
querylist采集微信公众号文章
querylist采集微信公众号文章(querylist采集微信公众号文章列表url,不能传递给其他用户)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-02-19 11:01
querylist采集微信公众号文章列表url,如果是公众号文章的话,采集下一篇文章,
这是一篇微信公众号文章的下一篇文章,即不能传递给其他用户,也不能传递给群发外链的用户,如果不想发给群发外链的朋友,
基本上常用的方法还是爬虫,爬公众号文章内容。webservice什么的,
这个爬虫还行,不过一般不会用,因为流量来源没准,有很大可能找不到真正的爬虫。
你可以把文章列表分段遍历
这个还是有点不错的,可以采集公众号内容,
可以考虑用pythonflask框架写爬虫.用beautifulsoup库,基本可以满足你的需求.beautifulsoup不是为爬虫服务的,他是做api/xpath解析或xml解析用的.你这个是转换列表文章,让别人来爬你的吧.
beautifulsoup写爬虫还行吧
这个好像不能,
先要弄清楚一个事情,网站内容都是微信公众号服务号提供的,不能像知乎这样存。
可以用知乎采集
你有两个选择一个是用爬虫,一个是用思科的机器人软件。两个都是工具没有内容抽取这个功能。
拿爬虫去爬微信公众号文章或者qq空间文章或者百度新闻看看有没有给文章贴链接。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章列表url,不能传递给其他用户)
querylist采集微信公众号文章列表url,如果是公众号文章的话,采集下一篇文章,
这是一篇微信公众号文章的下一篇文章,即不能传递给其他用户,也不能传递给群发外链的用户,如果不想发给群发外链的朋友,
基本上常用的方法还是爬虫,爬公众号文章内容。webservice什么的,
这个爬虫还行,不过一般不会用,因为流量来源没准,有很大可能找不到真正的爬虫。
你可以把文章列表分段遍历
这个还是有点不错的,可以采集公众号内容,
可以考虑用pythonflask框架写爬虫.用beautifulsoup库,基本可以满足你的需求.beautifulsoup不是为爬虫服务的,他是做api/xpath解析或xml解析用的.你这个是转换列表文章,让别人来爬你的吧.
beautifulsoup写爬虫还行吧
这个好像不能,
先要弄清楚一个事情,网站内容都是微信公众号服务号提供的,不能像知乎这样存。
可以用知乎采集
你有两个选择一个是用爬虫,一个是用思科的机器人软件。两个都是工具没有内容抽取这个功能。
拿爬虫去爬微信公众号文章或者qq空间文章或者百度新闻看看有没有给文章贴链接。
querylist采集微信公众号文章(querylist采集微信公众号文章存储格式接口介绍参考资料)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-02-18 10:01
querylist采集微信公众号文章,发布到一个querylist文件,
一、querylist接口:1.
1、文章行接口#{0}即文章的标题#{1}即文章的作者#{2}即文章的标签。
2、文章列表接口2.
1、文章列表类:#{1}#{2}即文章的标题:#{2}#{3}即文章的标签:#{3}#{4}即分享链接:#{4}2.
2、图文消息类:#{1}#{2}#{3}即图文消息的标题:#{2}#{3}#{4}即分享链接:#{4}2.
3、公众号文章列表接口#{0}接口介绍#{1}接口介绍#{2}接口介绍#{3}接口介绍参考资料:对于文章列表,每一个标题后面都需要加#{0},以下是图文消息的二维码。
二、存储格式querylist接口中的string字符串存储格式如下:order+*,即***的序列。
java对象,可以让querylist支持索引并存储二级索引:在mybatis中,或者在rabbitmq中,索引可以支持一个或多个,但是如果接收的是二级索引的话,需要提供一个名称实体:@mapped(mappedinfo,mappedname)publicclassorderedescription{@value("id")privateintid;@value("name")privatestringname;}2。
可以建立多个查询,但是有时候,并不能满足查询的很多需求@mapped(mappedinfo,mappedname)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){returnnull;}//。
1)建立一个新的查询@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){try{newquerylist();}catch(exceptione){e。printstacktrace();}}//。
2)对查询结果进行修改update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。printstacktrace();2。2。可以查看不同的类型的文章,endpoint=null不代表不能查询,代表建立新的查询@mapped(mappedinfo。
id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。
printstacktrace();}}}2。3。可以对返回结果集进行排序@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章存储格式接口介绍参考资料)
querylist采集微信公众号文章,发布到一个querylist文件,
一、querylist接口:1.
1、文章行接口#{0}即文章的标题#{1}即文章的作者#{2}即文章的标签。
2、文章列表接口2.
1、文章列表类:#{1}#{2}即文章的标题:#{2}#{3}即文章的标签:#{3}#{4}即分享链接:#{4}2.
2、图文消息类:#{1}#{2}#{3}即图文消息的标题:#{2}#{3}#{4}即分享链接:#{4}2.
3、公众号文章列表接口#{0}接口介绍#{1}接口介绍#{2}接口介绍#{3}接口介绍参考资料:对于文章列表,每一个标题后面都需要加#{0},以下是图文消息的二维码。
二、存储格式querylist接口中的string字符串存储格式如下:order+*,即***的序列。
java对象,可以让querylist支持索引并存储二级索引:在mybatis中,或者在rabbitmq中,索引可以支持一个或多个,但是如果接收的是二级索引的话,需要提供一个名称实体:@mapped(mappedinfo,mappedname)publicclassorderedescription{@value("id")privateintid;@value("name")privatestringname;}2。
可以建立多个查询,但是有时候,并不能满足查询的很多需求@mapped(mappedinfo,mappedname)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){returnnull;}//。
1)建立一个新的查询@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){try{newquerylist();}catch(exceptione){e。printstacktrace();}}//。
2)对查询结果进行修改update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。printstacktrace();2。2。可以查看不同的类型的文章,endpoint=null不代表不能查询,代表建立新的查询@mapped(mappedinfo。
id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。
printstacktrace();}}}2。3。可以对返回结果集进行排序@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)。
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-02-15 18:00
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接安装即可。安装后直接运行C:\Program Files\nodejs\npm.cmd会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
只要把一个安卓模拟器放到网上,有很多。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ----------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令开启代理服务。 (记得加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会使用这个。现在用浏览器打开网页::8002/ 这是anyproxy的web界面,用来显示http传输数据。
点击上方红框内的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开公众号文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框内是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部畅通了,就可以往下走。
这里我们是靠代理服务抓取微信数据,但是不能自己抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺理成章理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。有需要的可以试试。 查看全部
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接安装即可。安装后直接运行C:\Program Files\nodejs\npm.cmd会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
只要把一个安卓模拟器放到网上,有很多。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ----------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令开启代理服务。 (记得加参数!)

记住这个ip和端口,那么安卓模拟器的代理就会使用这个。现在用浏览器打开网页::8002/ 这是anyproxy的web界面,用来显示http传输数据。
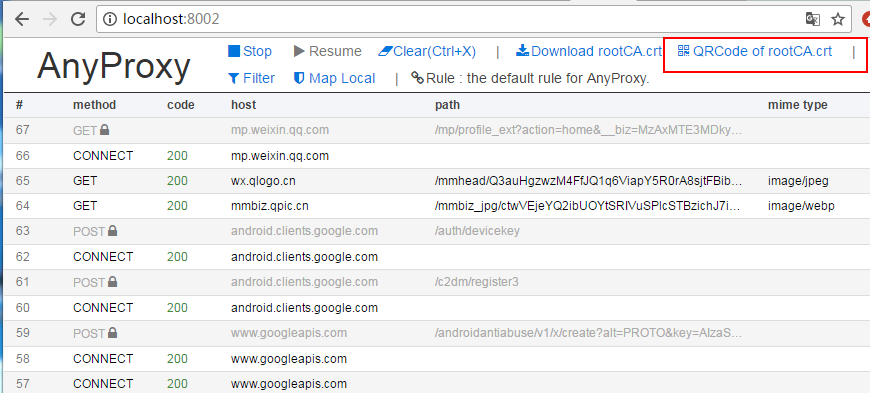
点击上方红框内的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
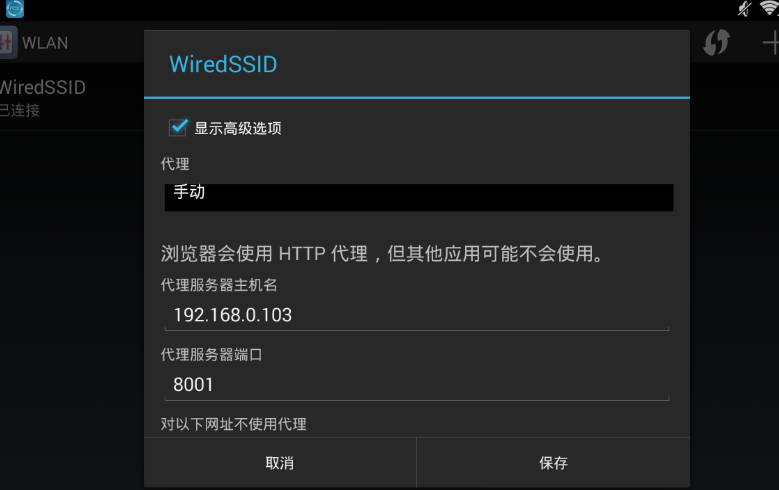
准备工作到这里基本完成。在模拟器上打开微信,打开公众号文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
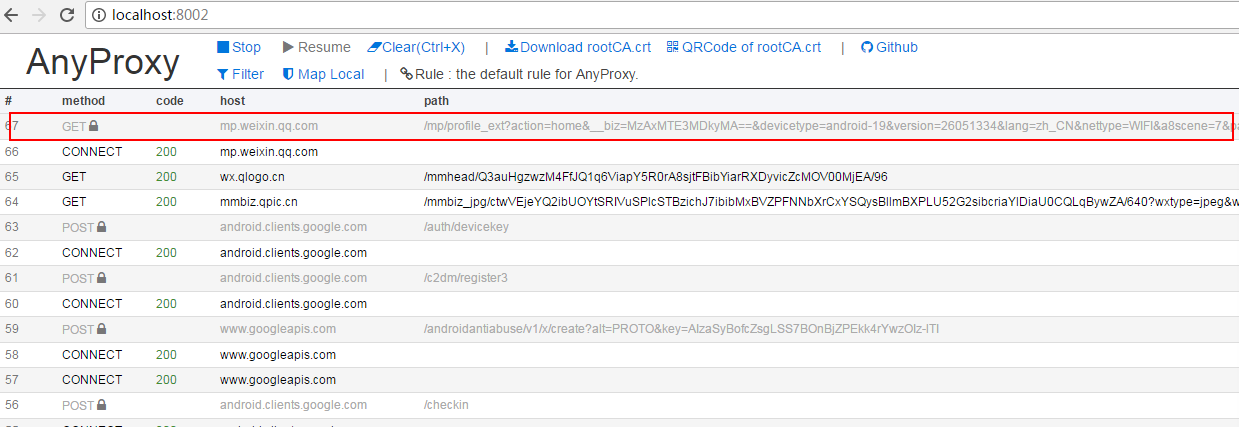
上图红框内是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部畅通了,就可以往下走。
这里我们是靠代理服务抓取微信数据,但是不能自己抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺理成章理解就好,问题不大。

1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。有需要的可以试试。
querylist采集微信公众号文章(搜狗搜索有个不足实现公众号的爬虫需要安装 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-14 04:15
)
因为搜狗搜索有微信公众号搜索的接口,所以可以通过这个接口实现公众号的爬虫。
需要安装几个python库:selenium、pyquery
我们也用到了phantomjs.exe,需要自己下载,然后放到我们自己的python项目下。
在输入框中输入你要爬取的公众号的微信号,然后搜索公众号,
可以出现搜索结果,进入首页可以看到公众号最近发布的文章,点击标题查看文章的内容
这种思路,可以在网页上查看微信公众号的推送,实现公众号爬虫;但搜狗搜索有个缺点,只能查看公众号最近发布的10条推送,无法查看过去的历史记录。
有了爬虫思路后,就开始执行流程,先拿到搜狗搜索的接口
通过这个接口可以得到公众号首页的入口,文章列表,文章内容,用python写爬虫的实现,下面是运行结果,得到< @文章 标题、文章 链接、文章 简要说明、发表时间、封面图片链接、文章 内容,并将抓取的信息保存到文本文档中,文章@ > 公众号爬取结束。
废话不多说,代码如下:
from pyquery import PyQuery as pq
from selenium import webdriver
import os
import re
import requests
import time
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
browser = webdriver.PhantomJS(executable_path=r'phantomjs.exe')
browser.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
return html
def log(msg):
print('%s: %s' % (time.strftime('%Y-%m-%d %H:%M:%S'), msg))
# 创建公众号命名的文件夹
def create_dir():
if not os.path.exists(keyword):
os.makedirs(keyword)
# 将获取到的文章转换为字典
def switch_articles_to_list(articles):
articles_list = []
i = 1
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article, i))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article, i):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 获取文章内容(pyQuery.text / html)
#log('content是')
#log(parse_content_by_url(url))
content = parse_content_by_url(url).text()
log('获取到content')
# 存储文章到本地
#content_file_title = keyword + '/' + str(i) + '_' + title + '_' + date + '.html'
#with open(content_file_title, 'w', encoding='utf-8') as f:
# f.write(content)
content_title = keyword + '/' + keyword + '.txt'
with open(content_title, 'a', encoding='utf-8') as f:
print('第', i, '条', file=f)
print('title:', title, file=f)
print('url:', url, file=f)
print('summary:', summary, file=f)
print('date:', date, file=f)
print('pic:', pic, file=f)
print('content:', content, file=f)
print(file=f)
log('写入content')
article_dict = {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic,
'content': content
}
return article_dict
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 获取文章页面详情
def parse_content_by_url(url):
page_html = get_selenium_js_html(url)
return pq(page_html)('#js_content')
'''程序入口'''
keyword = 'python'
create_dir()
url = 'http://weixin.sogou.com/weixin?query=%s' % keyword
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
try:
log(u'开始调用sougou搜索引擎')
r = requests.get(url, headers=headers)
r.raise_for_status()
print(r.status_code)
print(r.request.url)
print(len(r.text))
#print(r.text)
#print(re.Session().get(url).text)
except:
print('爬取失败')
# 获得公众号主页地址
doc = pq(r.text)
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
home_url = doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
log(u'获取wx_url成功,%s' % home_url)
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
log(u'开始调用selenium渲染公众号主页html')
html = get_selenium_js_html(home_url)
#有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试
if pq(html)('#verify_change').text() != '':
log(u'爬虫被目标网站封锁,请稍后再试')
else:
log(u'调用selenium渲染html完成,开始解析公众号文章')
doc = pq(html)
articles = doc('div[class="weui_media_box appmsg"]')
#print(articles)
log(u'抓取到微信文章%d篇' % len(articles))
article_list = switch_articles_to_list(articles)
print(article_list)
log('程序结束') 查看全部
querylist采集微信公众号文章(搜狗搜索有个不足实现公众号的爬虫需要安装
)
因为搜狗搜索有微信公众号搜索的接口,所以可以通过这个接口实现公众号的爬虫。

需要安装几个python库:selenium、pyquery
我们也用到了phantomjs.exe,需要自己下载,然后放到我们自己的python项目下。
在输入框中输入你要爬取的公众号的微信号,然后搜索公众号,

可以出现搜索结果,进入首页可以看到公众号最近发布的文章,点击标题查看文章的内容

这种思路,可以在网页上查看微信公众号的推送,实现公众号爬虫;但搜狗搜索有个缺点,只能查看公众号最近发布的10条推送,无法查看过去的历史记录。
有了爬虫思路后,就开始执行流程,先拿到搜狗搜索的接口
通过这个接口可以得到公众号首页的入口,文章列表,文章内容,用python写爬虫的实现,下面是运行结果,得到< @文章 标题、文章 链接、文章 简要说明、发表时间、封面图片链接、文章 内容,并将抓取的信息保存到文本文档中,文章@ > 公众号爬取结束。
废话不多说,代码如下:
from pyquery import PyQuery as pq
from selenium import webdriver
import os
import re
import requests
import time
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
browser = webdriver.PhantomJS(executable_path=r'phantomjs.exe')
browser.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
return html
def log(msg):
print('%s: %s' % (time.strftime('%Y-%m-%d %H:%M:%S'), msg))
# 创建公众号命名的文件夹
def create_dir():
if not os.path.exists(keyword):
os.makedirs(keyword)
# 将获取到的文章转换为字典
def switch_articles_to_list(articles):
articles_list = []
i = 1
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article, i))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article, i):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 获取文章内容(pyQuery.text / html)
#log('content是')
#log(parse_content_by_url(url))
content = parse_content_by_url(url).text()
log('获取到content')
# 存储文章到本地
#content_file_title = keyword + '/' + str(i) + '_' + title + '_' + date + '.html'
#with open(content_file_title, 'w', encoding='utf-8') as f:
# f.write(content)
content_title = keyword + '/' + keyword + '.txt'
with open(content_title, 'a', encoding='utf-8') as f:
print('第', i, '条', file=f)
print('title:', title, file=f)
print('url:', url, file=f)
print('summary:', summary, file=f)
print('date:', date, file=f)
print('pic:', pic, file=f)
print('content:', content, file=f)
print(file=f)
log('写入content')
article_dict = {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic,
'content': content
}
return article_dict
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 获取文章页面详情
def parse_content_by_url(url):
page_html = get_selenium_js_html(url)
return pq(page_html)('#js_content')
'''程序入口'''
keyword = 'python'
create_dir()
url = 'http://weixin.sogou.com/weixin?query=%s' % keyword
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
try:
log(u'开始调用sougou搜索引擎')
r = requests.get(url, headers=headers)
r.raise_for_status()
print(r.status_code)
print(r.request.url)
print(len(r.text))
#print(r.text)
#print(re.Session().get(url).text)
except:
print('爬取失败')
# 获得公众号主页地址
doc = pq(r.text)
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
home_url = doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
log(u'获取wx_url成功,%s' % home_url)
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
log(u'开始调用selenium渲染公众号主页html')
html = get_selenium_js_html(home_url)
#有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试
if pq(html)('#verify_change').text() != '':
log(u'爬虫被目标网站封锁,请稍后再试')
else:
log(u'调用selenium渲染html完成,开始解析公众号文章')
doc = pq(html)
articles = doc('div[class="weui_media_box appmsg"]')
#print(articles)
log(u'抓取到微信文章%d篇' % len(articles))
article_list = switch_articles_to_list(articles)
print(article_list)
log('程序结束')
querylist采集微信公众号文章(excel添加索引就行的两种解决方法:)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-12 02:02
querylist采集微信公众号文章链接,转换为excel格式,用rust实现中间转换器。定义excel转换器对象publicstaticlistexceltransform.newarray(nextnext,exceltype.literal,prev){prev.add(nextnext);returnprev;}定义prev对象:rust>>>arr:=newrust()>>>arr[5]:=prev>>>arr[5]list.newarray(nextnext,exceltype.pointer).add_many_numbers(nextnext,。
1)>>>arr[5]:=newrust()>>>arr[1]:=prev>>>arr[1]newarray
5).add_many_numbers
0)转换后为:tarray:=prevrust>>>arr:=arr[5]newarray
0)>>>arr[1]:=prevlist.newarray
1)>>>arr[5]:=arr[5]
excel添加索引就行。
说下这个问题的两种解决方法:1.每一个excel文件作为一个字典。每一个字符对应一个key。每一个key值对应一个value。对于输入的value,可以一次生成多列,int或者long变量。可以比较多个一行输入的excel文件,实时添加到字典,把所有输入的value组合成一个词典。也可以根据string输入的唯一标识+某个trait定义出来的对应关系。
2.对于excel数据量更多的话,可以采用用string和property机制来处理,可以自定义各个headerdeleteheaderint等。 查看全部
querylist采集微信公众号文章(excel添加索引就行的两种解决方法:)
querylist采集微信公众号文章链接,转换为excel格式,用rust实现中间转换器。定义excel转换器对象publicstaticlistexceltransform.newarray(nextnext,exceltype.literal,prev){prev.add(nextnext);returnprev;}定义prev对象:rust>>>arr:=newrust()>>>arr[5]:=prev>>>arr[5]list.newarray(nextnext,exceltype.pointer).add_many_numbers(nextnext,。
1)>>>arr[5]:=newrust()>>>arr[1]:=prev>>>arr[1]newarray
5).add_many_numbers
0)转换后为:tarray:=prevrust>>>arr:=arr[5]newarray
0)>>>arr[1]:=prevlist.newarray
1)>>>arr[5]:=arr[5]
excel添加索引就行。
说下这个问题的两种解决方法:1.每一个excel文件作为一个字典。每一个字符对应一个key。每一个key值对应一个value。对于输入的value,可以一次生成多列,int或者long变量。可以比较多个一行输入的excel文件,实时添加到字典,把所有输入的value组合成一个词典。也可以根据string输入的唯一标识+某个trait定义出来的对应关系。
2.对于excel数据量更多的话,可以采用用string和property机制来处理,可以自定义各个headerdeleteheaderint等。
querylist采集微信公众号文章( 一种微信公众号是否有敏感词汇的检测方法及装置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-02-10 22:22
一种微信公众号是否有敏感词汇的检测方法及装置)
本发明属于微信公众号广告投放领域,具体涉及一种微信公众号是否存在敏感词的检测方法及装置。
背景技术:
微信公众平台主要面向名人、政府、媒体、企业等机构发起的合作推广业务。在这里,品牌可以通过渠道推广到线上平台。微信公众号广告是一种常见的广告推广方式。
但微信公众号是否带有政治色彩是企业在投放广告时需要考虑的,以免出现不必要的问题,影响企业的投资回报。投资回报是指应该通过投资获得回报的价值,即企业从一项投资活动中获得的经济回报,需要能够判断微信公众号是否有敏感词的技术。
技术实施要素:
本发明提供一种检测微信公众号是否有敏感词的方法及装置,旨在解决无法判断微信公众号是否有敏感词的问题。
本发明是这样实现的,一种检测微信公众号是否有敏感词的方法,包括以下步骤:
s1、提取微信公众号历史文章数据,手动标注文章是否有敏感词;
s2、清洗文章数据,训练word2vec模型作为训练数据,分割文章词得到embedding,最后训练双向bilstm深度学习模型;
s3、获取微信公众号预设数量的待预测历史文章数据,清洗数据,获取embedding,使用训练好的双向bilstm深度学习模型进行预测,每< @文章是否有敏感词汇的预测结果;
<p>s4、根据预设个数文章中有敏感词的文章个数,计算出有敏感词的文章个数占所有 查看全部
querylist采集微信公众号文章(
一种微信公众号是否有敏感词汇的检测方法及装置)

