
从网页抓取数据
从网页抓取数据(世界互联网、移动互联网的规划与应用的运用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 14:15
世界互联网和移动互联网的规划急剧增加,每天都在发生无数的信息。采集大量信息的网页中的数据,然后在工作和日常生活中使用它,现在非常普遍,也进化到了大数据时代。趋势。
随着信息量的增加和网页结构的杂乱,数据获取的难度也在不断增加。关于过去的几个数据需求,你可以通过手动复制粘贴来轻松采集。例如,为了丰富您的博客或证明学术报告,我们会从互联网上提取一些文章、期刊和图片。还有很多。现在,我们对数据的使用变得越来越广泛。企业需要大量的数据来分析业务发展趋势,挖掘潜在机会,做出正确的决策和计划;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据就无法快速发展。
这些数据大部分来自公开的互联网,来自人们在网页中输入的许多文本、图片和其他潜在有价值的信息。这些信息数据由于数量巨大,已经无法通过人工采集的方式获得。因此,网页抓取进入了人们的视野,取代人工采集成为数据获取的最新捷径。
如今,有两种类型的网络抓取工具,拥有大量的用户。一种是源码分析型。通过HTTP协议直接请求网页源代码,设置采集规则,完成网页数据的抓取,无论是图片、文本还是文件。它可以被抓取。这种爬行的优点是稳定,速度非常快。用户需要了解网页源代码的相关常识,然后设置爬取的东西,然后就可以完全交给东西来采集NS了。这种时下流行的抓取工具,在优采云采集器中还收录了更多的功能,比如数据替换、过滤、重新重置等处理和数据发布;另外,优采云
另一种是利用特定的网页元素定位和爬虫引擎来模拟打开网页,点击网页内容的思路,采集浏览器已经可视化的内容。它的优势在于它的可视化和敏捷性。它可能没有优采云采集器类爬虫那么快,但处理杂乱网页更容易,比如优采云系列优采云浏览器中的另一款产品。两者都有自己的优势。用户可以根据自己的需要重点选择。对于更高的爬取需求,可以部署和使用两种类型的软件。为了对接方便,可以选择两个同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取都变得简单了,就像人类每一次巨大的创造都会引领时代的进步一样,大数据时代的大趋势也需要我们保持与时俱进,用人才分配行为,用数据赢得未来。而为了获取数据,网络爬虫会带来真正的高效率。 查看全部
从网页抓取数据(世界互联网、移动互联网的规划与应用的运用方法)
世界互联网和移动互联网的规划急剧增加,每天都在发生无数的信息。采集大量信息的网页中的数据,然后在工作和日常生活中使用它,现在非常普遍,也进化到了大数据时代。趋势。
随着信息量的增加和网页结构的杂乱,数据获取的难度也在不断增加。关于过去的几个数据需求,你可以通过手动复制粘贴来轻松采集。例如,为了丰富您的博客或证明学术报告,我们会从互联网上提取一些文章、期刊和图片。还有很多。现在,我们对数据的使用变得越来越广泛。企业需要大量的数据来分析业务发展趋势,挖掘潜在机会,做出正确的决策和计划;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据就无法快速发展。
这些数据大部分来自公开的互联网,来自人们在网页中输入的许多文本、图片和其他潜在有价值的信息。这些信息数据由于数量巨大,已经无法通过人工采集的方式获得。因此,网页抓取进入了人们的视野,取代人工采集成为数据获取的最新捷径。
如今,有两种类型的网络抓取工具,拥有大量的用户。一种是源码分析型。通过HTTP协议直接请求网页源代码,设置采集规则,完成网页数据的抓取,无论是图片、文本还是文件。它可以被抓取。这种爬行的优点是稳定,速度非常快。用户需要了解网页源代码的相关常识,然后设置爬取的东西,然后就可以完全交给东西来采集NS了。这种时下流行的抓取工具,在优采云采集器中还收录了更多的功能,比如数据替换、过滤、重新重置等处理和数据发布;另外,优采云
另一种是利用特定的网页元素定位和爬虫引擎来模拟打开网页,点击网页内容的思路,采集浏览器已经可视化的内容。它的优势在于它的可视化和敏捷性。它可能没有优采云采集器类爬虫那么快,但处理杂乱网页更容易,比如优采云系列优采云浏览器中的另一款产品。两者都有自己的优势。用户可以根据自己的需要重点选择。对于更高的爬取需求,可以部署和使用两种类型的软件。为了对接方便,可以选择两个同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取都变得简单了,就像人类每一次巨大的创造都会引领时代的进步一样,大数据时代的大趋势也需要我们保持与时俱进,用人才分配行为,用数据赢得未来。而为了获取数据,网络爬虫会带来真正的高效率。
从网页抓取数据(Python如何从网页下载图像?带你了解如何使用requests)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-21 14:14
Python 如何从网页下载图片?本文将向您介绍如何使用请求和 BeautifulSoup 库在 Python 中从单个网页中提取和下载图像。
您有没有想过下载网页上的所有图片? Python 如何从网页中下载所有图像?在本教程中,您将学习如何构建 Python 爬虫以从网页中的给定 URL 检索所有图像,并使用请求和 BeautifulSoup 库下载它们。
Python从网页下载图片介绍:首先,我们需要很多依赖,我们来安装它们:
pip3 install requests bs4 tqdm
打开一个新的 Python 文件并导入必要的模块:
import requests
import os
from tqdm import tqdm
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin, urlparse
Python 如何从网页下载图片?首先,我们创建一个URL验证器来确保传入的URL是有效的,因为有些网站把编码数据放在了URL位置,所以我们需要跳过这些:
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
urlparse() 函数将 URL 解析为六个部分。我们只需要检查netloc(域名)和scheme(协议)是否存在即可。
其次,我会写核心函数来获取网页的所有图片网址:
def get_all_images(url):
"""
Returns all image URLs on a single `url`
"""
soup = bs(requests.get(url).content, "html.parser")
网页的HTML内容在soup对象中。要提取HTML中的所有img标签,我们需要使用soup.find_all("img")方法。让我们看看它的作用:
urls = []
for img in tqdm(soup.find_all("img"), "Extracting images"):
img_url = img.attrs.get("src")
if not img_url:
# if img does not contain src attribute, just skip
continue
这将检索所有 img 元素作为 Python 列表。
Python 从网络下载所有图像:我将它包装在 tqdm 对象中只是为了打印进度条。要获取 img 标签的 URL,有一个 src 属性。但是,有些标签不收录 src 属性,我们使用上面的 continue 语句跳过这些标签。
现在我们需要确保 URL 是绝对的:
# make the URL absolute by joining domain with the URL that is just extracted
img_url = urljoin(url, img_url)
有些 URL 收录我们不喜欢的 HTTP GET 键值对(以“/image.png?c=3.2.5”结尾),让我们删除它们:
try:
pos = img_url.index("?")
img_url = img_url[:pos]
except ValueError:
pass
我们得到'?'的位置字符,然后把后面的所有东西都删掉,如果没有,就会引发ValueError,这就是为什么我把它包裹在一个try/except块中(当然你可以更好的方式来实现它,如果是这样,请在下面的评论中与我们分享)。
现在让我们确保每个 URL 都有效并返回所有图像 URL:
# finally, if the url is valid
if is_valid(img_url):
urls.append(img_url)
return urls
Python从网页下载图片的例子介绍:既然我们有了一个抓取所有图片网址的函数,我们还需要一个使用Python从网页下载文件的函数。我从本教程中介绍了以下功能:
def download(url, pathname):
"""
Downloads a file given an URL and puts it in the folder `pathname`
"""
# if path doesn't exist, make that path dir
if not os.path.isdir(pathname):
os.makedirs(pathname)
# download the body of response by chunk, not immediately
response = requests.get(url, stream=True)
# get the total file size
file_size = int(response.headers.get("Content-Length", 0))
# get the file name
filename = os.path.join(pathname, url.split("/")[-1])
# progress bar, changing the unit to bytes instead of iteration (default by tqdm)
progress = tqdm(response.iter_content(1024), f"Downloading {filename}", total=file_size, unit="B", unit_scale=True, unit_divisor=1024)
with open(filename, "wb") as f:
for data in progress.iterable:
# write data read to the file
f.write(data)
# update the progress bar manually
progress.update(len(data))
复制上面的函数基本上就是使用了要下载的文件的url和文件所在文件夹的路径名。
相关:如何在 Python 中将 HTML 表格转换为 CSV 文件。
最后,这是主要功能:
def main(url, path):
# get all images
imgs = get_all_images(url)
for img in imgs:
# for each image, download it
download(img, path)
Python从一个网页下载所有图片:从这个页面获取所有图片的网址,并一一下载。让我们测试一下:
main("https://yandex.com/images/", "yandex-images")
这将从该 URL 下载所有图像并将它们存储在将自动创建的文件夹“yandex-images”中。
Python 如何从网页下载图片?但请注意,有些网站 使用 Javascript 加载数据。在这种情况下,您应该使用 requests_html 库。我做了另一个脚本,对原创脚本做了一些调整,并处理了 Javascript 渲染,请点击这里查看。
好的,我们完成了!以下是您可以实施以扩展代码的一些想法: 查看全部
从网页抓取数据(Python如何从网页下载图像?带你了解如何使用requests)
Python 如何从网页下载图片?本文将向您介绍如何使用请求和 BeautifulSoup 库在 Python 中从单个网页中提取和下载图像。
您有没有想过下载网页上的所有图片? Python 如何从网页中下载所有图像?在本教程中,您将学习如何构建 Python 爬虫以从网页中的给定 URL 检索所有图像,并使用请求和 BeautifulSoup 库下载它们。
Python从网页下载图片介绍:首先,我们需要很多依赖,我们来安装它们:
pip3 install requests bs4 tqdm
打开一个新的 Python 文件并导入必要的模块:
import requests
import os
from tqdm import tqdm
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin, urlparse
Python 如何从网页下载图片?首先,我们创建一个URL验证器来确保传入的URL是有效的,因为有些网站把编码数据放在了URL位置,所以我们需要跳过这些:
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
urlparse() 函数将 URL 解析为六个部分。我们只需要检查netloc(域名)和scheme(协议)是否存在即可。
其次,我会写核心函数来获取网页的所有图片网址:
def get_all_images(url):
"""
Returns all image URLs on a single `url`
"""
soup = bs(requests.get(url).content, "html.parser")
网页的HTML内容在soup对象中。要提取HTML中的所有img标签,我们需要使用soup.find_all("img")方法。让我们看看它的作用:
urls = []
for img in tqdm(soup.find_all("img"), "Extracting images"):
img_url = img.attrs.get("src")
if not img_url:
# if img does not contain src attribute, just skip
continue
这将检索所有 img 元素作为 Python 列表。
Python 从网络下载所有图像:我将它包装在 tqdm 对象中只是为了打印进度条。要获取 img 标签的 URL,有一个 src 属性。但是,有些标签不收录 src 属性,我们使用上面的 continue 语句跳过这些标签。
现在我们需要确保 URL 是绝对的:
# make the URL absolute by joining domain with the URL that is just extracted
img_url = urljoin(url, img_url)
有些 URL 收录我们不喜欢的 HTTP GET 键值对(以“/image.png?c=3.2.5”结尾),让我们删除它们:
try:
pos = img_url.index("?")
img_url = img_url[:pos]
except ValueError:
pass
我们得到'?'的位置字符,然后把后面的所有东西都删掉,如果没有,就会引发ValueError,这就是为什么我把它包裹在一个try/except块中(当然你可以更好的方式来实现它,如果是这样,请在下面的评论中与我们分享)。
现在让我们确保每个 URL 都有效并返回所有图像 URL:
# finally, if the url is valid
if is_valid(img_url):
urls.append(img_url)
return urls
Python从网页下载图片的例子介绍:既然我们有了一个抓取所有图片网址的函数,我们还需要一个使用Python从网页下载文件的函数。我从本教程中介绍了以下功能:
def download(url, pathname):
"""
Downloads a file given an URL and puts it in the folder `pathname`
"""
# if path doesn't exist, make that path dir
if not os.path.isdir(pathname):
os.makedirs(pathname)
# download the body of response by chunk, not immediately
response = requests.get(url, stream=True)
# get the total file size
file_size = int(response.headers.get("Content-Length", 0))
# get the file name
filename = os.path.join(pathname, url.split("/")[-1])
# progress bar, changing the unit to bytes instead of iteration (default by tqdm)
progress = tqdm(response.iter_content(1024), f"Downloading {filename}", total=file_size, unit="B", unit_scale=True, unit_divisor=1024)
with open(filename, "wb") as f:
for data in progress.iterable:
# write data read to the file
f.write(data)
# update the progress bar manually
progress.update(len(data))
复制上面的函数基本上就是使用了要下载的文件的url和文件所在文件夹的路径名。
相关:如何在 Python 中将 HTML 表格转换为 CSV 文件。
最后,这是主要功能:
def main(url, path):
# get all images
imgs = get_all_images(url)
for img in imgs:
# for each image, download it
download(img, path)
Python从一个网页下载所有图片:从这个页面获取所有图片的网址,并一一下载。让我们测试一下:
main("https://yandex.com/images/", "yandex-images")
这将从该 URL 下载所有图像并将它们存储在将自动创建的文件夹“yandex-images”中。
Python 如何从网页下载图片?但请注意,有些网站 使用 Javascript 加载数据。在这种情况下,您应该使用 requests_html 库。我做了另一个脚本,对原创脚本做了一些调整,并处理了 Javascript 渲染,请点击这里查看。
好的,我们完成了!以下是您可以实施以扩展代码的一些想法:
从网页抓取数据(从当当网上采集数据的过程为例,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-19 19:10
所谓“网页数据抓取”,也就是网页数据采集、网页数据采集等,就是从我们平时通过浏览器查看的网页中提取需要的数据信息,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴的方式。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细解释一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站出于数据保护的原因会限制数据显示的数量,比如数据最多可以显示100页,超过100页的数据就不显示了。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入下级目录,也就是更小的分类级别,才能获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入最底层的目录,这里显示的是该目录下可以显示的所有数据项的列表,我们可以称之为底层列表页,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每一页的数据项。通过每个数据项上的链接,您可以输入最终数据。该页面,我们称之为详细信息页面。如下所示:
至此,获取详细数据的路径已经明确。接下来我们要分析详细页面上有用的数据项,然后有针对性地编写数据采集程序,然后我们就可以抓取到我们感兴趣的数据了。
以下是作者编写的当当网图书数据的网页数据爬取程序的部分代码:
以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。 查看全部
从网页抓取数据(从当当网上采集数据的过程为例,你了解多少?)
所谓“网页数据抓取”,也就是网页数据采集、网页数据采集等,就是从我们平时通过浏览器查看的网页中提取需要的数据信息,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴的方式。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细解释一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:

因为很多网站出于数据保护的原因会限制数据显示的数量,比如数据最多可以显示100页,超过100页的数据就不显示了。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入下级目录,也就是更小的分类级别,才能获得更多的数据。
点击一级目录,进入二级图书目录,如下图:

同理,依次点击每一级目录,最后可以进入最底层的目录,这里显示的是该目录下可以显示的所有数据项的列表,我们可以称之为底层列表页,如图:

当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每一页的数据项。通过每个数据项上的链接,您可以输入最终数据。该页面,我们称之为详细信息页面。如下所示:
至此,获取详细数据的路径已经明确。接下来我们要分析详细页面上有用的数据项,然后有针对性地编写数据采集程序,然后我们就可以抓取到我们感兴趣的数据了。
以下是作者编写的当当网图书数据的网页数据爬取程序的部分代码:

以下是作者采集得到的部分图书信息样本数据:

至此,一个完整的网页数据抓取过程就完成了。
从网页抓取数据(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-19 19:08
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
从网页抓取数据(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
从网页抓取数据( ViewXpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-19 19:02
ViewXpath)
使用 Xpath 从网页中获取数据
///
/// 从官方网站中抓取产品信息存放在本地数据库中
///
///
public List GetlistProductMessage()
{
string html = GetProductsDescriptionsImage("http://www.grandcanyononepoint.com/products");
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
HtmlNode rootNode = document.DocumentNode;
/*//*[@class='list-product']为元素的XPath标记实例,
* 表示所有使用class="list-product"的节点
*/
HtmlNodeCollection rootNodeList = rootNode.SelectNodes("//*[@class='list-product']");
List products = new List();
foreach (HtmlNode node in rootNodeList)
{
ProductMessage db_product = new ProductMessage();
HtmlDocument docu = new HtmlDocument();
docu.LoadHtml(node.InnerHtml);
HtmlNode ro = docu.DocumentNode;
db_product.Code = Formsub(ro.SelectSingleNode("//*[@style='float:right;']").InnerText);
string Code = db_product.Code;
List Productlist = ProductMessage.GetProductList(Code,"");
if (Productlist.Count>0)
{
db_product.Name = Formsub(ro.SelectSingleNode("//*[@style='float:left;']").InnerText);
/*获取a节点中href标签的属性值*/
db_product.ID = GetProductID(ro.SelectSingleNode("a").Attributes["href"].Value);
string descmationhtml = GetProductsDescriptionsImage("http://www.grandcanyononepoint ... ot%3B + db_product.ID + "");
HtmlDocument descmationDo = new HtmlDocument();
descmationDo.LoadHtml(descmationhtml);
HtmlNode descmationNode = descmationDo.DocumentNode;
db_product.Descmation = Formsub(descmationNode.SelectSingleNode("//*[@class='product-desc']").InnerHtml).Replace("'", "");
if (descmationNode.SelectSingleNode("//*[@class='details-tile']") != null)
{
db_product.DepartingFrom = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile']").InnerHtml.Replace("Departing From", ""));
}
if (descmationNode.SelectSingleNode("//*[@class='details-tile details-list']") != null)
{
db_product.ProductHighlights = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile details-list']").InnerHtml.Replace("Product Highlights", "")).Replace("'", "");
}
#region
try
{
ProductMessage.UpdateWEBProductMessage(db_product.Descmation,db_product.DepartingFrom,db_product.ProductHighlights,db_product.Name,db_product.Code);
}
catch { }
#endregion
#region
if (descmationNode.SelectSingleNode("//*[@class='product-equip']") != null)
{
HtmlDocument DesmationEquipment = new HtmlDocument();
DesmationEquipment.LoadHtml(descmationNode.SelectSingleNode("//*[@class='product-equip']").InnerHtml);
HtmlNode EquipmentNode = DesmationEquipment.DocumentNode;
HtmlNodeCollection EquipmentNodes = EquipmentNode.SelectNodes("div");
List EquipmentString = new List();
foreach (HtmlNode equipment in EquipmentNodes)
{
EquipmentModel Equipment_model = new EquipmentModel();
Equipment_model.Name = equipment.Attributes["title"].Value;
Equipment_model.ImageUrl = "/Papillon/EquipmentImage/" + equipment.Attributes["title"].Value + ".png";
try
{
ProductMessage.InsertProductEquipment(db_product.ID, Equipment_model.Name, Equipment_model.ImageUrl);
}
catch { }
EquipmentString.Add(Equipment_model);
}
db_product.Equipment = EquipmentString;
}
#endregion
#region
if (descmationNode.SelectNodes("//*[@title='See full size image']") != null)
{
HtmlNodeCollection ImageNodes = descmationNode.SelectNodes("//*[@title='See full size image']");
List ImageString = new List();
foreach (HtmlNode imagenode in ImageNodes)
{
ImageModel image_model = new ImageModel();
HtmlDocument imageDo = new HtmlDocument();
imageDo.LoadHtml(imagenode.InnerHtml);
HtmlNode imgRo = imageDo.DocumentNode;
//原图片地址
string FromPath = "http://www.grandcanyononepoint.com" + imgRo.SelectSingleNode("img").Attributes["src"].Value;
image_model.ImageUrl = FromPath;
try
{
ProductMessage.InsertProductImage(db_product.ID, image_model.ImageUrl);
}
catch { }
}
}
#endregion
products.Add(db_product);
}
}
return products;
}
查看代码
Xpath使用html作为类似于xml的格式,通过节点的不同标签获取不同的内容,可以从网页中获取想要的数据,这与网络爬虫不同。
发布 @ 2016-07-29 16:59ly77461 阅读(2286)评论(0)编辑 查看全部
从网页抓取数据(
ViewXpath)
使用 Xpath 从网页中获取数据


