
从网页抓取数据
从网页抓取数据( PowerQuery的数据清洗功能(示例中的列)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-12 15:01
PowerQuery的数据清洗功能(示例中的列)(组图))
1、点击“获取数据”>“网页”,在弹出的对话框中输入网址,点击“确定”
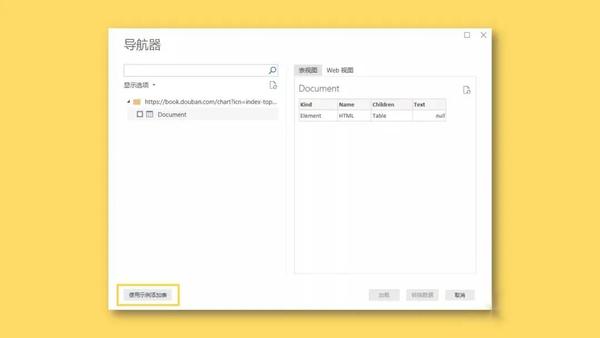
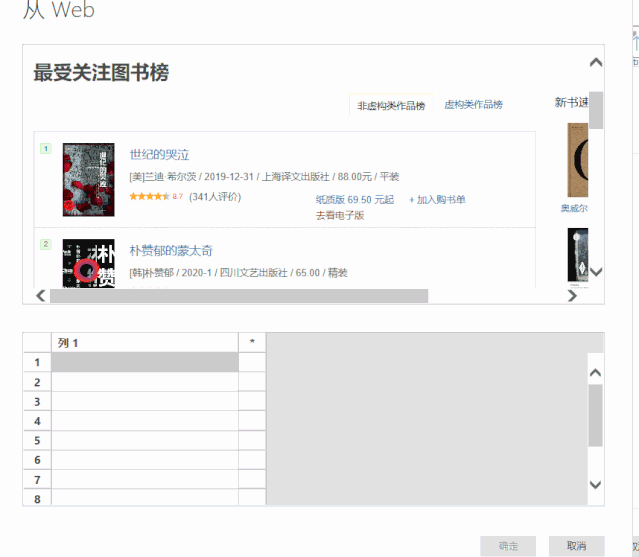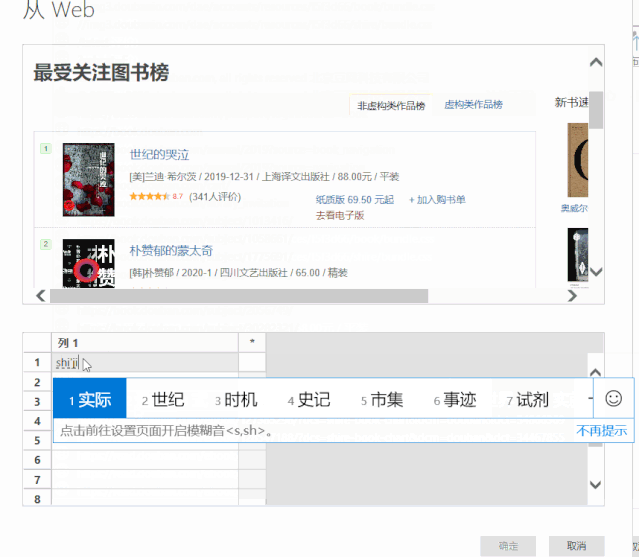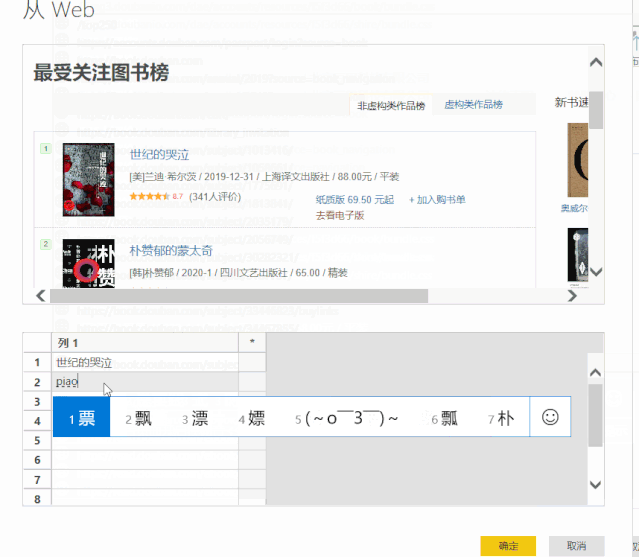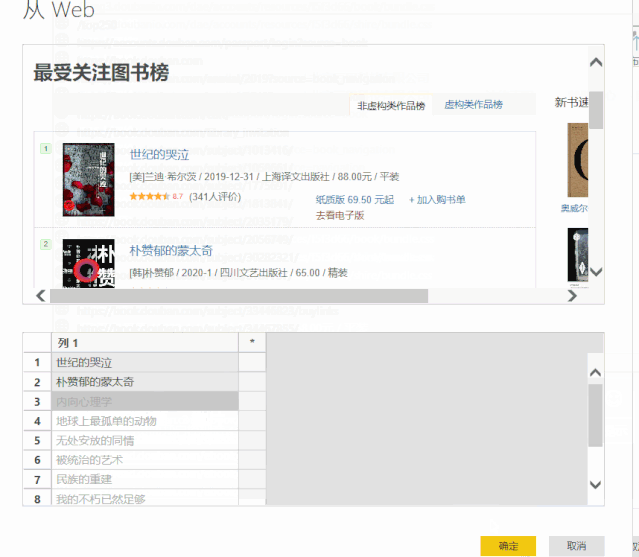
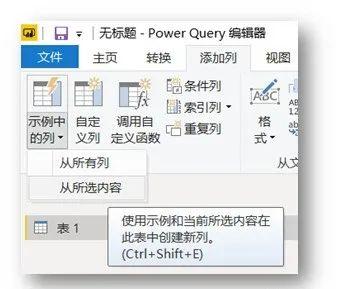
2、在弹出的“导航器”对话框中,选择左下角的“使用示例添加表格”。
3、接下来我们要做的就是提供一个我们需要在表中提取的数据的例子。
以抓取书名为例,可以看到,当我们提供两个书名时,Power BI 会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 捕获的数据就越准确
4、 使用相同的方法分别捕获我们需要的其他字段。
5、单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
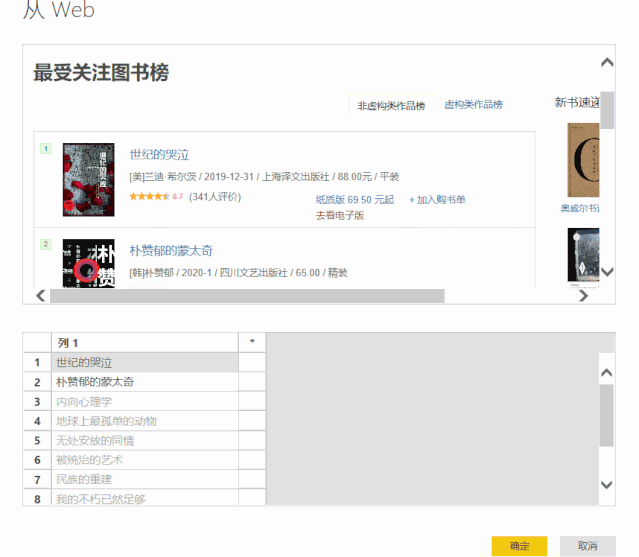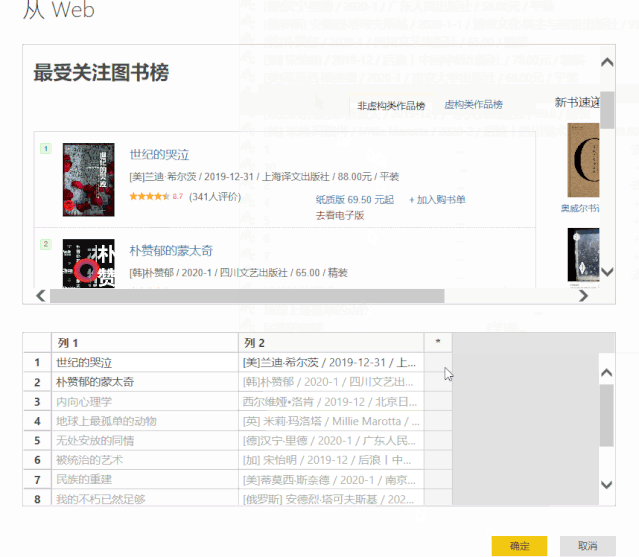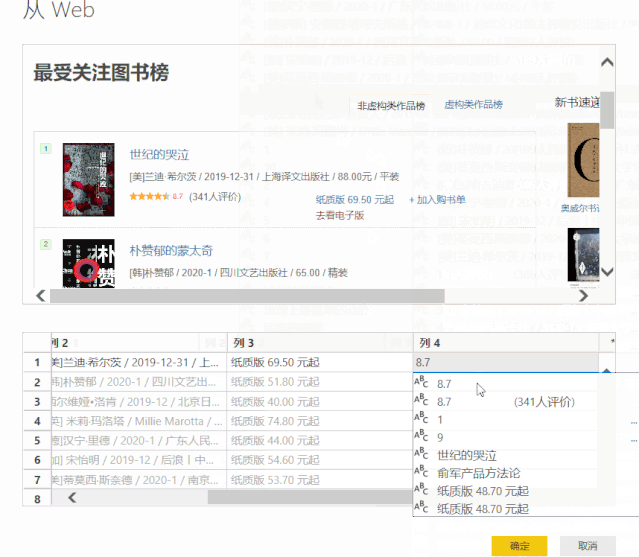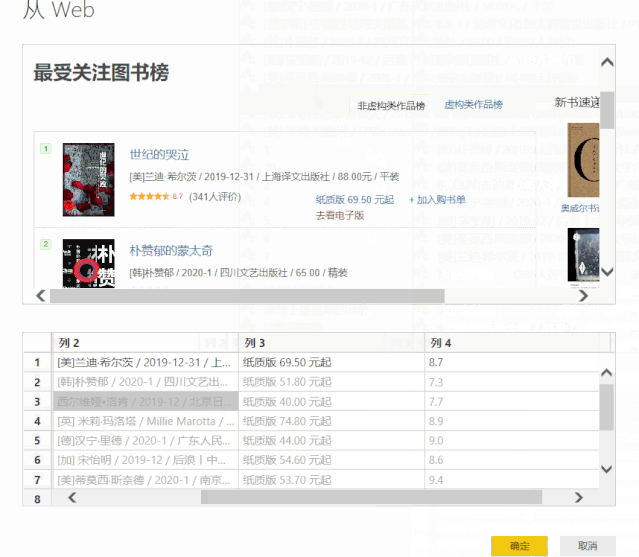
将“示例中的列”添加到 2Power Query
以上捕获的数据除了[作者]和[评级]列是正确的,其他列收录无用信息。 Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
“示例中的列”可以根据用户提供的示例提取信息。
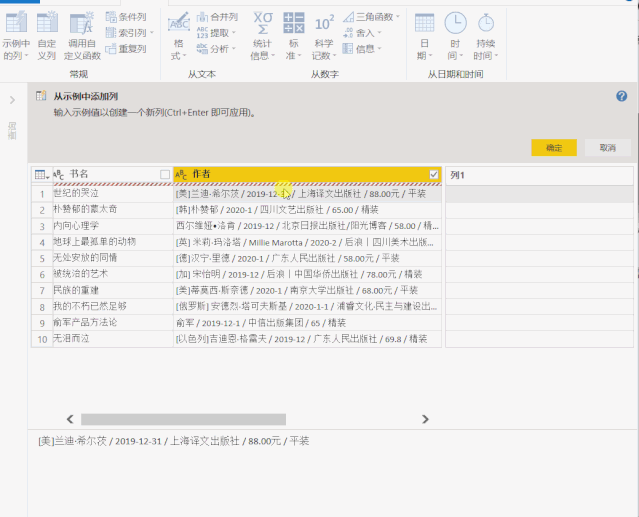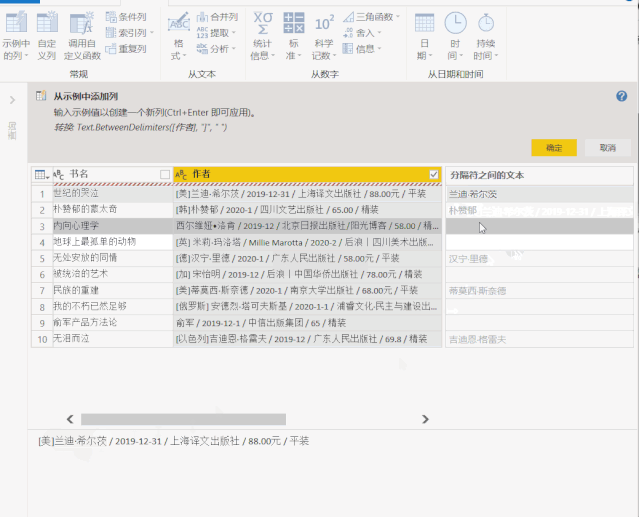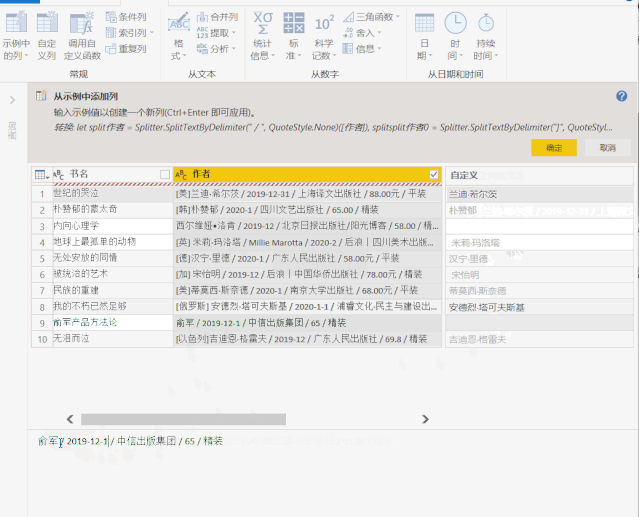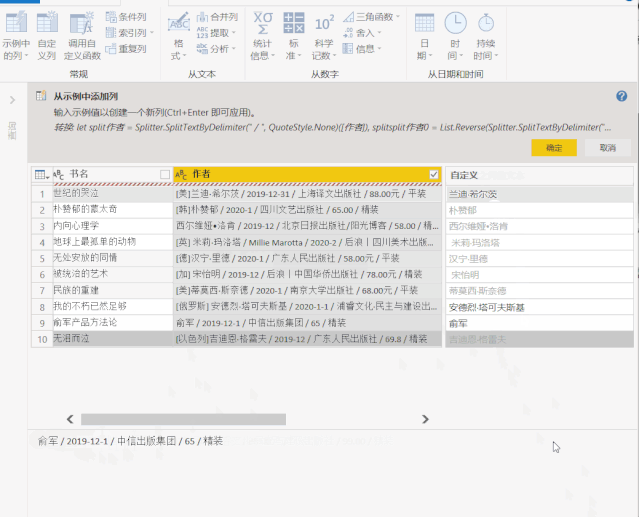
1、选择[作者]栏,点击“示例中的栏”左下角的小三角符号“添加栏”,在弹出的下拉菜单中选择“来自选择”选项。
2、在[Column 1]中提供了一个例子,Power BI会智能识别我们需要的数据
这里是复制原创列数据的快速输入示例
点击右上角的“确定”后,作者姓名将被提取到一个新列中。
-结束- 查看全部
从网页抓取数据(
PowerQuery的数据清洗功能(示例中的列)(组图))
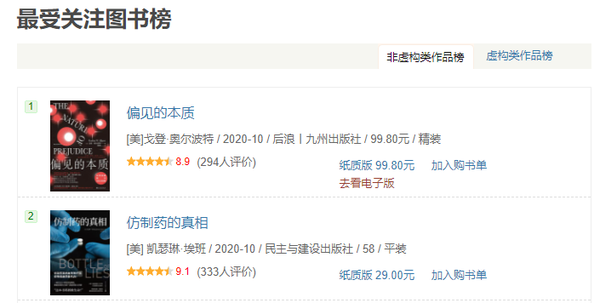
1、点击“获取数据”>“网页”,在弹出的对话框中输入网址,点击“确定”