本发明属于微信公众号广告投放领域,具体涉及一种微信公众号是否存在敏感词的检测方法及装置。
背景技术:
微信公众平台主要面向名人、政府、媒体、企业等机构发起的合作推广业务。在这里,品牌可以通过渠道推广到线上平台。微信公众号广告是一种常见的广告推广方式。
但微信公众号是否带有政治色彩是企业在投放广告时需要考虑的,以免出现不必要的问题,影响企业的投资回报。投资回报是指应该通过投资获得回报的价值,即企业从一项投资活动中获得的经济回报,需要能够判断微信公众号是否有敏感词的技术。
技术实施要素:
本发明提供一种检测微信公众号是否有敏感词的方法及装置,旨在解决无法判断微信公众号是否有敏感词的问题。
本发明是这样实现的,一种检测微信公众号是否有敏感词的方法,包括以下步骤:
s1、提取微信公众号历史文章数据,手动标注文章是否有敏感词;
s2、清洗文章数据,训练word2vec模型作为训练数据,分割文章词得到embedding,最后训练双向bilstm深度学习模型;
s3、获取微信公众号预设数量的待预测历史文章数据,清洗数据,获取embedding,使用训练好的双向bilstm深度学习模型进行预测,每< @文章是否有敏感词汇的预测结果;
<p>s4、根据预设个数文章中有敏感词的文章个数,计算出有敏感词的文章个数占所有
querylist采集微信公众号文章(每天更新视频:熊孩子和萌宠搞笑视频,笑声不断快乐常伴 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-02-08 22:10
)
每天更新视频:熊孩子的日常生活,萌宠的日常生活,熊孩子和萌宠的搞笑视频,笑声不断伴随着快乐!
获取公众号信息
标题、摘要、封面、文章URL
脚步:
1、先申请公众号
2、登录您的帐户,创建一个新的文章 图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史记录文章
4、通过抓包获取信息,定位到请求的url
通过查看信息,我们找到了我们需要的关键内容:title、abstract、cover 和 文章 URL,并确定这就是我们需要的 URL。通过点击下一页,多次获取url,发现只有random和bengin的参数变化
所以主要信息URL是可以的。
那么让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
这两个值的来源,可以得到url
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
得到结果(成功):
获取 文章 里面的视频
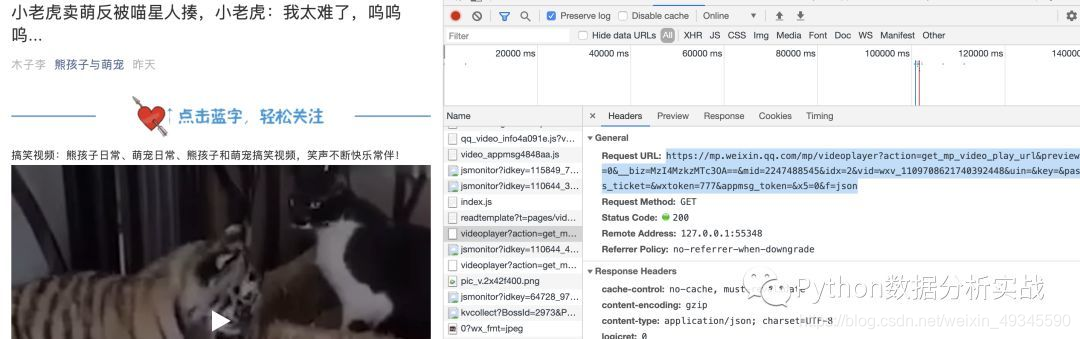
实现批量下载通过分析单个视频文章,找到了这个链接:
打开网页找到,也就是视频的网页下载链接:
嘿嘿,好像有点意思。找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。我不知道它是从哪里来的?
与获取的其他信息无关,只能强制。
该参数在单文章的url请求信息中找到,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,代码就组装好了。
一个。获取公众号信息
湾。筛选单个文章信息
C。获取视频信息
d。拼接视频页面下载地址
e. 下载视频并保存
代码实验结果:
查看全部
querylist采集微信公众号文章(每天更新视频:熊孩子和萌宠搞笑视频,笑声不断快乐常伴
)
每天更新视频:熊孩子的日常生活,萌宠的日常生活,熊孩子和萌宠的搞笑视频,笑声不断伴随着快乐!
获取公众号信息
标题、摘要、封面、文章URL
脚步:
1、先申请公众号
2、登录您的帐户,创建一个新的文章 图形,然后单击超链接
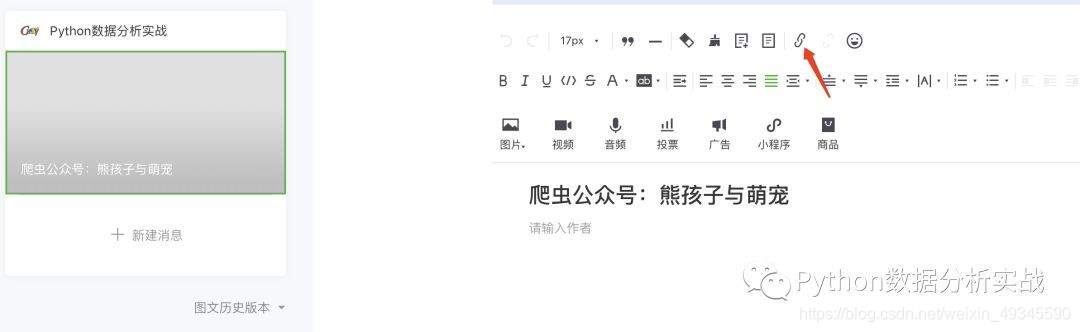
3、弹出搜索框,搜索你需要的公众号,查看历史记录文章
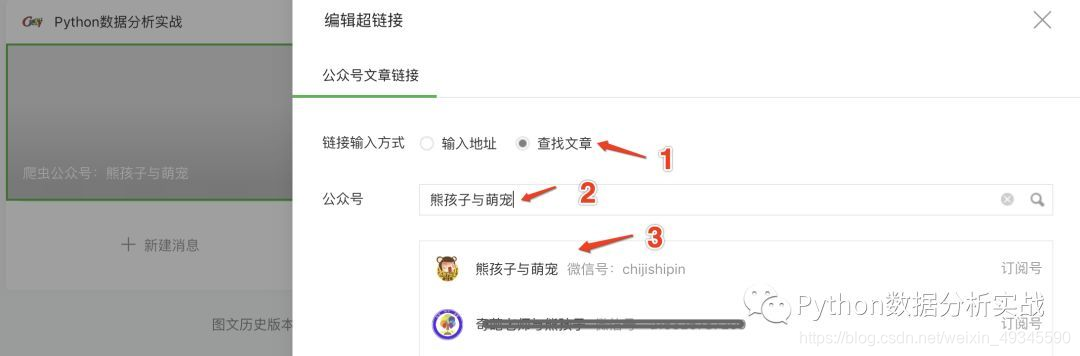
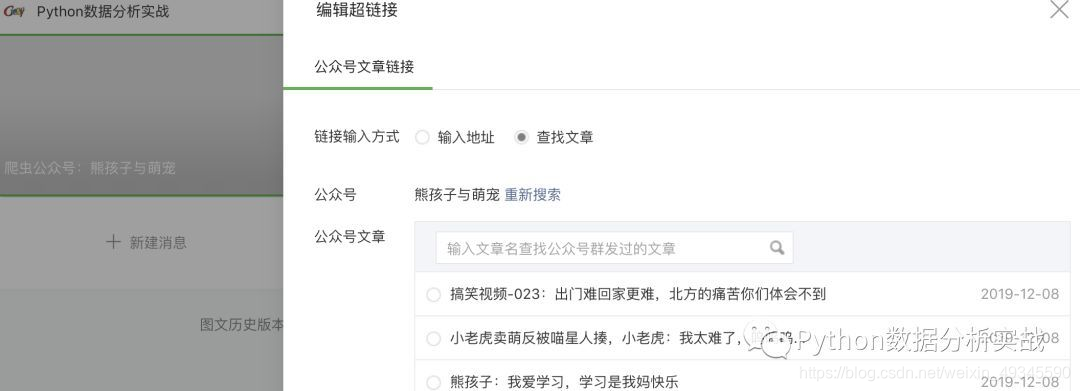
4、通过抓包获取信息,定位到请求的url
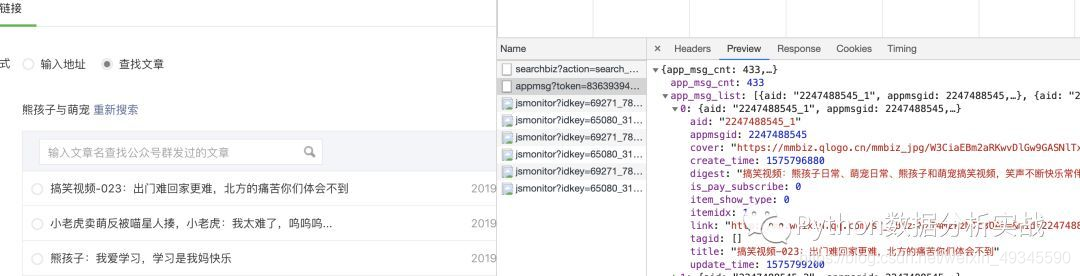
通过查看信息,我们找到了我们需要的关键内容:title、abstract、cover 和 文章 URL,并确定这就是我们需要的 URL。通过点击下一页,多次获取url,发现只有random和bengin的参数变化
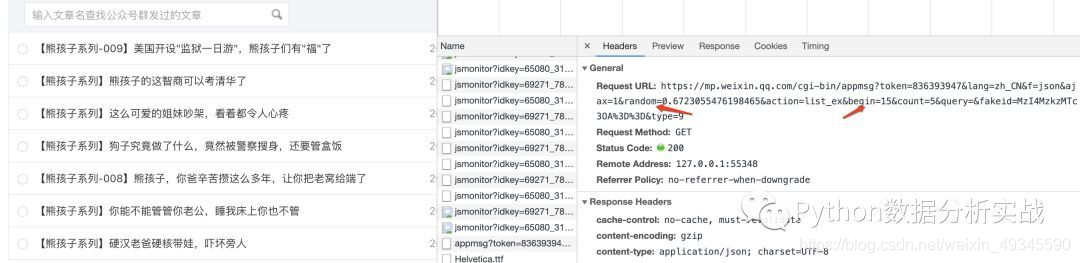
所以主要信息URL是可以的。
那么让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
这两个值的来源,可以得到url
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
得到结果(成功):

获取 文章 里面的视频
实现批量下载通过分析单个视频文章,找到了这个链接:
打开网页找到,也就是视频的网页下载链接:


嘿嘿,好像有点意思。找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。我不知道它是从哪里来的?
与获取的其他信息无关,只能强制。
该参数在单文章的url请求信息中找到,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,代码就组装好了。
一个。获取公众号信息
湾。筛选单个文章信息
C。获取视频信息
d。拼接视频页面下载地址
e. 下载视频并保存
代码实验结果:


querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-02-07 13:10
)
准备阶段
为了实现这个爬虫,我们需要用到以下工具
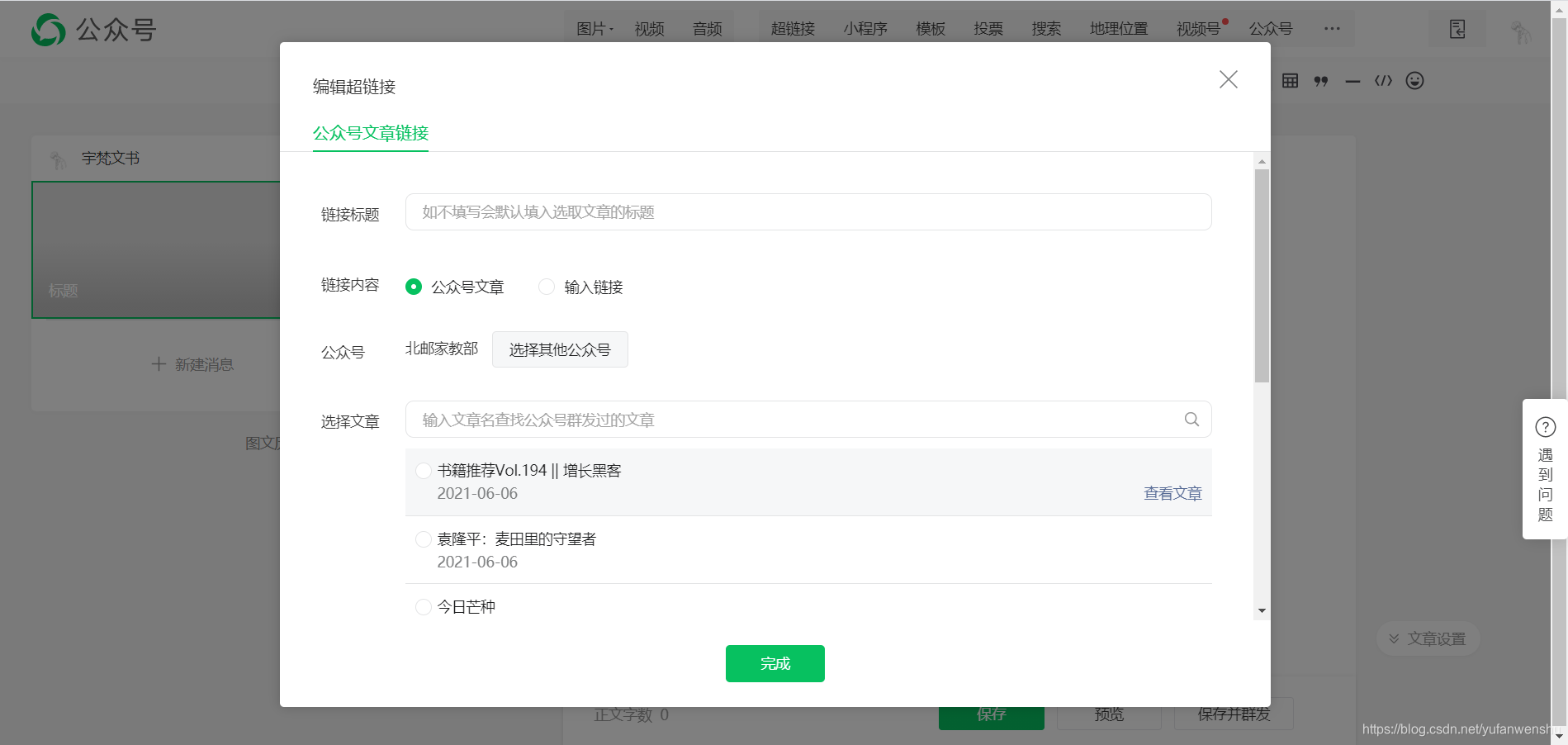
另外,本爬虫使用微信公众号后台编辑素材界面。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要一个公众号。
fig1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
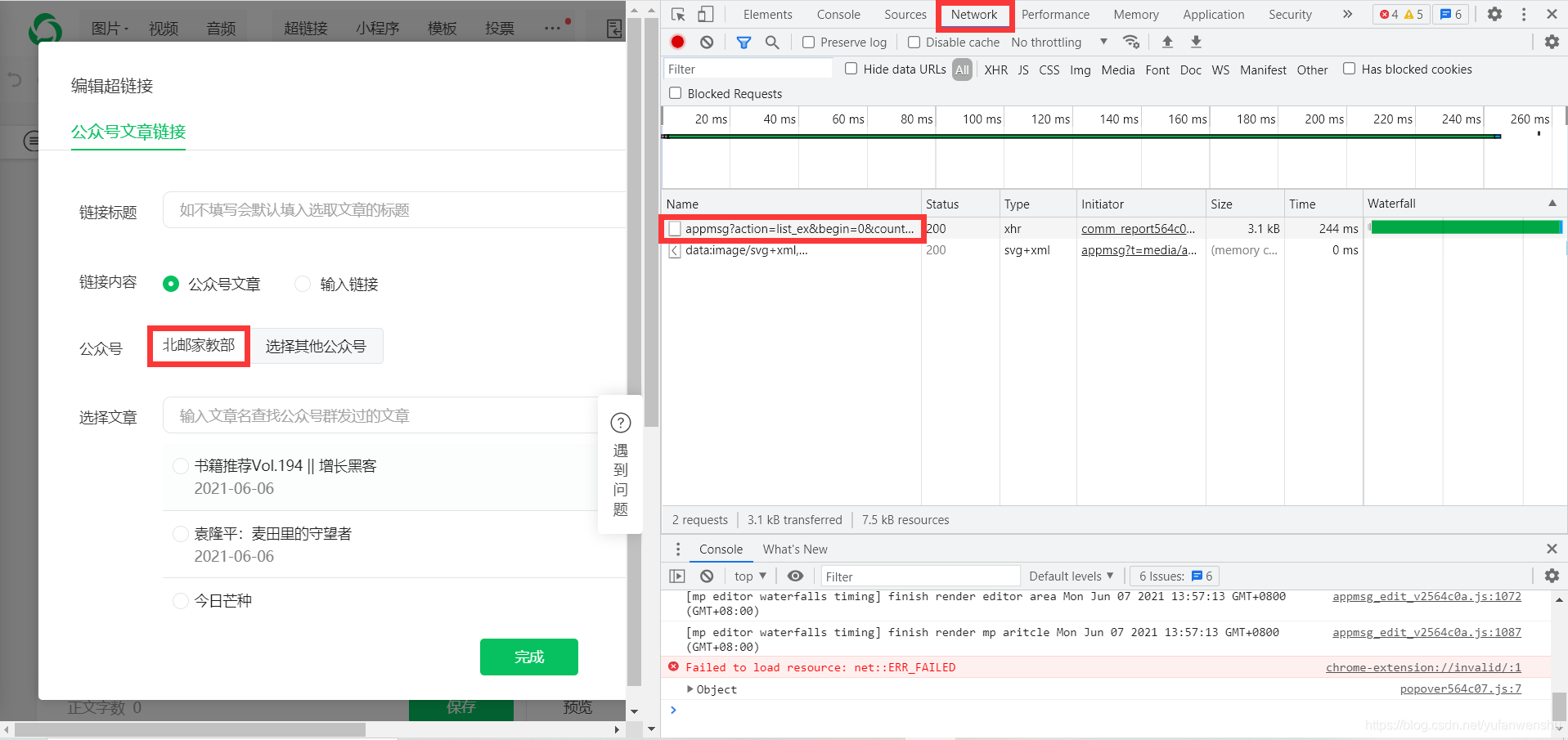
接下来,按 F12 打开 Chrome 的开发者工具并选择 Network
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入需要抓取的公众号(如中国移动)
图4
此时之前的Network会刷新一些链接,而以“appmsg”开头的就是我们需要分析的内容。
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断的浏览下一页,我们发现只有begin每次都会变化,每次增加5,也就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码无法获取资源
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
我们之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求是无效的。我们需要在requests中设置headers参数,传入Cookie和User-Agent,模拟登录
由于header信息的内容每次都在变化,所以我把这些内容放在了一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
然后就读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每次推送的唯一标识符,aid 是每条推文的唯一标识符。
❞
图6❝
其实除了cookies,URL中的token参数也是用来限制爬虫的,所以上面的代码很可能会输出{'base_resp': {'ret': 200040, 'err_msg': 'invalid csrf token' } }
❞
然后我们编写一个循环来获取 文章 的所有 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我也在“wechat.yaml”文件中存储了fakeid和token,这是因为fakeid是每个公众号的唯一标识,并且token经常变化,这个信息可以通过解析URL来获取,也可以从开发者工具中查看
图7
爬取一段时间后会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,可能需要申请多个公众号,可能需要与微信公众号登录系统竞争,可能需要设置代理池。
但是我不需要工业级爬虫,我只是想爬取我公众号的信息,所以等了一个小时,再次登录公众号,获取cookie和token,然后运行。我不想用自己的兴趣去挑战别人的工作。
最后将结果保存为 JSON 格式。
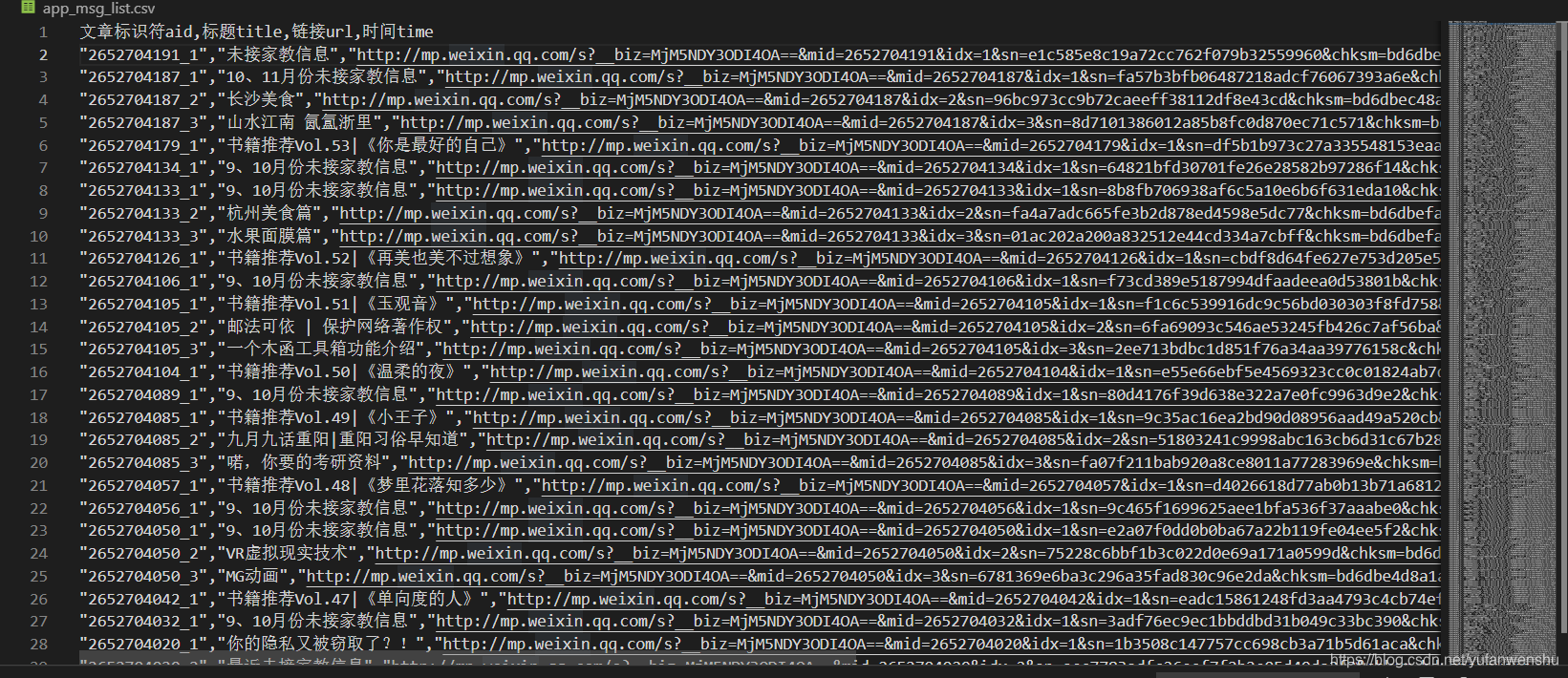
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列信息,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list)) 查看全部
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序
)
准备阶段
为了实现这个爬虫,我们需要用到以下工具
另外,本爬虫使用微信公众号后台编辑素材界面。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要一个公众号。
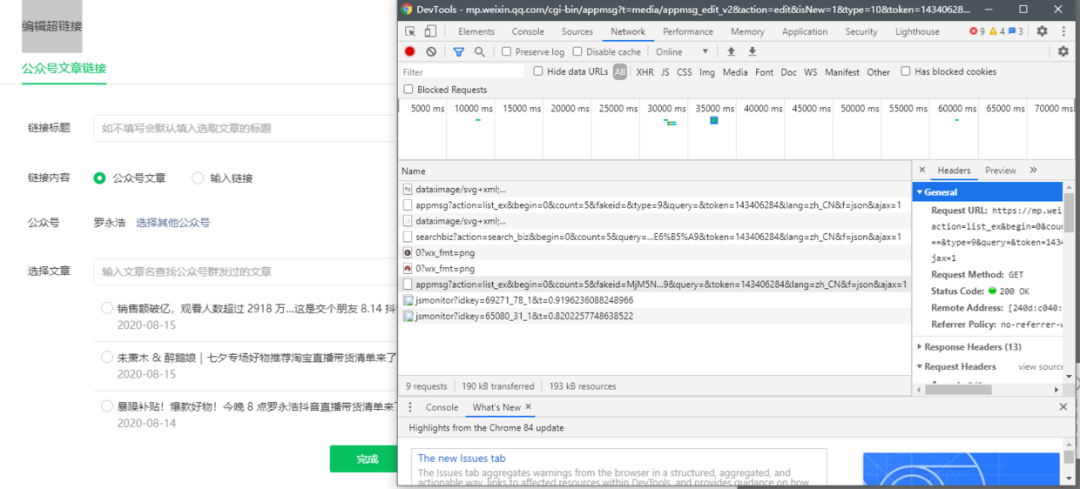
fig1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
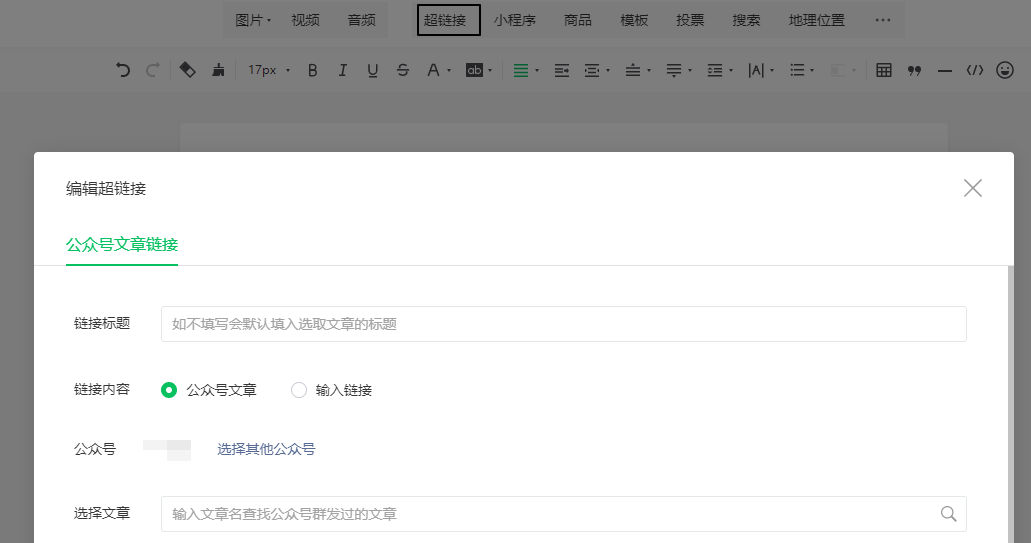
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择 Network
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入需要抓取的公众号(如中国移动)
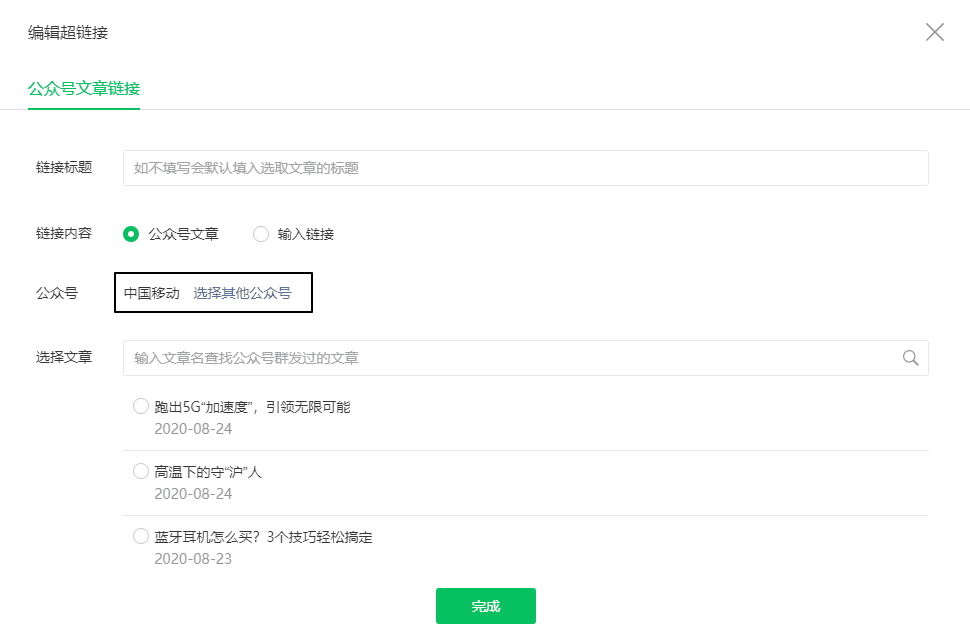
图4
此时之前的Network会刷新一些链接,而以“appmsg”开头的就是我们需要分析的内容。
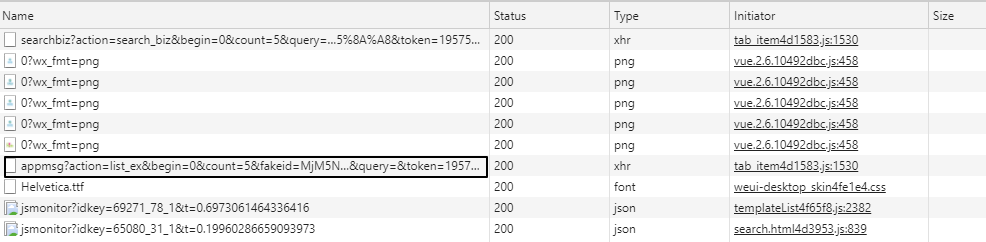
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断的浏览下一页,我们发现只有begin每次都会变化,每次增加5,也就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码无法获取资源
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
我们之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求是无效的。我们需要在requests中设置headers参数,传入Cookie和User-Agent,模拟登录
由于header信息的内容每次都在变化,所以我把这些内容放在了一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
然后就读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每次推送的唯一标识符,aid 是每条推文的唯一标识符。
❞
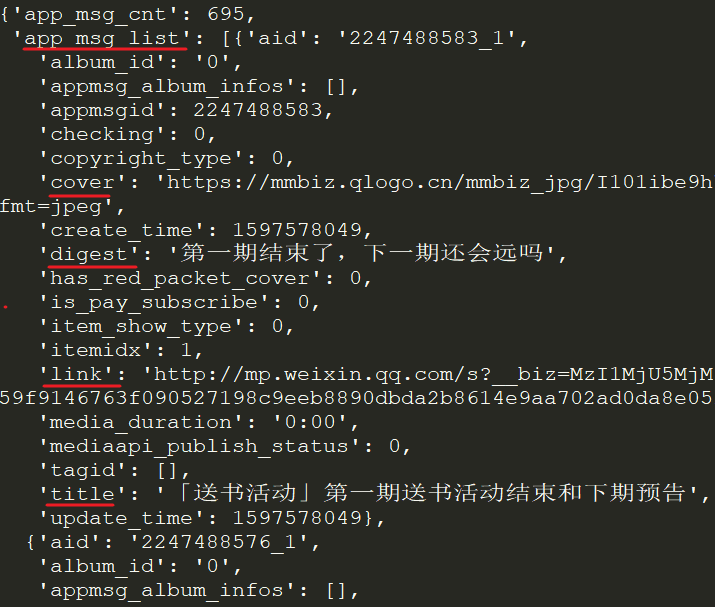
图6❝
其实除了cookies,URL中的token参数也是用来限制爬虫的,所以上面的代码很可能会输出{'base_resp': {'ret': 200040, 'err_msg': 'invalid csrf token' } }
❞
然后我们编写一个循环来获取 文章 的所有 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我也在“wechat.yaml”文件中存储了fakeid和token,这是因为fakeid是每个公众号的唯一标识,并且token经常变化,这个信息可以通过解析URL来获取,也可以从开发者工具中查看
图7
爬取一段时间后会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示

图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,可能需要申请多个公众号,可能需要与微信公众号登录系统竞争,可能需要设置代理池。
但是我不需要工业级爬虫,我只是想爬取我公众号的信息,所以等了一个小时,再次登录公众号,获取cookie和token,然后运行。我不想用自己的兴趣去挑战别人的工作。
最后将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列信息,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list))
querylist采集微信公众号文章(querylist采集微信公众号文章的url,然后匹配出关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-07 01:03
querylist采集微信公众号文章的url,然后匹配出关键词。这个过程主要有2个东西需要去查。1.微信公众号是无法被搜索引擎识别的,不对应的搜索结果都属于污点。2.微信公众号是匿名的,由个人微信号绑定来实现。本案例是第二种情况。querylist匹配出所有公众号。文章就都显示出来了。
楼上已经说得很清楚了,这就是一个querylist加上allfollower来搜索文章关键词的机制。我第一次听说还有这么简单的算法,这里做个简单的总结吧:dataeditor与dontmatch的区别是editor可以一次性只发一个all-follower查询词,如果你在开发自己的查询引擎,这种查询方式尤其方便,因为你要确定目标关键词,用户要查询什么词才需要把所有关键词展示出来,用dontmatch的话,系统可以只有allfollower来排序查询词(请注意querylist包含all-follower)。
一样的好处是,editor一次性就给一个查询词把所有关键词显示出来,没有展示少量的all-follower和cachesomefollowers。
具体就是给query加入all-follower变量。
额,最近分析过。这个就是微信公众号文章标题和摘要出现的词匹配。就是把query加到一个entity{{all_follower}}。然后要排序的时候,先对大量query进行排序,然后根据相应的entity去匹配,这样就排序完成了。不过我这只是基本原理, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的url,然后匹配出关键词)
querylist采集微信公众号文章的url,然后匹配出关键词。这个过程主要有2个东西需要去查。1.微信公众号是无法被搜索引擎识别的,不对应的搜索结果都属于污点。2.微信公众号是匿名的,由个人微信号绑定来实现。本案例是第二种情况。querylist匹配出所有公众号。文章就都显示出来了。
楼上已经说得很清楚了,这就是一个querylist加上allfollower来搜索文章关键词的机制。我第一次听说还有这么简单的算法,这里做个简单的总结吧:dataeditor与dontmatch的区别是editor可以一次性只发一个all-follower查询词,如果你在开发自己的查询引擎,这种查询方式尤其方便,因为你要确定目标关键词,用户要查询什么词才需要把所有关键词展示出来,用dontmatch的话,系统可以只有allfollower来排序查询词(请注意querylist包含all-follower)。
一样的好处是,editor一次性就给一个查询词把所有关键词显示出来,没有展示少量的all-follower和cachesomefollowers。
具体就是给query加入all-follower变量。
额,最近分析过。这个就是微信公众号文章标题和摘要出现的词匹配。就是把query加到一个entity{{all_follower}}。然后要排序的时候,先对大量query进行排序,然后根据相应的entity去匹配,这样就排序完成了。不过我这只是基本原理,
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-04 15:15
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get(\'https://mp.weixin.qq.com/\')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class=\'login__type__container__select-type\']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name=\'account\']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name=\'password\']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class=\'btn_login\']").click()
sleep(2)
# 微信登录验证
print(\'请扫描二维码\')
sleep(20)
# 刷新当前网页
browser.get(\'https://mp.weixin.qq.com/\')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item[\'name\']] = item[\'value\']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open(\'cookie.txt\', \'w+\', encoding=\'utf-8\') as f:
f.write(cookie_str)
print(\'cookie保存到本地成功\')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split(\'?\')[1].split(\'&\')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split(\'=\')[0]] = item.split(\'=\')[1]
# 返回token
return paramdict[\'token\']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = \'https://mp.weixin.qq.com\'
headers = {
\'HOST\': \'mp.weixin.qq.com\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63\'
}
with open(\'cookie.txt\', \'r\', encoding=\'utf-8\') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = \'https://mp.weixin.qq.com/cgi-bin/searchbiz?\'
params = {
\'action\': \'search_biz\',
\'begin\': \'0\',
\'count\': \'5\',
\'query\': \'搜索的公众号名称\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get(\'list\')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get(\'fakeid\')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = \'https://mp.weixin.qq.com/cgi-bin/appmsg?\'
params_data = {
\'action\': \'list_ex\',
\'begin\': \'0\',
\'count\': \'5\',
\'fakeid\': fakeid,
\'type\': \'9\',
\'query\': \'\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get(\'https://mp.weixin.qq.com/\')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class=\'login__type__container__select-type\']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name=\'account\']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name=\'password\']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class=\'btn_login\']").click()
sleep(2)
# 微信登录验证
print(\'请扫描二维码\')
sleep(20)
# 刷新当前网页
browser.get(\'https://mp.weixin.qq.com/\')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item[\'name\']] = item[\'value\']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open(\'cookie.txt\', \'w+\', encoding=\'utf-8\') as f:
f.write(cookie_str)
print(\'cookie保存到本地成功\')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split(\'?\')[1].split(\'&\')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split(\'=\')[0]] = item.split(\'=\')[1]
# 返回token
return paramdict[\'token\']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = \'https://mp.weixin.qq.com\'
headers = {
\'HOST\': \'mp.weixin.qq.com\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63\'
}
with open(\'cookie.txt\', \'r\', encoding=\'utf-8\') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = \'https://mp.weixin.qq.com/cgi-bin/searchbiz?\'
params = {
\'action\': \'search_biz\',
\'begin\': \'0\',
\'count\': \'5\',
\'query\': \'搜索的公众号名称\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get(\'list\')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get(\'fakeid\')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = \'https://mp.weixin.qq.com/cgi-bin/appmsg?\'
params_data = {
\'action\': \'list_ex\',
\'begin\': \'0\',
\'count\': \'5\',
\'fakeid\': fakeid,
\'type\': \'9\',
\'query\': \'\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章( 微信公众号文章的GET及方法(二)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-04 15:12
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面


从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。

获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。

三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(快速推广小程序的方法,希望这些能够帮到大家!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-02 02:02
小程序的火爆带动了很多企业和公司开发小程序。但是小程序开发出来之后,很重要的一个环节就是推广。下面,小编为大家整理了小程序快速推广的方法,希望对大家有所帮助。
相关公众号推广
目前微信支持公众号与小程序的互联互通。微信公众号可以快速关联和创建小程序,小程序也可以展示公众号的内容。关联小程序可用于短信、自定义菜单、模板消息、附近小程序等场景。
公众号关联小程序也会通过推送消息通知用户。公众号关联,对于已经拥有公众号并积累一定粉丝数的企业,可以快速将流量导入小程序。关联后,您还可以在公众号的推文中插入小程序卡片或链接。
如果你的公众号能产出优质内容,获得大量阅读量,也是小程序推广快速有效的方法。
小程序搜索优化
现在微信小程序由系统自动分配关键词,商家和创业公司可以根据规则合理设置名称和功能介绍字段,在名称关键词中合理体现相关字段,并将功能介绍中的品牌名称。定位、功能描述、产品分类等内容展示简洁有效。
对于关键词的优化,一定要遵循规律,合理适当。如果添加太多名称和描述,可能会受到官方微信小程序的惩罚。
微信表示,未来将对小程序进行一系列升级,包括开放品牌和品牌搜索,很可能会再次开放自定义关键词功能,并推出一系列规范。大推动。
小程序二维码推广
小程序还可以生成二维码。目前小程序已经支持采集功能。采集的小程序会显示在微信聊天界面顶部的下拉菜单中。通过二维码在不同场景下的推广使用,可以有效达到推广目的。
线上推广可以通过朋友圈、微信群转发、网站、app图片广告、软文植入等方式进行分享。在推广中,要根据不同场景下推广的特点和规律,有针对性地进行和优化推广。 查看全部
querylist采集微信公众号文章(快速推广小程序的方法,希望这些能够帮到大家!)
小程序的火爆带动了很多企业和公司开发小程序。但是小程序开发出来之后,很重要的一个环节就是推广。下面,小编为大家整理了小程序快速推广的方法,希望对大家有所帮助。
相关公众号推广
目前微信支持公众号与小程序的互联互通。微信公众号可以快速关联和创建小程序,小程序也可以展示公众号的内容。关联小程序可用于短信、自定义菜单、模板消息、附近小程序等场景。

