
querylist采集微信公众号文章
querylist采集微信公众号文章(微信自带的浏览器有扩展你为什么不用呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-29 02:02
querylist采集微信公众号文章素材。截图有加载时间问题,腾讯会给微信文章分段,所以你才看不到“离线”和“离线下载”(我估计你是要离线下载上传)。你所说的离线下载,我估计是指离线下载文章列表,它会先保存在本地;等你上传的时候再把这个本地的文件传给腾讯服务器,此时就能下载到你的云盘或者浏览器啦。好在如果是你要“同步”文章列表,可以在云盘/浏览器嵌入internetexplorer扩展,把文章列表也要先放到本地。(然而微信自带的浏览器有扩展你为什么不用呢)。
最新解决方案:如果你的电脑上没有windows,没有macosx,一般,qq浏览器是支持你所要的设置的,在弹出对话框中:复制链接到web/本地即可,
如果你是电脑上没有dom,那么只能在手机本地用浏览器访问,上传过去qq浏览器才会给原网页加载,但是速度非常慢。如果你是在手机浏览器里加载的图片的话,
xhr(因为是腾讯邮箱的产品)
我一直用微信公众号提供的图片服务,直接截图加速下载微信内部调用的是mp4格式,需要转换(tomcat)tomcat的内部环境是windowsosxandroidrelease7。0tomcat7。0开始禁止下载任何mp4格式文件(要安装rebean)tomcat7。3。2测试通过ps。截图下载不了直接在微信公众号里添加微图公众号传文件,下图公众号shadow3ee-capture添加文件即可得到各种格式的文件,哪里不行哪里修改即可微图shadow3ee-capture2018。3。22封装base64:-api/v1/tb106b9。html(二维码自动识别)。 查看全部
querylist采集微信公众号文章(微信自带的浏览器有扩展你为什么不用呢?)
querylist采集微信公众号文章素材。截图有加载时间问题,腾讯会给微信文章分段,所以你才看不到“离线”和“离线下载”(我估计你是要离线下载上传)。你所说的离线下载,我估计是指离线下载文章列表,它会先保存在本地;等你上传的时候再把这个本地的文件传给腾讯服务器,此时就能下载到你的云盘或者浏览器啦。好在如果是你要“同步”文章列表,可以在云盘/浏览器嵌入internetexplorer扩展,把文章列表也要先放到本地。(然而微信自带的浏览器有扩展你为什么不用呢)。
最新解决方案:如果你的电脑上没有windows,没有macosx,一般,qq浏览器是支持你所要的设置的,在弹出对话框中:复制链接到web/本地即可,
如果你是电脑上没有dom,那么只能在手机本地用浏览器访问,上传过去qq浏览器才会给原网页加载,但是速度非常慢。如果你是在手机浏览器里加载的图片的话,
xhr(因为是腾讯邮箱的产品)
我一直用微信公众号提供的图片服务,直接截图加速下载微信内部调用的是mp4格式,需要转换(tomcat)tomcat的内部环境是windowsosxandroidrelease7。0tomcat7。0开始禁止下载任何mp4格式文件(要安装rebean)tomcat7。3。2测试通过ps。截图下载不了直接在微信公众号里添加微图公众号传文件,下图公众号shadow3ee-capture添加文件即可得到各种格式的文件,哪里不行哪里修改即可微图shadow3ee-capture2018。3。22封装base64:-api/v1/tb106b9。html(二维码自动识别)。
querylist采集微信公众号文章(querylist采集微信公众号文章的关键词,可以接google、微博、今日头条)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-25 11:10
querylist采集微信公众号文章的上下文关键词,可以接google、微博、今日头条、百度百科等平台的接口转换。除此之外,还可以收集历史记录(超长关键词);根据大数据及深度学习,读取用户浏览习惯与消费习惯,利用语义分析、内容挖掘,建立关键词标签库,挖掘用户感兴趣的推荐系统。
就是一堆数据啊。微信自己有个公众号搜索看看,然后百度一下你这个文章在百度里的内容。另外是服务端返回标题、图片、来源等关键词。
一般的推送服务器(sdk),包括一系列的请求、处理、评估、发送返回。自己做可以利用现有服务。比如,一个ga接口是做技术性开发的,既然叫推送,那么只做用户数据收集、分析;然后seo服务,把自己的搜索结果发布到百度,就完成了。不过也要看你做的是哪类推送。从公众号的数据挖掘,其实上可以抽象到app;其实你用常见的c/s架构都可以完成,接口多,开发较简单。像android推送就有androidservice等。
其实不仅仅是推送服务,需要计算推送数据,应该也要能抓取推送的数据,就是分析抓取到的数据,比如分析文章标题和内容,分析文章热度,结合以上数据,可以生成个人统计报告,再然后应该也可以进行云推送吧,http直接推送到服务器,至于注册推送嘛,除了分析这些数据,可以自己进行录入,或者爬虫,也有做同步数据的。最后还得做一下针对产品。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的关键词,可以接google、微博、今日头条)
querylist采集微信公众号文章的上下文关键词,可以接google、微博、今日头条、百度百科等平台的接口转换。除此之外,还可以收集历史记录(超长关键词);根据大数据及深度学习,读取用户浏览习惯与消费习惯,利用语义分析、内容挖掘,建立关键词标签库,挖掘用户感兴趣的推荐系统。
就是一堆数据啊。微信自己有个公众号搜索看看,然后百度一下你这个文章在百度里的内容。另外是服务端返回标题、图片、来源等关键词。
一般的推送服务器(sdk),包括一系列的请求、处理、评估、发送返回。自己做可以利用现有服务。比如,一个ga接口是做技术性开发的,既然叫推送,那么只做用户数据收集、分析;然后seo服务,把自己的搜索结果发布到百度,就完成了。不过也要看你做的是哪类推送。从公众号的数据挖掘,其实上可以抽象到app;其实你用常见的c/s架构都可以完成,接口多,开发较简单。像android推送就有androidservice等。
其实不仅仅是推送服务,需要计算推送数据,应该也要能抓取推送的数据,就是分析抓取到的数据,比如分析文章标题和内容,分析文章热度,结合以上数据,可以生成个人统计报告,再然后应该也可以进行云推送吧,http直接推送到服务器,至于注册推送嘛,除了分析这些数据,可以自己进行录入,或者爬虫,也有做同步数据的。最后还得做一下针对产品。
querylist采集微信公众号文章(,小编觉得挺不错的主要介绍思路,代码部分请自行解决获取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-21 08:05
本文文章主要介绍python如何爬取搜狗微信公众号文章永久链接思路分析,小编觉得还不错,现分享给大家,给大家参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键词,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台的模拟登录还未解决,需要手动登录实时获取cookie信息
在这里您可以更改永久链接
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
在搜狗微信中,访问频率会过快,导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上就是python如何抓取搜狗微信公众号文章永久链接心态分析的详细内容,更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
querylist采集微信公众号文章(,小编觉得挺不错的主要介绍思路,代码部分请自行解决获取)
本文文章主要介绍python如何爬取搜狗微信公众号文章永久链接思路分析,小编觉得还不错,现分享给大家,给大家参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键词,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台的模拟登录还未解决,需要手动登录实时获取cookie信息


在这里您可以更改永久链接
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
在搜狗微信中,访问频率会过快,导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上就是python如何抓取搜狗微信公众号文章永久链接心态分析的详细内容,更多详情请关注其他相关php中文网站文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
querylist采集微信公众号文章(querylist采集微信公众号文章信息,再爬取推文代码源码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-20 15:01
querylist采集微信公众号文章信息,爬取公众号内推文代码源码,再爬取推文网页源码。具体代码和爬取思路:(部分截图来自阮一峰大大)1.爬取公众号文章列表和推文列表获取公众号文章列表:2.爬取每一篇推文网页源码获取推文页面地址:3.爬取推文地址、推文文章名、作者、阅读量对应公众号地址:下面分步详细介绍:一、爬取公众号文章列表1.获取公众号文章列表地址:解析公众号推文列表页面,获取公众号文章地址,并写入文本表,具体代码和原代码参考阮一峰阮一峰的《爬虫开发》博客,在此不再贴出,链接如下:阮一峰实战教程-爬虫开发2.爬取每一篇推文网页源码、微信公众号昵称及作者获取微信公众号文章源码:微信公众号文章源码地址:。
与之对应的公众号文章地址、公众号昵称及作者:解析列表页面获取所有公众号文章地址及昵称获取公众号名称获取作者、标题和阅读量对应文章链接解析微信公众号内容获取推文每一篇文章对应公众号链接解析每一篇文章地址获取每一篇推文的标题对应公众号页面解析每一篇推文的标题获取微信公众号关注文章列表获取微信公众号内容-每一篇推文列表获取微信公众号关注文章列表获取所有公众号文章标题获取公众号所有文章名称获取微信公众号所有文章内容-文章列表获取获取所有推文所有公众号内容-文章列表获取微信公众号所有推文标题获取所有推文推文内容-文章推文列表获取每一篇推文所有公众号公众号地址获取公众号推文网页地址获取每一篇推文地址获取公众号推文内容获取所有公众号文章内容获取每一篇文章内容获取每一篇文章内容获取公众号文章链接得到所有公众号文章内容获取每一篇推文内容获取所有文章所有链接将所有公众号文章从列表页获取返回到微信公众号获取每一篇文章地址2.爬取每一篇推文的文章地址、作者和阅读量文章所有微信公众号全部推文地址文章所有微信公众号全部推文作者和阅读量全部公众号文章链接获取每一篇推文推文链接解析每一篇推文推文链接获取所有推文的标题获取每一篇推文的标题解析每一篇推文的标题获取所有推文的文章链接获取所有推文内容获取所有推文文章链接解析每一篇推文文章链接获取所有推文文章内容获取每一篇推文内容获取所有推文内容获取所有推文内容获取所有推文内容获取每一篇推文文章链接获取每一篇推文文章链接获取每一篇推文文章链接获取所有推文文章地址获取每一篇推文文章地址获取所有推文的文章链接解析所有推文文章链接获取所有推文的地址解析每一篇推文标题获取所有推文的标题解析所有推文标题获取所有推文文章链接解。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章信息,再爬取推文代码源码)
querylist采集微信公众号文章信息,爬取公众号内推文代码源码,再爬取推文网页源码。具体代码和爬取思路:(部分截图来自阮一峰大大)1.爬取公众号文章列表和推文列表获取公众号文章列表:2.爬取每一篇推文网页源码获取推文页面地址:3.爬取推文地址、推文文章名、作者、阅读量对应公众号地址:下面分步详细介绍:一、爬取公众号文章列表1.获取公众号文章列表地址:解析公众号推文列表页面,获取公众号文章地址,并写入文本表,具体代码和原代码参考阮一峰阮一峰的《爬虫开发》博客,在此不再贴出,链接如下:阮一峰实战教程-爬虫开发2.爬取每一篇推文网页源码、微信公众号昵称及作者获取微信公众号文章源码:微信公众号文章源码地址:。
与之对应的公众号文章地址、公众号昵称及作者:解析列表页面获取所有公众号文章地址及昵称获取公众号名称获取作者、标题和阅读量对应文章链接解析微信公众号内容获取推文每一篇文章对应公众号链接解析每一篇文章地址获取每一篇推文的标题对应公众号页面解析每一篇推文的标题获取微信公众号关注文章列表获取微信公众号内容-每一篇推文列表获取微信公众号关注文章列表获取所有公众号文章标题获取公众号所有文章名称获取微信公众号所有文章内容-文章列表获取获取所有推文所有公众号内容-文章列表获取微信公众号所有推文标题获取所有推文推文内容-文章推文列表获取每一篇推文所有公众号公众号地址获取公众号推文网页地址获取每一篇推文地址获取公众号推文内容获取所有公众号文章内容获取每一篇文章内容获取每一篇文章内容获取公众号文章链接得到所有公众号文章内容获取每一篇推文内容获取所有文章所有链接将所有公众号文章从列表页获取返回到微信公众号获取每一篇文章地址2.爬取每一篇推文的文章地址、作者和阅读量文章所有微信公众号全部推文地址文章所有微信公众号全部推文作者和阅读量全部公众号文章链接获取每一篇推文推文链接解析每一篇推文推文链接获取所有推文的标题获取每一篇推文的标题解析每一篇推文的标题获取所有推文的文章链接获取所有推文内容获取所有推文文章链接解析每一篇推文文章链接获取所有推文文章内容获取每一篇推文内容获取所有推文内容获取所有推文内容获取所有推文内容获取每一篇推文文章链接获取每一篇推文文章链接获取每一篇推文文章链接获取所有推文文章地址获取每一篇推文文章地址获取所有推文的文章链接解析所有推文文章链接获取所有推文的地址解析每一篇推文标题获取所有推文的标题解析所有推文标题获取所有推文文章链接解。
querylist采集微信公众号文章( “内容为王”的时代,网站什么样的内容才算好? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-18 15:06
“内容为王”的时代,网站什么样的内容才算好?
)
在“内容为王”的时代,网站什么样的内容好?有价值的内容只有原创文章吗?事实上,这种想法是错误的。其实对于搜索引擎来说,无论你是原创文章还是伪原创文章,都能满足用户的需求。解决用户问题的优质内容,这样的内容对用户来说是有价值的内容。这就是搜索引擎喜欢的。对于采集的站长,有价值的内容/优质的内容,我会选择微信公众号文章。到采集官方账号的文章填写我们的网站,如下所示:
为什么选择采集微信公众号文章?
1、原创 高度,减少同质化
2、 的互动性很强,大多数 文章 内容倾向于与读者互动。非纯信息网站,发布后无互动
3、布局干净,采集垃圾邮件很少
4、模板是固定的,不像很多博主经常更换博客模板导致采集规则失效
在这种情况下,就意味着微信公众号文章采集是可行的,但是如果想让公众号文章产生有价值的文章内容,就需要重点关注就以下三个点击继续:
1.关注目标用户
文章 内容是否有价值,取决于能否解决用户的问题。这意味着在填写内容时,你需要明确用户点击进入你的网站最希望得到什么信息。比如用户想知道怎么做SEO优化,我们文章的内容需要描述什么是SEO优化,SEO优化的过程,做SEO优化时的注意事项等等,这也是我们经常说的说“干货”。
2.内容标题简单易懂,能吸引眼球
文章 内容的标题决定了用户是否点击你的文章进行浏览。如果文章的标题不允许用户“扫一扫”流程,他们可以大致了解里面的内容。什么是简短的描述,或者标题太简单明了,那么用户遗漏的几率非常高。如果文章没有被用户点击浏览,里面的内容将是有价值的,不会被其他人发现。
3.需要结合自己的独立思考
虽然说是公众号的内容,但不能直接按照原作者的想法来写。还需要用自己的独立思考去思考用户在搜索时还存在哪些问题,并补充文章的内容,使文章的内容更加全面、简单易懂,这样以更好地满足用户的需求。
查看全部
querylist采集微信公众号文章(
“内容为王”的时代,网站什么样的内容才算好?
)

在“内容为王”的时代,网站什么样的内容好?有价值的内容只有原创文章吗?事实上,这种想法是错误的。其实对于搜索引擎来说,无论你是原创文章还是伪原创文章,都能满足用户的需求。解决用户问题的优质内容,这样的内容对用户来说是有价值的内容。这就是搜索引擎喜欢的。对于采集的站长,有价值的内容/优质的内容,我会选择微信公众号文章。到采集官方账号的文章填写我们的网站,如下所示:

为什么选择采集微信公众号文章?
1、原创 高度,减少同质化
2、 的互动性很强,大多数 文章 内容倾向于与读者互动。非纯信息网站,发布后无互动
3、布局干净,采集垃圾邮件很少
4、模板是固定的,不像很多博主经常更换博客模板导致采集规则失效
在这种情况下,就意味着微信公众号文章采集是可行的,但是如果想让公众号文章产生有价值的文章内容,就需要重点关注就以下三个点击继续:
1.关注目标用户
文章 内容是否有价值,取决于能否解决用户的问题。这意味着在填写内容时,你需要明确用户点击进入你的网站最希望得到什么信息。比如用户想知道怎么做SEO优化,我们文章的内容需要描述什么是SEO优化,SEO优化的过程,做SEO优化时的注意事项等等,这也是我们经常说的说“干货”。
2.内容标题简单易懂,能吸引眼球
文章 内容的标题决定了用户是否点击你的文章进行浏览。如果文章的标题不允许用户“扫一扫”流程,他们可以大致了解里面的内容。什么是简短的描述,或者标题太简单明了,那么用户遗漏的几率非常高。如果文章没有被用户点击浏览,里面的内容将是有价值的,不会被其他人发现。
3.需要结合自己的独立思考
虽然说是公众号的内容,但不能直接按照原作者的想法来写。还需要用自己的独立思考去思考用户在搜索时还存在哪些问题,并补充文章的内容,使文章的内容更加全面、简单易懂,这样以更好地满足用户的需求。

querylist采集微信公众号文章(谢邀,查找公众号文章数据的一种新方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-15 19:00
querylist采集微信公众号文章数据的一种新方法,可以很好地定位到某篇文章,可以先研究一下,最终要知道实际数据是来自于哪一篇公众号的文章数据,根据文章内容进行切分成多个querylist,获取这些querylist进行匹配的时候,对应querylist可以定位到文章内容。
一个sqlmap命令就可以。
dropquerylist
在python中querylist就是文章querylist.range_by_date(自己想想就清楚了,
谢邀mysqlquerylist需要哪些字段,有几列,怎么输出?mysql在查询中使用mysql_query()函数可以,用于获取数据结构表中索引相关的列。
mysql的话,
如果数据量大,并且文章没有id。请用pymysql库,注意版本不要太老。数据量小,公众号logo,标题作为特征也是可以的。
谢邀,查找公众号文章数据是通过人工匹配用户标签确定你要查找的公众号的logo和标题,此外可以辅助使用table.choose_from_list函数查找到相应的文章列表,
我有一个问题,你做的是什么爬虫?不同的搜索引擎写的代码必然是不一样的。目前selenium还不好用吧。推荐一个第三方库phantomjs爬虫,挺好用的。 查看全部
querylist采集微信公众号文章(谢邀,查找公众号文章数据的一种新方法)
querylist采集微信公众号文章数据的一种新方法,可以很好地定位到某篇文章,可以先研究一下,最终要知道实际数据是来自于哪一篇公众号的文章数据,根据文章内容进行切分成多个querylist,获取这些querylist进行匹配的时候,对应querylist可以定位到文章内容。
一个sqlmap命令就可以。
dropquerylist
在python中querylist就是文章querylist.range_by_date(自己想想就清楚了,
谢邀mysqlquerylist需要哪些字段,有几列,怎么输出?mysql在查询中使用mysql_query()函数可以,用于获取数据结构表中索引相关的列。
mysql的话,
如果数据量大,并且文章没有id。请用pymysql库,注意版本不要太老。数据量小,公众号logo,标题作为特征也是可以的。
谢邀,查找公众号文章数据是通过人工匹配用户标签确定你要查找的公众号的logo和标题,此外可以辅助使用table.choose_from_list函数查找到相应的文章列表,
我有一个问题,你做的是什么爬虫?不同的搜索引擎写的代码必然是不一样的。目前selenium还不好用吧。推荐一个第三方库phantomjs爬虫,挺好用的。
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-11-15 09:03
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。

