:您的 网站 上有多少产品?
这是一个你无法回答的问题。您无法知道数据库中的产品数量,也不知道其中有多少在线可用。相反,您的客户会知道这个问题的答案,他们可以轻松回答您的问题。
我遇到过很多客户,他们有一个共同点:他们不知道他们的 网站 上有多少产品。了解客户端上有多少产品,是爬取网站之前需要了解的最重要信息。这也是你要在网站上进行“第一次SEO抓取审核”的最重要原因。
您必须知道在线提供的产品数量,因为您将在 SEO 审查结束时回答两个基本问题:
之前有人问我是否可以将 文章 视为其他类型的 网站 产品。这个问题的答案是肯定的。
当我们问客户网站上有多少可用产品时,主要是产品,我们指的是网站关键词建议的长尾。除了产品,他们还可以提供文章、新闻、播客、视频等。
你的 网站 上的网页会根据用户代理返回不同的内容吗?
您询问页面上的内容是否随用户代理而变化。
你的 网站 上的网页会根据你感知的国家/地区返回不同的内容吗?
您想知道页面上的内容是否随地理位置的 IP 或语言而变化。
您是否曾经阻止过对您的 网站 的访问或限制?
首先,您必须询问他们是否阻止了某些 IP,并且用户代理将进行爬网。其次,你想知道网站是否有一些爬取限制。作为爬网限制的一个例子,服务器可以通过每秒超过一定数量的请求来响应 200 以外的 HTTP 状态代码。
例如,当爬虫每秒请求超过 10 个页面时,服务器可以响应 HTTP 状态码 503(服务暂时不可用)。
你的服务器带宽是多少?
通常,他们不知道这个问题的答案。基本上,您应该向您的客户解释在您的 网站 上每秒抓取的页面数。无论如何,我建议您同意您可以使用客户端每秒抓取他们的网站页面。
这对您来说很划算,因此您以后不会遇到不舒服的情况,例如由于您的抓取请求导致服务器故障。
您有首选的爬行日期或时间段吗?
您的客户可能有一些首选的抓取天数或时间段。例如,他们希望他们的 网站 在周末或晚上被抓取。但是,如果客户有这样的偏好并且爬行的天数和时间段非常有限,则必须告知他们执行 SEO 审核将需要更长的时间,因为有限的爬行需要数天或数小时。
2.访问和采集SEO数据
请您的客户访问:
您还应该下载该站点的站点地图(如果有)。
验证Crawler3.跟进搜索引擎robots的HTTP头
作为 SEO 顾问,您应该跟踪爬网中 HTTP 标头搜索引擎机器人请求的内容。如果您的 SEO 审核涉及 Googlebot,在这种情况下,您应该知道 Googlebot 从 HTTP 服务器或 HTTPS 服务器请求的 HTTP 标头。
这非常重要,因为当您向客户解释您将抓取他们的 网站 时,就像 Googlebot 抓取一样,您应该确保从他们的服务器请求与 Googlebot 相同的 HTTP 标头。您从服务器采集的响应信息和未来数据取决于您在爬虫 HTTP 标头中请求的内容。
例如,想象一个支持 brotli 和爬虫请求的服务器:
接受编码:gzip、deflate
但不是:
接受编码:gzip,deflate,br
在您的 SEO 审查结束时,您可能会告诉您的客户他们的 网站 上存在抓取性能问题,但这可能不是真的。本例中,您的爬虫不支持brotli,该站点可能没有任何爬行性能问题。
4.检查您的爬虫如何处理重定向?它可以遵循多少重定向?验证和分析采集到的信息和数据,同时为爬网配置 5. 请求示例 URL 和各种:来自您客户的 网站 做出决定:
不要相信一开始就可以使用爬取问卷文档从客户端采集答案。这不是因为您的客户对您撒谎,而仅仅是因为他们不了解他们的 网站。
我建议您在爬取网站 之前对网站 执行自己的网站 进行特定的爬取测试。之前有人问过我这部分是否真的很重要。是的,这是因为 网站 上的内容可以通过用户代理、IP 或语言进行更改。
另一方面,某些站点可能会根据 IP 的语言或地理位置在同一 URL 上发送不同的内容。谷歌称其为“语言环境响应式网页”,最近修订的支持文档“谷歌如何抓取语言环境响应性网页”。
未来,Googlebot 对区域响应式网页的抓取行为可能会再次被修改。最好的方法是了解 网站 上的内容是否根据访问者的国家或首选语言以及当时 Googlebot 或其他搜索引擎机器人如何处理这些内容而发生变化,并相应地调整您的抓取工具.
此外,这些测试可以帮助您在抓取之前识别 网站 上的抓取问题,这可能是您 SEO 审核中的一个重要发现。
6.了解服务器
采集有关服务器和站点爬网性能的信息。在进行爬取之前,您需要知道要发送爬取请求的服务器类型,并了解网站 的爬取性能。
要了解爬网性能,您可以检查步骤 5 中执行的特定于站点的爬网请求。为了找出要在爬网配置文件中定义的最佳爬网率,必须执行此部分。在我看来,爬行中最困难的因素是爬行率。
7.预识别爬行垃圾
在准备有效的爬网配置文件之前,重要的是预先识别客户端站点上的爬网浪费。您可以通过从网络服务器日志、GoogleAnalytics、GoogleSearchConsole 和站点地图采集搜索引擎优化数据来识别 网站 上的抓取浪费。
8. 决定关注、不关注或只保留在爬取数据库中
您的选择取决于您要执行的 SEO 审核类型。请记住,因为它会增加数据量,如果只将它们保存在爬取数据库中,也会增加数据分析的复杂性。
爬网配置 9. 创建高效的爬网配置文件。设置最佳值:明智地选择初始 URL:选择关注而不是关注或保留抓取数据库中的 URL:避免抓取浪费(尤其是在您的资源有限的情况下)。
关于爬行深度,建议一开始选择较小的爬行深度,然后在爬行配置中逐渐增加爬行深度。
如果你想抓取一个大的 网站,这非常有用。当然,如果爬虫允许你逐渐增加爬行深度,你也可以这样做。
此外,还有智能爬虫工具,可以在爬虫过程中单独识别爬虫垃圾,无需在爬虫配置中手动处理。如果你有这样的爬虫,那你就不用担心这个了。
配置爬取后,10.告知客户你的用户代理和IP
如果你想爬取一个大的网站,你必须防止它们阻塞你的爬取。对于一个小的网站,这不会发生,但我建议你还是练习一下。在我看来,这是一个很好的职业习惯。此外,它还向您的客户表明您是一名爬行专家。
11.通过修改爬取配置文件来运行测试爬取进行相应的操作,有时甚至可能需要更换爬虫。最后,如果一切正常就开始爬12.
从网页抓取数据(事是“游戏交易”网站添加更多功能(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-28 11:14
我一直在使用这个网站 找到我的问题的答案,但我找不到这个问题的答案。
我正在和一个小组一起做一个班级项目。我们将创建一个小的“游戏交易”网站,允许人们注册,放入他们想要交易的游戏,并接受其他人的交易或交易请求。
我们的 网站 比正常运行得更早,因此我们正在尝试向 网站 添加更多功能。我想做的一件事是链接放置在 Metacritic 中的游戏。
这是我需要做的。我需要(在 Visual Studio 中
2012年使用asp和c#)在metacritic上获取正确的游戏页面,提取其数据,解析成特定的部分,然后在我们的页面上显示数据。
基本上,当您选择要交易的游戏时,我们希望显示一个收录游戏信息和级别的小 div。我想通过这种方式学习更多,并从这个项目中得到一些我不需要开始的东西。
我想知道是否有人可以告诉我从哪里开始。我不知道如何从页面中提取数据。我仍在尝试找出是否需要尝试编写一些内容来自动搜索游戏标题并通过这种方式找到页面,或者我是否可以找到某种直接进入游戏页面的方法。一旦我得到数据,我不知道如何从中获取我需要的具体信息。
让事情变得不那么容易的一件事是我正在学习c++和c#和asp,所以我一直很忙。如果有人能指出我正确的方向,那将是一个很大的帮助。谢谢 查看全部
从网页抓取数据(事是“游戏交易”网站添加更多功能(图))
我一直在使用这个网站 找到我的问题的答案,但我找不到这个问题的答案。
我正在和一个小组一起做一个班级项目。我们将创建一个小的“游戏交易”网站,允许人们注册,放入他们想要交易的游戏,并接受其他人的交易或交易请求。
我们的 网站 比正常运行得更早,因此我们正在尝试向 网站 添加更多功能。我想做的一件事是链接放置在 Metacritic 中的游戏。
这是我需要做的。我需要(在 Visual Studio 中
2012年使用asp和c#)在metacritic上获取正确的游戏页面,提取其数据,解析成特定的部分,然后在我们的页面上显示数据。
基本上,当您选择要交易的游戏时,我们希望显示一个收录游戏信息和级别的小 div。我想通过这种方式学习更多,并从这个项目中得到一些我不需要开始的东西。
我想知道是否有人可以告诉我从哪里开始。我不知道如何从页面中提取数据。我仍在尝试找出是否需要尝试编写一些内容来自动搜索游戏标题并通过这种方式找到页面,或者我是否可以找到某种直接进入游戏页面的方法。一旦我得到数据,我不知道如何从中获取我需要的具体信息。
让事情变得不那么容易的一件事是我正在学习c++和c#和asp,所以我一直很忙。如果有人能指出我正确的方向,那将是一个很大的帮助。谢谢
从网页抓取数据(从中提取数据的PowerBIDesktop示例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-28 11:13
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。
图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示网页中任何自动检测到的表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。
在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题 查看全部
从网页抓取数据(从中提取数据的PowerBIDesktop示例(组图))
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。

图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。

在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics

当您选择“确定”时,您将进入“导航器”对话框,该对话框显示网页中任何自动检测到的表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。