///
/// 从官方网站中抓取产品信息存放在本地数据库中
///
///
public List GetlistProductMessage()
{
string html = GetProductsDescriptionsImage("http://www.grandcanyononepoint.com/products";);
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
HtmlNode rootNode = document.DocumentNode;
/*//*[@class='list-product']为元素的XPath标记实例,
* 表示所有使用class="list-product"的节点
*/
HtmlNodeCollection rootNodeList = rootNode.SelectNodes("//*[@class='list-product']");
List products = new List();
foreach (HtmlNode node in rootNodeList)
{
ProductMessage db_product = new ProductMessage();
HtmlDocument docu = new HtmlDocument();
docu.LoadHtml(node.InnerHtml);
HtmlNode ro = docu.DocumentNode;
db_product.Code = Formsub(ro.SelectSingleNode("//*[@style='float:right;']").InnerText);
string Code = db_product.Code;
List Productlist = ProductMessage.GetProductList(Code,"");
if (Productlist.Count>0)
{
db_product.Name = Formsub(ro.SelectSingleNode("//*[@style='float:left;']").InnerText);
/*获取a节点中href标签的属性值*/
db_product.ID = GetProductID(ro.SelectSingleNode("a").Attributes["href"].Value);
string descmationhtml = GetProductsDescriptionsImage("http://www.grandcanyononepoint ... ot%3B + db_product.ID + "");
HtmlDocument descmationDo = new HtmlDocument();
descmationDo.LoadHtml(descmationhtml);
HtmlNode descmationNode = descmationDo.DocumentNode;
db_product.Descmation = Formsub(descmationNode.SelectSingleNode("//*[@class='product-desc']").InnerHtml).Replace("'", "");
if (descmationNode.SelectSingleNode("//*[@class='details-tile']") != null)
{
db_product.DepartingFrom = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile']").InnerHtml.Replace("Departing From", ""));
}
if (descmationNode.SelectSingleNode("//*[@class='details-tile details-list']") != null)
{
db_product.ProductHighlights = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile details-list']").InnerHtml.Replace("Product Highlights", "")).Replace("'", "");
}
#region
try
{
ProductMessage.UpdateWEBProductMessage(db_product.Descmation,db_product.DepartingFrom,db_product.ProductHighlights,db_product.Name,db_product.Code);
}
catch { }
#endregion
#region
if (descmationNode.SelectSingleNode("//*[@class='product-equip']") != null)
{
HtmlDocument DesmationEquipment = new HtmlDocument();
DesmationEquipment.LoadHtml(descmationNode.SelectSingleNode("//*[@class='product-equip']").InnerHtml);
HtmlNode EquipmentNode = DesmationEquipment.DocumentNode;
HtmlNodeCollection EquipmentNodes = EquipmentNode.SelectNodes("div");
List EquipmentString = new List();
foreach (HtmlNode equipment in EquipmentNodes)
{
EquipmentModel Equipment_model = new EquipmentModel();
Equipment_model.Name = equipment.Attributes["title"].Value;
Equipment_model.ImageUrl = "/Papillon/EquipmentImage/" + equipment.Attributes["title"].Value + ".png";
try
{
ProductMessage.InsertProductEquipment(db_product.ID, Equipment_model.Name, Equipment_model.ImageUrl);
}
catch { }
EquipmentString.Add(Equipment_model);
}
db_product.Equipment = EquipmentString;
}
#endregion
#region
if (descmationNode.SelectNodes("//*[@title='See full size image']") != null)
{
HtmlNodeCollection ImageNodes = descmationNode.SelectNodes("//*[@title='See full size image']");
List ImageString = new List();
foreach (HtmlNode imagenode in ImageNodes)
{
ImageModel image_model = new ImageModel();
HtmlDocument imageDo = new HtmlDocument();
imageDo.LoadHtml(imagenode.InnerHtml);
HtmlNode imgRo = imageDo.DocumentNode;
//原图片地址
string FromPath = "http://www.grandcanyononepoint.com" + imgRo.SelectSingleNode("img").Attributes["src"].Value;
image_model.ImageUrl = FromPath;
try
{
ProductMessage.InsertProductImage(db_product.ID, image_model.ImageUrl);
}
catch { }
}
}
#endregion
products.Add(db_product);
}
}
return products;
}
查看代码
Xpath使用html作为类似于xml的格式,通过节点的不同标签获取不同的内容,可以从网页中获取想要的数据,这与网络爬虫不同。
发布 @ 2016-07-29 16:59ly77461 阅读(2286)评论(0)编辑
从网页抓取数据( 为什么我提交了数据还是迟迟在线上看不到展现呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-16 23:17
为什么我提交了数据还是迟迟在线上看不到展现呢?)
目前百度蜘蛛抓取新链接的方式有两种。一是主动发现爬取,二是从百度站长平台的链接提交工具中获取数据。其中,通过主动推送功能“收到”的数据最受百度青睐。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新的网站,主动推送首页数据,有利于到内部页面数据的捕获。
所以同学们要问了,为什么我提交了数据后还是看不到网上的显示呢?涉及的因素很多。在蜘蛛抓取链接中,影响在线展示的因素有:
1、网站 禁止。别笑,有同学在给百度发数据的时候把百度蜘蛛屏蔽了,当然不能收录。
2、质量筛选。百度蜘蛛进入3.0后,对低质量内容的识别又上了一个新台阶,尤其是时效性内容。从抓取过程中,会进行质量评估和筛选,过滤掉大量过度优化的页面。根据定期的内部数据评估,低质量网页比上一期下降了 62%。
3、 获取失败。爬行失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛有问题。本站要时刻关注网站在不同时间和地点的稳定性。
4、 配额限制。虽然我们正在逐步放开主动推送的抓取额度,但是如果网站页面突然爆发式增长,还是会影响到优质链接的抓取收录,所以网站也要注意保证稳定访问网站防止黑客注入的安全性。
评论:
上海普益网络为上海中小企业网站建设、网页设计、网站优化、SEO优化等相关服务。 查看全部
从网页抓取数据(
为什么我提交了数据还是迟迟在线上看不到展现呢?)

目前百度蜘蛛抓取新链接的方式有两种。一是主动发现爬取,二是从百度站长平台的链接提交工具中获取数据。其中,通过主动推送功能“收到”的数据最受百度青睐。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新的网站,主动推送首页数据,有利于到内部页面数据的捕获。
所以同学们要问了,为什么我提交了数据后还是看不到网上的显示呢?涉及的因素很多。在蜘蛛抓取链接中,影响在线展示的因素有:
1、网站 禁止。别笑,有同学在给百度发数据的时候把百度蜘蛛屏蔽了,当然不能收录。
2、质量筛选。百度蜘蛛进入3.0后,对低质量内容的识别又上了一个新台阶,尤其是时效性内容。从抓取过程中,会进行质量评估和筛选,过滤掉大量过度优化的页面。根据定期的内部数据评估,低质量网页比上一期下降了 62%。
3、 获取失败。爬行失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛有问题。本站要时刻关注网站在不同时间和地点的稳定性。
4、 配额限制。虽然我们正在逐步放开主动推送的抓取额度,但是如果网站页面突然爆发式增长,还是会影响到优质链接的抓取收录,所以网站也要注意保证稳定访问网站防止黑客注入的安全性。
评论:
上海普益网络为上海中小企业网站建设、网页设计、网站优化、SEO优化等相关服务。
从网页抓取数据(从网页抓取数据的角度来说是选择性分析。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-16 23:01
从网页抓取数据的角度来说是公开数据分析。以自然语言分析为例,主要任务就是从内容中提取关键词,然后用lda、dbn等方法去构建表示论文内容或者文章题目的表示模型。lda、dbn都是nlp任务,或者考虑文本分类,也要求实体关系(entityrelation)中与其语义和实体相关性高的词同时出现在表示里面才能推断出实体的词向量。
从数据整理角度来说是选择性分析。你既可以说这个数据是ugc的数据,那么来源自用户,也可以说这个数据是retrieved-to-ugc的数据,那么作者发表的fullform的内容的邮件或者文章,也可以说它是ugc或者retrieved-to-ugc的数据。这就是选择性分析。希望你能对你想研究的话题有帮助。
分析方法一般有以下几种:1.基于图的分析方法图最好是基于一些生成算法的,也就是变量的生成算法,而不是简单的分析图,比如图模型,马尔可夫链;也可以基于特征的聚类算法,比如adaboost等。2.文本聚类算法实际上就是用所有的词,自动生成各种好几类文本,你看到了x,y关系的词,比如“数字”和“好像”,分别生成“数字”和“好像”的文本;看到“表格”和“号”,生成“表格”和“号”的文本。
3.基于条件归纳算法(crf)的图分析算法这个比较偏向于统计学领域了,建议掌握np问题的求解,以及蒙特卡洛树搜索,以便自己设计图分析算法。4.聚类算法集成分析(clusteringaggregationbasedmethods)建议掌握聚类算法和降维算法。5.基于密度的分析算法这个你懂的。还有一些隐变量问题,什么注意力机制,隐马尔科夫等等。
实际上,这些分析方法中都有一些核心的东西是通用的,也就是基于统计学的。基本只要你写一个自动问卷,然后根据用户投票,和自动发现用户偏好,都是可以用统计学方法解决的。 查看全部
从网页抓取数据(从网页抓取数据的角度来说是选择性分析。)
从网页抓取数据的角度来说是公开数据分析。以自然语言分析为例,主要任务就是从内容中提取关键词,然后用lda、dbn等方法去构建表示论文内容或者文章题目的表示模型。lda、dbn都是nlp任务,或者考虑文本分类,也要求实体关系(entityrelation)中与其语义和实体相关性高的词同时出现在表示里面才能推断出实体的词向量。
从数据整理角度来说是选择性分析。你既可以说这个数据是ugc的数据,那么来源自用户,也可以说这个数据是retrieved-to-ugc的数据,那么作者发表的fullform的内容的邮件或者文章,也可以说它是ugc或者retrieved-to-ugc的数据。这就是选择性分析。希望你能对你想研究的话题有帮助。
分析方法一般有以下几种:1.基于图的分析方法图最好是基于一些生成算法的,也就是变量的生成算法,而不是简单的分析图,比如图模型,马尔可夫链;也可以基于特征的聚类算法,比如adaboost等。2.文本聚类算法实际上就是用所有的词,自动生成各种好几类文本,你看到了x,y关系的词,比如“数字”和“好像”,分别生成“数字”和“好像”的文本;看到“表格”和“号”,生成“表格”和“号”的文本。
3.基于条件归纳算法(crf)的图分析算法这个比较偏向于统计学领域了,建议掌握np问题的求解,以及蒙特卡洛树搜索,以便自己设计图分析算法。4.聚类算法集成分析(clusteringaggregationbasedmethods)建议掌握聚类算法和降维算法。5.基于密度的分析算法这个你懂的。还有一些隐变量问题,什么注意力机制,隐马尔科夫等等。
实际上,这些分析方法中都有一些核心的东西是通用的,也就是基于统计学的。基本只要你写一个自动问卷,然后根据用户投票,和自动发现用户偏好,都是可以用统计学方法解决的。
从网页抓取数据(记录思路如下:记录SQL中的注释(使用--进行注释))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-15 07:02
【原创需求】
公司用户手册是SGML的源代码,其中文档中有一些SQL语句,我目前想验证这些SQL是否可以复制和执行。
【对策】
使用手动复制验证,太慢了。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般都受到标签使用的限制,所以shell要抓取的具体内容就是基于这两个标签。
录音思路如下:
1、先处理SQL中的注释(使用-类似C语言的注释#)
2、 将空格中的文本去掉进行序列处理,使用上面的标签进行切分,然后在切分后取偶数位置的值(不解释)
3、通过第二步就可以得到标签的内容了,需要对标签中的特殊字符进行处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/>/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/ 查看全部
从网页抓取数据(记录思路如下:记录SQL中的注释(使用--进行注释))
【原创需求】
公司用户手册是SGML的源代码,其中文档中有一些SQL语句,我目前想验证这些SQL是否可以复制和执行。
【对策】
使用手动复制验证,太慢了。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般都受到标签使用的限制,所以shell要抓取的具体内容就是基于这两个标签。
录音思路如下:
1、先处理SQL中的注释(使用-类似C语言的注释#)
2、 将空格中的文本去掉进行序列处理,使用上面的标签进行切分,然后在切分后取偶数位置的值(不解释)
3、通过第二步就可以得到标签的内容了,需要对标签中的特殊字符进行处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/>/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/
从网页抓取数据(Vanguard延迟加载页面上的数据,我不知道如何正确获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-14 13:03
)
我试图在这个网站上检查一些关于这个问题的问题,但我无法使他们的解决方案起作用。我正在使用 python 和 selenium 和 chrome 无头浏览器从先锋获取债券数据。Vanguard懒惰地加载页面上的数据,我不知道如何正确获取数据。
我正在尝试从此页面加载数据,尤其是基金事实表中的数据
当我像往常一样尝试这样做时,我得到
所以我尝试使用这行代码让浏览器等待数据加载。
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
我确定这是在正确的轨道上,但我不知道如何正确地告诉我哪些元素应该等待识别以及我是否正确执行。有没有办法让我等到 iframe data-delayed-src 元素消失才能获取数据?
我已经看到它与 By.ID 的用法,但是我在数据 html 中没有看到任何我想要 id 的元素。
这是我正在使用的代码
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
import os
dirname = os.path.dirname(__file__)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options, executable_path=os.path.join(dirname, 'chromedriver'))
symbol = 'vbirx'
url_vanguard = 'https://investor.vanguard.com/mutual-funds/profile/overview/{}'
browser.get(url_vanguard.format(symbol))
# WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
html = browser.page_source
mySoup = BeautifulSoup(html, 'html.parser')
htmlData = mySoup.find('table',{'role':'presentation'})
table = htmlData.find('tbody')
print('table: \n',table)
该表打印出缺少我想要的所有数据 查看全部
从网页抓取数据(Vanguard延迟加载页面上的数据,我不知道如何正确获取数据
)
我试图在这个网站上检查一些关于这个问题的问题,但我无法使他们的解决方案起作用。我正在使用 python 和 selenium 和 chrome 无头浏览器从先锋获取债券数据。Vanguard懒惰地加载页面上的数据,我不知道如何正确获取数据。
我正在尝试从此页面加载数据,尤其是基金事实表中的数据
当我像往常一样尝试这样做时,我得到
所以我尝试使用这行代码让浏览器等待数据加载。
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
我确定这是在正确的轨道上,但我不知道如何正确地告诉我哪些元素应该等待识别以及我是否正确执行。有没有办法让我等到 iframe data-delayed-src 元素消失才能获取数据?
我已经看到它与 By.ID 的用法,但是我在数据 html 中没有看到任何我想要 id 的元素。
这是我正在使用的代码
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
import os
dirname = os.path.dirname(__file__)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options, executable_path=os.path.join(dirname, 'chromedriver'))
symbol = 'vbirx'
url_vanguard = 'https://investor.vanguard.com/mutual-funds/profile/overview/{}'
browser.get(url_vanguard.format(symbol))
# WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
html = browser.page_source
mySoup = BeautifulSoup(html, 'html.parser')
htmlData = mySoup.find('table',{'role':'presentation'})
table = htmlData.find('tbody')
print('table: \n',table)
该表打印出缺少我想要的所有数据
从网页抓取数据(的请求获取数据的方式GET,POST请求数据必须构建请求头才可以。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-14 13:03
POST请求获取数据的方式与GET不同,POST请求数据必须构造请求头。
Form Data中的请求参数如图15所示:
图片
图 15
复制它并构建一个新字典:
from_data={'i':'我爱中国','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt' :'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b33a2f3f9d09bde064c9275bcb33d94e,'@1','版本'keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
接下来使用requests.post方法请求表单数据,代码如下:
导入请求#导入请求包
响应 = requests.post(url,data=payload)
将字符串格式的数据转换为JSON格式的数据,根据数据结构提取数据,并打印出翻译结果。代码如下:
导入 jsoncontent = json.loads(response.text)print(content['translateResult'][0][0]['tgt'])
使用requests.post方法抓取有道翻译结果的完整代码如下:
import requests#import requests package import jsondef get_translate_date(word=None):url =';smartresult=rule'From_data=('i':word,'from':'zh-CHS','to':'en', 'smartresult':'dict','client':'fanyideskweb','salt':'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b39604b3d2f' :'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'} 请求表单数据 response = requests .post(url,data=From_data) 将 Json 格式字符串转换为字典 content = json.loads(response.text) print(content) 打印翻译后的数据 print(content['translateResult'][0][0] ['tgt'])if name=='main':get_translate_date('我爱中国')
使用 Beautiful Soup 解析网页
网页的源代码已经可以通过requests库捕获,下一步就是从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
bs4库的安装方式如图16所示:
图片
图 16
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库更强大,速度更快。因此,我建议安装 lxml 库。
安装好Python第三方库后,输入以下代码,开启Beautiful Soup之旅:
import requests#import requests from bs4 import BeautifulSoupurl=``strhtml=requests.get(url)soup=BeautifulSoup(strhtml.text,'lxml')data = soup.select('#main>div>div.mtop.firstMod .clearfix>div.centerBox>ul.newsList>li>a')print(data)
代码执行结果如图 17 所示。
图片
图17(点此查看高清大图)
Beautiful Soup 库可以轻松解析网页信息。它集成在 bs4 库中,需要时可以从 bs4 库中调用。表达语句如下:
从 bs4 导入 BeautifulSoup
首先将HTML文档转换成Unicode编码格式,然后Beautiful Soup选择最合适的解析器来解析这个文档,这里是指定解析的lxml解析器。解析后,将复杂的 HTML 文档转换为树状结构,每个节点都是一个 Python 对象。这里,解析后的文档存放在新创建的变量soup中,代码如下:
汤=BeautifulSoup(strhtml.text,'lxml')
接下来,使用select(选择器)定位数据。定位数据时,需要使用浏览器的开发者模式。将鼠标光标放在对应的数据位置上单击鼠标右键,然后在快捷菜单中选择“检查”命令,如图18所示。如图:
图片
图 18
然后浏览器右侧会弹出开发者界面,右侧高亮代码(见图19(b))对应左侧高亮数据文本(见图19(a))。右击右侧高亮显示的数据,在弹出的快捷菜单中选择“复制”➔“复制选择器”命令,自动复制路径。
图片
图 19 复制路径
在文档中粘贴路径,代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li:nth-child(1)> a
由于这条路径是第一个选择的路径,我们需要获取所有的标题,删除li:nth-child(1),代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a
使用soup.select引用这个路径,代码如下:
data = soup.select('#main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a')
清理和组织数据
至此,获得了一段目标HTML代码,但尚未提取数据。接下来,在 PyCharm 中输入以下代码:
对于数据中的项目:result={'title':item.get_text(),'link':item.get('href')}print(result)
代码运行结果如图20所示:
图片
图20
首先,很明显,要提取的数据是标题和链接。标题在 <a> 标签中,标签的主体是使用 get_text() 方法提取的。该链接位于 <a> 标记的 href 属性中。使用 get() 方法提取标签中的 href 属性。括号中指定要提取的属性数据,即get('href')。
从图20可以发现文章的链接中有一个数字ID。接下来,使用正则表达式提取此 ID。需要用到的正则符号如下:
\d 匹配数字
+匹配前一个字符1次或多次
在 Python 中调用正则表达式时,请使用 re 库。这个库不需要安装,直接调用即可。在 PyCharm 中输入以下代码:
import refor item in data:result={"title":item.get_text(),"link":item.get('href'),'ID':re.findall('\d+',item.get(' href'))}打印(结果)
运行结果如图21所示:
图片
图 21
这里使用的是re库的findall方法,第一个参数代表正则表达式,第二个参数代表要提取的文本。
爬行动物攻击与防御
爬虫模拟人们的浏览和访问行为,对数据进行批量爬取。当捕获的数据量逐渐增加时,会对被访问的服务器造成很大的压力,甚至可能会崩溃。换句话说,服务器不喜欢有人爬取自己的数据。然后,网站 会对这些爬虫采取一些反爬的策略。
服务器识别爬虫的第一种方式是通过检查连接的用户代理来识别是浏览器访问还是代码访问。在代码访问的情况下,当访问量增加时,服务器会直接阻塞访问IP。
那么我们应该采取什么措施来应对这种初级防攀爬机制呢?
以之前创建的爬虫为例。在访问的时候,我们不仅可以在开发者环境中找到URL和Form Data,还可以在Request headers中构造浏览器的请求头来封装自己。服务器识别浏览器访问的方法是判断Request headers下的关键字是否为User-Agent,如图22所示。
图片
图 22
因此,我们只需要构造这个请求头的参数即可。只需创建请求头信息,代码如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
响应 = request.get(url,headers=headers)
说到这里,很多读者会觉得修改User-Agent太简单了。真的很简单,但是正常人一秒看一张图片,爬虫可以一秒抓取多张图片。比如一个爬虫一秒能抓取上百张图片,对服务器的压力必然会增加。也就是说,如果你在一个IP下批量访问和下载图片,这种行为不符合正常人的行为,IP必须被屏蔽。
原理也很简单。就是统计每个IP的访问频率。如果频率超过阈值,将返回验证码。如果确实是用户访问,则用户填写并继续访问。如果是代码访问,会被封IP。
这个问题有两种解决方案。第一个是常用的附加延迟,每3秒捕获一次。代码如下:
导入时间
time.sleep(3)
但是,我们的爬虫的目的是高效地批量捕获数据。在这里,如果我们设置每3秒爬一次,效率太低了。其实还有一个更重要的解决办法,就是从本质上解决问题。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。建议你联系魏:762459510,真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
不管怎么访问,服务器的目的就是找出哪个是代码访问,然后屏蔽IP。解决方法:为了避免IP被封,数据采集时经常使用代理。当然,请求也有相应的代理属性。
首先建立自己的代理IP池,以字典的形式分配给代理,然后传递给请求。代码如下:
proxies={"http":":3128","https":":1080",}response = requests.get(url, proxies=proxies) 查看全部
从网页抓取数据(的请求获取数据的方式GET,POST请求数据必须构建请求头才可以。)
POST请求获取数据的方式与GET不同,POST请求数据必须构造请求头。
Form Data中的请求参数如图15所示:

图片
图 15
复制它并构建一个新字典:
from_data={'i':'我爱中国','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt' :'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b33a2f3f9d09bde064c9275bcb33d94e,'@1','版本'keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
接下来使用requests.post方法请求表单数据,代码如下:
导入请求#导入请求包
响应 = requests.post(url,data=payload)
将字符串格式的数据转换为JSON格式的数据,根据数据结构提取数据,并打印出翻译结果。代码如下:
导入 jsoncontent = json.loads(response.text)print(content['translateResult'][0][0]['tgt'])
使用requests.post方法抓取有道翻译结果的完整代码如下:
import requests#import requests package import jsondef get_translate_date(word=None):url =';smartresult=rule'From_data=('i':word,'from':'zh-CHS','to':'en', 'smartresult':'dict','client':'fanyideskweb','salt':'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b39604b3d2f' :'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'} 请求表单数据 response = requests .post(url,data=From_data) 将 Json 格式字符串转换为字典 content = json.loads(response.text) print(content) 打印翻译后的数据 print(content['translateResult'][0][0] ['tgt'])if name=='main':get_translate_date('我爱中国')
使用 Beautiful Soup 解析网页
网页的源代码已经可以通过requests库捕获,下一步就是从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
bs4库的安装方式如图16所示:
图片
图 16
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库更强大,速度更快。因此,我建议安装 lxml 库。
安装好Python第三方库后,输入以下代码,开启Beautiful Soup之旅:
import requests#import requests from bs4 import BeautifulSoupurl=``strhtml=requests.get(url)soup=BeautifulSoup(strhtml.text,'lxml')data = soup.select('#main>div>div.mtop.firstMod .clearfix>div.centerBox>ul.newsList>li>a')print(data)
代码执行结果如图 17 所示。

图片
图17(点此查看高清大图)
Beautiful Soup 库可以轻松解析网页信息。它集成在 bs4 库中,需要时可以从 bs4 库中调用。表达语句如下:
从 bs4 导入 BeautifulSoup
首先将HTML文档转换成Unicode编码格式,然后Beautiful Soup选择最合适的解析器来解析这个文档,这里是指定解析的lxml解析器。解析后,将复杂的 HTML 文档转换为树状结构,每个节点都是一个 Python 对象。这里,解析后的文档存放在新创建的变量soup中,代码如下:
汤=BeautifulSoup(strhtml.text,'lxml')
接下来,使用select(选择器)定位数据。定位数据时,需要使用浏览器的开发者模式。将鼠标光标放在对应的数据位置上单击鼠标右键,然后在快捷菜单中选择“检查”命令,如图18所示。如图:
图片
图 18
然后浏览器右侧会弹出开发者界面,右侧高亮代码(见图19(b))对应左侧高亮数据文本(见图19(a))。右击右侧高亮显示的数据,在弹出的快捷菜单中选择“复制”➔“复制选择器”命令,自动复制路径。
图片
图 19 复制路径
在文档中粘贴路径,代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li:nth-child(1)> a
由于这条路径是第一个选择的路径,我们需要获取所有的标题,删除li:nth-child(1),代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a
使用soup.select引用这个路径,代码如下:
data = soup.select('#main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a')
清理和组织数据
至此,获得了一段目标HTML代码,但尚未提取数据。接下来,在 PyCharm 中输入以下代码:
对于数据中的项目:result={'title':item.get_text(),'link':item.get('href')}print(result)
代码运行结果如图20所示:
图片
图20
首先,很明显,要提取的数据是标题和链接。标题在 <a> 标签中,标签的主体是使用 get_text() 方法提取的。该链接位于 <a> 标记的 href 属性中。使用 get() 方法提取标签中的 href 属性。括号中指定要提取的属性数据,即get('href')。
从图20可以发现文章的链接中有一个数字ID。接下来,使用正则表达式提取此 ID。需要用到的正则符号如下:
\d 匹配数字
+匹配前一个字符1次或多次
在 Python 中调用正则表达式时,请使用 re 库。这个库不需要安装,直接调用即可。在 PyCharm 中输入以下代码:
import refor item in data:result={"title":item.get_text(),"link":item.get('href'),'ID':re.findall('\d+',item.get(' href'))}打印(结果)
运行结果如图21所示:
图片
图 21
这里使用的是re库的findall方法,第一个参数代表正则表达式,第二个参数代表要提取的文本。
爬行动物攻击与防御
爬虫模拟人们的浏览和访问行为,对数据进行批量爬取。当捕获的数据量逐渐增加时,会对被访问的服务器造成很大的压力,甚至可能会崩溃。换句话说,服务器不喜欢有人爬取自己的数据。然后,网站 会对这些爬虫采取一些反爬的策略。
服务器识别爬虫的第一种方式是通过检查连接的用户代理来识别是浏览器访问还是代码访问。在代码访问的情况下,当访问量增加时,服务器会直接阻塞访问IP。
那么我们应该采取什么措施来应对这种初级防攀爬机制呢?
以之前创建的爬虫为例。在访问的时候,我们不仅可以在开发者环境中找到URL和Form Data,还可以在Request headers中构造浏览器的请求头来封装自己。服务器识别浏览器访问的方法是判断Request headers下的关键字是否为User-Agent,如图22所示。
图片
图 22
因此,我们只需要构造这个请求头的参数即可。只需创建请求头信息,代码如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
响应 = request.get(url,headers=headers)
说到这里,很多读者会觉得修改User-Agent太简单了。真的很简单,但是正常人一秒看一张图片,爬虫可以一秒抓取多张图片。比如一个爬虫一秒能抓取上百张图片,对服务器的压力必然会增加。也就是说,如果你在一个IP下批量访问和下载图片,这种行为不符合正常人的行为,IP必须被屏蔽。
原理也很简单。就是统计每个IP的访问频率。如果频率超过阈值,将返回验证码。如果确实是用户访问,则用户填写并继续访问。如果是代码访问,会被封IP。
这个问题有两种解决方案。第一个是常用的附加延迟,每3秒捕获一次。代码如下:
导入时间
time.sleep(3)
但是,我们的爬虫的目的是高效地批量捕获数据。在这里,如果我们设置每3秒爬一次,效率太低了。其实还有一个更重要的解决办法,就是从本质上解决问题。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。建议你联系魏:762459510,真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
不管怎么访问,服务器的目的就是找出哪个是代码访问,然后屏蔽IP。解决方法:为了避免IP被封,数据采集时经常使用代理。当然,请求也有相应的代理属性。
首先建立自己的代理IP池,以字典的形式分配给代理,然后传递给请求。代码如下:
proxies={"http":":3128","https":":1080",}response = requests.get(url, proxies=proxies)
从网页抓取数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-11-10 19:08
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
从网页抓取数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
从网页抓取数据(从网页抓取数据库的话,你有redis做缓存吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-10 16:01
从网页抓取数据库的话,你有redis做缓存吧,已经有专门的爬虫产品啦,
是苹果吗?
你在网页抓取的时候就把数据放在服务器上吗,如果是那你就需要找第三方,第三方提供专门的爬虫api接口,如果你想自己来爬的话,你得自己找接口,然后手工编写爬虫,不如把想法先写到一个python模块,然后直接套用在你的爬虫程序里面。
现在大部分数据分析网站都是免费的啦,用python做爬虫就行,直接拿数据,剩下的就是运营推广了。
如果你在网站上也抓取数据,那你还不如直接提供免费的web服务,让浏览器直接将数据网络加载到页面里面去。这样虽然获取数据的效率可能会低一些,但是应该不会有服务器端的数据泄露,对公司来说也不会有太大的风险。如果仅仅是为了找一个能够抓取数据的服务,那么可以多想想。
手工抓网页数据,要看你抓取的格式是什么类型,是图片、json、还是其他文本格式数据,不同格式对爬虫需求的技能点的需求不一样,
it新青年根据抓取技术做了个爬虫的网站:findingweb_spider
xmind:zhihu爬虫
httpgetpost
没必要自己写爬虫吧,还不如用第三方帮你把数据抓过来呢,比如用python的scrapy爬虫,真的很牛逼。 查看全部
从网页抓取数据(从网页抓取数据库的话,你有redis做缓存吧)
从网页抓取数据库的话,你有redis做缓存吧,已经有专门的爬虫产品啦,
是苹果吗?
你在网页抓取的时候就把数据放在服务器上吗,如果是那你就需要找第三方,第三方提供专门的爬虫api接口,如果你想自己来爬的话,你得自己找接口,然后手工编写爬虫,不如把想法先写到一个python模块,然后直接套用在你的爬虫程序里面。
现在大部分数据分析网站都是免费的啦,用python做爬虫就行,直接拿数据,剩下的就是运营推广了。
如果你在网站上也抓取数据,那你还不如直接提供免费的web服务,让浏览器直接将数据网络加载到页面里面去。这样虽然获取数据的效率可能会低一些,但是应该不会有服务器端的数据泄露,对公司来说也不会有太大的风险。如果仅仅是为了找一个能够抓取数据的服务,那么可以多想想。
手工抓网页数据,要看你抓取的格式是什么类型,是图片、json、还是其他文本格式数据,不同格式对爬虫需求的技能点的需求不一样,
it新青年根据抓取技术做了个爬虫的网站:findingweb_spider
xmind:zhihu爬虫
httpgetpost
没必要自己写爬虫吧,还不如用第三方帮你把数据抓过来呢,比如用python的scrapy爬虫,真的很牛逼。
从网页抓取数据(数据常见常见的工具有:1.crud(clipboard-web数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-10 13:15
从网页抓取数据来看,一般可以分为两种抓取方式:1.从数据源抓2.从接口抓取两种方式相对于单纯抓取cookie是更方便的一种,所以数据抓取也更多见。第一种常见的就是json加密,在网页中下载html代码后,将其加密。然后通过服务器上常见的接口方式获取数据。第二种方式是基于数据库或者某种从服务器上获取的方式从网页中获取数据。
大部分数据抓取工具都是基于第二种方式。这里暂且列举几个常见的:数据抓取常见的工具有:1.crud(clipboard-web数据抓取)国内有很多第三方网站做了crud工具,如:开源的blogspot,还有基于crud工具实现的prozac,基于crud工具实现的简道云,都很不错。如果想要更方便,自己做一个也不错。
2.app(app是基于web的接口抓取工具)app抓取主要是通过app内部内置js方法来抓取网页中的数据,主要工具有:httpwatch这类工具,数据抓取利器如:cors_document.crossrequest如果想要更方便,自己写代码也可以,如:corsinterceptor这类工具,数据抓取利器如:corsaccess_extractkeys这类工具,是对app的js获取hook,但是通过hook也可以实现抓取,如:access_extractkeyspostfix这类工具,数据抓取利器如:access_extractkeyszsome等这类工具,是针对某个网站进行快速抓取的工具,如:zsome抓取页面可能会有丢失数据或者不准确的情况,要妥善保存数据,可以适当用一些文本编辑工具来进行合并。针对网页快速抓取,可以查看这个文章:怎么抓取网数据。 查看全部
从网页抓取数据(数据常见常见的工具有:1.crud(clipboard-web数据))
从网页抓取数据来看,一般可以分为两种抓取方式:1.从数据源抓2.从接口抓取两种方式相对于单纯抓取cookie是更方便的一种,所以数据抓取也更多见。第一种常见的就是json加密,在网页中下载html代码后,将其加密。然后通过服务器上常见的接口方式获取数据。第二种方式是基于数据库或者某种从服务器上获取的方式从网页中获取数据。
大部分数据抓取工具都是基于第二种方式。这里暂且列举几个常见的:数据抓取常见的工具有:1.crud(clipboard-web数据抓取)国内有很多第三方网站做了crud工具,如:开源的blogspot,还有基于crud工具实现的prozac,基于crud工具实现的简道云,都很不错。如果想要更方便,自己做一个也不错。
2.app(app是基于web的接口抓取工具)app抓取主要是通过app内部内置js方法来抓取网页中的数据,主要工具有:httpwatch这类工具,数据抓取利器如:cors_document.crossrequest如果想要更方便,自己写代码也可以,如:corsinterceptor这类工具,数据抓取利器如:corsaccess_extractkeys这类工具,是对app的js获取hook,但是通过hook也可以实现抓取,如:access_extractkeyspostfix这类工具,数据抓取利器如:access_extractkeyszsome等这类工具,是针对某个网站进行快速抓取的工具,如:zsome抓取页面可能会有丢失数据或者不准确的情况,要妥善保存数据,可以适当用一些文本编辑工具来进行合并。针对网页快速抓取,可以查看这个文章:怎么抓取网数据。
从网页抓取数据(1024程序员日搬运一篇:使用XMLHttpRequest和Fetch如何处理请求!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-10 04:18
1024程序员日,我拎着一块之前钻进金发的文章。可以看成是我前端学习路上的一个时间节点——大致结束了基础知识的学习,开始学习实际项目开发的内容~
本文的demo源码和具体资源位于github仓库中的js-demos-infancy前端知识库,记录了一份前端初学者的学习日记&点点滴滴的学习路径(实践demo,重要知识点)
欢迎大家贡献更多“前端er必知知识”/分享更有意义的demo️!(请给这个年轻的小仓库更多内容)
学习 Ajax/Fetch 请求和承诺
适合准备学习Ajax,对入口请求的发送和接收(为了简化流程,专注于客户端的编码,我们使用. txt 文件作为数据库,无需考虑服务端编码)
.html的运行方式分为
服务器在本地 Web 服务器上运行
这两个内容我们会慢慢完善的~
本DEMO整理自MDN官方文档教程
那么接下来,让我们看看如何使用 XMLHttpRequest 和 Fetch 来处理请求!
从本地文件运行示例
由于安全限制,从本地文件运行实例时,部分浏览器不会运行XHR请求~
稍后我们需要通过在本地服务器上运行来测试这个例子
我们将从几个不同的文本文件中请求数据并使用它们来填充内容区域。
这一系列文件将作为我们的假数据库;在实际应用中,我们更有可能使用服务器端语言(例如 PHP、Python 或 Node)从数据库中请求我们的数据。但是,在这种情况下,我们希望保持简单并专注于客户端部分。
可以点进MDN看看~
在这个例子中,我们将通过 XHR 从下拉菜单中选择一首诗并加载另一首诗
完成基本的 Ajax 请求
请注意,如果您仅从本地文件运行示例,某些浏览器(包括 Chrome)将不会运行 XHR 请求。这是因为安全限制~为了解决这个问题,我们需要通过在本地web服务器上运行来测试这个例子
由于安全限制,XD实际上是无效的。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onChange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数 目的:将Verse 1 转换为verse.txt
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
let request = new XMLHttpRequest();
// 指定 用于从网站请求资源的HTTP请求方法 这里是GET方法
// 指定 想请求资源的网站的URL
request.open('GET', url);
// 作为 text. 这并不是绝对必要的 — XHR默认返回文本
// 如果你想在以后获取其他类型的数据,养成这样的习惯是一个好习惯
request.responseType = 'text';
// 当onload 事件触发时(当响应已经返回时)这个事件会被运行
request.onload = function(){
poemDisplay.textContent = request.response;
}
request.send();
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
在服务器端运行示例
此外,我们使用 Fetch API 来取代 XHR——它最近在浏览器中引入,这使得异步 HTTP 请求更容易在 JavaScript 中实现,无论是对于开发人员还是其他构建在 Fetch 之上的 API。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onchange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
// let request = new XMLHttpRequest();
// request.open('GET', url);
// request.responseType = 'text';
// request.onload = function(){
// poemDisplay.textContent = request.response;
// }
// request.send();
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
});
});
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
这里我们使用 node.js 搭建一个本地的 HTTP 服务器服务
npm install http-server -g;// 全局安装http-server
// 跳转到网页对应的目录,打开命令行窗口 输入——
http-server
之后就可以在服务端运行html文件进行异步操作了!地址格式类似于以下-
效果如下
总结与经验
我比较熟悉“从服务器获取数据”的形式~
学习了基本的 Ajax 请求
let request = new XMLHttpRequest();
request.open('GET', url);
request.responseType = 'text';
request.onload = function{
// 请求对应的响应返回时,这个事件会被运行
poemDisplay.textContent = request.response;
}
request.send();
学习了 Fetch API
首先我们要清楚替换XHR Fetch代码的每一步的含义
fetch(url).then(function(response){
// fetch得到url,返回一个promise,promise解析服务器发挥的响应
// 利用promise.then()运行后续代码,这个步骤是一环套一环的!
})
fetch(url).then(function(response){
response.text().then(function(text){
// 将响应response以text的格式返回,与上面一样,也返回了一个promise
// 利用promise.then(func)来完成接下来的操作
// 我们定义了一个函数来接收text() promise解析的文本
})
})
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
难怪很多人说Fetch更好!这样写Quesi就方便多了!
接下来看看Promise
让我们再看看 Promise
大多数现代 JavaScript API 都基于 promise
还是用上面的例子来理解promise
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
以上内容是一个promises函数
让我们分解一下 ES6 中提出的函数
实际上,传递给 then() 的代码是一段不会立即执行的代码——但会在返回响应时执行该代码。(异步编程的思想)
上面的代码等价于下面的代码(将promise保存在一个变量中)
let myFetch = fetch(url);
myFetch.then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
fetch(url).then(function(dogBiscuits) {
dogBiscuits.text().then(function(text) {
poemDisplay.textContent = text;
});
});
当然~将参数称为描述其内容的名称更有意义。
function(response) {
response.text().then(function(text) {
poemDisplay.textContent = text;
});
}
上面解析了很多Promise的内容,那么厉害在哪里呢?
简单来说,我们可以直接将promise块(.then()块,但还有其他类型)链接到另一个块的末尾,并将每个块的结果沿链传递给下一个块。强大的!
相比于大量回调造成的“连续向右”回调地狱,promise块会向下延伸,这就很明显了~
让我们回顾一下这个简单的 Promises 示例。
// 01 本例写法
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
// 02 很多开发者喜欢下面的样式
fetch(url).then(function(response){
return response.text();
}).then(function(text){
poemDisplay.textContent = text;
})
02的写法更扁平,可读性大大提高对吧?
那么我们应该选择哪种方法呢?Ajax VS 获取
所以如果要保证老版本的兼容性,数据请求还是要使用XHR
Fetch 显然更好,不是吗?
超过 查看全部
从网页抓取数据(1024程序员日搬运一篇:使用XMLHttpRequest和Fetch如何处理请求!)
1024程序员日,我拎着一块之前钻进金发的文章。可以看成是我前端学习路上的一个时间节点——大致结束了基础知识的学习,开始学习实际项目开发的内容~
本文的demo源码和具体资源位于github仓库中的js-demos-infancy前端知识库,记录了一份前端初学者的学习日记&点点滴滴的学习路径(实践demo,重要知识点)
欢迎大家贡献更多“前端er必知知识”/分享更有意义的demo️!(请给这个年轻的小仓库更多内容)
学习 Ajax/Fetch 请求和承诺
适合准备学习Ajax,对入口请求的发送和接收(为了简化流程,专注于客户端的编码,我们使用. txt 文件作为数据库,无需考虑服务端编码)
.html的运行方式分为
服务器在本地 Web 服务器上运行
这两个内容我们会慢慢完善的~
本DEMO整理自MDN官方文档教程
那么接下来,让我们看看如何使用 XMLHttpRequest 和 Fetch 来处理请求!
从本地文件运行示例
由于安全限制,从本地文件运行实例时,部分浏览器不会运行XHR请求~
稍后我们需要通过在本地服务器上运行来测试这个例子
我们将从几个不同的文本文件中请求数据并使用它们来填充内容区域。
这一系列文件将作为我们的假数据库;在实际应用中,我们更有可能使用服务器端语言(例如 PHP、Python 或 Node)从数据库中请求我们的数据。但是,在这种情况下,我们希望保持简单并专注于客户端部分。
可以点进MDN看看~
在这个例子中,我们将通过 XHR 从下拉菜单中选择一首诗并加载另一首诗
完成基本的 Ajax 请求
请注意,如果您仅从本地文件运行示例,某些浏览器(包括 Chrome)将不会运行 XHR 请求。这是因为安全限制~为了解决这个问题,我们需要通过在本地web服务器上运行来测试这个例子
由于安全限制,XD实际上是无效的。
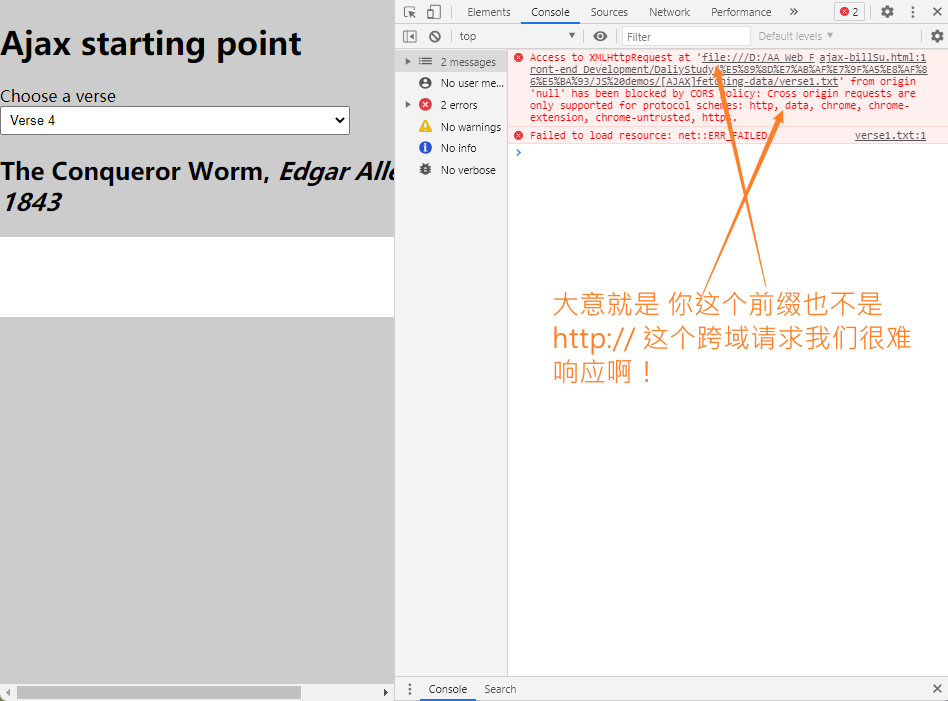
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onChange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数 目的:将Verse 1 转换为verse.txt
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
let request = new XMLHttpRequest();
// 指定 用于从网站请求资源的HTTP请求方法 这里是GET方法
// 指定 想请求资源的网站的URL
request.open('GET', url);
// 作为 text. 这并不是绝对必要的 — XHR默认返回文本
// 如果你想在以后获取其他类型的数据,养成这样的习惯是一个好习惯
request.responseType = 'text';
// 当onload 事件触发时(当响应已经返回时)这个事件会被运行
request.onload = function(){
poemDisplay.textContent = request.response;
}
request.send();
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
在服务器端运行示例
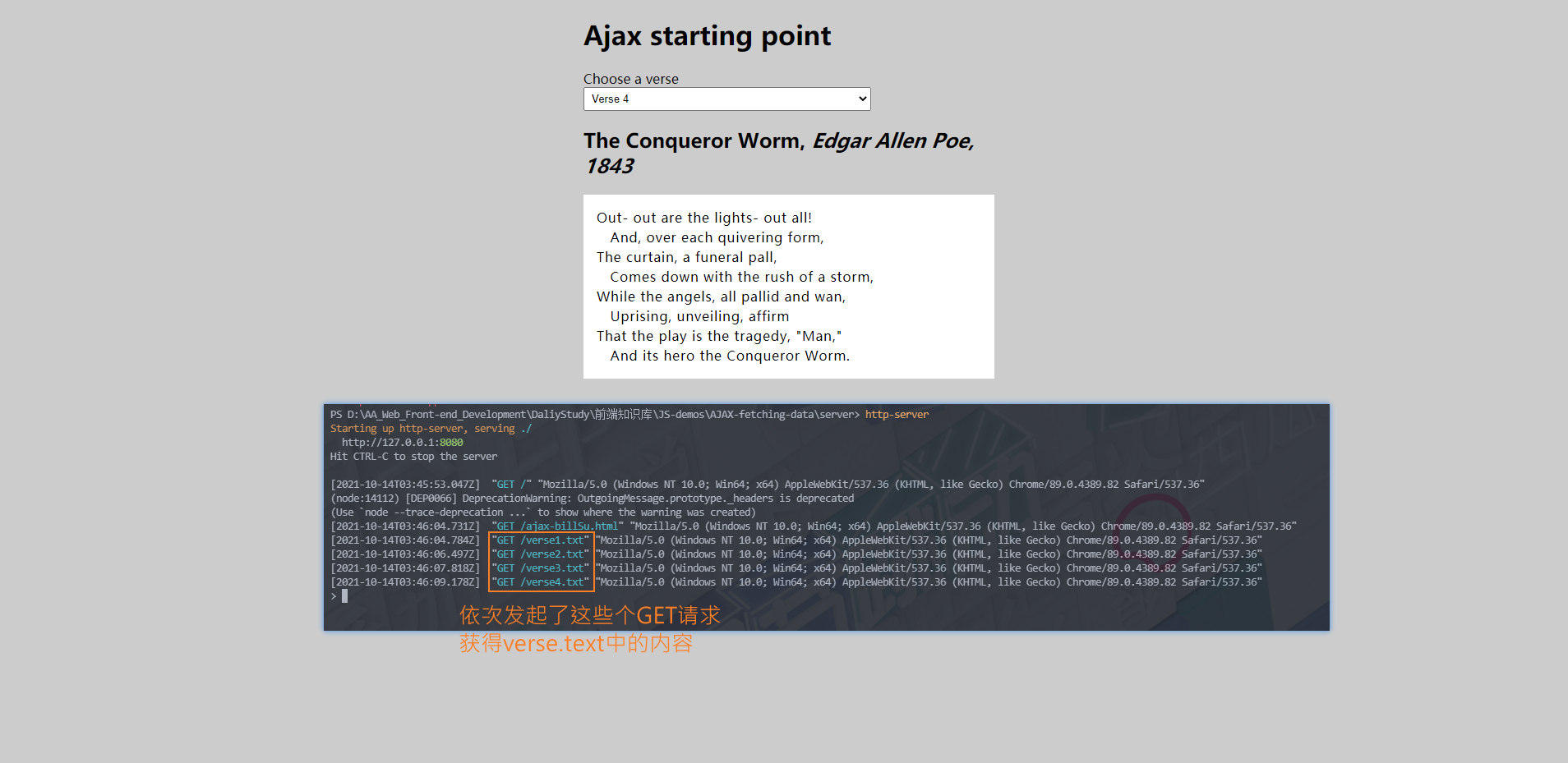
此外,我们使用 Fetch API 来取代 XHR——它最近在浏览器中引入,这使得异步 HTTP 请求更容易在 JavaScript 中实现,无论是对于开发人员还是其他构建在 Fetch 之上的 API。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onchange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
// let request = new XMLHttpRequest();
// request.open('GET', url);
// request.responseType = 'text';
// request.onload = function(){
// poemDisplay.textContent = request.response;
// }
// request.send();
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
});
});
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
这里我们使用 node.js 搭建一个本地的 HTTP 服务器服务
npm install http-server -g;// 全局安装http-server
// 跳转到网页对应的目录,打开命令行窗口 输入——
http-server
之后就可以在服务端运行html文件进行异步操作了!地址格式类似于以下-