2、在弹出的“导航器”对话框中,选择左下角的“使用示例添加表格”。
3、接下来我们要做的就是提供一个我们需要在表中提取的数据的例子。
以抓取书名为例,可以看到,当我们提供两个书名时,Power BI 会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 捕获的数据就越准确
4、 使用相同的方法分别捕获我们需要的其他字段。
5、单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。

将“示例中的列”添加到 2Power Query
以上捕获的数据除了[作者]和[评级]列是正确的,其他列收录无用信息。 Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
“示例中的列”可以根据用户提供的示例提取信息。
1、选择[作者]栏,点击“示例中的栏”左下角的小三角符号“添加栏”,在弹出的下拉菜单中选择“来自选择”选项。
2、在[Column 1]中提供了一个例子,Power BI会智能识别我们需要的数据
这里是复制原创列数据的快速输入示例
点击右上角的“确定”后,作者姓名将被提取到一个新列中。
-结束-
从网页抓取数据(网络爬虫的构架3、以抓取一个网页的内容为目的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-12 14:12
(一)Data Capture 概览如何将非结构化数据转化为结构化数据?(二)Grab 逻辑——ETL
什么是 ETL?
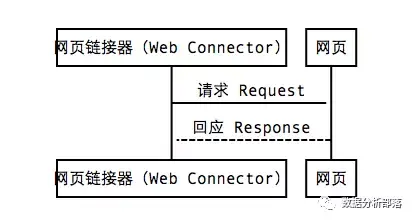
(三)准备前的数据采集1."Web Crawler"架构 Web Crawler架构
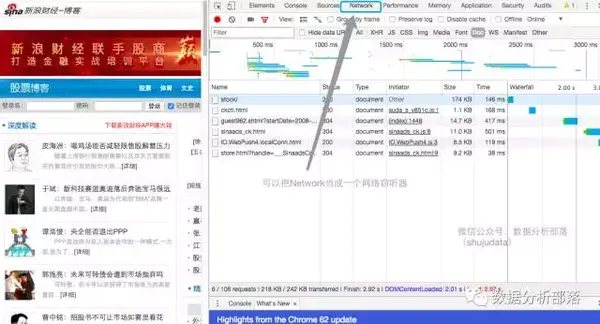
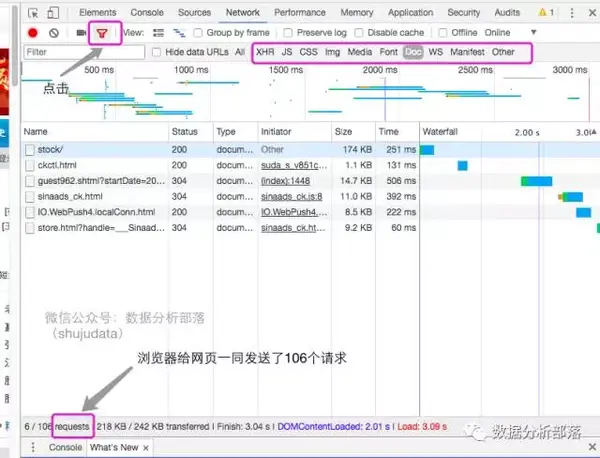
2、如何理解“网络爬虫”架构来研究量化投资策略,第一步是获取我们需要的数据。在实践中,比较实用的数据来源是新浪财经的数据。下面我们以新浪财经以财经为例,为大家梳理一下网络爬虫的结构3、以抓取网页内容为目的,如何观察网页我们有新浪财经股票博客信息,如何应该把这个信息,包括标题和时间都抢过来吗? (1)使用开发者工具观察
(2)观察Requests的组成
通常来说文章和news会放在Doc下,我们接下来要爬取的链接就隐藏在106个链接之一中;
(3)观察HTTP请求和返回内容。我们可以在Document下找到文章和新闻内容。为什么?因为只要是有上述类型内容的网页,他们都需要被搜索引擎搜索到。对于搜索引擎来说,Document的内容是最好的,所以大多数情况下,只要找到Document下的第一个链接,就可以准备爬取文章和新闻内容;只有很小的一部分部分会看到XHR等部分;下面,jacky(数据分析部落公众号:shujudata)分享实际操作;
确定网页的访问方式
上面,我们观察网页后,会发现response下的数据是放在html页面中的。 HTML 收录网页的标签。这些标签描述了网页的行为。我们得到的响应是html,里面收录它的数据和它的标签,这样的数据不是结构化数据,我们还需要进一步处理,那么如何将非结构化数据处理成结构化数据呢?请参考jacky的第二次分享,谢谢大家! 查看全部
从网页抓取数据(网络爬虫的构架3、以抓取一个网页的内容为目的)
(一)Data Capture 概览如何将非结构化数据转化为结构化数据?(二)Grab 逻辑——ETL
什么是 ETL?
(三)准备前的数据采集1."Web Crawler"架构 Web Crawler架构
2、如何理解“网络爬虫”架构来研究量化投资策略,第一步是获取我们需要的数据。在实践中,比较实用的数据来源是新浪财经的数据。下面我们以新浪财经以财经为例,为大家梳理一下网络爬虫的结构3、以抓取网页内容为目的,如何观察网页我们有新浪财经股票博客信息,如何应该把这个信息,包括标题和时间都抢过来吗? (1)使用开发者工具观察
(2)观察Requests的组成
通常来说文章和news会放在Doc下,我们接下来要爬取的链接就隐藏在106个链接之一中;
(3)观察HTTP请求和返回内容。我们可以在Document下找到文章和新闻内容。为什么?因为只要是有上述类型内容的网页,他们都需要被搜索引擎搜索到。对于搜索引擎来说,Document的内容是最好的,所以大多数情况下,只要找到Document下的第一个链接,就可以准备爬取文章和新闻内容;只有很小的一部分部分会看到XHR等部分;下面,jacky(数据分析部落公众号:shujudata)分享实际操作;
确定网页的访问方式
上面,我们观察网页后,会发现response下的数据是放在html页面中的。 HTML 收录网页的标签。这些标签描述了网页的行为。我们得到的响应是html,里面收录它的数据和它的标签,这样的数据不是结构化数据,我们还需要进一步处理,那么如何将非结构化数据处理成结构化数据呢?请参考jacky的第二次分享,谢谢大家!
从网页抓取数据(1.什么是抓取和收录,从基本概念及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-12 14:11
很多SEO从业者有一个很苦恼的问题:网站建好了,为什么搜索引擎没有收录我的网站?页面收录是网站争夺排名的最基本条件。没有收录,就没有展示,也就无法争夺排名获取SEO流量。
本文将围绕抓包和收录两点,从基本概念、常见问题和解决方案三个维度展开讨论,希望对大家有用。
1.什么是爬取,收录,爬取配额?
先简单介绍一下爬取,收录,三个词条爬取配额。
①爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
②收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
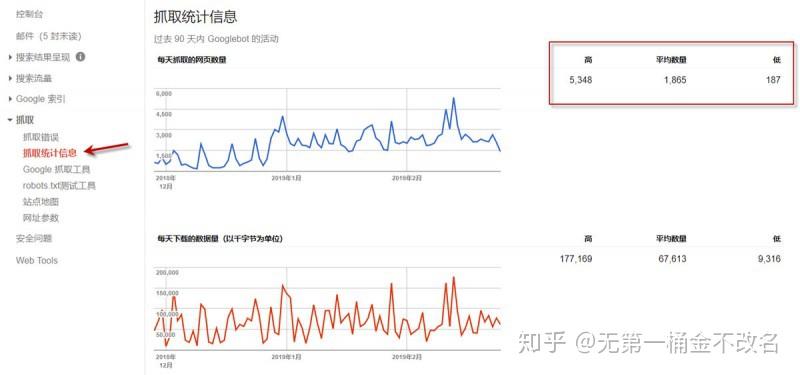
③抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
2.如何查看网站的收录情况?
了解基本概念后,我们如何判断网站或者页面是否为收录?
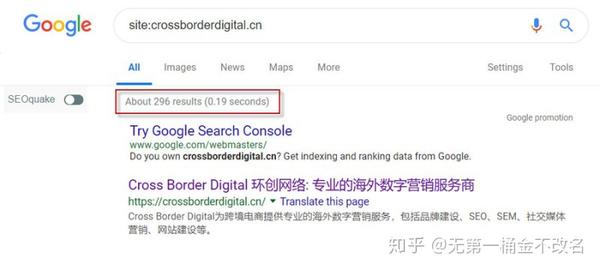
①通过站点命令。谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,可以在宏观层面查看一个网站已经收录的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录网站的网页数量约为296个。
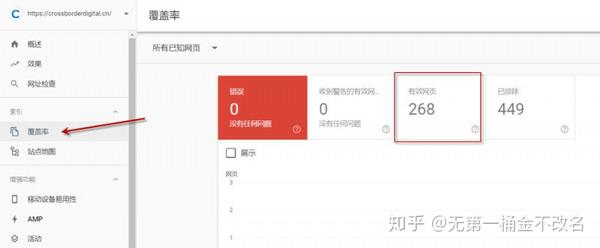
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的268 页;
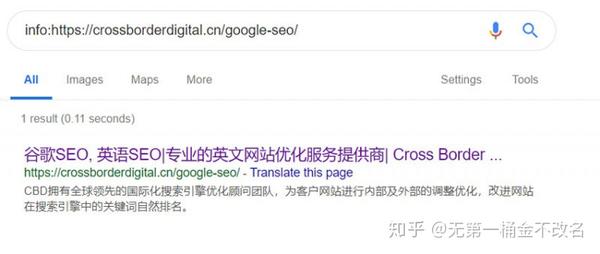
③如果要查看特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果有返回结果,页面已经是收录,如下图:
3.为什么搜索引擎不是收录网站页面?
网站页面不是收录的原因有很多。以下是一些常见的原因供您参考:
①元标签“Noindex”使用不当
如果代码被添加到页面的Meta标签中,它告诉搜索引擎不要索引该页面;
②Robots文件中Disallow的错误使用
如果User-agent: * Disallow: /ABC/ 代码被添加到网站 的Robots 文件中,它会告诉搜索引擎不要索引ABC 目录中的所有页面。 Robots 文件中命令的优先级高于页面 Meta 标签中的命令。谷歌会严格遵循Robots文件中的命令,但是页面Meta中的命令有时会被忽略。例如,即使某个页面在Meta代码中明确添加了Index指令,但在Robots文件中为Disallow,搜索引擎也不会收录这个页面。
③网站缺少站点地图文件
站点地图文件是搜索引擎抓取网站页面的有效方式之一。如果网站缺少站点地图文件,或者站点地图不收录页面URL,这可能会导致网站或页面不是收录。 ④错误使用301和302重定向
有些网站由于cms后台设置不正确导致多页跳转,比如A页302跳转到B页,B页301跳转到C页。这种多次跳转或者混合使用跳转命令不利于抓取页面。很多网站处理www格式的URL跳转到没有www的URL,或者http跳转到https等,容易出现这种情况。类问题。
⑤错误使用Canonical标签
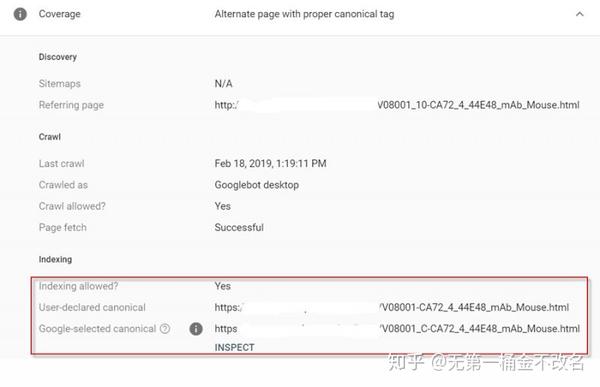
Canonical 标签主要用于两个页面之间的内容相同,但 URL 不同的情况。例如,很多有SEM投放需求的站长需要在Landing Page中添加多个UTM跟踪参数,以便跟踪广告效果; Canonical tag 这批网址可以标准化,让搜索引擎了解这些不同网址之间的关系,避免内容重复和权重分散。但是如果A和B两个页面之间的内容不同,但是在A页面添加了指向B页面的Canonical标签,这会导致搜索引擎不能很好地理解页面之间的关系,所以是不是收录目标页面。
⑥网站或者页面很新
对于新上线的网站或页面,搜索引擎抓取页面需要几天时间。所以如果新上线的网站不是收录,可以耐心等几天再查。 ⑦网址太复杂或错误
部分网站网址收录很多动态参数,语义不清晰,或者网址使用了中文等非英文内容,不利于搜索引擎和收录页面的理解。如果你对网址优化一窍不通,可以参考这篇博文:分享12个网址优化技巧,助你提升网站SEO友好度
⑧页面层次太深
网站 的扁平化有利于爬虫爬取页面。页面越深,爬虫接触页面的几率越低,被搜索引擎收录接触的几率越低。简单的理解就是,当书店里的一本书放在最底层的一角时,买家看到的机会就大大减少了。
⑨网站或页面内容价值低
我曾经遇到一个客户,因为技术人员把包括视频和图片在内的所有多媒体文件放在一个目录中,该目录被Robots文件中的Disallow删除,导致搜索引擎爬虫看到的页面内容和真实用户看到的不一样。站长可能认为这个页面内容丰富,但在爬虫眼中,它是一个空白页面。如下图,左边是爬虫看到的空白页面,右边是用户看到的实际页面。这样低质量的内容页面搜索引擎也不愿意收录。
⑩ 重复页面内容
比较低的网站都是由采集other网站的数据生成的。这种内容高度重复的页面,也不愿意被搜索引擎收录。
⑪网站被惩罚
如果网站因黑帽等非法手段被谷歌人工处罚,该类网站和页面将不会是收录。
4.网站收录问题如何解决?
①正确设置网站的Robots文件和htaccess文件,保证搜索引擎爬虫能够正确读取页面内容
如果您是 Chrome 浏览器用户,您可以安装 User Agent Switcher 插件来模拟 Googlebot 对页面的访问,并检查页面内容是否正确显示给爬虫。
如果网站已经验证了Google Search Console,您也可以使用旧版Google Search Console中的Google爬虫来预览爬取效果;
②确保页面上Meta Robots标签配置正确,使用noindex指令没有错误
默认的 Meta Robots 处于索引状态,因此页面的 Robots 标签可以留空。 Chrome浏览器用户可以使用插件SEO Meta in 1 点击查看。只需打开页面,点击插件即可查看页面相关的Meta信息。
③制作站点地图文件
同时在 Google Search Console 后台或 Bing 站长后台提交 Sitemap 文件,定期更新 Sitemap 文件并通知搜索引擎。
如果有一些关键页面希望谷歌尽快收录,可以通过旧版谷歌搜索控制台的爬虫提交,点击索引。一般不会被惩罚的网站或页面,但一天之内就可以被收录。不过这种方式每天最多只能提交10页,而且谷歌已经宣布在新版谷歌搜索控制台中取消这个工具,取而代之的是“网址检查”工具。
④添加页面的链接入口
链接入口包括站内链接和站外链接。您可以添加站内链接,例如网站 导航、页面底部的页脚、面包屑导航、网站 侧边栏、正文内容和相关推荐。站外链接的方式和渠道有很多:比如维基百科(我们有专业的维基百科词条创建服务,请联系我们)、Guestpost Outreach、品牌链接回收、资源链接等,我想知道的更详细更丰富外链构建方法参考这个文章:8种获取优质外链的方法
⑤优化页面的URL格式和层次
尽量简化页面URL的长度,单词之间用“-”代替空格或%等特殊字符,降低页面层次;扁平的网站结构更有利于爬虫抓取网站。
⑥301/302重定向和Canonical标签的正确使用
对于离线页面或URL更改,建议使用301永久重定向,将旧页面指向新的目标页面。如果确定页面永久下线,您也可以如实返回404识别码。对于内容相同的页面,合理使用Canonical标签。有些电商网站在产品聚合页面下有多个tab,比如第1页、第2页、第3页……,为了聚合第1页的权重,误认为Canonical点了第2页、第3页和其他页面到第1页,容易导致后面的页面没有被索引。
⑦使用上一个和下一个标签
对于大型电商网站,如果某个分类下有多个tab,可以在每个tab中添加rel=”prev”(上一页)和rel=”next”(在声明下) 一个页面),以便搜索引擎了解该页面系列之间的关系,并给予列表页第一页更多的权重和排名。
一个。在第1页/第1页的部分,添加: 查看全部
从网页抓取数据(1.什么是抓取和收录,从基本概念及解决方法)
很多SEO从业者有一个很苦恼的问题:网站建好了,为什么搜索引擎没有收录我的网站?页面收录是网站争夺排名的最基本条件。没有收录,就没有展示,也就无法争夺排名获取SEO流量。
本文将围绕抓包和收录两点,从基本概念、常见问题和解决方案三个维度展开讨论,希望对大家有用。
1.什么是爬取,收录,爬取配额?
先简单介绍一下爬取,收录,三个词条爬取配额。
①爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
②收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
③抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
2.如何查看网站的收录情况?
了解基本概念后,我们如何判断网站或者页面是否为收录?
①通过站点命令。谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,可以在宏观层面查看一个网站已经收录的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录网站的网页数量约为296个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的268 页;
③如果要查看特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果有返回结果,页面已经是收录,如下图:
3.为什么搜索引擎不是收录网站页面?
网站页面不是收录的原因有很多。以下是一些常见的原因供您参考:
①元标签“Noindex”使用不当
如果代码被添加到页面的Meta标签中,它告诉搜索引擎不要索引该页面;
②Robots文件中Disallow的错误使用
如果User-agent: * Disallow: /ABC/ 代码被添加到网站 的Robots 文件中,它会告诉搜索引擎不要索引ABC 目录中的所有页面。 Robots 文件中命令的优先级高于页面 Meta 标签中的命令。谷歌会严格遵循Robots文件中的命令,但是页面Meta中的命令有时会被忽略。例如,即使某个页面在Meta代码中明确添加了Index指令,但在Robots文件中为Disallow,搜索引擎也不会收录这个页面。
③网站缺少站点地图文件
站点地图文件是搜索引擎抓取网站页面的有效方式之一。如果网站缺少站点地图文件,或者站点地图不收录页面URL,这可能会导致网站或页面不是收录。 ④错误使用301和302重定向
有些网站由于cms后台设置不正确导致多页跳转,比如A页302跳转到B页,B页301跳转到C页。这种多次跳转或者混合使用跳转命令不利于抓取页面。很多网站处理www格式的URL跳转到没有www的URL,或者http跳转到https等,容易出现这种情况。类问题。
⑤错误使用Canonical标签
Canonical 标签主要用于两个页面之间的内容相同,但 URL 不同的情况。例如,很多有SEM投放需求的站长需要在Landing Page中添加多个UTM跟踪参数,以便跟踪广告效果; Canonical tag 这批网址可以标准化,让搜索引擎了解这些不同网址之间的关系,避免内容重复和权重分散。但是如果A和B两个页面之间的内容不同,但是在A页面添加了指向B页面的Canonical标签,这会导致搜索引擎不能很好地理解页面之间的关系,所以是不是收录目标页面。
⑥网站或者页面很新
对于新上线的网站或页面,搜索引擎抓取页面需要几天时间。所以如果新上线的网站不是收录,可以耐心等几天再查。 ⑦网址太复杂或错误
部分网站网址收录很多动态参数,语义不清晰,或者网址使用了中文等非英文内容,不利于搜索引擎和收录页面的理解。如果你对网址优化一窍不通,可以参考这篇博文:分享12个网址优化技巧,助你提升网站SEO友好度
⑧页面层次太深
网站 的扁平化有利于爬虫爬取页面。页面越深,爬虫接触页面的几率越低,被搜索引擎收录接触的几率越低。简单的理解就是,当书店里的一本书放在最底层的一角时,买家看到的机会就大大减少了。