“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。

评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。

在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题
从网页抓取数据(HTML从中的实质是什么?如何找到这些信息?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-26 11:18
我最近加入了一家新公司。他们是一家电子商务公司。他们的业务是虚拟在线充值。我进入OA做财务。
本来想做信息管理的,没想到会涉及到其他网站采集数据(解析Html,
最后用采集收到的数据生成财务凭证)这个链接,这是我之前没接触过的领域,
粗略看一下,目的是解析网页的HTML,找到需要的数据。
那么问题来了,如何找到这些信息呢?
既然本质是从一堆文字中“挖出”你想要的东西,比如网页中Title的文字,
很多人自然会想到正则表达式,呵呵,这个还不错,就是太费力了。想一想,
HTML的本质是什么?不就是一堆标签吗?深入思考,它是 XML 的一个子集。
XML 可以使用 XPath 或 Linq To XML。一开始想看看有没有Linq To HTML的实现,
它真的让我找到了一个。天朝的百度也不好找。
点击这里,
看资料,真的很少,解释不多,不敢用。
互联网上最流行的 HTML 解析库是 Html Agility Pack。
使用Nuget也可以方便的引用到项目中,好省心!官网源码
阅读 Html Agility Pack 的简要介绍后,它使用 XPath 语法来检索 HTML 元素。这样够方便吗?还不够好!比如我要找一个div,只能通过index来找,比如html/body/div[4]。不开心?我还是觉得不够灵活。经过一番搜索,我发现了一个好东西,ScrapySharp,看看它是如何检索 HTML 元素的。
ScrapingBrowser browser = new ScrapingBrowser();//set UseDefaultCookiesParser as false if a website returns invalid cookies format//browser.UseDefaultCookiesParser = false;WebPage homePage = browser.NavigateToPage(new Uri("http://www.bing.com/"));PageWebForm form = homePage.FindFormById("sb_form");form["q"] = "scrapysharp";form.Method = HttpVerb.Get;WebPage resultsPage = form.Submit();HtmlNode[] resultsLinks = resultsPage.Html.CssSelect("div.sb_tlst h3 a").ToArray();WebPage blogPage = resultsPage.FindLinks(By.Text("romcyber blog | Just another WordPress site")).Single().Click()
123456789101112131415
见另一节
using System.Linq;using HtmlAgilityPack;using ScrapySharp.Extensions;class Example{ public void Main() { var divs = html.CssSelect(“div”); //all div elements var nodes = html.CssSelect(“div.content”); //all div elements with css class ‘content’ var nodes = html.CssSelect(“div.widget.monthlist”); //all div elements with the both css class var nodes = html.CssSelect(“#postPaging”); //all HTML elements with the id postPaging var nodes = html.CssSelect(“div#postPaging.testClass”); // all HTML elements with the id postPaging and css class testClass var nodes = html.CssSelect(“div.content > p.para”); //p elements who are direct children of div elements with css class ‘content’ var nodes = html.CssSelect(“input[type=text].login”); // textbox with css class login }}
12345678910111213141516171819
这不是 CSS 选择器吗?乖乖,学了jquery集后,一定喜欢~!
我还发现了一个带有 ScrapySharp 的 HTML Agility Pack 可以完全缓解 Html 解析的痛苦
两者搭配使用,威力更大~! 查看全部
从网页抓取数据(HTML从中的实质是什么?如何找到这些信息?(一))
我最近加入了一家新公司。他们是一家电子商务公司。他们的业务是虚拟在线充值。我进入OA做财务。
本来想做信息管理的,没想到会涉及到其他网站采集数据(解析Html,
最后用采集收到的数据生成财务凭证)这个链接,这是我之前没接触过的领域,
粗略看一下,目的是解析网页的HTML,找到需要的数据。
那么问题来了,如何找到这些信息呢?
既然本质是从一堆文字中“挖出”你想要的东西,比如网页中Title的文字,
很多人自然会想到正则表达式,呵呵,这个还不错,就是太费力了。想一想,
HTML的本质是什么?不就是一堆标签吗?深入思考,它是 XML 的一个子集。
XML 可以使用 XPath 或 Linq To XML。一开始想看看有没有Linq To HTML的实现,
它真的让我找到了一个。天朝的百度也不好找。
点击这里,
看资料,真的很少,解释不多,不敢用。
互联网上最流行的 HTML 解析库是 Html Agility Pack。
使用Nuget也可以方便的引用到项目中,好省心!官网源码
阅读 Html Agility Pack 的简要介绍后,它使用 XPath 语法来检索 HTML 元素。这样够方便吗?还不够好!比如我要找一个div,只能通过index来找,比如html/body/div[4]。不开心?我还是觉得不够灵活。经过一番搜索,我发现了一个好东西,ScrapySharp,看看它是如何检索 HTML 元素的。
ScrapingBrowser browser = new ScrapingBrowser();//set UseDefaultCookiesParser as false if a website returns invalid cookies format//browser.UseDefaultCookiesParser = false;WebPage homePage = browser.NavigateToPage(new Uri("http://www.bing.com/";));PageWebForm form = homePage.FindFormById("sb_form");form["q"] = "scrapysharp";form.Method = HttpVerb.Get;WebPage resultsPage = form.Submit();HtmlNode[] resultsLinks = resultsPage.Html.CssSelect("div.sb_tlst h3 a").ToArray();WebPage blogPage = resultsPage.FindLinks(By.Text("romcyber blog | Just another WordPress site")).Single().Click()
123456789101112131415
见另一节
using System.Linq;using HtmlAgilityPack;using ScrapySharp.Extensions;class Example{ public void Main() { var divs = html.CssSelect(“div”); //all div elements var nodes = html.CssSelect(“div.content”); //all div elements with css class ‘content’ var nodes = html.CssSelect(“div.widget.monthlist”); //all div elements with the both css class var nodes = html.CssSelect(“#postPaging”); //all HTML elements with the id postPaging var nodes = html.CssSelect(“div#postPaging.testClass”); // all HTML elements with the id postPaging and css class testClass var nodes = html.CssSelect(“div.content > p.para”); //p elements who are direct children of div elements with css class ‘content’ var nodes = html.CssSelect(“input[type=text].login”); // textbox with css class login }}
12345678910111213141516171819
这不是 CSS 选择器吗?乖乖,学了jquery集后,一定喜欢~!
我还发现了一个带有 ScrapySharp 的 HTML Agility Pack 可以完全缓解 Html 解析的痛苦
两者搭配使用,威力更大~!
从网页抓取数据(Web数据收集有甚么用途吗?(Webscraping)是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-20 04:21
什么是网络数据采集
Web数据采集(Web抓取,也称为Web数据捕获)指的是一种计算机软件技术,用于防止信息丢失网站. Web数据捕获方法模仿读卡器的动作,可以提取出可以在读卡器上显示的任何数据,也称为屏幕捕获。Web数据捕获的最终目标是从大量Web页面中提取非布局信息,并以布局样式(CSV、JSON、XML、access、MSSQL、mysql等)存储
简言之,web数据采集就是从指定的网站数据中捕获所需的非布局信息数据,经过处理后作为同一模式的本地数据文件进行分析和存储,或者直接存储在本地数据库中
为什么要采集网络数据
互联网是一个巨大且快速增长的信息资本。然而,大多数信息是以文本形式存在的,没有版面,这使得信息的查询变得困难
数据采集和提取是从策略网页中提取一些数据以形成相同的本地数据模式的过程。这些数据最初仅以文本形式存在于可见网页中
假设您是团购导航站的运营商,您将如何获得每个团购站的信息?哦,不要把时间浪费在手动复制和粘贴上。你甚至不能使用复制和粘贴。您需要一个数据采集脚本来从每个团购网站获取数据并将其更新到本地数据库。专业的web数据捕获服务是采集web数据最简洁的方式。这使工作非常简单
网络数据采集的用途是什么
任何业务运营成功的基础是拥有大量的策略用户和专业数据。谁能控制用户谁就可以带头。Web数据捕获服务可以帮助您快速获取大量的政策用户和专业数据,让您在降低运营成本的同时,快速抓住机遇,占领制高点。许多客户直接受益于我们的服务或定制软件
许多客户直接受益于我们的服务或定制软件
您可以在以下领域使用我们的服务:
*你的潜在客户名单
*从竞争对手那里采集您感兴趣的信息
*捕获新兴业务数据
*建立自己的产品目录
*整合行业信息并协助制定业务决策计划
*确认新客户,增加新订单;发掘老客户并获得新的好处
*
网络数据采集的好处是什么
简单:你不需要使用任何软件。只要告诉我们您需要什么以及您的政策网站是什么,我们就可以为您获取我们捕获的数据
灵活性:您可以从任何网站获取任何数据,尤其是动态网站@
快速:对于需要20个个人工作日的工作,我们可以在几个小时内完成。因此,你不仅可以节省你的时间、精力和金钱,还可以使你领先于竞争对手
确保:提取结果的每一列都是您所需要的,并且有很多。我们将根据您的要求筛选和验证数据
低成本:与您获得的数据和服务相比,您花费的成本很小。更重要的是,你可以节省无法用金钱衡量的精神和时间,以及你付出的几倍于人力和设备的投资
网络数据采集合法吗
Web数据捕获方法的原理类似于搜索引擎的爬虫,因此是合法的 查看全部
从网页抓取数据(Web数据收集有甚么用途吗?(Webscraping)是什么)
什么是网络数据采集
Web数据采集(Web抓取,也称为Web数据捕获)指的是一种计算机软件技术,用于防止信息丢失网站. Web数据捕获方法模仿读卡器的动作,可以提取出可以在读卡器上显示的任何数据,也称为屏幕捕获。Web数据捕获的最终目标是从大量Web页面中提取非布局信息,并以布局样式(CSV、JSON、XML、access、MSSQL、mysql等)存储
简言之,web数据采集就是从指定的网站数据中捕获所需的非布局信息数据,经过处理后作为同一模式的本地数据文件进行分析和存储,或者直接存储在本地数据库中
为什么要采集网络数据
互联网是一个巨大且快速增长的信息资本。然而,大多数信息是以文本形式存在的,没有版面,这使得信息的查询变得困难
数据采集和提取是从策略网页中提取一些数据以形成相同的本地数据模式的过程。这些数据最初仅以文本形式存在于可见网页中
假设您是团购导航站的运营商,您将如何获得每个团购站的信息?哦,不要把时间浪费在手动复制和粘贴上。你甚至不能使用复制和粘贴。您需要一个数据采集脚本来从每个团购网站获取数据并将其更新到本地数据库。专业的web数据捕获服务是采集web数据最简洁的方式。这使工作非常简单
网络数据采集的用途是什么
任何业务运营成功的基础是拥有大量的策略用户和专业数据。谁能控制用户谁就可以带头。Web数据捕获服务可以帮助您快速获取大量的政策用户和专业数据,让您在降低运营成本的同时,快速抓住机遇,占领制高点。许多客户直接受益于我们的服务或定制软件
许多客户直接受益于我们的服务或定制软件
您可以在以下领域使用我们的服务:
*你的潜在客户名单
*从竞争对手那里采集您感兴趣的信息
*捕获新兴业务数据
*建立自己的产品目录
*整合行业信息并协助制定业务决策计划
*确认新客户,增加新订单;发掘老客户并获得新的好处
*
网络数据采集的好处是什么
简单:你不需要使用任何软件。只要告诉我们您需要什么以及您的政策网站是什么,我们就可以为您获取我们捕获的数据
灵活性:您可以从任何网站获取任何数据,尤其是动态网站@
快速:对于需要20个个人工作日的工作,我们可以在几个小时内完成。因此,你不仅可以节省你的时间、精力和金钱,还可以使你领先于竞争对手
确保:提取结果的每一列都是您所需要的,并且有很多。我们将根据您的要求筛选和验证数据
低成本:与您获得的数据和服务相比,您花费的成本很小。更重要的是,你可以节省无法用金钱衡量的精神和时间,以及你付出的几倍于人力和设备的投资
网络数据采集合法吗
Web数据捕获方法的原理类似于搜索引擎的爬虫,因此是合法的
从网页抓取数据( 如何向完全没有背景知识的人解释爬虫为何物? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-20 04:21
如何向完全没有背景知识的人解释爬虫为何物?
)
“当我们在网站上看到一系列地址信息、商品信息,甚至天气、新闻等真实信息,但由于数量庞大,很难通过手动复制和粘贴完全获取时,爬虫可以代替您完成所有工作
-“如何向没有背景知识的人解释爬行动物是什么?”
-“爬虫程序是一种程序,它可以浏览网页,并根据特定规则为您复制和粘贴内容。”
是的,听起来很高级。你想写代码吗?!在互联网上搜索Python+scratch功能强大,具有爆炸性。但即便如此,对于一些仅用于江湖紧急救援的简单网站数据采集来说,还是有点小题大做,普通用户可能会专注于安装Python+scratch软件包
韦伯夏普首次亮相
此时,一个chrome的爬虫插件脱颖而出!(它的名字是web scraper。web可以指网络爬虫和在线爬虫。这是一个双关语(或者我想太多了…)
这里省略了如何安装插件,在网站.简而言之,安装完成后,按chrome下的F12启动
吃椰子
别说太多,来看看椰子!哦,不,栗子
让我们在天猫上攀登“业庆”的价格吧
一,
打开页面
让我们看看我们感兴趣的“椰子绿和价格”页面
没错!我对椰子绿很感兴趣
二,
大声说出爬行动物的界面
因此,我们根据提示打开在线爬虫界面
最右边的web scraper标签是我们以前安装的crawler插件。从现在开始,我们需要为crawler建立复制和粘贴数据的规则,以防止获取一些不应该获取的不需要的数据
三,
制定规则
如前所述,爬虫是指浏览网页并为您复制和粘贴内容的东西,因此它应该模拟您的行为。首先,您打开此界面,知道此网页是“我想要的数据起点”,因此对于爬虫来说,这是它的根。因此,让我们创建一个新的爬虫并告诉他:
我们点击新建站点地图创建一个爬虫,并给它一个名称~顺便说一下,告诉它起点(当前浏览器中的网址)。然后我们将进入爬虫的根目录(淘宝):
四,
选择元素
然后我们开始获取每个商品的集合,单击添加新选择器,添加过滤器,并选择所有“椰子绿商品”元素:
同样,取一个名称,选择类型作为元素,选择商品元素。当选择两个相同的属性元素时,插件将自动检查页面上的所有属性元素
单击完成选择以完成选择并勾选多个。保存选择器
此时,我们只需要从先前筛选的项目元素中获取所需字段。同样,我们在项目目录中创建一些选择器。因为我们需要获取文本信息,所以需要将类型更改为文本
此时,一个简单的单页爬虫已经准备就绪。您也可以在sitemap的下拉菜单中选择graph来查看爬虫的结构
五,
单击“刮擦”开始攀爬
六,
下载数据
之后,数据将在窗口中自动生成。该插件具有导出为CSV的功能,只需单击一下即可下载。如果您意外关闭它,则无所谓。您可以在浏览器中看到最后捕获的数据
翻一页怎么样
如果你想翻页,那就更难了。Rocket Jun可能给出了一个想法:正如将遍历并获取项中的元素一样,同样地,在根目录中创建一个翻页链接选择器来实现“下一页”功能
将项目链接到链接选择器,并将链接选择器和先前创建的项目选择器链接到您自己,以实现无休止的循环,直到下一页不存在或下一页不可用
建立循环后,可以如下所示:
那又怎样
你可能会问:那又怎样
Rocket Jun使用此工具了解了全国各地销售的数百辆二手宝马3系车的价格。看看不同年龄段的宝马3系车在使用数年后的价格下降情况~
查看全部
从网页抓取数据(
如何向完全没有背景知识的人解释爬虫为何物?
)


“当我们在网站上看到一系列地址信息、商品信息,甚至天气、新闻等真实信息,但由于数量庞大,很难通过手动复制和粘贴完全获取时,爬虫可以代替您完成所有工作
-“如何向没有背景知识的人解释爬行动物是什么?”
-“爬虫程序是一种程序,它可以浏览网页,并根据特定规则为您复制和粘贴内容。”
是的,听起来很高级。你想写代码吗?!在互联网上搜索Python+scratch功能强大,具有爆炸性。但即便如此,对于一些仅用于江湖紧急救援的简单网站数据采集来说,还是有点小题大做,普通用户可能会专注于安装Python+scratch软件包
韦伯夏普首次亮相
此时,一个chrome的爬虫插件脱颖而出!(它的名字是web scraper。web可以指网络爬虫和在线爬虫。这是一个双关语(或者我想太多了…)
这里省略了如何安装插件,在网站.简而言之,安装完成后,按chrome下的F12启动
吃椰子
别说太多,来看看椰子!哦,不,栗子
让我们在天猫上攀登“业庆”的价格吧
一,
打开页面
让我们看看我们感兴趣的“椰子绿和价格”页面

没错!我对椰子绿很感兴趣
二,
大声说出爬行动物的界面
因此,我们根据提示打开在线爬虫界面

最右边的web scraper标签是我们以前安装的crawler插件。从现在开始,我们需要为crawler建立复制和粘贴数据的规则,以防止获取一些不应该获取的不需要的数据
三,
制定规则
如前所述,爬虫是指浏览网页并为您复制和粘贴内容的东西,因此它应该模拟您的行为。首先,您打开此界面,知道此网页是“我想要的数据起点”,因此对于爬虫来说,这是它的根。因此,让我们创建一个新的爬虫并告诉他:

我们点击新建站点地图创建一个爬虫,并给它一个名称~顺便说一下,告诉它起点(当前浏览器中的网址)。然后我们将进入爬虫的根目录(淘宝):

四,
选择元素
然后我们开始获取每个商品的集合,单击添加新选择器,添加过滤器,并选择所有“椰子绿商品”元素:

同样,取一个名称,选择类型作为元素,选择商品元素。当选择两个相同的属性元素时,插件将自动检查页面上的所有属性元素
单击完成选择以完成选择并勾选多个。保存选择器
此时,我们只需要从先前筛选的项目元素中获取所需字段。同样,我们在项目目录中创建一些选择器。因为我们需要获取文本信息,所以需要将类型更改为文本

此时,一个简单的单页爬虫已经准备就绪。您也可以在sitemap的下拉菜单中选择graph来查看爬虫的结构

五,
单击“刮擦”开始攀爬

六,
下载数据
之后,数据将在窗口中自动生成。该插件具有导出为CSV的功能,只需单击一下即可下载。如果您意外关闭它,则无所谓。您可以在浏览器中看到最后捕获的数据
翻一页怎么样
如果你想翻页,那就更难了。Rocket Jun可能给出了一个想法:正如将遍历并获取项中的元素一样,同样地,在根目录中创建一个翻页链接选择器来实现“下一页”功能
将项目链接到链接选择器,并将链接选择器和先前创建的项目选择器链接到您自己,以实现无休止的循环,直到下一页不存在或下一页不可用

建立循环后,可以如下所示:

那又怎样
你可能会问:那又怎样
Rocket Jun使用此工具了解了全国各地销售的数百辆二手宝马3系车的价格。看看不同年龄段的宝马3系车在使用数年后的价格下降情况~

