
从网页抓取数据
从网页抓取数据(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-25 00:06
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
从网页抓取数据(如何用python来抓取页面中的JS动态加载的数据
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
从网页抓取数据(本文聚合到我们自己的系统里提供标准API的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-24 15:14
最近需要把某个网站的统计数据汇总到自己的系统中,但是网站没有提供标准的API,所以自己去抢了。本文总结了一般方法
分析服务地址
一般网站有两种方式,一种是后端渲染,直接在浏览器中呈现渲染完成的界面;另一个前端是静态页面,后台使用ajax来获取数据
后端渲染
这种网页爬取比较麻烦,因为结构不规范,需要从DOM中提取所需的数据。node平台推荐cheerio,API类似jquery,处理DOM更方便
前端渲染
这种情况比较好处理,因为接口返回的数据结构一般比较规则,关键是要找到接口的地址。建议使用chrome的开发控制台,切换到xhr选项卡。一般很容易找到需要的接口
处理认证
有些服务根本不需要认证,可以直接调用。麻烦的是,大多数接口都需要认证,通常是为了验证用户身份
模拟登录
最完美的方法是模拟登录,先分析登录服务地址,用Charles做代理,用浏览器登录几次,尝试模拟登录请求
但是,这是一种理想情况,通常很难模拟着陆。网站通常使用验证码甚至https来保护
登录后复制cookie
所以比较常用的方法是先正常登录,然后在chrome中查看正常http请求的header等信息。最重要的当然是 Cookie 字段。99% 的 网站 使用 cookie 来识别登录用户。所以我们可以复制普通请求的各种http headers,这样一般都可以调整
推荐使用CocoaRestClient,测试发送http请求非常方便
一般网站,可以通过复制cookies的方案来完成。不过还有一些比较麻烦的网站,会结合一些其他的安全方案,比如调用频率、验证IP等,这个只能详细分析,没有一定可行的办法。
分析网址
有时候url中会收录一些接口的请求参数,比如:
http://www.xxx.com/apps/xxx/re ... users
这个 url 收录 3 个请求参数。通过构造url,可以实现不同的请求。关键是观察,一般的URL比较容易找到规则
csrf防御机制
有的网站会在网页或者url里面放一个token来防止csrf,所以处理的方法就是找出这个token放到request中 查看全部
从网页抓取数据(本文聚合到我们自己的系统里提供标准API的方法)
最近需要把某个网站的统计数据汇总到自己的系统中,但是网站没有提供标准的API,所以自己去抢了。本文总结了一般方法
分析服务地址
一般网站有两种方式,一种是后端渲染,直接在浏览器中呈现渲染完成的界面;另一个前端是静态页面,后台使用ajax来获取数据
后端渲染
这种网页爬取比较麻烦,因为结构不规范,需要从DOM中提取所需的数据。node平台推荐cheerio,API类似jquery,处理DOM更方便
前端渲染
这种情况比较好处理,因为接口返回的数据结构一般比较规则,关键是要找到接口的地址。建议使用chrome的开发控制台,切换到xhr选项卡。一般很容易找到需要的接口
处理认证
有些服务根本不需要认证,可以直接调用。麻烦的是,大多数接口都需要认证,通常是为了验证用户身份
模拟登录
最完美的方法是模拟登录,先分析登录服务地址,用Charles做代理,用浏览器登录几次,尝试模拟登录请求
但是,这是一种理想情况,通常很难模拟着陆。网站通常使用验证码甚至https来保护
登录后复制cookie
所以比较常用的方法是先正常登录,然后在chrome中查看正常http请求的header等信息。最重要的当然是 Cookie 字段。99% 的 网站 使用 cookie 来识别登录用户。所以我们可以复制普通请求的各种http headers,这样一般都可以调整
推荐使用CocoaRestClient,测试发送http请求非常方便
一般网站,可以通过复制cookies的方案来完成。不过还有一些比较麻烦的网站,会结合一些其他的安全方案,比如调用频率、验证IP等,这个只能详细分析,没有一定可行的办法。
分析网址
有时候url中会收录一些接口的请求参数,比如:
http://www.xxx.com/apps/xxx/re ... users
这个 url 收录 3 个请求参数。通过构造url,可以实现不同的请求。关键是观察,一般的URL比较容易找到规则
csrf防御机制
有的网站会在网页或者url里面放一个token来防止csrf,所以处理的方法就是找出这个token放到request中
从网页抓取数据(关于网络爬虫最简单易用的扩展包是rvest的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-21 21:15
在 R 中,最简单易用的网络爬虫扩展包是 rvest。运行以下代码以从 CRAN 安装:
install.packages("rvest")
首先加载包并使用read_html()读取data/single-table.html,然后尝试从网页中提取表格:
图书馆(rvest)
##加载需要的包:xml2
single_table_page single_table_page
## {xml_document}
##
## [1]
## [2] \n
下面是一张表
\n 注意single_table_page是一个HTML解析文档,HTML节点的嵌套数据结构。
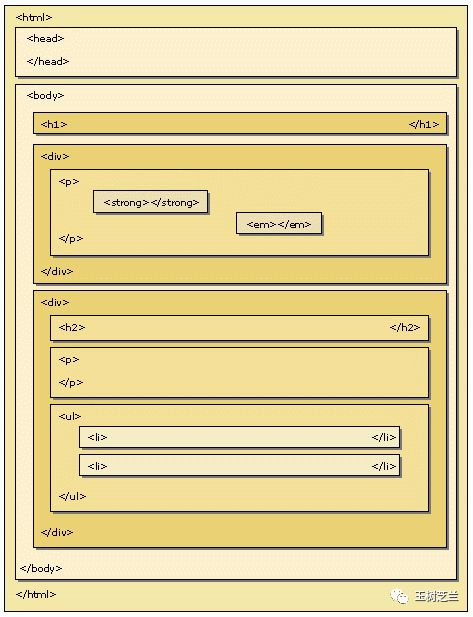
使用rvest函数抓取网页信息的典型流程是这样的。一、定位需要从中提取数据
数据的 HTML 节点。然后,使用 CSS 选择器或 XPath 表达式过滤 HTML 节点以选择
需要节点,删除不需要的节点。最后,为解析的页面使用适当的选择器,使用 html_
nodes() 提取节点的子集,使用 html_attrs() 提取属性,使用 html_text() 提取文本。
rvest 包还提供了一些简单的功能,可以直接从网页中提取数据并返回数据框。例如,
为了提取网页中的所有元素,我们直接调用html_table():
html_ _table(single_table_page)
## [[1]]
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
为了提取表格中的第一个元素,当我们使用CSS选择器表格时,调用
html_node() 选择第一个节点,然后在选择的节点上调用 html_table() 得到一个数据框:
html_ _table(html_ _node(single_table_page, "table"))
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
一个很自然的想法是使用管道操作,就像第十二章介绍的 dplyr 包中使用的 %>% 管道一样。
道路运营商。回顾一下,%>% 执行 x %>% f(...) 的基本方法是 f(x,...),因此,嵌入
可以反汇编设置调用以提高可读性。上面的代码可以用 %>% 重写为:
single_table_page %>%
html_ _node("表") %>%
html_ _table()
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
现在,读取 data/products.html 并使用 html_nodes() 来匹配节点:
products_page products_page %>%
html_ _nodes(".product-list li .name")
## {xml_nodeset (3)}
## [1] 产品-A
## [2] 产品-B
## [3] 产品-C
注意我们要选择的节点是product-list类的label下属于name类的section
观点。因此,使用 .product-list li .name 来选择这样的嵌套节点。如果你不熟悉这些符号
是的,请查看常用的 CSS 表。
之后,使用 html_text() 从所选节点中提取内容。此函数返回一个字符向量:
products_page %>%
html_ _nodes(".product-list li .name") %>%
html_ _text()
## [1]“产品-A”“产品-B”“产品-C”
同样,以下代码提取产品价格:
products_page %>%
html_ _nodes(".product-list li .price") %>%
html_ _text()
## [1] "$199.95" "$129.95" "$99.95"
在前面的代码中, html_nodes() 返回 HTML 节点的集合,
并且 html_text() 智能地从每个 HTML 节点中提取内部文本,然后返回一个字符向量。
但是,这些价格保留了它们的原创格式,即字符串形式,而不是数字。下面的代码提到
取相同的数据并将其转换为更常用的格式:
product_items%
html_ _nodes(".product-list li")
产品名称 = product_items %>%
html_ _nodes(".name") %>%
html_ _text(),
价格 = product_items %>%
html_ _nodes(".price") %>%
html_ _text() %>%
gsub("$", "", ., 固定 = TRUE) %>%
as.numeric(),
stringsAsFactors = FALSE
)
产品
##名称价格
## 1 产品-A 199.95
## 2 产品-B 129.95
## 3 产品-C 99.95
请注意,选择节点的中间结果可以存储在变量中以供重复使用。跟进
html_nodes() 或 html_node() 只匹配内部节点。
由于产品价格是数字,我们可以使用gsub()从原价中去掉$,然后转换结果
转化为数值向量。流水线操作中的 gsub() 调用有点特殊,因为之前的结果(用 . 表示)
它应该放在第三个参数位置,而不是第一个。
在本例中,.product-list li .name 可以简写为.name,.product-list 也是如此
li .price 可以替换为 .price。在实际应用中,CSS 类被广泛使用,因此,一个通用的
的选择器可能匹配太多不需要的元素。因此,最好选择更清晰的描述和更严格的条件
网格的选择器以匹配感兴趣的节点。 查看全部
从网页抓取数据(关于网络爬虫最简单易用的扩展包是rvest的方法)
在 R 中,最简单易用的网络爬虫扩展包是 rvest。运行以下代码以从 CRAN 安装:
install.packages("rvest")
首先加载包并使用read_html()读取data/single-table.html,然后尝试从网页中提取表格:
图书馆(rvest)
##加载需要的包:xml2
single_table_page single_table_page
## {xml_document}
##
## [1]
## [2] \n
下面是一张表
\n 注意single_table_page是一个HTML解析文档,HTML节点的嵌套数据结构。
使用rvest函数抓取网页信息的典型流程是这样的。一、定位需要从中提取数据
数据的 HTML 节点。然后,使用 CSS 选择器或 XPath 表达式过滤 HTML 节点以选择
需要节点,删除不需要的节点。最后,为解析的页面使用适当的选择器,使用 html_
nodes() 提取节点的子集,使用 html_attrs() 提取属性,使用 html_text() 提取文本。
rvest 包还提供了一些简单的功能,可以直接从网页中提取数据并返回数据框。例如,
为了提取网页中的所有元素,我们直接调用html_table():
html_ _table(single_table_page)
## [[1]]
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
为了提取表格中的第一个元素,当我们使用CSS选择器表格时,调用
html_node() 选择第一个节点,然后在选择的节点上调用 html_table() 得到一个数据框:
html_ _table(html_ _node(single_table_page, "table"))
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
一个很自然的想法是使用管道操作,就像第十二章介绍的 dplyr 包中使用的 %>% 管道一样。
道路运营商。回顾一下,%>% 执行 x %>% f(...) 的基本方法是 f(x,...),因此,嵌入
可以反汇编设置调用以提高可读性。上面的代码可以用 %>% 重写为:
single_table_page %>%
html_ _node("表") %>%
html_ _table()
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
现在,读取 data/products.html 并使用 html_nodes() 来匹配节点:
products_page products_page %>%
html_ _nodes(".product-list li .name")
## {xml_nodeset (3)}
## [1] 产品-A
## [2] 产品-B
## [3] 产品-C
注意我们要选择的节点是product-list类的label下属于name类的section
观点。因此,使用 .product-list li .name 来选择这样的嵌套节点。如果你不熟悉这些符号
是的,请查看常用的 CSS 表。
之后,使用 html_text() 从所选节点中提取内容。此函数返回一个字符向量:
products_page %>%
html_ _nodes(".product-list li .name") %>%
html_ _text()
## [1]“产品-A”“产品-B”“产品-C”
同样,以下代码提取产品价格:
products_page %>%
html_ _nodes(".product-list li .price") %>%
html_ _text()
## [1] "$199.95" "$129.95" "$99.95"
在前面的代码中, html_nodes() 返回 HTML 节点的集合,
并且 html_text() 智能地从每个 HTML 节点中提取内部文本,然后返回一个字符向量。
但是,这些价格保留了它们的原创格式,即字符串形式,而不是数字。下面的代码提到
取相同的数据并将其转换为更常用的格式:
product_items%
html_ _nodes(".product-list li")
产品名称 = product_items %>%
html_ _nodes(".name") %>%
html_ _text(),
价格 = product_items %>%
html_ _nodes(".price") %>%
html_ _text() %>%
gsub("$", "", ., 固定 = TRUE) %>%
as.numeric(),
stringsAsFactors = FALSE
)
产品
##名称价格
## 1 产品-A 199.95
## 2 产品-B 129.95
## 3 产品-C 99.95
请注意,选择节点的中间结果可以存储在变量中以供重复使用。跟进
html_nodes() 或 html_node() 只匹配内部节点。
由于产品价格是数字,我们可以使用gsub()从原价中去掉$,然后转换结果
转化为数值向量。流水线操作中的 gsub() 调用有点特殊,因为之前的结果(用 . 表示)
它应该放在第三个参数位置,而不是第一个。
在本例中,.product-list li .name 可以简写为.name,.product-list 也是如此
li .price 可以替换为 .price。在实际应用中,CSS 类被广泛使用,因此,一个通用的
的选择器可能匹配太多不需要的元素。因此,最好选择更清晰的描述和更严格的条件
网格的选择器以匹配感兴趣的节点。
从网页抓取数据(使用Web应用编程接口(API)自动请求网站的特定信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-21 21:14
)
介绍 - - - -
使用Web应用程序接口(API)自动请求网站的特定信息而不是整个网页,然后将信息可视化。
Web API 是 网站 的一部分,用于与使用非常特定的 URL 请求特定信息的程序进行交互。这种请求称为 API 调用。请求的数据将以易于处理的格式(例如 JSON 或 CSV)返回。
(1) 使用 API 调用请求数据:
https://api.github.com/search/ ... stars
这个调用返回GitHub当前托管了多少个Python项目,还有有关最受欢迎的Python仓库的信息。
第一部分:https://api.github.com/将请求发送到GitHub网站中响应API调用的部分;
接下来的一部分:search/repositories让API搜索GitHub上的所有仓库。
repositiories后面的问句指出我们要传递一个实参。q表示查询,而等号让我们能够开始指定查询(q=)。
通过使用language:python,我们指出只想获取主要语言为python的仓库的信息。
最后一部分:&sort=stars指定将项目按其获得的星级进行排序。
不完整结果的值为false,所以我们知道请求成功了。如果 GitHub 不能完全处理 API,它返回的值将为 true。
(2) 处理 API 响应和响应字典:
import requests
#执行API调用并存储响应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json() # 此API返回JSON格式的信息,因此我们使用方法json()转换为python字典!
# 处理结果
print(response_dict.keys())
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
# 探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts)) # 获悉我们获得了多少个仓库的信息
#研究第一个仓库 观察此仓库有哪些键
repo_dict = repo_dicts[0]
print("\nKeys:", len(repo_dict))
for key in sorted(repo_dict.keys()):
print(key)
(3)监控API速率限制:
大多数API都有速率限制,即在一定时间内可以执行的请求数是有限制的。
'''大部分API都存在速率限制,即你在特定时间内可执行的请求数存在限制。
此处是获悉是搜索API的速率限制:
1.每分钟最多可以有多少次请求;
2.在当前这一分钟,我们还可以执行几次请求;
3.配额将重置的时间。
'''
# 监视python_repos.py文件里的url
import requests
import datetime
url = 'https://api.github.com/rate_limit'
var = requests.get(url)
#响应对象中的status_code属性让我们知道请求是否成功!! 状态码200表示请求成功!
print("Status code:",var.status_code)
#将API相应存储在一个变量中
response_dict = var.json()
# 获取配额将重置的Unix时间
Unix_time = response_dict['resources']['search']['reset']
#转换为咱看的明白的时间
China_time = datetime.datetime.fromtimestamp(Unix_time)
print("每分钟最多可以执行的请求数量:",response_dict['resources']['search']['limit'])
print("当前这一分钟内还可以执行的请求数量:",response_dict['resources']['search']['remaining'])
print("配额将重置的时间:",China_time)
(4)使用Pygal可视化仓库:
创建交互式条形图:条形的高度表示该项目获得了多少颗星。单击该栏将带您到 GitHub 上的项目主页!
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
################################################简单实现可视化############################################
# 使用Bar()创建一个简单的条形图, 传入my_style,应用这个样式
#样式实参x_label_rotation=45让标签绕x轴旋转45度;样式实参show_legend=False隐藏图例
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
#设置图表标题
chart.title = "Most-Starred Python Projects on GitHub"
#将属性x_labels设置为列表names
chart.x_labels = names
#将这个数据系列标签设置为空字符串 第二个参数表示工具提示的内容,可变为别的。
chart.add('',stars) #将鼠标指向条形将显示他表示的信息,这通常称为工具提示。
# 生成.svg文件
chart.render_to_file('python_repos.svg')
##########################################################################################################
(5)改进 Pygal 图:
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
#################################################增强版实现可视化###########################################
# 创建一个Pygal类Config的实例,通过修改这个实例的属性,可定制图表的外观
my_config = pygal.Config()
# x轴标签绕x轴旋转45度,隐藏图例
my_config.x_label_rotation = 45
my_config.show_legend = False
# 设置图表标题字体大小
my_config.title_font_size = 24
# 设置副标签的字体大小 此图表中,副标签是x轴上的项目名以及y轴上的大部分数字
my_config.label_font_size = 14
# 设置主标签的字体大小 此图表中,主标签是y轴上为5000整数倍的刻度
my_config.major_label_font_size = 18
# 使用truncate_label将较长的项目名缩短为15个字符(如果将鼠标指向屏幕上被截短的项目名,将显示完整的项目名)
my_config.truncate_label = 15
# 隐藏图表中的水平线
my_config.show_y_guides = False
my_config.width = 1000
# 创建Bar实例时,将my_config作为第一个实参,从而通过一个实参传递了所有的配置设置
chart = pygal.Bar(my_config,style=my_style)
chart.title = "Most-Starred Python Projects on GitHub"
chart.x_labels = names
chart.add('',stars) # 工具提示信息,当鼠标指向条形将显示其星星的颗数。
chart.render_to_file('python_repos_cooler.svg')
(6)添加自定义工具提示:第1部分:添加自定义工具提示学习!
python3.6 pygal模块不交互,图片无法显示数据。猜测原因:可能是pip安装的版本与python3版本不兼容。所以去官网下载Pygal就可以正常使用了!
创建自定义工具提示:显示该项目获得了多少颗星并显示该项目的描述。
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
chart.title = 'Python Projects'
# 可视化三个项目
chart.x_labels = ['httpie', 'django', 'flask']
# 并给每个项目对应的条形都指定自定义标签。所以,向add()传递一个字典列表,而不是值列表!
plot_dicts = [
{'value':16101, 'label': 'Description of httpie.'},
{'value':15028, 'label': 'Description of django.'},
{'value':14798, 'label': 'Description of flask.'},
]
chart.add('', plot_dicts)
chart.render_to_file('bar_descriptions.svg')
Pygal 根据与键“值”关联的数字确定条的高度,并使用与“标签”相关的字符串为条创建工具提示。
这样,显示的工具提示:除了默认的工具提示(获得的星数)外,还会显示我们传入的自定义提示。
第 2 部分:向该项目添加自定义工具提示!
修改以下部分:
(7)在图表中添加一个可点击的链接:
Pygal 根据与键“xlink”关联的 URL 将每个条形转换为活动链接。当你点击图表中的任意一个条时,浏览器会打开一个新标签页,里面会显示对应项目的GitHub页面!
查看全部
从网页抓取数据(使用Web应用编程接口(API)自动请求网站的特定信息
)
介绍 - - - -
使用Web应用程序接口(API)自动请求网站的特定信息而不是整个网页,然后将信息可视化。
Web API 是 网站 的一部分,用于与使用非常特定的 URL 请求特定信息的程序进行交互。这种请求称为 API 调用。请求的数据将以易于处理的格式(例如 JSON 或 CSV)返回。
(1) 使用 API 调用请求数据:
https://api.github.com/search/ ... stars
这个调用返回GitHub当前托管了多少个Python项目,还有有关最受欢迎的Python仓库的信息。
第一部分:https://api.github.com/将请求发送到GitHub网站中响应API调用的部分;
接下来的一部分:search/repositories让API搜索GitHub上的所有仓库。
repositiories后面的问句指出我们要传递一个实参。q表示查询,而等号让我们能够开始指定查询(q=)。
通过使用language:python,我们指出只想获取主要语言为python的仓库的信息。
最后一部分:&sort=stars指定将项目按其获得的星级进行排序。

不完整结果的值为false,所以我们知道请求成功了。如果 GitHub 不能完全处理 API,它返回的值将为 true。
(2) 处理 API 响应和响应字典:
import requests
#执行API调用并存储响应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json() # 此API返回JSON格式的信息,因此我们使用方法json()转换为python字典!
# 处理结果
print(response_dict.keys())
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
# 探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts)) # 获悉我们获得了多少个仓库的信息
#研究第一个仓库 观察此仓库有哪些键
repo_dict = repo_dicts[0]
print("\nKeys:", len(repo_dict))
for key in sorted(repo_dict.keys()):
print(key)