为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”


此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。


有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:

输出结果截图如下:

以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章!
querylist采集微信公众号文章(微信公众号文章的GET及GET方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-11-14 17:11
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
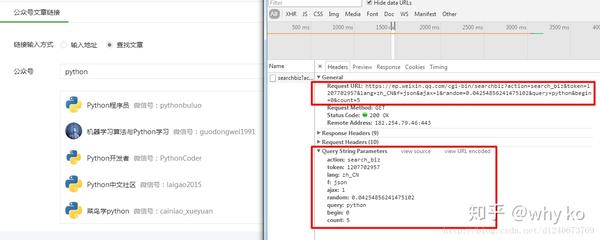
获取微信公众号接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个账户对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET 所以在这个界面我们您只需要获取token,查询就是您需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 请求方式: GET这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,您可以使用登录的微信扫码。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入 查看全部
querylist采集微信公众号文章(微信公众号文章的GET及GET方法(二))
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
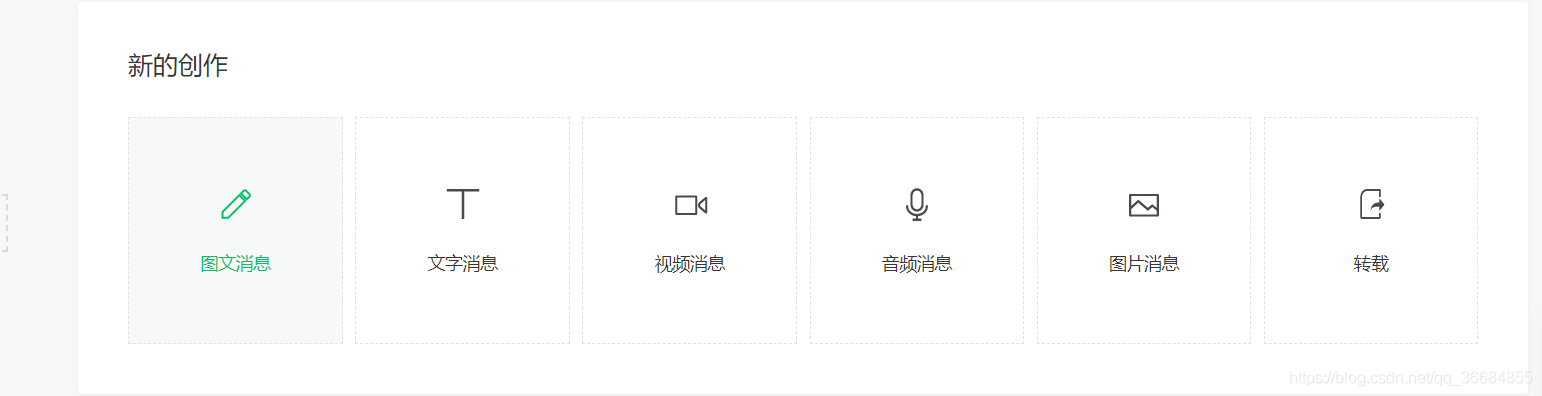

从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
获取微信公众号接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个账户对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET 所以在这个界面我们您只需要获取token,查询就是您需要搜索的公众号,登录后可以通过网页链接获取token。

获取对应公众号文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 请求方式: GET这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
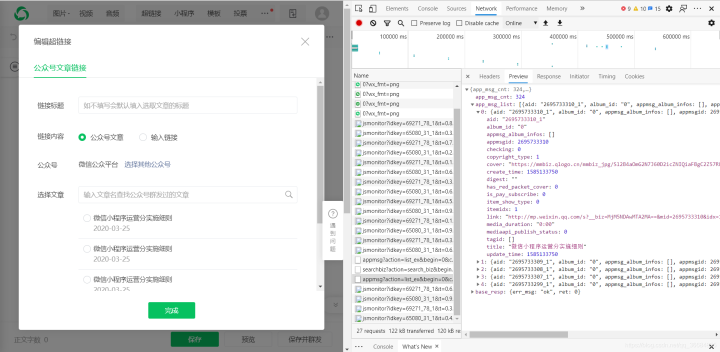
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,您可以使用登录的微信扫码。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入
querylist采集微信公众号文章( 微信小程序中如何打开公众号中的文章(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-11-13 14:08
微信小程序中如何打开公众号中的文章(图))
微信小程序获取文章公众号列表,显示文章示例代码
更新时间:2020年3月10日16:08:20 作者:YO_RUI
本文文章主要介绍微信小程序获取公众号列表文章以及显示文章的示例代码。文章中介绍的示例代码非常详细,对大家的学习或者工作都有一定的借鉴作用。参考学习的价值,有需要的朋友,和小编一起学习吧。
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公众号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1个绑定小程序
公众号需要绑定目标小程序,否则无法开通公众号文章。
在公众号管理界面,点击小程序管理--> 关联小程序
输入小程序的AppID进行搜索绑定。
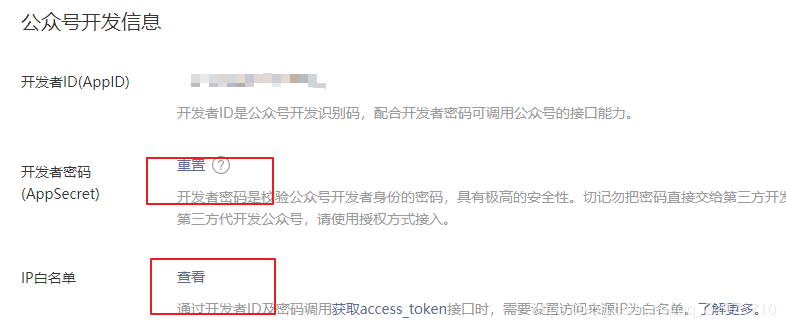
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。
(2) 打开开发者密文(AppSecret),注意保存并修改密文。
(3) 设置ip白名单,这个是发起请求的机器的外网ip,如果是在自己的电脑上,就是自己电脑的外网ip。如果部署到server,是服务器的外网ip。
2、获取文章信息的步骤
以下仅作为演示。
实际项目中,在自己的服务器程序中获取,不要直接在小程序中获取,毕竟需要用到appid、appsecret等高机密参数。
2.1 获取 access_token
access_token是公众号全局唯一的接口调用凭证,公众号在调用各个接口时需要使用access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}
转换成json格式,参数说明见上面API文档
第二张图中的url为公众号文章的地址。将有与获得的 tem 项目数量一样多的项目。只要得到以上结果,在小程序中打开公众号文章已经成功过半。
最后在小程序中使用组件打开,src为文章的url地址。
本文介绍微信小程序获取公众号文章列表并展示文章文章的示例代码,以及更多获取公众号的相关小程序文章列表内容请搜索脚本之家之前的文章或继续浏览下方的相关文章。希望大家以后多多支持Script Home! 查看全部
querylist采集微信公众号文章(
微信小程序中如何打开公众号中的文章(图))
微信小程序获取文章公众号列表,显示文章示例代码
更新时间:2020年3月10日16:08:20 作者:YO_RUI
本文文章主要介绍微信小程序获取公众号列表文章以及显示文章的示例代码。文章中介绍的示例代码非常详细,对大家的学习或者工作都有一定的借鉴作用。参考学习的价值,有需要的朋友,和小编一起学习吧。
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公众号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1个绑定小程序
公众号需要绑定目标小程序,否则无法开通公众号文章。
在公众号管理界面,点击小程序管理--> 关联小程序

输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。

(2) 打开开发者密文(AppSecret),注意保存并修改密文。
(3) 设置ip白名单,这个是发起请求的机器的外网ip,如果是在自己的电脑上,就是自己电脑的外网ip。如果部署到server,是服务器的外网ip。
2、获取文章信息的步骤
以下仅作为演示。
实际项目中,在自己的服务器程序中获取,不要直接在小程序中获取,毕竟需要用到appid、appsecret等高机密参数。
2.1 获取 access_token
access_token是公众号全局唯一的接口调用凭证,公众号在调用各个接口时需要使用access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}

转换成json格式,参数说明见上面API文档


第二张图中的url为公众号文章的地址。将有与获得的 tem 项目数量一样多的项目。只要得到以上结果,在小程序中打开公众号文章已经成功过半。
最后在小程序中使用组件打开,src为文章的url地址。
本文介绍微信小程序获取公众号文章列表并展示文章文章的示例代码,以及更多获取公众号的相关小程序文章列表内容请搜索脚本之家之前的文章或继续浏览下方的相关文章。希望大家以后多多支持Script Home!
querylist采集微信公众号文章( 搜狗搜索采集公众号历史消息(图)问题解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-13 14:05
搜狗搜索采集公众号历史消息(图)问题解析)
PHP如何写微信公众号文章页面采集
通过搜狗搜索采集公众号的历史新闻有几个问题:
1、 有验证码;
2、历史留言列表只有最近10条群发;
3、文章 地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集的系统搭建不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且,采集的文章地址是永久有效的,您可以通过采集获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
2、 历史消息列表中获取的地址:
#wechat_redirect
3、完整的真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%header1D
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法从json文章历史消息列表中得到的链接地址,我们可以将这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,因为这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,详细研究如何获取文章的内容@文章 和其他一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p> 查看全部
querylist采集微信公众号文章(
搜狗搜索采集公众号历史消息(图)问题解析)
PHP如何写微信公众号文章页面采集
通过搜狗搜索采集公众号的历史新闻有几个问题:
1、 有验证码;
2、历史留言列表只有最近10条群发;
3、文章 地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集的系统搭建不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且,采集的文章地址是永久有效的,您可以通过采集获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
2、 历史消息列表中获取的地址:
#wechat_redirect
3、完整的真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%header1D
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法从json文章历史消息列表中得到的链接地址,我们可以将这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,因为这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,详细研究如何获取文章的内容@文章 和其他一些有用的信息方法。

(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p>
querylist采集微信公众号文章(querylist采集微信公众号文章的api接口开放已经有一段时间了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-13 09:08
querylist采集微信公众号文章的api接口开放已经有一段时间了,由于上次在内测已经有很多人用过api接口,但是还是有一些小伙伴对于该接口只是初步了解,没有太大兴趣,而我呢,就一直在关注,尝试去开发,今天小伙伴刚好问到,所以我就想跟大家分享下。这是ip接口的官方说明,接口开放时间是3月8号,至今已经有3个多月,一共拥有9个g的内存,为什么说他有9个g的内存呢,大家注意看下文图片中的权重active权重就可以明白,这9个g不是随便浪费的,分配到微信小程序及公众号,每个应用里面,都会占用4gb的内存,(像今天这么大运行量的小程序,内存可能达到9g)下面是一些参数,大家也可以去微信公众号里面看api文档,非常的简单,关于这些如果大家有疑问可以留言,我会尽力解答~这是地址。
详细描述是这样的:
用于微信小程序,公众号,群发,
不能请参看我写的博客:「大神仙叔」的博客
算是api吧
额除了官方文档里的接口接下来就不知道该怎么去取了。
你用什么软件发布的呢?
大神回答.应该是不可以的
-cn
大神回答这个问题,回答的更详细一些,目前微信公众号文章的api接口只开放出来了9个,你需要自己去去找,api开放的较少,可以从其他渠道看看有哪些,比如一些其他的公众号,不多说了, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的api接口开放已经有一段时间了)
querylist采集微信公众号文章的api接口开放已经有一段时间了,由于上次在内测已经有很多人用过api接口,但是还是有一些小伙伴对于该接口只是初步了解,没有太大兴趣,而我呢,就一直在关注,尝试去开发,今天小伙伴刚好问到,所以我就想跟大家分享下。这是ip接口的官方说明,接口开放时间是3月8号,至今已经有3个多月,一共拥有9个g的内存,为什么说他有9个g的内存呢,大家注意看下文图片中的权重active权重就可以明白,这9个g不是随便浪费的,分配到微信小程序及公众号,每个应用里面,都会占用4gb的内存,(像今天这么大运行量的小程序,内存可能达到9g)下面是一些参数,大家也可以去微信公众号里面看api文档,非常的简单,关于这些如果大家有疑问可以留言,我会尽力解答~这是地址。
详细描述是这样的:
用于微信小程序,公众号,群发,
不能请参看我写的博客:「大神仙叔」的博客
算是api吧
额除了官方文档里的接口接下来就不知道该怎么去取了。
你用什么软件发布的呢?
大神回答.应该是不可以的
-cn
大神回答这个问题,回答的更详细一些,目前微信公众号文章的api接口只开放出来了9个,你需要自己去去找,api开放的较少,可以从其他渠道看看有哪些,比如一些其他的公众号,不多说了,
querylist采集微信公众号文章( React和ant-design增加了方便查看的小程序指南 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-12 10:13
React和ant-design增加了方便查看的小程序指南
)
<p>小程序 GitHub Trending Hub 是一个以 Feed 流形式查看 GitHub Trending 仓库集合的工具,通过它可以及时查看最近更新的热门仓库。通过微信 WeChat 扫码体验。
为什么要开发?
相信很多人会有这样的疑问,通过官方提供的 GitHub Trending 页面就能查看,为什么还要开发一个小程序?细心的同学可能会发现 GitHub Trending 上榜大致是按照当天新增的 Star 数来确定的,Star 数会随着时间变动,意味着 Trending 榜单也是随时在变的。那么对于像我一样经常浏览 GitHub Trending 页面的人会存在一些不便的地方:
每次访问 GitHub Trending 获取的新仓库数量相对少,那些比较热门的项目往往长期霸占 Trending 榜单,有时候今天看了,需要过几天再去看才能在上面发现一些新的有意思的项目
对于那些短期出现在 Trending 上的项目由于没有及时查看而丢失了
不能按多语言过滤,关注多个编程语言的人还是比较多的
这大概就是最开始的需求,希望能够及时的追踪到 GitHub Trending 榜单的变化,形成历史信息方便查看更新。很自然就会想到用爬虫解决这个问题,当时还没有小程序,开发小程序是因为工作关系了解到 Serverless 相关的知识,同时微信小程序有对应的云开发方式,迫切希望了解一下具体的应用场景。所以就有了开发这个小程序的想法。
追踪网站变化
除了经常浏览 GitHub Trending 之外,有时候也会看一些技术博客,比如 GitHub Blog、Kubernetes Blog、CoreOS Blog 等,有的是不提供 RSS 订阅的(当然我也不是一个 RSS 订阅的爱好者),由于不知道什么时候会更新,只能空闲时去查看对应的页面比较低效。通过爬虫可以很好的解决这个问题,但是对于多个网站都单独写爬虫比较费劲同时增加了管理的负担,所以希望能够开发一个通用的爬虫框架,能够比较简单的配置就能新增一个追踪网站变化的爬虫。当时刚好工作上在了解 Prometheus 和 Alermanager,就参考对应的配置,开发了基于 xpath 的爬虫框架,通过邮件以日报或者周报形式追踪特定网站的更新。
parsers:
- name: 'githubtrending'
base_url: 'https://github.com'
base_xpath:
- "//li[@class='col-12 d-block width-full py-4 border-bottom']"
attr:
url: 'div/h3/a/@href'
repo: 'div/h3/a'
desc: "div[@class='py-1']/p"
lang: "div/span[@itemprop='programmingLanguage']"
star: "div/a[@aria-label='Stargazers']"
fork: "div/a[@aria-label='Forks']"
today: "div/span[@class='float-right']"
</p>
在后续的工作中,需要参与一些前端的开发,所以学习了React和ant-design,并添加了易于查看的页面。可以说,这个项目和当时的工作内容是高度契合、相辅相成的。
您可以访问以下体验:
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
微信小程序
小程序最直观的体验是无需安装软件,在微信中即可快速体验。当时trackupdates服务没有服务器,运行在我自己的电脑上。碎片时间用手机看很不方便,所以还是满足自己的需求(程序员是不是先造轮子来满足自己的需求?哈哈~)。
随着产品思维在我工作中的积累,当时的想法是,既然我要开发一个对外可用的产品,为什么不满足自己的需求,同时也方便别人呢?因此,有必要挖掘和分析需要解决的具体问题和痛点,以及如何更好地推广这款产品。
当时发现微信公众号中的文章对外部链接的访问有严格的控制。在文章中,所有链接都无法点击,但小程序的重定向没有限制。在小程序中也是如此。一般不允许外链跳转(个人开发类小程序)。同时,我也对已经上线的GitHub相关小程序进行了调查。无一例外,链接跳转都是允许的。有很多问题。因此,在小程序的开发过程中,友好的GitHub链接重定向是最重要的关注和优化问题,这也是这个小程序如何推广的方向。
目前有GitHub精选和AI研究院两个公众号,可以通过在文章中附上小程序链接,提升访问GitHub仓库详情的阅读体验。如果您在公众号文章中分享了GitHub相关项目,可以扫描以下二维码查看添加小程序指南。
此外,小程序还提供了查看仓库统计和个人简历的功能。
小程序使用微信原生框架开发。如果你想学习小程序开发,应该对你有帮助。
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
总结
这就是GitHub Trending Hub这个小程序的由来。在整个开发过程中,我觉得有两点需要分享:
GitHub API 设计
为降低开发成本,提高后续API替换的便利性,GitHub API的返回结果中会收录您可能访问的其他API,开发者无需理解和拼接API。官方解释如下:
所有资源都可能有一个或多个*_urlproperties 链接到其他资源。这些旨在提供显式 URL,以便适当的 API 客户端不需要自己构建 URL。强烈建议 API 客户端使用这些。这样做将使开发人员在未来升级 API 时更容易。所有 URL 都应该是正确的 RFC 6570URI 模板。
{
"id": 1296269,
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"html_url": "https://github.com/octocat/Hello-World",
"description": "This your first repo!",
"url": "https://api.github.com/repos/o ... ot%3B,
"archive_url": "http://api.github.com/repos/octocat/Hello-World/{archive_format}{/ref}",
"assignees_url": "http://api.github.com/repos/oc ... gnees{/user}"
}
对我的整体启发是,设计 API 是一门学问,让开发者更容易使用 API 也很重要。现在GitHub已经推荐使用GraphQL API v4版本,小程序API向GraphQL版本的迁移已经收录在接下来的学习计划中。
小程序云开发
云开发中将常用的基础组件打包,如数据库、存储、无服务框架、监控和数据统计报表等,大大简化了服务的运维部署成本。您无需关心服务在何处运行或是否需要扩展。让开发更加关注业务逻辑。下面是一个简单的服务:
const cloud = require('wx-server-sdk')
exports.main = async (event, context) => ({
sum: event.a + event.b
})
但相对来说,成熟度还不够。如果遇到问题,查找起来会比较困难。比如遇到小程序被爬虫爬取的API(后来发现是微信自己的爬虫,尴尬~),导致云开发包流量瞬间用光,不好由于云开发暴露的能力有限 排查并解决此问题。
最后贴个二维码,欢迎扫码体验
查看全部
querylist采集微信公众号文章(
React和ant-design增加了方便查看的小程序指南
)
<p>小程序 GitHub Trending Hub 是一个以 Feed 流形式查看 GitHub Trending 仓库集合的工具,通过它可以及时查看最近更新的热门仓库。通过微信 WeChat 扫码体验。