从网页抓取数据(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-17 23:25
)
文章目录
站长之家注:在大数据时代,如何有效获取数据已成为推动商业决策的关键技能。分析市场趋势和监控竞争对手都需要数据采集. 网页捕获是数据采集的主要方法之一@
在本文中,克里斯托弗·齐塔将向您展示三种通过互联网赚钱的方法。学习整个过程只需几个小时,使用的代码不到50行
通过自动程序在airbnb上以最少的费用入住最好的酒店
自动化程序可以用来执行特定的操作,你可以把它们卖给那些没有技术能力赚钱的人
为了展示如何创建和销售自动化程序,Christopher zita创建了airbnb自动捕获程序。该程序允许用户输入位置。它将捕获airbnb在该地点提供的所有房屋数据,包括价格、等级、允许进入的客人数量等。所有这些都是通过捕获airbnb上的数据完成的
为了演示程序的实际操作,Christopher zita在程序中进入罗马,然后在几秒钟内获得272 airbnb的相关数据:
现在,查看所有房屋数据并对其进行过滤非常容易。以克里斯托弗·齐塔的家人为例。他们家有四口人。如果他们想去罗马,他们会在airbnb上找一家价格合理、至少有两张床的酒店。在获得此表中的数据后,Excel可以非常轻松地对其进行筛选。从这272个结果中,发现7家酒店符合要求
克里斯托弗·齐塔选择了七家酒店。因为通过数据对比可以看出,这家酒店的评级很高,是七家酒店中最便宜的,每晚只收61美元。选择所需链接后,只需将链接复制到浏览器并订阅即可
在旅行和度假时,找到一家旅馆是一项艰巨的任务。为此,有些人愿意通过付费来简化流程。有了这个自动程序,你可以在5分钟内以低价预订一个满意的房间
抓取特定商品的价格数据,以最低价格购买
网络爬网最常见的用途之一是从网站. 创建一个程序以捕获特定产品的价格数据。当价格下降到一定程度时,它会在产品售完之前自动购买产品
接下来,Christopher zita将向您展示一种省钱和赚钱的方法:
每个电子商务网站将有数量有限的特价商品。它们将显示商品的原价和折扣价,但通常不会显示在原价基础上进行了多少折扣。例如,如果一块手表的初始价格是350美元,而促销价格是300美元,你会认为50美元的折扣不是一个小数目,但实际上只是一个小数目14.2%折扣。如果一件T恤衫的初始价格是50美元,销售价格是40美元,你会认为它不便宜多少,但事实上,它的折扣率比手表高20%。因此,你可以通过购买折扣率最高的产品来省钱/赚钱
接下来,以哈德逊湾为例进行数据捕获实验,通过获取所有商品的原价和折扣价,找到折扣率最高的商品
捕获网站数据后,我们获得了900多种商品的数据,其中只有Perry Ellis纯色衬衫的折扣率超过50%
由于时间有限的折扣,这件衬衫的价格很快就会回升到90美元左右。因此,如果您现在以40美元的价格购买,在限时优惠后以60美元的价格出售,您仍然可以赚取20美元
这是一种方法。如果你找到合适的利基市场,你可能会赚很多钱
抓取宣传数据并将其可视化
网络上有数以百万计的免费数据集,这些数据通常很容易采集。当然,有些数据不容易获得,需要花费大量时间进行可视化。这就是销售数据的演变过程。天燕支票、企业支票等公司专注于获取企业工商变更信息并将其可视化,然后以“购买会员进行检查”的形式销售给用户
该公司的体育数据也有类似的模型网站BigDataBall,通过出售玩家的游戏数据和其他统计信息,用户将在网站赛季收取30美元的费用。他们设定价格不是因为网站有数据,而是因为他们获取数据,将其分类,然后以易于阅读和清晰的结构显示
现在,Christopher zita需要做的是免费获得与bigdataball相同的数据,然后将其放入结构化数据集中。Bigdataball并不是唯一拥有这些数据的网站。它有相同的数据。然而,网站并没有结构化数据,因此用户很难过滤和下载所需的数据集。Christopher zita使用网页捕获工具捕获网页中的所有玩家数据
所有NBA球员日志的结构化数据集
到目前为止,他本赛季已经赢得了16000多份球员记录。通过网络捕获,克里斯托弗·齐塔获得了数据,并在几分钟内节省了30美元
当然,与bigdataball一样,Christopher zita也可以使用网页抓取工具查找难以手动获取的数据,让计算机完成工作,然后将数据可视化并出售给对这些数据感兴趣的人
总结
如今,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果你在适当的情况下运用它,你可以很容易地赚钱
注:原文由媒体编辑而成,原文标题为“如何利用网络抓取赚钱”
每天都有一个超级实用的创业案例,扫描代码并关注[站长愿景]↓↓
查看全部
从网页抓取数据(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能
)
文章目录
站长之家注:在大数据时代,如何有效获取数据已成为推动商业决策的关键技能。分析市场趋势和监控竞争对手都需要数据采集. 网页捕获是数据采集的主要方法之一@
在本文中,克里斯托弗·齐塔将向您展示三种通过互联网赚钱的方法。学习整个过程只需几个小时,使用的代码不到50行
通过自动程序在airbnb上以最少的费用入住最好的酒店
自动化程序可以用来执行特定的操作,你可以把它们卖给那些没有技术能力赚钱的人
为了展示如何创建和销售自动化程序,Christopher zita创建了airbnb自动捕获程序。该程序允许用户输入位置。它将捕获airbnb在该地点提供的所有房屋数据,包括价格、等级、允许进入的客人数量等。所有这些都是通过捕获airbnb上的数据完成的
为了演示程序的实际操作,Christopher zita在程序中进入罗马,然后在几秒钟内获得272 airbnb的相关数据:

现在,查看所有房屋数据并对其进行过滤非常容易。以克里斯托弗·齐塔的家人为例。他们家有四口人。如果他们想去罗马,他们会在airbnb上找一家价格合理、至少有两张床的酒店。在获得此表中的数据后,Excel可以非常轻松地对其进行筛选。从这272个结果中,发现7家酒店符合要求

克里斯托弗·齐塔选择了七家酒店。因为通过数据对比可以看出,这家酒店的评级很高,是七家酒店中最便宜的,每晚只收61美元。选择所需链接后,只需将链接复制到浏览器并订阅即可

在旅行和度假时,找到一家旅馆是一项艰巨的任务。为此,有些人愿意通过付费来简化流程。有了这个自动程序,你可以在5分钟内以低价预订一个满意的房间
抓取特定商品的价格数据,以最低价格购买
网络爬网最常见的用途之一是从网站. 创建一个程序以捕获特定产品的价格数据。当价格下降到一定程度时,它会在产品售完之前自动购买产品

接下来,Christopher zita将向您展示一种省钱和赚钱的方法:
每个电子商务网站将有数量有限的特价商品。它们将显示商品的原价和折扣价,但通常不会显示在原价基础上进行了多少折扣。例如,如果一块手表的初始价格是350美元,而促销价格是300美元,你会认为50美元的折扣不是一个小数目,但实际上只是一个小数目14.2%折扣。如果一件T恤衫的初始价格是50美元,销售价格是40美元,你会认为它不便宜多少,但事实上,它的折扣率比手表高20%。因此,你可以通过购买折扣率最高的产品来省钱/赚钱
接下来,以哈德逊湾为例进行数据捕获实验,通过获取所有商品的原价和折扣价,找到折扣率最高的商品

捕获网站数据后,我们获得了900多种商品的数据,其中只有Perry Ellis纯色衬衫的折扣率超过50%

由于时间有限的折扣,这件衬衫的价格很快就会回升到90美元左右。因此,如果您现在以40美元的价格购买,在限时优惠后以60美元的价格出售,您仍然可以赚取20美元
这是一种方法。如果你找到合适的利基市场,你可能会赚很多钱
抓取宣传数据并将其可视化
网络上有数以百万计的免费数据集,这些数据通常很容易采集。当然,有些数据不容易获得,需要花费大量时间进行可视化。这就是销售数据的演变过程。天燕支票、企业支票等公司专注于获取企业工商变更信息并将其可视化,然后以“购买会员进行检查”的形式销售给用户
该公司的体育数据也有类似的模型网站BigDataBall,通过出售玩家的游戏数据和其他统计信息,用户将在网站赛季收取30美元的费用。他们设定价格不是因为网站有数据,而是因为他们获取数据,将其分类,然后以易于阅读和清晰的结构显示

现在,Christopher zita需要做的是免费获得与bigdataball相同的数据,然后将其放入结构化数据集中。Bigdataball并不是唯一拥有这些数据的网站。它有相同的数据。然而,网站并没有结构化数据,因此用户很难过滤和下载所需的数据集。Christopher zita使用网页捕获工具捕获网页中的所有玩家数据

所有NBA球员日志的结构化数据集
到目前为止,他本赛季已经赢得了16000多份球员记录。通过网络捕获,克里斯托弗·齐塔获得了数据,并在几分钟内节省了30美元
当然,与bigdataball一样,Christopher zita也可以使用网页抓取工具查找难以手动获取的数据,让计算机完成工作,然后将数据可视化并出售给对这些数据感兴趣的人
总结
如今,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果你在适当的情况下运用它,你可以很容易地赚钱
注:原文由媒体编辑而成,原文标题为“如何利用网络抓取赚钱”
每天都有一个超级实用的创业案例,扫描代码并关注[站长愿景]↓↓

从网页抓取数据(从网页抓取数据,然后分析其结构,找到产品在哪些网站进行了售卖)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-15 23:06
从网页抓取数据,然后分析其结构,通过关联查询,找到产品在哪些网站进行了售卖,并把抓取的这些数据表放在数据库里进行统计分析(是否有优惠券、发货时间、发货地址等等,总之就是商品信息),当然实际上应该还会进行一些其他处理,比如社交网络的分析,进行一些推荐。
作为一名卖家的老总,你要明白别人是怎么卖东西给你的,如果别人在卖这件产品之前已经编写好了卖给你的代码,你需要自己的产品推荐和商品管理才能卖出去你手上的这件产品,当然手上已经有顾客订单,比如说一大群的顾客买了你的商品,那么就需要考虑顾客更偏好于哪些商品,比如说你的鞋子偏向于休闲,偏向于搭配。那么你应该给他推荐一些休闲品牌的鞋子。
这样提高顾客的体验。当顾客买了之后,就考虑怎么把这些数据分析好之后进行推广,和引流。比如说把商品推送给老客户。通过一些推广活动让更多的人看到你的商品。这些都是要找到卖什么产品才可以去做的。
大概方向有这么几类:1.卖到哪里去2.买多少3.卖给谁
1.从网页抓取海量信息,进行结构化分析2.根据自己的分析,给产品进行广告投放,
可以理解为抓取海量信息,但后台需要进行数据挖掘,进行定向投放,海量广告位投放, 查看全部
从网页抓取数据(从网页抓取数据,然后分析其结构,找到产品在哪些网站进行了售卖)
从网页抓取数据,然后分析其结构,通过关联查询,找到产品在哪些网站进行了售卖,并把抓取的这些数据表放在数据库里进行统计分析(是否有优惠券、发货时间、发货地址等等,总之就是商品信息),当然实际上应该还会进行一些其他处理,比如社交网络的分析,进行一些推荐。
作为一名卖家的老总,你要明白别人是怎么卖东西给你的,如果别人在卖这件产品之前已经编写好了卖给你的代码,你需要自己的产品推荐和商品管理才能卖出去你手上的这件产品,当然手上已经有顾客订单,比如说一大群的顾客买了你的商品,那么就需要考虑顾客更偏好于哪些商品,比如说你的鞋子偏向于休闲,偏向于搭配。那么你应该给他推荐一些休闲品牌的鞋子。
这样提高顾客的体验。当顾客买了之后,就考虑怎么把这些数据分析好之后进行推广,和引流。比如说把商品推送给老客户。通过一些推广活动让更多的人看到你的商品。这些都是要找到卖什么产品才可以去做的。
大概方向有这么几类:1.卖到哪里去2.买多少3.卖给谁
1.从网页抓取海量信息,进行结构化分析2.根据自己的分析,给产品进行广告投放,
可以理解为抓取海量信息,但后台需要进行数据挖掘,进行定向投放,海量广告位投放,
从网页抓取数据(从网页抓取数据,要完整打包压缩为json格式的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-14 02:04
从网页抓取数据,要完整打包压缩为json格式的数据,比如js都是javascript和css都是css之类的。这样dom树就完整了。你提到的字体展示什么的,不是一次就要全文获取,那是很多网页都有的功能吗?很少去抓取javascript和css,那是chrome的能力。javascript可以按文件获取,甚至可以用javascript的变量function抓取。
你需要jqueryitems.all就是你要的
首先你要安装$npminstall-gjquery用jquery要把文件夹一层一层抓
据我所知,
javascript也不行?
除了chrome自带的javascript,
javascript很难抓
一般浏览器都自带了抓取数据文件的驱动。你可以用jsonrpc的方式访问一个googleaccount下的文件夹,
你还要注意抓取数据是要按照json格式
谢邀
写个脚本。爬虫根据你的类别构造一份比对表。或者直接从目录读一个字典出来。
虽然我只能安利个scrapy框架。但是我还是有一些自己的看法啊题主喜欢抓取网页信息,而javascript这种东西说到底是浏览器的高级脚本技术而已,用不到浏览器的核心,加之实际上没有什么必要,因此就chrome来说还是可以用document.cookie,我一直觉得javascript的成功一半取决于webkit的存在而另一半就是webkit能够支持一个local这样神奇的标准,但是用户输入相关字段是否会被记录关注到,var是没用的,我们能做的只是如同计算机登录网站一样得到一串唯一的值,有这样的一个便捷设定么?浏览器cookie不起作用,所以如果想抓取javascript的话,只能是安装一个浏览器插件再配合相应的api抓取相关字段,当然你用什么都可以,记得注意cookie这个东西不可以把自己注入进去,不然你会哭的。所以多用现有框架其实并不是件坏事。 查看全部
从网页抓取数据(从网页抓取数据,要完整打包压缩为json格式的数据)
从网页抓取数据,要完整打包压缩为json格式的数据,比如js都是javascript和css都是css之类的。这样dom树就完整了。你提到的字体展示什么的,不是一次就要全文获取,那是很多网页都有的功能吗?很少去抓取javascript和css,那是chrome的能力。javascript可以按文件获取,甚至可以用javascript的变量function抓取。
你需要jqueryitems.all就是你要的
首先你要安装$npminstall-gjquery用jquery要把文件夹一层一层抓
据我所知,
javascript也不行?
除了chrome自带的javascript,
javascript很难抓
一般浏览器都自带了抓取数据文件的驱动。你可以用jsonrpc的方式访问一个googleaccount下的文件夹,
你还要注意抓取数据是要按照json格式
谢邀
写个脚本。爬虫根据你的类别构造一份比对表。或者直接从目录读一个字典出来。
虽然我只能安利个scrapy框架。但是我还是有一些自己的看法啊题主喜欢抓取网页信息,而javascript这种东西说到底是浏览器的高级脚本技术而已,用不到浏览器的核心,加之实际上没有什么必要,因此就chrome来说还是可以用document.cookie,我一直觉得javascript的成功一半取决于webkit的存在而另一半就是webkit能够支持一个local这样神奇的标准,但是用户输入相关字段是否会被记录关注到,var是没用的,我们能做的只是如同计算机登录网站一样得到一串唯一的值,有这样的一个便捷设定么?浏览器cookie不起作用,所以如果想抓取javascript的话,只能是安装一个浏览器插件再配合相应的api抓取相关字段,当然你用什么都可以,记得注意cookie这个东西不可以把自己注入进去,不然你会哭的。所以多用现有框架其实并不是件坏事。
从网页抓取数据(从网上抓取数据的方法总结,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-10-10 16:34
首先要知道的是,有很多方法可以从互联网上抓取数据。抓取的来源主要有两种,一种是html网页,一种是json。
从网上抓取这两个东西的时候,不用全用R,用java、php、python之类的就可以快速完成任务。问题的关键在于文档的解析。至于通过网站获取json接口,这是老手的经验。
文档对象模型
不管你使用任何语言或工具,重要的是你必须了解文档对象模型——这很重要!如果你对文档对象模型有深刻的理解,从网上抓取数据就像回家一样容易。
上图是对文档对象模型的直观印象。您打开的任何网页都可以转换为上图。一个文档就是一个页面,然后从根开始,一直向下细分。学过数据结构就好了,没学也没关系,你要知道的是,它是一棵“树”——如果把它倒过来,会更生动,我们总是从根 出发去寻找一些东西。例如,假设我要访问写着"text:"my link"的节点,我们需要从根元素开始,然后找到元素,然后找到元素,然后找到我们要找的节点。这些节点是路径和引导我们可以从根节点中找到我们需要的节点,路径很重要,一旦理解了就可以使用java的jsoup,或者php'
我将引用 W3School 提供的另一个示例
哈利波特
JK罗琳
2005年
29.99
这是一个xml文件,是另一种用图片表示文档的方式,如上图,它们没有什么不同。第一行规定它是一个xml文件。从一开始,它将是根节点,然后是诸如下面的节点。
那么下面,直接引用w3school的原文,里面介绍了节点的分类,类似于人类社会种族的分类,很简单:
上述 XML 文档中的节点示例:
(文档节点)
J K. Rowling(元素节点)(属性节点)
基本值(或原子值,Atomic value)基本值是一个没有父节点或子节点的节点。
基本值示例:
J K.罗琳“en”
物品
项目是基本值或节点。
节点关系
父级(Parent) 每个元素和属性都有一个父级。
在以下示例中, book 元素是 title、author、year 和 price 元素的父元素:
哈利波特 J K. 罗琳 2005
29.99
Children 元素节点可以有零个、一个或多个子节点。
在下面的例子中,title、author、year 和 price 元素都是 book 元素的子元素:
哈利波特 J K. 罗琳 2005
29.99
具有相同父节点的兄弟节点
在以下示例中,title、author、year 和 price 元素都是同级元素:
哈利波特 J K. 罗琳 2005
29.99
祖先(Ancestor)节点的父节点、父节点的父节点等等。
在以下示例中,title 元素的祖先是 book 元素和 bookstore 元素:
哈利波特 J K. 罗琳 2005
29.99
后代节点的子节点、子节点的子节点等。
在以下示例中, bookstore 的后代是 book、title、author、year 和 price 元素:
哈利波特 J K. 罗琳 2005
29.99 查看全部
从网页抓取数据(从网上抓取数据的方法总结,你知道几个?)
首先要知道的是,有很多方法可以从互联网上抓取数据。抓取的来源主要有两种,一种是html网页,一种是json。
从网上抓取这两个东西的时候,不用全用R,用java、php、python之类的就可以快速完成任务。问题的关键在于文档的解析。至于通过网站获取json接口,这是老手的经验。
文档对象模型
不管你使用任何语言或工具,重要的是你必须了解文档对象模型——这很重要!如果你对文档对象模型有深刻的理解,从网上抓取数据就像回家一样容易。
上图是对文档对象模型的直观印象。您打开的任何网页都可以转换为上图。一个文档就是一个页面,然后从根开始,一直向下细分。学过数据结构就好了,没学也没关系,你要知道的是,它是一棵“树”——如果把它倒过来,会更生动,我们总是从根 出发去寻找一些东西。例如,假设我要访问写着"text:"my link"的节点,我们需要从根元素开始,然后找到元素,然后找到元素,然后找到我们要找的节点。这些节点是路径和引导我们可以从根节点中找到我们需要的节点,路径很重要,一旦理解了就可以使用java的jsoup,或者php'
我将引用 W3School 提供的另一个示例
哈利波特
JK罗琳
2005年
29.99
这是一个xml文件,是另一种用图片表示文档的方式,如上图,它们没有什么不同。第一行规定它是一个xml文件。从一开始,它将是根节点,然后是诸如下面的节点。
那么下面,直接引用w3school的原文,里面介绍了节点的分类,类似于人类社会种族的分类,很简单:
上述 XML 文档中的节点示例:
(文档节点)
J K. Rowling(元素节点)(属性节点)
基本值(或原子值,Atomic value)基本值是一个没有父节点或子节点的节点。
基本值示例:
J K.罗琳“en”
物品
项目是基本值或节点。
节点关系
父级(Parent) 每个元素和属性都有一个父级。
在以下示例中, book 元素是 title、author、year 和 price 元素的父元素:
哈利波特 J K. 罗琳 2005
29.99
Children 元素节点可以有零个、一个或多个子节点。
在下面的例子中,title、author、year 和 price 元素都是 book 元素的子元素:
哈利波特 J K. 罗琳 2005
29.99
具有相同父节点的兄弟节点
在以下示例中,title、author、year 和 price 元素都是同级元素:
哈利波特 J K. 罗琳 2005
29.99
祖先(Ancestor)节点的父节点、父节点的父节点等等。
在以下示例中,title 元素的祖先是 book 元素和 bookstore 元素:
哈利波特 J K. 罗琳 2005
29.99
后代节点的子节点、子节点的子节点等。
在以下示例中, bookstore 的后代是 book、title、author、year 和 price 元素:
哈利波特 J K. 罗琳 2005
29.99
从网页抓取数据( 如何用PowerBI批量采集多个网页的数据(一)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-10-09 07:13
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不会再有延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论: 查看全部
从网页抓取数据(
如何用PowerBI批量采集多个网页的数据(一)?)
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI采集第一页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试采集一页,如果可以采集,则使用上面的步骤,如果采集不行当它到达时,不会再有延迟。
现在打开 PowerBI 并尝试抓取您感兴趣的 网站 数据。
Power Query 系列评论:
从网页抓取数据( Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2021-10-09 07:13
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。
方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?
这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。 查看全部
从网页抓取数据(
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。
方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?
这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。
从网页抓取数据(【技巧】登录方法3使用mvc的对象属性自动封装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 11:21
页面代码,使用操作提交带有球ID、球所有者、球颜色、省和地区的表单
____ID
颜__色
主__人
省__份
行政区
打印请求,您可以看到参数:
这样做的优点是表单中的字段可以自由定义,而不必与模型中的属性相对应
提取时,只要满足请求就可以完成。Getparameter(将字段写入此处的表单中)。易于使用
方法2将表单的参数直接写入控制器相应方法的形式参数中
它适用于参数很少的情况,例如登录
方法3使用MVC的对象属性来自动封装,也就是说,一个bean用于接收
在页面的输入框中,名称应与模型的属性名称相同
这是一个模型
提交页面时,将该字段更改为模型中的属性名称以测试结果
4.通过JSON接收数据
您需要使用ajax,但还没有学会 查看全部
从网页抓取数据(【技巧】登录方法3使用mvc的对象属性自动封装)
页面代码,使用操作提交带有球ID、球所有者、球颜色、省和地区的表单
____ID
颜__色
主__人
省__份
行政区
打印请求,您可以看到参数:
这样做的优点是表单中的字段可以自由定义,而不必与模型中的属性相对应
提取时,只要满足请求就可以完成。Getparameter(将字段写入此处的表单中)。易于使用
方法2将表单的参数直接写入控制器相应方法的形式参数中
它适用于参数很少的情况,例如登录
方法3使用MVC的对象属性来自动封装,也就是说,一个bean用于接收
在页面的输入框中,名称应与模型的属性名称相同
这是一个模型
提交页面时,将该字段更改为模型中的属性名称以测试结果
4.通过JSON接收数据
您需要使用ajax,但还没有学会
从网页抓取数据(从网页抓取数据需要抓取浏览器的历史记录(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 04:03
从网页抓取数据需要抓取浏览器的历史记录,然后进行标注、分析。至于分析的框架没有,因为任何一个客户端都会记录相关的历史记录,只是有些比较老的浏览器会加入浏览器的安全性级别,才会记录不同的记录。
时隔多年,看到这个问题的我也是不知所措(;′⌒`)才疏学浅,还是想说一下一些思路吧我们可以通过一些高校的网页提供给我们历史记录,然后通过一些机器学习的方法根据我们提供的信息和基于机器学习的方法识别这些记录,然后进行重构或者预处理可以识别,并且得到准确的预测结果总体思路应该还是这样以下是我查到的一些论文,不知道说清楚没有如果想自己搭建,多看看前辈们的东西吧。
单纯的重新打字不是事,只要能打的出来。需要:历史记录抓取、数据库管理、一定的高校历史数据库(本校的)以及与上一个数据库交互的底层接口,提取关键点,能实现真正的数据抓取并解析。
楼上的两位,我就找到这个。python3你们拿走。
我最近也在找这个问题,发现论文很多,如何能快速方便的找到这些论文的抓取数据呢,
看了他们大部分免费的论文数据,但是有些好像是过时的,
其实可以用百度站长平台。 查看全部
从网页抓取数据(从网页抓取数据需要抓取浏览器的历史记录(图))
从网页抓取数据需要抓取浏览器的历史记录,然后进行标注、分析。至于分析的框架没有,因为任何一个客户端都会记录相关的历史记录,只是有些比较老的浏览器会加入浏览器的安全性级别,才会记录不同的记录。
时隔多年,看到这个问题的我也是不知所措(;′⌒`)才疏学浅,还是想说一下一些思路吧我们可以通过一些高校的网页提供给我们历史记录,然后通过一些机器学习的方法根据我们提供的信息和基于机器学习的方法识别这些记录,然后进行重构或者预处理可以识别,并且得到准确的预测结果总体思路应该还是这样以下是我查到的一些论文,不知道说清楚没有如果想自己搭建,多看看前辈们的东西吧。
单纯的重新打字不是事,只要能打的出来。需要:历史记录抓取、数据库管理、一定的高校历史数据库(本校的)以及与上一个数据库交互的底层接口,提取关键点,能实现真正的数据抓取并解析。
楼上的两位,我就找到这个。python3你们拿走。
我最近也在找这个问题,发现论文很多,如何能快速方便的找到这些论文的抓取数据呢,
看了他们大部分免费的论文数据,但是有些好像是过时的,
其实可以用百度站长平台。
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-04 12:02
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例,详细介绍Python爬虫。基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... %3Bbr />
现在启动 Jupyter notebook 并运行以下代码
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为它足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整的代码