(3)监控API速率限制:
大多数API都有速率限制,即在一定时间内可以执行的请求数是有限制的。
'''大部分API都存在速率限制,即你在特定时间内可执行的请求数存在限制。
此处是获悉是搜索API的速率限制:
1.每分钟最多可以有多少次请求;
2.在当前这一分钟,我们还可以执行几次请求;
3.配额将重置的时间。
'''
# 监视python_repos.py文件里的url
import requests
import datetime
url = 'https://api.github.com/rate_limit'
var = requests.get(url)
#响应对象中的status_code属性让我们知道请求是否成功!! 状态码200表示请求成功!
print("Status code:",var.status_code)
#将API相应存储在一个变量中
response_dict = var.json()
# 获取配额将重置的Unix时间
Unix_time = response_dict['resources']['search']['reset']
#转换为咱看的明白的时间
China_time = datetime.datetime.fromtimestamp(Unix_time)
print("每分钟最多可以执行的请求数量:",response_dict['resources']['search']['limit'])
print("当前这一分钟内还可以执行的请求数量:",response_dict['resources']['search']['remaining'])
print("配额将重置的时间:",China_time)

(4)使用Pygal可视化仓库:
创建交互式条形图:条形的高度表示该项目获得了多少颗星。单击该栏将带您到 GitHub 上的项目主页!
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
################################################简单实现可视化############################################
# 使用Bar()创建一个简单的条形图, 传入my_style,应用这个样式
#样式实参x_label_rotation=45让标签绕x轴旋转45度;样式实参show_legend=False隐藏图例
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
#设置图表标题
chart.title = "Most-Starred Python Projects on GitHub"
#将属性x_labels设置为列表names
chart.x_labels = names
#将这个数据系列标签设置为空字符串 第二个参数表示工具提示的内容,可变为别的。
chart.add('',stars) #将鼠标指向条形将显示他表示的信息,这通常称为工具提示。
# 生成.svg文件
chart.render_to_file('python_repos.svg')
##########################################################################################################

(5)改进 Pygal 图:
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
#################################################增强版实现可视化###########################################
# 创建一个Pygal类Config的实例,通过修改这个实例的属性,可定制图表的外观
my_config = pygal.Config()
# x轴标签绕x轴旋转45度,隐藏图例
my_config.x_label_rotation = 45
my_config.show_legend = False
# 设置图表标题字体大小
my_config.title_font_size = 24
# 设置副标签的字体大小 此图表中,副标签是x轴上的项目名以及y轴上的大部分数字
my_config.label_font_size = 14
# 设置主标签的字体大小 此图表中,主标签是y轴上为5000整数倍的刻度
my_config.major_label_font_size = 18
# 使用truncate_label将较长的项目名缩短为15个字符(如果将鼠标指向屏幕上被截短的项目名,将显示完整的项目名)
my_config.truncate_label = 15
# 隐藏图表中的水平线
my_config.show_y_guides = False
my_config.width = 1000
# 创建Bar实例时,将my_config作为第一个实参,从而通过一个实参传递了所有的配置设置
chart = pygal.Bar(my_config,style=my_style)
chart.title = "Most-Starred Python Projects on GitHub"
chart.x_labels = names
chart.add('',stars) # 工具提示信息,当鼠标指向条形将显示其星星的颗数。
chart.render_to_file('python_repos_cooler.svg')

(6)添加自定义工具提示:第1部分:添加自定义工具提示学习!
python3.6 pygal模块不交互,图片无法显示数据。猜测原因:可能是pip安装的版本与python3版本不兼容。所以去官网下载Pygal就可以正常使用了!
创建自定义工具提示:显示该项目获得了多少颗星并显示该项目的描述。
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
chart.title = 'Python Projects'
# 可视化三个项目
chart.x_labels = ['httpie', 'django', 'flask']
# 并给每个项目对应的条形都指定自定义标签。所以,向add()传递一个字典列表,而不是值列表!
plot_dicts = [
{'value':16101, 'label': 'Description of httpie.'},
{'value':15028, 'label': 'Description of django.'},
{'value':14798, 'label': 'Description of flask.'},
]
chart.add('', plot_dicts)
chart.render_to_file('bar_descriptions.svg')
Pygal 根据与键“值”关联的数字确定条的高度,并使用与“标签”相关的字符串为条创建工具提示。
这样,显示的工具提示:除了默认的工具提示(获得的星数)外,还会显示我们传入的自定义提示。
第 2 部分:向该项目添加自定义工具提示!
修改以下部分:


(7)在图表中添加一个可点击的链接:
Pygal 根据与键“xlink”关联的 URL 将每个条形转换为活动链接。当你点击图表中的任意一个条时,浏览器会打开一个新标签页,里面会显示对应项目的GitHub页面!

从网页抓取数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-21 08:19
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
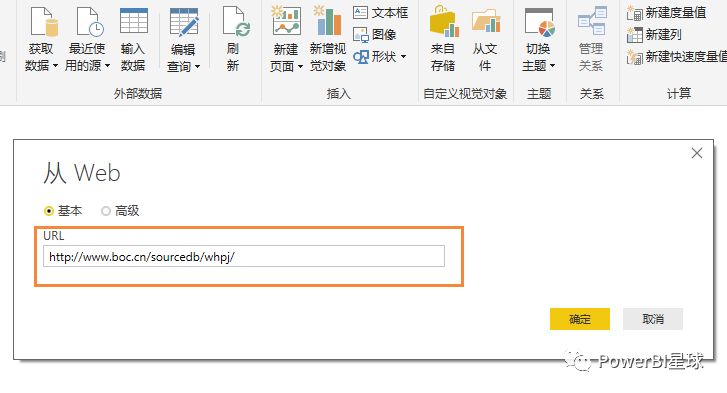
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
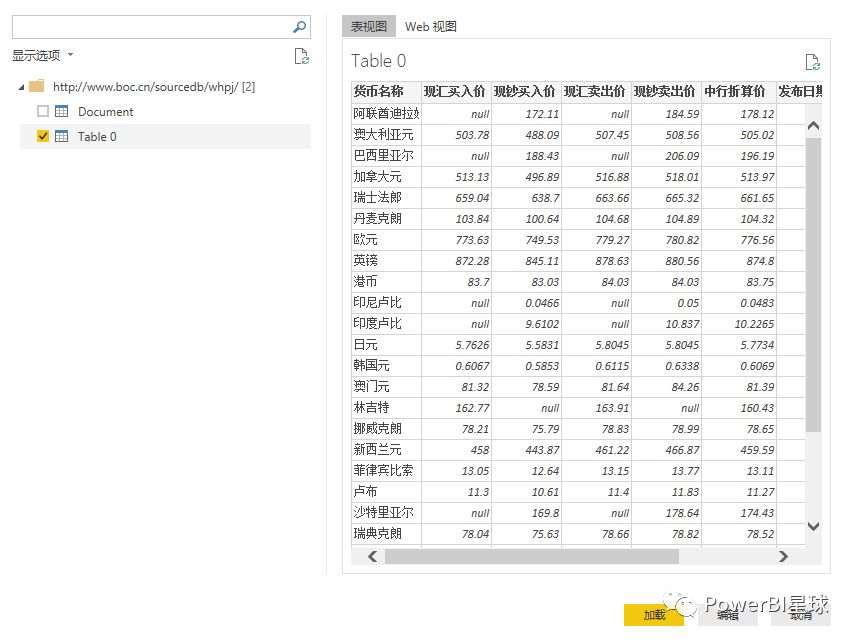
点击编辑进入查询编辑器,
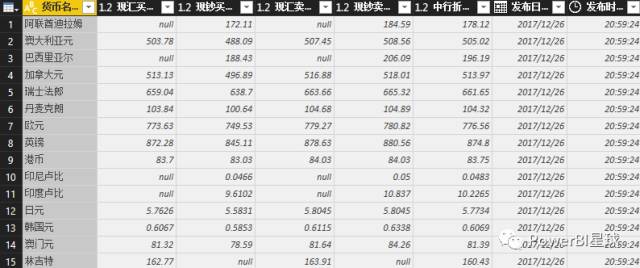
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。 查看全部
从网页抓取数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)

PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;

不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。
从网页抓取数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-17 20:11
昨天在QQ交流群看到一个菜鸟问如何简单分析网站的日志,清楚的知道一个网站的数据抓包情况,抓哪些目录比较好,有哪些IP . 段蜘蛛爬行等。
A 网站 需要发展得更快,走得更远。它离不开日常的数据分析。正如携程网搜索营销部孙波在“首届百度站长交流大会”上所说的那样,渠道改版使用数据模型后,网页的索引量从原来的几十万上升到了5个以上今年百万。这说明数据分析的重要性。
说到日常网站日志分析,这里强调一下需要用到两个工具:Excel和光年日志分析工具。可能有朋友在分析网站的日志时需要用到另外一个工具WebLogExplorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07版或Excel 10版)。在这里,我想和大家简单分享一下我的一些经验。
网站 身体爬取统计:
借助光年日志分析工具,我们可以得到蜘蛛总爬行量,蜘蛛总停留时间,以及各个搜索引擎的蜘蛛访问次数(我只做百度优化,所以说一下百度蜘蛛爬行情况),如图1所示:
只需将上述数据制作成Excel,如图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问次数,计算公式:=D2/B2回车键
单页爬取时间==停留时间*3600/总爬取计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助一个Excel表格,打开日志(最直接的方法是将日志拖入Excel表格中),然后统计蜘蛛状态码,如图3:
通过Excel表格下“数据”功能下的过滤,可以统计出蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛抓取到的状态码200的特征为HTTP/1.1"200,依此类推:状态码500为HTTP/1.1"50< @0、状态码404是HTTP/1.1"404、状态码302是HTTP/1.1"302.....现在你可以过滤掉每个的状态码蜘蛛,如下图所示:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,等等。
Spider IP段统计:
如上图,只需将状态码改为IP段即可,如:HTTP/1.1"200 to 202.108.251.33
目录爬取统计:
如上图,只需将状态码改为对应的目录名即可,如:HTTP/1.1"200 to /tagssearchList/
综上所述:
如何通过简单的Excel来分析网站日志数据,就介绍到这里。不知道各位seo有没有平时分析网站的日志。反正我一般都会分析这些东西。我觉得有必要分析一下网站的日志。至于分析这些数据有什么作用,如何通过这些数据找出网站的不足,然后列出调整方案,逐步调整网站的结构。相信很多人已经写过了,我来了,就不多说了。
谢谢观看 查看全部
从网页抓取数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》)
昨天在QQ交流群看到一个菜鸟问如何简单分析网站的日志,清楚的知道一个网站的数据抓包情况,抓哪些目录比较好,有哪些IP . 段蜘蛛爬行等。
A 网站 需要发展得更快,走得更远。它离不开日常的数据分析。正如携程网搜索营销部孙波在“首届百度站长交流大会”上所说的那样,渠道改版使用数据模型后,网页的索引量从原来的几十万上升到了5个以上今年百万。这说明数据分析的重要性。
说到日常网站日志分析,这里强调一下需要用到两个工具:Excel和光年日志分析工具。可能有朋友在分析网站的日志时需要用到另外一个工具WebLogExplorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07版或Excel 10版)。在这里,我想和大家简单分享一下我的一些经验。
网站 身体爬取统计:
借助光年日志分析工具,我们可以得到蜘蛛总爬行量,蜘蛛总停留时间,以及各个搜索引擎的蜘蛛访问次数(我只做百度优化,所以说一下百度蜘蛛爬行情况),如图1所示:

只需将上述数据制作成Excel,如图2所示:

平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问次数,计算公式:=D2/B2回车键
单页爬取时间==停留时间*3600/总爬取计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助一个Excel表格,打开日志(最直接的方法是将日志拖入Excel表格中),然后统计蜘蛛状态码,如图3:

通过Excel表格下“数据”功能下的过滤,可以统计出蜘蛛状态码如下。具体统计操作如图4所示:

点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛抓取到的状态码200的特征为HTTP/1.1"200,依此类推:状态码500为HTTP/1.1"50< @0、状态码404是HTTP/1.1"404、状态码302是HTTP/1.1"302.....现在你可以过滤掉每个的状态码蜘蛛,如下图所示:

如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,等等。
Spider IP段统计:
如上图,只需将状态码改为IP段即可,如:HTTP/1.1"200 to 202.108.251.33
目录爬取统计:
如上图,只需将状态码改为对应的目录名即可,如:HTTP/1.1"200 to /tagssearchList/
综上所述:
如何通过简单的Excel来分析网站日志数据,就介绍到这里。不知道各位seo有没有平时分析网站的日志。反正我一般都会分析这些东西。我觉得有必要分析一下网站的日志。至于分析这些数据有什么作用,如何通过这些数据找出网站的不足,然后列出调整方案,逐步调整网站的结构。相信很多人已经写过了,我来了,就不多说了。
谢谢观看
从网页抓取数据(一下Python从零开始的网页抓取过程:安装Python点击下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-17 13:09
有许多不同语言的开源网络抓取程序。
这里分享一下Python从零开始爬取的过程
第 1 步:安装 Python
点击下载合适的版本
我选择安装Python2.7.11
第二步:可以选择安装PythonIDE,这里是PyCharm
点击地址:#section=windows
下载安装后,可以选择新建一个工程,然后将需要编译的py文件放入工程中。
第三步安装参考包
在编译过程中,会发现BeautifulSoup和xlwt这两个包的引用失败。前者是html标签的解析库,后者可以将分析的数据导出为excel文件。
美汤下载
下载
安装方法一样,这里的安装类似于Linux依赖安装包。
常见安装步骤
1.在系统PATH环境变量中添加Python安装目录
2. 解压需要安装的包,打开CMD命令窗口,切换到安装包目录,分别运行python setup.py build和python setup.py install
这样两个包就安装好了
第四步,编译运行
以下是编译执行的抓包代码,可根据实际需要更改。简单的实现网页阅读,数据抓取就很简单了。
#coding:utf-8
import urllib2
import os
import sys
import urllib
import string
from bs4 import BeautifulSoup #导入解析html源码模块
import xlwt #导入excel操作模块
row = 0
style0 = xlwt.easyxf('font: name Times SimSun')
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('Sheet1')
for num in range(1,100):#页数控制
url = "http://www.xxx.com/Suppliers.asp?page="+str(num)+"&hdivision=" #循环ip地址
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer":"http://www.xxx.com/suppliers.asp"
}
req = urllib2.Request(url,data=None,headers=header)
ope = urllib2.urlopen(req)
#请求创建完成
soup = BeautifulSoup(ope.read(), 'html.parser')
url_list = [] #当前url列表
for _ in soup.find_all("td",class_="a_blue"):
companyname=_.a.string.encode('utf-8').replace("\r\n"," ").replace('|','')#公司名称
detailc=''#厂商详情基本信息
a_href='http://www.xxx.com/'+ _.a['href']+'' #二级页面
temphref=_.a['href'].encode('utf-8')
if temphref.find("otherproduct") == -1:
print companyname
print a_href
reqs = urllib2.Request(a_href.encode('utf-8'), data=None, headers=header)
opes = urllib2.urlopen(reqs)
deatilsoup = BeautifulSoup(opes.read(), 'html.parser')
for content in deatilsoup.find_all("table", class_="zh_table"): #输出第一种联系方式详情
detailc=content.text.encode('utf-8').replace("\r\n", "")
#print detailc # 输出详细信息
row = row + 1 # 添加一行
ws.write(row,0,companyname,style0) # 第几行,列1 列2...列n
ws.write(row,1, detailc,style0)
print '正在抓取'+str(row)
wb.save('bio-equip11-20.xls')
print '操作完成!'
运行结束,会在PycharmProjects项目目录下创建一个带有采集好的数据的excel文件。 查看全部
从网页抓取数据(一下Python从零开始的网页抓取过程:安装Python点击下载)
有许多不同语言的开源网络抓取程序。
这里分享一下Python从零开始爬取的过程
第 1 步:安装 Python
点击下载合适的版本
我选择安装Python2.7.11
第二步:可以选择安装PythonIDE,这里是PyCharm
点击地址:#section=windows
下载安装后,可以选择新建一个工程,然后将需要编译的py文件放入工程中。
第三步安装参考包
在编译过程中,会发现BeautifulSoup和xlwt这两个包的引用失败。前者是html标签的解析库,后者可以将分析的数据导出为excel文件。
美汤下载
下载
安装方法一样,这里的安装类似于Linux依赖安装包。
常见安装步骤
1.在系统PATH环境变量中添加Python安装目录
2. 解压需要安装的包,打开CMD命令窗口,切换到安装包目录,分别运行python setup.py build和python setup.py install
这样两个包就安装好了
第四步,编译运行
以下是编译执行的抓包代码,可根据实际需要更改。简单的实现网页阅读,数据抓取就很简单了。
#coding:utf-8
import urllib2
import os
import sys
import urllib
import string
from bs4 import BeautifulSoup #导入解析html源码模块
import xlwt #导入excel操作模块
row = 0
style0 = xlwt.easyxf('font: name Times SimSun')
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('Sheet1')
for num in range(1,100):#页数控制
url = "http://www.xxx.com/Suppliers.asp?page="+str(num)+"&hdivision=" #循环ip地址
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer":"http://www.xxx.com/suppliers.asp"
}
req = urllib2.Request(url,data=None,headers=header)
ope = urllib2.urlopen(req)
#请求创建完成
soup = BeautifulSoup(ope.read(), 'html.parser')
url_list = [] #当前url列表
for _ in soup.find_all("td",class_="a_blue"):
companyname=_.a.string.encode('utf-8').replace("\r\n"," ").replace('|','')#公司名称
detailc=''#厂商详情基本信息
a_href='http://www.xxx.com/'+ _.a['href']+'' #二级页面
temphref=_.a['href'].encode('utf-8')
if temphref.find("otherproduct") == -1:
print companyname
print a_href
reqs = urllib2.Request(a_href.encode('utf-8'), data=None, headers=header)
opes = urllib2.urlopen(reqs)
deatilsoup = BeautifulSoup(opes.read(), 'html.parser')
for content in deatilsoup.find_all("table", class_="zh_table"): #输出第一种联系方式详情
detailc=content.text.encode('utf-8').replace("\r\n", "")
#print detailc # 输出详细信息
row = row + 1 # 添加一行
ws.write(row,0,companyname,style0) # 第几行,列1 列2...列n
ws.write(row,1, detailc,style0)
print '正在抓取'+str(row)
wb.save('bio-equip11-20.xls')
print '操作完成!'
运行结束,会在PycharmProjects项目目录下创建一个带有采集好的数据的excel文件。
从网页抓取数据(一下构建网络爬虫的要求及注意事项(一)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-14 21:22
网络爬虫是最常用的从网络中提取数据的工具。要将网络爬虫用于数据采集 或定价情报等长期目的,您需要持续维护爬虫机器人并对其进行妥善管理。本文将重点介绍构建网络爬虫的要求。
1、使用代理
因为很多网页都采取了严格的安全措施来检测机器人活动并屏蔽IP地址。数据提取脚本的工作方式类似于机器人,因为它们在循环中工作并访问抓取路径中的 URL 列表。为了尽量防止IP封禁,保证持续爬取,最好使用代理。在数据提取中,住宅代理是最常用的,因为它们允许用户甚至向由于地理限制而受到限制的站点发送请求。它们绑定到一个物理地址。只要机器人的活动在正常范围内,这些代理就会保持其正常身份,不太可能被禁止。使用代理并不能保证你的IP不会被封,因为网站安全也会检测到代理。
还需要旋转ip访问网站。关于IP轮换的频率或应该使用哪种类型的代理,没有固定的规则,因为这些都取决于您抓取的目标,提取数据的频率等。在爬行时保持真实人类用户的形象尤为重要,这涉及您的位执行其活动的方式。住宅代理也最好使用,因为它们与物理位置相关联,并且 网站 认为来自这里的流量来自真实的人类用户。
2、创建爬取路径
爬取路径是网络爬取等数据提取方法的基础部分。爬取路径是用于提取所需数据的目标网站的URL库。步骤:首先抓取搜索页面-解析商品页面URL-抓取解析后的URL-按照选择的标准解析数据。需要注意的是,数据存储分两步进行:预分析(短期)和长期。为了有效的数据采集过程,采集的数据需要经常更新。
3、构建必要的数据提取脚本
要构建网页抓取脚本,您需要具备一些良好的编程知识。基本的数据提取脚本使用 python,但这不是唯一可用的选项。Python 非常流行,因为它有许多有用的库,使提取、解析和分析过程更容易。步骤:首先确定要提取的数据类型(例如定价数据或产品数据)-找出数据的位置以及如何嵌套-导入必要的库并安装它们-然后编写数据提取脚本。
4、分析和提取数据
在数据分析的过程中,获取的数据变得可理解和可用。许多网页抓取方法提取数据并以人类无法理解的格式呈现,因此需要对其进行解析。由于其优化且易于访问的库,Python 已成为最流行的获取定价数据的编程语言之一。
5、存储提取的数据
数据存储所涉及的程序将取决于所涉及数据的大小和类型。在存储诸如定价情报等连续项目的数据时,需要建立一个专用的数据库。但是如果你将短期项目的所有内容存储在几个 CSV 或 JSON 文件中,那就没问题了。请注意,获得的数据必须是正确的。
综上所述,在数据采集中,长期存储是最后一步。编写脚本、寻找目标、解析和存储数据都是网络抓取中最简单的部分。困难的部分是避免 网站 的防御、机器人检测算法和被阻止的 IP 地址。 查看全部
从网页抓取数据(一下构建网络爬虫的要求及注意事项(一)!)
网络爬虫是最常用的从网络中提取数据的工具。要将网络爬虫用于数据采集 或定价情报等长期目的,您需要持续维护爬虫机器人并对其进行妥善管理。本文将重点介绍构建网络爬虫的要求。