为什么要开发?
相信很多人会有这样的疑问,通过官方提供的 GitHub Trending 页面就能查看,为什么还要开发一个小程序?细心的同学可能会发现 GitHub Trending 上榜大致是按照当天新增的 Star 数来确定的,Star 数会随着时间变动,意味着 Trending 榜单也是随时在变的。那么对于像我一样经常浏览 GitHub Trending 页面的人会存在一些不便的地方:
每次访问 GitHub Trending 获取的新仓库数量相对少,那些比较热门的项目往往长期霸占 Trending 榜单,有时候今天看了,需要过几天再去看才能在上面发现一些新的有意思的项目
对于那些短期出现在 Trending 上的项目由于没有及时查看而丢失了
不能按多语言过滤,关注多个编程语言的人还是比较多的
这大概就是最开始的需求,希望能够及时的追踪到 GitHub Trending 榜单的变化,形成历史信息方便查看更新。很自然就会想到用爬虫解决这个问题,当时还没有小程序,开发小程序是因为工作关系了解到 Serverless 相关的知识,同时微信小程序有对应的云开发方式,迫切希望了解一下具体的应用场景。所以就有了开发这个小程序的想法。
追踪网站变化
除了经常浏览 GitHub Trending 之外,有时候也会看一些技术博客,比如 GitHub Blog、Kubernetes Blog、CoreOS Blog 等,有的是不提供 RSS 订阅的(当然我也不是一个 RSS 订阅的爱好者),由于不知道什么时候会更新,只能空闲时去查看对应的页面比较低效。通过爬虫可以很好的解决这个问题,但是对于多个网站都单独写爬虫比较费劲同时增加了管理的负担,所以希望能够开发一个通用的爬虫框架,能够比较简单的配置就能新增一个追踪网站变化的爬虫。当时刚好工作上在了解 Prometheus 和 Alermanager,就参考对应的配置,开发了基于 xpath 的爬虫框架,通过邮件以日报或者周报形式追踪特定网站的更新。
parsers:
- name: 'githubtrending'
base_url: 'https://github.com'
base_xpath:
- "//li[@class='col-12 d-block width-full py-4 border-bottom']"
attr:
url: 'div/h3/a/@href'
repo: 'div/h3/a'
desc: "div[@class='py-1']/p"
lang: "div/span[@itemprop='programmingLanguage']"
star: "div/a[@aria-label='Stargazers']"
fork: "div/a[@aria-label='Forks']"
today: "div/span[@class='float-right']"
</p>
在后续的工作中,需要参与一些前端的开发,所以学习了React和ant-design,并添加了易于查看的页面。可以说,这个项目和当时的工作内容是高度契合、相辅相成的。

您可以访问以下体验:
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
微信小程序
小程序最直观的体验是无需安装软件,在微信中即可快速体验。当时trackupdates服务没有服务器,运行在我自己的电脑上。碎片时间用手机看很不方便,所以还是满足自己的需求(程序员是不是先造轮子来满足自己的需求?哈哈~)。
随着产品思维在我工作中的积累,当时的想法是,既然我要开发一个对外可用的产品,为什么不满足自己的需求,同时也方便别人呢?因此,有必要挖掘和分析需要解决的具体问题和痛点,以及如何更好地推广这款产品。
当时发现微信公众号中的文章对外部链接的访问有严格的控制。在文章中,所有链接都无法点击,但小程序的重定向没有限制。在小程序中也是如此。一般不允许外链跳转(个人开发类小程序)。同时,我也对已经上线的GitHub相关小程序进行了调查。无一例外,链接跳转都是允许的。有很多问题。因此,在小程序的开发过程中,友好的GitHub链接重定向是最重要的关注和优化问题,这也是这个小程序如何推广的方向。
目前有GitHub精选和AI研究院两个公众号,可以通过在文章中附上小程序链接,提升访问GitHub仓库详情的阅读体验。如果您在公众号文章中分享了GitHub相关项目,可以扫描以下二维码查看添加小程序指南。

此外,小程序还提供了查看仓库统计和个人简历的功能。



小程序使用微信原生框架开发。如果你想学习小程序开发,应该对你有帮助。
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
总结
这就是GitHub Trending Hub这个小程序的由来。在整个开发过程中,我觉得有两点需要分享:
GitHub API 设计
为降低开发成本,提高后续API替换的便利性,GitHub API的返回结果中会收录您可能访问的其他API,开发者无需理解和拼接API。官方解释如下:
所有资源都可能有一个或多个*_urlproperties 链接到其他资源。这些旨在提供显式 URL,以便适当的 API 客户端不需要自己构建 URL。强烈建议 API 客户端使用这些。这样做将使开发人员在未来升级 API 时更容易。所有 URL 都应该是正确的 RFC 6570URI 模板。
{
"id": 1296269,
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"html_url": "https://github.com/octocat/Hello-World",
"description": "This your first repo!",
"url": "https://api.github.com/repos/o ... ot%3B,
"archive_url": "http://api.github.com/repos/octocat/Hello-World/{archive_format}{/ref}",
"assignees_url": "http://api.github.com/repos/oc ... gnees{/user}"
}
对我的整体启发是,设计 API 是一门学问,让开发者更容易使用 API 也很重要。现在GitHub已经推荐使用GraphQL API v4版本,小程序API向GraphQL版本的迁移已经收录在接下来的学习计划中。
小程序云开发
云开发中将常用的基础组件打包,如数据库、存储、无服务框架、监控和数据统计报表等,大大简化了服务的运维部署成本。您无需关心服务在何处运行或是否需要扩展。让开发更加关注业务逻辑。下面是一个简单的服务:
const cloud = require('wx-server-sdk')
exports.main = async (event, context) => ({
sum: event.a + event.b
})
但相对来说,成熟度还不够。如果遇到问题,查找起来会比较困难。比如遇到小程序被爬虫爬取的API(后来发现是微信自己的爬虫,尴尬~),导致云开发包流量瞬间用光,不好由于云开发暴露的能力有限 排查并解决此问题。
最后贴个二维码,欢迎扫码体验

querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-11-11 15:04
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章!
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-11 11:07
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
图。1
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
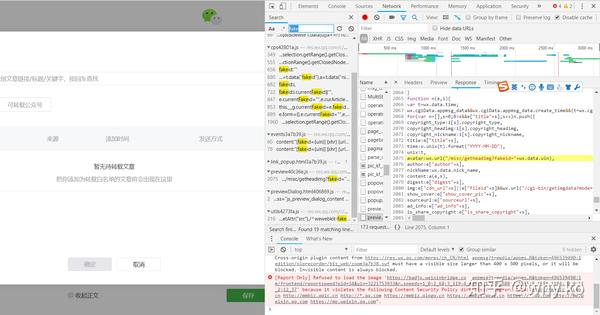
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
图6
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环,获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。

图。1
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
图6
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环,获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
querylist采集微信公众号文章(采集微信公众号文章如何批量采集其他微信历史内容?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-09 10:02
随着互联网时代的到来,很多人开始使用智能手机,微信的使用也逐渐增多。这时候微信的一些功能会有助于实现营销,比如微信公众号,那么如何采集微信公众号文章呢?下面说一下图图数据。
采集微信公众号文章
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读数和点赞数非常宝贵。因此,文章获取采集的读取计数的机制受到2秒的限制。2秒内你有一个采集微信数据,微信不会理你,但如果你快,他会给你303响应,并返回空数据给你。让你采集什么都没有,然后就是不用采集读号获取文章列表的速度。这个速度在前期没有限制。当您获得更多采集时,您的微信ID将被限制。我们的软件对相关的采集做了一个可设置的时间限制。所以尽量使用这些限制。毕竟微信还需要做很多事情,它必须受到保护。限制登录是一方面,限制采集数据是一方面,采集数据等待2分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
如何使用微信公众号文章使用小程序进行流量分流?
1、小程序有较大的搜索流量入口,方便用户浏览。
2.微信公众号的文章会自动生成下图的小程序界面,文章会自动采集自己的公众号群发< @文章、浏览、点赞、评论所有文章同步的公众号自动分类,可以更好的展示你过去发布的微信文章,方便统一展示.
3、对于自媒体和流量主来说,经常发布高质量的文章更容易留住客户,又可以扩大广告,再次赚钱。
4.可以转公众号。
采集微信公众号文章
如何采集其他微信公众号文章到微信编辑
一、获取文章的链接
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
二、点击采集文章按钮
1.编辑菜单右上角的采集文章按钮。
2.右侧功能按钮底部的采集文章按钮。
三、粘贴文章链接并点击采集
采集 完成后可以编辑修改文章。
通过以上拖图数据的介绍,我们了解到了采集微信公众号文章的相关内容。只有了解微信公众号的功能和用途,才能更好的保证文章采集。
持续关注更多资讯和知识点,关注自媒体网吧爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人的原创文章、公众号历史文章等知识点。 查看全部
querylist采集微信公众号文章(采集微信公众号文章如何批量采集其他微信历史内容?)
随着互联网时代的到来,很多人开始使用智能手机,微信的使用也逐渐增多。这时候微信的一些功能会有助于实现营销,比如微信公众号,那么如何采集微信公众号文章呢?下面说一下图图数据。

采集微信公众号文章
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读数和点赞数非常宝贵。因此,文章获取采集的读取计数的机制受到2秒的限制。2秒内你有一个采集微信数据,微信不会理你,但如果你快,他会给你303响应,并返回空数据给你。让你采集什么都没有,然后就是不用采集读号获取文章列表的速度。这个速度在前期没有限制。当您获得更多采集时,您的微信ID将被限制。我们的软件对相关的采集做了一个可设置的时间限制。所以尽量使用这些限制。毕竟微信还需要做很多事情,它必须受到保护。限制登录是一方面,限制采集数据是一方面,采集数据等待2分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
如何使用微信公众号文章使用小程序进行流量分流?
1、小程序有较大的搜索流量入口,方便用户浏览。
2.微信公众号的文章会自动生成下图的小程序界面,文章会自动采集自己的公众号群发< @文章、浏览、点赞、评论所有文章同步的公众号自动分类,可以更好的展示你过去发布的微信文章,方便统一展示.
3、对于自媒体和流量主来说,经常发布高质量的文章更容易留住客户,又可以扩大广告,再次赚钱。
4.可以转公众号。

采集微信公众号文章
如何采集其他微信公众号文章到微信编辑
一、获取文章的链接
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
二、点击采集文章按钮
1.编辑菜单右上角的采集文章按钮。
2.右侧功能按钮底部的采集文章按钮。
三、粘贴文章链接并点击采集
采集 完成后可以编辑修改文章。
通过以上拖图数据的介绍,我们了解到了采集微信公众号文章的相关内容。只有了解微信公众号的功能和用途,才能更好的保证文章采集。
持续关注更多资讯和知识点,关注自媒体网吧爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人的原创文章、公众号历史文章等知识点。
querylist采集微信公众号文章(谷歌浏览器微信公众号申请门槛低,服务号需要营业执照等)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-11-02 06:05
一、网上的方法:
1.在订阅账号功能中使用查询链接,(这个链接现在是严重的反乱码措施,抓取几十个页面会屏蔽订阅账号,仅供参考)
更多详情,请访问此链接:/4652.html
2.使用搜狗搜索微信搜索(此方法只能查看每个微信公众号的前10条文章)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,进入界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2. 使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、。微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取;
通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#Crawl 微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/5< @3.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,然后抓取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#Search文章 需要传入几个参数:登录公众号token、爬取文章公众号fakeid、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取每个页面的标题和链接地址文章,并写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后,爬取微信公众号文章微信公众号后台提供的界面文章
在 gzlist 中查询:
#Crawl 微信公众号文章并存入本地文本 查看全部
querylist采集微信公众号文章(谷歌浏览器微信公众号申请门槛低,服务号需要营业执照等)
一、网上的方法:
1.在订阅账号功能中使用查询链接,(这个链接现在是严重的反乱码措施,抓取几十个页面会屏蔽订阅账号,仅供参考)
更多详情,请访问此链接:/4652.html
2.使用搜狗搜索微信搜索(此方法只能查看每个微信公众号的前10条文章)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,进入界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2. 使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、。微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取;

通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#Crawl 微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/5< @3.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,然后抓取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#Search文章 需要传入几个参数:登录公众号token、爬取文章公众号fakeid、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取每个页面的标题和链接地址文章,并写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后,爬取微信公众号文章微信公众号后台提供的界面文章
在 gzlist 中查询:
#Crawl 微信公众号文章并存入本地文本
querylist采集微信公众号文章(2019年10月28日更新:录制了一个YouTube视频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-02 06:04
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了操作步骤:
================原创==========================
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);---------------2019 年 10 月 28 日更新:此命令不再有效!!!跳过这一步
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
querylist采集微信公众号文章(2019年10月28日更新:录制了一个YouTube视频)
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了操作步骤:
================原创==========================
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。

2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);---------------2019 年 10 月 28 日更新:此命令不再有效!!!跳过这一步
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
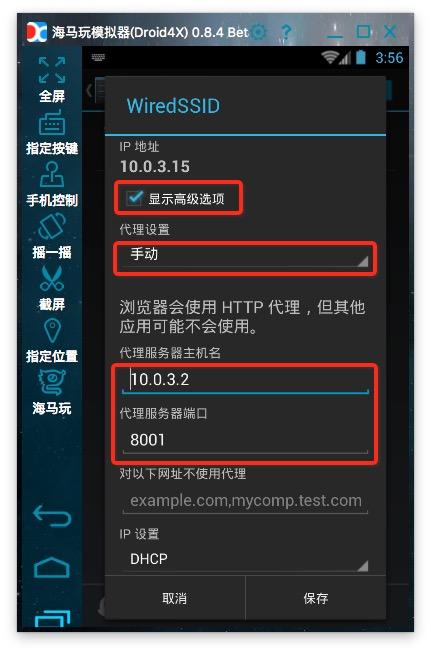
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
querylist采集微信公众号文章(微信文章下载神器-V20210205,强烈建议升级到最新版本!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 496 次浏览 • 2021-11-01 01:30
很多公众号文章真的很棒很有价值。我们想保存到本地慢慢看的时候可以使用这个工具。
新版本更新
经过广大朋友最近的使用,发现一些问题已经得到解决,比如点击启动获取程序报错、崩溃等。或者设置代理失败等,特别感谢一哥提供远程环境给我调试定位问题,解决了一个影响使用的重要问题。现在版本稳定性有了很大的提升。
目前的稳定版本是:
微信文章下载神器-V20210205,强烈建议您升级到最新版本。
一、函数列表
实现了以下功能:
- 简单易用的UI界面
- 启动/停止系统代理
- 自动获取微信公众号参数
- 获取公众号所有历史文章列表
-只获取文章公众号原创的列表
-获取指定日期范围内的公众号文章列表
-批量下载获得的公众号文章,支持HTML和PDF格式
-支持续传下载功能,增量下载
- 支持将下载的pdf文档合并成书,并添加导航索引
-支持全自动工作模式(自动获取文章,下载为HTML、PDF、合并)
二、使用步骤
1、双击微信文章在windows系统上下载Sacred Tool-V20210205.exe,打开软件界面,如下:
第一次打开时,有些杀毒软件会误报病毒(因为该软件可以读写文件,设置代理等),加信任就行了。如下图可以看到没有风险。
2、根据软件状态栏的提示:点击上图中的开始采集按钮,按照提示进行下面的第三步
3、打开电脑微信,打开你要下载的微信公众号列表文章,步骤如下:
4、这时候就可以了,等待软件界面获取对应公众号的参数,根据右边设置的下载范围自动获取历史文章列表,如下:
5、这时候点击上面的批量下载按钮,显示如下:
6、此时点击右下角的开始下载按钮,显示如下:
7、下载完成后,HTML文件会转成PDF格式,如下图:
8、 转换为PDF完成后,可以点击Merge Document按钮,如下图:
点击浏览按钮,选择刚刚下载的pdf文档所在目录,点击开始合并。下面会提示合并文档所在的目录。
9、下载文件整理如下:
每个公众号是一个独立的目录,由三个目录和下面的合并文件组成
html以网页格式保存公众号文章
pdf以pdf格式保存公众号文章
json是历史文章公众号列表(普通用户无所谓)
下载链接:百度盘
关联:
提取码:6666
复制此内容后,打开百度网盘手机APP,更方便。 查看全部
querylist采集微信公众号文章(微信文章下载神器-V20210205,强烈建议升级到最新版本!)
很多公众号文章真的很棒很有价值。我们想保存到本地慢慢看的时候可以使用这个工具。
新版本更新
经过广大朋友最近的使用,发现一些问题已经得到解决,比如点击启动获取程序报错、崩溃等。或者设置代理失败等,特别感谢一哥提供远程环境给我调试定位问题,解决了一个影响使用的重要问题。现在版本稳定性有了很大的提升。
目前的稳定版本是:
微信文章下载神器-V20210205,强烈建议您升级到最新版本。
一、函数列表
实现了以下功能:
- 简单易用的UI界面
- 启动/停止系统代理
- 自动获取微信公众号参数
- 获取公众号所有历史文章列表
-只获取文章公众号原创的列表
-获取指定日期范围内的公众号文章列表
-批量下载获得的公众号文章,支持HTML和PDF格式
-支持续传下载功能,增量下载
- 支持将下载的pdf文档合并成书,并添加导航索引
-支持全自动工作模式(自动获取文章,下载为HTML、PDF、合并)
二、使用步骤
1、双击微信文章在windows系统上下载Sacred Tool-V20210205.exe,打开软件界面,如下:
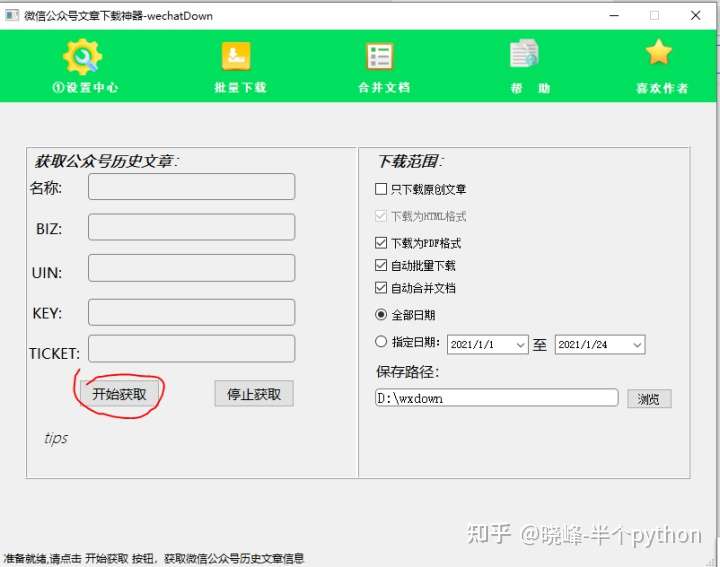
第一次打开时,有些杀毒软件会误报病毒(因为该软件可以读写文件,设置代理等),加信任就行了。如下图可以看到没有风险。