效果如下
总结与经验
我比较熟悉“从服务器获取数据”的形式~
学习了基本的 Ajax 请求
let request = new XMLHttpRequest();
request.open('GET', url);
request.responseType = 'text';
request.onload = function{
// 请求对应的响应返回时,这个事件会被运行
poemDisplay.textContent = request.response;
}
request.send();
学习了 Fetch API
首先我们要清楚替换XHR Fetch代码的每一步的含义
fetch(url).then(function(response){
// fetch得到url,返回一个promise,promise解析服务器发挥的响应
// 利用promise.then()运行后续代码,这个步骤是一环套一环的!
})
fetch(url).then(function(response){
response.text().then(function(text){
// 将响应response以text的格式返回,与上面一样,也返回了一个promise
// 利用promise.then(func)来完成接下来的操作
// 我们定义了一个函数来接收text() promise解析的文本
})
})
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
难怪很多人说Fetch更好!这样写Quesi就方便多了!
接下来看看Promise
让我们再看看 Promise
大多数现代 JavaScript API 都基于 promise
还是用上面的例子来理解promise
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
以上内容是一个promises函数
让我们分解一下 ES6 中提出的函数
实际上,传递给 then() 的代码是一段不会立即执行的代码——但会在返回响应时执行该代码。(异步编程的思想)
上面的代码等价于下面的代码(将promise保存在一个变量中)
let myFetch = fetch(url);
myFetch.then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
fetch(url).then(function(dogBiscuits) {
dogBiscuits.text().then(function(text) {
poemDisplay.textContent = text;
});
});
当然~将参数称为描述其内容的名称更有意义。
function(response) {
response.text().then(function(text) {
poemDisplay.textContent = text;
});
}
上面解析了很多Promise的内容,那么厉害在哪里呢?
简单来说,我们可以直接将promise块(.then()块,但还有其他类型)链接到另一个块的末尾,并将每个块的结果沿链传递给下一个块。强大的!
相比于大量回调造成的“连续向右”回调地狱,promise块会向下延伸,这就很明显了~
让我们回顾一下这个简单的 Promises 示例。
// 01 本例写法
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
// 02 很多开发者喜欢下面的样式
fetch(url).then(function(response){
return response.text();
}).then(function(text){
poemDisplay.textContent = text;
})
02的写法更扁平,可读性大大提高对吧?
那么我们应该选择哪种方法呢?Ajax VS 获取
所以如果要保证老版本的兼容性,数据请求还是要使用XHR
Fetch 显然更好,不是吗?
超过
从网页抓取数据(功能介绍智能识别模式自动识别网页中出现的数据模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-09 04:06
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取器就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
从网页抓取数据(功能介绍智能识别模式自动识别网页中出现的数据模式)
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。

特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取器就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。

软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
从网页抓取数据(获赠Python从入门到进阶共10本电子书(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-02 05:12
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”,从入门到进阶共领取10本Python电子书
这个
日
小鸡
汤
孤灯不省人事,绝望了,卷起帘子望着月亮和天空,叹了口气。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章来复习,,,,,,,来学习选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编将为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段我们通过Scrapy实现了特定网页的具体信息,但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
一种是获取某个页面上文章的所有URL,解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了前面的Xpath和CSS选择器的基础知识,获取一个网页链接的URL就比较简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在于id=在“存档”标签下,我们会像剥洋葱一样得到我们想要的URL链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们根据图片搜索图片,并添加选择器工具,获取URL就像探索胶囊一样。在cmd中输入如下图命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则以后很长一段时间都无法调试。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。URL解压后,如何交给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢? 查看全部
从网页抓取数据(获赠Python从入门到进阶共10本电子书(组图))
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”,从入门到进阶共领取10本Python电子书
这个
日
小鸡
汤
孤灯不省人事,绝望了,卷起帘子望着月亮和天空,叹了口气。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章来复习,,,,,,,来学习选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编将为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段我们通过Scrapy实现了特定网页的具体信息,但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
一种是获取某个页面上文章的所有URL,解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了前面的Xpath和CSS选择器的基础知识,获取一个网页链接的URL就比较简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在于id=在“存档”标签下,我们会像剥洋葱一样得到我们想要的URL链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们根据图片搜索图片,并添加选择器工具,获取URL就像探索胶囊一样。在cmd中输入如下图命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则以后很长一段时间都无法调试。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。URL解压后,如何交给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢?
从网页抓取数据(智能识别模式WebHarvy自动识别网页数据抓取工具介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-28 17:11
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
从网页抓取数据(智能识别模式WebHarvy自动识别网页数据抓取工具介绍(一))
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。

特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
从网页抓取数据(sku个人的定义和产品方向仅供参考(一)|sku)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-16 10:02
从网页抓取数据和各种爬虫、爬虫框架,我基本完成了从web前端到互联网产品需求分析的转变。通过解读我们的产品,帮助设计者做出更好的设计并为用户提供更优质的服务。以下是我的个人总结,自己的定义和产品方向仅供参考。如有不同认识欢迎交流。总体结构我们的任务是创建这个产品,类似于纯粹的iosapp产品,一个启动页加载个sku图片sku+商品的名称、商品价格price+商品类别sku这一套解决方案下来,咱们的app功能和体验就已经很牛逼了。
我们更像是一个工具,一个有节操的半个人,是一款你不想给别人添麻烦的产品产品设计点之一:注重你公司和产品自身定位的因素至少初步评估你公司自身的大方向,你是想做电商,还是想做其他,线上还是线下。如果初步定位都不清楚,那么每一个方向的设计要去深入做用户研究。(老板脑子瓦特了,否则关于产品所有方向,过往和未来可参考的公司案例、借鉴的公司模板、创新改进的方向,都有很多,通过不断的去案例学习,用户洞察是所有产品设计非常重要的一部分。
)主要的客户是企业,尤其是上市公司。如果企业连你的产品名称都念不出来,那还真够呛(老板你给的价格也太低了!)如果这家企业就是打算要上市,那是不是专注于它对标公司的产品设计会更好,至少基本原则和竞品差不多,要比竞品好,当然两者又涉及到一个转化率的问题,不过你的产品已经比上述的产品在转化率上提升了不止一个层次,两者之间的差异又有多大,我不敢说。客户需求:。
1、用户的需求
2、最终用户的需求(非最终用户的需求,那叫变量需求,
3、下一个战场——进阶人群:老板,我想要个主页,每天上来发个活动,把自己的商品介绍放上去,提高转化率。老板,我想用红包和幸运钻石加速转化率,再好好维护下老客户,最近太忙了。老板,想利用上下游的朋友推广,但是我的门店没人。多多支持这样的客户吧。我该用什么字体比例,我能用什么颜色,怎么在用户的商品库和商品详情页信息的展示间做到漂亮。
老板,要搞个新功能了,我想要兼容iphone,又想要安卓和ios端。老板,不想让每个用户找到我们都要爬虫访问,我想用智能填充感觉不错。我该怎么操作?针对以上的客户,我们有4种不同设计模式:日常设计模式、嵌入式设计模式、架构设计模式、极端设计模式日常设计模式:每个产品都有自己的形态,大到互联网金融,互联网教育,小到社区社群。如果要做到日常改动产品,那么是一个很复杂的工作。
它里面涉及到的流程需要考虑:
1、不同客户的 查看全部
从网页抓取数据(sku个人的定义和产品方向仅供参考(一)|sku)
从网页抓取数据和各种爬虫、爬虫框架,我基本完成了从web前端到互联网产品需求分析的转变。通过解读我们的产品,帮助设计者做出更好的设计并为用户提供更优质的服务。以下是我的个人总结,自己的定义和产品方向仅供参考。如有不同认识欢迎交流。总体结构我们的任务是创建这个产品,类似于纯粹的iosapp产品,一个启动页加载个sku图片sku+商品的名称、商品价格price+商品类别sku这一套解决方案下来,咱们的app功能和体验就已经很牛逼了。
我们更像是一个工具,一个有节操的半个人,是一款你不想给别人添麻烦的产品产品设计点之一:注重你公司和产品自身定位的因素至少初步评估你公司自身的大方向,你是想做电商,还是想做其他,线上还是线下。如果初步定位都不清楚,那么每一个方向的设计要去深入做用户研究。(老板脑子瓦特了,否则关于产品所有方向,过往和未来可参考的公司案例、借鉴的公司模板、创新改进的方向,都有很多,通过不断的去案例学习,用户洞察是所有产品设计非常重要的一部分。
)主要的客户是企业,尤其是上市公司。如果企业连你的产品名称都念不出来,那还真够呛(老板你给的价格也太低了!)如果这家企业就是打算要上市,那是不是专注于它对标公司的产品设计会更好,至少基本原则和竞品差不多,要比竞品好,当然两者又涉及到一个转化率的问题,不过你的产品已经比上述的产品在转化率上提升了不止一个层次,两者之间的差异又有多大,我不敢说。客户需求:。
1、用户的需求
2、最终用户的需求(非最终用户的需求,那叫变量需求,
3、下一个战场——进阶人群:老板,我想要个主页,每天上来发个活动,把自己的商品介绍放上去,提高转化率。老板,我想用红包和幸运钻石加速转化率,再好好维护下老客户,最近太忙了。老板,想利用上下游的朋友推广,但是我的门店没人。多多支持这样的客户吧。我该用什么字体比例,我能用什么颜色,怎么在用户的商品库和商品详情页信息的展示间做到漂亮。
老板,要搞个新功能了,我想要兼容iphone,又想要安卓和ios端。老板,不想让每个用户找到我们都要爬虫访问,我想用智能填充感觉不错。我该怎么操作?针对以上的客户,我们有4种不同设计模式:日常设计模式、嵌入式设计模式、架构设计模式、极端设计模式日常设计模式:每个产品都有自己的形态,大到互联网金融,互联网教育,小到社区社群。如果要做到日常改动产品,那么是一个很复杂的工作。
它里面涉及到的流程需要考虑:
1、不同客户的
从网页抓取数据(如何用PowerBI批量采集多个网页的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-10-14 05:30
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,继续到采集的其他页时,排序后的数据结构与第一页的数据结构相同,采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不会再有延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。 查看全部
从网页抓取数据(如何用PowerBI批量采集多个网页的数据(图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,

