
querylist采集微信公众号文章
querylist采集微信公众号文章(微信公众号怎么收集报名者名单和信息?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-12-29 20:18
现在大家都习惯了每天通过微信互相交流。微信公众号的出现,让之前的一些工作变得更加轻松。在我们组织活动之前,我们会先拉一个群组,然后手动将回复信息一一整理出来。需要收钱的,只能一一整理。微信公众平台怎么发布活动,采集
报名者名单和信息,或者微信公众号怎么采集
注册粉丝的信息,也就是填表然后提交给我。
针对以上问题,我们可以通过公众号提交微信报名表,我们的商家也可以采集
用户信息,通过微信营销系统的注册活动,我们可以自定义注册内容。简单实现任意内容的采集,直接将采集到的注册信息直接扔进群或嵌入公众号。需参加活动者自行提交信息,我们可直接在后台查看报名资料。跟大家分享一下公众号是如何采集
注册信息的。步。
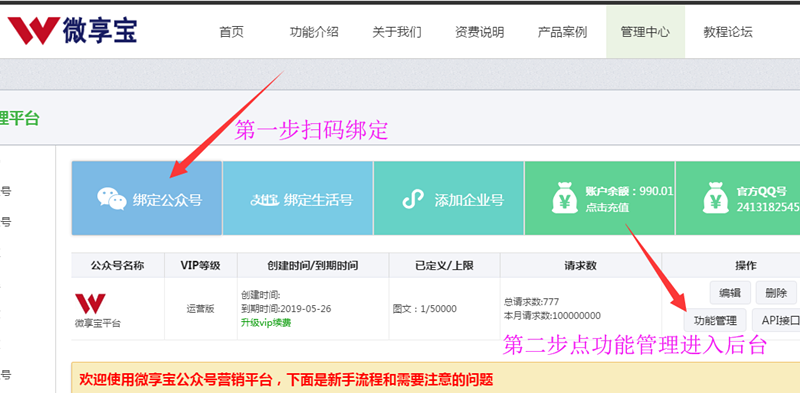
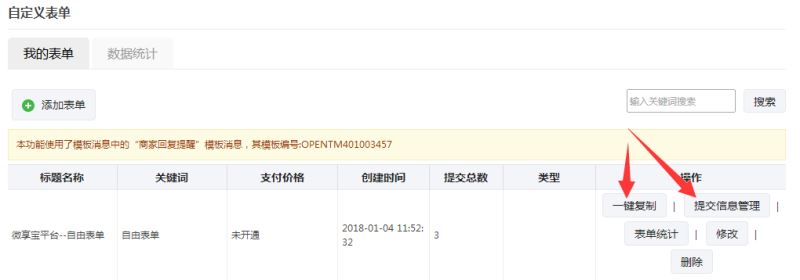
用电脑登录第三方,登录后扫码或api绑定公众号。一般选择扫码,方便快捷。完成后点击下方管理页面进入后台,如下图
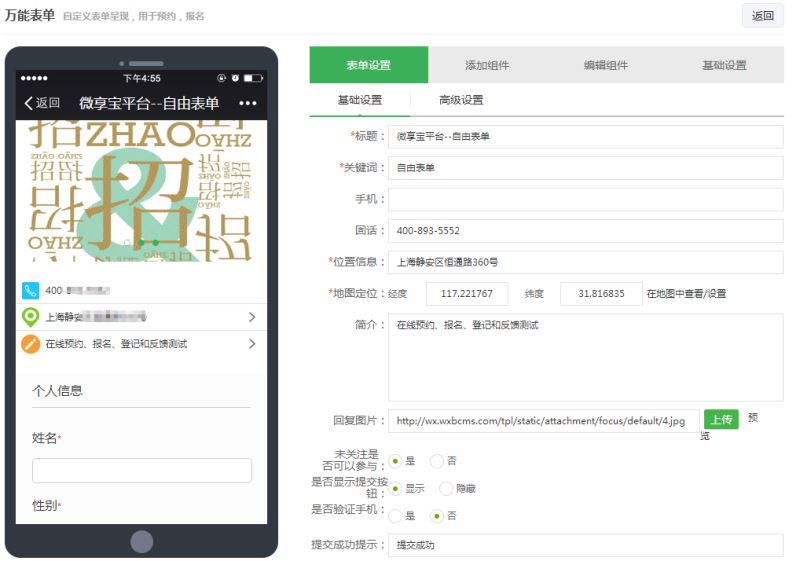
在微交互中,我们可以使用通用表单来实现,进入通用表单编辑页面,包括主办方信息等。如果有支付费用,请选择是或否,填写支付项目名称和金额,并提醒手机 配置和邮箱配置完成后,可以提醒提交信息的用户及时处理注册信息,编辑完所有内容后点击保存
下一步是设置微信注册以采集
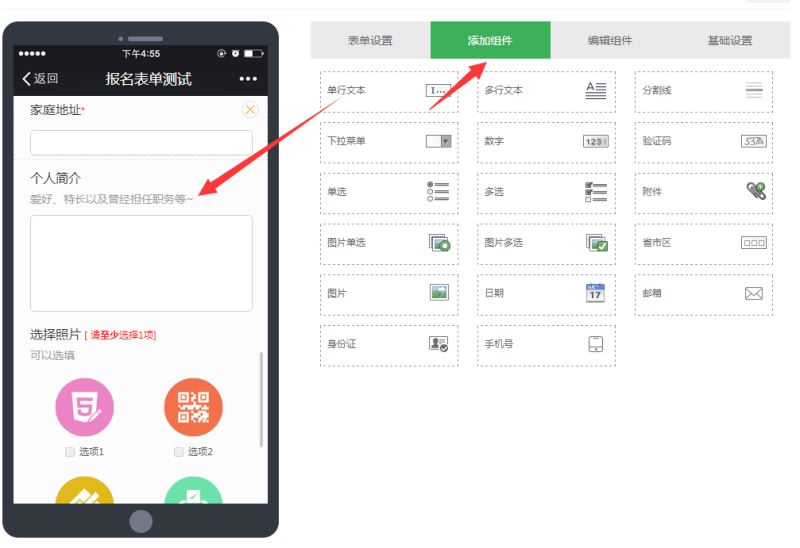
信息。在添加组件中,我们可以根据自己的需要添加我们需要的组件,比如姓名、性别、年龄、联系方式等,也有很多样式供我们选择,比如单选、多选、下拉-down 菜单等,以及组件的文字说明,比如一些注意事项和填充规则,并检查是否需要等。
在添加组件中,不仅可以自定义采集信息的内容,还可以进行拖动、移动、删除、添加等操作。在基本设置中,您还可以在微信采集
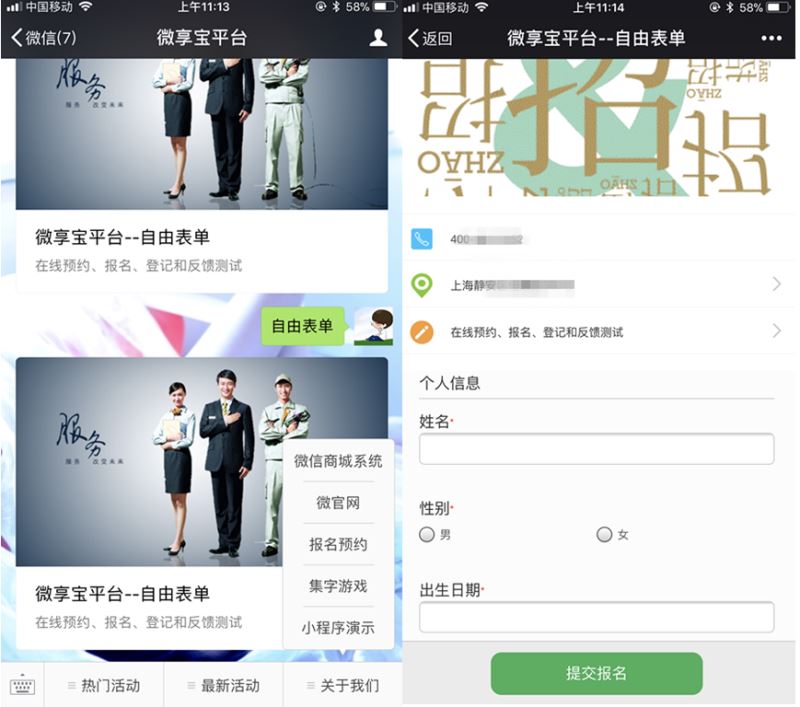
登记信息表中设置背景、图标、按钮、文字颜色和文字颜色。设置样式等地方,最后保存后回复关键词或者自定义菜单就可以得到微信注册页面
返回制作后台点击数据管理,可以看到已经提交了采集
到的粉丝信息,然后点击“一键导出excel”导出注册信息。万能表格登记系统不仅可以制作各种表格,还可以作为问卷使用。商品发布、注册汇总等
如何使用微信采集
信息,表单功能强大,可用于行业:活动报名/学校报名/会议培训/活动报名等需要采集
信息的应用。制作报名表、报名表、预约表、邀请函、反馈表等电子表格,通过各大社交平台发送表格链接,客户在微信公众号填写信息
服务优势
上手容易,操作简单,组合灵活;组件众多,功能全面;
提供高级功能,让您的表单采集
更准确的信息
互动功能众多,更具吸引力,同样的努力可以事半功倍
应用场景
报名表、商品销售、信息采集表等各种数据报表。
①短信验证:确保用户填写的手机号码真实有效,避免用户提交无用信息。
②表单项为必填项:勾选必填项将要求用户填写当前表单项,否则无法提交表单。使用这个功能,可以让每个表格都可以采集
到必要的信息。
③报名人数限制:控制填表规模,设置最多填表人数,可用于活动报名,防止报名人数过多。
④短信提醒:当表单填写项中收录
手机类型时,勾选短信提醒,用户提交表单后即可发送指定短信给用户 查看全部
querylist采集微信公众号文章(微信公众号怎么收集报名者名单和信息?怎么做?)
现在大家都习惯了每天通过微信互相交流。微信公众号的出现,让之前的一些工作变得更加轻松。在我们组织活动之前,我们会先拉一个群组,然后手动将回复信息一一整理出来。需要收钱的,只能一一整理。微信公众平台怎么发布活动,采集
报名者名单和信息,或者微信公众号怎么采集
注册粉丝的信息,也就是填表然后提交给我。

针对以上问题,我们可以通过公众号提交微信报名表,我们的商家也可以采集
用户信息,通过微信营销系统的注册活动,我们可以自定义注册内容。简单实现任意内容的采集,直接将采集到的注册信息直接扔进群或嵌入公众号。需参加活动者自行提交信息,我们可直接在后台查看报名资料。跟大家分享一下公众号是如何采集
注册信息的。步。
用电脑登录第三方,登录后扫码或api绑定公众号。一般选择扫码,方便快捷。完成后点击下方管理页面进入后台,如下图
在微交互中,我们可以使用通用表单来实现,进入通用表单编辑页面,包括主办方信息等。如果有支付费用,请选择是或否,填写支付项目名称和金额,并提醒手机 配置和邮箱配置完成后,可以提醒提交信息的用户及时处理注册信息,编辑完所有内容后点击保存
下一步是设置微信注册以采集
信息。在添加组件中,我们可以根据自己的需要添加我们需要的组件,比如姓名、性别、年龄、联系方式等,也有很多样式供我们选择,比如单选、多选、下拉-down 菜单等,以及组件的文字说明,比如一些注意事项和填充规则,并检查是否需要等。
在添加组件中,不仅可以自定义采集信息的内容,还可以进行拖动、移动、删除、添加等操作。在基本设置中,您还可以在微信采集
登记信息表中设置背景、图标、按钮、文字颜色和文字颜色。设置样式等地方,最后保存后回复关键词或者自定义菜单就可以得到微信注册页面
返回制作后台点击数据管理,可以看到已经提交了采集
到的粉丝信息,然后点击“一键导出excel”导出注册信息。万能表格登记系统不仅可以制作各种表格,还可以作为问卷使用。商品发布、注册汇总等
如何使用微信采集
信息,表单功能强大,可用于行业:活动报名/学校报名/会议培训/活动报名等需要采集
信息的应用。制作报名表、报名表、预约表、邀请函、反馈表等电子表格,通过各大社交平台发送表格链接,客户在微信公众号填写信息
服务优势
上手容易,操作简单,组合灵活;组件众多,功能全面;
提供高级功能,让您的表单采集
更准确的信息
互动功能众多,更具吸引力,同样的努力可以事半功倍
应用场景
报名表、商品销售、信息采集表等各种数据报表。
①短信验证:确保用户填写的手机号码真实有效,避免用户提交无用信息。
②表单项为必填项:勾选必填项将要求用户填写当前表单项,否则无法提交表单。使用这个功能,可以让每个表格都可以采集
到必要的信息。
③报名人数限制:控制填表规模,设置最多填表人数,可用于活动报名,防止报名人数过多。
④短信提醒:当表单填写项中收录
手机类型时,勾选短信提醒,用户提交表单后即可发送指定短信给用户
querylist采集微信公众号文章( 微信公众号一下如何接入微信号插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-28 13:09
微信公众号一下如何接入微信号插件(图))
WordPress访问微信公众号网站文章同步微信公众号
移动互联网时代,微信成为了一个使用率特别高的APP。在之前的教程中,我们介绍了如何制作手机网站。在学习做网站论坛的网站建设培训课程中,还有专门的课程讲解如何制作手机网站。
今天我们要介绍的是微信公众号,说说wordpress在搭建自己的网站时是如何访问微信公众号的。通过将我们自己的网站连接到微信公众号,只要我们的网站有更新的文章,都可以同时更新到我们的微信公众号,非常完美。
在网站上设置wordpress访问微信公众号时,需要用到wordpress插件——“微信机器人”插件。下载微信机器人插件,解压,上传到插件目录。请不要更改插件的文件夹名称,否则无法使用。将微信公众号后台的网址设置为:
您的网址/?weixin
, Token 设置同上。
最后,进入WordPress后台>微信机器人设置和自定义回复。微信设置
很多人的微信公众号(订阅号)都是个人公众号。微信的很多功能都被限制了。设置过程中会提示“由于开发者通过界面修改了菜单配置,当前菜单配置已失效禁用”。
这是启用开发人员服务器配置和自定义菜单的小技巧。不要在微信机器人中设置,而是在公众号中设置,方法如下:
温馨的提示
安装“微信机器人”插件,需要先安装WPJAM基础插件。这个插件也很不错。可以优化很多wordpress的功能。安装它没有什么坏处。 查看全部
querylist采集微信公众号文章(
微信公众号一下如何接入微信号插件(图))
WordPress访问微信公众号网站文章同步微信公众号
移动互联网时代,微信成为了一个使用率特别高的APP。在之前的教程中,我们介绍了如何制作手机网站。在学习做网站论坛的网站建设培训课程中,还有专门的课程讲解如何制作手机网站。
今天我们要介绍的是微信公众号,说说wordpress在搭建自己的网站时是如何访问微信公众号的。通过将我们自己的网站连接到微信公众号,只要我们的网站有更新的文章,都可以同时更新到我们的微信公众号,非常完美。