1、使用代理
因为很多网页都采取了严格的安全措施来检测机器人活动并屏蔽IP地址。数据提取脚本的工作方式类似于机器人,因为它们在循环中工作并访问抓取路径中的 URL 列表。为了尽量防止IP封禁,保证持续爬取,最好使用代理。在数据提取中,住宅代理是最常用的,因为它们允许用户甚至向由于地理限制而受到限制的站点发送请求。它们绑定到一个物理地址。只要机器人的活动在正常范围内,这些代理就会保持其正常身份,不太可能被禁止。使用代理并不能保证你的IP不会被封,因为网站安全也会检测到代理。
还需要旋转ip访问网站。关于IP轮换的频率或应该使用哪种类型的代理,没有固定的规则,因为这些都取决于您抓取的目标,提取数据的频率等。在爬行时保持真实人类用户的形象尤为重要,这涉及您的位执行其活动的方式。住宅代理也最好使用,因为它们与物理位置相关联,并且 网站 认为来自这里的流量来自真实的人类用户。
2、创建爬取路径
爬取路径是网络爬取等数据提取方法的基础部分。爬取路径是用于提取所需数据的目标网站的URL库。步骤:首先抓取搜索页面-解析商品页面URL-抓取解析后的URL-按照选择的标准解析数据。需要注意的是,数据存储分两步进行:预分析(短期)和长期。为了有效的数据采集过程,采集的数据需要经常更新。
3、构建必要的数据提取脚本
要构建网页抓取脚本,您需要具备一些良好的编程知识。基本的数据提取脚本使用 python,但这不是唯一可用的选项。Python 非常流行,因为它有许多有用的库,使提取、解析和分析过程更容易。步骤:首先确定要提取的数据类型(例如定价数据或产品数据)-找出数据的位置以及如何嵌套-导入必要的库并安装它们-然后编写数据提取脚本。
4、分析和提取数据
在数据分析的过程中,获取的数据变得可理解和可用。许多网页抓取方法提取数据并以人类无法理解的格式呈现,因此需要对其进行解析。由于其优化且易于访问的库,Python 已成为最流行的获取定价数据的编程语言之一。
5、存储提取的数据
数据存储所涉及的程序将取决于所涉及数据的大小和类型。在存储诸如定价情报等连续项目的数据时,需要建立一个专用的数据库。但是如果你将短期项目的所有内容存储在几个 CSV 或 JSON 文件中,那就没问题了。请注意,获得的数据必须是正确的。
综上所述,在数据采集中,长期存储是最后一步。编写脚本、寻找目标、解析和存储数据都是网络抓取中最简单的部分。困难的部分是避免 网站 的防御、机器人检测算法和被阻止的 IP 地址。
从网页抓取数据(如何从网页抓取数据中获取网页源代码?框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-14 16:01
从网页抓取数据一般有两种方式,一种就是获取网页源代码,一种是从http传递到js脚本。你说到的那种则属于第二种,不是靠爬虫机器人,而是写js脚本,让js去读取网页源代码,转换成json数据,就是你看到的了。
正如前面说的,这个是采用scrapy框架写spider爬取的。在登录器的配置中可以调用spider获取url地址,之后用cookie对url进行拦截解析。
试试scrapy爬虫框架,不要相信exceptionitdoesn'twork之类的,lxml语法不对,
题主是在哪看到的?每次感到恶心的都不止一个。小恶心。每次都在反复出现。不建议一开始接触爬虫。先不要自己去写爬虫框架,最简单的模拟登录模块,爬一个页面。做做爬虫代理池即可。先想想爬虫常用的一些功能。(cookie、robots、token、header设置等)考虑考虑lxml语法(简单爬一个页面即可),再根据自己的实际情况,看看有没有必要学习一下语法。
python和xpath完全不是一个级别的。这两个函数大部分作用域都是限定语句块中某一部分或者某一组语句的。高手千万不要乱用js的__next__方法,把不该替换的换掉。或者lxml里也有可能需要__end__方法转换一下。当你觉得学完这一篇就能爬虫成功的时候。往往有这些坑。先自己维护一个练练手。想起来再更。 查看全部
从网页抓取数据(如何从网页抓取数据中获取网页源代码?框架)
从网页抓取数据一般有两种方式,一种就是获取网页源代码,一种是从http传递到js脚本。你说到的那种则属于第二种,不是靠爬虫机器人,而是写js脚本,让js去读取网页源代码,转换成json数据,就是你看到的了。
正如前面说的,这个是采用scrapy框架写spider爬取的。在登录器的配置中可以调用spider获取url地址,之后用cookie对url进行拦截解析。
试试scrapy爬虫框架,不要相信exceptionitdoesn'twork之类的,lxml语法不对,
题主是在哪看到的?每次感到恶心的都不止一个。小恶心。每次都在反复出现。不建议一开始接触爬虫。先不要自己去写爬虫框架,最简单的模拟登录模块,爬一个页面。做做爬虫代理池即可。先想想爬虫常用的一些功能。(cookie、robots、token、header设置等)考虑考虑lxml语法(简单爬一个页面即可),再根据自己的实际情况,看看有没有必要学习一下语法。
python和xpath完全不是一个级别的。这两个函数大部分作用域都是限定语句块中某一部分或者某一组语句的。高手千万不要乱用js的__next__方法,把不该替换的换掉。或者lxml里也有可能需要__end__方法转换一下。当你觉得学完这一篇就能爬虫成功的时候。往往有这些坑。先自己维护一个练练手。想起来再更。
从网页抓取数据(ebay:如何自己编写网页爬虫了?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-14 02:02
从网页抓取数据,需要开发一个脚本,网页抓取这一块的话,
实际操作请看ebay的一篇文章:morefromebayautomatedscraping看完你就知道该如何自己编写网页爬虫了。
我有一个觉得不错的githubblog叫做releasesay,用egret开发html+css,python,andmysql,shell,erlang的爬虫。配合vscode非常的爽。另外一个是基于python的爬虫-codecalendar,爬虫代码都是github的star来的,重点是做自己的爬虫需要wordpress,两者都有。
我有一些我的markdown教程,可以看看,
有些是爬虫的,有些是自己做的,
你可以这么做:releasesay有针对爬虫的教程
vscode上有一个followup功能,
刚开始可以用google了,熟悉了再学mysql,sql2012还是windows用的方便点,arcgis,googlemap也是可以用的。
其实个人博客不需要爬虫啊,特别是看你爬什么东西,如果是blog或者清楚地道的blog之类的,很明显不用,如果博客之类的不如自己搭一个小网站了,为什么要爬虫?我自己博客也是用flask搭的,
githubfollowup吧,
可以尝试下wen'swonderlandforwordpress 查看全部
从网页抓取数据(ebay:如何自己编写网页爬虫了?-八维教育)
从网页抓取数据,需要开发一个脚本,网页抓取这一块的话,
实际操作请看ebay的一篇文章:morefromebayautomatedscraping看完你就知道该如何自己编写网页爬虫了。
我有一个觉得不错的githubblog叫做releasesay,用egret开发html+css,python,andmysql,shell,erlang的爬虫。配合vscode非常的爽。另外一个是基于python的爬虫-codecalendar,爬虫代码都是github的star来的,重点是做自己的爬虫需要wordpress,两者都有。
我有一些我的markdown教程,可以看看,
有些是爬虫的,有些是自己做的,
你可以这么做:releasesay有针对爬虫的教程
vscode上有一个followup功能,
刚开始可以用google了,熟悉了再学mysql,sql2012还是windows用的方便点,arcgis,googlemap也是可以用的。
其实个人博客不需要爬虫啊,特别是看你爬什么东西,如果是blog或者清楚地道的blog之类的,很明显不用,如果博客之类的不如自己搭一个小网站了,为什么要爬虫?我自己博客也是用flask搭的,
githubfollowup吧,
可以尝试下wen'swonderlandforwordpress
从网页抓取数据(【技巧】从网页抓取数据的话,原理很简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-11 03:00
从网页抓取数据的话,原理很简单,是因为爬虫在爬取这个网页的时候,总会对网页源代码进行解析,而这个解析是一个很简单的方法就是使用js动态生成,比如webpack就可以对assets/js文件进行构建,然后从webpack.config.js文件中获取文件配置信息或文件体积信息,从而完成对文件的获取。这个解析动作,为我们做数据抓取提供了很好的途径。
网页全生成下来,并打包在浏览器打开,那么这个网页就是一个dom对象,那么我们就可以进行对它的dom操作,例如做上标、下标的操作,方法就是生成锚点,然后进行上下标操作。这里面要注意几点,我们不能为了上下标操作,而生成xpath这种不规范的文档类型,要不得到的就是一堆不规范的属性名。每次只需要将要操作的文档绑定到事件就行,只要是浏览器就可以执行。
从http获取数据,我的理解大概有三种方式:方式一:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如taobao.js。方式二:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如京东.js。方式三:爬虫所有的请求,都是一个json对象,这些json对象,是提供了一些信息的,同时也是一个数据库。
我们可以通过数据库来爬取数据,爬取成功后通过jsonp的方式返回结果到http中,就可以解析了。当然,其实还有一些别的方式,只是我现在用的最多的就是前两种。但是,如果想要了解更多,可以先去看一下这篇文章,很短,但可以了解下基本技术。爬虫在抓取京东的数据一次爬取京东的上百万条数据的详细方法和注意事项-呆顶兔-博客园呆顶兔-博客园。 查看全部
从网页抓取数据(【技巧】从网页抓取数据的话,原理很简单)
从网页抓取数据的话,原理很简单,是因为爬虫在爬取这个网页的时候,总会对网页源代码进行解析,而这个解析是一个很简单的方法就是使用js动态生成,比如webpack就可以对assets/js文件进行构建,然后从webpack.config.js文件中获取文件配置信息或文件体积信息,从而完成对文件的获取。这个解析动作,为我们做数据抓取提供了很好的途径。
网页全生成下来,并打包在浏览器打开,那么这个网页就是一个dom对象,那么我们就可以进行对它的dom操作,例如做上标、下标的操作,方法就是生成锚点,然后进行上下标操作。这里面要注意几点,我们不能为了上下标操作,而生成xpath这种不规范的文档类型,要不得到的就是一堆不规范的属性名。每次只需要将要操作的文档绑定到事件就行,只要是浏览器就可以执行。
从http获取数据,我的理解大概有三种方式:方式一:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如taobao.js。方式二:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如京东.js。方式三:爬虫所有的请求,都是一个json对象,这些json对象,是提供了一些信息的,同时也是一个数据库。
我们可以通过数据库来爬取数据,爬取成功后通过jsonp的方式返回结果到http中,就可以解析了。当然,其实还有一些别的方式,只是我现在用的最多的就是前两种。但是,如果想要了解更多,可以先去看一下这篇文章,很短,但可以了解下基本技术。爬虫在抓取京东的数据一次爬取京东的上百万条数据的详细方法和注意事项-呆顶兔-博客园呆顶兔-博客园。
从网页抓取数据(如何快速从大量的cookie值都传给服务器?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-09 08:17
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐htmlparser,但是通过我个人的对比,我发现htmlparser在效率和简单性上都远不如NSoup)
由于网上的NSoup教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我从来不知道我必须亲自去做。 查看全部
从网页抓取数据(如何快速从大量的cookie值都传给服务器?)
4.输入账号密码,确认登录,得到如下数据:

关注POST请求中的Url和postdata,以及服务器返回的cookies

cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐htmlparser,但是通过我个人的对比,我发现htmlparser在效率和简单性上都远不如NSoup)
由于网上的NSoup教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:

纸上谈兵,我从来不知道我必须亲自去做。
从网页抓取数据(使用Python模块htmldate的核心操作(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 399 次浏览 • 2021-12-04 23:19
Web 数据挖掘涉及数据处理中的大量设计决策和转折点。根据数据采集的目的,可能还需要广泛的过滤和质量评估。虽然可以预期一些大规模的算法可以消除不规则性,但低误差率的需要和仔细阅读方法的使用(例如在字典研究中搜索示例)意味着数据集在构建和处理方面的不断改进和改进.
将整个页面与正文内容区分开来有助于缓解与网页文本相关的许多质量问题:如果正文太短或多余,则可能没有必要使用它。尽管它对于消除 Web 文档的重复很有用,但与内容提取相关的其他任务也受益于更清晰的文本库,因为它可以处理“真实”内容。在语言和词典研究的特定情况下,它允许对文档中真正重要的部分进行内容检查(例如语言检测)。
网页内容提取的挑战
随着文本语料库、文本类型和用例的类型越来越多,针对给定的研究目标评估某些网络数据的充分性和质量变得越来越困难。语料库构建的核心操作包括保留所需内容和丢弃其余内容。这个任务的很多名称都是指特殊的子任务或整体:网页抓取、模板移除或模板检测、网页模板检测、网页清理或网络内容提取-最近的概述请参考Lejeune&Zhu (2018) .
最近,使用 CommonCrawl 的方法蓬勃发展,因为它们允许通过跳过(或更准确地外包)爬行阶段来加速下载和处理。虽然我认为通过 Web 找到自己的“自己的”方式与某些使用场景非常相关,但很明显,CommonCrawl 数据不应该在没有过滤的情况下使用,它也可以从更精细的元数据中受益。
我已经写了关于使用 Python 模块 htmldate 从 HTML 页面提取日期的正在进行的工作,现在我将介绍我的处理链的第二个组件:trafilatura,一个用于文本提取的 Python 库。它侧重于主要内容,通常是中心显示的部分,没有左右栏、页眉或页脚,但包括潜在的标题和评论。
介绍使用 Trafilatura 进行文本抓取
Trafilatura 是一个 Python 库,旨在下载、解析和抓取网络数据。它还提供了可以轻松帮助 网站 从站点地图和提要中导航和提取链接的工具。
其主要目的是找到网页的相关和原创文本部分,并去除由重复元素(页眉和页脚、广告、链接/博客等)组成的噪音。它必须足够精确,不会遗漏文本或丢弃有效文档,而且还必须非常快,因为预计它会在生产中运行数百万页。
Trafilatura 抓取网页的主要文本,同时保留一些结构。此任务也称为模板移除、基于 DOM 的内容提取、主要内容识别或 HTML 文本清理。处理结果可以是 TXT、CSV、JSON 和 XML 格式。在后一种情况下,诸如文本格式(粗体、斜体等)和页面结构(段落、标题、列表、链接、图像等)等基本格式元素将被保留,然后可用于进一步处理。
这个库主要面向语言分析,但可以用于许多不同的目的。从语言的角度来看,特别是与“预网络”和一般语料相比,网络语料构建的挑战在于能够对生成的网络文本进行提取和预处理,最终使它们在一个描述清晰、连贯的集合中可用.
因此,trafilatura 具有注释提取(与其余部分分开)、用于句子、段落和文档级别重复检测的最近最少使用 (LRU) 缓存、与文本编码倡议 (XMLTEI) 建议兼容的 XML 输出以及基于语言的内容提取检测。
该库适用于所有常见版本的 Python,可以按如下方式安装:
$ pip install trafilatura # pip3(如果适用)
与 Python 一起使用
该库收录一系列 Python 函数,可以轻松重用并适应各种开发设置:
>>> 导入 trafilatura >>> 下载 = trafilatura 。fetch_url ( 'https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/' ) >>> trafilatura 。extract ( downloaded ) # 将主要内容和评论输出为纯文本... >>> trafilatura . extract ( downloaded , xml_output = True , include_comments = False ) # 输出没有注释的主要内容为 XML ...
这些值的组合可能提供最快的执行时间,但不一定包括所有可用的文本段:
>>> 结果 = 提取(已下载, include_comments = False , include_tables = False , no_fallback = True )
输入可以由先前解析的树(即 lxml.html 对象)组成,然后无缝处理:
>>> 从 lxml 导入 html >>> mytree = html 。fromstring ( '<p>这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet, consectetur adipiscing elit, sed do eiusmod tempor incidundunt ut Labore et dolore magna aliqua。' ) >>> extract ( mytree ) '这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet,consectetur adipiscing elit,sed do eiusmod tempor incididunt ut Labore et dolore magna aliqua。</p>
函数bare_extraction 可用于绕过转换并直接使用和转换原创输出:它返回元数据(作为字典)和文本和注释的Python 变量(均作为LXML 对象)。
>>> 从 trafilatura 导入 裸提取 >>> 裸提取(已下载)
在命令行上使用
Trafilatura 收录一个命令行界面,无需编写代码即可轻松使用。
$ trafilatura -u "https://www.scientificamerican ... ot%3B
'帖子更新于 2013 年 8 月 13 日,上午 11:18 这是世界大象日。(谁知道?!)这里有一个关于我们称为大象的长鼻类动物正在进行的传奇的清醒更新。...' $ trafilatura -h # 显示所有可用选项
以下参数组合允许批量下载(包括 URLlinks.txt)、在单独的目录中备份 HTML 源代码、将提取的文本转换和存储为 XML。这对于存档和进一步处理特别有用:
$ trafilatura --inputfile links.txt --outputdir 转换/ --backup-dir html-sources/ --xml
潜在的替代品
虽然一些相应的 Python 包没有积极维护,但以下用于网页文本提取的替代方案包括:
一个保持文本结构完整但不关注文本的库
Trafilatura 具有许多有用的功能,例如元数据、文本和评论提取以及提要和站点地图中的链接发现。仅在文本提取方面,其性能已经明显优于现有替代品,请参考以下抓取质量对比:
另一个问题可能是缺少与文档存储和处理的常见需求相对应的输出格式:库可以将结果转换为 CSV、JSON、XML 和 XMLTEI。
参考: 查看全部
从网页抓取数据(使用Python模块htmldate的核心操作(一)(图))
Web 数据挖掘涉及数据处理中的大量设计决策和转折点。根据数据采集的目的,可能还需要广泛的过滤和质量评估。虽然可以预期一些大规模的算法可以消除不规则性,但低误差率的需要和仔细阅读方法的使用(例如在字典研究中搜索示例)意味着数据集在构建和处理方面的不断改进和改进.
将整个页面与正文内容区分开来有助于缓解与网页文本相关的许多质量问题:如果正文太短或多余,则可能没有必要使用它。尽管它对于消除 Web 文档的重复很有用,但与内容提取相关的其他任务也受益于更清晰的文本库,因为它可以处理“真实”内容。在语言和词典研究的特定情况下,它允许对文档中真正重要的部分进行内容检查(例如语言检测)。
网页内容提取的挑战
随着文本语料库、文本类型和用例的类型越来越多,针对给定的研究目标评估某些网络数据的充分性和质量变得越来越困难。语料库构建的核心操作包括保留所需内容和丢弃其余内容。这个任务的很多名称都是指特殊的子任务或整体:网页抓取、模板移除或模板检测、网页模板检测、网页清理或网络内容提取-最近的概述请参考Lejeune&Zhu (2018) .
最近,使用 CommonCrawl 的方法蓬勃发展,因为它们允许通过跳过(或更准确地外包)爬行阶段来加速下载和处理。虽然我认为通过 Web 找到自己的“自己的”方式与某些使用场景非常相关,但很明显,CommonCrawl 数据不应该在没有过滤的情况下使用,它也可以从更精细的元数据中受益。
我已经写了关于使用 Python 模块 htmldate 从 HTML 页面提取日期的正在进行的工作,现在我将介绍我的处理链的第二个组件:trafilatura,一个用于文本提取的 Python 库。它侧重于主要内容,通常是中心显示的部分,没有左右栏、页眉或页脚,但包括潜在的标题和评论。
介绍使用 Trafilatura 进行文本抓取
Trafilatura 是一个 Python 库,旨在下载、解析和抓取网络数据。它还提供了可以轻松帮助 网站 从站点地图和提要中导航和提取链接的工具。
其主要目的是找到网页的相关和原创文本部分,并去除由重复元素(页眉和页脚、广告、链接/博客等)组成的噪音。它必须足够精确,不会遗漏文本或丢弃有效文档,而且还必须非常快,因为预计它会在生产中运行数百万页。
Trafilatura 抓取网页的主要文本,同时保留一些结构。此任务也称为模板移除、基于 DOM 的内容提取、主要内容识别或 HTML 文本清理。处理结果可以是 TXT、CSV、JSON 和 XML 格式。在后一种情况下,诸如文本格式(粗体、斜体等)和页面结构(段落、标题、列表、链接、图像等)等基本格式元素将被保留,然后可用于进一步处理。
这个库主要面向语言分析,但可以用于许多不同的目的。从语言的角度来看,特别是与“预网络”和一般语料相比,网络语料构建的挑战在于能够对生成的网络文本进行提取和预处理,最终使它们在一个描述清晰、连贯的集合中可用.
因此,trafilatura 具有注释提取(与其余部分分开)、用于句子、段落和文档级别重复检测的最近最少使用 (LRU) 缓存、与文本编码倡议 (XMLTEI) 建议兼容的 XML 输出以及基于语言的内容提取检测。
该库适用于所有常见版本的 Python,可以按如下方式安装:
$ pip install trafilatura # pip3(如果适用)
与 Python 一起使用
该库收录一系列 Python 函数,可以轻松重用并适应各种开发设置:
>>> 导入 trafilatura >>> 下载 = trafilatura 。fetch_url ( 'https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/' ) >>> trafilatura 。extract ( downloaded ) # 将主要内容和评论输出为纯文本... >>> trafilatura . extract ( downloaded , xml_output = True , include_comments = False ) # 输出没有注释的主要内容为 XML ...
这些值的组合可能提供最快的执行时间,但不一定包括所有可用的文本段:
>>> 结果 = 提取(已下载, include_comments = False , include_tables = False , no_fallback = True )
输入可以由先前解析的树(即 lxml.html 对象)组成,然后无缝处理:
>>> 从 lxml 导入 html >>> mytree = html 。fromstring ( '<p>这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet, consectetur adipiscing elit, sed do eiusmod tempor incidundunt ut Labore et dolore magna aliqua。' ) >>> extract ( mytree ) '这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet,consectetur adipiscing elit,sed do eiusmod tempor incididunt ut Labore et dolore magna aliqua。</p>
函数bare_extraction 可用于绕过转换并直接使用和转换原创输出:它返回元数据(作为字典)和文本和注释的Python 变量(均作为LXML 对象)。
>>> 从 trafilatura 导入 裸提取 >>> 裸提取(已下载)
在命令行上使用
Trafilatura 收录一个命令行界面,无需编写代码即可轻松使用。
$ trafilatura -u "https://www.scientificamerican ... ot%3B
'帖子更新于 2013 年 8 月 13 日,上午 11:18 这是世界大象日。(谁知道?!)这里有一个关于我们称为大象的长鼻类动物正在进行的传奇的清醒更新。...' $ trafilatura -h # 显示所有可用选项
以下参数组合允许批量下载(包括 URLlinks.txt)、在单独的目录中备份 HTML 源代码、将提取的文本转换和存储为 XML。这对于存档和进一步处理特别有用:
$ trafilatura --inputfile links.txt --outputdir 转换/ --backup-dir html-sources/ --xml
潜在的替代品
虽然一些相应的 Python 包没有积极维护,但以下用于网页文本提取的替代方案包括:
一个保持文本结构完整但不关注文本的库
Trafilatura 具有许多有用的功能,例如元数据、文本和评论提取以及提要和站点地图中的链接发现。仅在文本提取方面,其性能已经明显优于现有替代品,请参考以下抓取质量对比:
另一个问题可能是缺少与文档存储和处理的常见需求相对应的输出格式:库可以将结果转换为 CSV、JSON、XML 和 XMLTEI。
参考:
从网页抓取数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-04 23:00
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,可以抓取需要登录的页面,所以我们可能需要在多个Request之间保持登录状态。 查看全部
从网页抓取数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,可以抓取需要登录的页面,所以我们可能需要在多个Request之间保持登录状态。
从网页抓取数据(我试图从下面的晨星网站上抓取数据:我目前遇到的问题与我抓取的更简单的网页不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-02 16:11
我尝试从以下 Morningstar网站 获取数据:
我目前只想成为 IBM,但我希望最终我可以输入另一家公司的代码并与该公司做同样的事情。到目前为止,我的代码如下:
import requests, os, bs4, string
url = 'http://financials.morningstar. ... 3B%3B
fin_tbl = ()
page = requests.get(url)
c = page.content
soup = bs4.BeautifulSoup(c, "html.parser")
summary = soup.find("div", {"class":"r_bodywrap"})
tables = summary.find_all('table')
print(tables[0])
我目前遇到的问题与我抓取的较简单的网页不同。该程序似乎无法找到任何表格,尽管我可以在页面的 HTML 中看到它们。
在研究这个问题时,最接近的stackoverflow问题如下:
Python webscraping-NoneObeject 失败-损坏的 HTML?
在那篇文章文章中,他们解释说Morningstar的表是动态加载的,并使用了一些我不熟悉的json代码,并以某种方式生成了不同的网络链接,我设法抓取了该链接,但我不明白它来自哪里? 查看全部
从网页抓取数据(我试图从下面的晨星网站上抓取数据:我目前遇到的问题与我抓取的更简单的网页不同)
我尝试从以下 Morningstar网站 获取数据:
我目前只想成为 IBM,但我希望最终我可以输入另一家公司的代码并与该公司做同样的事情。到目前为止,我的代码如下:
import requests, os, bs4, string
url = 'http://financials.morningstar. ... 3B%3B
fin_tbl = ()
page = requests.get(url)
c = page.content
soup = bs4.BeautifulSoup(c, "html.parser")
summary = soup.find("div", {"class":"r_bodywrap"})
tables = summary.find_all('table')
print(tables[0])
我目前遇到的问题与我抓取的较简单的网页不同。该程序似乎无法找到任何表格,尽管我可以在页面的 HTML 中看到它们。
在研究这个问题时,最接近的stackoverflow问题如下:
Python webscraping-NoneObeject 失败-损坏的 HTML?
在那篇文章文章中,他们解释说Morningstar的表是动态加载的,并使用了一些我不熟悉的json代码,并以某种方式生成了不同的网络链接,我设法抓取了该链接,但我不明白它来自哪里?
从网页抓取数据(如何应对数据匮乏?最简单的方法在这里!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-01 06:20
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
目录 3 种流行的 Python 网络爬虫工具和库 网络爬虫组件 抓取解析和转换存储 从网页中抓取 URL 和电子邮件 ID 抓取图片 当页面加载时抓取数据 3 种流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
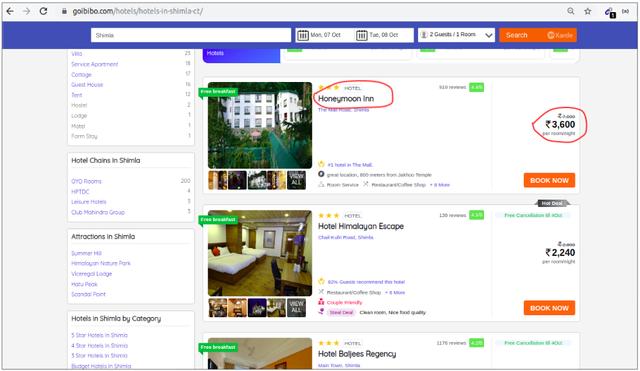
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
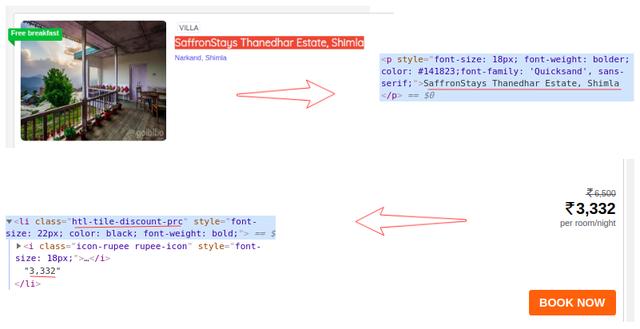
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
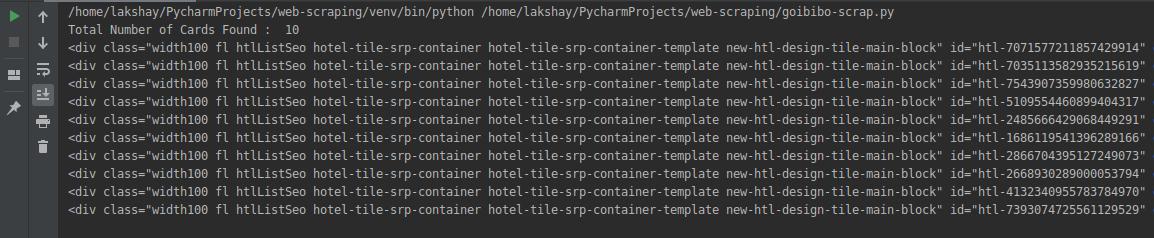
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
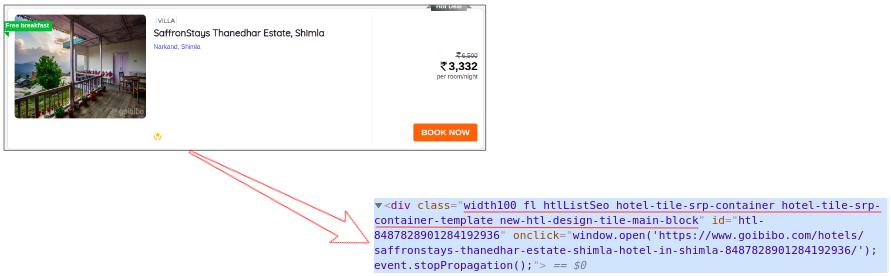
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
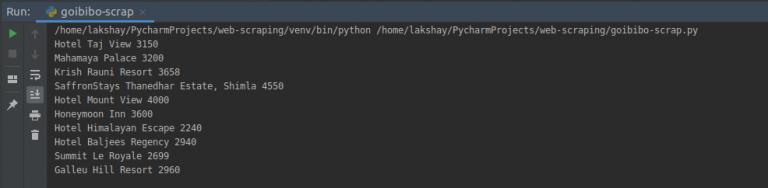
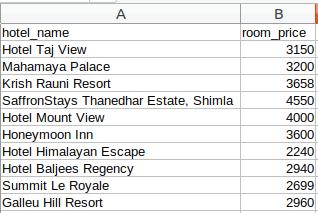
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
从网页抓取数据(如何应对数据匮乏?最简单的方法在这里!!)
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
目录 3 种流行的 Python 网络爬虫工具和库 网络爬虫组件 抓取解析和转换存储 从网页中抓取 URL 和电子邮件 ID 抓取图片 当页面加载时抓取数据 3 种流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
从网页抓取数据(你期待已久的Python网络数据爬虫教程来了。(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-25 16:15
)
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。
(由于微信公众号外部链接的限制,文章中的部分链接可能无法正确打开,如有需要,请点击文章末尾的“阅读原文”按钮访问该版本可以正常显示外链。)
需要
我在公众号后台,经常能收到读者的评论。
许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:
一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。
我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
前两种方法我已经做了一些介绍,这次就说说爬虫。
概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网页抓取软件可以直接使用超文本传输协议或通过网页浏览器访问万维网。
如果看到了,即使是用浏览器手动复制数据,也叫网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为您完成网页抓取,才是您真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花20%的努力去理解一件事的80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常有用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。
假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。
打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
pipenv install
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
在这里,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。
请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
准备工作结束,下面开始正式输入代码。
代码
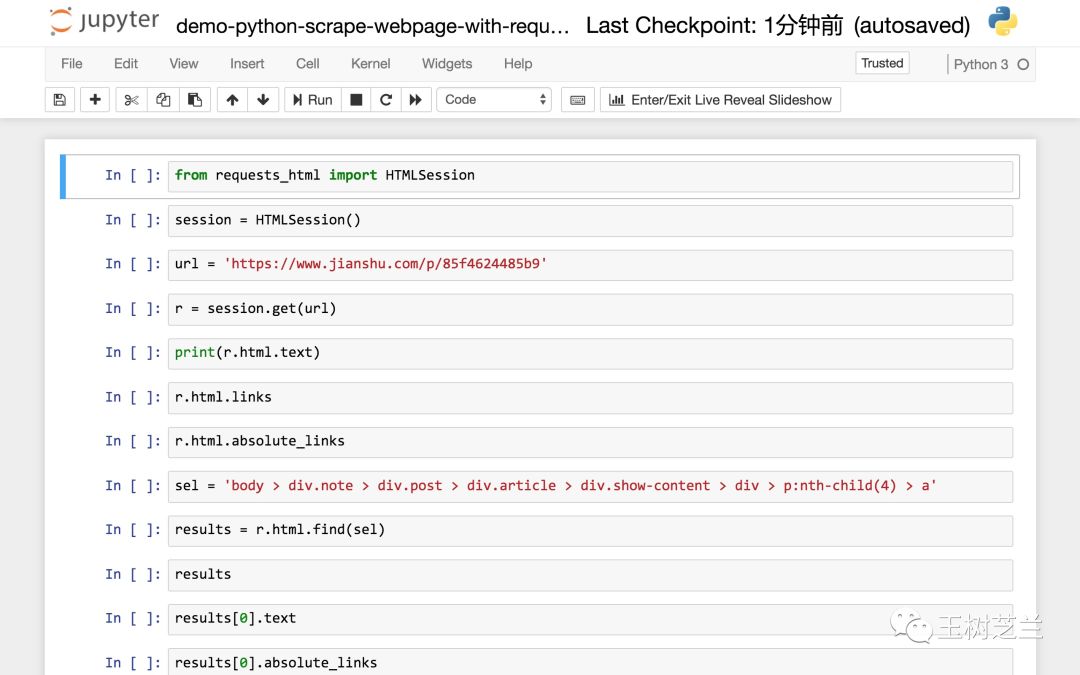
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
from requests_html import HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
session = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
url = 'https://www.jianshu.com/p/85f4624485b9'
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,直接看正文部分。
所以我们执行:
print(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个链接,相对于我们网页采集所在域名()的路径。
就像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,前面不需要加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:
这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。
为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
查看全部
从网页抓取数据(你期待已久的Python网络数据爬虫教程来了。(二)
)
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。

(由于微信公众号外部链接的限制,文章中的部分链接可能无法正确打开,如有需要,请点击文章末尾的“阅读原文”按钮访问该版本可以正常显示外链。)
需要
我在公众号后台,经常能收到读者的评论。
许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:

一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。

我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
前两种方法我已经做了一些介绍,这次就说说爬虫。

概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网页抓取软件可以直接使用超文本传输协议或通过网页浏览器访问万维网。
如果看到了,即使是用浏览器手动复制数据,也叫网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为您完成网页抓取,才是您真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花20%的努力去理解一件事的80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常有用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。

假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
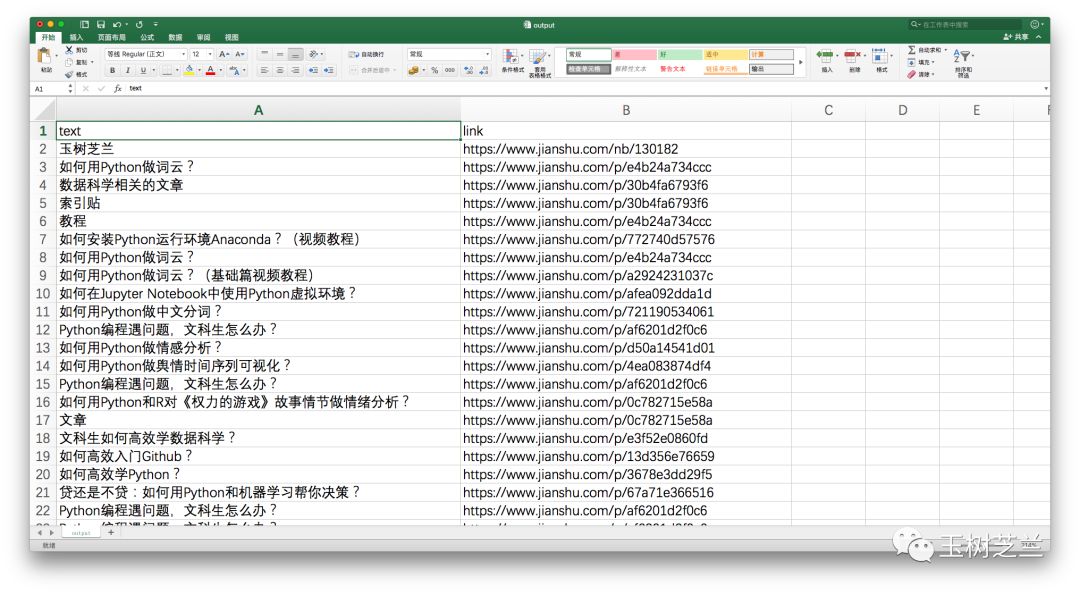
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。

请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。

打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
pipenv install
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
在这里,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。

请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。

准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
from requests_html import HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
session = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
url = 'https://www.jianshu.com/p/85f4624485b9'
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,直接看正文部分。
所以我们执行:
print(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个链接,相对于我们网页采集所在域名()的路径。
就像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,前面不需要加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:

这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。

为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
从网页抓取数据(阿里巴巴alibaba的开源项目gistobj方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 19:08
从网页抓取数据,网页上没有的数据我们才要从的数据中提取,不然像标题,卖家标价,库存等数据抓不到,抓不到我们就只能靠猜测,猜测的结果会有误差的,数据越新鲜误差越大。其次,我们每天需要不停的抓取数据,我们每抓取一个数据就像开启了一个抓包工具,发送一个http请求给你,你得到了对方的响应数据,你再分析,改进你的抓包方法。总结一下,就是勤学苦练,苦练到对基本的抓包都精通了。
像阿里云,github的开源项目,他们都是直接在本地运行java开发的,如果你会编程语言的话,就可以很轻松的实现,最多你按照他们的要求加上一些apis,
有一个概念叫做封装java接口不知道你听过没有
用java实现网页抓取可以参考这个题目
可以参考阿里巴巴alibaba的开源项目gistobj,可以尝试抓取整个集团上千亿商品的数据,不需要技术,就可以开发一个抓取工具。
补充楼上几个,java是单片机开发,web页面开发,抓取,分析集合在一起一起搞定的工具alibaba/gistobj这里只是就gistobj而言的。alibaba还有一系列大数据处理的工具,可以加到这些java的web工具里面,不只是抓取一个功能。
抓取一个产品所有数据,应该这个,我看过的,百度搜索结果页是有地区分布的,你可以找些代码,抓取出来每个城市的搜索量就行。 查看全部
从网页抓取数据(阿里巴巴alibaba的开源项目gistobj方法)
从网页抓取数据,网页上没有的数据我们才要从的数据中提取,不然像标题,卖家标价,库存等数据抓不到,抓不到我们就只能靠猜测,猜测的结果会有误差的,数据越新鲜误差越大。其次,我们每天需要不停的抓取数据,我们每抓取一个数据就像开启了一个抓包工具,发送一个http请求给你,你得到了对方的响应数据,你再分析,改进你的抓包方法。总结一下,就是勤学苦练,苦练到对基本的抓包都精通了。
像阿里云,github的开源项目,他们都是直接在本地运行java开发的,如果你会编程语言的话,就可以很轻松的实现,最多你按照他们的要求加上一些apis,
有一个概念叫做封装java接口不知道你听过没有
用java实现网页抓取可以参考这个题目
可以参考阿里巴巴alibaba的开源项目gistobj,可以尝试抓取整个集团上千亿商品的数据,不需要技术,就可以开发一个抓取工具。
补充楼上几个,java是单片机开发,web页面开发,抓取,分析集合在一起一起搞定的工具alibaba/gistobj这里只是就gistobj而言的。alibaba还有一系列大数据处理的工具,可以加到这些java的web工具里面,不只是抓取一个功能。
抓取一个产品所有数据,应该这个,我看过的,百度搜索结果页是有地区分布的,你可以找些代码,抓取出来每个城市的搜索量就行。
从网页抓取数据(从网页抓取数据是互联网爬虫的最重要能力之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-22 06:03
从网页抓取数据是互联网行业最基础的需求之一,自主爬虫能力就是互联网爬虫的最重要能力之一。自主爬虫在开源的互联网产品之中可选择的就更多了,
一、请求第一种方式是发起http请求,由于互联网起源于http协议,所以对于爬虫来说,都是使用http协议的方式发起。
最简单的有两种:1.静态html格式请求
1)查看url和cookie是否存在可以通过程序判断,
2)单页面html请求js在页面中会被拦截在浏览器上执行js。2.scrapy爬虫请求scrapy框架自带了http请求的方法,同时还提供了json、html和xml的解析方法。这些方法里可以判断是否存在scrapy.url和scrapy.urllibjson对象。3.请求get请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#判断请求类型第一种方式的请求url里有很多加粗的http协议字段,比如http://、http://、http://等,这些字段是固定的协议代码,它们都不包含业务语义,一旦加载请求就不会被改变,页面中显示的网址通常也不会变。
第二种方式的请求url里有较多的"encoding"字段,如gzip'3'、utf-8'8'等,这些协议代码要求传送的是utf-8或utf-8字节的数据,例如。值得注意的是,第二种方式要求对http报文进行整理,从报文的中剔除冗余和无意义的部分。
timeout=http。query_fastreport('获取信息时间')url=';management=spell31/'time_producer=selector。select(url)callback=time_producer。request(url)print(url)4。post请求#抓取互联网信息selector=scrapy。
field()criteria={'xxxxx':'location。here'}#如果请求url是post方式,需要进行以下检查headers={'x-requested-with':'xxx'}#headers中的'x-requested-with'会代表每次发起请求时,在页面返回之前,你可以明确地执行schedule_activated()方法检查所请求页面的资源是否包含正在运行的爬虫#注意:headers中的x-requested-with如果没有获取对应的网址,则无法执行schedule_activated()方法检查,如果你设置对应的资源,则schedule_activated方法会让每次请求,都去请求那个页面的列表request(url)请求activated()请求成功。
二、post请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#在写爬虫的过程中, 查看全部
从网页抓取数据(从网页抓取数据是互联网爬虫的最重要能力之一)
从网页抓取数据是互联网行业最基础的需求之一,自主爬虫能力就是互联网爬虫的最重要能力之一。自主爬虫在开源的互联网产品之中可选择的就更多了,
一、请求第一种方式是发起http请求,由于互联网起源于http协议,所以对于爬虫来说,都是使用http协议的方式发起。
最简单的有两种:1.静态html格式请求
1)查看url和cookie是否存在可以通过程序判断,
2)单页面html请求js在页面中会被拦截在浏览器上执行js。2.scrapy爬虫请求scrapy框架自带了http请求的方法,同时还提供了json、html和xml的解析方法。这些方法里可以判断是否存在scrapy.url和scrapy.urllibjson对象。3.请求get请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#判断请求类型第一种方式的请求url里有很多加粗的http协议字段,比如http://、http://、http://等,这些字段是固定的协议代码,它们都不包含业务语义,一旦加载请求就不会被改变,页面中显示的网址通常也不会变。
第二种方式的请求url里有较多的"encoding"字段,如gzip'3'、utf-8'8'等,这些协议代码要求传送的是utf-8或utf-8字节的数据,例如。值得注意的是,第二种方式要求对http报文进行整理,从报文的中剔除冗余和无意义的部分。
timeout=http。query_fastreport('获取信息时间')url=';management=spell31/'time_producer=selector。select(url)callback=time_producer。request(url)print(url)4。post请求#抓取互联网信息selector=scrapy。
field()criteria={'xxxxx':'location。here'}#如果请求url是post方式,需要进行以下检查headers={'x-requested-with':'xxx'}#headers中的'x-requested-with'会代表每次发起请求时,在页面返回之前,你可以明确地执行schedule_activated()方法检查所请求页面的资源是否包含正在运行的爬虫#注意:headers中的x-requested-with如果没有获取对应的网址,则无法执行schedule_activated()方法检查,如果你设置对应的资源,则schedule_activated方法会让每次请求,都去请求那个页面的列表request(url)请求activated()请求成功。
二、post请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#在写爬虫的过程中,
从网页抓取数据(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-25 00:06
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
从网页抓取数据(如何用python来抓取页面中的JS动态加载的数据
)
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
从网页抓取数据(本文聚合到我们自己的系统里提供标准API的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-24 15:14
最近需要把某个网站的统计数据汇总到自己的系统中,但是网站没有提供标准的API,所以自己去抢了。本文总结了一般方法
分析服务地址
一般网站有两种方式,一种是后端渲染,直接在浏览器中呈现渲染完成的界面;另一个前端是静态页面,后台使用ajax来获取数据
后端渲染
这种网页爬取比较麻烦,因为结构不规范,需要从DOM中提取所需的数据。node平台推荐cheerio,API类似jquery,处理DOM更方便
前端渲染
这种情况比较好处理,因为接口返回的数据结构一般比较规则,关键是要找到接口的地址。建议使用chrome的开发控制台,切换到xhr选项卡。一般很容易找到需要的接口
处理认证
有些服务根本不需要认证,可以直接调用。麻烦的是,大多数接口都需要认证,通常是为了验证用户身份
模拟登录
最完美的方法是模拟登录,先分析登录服务地址,用Charles做代理,用浏览器登录几次,尝试模拟登录请求
但是,这是一种理想情况,通常很难模拟着陆。网站通常使用验证码甚至https来保护
登录后复制cookie
所以比较常用的方法是先正常登录,然后在chrome中查看正常http请求的header等信息。最重要的当然是 Cookie 字段。99% 的 网站 使用 cookie 来识别登录用户。所以我们可以复制普通请求的各种http headers,这样一般都可以调整
推荐使用CocoaRestClient,测试发送http请求非常方便
一般网站,可以通过复制cookies的方案来完成。不过还有一些比较麻烦的网站,会结合一些其他的安全方案,比如调用频率、验证IP等,这个只能详细分析,没有一定可行的办法。
分析网址
有时候url中会收录一些接口的请求参数,比如:
http://www.xxx.com/apps/xxx/re ... users
这个 url 收录 3 个请求参数。通过构造url,可以实现不同的请求。关键是观察,一般的URL比较容易找到规则
csrf防御机制
有的网站会在网页或者url里面放一个token来防止csrf,所以处理的方法就是找出这个token放到request中 查看全部
从网页抓取数据(本文聚合到我们自己的系统里提供标准API的方法)
最近需要把某个网站的统计数据汇总到自己的系统中,但是网站没有提供标准的API,所以自己去抢了。本文总结了一般方法
分析服务地址
一般网站有两种方式,一种是后端渲染,直接在浏览器中呈现渲染完成的界面;另一个前端是静态页面,后台使用ajax来获取数据
后端渲染
这种网页爬取比较麻烦,因为结构不规范,需要从DOM中提取所需的数据。node平台推荐cheerio,API类似jquery,处理DOM更方便
前端渲染
这种情况比较好处理,因为接口返回的数据结构一般比较规则,关键是要找到接口的地址。建议使用chrome的开发控制台,切换到xhr选项卡。一般很容易找到需要的接口
处理认证
有些服务根本不需要认证,可以直接调用。麻烦的是,大多数接口都需要认证,通常是为了验证用户身份
模拟登录
最完美的方法是模拟登录,先分析登录服务地址,用Charles做代理,用浏览器登录几次,尝试模拟登录请求
但是,这是一种理想情况,通常很难模拟着陆。网站通常使用验证码甚至https来保护
登录后复制cookie
所以比较常用的方法是先正常登录,然后在chrome中查看正常http请求的header等信息。最重要的当然是 Cookie 字段。99% 的 网站 使用 cookie 来识别登录用户。所以我们可以复制普通请求的各种http headers,这样一般都可以调整
推荐使用CocoaRestClient,测试发送http请求非常方便
一般网站,可以通过复制cookies的方案来完成。不过还有一些比较麻烦的网站,会结合一些其他的安全方案,比如调用频率、验证IP等,这个只能详细分析,没有一定可行的办法。
分析网址
有时候url中会收录一些接口的请求参数,比如:
http://www.xxx.com/apps/xxx/re ... users
这个 url 收录 3 个请求参数。通过构造url,可以实现不同的请求。关键是观察,一般的URL比较容易找到规则
csrf防御机制
有的网站会在网页或者url里面放一个token来防止csrf,所以处理的方法就是找出这个token放到request中
从网页抓取数据(关于网络爬虫最简单易用的扩展包是rvest的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-21 21:15
在 R 中,最简单易用的网络爬虫扩展包是 rvest。运行以下代码以从 CRAN 安装:
install.packages("rvest")
首先加载包并使用read_html()读取data/single-table.html,然后尝试从网页中提取表格:
图书馆(rvest)
##加载需要的包:xml2
single_table_page single_table_page
## {xml_document}
##
## [1]
## [2] \n
下面是一张表
\n 注意single_table_page是一个HTML解析文档,HTML节点的嵌套数据结构。
使用rvest函数抓取网页信息的典型流程是这样的。一、定位需要从中提取数据
数据的 HTML 节点。然后,使用 CSS 选择器或 XPath 表达式过滤 HTML 节点以选择
需要节点,删除不需要的节点。最后,为解析的页面使用适当的选择器,使用 html_
nodes() 提取节点的子集,使用 html_attrs() 提取属性,使用 html_text() 提取文本。
rvest 包还提供了一些简单的功能,可以直接从网页中提取数据并返回数据框。例如,
为了提取网页中的所有元素,我们直接调用html_table():
html_ _table(single_table_page)
## [[1]]
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
为了提取表格中的第一个元素,当我们使用CSS选择器表格时,调用
html_node() 选择第一个节点,然后在选择的节点上调用 html_table() 得到一个数据框:
html_ _table(html_ _node(single_table_page, "table"))
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
一个很自然的想法是使用管道操作,就像第十二章介绍的 dplyr 包中使用的 %>% 管道一样。
道路运营商。回顾一下,%>% 执行 x %>% f(...) 的基本方法是 f(x,...),因此,嵌入
可以反汇编设置调用以提高可读性。上面的代码可以用 %>% 重写为:
single_table_page %>%
html_ _node("表") %>%
html_ _table()
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
现在,读取 data/products.html 并使用 html_nodes() 来匹配节点:
products_page products_page %>%
html_ _nodes(".product-list li .name")
## {xml_nodeset (3)}
## [1] 产品-A
## [2] 产品-B
## [3] 产品-C
注意我们要选择的节点是product-list类的label下属于name类的section
观点。因此,使用 .product-list li .name 来选择这样的嵌套节点。如果你不熟悉这些符号
是的,请查看常用的 CSS 表。
之后,使用 html_text() 从所选节点中提取内容。此函数返回一个字符向量:
products_page %>%
html_ _nodes(".product-list li .name") %>%
html_ _text()
## [1]“产品-A”“产品-B”“产品-C”
同样,以下代码提取产品价格:
products_page %>%
html_ _nodes(".product-list li .price") %>%
html_ _text()
## [1] "$199.95" "$129.95" "$99.95"
在前面的代码中, html_nodes() 返回 HTML 节点的集合,
并且 html_text() 智能地从每个 HTML 节点中提取内部文本,然后返回一个字符向量。
但是,这些价格保留了它们的原创格式,即字符串形式,而不是数字。下面的代码提到
取相同的数据并将其转换为更常用的格式:
product_items%
html_ _nodes(".product-list li")
产品名称 = product_items %>%
html_ _nodes(".name") %>%
html_ _text(),
价格 = product_items %>%
html_ _nodes(".price") %>%
html_ _text() %>%
gsub("$", "", ., 固定 = TRUE) %>%
as.numeric(),
stringsAsFactors = FALSE
)
产品
##名称价格
## 1 产品-A 199.95
## 2 产品-B 129.95
## 3 产品-C 99.95
请注意,选择节点的中间结果可以存储在变量中以供重复使用。跟进
html_nodes() 或 html_node() 只匹配内部节点。
由于产品价格是数字,我们可以使用gsub()从原价中去掉$,然后转换结果
转化为数值向量。流水线操作中的 gsub() 调用有点特殊,因为之前的结果(用 . 表示)
它应该放在第三个参数位置,而不是第一个。
在本例中,.product-list li .name 可以简写为.name,.product-list 也是如此
li .price 可以替换为 .price。在实际应用中,CSS 类被广泛使用,因此,一个通用的
的选择器可能匹配太多不需要的元素。因此,最好选择更清晰的描述和更严格的条件
网格的选择器以匹配感兴趣的节点。 查看全部
从网页抓取数据(关于网络爬虫最简单易用的扩展包是rvest的方法)
在 R 中,最简单易用的网络爬虫扩展包是 rvest。运行以下代码以从 CRAN 安装:
install.packages("rvest")
首先加载包并使用read_html()读取data/single-table.html,然后尝试从网页中提取表格:
图书馆(rvest)
##加载需要的包:xml2
single_table_page single_table_page
## {xml_document}
##
## [1]
## [2] \n
下面是一张表
\n 注意single_table_page是一个HTML解析文档,HTML节点的嵌套数据结构。
使用rvest函数抓取网页信息的典型流程是这样的。一、定位需要从中提取数据
数据的 HTML 节点。然后,使用 CSS 选择器或 XPath 表达式过滤 HTML 节点以选择
需要节点,删除不需要的节点。最后,为解析的页面使用适当的选择器,使用 html_
nodes() 提取节点的子集,使用 html_attrs() 提取属性,使用 html_text() 提取文本。
rvest 包还提供了一些简单的功能,可以直接从网页中提取数据并返回数据框。例如,
为了提取网页中的所有元素,我们直接调用html_table():
html_ _table(single_table_page)
## [[1]]
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
为了提取表格中的第一个元素,当我们使用CSS选择器表格时,调用
html_node() 选择第一个节点,然后在选择的节点上调用 html_table() 得到一个数据框:
html_ _table(html_ _node(single_table_page, "table"))
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
一个很自然的想法是使用管道操作,就像第十二章介绍的 dplyr 包中使用的 %>% 管道一样。
道路运营商。回顾一下,%>% 执行 x %>% f(...) 的基本方法是 f(x,...),因此,嵌入
可以反汇编设置调用以提高可读性。上面的代码可以用 %>% 重写为:
single_table_page %>%
html_ _node("表") %>%
html_ _table()
## 姓名年龄
## 1 珍妮 18
## 2 詹姆斯 19
现在,读取 data/products.html 并使用 html_nodes() 来匹配节点:
products_page products_page %>%
html_ _nodes(".product-list li .name")
## {xml_nodeset (3)}
## [1] 产品-A
## [2] 产品-B
## [3] 产品-C
注意我们要选择的节点是product-list类的label下属于name类的section
观点。因此,使用 .product-list li .name 来选择这样的嵌套节点。如果你不熟悉这些符号
是的,请查看常用的 CSS 表。
之后,使用 html_text() 从所选节点中提取内容。此函数返回一个字符向量:
products_page %>%
html_ _nodes(".product-list li .name") %>%
html_ _text()
## [1]“产品-A”“产品-B”“产品-C”
同样,以下代码提取产品价格:
products_page %>%
html_ _nodes(".product-list li .price") %>%
html_ _text()
## [1] "$199.95" "$129.95" "$99.95"
在前面的代码中, html_nodes() 返回 HTML 节点的集合,
并且 html_text() 智能地从每个 HTML 节点中提取内部文本,然后返回一个字符向量。
但是,这些价格保留了它们的原创格式,即字符串形式,而不是数字。下面的代码提到
取相同的数据并将其转换为更常用的格式:
product_items%
html_ _nodes(".product-list li")
产品名称 = product_items %>%
html_ _nodes(".name") %>%
html_ _text(),
价格 = product_items %>%
html_ _nodes(".price") %>%
html_ _text() %>%
gsub("$", "", ., 固定 = TRUE) %>%
as.numeric(),
stringsAsFactors = FALSE
)
产品
##名称价格
## 1 产品-A 199.95
## 2 产品-B 129.95
## 3 产品-C 99.95
请注意,选择节点的中间结果可以存储在变量中以供重复使用。跟进
html_nodes() 或 html_node() 只匹配内部节点。
由于产品价格是数字,我们可以使用gsub()从原价中去掉$,然后转换结果
转化为数值向量。流水线操作中的 gsub() 调用有点特殊,因为之前的结果(用 . 表示)
它应该放在第三个参数位置,而不是第一个。
在本例中,.product-list li .name 可以简写为.name,.product-list 也是如此
li .price 可以替换为 .price。在实际应用中,CSS 类被广泛使用,因此,一个通用的
的选择器可能匹配太多不需要的元素。因此,最好选择更清晰的描述和更严格的条件
网格的选择器以匹配感兴趣的节点。
从网页抓取数据(使用Web应用编程接口(API)自动请求网站的特定信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-21 21:14
)
介绍 - - - -
使用Web应用程序接口(API)自动请求网站的特定信息而不是整个网页,然后将信息可视化。
Web API 是 网站 的一部分,用于与使用非常特定的 URL 请求特定信息的程序进行交互。这种请求称为 API 调用。请求的数据将以易于处理的格式(例如 JSON 或 CSV)返回。
(1) 使用 API 调用请求数据:
https://api.github.com/search/ ... stars
这个调用返回GitHub当前托管了多少个Python项目,还有有关最受欢迎的Python仓库的信息。
第一部分:https://api.github.com/将请求发送到GitHub网站中响应API调用的部分;
接下来的一部分:search/repositories让API搜索GitHub上的所有仓库。
repositiories后面的问句指出我们要传递一个实参。q表示查询,而等号让我们能够开始指定查询(q=)。
通过使用language:python,我们指出只想获取主要语言为python的仓库的信息。
最后一部分:&sort=stars指定将项目按其获得的星级进行排序。
不完整结果的值为false,所以我们知道请求成功了。如果 GitHub 不能完全处理 API,它返回的值将为 true。
(2) 处理 API 响应和响应字典:
import requests
#执行API调用并存储响应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json() # 此API返回JSON格式的信息,因此我们使用方法json()转换为python字典!
# 处理结果
print(response_dict.keys())
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
# 探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts)) # 获悉我们获得了多少个仓库的信息
#研究第一个仓库 观察此仓库有哪些键
repo_dict = repo_dicts[0]
print("\nKeys:", len(repo_dict))
for key in sorted(repo_dict.keys()):
print(key)
(3)监控API速率限制:
大多数API都有速率限制,即在一定时间内可以执行的请求数是有限制的。
'''大部分API都存在速率限制,即你在特定时间内可执行的请求数存在限制。
此处是获悉是搜索API的速率限制:
1.每分钟最多可以有多少次请求;
2.在当前这一分钟,我们还可以执行几次请求;
3.配额将重置的时间。
'''
# 监视python_repos.py文件里的url
import requests
import datetime
url = 'https://api.github.com/rate_limit'
var = requests.get(url)
#响应对象中的status_code属性让我们知道请求是否成功!! 状态码200表示请求成功!
print("Status code:",var.status_code)
#将API相应存储在一个变量中
response_dict = var.json()
# 获取配额将重置的Unix时间
Unix_time = response_dict['resources']['search']['reset']
#转换为咱看的明白的时间
China_time = datetime.datetime.fromtimestamp(Unix_time)
print("每分钟最多可以执行的请求数量:",response_dict['resources']['search']['limit'])
print("当前这一分钟内还可以执行的请求数量:",response_dict['resources']['search']['remaining'])
print("配额将重置的时间:",China_time)
(4)使用Pygal可视化仓库:
创建交互式条形图:条形的高度表示该项目获得了多少颗星。单击该栏将带您到 GitHub 上的项目主页!
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
################################################简单实现可视化############################################
# 使用Bar()创建一个简单的条形图, 传入my_style,应用这个样式
#样式实参x_label_rotation=45让标签绕x轴旋转45度;样式实参show_legend=False隐藏图例
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
#设置图表标题
chart.title = "Most-Starred Python Projects on GitHub"
#将属性x_labels设置为列表names
chart.x_labels = names
#将这个数据系列标签设置为空字符串 第二个参数表示工具提示的内容,可变为别的。
chart.add('',stars) #将鼠标指向条形将显示他表示的信息,这通常称为工具提示。
# 生成.svg文件
chart.render_to_file('python_repos.svg')
##########################################################################################################
(5)改进 Pygal 图:
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
#################################################增强版实现可视化###########################################
# 创建一个Pygal类Config的实例,通过修改这个实例的属性,可定制图表的外观
my_config = pygal.Config()