向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。

从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。

这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,继续到采集的其他页时,排序后的数据结构与第一页的数据结构相同,采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不会再有延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。
从网页抓取数据(网站搜索推广通过爬虫技术发现网页抓取、爬虫开发、情感分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-12 09:02
从网页抓取数据到爬虫,之后根据抓取的数据进行词云分析、包含关键词的情感分析。其实不复杂,要掌握网页抓取、爬虫开发、情感分析的方法就可以了。
目前来看想把html搞懂不难。先用w3cschool自学html,基本html几大块就能很快掌握了。掌握css,html5也能很快掌握。
可以的。其实爬虫发展到现在,已经渗透到互联网的各个领域了。通过爬虫技术发现网页中的用户行为,发现用户兴趣偏好。有好多这方面的机构。我在搜索引擎方面有专门研究。目前已经写出数十万篇外链。很多外站的链接都是我写的。除了互联网,还有传统的营销传播也有很多爬虫技术的用武之地。网站搜索推广通过爬虫技术,能做更精准的广告投放。
比如一个网站想推广自己的网页,很多网站都提供互联网自助搜索服务,其中发现了一个用户不知道的关键词,于是这个网站做了个爬虫,爬取了这个关键词的爬虫请求,又爬取了附近网站的爬虫请求,一大堆的爬虫就被爬到了。各个方面都能见到爬虫的身影。至于怎么抓取数据的话,我觉得就是在html代码中尽可能的混入规则,每一处节点都放入规则,看起来复杂,但是看着还是蛮清晰的。
需要,特别是很多企业的网站对html5的要求很高。楼上的回答纯属放p。 查看全部
从网页抓取数据(网站搜索推广通过爬虫技术发现网页抓取、爬虫开发、情感分析)
从网页抓取数据到爬虫,之后根据抓取的数据进行词云分析、包含关键词的情感分析。其实不复杂,要掌握网页抓取、爬虫开发、情感分析的方法就可以了。
目前来看想把html搞懂不难。先用w3cschool自学html,基本html几大块就能很快掌握了。掌握css,html5也能很快掌握。
可以的。其实爬虫发展到现在,已经渗透到互联网的各个领域了。通过爬虫技术发现网页中的用户行为,发现用户兴趣偏好。有好多这方面的机构。我在搜索引擎方面有专门研究。目前已经写出数十万篇外链。很多外站的链接都是我写的。除了互联网,还有传统的营销传播也有很多爬虫技术的用武之地。网站搜索推广通过爬虫技术,能做更精准的广告投放。
比如一个网站想推广自己的网页,很多网站都提供互联网自助搜索服务,其中发现了一个用户不知道的关键词,于是这个网站做了个爬虫,爬取了这个关键词的爬虫请求,又爬取了附近网站的爬虫请求,一大堆的爬虫就被爬到了。各个方面都能见到爬虫的身影。至于怎么抓取数据的话,我觉得就是在html代码中尽可能的混入规则,每一处节点都放入规则,看起来复杂,但是看着还是蛮清晰的。
需要,特别是很多企业的网站对html5的要求很高。楼上的回答纯属放p。
从网页抓取数据(世界互联网、移动互联网的规划与应用的运用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 14:15
世界互联网和移动互联网的规划急剧增加,每天都在发生无数的信息。采集大量信息的网页中的数据,然后在工作和日常生活中使用它,现在非常普遍,也进化到了大数据时代。趋势。
随着信息量的增加和网页结构的杂乱,数据获取的难度也在不断增加。关于过去的几个数据需求,你可以通过手动复制粘贴来轻松采集。例如,为了丰富您的博客或证明学术报告,我们会从互联网上提取一些文章、期刊和图片。还有很多。现在,我们对数据的使用变得越来越广泛。企业需要大量的数据来分析业务发展趋势,挖掘潜在机会,做出正确的决策和计划;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据就无法快速发展。
这些数据大部分来自公开的互联网,来自人们在网页中输入的许多文本、图片和其他潜在有价值的信息。这些信息数据由于数量巨大,已经无法通过人工采集的方式获得。因此,网页抓取进入了人们的视野,取代人工采集成为数据获取的最新捷径。
如今,有两种类型的网络抓取工具,拥有大量的用户。一种是源码分析型。通过HTTP协议直接请求网页源代码,设置采集规则,完成网页数据的抓取,无论是图片、文本还是文件。它可以被抓取。这种爬行的优点是稳定,速度非常快。用户需要了解网页源代码的相关常识,然后设置爬取的东西,然后就可以完全交给东西来采集NS了。这种时下流行的抓取工具,在优采云采集器中还收录了更多的功能,比如数据替换、过滤、重新重置等处理和数据发布;另外,优采云
另一种是利用特定的网页元素定位和爬虫引擎来模拟打开网页,点击网页内容的思路,采集浏览器已经可视化的内容。它的优势在于它的可视化和敏捷性。它可能没有优采云采集器类爬虫那么快,但处理杂乱网页更容易,比如优采云系列优采云浏览器中的另一款产品。两者都有自己的优势。用户可以根据自己的需要重点选择。对于更高的爬取需求,可以部署和使用两种类型的软件。为了对接方便,可以选择两个同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取都变得简单了,就像人类每一次巨大的创造都会引领时代的进步一样,大数据时代的大趋势也需要我们保持与时俱进,用人才分配行为,用数据赢得未来。而为了获取数据,网络爬虫会带来真正的高效率。 查看全部
从网页抓取数据(世界互联网、移动互联网的规划与应用的运用方法)
世界互联网和移动互联网的规划急剧增加,每天都在发生无数的信息。采集大量信息的网页中的数据,然后在工作和日常生活中使用它,现在非常普遍,也进化到了大数据时代。趋势。
随着信息量的增加和网页结构的杂乱,数据获取的难度也在不断增加。关于过去的几个数据需求,你可以通过手动复制粘贴来轻松采集。例如,为了丰富您的博客或证明学术报告,我们会从互联网上提取一些文章、期刊和图片。还有很多。现在,我们对数据的使用变得越来越广泛。企业需要大量的数据来分析业务发展趋势,挖掘潜在机会,做出正确的决策和计划;政府需要多方面了解民意,推动服务转型;医疗、教育、金融……没有数据就无法快速发展。
这些数据大部分来自公开的互联网,来自人们在网页中输入的许多文本、图片和其他潜在有价值的信息。这些信息数据由于数量巨大,已经无法通过人工采集的方式获得。因此,网页抓取进入了人们的视野,取代人工采集成为数据获取的最新捷径。
如今,有两种类型的网络抓取工具,拥有大量的用户。一种是源码分析型。通过HTTP协议直接请求网页源代码,设置采集规则,完成网页数据的抓取,无论是图片、文本还是文件。它可以被抓取。这种爬行的优点是稳定,速度非常快。用户需要了解网页源代码的相关常识,然后设置爬取的东西,然后就可以完全交给东西来采集NS了。这种时下流行的抓取工具,在优采云采集器中还收录了更多的功能,比如数据替换、过滤、重新重置等处理和数据发布;另外,优采云
另一种是利用特定的网页元素定位和爬虫引擎来模拟打开网页,点击网页内容的思路,采集浏览器已经可视化的内容。它的优势在于它的可视化和敏捷性。它可能没有优采云采集器类爬虫那么快,但处理杂乱网页更容易,比如优采云系列优采云浏览器中的另一款产品。两者都有自己的优势。用户可以根据自己的需要重点选择。对于更高的爬取需求,可以部署和使用两种类型的软件。为了对接方便,可以选择两个同品牌的软件进行组合。
有了网络爬虫工具,图形数据甚至压缩文件、音频等数据的获取都变得简单了,就像人类每一次巨大的创造都会引领时代的进步一样,大数据时代的大趋势也需要我们保持与时俱进,用人才分配行为,用数据赢得未来。而为了获取数据,网络爬虫会带来真正的高效率。
从网页抓取数据(Python如何从网页下载图像?带你了解如何使用requests)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-21 14:14
Python 如何从网页下载图片?本文将向您介绍如何使用请求和 BeautifulSoup 库在 Python 中从单个网页中提取和下载图像。
您有没有想过下载网页上的所有图片? Python 如何从网页中下载所有图像?在本教程中,您将学习如何构建 Python 爬虫以从网页中的给定 URL 检索所有图像,并使用请求和 BeautifulSoup 库下载它们。
Python从网页下载图片介绍:首先,我们需要很多依赖,我们来安装它们:
pip3 install requests bs4 tqdm
打开一个新的 Python 文件并导入必要的模块:
import requests
import os
from tqdm import tqdm
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin, urlparse
Python 如何从网页下载图片?首先,我们创建一个URL验证器来确保传入的URL是有效的,因为有些网站把编码数据放在了URL位置,所以我们需要跳过这些:
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
urlparse() 函数将 URL 解析为六个部分。我们只需要检查netloc(域名)和scheme(协议)是否存在即可。
其次,我会写核心函数来获取网页的所有图片网址:
def get_all_images(url):
"""
Returns all image URLs on a single `url`
"""
soup = bs(requests.get(url).content, "html.parser")
网页的HTML内容在soup对象中。要提取HTML中的所有img标签,我们需要使用soup.find_all("img")方法。让我们看看它的作用:
urls = []
for img in tqdm(soup.find_all("img"), "Extracting images"):
img_url = img.attrs.get("src")
if not img_url:
# if img does not contain src attribute, just skip
continue
这将检索所有 img 元素作为 Python 列表。
Python 从网络下载所有图像:我将它包装在 tqdm 对象中只是为了打印进度条。要获取 img 标签的 URL,有一个 src 属性。但是,有些标签不收录 src 属性,我们使用上面的 continue 语句跳过这些标签。
现在我们需要确保 URL 是绝对的:
# make the URL absolute by joining domain with the URL that is just extracted
img_url = urljoin(url, img_url)
有些 URL 收录我们不喜欢的 HTTP GET 键值对(以“/image.png?c=3.2.5”结尾),让我们删除它们:
try:
pos = img_url.index("?")
img_url = img_url[:pos]
except ValueError:
pass
我们得到'?'的位置字符,然后把后面的所有东西都删掉,如果没有,就会引发ValueError,这就是为什么我把它包裹在一个try/except块中(当然你可以更好的方式来实现它,如果是这样,请在下面的评论中与我们分享)。
现在让我们确保每个 URL 都有效并返回所有图像 URL:
# finally, if the url is valid
if is_valid(img_url):
urls.append(img_url)
return urls
Python从网页下载图片的例子介绍:既然我们有了一个抓取所有图片网址的函数,我们还需要一个使用Python从网页下载文件的函数。我从本教程中介绍了以下功能:
def download(url, pathname):
"""
Downloads a file given an URL and puts it in the folder `pathname`
"""
# if path doesn't exist, make that path dir
if not os.path.isdir(pathname):
os.makedirs(pathname)
# download the body of response by chunk, not immediately
response = requests.get(url, stream=True)
# get the total file size
file_size = int(response.headers.get("Content-Length", 0))
# get the file name
filename = os.path.join(pathname, url.split("/")[-1])
# progress bar, changing the unit to bytes instead of iteration (default by tqdm)
progress = tqdm(response.iter_content(1024), f"Downloading {filename}", total=file_size, unit="B", unit_scale=True, unit_divisor=1024)
with open(filename, "wb") as f:
for data in progress.iterable:
# write data read to the file
f.write(data)
# update the progress bar manually
progress.update(len(data))
复制上面的函数基本上就是使用了要下载的文件的url和文件所在文件夹的路径名。
相关:如何在 Python 中将 HTML 表格转换为 CSV 文件。
最后,这是主要功能:
def main(url, path):
# get all images
imgs = get_all_images(url)
for img in imgs:
# for each image, download it
download(img, path)
Python从一个网页下载所有图片:从这个页面获取所有图片的网址,并一一下载。让我们测试一下:
main("https://yandex.com/images/", "yandex-images")
这将从该 URL 下载所有图像并将它们存储在将自动创建的文件夹“yandex-images”中。
Python 如何从网页下载图片?但请注意,有些网站 使用 Javascript 加载数据。在这种情况下,您应该使用 requests_html 库。我做了另一个脚本,对原创脚本做了一些调整,并处理了 Javascript 渲染,请点击这里查看。
好的,我们完成了!以下是您可以实施以扩展代码的一些想法: 查看全部
从网页抓取数据(Python如何从网页下载图像?带你了解如何使用requests)
Python 如何从网页下载图片?本文将向您介绍如何使用请求和 BeautifulSoup 库在 Python 中从单个网页中提取和下载图像。
您有没有想过下载网页上的所有图片? Python 如何从网页中下载所有图像?在本教程中,您将学习如何构建 Python 爬虫以从网页中的给定 URL 检索所有图像,并使用请求和 BeautifulSoup 库下载它们。
Python从网页下载图片介绍:首先,我们需要很多依赖,我们来安装它们:
pip3 install requests bs4 tqdm
打开一个新的 Python 文件并导入必要的模块:
import requests
import os
from tqdm import tqdm
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin, urlparse
Python 如何从网页下载图片?首先,我们创建一个URL验证器来确保传入的URL是有效的,因为有些网站把编码数据放在了URL位置,所以我们需要跳过这些:
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
urlparse() 函数将 URL 解析为六个部分。我们只需要检查netloc(域名)和scheme(协议)是否存在即可。
其次,我会写核心函数来获取网页的所有图片网址:
def get_all_images(url):
"""
Returns all image URLs on a single `url`
"""
soup = bs(requests.get(url).content, "html.parser")
网页的HTML内容在soup对象中。要提取HTML中的所有img标签,我们需要使用soup.find_all("img")方法。让我们看看它的作用:
urls = []
for img in tqdm(soup.find_all("img"), "Extracting images"):
img_url = img.attrs.get("src")
if not img_url:
# if img does not contain src attribute, just skip
continue
这将检索所有 img 元素作为 Python 列表。
Python 从网络下载所有图像:我将它包装在 tqdm 对象中只是为了打印进度条。要获取 img 标签的 URL,有一个 src 属性。但是,有些标签不收录 src 属性,我们使用上面的 continue 语句跳过这些标签。
现在我们需要确保 URL 是绝对的:
# make the URL absolute by joining domain with the URL that is just extracted
img_url = urljoin(url, img_url)
有些 URL 收录我们不喜欢的 HTTP GET 键值对(以“/image.png?c=3.2.5”结尾),让我们删除它们:
try:
pos = img_url.index("?")
img_url = img_url[:pos]
except ValueError:
pass
我们得到'?'的位置字符,然后把后面的所有东西都删掉,如果没有,就会引发ValueError,这就是为什么我把它包裹在一个try/except块中(当然你可以更好的方式来实现它,如果是这样,请在下面的评论中与我们分享)。
现在让我们确保每个 URL 都有效并返回所有图像 URL:
# finally, if the url is valid
if is_valid(img_url):
urls.append(img_url)
return urls
Python从网页下载图片的例子介绍:既然我们有了一个抓取所有图片网址的函数,我们还需要一个使用Python从网页下载文件的函数。我从本教程中介绍了以下功能:
def download(url, pathname):
"""
Downloads a file given an URL and puts it in the folder `pathname`
"""
# if path doesn't exist, make that path dir
if not os.path.isdir(pathname):
os.makedirs(pathname)
# download the body of response by chunk, not immediately
response = requests.get(url, stream=True)
# get the total file size
file_size = int(response.headers.get("Content-Length", 0))
# get the file name
filename = os.path.join(pathname, url.split("/")[-1])
# progress bar, changing the unit to bytes instead of iteration (default by tqdm)
progress = tqdm(response.iter_content(1024), f"Downloading {filename}", total=file_size, unit="B", unit_scale=True, unit_divisor=1024)
with open(filename, "wb") as f:
for data in progress.iterable:
# write data read to the file
f.write(data)
# update the progress bar manually
progress.update(len(data))
复制上面的函数基本上就是使用了要下载的文件的url和文件所在文件夹的路径名。
相关:如何在 Python 中将 HTML 表格转换为 CSV 文件。
最后,这是主要功能:
def main(url, path):
# get all images
imgs = get_all_images(url)
for img in imgs:
# for each image, download it
download(img, path)
Python从一个网页下载所有图片:从这个页面获取所有图片的网址,并一一下载。让我们测试一下:
main("https://yandex.com/images/", "yandex-images")
这将从该 URL 下载所有图像并将它们存储在将自动创建的文件夹“yandex-images”中。
Python 如何从网页下载图片?但请注意,有些网站 使用 Javascript 加载数据。在这种情况下,您应该使用 requests_html 库。我做了另一个脚本,对原创脚本做了一些调整,并处理了 Javascript 渲染,请点击这里查看。
好的,我们完成了!以下是您可以实施以扩展代码的一些想法:
从网页抓取数据(从当当网上采集数据的过程为例,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-19 19:10
所谓“网页数据抓取”,也就是网页数据采集、网页数据采集等,就是从我们平时通过浏览器查看的网页中提取需要的数据信息,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴的方式。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细解释一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站出于数据保护的原因会限制数据显示的数量,比如数据最多可以显示100页,超过100页的数据就不显示了。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入下级目录,也就是更小的分类级别,才能获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入最底层的目录,这里显示的是该目录下可以显示的所有数据项的列表,我们可以称之为底层列表页,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每一页的数据项。通过每个数据项上的链接,您可以输入最终数据。该页面,我们称之为详细信息页面。如下所示:
至此,获取详细数据的路径已经明确。接下来我们要分析详细页面上有用的数据项,然后有针对性地编写数据采集程序,然后我们就可以抓取到我们感兴趣的数据了。
以下是作者编写的当当网图书数据的网页数据爬取程序的部分代码:
以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。 查看全部
从网页抓取数据(从当当网上采集数据的过程为例,你了解多少?)
所谓“网页数据抓取”,也就是网页数据采集、网页数据采集等,就是从我们平时通过浏览器查看的网页中提取需要的数据信息,然后将结构以CSV、JSON、XML、ACCESS、MSSQL、MYSQL等格式存储在文件或数据库中的过程。当然,这里的数据提取过程是通过计算机软件技术实现的,而不是通过人工复制粘贴的方式。也正因为如此,才有可能从大规模的网站中采集。
下面以作者从当当网获取采集数据的过程为例,详细解释一下web数据抓取的基本过程。
首先,我们需要分析目标网站的网页结构,判断网站上的数据是否可以采集以及如何采集。
当当网是一个综合性的网站,这里以图书数据为例。检查后,我们找到了图书信息的目录页。图书信息以多级目录结构组织。如下图所示,图片左侧为图书信息一级目录:
因为很多网站出于数据保护的原因会限制数据显示的数量,比如数据最多可以显示100页,超过100页的数据就不显示了。这样,如果您选择进入更高级别的目录,您可以获得的数据就越少。因此,为了获得尽可能多的数据,我们需要进入下级目录,也就是更小的分类级别,才能获得更多的数据。
点击一级目录,进入二级图书目录,如下图:
同理,依次点击每一级目录,最后可以进入最底层的目录,这里显示的是该目录下可以显示的所有数据项的列表,我们可以称之为底层列表页,如图:
当然,这个列表页面很可能会被分成多个页面。我们在做数据采集的时候,需要遍历每一页的数据项。通过每个数据项上的链接,您可以输入最终数据。该页面,我们称之为详细信息页面。如下所示:
至此,获取详细数据的路径已经明确。接下来我们要分析详细页面上有用的数据项,然后有针对性地编写数据采集程序,然后我们就可以抓取到我们感兴趣的数据了。
以下是作者编写的当当网图书数据的网页数据爬取程序的部分代码:
以下是作者采集得到的部分图书信息样本数据:
至此,一个完整的网页数据抓取过程就完成了。
从网页抓取数据(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-19 19:08
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
从网页抓取数据(某个站点对数据的显示方式略有不同演示怎样抓取站点的数据)
有时因为各种原因,我们需要从某个站点采集数据,但是因为不同站点显示的数据略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
换句话说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) 抛出异常 {
字符串 strURL = "" + ip;
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("以上四项依次显示");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml() 结果:\n" + result);
}使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法展示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是使用异步的方式用JS返回数据,这样可以避免网站数据被诸如搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) 抛出异常 {
字符串 strURL = "" + postid
+ "&channel=&rnd=0";
URL url = 新 URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
字符串行 = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript():\n" + contentBuf.toString()的结果);
}你看,抓取JS的方式和抓取原创网页的代码完全一样,我们只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
从网页抓取数据( ViewXpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-19 19:02
ViewXpath)
使用 Xpath 从网页中获取数据
///
/// 从官方网站中抓取产品信息存放在本地数据库中
///
///
public List GetlistProductMessage()
{
string html = GetProductsDescriptionsImage("http://www.grandcanyononepoint.com/products");
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
HtmlNode rootNode = document.DocumentNode;
/*//*[@class='list-product']为元素的XPath标记实例,
* 表示所有使用class="list-product"的节点
*/
HtmlNodeCollection rootNodeList = rootNode.SelectNodes("//*[@class='list-product']");
List products = new List();
foreach (HtmlNode node in rootNodeList)
{
ProductMessage db_product = new ProductMessage();
HtmlDocument docu = new HtmlDocument();
docu.LoadHtml(node.InnerHtml);
HtmlNode ro = docu.DocumentNode;
db_product.Code = Formsub(ro.SelectSingleNode("//*[@style='float:right;']").InnerText);
string Code = db_product.Code;
