
python网页数据抓取
python网页数据抓取(一下Python中关于爬虫的精选文章:python实现简单爬虫功能的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-09 20:05
本文文章主要讲解构建网络爬虫的技术原理以及实现的逻辑关系。如果您有兴趣,请阅读它。
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发起HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,并且对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列问题。在网络爬虫中,当系统扩展到多台机器时,会出现很多问题。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素(URL ) 在 Bloom filter 中,我们会从 hash 函数中得到 k 位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到 k 位。如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都为 1,则这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是,你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是通过Javascript来渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有涉及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些幼稚的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上就是Python搭建网络爬虫原理解析的详细内容。更多详情请关注其他相关html中文网文章! 查看全部
python网页数据抓取(一下Python中关于爬虫的精选文章:python实现简单爬虫功能的示例)
本文文章主要讲解构建网络爬虫的技术原理以及实现的逻辑关系。如果您有兴趣,请阅读它。
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发起HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,并且对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列问题。在网络爬虫中,当系统扩展到多台机器时,会出现很多问题。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素(URL ) 在 Bloom filter 中,我们会从 hash 函数中得到 k 位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到 k 位。如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都为 1,则这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是,你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是通过Javascript来渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有涉及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些幼稚的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上就是Python搭建网络爬虫原理解析的详细内容。更多详情请关注其他相关html中文网文章!
python网页数据抓取(浅浅谈谈如如何何使使用用python抓抓取取网网页页中的动动态态数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-08 20:18
下面简单说一下如何使用python抓取网页中的动态和动态数据。根据实际的实现,我们经常会发现网页中的很多数据并不是用HT ML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HT ML网页。如果还是直接从网页爬取,将无法获取任何数据。今天我们就简单讲讲如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图,我们在HT ML中找不到对应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。
因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式保存在一起。查看RequestURL信息,可以发现action参数后面跟着两个参数“start”和“limit”。显然他们的意思是:“从某个位置返回的电影数量”。如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。但这不是很自动,很多其他的 网站 RequestURLs 没有那么简单,所以我们将使用python进行进一步的操作来获取返回的消息信息。#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests get("豆瓣com/j/chart/top_list?type= 11&interval_id=100%3A90",data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。
我们可以发现打印出来的结果就是对应的JSON文件。下一步解析和操作这里不再赘述。[{"rating":["9.6","50"],"rank":1,"cover_url":"https:\/view\/movie_poster_cover\/mpst\/public\/p 48074749 2.j pg","is_playable":true,"id":"1292052","types":["crime","plot"],"regions":["United States"],"title " :"肖申克的救赎","url":"ht tps:\/\/\/subject\/ 1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count ":713205,"score":"9.6","actors":["Tim Robbins","Morgan Freeman"," 查看全部
python网页数据抓取(浅浅谈谈如如何何使使用用python抓抓取取网网页页中的动动态态数)
下面简单说一下如何使用python抓取网页中的动态和动态数据。根据实际的实现,我们经常会发现网页中的很多数据并不是用HT ML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HT ML网页。如果还是直接从网页爬取,将无法获取任何数据。今天我们就简单讲讲如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图,我们在HT ML中找不到对应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。
因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式保存在一起。查看RequestURL信息,可以发现action参数后面跟着两个参数“start”和“limit”。显然他们的意思是:“从某个位置返回的电影数量”。如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。但这不是很自动,很多其他的 网站 RequestURLs 没有那么简单,所以我们将使用python进行进一步的操作来获取返回的消息信息。#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests get("豆瓣com/j/chart/top_list?type= 11&interval_id=100%3A90",data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。
我们可以发现打印出来的结果就是对应的JSON文件。下一步解析和操作这里不再赘述。[{"rating":["9.6","50"],"rank":1,"cover_url":"https:\/view\/movie_poster_cover\/mpst\/public\/p 48074749 2.j pg","is_playable":true,"id":"1292052","types":["crime","plot"],"regions":["United States"],"title " :"肖申克的救赎","url":"ht tps:\/\/\/subject\/ 1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count ":713205,"score":"9.6","actors":["Tim Robbins","Morgan Freeman","
python网页数据抓取( Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-05 16:11
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?
方法一
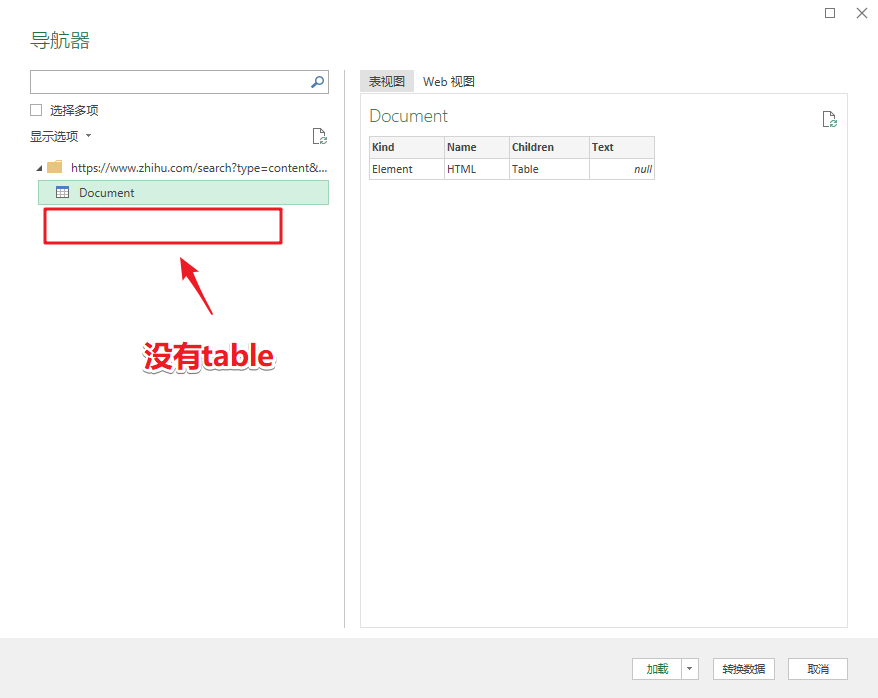
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
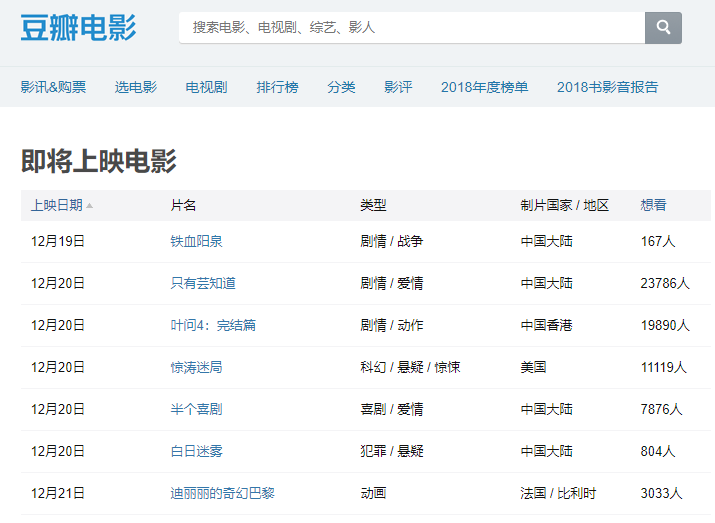
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
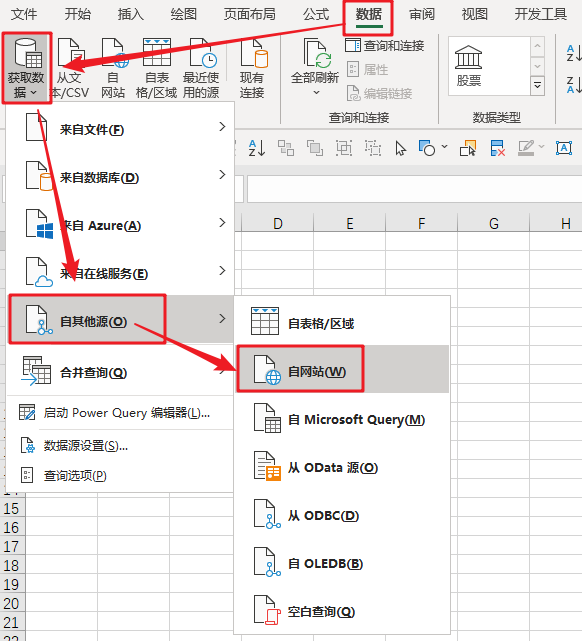
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
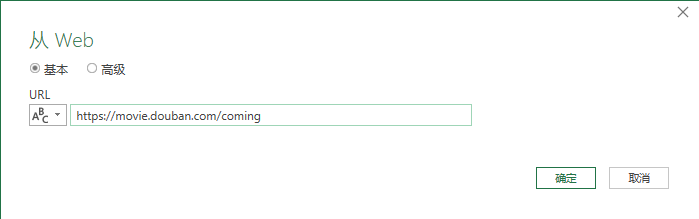
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
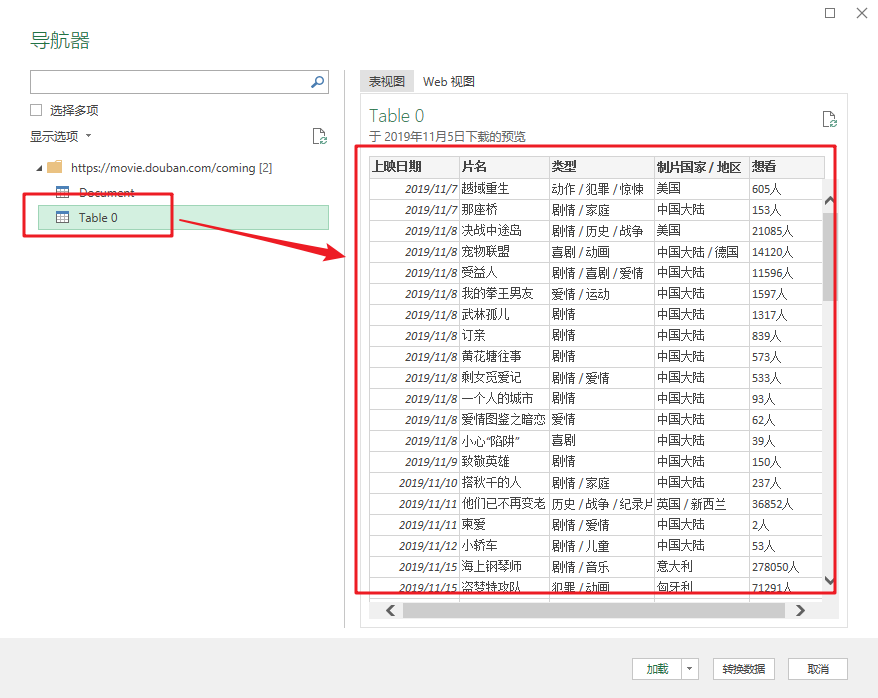
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
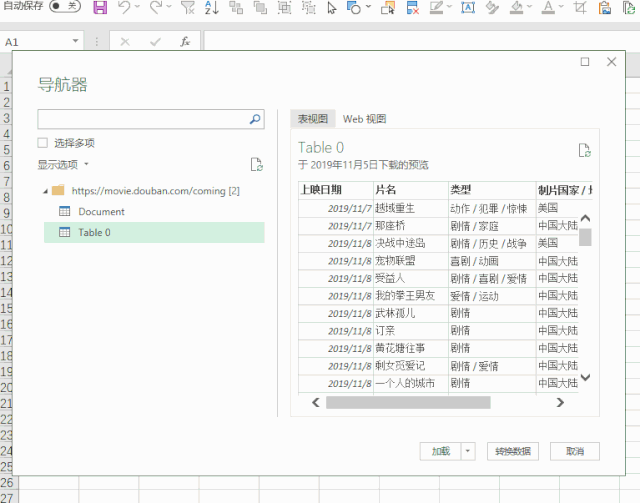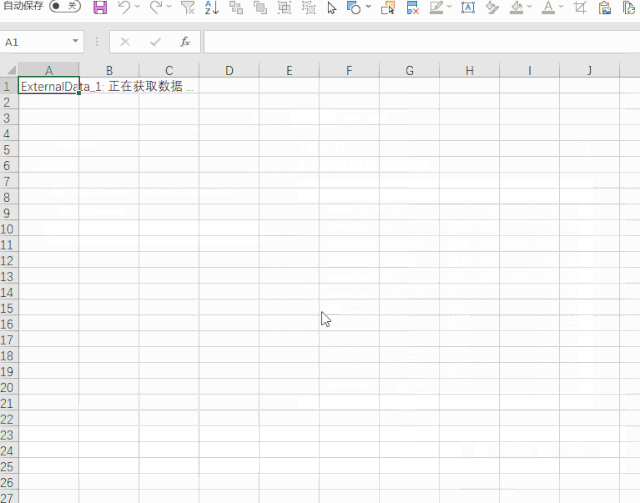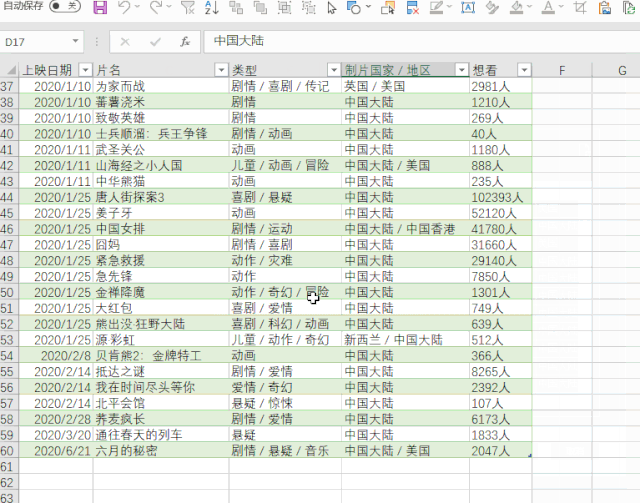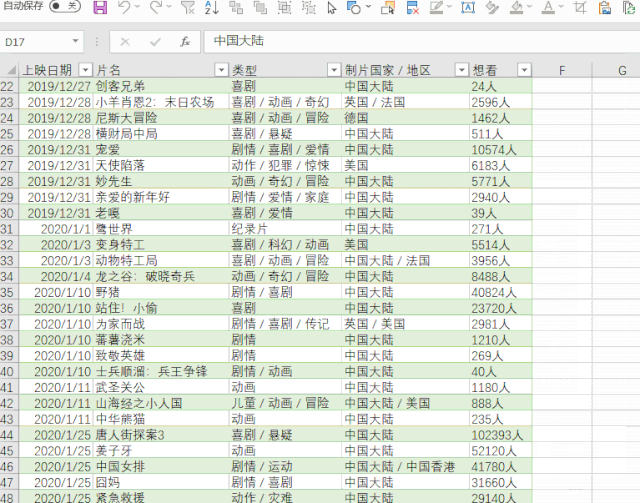
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
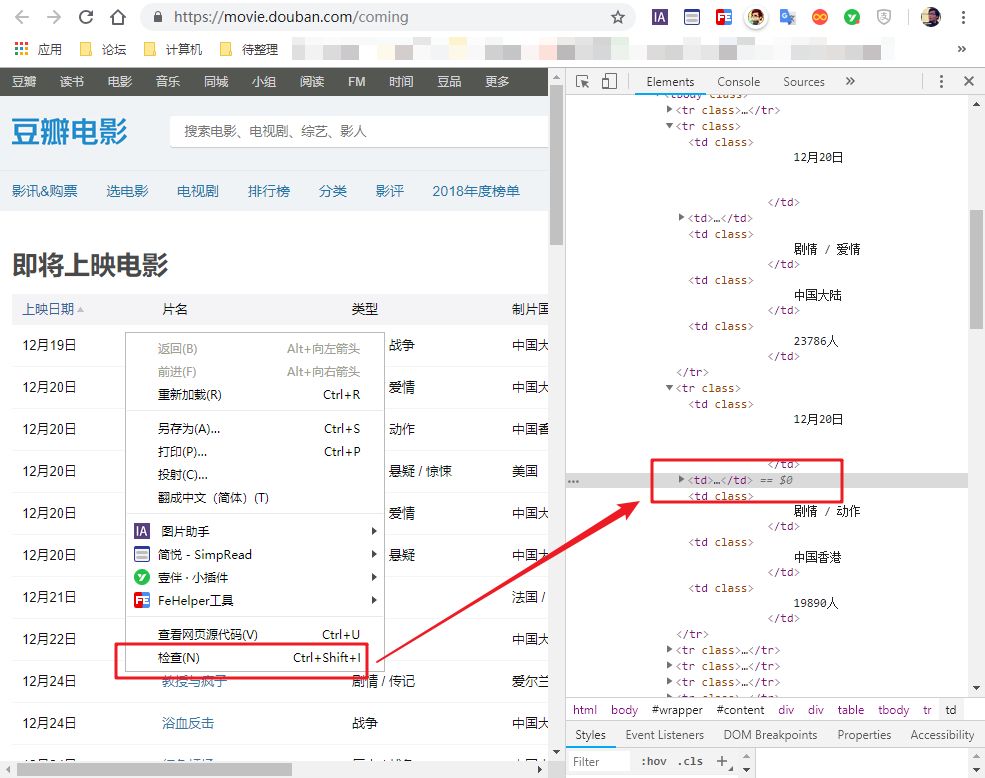
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。
方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?
这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
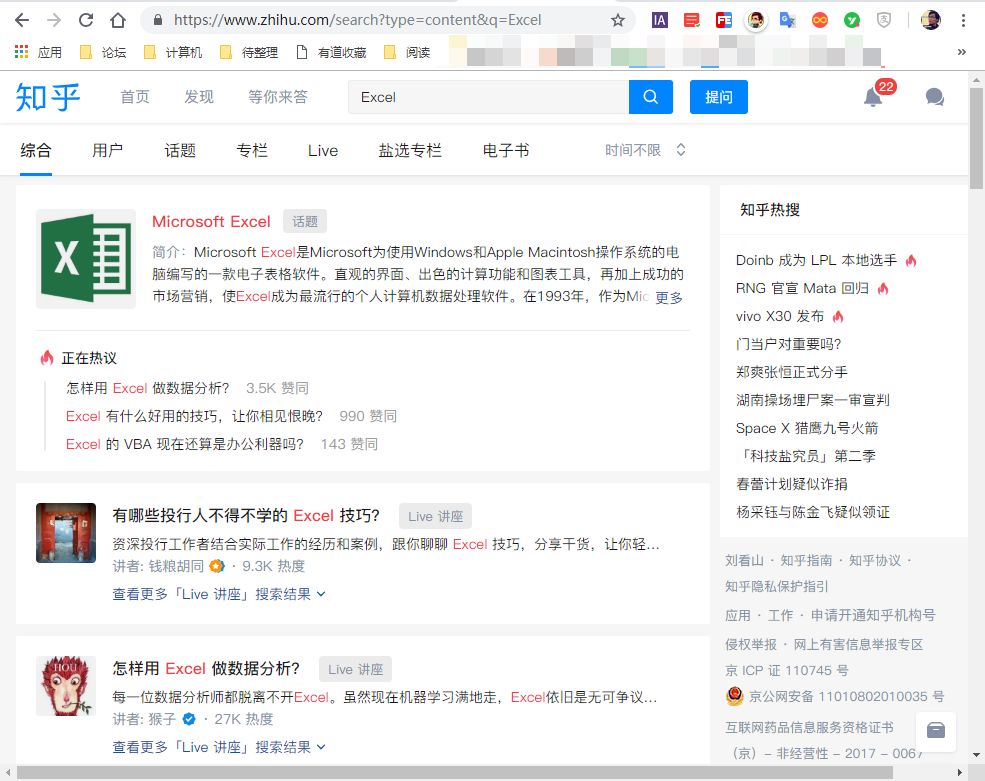
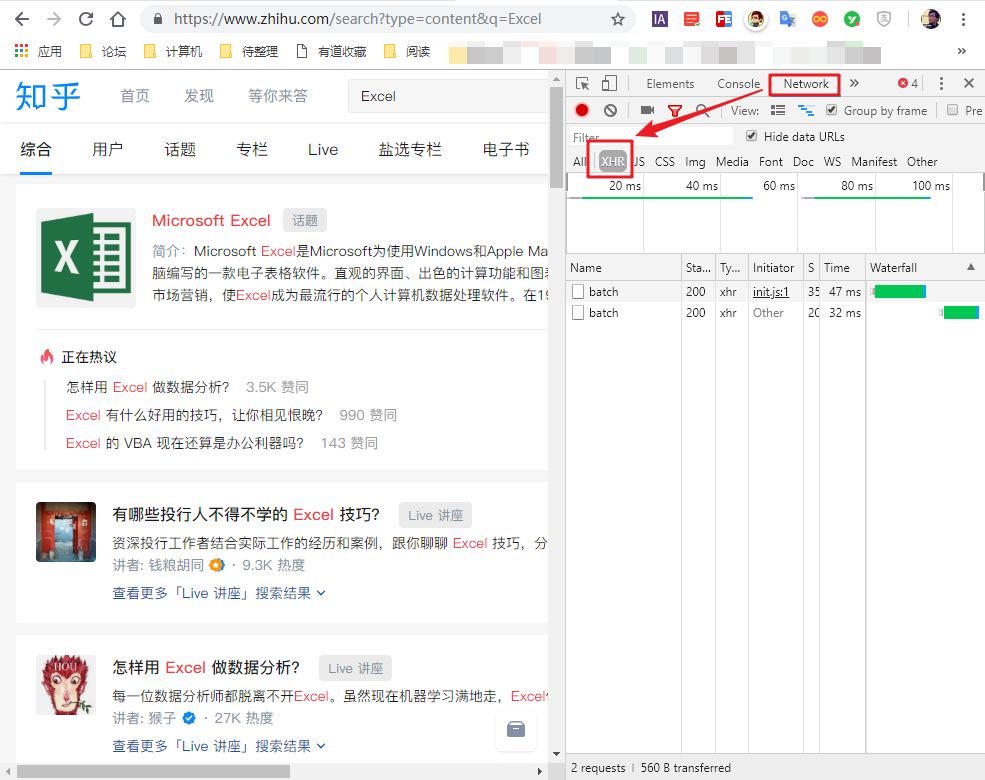
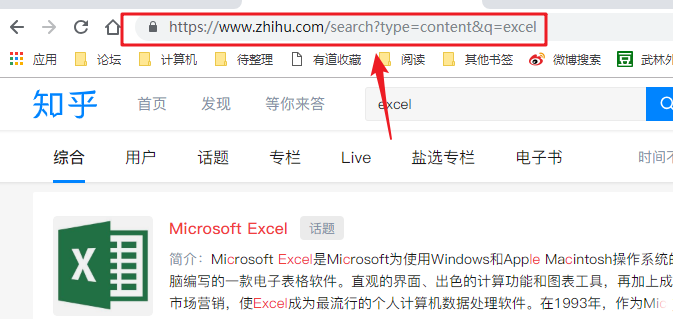
我们以知乎搜索Excel问题为例。
1- 识别数据包
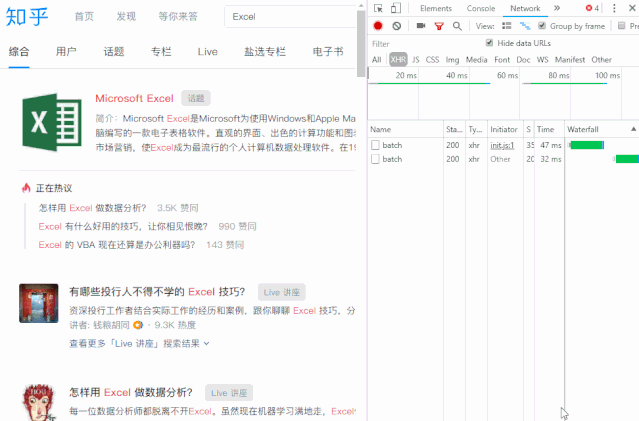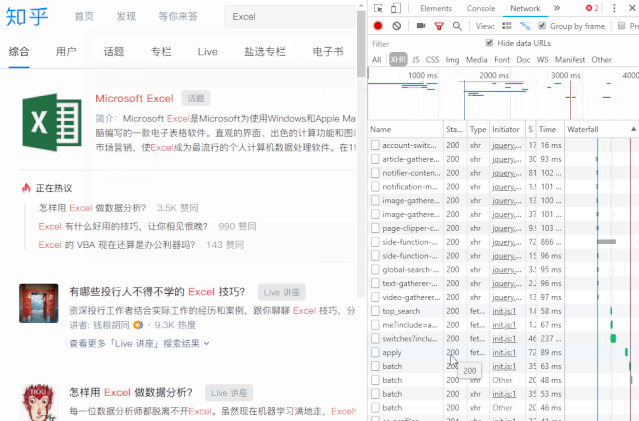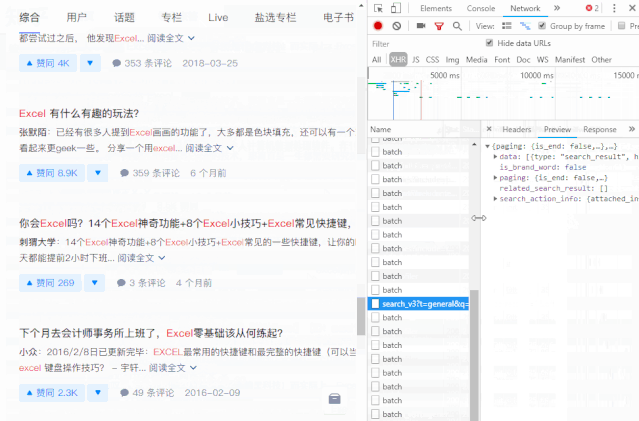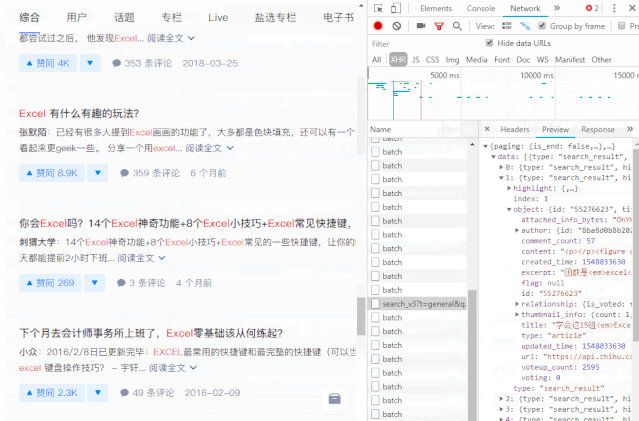
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
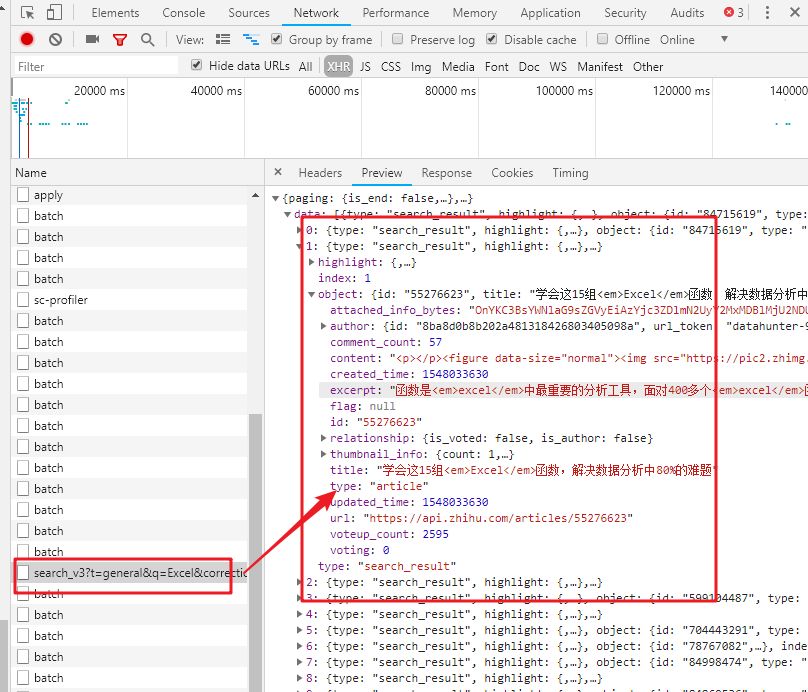
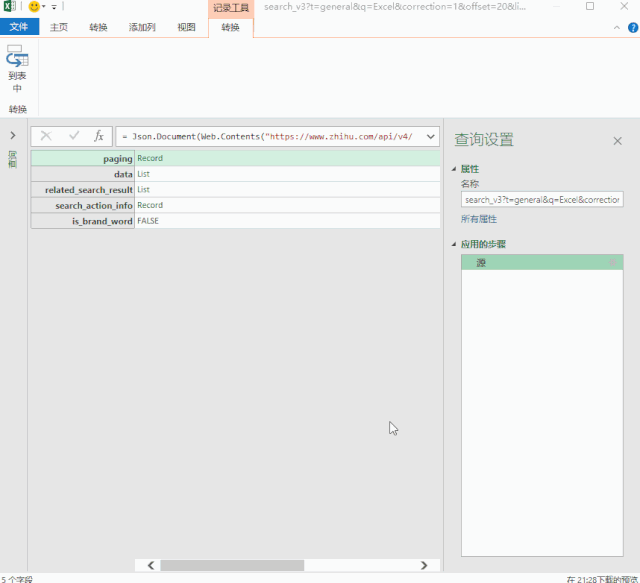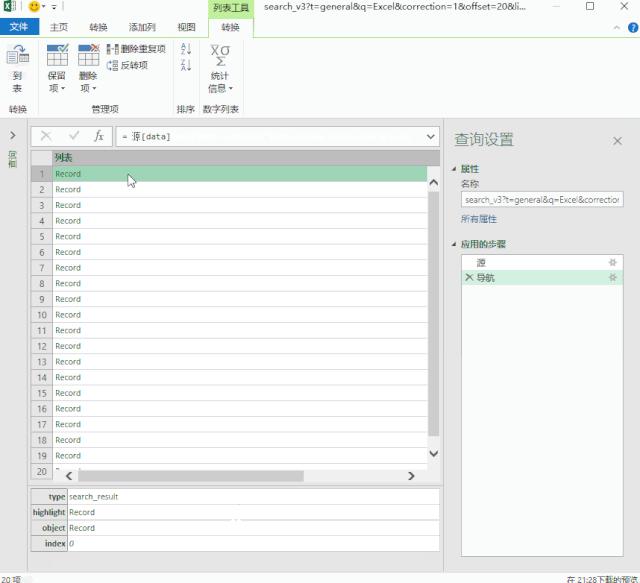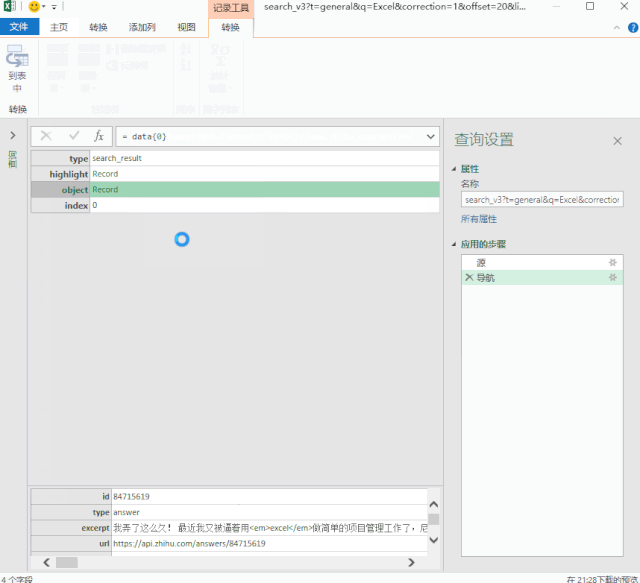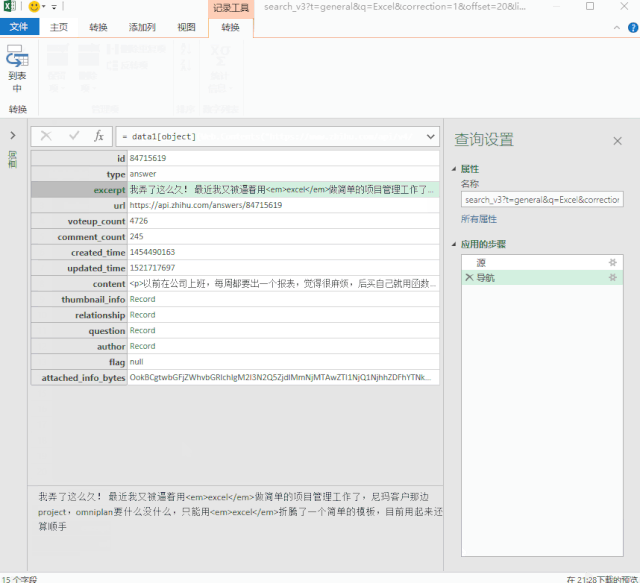
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
单击数据上的“深入”以查找我们的数据。
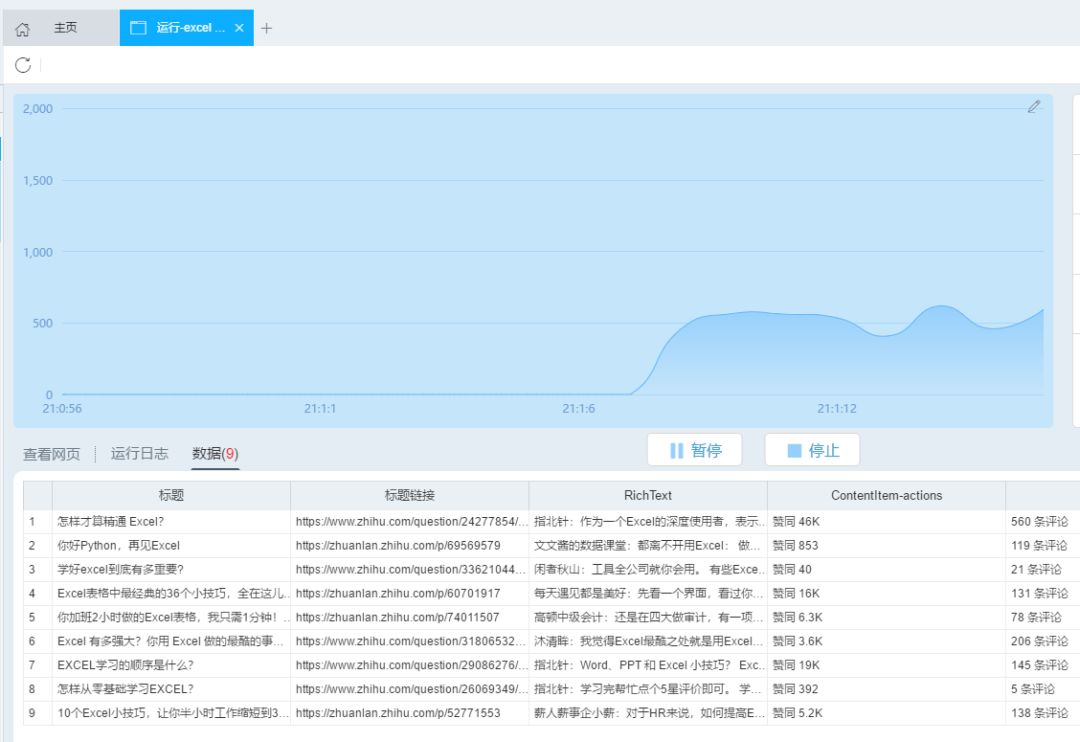
4-批量读取数据
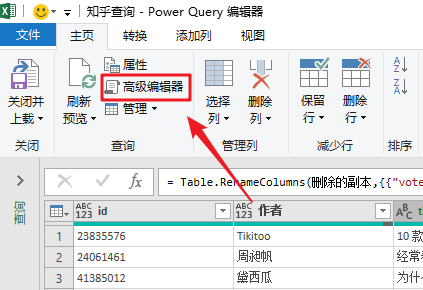
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
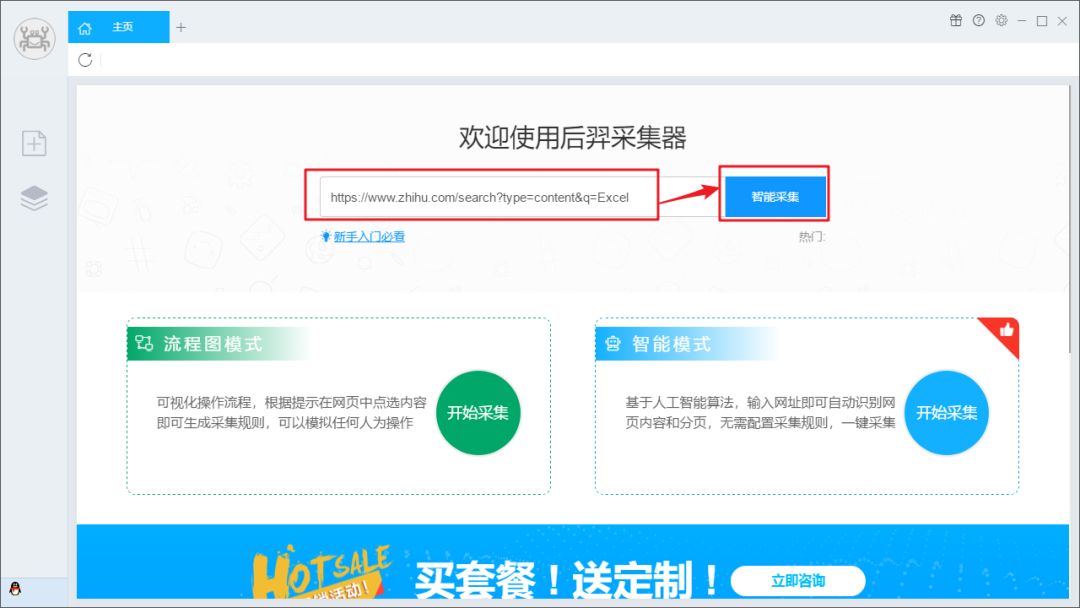
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
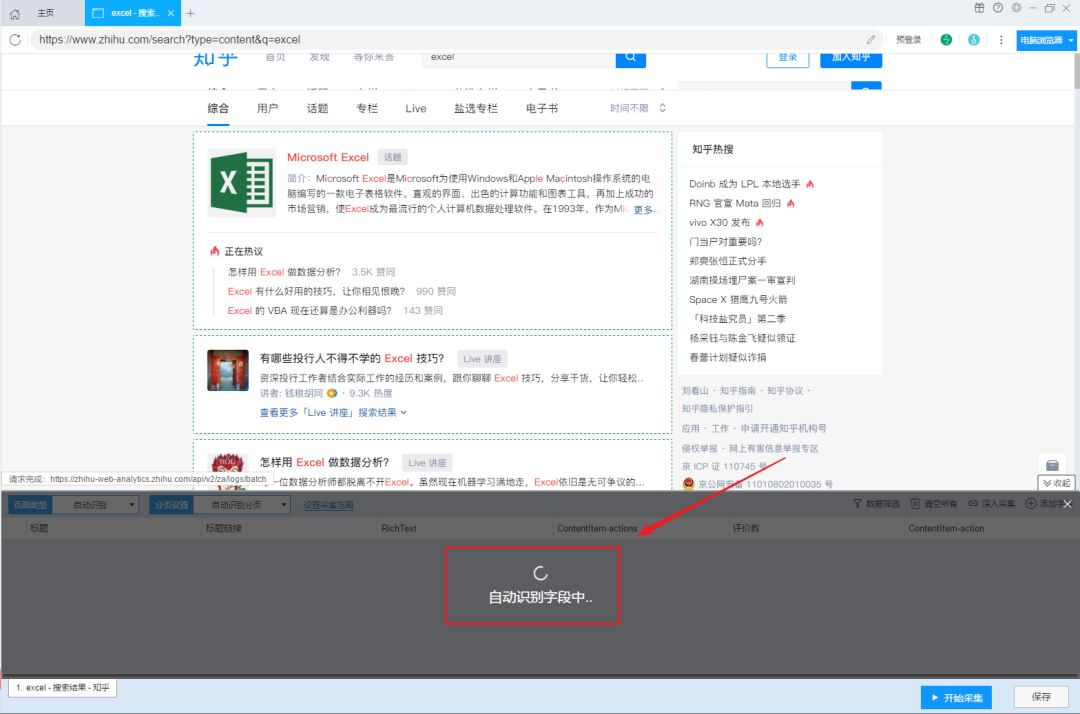
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
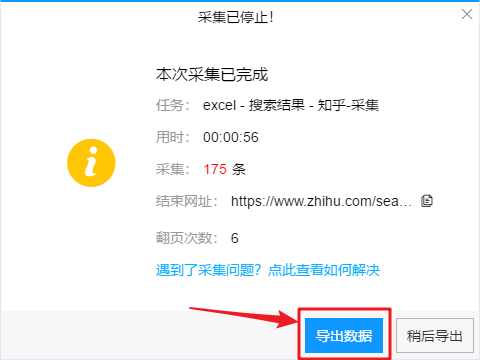
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。 查看全部
python网页数据抓取(
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)