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br /> 查看全部
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例,详细介绍Python爬虫。基本流程。如果您还处于初始爬虫阶段或者不了解爬虫的具体工作流程,那么您应该仔细阅读本文!
第 1 步:尝试请求
先到b站首页,点击排行榜,复制链接
https://www.bilibili.com/ranki ... %3Bbr />
现在启动 Jupyter notebook 并运行以下代码
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第二步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。
在 Python 中有很多方法可以解析网页。您可以使用正则表达式,也可以使用 BeautifulSoup、pyquery 或 lxml。本文将基于 BeautifulSoup 来解释它们。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步:提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签。在列表页面上按 F12 并按照下面的说明找到它。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' 否则会出现中文乱码的问题
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
概括
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜正是因为它足够简单,希望通过这个案例,让大家了解爬取的基本过程,最后附上完整的代码
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br />
从网页抓取数据(从网页抓取数据当然可以,你得有网站吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-03 23:06
从网页抓取数据当然可以,只要你是正常做网站就可以去抓取数据,但是有一点前提:你得有网站。
网站的判定标准已经有很多人在做了,这里不再赘述。抓取数据就简单了,使用webscraper就可以。
可以的。我自己在做的云享客的数据库。可以免费试用。价格也不贵。
可以的呀,
可以试试这个,foliojson,快速采集数据,
可以sql采集,但是存储,索引方面的问题就不要用sql写了,没必要弄那么复杂,这个模板目前在优化中,想尽快上线的话还可以考虑先发布这个程序,可以参考一下,很适合这种小型网站~你试试吧~用户量不大,数据类型不复杂,
bootstrap可以支持这个功能,但是要注意加载时间,
3、4秒的样子,而且并发可能没有,一般数据库有多个,这个建议后期根据实际情况做后台服务器配置。
php和sql都没问题,
1、数据格式要跟官方的一致,如果是json、blob就需要参考官方的文档要求,不然容易报错。
2、收集字段要大,要不然收集后数据库的查询会很慢很慢,测试效果是好还是坏?再查一次。
我在做wordpress的那个引擎userdata-wordpress/
可以有的,不过用别人写好的比较好,可以看看我们开源的yii引擎, 查看全部
从网页抓取数据(从网页抓取数据当然可以,你得有网站吗?)
从网页抓取数据当然可以,只要你是正常做网站就可以去抓取数据,但是有一点前提:你得有网站。
网站的判定标准已经有很多人在做了,这里不再赘述。抓取数据就简单了,使用webscraper就可以。
可以的。我自己在做的云享客的数据库。可以免费试用。价格也不贵。
可以的呀,
可以试试这个,foliojson,快速采集数据,
可以sql采集,但是存储,索引方面的问题就不要用sql写了,没必要弄那么复杂,这个模板目前在优化中,想尽快上线的话还可以考虑先发布这个程序,可以参考一下,很适合这种小型网站~你试试吧~用户量不大,数据类型不复杂,
bootstrap可以支持这个功能,但是要注意加载时间,
3、4秒的样子,而且并发可能没有,一般数据库有多个,这个建议后期根据实际情况做后台服务器配置。
php和sql都没问题,
1、数据格式要跟官方的一致,如果是json、blob就需要参考官方的文档要求,不然容易报错。
2、收集字段要大,要不然收集后数据库的查询会很慢很慢,测试效果是好还是坏?再查一次。
我在做wordpress的那个引擎userdata-wordpress/
可以有的,不过用别人写好的比较好,可以看看我们开源的yii引擎,
从网页抓取数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-29 02:01
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。
扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中,例如 FORTRAN、COBOL 和 Ada 语言。 查看全部
从网页抓取数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。
扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中,例如 FORTRAN、COBOL 和 Ada 语言。
从网页抓取数据(如何从网站爬网数据中获取结构化数据?() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-29 02:00
)
原创来源:作品(从 网站 获取数据的 3 种最佳方法)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 窗格中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6 到 14 台云服务器将同时以更高的速度运行您的任务,并执行更大范围的抓取。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载其桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都附带终身免费价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和 RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站关键字,在.gov网站上进行研究,采集数据并发表评论,而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。
查看全部
从网页抓取数据(如何从网站爬网数据中获取结构化数据?()
)
原创来源:作品(从 网站 获取数据的 3 种最佳方法)/ 网站 名称(Octoparse)
原创链接:从网站抓取数据的最佳 3 种方法
这几年,对爬取数据的需求越来越大。爬取的数据可用于不同领域的评估或预测。在这里,我想谈谈我们可以用来从网站 中抓取数据的三种方法。
1.使用网站API
许多大型社交媒体网站,例如 Facebook、Twitter、Instagram、StackOverflow,都提供 API 供用户访问其数据。有时,您可以选择官方 API 来获取结构化数据。如下面的 Facebook Graph API 所示,您需要选择要查询的字段,然后对数据进行排序、执行 URL 查找、发出请求等。要了解更多信息,请参阅 /docs/graph-api/using-graph-api。
2.创建自己的搜索引擎
但是,并非所有 网站 都为用户提供 API。一些网站由于技术限制或其他原因拒绝提供任何公共API。有人可能会提出RSS提要,但由于它们的使用受到限制,我不会对其提出建议或评论。在这种情况下,我想讨论的是,我们可以构建自己的爬虫来处理这种情况。
搜索引擎是如何工作的?换句话说,爬虫是一种生成可以由提取程序提供的 URL 列表的方法。 爬虫可以定义为查找 URL 的工具。首先,您需要为爬虫提供一个要启动的网页,它们将跟踪该页面上的所有这些链接。然后,这个过程将继续循环。
然后,我们可以继续构建自己的爬虫。众所周知,Python是一门开源的编程语言,你可以找到很多有用的函数库。在这里,我推荐使用 BeautifulSoup(Python 库),因为它易于使用且具有许多直观的字符。更准确地说,我将使用两个 Python 模块来抓取数据。
BeautifulSoup 无法为我们获取网页。这就是我将 urllib2 与 BeautifulSoup 库结合使用的原因。然后,我们需要处理 HTML 标记以找到页面标记和右侧表格中的所有链接。之后,遍历每一行 (tr),然后将 tr (td) 的每个元素分配给一个变量并将其附加到列表中。首先让我们看一下表格的HTML结构(我不会从表格标题中提取信息)。
通过采用这种方法,您的搜索引擎是定制的。它可以处理API提取中遇到的某些困难。您可以使用代理来防止它被某些网站 等阻止,整个过程都在您的控制之下。这种方法对于具有编码技能的人来说应该是有意义的。您抓取的数据框应如下图所示。
3.使用现成的爬虫工具
但是,自行以编程方式抓取 网站 可能会很耗时。对于没有任何编码技能的人来说,这将是一项艰巨的任务。因此,我想介绍一些搜索引擎工具。
八度分析
Octoparse 是一个强大的基于 Visual Windows 的 Web 数据搜索器。用户可以通过其简单友好的用户界面轻松掌握该工具。要使用它,您需要在本地桌面上下载此应用程序。
如下图所示,您可以在 Workflow Designer 窗格中单击并拖动这些块来自定义您自己的任务。Octoparse 提供两种版本的爬虫服务订阅计划免费版和付费版。两者都可以满足用户的基本爬取或爬取需求。使用免费版本,您可以在本地运行任务。
如果您从免费版本切换到付费版本,您可以通过将任务上传到云平台来使用基于云的服务。6 到 14 台云服务器将同时以更高的速度运行您的任务,并执行更大范围的抓取。此外,您可以使用 Octoparse 的匿名代理功能自动提取数据,不留任何痕迹。这个功能可以轮流使用大量的IP,可以防止你被某些网站屏蔽。这是一个介绍 Octoparse 云提取的视频。
Octoparse 还提供 API 以将您的系统实时连接到您抓取的数据。您可以将 Octoparse 数据导入您自己的数据库,也可以使用 API 请求访问您的帐户数据。完成任务配置后,您可以将数据导出为各种格式,如CSV、Excel、HTML、TXT 和数据库(MySQL、SQL Server 和Oracle)。
进口
Import.io 也被称为网络爬虫,涵盖所有不同层次的搜索需求。它提供了一个神奇的工具,无需任何培训即可将站点转换为表格。如果需要抓取更复杂的网站,建议用户下载其桌面应用。构建 API 后,他们将提供许多简单的集成选项,例如 Google Sheets、Plot.ly、Excel 以及 GET 和 POST 请求。当您认为所有这些都附带终身免费价格标签和强大的支持团队时,import.io 无疑是那些寻找结构化数据的人的首选。它们还为寻求更大或更复杂数据提取的公司提供企业级支付选项。
本善达
Mozenda 是另一个用户友好的网络数据提取器。它有一个指向用户的点击式 UI,无需任何编码技能即可使用。Mozenda 还消除了自动化和发布提取数据的麻烦。一次告诉Mozenda你想要什么数据,然后不管你需要多少次都可以得到。此外,它还允许使用 REST API 进行高级编程,用户可以直接连接 Mozenda 帐户。它还提供基于云的服务和 IP 轮换。
刮框
SEO 专家、在线营销人员甚至垃圾邮件发送者都应该非常熟悉 ScrapeBox,它具有非常人性化的界面。用户可以轻松地从网站 采集数据以获取电子邮件、查看页面排名、验证工作代理和 RSS 提交。通过使用数以千计的轮换代理,您将能够隐藏竞争对手的网站关键字,在.gov网站上进行研究,采集数据并发表评论,而不会被阻止或检测到。
谷歌网络爬虫插件
如果人们只是想以简单的方式抓取数据,我建议您选择 Google Web Scraper 插件。它是一种基于浏览器的网页抓取工具,其工作方式类似于 Firefox 的 Outwit Hub。您可以将其作为扩展下载并安装在浏览器中。您需要突出显示要抓取的数据字段,右键单击并选择“Scrape like...”。与您突出显示的内容类似的任何内容都将显示在准备导出的表格中,并且与 Google Docs 兼容。最新版本的电子表格仍有一些错误。虽然操作简单,应该会吸引所有用户的注意力,但它无法抓取图像和抓取大量数据。
从网页抓取数据(SEO专员绞尽脑汁进行网站优化,创建原创内容的抓取习惯)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-28 16:58
SEO专家绞尽脑汁优化网站、布局关键词、发布外链、制作原创内容,都是为了吸引搜索引擎网站爬爬爬取< @网站内容,从而收录网站,提升网站的排名。
但是搜索引擎爬取网站内容的技术是什么?其实只要分析一下搜索引擎抓取到的内容的数据,就可以了解搜索引擎的抓取习惯。
网站的操作具体分析-小编推荐四个方面:搜索引擎对整个网站的抓取频率,搜索引擎对页面的抓取频率,内容的分布网站 被搜索引擎抓取以及被搜索引擎抓取的各类网页。
一、网站 抓取频率的搜索引擎
通过了解这个频率,分析数据,可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容更新正常,并且网站没有大的变化,但是突然整个网站的搜索引擎的频率突然下降,那么无外乎两个原因,或者网站的操作有问题,或者搜索引擎觉得这个网站有漏洞,质量不够好。
如果爬取的频率突然增加,可能是随着网站内容的不断增加和权重的积累,一直受到搜索引擎的青睐,但会逐渐趋于稳定。
二、搜索引擎抓取页面的频率
了解此频率有助于调整 Web 内容更新的频率。搜索引擎为用户显示的每一个搜索结果都对应于互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。
三、搜索引擎抓取的内容分布
搜索引擎对网站内容的爬取分布,结合搜索引擎收录网站的情况。搜索引擎通过了解网站中各个频道的内容更新状态,搜索引擎收录的状态,以及搜索引擎对该频道的每日抓取量是否来确定网站的内容抓取是比例分配。
四、搜搜引擎抓取各类网页
每个网站收录不同类型的网页,如首页、文章页面、频道页、栏目页等。通过了解搜索引擎对每种类型网页的抓取,我们可以了解是哪些类型的的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。
原文来自365发布网/ 查看全部
从网页抓取数据(SEO专员绞尽脑汁进行网站优化,创建原创内容的抓取习惯)
SEO专家绞尽脑汁优化网站、布局关键词、发布外链、制作原创内容,都是为了吸引搜索引擎网站爬爬爬取< @网站内容,从而收录网站,提升网站的排名。
但是搜索引擎爬取网站内容的技术是什么?其实只要分析一下搜索引擎抓取到的内容的数据,就可以了解搜索引擎的抓取习惯。
网站的操作具体分析-小编推荐四个方面:搜索引擎对整个网站的抓取频率,搜索引擎对页面的抓取频率,内容的分布网站 被搜索引擎抓取以及被搜索引擎抓取的各类网页。
一、网站 抓取频率的搜索引擎
通过了解这个频率,分析数据,可以大致了解网站在搜索引擎眼中的整体形象。如果网站的内容更新正常,并且网站没有大的变化,但是突然整个网站的搜索引擎的频率突然下降,那么无外乎两个原因,或者网站的操作有问题,或者搜索引擎觉得这个网站有漏洞,质量不够好。
如果爬取的频率突然增加,可能是随着网站内容的不断增加和权重的积累,一直受到搜索引擎的青睐,但会逐渐趋于稳定。
二、搜索引擎抓取页面的频率
了解此频率有助于调整 Web 内容更新的频率。搜索引擎为用户显示的每一个搜索结果都对应于互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。
三、搜索引擎抓取的内容分布
搜索引擎对网站内容的爬取分布,结合搜索引擎收录网站的情况。搜索引擎通过了解网站中各个频道的内容更新状态,搜索引擎收录的状态,以及搜索引擎对该频道的每日抓取量是否来确定网站的内容抓取是比例分配。
四、搜搜引擎抓取各类网页
每个网站收录不同类型的网页,如首页、文章页面、频道页、栏目页等。通过了解搜索引擎对每种类型网页的抓取,我们可以了解是哪些类型的的网页搜索引擎更喜欢抓取,这将有助于我们调整网站的结构。
原文来自365发布网/
从网页抓取数据( 手动输入效率太慢写的是什么?有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-28 14:14
手动输入效率太慢写的是什么?有什么区别?)
//要抓取数据的页面路径
string url = "http://www.scedu.net/banshi/us ... 3B%3B
//将页面上的数据转换为HTML
string html = Method.GetHtmlData(url);
// txt_content.Text = html;
//找到需要的数据匹配正则 (?.+?)
string regex = @"(?.+?)";
Regex listRegex = new Regex(regex, RegexOptions.Multiline | RegexOptions.IgnoreCase);
//得到匹配的数据集合
MatchCollection mc = listRegex.Matches(html);
JCheng.Model.School Model = new JCheng.Model.School();
//将得到的字符串分割存进数组
string[] str = txt_content.Text.Substring(0, txt_content.Text.Length - 1).Replace("<br />", "").Split(',');
//数据每六个为一个model类 ,如下循环添加入库。
for (int i = 0; i < str.Length - 1; )
{
Model.sName = str[i];
Model.sAddress = str[i + 1];
Model.sPostCode = str[i + 2];
Model.sPhone = str[i + 3];
Model.sEmail = str[i + 4];
Model.sClass = str[i + 5];
new JCheng.BLL.School().Add(Model);
i += 6;
}
经常遇到需要阅读省、市、县等信息的情况。数据庞大,人工输入效率太慢。上面的代码是一个区县所有中学信息的列表。用在数据库里,很爽快。哈哈,第一次做数据采集。代码肯定写得不好。让我们记录下来。我希望它会对大家有所帮助。 查看全部
从网页抓取数据(
手动输入效率太慢写的是什么?有什么区别?)
//要抓取数据的页面路径
string url = "http://www.scedu.net/banshi/us ... 3B%3B
//将页面上的数据转换为HTML
string html = Method.GetHtmlData(url);
// txt_content.Text = html;
//找到需要的数据匹配正则 (?.+?)
string regex = @"(?.+?)";