⑨网站或页面内容价值低
我曾经遇到一个客户,因为技术人员把包括视频和图片在内的所有多媒体文件放在一个目录中,该目录被Robots文件中的Disallow删除,导致搜索引擎爬虫看到的页面内容和真实用户看到的不一样。站长可能认为这个页面内容丰富,但在爬虫眼中,它是一个空白页面。如下图,左边是爬虫看到的空白页面,右边是用户看到的实际页面。这样低质量的内容页面搜索引擎也不愿意收录。
⑩ 重复页面内容
比较低的网站都是由采集other网站的数据生成的。这种内容高度重复的页面,也不愿意被搜索引擎收录。
⑪网站被惩罚
如果网站因黑帽等非法手段被谷歌人工处罚,该类网站和页面将不会是收录。
4.网站收录问题如何解决?
①正确设置网站的Robots文件和htaccess文件,保证搜索引擎爬虫能够正确读取页面内容
如果您是 Chrome 浏览器用户,您可以安装 User Agent Switcher 插件来模拟 Googlebot 对页面的访问,并检查页面内容是否正确显示给爬虫。
如果网站已经验证了Google Search Console,您也可以使用旧版Google Search Console中的Google爬虫来预览爬取效果;
②确保页面上Meta Robots标签配置正确,使用noindex指令没有错误
默认的 Meta Robots 处于索引状态,因此页面的 Robots 标签可以留空。 Chrome浏览器用户可以使用插件SEO Meta in 1 点击查看。只需打开页面,点击插件即可查看页面相关的Meta信息。
③制作站点地图文件
同时在 Google Search Console 后台或 Bing 站长后台提交 Sitemap 文件,定期更新 Sitemap 文件并通知搜索引擎。
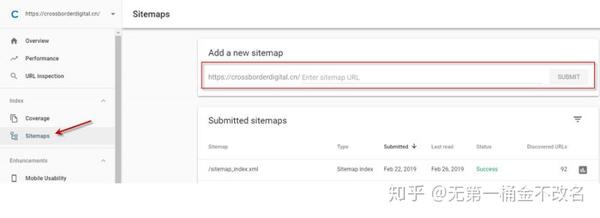
如果有一些关键页面希望谷歌尽快收录,可以通过旧版谷歌搜索控制台的爬虫提交,点击索引。一般不会被惩罚的网站或页面,但一天之内就可以被收录。不过这种方式每天最多只能提交10页,而且谷歌已经宣布在新版谷歌搜索控制台中取消这个工具,取而代之的是“网址检查”工具。
④添加页面的链接入口
链接入口包括站内链接和站外链接。您可以添加站内链接,例如网站 导航、页面底部的页脚、面包屑导航、网站 侧边栏、正文内容和相关推荐。站外链接的方式和渠道有很多:比如维基百科(我们有专业的维基百科词条创建服务,请联系我们)、Guestpost Outreach、品牌链接回收、资源链接等,我想知道的更详细更丰富外链构建方法参考这个文章:8种获取优质外链的方法
⑤优化页面的URL格式和层次
尽量简化页面URL的长度,单词之间用“-”代替空格或%等特殊字符,降低页面层次;扁平的网站结构更有利于爬虫抓取网站。
⑥301/302重定向和Canonical标签的正确使用
对于离线页面或URL更改,建议使用301永久重定向,将旧页面指向新的目标页面。如果确定页面永久下线,您也可以如实返回404识别码。对于内容相同的页面,合理使用Canonical标签。有些电商网站在产品聚合页面下有多个tab,比如第1页、第2页、第3页……,为了聚合第1页的权重,误认为Canonical点了第2页、第3页和其他页面到第1页,容易导致后面的页面没有被索引。
⑦使用上一个和下一个标签
对于大型电商网站,如果某个分类下有多个tab,可以在每个tab中添加rel=”prev”(上一页)和rel=”next”(在声明下) 一个页面),以便搜索引擎了解该页面系列之间的关系,并给予列表页第一页更多的权重和排名。
一个。在第1页/第1页的部分,添加:
从网页抓取数据(如何用Python搞点Soup库获取2018年100强企业信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-12 14:10
写在顶部的这个简单的 Python 教程中,我们总共采取了以下步骤来抓取网页内容:
作为数据科学家,大多数人的首要任务是进行网络爬虫。那个时候,我对用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。如今,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取网站——例如,从Fast Track获取2018年100强企业的信息。使用脚本实现信息获取过程的自动化,不仅节省了人工整理的时间,还可以将企业所有数据整理成一个结构化的文件,以便进一步分析查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上(/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.js)。 py),欢迎你来取。
准备开始
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要什么库?”
有几个不同的库可用于网络抓取,包括:
● 美汤
● 请求
● Scrapy
● 硒
今天我们计划使用 Beautiful Soup 库。您只需要使用pip(Python包管理工具)即可轻松安装到您的电脑上:
检查网页
为了确定要抓取网页的哪些元素,您需要先检查网页的结构。
以 Tech Track Top 100 Companies 页面 (fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
在要查看的网页元素上右击,选择“check”查看具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表格的主体在这个标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种REST客户端(例如Insomnia)来发起请求并输出返回值。
刷新页面后,Network标签的内容更新
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
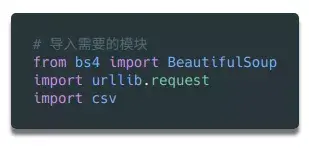
首先要导入代码中需要用到的各个模块。上面我们已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
接下来,我们需要准备需要抓取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的URL并将其赋值给变量即可:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行——100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
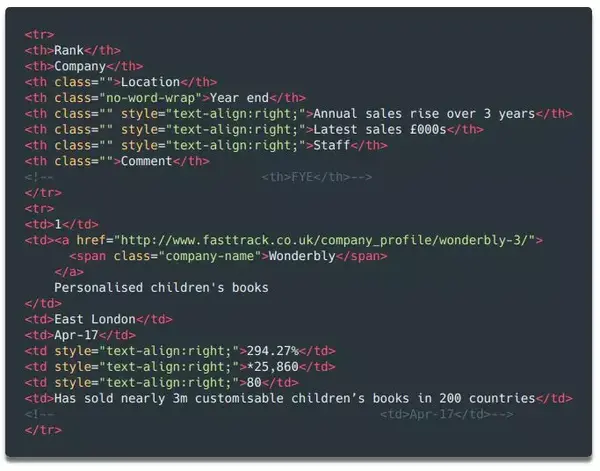
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
如您所见,该表共有 8 列,分别为 Rank、Company、Location、Year End、Annual Sales Rise、Latest Sales(今年的销售额)、Staff(员工人数)和 Comments(评论)。这些就是我们需要的数据。
这样的结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并将其存储在在变量中,方便以后写csv或者json文件。
遍历所有元素并将它们存储在变量中
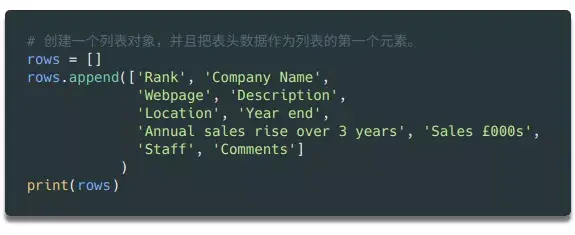
在Python中,如果需要处理大量数据,需要写入文件,list对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后面的数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多一些,例如网页和说明。请仔细看上面打印的汤变量数据——在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
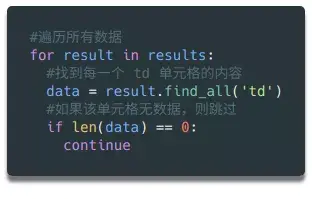
如何循环读取数据:
因为第一行数据是html表格的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
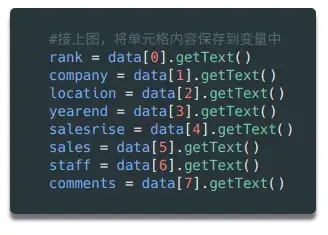
接下来,我们读取数据的内容并将其赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去掉多余的字符,导出需要的数据。
数据清洗
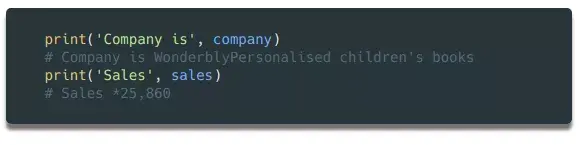
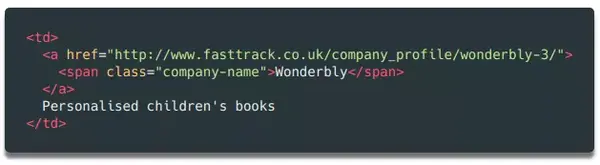
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还有一些需要清除的字符,比如备注等。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个单元格中还有一个元素,里面只收录了公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。以后会用到!
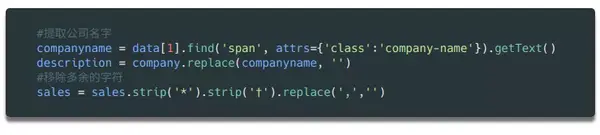
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样就只剩下描述了在变量中。
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
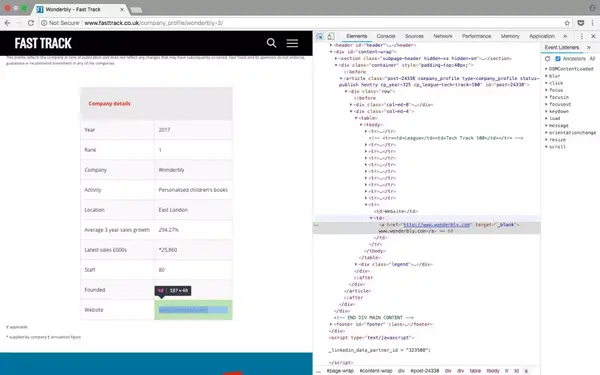
我们最不想保存的是网站 公司的链接。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表格。在大多数情况下,表单中有指向 company网站 的链接。
在公司详细信息页面上查看表格中的链接
为了抓取每个表中的 URL 并将其保存在一个变量中,我们需要执行以下步骤:
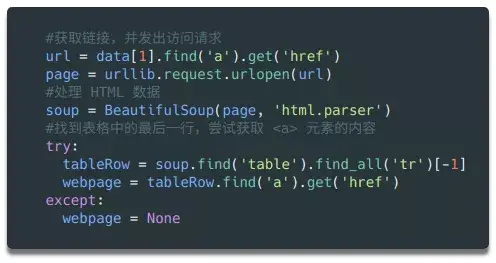
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以找到表格最后一行的元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中(还在循环体中)之后,我们就可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要简单的几行代码就可以将列表对象保存为文件。
最后,让我们运行这段python代码。如果一切顺利,您会在目录中找到一个收录 100 行数据的 csv 文件。你可以用python轻松阅读和处理它。
总结
如果有什么不明白的,请在下方留言,我会尽力解答!
祝您的爬虫之旅有一个好的开始!
重组-欧剃
来源-/data-science-skills-web-scraping-using-python-d1a85ef607ed(作者:Kerry Parker)
知乎机构号:来自硅谷的终身学习平台-宇田学习城(),专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从从头掌握数据分析、机器学习、深度学习、人工智能、无人驾驶等前沿技术,激发未来无限可能!
知乎Column:Uda学习笔记,欢迎所有喜欢Uda的学习者,在这里分享所学,交流技术,结识朋友。欢迎您积极贡献。 查看全部
从网页抓取数据(如何用Python搞点Soup库获取2018年100强企业信息)
写在顶部的这个简单的 Python 教程中,我们总共采取了以下步骤来抓取网页内容:
作为数据科学家,大多数人的首要任务是进行网络爬虫。那个时候,我对用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。如今,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取网站——例如,从Fast Track获取2018年100强企业的信息。使用脚本实现信息获取过程的自动化,不仅节省了人工整理的时间,还可以将企业所有数据整理成一个结构化的文件,以便进一步分析查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上(/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.js)。 py),欢迎你来取。
准备开始
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要什么库?”
有几个不同的库可用于网络抓取,包括:
● 美汤
● 请求
● Scrapy
● 硒
今天我们计划使用 Beautiful Soup 库。您只需要使用pip(Python包管理工具)即可轻松安装到您的电脑上:
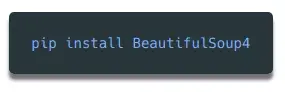
检查网页
为了确定要抓取网页的哪些元素,您需要先检查网页的结构。
以 Tech Track Top 100 Companies 页面 (fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
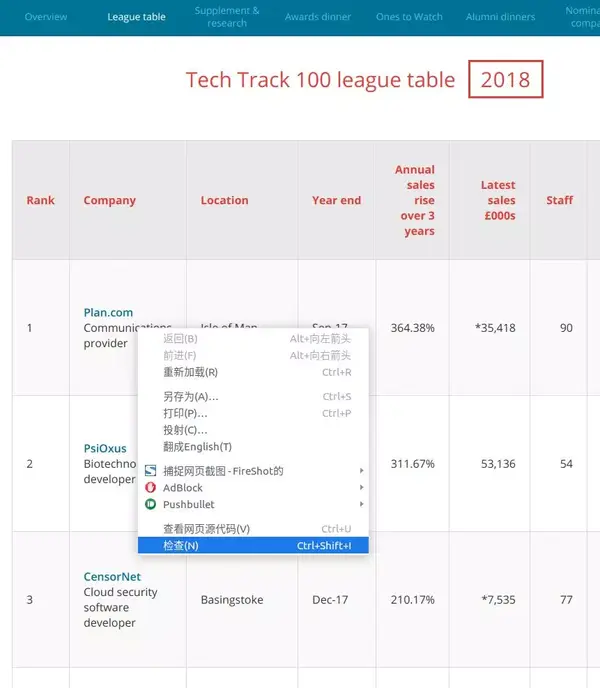
在要查看的网页元素上右击,选择“check”查看具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表格的主体在这个标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种REST客户端(例如Insomnia)来发起请求并输出返回值。
刷新页面后,Network标签的内容更新
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要导入代码中需要用到的各个模块。上面我们已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
接下来,我们需要准备需要抓取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的URL并将其赋值给变量即可:

接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行——100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
如您所见,该表共有 8 列,分别为 Rank、Company、Location、Year End、Annual Sales Rise、Latest Sales(今年的销售额)、Staff(员工人数)和 Comments(评论)。这些就是我们需要的数据。
这样的结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并将其存储在在变量中,方便以后写csv或者json文件。
遍历所有元素并将它们存储在变量中
在Python中,如果需要处理大量数据,需要写入文件,list对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后面的数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多一些,例如网页和说明。请仔细看上面打印的汤变量数据——在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
如何循环读取数据:
因为第一行数据是html表格的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去掉多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还有一些需要清除的字符,比如备注等。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个单元格中还有一个元素,里面只收录了公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样就只剩下描述了在变量中。
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们最不想保存的是网站 公司的链接。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表格。在大多数情况下,表单中有指向 company网站 的链接。
在公司详细信息页面上查看表格中的链接
为了抓取每个表中的 URL 并将其保存在一个变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以找到表格最后一行的元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中(还在循环体中)之后,我们就可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
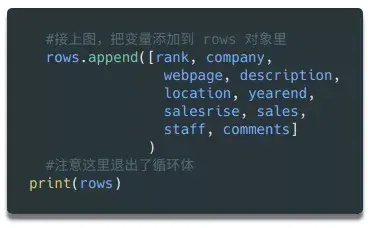
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要简单的几行代码就可以将列表对象保存为文件。
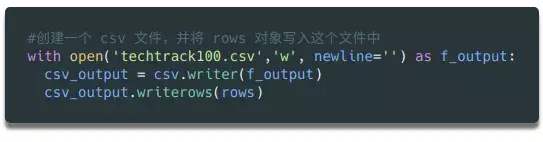
最后,让我们运行这段python代码。如果一切顺利,您会在目录中找到一个收录 100 行数据的 csv 文件。你可以用python轻松阅读和处理它。
总结
如果有什么不明白的,请在下方留言,我会尽力解答!
祝您的爬虫之旅有一个好的开始!
重组-欧剃
来源-/data-science-skills-web-scraping-using-python-d1a85ef607ed(作者:Kerry Parker)
知乎机构号:来自硅谷的终身学习平台-宇田学习城(),专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从从头掌握数据分析、机器学习、深度学习、人工智能、无人驾驶等前沿技术,激发未来无限可能!
知乎Column:Uda学习笔记,欢迎所有喜欢Uda的学习者,在这里分享所学,交流技术,结识朋友。欢迎您积极贡献。
从网页抓取数据(“劈柴”掌权这几年,谷歌怎么就成了另一个百度?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-11 20:06
这几年,“词柴”掌权,谷歌是如何成为另一个百度的?
分裂,可能没有一个。在 Jeff Dean 的开发和领导下,Google 将分布式计算系统应用到公司的广告、网络爬取、索引等系统中,并很早就成立了专门从事机器学习/深度学习的研究部门。迪恩本人也是谷歌的老手,
硅星2021-04-17
普利策奖获奖记者使用哪些工具?深度报道的辅助“神器”
ython 的一个免费开源的数据处理模块,集成了数据库、电子表格、可视化等程序的功能,可以集中完成网页爬取、数据分析、图表处理。图片来源:搜狐新闻 Excel:如果你不会编程,一些基础工具也能帮上忙
全媒体集团 ©2020-08-05
世界那么大,你不想去看吗?教你判断辞职时机是否合适
在线完成这项工作。 2、网店编程:毕竟电子商务和社交媒体的商业活动如火如荼。 3、网站测试和爬网:在网站发布之前,各家公司都希望自己的网站能按照既定的轨道走,所以公司不会招募网站testers
TECH2IPO / Transcend©2016-05-11
利与弊:互联网巨头打通幕后追踪平台
这就是方法。有的人在注册的时候还会登录失踪人员的地址和电话号码。目前,该信息公开显示在网页上。一个简单的网络爬虫程序就可以获取所有的电话号码。在谷歌寻人服务中,查看失踪人员或失踪人员的电话号码,有一步输入验证
杨淼。 2013-04-25
京东屏蔽易淘价格搜索和插件是否违法?
破坏社会和经济秩序的行为。笔者认为,虽然现行法律没有规定网站有权使用技术手段阻止搜索引擎的网络爬行,但搜索引擎也应该遵循公认的搜索引擎爬取数据的原则,否则涉嫌扰乱经济秩序和违反诚信。问题二、京东
尤云庭律师 2012-08-28 查看全部
从网页抓取数据(“劈柴”掌权这几年,谷歌怎么就成了另一个百度?)
这几年,“词柴”掌权,谷歌是如何成为另一个百度的?
分裂,可能没有一个。在 Jeff Dean 的开发和领导下,Google 将分布式计算系统应用到公司的广告、网络爬取、索引等系统中,并很早就成立了专门从事机器学习/深度学习的研究部门。迪恩本人也是谷歌的老手,
硅星2021-04-17
普利策奖获奖记者使用哪些工具?深度报道的辅助“神器”
ython 的一个免费开源的数据处理模块,集成了数据库、电子表格、可视化等程序的功能,可以集中完成网页爬取、数据分析、图表处理。图片来源:搜狐新闻 Excel:如果你不会编程,一些基础工具也能帮上忙
全媒体集团 ©2020-08-05
世界那么大,你不想去看吗?教你判断辞职时机是否合适
在线完成这项工作。 2、网店编程:毕竟电子商务和社交媒体的商业活动如火如荼。 3、网站测试和爬网:在网站发布之前,各家公司都希望自己的网站能按照既定的轨道走,所以公司不会招募网站testers
TECH2IPO / Transcend©2016-05-11
利与弊:互联网巨头打通幕后追踪平台
这就是方法。有的人在注册的时候还会登录失踪人员的地址和电话号码。目前,该信息公开显示在网页上。一个简单的网络爬虫程序就可以获取所有的电话号码。在谷歌寻人服务中,查看失踪人员或失踪人员的电话号码,有一步输入验证
杨淼。 2013-04-25
京东屏蔽易淘价格搜索和插件是否违法?
破坏社会和经济秩序的行为。笔者认为,虽然现行法律没有规定网站有权使用技术手段阻止搜索引擎的网络爬行,但搜索引擎也应该遵循公认的搜索引擎爬取数据的原则,否则涉嫌扰乱经济秩序和违反诚信。问题二、京东
尤云庭律师 2012-08-28
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-11 20:04
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,请仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码
import requests from bs4 import BeautifulSoup import csv import pandas as pd url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url }) keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products) ### 使用pandas写入数据 pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,请仔细阅读本文!