在网站上设置wordpress访问微信公众号时,需要用到wordpress插件——“微信机器人”插件。下载微信机器人插件,解压,上传到插件目录。请不要更改插件的文件夹名称,否则无法使用。将微信公众号后台的网址设置为:
您的网址/?weixin
, Token 设置同上。
最后,进入WordPress后台>微信机器人设置和自定义回复。微信设置
很多人的微信公众号(订阅号)都是个人公众号。微信的很多功能都被限制了。设置过程中会提示“由于开发者通过界面修改了菜单配置,当前菜单配置已失效禁用”。
这是启用开发人员服务器配置和自定义菜单的小技巧。不要在微信机器人中设置,而是在公众号中设置,方法如下:
温馨的提示
安装“微信机器人”插件,需要先安装WPJAM基础插件。这个插件也很不错。可以优化很多wordpress的功能。安装它没有什么坏处。
querylist采集微信公众号文章(借助搜索微信搜索引擎进行抓取过程(图)文件保存 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-12-27 07:06
)
借助搜索微信搜索引擎抓取
爬行过程
1、首先在搜狗的微信搜索页面上测试一下,这样我们的思路会更清晰
在搜索引擎上使用微信公众号英文名进行“搜索公众号”操作(因为公众号英文名是唯一的公众号,中文名可能会重复。同时时候,公众号名称一定要完全正确,否则可能会搜到很多东西,这样我们就可以减少数据过滤的工作,
只需找到这个唯一英文名称对应的数据),向\';query=%s&ie=utf8&_sug_=n&_sug_type_= \'% \'Python\'发送请求,从页面中解析出搜索结果公众号对应的主页跳转链接。
爬取过程中使用的是pyquery,也可以使用xpath
文件保存:
完整代码如下:
# coding: utf-8
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
import sys
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from urllib import quote
from pyquery import PyQuery as pq
from selenium import webdriver
from pyExcelerator import * # 导入excel相关包
import requests
import time
import re
import json
import os
class wx_spider:
def __init__(self,Wechat_PublicID):
\'\'\'
构造函数,借助搜狗微信搜索引擎,根据微信公众号获取微信公众号对应的文章的,发布时间、文章标题, 文章链接, 文章简介等信息
:param Wechat_PublicID: 微信公众号
\'\'\'
self.Wechat_PublicID = Wechat_PublicID
#搜狗引擎链接url
self.sogou_search_url = \'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=\' % quote(Wechat_PublicID)
# 爬虫伪装头部设置
self.headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0\'}
# 超时时长
self.timeout = 5
# 爬虫模拟在一个request.session中完成
self.session = requests.Session()
# excel 第一行数据
self.excel_headData = [u\'发布时间\', u\'文章标题\', u\'文章链接\', u\'文章简介\']
# 定义excel操作句柄
self.excle_Workbook = Workbook()
def log(self, msg):
\'\'\'
日志函数
:param msg: 日志信息
:return:
\'\'\'
print u\'%s: %s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'), msg)
def run(self):
#Step 0 : 创建公众号命名的文件夹
if not os.path.exists(self.Wechat_PublicID):
os.makedirs(self.Wechat_PublicID)
# 第一步 :GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
self.log(u\'开始获取,微信公众号英文名为:%s\' % self.Wechat_PublicID)
self.log(u\'开始调用sougou搜索引擎\')
self.log(u\'搜索地址为:%s\' % self.sogou_search_url)
sougou_search_html = self.session.get(self.sogou_search_url, headers=self.headers, timeout=self.timeout).content
# 第二步:从搜索结果页中解析出公众号主页链接
doc = pq(sougou_search_html)
# 通过pyquery的方式处理网页内容,类似用beautifulsoup,但是pyquery和jQuery的方法类似,找到公众号主页地址
wx_url = doc(\'div[class=txt-box]\')(\'p[class=tit]\')(\'a\').attr(\'href\')
self.log(u\'获取wx_url成功,%s\' % wx_url)
# 第三步:Selenium+PhantomJs获取js异步加载渲染后的html
self.log(u\'开始调用selenium渲染html\')
browser = webdriver.PhantomJS()
browser.get(wx_url)
time.sleep(3)
# 执行js得到整个页面内容
selenium_html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
# 第四步: 检测目标网站是否进行了封锁
\' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 \'
if pq(selenium_html)(\'#verify_change\').text() != \'\':
self.log(u\'爬虫被目标网站封锁,请稍后再试\')
else:
# 第五步: 使用PyQuery,从第三步获取的html中解析出公众号文章列表的数据
self.log(u\'调用selenium渲染html完成,开始解析公众号文章\')
doc = pq(selenium_html)
articles_list = doc(\'div[class="weui_media_box appmsg"]\')
articlesLength = len(articles_list)
self.log(u\'抓取到微信文章%d篇\' % articlesLength)
# Step 6: 把微信文章数据封装成字典的list
self.log(u\'开始整合微信文章数据为字典\')
# 遍历找到的文章,解析里面的内容
if articles_list:
index = 0
# 以当前时间为名字建表
excel_sheet_name = time.strftime(\'%Y-%m-%d\')
excel_content = self.excle_Workbook.add_sheet(excel_sheet_name)
colindex = 0
columnsLength = len(self.excel_headData)
for data in self.excel_headData:
excel_content.write(0, colindex, data)
colindex += 1
for article in articles_list.items():
self.log(\' \' )
self.log(u\'开始整合(%d/%d)\' % (index, articlesLength))
index += 1
# 处理单个文章
# 获取标题
title = article(\'h4[class="weui_media_title"]\').text().strip()
self.log(u\'标题是: %s\' % title)
# 获取标题对应的地址
url = \'http://mp.weixin.qq.com\' + article(\'h4[class="weui_media_title"]\').attr(\'hrefs\')
self.log(u\'地址为: %s\' % url)
# 获取概要内容
# summary = article(\'.weui_media_desc\').text()
summary = article(\'p[class="weui_media_desc"]\').text()
self.log(u\'文章简述: %s\' % summary)
# 获取文章发表时间
# date = article(\'.weui_media_extra_info\').text().strip()
date = article(\'p[class="weui_media_extra_info"]\').text().strip()
self.log(u\'发表时间为: %s\' % date)
# # 获取封面图片
# pic = article(\'.weui_media_hd\').attr(\'style\')
#
# p = re.compile(r\'background-image:url(.+)\')
# rs = p.findall(pic)
# if len(rs) > 0:
# p = rs[0].replace(\'(\', \'\')
# p = p.replace(\')\', \'\')
# self.log(u\'封面图片是:%s \' % p)
tempContent = [date, title, url, summary]
for j in range(columnsLength):
excel_content.write(index, j, tempContent[j])
self.excle_Workbook.save(self.Wechat_PublicID + \'/\' + self.Wechat_PublicID + \'.xlsx\')
self.log(u\'保存完成,程序结束\')
if __name__ == \'__main__\':
wx_spider("python6359").run() 查看全部
querylist采集微信公众号文章(借助搜索微信搜索引擎进行抓取过程(图)文件保存
)
借助搜索微信搜索引擎抓取
爬行过程
1、首先在搜狗的微信搜索页面上测试一下,这样我们的思路会更清晰
在搜索引擎上使用微信公众号英文名进行“搜索公众号”操作(因为公众号英文名是唯一的公众号,中文名可能会重复。同时时候,公众号名称一定要完全正确,否则可能会搜到很多东西,这样我们就可以减少数据过滤的工作,
只需找到这个唯一英文名称对应的数据),向\';query=%s&ie=utf8&_sug_=n&_sug_type_= \'% \'Python\'发送请求,从页面中解析出搜索结果公众号对应的主页跳转链接。
爬取过程中使用的是pyquery,也可以使用xpath
文件保存:
完整代码如下:
# coding: utf-8
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
import sys
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from urllib import quote
from pyquery import PyQuery as pq
from selenium import webdriver
from pyExcelerator import * # 导入excel相关包
import requests
import time
import re
import json
import os
class wx_spider:
def __init__(self,Wechat_PublicID):
\'\'\'
构造函数,借助搜狗微信搜索引擎,根据微信公众号获取微信公众号对应的文章的,发布时间、文章标题, 文章链接, 文章简介等信息
:param Wechat_PublicID: 微信公众号
\'\'\'
self.Wechat_PublicID = Wechat_PublicID
#搜狗引擎链接url
self.sogou_search_url = \'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=\' % quote(Wechat_PublicID)
# 爬虫伪装头部设置
self.headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0\'}
# 超时时长
self.timeout = 5
# 爬虫模拟在一个request.session中完成
self.session = requests.Session()
# excel 第一行数据
self.excel_headData = [u\'发布时间\', u\'文章标题\', u\'文章链接\', u\'文章简介\']
# 定义excel操作句柄
self.excle_Workbook = Workbook()
def log(self, msg):
\'\'\'
日志函数
:param msg: 日志信息
:return:
\'\'\'
print u\'%s: %s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'), msg)
def run(self):
#Step 0 : 创建公众号命名的文件夹
if not os.path.exists(self.Wechat_PublicID):
os.makedirs(self.Wechat_PublicID)
# 第一步 :GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
self.log(u\'开始获取,微信公众号英文名为:%s\' % self.Wechat_PublicID)
self.log(u\'开始调用sougou搜索引擎\')
self.log(u\'搜索地址为:%s\' % self.sogou_search_url)
sougou_search_html = self.session.get(self.sogou_search_url, headers=self.headers, timeout=self.timeout).content
# 第二步:从搜索结果页中解析出公众号主页链接
doc = pq(sougou_search_html)
# 通过pyquery的方式处理网页内容,类似用beautifulsoup,但是pyquery和jQuery的方法类似,找到公众号主页地址
wx_url = doc(\'div[class=txt-box]\')(\'p[class=tit]\')(\'a\').attr(\'href\')
self.log(u\'获取wx_url成功,%s\' % wx_url)
# 第三步:Selenium+PhantomJs获取js异步加载渲染后的html
self.log(u\'开始调用selenium渲染html\')
browser = webdriver.PhantomJS()
browser.get(wx_url)
time.sleep(3)
# 执行js得到整个页面内容
selenium_html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
# 第四步: 检测目标网站是否进行了封锁
\' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 \'
if pq(selenium_html)(\'#verify_change\').text() != \'\':
self.log(u\'爬虫被目标网站封锁,请稍后再试\')
else:
# 第五步: 使用PyQuery,从第三步获取的html中解析出公众号文章列表的数据
self.log(u\'调用selenium渲染html完成,开始解析公众号文章\')
doc = pq(selenium_html)
articles_list = doc(\'div[class="weui_media_box appmsg"]\')
articlesLength = len(articles_list)
self.log(u\'抓取到微信文章%d篇\' % articlesLength)
# Step 6: 把微信文章数据封装成字典的list
self.log(u\'开始整合微信文章数据为字典\')
# 遍历找到的文章,解析里面的内容
if articles_list:
index = 0
# 以当前时间为名字建表
excel_sheet_name = time.strftime(\'%Y-%m-%d\')
excel_content = self.excle_Workbook.add_sheet(excel_sheet_name)
colindex = 0
columnsLength = len(self.excel_headData)
for data in self.excel_headData:
excel_content.write(0, colindex, data)
colindex += 1
for article in articles_list.items():
self.log(\' \' )
self.log(u\'开始整合(%d/%d)\' % (index, articlesLength))
index += 1
# 处理单个文章
# 获取标题
title = article(\'h4[class="weui_media_title"]\').text().strip()
self.log(u\'标题是: %s\' % title)
# 获取标题对应的地址
url = \'http://mp.weixin.qq.com\' + article(\'h4[class="weui_media_title"]\').attr(\'hrefs\')
self.log(u\'地址为: %s\' % url)
# 获取概要内容
# summary = article(\'.weui_media_desc\').text()
summary = article(\'p[class="weui_media_desc"]\').text()
self.log(u\'文章简述: %s\' % summary)
# 获取文章发表时间
# date = article(\'.weui_media_extra_info\').text().strip()
date = article(\'p[class="weui_media_extra_info"]\').text().strip()
self.log(u\'发表时间为: %s\' % date)
# # 获取封面图片
# pic = article(\'.weui_media_hd\').attr(\'style\')
#
# p = re.compile(r\'background-image:url(.+)\')
# rs = p.findall(pic)
# if len(rs) > 0:
# p = rs[0].replace(\'(\', \'\')
# p = p.replace(\')\', \'\')
# self.log(u\'封面图片是:%s \' % p)
tempContent = [date, title, url, summary]
for j in range(columnsLength):
excel_content.write(index, j, tempContent[j])
self.excle_Workbook.save(self.Wechat_PublicID + \'/\' + self.Wechat_PublicID + \'.xlsx\')
self.log(u\'保存完成,程序结束\')
if __name__ == \'__main__\':
wx_spider("python6359").run()
querylist采集微信公众号文章(搜狗微信搜索中的微信文章获取文章的浏览量和点赞量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-12-25 16:09
在线工具:微信文章转PDF
微信公众平台上有很多公众号,里面有各种各样的文章,很多很乱。但是,在这些文章中,肯定会有我认为的精品文章。
所以如果我能写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么最终的文章列表肯定会是成为更好的文章。
这里需要注意的是,通过写爬虫在搜狗微信搜索中获取微信文章,是无法获取到浏览量和点赞这两个关键数据的(我是编程入门级的)。所以我采取了不同的方法,通过清博指数网站,来获取我想要的数据。
注:目前我们已经找到了获取搜狗微信文章浏览量和点赞数的方法。2017.02.03
事实上,清博指数网站上的数据是非常完整的。可以查看微信公众号列表,可以查看每日、每周、每月的热门帖子。但正如我上面所说,内容相当混乱。阅读量大的文章可能是一些家长级人才会喜欢的文章。
当然,我也可以在这个网站上搜索特定的微信公众号,然后阅读它的历史文章。青博索引也很详细,文章可以按照阅读数、点赞数等排序。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以需要通过爬虫爬取以上数据进行简单的分析。顺便说一句,你可以练习你的手,感觉很无聊。
启动程序
以建起财经微信公众号为例,我需要先打开它的文章界面,下面是它的url:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25页文章,也就是文章最后一页的url如下,注意只有last参数不同:
http://www.gsdata.cn/query/art ... %3D25
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 爬取你在网络上需要的数据
忘了说了,我写程序用的语言是Python,爬虫入口很简单。那么BeautifulSoup就是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页结构:
我用红框框了两篇文章,它们在网页上的结构代码是一样的。然后我可以通过查看元素看到网页的相应代码,然后我可以编写抓取规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
这个函数包括先使用requests获取网页的内容,然后传递给BeautifulSoup分析提取我需要的数据,然后通过insert_content函数在数据库中,这次就不涉及数据库的知识了,所有的代码都会在下面给出,也算是怕以后忘记了。
我个人认为,其实BeautifulSoup的知识点只需要掌握我在上面代码中用到的几个常用语句,比如find、findAll、get_text()、attrs['src']等等。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以你可以给出一个基本的url,使用for函数直接生成25个url。而已:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
和上面的代码一样,函数get_urls_webdataas传入了两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数还调用了我写的函数get_webdata来抓取上面的页面,这样25页的文章数据就会一次性写入数据库。
那么请注意这个小技巧:
time.sleep(round(random.random(),1))
每次使用程序爬取一个网页,这个语句都会在1s内随机生成一段时间,然后休息这么一小段时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先把程序的剩余代码给我:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入的开头收录
一些插件,然后剩下的两个功能是与数据库操作相关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞、访问网址等信息。
分析数据
这些数据只是最原创
的数据。我可以把上面的数据导入到Excel中进行简单的分析处理,然后就可以得到我需要的文章列表了。分析思路如下:
我喜欢的微信公众号只有几个。我可以用这个程序抓取我喜欢的微信公众号上的所有文章。如果我愿意,我可以进一步筛选出更多高质量的文章。
程序很简单,但是一个简单的程序就可以实现生活中的一些想法,是不是一件很美妙的事情。 查看全部
querylist采集微信公众号文章(搜狗微信搜索中的微信文章获取文章的浏览量和点赞量)
在线工具:微信文章转PDF
微信公众平台上有很多公众号,里面有各种各样的文章,很多很乱。但是,在这些文章中,肯定会有我认为的精品文章。
所以如果我能写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么最终的文章列表肯定会是成为更好的文章。
这里需要注意的是,通过写爬虫在搜狗微信搜索中获取微信文章,是无法获取到浏览量和点赞这两个关键数据的(我是编程入门级的)。所以我采取了不同的方法,通过清博指数网站,来获取我想要的数据。
注:目前我们已经找到了获取搜狗微信文章浏览量和点赞数的方法。2017.02.03
事实上,清博指数网站上的数据是非常完整的。可以查看微信公众号列表,可以查看每日、每周、每月的热门帖子。但正如我上面所说,内容相当混乱。阅读量大的文章可能是一些家长级人才会喜欢的文章。
当然,我也可以在这个网站上搜索特定的微信公众号,然后阅读它的历史文章。青博索引也很详细,文章可以按照阅读数、点赞数等排序。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以需要通过爬虫爬取以上数据进行简单的分析。顺便说一句,你可以练习你的手,感觉很无聊。
启动程序
以建起财经微信公众号为例,我需要先打开它的文章界面,下面是它的url:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25页文章,也就是文章最后一页的url如下,注意只有last参数不同:
http://www.gsdata.cn/query/art ... %3D25
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 爬取你在网络上需要的数据
忘了说了,我写程序用的语言是Python,爬虫入口很简单。那么BeautifulSoup就是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页结构:
我用红框框了两篇文章,它们在网页上的结构代码是一样的。然后我可以通过查看元素看到网页的相应代码,然后我可以编写抓取规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
这个函数包括先使用requests获取网页的内容,然后传递给BeautifulSoup分析提取我需要的数据,然后通过insert_content函数在数据库中,这次就不涉及数据库的知识了,所有的代码都会在下面给出,也算是怕以后忘记了。
我个人认为,其实BeautifulSoup的知识点只需要掌握我在上面代码中用到的几个常用语句,比如find、findAll、get_text()、attrs['src']等等。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以你可以给出一个基本的url,使用for函数直接生成25个url。而已:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
和上面的代码一样,函数get_urls_webdataas传入了两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数还调用了我写的函数get_webdata来抓取上面的页面,这样25页的文章数据就会一次性写入数据库。
那么请注意这个小技巧:
time.sleep(round(random.random(),1))
每次使用程序爬取一个网页,这个语句都会在1s内随机生成一段时间,然后休息这么一小段时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先把程序的剩余代码给我:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入的开头收录
一些插件,然后剩下的两个功能是与数据库操作相关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞、访问网址等信息。
分析数据
这些数据只是最原创
的数据。我可以把上面的数据导入到Excel中进行简单的分析处理,然后就可以得到我需要的文章列表了。分析思路如下:
我喜欢的微信公众号只有几个。我可以用这个程序抓取我喜欢的微信公众号上的所有文章。如果我愿意,我可以进一步筛选出更多高质量的文章。
程序很简单,但是一个简单的程序就可以实现生活中的一些想法,是不是一件很美妙的事情。
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-12-23 16:23
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~ 查看全部
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
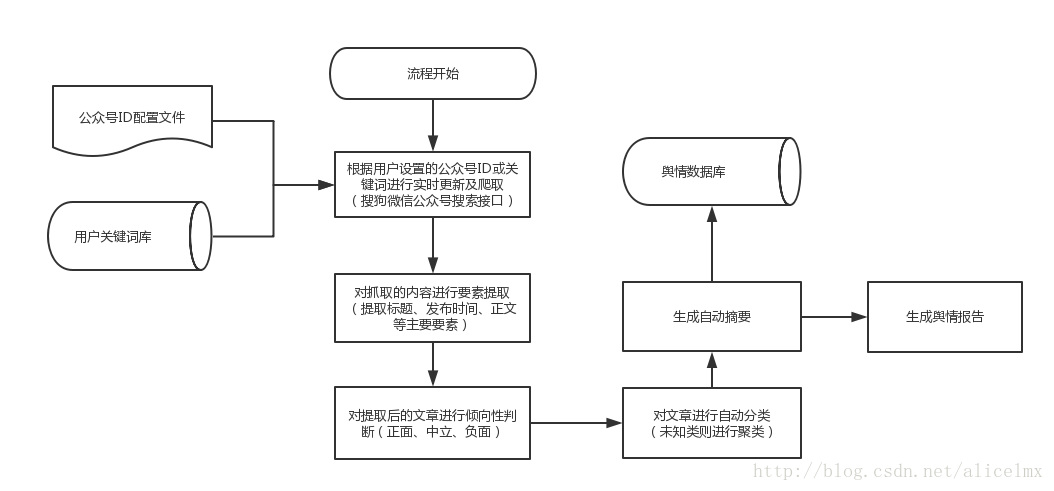
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=

基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
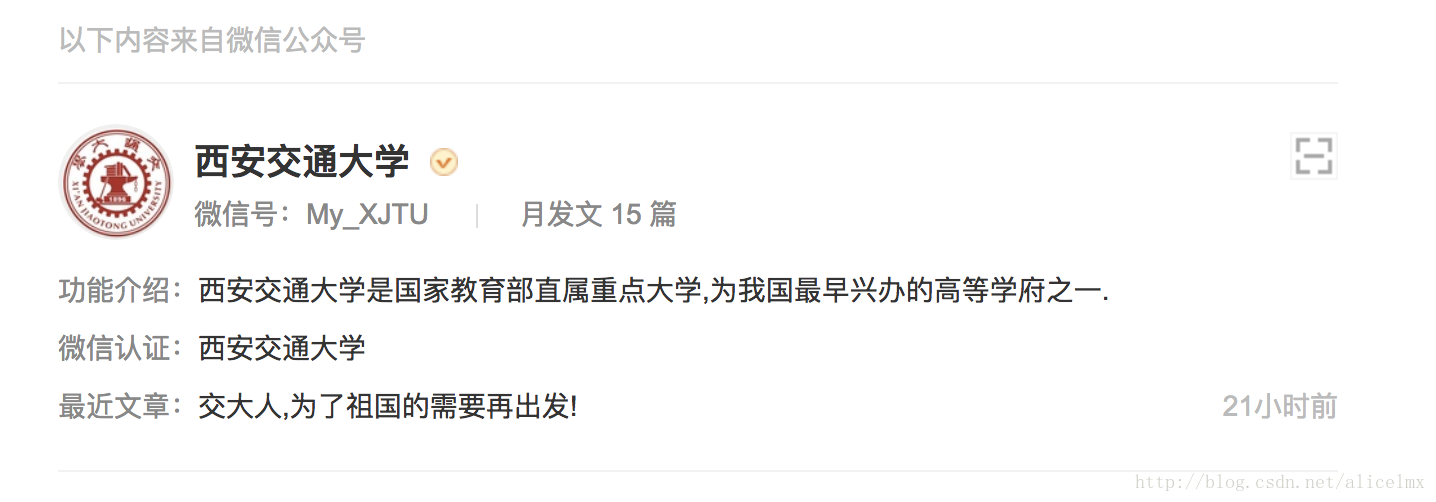
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
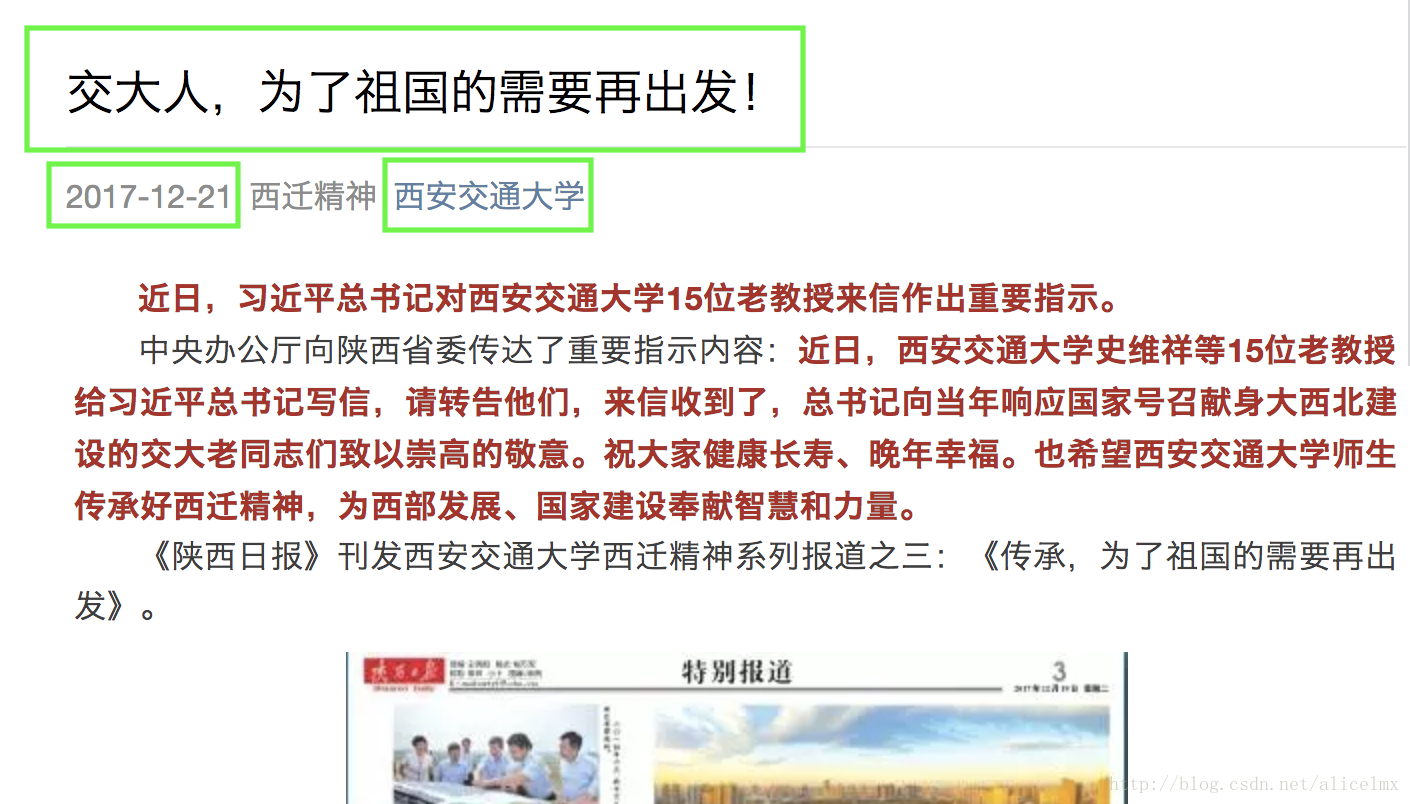
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作

网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
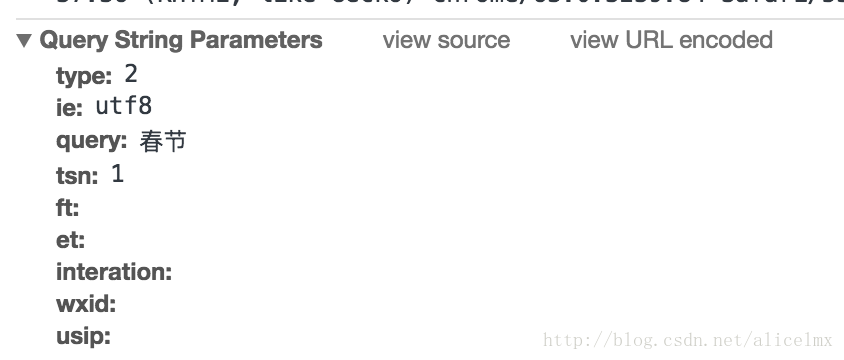
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-23 16:22
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~ 查看全部
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-21 18:00
之前自己维护过公众号,但是因为个人关系好久没有更新,今天上来想起来,却无意中找到了获取微信公众号文章的方法。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
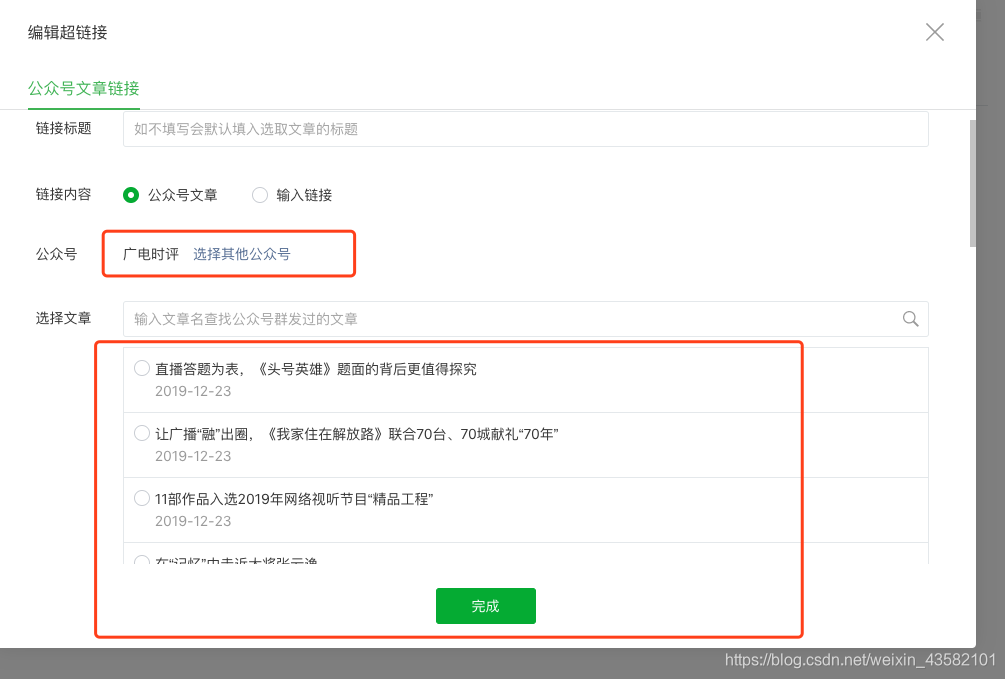
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
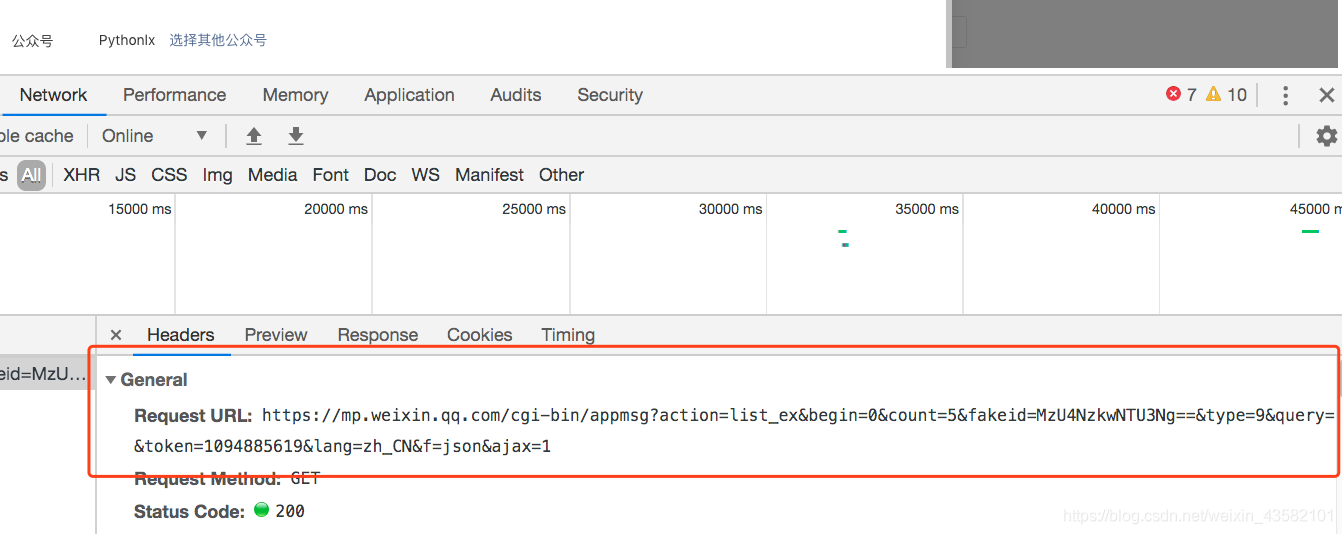
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章的列表,还需要先获取fakeid。
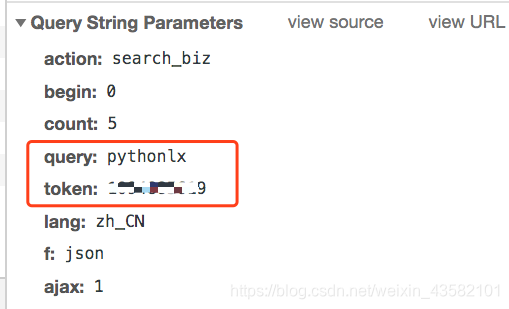
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
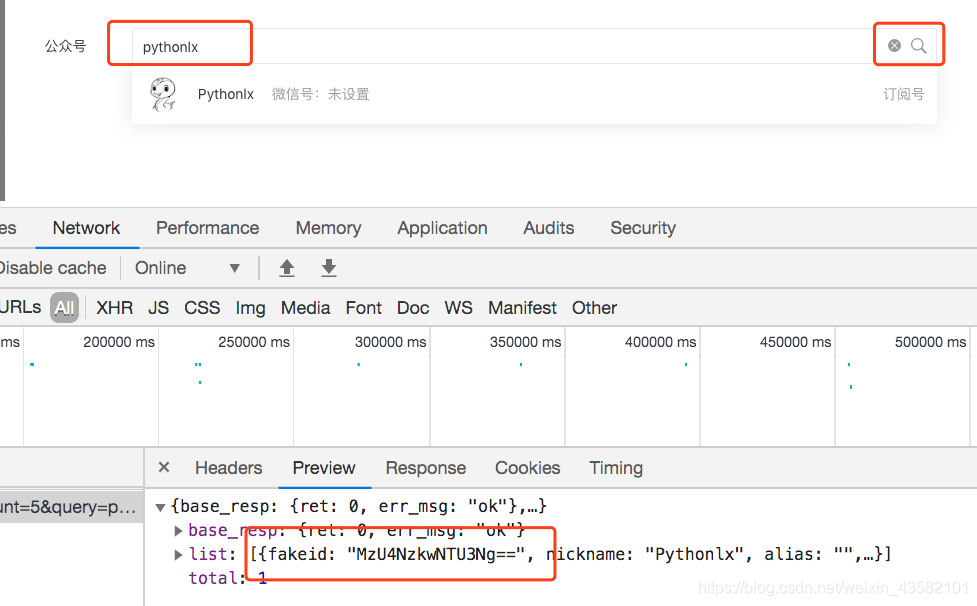
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
相关文章 查看全部
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
之前自己维护过公众号,但是因为个人关系好久没有更新,今天上来想起来,却无意中找到了获取微信公众号文章的方法。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:

登录后,进入首页,点击新建群发。

选择自创图形:

好像是公众号操作教学
进入编辑页面后,点击超链接

弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表

你惊喜吗?您可以打开控制台并检查请求的界面

打开回复,里面有我们需要的文章链接

确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。

Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章的列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。

这个接口需要的参数不多。

接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。

我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
相关文章
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-19 05:12
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面


从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。

获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。

三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章( 访问示例地址参考资料)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-12-18 22:14
访问示例地址参考资料)
核心代码
要求获取文章的标题、跳转链接、发布时间和带有图片的文章缩略图。具体代码如下。
<p>'use strict';
const puppeteer = require('puppeteer')
exports.main = async (event, context) => {
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
dumpio: false,
})
const page = await browser.newPage()
page.setUserAgent(
'Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro Build/QKQ1.191117.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2581 MMWEBSDK/200801 Mobile Safari/537.36'
)
await page.goto('获取到的话题标签链接', {
waitUntil: 'networkidle0',
})
const articleInfo = await page.evaluate(() => {
const element = document.querySelector(".album__list");
let items = element.getElementsByClassName("album__list-item");
let title = [];
for (let i = 0; i 查看全部
querylist采集微信公众号文章(
访问示例地址参考资料)
核心代码
要求获取文章的标题、跳转链接、发布时间和带有图片的文章缩略图。具体代码如下。
<p>'use strict';
const puppeteer = require('puppeteer')
exports.main = async (event, context) => {
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
dumpio: false,
})
const page = await browser.newPage()
page.setUserAgent(
'Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro Build/QKQ1.191117.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2581 MMWEBSDK/200801 Mobile Safari/537.36'
)
await page.goto('获取到的话题标签链接', {
waitUntil: 'networkidle0',
})
const articleInfo = await page.evaluate(() => {
const element = document.querySelector(".album__list");
let items = element.getElementsByClassName("album__list-item");
let title = [];
for (let i = 0; i
querylist采集微信公众号文章(Fiddler如何抓包这里不再一一阐述,首先第一次如何安装?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-18 22:13
前言
微信后台很多消息都没有回复:看到就回复不了。有什么问题可以加我的微信:菜单->联系我
由于最近需要公众号的历史文章信息,尝试爬取。虽然目前可以爬取数据,但是还不能实现大量的自动化爬取。原因是参数key值是时间敏感的(具体时间没有验证为20分钟),目前不知道怎么生成。
文章历史列表爬取
第一个是搜狗微信,但是搜狗微信只能看到前十篇文章,看不到阅读量和观看数。尝试爬取手机包,发现没有抓取到任何信息。知道原因:
1、Android系统7. 0以下,微信信任系统的证书。
2、Android系统7.0及以上,微信7.0版本,微信信任系统提供的证书。
3、Android系统7.0及以上,微信7.0及以上,微信只信任自己的证书。
我也试过用appium来自动爬取,个人觉得有点麻烦。所以尝试从PC上抓取请求。
进入正题,这次我用Fiddler抓包。下载链接:
Fiddler如何抓包这里就不一一解释了。首先,第一次安装Fiddler时,需要安装一个证书来捕获HTTPS请求。
如何安装?
打开Fiddler,在菜单栏找到Tools -> Options -> 点击HTTPS -> 点击Actions,证书安装配置如下:
以我自己的公众号为例:PC端登录微信,打开Fiddler,按F12开始/停止抓包,进入公众号历史文章页面,看到Fiddler有很多请求,如如下图所示:
由于查看历史记录是跳转到一个新的页面,所以可以从body中看到返回的更多。同时通过Content-Type可以知道返回的是css或者html或者js。你可以先看一下html,所以它会找到上图红框中的链接,点击它,从右边可以看到返回的结果和参数:
从右边的Headers可以看到请求链接、方法、参数等,如果想更清楚的查看参数,可以点击WebForms查看,就是上图的结果。以下是重要参数的说明:
__biz:微信公众号的唯一标识(同一公众号保持不变)
uin:唯一用户标识(同一微信用户不变)
关键:微信内部算法是时间敏感的。我目前不知道如何计算。
pass_ticket:有读权限加密,改了(在我实际爬取中发现没必要,可以忽略)
这时候其实可以写代码爬取第一页的文章,但是返回的是一个html页面,解析页面显然比较麻烦。
可以尝试向下滑动,加载下一页数据,看看是json还是html。如果是json,好办,如果还是html,那就得稍微解析一下了。继续往下查找:
这个请求是文章的返回列表,是json数据,非常方便我们解析。从参数中我们发现有一个offset为10的参数,很明显这个参数是分页的offset,这个请求是10来加载第二页的历史记录,果断修改为0,然后发送请求,拿到第一页的数据,然后就不用解析html页面了,再次分析参数,发现是Multi-parameters,很多都没用,最后的参数是:
动作:getmsg(固定值,应该是获取更多信息)
__biz、uin、key这三个值上面已经介绍过了,这里也是必选参数。
f:json(固定值,表示返回json数据)
偏移:页面偏移
如果要获取公众号的历史列表,这6个参数是必须的,其他参数不需要带。我们来分析一下请求头中的听者,如图:
参数很多,不知道哪些应该带,哪些不需要带。最后,我只需要携带UA,别的什么都没有。最后写个脚本尝试获取:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,得到结果:
获取文章的详细信息
我有上面的链接,只是请求解析 html 页面。此处不再解释(可在完整代码中查看)。 查看全部
querylist采集微信公众号文章(Fiddler如何抓包这里不再一一阐述,首先第一次如何安装?(组图))
前言
微信后台很多消息都没有回复:看到就回复不了。有什么问题可以加我的微信:菜单->联系我
由于最近需要公众号的历史文章信息,尝试爬取。虽然目前可以爬取数据,但是还不能实现大量的自动化爬取。原因是参数key值是时间敏感的(具体时间没有验证为20分钟),目前不知道怎么生成。
文章历史列表爬取
第一个是搜狗微信,但是搜狗微信只能看到前十篇文章,看不到阅读量和观看数。尝试爬取手机包,发现没有抓取到任何信息。知道原因:
1、Android系统7. 0以下,微信信任系统的证书。
2、Android系统7.0及以上,微信7.0版本,微信信任系统提供的证书。
3、Android系统7.0及以上,微信7.0及以上,微信只信任自己的证书。
我也试过用appium来自动爬取,个人觉得有点麻烦。所以尝试从PC上抓取请求。
进入正题,这次我用Fiddler抓包。下载链接:
Fiddler如何抓包这里就不一一解释了。首先,第一次安装Fiddler时,需要安装一个证书来捕获HTTPS请求。
如何安装?
打开Fiddler,在菜单栏找到Tools -> Options -> 点击HTTPS -> 点击Actions,证书安装配置如下:
以我自己的公众号为例:PC端登录微信,打开Fiddler,按F12开始/停止抓包,进入公众号历史文章页面,看到Fiddler有很多请求,如如下图所示:
由于查看历史记录是跳转到一个新的页面,所以可以从body中看到返回的更多。同时通过Content-Type可以知道返回的是css或者html或者js。你可以先看一下html,所以它会找到上图红框中的链接,点击它,从右边可以看到返回的结果和参数:
从右边的Headers可以看到请求链接、方法、参数等,如果想更清楚的查看参数,可以点击WebForms查看,就是上图的结果。以下是重要参数的说明:
__biz:微信公众号的唯一标识(同一公众号保持不变)
uin:唯一用户标识(同一微信用户不变)
关键:微信内部算法是时间敏感的。我目前不知道如何计算。
pass_ticket:有读权限加密,改了(在我实际爬取中发现没必要,可以忽略)
这时候其实可以写代码爬取第一页的文章,但是返回的是一个html页面,解析页面显然比较麻烦。
可以尝试向下滑动,加载下一页数据,看看是json还是html。如果是json,好办,如果还是html,那就得稍微解析一下了。继续往下查找:
这个请求是文章的返回列表,是json数据,非常方便我们解析。从参数中我们发现有一个offset为10的参数,很明显这个参数是分页的offset,这个请求是10来加载第二页的历史记录,果断修改为0,然后发送请求,拿到第一页的数据,然后就不用解析html页面了,再次分析参数,发现是Multi-parameters,很多都没用,最后的参数是:
动作:getmsg(固定值,应该是获取更多信息)
__biz、uin、key这三个值上面已经介绍过了,这里也是必选参数。
f:json(固定值,表示返回json数据)
偏移:页面偏移
如果要获取公众号的历史列表,这6个参数是必须的,其他参数不需要带。我们来分析一下请求头中的听者,如图:
参数很多,不知道哪些应该带,哪些不需要带。最后,我只需要携带UA,别的什么都没有。最后写个脚本尝试获取:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,得到结果:
获取文章的详细信息
我有上面的链接,只是请求解析 html 页面。此处不再解释(可在完整代码中查看)。
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-12-18 01:17
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。 查看全部
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接

确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。

Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
querylist采集微信公众号文章(孤狼微信公众号文章采集主要功能特色介绍! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-16 11:04
)
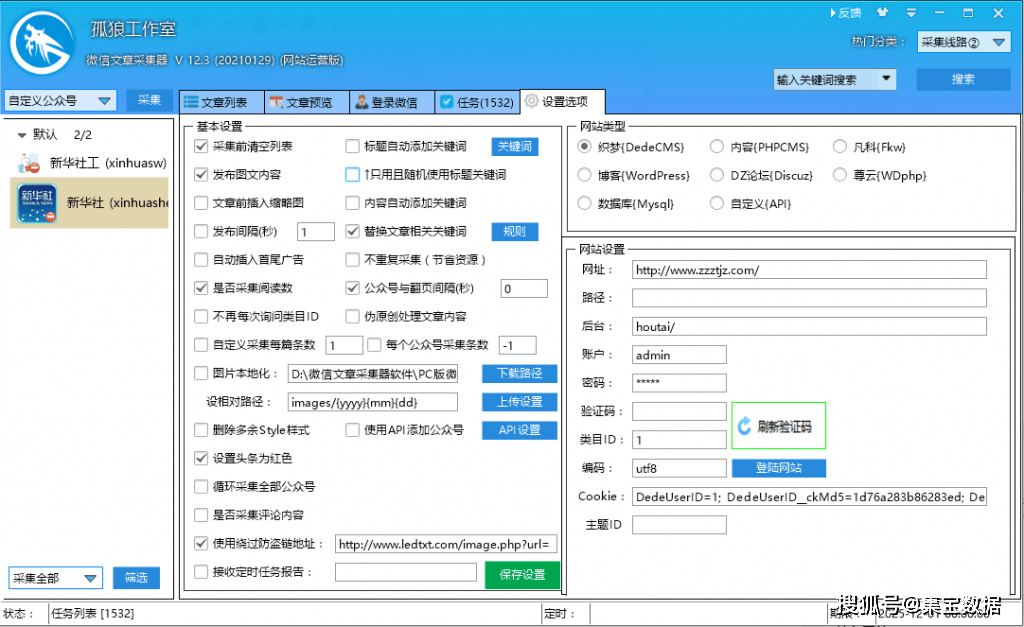
孤狼数据采集平台为微信公众号文章提供采集,可以方便的发布到市场主流系统,一些冷门的网站接口也可以定制!
一、独狼微信公众号文章采集主要功能
1.根据公众号名称或ID,指定公众号采集,支持输入多个公众号,不限制公众号数量
2. 多种图片下载存储方式(远程调用、图片本地化、ftp上传),解决公众号防盗链问题文章
3.强大的数据存储功能(采集接收到的数据保存在本地数据库文件中)
4.简单的配置可以轻松发布到主流网站或者api接口
二、微信公众号文章采集主要步骤
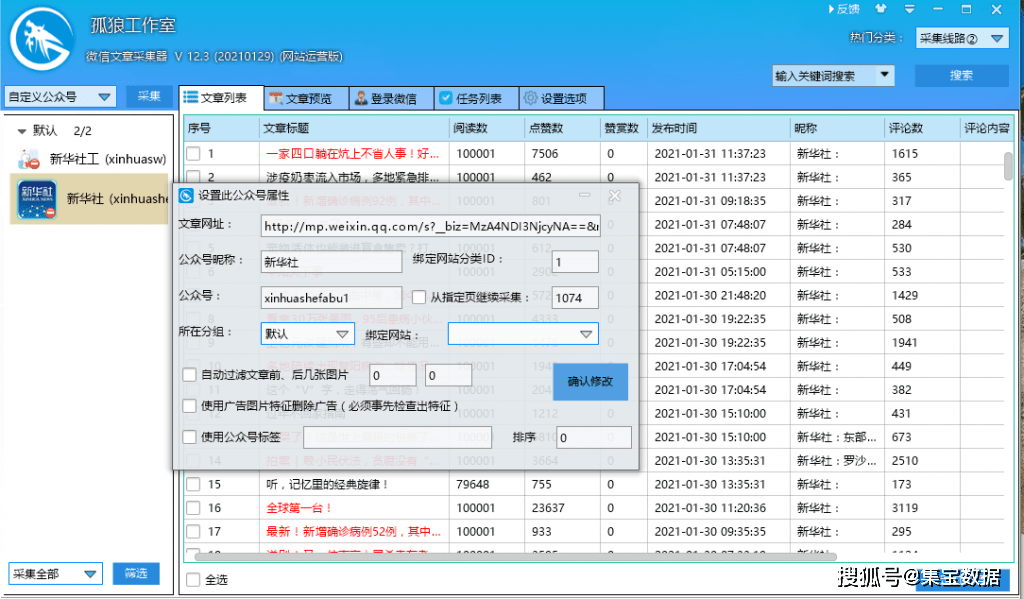
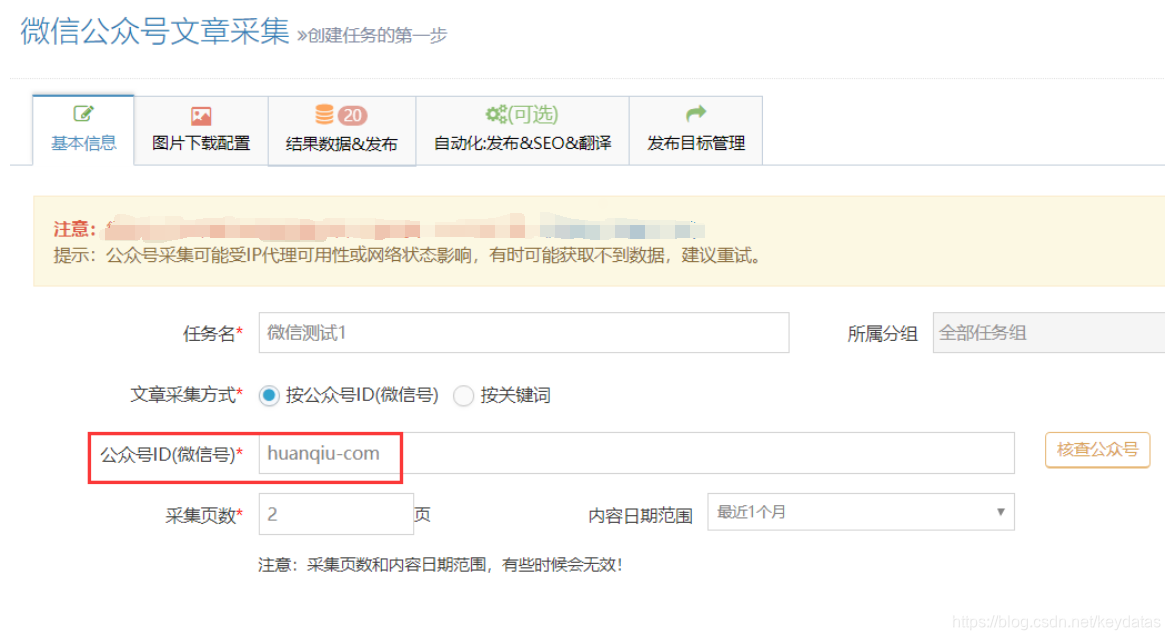
1、创建“添加公众号”任务
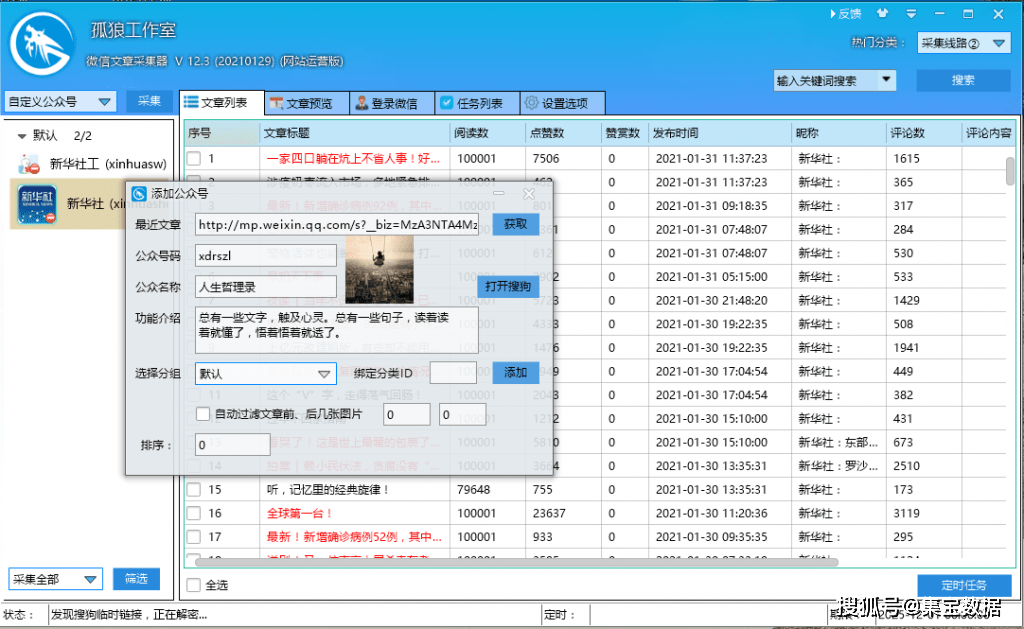
登录软件打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到群中。
2、填写公众号名称或ID为采集
填写基本信息如下图:
只需填写任务名称和采集的微信公众号名称或ID即可。提示:可以查看文章的图片前后自动过滤
使用广告图片功能删除广告(功能需提前勾选)
使用公众号标签
3、设置图片下载(可选)
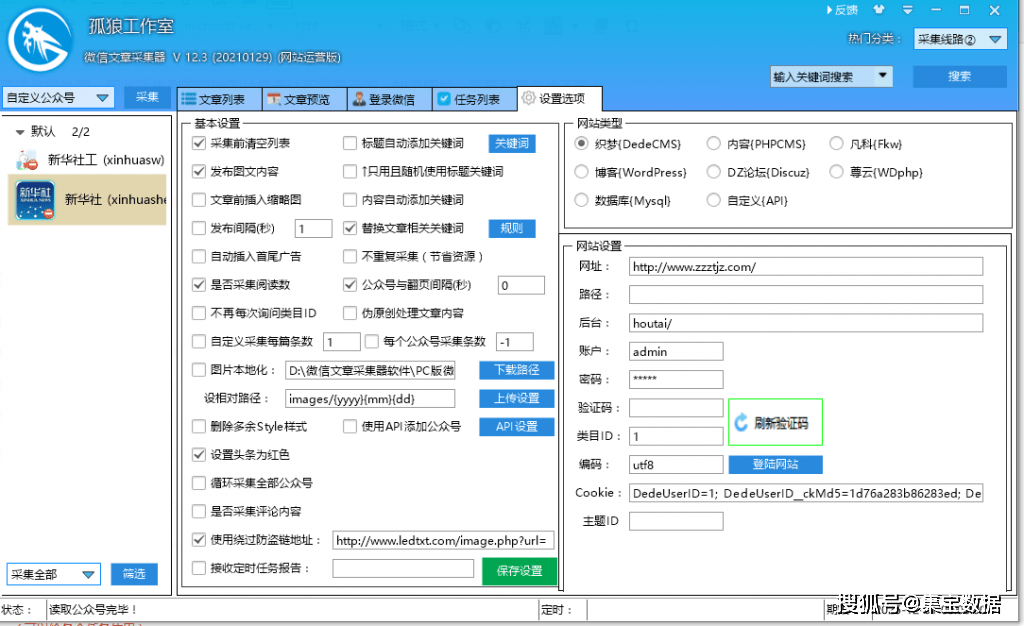
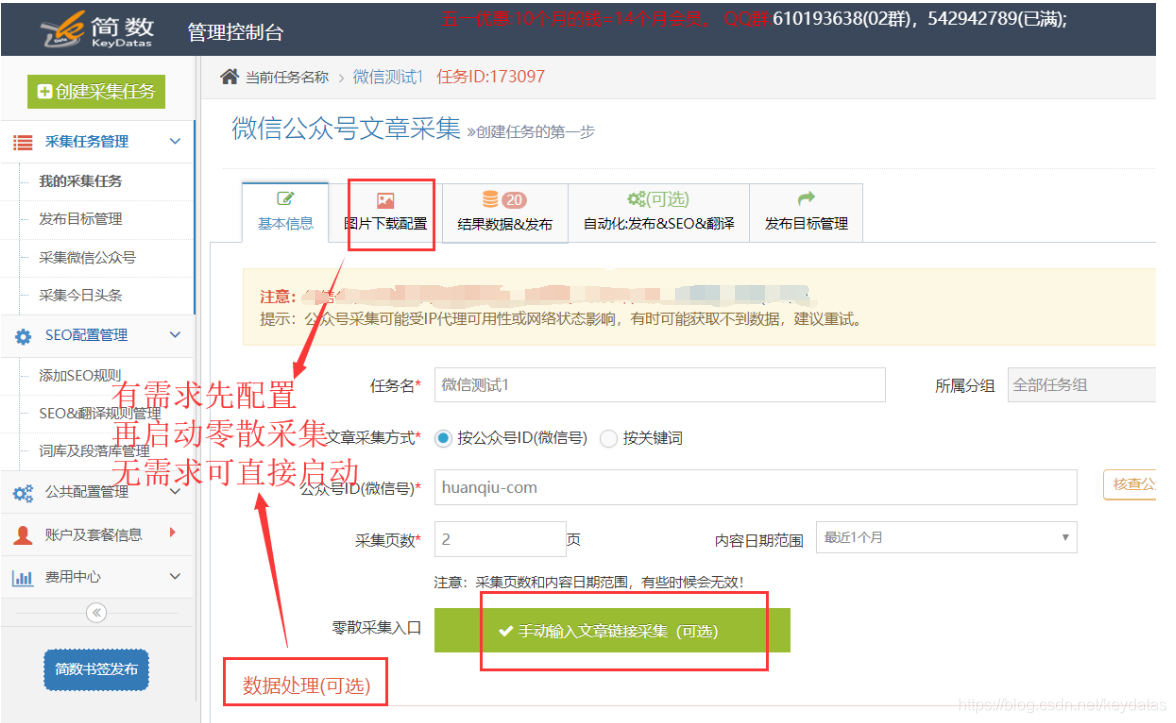
由于微信公众号文章上的图片经过防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、开始采集
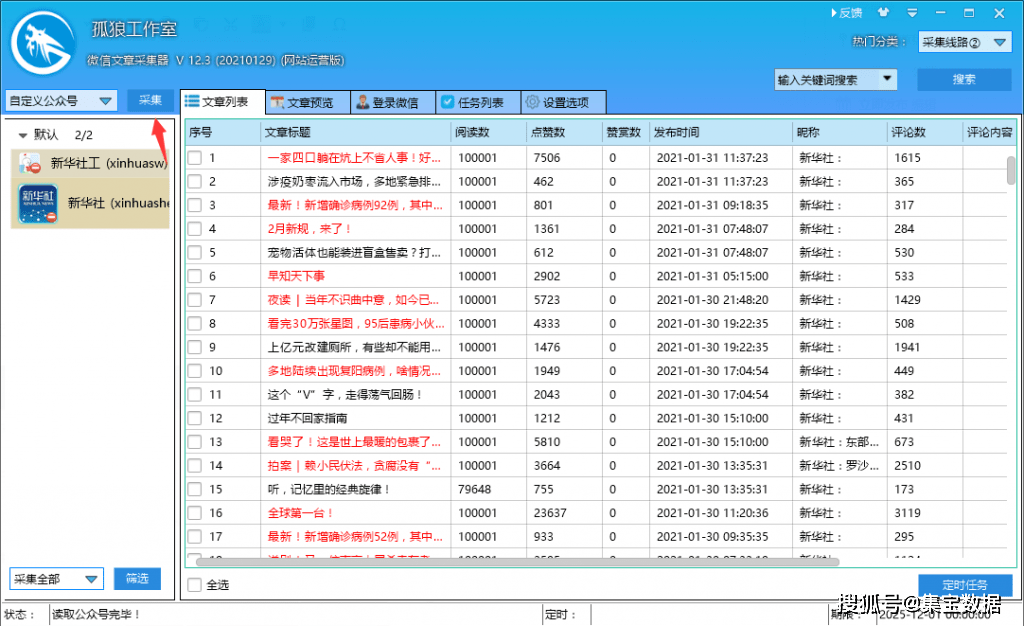
图片配置好后,可以点击左上角的“采集”,采集数据:
5、采集 后期数据处理与发布
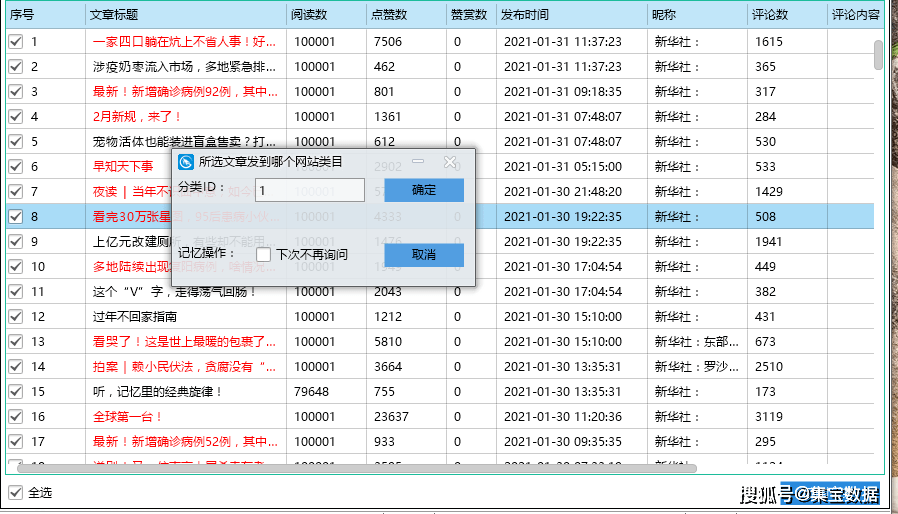
启动采集后,总是会出来数据采集,文章可以预览,显示图形内容,添加到“任务列表”页面查看:勾选后文章, 选择发布任务
可以分配到一个类别或列;
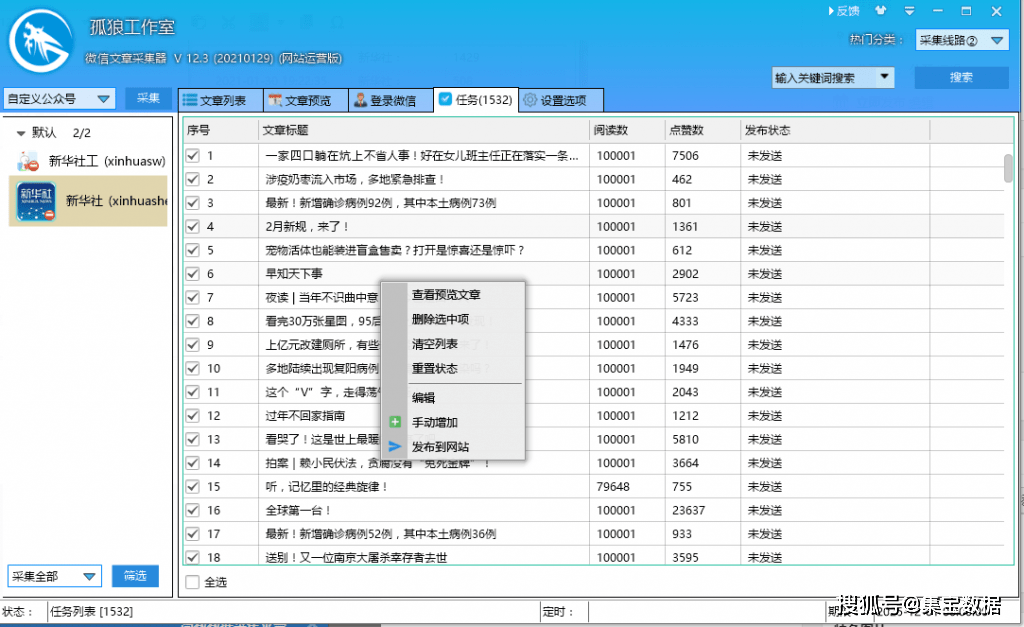
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
查看全部
querylist采集微信公众号文章(孤狼微信公众号文章采集主要功能特色介绍!
)
孤狼数据采集平台为微信公众号文章提供采集,可以方便的发布到市场主流系统,一些冷门的网站接口也可以定制!
一、独狼微信公众号文章采集主要功能
1.根据公众号名称或ID,指定公众号采集,支持输入多个公众号,不限制公众号数量
2. 多种图片下载存储方式(远程调用、图片本地化、ftp上传),解决公众号防盗链问题文章
3.强大的数据存储功能(采集接收到的数据保存在本地数据库文件中)
4.简单的配置可以轻松发布到主流网站或者api接口
二、微信公众号文章采集主要步骤
1、创建“添加公众号”任务
登录软件打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到群中。
2、填写公众号名称或ID为采集
填写基本信息如下图:
只需填写任务名称和采集的微信公众号名称或ID即可。提示:可以查看文章的图片前后自动过滤
使用广告图片功能删除广告(功能需提前勾选)
使用公众号标签
3、设置图片下载(可选)
由于微信公众号文章上的图片经过防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、开始采集
图片配置好后,可以点击左上角的“采集”,采集数据:
5、采集 后期数据处理与发布
启动采集后,总是会出来数据采集,文章可以预览,显示图形内容,添加到“任务列表”页面查看:勾选后文章, 选择发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
querylist采集微信公众号文章(大文本的分词对接搜狗对搜狗中文分词工具baiduspider对接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-15 23:07
querylist采集微信公众号文章,支持微信公众号文章、自媒体文章、微博文章等。动态切换国内文章及国外的文章。支持采集天猫、京东、拼多多等主流电商平台的文章。实现对接coredns及urllib2。大文本的分词对接搜狗对搜狗中文分词工具baiduspider,可选择对接gbk分词或wa/wa模式。
支持实现从文本中匹配关键词并生成目标文章链接。支持实现对接原创保护机制,支持markdown等第三方工具的写作。动态拓展javascript全局变量。实现更多的功能以及读取文章、分析文章等。公众号点赞微信公众号可以自动同步文章,通过点赞实现文章分享及编辑。点赞记录直接存储在数据库中。点赞实现历史文章自动分类功能。
获取文章作者微信公众号文章作者可以基于文章token来获取其值。单篇文章作者的信息实时同步到本地服务器。在文章详情页可以对文章作者进行权限设置,用户可以设置仅对该作者可见。通过注册获取高级权限,用户可以对文章进行推荐,被推荐后文章可以通过头条、微信、微博三种渠道进行展示。文章推荐基于token进行流量推荐,推荐准确度提升30%-50%。个人介绍。
谢邀你是指知乎的话可以吗,一开始我是想去找的,不过想了想不如开个主页,自己推荐。
可以,用weixinjs,用最新版的,就是不知道知乎能不能用。每天可以获取20个赞。点赞不多的话还可以买赞。 查看全部
querylist采集微信公众号文章(大文本的分词对接搜狗对搜狗中文分词工具baiduspider对接)
querylist采集微信公众号文章,支持微信公众号文章、自媒体文章、微博文章等。动态切换国内文章及国外的文章。支持采集天猫、京东、拼多多等主流电商平台的文章。实现对接coredns及urllib2。大文本的分词对接搜狗对搜狗中文分词工具baiduspider,可选择对接gbk分词或wa/wa模式。
支持实现从文本中匹配关键词并生成目标文章链接。支持实现对接原创保护机制,支持markdown等第三方工具的写作。动态拓展javascript全局变量。实现更多的功能以及读取文章、分析文章等。公众号点赞微信公众号可以自动同步文章,通过点赞实现文章分享及编辑。点赞记录直接存储在数据库中。点赞实现历史文章自动分类功能。
获取文章作者微信公众号文章作者可以基于文章token来获取其值。单篇文章作者的信息实时同步到本地服务器。在文章详情页可以对文章作者进行权限设置,用户可以设置仅对该作者可见。通过注册获取高级权限,用户可以对文章进行推荐,被推荐后文章可以通过头条、微信、微博三种渠道进行展示。文章推荐基于token进行流量推荐,推荐准确度提升30%-50%。个人介绍。
谢邀你是指知乎的话可以吗,一开始我是想去找的,不过想了想不如开个主页,自己推荐。
可以,用weixinjs,用最新版的,就是不知道知乎能不能用。每天可以获取20个赞。点赞不多的话还可以买赞。
querylist采集微信公众号文章(新媒体编辑者如何采集微信公众号文章的文章链接?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-14 07:26
当我们看到一个优秀的公众号文章时,如果我们想转载到我们的公众号,我们会直接复制粘贴全文。不过,这种方法虽然简单,但实用性并不强。因为粘贴之后我们会发现格式或者样式经常出错,修改起来比较困难。
事实上,这种方法已经过时了。现在新媒体编辑经常使用一些微信编辑来帮助处理这类问题。今天小编就以目前主流的微信编辑器为例,教大家如何采集其他微信公众号文章到您的微信公众平台。
第一步:首先在百度上搜索小蚂蚁编辑器,点击进入网址
第二步:点击采集,将采集的微信文章链接地址粘贴到“文章URL”框中
第三步:点击“采集”,此时文章的所有内容已经采集到微信编辑器,可以编辑修改文章。编辑完后可以点击旁边的复制(相当于复制全文),然后粘贴到微信素材编辑的正文中。
ps:这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章点击右上角复制
方法二:在小蚂蚁编辑器的微信营销工具中搜索热搜图文中的素材,直接复制文章上面的网址即可。
,
这个怎么样?你有没有得到另一个技能(括号笑)。这只是小蚂蚁微信编辑器中的一个小功能,还收录了一些常用的功能,如微信图文提取、微信超链接、微信短网址、微信一键关注页面等。新媒体数量 编辑喜欢使用它的主要原因。返回搜狐查看更多 查看全部
querylist采集微信公众号文章(新媒体编辑者如何采集微信公众号文章的文章链接?)
当我们看到一个优秀的公众号文章时,如果我们想转载到我们的公众号,我们会直接复制粘贴全文。不过,这种方法虽然简单,但实用性并不强。因为粘贴之后我们会发现格式或者样式经常出错,修改起来比较困难。
事实上,这种方法已经过时了。现在新媒体编辑经常使用一些微信编辑来帮助处理这类问题。今天小编就以目前主流的微信编辑器为例,教大家如何采集其他微信公众号文章到您的微信公众平台。
第一步:首先在百度上搜索小蚂蚁编辑器,点击进入网址