# x轴标签绕x轴旋转45度,隐藏图例
my_config.x_label_rotation = 45
my_config.show_legend = False
# 设置图表标题字体大小
my_config.title_font_size = 24
# 设置副标签的字体大小 此图表中,副标签是x轴上的项目名以及y轴上的大部分数字
my_config.label_font_size = 14
# 设置主标签的字体大小 此图表中,主标签是y轴上为5000整数倍的刻度
my_config.major_label_font_size = 18
# 使用truncate_label将较长的项目名缩短为15个字符(如果将鼠标指向屏幕上被截短的项目名,将显示完整的项目名)
my_config.truncate_label = 15
# 隐藏图表中的水平线
my_config.show_y_guides = False
my_config.width = 1000
# 创建Bar实例时,将my_config作为第一个实参,从而通过一个实参传递了所有的配置设置
chart = pygal.Bar(my_config,style=my_style)
chart.title = "Most-Starred Python Projects on GitHub"
chart.x_labels = names
chart.add('',stars) # 工具提示信息,当鼠标指向条形将显示其星星的颗数。
chart.render_to_file('python_repos_cooler.svg')
(6)添加自定义工具提示:第1部分:添加自定义工具提示学习!
python3.6 pygal模块不交互,图片无法显示数据。猜测原因:可能是pip安装的版本与python3版本不兼容。所以去官网下载Pygal就可以正常使用了!
创建自定义工具提示:显示该项目获得了多少颗星并显示该项目的描述。
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
chart.title = 'Python Projects'
# 可视化三个项目
chart.x_labels = ['httpie', 'django', 'flask']
# 并给每个项目对应的条形都指定自定义标签。所以,向add()传递一个字典列表,而不是值列表!
plot_dicts = [
{'value':16101, 'label': 'Description of httpie.'},
{'value':15028, 'label': 'Description of django.'},
{'value':14798, 'label': 'Description of flask.'},
]
chart.add('', plot_dicts)
chart.render_to_file('bar_descriptions.svg')
Pygal 根据与键“值”关联的数字确定条的高度,并使用与“标签”相关的字符串为条创建工具提示。
这样,显示的工具提示:除了默认的工具提示(获得的星数)外,还会显示我们传入的自定义提示。
第 2 部分:向该项目添加自定义工具提示!
修改以下部分:
(7)在图表中添加一个可点击的链接:
Pygal 根据与键“xlink”关联的 URL 将每个条形转换为活动链接。当你点击图表中的任意一个条时,浏览器会打开一个新标签页,里面会显示对应项目的GitHub页面!
查看全部
从网页抓取数据(使用Web应用编程接口(API)自动请求网站的特定信息
)
介绍 - - - -
使用Web应用程序接口(API)自动请求网站的特定信息而不是整个网页,然后将信息可视化。
Web API 是 网站 的一部分,用于与使用非常特定的 URL 请求特定信息的程序进行交互。这种请求称为 API 调用。请求的数据将以易于处理的格式(例如 JSON 或 CSV)返回。
(1) 使用 API 调用请求数据:
https://api.github.com/search/ ... stars
这个调用返回GitHub当前托管了多少个Python项目,还有有关最受欢迎的Python仓库的信息。
第一部分:https://api.github.com/将请求发送到GitHub网站中响应API调用的部分;
接下来的一部分:search/repositories让API搜索GitHub上的所有仓库。
repositiories后面的问句指出我们要传递一个实参。q表示查询,而等号让我们能够开始指定查询(q=)。
通过使用language:python,我们指出只想获取主要语言为python的仓库的信息。
最后一部分:&sort=stars指定将项目按其获得的星级进行排序。
不完整结果的值为false,所以我们知道请求成功了。如果 GitHub 不能完全处理 API,它返回的值将为 true。
(2) 处理 API 响应和响应字典:
import requests
#执行API调用并存储响应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json() # 此API返回JSON格式的信息,因此我们使用方法json()转换为python字典!
# 处理结果
print(response_dict.keys())
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
# 探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts)) # 获悉我们获得了多少个仓库的信息
#研究第一个仓库 观察此仓库有哪些键
repo_dict = repo_dicts[0]
print("\nKeys:", len(repo_dict))
for key in sorted(repo_dict.keys()):
print(key)
(3)监控API速率限制:
大多数API都有速率限制,即在一定时间内可以执行的请求数是有限制的。
'''大部分API都存在速率限制,即你在特定时间内可执行的请求数存在限制。
此处是获悉是搜索API的速率限制:
1.每分钟最多可以有多少次请求;
2.在当前这一分钟,我们还可以执行几次请求;
3.配额将重置的时间。
'''
# 监视python_repos.py文件里的url
import requests
import datetime
url = 'https://api.github.com/rate_limit'
var = requests.get(url)
#响应对象中的status_code属性让我们知道请求是否成功!! 状态码200表示请求成功!
print("Status code:",var.status_code)
#将API相应存储在一个变量中
response_dict = var.json()
# 获取配额将重置的Unix时间
Unix_time = response_dict['resources']['search']['reset']
#转换为咱看的明白的时间
China_time = datetime.datetime.fromtimestamp(Unix_time)
print("每分钟最多可以执行的请求数量:",response_dict['resources']['search']['limit'])
print("当前这一分钟内还可以执行的请求数量:",response_dict['resources']['search']['remaining'])
print("配额将重置的时间:",China_time)
(4)使用Pygal可视化仓库:
创建交互式条形图:条形的高度表示该项目获得了多少颗星。单击该栏将带您到 GitHub 上的项目主页!
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
################################################简单实现可视化############################################
# 使用Bar()创建一个简单的条形图, 传入my_style,应用这个样式
#样式实参x_label_rotation=45让标签绕x轴旋转45度;样式实参show_legend=False隐藏图例
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
#设置图表标题
chart.title = "Most-Starred Python Projects on GitHub"
#将属性x_labels设置为列表names
chart.x_labels = names
#将这个数据系列标签设置为空字符串 第二个参数表示工具提示的内容,可变为别的。
chart.add('',stars) #将鼠标指向条形将显示他表示的信息,这通常称为工具提示。
# 生成.svg文件
chart.render_to_file('python_repos.svg')
##########################################################################################################
(5)改进 Pygal 图:
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#执行API调用并存储相应
url = 'https://api.github.com/search/ ... 39%3B
r = requests.get(url)
print("Status code:",r.status_code)
#将API响应存储在一个变量中
response_dict = r.json()
# total_count表示GitHub总共有多少个Python项目
print("Total repositories:",response_dict['total_count'])
#探索有关仓库的信息
# 与items相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。
repo_dicts = response_dict['items']
#研究第一个仓库
repo_dict = repo_dicts[0]
# 存储项目名以及相应项目获得的星数
names,stars = [],[]
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
#可视化
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
#################################################增强版实现可视化###########################################
# 创建一个Pygal类Config的实例,通过修改这个实例的属性,可定制图表的外观
my_config = pygal.Config()
# x轴标签绕x轴旋转45度,隐藏图例
my_config.x_label_rotation = 45
my_config.show_legend = False
# 设置图表标题字体大小
my_config.title_font_size = 24
# 设置副标签的字体大小 此图表中,副标签是x轴上的项目名以及y轴上的大部分数字
my_config.label_font_size = 14
# 设置主标签的字体大小 此图表中,主标签是y轴上为5000整数倍的刻度
my_config.major_label_font_size = 18
# 使用truncate_label将较长的项目名缩短为15个字符(如果将鼠标指向屏幕上被截短的项目名,将显示完整的项目名)
my_config.truncate_label = 15
# 隐藏图表中的水平线
my_config.show_y_guides = False
my_config.width = 1000
# 创建Bar实例时,将my_config作为第一个实参,从而通过一个实参传递了所有的配置设置
chart = pygal.Bar(my_config,style=my_style)
chart.title = "Most-Starred Python Projects on GitHub"
chart.x_labels = names
chart.add('',stars) # 工具提示信息,当鼠标指向条形将显示其星星的颗数。
chart.render_to_file('python_repos_cooler.svg')
(6)添加自定义工具提示:第1部分:添加自定义工具提示学习!
python3.6 pygal模块不交互,图片无法显示数据。猜测原因:可能是pip安装的版本与python3版本不兼容。所以去官网下载Pygal就可以正常使用了!
创建自定义工具提示:显示该项目获得了多少颗星并显示该项目的描述。
import requests
import pygal
# 引入要应用于图表的Pygal样式
from pygal.style import LightColorizedStyle as LCS,LightenStyle as LS
#定义一个样式:基色设置为深蓝色;传递实参base_style,以使用LightColorizedStyle类
my_style = LS('#333366',base_style=LCS)
chart = pygal.Bar(style=my_style,x_label_rotation=45,show_legend=False)
chart.title = 'Python Projects'
# 可视化三个项目
chart.x_labels = ['httpie', 'django', 'flask']
# 并给每个项目对应的条形都指定自定义标签。所以,向add()传递一个字典列表,而不是值列表!
plot_dicts = [
{'value':16101, 'label': 'Description of httpie.'},
{'value':15028, 'label': 'Description of django.'},
{'value':14798, 'label': 'Description of flask.'},
]
chart.add('', plot_dicts)
chart.render_to_file('bar_descriptions.svg')
Pygal 根据与键“值”关联的数字确定条的高度,并使用与“标签”相关的字符串为条创建工具提示。
这样,显示的工具提示:除了默认的工具提示(获得的星数)外,还会显示我们传入的自定义提示。
第 2 部分:向该项目添加自定义工具提示!
修改以下部分:
(7)在图表中添加一个可点击的链接:
Pygal 根据与键“xlink”关联的 URL 将每个条形转换为活动链接。当你点击图表中的任意一个条时,浏览器会打开一个新标签页,里面会显示对应项目的GitHub页面!
从网页抓取数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-21 08:19
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。 查看全部
从网页抓取数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
其实大家接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将其导入 PowerBI 后,下一步就是对数据进行处理。这是我们真正需要掌握的核心技能。
从网页抓取数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-17 20:11
昨天在QQ交流群看到一个菜鸟问如何简单分析网站的日志,清楚的知道一个网站的数据抓包情况,抓哪些目录比较好,有哪些IP . 段蜘蛛爬行等。
A 网站 需要发展得更快,走得更远。它离不开日常的数据分析。正如携程网搜索营销部孙波在“首届百度站长交流大会”上所说的那样,渠道改版使用数据模型后,网页的索引量从原来的几十万上升到了5个以上今年百万。这说明数据分析的重要性。
说到日常网站日志分析,这里强调一下需要用到两个工具:Excel和光年日志分析工具。可能有朋友在分析网站的日志时需要用到另外一个工具WebLogExplorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07版或Excel 10版)。在这里,我想和大家简单分享一下我的一些经验。
网站 身体爬取统计:
借助光年日志分析工具,我们可以得到蜘蛛总爬行量,蜘蛛总停留时间,以及各个搜索引擎的蜘蛛访问次数(我只做百度优化,所以说一下百度蜘蛛爬行情况),如图1所示:
只需将上述数据制作成Excel,如图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问次数,计算公式:=D2/B2回车键
单页爬取时间==停留时间*3600/总爬取计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助一个Excel表格,打开日志(最直接的方法是将日志拖入Excel表格中),然后统计蜘蛛状态码,如图3:
通过Excel表格下“数据”功能下的过滤,可以统计出蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛抓取到的状态码200的特征为HTTP/1.1"200,依此类推:状态码500为HTTP/1.1"50< @0、状态码404是HTTP/1.1"404、状态码302是HTTP/1.1"302.....现在你可以过滤掉每个的状态码蜘蛛,如下图所示:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,等等。
Spider IP段统计:
如上图,只需将状态码改为IP段即可,如:HTTP/1.1"200 to 202.108.251.33
目录爬取统计:
如上图,只需将状态码改为对应的目录名即可,如:HTTP/1.1"200 to /tagssearchList/
综上所述:
如何通过简单的Excel来分析网站日志数据,就介绍到这里。不知道各位seo有没有平时分析网站的日志。反正我一般都会分析这些东西。我觉得有必要分析一下网站的日志。至于分析这些数据有什么作用,如何通过这些数据找出网站的不足,然后列出调整方案,逐步调整网站的结构。相信很多人已经写过了,我来了,就不多说了。
谢谢观看 查看全部
从网页抓取数据(携程旅行网页搜索营销部孙波在《首届百度站长交流会》)
昨天在QQ交流群看到一个菜鸟问如何简单分析网站的日志,清楚的知道一个网站的数据抓包情况,抓哪些目录比较好,有哪些IP . 段蜘蛛爬行等。
A 网站 需要发展得更快,走得更远。它离不开日常的数据分析。正如携程网搜索营销部孙波在“首届百度站长交流大会”上所说的那样,渠道改版使用数据模型后,网页的索引量从原来的几十万上升到了5个以上今年百万。这说明数据分析的重要性。
说到日常网站日志分析,这里强调一下需要用到两个工具:Excel和光年日志分析工具。可能有朋友在分析网站的日志时需要用到另外一个工具WebLogExplorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07版或Excel 10版)。在这里,我想和大家简单分享一下我的一些经验。
网站 身体爬取统计:
借助光年日志分析工具,我们可以得到蜘蛛总爬行量,蜘蛛总停留时间,以及各个搜索引擎的蜘蛛访问次数(我只做百度优化,所以说一下百度蜘蛛爬行情况),如图1所示:
只需将上述数据制作成Excel,如图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问次数,计算公式:=D2/B2回车键
单页爬取时间==停留时间*3600/总爬取计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助一个Excel表格,打开日志(最直接的方法是将日志拖入Excel表格中),然后统计蜘蛛状态码,如图3:
通过Excel表格下“数据”功能下的过滤,可以统计出蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛抓取到的状态码200的特征为HTTP/1.1"200,依此类推:状态码500为HTTP/1.1"50< @0、状态码404是HTTP/1.1"404、状态码302是HTTP/1.1"302.....现在你可以过滤掉每个的状态码蜘蛛,如下图所示:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,等等。
Spider IP段统计:
如上图,只需将状态码改为IP段即可,如:HTTP/1.1"200 to 202.108.251.33
目录爬取统计:
如上图,只需将状态码改为对应的目录名即可,如:HTTP/1.1"200 to /tagssearchList/
综上所述:
如何通过简单的Excel来分析网站日志数据,就介绍到这里。不知道各位seo有没有平时分析网站的日志。反正我一般都会分析这些东西。我觉得有必要分析一下网站的日志。至于分析这些数据有什么作用,如何通过这些数据找出网站的不足,然后列出调整方案,逐步调整网站的结构。相信很多人已经写过了,我来了,就不多说了。
谢谢观看
从网页抓取数据(一下Python从零开始的网页抓取过程:安装Python点击下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-17 13:09
有许多不同语言的开源网络抓取程序。
这里分享一下Python从零开始爬取的过程
第 1 步:安装 Python
点击下载合适的版本
我选择安装Python2.7.11
第二步:可以选择安装PythonIDE,这里是PyCharm
点击地址:#section=windows
下载安装后,可以选择新建一个工程,然后将需要编译的py文件放入工程中。
第三步安装参考包
在编译过程中,会发现BeautifulSoup和xlwt这两个包的引用失败。前者是html标签的解析库,后者可以将分析的数据导出为excel文件。
美汤下载
下载
安装方法一样,这里的安装类似于Linux依赖安装包。
常见安装步骤
1.在系统PATH环境变量中添加Python安装目录
2. 解压需要安装的包,打开CMD命令窗口,切换到安装包目录,分别运行python setup.py build和python setup.py install
这样两个包就安装好了
第四步,编译运行
以下是编译执行的抓包代码,可根据实际需要更改。简单的实现网页阅读,数据抓取就很简单了。
#coding:utf-8
import urllib2
import os
import sys
import urllib
import string
from bs4 import BeautifulSoup #导入解析html源码模块
import xlwt #导入excel操作模块
row = 0
style0 = xlwt.easyxf('font: name Times SimSun')
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('Sheet1')
for num in range(1,100):#页数控制
url = "http://www.xxx.com/Suppliers.asp?page="+str(num)+"&hdivision=" #循环ip地址
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer":"http://www.xxx.com/suppliers.asp"
}
req = urllib2.Request(url,data=None,headers=header)
ope = urllib2.urlopen(req)
#请求创建完成
soup = BeautifulSoup(ope.read(), 'html.parser')
url_list = [] #当前url列表
for _ in soup.find_all("td",class_="a_blue"):
companyname=_.a.string.encode('utf-8').replace("\r\n"," ").replace('|','')#公司名称
detailc=''#厂商详情基本信息
a_href='http://www.xxx.com/'+ _.a['href']+'' #二级页面
temphref=_.a['href'].encode('utf-8')
if temphref.find("otherproduct") == -1:
print companyname
print a_href
reqs = urllib2.Request(a_href.encode('utf-8'), data=None, headers=header)
opes = urllib2.urlopen(reqs)
deatilsoup = BeautifulSoup(opes.read(), 'html.parser')
for content in deatilsoup.find_all("table", class_="zh_table"): #输出第一种联系方式详情
detailc=content.text.encode('utf-8').replace("\r\n", "")
#print detailc # 输出详细信息
row = row + 1 # 添加一行
ws.write(row,0,companyname,style0) # 第几行,列1 列2...列n
ws.write(row,1, detailc,style0)
print '正在抓取'+str(row)
wb.save('bio-equip11-20.xls')
print '操作完成!'
运行结束,会在PycharmProjects项目目录下创建一个带有采集好的数据的excel文件。 查看全部
从网页抓取数据(一下Python从零开始的网页抓取过程:安装Python点击下载)
有许多不同语言的开源网络抓取程序。
这里分享一下Python从零开始爬取的过程
第 1 步:安装 Python
点击下载合适的版本
我选择安装Python2.7.11
第二步:可以选择安装PythonIDE,这里是PyCharm
点击地址:#section=windows
下载安装后,可以选择新建一个工程,然后将需要编译的py文件放入工程中。
第三步安装参考包
在编译过程中,会发现BeautifulSoup和xlwt这两个包的引用失败。前者是html标签的解析库,后者可以将分析的数据导出为excel文件。
美汤下载
下载
安装方法一样,这里的安装类似于Linux依赖安装包。
常见安装步骤
1.在系统PATH环境变量中添加Python安装目录
2. 解压需要安装的包,打开CMD命令窗口,切换到安装包目录,分别运行python setup.py build和python setup.py install
这样两个包就安装好了
第四步,编译运行
以下是编译执行的抓包代码,可根据实际需要更改。简单的实现网页阅读,数据抓取就很简单了。
#coding:utf-8
import urllib2
import os
import sys
import urllib
import string
from bs4 import BeautifulSoup #导入解析html源码模块
import xlwt #导入excel操作模块
row = 0
style0 = xlwt.easyxf('font: name Times SimSun')
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('Sheet1')
for num in range(1,100):#页数控制
url = "http://www.xxx.com/Suppliers.asp?page="+str(num)+"&hdivision=" #循环ip地址
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Referer":"http://www.xxx.com/suppliers.asp"
}
req = urllib2.Request(url,data=None,headers=header)
ope = urllib2.urlopen(req)
#请求创建完成
soup = BeautifulSoup(ope.read(), 'html.parser')
url_list = [] #当前url列表
for _ in soup.find_all("td",class_="a_blue"):
companyname=_.a.string.encode('utf-8').replace("\r\n"," ").replace('|','')#公司名称
detailc=''#厂商详情基本信息
a_href='http://www.xxx.com/'+ _.a['href']+'' #二级页面
temphref=_.a['href'].encode('utf-8')
if temphref.find("otherproduct") == -1:
print companyname
print a_href
reqs = urllib2.Request(a_href.encode('utf-8'), data=None, headers=header)
opes = urllib2.urlopen(reqs)
deatilsoup = BeautifulSoup(opes.read(), 'html.parser')
for content in deatilsoup.find_all("table", class_="zh_table"): #输出第一种联系方式详情
detailc=content.text.encode('utf-8').replace("\r\n", "")
#print detailc # 输出详细信息
row = row + 1 # 添加一行
ws.write(row,0,companyname,style0) # 第几行,列1 列2...列n
ws.write(row,1, detailc,style0)
print '正在抓取'+str(row)
wb.save('bio-equip11-20.xls')
print '操作完成!'
运行结束,会在PycharmProjects项目目录下创建一个带有采集好的数据的excel文件。
从网页抓取数据(一下构建网络爬虫的要求及注意事项(一)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-14 21:22
网络爬虫是最常用的从网络中提取数据的工具。要将网络爬虫用于数据采集 或定价情报等长期目的,您需要持续维护爬虫机器人并对其进行妥善管理。本文将重点介绍构建网络爬虫的要求。
1、使用代理
因为很多网页都采取了严格的安全措施来检测机器人活动并屏蔽IP地址。数据提取脚本的工作方式类似于机器人,因为它们在循环中工作并访问抓取路径中的 URL 列表。为了尽量防止IP封禁,保证持续爬取,最好使用代理。在数据提取中,住宅代理是最常用的,因为它们允许用户甚至向由于地理限制而受到限制的站点发送请求。它们绑定到一个物理地址。只要机器人的活动在正常范围内,这些代理就会保持其正常身份,不太可能被禁止。使用代理并不能保证你的IP不会被封,因为网站安全也会检测到代理。
