
python网页数据抓取
python网页数据抓取( 数据科学越来越怎么抓网页数据(一)_Python学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-09 01:21
数据科学越来越怎么抓网页数据(一)_Python学习)
前言:数据科学越来越流行,网页是一个很大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常用的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计计算语言(R、Matlab)都可以实现和网站交互包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。第 1 步:熟悉 Python 的基本语法。如果您已经熟悉 Python,请跳至第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。
我推荐的可能不适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看课程评论再决定。第 2 步:了解如何与 网站 建立链接并获取网页数据。访问以获取更多信息。编写脚本与网站交互,熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,只知道一个,其他类似。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎补充。对于基本的网页抓取,前三个模块就足够了。
1.# 导入模块urllib2
2.导入 urllib2
3.。
4.# 查询任意一个文章,比如On random graph。对于每个查询 google 。更多。
5.# 学者有一个url,这个url形成的规则要自己分析。.
6.查询 = 'On+random+graph'
7.url ='#39; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
8.# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
9.# Google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
10.#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器与 网站 交互
11.#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
12.header = {'主机':'',
13.'用户代理': 'Mozilla/5.0 (Windows NT6.1; rv:26.0) Gecko/20100101 Firefox/2 6.0',
14.'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
15.'Accept-Encoding': 'gzip, deflate',
16.'连接':'保持活动'}
17.#建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象。/bbs
18.req = urllib2.Request(url, headers =header)
19.con = urllib2.urlopen(req)
20.#在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
21.doc = con.read()。
22.#关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
23.#所以作为一个守法的好公民,还是关闭连接比较好。
24.con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。步骤 三、 解析网页。飤鐢pet 咁勽潧 – 涓€浜╀银咗湴以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,你需要解析这个网页。解析网页的方法:不需要编写脚本,也不需要查询数据库上的数据,可以直接在notepad++上结合正则表达式使用。如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:(2) BeautifulSoup module. BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody -> tr,对于tbody节点,tr的子节点很多。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。网上有很多相关的说明,这里就不赘述了,只演示一个简单的代码:( 3) 结合使用以上两种方法。
1.#导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
2.导入 BeautifulSoup
3.导入重新。来自:/bbs
4.# 生成一个soup对象,第2步中提到了doc - google 1point3acres
5.汤=BeautifulSoup.BeautifulSoup(doc)
6.# 获取论文标题、作者、简短描述、引用次数、版次次数、文章 引用列表的超链接
7.#这里也用到了一些正则表达式,如果不熟悉,应该先无知。至于“类”:在“gs_rt”中
8.# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
9.# 让这个很简单,就是一个小网页,就可以知道对应html标签的位置和属性,
10.# 效果很好。
11.paper_name = soup.html.body.find('h3',{'class' : 'gs_rt'}).text
12.paper_name = re.sub(r'[.*]', '',paper_name) # 去掉'[]'标签,比如'[PDF]'.1point3acres
13.paper_author =soup.html.body.find('div', {'class' : 'gs_a'}).text
14.paper_desc = soup.html.body.find('div',{'class' : 'gs_rs'}).text
15.temp_str = soup.html.body.find('div',{'class' : 'gs_fl'}).text.更多信息
16.temp_re =re.match(r'[A-Za-zs]+(d*)[A-Za-zs]+(d*)', temp_str)
17.citeTimes = temp_re.group(1)
18.versionNum = temp_re.group(2)
19.如果 citeTimes == '':
20. citeTimes = '0'。更多信息
21.如果版本号 == '':
22. 版本号 = '0'。更多信息
23.citedPaper_href =soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
复制代码
.from: /bbs 这些是我正在分析引文网络的一个项目的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区的ip一时间无法登录googlescholar。第 4 步:访问数据。/bbs 终于抓到数据了,现在只存到内存中,必须保存好才能使用。(1) 最简单的方法是将数据写入txt文件,可以用Python实现,代码如下:
1.# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示将其添加到其中。
2.#还有其他参数,比如'r'只能读不能写,'w'可以写但删除原记录等。
3.file = open('webdata.txt','a')
4.line = paper_name + '#' + paper_author +'#' + paper_desc + '#' + citeTimes + 'n'。
5.#目标文件的write方法将字符串行写入文件
6.file = file.write(line)
7.# 再次做一个随心所欲关闭文件的好青年
8.file.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是非常简单的;数据库开放系统学习,w3school作为参考或作为手册使用,/bbsPython能链接数据库的前提是数据库是开放的,我用win7 + MySQL5.5,数据库是当地的。
1.% 可以使用cmd打开数据库。启动命令为: . 访问更多。
启动 mysql55. /bbs
3.% 平仓订单为:
停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
1.# 导入 MySQLdb 模块。链条已连接。1点3英亩
2.导入 MySQLdb
3.#与服务器建立链接,host为服务器ip,我的mysql数据库建在这台机器上,默认为127.0.0.1,
4.# 可以相应地输入用户、密码和数据库名称。默认端口号为3306,charset为编码方式。
5.#默认是utf8(也可能是gbk,看安装的版本)。
6.conn = MySQLdb.connect(host='127.0.0.1',user='root', passwd='yourPassword', db='dbname' , 端口=3306, 字符集='utf8')
7.# 创建光标
8.cur = conn.cursor()
9.#通过对象cur的execute()方法执行SQL语句
10.cur.execute("select * fromciteRelation where paperName = 'On Random Graph'")
11.# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
12.#i代表查询结果中的i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
13.list = cur.fetchall()
14.#还可以进行delete、drop、insert、update等操作,比如:
15.sql = "更新 studentCourseRecordset 失败 = 1 其中 studentID = '%s' 和 termID = '%s' 和 courseID ='%s'" %(studentID,course[0],course[1])
16.cur.execute(sql)
17.#与查询不同,在执行delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
19.#和往常一样,使用完记得关闭光标,再关闭链接
20.cur.close()
21.conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。./bbs 关于编码问题,附上我看到的一篇博文: ./bbs 后记:上面介绍了抓取网页数据的方法。数据捕获只是一小步。如何分析数据是大学的问题。欢迎讨论。以上内容如有不明之处,欢迎交流。.waral是长链,特别注意:网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器相对宽松的时间(如清晨)。网站很多,不要用三分之一英亩来测试。Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里运行的时候程序暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去去健身房,结果出来了。更新:2014年2月15日,改了几个错别字;增加了相关课程链接;增加了udacity CS101的介绍;增加了MySQLdb模块的介绍。2014年2月16日,
原文来源于微信公众号(PPV类数据科学社区): 查看全部
python网页数据抓取(
数据科学越来越怎么抓网页数据(一)_Python学习)

前言:数据科学越来越流行,网页是一个很大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常用的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计计算语言(R、Matlab)都可以实现和网站交互包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。第 1 步:熟悉 Python 的基本语法。如果您已经熟悉 Python,请跳至第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。
我推荐的可能不适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看课程评论再决定。第 2 步:了解如何与 网站 建立链接并获取网页数据。访问以获取更多信息。编写脚本与网站交互,熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,只知道一个,其他类似。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎补充。对于基本的网页抓取,前三个模块就足够了。
1.# 导入模块urllib2
2.导入 urllib2
3.。
4.# 查询任意一个文章,比如On random graph。对于每个查询 google 。更多。
5.# 学者有一个url,这个url形成的规则要自己分析。.
6.查询 = 'On+random+graph'
7.url ='#39; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
8.# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
9.# Google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
10.#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器与 网站 交互
11.#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
12.header = {'主机':'',
13.'用户代理': 'Mozilla/5.0 (Windows NT6.1; rv:26.0) Gecko/20100101 Firefox/2 6.0',
14.'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
15.'Accept-Encoding': 'gzip, deflate',
16.'连接':'保持活动'}
17.#建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象。/bbs
18.req = urllib2.Request(url, headers =header)
19.con = urllib2.urlopen(req)
20.#在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
21.doc = con.read()。
22.#关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
23.#所以作为一个守法的好公民,还是关闭连接比较好。
24.con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。步骤 三、 解析网页。飤鐢pet 咁勽潧 – 涓€浜╀银咗湴以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,你需要解析这个网页。解析网页的方法:不需要编写脚本,也不需要查询数据库上的数据,可以直接在notepad++上结合正则表达式使用。如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:(2) BeautifulSoup module. BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody -> tr,对于tbody节点,tr的子节点很多。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。网上有很多相关的说明,这里就不赘述了,只演示一个简单的代码:( 3) 结合使用以上两种方法。
1.#导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
2.导入 BeautifulSoup
3.导入重新。来自:/bbs
4.# 生成一个soup对象,第2步中提到了doc - google 1point3acres
5.汤=BeautifulSoup.BeautifulSoup(doc)
6.# 获取论文标题、作者、简短描述、引用次数、版次次数、文章 引用列表的超链接
7.#这里也用到了一些正则表达式,如果不熟悉,应该先无知。至于“类”:在“gs_rt”中
8.# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
9.# 让这个很简单,就是一个小网页,就可以知道对应html标签的位置和属性,
10.# 效果很好。
11.paper_name = soup.html.body.find('h3',{'class' : 'gs_rt'}).text
12.paper_name = re.sub(r'[.*]', '',paper_name) # 去掉'[]'标签,比如'[PDF]'.1point3acres
13.paper_author =soup.html.body.find('div', {'class' : 'gs_a'}).text
14.paper_desc = soup.html.body.find('div',{'class' : 'gs_rs'}).text
15.temp_str = soup.html.body.find('div',{'class' : 'gs_fl'}).text.更多信息
16.temp_re =re.match(r'[A-Za-zs]+(d*)[A-Za-zs]+(d*)', temp_str)
17.citeTimes = temp_re.group(1)
18.versionNum = temp_re.group(2)
19.如果 citeTimes == '':
20. citeTimes = '0'。更多信息
21.如果版本号 == '':
22. 版本号 = '0'。更多信息
23.citedPaper_href =soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
复制代码
.from: /bbs 这些是我正在分析引文网络的一个项目的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区的ip一时间无法登录googlescholar。第 4 步:访问数据。/bbs 终于抓到数据了,现在只存到内存中,必须保存好才能使用。(1) 最简单的方法是将数据写入txt文件,可以用Python实现,代码如下:
1.# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示将其添加到其中。
2.#还有其他参数,比如'r'只能读不能写,'w'可以写但删除原记录等。
3.file = open('webdata.txt','a')
4.line = paper_name + '#' + paper_author +'#' + paper_desc + '#' + citeTimes + 'n'。
5.#目标文件的write方法将字符串行写入文件
6.file = file.write(line)
7.# 再次做一个随心所欲关闭文件的好青年
8.file.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是非常简单的;数据库开放系统学习,w3school作为参考或作为手册使用,/bbsPython能链接数据库的前提是数据库是开放的,我用win7 + MySQL5.5,数据库是当地的。
1.% 可以使用cmd打开数据库。启动命令为: . 访问更多。
启动 mysql55. /bbs
3.% 平仓订单为:
停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
1.# 导入 MySQLdb 模块。链条已连接。1点3英亩
2.导入 MySQLdb
3.#与服务器建立链接,host为服务器ip,我的mysql数据库建在这台机器上,默认为127.0.0.1,
4.# 可以相应地输入用户、密码和数据库名称。默认端口号为3306,charset为编码方式。
5.#默认是utf8(也可能是gbk,看安装的版本)。
6.conn = MySQLdb.connect(host='127.0.0.1',user='root', passwd='yourPassword', db='dbname' , 端口=3306, 字符集='utf8')
7.# 创建光标
8.cur = conn.cursor()
9.#通过对象cur的execute()方法执行SQL语句
10.cur.execute("select * fromciteRelation where paperName = 'On Random Graph'")
11.# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
12.#i代表查询结果中的i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
13.list = cur.fetchall()
14.#还可以进行delete、drop、insert、update等操作,比如:
15.sql = "更新 studentCourseRecordset 失败 = 1 其中 studentID = '%s' 和 termID = '%s' 和 courseID ='%s'" %(studentID,course[0],course[1])
16.cur.execute(sql)
17.#与查询不同,在执行delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
19.#和往常一样,使用完记得关闭光标,再关闭链接
20.cur.close()
21.conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。./bbs 关于编码问题,附上我看到的一篇博文: ./bbs 后记:上面介绍了抓取网页数据的方法。数据捕获只是一小步。如何分析数据是大学的问题。欢迎讨论。以上内容如有不明之处,欢迎交流。.waral是长链,特别注意:网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器相对宽松的时间(如清晨)。网站很多,不要用三分之一英亩来测试。Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里运行的时候程序暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去去健身房,结果出来了。更新:2014年2月15日,改了几个错别字;增加了相关课程链接;增加了udacity CS101的介绍;增加了MySQLdb模块的介绍。2014年2月16日,
原文来源于微信公众号(PPV类数据科学社区):
python网页数据抓取(和服务器之间被用到的方法是:GET和POST。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-06 08:24
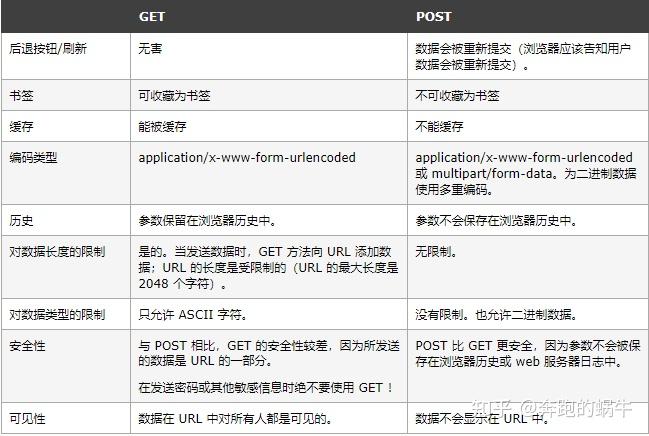
客户端和服务器之间最常用的两种请求-响应方法是:GET 和 POST。
GET - 从指定资源请求数据;
POST - 将要处理的数据提交到指定的资源;
两者比较:
2、我们来看看这两种捕获方式的异同;
(1)获取方法
GET 方法是最常用和最简单的,默认的 HTTP 请求方法是 GET。
一般用于我们从服务器获取数据,无需其他转换直接输入URL即可,即所有需要请求的信息都收录在URL中。
* 没有请求正文
* 数据必须在1K以内!
* GET请求数据会暴露在浏览器的地址栏中
有关获取请求的其他一些说明:
常用操作:
① 如果浏览器地址栏直接给出URL,那么一定是GET请求;
②点击页面上的超链接也必须是GET请求;
③ 提交表单时,表单默认使用GET请求,但可以设置为POST;
get请求是在url后面拼接传递参数,但是如果参数是中文的,需要转码,否则会报错。
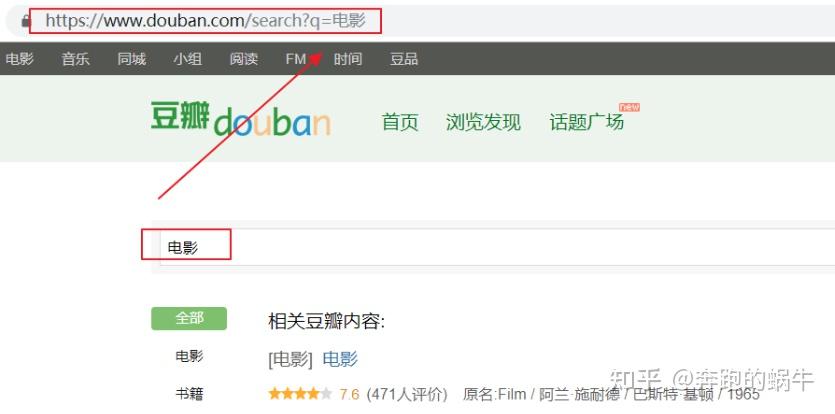
比如我们访问豆瓣官网,在搜索框中输入关键词“电影”:
可以看到浏览器中的请求是/search?q=movie
如果我们直接模拟上面的url请求,会报如下错误:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 14-15: ordinal not in range(128)
原因是在使用浏览器访问的时候会自动帮我们转码参数,而现在我们使用代码访问,所以需要我们自己处理。
from urllib.request import urlopen
from urllib.request import Request
from random import choice
# 1.爬取站点访问地址
url = "https://www.douban.com/search?q=电影"
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers)
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
修改,然后引入urlencode函数对url的参数进行转码,就可以正常访问了;
省略..
from urllib.parse import urlencode
# 1.爬取站点访问地址
args = {'q': '电影'}
url = "https://www.douban.com/search?{}".format(urlencode(args))
省略...
从这些可以看出get方法获取的内容是稳定的(即每个人打开某个网页时获取的信息都是一样的),但是使用post的时候需要输入具体的信息,所以获得的网页将是具体的。我们会解决的。
仅仅通过文字描述可能并不容易理解。建议大家在入门的时候看一些配套视频,加深对基本概念的印象,然后在实际操作中更好的理解每一步的含义。
这里推荐免费学习公开课,点击下方跳转
(2)发布方法
post用于向服务器发送数据以创建/更新资源。
通过 post 发送到服务器的数据存储在 HTTP 请求的请求体中:
POST /test/demo_form.php HTTP/1.1
Host: w3school.com.cn
name1=value1&name2=value2
post获取的内容不能仅通过URL获取,还需要提交一些额外的信息。
这种信息在不同的网页中发挥着不同的作用。例如,在查询天气的网页中,可能是输入城市信息;在登录某些网页时,它也是账号和密码的载体。
发帖请求:
① 数据不会出现在地址栏
② 数据大小没有上限
③ 有请求体
④ 如果请求正文中有中文,将使用 URL 编码!
关于发布请求的其他一些说明:
一般HTTP请求提交数据需要编码成URL编码格式,然后作为URL的一部分,或者作为参数传递给Request对象。
特别点:
Request请求对象中有一个data参数,post请求通过Request对象中的data属性传递参数来存储请求体数据。
data 是一个字典,其中收录匹配的键值对。
我们在这里模拟一个登录请求:
from urllib.request import urlopen
from urllib.request import Request
from random import choice
from urllib.parse import urlencode
# 1.url与参数处理
url = "https://www.douban.com/"
args = {
'name': 'abcdef123456',
'password': '123456'
}
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers, data=urlencode(args).encode())
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
如果没有添加encode()函数,会报错:
TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
发帖请求做百度翻译:
import urllib.request as ur
import urllib.parse as up
import json
word= input('请输入要翻译的英语:')
data={
'kw':word
}
data_url = up.urlencode(data)
request = ur.Request(url='https://fanyi.baidu.com/sug',data=data_url.encode('utf-8'))
reponse = ur.urlopen(request).read()
ret = json.loads(reponse)
#print(ret)
translate = ret['data'][0]['v']
print(translate)
3、总结:
Get请求和Post请求的区别
1)get 在浏览器回滚时是无害的,post 会再次提交请求;
2)get生成的url地址可以采集(标注),但不能post;
3)get请求只能是url编码,post可以多种方式编码;
4)get请求参数会完全保存在浏览器历史中,post不会(隐身浏览);
5) 对于参数的数据类型,get只接受ASCII字符,post没有限制;
6)Get请求的url中传入的参数长度有限制,post没有;
7)get比post安全,因为参数直接暴露在url中,不能用来传递敏感信息;
8)get参数放在url中,post参数放在请求体中;
注意: 查看全部
python网页数据抓取(和服务器之间被用到的方法是:GET和POST。)
客户端和服务器之间最常用的两种请求-响应方法是:GET 和 POST。
GET - 从指定资源请求数据;
POST - 将要处理的数据提交到指定的资源;
两者比较:
2、我们来看看这两种捕获方式的异同;
(1)获取方法
GET 方法是最常用和最简单的,默认的 HTTP 请求方法是 GET。
一般用于我们从服务器获取数据,无需其他转换直接输入URL即可,即所有需要请求的信息都收录在URL中。
* 没有请求正文
* 数据必须在1K以内!
* GET请求数据会暴露在浏览器的地址栏中
有关获取请求的其他一些说明:
常用操作:
① 如果浏览器地址栏直接给出URL,那么一定是GET请求;
②点击页面上的超链接也必须是GET请求;
③ 提交表单时,表单默认使用GET请求,但可以设置为POST;
get请求是在url后面拼接传递参数,但是如果参数是中文的,需要转码,否则会报错。
比如我们访问豆瓣官网,在搜索框中输入关键词“电影”:
可以看到浏览器中的请求是/search?q=movie
如果我们直接模拟上面的url请求,会报如下错误:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 14-15: ordinal not in range(128)
原因是在使用浏览器访问的时候会自动帮我们转码参数,而现在我们使用代码访问,所以需要我们自己处理。
from urllib.request import urlopen
from urllib.request import Request
from random import choice
# 1.爬取站点访问地址
url = "https://www.douban.com/search?q=电影"
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers)
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
修改,然后引入urlencode函数对url的参数进行转码,就可以正常访问了;
省略..
from urllib.parse import urlencode
# 1.爬取站点访问地址
args = {'q': '电影'}
url = "https://www.douban.com/search?{}".format(urlencode(args))
省略...
从这些可以看出get方法获取的内容是稳定的(即每个人打开某个网页时获取的信息都是一样的),但是使用post的时候需要输入具体的信息,所以获得的网页将是具体的。我们会解决的。
仅仅通过文字描述可能并不容易理解。建议大家在入门的时候看一些配套视频,加深对基本概念的印象,然后在实际操作中更好的理解每一步的含义。
这里推荐免费学习公开课,点击下方跳转
(2)发布方法
post用于向服务器发送数据以创建/更新资源。
通过 post 发送到服务器的数据存储在 HTTP 请求的请求体中:
POST /test/demo_form.php HTTP/1.1
Host: w3school.com.cn
name1=value1&name2=value2
post获取的内容不能仅通过URL获取,还需要提交一些额外的信息。
这种信息在不同的网页中发挥着不同的作用。例如,在查询天气的网页中,可能是输入城市信息;在登录某些网页时,它也是账号和密码的载体。
发帖请求:
① 数据不会出现在地址栏
② 数据大小没有上限
③ 有请求体
④ 如果请求正文中有中文,将使用 URL 编码!
关于发布请求的其他一些说明:
一般HTTP请求提交数据需要编码成URL编码格式,然后作为URL的一部分,或者作为参数传递给Request对象。
特别点:
Request请求对象中有一个data参数,post请求通过Request对象中的data属性传递参数来存储请求体数据。
data 是一个字典,其中收录匹配的键值对。
我们在这里模拟一个登录请求:
from urllib.request import urlopen
from urllib.request import Request
from random import choice
from urllib.parse import urlencode
# 1.url与参数处理
url = "https://www.douban.com/"
args = {
'name': 'abcdef123456',
'password': '123456'
}
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers, data=urlencode(args).encode())
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
如果没有添加encode()函数,会报错:
TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
发帖请求做百度翻译:
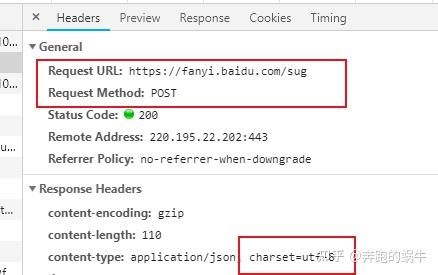
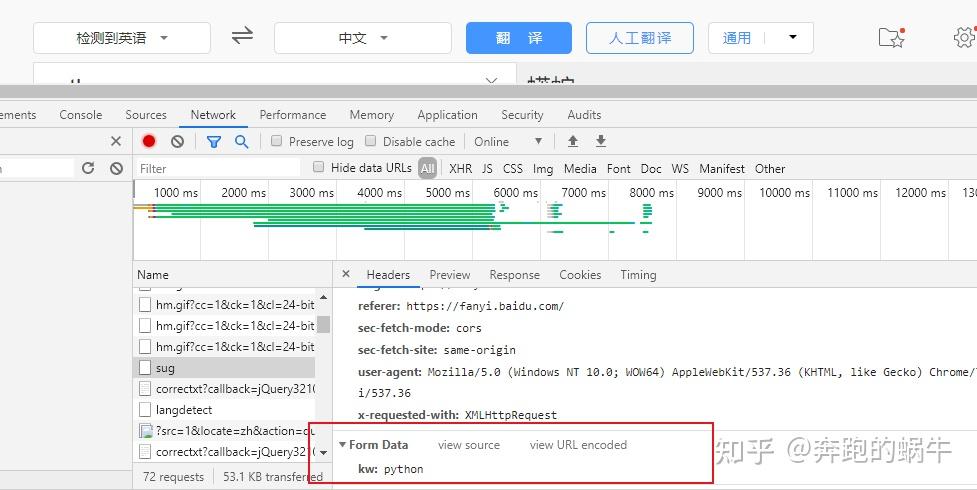

