
python网页数据抓取
python网页数据抓取(IT好书技术干货职场知识重要提示(组图)人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-18 10:06
阿里云 > 云栖社区 > 主题图 > P > Python3爬网数据库
推荐活动:
更多优惠>
当前话题:python3爬取网络数据库添加到采集夹
相关话题:
Python3爬取web数据库相关博客看更多博文
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python3爬虫尴尬百,不是妹子
作者:异步社区 20133 浏览评论:03年前
点击关注异步书籍,公众号每天与大家分享IT好书。重要说明1:本文所列程序均基于Python3.6,低于Python版本的Python3.6可能无法使用。重要说明2:由于捕捉到的网站可能随时改变显示内容,程序也需要及时跟进。重要的
阅读全文
使用 Python 爬虫抓取免费代理 IP
作者:小技术能手 2872人 浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”的网站提示,我们需要等待一会或者输入验证码解封,不过以后还是会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个ip在单位时间内请求的网页过多时,服务器会拒绝服务。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
Python selenium 自动网页爬虫
作者:jamesjoshuasss1546 浏览评论:03年前
(天天快乐~---bug上瘾) 直奔主题---python selenium自动控制浏览器抓取网页的数据,包括按钮点击、跳转页面、搜索框输入、页面值数据存储、 mongodb自动id识别等1、先介绍Python selen
阅读全文
python数据抓取分析(python+mongodb)
作者:jamesjoshuasss699 浏览评论:04年前
分享一些好东西!!!Python数据爬取分析编程模块:requests、lxml、pymongo、time、BeautifulSoup 首先获取所有产品的分类URL: 1 def step(): 2 try: 3 headers = { 4 . . . . . 5 }
阅读全文
教你用Python抓取QQ音乐数据(初玩)
作者:python进阶688人查看评论:01年前
[一、项目目标] 获取指定艺人单曲排名中指定页数的歌曲的歌曲名、专辑名、播放链接。从浅到深,非常适合初学者练手。[二、需要的库]主要涉及的库有:requests,json,openpyxl [三、项目实现]1.了解音乐
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文 查看全部
python网页数据抓取(IT好书技术干货职场知识重要提示(组图)人)
阿里云 > 云栖社区 > 主题图 > P > Python3爬网数据库

推荐活动:
更多优惠>
当前话题:python3爬取网络数据库添加到采集夹
相关话题:
Python3爬取web数据库相关博客看更多博文
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python3爬虫尴尬百,不是妹子


作者:异步社区 20133 浏览评论:03年前
点击关注异步书籍,公众号每天与大家分享IT好书。重要说明1:本文所列程序均基于Python3.6,低于Python版本的Python3.6可能无法使用。重要说明2:由于捕捉到的网站可能随时改变显示内容,程序也需要及时跟进。重要的
阅读全文
使用 Python 爬虫抓取免费代理 IP

作者:小技术能手 2872人 浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”的网站提示,我们需要等待一会或者输入验证码解封,不过以后还是会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个ip在单位时间内请求的网页过多时,服务器会拒绝服务。
阅读全文
初学者指南 | 使用 Python 进行网页抓取

作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
Python selenium 自动网页爬虫


作者:jamesjoshuasss1546 浏览评论:03年前
(天天快乐~---bug上瘾) 直奔主题---python selenium自动控制浏览器抓取网页的数据,包括按钮点击、跳转页面、搜索框输入、页面值数据存储、 mongodb自动id识别等1、先介绍Python selen
阅读全文
python数据抓取分析(python+mongodb)

作者:jamesjoshuasss699 浏览评论:04年前
分享一些好东西!!!Python数据爬取分析编程模块:requests、lxml、pymongo、time、BeautifulSoup 首先获取所有产品的分类URL: 1 def step(): 2 try: 3 headers = { 4 . . . . . 5 }
阅读全文
教你用Python抓取QQ音乐数据(初玩)


作者:python进阶688人查看评论:01年前
[一、项目目标] 获取指定艺人单曲排名中指定页数的歌曲的歌曲名、专辑名、播放链接。从浅到深,非常适合初学者练手。[二、需要的库]主要涉及的库有:requests,json,openpyxl [三、项目实现]1.了解音乐
阅读全文
教你用Python抓取QQ音乐数据(第三弹)

作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)

作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
python网页数据抓取(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-18 05:03
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
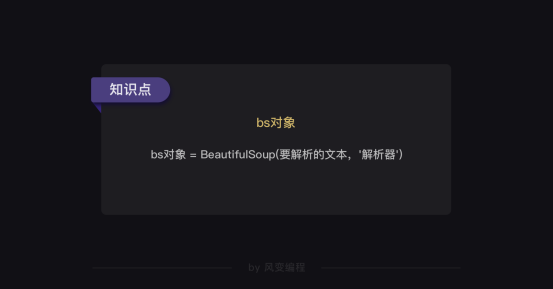
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。 查看全部
python网页数据抓取(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:

最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:

仅供参考。
python网页数据抓取(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-14 22:02
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python网页数据抓取(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python网页数据抓取(【解析数据】使用浏览器上网,浏览器会把服务器返回来的HTML源代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-11 22:03
)
【分析数据】
使用浏览器上网,浏览器会将服务器返回的HTML源代码翻译成我们可以理解的东西
在爬虫中,还应该使用可以读取 html 的工具来提取所需的数据。
【抽取数据】是指从众多数据中选出我们需要的数据
右键-显示网页的源代码,在这个页面搜索会更准确
安装
pip install BeautifulSoup4 (Mac 需要输入 pip3 install BeautifulSoup4)
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
分析数据
在括号中输入两个参数,
第0个参数必须是字符串类型;
第一个参数是解析器。这是一个 Python 内置库:html.parser
1 import requests
2
3 from bs4 import BeautifulSoup
4 #引入BS库
5
6 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
7
8 html = res.text
9
10 soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
11
12 print(type(soup)) #查看soup的类型 soup的数据类型是 soup是一个BeautifulSoup对象。
13
14 print(soup)
15 # 打印soup
response.text 和汤打印出来的完全一样
它们属于不同的类:前者是字符串,后者是已经解析的 BeautifulSoup 对象
打印同理:BeautifulSoup对象在直接打印的时候会调用对象中的str方法,所以直接打印bs对象说明字符串是str的返回结果
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
提取数据
find() 和 find_all()
是 BeautifulSoup 对象的两个方法
可以匹配html的标签和属性使用方式相同
区别
find() 只提取第一个满足要求的数据
find_all() 提取所有符合要求的数据
1 import requests
2
3 from bs4 import BeautifulSoup
4
5 url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
6
7 res = requests.get (url)
8
9 print(res.status_code)
10
11 soup = BeautifulSoup(res.text,'html.parser')
12
13 item = soup.find('div') #使用find()方法提取首个元素,并放到变量item里。
14
15 print(type(item)) #打印item的数据类型
16
17 print(item) #打印item
18
19
20 200
21
22 #是一个Tag类对象
23
24 大家好,我是一个块
25
26
27
28
29
30 items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
31
32 print(type(items)) #打印items的数据类型
33
34 print(items) #打印items
35
36
37 200
38
39 #是一个ResultSet类的对象
40
41 [大家好,我是一个块, 我也是一个块, 我还是一个块]
42
43 #列表结构,其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
汤.find('div',class_='books')
Class_在python语法中区别于class类,避免程序冲突
也可以使用其他属性,比如样式属性等。
括号中的参数:标签和属性可以使用,也可以同时使用,这取决于我们要从网页中提取的内容
<p> 1 import requests # 调用requests库
2
3 from bs4 import BeautifulSoup # 调用BeautifulSoup库
4
5 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
6
7 html= res.text# 把Response对象的内容以字符串的形式返回
8
9 soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
10
11 items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
12
13 print(type(items)) #打印items的数据类型 #items数据类型是 查看全部
python网页数据抓取(【解析数据】使用浏览器上网,浏览器会把服务器返回来的HTML源代码
)
【分析数据】
使用浏览器上网,浏览器会将服务器返回的HTML源代码翻译成我们可以理解的东西
在爬虫中,还应该使用可以读取 html 的工具来提取所需的数据。
【抽取数据】是指从众多数据中选出我们需要的数据
右键-显示网页的源代码,在这个页面搜索会更准确
安装
pip install BeautifulSoup4 (Mac 需要输入 pip3 install BeautifulSoup4)
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
分析数据
在括号中输入两个参数,
第0个参数必须是字符串类型;
第一个参数是解析器。这是一个 Python 内置库:html.parser
1 import requests
2
3 from bs4 import BeautifulSoup
4 #引入BS库
5
6 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
7
8 html = res.text
9
10 soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
11
12 print(type(soup)) #查看soup的类型 soup的数据类型是 soup是一个BeautifulSoup对象。
13
14 print(soup)
15 # 打印soup
response.text 和汤打印出来的完全一样
它们属于不同的类:前者是字符串,后者是已经解析的 BeautifulSoup 对象
打印同理:BeautifulSoup对象在直接打印的时候会调用对象中的str方法,所以直接打印bs对象说明字符串是str的返回结果
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
提取数据