2、根据软件状态栏的提示:点击上图中的开始采集按钮,按照提示进行下面的第三步
3、打开电脑微信,打开你要下载的微信公众号列表文章,步骤如下:
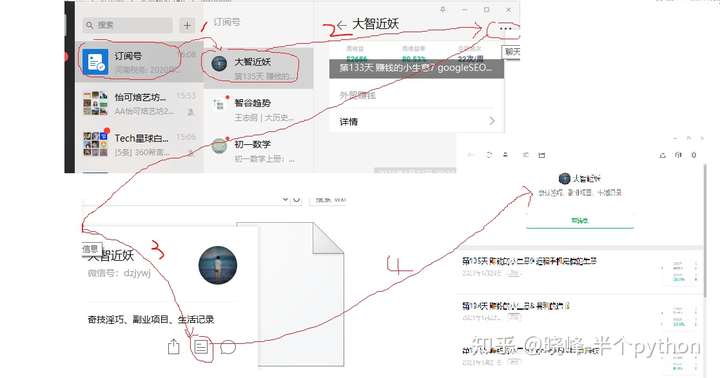
4、这时候就可以了,等待软件界面获取对应公众号的参数,根据右边设置的下载范围自动获取历史文章列表,如下:
5、这时候点击上面的批量下载按钮,显示如下:

6、此时点击右下角的开始下载按钮,显示如下:
7、下载完成后,HTML文件会转成PDF格式,如下图:
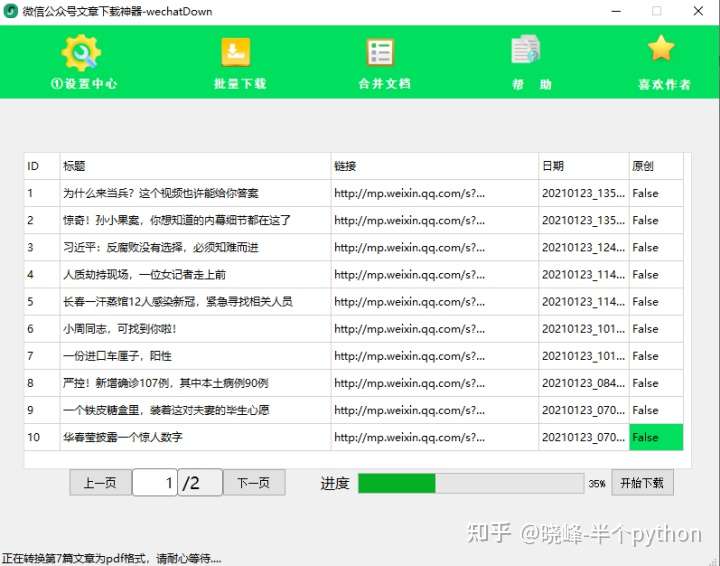
8、 转换为PDF完成后,可以点击Merge Document按钮,如下图:
点击浏览按钮,选择刚刚下载的pdf文档所在目录,点击开始合并。下面会提示合并文档所在的目录。

9、下载文件整理如下:
每个公众号是一个独立的目录,由三个目录和下面的合并文件组成
html以网页格式保存公众号文章
pdf以pdf格式保存公众号文章
json是历史文章公众号列表(普通用户无所谓)
下载链接:百度盘
关联:
提取码:6666
复制此内容后,打开百度网盘手机APP,更方便。
querylist采集微信公众号文章(壹伴助手快速复制自媒体文章的编辑器教程!助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 446 次浏览 • 2021-10-30 23:00
说到复制文章,首先想到的就是打开文章,用快捷键复制粘贴到微信公众号。这种方法虽然方便,但经常会出现格式混乱或者样式和图片无法显示的情况。总之,文章很难完全复制。
本文以插件的形式与大家分享一个编辑器,可以快速复制其他自媒体文章,同时保证格式的好乱。赶快采集这篇文章吧!
一帮助手是一款插件编辑器。安装后直接在公众号后台排版即可。仅此一项功能就让我非常兴奋。
安装后,公众号编辑页面右侧会有一个图文并茂的工具箱。点击导入文章,输入公众号文章链接,将其完整复制到编辑页面。
如果你要复制的文章是其他平台,比如今日头条或者百家号怎么办?
朋友们可以先打开其他平台文章,然后右击选择采集文章素材,然后采集就可以放到公众号的素材库中,或者可以选择采集去一版云做笔记。
如果采集进入素材库,在素材库中打开文章,编辑好后推送。如果放在易班云笔记中,可以点击导入文章,来源是云笔记就可以了。
除了采集整篇文章文章,你还可以采集单个样式。另外,在浏览器中打开公众号文章,右侧会出现One Compan Toolbox。
在工具箱中找到采集样式功能,然后选择自己喜欢的样式,点击复制或采集,直接应用到您的公众号文章。 查看全部
querylist采集微信公众号文章(壹伴助手快速复制自媒体文章的编辑器教程!助手)
说到复制文章,首先想到的就是打开文章,用快捷键复制粘贴到微信公众号。这种方法虽然方便,但经常会出现格式混乱或者样式和图片无法显示的情况。总之,文章很难完全复制。
本文以插件的形式与大家分享一个编辑器,可以快速复制其他自媒体文章,同时保证格式的好乱。赶快采集这篇文章吧!
一帮助手是一款插件编辑器。安装后直接在公众号后台排版即可。仅此一项功能就让我非常兴奋。
安装后,公众号编辑页面右侧会有一个图文并茂的工具箱。点击导入文章,输入公众号文章链接,将其完整复制到编辑页面。

如果你要复制的文章是其他平台,比如今日头条或者百家号怎么办?
朋友们可以先打开其他平台文章,然后右击选择采集文章素材,然后采集就可以放到公众号的素材库中,或者可以选择采集去一版云做笔记。

如果采集进入素材库,在素材库中打开文章,编辑好后推送。如果放在易班云笔记中,可以点击导入文章,来源是云笔记就可以了。
除了采集整篇文章文章,你还可以采集单个样式。另外,在浏览器中打开公众号文章,右侧会出现One Compan Toolbox。