import urllib.request as ur
import urllib.parse as up
import json
word= input('请输入要翻译的英语:')
data={
'kw':word
}
data_url = up.urlencode(data)
request = ur.Request(url='https://fanyi.baidu.com/sug',data=data_url.encode('utf-8'))
reponse = ur.urlopen(request).read()
ret = json.loads(reponse)
#print(ret)
translate = ret['data'][0]['v']
print(translate)
3、总结:
Get请求和Post请求的区别
1)get 在浏览器回滚时是无害的,post 会再次提交请求;
2)get生成的url地址可以采集(标注),但不能post;
3)get请求只能是url编码,post可以多种方式编码;
4)get请求参数会完全保存在浏览器历史中,post不会(隐身浏览);
5) 对于参数的数据类型,get只接受ASCII字符,post没有限制;
6)Get请求的url中传入的参数长度有限制,post没有;
7)get比post安全,因为参数直接暴露在url中,不能用来传递敏感信息;
8)get参数放在url中,post参数放在请求体中;
注意:
python网页数据抓取( Python请求PythonRequests库被称为HTTPforHumans库下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-06 08:22
Python请求PythonRequests库被称为HTTPforHumans库下载)
1urllib.error
2
其中收录抛出的异常
1urllib.request
2
1urllib.parse
2
用于解析 URL,以及
1urllib.robotparser
2
用于解析 robots.txt 文件的内容。Urllib 并不容易使用,但可以帮助您进行身份验证、cookie、URL 编码和代理等。它应该只在需要对请求进行高级控制时使用。
如何安装 Urlli
如前所述,Urllib 包已收录在标准 python 库中,因此您无需再次安装。只需将其导入您的代码并使用它。
urllib 代码示例
以下代码将向维基百科的主页发送 GET 请求并打印出响应。响应将是页面的整个 HTML。
1import urllib.request as rq
2
3get_content = rq.urlopen("https://en.wikipedia.org/wiki/Main_Page")
4
5print(get_content.read().decode("utf-8"))
6
Python 请求
Python Requests 库,称为 Python HTTP for Humans,是一个第三方库,旨在简化处理 HTTP 请求和 URL 的过程。它建立在 Urllib 之上,并提供易于使用的界面。
除了比 urllib 更易于使用之外,它还具有更好的文档。说到人气,可以说 Requests 是最受欢迎的 Python 库之一,因为它是下载次数最多的 Python 包。它支持国际化、会话 cookie 和身份验证,以及连接池和超时,以及多部分文件上传。
如何安装
Python Requests 是第三方包,所以需要先安装后才能使用。推荐的安装方式是使用 pip 命令。
1>> pip install requests
2
Python 请求代码示例
下面的代码将下载与 Urllib 下载的相同页面,因此您可以进行比较,即使您在使用其高级功能时存在差异。
1>> import requests
2
3>>get_content = requests.get("https://en.wikipedia.org/wiki/Main_Page")
4
5>> print(get_content.text)
6
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
1pip install requests
2
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
1chromedriver.exe
2
文档
1from selenium import webdriver
2
3from selenium.webdriver.common.keys import Keys
4
5driver = webdriver.Chrome()
6
7driver.get("https://www.indeed.com/")
8
9amazon_search = driver.find_element_by_id("twotabsearchtextbox")
10
11amazon_search.send_keys("Web scraping for python developers")
12
13amazon_search.send_keys(Keys.RETURN)
14
15driver.close()
16
使用 python 和 Selenium,你可以像这样 网站 这样跨不同的工作平台为 python 开发人员找到当前的职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monsters 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
1pip install beautifulsoup4
2
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
1import requests
2
3from bs4 import BeautifulSoup
4
5
6
7url = "https://en.wikipedia.org/wiki/ ... ot%3B
8
9page_content = requests.get(url).text
10
11soup = BeautifulSoup(page_content, "html.parser")
12
13table = soup.find("table", {"class": "wikitable"})
14
15lga_trs = table.find_all("tr")[1:]
16
17for i in lga_trs:
18
19tds = i.find_all("td")
20
21td1 = tds[0].find("a")
22
23td2 = tds[1].find("a")
24
25l_name = td1.contents[0]
26
27l_url = td1["href"]
28
29l_state = td2["title"]
30
31l_state_url = td2["href"]
32
33print([l_name,l_url, l_state, l_state_url])
34
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
1pip install lxml
2
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,它收录了开发 Web 爬虫时需要的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
1pip install scrapy
2
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构,并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI,用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
1pip install pyspider
2
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
1from pyspider.libs.base_handler import *
2
3class Handler(BaseHandler):
4
5crawl_config = {}
6
7@every(minutes=24 * 60)
8
9def on_start(self):
10
11self.crawl("https://scrapy.org/", callback=self.index_page)
12
13@config(age=10 * 24 * 60 * 60)
14
15def index_page(self, response):
16
17for each in response.doc('a][href^="http"]').items():
18
19self.crawl(each.attr.href, callback=self.detail_page)
20
21
22
23def detail_page(self, response):
24
25return {"url": response.url, "title": response.doc('title').text()
26
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
1pyspider
2
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,那么使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果该站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。 查看全部
python网页数据抓取(
Python请求PythonRequests库被称为HTTPforHumans库下载)
1urllib.error
2
其中收录抛出的异常
1urllib.request
2
1urllib.parse
2
用于解析 URL,以及
1urllib.robotparser
2
用于解析 robots.txt 文件的内容。Urllib 并不容易使用,但可以帮助您进行身份验证、cookie、URL 编码和代理等。它应该只在需要对请求进行高级控制时使用。
如何安装 Urlli
如前所述,Urllib 包已收录在标准 python 库中,因此您无需再次安装。只需将其导入您的代码并使用它。
urllib 代码示例
以下代码将向维基百科的主页发送 GET 请求并打印出响应。响应将是页面的整个 HTML。
1import urllib.request as rq
2
3get_content = rq.urlopen("https://en.wikipedia.org/wiki/Main_Page";)
4
5print(get_content.read().decode("utf-8"))
6
Python 请求
Python Requests 库,称为 Python HTTP for Humans,是一个第三方库,旨在简化处理 HTTP 请求和 URL 的过程。它建立在 Urllib 之上,并提供易于使用的界面。
除了比 urllib 更易于使用之外,它还具有更好的文档。说到人气,可以说 Requests 是最受欢迎的 Python 库之一,因为它是下载次数最多的 Python 包。它支持国际化、会话 cookie 和身份验证,以及连接池和超时,以及多部分文件上传。
如何安装
Python Requests 是第三方包,所以需要先安装后才能使用。推荐的安装方式是使用 pip 命令。
1>> pip install requests
2
Python 请求代码示例
下面的代码将下载与 Urllib 下载的相同页面,因此您可以进行比较,即使您在使用其高级功能时存在差异。
1>> import requests
2
3>>get_content = requests.get("https://en.wikipedia.org/wiki/Main_Page";)
4
5>> print(get_content.text)
6
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
1pip install requests
2
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
1chromedriver.exe
2
文档
1from selenium import webdriver
2
3from selenium.webdriver.common.keys import Keys
4
5driver = webdriver.Chrome()
6
7driver.get("https://www.indeed.com/";)
8
9amazon_search = driver.find_element_by_id("twotabsearchtextbox")
10
11amazon_search.send_keys("Web scraping for python developers")
12
13amazon_search.send_keys(Keys.RETURN)
14
15driver.close()
16
使用 python 和 Selenium,你可以像这样 网站 这样跨不同的工作平台为 python 开发人员找到当前的职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monsters 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
1pip install beautifulsoup4
2
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
1import requests
2
3from bs4 import BeautifulSoup
4
5
6
7url = "https://en.wikipedia.org/wiki/ ... ot%3B
8
9page_content = requests.get(url).text
10
11soup = BeautifulSoup(page_content, "html.parser")
12
13table = soup.find("table", {"class": "wikitable"})
14
15lga_trs = table.find_all("tr")[1:]
16
17for i in lga_trs:
18
19tds = i.find_all("td")
20
21td1 = tds[0].find("a")
22
23td2 = tds[1].find("a")
24
25l_name = td1.contents[0]
26
27l_url = td1["href"]
28
29l_state = td2["title"]
30
31l_state_url = td2["href"]
32
33print([l_name,l_url, l_state, l_state_url])
34
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
1pip install lxml
2
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,它收录了开发 Web 爬虫时需要的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
1pip install scrapy
2
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构,并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI,用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
1pip install pyspider
2
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
1from pyspider.libs.base_handler import *
2
3class Handler(BaseHandler):
4
5crawl_config = {}
6
7@every(minutes=24 * 60)
8
9def on_start(self):
10
11self.crawl("https://scrapy.org/", callback=self.index_page)
12
13@config(age=10 * 24 * 60 * 60)
14
15def index_page(self, response):
16
17for each in response.doc('a][href^="http"]').items():
18
19self.crawl(each.attr.href, callback=self.detail_page)
20
21
22
23def detail_page(self, response):
24
25return {"url": response.url, "title": response.doc('title').text()
26
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
1pyspider
2
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,那么使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果该站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-06 00:20
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
刚整理了一套2018最新0基础入门和进阶教程,无私分享,加Python学习qun:227-435-450搞定,附:开发工具和安装包,系统学习路线图
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。 查看全部
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
刚整理了一套2018最新0基础入门和进阶教程,无私分享,加Python学习qun:227-435-450搞定,附:开发工具和安装包,系统学习路线图
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
python网页数据抓取(Python中的正则表达式教程输出结果及总结表(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-01 23:06
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:
抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8
import re, urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
html = html.decode('utf-8') #python3版本中需要加入
links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)
titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)
tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)
span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags):
span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警
山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警
强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警
地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span > ul > li.waring > a:nth-child(1)
因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:
#alarmtip > ul > li.waring > a
代码:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.html
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
tree = lxml.html.fromstring(html)
content = tree.cssselect('li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
######### 添加到列表中
link = []
title = []
tag = []
for n in content:
link.append(url+n.get('href'))
title.append(n.get('title'))
tag.append(n.text)
######## 添加到字典中
for n in content:
data = {
'tag' : n.text,
'link' : url+n.get('href'),
'title' : n.get('title')
}
五、总结
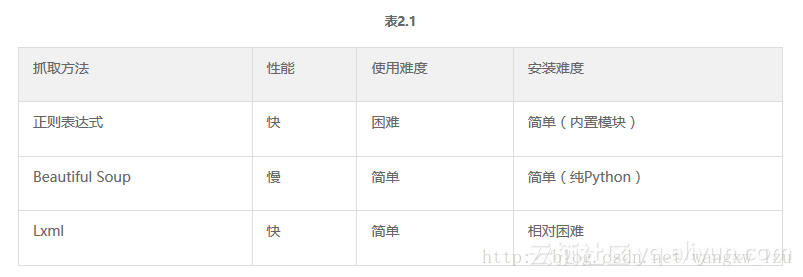
表格2.1总结了每种抓取方式的优缺点。
源码链接
参考资料: 查看全部
python网页数据抓取(Python中的正则表达式教程输出结果及总结表(一))
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:

抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8
import re, urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
html = html.decode('utf-8') #python3版本中需要加入
links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)
titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)
tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)
span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags):
span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警
山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警
强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警
地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span > ul > li.waring > a:nth-child(1)
因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:
#alarmtip > ul > li.waring > a
代码:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.html
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
tree = lxml.html.fromstring(html)
content = tree.cssselect('li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
######### 添加到列表中
link = []
title = []
tag = []
for n in content:
link.append(url+n.get('href'))
title.append(n.get('title'))
tag.append(n.text)
######## 添加到字典中
for n in content:
data = {
'tag' : n.text,
'link' : url+n.get('href'),
'title' : n.get('title')
}
五、总结
表格2.1总结了每种抓取方式的优缺点。
源码链接
参考资料:
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-01 20:14
网络爬虫简介(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者):
它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。爬虫能做什么?
你可以使用爬虫爬取图片、爬取视频等你想爬取的数据,只要你可以通过浏览器访问的数据都可以通过爬虫获取。当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户在浏览器中看到的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)网页数据存储在一个文件中
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
至此,我们从网页中获取的数据已经保存在我们指定的文件中,如下图
网络访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的数据大部分是文本或者数字信息,代码对我们没有用处。所以我们接下来要做的就是清除无用的数据。(这里我会从警方新闻中获取内容)
3)提取内容
分析网页以找到您需要的“警察新闻”
内容范围
如何提取表格的内容?
如果模式收录一个组,它将返回匹配的
组列表
常用表达
使用正则表达式匹配
'(.*?) 查看全部
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网络爬虫简介(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者):
它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。爬虫能做什么?
你可以使用爬虫爬取图片、爬取视频等你想爬取的数据,只要你可以通过浏览器访问的数据都可以通过爬虫获取。当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户在浏览器中看到的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)网页数据存储在一个文件中
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
至此,我们从网页中获取的数据已经保存在我们指定的文件中,如下图

网络访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的数据大部分是文本或者数字信息,代码对我们没有用处。所以我们接下来要做的就是清除无用的数据。(这里我会从警方新闻中获取内容)
3)提取内容
分析网页以找到您需要的“警察新闻”
内容范围
如何提取表格的内容?
如果模式收录一个组,它将返回匹配的
组列表
常用表达
使用正则表达式匹配
'(.*?)
python网页数据抓取(用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-01 16:00
编译:欧莎
作为数据科学家的首要任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取一个网站——比如从Fast Track获取2018年百强企业的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫的示例代码,本文用到的所有代码都在GitHub()上,欢迎你去拿。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
美丽的汤
要求
刮擦
硒
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
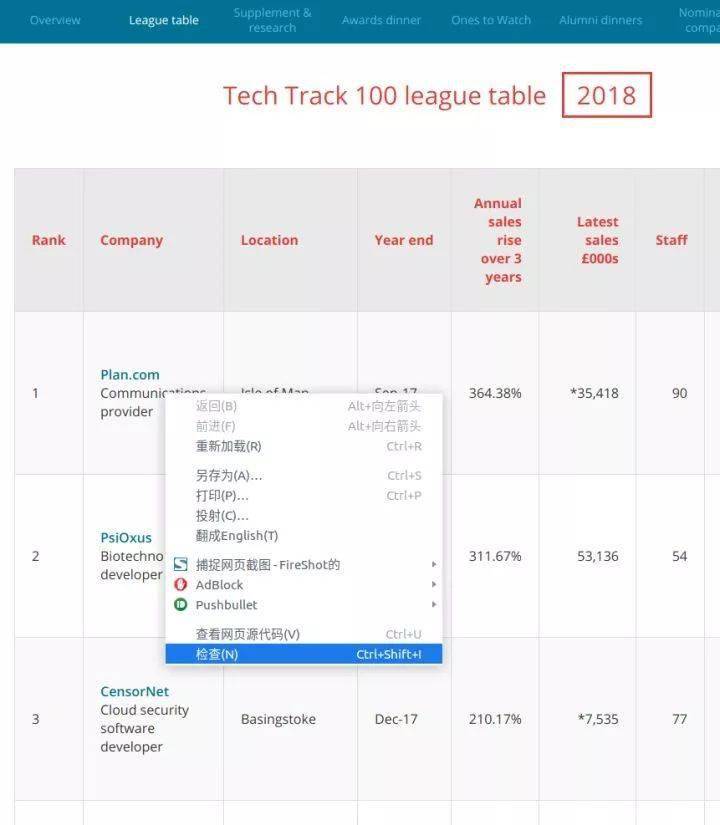
以Tech Track Top 100 Enterprises页面(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例,在表格上右击选择“查看” 。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面中,并且
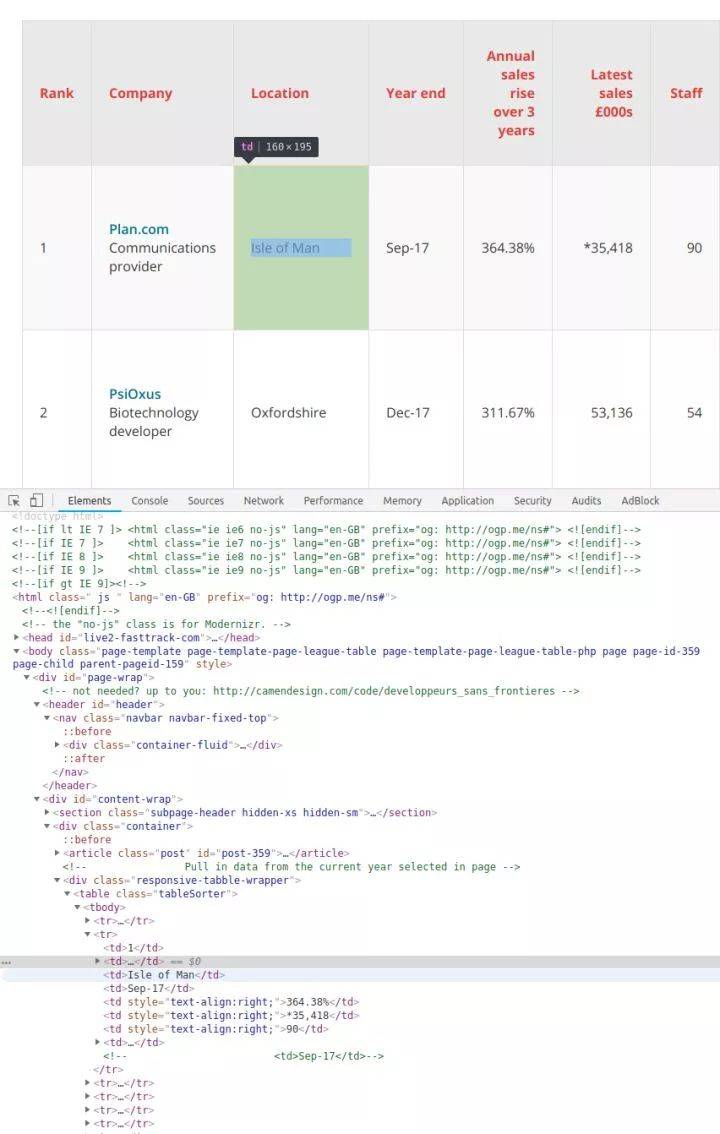
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:
每一行都在一个
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(例如
失眠
) 发起请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:
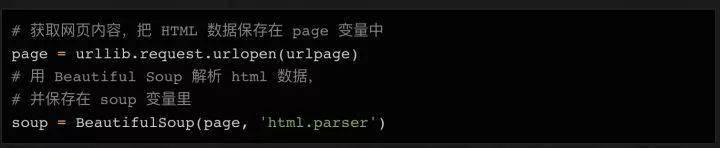
接下来,我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,将处理结果存储在soup变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
因为一切都在桌子上(
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。
看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
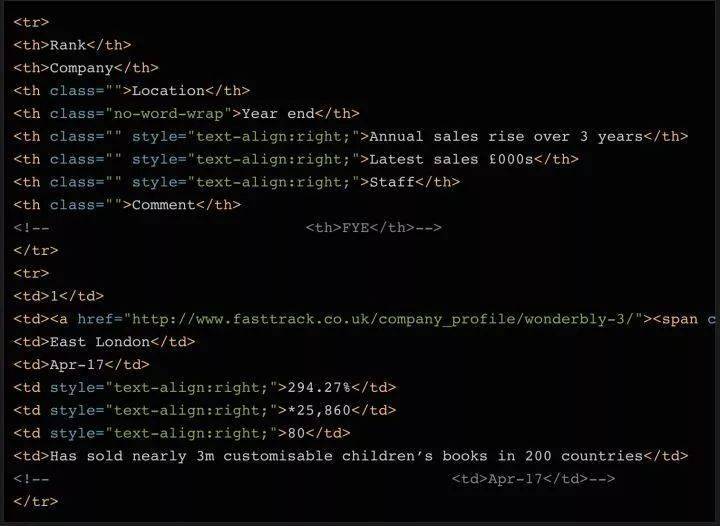
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面中是一致的(尽管在其他 网站 上可能没有那么简单!),所以我们可以再次使用 find_all 方法,通过搜索
元素,逐行提取数据,将其存储在变量中,稍后将其写入csv或json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填写初始表头(方便以后在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能会注意到我输入的表头比网页上的表格多了几个列名,比如Webpage(网页)和Deion(描述),请仔细看看上面打印的soup变量数据——数据第二行第二列不仅收录公司名称,还收录公司的网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
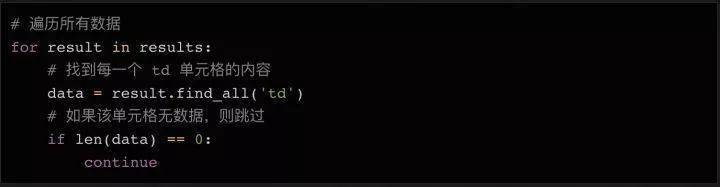
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为标题使用
标签,不使用标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。
我们想将公司变量的内容分成两部分:公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
要删除 sales 变量中的多余字符,我们可以使用一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
在原创快速通道页面上,找到您需要访问的公司详情页面的链接。
发起对公司详细信息页面链接的请求
使用Beautifulsoup处理得到的html数据
找到所需的链接元素
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
用 BeautifulSoup 处理得到的 html 数据
循环遍历汤对象以搜索所需的 html 元素
做简单的数据清洗
将数据写入 csv 文件
如果有什么不明白的,请在下方留言,我会尽力为您解答!
附:本文所有代码()
为您的爬行动物之旅有个美好的开始! 查看全部
python网页数据抓取(用脚本将获取信息上获取2018年100强企业的信息)
编译:欧莎
作为数据科学家的首要任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取一个网站——比如从Fast Track获取2018年百强企业的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫的示例代码,本文用到的所有代码都在GitHub()上,欢迎你去拿。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
美丽的汤
要求
刮擦
硒
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:

安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以Tech Track Top 100 Enterprises页面(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例,在表格上右击选择“查看” 。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面中,并且
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:

每一行都在一个
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(例如
失眠
) 发起请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。

接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:

接下来,我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,将处理结果存储在soup变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
因为一切都在桌子上(
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。

看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面中是一致的(尽管在其他 网站 上可能没有那么简单!),所以我们可以再次使用 find_all 方法,通过搜索
元素,逐行提取数据,将其存储在变量中,稍后将其写入csv或json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填写初始表头(方便以后在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。

这将打印我们刚刚添加到列表对象行的第一行标题。
你可能会注意到我输入的表头比网页上的表格多了几个列名,比如Webpage(网页)和Deion(描述),请仔细看看上面打印的soup变量数据——数据第二行第二列不仅收录公司名称,还收录公司的网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为标题使用
标签,不使用标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
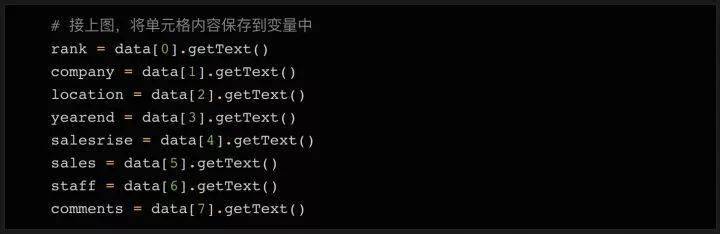
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。

我们想将公司变量的内容分成两部分:公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
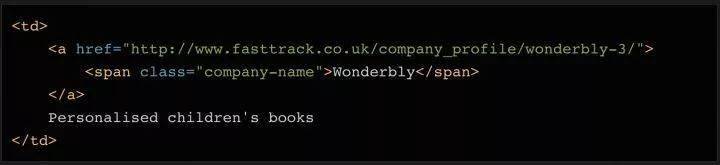
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
要删除 sales 变量中的多余字符,我们可以使用一次 strip 方法。

我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
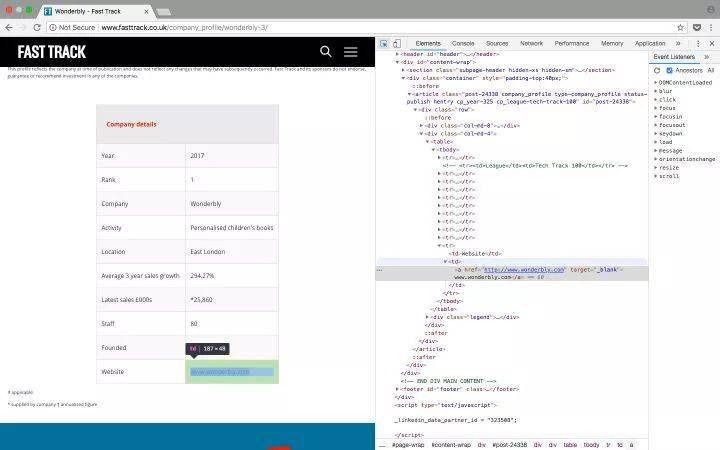
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
在原创快速通道页面上,找到您需要访问的公司详情页面的链接。
发起对公司详细信息页面链接的请求
使用Beautifulsoup处理得到的html数据
找到所需的链接元素
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
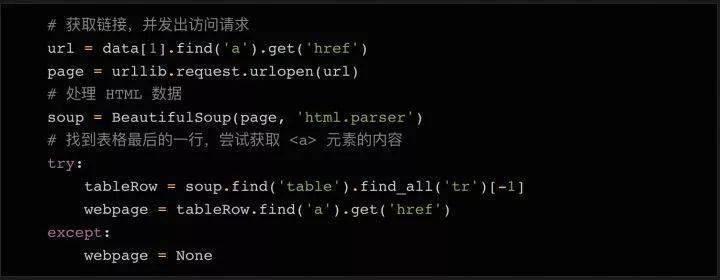
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
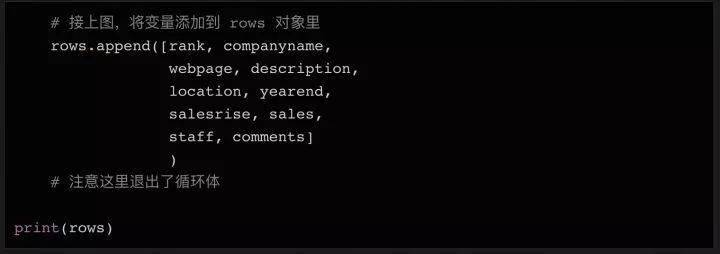
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。