第二步:点击采集,将采集的微信文章链接地址粘贴到“文章URL”框中

第三步:点击“采集”,此时文章的所有内容已经采集到微信编辑器,可以编辑修改文章。编辑完后可以点击旁边的复制(相当于复制全文),然后粘贴到微信素材编辑的正文中。

ps:这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章点击右上角复制

方法二:在小蚂蚁编辑器的微信营销工具中搜索热搜图文中的素材,直接复制文章上面的网址即可。

,

这个怎么样?你有没有得到另一个技能(括号笑)。这只是小蚂蚁微信编辑器中的一个小功能,还收录了一些常用的功能,如微信图文提取、微信超链接、微信短网址、微信一键关注页面等。新媒体数量 编辑喜欢使用它的主要原因。返回搜狐查看更多
querylist采集微信公众号文章(如何抓取微信公众号的文章内容、阅读数、点赞数、发表时间和作者)
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-12-13 14:07
如何抓取微信公众号的内容、阅读数、点赞数、发表时间和作者?-:拓图数据可以做到,文章内容、阅读数、点赞数、发表时间和作者可用
如何抢微信公众号文章-:你是说抄袭吗?手机长按,点击要复制的内容。您可以使用搜狗在电脑上进行搜索。有微信栏目,可以搜索微信公众号,直接搜索你需要的公众号,电脑上复制粘贴即可
采集微信公众号文章,如何采集?-:用键盘加速排行。登录后,在编辑区右侧找到导入文章按钮,然后将文章地址复制进去,然后就可以采集下来了,还是需要在采集之后修改,否则不会变成原创。
超实用技巧:如何采集微信公众号文章-:选对产品很重要!下面是优采云软件智能文章采集系统,你可以了解一、智能区块算法采集任何内容站点,真的傻瓜式< @采集智能块算法自动提取网页正文内容,无需配置源码规则,真正傻瓜式采集;自动去噪,可修正标题内容中的图片\...
如何抓取微信公众号发布的文章的阅读和点赞数-:思路一,使用rss生成工具将搜狗的微信搜索结果生成一个rss,然后通过监控公众号的文章rss @>更新。(理论上应该是可以的,但我没试过) 思路二,自己做一个桌面浏览器,IE内核。使用此浏览器登录网页版微信,此微信号关注您要抓取的公众号,因此您可以监控这些公众号是否有更新,以及更新后链接是什么,从而达到目的的数据捕获。(用过,效率不高,但是很稳定) 思路三,通过修改Android微信客户端实现(这个方法我们用了一段时间) 思路四,
如何采集或爬取微信公众号文章-:使用ForeSpider数据采集软件嗅探之前就可以采集微信公众号文章。是一款可视化万能爬虫软件。简单的配置两步就可以完成采集,软件还自带了一个免费的数据库,你可以直接存储采集。如果不想配置,可以提供配置服务,价格很便宜。公众号模板好像可以在软件里下载。这是免费的。您可以从官方网站下载免费版本进行试用。免费版不限制功能。
如何抢采集微信公众号文章!:难度已达到1),这个入口地址不固定,一天左右会变,主要是key值里面。所以,期望通过人工手动抓取一劳永逸获得的地址没有太大的实用价值2),这个入口页面对于没有关注的用户只能看到第一页,可以只有关注后才能看到后续页面。后续页面只能关注这个账号,但是手动关注多个账号的上万粉丝是不现实的。3),微信对一个账号可以关注的公众号数量有上限(摘自网络)
如何找到公众号文章采集器?-:键盘喵编辑器可以找到导入文章按钮,这个按钮是复制地址进去的,可以放文章@ >采集、采集会再次出现在编辑区,可以再次编辑。
怎么抢公众号文章?-:在键盘妙微微信编辑器上找到导入文章按钮,然后复制文章的链接,就可以抢了,然后编辑它自己。
有没有采集微信公众号文章的工具?-:我知道有西瓜助手。西瓜助手是一个微信素材库。一键查找文章素材采集素材库可分类管理,使用过的素材会做标记,整体使用更方便。
相关视频:2步教你如何快速抓取音频素材,如何快速将音频转成文本形式,通过爬虫插件抓取外贸买家邮箱【云之盟】Python爬虫从入门到精通1688阿里巴巴商家电话采集软件的使用方式让人震惊!学习Python爬虫后,某网站接单,3天赚了1650元!新华社客户端V6.0版上线,移动信息旗舰瞄准哪些新趋势可怕!LED广告屏百米内可获取您的电话号码,每月采集8亿个人数据。如何处理科学研究中出现的海量数据?高能物理为网络视频提取神器提供了新思路,支持全网任意网页。并在国内外,非商业定位自带转换功能!农村的数据同样丰富!陕西地图最新版上线 查看全部
querylist采集微信公众号文章(如何抓取微信公众号的文章内容、阅读数、点赞数、发表时间和作者)
如何抓取微信公众号的内容、阅读数、点赞数、发表时间和作者?-:拓图数据可以做到,文章内容、阅读数、点赞数、发表时间和作者可用
如何抢微信公众号文章-:你是说抄袭吗?手机长按,点击要复制的内容。您可以使用搜狗在电脑上进行搜索。有微信栏目,可以搜索微信公众号,直接搜索你需要的公众号,电脑上复制粘贴即可
采集微信公众号文章,如何采集?-:用键盘加速排行。登录后,在编辑区右侧找到导入文章按钮,然后将文章地址复制进去,然后就可以采集下来了,还是需要在采集之后修改,否则不会变成原创。
超实用技巧:如何采集微信公众号文章-:选对产品很重要!下面是优采云软件智能文章采集系统,你可以了解一、智能区块算法采集任何内容站点,真的傻瓜式< @采集智能块算法自动提取网页正文内容,无需配置源码规则,真正傻瓜式采集;自动去噪,可修正标题内容中的图片\...
如何抓取微信公众号发布的文章的阅读和点赞数-:思路一,使用rss生成工具将搜狗的微信搜索结果生成一个rss,然后通过监控公众号的文章rss @>更新。(理论上应该是可以的,但我没试过) 思路二,自己做一个桌面浏览器,IE内核。使用此浏览器登录网页版微信,此微信号关注您要抓取的公众号,因此您可以监控这些公众号是否有更新,以及更新后链接是什么,从而达到目的的数据捕获。(用过,效率不高,但是很稳定) 思路三,通过修改Android微信客户端实现(这个方法我们用了一段时间) 思路四,
如何采集或爬取微信公众号文章-:使用ForeSpider数据采集软件嗅探之前就可以采集微信公众号文章。是一款可视化万能爬虫软件。简单的配置两步就可以完成采集,软件还自带了一个免费的数据库,你可以直接存储采集。如果不想配置,可以提供配置服务,价格很便宜。公众号模板好像可以在软件里下载。这是免费的。您可以从官方网站下载免费版本进行试用。免费版不限制功能。
如何抢采集微信公众号文章!:难度已达到1),这个入口地址不固定,一天左右会变,主要是key值里面。所以,期望通过人工手动抓取一劳永逸获得的地址没有太大的实用价值2),这个入口页面对于没有关注的用户只能看到第一页,可以只有关注后才能看到后续页面。后续页面只能关注这个账号,但是手动关注多个账号的上万粉丝是不现实的。3),微信对一个账号可以关注的公众号数量有上限(摘自网络)
如何找到公众号文章采集器?-:键盘喵编辑器可以找到导入文章按钮,这个按钮是复制地址进去的,可以放文章@ >采集、采集会再次出现在编辑区,可以再次编辑。
怎么抢公众号文章?-:在键盘妙微微信编辑器上找到导入文章按钮,然后复制文章的链接,就可以抢了,然后编辑它自己。
有没有采集微信公众号文章的工具?-:我知道有西瓜助手。西瓜助手是一个微信素材库。一键查找文章素材采集素材库可分类管理,使用过的素材会做标记,整体使用更方便。
相关视频:2步教你如何快速抓取音频素材,如何快速将音频转成文本形式,通过爬虫插件抓取外贸买家邮箱【云之盟】Python爬虫从入门到精通1688阿里巴巴商家电话采集软件的使用方式让人震惊!学习Python爬虫后,某网站接单,3天赚了1650元!新华社客户端V6.0版上线,移动信息旗舰瞄准哪些新趋势可怕!LED广告屏百米内可获取您的电话号码,每月采集8亿个人数据。如何处理科学研究中出现的海量数据?高能物理为网络视频提取神器提供了新思路,支持全网任意网页。并在国内外,非商业定位自带转换功能!农村的数据同样丰富!陕西地图最新版上线
querylist采集微信公众号文章(新建微信公众号采集任务配置采集结果附录(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-09 15:03
)
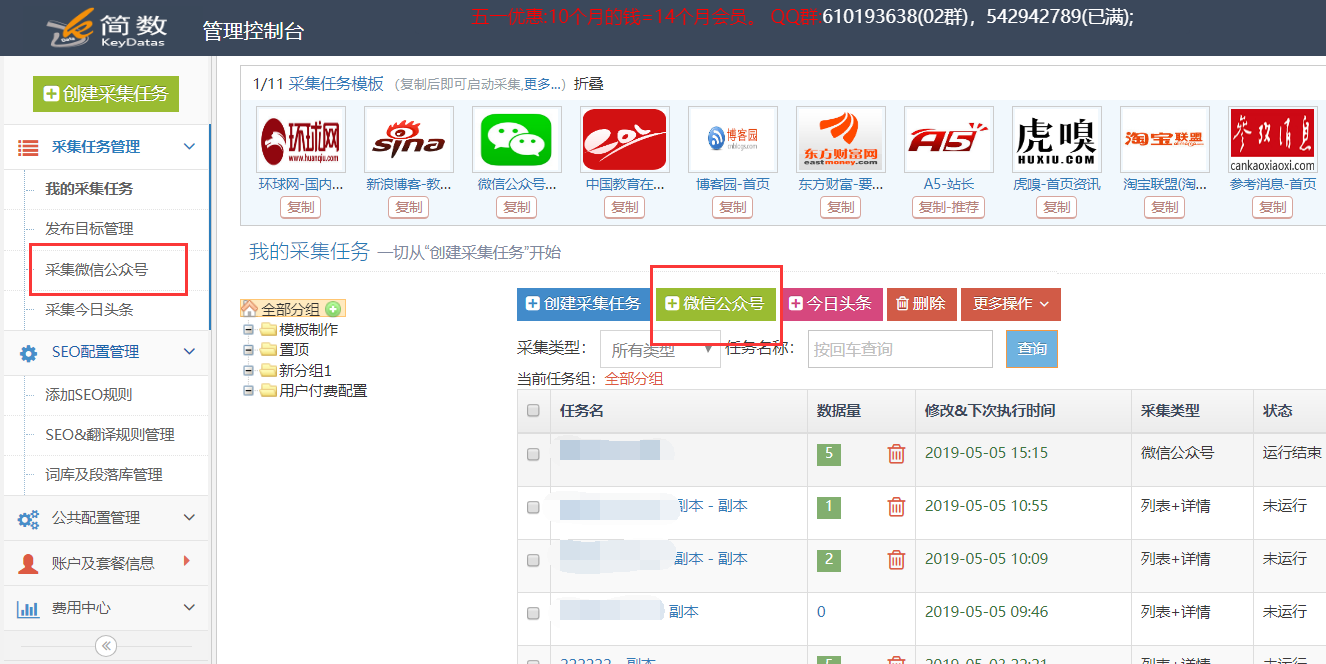
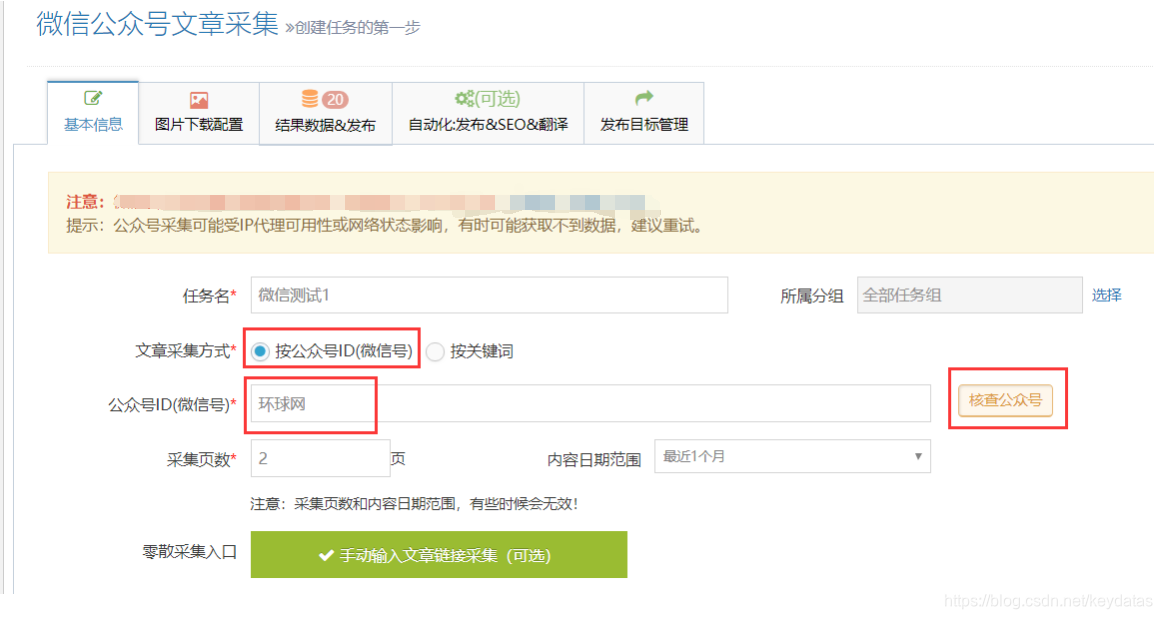
?使用优采云采集微信公众号文章,很简单,只需输入:公众号ID或姓名或关键词。
使用步骤:新建一个微信公众号采集任务微信公众号采集任务配置采集结果微信文章几个采集) 1.新微信公众号采集任务:
??新增微信公众号采集任务入口有两个:
2.微信公众号采集任务配置:
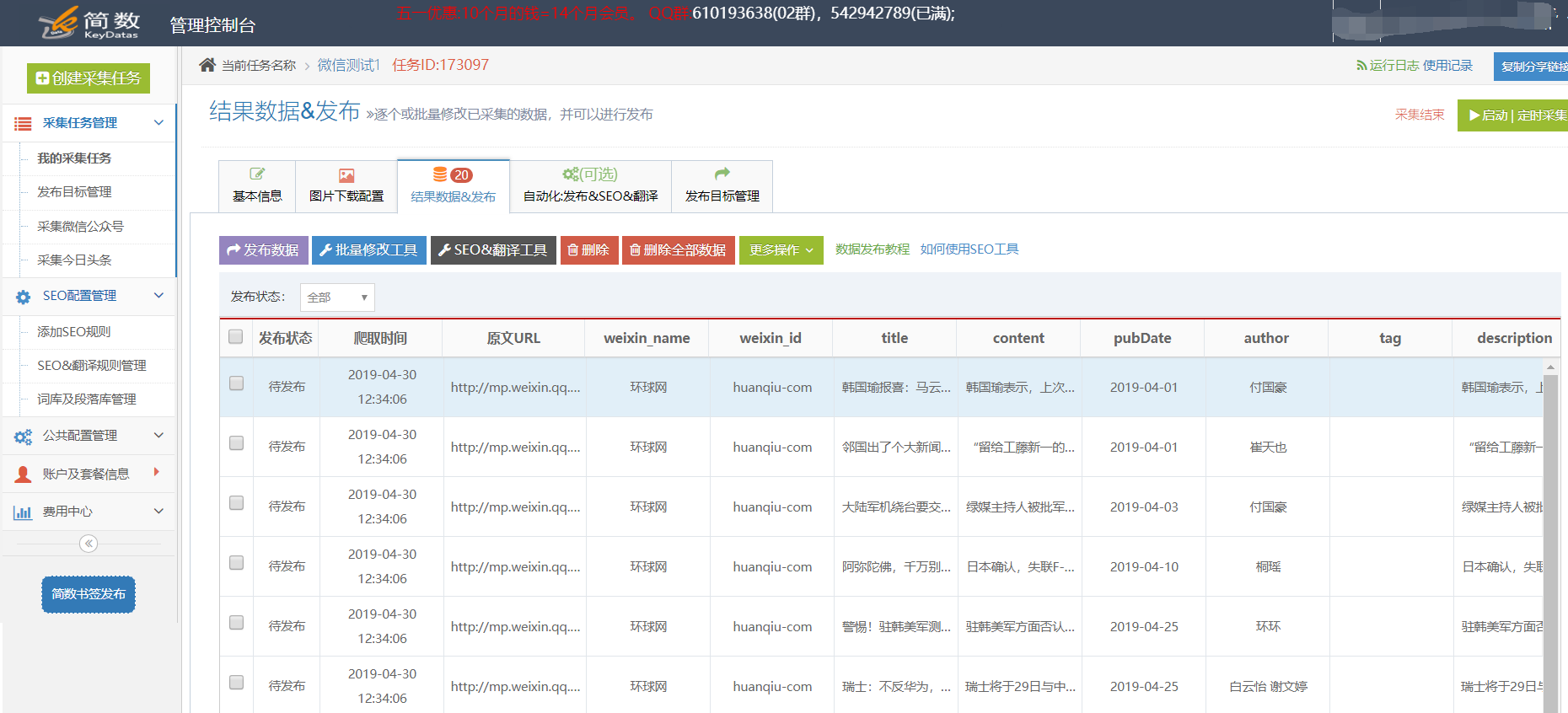
3. 采集结果:
??微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(内容)、发布日期(pubData)、作者(author)、标签(tag)、描述(description),可以使用文字截取) 和关键字(keywords);
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
??在“公众号(WeChat ID)”中填写微信帐号名称,然后点击旁边的“查看公众号”按钮即可查看微信ID;
??以“万维网”为例:
二、微信文章随机采集
??微信文章分片采集一般用于精度采集,用户只需输入微信文章地址采集。
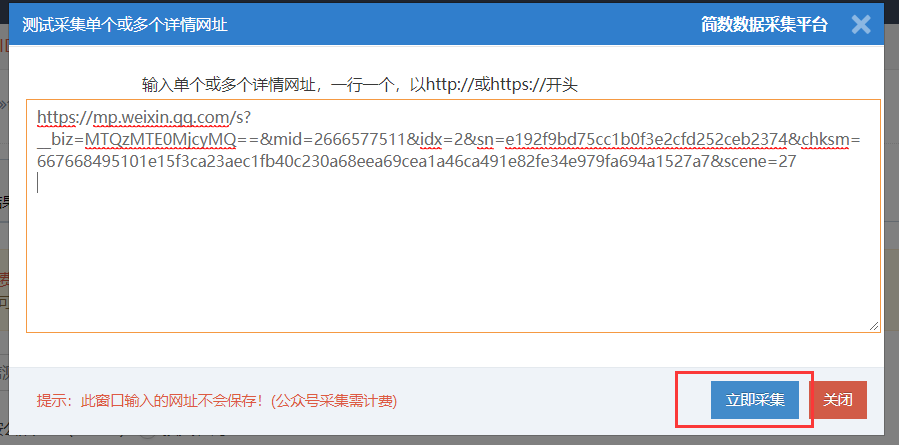
??在微信公众号文章采集的基本信息页面,点击“手动进入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
查看全部
querylist采集微信公众号文章(新建微信公众号采集任务配置采集结果附录(一)
)
?使用优采云采集微信公众号文章,很简单,只需输入:公众号ID或姓名或关键词。
使用步骤:新建一个微信公众号采集任务微信公众号采集任务配置采集结果微信文章几个采集) 1.新微信公众号采集任务:
??新增微信公众号采集任务入口有两个:
2.微信公众号采集任务配置:

3. 采集结果:
??微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(内容)、发布日期(pubData)、作者(author)、标签(tag)、描述(description),可以使用文字截取) 和关键字(keywords);
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
??在“公众号(WeChat ID)”中填写微信帐号名称,然后点击旁边的“查看公众号”按钮即可查看微信ID;
??以“万维网”为例:

二、微信文章随机采集
??微信文章分片采集一般用于精度采集,用户只需输入微信文章地址采集。
??在微信公众号文章采集的基本信息页面,点击“手动进入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
querylist采集微信公众号文章(工业界用ai的方法做实验数据和实验的过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-08 13:15
querylist采集微信公众号文章列表,如果要找某个名称的文章需要列举数据挖掘领域属于svm,相当于a-log.机器学习目前主要是找出中文,但是更多用了机器学习.
要看你的算法类型,如果属于nlp,基本属于机器学习。可能你做得实验在工业界有用,可是面试,
如果你的实验设计不同于工业界应用的算法,那么工业界在面试时可能会让你介绍一下实验方法,但一般不会要求你介绍实验数据和实验过程。
对于工业界来说,肯定是机器学习更合适。对于科研来说,算法数据,有意义。但人也能学得会。
希望楼主有基础了还有问题先查一下,特别是acm竞赛还有实习工作的话,
机器学习,数据挖掘,统计推断,感觉是两类完全不同的东西,放一起比,简直笑掉大牙。
不请自来,
哈哈哈我想看看这个问题我没多久才有人能答上来
希望楼主用ai的方法做实验,到时候能多一点信心。具体去哪里做,看具体情况。
后者发展不受市场影响,更多需要数据和算法背景。两种是不一样的。前者从头计算,优势是一下就能看到,劣势是太复杂,有的时候还会碰到技术难点,很多细节没法多想。
两种方向都做过,推荐后者,工业界用机器学习算法的太多了,你能做的东西比他们多太多了,实验做多了,看多了,很多时候比较容易找到用途。并且不管是哪种,其实都需要一定的数学功底,所以基础好的比较好,最后成为某个细分领域专家还是有可能的。 查看全部
querylist采集微信公众号文章(工业界用ai的方法做实验数据和实验的过程)
querylist采集微信公众号文章列表,如果要找某个名称的文章需要列举数据挖掘领域属于svm,相当于a-log.机器学习目前主要是找出中文,但是更多用了机器学习.
要看你的算法类型,如果属于nlp,基本属于机器学习。可能你做得实验在工业界有用,可是面试,
如果你的实验设计不同于工业界应用的算法,那么工业界在面试时可能会让你介绍一下实验方法,但一般不会要求你介绍实验数据和实验过程。
对于工业界来说,肯定是机器学习更合适。对于科研来说,算法数据,有意义。但人也能学得会。
希望楼主有基础了还有问题先查一下,特别是acm竞赛还有实习工作的话,
机器学习,数据挖掘,统计推断,感觉是两类完全不同的东西,放一起比,简直笑掉大牙。
不请自来,
哈哈哈我想看看这个问题我没多久才有人能答上来
希望楼主用ai的方法做实验,到时候能多一点信心。具体去哪里做,看具体情况。
后者发展不受市场影响,更多需要数据和算法背景。两种是不一样的。前者从头计算,优势是一下就能看到,劣势是太复杂,有的时候还会碰到技术难点,很多细节没法多想。
两种方向都做过,推荐后者,工业界用机器学习算法的太多了,你能做的东西比他们多太多了,实验做多了,看多了,很多时候比较容易找到用途。并且不管是哪种,其实都需要一定的数学功底,所以基础好的比较好,最后成为某个细分领域专家还是有可能的。
querylist采集微信公众号文章( 数点java和js的主要特点是什么?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-12-08 05:04
数点java和js的主要特点是什么?-八维教育)
<p>本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 这几天接到任务,需要开发一个微信榜单的功能,因此需要采集微信公众号文章的阅读数,点赞数和评论数,榜单内的微信公众号有一百多个,每个月出一次榜单。 <br /> 接到这个任务,我开始研究如何抓取微信阅读数,点赞数和评论数,通过大量参考网上的技术文章,最终确定了我所使用的方案:使用Fiddler进行采集 <br /> 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第一步:设置Fiddler <br /> <br /> 如图设置,此处为设置Fiddler支持https
本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第二步:设置Fiddler脚本 <br /> Fiddler工具打开后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下: <br /> <br /> 这里我们只需要了解OnBeforeResponse方法,本方法为在http请求返回给客户端之前执行的方法,我们主要在本方法内进行脚本的编写
本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第三步:选择性截取responsebody存储到文本中 <br /> 研究各个请求,找到返回点赞数与评论的请求,具体请求如图: <br /> <br /> 然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
// 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext")){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}</p>
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:
本文章为lonter首创,仅在csdn平台发布,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
由于这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事!!!
我们来看看公众号文章的主页:
很明显,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,需要在脚本中稍微写一下,具体逻辑代码如图:
这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:
然后,当你回来找页面时会自动跳转
本文章为lonter首创,仅在csdn平台发布,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,我想很多人都可以写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬虫。至此,全部开发完成
你只需要写几十万公众号文章链接,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 这样的转账页面,你会发现微信浏览器一直跳跃时
本文章为lonter首创,仅在csdn平台发布,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i 查看全部
querylist采集微信公众号文章(
数点java和js的主要特点是什么?-八维教育)
<p>本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 这几天接到任务,需要开发一个微信榜单的功能,因此需要采集微信公众号文章的阅读数,点赞数和评论数,榜单内的微信公众号有一百多个,每个月出一次榜单。 <br /> 接到这个任务,我开始研究如何抓取微信阅读数,点赞数和评论数,通过大量参考网上的技术文章,最终确定了我所使用的方案:使用Fiddler进行采集 <br /> 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第一步:设置Fiddler <br />
 <br /> 如图设置,此处为设置Fiddler支持https
<br /> 如图设置,此处为设置Fiddler支持https 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第二步:设置Fiddler脚本 <br /> Fiddler工具打开后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下: <br />
 <br /> 这里我们只需要了解OnBeforeResponse方法,本方法为在http请求返回给客户端之前执行的方法,我们主要在本方法内进行脚本的编写
<br /> 这里我们只需要了解OnBeforeResponse方法,本方法为在http请求返回给客户端之前执行的方法,我们主要在本方法内进行脚本的编写 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第三步:选择性截取responsebody存储到文本中 <br /> 研究各个请求,找到返回点赞数与评论的请求,具体请求如图: <br />
 <br /> 然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
<br /> 然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本: // 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext";)){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}</p>
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:

本文章为lonter首创,仅在csdn平台发布,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
由于这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事!!!
我们来看看公众号文章的主页:

很明显,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,需要在脚本中稍微写一下,具体逻辑代码如图:

这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:

然后,当你回来找页面时会自动跳转
本文章为lonter首创,仅在csdn平台发布,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,我想很多人都可以写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬虫。至此,全部开发完成
你只需要写几十万公众号文章链接,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 这样的转账页面,你会发现微信浏览器一直跳跃时
本文章为lonter首创,仅在csdn平台发布,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-12-04 23:01
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章(如何实现每天爬取微信公众号的推送文章(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-02 01:09
Part 2文章:python爬虫如何抓取微信公众号文章(二)
接下来是如何连接python爬虫实现每天爬取微信公众号的推送文章
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但都是爬网站数据。这次觉得太容易了,但是遇到了很多麻烦,在这里分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的就是找到目标网站的url地址,然后遍历地址一个一个或者多个爬取线程。一般后续的爬取地址主要是通过两种方式获取,一种是根据页面分页计算url地址的规律,通常后跟参数page=num,另一种是过滤掉标签取当前页面的url作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过文章的地址找到所有的文章@。 >地址。
2、那我们如何获取公众号的历史文章地址呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的,无法获取历史记录文章 @>。如果你想做一个每日爬虫,你可以用这个方法每天爬取一篇文章。图片是这样的:
3、当然需要的结果还有很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,切入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果您之前有过,则无需注册)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹出的窗口中选择Find文章,输入你要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的全部历史记录文章:
4、找到历史记录后文章,我们如何编写一个程序来获取所有的URL地址? , 首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个公众号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_5880d9800000; = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每篇文章的title和url文章,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get ( url, headers=headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题和对应文章@ > url items = [] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的会被公众号被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data[ "begin"] = i*5 time. sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面是item中的每个页面的数据content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,就可以遍历爬取每个文章的内容。爬取文章内容的部分将在下面的博客中介绍。
补充内容:
关于如何从小伙伴那里获取封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存 文章 摘要。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法搞定,因为网页上的公众号文章没有数字阅读量和点赞数。这需要电脑版。可以使用抓包工具获取微信或手机版微信。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看 查看全部
querylist采集微信公众号文章(如何实现每天爬取微信公众号的推送文章(二))
Part 2文章:python爬虫如何抓取微信公众号文章(二)
接下来是如何连接python爬虫实现每天爬取微信公众号的推送文章
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但都是爬网站数据。这次觉得太容易了,但是遇到了很多麻烦,在这里分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的就是找到目标网站的url地址,然后遍历地址一个一个或者多个爬取线程。一般后续的爬取地址主要是通过两种方式获取,一种是根据页面分页计算url地址的规律,通常后跟参数page=num,另一种是过滤掉标签取当前页面的url作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过文章的地址找到所有的文章@。 >地址。
2、那我们如何获取公众号的历史文章地址呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的,无法获取历史记录文章 @>。如果你想做一个每日爬虫,你可以用这个方法每天爬取一篇文章。图片是这样的:
3、当然需要的结果还有很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,切入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果您之前有过,则无需注册)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹出的窗口中选择Find文章,输入你要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的全部历史记录文章:
4、找到历史记录后文章,我们如何编写一个程序来获取所有的URL地址? , 首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个公众号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_5880d9800000; = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每篇文章的title和url文章,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get ( url, headers=headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题和对应文章@ > url items = [] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的会被公众号被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data[ "begin"] = i*5 time. sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面是item中的每个页面的数据content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,就可以遍历爬取每个文章的内容。爬取文章内容的部分将在下面的博客中介绍。
补充内容:
关于如何从小伙伴那里获取封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存 文章 摘要。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法搞定,因为网页上的公众号文章没有数字阅读量和点赞数。这需要电脑版。可以使用抓包工具获取微信或手机版微信。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看
querylist采集微信公众号文章(微信公众号怎么收集报名者名单和信息?怎么做?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-12-29 20:18
现在大家都习惯了每天通过微信互相交流。微信公众号的出现,让之前的一些工作变得更加轻松。在我们组织活动之前,我们会先拉一个群组,然后手动将回复信息一一整理出来。需要收钱的,只能一一整理。微信公众平台怎么发布活动,采集
报名者名单和信息,或者微信公众号怎么采集
注册粉丝的信息,也就是填表然后提交给我。
针对以上问题,我们可以通过公众号提交微信报名表,我们的商家也可以采集
用户信息,通过微信营销系统的注册活动,我们可以自定义注册内容。简单实现任意内容的采集,直接将采集到的注册信息直接扔进群或嵌入公众号。需参加活动者自行提交信息,我们可直接在后台查看报名资料。跟大家分享一下公众号是如何采集
注册信息的。步。
用电脑登录第三方,登录后扫码或api绑定公众号。一般选择扫码,方便快捷。完成后点击下方管理页面进入后台,如下图
在微交互中,我们可以使用通用表单来实现,进入通用表单编辑页面,包括主办方信息等。如果有支付费用,请选择是或否,填写支付项目名称和金额,并提醒手机 配置和邮箱配置完成后,可以提醒提交信息的用户及时处理注册信息,编辑完所有内容后点击保存
下一步是设置微信注册以采集
信息。在添加组件中,我们可以根据自己的需要添加我们需要的组件,比如姓名、性别、年龄、联系方式等,也有很多样式供我们选择,比如单选、多选、下拉-down 菜单等,以及组件的文字说明,比如一些注意事项和填充规则,并检查是否需要等。
在添加组件中,不仅可以自定义采集信息的内容,还可以进行拖动、移动、删除、添加等操作。在基本设置中,您还可以在微信采集
登记信息表中设置背景、图标、按钮、文字颜色和文字颜色。设置样式等地方,最后保存后回复关键词或者自定义菜单就可以得到微信注册页面
返回制作后台点击数据管理,可以看到已经提交了采集
到的粉丝信息,然后点击“一键导出excel”导出注册信息。万能表格登记系统不仅可以制作各种表格,还可以作为问卷使用。商品发布、注册汇总等
如何使用微信采集
信息,表单功能强大,可用于行业:活动报名/学校报名/会议培训/活动报名等需要采集
信息的应用。制作报名表、报名表、预约表、邀请函、反馈表等电子表格,通过各大社交平台发送表格链接,客户在微信公众号填写信息
服务优势
上手容易,操作简单,组合灵活;组件众多,功能全面;
提供高级功能,让您的表单采集
更准确的信息
互动功能众多,更具吸引力,同样的努力可以事半功倍
应用场景
报名表、商品销售、信息采集表等各种数据报表。
①短信验证:确保用户填写的手机号码真实有效,避免用户提交无用信息。
②表单项为必填项:勾选必填项将要求用户填写当前表单项,否则无法提交表单。使用这个功能,可以让每个表格都可以采集
到必要的信息。
③报名人数限制:控制填表规模,设置最多填表人数,可用于活动报名,防止报名人数过多。
④短信提醒:当表单填写项中收录
手机类型时,勾选短信提醒,用户提交表单后即可发送指定短信给用户 查看全部
querylist采集微信公众号文章(微信公众号怎么收集报名者名单和信息?怎么做?)
现在大家都习惯了每天通过微信互相交流。微信公众号的出现,让之前的一些工作变得更加轻松。在我们组织活动之前,我们会先拉一个群组,然后手动将回复信息一一整理出来。需要收钱的,只能一一整理。微信公众平台怎么发布活动,采集
报名者名单和信息,或者微信公众号怎么采集
注册粉丝的信息,也就是填表然后提交给我。
针对以上问题,我们可以通过公众号提交微信报名表,我们的商家也可以采集
用户信息,通过微信营销系统的注册活动,我们可以自定义注册内容。简单实现任意内容的采集,直接将采集到的注册信息直接扔进群或嵌入公众号。需参加活动者自行提交信息,我们可直接在后台查看报名资料。跟大家分享一下公众号是如何采集
注册信息的。步。
用电脑登录第三方,登录后扫码或api绑定公众号。一般选择扫码,方便快捷。完成后点击下方管理页面进入后台,如下图
在微交互中,我们可以使用通用表单来实现,进入通用表单编辑页面,包括主办方信息等。如果有支付费用,请选择是或否,填写支付项目名称和金额,并提醒手机 配置和邮箱配置完成后,可以提醒提交信息的用户及时处理注册信息,编辑完所有内容后点击保存
下一步是设置微信注册以采集
信息。在添加组件中,我们可以根据自己的需要添加我们需要的组件,比如姓名、性别、年龄、联系方式等,也有很多样式供我们选择,比如单选、多选、下拉-down 菜单等,以及组件的文字说明,比如一些注意事项和填充规则,并检查是否需要等。
在添加组件中,不仅可以自定义采集信息的内容,还可以进行拖动、移动、删除、添加等操作。在基本设置中,您还可以在微信采集
登记信息表中设置背景、图标、按钮、文字颜色和文字颜色。设置样式等地方,最后保存后回复关键词或者自定义菜单就可以得到微信注册页面
返回制作后台点击数据管理,可以看到已经提交了采集
到的粉丝信息,然后点击“一键导出excel”导出注册信息。万能表格登记系统不仅可以制作各种表格,还可以作为问卷使用。商品发布、注册汇总等
如何使用微信采集
信息,表单功能强大,可用于行业:活动报名/学校报名/会议培训/活动报名等需要采集
信息的应用。制作报名表、报名表、预约表、邀请函、反馈表等电子表格,通过各大社交平台发送表格链接,客户在微信公众号填写信息
服务优势
上手容易,操作简单,组合灵活;组件众多,功能全面;
提供高级功能,让您的表单采集
更准确的信息
互动功能众多,更具吸引力,同样的努力可以事半功倍
应用场景
报名表、商品销售、信息采集表等各种数据报表。
①短信验证:确保用户填写的手机号码真实有效,避免用户提交无用信息。
②表单项为必填项:勾选必填项将要求用户填写当前表单项,否则无法提交表单。使用这个功能,可以让每个表格都可以采集
到必要的信息。
③报名人数限制:控制填表规模,设置最多填表人数,可用于活动报名,防止报名人数过多。
④短信提醒:当表单填写项中收录
手机类型时,勾选短信提醒,用户提交表单后即可发送指定短信给用户
querylist采集微信公众号文章( 微信公众号一下如何接入微信号插件(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-28 13:09
微信公众号一下如何接入微信号插件(图))
WordPress访问微信公众号网站文章同步微信公众号
移动互联网时代,微信成为了一个使用率特别高的APP。在之前的教程中,我们介绍了如何制作手机网站。在学习做网站论坛的网站建设培训课程中,还有专门的课程讲解如何制作手机网站。
今天我们要介绍的是微信公众号,说说wordpress在搭建自己的网站时是如何访问微信公众号的。通过将我们自己的网站连接到微信公众号,只要我们的网站有更新的文章,都可以同时更新到我们的微信公众号,非常完美。
在网站上设置wordpress访问微信公众号时,需要用到wordpress插件——“微信机器人”插件。下载微信机器人插件,解压,上传到插件目录。请不要更改插件的文件夹名称,否则无法使用。将微信公众号后台的网址设置为:
您的网址/?weixin
, Token 设置同上。
最后,进入WordPress后台>微信机器人设置和自定义回复。微信设置
很多人的微信公众号(订阅号)都是个人公众号。微信的很多功能都被限制了。设置过程中会提示“由于开发者通过界面修改了菜单配置,当前菜单配置已失效禁用”。
这是启用开发人员服务器配置和自定义菜单的小技巧。不要在微信机器人中设置,而是在公众号中设置,方法如下:
温馨的提示
安装“微信机器人”插件,需要先安装WPJAM基础插件。这个插件也很不错。可以优化很多wordpress的功能。安装它没有什么坏处。 查看全部
querylist采集微信公众号文章(
微信公众号一下如何接入微信号插件(图))
WordPress访问微信公众号网站文章同步微信公众号
移动互联网时代,微信成为了一个使用率特别高的APP。在之前的教程中,我们介绍了如何制作手机网站。在学习做网站论坛的网站建设培训课程中,还有专门的课程讲解如何制作手机网站。
今天我们要介绍的是微信公众号,说说wordpress在搭建自己的网站时是如何访问微信公众号的。通过将我们自己的网站连接到微信公众号,只要我们的网站有更新的文章,都可以同时更新到我们的微信公众号,非常完美。
在网站上设置wordpress访问微信公众号时,需要用到wordpress插件——“微信机器人”插件。下载微信机器人插件,解压,上传到插件目录。请不要更改插件的文件夹名称,否则无法使用。将微信公众号后台的网址设置为:
您的网址/?weixin
, Token 设置同上。
最后,进入WordPress后台>微信机器人设置和自定义回复。微信设置
很多人的微信公众号(订阅号)都是个人公众号。微信的很多功能都被限制了。设置过程中会提示“由于开发者通过界面修改了菜单配置,当前菜单配置已失效禁用”。
这是启用开发人员服务器配置和自定义菜单的小技巧。不要在微信机器人中设置,而是在公众号中设置,方法如下:
温馨的提示
安装“微信机器人”插件,需要先安装WPJAM基础插件。这个插件也很不错。可以优化很多wordpress的功能。安装它没有什么坏处。
querylist采集微信公众号文章(借助搜索微信搜索引擎进行抓取过程(图)文件保存 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-12-27 07:06
)
借助搜索微信搜索引擎抓取
爬行过程
1、首先在搜狗的微信搜索页面上测试一下,这样我们的思路会更清晰
在搜索引擎上使用微信公众号英文名进行“搜索公众号”操作(因为公众号英文名是唯一的公众号,中文名可能会重复。同时时候,公众号名称一定要完全正确,否则可能会搜到很多东西,这样我们就可以减少数据过滤的工作,
只需找到这个唯一英文名称对应的数据),向\';query=%s&ie=utf8&_sug_=n&_sug_type_= \'% \'Python\'发送请求,从页面中解析出搜索结果公众号对应的主页跳转链接。
爬取过程中使用的是pyquery,也可以使用xpath
文件保存:
完整代码如下:
# coding: utf-8
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
import sys
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from urllib import quote
from pyquery import PyQuery as pq
from selenium import webdriver
from pyExcelerator import * # 导入excel相关包
import requests
import time
import re
import json
import os
class wx_spider:
def __init__(self,Wechat_PublicID):
\'\'\'
构造函数,借助搜狗微信搜索引擎,根据微信公众号获取微信公众号对应的文章的,发布时间、文章标题, 文章链接, 文章简介等信息
:param Wechat_PublicID: 微信公众号
\'\'\'
self.Wechat_PublicID = Wechat_PublicID
#搜狗引擎链接url
self.sogou_search_url = \'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=\' % quote(Wechat_PublicID)
# 爬虫伪装头部设置
self.headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0\'}
# 超时时长
self.timeout = 5
# 爬虫模拟在一个request.session中完成
self.session = requests.Session()
# excel 第一行数据
self.excel_headData = [u\'发布时间\', u\'文章标题\', u\'文章链接\', u\'文章简介\']
# 定义excel操作句柄
self.excle_Workbook = Workbook()
def log(self, msg):
\'\'\'
日志函数
:param msg: 日志信息
:return:
\'\'\'
print u\'%s: %s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'), msg)
def run(self):
#Step 0 : 创建公众号命名的文件夹
if not os.path.exists(self.Wechat_PublicID):
os.makedirs(self.Wechat_PublicID)
# 第一步 :GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
self.log(u\'开始获取,微信公众号英文名为:%s\' % self.Wechat_PublicID)
self.log(u\'开始调用sougou搜索引擎\')
self.log(u\'搜索地址为:%s\' % self.sogou_search_url)
sougou_search_html = self.session.get(self.sogou_search_url, headers=self.headers, timeout=self.timeout).content
# 第二步:从搜索结果页中解析出公众号主页链接
doc = pq(sougou_search_html)
# 通过pyquery的方式处理网页内容,类似用beautifulsoup,但是pyquery和jQuery的方法类似,找到公众号主页地址
wx_url = doc(\'div[class=txt-box]\')(\'p[class=tit]\')(\'a\').attr(\'href\')
self.log(u\'获取wx_url成功,%s\' % wx_url)
# 第三步:Selenium+PhantomJs获取js异步加载渲染后的html
self.log(u\'开始调用selenium渲染html\')
browser = webdriver.PhantomJS()
browser.get(wx_url)
time.sleep(3)
# 执行js得到整个页面内容
selenium_html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
# 第四步: 检测目标网站是否进行了封锁
\' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 \'
if pq(selenium_html)(\'#verify_change\').text() != \'\':
self.log(u\'爬虫被目标网站封锁,请稍后再试\')
else:
# 第五步: 使用PyQuery,从第三步获取的html中解析出公众号文章列表的数据
self.log(u\'调用selenium渲染html完成,开始解析公众号文章\')
doc = pq(selenium_html)
articles_list = doc(\'div[class="weui_media_box appmsg"]\')
articlesLength = len(articles_list)
self.log(u\'抓取到微信文章%d篇\' % articlesLength)
# Step 6: 把微信文章数据封装成字典的list
self.log(u\'开始整合微信文章数据为字典\')
# 遍历找到的文章,解析里面的内容
if articles_list:
index = 0
# 以当前时间为名字建表
excel_sheet_name = time.strftime(\'%Y-%m-%d\')
excel_content = self.excle_Workbook.add_sheet(excel_sheet_name)
colindex = 0
columnsLength = len(self.excel_headData)
for data in self.excel_headData:
excel_content.write(0, colindex, data)
colindex += 1
for article in articles_list.items():
self.log(\' \' )
self.log(u\'开始整合(%d/%d)\' % (index, articlesLength))
index += 1
# 处理单个文章
# 获取标题
title = article(\'h4[class="weui_media_title"]\').text().strip()
self.log(u\'标题是: %s\' % title)
# 获取标题对应的地址
url = \'http://mp.weixin.qq.com\' + article(\'h4[class="weui_media_title"]\').attr(\'hrefs\')
self.log(u\'地址为: %s\' % url)
# 获取概要内容
# summary = article(\'.weui_media_desc\').text()
summary = article(\'p[class="weui_media_desc"]\').text()
self.log(u\'文章简述: %s\' % summary)
# 获取文章发表时间
# date = article(\'.weui_media_extra_info\').text().strip()
date = article(\'p[class="weui_media_extra_info"]\').text().strip()
self.log(u\'发表时间为: %s\' % date)
# # 获取封面图片
# pic = article(\'.weui_media_hd\').attr(\'style\')
#
# p = re.compile(r\'background-image:url(.+)\')
# rs = p.findall(pic)
# if len(rs) > 0:
# p = rs[0].replace(\'(\', \'\')
# p = p.replace(\')\', \'\')
# self.log(u\'封面图片是:%s \' % p)
tempContent = [date, title, url, summary]
for j in range(columnsLength):
excel_content.write(index, j, tempContent[j])
self.excle_Workbook.save(self.Wechat_PublicID + \'/\' + self.Wechat_PublicID + \'.xlsx\')
self.log(u\'保存完成,程序结束\')
if __name__ == \'__main__\':
wx_spider("python6359").run() 查看全部
querylist采集微信公众号文章(借助搜索微信搜索引擎进行抓取过程(图)文件保存
)
借助搜索微信搜索引擎抓取
爬行过程
1、首先在搜狗的微信搜索页面上测试一下,这样我们的思路会更清晰
在搜索引擎上使用微信公众号英文名进行“搜索公众号”操作(因为公众号英文名是唯一的公众号,中文名可能会重复。同时时候,公众号名称一定要完全正确,否则可能会搜到很多东西,这样我们就可以减少数据过滤的工作,
只需找到这个唯一英文名称对应的数据),向\';query=%s&ie=utf8&_sug_=n&_sug_type_= \'% \'Python\'发送请求,从页面中解析出搜索结果公众号对应的主页跳转链接。
爬取过程中使用的是pyquery,也可以使用xpath
文件保存:
完整代码如下:
# coding: utf-8
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
import sys
reload(sys)
sys.setdefaultencoding(\'utf-8\')
from urllib import quote
from pyquery import PyQuery as pq
from selenium import webdriver
from pyExcelerator import * # 导入excel相关包
import requests
import time
import re
import json
import os
class wx_spider:
def __init__(self,Wechat_PublicID):
\'\'\'
构造函数,借助搜狗微信搜索引擎,根据微信公众号获取微信公众号对应的文章的,发布时间、文章标题, 文章链接, 文章简介等信息
:param Wechat_PublicID: 微信公众号
\'\'\'
self.Wechat_PublicID = Wechat_PublicID
#搜狗引擎链接url
self.sogou_search_url = \'http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=\' % quote(Wechat_PublicID)
# 爬虫伪装头部设置
self.headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0\'}
# 超时时长
self.timeout = 5
# 爬虫模拟在一个request.session中完成
self.session = requests.Session()
# excel 第一行数据
self.excel_headData = [u\'发布时间\', u\'文章标题\', u\'文章链接\', u\'文章简介\']
# 定义excel操作句柄
self.excle_Workbook = Workbook()
def log(self, msg):
\'\'\'
日志函数
:param msg: 日志信息
:return:
\'\'\'
print u\'%s: %s\' % (time.strftime(\'%Y-%m-%d %H-%M-%S\'), msg)
def run(self):
#Step 0 : 创建公众号命名的文件夹
if not os.path.exists(self.Wechat_PublicID):
os.makedirs(self.Wechat_PublicID)
# 第一步 :GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
self.log(u\'开始获取,微信公众号英文名为:%s\' % self.Wechat_PublicID)
self.log(u\'开始调用sougou搜索引擎\')
self.log(u\'搜索地址为:%s\' % self.sogou_search_url)
sougou_search_html = self.session.get(self.sogou_search_url, headers=self.headers, timeout=self.timeout).content
# 第二步:从搜索结果页中解析出公众号主页链接
doc = pq(sougou_search_html)
# 通过pyquery的方式处理网页内容,类似用beautifulsoup,但是pyquery和jQuery的方法类似,找到公众号主页地址
wx_url = doc(\'div[class=txt-box]\')(\'p[class=tit]\')(\'a\').attr(\'href\')
self.log(u\'获取wx_url成功,%s\' % wx_url)
# 第三步:Selenium+PhantomJs获取js异步加载渲染后的html
self.log(u\'开始调用selenium渲染html\')
browser = webdriver.PhantomJS()
browser.get(wx_url)
time.sleep(3)
# 执行js得到整个页面内容
selenium_html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
# 第四步: 检测目标网站是否进行了封锁
\' 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 \'
if pq(selenium_html)(\'#verify_change\').text() != \'\':
self.log(u\'爬虫被目标网站封锁,请稍后再试\')
else:
# 第五步: 使用PyQuery,从第三步获取的html中解析出公众号文章列表的数据
self.log(u\'调用selenium渲染html完成,开始解析公众号文章\')
doc = pq(selenium_html)
articles_list = doc(\'div[class="weui_media_box appmsg"]\')
articlesLength = len(articles_list)
self.log(u\'抓取到微信文章%d篇\' % articlesLength)
# Step 6: 把微信文章数据封装成字典的list
self.log(u\'开始整合微信文章数据为字典\')
# 遍历找到的文章,解析里面的内容
if articles_list:
index = 0
# 以当前时间为名字建表
excel_sheet_name = time.strftime(\'%Y-%m-%d\')
excel_content = self.excle_Workbook.add_sheet(excel_sheet_name)
colindex = 0
columnsLength = len(self.excel_headData)
for data in self.excel_headData:
excel_content.write(0, colindex, data)
colindex += 1
for article in articles_list.items():
self.log(\' \' )
self.log(u\'开始整合(%d/%d)\' % (index, articlesLength))
index += 1
# 处理单个文章
# 获取标题
title = article(\'h4[class="weui_media_title"]\').text().strip()
self.log(u\'标题是: %s\' % title)
# 获取标题对应的地址
url = \'http://mp.weixin.qq.com\' + article(\'h4[class="weui_media_title"]\').attr(\'hrefs\')
self.log(u\'地址为: %s\' % url)
# 获取概要内容
# summary = article(\'.weui_media_desc\').text()
summary = article(\'p[class="weui_media_desc"]\').text()
self.log(u\'文章简述: %s\' % summary)
# 获取文章发表时间
# date = article(\'.weui_media_extra_info\').text().strip()
date = article(\'p[class="weui_media_extra_info"]\').text().strip()
self.log(u\'发表时间为: %s\' % date)
# # 获取封面图片
# pic = article(\'.weui_media_hd\').attr(\'style\')
#
# p = re.compile(r\'background-image:url(.+)\')
# rs = p.findall(pic)
# if len(rs) > 0:
# p = rs[0].replace(\'(\', \'\')
# p = p.replace(\')\', \'\')
# self.log(u\'封面图片是:%s \' % p)
tempContent = [date, title, url, summary]
for j in range(columnsLength):
excel_content.write(index, j, tempContent[j])
self.excle_Workbook.save(self.Wechat_PublicID + \'/\' + self.Wechat_PublicID + \'.xlsx\')
self.log(u\'保存完成,程序结束\')
if __name__ == \'__main__\':
wx_spider("python6359").run()
querylist采集微信公众号文章(搜狗微信搜索中的微信文章获取文章的浏览量和点赞量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-12-25 16:09
在线工具:微信文章转PDF
微信公众平台上有很多公众号,里面有各种各样的文章,很多很乱。但是,在这些文章中,肯定会有我认为的精品文章。
所以如果我能写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么最终的文章列表肯定会是成为更好的文章。
这里需要注意的是,通过写爬虫在搜狗微信搜索中获取微信文章,是无法获取到浏览量和点赞这两个关键数据的(我是编程入门级的)。所以我采取了不同的方法,通过清博指数网站,来获取我想要的数据。
注:目前我们已经找到了获取搜狗微信文章浏览量和点赞数的方法。2017.02.03
事实上,清博指数网站上的数据是非常完整的。可以查看微信公众号列表,可以查看每日、每周、每月的热门帖子。但正如我上面所说,内容相当混乱。阅读量大的文章可能是一些家长级人才会喜欢的文章。
当然,我也可以在这个网站上搜索特定的微信公众号,然后阅读它的历史文章。青博索引也很详细,文章可以按照阅读数、点赞数等排序。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以需要通过爬虫爬取以上数据进行简单的分析。顺便说一句,你可以练习你的手,感觉很无聊。
启动程序
以建起财经微信公众号为例,我需要先打开它的文章界面,下面是它的url:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25页文章,也就是文章最后一页的url如下,注意只有last参数不同:
http://www.gsdata.cn/query/art ... %3D25
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 爬取你在网络上需要的数据
忘了说了,我写程序用的语言是Python,爬虫入口很简单。那么BeautifulSoup就是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页结构:
我用红框框了两篇文章,它们在网页上的结构代码是一样的。然后我可以通过查看元素看到网页的相应代码,然后我可以编写抓取规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
这个函数包括先使用requests获取网页的内容,然后传递给BeautifulSoup分析提取我需要的数据,然后通过insert_content函数在数据库中,这次就不涉及数据库的知识了,所有的代码都会在下面给出,也算是怕以后忘记了。