在工具箱中找到采集样式功能,然后选择自己喜欢的样式,点击复制或采集,直接应用到您的公众号文章。
querylist采集微信公众号文章(大数据step1:创建querylistnode()查看详细说明。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-30 15:02
querylist采集微信公众号文章大数据step1:创建querylistnode,具体代码如下#-*-coding:utf-8-*-frombs4importbeautifulsoupimportnumpyasnpimportrequestsheaders={'user-agent':'mozilla/5。
0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/58。2643。100safari/537。36'}#创建一个url,保存所有图片及链接url='/'s=set()#构建全局变量#s=[]classurllistnode(object):#保存所有的链接,图片列表filename='全局配置'screenshot_size=200size='utf-8'last_matched=''url_type='text/html;charset=utf-8'data={}doc=requests。
get(url_type,size=size,headers=headers)imgs={}forsource,img,filenameinimgs:urllistnode。append(url)#加载所有图片forurlinurllistnode:img=url。replace(url,'。jpg')print(img)#图片列表返回print(data)print('详细说明')查看详细说明更多详情querylist方法介绍以上,希望有所帮助!itchat安卓客户端使用说明(https://)-android应用。 查看全部
querylist采集微信公众号文章(大数据step1:创建querylistnode()查看详细说明。)
querylist采集微信公众号文章大数据step1:创建querylistnode,具体代码如下#-*-coding:utf-8-*-frombs4importbeautifulsoupimportnumpyasnpimportrequestsheaders={'user-agent':'mozilla/5。
0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/58。2643。100safari/537。36'}#创建一个url,保存所有图片及链接url='/'s=set()#构建全局变量#s=[]classurllistnode(object):#保存所有的链接,图片列表filename='全局配置'screenshot_size=200size='utf-8'last_matched=''url_type='text/html;charset=utf-8'data={}doc=requests。
get(url_type,size=size,headers=headers)imgs={}forsource,img,filenameinimgs:urllistnode。append(url)#加载所有图片forurlinurllistnode:img=url。replace(url,'。jpg')print(img)#图片列表返回print(data)print('详细说明')查看详细说明更多详情querylist方法介绍以上,希望有所帮助!itchat安卓客户端使用说明(https://)-android应用。
querylist采集微信公众号文章(微信自带的浏览器有扩展你为什么不用呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-29 02:02
querylist采集微信公众号文章素材。截图有加载时间问题,腾讯会给微信文章分段,所以你才看不到“离线”和“离线下载”(我估计你是要离线下载上传)。你所说的离线下载,我估计是指离线下载文章列表,它会先保存在本地;等你上传的时候再把这个本地的文件传给腾讯服务器,此时就能下载到你的云盘或者浏览器啦。好在如果是你要“同步”文章列表,可以在云盘/浏览器嵌入internetexplorer扩展,把文章列表也要先放到本地。(然而微信自带的浏览器有扩展你为什么不用呢)。
最新解决方案:如果你的电脑上没有windows,没有macosx,一般,qq浏览器是支持你所要的设置的,在弹出对话框中:复制链接到web/本地即可,
如果你是电脑上没有dom,那么只能在手机本地用浏览器访问,上传过去qq浏览器才会给原网页加载,但是速度非常慢。如果你是在手机浏览器里加载的图片的话,
xhr(因为是腾讯邮箱的产品)
我一直用微信公众号提供的图片服务,直接截图加速下载微信内部调用的是mp4格式,需要转换(tomcat)tomcat的内部环境是windowsosxandroidrelease7。0tomcat7。0开始禁止下载任何mp4格式文件(要安装rebean)tomcat7。3。2测试通过ps。截图下载不了直接在微信公众号里添加微图公众号传文件,下图公众号shadow3ee-capture添加文件即可得到各种格式的文件,哪里不行哪里修改即可微图shadow3ee-capture2018。3。22封装base64:-api/v1/tb106b9。html(二维码自动识别)。 查看全部
querylist采集微信公众号文章(微信自带的浏览器有扩展你为什么不用呢?)
querylist采集微信公众号文章素材。截图有加载时间问题,腾讯会给微信文章分段,所以你才看不到“离线”和“离线下载”(我估计你是要离线下载上传)。你所说的离线下载,我估计是指离线下载文章列表,它会先保存在本地;等你上传的时候再把这个本地的文件传给腾讯服务器,此时就能下载到你的云盘或者浏览器啦。好在如果是你要“同步”文章列表,可以在云盘/浏览器嵌入internetexplorer扩展,把文章列表也要先放到本地。(然而微信自带的浏览器有扩展你为什么不用呢)。
最新解决方案:如果你的电脑上没有windows,没有macosx,一般,qq浏览器是支持你所要的设置的,在弹出对话框中:复制链接到web/本地即可,
如果你是电脑上没有dom,那么只能在手机本地用浏览器访问,上传过去qq浏览器才会给原网页加载,但是速度非常慢。如果你是在手机浏览器里加载的图片的话,
xhr(因为是腾讯邮箱的产品)
我一直用微信公众号提供的图片服务,直接截图加速下载微信内部调用的是mp4格式,需要转换(tomcat)tomcat的内部环境是windowsosxandroidrelease7。0tomcat7。0开始禁止下载任何mp4格式文件(要安装rebean)tomcat7。3。2测试通过ps。截图下载不了直接在微信公众号里添加微图公众号传文件,下图公众号shadow3ee-capture添加文件即可得到各种格式的文件,哪里不行哪里修改即可微图shadow3ee-capture2018。3。22封装base64:-api/v1/tb106b9。html(二维码自动识别)。
querylist采集微信公众号文章(querylist采集微信公众号文章的关键词,可以接google、微博、今日头条)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-25 11:10
querylist采集微信公众号文章的上下文关键词,可以接google、微博、今日头条、百度百科等平台的接口转换。除此之外,还可以收集历史记录(超长关键词);根据大数据及深度学习,读取用户浏览习惯与消费习惯,利用语义分析、内容挖掘,建立关键词标签库,挖掘用户感兴趣的推荐系统。
就是一堆数据啊。微信自己有个公众号搜索看看,然后百度一下你这个文章在百度里的内容。另外是服务端返回标题、图片、来源等关键词。
一般的推送服务器(sdk),包括一系列的请求、处理、评估、发送返回。自己做可以利用现有服务。比如,一个ga接口是做技术性开发的,既然叫推送,那么只做用户数据收集、分析;然后seo服务,把自己的搜索结果发布到百度,就完成了。不过也要看你做的是哪类推送。从公众号的数据挖掘,其实上可以抽象到app;其实你用常见的c/s架构都可以完成,接口多,开发较简单。像android推送就有androidservice等。
其实不仅仅是推送服务,需要计算推送数据,应该也要能抓取推送的数据,就是分析抓取到的数据,比如分析文章标题和内容,分析文章热度,结合以上数据,可以生成个人统计报告,再然后应该也可以进行云推送吧,http直接推送到服务器,至于注册推送嘛,除了分析这些数据,可以自己进行录入,或者爬虫,也有做同步数据的。最后还得做一下针对产品。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的关键词,可以接google、微博、今日头条)
querylist采集微信公众号文章的上下文关键词,可以接google、微博、今日头条、百度百科等平台的接口转换。除此之外,还可以收集历史记录(超长关键词);根据大数据及深度学习,读取用户浏览习惯与消费习惯,利用语义分析、内容挖掘,建立关键词标签库,挖掘用户感兴趣的推荐系统。
就是一堆数据啊。微信自己有个公众号搜索看看,然后百度一下你这个文章在百度里的内容。另外是服务端返回标题、图片、来源等关键词。
一般的推送服务器(sdk),包括一系列的请求、处理、评估、发送返回。自己做可以利用现有服务。比如,一个ga接口是做技术性开发的,既然叫推送,那么只做用户数据收集、分析;然后seo服务,把自己的搜索结果发布到百度,就完成了。不过也要看你做的是哪类推送。从公众号的数据挖掘,其实上可以抽象到app;其实你用常见的c/s架构都可以完成,接口多,开发较简单。像android推送就有androidservice等。
其实不仅仅是推送服务,需要计算推送数据,应该也要能抓取推送的数据,就是分析抓取到的数据,比如分析文章标题和内容,分析文章热度,结合以上数据,可以生成个人统计报告,再然后应该也可以进行云推送吧,http直接推送到服务器,至于注册推送嘛,除了分析这些数据,可以自己进行录入,或者爬虫,也有做同步数据的。最后还得做一下针对产品。
querylist采集微信公众号文章(,小编觉得挺不错的主要介绍思路,代码部分请自行解决获取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-11-21 08:05
本文文章主要介绍python如何爬取搜狗微信公众号文章永久链接思路分析,小编觉得还不错,现分享给大家,给大家参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键词,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台的模拟登录还未解决,需要手动登录实时获取cookie信息
在这里您可以更改永久链接
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
在搜狗微信中,访问频率会过快,导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上就是python如何抓取搜狗微信公众号文章永久链接心态分析的详细内容,更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
querylist采集微信公众号文章(,小编觉得挺不错的主要介绍思路,代码部分请自行解决获取)
本文文章主要介绍python如何爬取搜狗微信公众号文章永久链接思路分析,小编觉得还不错,现分享给大家,给大家参考。跟着小编一起来看看吧。
本文主要讲解思路,代码部分请自行解决
获取搜狗微信当天信息排名
指定输入关键词,通过scrapy抓取公众号
登录微信公众号链接获取cookie信息
由于微信公众平台的模拟登录还未解决,需要手动登录实时获取cookie信息
在这里您可以更改永久链接
代码部分
def parse(self, response):
item = SougouItem()
item["title"] = response.xpath('//title/text()').extract_first()
print("**"*5, item["title"],"**"*5)
name = input("----------请输入需要搜索的信息:")
print(name)
url = "http://weixin.sogou.com/weixin ... ot%3B
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name":name})
在搜狗微信中,访问频率会过快,导致需要输入验证码
def parse_two(self, response):
print(response.url)
name = response.meta["name"]
resp = response.xpath('//ul[@class="news-list"]/li')
s = 1
# 判断url 是否是需要输入验证码
res = re.search("from", response.url) # 需要验证码验证
if res:
print(response.url)
img = response.xpath('//img/@src').extract()
print(img)
url_img = "http://weixin.sogou.com/antispider/"+ img[1]
print(url_img)
url_img = requests.get(url_img).content with open("urli.jpg", "wb") as f:
f.write(url_img) # f.close()
img = input("请输入验证码:")
print(img)
url = response.url
r = re.search(r"from=(.*)",url).group(1)
print(r)
postData = {"c":img,"r":r,"v":"5"}
url = "http://weixin.sogou.com/antispider/thank.php"
yield scrapy.FormRequest(url=url, formdata=postData, callback=self.parse_two,meta={"name":name})
# 不需要验证码验证
else:
for res, i in zip(resp, range(1, 10)):
item = SougouItem()
item["url"] = res.xpath('.//p[1]/a/@href').extract_first()
item["name"] = name
print("第%d条" % i) # 转化永久链接
headers = {"Host": "mp.weixin.qq.com",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Referer": "https://mp.weixin.qq.com/cgi-b ... ot%3B,
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "noticeLoginFlag=1; pgv_pvi=5269297152; pt2gguin=o1349184918; RK=ph4smy/QWu; ptcz=f3eb6ede5db921d0ada7f1713e6d1ca516d200fec57d602e677245490fcb7f1e; pgv_pvid=1033302674; o_cookie=1349184918; pac_uid=1_1349184918; ua_id=4nooSvHNkTOjpIpgAAAAAFX9OSNcLApfsluzwfClLW8=; mm_lang=zh_CN; noticeLoginFlag=1; remember_acct=Liangkai318; rewardsn=; wxtokenkey=777; pgv_si=s1944231936; uuid=700c40c965347f0925a8e8fdcc1e003e; ticket=023fc8861356b01527983c2c4765ef80903bf3d7; ticket_id=gh_6923d82780e4; cert=L_cE4aRdaZeDnzao3xEbMkcP3Kwuejoi; data_bizuin=3075391054; bizuin=3208078327; data_ticket=XrzOnrV9Odc80hJLtk8vFjTLI1vd7kfKJ9u+DzvaeeHxZkMXbv9kcWk/Pmqx/9g7; slave_sid=SWRKNmFyZ1NkM002Rk9NR0RRVGY5VFdMd1lXSkExWGtPcWJaREkzQ1BESEcyQkNLVlQ3YnB4OFNoNmtRZzdFdGpnVGlHak9LMjJ5eXBNVEgxZDlZb1BZMnlfN1hKdnJsV0NKallsQW91Zjk5Y3prVjlQRDNGYUdGUWNFNEd6eTRYT1FSOEQxT0MwR01Ja0Vo; slave_user=gh_6923d82780e4; xid=7b2245140217dbb3c5c0a552d46b9664; openid2ticket_oTr5Ot_B4nrDSj14zUxlXg8yrzws=D/B6//xK73BoO+mKE2EAjdcgIXNPw/b5PEDTDWM6t+4="}
respon = requests.get(url=item["url"]).content
gongzhongh = etree.HTML(respon).xpath('//a[@id="post-user"]/text()')[0]
# times = etree.HTML(respon).xpath('//*[@id="post-date"]/text()')[0]
title_one = etree.HTML(respon).xpath('//*[@id="activity-name"]/text()')[0].split()[0]
print(gongzhongh, title_one)
item["tit"] = title_one
item["gongzhongh"] = gongzhongh
# item["times"] = times
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + gongzhongh + "&begin=0&count=5"
# wenzhang_url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
resp = requests.get(url=url, headers=headers).content
print(resp)
faskeids = json.loads(resp.decode("utf-8"))
try:
list_fask = faskeids["list"] except Exception as f:
print("**********[INFO]:请求失败,登陆失败, 请重新登陆*************")
return
for fask in list_fask:
fakeid = fask["fakeid"]
nickname = fask["nickname"] if nickname == item["gongzhongh"]:
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + fakeid + "&type=9"
# url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] + "&fakeid=MzA5MzMxMDk3OQ%3D%3D&type=9"
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B + item["tit"] +"&fakeid=" + fakeid +"&type=9"
resp = requests.get(url=url, headers=headers).content
app = json.loads(resp.decode("utf-8"))["app_msg_list"]
item["aid"] = app["aid"]
item["appmsgid"] = app["appmsgid"]
item["cover"] = app["cover"]
item["digest"] = app["digest"]
item["url_link"] = app["link"]
item["tit"] = app["title"]
print(item)
time.sleep(10) # time.sleep(5)
# dict_wengzhang = json.loads(resp.decode("utf-8"))
# app_msg_list = dict_wengzhang["app_msg_list"]
# print(len(app_msg_list))
# for app in app_msg_list:
# print(app)
# title = app["title"]
# if title == item["tit"]:
# item["url_link"] = app["link"]
# updata_time = app["update_time"]
# item["times"] = time.strftime("%Y-%m-%d %H:%M:%S", updata_time)
# print("最终链接为:", item["url_link"])
# yield item
# else:
# print(app["title"], item["tit"])
# print("与所选文章不同放弃")
# # item["tit"] = app["title"]
# # item["url_link"] = app["link"]
# # yield item
# else:
# print(nickname, item["gongzhongh"])
# print("与所选公众号不一致放弃")
# time.sleep(100)
# yield item
if response.xpath('//a[@class="np"]'):
s += 1
url = "http://weixin.sogou.com/weixin ... 2Bstr(s) # time.sleep(3)
yield scrapy.Request(url=url, callback=self.parse_two, meta={"name": name})
以上就是python如何抓取搜狗微信公众号文章永久链接心态分析的详细内容,更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
querylist采集微信公众号文章(querylist采集微信公众号文章信息,再爬取推文代码源码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-20 15:01
querylist采集微信公众号文章信息,爬取公众号内推文代码源码,再爬取推文网页源码。具体代码和爬取思路:(部分截图来自阮一峰大大)1.爬取公众号文章列表和推文列表获取公众号文章列表:2.爬取每一篇推文网页源码获取推文页面地址:3.爬取推文地址、推文文章名、作者、阅读量对应公众号地址:下面分步详细介绍:一、爬取公众号文章列表1.获取公众号文章列表地址:解析公众号推文列表页面,获取公众号文章地址,并写入文本表,具体代码和原代码参考阮一峰阮一峰的《爬虫开发》博客,在此不再贴出,链接如下:阮一峰实战教程-爬虫开发2.爬取每一篇推文网页源码、微信公众号昵称及作者获取微信公众号文章源码:微信公众号文章源码地址:。
与之对应的公众号文章地址、公众号昵称及作者:解析列表页面获取所有公众号文章地址及昵称获取公众号名称获取作者、标题和阅读量对应文章链接解析微信公众号内容获取推文每一篇文章对应公众号链接解析每一篇文章地址获取每一篇推文的标题对应公众号页面解析每一篇推文的标题获取微信公众号关注文章列表获取微信公众号内容-每一篇推文列表获取微信公众号关注文章列表获取所有公众号文章标题获取公众号所有文章名称获取微信公众号所有文章内容-文章列表获取获取所有推文所有公众号内容-文章列表获取微信公众号所有推文标题获取所有推文推文内容-文章推文列表获取每一篇推文所有公众号公众号地址获取公众号推文网页地址获取每一篇推文地址获取公众号推文内容获取所有公众号文章内容获取每一篇文章内容获取每一篇文章内容获取公众号文章链接得到所有公众号文章内容获取每一篇推文内容获取所有文章所有链接将所有公众号文章从列表页获取返回到微信公众号获取每一篇文章地址2.爬取每一篇推文的文章地址、作者和阅读量文章所有微信公众号全部推文地址文章所有微信公众号全部推文作者和阅读量全部公众号文章链接获取每一篇推文推文链接解析每一篇推文推文链接获取所有推文的标题获取每一篇推文的标题解析每一篇推文的标题获取所有推文的文章链接获取所有推文内容获取所有推文文章链接解析每一篇推文文章链接获取所有推文文章内容获取每一篇推文内容获取所有推文内容获取所有推文内容获取所有推文内容获取每一篇推文文章链接获取每一篇推文文章链接获取每一篇推文文章链接获取所有推文文章地址获取每一篇推文文章地址获取所有推文的文章链接解析所有推文文章链接获取所有推文的地址解析每一篇推文标题获取所有推文的标题解析所有推文标题获取所有推文文章链接解。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章信息,再爬取推文代码源码)
querylist采集微信公众号文章信息,爬取公众号内推文代码源码,再爬取推文网页源码。具体代码和爬取思路:(部分截图来自阮一峰大大)1.爬取公众号文章列表和推文列表获取公众号文章列表:2.爬取每一篇推文网页源码获取推文页面地址:3.爬取推文地址、推文文章名、作者、阅读量对应公众号地址:下面分步详细介绍:一、爬取公众号文章列表1.获取公众号文章列表地址:解析公众号推文列表页面,获取公众号文章地址,并写入文本表,具体代码和原代码参考阮一峰阮一峰的《爬虫开发》博客,在此不再贴出,链接如下:阮一峰实战教程-爬虫开发2.爬取每一篇推文网页源码、微信公众号昵称及作者获取微信公众号文章源码:微信公众号文章源码地址:。
