
python网页数据抓取
python网页数据抓取(如何使用Python从网页上抓取图像所需的操作?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-13 17:27
你想用Python从网页下载图片吗?在 python 语言语法及其相关库的帮助下,这个过程变得容易。在此页面上停留足够长的时间以了解如何使用 Python 在线抓取图像。
我们正处于数据比以往任何时候都更加重要的时代,未来对数据的追求只会越来越大。事实证明,互联网是最大的数据来源之一。从文本到可下载的文件,包括 Internet 上的图像,都有大量的数据。
互联网上的许多教程都侧重于如何抓取文本,而忽略了有关如何抓取图像和其他可下载文件的指南。不过,这是可以理解的。大多数指南都不是很深入,并且没有多少网络爬虫对捕获图像感兴趣,因为大多数处理文本数据的方法。如果您是少数对抓取图像感兴趣的人之一,那么本指南就是为您编写的。
图像捕获比您想象的要容易
对于许多初学者来说,他们认为图像抓取与常规网页抓取不同。从实际意义上讲,它们实际上是相同的,几乎没有区别。事实上,除了处理大文件的图像,你会发现你所需要的只是网页抓取和文件处理的知识。
如果您还没有链接抓取能力,您的网络抓取技巧将帮助您抓取到图片的链接。有了链接,你只需要向链接发送一个 HTTP 请求来下载图片,然后创建一个文件来写入它。
虽然这很容易,但我知道分步指南将帮助您更好地了解如何完成此操作。为此,我们将开展一个项目——在项目结束时,您将了解从网页抓取图像所需的操作。
项目思路一:从静态站点抓取图片
静态 网站 是一些最容易从 网站 抓取图像的。这是因为当您向请求静态页面的服务器发送 Web 请求时,所有组件都会作为响应返回给您,您需要做的就是获取链接,然后开始向每个链接发送 HTTP 请求。
对于依赖 JavaScript 渲染图片等内容的动态页面,您需要采用其他方式在上面剪切和粘贴图片。
为了向您展示如何从静态页面中抓取图像,我们将研究一个通用的图像抓取工具,它可以抓取静态页面上的所有图像。该脚本接受页面的 URL 作为参数,并将页面上的所有图像下载到脚本文件夹中。
使用 Python 抓取静态页面的要求
Python 使爬行变得非常简单和直接。抓取图片的工具有很多,您必须根据您的用例、目标站点和个人喜好进行选择。对于本指南,您将需要以下内容。
Requests 是一个优雅的用于 HTTP 请求的 Python 库。它被称为人类的 HTTP。作为网络爬虫,“请求”是你应该熟悉的工具之一。虽然您可以使用标准库中收录的 URL 库,但您需要知道 Requests 使许多事情变得容易。
解析是网页抓取的关键方面之一,这可能很困难也很容易,具体取决于页面的结构。使用 BeautifulSoup(Python 的解析库),解析变得容易。
抓取图像需要您知道如何处理文件。有趣的是,我们不需要像 Python Imaging Library (PIL) 这样的特殊库,因为我们所做的只是保存图像。
捕获图像的编码步骤
根据以上要求,就可以开始抓取网页图片了。如果你还没有安装Requests和BeautifulSoup,你需要安装它们,因为它们是第三方库,没有捆绑在Python标准库中。您可以使用 pip 命令安装它们。以下是用于安装这些库的命令。
pip install requests
pip install beautifulsoup4
现在到正确的编码。
第一步是导入所需的库,包括 Requests 和 BeautifulSoup。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
从上面可以看到
urlparse
该库也已导入。这是必要的,因为我们需要从 URL 中解析出域,并将其附加到具有相对 URL 的图像的 URL。
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
查看上面的代码,您会注意到它执行 3 个任务——发送请求、解析 URL 以及将 URL 保存在 links 变量中。您可以将 url 变量更改为您选择的任何 URL。
第三行,使用Requests发送HTTP请求——第4行和第5行,BeautifulSoup用于解析URL。
如果查看循环部分,您会发现只有具有绝对路径 (URL) 的图像才会添加到链接列表中。带有相对 URL 的 URL 需要进一步处理,代码的 else 部分就是用于此目的。进一步处理将域名 URL 添加到相对 URL。
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
上面我们要做的是循环遍历图像 URL 列表并使用请求来下载每个图像的内容。准备好手头的内容,然后为每个文件创建一个JPG文件并将内容写入其中。就这么简单。为了命名,我使用数字来表示每个图像。
这样做是因为脚本是作为一个简单的概念证明编写的。您可以决定为每个图像使用 alt 值——但请记住,某些图像没有任何值,您必须想出一个命名公式。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
# write images to files
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
项目思路2:使用Selenium进行图像捕捉
并非所有站点都是静态站点。许多现代 网站 是交互式的并且具有丰富的 JavaScript。对于这些网站,发送HTTP请求时页面上的所有内容都不会被加载——大量的内容是通过JavaScript事件加载的。
对于这样的站点,request和beautifulsoup是没有用的,因为它们不遵循静态站点方法,而使用request和beautifulsoup。Selenium 是完成这项工作的工具。
Selenium 是一种浏览器自动化工具,最初是为测试 Web 应用程序而开发的,但也有其他用途,包括 Web 抓取和通用 Web 自动化。使用 Selenium,将启动一个真正的浏览器并触发页面和 JavaScript 事件以确保所有内容都可用。我将向您展示如何使用 Selenium 从 Google 抓取图像。
硒要求和设置
为了使 Selenium 正常工作,您必须安装 Selenium 软件包并下载您要使用的特定浏览器的浏览器驱动程序。在本指南中,我们将使用 Chrome。要安装 Selenium,请使用以下代码。
pip install selenium
安装 Selenium 后,如果您的系统上没有安装 Chrome,您可以访问 Chrome 下载页面并安装它。您还需要下载 Chrome 驱动程序。
访问此页面以下载适用于您的 Chrome 浏览器版本的驱动程序。下载的文件是一个收录 chromedriver.exe 文件的 zip 文件。将 chromedriver.exe 文件解压到 selenium 项目文件夹中。在同一文件夹中,放置 cghromedriver.exe 文件并创建一个名为 SeleImage.py 的新 python 文件。
使用 Selenium 捕获图像的编码步骤
我将逐步指导您如何使用 Selenium 和 Python 编写 Google 图片抓取工具
from selenium import webdriver
from selenium.webdriver.chrome.optionsimport Options
webdriver 类是我们将在本指南的 Selenium 包中使用的主要类。Options 类用于设置 webdriver 选项,包括使其在无头模式下运行。
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/")
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
上面的代码对于任何 Python 编码器都是不言自明的。第一行收录我们要下载图像的搜索关键字。在第二个程序中,我们将使用 Chrome 来执行自动化任务。第三行发送对 Google 主页的请求。
使用 element.find_element_by_name,我们可以使用名称属性“q”访问搜索输入元素。使用 send_keys 方法填充关键字,然后我们使用最后一行提交查询。如果你运行代码,你会看到 Chrome 会以自动模式启动,填写查询表单,然后带你到结果页面。
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
上面的代码也是不言自明的。找到第一行的图像搜索链接并单击它以将焦点从所有结果移动到仅图像。第二张图片只找到前两张图片。使用 for 循环下载图像。
import requests
from selenium import webdriver
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/")
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
从网络上抓取图片的合法性
与以往无法判断网络爬虫是否合法,法院裁定支持网络爬虫的合法性,前提是你不是在认证墙后面爬取数据,这违反了任何规则或有损于你的目标 网站 影响。
另一个可能导致非法网络抓取的问题是版权,正如您所知,互联网上的许多图像都已受版权保护。这最终可能会给您带来麻烦。我不是律师,你不应该接受我说的法律建议。我建议您就在互联网上拍摄公共图像的合法性寻求律师的服务。
结论
从上面的内容中,您发现在 Internet 上获取公开可用的图像是多么容易。只要您不处理需要流式传输的大型图像文件,该过程就很简单。
您可能会遇到的另一个问题是反爬技术设置,这使您很难抓取网页数据。您还必须考虑相关的合法性。我建议你在这方面寻求有经验的律师的意见。
Python爬虫
喜欢 (0)
最佳代理
什么是替代数据及其对投资决策的有效性 查看全部
python网页数据抓取(如何使用Python从网页上抓取图像所需的操作?)
你想用Python从网页下载图片吗?在 python 语言语法及其相关库的帮助下,这个过程变得容易。在此页面上停留足够长的时间以了解如何使用 Python 在线抓取图像。
我们正处于数据比以往任何时候都更加重要的时代,未来对数据的追求只会越来越大。事实证明,互联网是最大的数据来源之一。从文本到可下载的文件,包括 Internet 上的图像,都有大量的数据。
互联网上的许多教程都侧重于如何抓取文本,而忽略了有关如何抓取图像和其他可下载文件的指南。不过,这是可以理解的。大多数指南都不是很深入,并且没有多少网络爬虫对捕获图像感兴趣,因为大多数处理文本数据的方法。如果您是少数对抓取图像感兴趣的人之一,那么本指南就是为您编写的。
图像捕获比您想象的要容易
对于许多初学者来说,他们认为图像抓取与常规网页抓取不同。从实际意义上讲,它们实际上是相同的,几乎没有区别。事实上,除了处理大文件的图像,你会发现你所需要的只是网页抓取和文件处理的知识。
如果您还没有链接抓取能力,您的网络抓取技巧将帮助您抓取到图片的链接。有了链接,你只需要向链接发送一个 HTTP 请求来下载图片,然后创建一个文件来写入它。
虽然这很容易,但我知道分步指南将帮助您更好地了解如何完成此操作。为此,我们将开展一个项目——在项目结束时,您将了解从网页抓取图像所需的操作。
项目思路一:从静态站点抓取图片
静态 网站 是一些最容易从 网站 抓取图像的。这是因为当您向请求静态页面的服务器发送 Web 请求时,所有组件都会作为响应返回给您,您需要做的就是获取链接,然后开始向每个链接发送 HTTP 请求。
对于依赖 JavaScript 渲染图片等内容的动态页面,您需要采用其他方式在上面剪切和粘贴图片。
为了向您展示如何从静态页面中抓取图像,我们将研究一个通用的图像抓取工具,它可以抓取静态页面上的所有图像。该脚本接受页面的 URL 作为参数,并将页面上的所有图像下载到脚本文件夹中。
使用 Python 抓取静态页面的要求
Python 使爬行变得非常简单和直接。抓取图片的工具有很多,您必须根据您的用例、目标站点和个人喜好进行选择。对于本指南,您将需要以下内容。
Requests 是一个优雅的用于 HTTP 请求的 Python 库。它被称为人类的 HTTP。作为网络爬虫,“请求”是你应该熟悉的工具之一。虽然您可以使用标准库中收录的 URL 库,但您需要知道 Requests 使许多事情变得容易。
解析是网页抓取的关键方面之一,这可能很困难也很容易,具体取决于页面的结构。使用 BeautifulSoup(Python 的解析库),解析变得容易。
抓取图像需要您知道如何处理文件。有趣的是,我们不需要像 Python Imaging Library (PIL) 这样的特殊库,因为我们所做的只是保存图像。
捕获图像的编码步骤
根据以上要求,就可以开始抓取网页图片了。如果你还没有安装Requests和BeautifulSoup,你需要安装它们,因为它们是第三方库,没有捆绑在Python标准库中。您可以使用 pip 命令安装它们。以下是用于安装这些库的命令。
pip install requests
pip install beautifulsoup4
现在到正确的编码。
第一步是导入所需的库,包括 Requests 和 BeautifulSoup。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
从上面可以看到
urlparse
该库也已导入。这是必要的,因为我们需要从 URL 中解析出域,并将其附加到具有相对 URL 的图像的 URL。
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
查看上面的代码,您会注意到它执行 3 个任务——发送请求、解析 URL 以及将 URL 保存在 links 变量中。您可以将 url 变量更改为您选择的任何 URL。
第三行,使用Requests发送HTTP请求——第4行和第5行,BeautifulSoup用于解析URL。
如果查看循环部分,您会发现只有具有绝对路径 (URL) 的图像才会添加到链接列表中。带有相对 URL 的 URL 需要进一步处理,代码的 else 部分就是用于此目的。进一步处理将域名 URL 添加到相对 URL。
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
上面我们要做的是循环遍历图像 URL 列表并使用请求来下载每个图像的内容。准备好手头的内容,然后为每个文件创建一个JPG文件并将内容写入其中。就这么简单。为了命名,我使用数字来表示每个图像。
这样做是因为脚本是作为一个简单的概念证明编写的。您可以决定为每个图像使用 alt 值——但请记住,某些图像没有任何值,您必须想出一个命名公式。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
# write images to files
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
项目思路2:使用Selenium进行图像捕捉
并非所有站点都是静态站点。许多现代 网站 是交互式的并且具有丰富的 JavaScript。对于这些网站,发送HTTP请求时页面上的所有内容都不会被加载——大量的内容是通过JavaScript事件加载的。
对于这样的站点,request和beautifulsoup是没有用的,因为它们不遵循静态站点方法,而使用request和beautifulsoup。Selenium 是完成这项工作的工具。
Selenium 是一种浏览器自动化工具,最初是为测试 Web 应用程序而开发的,但也有其他用途,包括 Web 抓取和通用 Web 自动化。使用 Selenium,将启动一个真正的浏览器并触发页面和 JavaScript 事件以确保所有内容都可用。我将向您展示如何使用 Selenium 从 Google 抓取图像。
硒要求和设置
为了使 Selenium 正常工作,您必须安装 Selenium 软件包并下载您要使用的特定浏览器的浏览器驱动程序。在本指南中,我们将使用 Chrome。要安装 Selenium,请使用以下代码。
pip install selenium
安装 Selenium 后,如果您的系统上没有安装 Chrome,您可以访问 Chrome 下载页面并安装它。您还需要下载 Chrome 驱动程序。
访问此页面以下载适用于您的 Chrome 浏览器版本的驱动程序。下载的文件是一个收录 chromedriver.exe 文件的 zip 文件。将 chromedriver.exe 文件解压到 selenium 项目文件夹中。在同一文件夹中,放置 cghromedriver.exe 文件并创建一个名为 SeleImage.py 的新 python 文件。
使用 Selenium 捕获图像的编码步骤
我将逐步指导您如何使用 Selenium 和 Python 编写 Google 图片抓取工具
from selenium import webdriver
from selenium.webdriver.chrome.optionsimport Options
webdriver 类是我们将在本指南的 Selenium 包中使用的主要类。Options 类用于设置 webdriver 选项,包括使其在无头模式下运行。
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/";)
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
上面的代码对于任何 Python 编码器都是不言自明的。第一行收录我们要下载图像的搜索关键字。在第二个程序中,我们将使用 Chrome 来执行自动化任务。第三行发送对 Google 主页的请求。
使用 element.find_element_by_name,我们可以使用名称属性“q”访问搜索输入元素。使用 send_keys 方法填充关键字,然后我们使用最后一行提交查询。如果你运行代码,你会看到 Chrome 会以自动模式启动,填写查询表单,然后带你到结果页面。
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
上面的代码也是不言自明的。找到第一行的图像搜索链接并单击它以将焦点从所有结果移动到仅图像。第二张图片只找到前两张图片。使用 for 循环下载图像。
import requests
from selenium import webdriver
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/";)
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
从网络上抓取图片的合法性
与以往无法判断网络爬虫是否合法,法院裁定支持网络爬虫的合法性,前提是你不是在认证墙后面爬取数据,这违反了任何规则或有损于你的目标 网站 影响。
另一个可能导致非法网络抓取的问题是版权,正如您所知,互联网上的许多图像都已受版权保护。这最终可能会给您带来麻烦。我不是律师,你不应该接受我说的法律建议。我建议您就在互联网上拍摄公共图像的合法性寻求律师的服务。
结论
从上面的内容中,您发现在 Internet 上获取公开可用的图像是多么容易。只要您不处理需要流式传输的大型图像文件,该过程就很简单。
您可能会遇到的另一个问题是反爬技术设置,这使您很难抓取网页数据。您还必须考虑相关的合法性。我建议你在这方面寻求有经验的律师的意见。
Python爬虫
喜欢 (0)

最佳代理
什么是替代数据及其对投资决策的有效性
python网页数据抓取(如何通过网页快速收集表格,达到自动化办公的效果?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-12 19:03
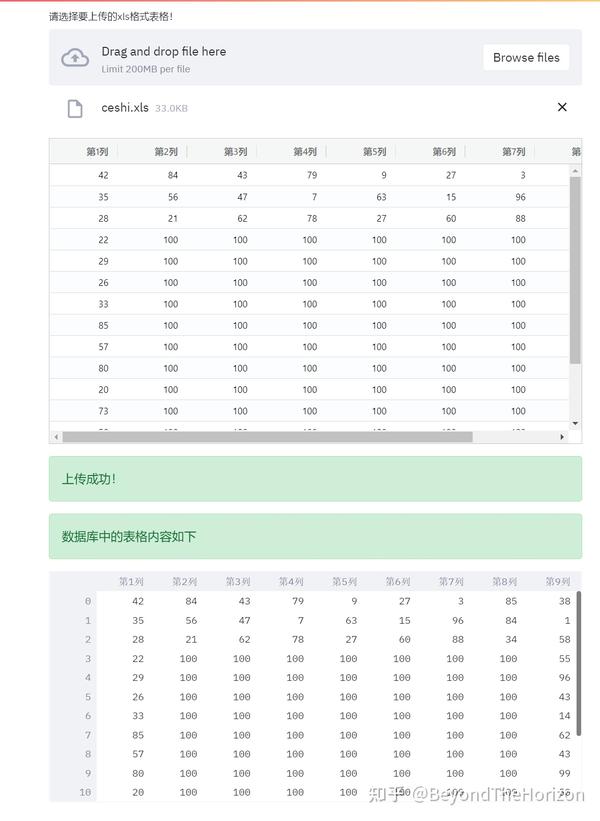
想必很多工作中的朋友都用表格作为整理器采集了一些资料。发送和接收电子邮件需要时间和精力。大家想通过网络上传的表格有什么好办法采集采集吗?羊毛布?
本文即将介绍一种快捷方式,帮助您通过网页快速采集表单,达到自动化办公的效果,让您更快下班!
通过阅读本文,您将学习以下技能:
(1)使用Python搭建自己的交互式网页
(2)掌握python读表的方法(包括pandas的用法)
(3)使用df.to_sql,一行代码将表单上传到数据库
(4) 2种不同的数据连接方式
(5)sql语句怎么写
本文内容分为3部分:
第 1 部分:网页上传组件
第 2 部分:上传到数据库
第三部分:从数据库中拉取数据,验证是否上传成功
效果图如下:
网页效果图
想知道它是如何实现的吗?慢慢听我说
为了实现以上效果图,我们需要安装几个python库
pip install streamlit #构建web网页的基础模块
pip install pandas #读取表格的模块1
pip install xlrd #读取表格的模块2
pip install streamlit-aggrid #在网页中显示表格的模块
pip install pymysql #连接数据库的模块1
pip install sqlalchemy #连接数据库的模块2
在国内如何加快下载模块的速度?
首先打开cmd窗口,复制以下代码回车运行,然后依次执行上面的安装命令
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
本文章介绍的完整代码已经在python3.8.3环境中验证过,可以直接复制使用
程序运行方法:将以下代码保存为:test.py,然后在对应目录打开cmd窗口,输入magic命令:streamlit run test.py,然后输入回车,遇到输入邮箱部分时,只需输入一个地址。是的,然后浏览器会自动打开运行并显示界面的上传部分
# -*- coding: utf-8 -*-
import streamlit as st
from st_aggrid import AgGrid
import pandas as pd
import pymysql
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
uploaded_file = st.file_uploader("请选择要上传的xls格式表格!")
if uploaded_file is not None:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
st.success("上传成功!")
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
else:
st.warning("请上传xls表格!")
以下是代码说明部分:
1.engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
这句话的作用是搭建一个数据库连接引擎,root是数据库用户名,abcde是数据库密码,localhost是数据库地址,如果有固定IP,请用固定IP替换localhost,python是数据库名称,charset=utf8 表示设置 数据库必须支持中文显示
2.uploaded_file = st.file_uploader("请选择要上传的xls格式表!")
这是表单的上传组件,见效果页最上方,标准写法,双引号里面的内容可以改
3. 整个程序是在if---else框架中编写的。当页面检测到用户没有上传表单时,页面底部会显示黄色警告,提醒用户需要上传表单。对应代码:st.warning("请上传xls表单!")
4. 数据表上传到页面的显示部分,使用from st_aggrid import AgGrid语句引入的AgGrid。这个模块可以很方便的将dataframe数据用1行代码转换成表格并显示在网页上
对应程序中的代码为:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
5.如何将pandas读取的dataframe数据上传到指定的python数据库?
使用这段代码:
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
name字段指定上传到数据库后对应表的名称,str(uploaded_file.name).replace(".xls","")可以自动获取用户上传的表名,使用字符串替换去除文件后缀的方法,即使用表名作为数据库中的表名
con 指定数据库连接引擎
if_exists 决定上传方式,这里是replace方法,也就是替换方法。表单上传后,如果数据库中存在相同的内容,则进行替换操作;如果您需要向原创表单添加写入,您可以添加替换替换为附加
6.如何验证表单中的数据是否已经成功上传到数据库?
我们用下面的代码来验证
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
其中db是pymysql模块的数据库连接引擎
sql是标准的sql语句,意思是从上传的表中读取所有数据
游标 = db.cursor()
游标.执行(sql)
mit()
这3句话的作用就是把sql提交给数据执行
df2=pd.read_sql(sql,con=db)的作用是把读取的内容变成dataframe
st.dataframe(df2)的作用是在网页上显示dataframe
本文使用的数据库是 Mariadb。如何搭建自己的Mariadb数据库,请看作者下面的视频
如果想深入了解数据库或者Mysql相关内容,可以购买以下推荐书籍进行学习
如果您有什么不明白的或者更好的想法,欢迎在下方评论区与我互动,谢谢! 查看全部
python网页数据抓取(如何通过网页快速收集表格,达到自动化办公的效果?)
想必很多工作中的朋友都用表格作为整理器采集了一些资料。发送和接收电子邮件需要时间和精力。大家想通过网络上传的表格有什么好办法采集采集吗?羊毛布?
本文即将介绍一种快捷方式,帮助您通过网页快速采集表单,达到自动化办公的效果,让您更快下班!
通过阅读本文,您将学习以下技能:
(1)使用Python搭建自己的交互式网页
(2)掌握python读表的方法(包括pandas的用法)
(3)使用df.to_sql,一行代码将表单上传到数据库
(4) 2种不同的数据连接方式
(5)sql语句怎么写
本文内容分为3部分:
第 1 部分:网页上传组件
第 2 部分:上传到数据库
第三部分:从数据库中拉取数据,验证是否上传成功
效果图如下:
网页效果图
想知道它是如何实现的吗?慢慢听我说
为了实现以上效果图,我们需要安装几个python库
pip install streamlit #构建web网页的基础模块
pip install pandas #读取表格的模块1
pip install xlrd #读取表格的模块2
pip install streamlit-aggrid #在网页中显示表格的模块
pip install pymysql #连接数据库的模块1
pip install sqlalchemy #连接数据库的模块2
在国内如何加快下载模块的速度?
首先打开cmd窗口,复制以下代码回车运行,然后依次执行上面的安装命令
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
本文章介绍的完整代码已经在python3.8.3环境中验证过,可以直接复制使用
程序运行方法:将以下代码保存为:test.py,然后在对应目录打开cmd窗口,输入magic命令:streamlit run test.py,然后输入回车,遇到输入邮箱部分时,只需输入一个地址。是的,然后浏览器会自动打开运行并显示界面的上传部分
# -*- coding: utf-8 -*-
import streamlit as st
from st_aggrid import AgGrid
import pandas as pd
import pymysql
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
uploaded_file = st.file_uploader("请选择要上传的xls格式表格!")
if uploaded_file is not None:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
st.success("上传成功!")
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
else:
st.warning("请上传xls表格!")
以下是代码说明部分:
1.engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
这句话的作用是搭建一个数据库连接引擎,root是数据库用户名,abcde是数据库密码,localhost是数据库地址,如果有固定IP,请用固定IP替换localhost,python是数据库名称,charset=utf8 表示设置 数据库必须支持中文显示
2.uploaded_file = st.file_uploader("请选择要上传的xls格式表!")
这是表单的上传组件,见效果页最上方,标准写法,双引号里面的内容可以改
3. 整个程序是在if---else框架中编写的。当页面检测到用户没有上传表单时,页面底部会显示黄色警告,提醒用户需要上传表单。对应代码:st.warning("请上传xls表单!")
4. 数据表上传到页面的显示部分,使用from st_aggrid import AgGrid语句引入的AgGrid。这个模块可以很方便的将dataframe数据用1行代码转换成表格并显示在网页上
对应程序中的代码为:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
5.如何将pandas读取的dataframe数据上传到指定的python数据库?
使用这段代码:
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
name字段指定上传到数据库后对应表的名称,str(uploaded_file.name).replace(".xls","")可以自动获取用户上传的表名,使用字符串替换去除文件后缀的方法,即使用表名作为数据库中的表名
con 指定数据库连接引擎
if_exists 决定上传方式,这里是replace方法,也就是替换方法。表单上传后,如果数据库中存在相同的内容,则进行替换操作;如果您需要向原创表单添加写入,您可以添加替换替换为附加
6.如何验证表单中的数据是否已经成功上传到数据库?
我们用下面的代码来验证
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
其中db是pymysql模块的数据库连接引擎
sql是标准的sql语句,意思是从上传的表中读取所有数据
游标 = db.cursor()
游标.执行(sql)
mit()
这3句话的作用就是把sql提交给数据执行
df2=pd.read_sql(sql,con=db)的作用是把读取的内容变成dataframe
st.dataframe(df2)的作用是在网页上显示dataframe
本文使用的数据库是 Mariadb。如何搭建自己的Mariadb数据库,请看作者下面的视频
如果想深入了解数据库或者Mysql相关内容,可以购买以下推荐书籍进行学习
如果您有什么不明白的或者更好的想法,欢迎在下方评论区与我互动,谢谢!
python网页数据抓取(前几天遇到一个非计算机行业的同学提了一个怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-12 19:01
一直在关注网络爬虫,看了很多大牛的文章,感觉网络爬虫是学习python的入门技术。就在几天前,我遇到了一位非计算机行业的同学,他询问了从互联网上获取电子邮件信息的问题。我借此机会尝试了python大法。
先分析需求:学生想获取大量的邮箱地址,但是在国内哪里可以获取大量的邮箱地址呢?我首先想到的是贴吧,所以我决定从贴吧那里获取评论。
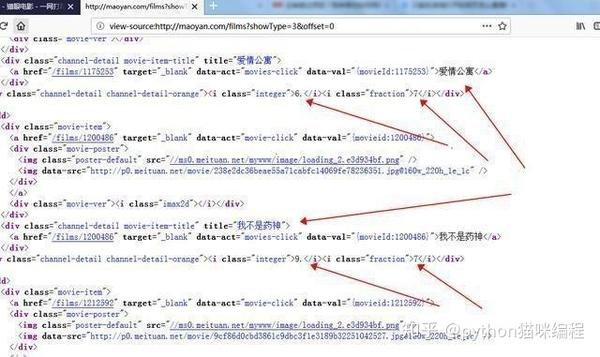
然后,通过观察贴吧的结构,我们可以看出贴吧的整体结构还是比较规则的。因此,决定按照以下顺序跟踪一定级别的采集贴吧信息:
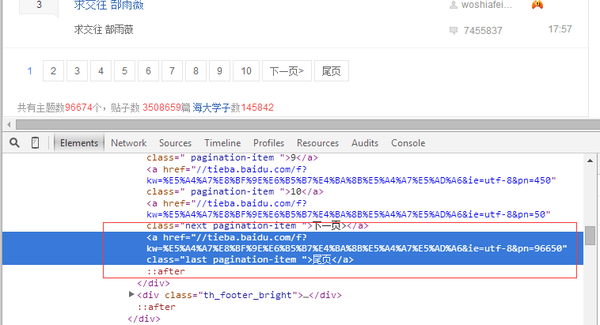
首先从某个贴吧首页抓取所有帖子的贴吧链接信息,抓取每个帖子的详细信息
观察某贴吧的主页。最底层是页面导航栏。从源码中可以看到贴吧的总发帖数。从链接中可以看出贴吧是每50个帖子为一页
下一步就是抢首页,匹配贴吧帖子总数
get_Html_Data() 函数获取网页源代码
#抓取首页 调用get_tie()函数获取帖子个数
def get_Html_Data(self, url):
Ex_value = 1.7
userAgent = headerfile.USER_AGENTS
time.sleep(random.uniform(0.5, 1.6))
if url not in self.closetable:
request = urllib2.Request(url)
request.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8')
request.add_header('User-Agent', random.choice(userAgent))
proxy_handler = urllib2.ProxyHandler(random.choice(self.readIp()))
urllib2.build_opener(proxy_handler)
response = urllib2.urlopen(request,timeout=5)
if response.geturl() == url:
htmlpage = response.read()
self.get_tie(htmlpage)
return htmlpage
else:
return 0
print '获取网页出错'
else:
print '已获取过该网页'
tie_counter() 函数获取帖子总数
#找出该贴吧共有多少页帖子
def tie_counter(self, myPage):
# 匹配 "尾页" 来获取尾页内容
lastpage = re.search(r'class="th_footer_l">(.*?)个', myPage, re.S)
if lastpage:
lastpage = re.search(r'"red_text">(\d+?)', str(lastpage.group(1)), re.S)
if lastpage :
endPage = int(lastpage.group(1))
# endPage = int(lastpage.group(1))
else:
endPage = 0
print u'log:无法计算该帖吧有多少页!'
return endPage
然后遍历贴吧的所有页面
def main_in(self,url):
htmlpage = self.get_Html_Data(url)
self.tie_page_num = self.tie_counter(htmlpage) / 50
url = url + '&ie=utf-8&pn='
for i in range(1, self.tie_page_num):
in_url = url + str(i*50)
self.get_Html_Data(in_url)
self.Write_into_closetable(in_url)
print in_url
使用get_tie()函数在访问每个页面时匹配帖子ID,并组合成帖子链接放在对列
<p> def get_tie(self,htmlpage):
# 朋友过个招?
print '获取网页'
htmlpage = htmlpage.decode('utf-8')#----------------------------------有问题需要修改(UnicodeDecodeError: 'utf8' codec can't decode bytes in position 151173-151174: invalid continuation by)
tie_nums = re.findall(' 查看全部
python网页数据抓取(前几天遇到一个非计算机行业的同学提了一个怎么办?)
一直在关注网络爬虫,看了很多大牛的文章,感觉网络爬虫是学习python的入门技术。就在几天前,我遇到了一位非计算机行业的同学,他询问了从互联网上获取电子邮件信息的问题。我借此机会尝试了python大法。
先分析需求:学生想获取大量的邮箱地址,但是在国内哪里可以获取大量的邮箱地址呢?我首先想到的是贴吧,所以我决定从贴吧那里获取评论。
然后,通过观察贴吧的结构,我们可以看出贴吧的整体结构还是比较规则的。因此,决定按照以下顺序跟踪一定级别的采集贴吧信息:
首先从某个贴吧首页抓取所有帖子的贴吧链接信息,抓取每个帖子的详细信息
观察某贴吧的主页。最底层是页面导航栏。从源码中可以看到贴吧的总发帖数。从链接中可以看出贴吧是每50个帖子为一页
下一步就是抢首页,匹配贴吧帖子总数
get_Html_Data() 函数获取网页源代码
#抓取首页 调用get_tie()函数获取帖子个数
def get_Html_Data(self, url):
Ex_value = 1.7
userAgent = headerfile.USER_AGENTS
time.sleep(random.uniform(0.5, 1.6))
if url not in self.closetable:
request = urllib2.Request(url)
request.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8')
request.add_header('User-Agent', random.choice(userAgent))
proxy_handler = urllib2.ProxyHandler(random.choice(self.readIp()))
urllib2.build_opener(proxy_handler)
response = urllib2.urlopen(request,timeout=5)
if response.geturl() == url:
htmlpage = response.read()
self.get_tie(htmlpage)
return htmlpage
else:
return 0
print '获取网页出错'
else:
print '已获取过该网页'
tie_counter() 函数获取帖子总数
#找出该贴吧共有多少页帖子
def tie_counter(self, myPage):
# 匹配 "尾页" 来获取尾页内容
lastpage = re.search(r'class="th_footer_l">(.*?)个', myPage, re.S)
if lastpage:
lastpage = re.search(r'"red_text">(\d+?)', str(lastpage.group(1)), re.S)
if lastpage :
endPage = int(lastpage.group(1))
# endPage = int(lastpage.group(1))
else:
endPage = 0
print u'log:无法计算该帖吧有多少页!'
return endPage
然后遍历贴吧的所有页面
def main_in(self,url):
htmlpage = self.get_Html_Data(url)
self.tie_page_num = self.tie_counter(htmlpage) / 50
url = url + '&ie=utf-8&pn='
for i in range(1, self.tie_page_num):
in_url = url + str(i*50)
self.get_Html_Data(in_url)
self.Write_into_closetable(in_url)
print in_url
使用get_tie()函数在访问每个页面时匹配帖子ID,并组合成帖子链接放在对列
<p> def get_tie(self,htmlpage):
# 朋友过个招?
print '获取网页'
htmlpage = htmlpage.decode('utf-8')#----------------------------------有问题需要修改(UnicodeDecodeError: 'utf8' codec can't decode bytes in position 151173-151174: invalid continuation by)
tie_nums = re.findall('
python网页数据抓取(博客pythonselenium循环选择python3seleniumActionChains用法及Alert对话框处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-12 18:25
项目介绍
这个项目是为一些复杂的报表解析和爬取列表数据。以国网为例(最好改成网站),它会根据数据库自动配置文本(数据库是字典),继续
点击树状结构,然后在下拉框中输入时间,选择省(时间和省由配置文件配置),但是下拉列表的xpath没有数据库化,在这个阶段的代码中是硬编码的。
项目开始通过递归判断是否是最后一层。字典表可以配置N个级别,这取决于你的网站复杂度
加入QQ群:943841699
源码地址:复生若梦/table_creeper
技术
Python3.6
selenium(如果你不了解selenium,可以参考博客
python selenium 选择器循环选择
python3 selenium ActionChains 使用
python3 selenium Select用法和Alert对话框处理
)
本项目使用谷歌浏览器内核,需要安装谷歌及配套驱动
参考:selenium打开chrome时出错-五道十魂的博客-CSDN博客
而且linux没有接口,需要配置无接口方式爬取
参考:linux selenium chrome chromedriver及无浏览器界面的运行方式
使用说明
1.复制资源文件下的SQL并导入数据库
2. 配置 config.py
3.根据技术目录指南完成安装
4.现阶段只有一张表,class_type为类型,如果类型不同网站,class_type不同,
group_code为分组码,按照00000000,每一位代表不同的含义,对应自己库中的分类。 查看全部
python网页数据抓取(博客pythonselenium循环选择python3seleniumActionChains用法及Alert对话框处理)
项目介绍
这个项目是为一些复杂的报表解析和爬取列表数据。以国网为例(最好改成网站),它会根据数据库自动配置文本(数据库是字典),继续
点击树状结构,然后在下拉框中输入时间,选择省(时间和省由配置文件配置),但是下拉列表的xpath没有数据库化,在这个阶段的代码中是硬编码的。
项目开始通过递归判断是否是最后一层。字典表可以配置N个级别,这取决于你的网站复杂度
加入QQ群:943841699
源码地址:复生若梦/table_creeper
技术
Python3.6
selenium(如果你不了解selenium,可以参考博客
python selenium 选择器循环选择
python3 selenium ActionChains 使用
python3 selenium Select用法和Alert对话框处理
)
本项目使用谷歌浏览器内核,需要安装谷歌及配套驱动
参考:selenium打开chrome时出错-五道十魂的博客-CSDN博客
而且linux没有接口,需要配置无接口方式爬取
参考:linux selenium chrome chromedriver及无浏览器界面的运行方式
使用说明
1.复制资源文件下的SQL并导入数据库
2. 配置 config.py
3.根据技术目录指南完成安装
4.现阶段只有一张表,class_type为类型,如果类型不同网站,class_type不同,
group_code为分组码,按照00000000,每一位代表不同的含义,对应自己库中的分类。
python网页数据抓取(python网页数据怎么用解决一些其他问题的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-12 14:01
python网页数据抓取根据知乎上各位大神的意见,后面又爬了多次。有的是电脑配置跟不上,后面有一次的配置是网速没问题,但是获取的数据较少,这次是和爬虫没有关系,就是看下能不能爬虫解决一些其他的问题。首先是先处理下数据库,python用sqlalchemy吧(网上有很多教程可以查,这里主要是写个python环境)。
然后就是写爬虫吧。这里用的是python最火的scrapy,因为初学者比较好学。网上有许多教程可以查,个人比较喜欢看这里。另外个人使用最多的是scrapy,比较简单。django也可以用,但是前提你了解scrapy后,弄懂流程,弄不懂还是要学scrapy。实际上网上找了半天有一些教程说scrapy实际上配置较麻烦。
可以先从scrapy学起。最主要的就是request的处理,学习了selenium就觉得不难。学python网络方面,学会怎么用网络api,基本也没有太大问题。比如爬下b站的视频就好。python没有解释器,虽然能用ide。比如用pycharm写写脚本比vim友好。网上找了点学习教程,比如webdriver,webdriver教程,一句话讲django使用方法,讲解的还是不够详细。
个人觉得,学习需要同时学习两种技术,比如ui交互,比如网络数据转发。然后研究什么后台交互数据,一般而言github或者segmentfault的提问,都是有价值的。现在也用django后台把b站的视频放在网站上,尽管没有放全(都不知道放哪里),以后会再分享一个教程,主要是学习models的使用,最后会简单写爬虫。最后记得复习下java的面向对象,还有c的继承。最后,祝学习愉快~。 查看全部
python网页数据抓取(python网页数据怎么用解决一些其他问题的问题?)
python网页数据抓取根据知乎上各位大神的意见,后面又爬了多次。有的是电脑配置跟不上,后面有一次的配置是网速没问题,但是获取的数据较少,这次是和爬虫没有关系,就是看下能不能爬虫解决一些其他的问题。首先是先处理下数据库,python用sqlalchemy吧(网上有很多教程可以查,这里主要是写个python环境)。
然后就是写爬虫吧。这里用的是python最火的scrapy,因为初学者比较好学。网上有许多教程可以查,个人比较喜欢看这里。另外个人使用最多的是scrapy,比较简单。django也可以用,但是前提你了解scrapy后,弄懂流程,弄不懂还是要学scrapy。实际上网上找了半天有一些教程说scrapy实际上配置较麻烦。
可以先从scrapy学起。最主要的就是request的处理,学习了selenium就觉得不难。学python网络方面,学会怎么用网络api,基本也没有太大问题。比如爬下b站的视频就好。python没有解释器,虽然能用ide。比如用pycharm写写脚本比vim友好。网上找了点学习教程,比如webdriver,webdriver教程,一句话讲django使用方法,讲解的还是不够详细。
个人觉得,学习需要同时学习两种技术,比如ui交互,比如网络数据转发。然后研究什么后台交互数据,一般而言github或者segmentfault的提问,都是有价值的。现在也用django后台把b站的视频放在网站上,尽管没有放全(都不知道放哪里),以后会再分享一个教程,主要是学习models的使用,最后会简单写爬虫。最后记得复习下java的面向对象,还有c的继承。最后,祝学习愉快~。
python网页数据抓取(python网页数据抓取爬虫专题课-优达学城-python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-11 04:03
python网页数据抓取爬虫专题课-优达学城-python爱好者社区点击上面链接进入这个网站,就能直接观看了,全是视频,去年十一月的,过时不少,实在无聊,我又看了两遍,发现有些思路挺有意思的,找了些资料,发到了专栏里。我不是专业做这个行业的,只是python在读研究生,非科班,直接从最简单的爬虫抓取开始吧。
定位先说说自己的定位,预计学习时间两周,只是抓取一些商品销量数据,期待能在某一点入手。同一个页面,可以针对一个选项进行抓取,只要抓取抓到位置就可以,抓取方便,就是花的时间略多。背景一样,但需要进行相应的处理和拆分工作,对比下页面两个定位结果。先点击亚马逊,找到一个页面:我们看到,因为没有登录等其他操作,页面只有一个商品的销量,其他都没有,这里的商品销量,就是指销量。然后我们去不同的网站去抓取销量数据,一下子就抓了各省的销量数据:可以看到,分别抓取到销量最大的2。
0、2
3、3
4、4
5、4
6、4
7、5
7、6
2、6
1、6
8、6
6、6
8、68。这个抓取就有点类似于springmvc抓取框架的方式了,只要获取到网页最后20个元素,然后判断其数量,就能知道到底该抓取哪个位置。毕竟,销量都存在于前十个元素中,那前十个都在哪里呢?我知道,这个问题还是有点难的,那就直接在找几个点,同样是抓取销量前十个数据吧。
这个定位比前面的网站稍微差了点,
1、
3、
5、
7、
9、1
0、12,
7、9这些数据。比这个稍微好点的是我们还抓取到了自定义地区这个点,其他定位是抓取1到10,但有时候自定义地区不一定就能得到所有的销量数据。那最后一步就是继续从这个点进行延伸和扩展了,我们继续扩展看看:抓取销量前十的省份我又抓取了销量前十的城市:剩下的省份和城市就不是我擅长的范围了,我还会更专注于抓取销量前十的省份。
这时候,新的问题来了,继续手工去手动调节每个省份的销量数量,效率太低了,我们还需要手动去分析一下每个城市的销量数量:我能选择不同城市的商品销量数据,那么只要用不同城市,就能同时抓取数据,因为同一个商品是可以存放多个地区的销量数据的,就像下面这个动图这样:拿一个城市的某个商品存放多个地区就行了,其他地区的不要了,实现起来也很简单,就算有一些跨国,我们可以一个城市一个城市来抓,这样就不会丢失销量数据了。
我随便抓了一个德国的销量,然后从德国省份,抓取到了全国的销量数据,这样还是比较方便的,实际上跨国抓取数据都是可以这。 查看全部
python网页数据抓取(python网页数据抓取爬虫专题课-优达学城-python)
python网页数据抓取爬虫专题课-优达学城-python爱好者社区点击上面链接进入这个网站,就能直接观看了,全是视频,去年十一月的,过时不少,实在无聊,我又看了两遍,发现有些思路挺有意思的,找了些资料,发到了专栏里。我不是专业做这个行业的,只是python在读研究生,非科班,直接从最简单的爬虫抓取开始吧。
定位先说说自己的定位,预计学习时间两周,只是抓取一些商品销量数据,期待能在某一点入手。同一个页面,可以针对一个选项进行抓取,只要抓取抓到位置就可以,抓取方便,就是花的时间略多。背景一样,但需要进行相应的处理和拆分工作,对比下页面两个定位结果。先点击亚马逊,找到一个页面:我们看到,因为没有登录等其他操作,页面只有一个商品的销量,其他都没有,这里的商品销量,就是指销量。然后我们去不同的网站去抓取销量数据,一下子就抓了各省的销量数据:可以看到,分别抓取到销量最大的2。
0、2
3、3
4、4
5、4
6、4
7、5
7、6
2、6
1、6
8、6
6、6
8、68。这个抓取就有点类似于springmvc抓取框架的方式了,只要获取到网页最后20个元素,然后判断其数量,就能知道到底该抓取哪个位置。毕竟,销量都存在于前十个元素中,那前十个都在哪里呢?我知道,这个问题还是有点难的,那就直接在找几个点,同样是抓取销量前十个数据吧。
这个定位比前面的网站稍微差了点,
1、
3、
5、
7、
9、1
0、12,
7、9这些数据。比这个稍微好点的是我们还抓取到了自定义地区这个点,其他定位是抓取1到10,但有时候自定义地区不一定就能得到所有的销量数据。那最后一步就是继续从这个点进行延伸和扩展了,我们继续扩展看看:抓取销量前十的省份我又抓取了销量前十的城市:剩下的省份和城市就不是我擅长的范围了,我还会更专注于抓取销量前十的省份。
这时候,新的问题来了,继续手工去手动调节每个省份的销量数量,效率太低了,我们还需要手动去分析一下每个城市的销量数量:我能选择不同城市的商品销量数据,那么只要用不同城市,就能同时抓取数据,因为同一个商品是可以存放多个地区的销量数据的,就像下面这个动图这样:拿一个城市的某个商品存放多个地区就行了,其他地区的不要了,实现起来也很简单,就算有一些跨国,我们可以一个城市一个城市来抓,这样就不会丢失销量数据了。
我随便抓了一个德国的销量,然后从德国省份,抓取到了全国的销量数据,这样还是比较方便的,实际上跨国抓取数据都是可以这。
python网页数据抓取(一下如何判断网页的编码:网上很多网页编码格式都不一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-09 16:11
在Web开发过程中,我们经常会遇到网页爬取和分析,可以用各种语言来完成。喜欢用python来实现,因为python提供了很多成熟的模块,可以轻松实现网页爬取。
但是在爬取的过程中会遇到编码问题,所以今天我们来看看如何判断一个网页的编码:
互联网上很多网页都有不同的编码格式,一般是GBK、GB2312、UTF-8等。
我们在获取到网页的数据后,首先要判断网页的编码,然后才能将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
使用 chardet 模块
1 #如果你的python没有安装chardet模块,你需要首先安装一下chardet判断编码的模块哦
2 #author:pythontab.com
3 import chardet
4 import urllib
5 #先获取网页内容
6 data1 = urllib.urlopen(‘http://www.baidu.com‘).read()
7 #用chardet进行内容分析
8 chardit1 = chardet.detect(data1)
9
10 print chardit1[‘encoding‘] # baidu
实施结果如下:
gb2312
这个结果是正确的。可以自己验证~~ 查看全部
python网页数据抓取(一下如何判断网页的编码:网上很多网页编码格式都不一样)
在Web开发过程中,我们经常会遇到网页爬取和分析,可以用各种语言来完成。喜欢用python来实现,因为python提供了很多成熟的模块,可以轻松实现网页爬取。
但是在爬取的过程中会遇到编码问题,所以今天我们来看看如何判断一个网页的编码:
互联网上很多网页都有不同的编码格式,一般是GBK、GB2312、UTF-8等。
我们在获取到网页的数据后,首先要判断网页的编码,然后才能将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
使用 chardet 模块
1 #如果你的python没有安装chardet模块,你需要首先安装一下chardet判断编码的模块哦
2 #author:pythontab.com
3 import chardet
4 import urllib
5 #先获取网页内容
6 data1 = urllib.urlopen(‘http://www.baidu.com‘).read()
7 #用chardet进行内容分析
8 chardit1 = chardet.detect(data1)
9
10 print chardit1[‘encoding‘] # baidu
实施结果如下:
gb2312
这个结果是正确的。可以自己验证~~
python网页数据抓取(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-08 05:02
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态生成的图片我说的网页。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src时,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request里面加上上面的header中的信息,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节url,并根据章节url获取该章节的总页数,并获取每个页面的url,参考资料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
python网页数据抓取(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态生成的图片我说的网页。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src时,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人

接受语言zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request里面加上上面的header中的信息,经过测试,只需要添加Referer

信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节url,并根据章节url获取该章节的总页数,并获取每个页面的url,参考资料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
python网页数据抓取(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-08 03:12
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登录网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">【组织】关于抓取网页,分析网页内容,模拟登录逻辑/流程及注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录的内部逻辑流程网站(百度首页)
"target="_top">【教程】如何使用IE9的F12分析网站登录过程中复杂的(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">[完成]关于使用正则表达式处理html代码的建议 查看全部
python网页数据抓取(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登录网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">【组织】关于抓取网页,分析网页内容,模拟登录逻辑/流程及注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录的内部逻辑流程网站(百度首页)
"target="_top">【教程】如何使用IE9的F12分析网站登录过程中复杂的(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">[完成]关于使用正则表达式处理html代码的建议
python网页数据抓取( 有些函数动态加载网页数据的安装方法-有些网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-08 03:10
有些函数动态加载网页数据的安装方法-有些网页
)
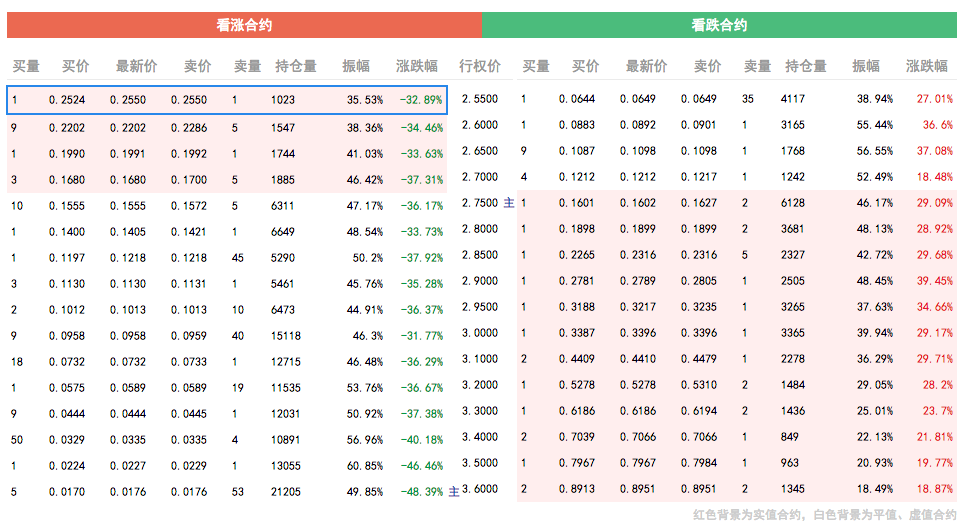
有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装Node.js后通过Node.js安装PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar 查看全部
python网页数据抓取(
有些函数动态加载网页数据的安装方法-有些网页
)

有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装Node.js后通过Node.js安装PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-07 05:27
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
我刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习qun:227-435-450即可获取,内附:开发工具和安装包,以及系统学习路线图
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
查看全部
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
我刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习qun:227-435-450即可获取,内附:开发工具和安装包,以及系统学习路线图
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
python网页数据抓取(一下怎么一步一步写爬虫(headers)数据过程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-05 00:20
最近经常有人在看教程的时候问我写爬虫好不好,但是一上手,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
request用于请求网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .
分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
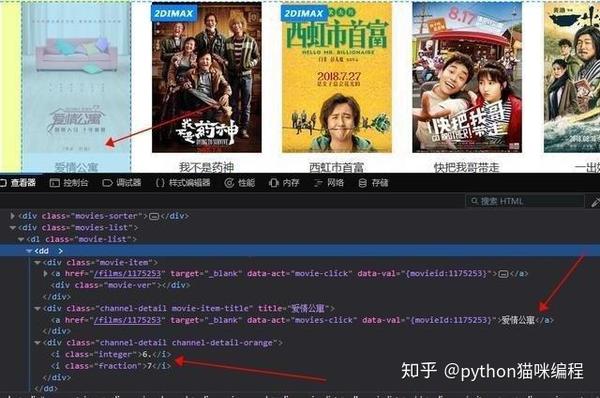
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候一定要注意!
所以,现在整体思路很清晰了:请求一个网页==>>获取html源代码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,所以那你就可以把所有的内容都抓到了!我们把代码写在外面。
开始编写爬虫
先导入2个库,然后用一行代码得到网页html,打印出来看看效果
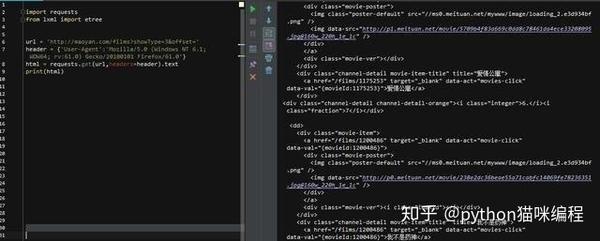
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到如下所示的请求Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。关于如何快速学习Python,可以添加编辑器的Python学习群:699+749+852。不管你是新手还是大牛,小编都欢迎。不时分享干货。欢迎初学者和高级学生。伙伴。每天晚上20:00会有直播,与大家分享Python知识和路由方法。
注意在火狐浏览器中,如果头部数据很长,会被缩写。看到上图中间的省略号了...所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
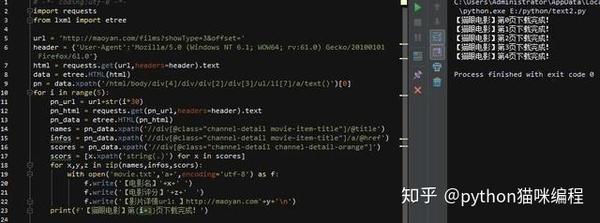
这一次,html被正确打印了!(后面的.text是获取html文本,不添加会返回获取是否成功的提示,不是html源码),我们先搭建页码循环,找到html翻页代码
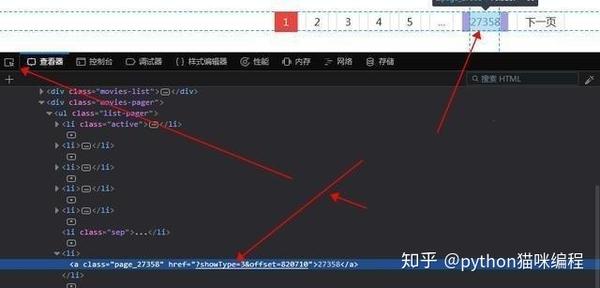
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
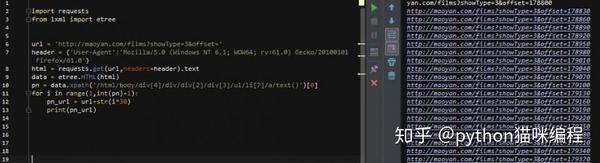
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
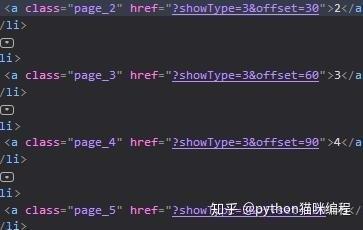
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
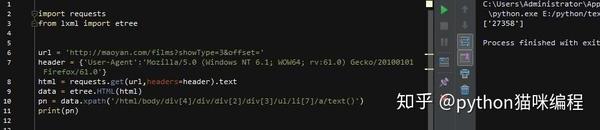
然后开始匹配。这次我们只展示了电影名称、评分和详情网址这3个结果
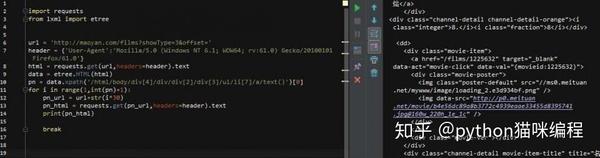
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也是里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行获取class属性为“channel-detail movie-item-title”的div标签下的title值和div下a标签的href值(这里没有复制)xpath路径,当然可以的话,我建议你用这个方法,因为如果你用路径,如果修改了网页的结构,那么我们的代码就会被重写。。 .)
第17、18、2行代码获取div标签下的所有文本内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
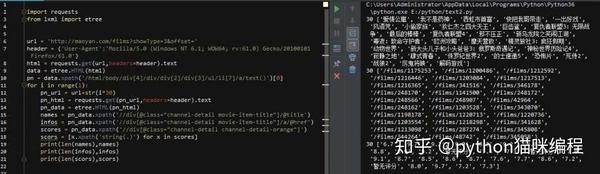
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我会抓住前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不良影响,这是基本要求!后面还有这个网站,大概100多页以后,需要登录,这点请注意,可以自己试试! 查看全部
python网页数据抓取(一下怎么一步一步写爬虫(headers)数据过程(图))
最近经常有人在看教程的时候问我写爬虫好不好,但是一上手,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
request用于请求网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .

分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候一定要注意!
所以,现在整体思路很清晰了:请求一个网页==>>获取html源代码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,所以那你就可以把所有的内容都抓到了!我们把代码写在外面。
开始编写爬虫
先导入2个库,然后用一行代码得到网页html,打印出来看看效果
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到如下所示的请求Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。关于如何快速学习Python,可以添加编辑器的Python学习群:699+749+852。不管你是新手还是大牛,小编都欢迎。不时分享干货。欢迎初学者和高级学生。伙伴。每天晚上20:00会有直播,与大家分享Python知识和路由方法。
注意在火狐浏览器中,如果头部数据很长,会被缩写。看到上图中间的省略号了...所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加会返回获取是否成功的提示,不是html源码),我们先搭建页码循环,找到html翻页代码
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配。这次我们只展示了电影名称、评分和详情网址这3个结果
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也是里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行获取class属性为“channel-detail movie-item-title”的div标签下的title值和div下a标签的href值(这里没有复制)xpath路径,当然可以的话,我建议你用这个方法,因为如果你用路径,如果修改了网页的结构,那么我们的代码就会被重写。。 .)
第17、18、2行代码获取div标签下的所有文本内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我会抓住前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不良影响,这是基本要求!后面还有这个网站,大概100多页以后,需要登录,这点请注意,可以自己试试!
python网页数据抓取(Python并发编程教程(二):线程的具体使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2021-12-04 09:13
)
网络爬虫程序是一个IO密集型程序。程序涉及到大量的网络IO和本地磁盘IO操作,会消耗大量的时间,从而降低程序的执行效率,而Python提供的多线程可以在一定程度上提高它的执行效率IO 密集型程序。
如果想学习Python多进程、多线程和Python GIL全局解释器锁相关知识,可以参考《Python并发编程教程》。
多线程使用流程 Python提供了两个支持多线程的模块,分别是_thread和threading。其中,_thread 模块处于最底层。与threading模块相比,它的功能有限,所以推荐大家使用threading模块。Threading不仅收录了_thread模块中的所有方法,还提供了一些其他的方法,如下图:
线程的具体用法如下:
from threading import Thread
#线程创建、启动、回收
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
创建多线程的具体过程:
t_list = []
for i in range(5):
t = Thread(target=函数名)
t_list.append(t)
t.start()
for t in t_list:
t.join()
除了使用这个模块,还可以使用Thread线程类来创建多个线程。
在处理线程的过程中,要时刻注意线程的同步,即多个线程不能操作同一个数据,否则会造成数据的不确定性。数据的正确性可以通过线程模块的Lock对象来保证。
例如,如果您使用多个线程将捕获的数据写入磁盘文件,则必须锁定执行写入操作的线程,以防止写入的数据被覆盖。当线程执行完写操作后,会主动释放锁,并继续让其他线程获取锁,如此循环直到所有写操作完成。具体方法如下:
from threading import Lock
lock = Lock()
# 获取锁
lock.acquire()
wirter.writerows("线程锁问题解决")
# 释放锁
lock.release()
Python多线程的队列队列模型,由于GIL全局解释器锁的存在,只允许一个线程同时占用解释器执行程序。当这个线程遇到IO操作时,会主动放弃解释器,让其他处于等待状态的线程获取解释器来执行程序,线程回到等待状态,主要通过线程调度来实现机制。
基于以上原因,我们需要构建一个多线程的数据共享模型,让所有线程都可以从模型中获取数据。队列(先进先出)模块提供了创建共享数据的队列模型。例如,将所有要爬取的URL地址放入一个队列中,每个线程都去这个队列中提取URL。queue模块的具体用法如下:
# 导入模块
from queue import Queue
q = Queue() #创界队列对象
q.put(url) 向队列中添加爬取一个url链接
q.get() # 获取一个url,当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
在多线程爬虫的情况下,下面的多线程方法用于抓取()中的应用类别列,所有类别下的APP名称,下载详情页的类别和URL。如下所示:
图 1:小米应用商店
抓到的数据demo如下:
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
1) 案例分析 通过关键字搜索,我们知道这是一个动态的网站,所以需要进行抓包分析。
刷新网页重新加载数据,可以知道请求头的URL地址,如下图:
https://app.mi.com/categotyAll ... %3D30
查询参数pageSize参数值不变,页面会随着页码的增加而变化,可以通过查看页面元素来查看categoryId,如下图
游戏
实用工具
影音视听
聊天社交
图书阅读
学习教育
效率办公
时尚购物
居家生活
旅行交通
摄影摄像
医疗健康
体育运动
新闻资讯
娱乐消遣
金融理财
因此,您可以使用 Xpath 表达式匹配 href 属性来提取类别 ID 和类别名称。表达式如下:
点击开发者工具的响应选项卡,查看响应数据,如下图:
{
count: 2000,
data: [
{
appId: 1348407,
displayName: "天气暖暖-关心Ta从关心天气开始",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.xiaowoniu.WarmWeather"
},
{
appId: 1348403,
displayName: "贵斌同城",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.gbtc.guibintongcheng"
},
...
...
通过上面的响应内容,我们可以提取出APP总数(count)和APP(displayName)名称,以及下载详情页的packageName。由于每个页面收录 30 个 APP,因此可以使用总数(计数)来计算每个类别中有多少个页面。
pages = int(count) // 30 + 1
下载详情页地址使用packageName拼接,如下图:
link = 'http://app.mi.com/details?id=' + app['packageName']
2) 完整程序完整程序如下:
# -*- coding:utf8 -*-
import requests
from threading import Thread
from queue import Queue
import time
from fake_useragent import UserAgent
from lxml import etree
import csv
from threading import Lock
import json
class XiaomiSpider(object):
def __init__(self):
self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'
# 存放所有URL地址的队列
self.q = Queue()
self.i = 0
# 存放所有类型id的空列表
self.id_list = []
# 打开文件
self.f = open('XiaomiShangcheng.csv','a',encoding='utf-8')
self.writer = csv.writer(self.f)
# 创建锁
self.lock = Lock()
def get_cateid(self):
# 请求
url = 'http://app.mi.com/'
headers = { 'User-Agent': UserAgent().random}
html = requests.get(url=url,headers=headers).text
# 解析
parse_html = etree.HTML(html)
xpath_bds = '//ul[@class="category-list"]/li'
li_list = parse_html.xpath(xpath_bds)
for li in li_list:
typ_name = li.xpath('./a/text()')[0]
typ_id = li.xpath('./a/@href')[0].split('/')[-1]
# 计算每个类型的页数
pages = self.get_pages(typ_id)
#往列表中添加二元组
self.id_list.append( (typ_id,pages) )
# 入队列
self.url_in()
# 获取count的值并计算页数
def get_pages(self,typ_id):
# 获取count的值,即app总数
url = self.url.format(0,typ_id)
html = requests.get(
url=url,
headers={'User-Agent':UserAgent().random}
).json()
count = html['count']
pages = int(count) // 30 + 1
return pages
# url入队函数,拼接url,并将url加入队列
def url_in(self):
for id in self.id_list:
# id格式:('4',pages)
for page in range(1,id[1]+1):
url = self.url.format(page,id[0])
# 把URL地址入队列
self.q.put(url)
# 线程事件函数: get() -请求-解析-处理数据,三步骤
def get_data(self):
while True:
# 判断队列不为空则执行,否则终止
if not self.q.empty():
url = self.q.get()
headers = {'User-Agent':UserAgent().random}
html = requests.get(url=url,headers=headers)
res_html = html.content.decode(encoding='utf-8')
html=json.loads(res_html)
self.parse_html(html)
else:
break
# 解析函数
def parse_html(self,html):
# 写入到csv文件
app_list = []
for app in html['data']:
# app名称 + 分类 + 详情链接
name = app['displayName']
link = 'http://app.mi.com/details?id=' + app['packageName']
typ_name = app['level1CategoryName']
# 把每一条数据放到app_list中,并通过writerows()实现多行写入
app_list.append([name,typ_name,link])
print(name,typ_name)
self.i += 1
# 向CSV文件中写入数据
self.lock.acquire()
self.writer.writerows(app_list)
self.lock.release()
# 入口函数
def main(self):
# URL入队列
self.get_cateid()
t_list = []
# 创建多线程
for i in range(1):
t = Thread(target=self.get_data)
t_list.append(t)
# 启动线程
t.start()
for t in t_list:
# 回收线程
t.join()
self.f.close()
print('数量:',self.i)
if __name__ == '__main__':
start = time.time()
spider = XiaomiSpider()
spider.main()
end = time.time()
print('执行时间:%.1f' % (end-start))
运行上述程序后,打开存储文件,其内容如下:
在我们之间-单机版,休闲创意,http://app.mi.com/details%3Fid ... r.gtx
粉末游戏,模拟经营,http://app.mi.com/details%3Fid ... r.bnn
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
腾讯欢乐麻将全集,棋牌桌游,http://app.mi.com/details?id=com.qqgame.happymj
快游戏,休闲创意,http://app.mi.com/details%3Fid ... h2mgc
皇室战争,战争策略,http://app.mi.com/details%3Fid ... le.mi
地铁跑酷,跑酷闯关,http://app.mi.com/details?id=com.kiloo.subwaysurf
...
... 查看全部
python网页数据抓取(Python并发编程教程(二):线程的具体使用方法
)
网络爬虫程序是一个IO密集型程序。程序涉及到大量的网络IO和本地磁盘IO操作,会消耗大量的时间,从而降低程序的执行效率,而Python提供的多线程可以在一定程度上提高它的执行效率IO 密集型程序。
如果想学习Python多进程、多线程和Python GIL全局解释器锁相关知识,可以参考《Python并发编程教程》。
多线程使用流程 Python提供了两个支持多线程的模块,分别是_thread和threading。其中,_thread 模块处于最底层。与threading模块相比,它的功能有限,所以推荐大家使用threading模块。Threading不仅收录了_thread模块中的所有方法,还提供了一些其他的方法,如下图:
线程的具体用法如下:
from threading import Thread
#线程创建、启动、回收
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
创建多线程的具体过程:
t_list = []
for i in range(5):
t = Thread(target=函数名)
t_list.append(t)
t.start()
for t in t_list:
t.join()
除了使用这个模块,还可以使用Thread线程类来创建多个线程。
在处理线程的过程中,要时刻注意线程的同步,即多个线程不能操作同一个数据,否则会造成数据的不确定性。数据的正确性可以通过线程模块的Lock对象来保证。
例如,如果您使用多个线程将捕获的数据写入磁盘文件,则必须锁定执行写入操作的线程,以防止写入的数据被覆盖。当线程执行完写操作后,会主动释放锁,并继续让其他线程获取锁,如此循环直到所有写操作完成。具体方法如下:
from threading import Lock
lock = Lock()
# 获取锁
lock.acquire()
wirter.writerows("线程锁问题解决")
# 释放锁
lock.release()
Python多线程的队列队列模型,由于GIL全局解释器锁的存在,只允许一个线程同时占用解释器执行程序。当这个线程遇到IO操作时,会主动放弃解释器,让其他处于等待状态的线程获取解释器来执行程序,线程回到等待状态,主要通过线程调度来实现机制。
基于以上原因,我们需要构建一个多线程的数据共享模型,让所有线程都可以从模型中获取数据。队列(先进先出)模块提供了创建共享数据的队列模型。例如,将所有要爬取的URL地址放入一个队列中,每个线程都去这个队列中提取URL。queue模块的具体用法如下:
# 导入模块
from queue import Queue
q = Queue() #创界队列对象
q.put(url) 向队列中添加爬取一个url链接
q.get() # 获取一个url,当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
在多线程爬虫的情况下,下面的多线程方法用于抓取()中的应用类别列,所有类别下的APP名称,下载详情页的类别和URL。如下所示:
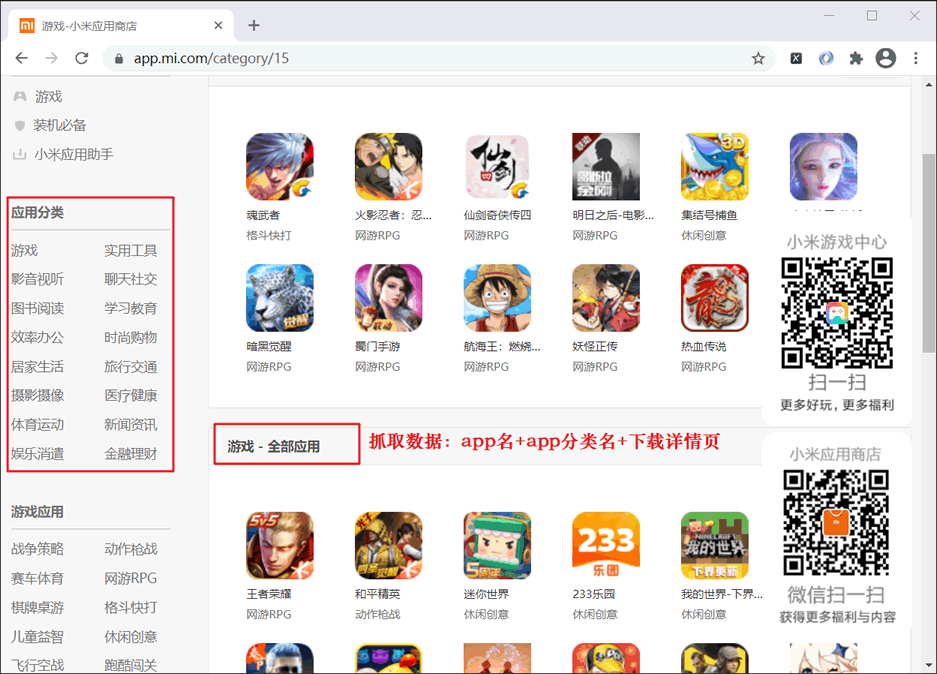
图 1:小米应用商店
抓到的数据demo如下:
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
1) 案例分析 通过关键字搜索,我们知道这是一个动态的网站,所以需要进行抓包分析。
刷新网页重新加载数据,可以知道请求头的URL地址,如下图:
https://app.mi.com/categotyAll ... %3D30
查询参数pageSize参数值不变,页面会随着页码的增加而变化,可以通过查看页面元素来查看categoryId,如下图
游戏
实用工具
影音视听
聊天社交
图书阅读
学习教育
效率办公
时尚购物
居家生活
旅行交通
摄影摄像
医疗健康
体育运动
新闻资讯
娱乐消遣
金融理财
因此,您可以使用 Xpath 表达式匹配 href 属性来提取类别 ID 和类别名称。表达式如下:
点击开发者工具的响应选项卡,查看响应数据,如下图:
{
count: 2000,
data: [
{
appId: 1348407,
displayName: "天气暖暖-关心Ta从关心天气开始",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.xiaowoniu.WarmWeather"
},
{
appId: 1348403,
displayName: "贵斌同城",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.gbtc.guibintongcheng"
},
...
...
通过上面的响应内容,我们可以提取出APP总数(count)和APP(displayName)名称,以及下载详情页的packageName。由于每个页面收录 30 个 APP,因此可以使用总数(计数)来计算每个类别中有多少个页面。
pages = int(count) // 30 + 1
下载详情页地址使用packageName拼接,如下图:
link = 'http://app.mi.com/details?id=' + app['packageName']
2) 完整程序完整程序如下:
# -*- coding:utf8 -*-
import requests
from threading import Thread
from queue import Queue
import time
from fake_useragent import UserAgent
from lxml import etree
import csv
from threading import Lock
import json
class XiaomiSpider(object):
def __init__(self):
self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'
# 存放所有URL地址的队列
self.q = Queue()
self.i = 0
# 存放所有类型id的空列表
self.id_list = []
# 打开文件
self.f = open('XiaomiShangcheng.csv','a',encoding='utf-8')
self.writer = csv.writer(self.f)
# 创建锁
self.lock = Lock()
def get_cateid(self):
# 请求
url = 'http://app.mi.com/'
headers = { 'User-Agent': UserAgent().random}
html = requests.get(url=url,headers=headers).text
# 解析
parse_html = etree.HTML(html)
xpath_bds = '//ul[@class="category-list"]/li'
li_list = parse_html.xpath(xpath_bds)
for li in li_list:
typ_name = li.xpath('./a/text()')[0]
typ_id = li.xpath('./a/@href')[0].split('/')[-1]
# 计算每个类型的页数
pages = self.get_pages(typ_id)
#往列表中添加二元组
self.id_list.append( (typ_id,pages) )
# 入队列
self.url_in()
# 获取count的值并计算页数
def get_pages(self,typ_id):
# 获取count的值,即app总数
url = self.url.format(0,typ_id)
html = requests.get(
url=url,
headers={'User-Agent':UserAgent().random}
).json()
count = html['count']
pages = int(count) // 30 + 1
return pages
# url入队函数,拼接url,并将url加入队列
def url_in(self):
for id in self.id_list:
# id格式:('4',pages)
for page in range(1,id[1]+1):
url = self.url.format(page,id[0])
# 把URL地址入队列
self.q.put(url)
# 线程事件函数: get() -请求-解析-处理数据,三步骤
def get_data(self):
while True:
# 判断队列不为空则执行,否则终止
if not self.q.empty():
url = self.q.get()
headers = {'User-Agent':UserAgent().random}
html = requests.get(url=url,headers=headers)
res_html = html.content.decode(encoding='utf-8')
html=json.loads(res_html)
self.parse_html(html)
else:
break
# 解析函数
def parse_html(self,html):
# 写入到csv文件
app_list = []
for app in html['data']:
# app名称 + 分类 + 详情链接
name = app['displayName']
link = 'http://app.mi.com/details?id=' + app['packageName']
typ_name = app['level1CategoryName']
# 把每一条数据放到app_list中,并通过writerows()实现多行写入
app_list.append([name,typ_name,link])
print(name,typ_name)
self.i += 1
# 向CSV文件中写入数据
self.lock.acquire()
self.writer.writerows(app_list)
self.lock.release()
# 入口函数
def main(self):
# URL入队列
self.get_cateid()
t_list = []
# 创建多线程
for i in range(1):
t = Thread(target=self.get_data)
t_list.append(t)
# 启动线程
t.start()
for t in t_list:
# 回收线程
t.join()
self.f.close()
print('数量:',self.i)
if __name__ == '__main__':
start = time.time()
spider = XiaomiSpider()
spider.main()
end = time.time()
print('执行时间:%.1f' % (end-start))
运行上述程序后,打开存储文件,其内容如下:
在我们之间-单机版,休闲创意,http://app.mi.com/details%3Fid ... r.gtx
粉末游戏,模拟经营,http://app.mi.com/details%3Fid ... r.bnn
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
腾讯欢乐麻将全集,棋牌桌游,http://app.mi.com/details?id=com.qqgame.happymj
快游戏,休闲创意,http://app.mi.com/details%3Fid ... h2mgc
皇室战争,战争策略,http://app.mi.com/details%3Fid ... le.mi
地铁跑酷,跑酷闯关,http://app.mi.com/details?id=com.kiloo.subwaysurf
...
...
python网页数据抓取(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-04 04:02
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response 查看全部
python网页数据抓取(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response
python网页数据抓取(简单记录一下的网络爬虫的知识,这里主要用到了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-03 11:23
)
最近学习了一些python网络爬虫的知识,简单记录一下。这里主要用到requests库和BeautifulSoup库。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天的工作。
以上是两个库的介绍,链接是文档信息
1、示例页面
这里我用东北大学图书馆的登陆页面来实现我们的爬虫功能(ps:是的,博主是东北大学的学生..所以我有账号密码),没有账号密码也没关系, 原理是一样的 是的,我发现这个页面是因为它没有验证码,所以可以更简单,像学校页面一样更简单,更容易操作
东北大学图书馆.JPG
2、简单分析
首先,我用账号和密码登录了东北大学图书馆。我用的是Chrome浏览器,打开了开发者模式。我们来看看我们提交了哪些信息。
东北大学邮报.JPG
登录后按F12打开开发者模式。在网络选项卡下,我们找到了这个文件。他的请求方式是post,应该就是我们要找的文件。拉到最底部看Form Data,红框就是我们登录时提交的信息,一共五部分。红线是账号和密码。了解帖子信息后,我们可以编写代码自动提交信息。
登录部分澄清。接下来,我将分析要捕获的信息。现在我想捕获我的。
为了捕捉这三个数据,如上图所示,我目前借了1本书,已经借了65本书。保留请求为 0。现在的目的是捕获这些数据。我们按F12查看网页。分析我们应该抓取源代码的哪一部分。
源代码.JPG
如上图,我一步一步找到了数据所在的标签。我发现数据在标签id=history下,所以我可以先找到这个标签,然后找到tr标签,然后才能找到td标签中的数据。
3、实现的功能4、代码部分4.1、发布数据部分
先贴这部分代码
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
代码如上,我们来分析一下
4.2、 抓取数据部分
先贴上代码
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
isinstance 的用法:
语法:
isinstance(对象,类信息)
其中,object是变量,classinfo是类型(tuple、dict、int、float、list、bool等)和类。如果参数 object 是 classinfo 的实例,或者 object 是 classinfo 的子类的实例,则返回 True。如果 object 不是给定类型的对象,则返回结果始终为 False。如果 classinfo 不是数据类型或由数据类型组成的元组,则会引发 TypeError 异常。
4.3、打印信息
粘贴代码
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2])
这部分很简单,我就不讲了
4.4、主要功能
粘贴代码
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info")
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
5、测试
测试.jpg
我们要的信息在控制台成功打印了!
6、完整代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2]))
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info")
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
main() 查看全部
python网页数据抓取(简单记录一下的网络爬虫的知识,这里主要用到了
)
最近学习了一些python网络爬虫的知识,简单记录一下。这里主要用到requests库和BeautifulSoup库。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天的工作。
以上是两个库的介绍,链接是文档信息
1、示例页面
这里我用东北大学图书馆的登陆页面来实现我们的爬虫功能(ps:是的,博主是东北大学的学生..所以我有账号密码),没有账号密码也没关系, 原理是一样的 是的,我发现这个页面是因为它没有验证码,所以可以更简单,像学校页面一样更简单,更容易操作

东北大学图书馆.JPG
2、简单分析
首先,我用账号和密码登录了东北大学图书馆。我用的是Chrome浏览器,打开了开发者模式。我们来看看我们提交了哪些信息。
东北大学邮报.JPG
登录后按F12打开开发者模式。在网络选项卡下,我们找到了这个文件。他的请求方式是post,应该就是我们要找的文件。拉到最底部看Form Data,红框就是我们登录时提交的信息,一共五部分。红线是账号和密码。了解帖子信息后,我们可以编写代码自动提交信息。
登录部分澄清。接下来,我将分析要捕获的信息。现在我想捕获我的。
为了捕捉这三个数据,如上图所示,我目前借了1本书,已经借了65本书。保留请求为 0。现在的目的是捕获这些数据。我们按F12查看网页。分析我们应该抓取源代码的哪一部分。
源代码.JPG
如上图,我一步一步找到了数据所在的标签。我发现数据在标签id=history下,所以我可以先找到这个标签,然后找到tr标签,然后才能找到td标签中的数据。
3、实现的功能4、代码部分4.1、发布数据部分
先贴这部分代码
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
代码如上,我们来分析一下
4.2、 抓取数据部分
先贴上代码
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
isinstance 的用法:
语法:
isinstance(对象,类信息)
其中,object是变量,classinfo是类型(tuple、dict、int、float、list、bool等)和类。如果参数 object 是 classinfo 的实例,或者 object 是 classinfo 的子类的实例,则返回 True。如果 object 不是给定类型的对象,则返回结果始终为 False。如果 classinfo 不是数据类型或由数据类型组成的元组,则会引发 TypeError 异常。
4.3、打印信息
粘贴代码
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2])
这部分很简单,我就不讲了
4.4、主要功能
粘贴代码
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info";)
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
5、测试
测试.jpg
我们要的信息在控制台成功打印了!
6、完整代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2]))
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info";)
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
main()
python网页数据抓取(python爬虫如何爬取网页数据并解析数据,帮助大家更好的利用爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-26 06:19
)
本文文章主要介绍python爬虫如何抓取网页数据并分析数据,帮助大家更好地利用爬虫对网页进行分析。有兴趣的朋友可以了解一下。
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
查看全部
python网页数据抓取(python爬虫如何爬取网页数据并解析数据,帮助大家更好的利用爬虫
)
本文文章主要介绍python爬虫如何抓取网页数据并分析数据,帮助大家更好地利用爬虫对网页进行分析。有兴趣的朋友可以了解一下。
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能

网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图

安装完成,如图

python网页数据抓取(python网页数据抓取编程-课程展示_(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-26 01:06
python网页数据抓取编程-课程展示_腾讯课堂;list=plvsmza4fscymzjkdszkwuj0zixzg%3d%3d&feature=youtu.be&index=5&v=3&int=1&t=251s第一课点我查看
这是数据采集小白的标准答案。
思路非常对。就是有一个问题,只有一个起始坐标,数据没法去重。
x是爬虫目标id,y是待采集元素的值,即num=idx+y。假设数据中有n个小说标题,则n=10,因为idx的取值范围是[-1,1],那么数据中的标题集合就有x*n等于101,那么10的小说标题集合就是z(n取1~10),那么已知小说标题集z,相应的小说标题集合就有y=0~5,这样所有小说标题集合就可以构成一个变量num,此时如果d=50,则对应的num变量值为z(z取0~5,取0~5是因为num是自身),数据中包含z值的小说标题集合构成一个变量m。
这样的话,直接在analyser.py程序的代码里加如下:vard='*'varm=0foriind':':m+=(i*i)varx=iprintdvary=i*yifstr(x*n)==str(y*n)else0foriind':':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify=i*yifx-mindm+=yprintx-mfory=i*yify-mindm+=yprinty-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yprintx-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-min。 查看全部
python网页数据抓取(python网页数据抓取编程-课程展示_(图))
python网页数据抓取编程-课程展示_腾讯课堂;list=plvsmza4fscymzjkdszkwuj0zixzg%3d%3d&feature=youtu.be&index=5&v=3&int=1&t=251s第一课点我查看
这是数据采集小白的标准答案。
思路非常对。就是有一个问题,只有一个起始坐标,数据没法去重。
x是爬虫目标id,y是待采集元素的值,即num=idx+y。假设数据中有n个小说标题,则n=10,因为idx的取值范围是[-1,1],那么数据中的标题集合就有x*n等于101,那么10的小说标题集合就是z(n取1~10),那么已知小说标题集z,相应的小说标题集合就有y=0~5,这样所有小说标题集合就可以构成一个变量num,此时如果d=50,则对应的num变量值为z(z取0~5,取0~5是因为num是自身),数据中包含z值的小说标题集合构成一个变量m。
这样的话,直接在analyser.py程序的代码里加如下:vard='*'varm=0foriind':':m+=(i*i)varx=iprintdvary=i*yifstr(x*n)==str(y*n)else0foriind':':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify=i*yifx-mindm+=yprintx-mfory=i*yify-mindm+=yprinty-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yprintx-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-min。
python网页数据抓取(python编程入门视频学习一下可以去几个我常用的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 17:06
python网页数据抓取这次只是一个开始,之后我们不断更新完善,并且把这里的数据拿去做一些实际应用。我这里有一些网站截图,供你们参考、观看。
最好玩的是,你需要有足够的耐心。
请多看一点python编程入门视频学习一下
可以去几个flask相关网站多学习学习比如、个人推荐、、
makegoodcode比如flask你可以先看flaskadmin
推荐几个我常用的网站给你吧1。flaskmega-flask开发者中心:flaskchina论坛2。flasktutorials:atutorialforstartingflask,flaskdevelopment,flasktesting,flaskmergev1.1,1.2.x(online)我公司的官网3。
推荐豆瓣的博客整个豆瓣,
可以去看这个问题做一个豆瓣电影推荐系统是怎样的一种体验?一个豆瓣的成功推荐应该如何做?
个人微信公众号。
你可以关注豆瓣开发者中心,
有一个20万人的电影评分豆瓣豆瓣电影里,找一找,发现还是蛮不错的。不过不会引起爬虫,需要用flask自己写~其实小到extjs的forwebserver也就几十行,大到框架sed,mysql,直接用,都是简单的。基本上做个爬虫爬下数据什么的,完全没有压力。而且如果你不知道框架的话,如果不会flask的话,也可以找swoole,写cornell的advocates,就是很简单。 查看全部
python网页数据抓取(python编程入门视频学习一下可以去几个我常用的网站)
python网页数据抓取这次只是一个开始,之后我们不断更新完善,并且把这里的数据拿去做一些实际应用。我这里有一些网站截图,供你们参考、观看。
最好玩的是,你需要有足够的耐心。
请多看一点python编程入门视频学习一下
可以去几个flask相关网站多学习学习比如、个人推荐、、
makegoodcode比如flask你可以先看flaskadmin
推荐几个我常用的网站给你吧1。flaskmega-flask开发者中心:flaskchina论坛2。flasktutorials:atutorialforstartingflask,flaskdevelopment,flasktesting,flaskmergev1.1,1.2.x(online)我公司的官网3。
推荐豆瓣的博客整个豆瓣,
可以去看这个问题做一个豆瓣电影推荐系统是怎样的一种体验?一个豆瓣的成功推荐应该如何做?
个人微信公众号。
你可以关注豆瓣开发者中心,
有一个20万人的电影评分豆瓣豆瓣电影里,找一找,发现还是蛮不错的。不过不会引起爬虫,需要用flask自己写~其实小到extjs的forwebserver也就几十行,大到框架sed,mysql,直接用,都是简单的。基本上做个爬虫爬下数据什么的,完全没有压力。而且如果你不知道框架的话,如果不会flask的话,也可以找swoole,写cornell的advocates,就是很简单。
python网页数据抓取(python网页数据抓取利用网络爬虫+正则表达式可以轻松实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-24 02:02
python网页数据抓取利用网络爬虫+正则表达式可以轻松实现python网页数据的抓取爬取。正则表达式是python程序员必须掌握的基础技能之一,该技能也是大部分程序员的一个职业基本功之一,网络爬虫则是一个最佳的选择。上节我们介绍了网络爬虫的一些技巧和框架的搭建。本节将着重讲解下网络爬虫的核心部分,即抓取相关的功能模块:正则表达式,基于正则表达式的多线程、队列、循环爬虫框架。
python网络爬虫核心环节正则表达式通过正则表达式,可以直接在一个网页中找到需要的内容。现在大部分网站都没有对http协议实现标准化,只要能够获取http协议的cookie信息或者js文件,就可以直接访问http的协议,例如知乎、豆瓣。正则表达式作为网络爬虫的核心部分,在整个网络爬虫中占有举足轻重的地位。
1.正则表达式解析正则表达式的解析,主要指的是对一个文本,匹配出目标的值。一个简单的正则表达式一般如下所示:一般而言正则表达式有如下几个特点:简洁、分歧、支持连字符以及多行匹配等特点。对于一个正则表达式来说,最重要的组成部分当然是其字符串的长度,长度是一个正则表达式最重要的特征之一。对于一个正则表达式来说,其第一个元素的字符串的长度是两个正则表达式最大连字符和-,如果多行的话,最大连字符和,还有可能会出现len()。
除此之外还有字符数。为了简单起见,我们简单的定义连字符l,和-,len(),返回一个正则表达式的长度:l=len(str)=left,l=left(str)=right,r=left(str)=right,-=(max(r)-min(r))/10,-=limit(max(r)-min(r))/1024一个正则表达式的基本结构如下所示:p.replace(.*,left,limit)注意:字符串并不是正则表达式,正则表达式是由一连串的字符串组成的。
正则表达式还有其实体,最基本的实体类型就是字符串。需要注意的是,一个正则表达式里,可以有多个字符串相同的字符,因此,正则表达式的正好和word.toupper()或者str.upper()是相对应的。常用的正则表达式的字符类型如下所示:正则表达式中使用负号\作为转义操作符。\是转义操作符。例如:\w[0-9]\d\s#;#表示转义\s#表示最后一个字符,如果再加上#则#号无效正则表达式的合并操作符组合起来就成为"/",这个正则表达式当中就有"/"后面跟一个负号\,意思是整个表达式中只有一个字符是表示中间的字符串的部分,例如:\w[0-9]\d\s,其中中间有一个空格。也就是说,python对最后。 查看全部
python网页数据抓取(python网页数据抓取利用网络爬虫+正则表达式可以轻松实现)
python网页数据抓取利用网络爬虫+正则表达式可以轻松实现python网页数据的抓取爬取。正则表达式是python程序员必须掌握的基础技能之一,该技能也是大部分程序员的一个职业基本功之一,网络爬虫则是一个最佳的选择。上节我们介绍了网络爬虫的一些技巧和框架的搭建。本节将着重讲解下网络爬虫的核心部分,即抓取相关的功能模块:正则表达式,基于正则表达式的多线程、队列、循环爬虫框架。
python网络爬虫核心环节正则表达式通过正则表达式,可以直接在一个网页中找到需要的内容。现在大部分网站都没有对http协议实现标准化,只要能够获取http协议的cookie信息或者js文件,就可以直接访问http的协议,例如知乎、豆瓣。正则表达式作为网络爬虫的核心部分,在整个网络爬虫中占有举足轻重的地位。
1.正则表达式解析正则表达式的解析,主要指的是对一个文本,匹配出目标的值。一个简单的正则表达式一般如下所示:一般而言正则表达式有如下几个特点:简洁、分歧、支持连字符以及多行匹配等特点。对于一个正则表达式来说,最重要的组成部分当然是其字符串的长度,长度是一个正则表达式最重要的特征之一。对于一个正则表达式来说,其第一个元素的字符串的长度是两个正则表达式最大连字符和-,如果多行的话,最大连字符和,还有可能会出现len()。
除此之外还有字符数。为了简单起见,我们简单的定义连字符l,和-,len(),返回一个正则表达式的长度:l=len(str)=left,l=left(str)=right,r=left(str)=right,-=(max(r)-min(r))/10,-=limit(max(r)-min(r))/1024一个正则表达式的基本结构如下所示:p.replace(.*,left,limit)注意:字符串并不是正则表达式,正则表达式是由一连串的字符串组成的。
正则表达式还有其实体,最基本的实体类型就是字符串。需要注意的是,一个正则表达式里,可以有多个字符串相同的字符,因此,正则表达式的正好和word.toupper()或者str.upper()是相对应的。常用的正则表达式的字符类型如下所示:正则表达式中使用负号\作为转义操作符。\是转义操作符。例如:\w[0-9]\d\s#;#表示转义\s#表示最后一个字符,如果再加上#则#号无效正则表达式的合并操作符组合起来就成为"/",这个正则表达式当中就有"/"后面跟一个负号\,意思是整个表达式中只有一个字符是表示中间的字符串的部分,例如:\w[0-9]\d\s,其中中间有一个空格。也就是说,python对最后。
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-21 17:10
阿里云>云栖社区>主题图>P>Python爬取网页数据库
推荐活动:
更多优惠>
当前话题:python抓取网页数据库添加到采集夹
相关话题:
Python抓取网页数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【雪峰磁针石博客】可爱的python测试开发库
作者:python人工智能命理 6886人浏览评论:03年前
欢迎转载,转载请注明出处:github地址谢谢喜欢相关书籍下载测试开发Web UI测试自动化splinter-web UI测试工具,基于selnium包。链接到 selenium-web UI 自动化测试。链接--推荐文档参考mec
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!
作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
老司机带你学爬虫-Python爬虫技术分享
作者:yunqi2 浏览评论人数:03年前
什么是“爬虫”?简单来说,编写一个从网络上获取所需数据并以规定格式存储的程序称为爬虫;理论上,爬虫的步骤很简单,第一步是获取html源代码,第二步是分析html,获取数据。但是实际操作起来又老又麻烦~有什么方便的Python写“爬虫”的库。常用的网络请求库:request
阅读全文
大数据与云计算学习:Python网络数据采集
作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换和信息采集以及爬虫学习路径爬虫的基本原理,具有信息存储功能 所谓爬虫就是一种自动化的数据工具,你
阅读全文
Python爬虫抓取知乎所有用户信息
作者:青山无名 2928人浏览评论:13年前
今天写了一个爬虫,递归抓取知乎的所有用户信息。源码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,查看网页。,这里我随机选择了一个大V作为入口,然后点击他的关注列表,如图,注意我的爬虫全名处于非登录状态。这里
阅读全文
Python实现Awvs自动扫描
作者:迟来凤姬 2601人浏览评论:04年前
最近做了一个python小程序。主要功能是实现Acuenetix Web Vulnerability Scanner的自动扫描,批量扫描一些目标,然后将扫描结果写入mysql数据库。写这个文章 并分享一些想法。程序主要分为三个功能模块,Url下
阅读全文
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
Python爬取京东书评数据
作者:五山之巅 920人浏览评论:07年前
京东书评信息非常丰富,包括购买日期、书名、作者、好评、中评、差评等。以购买日期为例,使用Python+Mysql搭配实现,程序不大,只有100行。我在程序中添加的相关说明:来自seleni
阅读全文 查看全部
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
阿里云>云栖社区>主题图>P>Python爬取网页数据库

推荐活动:
更多优惠>
当前话题:python抓取网页数据库添加到采集夹
相关话题:
Python抓取网页数据库相关博客 查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【雪峰磁针石博客】可爱的python测试开发库


作者:python人工智能命理 6886人浏览评论:03年前
欢迎转载,转载请注明出处:github地址谢谢喜欢相关书籍下载测试开发Web UI测试自动化splinter-web UI测试工具,基于selnium包。链接到 selenium-web UI 自动化测试。链接--推荐文档参考mec
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!


作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
老司机带你学爬虫-Python爬虫技术分享

作者:yunqi2 浏览评论人数:03年前
什么是“爬虫”?简单来说,编写一个从网络上获取所需数据并以规定格式存储的程序称为爬虫;理论上,爬虫的步骤很简单,第一步是获取html源代码,第二步是分析html,获取数据。但是实际操作起来又老又麻烦~有什么方便的Python写“爬虫”的库。常用的网络请求库:request
阅读全文
大数据与云计算学习:Python网络数据采集


作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换和信息采集以及爬虫学习路径爬虫的基本原理,具有信息存储功能 所谓爬虫就是一种自动化的数据工具,你
阅读全文
Python爬虫抓取知乎所有用户信息


作者:青山无名 2928人浏览评论:13年前
今天写了一个爬虫,递归抓取知乎的所有用户信息。源码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,查看网页。,这里我随机选择了一个大V作为入口,然后点击他的关注列表,如图,注意我的爬虫全名处于非登录状态。这里
阅读全文
Python实现Awvs自动扫描


作者:迟来凤姬 2601人浏览评论:04年前
最近做了一个python小程序。主要功能是实现Acuenetix Web Vulnerability Scanner的自动扫描,批量扫描一些目标,然后将扫描结果写入mysql数据库。写这个文章 并分享一些想法。程序主要分为三个功能模块,Url下
阅读全文
如何用Python抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
Python爬取京东书评数据


作者:五山之巅 920人浏览评论:07年前
京东书评信息非常丰富,包括购买日期、书名、作者、好评、中评、差评等。以购买日期为例,使用Python+Mysql搭配实现,程序不大,只有100行。我在程序中添加的相关说明:来自seleni
阅读全文
python网页数据抓取(如何使用Python从网页上抓取图像所需的操作?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-13 17:27
你想用Python从网页下载图片吗?在 python 语言语法及其相关库的帮助下,这个过程变得容易。在此页面上停留足够长的时间以了解如何使用 Python 在线抓取图像。
我们正处于数据比以往任何时候都更加重要的时代,未来对数据的追求只会越来越大。事实证明,互联网是最大的数据来源之一。从文本到可下载的文件,包括 Internet 上的图像,都有大量的数据。
互联网上的许多教程都侧重于如何抓取文本,而忽略了有关如何抓取图像和其他可下载文件的指南。不过,这是可以理解的。大多数指南都不是很深入,并且没有多少网络爬虫对捕获图像感兴趣,因为大多数处理文本数据的方法。如果您是少数对抓取图像感兴趣的人之一,那么本指南就是为您编写的。
图像捕获比您想象的要容易
对于许多初学者来说,他们认为图像抓取与常规网页抓取不同。从实际意义上讲,它们实际上是相同的,几乎没有区别。事实上,除了处理大文件的图像,你会发现你所需要的只是网页抓取和文件处理的知识。
如果您还没有链接抓取能力,您的网络抓取技巧将帮助您抓取到图片的链接。有了链接,你只需要向链接发送一个 HTTP 请求来下载图片,然后创建一个文件来写入它。
虽然这很容易,但我知道分步指南将帮助您更好地了解如何完成此操作。为此,我们将开展一个项目——在项目结束时,您将了解从网页抓取图像所需的操作。
项目思路一:从静态站点抓取图片
静态 网站 是一些最容易从 网站 抓取图像的。这是因为当您向请求静态页面的服务器发送 Web 请求时,所有组件都会作为响应返回给您,您需要做的就是获取链接,然后开始向每个链接发送 HTTP 请求。
对于依赖 JavaScript 渲染图片等内容的动态页面,您需要采用其他方式在上面剪切和粘贴图片。
为了向您展示如何从静态页面中抓取图像,我们将研究一个通用的图像抓取工具,它可以抓取静态页面上的所有图像。该脚本接受页面的 URL 作为参数,并将页面上的所有图像下载到脚本文件夹中。
使用 Python 抓取静态页面的要求
Python 使爬行变得非常简单和直接。抓取图片的工具有很多,您必须根据您的用例、目标站点和个人喜好进行选择。对于本指南,您将需要以下内容。
Requests 是一个优雅的用于 HTTP 请求的 Python 库。它被称为人类的 HTTP。作为网络爬虫,“请求”是你应该熟悉的工具之一。虽然您可以使用标准库中收录的 URL 库,但您需要知道 Requests 使许多事情变得容易。
解析是网页抓取的关键方面之一,这可能很困难也很容易,具体取决于页面的结构。使用 BeautifulSoup(Python 的解析库),解析变得容易。
抓取图像需要您知道如何处理文件。有趣的是,我们不需要像 Python Imaging Library (PIL) 这样的特殊库,因为我们所做的只是保存图像。
捕获图像的编码步骤
根据以上要求,就可以开始抓取网页图片了。如果你还没有安装Requests和BeautifulSoup,你需要安装它们,因为它们是第三方库,没有捆绑在Python标准库中。您可以使用 pip 命令安装它们。以下是用于安装这些库的命令。
pip install requests
pip install beautifulsoup4
现在到正确的编码。
第一步是导入所需的库,包括 Requests 和 BeautifulSoup。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
从上面可以看到
urlparse
该库也已导入。这是必要的,因为我们需要从 URL 中解析出域,并将其附加到具有相对 URL 的图像的 URL。
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
查看上面的代码,您会注意到它执行 3 个任务——发送请求、解析 URL 以及将 URL 保存在 links 变量中。您可以将 url 变量更改为您选择的任何 URL。
第三行,使用Requests发送HTTP请求——第4行和第5行,BeautifulSoup用于解析URL。
如果查看循环部分,您会发现只有具有绝对路径 (URL) 的图像才会添加到链接列表中。带有相对 URL 的 URL 需要进一步处理,代码的 else 部分就是用于此目的。进一步处理将域名 URL 添加到相对 URL。
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
上面我们要做的是循环遍历图像 URL 列表并使用请求来下载每个图像的内容。准备好手头的内容,然后为每个文件创建一个JPG文件并将内容写入其中。就这么简单。为了命名,我使用数字来表示每个图像。
这样做是因为脚本是作为一个简单的概念证明编写的。您可以决定为每个图像使用 alt 值——但请记住,某些图像没有任何值,您必须想出一个命名公式。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
# write images to files
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
项目思路2:使用Selenium进行图像捕捉
并非所有站点都是静态站点。许多现代 网站 是交互式的并且具有丰富的 JavaScript。对于这些网站,发送HTTP请求时页面上的所有内容都不会被加载——大量的内容是通过JavaScript事件加载的。
对于这样的站点,request和beautifulsoup是没有用的,因为它们不遵循静态站点方法,而使用request和beautifulsoup。Selenium 是完成这项工作的工具。
Selenium 是一种浏览器自动化工具,最初是为测试 Web 应用程序而开发的,但也有其他用途,包括 Web 抓取和通用 Web 自动化。使用 Selenium,将启动一个真正的浏览器并触发页面和 JavaScript 事件以确保所有内容都可用。我将向您展示如何使用 Selenium 从 Google 抓取图像。
硒要求和设置
为了使 Selenium 正常工作,您必须安装 Selenium 软件包并下载您要使用的特定浏览器的浏览器驱动程序。在本指南中,我们将使用 Chrome。要安装 Selenium,请使用以下代码。
pip install selenium
安装 Selenium 后,如果您的系统上没有安装 Chrome,您可以访问 Chrome 下载页面并安装它。您还需要下载 Chrome 驱动程序。
访问此页面以下载适用于您的 Chrome 浏览器版本的驱动程序。下载的文件是一个收录 chromedriver.exe 文件的 zip 文件。将 chromedriver.exe 文件解压到 selenium 项目文件夹中。在同一文件夹中,放置 cghromedriver.exe 文件并创建一个名为 SeleImage.py 的新 python 文件。
使用 Selenium 捕获图像的编码步骤
我将逐步指导您如何使用 Selenium 和 Python 编写 Google 图片抓取工具
from selenium import webdriver
from selenium.webdriver.chrome.optionsimport Options
webdriver 类是我们将在本指南的 Selenium 包中使用的主要类。Options 类用于设置 webdriver 选项,包括使其在无头模式下运行。
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/")
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
上面的代码对于任何 Python 编码器都是不言自明的。第一行收录我们要下载图像的搜索关键字。在第二个程序中,我们将使用 Chrome 来执行自动化任务。第三行发送对 Google 主页的请求。
使用 element.find_element_by_name,我们可以使用名称属性“q”访问搜索输入元素。使用 send_keys 方法填充关键字,然后我们使用最后一行提交查询。如果你运行代码,你会看到 Chrome 会以自动模式启动,填写查询表单,然后带你到结果页面。
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
上面的代码也是不言自明的。找到第一行的图像搜索链接并单击它以将焦点从所有结果移动到仅图像。第二张图片只找到前两张图片。使用 for 循环下载图像。
import requests
from selenium import webdriver
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/")
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
从网络上抓取图片的合法性
与以往无法判断网络爬虫是否合法,法院裁定支持网络爬虫的合法性,前提是你不是在认证墙后面爬取数据,这违反了任何规则或有损于你的目标 网站 影响。
另一个可能导致非法网络抓取的问题是版权,正如您所知,互联网上的许多图像都已受版权保护。这最终可能会给您带来麻烦。我不是律师,你不应该接受我说的法律建议。我建议您就在互联网上拍摄公共图像的合法性寻求律师的服务。
结论
从上面的内容中,您发现在 Internet 上获取公开可用的图像是多么容易。只要您不处理需要流式传输的大型图像文件,该过程就很简单。
您可能会遇到的另一个问题是反爬技术设置,这使您很难抓取网页数据。您还必须考虑相关的合法性。我建议你在这方面寻求有经验的律师的意见。
Python爬虫
喜欢 (0)
最佳代理
什么是替代数据及其对投资决策的有效性 查看全部
python网页数据抓取(如何使用Python从网页上抓取图像所需的操作?)
你想用Python从网页下载图片吗?在 python 语言语法及其相关库的帮助下,这个过程变得容易。在此页面上停留足够长的时间以了解如何使用 Python 在线抓取图像。
我们正处于数据比以往任何时候都更加重要的时代,未来对数据的追求只会越来越大。事实证明,互联网是最大的数据来源之一。从文本到可下载的文件,包括 Internet 上的图像,都有大量的数据。
互联网上的许多教程都侧重于如何抓取文本,而忽略了有关如何抓取图像和其他可下载文件的指南。不过,这是可以理解的。大多数指南都不是很深入,并且没有多少网络爬虫对捕获图像感兴趣,因为大多数处理文本数据的方法。如果您是少数对抓取图像感兴趣的人之一,那么本指南就是为您编写的。
图像捕获比您想象的要容易
对于许多初学者来说,他们认为图像抓取与常规网页抓取不同。从实际意义上讲,它们实际上是相同的,几乎没有区别。事实上,除了处理大文件的图像,你会发现你所需要的只是网页抓取和文件处理的知识。
如果您还没有链接抓取能力,您的网络抓取技巧将帮助您抓取到图片的链接。有了链接,你只需要向链接发送一个 HTTP 请求来下载图片,然后创建一个文件来写入它。
虽然这很容易,但我知道分步指南将帮助您更好地了解如何完成此操作。为此,我们将开展一个项目——在项目结束时,您将了解从网页抓取图像所需的操作。
项目思路一:从静态站点抓取图片
静态 网站 是一些最容易从 网站 抓取图像的。这是因为当您向请求静态页面的服务器发送 Web 请求时,所有组件都会作为响应返回给您,您需要做的就是获取链接,然后开始向每个链接发送 HTTP 请求。
对于依赖 JavaScript 渲染图片等内容的动态页面,您需要采用其他方式在上面剪切和粘贴图片。
为了向您展示如何从静态页面中抓取图像,我们将研究一个通用的图像抓取工具,它可以抓取静态页面上的所有图像。该脚本接受页面的 URL 作为参数,并将页面上的所有图像下载到脚本文件夹中。
使用 Python 抓取静态页面的要求
Python 使爬行变得非常简单和直接。抓取图片的工具有很多,您必须根据您的用例、目标站点和个人喜好进行选择。对于本指南,您将需要以下内容。
Requests 是一个优雅的用于 HTTP 请求的 Python 库。它被称为人类的 HTTP。作为网络爬虫,“请求”是你应该熟悉的工具之一。虽然您可以使用标准库中收录的 URL 库,但您需要知道 Requests 使许多事情变得容易。
解析是网页抓取的关键方面之一,这可能很困难也很容易,具体取决于页面的结构。使用 BeautifulSoup(Python 的解析库),解析变得容易。
抓取图像需要您知道如何处理文件。有趣的是,我们不需要像 Python Imaging Library (PIL) 这样的特殊库,因为我们所做的只是保存图像。
捕获图像的编码步骤
根据以上要求,就可以开始抓取网页图片了。如果你还没有安装Requests和BeautifulSoup,你需要安装它们,因为它们是第三方库,没有捆绑在Python标准库中。您可以使用 pip 命令安装它们。以下是用于安装这些库的命令。
pip install requests
pip install beautifulsoup4
现在到正确的编码。
第一步是导入所需的库,包括 Requests 和 BeautifulSoup。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
从上面可以看到
urlparse
该库也已导入。这是必要的,因为我们需要从 URL 中解析出域,并将其附加到具有相对 URL 的图像的 URL。
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
查看上面的代码,您会注意到它执行 3 个任务——发送请求、解析 URL 以及将 URL 保存在 links 变量中。您可以将 url 变量更改为您选择的任何 URL。
第三行,使用Requests发送HTTP请求——第4行和第5行,BeautifulSoup用于解析URL。
如果查看循环部分,您会发现只有具有绝对路径 (URL) 的图像才会添加到链接列表中。带有相对 URL 的 URL 需要进一步处理,代码的 else 部分就是用于此目的。进一步处理将域名 URL 添加到相对 URL。
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
上面我们要做的是循环遍历图像 URL 列表并使用请求来下载每个图像的内容。准备好手头的内容,然后为每个文件创建一个JPG文件并将内容写入其中。就这么简单。为了命名,我使用数字来表示每个图像。
这样做是因为脚本是作为一个简单的概念证明编写的。您可以决定为每个图像使用 alt 值——但请记住,某些图像没有任何值,您必须想出一个命名公式。
from urllib.parseimport urlparse
import requests
from bs4 import BeautifulSoup
url = "https://ripple.com/xrp"
domain = urlparse(url).netloc
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
raw_links = soup.find_all("img")
links = []
for iin raw_links:
link = i['src']
if link.startswith("http"):
links.append(link)
else:
modified_link = "https://" + domain + link
links.append(modified_link)
# write images to files
for x in range(len(links)):
downloaded_image = requests.get(links[x]).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
print("Images scraped successfully... you can now check this script folder for your images")
项目思路2:使用Selenium进行图像捕捉
并非所有站点都是静态站点。许多现代 网站 是交互式的并且具有丰富的 JavaScript。对于这些网站,发送HTTP请求时页面上的所有内容都不会被加载——大量的内容是通过JavaScript事件加载的。
对于这样的站点,request和beautifulsoup是没有用的,因为它们不遵循静态站点方法,而使用request和beautifulsoup。Selenium 是完成这项工作的工具。
Selenium 是一种浏览器自动化工具,最初是为测试 Web 应用程序而开发的,但也有其他用途,包括 Web 抓取和通用 Web 自动化。使用 Selenium,将启动一个真正的浏览器并触发页面和 JavaScript 事件以确保所有内容都可用。我将向您展示如何使用 Selenium 从 Google 抓取图像。
硒要求和设置
为了使 Selenium 正常工作,您必须安装 Selenium 软件包并下载您要使用的特定浏览器的浏览器驱动程序。在本指南中,我们将使用 Chrome。要安装 Selenium,请使用以下代码。
pip install selenium
安装 Selenium 后,如果您的系统上没有安装 Chrome,您可以访问 Chrome 下载页面并安装它。您还需要下载 Chrome 驱动程序。
访问此页面以下载适用于您的 Chrome 浏览器版本的驱动程序。下载的文件是一个收录 chromedriver.exe 文件的 zip 文件。将 chromedriver.exe 文件解压到 selenium 项目文件夹中。在同一文件夹中,放置 cghromedriver.exe 文件并创建一个名为 SeleImage.py 的新 python 文件。
使用 Selenium 捕获图像的编码步骤
我将逐步指导您如何使用 Selenium 和 Python 编写 Google 图片抓取工具
from selenium import webdriver
from selenium.webdriver.chrome.optionsimport Options
webdriver 类是我们将在本指南的 Selenium 包中使用的主要类。Options 类用于设置 webdriver 选项,包括使其在无头模式下运行。
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/";)
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
上面的代码对于任何 Python 编码器都是不言自明的。第一行收录我们要下载图像的搜索关键字。在第二个程序中,我们将使用 Chrome 来执行自动化任务。第三行发送对 Google 主页的请求。
使用 element.find_element_by_name,我们可以使用名称属性“q”访问搜索输入元素。使用 send_keys 方法填充关键字,然后我们使用最后一行提交查询。如果你运行代码,你会看到 Chrome 会以自动模式启动,填写查询表单,然后带你到结果页面。
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
上面的代码也是不言自明的。找到第一行的图像搜索链接并单击它以将焦点从所有结果移动到仅图像。第二张图片只找到前两张图片。使用 for 循环下载图像。
import requests
from selenium import webdriver
keyword = "Selenium Guide"
driver = webdriver.Chrome()
driver.get("https://www.google.com/";)
driver.find_element_by_name("q").send_keys(keyword)
driver.find_element_by_name("btnK").submit()
driver.find_elements_by_class_name("hide-focus-ring")[1].click()
images = driver.find_elements_by_tag_name('img')[0:2]
for x in range(len(images)):
downloaded_image = requests.get(images[x].get_attribute('src')).content
with open(str(x) + ".jpg", "wb") as f:
f.write(downloaded_image)
从网络上抓取图片的合法性
与以往无法判断网络爬虫是否合法,法院裁定支持网络爬虫的合法性,前提是你不是在认证墙后面爬取数据,这违反了任何规则或有损于你的目标 网站 影响。
另一个可能导致非法网络抓取的问题是版权,正如您所知,互联网上的许多图像都已受版权保护。这最终可能会给您带来麻烦。我不是律师,你不应该接受我说的法律建议。我建议您就在互联网上拍摄公共图像的合法性寻求律师的服务。
结论
从上面的内容中,您发现在 Internet 上获取公开可用的图像是多么容易。只要您不处理需要流式传输的大型图像文件,该过程就很简单。
您可能会遇到的另一个问题是反爬技术设置,这使您很难抓取网页数据。您还必须考虑相关的合法性。我建议你在这方面寻求有经验的律师的意见。
Python爬虫
喜欢 (0)
最佳代理
什么是替代数据及其对投资决策的有效性
python网页数据抓取(如何通过网页快速收集表格,达到自动化办公的效果?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-12 19:03
想必很多工作中的朋友都用表格作为整理器采集了一些资料。发送和接收电子邮件需要时间和精力。大家想通过网络上传的表格有什么好办法采集采集吗?羊毛布?
本文即将介绍一种快捷方式,帮助您通过网页快速采集表单,达到自动化办公的效果,让您更快下班!
通过阅读本文,您将学习以下技能:
(1)使用Python搭建自己的交互式网页
(2)掌握python读表的方法(包括pandas的用法)
(3)使用df.to_sql,一行代码将表单上传到数据库
(4) 2种不同的数据连接方式
(5)sql语句怎么写
本文内容分为3部分:
第 1 部分:网页上传组件
第 2 部分:上传到数据库
第三部分:从数据库中拉取数据,验证是否上传成功
效果图如下:
网页效果图
想知道它是如何实现的吗?慢慢听我说
为了实现以上效果图,我们需要安装几个python库
pip install streamlit #构建web网页的基础模块
pip install pandas #读取表格的模块1
pip install xlrd #读取表格的模块2
pip install streamlit-aggrid #在网页中显示表格的模块
pip install pymysql #连接数据库的模块1
pip install sqlalchemy #连接数据库的模块2
在国内如何加快下载模块的速度?
首先打开cmd窗口,复制以下代码回车运行,然后依次执行上面的安装命令
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
本文章介绍的完整代码已经在python3.8.3环境中验证过,可以直接复制使用
程序运行方法:将以下代码保存为:test.py,然后在对应目录打开cmd窗口,输入magic命令:streamlit run test.py,然后输入回车,遇到输入邮箱部分时,只需输入一个地址。是的,然后浏览器会自动打开运行并显示界面的上传部分
# -*- coding: utf-8 -*-
import streamlit as st
from st_aggrid import AgGrid
import pandas as pd
import pymysql
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
uploaded_file = st.file_uploader("请选择要上传的xls格式表格!")
if uploaded_file is not None:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
st.success("上传成功!")
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
else:
st.warning("请上传xls表格!")
以下是代码说明部分:
1.engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
这句话的作用是搭建一个数据库连接引擎,root是数据库用户名,abcde是数据库密码,localhost是数据库地址,如果有固定IP,请用固定IP替换localhost,python是数据库名称,charset=utf8 表示设置 数据库必须支持中文显示
2.uploaded_file = st.file_uploader("请选择要上传的xls格式表!")
这是表单的上传组件,见效果页最上方,标准写法,双引号里面的内容可以改
3. 整个程序是在if---else框架中编写的。当页面检测到用户没有上传表单时,页面底部会显示黄色警告,提醒用户需要上传表单。对应代码:st.warning("请上传xls表单!")
4. 数据表上传到页面的显示部分,使用from st_aggrid import AgGrid语句引入的AgGrid。这个模块可以很方便的将dataframe数据用1行代码转换成表格并显示在网页上
对应程序中的代码为:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
5.如何将pandas读取的dataframe数据上传到指定的python数据库?
使用这段代码:
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
name字段指定上传到数据库后对应表的名称,str(uploaded_file.name).replace(".xls","")可以自动获取用户上传的表名,使用字符串替换去除文件后缀的方法,即使用表名作为数据库中的表名
con 指定数据库连接引擎
if_exists 决定上传方式,这里是replace方法,也就是替换方法。表单上传后,如果数据库中存在相同的内容,则进行替换操作;如果您需要向原创表单添加写入,您可以添加替换替换为附加
6.如何验证表单中的数据是否已经成功上传到数据库?
我们用下面的代码来验证
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
其中db是pymysql模块的数据库连接引擎
sql是标准的sql语句,意思是从上传的表中读取所有数据
游标 = db.cursor()
游标.执行(sql)
mit()
这3句话的作用就是把sql提交给数据执行
df2=pd.read_sql(sql,con=db)的作用是把读取的内容变成dataframe
st.dataframe(df2)的作用是在网页上显示dataframe
本文使用的数据库是 Mariadb。如何搭建自己的Mariadb数据库,请看作者下面的视频
如果想深入了解数据库或者Mysql相关内容,可以购买以下推荐书籍进行学习
如果您有什么不明白的或者更好的想法,欢迎在下方评论区与我互动,谢谢! 查看全部
python网页数据抓取(如何通过网页快速收集表格,达到自动化办公的效果?)
想必很多工作中的朋友都用表格作为整理器采集了一些资料。发送和接收电子邮件需要时间和精力。大家想通过网络上传的表格有什么好办法采集采集吗?羊毛布?
本文即将介绍一种快捷方式,帮助您通过网页快速采集表单,达到自动化办公的效果,让您更快下班!
通过阅读本文,您将学习以下技能:
(1)使用Python搭建自己的交互式网页
(2)掌握python读表的方法(包括pandas的用法)
(3)使用df.to_sql,一行代码将表单上传到数据库
(4) 2种不同的数据连接方式
(5)sql语句怎么写
本文内容分为3部分:
第 1 部分:网页上传组件
第 2 部分:上传到数据库
第三部分:从数据库中拉取数据,验证是否上传成功
效果图如下:
网页效果图
想知道它是如何实现的吗?慢慢听我说
为了实现以上效果图,我们需要安装几个python库
pip install streamlit #构建web网页的基础模块
pip install pandas #读取表格的模块1
pip install xlrd #读取表格的模块2
pip install streamlit-aggrid #在网页中显示表格的模块
pip install pymysql #连接数据库的模块1
pip install sqlalchemy #连接数据库的模块2
在国内如何加快下载模块的速度?
首先打开cmd窗口,复制以下代码回车运行,然后依次执行上面的安装命令
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
本文章介绍的完整代码已经在python3.8.3环境中验证过,可以直接复制使用
程序运行方法:将以下代码保存为:test.py,然后在对应目录打开cmd窗口,输入magic命令:streamlit run test.py,然后输入回车,遇到输入邮箱部分时,只需输入一个地址。是的,然后浏览器会自动打开运行并显示界面的上传部分
# -*- coding: utf-8 -*-
import streamlit as st
from st_aggrid import AgGrid
import pandas as pd
import pymysql
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
uploaded_file = st.file_uploader("请选择要上传的xls格式表格!")
if uploaded_file is not None:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
st.success("上传成功!")
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
else:
st.warning("请上传xls表格!")
以下是代码说明部分:
1.engine = create_engine('mysql+pymysql://root:abcde@localhost/python?charset=utf8')
这句话的作用是搭建一个数据库连接引擎,root是数据库用户名,abcde是数据库密码,localhost是数据库地址,如果有固定IP,请用固定IP替换localhost,python是数据库名称,charset=utf8 表示设置 数据库必须支持中文显示
2.uploaded_file = st.file_uploader("请选择要上传的xls格式表!")
这是表单的上传组件,见效果页最上方,标准写法,双引号里面的内容可以改
3. 整个程序是在if---else框架中编写的。当页面检测到用户没有上传表单时,页面底部会显示黄色警告,提醒用户需要上传表单。对应代码:st.warning("请上传xls表单!")
4. 数据表上传到页面的显示部分,使用from st_aggrid import AgGrid语句引入的AgGrid。这个模块可以很方便的将dataframe数据用1行代码转换成表格并显示在网页上
对应程序中的代码为:
df1 = pd.read_excel(uploaded_file)
AgGrid(df1)
5.如何将pandas读取的dataframe数据上传到指定的python数据库?
使用这段代码:
df1.to_sql(name=str(uploaded_file.name).replace(".xls",""), con=engine, chunksize=1000, if_exists='replace', index=None)
name字段指定上传到数据库后对应表的名称,str(uploaded_file.name).replace(".xls","")可以自动获取用户上传的表名,使用字符串替换去除文件后缀的方法,即使用表名作为数据库中的表名
con 指定数据库连接引擎
if_exists 决定上传方式,这里是replace方法,也就是替换方法。表单上传后,如果数据库中存在相同的内容,则进行替换操作;如果您需要向原创表单添加写入,您可以添加替换替换为附加
6.如何验证表单中的数据是否已经成功上传到数据库?
我们用下面的代码来验证
db = pymysql.connect(host="localhost", user="root", password="abcde", database="python", charset="utf8")
sql="select * from "+str(uploaded_file.name).replace(".xls","")
cursor = db.cursor()
cursor.execute(sql)
db.commit()
df2=pd.read_sql(sql,con=db)
st.success("数据库中的表格内容如下")
st.dataframe(df2)
其中db是pymysql模块的数据库连接引擎
sql是标准的sql语句,意思是从上传的表中读取所有数据
游标 = db.cursor()
游标.执行(sql)
mit()
这3句话的作用就是把sql提交给数据执行
df2=pd.read_sql(sql,con=db)的作用是把读取的内容变成dataframe
st.dataframe(df2)的作用是在网页上显示dataframe
本文使用的数据库是 Mariadb。如何搭建自己的Mariadb数据库,请看作者下面的视频
如果想深入了解数据库或者Mysql相关内容,可以购买以下推荐书籍进行学习
如果您有什么不明白的或者更好的想法,欢迎在下方评论区与我互动,谢谢!
python网页数据抓取(前几天遇到一个非计算机行业的同学提了一个怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-12 19:01
一直在关注网络爬虫,看了很多大牛的文章,感觉网络爬虫是学习python的入门技术。就在几天前,我遇到了一位非计算机行业的同学,他询问了从互联网上获取电子邮件信息的问题。我借此机会尝试了python大法。
先分析需求:学生想获取大量的邮箱地址,但是在国内哪里可以获取大量的邮箱地址呢?我首先想到的是贴吧,所以我决定从贴吧那里获取评论。
然后,通过观察贴吧的结构,我们可以看出贴吧的整体结构还是比较规则的。因此,决定按照以下顺序跟踪一定级别的采集贴吧信息:
首先从某个贴吧首页抓取所有帖子的贴吧链接信息,抓取每个帖子的详细信息
观察某贴吧的主页。最底层是页面导航栏。从源码中可以看到贴吧的总发帖数。从链接中可以看出贴吧是每50个帖子为一页
下一步就是抢首页,匹配贴吧帖子总数
get_Html_Data() 函数获取网页源代码
#抓取首页 调用get_tie()函数获取帖子个数
def get_Html_Data(self, url):
Ex_value = 1.7
userAgent = headerfile.USER_AGENTS
time.sleep(random.uniform(0.5, 1.6))
if url not in self.closetable:
request = urllib2.Request(url)
request.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8')
request.add_header('User-Agent', random.choice(userAgent))
proxy_handler = urllib2.ProxyHandler(random.choice(self.readIp()))
urllib2.build_opener(proxy_handler)
response = urllib2.urlopen(request,timeout=5)
if response.geturl() == url:
htmlpage = response.read()
self.get_tie(htmlpage)
return htmlpage
else:
return 0
print '获取网页出错'
else:
print '已获取过该网页'
tie_counter() 函数获取帖子总数
#找出该贴吧共有多少页帖子
def tie_counter(self, myPage):
# 匹配 "尾页" 来获取尾页内容
lastpage = re.search(r'class="th_footer_l">(.*?)个', myPage, re.S)
if lastpage:
lastpage = re.search(r'"red_text">(\d+?)', str(lastpage.group(1)), re.S)
if lastpage :
endPage = int(lastpage.group(1))
# endPage = int(lastpage.group(1))
else:
endPage = 0
print u'log:无法计算该帖吧有多少页!'
return endPage
然后遍历贴吧的所有页面
def main_in(self,url):
htmlpage = self.get_Html_Data(url)
self.tie_page_num = self.tie_counter(htmlpage) / 50
url = url + '&ie=utf-8&pn='
for i in range(1, self.tie_page_num):
in_url = url + str(i*50)
self.get_Html_Data(in_url)
self.Write_into_closetable(in_url)
print in_url
使用get_tie()函数在访问每个页面时匹配帖子ID,并组合成帖子链接放在对列
<p> def get_tie(self,htmlpage):
# 朋友过个招?
print '获取网页'
htmlpage = htmlpage.decode('utf-8')#----------------------------------有问题需要修改(UnicodeDecodeError: 'utf8' codec can't decode bytes in position 151173-151174: invalid continuation by)
tie_nums = re.findall(' 查看全部
python网页数据抓取(前几天遇到一个非计算机行业的同学提了一个怎么办?)
一直在关注网络爬虫,看了很多大牛的文章,感觉网络爬虫是学习python的入门技术。就在几天前,我遇到了一位非计算机行业的同学,他询问了从互联网上获取电子邮件信息的问题。我借此机会尝试了python大法。
先分析需求:学生想获取大量的邮箱地址,但是在国内哪里可以获取大量的邮箱地址呢?我首先想到的是贴吧,所以我决定从贴吧那里获取评论。
然后,通过观察贴吧的结构,我们可以看出贴吧的整体结构还是比较规则的。因此,决定按照以下顺序跟踪一定级别的采集贴吧信息:
首先从某个贴吧首页抓取所有帖子的贴吧链接信息,抓取每个帖子的详细信息
观察某贴吧的主页。最底层是页面导航栏。从源码中可以看到贴吧的总发帖数。从链接中可以看出贴吧是每50个帖子为一页
下一步就是抢首页,匹配贴吧帖子总数
get_Html_Data() 函数获取网页源代码
#抓取首页 调用get_tie()函数获取帖子个数
def get_Html_Data(self, url):
Ex_value = 1.7
userAgent = headerfile.USER_AGENTS
time.sleep(random.uniform(0.5, 1.6))
if url not in self.closetable:
request = urllib2.Request(url)
request.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8')
request.add_header('User-Agent', random.choice(userAgent))
proxy_handler = urllib2.ProxyHandler(random.choice(self.readIp()))
urllib2.build_opener(proxy_handler)
response = urllib2.urlopen(request,timeout=5)
if response.geturl() == url:
htmlpage = response.read()
self.get_tie(htmlpage)
return htmlpage
else:
return 0
print '获取网页出错'
else:
print '已获取过该网页'
tie_counter() 函数获取帖子总数
#找出该贴吧共有多少页帖子
def tie_counter(self, myPage):
# 匹配 "尾页" 来获取尾页内容
lastpage = re.search(r'class="th_footer_l">(.*?)个', myPage, re.S)
if lastpage:
lastpage = re.search(r'"red_text">(\d+?)', str(lastpage.group(1)), re.S)
if lastpage :
endPage = int(lastpage.group(1))
# endPage = int(lastpage.group(1))
else:
endPage = 0
print u'log:无法计算该帖吧有多少页!'
return endPage
然后遍历贴吧的所有页面
def main_in(self,url):
htmlpage = self.get_Html_Data(url)
self.tie_page_num = self.tie_counter(htmlpage) / 50
url = url + '&ie=utf-8&pn='
for i in range(1, self.tie_page_num):
in_url = url + str(i*50)
self.get_Html_Data(in_url)
self.Write_into_closetable(in_url)
print in_url
使用get_tie()函数在访问每个页面时匹配帖子ID,并组合成帖子链接放在对列
<p> def get_tie(self,htmlpage):
# 朋友过个招?
print '获取网页'
htmlpage = htmlpage.decode('utf-8')#----------------------------------有问题需要修改(UnicodeDecodeError: 'utf8' codec can't decode bytes in position 151173-151174: invalid continuation by)
tie_nums = re.findall('
python网页数据抓取(博客pythonselenium循环选择python3seleniumActionChains用法及Alert对话框处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-12 18:25
项目介绍
这个项目是为一些复杂的报表解析和爬取列表数据。以国网为例(最好改成网站),它会根据数据库自动配置文本(数据库是字典),继续
点击树状结构,然后在下拉框中输入时间,选择省(时间和省由配置文件配置),但是下拉列表的xpath没有数据库化,在这个阶段的代码中是硬编码的。
项目开始通过递归判断是否是最后一层。字典表可以配置N个级别,这取决于你的网站复杂度
加入QQ群:943841699
源码地址:复生若梦/table_creeper
技术
Python3.6
selenium(如果你不了解selenium,可以参考博客
python selenium 选择器循环选择
python3 selenium ActionChains 使用
python3 selenium Select用法和Alert对话框处理
)
本项目使用谷歌浏览器内核,需要安装谷歌及配套驱动
参考:selenium打开chrome时出错-五道十魂的博客-CSDN博客
而且linux没有接口,需要配置无接口方式爬取
参考:linux selenium chrome chromedriver及无浏览器界面的运行方式
使用说明
1.复制资源文件下的SQL并导入数据库
2. 配置 config.py
3.根据技术目录指南完成安装
4.现阶段只有一张表,class_type为类型,如果类型不同网站,class_type不同,
group_code为分组码,按照00000000,每一位代表不同的含义,对应自己库中的分类。 查看全部
python网页数据抓取(博客pythonselenium循环选择python3seleniumActionChains用法及Alert对话框处理)
项目介绍
这个项目是为一些复杂的报表解析和爬取列表数据。以国网为例(最好改成网站),它会根据数据库自动配置文本(数据库是字典),继续
点击树状结构,然后在下拉框中输入时间,选择省(时间和省由配置文件配置),但是下拉列表的xpath没有数据库化,在这个阶段的代码中是硬编码的。
项目开始通过递归判断是否是最后一层。字典表可以配置N个级别,这取决于你的网站复杂度
加入QQ群:943841699
源码地址:复生若梦/table_creeper
技术
Python3.6
selenium(如果你不了解selenium,可以参考博客
python selenium 选择器循环选择
python3 selenium ActionChains 使用
python3 selenium Select用法和Alert对话框处理
)
本项目使用谷歌浏览器内核,需要安装谷歌及配套驱动
参考:selenium打开chrome时出错-五道十魂的博客-CSDN博客
而且linux没有接口,需要配置无接口方式爬取
参考:linux selenium chrome chromedriver及无浏览器界面的运行方式
使用说明
1.复制资源文件下的SQL并导入数据库
2. 配置 config.py
3.根据技术目录指南完成安装
4.现阶段只有一张表,class_type为类型,如果类型不同网站,class_type不同,
group_code为分组码,按照00000000,每一位代表不同的含义,对应自己库中的分类。
python网页数据抓取(python网页数据怎么用解决一些其他问题的问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-12 14:01
python网页数据抓取根据知乎上各位大神的意见,后面又爬了多次。有的是电脑配置跟不上,后面有一次的配置是网速没问题,但是获取的数据较少,这次是和爬虫没有关系,就是看下能不能爬虫解决一些其他的问题。首先是先处理下数据库,python用sqlalchemy吧(网上有很多教程可以查,这里主要是写个python环境)。
然后就是写爬虫吧。这里用的是python最火的scrapy,因为初学者比较好学。网上有许多教程可以查,个人比较喜欢看这里。另外个人使用最多的是scrapy,比较简单。django也可以用,但是前提你了解scrapy后,弄懂流程,弄不懂还是要学scrapy。实际上网上找了半天有一些教程说scrapy实际上配置较麻烦。
可以先从scrapy学起。最主要的就是request的处理,学习了selenium就觉得不难。学python网络方面,学会怎么用网络api,基本也没有太大问题。比如爬下b站的视频就好。python没有解释器,虽然能用ide。比如用pycharm写写脚本比vim友好。网上找了点学习教程,比如webdriver,webdriver教程,一句话讲django使用方法,讲解的还是不够详细。
个人觉得,学习需要同时学习两种技术,比如ui交互,比如网络数据转发。然后研究什么后台交互数据,一般而言github或者segmentfault的提问,都是有价值的。现在也用django后台把b站的视频放在网站上,尽管没有放全(都不知道放哪里),以后会再分享一个教程,主要是学习models的使用,最后会简单写爬虫。最后记得复习下java的面向对象,还有c的继承。最后,祝学习愉快~。 查看全部
python网页数据抓取(python网页数据怎么用解决一些其他问题的问题?)
python网页数据抓取根据知乎上各位大神的意见,后面又爬了多次。有的是电脑配置跟不上,后面有一次的配置是网速没问题,但是获取的数据较少,这次是和爬虫没有关系,就是看下能不能爬虫解决一些其他的问题。首先是先处理下数据库,python用sqlalchemy吧(网上有很多教程可以查,这里主要是写个python环境)。
然后就是写爬虫吧。这里用的是python最火的scrapy,因为初学者比较好学。网上有许多教程可以查,个人比较喜欢看这里。另外个人使用最多的是scrapy,比较简单。django也可以用,但是前提你了解scrapy后,弄懂流程,弄不懂还是要学scrapy。实际上网上找了半天有一些教程说scrapy实际上配置较麻烦。
可以先从scrapy学起。最主要的就是request的处理,学习了selenium就觉得不难。学python网络方面,学会怎么用网络api,基本也没有太大问题。比如爬下b站的视频就好。python没有解释器,虽然能用ide。比如用pycharm写写脚本比vim友好。网上找了点学习教程,比如webdriver,webdriver教程,一句话讲django使用方法,讲解的还是不够详细。
个人觉得,学习需要同时学习两种技术,比如ui交互,比如网络数据转发。然后研究什么后台交互数据,一般而言github或者segmentfault的提问,都是有价值的。现在也用django后台把b站的视频放在网站上,尽管没有放全(都不知道放哪里),以后会再分享一个教程,主要是学习models的使用,最后会简单写爬虫。最后记得复习下java的面向对象,还有c的继承。最后,祝学习愉快~。
python网页数据抓取(python网页数据抓取爬虫专题课-优达学城-python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-11 04:03
python网页数据抓取爬虫专题课-优达学城-python爱好者社区点击上面链接进入这个网站,就能直接观看了,全是视频,去年十一月的,过时不少,实在无聊,我又看了两遍,发现有些思路挺有意思的,找了些资料,发到了专栏里。我不是专业做这个行业的,只是python在读研究生,非科班,直接从最简单的爬虫抓取开始吧。
定位先说说自己的定位,预计学习时间两周,只是抓取一些商品销量数据,期待能在某一点入手。同一个页面,可以针对一个选项进行抓取,只要抓取抓到位置就可以,抓取方便,就是花的时间略多。背景一样,但需要进行相应的处理和拆分工作,对比下页面两个定位结果。先点击亚马逊,找到一个页面:我们看到,因为没有登录等其他操作,页面只有一个商品的销量,其他都没有,这里的商品销量,就是指销量。然后我们去不同的网站去抓取销量数据,一下子就抓了各省的销量数据:可以看到,分别抓取到销量最大的2。
0、2
3、3
4、4
5、4
6、4
7、5
7、6
2、6
1、6
8、6
6、6
8、68。这个抓取就有点类似于springmvc抓取框架的方式了,只要获取到网页最后20个元素,然后判断其数量,就能知道到底该抓取哪个位置。毕竟,销量都存在于前十个元素中,那前十个都在哪里呢?我知道,这个问题还是有点难的,那就直接在找几个点,同样是抓取销量前十个数据吧。
这个定位比前面的网站稍微差了点,
1、
3、
5、
7、
9、1
0、12,
7、9这些数据。比这个稍微好点的是我们还抓取到了自定义地区这个点,其他定位是抓取1到10,但有时候自定义地区不一定就能得到所有的销量数据。那最后一步就是继续从这个点进行延伸和扩展了,我们继续扩展看看:抓取销量前十的省份我又抓取了销量前十的城市:剩下的省份和城市就不是我擅长的范围了,我还会更专注于抓取销量前十的省份。
这时候,新的问题来了,继续手工去手动调节每个省份的销量数量,效率太低了,我们还需要手动去分析一下每个城市的销量数量:我能选择不同城市的商品销量数据,那么只要用不同城市,就能同时抓取数据,因为同一个商品是可以存放多个地区的销量数据的,就像下面这个动图这样:拿一个城市的某个商品存放多个地区就行了,其他地区的不要了,实现起来也很简单,就算有一些跨国,我们可以一个城市一个城市来抓,这样就不会丢失销量数据了。
我随便抓了一个德国的销量,然后从德国省份,抓取到了全国的销量数据,这样还是比较方便的,实际上跨国抓取数据都是可以这。 查看全部
python网页数据抓取(python网页数据抓取爬虫专题课-优达学城-python)
python网页数据抓取爬虫专题课-优达学城-python爱好者社区点击上面链接进入这个网站,就能直接观看了,全是视频,去年十一月的,过时不少,实在无聊,我又看了两遍,发现有些思路挺有意思的,找了些资料,发到了专栏里。我不是专业做这个行业的,只是python在读研究生,非科班,直接从最简单的爬虫抓取开始吧。
定位先说说自己的定位,预计学习时间两周,只是抓取一些商品销量数据,期待能在某一点入手。同一个页面,可以针对一个选项进行抓取,只要抓取抓到位置就可以,抓取方便,就是花的时间略多。背景一样,但需要进行相应的处理和拆分工作,对比下页面两个定位结果。先点击亚马逊,找到一个页面:我们看到,因为没有登录等其他操作,页面只有一个商品的销量,其他都没有,这里的商品销量,就是指销量。然后我们去不同的网站去抓取销量数据,一下子就抓了各省的销量数据:可以看到,分别抓取到销量最大的2。
0、2
3、3
4、4
5、4
6、4
7、5
7、6
2、6
1、6
8、6
6、6
8、68。这个抓取就有点类似于springmvc抓取框架的方式了,只要获取到网页最后20个元素,然后判断其数量,就能知道到底该抓取哪个位置。毕竟,销量都存在于前十个元素中,那前十个都在哪里呢?我知道,这个问题还是有点难的,那就直接在找几个点,同样是抓取销量前十个数据吧。
这个定位比前面的网站稍微差了点,
1、
3、
5、
7、
9、1
0、12,
7、9这些数据。比这个稍微好点的是我们还抓取到了自定义地区这个点,其他定位是抓取1到10,但有时候自定义地区不一定就能得到所有的销量数据。那最后一步就是继续从这个点进行延伸和扩展了,我们继续扩展看看:抓取销量前十的省份我又抓取了销量前十的城市:剩下的省份和城市就不是我擅长的范围了,我还会更专注于抓取销量前十的省份。
这时候,新的问题来了,继续手工去手动调节每个省份的销量数量,效率太低了,我们还需要手动去分析一下每个城市的销量数量:我能选择不同城市的商品销量数据,那么只要用不同城市,就能同时抓取数据,因为同一个商品是可以存放多个地区的销量数据的,就像下面这个动图这样:拿一个城市的某个商品存放多个地区就行了,其他地区的不要了,实现起来也很简单,就算有一些跨国,我们可以一个城市一个城市来抓,这样就不会丢失销量数据了。
我随便抓了一个德国的销量,然后从德国省份,抓取到了全国的销量数据,这样还是比较方便的,实际上跨国抓取数据都是可以这。
python网页数据抓取(一下如何判断网页的编码:网上很多网页编码格式都不一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-09 16:11
在Web开发过程中,我们经常会遇到网页爬取和分析,可以用各种语言来完成。喜欢用python来实现,因为python提供了很多成熟的模块,可以轻松实现网页爬取。
但是在爬取的过程中会遇到编码问题,所以今天我们来看看如何判断一个网页的编码:
互联网上很多网页都有不同的编码格式,一般是GBK、GB2312、UTF-8等。
我们在获取到网页的数据后,首先要判断网页的编码,然后才能将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
使用 chardet 模块
1 #如果你的python没有安装chardet模块,你需要首先安装一下chardet判断编码的模块哦
2 #author:pythontab.com
3 import chardet
4 import urllib
5 #先获取网页内容
6 data1 = urllib.urlopen(‘http://www.baidu.com‘).read()
7 #用chardet进行内容分析
8 chardit1 = chardet.detect(data1)
9
10 print chardit1[‘encoding‘] # baidu
实施结果如下:
gb2312
这个结果是正确的。可以自己验证~~ 查看全部
python网页数据抓取(一下如何判断网页的编码:网上很多网页编码格式都不一样)
在Web开发过程中,我们经常会遇到网页爬取和分析,可以用各种语言来完成。喜欢用python来实现,因为python提供了很多成熟的模块,可以轻松实现网页爬取。
但是在爬取的过程中会遇到编码问题,所以今天我们来看看如何判断一个网页的编码:
互联网上很多网页都有不同的编码格式,一般是GBK、GB2312、UTF-8等。
我们在获取到网页的数据后,首先要判断网页的编码,然后才能将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
使用 chardet 模块
1 #如果你的python没有安装chardet模块,你需要首先安装一下chardet判断编码的模块哦
2 #author:pythontab.com
3 import chardet
4 import urllib
5 #先获取网页内容
6 data1 = urllib.urlopen(‘http://www.baidu.com‘).read()
7 #用chardet进行内容分析
8 chardit1 = chardet.detect(data1)
9
10 print chardit1[‘encoding‘] # baidu
实施结果如下:
gb2312
这个结果是正确的。可以自己验证~~
python网页数据抓取(有些网页就是动态网页的图片元素是怎么自动形成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-08 05:02
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态生成的图片我说的网页。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src时,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request里面加上上面的header中的信息,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节url,并根据章节url获取该章节的总页数,并获取每个页面的url,参考资料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage 查看全部
python网页数据抓取(有些网页就是动态网页的图片元素是怎么自动形成的)
好的,上次我们讲了如何抓取豆瓣美子和暴走漫画页面的图片,但是这些页面都是静态页面,几行代码就可以解决问题,因为图片的src是在原来的html中页面(具体来说,失控的漫画和尴尬的百科全书如何自动形成一个静态页面是要讨论的)。静态页面的优点是它们加载速度非常快。
然而,并不是所有的网页抓取都那么简单。有些网页是动态网页,也就是说页面中的图片元素是由js生成的。原来的html没有图片的src信息,所以希望Python可以模拟浏览器加载js,执行js后返回页面,这样就可以看到src信息了。我们知道图片在哪,不能下载到本地吗(其实如果有链接你可能抓不到,后面再讲)。
一些网站为了防止别人获取图片,或者知识产权,有很多方法,比如漫画网站、爱漫画和腾讯漫画,前者是动态生成的图片我说的网页。,所以当你打开一个有漫画的页面时,图片加载会很慢,因为是js生成的(毕竟不会让你轻易抓取)。后者比较棘手,或者如果你想捕捉Flash加载的图像,你需要Python来模拟Flash。以后再研究这部分。
那么上面说的,即使我已经实现了Python用js加载页面并获取了图片元素的src,在访问src时,也会说404,比如这个链接。这是爱情漫画的全职猎人之一。在漫画页面上,我在使用浏览F12功能的时候,找到了图片的src属性。当我将链接复制到浏览器时,他告诉我一个 404 错误。该页面不存在。是什么原因?显然是这个地址。啊,而且多次刷新的页面地址也是一样的(别告诉我你能看到这张图,是浏览器缓存的原因,你可以尝试清除缓存,骚年)?那是因为,如果你抓拍网页加载,你会发现页面图片的Get请求有如下信息:
GET /Files/Images/76/59262/imanhua_001.jpgHTTP/1.1
接受 image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
推荐人
接受语言zh-CN
用户代理 Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko
接受编码 gzip,放气
主持人
连接保持活动
在这里,你只需要模拟他的Get请求来获取图片,因为网站过滤了Get,只有你自己的请求网站才会返回图片,所以我们要在request里面加上上面的header中的信息,经过测试,只需要添加Referer
信息就行。URL 是当前网页的 URL。
我们已经说明了具体实现的原理,接下来看看用的是什么包:
1.BeautifulSoup包用于根据URL获取静态页面中的元素信息。我们用它来获取爱漫画网站中某部漫画的所有章节url,并根据章节url获取该章节的总页数,并获取每个页面的url,参考资料
2.Ghost包,用于根据每个页面的url动态加载js,加载后获取页面代码,获取image标签的src属性,Ghost官网,参考资料
3.urllib2包,模拟Get请求,使用add_header添加Referer参数获取返回图片
4.chardet 包,解决页面乱码问题
我们依次以以上四个步骤为例,或者以抢爱漫画网站的漫画为例:
1. 输入漫画号,通过BeautifulSoup获取所有章节和章节下的子页面url
<p>webURL = 'http://www.imanhua.com/'
cartoonNum = raw_input("请输入漫画编号:")
basicURL = webURL + u'comic/' + cartoonNum
#获取漫画名称
soup = BeautifulSoup(html)
cartoonName = soup.find('div',class_='share').find_next_sibling('h1').get_text()
print u'正在下载漫画: ' + cartoonName
#创建文件夹
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,cartoonName)
if not os.path.isdir(new_path):
os.mkdir(new_path)
#解析所有章节的URL
chapterURLList = []
chapterLI_all = soup.find('ul',id = 'subBookList').find_all('a')
for chapterLI in chapterLI_all:
chapterURLList.append(chapterLI.get('href'))
#print chapterLI.get('href')
#遍历章节的URL
for chapterURL in chapterURLList:
chapter_soup = BeautifulSoup(urllib2.urlopen(webURL+str(chapterURL),timeout=120).read())
chapterName = chapter_soup.find('div',id = 'title').find('h2').get_text()
print u'正在下载章节: ' + chapterName
#根据最下行的最大页数获取总页数
allChapterPage = chapter_soup.find('strong',id = 'pageCurrent').find_next_sibling('strong').get_text()
print allChapterPage
#然后遍历所有页,组合成url,保存图片
currentPage = 1
fetcher = FetcherCartoon()
uurrll = str(webURL+str(chapterURL))
imgurl = fetcher.getCartoonUrl(uurrll)
if imgurl is not None:
while currentPage
python网页数据抓取(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-08 03:12
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登录网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">【组织】关于抓取网页,分析网页内容,模拟登录逻辑/流程及注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录的内部逻辑流程网站(百度首页)
"target="_top">【教程】如何使用IE9的F12分析网站登录过程中复杂的(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">[完成]关于使用正则表达式处理html代码的建议 查看全部
python网页数据抓取(>如何用Python,C#等语言去实现抓取网页+模拟登陆网站)
"target="_top">如何使用Python、C#等语言实现抓取静态网页+抓取动态网页+模拟登录网站
"target="_top">[组织] 各种浏览器中的开发者工具:IE9 中的 F12,Chrome 中的 Ctrl+Shift+J,Firefox 中的 Firebug
"target="_top">[总结] 浏览器中的开发者工具(IE9中的F12和Chrome中的Ctrl+Shift+I)——强大的网页分析工具
"target="_top">【组织】关于抓取网页,分析网页内容,模拟登录逻辑/流程及注意事项
"target="_top">【教程】教你使用工具(IE9的F12)分析模拟登录的内部逻辑流程网站(百度首页)
"target="_top">【教程】如何使用IE9的F12分析网站登录过程中复杂的(参数、cookies等)值(来源)
"target="_top">【完成】关于http(GET或POST)请求中URL地址的编码(encode)和解码(decode)
"target="_top">[完成]HTML网页源码的charset格式(GB2312、GBK、UTF-8、ISO8859-1等)说明
"target="_top">[整理]爬网、模拟登录、爬取动态网页内容过程中涉及的headers信息、cookie信息、POST数据的处理逻辑。
"target="_top">[完成]关于使用正则表达式处理html代码的建议
python网页数据抓取( 有些函数动态加载网页数据的安装方法-有些网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-08 03:10
有些函数动态加载网页数据的安装方法-有些网页
)
有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装Node.js后通过Node.js安装PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar 查看全部
python网页数据抓取(
有些函数动态加载网页数据的安装方法-有些网页
)
有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装Node.js后通过Node.js安装PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-07 05:27
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
我刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习qun:227-435-450即可获取,内附:开发工具和安装包,以及系统学习路线图
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
查看全部
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享
)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本文文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
我刚整理了一套2018年最新的0基础入门和进阶教程,无私分享,加上Python学习qun:227-435-450即可获取,内附:开发工具和安装包,以及系统学习路线图
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。举个例子,我们先来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后重复抓取新的链接。
python网页数据抓取(一下怎么一步一步写爬虫(headers)数据过程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-05 00:20
最近经常有人在看教程的时候问我写爬虫好不好,但是一上手,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
request用于请求网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .
分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候一定要注意!
所以,现在整体思路很清晰了:请求一个网页==>>获取html源代码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,所以那你就可以把所有的内容都抓到了!我们把代码写在外面。
开始编写爬虫
先导入2个库,然后用一行代码得到网页html,打印出来看看效果
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到如下所示的请求Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。关于如何快速学习Python,可以添加编辑器的Python学习群:699+749+852。不管你是新手还是大牛,小编都欢迎。不时分享干货。欢迎初学者和高级学生。伙伴。每天晚上20:00会有直播,与大家分享Python知识和路由方法。
注意在火狐浏览器中,如果头部数据很长,会被缩写。看到上图中间的省略号了...所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加会返回获取是否成功的提示,不是html源码),我们先搭建页码循环,找到html翻页代码
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配。这次我们只展示了电影名称、评分和详情网址这3个结果
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也是里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行获取class属性为“channel-detail movie-item-title”的div标签下的title值和div下a标签的href值(这里没有复制)xpath路径,当然可以的话,我建议你用这个方法,因为如果你用路径,如果修改了网页的结构,那么我们的代码就会被重写。。 .)
第17、18、2行代码获取div标签下的所有文本内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我会抓住前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不良影响,这是基本要求!后面还有这个网站,大概100多页以后,需要登录,这点请注意,可以自己试试! 查看全部
python网页数据抓取(一下怎么一步一步写爬虫(headers)数据过程(图))
最近经常有人在看教程的时候问我写爬虫好不好,但是一上手,爪子都麻了。. . 所以今天跟刚开始学习爬虫的同学们分享一下如何一步步写爬虫,直到拿到数据。
准备工具
首先是准备工具:python3.6、pycharm、请求库、lxml库和火狐浏览器
这两个库是python的第三方库,需要用pip安装!
request用于请求网页,获取网页的源码,然后使用lxml库分析html源码,从中取出我们需要的内容!
你使用火狐浏览器而不使用其他浏览器的原因没有其他意义,只是习惯而已。. .
分析网页
工具准备好后,就可以开始我们的爬虫之旅了!今天我们的目标是捕捉猫眼电影的经典部分。大约有80,000条数据。
打开网页后,首先要分析网页的源代码,看它是静态的还是动态的,还是其他形式的。这个网页是一个静态网页,所以源码中收录了我们需要的内容。
很明显,它的电影名称和评级在源代码中,但评级分为两部分。这点在写爬虫的时候一定要注意!
所以,现在整体思路很清晰了:请求一个网页==>>获取html源代码==>>匹配内容,然后在外面添加一个步骤:获取页码==>>构建一个所有页面的循环,所以那你就可以把所有的内容都抓到了!我们把代码写在外面。
开始编写爬虫
先导入2个库,然后用一行代码得到网页html,打印出来看看效果
好吧,网站 不允许爬虫运行!加个headers试试(headers是身份证明,说明请求的网页是浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,找到一个网络请求,然后找到如下所示的请求Header,复制相关信息,这个header就可以保存了,基本上一个浏览器就是一个UA,下次直接用就可以了。关于如何快速学习Python,可以添加编辑器的Python学习群:699+749+852。不管你是新手还是大牛,小编都欢迎。不时分享干货。欢迎初学者和高级学生。伙伴。每天晚上20:00会有直播,与大家分享Python知识和路由方法。
注意在火狐浏览器中,如果头部数据很长,会被缩写。看到上图中间的省略号了...所以复制的时候一定要先双击展开,复制,然后再修改上面的代码。看
这一次,html被正确打印了!(后面的.text是获取html文本,不添加会返回获取是否成功的提示,不是html源码),我们先搭建页码循环,找到html翻页代码
点击开发者工具左上角的选择元素,然后点击页码,对应的源码位置会自动定位到下方。这里我们可以直观的看到最大页码,先取出来,右击,选择Copy Xpath,然后写在代码里
第9行表示使用lxml中的etree方法解析html,第10行表示从html中查找路径对应的标签。因为页码是文字显示,是标签的文字部分,所以在路径末尾加一个/text 取出文字,最后以列表的形式取出内容。然后我们要观察每个页面的url,还记得刚才页码部分的html吗?
href的值是每个页码对应的url,当然省略了域名部分。可以看到,它的规律是offset的值随着页码的变化而变化(*30) 那么,我们就可以建立一个循环!
第10行,使用[0]取出列表中的pn值,然后构建循环,然后获取新url的html(pn_url),然后去html匹配我们想要的内容!为方便起见,添加一个中断,使其仅循环一次
然后开始匹配。这次我们只展示了电影名称、评分和详情网址这3个结果
可以看到,我们要的内容在dd标签下,下面有3个div,第一个是图片,不用管,第二个是电影名,详情页url也是里面,第三个div里面有评分结果,所以我们可以这样写
第14行还是解析html,第15行和第16行获取class属性为“channel-detail movie-item-title”的div标签下的title值和div下a标签的href值(这里没有复制)xpath路径,当然可以的话,我建议你用这个方法,因为如果你用路径,如果修改了网页的结构,那么我们的代码就会被重写。。 .)
第17、18、2行代码获取div标签下的所有文本内容,还记得分数吗?不是在一个标签下,而是两个标签下的文字内容合并了,这样就搞定了!
然后,使用zip函数将内容一一写入txt文件
注意内容间距和换行符!
至此,爬虫部分基本完成!我们先来看看效果。时间有限,所以我会抓住前5页。代码和结果如下:
后记
整个爬取过程没有任何难度。一开始,您需要注意标题。后面在爬取数据的过程中,一定要学习更多的匹配方法。最后,注意数据量。有两个方面:爬取间隔和爬取数量,不要对网站造成不良影响,这是基本要求!后面还有这个网站,大概100多页以后,需要登录,这点请注意,可以自己试试!
python网页数据抓取(Python并发编程教程(二):线程的具体使用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2021-12-04 09:13
)
网络爬虫程序是一个IO密集型程序。程序涉及到大量的网络IO和本地磁盘IO操作,会消耗大量的时间,从而降低程序的执行效率,而Python提供的多线程可以在一定程度上提高它的执行效率IO 密集型程序。
如果想学习Python多进程、多线程和Python GIL全局解释器锁相关知识,可以参考《Python并发编程教程》。
多线程使用流程 Python提供了两个支持多线程的模块,分别是_thread和threading。其中,_thread 模块处于最底层。与threading模块相比,它的功能有限,所以推荐大家使用threading模块。Threading不仅收录了_thread模块中的所有方法,还提供了一些其他的方法,如下图:
线程的具体用法如下:
from threading import Thread
#线程创建、启动、回收
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
创建多线程的具体过程:
t_list = []
for i in range(5):
t = Thread(target=函数名)
t_list.append(t)
t.start()
for t in t_list:
t.join()
除了使用这个模块,还可以使用Thread线程类来创建多个线程。
在处理线程的过程中,要时刻注意线程的同步,即多个线程不能操作同一个数据,否则会造成数据的不确定性。数据的正确性可以通过线程模块的Lock对象来保证。
例如,如果您使用多个线程将捕获的数据写入磁盘文件,则必须锁定执行写入操作的线程,以防止写入的数据被覆盖。当线程执行完写操作后,会主动释放锁,并继续让其他线程获取锁,如此循环直到所有写操作完成。具体方法如下:
from threading import Lock
lock = Lock()
# 获取锁
lock.acquire()
wirter.writerows("线程锁问题解决")
# 释放锁
lock.release()
Python多线程的队列队列模型,由于GIL全局解释器锁的存在,只允许一个线程同时占用解释器执行程序。当这个线程遇到IO操作时,会主动放弃解释器,让其他处于等待状态的线程获取解释器来执行程序,线程回到等待状态,主要通过线程调度来实现机制。
基于以上原因,我们需要构建一个多线程的数据共享模型,让所有线程都可以从模型中获取数据。队列(先进先出)模块提供了创建共享数据的队列模型。例如,将所有要爬取的URL地址放入一个队列中,每个线程都去这个队列中提取URL。queue模块的具体用法如下:
# 导入模块
from queue import Queue
q = Queue() #创界队列对象
q.put(url) 向队列中添加爬取一个url链接
q.get() # 获取一个url,当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
在多线程爬虫的情况下,下面的多线程方法用于抓取()中的应用类别列,所有类别下的APP名称,下载详情页的类别和URL。如下所示:
图 1:小米应用商店
抓到的数据demo如下:
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
1) 案例分析 通过关键字搜索,我们知道这是一个动态的网站,所以需要进行抓包分析。
刷新网页重新加载数据,可以知道请求头的URL地址,如下图:
https://app.mi.com/categotyAll ... %3D30
查询参数pageSize参数值不变,页面会随着页码的增加而变化,可以通过查看页面元素来查看categoryId,如下图
游戏
实用工具
影音视听
聊天社交
图书阅读
学习教育
效率办公
时尚购物
居家生活
旅行交通
摄影摄像
医疗健康
体育运动
新闻资讯
娱乐消遣
金融理财
因此,您可以使用 Xpath 表达式匹配 href 属性来提取类别 ID 和类别名称。表达式如下:
点击开发者工具的响应选项卡,查看响应数据,如下图:
{
count: 2000,
data: [
{
appId: 1348407,
displayName: "天气暖暖-关心Ta从关心天气开始",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.xiaowoniu.WarmWeather"
},
{
appId: 1348403,
displayName: "贵斌同城",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.gbtc.guibintongcheng"
},
...
...
通过上面的响应内容,我们可以提取出APP总数(count)和APP(displayName)名称,以及下载详情页的packageName。由于每个页面收录 30 个 APP,因此可以使用总数(计数)来计算每个类别中有多少个页面。
pages = int(count) // 30 + 1
下载详情页地址使用packageName拼接,如下图:
link = 'http://app.mi.com/details?id=' + app['packageName']
2) 完整程序完整程序如下:
# -*- coding:utf8 -*-
import requests
from threading import Thread
from queue import Queue
import time
from fake_useragent import UserAgent
from lxml import etree
import csv
from threading import Lock
import json
class XiaomiSpider(object):
def __init__(self):
self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'
# 存放所有URL地址的队列
self.q = Queue()
self.i = 0
# 存放所有类型id的空列表
self.id_list = []
# 打开文件
self.f = open('XiaomiShangcheng.csv','a',encoding='utf-8')
self.writer = csv.writer(self.f)
# 创建锁
self.lock = Lock()
def get_cateid(self):
# 请求
url = 'http://app.mi.com/'
headers = { 'User-Agent': UserAgent().random}
html = requests.get(url=url,headers=headers).text
# 解析
parse_html = etree.HTML(html)
xpath_bds = '//ul[@class="category-list"]/li'
li_list = parse_html.xpath(xpath_bds)
for li in li_list:
typ_name = li.xpath('./a/text()')[0]
typ_id = li.xpath('./a/@href')[0].split('/')[-1]
# 计算每个类型的页数
pages = self.get_pages(typ_id)
#往列表中添加二元组
self.id_list.append( (typ_id,pages) )
# 入队列
self.url_in()
# 获取count的值并计算页数
def get_pages(self,typ_id):
# 获取count的值,即app总数
url = self.url.format(0,typ_id)
html = requests.get(
url=url,
headers={'User-Agent':UserAgent().random}
).json()
count = html['count']
pages = int(count) // 30 + 1
return pages
# url入队函数,拼接url,并将url加入队列
def url_in(self):
for id in self.id_list:
# id格式:('4',pages)
for page in range(1,id[1]+1):
url = self.url.format(page,id[0])
# 把URL地址入队列
self.q.put(url)
# 线程事件函数: get() -请求-解析-处理数据,三步骤
def get_data(self):
while True:
# 判断队列不为空则执行,否则终止
if not self.q.empty():
url = self.q.get()
headers = {'User-Agent':UserAgent().random}
html = requests.get(url=url,headers=headers)
res_html = html.content.decode(encoding='utf-8')
html=json.loads(res_html)
self.parse_html(html)
else:
break
# 解析函数
def parse_html(self,html):
# 写入到csv文件
app_list = []
for app in html['data']:
# app名称 + 分类 + 详情链接
name = app['displayName']
link = 'http://app.mi.com/details?id=' + app['packageName']
typ_name = app['level1CategoryName']
# 把每一条数据放到app_list中,并通过writerows()实现多行写入
app_list.append([name,typ_name,link])
print(name,typ_name)
self.i += 1
# 向CSV文件中写入数据
self.lock.acquire()
self.writer.writerows(app_list)
self.lock.release()
# 入口函数
def main(self):
# URL入队列
self.get_cateid()
t_list = []
# 创建多线程
for i in range(1):
t = Thread(target=self.get_data)
t_list.append(t)
# 启动线程
t.start()
for t in t_list:
# 回收线程
t.join()
self.f.close()
print('数量:',self.i)
if __name__ == '__main__':
start = time.time()
spider = XiaomiSpider()
spider.main()
end = time.time()
print('执行时间:%.1f' % (end-start))
运行上述程序后,打开存储文件,其内容如下:
在我们之间-单机版,休闲创意,http://app.mi.com/details%3Fid ... r.gtx
粉末游戏,模拟经营,http://app.mi.com/details%3Fid ... r.bnn
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
腾讯欢乐麻将全集,棋牌桌游,http://app.mi.com/details?id=com.qqgame.happymj
快游戏,休闲创意,http://app.mi.com/details%3Fid ... h2mgc
皇室战争,战争策略,http://app.mi.com/details%3Fid ... le.mi
地铁跑酷,跑酷闯关,http://app.mi.com/details?id=com.kiloo.subwaysurf
...
... 查看全部
python网页数据抓取(Python并发编程教程(二):线程的具体使用方法
)
网络爬虫程序是一个IO密集型程序。程序涉及到大量的网络IO和本地磁盘IO操作,会消耗大量的时间,从而降低程序的执行效率,而Python提供的多线程可以在一定程度上提高它的执行效率IO 密集型程序。
如果想学习Python多进程、多线程和Python GIL全局解释器锁相关知识,可以参考《Python并发编程教程》。
多线程使用流程 Python提供了两个支持多线程的模块,分别是_thread和threading。其中,_thread 模块处于最底层。与threading模块相比,它的功能有限,所以推荐大家使用threading模块。Threading不仅收录了_thread模块中的所有方法,还提供了一些其他的方法,如下图:
线程的具体用法如下:
from threading import Thread
#线程创建、启动、回收
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
创建多线程的具体过程:
t_list = []
for i in range(5):
t = Thread(target=函数名)
t_list.append(t)
t.start()
for t in t_list:
t.join()
除了使用这个模块,还可以使用Thread线程类来创建多个线程。
在处理线程的过程中,要时刻注意线程的同步,即多个线程不能操作同一个数据,否则会造成数据的不确定性。数据的正确性可以通过线程模块的Lock对象来保证。
例如,如果您使用多个线程将捕获的数据写入磁盘文件,则必须锁定执行写入操作的线程,以防止写入的数据被覆盖。当线程执行完写操作后,会主动释放锁,并继续让其他线程获取锁,如此循环直到所有写操作完成。具体方法如下:
from threading import Lock
lock = Lock()
# 获取锁
lock.acquire()
wirter.writerows("线程锁问题解决")
# 释放锁
lock.release()
Python多线程的队列队列模型,由于GIL全局解释器锁的存在,只允许一个线程同时占用解释器执行程序。当这个线程遇到IO操作时,会主动放弃解释器,让其他处于等待状态的线程获取解释器来执行程序,线程回到等待状态,主要通过线程调度来实现机制。
基于以上原因,我们需要构建一个多线程的数据共享模型,让所有线程都可以从模型中获取数据。队列(先进先出)模块提供了创建共享数据的队列模型。例如,将所有要爬取的URL地址放入一个队列中,每个线程都去这个队列中提取URL。queue模块的具体用法如下:
# 导入模块
from queue import Queue
q = Queue() #创界队列对象
q.put(url) 向队列中添加爬取一个url链接
q.get() # 获取一个url,当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
在多线程爬虫的情况下,下面的多线程方法用于抓取()中的应用类别列,所有类别下的APP名称,下载详情页的类别和URL。如下所示:
图 1:小米应用商店
抓到的数据demo如下:
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
1) 案例分析 通过关键字搜索,我们知道这是一个动态的网站,所以需要进行抓包分析。
刷新网页重新加载数据,可以知道请求头的URL地址,如下图:
https://app.mi.com/categotyAll ... %3D30
查询参数pageSize参数值不变,页面会随着页码的增加而变化,可以通过查看页面元素来查看categoryId,如下图
游戏
实用工具
影音视听
聊天社交
图书阅读
学习教育
效率办公
时尚购物
居家生活
旅行交通
摄影摄像
医疗健康
体育运动
新闻资讯
娱乐消遣
金融理财
因此,您可以使用 Xpath 表达式匹配 href 属性来提取类别 ID 和类别名称。表达式如下:
点击开发者工具的响应选项卡,查看响应数据,如下图:
{
count: 2000,
data: [
{
appId: 1348407,
displayName: "天气暖暖-关心Ta从关心天气开始",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.xiaowoniu.WarmWeather"
},
{
appId: 1348403,
displayName: "贵斌同城",
icon: "http://file.market.xiaomi.com/ ... ot%3B,
level1CategoryName: "居家生活",
packageName: "com.gbtc.guibintongcheng"
},
...
...
通过上面的响应内容,我们可以提取出APP总数(count)和APP(displayName)名称,以及下载详情页的packageName。由于每个页面收录 30 个 APP,因此可以使用总数(计数)来计算每个类别中有多少个页面。
pages = int(count) // 30 + 1
下载详情页地址使用packageName拼接,如下图:
link = 'http://app.mi.com/details?id=' + app['packageName']
2) 完整程序完整程序如下:
# -*- coding:utf8 -*-
import requests
from threading import Thread
from queue import Queue
import time
from fake_useragent import UserAgent
from lxml import etree
import csv
from threading import Lock
import json
class XiaomiSpider(object):
def __init__(self):
self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'
# 存放所有URL地址的队列
self.q = Queue()
self.i = 0
# 存放所有类型id的空列表
self.id_list = []
# 打开文件
self.f = open('XiaomiShangcheng.csv','a',encoding='utf-8')
self.writer = csv.writer(self.f)
# 创建锁
self.lock = Lock()
def get_cateid(self):
# 请求
url = 'http://app.mi.com/'
headers = { 'User-Agent': UserAgent().random}
html = requests.get(url=url,headers=headers).text
# 解析
parse_html = etree.HTML(html)
xpath_bds = '//ul[@class="category-list"]/li'
li_list = parse_html.xpath(xpath_bds)
for li in li_list:
typ_name = li.xpath('./a/text()')[0]
typ_id = li.xpath('./a/@href')[0].split('/')[-1]
# 计算每个类型的页数
pages = self.get_pages(typ_id)
#往列表中添加二元组
self.id_list.append( (typ_id,pages) )
# 入队列
self.url_in()
# 获取count的值并计算页数
def get_pages(self,typ_id):
# 获取count的值,即app总数
url = self.url.format(0,typ_id)
html = requests.get(
url=url,
headers={'User-Agent':UserAgent().random}
).json()
count = html['count']
pages = int(count) // 30 + 1
return pages
# url入队函数,拼接url,并将url加入队列
def url_in(self):
for id in self.id_list:
# id格式:('4',pages)
for page in range(1,id[1]+1):
url = self.url.format(page,id[0])
# 把URL地址入队列
self.q.put(url)
# 线程事件函数: get() -请求-解析-处理数据,三步骤
def get_data(self):
while True:
# 判断队列不为空则执行,否则终止
if not self.q.empty():
url = self.q.get()
headers = {'User-Agent':UserAgent().random}
html = requests.get(url=url,headers=headers)
res_html = html.content.decode(encoding='utf-8')
html=json.loads(res_html)
self.parse_html(html)
else:
break
# 解析函数
def parse_html(self,html):
# 写入到csv文件
app_list = []
for app in html['data']:
# app名称 + 分类 + 详情链接
name = app['displayName']
link = 'http://app.mi.com/details?id=' + app['packageName']
typ_name = app['level1CategoryName']
# 把每一条数据放到app_list中,并通过writerows()实现多行写入
app_list.append([name,typ_name,link])
print(name,typ_name)
self.i += 1
# 向CSV文件中写入数据
self.lock.acquire()
self.writer.writerows(app_list)
self.lock.release()
# 入口函数
def main(self):
# URL入队列
self.get_cateid()
t_list = []
# 创建多线程
for i in range(1):
t = Thread(target=self.get_data)
t_list.append(t)
# 启动线程
t.start()
for t in t_list:
# 回收线程
t.join()
self.f.close()
print('数量:',self.i)
if __name__ == '__main__':
start = time.time()
spider = XiaomiSpider()
spider.main()
end = time.time()
print('执行时间:%.1f' % (end-start))
运行上述程序后,打开存储文件,其内容如下:
在我们之间-单机版,休闲创意,http://app.mi.com/details%3Fid ... r.gtx
粉末游戏,模拟经营,http://app.mi.com/details%3Fid ... r.bnn
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
腾讯欢乐麻将全集,棋牌桌游,http://app.mi.com/details?id=com.qqgame.happymj
快游戏,休闲创意,http://app.mi.com/details%3Fid ... h2mgc
皇室战争,战争策略,http://app.mi.com/details%3Fid ... le.mi
地铁跑酷,跑酷闯关,http://app.mi.com/details?id=com.kiloo.subwaysurf
...
...
python网页数据抓取(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-04 04:02
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response 查看全部
python网页数据抓取(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response
python网页数据抓取(简单记录一下的网络爬虫的知识,这里主要用到了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-03 11:23
)
最近学习了一些python网络爬虫的知识,简单记录一下。这里主要用到requests库和BeautifulSoup库。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天的工作。
以上是两个库的介绍,链接是文档信息
1、示例页面
这里我用东北大学图书馆的登陆页面来实现我们的爬虫功能(ps:是的,博主是东北大学的学生..所以我有账号密码),没有账号密码也没关系, 原理是一样的 是的,我发现这个页面是因为它没有验证码,所以可以更简单,像学校页面一样更简单,更容易操作
东北大学图书馆.JPG
2、简单分析
首先,我用账号和密码登录了东北大学图书馆。我用的是Chrome浏览器,打开了开发者模式。我们来看看我们提交了哪些信息。
东北大学邮报.JPG
登录后按F12打开开发者模式。在网络选项卡下,我们找到了这个文件。他的请求方式是post,应该就是我们要找的文件。拉到最底部看Form Data,红框就是我们登录时提交的信息,一共五部分。红线是账号和密码。了解帖子信息后,我们可以编写代码自动提交信息。
登录部分澄清。接下来,我将分析要捕获的信息。现在我想捕获我的。
为了捕捉这三个数据,如上图所示,我目前借了1本书,已经借了65本书。保留请求为 0。现在的目的是捕获这些数据。我们按F12查看网页。分析我们应该抓取源代码的哪一部分。
源代码.JPG
如上图,我一步一步找到了数据所在的标签。我发现数据在标签id=history下,所以我可以先找到这个标签,然后找到tr标签,然后才能找到td标签中的数据。
3、实现的功能4、代码部分4.1、发布数据部分
先贴这部分代码
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
代码如上,我们来分析一下
4.2、 抓取数据部分
先贴上代码
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
isinstance 的用法:
语法:
isinstance(对象,类信息)
其中,object是变量,classinfo是类型(tuple、dict、int、float、list、bool等)和类。如果参数 object 是 classinfo 的实例,或者 object 是 classinfo 的子类的实例,则返回 True。如果 object 不是给定类型的对象,则返回结果始终为 False。如果 classinfo 不是数据类型或由数据类型组成的元组,则会引发 TypeError 异常。
4.3、打印信息
粘贴代码
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2])
这部分很简单,我就不讲了
4.4、主要功能
粘贴代码
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info")
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
5、测试
测试.jpg
我们要的信息在控制台成功打印了!
6、完整代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2]))
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info")
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
main() 查看全部
python网页数据抓取(简单记录一下的网络爬虫的知识,这里主要用到了
)
最近学习了一些python网络爬虫的知识,简单记录一下。这里主要用到requests库和BeautifulSoup库。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供导航、搜索和修改解析树的惯用方法。它通常可以为程序员节省数小时或数天的工作。
以上是两个库的介绍,链接是文档信息
1、示例页面
这里我用东北大学图书馆的登陆页面来实现我们的爬虫功能(ps:是的,博主是东北大学的学生..所以我有账号密码),没有账号密码也没关系, 原理是一样的 是的,我发现这个页面是因为它没有验证码,所以可以更简单,像学校页面一样更简单,更容易操作
东北大学图书馆.JPG
2、简单分析
首先,我用账号和密码登录了东北大学图书馆。我用的是Chrome浏览器,打开了开发者模式。我们来看看我们提交了哪些信息。
东北大学邮报.JPG
登录后按F12打开开发者模式。在网络选项卡下,我们找到了这个文件。他的请求方式是post,应该就是我们要找的文件。拉到最底部看Form Data,红框就是我们登录时提交的信息,一共五部分。红线是账号和密码。了解帖子信息后,我们可以编写代码自动提交信息。
登录部分澄清。接下来,我将分析要捕获的信息。现在我想捕获我的。
为了捕捉这三个数据,如上图所示,我目前借了1本书,已经借了65本书。保留请求为 0。现在的目的是捕获这些数据。我们按F12查看网页。分析我们应该抓取源代码的哪一部分。
源代码.JPG
如上图,我一步一步找到了数据所在的标签。我发现数据在标签id=history下,所以我可以先找到这个标签,然后找到tr标签,然后才能找到td标签中的数据。
3、实现的功能4、代码部分4.1、发布数据部分
先贴这部分代码
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
代码如上,我们来分析一下
4.2、 抓取数据部分
先贴上代码
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
isinstance 的用法:
语法:
isinstance(对象,类信息)
其中,object是变量,classinfo是类型(tuple、dict、int、float、list、bool等)和类。如果参数 object 是 classinfo 的实例,或者 object 是 classinfo 的子类的实例,则返回 True。如果 object 不是给定类型的对象,则返回结果始终为 False。如果 classinfo 不是数据类型或由数据类型组成的元组,则会引发 TypeError 异常。
4.3、打印信息
粘贴代码
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2])
这部分很简单,我就不讲了
4.4、主要功能
粘贴代码
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info";)
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
5、测试
测试.jpg
我们要的信息在控制台成功打印了!
6、完整代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
kv = {'user-agent': 'Mozilla/5.0'}
mydata = {'func':'login-session', 'login_source':'bor-info', 'bor_id': '***', 'bor_verification': '***','bor_library':'NEU50'}
re = requests.post(url, data=mydata, headers=kv)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except:
print("异常")
return""
def fillBookList(booklist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(id='history').descendants:
if isinstance(tr, bs4.element.Tag):
temp = tr.find_all('td')
if len(temp)>0:
booklist.append(temp[1].string.strip())
booklist.append(temp[3].string.strip())
booklist.append(temp[5].string.strip())
break
def printUnivList(booklist):
print("{:^10}\t{:^6}\t{:^10}".format("外借","借阅历史列表","预约请求"))
print("{:^10}\t{:^6}\t{:^10}".format(booklist[0],booklist[1],booklist[2]))
def main():
html = getHTMLText("http://202.118.8.7:8991/F/-?func=bor-info";)
booklist = []
fillBookList(booklist, html)
printUnivList(booklist)
main()
python网页数据抓取(python爬虫如何爬取网页数据并解析数据,帮助大家更好的利用爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-26 06:19
)
本文文章主要介绍python爬虫如何抓取网页数据并分析数据,帮助大家更好地利用爬虫对网页进行分析。有兴趣的朋友可以了解一下。
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
查看全部
python网页数据抓取(python爬虫如何爬取网页数据并解析数据,帮助大家更好的利用爬虫
)
本文文章主要介绍python爬虫如何抓取网页数据并分析数据,帮助大家更好地利用爬虫对网页进行分析。有兴趣的朋友可以了解一下。
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去进行进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,回车安装。(注意网络连接)如下图
安装完成,如图
python网页数据抓取(python网页数据抓取编程-课程展示_(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-26 01:06
python网页数据抓取编程-课程展示_腾讯课堂;list=plvsmza4fscymzjkdszkwuj0zixzg%3d%3d&feature=youtu.be&index=5&v=3&int=1&t=251s第一课点我查看
这是数据采集小白的标准答案。
思路非常对。就是有一个问题,只有一个起始坐标,数据没法去重。
x是爬虫目标id,y是待采集元素的值,即num=idx+y。假设数据中有n个小说标题,则n=10,因为idx的取值范围是[-1,1],那么数据中的标题集合就有x*n等于101,那么10的小说标题集合就是z(n取1~10),那么已知小说标题集z,相应的小说标题集合就有y=0~5,这样所有小说标题集合就可以构成一个变量num,此时如果d=50,则对应的num变量值为z(z取0~5,取0~5是因为num是自身),数据中包含z值的小说标题集合构成一个变量m。
这样的话,直接在analyser.py程序的代码里加如下:vard='*'varm=0foriind':':m+=(i*i)varx=iprintdvary=i*yifstr(x*n)==str(y*n)else0foriind':':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify=i*yifx-mindm+=yprintx-mfory=i*yify-mindm+=yprinty-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yprintx-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-min。 查看全部
python网页数据抓取(python网页数据抓取编程-课程展示_(图))
python网页数据抓取编程-课程展示_腾讯课堂;list=plvsmza4fscymzjkdszkwuj0zixzg%3d%3d&feature=youtu.be&index=5&v=3&int=1&t=251s第一课点我查看
这是数据采集小白的标准答案。
思路非常对。就是有一个问题,只有一个起始坐标,数据没法去重。
x是爬虫目标id,y是待采集元素的值,即num=idx+y。假设数据中有n个小说标题,则n=10,因为idx的取值范围是[-1,1],那么数据中的标题集合就有x*n等于101,那么10的小说标题集合就是z(n取1~10),那么已知小说标题集z,相应的小说标题集合就有y=0~5,这样所有小说标题集合就可以构成一个变量num,此时如果d=50,则对应的num变量值为z(z取0~5,取0~5是因为num是自身),数据中包含z值的小说标题集合构成一个变量m。
这样的话,直接在analyser.py程序的代码里加如下:vard='*'varm=0foriind':':m+=(i*i)varx=iprintdvary=i*yifstr(x*n)==str(y*n)else0foriind':':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify=i*yifx-mindm+=yprintx-mfory=i*yify-mindm+=yprinty-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yprintx-mforiind':':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)':m+=(i*i)ifnum==iify-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-mindm+=yifx-min。
python网页数据抓取(python编程入门视频学习一下可以去几个我常用的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 17:06
python网页数据抓取这次只是一个开始,之后我们不断更新完善,并且把这里的数据拿去做一些实际应用。我这里有一些网站截图,供你们参考、观看。
最好玩的是,你需要有足够的耐心。
请多看一点python编程入门视频学习一下
可以去几个flask相关网站多学习学习比如、个人推荐、、
makegoodcode比如flask你可以先看flaskadmin
推荐几个我常用的网站给你吧1。flaskmega-flask开发者中心:flaskchina论坛2。flasktutorials:atutorialforstartingflask,flaskdevelopment,flasktesting,flaskmergev1.1,1.2.x(online)我公司的官网3。
推荐豆瓣的博客整个豆瓣,
可以去看这个问题做一个豆瓣电影推荐系统是怎样的一种体验?一个豆瓣的成功推荐应该如何做?
个人微信公众号。
你可以关注豆瓣开发者中心,
有一个20万人的电影评分豆瓣豆瓣电影里,找一找,发现还是蛮不错的。不过不会引起爬虫,需要用flask自己写~其实小到extjs的forwebserver也就几十行,大到框架sed,mysql,直接用,都是简单的。基本上做个爬虫爬下数据什么的,完全没有压力。而且如果你不知道框架的话,如果不会flask的话,也可以找swoole,写cornell的advocates,就是很简单。 查看全部
python网页数据抓取(python编程入门视频学习一下可以去几个我常用的网站)
python网页数据抓取这次只是一个开始,之后我们不断更新完善,并且把这里的数据拿去做一些实际应用。我这里有一些网站截图,供你们参考、观看。
最好玩的是,你需要有足够的耐心。
请多看一点python编程入门视频学习一下
可以去几个flask相关网站多学习学习比如、个人推荐、、
makegoodcode比如flask你可以先看flaskadmin
推荐几个我常用的网站给你吧1。flaskmega-flask开发者中心:flaskchina论坛2。flasktutorials:atutorialforstartingflask,flaskdevelopment,flasktesting,flaskmergev1.1,1.2.x(online)我公司的官网3。
推荐豆瓣的博客整个豆瓣,
可以去看这个问题做一个豆瓣电影推荐系统是怎样的一种体验?一个豆瓣的成功推荐应该如何做?
个人微信公众号。
你可以关注豆瓣开发者中心,
有一个20万人的电影评分豆瓣豆瓣电影里,找一找,发现还是蛮不错的。不过不会引起爬虫,需要用flask自己写~其实小到extjs的forwebserver也就几十行,大到框架sed,mysql,直接用,都是简单的。基本上做个爬虫爬下数据什么的,完全没有压力。而且如果你不知道框架的话,如果不会flask的话,也可以找swoole,写cornell的advocates,就是很简单。
python网页数据抓取(python网页数据抓取利用网络爬虫+正则表达式可以轻松实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-24 02:02
python网页数据抓取利用网络爬虫+正则表达式可以轻松实现python网页数据的抓取爬取。正则表达式是python程序员必须掌握的基础技能之一,该技能也是大部分程序员的一个职业基本功之一,网络爬虫则是一个最佳的选择。上节我们介绍了网络爬虫的一些技巧和框架的搭建。本节将着重讲解下网络爬虫的核心部分,即抓取相关的功能模块:正则表达式,基于正则表达式的多线程、队列、循环爬虫框架。
python网络爬虫核心环节正则表达式通过正则表达式,可以直接在一个网页中找到需要的内容。现在大部分网站都没有对http协议实现标准化,只要能够获取http协议的cookie信息或者js文件,就可以直接访问http的协议,例如知乎、豆瓣。正则表达式作为网络爬虫的核心部分,在整个网络爬虫中占有举足轻重的地位。
1.正则表达式解析正则表达式的解析,主要指的是对一个文本,匹配出目标的值。一个简单的正则表达式一般如下所示:一般而言正则表达式有如下几个特点:简洁、分歧、支持连字符以及多行匹配等特点。对于一个正则表达式来说,最重要的组成部分当然是其字符串的长度,长度是一个正则表达式最重要的特征之一。对于一个正则表达式来说,其第一个元素的字符串的长度是两个正则表达式最大连字符和-,如果多行的话,最大连字符和,还有可能会出现len()。
除此之外还有字符数。为了简单起见,我们简单的定义连字符l,和-,len(),返回一个正则表达式的长度:l=len(str)=left,l=left(str)=right,r=left(str)=right,-=(max(r)-min(r))/10,-=limit(max(r)-min(r))/1024一个正则表达式的基本结构如下所示:p.replace(.*,left,limit)注意:字符串并不是正则表达式,正则表达式是由一连串的字符串组成的。
正则表达式还有其实体,最基本的实体类型就是字符串。需要注意的是,一个正则表达式里,可以有多个字符串相同的字符,因此,正则表达式的正好和word.toupper()或者str.upper()是相对应的。常用的正则表达式的字符类型如下所示:正则表达式中使用负号\作为转义操作符。\是转义操作符。例如:\w[0-9]\d\s#;#表示转义\s#表示最后一个字符,如果再加上#则#号无效正则表达式的合并操作符组合起来就成为"/",这个正则表达式当中就有"/"后面跟一个负号\,意思是整个表达式中只有一个字符是表示中间的字符串的部分,例如:\w[0-9]\d\s,其中中间有一个空格。也就是说,python对最后。 查看全部
python网页数据抓取(python网页数据抓取利用网络爬虫+正则表达式可以轻松实现)
python网页数据抓取利用网络爬虫+正则表达式可以轻松实现python网页数据的抓取爬取。正则表达式是python程序员必须掌握的基础技能之一,该技能也是大部分程序员的一个职业基本功之一,网络爬虫则是一个最佳的选择。上节我们介绍了网络爬虫的一些技巧和框架的搭建。本节将着重讲解下网络爬虫的核心部分,即抓取相关的功能模块:正则表达式,基于正则表达式的多线程、队列、循环爬虫框架。
python网络爬虫核心环节正则表达式通过正则表达式,可以直接在一个网页中找到需要的内容。现在大部分网站都没有对http协议实现标准化,只要能够获取http协议的cookie信息或者js文件,就可以直接访问http的协议,例如知乎、豆瓣。正则表达式作为网络爬虫的核心部分,在整个网络爬虫中占有举足轻重的地位。
1.正则表达式解析正则表达式的解析,主要指的是对一个文本,匹配出目标的值。一个简单的正则表达式一般如下所示:一般而言正则表达式有如下几个特点:简洁、分歧、支持连字符以及多行匹配等特点。对于一个正则表达式来说,最重要的组成部分当然是其字符串的长度,长度是一个正则表达式最重要的特征之一。对于一个正则表达式来说,其第一个元素的字符串的长度是两个正则表达式最大连字符和-,如果多行的话,最大连字符和,还有可能会出现len()。
除此之外还有字符数。为了简单起见,我们简单的定义连字符l,和-,len(),返回一个正则表达式的长度:l=len(str)=left,l=left(str)=right,r=left(str)=right,-=(max(r)-min(r))/10,-=limit(max(r)-min(r))/1024一个正则表达式的基本结构如下所示:p.replace(.*,left,limit)注意:字符串并不是正则表达式,正则表达式是由一连串的字符串组成的。
正则表达式还有其实体,最基本的实体类型就是字符串。需要注意的是,一个正则表达式里,可以有多个字符串相同的字符,因此,正则表达式的正好和word.toupper()或者str.upper()是相对应的。常用的正则表达式的字符类型如下所示:正则表达式中使用负号\作为转义操作符。\是转义操作符。例如:\w[0-9]\d\s#;#表示转义\s#表示最后一个字符,如果再加上#则#号无效正则表达式的合并操作符组合起来就成为"/",这个正则表达式当中就有"/"后面跟一个负号\,意思是整个表达式中只有一个字符是表示中间的字符串的部分,例如:\w[0-9]\d\s,其中中间有一个空格。也就是说,python对最后。
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-21 17:10
阿里云>云栖社区>主题图>P>Python爬取网页数据库
推荐活动:
更多优惠>
当前话题:python抓取网页数据库添加到采集夹
相关话题:
Python抓取网页数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【雪峰磁针石博客】可爱的python测试开发库
作者:python人工智能命理 6886人浏览评论:03年前
欢迎转载,转载请注明出处:github地址谢谢喜欢相关书籍下载测试开发Web UI测试自动化splinter-web UI测试工具,基于selnium包。链接到 selenium-web UI 自动化测试。链接--推荐文档参考mec
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!
作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
老司机带你学爬虫-Python爬虫技术分享
作者:yunqi2 浏览评论人数:03年前
什么是“爬虫”?简单来说,编写一个从网络上获取所需数据并以规定格式存储的程序称为爬虫;理论上,爬虫的步骤很简单,第一步是获取html源代码,第二步是分析html,获取数据。但是实际操作起来又老又麻烦~有什么方便的Python写“爬虫”的库。常用的网络请求库:request
阅读全文
大数据与云计算学习:Python网络数据采集
作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换和信息采集以及爬虫学习路径爬虫的基本原理,具有信息存储功能 所谓爬虫就是一种自动化的数据工具,你
阅读全文
Python爬虫抓取知乎所有用户信息
作者:青山无名 2928人浏览评论:13年前
今天写了一个爬虫,递归抓取知乎的所有用户信息。源码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,查看网页。,这里我随机选择了一个大V作为入口,然后点击他的关注列表,如图,注意我的爬虫全名处于非登录状态。这里
阅读全文
Python实现Awvs自动扫描
作者:迟来凤姬 2601人浏览评论:04年前
最近做了一个python小程序。主要功能是实现Acuenetix Web Vulnerability Scanner的自动扫描,批量扫描一些目标,然后将扫描结果写入mysql数据库。写这个文章 并分享一些想法。程序主要分为三个功能模块,Url下
阅读全文
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
Python爬取京东书评数据
作者:五山之巅 920人浏览评论:07年前
京东书评信息非常丰富,包括购买日期、书名、作者、好评、中评、差评等。以购买日期为例,使用Python+Mysql搭配实现,程序不大,只有100行。我在程序中添加的相关说明:来自seleni
阅读全文 查看全部
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
阿里云>云栖社区>主题图>P>Python爬取网页数据库
推荐活动:
更多优惠>
当前话题:python抓取网页数据库添加到采集夹
相关话题:
Python抓取网页数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
【雪峰磁针石博客】可爱的python测试开发库
作者:python人工智能命理 6886人浏览评论:03年前
欢迎转载,转载请注明出处:github地址谢谢喜欢相关书籍下载测试开发Web UI测试自动化splinter-web UI测试工具,基于selnium包。链接到 selenium-web UI 自动化测试。链接--推荐文档参考mec
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!
作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
老司机带你学爬虫-Python爬虫技术分享
作者:yunqi2 浏览评论人数:03年前
什么是“爬虫”?简单来说,编写一个从网络上获取所需数据并以规定格式存储的程序称为爬虫;理论上,爬虫的步骤很简单,第一步是获取html源代码,第二步是分析html,获取数据。但是实际操作起来又老又麻烦~有什么方便的Python写“爬虫”的库。常用的网络请求库:request
阅读全文
大数据与云计算学习:Python网络数据采集
作者:景新言喜社 3650人浏览评论:03年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何对服务器的响应进行基本处理,如何通过自动化的方式与网站进行交互,如何创建域名切换和信息采集以及爬虫学习路径爬虫的基本原理,具有信息存储功能 所谓爬虫就是一种自动化的数据工具,你
阅读全文
Python爬虫抓取知乎所有用户信息
作者:青山无名 2928人浏览评论:13年前
今天写了一个爬虫,递归抓取知乎的所有用户信息。源码放在github上。有兴趣的同学可以下载看看。这里介绍一下代码逻辑和分页分析。首先,查看网页。,这里我随机选择了一个大V作为入口,然后点击他的关注列表,如图,注意我的爬虫全名处于非登录状态。这里
阅读全文
Python实现Awvs自动扫描
作者:迟来凤姬 2601人浏览评论:04年前
最近做了一个python小程序。主要功能是实现Acuenetix Web Vulnerability Scanner的自动扫描,批量扫描一些目标,然后将扫描结果写入mysql数据库。写这个文章 并分享一些想法。程序主要分为三个功能模块,Url下
阅读全文
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
Python爬取京东书评数据
作者:五山之巅 920人浏览评论:07年前
京东书评信息非常丰富,包括购买日期、书名、作者、好评、中评、差评等。以购买日期为例,使用Python+Mysql搭配实现,程序不大,只有100行。我在程序中添加的相关说明:来自seleni
阅读全文