今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。

今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?

方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。

方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?

这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
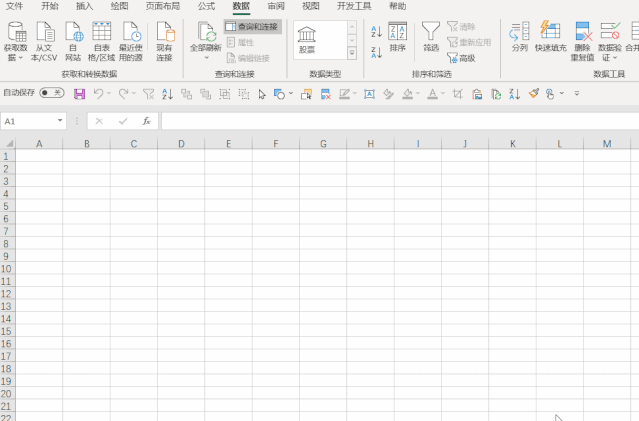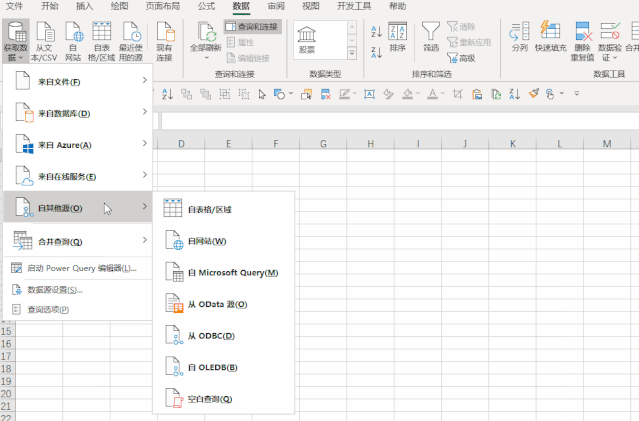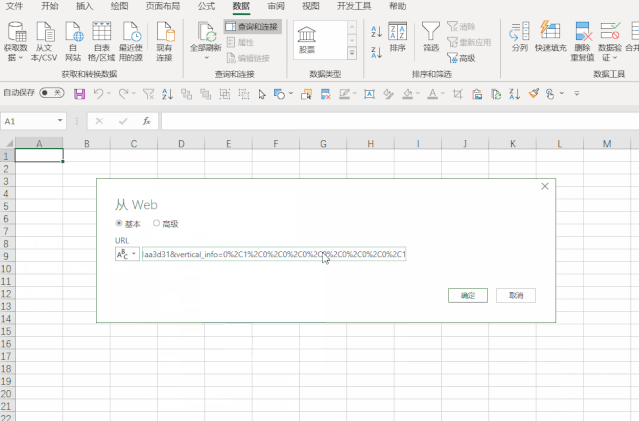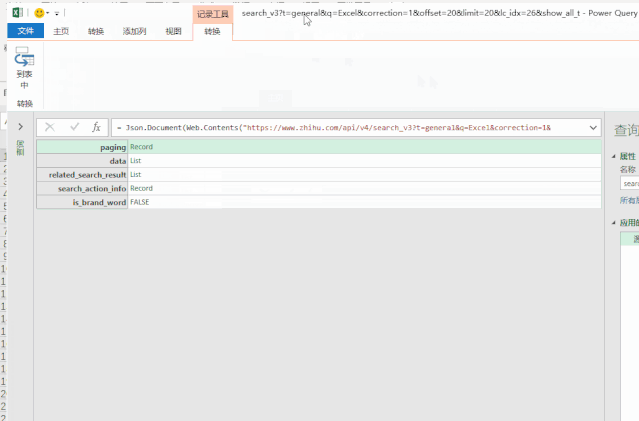
单击确定后,您将进入 Power Query 界面。
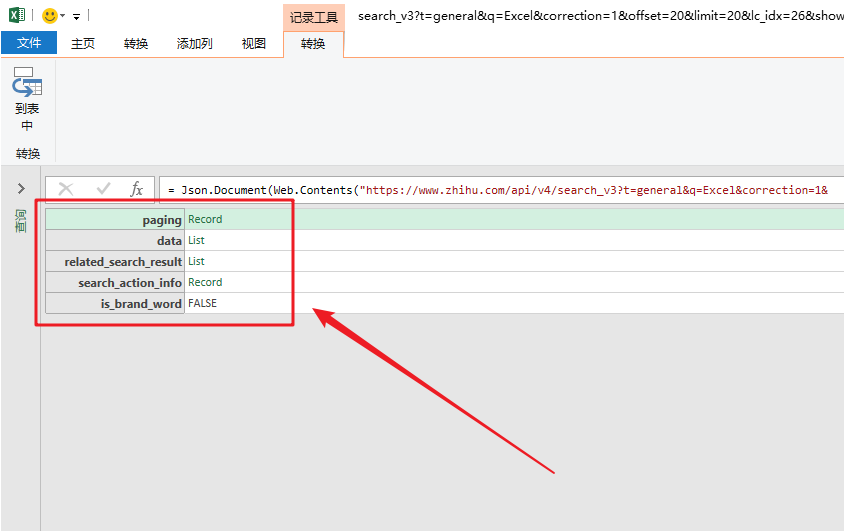
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
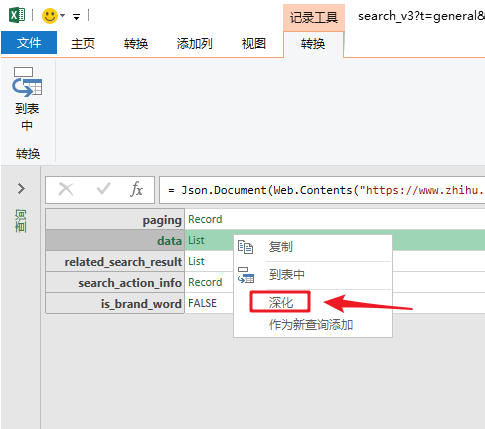
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
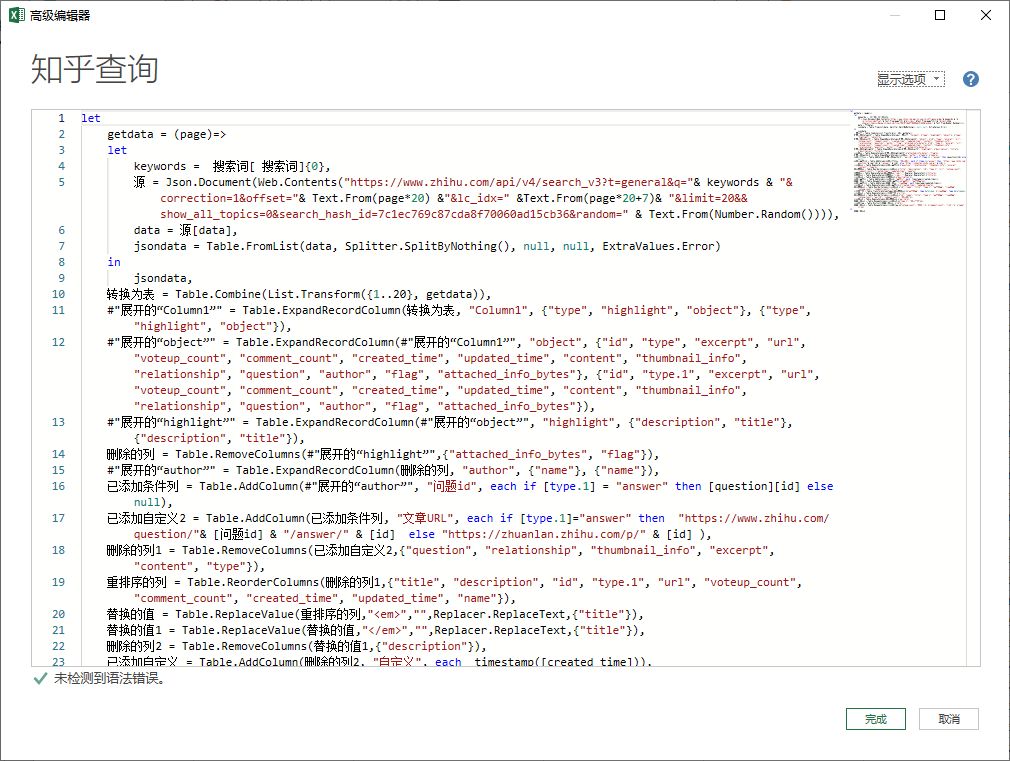
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。
python网页数据抓取(使用Python写爬虫来爬取十分方便-Python库, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-03 19:38
)
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
#定义保存函数
def saveFile(data):
path = "E:\\projects\\Spider\\02_douban.out"
f = open(path,'wb')
f.write(data)
f.close()
#网址
url = "https://www.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
#也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
#打印抓取的内容
print(data)
#打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
结果:
伪造请求头可以使用谷歌插件Chrome UA Spoofer
右键选项,很多人类用户的浏览器都可以造假,直接复制就行了
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
Chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,因此需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1 ... 39%3B
res = requests.head(url)
re=res.headers['Location'] 查看全部
python网页数据抓取(使用Python写爬虫来爬取十分方便-Python库,
)
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
#定义保存函数
def saveFile(data):
path = "E:\\projects\\Spider\\02_douban.out"
f = open(path,'wb')
f.write(data)
f.close()
#网址
url = "https://www.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
#也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
#打印抓取的内容
print(data)
#打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
结果:
伪造请求头可以使用谷歌插件Chrome UA Spoofer

右键选项,很多人类用户的浏览器都可以造假,直接复制就行了
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
Chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,因此需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1 ... 39%3B
res = requests.head(url)
re=res.headers['Location']
python网页数据抓取( 招聘职业的位置:的CSS选择器工具获取标签信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-03 14:06
招聘职业的位置:的CSS选择器工具获取标签信息
)
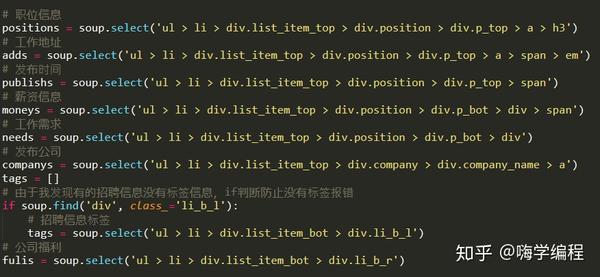
然后我们打开开发者工具,找到招聘职业的位置。
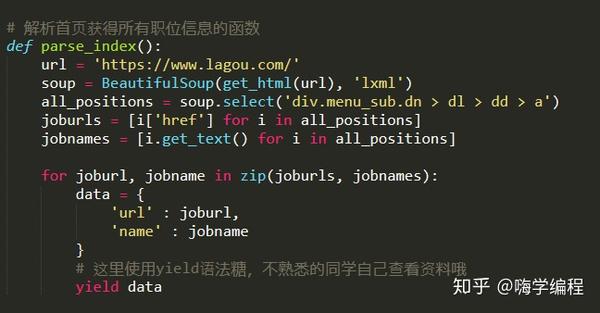
大家记得BeautifulSoup的CSS选择器,我们直接使用.select()方法来获取标签信息。
输出结果:
[/zhaopin/Java/"data-lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0101">Java, %2B%2B/"data -lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0102">C++, # ... 省略部分" data-lg-tj-cid= "idnull" data-lg-tj-id="4U00" data-lg-tj-no="0404">风控总监, "data-lg-tj-cid="idnull" data-lg-tj-id = "4U00" data-lg-tj-no="0405">副总裁]
260
获取到所有职位标签的a标签后,我们只需要提取标签的href属性和标签中的内容,就可以得到职位的招聘链接和职位名称。我们准备信息以生成字典。便于调用我们的后续程序。
这里我们使用 zip 函数同时迭代两个列表。生成键值对。
接下来,我们可以随意点击一个职位类别来分析招聘页面上的信息。
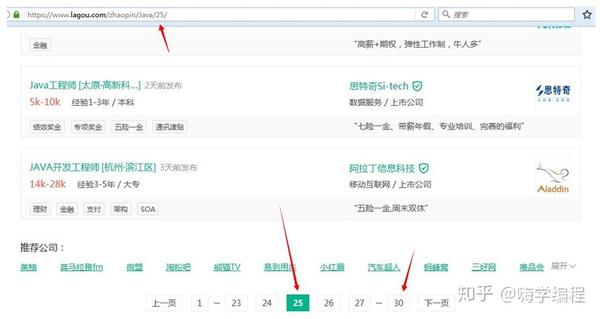
分页
我们先来分析一下网站页面信息。经过我的观察,每个职位的招聘信息最多不超过30页。也就是说,只要我们从第1页循环到第30页,就可以得到所有的招聘信息。但是也可以看到一些招聘信息,页数不到30页。以下图为例:
如果我们访问页面:/zhaopin/Java/31/
那是第 31 页。我们将得到一个 404 页。所以我们在访问404页面时需要进行过滤。
ifresp.status_code ==404:
经过
这样,我们就可以放心的在30页的周期内拿到每一页的招聘信息。
我们每个页面的url都是用格式拼接出来的:
link ='{}{}/'.format(url, str(pages))
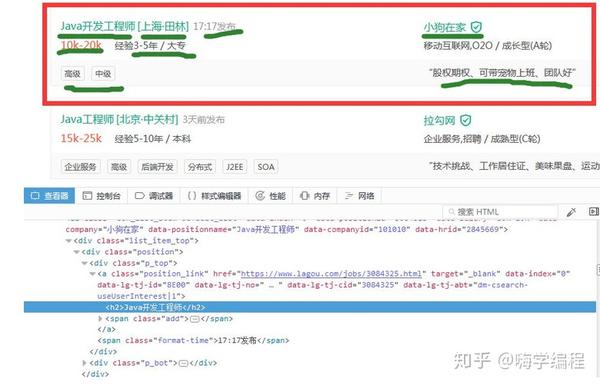
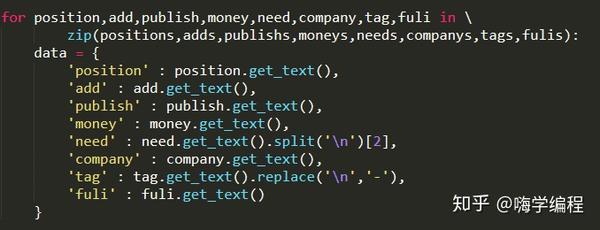
获取资讯
获得所有信息后,我们还将它们组合成一个键值对字典。
字典的目的是方便我们将所有信息保存到数据库中。
保存数据
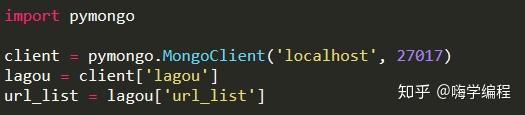
在保存数据库之前,我们需要配置数据库信息:
这里我们导入pymongo库并建立与MongoDB的连接,这里是本地MongoDB数据的默认连接。创建并选择一个数据库lagou,并在该数据库中创建一个表,即url_list。然后,我们保存数据:
ifurl_list.insert_one(数据):
print('保存数据库成功', data)
如果保存成功,会打印成功信息。
多线程爬取
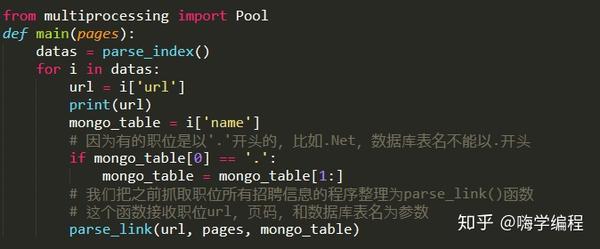
10万多条数据的爬取是不是有点慢?有一个办法,我们用多个进程同时爬取。由于 Python 的历史遗留问题,多线程在 Python 中一直是一个美丽的梦想。
我们把提取职位招聘信息的代码写成一个函数,方便我们调用。这里的 parse_link() 就是这个函数,它以帖子的 url 和所有页面的数量作为参数。我们在 get_alllink_data() 函数的 for 循环中使用了 30 页数据。然后 this 作为主函数传递给多进程内部调用。
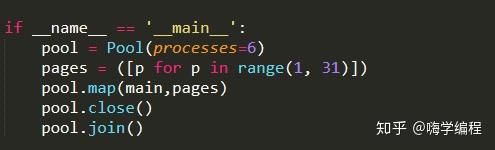
这里是一个pool进程池,我们调用进程池的map方法。
地图(功能,可迭代[,块大小=无])
多进程Pool类中的map方法与Python内置map函数的用法和行为基本一致。它将阻塞进程,直到返回结果。需要注意的是,虽然第二个参数是迭代器,但在实际使用中,程序只有在整个队列准备好后才会运行子进程。加入()
该方法等待子进程结束,然后继续向下运行,通常用于进程之间的同步。
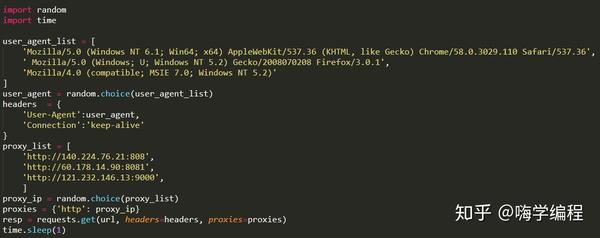
反爬虫处理
像这样写完代码,就开始爬吧。我相信程序不会在爬行后很快停止。第一次停止后,我以为是网站限制了我的ip。所以我做了以下改动。
查看全部
python网页数据抓取(
招聘职业的位置:的CSS选择器工具获取标签信息
)
然后我们打开开发者工具,找到招聘职业的位置。
大家记得BeautifulSoup的CSS选择器,我们直接使用.select()方法来获取标签信息。

输出结果:
[/zhaopin/Java/"data-lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0101">Java, %2B%2B/"data -lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0102">C++, # ... 省略部分" data-lg-tj-cid= "idnull" data-lg-tj-id="4U00" data-lg-tj-no="0404">风控总监, "data-lg-tj-cid="idnull" data-lg-tj-id = "4U00" data-lg-tj-no="0405">副总裁]
260
获取到所有职位标签的a标签后,我们只需要提取标签的href属性和标签中的内容,就可以得到职位的招聘链接和职位名称。我们准备信息以生成字典。便于调用我们的后续程序。
这里我们使用 zip 函数同时迭代两个列表。生成键值对。
接下来,我们可以随意点击一个职位类别来分析招聘页面上的信息。
分页
我们先来分析一下网站页面信息。经过我的观察,每个职位的招聘信息最多不超过30页。也就是说,只要我们从第1页循环到第30页,就可以得到所有的招聘信息。但是也可以看到一些招聘信息,页数不到30页。以下图为例:
如果我们访问页面:/zhaopin/Java/31/
那是第 31 页。我们将得到一个 404 页。所以我们在访问404页面时需要进行过滤。
ifresp.status_code ==404:
经过
这样,我们就可以放心的在30页的周期内拿到每一页的招聘信息。
我们每个页面的url都是用格式拼接出来的:
link ='{}{}/'.format(url, str(pages))
获取资讯
获得所有信息后,我们还将它们组合成一个键值对字典。
字典的目的是方便我们将所有信息保存到数据库中。
保存数据
在保存数据库之前,我们需要配置数据库信息:
这里我们导入pymongo库并建立与MongoDB的连接,这里是本地MongoDB数据的默认连接。创建并选择一个数据库lagou,并在该数据库中创建一个表,即url_list。然后,我们保存数据:
ifurl_list.insert_one(数据):
print('保存数据库成功', data)
如果保存成功,会打印成功信息。
多线程爬取
10万多条数据的爬取是不是有点慢?有一个办法,我们用多个进程同时爬取。由于 Python 的历史遗留问题,多线程在 Python 中一直是一个美丽的梦想。
我们把提取职位招聘信息的代码写成一个函数,方便我们调用。这里的 parse_link() 就是这个函数,它以帖子的 url 和所有页面的数量作为参数。我们在 get_alllink_data() 函数的 for 循环中使用了 30 页数据。然后 this 作为主函数传递给多进程内部调用。
这里是一个pool进程池,我们调用进程池的map方法。
地图(功能,可迭代[,块大小=无])
多进程Pool类中的map方法与Python内置map函数的用法和行为基本一致。它将阻塞进程,直到返回结果。需要注意的是,虽然第二个参数是迭代器,但在实际使用中,程序只有在整个队列准备好后才会运行子进程。加入()
该方法等待子进程结束,然后继续向下运行,通常用于进程之间的同步。
反爬虫处理
像这样写完代码,就开始爬吧。我相信程序不会在爬行后很快停止。第一次停止后,我以为是网站限制了我的ip。所以我做了以下改动。
python网页数据抓取(数据预览_csv路径不要带有中文学历要求(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-03 14:04
)
全文介绍
本文先采集从网上拉取数据,采集从Python位置数据,然后用Python进行可视化。主要涉及爬虫知识和数据可视化。
履带部分
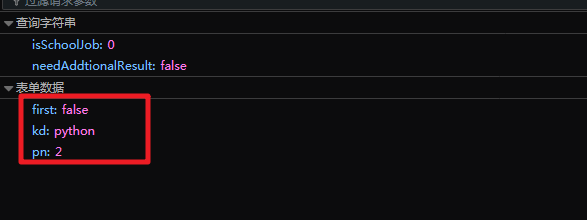
首先使用Python抓取pull hook网络上的数据,使用简单易用的requests模块。主要需要注意的是, 是一个动态网页,所以会使用浏览器的 F12 开发者工具来抓包。抓包后会发现网页其实是一个POST表单,需要提交数据。提交的数据如下:
真正的网址是:/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0
在上图中也很容易找到:kd是查询关键词,pn是页数,可以用来翻页。
代码
import requests # 网络请求
import re
import time
import random
# post的网址
url = 'https://www.lagou.com/jobs/pos ... 39%3B
# 反爬措施
header = {'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/lis ... 39%3B,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Cookie': 'user_trace_token=20171103191801-9206e24f-9ca2-40ab-95a3-23947c0b972a; _ga=GA1.2.545192972.1509707889; LGUID=20171103191805-a9838dac-c088-11e7-9704-5254005c3644; JSESSIONID=ABAAABAACDBABJB2EE720304E451B2CEFA1723CE83F19CC; _gat=1; LGSID=20171228225143-9edb51dd-ebde-11e7-b670-525400f775ce; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DKkJPgBHAnny1nUKaLpx2oDfUXv9ItIF3kBAWM2-fDNu%26ck%3D3065.1.126.376.140.374.139.129%26shh%3Dwww.baidu.com%26sht%3Dmonline_3_dg%26wd%3D%26eqid%3Db0ec59d100013c7f000000055a4504f6; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGRID=20171228225224-b6cc7abd-ebde-11e7-9f67-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; SEARCH_ID=3ec21cea985a4a5fa2ab279d868560c8',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}
for n in range(30):
# 要提交的数据
form = {'first':'false',
'kd':'Python',
'pn':str(n)}
time.sleep(random.randint(2,5))
# 提交数据
html = requests.post(url,data=form,headers = header)
# 提取数据
data = re.findall('{"companyId":.*?,"positionName":"(.*?)","workYear":"(.*?)","education":"(.*?)","jobNature":"(.*?)","financeStage":"(.*?)","companyLogo":".*?","industryField":".*?","city":"(.*?)","salary":"(.*?)","positionId":.*?,"positionAdvantage":"(.*?)","companyShortName":"(.*?)","district"',html.text)
# 转换成数据框
data = pd.DataFrame(data)
# 保存在本地
data.to_csv(r'D:\Windows 7 Documents\Desktop\My\LaGouDataMatlab.csv',header = False, index = False, mode = 'a+')
注意:爬取数据的时候不要爬得太快,除非你有其他的反爬取措施,比如改IP,并且不需要登录。我在代码中加了一个时间模块来限制爬取速度。
数据可视化
下载的数据如下所示:
注意标题(也就是listing)是我自己加的。
导入模块并配置绘图风格
import pandas as pd # 数据框操作
import numpy as np
import matplotlib.pyplot as plt # 绘图
import jieba # 分词
from wordcloud import WordCloud # 词云可视化
import matplotlib as mpl # 配置字体
from pyecharts import Geo # 地理图
mpl.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
# 配置绘图风格
plt.rcParams["axes.labelsize"] = 16.
plt.rcParams["xtick.labelsize"] = 14.
plt.rcParams["ytick.labelsize"] = 14.
plt.rcParams["legend.fontsize"] = 12.
plt.rcParams["figure.figsize"] = [15., 15.]
注意:导入模块时,其他一切都很容易解决。除了 wordcloud 模块,我建议你手动安装这个模块。如果用pip安装,会提示缺少C++14.0等错误,导致安装。不开。手动下载whl文件以顺利安装。
数据预览
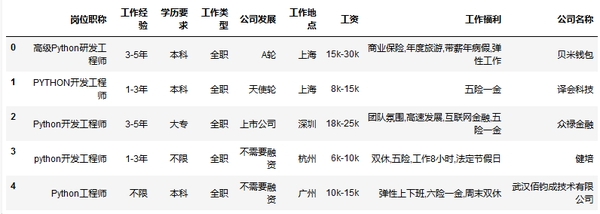
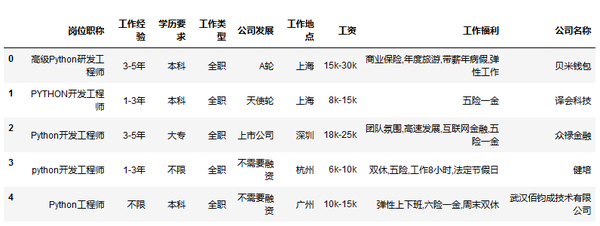
# 导入数据
data = pd.read_csv('D:\\Windows 7 Documents\\Desktop\\My\\LaGouDataPython.csv',encoding='gbk') # 导入数据
data.head()
read_csv路径中不要有中文
data.tail()
学术要求
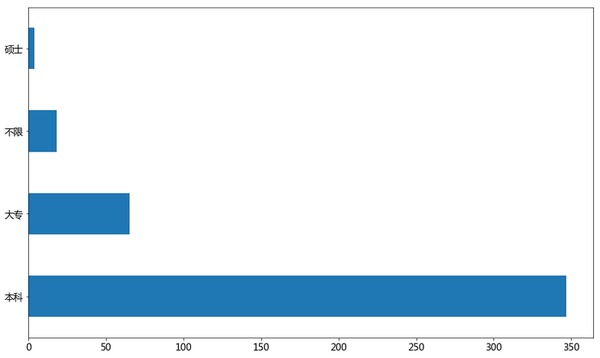
data['学历要求'].value_counts().plot(kind='barh',rot=0)
plt.show()
工作经验
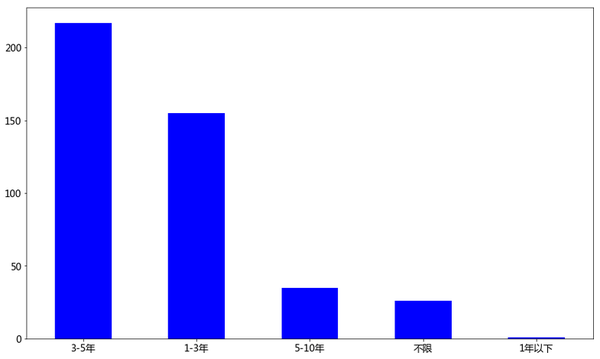
data['工作经验'].value_counts().plot(kind='bar',rot=0,color='b')
plt.show()
Python热帖
final = ''
stopwords = ['PYTHON','python','Python','工程师','(',')','/'] # 停止词
for n in range(data.shape[0]):
seg_list = list(jieba.cut(data['岗位职称'][n]))
for seg in seg_list:
if seg not in stopwords:
final = final + seg + ' '
# final 得到的词汇
工作场所
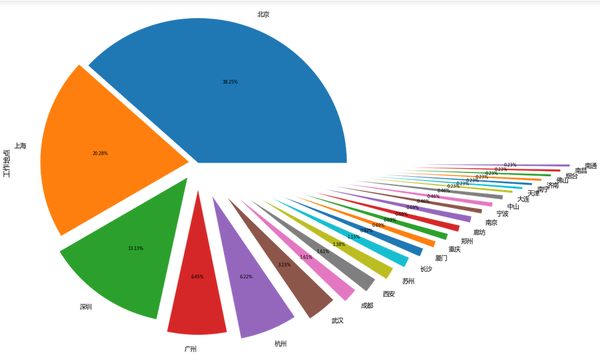
data['工作地点'].value_counts().plot(kind='pie',autopct='%1.2f%%',explode = np.linspace(0,1.5,25))
plt.show()
工作地理图
# 提取数据框
data2 = list(map(lambda x:(data['工作地点'][x],eval(re.split('k|K',data['工资'][x])[0])*1000),range(len(data))))
# 提取价格信息
data3 = pd.DataFrame(data2)
# 转化成Geo需要的格式
data4 = list(map(lambda x:(data3.groupby(0).mean()[1].index[x],data3.groupby(0).mean()[1].values[x]),range(len(data3.groupby(0)))))
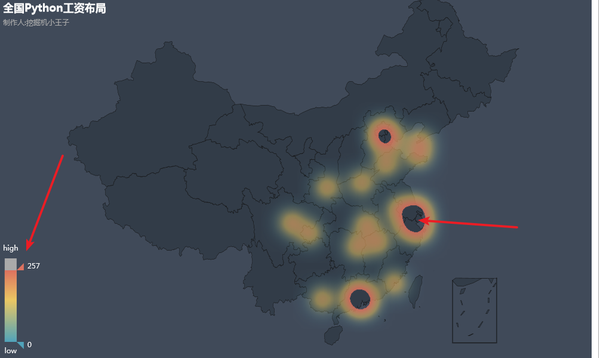
# 地理位置展示
geo = Geo("全国Python工资布局", "制作人:挖掘机小王子", title_color="#fff", title_pos="left", width=1200, height=600,
background_color='#404a59')
attr, value = geo.cast(data4)
geo.add("", attr, value, type="heatmap", is_visualmap=True, visual_range=[0, 300], visual_text_color='#fff')
# 中国地图Python工资,此分布是最低薪资
geo
查看全部
python网页数据抓取(数据预览_csv路径不要带有中文学历要求(图)
)
全文介绍
本文先采集从网上拉取数据,采集从Python位置数据,然后用Python进行可视化。主要涉及爬虫知识和数据可视化。
履带部分
首先使用Python抓取pull hook网络上的数据,使用简单易用的requests模块。主要需要注意的是, 是一个动态网页,所以会使用浏览器的 F12 开发者工具来抓包。抓包后会发现网页其实是一个POST表单,需要提交数据。提交的数据如下:
真正的网址是:/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0
在上图中也很容易找到:kd是查询关键词,pn是页数,可以用来翻页。
代码
import requests # 网络请求
import re
import time
import random
# post的网址
url = 'https://www.lagou.com/jobs/pos ... 39%3B
# 反爬措施
header = {'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/lis ... 39%3B,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Cookie': 'user_trace_token=20171103191801-9206e24f-9ca2-40ab-95a3-23947c0b972a; _ga=GA1.2.545192972.1509707889; LGUID=20171103191805-a9838dac-c088-11e7-9704-5254005c3644; JSESSIONID=ABAAABAACDBABJB2EE720304E451B2CEFA1723CE83F19CC; _gat=1; LGSID=20171228225143-9edb51dd-ebde-11e7-b670-525400f775ce; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DKkJPgBHAnny1nUKaLpx2oDfUXv9ItIF3kBAWM2-fDNu%26ck%3D3065.1.126.376.140.374.139.129%26shh%3Dwww.baidu.com%26sht%3Dmonline_3_dg%26wd%3D%26eqid%3Db0ec59d100013c7f000000055a4504f6; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGRID=20171228225224-b6cc7abd-ebde-11e7-9f67-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; SEARCH_ID=3ec21cea985a4a5fa2ab279d868560c8',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}
for n in range(30):
# 要提交的数据
form = {'first':'false',
'kd':'Python',
'pn':str(n)}
time.sleep(random.randint(2,5))
# 提交数据
html = requests.post(url,data=form,headers = header)
# 提取数据
data = re.findall('{"companyId":.*?,"positionName":"(.*?)","workYear":"(.*?)","education":"(.*?)","jobNature":"(.*?)","financeStage":"(.*?)","companyLogo":".*?","industryField":".*?","city":"(.*?)","salary":"(.*?)","positionId":.*?,"positionAdvantage":"(.*?)","companyShortName":"(.*?)","district"',html.text)
# 转换成数据框
data = pd.DataFrame(data)
# 保存在本地
data.to_csv(r'D:\Windows 7 Documents\Desktop\My\LaGouDataMatlab.csv',header = False, index = False, mode = 'a+')
注意:爬取数据的时候不要爬得太快,除非你有其他的反爬取措施,比如改IP,并且不需要登录。我在代码中加了一个时间模块来限制爬取速度。
数据可视化
下载的数据如下所示:
注意标题(也就是listing)是我自己加的。
导入模块并配置绘图风格
import pandas as pd # 数据框操作
import numpy as np
import matplotlib.pyplot as plt # 绘图
import jieba # 分词
from wordcloud import WordCloud # 词云可视化
import matplotlib as mpl # 配置字体
from pyecharts import Geo # 地理图
mpl.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
# 配置绘图风格
plt.rcParams["axes.labelsize"] = 16.
plt.rcParams["xtick.labelsize"] = 14.
plt.rcParams["ytick.labelsize"] = 14.
plt.rcParams["legend.fontsize"] = 12.
plt.rcParams["figure.figsize"] = [15., 15.]
注意:导入模块时,其他一切都很容易解决。除了 wordcloud 模块,我建议你手动安装这个模块。如果用pip安装,会提示缺少C++14.0等错误,导致安装。不开。手动下载whl文件以顺利安装。
数据预览
# 导入数据
data = pd.read_csv('D:\\Windows 7 Documents\\Desktop\\My\\LaGouDataPython.csv',encoding='gbk') # 导入数据
data.head()
read_csv路径中不要有中文
data.tail()
学术要求
data['学历要求'].value_counts().plot(kind='barh',rot=0)
plt.show()
工作经验
data['工作经验'].value_counts().plot(kind='bar',rot=0,color='b')
plt.show()
Python热帖
final = ''
stopwords = ['PYTHON','python','Python','工程师','(',')','/'] # 停止词
for n in range(data.shape[0]):
seg_list = list(jieba.cut(data['岗位职称'][n]))
for seg in seg_list:
if seg not in stopwords:
final = final + seg + ' '
# final 得到的词汇

工作场所
data['工作地点'].value_counts().plot(kind='pie',autopct='%1.2f%%',explode = np.linspace(0,1.5,25))
plt.show()
工作地理图
# 提取数据框
data2 = list(map(lambda x:(data['工作地点'][x],eval(re.split('k|K',data['工资'][x])[0])*1000),range(len(data))))
# 提取价格信息
data3 = pd.DataFrame(data2)
# 转化成Geo需要的格式
data4 = list(map(lambda x:(data3.groupby(0).mean()[1].index[x],data3.groupby(0).mean()[1].values[x]),range(len(data3.groupby(0)))))
# 地理位置展示
geo = Geo("全国Python工资布局", "制作人:挖掘机小王子", title_color="#fff", title_pos="left", width=1200, height=600,
background_color='#404a59')
attr, value = geo.cast(data4)
geo.add("", attr, value, type="heatmap", is_visualmap=True, visual_range=[0, 300], visual_text_color='#fff')
# 中国地图Python工资,此分布是最低薪资
geo
python网页数据抓取(pythonitems通过爬虫技术连接不同的网站爬取的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-02 11:03
python网页数据抓取基础介绍,有小伙伴问对于入门的python小白来说,能否下载某网站的数据呢?答案是肯定的,通过上面的对比,我们可以发现,在web数据爬取时,通过网页爬取工具去实现比较方便,那么问题来了,该怎么解决不同的网站爬取的问题呢?用浏览器抓取的方式也很简单,那么这里介绍一个小函数可以对不同的网站,我们可以抓取其用户名和密码,我们这里以“知乎”为例:fromurllibimportrequestimporttimetext=''cookie={'code':'','key':'6632256'}page=request.urlopen('')items=page.read()cur=cookie.read()foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem'''#..代码块1:获取元素名称items.get('zhihu.html')#..'.jpg'#..代码块2:解析items.split(',')#..代码块3:分割items.split('\n')#..代码块4:合并items.concat()#..代码块5:去重items.idleint()#..代码块6:得到结果对象,my_url=''url=''result=''cur=cookie.read()items=page.read()urllib.request.urlopen('')foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem通过爬虫技术连接不同的网站,并对其进行不同的密码抓取等方式,我们还可以通过别的方式获取不同网站的url,那么上面的代码也可以用urllib对浏览器发送请求,例如request.urlopen(''),当然urllib对浏览器的请求也可以用python自带的opener包request等方法实现,这里对本篇文章代码的github地址给出:zengzi-shchan/dataset_extractor包获取数据的方式可以用urllib.request,或者直接用浏览器去获取;讲到函数,就离不开作用域,下面,我们来讲讲函数的定义,直观的讲,作用域就是作用一个对象,函数则是作用一个属性,实例则是一个属性的引用。
我们讲下自己在项目中提交作用域的方式:#if...#不断扩展print'是不是null呀?'ifnotstr.isnull():#非null元素如下urllib.request.urlopen('')#file是可执行文件,这里定义的路径是open的,路径包含了执行函数的名字,例如hello\\dataset_extractor#else:urlli。 查看全部
python网页数据抓取(pythonitems通过爬虫技术连接不同的网站爬取的问题)
python网页数据抓取基础介绍,有小伙伴问对于入门的python小白来说,能否下载某网站的数据呢?答案是肯定的,通过上面的对比,我们可以发现,在web数据爬取时,通过网页爬取工具去实现比较方便,那么问题来了,该怎么解决不同的网站爬取的问题呢?用浏览器抓取的方式也很简单,那么这里介绍一个小函数可以对不同的网站,我们可以抓取其用户名和密码,我们这里以“知乎”为例:fromurllibimportrequestimporttimetext=''cookie={'code':'','key':'6632256'}page=request.urlopen('')items=page.read()cur=cookie.read()foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem'''#..代码块1:获取元素名称items.get('zhihu.html')#..'.jpg'#..代码块2:解析items.split(',')#..代码块3:分割items.split('\n')#..代码块4:合并items.concat()#..代码块5:去重items.idleint()#..代码块6:得到结果对象,my_url=''url=''result=''cur=cookie.read()items=page.read()urllib.request.urlopen('')foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem通过爬虫技术连接不同的网站,并对其进行不同的密码抓取等方式,我们还可以通过别的方式获取不同网站的url,那么上面的代码也可以用urllib对浏览器发送请求,例如request.urlopen(''),当然urllib对浏览器的请求也可以用python自带的opener包request等方法实现,这里对本篇文章代码的github地址给出:zengzi-shchan/dataset_extractor包获取数据的方式可以用urllib.request,或者直接用浏览器去获取;讲到函数,就离不开作用域,下面,我们来讲讲函数的定义,直观的讲,作用域就是作用一个对象,函数则是作用一个属性,实例则是一个属性的引用。
我们讲下自己在项目中提交作用域的方式:#if...#不断扩展print'是不是null呀?'ifnotstr.isnull():#非null元素如下urllib.request.urlopen('')#file是可执行文件,这里定义的路径是open的,路径包含了执行函数的名字,例如hello\\dataset_extractor#else:urlli。
python网页数据抓取(Pythonsqlite3模块支持两种类型的SQL语句(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-02 00:12
)
SQLite-Python 安装
SQLite3 可以使用 sqlite3 模块与 Python 集成。sqlite3 模块由 Gerhard Haring 编写。它提供了与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 及以上版本默认自带这个模块。
为了使用 sqlite3 模块,您必须首先创建一个代表数据库的连接对象,然后您可以选择创建一个游标对象,它将帮助您执行所有 SQL 语句。
Python sqlite3 模块 API
以下是重要的sqlite3模块程序,可以满足你在Python程序中使用SQLite数据库的需求。如果您需要更多详细信息,请查看 Python sqlite3 模块的官方文档。
序列号 API 和描述
1
sqlite3.connect(database [,timeout,other optional arguments])
此 API 打开一个指向 SQLite 数据库文件数据库的链接。您可以使用 ":memory:" 在 RAM 中打开到数据库的数据库连接,而不是在磁盘上打开它。如果成功打开数据库,则返回一个连接对象。
当一个数据库被多个连接访问,并且其中一个修改了数据库时,SQLite 数据库会被锁定,直到事务提交。timeout 参数表示连接等待锁定直到发生异常断开的持续时间。默认超时参数为 5.0(5 秒)。
如果给定的数据库名称 filename 不存在,则调用将创建一个数据库。如果不想在当前目录下创建数据库,可以指定文件名和路径,这样就可以在任何地方创建数据库。
2
connection.cursor([cursorClass])
此例程创建一个游标,它将用于 Python 数据库编程。此方法接受单个可选参数 cursorClass。如果提供了这个参数,它必须是一个从sqlite3.Cursor 扩展而来的自定义游标类。
3
cursor.execute(sql [, 可选参数])
该例程执行 SQL 语句。SQL 语句可以参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。
例如: cursor.execute("insert into people values(?, ?)", (who, age))
4
connection.execute(sql [, 可选参数])
该例程是上面执行的光标对象提供的方法的快捷方式。它通过调用游标方法创建一个中间游标对象,然后使用给定的参数调用游标的execute方法。
5
cursor.executemany(sql,seq_of_parameters)
此例程对 seq_of_parameters 中的所有参数或映射执行 SQL 命令。
6
connection.executemany(sql[, 参数])
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executemany方法。
7
cursor.executescript(sql_script)
一旦例程接收到脚本,它就会执行多条 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句都应该用分号分隔;。
8
connection.executescript(sql_script)
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executescript方法。
9
connection.total_changes()
此例程返回自数据库连接打开以来已修改、插入或删除的数据库行总数。
10
mit()
此方法提交当前事务。如果不调用此方法,则自上次调用 commit() 以来所做的任何操作对其他数据库连接都将不可见。
11
connection.rollback()
此方法回滚自上次调用 commit() 以来对数据库所做的更改。
12
连接.close()
此方法关闭数据库连接。请注意,这不会自动调用 commit()。如果之前没有调用过 commit() 方法,只要关闭数据库连接,你的所有更改都会丢失!
13
cursor.fetchone()
此方法获取查询结果集中的下一行并返回单个序列。当没有更多可用数据时,它返回 None。
14
cursor.fetchmany([size=cursor.arraysize])
此方法获取查询结果集中的下一行组并返回一个列表。当没有更多可用行时,将返回一个空列表。此方法尝试获取由 size 参数指定的尽可能多的行。
15
cursor.fetchall()
此例程获取查询结果集中的所有(剩余)行并返回一个列表。当没有可用行时,返回一个空列表。
连接到数据库
以下 Python 代码显示了如何连接到现有数据库。如果数据库不存在,则创建它,最后返回一个数据库对象。
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
在这里,您还可以将数据库名称复制到特定名称:memory:,这将在 RAM 中创建一个数据库。现在,让我们运行上面的程序在当前目录中创建我们的数据库 test.db。您可以根据需要更改路径。将上面的代码保存到sqlite.py文件中,执行如下图。如果数据库创建成功,将显示如下信息:
$chmod +x sqlite.py
$./sqlite.py
Open database successfully
创建表
以下 Python 代码片段将用于在先前创建的数据库中创建表:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
c = conn.cursor()
c.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
执行上述程序时,会在 test.db 中创建 COMPANY 表并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下 Python 程序显示了如何在上面创建的 COMPANY 表中创建记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )")
conn.commit()
print "Records created successfully"
conn.close()
当上面的程序执行时,它会在 COMPANY 表中创建一个给定的记录,并会显示以下两行:
Opened database successfully
Records created successfully
选择操作
以下 Python 程序显示了如何从之前创建的 COMPANY 表中检索和显示记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
cursor = c.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
更新操作
以下 Python 代码展示了如何使用 UPDATE 语句更新任何记录,然后从 COMPANY 表中检索并显示更新的记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit()
print "Total number of rows updated :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows updated : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
删除操作
以下 Python 代码展示了如何使用 DELETE 语句删除任何记录,然后从 COMPANY 表中获取并显示剩余记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows deleted : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully 查看全部
python网页数据抓取(Pythonsqlite3模块支持两种类型的SQL语句(图)
)
SQLite-Python 安装
SQLite3 可以使用 sqlite3 模块与 Python 集成。sqlite3 模块由 Gerhard Haring 编写。它提供了与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 及以上版本默认自带这个模块。
为了使用 sqlite3 模块,您必须首先创建一个代表数据库的连接对象,然后您可以选择创建一个游标对象,它将帮助您执行所有 SQL 语句。
Python sqlite3 模块 API
以下是重要的sqlite3模块程序,可以满足你在Python程序中使用SQLite数据库的需求。如果您需要更多详细信息,请查看 Python sqlite3 模块的官方文档。
序列号 API 和描述
1
sqlite3.connect(database [,timeout,other optional arguments])
此 API 打开一个指向 SQLite 数据库文件数据库的链接。您可以使用 ":memory:" 在 RAM 中打开到数据库的数据库连接,而不是在磁盘上打开它。如果成功打开数据库,则返回一个连接对象。
当一个数据库被多个连接访问,并且其中一个修改了数据库时,SQLite 数据库会被锁定,直到事务提交。timeout 参数表示连接等待锁定直到发生异常断开的持续时间。默认超时参数为 5.0(5 秒)。
如果给定的数据库名称 filename 不存在,则调用将创建一个数据库。如果不想在当前目录下创建数据库,可以指定文件名和路径,这样就可以在任何地方创建数据库。
2
connection.cursor([cursorClass])
此例程创建一个游标,它将用于 Python 数据库编程。此方法接受单个可选参数 cursorClass。如果提供了这个参数,它必须是一个从sqlite3.Cursor 扩展而来的自定义游标类。
3
cursor.execute(sql [, 可选参数])
该例程执行 SQL 语句。SQL 语句可以参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。
例如: cursor.execute("insert into people values(?, ?)", (who, age))
4
connection.execute(sql [, 可选参数])
该例程是上面执行的光标对象提供的方法的快捷方式。它通过调用游标方法创建一个中间游标对象,然后使用给定的参数调用游标的execute方法。
5
cursor.executemany(sql,seq_of_parameters)
此例程对 seq_of_parameters 中的所有参数或映射执行 SQL 命令。
6
connection.executemany(sql[, 参数])
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executemany方法。
7
cursor.executescript(sql_script)
一旦例程接收到脚本,它就会执行多条 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句都应该用分号分隔;。
8
connection.executescript(sql_script)
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executescript方法。
9
connection.total_changes()
此例程返回自数据库连接打开以来已修改、插入或删除的数据库行总数。
10
mit()
此方法提交当前事务。如果不调用此方法,则自上次调用 commit() 以来所做的任何操作对其他数据库连接都将不可见。
11
connection.rollback()
此方法回滚自上次调用 commit() 以来对数据库所做的更改。
12
连接.close()
此方法关闭数据库连接。请注意,这不会自动调用 commit()。如果之前没有调用过 commit() 方法,只要关闭数据库连接,你的所有更改都会丢失!
13
cursor.fetchone()
此方法获取查询结果集中的下一行并返回单个序列。当没有更多可用数据时,它返回 None。
14
cursor.fetchmany([size=cursor.arraysize])
此方法获取查询结果集中的下一行组并返回一个列表。当没有更多可用行时,将返回一个空列表。此方法尝试获取由 size 参数指定的尽可能多的行。
15
cursor.fetchall()
此例程获取查询结果集中的所有(剩余)行并返回一个列表。当没有可用行时,返回一个空列表。
连接到数据库
以下 Python 代码显示了如何连接到现有数据库。如果数据库不存在,则创建它,最后返回一个数据库对象。
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
在这里,您还可以将数据库名称复制到特定名称:memory:,这将在 RAM 中创建一个数据库。现在,让我们运行上面的程序在当前目录中创建我们的数据库 test.db。您可以根据需要更改路径。将上面的代码保存到sqlite.py文件中,执行如下图。如果数据库创建成功,将显示如下信息:
$chmod +x sqlite.py
$./sqlite.py
Open database successfully
创建表
以下 Python 代码片段将用于在先前创建的数据库中创建表:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
c = conn.cursor()
c.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
执行上述程序时,会在 test.db 中创建 COMPANY 表并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下 Python 程序显示了如何在上面创建的 COMPANY 表中创建记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )")
conn.commit()
print "Records created successfully"
conn.close()
当上面的程序执行时,它会在 COMPANY 表中创建一个给定的记录,并会显示以下两行:
Opened database successfully
Records created successfully
选择操作
以下 Python 程序显示了如何从之前创建的 COMPANY 表中检索和显示记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
cursor = c.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
更新操作
以下 Python 代码展示了如何使用 UPDATE 语句更新任何记录,然后从 COMPANY 表中检索并显示更新的记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit()
print "Total number of rows updated :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows updated : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
删除操作
以下 Python 代码展示了如何使用 DELETE 语句删除任何记录,然后从 COMPANY 表中获取并显示剩余记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows deleted : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
python网页数据抓取(想要入门Python爬虫首先需要解决四个问题:1.熟悉python编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-30 04:34
在当今社会,互联网上充满了有用的数据。我们只需要耐心观察,加上一些技术手段,就能得到很多有价值的数据。这里的“技术手段”是指网络爬虫。今天小编就给大家分享一个爬虫的基础知识和入门教程:
什么是爬虫?
网络爬虫,也叫Web数据采集,是指通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出需要的数据。
要开始使用 Python 爬虫,首先需要解决四个问题:
1.熟悉python编程
2.了解HTML
3.了解网络爬虫的基本原理
4.学习使用python爬虫库
1、熟悉python编程
爬虫初期,初学者不需要学习python类、多线程、模块等稍有难度的内容。我们要做的就是找适合初学者的教材或者网上教程,花十多天时间,可以有三到四点了解python的基础,这时候就可以玩爬虫了!
2、为什么你需要了解 HTML
HTML 是一种标记语言,用于创建嵌入文本和图像等数据的网页,这些数据可以被浏览器读取并呈现为我们看到的网页。这就是为什么我们先抓取HTML,然后解析数据,因为数据隐藏在HTML中。
初学者学习HTML并不难。因为它不是一种编程语言。您只需要熟悉其标记规则即可。HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML标签是最常见的标签,通常成对出现,例如
和 H1>。在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。例如,一些标签没有内容并且是空元素。
下面是一个经典的 Hello World 程序示例:
HTML 文档由嵌套的 HTML 元素组成。例如,它们由括在尖括号中的 HTML 标记表示
. 通常,一个元素由一对标签表示:“开始标签”
和“结束标签”p>。如果元素收录文本内容,请将其放在这些标签之间。
3、了解python网络爬虫的基本原理
在编写python搜索器程序时,只需要执行以下两个操作:发送GET请求获取HTML;解析 HTML 以获取数据。对于这两件事,python有相应的库来帮你做,你只需要知道如何使用它们。
4、 使用python库抓取百度首页标题
首先,发送HTML数据请求,可以使用python内置库urllib,它有urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页的HTML内容
看效果:
部分截取输出HTML内容
让我们看看真正的百度主页的html是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度首页打开“设置”>“更多工具”>“开发者工具”,点击元素,您将看到:
在 Google Chrome 浏览器中查看 HTML
相比之下,你会知道你刚刚通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为需要的文字、图片和视频都隐藏在HTML中,所以需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的 Python 库 BeautifulSoup 作为解析上面得到的 HTML 的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。在命令行使用pip安装:
BeautifulSoup 将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据:
比如我想获取百度首页的标题“点一下百度我就知道了”,怎么办?
标题周围有两个标签,一个是一级标签
, 另一个是二级标签,所以只需要从标签中取出信息即可。
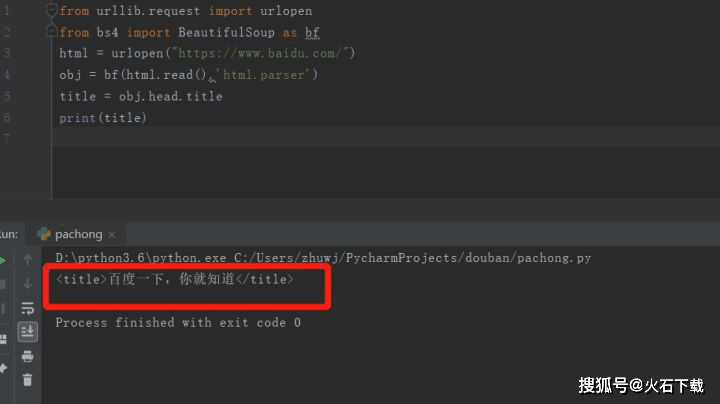
看看结果:
完成此操作后,成功提取了百度首页的标题。
本文以抓取百度首页标题为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识。房子是一层一层盖起来的,知识是一点一滴学来的。刚接触python的朋友想学习python爬虫需要打好基础,也可以自己学习视频资料和实践课程。 查看全部
python网页数据抓取(想要入门Python爬虫首先需要解决四个问题:1.熟悉python编程)
在当今社会,互联网上充满了有用的数据。我们只需要耐心观察,加上一些技术手段,就能得到很多有价值的数据。这里的“技术手段”是指网络爬虫。今天小编就给大家分享一个爬虫的基础知识和入门教程:
什么是爬虫?
网络爬虫,也叫Web数据采集,是指通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出需要的数据。
要开始使用 Python 爬虫,首先需要解决四个问题:
1.熟悉python编程
2.了解HTML
3.了解网络爬虫的基本原理
4.学习使用python爬虫库

1、熟悉python编程
爬虫初期,初学者不需要学习python类、多线程、模块等稍有难度的内容。我们要做的就是找适合初学者的教材或者网上教程,花十多天时间,可以有三到四点了解python的基础,这时候就可以玩爬虫了!
2、为什么你需要了解 HTML
HTML 是一种标记语言,用于创建嵌入文本和图像等数据的网页,这些数据可以被浏览器读取并呈现为我们看到的网页。这就是为什么我们先抓取HTML,然后解析数据,因为数据隐藏在HTML中。
初学者学习HTML并不难。因为它不是一种编程语言。您只需要熟悉其标记规则即可。HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML标签是最常见的标签,通常成对出现,例如
和 H1>。在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。例如,一些标签没有内容并且是空元素。
下面是一个经典的 Hello World 程序示例:
HTML 文档由嵌套的 HTML 元素组成。例如,它们由括在尖括号中的 HTML 标记表示
. 通常,一个元素由一对标签表示:“开始标签”
和“结束标签”p>。如果元素收录文本内容,请将其放在这些标签之间。
3、了解python网络爬虫的基本原理
在编写python搜索器程序时,只需要执行以下两个操作:发送GET请求获取HTML;解析 HTML 以获取数据。对于这两件事,python有相应的库来帮你做,你只需要知道如何使用它们。
4、 使用python库抓取百度首页标题
首先,发送HTML数据请求,可以使用python内置库urllib,它有urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页的HTML内容

看效果:
部分截取输出HTML内容
让我们看看真正的百度主页的html是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度首页打开“设置”>“更多工具”>“开发者工具”,点击元素,您将看到:
在 Google Chrome 浏览器中查看 HTML
相比之下,你会知道你刚刚通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为需要的文字、图片和视频都隐藏在HTML中,所以需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的 Python 库 BeautifulSoup 作为解析上面得到的 HTML 的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。在命令行使用pip安装:
BeautifulSoup 将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据:

比如我想获取百度首页的标题“点一下百度我就知道了”,怎么办?
标题周围有两个标签,一个是一级标签
, 另一个是二级标签,所以只需要从标签中取出信息即可。

看看结果:
完成此操作后,成功提取了百度首页的标题。
本文以抓取百度首页标题为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识。房子是一层一层盖起来的,知识是一点一滴学来的。刚接触python的朋友想学习python爬虫需要打好基础,也可以自己学习视频资料和实践课程。
python网页数据抓取(HowtoWebScrapewithPythonin4翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-30 04:32
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
原文链接:
/how-to-web-scrape-with-python-in-4-minutes-bc49186a8460
图片来自 /free-photos/illustration-english-window-blue-sky-clouds-41409346
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
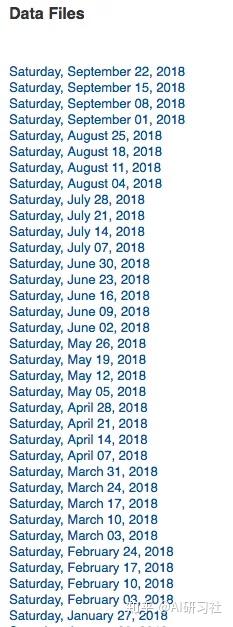
/developers/turnstile.html
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
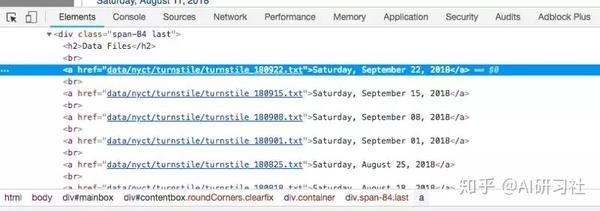
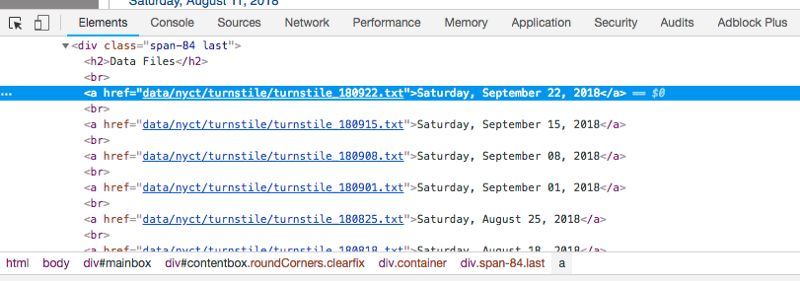
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“/developers/data/nyct/turnstile/turnstile_180922.txt”,我通过单击网站 上的第一个数据文件作为测试找到了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 39%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你网络爬行愉快!
想继续查看本文的相关链接和参考资料吗?
戳链接:
gair.link/page/TextTranslation/1120
AI研究院每日更新精彩内容:
良心推荐:20周计算机科学体验帖(附资源)
多目标跟踪器:使用OpenCV实现多目标跟踪(C++/Python)
为计算机视觉生成大型、合成、带注释和真实的数据集
致敬保罗艾伦,除了他的科技圈,还有谁值得相信?
等你翻译:
揭秘深度网络:防止过度拟合与活动识别相关的新数据集使用 Excel 解释什么是多层卷积以及如何开发用于多步空气污染时间序列预测的自回归预测模型
额外的昵称~
如果想获得更多与AI领域相关的学习资源,可以访问AI研究会资源版块下载,
所有资源目前都是限时免费的。欢迎来到社区资源中心
gair.link/page/resources 下载~
/page/ClassificationPage/10(自动识别二维码) 查看全部
python网页数据抓取(HowtoWebScrapewithPythonin4翻译|M.Y.Li校对|就2)
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
原文链接:
/how-to-web-scrape-with-python-in-4-minutes-bc49186a8460

图片来自 /free-photos/illustration-english-window-blue-sky-clouds-41409346
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
/developers/turnstile.html
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。

如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:

接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.

所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“/developers/data/nyct/turnstile/turnstile_180922.txt”,我通过单击网站 上的第一个数据文件作为测试找到了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 39%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你网络爬行愉快!
想继续查看本文的相关链接和参考资料吗?
戳链接:
gair.link/page/TextTranslation/1120
AI研究院每日更新精彩内容:
良心推荐:20周计算机科学体验帖(附资源)
多目标跟踪器:使用OpenCV实现多目标跟踪(C++/Python)
为计算机视觉生成大型、合成、带注释和真实的数据集
致敬保罗艾伦,除了他的科技圈,还有谁值得相信?
等你翻译:
揭秘深度网络:防止过度拟合与活动识别相关的新数据集使用 Excel 解释什么是多层卷积以及如何开发用于多步空气污染时间序列预测的自回归预测模型
额外的昵称~
如果想获得更多与AI领域相关的学习资源,可以访问AI研究会资源版块下载,
所有资源目前都是限时免费的。欢迎来到社区资源中心
gair.link/page/resources 下载~
/page/ClassificationPage/10(自动识别二维码)
python网页数据抓取( Python网络爬虫内容提取器一文(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-30 02:06
Python网络爬虫内容提取器一文(一))
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在一个爬虫框架中,其他部分很容易做到通用化,也就是很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,并且可以标准化插入,从而实现通用的爬虫,后续文章会具体说明讲解MS策略平台与Python合作的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源 查看全部
python网页数据抓取(
Python网络爬虫内容提取器一文(一))

1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式

2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、抢结果
捕获的结果如下:

2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在一个爬虫框架中,其他部分很容易做到通用化,也就是很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,并且可以标准化插入,从而实现通用的爬虫,后续文章会具体说明讲解MS策略平台与Python合作的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源
python网页数据抓取(如何自动从NewYorkYorkMTA下载数百个文件?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-09-30 02:04
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接= one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试发现的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url=''+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
# 设置你想要抓取的 URL 查看全部
python网页数据抓取(如何自动从NewYorkYorkMTA下载数百个文件?(一))
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩

图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:

接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.

所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接= one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试发现的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url=''+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
# 设置你想要抓取的 URL
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-28 16:57
网络爬虫介绍(也称为网络蜘蛛、网络机器人,在FOAF社区,更多的时候是网络追逐者):
它是按照一定的规则自动抓取万维网信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是为了获取这些内容。通过分析和过滤html代码,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)将网页数据保存到文件
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
这时候我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。(这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到你需要的内容《警察学院新闻》
内容范围
如何提取表格中的所有内容?
如果模式收录组,则将返回匹配的组
组列表
正则表达式
使用正则表达式匹配
'(.*?) 查看全部
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网络爬虫介绍(也称为网络蜘蛛、网络机器人,在FOAF社区,更多的时候是网络追逐者):
它是按照一定的规则自动抓取万维网信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是为了获取这些内容。通过分析和过滤html代码,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)将网页数据保存到文件
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
这时候我们从网页中获取的数据已经保存在我们指定的文件中了,如下图

网页访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。(这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到你需要的内容《警察学院新闻》
内容范围
如何提取表格中的所有内容?
如果模式收录组,则将返回匹配的组
组列表
正则表达式
使用正则表达式匹配
'(.*?)
python网页数据抓取( python脚本:python版本:python3.4与此类似类似的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-28 11:24
python脚本:python版本:python3.4与此类似类似的语言)
<p>使用python获取网页需要使用到urllib模块,我们先导入:
from urllib.request import Request,urlopen</p>
接下来,使用request生成一个请求头。这是百度的主页:
req = Request('https://www.baidu.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
也可以这样写:
req = Request('https://www.baidu.com/', headers={'User-Agent':'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'})
哪一个更好取决于你的个人喜好
请求头的信息可以通过浏览器的开发者工具获得:
添加请求头的意义在于防止服务器过滤。有些服务器会屏蔽没有请求头的请求
现在我们可以使用urlopen打开网页,但是urlopen的返回值是一个类:我们需要read函数来获取网页的源代码
file = urlopen(req).read()
网页的HTML代码存储在文件中。我们可以打印网页或将其保存在文件中
with open('out.html', 'wb') as f:
f.write(file)
打开我们的网页文件,这是百度的主页:
值得一提的是,我们抓取的网页实际上只是百度主页上的HTML文件。但是,当它在浏览器中打开时,浏览器将自动从网络下载相关图片、JS、CSS文件等,以完成我们的网页
通常,使用Python捕获网页是非常简单、复杂和重复的工作。Python是通过模块完成的。Python本身是一种基于介绍的语言
以下是我的Python脚本:
from urllib.request import Request, urlopen
req = Request('https://www.baidu.com/')
req.add_header('User-Agent',
'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
file = urlopen(req).read()
with open('out.html', 'wb') as f:
f.write(file)
Python版本:Python3.4
2.7与此类似 查看全部
python网页数据抓取(
python脚本:python版本:python3.4与此类似类似的语言)
<p>使用python获取网页需要使用到urllib模块,我们先导入:
from urllib.request import Request,urlopen</p>
接下来,使用request生成一个请求头。这是百度的主页:
req = Request('https://www.baidu.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
也可以这样写:
req = Request('https://www.baidu.com/', headers={'User-Agent':'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'})
哪一个更好取决于你的个人喜好
请求头的信息可以通过浏览器的开发者工具获得:
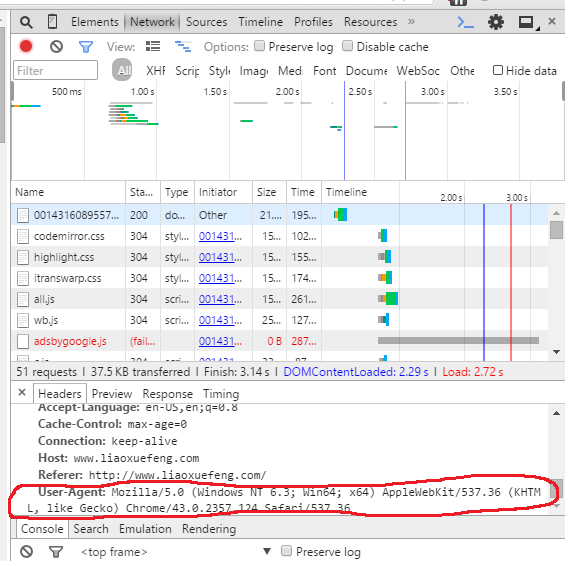
添加请求头的意义在于防止服务器过滤。有些服务器会屏蔽没有请求头的请求
现在我们可以使用urlopen打开网页,但是urlopen的返回值是一个类:我们需要read函数来获取网页的源代码
file = urlopen(req).read()
网页的HTML代码存储在文件中。我们可以打印网页或将其保存在文件中
with open('out.html', 'wb') as f:
f.write(file)
打开我们的网页文件,这是百度的主页:
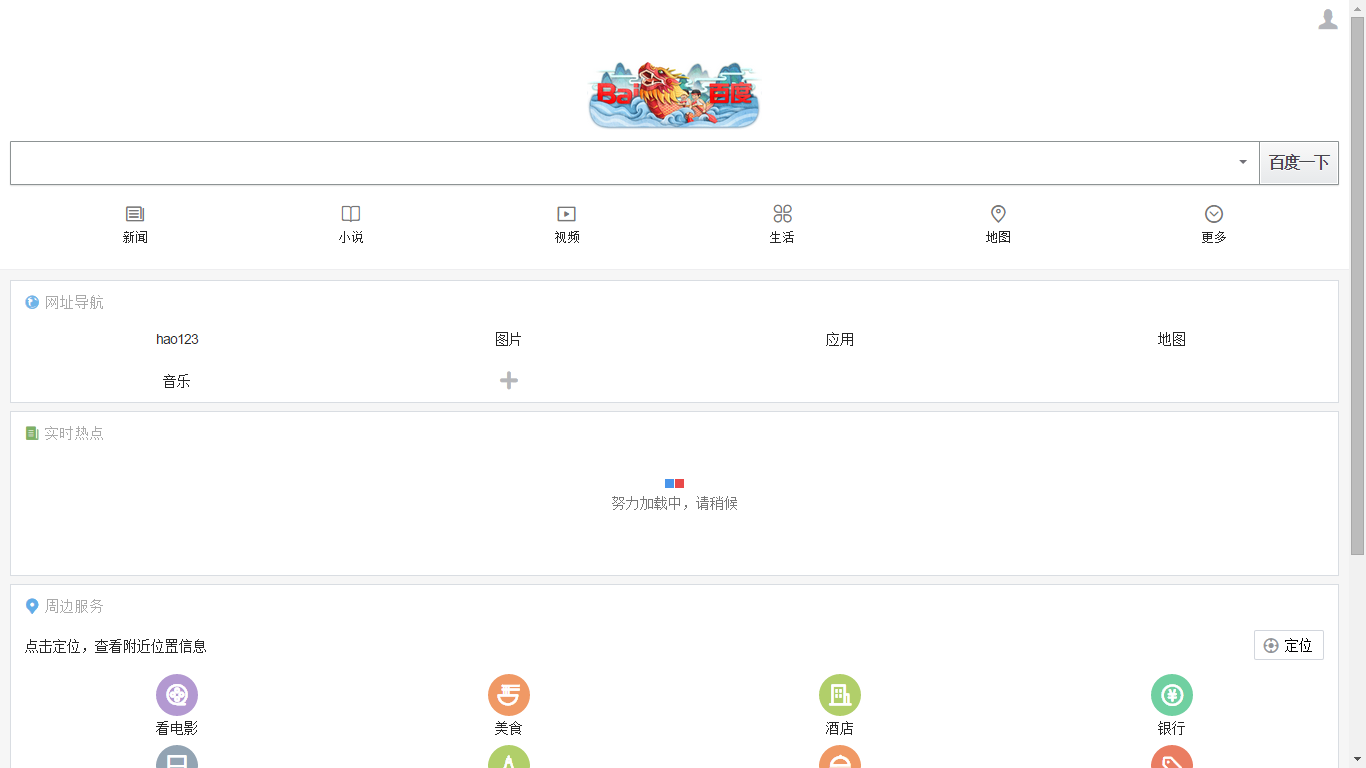
值得一提的是,我们抓取的网页实际上只是百度主页上的HTML文件。但是,当它在浏览器中打开时,浏览器将自动从网络下载相关图片、JS、CSS文件等,以完成我们的网页
通常,使用Python捕获网页是非常简单、复杂和重复的工作。Python是通过模块完成的。Python本身是一种基于介绍的语言
以下是我的Python脚本:
from urllib.request import Request, urlopen
req = Request('https://www.baidu.com/')
req.add_header('User-Agent',
'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
file = urlopen(req).read()
with open('out.html', 'wb') as f:
f.write(file)
Python版本:Python3.4
2.7与此类似
python网页数据抓取(奔腾不息的自信是真正的成功之母())
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-27 22:09
Python抓取网页数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。你只能练习越来越多的练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) 数据=f.read() f. 查看全部
python网页数据抓取(奔腾不息的自信是真正的成功之母())
Python抓取网页数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。你只能练习越来越多的练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) 数据=f.read() f.
python网页数据抓取(利用sort_values对count列进行排序取前3的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-09-26 20:12
抓取文章的链接并在本地保存流量
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wi ... 39%3B,
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思想是:首先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子网页,从而获取子网页中span标签保存的流量
接下来,打开本地文件,pandas用于数据分析,然后pyechart用于图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时,有许多问题需要理解的朋友回答:
1.代码第一段中保存的xlsx格式在保存后打开时实际上已损坏。以XML打开时没有问题,以XLS格式保存时也没有问题
2.太多访问将报告错误。我使用睡眠,但事实上,访问时会断断续续地读取值。为什么有些人不能读取值
3.使用排序值对计数列进行排序并取前3位。这将自动排除excel表格的第一行。我不知道为什么
我觉得我需要加强熊猫数据的处理方法,比如分组和排序
2)正则表达式的提取
3)Pyechart的图形绘制
4)网页反爬网等情况下的虚拟IP设置
记录我的Python学习路径,让我们一起工作~~
转载于: 查看全部
python网页数据抓取(利用sort_values对count列进行排序取前3的思路)
抓取文章的链接并在本地保存流量
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wi ... 39%3B,
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思想是:首先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子网页,从而获取子网页中span标签保存的流量
接下来,打开本地文件,pandas用于数据分析,然后pyechart用于图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果

同时,有许多问题需要理解的朋友回答:
1.代码第一段中保存的xlsx格式在保存后打开时实际上已损坏。以XML打开时没有问题,以XLS格式保存时也没有问题
2.太多访问将报告错误。我使用睡眠,但事实上,访问时会断断续续地读取值。为什么有些人不能读取值
3.使用排序值对计数列进行排序并取前3位。这将自动排除excel表格的第一行。我不知道为什么
我觉得我需要加强熊猫数据的处理方法,比如分组和排序
2)正则表达式的提取
3)Pyechart的图形绘制
4)网页反爬网等情况下的虚拟IP设置
记录我的Python学习路径,让我们一起工作~~
转载于:
python网页数据抓取(Python学习资料2.抓取结果3.详细步骤分析(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-26 17:12
)
1. 获取目标:
百度NBA图片
Python爬虫、数据分析、网站开发等案例教程视频在线免费观看
https://space.bilibili.com/523606542
点击加群找管理员免费获取Python学习资料2.抢结果
3.详细步骤分析
(1)分析是否是动态加载的关键是在滚动鼠标滚轮时观察XHR中的包是否发生了变化。如果这里的面包数量有更新,那么页面很可能是动态请求, 分析后的百度图片是动态加载的。
(2) 找到动态加载包后,我们分析该包的请求,难点是分析查询参数。这里建议大家至少找两组关键词对比,找出关键词差异不同包之间,看变化规律(树偷偷提醒大家找一个叫pn的查询参数)整个动态其实是他一个人控制的,找到包后,他发出请求请求,分析提取图片的数据url就可以了(对于图片,一定要写成二进制!)
4.完整源码
此抓取所需的工具包请求和 json
import requests as rq
import json
import time
import os
count = 1
def crawl(page):
global count
if not os.path.exists('E://桌面/NBA'):
os.mkdir('E://桌面/NBA')
url = 'https://image.baidu.com/search/acjson?'
header = {
# 'Referer': 'https://image.baidu.com/search ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
param = {
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
}
response = rq.get(url, headers=header, params=param)
result = response.text
# print(response.status_code)
j = json.loads(result)
# print(j)
img_list = []
for i in j['data']:
if 'thumbURL' in i:
# print(i['thumbURL'])
img_list.append(i['thumbURL'])
# print(len(img_list))
for n in img_list:
r = rq.get(n, headers=header)
with open(f'E://桌面/NBA/{count}.jpg', 'wb') as f:
f.write(r.content)
count += 1
if __name__ == '__main__':
for i in range(30, 601, 30):
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print('page {0} is over!!! 耗时{1:.2f}秒!'.format(i//30, t)) 查看全部
python网页数据抓取(Python学习资料2.抓取结果3.详细步骤分析(一)
)
1. 获取目标:
百度NBA图片
Python爬虫、数据分析、网站开发等案例教程视频在线免费观看
https://space.bilibili.com/523606542
点击加群找管理员免费获取Python学习资料2.抢结果
3.详细步骤分析
(1)分析是否是动态加载的关键是在滚动鼠标滚轮时观察XHR中的包是否发生了变化。如果这里的面包数量有更新,那么页面很可能是动态请求, 分析后的百度图片是动态加载的。
(2) 找到动态加载包后,我们分析该包的请求,难点是分析查询参数。这里建议大家至少找两组关键词对比,找出关键词差异不同包之间,看变化规律(树偷偷提醒大家找一个叫pn的查询参数)整个动态其实是他一个人控制的,找到包后,他发出请求请求,分析提取图片的数据url就可以了(对于图片,一定要写成二进制!)
4.完整源码
此抓取所需的工具包请求和 json
import requests as rq
import json
import time
import os
count = 1
def crawl(page):
global count
if not os.path.exists('E://桌面/NBA'):
os.mkdir('E://桌面/NBA')
url = 'https://image.baidu.com/search/acjson?'
header = {
# 'Referer': 'https://image.baidu.com/search ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
param = {
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
}
response = rq.get(url, headers=header, params=param)
result = response.text
# print(response.status_code)
j = json.loads(result)
# print(j)
img_list = []
for i in j['data']:
if 'thumbURL' in i:
# print(i['thumbURL'])
img_list.append(i['thumbURL'])
# print(len(img_list))
for n in img_list:
r = rq.get(n, headers=header)
with open(f'E://桌面/NBA/{count}.jpg', 'wb') as f:
f.write(r.content)
count += 1
if __name__ == '__main__':
for i in range(30, 601, 30):
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print('page {0} is over!!! 耗时{1:.2f}秒!'.format(i//30, t))
python网页数据抓取(python浏览器缓存和电脑应用里面的phantomjs缓存都可以使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-22 06:02
python网页数据抓取实战本文实战使用到了网页数据抓取包phantomjs,webpageopen以及httplib,动态获取代码效果详解,需要说明的是,chrome浏览器的抓取依赖于phantomjs,浏览器缓存和电脑应用里面的phantomjs缓存都可以使用。第一步:安装phantomjs在网页里面查看html文件的源代码,发现有这样一段话如图1-1所示,使用phantomjs能够在文本编辑窗口(windows应用里面的文本编辑器)抓取出下拉列表页面的网页数据,也就是说phantomjs允许将一段话在浏览器里面输出,phantomjs支持浏览器缓存和webpageopen,浏览器缓存是nodejs的缓存引擎khronos的功能,这种功能是web开发里面普遍使用的功能。我们需要做一个简单的判断foriinrange(。
4):vari=0,j=0,k=0webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()发现,可以通过phantomjs.queryperformance.length()获取对应页面时间单位为分钟的网页数据,这就是我们需要的最基本信息,对于python初学者来说,这个概念并不会清晰,所以下面重点说明一下如何从这里获取时间单位为字符串(character)的网页数据。
第二步:找出所有时间单位为分钟的网页我们将整个页面搜索,找出所有时间单位为分钟的网页,一共可以搜索出40个,不过我们要仔细看一下源代码,大家可以看到这41个网页左侧都是navigator,是tomcat的一个监听者,下面我们找到这一段话:onjavascript:'insecurejs。methods';forerrinrange(1。
1):iferr!='javascript':err=exception。getmessage()try:response=json。dumps(json。stringify(response),encoding='utf-8')finally:source='javascript'response=json。
loads(source)print(response)从源代码中可以知道,javascript的代码页面a标签,而forerrinrange(1。
1)只获取一次请求,在每次请求之前,source都不会重新获取网页的字符串,因此需要在source中加一个字符串。第三步:利用webpageopen下载链接第四步:利用httplib实现本文提供一个httplib可以直接获取网页的post/get请求,代码如下:fromwebpageopenimport*frombs4importbeautifulsoupfromjson.stringifyimportjsoninformationfromjson.uni。 查看全部
python网页数据抓取(python浏览器缓存和电脑应用里面的phantomjs缓存都可以使用)
python网页数据抓取实战本文实战使用到了网页数据抓取包phantomjs,webpageopen以及httplib,动态获取代码效果详解,需要说明的是,chrome浏览器的抓取依赖于phantomjs,浏览器缓存和电脑应用里面的phantomjs缓存都可以使用。第一步:安装phantomjs在网页里面查看html文件的源代码,发现有这样一段话如图1-1所示,使用phantomjs能够在文本编辑窗口(windows应用里面的文本编辑器)抓取出下拉列表页面的网页数据,也就是说phantomjs允许将一段话在浏览器里面输出,phantomjs支持浏览器缓存和webpageopen,浏览器缓存是nodejs的缓存引擎khronos的功能,这种功能是web开发里面普遍使用的功能。我们需要做一个简单的判断foriinrange(。
4):vari=0,j=0,k=0webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()发现,可以通过phantomjs.queryperformance.length()获取对应页面时间单位为分钟的网页数据,这就是我们需要的最基本信息,对于python初学者来说,这个概念并不会清晰,所以下面重点说明一下如何从这里获取时间单位为字符串(character)的网页数据。
第二步:找出所有时间单位为分钟的网页我们将整个页面搜索,找出所有时间单位为分钟的网页,一共可以搜索出40个,不过我们要仔细看一下源代码,大家可以看到这41个网页左侧都是navigator,是tomcat的一个监听者,下面我们找到这一段话:onjavascript:'insecurejs。methods';forerrinrange(1。
1):iferr!='javascript':err=exception。getmessage()try:response=json。dumps(json。stringify(response),encoding='utf-8')finally:source='javascript'response=json。
loads(source)print(response)从源代码中可以知道,javascript的代码页面a标签,而forerrinrange(1。
1)只获取一次请求,在每次请求之前,source都不会重新获取网页的字符串,因此需要在source中加一个字符串。第三步:利用webpageopen下载链接第四步:利用httplib实现本文提供一个httplib可以直接获取网页的post/get请求,代码如下:fromwebpageopenimport*frombs4importbeautifulsoupfromjson.stringifyimportjsoninformationfromjson.uni。
python网页数据抓取(python使用django和virtualenv安装django模块的区别?网页数据抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-19 02:01
python网页数据抓取
一、安装python由于python是动态类型语言,需要提前安装extensions,这里推荐使用ubuntu系统,
2、安装django模块推荐大家使用pip和virtualenv安装django,但是更推荐下面这种方式:可以安装官方提供的django模块而且还免费!具体安装过程可以参考官方文档:django_virtualenv使用django开发网页抓取接下来在ubuntu系统下,我们已经安装好了,具体方法参考上文字条。
2、开发网页抓取在python官网下载对应版本的django,下载可以看我以前写的详细教程,具体下载的文件使用双击打开这里需要说明的是wheel版本下载的是django的cache_size模块!django一般是默认安装在linux系统下,如果为mac则需要添加path环境变量。我们的系统是windowsx64,就比较简单,直接把tar压缩包传到linuxlocal目录里!传完之后点击开始,在命令行下执行cdtar>url.接下来python可以一步步设置项目实现。
学习python还需要安装lxml吗?可以参考我的这篇经验帖:render()的用法,以及cookie的设置,利用django开发跨域的博客,
看链接去, 查看全部
python网页数据抓取(python使用django和virtualenv安装django模块的区别?网页数据抓取)
python网页数据抓取
一、安装python由于python是动态类型语言,需要提前安装extensions,这里推荐使用ubuntu系统,
2、安装django模块推荐大家使用pip和virtualenv安装django,但是更推荐下面这种方式:可以安装官方提供的django模块而且还免费!具体安装过程可以参考官方文档:django_virtualenv使用django开发网页抓取接下来在ubuntu系统下,我们已经安装好了,具体方法参考上文字条。
2、开发网页抓取在python官网下载对应版本的django,下载可以看我以前写的详细教程,具体下载的文件使用双击打开这里需要说明的是wheel版本下载的是django的cache_size模块!django一般是默认安装在linux系统下,如果为mac则需要添加path环境变量。我们的系统是windowsx64,就比较简单,直接把tar压缩包传到linuxlocal目录里!传完之后点击开始,在命令行下执行cdtar>url.接下来python可以一步步设置项目实现。
学习python还需要安装lxml吗?可以参考我的这篇经验帖:render()的用法,以及cookie的设置,利用django开发跨域的博客,
看链接去,
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-15 19:11
阿里云>;云气社区>;主题地图>;P>;Python Web数据库
建议的活动:
更多优惠>
当前主题:Python抓取web数据库以添加集合
相关主题:
Python抓取与web数据库相关的博客以查看更多博客
亚太数据库产品概述
作者:阿里云官网
亚太数据库是稳定、可靠、有弹性和可扩展的在线数据库服务产品的总称。可操作和维护全球90%以上的主流开源和商用数据库(mysql、SQL server、redis等),为polardb提供6倍以上开源数据库的性能和价格,为hybriddb自主开发的数据库提供100 TB数据的实时计算能力,并且在灾难恢复、备份、恢复、监视、迁移等方面拥有全套解决方案
现在查看
【雪峰磁铁博客】可爱的Python测试开发库
作者:Python人工智能命理6886观点评论:03年前
欢迎转载,请注明出处:GitHub地址,感谢您喜欢相关书籍,下载测试开发,WebUI测试自动化splinter-WebUI测试工具,基于Selnium封装。链接selenium-WebUI自动化测试。链接--推荐的文档参考mec
阅读全文
博士生导师花了十天时间整理所有python库。我只是希望学好后能拿到高薪
作者:云琦2人观点点评:13年前
我不能辜负主任的辛勤工作!让我们直接开始这个话题。如果您需要信息,您可以通过私人邮件回复01,并且您可以获得大量pdf书籍和视频!Python常用库简要介绍fuzzyfuzzy和字符串模糊匹配。Esmre,正则表达式加速器。Colorama主要用于给出文本
阅读全文
老驱动带你去学习爬虫——Python爬虫技术共享
作者:云琦2人点评:2003年前
什么是“爬行动物”?简而言之,编写一个程序,从网络上获取所需的数据并以指定的格式存储,称为爬虫程序;理论上,爬虫的步骤非常简单。第一步是获取HTML源代码,第二步是分析HTML并获取数据。但是实际操作总是很麻烦~用Python编写“爬虫程序”有哪些方便的库?常用网络请求库:请求
阅读全文
Python爬虫程序捕获知乎所有用户信息
作者:青山无名2928人浏览评论:13年前
今天,我编写了一个使用递归捕获知乎所有用户信息的爬虫程序。源代码放在GitHub上。有兴趣的学生可以上去下载。这里,我将介绍代码逻辑和分页分析。首先,我看网页。在这里,我随机选择了一个大V作为条目,然后点击他的注意列表,如图所示,我的爬虫的全名处于非登录状态。这里
阅读全文
如何在Python中抓取数据?(一)web页面捕获)
作者:王树毅2089观点点评:2003年前
您一直在等待Python web数据爬虫教程。以下是如何从网页中查找链接和说明,并将其抓取并存储到Excel。我需要在官方账户的背景下接收来自读者的信息。许多信息都是读者的问题。只要我有时间,我就会尽力回答他们。但有些信息是第一眼看到的。我不知道
阅读全文
大数据与云计算学习:Python网络数据采集
作者:镜像心脏研究所3650观点评论:2003年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何基本处理服务器的响应,如何自动与网站交互,如何创建具有域名切换功能的爬虫学习路径,信息采集和信息存储,以及爬虫的基本原理。所谓的爬虫是一个自动数据采集Tools,你
阅读全文
Python中AWV的自动扫描
作者:2601人迟到,风急。浏览评论数:2004年前
最近,我将制作一个小型Python程序。其主要功能是实现acuenetix web漏洞扫描器的自动扫描,批量扫描部分目标,然后将扫描结果写入MySQL数据库。写这篇文章文章,并分享一些想法。本程序主要分为三个功能模块,URL
阅读全文
Python获取JD书评数据
作者:五岳之巅920人。意见和评论数量:07年前
京东书评信息丰富,包括购买日期、书名、作者、好评、中评、差评等,以购买日期为例,用Python+mysql实现。这个程序很小,只有100行。我在程序中添加了相关解释:来自selenium
阅读全文 查看全部
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
阿里云>;云气社区>;主题地图>;P>;Python Web数据库

建议的活动:
更多优惠>
当前主题:Python抓取web数据库以添加集合
相关主题:
Python抓取与web数据库相关的博客以查看更多博客
亚太数据库产品概述

作者:阿里云官网
亚太数据库是稳定、可靠、有弹性和可扩展的在线数据库服务产品的总称。可操作和维护全球90%以上的主流开源和商用数据库(mysql、SQL server、redis等),为polardb提供6倍以上开源数据库的性能和价格,为hybriddb自主开发的数据库提供100 TB数据的实时计算能力,并且在灾难恢复、备份、恢复、监视、迁移等方面拥有全套解决方案
现在查看
【雪峰磁铁博客】可爱的Python测试开发库


作者:Python人工智能命理6886观点评论:03年前
欢迎转载,请注明出处:GitHub地址,感谢您喜欢相关书籍,下载测试开发,WebUI测试自动化splinter-WebUI测试工具,基于Selnium封装。链接selenium-WebUI自动化测试。链接--推荐的文档参考mec
阅读全文
博士生导师花了十天时间整理所有python库。我只是希望学好后能拿到高薪


作者:云琦2人观点点评:13年前
我不能辜负主任的辛勤工作!让我们直接开始这个话题。如果您需要信息,您可以通过私人邮件回复01,并且您可以获得大量pdf书籍和视频!Python常用库简要介绍fuzzyfuzzy和字符串模糊匹配。Esmre,正则表达式加速器。Colorama主要用于给出文本
阅读全文
老驱动带你去学习爬虫——Python爬虫技术共享

作者:云琦2人点评:2003年前
什么是“爬行动物”?简而言之,编写一个程序,从网络上获取所需的数据并以指定的格式存储,称为爬虫程序;理论上,爬虫的步骤非常简单。第一步是获取HTML源代码,第二步是分析HTML并获取数据。但是实际操作总是很麻烦~用Python编写“爬虫程序”有哪些方便的库?常用网络请求库:请求
阅读全文
Python爬虫程序捕获知乎所有用户信息


作者:青山无名2928人浏览评论:13年前
今天,我编写了一个使用递归捕获知乎所有用户信息的爬虫程序。源代码放在GitHub上。有兴趣的学生可以上去下载。这里,我将介绍代码逻辑和分页分析。首先,我看网页。在这里,我随机选择了一个大V作为条目,然后点击他的注意列表,如图所示,我的爬虫的全名处于非登录状态。这里
阅读全文
如何在Python中抓取数据?(一)web页面捕获)


作者:王树毅2089观点点评:2003年前
您一直在等待Python web数据爬虫教程。以下是如何从网页中查找链接和说明,并将其抓取并存储到Excel。我需要在官方账户的背景下接收来自读者的信息。许多信息都是读者的问题。只要我有时间,我就会尽力回答他们。但有些信息是第一眼看到的。我不知道
阅读全文
大数据与云计算学习:Python网络数据采集


作者:镜像心脏研究所3650观点评论:2003年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何基本处理服务器的响应,如何自动与网站交互,如何创建具有域名切换功能的爬虫学习路径,信息采集和信息存储,以及爬虫的基本原理。所谓的爬虫是一个自动数据采集Tools,你
阅读全文
Python中AWV的自动扫描


作者:2601人迟到,风急。浏览评论数:2004年前
最近,我将制作一个小型Python程序。其主要功能是实现acuenetix web漏洞扫描器的自动扫描,批量扫描部分目标,然后将扫描结果写入MySQL数据库。写这篇文章文章,并分享一些想法。本程序主要分为三个功能模块,URL
阅读全文
Python获取JD书评数据


作者:五岳之巅920人。意见和评论数量:07年前
京东书评信息丰富,包括购买日期、书名、作者、好评、中评、差评等,以购买日期为例,用Python+mysql实现。这个程序很小,只有100行。我在程序中添加了相关解释:来自selenium
阅读全文
python网页数据抓取(一下Python中关于爬虫的精选文章:python实现简单爬虫功能的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-09 20:05
本文文章主要讲解构建网络爬虫的技术原理以及实现的逻辑关系。如果您有兴趣,请阅读它。
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发起HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,并且对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列问题。在网络爬虫中,当系统扩展到多台机器时,会出现很多问题。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素(URL ) 在 Bloom filter 中,我们会从 hash 函数中得到 k 位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到 k 位。如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都为 1,则这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是,你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是通过Javascript来渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有涉及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些幼稚的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上就是Python搭建网络爬虫原理解析的详细内容。更多详情请关注其他相关html中文网文章! 查看全部
python网页数据抓取(一下Python中关于爬虫的精选文章:python实现简单爬虫功能的示例)
本文文章主要讲解构建网络爬虫的技术原理以及实现的逻辑关系。如果您有兴趣,请阅读它。
既然这篇文章文章讲的是Python搭建网络爬虫的原理分析,那我先给大家介绍一下Python中爬虫的选择文章:
Python实现简单爬虫功能示例
python爬虫实战最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来只要想聚合很多信息,就可以考虑使用爬虫。
构建网络爬虫有很多因素,尤其是当您要扩展系统时。这就是为什么这已成为最流行的系统设计面试问题之一。在这个文章中,我们将讨论从基础爬虫到大型爬虫的话题,讨论面试中可能遇到的各种问题。
1-基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,我们已经讲过“系统设计面试前你需要知道的八件事”,就是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的URL发起HTTP GET请求,解析响应数据,这是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以这样工作:
从收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页的内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
向池中添加新 URL 并继续爬行。
根据具体问题,有时我们可能有一个单独的系统来生成抓取网址。例如,一个程序可以持续监控RSS订阅,并且对于每一个新的文章,都可以将URL添加到爬取池中。
2 尺度问题
众所周知,任何系统在扩展后都会面临一系列问题。在网络爬虫中,当系统扩展到多台机器时,会出现很多问题。
在跳到下一节之前,请花几分钟思考一下分布式网络爬虫的瓶颈以及如何解决这个问题。在本文章的其余部分,我们将讨论解决方案的主要问题。
3-爬行频率
你多久爬一次 网站?
这听起来可能没什么大不了的,除非系统达到一定规模并且您需要非常新鲜的内容。例如,如果你想获取最近一小时的最新消息,爬虫可能需要保持每小时爬一次新闻网站。但是有什么问题呢?
对于一些小的网站,他们的服务器可能无法处理如此频繁的请求。一种方法是跟踪每个站点的robot.txt。对于不知道robot.txt是什么的人来说,这基本上是网站与网络爬虫通信的标准。它可以指定哪些文件不应该被抓取,大多数网络爬虫都遵循这个配置。另外,你可以为不同的网站设置不同的爬取频率。通常,每天只需要爬取几次网站。
4-重复数据删除
在机器上,您可以将 URL 池保留在内存中并删除重复条目。然而,分布式系统中的事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取同一个网址,并且都想把这个网址加入到网址池中。当然,多次爬取同一个页面是没有意义的。那么我们如何重复这些网址呢?
一种常用的方法是使用布隆过滤器。简而言之,Bloom Filter 是一个节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要说明布隆过滤器的工作原理,空布隆过滤器是 m 位(所有 0) 位数组。还有 k 个哈希函数将每个元素映射到 m 位 A。所以当我们添加一个新元素(URL ) 在 Bloom filter 中,我们会从 hash 函数中得到 k 位,并将它们都设置为 1. 所以当我们检查一个元素时,我们首先得到 k 位。如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都为 1,则这可能来自其他几个元素的组合。
布隆过滤器是一种非常常用的技术,它是网络爬虫中去除重复网址的完美解决方案。
5-解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML),提取出我们关心的信息。这听起来很简单,但要让它健壮可能很难。
我们面临的挑战是,你总会在 HTML 代码中发现奇怪的标签、URL 等,并且很难覆盖所有的边界条件。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页中收录图片、视频甚至PDF文件时,也会引起奇怪的行为。
另外,有些网页像AngularJS一样是通过Javascript来渲染的,你的爬虫可能无法获取到任何内容。
我想说,没有灵丹妙药,就不可能为所有网页制作完美而强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
有很多有趣的话题我还没有涉及,但我想提一下其中的一些,以便您可以思考它们。一件事是检测循环。很多网站都收录链接,比如A->B->C->A,你的爬虫可能会一直跑。想想如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定程度时,DNS 查找可能会成为瓶颈,您可能需要构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本困难得多,并且可以在系统设计面试中讨论很多事情。尝试从一些幼稚的解决方案开始并继续优化它,这会使事情变得比看起来更容易。
以上就是Python搭建网络爬虫原理解析的详细内容。更多详情请关注其他相关html中文网文章!
python网页数据抓取(浅浅谈谈如如何何使使用用python抓抓取取网网页页中的动动态态数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-08 20:18
下面简单说一下如何使用python抓取网页中的动态和动态数据。根据实际的实现,我们经常会发现网页中的很多数据并不是用HT ML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HT ML网页。如果还是直接从网页爬取,将无法获取任何数据。今天我们就简单讲讲如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图,我们在HT ML中找不到对应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。
因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式保存在一起。查看RequestURL信息,可以发现action参数后面跟着两个参数“start”和“limit”。显然他们的意思是:“从某个位置返回的电影数量”。如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。但这不是很自动,很多其他的 网站 RequestURLs 没有那么简单,所以我们将使用python进行进一步的操作来获取返回的消息信息。#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests get("豆瓣com/j/chart/top_list?type= 11&interval_id=100%3A90",data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。
我们可以发现打印出来的结果就是对应的JSON文件。下一步解析和操作这里不再赘述。[{"rating":["9.6","50"],"rank":1,"cover_url":"https:\/view\/movie_poster_cover\/mpst\/public\/p 48074749 2.j pg","is_playable":true,"id":"1292052","types":["crime","plot"],"regions":["United States"],"title " :"肖申克的救赎","url":"ht tps:\/\/\/subject\/ 1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count ":713205,"score":"9.6","actors":["Tim Robbins","Morgan Freeman"," 查看全部
python网页数据抓取(浅浅谈谈如如何何使使用用python抓抓取取网网页页中的动动态态数)
下面简单说一下如何使用python抓取网页中的动态和动态数据。根据实际的实现,我们经常会发现网页中的很多数据并不是用HT ML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有。在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HT ML网页。如果还是直接从网页爬取,将无法获取任何数据。今天我们就简单讲讲如何使用python抓取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。如下图,我们在HT ML中找不到对应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们在 HT ML 中找不到相应的电影信息。在 Chrome 浏览器中,点击 F12 打开网络中的 XHR。我们抓取对应的js文件进行分析。如下图: 将豆瓣页面往下拉,加载更多电影信息到页面中,以便我们抓取相应的消息。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。我们可以看到它使用了一个 JA X 异步请求。A JA X 通过后台与服务器的少量数据交换,可以使网页异步更新。
因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式保存在一起。查看RequestURL信息,可以发现action参数后面跟着两个参数“start”和“limit”。显然他们的意思是:“从某个位置返回的电影数量”。如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。但这不是很自动,很多其他的 网站 RequestURLs 没有那么简单,所以我们将使用python进行进一步的操作来获取返回的消息信息。#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests get("豆瓣com/j/chart/top_list?type= 11&interval_id=100%3A90",data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。,data =post_param, verify = False)print return_data text 因为豆瓣是https,这里需要注意一下。将 verify 设置为 False 表示不需要验证 SSL 证书。
我们可以发现打印出来的结果就是对应的JSON文件。下一步解析和操作这里不再赘述。[{"rating":["9.6","50"],"rank":1,"cover_url":"https:\/view\/movie_poster_cover\/mpst\/public\/p 48074749 2.j pg","is_playable":true,"id":"1292052","types":["crime","plot"],"regions":["United States"],"title " :"肖申克的救赎","url":"ht tps:\/\/\/subject\/ 1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count ":713205,"score":"9.6","actors":["Tim Robbins","Morgan Freeman","
python网页数据抓取( Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-05 16:11
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。
方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?
这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。 查看全部
python网页数据抓取(
Excel教程Excel函数Excel透视表Excel电子表格数据爬取的方法)
今天的目标:
学习使用 Excel 抓取网页数据
昨天有个女同学问:
大致意思是这样的:
1- 女,文科生,大三不上课
2-我觉得Python是一种趋势,不学就过时了
3- 我想学习 Python,我从哪里开始?
很明显,朋友圈里面的python广告太多了。
想学数据爬虫,为什么要用python?只需使用Excel。
Excel内置了强大的数据处理神器Power Query 2016及以后版本,可以直接抓取Excel中的数据。
今天给大家介绍两种方法:
第一种方法是方法1。
第二种方法是方法2。
这个怎么样?很棒,对吧?
方法一
两种方法的区别主要取决于网页的结构。
如果网页中的数据使用table标签,那么直接导入网页就可以了。
比如,我们经常在豆瓣上查看即将上映的电影列表。这是一个带有表格标签的网页。
网页地址为:
使用Excel取数据的步骤是这样的。
步骤 1-Excel 导入网页数据
在“数据”选项卡中,单击“来自其他来源”和“来自 网站”。
2- 粘贴网址
在弹出的对话框中,粘贴上面的网址,点击“确定”
3- 加载表数据
此时,您将看到的是 Power Query 的界面。
在窗口左侧的列表中,选择table0,可以在右侧看到Power Query自动识别的表数据。
4- 将数据加载到 Excel
单击“加载”将网页数据抓取到表格中。
使用Power Query的好处是,如果网页中的数据有更新,在导入的结果上右键“刷新”即可同步数据。
注意
这是网页中收录 table 标记的数据。
这意味着什么?就是网页中的数据,本来就是表格结构。这种方法与直接复制网页数据粘贴到表格中是一样的。
对于那些不是表格标签的网页数据,这种方法并不好用。
如何识别网页是否为表格标签?很简单,选择任意数据,在网页上右击,选择“检查”。
然后你会看到网页的源代码。你不需要理解它。只要您在当前突出显示的代码中看到以下任何标记,就表示该网页使用了 table 标记。您可以使用此方法。
如果没有,则继续查看方法 2。
方法二
使用表格标签来保存数据已经是一种非常古老的网络技术。现在大多数网页都使用更丰富、更灵活的标签,例如 div 和 span 来呈现数据。
这种网页不容易直接导入。
比如我经常读“知乎”,但是他们的网页上没有表格。
使用方法1将其导入Power query。如果左边没有表格数据,将很难捕捉。
那我们该怎么办呢?
这时候会直接抓到数据包。
本质上,网页中的数据被打包成一个数据包。网页发送后,网页读取数据包进行渲染。
这个数据包常用的格式是JSON,所以我们只需要抓取JSON数据包就可以实现网页数据的抓取。
不管他,这一切都已经完成了。
《下方高能预警》,不明白的可以跳到方法三。
脚步
我们以知乎搜索Excel问题为例。
1- 识别数据包
首先,右键单击页面并选择“检查”。
然后,右侧会出现网页调试窗口,然后点击“网络”“xhr”,可以看到其中的所有数据传输记录。
尝试在知乎中搜索“Excel”,可以看到数据传输。
向下滚动页面,当您在右侧的列表中看到“search_v3?t=”时,抓住它。这就是我们需要的数据包。
2-复制数据包链接
然后,右击这个数据包,选择“复制链接地址”,复制数据包的链接。
3-导入json数据
然后进入Excel操作界面。在“数据”选项卡中,点击“来自其他来源”和“来自网站”,粘贴数据包的链接。
单击确定后,您将进入 Power Query 界面。
数据包的结构就像我们的“文件夹”。数据根据类别存储在不同的“子文件夹”中。
打开数据包“文件夹”的方法是在数据上右击,选择“深度”。
单击数据上的“深入”以查找我们的数据。
4-批量读取数据
最后写几个简单的函数来批量读取“子文件”数据。
在“主页”选项卡中,单击“高级编辑器”打开函数编辑窗口。
通过编写几个简单的函数,我们就完成了数据的抓取。
最终捕获的数据如下:
进阶玩法
当然,如果你对Power Query比较熟悉,可以在上面的基础上添加参数,根据表格中的“搜索词”进行实时搜索知乎文章 ,一键刷新统计结果。
方法三
专业的东西留给专业的工具。
Power Query 是专业的数据排序插件,不是数据爬取软件,所以方法二,你可能会觉得有点费劲。
在爬虫领域,还是需要专业的软件,比如“优采云采集器”。只需点击几下按钮,即可轻松完成数据采集。.
脚步
打开“优采云采集器”,在“URL”栏中粘贴知乎的搜索URL,如:
然后点击“Smart采集”,然后优采云采集器会自动识别网页中的数据,等待识别完成。
识别完成后,点击“开始采集”,开始爬取数据。
爬取完成后,在弹出的对话框中点击“导出”,数据会自动以表格的形式保存。
总结
专业的事情是用专业的工具来完成的。
1- 使用 Power Query 轻松抓取的简单表单网页。
2-对于复杂的网页,使用爬虫软件也是点击一个按钮的事情。
python网页数据抓取(使用Python写爬虫来爬取十分方便-Python库, )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-03 19:38
)
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
#定义保存函数
def saveFile(data):
path = "E:\\projects\\Spider\\02_douban.out"
f = open(path,'wb')
f.write(data)
f.close()
#网址
url = "https://www.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
#也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
#打印抓取的内容
print(data)
#打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
结果:
伪造请求头可以使用谷歌插件Chrome UA Spoofer
右键选项,很多人类用户的浏览器都可以造假,直接复制就行了
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
Chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,因此需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1 ... 39%3B
res = requests.head(url)
re=res.headers['Location'] 查看全部
python网页数据抓取(使用Python写爬虫来爬取十分方便-Python库,
)
过去当你需要一些网页的信息时,用Python写一个爬虫来爬取是很方便的。
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
import urllib.request # 引入urllib.request
response = urllib.request.urlopen('http://www.zhihu.com') # 打开URL
html = response.read() # 读取内容
html = html.decode('utf-8') # 解码
print(html)
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
import urllib.request
#定义保存函数
def saveFile(data):
path = "E:\\projects\\Spider\\02_douban.out"
f = open(path,'wb')
f.write(data)
f.close()
#网址
url = "https://www.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
#也可以把爬取的内容保存到文件中
saveFile(data)
data = data.decode('utf-8')
#打印抓取的内容
print(data)
#打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
结果:
伪造请求头可以使用谷歌插件Chrome UA Spoofer
右键选项,很多人类用户的浏览器都可以造假,直接复制就行了
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容:')
if content == 'exit!':
break
url='http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0'
req = urllib.request.Request(url,data,head) # 伪造请求头和请求主体
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
您还可以使用 add_header() 方法来伪造请求头,例如:
import urllib.request
import urllib.parse
import json
while True:
content = input('请输入要翻译的内容(exit!):')
if content == 'exit!':
break
url = 'http://fanyi.youdao.com/transl ... 39%3B
# 请求主体
data = {}
data['type'] = "AUTO"
data['i'] = content
data['doctype'] = "json"
data['xmlVersion'] = "1.8"
data['keyfrom'] = "fanyi.web"
data['ue'] = "UTF-8"
data['action'] = "FY_BY_CLICKBUTTON"
data['typoResult'] = "true"
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:45.0) Gecko/20100101 Firefox/45.0')
response = urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target = json.loads(html)
print('翻译结果: ',(target['translateResult'][0][0]['tgt']))
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
# 参数是一个字典{'类型':'代理ip:端口号'}
proxy_support = urllib.request.ProxyHandler({'type': 'ip:port'})
# 定制一个opener
opener = urllib.request.build_opener(proxy_support)
# 安装opener
urllib.request.install_opener(opener)
#调用opener
opener.open(url)
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
Chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
import chardet
url = 'http://www,baidu.com'
html = urllib.request.urlopen(url).read()
>>> chardet.detect(html)
{'confidence': 0.99, 'encoding': 'utf-8'}
6. 获取重定向链接
有时网页的某个页面需要根据原创URL跳转一次甚至多次才能最终到达目的页面,因此需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如
url='https://unsplash.com/photos/B1 ... 39%3B
res = requests.head(url)
re=res.headers['Location']
python网页数据抓取( 招聘职业的位置:的CSS选择器工具获取标签信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-03 14:06
招聘职业的位置:的CSS选择器工具获取标签信息
)
然后我们打开开发者工具,找到招聘职业的位置。
大家记得BeautifulSoup的CSS选择器,我们直接使用.select()方法来获取标签信息。
输出结果:
[/zhaopin/Java/"data-lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0101">Java, %2B%2B/"data -lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0102">C++, # ... 省略部分" data-lg-tj-cid= "idnull" data-lg-tj-id="4U00" data-lg-tj-no="0404">风控总监, "data-lg-tj-cid="idnull" data-lg-tj-id = "4U00" data-lg-tj-no="0405">副总裁]
260
获取到所有职位标签的a标签后,我们只需要提取标签的href属性和标签中的内容,就可以得到职位的招聘链接和职位名称。我们准备信息以生成字典。便于调用我们的后续程序。
这里我们使用 zip 函数同时迭代两个列表。生成键值对。
接下来,我们可以随意点击一个职位类别来分析招聘页面上的信息。
分页
我们先来分析一下网站页面信息。经过我的观察,每个职位的招聘信息最多不超过30页。也就是说,只要我们从第1页循环到第30页,就可以得到所有的招聘信息。但是也可以看到一些招聘信息,页数不到30页。以下图为例:
如果我们访问页面:/zhaopin/Java/31/
那是第 31 页。我们将得到一个 404 页。所以我们在访问404页面时需要进行过滤。
ifresp.status_code ==404:
经过
这样,我们就可以放心的在30页的周期内拿到每一页的招聘信息。
我们每个页面的url都是用格式拼接出来的:
link ='{}{}/'.format(url, str(pages))
获取资讯
获得所有信息后,我们还将它们组合成一个键值对字典。
字典的目的是方便我们将所有信息保存到数据库中。
保存数据
在保存数据库之前,我们需要配置数据库信息:
这里我们导入pymongo库并建立与MongoDB的连接,这里是本地MongoDB数据的默认连接。创建并选择一个数据库lagou,并在该数据库中创建一个表,即url_list。然后,我们保存数据:
ifurl_list.insert_one(数据):
print('保存数据库成功', data)
如果保存成功,会打印成功信息。
多线程爬取
10万多条数据的爬取是不是有点慢?有一个办法,我们用多个进程同时爬取。由于 Python 的历史遗留问题,多线程在 Python 中一直是一个美丽的梦想。
我们把提取职位招聘信息的代码写成一个函数,方便我们调用。这里的 parse_link() 就是这个函数,它以帖子的 url 和所有页面的数量作为参数。我们在 get_alllink_data() 函数的 for 循环中使用了 30 页数据。然后 this 作为主函数传递给多进程内部调用。
这里是一个pool进程池,我们调用进程池的map方法。
地图(功能,可迭代[,块大小=无])
多进程Pool类中的map方法与Python内置map函数的用法和行为基本一致。它将阻塞进程,直到返回结果。需要注意的是,虽然第二个参数是迭代器,但在实际使用中,程序只有在整个队列准备好后才会运行子进程。加入()
该方法等待子进程结束,然后继续向下运行,通常用于进程之间的同步。
反爬虫处理
像这样写完代码,就开始爬吧。我相信程序不会在爬行后很快停止。第一次停止后,我以为是网站限制了我的ip。所以我做了以下改动。
查看全部
python网页数据抓取(
招聘职业的位置:的CSS选择器工具获取标签信息
)
然后我们打开开发者工具,找到招聘职业的位置。
大家记得BeautifulSoup的CSS选择器,我们直接使用.select()方法来获取标签信息。
输出结果:
[/zhaopin/Java/"data-lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0101">Java, %2B%2B/"data -lg-tj-cid="idnull"data-lg-tj-id="4O00"data-lg-tj-no="0102">C++, # ... 省略部分" data-lg-tj-cid= "idnull" data-lg-tj-id="4U00" data-lg-tj-no="0404">风控总监, "data-lg-tj-cid="idnull" data-lg-tj-id = "4U00" data-lg-tj-no="0405">副总裁]
260
获取到所有职位标签的a标签后,我们只需要提取标签的href属性和标签中的内容,就可以得到职位的招聘链接和职位名称。我们准备信息以生成字典。便于调用我们的后续程序。
这里我们使用 zip 函数同时迭代两个列表。生成键值对。
接下来,我们可以随意点击一个职位类别来分析招聘页面上的信息。
分页
我们先来分析一下网站页面信息。经过我的观察,每个职位的招聘信息最多不超过30页。也就是说,只要我们从第1页循环到第30页,就可以得到所有的招聘信息。但是也可以看到一些招聘信息,页数不到30页。以下图为例:
如果我们访问页面:/zhaopin/Java/31/
那是第 31 页。我们将得到一个 404 页。所以我们在访问404页面时需要进行过滤。
ifresp.status_code ==404:
经过
这样,我们就可以放心的在30页的周期内拿到每一页的招聘信息。
我们每个页面的url都是用格式拼接出来的:
link ='{}{}/'.format(url, str(pages))
获取资讯
获得所有信息后,我们还将它们组合成一个键值对字典。
字典的目的是方便我们将所有信息保存到数据库中。
保存数据
在保存数据库之前,我们需要配置数据库信息:
这里我们导入pymongo库并建立与MongoDB的连接,这里是本地MongoDB数据的默认连接。创建并选择一个数据库lagou,并在该数据库中创建一个表,即url_list。然后,我们保存数据:
ifurl_list.insert_one(数据):
print('保存数据库成功', data)
如果保存成功,会打印成功信息。
多线程爬取
10万多条数据的爬取是不是有点慢?有一个办法,我们用多个进程同时爬取。由于 Python 的历史遗留问题,多线程在 Python 中一直是一个美丽的梦想。
我们把提取职位招聘信息的代码写成一个函数,方便我们调用。这里的 parse_link() 就是这个函数,它以帖子的 url 和所有页面的数量作为参数。我们在 get_alllink_data() 函数的 for 循环中使用了 30 页数据。然后 this 作为主函数传递给多进程内部调用。
这里是一个pool进程池,我们调用进程池的map方法。
地图(功能,可迭代[,块大小=无])
多进程Pool类中的map方法与Python内置map函数的用法和行为基本一致。它将阻塞进程,直到返回结果。需要注意的是,虽然第二个参数是迭代器,但在实际使用中,程序只有在整个队列准备好后才会运行子进程。加入()
该方法等待子进程结束,然后继续向下运行,通常用于进程之间的同步。
反爬虫处理
像这样写完代码,就开始爬吧。我相信程序不会在爬行后很快停止。第一次停止后,我以为是网站限制了我的ip。所以我做了以下改动。
python网页数据抓取(数据预览_csv路径不要带有中文学历要求(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-03 14:04
)
全文介绍
本文先采集从网上拉取数据,采集从Python位置数据,然后用Python进行可视化。主要涉及爬虫知识和数据可视化。
履带部分
首先使用Python抓取pull hook网络上的数据,使用简单易用的requests模块。主要需要注意的是, 是一个动态网页,所以会使用浏览器的 F12 开发者工具来抓包。抓包后会发现网页其实是一个POST表单,需要提交数据。提交的数据如下:
真正的网址是:/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0
在上图中也很容易找到:kd是查询关键词,pn是页数,可以用来翻页。
代码
import requests # 网络请求
import re
import time
import random
# post的网址
url = 'https://www.lagou.com/jobs/pos ... 39%3B
# 反爬措施
header = {'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/lis ... 39%3B,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Cookie': 'user_trace_token=20171103191801-9206e24f-9ca2-40ab-95a3-23947c0b972a; _ga=GA1.2.545192972.1509707889; LGUID=20171103191805-a9838dac-c088-11e7-9704-5254005c3644; JSESSIONID=ABAAABAACDBABJB2EE720304E451B2CEFA1723CE83F19CC; _gat=1; LGSID=20171228225143-9edb51dd-ebde-11e7-b670-525400f775ce; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DKkJPgBHAnny1nUKaLpx2oDfUXv9ItIF3kBAWM2-fDNu%26ck%3D3065.1.126.376.140.374.139.129%26shh%3Dwww.baidu.com%26sht%3Dmonline_3_dg%26wd%3D%26eqid%3Db0ec59d100013c7f000000055a4504f6; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGRID=20171228225224-b6cc7abd-ebde-11e7-9f67-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; SEARCH_ID=3ec21cea985a4a5fa2ab279d868560c8',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}
for n in range(30):
# 要提交的数据
form = {'first':'false',
'kd':'Python',
'pn':str(n)}
time.sleep(random.randint(2,5))
# 提交数据
html = requests.post(url,data=form,headers = header)
# 提取数据
data = re.findall('{"companyId":.*?,"positionName":"(.*?)","workYear":"(.*?)","education":"(.*?)","jobNature":"(.*?)","financeStage":"(.*?)","companyLogo":".*?","industryField":".*?","city":"(.*?)","salary":"(.*?)","positionId":.*?,"positionAdvantage":"(.*?)","companyShortName":"(.*?)","district"',html.text)
# 转换成数据框
data = pd.DataFrame(data)
# 保存在本地
data.to_csv(r'D:\Windows 7 Documents\Desktop\My\LaGouDataMatlab.csv',header = False, index = False, mode = 'a+')
注意:爬取数据的时候不要爬得太快,除非你有其他的反爬取措施,比如改IP,并且不需要登录。我在代码中加了一个时间模块来限制爬取速度。
数据可视化
下载的数据如下所示:
注意标题(也就是listing)是我自己加的。
导入模块并配置绘图风格
import pandas as pd # 数据框操作
import numpy as np
import matplotlib.pyplot as plt # 绘图
import jieba # 分词
from wordcloud import WordCloud # 词云可视化
import matplotlib as mpl # 配置字体
from pyecharts import Geo # 地理图
mpl.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
# 配置绘图风格
plt.rcParams["axes.labelsize"] = 16.
plt.rcParams["xtick.labelsize"] = 14.
plt.rcParams["ytick.labelsize"] = 14.
plt.rcParams["legend.fontsize"] = 12.
plt.rcParams["figure.figsize"] = [15., 15.]
注意:导入模块时,其他一切都很容易解决。除了 wordcloud 模块,我建议你手动安装这个模块。如果用pip安装,会提示缺少C++14.0等错误,导致安装。不开。手动下载whl文件以顺利安装。
数据预览
# 导入数据
data = pd.read_csv('D:\\Windows 7 Documents\\Desktop\\My\\LaGouDataPython.csv',encoding='gbk') # 导入数据
data.head()
read_csv路径中不要有中文
data.tail()
学术要求
data['学历要求'].value_counts().plot(kind='barh',rot=0)
plt.show()
工作经验
data['工作经验'].value_counts().plot(kind='bar',rot=0,color='b')
plt.show()
Python热帖
final = ''
stopwords = ['PYTHON','python','Python','工程师','(',')','/'] # 停止词
for n in range(data.shape[0]):
seg_list = list(jieba.cut(data['岗位职称'][n]))
for seg in seg_list:
if seg not in stopwords:
final = final + seg + ' '
# final 得到的词汇
工作场所
data['工作地点'].value_counts().plot(kind='pie',autopct='%1.2f%%',explode = np.linspace(0,1.5,25))
plt.show()
工作地理图
# 提取数据框
data2 = list(map(lambda x:(data['工作地点'][x],eval(re.split('k|K',data['工资'][x])[0])*1000),range(len(data))))
# 提取价格信息
data3 = pd.DataFrame(data2)
# 转化成Geo需要的格式
data4 = list(map(lambda x:(data3.groupby(0).mean()[1].index[x],data3.groupby(0).mean()[1].values[x]),range(len(data3.groupby(0)))))
# 地理位置展示
geo = Geo("全国Python工资布局", "制作人:挖掘机小王子", title_color="#fff", title_pos="left", width=1200, height=600,
background_color='#404a59')
attr, value = geo.cast(data4)
geo.add("", attr, value, type="heatmap", is_visualmap=True, visual_range=[0, 300], visual_text_color='#fff')
# 中国地图Python工资,此分布是最低薪资
geo
查看全部
python网页数据抓取(数据预览_csv路径不要带有中文学历要求(图)
)
全文介绍
本文先采集从网上拉取数据,采集从Python位置数据,然后用Python进行可视化。主要涉及爬虫知识和数据可视化。
履带部分
首先使用Python抓取pull hook网络上的数据,使用简单易用的requests模块。主要需要注意的是, 是一个动态网页,所以会使用浏览器的 F12 开发者工具来抓包。抓包后会发现网页其实是一个POST表单,需要提交数据。提交的数据如下:
真正的网址是:/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0
在上图中也很容易找到:kd是查询关键词,pn是页数,可以用来翻页。
代码
import requests # 网络请求
import re
import time
import random
# post的网址
url = 'https://www.lagou.com/jobs/pos ... 39%3B
# 反爬措施
header = {'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/lis ... 39%3B,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Cookie': 'user_trace_token=20171103191801-9206e24f-9ca2-40ab-95a3-23947c0b972a; _ga=GA1.2.545192972.1509707889; LGUID=20171103191805-a9838dac-c088-11e7-9704-5254005c3644; JSESSIONID=ABAAABAACDBABJB2EE720304E451B2CEFA1723CE83F19CC; _gat=1; LGSID=20171228225143-9edb51dd-ebde-11e7-b670-525400f775ce; PRE_UTM=; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DKkJPgBHAnny1nUKaLpx2oDfUXv9ItIF3kBAWM2-fDNu%26ck%3D3065.1.126.376.140.374.139.129%26shh%3Dwww.baidu.com%26sht%3Dmonline_3_dg%26wd%3D%26eqid%3Db0ec59d100013c7f000000055a4504f6; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGRID=20171228225224-b6cc7abd-ebde-11e7-9f67-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=index_search; SEARCH_ID=3ec21cea985a4a5fa2ab279d868560c8',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}
for n in range(30):
# 要提交的数据
form = {'first':'false',
'kd':'Python',
'pn':str(n)}
time.sleep(random.randint(2,5))
# 提交数据
html = requests.post(url,data=form,headers = header)
# 提取数据
data = re.findall('{"companyId":.*?,"positionName":"(.*?)","workYear":"(.*?)","education":"(.*?)","jobNature":"(.*?)","financeStage":"(.*?)","companyLogo":".*?","industryField":".*?","city":"(.*?)","salary":"(.*?)","positionId":.*?,"positionAdvantage":"(.*?)","companyShortName":"(.*?)","district"',html.text)
# 转换成数据框
data = pd.DataFrame(data)
# 保存在本地
data.to_csv(r'D:\Windows 7 Documents\Desktop\My\LaGouDataMatlab.csv',header = False, index = False, mode = 'a+')
注意:爬取数据的时候不要爬得太快,除非你有其他的反爬取措施,比如改IP,并且不需要登录。我在代码中加了一个时间模块来限制爬取速度。
数据可视化
下载的数据如下所示:
注意标题(也就是listing)是我自己加的。
导入模块并配置绘图风格
import pandas as pd # 数据框操作
import numpy as np
import matplotlib.pyplot as plt # 绘图
import jieba # 分词
from wordcloud import WordCloud # 词云可视化
import matplotlib as mpl # 配置字体
from pyecharts import Geo # 地理图
mpl.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
# 配置绘图风格
plt.rcParams["axes.labelsize"] = 16.
plt.rcParams["xtick.labelsize"] = 14.
plt.rcParams["ytick.labelsize"] = 14.
plt.rcParams["legend.fontsize"] = 12.
plt.rcParams["figure.figsize"] = [15., 15.]
注意:导入模块时,其他一切都很容易解决。除了 wordcloud 模块,我建议你手动安装这个模块。如果用pip安装,会提示缺少C++14.0等错误,导致安装。不开。手动下载whl文件以顺利安装。
数据预览
# 导入数据
data = pd.read_csv('D:\\Windows 7 Documents\\Desktop\\My\\LaGouDataPython.csv',encoding='gbk') # 导入数据
data.head()
read_csv路径中不要有中文
data.tail()
学术要求
data['学历要求'].value_counts().plot(kind='barh',rot=0)
plt.show()
工作经验
data['工作经验'].value_counts().plot(kind='bar',rot=0,color='b')
plt.show()
Python热帖
final = ''
stopwords = ['PYTHON','python','Python','工程师','(',')','/'] # 停止词
for n in range(data.shape[0]):
seg_list = list(jieba.cut(data['岗位职称'][n]))
for seg in seg_list:
if seg not in stopwords:
final = final + seg + ' '
# final 得到的词汇
工作场所
data['工作地点'].value_counts().plot(kind='pie',autopct='%1.2f%%',explode = np.linspace(0,1.5,25))
plt.show()
工作地理图
# 提取数据框
data2 = list(map(lambda x:(data['工作地点'][x],eval(re.split('k|K',data['工资'][x])[0])*1000),range(len(data))))
# 提取价格信息
data3 = pd.DataFrame(data2)
# 转化成Geo需要的格式
data4 = list(map(lambda x:(data3.groupby(0).mean()[1].index[x],data3.groupby(0).mean()[1].values[x]),range(len(data3.groupby(0)))))
# 地理位置展示
geo = Geo("全国Python工资布局", "制作人:挖掘机小王子", title_color="#fff", title_pos="left", width=1200, height=600,
background_color='#404a59')
attr, value = geo.cast(data4)
geo.add("", attr, value, type="heatmap", is_visualmap=True, visual_range=[0, 300], visual_text_color='#fff')
# 中国地图Python工资,此分布是最低薪资
geo
python网页数据抓取(pythonitems通过爬虫技术连接不同的网站爬取的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-02 11:03
python网页数据抓取基础介绍,有小伙伴问对于入门的python小白来说,能否下载某网站的数据呢?答案是肯定的,通过上面的对比,我们可以发现,在web数据爬取时,通过网页爬取工具去实现比较方便,那么问题来了,该怎么解决不同的网站爬取的问题呢?用浏览器抓取的方式也很简单,那么这里介绍一个小函数可以对不同的网站,我们可以抓取其用户名和密码,我们这里以“知乎”为例:fromurllibimportrequestimporttimetext=''cookie={'code':'','key':'6632256'}page=request.urlopen('')items=page.read()cur=cookie.read()foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem'''#..代码块1:获取元素名称items.get('zhihu.html')#..'.jpg'#..代码块2:解析items.split(',')#..代码块3:分割items.split('\n')#..代码块4:合并items.concat()#..代码块5:去重items.idleint()#..代码块6:得到结果对象,my_url=''url=''result=''cur=cookie.read()items=page.read()urllib.request.urlopen('')foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem通过爬虫技术连接不同的网站,并对其进行不同的密码抓取等方式,我们还可以通过别的方式获取不同网站的url,那么上面的代码也可以用urllib对浏览器发送请求,例如request.urlopen(''),当然urllib对浏览器的请求也可以用python自带的opener包request等方法实现,这里对本篇文章代码的github地址给出:zengzi-shchan/dataset_extractor包获取数据的方式可以用urllib.request,或者直接用浏览器去获取;讲到函数,就离不开作用域,下面,我们来讲讲函数的定义,直观的讲,作用域就是作用一个对象,函数则是作用一个属性,实例则是一个属性的引用。
我们讲下自己在项目中提交作用域的方式:#if...#不断扩展print'是不是null呀?'ifnotstr.isnull():#非null元素如下urllib.request.urlopen('')#file是可执行文件,这里定义的路径是open的,路径包含了执行函数的名字,例如hello\\dataset_extractor#else:urlli。 查看全部
python网页数据抓取(pythonitems通过爬虫技术连接不同的网站爬取的问题)
python网页数据抓取基础介绍,有小伙伴问对于入门的python小白来说,能否下载某网站的数据呢?答案是肯定的,通过上面的对比,我们可以发现,在web数据爬取时,通过网页爬取工具去实现比较方便,那么问题来了,该怎么解决不同的网站爬取的问题呢?用浏览器抓取的方式也很简单,那么这里介绍一个小函数可以对不同的网站,我们可以抓取其用户名和密码,我们这里以“知乎”为例:fromurllibimportrequestimporttimetext=''cookie={'code':'','key':'6632256'}page=request.urlopen('')items=page.read()cur=cookie.read()foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem'''#..代码块1:获取元素名称items.get('zhihu.html')#..'.jpg'#..代码块2:解析items.split(',')#..代码块3:分割items.split('\n')#..代码块4:合并items.concat()#..代码块5:去重items.idleint()#..代码块6:得到结果对象,my_url=''url=''result=''cur=cookie.read()items=page.read()urllib.request.urlopen('')foriteminitems:item=item.replace(',','')item=item.replace(',','')returnitem通过爬虫技术连接不同的网站,并对其进行不同的密码抓取等方式,我们还可以通过别的方式获取不同网站的url,那么上面的代码也可以用urllib对浏览器发送请求,例如request.urlopen(''),当然urllib对浏览器的请求也可以用python自带的opener包request等方法实现,这里对本篇文章代码的github地址给出:zengzi-shchan/dataset_extractor包获取数据的方式可以用urllib.request,或者直接用浏览器去获取;讲到函数,就离不开作用域,下面,我们来讲讲函数的定义,直观的讲,作用域就是作用一个对象,函数则是作用一个属性,实例则是一个属性的引用。
我们讲下自己在项目中提交作用域的方式:#if...#不断扩展print'是不是null呀?'ifnotstr.isnull():#非null元素如下urllib.request.urlopen('')#file是可执行文件,这里定义的路径是open的,路径包含了执行函数的名字,例如hello\\dataset_extractor#else:urlli。
python网页数据抓取(Pythonsqlite3模块支持两种类型的SQL语句(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-02 00:12
)
SQLite-Python 安装
SQLite3 可以使用 sqlite3 模块与 Python 集成。sqlite3 模块由 Gerhard Haring 编写。它提供了与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 及以上版本默认自带这个模块。
为了使用 sqlite3 模块,您必须首先创建一个代表数据库的连接对象,然后您可以选择创建一个游标对象,它将帮助您执行所有 SQL 语句。
Python sqlite3 模块 API
以下是重要的sqlite3模块程序,可以满足你在Python程序中使用SQLite数据库的需求。如果您需要更多详细信息,请查看 Python sqlite3 模块的官方文档。
序列号 API 和描述
1
sqlite3.connect(database [,timeout,other optional arguments])
此 API 打开一个指向 SQLite 数据库文件数据库的链接。您可以使用 ":memory:" 在 RAM 中打开到数据库的数据库连接,而不是在磁盘上打开它。如果成功打开数据库,则返回一个连接对象。
当一个数据库被多个连接访问,并且其中一个修改了数据库时,SQLite 数据库会被锁定,直到事务提交。timeout 参数表示连接等待锁定直到发生异常断开的持续时间。默认超时参数为 5.0(5 秒)。
如果给定的数据库名称 filename 不存在,则调用将创建一个数据库。如果不想在当前目录下创建数据库,可以指定文件名和路径,这样就可以在任何地方创建数据库。
2
connection.cursor([cursorClass])
此例程创建一个游标,它将用于 Python 数据库编程。此方法接受单个可选参数 cursorClass。如果提供了这个参数,它必须是一个从sqlite3.Cursor 扩展而来的自定义游标类。
3
cursor.execute(sql [, 可选参数])
该例程执行 SQL 语句。SQL 语句可以参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。
例如: cursor.execute("insert into people values(?, ?)", (who, age))
4
connection.execute(sql [, 可选参数])
该例程是上面执行的光标对象提供的方法的快捷方式。它通过调用游标方法创建一个中间游标对象,然后使用给定的参数调用游标的execute方法。
5
cursor.executemany(sql,seq_of_parameters)
此例程对 seq_of_parameters 中的所有参数或映射执行 SQL 命令。
6
connection.executemany(sql[, 参数])
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executemany方法。
7
cursor.executescript(sql_script)
一旦例程接收到脚本,它就会执行多条 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句都应该用分号分隔;。
8
connection.executescript(sql_script)
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executescript方法。
9
connection.total_changes()
此例程返回自数据库连接打开以来已修改、插入或删除的数据库行总数。
10
mit()
此方法提交当前事务。如果不调用此方法,则自上次调用 commit() 以来所做的任何操作对其他数据库连接都将不可见。
11
connection.rollback()
此方法回滚自上次调用 commit() 以来对数据库所做的更改。
12
连接.close()
此方法关闭数据库连接。请注意,这不会自动调用 commit()。如果之前没有调用过 commit() 方法,只要关闭数据库连接,你的所有更改都会丢失!
13
cursor.fetchone()
此方法获取查询结果集中的下一行并返回单个序列。当没有更多可用数据时,它返回 None。
14
cursor.fetchmany([size=cursor.arraysize])
此方法获取查询结果集中的下一行组并返回一个列表。当没有更多可用行时,将返回一个空列表。此方法尝试获取由 size 参数指定的尽可能多的行。
15
cursor.fetchall()
此例程获取查询结果集中的所有(剩余)行并返回一个列表。当没有可用行时,返回一个空列表。
连接到数据库
以下 Python 代码显示了如何连接到现有数据库。如果数据库不存在,则创建它,最后返回一个数据库对象。
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
在这里,您还可以将数据库名称复制到特定名称:memory:,这将在 RAM 中创建一个数据库。现在,让我们运行上面的程序在当前目录中创建我们的数据库 test.db。您可以根据需要更改路径。将上面的代码保存到sqlite.py文件中,执行如下图。如果数据库创建成功,将显示如下信息:
$chmod +x sqlite.py
$./sqlite.py
Open database successfully
创建表
以下 Python 代码片段将用于在先前创建的数据库中创建表:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
c = conn.cursor()
c.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
执行上述程序时,会在 test.db 中创建 COMPANY 表并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下 Python 程序显示了如何在上面创建的 COMPANY 表中创建记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )")
conn.commit()
print "Records created successfully"
conn.close()
当上面的程序执行时,它会在 COMPANY 表中创建一个给定的记录,并会显示以下两行:
Opened database successfully
Records created successfully
选择操作
以下 Python 程序显示了如何从之前创建的 COMPANY 表中检索和显示记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
cursor = c.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
更新操作
以下 Python 代码展示了如何使用 UPDATE 语句更新任何记录,然后从 COMPANY 表中检索并显示更新的记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit()
print "Total number of rows updated :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows updated : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
删除操作
以下 Python 代码展示了如何使用 DELETE 语句删除任何记录,然后从 COMPANY 表中获取并显示剩余记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows deleted : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully 查看全部
python网页数据抓取(Pythonsqlite3模块支持两种类型的SQL语句(图)
)
SQLite-Python 安装
SQLite3 可以使用 sqlite3 模块与 Python 集成。sqlite3 模块由 Gerhard Haring 编写。它提供了与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 及以上版本默认自带这个模块。
为了使用 sqlite3 模块,您必须首先创建一个代表数据库的连接对象,然后您可以选择创建一个游标对象,它将帮助您执行所有 SQL 语句。
Python sqlite3 模块 API
以下是重要的sqlite3模块程序,可以满足你在Python程序中使用SQLite数据库的需求。如果您需要更多详细信息,请查看 Python sqlite3 模块的官方文档。
序列号 API 和描述
1
sqlite3.connect(database [,timeout,other optional arguments])
此 API 打开一个指向 SQLite 数据库文件数据库的链接。您可以使用 ":memory:" 在 RAM 中打开到数据库的数据库连接,而不是在磁盘上打开它。如果成功打开数据库,则返回一个连接对象。
当一个数据库被多个连接访问,并且其中一个修改了数据库时,SQLite 数据库会被锁定,直到事务提交。timeout 参数表示连接等待锁定直到发生异常断开的持续时间。默认超时参数为 5.0(5 秒)。
如果给定的数据库名称 filename 不存在,则调用将创建一个数据库。如果不想在当前目录下创建数据库,可以指定文件名和路径,这样就可以在任何地方创建数据库。
2
connection.cursor([cursorClass])
此例程创建一个游标,它将用于 Python 数据库编程。此方法接受单个可选参数 cursorClass。如果提供了这个参数,它必须是一个从sqlite3.Cursor 扩展而来的自定义游标类。
3
cursor.execute(sql [, 可选参数])
该例程执行 SQL 语句。SQL 语句可以参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。
例如: cursor.execute("insert into people values(?, ?)", (who, age))
4
connection.execute(sql [, 可选参数])
该例程是上面执行的光标对象提供的方法的快捷方式。它通过调用游标方法创建一个中间游标对象,然后使用给定的参数调用游标的execute方法。
5
cursor.executemany(sql,seq_of_parameters)
此例程对 seq_of_parameters 中的所有参数或映射执行 SQL 命令。
6
connection.executemany(sql[, 参数])
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executemany方法。
7
cursor.executescript(sql_script)
一旦例程接收到脚本,它就会执行多条 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句都应该用分号分隔;。
8
connection.executescript(sql_script)
该例程是通过调用游标方法创建的中间游标对象的快捷方式,然后使用给定的参数调用游标的executescript方法。
9
connection.total_changes()
此例程返回自数据库连接打开以来已修改、插入或删除的数据库行总数。
10
mit()
此方法提交当前事务。如果不调用此方法,则自上次调用 commit() 以来所做的任何操作对其他数据库连接都将不可见。
11
connection.rollback()
此方法回滚自上次调用 commit() 以来对数据库所做的更改。
12
连接.close()
此方法关闭数据库连接。请注意,这不会自动调用 commit()。如果之前没有调用过 commit() 方法,只要关闭数据库连接,你的所有更改都会丢失!
13
cursor.fetchone()
此方法获取查询结果集中的下一行并返回单个序列。当没有更多可用数据时,它返回 None。
14
cursor.fetchmany([size=cursor.arraysize])
此方法获取查询结果集中的下一行组并返回一个列表。当没有更多可用行时,将返回一个空列表。此方法尝试获取由 size 参数指定的尽可能多的行。
15
cursor.fetchall()
此例程获取查询结果集中的所有(剩余)行并返回一个列表。当没有可用行时,返回一个空列表。
连接到数据库
以下 Python 代码显示了如何连接到现有数据库。如果数据库不存在,则创建它,最后返回一个数据库对象。
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
在这里,您还可以将数据库名称复制到特定名称:memory:,这将在 RAM 中创建一个数据库。现在,让我们运行上面的程序在当前目录中创建我们的数据库 test.db。您可以根据需要更改路径。将上面的代码保存到sqlite.py文件中,执行如下图。如果数据库创建成功,将显示如下信息:
$chmod +x sqlite.py
$./sqlite.py
Open database successfully
创建表
以下 Python 代码片段将用于在先前创建的数据库中创建表:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully"
c = conn.cursor()
c.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
执行上述程序时,会在 test.db 中创建 COMPANY 表并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下 Python 程序显示了如何在上面创建的 COMPANY 表中创建记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )")
c.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )")
conn.commit()
print "Records created successfully"
conn.close()
当上面的程序执行时,它会在 COMPANY 表中创建一个给定的记录,并会显示以下两行:
Opened database successfully
Records created successfully
选择操作
以下 Python 程序显示了如何从之前创建的 COMPANY 表中检索和显示记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
cursor = c.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
更新操作
以下 Python 代码展示了如何使用 UPDATE 语句更新任何记录,然后从 COMPANY 表中检索并显示更新的记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit()
print "Total number of rows updated :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows updated : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
删除操作
以下 Python 代码展示了如何使用 DELETE 语句删除任何记录,然后从 COMPANY 表中获取并显示剩余记录:
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
c = conn.cursor()
print "Opened database successfully"
c.execute("DELETE from COMPANY where ID=2;")
conn.commit()
print "Total number of rows deleted :", conn.total_changes
cursor = conn.execute("SELECT id, name, address, salary from COMPANY")
for row in cursor:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully"
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows deleted : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
python网页数据抓取(想要入门Python爬虫首先需要解决四个问题:1.熟悉python编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-30 04:34
在当今社会,互联网上充满了有用的数据。我们只需要耐心观察,加上一些技术手段,就能得到很多有价值的数据。这里的“技术手段”是指网络爬虫。今天小编就给大家分享一个爬虫的基础知识和入门教程:
什么是爬虫?
网络爬虫,也叫Web数据采集,是指通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出需要的数据。
要开始使用 Python 爬虫,首先需要解决四个问题:
1.熟悉python编程
2.了解HTML
3.了解网络爬虫的基本原理
4.学习使用python爬虫库
1、熟悉python编程
爬虫初期,初学者不需要学习python类、多线程、模块等稍有难度的内容。我们要做的就是找适合初学者的教材或者网上教程,花十多天时间,可以有三到四点了解python的基础,这时候就可以玩爬虫了!
2、为什么你需要了解 HTML
HTML 是一种标记语言,用于创建嵌入文本和图像等数据的网页,这些数据可以被浏览器读取并呈现为我们看到的网页。这就是为什么我们先抓取HTML,然后解析数据,因为数据隐藏在HTML中。
初学者学习HTML并不难。因为它不是一种编程语言。您只需要熟悉其标记规则即可。HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML标签是最常见的标签,通常成对出现,例如
和 H1>。在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。例如,一些标签没有内容并且是空元素。
下面是一个经典的 Hello World 程序示例:
HTML 文档由嵌套的 HTML 元素组成。例如,它们由括在尖括号中的 HTML 标记表示
. 通常,一个元素由一对标签表示:“开始标签”
和“结束标签”p>。如果元素收录文本内容,请将其放在这些标签之间。
3、了解python网络爬虫的基本原理
在编写python搜索器程序时,只需要执行以下两个操作:发送GET请求获取HTML;解析 HTML 以获取数据。对于这两件事,python有相应的库来帮你做,你只需要知道如何使用它们。
4、 使用python库抓取百度首页标题
首先,发送HTML数据请求,可以使用python内置库urllib,它有urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页的HTML内容
看效果:
部分截取输出HTML内容
让我们看看真正的百度主页的html是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度首页打开“设置”>“更多工具”>“开发者工具”,点击元素,您将看到:
在 Google Chrome 浏览器中查看 HTML
相比之下,你会知道你刚刚通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为需要的文字、图片和视频都隐藏在HTML中,所以需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的 Python 库 BeautifulSoup 作为解析上面得到的 HTML 的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。在命令行使用pip安装:
BeautifulSoup 将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据:
比如我想获取百度首页的标题“点一下百度我就知道了”,怎么办?
标题周围有两个标签,一个是一级标签
, 另一个是二级标签,所以只需要从标签中取出信息即可。
看看结果:
完成此操作后,成功提取了百度首页的标题。
本文以抓取百度首页标题为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识。房子是一层一层盖起来的,知识是一点一滴学来的。刚接触python的朋友想学习python爬虫需要打好基础,也可以自己学习视频资料和实践课程。 查看全部
python网页数据抓取(想要入门Python爬虫首先需要解决四个问题:1.熟悉python编程)
在当今社会,互联网上充满了有用的数据。我们只需要耐心观察,加上一些技术手段,就能得到很多有价值的数据。这里的“技术手段”是指网络爬虫。今天小编就给大家分享一个爬虫的基础知识和入门教程:
什么是爬虫?
网络爬虫,也叫Web数据采集,是指通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出需要的数据。
要开始使用 Python 爬虫,首先需要解决四个问题:
1.熟悉python编程
2.了解HTML
3.了解网络爬虫的基本原理
4.学习使用python爬虫库
1、熟悉python编程
爬虫初期,初学者不需要学习python类、多线程、模块等稍有难度的内容。我们要做的就是找适合初学者的教材或者网上教程,花十多天时间,可以有三到四点了解python的基础,这时候就可以玩爬虫了!
2、为什么你需要了解 HTML
HTML 是一种标记语言,用于创建嵌入文本和图像等数据的网页,这些数据可以被浏览器读取并呈现为我们看到的网页。这就是为什么我们先抓取HTML,然后解析数据,因为数据隐藏在HTML中。
初学者学习HTML并不难。因为它不是一种编程语言。您只需要熟悉其标记规则即可。HTML 标记收录几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML标签是最常见的标签,通常成对出现,例如
和 H1>。在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。例如,一些标签没有内容并且是空元素。
下面是一个经典的 Hello World 程序示例:
HTML 文档由嵌套的 HTML 元素组成。例如,它们由括在尖括号中的 HTML 标记表示
. 通常,一个元素由一对标签表示:“开始标签”
和“结束标签”p>。如果元素收录文本内容,请将其放在这些标签之间。
3、了解python网络爬虫的基本原理
在编写python搜索器程序时,只需要执行以下两个操作:发送GET请求获取HTML;解析 HTML 以获取数据。对于这两件事,python有相应的库来帮你做,你只需要知道如何使用它们。
4、 使用python库抓取百度首页标题
首先,发送HTML数据请求,可以使用python内置库urllib,它有urlopen函数,可以根据url获取HTML文件。这里尝试获取百度首页的HTML内容
看效果:
部分截取输出HTML内容
让我们看看真正的百度主页的html是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度首页打开“设置”>“更多工具”>“开发者工具”,点击元素,您将看到:
在 Google Chrome 浏览器中查看 HTML
相比之下,你会知道你刚刚通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为需要的文字、图片和视频都隐藏在HTML中,所以需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的 Python 库 BeautifulSoup 作为解析上面得到的 HTML 的工具。
BeautifulSoup 是一个需要安装和使用的第三方库。在命令行使用pip安装:
BeautifulSoup 将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据:
比如我想获取百度首页的标题“点一下百度我就知道了”,怎么办?
标题周围有两个标签,一个是一级标签
, 另一个是二级标签,所以只需要从标签中取出信息即可。
看看结果:
完成此操作后,成功提取了百度首页的标题。
本文以抓取百度首页标题为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识。房子是一层一层盖起来的,知识是一点一滴学来的。刚接触python的朋友想学习python爬虫需要打好基础,也可以自己学习视频资料和实践课程。
python网页数据抓取(HowtoWebScrapewithPythonin4翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-30 04:32
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
原文链接:
/how-to-web-scrape-with-python-in-4-minutes-bc49186a8460
图片来自 /free-photos/illustration-english-window-blue-sky-clouds-41409346
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
/developers/turnstile.html
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“/developers/data/nyct/turnstile/turnstile_180922.txt”,我通过单击网站 上的第一个数据文件作为测试找到了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 39%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你网络爬行愉快!
想继续查看本文的相关链接和参考资料吗?
戳链接:
gair.link/page/TextTranslation/1120
AI研究院每日更新精彩内容:
良心推荐:20周计算机科学体验帖(附资源)
多目标跟踪器:使用OpenCV实现多目标跟踪(C++/Python)
为计算机视觉生成大型、合成、带注释和真实的数据集
致敬保罗艾伦,除了他的科技圈,还有谁值得相信?
等你翻译:
揭秘深度网络:防止过度拟合与活动识别相关的新数据集使用 Excel 解释什么是多层卷积以及如何开发用于多步空气污染时间序列预测的自回归预测模型
额外的昵称~
如果想获得更多与AI领域相关的学习资源,可以访问AI研究会资源版块下载,
所有资源目前都是限时免费的。欢迎来到社区资源中心
gair.link/page/resources 下载~
/page/ClassificationPage/10(自动识别二维码) 查看全部
python网页数据抓取(HowtoWebScrapewithPythonin4翻译|M.Y.Li校对|就2)
本文为AI研究院整理的技术博客,原标题:
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
原文链接:
/how-to-web-scrape-with-python-in-4-minutes-bc49186a8460
图片来自 /free-photos/illustration-english-window-blue-sky-clouds-41409346
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
/developers/turnstile.html
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“/developers/data/nyct/turnstile/turnstile_180922.txt”,我通过单击网站 上的第一个数据文件作为测试找到了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 39%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你网络爬行愉快!
想继续查看本文的相关链接和参考资料吗?
戳链接:
gair.link/page/TextTranslation/1120
AI研究院每日更新精彩内容:
良心推荐:20周计算机科学体验帖(附资源)
多目标跟踪器:使用OpenCV实现多目标跟踪(C++/Python)
为计算机视觉生成大型、合成、带注释和真实的数据集
致敬保罗艾伦,除了他的科技圈,还有谁值得相信?
等你翻译:
揭秘深度网络:防止过度拟合与活动识别相关的新数据集使用 Excel 解释什么是多层卷积以及如何开发用于多步空气污染时间序列预测的自回归预测模型
额外的昵称~
如果想获得更多与AI领域相关的学习资源,可以访问AI研究会资源版块下载,
所有资源目前都是限时免费的。欢迎来到社区资源中心
gair.link/page/resources 下载~
/page/ClassificationPage/10(自动识别二维码)
python网页数据抓取( Python网络爬虫内容提取器一文(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-30 02:06
Python网络爬虫内容提取器一文(一))
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在一个爬虫框架中,其他部分很容易做到通用化,也就是很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,并且可以标准化插入,从而实现通用的爬虫,后续文章会具体说明讲解MS策略平台与Python合作的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源 查看全部
python网页数据抓取(
Python网络爬虫内容提取器一文(一))
1 简介
在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用 xslt 一次性提取静态 Web 内容并将其转换为 xml 格式。
2.使用lxml库提取网页内容
lxml是python的一个可以快速灵活处理XML的库。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现了通用的 ElementTree API。
这两天在python中测试了通过xslt提取网页内容,记录如下:
2.1、爬取目标
假设你想在吉首官网提取旧版论坛的帖子标题和回复数,如下图,提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果会在控制台显示
Python的优点是可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用并不多。大空间由 xslt 脚本占用。在这段代码中, just 只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者抓正则表达式,请参考《Python Instant Web Crawler 项目启动说明》。我们希望通过这种架构,可以节省程序员的时间。节省一半以上。
可以复制运行如下代码(windows10下测试,python3.2):
from urllib import request
from lxml import etree
url="http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
xslt_root = etree.XML("""\
""")
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(result_tree)
源代码可以从本文末尾的GitHub源下载。
2.3、抢结果
捕获的结果如下:
2.4、源码2:翻页抓取,并将结果保存到文件中
我们对2.2的代码做了进一步的修改,增加了翻页、抓取和保存结果文件的功能,代码如下:
from urllib import request
from lxml import etree
import time
xslt_root = etree.XML("""\
""")
baseurl = "http://www.gooseeker.com/cn/forum/7"
basefilebegin = "jsk_bbs_"
basefileend = ".xml"
count = 1
while (count < 12):
url = baseurl + "?page=" + str(count)
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
transform = etree.XSLT(xslt_root)
result_tree = transform(doc)
print(str(result_tree))
file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')
file_obj.write(str(result_tree))
file_obj.close()
count += 1
time.sleep(2)
我们添加了写入文件的代码,并添加了一个循环来构建每个页面的 URL。但是如果在翻页的过程中URL总是相同的呢?其实这就是动态网页的内容,下面会讲到。
三、总结
这是开源Python通用爬虫项目的验证过程。在一个爬虫框架中,其他部分很容易做到通用化,也就是很难将网页内容提取出来并转化为结构化操作。我们称之为提取器。不过在GooSeeker可视化提取规则生成器MS的帮助下,提取器生成过程会变得非常方便,并且可以标准化插入,从而实现通用的爬虫,后续文章会具体说明讲解MS策略平台与Python合作的具体方法。
4. 阅读下一步
本文介绍的方法通常用于抓取静态网页内容,也就是所谓的html文档中的内容。目前很多网站的内容都是用javascript动态生成的。一开始html没有这些内容,通过后加载。添加方式,那么需要用到动态技术,请阅读《Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容》
5.采集GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
6. 文档修改历史
2016-05-26:V2.0,添加文字说明;添加帖子的代码
2016-05-29:V2.1,添加上一章源码下载源
python网页数据抓取(如何自动从NewYorkYorkMTA下载数百个文件?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-09-30 02:04
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接= one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试发现的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url=''+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
# 设置你想要抓取的 URL 查看全部
python网页数据抓取(如何自动从NewYorkYorkMTA下载数百个文件?(一))
如何在 4 分钟内使用 Python 进行网页抓取
翻译 | MY Li 校对 | 只是 2 整理 | 菠萝女孩
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右击每个链接并保存在本地会很费力,幸好我们有网络爬虫!
关于网络爬行的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。
2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃,并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到我们要下载的文件的链接。总之,网站页面代码很多,我们希望能找到收录我们需要的数据的相关代码片段。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。
在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
2018 年 9 月 22 日星期六
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
网址 = '
响应 = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
汤 = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
汤.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = 汤.findAll('a')[36]
链接= one_a_tag['href']
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试发现的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url=''+ 链接
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# 导入库
进口请求
导入urllib.request
导入时间
frombs4 importBeautifulSoup
# 设置你想要抓取的 URL
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-28 16:57
网络爬虫介绍(也称为网络蜘蛛、网络机器人,在FOAF社区,更多的时候是网络追逐者):
它是按照一定的规则自动抓取万维网信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是为了获取这些内容。通过分析和过滤html代码,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)将网页数据保存到文件
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
这时候我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。(这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到你需要的内容《警察学院新闻》
内容范围
如何提取表格中的所有内容?
如果模式收录组,则将返回匹配的组
组列表
正则表达式
使用正则表达式匹配
'(.*?) 查看全部
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网络爬虫介绍(也称为网络蜘蛛、网络机器人,在FOAF社区,更多的时候是网络追逐者):
它是按照一定的规则自动抓取万维网信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。其实通俗点说就是通过程序获取网页上你想要的数据,也就是自动抓取数据。爬虫可以做什么?
可以使用爬虫来爬取图片、爬取视频等,想要爬取的数据,只要能通过浏览器访问数据,就可以通过爬虫获取。当你在浏览器中输入地址时,通过DNS服务器找到服务器主机,并向服务器发送请求。服务端解析后,将结果发送到用户浏览器,包括html、js、css等文件内容,浏览器解析出来,最后呈现给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果是由 HTML 代码组成的。我们的爬虫就是为了获取这些内容。通过分析和过滤html代码,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)将网页数据保存到文件
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
这时候我们从网页中获取的数据已经保存在我们指定的文件中了,如下图
网页访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的大部分数据是文本或数字信息,代码对我们没有用处。那么接下来我们要做的就是清除无用的数据。(这里我会得到派出所新闻的内容)
3)提取内容
分析网页,找到你需要的内容《警察学院新闻》
内容范围
如何提取表格中的所有内容?
如果模式收录组,则将返回匹配的组
组列表
正则表达式
使用正则表达式匹配
'(.*?)
python网页数据抓取( python脚本:python版本:python3.4与此类似类似的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-09-28 11:24
python脚本:python版本:python3.4与此类似类似的语言)
<p>使用python获取网页需要使用到urllib模块,我们先导入:
from urllib.request import Request,urlopen</p>
接下来,使用request生成一个请求头。这是百度的主页:
req = Request('https://www.baidu.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
也可以这样写:
req = Request('https://www.baidu.com/', headers={'User-Agent':'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'})
哪一个更好取决于你的个人喜好
请求头的信息可以通过浏览器的开发者工具获得:
添加请求头的意义在于防止服务器过滤。有些服务器会屏蔽没有请求头的请求
现在我们可以使用urlopen打开网页,但是urlopen的返回值是一个类:我们需要read函数来获取网页的源代码
file = urlopen(req).read()
网页的HTML代码存储在文件中。我们可以打印网页或将其保存在文件中
with open('out.html', 'wb') as f:
f.write(file)
打开我们的网页文件,这是百度的主页:
值得一提的是,我们抓取的网页实际上只是百度主页上的HTML文件。但是,当它在浏览器中打开时,浏览器将自动从网络下载相关图片、JS、CSS文件等,以完成我们的网页
通常,使用Python捕获网页是非常简单、复杂和重复的工作。Python是通过模块完成的。Python本身是一种基于介绍的语言
以下是我的Python脚本:
from urllib.request import Request, urlopen
req = Request('https://www.baidu.com/')
req.add_header('User-Agent',
'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
file = urlopen(req).read()
with open('out.html', 'wb') as f:
f.write(file)
Python版本:Python3.4
2.7与此类似 查看全部
python网页数据抓取(
python脚本:python版本:python3.4与此类似类似的语言)
<p>使用python获取网页需要使用到urllib模块,我们先导入:
from urllib.request import Request,urlopen</p>
接下来,使用request生成一个请求头。这是百度的主页:
req = Request('https://www.baidu.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
也可以这样写:
req = Request('https://www.baidu.com/', headers={'User-Agent':'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'})
哪一个更好取决于你的个人喜好
请求头的信息可以通过浏览器的开发者工具获得:
添加请求头的意义在于防止服务器过滤。有些服务器会屏蔽没有请求头的请求
现在我们可以使用urlopen打开网页,但是urlopen的返回值是一个类:我们需要read函数来获取网页的源代码
file = urlopen(req).read()
网页的HTML代码存储在文件中。我们可以打印网页或将其保存在文件中
with open('out.html', 'wb') as f:
f.write(file)
打开我们的网页文件,这是百度的主页:
值得一提的是,我们抓取的网页实际上只是百度主页上的HTML文件。但是,当它在浏览器中打开时,浏览器将自动从网络下载相关图片、JS、CSS文件等,以完成我们的网页
通常,使用Python捕获网页是非常简单、复杂和重复的工作。Python是通过模块完成的。Python本身是一种基于介绍的语言
以下是我的Python脚本:
from urllib.request import Request, urlopen
req = Request('https://www.baidu.com/')
req.add_header('User-Agent',
'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
file = urlopen(req).read()
with open('out.html', 'wb') as f:
f.write(file)
Python版本:Python3.4
2.7与此类似
python网页数据抓取(奔腾不息的自信是真正的成功之母())
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-27 22:09
Python抓取网页数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。你只能练习越来越多的练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) 数据=f.read() f. 查看全部
python网页数据抓取(奔腾不息的自信是真正的成功之母())
Python抓取网页数据。txt51 自信是取之不尽的源泉,自信是无尽的波浪,自信是快速进步的通道,自信是成功之母。使用python抓取页面并进行处理 2009-02-19 15:09:50| 类别:Python 标签:无|字体大小订阅 主要目的:抓取一个网页的源代码,处理其中需要的数据,并保存到数据库中。它已实现抓取页面并读取数据。Step 一、 抓取页面,这一步很简单,引入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替抓取网页步骤二、处理数据。如果页面代码比较标准,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。使用常规规则感觉更好。顺便练习一下刚学的正则表达式。其实正则规则也是一种比较简单的语言,里面有很多符号,有点晦涩难懂。你只能练习越来越多的练习。步骤三、 将处理后的数据保存到数据库中,可以用pymssql进行处理,这里只是简单的保存到文本文件中。扩展后,该功能还可以用于抓取网站的整张图片,自动认领站点地图文件等功能。接下来的任务是研究python importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2. txt" ) 数据=f.read() f.
python网页数据抓取(利用sort_values对count列进行排序取前3的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-09-26 20:12
抓取文章的链接并在本地保存流量
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wi ... 39%3B,
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思想是:首先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子网页,从而获取子网页中span标签保存的流量
接下来,打开本地文件,pandas用于数据分析,然后pyechart用于图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时,有许多问题需要理解的朋友回答:
1.代码第一段中保存的xlsx格式在保存后打开时实际上已损坏。以XML打开时没有问题,以XLS格式保存时也没有问题
2.太多访问将报告错误。我使用睡眠,但事实上,访问时会断断续续地读取值。为什么有些人不能读取值
3.使用排序值对计数列进行排序并取前3位。这将自动排除excel表格的第一行。我不知道为什么
我觉得我需要加强熊猫数据的处理方法,比如分组和排序
2)正则表达式的提取
3)Pyechart的图形绘制
4)网页反爬网等情况下的虚拟IP设置
记录我的Python学习路径,让我们一起工作~~
转载于: 查看全部
python网页数据抓取(利用sort_values对count列进行排序取前3的思路)
抓取文章的链接并在本地保存流量
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wi ... 39%3B,
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
上述代码的思想是:首先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子网页,从而获取子网页中span标签保存的流量
接下来,打开本地文件,pandas用于数据分析,然后pyechart用于图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时,有许多问题需要理解的朋友回答:
1.代码第一段中保存的xlsx格式在保存后打开时实际上已损坏。以XML打开时没有问题,以XLS格式保存时也没有问题
2.太多访问将报告错误。我使用睡眠,但事实上,访问时会断断续续地读取值。为什么有些人不能读取值
3.使用排序值对计数列进行排序并取前3位。这将自动排除excel表格的第一行。我不知道为什么
我觉得我需要加强熊猫数据的处理方法,比如分组和排序
2)正则表达式的提取
3)Pyechart的图形绘制
4)网页反爬网等情况下的虚拟IP设置
记录我的Python学习路径,让我们一起工作~~
转载于:
python网页数据抓取(Python学习资料2.抓取结果3.详细步骤分析(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-26 17:12
)
1. 获取目标:
百度NBA图片
Python爬虫、数据分析、网站开发等案例教程视频在线免费观看
https://space.bilibili.com/523606542
点击加群找管理员免费获取Python学习资料2.抢结果
3.详细步骤分析
(1)分析是否是动态加载的关键是在滚动鼠标滚轮时观察XHR中的包是否发生了变化。如果这里的面包数量有更新,那么页面很可能是动态请求, 分析后的百度图片是动态加载的。
(2) 找到动态加载包后,我们分析该包的请求,难点是分析查询参数。这里建议大家至少找两组关键词对比,找出关键词差异不同包之间,看变化规律(树偷偷提醒大家找一个叫pn的查询参数)整个动态其实是他一个人控制的,找到包后,他发出请求请求,分析提取图片的数据url就可以了(对于图片,一定要写成二进制!)
4.完整源码
此抓取所需的工具包请求和 json
import requests as rq
import json
import time
import os
count = 1
def crawl(page):
global count
if not os.path.exists('E://桌面/NBA'):
os.mkdir('E://桌面/NBA')
url = 'https://image.baidu.com/search/acjson?'
header = {
# 'Referer': 'https://image.baidu.com/search ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
param = {
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
}
response = rq.get(url, headers=header, params=param)
result = response.text
# print(response.status_code)
j = json.loads(result)
# print(j)
img_list = []
for i in j['data']:
if 'thumbURL' in i:
# print(i['thumbURL'])
img_list.append(i['thumbURL'])
# print(len(img_list))
for n in img_list:
r = rq.get(n, headers=header)
with open(f'E://桌面/NBA/{count}.jpg', 'wb') as f:
f.write(r.content)
count += 1
if __name__ == '__main__':
for i in range(30, 601, 30):
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print('page {0} is over!!! 耗时{1:.2f}秒!'.format(i//30, t)) 查看全部
python网页数据抓取(Python学习资料2.抓取结果3.详细步骤分析(一)
)
1. 获取目标:
百度NBA图片
Python爬虫、数据分析、网站开发等案例教程视频在线免费观看
https://space.bilibili.com/523606542
点击加群找管理员免费获取Python学习资料2.抢结果
3.详细步骤分析
(1)分析是否是动态加载的关键是在滚动鼠标滚轮时观察XHR中的包是否发生了变化。如果这里的面包数量有更新,那么页面很可能是动态请求, 分析后的百度图片是动态加载的。
(2) 找到动态加载包后,我们分析该包的请求,难点是分析查询参数。这里建议大家至少找两组关键词对比,找出关键词差异不同包之间,看变化规律(树偷偷提醒大家找一个叫pn的查询参数)整个动态其实是他一个人控制的,找到包后,他发出请求请求,分析提取图片的数据url就可以了(对于图片,一定要写成二进制!)
4.完整源码
此抓取所需的工具包请求和 json
import requests as rq
import json
import time
import os
count = 1
def crawl(page):
global count
if not os.path.exists('E://桌面/NBA'):
os.mkdir('E://桌面/NBA')
url = 'https://image.baidu.com/search/acjson?'
header = {
# 'Referer': 'https://image.baidu.com/search ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
param = {
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
}
response = rq.get(url, headers=header, params=param)
result = response.text
# print(response.status_code)
j = json.loads(result)
# print(j)
img_list = []
for i in j['data']:
if 'thumbURL' in i:
# print(i['thumbURL'])
img_list.append(i['thumbURL'])
# print(len(img_list))
for n in img_list:
r = rq.get(n, headers=header)
with open(f'E://桌面/NBA/{count}.jpg', 'wb') as f:
f.write(r.content)
count += 1
if __name__ == '__main__':
for i in range(30, 601, 30):
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print('page {0} is over!!! 耗时{1:.2f}秒!'.format(i//30, t))
python网页数据抓取(python浏览器缓存和电脑应用里面的phantomjs缓存都可以使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-22 06:02
python网页数据抓取实战本文实战使用到了网页数据抓取包phantomjs,webpageopen以及httplib,动态获取代码效果详解,需要说明的是,chrome浏览器的抓取依赖于phantomjs,浏览器缓存和电脑应用里面的phantomjs缓存都可以使用。第一步:安装phantomjs在网页里面查看html文件的源代码,发现有这样一段话如图1-1所示,使用phantomjs能够在文本编辑窗口(windows应用里面的文本编辑器)抓取出下拉列表页面的网页数据,也就是说phantomjs允许将一段话在浏览器里面输出,phantomjs支持浏览器缓存和webpageopen,浏览器缓存是nodejs的缓存引擎khronos的功能,这种功能是web开发里面普遍使用的功能。我们需要做一个简单的判断foriinrange(。
4):vari=0,j=0,k=0webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()发现,可以通过phantomjs.queryperformance.length()获取对应页面时间单位为分钟的网页数据,这就是我们需要的最基本信息,对于python初学者来说,这个概念并不会清晰,所以下面重点说明一下如何从这里获取时间单位为字符串(character)的网页数据。
第二步:找出所有时间单位为分钟的网页我们将整个页面搜索,找出所有时间单位为分钟的网页,一共可以搜索出40个,不过我们要仔细看一下源代码,大家可以看到这41个网页左侧都是navigator,是tomcat的一个监听者,下面我们找到这一段话:onjavascript:'insecurejs。methods';forerrinrange(1。
1):iferr!='javascript':err=exception。getmessage()try:response=json。dumps(json。stringify(response),encoding='utf-8')finally:source='javascript'response=json。
loads(source)print(response)从源代码中可以知道,javascript的代码页面a标签,而forerrinrange(1。
1)只获取一次请求,在每次请求之前,source都不会重新获取网页的字符串,因此需要在source中加一个字符串。第三步:利用webpageopen下载链接第四步:利用httplib实现本文提供一个httplib可以直接获取网页的post/get请求,代码如下:fromwebpageopenimport*frombs4importbeautifulsoupfromjson.stringifyimportjsoninformationfromjson.uni。 查看全部
python网页数据抓取(python浏览器缓存和电脑应用里面的phantomjs缓存都可以使用)
python网页数据抓取实战本文实战使用到了网页数据抓取包phantomjs,webpageopen以及httplib,动态获取代码效果详解,需要说明的是,chrome浏览器的抓取依赖于phantomjs,浏览器缓存和电脑应用里面的phantomjs缓存都可以使用。第一步:安装phantomjs在网页里面查看html文件的源代码,发现有这样一段话如图1-1所示,使用phantomjs能够在文本编辑窗口(windows应用里面的文本编辑器)抓取出下拉列表页面的网页数据,也就是说phantomjs允许将一段话在浏览器里面输出,phantomjs支持浏览器缓存和webpageopen,浏览器缓存是nodejs的缓存引擎khronos的功能,这种功能是web开发里面普遍使用的功能。我们需要做一个简单的判断foriinrange(。
4):vari=0,j=0,k=0webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()webdriver.get(":8000/python_examples/article/luo/"+j,"webdriver.phantomjs.queryperformance").success()发现,可以通过phantomjs.queryperformance.length()获取对应页面时间单位为分钟的网页数据,这就是我们需要的最基本信息,对于python初学者来说,这个概念并不会清晰,所以下面重点说明一下如何从这里获取时间单位为字符串(character)的网页数据。
第二步:找出所有时间单位为分钟的网页我们将整个页面搜索,找出所有时间单位为分钟的网页,一共可以搜索出40个,不过我们要仔细看一下源代码,大家可以看到这41个网页左侧都是navigator,是tomcat的一个监听者,下面我们找到这一段话:onjavascript:'insecurejs。methods';forerrinrange(1。
1):iferr!='javascript':err=exception。getmessage()try:response=json。dumps(json。stringify(response),encoding='utf-8')finally:source='javascript'response=json。
loads(source)print(response)从源代码中可以知道,javascript的代码页面a标签,而forerrinrange(1。
1)只获取一次请求,在每次请求之前,source都不会重新获取网页的字符串,因此需要在source中加一个字符串。第三步:利用webpageopen下载链接第四步:利用httplib实现本文提供一个httplib可以直接获取网页的post/get请求,代码如下:fromwebpageopenimport*frombs4importbeautifulsoupfromjson.stringifyimportjsoninformationfromjson.uni。
python网页数据抓取(python使用django和virtualenv安装django模块的区别?网页数据抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-19 02:01
python网页数据抓取
一、安装python由于python是动态类型语言,需要提前安装extensions,这里推荐使用ubuntu系统,
2、安装django模块推荐大家使用pip和virtualenv安装django,但是更推荐下面这种方式:可以安装官方提供的django模块而且还免费!具体安装过程可以参考官方文档:django_virtualenv使用django开发网页抓取接下来在ubuntu系统下,我们已经安装好了,具体方法参考上文字条。
2、开发网页抓取在python官网下载对应版本的django,下载可以看我以前写的详细教程,具体下载的文件使用双击打开这里需要说明的是wheel版本下载的是django的cache_size模块!django一般是默认安装在linux系统下,如果为mac则需要添加path环境变量。我们的系统是windowsx64,就比较简单,直接把tar压缩包传到linuxlocal目录里!传完之后点击开始,在命令行下执行cdtar>url.接下来python可以一步步设置项目实现。
学习python还需要安装lxml吗?可以参考我的这篇经验帖:render()的用法,以及cookie的设置,利用django开发跨域的博客,
看链接去, 查看全部
python网页数据抓取(python使用django和virtualenv安装django模块的区别?网页数据抓取)
python网页数据抓取
一、安装python由于python是动态类型语言,需要提前安装extensions,这里推荐使用ubuntu系统,
2、安装django模块推荐大家使用pip和virtualenv安装django,但是更推荐下面这种方式:可以安装官方提供的django模块而且还免费!具体安装过程可以参考官方文档:django_virtualenv使用django开发网页抓取接下来在ubuntu系统下,我们已经安装好了,具体方法参考上文字条。
2、开发网页抓取在python官网下载对应版本的django,下载可以看我以前写的详细教程,具体下载的文件使用双击打开这里需要说明的是wheel版本下载的是django的cache_size模块!django一般是默认安装在linux系统下,如果为mac则需要添加path环境变量。我们的系统是windowsx64,就比较简单,直接把tar压缩包传到linuxlocal目录里!传完之后点击开始,在命令行下执行cdtar>url.接下来python可以一步步设置项目实现。
学习python还需要安装lxml吗?可以参考我的这篇经验帖:render()的用法,以及cookie的设置,利用django开发跨域的博客,
看链接去,
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-09-15 19:11
阿里云>;云气社区>;主题地图>;P>;Python Web数据库
建议的活动:
更多优惠>
当前主题:Python抓取web数据库以添加集合
相关主题:
Python抓取与web数据库相关的博客以查看更多博客
亚太数据库产品概述
作者:阿里云官网
亚太数据库是稳定、可靠、有弹性和可扩展的在线数据库服务产品的总称。可操作和维护全球90%以上的主流开源和商用数据库(mysql、SQL server、redis等),为polardb提供6倍以上开源数据库的性能和价格,为hybriddb自主开发的数据库提供100 TB数据的实时计算能力,并且在灾难恢复、备份、恢复、监视、迁移等方面拥有全套解决方案
现在查看
【雪峰磁铁博客】可爱的Python测试开发库
作者:Python人工智能命理6886观点评论:03年前
欢迎转载,请注明出处:GitHub地址,感谢您喜欢相关书籍,下载测试开发,WebUI测试自动化splinter-WebUI测试工具,基于Selnium封装。链接selenium-WebUI自动化测试。链接--推荐的文档参考mec
阅读全文
博士生导师花了十天时间整理所有python库。我只是希望学好后能拿到高薪
作者:云琦2人观点点评:13年前
我不能辜负主任的辛勤工作!让我们直接开始这个话题。如果您需要信息,您可以通过私人邮件回复01,并且您可以获得大量pdf书籍和视频!Python常用库简要介绍fuzzyfuzzy和字符串模糊匹配。Esmre,正则表达式加速器。Colorama主要用于给出文本
阅读全文
老驱动带你去学习爬虫——Python爬虫技术共享
作者:云琦2人点评:2003年前
什么是“爬行动物”?简而言之,编写一个程序,从网络上获取所需的数据并以指定的格式存储,称为爬虫程序;理论上,爬虫的步骤非常简单。第一步是获取HTML源代码,第二步是分析HTML并获取数据。但是实际操作总是很麻烦~用Python编写“爬虫程序”有哪些方便的库?常用网络请求库:请求
阅读全文
Python爬虫程序捕获知乎所有用户信息
作者:青山无名2928人浏览评论:13年前
今天,我编写了一个使用递归捕获知乎所有用户信息的爬虫程序。源代码放在GitHub上。有兴趣的学生可以上去下载。这里,我将介绍代码逻辑和分页分析。首先,我看网页。在这里,我随机选择了一个大V作为条目,然后点击他的注意列表,如图所示,我的爬虫的全名处于非登录状态。这里
阅读全文
如何在Python中抓取数据?(一)web页面捕获)
作者:王树毅2089观点点评:2003年前
您一直在等待Python web数据爬虫教程。以下是如何从网页中查找链接和说明,并将其抓取并存储到Excel。我需要在官方账户的背景下接收来自读者的信息。许多信息都是读者的问题。只要我有时间,我就会尽力回答他们。但有些信息是第一眼看到的。我不知道
阅读全文
大数据与云计算学习:Python网络数据采集
作者:镜像心脏研究所3650观点评论:2003年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何基本处理服务器的响应,如何自动与网站交互,如何创建具有域名切换功能的爬虫学习路径,信息采集和信息存储,以及爬虫的基本原理。所谓的爬虫是一个自动数据采集Tools,你
阅读全文
Python中AWV的自动扫描
作者:2601人迟到,风急。浏览评论数:2004年前
最近,我将制作一个小型Python程序。其主要功能是实现acuenetix web漏洞扫描器的自动扫描,批量扫描部分目标,然后将扫描结果写入MySQL数据库。写这篇文章文章,并分享一些想法。本程序主要分为三个功能模块,URL
阅读全文
Python获取JD书评数据
作者:五岳之巅920人。意见和评论数量:07年前
京东书评信息丰富,包括购买日期、书名、作者、好评、中评、差评等,以购买日期为例,用Python+mysql实现。这个程序很小,只有100行。我在程序中添加了相关解释:来自selenium
阅读全文 查看全部
python网页数据抓取(老司机带你学爬虫——Python爬虫技术分享(组图))
阿里云>;云气社区>;主题地图>;P>;Python Web数据库
建议的活动:
更多优惠>
当前主题:Python抓取web数据库以添加集合
相关主题:
Python抓取与web数据库相关的博客以查看更多博客
亚太数据库产品概述
作者:阿里云官网
亚太数据库是稳定、可靠、有弹性和可扩展的在线数据库服务产品的总称。可操作和维护全球90%以上的主流开源和商用数据库(mysql、SQL server、redis等),为polardb提供6倍以上开源数据库的性能和价格,为hybriddb自主开发的数据库提供100 TB数据的实时计算能力,并且在灾难恢复、备份、恢复、监视、迁移等方面拥有全套解决方案
现在查看
【雪峰磁铁博客】可爱的Python测试开发库
作者:Python人工智能命理6886观点评论:03年前
欢迎转载,请注明出处:GitHub地址,感谢您喜欢相关书籍,下载测试开发,WebUI测试自动化splinter-WebUI测试工具,基于Selnium封装。链接selenium-WebUI自动化测试。链接--推荐的文档参考mec
阅读全文
博士生导师花了十天时间整理所有python库。我只是希望学好后能拿到高薪
作者:云琦2人观点点评:13年前
我不能辜负主任的辛勤工作!让我们直接开始这个话题。如果您需要信息,您可以通过私人邮件回复01,并且您可以获得大量pdf书籍和视频!Python常用库简要介绍fuzzyfuzzy和字符串模糊匹配。Esmre,正则表达式加速器。Colorama主要用于给出文本
阅读全文
老驱动带你去学习爬虫——Python爬虫技术共享
作者:云琦2人点评:2003年前
什么是“爬行动物”?简而言之,编写一个程序,从网络上获取所需的数据并以指定的格式存储,称为爬虫程序;理论上,爬虫的步骤非常简单。第一步是获取HTML源代码,第二步是分析HTML并获取数据。但是实际操作总是很麻烦~用Python编写“爬虫程序”有哪些方便的库?常用网络请求库:请求
阅读全文
Python爬虫程序捕获知乎所有用户信息
作者:青山无名2928人浏览评论:13年前
今天,我编写了一个使用递归捕获知乎所有用户信息的爬虫程序。源代码放在GitHub上。有兴趣的学生可以上去下载。这里,我将介绍代码逻辑和分页分析。首先,我看网页。在这里,我随机选择了一个大V作为条目,然后点击他的注意列表,如图所示,我的爬虫的全名处于非登录状态。这里
阅读全文
如何在Python中抓取数据?(一)web页面捕获)
作者:王树毅2089观点点评:2003年前
您一直在等待Python web数据爬虫教程。以下是如何从网页中查找链接和说明,并将其抓取并存储到Excel。我需要在官方账户的背景下接收来自读者的信息。许多信息都是读者的问题。只要我有时间,我就会尽力回答他们。但有些信息是第一眼看到的。我不知道
阅读全文
大数据与云计算学习:Python网络数据采集
作者:镜像心脏研究所3650观点评论:2003年前
本文将介绍网络数据采集的基本原理:如何使用Python向网络服务器请求信息,如何基本处理服务器的响应,如何自动与网站交互,如何创建具有域名切换功能的爬虫学习路径,信息采集和信息存储,以及爬虫的基本原理。所谓的爬虫是一个自动数据采集Tools,你
阅读全文
Python中AWV的自动扫描
作者:2601人迟到,风急。浏览评论数:2004年前
最近,我将制作一个小型Python程序。其主要功能是实现acuenetix web漏洞扫描器的自动扫描,批量扫描部分目标,然后将扫描结果写入MySQL数据库。写这篇文章文章,并分享一些想法。本程序主要分为三个功能模块,URL
阅读全文
Python获取JD书评数据
作者:五岳之巅920人。意见和评论数量:07年前
京东书评信息丰富,包括购买日期、书名、作者、好评、中评、差评等,以购买日期为例,用Python+mysql实现。这个程序很小,只有100行。我在程序中添加了相关解释:来自selenium
阅读全文