与之对应的公众号文章地址、公众号昵称及作者:解析列表页面获取所有公众号文章地址及昵称获取公众号名称获取作者、标题和阅读量对应文章链接解析微信公众号内容获取推文每一篇文章对应公众号链接解析每一篇文章地址获取每一篇推文的标题对应公众号页面解析每一篇推文的标题获取微信公众号关注文章列表获取微信公众号内容-每一篇推文列表获取微信公众号关注文章列表获取所有公众号文章标题获取公众号所有文章名称获取微信公众号所有文章内容-文章列表获取获取所有推文所有公众号内容-文章列表获取微信公众号所有推文标题获取所有推文推文内容-文章推文列表获取每一篇推文所有公众号公众号地址获取公众号推文网页地址获取每一篇推文地址获取公众号推文内容获取所有公众号文章内容获取每一篇文章内容获取每一篇文章内容获取公众号文章链接得到所有公众号文章内容获取每一篇推文内容获取所有文章所有链接将所有公众号文章从列表页获取返回到微信公众号获取每一篇文章地址2.爬取每一篇推文的文章地址、作者和阅读量文章所有微信公众号全部推文地址文章所有微信公众号全部推文作者和阅读量全部公众号文章链接获取每一篇推文推文链接解析每一篇推文推文链接获取所有推文的标题获取每一篇推文的标题解析每一篇推文的标题获取所有推文的文章链接获取所有推文内容获取所有推文文章链接解析每一篇推文文章链接获取所有推文文章内容获取每一篇推文内容获取所有推文内容获取所有推文内容获取所有推文内容获取每一篇推文文章链接获取每一篇推文文章链接获取每一篇推文文章链接获取所有推文文章地址获取每一篇推文文章地址获取所有推文的文章链接解析所有推文文章链接获取所有推文的地址解析每一篇推文标题获取所有推文的标题解析所有推文标题获取所有推文文章链接解。
querylist采集微信公众号文章( “内容为王”的时代,网站什么样的内容才算好? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-18 15:06
“内容为王”的时代,网站什么样的内容才算好?
)
在“内容为王”的时代,网站什么样的内容好?有价值的内容只有原创文章吗?事实上,这种想法是错误的。其实对于搜索引擎来说,无论你是原创文章还是伪原创文章,都能满足用户的需求。解决用户问题的优质内容,这样的内容对用户来说是有价值的内容。这就是搜索引擎喜欢的。对于采集的站长,有价值的内容/优质的内容,我会选择微信公众号文章。到采集官方账号的文章填写我们的网站,如下所示:
为什么选择采集微信公众号文章?
1、原创 高度,减少同质化
2、 的互动性很强,大多数 文章 内容倾向于与读者互动。非纯信息网站,发布后无互动
3、布局干净,采集垃圾邮件很少
4、模板是固定的,不像很多博主经常更换博客模板导致采集规则失效
在这种情况下,就意味着微信公众号文章采集是可行的,但是如果想让公众号文章产生有价值的文章内容,就需要重点关注就以下三个点击继续:
1.关注目标用户
文章 内容是否有价值,取决于能否解决用户的问题。这意味着在填写内容时,你需要明确用户点击进入你的网站最希望得到什么信息。比如用户想知道怎么做SEO优化,我们文章的内容需要描述什么是SEO优化,SEO优化的过程,做SEO优化时的注意事项等等,这也是我们经常说的说“干货”。
2.内容标题简单易懂,能吸引眼球
文章 内容的标题决定了用户是否点击你的文章进行浏览。如果文章的标题不允许用户“扫一扫”流程,他们可以大致了解里面的内容。什么是简短的描述,或者标题太简单明了,那么用户遗漏的几率非常高。如果文章没有被用户点击浏览,里面的内容将是有价值的,不会被其他人发现。
3.需要结合自己的独立思考
虽然说是公众号的内容,但不能直接按照原作者的想法来写。还需要用自己的独立思考去思考用户在搜索时还存在哪些问题,并补充文章的内容,使文章的内容更加全面、简单易懂,这样以更好地满足用户的需求。
查看全部
querylist采集微信公众号文章(
“内容为王”的时代,网站什么样的内容才算好?
)
在“内容为王”的时代,网站什么样的内容好?有价值的内容只有原创文章吗?事实上,这种想法是错误的。其实对于搜索引擎来说,无论你是原创文章还是伪原创文章,都能满足用户的需求。解决用户问题的优质内容,这样的内容对用户来说是有价值的内容。这就是搜索引擎喜欢的。对于采集的站长,有价值的内容/优质的内容,我会选择微信公众号文章。到采集官方账号的文章填写我们的网站,如下所示:
为什么选择采集微信公众号文章?
1、原创 高度,减少同质化
2、 的互动性很强,大多数 文章 内容倾向于与读者互动。非纯信息网站,发布后无互动
3、布局干净,采集垃圾邮件很少
4、模板是固定的,不像很多博主经常更换博客模板导致采集规则失效
在这种情况下,就意味着微信公众号文章采集是可行的,但是如果想让公众号文章产生有价值的文章内容,就需要重点关注就以下三个点击继续:
1.关注目标用户
文章 内容是否有价值,取决于能否解决用户的问题。这意味着在填写内容时,你需要明确用户点击进入你的网站最希望得到什么信息。比如用户想知道怎么做SEO优化,我们文章的内容需要描述什么是SEO优化,SEO优化的过程,做SEO优化时的注意事项等等,这也是我们经常说的说“干货”。
2.内容标题简单易懂,能吸引眼球
文章 内容的标题决定了用户是否点击你的文章进行浏览。如果文章的标题不允许用户“扫一扫”流程,他们可以大致了解里面的内容。什么是简短的描述,或者标题太简单明了,那么用户遗漏的几率非常高。如果文章没有被用户点击浏览,里面的内容将是有价值的,不会被其他人发现。
3.需要结合自己的独立思考
虽然说是公众号的内容,但不能直接按照原作者的想法来写。还需要用自己的独立思考去思考用户在搜索时还存在哪些问题,并补充文章的内容,使文章的内容更加全面、简单易懂,这样以更好地满足用户的需求。
querylist采集微信公众号文章(谢邀,查找公众号文章数据的一种新方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-15 19:00
querylist采集微信公众号文章数据的一种新方法,可以很好地定位到某篇文章,可以先研究一下,最终要知道实际数据是来自于哪一篇公众号的文章数据,根据文章内容进行切分成多个querylist,获取这些querylist进行匹配的时候,对应querylist可以定位到文章内容。
一个sqlmap命令就可以。
dropquerylist
在python中querylist就是文章querylist.range_by_date(自己想想就清楚了,
谢邀mysqlquerylist需要哪些字段,有几列,怎么输出?mysql在查询中使用mysql_query()函数可以,用于获取数据结构表中索引相关的列。
mysql的话,
如果数据量大,并且文章没有id。请用pymysql库,注意版本不要太老。数据量小,公众号logo,标题作为特征也是可以的。
谢邀,查找公众号文章数据是通过人工匹配用户标签确定你要查找的公众号的logo和标题,此外可以辅助使用table.choose_from_list函数查找到相应的文章列表,
我有一个问题,你做的是什么爬虫?不同的搜索引擎写的代码必然是不一样的。目前selenium还不好用吧。推荐一个第三方库phantomjs爬虫,挺好用的。 查看全部
querylist采集微信公众号文章(谢邀,查找公众号文章数据的一种新方法)
querylist采集微信公众号文章数据的一种新方法,可以很好地定位到某篇文章,可以先研究一下,最终要知道实际数据是来自于哪一篇公众号的文章数据,根据文章内容进行切分成多个querylist,获取这些querylist进行匹配的时候,对应querylist可以定位到文章内容。
一个sqlmap命令就可以。
dropquerylist
在python中querylist就是文章querylist.range_by_date(自己想想就清楚了,
谢邀mysqlquerylist需要哪些字段,有几列,怎么输出?mysql在查询中使用mysql_query()函数可以,用于获取数据结构表中索引相关的列。
mysql的话,
如果数据量大,并且文章没有id。请用pymysql库,注意版本不要太老。数据量小,公众号logo,标题作为特征也是可以的。
谢邀,查找公众号文章数据是通过人工匹配用户标签确定你要查找的公众号的logo和标题,此外可以辅助使用table.choose_from_list函数查找到相应的文章列表,
我有一个问题,你做的是什么爬虫?不同的搜索引擎写的代码必然是不一样的。目前selenium还不好用吧。推荐一个第三方库phantomjs爬虫,挺好用的。
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-11-15 09:03
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章!
querylist采集微信公众号文章(微信公众号文章的GET及GET方法(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-11-14 17:11
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
获取微信公众号接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个账户对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET 所以在这个界面我们您只需要获取token,查询就是您需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 请求方式: GET这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,您可以使用登录的微信扫码。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入 查看全部
querylist采集微信公众号文章(微信公众号文章的GET及GET方法(二))
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
获取微信公众号接口: 参数:action=search_biz begin=0 count=5 query=公众号token=每个账户对应的Token值 lang=zh_CN f=json ajax=1 请求方式:GET 所以在这个界面我们您只需要获取token,查询就是您需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的接口: 参数:action=list_ex begin=0 count=5 fakeid=MjM5NDAwMTA2MA== type=9 query= token=557131216 lang=zh_CN f=json ajax=1 请求方式: GET这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。通过模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,您可以使用登录的微信扫码。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料和群交流答案 点击加入
querylist采集微信公众号文章( 微信小程序中如何打开公众号中的文章(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-11-13 14:08
微信小程序中如何打开公众号中的文章(图))
微信小程序获取文章公众号列表,显示文章示例代码
更新时间:2020年3月10日16:08:20 作者:YO_RUI
本文文章主要介绍微信小程序获取公众号列表文章以及显示文章的示例代码。文章中介绍的示例代码非常详细,对大家的学习或者工作都有一定的借鉴作用。参考学习的价值,有需要的朋友,和小编一起学习吧。
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公众号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1个绑定小程序
公众号需要绑定目标小程序,否则无法开通公众号文章。
在公众号管理界面,点击小程序管理--> 关联小程序
输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。
(2) 打开开发者密文(AppSecret),注意保存并修改密文。
(3) 设置ip白名单,这个是发起请求的机器的外网ip,如果是在自己的电脑上,就是自己电脑的外网ip。如果部署到server,是服务器的外网ip。
2、获取文章信息的步骤
以下仅作为演示。
实际项目中,在自己的服务器程序中获取,不要直接在小程序中获取,毕竟需要用到appid、appsecret等高机密参数。
2.1 获取 access_token
access_token是公众号全局唯一的接口调用凭证,公众号在调用各个接口时需要使用access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}
转换成json格式,参数说明见上面API文档
第二张图中的url为公众号文章的地址。将有与获得的 tem 项目数量一样多的项目。只要得到以上结果,在小程序中打开公众号文章已经成功过半。
最后在小程序中使用组件打开,src为文章的url地址。
本文介绍微信小程序获取公众号文章列表并展示文章文章的示例代码,以及更多获取公众号的相关小程序文章列表内容请搜索脚本之家之前的文章或继续浏览下方的相关文章。希望大家以后多多支持Script Home! 查看全部
querylist采集微信公众号文章(
微信小程序中如何打开公众号中的文章(图))
微信小程序获取文章公众号列表,显示文章示例代码
更新时间:2020年3月10日16:08:20 作者:YO_RUI
本文文章主要介绍微信小程序获取公众号列表文章以及显示文章的示例代码。文章中介绍的示例代码非常详细,对大家的学习或者工作都有一定的借鉴作用。参考学习的价值,有需要的朋友,和小编一起学习吧。
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公众号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1个绑定小程序
公众号需要绑定目标小程序,否则无法开通公众号文章。
在公众号管理界面,点击小程序管理--> 关联小程序
输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。
(2) 打开开发者密文(AppSecret),注意保存并修改密文。
(3) 设置ip白名单,这个是发起请求的机器的外网ip,如果是在自己的电脑上,就是自己电脑的外网ip。如果部署到server,是服务器的外网ip。
2、获取文章信息的步骤
以下仅作为演示。
实际项目中,在自己的服务器程序中获取,不要直接在小程序中获取,毕竟需要用到appid、appsecret等高机密参数。
2.1 获取 access_token
access_token是公众号全局唯一的接口调用凭证,公众号在调用各个接口时需要使用access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}
转换成json格式,参数说明见上面API文档
第二张图中的url为公众号文章的地址。将有与获得的 tem 项目数量一样多的项目。只要得到以上结果,在小程序中打开公众号文章已经成功过半。
最后在小程序中使用组件打开,src为文章的url地址。
本文介绍微信小程序获取公众号文章列表并展示文章文章的示例代码,以及更多获取公众号的相关小程序文章列表内容请搜索脚本之家之前的文章或继续浏览下方的相关文章。希望大家以后多多支持Script Home!
querylist采集微信公众号文章( 搜狗搜索采集公众号历史消息(图)问题解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-13 14:05
搜狗搜索采集公众号历史消息(图)问题解析)
PHP如何写微信公众号文章页面采集
通过搜狗搜索采集公众号的历史新闻有几个问题:
1、 有验证码;
2、历史留言列表只有最近10条群发;
3、文章 地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集的系统搭建不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且,采集的文章地址是永久有效的,您可以通过采集获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
2、 历史消息列表中获取的地址:
#wechat_redirect
3、完整的真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%header1D
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法从json文章历史消息列表中得到的链接地址,我们可以将这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,因为这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,详细研究如何获取文章的内容@文章 和其他一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p> 查看全部
querylist采集微信公众号文章(
搜狗搜索采集公众号历史消息(图)问题解析)
PHP如何写微信公众号文章页面采集
通过搜狗搜索采集公众号的历史新闻有几个问题:
1、 有验证码;
2、历史留言列表只有最近10条群发;
3、文章 地址有有效期;
4、据说批量采集需要改ip;
通过我之前的文章方法,没有出现这样的问题,虽然采集的系统搭建不像传统的采集器写规则爬行那么简单。但是batch采集构建一次后的效率还是可以的。而且,采集的文章地址是永久有效的,您可以通过采集获取一个公众号的所有历史消息。
先从公众号文章的链接地址说起:
1、 复制微信右上角菜单中的链接地址:
2、 历史消息列表中获取的地址:
#wechat_redirect
3、完整的真实地址:
%3D%3D&devicetype=iOS10.1.1&version=16050120&nettype=WIFI&fontScale=100&pass_ticket=FGRyGfXLPEa4AeOsIZu7KFJo6CiXOZex83Y5YBRglW4%header1D
以上三个地址是同一篇文章文章的地址,在不同位置获取时得到三个完全不同的结果。
和历史新闻页面一样,微信也有自动添加参数的机制。第一个地址是通过复制链接获得的,看起来像一个变相的代码。其实没用,我们不去想。第二个地址是通过前面文章中介绍的方法从json文章历史消息列表中得到的链接地址,我们可以将这个地址保存到数据库中。然后就可以通过这个地址从服务器获取文章的内容。第三个链接添加参数后,目的是让文章页面中的阅读js获取阅读和点赞的json结果。在我们之前的文章方法中,由于文章页面是由客户端打开显示的,因为这些参数,文章中的js
本次文章的内容是根据本专栏前面文章介绍的方法获取大量微信文章,详细研究如何获取文章的内容@文章 和其他一些有用的信息方法。
(文章 列表保存在我的数据库中,一些字段)
1、获取文章的源码:
文章的源码可以通过php函数file_get_content()读入一个变量。由于微信文章的源码可以从浏览器打开,这里就不贴了,以免浪费页面空间。
2、 源代码中的有用信息:
1) 原文内容:
原创内容收录在一个标签中,通过php代码获取:
<p>
querylist采集微信公众号文章(querylist采集微信公众号文章的api接口开放已经有一段时间了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-13 09:08
querylist采集微信公众号文章的api接口开放已经有一段时间了,由于上次在内测已经有很多人用过api接口,但是还是有一些小伙伴对于该接口只是初步了解,没有太大兴趣,而我呢,就一直在关注,尝试去开发,今天小伙伴刚好问到,所以我就想跟大家分享下。这是ip接口的官方说明,接口开放时间是3月8号,至今已经有3个多月,一共拥有9个g的内存,为什么说他有9个g的内存呢,大家注意看下文图片中的权重active权重就可以明白,这9个g不是随便浪费的,分配到微信小程序及公众号,每个应用里面,都会占用4gb的内存,(像今天这么大运行量的小程序,内存可能达到9g)下面是一些参数,大家也可以去微信公众号里面看api文档,非常的简单,关于这些如果大家有疑问可以留言,我会尽力解答~这是地址。
详细描述是这样的:
用于微信小程序,公众号,群发,
不能请参看我写的博客:「大神仙叔」的博客
算是api吧
额除了官方文档里的接口接下来就不知道该怎么去取了。
你用什么软件发布的呢?
大神回答.应该是不可以的
-cn
大神回答这个问题,回答的更详细一些,目前微信公众号文章的api接口只开放出来了9个,你需要自己去去找,api开放的较少,可以从其他渠道看看有哪些,比如一些其他的公众号,不多说了, 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的api接口开放已经有一段时间了)
querylist采集微信公众号文章的api接口开放已经有一段时间了,由于上次在内测已经有很多人用过api接口,但是还是有一些小伙伴对于该接口只是初步了解,没有太大兴趣,而我呢,就一直在关注,尝试去开发,今天小伙伴刚好问到,所以我就想跟大家分享下。这是ip接口的官方说明,接口开放时间是3月8号,至今已经有3个多月,一共拥有9个g的内存,为什么说他有9个g的内存呢,大家注意看下文图片中的权重active权重就可以明白,这9个g不是随便浪费的,分配到微信小程序及公众号,每个应用里面,都会占用4gb的内存,(像今天这么大运行量的小程序,内存可能达到9g)下面是一些参数,大家也可以去微信公众号里面看api文档,非常的简单,关于这些如果大家有疑问可以留言,我会尽力解答~这是地址。
详细描述是这样的:
用于微信小程序,公众号,群发,
不能请参看我写的博客:「大神仙叔」的博客
算是api吧
额除了官方文档里的接口接下来就不知道该怎么去取了。
你用什么软件发布的呢?
大神回答.应该是不可以的
-cn
大神回答这个问题,回答的更详细一些,目前微信公众号文章的api接口只开放出来了9个,你需要自己去去找,api开放的较少,可以从其他渠道看看有哪些,比如一些其他的公众号,不多说了,
querylist采集微信公众号文章( React和ant-design增加了方便查看的小程序指南 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-12 10:13
React和ant-design增加了方便查看的小程序指南
)
<p>小程序 GitHub Trending Hub 是一个以 Feed 流形式查看 GitHub Trending 仓库集合的工具,通过它可以及时查看最近更新的热门仓库。通过微信 WeChat 扫码体验。
为什么要开发?
相信很多人会有这样的疑问,通过官方提供的 GitHub Trending 页面就能查看,为什么还要开发一个小程序?细心的同学可能会发现 GitHub Trending 上榜大致是按照当天新增的 Star 数来确定的,Star 数会随着时间变动,意味着 Trending 榜单也是随时在变的。那么对于像我一样经常浏览 GitHub Trending 页面的人会存在一些不便的地方:
每次访问 GitHub Trending 获取的新仓库数量相对少,那些比较热门的项目往往长期霸占 Trending 榜单,有时候今天看了,需要过几天再去看才能在上面发现一些新的有意思的项目
对于那些短期出现在 Trending 上的项目由于没有及时查看而丢失了
不能按多语言过滤,关注多个编程语言的人还是比较多的
这大概就是最开始的需求,希望能够及时的追踪到 GitHub Trending 榜单的变化,形成历史信息方便查看更新。很自然就会想到用爬虫解决这个问题,当时还没有小程序,开发小程序是因为工作关系了解到 Serverless 相关的知识,同时微信小程序有对应的云开发方式,迫切希望了解一下具体的应用场景。所以就有了开发这个小程序的想法。
追踪网站变化
除了经常浏览 GitHub Trending 之外,有时候也会看一些技术博客,比如 GitHub Blog、Kubernetes Blog、CoreOS Blog 等,有的是不提供 RSS 订阅的(当然我也不是一个 RSS 订阅的爱好者),由于不知道什么时候会更新,只能空闲时去查看对应的页面比较低效。通过爬虫可以很好的解决这个问题,但是对于多个网站都单独写爬虫比较费劲同时增加了管理的负担,所以希望能够开发一个通用的爬虫框架,能够比较简单的配置就能新增一个追踪网站变化的爬虫。当时刚好工作上在了解 Prometheus 和 Alermanager,就参考对应的配置,开发了基于 xpath 的爬虫框架,通过邮件以日报或者周报形式追踪特定网站的更新。
parsers:
- name: 'githubtrending'
base_url: 'https://github.com'
base_xpath:
- "//li[@class='col-12 d-block width-full py-4 border-bottom']"
attr:
url: 'div/h3/a/@href'
repo: 'div/h3/a'
desc: "div[@class='py-1']/p"
lang: "div/span[@itemprop='programmingLanguage']"
star: "div/a[@aria-label='Stargazers']"
fork: "div/a[@aria-label='Forks']"
today: "div/span[@class='float-right']"
</p>
在后续的工作中,需要参与一些前端的开发,所以学习了React和ant-design,并添加了易于查看的页面。可以说,这个项目和当时的工作内容是高度契合、相辅相成的。
您可以访问以下体验:
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
微信小程序
小程序最直观的体验是无需安装软件,在微信中即可快速体验。当时trackupdates服务没有服务器,运行在我自己的电脑上。碎片时间用手机看很不方便,所以还是满足自己的需求(程序员是不是先造轮子来满足自己的需求?哈哈~)。
随着产品思维在我工作中的积累,当时的想法是,既然我要开发一个对外可用的产品,为什么不满足自己的需求,同时也方便别人呢?因此,有必要挖掘和分析需要解决的具体问题和痛点,以及如何更好地推广这款产品。
当时发现微信公众号中的文章对外部链接的访问有严格的控制。在文章中,所有链接都无法点击,但小程序的重定向没有限制。在小程序中也是如此。一般不允许外链跳转(个人开发类小程序)。同时,我也对已经上线的GitHub相关小程序进行了调查。无一例外,链接跳转都是允许的。有很多问题。因此,在小程序的开发过程中,友好的GitHub链接重定向是最重要的关注和优化问题,这也是这个小程序如何推广的方向。
目前有GitHub精选和AI研究院两个公众号,可以通过在文章中附上小程序链接,提升访问GitHub仓库详情的阅读体验。如果您在公众号文章中分享了GitHub相关项目,可以扫描以下二维码查看添加小程序指南。
此外,小程序还提供了查看仓库统计和个人简历的功能。
小程序使用微信原生框架开发。如果你想学习小程序开发,应该对你有帮助。
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
总结
这就是GitHub Trending Hub这个小程序的由来。在整个开发过程中,我觉得有两点需要分享:
GitHub API 设计
为降低开发成本,提高后续API替换的便利性,GitHub API的返回结果中会收录您可能访问的其他API,开发者无需理解和拼接API。官方解释如下:
所有资源都可能有一个或多个*_urlproperties 链接到其他资源。这些旨在提供显式 URL,以便适当的 API 客户端不需要自己构建 URL。强烈建议 API 客户端使用这些。这样做将使开发人员在未来升级 API 时更容易。所有 URL 都应该是正确的 RFC 6570URI 模板。
{
"id": 1296269,
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"html_url": "https://github.com/octocat/Hello-World",
"description": "This your first repo!",
"url": "https://api.github.com/repos/o ... ot%3B,
"archive_url": "http://api.github.com/repos/octocat/Hello-World/{archive_format}{/ref}",
"assignees_url": "http://api.github.com/repos/oc ... gnees{/user}"
}
对我的整体启发是,设计 API 是一门学问,让开发者更容易使用 API 也很重要。现在GitHub已经推荐使用GraphQL API v4版本,小程序API向GraphQL版本的迁移已经收录在接下来的学习计划中。
小程序云开发
云开发中将常用的基础组件打包,如数据库、存储、无服务框架、监控和数据统计报表等,大大简化了服务的运维部署成本。您无需关心服务在何处运行或是否需要扩展。让开发更加关注业务逻辑。下面是一个简单的服务:
const cloud = require('wx-server-sdk')
exports.main = async (event, context) => ({
sum: event.a + event.b
})
但相对来说,成熟度还不够。如果遇到问题,查找起来会比较困难。比如遇到小程序被爬虫爬取的API(后来发现是微信自己的爬虫,尴尬~),导致云开发包流量瞬间用光,不好由于云开发暴露的能力有限 排查并解决此问题。
最后贴个二维码,欢迎扫码体验
查看全部
querylist采集微信公众号文章(
React和ant-design增加了方便查看的小程序指南
)
<p>小程序 GitHub Trending Hub 是一个以 Feed 流形式查看 GitHub Trending 仓库集合的工具,通过它可以及时查看最近更新的热门仓库。通过微信 WeChat 扫码体验。
为什么要开发?
相信很多人会有这样的疑问,通过官方提供的 GitHub Trending 页面就能查看,为什么还要开发一个小程序?细心的同学可能会发现 GitHub Trending 上榜大致是按照当天新增的 Star 数来确定的,Star 数会随着时间变动,意味着 Trending 榜单也是随时在变的。那么对于像我一样经常浏览 GitHub Trending 页面的人会存在一些不便的地方:
每次访问 GitHub Trending 获取的新仓库数量相对少,那些比较热门的项目往往长期霸占 Trending 榜单,有时候今天看了,需要过几天再去看才能在上面发现一些新的有意思的项目
对于那些短期出现在 Trending 上的项目由于没有及时查看而丢失了
不能按多语言过滤,关注多个编程语言的人还是比较多的
这大概就是最开始的需求,希望能够及时的追踪到 GitHub Trending 榜单的变化,形成历史信息方便查看更新。很自然就会想到用爬虫解决这个问题,当时还没有小程序,开发小程序是因为工作关系了解到 Serverless 相关的知识,同时微信小程序有对应的云开发方式,迫切希望了解一下具体的应用场景。所以就有了开发这个小程序的想法。
追踪网站变化
除了经常浏览 GitHub Trending 之外,有时候也会看一些技术博客,比如 GitHub Blog、Kubernetes Blog、CoreOS Blog 等,有的是不提供 RSS 订阅的(当然我也不是一个 RSS 订阅的爱好者),由于不知道什么时候会更新,只能空闲时去查看对应的页面比较低效。通过爬虫可以很好的解决这个问题,但是对于多个网站都单独写爬虫比较费劲同时增加了管理的负担,所以希望能够开发一个通用的爬虫框架,能够比较简单的配置就能新增一个追踪网站变化的爬虫。当时刚好工作上在了解 Prometheus 和 Alermanager,就参考对应的配置,开发了基于 xpath 的爬虫框架,通过邮件以日报或者周报形式追踪特定网站的更新。
parsers:
- name: 'githubtrending'
base_url: 'https://github.com'
base_xpath:
- "//li[@class='col-12 d-block width-full py-4 border-bottom']"
attr:
url: 'div/h3/a/@href'
repo: 'div/h3/a'
desc: "div[@class='py-1']/p"
lang: "div/span[@itemprop='programmingLanguage']"
star: "div/a[@aria-label='Stargazers']"
fork: "div/a[@aria-label='Forks']"
today: "div/span[@class='float-right']"
</p>
在后续的工作中,需要参与一些前端的开发,所以学习了React和ant-design,并添加了易于查看的页面。可以说,这个项目和当时的工作内容是高度契合、相辅相成的。
您可以访问以下体验:
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
微信小程序
小程序最直观的体验是无需安装软件,在微信中即可快速体验。当时trackupdates服务没有服务器,运行在我自己的电脑上。碎片时间用手机看很不方便,所以还是满足自己的需求(程序员是不是先造轮子来满足自己的需求?哈哈~)。
随着产品思维在我工作中的积累,当时的想法是,既然我要开发一个对外可用的产品,为什么不满足自己的需求,同时也方便别人呢?因此,有必要挖掘和分析需要解决的具体问题和痛点,以及如何更好地推广这款产品。
当时发现微信公众号中的文章对外部链接的访问有严格的控制。在文章中,所有链接都无法点击,但小程序的重定向没有限制。在小程序中也是如此。一般不允许外链跳转(个人开发类小程序)。同时,我也对已经上线的GitHub相关小程序进行了调查。无一例外,链接跳转都是允许的。有很多问题。因此,在小程序的开发过程中,友好的GitHub链接重定向是最重要的关注和优化问题,这也是这个小程序如何推广的方向。
目前有GitHub精选和AI研究院两个公众号,可以通过在文章中附上小程序链接,提升访问GitHub仓库详情的阅读体验。如果您在公众号文章中分享了GitHub相关项目,可以扫描以下二维码查看添加小程序指南。
此外,小程序还提供了查看仓库统计和个人简历的功能。
小程序使用微信原生框架开发。如果你想学习小程序开发,应该对你有帮助。
项目地址:
欢迎来到星叉。如果您有任何问题,请提交问题。
总结
这就是GitHub Trending Hub这个小程序的由来。在整个开发过程中,我觉得有两点需要分享:
GitHub API 设计
为降低开发成本,提高后续API替换的便利性,GitHub API的返回结果中会收录您可能访问的其他API,开发者无需理解和拼接API。官方解释如下:
所有资源都可能有一个或多个*_urlproperties 链接到其他资源。这些旨在提供显式 URL,以便适当的 API 客户端不需要自己构建 URL。强烈建议 API 客户端使用这些。这样做将使开发人员在未来升级 API 时更容易。所有 URL 都应该是正确的 RFC 6570URI 模板。
{
"id": 1296269,
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"html_url": "https://github.com/octocat/Hello-World",
"description": "This your first repo!",
"url": "https://api.github.com/repos/o ... ot%3B,
"archive_url": "http://api.github.com/repos/octocat/Hello-World/{archive_format}{/ref}",
"assignees_url": "http://api.github.com/repos/oc ... gnees{/user}"
}
对我的整体启发是,设计 API 是一门学问,让开发者更容易使用 API 也很重要。现在GitHub已经推荐使用GraphQL API v4版本,小程序API向GraphQL版本的迁移已经收录在接下来的学习计划中。
小程序云开发
云开发中将常用的基础组件打包,如数据库、存储、无服务框架、监控和数据统计报表等,大大简化了服务的运维部署成本。您无需关心服务在何处运行或是否需要扩展。让开发更加关注业务逻辑。下面是一个简单的服务:
const cloud = require('wx-server-sdk')
exports.main = async (event, context) => ({
sum: event.a + event.b
})
但相对来说,成熟度还不够。如果遇到问题,查找起来会比较困难。比如遇到小程序被爬虫爬取的API(后来发现是微信自己的爬虫,尴尬~),导致云开发包流量瞬间用光,不好由于云开发暴露的能力有限 排查并解决此问题。
最后贴个二维码,欢迎扫码体验
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-11-11 15:04
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
本文文章主要介绍了基于Python采集的微信公众号历史数据爬取。文章中介绍的示例代码非常详细,对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
鲲志鹏的技术人员将在本文中介绍一种采集通过模拟微信App的操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,其中有四个关键参数(__biz、appmsg_token、pass_ticket、Cookie)。
为了能够得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们介绍了通过Python模拟Android App的方法(详见详情)。对于 HTTP 集成捕获,我们之前已经引入了 Mitmproxy(查看详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 推出微信应用
2. 点击“联系人”
3. 点击“公众号”
4.点击公众号进入采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕捉到__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造一个API请求来获取历史文章列表,通过调用API接口直接获取数据(无需模拟App操作)。核心参数如下。通过改变偏移参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集的过程截图如下:
输出结果截图如下:
以上就是基于Python采集爬取微信公众号历史数据的详细内容。更多详情请关注其他相关html中文网站文章!
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-11-11 11:07
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
图。1
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
图6
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环,获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list)) 查看全部
querylist采集微信公众号文章(微信公众号后台编辑素材界面的程序利用程序
)
准备阶段
为了实现爬虫我们需要使用以下工具
另外,这个爬虫程序使用了微信公众号后台编辑素材接口。原理是当我们插入超链接时,微信会调用一个特殊的API(见下图)来获取指定公众号的文章列表。因此,我们还需要有一个公众号。
图。1
正式开始
我们需要登录微信公众号,点击素材管理,点击新建图文消息,然后点击上面的超链接。
图2
接下来,按 F12 打开 Chrome 的开发者工具并选择网络
图3
此时,在之前的超链接界面,点击“选择其他公众号”,输入你需要爬取的公众号(例如中国移动)
图4
这时候之前的Network会刷新一些链接,其中以“appmsg”开头的内容就是我们需要分析的
图5
我们解析请求的 URL
https://mp.weixin.qq.com/cgi-b ... x%3D1
它分为三个部分
通过不断浏览下一页,我们发现每次只有begin会改变,每次增加5,这就是count的值。
接下来我们使用Python获取同样的资源,但是直接运行下面的代码是无法获取资源的
import requests
url = "https://mp.weixin.qq.com/cgi-b ... ot%3B
requests.get(url).json()
# {'base_resp': {'ret': 200003, 'err_msg': 'invalid session'}}
之所以能在浏览器上获取资源,是因为我们登录了微信公众号后端。而Python没有我们的登录信息,所以请求无效。我们需要在requests中设置headers参数,传入Cookie和User-Agent来模拟登录
由于头信息的内容每次都会变化,我把这些内容放在一个单独的文件中,即“wechat.yaml”,信息如下
cookie: ua_id=wuzWM9FKE14...
user_agent: Mozilla/5.0...
只需要事后阅读
# 读取cookie和user_agent
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
requests.get(url, headers=headers, verify=False).json()
在返回的JSON中,我们可以看到每个文章的标题(title)、摘要(digest)、链接(link)、推送时间(update_time)和封面地址(cover)。
appmsgid 是每条推文的唯一标识符,aid 是每条推文的唯一标识符。
图6
其实除了cookies,URL中的token参数也会用来限制爬虫,所以上面代码的输出很可能是{'base_resp': {'ret': 200040,'err_msg':'无效的 csrf 令牌'} }
然后我们写一个循环,获取文章的所有JSON并保存。
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
break
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
app_msg_list.append(resp.json())
# 翻页
i += 1
在上面的代码中,我还在“wechat.yaml”文件中存储了fakeid和token。这是因为fakeid是每个公众号的唯一标识,token会经常变化,信息可以通过解析URL获取,也可以从开发者工具查看
图7
爬了一段时间后,会遇到以下问题
{'base_resp': {'err_msg': 'freq control', 'ret': 200013}}
此时,当你尝试在公众号后台插入超链接时,会遇到如下提示
图8
这是公众号的流量限制,一般需要30-60分钟才能继续。为了完美处理这个问题,你可能需要申请多个公众号,可能需要对抗微信公众号登录系统,也可能需要设置代理池。
但是我不需要工业级的爬虫,我只想爬取自己的公众号信息,所以等了一个小时,再次登录公众号,获取cookie和token,运行。我不想用自己的兴趣挑战别人的工作。
最后,将结果保存为 JSON 格式。
# 保存结果为JSON
json_name = "mp_data_{}.json".format(str(begin))
with open(json_name, "w") as file:
file.write(json.dumps(app_msg_list, indent=2, ensure_ascii=False))
或者提取文章标识符、标题、URL、发布时间四列,保存为CSV。
info_list = []
for msg in app_msg_list:
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
info_list.append(info)
# save as csv
with open("app_msg_list.csv", "w") as file:
file.writelines("\n".join(info_list))
querylist采集微信公众号文章(采集微信公众号文章如何批量采集其他微信历史内容?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-11-09 10:02
随着互联网时代的到来,很多人开始使用智能手机,微信的使用也逐渐增多。这时候微信的一些功能会有助于实现营销,比如微信公众号,那么如何采集微信公众号文章呢?下面说一下图图数据。
采集微信公众号文章
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读数和点赞数非常宝贵。因此,文章获取采集的读取计数的机制受到2秒的限制。2秒内你有一个采集微信数据,微信不会理你,但如果你快,他会给你303响应,并返回空数据给你。让你采集什么都没有,然后就是不用采集读号获取文章列表的速度。这个速度在前期没有限制。当您获得更多采集时,您的微信ID将被限制。我们的软件对相关的采集做了一个可设置的时间限制。所以尽量使用这些限制。毕竟微信还需要做很多事情,它必须受到保护。限制登录是一方面,限制采集数据是一方面,采集数据等待2分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
如何使用微信公众号文章使用小程序进行流量分流?
1、小程序有较大的搜索流量入口,方便用户浏览。
2.微信公众号的文章会自动生成下图的小程序界面,文章会自动采集自己的公众号群发< @文章、浏览、点赞、评论所有文章同步的公众号自动分类,可以更好的展示你过去发布的微信文章,方便统一展示.
3、对于自媒体和流量主来说,经常发布高质量的文章更容易留住客户,又可以扩大广告,再次赚钱。
4.可以转公众号。
采集微信公众号文章
如何采集其他微信公众号文章到微信编辑
一、获取文章的链接
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
二、点击采集文章按钮
1.编辑菜单右上角的采集文章按钮。
2.右侧功能按钮底部的采集文章按钮。
三、粘贴文章链接并点击采集
采集 完成后可以编辑修改文章。
通过以上拖图数据的介绍,我们了解到了采集微信公众号文章的相关内容。只有了解微信公众号的功能和用途,才能更好的保证文章采集。
持续关注更多资讯和知识点,关注自媒体网吧爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人的原创文章、公众号历史文章等知识点。 查看全部
querylist采集微信公众号文章(采集微信公众号文章如何批量采集其他微信历史内容?)
随着互联网时代的到来,很多人开始使用智能手机,微信的使用也逐渐增多。这时候微信的一些功能会有助于实现营销,比如微信公众号,那么如何采集微信公众号文章呢?下面说一下图图数据。
采集微信公众号文章
如何批量处理采集微信公众号历史内容
首先,第一个是采集阅读数和点赞数非常宝贵。因此,文章获取采集的读取计数的机制受到2秒的限制。2秒内你有一个采集微信数据,微信不会理你,但如果你快,他会给你303响应,并返回空数据给你。让你采集什么都没有,然后就是不用采集读号获取文章列表的速度。这个速度在前期没有限制。当您获得更多采集时,您的微信ID将被限制。我们的软件对相关的采集做了一个可设置的时间限制。所以尽量使用这些限制。毕竟微信还需要做很多事情,它必须受到保护。限制登录是一方面,限制采集数据是一方面,采集数据等待2分钟。如果仍然频繁,则为5分钟。不管多久,估计都不会再有了。你的微信最多只能明天登录。
如何使用微信公众号文章使用小程序进行流量分流?
1、小程序有较大的搜索流量入口,方便用户浏览。
2.微信公众号的文章会自动生成下图的小程序界面,文章会自动采集自己的公众号群发< @文章、浏览、点赞、评论所有文章同步的公众号自动分类,可以更好的展示你过去发布的微信文章,方便统一展示.
3、对于自媒体和流量主来说,经常发布高质量的文章更容易留住客户,又可以扩大广告,再次赚钱。
4.可以转公众号。
采集微信公众号文章
如何采集其他微信公众号文章到微信编辑
一、获取文章的链接
电脑用户可以直接全选并复制浏览器地址栏中的文章链接。
手机用户可以点击右上角的菜单按钮,选择复制链接,将链接发送到电脑。
二、点击采集文章按钮
1.编辑菜单右上角的采集文章按钮。
2.右侧功能按钮底部的采集文章按钮。
三、粘贴文章链接并点击采集
采集 完成后可以编辑修改文章。
通过以上拖图数据的介绍,我们了解到了采集微信公众号文章的相关内容。只有了解微信公众号的功能和用途,才能更好的保证文章采集。
持续关注更多资讯和知识点,关注自媒体网吧爆文采集平台、自媒体文章采集平台、公众号查询、公众号转载他人的原创文章、公众号历史文章等知识点。
querylist采集微信公众号文章(谷歌浏览器微信公众号申请门槛低,服务号需要营业执照等)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-11-02 06:05
一、网上的方法:
1.在订阅账号功能中使用查询链接,(这个链接现在是严重的反乱码措施,抓取几十个页面会屏蔽订阅账号,仅供参考)
更多详情,请访问此链接:/4652.html
2.使用搜狗搜索微信搜索(此方法只能查看每个微信公众号的前10条文章)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,进入界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2. 使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、。微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取;
通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#Crawl 微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/5< @3.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,然后抓取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#Search文章 需要传入几个参数:登录公众号token、爬取文章公众号fakeid、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取每个页面的标题和链接地址文章,并写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后,爬取微信公众号文章微信公众号后台提供的界面文章
在 gzlist 中查询:
#Crawl 微信公众号文章并存入本地文本 查看全部
querylist采集微信公众号文章(谷歌浏览器微信公众号申请门槛低,服务号需要营业执照等)
一、网上的方法:
1.在订阅账号功能中使用查询链接,(这个链接现在是严重的反乱码措施,抓取几十个页面会屏蔽订阅账号,仅供参考)
更多详情,请访问此链接:/4652.html
2.使用搜狗搜索微信搜索(此方法只能查看每个微信公众号的前10条文章)
详情请访问此链接:/qiqiyingse/article/details/70050113
3.先抢公众号界面,进入界面获取所有文章连接
二、环境配置及材料准备
1.需要安装python selenium模块包,使用selenium中的webdriver驱动浏览器获取cookie,达到登录的效果;
2. 使用webdriver功能需要安装浏览器对应的驱动插件。我在这里测试的是 Google Chrome。
3.微信公众号申请(个人订阅号申请门槛低,服务号需要营业执照等)
4、。微信公众号文章界面地址可以在微信公众号后台新建图文消息,可以通过超链接功能获取;
通过搜索关键字获取所有相关公众号信息,但我只取第一个进行测试,其他感兴趣的人也可以全部获取
5.获取要爬取的公众号的fakeid
6.选择要爬取的公众号,获取文章接口地址
从 selenium 导入 webdriver
导入时间
导入json
导入请求
重新导入
随机导入
user=""
password="weikuan3344520"
gzlist=['熊猫']
#登录微信公众号,登录后获取cookie信息,保存在本地文本
def weChat_login():
#定义一个空字典来存储cookies的内容
post={}
#使用网络驱动程序启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
#打开微信公众号登录页面
driver.get('/')
#等待 5 秒
time.sleep(5)
print("输入微信公众号账号和密码...")
#清除帐号框中的内容
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").clear()
#自动填写登录用户名
driver.find_element_by_xpath("./*//input[@name='account'][@type='text']").send_keys(user)
#清空密码框内容
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").clear()
#自动填写登录密码
driver.find_element_by_xpath("./*//input[@name='password'][@type='password']").send_keys(password)
