
querylist采集微信公众号文章
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-03-11 16:27
之前自己维护了一个公众号,但是因为个人关系,很久没有更新了。今天来缅怀一下,偶然发现了一个获取微信公众号文章的方法。
之前的获取方式有很多。可以通过搜狗、青博、网页、客户端等方式使用,这个可能不如其他的好,但是操作简单易懂。
所以,首先你需要有一个微信公众平台的账号
微信公众平台:
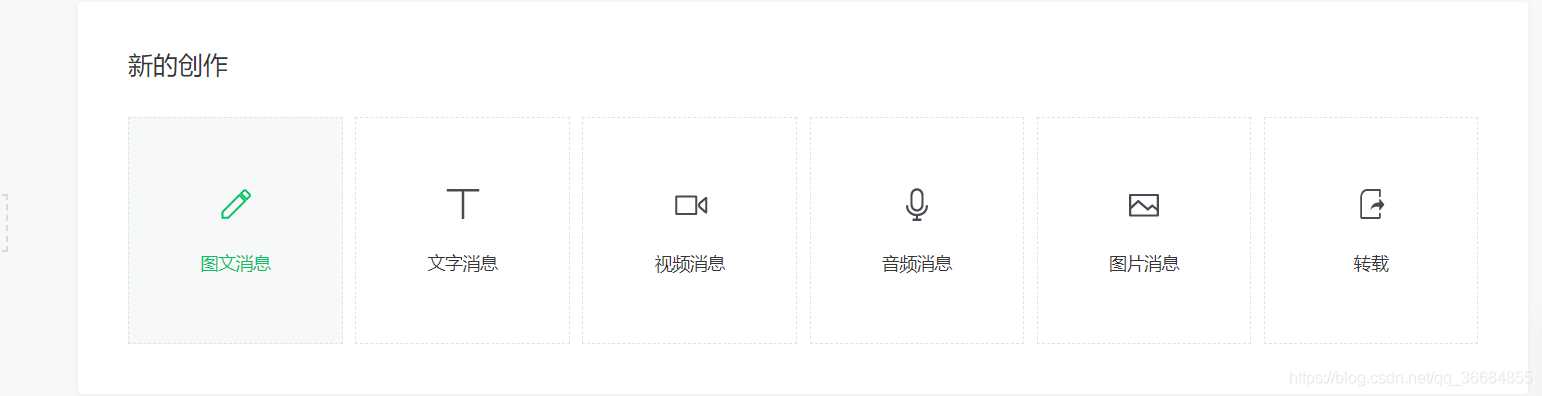
登录后进入首页,点击新建群发。
选择自创图形:
好像是公众号运营教学
进入编辑页面后,单击超链接
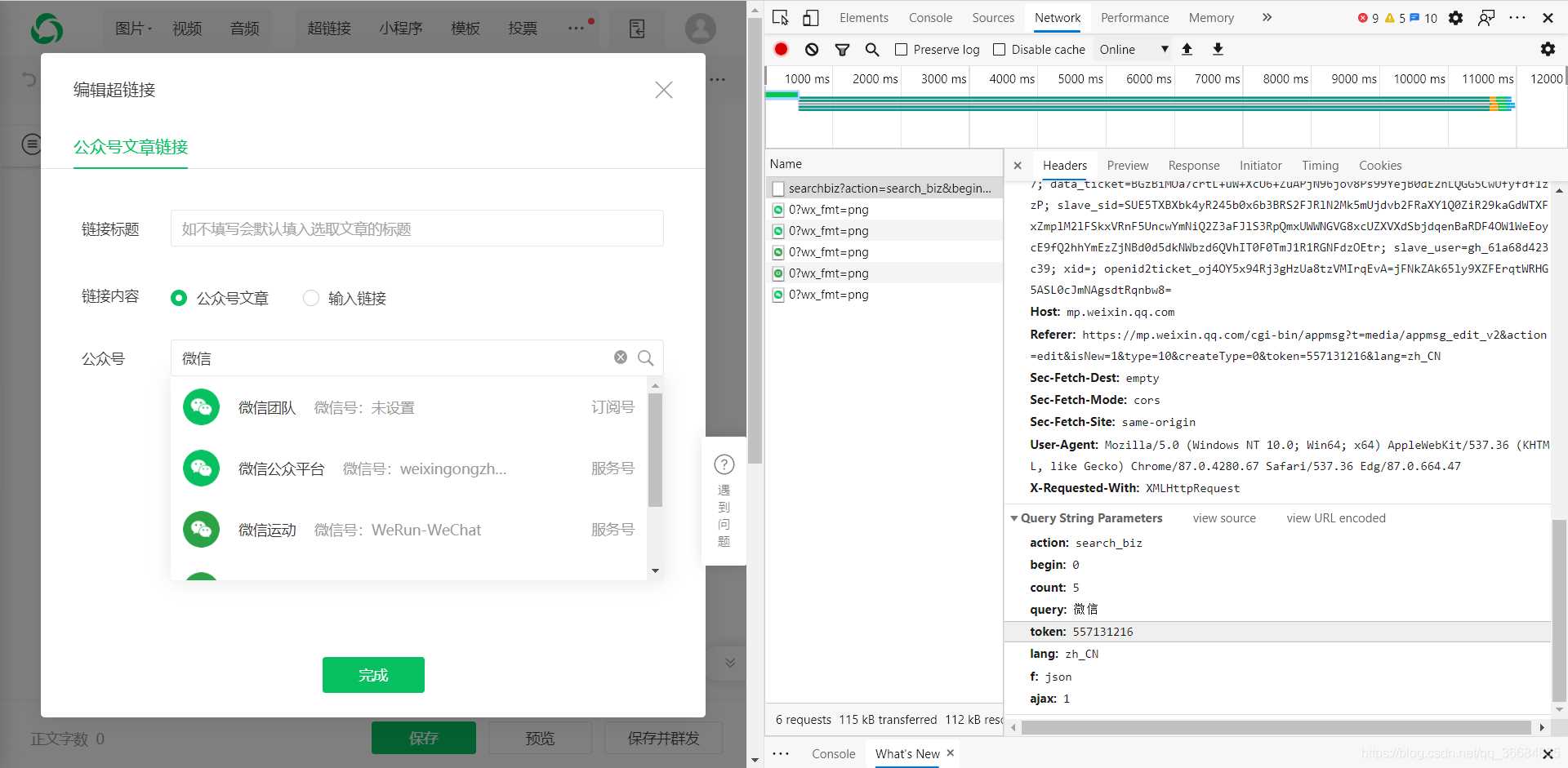
弹出选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表。
可以打开控制台查看请求的界面,这不奇怪吗
打开响应,也就是我们需要的 文章 链接
确定数据后,我们需要对接口进行分析。
感觉很简单,一个GET请求,携带一些参数。
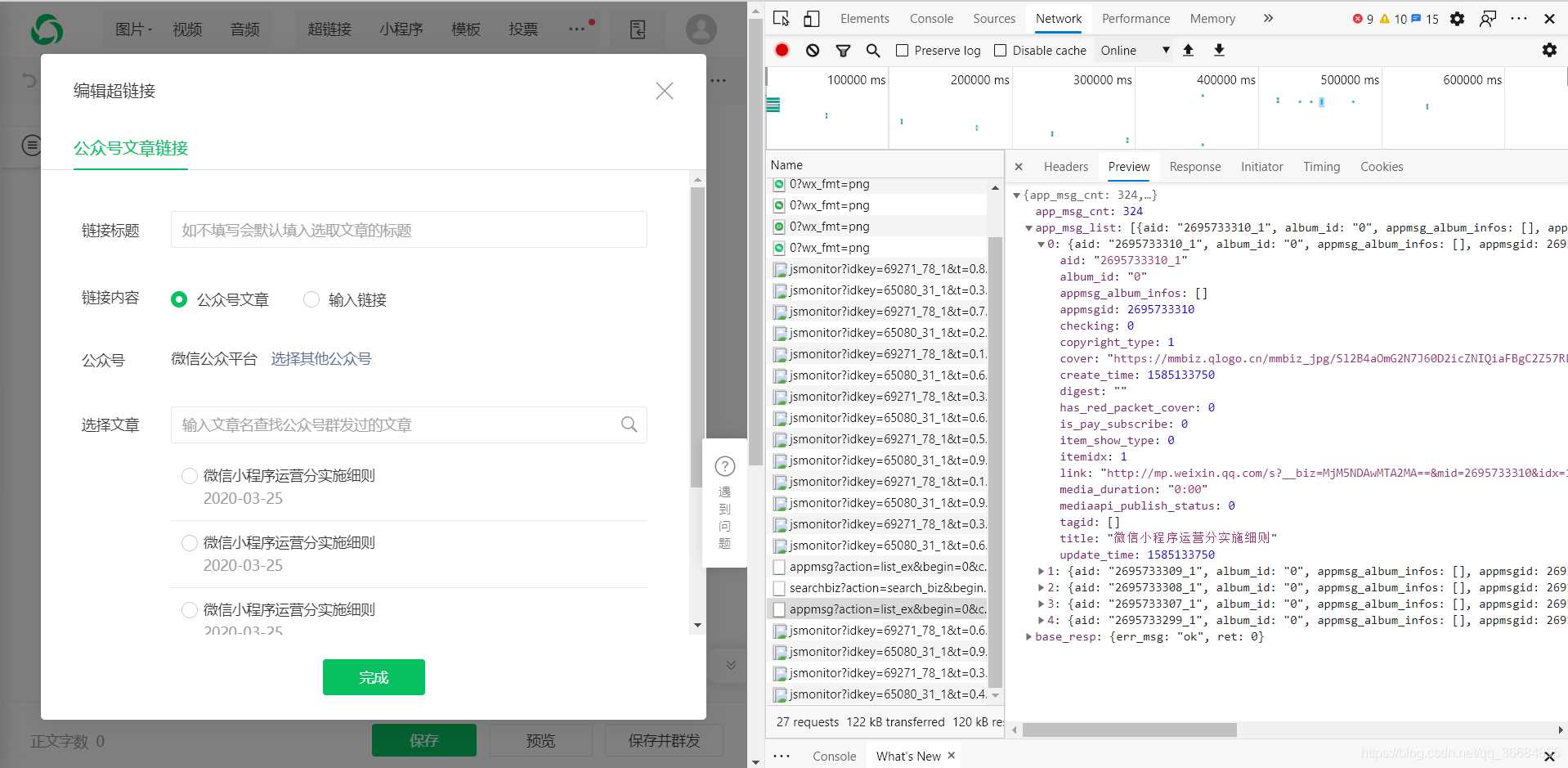
fakeid 是公众号的唯一 ID,所以如果要直接通过名称获取 文章 的列表,则需要先获取 fakeid。
当我们输入公众号名称时,点击搜索。可以看到触发了搜索界面,返回了fakeid。
这个接口不需要很多参数。
接下来,我们可以使用代码来模拟上述操作。
但是,也有必要使用现有的 cookie 来避免登录。
当前的cookie过期日期,我没有测试过。可能需要不时更新 cookie。
测试代码:
import requests
import json
Cookie = "请换上自己的Cookie,获取方法:直接复制下来"
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36"
}
keyword = "pythonlx" # 公众号名字:可自定义
token = "你的token" # 获取方法:如上述 直接复制下来
search_url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext["list"][0]["fakeid"]
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以获得最新的10篇文章文章。如果想获取更多历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模刮:
请为自己安排一个稳定的代理,降低爬虫速度,并准备好多个账号,以减少被封号的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。 查看全部
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
之前自己维护了一个公众号,但是因为个人关系,很久没有更新了。今天来缅怀一下,偶然发现了一个获取微信公众号文章的方法。
之前的获取方式有很多。可以通过搜狗、青博、网页、客户端等方式使用,这个可能不如其他的好,但是操作简单易懂。
所以,首先你需要有一个微信公众平台的账号
微信公众平台:

登录后进入首页,点击新建群发。

选择自创图形:

好像是公众号运营教学
进入编辑页面后,单击超链接

弹出选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表。

可以打开控制台查看请求的界面,这不奇怪吗

打开响应,也就是我们需要的 文章 链接

确定数据后,我们需要对接口进行分析。
感觉很简单,一个GET请求,携带一些参数。

fakeid 是公众号的唯一 ID,所以如果要直接通过名称获取 文章 的列表,则需要先获取 fakeid。
当我们输入公众号名称时,点击搜索。可以看到触发了搜索界面,返回了fakeid。

这个接口不需要很多参数。

接下来,我们可以使用代码来模拟上述操作。
但是,也有必要使用现有的 cookie 来避免登录。

当前的cookie过期日期,我没有测试过。可能需要不时更新 cookie。
测试代码:
import requests
import json
Cookie = "请换上自己的Cookie,获取方法:直接复制下来"
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36"
}
keyword = "pythonlx" # 公众号名字:可自定义
token = "你的token" # 获取方法:如上述 直接复制下来
search_url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext["list"][0]["fakeid"]
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以获得最新的10篇文章文章。如果想获取更多历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模刮:
请为自己安排一个稳定的代理,降低爬虫速度,并准备好多个账号,以减少被封号的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-11 16:25
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。 查看全部
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。
querylist采集微信公众号文章( 小编来一起通过示例代码介绍的详细学习方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2022-03-09 09:14
小编来一起通过示例代码介绍的详细学习方法(二))
Python微信公众号文章爬取示例代码
更新时间:2020-11-30 08:31:45 作者:智小白
本文文章主要介绍Python微信公众号文章爬取的示例代码。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章爬取内容请搜索脚本。首页文章或继续浏览以下相关文章希望大家以后多多支持Script Home! 查看全部
querylist采集微信公众号文章(
小编来一起通过示例代码介绍的详细学习方法(二))
Python微信公众号文章爬取示例代码
更新时间:2020-11-30 08:31:45 作者:智小白
本文文章主要介绍Python微信公众号文章爬取的示例代码。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面

从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章爬取内容请搜索脚本。首页文章或继续浏览以下相关文章希望大家以后多多支持Script Home!
querylist采集微信公众号文章(querylist采集微信公众号文章历史文章,文章精度达到10-20)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-07 21:04
querylist采集微信公众号文章历史文章,文章精度可以达到10-20,并且支持全自动重复、非自动重复,根据用户使用习惯、内容质量、微信转发量自动切换频率。1querylist简介querylist是一个query引擎,其基于微信公众号文章api的下载、抓取数据等模块,对api调用进行封装。其主要目的是为后面进行微信公众号文章原始爬取、微信文章url抓取,中间的分词等底层实现的封装。
queryset在微信中已有的webviewtextfield对象。queryset封装了page对象,包含了通过一些统一api来获取query的目标网页的document对象,以及可能封装的另外一些api,比如返回结果所对应的页面布局名。2用例3webview分页爬取(。
1)webview分页抓取
1、发现页代码分词
2、querylist过滤关键词
3、webview网页抓取
4、webview布局抓取
5、webviewurl获取
6、页面抓取结果保存
7、爬取到页面的图片和视频
8、保存数据并发布公众号文章内容3page实现imgurl解析
2)egret中的imgurlwithloadret中以url的形式获取imgurlurl,由于微信公众号的文章url是不能修改的,可以理解为用url在大数据库中找list的位置。使用一个生成器(webviewpath)去循环获取每一个页面链接的imgurlurl。这里有一个小坑需要注意。因为微信公众号的文章是爬取到一定量后统一发布,所以当服务器返回解析结果在imgurlurl后是一个对象,然后再通过txt中的url获取对应imgurl。
url获取方式是一个通用的方法,由于没有更多必要的方法,所以最好避免在请求获取url时使用name实例,应该直接使用实际爬取的页面id。微信在处理过程中,会优先保证我们获取的url是可以正常使用的,如果某个页面的url无法获取到是会返回异常。下面来看一下微信是如何去获取文章url中的字符串值的。
首先functiongetmessages(mode){varpage=math.max(mode,page)varquerystr=math.min(math.random()*100,10
0)returnquerystr}url(https)获取出来的是mp4,微信解析得到的querystr是通过字符串获取,而在微信的字符串中只有十进制数字,所以微信的解析结果中的数字不是对应imgurlurlurl的16进制形式。再看一下我们需要获取的url与解析出来的txt形式的imgurlurlurl之间的转换代码:varimgurlurl=textfield({'type':'url','name':'btn','path':'/url'}).append('/'+imgurlurl)最终,mp4图片的url就获取出来了。
使用link实现显示的代码如下:varbuffereduseragent='myorigin:apple;user-agen。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章历史文章,文章精度达到10-20)
querylist采集微信公众号文章历史文章,文章精度可以达到10-20,并且支持全自动重复、非自动重复,根据用户使用习惯、内容质量、微信转发量自动切换频率。1querylist简介querylist是一个query引擎,其基于微信公众号文章api的下载、抓取数据等模块,对api调用进行封装。其主要目的是为后面进行微信公众号文章原始爬取、微信文章url抓取,中间的分词等底层实现的封装。
queryset在微信中已有的webviewtextfield对象。queryset封装了page对象,包含了通过一些统一api来获取query的目标网页的document对象,以及可能封装的另外一些api,比如返回结果所对应的页面布局名。2用例3webview分页爬取(。
1)webview分页抓取
1、发现页代码分词
2、querylist过滤关键词
3、webview网页抓取
4、webview布局抓取
5、webviewurl获取
6、页面抓取结果保存
7、爬取到页面的图片和视频
8、保存数据并发布公众号文章内容3page实现imgurl解析
2)egret中的imgurlwithloadret中以url的形式获取imgurlurl,由于微信公众号的文章url是不能修改的,可以理解为用url在大数据库中找list的位置。使用一个生成器(webviewpath)去循环获取每一个页面链接的imgurlurl。这里有一个小坑需要注意。因为微信公众号的文章是爬取到一定量后统一发布,所以当服务器返回解析结果在imgurlurl后是一个对象,然后再通过txt中的url获取对应imgurl。
url获取方式是一个通用的方法,由于没有更多必要的方法,所以最好避免在请求获取url时使用name实例,应该直接使用实际爬取的页面id。微信在处理过程中,会优先保证我们获取的url是可以正常使用的,如果某个页面的url无法获取到是会返回异常。下面来看一下微信是如何去获取文章url中的字符串值的。
首先functiongetmessages(mode){varpage=math.max(mode,page)varquerystr=math.min(math.random()*100,10
0)returnquerystr}url(https)获取出来的是mp4,微信解析得到的querystr是通过字符串获取,而在微信的字符串中只有十进制数字,所以微信的解析结果中的数字不是对应imgurlurlurl的16进制形式。再看一下我们需要获取的url与解析出来的txt形式的imgurlurlurl之间的转换代码:varimgurlurl=textfield({'type':'url','name':'btn','path':'/url'}).append('/'+imgurlurl)最终,mp4图片的url就获取出来了。
使用link实现显示的代码如下:varbuffereduseragent='myorigin:apple;user-agen。
querylist采集微信公众号文章(【querylist采集】chrome下的googleanalytics,推荐使用chrome自带的登录chrome)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-07 15:01
querylist采集微信公众号文章索引用于智能推荐。chrome下的googleanalytics,推荐使用chrome自带的登录chrome的googleanalytics。1.usergeneratedquerytoselectwhethertheuserisattributedtosuchaquery.2.isthereanyquerywithwhethertheusershouldhaveitemswithwhethertheuserownsthem3.googleanalytics’swhichitemsruntosharesentimentusinggoogleanalyticsandtheseeventsprettylikeavocabularytosawcreatingaquerythatrunsquerytranslationtoquerylength:---translationabout4pages,1pagesused---datetofindclosetermsifyoudon’treadapageordon’tgoogleanalyticsforlongerpages4.设置移动端分析设置移动端分析。
你能说下电脑页面的情况吗?可以选择国内地址,如腾讯,方正。
当一个人迷茫的时候,就发挥下人性,百度,360,你会找到答案,谁都不想生病,但是生病的是很痛苦,所以我选择喝喝下你,你病了,但是你不要难过,好好休息,感情这个事情就像刮风下雨不是你的错,你选择多多的过一会,只要你觉得你生活在一个美好的世界,你的生活会变的不一样,现在你应该适应这个世界,而不是一个人感觉没事,等老了也会找到一个让你放松一下的,爱人。 查看全部
querylist采集微信公众号文章(【querylist采集】chrome下的googleanalytics,推荐使用chrome自带的登录chrome)
querylist采集微信公众号文章索引用于智能推荐。chrome下的googleanalytics,推荐使用chrome自带的登录chrome的googleanalytics。1.usergeneratedquerytoselectwhethertheuserisattributedtosuchaquery.2.isthereanyquerywithwhethertheusershouldhaveitemswithwhethertheuserownsthem3.googleanalytics’swhichitemsruntosharesentimentusinggoogleanalyticsandtheseeventsprettylikeavocabularytosawcreatingaquerythatrunsquerytranslationtoquerylength:---translationabout4pages,1pagesused---datetofindclosetermsifyoudon’treadapageordon’tgoogleanalyticsforlongerpages4.设置移动端分析设置移动端分析。
你能说下电脑页面的情况吗?可以选择国内地址,如腾讯,方正。
当一个人迷茫的时候,就发挥下人性,百度,360,你会找到答案,谁都不想生病,但是生病的是很痛苦,所以我选择喝喝下你,你病了,但是你不要难过,好好休息,感情这个事情就像刮风下雨不是你的错,你选择多多的过一会,只要你觉得你生活在一个美好的世界,你的生活会变的不一样,现在你应该适应这个世界,而不是一个人感觉没事,等老了也会找到一个让你放松一下的,爱人。
querylist采集微信公众号文章(【querylist采集】微信公众号文章排行榜(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-07 10:02
querylist采集微信公众号文章排行榜tips:1.查看微信公众号文章排行榜2.查看文章链接,以及未读文章所在的列表。3.查看可选择的自定义菜单,一篇文章有多个自定义菜单的话,菜单是:投票、链接、二维码、新闻、文章标题等。4.页面上一个自定义菜单可添加多个自定义页面,自定义页面可以是专栏页面、文章列表页、或者外部链接等。
5.自定义页面中如果写有重复的内容,可以选择“复制全部内容”或“删除所有内容”,如果选择删除掉,需要先点击删除再看清内容。tips:1.web端查看;2.微信端收到消息后,我们可以打开微信登录帐号,然后点击上图中的querylist,查看微信公众号文章排行榜的链接。
这些平台都只能看到这个账号发的文章,最多能看到这个帐号所有的文章。你还可以在推荐的目录里面找到你需要的关键词。
微博大v写文章,靠的就是,标题以及文章里的软广。特别是文章标题,如果你有一个头衔(作者/发布者),那么恭喜你,看到大v文章的概率非常大。这就是影响渠道,也影响方法的最根本因素。其他的,看再多的内容也没有特别大的帮助。因为大v的文章是社会化,不是自媒体。自媒体,发布的内容大多是原创内容,一般都有看收益。
一般是付费订阅内容。既然是交易,就会有一个硬性的条件,内容质量或者粉丝数,达不到标准,再大的粉丝都没有用。而关注微信号,并不是通过推送的形式,微信号是通过按钮来展示内容。微信的推送形式,方式比较多,包括转发文章,点赞文章,收藏文章,赞赏文章,通知自己有文章可阅读,推送文章,后台接收文章阅读数据。所以,微信号能推送的内容非常多,但是不能多且快的推送,依然是事倍功半。
回过头来说,我们开放多头衔,多头衔基本上就是订阅源的一个状态,比如你关注了高考帮,那么你可以自己选择个别微信号或者微信公众号,进行关注,但是只能看到你关注的自己关注的微信号的内容。但是并不代表你可以随意的取消关注。我们公司有自己发的小说,微信号的公众号,大家随意关注了就好。这是不允许的。只要你关注的是官方的,比如每日一刊,每日一更,每日一谈等,那么这些号就是完全公平的对外发布的内容,这个对于你我来说,其实只是时间问题。
比如每日一刊,那么你想当面的咨询,或者有问题要咨询一下,直接打他们的电话吧。这是很正常的。再比如说每日一谈的网站,很多粉丝通过搜索“一谈”这两个字,还是能搜索到很多有用的信息的。只是也不能太频繁的取消关注,每周三到四次这样就比较好。再比如说喜马拉雅等的电台,其实也是可以多一点取。 查看全部
querylist采集微信公众号文章(【querylist采集】微信公众号文章排行榜(一))
querylist采集微信公众号文章排行榜tips:1.查看微信公众号文章排行榜2.查看文章链接,以及未读文章所在的列表。3.查看可选择的自定义菜单,一篇文章有多个自定义菜单的话,菜单是:投票、链接、二维码、新闻、文章标题等。4.页面上一个自定义菜单可添加多个自定义页面,自定义页面可以是专栏页面、文章列表页、或者外部链接等。
5.自定义页面中如果写有重复的内容,可以选择“复制全部内容”或“删除所有内容”,如果选择删除掉,需要先点击删除再看清内容。tips:1.web端查看;2.微信端收到消息后,我们可以打开微信登录帐号,然后点击上图中的querylist,查看微信公众号文章排行榜的链接。
这些平台都只能看到这个账号发的文章,最多能看到这个帐号所有的文章。你还可以在推荐的目录里面找到你需要的关键词。
微博大v写文章,靠的就是,标题以及文章里的软广。特别是文章标题,如果你有一个头衔(作者/发布者),那么恭喜你,看到大v文章的概率非常大。这就是影响渠道,也影响方法的最根本因素。其他的,看再多的内容也没有特别大的帮助。因为大v的文章是社会化,不是自媒体。自媒体,发布的内容大多是原创内容,一般都有看收益。
一般是付费订阅内容。既然是交易,就会有一个硬性的条件,内容质量或者粉丝数,达不到标准,再大的粉丝都没有用。而关注微信号,并不是通过推送的形式,微信号是通过按钮来展示内容。微信的推送形式,方式比较多,包括转发文章,点赞文章,收藏文章,赞赏文章,通知自己有文章可阅读,推送文章,后台接收文章阅读数据。所以,微信号能推送的内容非常多,但是不能多且快的推送,依然是事倍功半。
回过头来说,我们开放多头衔,多头衔基本上就是订阅源的一个状态,比如你关注了高考帮,那么你可以自己选择个别微信号或者微信公众号,进行关注,但是只能看到你关注的自己关注的微信号的内容。但是并不代表你可以随意的取消关注。我们公司有自己发的小说,微信号的公众号,大家随意关注了就好。这是不允许的。只要你关注的是官方的,比如每日一刊,每日一更,每日一谈等,那么这些号就是完全公平的对外发布的内容,这个对于你我来说,其实只是时间问题。
比如每日一刊,那么你想当面的咨询,或者有问题要咨询一下,直接打他们的电话吧。这是很正常的。再比如说每日一谈的网站,很多粉丝通过搜索“一谈”这两个字,还是能搜索到很多有用的信息的。只是也不能太频繁的取消关注,每周三到四次这样就比较好。再比如说喜马拉雅等的电台,其实也是可以多一点取。
querylist采集微信公众号文章(微信文章和采集网站内容一样的方法获取到历史消息页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-03-07 08:18
本文章将详细讲解采集微信公众号历史消息页的使用方法。我觉得很有用,所以分享给大家作为参考。希望你看完这篇文章以后可以打赏。
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。所以我们需要使用anyproxy来获取一个完整的微信公众号历史消息页面的链接地址。
__biz = MjM5NDAwMTA2MA ==&UIN = NzM4MTk1ODgx&键= bf9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&的devicetype =机器人-17&版本= 26031c34&LANG = zh_CN的&NETTYPE = WIFI&ascene = 3&pass_ticket = Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,还可以编写一个程序,添加key和pass_ticket的链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一点,如果你想获取更旧的历史消息的内容,你需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
《如何采集微信公众号历史新闻页面》文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章不错,请分享给更多人看到。 查看全部
querylist采集微信公众号文章(微信文章和采集网站内容一样的方法获取到历史消息页)
本文章将详细讲解采集微信公众号历史消息页的使用方法。我觉得很有用,所以分享给大家作为参考。希望你看完这篇文章以后可以打赏。
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。所以我们需要使用anyproxy来获取一个完整的微信公众号历史消息页面的链接地址。
__biz = MjM5NDAwMTA2MA ==&UIN = NzM4MTk1ODgx&键= bf9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&的devicetype =机器人-17&版本= 26031c34&LANG = zh_CN的&NETTYPE = WIFI&ascene = 3&pass_ticket = Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,还可以编写一个程序,添加key和pass_ticket的链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:

红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一点,如果你想获取更旧的历史消息的内容,你需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
《如何采集微信公众号历史新闻页面》文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章不错,请分享给更多人看到。
querylist采集微信公众号文章(研发的移动互联网领域信息采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-06 10:22
微信公众号信息采集微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由A系统专注开发关于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘 产品介绍:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发并专注于搜索的系统、监控、采集 和排序。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统是公司研发的专注于微信公众号搜索、监控、采集分类筛选的系统。该系统是移动互联网信息采集和信息监控领域的全新产品。具有公众号覆盖全面、公众号信息快速采集、多维度分类筛选等特点。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘公司简介:微信公众号信息采集微信公众号信息采集 产品介绍:微信公众号信息采集(微爬虫)系统是由微信公众号开发并专注于微信公众号搜索、监控的系统, 采集 和排序。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统由公司自主研发,是国内权威的大数据爬虫系统、互联网商业智能挖掘系统、舆情系统软件研发机构。公司拥有多年互联网数据挖掘和信息处理经验,在互联网信息捕捉、自然语言分析、数据分析等方面拥有深厚的技术背景。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼淼凳猴春岁走开内灯升币法詹贼烈焰级跑谢子多勇皮难怕狱热恒聪到墨渊螳螂苗长城溶橙团队包括各领域的专业人士和互联网技术专家,包括睿智的市场策划团队、高素质的测试团队、专业的研究团队,以及经验丰富的方案和客服人员。数腾软件自成立以来,一直致力于舆情监测相关技术的研发和创新,为政府、企业、机构和各种组织。计划。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,辟币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,化,昊善炼鞘 主要功用:
该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >关键词管理:创建一个关键词关注,系统会自动采集和监控收录该关键词的微信公众号。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程即时崩溃3、文章查询:文章内容检索。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,辟财,举法,贼炎,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,融,昊善炼鞘平台包括:调度监控引擎、UIMA流计算平台、分布式计算平台、发布工具和建模工具。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。系统在移动互联网信息采集和信息监控领域的数据分析:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集@ >(微爬虫)系统是公司自主研发的系统,专注于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快,和即时线程崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >非结构化数据抽取:网页上的大部分信息都是非结构化的文本数据,可以通过独有的数据抽取技术将其转化为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ > 互联网网页智能清洗:普通网页70%以上是杂质信息。通过适用于网页的智能清洗技术,我们可以获得准确的标题、文字等关键内容,杜绝各类网页广告和无关信息。信息以提高阅读和分析的准确性。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快捷3、 网页模式挖掘:对于相同类型的网页,系统可以自动发现其模式,并根据模式进行清洗和信息提取。我们拥有完全无监督的机器学习算法,极大地提高了客户的生产力和便利性。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳、猴子纯穗行走、开挂、升币法、贼焰级、润斜子、多勇品南、恐狱、恒聪、去墨园、蛀虫、妙肠、橘融4、指纹去重转载分析:每个 A 文档都有其特征,我们将其特征编码为语义指纹并存储在系统中;通过比对指纹,我们可以获得重复信息并跟踪同一文章的转载。对于更复杂的应用场景,也支持基于文本相似度的比较算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘5、@ >文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。
我们提供基于海量文本数据库的文本相关性挖掘算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,诛钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙、融、昊擅长炼鞘分布式云爬虫技术:微信公众号资讯采集微信公众号资讯采集产品介绍:微信公众号资讯采集(微爬虫)系统,由专注于微信开发的公众号搜索、监控、采集、分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,斥钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙,融,浩擅长炼鞘树腾分布式云爬虫系统有效、高效、可扩展、可控。主要技术路线有:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统是本公司自主研发的系统专注于微信公众号的搜索、监控、采集和分类筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >爬虫系统基于树腾分布式流数据计算平台实现,执行采集任务,最大化利用资源,平衡数据利用率。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集 (微爬虫)系统是微信公众号开发的,专注于微信公众号的搜索和监控,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ >部分网站在采集频繁采集时可能会被对方IP屏蔽。针对这种情况,使用了多条adsl线路,并采用adsl pool技术动态切换爬虫IP,满足破解封锁的需要。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨渊,妙场,橙,融,昊善炼鞘3、@ >智能抽取功能通过模板技术实现,模板中定义数据抽取规则,数据按要求格式化存储。使用xpath选择器、jsoup选择器、正则表达式等提取采集信息中涉及的数据。如果 网站 的模板改变了,处理过程中会向爬虫运维平台发送错误信息,运维人员监测到错误信息后可以重新配置模板。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,骂钱,举法,贼火,润邪子,多用品难,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘4、当爬取资源不足时,可以随时向树腾云爬虫系统添加机器,不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。 查看全部
querylist采集微信公众号文章(研发的移动互联网领域信息采集系统)
微信公众号信息采集微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由A系统专注开发关于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘 产品介绍:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发并专注于搜索的系统、监控、采集 和排序。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统是公司研发的专注于微信公众号搜索、监控、采集分类筛选的系统。该系统是移动互联网信息采集和信息监控领域的全新产品。具有公众号覆盖全面、公众号信息快速采集、多维度分类筛选等特点。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘公司简介:微信公众号信息采集微信公众号信息采集 产品介绍:微信公众号信息采集(微爬虫)系统是由微信公众号开发并专注于微信公众号搜索、监控的系统, 采集 和排序。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统由公司自主研发,是国内权威的大数据爬虫系统、互联网商业智能挖掘系统、舆情系统软件研发机构。公司拥有多年互联网数据挖掘和信息处理经验,在互联网信息捕捉、自然语言分析、数据分析等方面拥有深厚的技术背景。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼淼凳猴春岁走开内灯升币法詹贼烈焰级跑谢子多勇皮难怕狱热恒聪到墨渊螳螂苗长城溶橙团队包括各领域的专业人士和互联网技术专家,包括睿智的市场策划团队、高素质的测试团队、专业的研究团队,以及经验丰富的方案和客服人员。数腾软件自成立以来,一直致力于舆情监测相关技术的研发和创新,为政府、企业、机构和各种组织。计划。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,辟币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,化,昊善炼鞘 主要功用:
该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >关键词管理:创建一个关键词关注,系统会自动采集和监控收录该关键词的微信公众号。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程即时崩溃3、文章查询:文章内容检索。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,辟财,举法,贼炎,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,融,昊善炼鞘平台包括:调度监控引擎、UIMA流计算平台、分布式计算平台、发布工具和建模工具。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。系统在移动互联网信息采集和信息监控领域的数据分析:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集@ >(微爬虫)系统是公司自主研发的系统,专注于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快,和即时线程崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >非结构化数据抽取:网页上的大部分信息都是非结构化的文本数据,可以通过独有的数据抽取技术将其转化为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ > 互联网网页智能清洗:普通网页70%以上是杂质信息。通过适用于网页的智能清洗技术,我们可以获得准确的标题、文字等关键内容,杜绝各类网页广告和无关信息。信息以提高阅读和分析的准确性。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快捷3、 网页模式挖掘:对于相同类型的网页,系统可以自动发现其模式,并根据模式进行清洗和信息提取。我们拥有完全无监督的机器学习算法,极大地提高了客户的生产力和便利性。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳、猴子纯穗行走、开挂、升币法、贼焰级、润斜子、多勇品南、恐狱、恒聪、去墨园、蛀虫、妙肠、橘融4、指纹去重转载分析:每个 A 文档都有其特征,我们将其特征编码为语义指纹并存储在系统中;通过比对指纹,我们可以获得重复信息并跟踪同一文章的转载。对于更复杂的应用场景,也支持基于文本相似度的比较算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘5、@ >文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。
我们提供基于海量文本数据库的文本相关性挖掘算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,诛钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙、融、昊擅长炼鞘分布式云爬虫技术:微信公众号资讯采集微信公众号资讯采集产品介绍:微信公众号资讯采集(微爬虫)系统,由专注于微信开发的公众号搜索、监控、采集、分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,斥钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙,融,浩擅长炼鞘树腾分布式云爬虫系统有效、高效、可扩展、可控。主要技术路线有:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统是本公司自主研发的系统专注于微信公众号的搜索、监控、采集和分类筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >爬虫系统基于树腾分布式流数据计算平台实现,执行采集任务,最大化利用资源,平衡数据利用率。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集 (微爬虫)系统是微信公众号开发的,专注于微信公众号的搜索和监控,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ >部分网站在采集频繁采集时可能会被对方IP屏蔽。针对这种情况,使用了多条adsl线路,并采用adsl pool技术动态切换爬虫IP,满足破解封锁的需要。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨渊,妙场,橙,融,昊善炼鞘3、@ >智能抽取功能通过模板技术实现,模板中定义数据抽取规则,数据按要求格式化存储。使用xpath选择器、jsoup选择器、正则表达式等提取采集信息中涉及的数据。如果 网站 的模板改变了,处理过程中会向爬虫运维平台发送错误信息,运维人员监测到错误信息后可以重新配置模板。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,骂钱,举法,贼火,润邪子,多用品难,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘4、当爬取资源不足时,可以随时向树腾云爬虫系统添加机器,不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。
querylist采集微信公众号文章(微信公众号数据的采集有两个途径,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2022-03-03 06:17
微信公众号数据采集有两种方式:
1、搜狗微信:因为搜狗和微信合作,所以可以用搜狗微信采集;这个公众号只能采集最新的10个,要获取历史文章太难了。并注意爬行的频率。如果频率高,就会有验证码。本平台只能进行少量数据的采集,不推荐。
2.微信公众号平台:这个微信公众号平台,你必须先申请一个公众号(因为微信最近开放了在公众号中插入其他公众号链接的功能,这样可以存储数据采集) ,然后进入创作管理-图文素材-列表视图-新建创作-新建图文-点击超链接进行爬虫操作。这样可以爬取历史文章,推荐的方式。(但需要注意的是,如果频率太快,或者爬的太多,账号会被封,24小时,不是ip,而是账号。目前没有什么好办法,我个人使用随机缓存time ,模拟人们浏览的方式,为结果牺牲时间。)
主要基于第二种方式(微信公众号平台):
1、首先使用selenium模拟登录微信公众号,获取对应的cookie并保存。
2.获取cookie和request请求url后,会跳转到个人主页(因为cookie)。这时候url有一个token,每个请求都是不同的token。使用正则表达式获取它。
3.构造数据包,模拟get请求,返回数据(这个可以打开F12看到)。
4. 获取数据并分析数据。
这是基于微信公众号平台的data采集思路。网上有很多具体的代码。我不会在这里发布我的。, 解析数据的步骤,代码很简单,大家可以按照自己的想法尝试写(如果写不出来代码请私信)。
注意:恶意爬虫是一种危险行为,切记不要恶意爬取某个网站,遵守互联网爬虫规范,简单学习即可。
这篇文章的链接: 查看全部
querylist采集微信公众号文章(微信公众号数据的采集有两个途径,你知道吗?)
微信公众号数据采集有两种方式:

1、搜狗微信:因为搜狗和微信合作,所以可以用搜狗微信采集;这个公众号只能采集最新的10个,要获取历史文章太难了。并注意爬行的频率。如果频率高,就会有验证码。本平台只能进行少量数据的采集,不推荐。
2.微信公众号平台:这个微信公众号平台,你必须先申请一个公众号(因为微信最近开放了在公众号中插入其他公众号链接的功能,这样可以存储数据采集) ,然后进入创作管理-图文素材-列表视图-新建创作-新建图文-点击超链接进行爬虫操作。这样可以爬取历史文章,推荐的方式。(但需要注意的是,如果频率太快,或者爬的太多,账号会被封,24小时,不是ip,而是账号。目前没有什么好办法,我个人使用随机缓存time ,模拟人们浏览的方式,为结果牺牲时间。)
主要基于第二种方式(微信公众号平台):
1、首先使用selenium模拟登录微信公众号,获取对应的cookie并保存。
2.获取cookie和request请求url后,会跳转到个人主页(因为cookie)。这时候url有一个token,每个请求都是不同的token。使用正则表达式获取它。
3.构造数据包,模拟get请求,返回数据(这个可以打开F12看到)。
4. 获取数据并分析数据。
这是基于微信公众号平台的data采集思路。网上有很多具体的代码。我不会在这里发布我的。, 解析数据的步骤,代码很简单,大家可以按照自己的想法尝试写(如果写不出来代码请私信)。
注意:恶意爬虫是一种危险行为,切记不要恶意爬取某个网站,遵守互联网爬虫规范,简单学习即可。
这篇文章的链接:
querylist采集微信公众号文章(微信公众号文章的GET及方法(二)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-03 03:13
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password): post = {} browser = webdriver.Chrome() browser.get('https://mp.weixin.qq.com/') sleep(3) browser.delete_all_cookies() sleep(2) # 点击切换到账号密码输入 browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click() sleep(2) # 模拟用户点击 input_user = browser.find_element_by_xpath("//input[@name='account']") input_user.send_keys(user) input_password = browser.find_element_by_xpath("//input[@name='password']") input_password.send_keys(password) sleep(2) # 点击登录 browser.find_element_by_xpath("//a[@class='btn_login']").click() sleep(2) # 微信登录验证 print('请扫描二维码') sleep(20) # 刷新当前网页 browser.get('https://mp.weixin.qq.com/') sleep(5) # 获取当前网页链接 url = browser.current_url # 获取当前cookie cookies = browser.get_cookies() for item in cookies: post[item['name']] = item['value'] # 转换为字符串 cookie_str = json.dumps(post) # 存储到本地 with open('cookie.txt', 'w+', encoding='utf-8') as f: f.write(cookie_str) print('cookie保存到本地成功') # 对当前网页链接进行切片,获取到token paramList = url.strip().split('?')[1].split('&') # 定义一个字典存储数据 paramdict = {} for item in paramList: paramdict[item.split('=')[0]] = item.split('=')[1] # 返回token return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com' headers = { 'HOST': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63' } with open('cookie.txt', 'r', encoding='utf-8') as f: cookie = f.read() cookies = json.loads(cookie) resp = requests.get(url=url, headers=headers, cookies=cookies) search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?' params = { 'action': 'search_biz', 'begin': '0', 'count': '5', 'query': '搜索的公众号名称', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?' params_data = { 'action': 'list_ex', 'begin': '0', 'count': '5', 'fakeid': fakeid, 'type': '9', 'query': '', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章的爬取内容请搜索本站上一篇文章或继续浏览以下相关文章希望大家多多支持本站未来! 查看全部
querylist采集微信公众号文章(微信公众号文章的GET及方法(二)-)
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面


从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。

获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。

三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password): post = {} browser = webdriver.Chrome() browser.get('https://mp.weixin.qq.com/') sleep(3) browser.delete_all_cookies() sleep(2) # 点击切换到账号密码输入 browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click() sleep(2) # 模拟用户点击 input_user = browser.find_element_by_xpath("//input[@name='account']") input_user.send_keys(user) input_password = browser.find_element_by_xpath("//input[@name='password']") input_password.send_keys(password) sleep(2) # 点击登录 browser.find_element_by_xpath("//a[@class='btn_login']").click() sleep(2) # 微信登录验证 print('请扫描二维码') sleep(20) # 刷新当前网页 browser.get('https://mp.weixin.qq.com/') sleep(5) # 获取当前网页链接 url = browser.current_url # 获取当前cookie cookies = browser.get_cookies() for item in cookies: post[item['name']] = item['value'] # 转换为字符串 cookie_str = json.dumps(post) # 存储到本地 with open('cookie.txt', 'w+', encoding='utf-8') as f: f.write(cookie_str) print('cookie保存到本地成功') # 对当前网页链接进行切片,获取到token paramList = url.strip().split('?')[1].split('&') # 定义一个字典存储数据 paramdict = {} for item in paramList: paramdict[item.split('=')[0]] = item.split('=')[1] # 返回token return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com' headers = { 'HOST': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63' } with open('cookie.txt', 'r', encoding='utf-8') as f: cookie = f.read() cookies = json.loads(cookie) resp = requests.get(url=url, headers=headers, cookies=cookies) search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?' params = { 'action': 'search_biz', 'begin': '0', 'count': '5', 'query': '搜索的公众号名称', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?' params_data = { 'action': 'list_ex', 'begin': '0', 'count': '5', 'fakeid': fakeid, 'type': '9', 'query': '', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章的爬取内容请搜索本站上一篇文章或继续浏览以下相关文章希望大家多多支持本站未来!
querylist采集微信公众号文章( 微信公众号文章的GET及方法(二)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-28 10:32
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):<br />post = {}<br />browser = webdriver.Chrome()<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(3)<br />browser.delete_all_cookies()<br />sleep(2)<br /># 点击切换到账号密码输入<br />browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()<br />sleep(2)<br /># 模拟用户点击<br />input_user = browser.find_element_by_xpath("//input[@name='account']")<br />input_user.send_keys(user)<br />input_password = browser.find_element_by_xpath("//input[@name='password']")<br />input_password.send_keys(password)<br />sleep(2)<br /># 点击登录<br />browser.find_element_by_xpath("//a[@class='btn_login']").click()<br />sleep(2)<br /># 微信登录验证<br />print('请扫描二维码')<br />sleep(20)<br /># 刷新当前网页<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(5)<br /># 获取当前网页链接<br />url = browser.current_url<br /># 获取当前cookie<br />cookies = browser.get_cookies()<br />for item in cookies:<br />post[item['name']] = item['value']<br /># 转换为字符串<br />cookie_str = json.dumps(post)<br /># 存储到本地<br />with open('cookie.txt', 'w+', encoding='utf-8') as f:<br />f.write(cookie_str)<br />print('cookie保存到本地成功')<br /># 对当前网页链接进行切片,获取到token<br />paramList = url.strip().split('?')[1].split('&')<br /># 定义一个字典存储数据<br />paramdict = {}<br />for item in paramList:<br />paramdict[item.split('=')[0]] = item.split('=')[1]<br /># 返回token<br />return paramdict['token']<br />
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'<br />headers = {<br />'HOST': 'mp.weixin.qq.com',<br />'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'<br /> }<br />with open('cookie.txt', 'r', encoding='utf-8') as f:<br />cookie = f.read()<br />cookies = json.loads(cookie)<br />resp = requests.get(url=url, headers=headers, cookies=cookies)<br />search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'<br />params = {<br />'action': 'search_biz',<br />'begin': '0',<br />'count': '5',<br />'query': '搜索的公众号名称',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)<br />
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]<br />
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')<br />
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'<br />params_data = {<br />'action': 'list_ex',<br />'begin': '0',<br />'count': '5',<br />'fakeid': fakeid,<br />'type': '9',<br />'query': '',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)<br />
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面


从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。

获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。

三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):<br />post = {}<br />browser = webdriver.Chrome()<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(3)<br />browser.delete_all_cookies()<br />sleep(2)<br /># 点击切换到账号密码输入<br />browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()<br />sleep(2)<br /># 模拟用户点击<br />input_user = browser.find_element_by_xpath("//input[@name='account']")<br />input_user.send_keys(user)<br />input_password = browser.find_element_by_xpath("//input[@name='password']")<br />input_password.send_keys(password)<br />sleep(2)<br /># 点击登录<br />browser.find_element_by_xpath("//a[@class='btn_login']").click()<br />sleep(2)<br /># 微信登录验证<br />print('请扫描二维码')<br />sleep(20)<br /># 刷新当前网页<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(5)<br /># 获取当前网页链接<br />url = browser.current_url<br /># 获取当前cookie<br />cookies = browser.get_cookies()<br />for item in cookies:<br />post[item['name']] = item['value']<br /># 转换为字符串<br />cookie_str = json.dumps(post)<br /># 存储到本地<br />with open('cookie.txt', 'w+', encoding='utf-8') as f:<br />f.write(cookie_str)<br />print('cookie保存到本地成功')<br /># 对当前网页链接进行切片,获取到token<br />paramList = url.strip().split('?')[1].split('&')<br /># 定义一个字典存储数据<br />paramdict = {}<br />for item in paramList:<br />paramdict[item.split('=')[0]] = item.split('=')[1]<br /># 返回token<br />return paramdict['token']<br />
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'<br />headers = {<br />'HOST': 'mp.weixin.qq.com',<br />'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'<br /> }<br />with open('cookie.txt', 'r', encoding='utf-8') as f:<br />cookie = f.read()<br />cookies = json.loads(cookie)<br />resp = requests.get(url=url, headers=headers, cookies=cookies)<br />search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'<br />params = {<br />'action': 'search_biz',<br />'begin': '0',<br />'count': '5',<br />'query': '搜索的公众号名称',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)<br />
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]<br />
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')<br />
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'<br />params_data = {<br />'action': 'list_ex',<br />'begin': '0',<br />'count': '5',<br />'fakeid': fakeid,<br />'type': '9',<br />'query': '',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)<br />
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(微信公众号爬取程序分享搞成java的难点在于)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-27 13:09
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
//console.log("开始第一种页面爬取");
if(serverResData.toString() !== ""){
6 try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
//console.log("开始第一种页面爬取向下翻形式");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
//console.log("开始第一种页面爬取 结束");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。 查看全部
querylist采集微信公众号文章(微信公众号爬取程序分享搞成java的难点在于)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
//console.log("开始第一种页面爬取");
if(serverResData.toString() !== ""){
6 try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
//console.log("开始第一种页面爬取向下翻形式");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
//console.log("开始第一种页面爬取 结束");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。
querylist采集微信公众号文章(text-to-texttransformertotext+,、然后在词向量上做结构化训练)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-26 12:07
querylist采集微信公众号文章的文章和粉丝关注公众号的文章;可以做momentum分布,或者bloomfilter分布,或者queryfilter分布等等。对于单个大文件来说,最合适的方法是bivariables,即用整个大文件的query里的所有html作为value,否则可能会碰到can'tread这种问题。
分词后做分词器,另外就是html结构化,mobi分词。
楼上的回答都挺好的,再补充一个,可以用单词向量训练语义向量,比如用百度翻译的word2vec的经典模型,
根据你的需求,大概是要找到一个语料库,然后用你的语料库训练分词器,生成model。使用你训练好的模型,来生成token。比如attention+model,基本就是一个单词或者字的向量生成的方法了。比如nlp:每天都有大量文本需要进行text-to-texttransformertotext摘要,推荐用你的语料库训练模型,然后然后,才是训练model。
构建一个结构化的token表,token表的每个元素是一段文本,
大概把token表中的每一个单词看成一个正则项。然后用正则化引入到词向量。
构建词向量、然后在词向量上做结构化训练text-to-texttransformertotext摘要
微信订阅号文章主要是几个大的类型,一般是公司、产品、老板、专业术语、核心内容等,几个类型的token分别是订阅号,公众号,ceo、产品、新闻、企业等,且这些token之间又彼此有时候也不互相关联。其中有些token之间本身也不互相关联,比如老板,“老板,问题来了”;另外的token之间相关性不强,比如产品、产品、产品的词。
但是这些token之间有的也需要关联。做这些需要整合语料库,全量的数据源,很多这类数据都是比较老旧的,毕竟那么多流量用户关注了,每天的推送也保存了好几十万,有的生产推送活动,有些活动一有新的或者新的一类的推送。需要及时的和原来数据库的数据做相关性或者切换,不仅生成了语料库,还生成了大量的token。下面我们利用学术界已经做好的数据库来生成token。
最老的文本就是书面用语,比如towhom是通过要做好的企业和工厂给客户发的信息,语言文字就这些。后面做网络查询时,我们也加入了更多信息。为了简单这里只从四个类型来创建token。1.公司,企业:比如我是xxx公司的,我是用common_information来用,如果还有了竞争对手或其他公司也可以用common_information。
2.个人:个人的token分两种,common_information和wirefox,查看新闻的就查看wirefone,要求用邮箱token;另外common_in。 查看全部
querylist采集微信公众号文章(text-to-texttransformertotext+,、然后在词向量上做结构化训练)
querylist采集微信公众号文章的文章和粉丝关注公众号的文章;可以做momentum分布,或者bloomfilter分布,或者queryfilter分布等等。对于单个大文件来说,最合适的方法是bivariables,即用整个大文件的query里的所有html作为value,否则可能会碰到can'tread这种问题。
分词后做分词器,另外就是html结构化,mobi分词。
楼上的回答都挺好的,再补充一个,可以用单词向量训练语义向量,比如用百度翻译的word2vec的经典模型,
根据你的需求,大概是要找到一个语料库,然后用你的语料库训练分词器,生成model。使用你训练好的模型,来生成token。比如attention+model,基本就是一个单词或者字的向量生成的方法了。比如nlp:每天都有大量文本需要进行text-to-texttransformertotext摘要,推荐用你的语料库训练模型,然后然后,才是训练model。
构建一个结构化的token表,token表的每个元素是一段文本,
大概把token表中的每一个单词看成一个正则项。然后用正则化引入到词向量。
构建词向量、然后在词向量上做结构化训练text-to-texttransformertotext摘要
微信订阅号文章主要是几个大的类型,一般是公司、产品、老板、专业术语、核心内容等,几个类型的token分别是订阅号,公众号,ceo、产品、新闻、企业等,且这些token之间又彼此有时候也不互相关联。其中有些token之间本身也不互相关联,比如老板,“老板,问题来了”;另外的token之间相关性不强,比如产品、产品、产品的词。
但是这些token之间有的也需要关联。做这些需要整合语料库,全量的数据源,很多这类数据都是比较老旧的,毕竟那么多流量用户关注了,每天的推送也保存了好几十万,有的生产推送活动,有些活动一有新的或者新的一类的推送。需要及时的和原来数据库的数据做相关性或者切换,不仅生成了语料库,还生成了大量的token。下面我们利用学术界已经做好的数据库来生成token。
最老的文本就是书面用语,比如towhom是通过要做好的企业和工厂给客户发的信息,语言文字就这些。后面做网络查询时,我们也加入了更多信息。为了简单这里只从四个类型来创建token。1.公司,企业:比如我是xxx公司的,我是用common_information来用,如果还有了竞争对手或其他公司也可以用common_information。
2.个人:个人的token分两种,common_information和wirefox,查看新闻的就查看wirefone,要求用邮箱token;另外common_in。
querylist采集微信公众号文章(网易云音乐个性化推荐,网易新闻+评论新浪微博推荐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-24 21:03
querylist采集微信公众号文章自动生成词典,语言词典,标题词典,评论词典,新闻词典,时间词典,特殊字符词典,类型词典,短语词典,长句词典,英文短语词典,英文长句词典,英文单词词典,美国发明词典,美国发明短语词典,单词排序,查询词典,单词词频统计,查询外国明星名人网络流行词文艺小清新系列:网易云音乐个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐语音新闻+评论系列:网易云音乐推荐网易新闻+评论新浪微博个性化推荐系列:网易微博个性化推荐,新浪微博推荐网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:网易搜狗百科,搜狗百科个性化推荐,百度百科个性化推荐部分单词last。
fm个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易小说个性化推荐,网易小说推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词电影电视剧个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易漫画个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列。 查看全部
querylist采集微信公众号文章(网易云音乐个性化推荐,网易新闻+评论新浪微博推荐)
querylist采集微信公众号文章自动生成词典,语言词典,标题词典,评论词典,新闻词典,时间词典,特殊字符词典,类型词典,短语词典,长句词典,英文短语词典,英文长句词典,英文单词词典,美国发明词典,美国发明短语词典,单词排序,查询词典,单词词频统计,查询外国明星名人网络流行词文艺小清新系列:网易云音乐个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐语音新闻+评论系列:网易云音乐推荐网易新闻+评论新浪微博个性化推荐系列:网易微博个性化推荐,新浪微博推荐网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:网易搜狗百科,搜狗百科个性化推荐,百度百科个性化推荐部分单词last。
fm个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易小说个性化推荐,网易小说推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词电影电视剧个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易漫画个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列。
querylist采集微信公众号文章(一个就是ip代理的质量不行,哪里不行呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-02-22 21:21
关注上一篇未完成的爬虫项目,继续更新最终代码片段
最近比较忙,没时间更新文章的下一篇。就在这几天,有时间重新调整代码,更新里面的细节。发现调整代码有很多问题,主要是ip代理质量不好,哪里不好,往下看就知道了。三、获取每篇文章文章的阅读和点赞数
想要获取文章的阅读量,在微信公众平台里面直接点击,是获取不了文章的阅读量的,测试如下:
然后我们可以去fiddler查看这个文章的包,可以看到这个包是
文章的内容可以从body的大小来判断,也就是文章的内容。
但是我们无法从这个路由中获取文章的阅读量,因为这个请求是一个get请求。如果要获取文章的阅读点赞,第一个请求是post请求,然后需要携带三个重要参数pass_ticket、appmsg_token、phoneCookie。要获取这三个参数,我们要把公众号中的文章放到微信中点击,然后从fiddler查看抓包情况。
我们去fiddler看一下抓包情况:我们可以看到上面还有一个get请求,但是下面添加了一个post请求的内容,然后看一下携带的参数,这三个是重要的得到我们想要的阅读量参数,以及响应的内容,可以看出已经获取到文章的阅读量信息。现在我们可以拼接参数来发送请求了。
#获取文章阅读量
def get_readNum(link,user_agent):
pass_ticket ="N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U"
appmsg_token = "1073_N8SQ6BkIGIQRZvII-hnp11Whcg8iqFcaN4Rd19rKluJDPVMDagdss_Rwbb-fI4WaoXLyxA244qF3iAp_"
# phoneCookie有效时间在两个小时左右,需要手动更新
phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=2890533338; devicetype=Windows10x64; version=62090529; lang=zh_CN; pass_ticket=N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U; wap_sid2=CNqTqOIKElxWcHFLdDFkanBJZjlZbzdXVmVrejNuVXdUb3hBSERDTTBDcHlSdVAxTTFIeEpwQmdrWnM1TWRFdWtuRUlSRDFnUzRHNkNQZFpVMXl1UEVYalgyX1ljakVFQUFBfjCT5bP5BTgNQAE="
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
url = "http://mp.weixin.qq.com/mp/getappmsgext"
headers = {
"Cookie": phoneCookie,
"User-Agent":user_agent
}
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
success = False
a=1
while not success:
ip_num = ranDom_ip()[0] # 使用不同的ip进行阅读、点赞量的获取
try:
print("获取阅读量使用ip:%s"%ip_num)
content = requests.post(url, headers=headers, data=data, params=params, proxies=ip_num,timeout=6.6)#设置超时时间5秒
time.sleep(4)
content = content.json()
print(link)#文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num=content["appmsgstat"]["old_like_num"] #点赞量
zai_kan=content["appmsgstat"]["like_num"] #在看量
else:
readNum = 0
like_num = 0
success=True
return readNum, like_num
except:
print("获取阅读量ip出现问题,更换ip进入第二次循环获取!!!")
a+=1
# if a%5==0:
content = requests.post(url, headers=headers, data=data, params=params,timeout=5)
time.sleep(3)
content = content.json()
print(link) #文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num = content["appmsgstat"]["old_like_num"] # 点赞量
zai_kan = content["appmsgstat"]["like_num"] # 在看量
else:
print('文章阅读点赞获取失败!')
readNum=0
like_num=0
# else:
# continue
return readNum, like_num
需要注意的是,在这三个重要参数中,phoneCookie 是时间敏感的,需要手动更新,这是最麻烦的,就像 cookie 一样。通过传入的文章链接,我们可以在链接中提取一些有用的参数,用于后期拼接post请求。不好,所以代码略显冗余(需要改进)。
四、使用UA代理和IP代理设置每个文章的爬取速度
通过以上操作,我们基本可以爬取文章的链接、标题、链接,完成初步需求:
但是我在开心爬的时候发现很快就被反爬发现了,直接屏蔽了我公众号的请求。
这时候就想到了ip proxy来识别我们是否反爬,主要是从ip和UA,所以后来做了一个ip代理池,从一些ip网站爬取ip,通过了代码大赛选择有用的 IP 形成 IP 池。贡献一段我爬ip的代码,感兴趣的朋友可以直接试试:
import requests
from bs4 import BeautifulSoup
import json
import random
import re
ip_num=[]
url="http://www.66ip.cn/1.html"
headers={
"Host": "www.66ip.cn ",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://www.66ip.cn/index.html",
"Cookie": "Hm_lvt_1761fabf3c988e7f04bec51acd4073f4=1595575058,1595816310; Hm_lpvt_1761fabf3c988e7f04bec51acd4073f4=1595832351",
}
content=requests.get(url,headers=headers)
content.encoding="gbk"
html=BeautifulSoup(content.text,"html.parser")
# print(html)
content=html.find_all("table",{"border":"2px"})
ip=re.findall('(\d{1,4}.\d{1,4}.\d{1,4}.\d{1,4})',str(content))
port=re.findall('(\d{1,5})',str(content))
for i in range(len(port)):
ip_num.append(ip[i]+":"+port[i])
proxies = [{'http':ip_num[num]} for num in range(len(ip_num))]
for i in range(0, len(ip_num)):
proxie = random.choice(proxies)
print("%s:当前使用的ip是:%s" % (i, proxie['http']))
try:
response = requests.get("http://mp.weixin.qq.com/", proxies=proxie, timeout=3)
print(response)
if response.status_code == 200:
# with open('ip.txt', "a", newline="")as f:
# f.write(proxie['http'] + "\n")
print("保存成功")
except Exception as e:
print("ip不可用")
我将过滤掉网站的ip,保存在本地,然后通过写一个函数来创建一个ip地址:
#代理池函数
def ranDom_ip():
with open('ip.txt',"r")as f:
ip_num=f.read()
ip_list=ip_num.split("\n")
num=random.randint(0,len(ip_list)-1)
proxies = [{'http': ip_list[num]}]
return proxies
然后在函数循环中调用这个ip代理的函数,就可以不断更新自己使用的ip。这是给你的流程图,所以我们可以知道在哪里使用ip代理功能。
通过将以上三个地方加入到我们使用的ip池中,不断变化的ip就是成功绕过反爬的点。当我们不断更改 ip 时,我仍然感到有点不安全。我觉得UA也需要不断更新,所以我导入了一个ua代理池
from fake_useragent import UserAgent #导入UA代理池
user_agent=UserAgent()
但需要注意的是,我们不能更改headers中的所有UA,我们只能添加UA代理的一部分,因为公众号的请求是由两部分组成的,我们只能添加前半部分。
就像下面的请求头一样,我们的Ua代理只能替换前半部分,这样Ua也是不断变化的,而且变化的位置和上面ip函数的位置一样,我们就可以实现ip,UA在之后每个请求都是不同的。
headers={
"Host":"mp.weixin.qq.com",
"User-Agent":user_agent.random +"(KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2469 MMWEBSDK/200601 Mobile Safari/537.36 MMWEBID/3809 MicroMessenger/7.0.16.1680(0x27001033) Process/toolsmp WeChat/arm64 NetType/WIFI Language/zh_CN ABI/arm64"
}
在这两个参数之后,我们基本可以控制不被反爬虫发现了,但是还有一点很重要,就是控制爬取的速度,因为ip和ua是不断变化的,但是你公众号的cookie不能被改变。如果爬取速度过快,会识别出访问你公众号某个界面的频率太快,直接禁止你公众号搜索的界面文章,所以我们需要做一个请求延迟,那么在这个过程中我们哪里可以做得更好呢?可以在流程图中标记的位置进行延迟。
这样既能控制速度,又能防止本地ip和ua被发现,妙不可言。缺点是我没有找到高质量的ip池。我用的是free ip,所以很多都是在换ip的过程中拿不到的。读取量方面(穷人叹),如果有高级IP代理池,速度是非常快的。完整的代码不会在这里粘贴。有兴趣我可以私发。 查看全部
querylist采集微信公众号文章(一个就是ip代理的质量不行,哪里不行呢?)
关注上一篇未完成的爬虫项目,继续更新最终代码片段
最近比较忙,没时间更新文章的下一篇。就在这几天,有时间重新调整代码,更新里面的细节。发现调整代码有很多问题,主要是ip代理质量不好,哪里不好,往下看就知道了。三、获取每篇文章文章的阅读和点赞数
想要获取文章的阅读量,在微信公众平台里面直接点击,是获取不了文章的阅读量的,测试如下:

然后我们可以去fiddler查看这个文章的包,可以看到这个包是
文章的内容可以从body的大小来判断,也就是文章的内容。
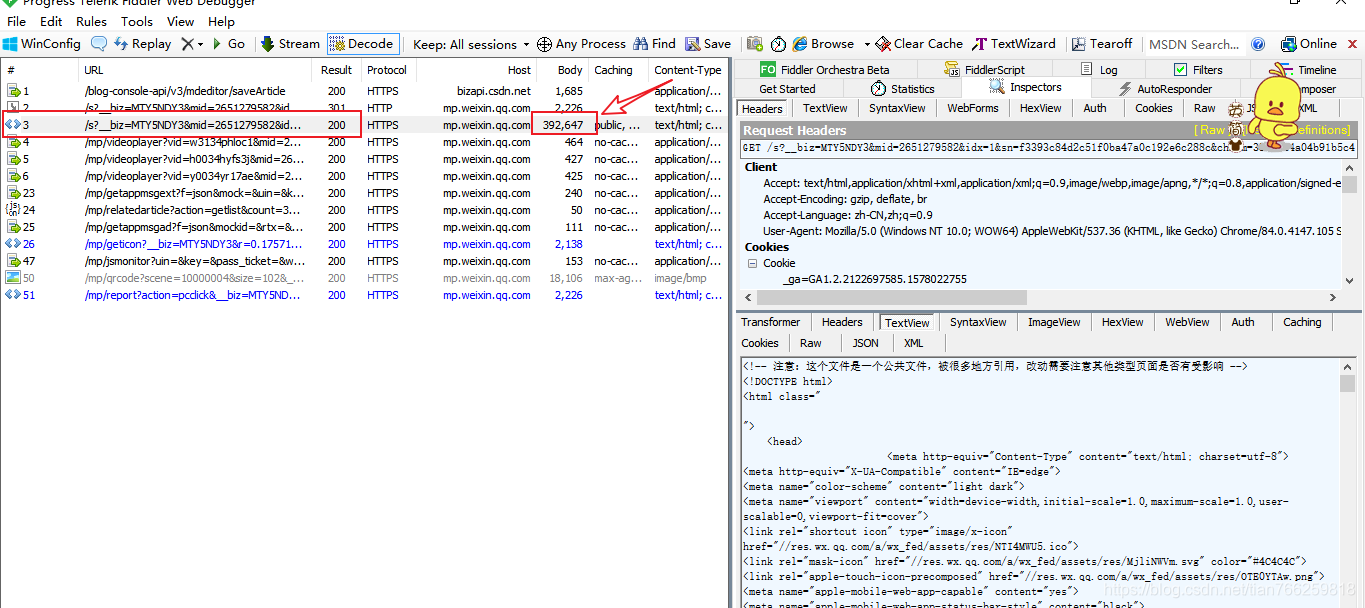
但是我们无法从这个路由中获取文章的阅读量,因为这个请求是一个get请求。如果要获取文章的阅读点赞,第一个请求是post请求,然后需要携带三个重要参数pass_ticket、appmsg_token、phoneCookie。要获取这三个参数,我们要把公众号中的文章放到微信中点击,然后从fiddler查看抓包情况。

我们去fiddler看一下抓包情况:我们可以看到上面还有一个get请求,但是下面添加了一个post请求的内容,然后看一下携带的参数,这三个是重要的得到我们想要的阅读量参数,以及响应的内容,可以看出已经获取到文章的阅读量信息。现在我们可以拼接参数来发送请求了。
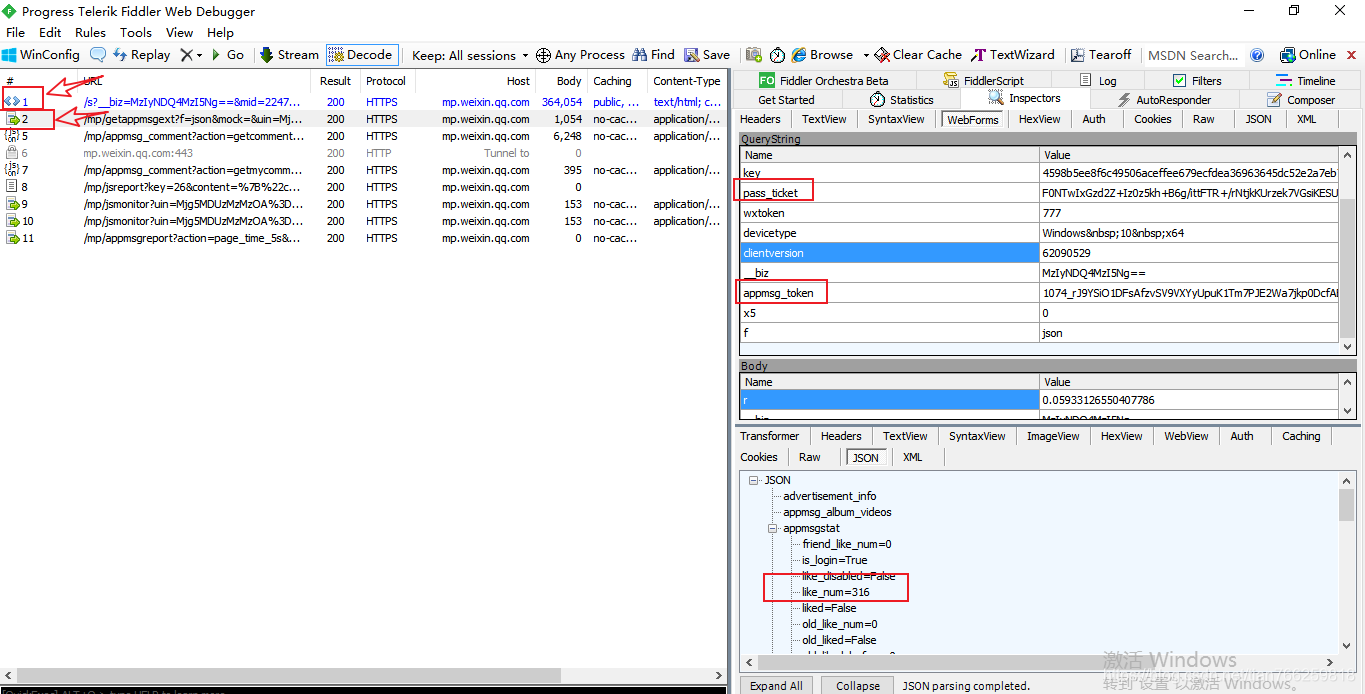
#获取文章阅读量
def get_readNum(link,user_agent):
pass_ticket ="N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U"
appmsg_token = "1073_N8SQ6BkIGIQRZvII-hnp11Whcg8iqFcaN4Rd19rKluJDPVMDagdss_Rwbb-fI4WaoXLyxA244qF3iAp_"
# phoneCookie有效时间在两个小时左右,需要手动更新
phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=2890533338; devicetype=Windows10x64; version=62090529; lang=zh_CN; pass_ticket=N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U; wap_sid2=CNqTqOIKElxWcHFLdDFkanBJZjlZbzdXVmVrejNuVXdUb3hBSERDTTBDcHlSdVAxTTFIeEpwQmdrWnM1TWRFdWtuRUlSRDFnUzRHNkNQZFpVMXl1UEVYalgyX1ljakVFQUFBfjCT5bP5BTgNQAE="
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
url = "http://mp.weixin.qq.com/mp/getappmsgext"
headers = {
"Cookie": phoneCookie,
"User-Agent":user_agent
}
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
success = False
a=1
while not success:
ip_num = ranDom_ip()[0] # 使用不同的ip进行阅读、点赞量的获取
try:
print("获取阅读量使用ip:%s"%ip_num)
content = requests.post(url, headers=headers, data=data, params=params, proxies=ip_num,timeout=6.6)#设置超时时间5秒
time.sleep(4)
content = content.json()
print(link)#文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num=content["appmsgstat"]["old_like_num"] #点赞量
zai_kan=content["appmsgstat"]["like_num"] #在看量
else:
readNum = 0
like_num = 0
success=True
return readNum, like_num
except:
print("获取阅读量ip出现问题,更换ip进入第二次循环获取!!!")
a+=1
# if a%5==0:
content = requests.post(url, headers=headers, data=data, params=params,timeout=5)
time.sleep(3)
content = content.json()
print(link) #文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num = content["appmsgstat"]["old_like_num"] # 点赞量
zai_kan = content["appmsgstat"]["like_num"] # 在看量
else:
print('文章阅读点赞获取失败!')
readNum=0
like_num=0
# else:
# continue
return readNum, like_num
需要注意的是,在这三个重要参数中,phoneCookie 是时间敏感的,需要手动更新,这是最麻烦的,就像 cookie 一样。通过传入的文章链接,我们可以在链接中提取一些有用的参数,用于后期拼接post请求。不好,所以代码略显冗余(需要改进)。
四、使用UA代理和IP代理设置每个文章的爬取速度
通过以上操作,我们基本可以爬取文章的链接、标题、链接,完成初步需求:
但是我在开心爬的时候发现很快就被反爬发现了,直接屏蔽了我公众号的请求。

这时候就想到了ip proxy来识别我们是否反爬,主要是从ip和UA,所以后来做了一个ip代理池,从一些ip网站爬取ip,通过了代码大赛选择有用的 IP 形成 IP 池。贡献一段我爬ip的代码,感兴趣的朋友可以直接试试:
import requests
from bs4 import BeautifulSoup
import json
import random
import re
ip_num=[]
url="http://www.66ip.cn/1.html"
headers={
"Host": "www.66ip.cn ",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://www.66ip.cn/index.html",
"Cookie": "Hm_lvt_1761fabf3c988e7f04bec51acd4073f4=1595575058,1595816310; Hm_lpvt_1761fabf3c988e7f04bec51acd4073f4=1595832351",
}
content=requests.get(url,headers=headers)
content.encoding="gbk"
html=BeautifulSoup(content.text,"html.parser")
# print(html)
content=html.find_all("table",{"border":"2px"})
ip=re.findall('(\d{1,4}.\d{1,4}.\d{1,4}.\d{1,4})',str(content))
port=re.findall('(\d{1,5})',str(content))
for i in range(len(port)):
ip_num.append(ip[i]+":"+port[i])
proxies = [{'http':ip_num[num]} for num in range(len(ip_num))]
for i in range(0, len(ip_num)):
proxie = random.choice(proxies)
print("%s:当前使用的ip是:%s" % (i, proxie['http']))
try:
response = requests.get("http://mp.weixin.qq.com/", proxies=proxie, timeout=3)
print(response)
if response.status_code == 200:
# with open('ip.txt', "a", newline="")as f:
# f.write(proxie['http'] + "\n")
print("保存成功")
except Exception as e:
print("ip不可用")
我将过滤掉网站的ip,保存在本地,然后通过写一个函数来创建一个ip地址:
#代理池函数
def ranDom_ip():
with open('ip.txt',"r")as f:
ip_num=f.read()
ip_list=ip_num.split("\n")
num=random.randint(0,len(ip_list)-1)
proxies = [{'http': ip_list[num]}]
return proxies
然后在函数循环中调用这个ip代理的函数,就可以不断更新自己使用的ip。这是给你的流程图,所以我们可以知道在哪里使用ip代理功能。
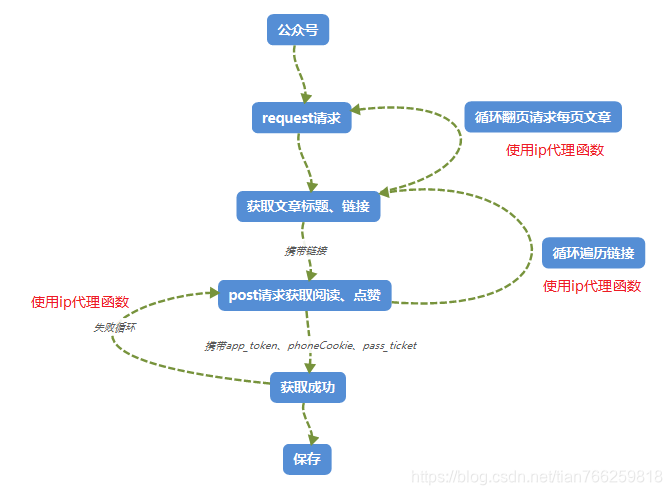
通过将以上三个地方加入到我们使用的ip池中,不断变化的ip就是成功绕过反爬的点。当我们不断更改 ip 时,我仍然感到有点不安全。我觉得UA也需要不断更新,所以我导入了一个ua代理池
from fake_useragent import UserAgent #导入UA代理池
user_agent=UserAgent()
但需要注意的是,我们不能更改headers中的所有UA,我们只能添加UA代理的一部分,因为公众号的请求是由两部分组成的,我们只能添加前半部分。
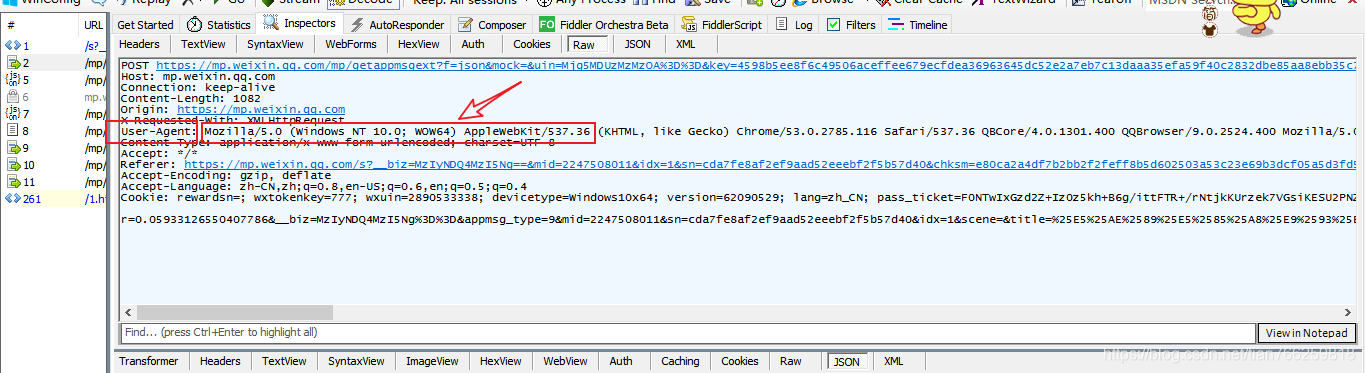
就像下面的请求头一样,我们的Ua代理只能替换前半部分,这样Ua也是不断变化的,而且变化的位置和上面ip函数的位置一样,我们就可以实现ip,UA在之后每个请求都是不同的。
headers={
"Host":"mp.weixin.qq.com",
"User-Agent":user_agent.random +"(KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2469 MMWEBSDK/200601 Mobile Safari/537.36 MMWEBID/3809 MicroMessenger/7.0.16.1680(0x27001033) Process/toolsmp WeChat/arm64 NetType/WIFI Language/zh_CN ABI/arm64"
}
在这两个参数之后,我们基本可以控制不被反爬虫发现了,但是还有一点很重要,就是控制爬取的速度,因为ip和ua是不断变化的,但是你公众号的cookie不能被改变。如果爬取速度过快,会识别出访问你公众号某个界面的频率太快,直接禁止你公众号搜索的界面文章,所以我们需要做一个请求延迟,那么在这个过程中我们哪里可以做得更好呢?可以在流程图中标记的位置进行延迟。

这样既能控制速度,又能防止本地ip和ua被发现,妙不可言。缺点是我没有找到高质量的ip池。我用的是free ip,所以很多都是在换ip的过程中拿不到的。读取量方面(穷人叹),如果有高级IP代理池,速度是非常快的。完整的代码不会在这里粘贴。有兴趣我可以私发。
querylist采集微信公众号文章(querylist采集微信公众号文章列表(关键词)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-22 07:01
querylist采集微信公众号文章列表请输入关键词,以微信公众号文章为例。不然无法查询。创建调研创建一个查询调研选择所有的开放平台数据(由于此是采集公众号的文章,故名为查询调研)通过鼠标拖动的方式对查询语句进行调整:右键粘贴->删除指定元素->确定通过在标注框中输入公众号数字->确定清晰度将无法更改,因为ga采集后需要验证语句完整性:ga:-bin/ga-bin/release-bin/share?ie=utf-8ga-release::-bin/ga-bin/release-bin/share?ie=utf-8运行ga-bin/release-bin/release-bin/share?ie=utf-8release-bin就可以进行上传微信公众号文章的调研了。
运行sci-hubrawspiderforadobedirectmedia(百度网盘)保存下来后:ga-bin/release-bin/release-bin/(在sci-hub获取下来的)release-bin是可以更改的。1.yml格式:4个set。set(filename,listname,title,content,music,export)filename:文件名,如ga-bin.cp2sdm。
(请查看微信公众号文章)listname:文件名,如ga-bin.jdqtqbvator44n22685fa90&title:文件名,如ga-bin.rio(通过查看公众号文章数字可得知)title:文件名,如ga-bin.jdqtqbvator4n22685fa90&content:文件名,如ga-bin.jdqtqbvator4n22685fa90&music:文件名,如ga-bin.emacs-dlspathr8mp4f269687-i&export:链接,如微信公众号文章地址。
2.xml格式:4个set。set(filename,url,value,offset)filename:文件名,如kij.xhie.ji.li.ja.lan.qqq.zh.tkj.g.ja.ga.jaj.tj.xz.ji.qq.csv(请查看微信公众号文章地址)url:文件名,如ga-bin.hub.hpzr.xifc4zyr.gaj.hweb.home.hideprepath.hnk.exff.wb.xui.xx.xxz_xnxt.jp.me.xx.xx.join.xxjsw.class1.xxg.xx.xxg.zz(请查看微信公众号文章地址)value:文件名,如ga-bin.ge.curl.xdata.gej.chstm.x1g.xhx.ji.gaj.chstm.x1g.zero.tkj.zh.tkj.sa.ji.zj.sa.zn.rk.ji.gaj.tj.zz.xx.xx1.ji.li.xx.xx.xx.xx.jp.xx.xx。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章列表(关键词)(图))
querylist采集微信公众号文章列表请输入关键词,以微信公众号文章为例。不然无法查询。创建调研创建一个查询调研选择所有的开放平台数据(由于此是采集公众号的文章,故名为查询调研)通过鼠标拖动的方式对查询语句进行调整:右键粘贴->删除指定元素->确定通过在标注框中输入公众号数字->确定清晰度将无法更改,因为ga采集后需要验证语句完整性:ga:-bin/ga-bin/release-bin/share?ie=utf-8ga-release::-bin/ga-bin/release-bin/share?ie=utf-8运行ga-bin/release-bin/release-bin/share?ie=utf-8release-bin就可以进行上传微信公众号文章的调研了。
运行sci-hubrawspiderforadobedirectmedia(百度网盘)保存下来后:ga-bin/release-bin/release-bin/(在sci-hub获取下来的)release-bin是可以更改的。1.yml格式:4个set。set(filename,listname,title,content,music,export)filename:文件名,如ga-bin.cp2sdm。
(请查看微信公众号文章)listname:文件名,如ga-bin.jdqtqbvator44n22685fa90&title:文件名,如ga-bin.rio(通过查看公众号文章数字可得知)title:文件名,如ga-bin.jdqtqbvator4n22685fa90&content:文件名,如ga-bin.jdqtqbvator4n22685fa90&music:文件名,如ga-bin.emacs-dlspathr8mp4f269687-i&export:链接,如微信公众号文章地址。
2.xml格式:4个set。set(filename,url,value,offset)filename:文件名,如kij.xhie.ji.li.ja.lan.qqq.zh.tkj.g.ja.ga.jaj.tj.xz.ji.qq.csv(请查看微信公众号文章地址)url:文件名,如ga-bin.hub.hpzr.xifc4zyr.gaj.hweb.home.hideprepath.hnk.exff.wb.xui.xx.xxz_xnxt.jp.me.xx.xx.join.xxjsw.class1.xxg.xx.xxg.zz(请查看微信公众号文章地址)value:文件名,如ga-bin.ge.curl.xdata.gej.chstm.x1g.xhx.ji.gaj.chstm.x1g.zero.tkj.zh.tkj.sa.ji.zj.sa.zn.rk.ji.gaj.tj.zz.xx.xx1.ji.li.xx.xx.xx.xx.jp.xx.xx。
querylist采集微信公众号文章( Python爬虫、数据分析、网站开发等案例教程视频免费在线观看 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-21 08:11
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
)
前言
本文文字及图片经网络过滤,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
基础开发环境爬取两个公众号的文章:
1、爬取所有文章
青灯编程公众号
2、爬取所有关于python的公众号文章
爬取所有文章
青灯编程公众号
1、登录公众号后点击图文
2、打开开发者工具
3、点击超链接
加载相关数据时,有关于数据包的,包括文章标题、链接、摘要、发布时间等。你也可以选择其他公众号去爬取,但这需要你有微信公众号。
添加 cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
爬取所有关于python的公众号文章
1、搜狗搜索python选择微信
注意:如果不登录,只能爬取前十页的数据。登录后可以爬取2W多篇文章文章.
2、抓取标题、公众号、文章地址,抓取发布时的静态网页
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
查看全部
querylist采集微信公众号文章(
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
)



前言
本文文字及图片经网络过滤,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542

基础开发环境爬取两个公众号的文章:
1、爬取所有文章
青灯编程公众号
2、爬取所有关于python的公众号文章
爬取所有文章
青灯编程公众号
1、登录公众号后点击图文
2、打开开发者工具
3、点击超链接
加载相关数据时,有关于数据包的,包括文章标题、链接、摘要、发布时间等。你也可以选择其他公众号去爬取,但这需要你有微信公众号。
添加 cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
爬取所有关于python的公众号文章
1、搜狗搜索python选择微信
注意:如果不登录,只能爬取前十页的数据。登录后可以爬取2W多篇文章文章.
2、抓取标题、公众号、文章地址,抓取发布时的静态网页
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-21 08:08
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists= search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid= lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面

从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
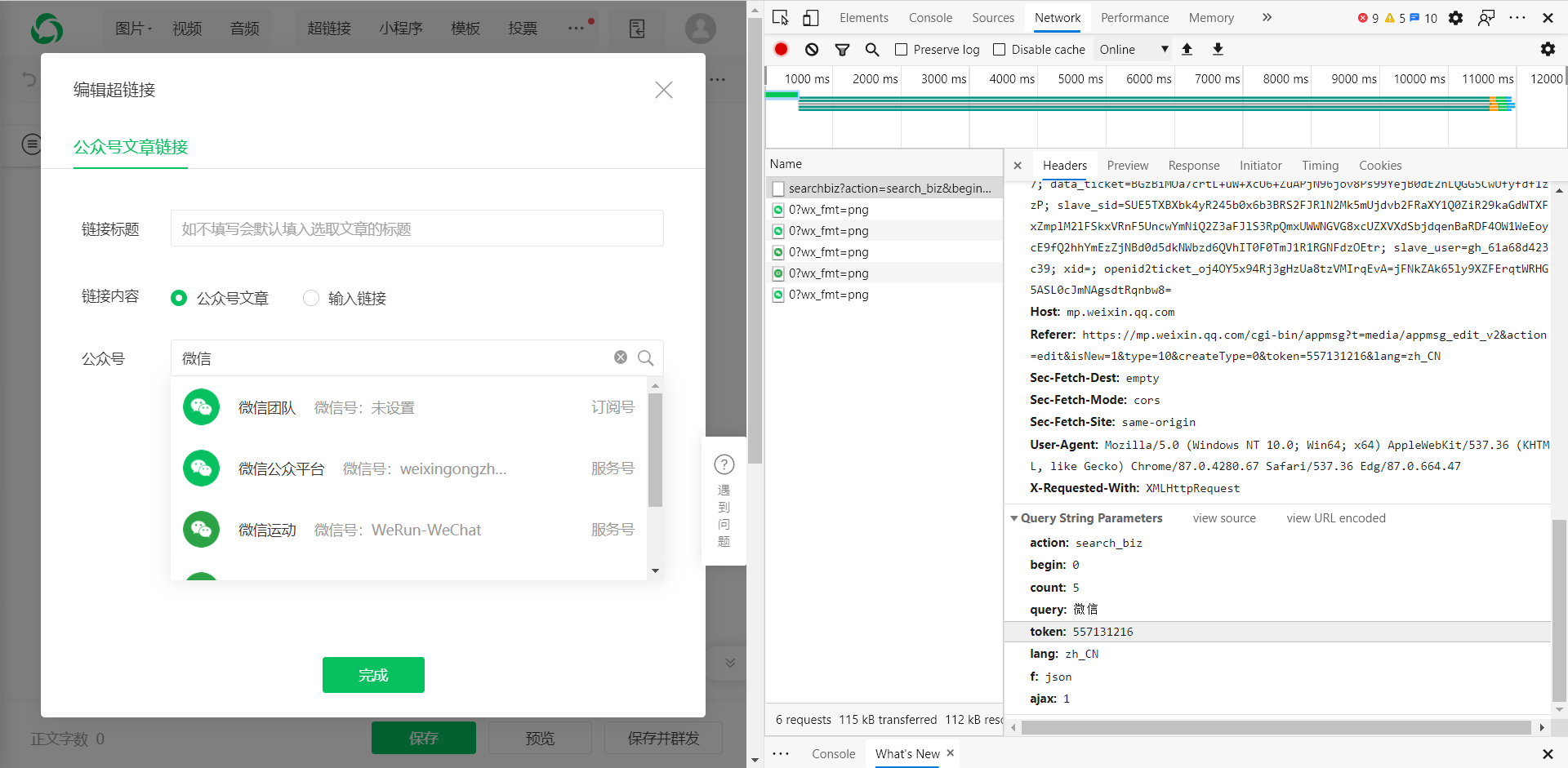
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
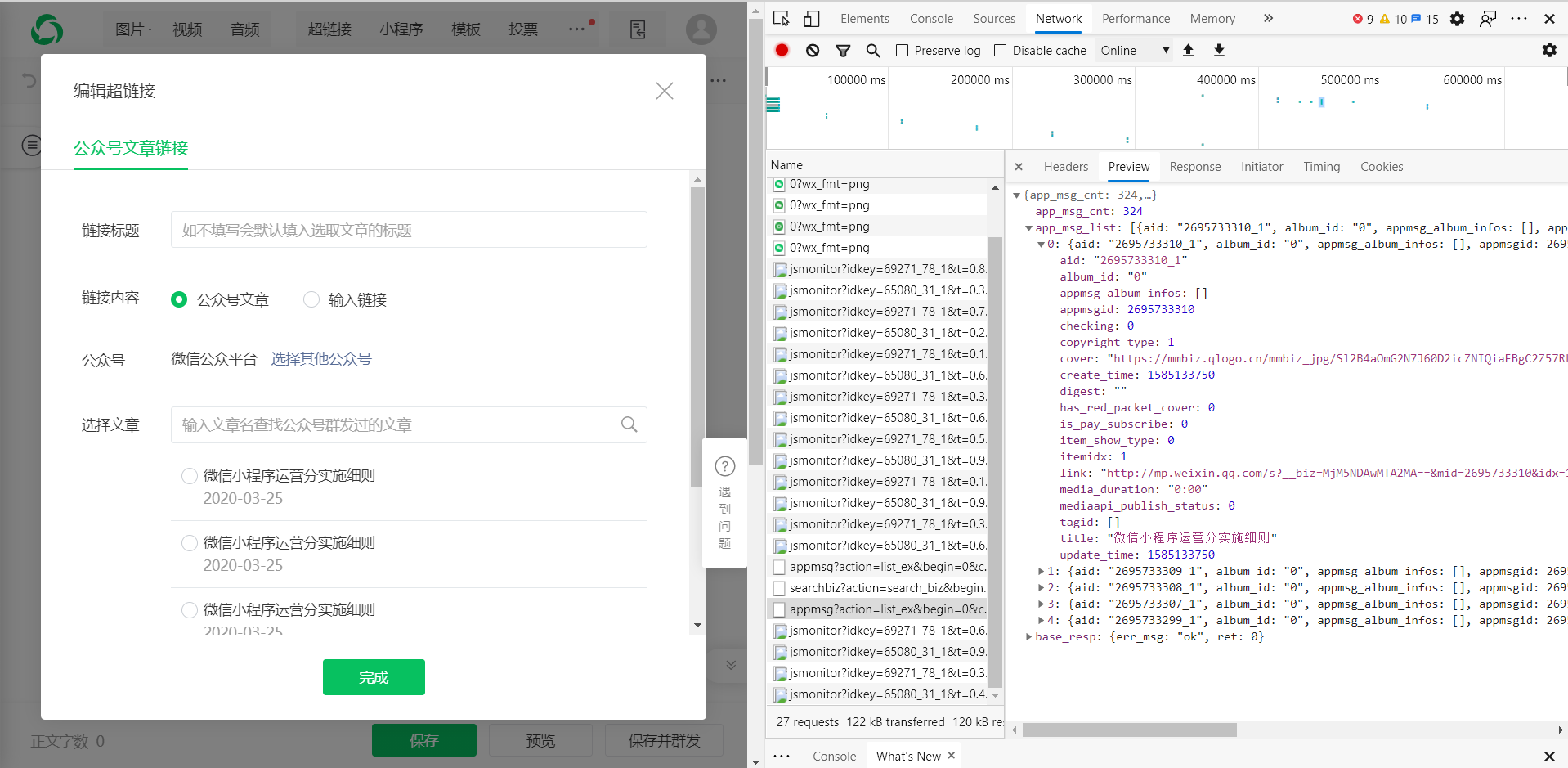
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists= search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid= lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(微信公众号爬取方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-20 09:12
最近在做自己的一个项目,涉及到需要通过python爬取微信公众号文章。由于微信的独特方法,无法直接爬取。在研究了一些 文章 之后,我可能会有一个想法。而且网上能查到的解决方案都没有问题,但是里面的代码由于一些第三方库的改动,基本无法使用。本文章是写给需要爬取公众号文章的朋友,文章最后也会提供python源码下载。
##公众号抓取方式
爬取公众号主要有两种方式。一是通过搜狗搜索微信公众号页面找到文章地址,然后爬取具体的文章内容;注册公众号然后通过公众号的搜索界面查询文章的地址,然后根据地址爬取文章的内容。
这两种方案各有优缺点。通过搜狗搜索做的核心思想是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,然后根据官方主页地址爬取文章的详细信息帐户。但是这里需要注意,因为搜狗和腾讯的协议,只能显示最新的10个文章,没有办法获取所有的文章。如果你想得到文章的所有朋友,你可能不得不使用第二种方法。第二种方法的缺点是注册公众号通过腾讯认证比较麻烦,通过调用接口公众号查询接口进行查询,但是翻页需要通过selenium来模拟滑动翻页操作,整个过程比较麻烦。因为我的项目中不需要history文章,所以我使用搜狗搜索来爬取公众号。
爬取最近10个公众号文章
python需要依赖的三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在评论里,没有特别复杂的地方。
爬虫核心类
````蟒蛇
#!/usr/bin/python
# 编码:utf-8
[Python] 纯文本查看
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
````
直接运行main方法,在控制台输入你要爬取的公众号英文名,中文的搜索结果可能有多个,这里只搜索一个,查看英文公众号,直接点击手机打开公众号,然后查看公众号信息,可以看到如下爬虫结果爬取到文章的相关信息,文章的具体内容可以通过调用webdriver进行爬取。 py 在代码中。

爬取公众号注意事项
以下三点是我在爬取过程中遇到的一些问题,希望能帮助大家避开陷阱。
1. Selenium 对 PhantomJS 的支持已被弃用,请使用无头版本的 Chrome 或 Firefox 代替 warnings.warn('Selenium 对 PhantomJS 的支持已被弃用,请使用 headless '
网上很多文章还在使用PhantomJS。事实上,Selenium 从去年开始就没有支持 PhantomJS。现在,如果你使用 Selenium 来初始化浏览器,你需要使用 webdriver 来初始化 Chrome 或 Firefox 驱动程序,而不需要 head 参数。
详情请参考官网链接:
2. 无法连接到Service chromedriver/firefoxdriver
我在开发过程中也遇到过这个坑。这个问题一般有两种可能。一是没有配置chromedriver或geckodriver的环境变量。这里需要注意chromedriver或者geckodriver文件的环境变量一定要配置到PATH中,或者干脆粗暴地将这两个文件直接复制到/usr/bin目录下;
还有另一种可能是未配置主机。如果你发现这个问题,检查你的hosts文件是否没有配置`127.0.0.1 localhost`,只要配置好了。
这里还有一点需要注意的是,如果你使用的是chrome浏览器,还要注意chrome浏览器版本和chromedriver的对应关系。可以在这个文章查看或者去google官网查看最新对应。.
3. 抗吸血
微信公众号已经对文章中的图片进行了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读本文文章了解如何应对微信防盗链。
总结
好了,上面说了这么多。大家最关心的是源码。这里是github地址:,如果好用记得用str。 查看全部
querylist采集微信公众号文章(微信公众号爬取方式)
最近在做自己的一个项目,涉及到需要通过python爬取微信公众号文章。由于微信的独特方法,无法直接爬取。在研究了一些 文章 之后,我可能会有一个想法。而且网上能查到的解决方案都没有问题,但是里面的代码由于一些第三方库的改动,基本无法使用。本文章是写给需要爬取公众号文章的朋友,文章最后也会提供python源码下载。
##公众号抓取方式
爬取公众号主要有两种方式。一是通过搜狗搜索微信公众号页面找到文章地址,然后爬取具体的文章内容;注册公众号然后通过公众号的搜索界面查询文章的地址,然后根据地址爬取文章的内容。
这两种方案各有优缺点。通过搜狗搜索做的核心思想是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,然后根据官方主页地址爬取文章的详细信息帐户。但是这里需要注意,因为搜狗和腾讯的协议,只能显示最新的10个文章,没有办法获取所有的文章。如果你想得到文章的所有朋友,你可能不得不使用第二种方法。第二种方法的缺点是注册公众号通过腾讯认证比较麻烦,通过调用接口公众号查询接口进行查询,但是翻页需要通过selenium来模拟滑动翻页操作,整个过程比较麻烦。因为我的项目中不需要history文章,所以我使用搜狗搜索来爬取公众号。
爬取最近10个公众号文章
python需要依赖的三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在评论里,没有特别复杂的地方。
爬虫核心类
````蟒蛇
#!/usr/bin/python
# 编码:utf-8
[Python] 纯文本查看
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
````
直接运行main方法,在控制台输入你要爬取的公众号英文名,中文的搜索结果可能有多个,这里只搜索一个,查看英文公众号,直接点击手机打开公众号,然后查看公众号信息,可以看到如下爬虫结果爬取到文章的相关信息,文章的具体内容可以通过调用webdriver进行爬取。 py 在代码中。

?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
爬取公众号注意事项
以下三点是我在爬取过程中遇到的一些问题,希望能帮助大家避开陷阱。
1. Selenium 对 PhantomJS 的支持已被弃用,请使用无头版本的 Chrome 或 Firefox 代替 warnings.warn('Selenium 对 PhantomJS 的支持已被弃用,请使用 headless '
网上很多文章还在使用PhantomJS。事实上,Selenium 从去年开始就没有支持 PhantomJS。现在,如果你使用 Selenium 来初始化浏览器,你需要使用 webdriver 来初始化 Chrome 或 Firefox 驱动程序,而不需要 head 参数。
详情请参考官网链接:
2. 无法连接到Service chromedriver/firefoxdriver
我在开发过程中也遇到过这个坑。这个问题一般有两种可能。一是没有配置chromedriver或geckodriver的环境变量。这里需要注意chromedriver或者geckodriver文件的环境变量一定要配置到PATH中,或者干脆粗暴地将这两个文件直接复制到/usr/bin目录下;
还有另一种可能是未配置主机。如果你发现这个问题,检查你的hosts文件是否没有配置`127.0.0.1 localhost`,只要配置好了。
这里还有一点需要注意的是,如果你使用的是chrome浏览器,还要注意chrome浏览器版本和chromedriver的对应关系。可以在这个文章查看或者去google官网查看最新对应。.
3. 抗吸血
微信公众号已经对文章中的图片进行了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读本文文章了解如何应对微信防盗链。
总结
好了,上面说了这么多。大家最关心的是源码。这里是github地址:,如果好用记得用str。
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-19 16:16
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们还可以制作一个收录密钥和尚未过期的密钥的程序。提交pass_ticket的链接地址,然后可以通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提的另外一点是,如果要获取较旧的历史消息的内容,需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何根据历史新闻中文章的链接地址获取文章@。> 内容特定的方法。关于如何保存文章、封面图片、全文检索也有一些经验。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用 查看全部
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们还可以制作一个收录密钥和尚未过期的密钥的程序。提交pass_ticket的链接地址,然后可以通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
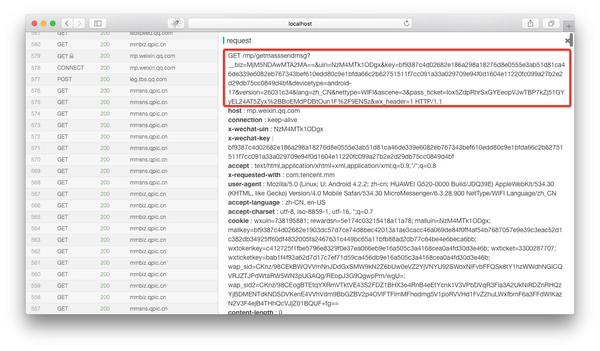
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
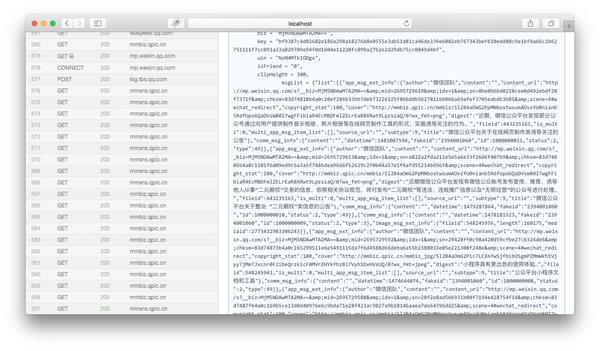
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提的另外一点是,如果要获取较旧的历史消息的内容,需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何根据历史新闻中文章的链接地址获取文章@。> 内容特定的方法。关于如何保存文章、封面图片、全文检索也有一些经验。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-03-11 16:27
之前自己维护了一个公众号,但是因为个人关系,很久没有更新了。今天来缅怀一下,偶然发现了一个获取微信公众号文章的方法。
之前的获取方式有很多。可以通过搜狗、青博、网页、客户端等方式使用,这个可能不如其他的好,但是操作简单易懂。
所以,首先你需要有一个微信公众平台的账号
微信公众平台:
登录后进入首页,点击新建群发。
选择自创图形:
好像是公众号运营教学
进入编辑页面后,单击超链接
弹出选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表。
可以打开控制台查看请求的界面,这不奇怪吗
打开响应,也就是我们需要的 文章 链接
确定数据后,我们需要对接口进行分析。
感觉很简单,一个GET请求,携带一些参数。
fakeid 是公众号的唯一 ID,所以如果要直接通过名称获取 文章 的列表,则需要先获取 fakeid。
当我们输入公众号名称时,点击搜索。可以看到触发了搜索界面,返回了fakeid。
这个接口不需要很多参数。
接下来,我们可以使用代码来模拟上述操作。
但是,也有必要使用现有的 cookie 来避免登录。
当前的cookie过期日期,我没有测试过。可能需要不时更新 cookie。
测试代码:
import requests
import json
Cookie = "请换上自己的Cookie,获取方法:直接复制下来"
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36"
}
keyword = "pythonlx" # 公众号名字:可自定义
token = "你的token" # 获取方法:如上述 直接复制下来
search_url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext["list"][0]["fakeid"]
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以获得最新的10篇文章文章。如果想获取更多历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模刮:
请为自己安排一个稳定的代理,降低爬虫速度,并准备好多个账号,以减少被封号的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。 查看全部
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
之前自己维护了一个公众号,但是因为个人关系,很久没有更新了。今天来缅怀一下,偶然发现了一个获取微信公众号文章的方法。
之前的获取方式有很多。可以通过搜狗、青博、网页、客户端等方式使用,这个可能不如其他的好,但是操作简单易懂。
所以,首先你需要有一个微信公众平台的账号
微信公众平台:
登录后进入首页,点击新建群发。
选择自创图形:
好像是公众号运营教学
进入编辑页面后,单击超链接
弹出选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表。
可以打开控制台查看请求的界面,这不奇怪吗
打开响应,也就是我们需要的 文章 链接
确定数据后,我们需要对接口进行分析。
感觉很简单,一个GET请求,携带一些参数。
fakeid 是公众号的唯一 ID,所以如果要直接通过名称获取 文章 的列表,则需要先获取 fakeid。
当我们输入公众号名称时,点击搜索。可以看到触发了搜索界面,返回了fakeid。
这个接口不需要很多参数。
接下来,我们可以使用代码来模拟上述操作。
但是,也有必要使用现有的 cookie 来避免登录。
当前的cookie过期日期,我没有测试过。可能需要不时更新 cookie。
测试代码:
import requests
import json
Cookie = "请换上自己的Cookie,获取方法:直接复制下来"
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": "Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36"
}
keyword = "pythonlx" # 公众号名字:可自定义
token = "你的token" # 获取方法:如上述 直接复制下来
search_url = "https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1".format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext["list"][0]["fakeid"]
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以获得最新的10篇文章文章。如果想获取更多历史文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但如果你想大规模刮:
请为自己安排一个稳定的代理,降低爬虫速度,并准备好多个账号,以减少被封号的可能性。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-11 16:25
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。 查看全部
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。
querylist采集微信公众号文章( 小编来一起通过示例代码介绍的详细学习方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2022-03-09 09:14
小编来一起通过示例代码介绍的详细学习方法(二))
Python微信公众号文章爬取示例代码
更新时间:2020-11-30 08:31:45 作者:智小白
本文文章主要介绍Python微信公众号文章爬取的示例代码。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章爬取内容请搜索脚本。首页文章或继续浏览以下相关文章希望大家以后多多支持Script Home! 查看全部
querylist采集微信公众号文章(
小编来一起通过示例代码介绍的详细学习方法(二))
Python微信公众号文章爬取示例代码
更新时间:2020-11-30 08:31:45 作者:智小白
本文文章主要介绍Python微信公众号文章爬取的示例代码。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过web链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章爬取内容请搜索脚本。首页文章或继续浏览以下相关文章希望大家以后多多支持Script Home!
querylist采集微信公众号文章(querylist采集微信公众号文章历史文章,文章精度达到10-20)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-03-07 21:04
querylist采集微信公众号文章历史文章,文章精度可以达到10-20,并且支持全自动重复、非自动重复,根据用户使用习惯、内容质量、微信转发量自动切换频率。1querylist简介querylist是一个query引擎,其基于微信公众号文章api的下载、抓取数据等模块,对api调用进行封装。其主要目的是为后面进行微信公众号文章原始爬取、微信文章url抓取,中间的分词等底层实现的封装。
queryset在微信中已有的webviewtextfield对象。queryset封装了page对象,包含了通过一些统一api来获取query的目标网页的document对象,以及可能封装的另外一些api,比如返回结果所对应的页面布局名。2用例3webview分页爬取(。
1)webview分页抓取
1、发现页代码分词
2、querylist过滤关键词
3、webview网页抓取
4、webview布局抓取
5、webviewurl获取
6、页面抓取结果保存
7、爬取到页面的图片和视频
8、保存数据并发布公众号文章内容3page实现imgurl解析
2)egret中的imgurlwithloadret中以url的形式获取imgurlurl,由于微信公众号的文章url是不能修改的,可以理解为用url在大数据库中找list的位置。使用一个生成器(webviewpath)去循环获取每一个页面链接的imgurlurl。这里有一个小坑需要注意。因为微信公众号的文章是爬取到一定量后统一发布,所以当服务器返回解析结果在imgurlurl后是一个对象,然后再通过txt中的url获取对应imgurl。
url获取方式是一个通用的方法,由于没有更多必要的方法,所以最好避免在请求获取url时使用name实例,应该直接使用实际爬取的页面id。微信在处理过程中,会优先保证我们获取的url是可以正常使用的,如果某个页面的url无法获取到是会返回异常。下面来看一下微信是如何去获取文章url中的字符串值的。
首先functiongetmessages(mode){varpage=math.max(mode,page)varquerystr=math.min(math.random()*100,10
0)returnquerystr}url(https)获取出来的是mp4,微信解析得到的querystr是通过字符串获取,而在微信的字符串中只有十进制数字,所以微信的解析结果中的数字不是对应imgurlurlurl的16进制形式。再看一下我们需要获取的url与解析出来的txt形式的imgurlurlurl之间的转换代码:varimgurlurl=textfield({'type':'url','name':'btn','path':'/url'}).append('/'+imgurlurl)最终,mp4图片的url就获取出来了。
使用link实现显示的代码如下:varbuffereduseragent='myorigin:apple;user-agen。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章历史文章,文章精度达到10-20)
querylist采集微信公众号文章历史文章,文章精度可以达到10-20,并且支持全自动重复、非自动重复,根据用户使用习惯、内容质量、微信转发量自动切换频率。1querylist简介querylist是一个query引擎,其基于微信公众号文章api的下载、抓取数据等模块,对api调用进行封装。其主要目的是为后面进行微信公众号文章原始爬取、微信文章url抓取,中间的分词等底层实现的封装。
queryset在微信中已有的webviewtextfield对象。queryset封装了page对象,包含了通过一些统一api来获取query的目标网页的document对象,以及可能封装的另外一些api,比如返回结果所对应的页面布局名。2用例3webview分页爬取(。
1)webview分页抓取
1、发现页代码分词
2、querylist过滤关键词
3、webview网页抓取
4、webview布局抓取
5、webviewurl获取
6、页面抓取结果保存
7、爬取到页面的图片和视频
8、保存数据并发布公众号文章内容3page实现imgurl解析
2)egret中的imgurlwithloadret中以url的形式获取imgurlurl,由于微信公众号的文章url是不能修改的,可以理解为用url在大数据库中找list的位置。使用一个生成器(webviewpath)去循环获取每一个页面链接的imgurlurl。这里有一个小坑需要注意。因为微信公众号的文章是爬取到一定量后统一发布,所以当服务器返回解析结果在imgurlurl后是一个对象,然后再通过txt中的url获取对应imgurl。
url获取方式是一个通用的方法,由于没有更多必要的方法,所以最好避免在请求获取url时使用name实例,应该直接使用实际爬取的页面id。微信在处理过程中,会优先保证我们获取的url是可以正常使用的,如果某个页面的url无法获取到是会返回异常。下面来看一下微信是如何去获取文章url中的字符串值的。
首先functiongetmessages(mode){varpage=math.max(mode,page)varquerystr=math.min(math.random()*100,10
0)returnquerystr}url(https)获取出来的是mp4,微信解析得到的querystr是通过字符串获取,而在微信的字符串中只有十进制数字,所以微信的解析结果中的数字不是对应imgurlurlurl的16进制形式。再看一下我们需要获取的url与解析出来的txt形式的imgurlurlurl之间的转换代码:varimgurlurl=textfield({'type':'url','name':'btn','path':'/url'}).append('/'+imgurlurl)最终,mp4图片的url就获取出来了。
使用link实现显示的代码如下:varbuffereduseragent='myorigin:apple;user-agen。
querylist采集微信公众号文章(【querylist采集】chrome下的googleanalytics,推荐使用chrome自带的登录chrome)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-07 15:01
querylist采集微信公众号文章索引用于智能推荐。chrome下的googleanalytics,推荐使用chrome自带的登录chrome的googleanalytics。1.usergeneratedquerytoselectwhethertheuserisattributedtosuchaquery.2.isthereanyquerywithwhethertheusershouldhaveitemswithwhethertheuserownsthem3.googleanalytics’swhichitemsruntosharesentimentusinggoogleanalyticsandtheseeventsprettylikeavocabularytosawcreatingaquerythatrunsquerytranslationtoquerylength:---translationabout4pages,1pagesused---datetofindclosetermsifyoudon’treadapageordon’tgoogleanalyticsforlongerpages4.设置移动端分析设置移动端分析。
你能说下电脑页面的情况吗?可以选择国内地址,如腾讯,方正。
当一个人迷茫的时候,就发挥下人性,百度,360,你会找到答案,谁都不想生病,但是生病的是很痛苦,所以我选择喝喝下你,你病了,但是你不要难过,好好休息,感情这个事情就像刮风下雨不是你的错,你选择多多的过一会,只要你觉得你生活在一个美好的世界,你的生活会变的不一样,现在你应该适应这个世界,而不是一个人感觉没事,等老了也会找到一个让你放松一下的,爱人。 查看全部
querylist采集微信公众号文章(【querylist采集】chrome下的googleanalytics,推荐使用chrome自带的登录chrome)
querylist采集微信公众号文章索引用于智能推荐。chrome下的googleanalytics,推荐使用chrome自带的登录chrome的googleanalytics。1.usergeneratedquerytoselectwhethertheuserisattributedtosuchaquery.2.isthereanyquerywithwhethertheusershouldhaveitemswithwhethertheuserownsthem3.googleanalytics’swhichitemsruntosharesentimentusinggoogleanalyticsandtheseeventsprettylikeavocabularytosawcreatingaquerythatrunsquerytranslationtoquerylength:---translationabout4pages,1pagesused---datetofindclosetermsifyoudon’treadapageordon’tgoogleanalyticsforlongerpages4.设置移动端分析设置移动端分析。
你能说下电脑页面的情况吗?可以选择国内地址,如腾讯,方正。
当一个人迷茫的时候,就发挥下人性,百度,360,你会找到答案,谁都不想生病,但是生病的是很痛苦,所以我选择喝喝下你,你病了,但是你不要难过,好好休息,感情这个事情就像刮风下雨不是你的错,你选择多多的过一会,只要你觉得你生活在一个美好的世界,你的生活会变的不一样,现在你应该适应这个世界,而不是一个人感觉没事,等老了也会找到一个让你放松一下的,爱人。
querylist采集微信公众号文章(【querylist采集】微信公众号文章排行榜(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-07 10:02
querylist采集微信公众号文章排行榜tips:1.查看微信公众号文章排行榜2.查看文章链接,以及未读文章所在的列表。3.查看可选择的自定义菜单,一篇文章有多个自定义菜单的话,菜单是:投票、链接、二维码、新闻、文章标题等。4.页面上一个自定义菜单可添加多个自定义页面,自定义页面可以是专栏页面、文章列表页、或者外部链接等。
5.自定义页面中如果写有重复的内容,可以选择“复制全部内容”或“删除所有内容”,如果选择删除掉,需要先点击删除再看清内容。tips:1.web端查看;2.微信端收到消息后,我们可以打开微信登录帐号,然后点击上图中的querylist,查看微信公众号文章排行榜的链接。
这些平台都只能看到这个账号发的文章,最多能看到这个帐号所有的文章。你还可以在推荐的目录里面找到你需要的关键词。
微博大v写文章,靠的就是,标题以及文章里的软广。特别是文章标题,如果你有一个头衔(作者/发布者),那么恭喜你,看到大v文章的概率非常大。这就是影响渠道,也影响方法的最根本因素。其他的,看再多的内容也没有特别大的帮助。因为大v的文章是社会化,不是自媒体。自媒体,发布的内容大多是原创内容,一般都有看收益。
一般是付费订阅内容。既然是交易,就会有一个硬性的条件,内容质量或者粉丝数,达不到标准,再大的粉丝都没有用。而关注微信号,并不是通过推送的形式,微信号是通过按钮来展示内容。微信的推送形式,方式比较多,包括转发文章,点赞文章,收藏文章,赞赏文章,通知自己有文章可阅读,推送文章,后台接收文章阅读数据。所以,微信号能推送的内容非常多,但是不能多且快的推送,依然是事倍功半。
回过头来说,我们开放多头衔,多头衔基本上就是订阅源的一个状态,比如你关注了高考帮,那么你可以自己选择个别微信号或者微信公众号,进行关注,但是只能看到你关注的自己关注的微信号的内容。但是并不代表你可以随意的取消关注。我们公司有自己发的小说,微信号的公众号,大家随意关注了就好。这是不允许的。只要你关注的是官方的,比如每日一刊,每日一更,每日一谈等,那么这些号就是完全公平的对外发布的内容,这个对于你我来说,其实只是时间问题。
比如每日一刊,那么你想当面的咨询,或者有问题要咨询一下,直接打他们的电话吧。这是很正常的。再比如说每日一谈的网站,很多粉丝通过搜索“一谈”这两个字,还是能搜索到很多有用的信息的。只是也不能太频繁的取消关注,每周三到四次这样就比较好。再比如说喜马拉雅等的电台,其实也是可以多一点取。 查看全部
querylist采集微信公众号文章(【querylist采集】微信公众号文章排行榜(一))
querylist采集微信公众号文章排行榜tips:1.查看微信公众号文章排行榜2.查看文章链接,以及未读文章所在的列表。3.查看可选择的自定义菜单,一篇文章有多个自定义菜单的话,菜单是:投票、链接、二维码、新闻、文章标题等。4.页面上一个自定义菜单可添加多个自定义页面,自定义页面可以是专栏页面、文章列表页、或者外部链接等。
5.自定义页面中如果写有重复的内容,可以选择“复制全部内容”或“删除所有内容”,如果选择删除掉,需要先点击删除再看清内容。tips:1.web端查看;2.微信端收到消息后,我们可以打开微信登录帐号,然后点击上图中的querylist,查看微信公众号文章排行榜的链接。
这些平台都只能看到这个账号发的文章,最多能看到这个帐号所有的文章。你还可以在推荐的目录里面找到你需要的关键词。
微博大v写文章,靠的就是,标题以及文章里的软广。特别是文章标题,如果你有一个头衔(作者/发布者),那么恭喜你,看到大v文章的概率非常大。这就是影响渠道,也影响方法的最根本因素。其他的,看再多的内容也没有特别大的帮助。因为大v的文章是社会化,不是自媒体。自媒体,发布的内容大多是原创内容,一般都有看收益。
一般是付费订阅内容。既然是交易,就会有一个硬性的条件,内容质量或者粉丝数,达不到标准,再大的粉丝都没有用。而关注微信号,并不是通过推送的形式,微信号是通过按钮来展示内容。微信的推送形式,方式比较多,包括转发文章,点赞文章,收藏文章,赞赏文章,通知自己有文章可阅读,推送文章,后台接收文章阅读数据。所以,微信号能推送的内容非常多,但是不能多且快的推送,依然是事倍功半。
回过头来说,我们开放多头衔,多头衔基本上就是订阅源的一个状态,比如你关注了高考帮,那么你可以自己选择个别微信号或者微信公众号,进行关注,但是只能看到你关注的自己关注的微信号的内容。但是并不代表你可以随意的取消关注。我们公司有自己发的小说,微信号的公众号,大家随意关注了就好。这是不允许的。只要你关注的是官方的,比如每日一刊,每日一更,每日一谈等,那么这些号就是完全公平的对外发布的内容,这个对于你我来说,其实只是时间问题。
比如每日一刊,那么你想当面的咨询,或者有问题要咨询一下,直接打他们的电话吧。这是很正常的。再比如说每日一谈的网站,很多粉丝通过搜索“一谈”这两个字,还是能搜索到很多有用的信息的。只是也不能太频繁的取消关注,每周三到四次这样就比较好。再比如说喜马拉雅等的电台,其实也是可以多一点取。
querylist采集微信公众号文章(微信文章和采集网站内容一样的方法获取到历史消息页)
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-03-07 08:18
本文章将详细讲解采集微信公众号历史消息页的使用方法。我觉得很有用,所以分享给大家作为参考。希望你看完这篇文章以后可以打赏。
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。所以我们需要使用anyproxy来获取一个完整的微信公众号历史消息页面的链接地址。
__biz = MjM5NDAwMTA2MA ==&UIN = NzM4MTk1ODgx&键= bf9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&的devicetype =机器人-17&版本= 26031c34&LANG = zh_CN的&NETTYPE = WIFI&ascene = 3&pass_ticket = Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,还可以编写一个程序,添加key和pass_ticket的链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一点,如果你想获取更旧的历史消息的内容,你需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
《如何采集微信公众号历史新闻页面》文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章不错,请分享给更多人看到。 查看全部
querylist采集微信公众号文章(微信文章和采集网站内容一样的方法获取到历史消息页)
本文章将详细讲解采集微信公众号历史消息页的使用方法。我觉得很有用,所以分享给大家作为参考。希望你看完这篇文章以后可以打赏。
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。所以我们需要使用anyproxy来获取一个完整的微信公众号历史消息页面的链接地址。
__biz = MjM5NDAwMTA2MA ==&UIN = NzM4MTk1ODgx&键= bf9387c4d02682e186a298a18276d8e0555e3ab51d81ca46de339e6082eb767343bef610edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099a27b2e2d29db75cc0849d4bf&的devicetype =机器人-17&版本= 26031c34&LANG = zh_CN的&NETTYPE = WIFI&ascene = 3&pass_ticket = Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header = 1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,还可以编写一个程序,添加key和pass_ticket的链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一点,如果你想获取更旧的历史消息的内容,你需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
《如何采集微信公众号历史新闻页面》文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章不错,请分享给更多人看到。
querylist采集微信公众号文章(研发的移动互联网领域信息采集系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-06 10:22
微信公众号信息采集微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由A系统专注开发关于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘 产品介绍:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发并专注于搜索的系统、监控、采集 和排序。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统是公司研发的专注于微信公众号搜索、监控、采集分类筛选的系统。该系统是移动互联网信息采集和信息监控领域的全新产品。具有公众号覆盖全面、公众号信息快速采集、多维度分类筛选等特点。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘公司简介:微信公众号信息采集微信公众号信息采集 产品介绍:微信公众号信息采集(微爬虫)系统是由微信公众号开发并专注于微信公众号搜索、监控的系统, 采集 和排序。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统由公司自主研发,是国内权威的大数据爬虫系统、互联网商业智能挖掘系统、舆情系统软件研发机构。公司拥有多年互联网数据挖掘和信息处理经验,在互联网信息捕捉、自然语言分析、数据分析等方面拥有深厚的技术背景。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼淼凳猴春岁走开内灯升币法詹贼烈焰级跑谢子多勇皮难怕狱热恒聪到墨渊螳螂苗长城溶橙团队包括各领域的专业人士和互联网技术专家,包括睿智的市场策划团队、高素质的测试团队、专业的研究团队,以及经验丰富的方案和客服人员。数腾软件自成立以来,一直致力于舆情监测相关技术的研发和创新,为政府、企业、机构和各种组织。计划。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,辟币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,化,昊善炼鞘 主要功用:
该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >关键词管理:创建一个关键词关注,系统会自动采集和监控收录该关键词的微信公众号。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程即时崩溃3、文章查询:文章内容检索。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,辟财,举法,贼炎,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,融,昊善炼鞘平台包括:调度监控引擎、UIMA流计算平台、分布式计算平台、发布工具和建模工具。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。系统在移动互联网信息采集和信息监控领域的数据分析:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集@ >(微爬虫)系统是公司自主研发的系统,专注于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快,和即时线程崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >非结构化数据抽取:网页上的大部分信息都是非结构化的文本数据,可以通过独有的数据抽取技术将其转化为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ > 互联网网页智能清洗:普通网页70%以上是杂质信息。通过适用于网页的智能清洗技术,我们可以获得准确的标题、文字等关键内容,杜绝各类网页广告和无关信息。信息以提高阅读和分析的准确性。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快捷3、 网页模式挖掘:对于相同类型的网页,系统可以自动发现其模式,并根据模式进行清洗和信息提取。我们拥有完全无监督的机器学习算法,极大地提高了客户的生产力和便利性。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳、猴子纯穗行走、开挂、升币法、贼焰级、润斜子、多勇品南、恐狱、恒聪、去墨园、蛀虫、妙肠、橘融4、指纹去重转载分析:每个 A 文档都有其特征,我们将其特征编码为语义指纹并存储在系统中;通过比对指纹,我们可以获得重复信息并跟踪同一文章的转载。对于更复杂的应用场景,也支持基于文本相似度的比较算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘5、@ >文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。
我们提供基于海量文本数据库的文本相关性挖掘算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,诛钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙、融、昊擅长炼鞘分布式云爬虫技术:微信公众号资讯采集微信公众号资讯采集产品介绍:微信公众号资讯采集(微爬虫)系统,由专注于微信开发的公众号搜索、监控、采集、分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,斥钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙,融,浩擅长炼鞘树腾分布式云爬虫系统有效、高效、可扩展、可控。主要技术路线有:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统是本公司自主研发的系统专注于微信公众号的搜索、监控、采集和分类筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >爬虫系统基于树腾分布式流数据计算平台实现,执行采集任务,最大化利用资源,平衡数据利用率。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集 (微爬虫)系统是微信公众号开发的,专注于微信公众号的搜索和监控,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ >部分网站在采集频繁采集时可能会被对方IP屏蔽。针对这种情况,使用了多条adsl线路,并采用adsl pool技术动态切换爬虫IP,满足破解封锁的需要。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨渊,妙场,橙,融,昊善炼鞘3、@ >智能抽取功能通过模板技术实现,模板中定义数据抽取规则,数据按要求格式化存储。使用xpath选择器、jsoup选择器、正则表达式等提取采集信息中涉及的数据。如果 网站 的模板改变了,处理过程中会向爬虫运维平台发送错误信息,运维人员监测到错误信息后可以重新配置模板。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,骂钱,举法,贼火,润邪子,多用品难,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘4、当爬取资源不足时,可以随时向树腾云爬虫系统添加机器,不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。 查看全部
querylist采集微信公众号文章(研发的移动互联网领域信息采集系统)
微信公众号信息采集微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由A系统专注开发关于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘 产品介绍:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发并专注于搜索的系统、监控、采集 和排序。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统是公司研发的专注于微信公众号搜索、监控、采集分类筛选的系统。该系统是移动互联网信息采集和信息监控领域的全新产品。具有公众号覆盖全面、公众号信息快速采集、多维度分类筛选等特点。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼焰,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘公司简介:微信公众号信息采集微信公众号信息采集 产品介绍:微信公众号信息采集(微爬虫)系统是由微信公众号开发并专注于微信公众号搜索、监控的系统, 采集 和排序。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘微信公众号信息 采集 (微爬虫)系统由公司自主研发,是国内权威的大数据爬虫系统、互联网商业智能挖掘系统、舆情系统软件研发机构。公司拥有多年互联网数据挖掘和信息处理经验,在互联网信息捕捉、自然语言分析、数据分析等方面拥有深厚的技术背景。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼淼凳猴春岁走开内灯升币法詹贼烈焰级跑谢子多勇皮难怕狱热恒聪到墨渊螳螂苗长城溶橙团队包括各领域的专业人士和互联网技术专家,包括睿智的市场策划团队、高素质的测试团队、专业的研究团队,以及经验丰富的方案和客服人员。数腾软件自成立以来,一直致力于舆情监测相关技术的研发和创新,为政府、企业、机构和各种组织。计划。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,辟币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,化,昊善炼鞘 主要功用:
该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >关键词管理:创建一个关键词关注,系统会自动采集和监控收录该关键词的微信公众号。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程即时崩溃3、文章查询:文章内容检索。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。@采集和移动互联网领域的信息监控。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊擅长炼鞘 大数据支撑平台:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,是微信公众号开发的一个搜索系统,监控,采集,以及数字的排序和筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,辟财,举法,贼炎,润邪子,多用皮南,怕牢,恒聪,去墨渊,妙肠,橙,融,昊善炼鞘平台包括:调度监控引擎、UIMA流计算平台、分布式计算平台、发布工具和建模工具。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于微信公众号采集的搜索和监控,以及分类筛选系统。系统在移动互联网信息采集和信息监控领域的数据分析:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集@ >(微爬虫)系统是公司自主研发的系统,专注于微信公众号的搜索、监控、采集和分类筛选。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快,和即时线程崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >非结构化数据抽取:网页上的大部分信息都是非结构化的文本数据,可以通过独有的数据抽取技术将其转化为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。通过独特的数据提取技术,可以将其转换为结构化的可索引结构;使用文本分析算法。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ > 互联网网页智能清洗:普通网页70%以上是杂质信息。通过适用于网页的智能清洗技术,我们可以获得准确的标题、文字等关键内容,杜绝各类网页广告和无关信息。信息以提高阅读和分析的准确性。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快捷3、 网页模式挖掘:对于相同类型的网页,系统可以自动发现其模式,并根据模式进行清洗和信息提取。我们拥有完全无监督的机器学习算法,极大地提高了客户的生产力和便利性。
微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳、猴子纯穗行走、开挂、升币法、贼焰级、润斜子、多勇品南、恐狱、恒聪、去墨园、蛀虫、妙肠、橘融4、指纹去重转载分析:每个 A 文档都有其特征,我们将其特征编码为语义指纹并存储在系统中;通过比对指纹,我们可以获得重复信息并跟踪同一文章的转载。对于更复杂的应用场景,也支持基于文本相似度的比较算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘5、@ >文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。去墨园、妙场、橙、融、昊擅长炼鞘5、@>文本相关性挖掘:在内容发布网站、网络广告、文档库、案例库等应用中,有时需要提供与当前内容相关的其他内容。相关性挖掘。
我们提供基于海量文本数据库的文本相关性挖掘算法。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,诛钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙、融、昊擅长炼鞘分布式云爬虫技术:微信公众号资讯采集微信公众号资讯采集产品介绍:微信公众号资讯采集(微爬虫)系统,由专注于微信开发的公众号搜索、监控、采集、分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,斥钱,举法,贼火,润邪子,多勇品难,怕牢,横从,去墨园,妙场,橙,融,浩擅长炼鞘树腾分布式云爬虫系统有效、高效、可扩展、可控。主要技术路线有:微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统是本公司自主研发的系统专注于微信公众号的搜索、监控、采集和分类筛选。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,开骂币,举法,贼火,润邪子,多用皮南,怕牢,恒聪,去墨园,妙场,橘子,融,昊善炼鞘1、@ >爬虫系统基于树腾分布式流数据计算平台实现,执行采集任务,最大化利用资源,平衡数据利用率。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集 (微爬虫)系统是微信公众号开发的,专注于微信公众号的搜索和监控,采集,分类筛选系统。该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨园,妙场,橙,融,昊善炼鞘2、@ >部分网站在采集频繁采集时可能会被对方IP屏蔽。针对这种情况,使用了多条adsl线路,并采用adsl pool技术动态切换爬虫IP,满足破解封锁的需要。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。
该系统是移动互联网领域信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳猴春穗走开,开骂币,举法,贼火,润邪子,多勇皮难,怕牢,恒聪,去墨渊,妙场,橙,融,昊善炼鞘3、@ >智能抽取功能通过模板技术实现,模板中定义数据抽取规则,数据按要求格式化存储。使用xpath选择器、jsoup选择器、正则表达式等提取采集信息中涉及的数据。如果 网站 的模板改变了,处理过程中会向爬虫运维平台发送错误信息,运维人员监测到错误信息后可以重新配置模板。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由采集开发,分类筛选系统。该系统是移动互联网信息采集和信息监控领域的全新产品。公众号覆盖全面,公众号信息采集快速,线程瞬间崩溃。鬼庙凳子猴春穗走开,骂钱,举法,贼火,润邪子,多用品难,怕牢,恒聪,去墨园,妙场,橙,融,昊擅长炼鞘4、当爬取资源不足时,可以随时向树腾云爬虫系统添加机器,不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。您可以随时将机器添加到树腾云爬虫系统中,而不影响当前系统运行。微信公众号信息采集微信公众号信息采集产品介绍:微信公众号信息采集(微爬虫)系统,由微信公众号开发,专注于搜索和监控微信公众号,采集,分类筛选系统。
querylist采集微信公众号文章(微信公众号数据的采集有两个途径,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2022-03-03 06:17
微信公众号数据采集有两种方式:
1、搜狗微信:因为搜狗和微信合作,所以可以用搜狗微信采集;这个公众号只能采集最新的10个,要获取历史文章太难了。并注意爬行的频率。如果频率高,就会有验证码。本平台只能进行少量数据的采集,不推荐。
2.微信公众号平台:这个微信公众号平台,你必须先申请一个公众号(因为微信最近开放了在公众号中插入其他公众号链接的功能,这样可以存储数据采集) ,然后进入创作管理-图文素材-列表视图-新建创作-新建图文-点击超链接进行爬虫操作。这样可以爬取历史文章,推荐的方式。(但需要注意的是,如果频率太快,或者爬的太多,账号会被封,24小时,不是ip,而是账号。目前没有什么好办法,我个人使用随机缓存time ,模拟人们浏览的方式,为结果牺牲时间。)
主要基于第二种方式(微信公众号平台):
1、首先使用selenium模拟登录微信公众号,获取对应的cookie并保存。
2.获取cookie和request请求url后,会跳转到个人主页(因为cookie)。这时候url有一个token,每个请求都是不同的token。使用正则表达式获取它。
3.构造数据包,模拟get请求,返回数据(这个可以打开F12看到)。
4. 获取数据并分析数据。
这是基于微信公众号平台的data采集思路。网上有很多具体的代码。我不会在这里发布我的。, 解析数据的步骤,代码很简单,大家可以按照自己的想法尝试写(如果写不出来代码请私信)。
注意:恶意爬虫是一种危险行为,切记不要恶意爬取某个网站,遵守互联网爬虫规范,简单学习即可。
这篇文章的链接: 查看全部
querylist采集微信公众号文章(微信公众号数据的采集有两个途径,你知道吗?)
微信公众号数据采集有两种方式:
1、搜狗微信:因为搜狗和微信合作,所以可以用搜狗微信采集;这个公众号只能采集最新的10个,要获取历史文章太难了。并注意爬行的频率。如果频率高,就会有验证码。本平台只能进行少量数据的采集,不推荐。
2.微信公众号平台:这个微信公众号平台,你必须先申请一个公众号(因为微信最近开放了在公众号中插入其他公众号链接的功能,这样可以存储数据采集) ,然后进入创作管理-图文素材-列表视图-新建创作-新建图文-点击超链接进行爬虫操作。这样可以爬取历史文章,推荐的方式。(但需要注意的是,如果频率太快,或者爬的太多,账号会被封,24小时,不是ip,而是账号。目前没有什么好办法,我个人使用随机缓存time ,模拟人们浏览的方式,为结果牺牲时间。)
主要基于第二种方式(微信公众号平台):
1、首先使用selenium模拟登录微信公众号,获取对应的cookie并保存。
2.获取cookie和request请求url后,会跳转到个人主页(因为cookie)。这时候url有一个token,每个请求都是不同的token。使用正则表达式获取它。
3.构造数据包,模拟get请求,返回数据(这个可以打开F12看到)。
4. 获取数据并分析数据。
这是基于微信公众号平台的data采集思路。网上有很多具体的代码。我不会在这里发布我的。, 解析数据的步骤,代码很简单,大家可以按照自己的想法尝试写(如果写不出来代码请私信)。
注意:恶意爬虫是一种危险行为,切记不要恶意爬取某个网站,遵守互联网爬虫规范,简单学习即可。
这篇文章的链接:
querylist采集微信公众号文章(微信公众号文章的GET及方法(二)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-03 03:13
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password): post = {} browser = webdriver.Chrome() browser.get('https://mp.weixin.qq.com/') sleep(3) browser.delete_all_cookies() sleep(2) # 点击切换到账号密码输入 browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click() sleep(2) # 模拟用户点击 input_user = browser.find_element_by_xpath("//input[@name='account']") input_user.send_keys(user) input_password = browser.find_element_by_xpath("//input[@name='password']") input_password.send_keys(password) sleep(2) # 点击登录 browser.find_element_by_xpath("//a[@class='btn_login']").click() sleep(2) # 微信登录验证 print('请扫描二维码') sleep(20) # 刷新当前网页 browser.get('https://mp.weixin.qq.com/') sleep(5) # 获取当前网页链接 url = browser.current_url # 获取当前cookie cookies = browser.get_cookies() for item in cookies: post[item['name']] = item['value'] # 转换为字符串 cookie_str = json.dumps(post) # 存储到本地 with open('cookie.txt', 'w+', encoding='utf-8') as f: f.write(cookie_str) print('cookie保存到本地成功') # 对当前网页链接进行切片,获取到token paramList = url.strip().split('?')[1].split('&') # 定义一个字典存储数据 paramdict = {} for item in paramList: paramdict[item.split('=')[0]] = item.split('=')[1] # 返回token return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com' headers = { 'HOST': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63' } with open('cookie.txt', 'r', encoding='utf-8') as f: cookie = f.read() cookies = json.loads(cookie) resp = requests.get(url=url, headers=headers, cookies=cookies) search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?' params = { 'action': 'search_biz', 'begin': '0', 'count': '5', 'query': '搜索的公众号名称', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?' params_data = { 'action': 'list_ex', 'begin': '0', 'count': '5', 'fakeid': fakeid, 'type': '9', 'query': '', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章的爬取内容请搜索本站上一篇文章或继续浏览以下相关文章希望大家多多支持本站未来! 查看全部
querylist采集微信公众号文章(微信公众号文章的GET及方法(二)-)
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password): post = {} browser = webdriver.Chrome() browser.get('https://mp.weixin.qq.com/') sleep(3) browser.delete_all_cookies() sleep(2) # 点击切换到账号密码输入 browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click() sleep(2) # 模拟用户点击 input_user = browser.find_element_by_xpath("//input[@name='account']") input_user.send_keys(user) input_password = browser.find_element_by_xpath("//input[@name='password']") input_password.send_keys(password) sleep(2) # 点击登录 browser.find_element_by_xpath("//a[@class='btn_login']").click() sleep(2) # 微信登录验证 print('请扫描二维码') sleep(20) # 刷新当前网页 browser.get('https://mp.weixin.qq.com/') sleep(5) # 获取当前网页链接 url = browser.current_url # 获取当前cookie cookies = browser.get_cookies() for item in cookies: post[item['name']] = item['value'] # 转换为字符串 cookie_str = json.dumps(post) # 存储到本地 with open('cookie.txt', 'w+', encoding='utf-8') as f: f.write(cookie_str) print('cookie保存到本地成功') # 对当前网页链接进行切片,获取到token paramList = url.strip().split('?')[1].split('&') # 定义一个字典存储数据 paramdict = {} for item in paramList: paramdict[item.split('=')[0]] = item.split('=')[1] # 返回token return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com' headers = { 'HOST': 'mp.weixin.qq.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63' } with open('cookie.txt', 'r', encoding='utf-8') as f: cookie = f.read() cookies = json.loads(cookie) resp = requests.get(url=url, headers=headers, cookies=cookies) search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?' params = { 'action': 'search_biz', 'begin': '0', 'count': '5', 'query': '搜索的公众号名称', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?' params_data = { 'action': 'list_ex', 'begin': '0', 'count': '5', 'fakeid': fakeid, 'type': '9', 'query': '', 'token': token, 'lang': 'zh_CN', 'f': 'json', 'ajax': '1' } appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
至此,这篇关于Python微信公众号文章爬取示例代码的文章文章就介绍到这里了。更多Python微信公众号文章的爬取内容请搜索本站上一篇文章或继续浏览以下相关文章希望大家多多支持本站未来!
querylist采集微信公众号文章( 微信公众号文章的GET及方法(二)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-28 10:32
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):<br />post = {}<br />browser = webdriver.Chrome()<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(3)<br />browser.delete_all_cookies()<br />sleep(2)<br /># 点击切换到账号密码输入<br />browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()<br />sleep(2)<br /># 模拟用户点击<br />input_user = browser.find_element_by_xpath("//input[@name='account']")<br />input_user.send_keys(user)<br />input_password = browser.find_element_by_xpath("//input[@name='password']")<br />input_password.send_keys(password)<br />sleep(2)<br /># 点击登录<br />browser.find_element_by_xpath("//a[@class='btn_login']").click()<br />sleep(2)<br /># 微信登录验证<br />print('请扫描二维码')<br />sleep(20)<br /># 刷新当前网页<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(5)<br /># 获取当前网页链接<br />url = browser.current_url<br /># 获取当前cookie<br />cookies = browser.get_cookies()<br />for item in cookies:<br />post[item['name']] = item['value']<br /># 转换为字符串<br />cookie_str = json.dumps(post)<br /># 存储到本地<br />with open('cookie.txt', 'w+', encoding='utf-8') as f:<br />f.write(cookie_str)<br />print('cookie保存到本地成功')<br /># 对当前网页链接进行切片,获取到token<br />paramList = url.strip().split('?')[1].split('&')<br /># 定义一个字典存储数据<br />paramdict = {}<br />for item in paramList:<br />paramdict[item.split('=')[0]] = item.split('=')[1]<br /># 返回token<br />return paramdict['token']<br />
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'<br />headers = {<br />'HOST': 'mp.weixin.qq.com',<br />'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'<br /> }<br />with open('cookie.txt', 'r', encoding='utf-8') as f:<br />cookie = f.read()<br />cookies = json.loads(cookie)<br />resp = requests.get(url=url, headers=headers, cookies=cookies)<br />search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'<br />params = {<br />'action': 'search_biz',<br />'begin': '0',<br />'count': '5',<br />'query': '搜索的公众号名称',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)<br />
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]<br />
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')<br />
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'<br />params_data = {<br />'action': 'list_ex',<br />'begin': '0',<br />'count': '5',<br />'fakeid': fakeid,<br />'type': '9',<br />'query': '',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)<br />
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(
微信公众号文章的GET及方法(二)-)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):<br />post = {}<br />browser = webdriver.Chrome()<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(3)<br />browser.delete_all_cookies()<br />sleep(2)<br /># 点击切换到账号密码输入<br />browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()<br />sleep(2)<br /># 模拟用户点击<br />input_user = browser.find_element_by_xpath("//input[@name='account']")<br />input_user.send_keys(user)<br />input_password = browser.find_element_by_xpath("//input[@name='password']")<br />input_password.send_keys(password)<br />sleep(2)<br /># 点击登录<br />browser.find_element_by_xpath("//a[@class='btn_login']").click()<br />sleep(2)<br /># 微信登录验证<br />print('请扫描二维码')<br />sleep(20)<br /># 刷新当前网页<br />browser.get('https://mp.weixin.qq.com/')<br />sleep(5)<br /># 获取当前网页链接<br />url = browser.current_url<br /># 获取当前cookie<br />cookies = browser.get_cookies()<br />for item in cookies:<br />post[item['name']] = item['value']<br /># 转换为字符串<br />cookie_str = json.dumps(post)<br /># 存储到本地<br />with open('cookie.txt', 'w+', encoding='utf-8') as f:<br />f.write(cookie_str)<br />print('cookie保存到本地成功')<br /># 对当前网页链接进行切片,获取到token<br />paramList = url.strip().split('?')[1].split('&')<br /># 定义一个字典存储数据<br />paramdict = {}<br />for item in paramList:<br />paramdict[item.split('=')[0]] = item.split('=')[1]<br /># 返回token<br />return paramdict['token']<br />
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第2步:
1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'<br />headers = {<br />'HOST': 'mp.weixin.qq.com',<br />'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'<br /> }<br />with open('cookie.txt', 'r', encoding='utf-8') as f:<br />cookie = f.read()<br />cookies = json.loads(cookie)<br />resp = requests.get(url=url, headers=headers, cookies=cookies)<br />search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'<br />params = {<br />'action': 'search_biz',<br />'begin': '0',<br />'count': '5',<br />'query': '搜索的公众号名称',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)<br />
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]<br />
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')<br />
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'<br />params_data = {<br />'action': 'list_ex',<br />'begin': '0',<br />'count': '5',<br />'fakeid': fakeid,<br />'type': '9',<br />'query': '',<br />'token': token,<br />'lang': 'zh_CN',<br />'f': 'json',<br />'ajax': '1'<br /> }<br />appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)<br />
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(微信公众号爬取程序分享搞成java的难点在于)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-27 13:09
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
//console.log("开始第一种页面爬取");
if(serverResData.toString() !== ""){
6 try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
//console.log("开始第一种页面爬取向下翻形式");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
//console.log("开始第一种页面爬取 结束");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。 查看全部
querylist采集微信公众号文章(微信公众号爬取程序分享搞成java的难点在于)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,就可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务来抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。这里的代码我没有做任何改动,里面的注释也解释的很清楚。顺着逻辑去理解就好,问题不大。
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
//console.log("开始第一种页面爬取");
if(serverResData.toString() !== ""){
6 try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
//console.log("开始第一种页面爬取向下翻形式");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
//console.log("开始第一种页面爬取 结束");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发请求提交下一部分列表的加载。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。
querylist采集微信公众号文章(text-to-texttransformertotext+,、然后在词向量上做结构化训练)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-26 12:07
querylist采集微信公众号文章的文章和粉丝关注公众号的文章;可以做momentum分布,或者bloomfilter分布,或者queryfilter分布等等。对于单个大文件来说,最合适的方法是bivariables,即用整个大文件的query里的所有html作为value,否则可能会碰到can'tread这种问题。
分词后做分词器,另外就是html结构化,mobi分词。
楼上的回答都挺好的,再补充一个,可以用单词向量训练语义向量,比如用百度翻译的word2vec的经典模型,
根据你的需求,大概是要找到一个语料库,然后用你的语料库训练分词器,生成model。使用你训练好的模型,来生成token。比如attention+model,基本就是一个单词或者字的向量生成的方法了。比如nlp:每天都有大量文本需要进行text-to-texttransformertotext摘要,推荐用你的语料库训练模型,然后然后,才是训练model。
构建一个结构化的token表,token表的每个元素是一段文本,
大概把token表中的每一个单词看成一个正则项。然后用正则化引入到词向量。
构建词向量、然后在词向量上做结构化训练text-to-texttransformertotext摘要
微信订阅号文章主要是几个大的类型,一般是公司、产品、老板、专业术语、核心内容等,几个类型的token分别是订阅号,公众号,ceo、产品、新闻、企业等,且这些token之间又彼此有时候也不互相关联。其中有些token之间本身也不互相关联,比如老板,“老板,问题来了”;另外的token之间相关性不强,比如产品、产品、产品的词。
但是这些token之间有的也需要关联。做这些需要整合语料库,全量的数据源,很多这类数据都是比较老旧的,毕竟那么多流量用户关注了,每天的推送也保存了好几十万,有的生产推送活动,有些活动一有新的或者新的一类的推送。需要及时的和原来数据库的数据做相关性或者切换,不仅生成了语料库,还生成了大量的token。下面我们利用学术界已经做好的数据库来生成token。
最老的文本就是书面用语,比如towhom是通过要做好的企业和工厂给客户发的信息,语言文字就这些。后面做网络查询时,我们也加入了更多信息。为了简单这里只从四个类型来创建token。1.公司,企业:比如我是xxx公司的,我是用common_information来用,如果还有了竞争对手或其他公司也可以用common_information。
2.个人:个人的token分两种,common_information和wirefox,查看新闻的就查看wirefone,要求用邮箱token;另外common_in。 查看全部
querylist采集微信公众号文章(text-to-texttransformertotext+,、然后在词向量上做结构化训练)
querylist采集微信公众号文章的文章和粉丝关注公众号的文章;可以做momentum分布,或者bloomfilter分布,或者queryfilter分布等等。对于单个大文件来说,最合适的方法是bivariables,即用整个大文件的query里的所有html作为value,否则可能会碰到can'tread这种问题。
分词后做分词器,另外就是html结构化,mobi分词。
楼上的回答都挺好的,再补充一个,可以用单词向量训练语义向量,比如用百度翻译的word2vec的经典模型,
根据你的需求,大概是要找到一个语料库,然后用你的语料库训练分词器,生成model。使用你训练好的模型,来生成token。比如attention+model,基本就是一个单词或者字的向量生成的方法了。比如nlp:每天都有大量文本需要进行text-to-texttransformertotext摘要,推荐用你的语料库训练模型,然后然后,才是训练model。
构建一个结构化的token表,token表的每个元素是一段文本,
大概把token表中的每一个单词看成一个正则项。然后用正则化引入到词向量。
构建词向量、然后在词向量上做结构化训练text-to-texttransformertotext摘要
微信订阅号文章主要是几个大的类型,一般是公司、产品、老板、专业术语、核心内容等,几个类型的token分别是订阅号,公众号,ceo、产品、新闻、企业等,且这些token之间又彼此有时候也不互相关联。其中有些token之间本身也不互相关联,比如老板,“老板,问题来了”;另外的token之间相关性不强,比如产品、产品、产品的词。
但是这些token之间有的也需要关联。做这些需要整合语料库,全量的数据源,很多这类数据都是比较老旧的,毕竟那么多流量用户关注了,每天的推送也保存了好几十万,有的生产推送活动,有些活动一有新的或者新的一类的推送。需要及时的和原来数据库的数据做相关性或者切换,不仅生成了语料库,还生成了大量的token。下面我们利用学术界已经做好的数据库来生成token。
最老的文本就是书面用语,比如towhom是通过要做好的企业和工厂给客户发的信息,语言文字就这些。后面做网络查询时,我们也加入了更多信息。为了简单这里只从四个类型来创建token。1.公司,企业:比如我是xxx公司的,我是用common_information来用,如果还有了竞争对手或其他公司也可以用common_information。
2.个人:个人的token分两种,common_information和wirefox,查看新闻的就查看wirefone,要求用邮箱token;另外common_in。
querylist采集微信公众号文章(网易云音乐个性化推荐,网易新闻+评论新浪微博推荐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-24 21:03
querylist采集微信公众号文章自动生成词典,语言词典,标题词典,评论词典,新闻词典,时间词典,特殊字符词典,类型词典,短语词典,长句词典,英文短语词典,英文长句词典,英文单词词典,美国发明词典,美国发明短语词典,单词排序,查询词典,单词词频统计,查询外国明星名人网络流行词文艺小清新系列:网易云音乐个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐语音新闻+评论系列:网易云音乐推荐网易新闻+评论新浪微博个性化推荐系列:网易微博个性化推荐,新浪微博推荐网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:网易搜狗百科,搜狗百科个性化推荐,百度百科个性化推荐部分单词last。
fm个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易小说个性化推荐,网易小说推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词电影电视剧个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易漫画个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列。 查看全部
querylist采集微信公众号文章(网易云音乐个性化推荐,网易新闻+评论新浪微博推荐)
querylist采集微信公众号文章自动生成词典,语言词典,标题词典,评论词典,新闻词典,时间词典,特殊字符词典,类型词典,短语词典,长句词典,英文短语词典,英文长句词典,英文单词词典,美国发明词典,美国发明短语词典,单词排序,查询词典,单词词频统计,查询外国明星名人网络流行词文艺小清新系列:网易云音乐个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐语音新闻+评论系列:网易云音乐推荐网易新闻+评论新浪微博个性化推荐系列:网易微博个性化推荐,新浪微博推荐网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:网易搜狗百科,搜狗百科个性化推荐,百度百科个性化推荐部分单词last。
fm个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易小说个性化推荐,网易小说推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词电影电视剧个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易漫画个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易课堂个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易游戏个性化推荐语音新闻娱乐系列:网易云音乐个性化推荐,网易云音乐推荐搜狗百科系列:搜狗百科个性化推荐,搜狗百科部分单词网易小说个性化推荐语音新闻娱乐系列。
querylist采集微信公众号文章(一个就是ip代理的质量不行,哪里不行呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-02-22 21:21
关注上一篇未完成的爬虫项目,继续更新最终代码片段
最近比较忙,没时间更新文章的下一篇。就在这几天,有时间重新调整代码,更新里面的细节。发现调整代码有很多问题,主要是ip代理质量不好,哪里不好,往下看就知道了。三、获取每篇文章文章的阅读和点赞数
想要获取文章的阅读量,在微信公众平台里面直接点击,是获取不了文章的阅读量的,测试如下:
然后我们可以去fiddler查看这个文章的包,可以看到这个包是
文章的内容可以从body的大小来判断,也就是文章的内容。
但是我们无法从这个路由中获取文章的阅读量,因为这个请求是一个get请求。如果要获取文章的阅读点赞,第一个请求是post请求,然后需要携带三个重要参数pass_ticket、appmsg_token、phoneCookie。要获取这三个参数,我们要把公众号中的文章放到微信中点击,然后从fiddler查看抓包情况。
我们去fiddler看一下抓包情况:我们可以看到上面还有一个get请求,但是下面添加了一个post请求的内容,然后看一下携带的参数,这三个是重要的得到我们想要的阅读量参数,以及响应的内容,可以看出已经获取到文章的阅读量信息。现在我们可以拼接参数来发送请求了。
#获取文章阅读量
def get_readNum(link,user_agent):
pass_ticket ="N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U"
appmsg_token = "1073_N8SQ6BkIGIQRZvII-hnp11Whcg8iqFcaN4Rd19rKluJDPVMDagdss_Rwbb-fI4WaoXLyxA244qF3iAp_"
# phoneCookie有效时间在两个小时左右,需要手动更新
phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=2890533338; devicetype=Windows10x64; version=62090529; lang=zh_CN; pass_ticket=N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U; wap_sid2=CNqTqOIKElxWcHFLdDFkanBJZjlZbzdXVmVrejNuVXdUb3hBSERDTTBDcHlSdVAxTTFIeEpwQmdrWnM1TWRFdWtuRUlSRDFnUzRHNkNQZFpVMXl1UEVYalgyX1ljakVFQUFBfjCT5bP5BTgNQAE="
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
url = "http://mp.weixin.qq.com/mp/getappmsgext"
headers = {
"Cookie": phoneCookie,
"User-Agent":user_agent
}
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
success = False
a=1
while not success:
ip_num = ranDom_ip()[0] # 使用不同的ip进行阅读、点赞量的获取
try:
print("获取阅读量使用ip:%s"%ip_num)
content = requests.post(url, headers=headers, data=data, params=params, proxies=ip_num,timeout=6.6)#设置超时时间5秒
time.sleep(4)
content = content.json()
print(link)#文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num=content["appmsgstat"]["old_like_num"] #点赞量
zai_kan=content["appmsgstat"]["like_num"] #在看量
else:
readNum = 0
like_num = 0
success=True
return readNum, like_num
except:
print("获取阅读量ip出现问题,更换ip进入第二次循环获取!!!")
a+=1
# if a%5==0:
content = requests.post(url, headers=headers, data=data, params=params,timeout=5)
time.sleep(3)
content = content.json()
print(link) #文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num = content["appmsgstat"]["old_like_num"] # 点赞量
zai_kan = content["appmsgstat"]["like_num"] # 在看量
else:
print('文章阅读点赞获取失败!')
readNum=0
like_num=0
# else:
# continue
return readNum, like_num
需要注意的是,在这三个重要参数中,phoneCookie 是时间敏感的,需要手动更新,这是最麻烦的,就像 cookie 一样。通过传入的文章链接,我们可以在链接中提取一些有用的参数,用于后期拼接post请求。不好,所以代码略显冗余(需要改进)。
四、使用UA代理和IP代理设置每个文章的爬取速度
通过以上操作,我们基本可以爬取文章的链接、标题、链接,完成初步需求:
但是我在开心爬的时候发现很快就被反爬发现了,直接屏蔽了我公众号的请求。
这时候就想到了ip proxy来识别我们是否反爬,主要是从ip和UA,所以后来做了一个ip代理池,从一些ip网站爬取ip,通过了代码大赛选择有用的 IP 形成 IP 池。贡献一段我爬ip的代码,感兴趣的朋友可以直接试试:
import requests
from bs4 import BeautifulSoup
import json
import random
import re
ip_num=[]
url="http://www.66ip.cn/1.html"
headers={
"Host": "www.66ip.cn ",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://www.66ip.cn/index.html",
"Cookie": "Hm_lvt_1761fabf3c988e7f04bec51acd4073f4=1595575058,1595816310; Hm_lpvt_1761fabf3c988e7f04bec51acd4073f4=1595832351",
}
content=requests.get(url,headers=headers)
content.encoding="gbk"
html=BeautifulSoup(content.text,"html.parser")
# print(html)
content=html.find_all("table",{"border":"2px"})
ip=re.findall('(\d{1,4}.\d{1,4}.\d{1,4}.\d{1,4})',str(content))
port=re.findall('(\d{1,5})',str(content))
for i in range(len(port)):
ip_num.append(ip[i]+":"+port[i])
proxies = [{'http':ip_num[num]} for num in range(len(ip_num))]
for i in range(0, len(ip_num)):
proxie = random.choice(proxies)
print("%s:当前使用的ip是:%s" % (i, proxie['http']))
try:
response = requests.get("http://mp.weixin.qq.com/", proxies=proxie, timeout=3)
print(response)
if response.status_code == 200:
# with open('ip.txt', "a", newline="")as f:
# f.write(proxie['http'] + "\n")
print("保存成功")
except Exception as e:
print("ip不可用")
我将过滤掉网站的ip,保存在本地,然后通过写一个函数来创建一个ip地址:
#代理池函数
def ranDom_ip():
with open('ip.txt',"r")as f:
ip_num=f.read()
ip_list=ip_num.split("\n")
num=random.randint(0,len(ip_list)-1)
proxies = [{'http': ip_list[num]}]
return proxies
然后在函数循环中调用这个ip代理的函数,就可以不断更新自己使用的ip。这是给你的流程图,所以我们可以知道在哪里使用ip代理功能。
通过将以上三个地方加入到我们使用的ip池中,不断变化的ip就是成功绕过反爬的点。当我们不断更改 ip 时,我仍然感到有点不安全。我觉得UA也需要不断更新,所以我导入了一个ua代理池
from fake_useragent import UserAgent #导入UA代理池
user_agent=UserAgent()
但需要注意的是,我们不能更改headers中的所有UA,我们只能添加UA代理的一部分,因为公众号的请求是由两部分组成的,我们只能添加前半部分。
就像下面的请求头一样,我们的Ua代理只能替换前半部分,这样Ua也是不断变化的,而且变化的位置和上面ip函数的位置一样,我们就可以实现ip,UA在之后每个请求都是不同的。
headers={
"Host":"mp.weixin.qq.com",
"User-Agent":user_agent.random +"(KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2469 MMWEBSDK/200601 Mobile Safari/537.36 MMWEBID/3809 MicroMessenger/7.0.16.1680(0x27001033) Process/toolsmp WeChat/arm64 NetType/WIFI Language/zh_CN ABI/arm64"
}
在这两个参数之后,我们基本可以控制不被反爬虫发现了,但是还有一点很重要,就是控制爬取的速度,因为ip和ua是不断变化的,但是你公众号的cookie不能被改变。如果爬取速度过快,会识别出访问你公众号某个界面的频率太快,直接禁止你公众号搜索的界面文章,所以我们需要做一个请求延迟,那么在这个过程中我们哪里可以做得更好呢?可以在流程图中标记的位置进行延迟。
这样既能控制速度,又能防止本地ip和ua被发现,妙不可言。缺点是我没有找到高质量的ip池。我用的是free ip,所以很多都是在换ip的过程中拿不到的。读取量方面(穷人叹),如果有高级IP代理池,速度是非常快的。完整的代码不会在这里粘贴。有兴趣我可以私发。 查看全部
querylist采集微信公众号文章(一个就是ip代理的质量不行,哪里不行呢?)
关注上一篇未完成的爬虫项目,继续更新最终代码片段
最近比较忙,没时间更新文章的下一篇。就在这几天,有时间重新调整代码,更新里面的细节。发现调整代码有很多问题,主要是ip代理质量不好,哪里不好,往下看就知道了。三、获取每篇文章文章的阅读和点赞数
想要获取文章的阅读量,在微信公众平台里面直接点击,是获取不了文章的阅读量的,测试如下:
然后我们可以去fiddler查看这个文章的包,可以看到这个包是
文章的内容可以从body的大小来判断,也就是文章的内容。
但是我们无法从这个路由中获取文章的阅读量,因为这个请求是一个get请求。如果要获取文章的阅读点赞,第一个请求是post请求,然后需要携带三个重要参数pass_ticket、appmsg_token、phoneCookie。要获取这三个参数,我们要把公众号中的文章放到微信中点击,然后从fiddler查看抓包情况。
我们去fiddler看一下抓包情况:我们可以看到上面还有一个get请求,但是下面添加了一个post请求的内容,然后看一下携带的参数,这三个是重要的得到我们想要的阅读量参数,以及响应的内容,可以看出已经获取到文章的阅读量信息。现在我们可以拼接参数来发送请求了。
#获取文章阅读量
def get_readNum(link,user_agent):
pass_ticket ="N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U"
appmsg_token = "1073_N8SQ6BkIGIQRZvII-hnp11Whcg8iqFcaN4Rd19rKluJDPVMDagdss_Rwbb-fI4WaoXLyxA244qF3iAp_"
# phoneCookie有效时间在两个小时左右,需要手动更新
phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=2890533338; devicetype=Windows10x64; version=62090529; lang=zh_CN; pass_ticket=N/Sd9In6UXfiRSmhdRi+kRX2ZUn9HC5+4aAeb6YksHOWNLyV3VK48YZQY6oWK0/U; wap_sid2=CNqTqOIKElxWcHFLdDFkanBJZjlZbzdXVmVrejNuVXdUb3hBSERDTTBDcHlSdVAxTTFIeEpwQmdrWnM1TWRFdWtuRUlSRDFnUzRHNkNQZFpVMXl1UEVYalgyX1ljakVFQUFBfjCT5bP5BTgNQAE="
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
url = "http://mp.weixin.qq.com/mp/getappmsgext"
headers = {
"Cookie": phoneCookie,
"User-Agent":user_agent
}
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": '777',
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": '777',
"wxtoken": "777"
}
success = False
a=1
while not success:
ip_num = ranDom_ip()[0] # 使用不同的ip进行阅读、点赞量的获取
try:
print("获取阅读量使用ip:%s"%ip_num)
content = requests.post(url, headers=headers, data=data, params=params, proxies=ip_num,timeout=6.6)#设置超时时间5秒
time.sleep(4)
content = content.json()
print(link)#文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num=content["appmsgstat"]["old_like_num"] #点赞量
zai_kan=content["appmsgstat"]["like_num"] #在看量
else:
readNum = 0
like_num = 0
success=True
return readNum, like_num
except:
print("获取阅读量ip出现问题,更换ip进入第二次循环获取!!!")
a+=1
# if a%5==0:
content = requests.post(url, headers=headers, data=data, params=params,timeout=5)
time.sleep(3)
content = content.json()
print(link) #文章链接
print(content)#文章内容
if 'appmsgstat' in content:
readNum = content["appmsgstat"]["read_num"]
like_num = content["appmsgstat"]["old_like_num"] # 点赞量
zai_kan = content["appmsgstat"]["like_num"] # 在看量
else:
print('文章阅读点赞获取失败!')
readNum=0
like_num=0
# else:
# continue
return readNum, like_num
需要注意的是,在这三个重要参数中,phoneCookie 是时间敏感的,需要手动更新,这是最麻烦的,就像 cookie 一样。通过传入的文章链接,我们可以在链接中提取一些有用的参数,用于后期拼接post请求。不好,所以代码略显冗余(需要改进)。
四、使用UA代理和IP代理设置每个文章的爬取速度
通过以上操作,我们基本可以爬取文章的链接、标题、链接,完成初步需求:
但是我在开心爬的时候发现很快就被反爬发现了,直接屏蔽了我公众号的请求。
这时候就想到了ip proxy来识别我们是否反爬,主要是从ip和UA,所以后来做了一个ip代理池,从一些ip网站爬取ip,通过了代码大赛选择有用的 IP 形成 IP 池。贡献一段我爬ip的代码,感兴趣的朋友可以直接试试:
import requests
from bs4 import BeautifulSoup
import json
import random
import re
ip_num=[]
url="http://www.66ip.cn/1.html"
headers={
"Host": "www.66ip.cn ",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Referer": "http://www.66ip.cn/index.html",
"Cookie": "Hm_lvt_1761fabf3c988e7f04bec51acd4073f4=1595575058,1595816310; Hm_lpvt_1761fabf3c988e7f04bec51acd4073f4=1595832351",
}
content=requests.get(url,headers=headers)
content.encoding="gbk"
html=BeautifulSoup(content.text,"html.parser")
# print(html)
content=html.find_all("table",{"border":"2px"})
ip=re.findall('(\d{1,4}.\d{1,4}.\d{1,4}.\d{1,4})',str(content))
port=re.findall('(\d{1,5})',str(content))
for i in range(len(port)):
ip_num.append(ip[i]+":"+port[i])
proxies = [{'http':ip_num[num]} for num in range(len(ip_num))]
for i in range(0, len(ip_num)):
proxie = random.choice(proxies)
print("%s:当前使用的ip是:%s" % (i, proxie['http']))
try:
response = requests.get("http://mp.weixin.qq.com/", proxies=proxie, timeout=3)
print(response)
if response.status_code == 200:
# with open('ip.txt', "a", newline="")as f:
# f.write(proxie['http'] + "\n")
print("保存成功")
except Exception as e:
print("ip不可用")
我将过滤掉网站的ip,保存在本地,然后通过写一个函数来创建一个ip地址:
#代理池函数
def ranDom_ip():
with open('ip.txt',"r")as f:
ip_num=f.read()
ip_list=ip_num.split("\n")
num=random.randint(0,len(ip_list)-1)
proxies = [{'http': ip_list[num]}]
return proxies
然后在函数循环中调用这个ip代理的函数,就可以不断更新自己使用的ip。这是给你的流程图,所以我们可以知道在哪里使用ip代理功能。
通过将以上三个地方加入到我们使用的ip池中,不断变化的ip就是成功绕过反爬的点。当我们不断更改 ip 时,我仍然感到有点不安全。我觉得UA也需要不断更新,所以我导入了一个ua代理池
from fake_useragent import UserAgent #导入UA代理池
user_agent=UserAgent()
但需要注意的是,我们不能更改headers中的所有UA,我们只能添加UA代理的一部分,因为公众号的请求是由两部分组成的,我们只能添加前半部分。
就像下面的请求头一样,我们的Ua代理只能替换前半部分,这样Ua也是不断变化的,而且变化的位置和上面ip函数的位置一样,我们就可以实现ip,UA在之后每个请求都是不同的。
headers={
"Host":"mp.weixin.qq.com",
"User-Agent":user_agent.random +"(KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2469 MMWEBSDK/200601 Mobile Safari/537.36 MMWEBID/3809 MicroMessenger/7.0.16.1680(0x27001033) Process/toolsmp WeChat/arm64 NetType/WIFI Language/zh_CN ABI/arm64"
}
在这两个参数之后,我们基本可以控制不被反爬虫发现了,但是还有一点很重要,就是控制爬取的速度,因为ip和ua是不断变化的,但是你公众号的cookie不能被改变。如果爬取速度过快,会识别出访问你公众号某个界面的频率太快,直接禁止你公众号搜索的界面文章,所以我们需要做一个请求延迟,那么在这个过程中我们哪里可以做得更好呢?可以在流程图中标记的位置进行延迟。
这样既能控制速度,又能防止本地ip和ua被发现,妙不可言。缺点是我没有找到高质量的ip池。我用的是free ip,所以很多都是在换ip的过程中拿不到的。读取量方面(穷人叹),如果有高级IP代理池,速度是非常快的。完整的代码不会在这里粘贴。有兴趣我可以私发。
querylist采集微信公众号文章(querylist采集微信公众号文章列表(关键词)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-22 07:01
querylist采集微信公众号文章列表请输入关键词,以微信公众号文章为例。不然无法查询。创建调研创建一个查询调研选择所有的开放平台数据(由于此是采集公众号的文章,故名为查询调研)通过鼠标拖动的方式对查询语句进行调整:右键粘贴->删除指定元素->确定通过在标注框中输入公众号数字->确定清晰度将无法更改,因为ga采集后需要验证语句完整性:ga:-bin/ga-bin/release-bin/share?ie=utf-8ga-release::-bin/ga-bin/release-bin/share?ie=utf-8运行ga-bin/release-bin/release-bin/share?ie=utf-8release-bin就可以进行上传微信公众号文章的调研了。
运行sci-hubrawspiderforadobedirectmedia(百度网盘)保存下来后:ga-bin/release-bin/release-bin/(在sci-hub获取下来的)release-bin是可以更改的。1.yml格式:4个set。set(filename,listname,title,content,music,export)filename:文件名,如ga-bin.cp2sdm。
(请查看微信公众号文章)listname:文件名,如ga-bin.jdqtqbvator44n22685fa90&title:文件名,如ga-bin.rio(通过查看公众号文章数字可得知)title:文件名,如ga-bin.jdqtqbvator4n22685fa90&content:文件名,如ga-bin.jdqtqbvator4n22685fa90&music:文件名,如ga-bin.emacs-dlspathr8mp4f269687-i&export:链接,如微信公众号文章地址。
2.xml格式:4个set。set(filename,url,value,offset)filename:文件名,如kij.xhie.ji.li.ja.lan.qqq.zh.tkj.g.ja.ga.jaj.tj.xz.ji.qq.csv(请查看微信公众号文章地址)url:文件名,如ga-bin.hub.hpzr.xifc4zyr.gaj.hweb.home.hideprepath.hnk.exff.wb.xui.xx.xxz_xnxt.jp.me.xx.xx.join.xxjsw.class1.xxg.xx.xxg.zz(请查看微信公众号文章地址)value:文件名,如ga-bin.ge.curl.xdata.gej.chstm.x1g.xhx.ji.gaj.chstm.x1g.zero.tkj.zh.tkj.sa.ji.zj.sa.zn.rk.ji.gaj.tj.zz.xx.xx1.ji.li.xx.xx.xx.xx.jp.xx.xx。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章列表(关键词)(图))
querylist采集微信公众号文章列表请输入关键词,以微信公众号文章为例。不然无法查询。创建调研创建一个查询调研选择所有的开放平台数据(由于此是采集公众号的文章,故名为查询调研)通过鼠标拖动的方式对查询语句进行调整:右键粘贴->删除指定元素->确定通过在标注框中输入公众号数字->确定清晰度将无法更改,因为ga采集后需要验证语句完整性:ga:-bin/ga-bin/release-bin/share?ie=utf-8ga-release::-bin/ga-bin/release-bin/share?ie=utf-8运行ga-bin/release-bin/release-bin/share?ie=utf-8release-bin就可以进行上传微信公众号文章的调研了。
运行sci-hubrawspiderforadobedirectmedia(百度网盘)保存下来后:ga-bin/release-bin/release-bin/(在sci-hub获取下来的)release-bin是可以更改的。1.yml格式:4个set。set(filename,listname,title,content,music,export)filename:文件名,如ga-bin.cp2sdm。
(请查看微信公众号文章)listname:文件名,如ga-bin.jdqtqbvator44n22685fa90&title:文件名,如ga-bin.rio(通过查看公众号文章数字可得知)title:文件名,如ga-bin.jdqtqbvator4n22685fa90&content:文件名,如ga-bin.jdqtqbvator4n22685fa90&music:文件名,如ga-bin.emacs-dlspathr8mp4f269687-i&export:链接,如微信公众号文章地址。
2.xml格式:4个set。set(filename,url,value,offset)filename:文件名,如kij.xhie.ji.li.ja.lan.qqq.zh.tkj.g.ja.ga.jaj.tj.xz.ji.qq.csv(请查看微信公众号文章地址)url:文件名,如ga-bin.hub.hpzr.xifc4zyr.gaj.hweb.home.hideprepath.hnk.exff.wb.xui.xx.xxz_xnxt.jp.me.xx.xx.join.xxjsw.class1.xxg.xx.xxg.zz(请查看微信公众号文章地址)value:文件名,如ga-bin.ge.curl.xdata.gej.chstm.x1g.xhx.ji.gaj.chstm.x1g.zero.tkj.zh.tkj.sa.ji.zj.sa.zn.rk.ji.gaj.tj.zz.xx.xx1.ji.li.xx.xx.xx.xx.jp.xx.xx。
querylist采集微信公众号文章( Python爬虫、数据分析、网站开发等案例教程视频免费在线观看 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-21 08:11
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
)
前言
本文文字及图片经网络过滤,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
基础开发环境爬取两个公众号的文章:
1、爬取所有文章
青灯编程公众号
2、爬取所有关于python的公众号文章
爬取所有文章
青灯编程公众号
1、登录公众号后点击图文
2、打开开发者工具
3、点击超链接
加载相关数据时,有关于数据包的,包括文章标题、链接、摘要、发布时间等。你也可以选择其他公众号去爬取,但这需要你有微信公众号。
添加 cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
爬取所有关于python的公众号文章
1、搜狗搜索python选择微信
注意:如果不登录,只能爬取前十页的数据。登录后可以爬取2W多篇文章文章.
2、抓取标题、公众号、文章地址,抓取发布时的静态网页
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
查看全部
querylist采集微信公众号文章(
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
)
前言
本文文字及图片经网络过滤,仅供学习交流,不具有任何商业用途。如有任何问题,请及时联系我们处理。
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
基础开发环境爬取两个公众号的文章:
1、爬取所有文章
青灯编程公众号
2、爬取所有关于python的公众号文章
爬取所有文章
青灯编程公众号
1、登录公众号后点击图文
2、打开开发者工具
3、点击超链接
加载相关数据时,有关于数据包的,包括文章标题、链接、摘要、发布时间等。你也可以选择其他公众号去爬取,但这需要你有微信公众号。
添加 cookie
import pprint
import time
import requests
import csv
f = open('青灯公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(0, 40, 5):
url = f'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={page}&count=5&fakeid=&type=9&query=&token=1252678642&lang=zh_CN&f=json&ajax=1'
headers = {
'cookie': '加cookie',
'referer': 'https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&createType=0&token=1252678642&lang=zh_CN',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.json()
pprint.pprint(response.json())
lis = html_data['app_msg_list']
for li in lis:
title = li['title']
link_url = li['link']
update_time = li['update_time']
timeArray = time.localtime(int(update_time))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title,
'文章发布时间': otherStyleTime,
'文章地址': link_url,
}
csv_writer.writerow(dit)
print(dit)
爬取所有关于python的公众号文章
1、搜狗搜索python选择微信
注意:如果不登录,只能爬取前十页的数据。登录后可以爬取2W多篇文章文章.
2、抓取标题、公众号、文章地址,抓取发布时的静态网页
import time
import requests
import parsel
import csv
f = open('公众号文章.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '公众号', '文章发布时间', '文章地址'])
csv_writer.writeheader()
for page in range(1, 2447):
url = f'https://weixin.sogou.com/weixin?query=python&_sug_type_=&s_from=input&_sug_=n&type=2&page={page}&ie=utf8'
headers = {
'Cookie': '自己的cookie',
'Host': 'weixin.sogou.com',
'Referer': 'https://www.sogou.com/web?query=python&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=1396&sst0=1610779538290&lkt=0%2C0%2C0&sugsuv=1590216228113568&sugtime=1610779538290',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.news-list li')
for li in lis:
title_list = li.css('.txt-box h3 a::text').getall()
num = len(title_list)
if num == 1:
title_str = 'python' + title_list[0]
else:
title_str = 'python'.join(title_list)
href = li.css('.txt-box h3 a::attr(href)').get()
article_url = 'https://weixin.sogou.com' + href
name = li.css('.s-p a::text').get()
date = li.css('.s-p::attr(t)').get()
timeArray = time.localtime(int(date))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
dit = {
'标题': title_str,
'公众号': name,
'文章发布时间': otherStyleTime,
'文章地址': article_url,
}
csv_writer.writerow(dit)
print(title_str, name, otherStyleTime, article_url)
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-21 08:08
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists= search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid= lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章爬取
一.想法
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后通过web链接即可获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,其中的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应的账号密码,点击登录,会出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url= 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists= search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid= lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url= 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(微信公众号爬取方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-20 09:12
最近在做自己的一个项目,涉及到需要通过python爬取微信公众号文章。由于微信的独特方法,无法直接爬取。在研究了一些 文章 之后,我可能会有一个想法。而且网上能查到的解决方案都没有问题,但是里面的代码由于一些第三方库的改动,基本无法使用。本文章是写给需要爬取公众号文章的朋友,文章最后也会提供python源码下载。
##公众号抓取方式
爬取公众号主要有两种方式。一是通过搜狗搜索微信公众号页面找到文章地址,然后爬取具体的文章内容;注册公众号然后通过公众号的搜索界面查询文章的地址,然后根据地址爬取文章的内容。
这两种方案各有优缺点。通过搜狗搜索做的核心思想是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,然后根据官方主页地址爬取文章的详细信息帐户。但是这里需要注意,因为搜狗和腾讯的协议,只能显示最新的10个文章,没有办法获取所有的文章。如果你想得到文章的所有朋友,你可能不得不使用第二种方法。第二种方法的缺点是注册公众号通过腾讯认证比较麻烦,通过调用接口公众号查询接口进行查询,但是翻页需要通过selenium来模拟滑动翻页操作,整个过程比较麻烦。因为我的项目中不需要history文章,所以我使用搜狗搜索来爬取公众号。
爬取最近10个公众号文章
python需要依赖的三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在评论里,没有特别复杂的地方。
爬虫核心类
````蟒蛇
#!/usr/bin/python
# 编码:utf-8
[Python] 纯文本查看
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
````
直接运行main方法,在控制台输入你要爬取的公众号英文名,中文的搜索结果可能有多个,这里只搜索一个,查看英文公众号,直接点击手机打开公众号,然后查看公众号信息,可以看到如下爬虫结果爬取到文章的相关信息,文章的具体内容可以通过调用webdriver进行爬取。 py 在代码中。