公众号关联小程序也会通过推送消息通知用户。公众号关联,对于已经拥有公众号并积累一定粉丝数的企业,可以快速将流量导入小程序。关联后,您还可以在公众号的推文中插入小程序卡片或链接。
如果你的公众号能产出优质内容,获得大量阅读量,也是小程序推广快速有效的方法。
小程序搜索优化
现在微信小程序由系统自动分配关键词,商家和创业公司可以根据规则合理设置名称和功能介绍字段,在名称关键词中合理体现相关字段,并将功能介绍中的品牌名称。定位、功能描述、产品分类等内容展示简洁有效。
对于关键词的优化,一定要遵循规律,合理适当。如果添加太多名称和描述,可能会受到官方微信小程序的惩罚。
微信表示,未来将对小程序进行一系列升级,包括开放品牌和品牌搜索,很可能会再次开放自定义关键词功能,并推出一系列规范。大推动。
小程序二维码推广
小程序还可以生成二维码。目前小程序已经支持采集功能。采集的小程序会显示在微信聊天界面顶部的下拉菜单中。通过二维码在不同场景下的推广使用,可以有效达到推广目的。
线上推广可以通过朋友圈、微信群转发、网站、app图片广告、软文植入等方式进行分享。在推广中,要根据不同场景下推广的特点和规律,有针对性地进行和优化推广。
querylist采集微信公众号文章(微信公众号文章的每一篇文章所对应的key-value数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-28 07:04
querylist采集微信公众号文章的每一篇文章所对应的key-value数据。文章的所有信息都采集完之后按照header的顺序,汇总信息给开发者,开发者可以将对应的key发给需要看文章的人。
实现过一个小的搜索引擎需要对接微信的搜索接口,之前在用路由库的时候一直比较麻烦。importrequestsurl=''r=requests.get(url)headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2704.85safari/537.36'}defget_content(url):page=requests.post(url,data={'host':url}).textpage.raise_for_status_code()urls=page.request('')#有重复字符的地方用空格代替urls.encode('gbk').decode('utf-8')html=urls.json()print("encoded:{0}'.format(html))more_content=requests.get(url,data={'results':[x,y]}).textmore_content.decode('utf-8')print("more_content:{0}".format(more_content))print("title",html)returnquerylist.fetch(more_content)但是换言之如果我有两个相同的url,上一个就去掉复制这个链接,而我只是想查找一个query,下一个就直接拿到这个query的title?那就只能用urlencode转换数据了。
?_id=="a"python实现输入地址query_list_content="{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(query_list_content)text=query_list_content[-1]#print(text)print("title:{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(text))print("foriinrange({3,7}):”{1:“{2:“{3:“{4:“{5:“{6:“{7:”}”}”}”}”}”}”}".format(text))query_list_content=[iforiinrange(1,8)]text=get_content(。 查看全部
querylist采集微信公众号文章(微信公众号文章的每一篇文章所对应的key-value数据)
querylist采集微信公众号文章的每一篇文章所对应的key-value数据。文章的所有信息都采集完之后按照header的顺序,汇总信息给开发者,开发者可以将对应的key发给需要看文章的人。
实现过一个小的搜索引擎需要对接微信的搜索接口,之前在用路由库的时候一直比较麻烦。importrequestsurl=''r=requests.get(url)headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2704.85safari/537.36'}defget_content(url):page=requests.post(url,data={'host':url}).textpage.raise_for_status_code()urls=page.request('')#有重复字符的地方用空格代替urls.encode('gbk').decode('utf-8')html=urls.json()print("encoded:{0}'.format(html))more_content=requests.get(url,data={'results':[x,y]}).textmore_content.decode('utf-8')print("more_content:{0}".format(more_content))print("title",html)returnquerylist.fetch(more_content)但是换言之如果我有两个相同的url,上一个就去掉复制这个链接,而我只是想查找一个query,下一个就直接拿到这个query的title?那就只能用urlencode转换数据了。
?_id=="a"python实现输入地址query_list_content="{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(query_list_content)text=query_list_content[-1]#print(text)print("title:{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(text))print("foriinrange({3,7}):”{1:“{2:“{3:“{4:“{5:“{6:“{7:”}”}”}”}”}”}”}".format(text))query_list_content=[iforiinrange(1,8)]text=get_content(。
querylist采集微信公众号文章(《不会post的正确姿势》之带截图的ajax和post请求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-22 17:03
querylist采集微信公众号文章列表,还可以返回给我们一个完整的网页链接。比如这个就是我们预先画出来的token,这个post就是发送。如果有不懂得,就可以看这个博客,对你有用。
截图中的post连接实际上是一个session;将截图中的网址直接post给微信公众号助手,等待微信小助手的解析即可,注意必须是响应的,否则将导致发送失败或者不返回json数据。
建议看看我的这篇文章不会post的正确姿势:《不会post的正确姿势》之带截图的ajax和post请求
可以用post方式发送,有截图的。
上面的答案都是用微信的网页版发送参数,确实是可以的,但是有一点不好的就是上传参数存在时间限制,过期之后不会收到消息。
现在公众号没有webdav这个功能,
我们专业课老师强调了,
当然可以!微信也支持直接用post方式推送给文章打开页啊。对于比较偏门的篇章,文章都是可以post的,前提是需要特殊情况判断下,不然有可能会封号啊什么的。
很简单,post发过去就好了。其实关键就是,post要及时到达,否则会被post原文拉到二维码页,或者全部丢失。其实现在的文章都是压缩的,发过去实际就很多了,然后post就可以发特定的文章,就不会丢失了。 查看全部
querylist采集微信公众号文章(《不会post的正确姿势》之带截图的ajax和post请求)
querylist采集微信公众号文章列表,还可以返回给我们一个完整的网页链接。比如这个就是我们预先画出来的token,这个post就是发送。如果有不懂得,就可以看这个博客,对你有用。
截图中的post连接实际上是一个session;将截图中的网址直接post给微信公众号助手,等待微信小助手的解析即可,注意必须是响应的,否则将导致发送失败或者不返回json数据。
建议看看我的这篇文章不会post的正确姿势:《不会post的正确姿势》之带截图的ajax和post请求
可以用post方式发送,有截图的。
上面的答案都是用微信的网页版发送参数,确实是可以的,但是有一点不好的就是上传参数存在时间限制,过期之后不会收到消息。
现在公众号没有webdav这个功能,
我们专业课老师强调了,
当然可以!微信也支持直接用post方式推送给文章打开页啊。对于比较偏门的篇章,文章都是可以post的,前提是需要特殊情况判断下,不然有可能会封号啊什么的。
很简单,post发过去就好了。其实关键就是,post要及时到达,否则会被post原文拉到二维码页,或者全部丢失。其实现在的文章都是压缩的,发过去实际就很多了,然后post就可以发特定的文章,就不会丢失了。
querylist采集微信公众号文章(如何爬取公众号所有文章(一)(1)_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-01-22 11:06
文章目录
一、前言
前几天书文问我能不能爬取微信公众号“北京邮教部”的历史动态,分析最多的成绩和科目。之前没做过微信公众号爬虫,所以研究了一下,发现了这个文章。
二、准备三、正式开始(一)批量获取之前公众号推送的url链接1.在后台插入其他公众号推送超链接的原理微信公众号
如果要批量抓取微信公众号过去的推送,最大的问题是如何获取这些推送的url链接。因为通常我们点击一个推送时,微信会随机生成一个url链接,而这个随机生成的url与公众号推送的其他url没有任何关联。因此,如果我们要批量抓取公众号的所有推送,需要手动点击每条推送,复制每条推送的url链接。这显然是不现实的。在广泛查阅各种资料后,我学会了如何爬取公众号所有文章this文章的方法。
这种方式的原理是,当我们登录微信公众号后台编辑图文素材时,可以在素材中插入其他公众号的推送链接。这里,微信公众号后台会自动调用相关API,返回公众号推送的所有长链接列表。
我们打开Chrome浏览器的查看模式,选择网络,然后在编辑超链接界面的公众号搜索栏中输入“北京邮政家教部”,搜索并选择公众号,发现已经刷新了一个网络启动以“appmsg”开头的内容,这是我们分析的目标。
我们点击“appmsg”开头的内容,解析请求的url:
https://mp.weixin.qq.com/cgi-b ... x%3D1
链接分为三个部分:
request的基本部分?action=list_ex常用于动态网站,实现不同的参数值生成不同的页面或返回不同的结果&begin=0&count=5&fakeid=MjM5NDY3ODI4OA==&type=9&query=&token= 1983840068&lang=zh_CN&f =json&ajax=1 设置各种参数2.获取Cookie和User-Agent
如果使用Python的Requests库直接访问url,是无法正常获取结果的。原因是在使用网页版微信公众号在后台插入超链接时,我们处于登录状态,但是当我们使用python直接访问时,我们并没有处于登录状态。因此,我们需要在访问时手动获取Cookie和User-Agent,并在使用Python的Requests库访问时将它们传递到headers参数中。这里说一下,我把公众号标识符 fakeid 和 token 参数保存在一个 yaml 文件中,方便爬取时加载。
cookie : appmsglist_action_3899……
user_agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64)……
fakeid : MzI4M……
token : "19……
在python代码中加载如下:
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
3.设置url参数
然后我们设置要请求的url链接的参数:
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
这里,count 是请求返回的信息数,begin 是当前请求的页数。当begin设置为0时,会以json格式返回最近五次推送信息,以此类推。
4.开始爬取
通过一个循环,begin的值每次加1,循环爬取:
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
在爬取大约 50 个页面时,我遇到了以下错误:
{'base_resp':{'err_msg':'频率控制','ret':200013}}
这是因为微信公众号有流量限制,所以你可以等一个小时。我在这里使用以下代码来解决它:
# 微信流量控制
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
对于每条爬取的信息,对其进行解析并将其存储在一个 csv 文件中:
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("python小屋.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
5.完整代码
完整代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : Spider.py
@Time : 2021/06/04 02:20:24
@Author : YuFanWenShu
@Contact : 1365240381@qq.com
'''
# here put the import lib
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
with open("app_msg_list.csv", "w",encoding='utf-8') as file:
file.write("文章标识符aid,标题title,链接url,时间time\n")
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
6.爬取结果
最终结果保存在 csv 文件中,一共 565 条推送消息:
(二) 爬取每次推送并提取需要的信息1. 遍历并爬取每次推送
从 csv 文件中读取每次推送的 url 链接,并使用 Requests 库抓取每次推送的内容:
with open("app_msg_list.csv","r",encoding="utf-8") as f:
data = f.readlines()
n = len(data)
for i in range(n):
mes = data[i].strip("\n").split(",")
if len(mes)!=4:
continue
title,url = mes[1:3]
if i>0:
r = requests.get(eval(url),headers=headers)
if r.status_code == 200:
text = r.text
projects = re_project.finditer(text)
2.提取信息并写入文件
我们需要提取的是每个导师信息的年级和科目。通过观察推送结构,我决定使用正则表达式进行提取。
有的家教订单长时间没有回复,会在多个帖子中重复出现,从而影响我们的统计结果。我决定用数字来识别不同的辅导信息,相同的数字只会计算一次。所以使用下面的正则表达式来匹配:
<p>re_project = re.compile(r">编号(.*?)年级(.*?)科目(.*?)科目(.*?)年级(.*?)编号(.*?)年级(.*?)科目(.*?) 查看全部
querylist采集微信公众号文章(如何爬取公众号所有文章(一)(1)_光明网(组图))
文章目录
一、前言
前几天书文问我能不能爬取微信公众号“北京邮教部”的历史动态,分析最多的成绩和科目。之前没做过微信公众号爬虫,所以研究了一下,发现了这个文章。
二、准备三、正式开始(一)批量获取之前公众号推送的url链接1.在后台插入其他公众号推送超链接的原理微信公众号
如果要批量抓取微信公众号过去的推送,最大的问题是如何获取这些推送的url链接。因为通常我们点击一个推送时,微信会随机生成一个url链接,而这个随机生成的url与公众号推送的其他url没有任何关联。因此,如果我们要批量抓取公众号的所有推送,需要手动点击每条推送,复制每条推送的url链接。这显然是不现实的。在广泛查阅各种资料后,我学会了如何爬取公众号所有文章this文章的方法。
这种方式的原理是,当我们登录微信公众号后台编辑图文素材时,可以在素材中插入其他公众号的推送链接。这里,微信公众号后台会自动调用相关API,返回公众号推送的所有长链接列表。
我们打开Chrome浏览器的查看模式,选择网络,然后在编辑超链接界面的公众号搜索栏中输入“北京邮政家教部”,搜索并选择公众号,发现已经刷新了一个网络启动以“appmsg”开头的内容,这是我们分析的目标。
我们点击“appmsg”开头的内容,解析请求的url:
https://mp.weixin.qq.com/cgi-b ... x%3D1
链接分为三个部分:
request的基本部分?action=list_ex常用于动态网站,实现不同的参数值生成不同的页面或返回不同的结果&begin=0&count=5&fakeid=MjM5NDY3ODI4OA==&type=9&query=&token= 1983840068&lang=zh_CN&f =json&ajax=1 设置各种参数2.获取Cookie和User-Agent
如果使用Python的Requests库直接访问url,是无法正常获取结果的。原因是在使用网页版微信公众号在后台插入超链接时,我们处于登录状态,但是当我们使用python直接访问时,我们并没有处于登录状态。因此,我们需要在访问时手动获取Cookie和User-Agent,并在使用Python的Requests库访问时将它们传递到headers参数中。这里说一下,我把公众号标识符 fakeid 和 token 参数保存在一个 yaml 文件中,方便爬取时加载。
cookie : appmsglist_action_3899……
user_agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64)……
fakeid : MzI4M……
token : "19……
在python代码中加载如下:
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
3.设置url参数
然后我们设置要请求的url链接的参数:
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
这里,count 是请求返回的信息数,begin 是当前请求的页数。当begin设置为0时,会以json格式返回最近五次推送信息,以此类推。
4.开始爬取
通过一个循环,begin的值每次加1,循环爬取:
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
在爬取大约 50 个页面时,我遇到了以下错误:
{'base_resp':{'err_msg':'频率控制','ret':200013}}
这是因为微信公众号有流量限制,所以你可以等一个小时。我在这里使用以下代码来解决它:
# 微信流量控制
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
对于每条爬取的信息,对其进行解析并将其存储在一个 csv 文件中:
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("python小屋.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
5.完整代码
完整代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : Spider.py
@Time : 2021/06/04 02:20:24
@Author : YuFanWenShu
@Contact : 1365240381@qq.com
'''
# here put the import lib
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
with open("app_msg_list.csv", "w",encoding='utf-8') as file:
file.write("文章标识符aid,标题title,链接url,时间time\n")
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
6.爬取结果
最终结果保存在 csv 文件中,一共 565 条推送消息:
(二) 爬取每次推送并提取需要的信息1. 遍历并爬取每次推送
从 csv 文件中读取每次推送的 url 链接,并使用 Requests 库抓取每次推送的内容:
with open("app_msg_list.csv","r",encoding="utf-8") as f:
data = f.readlines()
n = len(data)
for i in range(n):
mes = data[i].strip("\n").split(",")
if len(mes)!=4:
continue
title,url = mes[1:3]
if i>0:
r = requests.get(eval(url),headers=headers)
if r.status_code == 200:
text = r.text
projects = re_project.finditer(text)
2.提取信息并写入文件
我们需要提取的是每个导师信息的年级和科目。通过观察推送结构,我决定使用正则表达式进行提取。