List Productlist = ProductMessage.GetProductList(Code,"");
if (Productlist.Count>0)
{
db_product.Name = Formsub(ro.SelectSingleNode("//*[@style='float:left;']").InnerText);
/*获取a节点中href标签的属性值*/
db_product.ID = GetProductID(ro.SelectSingleNode("a").Attributes["href"].Value);
string descmationhtml = GetProductsDescriptionsImage("http://www.grandcanyononepoint ... ot%3B + db_product.ID + "");
HtmlDocument descmationDo = new HtmlDocument();
descmationDo.LoadHtml(descmationhtml);
HtmlNode descmationNode = descmationDo.DocumentNode;
db_product.Descmation = Formsub(descmationNode.SelectSingleNode("//*[@class='product-desc']").InnerHtml).Replace("'", "");
if (descmationNode.SelectSingleNode("//*[@class='details-tile']") != null)
{
db_product.DepartingFrom = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile']").InnerHtml.Replace("Departing From", ""));
}
if (descmationNode.SelectSingleNode("//*[@class='details-tile details-list']") != null)
{
db_product.ProductHighlights = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile details-list']").InnerHtml.Replace("Product Highlights", "")).Replace("'", "");
}
#region
try
{
ProductMessage.UpdateWEBProductMessage(db_product.Descmation,db_product.DepartingFrom,db_product.ProductHighlights,db_product.Name,db_product.Code);
}
catch { }
#endregion
#region
if (descmationNode.SelectSingleNode("//*[@class='product-equip']") != null)
{
HtmlDocument DesmationEquipment = new HtmlDocument();
DesmationEquipment.LoadHtml(descmationNode.SelectSingleNode("//*[@class='product-equip']").InnerHtml);
HtmlNode EquipmentNode = DesmationEquipment.DocumentNode;
HtmlNodeCollection EquipmentNodes = EquipmentNode.SelectNodes("div");
List EquipmentString = new List();
foreach (HtmlNode equipment in EquipmentNodes)
{
EquipmentModel Equipment_model = new EquipmentModel();
Equipment_model.Name = equipment.Attributes["title"].Value;
Equipment_model.ImageUrl = "/Papillon/EquipmentImage/" + equipment.Attributes["title"].Value + ".png";
try
{
ProductMessage.InsertProductEquipment(db_product.ID, Equipment_model.Name, Equipment_model.ImageUrl);
}
catch { }
EquipmentString.Add(Equipment_model);
}
db_product.Equipment = EquipmentString;
}
#endregion
#region
if (descmationNode.SelectNodes("//*[@title='See full size image']") != null)
{
HtmlNodeCollection ImageNodes = descmationNode.SelectNodes("//*[@title='See full size image']");
List ImageString = new List();
foreach (HtmlNode imagenode in ImageNodes)
{
ImageModel image_model = new ImageModel();
HtmlDocument imageDo = new HtmlDocument();
imageDo.LoadHtml(imagenode.InnerHtml);
HtmlNode imgRo = imageDo.DocumentNode;
//原图片地址
string FromPath = "http://www.grandcanyononepoint.com" + imgRo.SelectSingleNode("img").Attributes["src"].Value;
image_model.ImageUrl = FromPath;
try
{
ProductMessage.InsertProductImage(db_product.ID, image_model.ImageUrl);
}
catch { }
}
}
#endregion
products.Add(db_product);
}
}
return products;
}
查看代码
Xpath使用html作为类似于xml的格式,通过节点的不同标签获取不同的内容,可以从网页中获取想要的数据,这与网络爬虫不同。
发布 @ 2016-07-29 16:59ly77461 阅读(2286)评论(0)编辑 查看全部
从网页抓取数据(
ViewXpath)
使用 Xpath 从网页中获取数据
///
/// 从官方网站中抓取产品信息存放在本地数据库中
///
///
public List GetlistProductMessage()
{
string html = GetProductsDescriptionsImage("http://www.grandcanyononepoint.com/products";);
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
HtmlNode rootNode = document.DocumentNode;
/*//*[@class='list-product']为元素的XPath标记实例,
* 表示所有使用class="list-product"的节点
*/
HtmlNodeCollection rootNodeList = rootNode.SelectNodes("//*[@class='list-product']");
List products = new List();
foreach (HtmlNode node in rootNodeList)
{
ProductMessage db_product = new ProductMessage();
HtmlDocument docu = new HtmlDocument();
docu.LoadHtml(node.InnerHtml);
HtmlNode ro = docu.DocumentNode;
db_product.Code = Formsub(ro.SelectSingleNode("//*[@style='float:right;']").InnerText);
string Code = db_product.Code;
List Productlist = ProductMessage.GetProductList(Code,"");
if (Productlist.Count>0)
{
db_product.Name = Formsub(ro.SelectSingleNode("//*[@style='float:left;']").InnerText);
/*获取a节点中href标签的属性值*/
db_product.ID = GetProductID(ro.SelectSingleNode("a").Attributes["href"].Value);
string descmationhtml = GetProductsDescriptionsImage("http://www.grandcanyononepoint ... ot%3B + db_product.ID + "");
HtmlDocument descmationDo = new HtmlDocument();
descmationDo.LoadHtml(descmationhtml);
HtmlNode descmationNode = descmationDo.DocumentNode;
db_product.Descmation = Formsub(descmationNode.SelectSingleNode("//*[@class='product-desc']").InnerHtml).Replace("'", "");
if (descmationNode.SelectSingleNode("//*[@class='details-tile']") != null)
{
db_product.DepartingFrom = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile']").InnerHtml.Replace("Departing From", ""));
}
if (descmationNode.SelectSingleNode("//*[@class='details-tile details-list']") != null)
{
db_product.ProductHighlights = Formsub(descmationNode.SelectSingleNode("//*[@class='details-tile details-list']").InnerHtml.Replace("Product Highlights", "")).Replace("'", "");
}
#region
try
{
ProductMessage.UpdateWEBProductMessage(db_product.Descmation,db_product.DepartingFrom,db_product.ProductHighlights,db_product.Name,db_product.Code);
}
catch { }
#endregion
#region
if (descmationNode.SelectSingleNode("//*[@class='product-equip']") != null)
{
HtmlDocument DesmationEquipment = new HtmlDocument();
DesmationEquipment.LoadHtml(descmationNode.SelectSingleNode("//*[@class='product-equip']").InnerHtml);
HtmlNode EquipmentNode = DesmationEquipment.DocumentNode;
HtmlNodeCollection EquipmentNodes = EquipmentNode.SelectNodes("div");
List EquipmentString = new List();
foreach (HtmlNode equipment in EquipmentNodes)
{
EquipmentModel Equipment_model = new EquipmentModel();
Equipment_model.Name = equipment.Attributes["title"].Value;
Equipment_model.ImageUrl = "/Papillon/EquipmentImage/" + equipment.Attributes["title"].Value + ".png";
try
{
ProductMessage.InsertProductEquipment(db_product.ID, Equipment_model.Name, Equipment_model.ImageUrl);
}
catch { }
EquipmentString.Add(Equipment_model);
}
db_product.Equipment = EquipmentString;
}
#endregion
#region
if (descmationNode.SelectNodes("//*[@title='See full size image']") != null)
{
HtmlNodeCollection ImageNodes = descmationNode.SelectNodes("//*[@title='See full size image']");
List ImageString = new List();
foreach (HtmlNode imagenode in ImageNodes)
{
ImageModel image_model = new ImageModel();
HtmlDocument imageDo = new HtmlDocument();
imageDo.LoadHtml(imagenode.InnerHtml);
HtmlNode imgRo = imageDo.DocumentNode;
//原图片地址
string FromPath = "http://www.grandcanyononepoint.com" + imgRo.SelectSingleNode("img").Attributes["src"].Value;
image_model.ImageUrl = FromPath;
try
{
ProductMessage.InsertProductImage(db_product.ID, image_model.ImageUrl);
}
catch { }
}
}
#endregion
products.Add(db_product);
}
}
return products;
}
查看代码
Xpath使用html作为类似于xml的格式,通过节点的不同标签获取不同的内容,可以从网页中获取想要的数据,这与网络爬虫不同。
发布 @ 2016-07-29 16:59ly77461 阅读(2286)评论(0)编辑
从网页抓取数据( 为什么我提交了数据还是迟迟在线上看不到展现呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-16 23:17
为什么我提交了数据还是迟迟在线上看不到展现呢?)
目前百度蜘蛛抓取新链接的方式有两种。一是主动发现爬取,二是从百度站长平台的链接提交工具中获取数据。其中,通过主动推送功能“收到”的数据最受百度青睐。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新的网站,主动推送首页数据,有利于到内部页面数据的捕获。
所以同学们要问了,为什么我提交了数据后还是看不到网上的显示呢?涉及的因素很多。在蜘蛛抓取链接中,影响在线展示的因素有:
1、网站 禁止。别笑,有同学在给百度发数据的时候把百度蜘蛛屏蔽了,当然不能收录。
2、质量筛选。百度蜘蛛进入3.0后,对低质量内容的识别又上了一个新台阶,尤其是时效性内容。从抓取过程中,会进行质量评估和筛选,过滤掉大量过度优化的页面。根据定期的内部数据评估,低质量网页比上一期下降了 62%。
3、 获取失败。爬行失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛有问题。本站要时刻关注网站在不同时间和地点的稳定性。
4、 配额限制。虽然我们正在逐步放开主动推送的抓取额度,但是如果网站页面突然爆发式增长,还是会影响到优质链接的抓取收录,所以网站也要注意保证稳定访问网站防止黑客注入的安全性。
评论:
上海普益网络为上海中小企业网站建设、网页设计、网站优化、SEO优化等相关服务。 查看全部
从网页抓取数据(
为什么我提交了数据还是迟迟在线上看不到展现呢?)
目前百度蜘蛛抓取新链接的方式有两种。一是主动发现爬取,二是从百度站长平台的链接提交工具中获取数据。其中,通过主动推送功能“收到”的数据最受百度青睐。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新的网站,主动推送首页数据,有利于到内部页面数据的捕获。
所以同学们要问了,为什么我提交了数据后还是看不到网上的显示呢?涉及的因素很多。在蜘蛛抓取链接中,影响在线展示的因素有:
1、网站 禁止。别笑,有同学在给百度发数据的时候把百度蜘蛛屏蔽了,当然不能收录。
2、质量筛选。百度蜘蛛进入3.0后,对低质量内容的识别又上了一个新台阶,尤其是时效性内容。从抓取过程中,会进行质量评估和筛选,过滤掉大量过度优化的页面。根据定期的内部数据评估,低质量网页比上一期下降了 62%。
3、 获取失败。爬行失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛有问题。本站要时刻关注网站在不同时间和地点的稳定性。
4、 配额限制。虽然我们正在逐步放开主动推送的抓取额度,但是如果网站页面突然爆发式增长,还是会影响到优质链接的抓取收录,所以网站也要注意保证稳定访问网站防止黑客注入的安全性。
评论:
上海普益网络为上海中小企业网站建设、网页设计、网站优化、SEO优化等相关服务。
从网页抓取数据(从网页抓取数据的角度来说是选择性分析。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-16 23:01
从网页抓取数据的角度来说是公开数据分析。以自然语言分析为例,主要任务就是从内容中提取关键词,然后用lda、dbn等方法去构建表示论文内容或者文章题目的表示模型。lda、dbn都是nlp任务,或者考虑文本分类,也要求实体关系(entityrelation)中与其语义和实体相关性高的词同时出现在表示里面才能推断出实体的词向量。
从数据整理角度来说是选择性分析。你既可以说这个数据是ugc的数据,那么来源自用户,也可以说这个数据是retrieved-to-ugc的数据,那么作者发表的fullform的内容的邮件或者文章,也可以说它是ugc或者retrieved-to-ugc的数据。这就是选择性分析。希望你能对你想研究的话题有帮助。
分析方法一般有以下几种:1.基于图的分析方法图最好是基于一些生成算法的,也就是变量的生成算法,而不是简单的分析图,比如图模型,马尔可夫链;也可以基于特征的聚类算法,比如adaboost等。2.文本聚类算法实际上就是用所有的词,自动生成各种好几类文本,你看到了x,y关系的词,比如“数字”和“好像”,分别生成“数字”和“好像”的文本;看到“表格”和“号”,生成“表格”和“号”的文本。
3.基于条件归纳算法(crf)的图分析算法这个比较偏向于统计学领域了,建议掌握np问题的求解,以及蒙特卡洛树搜索,以便自己设计图分析算法。4.聚类算法集成分析(clusteringaggregationbasedmethods)建议掌握聚类算法和降维算法。5.基于密度的分析算法这个你懂的。还有一些隐变量问题,什么注意力机制,隐马尔科夫等等。
实际上,这些分析方法中都有一些核心的东西是通用的,也就是基于统计学的。基本只要你写一个自动问卷,然后根据用户投票,和自动发现用户偏好,都是可以用统计学方法解决的。 查看全部
从网页抓取数据(从网页抓取数据的角度来说是选择性分析。)
从网页抓取数据的角度来说是公开数据分析。以自然语言分析为例,主要任务就是从内容中提取关键词,然后用lda、dbn等方法去构建表示论文内容或者文章题目的表示模型。lda、dbn都是nlp任务,或者考虑文本分类,也要求实体关系(entityrelation)中与其语义和实体相关性高的词同时出现在表示里面才能推断出实体的词向量。
从数据整理角度来说是选择性分析。你既可以说这个数据是ugc的数据,那么来源自用户,也可以说这个数据是retrieved-to-ugc的数据,那么作者发表的fullform的内容的邮件或者文章,也可以说它是ugc或者retrieved-to-ugc的数据。这就是选择性分析。希望你能对你想研究的话题有帮助。
分析方法一般有以下几种:1.基于图的分析方法图最好是基于一些生成算法的,也就是变量的生成算法,而不是简单的分析图,比如图模型,马尔可夫链;也可以基于特征的聚类算法,比如adaboost等。2.文本聚类算法实际上就是用所有的词,自动生成各种好几类文本,你看到了x,y关系的词,比如“数字”和“好像”,分别生成“数字”和“好像”的文本;看到“表格”和“号”,生成“表格”和“号”的文本。
3.基于条件归纳算法(crf)的图分析算法这个比较偏向于统计学领域了,建议掌握np问题的求解,以及蒙特卡洛树搜索,以便自己设计图分析算法。4.聚类算法集成分析(clusteringaggregationbasedmethods)建议掌握聚类算法和降维算法。5.基于密度的分析算法这个你懂的。还有一些隐变量问题,什么注意力机制,隐马尔科夫等等。
实际上,这些分析方法中都有一些核心的东西是通用的,也就是基于统计学的。基本只要你写一个自动问卷,然后根据用户投票,和自动发现用户偏好,都是可以用统计学方法解决的。
从网页抓取数据(记录思路如下:记录SQL中的注释(使用--进行注释))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-15 07:02
【原创需求】
公司用户手册是SGML的源代码,其中文档中有一些SQL语句,我目前想验证这些SQL是否可以复制和执行。
【对策】
使用手动复制验证,太慢了。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般都受到标签使用的限制,所以shell要抓取的具体内容就是基于这两个标签。
录音思路如下:
1、先处理SQL中的注释(使用-类似C语言的注释#)
2、 将空格中的文本去掉进行序列处理,使用上面的标签进行切分,然后在切分后取偶数位置的值(不解释)
3、通过第二步就可以得到标签的内容了,需要对标签中的特殊字符进行处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/>/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/ 查看全部
从网页抓取数据(记录思路如下:记录SQL中的注释(使用--进行注释))
【原创需求】
公司用户手册是SGML的源代码,其中文档中有一些SQL语句,我目前想验证这些SQL是否可以复制和执行。
【对策】
使用手动复制验证,太慢了。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般都受到标签使用的限制,所以shell要抓取的具体内容就是基于这两个标签。
录音思路如下:
1、先处理SQL中的注释(使用-类似C语言的注释#)
2、 将空格中的文本去掉进行序列处理,使用上面的标签进行切分,然后在切分后取偶数位置的值(不解释)
3、通过第二步就可以得到标签的内容了,需要对标签中的特殊字符进行处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/>/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/
从网页抓取数据(Vanguard延迟加载页面上的数据,我不知道如何正确获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-14 13:03
)
我试图在这个网站上检查一些关于这个问题的问题,但我无法使他们的解决方案起作用。我正在使用 python 和 selenium 和 chrome 无头浏览器从先锋获取债券数据。Vanguard懒惰地加载页面上的数据,我不知道如何正确获取数据。
我正在尝试从此页面加载数据,尤其是基金事实表中的数据
当我像往常一样尝试这样做时,我得到
所以我尝试使用这行代码让浏览器等待数据加载。
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
我确定这是在正确的轨道上,但我不知道如何正确地告诉我哪些元素应该等待识别以及我是否正确执行。有没有办法让我等到 iframe data-delayed-src 元素消失才能获取数据?
我已经看到它与 By.ID 的用法,但是我在数据 html 中没有看到任何我想要 id 的元素。
这是我正在使用的代码
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
import os
dirname = os.path.dirname(__file__)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options, executable_path=os.path.join(dirname, 'chromedriver'))
symbol = 'vbirx'
url_vanguard = 'https://investor.vanguard.com/mutual-funds/profile/overview/{}'
browser.get(url_vanguard.format(symbol))
# WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
html = browser.page_source
mySoup = BeautifulSoup(html, 'html.parser')
htmlData = mySoup.find('table',{'role':'presentation'})
table = htmlData.find('tbody')
print('table: \n',table)
该表打印出缺少我想要的所有数据 查看全部
从网页抓取数据(Vanguard延迟加载页面上的数据,我不知道如何正确获取数据
)
我试图在这个网站上检查一些关于这个问题的问题,但我无法使他们的解决方案起作用。我正在使用 python 和 selenium 和 chrome 无头浏览器从先锋获取债券数据。Vanguard懒惰地加载页面上的数据,我不知道如何正确获取数据。
我正在尝试从此页面加载数据,尤其是基金事实表中的数据
当我像往常一样尝试这样做时,我得到
所以我尝试使用这行代码让浏览器等待数据加载。
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
我确定这是在正确的轨道上,但我不知道如何正确地告诉我哪些元素应该等待识别以及我是否正确执行。有没有办法让我等到 iframe data-delayed-src 元素消失才能获取数据?
我已经看到它与 By.ID 的用法,但是我在数据 html 中没有看到任何我想要 id 的元素。
这是我正在使用的代码
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
import os
dirname = os.path.dirname(__file__)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options, executable_path=os.path.join(dirname, 'chromedriver'))
symbol = 'vbirx'
url_vanguard = 'https://investor.vanguard.com/mutual-funds/profile/overview/{}'
browser.get(url_vanguard.format(symbol))
# WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "data-ng-class")))
html = browser.page_source
mySoup = BeautifulSoup(html, 'html.parser')
htmlData = mySoup.find('table',{'role':'presentation'})
table = htmlData.find('tbody')
print('table: \n',table)
该表打印出缺少我想要的所有数据
从网页抓取数据(的请求获取数据的方式GET,POST请求数据必须构建请求头才可以。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-14 13:03
POST请求获取数据的方式与GET不同,POST请求数据必须构造请求头。
Form Data中的请求参数如图15所示:
图片
图 15
复制它并构建一个新字典:
from_data={'i':'我爱中国','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt' :'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b33a2f3f9d09bde064c9275bcb33d94e,'@1','版本'keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
接下来使用requests.post方法请求表单数据,代码如下:
导入请求#导入请求包
响应 = requests.post(url,data=payload)
将字符串格式的数据转换为JSON格式的数据,根据数据结构提取数据,并打印出翻译结果。代码如下:
导入 jsoncontent = json.loads(response.text)print(content['translateResult'][0][0]['tgt'])
使用requests.post方法抓取有道翻译结果的完整代码如下:
import requests#import requests package import jsondef get_translate_date(word=None):url =';smartresult=rule'From_data=('i':word,'from':'zh-CHS','to':'en', 'smartresult':'dict','client':'fanyideskweb','salt':'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b39604b3d2f' :'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'} 请求表单数据 response = requests .post(url,data=From_data) 将 Json 格式字符串转换为字典 content = json.loads(response.text) print(content) 打印翻译后的数据 print(content['translateResult'][0][0] ['tgt'])if name=='main':get_translate_date('我爱中国')
使用 Beautiful Soup 解析网页
网页的源代码已经可以通过requests库捕获,下一步就是从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
bs4库的安装方式如图16所示:
图片
图 16
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库更强大,速度更快。因此,我建议安装 lxml 库。
安装好Python第三方库后,输入以下代码,开启Beautiful Soup之旅:
import requests#import requests from bs4 import BeautifulSoupurl=``strhtml=requests.get(url)soup=BeautifulSoup(strhtml.text,'lxml')data = soup.select('#main>div>div.mtop.firstMod .clearfix>div.centerBox>ul.newsList>li>a')print(data)
代码执行结果如图 17 所示。
图片
图17(点此查看高清大图)
Beautiful Soup 库可以轻松解析网页信息。它集成在 bs4 库中,需要时可以从 bs4 库中调用。表达语句如下:
从 bs4 导入 BeautifulSoup
首先将HTML文档转换成Unicode编码格式,然后Beautiful Soup选择最合适的解析器来解析这个文档,这里是指定解析的lxml解析器。解析后,将复杂的 HTML 文档转换为树状结构,每个节点都是一个 Python 对象。这里,解析后的文档存放在新创建的变量soup中,代码如下:
汤=BeautifulSoup(strhtml.text,'lxml')
接下来,使用select(选择器)定位数据。定位数据时,需要使用浏览器的开发者模式。将鼠标光标放在对应的数据位置上单击鼠标右键,然后在快捷菜单中选择“检查”命令,如图18所示。如图:
图片
图 18
然后浏览器右侧会弹出开发者界面,右侧高亮代码(见图19(b))对应左侧高亮数据文本(见图19(a))。右击右侧高亮显示的数据,在弹出的快捷菜单中选择“复制”➔“复制选择器”命令,自动复制路径。
图片
图 19 复制路径
在文档中粘贴路径,代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li:nth-child(1)> a
由于这条路径是第一个选择的路径,我们需要获取所有的标题,删除li:nth-child(1),代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a
使用soup.select引用这个路径,代码如下:
data = soup.select('#main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a')
清理和组织数据
至此,获得了一段目标HTML代码,但尚未提取数据。接下来,在 PyCharm 中输入以下代码:
对于数据中的项目:result={'title':item.get_text(),'link':item.get('href')}print(result)
代码运行结果如图20所示:
图片
图20
首先,很明显,要提取的数据是标题和链接。标题在 <a> 标签中,标签的主体是使用 get_text() 方法提取的。该链接位于 <a> 标记的 href 属性中。使用 get() 方法提取标签中的 href 属性。括号中指定要提取的属性数据,即get('href')。
从图20可以发现文章的链接中有一个数字ID。接下来,使用正则表达式提取此 ID。需要用到的正则符号如下:
\d 匹配数字
+匹配前一个字符1次或多次
在 Python 中调用正则表达式时,请使用 re 库。这个库不需要安装,直接调用即可。在 PyCharm 中输入以下代码:
import refor item in data:result={"title":item.get_text(),"link":item.get('href'),'ID':re.findall('\d+',item.get(' href'))}打印(结果)
运行结果如图21所示:
图片
图 21
这里使用的是re库的findall方法,第一个参数代表正则表达式,第二个参数代表要提取的文本。
爬行动物攻击与防御
爬虫模拟人们的浏览和访问行为,对数据进行批量爬取。当捕获的数据量逐渐增加时,会对被访问的服务器造成很大的压力,甚至可能会崩溃。换句话说,服务器不喜欢有人爬取自己的数据。然后,网站 会对这些爬虫采取一些反爬的策略。
服务器识别爬虫的第一种方式是通过检查连接的用户代理来识别是浏览器访问还是代码访问。在代码访问的情况下,当访问量增加时,服务器会直接阻塞访问IP。
那么我们应该采取什么措施来应对这种初级防攀爬机制呢?
以之前创建的爬虫为例。在访问的时候,我们不仅可以在开发者环境中找到URL和Form Data,还可以在Request headers中构造浏览器的请求头来封装自己。服务器识别浏览器访问的方法是判断Request headers下的关键字是否为User-Agent,如图22所示。
图片
图 22
因此,我们只需要构造这个请求头的参数即可。只需创建请求头信息,代码如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
响应 = request.get(url,headers=headers)
说到这里,很多读者会觉得修改User-Agent太简单了。真的很简单,但是正常人一秒看一张图片,爬虫可以一秒抓取多张图片。比如一个爬虫一秒能抓取上百张图片,对服务器的压力必然会增加。也就是说,如果你在一个IP下批量访问和下载图片,这种行为不符合正常人的行为,IP必须被屏蔽。
原理也很简单。就是统计每个IP的访问频率。如果频率超过阈值,将返回验证码。如果确实是用户访问,则用户填写并继续访问。如果是代码访问,会被封IP。
这个问题有两种解决方案。第一个是常用的附加延迟,每3秒捕获一次。代码如下:
导入时间
time.sleep(3)
但是,我们的爬虫的目的是高效地批量捕获数据。在这里,如果我们设置每3秒爬一次,效率太低了。其实还有一个更重要的解决办法,就是从本质上解决问题。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。建议你联系魏:762459510,真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
不管怎么访问,服务器的目的就是找出哪个是代码访问,然后屏蔽IP。解决方法:为了避免IP被封,数据采集时经常使用代理。当然,请求也有相应的代理属性。
首先建立自己的代理IP池,以字典的形式分配给代理,然后传递给请求。代码如下:
proxies={"http":":3128","https":":1080",}response = requests.get(url, proxies=proxies) 查看全部
从网页抓取数据(的请求获取数据的方式GET,POST请求数据必须构建请求头才可以。)
POST请求获取数据的方式与GET不同,POST请求数据必须构造请求头。
Form Data中的请求参数如图15所示:
图片
图 15
复制它并构建一个新字典:
from_data={'i':'我爱中国','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt' :'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b33a2f3f9d09bde064c9275bcb33d94e,'@1','版本'keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
接下来使用requests.post方法请求表单数据,代码如下:
导入请求#导入请求包
响应 = requests.post(url,data=payload)
将字符串格式的数据转换为JSON格式的数据,根据数据结构提取数据,并打印出翻译结果。代码如下:
导入 jsoncontent = json.loads(response.text)print(content['translateResult'][0][0]['tgt'])
使用requests.post方法抓取有道翻译结果的完整代码如下:
import requests#import requests package import jsondef get_translate_date(word=None):url =';smartresult=rule'From_data=('i':word,'from':'zh-CHS','to':'en', 'smartresult':'dict','client':'fanyideskweb','salt':'258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'25','bv':'b39604b3d2f' :'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'} 请求表单数据 response = requests .post(url,data=From_data) 将 Json 格式字符串转换为字典 content = json.loads(response.text) print(content) 打印翻译后的数据 print(content['translateResult'][0][0] ['tgt'])if name=='main':get_translate_date('我爱中国')
使用 Beautiful Soup 解析网页
网页的源代码已经可以通过requests库捕获,下一步就是从源代码中查找并提取数据。Beautiful Soup 是一个 Python 库,其主要功能是从网页中抓取数据。Beautiful Soup 已经移植到 bs4 库中,这意味着您需要在导入 Beautiful Soup 之前安装 bs4 库。
bs4库的安装方式如图16所示:
图片
图 16
安装完bs4库后,还需要安装lxml库。如果我们不安装 lxml 库,我们将使用 Python 的默认解析器。虽然 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器,也支持一些第三方解析器,但 lxml 库更强大,速度更快。因此,我建议安装 lxml 库。
安装好Python第三方库后,输入以下代码,开启Beautiful Soup之旅:
import requests#import requests from bs4 import BeautifulSoupurl=``strhtml=requests.get(url)soup=BeautifulSoup(strhtml.text,'lxml')data = soup.select('#main>div>div.mtop.firstMod .clearfix>div.centerBox>ul.newsList>li>a')print(data)
代码执行结果如图 17 所示。
图片
图17(点此查看高清大图)
Beautiful Soup 库可以轻松解析网页信息。它集成在 bs4 库中,需要时可以从 bs4 库中调用。表达语句如下:
从 bs4 导入 BeautifulSoup
首先将HTML文档转换成Unicode编码格式,然后Beautiful Soup选择最合适的解析器来解析这个文档,这里是指定解析的lxml解析器。解析后,将复杂的 HTML 文档转换为树状结构,每个节点都是一个 Python 对象。这里,解析后的文档存放在新创建的变量soup中,代码如下:
汤=BeautifulSoup(strhtml.text,'lxml')
接下来,使用select(选择器)定位数据。定位数据时,需要使用浏览器的开发者模式。将鼠标光标放在对应的数据位置上单击鼠标右键,然后在快捷菜单中选择“检查”命令,如图18所示。如图:
图片
图 18
然后浏览器右侧会弹出开发者界面,右侧高亮代码(见图19(b))对应左侧高亮数据文本(见图19(a))。右击右侧高亮显示的数据,在弹出的快捷菜单中选择“复制”➔“复制选择器”命令,自动复制路径。
图片
图 19 复制路径
在文档中粘贴路径,代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li:nth-child(1)> a
由于这条路径是第一个选择的路径,我们需要获取所有的标题,删除li:nth-child(1),代码如下:
main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a
使用soup.select引用这个路径,代码如下:
data = soup.select('#main> div> div.mtop.firstMod.clearfix> div.centerBox> ul.newsList> li> a')
清理和组织数据
至此,获得了一段目标HTML代码,但尚未提取数据。接下来,在 PyCharm 中输入以下代码:
对于数据中的项目:result={'title':item.get_text(),'link':item.get('href')}print(result)
代码运行结果如图20所示:
图片
图20
首先,很明显,要提取的数据是标题和链接。标题在 <a> 标签中,标签的主体是使用 get_text() 方法提取的。该链接位于 <a> 标记的 href 属性中。使用 get() 方法提取标签中的 href 属性。括号中指定要提取的属性数据,即get('href')。
从图20可以发现文章的链接中有一个数字ID。接下来,使用正则表达式提取此 ID。需要用到的正则符号如下:
\d 匹配数字
+匹配前一个字符1次或多次
在 Python 中调用正则表达式时,请使用 re 库。这个库不需要安装,直接调用即可。在 PyCharm 中输入以下代码:
import refor item in data:result={"title":item.get_text(),"link":item.get('href'),'ID':re.findall('\d+',item.get(' href'))}打印(结果)
运行结果如图21所示:
图片
图 21
这里使用的是re库的findall方法,第一个参数代表正则表达式,第二个参数代表要提取的文本。
爬行动物攻击与防御
爬虫模拟人们的浏览和访问行为,对数据进行批量爬取。当捕获的数据量逐渐增加时,会对被访问的服务器造成很大的压力,甚至可能会崩溃。换句话说,服务器不喜欢有人爬取自己的数据。然后,网站 会对这些爬虫采取一些反爬的策略。
服务器识别爬虫的第一种方式是通过检查连接的用户代理来识别是浏览器访问还是代码访问。在代码访问的情况下,当访问量增加时,服务器会直接阻塞访问IP。
那么我们应该采取什么措施来应对这种初级防攀爬机制呢?
以之前创建的爬虫为例。在访问的时候,我们不仅可以在开发者环境中找到URL和Form Data,还可以在Request headers中构造浏览器的请求头来封装自己。服务器识别浏览器访问的方法是判断Request headers下的关键字是否为User-Agent,如图22所示。
图片
图 22
因此,我们只需要构造这个请求头的参数即可。只需创建请求头信息,代码如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
响应 = request.get(url,headers=headers)
说到这里,很多读者会觉得修改User-Agent太简单了。真的很简单,但是正常人一秒看一张图片,爬虫可以一秒抓取多张图片。比如一个爬虫一秒能抓取上百张图片,对服务器的压力必然会增加。也就是说,如果你在一个IP下批量访问和下载图片,这种行为不符合正常人的行为,IP必须被屏蔽。
原理也很简单。就是统计每个IP的访问频率。如果频率超过阈值,将返回验证码。如果确实是用户访问,则用户填写并继续访问。如果是代码访问,会被封IP。
这个问题有两种解决方案。第一个是常用的附加延迟,每3秒捕获一次。代码如下:
导入时间
time.sleep(3)
但是,我们的爬虫的目的是高效地批量捕获数据。在这里,如果我们设置每3秒爬一次,效率太低了。其实还有一个更重要的解决办法,就是从本质上解决问题。最后,如果你的时间不是很紧,想快速提高,最重要的是你不怕吃苦。建议你联系魏:762459510,真的很好。很多人都在快速进步。你需要害怕困难。!可以去加进去看看~
不管怎么访问,服务器的目的就是找出哪个是代码访问,然后屏蔽IP。解决方法:为了避免IP被封,数据采集时经常使用代理。当然,请求也有相应的代理属性。
首先建立自己的代理IP池,以字典的形式分配给代理,然后传递给请求。代码如下:
proxies={"http":":3128","https":":1080",}response = requests.get(url, proxies=proxies)
从网页抓取数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-11-10 19:08
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
从网页抓取数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\\,标题和介绍都是\u4e09的形式。这些是我们需要处理的后续步骤!
先用replace函数去掉url中的\\,就可以得到url了,下面的\u4e09是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以以u"+unicode编码内容+"!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
从网页抓取数据(从网页抓取数据库的话,你有redis做缓存吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-10 16:01
从网页抓取数据库的话,你有redis做缓存吧,已经有专门的爬虫产品啦,
是苹果吗?
你在网页抓取的时候就把数据放在服务器上吗,如果是那你就需要找第三方,第三方提供专门的爬虫api接口,如果你想自己来爬的话,你得自己找接口,然后手工编写爬虫,不如把想法先写到一个python模块,然后直接套用在你的爬虫程序里面。
现在大部分数据分析网站都是免费的啦,用python做爬虫就行,直接拿数据,剩下的就是运营推广了。
如果你在网站上也抓取数据,那你还不如直接提供免费的web服务,让浏览器直接将数据网络加载到页面里面去。这样虽然获取数据的效率可能会低一些,但是应该不会有服务器端的数据泄露,对公司来说也不会有太大的风险。如果仅仅是为了找一个能够抓取数据的服务,那么可以多想想。
手工抓网页数据,要看你抓取的格式是什么类型,是图片、json、还是其他文本格式数据,不同格式对爬虫需求的技能点的需求不一样,
it新青年根据抓取技术做了个爬虫的网站:findingweb_spider
xmind:zhihu爬虫
httpgetpost
没必要自己写爬虫吧,还不如用第三方帮你把数据抓过来呢,比如用python的scrapy爬虫,真的很牛逼。 查看全部
从网页抓取数据(从网页抓取数据库的话,你有redis做缓存吧)
从网页抓取数据库的话,你有redis做缓存吧,已经有专门的爬虫产品啦,
是苹果吗?
你在网页抓取的时候就把数据放在服务器上吗,如果是那你就需要找第三方,第三方提供专门的爬虫api接口,如果你想自己来爬的话,你得自己找接口,然后手工编写爬虫,不如把想法先写到一个python模块,然后直接套用在你的爬虫程序里面。
现在大部分数据分析网站都是免费的啦,用python做爬虫就行,直接拿数据,剩下的就是运营推广了。
如果你在网站上也抓取数据,那你还不如直接提供免费的web服务,让浏览器直接将数据网络加载到页面里面去。这样虽然获取数据的效率可能会低一些,但是应该不会有服务器端的数据泄露,对公司来说也不会有太大的风险。如果仅仅是为了找一个能够抓取数据的服务,那么可以多想想。
手工抓网页数据,要看你抓取的格式是什么类型,是图片、json、还是其他文本格式数据,不同格式对爬虫需求的技能点的需求不一样,
it新青年根据抓取技术做了个爬虫的网站:findingweb_spider
xmind:zhihu爬虫
httpgetpost
没必要自己写爬虫吧,还不如用第三方帮你把数据抓过来呢,比如用python的scrapy爬虫,真的很牛逼。
从网页抓取数据(数据常见常见的工具有:1.crud(clipboard-web数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-10 13:15
从网页抓取数据来看,一般可以分为两种抓取方式:1.从数据源抓2.从接口抓取两种方式相对于单纯抓取cookie是更方便的一种,所以数据抓取也更多见。第一种常见的就是json加密,在网页中下载html代码后,将其加密。然后通过服务器上常见的接口方式获取数据。第二种方式是基于数据库或者某种从服务器上获取的方式从网页中获取数据。
大部分数据抓取工具都是基于第二种方式。这里暂且列举几个常见的:数据抓取常见的工具有:1.crud(clipboard-web数据抓取)国内有很多第三方网站做了crud工具,如:开源的blogspot,还有基于crud工具实现的prozac,基于crud工具实现的简道云,都很不错。如果想要更方便,自己做一个也不错。
2.app(app是基于web的接口抓取工具)app抓取主要是通过app内部内置js方法来抓取网页中的数据,主要工具有:httpwatch这类工具,数据抓取利器如:cors_document.crossrequest如果想要更方便,自己写代码也可以,如:corsinterceptor这类工具,数据抓取利器如:corsaccess_extractkeys这类工具,是对app的js获取hook,但是通过hook也可以实现抓取,如:access_extractkeyspostfix这类工具,数据抓取利器如:access_extractkeyszsome等这类工具,是针对某个网站进行快速抓取的工具,如:zsome抓取页面可能会有丢失数据或者不准确的情况,要妥善保存数据,可以适当用一些文本编辑工具来进行合并。针对网页快速抓取,可以查看这个文章:怎么抓取网数据。 查看全部
从网页抓取数据(数据常见常见的工具有:1.crud(clipboard-web数据))
从网页抓取数据来看,一般可以分为两种抓取方式:1.从数据源抓2.从接口抓取两种方式相对于单纯抓取cookie是更方便的一种,所以数据抓取也更多见。第一种常见的就是json加密,在网页中下载html代码后,将其加密。然后通过服务器上常见的接口方式获取数据。第二种方式是基于数据库或者某种从服务器上获取的方式从网页中获取数据。
大部分数据抓取工具都是基于第二种方式。这里暂且列举几个常见的:数据抓取常见的工具有:1.crud(clipboard-web数据抓取)国内有很多第三方网站做了crud工具,如:开源的blogspot,还有基于crud工具实现的prozac,基于crud工具实现的简道云,都很不错。如果想要更方便,自己做一个也不错。
2.app(app是基于web的接口抓取工具)app抓取主要是通过app内部内置js方法来抓取网页中的数据,主要工具有:httpwatch这类工具,数据抓取利器如:cors_document.crossrequest如果想要更方便,自己写代码也可以,如:corsinterceptor这类工具,数据抓取利器如:corsaccess_extractkeys这类工具,是对app的js获取hook,但是通过hook也可以实现抓取,如:access_extractkeyspostfix这类工具,数据抓取利器如:access_extractkeyszsome等这类工具,是针对某个网站进行快速抓取的工具,如:zsome抓取页面可能会有丢失数据或者不准确的情况,要妥善保存数据,可以适当用一些文本编辑工具来进行合并。针对网页快速抓取,可以查看这个文章:怎么抓取网数据。
从网页抓取数据(1024程序员日搬运一篇:使用XMLHttpRequest和Fetch如何处理请求!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-10 04:18
1024程序员日,我拎着一块之前钻进金发的文章。可以看成是我前端学习路上的一个时间节点——大致结束了基础知识的学习,开始学习实际项目开发的内容~
本文的demo源码和具体资源位于github仓库中的js-demos-infancy前端知识库,记录了一份前端初学者的学习日记&点点滴滴的学习路径(实践demo,重要知识点)
欢迎大家贡献更多“前端er必知知识”/分享更有意义的demo️!(请给这个年轻的小仓库更多内容)
学习 Ajax/Fetch 请求和承诺
适合准备学习Ajax,对入口请求的发送和接收(为了简化流程,专注于客户端的编码,我们使用. txt 文件作为数据库,无需考虑服务端编码)
.html的运行方式分为
服务器在本地 Web 服务器上运行
这两个内容我们会慢慢完善的~
本DEMO整理自MDN官方文档教程
那么接下来,让我们看看如何使用 XMLHttpRequest 和 Fetch 来处理请求!
从本地文件运行示例
由于安全限制,从本地文件运行实例时,部分浏览器不会运行XHR请求~
稍后我们需要通过在本地服务器上运行来测试这个例子
我们将从几个不同的文本文件中请求数据并使用它们来填充内容区域。
这一系列文件将作为我们的假数据库;在实际应用中,我们更有可能使用服务器端语言(例如 PHP、Python 或 Node)从数据库中请求我们的数据。但是,在这种情况下,我们希望保持简单并专注于客户端部分。
可以点进MDN看看~
在这个例子中,我们将通过 XHR 从下拉菜单中选择一首诗并加载另一首诗
完成基本的 Ajax 请求
请注意,如果您仅从本地文件运行示例,某些浏览器(包括 Chrome)将不会运行 XHR 请求。这是因为安全限制~为了解决这个问题,我们需要通过在本地web服务器上运行来测试这个例子
由于安全限制,XD实际上是无效的。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onChange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数 目的:将Verse 1 转换为verse.txt
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
let request = new XMLHttpRequest();
// 指定 用于从网站请求资源的HTTP请求方法 这里是GET方法
// 指定 想请求资源的网站的URL
request.open('GET', url);
// 作为 text. 这并不是绝对必要的 — XHR默认返回文本
// 如果你想在以后获取其他类型的数据,养成这样的习惯是一个好习惯
request.responseType = 'text';
// 当onload 事件触发时(当响应已经返回时)这个事件会被运行
request.onload = function(){
poemDisplay.textContent = request.response;
}
request.send();
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
在服务器端运行示例
此外,我们使用 Fetch API 来取代 XHR——它最近在浏览器中引入,这使得异步 HTTP 请求更容易在 JavaScript 中实现,无论是对于开发人员还是其他构建在 Fetch 之上的 API。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onchange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
// let request = new XMLHttpRequest();
// request.open('GET', url);