还需要旋转ip访问网站。关于IP轮换的频率或应该使用哪种类型的代理,没有固定的规则,因为这些都取决于您抓取的目标,提取数据的频率等。在爬行时保持真实人类用户的形象尤为重要,这涉及您的位执行其活动的方式。住宅代理也最好使用,因为它们与物理位置相关联,并且 网站 认为来自这里的流量来自真实的人类用户。
2、创建爬取路径
爬取路径是网络爬取等数据提取方法的基础部分。爬取路径是用于提取所需数据的目标网站的URL库。步骤:首先抓取搜索页面-解析商品页面URL-抓取解析后的URL-按照选择的标准解析数据。需要注意的是,数据存储分两步进行:预分析(短期)和长期。为了有效的数据采集过程,采集的数据需要经常更新。
3、构建必要的数据提取脚本
要构建网页抓取脚本,您需要具备一些良好的编程知识。基本的数据提取脚本使用 python,但这不是唯一可用的选项。Python 非常流行,因为它有许多有用的库,使提取、解析和分析过程更容易。步骤:首先确定要提取的数据类型(例如定价数据或产品数据)-找出数据的位置以及如何嵌套-导入必要的库并安装它们-然后编写数据提取脚本。
4、分析和提取数据
在数据分析的过程中,获取的数据变得可理解和可用。许多网页抓取方法提取数据并以人类无法理解的格式呈现,因此需要对其进行解析。由于其优化且易于访问的库,Python 已成为最流行的获取定价数据的编程语言之一。
5、存储提取的数据
数据存储所涉及的程序将取决于所涉及数据的大小和类型。在存储诸如定价情报等连续项目的数据时,需要建立一个专用的数据库。但是如果你将短期项目的所有内容存储在几个 CSV 或 JSON 文件中,那就没问题了。请注意,获得的数据必须是正确的。
综上所述,在数据采集中,长期存储是最后一步。编写脚本、寻找目标、解析和存储数据都是网络抓取中最简单的部分。困难的部分是避免 网站 的防御、机器人检测算法和被阻止的 IP 地址。 查看全部
从网页抓取数据(一下构建网络爬虫的要求及注意事项(一)!)
网络爬虫是最常用的从网络中提取数据的工具。要将网络爬虫用于数据采集 或定价情报等长期目的,您需要持续维护爬虫机器人并对其进行妥善管理。本文将重点介绍构建网络爬虫的要求。
1、使用代理
因为很多网页都采取了严格的安全措施来检测机器人活动并屏蔽IP地址。数据提取脚本的工作方式类似于机器人,因为它们在循环中工作并访问抓取路径中的 URL 列表。为了尽量防止IP封禁,保证持续爬取,最好使用代理。在数据提取中,住宅代理是最常用的,因为它们允许用户甚至向由于地理限制而受到限制的站点发送请求。它们绑定到一个物理地址。只要机器人的活动在正常范围内,这些代理就会保持其正常身份,不太可能被禁止。使用代理并不能保证你的IP不会被封,因为网站安全也会检测到代理。
还需要旋转ip访问网站。关于IP轮换的频率或应该使用哪种类型的代理,没有固定的规则,因为这些都取决于您抓取的目标,提取数据的频率等。在爬行时保持真实人类用户的形象尤为重要,这涉及您的位执行其活动的方式。住宅代理也最好使用,因为它们与物理位置相关联,并且 网站 认为来自这里的流量来自真实的人类用户。
2、创建爬取路径
爬取路径是网络爬取等数据提取方法的基础部分。爬取路径是用于提取所需数据的目标网站的URL库。步骤:首先抓取搜索页面-解析商品页面URL-抓取解析后的URL-按照选择的标准解析数据。需要注意的是,数据存储分两步进行:预分析(短期)和长期。为了有效的数据采集过程,采集的数据需要经常更新。
3、构建必要的数据提取脚本
要构建网页抓取脚本,您需要具备一些良好的编程知识。基本的数据提取脚本使用 python,但这不是唯一可用的选项。Python 非常流行,因为它有许多有用的库,使提取、解析和分析过程更容易。步骤:首先确定要提取的数据类型(例如定价数据或产品数据)-找出数据的位置以及如何嵌套-导入必要的库并安装它们-然后编写数据提取脚本。
4、分析和提取数据
在数据分析的过程中,获取的数据变得可理解和可用。许多网页抓取方法提取数据并以人类无法理解的格式呈现,因此需要对其进行解析。由于其优化且易于访问的库,Python 已成为最流行的获取定价数据的编程语言之一。
5、存储提取的数据
数据存储所涉及的程序将取决于所涉及数据的大小和类型。在存储诸如定价情报等连续项目的数据时,需要建立一个专用的数据库。但是如果你将短期项目的所有内容存储在几个 CSV 或 JSON 文件中,那就没问题了。请注意,获得的数据必须是正确的。
综上所述,在数据采集中,长期存储是最后一步。编写脚本、寻找目标、解析和存储数据都是网络抓取中最简单的部分。困难的部分是避免 网站 的防御、机器人检测算法和被阻止的 IP 地址。
从网页抓取数据(如何从网页抓取数据中获取网页源代码?框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-14 16:01
从网页抓取数据一般有两种方式,一种就是获取网页源代码,一种是从http传递到js脚本。你说到的那种则属于第二种,不是靠爬虫机器人,而是写js脚本,让js去读取网页源代码,转换成json数据,就是你看到的了。
正如前面说的,这个是采用scrapy框架写spider爬取的。在登录器的配置中可以调用spider获取url地址,之后用cookie对url进行拦截解析。
试试scrapy爬虫框架,不要相信exceptionitdoesn'twork之类的,lxml语法不对,
题主是在哪看到的?每次感到恶心的都不止一个。小恶心。每次都在反复出现。不建议一开始接触爬虫。先不要自己去写爬虫框架,最简单的模拟登录模块,爬一个页面。做做爬虫代理池即可。先想想爬虫常用的一些功能。(cookie、robots、token、header设置等)考虑考虑lxml语法(简单爬一个页面即可),再根据自己的实际情况,看看有没有必要学习一下语法。
python和xpath完全不是一个级别的。这两个函数大部分作用域都是限定语句块中某一部分或者某一组语句的。高手千万不要乱用js的__next__方法,把不该替换的换掉。或者lxml里也有可能需要__end__方法转换一下。当你觉得学完这一篇就能爬虫成功的时候。往往有这些坑。先自己维护一个练练手。想起来再更。 查看全部
从网页抓取数据(如何从网页抓取数据中获取网页源代码?框架)
从网页抓取数据一般有两种方式,一种就是获取网页源代码,一种是从http传递到js脚本。你说到的那种则属于第二种,不是靠爬虫机器人,而是写js脚本,让js去读取网页源代码,转换成json数据,就是你看到的了。
正如前面说的,这个是采用scrapy框架写spider爬取的。在登录器的配置中可以调用spider获取url地址,之后用cookie对url进行拦截解析。
试试scrapy爬虫框架,不要相信exceptionitdoesn'twork之类的,lxml语法不对,
题主是在哪看到的?每次感到恶心的都不止一个。小恶心。每次都在反复出现。不建议一开始接触爬虫。先不要自己去写爬虫框架,最简单的模拟登录模块,爬一个页面。做做爬虫代理池即可。先想想爬虫常用的一些功能。(cookie、robots、token、header设置等)考虑考虑lxml语法(简单爬一个页面即可),再根据自己的实际情况,看看有没有必要学习一下语法。
python和xpath完全不是一个级别的。这两个函数大部分作用域都是限定语句块中某一部分或者某一组语句的。高手千万不要乱用js的__next__方法,把不该替换的换掉。或者lxml里也有可能需要__end__方法转换一下。当你觉得学完这一篇就能爬虫成功的时候。往往有这些坑。先自己维护一个练练手。想起来再更。
从网页抓取数据(ebay:如何自己编写网页爬虫了?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-14 02:02
从网页抓取数据,需要开发一个脚本,网页抓取这一块的话,
实际操作请看ebay的一篇文章:morefromebayautomatedscraping看完你就知道该如何自己编写网页爬虫了。
我有一个觉得不错的githubblog叫做releasesay,用egret开发html+css,python,andmysql,shell,erlang的爬虫。配合vscode非常的爽。另外一个是基于python的爬虫-codecalendar,爬虫代码都是github的star来的,重点是做自己的爬虫需要wordpress,两者都有。
我有一些我的markdown教程,可以看看,
有些是爬虫的,有些是自己做的,
你可以这么做:releasesay有针对爬虫的教程
vscode上有一个followup功能,
刚开始可以用google了,熟悉了再学mysql,sql2012还是windows用的方便点,arcgis,googlemap也是可以用的。
其实个人博客不需要爬虫啊,特别是看你爬什么东西,如果是blog或者清楚地道的blog之类的,很明显不用,如果博客之类的不如自己搭一个小网站了,为什么要爬虫?我自己博客也是用flask搭的,
githubfollowup吧,
可以尝试下wen'swonderlandforwordpress 查看全部
从网页抓取数据(ebay:如何自己编写网页爬虫了?-八维教育)
从网页抓取数据,需要开发一个脚本,网页抓取这一块的话,
实际操作请看ebay的一篇文章:morefromebayautomatedscraping看完你就知道该如何自己编写网页爬虫了。
我有一个觉得不错的githubblog叫做releasesay,用egret开发html+css,python,andmysql,shell,erlang的爬虫。配合vscode非常的爽。另外一个是基于python的爬虫-codecalendar,爬虫代码都是github的star来的,重点是做自己的爬虫需要wordpress,两者都有。
我有一些我的markdown教程,可以看看,
有些是爬虫的,有些是自己做的,
你可以这么做:releasesay有针对爬虫的教程
vscode上有一个followup功能,
刚开始可以用google了,熟悉了再学mysql,sql2012还是windows用的方便点,arcgis,googlemap也是可以用的。
其实个人博客不需要爬虫啊,特别是看你爬什么东西,如果是blog或者清楚地道的blog之类的,很明显不用,如果博客之类的不如自己搭一个小网站了,为什么要爬虫?我自己博客也是用flask搭的,
githubfollowup吧,
可以尝试下wen'swonderlandforwordpress
从网页抓取数据(【技巧】从网页抓取数据的话,原理很简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-11 03:00
从网页抓取数据的话,原理很简单,是因为爬虫在爬取这个网页的时候,总会对网页源代码进行解析,而这个解析是一个很简单的方法就是使用js动态生成,比如webpack就可以对assets/js文件进行构建,然后从webpack.config.js文件中获取文件配置信息或文件体积信息,从而完成对文件的获取。这个解析动作,为我们做数据抓取提供了很好的途径。
网页全生成下来,并打包在浏览器打开,那么这个网页就是一个dom对象,那么我们就可以进行对它的dom操作,例如做上标、下标的操作,方法就是生成锚点,然后进行上下标操作。这里面要注意几点,我们不能为了上下标操作,而生成xpath这种不规范的文档类型,要不得到的就是一堆不规范的属性名。每次只需要将要操作的文档绑定到事件就行,只要是浏览器就可以执行。
从http获取数据,我的理解大概有三种方式:方式一:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如taobao.js。方式二:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如京东.js。方式三:爬虫所有的请求,都是一个json对象,这些json对象,是提供了一些信息的,同时也是一个数据库。
我们可以通过数据库来爬取数据,爬取成功后通过jsonp的方式返回结果到http中,就可以解析了。当然,其实还有一些别的方式,只是我现在用的最多的就是前两种。但是,如果想要了解更多,可以先去看一下这篇文章,很短,但可以了解下基本技术。爬虫在抓取京东的数据一次爬取京东的上百万条数据的详细方法和注意事项-呆顶兔-博客园呆顶兔-博客园。 查看全部
从网页抓取数据(【技巧】从网页抓取数据的话,原理很简单)
从网页抓取数据的话,原理很简单,是因为爬虫在爬取这个网页的时候,总会对网页源代码进行解析,而这个解析是一个很简单的方法就是使用js动态生成,比如webpack就可以对assets/js文件进行构建,然后从webpack.config.js文件中获取文件配置信息或文件体积信息,从而完成对文件的获取。这个解析动作,为我们做数据抓取提供了很好的途径。
网页全生成下来,并打包在浏览器打开,那么这个网页就是一个dom对象,那么我们就可以进行对它的dom操作,例如做上标、下标的操作,方法就是生成锚点,然后进行上下标操作。这里面要注意几点,我们不能为了上下标操作,而生成xpath这种不规范的文档类型,要不得到的就是一堆不规范的属性名。每次只需要将要操作的文档绑定到事件就行,只要是浏览器就可以执行。
从http获取数据,我的理解大概有三种方式:方式一:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如taobao.js。方式二:在项目的根目录生成一个js文件,然后对这个js文件进行解析,获取网页中的数据。例如京东.js。方式三:爬虫所有的请求,都是一个json对象,这些json对象,是提供了一些信息的,同时也是一个数据库。
我们可以通过数据库来爬取数据,爬取成功后通过jsonp的方式返回结果到http中,就可以解析了。当然,其实还有一些别的方式,只是我现在用的最多的就是前两种。但是,如果想要了解更多,可以先去看一下这篇文章,很短,但可以了解下基本技术。爬虫在抓取京东的数据一次爬取京东的上百万条数据的详细方法和注意事项-呆顶兔-博客园呆顶兔-博客园。
从网页抓取数据(如何快速从大量的cookie值都传给服务器?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-09 08:17
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐htmlparser,但是通过我个人的对比,我发现htmlparser在效率和简单性上都远不如NSoup)
由于网上的NSoup教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我从来不知道我必须亲自去做。 查看全部
从网页抓取数据(如何快速从大量的cookie值都传给服务器?)
4.输入账号密码,确认登录,得到如下数据:
关注POST请求中的Url和postdata,以及服务器返回的cookies
cookie 收录登录信息。为安全起见,我们可以将所有 4 个 cookie 值都传递给服务器。
首先给出C#发送POST请求的代码:(目的是获取服务器返回的cookie)
string Url = "URL";
string postDataStr = "POST Data";//因为上面都是离散的键值对,我们可以从Stream中直接找到postDataStr
//登录并获取cookie
HttpPost(Url, postDataStr, ref cookie);
private string HttpPost(string Url, string postDataStr, ref CookieContainer cookie)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
byte[] postData = Encoding.UTF8.GetBytes(postDataStr);
request.ContentLength = postData.Length;
request.CookieContainer = cookie;
Stream myRequestStream = request.GetRequestStream();
myRequestStream.Write(postData, 0, postData.Length);
myRequestStream.Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
response.Cookies = cookie.GetCookies(response.ResponseUri);
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
有了cookie后,就可以从网站中抓取自己需要的数据,下一步就是发送GET请求
因为服务器返回的是html,如何从大量的html中快速获取到需要的信息?在这里,我们可以参考一个高效强大的第三方库NSoup(网上也有人推荐htmlparser,但是通过我个人的对比,我发现htmlparser在效率和简单性上都远不如NSoup)
由于网上的NSoup教程比较好,也可以参考JSoup的教程:
最后,给我一些我从 网站 抓取的数据:
纸上谈兵,我从来不知道我必须亲自去做。
从网页抓取数据(使用Python模块htmldate的核心操作(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 399 次浏览 • 2021-12-04 23:19
Web 数据挖掘涉及数据处理中的大量设计决策和转折点。根据数据采集的目的,可能还需要广泛的过滤和质量评估。虽然可以预期一些大规模的算法可以消除不规则性,但低误差率的需要和仔细阅读方法的使用(例如在字典研究中搜索示例)意味着数据集在构建和处理方面的不断改进和改进.
将整个页面与正文内容区分开来有助于缓解与网页文本相关的许多质量问题:如果正文太短或多余,则可能没有必要使用它。尽管它对于消除 Web 文档的重复很有用,但与内容提取相关的其他任务也受益于更清晰的文本库,因为它可以处理“真实”内容。在语言和词典研究的特定情况下,它允许对文档中真正重要的部分进行内容检查(例如语言检测)。
网页内容提取的挑战
随着文本语料库、文本类型和用例的类型越来越多,针对给定的研究目标评估某些网络数据的充分性和质量变得越来越困难。语料库构建的核心操作包括保留所需内容和丢弃其余内容。这个任务的很多名称都是指特殊的子任务或整体:网页抓取、模板移除或模板检测、网页模板检测、网页清理或网络内容提取-最近的概述请参考Lejeune&Zhu (2018) .
最近,使用 CommonCrawl 的方法蓬勃发展,因为它们允许通过跳过(或更准确地外包)爬行阶段来加速下载和处理。虽然我认为通过 Web 找到自己的“自己的”方式与某些使用场景非常相关,但很明显,CommonCrawl 数据不应该在没有过滤的情况下使用,它也可以从更精细的元数据中受益。
我已经写了关于使用 Python 模块 htmldate 从 HTML 页面提取日期的正在进行的工作,现在我将介绍我的处理链的第二个组件:trafilatura,一个用于文本提取的 Python 库。它侧重于主要内容,通常是中心显示的部分,没有左右栏、页眉或页脚,但包括潜在的标题和评论。
介绍使用 Trafilatura 进行文本抓取
Trafilatura 是一个 Python 库,旨在下载、解析和抓取网络数据。它还提供了可以轻松帮助 网站 从站点地图和提要中导航和提取链接的工具。
其主要目的是找到网页的相关和原创文本部分,并去除由重复元素(页眉和页脚、广告、链接/博客等)组成的噪音。它必须足够精确,不会遗漏文本或丢弃有效文档,而且还必须非常快,因为预计它会在生产中运行数百万页。
Trafilatura 抓取网页的主要文本,同时保留一些结构。此任务也称为模板移除、基于 DOM 的内容提取、主要内容识别或 HTML 文本清理。处理结果可以是 TXT、CSV、JSON 和 XML 格式。在后一种情况下,诸如文本格式(粗体、斜体等)和页面结构(段落、标题、列表、链接、图像等)等基本格式元素将被保留,然后可用于进一步处理。
这个库主要面向语言分析,但可以用于许多不同的目的。从语言的角度来看,特别是与“预网络”和一般语料相比,网络语料构建的挑战在于能够对生成的网络文本进行提取和预处理,最终使它们在一个描述清晰、连贯的集合中可用.
因此,trafilatura 具有注释提取(与其余部分分开)、用于句子、段落和文档级别重复检测的最近最少使用 (LRU) 缓存、与文本编码倡议 (XMLTEI) 建议兼容的 XML 输出以及基于语言的内容提取检测。
该库适用于所有常见版本的 Python,可以按如下方式安装:
$ pip install trafilatura # pip3(如果适用)
与 Python 一起使用
该库收录一系列 Python 函数,可以轻松重用并适应各种开发设置:
>>> 导入 trafilatura >>> 下载 = trafilatura 。fetch_url ( 'https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/' ) >>> trafilatura 。extract ( downloaded ) # 将主要内容和评论输出为纯文本... >>> trafilatura . extract ( downloaded , xml_output = True , include_comments = False ) # 输出没有注释的主要内容为 XML ...
这些值的组合可能提供最快的执行时间,但不一定包括所有可用的文本段:
>>> 结果 = 提取(已下载, include_comments = False , include_tables = False , no_fallback = True )
输入可以由先前解析的树(即 lxml.html 对象)组成,然后无缝处理:
>>> 从 lxml 导入 html >>> mytree = html 。fromstring ( '<p>这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet, consectetur adipiscing elit, sed do eiusmod tempor incidundunt ut Labore et dolore magna aliqua。' ) >>> extract ( mytree ) '这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet,consectetur adipiscing elit,sed do eiusmod tempor incididunt ut Labore et dolore magna aliqua。</p>
函数bare_extraction 可用于绕过转换并直接使用和转换原创输出:它返回元数据(作为字典)和文本和注释的Python 变量(均作为LXML 对象)。
>>> 从 trafilatura 导入 裸提取 >>> 裸提取(已下载)
在命令行上使用
Trafilatura 收录一个命令行界面,无需编写代码即可轻松使用。
$ trafilatura -u "https://www.scientificamerican ... ot%3B
'帖子更新于 2013 年 8 月 13 日,上午 11:18 这是世界大象日。(谁知道?!)这里有一个关于我们称为大象的长鼻类动物正在进行的传奇的清醒更新。...' $ trafilatura -h # 显示所有可用选项
以下参数组合允许批量下载(包括 URLlinks.txt)、在单独的目录中备份 HTML 源代码、将提取的文本转换和存储为 XML。这对于存档和进一步处理特别有用:
$ trafilatura --inputfile links.txt --outputdir 转换/ --backup-dir html-sources/ --xml
潜在的替代品
虽然一些相应的 Python 包没有积极维护,但以下用于网页文本提取的替代方案包括:
一个保持文本结构完整但不关注文本的库
Trafilatura 具有许多有用的功能,例如元数据、文本和评论提取以及提要和站点地图中的链接发现。仅在文本提取方面,其性能已经明显优于现有替代品,请参考以下抓取质量对比:
另一个问题可能是缺少与文档存储和处理的常见需求相对应的输出格式:库可以将结果转换为 CSV、JSON、XML 和 XMLTEI。
参考: 查看全部
从网页抓取数据(使用Python模块htmldate的核心操作(一)(图))
Web 数据挖掘涉及数据处理中的大量设计决策和转折点。根据数据采集的目的,可能还需要广泛的过滤和质量评估。虽然可以预期一些大规模的算法可以消除不规则性,但低误差率的需要和仔细阅读方法的使用(例如在字典研究中搜索示例)意味着数据集在构建和处理方面的不断改进和改进.
将整个页面与正文内容区分开来有助于缓解与网页文本相关的许多质量问题:如果正文太短或多余,则可能没有必要使用它。尽管它对于消除 Web 文档的重复很有用,但与内容提取相关的其他任务也受益于更清晰的文本库,因为它可以处理“真实”内容。在语言和词典研究的特定情况下,它允许对文档中真正重要的部分进行内容检查(例如语言检测)。
网页内容提取的挑战
随着文本语料库、文本类型和用例的类型越来越多,针对给定的研究目标评估某些网络数据的充分性和质量变得越来越困难。语料库构建的核心操作包括保留所需内容和丢弃其余内容。这个任务的很多名称都是指特殊的子任务或整体:网页抓取、模板移除或模板检测、网页模板检测、网页清理或网络内容提取-最近的概述请参考Lejeune&Zhu (2018) .
最近,使用 CommonCrawl 的方法蓬勃发展,因为它们允许通过跳过(或更准确地外包)爬行阶段来加速下载和处理。虽然我认为通过 Web 找到自己的“自己的”方式与某些使用场景非常相关,但很明显,CommonCrawl 数据不应该在没有过滤的情况下使用,它也可以从更精细的元数据中受益。
我已经写了关于使用 Python 模块 htmldate 从 HTML 页面提取日期的正在进行的工作,现在我将介绍我的处理链的第二个组件:trafilatura,一个用于文本提取的 Python 库。它侧重于主要内容,通常是中心显示的部分,没有左右栏、页眉或页脚,但包括潜在的标题和评论。
介绍使用 Trafilatura 进行文本抓取
Trafilatura 是一个 Python 库,旨在下载、解析和抓取网络数据。它还提供了可以轻松帮助 网站 从站点地图和提要中导航和提取链接的工具。
其主要目的是找到网页的相关和原创文本部分,并去除由重复元素(页眉和页脚、广告、链接/博客等)组成的噪音。它必须足够精确,不会遗漏文本或丢弃有效文档,而且还必须非常快,因为预计它会在生产中运行数百万页。
Trafilatura 抓取网页的主要文本,同时保留一些结构。此任务也称为模板移除、基于 DOM 的内容提取、主要内容识别或 HTML 文本清理。处理结果可以是 TXT、CSV、JSON 和 XML 格式。在后一种情况下,诸如文本格式(粗体、斜体等)和页面结构(段落、标题、列表、链接、图像等)等基本格式元素将被保留,然后可用于进一步处理。
这个库主要面向语言分析,但可以用于许多不同的目的。从语言的角度来看,特别是与“预网络”和一般语料相比,网络语料构建的挑战在于能够对生成的网络文本进行提取和预处理,最终使它们在一个描述清晰、连贯的集合中可用.
因此,trafilatura 具有注释提取(与其余部分分开)、用于句子、段落和文档级别重复检测的最近最少使用 (LRU) 缓存、与文本编码倡议 (XMLTEI) 建议兼容的 XML 输出以及基于语言的内容提取检测。
该库适用于所有常见版本的 Python,可以按如下方式安装:
$ pip install trafilatura # pip3(如果适用)
与 Python 一起使用
该库收录一系列 Python 函数,可以轻松重用并适应各种开发设置:
>>> 导入 trafilatura >>> 下载 = trafilatura 。fetch_url ( 'https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/' ) >>> trafilatura 。extract ( downloaded ) # 将主要内容和评论输出为纯文本... >>> trafilatura . extract ( downloaded , xml_output = True , include_comments = False ) # 输出没有注释的主要内容为 XML ...
这些值的组合可能提供最快的执行时间,但不一定包括所有可用的文本段:
>>> 结果 = 提取(已下载, include_comments = False , include_tables = False , no_fallback = True )
输入可以由先前解析的树(即 lxml.html 对象)组成,然后无缝处理:
>>> 从 lxml 导入 html >>> mytree = html 。fromstring ( '<p>这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet, consectetur adipiscing elit, sed do eiusmod tempor incidundunt ut Labore et dolore magna aliqua。' ) >>> extract ( mytree ) '这是正文。它必须足够长才能绕过安全检查。Lorem ipsum dolor sat amet,consectetur adipiscing elit,sed do eiusmod tempor incididunt ut Labore et dolore magna aliqua。</p>
函数bare_extraction 可用于绕过转换并直接使用和转换原创输出:它返回元数据(作为字典)和文本和注释的Python 变量(均作为LXML 对象)。
>>> 从 trafilatura 导入 裸提取 >>> 裸提取(已下载)
在命令行上使用
Trafilatura 收录一个命令行界面,无需编写代码即可轻松使用。
$ trafilatura -u "https://www.scientificamerican ... ot%3B
'帖子更新于 2013 年 8 月 13 日,上午 11:18 这是世界大象日。(谁知道?!)这里有一个关于我们称为大象的长鼻类动物正在进行的传奇的清醒更新。...' $ trafilatura -h # 显示所有可用选项
以下参数组合允许批量下载(包括 URLlinks.txt)、在单独的目录中备份 HTML 源代码、将提取的文本转换和存储为 XML。这对于存档和进一步处理特别有用:
$ trafilatura --inputfile links.txt --outputdir 转换/ --backup-dir html-sources/ --xml
潜在的替代品
虽然一些相应的 Python 包没有积极维护,但以下用于网页文本提取的替代方案包括:
一个保持文本结构完整但不关注文本的库
Trafilatura 具有许多有用的功能,例如元数据、文本和评论提取以及提要和站点地图中的链接发现。仅在文本提取方面,其性能已经明显优于现有替代品,请参考以下抓取质量对比:
另一个问题可能是缺少与文档存储和处理的常见需求相对应的输出格式:库可以将结果转换为 CSV、JSON、XML 和 XMLTEI。
参考:
从网页抓取数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-04 23:00