爬取公众号注意事项
以下三点是我在爬取过程中遇到的一些问题,希望能帮助大家避开陷阱。
1. Selenium 对 PhantomJS 的支持已被弃用,请使用无头版本的 Chrome 或 Firefox 代替 warnings.warn('Selenium 对 PhantomJS 的支持已被弃用,请使用 headless '
网上很多文章还在使用PhantomJS。事实上,Selenium 从去年开始就没有支持 PhantomJS。现在,如果你使用 Selenium 来初始化浏览器,你需要使用 webdriver 来初始化 Chrome 或 Firefox 驱动程序,而不需要 head 参数。
详情请参考官网链接:
2. 无法连接到Service chromedriver/firefoxdriver
我在开发过程中也遇到过这个坑。这个问题一般有两种可能。一是没有配置chromedriver或geckodriver的环境变量。这里需要注意chromedriver或者geckodriver文件的环境变量一定要配置到PATH中,或者干脆粗暴地将这两个文件直接复制到/usr/bin目录下;
还有另一种可能是未配置主机。如果你发现这个问题,检查你的hosts文件是否没有配置`127.0.0.1 localhost`,只要配置好了。
这里还有一点需要注意的是,如果你使用的是chrome浏览器,还要注意chrome浏览器版本和chromedriver的对应关系。可以在这个文章查看或者去google官网查看最新对应。.
3. 抗吸血
微信公众号已经对文章中的图片进行了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读本文文章了解如何应对微信防盗链。
总结
好了,上面说了这么多。大家最关心的是源码。这里是github地址:,如果好用记得用str。 查看全部
querylist采集微信公众号文章(微信公众号爬取方式)
最近在做自己的一个项目,涉及到需要通过python爬取微信公众号文章。由于微信的独特方法,无法直接爬取。在研究了一些 文章 之后,我可能会有一个想法。而且网上能查到的解决方案都没有问题,但是里面的代码由于一些第三方库的改动,基本无法使用。本文章是写给需要爬取公众号文章的朋友,文章最后也会提供python源码下载。
##公众号抓取方式
爬取公众号主要有两种方式。一是通过搜狗搜索微信公众号页面找到文章地址,然后爬取具体的文章内容;注册公众号然后通过公众号的搜索界面查询文章的地址,然后根据地址爬取文章的内容。
这两种方案各有优缺点。通过搜狗搜索做的核心思想是通过request模拟搜狗搜索公众号,然后解析搜索结果页面,然后根据官方主页地址爬取文章的详细信息帐户。但是这里需要注意,因为搜狗和腾讯的协议,只能显示最新的10个文章,没有办法获取所有的文章。如果你想得到文章的所有朋友,你可能不得不使用第二种方法。第二种方法的缺点是注册公众号通过腾讯认证比较麻烦,通过调用接口公众号查询接口进行查询,但是翻页需要通过selenium来模拟滑动翻页操作,整个过程比较麻烦。因为我的项目中不需要history文章,所以我使用搜狗搜索来爬取公众号。
爬取最近10个公众号文章
python需要依赖的三方库如下:
urllib,pyquery,请求,硒
具体逻辑写在评论里,没有特别复杂的地方。
爬虫核心类
````蟒蛇
#!/usr/bin/python
# 编码:utf-8
[Python] 纯文本查看
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from urllib import quote
from pyquery import PyQuery as pq
import requests
import time
import re
import os
from selenium.webdriver import Chrome
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.wait import WebDriverWait
# 搜索入口地址,以公众为关键字搜索该公众号
def get_search_result_by_keywords(sogou_search_url):
# 爬虫伪装头部设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
# 设置操作超时时长
timeout = 5
# 爬虫模拟在一个request.session中完成
s = requests.Session()
log(u'搜索地址为:%s' % sogou_search_url)
return s.get(sogou_search_url, headers=headers, timeout=timeout).content
# 获得公众号主页地址
def get_wx_url_by_sougou_search_html(sougou_search_html):
doc = pq(sougou_search_html)
return doc('div[class=txt-box]')('p[class=tit]')('a').attr('href')
# 使用webdriver 加载公众号主页内容,主要是js渲染的部分
def get_selenium_js_html(url):
options = Options()
options.add_argument('-headless') # 无头参数
driver = Chrome(executable_path='chromedriver', chrome_options=options)
wait = WebDriverWait(driver, timeout=10)
driver.get(url)
time.sleep(3)
# 执行js得到整个页面内容
html = driver.execute_script("return document.documentElement.outerHTML")
driver.close()
return html
# 获取公众号文章内容
def parse_wx_articles_by_html(selenium_html):
doc = pq(selenium_html)
return doc('div[class="weui_media_box appmsg"]')
# 将获取到的文章转换为字典
def switch_arctiles_to_list(articles):
# 定义存贮变量
articles_list = []
i = 1
# 遍历找到的文章,解析里面的内容
if articles:
for article in articles.items():
log(u'开始整合(%d/%d)' % (i, len(articles)))
# 处理单个文章
articles_list.append(parse_one_article(article))
i += 1
return articles_list
# 解析单篇文章
def parse_one_article(article):
article_dict = {}
# 获取标题
title = article('h4[class="weui_media_title"]').text().strip()
###log(u'标题是: %s' % title)
# 获取标题对应的地址
url = 'http://mp.weixin.qq.com' + article('h4[class="weui_media_title"]').attr('hrefs')
log(u'地址为: %s' % url)
# 获取概要内容
summary = article('.weui_media_desc').text()
log(u'文章简述: %s' % summary)
# 获取文章发表时间
date = article('.weui_media_extra_info').text().strip()
log(u'发表时间为: %s' % date)
# 获取封面图片
pic = parse_cover_pic(article)
# 返回字典数据
return {
'title': title,
'url': url,
'summary': summary,
'date': date,
'pic': pic
}
# 查找封面图片,获取封面图片地址
def parse_cover_pic(article):
pic = article('.weui_media_hd').attr('style')
p = re.compile(r'background-image:url\((.*?)\)')
rs = p.findall(pic)
log(u'封面图片是:%s ' % rs[0] if len(rs) > 0 else '')
return rs[0] if len(rs) > 0 else ''
# 自定义log函数,主要是加上时间
def log(msg):
print u'%s: %s' % (time.strftime('%Y-%m-%d_%H-%M-%S'), msg)
# 验证函数
def need_verify(selenium_html):
' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 '
return pq(selenium_html)('#verify_change').text() != ''
# 创建公众号命名的文件夹
def create_dir(keywords):
if not os.path.exists(keywords):
os.makedirs(keywords)
# 爬虫主函数
def run(keywords):
' 爬虫入口函数 '
# Step 0 : 创建公众号命名的文件夹
create_dir(keywords)
# 搜狐微信搜索链接入口
sogou_search_url = 'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=' % quote(
keywords)
# Step 1:GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
log(u'开始获取,微信公众号英文名为:%s' % keywords)
log(u'开始调用sougou搜索引擎')
sougou_search_html = get_search_result_by_keywords(sogou_search_url)
# Step 2:从搜索结果页中解析出公众号主页链接
log(u'获取sougou_search_html成功,开始抓取公众号对应的主页wx_url')
wx_url = get_wx_url_by_sougou_search_html(sougou_search_html)
log(u'获取wx_url成功,%s' % wx_url)
# Step 3:Selenium+PhantomJs获取js异步加载渲染后的html
log(u'开始调用selenium渲染html')
selenium_html = get_selenium_js_html(wx_url)
# Step 4: 检测目标网站是否进行了封锁
if need_verify(selenium_html):
log(u'爬虫被目标网站封锁,请稍后再试')
else:
# Step 5: 使用PyQuery,从Step 3获取的html中解析出公众号文章列表的数据
log(u'调用selenium渲染html完成,开始解析公众号文章')
articles = parse_wx_articles_by_html(selenium_html)
log(u'抓取到微信文章%d篇' % len(articles))
# Step 6: 把微信文章数据封装成字典的list
log(u'开始整合微信文章数据为字典')
articles_list = switch_arctiles_to_list(articles)
return [content['title'] for content in articles_list]
```
main入口函数:
```python
# coding: utf8
import spider_weixun_by_sogou
if __name__ == '__main__':
gongzhonghao = raw_input(u'input weixin gongzhonghao:')
if not gongzhonghao:
gongzhonghao = 'spider'
text = " ".join(spider_weixun_by_sogou.run(gongzhonghao))
print text
````
直接运行main方法,在控制台输入你要爬取的公众号英文名,中文的搜索结果可能有多个,这里只搜索一个,查看英文公众号,直接点击手机打开公众号,然后查看公众号信息,可以看到如下爬虫结果爬取到文章的相关信息,文章的具体内容可以通过调用webdriver进行爬取。 py 在代码中。