// request.responseType = 'text';
// request.onload = function(){
// poemDisplay.textContent = request.response;
// }
// request.send();
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
});
});
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
这里我们使用 node.js 搭建一个本地的 HTTP 服务器服务
npm install http-server -g;// 全局安装http-server
// 跳转到网页对应的目录,打开命令行窗口 输入——
http-server
之后就可以在服务端运行html文件进行异步操作了!地址格式类似于以下-
效果如下
总结与经验
我比较熟悉“从服务器获取数据”的形式~
学习了基本的 Ajax 请求
let request = new XMLHttpRequest();
request.open('GET', url);
request.responseType = 'text';
request.onload = function{
// 请求对应的响应返回时,这个事件会被运行
poemDisplay.textContent = request.response;
}
request.send();
学习了 Fetch API
首先我们要清楚替换XHR Fetch代码的每一步的含义
fetch(url).then(function(response){
// fetch得到url,返回一个promise,promise解析服务器发挥的响应
// 利用promise.then()运行后续代码,这个步骤是一环套一环的!
})
fetch(url).then(function(response){
response.text().then(function(text){
// 将响应response以text的格式返回,与上面一样,也返回了一个promise
// 利用promise.then(func)来完成接下来的操作
// 我们定义了一个函数来接收text() promise解析的文本
})
})
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
难怪很多人说Fetch更好!这样写Quesi就方便多了!
接下来看看Promise
让我们再看看 Promise
大多数现代 JavaScript API 都基于 promise
还是用上面的例子来理解promise
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
以上内容是一个promises函数
让我们分解一下 ES6 中提出的函数
实际上,传递给 then() 的代码是一段不会立即执行的代码——但会在返回响应时执行该代码。(异步编程的思想)
上面的代码等价于下面的代码(将promise保存在一个变量中)
let myFetch = fetch(url);
myFetch.then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
fetch(url).then(function(dogBiscuits) {
dogBiscuits.text().then(function(text) {
poemDisplay.textContent = text;
});
});
当然~将参数称为描述其内容的名称更有意义。
function(response) {
response.text().then(function(text) {
poemDisplay.textContent = text;
});
}
上面解析了很多Promise的内容,那么厉害在哪里呢?
简单来说,我们可以直接将promise块(.then()块,但还有其他类型)链接到另一个块的末尾,并将每个块的结果沿链传递给下一个块。强大的!
相比于大量回调造成的“连续向右”回调地狱,promise块会向下延伸,这就很明显了~
让我们回顾一下这个简单的 Promises 示例。
// 01 本例写法
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
// 02 很多开发者喜欢下面的样式
fetch(url).then(function(response){
return response.text();
}).then(function(text){
poemDisplay.textContent = text;
})
02的写法更扁平,可读性大大提高对吧?
那么我们应该选择哪种方法呢?Ajax VS 获取
所以如果要保证老版本的兼容性,数据请求还是要使用XHR
Fetch 显然更好,不是吗?
超过 查看全部
从网页抓取数据(1024程序员日搬运一篇:使用XMLHttpRequest和Fetch如何处理请求!)
1024程序员日,我拎着一块之前钻进金发的文章。可以看成是我前端学习路上的一个时间节点——大致结束了基础知识的学习,开始学习实际项目开发的内容~
本文的demo源码和具体资源位于github仓库中的js-demos-infancy前端知识库,记录了一份前端初学者的学习日记&点点滴滴的学习路径(实践demo,重要知识点)
欢迎大家贡献更多“前端er必知知识”/分享更有意义的demo️!(请给这个年轻的小仓库更多内容)
学习 Ajax/Fetch 请求和承诺
适合准备学习Ajax,对入口请求的发送和接收(为了简化流程,专注于客户端的编码,我们使用. txt 文件作为数据库,无需考虑服务端编码)
.html的运行方式分为
服务器在本地 Web 服务器上运行
这两个内容我们会慢慢完善的~
本DEMO整理自MDN官方文档教程
那么接下来,让我们看看如何使用 XMLHttpRequest 和 Fetch 来处理请求!
从本地文件运行示例
由于安全限制,从本地文件运行实例时,部分浏览器不会运行XHR请求~
稍后我们需要通过在本地服务器上运行来测试这个例子
我们将从几个不同的文本文件中请求数据并使用它们来填充内容区域。
这一系列文件将作为我们的假数据库;在实际应用中,我们更有可能使用服务器端语言(例如 PHP、Python 或 Node)从数据库中请求我们的数据。但是,在这种情况下,我们希望保持简单并专注于客户端部分。
可以点进MDN看看~
在这个例子中,我们将通过 XHR 从下拉菜单中选择一首诗并加载另一首诗
完成基本的 Ajax 请求
请注意,如果您仅从本地文件运行示例,某些浏览器(包括 Chrome)将不会运行 XHR 请求。这是因为安全限制~为了解决这个问题,我们需要通过在本地web服务器上运行来测试这个例子
由于安全限制,XD实际上是无效的。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onChange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数 目的:将Verse 1 转换为verse.txt
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
let request = new XMLHttpRequest();
// 指定 用于从网站请求资源的HTTP请求方法 这里是GET方法
// 指定 想请求资源的网站的URL
request.open('GET', url);
// 作为 text. 这并不是绝对必要的 — XHR默认返回文本
// 如果你想在以后获取其他类型的数据,养成这样的习惯是一个好习惯
request.responseType = 'text';
// 当onload 事件触发时(当响应已经返回时)这个事件会被运行
request.onload = function(){
poemDisplay.textContent = request.response;
}
request.send();
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
在服务器端运行示例
此外,我们使用 Fetch API 来取代 XHR——它最近在浏览器中引入,这使得异步 HTTP 请求更容易在 JavaScript 中实现,无论是对于开发人员还是其他构建在 Fetch 之上的 API。
// 注意 如果只是从本地文件运行示例,
// 一些浏览器(包括Chrome)将不会运行XHR请求。这是因为安全限制~
// 为了解决这个问题,我们需要通过在本地web服务器上运行它来测试这个示例
const verseChoose = document.querySelector('select');
const poemDisplay = document.querySelector('pre');
verseChoose.onchange = function(){
const verse = verseChoose.value;// 获取到的诗 赋给verse变量
updateDisplay(verse);// 获取到的诗传给函数
}
function updateDisplay(verse){
// 将Verse 1 转换为verse.txt
verse = verse.replace(" ", "");// 将空格去掉(Web服务器的文件名无空格)
verse = verse.toLowerCase();
let url = verse + '.txt';
// 开始创建XHR请求 —— AJAX操作中的核心
// let request = new XMLHttpRequest();
// request.open('GET', url);
// request.responseType = 'text';
// request.onload = function(){
// poemDisplay.textContent = request.response;
// }
// request.send();
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
});
});
}
// 首次加载也要显示
updateDisplay('Verse 1');
verseChoose.value = 'Verse 1';
这里我们使用 node.js 搭建一个本地的 HTTP 服务器服务
npm install http-server -g;// 全局安装http-server
// 跳转到网页对应的目录,打开命令行窗口 输入——
http-server
之后就可以在服务端运行html文件进行异步操作了!地址格式类似于以下-
效果如下
总结与经验
我比较熟悉“从服务器获取数据”的形式~
学习了基本的 Ajax 请求
let request = new XMLHttpRequest();
request.open('GET', url);
request.responseType = 'text';
request.onload = function{
// 请求对应的响应返回时,这个事件会被运行
poemDisplay.textContent = request.response;
}
request.send();
学习了 Fetch API
首先我们要清楚替换XHR Fetch代码的每一步的含义
fetch(url).then(function(response){
// fetch得到url,返回一个promise,promise解析服务器发挥的响应
// 利用promise.then()运行后续代码,这个步骤是一环套一环的!
})
fetch(url).then(function(response){
response.text().then(function(text){
// 将响应response以text的格式返回,与上面一样,也返回了一个promise
// 利用promise.then(func)来完成接下来的操作
// 我们定义了一个函数来接收text() promise解析的文本
})
})
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
难怪很多人说Fetch更好!这样写Quesi就方便多了!
接下来看看Promise
让我们再看看 Promise
大多数现代 JavaScript API 都基于 promise
还是用上面的例子来理解promise
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
以上内容是一个promises函数
让我们分解一下 ES6 中提出的函数
实际上,传递给 then() 的代码是一段不会立即执行的代码——但会在返回响应时执行该代码。(异步编程的思想)
上面的代码等价于下面的代码(将promise保存在一个变量中)
let myFetch = fetch(url);
myFetch.then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
fetch(url).then(function(dogBiscuits) {
dogBiscuits.text().then(function(text) {
poemDisplay.textContent = text;
});
});
当然~将参数称为描述其内容的名称更有意义。
function(response) {
response.text().then(function(text) {
poemDisplay.textContent = text;
});
}
上面解析了很多Promise的内容,那么厉害在哪里呢?
简单来说,我们可以直接将promise块(.then()块,但还有其他类型)链接到另一个块的末尾,并将每个块的结果沿链传递给下一个块。强大的!
相比于大量回调造成的“连续向右”回调地狱,promise块会向下延伸,这就很明显了~
让我们回顾一下这个简单的 Promises 示例。
// 01 本例写法
fetch(url).then(function(response){
response.text().then(function(text){
poemDisplay.textContent = text;
})
})
// 02 很多开发者喜欢下面的样式
fetch(url).then(function(response){
return response.text();
}).then(function(text){
poemDisplay.textContent = text;
})
02的写法更扁平,可读性大大提高对吧?
那么我们应该选择哪种方法呢?Ajax VS 获取
所以如果要保证老版本的兼容性,数据请求还是要使用XHR
Fetch 显然更好,不是吗?
超过
从网页抓取数据(功能介绍智能识别模式自动识别网页中出现的数据模式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-09 04:06
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取器就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
从网页抓取数据(功能介绍智能识别模式自动识别网页中出现的数据模式)
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取器就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
从网页抓取数据(获赠Python从入门到进阶共10本电子书(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-02 05:12
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”,从入门到进阶共领取10本Python电子书
这个
日
小鸡
汤
孤灯不省人事,绝望了,卷起帘子望着月亮和天空,叹了口气。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章来复习,,,,,,,来学习选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编将为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段我们通过Scrapy实现了特定网页的具体信息,但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
一种是获取某个页面上文章的所有URL,解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了前面的Xpath和CSS选择器的基础知识,获取一个网页链接的URL就比较简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在于id=在“存档”标签下,我们会像剥洋葱一样得到我们想要的URL链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们根据图片搜索图片,并添加选择器工具,获取URL就像探索胶囊一样。在cmd中输入如下图命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则以后很长一段时间都无法调试。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。URL解压后,如何交给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢? 查看全部
从网页抓取数据(获赠Python从入门到进阶共10本电子书(组图))
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”,从入门到进阶共领取10本Python电子书
这个
日
小鸡
汤
孤灯不省人事,绝望了,卷起帘子望着月亮和天空,叹了口气。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章来复习,,,,,,,来学习选择器的具体用法,可以帮助自己更好的使用Scrapy爬虫框架。在接下来的几篇文章中,小编将为大家讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段我们通过Scrapy实现了特定网页的具体信息,但是没有实现所有页面的顺序提取。首先我们梳理一下爬行的思路。大体思路是:获取到第一页的URL后,再将第二页的URL发送给Scrapy,让Scrapy自动下载网页的信息,然后通过第二页的URL继续获取URL第三页。由于每个页面的网页结构是相同的,这样反复迭代就可以实现对整个网页的信息提取。具体的实现过程会通过Scrapy框架来实现。具体教程如下。
/执行/
1、首先,URL不再是特定文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要修改parse()函数,在这个函数中我们需要实现两件事。
一种是获取某个页面上文章的所有URL,解析得到每个文章中的具体网页内容。二是获取下一个网页的URL,交给Scrapy处理。下载完成后交给parse()函数进行下载。
有了前面的Xpath和CSS选择器的基础知识,获取一个网页链接的URL就比较简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个网址,文章列表存在于id=在“存档”标签下,我们会像剥洋葱一样得到我们想要的URL链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们根据图片搜索图片,并添加选择器工具,获取URL就像探索胶囊一样。在cmd中输入如下图命令进入shell调试窗口,事半功倍。再说一遍,这个网址是文章的所有网址,而不是某个文章的网址,否则以后很长一段时间都无法调试。
6、根据第四步对网页结构的分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。推荐朋友们在提取网页信息的时候可以经常使用,非常方便。
至此,第一页文章列表的所有URL都已获取。URL解压后,如何交给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢?
从网页抓取数据(智能识别模式WebHarvy自动识别网页数据抓取工具介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-28 17:11
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
从网页抓取数据(智能识别模式WebHarvy自动识别网页数据抓取工具介绍(一))
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
从网页抓取数据(sku个人的定义和产品方向仅供参考(一)|sku)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-16 10:02
从网页抓取数据和各种爬虫、爬虫框架,我基本完成了从web前端到互联网产品需求分析的转变。通过解读我们的产品,帮助设计者做出更好的设计并为用户提供更优质的服务。以下是我的个人总结,自己的定义和产品方向仅供参考。如有不同认识欢迎交流。总体结构我们的任务是创建这个产品,类似于纯粹的iosapp产品,一个启动页加载个sku图片sku+商品的名称、商品价格price+商品类别sku这一套解决方案下来,咱们的app功能和体验就已经很牛逼了。
我们更像是一个工具,一个有节操的半个人,是一款你不想给别人添麻烦的产品产品设计点之一:注重你公司和产品自身定位的因素至少初步评估你公司自身的大方向,你是想做电商,还是想做其他,线上还是线下。如果初步定位都不清楚,那么每一个方向的设计要去深入做用户研究。(老板脑子瓦特了,否则关于产品所有方向,过往和未来可参考的公司案例、借鉴的公司模板、创新改进的方向,都有很多,通过不断的去案例学习,用户洞察是所有产品设计非常重要的一部分。
)主要的客户是企业,尤其是上市公司。如果企业连你的产品名称都念不出来,那还真够呛(老板你给的价格也太低了!)如果这家企业就是打算要上市,那是不是专注于它对标公司的产品设计会更好,至少基本原则和竞品差不多,要比竞品好,当然两者又涉及到一个转化率的问题,不过你的产品已经比上述的产品在转化率上提升了不止一个层次,两者之间的差异又有多大,我不敢说。客户需求:。
1、用户的需求
2、最终用户的需求(非最终用户的需求,那叫变量需求,
3、下一个战场——进阶人群:老板,我想要个主页,每天上来发个活动,把自己的商品介绍放上去,提高转化率。老板,我想用红包和幸运钻石加速转化率,再好好维护下老客户,最近太忙了。老板,想利用上下游的朋友推广,但是我的门店没人。多多支持这样的客户吧。我该用什么字体比例,我能用什么颜色,怎么在用户的商品库和商品详情页信息的展示间做到漂亮。
老板,要搞个新功能了,我想要兼容iphone,又想要安卓和ios端。老板,不想让每个用户找到我们都要爬虫访问,我想用智能填充感觉不错。我该怎么操作?针对以上的客户,我们有4种不同设计模式:日常设计模式、嵌入式设计模式、架构设计模式、极端设计模式日常设计模式:每个产品都有自己的形态,大到互联网金融,互联网教育,小到社区社群。如果要做到日常改动产品,那么是一个很复杂的工作。
它里面涉及到的流程需要考虑:
1、不同客户的 查看全部
从网页抓取数据(sku个人的定义和产品方向仅供参考(一)|sku)
从网页抓取数据和各种爬虫、爬虫框架,我基本完成了从web前端到互联网产品需求分析的转变。通过解读我们的产品,帮助设计者做出更好的设计并为用户提供更优质的服务。以下是我的个人总结,自己的定义和产品方向仅供参考。如有不同认识欢迎交流。总体结构我们的任务是创建这个产品,类似于纯粹的iosapp产品,一个启动页加载个sku图片sku+商品的名称、商品价格price+商品类别sku这一套解决方案下来,咱们的app功能和体验就已经很牛逼了。
我们更像是一个工具,一个有节操的半个人,是一款你不想给别人添麻烦的产品产品设计点之一:注重你公司和产品自身定位的因素至少初步评估你公司自身的大方向,你是想做电商,还是想做其他,线上还是线下。如果初步定位都不清楚,那么每一个方向的设计要去深入做用户研究。(老板脑子瓦特了,否则关于产品所有方向,过往和未来可参考的公司案例、借鉴的公司模板、创新改进的方向,都有很多,通过不断的去案例学习,用户洞察是所有产品设计非常重要的一部分。
)主要的客户是企业,尤其是上市公司。如果企业连你的产品名称都念不出来,那还真够呛(老板你给的价格也太低了!)如果这家企业就是打算要上市,那是不是专注于它对标公司的产品设计会更好,至少基本原则和竞品差不多,要比竞品好,当然两者又涉及到一个转化率的问题,不过你的产品已经比上述的产品在转化率上提升了不止一个层次,两者之间的差异又有多大,我不敢说。客户需求:。
1、用户的需求
2、最终用户的需求(非最终用户的需求,那叫变量需求,
3、下一个战场——进阶人群:老板,我想要个主页,每天上来发个活动,把自己的商品介绍放上去,提高转化率。老板,我想用红包和幸运钻石加速转化率,再好好维护下老客户,最近太忙了。老板,想利用上下游的朋友推广,但是我的门店没人。多多支持这样的客户吧。我该用什么字体比例,我能用什么颜色,怎么在用户的商品库和商品详情页信息的展示间做到漂亮。
老板,要搞个新功能了,我想要兼容iphone,又想要安卓和ios端。老板,不想让每个用户找到我们都要爬虫访问,我想用智能填充感觉不错。我该怎么操作?针对以上的客户,我们有4种不同设计模式:日常设计模式、嵌入式设计模式、架构设计模式、极端设计模式日常设计模式:每个产品都有自己的形态,大到互联网金融,互联网教育,小到社区社群。如果要做到日常改动产品,那么是一个很复杂的工作。
它里面涉及到的流程需要考虑:
1、不同客户的
从网页抓取数据(如何用PowerBI批量采集多个网页的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-10-14 05:30
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,继续到采集的其他页时,排序后的数据结构与第一页的数据结构相同,采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不会再有延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。 查看全部
从网页抓取数据(如何用PowerBI批量采集多个网页的数据(图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,将页码输入第二行。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,继续到采集的其他页时,排序后的数据结构与第一页的数据结构相同,采集的数据可以直接使用;这里不做排序也没关系,可以等到采集所有网页数据排序在一起。
如果你想大批量的抓取网页数据,为了节省时间,可以不去整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预整理数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不会再有延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。
从网页抓取数据(网站搜索推广通过爬虫技术发现网页抓取、爬虫开发、情感分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-12 09:02
从网页抓取数据到爬虫,之后根据抓取的数据进行词云分析、包含关键词的情感分析。其实不复杂,要掌握网页抓取、爬虫开发、情感分析的方法就可以了。
目前来看想把html搞懂不难。先用w3cschool自学html,基本html几大块就能很快掌握了。掌握css,html5也能很快掌握。
可以的。其实爬虫发展到现在,已经渗透到互联网的各个领域了。通过爬虫技术发现网页中的用户行为,发现用户兴趣偏好。有好多这方面的机构。我在搜索引擎方面有专门研究。目前已经写出数十万篇外链。很多外站的链接都是我写的。除了互联网,还有传统的营销传播也有很多爬虫技术的用武之地。网站搜索推广通过爬虫技术,能做更精准的广告投放。
比如一个网站想推广自己的网页,很多网站都提供互联网自助搜索服务,其中发现了一个用户不知道的关键词,于是这个网站做了个爬虫,爬取了这个关键词的爬虫请求,又爬取了附近网站的爬虫请求,一大堆的爬虫就被爬到了。各个方面都能见到爬虫的身影。至于怎么抓取数据的话,我觉得就是在html代码中尽可能的混入规则,每一处节点都放入规则,看起来复杂,但是看着还是蛮清晰的。
需要,特别是很多企业的网站对html5的要求很高。楼上的回答纯属放p。 查看全部
从网页抓取数据(网站搜索推广通过爬虫技术发现网页抓取、爬虫开发、情感分析)
从网页抓取数据到爬虫,之后根据抓取的数据进行词云分析、包含关键词的情感分析。其实不复杂,要掌握网页抓取、爬虫开发、情感分析的方法就可以了。
目前来看想把html搞懂不难。先用w3cschool自学html,基本html几大块就能很快掌握了。掌握css,html5也能很快掌握。
可以的。其实爬虫发展到现在,已经渗透到互联网的各个领域了。通过爬虫技术发现网页中的用户行为,发现用户兴趣偏好。有好多这方面的机构。我在搜索引擎方面有专门研究。目前已经写出数十万篇外链。很多外站的链接都是我写的。除了互联网,还有传统的营销传播也有很多爬虫技术的用武之地。网站搜索推广通过爬虫技术,能做更精准的广告投放。
比如一个网站想推广自己的网页,很多网站都提供互联网自助搜索服务,其中发现了一个用户不知道的关键词,于是这个网站做了个爬虫,爬取了这个关键词的爬虫请求,又爬取了附近网站的爬虫请求,一大堆的爬虫就被爬到了。各个方面都能见到爬虫的身影。至于怎么抓取数据的话,我觉得就是在html代码中尽可能的混入规则,每一处节点都放入规则,看起来复杂,但是看着还是蛮清晰的。
需要,特别是很多企业的网站对html5的要求很高。楼上的回答纯属放p。