最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
用 BeautifulSoup 处理得到的 html 数据
循环遍历汤对象以搜索所需的 html 元素
做简单的数据清洗
将数据写入 csv 文件
如果有什么不明白的,请在下方留言,我会尽力为您解答!
附:本文所有代码()
为您的爬行动物之旅有个美好的开始!
python网页数据抓取(就是一个解析xml和html之类的库,用着还算顺手 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-01 06:17
)
Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。简而言之,它是一个解析xml和html的库,使用起来相当方便。
官网地址:
下面介绍使用python和Beautiful Soup来爬取网页上的PM2.5数据。
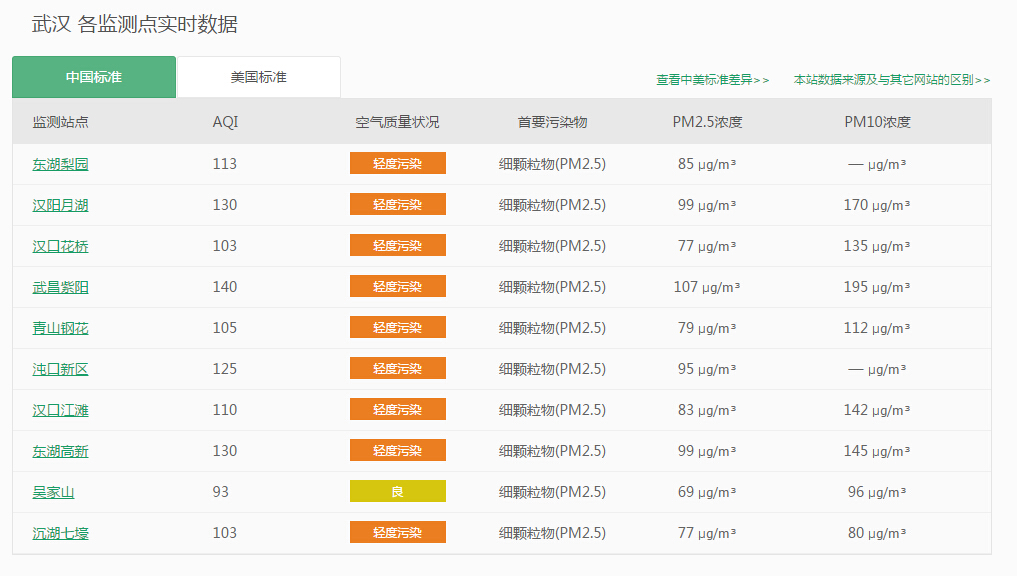
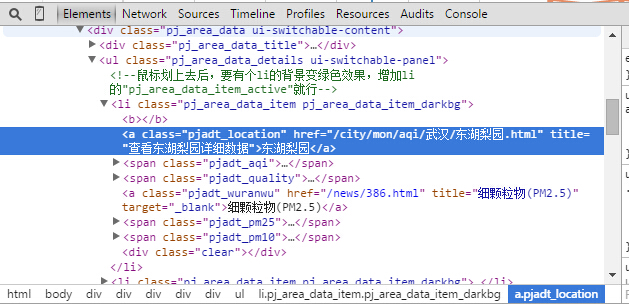
网站 的 PM2.5 个数据:
这个网站有对应的PM2.5数据,他们在几个地方都有监视器,大约每小时更新一次(有时,仪器的数据会丢失)。我们要采集的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用 Beautiful Soup 解析 html 内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以通过标签名(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以得到对应的文本,比如“hello”,就可以得到“hello”
具体的元素类需要借助浏览器的检查元素功能来查看。
写文字:
主要使用python的with语法,with可以保证出现异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是一个打开的文件流,这意味着将 print 打印的内容重定向到文件。
记录:
由于这个程序要在后台运行很长时间,所以最好把错误信息记录下来,方便调试。使用了python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
其中包括一些,设置日志的格式,以及日志文件的最大大小。
预定操作:
定期操作,可以在每天指定时间捕获PM2.5数据,结合卫星过境时间做进一步分析。python自带的sched模块也经常用到。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是一个获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,它将继续运行。
完整代码下载(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认后台运行。
爬取结果:
查看全部
python网页数据抓取(就是一个解析xml和html之类的库,用着还算顺手
)
Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。简而言之,它是一个解析xml和html的库,使用起来相当方便。
官网地址:
下面介绍使用python和Beautiful Soup来爬取网页上的PM2.5数据。
网站 的 PM2.5 个数据:
这个网站有对应的PM2.5数据,他们在几个地方都有监视器,大约每小时更新一次(有时,仪器的数据会丢失)。我们要采集的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用 Beautiful Soup 解析 html 内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以通过标签名(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以得到对应的文本,比如“hello”,就可以得到“hello”
具体的元素类需要借助浏览器的检查元素功能来查看。
写文字:
主要使用python的with语法,with可以保证出现异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是一个打开的文件流,这意味着将 print 打印的内容重定向到文件。
记录:
由于这个程序要在后台运行很长时间,所以最好把错误信息记录下来,方便调试。使用了python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
其中包括一些,设置日志的格式,以及日志文件的最大大小。
预定操作:
定期操作,可以在每天指定时间捕获PM2.5数据,结合卫星过境时间做进一步分析。python自带的sched模块也经常用到。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是一个获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,它将继续运行。
完整代码下载(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认后台运行。
爬取结果:

python网页数据抓取(如何通过URL打开一个网页的URL模块解析HTML二)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-29 23:27
二、打开 HTML 文档
上面描述了如何解析页面的URL。现在让我们解释如何通过 URL 打开网页。事实上,Python 附带的 urllib 和 urllib2 模块为我们提供了从 URL 中打开和检索数据的能力,当然也包括 HTML 文档。
importurllib
u=urllib.urlopen(webURL)
u=urllib.urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
要通过 urllib 模块中的 urlopen(url[,data]) 函数打开 HTML 文档,必须提供文档的 URL 地址,包括文件名。函数 urlopen 不仅可以打开位于远程 Web 服务器上的文件,还可以打开本地文件并返回一个类似文件的对象,通过该对象我们可以从 HTML 文档中读取数据。
打开 HTML 文档后,我们可以像普通文件一样使用 read([nbytes])、readline() 和 readlines() 函数读取文件。要读取整个 HTML 文档的内容,可以使用 read() 函数,它将文件内容作为字符串返回。
打开地址后,您可以使用 geturl() 函数获取被抓取页面的实际 URL。这很有用,因为 urlopen(或使用的 opener 对象)可能伴随着重定向。获取的网页网址可能与请求的网页网址不同。
另一个常用的函数是位于从urlopen返回的类文件对象中的info()函数。此函数返回有关 URL 位置的元数据,例如内容长度、内容类型等。下面通过更详细的示例来描述这些功能。
importurllib
webURL="
buffer=u.read()()print"从%s读取%d字节数据。\n"%(u.geturl(),len(buffer))#通过URL打开本地页面u= urllib. urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
以上代码运行结果如下:
日期:2009 年 6 月 26 日星期五:格林威治标准时间 22:11
服务器:Apache/2.2.9(Debian) DAV/2SVN/1.5.1mod_ssl/2.2.9OpenSSL/< @0.9.8g mod_wsgi/2.3Python/2.5.2Last-Modified: Thu,25Jun200909:44:54GMT
ETag:"105800d-46e7-46d29136f7180"接受范围:字节
内容长度:18151连接:关闭
内容类型:文本/html
已读取 18151 字节的数据。
内容类型:文本/html
Content-Length:865Last-modified: Fri,26Jun200910:16:10GMT
从 index.html 读取 865 字节的数据。
三、总结
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用程序,通常使用网页(即 HTML 文件)的解析。事实上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。在本文中,我们介绍了一个 Python 模块,它可以帮助简化打开位于本地和 Web 上的 HTML 文档。在下一篇文章中,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据,以处理链接、图像和 cookie 等特定内容。 查看全部
python网页数据抓取(如何通过URL打开一个网页的URL模块解析HTML二)
二、打开 HTML 文档
上面描述了如何解析页面的URL。现在让我们解释如何通过 URL 打开网页。事实上,Python 附带的 urllib 和 urllib2 模块为我们提供了从 URL 中打开和检索数据的能力,当然也包括 HTML 文档。
importurllib
u=urllib.urlopen(webURL)
u=urllib.urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
要通过 urllib 模块中的 urlopen(url[,data]) 函数打开 HTML 文档,必须提供文档的 URL 地址,包括文件名。函数 urlopen 不仅可以打开位于远程 Web 服务器上的文件,还可以打开本地文件并返回一个类似文件的对象,通过该对象我们可以从 HTML 文档中读取数据。
打开 HTML 文档后,我们可以像普通文件一样使用 read([nbytes])、readline() 和 readlines() 函数读取文件。要读取整个 HTML 文档的内容,可以使用 read() 函数,它将文件内容作为字符串返回。
打开地址后,您可以使用 geturl() 函数获取被抓取页面的实际 URL。这很有用,因为 urlopen(或使用的 opener 对象)可能伴随着重定向。获取的网页网址可能与请求的网页网址不同。
另一个常用的函数是位于从urlopen返回的类文件对象中的info()函数。此函数返回有关 URL 位置的元数据,例如内容长度、内容类型等。下面通过更详细的示例来描述这些功能。
importurllib
webURL="
buffer=u.read()()print"从%s读取%d字节数据。\n"%(u.geturl(),len(buffer))#通过URL打开本地页面u= urllib. urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
以上代码运行结果如下:
日期:2009 年 6 月 26 日星期五:格林威治标准时间 22:11
服务器:Apache/2.2.9(Debian) DAV/2SVN/1.5.1mod_ssl/2.2.9OpenSSL/< @0.9.8g mod_wsgi/2.3Python/2.5.2Last-Modified: Thu,25Jun200909:44:54GMT
ETag:"105800d-46e7-46d29136f7180"接受范围:字节
内容长度:18151连接:关闭
内容类型:文本/html
已读取 18151 字节的数据。
内容类型:文本/html
Content-Length:865Last-modified: Fri,26Jun200910:16:10GMT
从 index.html 读取 865 字节的数据。
三、总结
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用程序,通常使用网页(即 HTML 文件)的解析。事实上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。在本文中,我们介绍了一个 Python 模块,它可以帮助简化打开位于本地和 Web 上的 HTML 文档。在下一篇文章中,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据,以处理链接、图像和 cookie 等特定内容。
python网页数据抓取( 怎么用Python从多个网址中爬取内容?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-29 07:08
怎么用Python从多个网址中爬取内容?(图))
python批量抓取网页数据
如何使用 Python 从多个 URL 中抓取内容?
&&& 调用requests包,BeautifulSoup4包,可以实现,网页内容用excel写不是很好,建议写txt或者xml。如果要写入Excel,可以调用pandas包或者openpyxl包
如何使用Python爬虫批量获取网页所需信息
&&& python 是一种使用非常广泛的脚本语言。Google 的网页是用 python 编写的。python在生物信息学、统计学、网页制作、计算等诸多领域都展现出了强大的功能。python和其他脚本语言如java、R、Perl,可以直接在命令行运行脚本程序...
使用 python 抓取网络数据 -
&&& 使用python爬取web数据三步,使用scrapy(爬虫框架)1.定义item类2.开发蜘蛛类3.如果不会开发管道,可以看看“疯狂的 Python 讲座”
如何使用python爬取一个网站的页数
&&& 1. 这个要根据你的网站地址分析,构造网站的url,通过for循环进行统计输出,从而计算出一个网页的网页数网站。2. 由于你没有给出具体网站的地址,我只能告诉你如上的过程。希望采纳,希望对你有帮助......
如何使用python抓取网页数据
&&& 推荐:《pyspider爬虫教程(二):AJAX和HTTP)-forkworm因为AJAX实际上是通过HTTP传输数据的,所以我们可以通过Chrome开发者工具找到真正的请求,直接发起真正的请求即可获取数据通过抓取请求,AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般简称为XHR。
如何用最简单的Python爬取采集整个网站——
&&& 在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个随机的网站从一个链接到另一个链接,但是,如果我们需要系统地编目整个网站,或者搜索网站上的每一页,我们应该怎么做?我们需要 采集…
如何用 Python 抓取动态加载的网页数据——
&&& 动态网页爬取是一种典型的方法1. 直接查看动态网页的加载规则。如果是ajax,找出对python的ajax请求。如果是js去那个地方后生成的URL。弄清楚规则。然后让python生成URL。这是常用的方法2. 方法二,用python调用webkit内核、IE内核,或者有firefox内核的浏览器。然后保存浏览结果。通常你可以使用浏览器测试框架。他们内置了这些功能3. 方法3,通过http代理,抓取内容并组装。您甚至可以嵌入自己的 js 脚本进行挂钩。这种方法通常用于系统逆向工程软件
如何使用python爬取网页上的表格信息——
&&& 有点背景,当时想研究一下蛋白质和小分子复合物的三维结构的一些规律。首先,我必须有数据。数据从何而来?从分子复合物数据库中下载。这时候,手动一一下载显然是不可能的了……
Python爬虫问题,如何爬取多个页面——
&&& 将网页的页面源保存到数据库(mongodb),是否每次都要等待新的页面源和页面源在数据库中的hash值?该策略很容易处理。自己做。 查看全部
python网页数据抓取(
怎么用Python从多个网址中爬取内容?(图))
python批量抓取网页数据
如何使用 Python 从多个 URL 中抓取内容?
&&& 调用requests包,BeautifulSoup4包,可以实现,网页内容用excel写不是很好,建议写txt或者xml。如果要写入Excel,可以调用pandas包或者openpyxl包
如何使用Python爬虫批量获取网页所需信息
&&& python 是一种使用非常广泛的脚本语言。Google 的网页是用 python 编写的。python在生物信息学、统计学、网页制作、计算等诸多领域都展现出了强大的功能。python和其他脚本语言如java、R、Perl,可以直接在命令行运行脚本程序...
使用 python 抓取网络数据 -
&&& 使用python爬取web数据三步,使用scrapy(爬虫框架)1.定义item类2.开发蜘蛛类3.如果不会开发管道,可以看看“疯狂的 Python 讲座”
如何使用python爬取一个网站的页数
&&& 1. 这个要根据你的网站地址分析,构造网站的url,通过for循环进行统计输出,从而计算出一个网页的网页数网站。2. 由于你没有给出具体网站的地址,我只能告诉你如上的过程。希望采纳,希望对你有帮助......
如何使用python抓取网页数据
&&& 推荐:《pyspider爬虫教程(二):AJAX和HTTP)-forkworm因为AJAX实际上是通过HTTP传输数据的,所以我们可以通过Chrome开发者工具找到真正的请求,直接发起真正的请求即可获取数据通过抓取请求,AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般简称为XHR。
如何用最简单的Python爬取采集整个网站——
&&& 在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个随机的网站从一个链接到另一个链接,但是,如果我们需要系统地编目整个网站,或者搜索网站上的每一页,我们应该怎么做?我们需要 采集…
如何用 Python 抓取动态加载的网页数据——
&&& 动态网页爬取是一种典型的方法1. 直接查看动态网页的加载规则。如果是ajax,找出对python的ajax请求。如果是js去那个地方后生成的URL。弄清楚规则。然后让python生成URL。这是常用的方法2. 方法二,用python调用webkit内核、IE内核,或者有firefox内核的浏览器。然后保存浏览结果。通常你可以使用浏览器测试框架。他们内置了这些功能3. 方法3,通过http代理,抓取内容并组装。您甚至可以嵌入自己的 js 脚本进行挂钩。这种方法通常用于系统逆向工程软件
如何使用python爬取网页上的表格信息——
&&& 有点背景,当时想研究一下蛋白质和小分子复合物的三维结构的一些规律。首先,我必须有数据。数据从何而来?从分子复合物数据库中下载。这时候,手动一一下载显然是不可能的了……
Python爬虫问题,如何爬取多个页面——
&&& 将网页的页面源保存到数据库(mongodb),是否每次都要等待新的页面源和页面源在数据库中的hash值?该策略很容易处理。自己做。
python网页数据抓取(Python程序设计有所匹配及字符串与URL操作的相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-29 07:07
本文文章主要介绍Python抓取百度查询结果的方法,涉及Python正则匹配以及字符串和URL操作的相关技巧。有需要的朋友可以参考以下
本文示例介绍了Python爬取百度查询结果的方法。分享给大家,供大家参考。具体实现方法如下:
#win python 2.7.x
import re,sys,urllib,codecs
xh = urllib.urlopen("http://www.baidu.com/s?q1=123&rn=100").read().decode('utf-8')
rc = re.compile(r'(?P.*?)',re.I)
match = rc.finditer(xh)
rcr = re.compile(r']+>',re.I)
f = codecs.open("xiaohei.txt", "w", "utf-8")
for i in rc.finditer(xh):
ss = i.group(0)
s1 = rcr.sub('',ss)
print (s1)
f.write(s1)
f.close()
希望本文对您的 Python 编程有所帮助。 查看全部
python网页数据抓取(Python程序设计有所匹配及字符串与URL操作的相关技巧)
本文文章主要介绍Python抓取百度查询结果的方法,涉及Python正则匹配以及字符串和URL操作的相关技巧。有需要的朋友可以参考以下
本文示例介绍了Python爬取百度查询结果的方法。分享给大家,供大家参考。具体实现方法如下:
#win python 2.7.x
import re,sys,urllib,codecs
xh = urllib.urlopen("http://www.baidu.com/s?q1=123&rn=100";).read().decode('utf-8')
rc = re.compile(r'(?P.*?)',re.I)
match = rc.finditer(xh)
rcr = re.compile(r']+>',re.I)
f = codecs.open("xiaohei.txt", "w", "utf-8")
for i in rc.finditer(xh):
ss = i.group(0)
s1 = rcr.sub('',ss)
print (s1)
f.write(s1)
f.close()
希望本文对您的 Python 编程有所帮助。
python网页数据抓取(爬虫Python入门好学吗?学爬虫需要具备一定的Python基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 19:14
学习爬虫 Python 入门容易吗?
学习爬虫需要有一定的Python基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
Python爬虫入门的三个阶段:
1.零基阶段
从零开始学爬虫,系统上手,从0开始爬虫。除了必要的理论知识,更重要的是爬虫的实际应用。捕获主流网站数据的能力是这个阶段的学习目标。
学习重点:
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学习后,可以彻底玩转Scrapy框架,开发属于自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习重点:
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从此,拓展您的爬虫业务,提升您的核心竞争力。掌握app数据采集,实现数据可视化。
学习重点:
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。
很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。 查看全部
python网页数据抓取(爬虫Python入门好学吗?学爬虫需要具备一定的Python基础)
学习爬虫 Python 入门容易吗?
学习爬虫需要有一定的Python基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
Python爬虫入门的三个阶段:
1.零基阶段
从零开始学爬虫,系统上手,从0开始爬虫。除了必要的理论知识,更重要的是爬虫的实际应用。捕获主流网站数据的能力是这个阶段的学习目标。
学习重点:

二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学习后,可以彻底玩转Scrapy框架,开发属于自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习重点:

三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从此,拓展您的爬虫业务,提升您的核心竞争力。掌握app数据采集,实现数据可视化。
学习重点:

爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。
很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。
python网页数据抓取(提取(59,805805)()已确认))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-25 11:11
获取网页数据不返回结果问题描述票数:0 答案:1
我正在尝试从提到的 URL (59,805) 中提取数据。我正在使用 BeautifulSoup 并请求 Python 包。
下面是我正在尝试的代码,但它没有给我任何结果。下面是我尝试从中提取的 HTML 代码。结果应该是“已确认”,59,805
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
case_type = []
count = []
url = requests.get('https://www.covid19india.org/')
soup = bs(url.content,'html.parser')
for a in soup.findAll('div', attrs={'class':'level-item is-cherry fadeInUp'}):
b = a.find('h1')
c = a.find('h5')
case_type.append(c.text)
count.append(b.text)
df = pd.DataFrame({'Case Type':case_type, 'Count':count})
print(df)
来自该页面的 HTML 片段
Confirmed
[+115]
59,805
Active
39,914
Recovered
[+14]
17,901
1 个回答
投票
这个 网站 是在 React 中创建的,所以你得到的请求不会收录所有 网站 内容,因为它是动态加载的
如果您查看加载时发出的网站网络请求,您会看到此信息来自:
https://api.covid19india.org/data.json
所以你可以(假设你不影响网站性能/有权限)这样做:
r = requests.get('https://api.covid19india.org/data.json')
j = r.json()
confirmed = j['statewise'][0]['confirmed']
print(confirmed)
热门问题 查看全部
python网页数据抓取(提取(59,805805)()已确认))
获取网页数据不返回结果问题描述票数:0 答案:1
我正在尝试从提到的 URL (59,805) 中提取数据。我正在使用 BeautifulSoup 并请求 Python 包。
下面是我正在尝试的代码,但它没有给我任何结果。下面是我尝试从中提取的 HTML 代码。结果应该是“已确认”,59,805
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
case_type = []
count = []
url = requests.get('https://www.covid19india.org/')
soup = bs(url.content,'html.parser')
for a in soup.findAll('div', attrs={'class':'level-item is-cherry fadeInUp'}):
b = a.find('h1')
c = a.find('h5')
case_type.append(c.text)
count.append(b.text)
df = pd.DataFrame({'Case Type':case_type, 'Count':count})
print(df)
来自该页面的 HTML 片段
Confirmed
[+115]
59,805
Active
39,914
Recovered
[+14]
17,901
1 个回答
投票
这个 网站 是在 React 中创建的,所以你得到的请求不会收录所有 网站 内容,因为它是动态加载的
如果您查看加载时发出的网站网络请求,您会看到此信息来自:
https://api.covid19india.org/data.json
所以你可以(假设你不影响网站性能/有权限)这样做:
r = requests.get('https://api.covid19india.org/data.json')
j = r.json()
confirmed = j['statewise'][0]['confirmed']
print(confirmed)
热门问题
python网页数据抓取(奔腾不息的自信是真正的成功之母())
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-24 14:04
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。 查看全部
python网页数据抓取(奔腾不息的自信是真正的成功之母())
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。
python网页数据抓取(几款Python开源爬虫软件工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-23 10:07
说起Python,可以说是耳熟能详了。它是近年来非常流行的编程语言。大多数人使用它来开始爬虫,即使我也不例外。今天,我们就来看看几款Python开源爬虫软件工具。
一、快速侦察
QuickRecon 是一个简单的信息采集工具,可以帮助您查找子域名、执行区域传输、采集电子邮件地址和使用微格式查找关系等。QuickRecon 是用 python 编写的,支持 linux 和 windows 操作系统。
许可协议:GPLv3
开发语言:Python
操作系统:Windows、Linux
功能:查找子域名、采集电子邮件地址、查找关系等。
二、PyRailgun
这是一个非常简单易用的爬虫。一个简单、实用、高效的python网络爬虫爬取模块,支持爬取javascript渲染的页面。
许可协议:麻省理工学院
开发语言:Python
操作系统:跨平台、Windows、Linux、OS X
特点:简单、轻量、高效的网页抓取框架。
三、Scrapy
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现爬取网页内容和各种图片的爬虫,非常方便。
许可协议:BSD
开发语言:Python
操作系统:跨平台
特点:基于 Twisted 的异步处理框架,文档完整。 查看全部
python网页数据抓取(几款Python开源爬虫软件工具)
说起Python,可以说是耳熟能详了。它是近年来非常流行的编程语言。大多数人使用它来开始爬虫,即使我也不例外。今天,我们就来看看几款Python开源爬虫软件工具。
一、快速侦察
QuickRecon 是一个简单的信息采集工具,可以帮助您查找子域名、执行区域传输、采集电子邮件地址和使用微格式查找关系等。QuickRecon 是用 python 编写的,支持 linux 和 windows 操作系统。
许可协议:GPLv3
开发语言:Python
操作系统:Windows、Linux
功能:查找子域名、采集电子邮件地址、查找关系等。
二、PyRailgun
这是一个非常简单易用的爬虫。一个简单、实用、高效的python网络爬虫爬取模块,支持爬取javascript渲染的页面。
许可协议:麻省理工学院
开发语言:Python
操作系统:跨平台、Windows、Linux、OS X
特点:简单、轻量、高效的网页抓取框架。
三、Scrapy
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现爬取网页内容和各种图片的爬虫,非常方便。
许可协议:BSD
开发语言:Python
操作系统:跨平台
特点:基于 Twisted 的异步处理框架,文档完整。
python网页数据抓取( 利用万维网的力量为您的数据驱动策略提供信息吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-22 13:15
利用万维网的力量为您的数据驱动策略提供信息吗?
)
您想利用互联网的力量来制定您的数据驱动战略吗?
您是否希望在零售、在线销售、房地产和地理定位服务方面获得优势?
您想将 文章 和网页中的非结构化数据转化为真正的洞察吗?
您想开发尖端分析和可视化以利用万维网吗?
精通网络抓取(和相关分析)可以帮助您利用万维网上免费提供的数据和信息的力量,并将其转化为可行的见解
我的课程是通过真实的网页抓取示例进行实践培训 - 您将学习使用重要的 Python 网页抓取库 BeautifulSoup 并从不同的网页中获取信息和见解
我的课程为进行实际的、真实的网络抓取奠定了基础。通过学习本课程,您将在数据科学之旅中迈出重要的一步,并成为利用万维网的力量获得洞察力的专家。
本课程将帮助您使用名为 GoogleColab 的强大的基于云的 Python 环境熟练掌握 BeautifulSoup(用于网络抓取)、网络数据处理和分析。具体来说,您将
精通设置和使用 Google CoLab 进行 Python 数据科学任务
在维基百科页面上执行常见的网络抓取任务并提取相关信息
处理复杂的网页并提取信息
以可用的形式处理提取的信息
进行基本的地理编码
执行常见的分析和可视化任务
您将从事与 (a) 伦敦行政区地理编码 (b) 量化孟买房地产价格变化 (c) 提取财务报表等相关的实用小型案例研究。
为什么要上这门课?
作者拥有英国牛津大学的硕士学位(地理与环境)。他还在剑桥大学(热带生态与保护)完成了数据科学密集型博士学位。
作者在分析来自各种来源的真实数据和为国际同行评审期刊出版出版物方面拥有多年经验。
您将学习:
在 Google CoLab 中使用 Python 进行实际数据科学的能力
网络基础
爬取常见的维基百科页面信息
使用 BeautifulSoup(通用 Python 库)转换复杂的 Web 信息
基本地理编码
数据处理和清理以从抓取的数据中提取信息
分析抓取和清理的数据以获得可操作的见解
数据可视化
使用实际示例 – (a) 对伦敦行政区进行地理编码 (b) 获取孟买的公寓价格 (c) 提取亚马逊评论
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2 通道
类型:电子学习 | 语言:英语 + srt | 时长:51 节课(5h 47m)| 大小:2.25 GB
使用 Python 和 Google CoLab 从网页中检索信息以进行分析和洞察
查看全部
python网页数据抓取(
利用万维网的力量为您的数据驱动策略提供信息吗?
)