爬取公众号注意事项
以下三点是我在爬取过程中遇到的一些问题,希望能帮助大家避开陷阱。
1. Selenium 对 PhantomJS 的支持已被弃用,请使用无头版本的 Chrome 或 Firefox 代替 warnings.warn('Selenium 对 PhantomJS 的支持已被弃用,请使用 headless '
网上很多文章还在使用PhantomJS。事实上,Selenium 从去年开始就没有支持 PhantomJS。现在,如果你使用 Selenium 来初始化浏览器,你需要使用 webdriver 来初始化 Chrome 或 Firefox 驱动程序,而不需要 head 参数。
详情请参考官网链接:
2. 无法连接到Service chromedriver/firefoxdriver
我在开发过程中也遇到过这个坑。这个问题一般有两种可能。一是没有配置chromedriver或geckodriver的环境变量。这里需要注意chromedriver或者geckodriver文件的环境变量一定要配置到PATH中,或者干脆粗暴地将这两个文件直接复制到/usr/bin目录下;
还有另一种可能是未配置主机。如果你发现这个问题,检查你的hosts文件是否没有配置`127.0.0.1 localhost`,只要配置好了。
这里还有一点需要注意的是,如果你使用的是chrome浏览器,还要注意chrome浏览器版本和chromedriver的对应关系。可以在这个文章查看或者去google官网查看最新对应。.
3. 抗吸血
微信公众号已经对文章中的图片进行了防盗链处理,所以如果图片在公众号、小程序、PC浏览器以外的地方无法显示,建议您阅读本文文章了解如何应对微信防盗链。
总结
好了,上面说了这么多。大家最关心的是源码。这里是github地址:,如果好用记得用str。
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-19 16:16
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们还可以制作一个收录密钥和尚未过期的密钥的程序。提交pass_ticket的链接地址,然后可以通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提的另外一点是,如果要获取较旧的历史消息的内容,需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何根据历史新闻中文章的链接地址获取文章@。> 内容特定的方法。关于如何保存文章、封面图片、全文检索也有一些经验。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用 查看全部
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章和采集网站一样,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到过,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
因此,在这个地址过期之前,我们可以通过在浏览器中查看原文来获取文章历史消息列表。如果我们想自动分析内容,我们还可以制作一个收录密钥和尚未过期的密钥的程序。提交pass_ticket的链接地址,然后可以通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章文章中写的批处理采集方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就可以了。
在anyproxy的web界面中,如果证书配置正确,可以显示https的内容。web界面的地址是:8002,其中localhost可以换成自己的IP地址或者域名。从列表中找到以 getmasssendmsg 开头的记录。点击后,右侧会显示这条记录的详细信息:
红框部分是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提的另外一点是,如果要获取较旧的历史消息的内容,需要在手机或模拟器上下拉页面。下拉到最底部,微信会自动读取下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上一篇文章文章介绍的方法,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode将json解析成一个来自服务器的数组。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果您只需要采集的单个公众号的内容,您可以在每天群发后通过anyproxy获取带有key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何根据历史新闻中文章的链接地址获取文章@。> 内容特定的方法。关于如何保存文章、封面图片、全文检索也有一些经验。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面和采集分析
提高微信公众号文章采集的效率,anyproxy的高级使用