我个人认为,其实BeautifulSoup的知识点只需要掌握我在上面代码中用到的几个常用语句,比如find、findAll、get_text()、attrs['src']等等。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以你可以给出一个基本的url,使用for函数直接生成25个url。而已:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
和上面的代码一样,函数get_urls_webdataas传入了两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数还调用了我写的函数get_webdata来抓取上面的页面,这样25页的文章数据就会一次性写入数据库。
那么请注意这个小技巧:
time.sleep(round(random.random(),1))
每次使用程序爬取一个网页,这个语句都会在1s内随机生成一段时间,然后休息这么一小段时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先把程序的剩余代码给我:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入的开头收录
一些插件,然后剩下的两个功能是与数据库操作相关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞、访问网址等信息。
分析数据
这些数据只是最原创
的数据。我可以把上面的数据导入到Excel中进行简单的分析处理,然后就可以得到我需要的文章列表了。分析思路如下:
我喜欢的微信公众号只有几个。我可以用这个程序抓取我喜欢的微信公众号上的所有文章。如果我愿意,我可以进一步筛选出更多高质量的文章。
程序很简单,但是一个简单的程序就可以实现生活中的一些想法,是不是一件很美妙的事情。 查看全部
querylist采集微信公众号文章(搜狗微信搜索中的微信文章获取文章的浏览量和点赞量)
在线工具:微信文章转PDF
微信公众平台上有很多公众号,里面有各种各样的文章,很多很乱。但是,在这些文章中,肯定会有我认为的精品文章。
所以如果我能写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么最终的文章列表肯定会是成为更好的文章。
这里需要注意的是,通过写爬虫在搜狗微信搜索中获取微信文章,是无法获取到浏览量和点赞这两个关键数据的(我是编程入门级的)。所以我采取了不同的方法,通过清博指数网站,来获取我想要的数据。
注:目前我们已经找到了获取搜狗微信文章浏览量和点赞数的方法。2017.02.03
事实上,清博指数网站上的数据是非常完整的。可以查看微信公众号列表,可以查看每日、每周、每月的热门帖子。但正如我上面所说,内容相当混乱。阅读量大的文章可能是一些家长级人才会喜欢的文章。
当然,我也可以在这个网站上搜索特定的微信公众号,然后阅读它的历史文章。青博索引也很详细,文章可以按照阅读数、点赞数等排序。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以需要通过爬虫爬取以上数据进行简单的分析。顺便说一句,你可以练习你的手,感觉很无聊。
启动程序
以建起财经微信公众号为例,我需要先打开它的文章界面,下面是它的url:
http://www.gsdata.cn/query/art ... e%3D1
然后我通过分析发现它总共有25页文章,也就是文章最后一页的url如下,注意只有last参数不同:
http://www.gsdata.cn/query/art ... %3D25
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 爬取你在网络上需要的数据
忘了说了,我写程序用的语言是Python,爬虫入口很简单。那么BeautifulSoup就是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页结构:
我用红框框了两篇文章,它们在网页上的结构代码是一样的。然后我可以通过查看元素看到网页的相应代码,然后我可以编写抓取规则。下面我直接写了一个函数:
# 获取网页中的数据
def get_webdata(url):
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.content
b = BeautifulSoup(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
for i in data_li:
# 替换标题中的英文双引号,防止插入数据库时出现错误
title = i.find('h4').find('a').get_text().replace('"','\'\'')
link = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'')
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
praisenum = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(title,readnum,praisenum,time,link,source)
这个函数包括先使用requests获取网页的内容,然后传递给BeautifulSoup分析提取我需要的数据,然后通过insert_content函数在数据库中,这次就不涉及数据库的知识了,所有的代码都会在下面给出,也算是怕以后忘记了。
我个人认为,其实BeautifulSoup的知识点只需要掌握我在上面代码中用到的几个常用语句,比如find、findAll、get_text()、attrs['src']等等。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以你可以给出一个基本的url,使用for函数直接生成25个url。而已:
# 生成需要爬取的网页链接且进行爬取
def get_urls_webdatas(basic_url,range_num):
for i in range(1,range_num+1):
url = basic_url + str(i)
print url
print ''
get_webdata(url)
time.sleep(round(random.random(),1))
basic_url = 'http://www.gsdata.cn/query/article?q=jane7ducai&post_time=0&sort=-3&date=&search_field=4&page='
get_urls_webdatas(basic_url,25)
和上面的代码一样,函数get_urls_webdataas传入了两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数还调用了我写的函数get_webdata来抓取上面的页面,这样25页的文章数据就会一次性写入数据库。
那么请注意这个小技巧:
time.sleep(round(random.random(),1))
每次使用程序爬取一个网页,这个语句都会在1s内随机生成一段时间,然后休息这么一小段时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先把程序的剩余代码给我:
#coding:utf-8
import requests,MySQLdb,random,time
from bs4 import BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
return conn
def insert_content(title,readnum,praisenum,time,link,source):
conn = get_conn()
cur = conn.cursor()
print title,readnum
sql = 'insert into weixin.gsdata(title,readnum,praisenum,time,link,source) values ("%s","%s","%s","%s","%s","%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
在导入的开头收录
一些插件,然后剩下的两个功能是与数据库操作相关的功能。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以获取到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞、访问网址等信息。
分析数据
这些数据只是最原创
的数据。我可以把上面的数据导入到Excel中进行简单的分析处理,然后就可以得到我需要的文章列表了。分析思路如下:
我喜欢的微信公众号只有几个。我可以用这个程序抓取我喜欢的微信公众号上的所有文章。如果我愿意,我可以进一步筛选出更多高质量的文章。
程序很简单,但是一个简单的程序就可以实现生活中的一些想法,是不是一件很美妙的事情。
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-12-23 16:23
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~ 查看全部
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-23 16:22
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~ 查看全部
querylist采集微信公众号文章(微信公众号文章的舆情监控系统)
小明酱是2018年元旦更新的,文笔还是很粗糙的。如果您遇到爬虫问题,欢迎交流,评论区随时为您开放!
实习已经过去两周了,目前的任务量不是很大。我的老板人很好,他是一名军校学生,分配给我的任务比我想象的更接近我的研究方向。他做的是微信公众号文章的舆情监测系统。以下是系统图的整体设计流程:
目前第一周是爬取微信公众号文章,主要功能如下:
以上功能已经实现。真心觉得在项目中学习是最高效的方式,但同时也有不明白的问题。希望下周能掌握新知识,做一个总结。您不能只停留在插件编程中。.
下面我介绍一下思路流程GitHub代码点击这里:
大意
输入公众号获取爬虫起始地址
http://weixin.sogou.com/weixin ... 3D%2B公众号ID+&ie=utf8&_sug_=n&_sug_type_=
基于网页结构设计爬取规则
在这个阶段,我徘徊了很长时间。看到很多demo设计花哨的反拣货策略,让我心慌了半天。
1.第一级:找到指定公众号,获取公众号首页链接
2.Level 2:跳转到首页,找到文章的各个链接
3. Level 3:进入每个文章页面进行信息爬取,三个绿色框内的信息,以及页面的主要内容
主要思路是这样的,用chrome检查的部分就不细说了,是例行操作
网址:
但是当我把网址复制到浏览器时,他又回到了微信搜索的首页,哦,我该怎么办?我们先来看看开发者工具
以上参数只对应URL。专注于 tsn。表示访问在文章的一天内。我们应该提出以下要求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']
上面的问题解决了~
存储详情
数据存储量还是很大的,需要大量的样本来训练模型。它现在存储在数据库中,但值得我注意的一个细节是数据的编码。现在公众号的文章里有很多表情符号。,于是出现如下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")
解决方案参考:
对抗爬行动物
主要问题是验证码,但是如果爬行速度不是很快,是可以避免的。因此,采用以下两种策略:
import random
DOWNLOAD_DELAY = random.randint(1, 3)
总结页面元素匹配问题。以后我们会详细了解BeautifulSoup的翻页逻辑。这个只能自学自学了。考虑换页的逻辑数据库存储和编码问题。Navicat是新换的,感觉100分。这次配置完成后,放心使用代理IP,网上通过代码爬取的IP无法使用,浪费了很多时间,邪恶的tsn,学了一招笑死了。
爬行的基本思路很清晰,但其实我还没有完全掌握爬行,还有很多方面需要继续学习。正如行走所说的那样,我心急如焚,想尽快实现自己的目标,却忽略了正确的原则和基础,是绝对不可能掌握的。因此,在寒假期间,我希望能好好学习以下知识:
尤其是第二点非常非常重要。学习会可以证明你可以爬,而不是仅仅拼凑几段代码来运行,你会得到很多东西。同时也希望志同道合的朋友可以加我。微信,一起进步!哈哈我的微信欢迎私聊~
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-21 18:00
之前自己维护过公众号,但是因为个人关系好久没有更新,今天上来想起来,却无意中找到了获取微信公众号文章的方法。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章的列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
相关文章 查看全部
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
之前自己维护过公众号,但是因为个人关系好久没有更新,今天上来想起来,却无意中找到了获取微信公众号文章的方法。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章的列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
相关文章
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-19 05:12
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章( 访问示例地址参考资料)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-12-18 22:14
访问示例地址参考资料)
核心代码
要求获取文章的标题、跳转链接、发布时间和带有图片的文章缩略图。具体代码如下。
<p>'use strict';
const puppeteer = require('puppeteer')
exports.main = async (event, context) => {
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
dumpio: false,
})
const page = await browser.newPage()
page.setUserAgent(
'Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro Build/QKQ1.191117.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2581 MMWEBSDK/200801 Mobile Safari/537.36'
)
await page.goto('获取到的话题标签链接', {
waitUntil: 'networkidle0',
})
const articleInfo = await page.evaluate(() => {
const element = document.querySelector(".album__list");
let items = element.getElementsByClassName("album__list-item");
let title = [];
for (let i = 0; i 查看全部
querylist采集微信公众号文章(
访问示例地址参考资料)
核心代码
要求获取文章的标题、跳转链接、发布时间和带有图片的文章缩略图。具体代码如下。
<p>'use strict';
const puppeteer = require('puppeteer')
exports.main = async (event, context) => {
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
dumpio: false,
})
const page = await browser.newPage()
page.setUserAgent(
'Mozilla/5.0 (Linux; Android 10; Redmi K30 Pro Build/QKQ1.191117.002; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/78.0.3904.62 XWEB/2581 MMWEBSDK/200801 Mobile Safari/537.36'
)
await page.goto('获取到的话题标签链接', {
waitUntil: 'networkidle0',
})
const articleInfo = await page.evaluate(() => {
const element = document.querySelector(".album__list");
let items = element.getElementsByClassName("album__list-item");
let title = [];
for (let i = 0; i
querylist采集微信公众号文章(Fiddler如何抓包这里不再一一阐述,首先第一次如何安装?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-18 22:13
前言
微信后台很多消息都没有回复:看到就回复不了。有什么问题可以加我的微信:菜单->联系我
由于最近需要公众号的历史文章信息,尝试爬取。虽然目前可以爬取数据,但是还不能实现大量的自动化爬取。原因是参数key值是时间敏感的(具体时间没有验证为20分钟),目前不知道怎么生成。
文章历史列表爬取
第一个是搜狗微信,但是搜狗微信只能看到前十篇文章,看不到阅读量和观看数。尝试爬取手机包,发现没有抓取到任何信息。知道原因:
1、Android系统7. 0以下,微信信任系统的证书。
2、Android系统7.0及以上,微信7.0版本,微信信任系统提供的证书。
3、Android系统7.0及以上,微信7.0及以上,微信只信任自己的证书。
我也试过用appium来自动爬取,个人觉得有点麻烦。所以尝试从PC上抓取请求。
进入正题,这次我用Fiddler抓包。下载链接:
Fiddler如何抓包这里就不一一解释了。首先,第一次安装Fiddler时,需要安装一个证书来捕获HTTPS请求。
如何安装?
打开Fiddler,在菜单栏找到Tools -> Options -> 点击HTTPS -> 点击Actions,证书安装配置如下:
以我自己的公众号为例:PC端登录微信,打开Fiddler,按F12开始/停止抓包,进入公众号历史文章页面,看到Fiddler有很多请求,如如下图所示:
由于查看历史记录是跳转到一个新的页面,所以可以从body中看到返回的更多。同时通过Content-Type可以知道返回的是css或者html或者js。你可以先看一下html,所以它会找到上图红框中的链接,点击它,从右边可以看到返回的结果和参数:
从右边的Headers可以看到请求链接、方法、参数等,如果想更清楚的查看参数,可以点击WebForms查看,就是上图的结果。以下是重要参数的说明:
__biz:微信公众号的唯一标识(同一公众号保持不变)
uin:唯一用户标识(同一微信用户不变)
关键:微信内部算法是时间敏感的。我目前不知道如何计算。
pass_ticket:有读权限加密,改了(在我实际爬取中发现没必要,可以忽略)
这时候其实可以写代码爬取第一页的文章,但是返回的是一个html页面,解析页面显然比较麻烦。
可以尝试向下滑动,加载下一页数据,看看是json还是html。如果是json,好办,如果还是html,那就得稍微解析一下了。继续往下查找:
这个请求是文章的返回列表,是json数据,非常方便我们解析。从参数中我们发现有一个offset为10的参数,很明显这个参数是分页的offset,这个请求是10来加载第二页的历史记录,果断修改为0,然后发送请求,拿到第一页的数据,然后就不用解析html页面了,再次分析参数,发现是Multi-parameters,很多都没用,最后的参数是:
动作:getmsg(固定值,应该是获取更多信息)
__biz、uin、key这三个值上面已经介绍过了,这里也是必选参数。
f:json(固定值,表示返回json数据)
偏移:页面偏移
如果要获取公众号的历史列表,这6个参数是必须的,其他参数不需要带。我们来分析一下请求头中的听者,如图:
参数很多,不知道哪些应该带,哪些不需要带。最后,我只需要携带UA,别的什么都没有。最后写个脚本尝试获取:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,得到结果:
获取文章的详细信息
我有上面的链接,只是请求解析 html 页面。此处不再解释(可在完整代码中查看)。 查看全部
querylist采集微信公众号文章(Fiddler如何抓包这里不再一一阐述,首先第一次如何安装?(组图))
前言
微信后台很多消息都没有回复:看到就回复不了。有什么问题可以加我的微信:菜单->联系我
由于最近需要公众号的历史文章信息,尝试爬取。虽然目前可以爬取数据,但是还不能实现大量的自动化爬取。原因是参数key值是时间敏感的(具体时间没有验证为20分钟),目前不知道怎么生成。
文章历史列表爬取
第一个是搜狗微信,但是搜狗微信只能看到前十篇文章,看不到阅读量和观看数。尝试爬取手机包,发现没有抓取到任何信息。知道原因:
1、Android系统7. 0以下,微信信任系统的证书。
2、Android系统7.0及以上,微信7.0版本,微信信任系统提供的证书。
3、Android系统7.0及以上,微信7.0及以上,微信只信任自己的证书。
我也试过用appium来自动爬取,个人觉得有点麻烦。所以尝试从PC上抓取请求。
进入正题,这次我用Fiddler抓包。下载链接:
Fiddler如何抓包这里就不一一解释了。首先,第一次安装Fiddler时,需要安装一个证书来捕获HTTPS请求。
如何安装?
打开Fiddler,在菜单栏找到Tools -> Options -> 点击HTTPS -> 点击Actions,证书安装配置如下:
以我自己的公众号为例:PC端登录微信,打开Fiddler,按F12开始/停止抓包,进入公众号历史文章页面,看到Fiddler有很多请求,如如下图所示:
由于查看历史记录是跳转到一个新的页面,所以可以从body中看到返回的更多。同时通过Content-Type可以知道返回的是css或者html或者js。你可以先看一下html,所以它会找到上图红框中的链接,点击它,从右边可以看到返回的结果和参数:
从右边的Headers可以看到请求链接、方法、参数等,如果想更清楚的查看参数,可以点击WebForms查看,就是上图的结果。以下是重要参数的说明:
__biz:微信公众号的唯一标识(同一公众号保持不变)
uin:唯一用户标识(同一微信用户不变)
关键:微信内部算法是时间敏感的。我目前不知道如何计算。
pass_ticket:有读权限加密,改了(在我实际爬取中发现没必要,可以忽略)
这时候其实可以写代码爬取第一页的文章,但是返回的是一个html页面,解析页面显然比较麻烦。
可以尝试向下滑动,加载下一页数据,看看是json还是html。如果是json,好办,如果还是html,那就得稍微解析一下了。继续往下查找:
这个请求是文章的返回列表,是json数据,非常方便我们解析。从参数中我们发现有一个offset为10的参数,很明显这个参数是分页的offset,这个请求是10来加载第二页的历史记录,果断修改为0,然后发送请求,拿到第一页的数据,然后就不用解析html页面了,再次分析参数,发现是Multi-parameters,很多都没用,最后的参数是:
动作:getmsg(固定值,应该是获取更多信息)
__biz、uin、key这三个值上面已经介绍过了,这里也是必选参数。
f:json(固定值,表示返回json数据)
偏移:页面偏移
如果要获取公众号的历史列表,这6个参数是必须的,其他参数不需要带。我们来分析一下请求头中的听者,如图:
参数很多,不知道哪些应该带,哪些不需要带。最后,我只需要携带UA,别的什么都没有。最后写个脚本尝试获取:
import requests
url = "链接:http://链接:mp.weixin链接:.qq.com/mp/profile_ext"
headers= {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.18 NetType/WIFI Language/zh_CN'
}
param = {
'action': 'getmsg',
'__biz': 'MzU0NDg3NDg0Ng==',
'f': 'json',
'offset': 0,
'uin': 'MTY5OTE4Mzc5Nw==',
'key': '0295ce962daa06881b1fbddd606f47252d0273a7280069e55e1daa347620284614629cd08ef0413941d46dc737cf866bc3ed3012ec202ffa9379c2538035a662e9ffa3f84852a0299a6590811b17de96'
}
index_josn = requests.get(url, params=param, headers=headers)
print(index_josn.json())
print(index_josn.json().get('general_msg_list'))
获取json对象中的general_msg_list,得到结果:
获取文章的详细信息
我有上面的链接,只是请求解析 html 页面。此处不再解释(可在完整代码中查看)。
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-12-18 01:17
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。 查看全部
querylist采集微信公众号文章(一个获取微信公众号文章的方法,你知道吗?)
之前是自己维护一个公众号,但是因为个人关系好久没有更新,今天上来想起来,却偶然发现了微信公众号文章的获取方式。
之前的获取方式有很多,通过搜狗、清博、web、客户端等都可以,这个可能不太好,但是操作简单易懂。
所以。首先,您需要在微信公众平台上有一个账号
微信公众平台:
登录后,进入首页,点击新建群发。
选择自创图形:
好像是公众号操作教学
进入编辑页面后,点击超链接
弹出一个选择框,我们在框中输入对应的公众号名称,就会出现对应的文章列表
你惊喜吗?您可以打开控制台并检查请求的界面
打开回复,里面有我们需要的文章链接
确认数据后,我们需要对这个界面进行分析。
感觉非常简单。GET 请求携带一些参数。
Fakeid是公众号的唯一ID,所以如果想直接通过名字获取文章列表,还需要先获取fakeid。
当我们输入官方账号名称时,点击搜索。可以看到搜索界面被触发,返回fakeid。
这个接口需要的参数不多。
接下来我们就可以用代码来模拟上面的操作了。
但您还需要使用现有的 cookie 来避免登录。
我没有测试过当前cookie的有效期。可能需要及时更新 cookie。
测试代码:
import requests
import json
Cookie = '请换上自己的Cookie,获取方法:直接复制下来'
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
"Cookie": Cookie,
"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36'
}
keyword = 'pythonlx' # 公众号名字:可自定义
token = '你的token' # 获取方法:如上述 直接复制下来
search_url = 'https://mp.weixin.qq.com/cgi-b ... ry%3D{}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)
doc = requests.get(search_url,headers=headers).text
jstext = json.loads(doc)
fakeid = jstext['list'][0]['fakeid']
data = {
"token": token,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": 0,
"count": "5",
"query": "",
"fakeid": fakeid,
"type": "9",
}
json_test = requests.get(url, headers=headers, params=data).text
json_test = json.loads(json_test)
print(json_test)
这样就可以得到最新的10篇文章。如果想获取更多历史记录文章,可以修改数据中的“begin”参数,0为第一页,5为第二页,10为第三页(以此类推)
但是如果你想大规模爬行:
请自己安排一个稳定的代理,降低爬虫速度,准备多个账号,减少被屏蔽的可能性。
querylist采集微信公众号文章(孤狼微信公众号文章采集主要功能特色介绍! )
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-16 11:04
)
孤狼数据采集平台为微信公众号文章提供采集,可以方便的发布到市场主流系统,一些冷门的网站接口也可以定制!
一、独狼微信公众号文章采集主要功能
1.根据公众号名称或ID,指定公众号采集,支持输入多个公众号,不限制公众号数量
2. 多种图片下载存储方式(远程调用、图片本地化、ftp上传),解决公众号防盗链问题文章
3.强大的数据存储功能(采集接收到的数据保存在本地数据库文件中)
4.简单的配置可以轻松发布到主流网站或者api接口
二、微信公众号文章采集主要步骤
1、创建“添加公众号”任务
登录软件打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到群中。
2、填写公众号名称或ID为采集
填写基本信息如下图:
只需填写任务名称和采集的微信公众号名称或ID即可。提示:可以查看文章的图片前后自动过滤
使用广告图片功能删除广告(功能需提前勾选)
使用公众号标签
3、设置图片下载(可选)
由于微信公众号文章上的图片经过防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、开始采集
图片配置好后,可以点击左上角的“采集”,采集数据:
5、采集 后期数据处理与发布
启动采集后,总是会出来数据采集,文章可以预览,显示图形内容,添加到“任务列表”页面查看:勾选后文章, 选择发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
查看全部
querylist采集微信公众号文章(孤狼微信公众号文章采集主要功能特色介绍!
)
孤狼数据采集平台为微信公众号文章提供采集,可以方便的发布到市场主流系统,一些冷门的网站接口也可以定制!
一、独狼微信公众号文章采集主要功能
1.根据公众号名称或ID,指定公众号采集,支持输入多个公众号,不限制公众号数量
2. 多种图片下载存储方式(远程调用、图片本地化、ftp上传),解决公众号防盗链问题文章
3.强大的数据存储功能(采集接收到的数据保存在本地数据库文件中)
4.简单的配置可以轻松发布到主流网站或者api接口
二、微信公众号文章采集主要步骤
1、创建“添加公众号”任务
登录软件打开左上角“自定义公众号”,鼠标右键添加公众号框,点击获取软件自动获取公众号信息,然后添加到群中。
2、填写公众号名称或ID为采集
填写基本信息如下图:
只需填写任务名称和采集的微信公众号名称或ID即可。提示:可以查看文章的图片前后自动过滤
使用广告图片功能删除广告(功能需提前勾选)
使用公众号标签
3、设置图片下载(可选)
由于微信公众号文章上的图片经过防盗链处理,采集收到的原创图片无法正常显示。如果需要图片,需要配置图片下载:
您可以选择“上传设置(通过ftp返回您的服务器)”或直接远程调用。
4、开始采集
图片配置好后,可以点击左上角的“采集”,采集数据:
5、采集 后期数据处理与发布
启动采集后,总是会出来数据采集,文章可以预览,显示图形内容,添加到“任务列表”页面查看:勾选后文章, 选择发布任务
可以分配到一个类别或列;
在任务列表中,您可以发布:
最后选择发布到自己的系统。如果软件上现成的界面与你的网站界面匹配,直接填写网址、后台网址、账号密码等,点击登录成功。
querylist采集微信公众号文章(大文本的分词对接搜狗对搜狗中文分词工具baiduspider对接)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-15 23:07
querylist采集微信公众号文章,支持微信公众号文章、自媒体文章、微博文章等。动态切换国内文章及国外的文章。支持采集天猫、京东、拼多多等主流电商平台的文章。实现对接coredns及urllib2。大文本的分词对接搜狗对搜狗中文分词工具baiduspider,可选择对接gbk分词或wa/wa模式。
支持实现从文本中匹配关键词并生成目标文章链接。支持实现对接原创保护机制,支持markdown等第三方工具的写作。动态拓展javascript全局变量。实现更多的功能以及读取文章、分析文章等。公众号点赞微信公众号可以自动同步文章,通过点赞实现文章分享及编辑。点赞记录直接存储在数据库中。点赞实现历史文章自动分类功能。
获取文章作者微信公众号文章作者可以基于文章token来获取其值。单篇文章作者的信息实时同步到本地服务器。在文章详情页可以对文章作者进行权限设置,用户可以设置仅对该作者可见。通过注册获取高级权限,用户可以对文章进行推荐,被推荐后文章可以通过头条、微信、微博三种渠道进行展示。文章推荐基于token进行流量推荐,推荐准确度提升30%-50%。个人介绍。
谢邀你是指知乎的话可以吗,一开始我是想去找的,不过想了想不如开个主页,自己推荐。
可以,用weixinjs,用最新版的,就是不知道知乎能不能用。每天可以获取20个赞。点赞不多的话还可以买赞。 查看全部
querylist采集微信公众号文章(大文本的分词对接搜狗对搜狗中文分词工具baiduspider对接)
querylist采集微信公众号文章,支持微信公众号文章、自媒体文章、微博文章等。动态切换国内文章及国外的文章。支持采集天猫、京东、拼多多等主流电商平台的文章。实现对接coredns及urllib2。大文本的分词对接搜狗对搜狗中文分词工具baiduspider,可选择对接gbk分词或wa/wa模式。
支持实现从文本中匹配关键词并生成目标文章链接。支持实现对接原创保护机制,支持markdown等第三方工具的写作。动态拓展javascript全局变量。实现更多的功能以及读取文章、分析文章等。公众号点赞微信公众号可以自动同步文章,通过点赞实现文章分享及编辑。点赞记录直接存储在数据库中。点赞实现历史文章自动分类功能。
获取文章作者微信公众号文章作者可以基于文章token来获取其值。单篇文章作者的信息实时同步到本地服务器。在文章详情页可以对文章作者进行权限设置,用户可以设置仅对该作者可见。通过注册获取高级权限,用户可以对文章进行推荐,被推荐后文章可以通过头条、微信、微博三种渠道进行展示。文章推荐基于token进行流量推荐,推荐准确度提升30%-50%。个人介绍。
谢邀你是指知乎的话可以吗,一开始我是想去找的,不过想了想不如开个主页,自己推荐。
可以,用weixinjs,用最新版的,就是不知道知乎能不能用。每天可以获取20个赞。点赞不多的话还可以买赞。
querylist采集微信公众号文章(新媒体编辑者如何采集微信公众号文章的文章链接?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-14 07:26
当我们看到一个优秀的公众号文章时,如果我们想转载到我们的公众号,我们会直接复制粘贴全文。不过,这种方法虽然简单,但实用性并不强。因为粘贴之后我们会发现格式或者样式经常出错,修改起来比较困难。
事实上,这种方法已经过时了。现在新媒体编辑经常使用一些微信编辑来帮助处理这类问题。今天小编就以目前主流的微信编辑器为例,教大家如何采集其他微信公众号文章到您的微信公众平台。
第一步:首先在百度上搜索小蚂蚁编辑器,点击进入网址
第二步:点击采集,将采集的微信文章链接地址粘贴到“文章URL”框中
第三步:点击“采集”,此时文章的所有内容已经采集到微信编辑器,可以编辑修改文章。编辑完后可以点击旁边的复制(相当于复制全文),然后粘贴到微信素材编辑的正文中。
ps:这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章点击右上角复制
方法二:在小蚂蚁编辑器的微信营销工具中搜索热搜图文中的素材,直接复制文章上面的网址即可。
,
这个怎么样?你有没有得到另一个技能(括号笑)。这只是小蚂蚁微信编辑器中的一个小功能,还收录了一些常用的功能,如微信图文提取、微信超链接、微信短网址、微信一键关注页面等。新媒体数量 编辑喜欢使用它的主要原因。返回搜狐查看更多 查看全部
querylist采集微信公众号文章(新媒体编辑者如何采集微信公众号文章的文章链接?)
当我们看到一个优秀的公众号文章时,如果我们想转载到我们的公众号,我们会直接复制粘贴全文。不过,这种方法虽然简单,但实用性并不强。因为粘贴之后我们会发现格式或者样式经常出错,修改起来比较困难。
事实上,这种方法已经过时了。现在新媒体编辑经常使用一些微信编辑来帮助处理这类问题。今天小编就以目前主流的微信编辑器为例,教大家如何采集其他微信公众号文章到您的微信公众平台。
第一步:首先在百度上搜索小蚂蚁编辑器,点击进入网址
第二步:点击采集,将采集的微信文章链接地址粘贴到“文章URL”框中
第三步:点击“采集”,此时文章的所有内容已经采集到微信编辑器,可以编辑修改文章。编辑完后可以点击旁边的复制(相当于复制全文),然后粘贴到微信素材编辑的正文中。
ps:这里获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章点击右上角复制
方法二:在小蚂蚁编辑器的微信营销工具中搜索热搜图文中的素材,直接复制文章上面的网址即可。
,
这个怎么样?你有没有得到另一个技能(括号笑)。这只是小蚂蚁微信编辑器中的一个小功能,还收录了一些常用的功能,如微信图文提取、微信超链接、微信短网址、微信一键关注页面等。新媒体数量 编辑喜欢使用它的主要原因。返回搜狐查看更多
querylist采集微信公众号文章(如何抓取微信公众号的文章内容、阅读数、点赞数、发表时间和作者)
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-12-13 14:07
如何抓取微信公众号的内容、阅读数、点赞数、发表时间和作者?-:拓图数据可以做到,文章内容、阅读数、点赞数、发表时间和作者可用
如何抢微信公众号文章-:你是说抄袭吗?手机长按,点击要复制的内容。您可以使用搜狗在电脑上进行搜索。有微信栏目,可以搜索微信公众号,直接搜索你需要的公众号,电脑上复制粘贴即可
采集微信公众号文章,如何采集?-:用键盘加速排行。登录后,在编辑区右侧找到导入文章按钮,然后将文章地址复制进去,然后就可以采集下来了,还是需要在采集之后修改,否则不会变成原创。
超实用技巧:如何采集微信公众号文章-:选对产品很重要!下面是优采云软件智能文章采集系统,你可以了解一、智能区块算法采集任何内容站点,真的傻瓜式< @采集智能块算法自动提取网页正文内容,无需配置源码规则,真正傻瓜式采集;自动去噪,可修正标题内容中的图片\...
如何抓取微信公众号发布的文章的阅读和点赞数-:思路一,使用rss生成工具将搜狗的微信搜索结果生成一个rss,然后通过监控公众号的文章rss @>更新。(理论上应该是可以的,但我没试过) 思路二,自己做一个桌面浏览器,IE内核。使用此浏览器登录网页版微信,此微信号关注您要抓取的公众号,因此您可以监控这些公众号是否有更新,以及更新后链接是什么,从而达到目的的数据捕获。(用过,效率不高,但是很稳定) 思路三,通过修改Android微信客户端实现(这个方法我们用了一段时间) 思路四,
如何采集或爬取微信公众号文章-:使用ForeSpider数据采集软件嗅探之前就可以采集微信公众号文章。是一款可视化万能爬虫软件。简单的配置两步就可以完成采集,软件还自带了一个免费的数据库,你可以直接存储采集。如果不想配置,可以提供配置服务,价格很便宜。公众号模板好像可以在软件里下载。这是免费的。您可以从官方网站下载免费版本进行试用。免费版不限制功能。