您想利用互联网的力量来制定您的数据驱动战略吗?
您是否希望在零售、在线销售、房地产和地理定位服务方面获得优势?
您想将 文章 和网页中的非结构化数据转化为真正的洞察吗?
您想开发尖端分析和可视化以利用万维网吗?
精通网络抓取(和相关分析)可以帮助您利用万维网上免费提供的数据和信息的力量,并将其转化为可行的见解
我的课程是通过真实的网页抓取示例进行实践培训 - 您将学习使用重要的 Python 网页抓取库 BeautifulSoup 并从不同的网页中获取信息和见解
我的课程为进行实际的、真实的网络抓取奠定了基础。通过学习本课程,您将在数据科学之旅中迈出重要的一步,并成为利用万维网的力量获得洞察力的专家。
本课程将帮助您使用名为 GoogleColab 的强大的基于云的 Python 环境熟练掌握 BeautifulSoup(用于网络抓取)、网络数据处理和分析。具体来说,您将
精通设置和使用 Google CoLab 进行 Python 数据科学任务
在维基百科页面上执行常见的网络抓取任务并提取相关信息
处理复杂的网页并提取信息
以可用的形式处理提取的信息
进行基本的地理编码
执行常见的分析和可视化任务
您将从事与 (a) 伦敦行政区地理编码 (b) 量化孟买房地产价格变化 (c) 提取财务报表等相关的实用小型案例研究。
为什么要上这门课?
作者拥有英国牛津大学的硕士学位(地理与环境)。他还在剑桥大学(热带生态与保护)完成了数据科学密集型博士学位。
作者在分析来自各种来源的真实数据和为国际同行评审期刊出版出版物方面拥有多年经验。
您将学习:
在 Google CoLab 中使用 Python 进行实际数据科学的能力
网络基础
爬取常见的维基百科页面信息
使用 BeautifulSoup(通用 Python 库)转换复杂的 Web 信息
基本地理编码
数据处理和清理以从抓取的数据中提取信息
分析抓取和清理的数据以获得可操作的见解
数据可视化
使用实际示例 – (a) 对伦敦行政区进行地理编码 (b) 获取孟买的公寓价格 (c) 提取亚马逊评论
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2 通道
类型:电子学习 | 语言:英语 + srt | 时长:51 节课(5h 47m)| 大小:2.25 GB
使用 Python 和 Google CoLab 从网页中检索信息以进行分析和洞察
 https://www.loowp.com/wp-conte ... 0.jpg 593w" />
https://www.loowp.com/wp-conte ... 0.jpg 593w" /> python网页数据抓取(python3.X中编写代码以及在anaconda中的网络抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-20 10:13
我正在尝试根据地理位置抓取 Instagram 和 Twitter。我可以运行查询搜索,但在将网页重新加载到更多并将字段存储到数据框时遇到了挑战。
我确实找到了几个没有 API 密钥的网页抓取 twitter 和 Instagram 的例子。但它们与#tags 关键字有关。
我正在尝试根据地理位置和旧日期进行抓取。到目前为止,我已经在 python 3.X 和 anaconda 中编写了所有最新版本的软件包。
'''
Instagram - Components
"id": "1478232643287060472",
"dimensions": {"height": 1080, "width": 1080},
"owner": {"id": "351633262"},
"thumbnail_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"is_video": false,
"code": "BSDvMHOgw_4",
"date": 1490439084,
"taken-at=213385402"
"display_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"caption": "Hakuna jambo zuri kama kumpa Mungu shukrani kwa kila jambo.. \ud83d\ude4f\ud83c\udffe\nIts weekend\n#lifeistooshorttobeunhappy\n#Godisgood \n#happysoul \ud83d\ude00",
"comments": {"count": 42},
"likes": {"count": 3813}},
'''
import selenium
from selenium import webdriver
#from selenium import selenium
from bs4 import BeautifulSoup
import pandas
#geotags = pd.read_csv("geocodes.csv")
#parmalink =
query = geocode%3A35.68501%2C139.7514%2C30km%20since:2016-03-01%20until:2016-03-02&f=tweets
twitterURL = 'https://twitter.com/search?q=' + query
#instaURL = "https://www.instagram.com/expl ... ot%3B
browser = webdriver.Firefox()
browser.get(twitterURL)
content = browser.page_source
soup = BeautifulSoup(content)
print (soup)
我收到 Twitter 搜索查询的语法错误
对于 Instagram,我没有收到任何错误,但我无法重新加载更多帖子并写回 csv 数据框。
我还尝试在 Twitter 和 Instagram 中使用经纬度搜索进行搜索。
我在 csv 中有一个地理坐标列表,可用于输入或编写搜索查询。
任何完成位置抓取的方法都将不胜感激。
谢谢您的帮助!! 查看全部
python网页数据抓取(python3.X中编写代码以及在anaconda中的网络抓取)
我正在尝试根据地理位置抓取 Instagram 和 Twitter。我可以运行查询搜索,但在将网页重新加载到更多并将字段存储到数据框时遇到了挑战。
我确实找到了几个没有 API 密钥的网页抓取 twitter 和 Instagram 的例子。但它们与#tags 关键字有关。
我正在尝试根据地理位置和旧日期进行抓取。到目前为止,我已经在 python 3.X 和 anaconda 中编写了所有最新版本的软件包。
'''
Instagram - Components
"id": "1478232643287060472",
"dimensions": {"height": 1080, "width": 1080},
"owner": {"id": "351633262"},
"thumbnail_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"is_video": false,
"code": "BSDvMHOgw_4",
"date": 1490439084,
"taken-at=213385402"
"display_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"caption": "Hakuna jambo zuri kama kumpa Mungu shukrani kwa kila jambo.. \ud83d\ude4f\ud83c\udffe\nIts weekend\n#lifeistooshorttobeunhappy\n#Godisgood \n#happysoul \ud83d\ude00",
"comments": {"count": 42},
"likes": {"count": 3813}},
'''
import selenium
from selenium import webdriver
#from selenium import selenium
from bs4 import BeautifulSoup
import pandas
#geotags = pd.read_csv("geocodes.csv")
#parmalink =
query = geocode%3A35.68501%2C139.7514%2C30km%20since:2016-03-01%20until:2016-03-02&f=tweets
twitterURL = 'https://twitter.com/search?q=' + query
#instaURL = "https://www.instagram.com/expl ... ot%3B
browser = webdriver.Firefox()
browser.get(twitterURL)
content = browser.page_source
soup = BeautifulSoup(content)
print (soup)
我收到 Twitter 搜索查询的语法错误
对于 Instagram,我没有收到任何错误,但我无法重新加载更多帖子并写回 csv 数据框。
我还尝试在 Twitter 和 Instagram 中使用经纬度搜索进行搜索。
我在 csv 中有一个地理坐标列表,可用于输入或编写搜索查询。
任何完成位置抓取的方法都将不胜感激。
谢谢您的帮助!!
python网页数据抓取(Python基础知识:函数用于测试程序管理函数的执行顺序例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-20 10:12
)
如果服务器能正常响应,就会得到一个Response,就是要获取的页面内容。
解析内容
获取的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
二.准备工作1.网页路径规则
从 1 日开始显示
26日起上映
2.网址分析
页面收录250条电影数据,分为10页,每页25条
各页面URL的区别:最终值=(pages - 1)* 25
3.分析页面
使用Chrome开发者工具(F12)分析网页,在Elements下找到需要的数据位置
在页面中选择一个元素来检查它 Ctrl + Shift + C
网络下刷新URL后可以看到所有访问请求的时间线
Headers:发送给浏览器的当前访问信息
User-Agent:浏览器信息
需要登录的网页使用 cookie
4.编码规范
1.一般Python程序的第一行需要加上
#-*- coding: utf-8 -*-或者# coding=utf-8
这允许在代码中收录中文
2.在Python中,使用函数来实现单个函数或相关函数的代码段,可以提高可读性和代码复用,
函数块以 def关键词 开头,后跟空格、函数标识符的名称、括号 () 和冒号:
参数可以用括号传递,函数段缩进(制表符或四个空格,只能选择其中一个),
return 用于结束函数,可以返回一个值,也可以不带任何表达式(意思是返回None)
3.可以将main函数添加到Python文件中,用于测试程序
if __name__ == "__main__":
适合管理函数的执行顺序
例子:
#-*- coding: utf-8 -*-
def main():
print("hello")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
4.Python用#加注释来解释代码(段)的作用
三.引入模块1.模块(模块)
用于对 Python 代码(变量、函数、类)进行逻辑组织,本质上是一个 py 文件,用于提高代码的可维护性。
Python使用import来导入模块,比如import sys
例子:
test1 文件夹中有 t1.py
def add(a,b):
return a+b
我想在 test2 文件夹中的 t2.py 中调用 t1 中的函数
#引入自定义模块
from test1 import t1
print(t1.add(2,3))
#介绍系统的模块
import sys
import os
#引入第三方模块(这些是本项目要使用的模块)
import bs4 #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
由于我使用的工具是vs2019,它的第三方模块加载为
在这里输入你要查找的包名,比如bs4
只需点击 pip install bs4
该程序现在
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250"
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
saveData(savepath)
#爬取网页
def getData(baseurl):
datelist=[]
#2.逐一解析数据
return datalist
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
2.获取数据
Python一般使用urllib库来获取页面
获取页面数据
urllib 测试
urllib test_ai 的博客 - CSDN 博客
获取数据获取指定URL的网页内容
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=")
#爬取网页
def getData(baseurl):
datalist=[]
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
查看内容,发现获取到网页的数据
爬网
带循环结构的换页
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
当前代码
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=")
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
添加 BeautifulSoup 用于 html 文件解析
BeautifulSoup用于html文件解析 - 程序员大本营
补充re模块:正则表达式
re 模块:正则表达式_ai的博客 - CSDN博客
正则提取得到每部电影的相关信息
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
print(item)
创建指向视频第一页的超链接
. . . . . . . .
截断一部电影的item信息,提取所有需要的东西,然后添加一个循环
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,1): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
#print(item) #测试:查看电影item全部信息
data=[] #保存一部电影的全部信息
item=str(item)
print(item)
break
#影片详情的链接
link=re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,[0]表示如果有两个,只要第一个
print(link)
return datalist
将其保存到 html 文档中进行比较
1
肖申克的救赎
/ The Shawshank Redemption
/ 月黑高飞(港) / 刺激1995(台)
[可播放]
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
9.7
2523850人评价
希望让人自由。
</p>
将需要提取的相关东西转化为正则表达式,设置为全局变量
<p>#影片详情的链接的规则
findLink=re.compile(r'<a href="(.*?)">') #创建正则表达式,表示规则(字符串模式)
#影片图片
findImgSrc=re.compile(r' 查看全部
python网页数据抓取(Python基础知识:函数用于测试程序管理函数的执行顺序例子
)
如果服务器能正常响应,就会得到一个Response,就是要获取的页面内容。
解析内容
获取的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
二.准备工作1.网页路径规则
从 1 日开始显示
26日起上映
2.网址分析
页面收录250条电影数据,分为10页,每页25条
各页面URL的区别:最终值=(pages - 1)* 25
3.分析页面
使用Chrome开发者工具(F12)分析网页,在Elements下找到需要的数据位置
在页面中选择一个元素来检查它 Ctrl + Shift + C
网络下刷新URL后可以看到所有访问请求的时间线
Headers:发送给浏览器的当前访问信息
User-Agent:浏览器信息
需要登录的网页使用 cookie
4.编码规范
1.一般Python程序的第一行需要加上
#-*- coding: utf-8 -*-或者# coding=utf-8
这允许在代码中收录中文
2.在Python中,使用函数来实现单个函数或相关函数的代码段,可以提高可读性和代码复用,
函数块以 def关键词 开头,后跟空格、函数标识符的名称、括号 () 和冒号:
参数可以用括号传递,函数段缩进(制表符或四个空格,只能选择其中一个),
return 用于结束函数,可以返回一个值,也可以不带任何表达式(意思是返回None)
3.可以将main函数添加到Python文件中,用于测试程序
if __name__ == "__main__":
适合管理函数的执行顺序
例子:
#-*- coding: utf-8 -*-
def main():
print("hello")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
4.Python用#加注释来解释代码(段)的作用
三.引入模块1.模块(模块)
用于对 Python 代码(变量、函数、类)进行逻辑组织,本质上是一个 py 文件,用于提高代码的可维护性。
Python使用import来导入模块,比如import sys
例子:
test1 文件夹中有 t1.py
def add(a,b):
return a+b
我想在 test2 文件夹中的 t2.py 中调用 t1 中的函数
#引入自定义模块
from test1 import t1
print(t1.add(2,3))
#介绍系统的模块
import sys
import os
#引入第三方模块(这些是本项目要使用的模块)
import bs4 #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
由于我使用的工具是vs2019,它的第三方模块加载为

在这里输入你要查找的包名,比如bs4

只需点击 pip install bs4

该程序现在
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250"
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
saveData(savepath)
#爬取网页
def getData(baseurl):
datelist=[]
#2.逐一解析数据
return datalist
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
2.获取数据
Python一般使用urllib库来获取页面
获取页面数据
urllib 测试
urllib test_ai 的博客 - CSDN 博客
获取数据获取指定URL的网页内容
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=";)
#爬取网页
def getData(baseurl):
datalist=[]
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
查看内容,发现获取到网页的数据
爬网
带循环结构的换页
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
当前代码
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=";)
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
添加 BeautifulSoup 用于 html 文件解析
BeautifulSoup用于html文件解析 - 程序员大本营
补充re模块:正则表达式
re 模块:正则表达式_ai的博客 - CSDN博客
正则提取得到每部电影的相关信息
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
print(item)
创建指向视频第一页的超链接
. . . . . . . .
截断一部电影的item信息,提取所有需要的东西,然后添加一个循环
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,1): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
#print(item) #测试:查看电影item全部信息
data=[] #保存一部电影的全部信息
item=str(item)
print(item)
break
#影片详情的链接
link=re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,[0]表示如果有两个,只要第一个
print(link)
return datalist
将其保存到 html 文档中进行比较
1

肖申克的救赎
/ The Shawshank Redemption
/ 月黑高飞(港) / 刺激1995(台)
[可播放]
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
9.7
2523850人评价
希望让人自由。
</p>
将需要提取的相关东西转化为正则表达式,设置为全局变量
<p>#影片详情的链接的规则
findLink=re.compile(r'<a href="(.*?)">') #创建正则表达式,表示规则(字符串模式)
#影片图片
findImgSrc=re.compile(r'
python网页数据抓取(本节书摘来自异步社区《用Python写网络爬虫》第2章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-20 03:07
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可参考访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方式
现在我们了解了这个网页的结构,有三种方法可以从中抓取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您是正则表达式的新手,或者需要一些提示,您可以查看它以获得完整的介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
元素中的内容,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从以上结果可以看出,标签用于多个国家属性。为了隔离 area 属性,我们可以只选择其中的第二个元素,如下所示。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父级
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,要将双引号更改为单引号,
在标签之间添加额外的空格,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 除了添加和
标签使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局的小变化,如额外的空白和制表符属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。下面是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 可以正确解析属性和关闭标签周围缺少的引号,但模块不会添加和
标签。
解析输入后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
下面是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
W3C 在 `/2011/REC-css3-selectors-20110929/ 提出了 CSS3 规范。
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在这里找到。
需要注意的是,lxml 在内部实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他特征的格式,如图2.4。
从 Firebug 的显示中可以看出,表中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
抓取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方式的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 结论
表 2.1 总结了每种抓取方法的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些情况下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何爬取国家数据,接下来我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可以看出,用Python实现这个功能是非常简单的。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取这个版本的链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用这个爬虫来抓取其他网站了。下面对 lxml 抓取示例的代码进行了修改,以便可以在回调函数中使用它。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数来维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想进一步了解 Python 的特殊类方法,可以参考。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行此爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
有效!我们完成了我们的第一个工作数据抓取爬虫。 查看全部
python网页数据抓取(本节书摘来自异步社区《用Python写网络爬虫》第2章)
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可参考访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方式
现在我们了解了这个网页的结构,有三种方法可以从中抓取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您是正则表达式的新手,或者需要一些提示,您可以查看它以获得完整的介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
元素中的内容,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从以上结果可以看出,标签用于多个国家属性。为了隔离 area 属性,我们可以只选择其中的第二个元素,如下所示。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父级
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,要将双引号更改为单引号,
在标签之间添加额外的空格,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 除了添加和
标签使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局的小变化,如额外的空白和制表符属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。下面是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 可以正确解析属性和关闭标签周围缺少的引号,但模块不会添加和
标签。
解析输入后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
下面是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
W3C 在 `/2011/REC-css3-selectors-20110929/ 提出了 CSS3 规范。
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在这里找到。
需要注意的是,lxml 在内部实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他特征的格式,如图2.4。
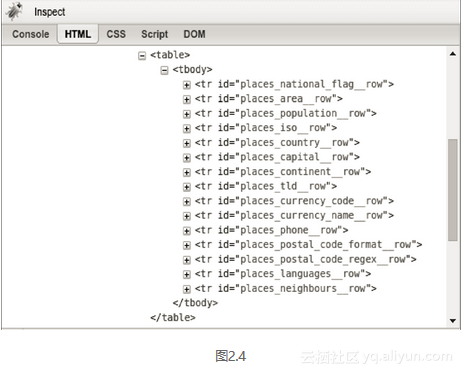
从 Firebug 的显示中可以看出,表中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
抓取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方式的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 结论
表 2.1 总结了每种抓取方法的优缺点。
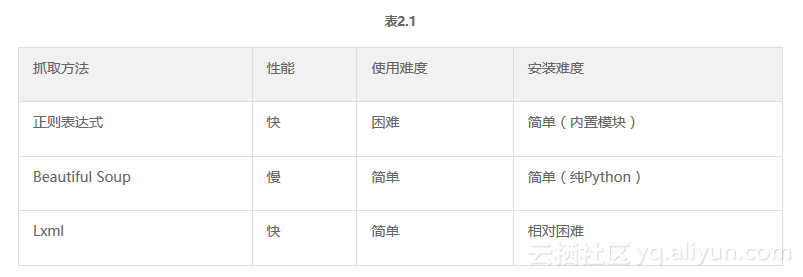
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些情况下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何爬取国家数据,接下来我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可以看出,用Python实现这个功能是非常简单的。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取这个版本的链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用这个爬虫来抓取其他网站了。下面对 lxml 抓取示例的代码进行了修改,以便可以在回调函数中使用它。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数来维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想进一步了解 Python 的特殊类方法,可以参考。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行此爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
有效!我们完成了我们的第一个工作数据抓取爬虫。
python网页数据抓取(前几天在看崔庆才老师的教程:网址结构网址url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-19 08:08
前几天在看崔庆才老师的教程,使用Scrapy抓取知乎用户信息,使用了递归。我之前写的爬虫将已知固定数据的url存储在列表中,然后遍历列表中的url。这次短书,我们用递归来试一试。
什么是递归
程序(或函数)调用自身的一种编程技术称为递归。一个过程或函数在其定义或规范中具有直接或间接调用自身的方法,这通常将一个大而复杂的问题转化为与原创问题相似的较小问题来解决。
递归的优点
1、降低题目难度
2、大大减少程序的代码大小
3、递归的威力在于使用有限语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓登录制的视频讲解,请点击链接
【python爬虫】如何抓到优质短书用户(请允许我放个广告)
关注获取项目源码
在这种情况下,我们需要抓取简书优质用户的信息,如昵称、id、文章的数量、采集数量、字数、获得的点赞数等。我们只捕获用户 ta 关注的人。至于这个ta的粉丝,我们不抓。相对来说,他关注的人,比他的粉丝素质更高。
从初始用户开始,比如邓旭东HIT关注的用户列表,得到邓旭东关注的25个用户A、B、C。
然后依次抓取这25个用户关注的用户
循环的前两个步骤
我们先来分析一下URL结构
网址网址分析
我们发现当我向下滚动关注列表时,页面底部会加载并且图像的左下角还有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
鼠标悬停在下面?page=3文件上方,浮动弹出一个URL
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页码是怎么构造的呢?
我们发现用户的follower数除以10,然后取整数,最大页数加1。
比如邓旭东关注了25个人,那么一共有三个页面:page=1, page=2, page=3
现在我们已经建立
既然有了URL,我们就开始分析网页源代码中要抓取的数据存放在哪里?
网页分析 查看全部
python网页数据抓取(前几天在看崔庆才老师的教程:网址结构网址url)
前几天在看崔庆才老师的教程,使用Scrapy抓取知乎用户信息,使用了递归。我之前写的爬虫将已知固定数据的url存储在列表中,然后遍历列表中的url。这次短书,我们用递归来试一试。
什么是递归
程序(或函数)调用自身的一种编程技术称为递归。一个过程或函数在其定义或规范中具有直接或间接调用自身的方法,这通常将一个大而复杂的问题转化为与原创问题相似的较小问题来解决。
递归的优点
1、降低题目难度
2、大大减少程序的代码大小
3、递归的威力在于使用有限语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓登录制的视频讲解,请点击链接
【python爬虫】如何抓到优质短书用户(请允许我放个广告)