Regex listRegex = new Regex(regex, RegexOptions.Multiline | RegexOptions.IgnoreCase);
//得到匹配的数据集合
MatchCollection mc = listRegex.Matches(html);
JCheng.Model.School Model = new JCheng.Model.School();
//将得到的字符串分割存进数组
string[] str = txt_content.Text.Substring(0, txt_content.Text.Length - 1).Replace("<br />", "").Split(',');
//数据每六个为一个model类 ,如下循环添加入库。
for (int i = 0; i < str.Length - 1; )
{
Model.sName = str[i];
Model.sAddress = str[i + 1];
Model.sPostCode = str[i + 2];
Model.sPhone = str[i + 3];
Model.sEmail = str[i + 4];
Model.sClass = str[i + 5];
new JCheng.BLL.School().Add(Model);
i += 6;
}
经常遇到需要阅读省、市、县等信息的情况。数据庞大,人工输入效率太慢。上面的代码是一个区县所有中学信息的列表。用在数据库里,很爽快。哈哈,第一次做数据采集。代码肯定写得不好。让我们记录下来。我希望它会对大家有所帮助。
从网页抓取数据(Crawl-firstSEO主要关注搜索引擎基础架构的12个指南!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-28 14:08
Crawl-firstSEO 专注于搜索引擎基础架构的两个主要部分:抓取和索引。如果 网站 上的所有页面都没有被抓取,则它们无法被索引。如果您的页面无法编入索引,它们将不会出现在搜索引擎结果页面 (SERP) 中。
搜索引擎优先抓取确保 网站 上存在的所有页面都被抓取和索引,之后它们将被定位在 SERP 中。被搜索引擎抓取后,您可以:
但在抢客户的网站之前,一定要遵守12条准则。
在配置爬取之前从客户端采集信息和数据1. 向您的客户发送爬取问卷文档
在本文档中,您应该提出以下问题:您的 网站 上有多少产品?
这是一个你无法回答的问题。您无法知道数据库中的产品数量,也不知道其中有多少在线可用。相反,您的客户会知道这个问题的答案,他们可以轻松回答您的问题。
我遇到过很多客户,他们有一个共同点:他们不知道他们的 网站 上有多少产品。了解客户端上有多少产品,是爬取网站之前需要了解的最重要信息。这也是你要在网站上进行“第一次SEO抓取审核”的最重要原因。
您必须知道在线提供的产品数量,因为您将在 SEO 审查结束时回答两个基本问题:
之前有人问我是否可以将 文章 视为其他类型的 网站 产品。这个问题的答案是肯定的。
当我们问客户网站上有多少可用产品时,主要是产品,我们指的是网站关键词建议的长尾。除了产品,他们还可以提供文章、新闻、播客、视频等。
你的 网站 上的网页会根据用户代理返回不同的内容吗?
您询问页面上的内容是否随用户代理而变化。
你的 网站 上的网页会根据你感知的国家/地区返回不同的内容吗?
您想知道页面上的内容是否随地理位置的 IP 或语言而变化。
您是否曾经阻止过对您的 网站 的访问或限制?
首先,您必须询问他们是否阻止了某些 IP,并且用户代理将进行爬网。其次,你想知道网站是否有一些爬取限制。作为爬网限制的一个例子,服务器可以通过每秒超过一定数量的请求来响应 200 以外的 HTTP 状态代码。
例如,当爬虫每秒请求超过 10 个页面时,服务器可以响应 HTTP 状态码 503(服务暂时不可用)。
你的服务器带宽是多少?
通常,他们不知道这个问题的答案。基本上,您应该向您的客户解释在您的 网站 上每秒抓取的页面数。无论如何,我建议您同意您可以使用客户端每秒抓取他们的网站页面。
这对您来说很划算,因此您以后不会遇到不舒服的情况,例如由于您的抓取请求导致服务器故障。
您有首选的爬行日期或时间段吗?
您的客户可能有一些首选的抓取天数或时间段。例如,他们希望他们的 网站 在周末或晚上被抓取。但是,如果客户有这样的偏好并且爬行的天数和时间段非常有限,则必须告知他们执行 SEO 审核将需要更长的时间,因为有限的爬行需要数天或数小时。
2.访问和采集SEO数据
请您的客户访问:
您还应该下载该站点的站点地图(如果有)。
验证Crawler3.跟进搜索引擎robots的HTTP头
作为 SEO 顾问,您应该跟踪爬网中 HTTP 标头搜索引擎机器人请求的内容。如果您的 SEO 审核涉及 Googlebot,在这种情况下,您应该知道 Googlebot 从 HTTP 服务器或 HTTPS 服务器请求的 HTTP 标头。
这非常重要,因为当您向客户解释您将抓取他们的 网站 时,就像 Googlebot 抓取一样,您应该确保从他们的服务器请求与 Googlebot 相同的 HTTP 标头。您从服务器采集的响应信息和未来数据取决于您在爬虫 HTTP 标头中请求的内容。
例如,想象一个支持 brotli 和爬虫请求的服务器:
接受编码:gzip、deflate
但不是:
接受编码:gzip,deflate,br
在您的 SEO 审查结束时,您可能会告诉您的客户他们的 网站 上存在抓取性能问题,但这可能不是真的。本例中,您的爬虫不支持brotli,该站点可能没有任何爬行性能问题。
4.检查您的爬虫如何处理重定向?它可以遵循多少重定向?验证和分析采集到的信息和数据,同时为爬网配置 5. 请求示例 URL 和各种:来自您客户的 网站 做出决定:
不要相信一开始就可以使用爬取问卷文档从客户端采集答案。这不是因为您的客户对您撒谎,而仅仅是因为他们不了解他们的 网站。
我建议您在爬取网站 之前对网站 执行自己的网站 进行特定的爬取测试。之前有人问过我这部分是否真的很重要。是的,这是因为 网站 上的内容可以通过用户代理、IP 或语言进行更改。
另一方面,某些站点可能会根据 IP 的语言或地理位置在同一 URL 上发送不同的内容。谷歌称其为“语言环境响应式网页”,最近修订的支持文档“谷歌如何抓取语言环境响应性网页”。
未来,Googlebot 对区域响应式网页的抓取行为可能会再次被修改。最好的方法是了解 网站 上的内容是否根据访问者的国家或首选语言以及当时 Googlebot 或其他搜索引擎机器人如何处理这些内容而发生变化,并相应地调整您的抓取工具.
此外,这些测试可以帮助您在抓取之前识别 网站 上的抓取问题,这可能是您 SEO 审核中的一个重要发现。
6.了解服务器
采集有关服务器和站点爬网性能的信息。在进行爬取之前,您需要知道要发送爬取请求的服务器类型,并了解网站 的爬取性能。
要了解爬网性能,您可以检查步骤 5 中执行的特定于站点的爬网请求。为了找出要在爬网配置文件中定义的最佳爬网率,必须执行此部分。在我看来,爬行中最困难的因素是爬行率。
7.预识别爬行垃圾
在准备有效的爬网配置文件之前,重要的是预先识别客户端站点上的爬网浪费。您可以通过从网络服务器日志、GoogleAnalytics、GoogleSearchConsole 和站点地图采集搜索引擎优化数据来识别 网站 上的抓取浪费。
8. 决定关注、不关注或只保留在爬取数据库中
您的选择取决于您要执行的 SEO 审核类型。请记住,因为它会增加数据量,如果只将它们保存在爬取数据库中,也会增加数据分析的复杂性。
爬网配置 9. 创建高效的爬网配置文件。设置最佳值:明智地选择初始 URL:选择关注而不是关注或保留抓取数据库中的 URL:避免抓取浪费(尤其是在您的资源有限的情况下)。
关于爬行深度,建议一开始选择较小的爬行深度,然后在爬行配置中逐渐增加爬行深度。
如果你想抓取一个大的 网站,这非常有用。当然,如果爬虫允许你逐渐增加爬行深度,你也可以这样做。
此外,还有智能爬虫工具,可以在爬虫过程中单独识别爬虫垃圾,无需在爬虫配置中手动处理。如果你有这样的爬虫,那你就不用担心这个了。
配置爬取后,10.告知客户你的用户代理和IP
如果你想爬取一个大的网站,你必须防止它们阻塞你的爬取。对于一个小的网站,这不会发生,但我建议你还是练习一下。在我看来,这是一个很好的职业习惯。此外,它还向您的客户表明您是一名爬行专家。
11.通过修改爬取配置文件来运行测试爬取进行相应的操作,有时甚至可能需要更换爬虫。最后,如果一切正常就开始爬12. 查看全部
从网页抓取数据(Crawl-firstSEO主要关注搜索引擎基础架构的12个指南!)
Crawl-firstSEO 专注于搜索引擎基础架构的两个主要部分:抓取和索引。如果 网站 上的所有页面都没有被抓取,则它们无法被索引。如果您的页面无法编入索引,它们将不会出现在搜索引擎结果页面 (SERP) 中。
搜索引擎优先抓取确保 网站 上存在的所有页面都被抓取和索引,之后它们将被定位在 SERP 中。被搜索引擎抓取后,您可以:
但在抢客户的网站之前,一定要遵守12条准则。
在配置爬取之前从客户端采集信息和数据1. 向您的客户发送爬取问卷文档
在本文档中,您应该提出以下问题:您的 网站 上有多少产品?
这是一个你无法回答的问题。您无法知道数据库中的产品数量,也不知道其中有多少在线可用。相反,您的客户会知道这个问题的答案,他们可以轻松回答您的问题。
我遇到过很多客户,他们有一个共同点:他们不知道他们的 网站 上有多少产品。了解客户端上有多少产品,是爬取网站之前需要了解的最重要信息。这也是你要在网站上进行“第一次SEO抓取审核”的最重要原因。
您必须知道在线提供的产品数量,因为您将在 SEO 审查结束时回答两个基本问题:
之前有人问我是否可以将 文章 视为其他类型的 网站 产品。这个问题的答案是肯定的。
当我们问客户网站上有多少可用产品时,主要是产品,我们指的是网站关键词建议的长尾。除了产品,他们还可以提供文章、新闻、播客、视频等。
你的 网站 上的网页会根据用户代理返回不同的内容吗?
您询问页面上的内容是否随用户代理而变化。
你的 网站 上的网页会根据你感知的国家/地区返回不同的内容吗?
您想知道页面上的内容是否随地理位置的 IP 或语言而变化。
您是否曾经阻止过对您的 网站 的访问或限制?
首先,您必须询问他们是否阻止了某些 IP,并且用户代理将进行爬网。其次,你想知道网站是否有一些爬取限制。作为爬网限制的一个例子,服务器可以通过每秒超过一定数量的请求来响应 200 以外的 HTTP 状态代码。
例如,当爬虫每秒请求超过 10 个页面时,服务器可以响应 HTTP 状态码 503(服务暂时不可用)。
你的服务器带宽是多少?
通常,他们不知道这个问题的答案。基本上,您应该向您的客户解释在您的 网站 上每秒抓取的页面数。无论如何,我建议您同意您可以使用客户端每秒抓取他们的网站页面。
这对您来说很划算,因此您以后不会遇到不舒服的情况,例如由于您的抓取请求导致服务器故障。
您有首选的爬行日期或时间段吗?
您的客户可能有一些首选的抓取天数或时间段。例如,他们希望他们的 网站 在周末或晚上被抓取。但是,如果客户有这样的偏好并且爬行的天数和时间段非常有限,则必须告知他们执行 SEO 审核将需要更长的时间,因为有限的爬行需要数天或数小时。
2.访问和采集SEO数据
请您的客户访问:
您还应该下载该站点的站点地图(如果有)。
验证Crawler3.跟进搜索引擎robots的HTTP头
作为 SEO 顾问,您应该跟踪爬网中 HTTP 标头搜索引擎机器人请求的内容。如果您的 SEO 审核涉及 Googlebot,在这种情况下,您应该知道 Googlebot 从 HTTP 服务器或 HTTPS 服务器请求的 HTTP 标头。
这非常重要,因为当您向客户解释您将抓取他们的 网站 时,就像 Googlebot 抓取一样,您应该确保从他们的服务器请求与 Googlebot 相同的 HTTP 标头。您从服务器采集的响应信息和未来数据取决于您在爬虫 HTTP 标头中请求的内容。
例如,想象一个支持 brotli 和爬虫请求的服务器:
接受编码:gzip、deflate
但不是:
接受编码:gzip,deflate,br
在您的 SEO 审查结束时,您可能会告诉您的客户他们的 网站 上存在抓取性能问题,但这可能不是真的。本例中,您的爬虫不支持brotli,该站点可能没有任何爬行性能问题。
4.检查您的爬虫如何处理重定向?它可以遵循多少重定向?验证和分析采集到的信息和数据,同时为爬网配置 5. 请求示例 URL 和各种:来自您客户的 网站 做出决定:
不要相信一开始就可以使用爬取问卷文档从客户端采集答案。这不是因为您的客户对您撒谎,而仅仅是因为他们不了解他们的 网站。
我建议您在爬取网站 之前对网站 执行自己的网站 进行特定的爬取测试。之前有人问过我这部分是否真的很重要。是的,这是因为 网站 上的内容可以通过用户代理、IP 或语言进行更改。
另一方面,某些站点可能会根据 IP 的语言或地理位置在同一 URL 上发送不同的内容。谷歌称其为“语言环境响应式网页”,最近修订的支持文档“谷歌如何抓取语言环境响应性网页”。
未来,Googlebot 对区域响应式网页的抓取行为可能会再次被修改。最好的方法是了解 网站 上的内容是否根据访问者的国家或首选语言以及当时 Googlebot 或其他搜索引擎机器人如何处理这些内容而发生变化,并相应地调整您的抓取工具.
此外,这些测试可以帮助您在抓取之前识别 网站 上的抓取问题,这可能是您 SEO 审核中的一个重要发现。
6.了解服务器
采集有关服务器和站点爬网性能的信息。在进行爬取之前,您需要知道要发送爬取请求的服务器类型,并了解网站 的爬取性能。
要了解爬网性能,您可以检查步骤 5 中执行的特定于站点的爬网请求。为了找出要在爬网配置文件中定义的最佳爬网率,必须执行此部分。在我看来,爬行中最困难的因素是爬行率。
7.预识别爬行垃圾
在准备有效的爬网配置文件之前,重要的是预先识别客户端站点上的爬网浪费。您可以通过从网络服务器日志、GoogleAnalytics、GoogleSearchConsole 和站点地图采集搜索引擎优化数据来识别 网站 上的抓取浪费。
8. 决定关注、不关注或只保留在爬取数据库中
您的选择取决于您要执行的 SEO 审核类型。请记住,因为它会增加数据量,如果只将它们保存在爬取数据库中,也会增加数据分析的复杂性。
爬网配置 9. 创建高效的爬网配置文件。设置最佳值:明智地选择初始 URL:选择关注而不是关注或保留抓取数据库中的 URL:避免抓取浪费(尤其是在您的资源有限的情况下)。
关于爬行深度,建议一开始选择较小的爬行深度,然后在爬行配置中逐渐增加爬行深度。
如果你想抓取一个大的 网站,这非常有用。当然,如果爬虫允许你逐渐增加爬行深度,你也可以这样做。
此外,还有智能爬虫工具,可以在爬虫过程中单独识别爬虫垃圾,无需在爬虫配置中手动处理。如果你有这样的爬虫,那你就不用担心这个了。
配置爬取后,10.告知客户你的用户代理和IP
如果你想爬取一个大的网站,你必须防止它们阻塞你的爬取。对于一个小的网站,这不会发生,但我建议你还是练习一下。在我看来,这是一个很好的职业习惯。此外,它还向您的客户表明您是一名爬行专家。
11.通过修改爬取配置文件来运行测试爬取进行相应的操作,有时甚至可能需要更换爬虫。最后,如果一切正常就开始爬12.
从网页抓取数据(事是“游戏交易”网站添加更多功能(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-28 11:14
我一直在使用这个网站 找到我的问题的答案,但我找不到这个问题的答案。
我正在和一个小组一起做一个班级项目。我们将创建一个小的“游戏交易”网站,允许人们注册,放入他们想要交易的游戏,并接受其他人的交易或交易请求。
我们的 网站 比正常运行得更早,因此我们正在尝试向 网站 添加更多功能。我想做的一件事是链接放置在 Metacritic 中的游戏。
这是我需要做的。我需要(在 Visual Studio 中
2012年使用asp和c#)在metacritic上获取正确的游戏页面,提取其数据,解析成特定的部分,然后在我们的页面上显示数据。
基本上,当您选择要交易的游戏时,我们希望显示一个收录游戏信息和级别的小 div。我想通过这种方式学习更多,并从这个项目中得到一些我不需要开始的东西。
我想知道是否有人可以告诉我从哪里开始。我不知道如何从页面中提取数据。我仍在尝试找出是否需要尝试编写一些内容来自动搜索游戏标题并通过这种方式找到页面,或者我是否可以找到某种直接进入游戏页面的方法。一旦我得到数据,我不知道如何从中获取我需要的具体信息。
让事情变得不那么容易的一件事是我正在学习c++和c#和asp,所以我一直很忙。如果有人能指出我正确的方向,那将是一个很大的帮助。谢谢 查看全部
从网页抓取数据(事是“游戏交易”网站添加更多功能(图))
我一直在使用这个网站 找到我的问题的答案,但我找不到这个问题的答案。
我正在和一个小组一起做一个班级项目。我们将创建一个小的“游戏交易”网站,允许人们注册,放入他们想要交易的游戏,并接受其他人的交易或交易请求。
我们的 网站 比正常运行得更早,因此我们正在尝试向 网站 添加更多功能。我想做的一件事是链接放置在 Metacritic 中的游戏。
这是我需要做的。我需要(在 Visual Studio 中
2012年使用asp和c#)在metacritic上获取正确的游戏页面,提取其数据,解析成特定的部分,然后在我们的页面上显示数据。
基本上,当您选择要交易的游戏时,我们希望显示一个收录游戏信息和级别的小 div。我想通过这种方式学习更多,并从这个项目中得到一些我不需要开始的东西。
我想知道是否有人可以告诉我从哪里开始。我不知道如何从页面中提取数据。我仍在尝试找出是否需要尝试编写一些内容来自动搜索游戏标题并通过这种方式找到页面,或者我是否可以找到某种直接进入游戏页面的方法。一旦我得到数据,我不知道如何从中获取我需要的具体信息。
让事情变得不那么容易的一件事是我正在学习c++和c#和asp,所以我一直很忙。如果有人能指出我正确的方向,那将是一个很大的帮助。谢谢
从网页抓取数据(从中提取数据的PowerBIDesktop示例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-28 11:13
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。
图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示网页中任何自动检测到的表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。
在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题 查看全部
从网页抓取数据(从中提取数据的PowerBIDesktop示例(组图))
通过提供示例获取网页数据
通过从网页获取数据,用户可以轻松地从网页中提取数据并将数据导入 Power BI Desktop。通常情况下,提取有序列表更容易,但网页上的数据不在有序列表中。即使数据是结构化且一致的,从此类页面获取数据也可能很困难。
有一个解决方案。使用“通过示例从 Web 获取数据”功能,您可以在连接器对话框中提供一个或多个示例,以实质上显示要从中提取数据的 Power BI Desktop。Power BI Desktop 采集页面上与示例匹配的其他数据。使用此解决方案,可以从网页中提取所有类型的数据,包括表格中的数据和其他非表格数据。
图中的价格仅供参考。
使用示例从 Web 获取数据
从“开始”功能区菜单中选择“获取数据”。在显示的对话框中,从左侧窗格的类别中选择“其他”,然后选择“Web”。选择“连接”以继续。