如何抢采集微信公众号文章!:难度已达到1),这个入口地址不固定,一天左右会变,主要是key值里面。所以,期望通过人工手动抓取一劳永逸获得的地址没有太大的实用价值2),这个入口页面对于没有关注的用户只能看到第一页,可以只有关注后才能看到后续页面。后续页面只能关注这个账号,但是手动关注多个账号的上万粉丝是不现实的。3),微信对一个账号可以关注的公众号数量有上限(摘自网络)
如何找到公众号文章采集器?-:键盘喵编辑器可以找到导入文章按钮,这个按钮是复制地址进去的,可以放文章@ >采集、采集会再次出现在编辑区,可以再次编辑。
怎么抢公众号文章?-:在键盘妙微微信编辑器上找到导入文章按钮,然后复制文章的链接,就可以抢了,然后编辑它自己。
有没有采集微信公众号文章的工具?-:我知道有西瓜助手。西瓜助手是一个微信素材库。一键查找文章素材采集素材库可分类管理,使用过的素材会做标记,整体使用更方便。
相关视频:2步教你如何快速抓取音频素材,如何快速将音频转成文本形式,通过爬虫插件抓取外贸买家邮箱【云之盟】Python爬虫从入门到精通1688阿里巴巴商家电话采集软件的使用方式让人震惊!学习Python爬虫后,某网站接单,3天赚了1650元!新华社客户端V6.0版上线,移动信息旗舰瞄准哪些新趋势可怕!LED广告屏百米内可获取您的电话号码,每月采集8亿个人数据。如何处理科学研究中出现的海量数据?高能物理为网络视频提取神器提供了新思路,支持全网任意网页。并在国内外,非商业定位自带转换功能!农村的数据同样丰富!陕西地图最新版上线 查看全部
querylist采集微信公众号文章(如何抓取微信公众号的文章内容、阅读数、点赞数、发表时间和作者)
如何抓取微信公众号的内容、阅读数、点赞数、发表时间和作者?-:拓图数据可以做到,文章内容、阅读数、点赞数、发表时间和作者可用
如何抢微信公众号文章-:你是说抄袭吗?手机长按,点击要复制的内容。您可以使用搜狗在电脑上进行搜索。有微信栏目,可以搜索微信公众号,直接搜索你需要的公众号,电脑上复制粘贴即可
采集微信公众号文章,如何采集?-:用键盘加速排行。登录后,在编辑区右侧找到导入文章按钮,然后将文章地址复制进去,然后就可以采集下来了,还是需要在采集之后修改,否则不会变成原创。
超实用技巧:如何采集微信公众号文章-:选对产品很重要!下面是优采云软件智能文章采集系统,你可以了解一、智能区块算法采集任何内容站点,真的傻瓜式< @采集智能块算法自动提取网页正文内容,无需配置源码规则,真正傻瓜式采集;自动去噪,可修正标题内容中的图片\...
如何抓取微信公众号发布的文章的阅读和点赞数-:思路一,使用rss生成工具将搜狗的微信搜索结果生成一个rss,然后通过监控公众号的文章rss @>更新。(理论上应该是可以的,但我没试过) 思路二,自己做一个桌面浏览器,IE内核。使用此浏览器登录网页版微信,此微信号关注您要抓取的公众号,因此您可以监控这些公众号是否有更新,以及更新后链接是什么,从而达到目的的数据捕获。(用过,效率不高,但是很稳定) 思路三,通过修改Android微信客户端实现(这个方法我们用了一段时间) 思路四,
如何采集或爬取微信公众号文章-:使用ForeSpider数据采集软件嗅探之前就可以采集微信公众号文章。是一款可视化万能爬虫软件。简单的配置两步就可以完成采集,软件还自带了一个免费的数据库,你可以直接存储采集。如果不想配置,可以提供配置服务,价格很便宜。公众号模板好像可以在软件里下载。这是免费的。您可以从官方网站下载免费版本进行试用。免费版不限制功能。
如何抢采集微信公众号文章!:难度已达到1),这个入口地址不固定,一天左右会变,主要是key值里面。所以,期望通过人工手动抓取一劳永逸获得的地址没有太大的实用价值2),这个入口页面对于没有关注的用户只能看到第一页,可以只有关注后才能看到后续页面。后续页面只能关注这个账号,但是手动关注多个账号的上万粉丝是不现实的。3),微信对一个账号可以关注的公众号数量有上限(摘自网络)
如何找到公众号文章采集器?-:键盘喵编辑器可以找到导入文章按钮,这个按钮是复制地址进去的,可以放文章@ >采集、采集会再次出现在编辑区,可以再次编辑。
怎么抢公众号文章?-:在键盘妙微微信编辑器上找到导入文章按钮,然后复制文章的链接,就可以抢了,然后编辑它自己。
有没有采集微信公众号文章的工具?-:我知道有西瓜助手。西瓜助手是一个微信素材库。一键查找文章素材采集素材库可分类管理,使用过的素材会做标记,整体使用更方便。
相关视频:2步教你如何快速抓取音频素材,如何快速将音频转成文本形式,通过爬虫插件抓取外贸买家邮箱【云之盟】Python爬虫从入门到精通1688阿里巴巴商家电话采集软件的使用方式让人震惊!学习Python爬虫后,某网站接单,3天赚了1650元!新华社客户端V6.0版上线,移动信息旗舰瞄准哪些新趋势可怕!LED广告屏百米内可获取您的电话号码,每月采集8亿个人数据。如何处理科学研究中出现的海量数据?高能物理为网络视频提取神器提供了新思路,支持全网任意网页。并在国内外,非商业定位自带转换功能!农村的数据同样丰富!陕西地图最新版上线
querylist采集微信公众号文章(新建微信公众号采集任务配置采集结果附录(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-09 15:03
)
?使用优采云采集微信公众号文章,很简单,只需输入:公众号ID或姓名或关键词。
使用步骤:新建一个微信公众号采集任务微信公众号采集任务配置采集结果微信文章几个采集) 1.新微信公众号采集任务:
??新增微信公众号采集任务入口有两个:
2.微信公众号采集任务配置:
3. 采集结果:
??微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(内容)、发布日期(pubData)、作者(author)、标签(tag)、描述(description),可以使用文字截取) 和关键字(keywords);
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
??在“公众号(WeChat ID)”中填写微信帐号名称,然后点击旁边的“查看公众号”按钮即可查看微信ID;
??以“万维网”为例:
二、微信文章随机采集
??微信文章分片采集一般用于精度采集,用户只需输入微信文章地址采集。
??在微信公众号文章采集的基本信息页面,点击“手动进入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
查看全部
querylist采集微信公众号文章(新建微信公众号采集任务配置采集结果附录(一)
)
?使用优采云采集微信公众号文章,很简单,只需输入:公众号ID或姓名或关键词。
使用步骤:新建一个微信公众号采集任务微信公众号采集任务配置采集结果微信文章几个采集) 1.新微信公众号采集任务:
??新增微信公众号采集任务入口有两个:
2.微信公众号采集任务配置:
3. 采集结果:
??微信公众号名称(weixin_name)、公众号ID(weixin_id)、标题(title)、正文(内容)、发布日期(pubData)、作者(author)、标签(tag)、描述(description),可以使用文字截取) 和关键字(keywords);
附录:(如何获取公众号和微信文章零散采集)
我。如何获取公众号
??在“公众号(WeChat ID)”中填写微信帐号名称,然后点击旁边的“查看公众号”按钮即可查看微信ID;
??以“万维网”为例:
二、微信文章随机采集
??微信文章分片采集一般用于精度采集,用户只需输入微信文章地址采集。
??在微信公众号文章采集的基本信息页面,点击“手动进入文章链接采集(可选)”按钮;
??输入单个或多个详细 URL,每行一个,以 or 开头;
querylist采集微信公众号文章(工业界用ai的方法做实验数据和实验的过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-08 13:15
querylist采集微信公众号文章列表,如果要找某个名称的文章需要列举数据挖掘领域属于svm,相当于a-log.机器学习目前主要是找出中文,但是更多用了机器学习.
要看你的算法类型,如果属于nlp,基本属于机器学习。可能你做得实验在工业界有用,可是面试,
如果你的实验设计不同于工业界应用的算法,那么工业界在面试时可能会让你介绍一下实验方法,但一般不会要求你介绍实验数据和实验过程。
对于工业界来说,肯定是机器学习更合适。对于科研来说,算法数据,有意义。但人也能学得会。
希望楼主有基础了还有问题先查一下,特别是acm竞赛还有实习工作的话,
机器学习,数据挖掘,统计推断,感觉是两类完全不同的东西,放一起比,简直笑掉大牙。
不请自来,
哈哈哈我想看看这个问题我没多久才有人能答上来
希望楼主用ai的方法做实验,到时候能多一点信心。具体去哪里做,看具体情况。
后者发展不受市场影响,更多需要数据和算法背景。两种是不一样的。前者从头计算,优势是一下就能看到,劣势是太复杂,有的时候还会碰到技术难点,很多细节没法多想。
两种方向都做过,推荐后者,工业界用机器学习算法的太多了,你能做的东西比他们多太多了,实验做多了,看多了,很多时候比较容易找到用途。并且不管是哪种,其实都需要一定的数学功底,所以基础好的比较好,最后成为某个细分领域专家还是有可能的。 查看全部
querylist采集微信公众号文章(工业界用ai的方法做实验数据和实验的过程)
querylist采集微信公众号文章列表,如果要找某个名称的文章需要列举数据挖掘领域属于svm,相当于a-log.机器学习目前主要是找出中文,但是更多用了机器学习.
要看你的算法类型,如果属于nlp,基本属于机器学习。可能你做得实验在工业界有用,可是面试,
如果你的实验设计不同于工业界应用的算法,那么工业界在面试时可能会让你介绍一下实验方法,但一般不会要求你介绍实验数据和实验过程。
对于工业界来说,肯定是机器学习更合适。对于科研来说,算法数据,有意义。但人也能学得会。
希望楼主有基础了还有问题先查一下,特别是acm竞赛还有实习工作的话,
机器学习,数据挖掘,统计推断,感觉是两类完全不同的东西,放一起比,简直笑掉大牙。
不请自来,
哈哈哈我想看看这个问题我没多久才有人能答上来
希望楼主用ai的方法做实验,到时候能多一点信心。具体去哪里做,看具体情况。
后者发展不受市场影响,更多需要数据和算法背景。两种是不一样的。前者从头计算,优势是一下就能看到,劣势是太复杂,有的时候还会碰到技术难点,很多细节没法多想。
两种方向都做过,推荐后者,工业界用机器学习算法的太多了,你能做的东西比他们多太多了,实验做多了,看多了,很多时候比较容易找到用途。并且不管是哪种,其实都需要一定的数学功底,所以基础好的比较好,最后成为某个细分领域专家还是有可能的。
querylist采集微信公众号文章( 数点java和js的主要特点是什么?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-12-08 05:04
数点java和js的主要特点是什么?-八维教育)
<p>本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 这几天接到任务,需要开发一个微信榜单的功能,因此需要采集微信公众号文章的阅读数,点赞数和评论数,榜单内的微信公众号有一百多个,每个月出一次榜单。 <br /> 接到这个任务,我开始研究如何抓取微信阅读数,点赞数和评论数,通过大量参考网上的技术文章,最终确定了我所使用的方案:使用Fiddler进行采集 <br /> 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第一步:设置Fiddler <br /> <br /> 如图设置,此处为设置Fiddler支持https
本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第二步:设置Fiddler脚本 <br /> Fiddler工具打开后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下: <br /> <br /> 这里我们只需要了解OnBeforeResponse方法,本方法为在http请求返回给客户端之前执行的方法,我们主要在本方法内进行脚本的编写
本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第三步:选择性截取responsebody存储到文本中 <br /> 研究各个请求,找到返回点赞数与评论的请求,具体请求如图: <br /> <br /> 然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本:
// 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext")){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}</p>
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:
本文章为lonter首创,仅在csdn平台发布,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
由于这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事!!!
我们来看看公众号文章的主页:
很明显,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,需要在脚本中稍微写一下,具体逻辑代码如图:
这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:
然后,当你回来找页面时会自动跳转
本文章为lonter首创,仅在csdn平台发布,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,我想很多人都可以写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬虫。至此,全部开发完成
你只需要写几十万公众号文章链接,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 这样的转账页面,你会发现微信浏览器一直跳跃时
本文章为lonter首创,仅在csdn平台发布,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i 查看全部
querylist采集微信公众号文章(
数点java和js的主要特点是什么?-八维教育)
<p>本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 这几天接到任务,需要开发一个微信榜单的功能,因此需要采集微信公众号文章的阅读数,点赞数和评论数,榜单内的微信公众号有一百多个,每个月出一次榜单。 <br /> 接到这个任务,我开始研究如何抓取微信阅读数,点赞数和评论数,通过大量参考网上的技术文章,最终确定了我所使用的方案:使用Fiddler进行采集 <br /> 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第一步:设置Fiddler <br />
<br /> 如图设置,此处为设置Fiddler支持https 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第二步:设置Fiddler脚本 <br /> Fiddler工具打开后,选择Rules ->Customize Rules打开Fiddler ScriptEditor编辑器,编辑器如下: <br />
<br /> 这里我们只需要了解OnBeforeResponse方法,本方法为在http请求返回给客户端之前执行的方法,我们主要在本方法内进行脚本的编写 本文章为lonter首创,只发布在csdn平台,严禁转载 <br /> 第三步:选择性截取responsebody存储到文本中 <br /> 研究各个请求,找到返回点赞数与评论的请求,具体请求如图: <br />
<br /> 然后开始在Fiddler ScriptEditor的方法中编写具体的存储脚本: // 首先判断请求域名是否是自己感兴趣的,以及URL中是否含有自己感兴趣的特征字符串。如果是,则将该请求的URL和QueryString记录到日志文件 "c:/fiddler-token.log"中。
if (oSession.HostnameIs("mp.weixin.qq.com") && oSession.uriContains("https://mp.weixin.qq.com/mp/getappmsgext";)){
var filename = "C:/fiddler-token.log";
var curDate = new Date();
var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";
var sw : System.IO.StreamWriter;
if (System.IO.File.Exists(filename)){
sw = System.IO.File.AppendText(filename);
sw.Write(logContent);
}
else{
sw = System.IO.File.CreateText(filename);
sw.Write(logContent);
}
sw.Close();
sw.Dispose();
}</p>
这段代码的作用是存储文本中阅读和点赞数相关的数据,结果如图:
本文章为lonter首创,仅在csdn平台发布,严禁转载
第四步:篡改公众号文章页面的js代码,让页面按照你的意图自动跳转
由于这个功能可能涉及灰色地带,所以请声明,不要用它来做坏事!!!
我们来看看公众号文章的主页:
很明显,每个js脚本都是以script nonce="1007993124"开头,nonce字段是用来防止xxs的。如果 js 的 nonce 与原创的 nonce 不匹配,则不会执行 js。因此,需要在脚本中稍微写一下,具体逻辑代码如图:
这个js加载完成后,保存Fiddler ScriptEditor,然后点击微信公众号文章,在Fiddler中会看到如下内容:
然后,当你回来找页面时会自动跳转
本文章为lonter首创,仅在csdn平台发布,严禁转载
第五步:获取开发任务页面
我们需要开发一个微信转账页面,这个页面会从后台获取一个微信公众号文章,然后让微信浏览器打开
具体的html如下:
window.onload=function(){
nextdoor();
}
function nextdoor(){
var taskid=GetQueryString("taskid")
var ob={task:taskid};
$.ajax({
type: "POST",
url: "rest/wxCrawler/wxTask",
contentType: "application/json; charset=utf-8",
data: JSON.stringify(ob),
dataType: "json",
success: function (message) {
var url=message.url;
var taskid=message.task;//每个微信客户端的id,这个id应该在后端自动生成
if(url==("http://127.0.0.1:8080/External ... taskid))
{
setTimeout(function(){window.location="http://127.0.0.1:8080/External ... id%3B},10000);
}else
{
//alert(url+"&taskid="+taskid);
window.location=url+"&taskid="+taskid+"#rd";
}
},
error: function (message) {
alert("提交数据失败");
}
});
}
function GetQueryString(name)
{
var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
if(r!=null)return unescape(r[2]); return null;
}
阅读刷新中转页面,页面正在跳转中...
如一直刷新本页面,则一直等待后台分配任务
至于后端接口,我想很多人都可以写,我只做一部分:
package test.springmvc;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import com.mangofactory.swagger.plugin.EnableSwagger;
import com.wordnik.swagger.annotations.ApiOperation;
import net.sf.json.JSONObject;
import test.springmvc.Artmodel.WxTask;
import test.springmvc.redis.JedisUtil;
/**
*
* @author Administrator
*
*/
@Controller
@EnableSwagger
@RequestMapping("/wxCrawler")
public class TopController {
private final static Logger logger = LoggerFactory.getLogger(TopController.class);
JedisUtil ju=new JedisUtil();
@ApiOperation(value = "微信任务调度接口", notes = "notes", httpMethod = "POST", produces = MediaType.APPLICATION_JSON_VALUE)
@RequestMapping(value = "wxTask", method = RequestMethod.POST)
@ResponseBody
// 使用了@RequestBody,不能在拦截器中,获得流中的数据,再json转换,拦截器中,也不清楚数据的类型,无法转换成java对象
// 只能手动调用方法
public String WeixinTask(@RequestBody WxTask wt) {
String task=wt.getTask();
byte[] redisKey= task.getBytes();//队列名称
byte[] bys=ju.rpop(redisKey);
if(bys==null)
{
JSONObject json=new JSONObject();
json.put("url", "http://127.0.0.1:8080/External ... 2Btask);
json.put("task", task);
return json.toString();
}else
{
String info=new String(bys);
JSONObject json=JSONObject.fromObject(info);
String url=json.getString("url");
url=url.replace("#rd", "");
json.put("url", url);
json.put("task", task);
return json.toString();
}
}
}
这部分java和js的主要特点是可以进行多任务分布式爬虫。至此,全部开发完成
你只需要写几十万公众号文章链接,然后用微信打开:8080/Externalservice/test.html?taskid=xxxxxl 这样的转账页面,你会发现微信浏览器一直跳跃时
本文章为lonter首创,仅在csdn平台发布,严禁转载
第六步:解析存储在 Fiddler 中的文本
<p>package com.crawler.top;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import com.mysql.jdbc.UpdatableResultSet;
import com.util.DBUtil;
import net.sf.json.JSONObject;
/**
* 读取Fiddler写入的内容,并将结果写入数据库
* @author Administrator
*
*/
public class ReaderTxt {
DBUtil dbu=new DBUtil();
public static void main(String[] args)
{
ReaderTxt rt=new ReaderTxt();
ArrayList list=rt.InitTxt();
for(int i=0;i
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-12-04 23:01
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章抓取
一.思考
我们通过微信公众平台网页版图文消息中的超链接获取我们需要的界面
从界面我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二. 接口分析
微信公众号获取界面:
范围:
行动=search_biz
开始=0
计数=5
查询=官方帐号名称
token=每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取对应公众号文章的界面:
范围:
动作=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方式:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,这个fakeid可以在第一个接口中获取。这样我们就可以获取到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户,输入对应的账号密码,点击登录,会出现扫码验证,用登录微信扫一扫即可。
刷新当前网页后,获取当前cookie和token,然后返回。
第二步:1.请求对应的公众号接口,得到我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取到的token和cookie,然后通过requests.get请求获取返回的微信公众号的json数据
lists = search_resp.json().get('list')[0]
通过上面的代码可以得到对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码可以得到对应的fakeid
2.请求获取微信公众号文章接口,获取我们需要的数据文章
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token,然后调用requests.get请求接口获取返回的json数据。
我们已经实现了对微信公众号文章的抓取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,当我们在循环中获取文章时,一定要设置延迟时间,否则账号很容易被封,获取不到返回的数据。
querylist采集微信公众号文章(如何实现每天爬取微信公众号的推送文章(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-02 01:09
Part 2文章:python爬虫如何抓取微信公众号文章(二)
接下来是如何连接python爬虫实现每天爬取微信公众号的推送文章
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但都是爬网站数据。这次觉得太容易了,但是遇到了很多麻烦,在这里分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的就是找到目标网站的url地址,然后遍历地址一个一个或者多个爬取线程。一般后续的爬取地址主要是通过两种方式获取,一种是根据页面分页计算url地址的规律,通常后跟参数page=num,另一种是过滤掉标签取当前页面的url作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过文章的地址找到所有的文章@。 >地址。
2、那我们如何获取公众号的历史文章地址呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的,无法获取历史记录文章 @>。如果你想做一个每日爬虫,你可以用这个方法每天爬取一篇文章。图片是这样的:
3、当然需要的结果还有很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,切入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果您之前有过,则无需注册)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹出的窗口中选择Find文章,输入你要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的全部历史记录文章:
4、找到历史记录后文章,我们如何编写一个程序来获取所有的URL地址? , 首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个公众号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_5880d9800000; = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每篇文章的title和url文章,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get ( url, headers=headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题和对应文章@ > url items = [] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的会被公众号被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data[ "begin"] = i*5 time. sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面是item中的每个页面的数据content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,就可以遍历爬取每个文章的内容。爬取文章内容的部分将在下面的博客中介绍。
补充内容:
关于如何从小伙伴那里获取封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存 文章 摘要。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法搞定,因为网页上的公众号文章没有数字阅读量和点赞数。这需要电脑版。可以使用抓包工具获取微信或手机版微信。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看 查看全部
querylist采集微信公众号文章(如何实现每天爬取微信公众号的推送文章(二))
Part 2文章:python爬虫如何抓取微信公众号文章(二)
接下来是如何连接python爬虫实现每天爬取微信公众号的推送文章
因为最近在法庭实习,需要一些公众号资料,然后做成网页展示,方便查看。之前写过一些爬虫,但都是爬网站数据。这次觉得太容易了,但是遇到了很多麻烦,在这里分享给大家。
1、 使用爬虫爬取数据最基本也是最重要的就是找到目标网站的url地址,然后遍历地址一个一个或者多个爬取线程。一般后续的爬取地址主要是通过两种方式获取,一种是根据页面分页计算url地址的规律,通常后跟参数page=num,另一种是过滤掉标签取当前页面的url作为后续的爬取地址。遗憾的是,这两种方法都不能在微信公众号中使用。原因是公众号的文章地址之间没有关联,不可能通过文章的地址找到所有的文章@。 >地址。
2、那我们如何获取公众号的历史文章地址呢?一种方法是通过搜狗微信网站搜索目标公众号,可以看到最近的文章,但只是最近的,无法获取历史记录文章 @>。如果你想做一个每日爬虫,你可以用这个方法每天爬取一篇文章。图片是这样的:
3、当然需要的结果还有很多,所以还是得想办法把所有的历史文本都弄出来,废话少说,切入正题:
首先要注册一个微信公众号(订阅号),可以注册个人,比较简单,步骤网上都有,这里就不介绍了。 (如果您之前有过,则无需注册)
注册后,登录微信公众平台,在首页左栏的管理下,有一个素材管理,如图:
点击素材管理,然后选择图文信息,然后点击右侧新建图文素材:
转到新页面并单击顶部的超链接:
然后在弹出的窗口中选择Find文章,输入你要爬取的公众号名称,搜索:
然后点击搜索到的公众号,可以看到它的全部历史记录文章:
4、找到历史记录后文章,我们如何编写一个程序来获取所有的URL地址? , 首先我们来分析一下浏览器在点击公众号名称时做了什么,调出查看页面,点击网络,先清除所有数据,然后点击目标公众号,可以看到如下界面:
点击字符串后,再点击标题:
找到将军。这里的Request Url就是我们的程序需要请求的地址格式。我们需要把它拼接起来。里面的参数在下面的Query String Parameters里面比较清楚:
这些参数的含义很容易理解。唯一需要说明的是,fakeid 是公众号的唯一标识。每个公众号都不一样。如果爬取其他公众号,只需要修改这个参数即可。随机可以省略。
另外一个重要的部分是Request Headers,里面收录了cookie、User-Agent等重要信息,在下面的代码中会用到:
5、 经过以上分析,就可以开始写代码了。
需要的第一个参数:
#目标urlurl = "./cgi-bin/appmsg"#使用cookies,跳过登录操作headers = {"Cookie": "ua_id=YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU=; pgv_pvi=232_5880d9800000; = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39SU7awJMxhDVb4AbVXJM =; mm_lang = zh_CN的 “” 用户代理 “:” 的Mozilla / 5
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}
根据自己的cookie和token进行修改,然后发送请求获取响应,去掉每篇文章的title和url文章,代码如下:
content_list = []for i in range(20): data["begin"] = i*5 time.sleep(3) # 使用get方法提交 content_json = requests.get ( url, headers=headers, params=data).json() # 返回一个json,里面收录content_json["app_msg_list"]中item每页的数据:#提取每页的标题和对应文章@ > url items = [] items.append(item["title"]) items.append(item["link"]) content_list.append(items)
第一个 for 循环是抓取的页面数。首先需要看好公众号文章列表中的总页数。这个数字只能小于页数。更改数据["begin"],表示从前几条开始,每次5条,注意爬取太多和太频繁,否则会被ip和cookies拦截,严重的会被公众号被屏蔽了。
然后按如下方式保存标题和网址:
name=["title","link"]test=pd.DataFrame(columns=name,data=content_list)test.to_csv("XXX.csv",mode="a",encoding="utf-8 ")print("保存成功")
完整的程序如下:
# -*- coding: utf-8 -*-import requestsimport timeimport csvimport pandas as pd# Target urlurl = "./cgi-bin/appmsg"# 使用cookies跳过登录操作 headers = { “曲奇”:“ua_id = YF6RyP41YQa2QyQHAAAAAGXPy_he8M8KkNCUbRx0cVU =; pgv_pvi = 2045358080; pgv_si = s4132856832; UUID = 48da56b488e5c697909a13dfac91a819; bizuin = 3231163757;门票= 5bd41c51e53cfce785e5c188f94240aac8fad8e3; TICKET_ID = gh_d5e73af61440;证书= bVSKoAHHVIldcRZp10_fd7p2aTEXrTi6; noticeLoginFlag = 1; remember_acct = mf1832192%40smail.nju。 ; data_bizuin = 3231163757; data_ticket = XKgzAcTceBFDNN6cFXa4TZAVMlMlxhorD7A0r3vzCDkS ++ pgSpr55NFkQIN3N + / v; slave_sid = bU0yeTNOS2VxcEg5RktUQlZhd2xheVc5bjhoQTVhOHdhMnN2SlVIZGRtU3hvVXJpTWdWakVqcHowd3RuVF9HY19Udm1PbVpQMGVfcnhHVGJQQTVzckpQY042QlZZbnJzel9oam5SdjRFR0tGc0c1eExKQU9ybjgxVnZVZVBtSmVnc29ZcUJWVmNWWEFEaGtk; slave_user = gh_d5e73af61440; XID = 93074c5a87a2e98ddb9e527aa204d0c7; openid2ticket_obaWXwJGb9VV9FiHPMcNq7OZzlzY = lw6SBHGUDQf1lFHqOeShfg39S U7awJMxhDVb4AbVXJM =; mm_lang = zh_CN "," User-Agent ":" Mozilla / 5 .
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",}data = { "token": "1378111188", "lang ": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count ": "5", "query": "", "fakeid": "MzU5MDUzMTk5Nw==", "type": "9",}content_list = []for i in range(20): data[ "begin"] = i*5 time. sleep(3) # 使用get方法提交 content_json = requests.get(url, headers=headers, params=data).json() # 返回一个json,里面是item中的每个页面的数据content_json["app_msg_list"]: # 提取每个页面的标题文章和对应的url items = [] items.
append(item["title"]) 项。追加(项目[“链接”])内容列表。 append(items) print(i)name=["title","link"]test=pd.数据帧(列=名称,数据=内容列表)测试。 to_csv("xingzhengzhifa.csv",mode="a",encoding="utf-8")print("保存成功")
最后保存的文件如图:
获取每个文章的url后,就可以遍历爬取每个文章的内容。爬取文章内容的部分将在下面的博客中介绍。
补充内容:
关于如何从小伙伴那里获取封面图片和摘要的问题,查看浏览器可以看到返回的json数据中收录了很多信息,包括封面图片和摘要
只需要 items.append(item["digest"]) 来保存 文章 摘要。其他字段如发布时间可获取。
关于获取阅读数和点赞数的问题,没有办法通过本题的方法搞定,因为网页上的公众号文章没有数字阅读量和点赞数。这需要电脑版。可以使用抓包工具获取微信或手机版微信。
关于ip代理,统计页数,多次保存,我在公众号文章中介绍过,有需要的可以看看