第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容

可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到

可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
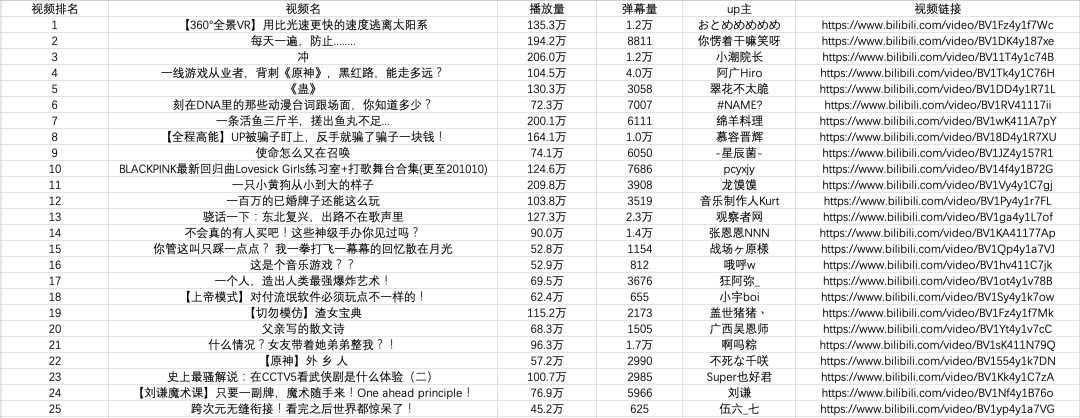
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码
import requests from bs4 import BeautifulSoup import csv import pandas as pd url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url }) keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products) ### 使用pandas写入数据 pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
从网页抓取数据(智能识别模式自动识别网页数据抓取工具的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-11 00:15
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
从网页抓取数据(智能识别模式自动识别网页数据抓取工具的功能介绍)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
从网页抓取数据(webharvy中文版来源于国外的网页浏览数据采集工具!原版是英文版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-09-11 00:13
webharvy中文版是来自国外的网页浏览数据采集tool!原版是英文的,如果你用得不好,我推荐这个!内容破解本地化,基本无障碍使用!可以轻松帮你提取网页采集中的图片、文档等资源,整理信息非常方便!
SysNucleus WebHarvy 软件介绍
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。捕获数据就像从网页导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,您可以提取不同网站的产品目录或搜索结果等不同类别的数据,例如房地产、电子商务、学术研究、娱乐、技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。
Webharvy 功能介绍
1、Vision 点选界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
2、智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站scraper 会自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
6、通代{过}{filter}服务器提取
要提取匿名性并防止网络服务器被网络软件阻止,您必须{over}{filter}选项通过代理服务器访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、Extract 分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、Extract 使用正则表达式
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。 查看全部
从网页抓取数据(webharvy中文版来源于国外的网页浏览数据采集工具!原版是英文版)
webharvy中文版是来自国外的网页浏览数据采集tool!原版是英文的,如果你用得不好,我推荐这个!内容破解本地化,基本无障碍使用!可以轻松帮你提取网页采集中的图片、文档等资源,整理信息非常方便!
SysNucleus WebHarvy 软件介绍
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。捕获数据就像从网页导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,您可以提取不同网站的产品目录或搜索结果等不同类别的数据,例如房地产、电子商务、学术研究、娱乐、技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。

Webharvy 功能介绍
1、Vision 点选界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
2、智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站scraper 会自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
6、通代{过}{filter}服务器提取
要提取匿名性并防止网络服务器被网络软件阻止,您必须{over}{filter}选项通过代理服务器访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、Extract 分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、Extract 使用正则表达式
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
从网页抓取数据(计算机学院大数据专业大三的错误出现,有纰漏之处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-11 00:10
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容
前言
网络爬虫的一般流程
一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:
二、常用的获取网页数据的方式2.1 URLlib
这里我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:超时发布链接
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
context:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 高级功能
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、Opener
开场导演:
5、cookie
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、Requests 库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、Requests 库安装
在终端运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
在上图中,我们可以看到方法名清楚地表达了发起的请求。 Get 是 GET,post 是 POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,响应的内容会自动读出并保存在文本变量中您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了上面的信息,response还提供了很多其他的信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用法类似于 urllib2。此外,请求的文档是完整的。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。如:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,在调用 url_set_cookies 设置 cookie 前后通过 GET 请求获取的 cookie 都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能有些人会感到惊讶,因为在之前的文章文章中我们使用了urllib2来发起同样的请求,但是结果还是空的。这确实有点奇怪,因为urllib2默认会忽略所有请求的cookies,即使是重定向的请求,请求会在一个请求中保存cookies(url_set_cookies请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨一下。
请求库的功能:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得urllib2上的很多练习都没有用,因为requests很简单易学!当然没有白费,urllib2是一个非常基础的网络库。许多其他网络库,包括请求,都是基于 urllib2 开发的。前面的练习有助于我们更好地理解网络,理解Python对网络的处理,这对我们以后开发可靠高效的爬虫大有裨益。
注意:
内容
响应以 unicode 编码。为了方便阅读,我们需要将其转换为中文。直接打印是不行的,因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符字符串编码成一个UTF-8字符串,最后转成dict方便输出。
三、Browser 简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图所示:
在这个页面调用Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看一个元素的源代码,点击左上角的元素定位器,可以选择网页中不同的元素,HTML源代码区会自动显示源代码指定元素的,通常CSS显示区域也会显示应用于该元素的样式。 Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,看到如下界面:
Chrome Network的交互区展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。 Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 K-V 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,状态行收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
需要 401 身份验证:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,而使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略。响应状态码代表服务器的处理结果,是我们调整爬虫爬取状态(如频率、ip)的重要参考。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候就得减慢爬取频率,或者重启Session,甚至改IP。
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。 查看全部
从网页抓取数据(计算机学院大数据专业大三的错误出现,有纰漏之处)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容

前言
网络爬虫的一般流程

一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:

二、常用的获取网页数据的方式2.1 URLlib
这里我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com";)
html = response.read().decode("utf-8")
print(html)

2.2、urllib.request
官方文档(有兴趣的可以查看):

1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:超时发布链接
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
context:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:

# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 高级功能
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、Opener
开场导演:
5、cookie

示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com";)
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、Requests 库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、Requests 库安装
在终端运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])

在上图中,我们可以看到方法名清楚地表达了发起的请求。 Get 是 GET,post 是 POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,响应的内容会自动读出并保存在文本变量中您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然

除了上面的信息,response还提供了很多其他的信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)

请求的大多数用法类似于 urllib2。此外,请求的文档是完整的。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。如:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

可以看到,在调用 url_set_cookies 设置 cookie 前后通过 GET 请求获取的 cookie 都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能有些人会感到惊讶,因为在之前的文章文章中我们使用了urllib2来发起同样的请求,但是结果还是空的。这确实有点奇怪,因为urllib2默认会忽略所有请求的cookies,即使是重定向的请求,请求会在一个请求中保存cookies(url_set_cookies请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨一下。
请求库的功能:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得urllib2上的很多练习都没有用,因为requests很简单易学!当然没有白费,urllib2是一个非常基础的网络库。许多其他网络库,包括请求,都是基于 urllib2 开发的。前面的练习有助于我们更好地理解网络,理解Python对网络的处理,这对我们以后开发可靠高效的爬虫大有裨益。
注意:
内容
响应以 unicode 编码。为了方便阅读,我们需要将其转换为中文。直接打印是不行的,因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符字符串编码成一个UTF-8字符串,最后转成dict方便输出。
三、Browser 简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图所示:

在这个页面调用Chrome Inspect,我们可以看到类似如下的界面:

通常我们最常用的功能是查看一个元素的源代码,点击左上角的元素定位器,可以选择网页中不同的元素,HTML源代码区会自动显示源代码指定元素的,通常CSS显示区域也会显示应用于该元素的样式。 Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,看到如下界面:

Chrome Network的交互区展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。 Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,看到如下界面:

在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 K-V 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,状态行收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
需要 401 身份验证:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,而使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略。响应状态码代表服务器的处理结果,是我们调整爬虫爬取状态(如频率、ip)的重要参考。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候就得减慢爬取频率,或者重启Session,甚至改IP。

美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。
从网页抓取数据(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-11 00:09
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果您的网址复杂或冗长。
优采云采集器免费网络爬虫软件_网络大数据爬取工具。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用的开源组件包括:DOM4J:解析XMLjericho-。
优采云·云采集服务平台网站内容提取工具的使用 网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据为我们的工作带来真正的价值?。
网页内容提取器可以帮助我们快速提取输入的 URL 链接中的所有图片、链接和网页文本内容。
阿里巴巴云为您提供免费网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 . 查看全部
从网页抓取数据(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果您的网址复杂或冗长。
优采云采集器免费网络爬虫软件_网络大数据爬取工具。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用的开源组件包括:DOM4J:解析XMLjericho-。
优采云·云采集服务平台网站内容提取工具的使用 网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据为我们的工作带来真正的价值?。
网页内容提取器可以帮助我们快速提取输入的 URL 链接中的所有图片、链接和网页文本内容。