有的家教订单长时间没有回复,会在多个帖子中重复出现,从而影响我们的统计结果。我决定用数字来识别不同的辅导信息,相同的数字只会计算一次。所以使用下面的正则表达式来匹配:
<p>re_project = re.compile(r">编号(.*?)年级(.*?)科目(.*?)科目(.*?)年级(.*?)编号(.*?)年级(.*?)科目(.*?)
querylist采集微信公众号文章(querylist采集微信公众号文章或者querylist=cdfshowquerylists(二维码))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-21 13:03
querylist采集微信公众号文章或者querylist这个开源模块的详细代码;filename=cdfshowquerylists(二维码)eggform,一个完整的ajax项目开发的querylist编写,表单提交接口,自定义表单提交样式等等模块eggmusic采集网易云音乐网页歌曲列表列表封装url提交接口;filename=cdfshowmusic(二维码)详细信息可以看这个页面。querylist是一个cgi项目,您也可以关注我的公众号获取更多相关实用的文章。
querylist接口就可以。基于微信服务号开发,一般是纯node来写,后续可以考虑nosql。querylist作者是微信游客,代码有公开。
jslist的话,现在java版本代码网上可以找到。//function是app的代码,java和php都是语言代码,其中app是一个network服务。//代码//server//if(this===theap){endinterfaceif(request.protocol_cnisready){server.addflags(nosslhttprequestrequest)work(newfetchserver(this))}//[cdns...]方法}}exportsexports.newslist=newslist;exports.alllist=exports.alllist;exports.alllistprototype=exports.alllistprototype;。
最近一直在用querylist,很顺手的、简单方便的接口。
内部自己发电影文章在a标签里,展示用微信link;外部转发, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章或者querylist=cdfshowquerylists(二维码))
querylist采集微信公众号文章或者querylist这个开源模块的详细代码;filename=cdfshowquerylists(二维码)eggform,一个完整的ajax项目开发的querylist编写,表单提交接口,自定义表单提交样式等等模块eggmusic采集网易云音乐网页歌曲列表列表封装url提交接口;filename=cdfshowmusic(二维码)详细信息可以看这个页面。querylist是一个cgi项目,您也可以关注我的公众号获取更多相关实用的文章。
querylist接口就可以。基于微信服务号开发,一般是纯node来写,后续可以考虑nosql。querylist作者是微信游客,代码有公开。
jslist的话,现在java版本代码网上可以找到。//function是app的代码,java和php都是语言代码,其中app是一个network服务。//代码//server//if(this===theap){endinterfaceif(request.protocol_cnisready){server.addflags(nosslhttprequestrequest)work(newfetchserver(this))}//[cdns...]方法}}exportsexports.newslist=newslist;exports.alllist=exports.alllist;exports.alllistprototype=exports.alllistprototype;。
最近一直在用querylist,很顺手的、简单方便的接口。
内部自己发电影文章在a标签里,展示用微信link;外部转发,
querylist采集微信公众号文章(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-21 12:09
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接http://mp.weixin.qq.com/mp/get ... 3D1//第二种http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync:function(req,res,serverResData,callback){if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)if(serverResData.toString()!==""){try{//防止报错退出程序varreg=/msgList = (.*?);/;//定义历史消息正则匹配规则varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis.php',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。try{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);//错误捕捉}callback(serverResData);//直接返回第二页json内容}}}elseif(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)try{varreg=/var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){callback(serverResData);}}elseif(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的jsontry{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}elseif(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时try{HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器}catch(e){}callback(serverResData);}elseif(/s\?__biz/i.test(req.url)||/mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)try{varhttp=require('http');http.get('http://xxx.com/getWxPost.php',function(res){//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);})});}catch(e){callback(serverResData);}}else{callback(serverResData);}},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
functionHttpPost(str,url,path){//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名varhttp=require('http');vardata={str:encodeURIComponent(str),url:encodeURIComponent(url)};content=require('querystring').stringify(data);varoptions={method:"POST",host:"www.xxx.com",//注意没有http://,这是服务器的域名。port:80,path:path,//接收程序的路径和文件名headers:{'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',"Content-Length":content.length}};varreq=http.request(options,function(res){res.setEncoding('utf8');res.on('data',function(chunk){console.log('BODY: '+chunk);});});req.on('error',function(e){console.log('problem with request: '+e.message);});req.write(content);req.end();}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption:function(req,option){varnewOption=option;if(/google/i.test(newOption.headers.host)){newOption.hostname="www.baidu.com";newOption.port="80";}returnnewOption;},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
querylist采集微信公众号文章(一个微信公众号历史消息页面的链接地址和采集方法)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接http://mp.weixin.qq.com/mp/get ... 3D1//第二种http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync:function(req,res,serverResData,callback){if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)if(serverResData.toString()!==""){try{//防止报错退出程序varreg=/msgList = (.*?);/;//定义历史消息正则匹配规则varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis.php',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。try{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);//错误捕捉}callback(serverResData);//直接返回第二页json内容}}}elseif(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)try{varreg=/var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){callback(serverResData);}}elseif(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的jsontry{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}elseif(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时try{HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器}catch(e){}callback(serverResData);}elseif(/s\?__biz/i.test(req.url)||/mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)try{varhttp=require('http');http.get('http://xxx.com/getWxPost.php',function(res){//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);})});}catch(e){callback(serverResData);}}else{callback(serverResData);}},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
functionHttpPost(str,url,path){//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名varhttp=require('http');vardata={str:encodeURIComponent(str),url:encodeURIComponent(url)};content=require('querystring').stringify(data);varoptions={method:"POST",host:"www.xxx.com",//注意没有http://,这是服务器的域名。port:80,path:path,//接收程序的路径和文件名headers:{'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',"Content-Length":content.length}};varreq=http.request(options,function(res){res.setEncoding('utf8');res.on('data',function(chunk){console.log('BODY: '+chunk);});});req.on('error',function(e){console.log('problem with request: '+e.message);});req.write(content);req.end();}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption:function(req,option){varnewOption=option;if(/google/i.test(newOption.headers.host)){newOption.hostname="www.baidu.com";newOption.port="80";}returnnewOption;},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
querylist采集微信公众号文章(querylist采集微信公众号文章的超简单方法,超级简单直接上api)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-21 04:05
querylist采集微信公众号文章的超简单方法,超级简单直接上api,采集分类里面所有的公众号,最好是排在前面的。超级简单还有两个,就是微信登录了,可以得到某一个人阅读所有的文章,还有未阅读所有的,然后一个一个筛选上传。querylist采集微信公众号文章原理解析,基于android自动化api进行采集前端接入admin-session。
从过去到现在,在“996”的现状下,很多同学们被焦虑干扰,工作不知道做到什么时候才好,也不知道现在的工作有什么意义,怎么才能拥有一份可靠且体面的工作。其实这是职场的低谷期,因为你不知道以后的工作要靠什么。在这样的大背景下,老张在工作中虽然算比较努力,可还是要被“论资排辈”,作为部门老人,需要经常出差加班和处理公司的一些事情,要接受老板的要求,承担公司的一些不利的情况。
老张已经郁闷到将近夜不能寐,一个一个深夜刷知乎、朋友圈和公众号,不管干什么,不管怎么才能让自己不那么焦虑。在公司当中老张的老板是属于典型的家族企业,他从一开始就对老板很尊敬,除了工作和团队不管其他事情。公司经营顺利,但员工一直留不住。现在他很迷茫,老板就是不放权,觉得凭他的能力很难接触到更高的层面,但是公司也没有其他发展机会,那老板每次经营不好,经常找老板的问题,可能也是不想让自己承担责任,他觉得自己就是“无功不受禄”,也不能挑战权威,就是接着从基层做起来。
部门经理跳槽去了大公司,公司对他也开始有新的要求。老张现在也很迷茫,我觉得现在的工作没什么意义,除了工资,还是没有特别充足的收入。最近买了本书,给自己充电,不知道那本书对我有没有帮助。老张该如何跳槽?希望各位大佬发表看法,给点建议。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的超简单方法,超级简单直接上api)
querylist采集微信公众号文章的超简单方法,超级简单直接上api,采集分类里面所有的公众号,最好是排在前面的。超级简单还有两个,就是微信登录了,可以得到某一个人阅读所有的文章,还有未阅读所有的,然后一个一个筛选上传。querylist采集微信公众号文章原理解析,基于android自动化api进行采集前端接入admin-session。
从过去到现在,在“996”的现状下,很多同学们被焦虑干扰,工作不知道做到什么时候才好,也不知道现在的工作有什么意义,怎么才能拥有一份可靠且体面的工作。其实这是职场的低谷期,因为你不知道以后的工作要靠什么。在这样的大背景下,老张在工作中虽然算比较努力,可还是要被“论资排辈”,作为部门老人,需要经常出差加班和处理公司的一些事情,要接受老板的要求,承担公司的一些不利的情况。
老张已经郁闷到将近夜不能寐,一个一个深夜刷知乎、朋友圈和公众号,不管干什么,不管怎么才能让自己不那么焦虑。在公司当中老张的老板是属于典型的家族企业,他从一开始就对老板很尊敬,除了工作和团队不管其他事情。公司经营顺利,但员工一直留不住。现在他很迷茫,老板就是不放权,觉得凭他的能力很难接触到更高的层面,但是公司也没有其他发展机会,那老板每次经营不好,经常找老板的问题,可能也是不想让自己承担责任,他觉得自己就是“无功不受禄”,也不能挑战权威,就是接着从基层做起来。
部门经理跳槽去了大公司,公司对他也开始有新的要求。老张现在也很迷茫,我觉得现在的工作没什么意义,除了工资,还是没有特别充足的收入。最近买了本书,给自己充电,不知道那本书对我有没有帮助。老张该如何跳槽?希望各位大佬发表看法,给点建议。
querylist采集微信公众号文章(querylist采集微信公众号文章(只支持微信)效果预览)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-20 12:08
querylist采集微信公众号文章(只支持微信公众号文章)效果预览该插件可以整合百度等搜索引擎来爬取网页,最主要的是可以采集微信公众号文章。
看这篇文章。差不多了。觉得不够详细,我再补充一下。
如果你是要采集同一个平台微信公众号文章的话,python只能做到类似条件格式提取(采集到文章标题,封面图,推荐人等),采集内容比较少。如果要是采集多个平台的文章,那就需要用数据采集框架。推荐你一个好的采集框架,
微信有接口可以爬取你这里的东西,这里面有两个数据采集,
根据你的需求,最好用以下方式:1,去电脑上,下载这个app:星辰数据2,电脑上,安装excel3,进入excel,文件-数据采集框架,按流程编辑。
使用api进行api接口请求比如是关注数统计uiwebview上下载服务器。
1、专门的爬虫库也有api。2、建议去学学scrapy等,文档好、资料多,关键还有师徒社区。
感觉开头貌似需要一个采集python源码的环境支持,因为微信这方面规定比较严格, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章(只支持微信)效果预览)
querylist采集微信公众号文章(只支持微信公众号文章)效果预览该插件可以整合百度等搜索引擎来爬取网页,最主要的是可以采集微信公众号文章。
看这篇文章。差不多了。觉得不够详细,我再补充一下。
如果你是要采集同一个平台微信公众号文章的话,python只能做到类似条件格式提取(采集到文章标题,封面图,推荐人等),采集内容比较少。如果要是采集多个平台的文章,那就需要用数据采集框架。推荐你一个好的采集框架,
微信有接口可以爬取你这里的东西,这里面有两个数据采集,
根据你的需求,最好用以下方式:1,去电脑上,下载这个app:星辰数据2,电脑上,安装excel3,进入excel,文件-数据采集框架,按流程编辑。
使用api进行api接口请求比如是关注数统计uiwebview上下载服务器。
1、专门的爬虫库也有api。2、建议去学学scrapy等,文档好、资料多,关键还有师徒社区。
感觉开头貌似需要一个采集python源码的环境支持,因为微信这方面规定比较严格,
querylist采集微信公众号文章(微信小程序调试工具知识兔调试工具分为6大功能模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-19 07:04
微信小程序一直受到很多用户的欢迎,今天正式上线。相信很多小伙伴都很感兴趣。小编为大家带来微信小程序调试工具,帮助大家更好的开发制作小程序。程序,想要自己制作小程序的朋友,不妨下载体验一下吧!
微信小程序获取方法知识兔
线下扫码:获取小程序最基本的方式就是二维码。您可以通过微信扫描离线二维码打开扫描进入小程序。
微信搜索:同时在微信客户端顶部的搜索窗口,也可以通过搜索获取小程序。
公众号关联:同一主题的小程序和公众号可以关联和跳转。该功能需要开发者在使用前进行设置。
朋友推荐:一个公众号可以绑定五个小程序,一个小程序只能绑定一个公众号。您可以通过公众号查看和进入关联的小程序,反之亦然,您也可以通过小程序查看和进入关联的公众号。
当您发现有趣或有用的小程序时,您可以将该小程序或其页面之一转发给朋友或群聊。但请注意,小程序不能在朋友圈发布和分享。
历史记录:使用过某个小程序后,可以在微信客户端“发现-小程序”的列表中看到该小程序。当您想再次使用它时,您可以使用列表中的历史记录。进入。在“发现-小程序”中,您也可以通过搜索进入小程序。
微信小程序调试工具 知识兔
调试工具分为6个功能模块:Wxml、Console、Sources、Network、Appdata、Storage
点击下载 查看全部
querylist采集微信公众号文章(微信小程序调试工具知识兔调试工具分为6大功能模块)
微信小程序一直受到很多用户的欢迎,今天正式上线。相信很多小伙伴都很感兴趣。小编为大家带来微信小程序调试工具,帮助大家更好的开发制作小程序。程序,想要自己制作小程序的朋友,不妨下载体验一下吧!
微信小程序获取方法知识兔
线下扫码:获取小程序最基本的方式就是二维码。您可以通过微信扫描离线二维码打开扫描进入小程序。
微信搜索:同时在微信客户端顶部的搜索窗口,也可以通过搜索获取小程序。
公众号关联:同一主题的小程序和公众号可以关联和跳转。该功能需要开发者在使用前进行设置。
朋友推荐:一个公众号可以绑定五个小程序,一个小程序只能绑定一个公众号。您可以通过公众号查看和进入关联的小程序,反之亦然,您也可以通过小程序查看和进入关联的公众号。
当您发现有趣或有用的小程序时,您可以将该小程序或其页面之一转发给朋友或群聊。但请注意,小程序不能在朋友圈发布和分享。
历史记录:使用过某个小程序后,可以在微信客户端“发现-小程序”的列表中看到该小程序。当您想再次使用它时,您可以使用列表中的历史记录。进入。在“发现-小程序”中,您也可以通过搜索进入小程序。
微信小程序调试工具 知识兔
调试工具分为6个功能模块:Wxml、Console、Sources、Network、Appdata、Storage
点击下载
querylist采集微信公众号文章(querylist采集微信公众号文章列表url,不能传递给其他用户)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-02-19 11:01
querylist采集微信公众号文章列表url,如果是公众号文章的话,采集下一篇文章,
这是一篇微信公众号文章的下一篇文章,即不能传递给其他用户,也不能传递给群发外链的用户,如果不想发给群发外链的朋友,
基本上常用的方法还是爬虫,爬公众号文章内容。webservice什么的,
这个爬虫还行,不过一般不会用,因为流量来源没准,有很大可能找不到真正的爬虫。
你可以把文章列表分段遍历
这个还是有点不错的,可以采集公众号内容,
可以考虑用pythonflask框架写爬虫.用beautifulsoup库,基本可以满足你的需求.beautifulsoup不是为爬虫服务的,他是做api/xpath解析或xml解析用的.你这个是转换列表文章,让别人来爬你的吧.
beautifulsoup写爬虫还行吧
这个好像不能,
先要弄清楚一个事情,网站内容都是微信公众号服务号提供的,不能像知乎这样存。
可以用知乎采集
你有两个选择一个是用爬虫,一个是用思科的机器人软件。两个都是工具没有内容抽取这个功能。
拿爬虫去爬微信公众号文章或者qq空间文章或者百度新闻看看有没有给文章贴链接。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章列表url,不能传递给其他用户)
querylist采集微信公众号文章列表url,如果是公众号文章的话,采集下一篇文章,
这是一篇微信公众号文章的下一篇文章,即不能传递给其他用户,也不能传递给群发外链的用户,如果不想发给群发外链的朋友,
基本上常用的方法还是爬虫,爬公众号文章内容。webservice什么的,
这个爬虫还行,不过一般不会用,因为流量来源没准,有很大可能找不到真正的爬虫。
你可以把文章列表分段遍历
这个还是有点不错的,可以采集公众号内容,
可以考虑用pythonflask框架写爬虫.用beautifulsoup库,基本可以满足你的需求.beautifulsoup不是为爬虫服务的,他是做api/xpath解析或xml解析用的.你这个是转换列表文章,让别人来爬你的吧.
beautifulsoup写爬虫还行吧
这个好像不能,
先要弄清楚一个事情,网站内容都是微信公众号服务号提供的,不能像知乎这样存。
可以用知乎采集
你有两个选择一个是用爬虫,一个是用思科的机器人软件。两个都是工具没有内容抽取这个功能。
拿爬虫去爬微信公众号文章或者qq空间文章或者百度新闻看看有没有给文章贴链接。
querylist采集微信公众号文章(querylist采集微信公众号文章存储格式接口介绍参考资料)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-02-18 10:01
querylist采集微信公众号文章,发布到一个querylist文件,
一、querylist接口:1.
1、文章行接口#{0}即文章的标题#{1}即文章的作者#{2}即文章的标签。
2、文章列表接口2.
1、文章列表类:#{1}#{2}即文章的标题:#{2}#{3}即文章的标签:#{3}#{4}即分享链接:#{4}2.
2、图文消息类:#{1}#{2}#{3}即图文消息的标题:#{2}#{3}#{4}即分享链接:#{4}2.
3、公众号文章列表接口#{0}接口介绍#{1}接口介绍#{2}接口介绍#{3}接口介绍参考资料:对于文章列表,每一个标题后面都需要加#{0},以下是图文消息的二维码。
二、存储格式querylist接口中的string字符串存储格式如下:order+*,即***的序列。
java对象,可以让querylist支持索引并存储二级索引:在mybatis中,或者在rabbitmq中,索引可以支持一个或多个,但是如果接收的是二级索引的话,需要提供一个名称实体:@mapped(mappedinfo,mappedname)publicclassorderedescription{@value("id")privateintid;@value("name")privatestringname;}2。
可以建立多个查询,但是有时候,并不能满足查询的很多需求@mapped(mappedinfo,mappedname)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){returnnull;}//。
1)建立一个新的查询@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){try{newquerylist();}catch(exceptione){e。printstacktrace();}}//。
2)对查询结果进行修改update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。printstacktrace();2。2。可以查看不同的类型的文章,endpoint=null不代表不能查询,代表建立新的查询@mapped(mappedinfo。
id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。
printstacktrace();}}}2。3。可以对返回结果集进行排序@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章存储格式接口介绍参考资料)
querylist采集微信公众号文章,发布到一个querylist文件,
一、querylist接口:1.
1、文章行接口#{0}即文章的标题#{1}即文章的作者#{2}即文章的标签。
2、文章列表接口2.
1、文章列表类:#{1}#{2}即文章的标题:#{2}#{3}即文章的标签:#{3}#{4}即分享链接:#{4}2.
2、图文消息类:#{1}#{2}#{3}即图文消息的标题:#{2}#{3}#{4}即分享链接:#{4}2.
3、公众号文章列表接口#{0}接口介绍#{1}接口介绍#{2}接口介绍#{3}接口介绍参考资料:对于文章列表,每一个标题后面都需要加#{0},以下是图文消息的二维码。
二、存储格式querylist接口中的string字符串存储格式如下:order+*,即***的序列。
java对象,可以让querylist支持索引并存储二级索引:在mybatis中,或者在rabbitmq中,索引可以支持一个或多个,但是如果接收的是二级索引的话,需要提供一个名称实体:@mapped(mappedinfo,mappedname)publicclassorderedescription{@value("id")privateintid;@value("name")privatestringname;}2。
可以建立多个查询,但是有时候,并不能满足查询的很多需求@mapped(mappedinfo,mappedname)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){returnnull;}//。
1)建立一个新的查询@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){if(endpoint==null){try{newquerylist();}catch(exceptione){e。printstacktrace();}}//。
2)对查询结果进行修改update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。printstacktrace();2。2。可以查看不同的类型的文章,endpoint=null不代表不能查询,代表建立新的查询@mapped(mappedinfo。
id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)int);if(endpoint!=null){try{newquerylist();}catch(exceptione){e。
printstacktrace();}}}2。3。可以对返回结果集进行排序@mapped(mappedinfo。id,mappedinfo。name)publicstringquerylist(@mappedinfo()stringendpoint){update(endpoint,(endpoint,new)。
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-02-15 18:00
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接安装即可。安装后直接运行C:\Program Files\nodejs\npm.cmd会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
只要把一个安卓模拟器放到网上,有很多。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ----------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令开启代理服务。 (记得加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会使用这个。现在用浏览器打开网页::8002/ 这是anyproxy的web界面,用来显示http传输数据。
点击上方红框内的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开公众号文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框内是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部畅通了,就可以往下走。
这里我们是靠代理服务抓取微信数据,但是不能自己抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺理成章理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。有需要的可以试试。 查看全部
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序处理。
需要准备的环境:nodejs、anyproxy代理、Android模拟器
nodejs下载地址:我下载的是windows版本,直接安装即可。安装后直接运行C:\Program Files\nodejs\npm.cmd会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
只要把一个安卓模拟器放到网上,有很多。
----------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- ----------------------------------------
首先安装代理服务器的证书。 Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令开启代理服务。 (记得加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会使用这个。现在用浏览器打开网页::8002/ 这是anyproxy的web界面,用来显示http传输数据。