关注获取项目源码
在这种情况下,我们需要抓取简书优质用户的信息,如昵称、id、文章的数量、采集数量、字数、获得的点赞数等。我们只捕获用户 ta 关注的人。至于这个ta的粉丝,我们不抓。相对来说,他关注的人,比他的粉丝素质更高。
从初始用户开始,比如邓旭东HIT关注的用户列表,得到邓旭东关注的25个用户A、B、C。
然后依次抓取这25个用户关注的用户
循环的前两个步骤
我们先来分析一下URL结构
网址网址分析
我们发现当我向下滚动关注列表时,页面底部会加载并且图像的左下角还有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
鼠标悬停在下面?page=3文件上方,浮动弹出一个URL
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页码是怎么构造的呢?
我们发现用户的follower数除以10,然后取整数,最大页数加1。
比如邓旭东关注了25个人,那么一共有三个页面:page=1, page=2, page=3
现在我们已经建立
既然有了URL,我们就开始分析网页源代码中要抓取的数据存放在哪里?
网页分析
python网页数据抓取( 数据科学越来越怎么抓网页数据(一)_Python学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-09 01:21
数据科学越来越怎么抓网页数据(一)_Python学习)
前言:数据科学越来越流行,网页是一个很大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常用的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计计算语言(R、Matlab)都可以实现和网站交互包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。第 1 步:熟悉 Python 的基本语法。如果您已经熟悉 Python,请跳至第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。
我推荐的可能不适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看课程评论再决定。第 2 步:了解如何与 网站 建立链接并获取网页数据。访问以获取更多信息。编写脚本与网站交互,熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,只知道一个,其他类似。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎补充。对于基本的网页抓取,前三个模块就足够了。
1.# 导入模块urllib2
2.导入 urllib2
3.。
4.# 查询任意一个文章,比如On random graph。对于每个查询 google 。更多。
5.# 学者有一个url,这个url形成的规则要自己分析。.
6.查询 = 'On+random+graph'
7.url ='#39; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
8.# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
9.# Google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
10.#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器与 网站 交互
11.#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
12.header = {'主机':'',
13.'用户代理': 'Mozilla/5.0 (Windows NT6.1; rv:26.0) Gecko/20100101 Firefox/2 6.0',
14.'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
15.'Accept-Encoding': 'gzip, deflate',
16.'连接':'保持活动'}
17.#建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象。/bbs
18.req = urllib2.Request(url, headers =header)
19.con = urllib2.urlopen(req)
20.#在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
21.doc = con.read()。
22.#关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
23.#所以作为一个守法的好公民,还是关闭连接比较好。
24.con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。步骤 三、 解析网页。飤鐢pet 咁勽潧 – 涓€浜╀银咗湴以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,你需要解析这个网页。解析网页的方法:不需要编写脚本,也不需要查询数据库上的数据,可以直接在notepad++上结合正则表达式使用。如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:(2) BeautifulSoup module. BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody -> tr,对于tbody节点,tr的子节点很多。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。网上有很多相关的说明,这里就不赘述了,只演示一个简单的代码:( 3) 结合使用以上两种方法。
1.#导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
2.导入 BeautifulSoup
3.导入重新。来自:/bbs
4.# 生成一个soup对象,第2步中提到了doc - google 1point3acres
5.汤=BeautifulSoup.BeautifulSoup(doc)
6.# 获取论文标题、作者、简短描述、引用次数、版次次数、文章 引用列表的超链接
7.#这里也用到了一些正则表达式,如果不熟悉,应该先无知。至于“类”:在“gs_rt”中
8.# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
9.# 让这个很简单,就是一个小网页,就可以知道对应html标签的位置和属性,
10.# 效果很好。
11.paper_name = soup.html.body.find('h3',{'class' : 'gs_rt'}).text
12.paper_name = re.sub(r'[.*]', '',paper_name) # 去掉'[]'标签,比如'[PDF]'.1point3acres
13.paper_author =soup.html.body.find('div', {'class' : 'gs_a'}).text
14.paper_desc = soup.html.body.find('div',{'class' : 'gs_rs'}).text
15.temp_str = soup.html.body.find('div',{'class' : 'gs_fl'}).text.更多信息
16.temp_re =re.match(r'[A-Za-zs]+(d*)[A-Za-zs]+(d*)', temp_str)
17.citeTimes = temp_re.group(1)
18.versionNum = temp_re.group(2)
19.如果 citeTimes == '':
20. citeTimes = '0'。更多信息
21.如果版本号 == '':
22. 版本号 = '0'。更多信息
23.citedPaper_href =soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
复制代码
.from: /bbs 这些是我正在分析引文网络的一个项目的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区的ip一时间无法登录googlescholar。第 4 步:访问数据。/bbs 终于抓到数据了,现在只存到内存中,必须保存好才能使用。(1) 最简单的方法是将数据写入txt文件,可以用Python实现,代码如下:
1.# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示将其添加到其中。
2.#还有其他参数,比如'r'只能读不能写,'w'可以写但删除原记录等。
3.file = open('webdata.txt','a')
4.line = paper_name + '#' + paper_author +'#' + paper_desc + '#' + citeTimes + 'n'。
5.#目标文件的write方法将字符串行写入文件
6.file = file.write(line)
7.# 再次做一个随心所欲关闭文件的好青年
8.file.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是非常简单的;数据库开放系统学习,w3school作为参考或作为手册使用,/bbsPython能链接数据库的前提是数据库是开放的,我用win7 + MySQL5.5,数据库是当地的。
1.% 可以使用cmd打开数据库。启动命令为: . 访问更多。
启动 mysql55. /bbs
3.% 平仓订单为:
停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
1.# 导入 MySQLdb 模块。链条已连接。1点3英亩
2.导入 MySQLdb
3.#与服务器建立链接,host为服务器ip,我的mysql数据库建在这台机器上,默认为127.0.0.1,
4.# 可以相应地输入用户、密码和数据库名称。默认端口号为3306,charset为编码方式。
5.#默认是utf8(也可能是gbk,看安装的版本)。
6.conn = MySQLdb.connect(host='127.0.0.1',user='root', passwd='yourPassword', db='dbname' , 端口=3306, 字符集='utf8')
7.# 创建光标
8.cur = conn.cursor()
9.#通过对象cur的execute()方法执行SQL语句
10.cur.execute("select * fromciteRelation where paperName = 'On Random Graph'")
11.# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
12.#i代表查询结果中的i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
13.list = cur.fetchall()
14.#还可以进行delete、drop、insert、update等操作,比如:
15.sql = "更新 studentCourseRecordset 失败 = 1 其中 studentID = '%s' 和 termID = '%s' 和 courseID ='%s'" %(studentID,course[0],course[1])
16.cur.execute(sql)
17.#与查询不同,在执行delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
19.#和往常一样,使用完记得关闭光标,再关闭链接
20.cur.close()
21.conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。./bbs 关于编码问题,附上我看到的一篇博文: ./bbs 后记:上面介绍了抓取网页数据的方法。数据捕获只是一小步。如何分析数据是大学的问题。欢迎讨论。以上内容如有不明之处,欢迎交流。.waral是长链,特别注意:网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器相对宽松的时间(如清晨)。网站很多,不要用三分之一英亩来测试。Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里运行的时候程序暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去去健身房,结果出来了。更新:2014年2月15日,改了几个错别字;增加了相关课程链接;增加了udacity CS101的介绍;增加了MySQLdb模块的介绍。2014年2月16日,
原文来源于微信公众号(PPV类数据科学社区): 查看全部
python网页数据抓取(
数据科学越来越怎么抓网页数据(一)_Python学习)
前言:数据科学越来越流行,网页是一个很大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常用的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计计算语言(R、Matlab)都可以实现和网站交互包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。第 1 步:熟悉 Python 的基本语法。如果您已经熟悉 Python,请跳至第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。跳到第 2 步。 Python 是一种相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。Python是一门相对容易上手的编程语言,如何上手取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。而如何上手则取决于编程基础。(1)如果你有一定的编程基础,建议看google的python课,链接这个是两天的短期培训课程(当然是全天),大概七个视频,每个之后video 给编程作业,每个作业一个小时内完成 这是我学python上的第二门课(第一门课是codecademy的python,很久以前看过,很多记不得了内容),我每天都看视频+编程作业用了一个多小时,六天完成,效果还不错,用python写基础程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。s python 课,链接这是一个为期两天的短期培训课程(当然是整整两天),大约七个视频,每个视频后给出编程作业,每个作业可以在一个小时内完成。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。这是我学python上的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不清了),每天都看视频+编程作业花了更多一个多小时,六天完成。效果还不错。用python编写基本程序没有问题。
我推荐的可能不适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看课程评论再决定。第 2 步:了解如何与 网站 建立链接并获取网页数据。访问以获取更多信息。编写脚本与网站交互,熟悉python和网页相关的几个模块(urllib、urllib2、httplib)之一,只知道一个,其他类似。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好,欢迎补充。对于基本的网页抓取,前三个模块就足够了。
1.# 导入模块urllib2
2.导入 urllib2
3.。
4.# 查询任意一个文章,比如On random graph。对于每个查询 google 。更多。
5.# 学者有一个url,这个url形成的规则要自己分析。.
6.查询 = 'On+random+graph'
7.url ='#39; + 查询 +'&btnG=&as_sdt=1%2C5&as_sdtp='
8.# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
9.# Google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
10.#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器与 网站 交互
11.#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
12.header = {'主机':'',
13.'用户代理': 'Mozilla/5.0 (Windows NT6.1; rv:26.0) Gecko/20100101 Firefox/2 6.0',
14.'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
15.'Accept-Encoding': 'gzip, deflate',
16.'连接':'保持活动'}
17.#建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象。/bbs
18.req = urllib2.Request(url, headers =header)
19.con = urllib2.urlopen(req)
20.#在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
21.doc = con.read()。
22.#关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
23.#所以作为一个守法的好公民,还是关闭连接比较好。
24.con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。步骤 三、 解析网页。飤鐢pet 咁勽潧 – 涓€浜╀银咗湴以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,你需要解析这个网页。解析网页的方法:不需要编写脚本,也不需要查询数据库上的数据,可以直接在notepad++上结合正则表达式使用。如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:(2) BeautifulSoup module. BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody -> tr,对于tbody节点,tr的子节点很多。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。网上有很多相关的说明,这里就不赘述了,只演示一个简单的代码:( 3) 结合使用以上两种方法。
1.#导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
2.导入 BeautifulSoup
3.导入重新。来自:/bbs
4.# 生成一个soup对象,第2步中提到了doc - google 1point3acres
5.汤=BeautifulSoup.BeautifulSoup(doc)
6.# 获取论文标题、作者、简短描述、引用次数、版次次数、文章 引用列表的超链接
7.#这里也用到了一些正则表达式,如果不熟悉,应该先无知。至于“类”:在“gs_rt”中
8.# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
9.# 让这个很简单,就是一个小网页,就可以知道对应html标签的位置和属性,
10.# 效果很好。
11.paper_name = soup.html.body.find('h3',{'class' : 'gs_rt'}).text
12.paper_name = re.sub(r'[.*]', '',paper_name) # 去掉'[]'标签,比如'[PDF]'.1point3acres
13.paper_author =soup.html.body.find('div', {'class' : 'gs_a'}).text
14.paper_desc = soup.html.body.find('div',{'class' : 'gs_rs'}).text
15.temp_str = soup.html.body.find('div',{'class' : 'gs_fl'}).text.更多信息
16.temp_re =re.match(r'[A-Za-zs]+(d*)[A-Za-zs]+(d*)', temp_str)
17.citeTimes = temp_re.group(1)
18.versionNum = temp_re.group(2)
19.如果 citeTimes == '':
20. citeTimes = '0'。更多信息
21.如果版本号 == '':
22. 版本号 = '0'。更多信息
23.citedPaper_href =soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
复制代码
.from: /bbs 这些是我正在分析引文网络的一个项目的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区的ip一时间无法登录googlescholar。第 4 步:访问数据。/bbs 终于抓到数据了,现在只存到内存中,必须保存好才能使用。(1) 最简单的方法是将数据写入txt文件,可以用Python实现,代码如下:
1.# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示将其添加到其中。
2.#还有其他参数,比如'r'只能读不能写,'w'可以写但删除原记录等。
3.file = open('webdata.txt','a')
4.line = paper_name + '#' + paper_author +'#' + paper_desc + '#' + citeTimes + 'n'。
5.#目标文件的write方法将字符串行写入文件
6.file = file.write(line)
7.# 再次做一个随心所欲关闭文件的好青年
8.file.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是非常简单的;数据库开放系统学习,w3school作为参考或作为手册使用,/bbsPython能链接数据库的前提是数据库是开放的,我用win7 + MySQL5.5,数据库是当地的。
1.% 可以使用cmd打开数据库。启动命令为: . 访问更多。
启动 mysql55. /bbs
3.% 平仓订单为:
停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
1.# 导入 MySQLdb 模块。链条已连接。1点3英亩
2.导入 MySQLdb
3.#与服务器建立链接,host为服务器ip,我的mysql数据库建在这台机器上,默认为127.0.0.1,
4.# 可以相应地输入用户、密码和数据库名称。默认端口号为3306,charset为编码方式。
5.#默认是utf8(也可能是gbk,看安装的版本)。
6.conn = MySQLdb.connect(host='127.0.0.1',user='root', passwd='yourPassword', db='dbname' , 端口=3306, 字符集='utf8')
7.# 创建光标
8.cur = conn.cursor()
9.#通过对象cur的execute()方法执行SQL语句
10.cur.execute("select * fromciteRelation where paperName = 'On Random Graph'")
11.# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
12.#i代表查询结果中的i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
13.list = cur.fetchall()
14.#还可以进行delete、drop、insert、update等操作,比如:
15.sql = "更新 studentCourseRecordset 失败 = 1 其中 studentID = '%s' 和 termID = '%s' 和 courseID ='%s'" %(studentID,course[0],course[1])
16.cur.execute(sql)
17.#与查询不同,在执行delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
19.#和往常一样,使用完记得关闭光标,再关闭链接
20.cur.close()
21.conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。./bbs 关于编码问题,附上我看到的一篇博文: ./bbs 后记:上面介绍了抓取网页数据的方法。数据捕获只是一小步。如何分析数据是大学的问题。欢迎讨论。以上内容如有不明之处,欢迎交流。.waral是长链,特别注意:网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器相对宽松的时间(如清晨)。网站很多,不要用三分之一英亩来测试。Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里运行的时候程序暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去去健身房,结果出来了。更新:2014年2月15日,改了几个错别字;增加了相关课程链接;增加了udacity CS101的介绍;增加了MySQLdb模块的介绍。2014年2月16日,
原文来源于微信公众号(PPV类数据科学社区):
python网页数据抓取(和服务器之间被用到的方法是:GET和POST。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-06 08:24
客户端和服务器之间最常用的两种请求-响应方法是:GET 和 POST。
GET - 从指定资源请求数据;
POST - 将要处理的数据提交到指定的资源;
两者比较:
2、我们来看看这两种捕获方式的异同;
(1)获取方法
GET 方法是最常用和最简单的,默认的 HTTP 请求方法是 GET。
一般用于我们从服务器获取数据,无需其他转换直接输入URL即可,即所有需要请求的信息都收录在URL中。
* 没有请求正文
* 数据必须在1K以内!
* GET请求数据会暴露在浏览器的地址栏中
有关获取请求的其他一些说明:
常用操作:
① 如果浏览器地址栏直接给出URL,那么一定是GET请求;
②点击页面上的超链接也必须是GET请求;
③ 提交表单时,表单默认使用GET请求,但可以设置为POST;
get请求是在url后面拼接传递参数,但是如果参数是中文的,需要转码,否则会报错。
比如我们访问豆瓣官网,在搜索框中输入关键词“电影”:
可以看到浏览器中的请求是/search?q=movie
如果我们直接模拟上面的url请求,会报如下错误:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 14-15: ordinal not in range(128)
原因是在使用浏览器访问的时候会自动帮我们转码参数,而现在我们使用代码访问,所以需要我们自己处理。
from urllib.request import urlopen
from urllib.request import Request
from random import choice
# 1.爬取站点访问地址
url = "https://www.douban.com/search?q=电影"
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers)
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
修改,然后引入urlencode函数对url的参数进行转码,就可以正常访问了;
省略..
from urllib.parse import urlencode
# 1.爬取站点访问地址
args = {'q': '电影'}
url = "https://www.douban.com/search?{}".format(urlencode(args))
省略...
从这些可以看出get方法获取的内容是稳定的(即每个人打开某个网页时获取的信息都是一样的),但是使用post的时候需要输入具体的信息,所以获得的网页将是具体的。我们会解决的。
仅仅通过文字描述可能并不容易理解。建议大家在入门的时候看一些配套视频,加深对基本概念的印象,然后在实际操作中更好的理解每一步的含义。
这里推荐免费学习公开课,点击下方跳转
(2)发布方法
post用于向服务器发送数据以创建/更新资源。
通过 post 发送到服务器的数据存储在 HTTP 请求的请求体中:
POST /test/demo_form.php HTTP/1.1
Host: w3school.com.cn
name1=value1&name2=value2
post获取的内容不能仅通过URL获取,还需要提交一些额外的信息。
这种信息在不同的网页中发挥着不同的作用。例如,在查询天气的网页中,可能是输入城市信息;在登录某些网页时,它也是账号和密码的载体。
发帖请求:
① 数据不会出现在地址栏
② 数据大小没有上限
③ 有请求体
④ 如果请求正文中有中文,将使用 URL 编码!
关于发布请求的其他一些说明:
一般HTTP请求提交数据需要编码成URL编码格式,然后作为URL的一部分,或者作为参数传递给Request对象。
特别点:
Request请求对象中有一个data参数,post请求通过Request对象中的data属性传递参数来存储请求体数据。
data 是一个字典,其中收录匹配的键值对。
我们在这里模拟一个登录请求:
from urllib.request import urlopen
from urllib.request import Request
from random import choice
from urllib.parse import urlencode
# 1.url与参数处理
url = "https://www.douban.com/"
args = {
'name': 'abcdef123456',
'password': '123456'
}
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers, data=urlencode(args).encode())
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
如果没有添加encode()函数,会报错:
TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
发帖请求做百度翻译:
import urllib.request as ur
import urllib.parse as up
import json
word= input('请输入要翻译的英语:')
data={
'kw':word
}
data_url = up.urlencode(data)
request = ur.Request(url='https://fanyi.baidu.com/sug',data=data_url.encode('utf-8'))
reponse = ur.urlopen(request).read()
ret = json.loads(reponse)
#print(ret)
translate = ret['data'][0]['v']
print(translate)
3、总结:
Get请求和Post请求的区别
1)get 在浏览器回滚时是无害的,post 会再次提交请求;
2)get生成的url地址可以采集(标注),但不能post;
3)get请求只能是url编码,post可以多种方式编码;
4)get请求参数会完全保存在浏览器历史中,post不会(隐身浏览);
5) 对于参数的数据类型,get只接受ASCII字符,post没有限制;
6)Get请求的url中传入的参数长度有限制,post没有;
7)get比post安全,因为参数直接暴露在url中,不能用来传递敏感信息;
8)get参数放在url中,post参数放在请求体中;
注意: 查看全部
python网页数据抓取(和服务器之间被用到的方法是:GET和POST。)
客户端和服务器之间最常用的两种请求-响应方法是:GET 和 POST。
GET - 从指定资源请求数据;
POST - 将要处理的数据提交到指定的资源;
两者比较:
2、我们来看看这两种捕获方式的异同;
(1)获取方法
GET 方法是最常用和最简单的,默认的 HTTP 请求方法是 GET。
一般用于我们从服务器获取数据,无需其他转换直接输入URL即可,即所有需要请求的信息都收录在URL中。
* 没有请求正文
* 数据必须在1K以内!
* GET请求数据会暴露在浏览器的地址栏中
有关获取请求的其他一些说明:
常用操作:
① 如果浏览器地址栏直接给出URL,那么一定是GET请求;
②点击页面上的超链接也必须是GET请求;
③ 提交表单时,表单默认使用GET请求,但可以设置为POST;
get请求是在url后面拼接传递参数,但是如果参数是中文的,需要转码,否则会报错。
比如我们访问豆瓣官网,在搜索框中输入关键词“电影”:
可以看到浏览器中的请求是/search?q=movie
如果我们直接模拟上面的url请求,会报如下错误:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 14-15: ordinal not in range(128)
原因是在使用浏览器访问的时候会自动帮我们转码参数,而现在我们使用代码访问,所以需要我们自己处理。
from urllib.request import urlopen
from urllib.request import Request
from random import choice
# 1.爬取站点访问地址
url = "https://www.douban.com/search?q=电影"
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers)
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
修改,然后引入urlencode函数对url的参数进行转码,就可以正常访问了;
省略..
from urllib.parse import urlencode
# 1.爬取站点访问地址
args = {'q': '电影'}
url = "https://www.douban.com/search?{}".format(urlencode(args))
省略...
从这些可以看出get方法获取的内容是稳定的(即每个人打开某个网页时获取的信息都是一样的),但是使用post的时候需要输入具体的信息,所以获得的网页将是具体的。我们会解决的。
仅仅通过文字描述可能并不容易理解。建议大家在入门的时候看一些配套视频,加深对基本概念的印象,然后在实际操作中更好的理解每一步的含义。
这里推荐免费学习公开课,点击下方跳转
(2)发布方法
post用于向服务器发送数据以创建/更新资源。
通过 post 发送到服务器的数据存储在 HTTP 请求的请求体中:
POST /test/demo_form.php HTTP/1.1
Host: w3school.com.cn
name1=value1&name2=value2
post获取的内容不能仅通过URL获取,还需要提交一些额外的信息。
这种信息在不同的网页中发挥着不同的作用。例如,在查询天气的网页中,可能是输入城市信息;在登录某些网页时,它也是账号和密码的载体。
发帖请求:
① 数据不会出现在地址栏
② 数据大小没有上限
③ 有请求体
④ 如果请求正文中有中文,将使用 URL 编码!
关于发布请求的其他一些说明:
一般HTTP请求提交数据需要编码成URL编码格式,然后作为URL的一部分,或者作为参数传递给Request对象。
特别点:
Request请求对象中有一个data参数,post请求通过Request对象中的data属性传递参数来存储请求体数据。
data 是一个字典,其中收录匹配的键值对。
我们在这里模拟一个登录请求:
from urllib.request import urlopen
from urllib.request import Request
from random import choice
from urllib.parse import urlencode
# 1.url与参数处理
url = "https://www.douban.com/"
args = {
'name': 'abcdef123456',
'password': '123456'
}
# 2.模拟多个浏览器的User-Agent(分别为Chrome、Firefox、Edge)
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"
]
# 3.随机设置请求头信息
headers = {
"User-Agent": choice(user_agents)
}
# 4.将请求头信息封装到Request对象中
req = Request(url, headers=headers, data=urlencode(args).encode())
# 5.发送请求并打印返回值
print(urlopen(req).read().decode())
如果没有添加encode()函数,会报错:
TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
发帖请求做百度翻译:
import urllib.request as ur
import urllib.parse as up
import json
word= input('请输入要翻译的英语:')
data={
'kw':word
}
data_url = up.urlencode(data)
request = ur.Request(url='https://fanyi.baidu.com/sug',data=data_url.encode('utf-8'))
reponse = ur.urlopen(request).read()
ret = json.loads(reponse)
#print(ret)
translate = ret['data'][0]['v']
print(translate)
3、总结:
Get请求和Post请求的区别
1)get 在浏览器回滚时是无害的,post 会再次提交请求;
2)get生成的url地址可以采集(标注),但不能post;
3)get请求只能是url编码,post可以多种方式编码;
4)get请求参数会完全保存在浏览器历史中,post不会(隐身浏览);
5) 对于参数的数据类型,get只接受ASCII字符,post没有限制;
6)Get请求的url中传入的参数长度有限制,post没有;
7)get比post安全,因为参数直接暴露在url中,不能用来传递敏感信息;
8)get参数放在url中,post参数放在请求体中;
注意:
python网页数据抓取( Python请求PythonRequests库被称为HTTPforHumans库下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-06 08:22
Python请求PythonRequests库被称为HTTPforHumans库下载)
1urllib.error
2
其中收录抛出的异常
1urllib.request
2
1urllib.parse
2
用于解析 URL,以及
1urllib.robotparser
2
用于解析 robots.txt 文件的内容。Urllib 并不容易使用,但可以帮助您进行身份验证、cookie、URL 编码和代理等。它应该只在需要对请求进行高级控制时使用。
如何安装 Urlli
如前所述,Urllib 包已收录在标准 python 库中,因此您无需再次安装。只需将其导入您的代码并使用它。
urllib 代码示例
以下代码将向维基百科的主页发送 GET 请求并打印出响应。响应将是页面的整个 HTML。
1import urllib.request as rq
2
3get_content = rq.urlopen("https://en.wikipedia.org/wiki/Main_Page")
4
5print(get_content.read().decode("utf-8"))
6
Python 请求
Python Requests 库,称为 Python HTTP for Humans,是一个第三方库,旨在简化处理 HTTP 请求和 URL 的过程。它建立在 Urllib 之上,并提供易于使用的界面。
除了比 urllib 更易于使用之外,它还具有更好的文档。说到人气,可以说 Requests 是最受欢迎的 Python 库之一,因为它是下载次数最多的 Python 包。它支持国际化、会话 cookie 和身份验证,以及连接池和超时,以及多部分文件上传。
如何安装
Python Requests 是第三方包,所以需要先安装后才能使用。推荐的安装方式是使用 pip 命令。
1>> pip install requests
2
Python 请求代码示例
下面的代码将下载与 Urllib 下载的相同页面,因此您可以进行比较,即使您在使用其高级功能时存在差异。
1>> import requests
2
3>>get_content = requests.get("https://en.wikipedia.org/wiki/Main_Page")
4
5>> print(get_content.text)
6
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
1pip install requests
2
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
1chromedriver.exe
2
文档
1from selenium import webdriver
2
3from selenium.webdriver.common.keys import Keys
4
5driver = webdriver.Chrome()
6
7driver.get("https://www.indeed.com/")
8
9amazon_search = driver.find_element_by_id("twotabsearchtextbox")
10
11amazon_search.send_keys("Web scraping for python developers")
12
13amazon_search.send_keys(Keys.RETURN)
14
15driver.close()
16
使用 python 和 Selenium,你可以像这样 网站 这样跨不同的工作平台为 python 开发人员找到当前的职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monsters 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