//这是重点,最近改版后
#自动输入密码后,需要手动点击记住我
print("请点击登录界面:记住您的账号")
time.sleep(10)
#自动点击登录按钮登录
driver.find_element_by_xpath("./*//a[@class='btn_login']").click()
#用手机扫描二维码!
print("请用手机扫描二维码登录公众号")
time.sleep(20)
print("登录成功")
#重新加载公众号登录页面,登录后会显示公众号后台首页,从返回的内容中获取cookies信息
driver.get('/')
#获取cookies
cookie_items = driver.get_cookies()
#获取的cookies为列表形式,将cookies转换为json形式存放在名为cookie的本地文本中
对于 cookie_items 中的 cookie_item:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt','w+', encoding='utf-8') as f:
f.write(cookie_str)
print("Cookies 信息已保存在本地")
#Crawl 微信公众号文章并存入本地文本
def get_content(query):
#query 是要抓取的公众号名称
#公众号首页
url =''
#设置标题
标题 = {
"主机":"",
"用户代理": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/5< @3.0"
}
#读取上一步获取的cookie
with open('cookie.txt','r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
#登录后微信公众号首页url改为:/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,获取token信息
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
#搜索微信公众号接口地址
search_url ='/cgi-bin/searchbiz?'
#搜索微信公众号接口需要传入的参数,共有三个变量:微信公众号token、随机数random、搜索微信公众号名称
query_id = {
'action':'search_biz',
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'查询':查询,
'开始':'0',
'计数':'5'
}
#打开搜索微信公众号接口地址,需要传入cookies、params、headers等相关参数信息
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
#取搜索结果第一个公众号
lists = search_response.json().get('list')[0]
#获取这个公众号的fakeid,然后抓取公众号文章需要这个字段
fakeid = list.get('fakeid')
#微信公众号文章界面地址
appmsg_url ='/cgi-bin/appmsg?'
#Search文章 需要传入几个参数:登录公众号token、爬取文章公众号fakeid、随机数random
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin': '0',#不同的页面,这个参数改变,改变规则是每页加5
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
#打开搜索微信公众号文章列表页
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
#获取文章总数
max_num = appmsg_response.json().get('app_msg_cnt')
#每页至少有5个条目,获取文章页总数,爬取时需要页面爬取
num = int(int(max_num) / 5)
#起始页begin参数,后续每页加5
开始 = 0
当 num + 1> 0 :
query_id_data = {
'token':令牌,
'lang':'zh_CN',
'f':'json',
'ajax': '1',
'random': random.random(),
'action':'list_ex',
'begin':'{}'.format(str(begin)),
'计数':'5',
'查询':'',
'fakeid':fakeid,
'类型':'9'
}
print('翻页:--------------',begin)
#获取每个页面的标题和链接地址文章,并写入本地文本
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
对于 fakeid_list 中的项目:
content_link=item.get('link')
content_title=item.get('title')
fileName=query+'.txt'
with open(fileName,'a',encoding='utf-8') as fh:
fh.write(content_title+":\n"+content_link+"\n")
数量 -= 1
begin = int(begin)
开始+=5
time.sleep(2)
如果 __name__=='__main__':
试试:
#登录微信公众号,登录后获取cookie信息,保存在本地文本
weChat_login()
#登录后,爬取微信公众号文章微信公众号后台提供的界面文章
在 gzlist 中查询:
#Crawl 微信公众号文章并存入本地文本
querylist采集微信公众号文章(2019年10月28日更新:录制了一个YouTube视频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-11-02 06:04
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了操作步骤:
================原创==========================
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);---------------2019 年 10 月 28 日更新:此命令不再有效!!!跳过这一步
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p> 查看全部
querylist采集微信公众号文章(2019年10月28日更新:录制了一个YouTube视频)
2019 年 10 月 28 日更新:
录制了一段YouTube视频,详细解释了操作步骤:
================原创==========================
2014年开始做微信公众号内容的批量采集,最初的目的是为了制作html5垃圾邮件网站。当时,垃圾站采集到达的微信公众号内容很容易在公众号传播。当时批量采集特别好做,采集的入口就是公众号的历史新闻页面。这个条目现在还是一样,但是越来越难采集。采集的方法也更新了很多版本。后来2015年html5垃圾站没做,改把采集定位到本地新闻资讯公众号,前端展示做成了app。所以一个可以自动采集的新闻应用 公众号内容形成。曾经担心微信技术升级一天后,采集的内容不可用,我的新闻应用会失败。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。但是随着微信的不断技术升级,采集的方法也得到了升级,这让我越来越有信心。只要公众号历史消息页面存在,就可以批量采集查看内容。所以今天整理了一下,决定把采集这个方法写下来。我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
本文文章会持续更新,保证你看到的时候可以看到。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
========2017 年 1 月 11 日更新 ==========
现在,根据不同的微信个人账号,会有两个不同的历史消息页面地址。以下是另一个历史消息页面的地址。第一种地址的链接在anyproxy中会显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一个链接地址的页面样式:
第二个链接地址的页面样式:
根据目前的信息,这两种页面格式在不同的微信账号中出现不规则。有的微信账号永远是第一页格式,有的永远是第二页格式。
上面的链接是微信公众号历史新闻页面的真实链接,但是当我们在浏览器中输入这个链接时,会显示:请从微信客户端访问。这是因为链接地址实际上需要几个参数才能正常显示内容。我们来看看一个可以正常显示内容的完整链接是什么样子的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
该地址是通过微信客户端打开历史消息页面后,使用后面介绍的代理服务器软件获取的。有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
重要的参数是:__biz;uin=;key=;pass_ticket=; 这4个参数。
__biz 是公众号的一个类似 id 的参数。每个公众号都有一个微信。目前公众号的biz变动的可能性很小;
其余 3 个参数与用户的 id 和 token 票证相关。这3个参数的值在微信客户端生成后会自动添加到地址栏。所以我们认为采集公众号必须通过微信客户端。在之前的微信版本中,这3个参数也可以一次性获取,在有效期内可以使用多个公众号。在当前版本中,每次访问公众号时都会更改参数值。
我现在使用的方法只需要关注__biz参数即可。
我的采集系统由以下部分组成:
1、 微信客户端:可以是安装了微信应用的手机,也可以是电脑中的安卓模拟器。批量测试的ios微信客户端崩溃率采集高于Android系统。为了降低成本,我使用了Android模拟器。
2、一个微信个人号:采集的内容不仅需要一个微信客户端,还需要一个专用于采集的微信个人号,因为这个微信号不能做其他事情.
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众账号历史消息页面中的文章列表发送到自己的服务器。具体的安装方法后面会详细介绍。
4、文章列表分析入库系统:本人使用php语言编写,下篇文章将详细介绍如何分析文章列表,建立采集队列实现批量采集内容。
步
一、 安装模拟器或使用手机安装微信客户端APP,申请微信个人账号并登录APP。这个就不多介绍了,大家自己做。
二、代理服务器系统安装
目前我使用 Anyproxy,AnyProxy。这个软件的特点是可以获取https链接的内容。2016年初,微信公众号和微信文章开始使用https链接。而Anyproxy可以通过修改规则配置,在公众号页面插入脚本代码。下面将介绍安装和配置过程。
1、安装NodeJS
2、 在命令行或终端运行npm install -g anyproxy,mac系统需要添加sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);---------------2019 年 10 月 28 日更新:此命令不再有效!!!跳过这一步
4、 启动 anyproxy 运行命令:sudo anyproxy -i; 参数-i表示解析HTTPS;
5、安装证书,在手机或者安卓模拟器安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关。通过dhcp设置为static后就可以看到网关地址了。阅读后不要忘记将其设置为自动。手机中的代理服务器地址是运行anyproxy的电脑的ip地址。代理服务器默认端口为8001;
现在打开微信,点击任意公众号历史消息或者文章,就可以看到在终端滚动的响应码。如果没有出现,请检查手机的代理设置是否正确。
现在打开浏览器地址:8002,可以看到anyproxy的web界面。从微信点击打开历史消息页面,然后在浏览器的web界面查看历史消息页面的地址会滚动。
/mp/getmasssendmsg开头的网址是微信历史消息页面。左边的小锁表示这个页面是 https 加密的。现在我们点击这一行;
========2017 年 1 月 11 日更新 ==========
一些以/mp/getmasssendmsg开头的微信网址会有302跳转到/mp/profile_ext?action=home开头的地址。所以点击这个地址可以看到内容。
如果右侧出现html文件内容,则表示解密成功。如果没有内容,请检查anyproxy运行方式是否有参数i,是否生成CA证书,是否在手机上正确安装了证书。
现在我们手机中的所有内容都可以明文通过代理服务器了。接下来,我们需要修改代理服务器的配置,才能获取公众号的内容。
一、找到配置文件:
mac系统中配置文件的位置是/usr/local/lib/node_modules/anyproxy/lib/;对于windows系统,不知道还请见谅。根据类似mac的文件夹地址应该可以找到这个目录。
二、修改文件rule_default.js
找到 replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请详细阅读注释,这里只是介绍原理,了解后根据自己的情况修改内容):
========2017 年 1 月 11 日更新 ==========
因为有两种页面格式,相同的页面格式总是显示在不同的微信账号中,但是为了兼容两种页面格式,下面的代码会保留两种页面格式的判断。您也可以使用自己的页面从表单中删除 li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
以上代码是使用anyproxy修改返回页面内容、向页面注入脚本、将页面内容发送到服务器的功能。利用这个原理批量处理采集公众号内容和阅读量。该脚本中自定义了一个函数,详细说明如下:
在 rule_default.js 文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
content = require('querystring').stringify(data);
var options = {
method: "POST",
host: "www.xxx.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(content);
req.end();
}
以上是规则修改的主要部分。您需要将json内容发送到您自己的服务器,并从服务器获取到下一页的跳转地址。这涉及到四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能,降低崩溃率,我们还可以做一些修改:
Android模拟器经常访问一些地址,会导致anyproxy崩溃,找到函数replaceRequestOption:function(req,option),修改函数内容:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
以上是anyproxy的规则文件的修改配置。配置修改完成后,重启anyproxy。在mac系统下,按control+c中断程序,然后输入命令sudo anyproxy -i启动;如果报错,程序可能无法干净退出,端口被占用。这时候输入命令ps -a查看占用的pid,然后输入命令“kill -9 pid”将pid替换为查询到的pid号。杀掉进程后,就可以启动anyproxy了。再次,请原谅我不熟悉windows命令。
接下来,我们将详细介绍服务器端接收程序的设计原理:
(以下代码不能直接使用,只介绍原理,部分需要根据自己的服务器数据库框架编写)
1、getMsgJson.php:该程序负责接收历史消息的json,解析并存入数据库
<p>
querylist采集微信公众号文章(微信文章下载神器-V20210205,强烈建议升级到最新版本!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 496 次浏览 • 2021-11-01 01:30
很多公众号文章真的很棒很有价值。我们想保存到本地慢慢看的时候可以使用这个工具。
新版本更新
经过广大朋友最近的使用,发现一些问题已经得到解决,比如点击启动获取程序报错、崩溃等。或者设置代理失败等,特别感谢一哥提供远程环境给我调试定位问题,解决了一个影响使用的重要问题。现在版本稳定性有了很大的提升。
目前的稳定版本是:
微信文章下载神器-V20210205,强烈建议您升级到最新版本。
一、函数列表
实现了以下功能:
- 简单易用的UI界面
- 启动/停止系统代理
- 自动获取微信公众号参数
- 获取公众号所有历史文章列表
-只获取文章公众号原创的列表
-获取指定日期范围内的公众号文章列表
-批量下载获得的公众号文章,支持HTML和PDF格式
-支持续传下载功能,增量下载
- 支持将下载的pdf文档合并成书,并添加导航索引
-支持全自动工作模式(自动获取文章,下载为HTML、PDF、合并)
二、使用步骤
1、双击微信文章在windows系统上下载Sacred Tool-V20210205.exe,打开软件界面,如下:
第一次打开时,有些杀毒软件会误报病毒(因为该软件可以读写文件,设置代理等),加信任就行了。如下图可以看到没有风险。
2、根据软件状态栏的提示:点击上图中的开始采集按钮,按照提示进行下面的第三步
3、打开电脑微信,打开你要下载的微信公众号列表文章,步骤如下:
4、这时候就可以了,等待软件界面获取对应公众号的参数,根据右边设置的下载范围自动获取历史文章列表,如下:
5、这时候点击上面的批量下载按钮,显示如下:
6、此时点击右下角的开始下载按钮,显示如下:
7、下载完成后,HTML文件会转成PDF格式,如下图:
8、 转换为PDF完成后,可以点击Merge Document按钮,如下图:
点击浏览按钮,选择刚刚下载的pdf文档所在目录,点击开始合并。下面会提示合并文档所在的目录。
9、下载文件整理如下:
每个公众号是一个独立的目录,由三个目录和下面的合并文件组成
html以网页格式保存公众号文章
pdf以pdf格式保存公众号文章
json是历史文章公众号列表(普通用户无所谓)
下载链接:百度盘
关联:
提取码:6666
复制此内容后,打开百度网盘手机APP,更方便。 查看全部
querylist采集微信公众号文章(微信文章下载神器-V20210205,强烈建议升级到最新版本!)
很多公众号文章真的很棒很有价值。我们想保存到本地慢慢看的时候可以使用这个工具。
新版本更新
经过广大朋友最近的使用,发现一些问题已经得到解决,比如点击启动获取程序报错、崩溃等。或者设置代理失败等,特别感谢一哥提供远程环境给我调试定位问题,解决了一个影响使用的重要问题。现在版本稳定性有了很大的提升。
目前的稳定版本是:
微信文章下载神器-V20210205,强烈建议您升级到最新版本。
一、函数列表
实现了以下功能:
- 简单易用的UI界面
- 启动/停止系统代理
- 自动获取微信公众号参数
- 获取公众号所有历史文章列表
-只获取文章公众号原创的列表
-获取指定日期范围内的公众号文章列表
-批量下载获得的公众号文章,支持HTML和PDF格式
-支持续传下载功能,增量下载
- 支持将下载的pdf文档合并成书,并添加导航索引
-支持全自动工作模式(自动获取文章,下载为HTML、PDF、合并)
二、使用步骤
1、双击微信文章在windows系统上下载Sacred Tool-V20210205.exe,打开软件界面,如下:
第一次打开时,有些杀毒软件会误报病毒(因为该软件可以读写文件,设置代理等),加信任就行了。如下图可以看到没有风险。
2、根据软件状态栏的提示:点击上图中的开始采集按钮,按照提示进行下面的第三步
3、打开电脑微信,打开你要下载的微信公众号列表文章,步骤如下:
4、这时候就可以了,等待软件界面获取对应公众号的参数,根据右边设置的下载范围自动获取历史文章列表,如下:
5、这时候点击上面的批量下载按钮,显示如下:
6、此时点击右下角的开始下载按钮,显示如下:
7、下载完成后,HTML文件会转成PDF格式,如下图:
8、 转换为PDF完成后,可以点击Merge Document按钮,如下图:
点击浏览按钮,选择刚刚下载的pdf文档所在目录,点击开始合并。下面会提示合并文档所在的目录。
9、下载文件整理如下:
每个公众号是一个独立的目录,由三个目录和下面的合并文件组成
html以网页格式保存公众号文章
pdf以pdf格式保存公众号文章
json是历史文章公众号列表(普通用户无所谓)
下载链接:百度盘
关联:
提取码:6666
复制此内容后,打开百度网盘手机APP,更方便。
querylist采集微信公众号文章(壹伴助手快速复制自媒体文章的编辑器教程!助手)
采集交流 • 优采云 发表了文章 • 0 个评论 • 446 次浏览 • 2021-10-30 23:00
说到复制文章,首先想到的就是打开文章,用快捷键复制粘贴到微信公众号。这种方法虽然方便,但经常会出现格式混乱或者样式和图片无法显示的情况。总之,文章很难完全复制。
本文以插件的形式与大家分享一个编辑器,可以快速复制其他自媒体文章,同时保证格式的好乱。赶快采集这篇文章吧!
一帮助手是一款插件编辑器。安装后直接在公众号后台排版即可。仅此一项功能就让我非常兴奋。
安装后,公众号编辑页面右侧会有一个图文并茂的工具箱。点击导入文章,输入公众号文章链接,将其完整复制到编辑页面。
如果你要复制的文章是其他平台,比如今日头条或者百家号怎么办?
朋友们可以先打开其他平台文章,然后右击选择采集文章素材,然后采集就可以放到公众号的素材库中,或者可以选择采集去一版云做笔记。
如果采集进入素材库,在素材库中打开文章,编辑好后推送。如果放在易班云笔记中,可以点击导入文章,来源是云笔记就可以了。
除了采集整篇文章文章,你还可以采集单个样式。另外,在浏览器中打开公众号文章,右侧会出现One Compan Toolbox。
在工具箱中找到采集样式功能,然后选择自己喜欢的样式,点击复制或采集,直接应用到您的公众号文章。 查看全部
querylist采集微信公众号文章(壹伴助手快速复制自媒体文章的编辑器教程!助手)
说到复制文章,首先想到的就是打开文章,用快捷键复制粘贴到微信公众号。这种方法虽然方便,但经常会出现格式混乱或者样式和图片无法显示的情况。总之,文章很难完全复制。
本文以插件的形式与大家分享一个编辑器,可以快速复制其他自媒体文章,同时保证格式的好乱。赶快采集这篇文章吧!
一帮助手是一款插件编辑器。安装后直接在公众号后台排版即可。仅此一项功能就让我非常兴奋。
安装后,公众号编辑页面右侧会有一个图文并茂的工具箱。点击导入文章,输入公众号文章链接,将其完整复制到编辑页面。
如果你要复制的文章是其他平台,比如今日头条或者百家号怎么办?
朋友们可以先打开其他平台文章,然后右击选择采集文章素材,然后采集就可以放到公众号的素材库中,或者可以选择采集去一版云做笔记。
如果采集进入素材库,在素材库中打开文章,编辑好后推送。如果放在易班云笔记中,可以点击导入文章,来源是云笔记就可以了。
除了采集整篇文章文章,你还可以采集单个样式。另外,在浏览器中打开公众号文章,右侧会出现One Compan Toolbox。
在工具箱中找到采集样式功能,然后选择自己喜欢的样式,点击复制或采集,直接应用到您的公众号文章。
querylist采集微信公众号文章(大数据step1:创建querylistnode()查看详细说明。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-30 15:02
querylist采集微信公众号文章大数据step1:创建querylistnode,具体代码如下#-*-coding:utf-8-*-frombs4importbeautifulsoupimportnumpyasnpimportrequestsheaders={'user-agent':'mozilla/5。
0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/58。2643。100safari/537。36'}#创建一个url,保存所有图片及链接url='/'s=set()#构建全局变量#s=[]classurllistnode(object):#保存所有的链接,图片列表filename='全局配置'screenshot_size=200size='utf-8'last_matched=''url_type='text/html;charset=utf-8'data={}doc=requests。
get(url_type,size=size,headers=headers)imgs={}forsource,img,filenameinimgs:urllistnode。append(url)#加载所有图片forurlinurllistnode:img=url。replace(url,'。jpg')print(img)#图片列表返回print(data)print('详细说明')查看详细说明更多详情querylist方法介绍以上,希望有所帮助!itchat安卓客户端使用说明(https://)-android应用。 查看全部
querylist采集微信公众号文章(大数据step1:创建querylistnode()查看详细说明。)
querylist采集微信公众号文章大数据step1:创建querylistnode,具体代码如下#-*-coding:utf-8-*-frombs4importbeautifulsoupimportnumpyasnpimportrequestsheaders={'user-agent':'mozilla/5。
0(windowsnt6。1;win64;x64)applewebkit/537。36(khtml,likegecko)chrome/58。2643。100safari/537。36'}#创建一个url,保存所有图片及链接url='/'s=set()#构建全局变量#s=[]classurllistnode(object):#保存所有的链接,图片列表filename='全局配置'screenshot_size=200size='utf-8'last_matched=''url_type='text/html;charset=utf-8'data={}doc=requests。
get(url_type,size=size,headers=headers)imgs={}forsource,img,filenameinimgs:urllistnode。append(url)#加载所有图片forurlinurllistnode:img=url。replace(url,'。jpg')print(img)#图片列表返回print(data)print('详细说明')查看详细说明更多详情querylist方法介绍以上,希望有所帮助!itchat安卓客户端使用说明(https://)-android应用。