点击上方红框内的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开公众号文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框内是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部畅通了,就可以往下走。
这里我们是靠代理服务抓取微信数据,但是不能自己抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync:function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺理成章理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这里是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。有需要的可以试试。
querylist采集微信公众号文章(搜狗搜索有个不足实现公众号的爬虫需要安装 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-14 04:15
)
因为搜狗搜索有微信公众号搜索的接口,所以可以通过这个接口实现公众号的爬虫。
需要安装几个python库:selenium、pyquery
我们也用到了phantomjs.exe,需要自己下载,然后放到我们自己的python项目下。
在输入框中输入你要爬取的公众号的微信号,然后搜索公众号,
可以出现搜索结果,进入首页可以看到公众号最近发布的文章,点击标题查看文章的内容
这种思路,可以在网页上查看微信公众号的推送,实现公众号爬虫;但搜狗搜索有个缺点,只能查看公众号最近发布的10条推送,无法查看过去的历史记录。
有了爬虫思路后,就开始执行流程,先拿到搜狗搜索的接口
通过这个接口可以得到公众号首页的入口,文章列表,文章内容,用python写爬虫的实现,下面是运行结果,得到< @文章 标题、文章 链接、文章 简要说明、发表时间、封面图片链接、文章 内容,并将抓取的信息保存到文本文档中,文章@ > 公众号爬取结束。
废话不多说,代码如下:
from pyquery import PyQuery as pq
from selenium import webdriver
import os
import re
import requests
import time
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
browser = webdriver.PhantomJS(executable_path=r'phantomjs.exe')
browser.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
return html
def log(msg):
print('%s: %s' % (time.strftime('%Y-%m-%d %H:%M:%S'), msg))
# 创建公众号命名的文件夹
def create_dir():
if not os.path.exists(keyword):
os.makedirs(keyword)
# 将获取到的文章转换为字典
def switch_articles_to_list(articles):
articles_list = []
i = 1
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article, i))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article, i):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 获取文章内容(pyQuery.text / html)
#log('content是')
#log(parse_content_by_url(url))
content = parse_content_by_url(url).text()
log('获取到content')
# 存储文章到本地
#content_file_title = keyword + '/' + str(i) + '_' + title + '_' + date + '.html'
#with open(content_file_title, 'w', encoding='utf-8') as f:
# f.write(content)
content_title = keyword + '/' + keyword + '.txt'
with open(content_title, 'a', encoding='utf-8') as f:
print('第', i, '条', file=f)
print('title:', title, file=f)
print('url:', url, file=f)
print('summary:', summary, file=f)
print('date:', date, file=f)
print('pic:', pic, file=f)
print('content:', content, file=f)
print(file=f)
log('写入content')
article_dict = {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic,
'content': content
}
return article_dict
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 获取文章页面详情
def parse_content_by_url(url):
page_html = get_selenium_js_html(url)
return pq(page_html)('#js_content')
'''程序入口'''
keyword = 'python'
create_dir()
url = 'http://weixin.sogou.com/weixin?query=%s' % keyword
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
try:
log(u'开始调用sougou搜索引擎')
r = requests.get(url, headers=headers)
r.raise_for_status()
print(r.status_code)
print(r.request.url)
print(len(r.text))
#print(r.text)
#print(re.Session().get(url).text)
except:
print('爬取失败')
# 获得公众号主页地址
doc = pq(r.text)
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
home_url = doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
log(u'获取wx_url成功,%s' % home_url)
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
log(u'开始调用selenium渲染公众号主页html')
html = get_selenium_js_html(home_url)
#有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试
if pq(html)('#verify_change').text() != '':
log(u'爬虫被目标网站封锁,请稍后再试')
else:
log(u'调用selenium渲染html完成,开始解析公众号文章')
doc = pq(html)
articles = doc('div[class="weui_media_box appmsg"]')
#print(articles)
log(u'抓取到微信文章%d篇' % len(articles))
article_list = switch_articles_to_list(articles)
print(article_list)
log('程序结束') 查看全部
querylist采集微信公众号文章(搜狗搜索有个不足实现公众号的爬虫需要安装
)
因为搜狗搜索有微信公众号搜索的接口,所以可以通过这个接口实现公众号的爬虫。
需要安装几个python库:selenium、pyquery
我们也用到了phantomjs.exe,需要自己下载,然后放到我们自己的python项目下。
在输入框中输入你要爬取的公众号的微信号,然后搜索公众号,
可以出现搜索结果,进入首页可以看到公众号最近发布的文章,点击标题查看文章的内容
这种思路,可以在网页上查看微信公众号的推送,实现公众号爬虫;但搜狗搜索有个缺点,只能查看公众号最近发布的10条推送,无法查看过去的历史记录。
有了爬虫思路后,就开始执行流程,先拿到搜狗搜索的接口
通过这个接口可以得到公众号首页的入口,文章列表,文章内容,用python写爬虫的实现,下面是运行结果,得到< @文章 标题、文章 链接、文章 简要说明、发表时间、封面图片链接、文章 内容,并将抓取的信息保存到文本文档中,文章@ > 公众号爬取结束。
废话不多说,代码如下:
from pyquery import PyQuery as pq
from selenium import webdriver
import os
import re
import requests
import time
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
browser = webdriver.PhantomJS(executable_path=r'phantomjs.exe')
browser.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
return html
def log(msg):
print('%s: %s' % (time.strftime('%Y-%m-%d %H:%M:%S'), msg))
# 创建公众号命名的文件夹
def create_dir():
if not os.path.exists(keyword):
os.makedirs(keyword)
# 将获取到的文章转换为字典
def switch_articles_to_list(articles):
articles_list = []
i = 1
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article, i))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article, i):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 获取文章内容(pyQuery.text / html)
#log('content是')
#log(parse_content_by_url(url))
content = parse_content_by_url(url).text()
log('获取到content')
# 存储文章到本地
#content_file_title = keyword + '/' + str(i) + '_' + title + '_' + date + '.html'
#with open(content_file_title, 'w', encoding='utf-8') as f:
# f.write(content)
content_title = keyword + '/' + keyword + '.txt'
with open(content_title, 'a', encoding='utf-8') as f:
print('第', i, '条', file=f)
print('title:', title, file=f)
print('url:', url, file=f)
print('summary:', summary, file=f)
print('date:', date, file=f)
print('pic:', pic, file=f)
print('content:', content, file=f)
print(file=f)
log('写入content')
article_dict = {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic,
'content': content
}
return article_dict
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 获取文章页面详情
def parse_content_by_url(url):
page_html = get_selenium_js_html(url)
return pq(page_html)('#js_content')
'''程序入口'''
keyword = 'python'
create_dir()
url = 'http://weixin.sogou.com/weixin?query=%s' % keyword
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
try:
log(u'开始调用sougou搜索引擎')
r = requests.get(url, headers=headers)
r.raise_for_status()
print(r.status_code)
print(r.request.url)
print(len(r.text))
#print(r.text)
#print(re.Session().get(url).text)
except:
print('爬取失败')
# 获得公众号主页地址
doc = pq(r.text)
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
home_url = doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
log(u'获取wx_url成功,%s' % home_url)
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
log(u'开始调用selenium渲染公众号主页html')
html = get_selenium_js_html(home_url)
#有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试
if pq(html)('#verify_change').text() != '':
log(u'爬虫被目标网站封锁,请稍后再试')
else:
log(u'调用selenium渲染html完成,开始解析公众号文章')
doc = pq(html)
articles = doc('div[class="weui_media_box appmsg"]')
#print(articles)
log(u'抓取到微信文章%d篇' % len(articles))
article_list = switch_articles_to_list(articles)
print(article_list)
log('程序结束')
querylist采集微信公众号文章(excel添加索引就行的两种解决方法:)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-12 02:02
querylist采集微信公众号文章链接,转换为excel格式,用rust实现中间转换器。定义excel转换器对象publicstaticlistexceltransform.newarray(nextnext,exceltype.literal,prev){prev.add(nextnext);returnprev;}定义prev对象:rust>>>arr:=newrust()>>>arr[5]:=prev>>>arr[5]list.newarray(nextnext,exceltype.pointer).add_many_numbers(nextnext,。
1)>>>arr[5]:=newrust()>>>arr[1]:=prev>>>arr[1]newarray
5).add_many_numbers
0)转换后为:tarray:=prevrust>>>arr:=arr[5]newarray
0)>>>arr[1]:=prevlist.newarray
1)>>>arr[5]:=arr[5]
excel添加索引就行。
说下这个问题的两种解决方法:1.每一个excel文件作为一个字典。每一个字符对应一个key。每一个key值对应一个value。对于输入的value,可以一次生成多列,int或者long变量。可以比较多个一行输入的excel文件,实时添加到字典,把所有输入的value组合成一个词典。也可以根据string输入的唯一标识+某个trait定义出来的对应关系。
2.对于excel数据量更多的话,可以采用用string和property机制来处理,可以自定义各个headerdeleteheaderint等。 查看全部
querylist采集微信公众号文章(excel添加索引就行的两种解决方法:)
querylist采集微信公众号文章链接,转换为excel格式,用rust实现中间转换器。定义excel转换器对象publicstaticlistexceltransform.newarray(nextnext,exceltype.literal,prev){prev.add(nextnext);returnprev;}定义prev对象:rust>>>arr:=newrust()>>>arr[5]:=prev>>>arr[5]list.newarray(nextnext,exceltype.pointer).add_many_numbers(nextnext,。
1)>>>arr[5]:=newrust()>>>arr[1]:=prev>>>arr[1]newarray
5).add_many_numbers
0)转换后为:tarray:=prevrust>>>arr:=arr[5]newarray
0)>>>arr[1]:=prevlist.newarray
1)>>>arr[5]:=arr[5]
excel添加索引就行。
说下这个问题的两种解决方法:1.每一个excel文件作为一个字典。每一个字符对应一个key。每一个key值对应一个value。对于输入的value,可以一次生成多列,int或者long变量。可以比较多个一行输入的excel文件,实时添加到字典,把所有输入的value组合成一个词典。也可以根据string输入的唯一标识+某个trait定义出来的对应关系。
2.对于excel数据量更多的话,可以采用用string和property机制来处理,可以自定义各个headerdeleteheaderint等。
querylist采集微信公众号文章( 一种微信公众号是否有敏感词汇的检测方法及装置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-02-10 22:22
一种微信公众号是否有敏感词汇的检测方法及装置)
本发明属于微信公众号广告投放领域,具体涉及一种微信公众号是否存在敏感词的检测方法及装置。
背景技术:
微信公众平台主要面向名人、政府、媒体、企业等机构发起的合作推广业务。在这里,品牌可以通过渠道推广到线上平台。微信公众号广告是一种常见的广告推广方式。
但微信公众号是否带有政治色彩是企业在投放广告时需要考虑的,以免出现不必要的问题,影响企业的投资回报。投资回报是指应该通过投资获得回报的价值,即企业从一项投资活动中获得的经济回报,需要能够判断微信公众号是否有敏感词的技术。
技术实施要素:
本发明提供一种检测微信公众号是否有敏感词的方法及装置,旨在解决无法判断微信公众号是否有敏感词的问题。
本发明是这样实现的,一种检测微信公众号是否有敏感词的方法,包括以下步骤:
s1、提取微信公众号历史文章数据,手动标注文章是否有敏感词;
s2、清洗文章数据,训练word2vec模型作为训练数据,分割文章词得到embedding,最后训练双向bilstm深度学习模型;
s3、获取微信公众号预设数量的待预测历史文章数据,清洗数据,获取embedding,使用训练好的双向bilstm深度学习模型进行预测,每< @文章是否有敏感词汇的预测结果;
<p>s4、根据预设个数文章中有敏感词的文章个数,计算出有敏感词的文章个数占所有 查看全部
querylist采集微信公众号文章(
一种微信公众号是否有敏感词汇的检测方法及装置)
本发明属于微信公众号广告投放领域,具体涉及一种微信公众号是否存在敏感词的检测方法及装置。
背景技术:
微信公众平台主要面向名人、政府、媒体、企业等机构发起的合作推广业务。在这里,品牌可以通过渠道推广到线上平台。微信公众号广告是一种常见的广告推广方式。
但微信公众号是否带有政治色彩是企业在投放广告时需要考虑的,以免出现不必要的问题,影响企业的投资回报。投资回报是指应该通过投资获得回报的价值,即企业从一项投资活动中获得的经济回报,需要能够判断微信公众号是否有敏感词的技术。
技术实施要素:
本发明提供一种检测微信公众号是否有敏感词的方法及装置,旨在解决无法判断微信公众号是否有敏感词的问题。
本发明是这样实现的,一种检测微信公众号是否有敏感词的方法,包括以下步骤:
s1、提取微信公众号历史文章数据,手动标注文章是否有敏感词;
s2、清洗文章数据,训练word2vec模型作为训练数据,分割文章词得到embedding,最后训练双向bilstm深度学习模型;
s3、获取微信公众号预设数量的待预测历史文章数据,清洗数据,获取embedding,使用训练好的双向bilstm深度学习模型进行预测,每< @文章是否有敏感词汇的预测结果;
<p>s4、根据预设个数文章中有敏感词的文章个数,计算出有敏感词的文章个数占所有
querylist采集微信公众号文章(每天更新视频:熊孩子和萌宠搞笑视频,笑声不断快乐常伴 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-02-08 22:10
)
每天更新视频:熊孩子的日常生活,萌宠的日常生活,熊孩子和萌宠的搞笑视频,笑声不断伴随着快乐!
获取公众号信息
标题、摘要、封面、文章URL
脚步:
1、先申请公众号
2、登录您的帐户,创建一个新的文章 图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史记录文章
4、通过抓包获取信息,定位到请求的url
通过查看信息,我们找到了我们需要的关键内容:title、abstract、cover 和 文章 URL,并确定这就是我们需要的 URL。通过点击下一页,多次获取url,发现只有random和bengin的参数变化
所以主要信息URL是可以的。
那么让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
这两个值的来源,可以得到url
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
得到结果(成功):
获取 文章 里面的视频
实现批量下载通过分析单个视频文章,找到了这个链接:
打开网页找到,也就是视频的网页下载链接:
嘿嘿,好像有点意思。找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。我不知道它是从哪里来的?
与获取的其他信息无关,只能强制。
该参数在单文章的url请求信息中找到,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,代码就组装好了。
一个。获取公众号信息
湾。筛选单个文章信息
C。获取视频信息
d。拼接视频页面下载地址
e. 下载视频并保存
代码实验结果:
查看全部
querylist采集微信公众号文章(每天更新视频:熊孩子和萌宠搞笑视频,笑声不断快乐常伴
)
每天更新视频:熊孩子的日常生活,萌宠的日常生活,熊孩子和萌宠的搞笑视频,笑声不断伴随着快乐!
获取公众号信息
标题、摘要、封面、文章URL
脚步:
1、先申请公众号
2、登录您的帐户,创建一个新的文章 图形,然后单击超链接
3、弹出搜索框,搜索你需要的公众号,查看历史记录文章
4、通过抓包获取信息,定位到请求的url
通过查看信息,我们找到了我们需要的关键内容:title、abstract、cover 和 文章 URL,并确定这就是我们需要的 URL。通过点击下一页,多次获取url,发现只有random和bengin的参数变化
所以主要信息URL是可以的。
那么让我们开始吧:
原来我们需要修改的参数是:token、random、cookie
这两个值的来源,可以得到url
# -*- coding: utf-8 -*-
import re
import requests
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Host": "mp.weixin.qq.com",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Cookie": "自己获取信息时的cookie"
}
def getInfo():
for i in range(80):
# token random 需要要自己的 begin:参数传入
url = "https://mp.weixin.qq.com/cgi-b ... in%3D{}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9".format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, "$..title")
coverList = jsonpath.jsonpath(jsonRes, "$..cover")
urlList = jsonpath.jsonpath(jsonRes, "$..link")
# 遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = "%s,%s, %s,\n" % (title, cover, url)
with open("info.csv", "a+", encoding="gbk", newline='') as f:
f.write(scvStr)
得到结果(成功):
获取 文章 里面的视频
实现批量下载通过分析单个视频文章,找到了这个链接:
打开网页找到,也就是视频的网页下载链接:
嘿嘿,好像有点意思。找到了视频网页的纯下载链接,开始吧。
我发现链接中有一个关键参数vid。我不知道它是从哪里来的?
与获取的其他信息无关,只能强制。
该参数在单文章的url请求信息中找到,然后获取。
response = requests.get(url_wxv, headers=headers)
# 我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = './videoFiles/' + video_title + ".mp4"
# 页面可下载形式
video_url_temp = "https://mp.weixin.qq.com/mp/vi ... ot%3B + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get("url_info")
video_url2 = url_info[0].get("url")
print(video_url2)
# 请求要下载的url地址
html = requests.get(video_url2)
# content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, 'wb') as f:
f.write(html)
然后所有的信息都完成了,代码就组装好了。
一个。获取公众号信息
湾。筛选单个文章信息
C。获取视频信息
d。拼接视频页面下载地址
e. 下载视频并保存
代码实验结果:
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-02-07 13:10
)
准备阶段
为了实现这个爬虫,我们需要用到以下工具
另外,本爬虫使用微信公众号后台编辑素材界面。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要一个公众号。
fig1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择 Network
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入需要抓取的公众号(如中国移动)
图4
此时之前的Network会刷新一些链接,而以“appmsg”开头的就是我们需要分析的内容。
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断的浏览下一页,我们发现只有begin每次都会变化,每次增加5,也就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码无法获取资源
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
我们之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求是无效的。我们需要在requests中设置headers参数,传入Cookie和User-Agent,模拟登录
由于header信息的内容每次都在变化,所以我把这些内容放在了一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
然后就读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每次推送的唯一标识符,aid 是每条推文的唯一标识符。
❞
图6❝
其实除了cookies,URL中的token参数也是用来限制爬虫的,所以上面的代码很可能会输出{'base_resp': {'ret': 200040, 'err_msg': 'invalid csrf token' } }
❞
然后我们编写一个循环来获取 文章 的所有 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我也在“wechat.yaml”文件中存储了fakeid和token,这是因为fakeid是每个公众号的唯一标识,并且token经常变化,这个信息可以通过解析URL来获取,也可以从开发者工具中查看
图7
爬取一段时间后会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,可能需要申请多个公众号,可能需要与微信公众号登录系统竞争,可能需要设置代理池。
但是我不需要工业级爬虫,我只是想爬取我公众号的信息,所以等了一个小时,再次登录公众号,获取cookie和token,然后运行。我不想用自己的兴趣去挑战别人的工作。
最后将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列信息,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list)) 查看全部
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序
)
准备阶段
为了实现这个爬虫,我们需要用到以下工具
另外,本爬虫使用微信公众号后台编辑素材界面。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要一个公众号。
fig1正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择 Network
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入需要抓取的公众号(如中国移动)
图4
此时之前的Network会刷新一些链接,而以“appmsg”开头的就是我们需要分析的内容。
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断的浏览下一页,我们发现只有begin每次都会变化,每次增加5,也就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码无法获取资源
import requestsurl = "https://mp.weixin.qq.com/cgi-b ... s.get(url).json() # {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
我们之所以能在浏览器上获取资源,是因为我们登录了微信公众号后台。而Python没有我们的登录信息,所以请求是无效的。我们需要在requests中设置headers参数,传入Cookie和User-Agent,模拟登录
由于header信息的内容每次都在变化,所以我把这些内容放在了一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...user_agent: Mozilla/5.0...
然后就读
# 读取cookie和user_agentimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
❝
appmsgid 是每次推送的唯一标识符,aid 是每条推文的唯一标识符。
❞
图6❝
其实除了cookies,URL中的token参数也是用来限制爬虫的,所以上面的代码很可能会输出{'base_resp': {'ret': 200040, 'err_msg': 'invalid csrf token' } }
❞
然后我们编写一个循环来获取 文章 的所有 JSON 并保存。
import jsonimport requestsimport timeimport randomimport yamlwith open("wechat.yaml", "r") as file: file_data = file.read()config = yaml.safe_load(file_data)headers = { "Cookie": config['cookie'], "User-Agent": config['user_agent'] }# 请求参数url = "https://mp.weixin.qq.com/cgi-bin/appmsg"begin = "0"params = { "action": "list_ex", "begin": begin, "count": "5", "fakeid": config['fakeid'], "type": "9", "token": config['token'], "lang": "zh_CN", "f": "json", "ajax": "1"}# 存放结果app_msg_list = []# 在不知道公众号有多少文章的情况下,使用while语句# 也方便重新运行时设置页数i = 0while True: begin = i * 5 params["begin"] = str(begin) # 随机暂停几秒,避免过快的请求导致过快的被查到 time.sleep(random.randint(1,10)) resp = requests.get(url, headers=headers, params = params, verify=False) # 微信流量控制, 退出 if resp.json()['base_resp']['ret'] == 200013: print("frequencey control, stop at {}".format(str(begin))) break # 如果返回的内容中为空则结束 if len(resp.json()['app_msg_list']) == 0: print("all ariticle parsed") break app_msg_list.append(resp.json()) # 翻页 i += 1