1pip install beautifulsoup4
2
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
1import requests
2
3from bs4 import BeautifulSoup
4
5
6
7url = "https://en.wikipedia.org/wiki/ ... ot%3B
8
9page_content = requests.get(url).text
10
11soup = BeautifulSoup(page_content, "html.parser")
12
13table = soup.find("table", {"class": "wikitable"})
14
15lga_trs = table.find_all("tr")[1:]
16
17for i in lga_trs:
18
19tds = i.find_all("td")
20
21td1 = tds[0].find("a")
22
23td2 = tds[1].find("a")
24
25l_name = td1.contents[0]
26
27l_url = td1["href"]
28
29l_state = td2["title"]
30
31l_state_url = td2["href"]
32
33print([l_name,l_url, l_state, l_state_url])
34
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
1pip install lxml
2
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,它收录了开发 Web 爬虫时需要的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
1pip install scrapy
2
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构,并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI,用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
1pip install pyspider
2
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
1from pyspider.libs.base_handler import *
2
3class Handler(BaseHandler):
4
5crawl_config = {}
6
7@every(minutes=24 * 60)
8
9def on_start(self):
10
11self.crawl("https://scrapy.org/", callback=self.index_page)
12
13@config(age=10 * 24 * 60 * 60)
14
15def index_page(self, response):
16
17for each in response.doc('a][href^="http"]').items():
18
19self.crawl(each.attr.href, callback=self.detail_page)
20
21
22
23def detail_page(self, response):
24
25return {"url": response.url, "title": response.doc('title').text()
26
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
1pyspider
2
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,那么使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果该站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。 查看全部
python网页数据抓取(
Python请求PythonRequests库被称为HTTPforHumans库下载)
1urllib.error
2
其中收录抛出的异常
1urllib.request
2
1urllib.parse
2
用于解析 URL,以及
1urllib.robotparser
2
用于解析 robots.txt 文件的内容。Urllib 并不容易使用,但可以帮助您进行身份验证、cookie、URL 编码和代理等。它应该只在需要对请求进行高级控制时使用。
如何安装 Urlli
如前所述,Urllib 包已收录在标准 python 库中,因此您无需再次安装。只需将其导入您的代码并使用它。
urllib 代码示例
以下代码将向维基百科的主页发送 GET 请求并打印出响应。响应将是页面的整个 HTML。
1import urllib.request as rq
2
3get_content = rq.urlopen("https://en.wikipedia.org/wiki/Main_Page";)
4
5print(get_content.read().decode("utf-8"))
6
Python 请求
Python Requests 库,称为 Python HTTP for Humans,是一个第三方库,旨在简化处理 HTTP 请求和 URL 的过程。它建立在 Urllib 之上,并提供易于使用的界面。
除了比 urllib 更易于使用之外,它还具有更好的文档。说到人气,可以说 Requests 是最受欢迎的 Python 库之一,因为它是下载次数最多的 Python 包。它支持国际化、会话 cookie 和身份验证,以及连接池和超时,以及多部分文件上传。
如何安装
Python Requests 是第三方包,所以需要先安装后才能使用。推荐的安装方式是使用 pip 命令。
1>> pip install requests
2
Python 请求代码示例
下面的代码将下载与 Urllib 下载的相同页面,因此您可以进行比较,即使您在使用其高级功能时存在差异。
1>> import requests
2
3>>get_content = requests.get("https://en.wikipedia.org/wiki/Main_Page";)
4
5>> print(get_content.text)
6
硒
Selenium Web Driver 是一个浏览器自动化工具——你用它做什么完全取决于你。它在网络爬虫中变得流行,因为它可以用来从 JavaScript 丰富的 网站 中爬取数据。Python Requests 库和 Scrapy 等传统工具无法渲染 JavaScript,因此您需要 Selenium 来执行此操作。
Selenium 可用于自动化许多浏览器,包括 Chrome 和 Firefox。在无头模式下运行时,您实际上不会看到浏览器打开,但它会模拟浏览器环境中的操作。使用 Selenium,您可以模拟鼠标和键盘操作、访问站点并获取您想要的任何内容。
如何安装硒
您需要满足两个要求才能使用 Selenium Web 驱动程序来自动化您的浏览器。其中包括 Selenium Python 绑定和浏览器驱动程序。在本文中,我们将使用 Chrome,因此您需要从此处下载 Chrome 驱动程序 - 确保它适用于您正在使用的 Chrome 版本。安装后,解压缩并将 chromedriver.exe 文件放在与 python 脚本相同的目录中。有了这个,您可以使用下面的 pip 命令安装 selenium python 绑定。
1pip install requests
2
硒代码示例
下面的代码展示了如何使用 Selenium 搜索亚马逊。请记住,脚本必须与
1chromedriver.exe
2
文档
1from selenium import webdriver
2
3from selenium.webdriver.common.keys import Keys
4
5driver = webdriver.Chrome()
6
7driver.get("https://www.indeed.com/";)
8
9amazon_search = driver.find_element_by_id("twotabsearchtextbox")
10
11amazon_search.send_keys("Web scraping for python developers")
12
13amazon_search.send_keys(Keys.RETURN)
14
15driver.close()
16
使用 python 和 Selenium,你可以像这样 网站 这样跨不同的工作平台为 python 开发人员找到当前的职位空缺和聚合数据,因此,你可以轻松地从 Glassdoor、flexjobs、monsters 等中刮取 python 开发人员数据。
美丽汤
BeautifulSoup 是一个用于解析 HTML 和 XML 文件的解析库。它将网页文档转换为解析树,以便您可以以 Pythonic 方式遍历和操作它。使用 BeautifulSoup,您可以解析出任何您想要的数据,只要它是 HTML 格式的。重要的是要知道 BeautifulSoup 没有自己的解析器,它位于其他解析器之上,例如 lxml,甚至是 python 标准库中可用的 html.parser。在解析网络数据时,
BeautifulSoup 是最受欢迎的选择。有趣的是,它很容易学习和掌握。用 BeautifulSoup 解析网页时,即使页面的 HTML 杂乱复杂,也没有问题。
如何安装 BeautifulSoup
像讨论的所有其他库一样,您可以通过 pip 安装它。在命令提示符中输入以下命令。
1pip install beautifulsoup4
2
BeautifulSoup 代码示例
下面是获取尼日利亚 LGA 列表并将其打印到控制台的代码。BeautifulSoup 没有下载网页的能力,所以我们将使用 Python Requests 库。
1import requests
2
3from bs4 import BeautifulSoup
4
5
6
7url = "https://en.wikipedia.org/wiki/ ... ot%3B
8
9page_content = requests.get(url).text
10
11soup = BeautifulSoup(page_content, "html.parser")
12
13table = soup.find("table", {"class": "wikitable"})
14
15lga_trs = table.find_all("tr")[1:]
16
17for i in lga_trs:
18
19tds = i.find_all("td")
20
21td1 = tds[0].find("a")
22
23td2 = tds[1].find("a")
24
25l_name = td1.contents[0]
26
27l_url = td1["href"]
28
29l_state = td2["title"]
30
31l_state_url = td2["href"]
32
33print([l_name,l_url, l_state, l_state_url])
34
lxml
从这个库的名称可以看出,它与 XML 有关。实际上,它是一个解析器——一个真正的解析器,而不是像 BeautifulSoup 那样位于解析器之上的解析库。除了 XML 文件,lxml 还可以用来解析 HTML 文件。您可能有兴趣知道 lxml 是 BeautifulSoup 用于将网页文档转换为要解析的树的解析器之一。
Lxml 解析速度非常快。但是,它很难学习和掌握。大多数网络爬虫并不是单独使用它,而是作为 BeautifulSoup 使用的解析器。所以实际上不需要代码示例,因为您不会单独使用它。
如何安装 Lxml
Lxml 在 Pypi 存储库中可用,因此您可以使用 pip 命令安装它。安装lxml的命令如下。
1pip install lxml
2
Python网页抓取框架
与仅用于一个功能的库不同,框架是一个完整的工具,它收录了开发 Web 爬虫时需要的大量功能,包括发送 HTTP 请求和解析它们的能力。
刮擦
Scrapy 是最流行的,可以说是最好的网络抓取框架,作为开源工具公开提供。它是由 Scrapinghub 创建的,并且仍然被广泛管理。
Scrapy 是一个完整的框架,因为它负责发送请求并从下载的页面解析所需的数据。Scrapy 是多线程的,是所有 Python 框架和库中最快的。它使复杂的网络爬虫的开发变得容易。但是,它的问题之一是它不呈现和执行 JavaScript,因此您需要为此使用 Selenium 或 Splash。知道它有一个陡峭的学习曲线也很重要。
如何安装 Scrapy
Scrapy 在 Pypi 上可用,因此您可以使用 pip 命令安装它。以下是在命令提示符/终端上运行以下载和安装 Scrapy 的命令。
1pip install scrapy
2
抓取代码示例
如前所述,Scrapy 是一个完整的框架,没有简单的学习曲线。对于代码示例,您需要编写大量代码,并且不会像上面那样工作。有关 Scrapy 代码示例,请访问 Scrapy 网站 的官方教程页面。
蜘蛛
Pyspider 是另一个为 Python 程序员编写的 Web 抓取框架,用于开发 Web 抓取工具。Pyspider 是一个强大的网络爬虫框架,可用于为现代网络创建网络爬虫。与 Scrapy 自身不渲染 JavaScript 不同,Pyspider 擅长这项工作。然而,在可靠性和成熟度方面,Scrapy 远远领先于 Pyspider。它允许分布式架构,并提供对 Python 2 和 Python 3 的支持。它支持大量的数据库系统,并带有强大的 WebUI,用于监控爬虫/爬虫的性能。要运行它,它需要在服务器上。
如何安装 Pyspider
Pyspider 可以使用下面的 pip 命令安装。
1pip install pyspider
2
PySpider 代码示例
下面的代码是 Pyspider 在其文档页面上提供的示例代码。它抓取 Scrapy 主页上的链接。
1from pyspider.libs.base_handler import *
2
3class Handler(BaseHandler):
4
5crawl_config = {}
6
7@every(minutes=24 * 60)
8
9def on_start(self):
10
11self.crawl("https://scrapy.org/", callback=self.index_page)
12
13@config(age=10 * 24 * 60 * 60)
14
15def index_page(self, response):
16
17for each in response.doc('a][href^="http"]').items():
18
19self.crawl(each.attr.href, callback=self.detail_page)
20
21
22
23def detail_page(self, response):
24
25return {"url": response.url, "title": response.doc('title').text()
26
如前所述,Pyspider 在服务器上运行。您的计算机充当服务器的服务器,并将从 localhost 进行侦听,因此运行:
1pyspider
2
命令和访问:5000/
综上所述
当谈到 Python 编程语言中可用于 Web 抓取的工具、库和框架的数量时,您需要知道有很多。
但是,您无法学习其中的每一个。如果您正在开发一个不需要复杂架构的简单爬虫,那么使用 Requests 和 BeautifulSoup 的组合将起作用 - 如果该站点是 JavaScript 密集型的,则添加 Selenium。
在这些方面,硒甚至可以单独使用。但是,当您期待开发复杂的网络爬虫或爬虫时,可以使用 Scrapy 框架。
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-06 00:20
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
刚整理了一套2018最新0基础入门和进阶教程,无私分享,加Python学习qun:227-435-450搞定,附:开发工具和安装包,系统学习路线图
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。 查看全部
python网页数据抓取(一套2018最新的0基础入门和进阶教程,无私分享)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
刚整理了一套2018最新0基础入门和进阶教程,无私分享,加Python学习qun:227-435-450搞定,附:开发工具和安装包,系统学习路线图
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
python网页数据抓取(Python中的正则表达式教程输出结果及总结表(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-01 23:06
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:
抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8
import re, urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
html = html.decode('utf-8') #python3版本中需要加入
links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)
titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)
tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)
span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags):
span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警
山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警
强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警
地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span > ul > li.waring > a:nth-child(1)
因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:
#alarmtip > ul > li.waring > a
代码:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.html
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
tree = lxml.html.fromstring(html)
content = tree.cssselect('li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
######### 添加到列表中
link = []
title = []
tag = []
for n in content:
link.append(url+n.get('href'))
title.append(n.get('title'))
tag.append(n.text)
######## 添加到字典中
for n in content:
data = {
'tag' : n.text,
'link' : url+n.get('href'),
'title' : n.get('title')
}
五、总结
表格2.1总结了每种抓取方式的优缺点。
源码链接
参考资料: 查看全部
python网页数据抓取(Python中的正则表达式教程输出结果及总结表(一))
摘要:这篇文章是关于使用Python实现网页数据抓取的三种方法;它们是正则表达式(re)、BeautifulSoup 模块和 lxml 模块。本文所有代码均在python3.5.
中运行
本文抓取的是[中央气象台](http://www.nmc.cn/)首页头条信息:
它的 HTML 层次结构是:
抓取href、title和tags的内容。
一、正则表达式
复制外层HTML:
高温预警
代码:
# coding=utf-8
import re, urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
html = html.decode('utf-8') #python3版本中需要加入
links = re.findall('<a target="_blank" href="(.+?)" title'/span,html)
titles = re.findall(span class="hljs-string"'a target="_blank" .+? title="(.+?)"'/span,html)
tags = re.findall(span class="hljs-string"'a target="_blank" .+? title=.+?(.+?)/a'/span,html)
span class="hljs-keyword"for/span span class="hljs-keyword"link/span,title,tag in zip(links,titles,tags):
span class="hljs-keyword"print/span(tag,url+span class="hljs-keyword"link/span,title)/code/pre/p
p正则表达式符号'.'表示匹配任何字符串(\n除外); '+' 表示匹配0个或多个前面的正则表达式; '? ' 表示匹配 0 或 1 个之前的正则表达式。更多信息请参考Python正则表达式教程/p
p输出如下:/p
ppre class="prettyprint"code class=" hljs avrasm"高温预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/megatemperaturespan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布高温橙色预警
山洪灾害气象预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/mountainfloodspan class="hljs-preprocessor".html/span 水利部和中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布山洪灾害气象预警
强对流天气预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/country/warning/strong_convectionspan class="hljs-preprocessor".html/span 中央气象台span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时继续发布强对流天气蓝色预警
地质灾害气象风险预警 http://wwwspan class="hljs-preprocessor".nmc/spanspan class="hljs-preprocessor".cn/span/publish/geohazardspan class="hljs-preprocessor".html/span 国土资源部与中国气象局span class="hljs-number"7/span月span class="hljs-number"13/span日span class="hljs-number"18/span时联合发布地质灾害气象风险预警/code/pre/p
p二、BeautifulSoup 模块/p
pBeautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供一个方便的界面来定位内容。/p
p复制选择器:/p
ppre class="prettyprint"code class=" hljs css"span class="hljs-id"#alarmtip/span > ul > li.waring > a:nth-child(1)
因为这里我们抓取的是多个数据,而不仅仅是第一个,所以需要改为:
#alarmtip > ul > li.waring > a
代码:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
三、lxml 模块
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。
代码:
import urllib.request,lxml.html
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
tree = lxml.html.fromstring(html)
content = tree.cssselect('li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)
输出结果同上。
四、将抓取的数据存储在列表或字典中
以 BeautifulSoup 模块为例:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
######### 添加到列表中
link = []
title = []
tag = []
for n in content:
link.append(url+n.get('href'))
title.append(n.get('title'))
tag.append(n.text)
######## 添加到字典中
for n in content:
data = {
'tag' : n.text,
'link' : url+n.get('href'),
'title' : n.get('title')
}
五、总结
表格2.1总结了每种抓取方式的优缺点。
源码链接
参考资料:
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-01 20:14
网络爬虫简介(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者):
它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。爬虫能做什么?
你可以使用爬虫爬取图片、爬取视频等你想爬取的数据,只要你可以通过浏览器访问的数据都可以通过爬虫获取。当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户在浏览器中看到的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)网页数据存储在一个文件中
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
至此,我们从网页中获取的数据已经保存在我们指定的文件中,如下图
网络访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的数据大部分是文本或者数字信息,代码对我们没有用处。所以我们接下来要做的就是清除无用的数据。(这里我会从警方新闻中获取内容)
3)提取内容
分析网页以找到您需要的“警察新闻”
内容范围
如何提取表格的内容?
如果模式收录一个组,它将返回匹配的
组列表
常用表达
使用正则表达式匹配
'(.*?) 查看全部
python网页数据抓取(网络爬虫(又被称为网页蜘蛛,网络机器人)可以做什么)
网络爬虫简介(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者):
它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。爬虫能做什么?
你可以使用爬虫爬取图片、爬取视频等你想爬取的数据,只要你可以通过浏览器访问的数据都可以通过爬虫获取。当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户在浏览器中看到的结果是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,我们可以从中获取我们想要的资源。页面获取
1) 根据 URL 获取网页
import urllib.request as req
# 根据URL获取网页:
# http://www.hnpolice.com/
url = 'http://www.hnpolice.com/'
webpage = req.urlopen(url) # 按照类文件的方式打开网页
# 读取网页的所有数据,并转换为uft-8编码
data = webpage.read().decode('utf-8')
print(data)
2)网页数据存储在一个文件中
# 将读取的网页数据写入文件:
outfile = open("enrollnudt.txt", 'w') # 打开文件
outfile.write(data) # 将网页数据写入文件
outfile.close()
至此,我们从网页中获取的数据已经保存在我们指定的文件中,如下图
网络访问
从图中可以看出,网页的所有数据都存储在本地,但是我们需要的数据大部分是文本或者数字信息,代码对我们没有用处。所以我们接下来要做的就是清除无用的数据。(这里我会从警方新闻中获取内容)
3)提取内容
分析网页以找到您需要的“警察新闻”
内容范围
如何提取表格的内容?
如果模式收录一个组,它将返回匹配的
组列表
常用表达
使用正则表达式匹配
'(.*?)
python网页数据抓取(用脚本将获取信息上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-01 16:00
编译:欧莎
作为数据科学家的首要任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取一个网站——比如从Fast Track获取2018年百强企业的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫的示例代码,本文用到的所有代码都在GitHub()上,欢迎你去拿。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
美丽的汤
要求
刮擦
硒
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以Tech Track Top 100 Enterprises页面(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例,在表格上右击选择“查看” 。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面中,并且
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:
每一行都在一个
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(例如
失眠
) 发起请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:
接下来,我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,将处理结果存储在soup变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
因为一切都在桌子上(
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。
看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面中是一致的(尽管在其他 网站 上可能没有那么简单!),所以我们可以再次使用 find_all 方法,通过搜索
元素,逐行提取数据,将其存储在变量中,稍后将其写入csv或json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填写初始表头(方便以后在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能会注意到我输入的表头比网页上的表格多了几个列名,比如Webpage(网页)和Deion(描述),请仔细看看上面打印的soup变量数据——数据第二行第二列不仅收录公司名称,还收录公司的网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为标题使用
标签,不使用标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。
我们想将公司变量的内容分成两部分:公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
要删除 sales 变量中的多余字符,我们可以使用一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
在原创快速通道页面上,找到您需要访问的公司详情页面的链接。
发起对公司详细信息页面链接的请求
使用Beautifulsoup处理得到的html数据
找到所需的链接元素
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
用 BeautifulSoup 处理得到的 html 数据
循环遍历汤对象以搜索所需的 html 元素
做简单的数据清洗
将数据写入 csv 文件
如果有什么不明白的,请在下方留言,我会尽力为您解答!
附:本文所有代码()
为您的爬行动物之旅有个美好的开始! 查看全部
python网页数据抓取(用脚本将获取信息上获取2018年100强企业的信息)
编译:欧莎
作为数据科学家的首要任务是进行网络抓取。那时,我对使用代码从 网站 获取数据一无所知,这是最合乎逻辑且易于访问的数据源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它是我几乎每天都在使用的为数不多的技术之一。
在今天的文章中,我将通过几个简单的例子来向大家展示如何爬取一个网站——比如从Fast Track获取2018年百强企业的信息。使用脚本自动化获取信息的过程,不仅可以节省人工排序的时间,而且可以将所有企业数据组织在一个结构化的文件中,便于进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫的示例代码,本文用到的所有代码都在GitHub()上,欢迎你去拿。
准备好工作了
每次你尝试用 Python 做某事时,你应该问的第一个问题是“我需要使用什么库”。
对于网络抓取,有几个不同的库可用,包括:
美丽的汤
要求
刮擦
硒
今天我们将使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了弄清楚要抓取网页的哪些元素,您需要首先检查网页的结构。
以Tech Track Top 100 Enterprises页面(%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例,在表格上右击选择“查看” 。在弹出的“开发者工具”中,我们可以看到页面中的每个元素,以及它收录的内容。
右键单击要查看的网页元素并选择“检查”以查看特定的 HTML 元素内容
由于数据存储在表中,因此只需要几行简单的代码即可直接获取完整信息。如果您想自己练习抓取 Web 内容,这是一个很好的示例。但请记住,现实往往不是那么简单。
在此示例中,所有 100 个结果都收录在同一页面中,并且
在表格页面,可以看到一张收录全部100条数据的表格,右键点击选择“inspect”,可以很容易的看到这个HTML表格的结构。收录内容的表体位于这样的标签中:
每一行都在一个
旁注:您还可以通过检查当前页面是否发送 HTTP GET 请求并获取该请求的返回值来获取页面上显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,方便后续处理。您可以单击开发人员工具中的 Network 类别(如果需要,您可以查看其中的 XHR 标签的内容)。此时可以刷新页面,页面上加载的所有请求和返回的内容都会在Network中列出。此外,您可以使用某种 REST 客户端(例如
失眠
) 发起请求并输出返回值。
刷新页面后,网络标签的内容更新了
使用 Beautiful Soup 库处理网页的 HTML 内容
在熟悉了网页的结构,了解了需要爬取的内容之后,我们终于要拿起代码开始工作了~
首先要做的是导入将在代码中使用的各种模块。我们在上面提到了 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是 urllib,它负责连接到目标地址并获取网页的内容。最后,我们需要能够将数据写入 CSV 文件并将其保存在本地硬盘上,因此我们将导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为 json 文件,则需要相应地导入 json 库。
接下来我们需要准备要爬取的目标URL。如上所述,这个页面已经收录了我们需要的一切,所以我们只需要复制完整的 URL 并将其分配给一个变量:
接下来,我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,将处理结果存储在soup变量中:
这时候可以尝试打印出soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空,或者返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要结合 urllib.error() 模块使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
因为一切都在桌子上(
如果您尝试打印所有行,应该有 101 行 -- 100 行内容,加上一个标题。
看看打印了什么,如果没问题,我们可以使用循环来获取所有数据。
如果你打印出 soup 对象的前 2 行,你可以看到每一行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年末)、Annual Sales Rise(年销售额增长)、Latest销售额(今年的销售额)、员工(员工人数)和评论。
这些都是我们需要的数据。
这种结构在整个页面中是一致的(尽管在其他 网站 上可能没有那么简单!),所以我们可以再次使用 find_all 方法,通过搜索
元素,逐行提取数据,将其存储在变量中,稍后将其写入csv或json文件。
循环遍历所有元素并存储在变量中
在 Python 中,列表对象在处理大量数据和写入文件时很有用。我们可以先声明一个空列表,填写初始表头(方便以后在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印我们刚刚添加到列表对象行的第一行标题。
你可能会注意到我输入的表头比网页上的表格多了几个列名,比如Webpage(网页)和Deion(描述),请仔细看看上面打印的soup变量数据——数据第二行第二列不仅收录公司名称,还收录公司的网站和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容并保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不读就跳过。因为标题使用
标签,不使用标签,所以我们简单的查询标签中的数据,丢弃空值。
接下来,我们读取数据的内容并将其分配给变量:
如上代码所示,我们将8列的内容依次存储到8个变量中。当然,有些数据的内容需要额外的清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们打印出公司变量的内容,我们可以看到它不仅收录公司名称,还收录描述和描述。如果我们打印出sales变量的内容,我们可以看到它还收录了一些需要清除的字符,例如备注符号。
我们想将公司变量的内容分成两部分:公司名称和描述。这可以通过几行代码来完成。查看对应的html代码,你会发现这个单元格中还有一个元素,而这个元素只有公司名称。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们稍后会使用它!
为了区分公司名称和描述这两个字段,我们使用find方法读取元素的内容,然后删除或替换公司变量中对应的内容,这样变量中就只剩下描述了。
要删除 sales 变量中的多余字符,我们可以使用一次 strip 方法。
我们要保存的最后一件事是指向公司 网站 的链接。如上所述,在第二栏中有一个指向公司详细信息页面的链接。每个公司的详细信息页面都有一个表单,在大多数情况下,是指向公司网站 的链接。
检查公司详细信息页面上表格中的链接
为了获取每个表中的 URL 并将其保存到变量中,我们需要执行以下步骤:
在原创快速通道页面上,找到您需要访问的公司详情页面的链接。
发起对公司详细信息页面链接的请求
使用Beautifulsoup处理得到的html数据
找到所需的链接元素
正如您在上面的屏幕截图中看到的,在查看了几个公司详细信息页面后,您会注意到公司的 URL 基本上在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,最后一行可能没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将变量设置为 None。在变量中拥有所有需要的数据后(仍在循环体中),我们可以将所有变量组合成一个列表,并将列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体结束后打印行的内容,这样您可以在将数据写入文件之前进行检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续分析处理。在 Python 中,我们只需几行代码就可以将列表对象保存到文件中。
最后让我们运行这段python代码,如果一切顺利,你会在目录中找到一个收录100行数据的csv文件,你可以很容易地用python读取和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
连接并获取网页内容
用 BeautifulSoup 处理得到的 html 数据
循环遍历汤对象以搜索所需的 html 元素
做简单的数据清洗
将数据写入 csv 文件
如果有什么不明白的,请在下方留言,我会尽力为您解答!
附:本文所有代码()
为您的爬行动物之旅有个美好的开始!
python网页数据抓取(就是一个解析xml和html之类的库,用着还算顺手 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-01 06:17
)
Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。简而言之,它是一个解析xml和html的库,使用起来相当方便。
官网地址:
下面介绍使用python和Beautiful Soup来爬取网页上的PM2.5数据。
网站 的 PM2.5 个数据:
这个网站有对应的PM2.5数据,他们在几个地方都有监视器,大约每小时更新一次(有时,仪器的数据会丢失)。我们要采集的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用 Beautiful Soup 解析 html 内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以通过标签名(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以得到对应的文本,比如“hello”,就可以得到“hello”
具体的元素类需要借助浏览器的检查元素功能来查看。
写文字:
主要使用python的with语法,with可以保证出现异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是一个打开的文件流,这意味着将 print 打印的内容重定向到文件。
记录:
由于这个程序要在后台运行很长时间,所以最好把错误信息记录下来,方便调试。使用了python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
其中包括一些,设置日志的格式,以及日志文件的最大大小。
预定操作:
定期操作,可以在每天指定时间捕获PM2.5数据,结合卫星过境时间做进一步分析。python自带的sched模块也经常用到。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是一个获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,它将继续运行。
完整代码下载(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认后台运行。
爬取结果:
查看全部
python网页数据抓取(就是一个解析xml和html之类的库,用着还算顺手
)
Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。简而言之,它是一个解析xml和html的库,使用起来相当方便。
官网地址:
下面介绍使用python和Beautiful Soup来爬取网页上的PM2.5数据。
网站 的 PM2.5 个数据:
这个网站有对应的PM2.5数据,他们在几个地方都有监视器,大约每小时更新一次(有时,仪器的数据会丢失)。我们要采集的数据是几个监测点的一些空气质量指标。
1 def getPM25():
2 url = "http://www.pm25.com/city/wuhan.html"
3
4 headers = {
5 "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
6 "Accept-Language":"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3",
7 "Connection":"keep-alive",
8 "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0",
9 }
10 try:
11 req = urllib2.Request(url,headers=headers)
12 response = urllib2.urlopen(req)
13 content = response.read()
14 response.close()
15 pm = BSoup(content,from_encoding="utf-8")
16 logging.info(pm.select(".citydata_updatetime")[0].get_text() + u" ")
17 with open('pm2dot5.txt','a') as f:
18 print>>f, pm.select(".citydata_updatetime")[0].get_text()
19 for locate in pm.select(".pj_area_data ul:nth-of-type(1) li"):
20 print>>f, locate.select(".pjadt_location")[0].get_text().rjust(15),"\t",\
21 locate.select(".pjadt_aqi")[0].get_text().rjust(15),"\t",\
22 locate.select(".pjadt_quality")[0].get_text().rjust(15),"\t",\
23 locate.select(".pjadt_wuranwu")[0].get_text().rjust(15),"\t",\
24 locate.select(".pjadt_pm25")[0].get_text().rjust(15),"\t",\
25 locate.select(".pjadt_pm10")[0].get_text().rjust(15)
26 print>>f, "\n\n\n"
27 return 0
28 except Exception,e:
29 logging.error(e)
30 return 1
主要使用python的库urllib2
提取标签内容
下面是使用 Beautiful Soup 解析 html 内容并提取标签中的值。具体功能请参考官方文档。
这里主要使用select方法和get_text方法。
select方法可以通过标签名(标签,如a、li、body)或css类或id来选择元素。
get_text 方法可以得到对应的文本,比如“hello”,就可以得到“hello”
具体的元素类需要借助浏览器的检查元素功能来查看。
写文字:
主要使用python的with语法,with可以保证出现异常时关闭打开的文件。同时使用了流重定向的一个小技巧,
print >> f, "hello" f 是一个打开的文件流,这意味着将 print 打印的内容重定向到文件。
记录:
由于这个程序要在后台运行很长时间,所以最好把错误信息记录下来,方便调试。使用了python自带的日志模块。
1 logging.basicConfig(level=logging.DEBUG,
2 format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
3 datefmt='%a, %d %b %Y %H:%M:%S',
4 filename='debug.log',
5 filemode='w')
6 console = logging.StreamHandler()
7 console.setLevel(logging.INFO)
8 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
9 console.setFormatter(formatter)
10 logging.getLogger('').addHandler(console)
11 Rthandler = RotatingFileHandler('debug.log', maxBytes=1*1024*1024,backupCount=5)
12 Rthandler.setLevel(logging.INFO)
13 formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
14 Rthandler.setFormatter(formatter)
15 logging.getLogger('').addHandler(Rthandler)
其中包括一些,设置日志的格式,以及日志文件的最大大小。
预定操作:
定期操作,可以在每天指定时间捕获PM2.5数据,结合卫星过境时间做进一步分析。python自带的sched模块也经常用到。
1 def run():
2 while True:
3 s = sched.scheduler(time.time, time.sleep)
4 s.enterabs(each_day_time(9,50,30), 1, getPM25, ())
5 try:
6 s.run()
7 except:
8 s.run()
9 time.sleep(60*60)
10 logging.info("second run")
11 while getPM25():
12 pass
13 time.sleep( 60*60)
14 logging.info("third run")
15 while getPM25():
16 pass
17 time.sleep(60*60)
18 logging.info("fourth run")
19 while getPM25():
20 pass
21 logging.info(u"\n\n等待下次运行...")
其中 each_day_time 是一个获取指定时间的函数
1 def each_day_time(hour,minute,sec):
2 today = datetime.datetime.today()
3 today = datetime.datetime(today.year,today.month,today.day,hour,minute,sec)
4 tomorrow = today + datetime.timedelta(days=1)
5 xtime = time.mktime(tomorrow.timetuple())
6 #xtime = time.mktime(today.timetuple())
7 return xtime
此外,如果指定的时间已过,它将继续运行。
完整代码下载(python 2.7):
另:直接双击pyw文件,会调用pythonw.exe执行,如果没有GUI,默认后台运行。
爬取结果:
python网页数据抓取(如何通过URL打开一个网页的URL模块解析HTML二)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-29 23:27
二、打开 HTML 文档
上面描述了如何解析页面的URL。现在让我们解释如何通过 URL 打开网页。事实上,Python 附带的 urllib 和 urllib2 模块为我们提供了从 URL 中打开和检索数据的能力,当然也包括 HTML 文档。
importurllib
u=urllib.urlopen(webURL)
u=urllib.urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
要通过 urllib 模块中的 urlopen(url[,data]) 函数打开 HTML 文档,必须提供文档的 URL 地址,包括文件名。函数 urlopen 不仅可以打开位于远程 Web 服务器上的文件,还可以打开本地文件并返回一个类似文件的对象,通过该对象我们可以从 HTML 文档中读取数据。
打开 HTML 文档后,我们可以像普通文件一样使用 read([nbytes])、readline() 和 readlines() 函数读取文件。要读取整个 HTML 文档的内容,可以使用 read() 函数,它将文件内容作为字符串返回。
打开地址后,您可以使用 geturl() 函数获取被抓取页面的实际 URL。这很有用,因为 urlopen(或使用的 opener 对象)可能伴随着重定向。获取的网页网址可能与请求的网页网址不同。
另一个常用的函数是位于从urlopen返回的类文件对象中的info()函数。此函数返回有关 URL 位置的元数据,例如内容长度、内容类型等。下面通过更详细的示例来描述这些功能。
importurllib
webURL="
buffer=u.read()()print"从%s读取%d字节数据。\n"%(u.geturl(),len(buffer))#通过URL打开本地页面u= urllib. urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
以上代码运行结果如下:
日期:2009 年 6 月 26 日星期五:格林威治标准时间 22:11
服务器:Apache/2.2.9(Debian) DAV/2SVN/1.5.1mod_ssl/2.2.9OpenSSL/< @0.9.8g mod_wsgi/2.3Python/2.5.2Last-Modified: Thu,25Jun200909:44:54GMT
ETag:"105800d-46e7-46d29136f7180"接受范围:字节
内容长度:18151连接:关闭
内容类型:文本/html
已读取 18151 字节的数据。
内容类型:文本/html
Content-Length:865Last-modified: Fri,26Jun200910:16:10GMT
从 index.html 读取 865 字节的数据。
三、总结
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用程序,通常使用网页(即 HTML 文件)的解析。事实上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。在本文中,我们介绍了一个 Python 模块,它可以帮助简化打开位于本地和 Web 上的 HTML 文档。在下一篇文章中,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据,以处理链接、图像和 cookie 等特定内容。 查看全部
python网页数据抓取(如何通过URL打开一个网页的URL模块解析HTML二)
二、打开 HTML 文档
上面描述了如何解析页面的URL。现在让我们解释如何通过 URL 打开网页。事实上,Python 附带的 urllib 和 urllib2 模块为我们提供了从 URL 中打开和检索数据的能力,当然也包括 HTML 文档。
importurllib
u=urllib.urlopen(webURL)
u=urllib.urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
要通过 urllib 模块中的 urlopen(url[,data]) 函数打开 HTML 文档,必须提供文档的 URL 地址,包括文件名。函数 urlopen 不仅可以打开位于远程 Web 服务器上的文件,还可以打开本地文件并返回一个类似文件的对象,通过该对象我们可以从 HTML 文档中读取数据。
打开 HTML 文档后,我们可以像普通文件一样使用 read([nbytes])、readline() 和 readlines() 函数读取文件。要读取整个 HTML 文档的内容,可以使用 read() 函数,它将文件内容作为字符串返回。
打开地址后,您可以使用 geturl() 函数获取被抓取页面的实际 URL。这很有用,因为 urlopen(或使用的 opener 对象)可能伴随着重定向。获取的网页网址可能与请求的网页网址不同。
另一个常用的函数是位于从urlopen返回的类文件对象中的info()函数。此函数返回有关 URL 位置的元数据,例如内容长度、内容类型等。下面通过更详细的示例来描述这些功能。
importurllib
webURL="
buffer=u.read()()print"从%s读取%d字节数据。\n"%(u.geturl(),len(buffer))#通过URL打开本地页面u= urllib. urlopen(localURL)
buffer=u.read()()print"从 %s 读取 %d 个字节的数据。\n"%(u.geturl(),len(buffer))
以上代码运行结果如下:
日期:2009 年 6 月 26 日星期五:格林威治标准时间 22:11
服务器:Apache/2.2.9(Debian) DAV/2SVN/1.5.1mod_ssl/2.2.9OpenSSL/< @0.9.8g mod_wsgi/2.3Python/2.5.2Last-Modified: Thu,25Jun200909:44:54GMT
ETag:"105800d-46e7-46d29136f7180"接受范围:字节
内容长度:18151连接:关闭
内容类型:文本/html
已读取 18151 字节的数据。
内容类型:文本/html
Content-Length:865Last-modified: Fri,26Jun200910:16:10GMT
从 index.html 读取 865 字节的数据。
三、总结
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用程序,通常使用网页(即 HTML 文件)的解析。事实上,通过 Python 语言提供的各种模块,我们可以在不借助 Web 服务器或 Web 浏览器的情况下解析和处理 HTML 文档。在本文中,我们介绍了一个 Python 模块,它可以帮助简化打开位于本地和 Web 上的 HTML 文档。在下一篇文章中,我们将讨论如何使用 Python 模块快速解析 HTML 文件中的数据,以处理链接、图像和 cookie 等特定内容。
python网页数据抓取( 怎么用Python从多个网址中爬取内容?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-29 07:08
怎么用Python从多个网址中爬取内容?(图))
python批量抓取网页数据
如何使用 Python 从多个 URL 中抓取内容?
&&& 调用requests包,BeautifulSoup4包,可以实现,网页内容用excel写不是很好,建议写txt或者xml。如果要写入Excel,可以调用pandas包或者openpyxl包
如何使用Python爬虫批量获取网页所需信息
&&& python 是一种使用非常广泛的脚本语言。Google 的网页是用 python 编写的。python在生物信息学、统计学、网页制作、计算等诸多领域都展现出了强大的功能。python和其他脚本语言如java、R、Perl,可以直接在命令行运行脚本程序...
使用 python 抓取网络数据 -
&&& 使用python爬取web数据三步,使用scrapy(爬虫框架)1.定义item类2.开发蜘蛛类3.如果不会开发管道,可以看看“疯狂的 Python 讲座”
如何使用python爬取一个网站的页数
&&& 1. 这个要根据你的网站地址分析,构造网站的url,通过for循环进行统计输出,从而计算出一个网页的网页数网站。2. 由于你没有给出具体网站的地址,我只能告诉你如上的过程。希望采纳,希望对你有帮助......
如何使用python抓取网页数据
&&& 推荐:《pyspider爬虫教程(二):AJAX和HTTP)-forkworm因为AJAX实际上是通过HTTP传输数据的,所以我们可以通过Chrome开发者工具找到真正的请求,直接发起真正的请求即可获取数据通过抓取请求,AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般简称为XHR。
如何用最简单的Python爬取采集整个网站——
&&& 在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个随机的网站从一个链接到另一个链接,但是,如果我们需要系统地编目整个网站,或者搜索网站上的每一页,我们应该怎么做?我们需要 采集…
如何用 Python 抓取动态加载的网页数据——
&&& 动态网页爬取是一种典型的方法1. 直接查看动态网页的加载规则。如果是ajax,找出对python的ajax请求。如果是js去那个地方后生成的URL。弄清楚规则。然后让python生成URL。这是常用的方法2. 方法二,用python调用webkit内核、IE内核,或者有firefox内核的浏览器。然后保存浏览结果。通常你可以使用浏览器测试框架。他们内置了这些功能3. 方法3,通过http代理,抓取内容并组装。您甚至可以嵌入自己的 js 脚本进行挂钩。这种方法通常用于系统逆向工程软件
如何使用python爬取网页上的表格信息——
&&& 有点背景,当时想研究一下蛋白质和小分子复合物的三维结构的一些规律。首先,我必须有数据。数据从何而来?从分子复合物数据库中下载。这时候,手动一一下载显然是不可能的了……
Python爬虫问题,如何爬取多个页面——
&&& 将网页的页面源保存到数据库(mongodb),是否每次都要等待新的页面源和页面源在数据库中的hash值?该策略很容易处理。自己做。 查看全部
python网页数据抓取(
怎么用Python从多个网址中爬取内容?(图))
python批量抓取网页数据
如何使用 Python 从多个 URL 中抓取内容?
&&& 调用requests包,BeautifulSoup4包,可以实现,网页内容用excel写不是很好,建议写txt或者xml。如果要写入Excel,可以调用pandas包或者openpyxl包
如何使用Python爬虫批量获取网页所需信息
&&& python 是一种使用非常广泛的脚本语言。Google 的网页是用 python 编写的。python在生物信息学、统计学、网页制作、计算等诸多领域都展现出了强大的功能。python和其他脚本语言如java、R、Perl,可以直接在命令行运行脚本程序...
使用 python 抓取网络数据 -
&&& 使用python爬取web数据三步,使用scrapy(爬虫框架)1.定义item类2.开发蜘蛛类3.如果不会开发管道,可以看看“疯狂的 Python 讲座”
如何使用python爬取一个网站的页数
&&& 1. 这个要根据你的网站地址分析,构造网站的url,通过for循环进行统计输出,从而计算出一个网页的网页数网站。2. 由于你没有给出具体网站的地址,我只能告诉你如上的过程。希望采纳,希望对你有帮助......
如何使用python抓取网页数据
&&& 推荐:《pyspider爬虫教程(二):AJAX和HTTP)-forkworm因为AJAX实际上是通过HTTP传输数据的,所以我们可以通过Chrome开发者工具找到真正的请求,直接发起真正的请求即可获取数据通过抓取请求,AJAX一般通过XMLHttpRequest对象接口发送请求,XMLHttpRequest一般简称为XHR。
如何用最简单的Python爬取采集整个网站——
&&& 在之前的文章 Python实现“维基百科六度分离理论”基础爬虫中,我们实现了一个随机的网站从一个链接到另一个链接,但是,如果我们需要系统地编目整个网站,或者搜索网站上的每一页,我们应该怎么做?我们需要 采集…
如何用 Python 抓取动态加载的网页数据——
&&& 动态网页爬取是一种典型的方法1. 直接查看动态网页的加载规则。如果是ajax,找出对python的ajax请求。如果是js去那个地方后生成的URL。弄清楚规则。然后让python生成URL。这是常用的方法2. 方法二,用python调用webkit内核、IE内核,或者有firefox内核的浏览器。然后保存浏览结果。通常你可以使用浏览器测试框架。他们内置了这些功能3. 方法3,通过http代理,抓取内容并组装。您甚至可以嵌入自己的 js 脚本进行挂钩。这种方法通常用于系统逆向工程软件
如何使用python爬取网页上的表格信息——
&&& 有点背景,当时想研究一下蛋白质和小分子复合物的三维结构的一些规律。首先,我必须有数据。数据从何而来?从分子复合物数据库中下载。这时候,手动一一下载显然是不可能的了……
Python爬虫问题,如何爬取多个页面——
&&& 将网页的页面源保存到数据库(mongodb),是否每次都要等待新的页面源和页面源在数据库中的hash值?该策略很容易处理。自己做。
python网页数据抓取(Python程序设计有所匹配及字符串与URL操作的相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-29 07:07
本文文章主要介绍Python抓取百度查询结果的方法,涉及Python正则匹配以及字符串和URL操作的相关技巧。有需要的朋友可以参考以下
本文示例介绍了Python爬取百度查询结果的方法。分享给大家,供大家参考。具体实现方法如下:
#win python 2.7.x
import re,sys,urllib,codecs
xh = urllib.urlopen("http://www.baidu.com/s?q1=123&rn=100").read().decode('utf-8')
rc = re.compile(r'(?P.*?)',re.I)
match = rc.finditer(xh)
rcr = re.compile(r']+>',re.I)
f = codecs.open("xiaohei.txt", "w", "utf-8")
for i in rc.finditer(xh):
ss = i.group(0)
s1 = rcr.sub('',ss)
print (s1)
f.write(s1)
f.close()
希望本文对您的 Python 编程有所帮助。 查看全部
python网页数据抓取(Python程序设计有所匹配及字符串与URL操作的相关技巧)
本文文章主要介绍Python抓取百度查询结果的方法,涉及Python正则匹配以及字符串和URL操作的相关技巧。有需要的朋友可以参考以下
本文示例介绍了Python爬取百度查询结果的方法。分享给大家,供大家参考。具体实现方法如下:
#win python 2.7.x
import re,sys,urllib,codecs
xh = urllib.urlopen("http://www.baidu.com/s?q1=123&rn=100";).read().decode('utf-8')
rc = re.compile(r'(?P.*?)',re.I)
match = rc.finditer(xh)
rcr = re.compile(r']+>',re.I)
f = codecs.open("xiaohei.txt", "w", "utf-8")
for i in rc.finditer(xh):
ss = i.group(0)
s1 = rcr.sub('',ss)
print (s1)
f.write(s1)
f.close()
希望本文对您的 Python 编程有所帮助。
python网页数据抓取(爬虫Python入门好学吗?学爬虫需要具备一定的Python基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-27 19:14
学习爬虫 Python 入门容易吗?
学习爬虫需要有一定的Python基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
Python爬虫入门的三个阶段:
1.零基阶段
从零开始学爬虫,系统上手,从0开始爬虫。除了必要的理论知识,更重要的是爬虫的实际应用。捕获主流网站数据的能力是这个阶段的学习目标。
学习重点:
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学习后,可以彻底玩转Scrapy框架,开发属于自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习重点:
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从此,拓展您的爬虫业务,提升您的核心竞争力。掌握app数据采集,实现数据可视化。
学习重点:
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。
很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。 查看全部
python网页数据抓取(爬虫Python入门好学吗?学爬虫需要具备一定的Python基础)
学习爬虫 Python 入门容易吗?
学习爬虫需要有一定的Python基础,有编程基础的Python爬虫比较容易学习。但是你要多看多练,要有自己的逻辑思路。使用 Python 来实现自己的学习目的是值得的。如果是入门学习和理解,开始学习不难,但是很难深入学习,尤其是大型项目。
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,模拟使用浏览器获取网页信息的过程。向服务器发送请求后,我们会得到返回的页面。解析完页面后,我们就可以提取出我们想要的部分信息,存储到指定的文档或数据库中。
Python爬虫入门的三个阶段:
1.零基阶段
从零开始学爬虫,系统上手,从0开始爬虫。除了必要的理论知识,更重要的是爬虫的实际应用。捕获主流网站数据的能力是这个阶段的学习目标。
学习重点:
二、主流框架
主流框架Scrapy,实现海量数据抓取,提升从原生爬虫到框架的能力。学习后,可以彻底玩转Scrapy框架,开发属于自己的分布式爬虫系统,完全胜任Python中级工程师的工作。获得高效捕获大量数据的能力。
学习重点:
三、爬虫
深度App数据抓取,爬虫能力提升,处理App数据抓取和数据可视化的能力不再局限于网络爬虫。从此,拓展您的爬虫业务,提升您的核心竞争力。掌握app数据采集,实现数据可视化。
学习重点:
爬虫 Python 应用在很多领域,比如爬取数据、进行市场调研和商业分析;作为机器学习和数据挖掘的原创数据;爬取优质资源:图片、文字、视频。
很容易掌握正确的方法,能够在短时间内爬取主流的网站数据。建议从爬虫 Python 入口开始就设置一个特定的目标。在目标的驱动下,学习会更有效率。
python网页数据抓取(提取(59,805805)()已确认))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-25 11:11
获取网页数据不返回结果问题描述票数:0 答案:1
我正在尝试从提到的 URL (59,805) 中提取数据。我正在使用 BeautifulSoup 并请求 Python 包。
下面是我正在尝试的代码,但它没有给我任何结果。下面是我尝试从中提取的 HTML 代码。结果应该是“已确认”,59,805
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
case_type = []
count = []
url = requests.get('https://www.covid19india.org/')
soup = bs(url.content,'html.parser')
for a in soup.findAll('div', attrs={'class':'level-item is-cherry fadeInUp'}):
b = a.find('h1')
c = a.find('h5')
case_type.append(c.text)
count.append(b.text)
df = pd.DataFrame({'Case Type':case_type, 'Count':count})
print(df)
来自该页面的 HTML 片段
Confirmed
[+115]
59,805
Active
39,914
Recovered
[+14]
17,901
1 个回答
投票
这个 网站 是在 React 中创建的,所以你得到的请求不会收录所有 网站 内容,因为它是动态加载的
如果您查看加载时发出的网站网络请求,您会看到此信息来自:
https://api.covid19india.org/data.json
所以你可以(假设你不影响网站性能/有权限)这样做:
r = requests.get('https://api.covid19india.org/data.json')
j = r.json()
confirmed = j['statewise'][0]['confirmed']
print(confirmed)
热门问题 查看全部
python网页数据抓取(提取(59,805805)()已确认))
获取网页数据不返回结果问题描述票数:0 答案:1
我正在尝试从提到的 URL (59,805) 中提取数据。我正在使用 BeautifulSoup 并请求 Python 包。
下面是我正在尝试的代码,但它没有给我任何结果。下面是我尝试从中提取的 HTML 代码。结果应该是“已确认”,59,805
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
case_type = []
count = []
url = requests.get('https://www.covid19india.org/')
soup = bs(url.content,'html.parser')
for a in soup.findAll('div', attrs={'class':'level-item is-cherry fadeInUp'}):
b = a.find('h1')
c = a.find('h5')
case_type.append(c.text)
count.append(b.text)
df = pd.DataFrame({'Case Type':case_type, 'Count':count})
print(df)
来自该页面的 HTML 片段
Confirmed
[+115]
59,805
Active
39,914
Recovered
[+14]
17,901
1 个回答
投票
这个 网站 是在 React 中创建的,所以你得到的请求不会收录所有 网站 内容,因为它是动态加载的
如果您查看加载时发出的网站网络请求,您会看到此信息来自:
https://api.covid19india.org/data.json
所以你可以(假设你不影响网站性能/有权限)这样做:
r = requests.get('https://api.covid19india.org/data.json')
j = r.json()
confirmed = j['statewise'][0]['confirmed']
print(confirmed)
热门问题
python网页数据抓取(奔腾不息的自信是真正的成功之母())
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-24 14:04
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。 查看全部
python网页数据抓取(奔腾不息的自信是真正的成功之母())
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。
python网页数据抓取(几款Python开源爬虫软件工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-23 10:07
说起Python,可以说是耳熟能详了。它是近年来非常流行的编程语言。大多数人使用它来开始爬虫,即使我也不例外。今天,我们就来看看几款Python开源爬虫软件工具。
一、快速侦察
QuickRecon 是一个简单的信息采集工具,可以帮助您查找子域名、执行区域传输、采集电子邮件地址和使用微格式查找关系等。QuickRecon 是用 python 编写的,支持 linux 和 windows 操作系统。
许可协议:GPLv3
开发语言:Python
操作系统:Windows、Linux
功能:查找子域名、采集电子邮件地址、查找关系等。
二、PyRailgun
这是一个非常简单易用的爬虫。一个简单、实用、高效的python网络爬虫爬取模块,支持爬取javascript渲染的页面。
许可协议:麻省理工学院
开发语言:Python
操作系统:跨平台、Windows、Linux、OS X
特点:简单、轻量、高效的网页抓取框架。
三、Scrapy
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现爬取网页内容和各种图片的爬虫,非常方便。
许可协议:BSD
开发语言:Python
操作系统:跨平台
特点:基于 Twisted 的异步处理框架,文档完整。 查看全部
python网页数据抓取(几款Python开源爬虫软件工具)
说起Python,可以说是耳熟能详了。它是近年来非常流行的编程语言。大多数人使用它来开始爬虫,即使我也不例外。今天,我们就来看看几款Python开源爬虫软件工具。
一、快速侦察
QuickRecon 是一个简单的信息采集工具,可以帮助您查找子域名、执行区域传输、采集电子邮件地址和使用微格式查找关系等。QuickRecon 是用 python 编写的,支持 linux 和 windows 操作系统。
许可协议:GPLv3
开发语言:Python
操作系统:Windows、Linux
功能:查找子域名、采集电子邮件地址、查找关系等。
二、PyRailgun
这是一个非常简单易用的爬虫。一个简单、实用、高效的python网络爬虫爬取模块,支持爬取javascript渲染的页面。
许可协议:麻省理工学院
开发语言:Python
操作系统:跨平台、Windows、Linux、OS X
特点:简单、轻量、高效的网页抓取框架。
三、Scrapy
Scrapy是一个基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需要自定义开发几个模块,就可以轻松实现爬取网页内容和各种图片的爬虫,非常方便。
许可协议:BSD
开发语言:Python
操作系统:跨平台
特点:基于 Twisted 的异步处理框架,文档完整。
python网页数据抓取( 利用万维网的力量为您的数据驱动策略提供信息吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-22 13:15
利用万维网的力量为您的数据驱动策略提供信息吗?
)
您想利用互联网的力量来制定您的数据驱动战略吗?
您是否希望在零售、在线销售、房地产和地理定位服务方面获得优势?
您想将 文章 和网页中的非结构化数据转化为真正的洞察吗?
您想开发尖端分析和可视化以利用万维网吗?
精通网络抓取(和相关分析)可以帮助您利用万维网上免费提供的数据和信息的力量,并将其转化为可行的见解
我的课程是通过真实的网页抓取示例进行实践培训 - 您将学习使用重要的 Python 网页抓取库 BeautifulSoup 并从不同的网页中获取信息和见解
我的课程为进行实际的、真实的网络抓取奠定了基础。通过学习本课程,您将在数据科学之旅中迈出重要的一步,并成为利用万维网的力量获得洞察力的专家。
本课程将帮助您使用名为 GoogleColab 的强大的基于云的 Python 环境熟练掌握 BeautifulSoup(用于网络抓取)、网络数据处理和分析。具体来说,您将
精通设置和使用 Google CoLab 进行 Python 数据科学任务
在维基百科页面上执行常见的网络抓取任务并提取相关信息
处理复杂的网页并提取信息
以可用的形式处理提取的信息
进行基本的地理编码
执行常见的分析和可视化任务
您将从事与 (a) 伦敦行政区地理编码 (b) 量化孟买房地产价格变化 (c) 提取财务报表等相关的实用小型案例研究。
为什么要上这门课?
作者拥有英国牛津大学的硕士学位(地理与环境)。他还在剑桥大学(热带生态与保护)完成了数据科学密集型博士学位。
作者在分析来自各种来源的真实数据和为国际同行评审期刊出版出版物方面拥有多年经验。
您将学习:
在 Google CoLab 中使用 Python 进行实际数据科学的能力
网络基础
爬取常见的维基百科页面信息
使用 BeautifulSoup(通用 Python 库)转换复杂的 Web 信息
基本地理编码
数据处理和清理以从抓取的数据中提取信息
分析抓取和清理的数据以获得可操作的见解
数据可视化
使用实际示例 – (a) 对伦敦行政区进行地理编码 (b) 获取孟买的公寓价格 (c) 提取亚马逊评论
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2 通道
类型:电子学习 | 语言:英语 + srt | 时长:51 节课(5h 47m)| 大小:2.25 GB
使用 Python 和 Google CoLab 从网页中检索信息以进行分析和洞察
查看全部
python网页数据抓取(
利用万维网的力量为您的数据驱动策略提供信息吗?
)
您想利用互联网的力量来制定您的数据驱动战略吗?
您是否希望在零售、在线销售、房地产和地理定位服务方面获得优势?
您想将 文章 和网页中的非结构化数据转化为真正的洞察吗?
您想开发尖端分析和可视化以利用万维网吗?
精通网络抓取(和相关分析)可以帮助您利用万维网上免费提供的数据和信息的力量,并将其转化为可行的见解
我的课程是通过真实的网页抓取示例进行实践培训 - 您将学习使用重要的 Python 网页抓取库 BeautifulSoup 并从不同的网页中获取信息和见解
我的课程为进行实际的、真实的网络抓取奠定了基础。通过学习本课程,您将在数据科学之旅中迈出重要的一步,并成为利用万维网的力量获得洞察力的专家。
本课程将帮助您使用名为 GoogleColab 的强大的基于云的 Python 环境熟练掌握 BeautifulSoup(用于网络抓取)、网络数据处理和分析。具体来说,您将
精通设置和使用 Google CoLab 进行 Python 数据科学任务
在维基百科页面上执行常见的网络抓取任务并提取相关信息
处理复杂的网页并提取信息
以可用的形式处理提取的信息
进行基本的地理编码
执行常见的分析和可视化任务
您将从事与 (a) 伦敦行政区地理编码 (b) 量化孟买房地产价格变化 (c) 提取财务报表等相关的实用小型案例研究。
为什么要上这门课?
作者拥有英国牛津大学的硕士学位(地理与环境)。他还在剑桥大学(热带生态与保护)完成了数据科学密集型博士学位。
作者在分析来自各种来源的真实数据和为国际同行评审期刊出版出版物方面拥有多年经验。
您将学习:
在 Google CoLab 中使用 Python 进行实际数据科学的能力
网络基础
爬取常见的维基百科页面信息
使用 BeautifulSoup(通用 Python 库)转换复杂的 Web 信息
基本地理编码
数据处理和清理以从抓取的数据中提取信息
分析抓取和清理的数据以获得可操作的见解
数据可视化
使用实际示例 – (a) 对伦敦行政区进行地理编码 (b) 获取孟买的公寓价格 (c) 提取亚马逊评论
MP4 | 视频:h264, 1280×720 | 音频:AAC,44.1 KHz,2 通道
类型:电子学习 | 语言:英语 + srt | 时长:51 节课(5h 47m)| 大小:2.25 GB
使用 Python 和 Google CoLab 从网页中检索信息以进行分析和洞察
https://www.loowp.com/wp-conte ... 0.jpg 593w" /> python网页数据抓取(python3.X中编写代码以及在anaconda中的网络抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-20 10:13
我正在尝试根据地理位置抓取 Instagram 和 Twitter。我可以运行查询搜索,但在将网页重新加载到更多并将字段存储到数据框时遇到了挑战。
我确实找到了几个没有 API 密钥的网页抓取 twitter 和 Instagram 的例子。但它们与#tags 关键字有关。
我正在尝试根据地理位置和旧日期进行抓取。到目前为止,我已经在 python 3.X 和 anaconda 中编写了所有最新版本的软件包。
'''
Instagram - Components
"id": "1478232643287060472",
"dimensions": {"height": 1080, "width": 1080},
"owner": {"id": "351633262"},
"thumbnail_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"is_video": false,
"code": "BSDvMHOgw_4",
"date": 1490439084,
"taken-at=213385402"