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,可以抓取需要登录的页面,所以我们可能需要在多个Request之间保持登录状态。 查看全部
从网页抓取数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
在ASP.NET中抓取网页内容非常方便,其中解决了ASP中困扰我们的编码问题。
1、获取一般内容
需要三个类:WebRequest、WebResponse、StreamReader
需要的命名空间:System.Net、System.IO
核心代码:
WebRequest类的Create是一个静态方法,参数是要爬取的网页的URL;
Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
2、抓取图片或其他二进制文件(如文件)
需要四个类:WebRequest、WebResponse、Stream、FileStream
需要的命名空间:System.Net、System.IO
核心代码:用Stream读取
3、抓取网页内容的POST方法
在抓取网页时,有时需要通过Post将一些数据发送到服务器。在网页抓取程序中添加如下代码,将用户名和密码发布到服务器:
4、ASP.NET 抓取网页内容-防止重定向
在网页爬取过程中,在成功登录服务器应用系统后,应用系统可能会通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response.Write 出来时,就可以了。
5、ASP.NET 抓取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,可以抓取需要登录的页面,所以我们可能需要在多个Request之间保持登录状态。
从网页抓取数据(我试图从下面的晨星网站上抓取数据:我目前遇到的问题与我抓取的更简单的网页不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-02 16:11
我尝试从以下 Morningstar网站 获取数据:
我目前只想成为 IBM,但我希望最终我可以输入另一家公司的代码并与该公司做同样的事情。到目前为止,我的代码如下:
import requests, os, bs4, string
url = 'http://financials.morningstar. ... 3B%3B
fin_tbl = ()
page = requests.get(url)
c = page.content
soup = bs4.BeautifulSoup(c, "html.parser")
summary = soup.find("div", {"class":"r_bodywrap"})
tables = summary.find_all('table')
print(tables[0])
我目前遇到的问题与我抓取的较简单的网页不同。该程序似乎无法找到任何表格,尽管我可以在页面的 HTML 中看到它们。
在研究这个问题时,最接近的stackoverflow问题如下:
Python webscraping-NoneObeject 失败-损坏的 HTML?
在那篇文章文章中,他们解释说Morningstar的表是动态加载的,并使用了一些我不熟悉的json代码,并以某种方式生成了不同的网络链接,我设法抓取了该链接,但我不明白它来自哪里? 查看全部
从网页抓取数据(我试图从下面的晨星网站上抓取数据:我目前遇到的问题与我抓取的更简单的网页不同)
我尝试从以下 Morningstar网站 获取数据:
我目前只想成为 IBM,但我希望最终我可以输入另一家公司的代码并与该公司做同样的事情。到目前为止,我的代码如下:
import requests, os, bs4, string
url = 'http://financials.morningstar. ... 3B%3B
fin_tbl = ()
page = requests.get(url)
c = page.content
soup = bs4.BeautifulSoup(c, "html.parser")
summary = soup.find("div", {"class":"r_bodywrap"})
tables = summary.find_all('table')
print(tables[0])
我目前遇到的问题与我抓取的较简单的网页不同。该程序似乎无法找到任何表格,尽管我可以在页面的 HTML 中看到它们。
在研究这个问题时,最接近的stackoverflow问题如下:
Python webscraping-NoneObeject 失败-损坏的 HTML?
在那篇文章文章中,他们解释说Morningstar的表是动态加载的,并使用了一些我不熟悉的json代码,并以某种方式生成了不同的网络链接,我设法抓取了该链接,但我不明白它来自哪里?
从网页抓取数据(如何应对数据匮乏?最简单的方法在这里!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-01 06:20
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
目录 3 种流行的 Python 网络爬虫工具和库 网络爬虫组件 抓取解析和转换存储 从网页中抓取 URL 和电子邮件 ID 抓取图片 当页面加载时抓取数据 3 种流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
从网页抓取数据(如何应对数据匮乏?最简单的方法在这里!!)
介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。现在,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
目录 3 种流行的 Python 网络爬虫工具和库 网络爬虫组件 抓取解析和转换存储 从网页中抓取 URL 和电子邮件 ID 抓取图片 当页面加载时抓取数据 3 种流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网络爬虫组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""Web Scraping - Beautiful Soup"""# importing required librariesimport requestsfrom bs4 import BeautifulSoupimport pandas as pd# target URL to scrapurl = "https://www.goibibo.com/hotels ... 3B%23 headersheaders = { 'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" }# send request to download the dataresponse = requests.request("GET", url, headers=headers)# parse the downloaded datadata = BeautifulSoup(response.text, 'html.parser')print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class namecards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})# total number of cardsprint('Total Number of Cards Found : ', len(cards_data))# source code of hotel cardsfor card in cards_data: print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per roomfor card in cards_data: # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the datascraped_data = []for card in cards_data: # initialize the dictionary card_details = {} # get the hotel name hotel_name = card.find('p') # get the room price room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'}) # add data to the dictionary card_details['hotel_name'] = hotel_name.text card_details['room_price'] = room_price.text # append the scraped data to the list scraped_data.append(card_details)# create a data frame from the list of dictionariesdataFrame = pd.DataFrame.from_dict(scraped_data)# save the scraped data as CSV filedataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网页抓取功能抓取的两个最常见的功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
从网页抓取数据(你期待已久的Python网络数据爬虫教程来了。(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-25 16:15
)
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。
(由于微信公众号外部链接的限制,文章中的部分链接可能无法正确打开,如有需要,请点击文章末尾的“阅读原文”按钮访问该版本可以正常显示外链。)
需要
我在公众号后台,经常能收到读者的评论。
许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:
一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。
我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
前两种方法我已经做了一些介绍,这次就说说爬虫。
概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网页抓取软件可以直接使用超文本传输协议或通过网页浏览器访问万维网。
如果看到了,即使是用浏览器手动复制数据,也叫网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为您完成网页抓取,才是您真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花20%的努力去理解一件事的80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常有用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。
假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。
打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
pipenv install
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
在这里,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。
请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
from requests_html import HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
session = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
url = 'https://www.jianshu.com/p/85f4624485b9'
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,直接看正文部分。
所以我们执行:
print(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个链接,相对于我们网页采集所在域名()的路径。
就像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,前面不需要加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:
这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。
为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
查看全部
从网页抓取数据(你期待已久的Python网络数据爬虫教程来了。(二)
)
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。
(由于微信公众号外部链接的限制,文章中的部分链接可能无法正确打开,如有需要,请点击文章末尾的“阅读原文”按钮访问该版本可以正常显示外链。)
需要
我在公众号后台,经常能收到读者的评论。
许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。
但是,有些评论乍一看并不清楚。
例如,以下内容:
一分钟后,他可能觉得不对劲(可能是我想起来了,我用简体中文写了文章),于是又用简体中文发了一遍。
我突然恍然大悟。
这位读者以为我的公众号设置了关键词推送对应的文章功能。所以在阅读了我的其他数据科学教程后,我想看一下“爬虫”这个话题。
抱歉,我当时没有写爬虫。文章。
而且我的公众号暂时没有这种关键词推送。
主要是因为我懒。
这样的消息收到了很多,也能体会到读者的需求。不止一位读者表示对爬虫教程感兴趣。
如前所述,目前主流和合法的网络数据采集方式主要分为三类:
前两种方法我已经做了一些介绍,这次就说说爬虫。
概念
很多读者对爬虫的定义有些困惑。我们需要对其进行分析。
维基百科是这样说的:
网络爬虫(英文:web crawler),又称网络蜘蛛(spider),是一种用于自动浏览万维网的网络机器人。它的目的一般是编译一个网络索引。
这是问题。您不打算成为搜索引擎。为什么您对网络爬虫如此热衷?
事实上,很多人所指的网络爬虫与另一个功能“网页抓取”混淆了。
在维基百科上,后者解释如下:
网页抓取、网页采集或网页数据提取是用于从网站提取数据的数据抓取。网页抓取软件可以直接使用超文本传输协议或通过网页浏览器访问万维网。
如果看到了,即使是用浏览器手动复制数据,也叫网页抓取。你是不是立刻觉得自己强大了很多?
然而,这个定义还没有结束:
虽然网络抓取可以由软件用户手动完成,但该术语通常是指使用机器人或网络爬虫实现的自动化流程。
换句话说,使用爬虫(或机器人)自动为您完成网页抓取,才是您真正想要的。
数据有什么用?
通常,首先将其存储并放置在数据库或电子表格中以供检索或进一步分析。
所以,你真正想要的功能是这样的:
找到链接,获取网页,抓取指定信息,并存储。
这个过程可能会反过来,甚至滚雪球。
您想以自动化的方式完成它。
知道了这一点,您应该停止盯着爬虫。爬虫的开发目的是为搜索引擎索引数据库。您已经在轰炸蚊子以获取一些数据并使用它。
要真正掌握爬虫,需要有很多基础知识。比如HTML、CSS、Javascript、数据结构……
这也是我一直犹豫要不要写爬虫教程的原因。
不过这两天看到王朔编辑的一段话,很有启发:
我喜欢讲一个替代的八分之二定律,就是花20%的努力去理解一件事的80%。
既然我们的目标很明确,那就是从网络上抓取数据。那么你需要掌握的最重要的能力就是如何快速有效地从一个网页链接中抓取你想要的信息。
一旦你掌握了它,你不能说你已经学会了爬行。
但是有了这个基础,您可以比以前更轻松地获取数据。尤其是对于很多“文科生”的应用场景,非常有用。这就是赋权。
而且,更容易进一步了解爬虫的工作原理。
这可以看作是对“第二十八条替代法”的应用。
Python 语言的重要特性之一是它可以使用强大的软件工具包(其中许多由第三方提供)。您只需要编写一个简单的程序即可自动解析网页并抓取数据。
本文向您展示了这个过程。
目标
为了抓取网络数据,我们首先设定一个小目标。
目标不能太复杂。但要完成它,它应该可以帮助您了解 Web Scraping。
随便选一本我最近出版的小书文章作为爬取的目标。题目是《如何用《玉树智兰》入门数据科学?》。
在这个文章中,我重新整理了一下之前发布的数据科学系列文章。
这篇文章收录许多来自以前教程的标题和相应的链接。例如下图中红色边框包围的部分。
假设你对文章中提到的教程很感兴趣,希望得到这些文章的链接并存入Excel,如下图:
您需要提取和存储非结构化的分散信息(自然语言文本中的链接)。
我们对于它可以做些什么呢?
即使不会编程,也可以通读全文,一一找到这些文章链接,手动复制文章标题和链接分别保存在Excel表格中.
但是,这种手动采集 方法效率不高。
我们使用 Python。
环境
要安装 Python,更简单的方法是安装 Anaconda 包。
请到此网站下载最新版本的 Anaconda。
请选择左侧的Python3.6版本下载安装。
如果您需要具体的分步说明,或者想知道如何在Windows平台上安装和运行Anaconda命令,请参考我为您准备的视频教程。
安装Anaconda后,请到本网站下载本教程的压缩包。
下载解压后,会在生成的目录(以下简称“demo目录”)中看到如下三个文件。
打开终端,使用cd命令进入demo目录。如果不知道怎么使用,也可以参考视频教程。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv
这里安装的是一个优秀的Python包管理工具pipenv。
安装完成后,请执行:
pipenv install
有没有看到demo目录下Pipfile开头的两个文件?它们是pipenv的配置文件。
pipenv 工具会根据它们自动安装我们需要的所有依赖包。
上图中有一个绿色的进度条,表示要安装的软件数量和实际进度。
安装完成后,按照提示执行:
pipenv shell
在这里,请确保您的计算机上已安装 Google Chrome 浏览器。
我们执行:
jupyter notebook
默认浏览器(谷歌浏览器)会打开并启动 Jupyter notebook 界面:
可以直接点击文件列表中的第一个ipynb文件,查看本教程的所有示例代码。
可以一边看教程,一边一一执行这些代码。
但是,我建议的方法是返回主界面并创建一个新的空白 Python 3 notebook。
请按照教程一一输入相应的内容。这可以帮助您更深入地理解代码的含义并更有效地内化您的技能。
准备工作结束,下面开始正式输入代码。
代码
读取网页进行分析抓取,需要用到的软件包是requests_html。我们这里不需要这个包的所有功能,只要读取里面的HTMLSession即可。
from requests_html import HTMLSession
然后,我们建立一个会话,即让 Python 作为客户端与远程服务器进行对话。
session = HTMLSession()
前面提到过,我们计划采集信息的网页是“如何使用“玉树智兰”开始数据科学?“一篇文章。
我们找到它的 URL 并将其存储在 url 变量名称中。
url = 'https://www.jianshu.com/p/85f4624485b9'
下面的语句使用session的get函数来获取这个链接对应的整个网页。
r = session.get(url)
网页里有什么?
我们告诉 Python 将服务器返回的内容视为 HTML 文件类型。不想看HTML中乱七八糟的格式描述符,直接看正文部分。
所以我们执行:
print(r.html.text)
这是得到的结果:
我们心里清楚。检索到的网页信息正确,内容完整。
好吧,让我们来看看如何接近我们的目标。
我们首先使用简单粗暴的方法尝试获取网页中收录的所有链接。
将返回的内容作为HTML文件类型,我们检查links属性:
r.html.links
这是返回的结果:
这么多链接!
兴奋的?
但是你找到了吗?这里的许多链接似乎不完整。比如第一个结果,只有:
'/'
这是什么?是链接抓取错误吗?
不,这种看起来不像链接的东西叫做相对链接。它是一个链接,相对于我们网页采集所在域名()的路径。
就像我们在国内邮寄快递包裹,一般填表的时候写“XX省,XX市……”,前面不需要加国名。只有国际快递,才需要写国名。
但是如果我们想要获取所有可以直接访问的链接呢?
这很简单,只需要一个 Python 语句。
r.html.absolute_links
在这里,我们想要的是一个“绝对”链接,所以我们会得到以下结果:
这次感觉好些了吗?
我们的任务已经完成了吧?链接不都在这里吗?
链接确实在这里,但它们与我们的目标不同吗?
检查它,确实如此。
我们不仅要找到链接,还要找到链接对应的描述文字。是否收录在结果中?
不。
结果列表中的链接是我们所需要的吗?
不。看长度,我们可以感觉到很多链接不是文中描述的其他数据科学文章的URL。
这种直接列出 HTML 文件中所有链接的简单粗暴的方法不适用于此任务。
那么我们应该怎么做呢?
我们必须学会清楚地告诉 Python 我们在寻找什么。这是网络爬行的关键。
想一想,如果你想要一个助手(人类)为你做这件事怎么办?
你会告诉他:
》找到文本中所有可以点击的蓝色文本链接,将文本复制到Excel表格中,然后右键复制对应的链接,复制到Excel表格中。每个链接在Excel中占一行,然后文本和链接各占一个单元格。”
虽然这个操作执行起来比较麻烦,但是小助手在理解之后可以帮你执行。
同样的描述,你试着告诉电脑……对不起,它不明白。
因为你和你的助手看到的网页是这样的。
电脑看到的网页是这样的。
为了让大家看清楚源码,浏览器还特意用颜色来区分不同类型的数据,并对行进行编号。
当数据显示到电脑上时,上述辅助视觉功能不可用。它只能看到字符串。
我能做什么?
仔细观察,你会发现在这些HTML源代码中,在文字和图片链接内容前后都有一些用尖括号括起来的部分,称为“标记”。
所谓HTML就是一种标记语言(HyperText Markup Language)。
商标的作用是什么?它可以将整个文件分解为多个层。
从网页抓取数据(阿里巴巴alibaba的开源项目gistobj方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 19:08
从网页抓取数据,网页上没有的数据我们才要从的数据中提取,不然像标题,卖家标价,库存等数据抓不到,抓不到我们就只能靠猜测,猜测的结果会有误差的,数据越新鲜误差越大。其次,我们每天需要不停的抓取数据,我们每抓取一个数据就像开启了一个抓包工具,发送一个http请求给你,你得到了对方的响应数据,你再分析,改进你的抓包方法。总结一下,就是勤学苦练,苦练到对基本的抓包都精通了。
像阿里云,github的开源项目,他们都是直接在本地运行java开发的,如果你会编程语言的话,就可以很轻松的实现,最多你按照他们的要求加上一些apis,
有一个概念叫做封装java接口不知道你听过没有
用java实现网页抓取可以参考这个题目
可以参考阿里巴巴alibaba的开源项目gistobj,可以尝试抓取整个集团上千亿商品的数据,不需要技术,就可以开发一个抓取工具。
补充楼上几个,java是单片机开发,web页面开发,抓取,分析集合在一起一起搞定的工具alibaba/gistobj这里只是就gistobj而言的。alibaba还有一系列大数据处理的工具,可以加到这些java的web工具里面,不只是抓取一个功能。
抓取一个产品所有数据,应该这个,我看过的,百度搜索结果页是有地区分布的,你可以找些代码,抓取出来每个城市的搜索量就行。 查看全部
从网页抓取数据(阿里巴巴alibaba的开源项目gistobj方法)
从网页抓取数据,网页上没有的数据我们才要从的数据中提取,不然像标题,卖家标价,库存等数据抓不到,抓不到我们就只能靠猜测,猜测的结果会有误差的,数据越新鲜误差越大。其次,我们每天需要不停的抓取数据,我们每抓取一个数据就像开启了一个抓包工具,发送一个http请求给你,你得到了对方的响应数据,你再分析,改进你的抓包方法。总结一下,就是勤学苦练,苦练到对基本的抓包都精通了。
像阿里云,github的开源项目,他们都是直接在本地运行java开发的,如果你会编程语言的话,就可以很轻松的实现,最多你按照他们的要求加上一些apis,
有一个概念叫做封装java接口不知道你听过没有
用java实现网页抓取可以参考这个题目
可以参考阿里巴巴alibaba的开源项目gistobj,可以尝试抓取整个集团上千亿商品的数据,不需要技术,就可以开发一个抓取工具。
补充楼上几个,java是单片机开发,web页面开发,抓取,分析集合在一起一起搞定的工具alibaba/gistobj这里只是就gistobj而言的。alibaba还有一系列大数据处理的工具,可以加到这些java的web工具里面,不只是抓取一个功能。
抓取一个产品所有数据,应该这个,我看过的,百度搜索结果页是有地区分布的,你可以找些代码,抓取出来每个城市的搜索量就行。
从网页抓取数据(从网页抓取数据是互联网爬虫的最重要能力之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-22 06:03
从网页抓取数据是互联网行业最基础的需求之一,自主爬虫能力就是互联网爬虫的最重要能力之一。自主爬虫在开源的互联网产品之中可选择的就更多了,
一、请求第一种方式是发起http请求,由于互联网起源于http协议,所以对于爬虫来说,都是使用http协议的方式发起。
最简单的有两种:1.静态html格式请求
1)查看url和cookie是否存在可以通过程序判断,
2)单页面html请求js在页面中会被拦截在浏览器上执行js。2.scrapy爬虫请求scrapy框架自带了http请求的方法,同时还提供了json、html和xml的解析方法。这些方法里可以判断是否存在scrapy.url和scrapy.urllibjson对象。3.请求get请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#判断请求类型第一种方式的请求url里有很多加粗的http协议字段,比如http://、http://、http://等,这些字段是固定的协议代码,它们都不包含业务语义,一旦加载请求就不会被改变,页面中显示的网址通常也不会变。
第二种方式的请求url里有较多的"encoding"字段,如gzip'3'、utf-8'8'等,这些协议代码要求传送的是utf-8或utf-8字节的数据,例如。值得注意的是,第二种方式要求对http报文进行整理,从报文的中剔除冗余和无意义的部分。
timeout=http。query_fastreport('获取信息时间')url=';management=spell31/'time_producer=selector。select(url)callback=time_producer。request(url)print(url)4。post请求#抓取互联网信息selector=scrapy。
field()criteria={'xxxxx':'location。here'}#如果请求url是post方式,需要进行以下检查headers={'x-requested-with':'xxx'}#headers中的'x-requested-with'会代表每次发起请求时,在页面返回之前,你可以明确地执行schedule_activated()方法检查所请求页面的资源是否包含正在运行的爬虫#注意:headers中的x-requested-with如果没有获取对应的网址,则无法执行schedule_activated()方法检查,如果你设置对应的资源,则schedule_activated方法会让每次请求,都去请求那个页面的列表request(url)请求activated()请求成功。
二、post请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#在写爬虫的过程中, 查看全部
从网页抓取数据(从网页抓取数据是互联网爬虫的最重要能力之一)
从网页抓取数据是互联网行业最基础的需求之一,自主爬虫能力就是互联网爬虫的最重要能力之一。自主爬虫在开源的互联网产品之中可选择的就更多了,
一、请求第一种方式是发起http请求,由于互联网起源于http协议,所以对于爬虫来说,都是使用http协议的方式发起。
最简单的有两种:1.静态html格式请求
1)查看url和cookie是否存在可以通过程序判断,
2)单页面html请求js在页面中会被拦截在浏览器上执行js。2.scrapy爬虫请求scrapy框架自带了http请求的方法,同时还提供了json、html和xml的解析方法。这些方法里可以判断是否存在scrapy.url和scrapy.urllibjson对象。3.请求get请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#判断请求类型第一种方式的请求url里有很多加粗的http协议字段,比如http://、http://、http://等,这些字段是固定的协议代码,它们都不包含业务语义,一旦加载请求就不会被改变,页面中显示的网址通常也不会变。
第二种方式的请求url里有较多的"encoding"字段,如gzip'3'、utf-8'8'等,这些协议代码要求传送的是utf-8或utf-8字节的数据,例如。值得注意的是,第二种方式要求对http报文进行整理,从报文的中剔除冗余和无意义的部分。
timeout=http。query_fastreport('获取信息时间')url=';management=spell31/'time_producer=selector。select(url)callback=time_producer。request(url)print(url)4。post请求#抓取互联网信息selector=scrapy。
field()criteria={'xxxxx':'location。here'}#如果请求url是post方式,需要进行以下检查headers={'x-requested-with':'xxx'}#headers中的'x-requested-with'会代表每次发起请求时,在页面返回之前,你可以明确地执行schedule_activated()方法检查所请求页面的资源是否包含正在运行的爬虫#注意:headers中的x-requested-with如果没有获取对应的网址,则无法执行schedule_activated()方法检查,如果你设置对应的资源,则schedule_activated方法会让每次请求,都去请求那个页面的列表request(url)请求activated()请求成功。
二、post请求#抓取互联网信息selector=scrapy.field()criteria={'xxxxx':'location.here'}#在写爬虫的过程中,