阿里巴巴云为您提供免费网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。

获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
从网页抓取数据( PowerQuery的数据清洗功能(示例中的列)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-12 15:01
PowerQuery的数据清洗功能(示例中的列)(组图))
1、点击“获取数据”>“网页”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“导航器”对话框中,选择左下角的“使用示例添加表格”。
3、接下来我们要做的就是提供一个我们需要在表中提取的数据的例子。
以抓取书名为例,可以看到,当我们提供两个书名时,Power BI 会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 捕获的数据就越准确
4、 使用相同的方法分别捕获我们需要的其他字段。
5、单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
将“示例中的列”添加到 2Power Query
以上捕获的数据除了[作者]和[评级]列是正确的,其他列收录无用信息。 Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
“示例中的列”可以根据用户提供的示例提取信息。
1、选择[作者]栏,点击“示例中的栏”左下角的小三角符号“添加栏”,在弹出的下拉菜单中选择“来自选择”选项。
2、在[Column 1]中提供了一个例子,Power BI会智能识别我们需要的数据
这里是复制原创列数据的快速输入示例
点击右上角的“确定”后,作者姓名将被提取到一个新列中。
-结束- 查看全部
从网页抓取数据(
PowerQuery的数据清洗功能(示例中的列)(组图))
1、点击“获取数据”>“网页”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“导航器”对话框中,选择左下角的“使用示例添加表格”。
3、接下来我们要做的就是提供一个我们需要在表中提取的数据的例子。
以抓取书名为例,可以看到,当我们提供两个书名时,Power BI 会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 捕获的数据就越准确
4、 使用相同的方法分别捕获我们需要的其他字段。
5、单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
将“示例中的列”添加到 2Power Query
以上捕获的数据除了[作者]和[评级]列是正确的,其他列收录无用信息。 Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
“示例中的列”可以根据用户提供的示例提取信息。
1、选择[作者]栏,点击“示例中的栏”左下角的小三角符号“添加栏”,在弹出的下拉菜单中选择“来自选择”选项。
2、在[Column 1]中提供了一个例子,Power BI会智能识别我们需要的数据
这里是复制原创列数据的快速输入示例
点击右上角的“确定”后,作者姓名将被提取到一个新列中。
-结束-
从网页抓取数据(网络爬虫的构架3、以抓取一个网页的内容为目的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-12 14:12
(一)Data Capture 概览如何将非结构化数据转化为结构化数据?(二)Grab 逻辑——ETL
什么是 ETL?
(三)准备前的数据采集1."Web Crawler"架构 Web Crawler架构
2、如何理解“网络爬虫”架构来研究量化投资策略,第一步是获取我们需要的数据。在实践中,比较实用的数据来源是新浪财经的数据。下面我们以新浪财经以财经为例,为大家梳理一下网络爬虫的结构3、以抓取网页内容为目的,如何观察网页我们有新浪财经股票博客信息,如何应该把这个信息,包括标题和时间都抢过来吗? (1)使用开发者工具观察
(2)观察Requests的组成
通常来说文章和news会放在Doc下,我们接下来要爬取的链接就隐藏在106个链接之一中;
(3)观察HTTP请求和返回内容。我们可以在Document下找到文章和新闻内容。为什么?因为只要是有上述类型内容的网页,他们都需要被搜索引擎搜索到。对于搜索引擎来说,Document的内容是最好的,所以大多数情况下,只要找到Document下的第一个链接,就可以准备爬取文章和新闻内容;只有很小的一部分部分会看到XHR等部分;下面,jacky(数据分析部落公众号:shujudata)分享实际操作;
确定网页的访问方式
上面,我们观察网页后,会发现response下的数据是放在html页面中的。 HTML 收录网页的标签。这些标签描述了网页的行为。我们得到的响应是html,里面收录它的数据和它的标签,这样的数据不是结构化数据,我们还需要进一步处理,那么如何将非结构化数据处理成结构化数据呢?请参考jacky的第二次分享,谢谢大家! 查看全部
从网页抓取数据(网络爬虫的构架3、以抓取一个网页的内容为目的)
(一)Data Capture 概览如何将非结构化数据转化为结构化数据?(二)Grab 逻辑——ETL
什么是 ETL?
(三)准备前的数据采集1."Web Crawler"架构 Web Crawler架构
2、如何理解“网络爬虫”架构来研究量化投资策略,第一步是获取我们需要的数据。在实践中,比较实用的数据来源是新浪财经的数据。下面我们以新浪财经以财经为例,为大家梳理一下网络爬虫的结构3、以抓取网页内容为目的,如何观察网页我们有新浪财经股票博客信息,如何应该把这个信息,包括标题和时间都抢过来吗? (1)使用开发者工具观察
(2)观察Requests的组成
通常来说文章和news会放在Doc下,我们接下来要爬取的链接就隐藏在106个链接之一中;
(3)观察HTTP请求和返回内容。我们可以在Document下找到文章和新闻内容。为什么?因为只要是有上述类型内容的网页,他们都需要被搜索引擎搜索到。对于搜索引擎来说,Document的内容是最好的,所以大多数情况下,只要找到Document下的第一个链接,就可以准备爬取文章和新闻内容;只有很小的一部分部分会看到XHR等部分;下面,jacky(数据分析部落公众号:shujudata)分享实际操作;
确定网页的访问方式
上面,我们观察网页后,会发现response下的数据是放在html页面中的。 HTML 收录网页的标签。这些标签描述了网页的行为。我们得到的响应是html,里面收录它的数据和它的标签,这样的数据不是结构化数据,我们还需要进一步处理,那么如何将非结构化数据处理成结构化数据呢?请参考jacky的第二次分享,谢谢大家!
从网页抓取数据(1.什么是抓取和收录,从基本概念及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-12 14:11
很多SEO从业者有一个很苦恼的问题:网站建好了,为什么搜索引擎没有收录我的网站?页面收录是网站争夺排名的最基本条件。没有收录,就没有展示,也就无法争夺排名获取SEO流量。
本文将围绕抓包和收录两点,从基本概念、常见问题和解决方案三个维度展开讨论,希望对大家有用。
1.什么是爬取,收录,爬取配额?
先简单介绍一下爬取,收录,三个词条爬取配额。
①爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
②收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
③抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
2.如何查看网站的收录情况?
了解基本概念后,我们如何判断网站或者页面是否为收录?
①通过站点命令。谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,可以在宏观层面查看一个网站已经收录的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录网站的网页数量约为296个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的268 页;
③如果要查看特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果有返回结果,页面已经是收录,如下图:
3.为什么搜索引擎不是收录网站页面?
网站页面不是收录的原因有很多。以下是一些常见的原因供您参考:
①元标签“Noindex”使用不当
如果代码被添加到页面的Meta标签中,它告诉搜索引擎不要索引该页面;
②Robots文件中Disallow的错误使用
如果User-agent: * Disallow: /ABC/ 代码被添加到网站 的Robots 文件中,它会告诉搜索引擎不要索引ABC 目录中的所有页面。 Robots 文件中命令的优先级高于页面 Meta 标签中的命令。谷歌会严格遵循Robots文件中的命令,但是页面Meta中的命令有时会被忽略。例如,即使某个页面在Meta代码中明确添加了Index指令,但在Robots文件中为Disallow,搜索引擎也不会收录这个页面。
③网站缺少站点地图文件
站点地图文件是搜索引擎抓取网站页面的有效方式之一。如果网站缺少站点地图文件,或者站点地图不收录页面URL,这可能会导致网站或页面不是收录。 ④错误使用301和302重定向
有些网站由于cms后台设置不正确导致多页跳转,比如A页302跳转到B页,B页301跳转到C页。这种多次跳转或者混合使用跳转命令不利于抓取页面。很多网站处理www格式的URL跳转到没有www的URL,或者http跳转到https等,容易出现这种情况。类问题。
⑤错误使用Canonical标签
Canonical 标签主要用于两个页面之间的内容相同,但 URL 不同的情况。例如,很多有SEM投放需求的站长需要在Landing Page中添加多个UTM跟踪参数,以便跟踪广告效果; Canonical tag 这批网址可以标准化,让搜索引擎了解这些不同网址之间的关系,避免内容重复和权重分散。但是如果A和B两个页面之间的内容不同,但是在A页面添加了指向B页面的Canonical标签,这会导致搜索引擎不能很好地理解页面之间的关系,所以是不是收录目标页面。
⑥网站或者页面很新
对于新上线的网站或页面,搜索引擎抓取页面需要几天时间。所以如果新上线的网站不是收录,可以耐心等几天再查。 ⑦网址太复杂或错误
部分网站网址收录很多动态参数,语义不清晰,或者网址使用了中文等非英文内容,不利于搜索引擎和收录页面的理解。如果你对网址优化一窍不通,可以参考这篇博文:分享12个网址优化技巧,助你提升网站SEO友好度
⑧页面层次太深
网站 的扁平化有利于爬虫爬取页面。页面越深,爬虫接触页面的几率越低,被搜索引擎收录接触的几率越低。简单的理解就是,当书店里的一本书放在最底层的一角时,买家看到的机会就大大减少了。
⑨网站或页面内容价值低
我曾经遇到一个客户,因为技术人员把包括视频和图片在内的所有多媒体文件放在一个目录中,该目录被Robots文件中的Disallow删除,导致搜索引擎爬虫看到的页面内容和真实用户看到的不一样。站长可能认为这个页面内容丰富,但在爬虫眼中,它是一个空白页面。如下图,左边是爬虫看到的空白页面,右边是用户看到的实际页面。这样低质量的内容页面搜索引擎也不愿意收录。
⑩ 重复页面内容
比较低的网站都是由采集other网站的数据生成的。这种内容高度重复的页面,也不愿意被搜索引擎收录。
⑪网站被惩罚
如果网站因黑帽等非法手段被谷歌人工处罚,该类网站和页面将不会是收录。
4.网站收录问题如何解决?
①正确设置网站的Robots文件和htaccess文件,保证搜索引擎爬虫能够正确读取页面内容
如果您是 Chrome 浏览器用户,您可以安装 User Agent Switcher 插件来模拟 Googlebot 对页面的访问,并检查页面内容是否正确显示给爬虫。
如果网站已经验证了Google Search Console,您也可以使用旧版Google Search Console中的Google爬虫来预览爬取效果;
②确保页面上Meta Robots标签配置正确,使用noindex指令没有错误
默认的 Meta Robots 处于索引状态,因此页面的 Robots 标签可以留空。 Chrome浏览器用户可以使用插件SEO Meta in 1 点击查看。只需打开页面,点击插件即可查看页面相关的Meta信息。
③制作站点地图文件
同时在 Google Search Console 后台或 Bing 站长后台提交 Sitemap 文件,定期更新 Sitemap 文件并通知搜索引擎。
如果有一些关键页面希望谷歌尽快收录,可以通过旧版谷歌搜索控制台的爬虫提交,点击索引。一般不会被惩罚的网站或页面,但一天之内就可以被收录。不过这种方式每天最多只能提交10页,而且谷歌已经宣布在新版谷歌搜索控制台中取消这个工具,取而代之的是“网址检查”工具。
④添加页面的链接入口
链接入口包括站内链接和站外链接。您可以添加站内链接,例如网站 导航、页面底部的页脚、面包屑导航、网站 侧边栏、正文内容和相关推荐。站外链接的方式和渠道有很多:比如维基百科(我们有专业的维基百科词条创建服务,请联系我们)、Guestpost Outreach、品牌链接回收、资源链接等,我想知道的更详细更丰富外链构建方法参考这个文章:8种获取优质外链的方法
⑤优化页面的URL格式和层次
尽量简化页面URL的长度,单词之间用“-”代替空格或%等特殊字符,降低页面层次;扁平的网站结构更有利于爬虫抓取网站。
⑥301/302重定向和Canonical标签的正确使用
对于离线页面或URL更改,建议使用301永久重定向,将旧页面指向新的目标页面。如果确定页面永久下线,您也可以如实返回404识别码。对于内容相同的页面,合理使用Canonical标签。有些电商网站在产品聚合页面下有多个tab,比如第1页、第2页、第3页……,为了聚合第1页的权重,误认为Canonical点了第2页、第3页和其他页面到第1页,容易导致后面的页面没有被索引。
⑦使用上一个和下一个标签
对于大型电商网站,如果某个分类下有多个tab,可以在每个tab中添加rel=”prev”(上一页)和rel=”next”(在声明下) 一个页面),以便搜索引擎了解该页面系列之间的关系,并给予列表页第一页更多的权重和排名。
一个。在第1页/第1页的部分,添加: 查看全部
从网页抓取数据(1.什么是抓取和收录,从基本概念及解决方法)
很多SEO从业者有一个很苦恼的问题:网站建好了,为什么搜索引擎没有收录我的网站?页面收录是网站争夺排名的最基本条件。没有收录,就没有展示,也就无法争夺排名获取SEO流量。
本文将围绕抓包和收录两点,从基本概念、常见问题和解决方案三个维度展开讨论,希望对大家有用。
1.什么是爬取,收录,爬取配额?
先简单介绍一下爬取,收录,三个词条爬取配额。
①爬行:
这是搜索引擎爬虫爬取网站的过程。谷歌官方的解释是——“爬行”是指寻找新的或更新的网页并将其添加到谷歌的过程; (点此查看谷歌官网文档)
②收录(索引):
是搜索引擎在其数据库中存储页面的结果,也称为索引。谷歌官方的解释是:谷歌的爬虫(“Googlebot”)已经访问了该页面,分析了其内容和含义,并将其存储在谷歌索引中。索引的网页可以显示在谷歌搜索结果中; (点此查看谷歌官网文档)
③抓取预算:
是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间上限。一般小的网站(几百或几千页)不用担心,搜索引擎分配的爬取配额不够;大网站(百万或千万页)会更多地考虑这个问题。如果搜索引擎每天爬取几万个页面,整个网站页面爬取可能需要几个月甚至一年的时间。通常,这些数据可以从 Google Search Console 的后端学习。如下图所示,红框内的平均值为网站分配的爬取配额。
通过一个例子让大家更好的理解爬取、收录和爬取配额:
搜索引擎比作一个巨大的图书馆,网站比作书店,书店里的书比作网站页面,蜘蛛爬虫比作图书馆买家。
为了丰富图书馆的藏书量,购书者会定期到书店查看是否有新书存货。翻书的过程可以理解为抓取;
当买家认为这本书有价值时,他会购买并带回图书馆采集。这本书合集就是我们所说的收录;
每个买家的购书预算有限,他会优先购买价值高的书籍。这个预算就是我们理解的抢配额。
2.如何查看网站的收录情况?
了解基本概念后,我们如何判断网站或者页面是否为收录?
①通过站点命令。谷歌、百度、必应等主流搜索引擎均支持站点命令。通过站点命令,可以在宏观层面查看一个网站已经收录的页面数量。这个值不准确,有一定的波动性,但有一定的参考价值。如下图所示,Google收录网站的网页数量约为296个。
②如果网站已经验证了Google Search Console,这样就可以得到网站被Google收录的精确值,如下图红框所示,Google收录了网站的268 页;
③如果要查看特定页面是否为收录,可以使用info命令。谷歌支持 info 命令,但百度和必应不支持。在谷歌中输入信息:URL。如果有返回结果,页面已经是收录,如下图:
3.为什么搜索引擎不是收录网站页面?
网站页面不是收录的原因有很多。以下是一些常见的原因供您参考:
①元标签“Noindex”使用不当
如果代码被添加到页面的Meta标签中,它告诉搜索引擎不要索引该页面;
②Robots文件中Disallow的错误使用
如果User-agent: * Disallow: /ABC/ 代码被添加到网站 的Robots 文件中,它会告诉搜索引擎不要索引ABC 目录中的所有页面。 Robots 文件中命令的优先级高于页面 Meta 标签中的命令。谷歌会严格遵循Robots文件中的命令,但是页面Meta中的命令有时会被忽略。例如,即使某个页面在Meta代码中明确添加了Index指令,但在Robots文件中为Disallow,搜索引擎也不会收录这个页面。
③网站缺少站点地图文件
站点地图文件是搜索引擎抓取网站页面的有效方式之一。如果网站缺少站点地图文件,或者站点地图不收录页面URL,这可能会导致网站或页面不是收录。 ④错误使用301和302重定向
有些网站由于cms后台设置不正确导致多页跳转,比如A页302跳转到B页,B页301跳转到C页。这种多次跳转或者混合使用跳转命令不利于抓取页面。很多网站处理www格式的URL跳转到没有www的URL,或者http跳转到https等,容易出现这种情况。类问题。
⑤错误使用Canonical标签
Canonical 标签主要用于两个页面之间的内容相同,但 URL 不同的情况。例如,很多有SEM投放需求的站长需要在Landing Page中添加多个UTM跟踪参数,以便跟踪广告效果; Canonical tag 这批网址可以标准化,让搜索引擎了解这些不同网址之间的关系,避免内容重复和权重分散。但是如果A和B两个页面之间的内容不同,但是在A页面添加了指向B页面的Canonical标签,这会导致搜索引擎不能很好地理解页面之间的关系,所以是不是收录目标页面。
⑥网站或者页面很新
对于新上线的网站或页面,搜索引擎抓取页面需要几天时间。所以如果新上线的网站不是收录,可以耐心等几天再查。 ⑦网址太复杂或错误
部分网站网址收录很多动态参数,语义不清晰,或者网址使用了中文等非英文内容,不利于搜索引擎和收录页面的理解。如果你对网址优化一窍不通,可以参考这篇博文:分享12个网址优化技巧,助你提升网站SEO友好度
⑧页面层次太深
网站 的扁平化有利于爬虫爬取页面。页面越深,爬虫接触页面的几率越低,被搜索引擎收录接触的几率越低。简单的理解就是,当书店里的一本书放在最底层的一角时,买家看到的机会就大大减少了。
⑨网站或页面内容价值低
我曾经遇到一个客户,因为技术人员把包括视频和图片在内的所有多媒体文件放在一个目录中,该目录被Robots文件中的Disallow删除,导致搜索引擎爬虫看到的页面内容和真实用户看到的不一样。站长可能认为这个页面内容丰富,但在爬虫眼中,它是一个空白页面。如下图,左边是爬虫看到的空白页面,右边是用户看到的实际页面。这样低质量的内容页面搜索引擎也不愿意收录。
⑩ 重复页面内容
比较低的网站都是由采集other网站的数据生成的。这种内容高度重复的页面,也不愿意被搜索引擎收录。
⑪网站被惩罚
如果网站因黑帽等非法手段被谷歌人工处罚,该类网站和页面将不会是收录。
4.网站收录问题如何解决?
①正确设置网站的Robots文件和htaccess文件,保证搜索引擎爬虫能够正确读取页面内容
如果您是 Chrome 浏览器用户,您可以安装 User Agent Switcher 插件来模拟 Googlebot 对页面的访问,并检查页面内容是否正确显示给爬虫。
如果网站已经验证了Google Search Console,您也可以使用旧版Google Search Console中的Google爬虫来预览爬取效果;
②确保页面上Meta Robots标签配置正确,使用noindex指令没有错误
默认的 Meta Robots 处于索引状态,因此页面的 Robots 标签可以留空。 Chrome浏览器用户可以使用插件SEO Meta in 1 点击查看。只需打开页面,点击插件即可查看页面相关的Meta信息。
③制作站点地图文件
同时在 Google Search Console 后台或 Bing 站长后台提交 Sitemap 文件,定期更新 Sitemap 文件并通知搜索引擎。
如果有一些关键页面希望谷歌尽快收录,可以通过旧版谷歌搜索控制台的爬虫提交,点击索引。一般不会被惩罚的网站或页面,但一天之内就可以被收录。不过这种方式每天最多只能提交10页,而且谷歌已经宣布在新版谷歌搜索控制台中取消这个工具,取而代之的是“网址检查”工具。
④添加页面的链接入口
链接入口包括站内链接和站外链接。您可以添加站内链接,例如网站 导航、页面底部的页脚、面包屑导航、网站 侧边栏、正文内容和相关推荐。站外链接的方式和渠道有很多:比如维基百科(我们有专业的维基百科词条创建服务,请联系我们)、Guestpost Outreach、品牌链接回收、资源链接等,我想知道的更详细更丰富外链构建方法参考这个文章:8种获取优质外链的方法