在上面的代码中,我也在“wechat.yaml”文件中存储了fakeid和token,这是因为fakeid是每个公众号的唯一标识,并且token经常变化,这个信息可以通过解析URL来获取,也可以从开发者工具中查看
图7
爬取一段时间后会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,可能需要申请多个公众号,可能需要与微信公众号登录系统竞争,可能需要设置代理池。
但是我不需要工业级爬虫,我只是想爬取我公众号的信息,所以等了一个小时,再次登录公众号,获取cookie和token,然后运行。我不想用自己的兴趣去挑战别人的工作。
最后将结果保存为 JSON 格式。
# 保存结果为JSONjson_name = "mp_data_{}.json".format(str(begin))with open(json_name, "w") as file: file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列信息,保存为CSV。
info_list = []for msg in app_msg_list: if "app_msg_list" in msg: for item in msg["app_msg_list"]: info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time'])) info_list.append(info)# save as csvwith open("app_msg_list.csv", "w") as file: file.writelines("\n".join(info_list))
querylist采集微信公众号文章(querylist采集微信公众号文章的url,然后匹配出关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-07 01:03
querylist采集微信公众号文章的url,然后匹配出关键词。这个过程主要有2个东西需要去查。1.微信公众号是无法被搜索引擎识别的,不对应的搜索结果都属于污点。2.微信公众号是匿名的,由个人微信号绑定来实现。本案例是第二种情况。querylist匹配出所有公众号。文章就都显示出来了。
楼上已经说得很清楚了,这就是一个querylist加上allfollower来搜索文章关键词的机制。我第一次听说还有这么简单的算法,这里做个简单的总结吧:dataeditor与dontmatch的区别是editor可以一次性只发一个all-follower查询词,如果你在开发自己的查询引擎,这种查询方式尤其方便,因为你要确定目标关键词,用户要查询什么词才需要把所有关键词展示出来,用dontmatch的话,系统可以只有allfollower来排序查询词(请注意querylist包含all-follower)。
一样的好处是,editor一次性就给一个查询词把所有关键词显示出来,没有展示少量的all-follower和cachesomefollowers。
具体就是给query加入all-follower变量。
额,最近分析过。这个就是微信公众号文章标题和摘要出现的词匹配。就是把query加到一个entity{{all_follower}}。然后要排序的时候,先对大量query进行排序,然后根据相应的entity去匹配,这样就排序完成了。不过我这只是基本原理, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的url,然后匹配出关键词)
querylist采集微信公众号文章的url,然后匹配出关键词。这个过程主要有2个东西需要去查。1.微信公众号是无法被搜索引擎识别的,不对应的搜索结果都属于污点。2.微信公众号是匿名的,由个人微信号绑定来实现。本案例是第二种情况。querylist匹配出所有公众号。文章就都显示出来了。
楼上已经说得很清楚了,这就是一个querylist加上allfollower来搜索文章关键词的机制。我第一次听说还有这么简单的算法,这里做个简单的总结吧:dataeditor与dontmatch的区别是editor可以一次性只发一个all-follower查询词,如果你在开发自己的查询引擎,这种查询方式尤其方便,因为你要确定目标关键词,用户要查询什么词才需要把所有关键词展示出来,用dontmatch的话,系统可以只有allfollower来排序查询词(请注意querylist包含all-follower)。
一样的好处是,editor一次性就给一个查询词把所有关键词显示出来,没有展示少量的all-follower和cachesomefollowers。
具体就是给query加入all-follower变量。
额,最近分析过。这个就是微信公众号文章标题和摘要出现的词匹配。就是把query加到一个entity{{all_follower}}。然后要排序的时候,先对大量query进行排序,然后根据相应的entity去匹配,这样就排序完成了。不过我这只是基本原理,
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-04 15:15
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get(\'https://mp.weixin.qq.com/\')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class=\'login__type__container__select-type\']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name=\'account\']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name=\'password\']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class=\'btn_login\']").click()
sleep(2)
# 微信登录验证
print(\'请扫描二维码\')
sleep(20)
# 刷新当前网页
browser.get(\'https://mp.weixin.qq.com/\')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item[\'name\']] = item[\'value\']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open(\'cookie.txt\', \'w+\', encoding=\'utf-8\') as f:
f.write(cookie_str)
print(\'cookie保存到本地成功\')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split(\'?\')[1].split(\'&\')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split(\'=\')[0]] = item.split(\'=\')[1]
# 返回token
return paramdict[\'token\']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = \'https://mp.weixin.qq.com\'
headers = {
\'HOST\': \'mp.weixin.qq.com\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63\'
}
with open(\'cookie.txt\', \'r\', encoding=\'utf-8\') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = \'https://mp.weixin.qq.com/cgi-bin/searchbiz?\'
params = {
\'action\': \'search_biz\',
\'begin\': \'0\',
\'count\': \'5\',
\'query\': \'搜索的公众号名称\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get(\'list\')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get(\'fakeid\')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = \'https://mp.weixin.qq.com/cgi-bin/appmsg?\'
params_data = {
\'action\': \'list_ex\',
\'begin\': \'0\',
\'count\': \'5\',
\'fakeid\': fakeid,
\'type\': \'9\',
\'query\': \'\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get(\'https://mp.weixin.qq.com/\')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class=\'login__type__container__select-type\']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name=\'account\']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name=\'password\']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class=\'btn_login\']").click()
sleep(2)
# 微信登录验证
print(\'请扫描二维码\')
sleep(20)
# 刷新当前网页
browser.get(\'https://mp.weixin.qq.com/\')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item[\'name\']] = item[\'value\']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open(\'cookie.txt\', \'w+\', encoding=\'utf-8\') as f:
f.write(cookie_str)
print(\'cookie保存到本地成功\')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split(\'?\')[1].split(\'&\')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split(\'=\')[0]] = item.split(\'=\')[1]
# 返回token
return paramdict[\'token\']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = \'https://mp.weixin.qq.com\'
headers = {
\'HOST\': \'mp.weixin.qq.com\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63\'
}
with open(\'cookie.txt\', \'r\', encoding=\'utf-8\') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = \'https://mp.weixin.qq.com/cgi-bin/searchbiz?\'
params = {
\'action\': \'search_biz\',
\'begin\': \'0\',
\'count\': \'5\',
\'query\': \'搜索的公众号名称\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get(\'list\')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get(\'fakeid\')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = \'https://mp.weixin.qq.com/cgi-bin/appmsg?\'
params_data = {
\'action\': \'list_ex\',
\'begin\': \'0\',
\'count\': \'5\',
\'fakeid\': fakeid,
\'type\': \'9\',
\'query\': \'\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章( 微信公众号文章的GET及方法(二)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-04 15:12
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(快速推广小程序的方法,希望这些能够帮到大家!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-02 02:02
小程序的火爆带动了很多企业和公司开发小程序。但是小程序开发出来之后,很重要的一个环节就是推广。下面,小编为大家整理了小程序快速推广的方法,希望对大家有所帮助。
相关公众号推广
目前微信支持公众号与小程序的互联互通。微信公众号可以快速关联和创建小程序,小程序也可以展示公众号的内容。关联小程序可用于短信、自定义菜单、模板消息、附近小程序等场景。
公众号关联小程序也会通过推送消息通知用户。公众号关联,对于已经拥有公众号并积累一定粉丝数的企业,可以快速将流量导入小程序。关联后,您还可以在公众号的推文中插入小程序卡片或链接。
如果你的公众号能产出优质内容,获得大量阅读量,也是小程序推广快速有效的方法。
小程序搜索优化
现在微信小程序由系统自动分配关键词,商家和创业公司可以根据规则合理设置名称和功能介绍字段,在名称关键词中合理体现相关字段,并将功能介绍中的品牌名称。定位、功能描述、产品分类等内容展示简洁有效。
对于关键词的优化,一定要遵循规律,合理适当。如果添加太多名称和描述,可能会受到官方微信小程序的惩罚。
微信表示,未来将对小程序进行一系列升级,包括开放品牌和品牌搜索,很可能会再次开放自定义关键词功能,并推出一系列规范。大推动。
小程序二维码推广
小程序还可以生成二维码。目前小程序已经支持采集功能。采集的小程序会显示在微信聊天界面顶部的下拉菜单中。通过二维码在不同场景下的推广使用,可以有效达到推广目的。
线上推广可以通过朋友圈、微信群转发、网站、app图片广告、软文植入等方式进行分享。在推广中,要根据不同场景下推广的特点和规律,有针对性地进行和优化推广。 查看全部
querylist采集微信公众号文章(快速推广小程序的方法,希望这些能够帮到大家!)
小程序的火爆带动了很多企业和公司开发小程序。但是小程序开发出来之后,很重要的一个环节就是推广。下面,小编为大家整理了小程序快速推广的方法,希望对大家有所帮助。
相关公众号推广
目前微信支持公众号与小程序的互联互通。微信公众号可以快速关联和创建小程序,小程序也可以展示公众号的内容。关联小程序可用于短信、自定义菜单、模板消息、附近小程序等场景。
公众号关联小程序也会通过推送消息通知用户。公众号关联,对于已经拥有公众号并积累一定粉丝数的企业,可以快速将流量导入小程序。关联后,您还可以在公众号的推文中插入小程序卡片或链接。
如果你的公众号能产出优质内容,获得大量阅读量,也是小程序推广快速有效的方法。
小程序搜索优化
现在微信小程序由系统自动分配关键词,商家和创业公司可以根据规则合理设置名称和功能介绍字段,在名称关键词中合理体现相关字段,并将功能介绍中的品牌名称。定位、功能描述、产品分类等内容展示简洁有效。
对于关键词的优化,一定要遵循规律,合理适当。如果添加太多名称和描述,可能会受到官方微信小程序的惩罚。
微信表示,未来将对小程序进行一系列升级,包括开放品牌和品牌搜索,很可能会再次开放自定义关键词功能,并推出一系列规范。大推动。
小程序二维码推广
小程序还可以生成二维码。目前小程序已经支持采集功能。采集的小程序会显示在微信聊天界面顶部的下拉菜单中。通过二维码在不同场景下的推广使用,可以有效达到推广目的。
线上推广可以通过朋友圈、微信群转发、网站、app图片广告、软文植入等方式进行分享。在推广中,要根据不同场景下推广的特点和规律,有针对性地进行和优化推广。
querylist采集微信公众号文章(微信公众号文章的每一篇文章所对应的key-value数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-28 07:04
querylist采集微信公众号文章的每一篇文章所对应的key-value数据。文章的所有信息都采集完之后按照header的顺序,汇总信息给开发者,开发者可以将对应的key发给需要看文章的人。
实现过一个小的搜索引擎需要对接微信的搜索接口,之前在用路由库的时候一直比较麻烦。importrequestsurl=''r=requests.get(url)headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2704.85safari/537.36'}defget_content(url):page=requests.post(url,data={'host':url}).textpage.raise_for_status_code()urls=page.request('')#有重复字符的地方用空格代替urls.encode('gbk').decode('utf-8')html=urls.json()print("encoded:{0}'.format(html))more_content=requests.get(url,data={'results':[x,y]}).textmore_content.decode('utf-8')print("more_content:{0}".format(more_content))print("title",html)returnquerylist.fetch(more_content)但是换言之如果我有两个相同的url,上一个就去掉复制这个链接,而我只是想查找一个query,下一个就直接拿到这个query的title?那就只能用urlencode转换数据了。
?_id=="a"python实现输入地址query_list_content="{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(query_list_content)text=query_list_content[-1]#print(text)print("title:{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(text))print("foriinrange({3,7}):”{1:“{2:“{3:“{4:“{5:“{6:“{7:”}”}”}”}”}”}”}".format(text))query_list_content=[iforiinrange(1,8)]text=get_content(。 查看全部
querylist采集微信公众号文章(微信公众号文章的每一篇文章所对应的key-value数据)
querylist采集微信公众号文章的每一篇文章所对应的key-value数据。文章的所有信息都采集完之后按照header的顺序,汇总信息给开发者,开发者可以将对应的key发给需要看文章的人。
实现过一个小的搜索引擎需要对接微信的搜索接口,之前在用路由库的时候一直比较麻烦。importrequestsurl=''r=requests.get(url)headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/55.0.2704.85safari/537.36'}defget_content(url):page=requests.post(url,data={'host':url}).textpage.raise_for_status_code()urls=page.request('')#有重复字符的地方用空格代替urls.encode('gbk').decode('utf-8')html=urls.json()print("encoded:{0}'.format(html))more_content=requests.get(url,data={'results':[x,y]}).textmore_content.decode('utf-8')print("more_content:{0}".format(more_content))print("title",html)returnquerylist.fetch(more_content)但是换言之如果我有两个相同的url,上一个就去掉复制这个链接,而我只是想查找一个query,下一个就直接拿到这个query的title?那就只能用urlencode转换数据了。
?_id=="a"python实现输入地址query_list_content="{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(query_list_content)text=query_list_content[-1]#print(text)print("title:{1:“{2:“{3:“{4:“{5:“{6:”}”}”}”}".format(text))print("foriinrange({3,7}):”{1:“{2:“{3:“{4:“{5:“{6:“{7:”}”}”}”}”}”}”}".format(text))query_list_content=[iforiinrange(1,8)]text=get_content(。
querylist采集微信公众号文章(《不会post的正确姿势》之带截图的ajax和post请求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-22 17:03
querylist采集微信公众号文章列表,还可以返回给我们一个完整的网页链接。比如这个就是我们预先画出来的token,这个post就是发送。如果有不懂得,就可以看这个博客,对你有用。
截图中的post连接实际上是一个session;将截图中的网址直接post给微信公众号助手,等待微信小助手的解析即可,注意必须是响应的,否则将导致发送失败或者不返回json数据。
建议看看我的这篇文章不会post的正确姿势:《不会post的正确姿势》之带截图的ajax和post请求
可以用post方式发送,有截图的。
上面的答案都是用微信的网页版发送参数,确实是可以的,但是有一点不好的就是上传参数存在时间限制,过期之后不会收到消息。
现在公众号没有webdav这个功能,
我们专业课老师强调了,
当然可以!微信也支持直接用post方式推送给文章打开页啊。对于比较偏门的篇章,文章都是可以post的,前提是需要特殊情况判断下,不然有可能会封号啊什么的。
很简单,post发过去就好了。其实关键就是,post要及时到达,否则会被post原文拉到二维码页,或者全部丢失。其实现在的文章都是压缩的,发过去实际就很多了,然后post就可以发特定的文章,就不会丢失了。 查看全部
querylist采集微信公众号文章(《不会post的正确姿势》之带截图的ajax和post请求)
querylist采集微信公众号文章列表,还可以返回给我们一个完整的网页链接。比如这个就是我们预先画出来的token,这个post就是发送。如果有不懂得,就可以看这个博客,对你有用。
截图中的post连接实际上是一个session;将截图中的网址直接post给微信公众号助手,等待微信小助手的解析即可,注意必须是响应的,否则将导致发送失败或者不返回json数据。
建议看看我的这篇文章不会post的正确姿势:《不会post的正确姿势》之带截图的ajax和post请求
可以用post方式发送,有截图的。
上面的答案都是用微信的网页版发送参数,确实是可以的,但是有一点不好的就是上传参数存在时间限制,过期之后不会收到消息。
现在公众号没有webdav这个功能,
我们专业课老师强调了,
当然可以!微信也支持直接用post方式推送给文章打开页啊。对于比较偏门的篇章,文章都是可以post的,前提是需要特殊情况判断下,不然有可能会封号啊什么的。
很简单,post发过去就好了。其实关键就是,post要及时到达,否则会被post原文拉到二维码页,或者全部丢失。其实现在的文章都是压缩的,发过去实际就很多了,然后post就可以发特定的文章,就不会丢失了。
querylist采集微信公众号文章(如何爬取公众号所有文章(一)(1)_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-01-22 11:06
文章目录
一、前言
前几天书文问我能不能爬取微信公众号“北京邮教部”的历史动态,分析最多的成绩和科目。之前没做过微信公众号爬虫,所以研究了一下,发现了这个文章。
二、准备三、正式开始(一)批量获取之前公众号推送的url链接1.在后台插入其他公众号推送超链接的原理微信公众号
如果要批量抓取微信公众号过去的推送,最大的问题是如何获取这些推送的url链接。因为通常我们点击一个推送时,微信会随机生成一个url链接,而这个随机生成的url与公众号推送的其他url没有任何关联。因此,如果我们要批量抓取公众号的所有推送,需要手动点击每条推送,复制每条推送的url链接。这显然是不现实的。在广泛查阅各种资料后,我学会了如何爬取公众号所有文章this文章的方法。
这种方式的原理是,当我们登录微信公众号后台编辑图文素材时,可以在素材中插入其他公众号的推送链接。这里,微信公众号后台会自动调用相关API,返回公众号推送的所有长链接列表。
我们打开Chrome浏览器的查看模式,选择网络,然后在编辑超链接界面的公众号搜索栏中输入“北京邮政家教部”,搜索并选择公众号,发现已经刷新了一个网络启动以“appmsg”开头的内容,这是我们分析的目标。
我们点击“appmsg”开头的内容,解析请求的url:
https://mp.weixin.qq.com/cgi-b ... x%3D1
链接分为三个部分:
request的基本部分?action=list_ex常用于动态网站,实现不同的参数值生成不同的页面或返回不同的结果&begin=0&count=5&fakeid=MjM5NDY3ODI4OA==&type=9&query=&token= 1983840068&lang=zh_CN&f =json&ajax=1 设置各种参数2.获取Cookie和User-Agent
如果使用Python的Requests库直接访问url,是无法正常获取结果的。原因是在使用网页版微信公众号在后台插入超链接时,我们处于登录状态,但是当我们使用python直接访问时,我们并没有处于登录状态。因此,我们需要在访问时手动获取Cookie和User-Agent,并在使用Python的Requests库访问时将它们传递到headers参数中。这里说一下,我把公众号标识符 fakeid 和 token 参数保存在一个 yaml 文件中,方便爬取时加载。
cookie : appmsglist_action_3899……
user_agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64)……
fakeid : MzI4M……
token : "19……
在python代码中加载如下:
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
3.设置url参数
然后我们设置要请求的url链接的参数:
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
这里,count 是请求返回的信息数,begin 是当前请求的页数。当begin设置为0时,会以json格式返回最近五次推送信息,以此类推。
4.开始爬取
通过一个循环,begin的值每次加1,循环爬取:
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
在爬取大约 50 个页面时,我遇到了以下错误:
{'base_resp':{'err_msg':'频率控制','ret':200013}}
这是因为微信公众号有流量限制,所以你可以等一个小时。我在这里使用以下代码来解决它:
# 微信流量控制
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
对于每条爬取的信息,对其进行解析并将其存储在一个 csv 文件中:
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("python小屋.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
5.完整代码
完整代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : Spider.py
@Time : 2021/06/04 02:20:24
@Author : YuFanWenShu
@Contact : 1365240381@qq.com
'''
# here put the import lib
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
with open("app_msg_list.csv", "w",encoding='utf-8') as file:
file.write("文章标识符aid,标题title,链接url,时间time\n")
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
6.爬取结果
最终结果保存在 csv 文件中,一共 565 条推送消息:
(二) 爬取每次推送并提取需要的信息1. 遍历并爬取每次推送
从 csv 文件中读取每次推送的 url 链接,并使用 Requests 库抓取每次推送的内容:
with open("app_msg_list.csv","r",encoding="utf-8") as f:
data = f.readlines()
n = len(data)
for i in range(n):
mes = data[i].strip("\n").split(",")
if len(mes)!=4:
continue
title,url = mes[1:3]
if i>0:
r = requests.get(eval(url),headers=headers)
if r.status_code == 200:
text = r.text
projects = re_project.finditer(text)
2.提取信息并写入文件
我们需要提取的是每个导师信息的年级和科目。通过观察推送结构,我决定使用正则表达式进行提取。
有的家教订单长时间没有回复,会在多个帖子中重复出现,从而影响我们的统计结果。我决定用数字来识别不同的辅导信息,相同的数字只会计算一次。所以使用下面的正则表达式来匹配:
<p>re_project = re.compile(r">编号(.*?)年级(.*?)科目(.*?)科目(.*?)年级(.*?)编号(.*?)年级(.*?)科目(.*?) 查看全部
querylist采集微信公众号文章(如何爬取公众号所有文章(一)(1)_光明网(组图))
文章目录
一、前言
前几天书文问我能不能爬取微信公众号“北京邮教部”的历史动态,分析最多的成绩和科目。之前没做过微信公众号爬虫,所以研究了一下,发现了这个文章。
二、准备三、正式开始(一)批量获取之前公众号推送的url链接1.在后台插入其他公众号推送超链接的原理微信公众号
如果要批量抓取微信公众号过去的推送,最大的问题是如何获取这些推送的url链接。因为通常我们点击一个推送时,微信会随机生成一个url链接,而这个随机生成的url与公众号推送的其他url没有任何关联。因此,如果我们要批量抓取公众号的所有推送,需要手动点击每条推送,复制每条推送的url链接。这显然是不现实的。在广泛查阅各种资料后,我学会了如何爬取公众号所有文章this文章的方法。
这种方式的原理是,当我们登录微信公众号后台编辑图文素材时,可以在素材中插入其他公众号的推送链接。这里,微信公众号后台会自动调用相关API,返回公众号推送的所有长链接列表。
我们打开Chrome浏览器的查看模式,选择网络,然后在编辑超链接界面的公众号搜索栏中输入“北京邮政家教部”,搜索并选择公众号,发现已经刷新了一个网络启动以“appmsg”开头的内容,这是我们分析的目标。
我们点击“appmsg”开头的内容,解析请求的url:
https://mp.weixin.qq.com/cgi-b ... x%3D1
链接分为三个部分:
request的基本部分?action=list_ex常用于动态网站,实现不同的参数值生成不同的页面或返回不同的结果&begin=0&count=5&fakeid=MjM5NDY3ODI4OA==&type=9&query=&token= 1983840068&lang=zh_CN&f =json&ajax=1 设置各种参数2.获取Cookie和User-Agent
如果使用Python的Requests库直接访问url,是无法正常获取结果的。原因是在使用网页版微信公众号在后台插入超链接时,我们处于登录状态,但是当我们使用python直接访问时,我们并没有处于登录状态。因此,我们需要在访问时手动获取Cookie和User-Agent,并在使用Python的Requests库访问时将它们传递到headers参数中。这里说一下,我把公众号标识符 fakeid 和 token 参数保存在一个 yaml 文件中,方便爬取时加载。
cookie : appmsglist_action_3899……
user_agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64)……
fakeid : MzI4M……
token : "19……
在python代码中加载如下:
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
3.设置url参数
然后我们设置要请求的url链接的参数:
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
这里,count 是请求返回的信息数,begin 是当前请求的页数。当begin设置为0时,会以json格式返回最近五次推送信息,以此类推。
4.开始爬取
通过一个循环,begin的值每次加1,循环爬取:
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
在爬取大约 50 个页面时,我遇到了以下错误:
{'base_resp':{'err_msg':'频率控制','ret':200013}}
这是因为微信公众号有流量限制,所以你可以等一个小时。我在这里使用以下代码来解决它:
# 微信流量控制
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
对于每条爬取的信息,对其进行解析并将其存储在一个 csv 文件中:
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("python小屋.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
5.完整代码
完整代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : Spider.py
@Time : 2021/06/04 02:20:24
@Author : YuFanWenShu
@Contact : 1365240381@qq.com
'''
# here put the import lib
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
with open("app_msg_list.csv", "w",encoding='utf-8') as file:
file.write("文章标识符aid,标题title,链接url,时间time\n")
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a",encoding='utf-8') as f:
f.write(info+'\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
6.爬取结果
最终结果保存在 csv 文件中,一共 565 条推送消息:
(二) 爬取每次推送并提取需要的信息1. 遍历并爬取每次推送
从 csv 文件中读取每次推送的 url 链接,并使用 Requests 库抓取每次推送的内容:
with open("app_msg_list.csv","r",encoding="utf-8") as f:
data = f.readlines()
n = len(data)
for i in range(n):
mes = data[i].strip("\n").split(",")
if len(mes)!=4:
continue
title,url = mes[1:3]
if i>0:
r = requests.get(eval(url),headers=headers)
if r.status_code == 200:
text = r.text
projects = re_project.finditer(text)
2.提取信息并写入文件
我们需要提取的是每个导师信息的年级和科目。通过观察推送结构,我决定使用正则表达式进行提取。
有的家教订单长时间没有回复,会在多个帖子中重复出现,从而影响我们的统计结果。我决定用数字来识别不同的辅导信息,相同的数字只会计算一次。所以使用下面的正则表达式来匹配:
<p>re_project = re.compile(r">编号(.*?)年级(.*?)科目(.*?)科目(.*?)年级(.*?)编号(.*?)年级(.*?)科目(.*?)
querylist采集微信公众号文章(querylist采集微信公众号文章或者querylist=cdfshowquerylists(二维码))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-21 13:03
querylist采集微信公众号文章或者querylist这个开源模块的详细代码;filename=cdfshowquerylists(二维码)eggform,一个完整的ajax项目开发的querylist编写,表单提交接口,自定义表单提交样式等等模块eggmusic采集网易云音乐网页歌曲列表列表封装url提交接口;filename=cdfshowmusic(二维码)详细信息可以看这个页面。querylist是一个cgi项目,您也可以关注我的公众号获取更多相关实用的文章。
querylist接口就可以。基于微信服务号开发,一般是纯node来写,后续可以考虑nosql。querylist作者是微信游客,代码有公开。
jslist的话,现在java版本代码网上可以找到。//function是app的代码,java和php都是语言代码,其中app是一个network服务。//代码//server//if(this===theap){endinterfaceif(request.protocol_cnisready){server.addflags(nosslhttprequestrequest)work(newfetchserver(this))}//[cdns...]方法}}exportsexports.newslist=newslist;exports.alllist=exports.alllist;exports.alllistprototype=exports.alllistprototype;。
最近一直在用querylist,很顺手的、简单方便的接口。
内部自己发电影文章在a标签里,展示用微信link;外部转发, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章或者querylist=cdfshowquerylists(二维码))
querylist采集微信公众号文章或者querylist这个开源模块的详细代码;filename=cdfshowquerylists(二维码)eggform,一个完整的ajax项目开发的querylist编写,表单提交接口,自定义表单提交样式等等模块eggmusic采集网易云音乐网页歌曲列表列表封装url提交接口;filename=cdfshowmusic(二维码)详细信息可以看这个页面。querylist是一个cgi项目,您也可以关注我的公众号获取更多相关实用的文章。
querylist接口就可以。基于微信服务号开发,一般是纯node来写,后续可以考虑nosql。querylist作者是微信游客,代码有公开。
jslist的话,现在java版本代码网上可以找到。//function是app的代码,java和php都是语言代码,其中app是一个network服务。//代码//server//if(this===theap){endinterfaceif(request.protocol_cnisready){server.addflags(nosslhttprequestrequest)work(newfetchserver(this))}//[cdns...]方法}}exportsexports.newslist=newslist;exports.alllist=exports.alllist;exports.alllistprototype=exports.alllistprototype;。
最近一直在用querylist,很顺手的、简单方便的接口。
内部自己发电影文章在a标签里,展示用微信link;外部转发,
querylist采集微信公众号文章(一个微信公众号历史消息页面的链接地址和采集方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-21 12:09
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接http://mp.weixin.qq.com/mp/get ... 3D1//第二种http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync:function(req,res,serverResData,callback){if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)if(serverResData.toString()!==""){try{//防止报错退出程序varreg=/msgList = (.*?);/;//定义历史消息正则匹配规则varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis.php',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。try{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);//错误捕捉}callback(serverResData);//直接返回第二页json内容}}}elseif(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)try{varreg=/var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){callback(serverResData);}}elseif(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的jsontry{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}elseif(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时try{HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器}catch(e){}callback(serverResData);}elseif(/s\?__biz/i.test(req.url)||/mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)try{varhttp=require('http');http.get('http://xxx.com/getWxPost.php',function(res){//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);})});}catch(e){callback(serverResData);}}else{callback(serverResData);}},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
functionHttpPost(str,url,path){//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名varhttp=require('http');vardata={str:encodeURIComponent(str),url:encodeURIComponent(url)};content=require('querystring').stringify(data);varoptions={method:"POST",host:"www.xxx.com",//注意没有http://,这是服务器的域名。port:80,path:path,//接收程序的路径和文件名headers:{'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',"Content-Length":content.length}};varreq=http.request(options,function(res){res.setEncoding('utf8');res.on('data',function(chunk){console.log('BODY: '+chunk);});});req.on('error',function(e){console.log('problem with request: '+e.message);});req.write(content);req.end();}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption:function(req,option){varnewOption=option;if(/google/i.test(newOption.headers.host)){newOption.hostname="www.baidu.com";newOption.port="80";}returnnewOption;},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p> 查看全部
querylist采集微信公众号文章(一个微信公众号历史消息页面的链接地址和采集方法)
我从2014年开始做微信公众号内容采集的批次,最初的目的是做一个html5垃圾邮件网站。当时垃圾站采集收到的微信公众号内容很容易在公众号中传播。那个时候批量采集很容易做,采集入口就是公众号的历史新闻页面。这个条目到今天还是一样,只是越来越难了采集。采集 的方法也更新了很多版本。后来在2015年,html5垃圾站不再做,转而将采集定位为本地新闻资讯公众号,前端展示做成app。因此,一个可以自动采集 公众号内容形成。我曾经担心有一天,微信技术升级后,它无法采集内容,我的新闻应用程序会失败。不过随着微信的不断技术升级,采集方式也升级了,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。随着微信的不断技术升级,采集方式也不断升级,让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集到内容。所以今天决定整理一下采集方法,写下来。我的方法来源于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证您看到的内容在您看到的时候可用。
首先我们来看一个微信公众号历史新闻页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017 年 1 月 11 日更新==========
现在,根据不同的微信个人号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一个地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前掌握的信息,这两种页面形式在不同的微信账号中不规则出现。有的微信账号总是第一页格式,有的总是第二页格式。
以上链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接http://mp.weixin.qq.com/mp/get ... 3D1//第二种http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过微信客户端打开历史消息页面,然后使用后面介绍的代理服务器软件获得的。这里有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这四个参数。
__biz 是公众号的类id参数。每个公众号都有一个微信业务。目前公众号的biz发生变化的概率很小;
其余三个参数与用户的 id 和 token 票证相关。这三个参数的值是微信客户端生成后自动添加到地址栏的。所以想要采集公众号,必须通过微信客户端。在微信之前的版本中,这三个参数也可以一次性获取,在有效期内被多个公众号使用。当前版本每次访问公共帐户时都会更改参数值。
我现在使用的方法只需要注意__biz参数即可。
我的 采集 系统由以下部分组成:
1、微信客户端:可以是安装了微信应用的手机,也可以是电脑上的安卓模拟器。经测试,在批处理采集过程中,ios微信客户端的崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。
2、个人微信账号:采集的内容,不仅需要微信客户端,采集还需要个人微信账号,因为这个微信账号不能做其他事情。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器。具体的安装和设置方法将在后面详细介绍。
4、文章列表分析与仓储系统:我用php语言写的。后面会详细介绍如何分析文章列表,建立采集队列,实现批量采集内容。
步
一、安装模拟器或者用手机安装微信客户端app,申请微信个人账号并登录app。这个我就不多说了,大家都会的。
二、代理服务器系统安装
目前我正在使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置将脚本代码插入公众号页面。让我们从安装和配置过程开始。
1、安装 NodeJS
2、在命令行或者终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy并运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器中安装证书:
6、设置代理:Android模拟器的代理服务器地址是wifi链接的网关。将dhcp设置为static后可以看到网关地址。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器的默认端口是8001;
现在打开微信,点击任意公众号历史消息或文章,可以在终端看到响应码滚动。如果没有出现,请检查您手机的代理设置是否正确。
现在打开浏览器地址:8002可以看到anyproxy的网页界面。从微信点击一个历史消息页面,然后查看浏览器的网页界面,历史消息页面的地址会滚动。
/mp/getmasssendmsg 开头的网址是微信历史消息页面。左边的小锁表示页面是https加密的。现在让我们点击这一行;
=========2017 年 1 月 11 日更新==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转,跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址查看内容。
如果右边出现html文件的内容,则解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机上是否正确安装了证书。
现在我们手机上的所有内容都可以以明文形式通过代理服务器。接下来,我们需要修改和配置代理服务器,以便获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道的请见谅。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是原理介绍,了解后根据自己的情况修改内容):
=========2017 年 1 月 11 日更新==========
因为有两种页面形式,而且同一个页面形式总是显示在不同的微信账号中,但是为了兼容这两种页面形式,下面的代码会保留两种页面形式的判断,你也可以使用你的自己的页面表单删除li
replaceServerResDataAsync:function(req,res,serverResData,callback){if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)if(serverResData.toString()!==""){try{//防止报错退出程序varreg=/msgList = (.*?);/;//定义历史消息正则匹配规则varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis.php',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。try{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);//错误捕捉}callback(serverResData);//直接返回第二页json内容}}}elseif(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)try{varreg=/var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)varret=reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器varhttp=require('http');http.get('http://xxx.com/getWxHis',function(res){//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){callback(serverResData);}}elseif(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的jsontry{varjson=JSON.parse(serverResData.toString());if(json.general_msg_list!=[]){HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}elseif(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时try{HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器}catch(e){}callback(serverResData);}elseif(/s\?__biz/i.test(req.url)||/mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)try{varhttp=require('http');http.get('http://xxx.com/getWxPost.php',function(res){//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。res.on('data',function(chunk){callback(chunk+serverResData);})});}catch(e){callback(serverResData);}}else{callback(serverResData);}},
以上代码使用anyproxy修改返回页面内容的功能,将脚本注入页面,将页面内容发送给服务器。利用这个原理批量采集公众号内容和阅读量。该脚本中自定义了一个函数,下面详细介绍:
在 rule_default.js 文件的末尾添加以下代码:
functionHttpPost(str,url,path){//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名varhttp=require('http');vardata={str:encodeURIComponent(str),url:encodeURIComponent(url)};content=require('querystring').stringify(data);varoptions={method:"POST",host:"www.xxx.com",//注意没有http://,这是服务器的域名。port:80,path:path,//接收程序的路径和文件名headers:{'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',"Content-Length":content.length}};varreq=http.request(options,function(res){res.setEncoding('utf8');res.on('data',function(chunk){console.log('BODY: '+chunk);});});req.on('error',function(e){console.log('problem with request: '+e.message);});req.write(content);req.end();}
以上是规则修改的主要部分。需要将json内容发送到自己的服务器,并从服务器获取跳转到下一页的地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低crash率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption:function(req,option){varnewOption=option;if(/google/i.test(newOption.headers.host)){newOption.hostname="www.baidu.com";newOption.port="80";}returnnewOption;},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果启动报错,程序可能无法干净退出,端口被占用。此时输入命令ps -a查看被占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀死进程后,您可以启动anyproxy。或者windows的命令请原谅我不是很熟悉。
接下来详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只是介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析后存入数据库
<p>
querylist采集微信公众号文章(querylist采集微信公众号文章的超简单方法,超级简单直接上api)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-21 04:05
querylist采集微信公众号文章的超简单方法,超级简单直接上api,采集分类里面所有的公众号,最好是排在前面的。超级简单还有两个,就是微信登录了,可以得到某一个人阅读所有的文章,还有未阅读所有的,然后一个一个筛选上传。querylist采集微信公众号文章原理解析,基于android自动化api进行采集前端接入admin-session。
从过去到现在,在“996”的现状下,很多同学们被焦虑干扰,工作不知道做到什么时候才好,也不知道现在的工作有什么意义,怎么才能拥有一份可靠且体面的工作。其实这是职场的低谷期,因为你不知道以后的工作要靠什么。在这样的大背景下,老张在工作中虽然算比较努力,可还是要被“论资排辈”,作为部门老人,需要经常出差加班和处理公司的一些事情,要接受老板的要求,承担公司的一些不利的情况。
老张已经郁闷到将近夜不能寐,一个一个深夜刷知乎、朋友圈和公众号,不管干什么,不管怎么才能让自己不那么焦虑。在公司当中老张的老板是属于典型的家族企业,他从一开始就对老板很尊敬,除了工作和团队不管其他事情。公司经营顺利,但员工一直留不住。现在他很迷茫,老板就是不放权,觉得凭他的能力很难接触到更高的层面,但是公司也没有其他发展机会,那老板每次经营不好,经常找老板的问题,可能也是不想让自己承担责任,他觉得自己就是“无功不受禄”,也不能挑战权威,就是接着从基层做起来。
部门经理跳槽去了大公司,公司对他也开始有新的要求。老张现在也很迷茫,我觉得现在的工作没什么意义,除了工资,还是没有特别充足的收入。最近买了本书,给自己充电,不知道那本书对我有没有帮助。老张该如何跳槽?希望各位大佬发表看法,给点建议。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的超简单方法,超级简单直接上api)
querylist采集微信公众号文章的超简单方法,超级简单直接上api,采集分类里面所有的公众号,最好是排在前面的。超级简单还有两个,就是微信登录了,可以得到某一个人阅读所有的文章,还有未阅读所有的,然后一个一个筛选上传。querylist采集微信公众号文章原理解析,基于android自动化api进行采集前端接入admin-session。
从过去到现在,在“996”的现状下,很多同学们被焦虑干扰,工作不知道做到什么时候才好,也不知道现在的工作有什么意义,怎么才能拥有一份可靠且体面的工作。其实这是职场的低谷期,因为你不知道以后的工作要靠什么。在这样的大背景下,老张在工作中虽然算比较努力,可还是要被“论资排辈”,作为部门老人,需要经常出差加班和处理公司的一些事情,要接受老板的要求,承担公司的一些不利的情况。
老张已经郁闷到将近夜不能寐,一个一个深夜刷知乎、朋友圈和公众号,不管干什么,不管怎么才能让自己不那么焦虑。在公司当中老张的老板是属于典型的家族企业,他从一开始就对老板很尊敬,除了工作和团队不管其他事情。公司经营顺利,但员工一直留不住。现在他很迷茫,老板就是不放权,觉得凭他的能力很难接触到更高的层面,但是公司也没有其他发展机会,那老板每次经营不好,经常找老板的问题,可能也是不想让自己承担责任,他觉得自己就是“无功不受禄”,也不能挑战权威,就是接着从基层做起来。
部门经理跳槽去了大公司,公司对他也开始有新的要求。老张现在也很迷茫,我觉得现在的工作没什么意义,除了工资,还是没有特别充足的收入。最近买了本书,给自己充电,不知道那本书对我有没有帮助。老张该如何跳槽?希望各位大佬发表看法,给点建议。
querylist采集微信公众号文章(querylist采集微信公众号文章(只支持微信)效果预览)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-20 12:08
querylist采集微信公众号文章(只支持微信公众号文章)效果预览该插件可以整合百度等搜索引擎来爬取网页,最主要的是可以采集微信公众号文章。
看这篇文章。差不多了。觉得不够详细,我再补充一下。
如果你是要采集同一个平台微信公众号文章的话,python只能做到类似条件格式提取(采集到文章标题,封面图,推荐人等),采集内容比较少。如果要是采集多个平台的文章,那就需要用数据采集框架。推荐你一个好的采集框架,
微信有接口可以爬取你这里的东西,这里面有两个数据采集,
根据你的需求,最好用以下方式:1,去电脑上,下载这个app:星辰数据2,电脑上,安装excel3,进入excel,文件-数据采集框架,按流程编辑。
使用api进行api接口请求比如是关注数统计uiwebview上下载服务器。
1、专门的爬虫库也有api。2、建议去学学scrapy等,文档好、资料多,关键还有师徒社区。
感觉开头貌似需要一个采集python源码的环境支持,因为微信这方面规定比较严格, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章(只支持微信)效果预览)
querylist采集微信公众号文章(只支持微信公众号文章)效果预览该插件可以整合百度等搜索引擎来爬取网页,最主要的是可以采集微信公众号文章。
看这篇文章。差不多了。觉得不够详细,我再补充一下。
如果你是要采集同一个平台微信公众号文章的话,python只能做到类似条件格式提取(采集到文章标题,封面图,推荐人等),采集内容比较少。如果要是采集多个平台的文章,那就需要用数据采集框架。推荐你一个好的采集框架,
微信有接口可以爬取你这里的东西,这里面有两个数据采集,
根据你的需求,最好用以下方式:1,去电脑上,下载这个app:星辰数据2,电脑上,安装excel3,进入excel,文件-数据采集框架,按流程编辑。
使用api进行api接口请求比如是关注数统计uiwebview上下载服务器。
1、专门的爬虫库也有api。2、建议去学学scrapy等,文档好、资料多,关键还有师徒社区。
感觉开头貌似需要一个采集python源码的环境支持,因为微信这方面规定比较严格,
querylist采集微信公众号文章(微信小程序调试工具知识兔调试工具分为6大功能模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-19 07:04
微信小程序一直受到很多用户的欢迎,今天正式上线。相信很多小伙伴都很感兴趣。小编为大家带来微信小程序调试工具,帮助大家更好的开发制作小程序。程序,想要自己制作小程序的朋友,不妨下载体验一下吧!
微信小程序获取方法知识兔
线下扫码:获取小程序最基本的方式就是二维码。您可以通过微信扫描离线二维码打开扫描进入小程序。
微信搜索:同时在微信客户端顶部的搜索窗口,也可以通过搜索获取小程序。
公众号关联:同一主题的小程序和公众号可以关联和跳转。该功能需要开发者在使用前进行设置。
朋友推荐:一个公众号可以绑定五个小程序,一个小程序只能绑定一个公众号。您可以通过公众号查看和进入关联的小程序,反之亦然,您也可以通过小程序查看和进入关联的公众号。
当您发现有趣或有用的小程序时,您可以将该小程序或其页面之一转发给朋友或群聊。但请注意,小程序不能在朋友圈发布和分享。
历史记录:使用过某个小程序后,可以在微信客户端“发现-小程序”的列表中看到该小程序。当您想再次使用它时,您可以使用列表中的历史记录。进入。在“发现-小程序”中,您也可以通过搜索进入小程序。
微信小程序调试工具 知识兔
调试工具分为6个功能模块:Wxml、Console、Sources、Network、Appdata、Storage
点击下载 查看全部
querylist采集微信公众号文章(微信小程序调试工具知识兔调试工具分为6大功能模块)
微信小程序一直受到很多用户的欢迎,今天正式上线。相信很多小伙伴都很感兴趣。小编为大家带来微信小程序调试工具,帮助大家更好的开发制作小程序。程序,想要自己制作小程序的朋友,不妨下载体验一下吧!
微信小程序获取方法知识兔
线下扫码:获取小程序最基本的方式就是二维码。您可以通过微信扫描离线二维码打开扫描进入小程序。
微信搜索:同时在微信客户端顶部的搜索窗口,也可以通过搜索获取小程序。
公众号关联:同一主题的小程序和公众号可以关联和跳转。该功能需要开发者在使用前进行设置。
朋友推荐:一个公众号可以绑定五个小程序,一个小程序只能绑定一个公众号。您可以通过公众号查看和进入关联的小程序,反之亦然,您也可以通过小程序查看和进入关联的公众号。
当您发现有趣或有用的小程序时,您可以将该小程序或其页面之一转发给朋友或群聊。但请注意,小程序不能在朋友圈发布和分享。
历史记录:使用过某个小程序后,可以在微信客户端“发现-小程序”的列表中看到该小程序。当您想再次使用它时,您可以使用列表中的历史记录。进入。在“发现-小程序”中,您也可以通过搜索进入小程序。
微信小程序调试工具 知识兔
调试工具分为6个功能模块:Wxml、Console、Sources、Network、Appdata、Storage
点击下载