在“From Web”中,输入要从中提取数据的网页的 URL。在本文中,我们将使用 Microsoft Store 网页并演示此连接器的工作原理。
如果您想按照说明操作,可以使用本文中使用的 Microsoft Store URL:
https://www.microsoft.com/stor ... ssics
当您选择“确定”时,您将进入“导航器”对话框,该对话框显示网页中任何自动检测到的表格。在下图所示的情况下,找不到任何表。选择“使用示例添加表”以提供示例。
“使用示例添加表格”提供了一个交互式窗口,您可以在其中预览网页的内容。为要提取的数据输入样本值。
在这个例子中,我们将提取页面上每个游戏的“名称”和“价格”。我们可以通过从每列的页面中指定几个示例来做到这一点。在输入示例时,Power Query 使用智能数据提取算法来提取符合示例输入模式的数据。
评论
推荐值仅收录长度小于或等于 128 个字符的值。
如果您对网页中提取的数据感到满意,请选择“确定”进入 Power Query 编辑器。您可以应用更多转换或调整数据的形状,例如将此数据与来自源的其他数据合并。
在这里,您可以在创建 Power BI Desktop 报表时创建可视对象或使用网页数据。
下一步
可以使用 Power BI Desktop 连接到各种数据。有关数据源的更多信息,请参阅以下资源:
此页面有用吗?
无论
谢谢。
主题
从网页抓取数据(HTML从中的实质是什么?如何找到这些信息?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-26 11:18
我最近加入了一家新公司。他们是一家电子商务公司。他们的业务是虚拟在线充值。我进入OA做财务。
本来想做信息管理的,没想到会涉及到其他网站采集数据(解析Html,
最后用采集收到的数据生成财务凭证)这个链接,这是我之前没接触过的领域,
粗略看一下,目的是解析网页的HTML,找到需要的数据。
那么问题来了,如何找到这些信息呢?
既然本质是从一堆文字中“挖出”你想要的东西,比如网页中Title的文字,
很多人自然会想到正则表达式,呵呵,这个还不错,就是太费力了。想一想,
HTML的本质是什么?不就是一堆标签吗?深入思考,它是 XML 的一个子集。
XML 可以使用 XPath 或 Linq To XML。一开始想看看有没有Linq To HTML的实现,
它真的让我找到了一个。天朝的百度也不好找。
点击这里,
看资料,真的很少,解释不多,不敢用。
互联网上最流行的 HTML 解析库是 Html Agility Pack。
使用Nuget也可以方便的引用到项目中,好省心!官网源码
阅读 Html Agility Pack 的简要介绍后,它使用 XPath 语法来检索 HTML 元素。这样够方便吗?还不够好!比如我要找一个div,只能通过index来找,比如html/body/div[4]。不开心?我还是觉得不够灵活。经过一番搜索,我发现了一个好东西,ScrapySharp,看看它是如何检索 HTML 元素的。
ScrapingBrowser browser = new ScrapingBrowser();//set UseDefaultCookiesParser as false if a website returns invalid cookies format//browser.UseDefaultCookiesParser = false;WebPage homePage = browser.NavigateToPage(new Uri("http://www.bing.com/"));PageWebForm form = homePage.FindFormById("sb_form");form["q"] = "scrapysharp";form.Method = HttpVerb.Get;WebPage resultsPage = form.Submit();HtmlNode[] resultsLinks = resultsPage.Html.CssSelect("div.sb_tlst h3 a").ToArray();WebPage blogPage = resultsPage.FindLinks(By.Text("romcyber blog | Just another WordPress site")).Single().Click()
123456789101112131415
见另一节
using System.Linq;using HtmlAgilityPack;using ScrapySharp.Extensions;class Example{ public void Main() { var divs = html.CssSelect(“div”); //all div elements var nodes = html.CssSelect(“div.content”); //all div elements with css class ‘content’ var nodes = html.CssSelect(“div.widget.monthlist”); //all div elements with the both css class var nodes = html.CssSelect(“#postPaging”); //all HTML elements with the id postPaging var nodes = html.CssSelect(“div#postPaging.testClass”); // all HTML elements with the id postPaging and css class testClass var nodes = html.CssSelect(“div.content > p.para”); //p elements who are direct children of div elements with css class ‘content’ var nodes = html.CssSelect(“input[type=text].login”); // textbox with css class login }}
12345678910111213141516171819
这不是 CSS 选择器吗?乖乖,学了jquery集后,一定喜欢~!
我还发现了一个带有 ScrapySharp 的 HTML Agility Pack 可以完全缓解 Html 解析的痛苦
两者搭配使用,威力更大~! 查看全部
从网页抓取数据(HTML从中的实质是什么?如何找到这些信息?(一))
我最近加入了一家新公司。他们是一家电子商务公司。他们的业务是虚拟在线充值。我进入OA做财务。
本来想做信息管理的,没想到会涉及到其他网站采集数据(解析Html,
最后用采集收到的数据生成财务凭证)这个链接,这是我之前没接触过的领域,
粗略看一下,目的是解析网页的HTML,找到需要的数据。
那么问题来了,如何找到这些信息呢?
既然本质是从一堆文字中“挖出”你想要的东西,比如网页中Title的文字,
很多人自然会想到正则表达式,呵呵,这个还不错,就是太费力了。想一想,
HTML的本质是什么?不就是一堆标签吗?深入思考,它是 XML 的一个子集。
XML 可以使用 XPath 或 Linq To XML。一开始想看看有没有Linq To HTML的实现,
它真的让我找到了一个。天朝的百度也不好找。
点击这里,
看资料,真的很少,解释不多,不敢用。
互联网上最流行的 HTML 解析库是 Html Agility Pack。
使用Nuget也可以方便的引用到项目中,好省心!官网源码
阅读 Html Agility Pack 的简要介绍后,它使用 XPath 语法来检索 HTML 元素。这样够方便吗?还不够好!比如我要找一个div,只能通过index来找,比如html/body/div[4]。不开心?我还是觉得不够灵活。经过一番搜索,我发现了一个好东西,ScrapySharp,看看它是如何检索 HTML 元素的。
ScrapingBrowser browser = new ScrapingBrowser();//set UseDefaultCookiesParser as false if a website returns invalid cookies format//browser.UseDefaultCookiesParser = false;WebPage homePage = browser.NavigateToPage(new Uri("http://www.bing.com/";));PageWebForm form = homePage.FindFormById("sb_form");form["q"] = "scrapysharp";form.Method = HttpVerb.Get;WebPage resultsPage = form.Submit();HtmlNode[] resultsLinks = resultsPage.Html.CssSelect("div.sb_tlst h3 a").ToArray();WebPage blogPage = resultsPage.FindLinks(By.Text("romcyber blog | Just another WordPress site")).Single().Click()
123456789101112131415
见另一节
using System.Linq;using HtmlAgilityPack;using ScrapySharp.Extensions;class Example{ public void Main() { var divs = html.CssSelect(“div”); //all div elements var nodes = html.CssSelect(“div.content”); //all div elements with css class ‘content’ var nodes = html.CssSelect(“div.widget.monthlist”); //all div elements with the both css class var nodes = html.CssSelect(“#postPaging”); //all HTML elements with the id postPaging var nodes = html.CssSelect(“div#postPaging.testClass”); // all HTML elements with the id postPaging and css class testClass var nodes = html.CssSelect(“div.content > p.para”); //p elements who are direct children of div elements with css class ‘content’ var nodes = html.CssSelect(“input[type=text].login”); // textbox with css class login }}
12345678910111213141516171819
这不是 CSS 选择器吗?乖乖,学了jquery集后,一定喜欢~!
我还发现了一个带有 ScrapySharp 的 HTML Agility Pack 可以完全缓解 Html 解析的痛苦
两者搭配使用,威力更大~!
从网页抓取数据(Web数据收集有甚么用途吗?(Webscraping)是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-20 04:21
什么是网络数据采集
Web数据采集(Web抓取,也称为Web数据捕获)指的是一种计算机软件技术,用于防止信息丢失网站. Web数据捕获方法模仿读卡器的动作,可以提取出可以在读卡器上显示的任何数据,也称为屏幕捕获。Web数据捕获的最终目标是从大量Web页面中提取非布局信息,并以布局样式(CSV、JSON、XML、access、MSSQL、mysql等)存储
简言之,web数据采集就是从指定的网站数据中捕获所需的非布局信息数据,经过处理后作为同一模式的本地数据文件进行分析和存储,或者直接存储在本地数据库中
为什么要采集网络数据
互联网是一个巨大且快速增长的信息资本。然而,大多数信息是以文本形式存在的,没有版面,这使得信息的查询变得困难
数据采集和提取是从策略网页中提取一些数据以形成相同的本地数据模式的过程。这些数据最初仅以文本形式存在于可见网页中
假设您是团购导航站的运营商,您将如何获得每个团购站的信息?哦,不要把时间浪费在手动复制和粘贴上。你甚至不能使用复制和粘贴。您需要一个数据采集脚本来从每个团购网站获取数据并将其更新到本地数据库。专业的web数据捕获服务是采集web数据最简洁的方式。这使工作非常简单
网络数据采集的用途是什么
任何业务运营成功的基础是拥有大量的策略用户和专业数据。谁能控制用户谁就可以带头。Web数据捕获服务可以帮助您快速获取大量的政策用户和专业数据,让您在降低运营成本的同时,快速抓住机遇,占领制高点。许多客户直接受益于我们的服务或定制软件
许多客户直接受益于我们的服务或定制软件
您可以在以下领域使用我们的服务:
*你的潜在客户名单
*从竞争对手那里采集您感兴趣的信息
*捕获新兴业务数据
*建立自己的产品目录
*整合行业信息并协助制定业务决策计划
*确认新客户,增加新订单;发掘老客户并获得新的好处
*
网络数据采集的好处是什么
简单:你不需要使用任何软件。只要告诉我们您需要什么以及您的政策网站是什么,我们就可以为您获取我们捕获的数据
灵活性:您可以从任何网站获取任何数据,尤其是动态网站@
快速:对于需要20个个人工作日的工作,我们可以在几个小时内完成。因此,你不仅可以节省你的时间、精力和金钱,还可以使你领先于竞争对手
确保:提取结果的每一列都是您所需要的,并且有很多。我们将根据您的要求筛选和验证数据
低成本:与您获得的数据和服务相比,您花费的成本很小。更重要的是,你可以节省无法用金钱衡量的精神和时间,以及你付出的几倍于人力和设备的投资
网络数据采集合法吗
Web数据捕获方法的原理类似于搜索引擎的爬虫,因此是合法的 查看全部
从网页抓取数据(Web数据收集有甚么用途吗?(Webscraping)是什么)
什么是网络数据采集
Web数据采集(Web抓取,也称为Web数据捕获)指的是一种计算机软件技术,用于防止信息丢失网站. Web数据捕获方法模仿读卡器的动作,可以提取出可以在读卡器上显示的任何数据,也称为屏幕捕获。Web数据捕获的最终目标是从大量Web页面中提取非布局信息,并以布局样式(CSV、JSON、XML、access、MSSQL、mysql等)存储
简言之,web数据采集就是从指定的网站数据中捕获所需的非布局信息数据,经过处理后作为同一模式的本地数据文件进行分析和存储,或者直接存储在本地数据库中
为什么要采集网络数据
互联网是一个巨大且快速增长的信息资本。然而,大多数信息是以文本形式存在的,没有版面,这使得信息的查询变得困难
数据采集和提取是从策略网页中提取一些数据以形成相同的本地数据模式的过程。这些数据最初仅以文本形式存在于可见网页中
假设您是团购导航站的运营商,您将如何获得每个团购站的信息?哦,不要把时间浪费在手动复制和粘贴上。你甚至不能使用复制和粘贴。您需要一个数据采集脚本来从每个团购网站获取数据并将其更新到本地数据库。专业的web数据捕获服务是采集web数据最简洁的方式。这使工作非常简单
网络数据采集的用途是什么
任何业务运营成功的基础是拥有大量的策略用户和专业数据。谁能控制用户谁就可以带头。Web数据捕获服务可以帮助您快速获取大量的政策用户和专业数据,让您在降低运营成本的同时,快速抓住机遇,占领制高点。许多客户直接受益于我们的服务或定制软件
许多客户直接受益于我们的服务或定制软件
您可以在以下领域使用我们的服务:
*你的潜在客户名单
*从竞争对手那里采集您感兴趣的信息
*捕获新兴业务数据
*建立自己的产品目录
*整合行业信息并协助制定业务决策计划
*确认新客户,增加新订单;发掘老客户并获得新的好处
*
网络数据采集的好处是什么
简单:你不需要使用任何软件。只要告诉我们您需要什么以及您的政策网站是什么,我们就可以为您获取我们捕获的数据
灵活性:您可以从任何网站获取任何数据,尤其是动态网站@
快速:对于需要20个个人工作日的工作,我们可以在几个小时内完成。因此,你不仅可以节省你的时间、精力和金钱,还可以使你领先于竞争对手
确保:提取结果的每一列都是您所需要的,并且有很多。我们将根据您的要求筛选和验证数据
低成本:与您获得的数据和服务相比,您花费的成本很小。更重要的是,你可以节省无法用金钱衡量的精神和时间,以及你付出的几倍于人力和设备的投资
网络数据采集合法吗
Web数据捕获方法的原理类似于搜索引擎的爬虫,因此是合法的
从网页抓取数据( 如何向完全没有背景知识的人解释爬虫为何物? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-20 04:21
如何向完全没有背景知识的人解释爬虫为何物?
)
“当我们在网站上看到一系列地址信息、商品信息,甚至天气、新闻等真实信息,但由于数量庞大,很难通过手动复制和粘贴完全获取时,爬虫可以代替您完成所有工作
-“如何向没有背景知识的人解释爬行动物是什么?”
-“爬虫程序是一种程序,它可以浏览网页,并根据特定规则为您复制和粘贴内容。”
是的,听起来很高级。你想写代码吗?!在互联网上搜索Python+scratch功能强大,具有爆炸性。但即便如此,对于一些仅用于江湖紧急救援的简单网站数据采集来说,还是有点小题大做,普通用户可能会专注于安装Python+scratch软件包
韦伯夏普首次亮相
此时,一个chrome的爬虫插件脱颖而出!(它的名字是web scraper。web可以指网络爬虫和在线爬虫。这是一个双关语(或者我想太多了…)
这里省略了如何安装插件,在网站.简而言之,安装完成后,按chrome下的F12启动
吃椰子
别说太多,来看看椰子!哦,不,栗子
让我们在天猫上攀登“业庆”的价格吧
一,
打开页面
让我们看看我们感兴趣的“椰子绿和价格”页面
没错!我对椰子绿很感兴趣
二,
大声说出爬行动物的界面
因此,我们根据提示打开在线爬虫界面
最右边的web scraper标签是我们以前安装的crawler插件。从现在开始,我们需要为crawler建立复制和粘贴数据的规则,以防止获取一些不应该获取的不需要的数据
三,
制定规则
如前所述,爬虫是指浏览网页并为您复制和粘贴内容的东西,因此它应该模拟您的行为。首先,您打开此界面,知道此网页是“我想要的数据起点”,因此对于爬虫来说,这是它的根。因此,让我们创建一个新的爬虫并告诉他:
我们点击新建站点地图创建一个爬虫,并给它一个名称~顺便说一下,告诉它起点(当前浏览器中的网址)。然后我们将进入爬虫的根目录(淘宝):
四,
选择元素
然后我们开始获取每个商品的集合,单击添加新选择器,添加过滤器,并选择所有“椰子绿商品”元素:
同样,取一个名称,选择类型作为元素,选择商品元素。当选择两个相同的属性元素时,插件将自动检查页面上的所有属性元素
单击完成选择以完成选择并勾选多个。保存选择器
此时,我们只需要从先前筛选的项目元素中获取所需字段。同样,我们在项目目录中创建一些选择器。因为我们需要获取文本信息,所以需要将类型更改为文本
此时,一个简单的单页爬虫已经准备就绪。您也可以在sitemap的下拉菜单中选择graph来查看爬虫的结构
五,
单击“刮擦”开始攀爬
六,
下载数据
之后,数据将在窗口中自动生成。该插件具有导出为CSV的功能,只需单击一下即可下载。如果您意外关闭它,则无所谓。您可以在浏览器中看到最后捕获的数据
翻一页怎么样
如果你想翻页,那就更难了。Rocket Jun可能给出了一个想法:正如将遍历并获取项中的元素一样,同样地,在根目录中创建一个翻页链接选择器来实现“下一页”功能
将项目链接到链接选择器,并将链接选择器和先前创建的项目选择器链接到您自己,以实现无休止的循环,直到下一页不存在或下一页不可用
建立循环后,可以如下所示:
那又怎样
你可能会问:那又怎样
Rocket Jun使用此工具了解了全国各地销售的数百辆二手宝马3系车的价格。看看不同年龄段的宝马3系车在使用数年后的价格下降情况~
查看全部
从网页抓取数据(
如何向完全没有背景知识的人解释爬虫为何物?
)
“当我们在网站上看到一系列地址信息、商品信息,甚至天气、新闻等真实信息,但由于数量庞大,很难通过手动复制和粘贴完全获取时,爬虫可以代替您完成所有工作
-“如何向没有背景知识的人解释爬行动物是什么?”
-“爬虫程序是一种程序,它可以浏览网页,并根据特定规则为您复制和粘贴内容。”
是的,听起来很高级。你想写代码吗?!在互联网上搜索Python+scratch功能强大,具有爆炸性。但即便如此,对于一些仅用于江湖紧急救援的简单网站数据采集来说,还是有点小题大做,普通用户可能会专注于安装Python+scratch软件包
韦伯夏普首次亮相
此时,一个chrome的爬虫插件脱颖而出!(它的名字是web scraper。web可以指网络爬虫和在线爬虫。这是一个双关语(或者我想太多了…)
这里省略了如何安装插件,在网站.简而言之,安装完成后,按chrome下的F12启动
吃椰子
别说太多,来看看椰子!哦,不,栗子
让我们在天猫上攀登“业庆”的价格吧
一,
打开页面
让我们看看我们感兴趣的“椰子绿和价格”页面
没错!我对椰子绿很感兴趣
二,
大声说出爬行动物的界面
因此,我们根据提示打开在线爬虫界面
最右边的web scraper标签是我们以前安装的crawler插件。从现在开始,我们需要为crawler建立复制和粘贴数据的规则,以防止获取一些不应该获取的不需要的数据
三,
制定规则
如前所述,爬虫是指浏览网页并为您复制和粘贴内容的东西,因此它应该模拟您的行为。首先,您打开此界面,知道此网页是“我想要的数据起点”,因此对于爬虫来说,这是它的根。因此,让我们创建一个新的爬虫并告诉他:
我们点击新建站点地图创建一个爬虫,并给它一个名称~顺便说一下,告诉它起点(当前浏览器中的网址)。然后我们将进入爬虫的根目录(淘宝):
四,
选择元素
然后我们开始获取每个商品的集合,单击添加新选择器,添加过滤器,并选择所有“椰子绿商品”元素:
同样,取一个名称,选择类型作为元素,选择商品元素。当选择两个相同的属性元素时,插件将自动检查页面上的所有属性元素
单击完成选择以完成选择并勾选多个。保存选择器
此时,我们只需要从先前筛选的项目元素中获取所需字段。同样,我们在项目目录中创建一些选择器。因为我们需要获取文本信息,所以需要将类型更改为文本
此时,一个简单的单页爬虫已经准备就绪。您也可以在sitemap的下拉菜单中选择graph来查看爬虫的结构
五,
单击“刮擦”开始攀爬
六,
下载数据
之后,数据将在窗口中自动生成。该插件具有导出为CSV的功能,只需单击一下即可下载。如果您意外关闭它,则无所谓。您可以在浏览器中看到最后捕获的数据
翻一页怎么样
如果你想翻页,那就更难了。Rocket Jun可能给出了一个想法:正如将遍历并获取项中的元素一样,同样地,在根目录中创建一个翻页链接选择器来实现“下一页”功能
将项目链接到链接选择器,并将链接选择器和先前创建的项目选择器链接到您自己,以实现无休止的循环,直到下一页不存在或下一页不可用
建立循环后,可以如下所示:
那又怎样
你可能会问:那又怎样
Rocket Jun使用此工具了解了全国各地销售的数百辆二手宝马3系车的价格。看看不同年龄段的宝马3系车在使用数年后的价格下降情况~
从网页抓取数据(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-17 23:25
)
文章目录
站长之家注:在大数据时代,如何有效获取数据已成为推动商业决策的关键技能。分析市场趋势和监控竞争对手都需要数据采集. 网页捕获是数据采集的主要方法之一@
在本文中,克里斯托弗·齐塔将向您展示三种通过互联网赚钱的方法。学习整个过程只需几个小时,使用的代码不到50行
通过自动程序在airbnb上以最少的费用入住最好的酒店
自动化程序可以用来执行特定的操作,你可以把它们卖给那些没有技术能力赚钱的人
为了展示如何创建和销售自动化程序,Christopher zita创建了airbnb自动捕获程序。该程序允许用户输入位置。它将捕获airbnb在该地点提供的所有房屋数据,包括价格、等级、允许进入的客人数量等。所有这些都是通过捕获airbnb上的数据完成的
为了演示程序的实际操作,Christopher zita在程序中进入罗马,然后在几秒钟内获得272 airbnb的相关数据:
现在,查看所有房屋数据并对其进行过滤非常容易。以克里斯托弗·齐塔的家人为例。他们家有四口人。如果他们想去罗马,他们会在airbnb上找一家价格合理、至少有两张床的酒店。在获得此表中的数据后,Excel可以非常轻松地对其进行筛选。从这272个结果中,发现7家酒店符合要求
克里斯托弗·齐塔选择了七家酒店。因为通过数据对比可以看出,这家酒店的评级很高,是七家酒店中最便宜的,每晚只收61美元。选择所需链接后,只需将链接复制到浏览器并订阅即可
在旅行和度假时,找到一家旅馆是一项艰巨的任务。为此,有些人愿意通过付费来简化流程。有了这个自动程序,你可以在5分钟内以低价预订一个满意的房间
抓取特定商品的价格数据,以最低价格购买
网络爬网最常见的用途之一是从网站. 创建一个程序以捕获特定产品的价格数据。当价格下降到一定程度时,它会在产品售完之前自动购买产品
接下来,Christopher zita将向您展示一种省钱和赚钱的方法:
每个电子商务网站将有数量有限的特价商品。它们将显示商品的原价和折扣价,但通常不会显示在原价基础上进行了多少折扣。例如,如果一块手表的初始价格是350美元,而促销价格是300美元,你会认为50美元的折扣不是一个小数目,但实际上只是一个小数目14.2%折扣。如果一件T恤衫的初始价格是50美元,销售价格是40美元,你会认为它不便宜多少,但事实上,它的折扣率比手表高20%。因此,你可以通过购买折扣率最高的产品来省钱/赚钱
接下来,以哈德逊湾为例进行数据捕获实验,通过获取所有商品的原价和折扣价,找到折扣率最高的商品
捕获网站数据后,我们获得了900多种商品的数据,其中只有Perry Ellis纯色衬衫的折扣率超过50%
由于时间有限的折扣,这件衬衫的价格很快就会回升到90美元左右。因此,如果您现在以40美元的价格购买,在限时优惠后以60美元的价格出售,您仍然可以赚取20美元
这是一种方法。如果你找到合适的利基市场,你可能会赚很多钱
抓取宣传数据并将其可视化
网络上有数以百万计的免费数据集,这些数据通常很容易采集。当然,有些数据不容易获得,需要花费大量时间进行可视化。这就是销售数据的演变过程。天燕支票、企业支票等公司专注于获取企业工商变更信息并将其可视化,然后以“购买会员进行检查”的形式销售给用户
该公司的体育数据也有类似的模型网站BigDataBall,通过出售玩家的游戏数据和其他统计信息,用户将在网站赛季收取30美元的费用。他们设定价格不是因为网站有数据,而是因为他们获取数据,将其分类,然后以易于阅读和清晰的结构显示
现在,Christopher zita需要做的是免费获得与bigdataball相同的数据,然后将其放入结构化数据集中。Bigdataball并不是唯一拥有这些数据的网站。它有相同的数据。然而,网站并没有结构化数据,因此用户很难过滤和下载所需的数据集。Christopher zita使用网页捕获工具捕获网页中的所有玩家数据
所有NBA球员日志的结构化数据集
到目前为止,他本赛季已经赢得了16000多份球员记录。通过网络捕获,克里斯托弗·齐塔获得了数据,并在几分钟内节省了30美元
当然,与bigdataball一样,Christopher zita也可以使用网页抓取工具查找难以手动获取的数据,让计算机完成工作,然后将数据可视化并出售给对这些数据感兴趣的人
总结
如今,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果你在适当的情况下运用它,你可以很容易地赚钱
注:原文由媒体编辑而成,原文标题为“如何利用网络抓取赚钱”
每天都有一个超级实用的创业案例,扫描代码并关注[站长愿景]↓↓
查看全部
从网页抓取数据(大数据时代,如何有效获取数据已成为驱动业务决策的关键技能
)
文章目录
站长之家注:在大数据时代,如何有效获取数据已成为推动商业决策的关键技能。分析市场趋势和监控竞争对手都需要数据采集. 网页捕获是数据采集的主要方法之一@
在本文中,克里斯托弗·齐塔将向您展示三种通过互联网赚钱的方法。学习整个过程只需几个小时,使用的代码不到50行
通过自动程序在airbnb上以最少的费用入住最好的酒店
自动化程序可以用来执行特定的操作,你可以把它们卖给那些没有技术能力赚钱的人
为了展示如何创建和销售自动化程序,Christopher zita创建了airbnb自动捕获程序。该程序允许用户输入位置。它将捕获airbnb在该地点提供的所有房屋数据,包括价格、等级、允许进入的客人数量等。所有这些都是通过捕获airbnb上的数据完成的
为了演示程序的实际操作,Christopher zita在程序中进入罗马,然后在几秒钟内获得272 airbnb的相关数据:
现在,查看所有房屋数据并对其进行过滤非常容易。以克里斯托弗·齐塔的家人为例。他们家有四口人。如果他们想去罗马,他们会在airbnb上找一家价格合理、至少有两张床的酒店。在获得此表中的数据后,Excel可以非常轻松地对其进行筛选。从这272个结果中,发现7家酒店符合要求
克里斯托弗·齐塔选择了七家酒店。因为通过数据对比可以看出,这家酒店的评级很高,是七家酒店中最便宜的,每晚只收61美元。选择所需链接后,只需将链接复制到浏览器并订阅即可
在旅行和度假时,找到一家旅馆是一项艰巨的任务。为此,有些人愿意通过付费来简化流程。有了这个自动程序,你可以在5分钟内以低价预订一个满意的房间
抓取特定商品的价格数据,以最低价格购买
网络爬网最常见的用途之一是从网站. 创建一个程序以捕获特定产品的价格数据。当价格下降到一定程度时,它会在产品售完之前自动购买产品
接下来,Christopher zita将向您展示一种省钱和赚钱的方法:
每个电子商务网站将有数量有限的特价商品。它们将显示商品的原价和折扣价,但通常不会显示在原价基础上进行了多少折扣。例如,如果一块手表的初始价格是350美元,而促销价格是300美元,你会认为50美元的折扣不是一个小数目,但实际上只是一个小数目14.2%折扣。如果一件T恤衫的初始价格是50美元,销售价格是40美元,你会认为它不便宜多少,但事实上,它的折扣率比手表高20%。因此,你可以通过购买折扣率最高的产品来省钱/赚钱
接下来,以哈德逊湾为例进行数据捕获实验,通过获取所有商品的原价和折扣价,找到折扣率最高的商品
捕获网站数据后,我们获得了900多种商品的数据,其中只有Perry Ellis纯色衬衫的折扣率超过50%
由于时间有限的折扣,这件衬衫的价格很快就会回升到90美元左右。因此,如果您现在以40美元的价格购买,在限时优惠后以60美元的价格出售,您仍然可以赚取20美元
这是一种方法。如果你找到合适的利基市场,你可能会赚很多钱
抓取宣传数据并将其可视化
网络上有数以百万计的免费数据集,这些数据通常很容易采集。当然,有些数据不容易获得,需要花费大量时间进行可视化。这就是销售数据的演变过程。天燕支票、企业支票等公司专注于获取企业工商变更信息并将其可视化,然后以“购买会员进行检查”的形式销售给用户
该公司的体育数据也有类似的模型网站BigDataBall,通过出售玩家的游戏数据和其他统计信息,用户将在网站赛季收取30美元的费用。他们设定价格不是因为网站有数据,而是因为他们获取数据,将其分类,然后以易于阅读和清晰的结构显示
现在,Christopher zita需要做的是免费获得与bigdataball相同的数据,然后将其放入结构化数据集中。Bigdataball并不是唯一拥有这些数据的网站。它有相同的数据。然而,网站并没有结构化数据,因此用户很难过滤和下载所需的数据集。Christopher zita使用网页捕获工具捕获网页中的所有玩家数据
所有NBA球员日志的结构化数据集
到目前为止,他本赛季已经赢得了16000多份球员记录。通过网络捕获,克里斯托弗·齐塔获得了数据,并在几分钟内节省了30美元
当然,与bigdataball一样,Christopher zita也可以使用网页抓取工具查找难以手动获取的数据,让计算机完成工作,然后将数据可视化并出售给对这些数据感兴趣的人
总结
如今,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果你在适当的情况下运用它,你可以很容易地赚钱
注:原文由媒体编辑而成,原文标题为“如何利用网络抓取赚钱”
每天都有一个超级实用的创业案例,扫描代码并关注[站长愿景]↓↓
从网页抓取数据(从网页抓取数据,然后分析其结构,找到产品在哪些网站进行了售卖)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-15 23:06
从网页抓取数据,然后分析其结构,通过关联查询,找到产品在哪些网站进行了售卖,并把抓取的这些数据表放在数据库里进行统计分析(是否有优惠券、发货时间、发货地址等等,总之就是商品信息),当然实际上应该还会进行一些其他处理,比如社交网络的分析,进行一些推荐。
作为一名卖家的老总,你要明白别人是怎么卖东西给你的,如果别人在卖这件产品之前已经编写好了卖给你的代码,你需要自己的产品推荐和商品管理才能卖出去你手上的这件产品,当然手上已经有顾客订单,比如说一大群的顾客买了你的商品,那么就需要考虑顾客更偏好于哪些商品,比如说你的鞋子偏向于休闲,偏向于搭配。那么你应该给他推荐一些休闲品牌的鞋子。
这样提高顾客的体验。当顾客买了之后,就考虑怎么把这些数据分析好之后进行推广,和引流。比如说把商品推送给老客户。通过一些推广活动让更多的人看到你的商品。这些都是要找到卖什么产品才可以去做的。
大概方向有这么几类:1.卖到哪里去2.买多少3.卖给谁
1.从网页抓取海量信息,进行结构化分析2.根据自己的分析,给产品进行广告投放,
可以理解为抓取海量信息,但后台需要进行数据挖掘,进行定向投放,海量广告位投放, 查看全部
从网页抓取数据(从网页抓取数据,然后分析其结构,找到产品在哪些网站进行了售卖)
从网页抓取数据,然后分析其结构,通过关联查询,找到产品在哪些网站进行了售卖,并把抓取的这些数据表放在数据库里进行统计分析(是否有优惠券、发货时间、发货地址等等,总之就是商品信息),当然实际上应该还会进行一些其他处理,比如社交网络的分析,进行一些推荐。
作为一名卖家的老总,你要明白别人是怎么卖东西给你的,如果别人在卖这件产品之前已经编写好了卖给你的代码,你需要自己的产品推荐和商品管理才能卖出去你手上的这件产品,当然手上已经有顾客订单,比如说一大群的顾客买了你的商品,那么就需要考虑顾客更偏好于哪些商品,比如说你的鞋子偏向于休闲,偏向于搭配。那么你应该给他推荐一些休闲品牌的鞋子。
这样提高顾客的体验。当顾客买了之后,就考虑怎么把这些数据分析好之后进行推广,和引流。比如说把商品推送给老客户。通过一些推广活动让更多的人看到你的商品。这些都是要找到卖什么产品才可以去做的。
大概方向有这么几类:1.卖到哪里去2.买多少3.卖给谁
1.从网页抓取海量信息,进行结构化分析2.根据自己的分析,给产品进行广告投放,
可以理解为抓取海量信息,但后台需要进行数据挖掘,进行定向投放,海量广告位投放,
从网页抓取数据(从网页抓取数据,要完整打包压缩为json格式的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-14 02:04
从网页抓取数据,要完整打包压缩为json格式的数据,比如js都是javascript和css都是css之类的。这样dom树就完整了。你提到的字体展示什么的,不是一次就要全文获取,那是很多网页都有的功能吗?很少去抓取javascript和css,那是chrome的能力。javascript可以按文件获取,甚至可以用javascript的变量function抓取。
你需要jqueryitems.all就是你要的
首先你要安装$npminstall-gjquery用jquery要把文件夹一层一层抓
据我所知,
javascript也不行?
除了chrome自带的javascript,
javascript很难抓
一般浏览器都自带了抓取数据文件的驱动。你可以用jsonrpc的方式访问一个googleaccount下的文件夹,
你还要注意抓取数据是要按照json格式
谢邀
写个脚本。爬虫根据你的类别构造一份比对表。或者直接从目录读一个字典出来。
虽然我只能安利个scrapy框架。但是我还是有一些自己的看法啊题主喜欢抓取网页信息,而javascript这种东西说到底是浏览器的高级脚本技术而已,用不到浏览器的核心,加之实际上没有什么必要,因此就chrome来说还是可以用document.cookie,我一直觉得javascript的成功一半取决于webkit的存在而另一半就是webkit能够支持一个local这样神奇的标准,但是用户输入相关字段是否会被记录关注到,var是没用的,我们能做的只是如同计算机登录网站一样得到一串唯一的值,有这样的一个便捷设定么?浏览器cookie不起作用,所以如果想抓取javascript的话,只能是安装一个浏览器插件再配合相应的api抓取相关字段,当然你用什么都可以,记得注意cookie这个东西不可以把自己注入进去,不然你会哭的。所以多用现有框架其实并不是件坏事。 查看全部
从网页抓取数据(从网页抓取数据,要完整打包压缩为json格式的数据)
从网页抓取数据,要完整打包压缩为json格式的数据,比如js都是javascript和css都是css之类的。这样dom树就完整了。你提到的字体展示什么的,不是一次就要全文获取,那是很多网页都有的功能吗?很少去抓取javascript和css,那是chrome的能力。javascript可以按文件获取,甚至可以用javascript的变量function抓取。
你需要jqueryitems.all就是你要的
首先你要安装$npminstall-gjquery用jquery要把文件夹一层一层抓
据我所知,
javascript也不行?
除了chrome自带的javascript,
javascript很难抓
一般浏览器都自带了抓取数据文件的驱动。你可以用jsonrpc的方式访问一个googleaccount下的文件夹,
你还要注意抓取数据是要按照json格式
谢邀
写个脚本。爬虫根据你的类别构造一份比对表。或者直接从目录读一个字典出来。
虽然我只能安利个scrapy框架。但是我还是有一些自己的看法啊题主喜欢抓取网页信息,而javascript这种东西说到底是浏览器的高级脚本技术而已,用不到浏览器的核心,加之实际上没有什么必要,因此就chrome来说还是可以用document.cookie,我一直觉得javascript的成功一半取决于webkit的存在而另一半就是webkit能够支持一个local这样神奇的标准,但是用户输入相关字段是否会被记录关注到,var是没用的,我们能做的只是如同计算机登录网站一样得到一串唯一的值,有这样的一个便捷设定么?浏览器cookie不起作用,所以如果想抓取javascript的话,只能是安装一个浏览器插件再配合相应的api抓取相关字段,当然你用什么都可以,记得注意cookie这个东西不可以把自己注入进去,不然你会哭的。所以多用现有框架其实并不是件坏事。