⑤优化页面的URL格式和层次
尽量简化页面URL的长度,单词之间用“-”代替空格或%等特殊字符,降低页面层次;扁平的网站结构更有利于爬虫抓取网站。
⑥301/302重定向和Canonical标签的正确使用
对于离线页面或URL更改,建议使用301永久重定向,将旧页面指向新的目标页面。如果确定页面永久下线,您也可以如实返回404识别码。对于内容相同的页面,合理使用Canonical标签。有些电商网站在产品聚合页面下有多个tab,比如第1页、第2页、第3页……,为了聚合第1页的权重,误认为Canonical点了第2页、第3页和其他页面到第1页,容易导致后面的页面没有被索引。
⑦使用上一个和下一个标签
对于大型电商网站,如果某个分类下有多个tab,可以在每个tab中添加rel=”prev”(上一页)和rel=”next”(在声明下) 一个页面),以便搜索引擎了解该页面系列之间的关系,并给予列表页第一页更多的权重和排名。
一个。在第1页/第1页的部分,添加:
从网页抓取数据(如何用Python搞点Soup库获取2018年100强企业信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-12 14:10
写在顶部的这个简单的 Python 教程中,我们总共采取了以下步骤来抓取网页内容:
作为数据科学家,大多数人的首要任务是进行网络爬虫。那个时候,我对用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。如今,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取网站——例如,从Fast Track获取2018年100强企业的信息。使用脚本实现信息获取过程的自动化,不仅节省了人工整理的时间,还可以将企业所有数据整理成一个结构化的文件,以便进一步分析查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上(/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.js)。 py),欢迎你来取。
准备开始
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要什么库?”
有几个不同的库可用于网络抓取,包括:
● 美汤
● 请求
● Scrapy
● 硒
今天我们计划使用 Beautiful Soup 库。您只需要使用pip(Python包管理工具)即可轻松安装到您的电脑上:
检查网页
为了确定要抓取网页的哪些元素,您需要先检查网页的结构。
以 Tech Track Top 100 Companies 页面 (fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
在要查看的网页元素上右击,选择“check”查看具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表格的主体在这个标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种REST客户端(例如Insomnia)来发起请求并输出返回值。
刷新页面后,Network标签的内容更新
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要导入代码中需要用到的各个模块。上面我们已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
接下来,我们需要准备需要抓取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的URL并将其赋值给变量即可:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行——100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
如您所见,该表共有 8 列,分别为 Rank、Company、Location、Year End、Annual Sales Rise、Latest Sales(今年的销售额)、Staff(员工人数)和 Comments(评论)。这些就是我们需要的数据。
这样的结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并将其存储在在变量中,方便以后写csv或者json文件。
遍历所有元素并将它们存储在变量中
在Python中,如果需要处理大量数据,需要写入文件,list对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后面的数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多一些,例如网页和说明。请仔细看上面打印的汤变量数据——在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
如何循环读取数据:
因为第一行数据是html表格的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去掉多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还有一些需要清除的字符,比如备注等。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个单元格中还有一个元素,里面只收录了公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样就只剩下描述了在变量中。
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们最不想保存的是网站 公司的链接。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表格。在大多数情况下,表单中有指向 company网站 的链接。
在公司详细信息页面上查看表格中的链接
为了抓取每个表中的 URL 并将其保存在一个变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以找到表格最后一行的元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中(还在循环体中)之后,我们就可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要简单的几行代码就可以将列表对象保存为文件。
最后,让我们运行这段python代码。如果一切顺利,您会在目录中找到一个收录 100 行数据的 csv 文件。你可以用python轻松阅读和处理它。
总结
如果有什么不明白的,请在下方留言,我会尽力解答!
祝您的爬虫之旅有一个好的开始!
重组-欧剃
来源-/data-science-skills-web-scraping-using-python-d1a85ef607ed(作者:Kerry Parker)
知乎机构号:来自硅谷的终身学习平台-宇田学习城(),专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从从头掌握数据分析、机器学习、深度学习、人工智能、无人驾驶等前沿技术,激发未来无限可能!
知乎Column:Uda学习笔记,欢迎所有喜欢Uda的学习者,在这里分享所学,交流技术,结识朋友。欢迎您积极贡献。 查看全部
从网页抓取数据(如何用Python搞点Soup库获取2018年100强企业信息)
写在顶部的这个简单的 Python 教程中,我们总共采取了以下步骤来抓取网页内容:
作为数据科学家,大多数人的首要任务是进行网络爬虫。那个时候,我对用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。如今,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取网站——例如,从Fast Track获取2018年100强企业的信息。使用脚本实现信息获取过程的自动化,不仅节省了人工整理的时间,还可以将企业所有数据整理成一个结构化的文件,以便进一步分析查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上(/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.js)。 py),欢迎你来取。
准备开始
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要什么库?”
有几个不同的库可用于网络抓取,包括:
● 美汤
● 请求
● Scrapy
● 硒
今天我们计划使用 Beautiful Soup 库。您只需要使用pip(Python包管理工具)即可轻松安装到您的电脑上:
检查网页
为了确定要抓取网页的哪些元素,您需要先检查网页的结构。
以 Tech Track Top 100 Companies 页面 (fasttrack.co.uk/league-tables/tech-track-100/league-table/) 为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
在要查看的网页元素上右击,选择“check”查看具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面上,可以看到一个收录全部100条数据的表格,右击它,选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表格的主体在这个标签中:
每一行都在一个标签中,也就是我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击 Network 类别(如果需要,您只能查看 XHR 标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种REST客户端(例如Insomnia)来发起请求并输出返回值。
刷新页面后,Network标签的内容更新
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要导入代码中需要用到的各个模块。上面我们已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
接下来,我们需要准备需要抓取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的URL并将其赋值给变量即可:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行——100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
如您所见,该表共有 8 列,分别为 Rank、Company、Location、Year End、Annual Sales Rise、Latest Sales(今年的销售额)、Staff(员工人数)和 Comments(评论)。这些就是我们需要的数据。
这样的结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并将其存储在在变量中,方便以后写csv或者json文件。
遍历所有元素并将它们存储在变量中
在Python中,如果需要处理大量数据,需要写入文件,list对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后面的数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多一些,例如网页和说明。请仔细看上面打印的汤变量数据——在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
如何循环读取数据:
因为第一行数据是html表格的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去掉多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还有一些需要清除的字符,比如备注等。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个单元格中还有一个元素,里面只收录了公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样就只剩下描述了在变量中。
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们最不想保存的是网站 公司的链接。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表格。在大多数情况下,表单中有指向 company网站 的链接。
在公司详细信息页面上查看表格中的链接
为了抓取每个表中的 URL 并将其保存在一个变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以找到表格最后一行的元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中(还在循环体中)之后,我们就可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要简单的几行代码就可以将列表对象保存为文件。
最后,让我们运行这段python代码。如果一切顺利,您会在目录中找到一个收录 100 行数据的 csv 文件。你可以用python轻松阅读和处理它。
总结
如果有什么不明白的,请在下方留言,我会尽力解答!
祝您的爬虫之旅有一个好的开始!
重组-欧剃
来源-/data-science-skills-web-scraping-using-python-d1a85ef607ed(作者:Kerry Parker)
知乎机构号:来自硅谷的终身学习平台-宇田学习城(),专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从从头掌握数据分析、机器学习、深度学习、人工智能、无人驾驶等前沿技术,激发未来无限可能!
知乎Column:Uda学习笔记,欢迎所有喜欢Uda的学习者,在这里分享所学,交流技术,结识朋友。欢迎您积极贡献。
从网页抓取数据(“劈柴”掌权这几年,谷歌怎么就成了另一个百度?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-11 20:06
这几年,“词柴”掌权,谷歌是如何成为另一个百度的?
分裂,可能没有一个。在 Jeff Dean 的开发和领导下,Google 将分布式计算系统应用到公司的广告、网络爬取、索引等系统中,并很早就成立了专门从事机器学习/深度学习的研究部门。迪恩本人也是谷歌的老手,
硅星2021-04-17
普利策奖获奖记者使用哪些工具?深度报道的辅助“神器”
ython 的一个免费开源的数据处理模块,集成了数据库、电子表格、可视化等程序的功能,可以集中完成网页爬取、数据分析、图表处理。图片来源:搜狐新闻 Excel:如果你不会编程,一些基础工具也能帮上忙
全媒体集团 ©2020-08-05
世界那么大,你不想去看吗?教你判断辞职时机是否合适
在线完成这项工作。 2、网店编程:毕竟电子商务和社交媒体的商业活动如火如荼。 3、网站测试和爬网:在网站发布之前,各家公司都希望自己的网站能按照既定的轨道走,所以公司不会招募网站testers
TECH2IPO / Transcend©2016-05-11
利与弊:互联网巨头打通幕后追踪平台
这就是方法。有的人在注册的时候还会登录失踪人员的地址和电话号码。目前,该信息公开显示在网页上。一个简单的网络爬虫程序就可以获取所有的电话号码。在谷歌寻人服务中,查看失踪人员或失踪人员的电话号码,有一步输入验证
杨淼。 2013-04-25
京东屏蔽易淘价格搜索和插件是否违法?
破坏社会和经济秩序的行为。笔者认为,虽然现行法律没有规定网站有权使用技术手段阻止搜索引擎的网络爬行,但搜索引擎也应该遵循公认的搜索引擎爬取数据的原则,否则涉嫌扰乱经济秩序和违反诚信。问题二、京东
尤云庭律师 2012-08-28 查看全部
从网页抓取数据(“劈柴”掌权这几年,谷歌怎么就成了另一个百度?)
这几年,“词柴”掌权,谷歌是如何成为另一个百度的?
分裂,可能没有一个。在 Jeff Dean 的开发和领导下,Google 将分布式计算系统应用到公司的广告、网络爬取、索引等系统中,并很早就成立了专门从事机器学习/深度学习的研究部门。迪恩本人也是谷歌的老手,
硅星2021-04-17
普利策奖获奖记者使用哪些工具?深度报道的辅助“神器”
ython 的一个免费开源的数据处理模块,集成了数据库、电子表格、可视化等程序的功能,可以集中完成网页爬取、数据分析、图表处理。图片来源:搜狐新闻 Excel:如果你不会编程,一些基础工具也能帮上忙
全媒体集团 ©2020-08-05
世界那么大,你不想去看吗?教你判断辞职时机是否合适
在线完成这项工作。 2、网店编程:毕竟电子商务和社交媒体的商业活动如火如荼。 3、网站测试和爬网:在网站发布之前,各家公司都希望自己的网站能按照既定的轨道走,所以公司不会招募网站testers
TECH2IPO / Transcend©2016-05-11
利与弊:互联网巨头打通幕后追踪平台
这就是方法。有的人在注册的时候还会登录失踪人员的地址和电话号码。目前,该信息公开显示在网页上。一个简单的网络爬虫程序就可以获取所有的电话号码。在谷歌寻人服务中,查看失踪人员或失踪人员的电话号码,有一步输入验证
杨淼。 2013-04-25
京东屏蔽易淘价格搜索和插件是否违法?
破坏社会和经济秩序的行为。笔者认为,虽然现行法律没有规定网站有权使用技术手段阻止搜索引擎的网络爬行,但搜索引擎也应该遵循公认的搜索引擎爬取数据的原则,否则涉嫌扰乱经济秩序和违反诚信。问题二、京东
尤云庭律师 2012-08-28
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-11 20:04
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,请仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码
import requests from bs4 import BeautifulSoup import csv import pandas as pd url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url }) keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products) ### 使用pandas写入数据 pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
从网页抓取数据(爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用 Python 爬虫,我们可以轻松地从互联网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍 Python爬虫的基本流程。如果您还处于初始爬虫阶段或不了解爬虫的具体工作流程,请仔细阅读本文!
第一步:尝试请求
首先进入b站首页,点击排行榜复制链接
https://www.bilibili.com/ranki ... 162.3
现在启动 Jupyter notebook 并运行以下代码
import requests url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' res = requests.get('url') print(res.status_code) #200
在上面的代码中,我们完成了以下三件事
可以看到返回值为200,说明服务器响应正常,可以继续。
第 2 步:解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象,现在可以使用.text查看其内容
可以看到返回了一个字符串,里面收录了我们需要的热门列表视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换为Web页面结构化数据,因此您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
在上面的代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用时需要开发一个解析器,这里使用的是html.parser。
然后您可以获得结构化元素之一及其属性。例如,您可以使用soup.title.text 来获取页面标题。你也可以使用soup.body、soup.p等来获取任何需要的元素。
第 3 步:提取内容
在上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
现在我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下面的说明找到
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码就可以这样写了
在上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取字段信息我们想要的是以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可自行进一步研究。
第 4 步:存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果不熟悉pandas,可以使用csv模块编写,需要注意设置encoding='utf-8-sig',否则会出现中文乱码问题