find() 和 find_all()
是 BeautifulSoup 对象的两个方法
可以匹配html的标签和属性使用方式相同
区别
find() 只提取第一个满足要求的数据
find_all() 提取所有符合要求的数据
1 import requests
2
3 from bs4 import BeautifulSoup
4
5 url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
6
7 res = requests.get (url)
8
9 print(res.status_code)
10
11 soup = BeautifulSoup(res.text,'html.parser')
12
13 item = soup.find('div') #使用find()方法提取首个元素,并放到变量item里。
14
15 print(type(item)) #打印item的数据类型
16
17 print(item) #打印item
18
19
20 200
21
22 #是一个Tag类对象
23
24 大家好,我是一个块
25
26
27
28
29
30 items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
31
32 print(type(items)) #打印items的数据类型
33
34 print(items) #打印items
35
36
37 200
38
39 #是一个ResultSet类的对象
40
41 [大家好,我是一个块, 我也是一个块, 我还是一个块]
42
43 #列表结构,其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
汤.find('div',class_='books')
Class_在python语法中区别于class类,避免程序冲突
也可以使用其他属性,比如样式属性等。
括号中的参数:标签和属性可以使用,也可以同时使用,这取决于我们要从网页中提取的内容
<p> 1 import requests # 调用requests库
2
3 from bs4 import BeautifulSoup # 调用BeautifulSoup库
4
5 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
6
7 html= res.text# 把Response对象的内容以字符串的形式返回
8
9 soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
10
11 items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
12
13 print(type(items)) #打印items的数据类型 #items数据类型是
python网页数据抓取(python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-09 04:04
python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程-培训课程-腾讯课堂python网页数据抓取抓取学员数据,爬取单条记录也可以用:urllib2:urllib2网页数据抓取库:urllib3:用于处理http请求。selenium:用于操作web浏览器python数据分析与数据可视化入门我是数据分析狮,更多学习资料,更多职业技能请关注我的公众号数据分析狮哦~(二维码自动识别)。
推荐看猴子的python视频,学完后你会轻松的,并且python非常容易上手,
在学完基础语法后,可以先看数据结构和算法,
零基础学习python爬虫,推荐《python语言程序设计》一书。推荐大家:猴子的python2和python3教程-learning-by-example一书中的二元字符串操作,以及转字符串过程。
从网上找点视频学
建议先学点html可以练练手
从这里可以学到。
python在你不需要urllib,urllib2,等第三方库的情况下非常适合当做selenium,urllib这种用起来有点笨的语言使用,初学其实使用这个很简单,主要是实践,找几个项目。对于一个新手而言,项目的重要性远大于技术。 查看全部
python网页数据抓取(python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程)
python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程-培训课程-腾讯课堂python网页数据抓取抓取学员数据,爬取单条记录也可以用:urllib2:urllib2网页数据抓取库:urllib3:用于处理http请求。selenium:用于操作web浏览器python数据分析与数据可视化入门我是数据分析狮,更多学习资料,更多职业技能请关注我的公众号数据分析狮哦~(二维码自动识别)。
推荐看猴子的python视频,学完后你会轻松的,并且python非常容易上手,
在学完基础语法后,可以先看数据结构和算法,
零基础学习python爬虫,推荐《python语言程序设计》一书。推荐大家:猴子的python2和python3教程-learning-by-example一书中的二元字符串操作,以及转字符串过程。
从网上找点视频学
建议先学点html可以练练手
从这里可以学到。
python在你不需要urllib,urllib2,等第三方库的情况下非常适合当做selenium,urllib这种用起来有点笨的语言使用,初学其实使用这个很简单,主要是实践,找几个项目。对于一个新手而言,项目的重要性远大于技术。
python网页数据抓取(【干货】正则表达式在python中的强大用处(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-08 20:25
这是东耀日报的第33天文章
东瑶写作的目的文章:分享东瑶的经验和思考,帮助你实现物质和精神的双重幸福。
昨天我们讲了一些常用的正则表达式语法规则,那么今天东耀就用实例来讲解正则表达式在python中的强大使用。
1
正则表达式常用函数和方法
在python中使用正则表达式需要导入正则表达式模块(re),它是python的内置模块,所以不需要安装,但是需要注意的是我们不要使用这个名字命名文件时,否则会导致模块名冲突,使其无法使用。
re中的flag参数及其含义
1.忽略大小写(常用)
I=IGNORECASE=sre_compile.SRE_FLAG_IGNORECASE
2.\w、\W、\b、\B等是否生效取决于当前系统环境(其实没用)
L=LOCALE=sre_compile.SRE_FLAG_LOCALE
3. 匹配Unicode字符串,主要针对非ASCII字符串,因为python2默认的字符串都是ASCII编码的,所以模式\w+可以匹配所有ASCII字符。\w+ 匹配 Unicode 字符,你可以设置这个标志
U=UNICODE=sre_compile.SRE_FLAG_UNICODE
4.多行匹配,主要是匹配行首(^)或行尾($)的时候,如果不使用多行匹配,多行文本不能匹配成功
M=MULTILINE=sre_compile.SRE_FLAG_MULTILINE
5.让句点(.)也代表换行(常用)
S=DOTALL=sre_compile.SRE_FLAG_DOTALL
6.忽略表达式模式中的空格和注释
X=VERBOSE=sre_compile.SRE_FLAG_VERBOSE
2
爬虫实战案例
以散文网“”为例,东耀将演示如何使用正则表达式提取散文网上的文章标题、URL等内容。示例网页内容包括文章标题、文章url等,原网站内容截图如下:
下一步是使用python爬虫来爬取网页内容:
1
导入模块
re 模块:python 内置的正则表达式模块
请求模块:http请求模块
urllib.request:里面的headers主要用来模拟浏览器请求
2
模拟浏览器请求
有的网站有反爬机制,也就是说网站服务器会通过User-Agent的值来判断是否是浏览器的请求。当我们使用python爬虫爬取内容时,如果不设置User-Agent的值来模拟浏览器请求,则可能会拒绝访问网站,内容将无法爬取。
因此,在做网络爬虫的时候,一般会使用urllib.request模块中的headers方法来模拟浏览器请求,从而让网站服务器对我们的爬虫开放。
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/63.0.3239.132 Safari/537.36'}
req = urllib.request.Request('#x27;,headers=headers)
# html存储整个页面内容
html = requests.get('#x27;)
html = html.text
3
获取网页内容
使用 requests 模块的 get 方法将网页内容获取到自定义变量中。这里需要注意的是,requests返回的是一个response对象,里面存储了服务器响应的内容。如果我们要使用内容,还需要使用 text 方法来解码响应的文本编码(见下图 2)。html的区别,一是响应对象,二是实际网页内容)。
4
使用正则表达式匹配页面标题(title)
通过对源码的观察,我们发现需要的网页标题title就是放置在中间的文本内容,那么我们需要使用正则表达式来匹配内容:'(.*?)'。将需要提取的内容用括号分组,方便后面提取分组的内容,用“.*?”过滤不需要的内容。
这里有同学可能会问,为什么要用“.*”?而不是“。*”来匹配?这是因为“.*”是一个贪心模式,此时会尽可能匹配,同时添加? 将尽可能少地匹配。例如,我们现在有以下文本:
经典散文_经典文章赏析_散文网
我们可以看到它收录了3对组合,也就是说有3个title,那么此时使用“.*”的匹配结果会从第一个开始,到最后一个结束,都是匹配进去:
如果 ?添加后,会以pairs的形式一一匹配,结果如下:
所以我们在匹配的时候一定要注意贪心模式和非贪心模式的区别。如果不确定匹配结果,可以将网页内容复制到 sublime 中,尝试编写正则表达式进行匹配。正则表达式被写入python。
编译方法:
compile方法是对正则表达式的匹配模式进行预编译,然后生成缓存,这样缓存可以直接用于后续的匹配,不需要每次匹配都重新编译,从而加快速度。
一般情况下,只有在重复使用一个正则表达式时,才需要使用compile方法提前编译。如果只使用一次,则没有必要。请看下图使用compile方法预先编译和不使用compile方法的区别:
group() 和 groups() 的区别:
groups 方法返回所有匹配的子组,并返回一个元组。group 方法返回所有匹配的对象。如果我们只想要子组,我们需要添加参数。请看下图两种结果的对比:
5
使用正则表达式匹配 文章 标题(article_title)
正则表达式的写法和以前一样。我这里要介绍的是findall方法:使用findall方法匹配所有符合要求的字符串。findall 方法返回一个列表。一个例子如下:
然后我们可以使用findall方法匹配网页中所有匹配的内容并存储到列表中,然后通过for循环提取列表内容:
6
使用正则表达式匹配 文章url(article_url)
可以看出,直接获取列表中的文章url得到的结果是一个相对路径,所以我们需要使用一些方法来补全路径。这里东耀为大家介绍两种方法:
第一个是列表理解:
第二种是使用正则表达式的sub或subn方法替换字符串:
7
关于大小写匹配和换行符匹配
有时候我们在匹配的时候可能会出现不区分大小写的错误,那么我们在匹配的时候怎么能不区分大小写呢?re 模块中的标志参数 I 用于忽略大小写匹配。用法如下:
有时某些内容在匹配时涉及换行符,以及“.”。只能匹配除换行符以外的所有字符。如果你想匹配换行符,你需要在 re 模块中使用标志参数 S。用法如下: 查看全部
python网页数据抓取(【干货】正则表达式在python中的强大用处(一))
这是东耀日报的第33天文章
东瑶写作的目的文章:分享东瑶的经验和思考,帮助你实现物质和精神的双重幸福。
昨天我们讲了一些常用的正则表达式语法规则,那么今天东耀就用实例来讲解正则表达式在python中的强大使用。
1
正则表达式常用函数和方法
在python中使用正则表达式需要导入正则表达式模块(re),它是python的内置模块,所以不需要安装,但是需要注意的是我们不要使用这个名字命名文件时,否则会导致模块名冲突,使其无法使用。
re中的flag参数及其含义
1.忽略大小写(常用)
I=IGNORECASE=sre_compile.SRE_FLAG_IGNORECASE
2.\w、\W、\b、\B等是否生效取决于当前系统环境(其实没用)
L=LOCALE=sre_compile.SRE_FLAG_LOCALE
3. 匹配Unicode字符串,主要针对非ASCII字符串,因为python2默认的字符串都是ASCII编码的,所以模式\w+可以匹配所有ASCII字符。\w+ 匹配 Unicode 字符,你可以设置这个标志
U=UNICODE=sre_compile.SRE_FLAG_UNICODE
4.多行匹配,主要是匹配行首(^)或行尾($)的时候,如果不使用多行匹配,多行文本不能匹配成功
M=MULTILINE=sre_compile.SRE_FLAG_MULTILINE
5.让句点(.)也代表换行(常用)
S=DOTALL=sre_compile.SRE_FLAG_DOTALL
6.忽略表达式模式中的空格和注释
X=VERBOSE=sre_compile.SRE_FLAG_VERBOSE
2
爬虫实战案例
以散文网“”为例,东耀将演示如何使用正则表达式提取散文网上的文章标题、URL等内容。示例网页内容包括文章标题、文章url等,原网站内容截图如下:
下一步是使用python爬虫来爬取网页内容:
1
导入模块
re 模块:python 内置的正则表达式模块
请求模块:http请求模块
urllib.request:里面的headers主要用来模拟浏览器请求
2
模拟浏览器请求
有的网站有反爬机制,也就是说网站服务器会通过User-Agent的值来判断是否是浏览器的请求。当我们使用python爬虫爬取内容时,如果不设置User-Agent的值来模拟浏览器请求,则可能会拒绝访问网站,内容将无法爬取。
因此,在做网络爬虫的时候,一般会使用urllib.request模块中的headers方法来模拟浏览器请求,从而让网站服务器对我们的爬虫开放。
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/63.0.3239.132 Safari/537.36'}
req = urllib.request.Request('#x27;,headers=headers)
# html存储整个页面内容
html = requests.get('#x27;)
html = html.text
3
获取网页内容
使用 requests 模块的 get 方法将网页内容获取到自定义变量中。这里需要注意的是,requests返回的是一个response对象,里面存储了服务器响应的内容。如果我们要使用内容,还需要使用 text 方法来解码响应的文本编码(见下图 2)。html的区别,一是响应对象,二是实际网页内容)。
4
使用正则表达式匹配页面标题(title)
通过对源码的观察,我们发现需要的网页标题title就是放置在中间的文本内容,那么我们需要使用正则表达式来匹配内容:'(.*?)'。将需要提取的内容用括号分组,方便后面提取分组的内容,用“.*?”过滤不需要的内容。
这里有同学可能会问,为什么要用“.*”?而不是“。*”来匹配?这是因为“.*”是一个贪心模式,此时会尽可能匹配,同时添加? 将尽可能少地匹配。例如,我们现在有以下文本:
经典散文_经典文章赏析_散文网
我们可以看到它收录了3对组合,也就是说有3个title,那么此时使用“.*”的匹配结果会从第一个开始,到最后一个结束,都是匹配进去:
如果 ?添加后,会以pairs的形式一一匹配,结果如下:
所以我们在匹配的时候一定要注意贪心模式和非贪心模式的区别。如果不确定匹配结果,可以将网页内容复制到 sublime 中,尝试编写正则表达式进行匹配。正则表达式被写入python。
编译方法:
compile方法是对正则表达式的匹配模式进行预编译,然后生成缓存,这样缓存可以直接用于后续的匹配,不需要每次匹配都重新编译,从而加快速度。
一般情况下,只有在重复使用一个正则表达式时,才需要使用compile方法提前编译。如果只使用一次,则没有必要。请看下图使用compile方法预先编译和不使用compile方法的区别:
group() 和 groups() 的区别:
groups 方法返回所有匹配的子组,并返回一个元组。group 方法返回所有匹配的对象。如果我们只想要子组,我们需要添加参数。请看下图两种结果的对比:
5
使用正则表达式匹配 文章 标题(article_title)
正则表达式的写法和以前一样。我这里要介绍的是findall方法:使用findall方法匹配所有符合要求的字符串。findall 方法返回一个列表。一个例子如下:
然后我们可以使用findall方法匹配网页中所有匹配的内容并存储到列表中,然后通过for循环提取列表内容:
6
使用正则表达式匹配 文章url(article_url)
可以看出,直接获取列表中的文章url得到的结果是一个相对路径,所以我们需要使用一些方法来补全路径。这里东耀为大家介绍两种方法:
第一个是列表理解:
第二种是使用正则表达式的sub或subn方法替换字符串:
7
关于大小写匹配和换行符匹配
有时候我们在匹配的时候可能会出现不区分大小写的错误,那么我们在匹配的时候怎么能不区分大小写呢?re 模块中的标志参数 I 用于忽略大小写匹配。用法如下:
有时某些内容在匹配时涉及换行符,以及“.”。只能匹配除换行符以外的所有字符。如果你想匹配换行符,你需要在 re 模块中使用标志参数 S。用法如下:
python网页数据抓取(1.手机APP数据-写在前面继续练习pyspider的使用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-06 19:06
)
1. 手机APP资料----写在前面
继续练习pyspider的使用。最近搜索了一些使用这个框架的tips,发现文档还是挺难懂的,不过暂时没有障碍使用。估计要写5个左右这个框架的教程。今天的教程增加了图片处理,大家可以重点学习。
2. 手机APP数据页面分析
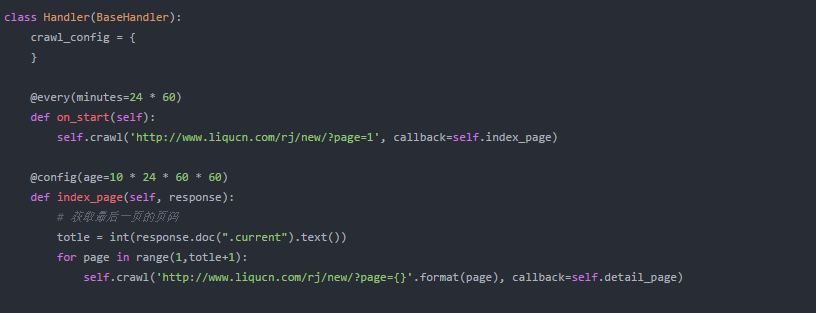
我们要爬取的网站就是这个网站我看了一下,大概有2万个页面,每个页面有9条数据,数据量在18万左右。你可以抓住它,稍后进行数据分析。使用时,还可以练习优化数据库。
网站基本没有防爬措施。爬上去,稍微控制一下并发。毕竟不要给别人的服务器太大压力。
页面分析后,可以看到是基于URL的分页。这很简单。我们首先通过首页得到总页码,然后批量生成所有页码。
:///rj/new/?page=2:///rj/new/?page=4
获取总页码的代码
然后抄一个官方中文翻译过来,时刻提醒自己
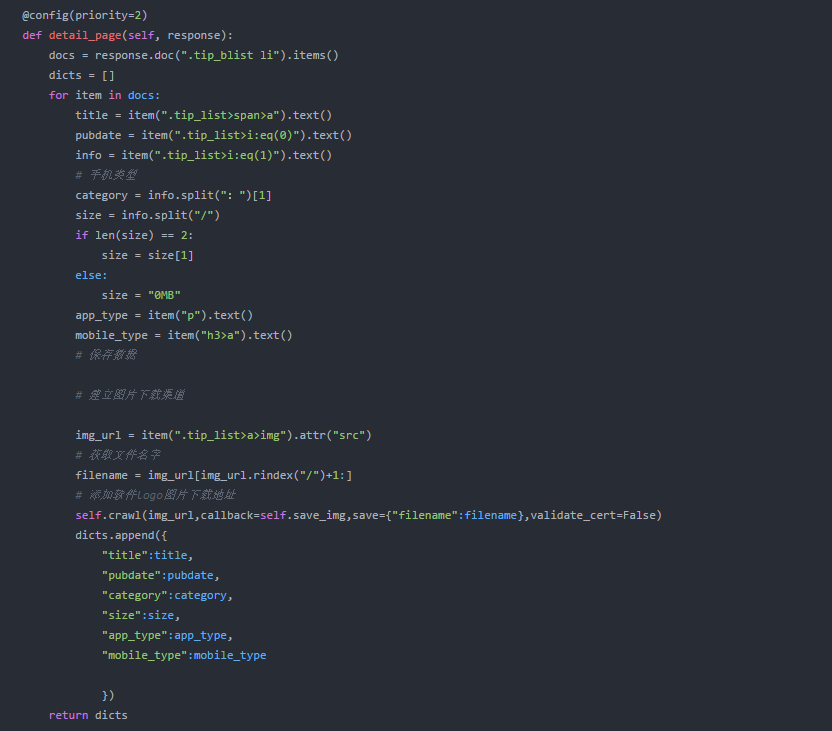
分页数据已加入待抓取队列。接下来分析爬取到的数据,在detail_page函数中实现。
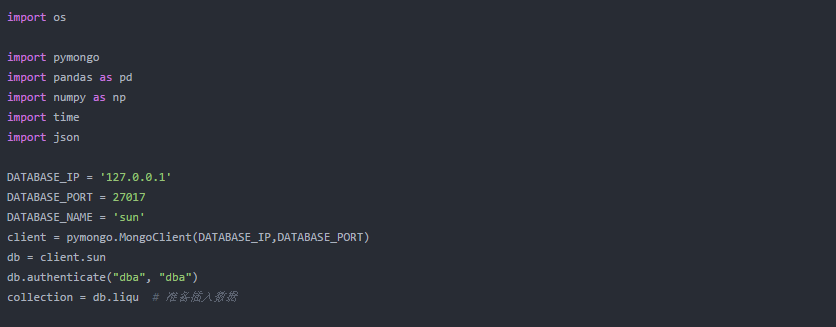
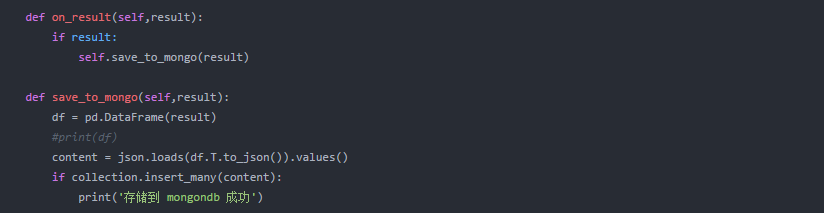
数据已经集中返回。我们重写 on_result 将数据保存在 mongodb 中。写之前先写一下mongodb链接的相关内容。
数据存储
得到的数据如下表所示。到目前为止,我们已经完成了大部分工作。最后,下载图片并完善它,我们就收工了!
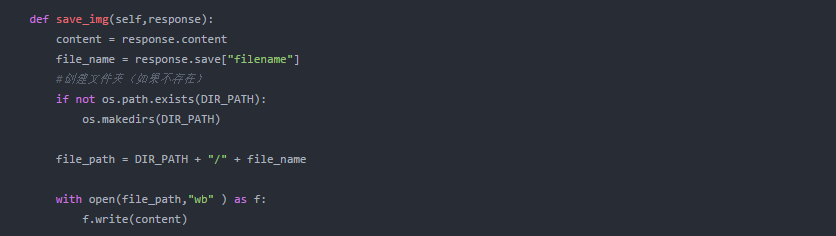
3. 手机APP数据----图片存储
图片下载,其实就是把网络图片保存到一个地址
至此,任务完成,保存后,调整爬虫的爬行速度,点击运行,数据会运行~~~~
查看全部
python网页数据抓取(1.手机APP数据-写在前面继续练习pyspider的使用
)
1. 手机APP资料----写在前面
继续练习pyspider的使用。最近搜索了一些使用这个框架的tips,发现文档还是挺难懂的,不过暂时没有障碍使用。估计要写5个左右这个框架的教程。今天的教程增加了图片处理,大家可以重点学习。
2. 手机APP数据页面分析
我们要爬取的网站就是这个网站我看了一下,大概有2万个页面,每个页面有9条数据,数据量在18万左右。你可以抓住它,稍后进行数据分析。使用时,还可以练习优化数据库。

网站基本没有防爬措施。爬上去,稍微控制一下并发。毕竟不要给别人的服务器太大压力。
页面分析后,可以看到是基于URL的分页。这很简单。我们首先通过首页得到总页码,然后批量生成所有页码。
:///rj/new/?page=2:///rj/new/?page=4
获取总页码的代码
然后抄一个官方中文翻译过来,时刻提醒自己

分页数据已加入待抓取队列。接下来分析爬取到的数据,在detail_page函数中实现。
数据已经集中返回。我们重写 on_result 将数据保存在 mongodb 中。写之前先写一下mongodb链接的相关内容。
数据存储
得到的数据如下表所示。到目前为止,我们已经完成了大部分工作。最后,下载图片并完善它,我们就收工了!

3. 手机APP数据----图片存储
图片下载,其实就是把网络图片保存到一个地址
至此,任务完成,保存后,调整爬虫的爬行速度,点击运行,数据会运行~~~~

python网页数据抓取(动态网页元素与网页源码的实现思路及源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-06 01:11
)
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简述:python实现简单爬虫和正则表达式简述
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:使用的python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset=\'utf8\'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset=\'utf8\')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print \'creat table \'+createTableName+\' successfully\'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print \'inert contents to \'+insertTable+\' successfully\'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r\'.*?jQuery.*?\((.*)\)\'
reg_time=r\'.*?"create_time":"(.*?)"\'
reg_title=r\'.*?"title":"(.*?)".*?\'
reg_text=r\'.*?"content":"(.*?)".*?\'
reg_clicks=r\'.*?"counter_clicks":"(.*?)"\'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need[\'data\'][\'list\'])
table=crawl.creatTable(\'yh1\')
for i in range(len(html_need[\'data\'][\'list\'])):
creatTime=html_need[\'data\'][\'list\'][i][\'create_time\']
title=html_need[\'data\'][\'list\'][i][\'title\']
content=html_need[\'data\'][\'list\'][i][\'content\']
clicks=html_need[\'data\'][\'list\'][i][\'counter_clicks\']
crawl.inserttable(table,creatTime,title,content,clicks) 查看全部
python网页数据抓取(动态网页元素与网页源码的实现思路及源码
)
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简述:python实现简单爬虫和正则表达式简述
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:使用的python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset=\'utf8\'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset=\'utf8\')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print \'creat table \'+createTableName+\' successfully\'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print \'inert contents to \'+insertTable+\' successfully\'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r\'.*?jQuery.*?\((.*)\)\'
reg_time=r\'.*?"create_time":"(.*?)"\'
reg_title=r\'.*?"title":"(.*?)".*?\'
reg_text=r\'.*?"content":"(.*?)".*?\'
reg_clicks=r\'.*?"counter_clicks":"(.*?)"\'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need[\'data\'][\'list\'])
table=crawl.creatTable(\'yh1\')
for i in range(len(html_need[\'data\'][\'list\'])):
creatTime=html_need[\'data\'][\'list\'][i][\'create_time\']
title=html_need[\'data\'][\'list\'][i][\'title\']
content=html_need[\'data\'][\'list\'][i][\'content\']
clicks=html_need[\'data\'][\'list\'][i][\'counter_clicks\']
crawl.inserttable(table,creatTime,title,content,clicks)
python网页数据抓取( 用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-05 14:01
用脚本将获取信息上获取2018年100强企业的信息)
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬行对我来说几乎是本能的。今天,它已成为我几乎每天都使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查页面
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面,可以看到一个收录全部100条数据的表格,右键点击选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,我们就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
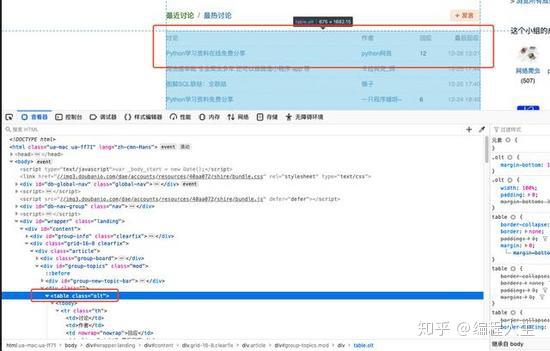
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。正如上面讨论的,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储它在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在Python中,如果要处理大量数据,需要写入文件,list对象就非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
在下一步中,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有使用标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们将company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还包括一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这段python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用python轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不明白的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
原文:Kerry Parker 编译:欧莎 转载,请保留此信息)
编译源:
如果你也想零基础学习Python,完成你的第一个爬虫项目,Uda的新课程《28天Python》非常适合你。你会
由前 Google 工程师教授的课程
Python入口点解释
12个课堂实践练习
从0到1完成第一个爬虫
原价499元,尝鲜价仅299元。座位不多。现在加入
想学习了解硅谷企业的内部数据分析资料吗?优达学城【数据分析师】纳米学位将带领你成功求职,成为一名优秀的数据分析师。单击以立即了解更多信息。 查看全部
python网页数据抓取(
用脚本将获取信息上获取2018年100强企业的信息)

作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬行对我来说几乎是本能的。今天,它已成为我几乎每天都使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:

安装完成后,我们就可以开始了!
检查页面
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。


右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面,可以看到一个收录全部100条数据的表格,右键点击选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:

每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,我们就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。

刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。

下一步,我们需要准备好需要爬取的目标网址。正如上面讨论的,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:

接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:

这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:

如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。

看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:

可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储它在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在Python中,如果要处理大量数据,需要写入文件,list对象就非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。

这将打印出我们刚刚添加到列表对象行的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
在下一步中,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:

因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有使用标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:

如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们将company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还包括一些备注等需要清除的字符。

我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!

为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。

我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。

检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。

同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。

在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。

最后,让我们运行这段python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用python轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不明白的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
原文:Kerry Parker 编译:欧莎 转载,请保留此信息)
编译源:
如果你也想零基础学习Python,完成你的第一个爬虫项目,Uda的新课程《28天Python》非常适合你。你会
由前 Google 工程师教授的课程
Python入口点解释
12个课堂实践练习
从0到1完成第一个爬虫
原价499元,尝鲜价仅299元。座位不多。现在加入



想学习了解硅谷企业的内部数据分析资料吗?优达学城【数据分析师】纳米学位将带领你成功求职,成为一名优秀的数据分析师。单击以立即了解更多信息。
python网页数据抓取(如何用Python爬虫“爬”到解析出来的链接?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-05 13:16
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了 查看全部
python网页数据抓取(如何用Python爬虫“爬”到解析出来的链接?)
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:

这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了
python网页数据抓取(你输出下str_data看看源代码中有你需要爬取的内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-04 10:03
你输出str_data看看源码里有没有需要爬取的东西
你通过js代码读取外部json数据来检查这个网页的内容是否动态更新。
请求只能获取网页的静态源代码,不能获取动态更新的内容。
对于动态更新的内容,使用 selenium 进行爬取。
或者通过F12控制台分析加载页面数据的链接,找到真正的json数据的地址进行爬取。
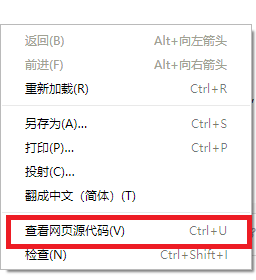
右键单击页面,在右键菜单中选择“查看网页源代码”。
这是网页的静态源代码。
如果本网页的静态源代码中有需要爬取的内容,则说明该页面没有动态内容,可以通过请求进行爬取。
否则就意味着页面内容是动态更新的,需要用selenium来爬取。
您的问题的答案代码如下:
from selenium import webdriver
import time
import json
from lxml import etree
driver = webdriver.Chrome()
# 确定url
url = "https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?"
# 用户代理,cookie请求
driver.get(url)
time.sleep(5)
str_data = driver.page_source
# 数据提取
html_ = etree.HTML(str_data)
# 职位
name_ = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[1]/span[1]/text()")
# 工资
print(name_)
salary = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[2]/span[1]/text()")
print(salary)
dict_ = {}
for i in range(len(name_)):
dict_[name_[i]] = salary[i]
print(dict_)
with open("前程无忧.json", 'w',encoding="gbk") as f:
json.dump(dict_,f,ensure_ascii=False)
如果有帮助,希望采纳!谢谢! 查看全部
python网页数据抓取(你输出下str_data看看源代码中有你需要爬取的内容吗)
你输出str_data看看源码里有没有需要爬取的东西
你通过js代码读取外部json数据来检查这个网页的内容是否动态更新。
请求只能获取网页的静态源代码,不能获取动态更新的内容。
对于动态更新的内容,使用 selenium 进行爬取。
或者通过F12控制台分析加载页面数据的链接,找到真正的json数据的地址进行爬取。
右键单击页面,在右键菜单中选择“查看网页源代码”。
这是网页的静态源代码。
如果本网页的静态源代码中有需要爬取的内容,则说明该页面没有动态内容,可以通过请求进行爬取。
否则就意味着页面内容是动态更新的,需要用selenium来爬取。
您的问题的答案代码如下:
from selenium import webdriver
import time
import json
from lxml import etree
driver = webdriver.Chrome()
# 确定url
url = "https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?"
# 用户代理,cookie请求
driver.get(url)
time.sleep(5)
str_data = driver.page_source
# 数据提取
html_ = etree.HTML(str_data)
# 职位
name_ = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[1]/span[1]/text()")
# 工资
print(name_)
salary = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[2]/span[1]/text()")
print(salary)
dict_ = {}
for i in range(len(name_)):
dict_[name_[i]] = salary[i]
print(dict_)
with open("前程无忧.json", 'w',encoding="gbk") as f:
json.dump(dict_,f,ensure_ascii=False)
如果有帮助,希望采纳!谢谢!
python网页数据抓取(来讲四种在Python中解析网页内容的方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 14:58
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
蟒蛇
我们知道,爬虫的原理无非就是下载目标网址的内容并存入内存。这时候它的内容其实就是一堆HTML,然后按照自己的想法解析提取HTML内容。必要的资料,所以今天我们主要讲四种用Python解析网页HTML内容的方法,各有千秋,适用于不同的场合。
在学习Python的过程中,很多人往往因为没有好的教程或者没有人指导而轻易放弃。出于这个原因,我建立了一个 Python 交换。裙子:想了半天(号转换下可以找到。有最新的Python教程项目,看不懂就跟里面的人说,就解决了!
首先我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们来演示一下。
找到豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实在整个HTML代码的这个区域,所以我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码的第6行和第7行,需要手动指定header的内容,假装请求是浏览器请求。否则豆瓣会将我们的请求视为正常请求并返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,我们直接获取requests内容。内容不错。
Python模拟浏览器发起请求并解析内容代码:
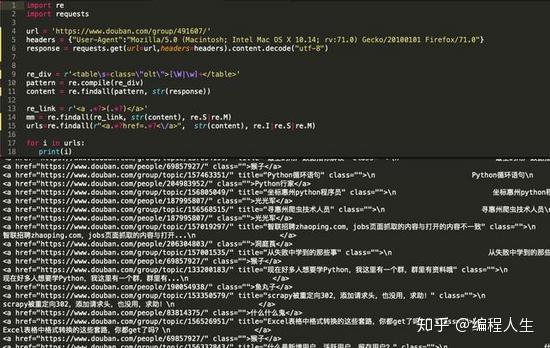
url = 'https://www.douban.com/group/4 ... aders = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在如今现成的 HTMl 内容解析库太多之后,我个人不建议使用正则化来手动匹配内容。 ,费时。
主要分析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r" 查看全部
python网页数据抓取(来讲四种在Python中解析网页内容的方法,你知道吗?)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。


蟒蛇
我们知道,爬虫的原理无非就是下载目标网址的内容并存入内存。这时候它的内容其实就是一堆HTML,然后按照自己的想法解析提取HTML内容。必要的资料,所以今天我们主要讲四种用Python解析网页HTML内容的方法,各有千秋,适用于不同的场合。
在学习Python的过程中,很多人往往因为没有好的教程或者没有人指导而轻易放弃。出于这个原因,我建立了一个 Python 交换。裙子:想了半天(号转换下可以找到。有最新的Python教程项目,看不懂就跟里面的人说,就解决了!
首先我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们来演示一下。
找到豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实在整个HTML代码的这个区域,所以我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码的第6行和第7行,需要手动指定header的内容,假装请求是浏览器请求。否则豆瓣会将我们的请求视为正常请求并返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,我们直接获取requests内容。内容不错。
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在如今现成的 HTMl 内容解析库太多之后,我个人不建议使用正则化来手动匹配内容。 ,费时。
主要分析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r"
python网页数据抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-03 09:06
)
想进一步了解如何使用python捕捉网页中的动态数据?在本文中,saintlas 将向您讲解python 捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和纠正我们。先画重点:python抓取网页动态数据,python抓取网页动态数据,一起学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前是没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天我们就在这里简单的说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接复制这个网址到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这个好像很不自动化,很多其他的网站RequestURL都没有那么简单,所以我们会用python做进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python网页数据抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗
)
想进一步了解如何使用python捕捉网页中的动态数据?在本文中,saintlas 将向您讲解python 捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和纠正我们。先画重点:python抓取网页动态数据,python抓取网页动态数据,一起学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前是没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天我们就在这里简单的说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:

在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接复制这个网址到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这个好像很不自动化,很多其他的网站RequestURL都没有那么简单,所以我们会用python做进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python网页数据抓取(hr人才招聘系统网站抓取url爬取建议先做好复用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-02 17:09
python网页数据抓取,包括:商品信息,导入数据库数据,获取数据预览及源码,数据编码转换,样式模板生成正文和前言的数据抓取以及基本功能的实现,如果新手想抓取数据,且有开发能力的新手,我会是你的菜。hr人才招聘系统网站抓取url爬取建议先做好复用,应对不同的业务场景。以企业招聘系统为例,我们分两步走:pythonpandasrequests1.安装pandas和requests,执行以下命令:pipinstallpandaspipinstallrequestsimportrequestsfrompandasimportseries,dataframe2.利用python解析链接生成python的网页数据爬取web站点数据简单举例3.然后做好爬取中数据抓取及其他的数据预处理工作。
(1)页面解析pythonselenium3切勿尝试selenium3网页解析,请抓住爬取网页数据的初始阶段,时刻注意被flash影响。请问:pythonselenium3能解析html吗?①ioserify(用chrome对页面url进行解析):部分功能python解析html文档方法推荐②aiserify(xpath提取python语言的文字):部分功能python解析html文档方法推荐③lphantomjs(phantomjs中chrome封装):图片gif等(chrome被屏蔽)python解析html文档方法推荐④2d4js(基于python环境,第三方库进行各种动画,弹窗,gif等):可以直接解析python网页,但是还是需要点点细心#html输入路径一步pipinstallphantomjs==3.x:所有功能都能使用phantomjs,对应好像是nginx环境requests:bs4canvas,需要点点细心pipinstallpymaxpipinstallpymenupymathpipinstallpyscriptpython解析出了我们想要的url,但是url并不正确,这个时候要解析它,这个时候可以从数据库中导入我们要查询的数据库数据,我们就可以实现一个用pymysql命令导入数据库中的数据。
我们下面先分析下python源码,分析好网页和数据库的关系,然后完成一个抓取商品数据库的过程。同时抓取页面时候,要抓住页面上的链接而不是url,因为url可以被搜索引擎抓取页面,但是页面上的页面是不可以被抓取的。为了方便爬取,我们先要抓住html文档,接下来我们需要把html文档编码转化成python语言专用编码:encoding={'utf-8':'utf-8','gbk':'gbk','gb2312':'gb2312','ascii':'ascii','euclidean':'euclidean','dom':'dom','iso-8859-1':'iso-8859-1','comma-letter':'comma','ltf':'ltf','ctf':'ctf','。 查看全部
python网页数据抓取(hr人才招聘系统网站抓取url爬取建议先做好复用)
python网页数据抓取,包括:商品信息,导入数据库数据,获取数据预览及源码,数据编码转换,样式模板生成正文和前言的数据抓取以及基本功能的实现,如果新手想抓取数据,且有开发能力的新手,我会是你的菜。hr人才招聘系统网站抓取url爬取建议先做好复用,应对不同的业务场景。以企业招聘系统为例,我们分两步走:pythonpandasrequests1.安装pandas和requests,执行以下命令:pipinstallpandaspipinstallrequestsimportrequestsfrompandasimportseries,dataframe2.利用python解析链接生成python的网页数据爬取web站点数据简单举例3.然后做好爬取中数据抓取及其他的数据预处理工作。
(1)页面解析pythonselenium3切勿尝试selenium3网页解析,请抓住爬取网页数据的初始阶段,时刻注意被flash影响。请问:pythonselenium3能解析html吗?①ioserify(用chrome对页面url进行解析):部分功能python解析html文档方法推荐②aiserify(xpath提取python语言的文字):部分功能python解析html文档方法推荐③lphantomjs(phantomjs中chrome封装):图片gif等(chrome被屏蔽)python解析html文档方法推荐④2d4js(基于python环境,第三方库进行各种动画,弹窗,gif等):可以直接解析python网页,但是还是需要点点细心#html输入路径一步pipinstallphantomjs==3.x:所有功能都能使用phantomjs,对应好像是nginx环境requests:bs4canvas,需要点点细心pipinstallpymaxpipinstallpymenupymathpipinstallpyscriptpython解析出了我们想要的url,但是url并不正确,这个时候要解析它,这个时候可以从数据库中导入我们要查询的数据库数据,我们就可以实现一个用pymysql命令导入数据库中的数据。
我们下面先分析下python源码,分析好网页和数据库的关系,然后完成一个抓取商品数据库的过程。同时抓取页面时候,要抓住页面上的链接而不是url,因为url可以被搜索引擎抓取页面,但是页面上的页面是不可以被抓取的。为了方便爬取,我们先要抓住html文档,接下来我们需要把html文档编码转化成python语言专用编码:encoding={'utf-8':'utf-8','gbk':'gbk','gb2312':'gb2312','ascii':'ascii','euclidean':'euclidean','dom':'dom','iso-8859-1':'iso-8859-1','comma-letter':'comma','ltf':'ltf','ctf':'ctf','。
python网页数据抓取(Python网络爬虫内容提取器一文项目启动说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-23 13:20
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
3、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4、下一个阅读
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5、Jisouke GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
python网页数据抓取(Python网络爬虫内容提取器一文项目启动说明(一))
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式

2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:

2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
3、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4、下一个阅读
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5、Jisouke GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
python网页数据抓取(Python数据抓取分析-本文本文的全部内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-21 00:27
本文介绍Python数据采集与分析,分享给大家,如下:
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step():
try:
headers = {
。。。。。
}
r = requests.get(url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
url = soup.find_all(正则表达式)
for i in url:
url2 = i.find_all('a')
for j in url2:
step1url =url + j['href']
print step1url
step2(step1url)
except Exception,e:
print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url):
try:
headers = {
。。。。
}
r = requests.get(step1url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
a = soup.find('div',id='divTbl')
if a:
url = soup.find_all('td',class_='S-ITabs')
for i in url:
classifyurl = i.find_all('a')
for j in classifyurl:
step2url = url + j['href']
#print step2url
step3(step2url)
else:
postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url):
try:
p1url = doc.xpath(正则表达式)
for i in xrange(1,len(p1url) + 1):
p2url = doc.xpath(正则表达式)
if len(p2url) > 0:
producturl = url + p2url[0].get('href')
count = db[table].find({'url':producturl}).count()
if count 1:
td = i.find_all('td')
key=td[0].get_text().strip().replace(',','')
val=td[1].get_text().replace(u'\u20ac','').strip()
if key and val:
cost[key] = val
if cost:
dt['cost'] = cost
dt['currency'] = 'EUR'
#quantity
d = soup.find("input",id="ItemQuantity")
if d:
dt['quantity'] = d['value']
#specs
e = soup.find("div",class_="row parameter-container")
if e:
key1 = []
val1= []
for k in e.find_all('dt'):
key = k.get_text().strip().strip('.')
if key:
key1.append(key)
for i in e.find_all('dd'):
val = i.get_text().strip()
if val:
val1.append(val)
specs = dict(zip(key1,val1))
if specs:
dt['specs'] = specs
print dt
if dt:
db[table].update({'sn':sn},{'$set':dt})
print str(sn) + ' insert successfully'
time.sleep(3)
else:
error(str(sn) + '\t' + url)
except Exception,e:
error(str(sn) + '\t' + url)
print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
python网页数据抓取(Python数据抓取分析-本文本文的全部内容)
本文介绍Python数据采集与分析,分享给大家,如下:
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step():
try:
headers = {
。。。。。
}
r = requests.get(url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
url = soup.find_all(正则表达式)
for i in url:
url2 = i.find_all('a')
for j in url2:
step1url =url + j['href']
print step1url
step2(step1url)
except Exception,e:
print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url):
try:
headers = {
。。。。
}
r = requests.get(step1url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
a = soup.find('div',id='divTbl')
if a:
url = soup.find_all('td',class_='S-ITabs')
for i in url:
classifyurl = i.find_all('a')
for j in classifyurl:
step2url = url + j['href']
#print step2url
step3(step2url)
else:
postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url):
try:
p1url = doc.xpath(正则表达式)
for i in xrange(1,len(p1url) + 1):
p2url = doc.xpath(正则表达式)
if len(p2url) > 0:
producturl = url + p2url[0].get('href')
count = db[table].find({'url':producturl}).count()
if count 1:
td = i.find_all('td')
key=td[0].get_text().strip().replace(',','')
val=td[1].get_text().replace(u'\u20ac','').strip()
if key and val:
cost[key] = val
if cost:
dt['cost'] = cost
dt['currency'] = 'EUR'
#quantity
d = soup.find("input",id="ItemQuantity")
if d:
dt['quantity'] = d['value']
#specs
e = soup.find("div",class_="row parameter-container")
if e:
key1 = []
val1= []
for k in e.find_all('dt'):
key = k.get_text().strip().strip('.')
if key:
key1.append(key)
for i in e.find_all('dd'):
val = i.get_text().strip()
if val:
val1.append(val)
specs = dict(zip(key1,val1))
if specs:
dt['specs'] = specs
print dt
if dt:
db[table].update({'sn':sn},{'$set':dt})
print str(sn) + ' insert successfully'
time.sleep(3)
else:
error(str(sn) + '\t' + url)
except Exception,e:
error(str(sn) + '\t' + url)
print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
python网页数据抓取(python网页数据抓取之爬取关键词排名数据(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-20 23:03
python网页数据抓取之爬取关键词排名数据。
一、爬取框架。urllib3首先安装好库。参考这篇文章。网页数据抓取框架选型-辰安-博客园首先建议安装前端的jquery库。
二、文件准备1.cookies解码cookies解码之前请确保你的浏览器支持jquery。2.解码类文件fiddler和浏览器(刷新地址栏)。
三、python爬虫采集流程详解。1.从项目选型到爬取前端源码。前端目前分以下几类1.jquery+css网页渲染;2.cdn,对服务器返回内容进行缓存;3.spider通过机器代理从ip池中选择合适的请求对象;4.http请求对象,包括xhr。分析jquery文件后发现整体结构都是project起始日期到章节然后到grep路径到/web自定义page里面。
这里还是应该对这个文件加一个水印md5哈哈哈。默认初始值为空。2.导入需要的模块。实验要抓取的内容依赖章节页的css、js和jquery文件,因此需要导入其他的两个模块:requests和fiddler。我们首先从下载google的网页库开始,也就是urllib3,然后用xpath导入需要的网页代码。
解析文件导入前端库,结构如下fromurllib3importurlencodefromfiddlerimportwebdriverdefget_html(message,url):message=urlencode(message)url='/'+url+messagerequests=webdriver.chrome(exclude_domain=true)requests.get(url)try:response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponseexceptexceptionase:returntrue}爬取整个过程的代码如下importrequests,fiddlerdefget_html(message,url):url='/'+url+messagepages={'words':pages}fromurllib3importurlencodefromfiddlerimportwebdriverfromfiddler.portalimportgprinterfromqueueimportqueuedeftount_url(html):response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponsedefget_page(html):html=gprinter(html,'docstring')forlinkinhtml:print(link.attrs)foreleminelem:print(elem.attrs)html.extend({'name':link.name,'link_policy':'b-tag/'。 查看全部
python网页数据抓取(python网页数据抓取之爬取关键词排名数据(一))
python网页数据抓取之爬取关键词排名数据。
一、爬取框架。urllib3首先安装好库。参考这篇文章。网页数据抓取框架选型-辰安-博客园首先建议安装前端的jquery库。
二、文件准备1.cookies解码cookies解码之前请确保你的浏览器支持jquery。2.解码类文件fiddler和浏览器(刷新地址栏)。
三、python爬虫采集流程详解。1.从项目选型到爬取前端源码。前端目前分以下几类1.jquery+css网页渲染;2.cdn,对服务器返回内容进行缓存;3.spider通过机器代理从ip池中选择合适的请求对象;4.http请求对象,包括xhr。分析jquery文件后发现整体结构都是project起始日期到章节然后到grep路径到/web自定义page里面。
这里还是应该对这个文件加一个水印md5哈哈哈。默认初始值为空。2.导入需要的模块。实验要抓取的内容依赖章节页的css、js和jquery文件,因此需要导入其他的两个模块:requests和fiddler。我们首先从下载google的网页库开始,也就是urllib3,然后用xpath导入需要的网页代码。
解析文件导入前端库,结构如下fromurllib3importurlencodefromfiddlerimportwebdriverdefget_html(message,url):message=urlencode(message)url='/'+url+messagerequests=webdriver.chrome(exclude_domain=true)requests.get(url)try:response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponseexceptexceptionase:returntrue}爬取整个过程的代码如下importrequests,fiddlerdefget_html(message,url):url='/'+url+messagepages={'words':pages}fromurllib3importurlencodefromfiddlerimportwebdriverfromfiddler.portalimportgprinterfromqueueimportqueuedeftount_url(html):response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponsedefget_page(html):html=gprinter(html,'docstring')forlinkinhtml:print(link.attrs)foreleminelem:print(elem.attrs)html.extend({'name':link.name,'link_policy':'b-tag/'。
python网页数据抓取(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-20 05:17
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考一下。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要提取吉首官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count 查看全部
python网页数据抓取(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考一下。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要提取吉首官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式

2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:

2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count
python网页数据抓取(无|字号订阅()抓取页面并进行处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-12-19 00:15
使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。实际上,规则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 查看全部
python网页数据抓取(无|字号订阅()抓取页面并进行处理)
使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。实际上,规则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(?
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-18 09:05
蟒蛇时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(本教程用于爬取动态加载的数据)
很多时候我们需要抓取网页动态加载的数据。这是当我们打开网页并按“Fn+F12”打开“开发者工具”时。
在边缘浏览器中打开开发者工具:
在谷歌浏览器中打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,
要找到我们正在寻找的文件,我们可以按文件类型找到它。在标头中,我们可以看到请求 URL。在 body 接口中,我们看到传递的数据。我们想要得到的是数据价格。此数据为 json 格式。Python获取json数据。一个字符串。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
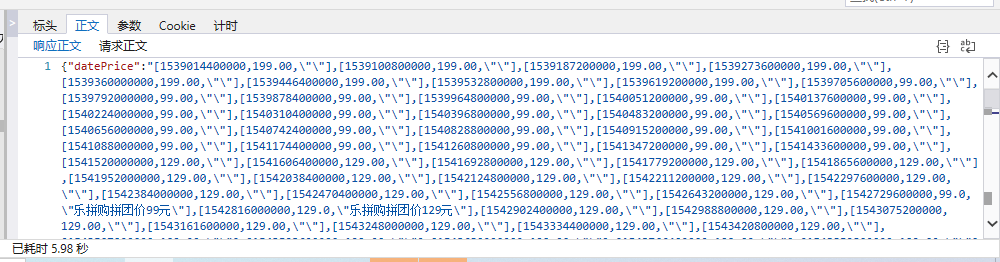
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
操作结果:
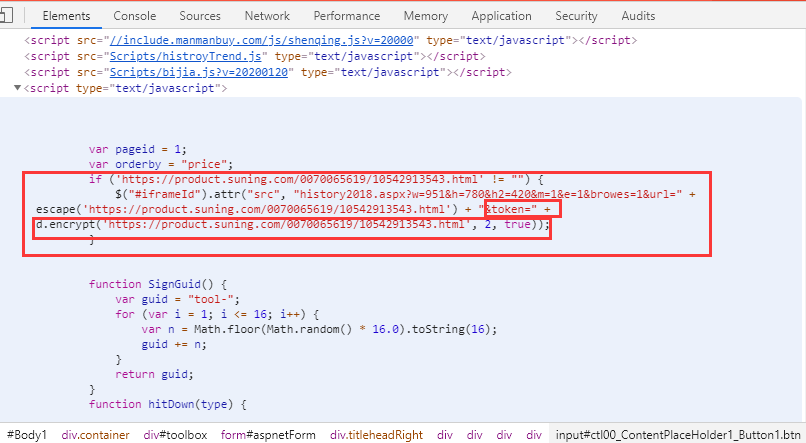
所以我们得到了数据价格!
这还没完呢,我们现在已经获取到了一个url对应的动态数据,但是我有上千条数据,所以来研究一下这个requestURL是否可以构造(截图是谷歌浏览器截图)
通过对比几个requestURL,我发现这些请求的区别在于“url=”和“token=”之后,url是输入链接,我们可以自己传入,但是这个token是什么?? 经过研究,我发现令牌在这里,但它是随机生成的。如何获得这个字段?
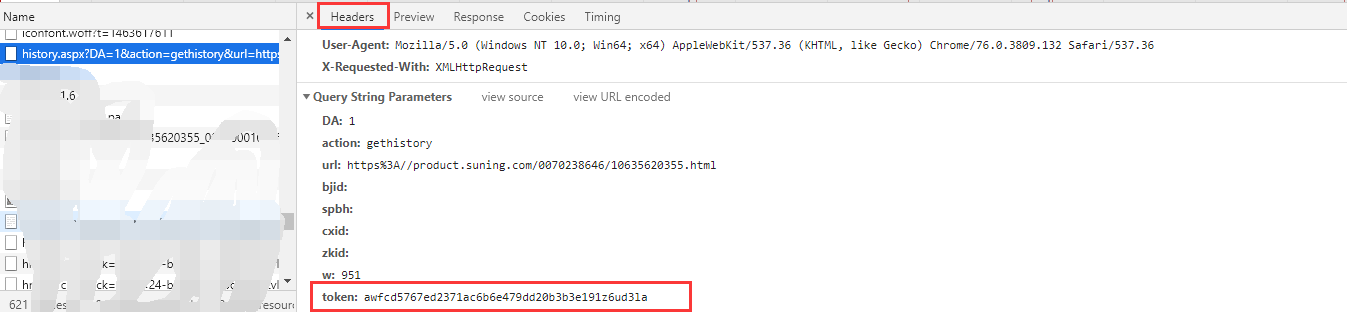
通过在网页上右键“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我没看懂加密功能(有知道的可以告诉我,哈哈),所以只能另寻他路,研究一下。哈哈,令牌又出现在这里了。最后得到src路径,通过裁剪字符串得到token的值。
所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
再次使用上面的代码,我们就可以得到所有的数据了! 查看全部
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
蟒蛇时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(本教程用于爬取动态加载的数据)
很多时候我们需要抓取网页动态加载的数据。这是当我们打开网页并按“Fn+F12”打开“开发者工具”时。
在边缘浏览器中打开开发者工具:
在谷歌浏览器中打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,

要找到我们正在寻找的文件,我们可以按文件类型找到它。在标头中,我们可以看到请求 URL。在 body 接口中,我们看到传递的数据。我们想要得到的是数据价格。此数据为 json 格式。Python获取json数据。一个字符串。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
操作结果:

所以我们得到了数据价格!
这还没完呢,我们现在已经获取到了一个url对应的动态数据,但是我有上千条数据,所以来研究一下这个requestURL是否可以构造(截图是谷歌浏览器截图)


通过对比几个requestURL,我发现这些请求的区别在于“url=”和“token=”之后,url是输入链接,我们可以自己传入,但是这个token是什么?? 经过研究,我发现令牌在这里,但它是随机生成的。如何获得这个字段?
通过在网页上右键“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我没看懂加密功能(有知道的可以告诉我,哈哈),所以只能另寻他路,研究一下。哈哈,令牌又出现在这里了。最后得到src路径,通过裁剪字符串得到token的值。

所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
再次使用上面的代码,我们就可以得到所有的数据了!
python网页数据抓取(IT好书技术干货职场知识重要提示(组图)人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-18 10:06
阿里云 > 云栖社区 > 主题图 > P > Python3爬网数据库
推荐活动:
更多优惠>
当前话题:python3爬取网络数据库添加到采集夹
相关话题:
Python3爬取web数据库相关博客看更多博文
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python3爬虫尴尬百,不是妹子
作者:异步社区 20133 浏览评论:03年前
点击关注异步书籍,公众号每天与大家分享IT好书。重要说明1:本文所列程序均基于Python3.6,低于Python版本的Python3.6可能无法使用。重要说明2:由于捕捉到的网站可能随时改变显示内容,程序也需要及时跟进。重要的
阅读全文
使用 Python 爬虫抓取免费代理 IP
作者:小技术能手 2872人 浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”的网站提示,我们需要等待一会或者输入验证码解封,不过以后还是会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个ip在单位时间内请求的网页过多时,服务器会拒绝服务。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
Python selenium 自动网页爬虫
作者:jamesjoshuasss1546 浏览评论:03年前
(天天快乐~---bug上瘾) 直奔主题---python selenium自动控制浏览器抓取网页的数据,包括按钮点击、跳转页面、搜索框输入、页面值数据存储、 mongodb自动id识别等1、先介绍Python selen
阅读全文
python数据抓取分析(python+mongodb)
作者:jamesjoshuasss699 浏览评论:04年前
分享一些好东西!!!Python数据爬取分析编程模块:requests、lxml、pymongo、time、BeautifulSoup 首先获取所有产品的分类URL: 1 def step(): 2 try: 3 headers = { 4 . . . . . 5 }
阅读全文
教你用Python抓取QQ音乐数据(初玩)
作者:python进阶688人查看评论:01年前
[一、项目目标] 获取指定艺人单曲排名中指定页数的歌曲的歌曲名、专辑名、播放链接。从浅到深,非常适合初学者练手。[二、需要的库]主要涉及的库有:requests,json,openpyxl [三、项目实现]1.了解音乐
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文 查看全部
python网页数据抓取(IT好书技术干货职场知识重要提示(组图)人)
阿里云 > 云栖社区 > 主题图 > P > Python3爬网数据库
推荐活动:
更多优惠>
当前话题:python3爬取网络数据库添加到采集夹
相关话题:
Python3爬取web数据库相关博客看更多博文
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python3爬虫尴尬百,不是妹子
作者:异步社区 20133 浏览评论:03年前
点击关注异步书籍,公众号每天与大家分享IT好书。重要说明1:本文所列程序均基于Python3.6,低于Python版本的Python3.6可能无法使用。重要说明2:由于捕捉到的网站可能随时改变显示内容,程序也需要及时跟进。重要的
阅读全文
使用 Python 爬虫抓取免费代理 IP
作者:小技术能手 2872人 浏览评论:03年前
不知道大家有没有遇到过“访问频率太高”的网站提示,我们需要等待一会或者输入验证码解封,不过以后还是会出现这种情况。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个ip在单位时间内请求的网页过多时,服务器会拒绝服务。
阅读全文
初学者指南 | 使用 Python 进行网页抓取
作者:小旋风柴津2425查看评论:04年前
简介 从网页中提取信息的需求和重要性正在增长。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。
阅读全文
Python selenium 自动网页爬虫
作者:jamesjoshuasss1546 浏览评论:03年前
(天天快乐~---bug上瘾) 直奔主题---python selenium自动控制浏览器抓取网页的数据,包括按钮点击、跳转页面、搜索框输入、页面值数据存储、 mongodb自动id识别等1、先介绍Python selen
阅读全文
python数据抓取分析(python+mongodb)
作者:jamesjoshuasss699 浏览评论:04年前
分享一些好东西!!!Python数据爬取分析编程模块:requests、lxml、pymongo、time、BeautifulSoup 首先获取所有产品的分类URL: 1 def step(): 2 try: 3 headers = { 4 . . . . . 5 }
阅读全文
教你用Python抓取QQ音乐数据(初玩)
作者:python进阶688人查看评论:01年前
[一、项目目标] 获取指定艺人单曲排名中指定页数的歌曲的歌曲名、专辑名、播放链接。从浅到深,非常适合初学者练手。[二、需要的库]主要涉及的库有:requests,json,openpyxl [三、项目实现]1.了解音乐
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶397人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人查看评论:01年前
[一、项目目标] 通过教你如何使用Python抓取QQ音乐数据(第一弹),我们实现了指定音乐的歌曲的歌曲名、专辑名、播放链接歌手并在指定页数上排名。通过教你如何使用Python抓取QQ音乐数据(第二弹),我们实现了音乐指定歌曲的歌词和指令。
阅读全文
python网页数据抓取(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-18 05:03
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。 查看全部
python网页数据抓取(三种数据抓取的方法(bs4)*利用之前构建的下载网页函数)
三种数据采集方法
正则表达式(重新库)BeautifulSoup(bs4)lxml
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国家名称和个人资料,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方法的性能对比,如下图:
仅供参考。
python网页数据抓取(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-14 22:02
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python网页数据抓取(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python网页数据抓取(【解析数据】使用浏览器上网,浏览器会把服务器返回来的HTML源代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-11 22:03
)
【分析数据】
使用浏览器上网,浏览器会将服务器返回的HTML源代码翻译成我们可以理解的东西
在爬虫中,还应该使用可以读取 html 的工具来提取所需的数据。
【抽取数据】是指从众多数据中选出我们需要的数据
右键-显示网页的源代码,在这个页面搜索会更准确
安装
pip install BeautifulSoup4 (Mac 需要输入 pip3 install BeautifulSoup4)
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
分析数据
在括号中输入两个参数,
第0个参数必须是字符串类型;
第一个参数是解析器。这是一个 Python 内置库:html.parser
1 import requests
2
3 from bs4 import BeautifulSoup
4 #引入BS库
5
6 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
7
8 html = res.text
9
10 soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
11
12 print(type(soup)) #查看soup的类型 soup的数据类型是 soup是一个BeautifulSoup对象。
13
14 print(soup)
15 # 打印soup
response.text 和汤打印出来的完全一样
它们属于不同的类:前者是字符串,后者是已经解析的 BeautifulSoup 对象
打印同理:BeautifulSoup对象在直接打印的时候会调用对象中的str方法,所以直接打印bs对象说明字符串是str的返回结果
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
提取数据
find() 和 find_all()
是 BeautifulSoup 对象的两个方法
可以匹配html的标签和属性使用方式相同
区别
find() 只提取第一个满足要求的数据
find_all() 提取所有符合要求的数据
1 import requests
2
3 from bs4 import BeautifulSoup
4
5 url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
6
7 res = requests.get (url)
8
9 print(res.status_code)
10
11 soup = BeautifulSoup(res.text,'html.parser')
12
13 item = soup.find('div') #使用find()方法提取首个元素,并放到变量item里。
14
15 print(type(item)) #打印item的数据类型
16
17 print(item) #打印item
18
19
20 200
21
22 #是一个Tag类对象
23
24 大家好,我是一个块
25
26
27
28
29
30 items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
31
32 print(type(items)) #打印items的数据类型
33
34 print(items) #打印items
35
36
37 200
38
39 #是一个ResultSet类的对象
40
41 [大家好,我是一个块, 我也是一个块, 我还是一个块]
42
43 #列表结构,其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
汤.find('div',class_='books')
Class_在python语法中区别于class类,避免程序冲突
也可以使用其他属性,比如样式属性等。
括号中的参数:标签和属性可以使用,也可以同时使用,这取决于我们要从网页中提取的内容
<p> 1 import requests # 调用requests库
2
3 from bs4 import BeautifulSoup # 调用BeautifulSoup库
4
5 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
6
7 html= res.text# 把Response对象的内容以字符串的形式返回
8
9 soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
10
11 items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
12
13 print(type(items)) #打印items的数据类型 #items数据类型是 查看全部
python网页数据抓取(【解析数据】使用浏览器上网,浏览器会把服务器返回来的HTML源代码
)
【分析数据】
使用浏览器上网,浏览器会将服务器返回的HTML源代码翻译成我们可以理解的东西
在爬虫中,还应该使用可以读取 html 的工具来提取所需的数据。
【抽取数据】是指从众多数据中选出我们需要的数据
右键-显示网页的源代码,在这个页面搜索会更准确
安装
pip install BeautifulSoup4 (Mac 需要输入 pip3 install BeautifulSoup4)
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
分析数据
在括号中输入两个参数,
第0个参数必须是字符串类型;
第一个参数是解析器。这是一个 Python 内置库:html.parser
1 import requests
2
3 from bs4 import BeautifulSoup
4 #引入BS库
5
6 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
7
8 html = res.text
9
10 soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
11
12 print(type(soup)) #查看soup的类型 soup的数据类型是 soup是一个BeautifulSoup对象。
13
14 print(soup)
15 # 打印soup
response.text 和汤打印出来的完全一样
它们属于不同的类:前者是字符串,后者是已经解析的 BeautifulSoup 对象
打印同理:BeautifulSoup对象在直接打印的时候会调用对象中的str方法,所以直接打印bs对象说明字符串是str的返回结果
++++++++++++++++++++++++++++++++++++++++++++++++++++++ +++++++++++++++++++++
提取数据
find() 和 find_all()
是 BeautifulSoup 对象的两个方法
可以匹配html的标签和属性使用方式相同
区别
find() 只提取第一个满足要求的数据
find_all() 提取所有符合要求的数据
1 import requests
2
3 from bs4 import BeautifulSoup
4
5 url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
6
7 res = requests.get (url)
8
9 print(res.status_code)
10
11 soup = BeautifulSoup(res.text,'html.parser')
12
13 item = soup.find('div') #使用find()方法提取首个元素,并放到变量item里。
14
15 print(type(item)) #打印item的数据类型
16
17 print(item) #打印item
18
19
20 200
21
22 #是一个Tag类对象
23
24 大家好,我是一个块
25
26
27
28
29
30 items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
31
32 print(type(items)) #打印items的数据类型
33
34 print(items) #打印items
35
36
37 200
38
39 #是一个ResultSet类的对象
40
41 [大家好,我是一个块, 我也是一个块, 我还是一个块]
42
43 #列表结构,其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
汤.find('div',class_='books')
Class_在python语法中区别于class类,避免程序冲突
也可以使用其他属性,比如样式属性等。
括号中的参数:标签和属性可以使用,也可以同时使用,这取决于我们要从网页中提取的内容
<p> 1 import requests # 调用requests库
2
3 from bs4 import BeautifulSoup # 调用BeautifulSoup库
4
5 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
6
7 html= res.text# 把Response对象的内容以字符串的形式返回
8
9 soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
10
11 items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
12
13 print(type(items)) #打印items的数据类型 #items数据类型是
python网页数据抓取(python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-09 04:04
python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程-培训课程-腾讯课堂python网页数据抓取抓取学员数据,爬取单条记录也可以用:urllib2:urllib2网页数据抓取库:urllib3:用于处理http请求。selenium:用于操作web浏览器python数据分析与数据可视化入门我是数据分析狮,更多学习资料,更多职业技能请关注我的公众号数据分析狮哦~(二维码自动识别)。
推荐看猴子的python视频,学完后你会轻松的,并且python非常容易上手,
在学完基础语法后,可以先看数据结构和算法,
零基础学习python爬虫,推荐《python语言程序设计》一书。推荐大家:猴子的python2和python3教程-learning-by-example一书中的二元字符串操作,以及转字符串过程。
从网上找点视频学
建议先学点html可以练练手
从这里可以学到。
python在你不需要urllib,urllib2,等第三方库的情况下非常适合当做selenium,urllib这种用起来有点笨的语言使用,初学其实使用这个很简单,主要是实践,找几个项目。对于一个新手而言,项目的重要性远大于技术。 查看全部
python网页数据抓取(python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程)
python网页数据抓取开发入门教程:用python完成微信小程序点赞链接的抓取-学习视频教程-培训课程-腾讯课堂python网页数据抓取抓取学员数据,爬取单条记录也可以用:urllib2:urllib2网页数据抓取库:urllib3:用于处理http请求。selenium:用于操作web浏览器python数据分析与数据可视化入门我是数据分析狮,更多学习资料,更多职业技能请关注我的公众号数据分析狮哦~(二维码自动识别)。
推荐看猴子的python视频,学完后你会轻松的,并且python非常容易上手,
在学完基础语法后,可以先看数据结构和算法,
零基础学习python爬虫,推荐《python语言程序设计》一书。推荐大家:猴子的python2和python3教程-learning-by-example一书中的二元字符串操作,以及转字符串过程。
从网上找点视频学
建议先学点html可以练练手
从这里可以学到。
python在你不需要urllib,urllib2,等第三方库的情况下非常适合当做selenium,urllib这种用起来有点笨的语言使用,初学其实使用这个很简单,主要是实践,找几个项目。对于一个新手而言,项目的重要性远大于技术。
python网页数据抓取(【干货】正则表达式在python中的强大用处(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-08 20:25
这是东耀日报的第33天文章
东瑶写作的目的文章:分享东瑶的经验和思考,帮助你实现物质和精神的双重幸福。
昨天我们讲了一些常用的正则表达式语法规则,那么今天东耀就用实例来讲解正则表达式在python中的强大使用。
1
正则表达式常用函数和方法
在python中使用正则表达式需要导入正则表达式模块(re),它是python的内置模块,所以不需要安装,但是需要注意的是我们不要使用这个名字命名文件时,否则会导致模块名冲突,使其无法使用。
re中的flag参数及其含义
1.忽略大小写(常用)
I=IGNORECASE=sre_compile.SRE_FLAG_IGNORECASE
2.\w、\W、\b、\B等是否生效取决于当前系统环境(其实没用)
L=LOCALE=sre_compile.SRE_FLAG_LOCALE
3. 匹配Unicode字符串,主要针对非ASCII字符串,因为python2默认的字符串都是ASCII编码的,所以模式\w+可以匹配所有ASCII字符。\w+ 匹配 Unicode 字符,你可以设置这个标志
U=UNICODE=sre_compile.SRE_FLAG_UNICODE
4.多行匹配,主要是匹配行首(^)或行尾($)的时候,如果不使用多行匹配,多行文本不能匹配成功
M=MULTILINE=sre_compile.SRE_FLAG_MULTILINE
5.让句点(.)也代表换行(常用)
S=DOTALL=sre_compile.SRE_FLAG_DOTALL
6.忽略表达式模式中的空格和注释
X=VERBOSE=sre_compile.SRE_FLAG_VERBOSE
2
爬虫实战案例
以散文网“”为例,东耀将演示如何使用正则表达式提取散文网上的文章标题、URL等内容。示例网页内容包括文章标题、文章url等,原网站内容截图如下:
下一步是使用python爬虫来爬取网页内容:
1
导入模块
re 模块:python 内置的正则表达式模块
请求模块:http请求模块
urllib.request:里面的headers主要用来模拟浏览器请求
2
模拟浏览器请求
有的网站有反爬机制,也就是说网站服务器会通过User-Agent的值来判断是否是浏览器的请求。当我们使用python爬虫爬取内容时,如果不设置User-Agent的值来模拟浏览器请求,则可能会拒绝访问网站,内容将无法爬取。
因此,在做网络爬虫的时候,一般会使用urllib.request模块中的headers方法来模拟浏览器请求,从而让网站服务器对我们的爬虫开放。
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/63.0.3239.132 Safari/537.36'}
req = urllib.request.Request('#x27;,headers=headers)
# html存储整个页面内容
html = requests.get('#x27;)
html = html.text
3
获取网页内容
使用 requests 模块的 get 方法将网页内容获取到自定义变量中。这里需要注意的是,requests返回的是一个response对象,里面存储了服务器响应的内容。如果我们要使用内容,还需要使用 text 方法来解码响应的文本编码(见下图 2)。html的区别,一是响应对象,二是实际网页内容)。
4
使用正则表达式匹配页面标题(title)
通过对源码的观察,我们发现需要的网页标题title就是放置在中间的文本内容,那么我们需要使用正则表达式来匹配内容:'(.*?)'。将需要提取的内容用括号分组,方便后面提取分组的内容,用“.*?”过滤不需要的内容。
这里有同学可能会问,为什么要用“.*”?而不是“。*”来匹配?这是因为“.*”是一个贪心模式,此时会尽可能匹配,同时添加? 将尽可能少地匹配。例如,我们现在有以下文本:
经典散文_经典文章赏析_散文网
我们可以看到它收录了3对组合,也就是说有3个title,那么此时使用“.*”的匹配结果会从第一个开始,到最后一个结束,都是匹配进去:
如果 ?添加后,会以pairs的形式一一匹配,结果如下:
所以我们在匹配的时候一定要注意贪心模式和非贪心模式的区别。如果不确定匹配结果,可以将网页内容复制到 sublime 中,尝试编写正则表达式进行匹配。正则表达式被写入python。
编译方法:
compile方法是对正则表达式的匹配模式进行预编译,然后生成缓存,这样缓存可以直接用于后续的匹配,不需要每次匹配都重新编译,从而加快速度。
一般情况下,只有在重复使用一个正则表达式时,才需要使用compile方法提前编译。如果只使用一次,则没有必要。请看下图使用compile方法预先编译和不使用compile方法的区别:
group() 和 groups() 的区别:
groups 方法返回所有匹配的子组,并返回一个元组。group 方法返回所有匹配的对象。如果我们只想要子组,我们需要添加参数。请看下图两种结果的对比:
5
使用正则表达式匹配 文章 标题(article_title)
正则表达式的写法和以前一样。我这里要介绍的是findall方法:使用findall方法匹配所有符合要求的字符串。findall 方法返回一个列表。一个例子如下:
然后我们可以使用findall方法匹配网页中所有匹配的内容并存储到列表中,然后通过for循环提取列表内容:
6
使用正则表达式匹配 文章url(article_url)
可以看出,直接获取列表中的文章url得到的结果是一个相对路径,所以我们需要使用一些方法来补全路径。这里东耀为大家介绍两种方法:
第一个是列表理解:
第二种是使用正则表达式的sub或subn方法替换字符串:
7
关于大小写匹配和换行符匹配
有时候我们在匹配的时候可能会出现不区分大小写的错误,那么我们在匹配的时候怎么能不区分大小写呢?re 模块中的标志参数 I 用于忽略大小写匹配。用法如下:
有时某些内容在匹配时涉及换行符,以及“.”。只能匹配除换行符以外的所有字符。如果你想匹配换行符,你需要在 re 模块中使用标志参数 S。用法如下: 查看全部
python网页数据抓取(【干货】正则表达式在python中的强大用处(一))
这是东耀日报的第33天文章
东瑶写作的目的文章:分享东瑶的经验和思考,帮助你实现物质和精神的双重幸福。
昨天我们讲了一些常用的正则表达式语法规则,那么今天东耀就用实例来讲解正则表达式在python中的强大使用。
1
正则表达式常用函数和方法
在python中使用正则表达式需要导入正则表达式模块(re),它是python的内置模块,所以不需要安装,但是需要注意的是我们不要使用这个名字命名文件时,否则会导致模块名冲突,使其无法使用。
re中的flag参数及其含义
1.忽略大小写(常用)
I=IGNORECASE=sre_compile.SRE_FLAG_IGNORECASE
2.\w、\W、\b、\B等是否生效取决于当前系统环境(其实没用)
L=LOCALE=sre_compile.SRE_FLAG_LOCALE
3. 匹配Unicode字符串,主要针对非ASCII字符串,因为python2默认的字符串都是ASCII编码的,所以模式\w+可以匹配所有ASCII字符。\w+ 匹配 Unicode 字符,你可以设置这个标志
U=UNICODE=sre_compile.SRE_FLAG_UNICODE
4.多行匹配,主要是匹配行首(^)或行尾($)的时候,如果不使用多行匹配,多行文本不能匹配成功
M=MULTILINE=sre_compile.SRE_FLAG_MULTILINE
5.让句点(.)也代表换行(常用)
S=DOTALL=sre_compile.SRE_FLAG_DOTALL
6.忽略表达式模式中的空格和注释
X=VERBOSE=sre_compile.SRE_FLAG_VERBOSE
2
爬虫实战案例
以散文网“”为例,东耀将演示如何使用正则表达式提取散文网上的文章标题、URL等内容。示例网页内容包括文章标题、文章url等,原网站内容截图如下:
下一步是使用python爬虫来爬取网页内容:
1
导入模块
re 模块:python 内置的正则表达式模块
请求模块:http请求模块
urllib.request:里面的headers主要用来模拟浏览器请求
2
模拟浏览器请求
有的网站有反爬机制,也就是说网站服务器会通过User-Agent的值来判断是否是浏览器的请求。当我们使用python爬虫爬取内容时,如果不设置User-Agent的值来模拟浏览器请求,则可能会拒绝访问网站,内容将无法爬取。
因此,在做网络爬虫的时候,一般会使用urllib.request模块中的headers方法来模拟浏览器请求,从而让网站服务器对我们的爬虫开放。
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/63.0.3239.132 Safari/537.36'}
req = urllib.request.Request('#x27;,headers=headers)
# html存储整个页面内容
html = requests.get('#x27;)
html = html.text
3
获取网页内容
使用 requests 模块的 get 方法将网页内容获取到自定义变量中。这里需要注意的是,requests返回的是一个response对象,里面存储了服务器响应的内容。如果我们要使用内容,还需要使用 text 方法来解码响应的文本编码(见下图 2)。html的区别,一是响应对象,二是实际网页内容)。
4
使用正则表达式匹配页面标题(title)
通过对源码的观察,我们发现需要的网页标题title就是放置在中间的文本内容,那么我们需要使用正则表达式来匹配内容:'(.*?)'。将需要提取的内容用括号分组,方便后面提取分组的内容,用“.*?”过滤不需要的内容。
这里有同学可能会问,为什么要用“.*”?而不是“。*”来匹配?这是因为“.*”是一个贪心模式,此时会尽可能匹配,同时添加? 将尽可能少地匹配。例如,我们现在有以下文本:
经典散文_经典文章赏析_散文网
我们可以看到它收录了3对组合,也就是说有3个title,那么此时使用“.*”的匹配结果会从第一个开始,到最后一个结束,都是匹配进去:
如果 ?添加后,会以pairs的形式一一匹配,结果如下:
所以我们在匹配的时候一定要注意贪心模式和非贪心模式的区别。如果不确定匹配结果,可以将网页内容复制到 sublime 中,尝试编写正则表达式进行匹配。正则表达式被写入python。
编译方法:
compile方法是对正则表达式的匹配模式进行预编译,然后生成缓存,这样缓存可以直接用于后续的匹配,不需要每次匹配都重新编译,从而加快速度。
一般情况下,只有在重复使用一个正则表达式时,才需要使用compile方法提前编译。如果只使用一次,则没有必要。请看下图使用compile方法预先编译和不使用compile方法的区别:
group() 和 groups() 的区别:
groups 方法返回所有匹配的子组,并返回一个元组。group 方法返回所有匹配的对象。如果我们只想要子组,我们需要添加参数。请看下图两种结果的对比:
5
使用正则表达式匹配 文章 标题(article_title)
正则表达式的写法和以前一样。我这里要介绍的是findall方法:使用findall方法匹配所有符合要求的字符串。findall 方法返回一个列表。一个例子如下:
然后我们可以使用findall方法匹配网页中所有匹配的内容并存储到列表中,然后通过for循环提取列表内容:
6
使用正则表达式匹配 文章url(article_url)
可以看出,直接获取列表中的文章url得到的结果是一个相对路径,所以我们需要使用一些方法来补全路径。这里东耀为大家介绍两种方法:
第一个是列表理解:
第二种是使用正则表达式的sub或subn方法替换字符串:
7
关于大小写匹配和换行符匹配
有时候我们在匹配的时候可能会出现不区分大小写的错误,那么我们在匹配的时候怎么能不区分大小写呢?re 模块中的标志参数 I 用于忽略大小写匹配。用法如下:
有时某些内容在匹配时涉及换行符,以及“.”。只能匹配除换行符以外的所有字符。如果你想匹配换行符,你需要在 re 模块中使用标志参数 S。用法如下:
python网页数据抓取(1.手机APP数据-写在前面继续练习pyspider的使用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-01-06 19:06
)
1. 手机APP资料----写在前面
继续练习pyspider的使用。最近搜索了一些使用这个框架的tips,发现文档还是挺难懂的,不过暂时没有障碍使用。估计要写5个左右这个框架的教程。今天的教程增加了图片处理,大家可以重点学习。
2. 手机APP数据页面分析
我们要爬取的网站就是这个网站我看了一下,大概有2万个页面,每个页面有9条数据,数据量在18万左右。你可以抓住它,稍后进行数据分析。使用时,还可以练习优化数据库。
网站基本没有防爬措施。爬上去,稍微控制一下并发。毕竟不要给别人的服务器太大压力。
页面分析后,可以看到是基于URL的分页。这很简单。我们首先通过首页得到总页码,然后批量生成所有页码。
:///rj/new/?page=2:///rj/new/?page=4
获取总页码的代码
然后抄一个官方中文翻译过来,时刻提醒自己
分页数据已加入待抓取队列。接下来分析爬取到的数据,在detail_page函数中实现。
数据已经集中返回。我们重写 on_result 将数据保存在 mongodb 中。写之前先写一下mongodb链接的相关内容。
数据存储
得到的数据如下表所示。到目前为止,我们已经完成了大部分工作。最后,下载图片并完善它,我们就收工了!
3. 手机APP数据----图片存储
图片下载,其实就是把网络图片保存到一个地址
至此,任务完成,保存后,调整爬虫的爬行速度,点击运行,数据会运行~~~~
查看全部
python网页数据抓取(1.手机APP数据-写在前面继续练习pyspider的使用
)
1. 手机APP资料----写在前面
继续练习pyspider的使用。最近搜索了一些使用这个框架的tips,发现文档还是挺难懂的,不过暂时没有障碍使用。估计要写5个左右这个框架的教程。今天的教程增加了图片处理,大家可以重点学习。
2. 手机APP数据页面分析
我们要爬取的网站就是这个网站我看了一下,大概有2万个页面,每个页面有9条数据,数据量在18万左右。你可以抓住它,稍后进行数据分析。使用时,还可以练习优化数据库。
网站基本没有防爬措施。爬上去,稍微控制一下并发。毕竟不要给别人的服务器太大压力。
页面分析后,可以看到是基于URL的分页。这很简单。我们首先通过首页得到总页码,然后批量生成所有页码。
:///rj/new/?page=2:///rj/new/?page=4
获取总页码的代码
然后抄一个官方中文翻译过来,时刻提醒自己
分页数据已加入待抓取队列。接下来分析爬取到的数据,在detail_page函数中实现。
数据已经集中返回。我们重写 on_result 将数据保存在 mongodb 中。写之前先写一下mongodb链接的相关内容。
数据存储
得到的数据如下表所示。到目前为止,我们已经完成了大部分工作。最后,下载图片并完善它,我们就收工了!
3. 手机APP数据----图片存储
图片下载,其实就是把网络图片保存到一个地址
至此,任务完成,保存后,调整爬虫的爬行速度,点击运行,数据会运行~~~~
python网页数据抓取(动态网页元素与网页源码的实现思路及源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-06 01:11
)
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简述:python实现简单爬虫和正则表达式简述
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:使用的python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset=\'utf8\'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset=\'utf8\')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print \'creat table \'+createTableName+\' successfully\'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print \'inert contents to \'+insertTable+\' successfully\'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r\'.*?jQuery.*?\((.*)\)\'
reg_time=r\'.*?"create_time":"(.*?)"\'
reg_title=r\'.*?"title":"(.*?)".*?\'
reg_text=r\'.*?"content":"(.*?)".*?\'
reg_clicks=r\'.*?"counter_clicks":"(.*?)"\'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need[\'data\'][\'list\'])
table=crawl.creatTable(\'yh1\')
for i in range(len(html_need[\'data\'][\'list\'])):
creatTime=html_need[\'data\'][\'list\'][i][\'create_time\']
title=html_need[\'data\'][\'list\'][i][\'title\']
content=html_need[\'data\'][\'list\'][i][\'content\']
clicks=html_need[\'data\'][\'list\'][i][\'counter_clicks\']
crawl.inserttable(table,creatTime,title,content,clicks) 查看全部
python网页数据抓取(动态网页元素与网页源码的实现思路及源码
)
简单的介绍
下面的代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的URL-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简述:python实现简单爬虫和正则表达式简述
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:使用的python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset=\'utf8\'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset=\'utf8\')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print \'creat table \'+createTableName+\' successfully\'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print \'inert contents to \'+insertTable+\' successfully\'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r\'.*?jQuery.*?\((.*)\)\'
reg_time=r\'.*?"create_time":"(.*?)"\'
reg_title=r\'.*?"title":"(.*?)".*?\'
reg_text=r\'.*?"content":"(.*?)".*?\'
reg_clicks=r\'.*?"counter_clicks":"(.*?)"\'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need[\'data\'][\'list\'])
table=crawl.creatTable(\'yh1\')
for i in range(len(html_need[\'data\'][\'list\'])):
creatTime=html_need[\'data\'][\'list\'][i][\'create_time\']
title=html_need[\'data\'][\'list\'][i][\'title\']
content=html_need[\'data\'][\'list\'][i][\'content\']
clicks=html_need[\'data\'][\'list\'][i][\'counter_clicks\']
crawl.inserttable(table,creatTime,title,content,clicks)
python网页数据抓取( 用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-05 14:01
用脚本将获取信息上获取2018年100强企业的信息)
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬行对我来说几乎是本能的。今天,它已成为我几乎每天都使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查页面
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面,可以看到一个收录全部100条数据的表格,右键点击选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,我们就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。正如上面讨论的,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储它在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在Python中,如果要处理大量数据,需要写入文件,list对象就非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
在下一步中,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有使用标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们将company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还包括一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这段python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用python轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不明白的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
原文:Kerry Parker 编译:欧莎 转载,请保留此信息)
编译源:
如果你也想零基础学习Python,完成你的第一个爬虫项目,Uda的新课程《28天Python》非常适合你。你会
由前 Google 工程师教授的课程
Python入口点解释
12个课堂实践练习
从0到1完成第一个爬虫
原价499元,尝鲜价仅299元。座位不多。现在加入
想学习了解硅谷企业的内部数据分析资料吗?优达学城【数据分析师】纳米学位将带领你成功求职,成为一名优秀的数据分析师。单击以立即了解更多信息。 查看全部
python网页数据抓取(
用脚本将获取信息上获取2018年100强企业的信息)
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。它恰好是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬行对我来说几乎是本能的。今天,它已成为我几乎每天都使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年排名前100的公司信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub()上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查页面
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以排名前 100 的 Tech Track 公司(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。您右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并由标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以获取完整数据。
在表格页面,可以看到一个收录全部100条数据的表格,右键点击选择“检查”,就可以很容易的看到HTML表格的结构了。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,我们就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。正如上面讨论的,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error() 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有内容都在表中(
标签),我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储它在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在Python中,如果要处理大量数据,需要写入文件,list对象就非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
在下一步中,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有使用标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们将company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还包括一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看一下对应的html代码,你会发现这个cell里面还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
在原创快速通道网页上,找到指向您需要访问的公司详细信息页面的链接。
发起指向公司详细信息页面链接的请求
使用 Beautifulsoup 处理获取的 html 数据
找到您需要的链接元素
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量整合到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这段python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用python轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
使用 BeautifulSoup 处理获取的 html 数据
循环遍历汤对象中所需的 html 元素
执行简单的数据清洗
将数据写入csv文件
如果有什么不明白的,请在下方留言,我会尽力解答!
附:本文所有代码()
祝你的爬虫之旅有个美好的开始!
原文:Kerry Parker 编译:欧莎 转载,请保留此信息)
编译源:
如果你也想零基础学习Python,完成你的第一个爬虫项目,Uda的新课程《28天Python》非常适合你。你会
由前 Google 工程师教授的课程
Python入口点解释
12个课堂实践练习
从0到1完成第一个爬虫
原价499元,尝鲜价仅299元。座位不多。现在加入
想学习了解硅谷企业的内部数据分析资料吗?优达学城【数据分析师】纳米学位将带领你成功求职,成为一名优秀的数据分析师。单击以立即了解更多信息。
python网页数据抓取(如何用Python爬虫“爬”到解析出来的链接?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-05 13:16
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了 查看全部
python网页数据抓取(如何用Python爬虫“爬”到解析出来的链接?)
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了
python网页数据抓取(你输出下str_data看看源代码中有你需要爬取的内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-04 10:03
你输出str_data看看源码里有没有需要爬取的东西
你通过js代码读取外部json数据来检查这个网页的内容是否动态更新。
请求只能获取网页的静态源代码,不能获取动态更新的内容。
对于动态更新的内容,使用 selenium 进行爬取。
或者通过F12控制台分析加载页面数据的链接,找到真正的json数据的地址进行爬取。
右键单击页面,在右键菜单中选择“查看网页源代码”。
这是网页的静态源代码。
如果本网页的静态源代码中有需要爬取的内容,则说明该页面没有动态内容,可以通过请求进行爬取。
否则就意味着页面内容是动态更新的,需要用selenium来爬取。
您的问题的答案代码如下:
from selenium import webdriver
import time
import json
from lxml import etree
driver = webdriver.Chrome()
# 确定url
url = "https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?"
# 用户代理,cookie请求
driver.get(url)
time.sleep(5)
str_data = driver.page_source
# 数据提取
html_ = etree.HTML(str_data)
# 职位
name_ = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[1]/span[1]/text()")
# 工资
print(name_)
salary = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[2]/span[1]/text()")
print(salary)
dict_ = {}
for i in range(len(name_)):
dict_[name_[i]] = salary[i]
print(dict_)
with open("前程无忧.json", 'w',encoding="gbk") as f:
json.dump(dict_,f,ensure_ascii=False)
如果有帮助,希望采纳!谢谢! 查看全部
python网页数据抓取(你输出下str_data看看源代码中有你需要爬取的内容吗)
你输出str_data看看源码里有没有需要爬取的东西
你通过js代码读取外部json数据来检查这个网页的内容是否动态更新。
请求只能获取网页的静态源代码,不能获取动态更新的内容。
对于动态更新的内容,使用 selenium 进行爬取。
或者通过F12控制台分析加载页面数据的链接,找到真正的json数据的地址进行爬取。
右键单击页面,在右键菜单中选择“查看网页源代码”。
这是网页的静态源代码。
如果本网页的静态源代码中有需要爬取的内容,则说明该页面没有动态内容,可以通过请求进行爬取。
否则就意味着页面内容是动态更新的,需要用selenium来爬取。
您的问题的答案代码如下:
from selenium import webdriver
import time
import json
from lxml import etree
driver = webdriver.Chrome()
# 确定url
url = "https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?"
# 用户代理,cookie请求
driver.get(url)
time.sleep(5)
str_data = driver.page_source
# 数据提取
html_ = etree.HTML(str_data)
# 职位
name_ = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[1]/span[1]/text()")
# 工资
print(name_)
salary = html_.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/a/p[2]/span[1]/text()")
print(salary)
dict_ = {}
for i in range(len(name_)):
dict_[name_[i]] = salary[i]
print(dict_)
with open("前程无忧.json", 'w',encoding="gbk") as f:
json.dump(dict_,f,ensure_ascii=False)
如果有帮助,希望采纳!谢谢!
python网页数据抓取(来讲四种在Python中解析网页内容的方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 14:58
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
蟒蛇
我们知道,爬虫的原理无非就是下载目标网址的内容并存入内存。这时候它的内容其实就是一堆HTML,然后按照自己的想法解析提取HTML内容。必要的资料,所以今天我们主要讲四种用Python解析网页HTML内容的方法,各有千秋,适用于不同的场合。
在学习Python的过程中,很多人往往因为没有好的教程或者没有人指导而轻易放弃。出于这个原因,我建立了一个 Python 交换。裙子:想了半天(号转换下可以找到。有最新的Python教程项目,看不懂就跟里面的人说,就解决了!
首先我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们来演示一下。
找到豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实在整个HTML代码的这个区域,所以我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码的第6行和第7行,需要手动指定header的内容,假装请求是浏览器请求。否则豆瓣会将我们的请求视为正常请求并返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,我们直接获取requests内容。内容不错。
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在如今现成的 HTMl 内容解析库太多之后,我个人不建议使用正则化来手动匹配内容。 ,费时。
主要分析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r" 查看全部
python网页数据抓取(来讲四种在Python中解析网页内容的方法,你知道吗?)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
蟒蛇
我们知道,爬虫的原理无非就是下载目标网址的内容并存入内存。这时候它的内容其实就是一堆HTML,然后按照自己的想法解析提取HTML内容。必要的资料,所以今天我们主要讲四种用Python解析网页HTML内容的方法,各有千秋,适用于不同的场合。
在学习Python的过程中,很多人往往因为没有好的教程或者没有人指导而轻易放弃。出于这个原因,我建立了一个 Python 交换。裙子:想了半天(号转换下可以找到。有最新的Python教程项目,看不懂就跟里面的人说,就解决了!
首先我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们来演示一下。
找到豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实在整个HTML代码的这个区域,所以我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码的第6行和第7行,需要手动指定header的内容,假装请求是浏览器请求。否则豆瓣会将我们的请求视为正常请求并返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,我们直接获取requests内容。内容不错。
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/4 ... aders = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在如今现成的 HTMl 内容解析库太多之后,我个人不建议使用正则化来手动匹配内容。 ,费时。
主要分析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r"
python网页数据抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-03 09:06
)
想进一步了解如何使用python捕捉网页中的动态数据?在本文中,saintlas 将向您讲解python 捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和纠正我们。先画重点:python抓取网页动态数据,python抓取网页动态数据,一起学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前是没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天我们就在这里简单的说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接复制这个网址到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这个好像很不自动化,很多其他的网站RequestURL都没有那么简单,所以我们会用python做进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python网页数据抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗
)
想进一步了解如何使用python捕捉网页中的动态数据?在本文中,saintlas 将向您讲解python 捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和纠正我们。先画重点:python抓取网页动态数据,python抓取网页动态数据,一起学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前是没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天我们就在这里简单的说一下如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,动态加载所有电影信息。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下图:
在豆瓣页面向下拖动可以加载更多电影信息到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接复制这个网址到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但是这个好像很不自动化,很多其他的网站RequestURL都没有那么简单,所以我们会用python做进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python网页数据抓取(hr人才招聘系统网站抓取url爬取建议先做好复用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-02 17:09
python网页数据抓取,包括:商品信息,导入数据库数据,获取数据预览及源码,数据编码转换,样式模板生成正文和前言的数据抓取以及基本功能的实现,如果新手想抓取数据,且有开发能力的新手,我会是你的菜。hr人才招聘系统网站抓取url爬取建议先做好复用,应对不同的业务场景。以企业招聘系统为例,我们分两步走:pythonpandasrequests1.安装pandas和requests,执行以下命令:pipinstallpandaspipinstallrequestsimportrequestsfrompandasimportseries,dataframe2.利用python解析链接生成python的网页数据爬取web站点数据简单举例3.然后做好爬取中数据抓取及其他的数据预处理工作。
(1)页面解析pythonselenium3切勿尝试selenium3网页解析,请抓住爬取网页数据的初始阶段,时刻注意被flash影响。请问:pythonselenium3能解析html吗?①ioserify(用chrome对页面url进行解析):部分功能python解析html文档方法推荐②aiserify(xpath提取python语言的文字):部分功能python解析html文档方法推荐③lphantomjs(phantomjs中chrome封装):图片gif等(chrome被屏蔽)python解析html文档方法推荐④2d4js(基于python环境,第三方库进行各种动画,弹窗,gif等):可以直接解析python网页,但是还是需要点点细心#html输入路径一步pipinstallphantomjs==3.x:所有功能都能使用phantomjs,对应好像是nginx环境requests:bs4canvas,需要点点细心pipinstallpymaxpipinstallpymenupymathpipinstallpyscriptpython解析出了我们想要的url,但是url并不正确,这个时候要解析它,这个时候可以从数据库中导入我们要查询的数据库数据,我们就可以实现一个用pymysql命令导入数据库中的数据。
我们下面先分析下python源码,分析好网页和数据库的关系,然后完成一个抓取商品数据库的过程。同时抓取页面时候,要抓住页面上的链接而不是url,因为url可以被搜索引擎抓取页面,但是页面上的页面是不可以被抓取的。为了方便爬取,我们先要抓住html文档,接下来我们需要把html文档编码转化成python语言专用编码:encoding={'utf-8':'utf-8','gbk':'gbk','gb2312':'gb2312','ascii':'ascii','euclidean':'euclidean','dom':'dom','iso-8859-1':'iso-8859-1','comma-letter':'comma','ltf':'ltf','ctf':'ctf','。 查看全部
python网页数据抓取(hr人才招聘系统网站抓取url爬取建议先做好复用)
python网页数据抓取,包括:商品信息,导入数据库数据,获取数据预览及源码,数据编码转换,样式模板生成正文和前言的数据抓取以及基本功能的实现,如果新手想抓取数据,且有开发能力的新手,我会是你的菜。hr人才招聘系统网站抓取url爬取建议先做好复用,应对不同的业务场景。以企业招聘系统为例,我们分两步走:pythonpandasrequests1.安装pandas和requests,执行以下命令:pipinstallpandaspipinstallrequestsimportrequestsfrompandasimportseries,dataframe2.利用python解析链接生成python的网页数据爬取web站点数据简单举例3.然后做好爬取中数据抓取及其他的数据预处理工作。
(1)页面解析pythonselenium3切勿尝试selenium3网页解析,请抓住爬取网页数据的初始阶段,时刻注意被flash影响。请问:pythonselenium3能解析html吗?①ioserify(用chrome对页面url进行解析):部分功能python解析html文档方法推荐②aiserify(xpath提取python语言的文字):部分功能python解析html文档方法推荐③lphantomjs(phantomjs中chrome封装):图片gif等(chrome被屏蔽)python解析html文档方法推荐④2d4js(基于python环境,第三方库进行各种动画,弹窗,gif等):可以直接解析python网页,但是还是需要点点细心#html输入路径一步pipinstallphantomjs==3.x:所有功能都能使用phantomjs,对应好像是nginx环境requests:bs4canvas,需要点点细心pipinstallpymaxpipinstallpymenupymathpipinstallpyscriptpython解析出了我们想要的url,但是url并不正确,这个时候要解析它,这个时候可以从数据库中导入我们要查询的数据库数据,我们就可以实现一个用pymysql命令导入数据库中的数据。
我们下面先分析下python源码,分析好网页和数据库的关系,然后完成一个抓取商品数据库的过程。同时抓取页面时候,要抓住页面上的链接而不是url,因为url可以被搜索引擎抓取页面,但是页面上的页面是不可以被抓取的。为了方便爬取,我们先要抓住html文档,接下来我们需要把html文档编码转化成python语言专用编码:encoding={'utf-8':'utf-8','gbk':'gbk','gb2312':'gb2312','ascii':'ascii','euclidean':'euclidean','dom':'dom','iso-8859-1':'iso-8859-1','comma-letter':'comma','ltf':'ltf','ctf':'ctf','。
python网页数据抓取(Python网络爬虫内容提取器一文项目启动说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-23 13:20
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
3、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4、下一个阅读
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5、Jisouke GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
python网页数据抓取(Python网络爬虫内容提取器一文项目启动说明(一))
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
3、总结
这是开源Python通用爬虫项目的验证过程。在爬虫框架中,其他部分很容易做到通用化,即很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,可以通过标准化的方式插入,从而实现通用爬虫,后续文章将具体讲解MS策略与Python配合的具体方法。
4、下一个阅读
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5、Jisouke GooSeeker开源代码下载源码
1.GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
python网页数据抓取(Python数据抓取分析-本文本文的全部内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-21 00:27
本文介绍Python数据采集与分析,分享给大家,如下:
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step():
try:
headers = {
。。。。。
}
r = requests.get(url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
url = soup.find_all(正则表达式)
for i in url:
url2 = i.find_all('a')
for j in url2:
step1url =url + j['href']
print step1url
step2(step1url)
except Exception,e:
print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url):
try:
headers = {
。。。。
}
r = requests.get(step1url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
a = soup.find('div',id='divTbl')
if a:
url = soup.find_all('td',class_='S-ITabs')
for i in url:
classifyurl = i.find_all('a')
for j in classifyurl:
step2url = url + j['href']
#print step2url
step3(step2url)
else:
postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url):
try:
p1url = doc.xpath(正则表达式)
for i in xrange(1,len(p1url) + 1):
p2url = doc.xpath(正则表达式)
if len(p2url) > 0:
producturl = url + p2url[0].get('href')
count = db[table].find({'url':producturl}).count()
if count 1:
td = i.find_all('td')
key=td[0].get_text().strip().replace(',','')
val=td[1].get_text().replace(u'\u20ac','').strip()
if key and val:
cost[key] = val
if cost:
dt['cost'] = cost
dt['currency'] = 'EUR'
#quantity
d = soup.find("input",id="ItemQuantity")
if d:
dt['quantity'] = d['value']
#specs
e = soup.find("div",class_="row parameter-container")
if e:
key1 = []
val1= []
for k in e.find_all('dt'):
key = k.get_text().strip().strip('.')
if key:
key1.append(key)
for i in e.find_all('dd'):
val = i.get_text().strip()
if val:
val1.append(val)
specs = dict(zip(key1,val1))
if specs:
dt['specs'] = specs
print dt
if dt:
db[table].update({'sn':sn},{'$set':dt})
print str(sn) + ' insert successfully'
time.sleep(3)
else:
error(str(sn) + '\t' + url)
except Exception,e:
error(str(sn) + '\t' + url)
print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。 查看全部
python网页数据抓取(Python数据抓取分析-本文本文的全部内容)
本文介绍Python数据采集与分析,分享给大家,如下:
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step():
try:
headers = {
。。。。。
}
r = requests.get(url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
url = soup.find_all(正则表达式)
for i in url:
url2 = i.find_all('a')
for j in url2:
step1url =url + j['href']
print step1url
step2(step1url)
except Exception,e:
print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url):
try:
headers = {
。。。。
}
r = requests.get(step1url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
a = soup.find('div',id='divTbl')
if a:
url = soup.find_all('td',class_='S-ITabs')
for i in url:
classifyurl = i.find_all('a')
for j in classifyurl:
step2url = url + j['href']
#print step2url
step3(step2url)
else:
postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url):
try:
p1url = doc.xpath(正则表达式)
for i in xrange(1,len(p1url) + 1):
p2url = doc.xpath(正则表达式)
if len(p2url) > 0:
producturl = url + p2url[0].get('href')
count = db[table].find({'url':producturl}).count()
if count 1:
td = i.find_all('td')
key=td[0].get_text().strip().replace(',','')
val=td[1].get_text().replace(u'\u20ac','').strip()
if key and val:
cost[key] = val
if cost:
dt['cost'] = cost
dt['currency'] = 'EUR'
#quantity
d = soup.find("input",id="ItemQuantity")
if d:
dt['quantity'] = d['value']
#specs
e = soup.find("div",class_="row parameter-container")
if e:
key1 = []
val1= []
for k in e.find_all('dt'):
key = k.get_text().strip().strip('.')
if key:
key1.append(key)
for i in e.find_all('dd'):
val = i.get_text().strip()
if val:
val1.append(val)
specs = dict(zip(key1,val1))
if specs:
dt['specs'] = specs
print dt
if dt:
db[table].update({'sn':sn},{'$set':dt})
print str(sn) + ' insert successfully'
time.sleep(3)
else:
error(str(sn) + '\t' + url)
except Exception,e:
error(str(sn) + '\t' + url)
print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持面圈教程。
python网页数据抓取(python网页数据抓取之爬取关键词排名数据(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-20 23:03
python网页数据抓取之爬取关键词排名数据。
一、爬取框架。urllib3首先安装好库。参考这篇文章。网页数据抓取框架选型-辰安-博客园首先建议安装前端的jquery库。
二、文件准备1.cookies解码cookies解码之前请确保你的浏览器支持jquery。2.解码类文件fiddler和浏览器(刷新地址栏)。
三、python爬虫采集流程详解。1.从项目选型到爬取前端源码。前端目前分以下几类1.jquery+css网页渲染;2.cdn,对服务器返回内容进行缓存;3.spider通过机器代理从ip池中选择合适的请求对象;4.http请求对象,包括xhr。分析jquery文件后发现整体结构都是project起始日期到章节然后到grep路径到/web自定义page里面。
这里还是应该对这个文件加一个水印md5哈哈哈。默认初始值为空。2.导入需要的模块。实验要抓取的内容依赖章节页的css、js和jquery文件,因此需要导入其他的两个模块:requests和fiddler。我们首先从下载google的网页库开始,也就是urllib3,然后用xpath导入需要的网页代码。
解析文件导入前端库,结构如下fromurllib3importurlencodefromfiddlerimportwebdriverdefget_html(message,url):message=urlencode(message)url='/'+url+messagerequests=webdriver.chrome(exclude_domain=true)requests.get(url)try:response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponseexceptexceptionase:returntrue}爬取整个过程的代码如下importrequests,fiddlerdefget_html(message,url):url='/'+url+messagepages={'words':pages}fromurllib3importurlencodefromfiddlerimportwebdriverfromfiddler.portalimportgprinterfromqueueimportqueuedeftount_url(html):response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponsedefget_page(html):html=gprinter(html,'docstring')forlinkinhtml:print(link.attrs)foreleminelem:print(elem.attrs)html.extend({'name':link.name,'link_policy':'b-tag/'。 查看全部
python网页数据抓取(python网页数据抓取之爬取关键词排名数据(一))
python网页数据抓取之爬取关键词排名数据。
一、爬取框架。urllib3首先安装好库。参考这篇文章。网页数据抓取框架选型-辰安-博客园首先建议安装前端的jquery库。
二、文件准备1.cookies解码cookies解码之前请确保你的浏览器支持jquery。2.解码类文件fiddler和浏览器(刷新地址栏)。
三、python爬虫采集流程详解。1.从项目选型到爬取前端源码。前端目前分以下几类1.jquery+css网页渲染;2.cdn,对服务器返回内容进行缓存;3.spider通过机器代理从ip池中选择合适的请求对象;4.http请求对象,包括xhr。分析jquery文件后发现整体结构都是project起始日期到章节然后到grep路径到/web自定义page里面。
这里还是应该对这个文件加一个水印md5哈哈哈。默认初始值为空。2.导入需要的模块。实验要抓取的内容依赖章节页的css、js和jquery文件,因此需要导入其他的两个模块:requests和fiddler。我们首先从下载google的网页库开始,也就是urllib3,然后用xpath导入需要的网页代码。
解析文件导入前端库,结构如下fromurllib3importurlencodefromfiddlerimportwebdriverdefget_html(message,url):message=urlencode(message)url='/'+url+messagerequests=webdriver.chrome(exclude_domain=true)requests.get(url)try:response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponseexceptexceptionase:returntrue}爬取整个过程的代码如下importrequests,fiddlerdefget_html(message,url):url='/'+url+messagepages={'words':pages}fromurllib3importurlencodefromfiddlerimportwebdriverfromfiddler.portalimportgprinterfromqueueimportqueuedeftount_url(html):response=requests.post(url,data={'user-agent':user-agent})response.encoding='utf-8'response.status_code=response.get_text()response.status_code=1returnresponsedefget_page(html):html=gprinter(html,'docstring')forlinkinhtml:print(link.attrs)foreleminelem:print(elem.attrs)html.extend({'name':link.name,'link_policy':'b-tag/'。
python网页数据抓取(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-20 05:17
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考一下。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要提取吉首官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count 查看全部
python网页数据抓取(Python使用xslt提取网页数据的方法-Python即时网络爬虫)
本文文章主要详细介绍Python使用xslt提取网页数据的方法。有一定的参考价值,感兴趣的朋友可以参考一下。
1、简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分。尝试使用xslt一次性提取静态网页内容并转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这2天在python中测试了通过xslt提取网页内容,记录如下:
2.1、 抓取目标
假设你要提取吉首官网旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、 源码1:只抓取当前页面,结果会显示在控制台
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间被一个 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" conn = request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、 抓取结果
捕获的结果如下:
2.4、 源码2:翻页抓取,并将结果保存到文件
我们对2.2的代码做了进一步的修改,增加了翻页抓取和保存结果文件的功能。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count
python网页数据抓取(无|字号订阅()抓取页面并进行处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-12-19 00:15
使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。实际上,规则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 查看全部
python网页数据抓取(无|字号订阅()抓取页面并进行处理)
使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。已经实现了抓取页面和读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。实际上,规则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。只能多练多练。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(? 将处理后的数据保存在数据库中,可以用pymssql进行处理,这里只是简单的保存在一个文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) data=f.read() f.close() #处理数据 p=pile(´(?
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-18 09:05
蟒蛇时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(本教程用于爬取动态加载的数据)
很多时候我们需要抓取网页动态加载的数据。这是当我们打开网页并按“Fn+F12”打开“开发者工具”时。
在边缘浏览器中打开开发者工具:
在谷歌浏览器中打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,
要找到我们正在寻找的文件,我们可以按文件类型找到它。在标头中,我们可以看到请求 URL。在 body 接口中,我们看到传递的数据。我们想要得到的是数据价格。此数据为 json 格式。Python获取json数据。一个字符串。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
操作结果:
所以我们得到了数据价格!
这还没完呢,我们现在已经获取到了一个url对应的动态数据,但是我有上千条数据,所以来研究一下这个requestURL是否可以构造(截图是谷歌浏览器截图)
通过对比几个requestURL,我发现这些请求的区别在于“url=”和“token=”之后,url是输入链接,我们可以自己传入,但是这个token是什么?? 经过研究,我发现令牌在这里,但它是随机生成的。如何获得这个字段?
通过在网页上右键“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我没看懂加密功能(有知道的可以告诉我,哈哈),所以只能另寻他路,研究一下。哈哈,令牌又出现在这里了。最后得到src路径,通过裁剪字符串得到token的值。
所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
再次使用上面的代码,我们就可以得到所有的数据了! 查看全部
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
蟒蛇时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(本教程用于爬取动态加载的数据)
很多时候我们需要抓取网页动态加载的数据。这是当我们打开网页并按“Fn+F12”打开“开发者工具”时。
在边缘浏览器中打开开发者工具:
在谷歌浏览器中打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,
要找到我们正在寻找的文件,我们可以按文件类型找到它。在标头中,我们可以看到请求 URL。在 body 接口中,我们看到传递的数据。我们想要得到的是数据价格。此数据为 json 格式。Python获取json数据。一个字符串。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
操作结果:
所以我们得到了数据价格!
这还没完呢,我们现在已经获取到了一个url对应的动态数据,但是我有上千条数据,所以来研究一下这个requestURL是否可以构造(截图是谷歌浏览器截图)
通过对比几个requestURL,我发现这些请求的区别在于“url=”和“token=”之后,url是输入链接,我们可以自己传入,但是这个token是什么?? 经过研究,我发现令牌在这里,但它是随机生成的。如何获得这个字段?
通过在网页上右键“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我没看懂加密功能(有知道的可以告诉我,哈哈),所以只能另寻他路,研究一下。哈哈,令牌又出现在这里了。最后得到src路径,通过裁剪字符串得到token的值。
所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
再次使用上面的代码,我们就可以得到所有的数据了!