"display_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"caption": "Hakuna jambo zuri kama kumpa Mungu shukrani kwa kila jambo.. \ud83d\ude4f\ud83c\udffe\nIts weekend\n#lifeistooshorttobeunhappy\n#Godisgood \n#happysoul \ud83d\ude00",
"comments": {"count": 42},
"likes": {"count": 3813}},
'''
import selenium
from selenium import webdriver
#from selenium import selenium
from bs4 import BeautifulSoup
import pandas
#geotags = pd.read_csv("geocodes.csv")
#parmalink =
query = geocode%3A35.68501%2C139.7514%2C30km%20since:2016-03-01%20until:2016-03-02&f=tweets
twitterURL = 'https://twitter.com/search?q=' + query
#instaURL = "https://www.instagram.com/expl ... ot%3B
browser = webdriver.Firefox()
browser.get(twitterURL)
content = browser.page_source
soup = BeautifulSoup(content)
print (soup)
我收到 Twitter 搜索查询的语法错误
对于 Instagram,我没有收到任何错误,但我无法重新加载更多帖子并写回 csv 数据框。
我还尝试在 Twitter 和 Instagram 中使用经纬度搜索进行搜索。
我在 csv 中有一个地理坐标列表,可用于输入或编写搜索查询。
任何完成位置抓取的方法都将不胜感激。
谢谢您的帮助!! 查看全部
python网页数据抓取(python3.X中编写代码以及在anaconda中的网络抓取)
我正在尝试根据地理位置抓取 Instagram 和 Twitter。我可以运行查询搜索,但在将网页重新加载到更多并将字段存储到数据框时遇到了挑战。
我确实找到了几个没有 API 密钥的网页抓取 twitter 和 Instagram 的例子。但它们与#tags 关键字有关。
我正在尝试根据地理位置和旧日期进行抓取。到目前为止,我已经在 python 3.X 和 anaconda 中编写了所有最新版本的软件包。
'''
Instagram - Components
"id": "1478232643287060472",
"dimensions": {"height": 1080, "width": 1080},
"owner": {"id": "351633262"},
"thumbnail_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"is_video": false,
"code": "BSDvMHOgw_4",
"date": 1490439084,
"taken-at=213385402"
"display_src": "https://instagram.fdel1-1.fna. ... ot%3B,
"caption": "Hakuna jambo zuri kama kumpa Mungu shukrani kwa kila jambo.. \ud83d\ude4f\ud83c\udffe\nIts weekend\n#lifeistooshorttobeunhappy\n#Godisgood \n#happysoul \ud83d\ude00",
"comments": {"count": 42},
"likes": {"count": 3813}},
'''
import selenium
from selenium import webdriver
#from selenium import selenium
from bs4 import BeautifulSoup
import pandas
#geotags = pd.read_csv("geocodes.csv")
#parmalink =
query = geocode%3A35.68501%2C139.7514%2C30km%20since:2016-03-01%20until:2016-03-02&f=tweets
twitterURL = 'https://twitter.com/search?q=' + query
#instaURL = "https://www.instagram.com/expl ... ot%3B
browser = webdriver.Firefox()
browser.get(twitterURL)
content = browser.page_source
soup = BeautifulSoup(content)
print (soup)
我收到 Twitter 搜索查询的语法错误
对于 Instagram,我没有收到任何错误,但我无法重新加载更多帖子并写回 csv 数据框。
我还尝试在 Twitter 和 Instagram 中使用经纬度搜索进行搜索。
我在 csv 中有一个地理坐标列表,可用于输入或编写搜索查询。
任何完成位置抓取的方法都将不胜感激。
谢谢您的帮助!!
python网页数据抓取(Python基础知识:函数用于测试程序管理函数的执行顺序例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-20 10:12
)
如果服务器能正常响应,就会得到一个Response,就是要获取的页面内容。
解析内容
获取的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
二.准备工作1.网页路径规则
从 1 日开始显示
26日起上映
2.网址分析
页面收录250条电影数据,分为10页,每页25条
各页面URL的区别:最终值=(pages - 1)* 25
3.分析页面
使用Chrome开发者工具(F12)分析网页,在Elements下找到需要的数据位置
在页面中选择一个元素来检查它 Ctrl + Shift + C
网络下刷新URL后可以看到所有访问请求的时间线
Headers:发送给浏览器的当前访问信息
User-Agent:浏览器信息
需要登录的网页使用 cookie
4.编码规范
1.一般Python程序的第一行需要加上
#-*- coding: utf-8 -*-或者# coding=utf-8
这允许在代码中收录中文
2.在Python中,使用函数来实现单个函数或相关函数的代码段,可以提高可读性和代码复用,
函数块以 def关键词 开头,后跟空格、函数标识符的名称、括号 () 和冒号:
参数可以用括号传递,函数段缩进(制表符或四个空格,只能选择其中一个),
return 用于结束函数,可以返回一个值,也可以不带任何表达式(意思是返回None)
3.可以将main函数添加到Python文件中,用于测试程序
if __name__ == "__main__":
适合管理函数的执行顺序
例子:
#-*- coding: utf-8 -*-
def main():
print("hello")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
4.Python用#加注释来解释代码(段)的作用
三.引入模块1.模块(模块)
用于对 Python 代码(变量、函数、类)进行逻辑组织,本质上是一个 py 文件,用于提高代码的可维护性。
Python使用import来导入模块,比如import sys
例子:
test1 文件夹中有 t1.py
def add(a,b):
return a+b
我想在 test2 文件夹中的 t2.py 中调用 t1 中的函数
#引入自定义模块
from test1 import t1
print(t1.add(2,3))
#介绍系统的模块
import sys
import os
#引入第三方模块(这些是本项目要使用的模块)
import bs4 #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
由于我使用的工具是vs2019,它的第三方模块加载为
在这里输入你要查找的包名,比如bs4
只需点击 pip install bs4
该程序现在
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250"
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
saveData(savepath)
#爬取网页
def getData(baseurl):
datelist=[]
#2.逐一解析数据
return datalist
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
2.获取数据
Python一般使用urllib库来获取页面
获取页面数据
urllib 测试
urllib test_ai 的博客 - CSDN 博客
获取数据获取指定URL的网页内容
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=")
#爬取网页
def getData(baseurl):
datalist=[]
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
查看内容,发现获取到网页的数据
爬网
带循环结构的换页
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
当前代码
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=")
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
添加 BeautifulSoup 用于 html 文件解析
BeautifulSoup用于html文件解析 - 程序员大本营
补充re模块:正则表达式
re 模块:正则表达式_ai的博客 - CSDN博客
正则提取得到每部电影的相关信息
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
print(item)
创建指向视频第一页的超链接
. . . . . . . .
截断一部电影的item信息,提取所有需要的东西,然后添加一个循环
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,1): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
#print(item) #测试:查看电影item全部信息
data=[] #保存一部电影的全部信息
item=str(item)
print(item)
break
#影片详情的链接
link=re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,[0]表示如果有两个,只要第一个
print(link)
return datalist
将其保存到 html 文档中进行比较
1
肖申克的救赎
/ The Shawshank Redemption
/ 月黑高飞(港) / 刺激1995(台)
[可播放]
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
9.7
2523850人评价
希望让人自由。
</p>
将需要提取的相关东西转化为正则表达式,设置为全局变量
<p>#影片详情的链接的规则
findLink=re.compile(r'<a href="(.*?)">') #创建正则表达式,表示规则(字符串模式)
#影片图片
findImgSrc=re.compile(r' 查看全部
python网页数据抓取(Python基础知识:函数用于测试程序管理函数的执行顺序例子
)
如果服务器能正常响应,就会得到一个Response,就是要获取的页面内容。
解析内容
获取的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
二.准备工作1.网页路径规则
从 1 日开始显示
26日起上映
2.网址分析
页面收录250条电影数据,分为10页,每页25条
各页面URL的区别:最终值=(pages - 1)* 25
3.分析页面
使用Chrome开发者工具(F12)分析网页,在Elements下找到需要的数据位置
在页面中选择一个元素来检查它 Ctrl + Shift + C
网络下刷新URL后可以看到所有访问请求的时间线
Headers:发送给浏览器的当前访问信息
User-Agent:浏览器信息
需要登录的网页使用 cookie
4.编码规范
1.一般Python程序的第一行需要加上
#-*- coding: utf-8 -*-或者# coding=utf-8
这允许在代码中收录中文
2.在Python中,使用函数来实现单个函数或相关函数的代码段,可以提高可读性和代码复用,
函数块以 def关键词 开头,后跟空格、函数标识符的名称、括号 () 和冒号:
参数可以用括号传递,函数段缩进(制表符或四个空格,只能选择其中一个),
return 用于结束函数,可以返回一个值,也可以不带任何表达式(意思是返回None)
3.可以将main函数添加到Python文件中,用于测试程序
if __name__ == "__main__":
适合管理函数的执行顺序
例子:
#-*- coding: utf-8 -*-
def main():
print("hello")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
4.Python用#加注释来解释代码(段)的作用
三.引入模块1.模块(模块)
用于对 Python 代码(变量、函数、类)进行逻辑组织,本质上是一个 py 文件,用于提高代码的可维护性。
Python使用import来导入模块,比如import sys
例子:
test1 文件夹中有 t1.py
def add(a,b):
return a+b
我想在 test2 文件夹中的 t2.py 中调用 t1 中的函数
#引入自定义模块
from test1 import t1
print(t1.add(2,3))
#介绍系统的模块
import sys
import os
#引入第三方模块(这些是本项目要使用的模块)
import bs4 #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
由于我使用的工具是vs2019,它的第三方模块加载为
在这里输入你要查找的包名,比如bs4
只需点击 pip install bs4
该程序现在
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250"
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
saveData(savepath)
#爬取网页
def getData(baseurl):
datelist=[]
#2.逐一解析数据
return datalist
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
2.获取数据
Python一般使用urllib库来获取页面
获取页面数据
urllib 测试
urllib test_ai 的博客 - CSDN 博客
获取数据获取指定URL的网页内容
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=";)
#爬取网页
def getData(baseurl):
datalist=[]
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
查看内容,发现获取到网页的数据
爬网
带循环结构的换页
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
当前代码
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网络数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath=".\\豆瓣电影Top250.xls" #当前文件夹下
#3.保存数据
#saveData(savepath)
askURL("https://movie.douban.com/top250?start=";)
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
return datalist
#得到一个指定URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送信息
head={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是高速浏览器,我们可以接受什么水平的信息)
request=urllib.request.Request(url,headers=head)
html=""
try:
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e: #捕获错误
if hasattr(e,"code"):
print(e.code) #打印错误代码
if hasattr(e,"reason"):
print(e.reason) #打印错误原因
return html
#保存数据
def saveData(savepath):
print("save.....")
if __name__ == "__main__": #当程序执行时
#调用函数
main()
添加 BeautifulSoup 用于 html 文件解析
BeautifulSoup用于html文件解析 - 程序员大本营
补充re模块:正则表达式
re 模块:正则表达式_ai的博客 - CSDN博客
正则提取得到每部电影的相关信息
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
print(item)
创建指向视频第一页的超链接
. . . . . . . .
截断一部电影的item信息,提取所有需要的东西,然后添加一个循环
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,1): #调用获取页面信息的函数,10次
url=baseurl + str(i*25)
html=askURL(url) #保存获取到的网页源码
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串,形成列表
#print(item) #测试:查看电影item全部信息
data=[] #保存一部电影的全部信息
item=str(item)
print(item)
break
#影片详情的链接
link=re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,[0]表示如果有两个,只要第一个
print(link)
return datalist
将其保存到 html 文档中进行比较
1
肖申克的救赎
/ The Shawshank Redemption
/ 月黑高飞(港) / 刺激1995(台)
[可播放]
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
9.7
2523850人评价
希望让人自由。
</p>
将需要提取的相关东西转化为正则表达式,设置为全局变量
<p>#影片详情的链接的规则
findLink=re.compile(r'<a href="(.*?)">') #创建正则表达式,表示规则(字符串模式)
#影片图片
findImgSrc=re.compile(r'
python网页数据抓取(本节书摘来自异步社区《用Python写网络爬虫》第2章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-20 03:07
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可参考访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方式
现在我们了解了这个网页的结构,有三种方法可以从中抓取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您是正则表达式的新手,或者需要一些提示,您可以查看它以获得完整的介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
元素中的内容,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从以上结果可以看出,标签用于多个国家属性。为了隔离 area 属性,我们可以只选择其中的第二个元素,如下所示。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父级
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,要将双引号更改为单引号,
在标签之间添加额外的空格,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 除了添加和
标签使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局的小变化,如额外的空白和制表符属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。下面是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 可以正确解析属性和关闭标签周围缺少的引号,但模块不会添加和
标签。
解析输入后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
下面是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
W3C 在 `/2011/REC-css3-selectors-20110929/ 提出了 CSS3 规范。
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在这里找到。
需要注意的是,lxml 在内部实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他特征的格式,如图2.4。
从 Firebug 的显示中可以看出,表中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
抓取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方式的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 结论
表 2.1 总结了每种抓取方法的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些情况下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何爬取国家数据,接下来我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可以看出,用Python实现这个功能是非常简单的。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取这个版本的链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用这个爬虫来抓取其他网站了。下面对 lxml 抓取示例的代码进行了修改,以便可以在回调函数中使用它。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数来维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想进一步了解 Python 的特殊类方法,可以参考。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行此爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
有效!我们完成了我们的第一个工作数据抓取爬虫。 查看全部
python网页数据抓取(本节书摘来自异步社区《用Python写网络爬虫》第2章)
本节节选自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多章节内容可参考访问云栖社区“异步社区”公众号查看。
2.2 三种网页抓取方式
现在我们了解了这个网页的结构,有三种方法可以从中抓取数据。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
2.2.1 正则表达式
如果您是正则表达式的新手,或者需要一些提示,您可以查看它以获得完整的介绍。
当我们使用正则表达式抓取区域数据时,首先需要尝试匹配
元素中的内容,如下图。
>>> import re
>>> url = 'http://example.webscraping.com/view/United
-Kingdom-239'
>>> html = download(url)
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png',
'244,820 square kilometres',
'62,348,447',
'GB',
'United Kingdom',
'London',
'EU',
'.uk',
'GBP',
'Pound',
'44',
'@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA',
'^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}
[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})
|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$',
'en-GB,cy-GB,gd',
'IE ']
从以上结果可以看出,标签用于多个国家属性。为了隔离 area 属性,我们可以只选择其中的第二个元素,如下所示。
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使这个正则表达式更健壮,我们可以将它作为父级
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,要将双引号更改为单引号,
在标签之间添加额外的空格,或更改 area_label 等。下面是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 除了添加和
标签使它成为一个完整的 HTML 文档。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # returns just the first match
Area
>>> ul.find_all('li') # returns all matches
[Area, Population]
要了解所有的方法和参数,可以参考 BeautifulSoup 的官方文档:.
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> url = 'http://example.webscraping.com/places/view/
United-Kingdom-239'
>>> html = download(url)
>>> soup = BeautifulSoup(html)
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the area tag
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局的小变化,如额外的空白和制表符属性,我们不必再担心了。
2.2.3 Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可供参考。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。下面是使用此模块解析相同的不完整 HTML 的示例。
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> tree = lxml.html.fromstring(broken_html) # parse the HTML
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 可以正确解析属性和关闭标签周围缺少的引号,但模块不会添加和
标签。
解析输入后,进入选择元素的步骤。此时,lxml 有几种不同的方法,例如类似于 Beautiful Soup 的 XPath 选择器和 find() 方法。但是,在本例和后续示例中,我们将使用 CSS 选择器,因为它们更简洁,可以在第 5 章解析动态内容时重复使用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
下面是使用 lxml 的 CSS 选择器提取区域数据的示例代码。
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
>>> area = td.text_content()
>>> print area
244,820 square kilometres
CSS 选择器的关键行已加粗。这行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器
CSS 选择器表示用于选择元素的模式。下面是一些常用选择器的示例。
选择所有标签:*
选择<a>标签:a
选择所有class="link"的元素:.link
选择class="link"的<a>标签:a.link
选择id="home"的<a>标签:a#home
选择父元素为<a>标签的所有子标签:a > span
选择<a>标签内部的所有标签:a span
选择title属性为"Home"的所有<a>标签:a[title=Home]
W3C 在 `/2011/REC-css3-selectors-20110929/ 提出了 CSS3 规范。
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在这里找到。
需要注意的是,lxml 在内部实际上将 CSS 选择器转换为等效的 XPath 选择器。
2.2.4 性能对比
为了更好地评估本章描述的三种抓取方法的权衡,我们需要比较它们的相对效率。通常,爬虫从网页中提取多个字段。因此,为了使比较更加真实,我们将在本章中实现每个爬虫的扩展版本,从国家页面中提取每个可用数据。首先,我们需要回到Firebug,检查国家页面其他特征的格式,如图2.4。
从 Firebug 的显示中可以看出,表中的每一行都有一个以 places_ 开头并以 __row 结尾的 ID。这些行中收录的国家/地区数据的格式与上面示例中的格式相同。下面是使用上述信息提取所有可用国家数据的实现代码。
FIELDS = ('area', 'population', 'iso', 'country', 'capital',
'continent', 'tld', 'currency_code', 'currency_name', 'phone',
'postal_code_format', 'postal_code_regex', 'languages',
'neighbours')
import re
def re_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)' % field, html).groups()[0]
return results
from bs4 import BeautifulSoup
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr',
id='places_%s__row' % field).find('td',
class_='w2p_fw').text
return results
import lxml.html
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_%s__row
> td.w2p_fw' % field)[0].text_content()
return results
抓取结果
现在我们已经完成了所有爬虫的代码实现,接下来通过下面的代码片段来测试这三种方式的相对性能。
import time
NUM_ITERATIONS = 1000 # number of times to test each scraper
html = download('http://example.webscraping.com/places/view/
United-Kingdom-239')
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', bs_scraper),
('Lxml', lxml_scraper)]:
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == re_scraper:
re.purge()
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
# record end time of scrape and output the total
end = time.time()
print '%s: %.2f seconds' % (name, end – start)
在这段代码中,每个爬虫会被执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。这里使用的下载函数还是上一章定义的。请注意,我们在粗体代码行中调用了 re.purge() 方法。默认情况下,正则表达式模块会缓存搜索结果,为了与其他爬虫比较公平,我们需要使用这种方法来清除缓存。
下面是在我的电脑上运行脚本的结果。
$ python performance.py
Regular expressions: 5.50 seconds
BeautifulSoup: 42.84 seconds
Lxml: 7.06 seconds
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 6 倍以上。事实上,这个结果是意料之中的,因为 lxml 和 regex 模块是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。一个有趣的事实是 lxml 的行为与正则表达式一样。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这种初始解析的开销会减少,lxml会更有竞争力。多么神奇的模块!
2.2.5 结论
表 2.1 总结了每种抓取方法的优缺点。
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,通常,lxml 是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 Beautiful Soup 仅在某些情况下有用。
2.2.6 添加链接爬虫的爬取回调
我们已经看到了如何爬取国家数据,接下来我们需要将其集成到上一章的链接爬虫中。为了重用这个爬虫代码去抓取其他网站,我们需要添加一个回调参数来处理抓取行为。回调是在某个事件发生后调用的函数(在这种情况下,在网页下载完成后)。爬取回调函数收录url和html两个参数,可以返回要爬取的url列表。下面是它的实现代码。可以看出,用Python实现这个功能是非常简单的。
def link_crawler(..., scrape_callback=None):
...
links = []
if scrape_callback:
links.extend(scrape_callback(url, html) or [])
...
在上面的代码片段中,我们将新添加的抓取回调函数代码加粗。如果想获取这个版本的链接爬虫的完整代码,可以访问org/wswp/code/src/tip/chapter02/link_crawler.py。
现在,我们只需要自定义传入的scrape_callback函数,就可以使用这个爬虫来抓取其他网站了。下面对 lxml 抓取示例的代码进行了修改,以便可以在回调函数中使用它。
def scrape_callback(url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = [tree.cssselect('table > tr#places_%s__row >
td.w2p_fw' % field)[0].text_content() for field in
FIELDS]
print url, row
上面的回调函数会抓取国家数据并显示出来。不过一般情况下,在爬取网站的时候,我们更希望能够重用这些数据,所以让我们扩展一下它的功能,把得到的数据保存在一个CSV表中。代码如下。
import csv
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'w'))
self.fields = ('area', 'population', 'iso', 'country',
'capital', 'continent', 'tld', 'currency_code',
'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages',
'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table >
tr#places_{}__row >
td.w2p_fw'.format(field))
[0].text_content())
self.writer.writerow(row)
为了实现这个回调,我们使用回调类而不是回调函数来维护 csv 中 writer 属性的状态。在构造函数中实例化csv的writer属性,然后在__call__方法中进行多次写入。注意__call__是一个特殊的方法,当一个对象作为函数调用时会调用,这也是链接爬虫中cache_callback的调用方式。也就是说,scrape_callback(url, html) 等价于调用 scrape_callback.__call__(url, html)。如果想进一步了解 Python 的特殊类方法,可以参考。
以下是将回调传递给链接爬虫的代码。
link_crawler('http://example.webscraping.com/', '/(index|view)',
max_depth=-1, scrape_callback=ScrapeCallback())
现在,当我们使用回调运行此爬虫时,程序会将结果写入 CSV 文件,我们可以使用 Excel 或 LibreOffice 等应用程序查看该文件,如图 2.5 所示。
有效!我们完成了我们的第一个工作数据抓取爬虫。
python网页数据抓取(前几天在看崔庆才老师的教程:网址结构网址url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-19 08:08
前几天在看崔庆才老师的教程,使用Scrapy抓取知乎用户信息,使用了递归。我之前写的爬虫将已知固定数据的url存储在列表中,然后遍历列表中的url。这次短书,我们用递归来试一试。
什么是递归
程序(或函数)调用自身的一种编程技术称为递归。一个过程或函数在其定义或规范中具有直接或间接调用自身的方法,这通常将一个大而复杂的问题转化为与原创问题相似的较小问题来解决。
递归的优点
1、降低题目难度
2、大大减少程序的代码大小
3、递归的威力在于使用有限语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓登录制的视频讲解,请点击链接
【python爬虫】如何抓到优质短书用户(请允许我放个广告)
关注获取项目源码
在这种情况下,我们需要抓取简书优质用户的信息,如昵称、id、文章的数量、采集数量、字数、获得的点赞数等。我们只捕获用户 ta 关注的人。至于这个ta的粉丝,我们不抓。相对来说,他关注的人,比他的粉丝素质更高。
从初始用户开始,比如邓旭东HIT关注的用户列表,得到邓旭东关注的25个用户A、B、C。
然后依次抓取这25个用户关注的用户
循环的前两个步骤
我们先来分析一下URL结构
网址网址分析
我们发现当我向下滚动关注列表时,页面底部会加载并且图像的左下角还有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
鼠标悬停在下面?page=3文件上方,浮动弹出一个URL
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页码是怎么构造的呢?
我们发现用户的follower数除以10,然后取整数,最大页数加1。
比如邓旭东关注了25个人,那么一共有三个页面:page=1, page=2, page=3
现在我们已经建立
既然有了URL,我们就开始分析网页源代码中要抓取的数据存放在哪里?
网页分析 查看全部
python网页数据抓取(前几天在看崔庆才老师的教程:网址结构网址url)
前几天在看崔庆才老师的教程,使用Scrapy抓取知乎用户信息,使用了递归。我之前写的爬虫将已知固定数据的url存储在列表中,然后遍历列表中的url。这次短书,我们用递归来试一试。
什么是递归
程序(或函数)调用自身的一种编程技术称为递归。一个过程或函数在其定义或规范中具有直接或间接调用自身的方法,这通常将一个大而复杂的问题转化为与原创问题相似的较小问题来解决。
递归的优点
1、降低题目难度
2、大大减少程序的代码大小
3、递归的威力在于使用有限语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓登录制的视频讲解,请点击链接
【python爬虫】如何抓到优质短书用户(请允许我放个广告)
关注获取项目源码
在这种情况下,我们需要抓取简书优质用户的信息,如昵称、id、文章的数量、采集数量、字数、获得的点赞数等。我们只捕获用户 ta 关注的人。至于这个ta的粉丝,我们不抓。相对来说,他关注的人,比他的粉丝素质更高。
从初始用户开始,比如邓旭东HIT关注的用户列表,得到邓旭东关注的25个用户A、B、C。
然后依次抓取这25个用户关注的用户
循环的前两个步骤
我们先来分析一下URL结构
网址网址分析
我们发现当我向下滚动关注列表时,页面底部会加载并且图像的左下角还有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
鼠标悬停在下面?page=3文件上方,浮动弹出一个URL
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页码是怎么构造的呢?
我们发现用户的follower数除以10,然后取整数,最大页数加1。
比如邓旭东关注了25个人,那么一共有三个页面:page=1, page=2, page=3
现在我们已经建立
既然有了URL,我们就开始分析网页源代码中要抓取的数据存放在哪里?
网页分析