import csv keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)
如果你熟悉pandas,你可以轻松地将字典转换为DataFrame,只需一行代码。
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
总结
到此我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都遵循以上四个步骤。
虽然看起来很简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有各种形式的反爬、加密,以及后续的数据分析、提取甚至存储。许多需要进一步探索和学习。
本文之所以选择B站视频热榜,正是因为它足够简单。希望通过这个案例,大家能够了解爬虫的基本过程,最后附上完整的代码
import requests from bs4 import BeautifulSoup import csv import pandas as pd url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "视频排名":rank, "视频名": name, "播放量": play, "弹幕量": comment, "up主": up, "视频链接": url }) keys = all_products[0].keys() with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products) ### 使用pandas写入数据 pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
从网页抓取数据(智能识别模式自动识别网页数据抓取工具的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-11 00:15
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
从网页抓取数据(智能识别模式自动识别网页数据抓取工具的功能介绍)
WebHarvy 是一个网页数据捕获工具。该软件可以从网页中提取文字和图片,然后输入网址打开。默认情况下使用内部浏览器。它支持扩展分析。它可以自动获取类似链接的列表。软件界面直观。易于使用。
功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络抓取工具。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。 WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面抓取数据。
更新日志
修复页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
从网页抓取数据(webharvy中文版来源于国外的网页浏览数据采集工具!原版是英文版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-09-11 00:13
webharvy中文版是来自国外的网页浏览数据采集tool!原版是英文的,如果你用得不好,我推荐这个!内容破解本地化,基本无障碍使用!可以轻松帮你提取网页采集中的图片、文档等资源,整理信息非常方便!
SysNucleus WebHarvy 软件介绍
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。捕获数据就像从网页导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,您可以提取不同网站的产品目录或搜索结果等不同类别的数据,例如房地产、电子商务、学术研究、娱乐、技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。
Webharvy 功能介绍
1、Vision 点选界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
2、智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站scraper 会自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
6、通代{过}{filter}服务器提取
要提取匿名性并防止网络服务器被网络软件阻止,您必须{over}{filter}选项通过代理服务器访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、Extract 分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、Extract 使用正则表达式
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。 查看全部
从网页抓取数据(webharvy中文版来源于国外的网页浏览数据采集工具!原版是英文版)
webharvy中文版是来自国外的网页浏览数据采集tool!原版是英文的,如果你用得不好,我推荐这个!内容破解本地化,基本无障碍使用!可以轻松帮你提取网页采集中的图片、文档等资源,整理信息非常方便!
SysNucleus WebHarvy 软件介绍
WebHarvy 是一个方便的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。捕获数据就像从网页导航到收录数据的页面并单击数据捕获一样简单。 WebHarvy 将智能识别网页上出现的数据模式。使用WebHarvy,您可以提取不同网站的产品目录或搜索结果等不同类别的数据,例如房地产、电子商务、学术研究、娱乐、技术等。 从网页中提取的数据可以以不同的格式保存。通常网页显示数据,例如多个页面上的搜索结果。
Webharvy 功能介绍
1、Vision 点选界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
2、智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站scraper 会自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
6、通代{过}{filter}服务器提取
要提取匿名性并防止网络服务器被网络软件阻止,您必须{over}{filter}选项通过代理服务器访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、Extract 分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、Extract 使用正则表达式
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
从网页抓取数据(计算机学院大数据专业大三的错误出现,有纰漏之处)
网站优化 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-11 00:10
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容
前言
网络爬虫的一般流程
一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:
二、常用的获取网页数据的方式2.1 URLlib
这里我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:超时发布链接
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
context:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 高级功能
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、Opener
开场导演:
5、cookie
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、Requests 库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、Requests 库安装
在终端运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
在上图中,我们可以看到方法名清楚地表达了发起的请求。 Get 是 GET,post 是 POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,响应的内容会自动读出并保存在文本变量中您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了上面的信息,response还提供了很多其他的信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用法类似于 urllib2。此外,请求的文档是完整的。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。如:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,在调用 url_set_cookies 设置 cookie 前后通过 GET 请求获取的 cookie 都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能有些人会感到惊讶,因为在之前的文章文章中我们使用了urllib2来发起同样的请求,但是结果还是空的。这确实有点奇怪,因为urllib2默认会忽略所有请求的cookies,即使是重定向的请求,请求会在一个请求中保存cookies(url_set_cookies请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨一下。
请求库的功能:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得urllib2上的很多练习都没有用,因为requests很简单易学!当然没有白费,urllib2是一个非常基础的网络库。许多其他网络库,包括请求,都是基于 urllib2 开发的。前面的练习有助于我们更好地理解网络,理解Python对网络的处理,这对我们以后开发可靠高效的爬虫大有裨益。
注意:
内容
响应以 unicode 编码。为了方便阅读,我们需要将其转换为中文。直接打印是不行的,因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符字符串编码成一个UTF-8字符串,最后转成dict方便输出。
三、Browser 简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图所示:
在这个页面调用Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看一个元素的源代码,点击左上角的元素定位器,可以选择网页中不同的元素,HTML源代码区会自动显示源代码指定元素的,通常CSS显示区域也会显示应用于该元素的样式。 Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,看到如下界面:
Chrome Network的交互区展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。 Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 K-V 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,状态行收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
需要 401 身份验证:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,而使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略。响应状态码代表服务器的处理结果,是我们调整爬虫爬取状态(如频率、ip)的重要参考。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候就得减慢爬取频率,或者重启Session,甚至改IP。
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。 查看全部
从网页抓取数据(计算机学院大数据专业大三的错误出现,有纰漏之处)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容
前言
网络爬虫的一般流程
一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:
二、常用的获取网页数据的方式2.1 URLlib
这里我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com";)
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout:超时发布链接
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
context:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None)
代码详情:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 高级功能
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、Opener
开场导演:
5、cookie
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com";)
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、Requests 库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。建议爬虫使用 Requests 库。
官方文档链接:
1、Requests 库安装
在终端运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
在上图中,我们可以看到方法名清楚地表达了发起的请求。 Get 是 GET,post 是 POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,响应的内容会自动读出并保存在文本变量中您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了上面的信息,response还提供了很多其他的信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用法类似于 urllib2。此外,请求的文档是完整的。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。如:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,在调用 url_set_cookies 设置 cookie 前后通过 GET 请求获取的 cookie 都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能有些人会感到惊讶,因为在之前的文章文章中我们使用了urllib2来发起同样的请求,但是结果还是空的。这确实有点奇怪,因为urllib2默认会忽略所有请求的cookies,即使是重定向的请求,请求会在一个请求中保存cookies(url_set_cookies请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨一下。
请求库的功能:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {'http':'http://username:password@host:port','http://username:password@host:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得urllib2上的很多练习都没有用,因为requests很简单易学!当然没有白费,urllib2是一个非常基础的网络库。许多其他网络库,包括请求,都是基于 urllib2 开发的。前面的练习有助于我们更好地理解网络,理解Python对网络的处理,这对我们以后开发可靠高效的爬虫大有裨益。
注意:
内容
响应以 unicode 编码。为了方便阅读,我们需要将其转换为中文。直接打印是不行的,因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符字符串编码成一个UTF-8字符串,最后转成dict方便输出。
三、Browser 简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图所示:
在这个页面调用Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看一个元素的源代码,点击左上角的元素定位器,可以选择网页中不同的元素,HTML源代码区会自动显示源代码指定元素的,通常CSS显示区域也会显示应用于该元素的样式。 Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择Network,看到如下界面:
Chrome Network的交互区展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。 Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 K-V 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,状态行收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
需要 401 身份验证:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:找不到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,而使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后尝试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略。响应状态码代表服务器的处理结果,是我们调整爬虫爬取状态(如频率、ip)的重要参考。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候就得减慢爬取频率,或者重启Session,甚至改IP。
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。
从网页抓取数据(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-11 00:09
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果您的网址复杂或冗长。
优采云采集器免费网络爬虫软件_网络大数据爬取工具。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用的开源组件包括:DOM4J:解析XMLjericho-。
优采云·云采集服务平台网站内容提取工具的使用 网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据为我们的工作带来真正的价值?。
网页内容提取器可以帮助我们快速提取输入的 URL 链接中的所有图片、链接和网页文本内容。
阿里巴巴云为您提供免费网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 . 查看全部
从网页抓取数据(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
网址就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的网站内容,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的网址) 如果您的网址复杂或冗长。
优采云采集器免费网络爬虫软件_网络大数据爬取工具。
智能网页内容抓取的实现和示例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用的开源组件包括:DOM4J:解析XMLjericho-。
优采云·云采集服务平台网站内容提取工具的使用 网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据为我们的工作带来真正的价值?。
网页内容提取器可以帮助我们快速提取输入的 URL 链接中的所有图片、链接和网页文本内容。
阿里巴巴云为您提供免费网站内容采集工具相关的6415产品文档和FAQ,以及简单的网卡、支付宝api扫码支付接口文档、it远程运维监控、电脑网络组成计算机什么和什么以及网络协议。
爬取网页内容的一个例子来自于通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .

