
python爬虫
python爬虫js加密篇—搜狗微信公号文章的爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-05-24 08:01
微信公众号的上一个版本中的反爬机制中并没有涉及到js加密,仅通过监控用户ip,单个ip访问很频繁会面临被封的风险;在新的版本中加入了js加密反爬机制,接下来我们来逐渐剖析一下文章爬取过程
打开搜狗页面搜狗陌陌页面,在输入框中输入任意关键词比如列车隧洞大火,搜下来的都是涉及关键词的公号文章列表
私信小编01 获取全套学习教程!
这里根据平时套路,直接借助开发者工具的选择工具,查看源码中列表中整篇文章的url,就是下边这个 href属性 标签
看到这个url,按照正常思路的话,就是直接做url拼接:搜狗主域名 + href 就是陌陌主要内容的url,形式如下
https
:
//weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS_yBZajb90fWf-LwgFP7QmnFtbELADqFzFqXa8Fplpd9nrYbnf-BG6fJQmhdTDKRUQC_zVYwjAHQRnKwtfQUOD-aNBz2bhtCuShQywQb837B12cBkYFsYkKXir7Y9WqlRBcZIrhUAYmFlBSVIg7YGFbBdu4rXklGlRslEFpw0lTmIX8pHfpQ9x6clCHaA92qoA9YOaIV2yOyrE-focNFXq7wdVqCwyPdzA..&type=2&query=%E7%81%AB%E8%BD%A6%E9%9A%A7%E9%81%93%E8%B5%B7%E7%81%AB
但是直接点这个链接返回的是402页面,需要输入验证码进行验证,而且验证码通过后仍然进不去;很明显这个url并不是文章的访问入口
经过测试,这篇文章的真实url是下边这些方式(直接通过点击页面标签打开即可):
https
:
//mp.weixin.qq.com/s?src=11×tamp=1567073292&ver=1820&signature=z2h7E*HznopGFidmtUA4PmXgi3ioRqV7XiYIqn9asMT3RCMKss6Y2nPUh7RG63nrwmRii77cL9LyDNJIVp1qpo5LHvQ8s754Q9HtCgbp5EPUP9HjosY7HWDwze6A2Qi7&new=1
是不是太太意外;这里开始就须要转变思路:不管怎样最好先抓一下包,这里我借助的工具是Fidder,关于Fidder怎样使用,可以参照这篇文章:
先从搜索页面的文章列表中步入文章的详情页,我们须要通过Fidder来监控一下文章的跳转情况:
看到没,惊奇地发觉有个 /link?url 开头的url跳转成功了,深入一下,我们再看一下这个链接返回的是哪些,点一下response部份的TextView;
返回的text文本是一串字符串组成的,即使不懂javascript,但上面大约意思就是构造一个url,格式与后面那种真实的url有一些相像呢,经测试以后发觉,返回的这个url就是获取文章内容的真实url
把这个访问成功的而且以link?url开头的url完整复制出来,与源码中的那种 link?url 放在一起,发现这个访问成功的url中多了两个参数一个是k一个是h
# 访问成功的:https://weixin.sogou.com/link% ... h%3Df
# 访问失败的:https://weixin.sogou.com/link% ... %25AB
现在基本爬取核心思路早已晓得了,主要就是破解这两个参数k和h,拼接成'真'的url( 以/cl.gif开头的 ),然后获取真url; 关于这两个参数的破解就是涉及到了js加密,需要进行调试,不懂的可以参考这篇文章:Chrome DevTools 中调试 JavaScript 入门;
第一步,回到源码中 link?url 位置的地方,因为前面两个参数的降低是因为我们触发了这个假的url,所以这儿须要对假的url进行窃听:
开发者工具[Elements] -> 右上角处的[Event Listeners] -> [click] -> 你须要监控的元素标签;
第二步,按流程浏览完前面所有过程时下边会有个js文件,点进去,并对js代码进行低格,发现参数k与h的构造方式:
其实还有一种参数定位的方式,在Google开发者选项中借助全局搜索[Search]就能快速定位,但是并不适用于这儿,因为这儿我们定位的参数都是单个元素,定位的准确度非常低
定位以后,参数k与h的定义十分清楚,没有过多函数嵌套,就是在一个简单的函数中,一个是生成一个随机数字,另一个在这个href标签的链接中获取其中的某一个字符,这里我们可以直python把这个功能实现:
url_list11
=
pq
(
res
.
text
)(
'.news-list li'
).
items
()
for
i
in
url_list11
:
url_list12
=
pq
(
i
(
'.img-box a'
).
attr
(
'href'
))
url_list12
=
str
(
url_list12
).
replace
(
'
'
,
''
).
replace
(
'
'
,
''
).
replace
(
'amp;'
,
''
)
(
url_list12
)
b
=
int
(
random
.
random
()
*
100
)
+
1
a
=
url_list12
.
find
(
"url="
)
result_link
=
url_list12
+
"&k="
+
str
(
b
)
+
"&h="
+
url_list12
[
a
+
4
+
21
+
b
:
a
+
4
+
21
+
b
+
1
]
a_url
=
"https://weixin.sogou.com"
+
result_link
好了,‘真’url也就能构造成功了,通过访问‘真’url来获取 真url(访问时记得加上headers),然后再获取我们须要的信息;然而结果却是下边这样的:
经测试发觉,原因是因为Cookie中最为核心的两个参数SUV和SUNID搜狗微信 反爬虫,而这两个参数在不断地发生改变
其中SUNID有固定得访问次数/时间限制,超过了限制直接变为无效,并且当访问网页恳求失败后,SUNID与SUV须要更换能够再度正常访问
SUV参数是在 ‘真’url 过度到 真url 中某个网页中Response里的Set-Cookie中生成的,也就是下边这个网页:
需要我们恳求这个链接,通过这个链接返回的Cookie,我们领到这个Cookie装入恳求头上面,再访问拼接好的 * ‘真’ url*
最后能够获取到真url最后恳求这个链接,解析出我们想要的数据( 注意用恳求头的时侯最好不要加Cookies搜狗微信 反爬虫,否则会导致访问失败 ) 当解决以上所有问题了,这里再测试一下,已经才能成功地领到我们想要的数据: 查看全部
今天这篇文章主要介绍的是关于微信公众号文章的爬取,其中上面主要涉及的反爬机制就是 js加密与cookies的设置 ;
微信公众号的上一个版本中的反爬机制中并没有涉及到js加密,仅通过监控用户ip,单个ip访问很频繁会面临被封的风险;在新的版本中加入了js加密反爬机制,接下来我们来逐渐剖析一下文章爬取过程
打开搜狗页面搜狗陌陌页面,在输入框中输入任意关键词比如列车隧洞大火,搜下来的都是涉及关键词的公号文章列表

私信小编01 获取全套学习教程!
这里根据平时套路,直接借助开发者工具的选择工具,查看源码中列表中整篇文章的url,就是下边这个 href属性 标签

看到这个url,按照正常思路的话,就是直接做url拼接:搜狗主域名 + href 就是陌陌主要内容的url,形式如下
https
:
//weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS_yBZajb90fWf-LwgFP7QmnFtbELADqFzFqXa8Fplpd9nrYbnf-BG6fJQmhdTDKRUQC_zVYwjAHQRnKwtfQUOD-aNBz2bhtCuShQywQb837B12cBkYFsYkKXir7Y9WqlRBcZIrhUAYmFlBSVIg7YGFbBdu4rXklGlRslEFpw0lTmIX8pHfpQ9x6clCHaA92qoA9YOaIV2yOyrE-focNFXq7wdVqCwyPdzA..&type=2&query=%E7%81%AB%E8%BD%A6%E9%9A%A7%E9%81%93%E8%B5%B7%E7%81%AB
但是直接点这个链接返回的是402页面,需要输入验证码进行验证,而且验证码通过后仍然进不去;很明显这个url并不是文章的访问入口

经过测试,这篇文章的真实url是下边这些方式(直接通过点击页面标签打开即可):
https
:
//mp.weixin.qq.com/s?src=11×tamp=1567073292&ver=1820&signature=z2h7E*HznopGFidmtUA4PmXgi3ioRqV7XiYIqn9asMT3RCMKss6Y2nPUh7RG63nrwmRii77cL9LyDNJIVp1qpo5LHvQ8s754Q9HtCgbp5EPUP9HjosY7HWDwze6A2Qi7&new=1
是不是太太意外;这里开始就须要转变思路:不管怎样最好先抓一下包,这里我借助的工具是Fidder,关于Fidder怎样使用,可以参照这篇文章:
先从搜索页面的文章列表中步入文章的详情页,我们须要通过Fidder来监控一下文章的跳转情况:
看到没,惊奇地发觉有个 /link?url 开头的url跳转成功了,深入一下,我们再看一下这个链接返回的是哪些,点一下response部份的TextView;

返回的text文本是一串字符串组成的,即使不懂javascript,但上面大约意思就是构造一个url,格式与后面那种真实的url有一些相像呢,经测试以后发觉,返回的这个url就是获取文章内容的真实url
把这个访问成功的而且以link?url开头的url完整复制出来,与源码中的那种 link?url 放在一起,发现这个访问成功的url中多了两个参数一个是k一个是h
# 访问成功的:https://weixin.sogou.com/link% ... h%3Df
# 访问失败的:https://weixin.sogou.com/link% ... %25AB
现在基本爬取核心思路早已晓得了,主要就是破解这两个参数k和h,拼接成'真'的url( 以/cl.gif开头的 ),然后获取真url; 关于这两个参数的破解就是涉及到了js加密,需要进行调试,不懂的可以参考这篇文章:Chrome DevTools 中调试 JavaScript 入门;
第一步,回到源码中 link?url 位置的地方,因为前面两个参数的降低是因为我们触发了这个假的url,所以这儿须要对假的url进行窃听:
开发者工具[Elements] -> 右上角处的[Event Listeners] -> [click] -> 你须要监控的元素标签;

第二步,按流程浏览完前面所有过程时下边会有个js文件,点进去,并对js代码进行低格,发现参数k与h的构造方式:

其实还有一种参数定位的方式,在Google开发者选项中借助全局搜索[Search]就能快速定位,但是并不适用于这儿,因为这儿我们定位的参数都是单个元素,定位的准确度非常低
定位以后,参数k与h的定义十分清楚,没有过多函数嵌套,就是在一个简单的函数中,一个是生成一个随机数字,另一个在这个href标签的链接中获取其中的某一个字符,这里我们可以直python把这个功能实现:
url_list11
=
pq
(
res
.
text
)(
'.news-list li'
).
items
()
for
i
in
url_list11
:
url_list12
=
pq
(
i
(
'.img-box a'
).
attr
(
'href'
))
url_list12
=
str
(
url_list12
).
replace
(
'
'
,
''
).
replace
(
'
'
,
''
).
replace
(
'amp;'
,
''
)
(
url_list12
)
b
=
int
(
random
.
random
()
*
100
)
+
1
a
=
url_list12
.
find
(
"url="
)
result_link
=
url_list12
+
"&k="
+
str
(
b
)
+
"&h="
+
url_list12
[
a
+
4
+
21
+
b
:
a
+
4
+
21
+
b
+
1
]
a_url
=
"https://weixin.sogou.com"
+
result_link
好了,‘真’url也就能构造成功了,通过访问‘真’url来获取 真url(访问时记得加上headers),然后再获取我们须要的信息;然而结果却是下边这样的:
经测试发觉,原因是因为Cookie中最为核心的两个参数SUV和SUNID搜狗微信 反爬虫,而这两个参数在不断地发生改变
其中SUNID有固定得访问次数/时间限制,超过了限制直接变为无效,并且当访问网页恳求失败后,SUNID与SUV须要更换能够再度正常访问
SUV参数是在 ‘真’url 过度到 真url 中某个网页中Response里的Set-Cookie中生成的,也就是下边这个网页:
需要我们恳求这个链接,通过这个链接返回的Cookie,我们领到这个Cookie装入恳求头上面,再访问拼接好的 * ‘真’ url*
最后能够获取到真url最后恳求这个链接,解析出我们想要的数据( 注意用恳求头的时侯最好不要加Cookies搜狗微信 反爬虫,否则会导致访问失败 ) 当解决以上所有问题了,这里再测试一下,已经才能成功地领到我们想要的数据:
干货丨推荐八款高效率的爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-05-24 08:01
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。 查看全部

Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。
网络爬虫 c++
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-05-22 08:01
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先... 查看全部

广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。

c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...

互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...

这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...

rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...

b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...

说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...

所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...

nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...

很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...

requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...

本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先...
Python爬虫必备工具汇总,并为你深析,为什么你应当要学爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-05-20 08:01
网络爬虫又称网路蜘蛛、网络机器人等爬虫软件 性能要求,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据所拟定的相应规则进行,即网络爬虫算法。
注意:如果须要Python爬虫的资料,就在文章底部哦
为什么要学Python爬虫?
原因很简单,我们可以借助爬虫技术,自动地从互联网中获取我们感兴趣的内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
在大数据时代,这一技能是必不可少的。
掌握Python技术,你应必备什么高效工具?
一、Xpath
Python中关于爬虫的包好多,推荐从Xpath开始爬虫软件 性能要求,Xpath的主要作用是用于解析网页,便于从中抽取数据。
这样出来,像豆瓣、腾讯新闻这类的网站就可以上手开始爬了。
二、抓包工具
可以用傲游,用傲游中的插件,可以便捷地查看网站收包分包信息。
三、基本的http抓取工具:scrapy
掌握后面的工具与技术后通常量级的数据基本没有问题了,但碰到十分复杂的情况时,你可能须要用到强悍的scrapy工具。
scrapy是十分强悍的爬虫框架,能轻松方便地建立request,还有强悍的selector才能便捷解析response,性能还超高,你可以将爬虫工程化、模块化。
学会scrapy你基本具备了爬虫工程师思维,可以自己搭建一些爬虫框架了。 查看全部

网络爬虫又称网路蜘蛛、网络机器人等爬虫软件 性能要求,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据所拟定的相应规则进行,即网络爬虫算法。

注意:如果须要Python爬虫的资料,就在文章底部哦
为什么要学Python爬虫?
原因很简单,我们可以借助爬虫技术,自动地从互联网中获取我们感兴趣的内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
在大数据时代,这一技能是必不可少的。
掌握Python技术,你应必备什么高效工具?

一、Xpath
Python中关于爬虫的包好多,推荐从Xpath开始爬虫软件 性能要求,Xpath的主要作用是用于解析网页,便于从中抽取数据。
这样出来,像豆瓣、腾讯新闻这类的网站就可以上手开始爬了。

二、抓包工具
可以用傲游,用傲游中的插件,可以便捷地查看网站收包分包信息。

三、基本的http抓取工具:scrapy
掌握后面的工具与技术后通常量级的数据基本没有问题了,但碰到十分复杂的情况时,你可能须要用到强悍的scrapy工具。
scrapy是十分强悍的爬虫框架,能轻松方便地建立request,还有强悍的selector才能便捷解析response,性能还超高,你可以将爬虫工程化、模块化。
学会scrapy你基本具备了爬虫工程师思维,可以自己搭建一些爬虫框架了。
Java做爬虫也太牛
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-05-20 08:00
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb 查看全部
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb
初学者的爬虫日志(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-05-19 08:02
言归正传,在接触网路爬虫这个名词,我的第一反应是它是啥东东百度爬虫日志,它能干啥,该如何做(。。。怎么觉得象在读书时在写论文。。。)。当然你可以百度,想了下还是不要贴百度的定义(不要打我),先说下自己对这个专业术语的理解吧,由于博主也才学几天理解十分狭隘,希望诸位读者理解,我个人觉得:网络爬虫就是个多样化的互联网信息采集程序(当然,以后可能有不同的理解,认知总不断变化地。)。它还能针对性对各网站的信息进行提取和分类(比如我要想知道天猫有多少家店面,各店家都是些谁如何办,你就运用爬虫技术爬取整个淘宝网)。说了这么多屁话,主要是希望你们对新事物有自己的看法,也希望读者老爷们多点耐心(这个话痨。。。。)
这次是真的“言归正传”,作为一个目标驱动型的学习者,我非常喜欢在学习一个新东西前制订“作战计划”,在做的过程中去学习,而不是学完后在做。比如我想去爬取糗事百科所有用户的用户名,我该如何做呢?有人说,先把python句型会用后,在学urllib或requests之类的库学会http请求的啥,然后去学正则抒发或BeautifulSoup,lxml 之类的库去解析啥,可能你还有去学一些后端的一些东西,比如html css,xml 之类的东东,接着还要去学一些mysql 或oracle,sqlite ,sqlserver之类数据库操作一些东东,我的天啊 ,我只是想知道晓得如何爬糗事百科网的用户名,怎么还要学这么多,许多人看着这长长的学习路线惊呆了,然后就gg了。所以,让我们回到最初的起点,从实际问题出发。首先,不去好使啥语言,会啥句型,不要去学啥urllib,lxml,xml,mysql 之类的东东,先仔细剖析下怎样去爬取糗事百科所有用户的用户名这个实际问题。
先想一下你是怎么晓得糗事百科网的他人的用户名,有人说,那还不简单,百度搜下糗事百科,打开糗事百科官网,不就听到了吗。对!就是这样简单,所有爬虫程序所干的事情都是这样的,它也是打开一个网站,然后按照所设规则提取出我们所须要的信息,然后保存出来 ,只不过一个是通过人眼看见,一个是爬虫程序手动提取信息,一个是记在头脑里(可能过下就忘了),一个是保存在c盘中(你只要不删掉,估计大约可能能保持20,30年)。虽然形式有所不同,但是她们的思想是共通的。简单来讲,就三步,打开网页-提取信息-保存信息。
那么,如何使程序能打开我们想要的网站呢?你可以试着通过百度搜下,比如哪些“如何用python打开网站之类的”,"python 打开网站的几种形式“ 之类的关键字,当然,你也可以去峰会csdn,知乎等峰会提问。我当时试着搜索下,搜到了这个网站。这个网站介绍了四种方式,这里就第一种为反例 ,代码如下:
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
在运行之前 ,先简单说下,我的python版本是2.7.12,所用的ide(集成开发环境)是pycharm,至于怎样下载这两软件可以参考下边两个网站:一个是python的官网: ;一个是pycharm的官网:,下载教程链接:
好了。运行开始。。。。。。,怎么运行不起!,这不科学啊!
先别急,看一下ide提示啥(哈 都是e文,和我一样英语弱的朋友快去背单词吧,你会利润终生),大概意思是这个文件不是 ascii,没有设置文件编码 。打开百度 ,输入如下关键字”如何为python设置文件编码“之类,你就可以晓得在文件开头原先还须要设置这一句”# -*- coding: utf-8 -*-“
让我们加上这一句开始运行,代码如下:
# -*- coding: utf-8 -*-
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
坑啊 ,怎么还是运行不上去 。。。我了个搽
冷静,冷静, 冷静啊 ,看一下ide提示啥 AttributeError: 'module' object has no attribute 'open' ,大概意思是说属性错误:“模块”对象没有属性“open” ,这他喵的啥意思。这个时侯你应当想这还不简单百度爬虫日志,直接把这句话复制到百度里搜下不就行了,我当时就是这样想在,然后浪费了10几分钟一无所获,最后只能自己解决了。 我又是如何解决的呢?首先 ,通过这个ide提示我晓得了错误出在这一句代码上content=urllib.open(url).read() , 然后我开始重新考量这端代码 ,从字面上看,这句话的意思是用urlib这个东西打开这个网站 ,然后在读取这个网站的内容,所以问题要么出在打开这个网站 上,要么是在读取上。接着 ,我就自动输入urllib. ,神奇的事情发生了(后来才晓得是代码手动补全),出现了如下界面,我看了这个urlopen 想了想, 试不试可以用这个来试下,果然成功了!(兴奋了)
完整代码: 查看全部
博主本人在先前就很好奇知乎那群答主的答案数据从那儿的, 别人说是从网上爬的(搞安全的朋友例外)。由于本人近来比较闲的,所以就起了学习写网路爬虫的心思(所以兴趣很重要!)。打开浏览器,百度了下网络爬虫,什么用python写网路爬虫的的比较多,所以就用它了(好随意的感觉). 然后我开始搜索有关用python写的网路爬虫的网路博客(主要是入门的教程指导类 ),看了下博客,怎么说呢,网上各博客主个个实力都不错,知识结构都十分的清晰,讲解的都十分细致,非常肤浅易懂,但总觉得少了点哪些,仔细想了下应当是大部分博客都重视知识本身,而漠视获取知识的过程(我认为这个最有意思),没啥成就感,自我觉得很无趣(总觉得有天朝教育的影子,我写你抄)。所以打算换个角度,从学习者角度写一些自觉得有意思的东西。
言归正传,在接触网路爬虫这个名词,我的第一反应是它是啥东东百度爬虫日志,它能干啥,该如何做(。。。怎么觉得象在读书时在写论文。。。)。当然你可以百度,想了下还是不要贴百度的定义(不要打我),先说下自己对这个专业术语的理解吧,由于博主也才学几天理解十分狭隘,希望诸位读者理解,我个人觉得:网络爬虫就是个多样化的互联网信息采集程序(当然,以后可能有不同的理解,认知总不断变化地。)。它还能针对性对各网站的信息进行提取和分类(比如我要想知道天猫有多少家店面,各店家都是些谁如何办,你就运用爬虫技术爬取整个淘宝网)。说了这么多屁话,主要是希望你们对新事物有自己的看法,也希望读者老爷们多点耐心(这个话痨。。。。)
这次是真的“言归正传”,作为一个目标驱动型的学习者,我非常喜欢在学习一个新东西前制订“作战计划”,在做的过程中去学习,而不是学完后在做。比如我想去爬取糗事百科所有用户的用户名,我该如何做呢?有人说,先把python句型会用后,在学urllib或requests之类的库学会http请求的啥,然后去学正则抒发或BeautifulSoup,lxml 之类的库去解析啥,可能你还有去学一些后端的一些东西,比如html css,xml 之类的东东,接着还要去学一些mysql 或oracle,sqlite ,sqlserver之类数据库操作一些东东,我的天啊 ,我只是想知道晓得如何爬糗事百科网的用户名,怎么还要学这么多,许多人看着这长长的学习路线惊呆了,然后就gg了。所以,让我们回到最初的起点,从实际问题出发。首先,不去好使啥语言,会啥句型,不要去学啥urllib,lxml,xml,mysql 之类的东东,先仔细剖析下怎样去爬取糗事百科所有用户的用户名这个实际问题。
先想一下你是怎么晓得糗事百科网的他人的用户名,有人说,那还不简单,百度搜下糗事百科,打开糗事百科官网,不就听到了吗。对!就是这样简单,所有爬虫程序所干的事情都是这样的,它也是打开一个网站,然后按照所设规则提取出我们所须要的信息,然后保存出来 ,只不过一个是通过人眼看见,一个是爬虫程序手动提取信息,一个是记在头脑里(可能过下就忘了),一个是保存在c盘中(你只要不删掉,估计大约可能能保持20,30年)。虽然形式有所不同,但是她们的思想是共通的。简单来讲,就三步,打开网页-提取信息-保存信息。
那么,如何使程序能打开我们想要的网站呢?你可以试着通过百度搜下,比如哪些“如何用python打开网站之类的”,"python 打开网站的几种形式“ 之类的关键字,当然,你也可以去峰会csdn,知乎等峰会提问。我当时试着搜索下,搜到了这个网站。这个网站介绍了四种方式,这里就第一种为反例 ,代码如下:
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
在运行之前 ,先简单说下,我的python版本是2.7.12,所用的ide(集成开发环境)是pycharm,至于怎样下载这两软件可以参考下边两个网站:一个是python的官网: ;一个是pycharm的官网:,下载教程链接:
好了。运行开始。。。。。。,怎么运行不起!,这不科学啊!

先别急,看一下ide提示啥(哈 都是e文,和我一样英语弱的朋友快去背单词吧,你会利润终生),大概意思是这个文件不是 ascii,没有设置文件编码 。打开百度 ,输入如下关键字”如何为python设置文件编码“之类,你就可以晓得在文件开头原先还须要设置这一句”# -*- coding: utf-8 -*-“
让我们加上这一句开始运行,代码如下:
# -*- coding: utf-8 -*-
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
坑啊 ,怎么还是运行不上去 。。。我了个搽

冷静,冷静, 冷静啊 ,看一下ide提示啥 AttributeError: 'module' object has no attribute 'open' ,大概意思是说属性错误:“模块”对象没有属性“open” ,这他喵的啥意思。这个时侯你应当想这还不简单百度爬虫日志,直接把这句话复制到百度里搜下不就行了,我当时就是这样想在,然后浪费了10几分钟一无所获,最后只能自己解决了。 我又是如何解决的呢?首先 ,通过这个ide提示我晓得了错误出在这一句代码上content=urllib.open(url).read() , 然后我开始重新考量这端代码 ,从字面上看,这句话的意思是用urlib这个东西打开这个网站 ,然后在读取这个网站的内容,所以问题要么出在打开这个网站 上,要么是在读取上。接着 ,我就自动输入urllib. ,神奇的事情发生了(后来才晓得是代码手动补全),出现了如下界面,我看了这个urlopen 想了想, 试不试可以用这个来试下,果然成功了!(兴奋了)

完整代码:
八爪鱼采集器能代替python爬虫吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 913 次浏览 • 2020-05-19 08:02
44 人赞成了该回答
作为同时使用八爪鱼采集器和写爬虫的非技术的莫名其妙喜欢自己寻思技术的互联网营运喵。。。我来说说心得看法。
八爪鱼有一些优势,比如学习成本低,可视化流程,快速搭建采集系统。能直接导入excel文件和导入到数据库中。降低采集成本,云采集提供10个节点,也能省事不少。
不好的地方就是,即使看似很简单了,而且还有更傻瓜化的smart模式,但是上面的坑只有用的多的人才清楚。关于这个我在我的博客里简单写了写,不过说实话心得太多,还没仔细整理。
首先上面的循环都是xpath元素定位,如果用单纯的傻瓜化点击定位的话,很生硬,大批量采集页面的时侯很容易出错。另外用这个工具的,因为便捷,小白太多,成天有人问普通问题,他们都不会看页面结构,也不懂xpath,很容易出现采集不全,无限翻页等问题。
但是八爪鱼采集器的ajax加载,模拟手机页面,过滤广告,滚动至页面底端等功能堪比利器,一个勾选才能搞定。写代码很麻烦的,实现这种功能费力。
八爪鱼虽然只是工具,自由度肯定完败编程。胜在便捷,快速,低成本。
八爪鱼判定语录较弱,无法进行复杂判定,也未能执行复杂逻辑。还有就是八爪鱼只有企业版能够解决验证码问题,一般版本未能接入打码平台。
还有一点就是没有ocr功能,58同城和赶集网采集的电话号码都是图片格式,python可以用开源图象辨识库解决,对接进去辨识便可。
这里更新一下:
之前写的觉得有片面性,毕竟是那个时代我的心境下写下来的。一段时间以后,思考了一下,数据采集的需求才是决定最终使用哪些工具的。如果我是大量数据采集需求的话,爬虫一定是不可避开的,因为代码的自由度更高。八爪鱼的目标我感觉也不是代替python,而是实现人人都能上手的采集器这个目标。
另一点就是python学习容易,部署简单,开源免费。即使只学了scrapy也能解决一些问题了,不过麻烦的就是原本一些工具里很简单选择能够搞定的功能八爪鱼采集器高级模式,必须靠自己写或则拷贝他人的代码能够实现,如果不是专职写爬虫的话,很快就想从入门到舍弃了……
综合写了一下对比和坑,放在知乎专栏里了八爪鱼采集器高级模式,有兴趣的可以去瞧瞧:
浅谈一下近来使用八爪鱼采集器碰到的坑(还有对比其他采集软件和爬虫) - 知乎专栏
编辑于 2017-12-17
深圳视界信息技术有限公司 CEO
10 人赞成了该回答
八爪鱼是工具,python是代码,八爪鱼的目标是使有须要采集网页的人都可以使用工具轻松达到目的,就这个目的来讲,八爪鱼就是要代替诸多公司自己爬虫工程师团队开发的python爬虫程序,我认为完全替代有点困难,总有些人就是一定要求自己开发的,这种就没办法了,但是从成本,效率,响应需求变化的能力,通用性,易用性,IP资源,防封能力,智能化程度,对使用人员的要求等等审视爬虫做的好不好的指标来看的话,八爪鱼目前所达到的技术和产品能力,一般的技术团队用python是难以达到的。
发布于 2017-07-04 查看全部

44 人赞成了该回答
作为同时使用八爪鱼采集器和写爬虫的非技术的莫名其妙喜欢自己寻思技术的互联网营运喵。。。我来说说心得看法。
八爪鱼有一些优势,比如学习成本低,可视化流程,快速搭建采集系统。能直接导入excel文件和导入到数据库中。降低采集成本,云采集提供10个节点,也能省事不少。
不好的地方就是,即使看似很简单了,而且还有更傻瓜化的smart模式,但是上面的坑只有用的多的人才清楚。关于这个我在我的博客里简单写了写,不过说实话心得太多,还没仔细整理。
首先上面的循环都是xpath元素定位,如果用单纯的傻瓜化点击定位的话,很生硬,大批量采集页面的时侯很容易出错。另外用这个工具的,因为便捷,小白太多,成天有人问普通问题,他们都不会看页面结构,也不懂xpath,很容易出现采集不全,无限翻页等问题。
但是八爪鱼采集器的ajax加载,模拟手机页面,过滤广告,滚动至页面底端等功能堪比利器,一个勾选才能搞定。写代码很麻烦的,实现这种功能费力。
八爪鱼虽然只是工具,自由度肯定完败编程。胜在便捷,快速,低成本。
八爪鱼判定语录较弱,无法进行复杂判定,也未能执行复杂逻辑。还有就是八爪鱼只有企业版能够解决验证码问题,一般版本未能接入打码平台。
还有一点就是没有ocr功能,58同城和赶集网采集的电话号码都是图片格式,python可以用开源图象辨识库解决,对接进去辨识便可。
这里更新一下:
之前写的觉得有片面性,毕竟是那个时代我的心境下写下来的。一段时间以后,思考了一下,数据采集的需求才是决定最终使用哪些工具的。如果我是大量数据采集需求的话,爬虫一定是不可避开的,因为代码的自由度更高。八爪鱼的目标我感觉也不是代替python,而是实现人人都能上手的采集器这个目标。
另一点就是python学习容易,部署简单,开源免费。即使只学了scrapy也能解决一些问题了,不过麻烦的就是原本一些工具里很简单选择能够搞定的功能八爪鱼采集器高级模式,必须靠自己写或则拷贝他人的代码能够实现,如果不是专职写爬虫的话,很快就想从入门到舍弃了……
综合写了一下对比和坑,放在知乎专栏里了八爪鱼采集器高级模式,有兴趣的可以去瞧瞧:
浅谈一下近来使用八爪鱼采集器碰到的坑(还有对比其他采集软件和爬虫) - 知乎专栏
编辑于 2017-12-17

深圳视界信息技术有限公司 CEO
10 人赞成了该回答
八爪鱼是工具,python是代码,八爪鱼的目标是使有须要采集网页的人都可以使用工具轻松达到目的,就这个目的来讲,八爪鱼就是要代替诸多公司自己爬虫工程师团队开发的python爬虫程序,我认为完全替代有点困难,总有些人就是一定要求自己开发的,这种就没办法了,但是从成本,效率,响应需求变化的能力,通用性,易用性,IP资源,防封能力,智能化程度,对使用人员的要求等等审视爬虫做的好不好的指标来看的话,八爪鱼目前所达到的技术和产品能力,一般的技术团队用python是难以达到的。
发布于 2017-07-04
【黑马程序员】Python爬虫是哪些?爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2020-05-19 08:01
【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708 查看全部

【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708
python爬虫有哪些用
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-05-18 08:03
一:python爬虫是哪些意思
python是多种语言实现的程序,爬虫又称网页机器人,也有人称为蚂蚁,python是可以根据规则去进行抓取网站上的所有有价值的信息,并且保存到本地,其实好多爬虫都是使用python开发的。
二:python爬虫有哪些用?爬虫可以做哪些?
网络爬虫是一种程序,可以抓取网路上的一切数据,比如网站上的图片和文字视频,只要我们能访问的数据都是可以获取到的,使用python爬虫去抓取而且下载到本地。
三:如何学习爬虫
学习爬虫之前,首先我们要学习一门语言,一般建议是学习Python,Python可以跨平台,相比其它语言来说,Python的爬虫库都是比较丰富的,其次就是要学习html知识,和抓包等相关知识,清楚爬虫的知识体系,新手在学习的时侯,首先要基础开始,在学习完基础以后,然后再去使用框架,其实更好的方式就是实战练习。
四:爬虫的简单原理
首先要先获得url,把url装入在队列中,等待抓取,然后进行解析dns,获得主机的ippython爬虫有啥用,就可以把网站给下载出来,保存到本地。
以上就是对python爬虫有什么用的全部介绍,如果你想了解更多有关Python教程,请关注php英文网。
以上就是python爬虫有什么用的详尽内容,更多请关注php中文网其它相关文章! 查看全部
python爬虫是哪些意思?python爬虫有哪些用?一些刚才python入门的菜鸟python爬虫有啥用,可能对这种问题并不是太熟悉,下面小编就为您整理关于python爬虫,希望对您有所帮助。

一:python爬虫是哪些意思
python是多种语言实现的程序,爬虫又称网页机器人,也有人称为蚂蚁,python是可以根据规则去进行抓取网站上的所有有价值的信息,并且保存到本地,其实好多爬虫都是使用python开发的。
二:python爬虫有哪些用?爬虫可以做哪些?
网络爬虫是一种程序,可以抓取网路上的一切数据,比如网站上的图片和文字视频,只要我们能访问的数据都是可以获取到的,使用python爬虫去抓取而且下载到本地。
三:如何学习爬虫

学习爬虫之前,首先我们要学习一门语言,一般建议是学习Python,Python可以跨平台,相比其它语言来说,Python的爬虫库都是比较丰富的,其次就是要学习html知识,和抓包等相关知识,清楚爬虫的知识体系,新手在学习的时侯,首先要基础开始,在学习完基础以后,然后再去使用框架,其实更好的方式就是实战练习。
四:爬虫的简单原理
首先要先获得url,把url装入在队列中,等待抓取,然后进行解析dns,获得主机的ippython爬虫有啥用,就可以把网站给下载出来,保存到本地。
以上就是对python爬虫有什么用的全部介绍,如果你想了解更多有关Python教程,请关注php英文网。
以上就是python爬虫有什么用的详尽内容,更多请关注php中文网其它相关文章!
网络爬虫的原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 809 次浏览 • 2020-05-18 08:02
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。 查看全部
互联网上,公开数据(各种网页)都是以http(或加密的http即https)协议传输的。所以,我们这儿介绍的爬虫技术都是基于http(https)协议的爬虫。
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'the_password@www.yuanrenxue.com/user/info?page=2'" rel="nofollow" target="_blank">http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。
python网络爬虫源代码(可直接抓取图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-05-18 08:01
在开始制做爬虫前,我们应当做好前期打算工作,找到要爬的网站,然后查看它的源代码我们此次爬豆瓣美眉网站,网址为:用到的工具:pycharm,这是它的图标...博文来自:zhang740000的博客
Python菜鸟写出漂亮的爬虫代码1初到大数据学习圈子的朋友可能对爬虫都有所耳闻,会认为是一个高大上的东西,仿佛九阳神功和乾坤大挪移一样,和他人说“老子会爬虫”,就觉得非常有颜值,但是又不知从何入手,...博文来自:夏洛克江户川
互联网是由一个个站点和网路设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前。网络爬虫,也叫网路蜘蛛(We...博文来自:阎松的博客
从链家网站爬虫广州符合条件的房源信息,并保存到文件,房源信息包括名称、建筑面积、总价、所在区域、套内面积等。其中所在区域、套内面积须要在详情页获取估算。主要使用了requests+Beautiful...博文
###写在题外的话爬虫,我还是大三的时侯,第一次据说网络爬虫 源码,当时我的学姐给我找的一个勤工俭学的项目,要求是在微博上爬出感兴趣的信息,结果很遗憾,第一次邂逅只是搽肩而过。然后,时间来到4年后的研二,在做信息检...博文来自:wsbxzz1的专栏
WechatSogou[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。DouBanSpider[2]-豆...博文来自:perry_Fan
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimportht...博文来自:程松
前几天,刘若英的《后来》电影版——《后来的我们》上映了,我身边也有小伙伴去看了,问了以后,他们说虽然这个影片对没有多少故事的我们代入感不够强,我没去看,一是因为独身猫一只,去电影院看影片纯属找虐,另一...博文来自:weixin_41032076的博客
本篇是在学习Python基础知识以后的一次小小尝试,这次将会爬取熊猫TV网页上的王者荣耀主播排行,在不依靠第三方框架的情况下演示一个爬虫的原理。一、实现Python爬虫的思路第一步:明确目的1.找到想...博文来自:梧雨北辰的博客
问题的来历前几天,在微信公众号(Python爬虫及算法)上有个人问了笔者一个问题,如何借助爬虫来实现如下的需求,需要爬取的网页如下(网址为:博文来自:但盼风雨来
首先要导出模块,然后输入须要爬虫的网址,接着打开一个文件(接收器)然后将网址中的东西缓冲到你的接收器中这样就可以实现简单的爬虫fromurllibimportrequestr=request.urlo...博文来自:xuanyugang的博客
爬虫是封装在WebCrawler类中的,Test.py调用爬虫的craw函数达到下载网页的功能。运用的算法:广度遍历关于网路爬虫的详尽信息请参考百度百科Test.py----------------...博文来自:Cashey1991的专栏
今天小编给你们分享一下怎样借助Python网络爬虫抓取微信朋友圈的动态信息,实际上假如单独的去爬取朋友圈的话,难度会特别大,因为陌陌没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌...博文来自:weixin_34252090的博客
来源:程序猿本文宽度为2863字,建议阅读5分钟本文为你分享零基础开始写爬虫的经验。刚开始接触爬虫的时侯,简直惊为天人,十几行代码,就可以将无数网页的信息全部获取出来,自动选定网页元素,自动整理成结构...博文来自:THU数据派
概述:第一次接触爬虫,从简单一点的爬取百度图片开始,话不多说,直接上手。前期打算:首先要配置环境,这里使用到的是requests第三方库,相比Beautifulsoup而言req...博文来自:heart__gx的博客
1、任务简介前段时间仍然在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方式,只有将网页源码抓取出来能够从...博文来自:罗思洋的博客
对职友集急聘网站的爬虫一、对职友集的python爬虫代码如下:输出结果:headers错误信息处理一、对职友集的python爬虫学习python那就要对自己将来的工作有一个研究网络爬虫 源码,现在就来瞧瞧,职友集上...博文来自:Prodigal
最近学习了一下python的基础知识,大家通常对“爬虫”这个词,一听就比较熟悉,都晓得是爬一些网站上的数据,然后做一些操作整理,得到人们想要的数据,但是如何写一个爬虫程序代码呢?相信很多人是不会的,今...博文来自:rmkloveme
爬虫:爬取全书网,获取数据,存到数据库工具:mysql,python3,MySQLdb模块:requests(pipinstallrequests),re(不需要安装)网址:博文来自:乐亦亦乐的博客
python作为人工智能或则大数据的宠儿,我自然要学习,作为一个小白,第一个实现的工能就是爬虫,爬数据,收集数据,我以我爬csdn博客的事情为反例,附上代码,大家一起学习这儿还使用了ip代理基数,一起...博文来自:Mr小颜朋友的博客
环境:Windows7+python3.6+Pycharm2017目标:抓取易迅商品列表页面信息:售价、评论数、商品名称-----以手机为例---全部文章:京东爬虫、链家爬虫、美团爬虫、微信公众号爬虫...博文来自:老王の博客
本文介绍两种爬取形式:1.正则表达式2.bs4解析Html以下为正则表达式爬虫,面向对象封装后的代码如下:以下为使用bs4爬取的代码:bs4面向对象封装后代码:......博文来自:python学习者的博客
2018年3月27日,继开学以来,开了软件工程和信息系统设计,想来想去也没哪些好的题目,干脆就想弄一个实用点的,于是形成了做“学生服务系统”想法。相信各大院校应当都有本校APP或超级课程表之类的...博文来自:跬步至以千里的博客
本文参考IMMOC中的python”开发简单爬虫“:。如果不足,希望见谅本文为原创,转载请标明出处:博文来自:014技术库房
python小白群交流:861480019手机笔记本挂机赚零钱群:一毛一毛挣903271585(每天手机登入之后不用管,一天有不到一块钱的收入,大部分软件可以一块钱提现一次)注意,申请时说明加入缘由...博文来自:chq1005613740的博客
(一)百度贴吧贴子用户与评论信息(二)豆瓣登陆脚本博文来自:PANGHAIFEI的博客
文章地址:在我们日常上网浏览网页的时侯,经常会见到一些好看的图片,我们就希望把那些图片保存下载,或者用户拿来做桌面壁...博文来自:不如缺钙的博客
大数据下的简单网路爬虫使用代码进行实现(本博文对易迅网站的某手机的评论进行爬取)...博文来自:data_bug的博客
以下总结的全是单机爬取的应对反爬策略1、设置爬取速率,由于爬虫发送恳求的速率比较快,会对服务器引起一定的影响,尽可能控制爬取速率,做到文明爬取2、重启路由器。并不是指化学上的拔插路由器,而是指模拟路...博文来自:菜到怀疑人生的博客
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整...博文来自:c350577169的博客
Python开发爬虫完整代码解析移除python一天时间,总算开发完了。说道爬虫,我认为有几个东西须要非常注意,一个是队列,告诉程序,有什么url要爬,第二个就是爬页面,肯定有元素缺位的,这个究其...博文来自:大壮的博客
这段时间公司要求抓全省的一类网站,网站虽然都是一类的,但是结构也是各有不同,目前是抓了几十个上百个测试,我使用的是scrapy多爬虫爬取,感觉也不是非常好,所以在找寻更好的方式或则框架,看看有没有一些峰会
本文主要囊括了Python编程的核心知识(暂不包括标准库及第三方库,后续会发布相应专题的文章)。首先,按次序依次展示了以下内容的一系列思维导图:基础知识,数据类型(数字,字符串,列表,元组,字典,集合...博文来自:的博客 查看全部
2019-8-3 18:5:0 | 作者:老铁SEO | | 人浏览
在开始制做爬虫前,我们应当做好前期打算工作,找到要爬的网站,然后查看它的源代码我们此次爬豆瓣美眉网站,网址为:用到的工具:pycharm,这是它的图标...博文来自:zhang740000的博客
Python菜鸟写出漂亮的爬虫代码1初到大数据学习圈子的朋友可能对爬虫都有所耳闻,会认为是一个高大上的东西,仿佛九阳神功和乾坤大挪移一样,和他人说“老子会爬虫”,就觉得非常有颜值,但是又不知从何入手,...博文来自:夏洛克江户川
互联网是由一个个站点和网路设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前。网络爬虫,也叫网路蜘蛛(We...博文来自:阎松的博客
从链家网站爬虫广州符合条件的房源信息,并保存到文件,房源信息包括名称、建筑面积、总价、所在区域、套内面积等。其中所在区域、套内面积须要在详情页获取估算。主要使用了requests+Beautiful...博文
###写在题外的话爬虫,我还是大三的时侯,第一次据说网络爬虫 源码,当时我的学姐给我找的一个勤工俭学的项目,要求是在微博上爬出感兴趣的信息,结果很遗憾,第一次邂逅只是搽肩而过。然后,时间来到4年后的研二,在做信息检...博文来自:wsbxzz1的专栏
WechatSogou[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。DouBanSpider[2]-豆...博文来自:perry_Fan
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimportht...博文来自:程松
前几天,刘若英的《后来》电影版——《后来的我们》上映了,我身边也有小伙伴去看了,问了以后,他们说虽然这个影片对没有多少故事的我们代入感不够强,我没去看,一是因为独身猫一只,去电影院看影片纯属找虐,另一...博文来自:weixin_41032076的博客
本篇是在学习Python基础知识以后的一次小小尝试,这次将会爬取熊猫TV网页上的王者荣耀主播排行,在不依靠第三方框架的情况下演示一个爬虫的原理。一、实现Python爬虫的思路第一步:明确目的1.找到想...博文来自:梧雨北辰的博客
问题的来历前几天,在微信公众号(Python爬虫及算法)上有个人问了笔者一个问题,如何借助爬虫来实现如下的需求,需要爬取的网页如下(网址为:博文来自:但盼风雨来
首先要导出模块,然后输入须要爬虫的网址,接着打开一个文件(接收器)然后将网址中的东西缓冲到你的接收器中这样就可以实现简单的爬虫fromurllibimportrequestr=request.urlo...博文来自:xuanyugang的博客
爬虫是封装在WebCrawler类中的,Test.py调用爬虫的craw函数达到下载网页的功能。运用的算法:广度遍历关于网路爬虫的详尽信息请参考百度百科Test.py----------------...博文来自:Cashey1991的专栏
今天小编给你们分享一下怎样借助Python网络爬虫抓取微信朋友圈的动态信息,实际上假如单独的去爬取朋友圈的话,难度会特别大,因为陌陌没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌...博文来自:weixin_34252090的博客
来源:程序猿本文宽度为2863字,建议阅读5分钟本文为你分享零基础开始写爬虫的经验。刚开始接触爬虫的时侯,简直惊为天人,十几行代码,就可以将无数网页的信息全部获取出来,自动选定网页元素,自动整理成结构...博文来自:THU数据派
概述:第一次接触爬虫,从简单一点的爬取百度图片开始,话不多说,直接上手。前期打算:首先要配置环境,这里使用到的是requests第三方库,相比Beautifulsoup而言req...博文来自:heart__gx的博客
1、任务简介前段时间仍然在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方式,只有将网页源码抓取出来能够从...博文来自:罗思洋的博客
对职友集急聘网站的爬虫一、对职友集的python爬虫代码如下:输出结果:headers错误信息处理一、对职友集的python爬虫学习python那就要对自己将来的工作有一个研究网络爬虫 源码,现在就来瞧瞧,职友集上...博文来自:Prodigal
最近学习了一下python的基础知识,大家通常对“爬虫”这个词,一听就比较熟悉,都晓得是爬一些网站上的数据,然后做一些操作整理,得到人们想要的数据,但是如何写一个爬虫程序代码呢?相信很多人是不会的,今...博文来自:rmkloveme
爬虫:爬取全书网,获取数据,存到数据库工具:mysql,python3,MySQLdb模块:requests(pipinstallrequests),re(不需要安装)网址:博文来自:乐亦亦乐的博客
python作为人工智能或则大数据的宠儿,我自然要学习,作为一个小白,第一个实现的工能就是爬虫,爬数据,收集数据,我以我爬csdn博客的事情为反例,附上代码,大家一起学习这儿还使用了ip代理基数,一起...博文来自:Mr小颜朋友的博客
环境:Windows7+python3.6+Pycharm2017目标:抓取易迅商品列表页面信息:售价、评论数、商品名称-----以手机为例---全部文章:京东爬虫、链家爬虫、美团爬虫、微信公众号爬虫...博文来自:老王の博客
本文介绍两种爬取形式:1.正则表达式2.bs4解析Html以下为正则表达式爬虫,面向对象封装后的代码如下:以下为使用bs4爬取的代码:bs4面向对象封装后代码:......博文来自:python学习者的博客
2018年3月27日,继开学以来,开了软件工程和信息系统设计,想来想去也没哪些好的题目,干脆就想弄一个实用点的,于是形成了做“学生服务系统”想法。相信各大院校应当都有本校APP或超级课程表之类的...博文来自:跬步至以千里的博客
本文参考IMMOC中的python”开发简单爬虫“:。如果不足,希望见谅本文为原创,转载请标明出处:博文来自:014技术库房
python小白群交流:861480019手机笔记本挂机赚零钱群:一毛一毛挣903271585(每天手机登入之后不用管,一天有不到一块钱的收入,大部分软件可以一块钱提现一次)注意,申请时说明加入缘由...博文来自:chq1005613740的博客
(一)百度贴吧贴子用户与评论信息(二)豆瓣登陆脚本博文来自:PANGHAIFEI的博客
文章地址:在我们日常上网浏览网页的时侯,经常会见到一些好看的图片,我们就希望把那些图片保存下载,或者用户拿来做桌面壁...博文来自:不如缺钙的博客
大数据下的简单网路爬虫使用代码进行实现(本博文对易迅网站的某手机的评论进行爬取)...博文来自:data_bug的博客
以下总结的全是单机爬取的应对反爬策略1、设置爬取速率,由于爬虫发送恳求的速率比较快,会对服务器引起一定的影响,尽可能控制爬取速率,做到文明爬取2、重启路由器。并不是指化学上的拔插路由器,而是指模拟路...博文来自:菜到怀疑人生的博客
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整...博文来自:c350577169的博客
Python开发爬虫完整代码解析移除python一天时间,总算开发完了。说道爬虫,我认为有几个东西须要非常注意,一个是队列,告诉程序,有什么url要爬,第二个就是爬页面,肯定有元素缺位的,这个究其...博文来自:大壮的博客
这段时间公司要求抓全省的一类网站,网站虽然都是一类的,但是结构也是各有不同,目前是抓了几十个上百个测试,我使用的是scrapy多爬虫爬取,感觉也不是非常好,所以在找寻更好的方式或则框架,看看有没有一些峰会
本文主要囊括了Python编程的核心知识(暂不包括标准库及第三方库,后续会发布相应专题的文章)。首先,按次序依次展示了以下内容的一系列思维导图:基础知识,数据类型(数字,字符串,列表,元组,字典,集合...博文来自:的博客
用PYTHON爬取车辆之家街车报价数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-05-16 08:07
用PYTHON爬虫—汽车之家街车报价爬取—斑点虾/数据咨询师爬 虫 的 价 值 爬 虫 的 原 理 爬 虫 的 实 例01爬 虫 的 价 值01 爬虫的价值? 爬取数据,进行市场督查和商业剖析知乎:爬取优质答案,为你筛选出各话题下最优质的内容。 淘宝、京东:抓取商品、评论及销量数据,对各类商品及用户 的消费场景进行剖析。 安居客、链家:抓取房产买卖及租售信息爬虫之家,分析楼市变化趋势、 做不同区域的楼价剖析。 智联:爬取各种职位信息,分析各行业人才需求情况及工资水 平。 雪球网:抓取雪球高回报用户的行为爬虫之家,对股票进行剖析和预测。01爬虫的价值? 作为机器学习、数据挖掘的原始数据? ? 比如你要做一个推荐系统,那么你可以去爬取更多维度的数据,做出更好的模型。 比如你要做图象辨识,你可以先去爬取大量的图片作为训练集进行训练。01爬虫的价值? 爬取优质的资源: 图片、文本、视频? 爬取知乎钓鱼贴\图片网站,获得福利图片。 ? 爬取微信公众号文章,分析新媒体内容营运策略。这些事情,原本我们也是可以自动完成的,但若果是单纯地复制粘贴,非常花费时间,比如你想获取100万行的数据,大 约需忘寝废食重复工作五年。而爬虫可以在一天之内帮你完成,而且完全不需要任何干预。02爬 虫 的 原 理02 爬虫的原理? 通用爬虫的框架02 爬虫的原理? 从爬虫角度对互联网进行界定02 爬虫的原理? 爬虫的基本流程解析页面发送恳求获得页面requests抽取并储存内容02 爬虫的原理? Requests 库的使用方式02 爬虫的原理? 爬取页面的通用代码框架03爬 虫 的 实 例03 爬虫的实例—汽车之家街车的报价找到街车的车型名称和价钱所在位置的Html03 爬虫的实例—汽车之家街车的报价导出模块定义街车的车型名称和价钱03 爬虫的实例—汽车之家街车的报价下载网页、解析网页、循环页数、获取列表03 爬虫的实例—汽车之家街车的报价保存数据至EXCELTHANKS!
基于Scrapy框架的分布式网路爬虫实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-05-14 08:09
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art 查看全部
龙源期刊网 基于 Scrapy 框架的分布式网路爬虫实现 作者:陶兴海 来源:《电子技术与软件工程》2017 年第 11 期 摘 要按照互联网实际情况,提出分布式爬虫模型,基于 Scrapy 框架,进行代码实现,且 该开发方法可以迅速进行对不同主题的数据爬取的移植,满足不同专业方向的基于互联网大数 据剖析须要。 【关键词】网络爬虫 Scrapy-redis 分布式 1 基本概念 分布式爬虫:分布式方法是以共同爬取为目标,形成多爬虫协同工作的模式,每个爬虫需 要独立完成单项爬取任务,下载网页并保存。 Scrapy-redis:一个三方的基于 redis 数据库实现的分布式方法,配合 scrapy 爬虫框架让 用,让 scrapy 具有了分布式爬取的功能。 2 分布式爬虫技术方案 Scrapy-redis 分布式爬虫的基本设计理念为主从模式,由作为主控端负责所有网络子爬虫 的管理,子爬虫只须要从主控端那儿接收任务分布式爬虫框架,并把新生成任务递交给主控端,在整个爬取的 过程中毋须与其他爬虫通讯。 主要有几个技术关键点: 2.1 子爬虫爬取任务的分发 通过在主控端安装一个 redis 数据库,维护统一的任务列表,子爬虫每次联接 redis 库调用 lpop()方法,生成一个任务,并生成一个 request,接下去就是就像通常爬虫工作。
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art
爬虫基本原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-05-14 08:08
本文分为如下几个部份
简单理解网路爬虫就是手动抓取网页信息的代码,可以简单理解成取代繁杂的复制粘贴操作的手段。
首先必须申明,爬虫的对象必须是你早已听到的网页,比如你不能说你想找到知乎上那个用户的关注人数最多,就希望通过写一个爬虫来帮你爬到答案。你必须明晰地晓得这个人,找到他的主页,然后才会用爬虫来抓取他页面上的信息。
下面我们用一个简单的事例来展示爬虫的工作流程。感觉多数教程第一篇都使用的是豆瓣top250,我们这儿换一个,抓取CSDN首页的文章标题,链接在这里,页面样子是这样的
抓取标题完整代码如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
这样才会复印出所有标题,展示一部分如下
上述过程是一个最简单的完整爬虫流程,可以看出它的功能就是把这些标题复制粘贴到一起,免不仅自动操作的冗长。其实爬虫通常就是做这些事的,比如我们须要用链家的数据进行剖析,看到链家的页面是这样的
我们想获取每位房屋的标题、几室几厅、多少平米、朝向、装修、价格等等数组(即指标),就可以通过爬虫进行定位,自动化抓取这100页所有房屋的那些数组信息。比如100页里有2000个房屋,总共抓取10个数组,爬虫运行结束就可以得到一个2000行10列的excel表格。
注:如果还没有安装里面两个库的读者可以在命令行下分别运行下边两行命令完成安装
pip install requests
pip install beautifulsoup4
知道了爬虫是拿来干哪些的以后,我们来介绍一些最常见到的概念
1.URL
URL英文称为统一资源定位符,其实可以理解成网页的链接,比如前面的就是一个URL。
但是更广义的URL不只是我们常听到的网页资源链接,而是资源在网页中的定位标示。我们一般说的网页是一个资源,网页中加载的每一张图片也是一个资源,它们在互联网中也有惟一的定位URL。比如我们从CSDN网页上随意找一张图片
这个链接就是这个图片资源的定位符,将这个链接输入浏览器中都会显示出这张图片网页爬虫,所以说这张图片也对应一个URL。
不过晓得如此回事就好,我们一般所说的传入URL指的就是把网页的链接传进去。上面代码中
r = requests.get('https://www.csdn.net/')
就是在将URL传入恳求函数。
2.网页恳求
说到网页恳求,就有必要讲一下我们平时浏览网页时,信息交互的模式大约是什么样的。我们平时用浏览器浏览网页的时侯,鼠标点了一个链接,比如你如今点击这儿,其实浏览器帮你向这个网页发送了恳求(request),维护网页的服务器(可以理解为CSDN公司里的一台笔记本,在维护这CSDN上的各个网页)收到了这个恳求,判定这个恳求是有效的,于是返回了一些响应信息(response)到浏览器,浏览器将这种信息进行渲染(可以理解成 处理成人能读懂的样子),就是你看见的网页的样子了。发送恳求与接收恳求的过程就和 发陌陌和收到回复的过程类似。
而如今我们要用代码来模拟滑鼠点击的过程。上面的requests.get就是使代码帮你向这个网页发送了这个恳求,如果恳求被判断为有效,网页的服务器也会把信息传送给你,传送回去的这种信息就被形参到变量r之中。所以这个变量r里就包含有我们想要的信息了,也包括这些我们想要提取的标题。
我们可以print(r.text)看一下上面有哪些东西
我们再看一下网页的源代码(如何读懂这个源码,以及这个源码如何查看下一节HTML会详尽提到)
源代码和r.text虽然是一模一样的东西。r.text虽然就是一个字符串,字符串中有我们刚才抓取到的所有标题,我们只要通过字符串匹配方式(比如正则表达式)将她们提取下来就可以了。这样说是不是觉得爬虫十分简单呢?只要这样傻蛋操作
r = requests.get('https://www.csdn.net/')
再直接从r.text字符串中提取信息即可。其实爬虫就是那么简单。
但是解析是如何回事呢,为什么刚才不直接用正则而要用bs4呢?因为便捷,但是正则也是完全可以的,只是相对麻烦一些、需要写更多的代码而已。
3.网页解析
网页解析虽然就从网页服务器返回给我们的信息中提取我们想要数据的过程。其实使用正则表达式提取我们要的标题的过程也可以称为网页解析。
因为当前绝大多数网页源代码都是用HTML语言写的,而HTML语言时特别有规律性的,比如我们要的所有文章标题都具有相同结构,也就是说它周围的字符串都是十分类似的,这样我们能够批量获取。所以就有大鳄专门封装了怎样从HTML代码中提取特定文本的库,也就是我们平常说的网页解析库,如bs4 lxml pyquery等,其实把她们当作处理字符串的就可以了。
为了更清楚地了解怎样对网页进行解析,我们须要先简略把握HTML代码的结构。
引用维基百科中的一段话来介绍HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被诸多网站用于设计令人赏心悦目的网页、网页应用程序以及移动应用程序的用户界面[1]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
为了使读者对HTML有更清楚的认识,我们来写一点简单的HTML代码。用文本编辑器(记事本也可以)创建一个名子为a.html的文件,在里面写下如下代码
<!DOCTYPE html>
<html>
<head>
<title>爬虫基本原理</title>
</head>
<body>
<h1>HTML介绍</h1>
<p>第一段</p>
<p>第二段</p>
</body>
</html>
保存,然后你双击这个文件,就会手动用浏览器打开,然后你还能见到下边这个样子的页面
你若果根据我的操作来做的话,你已然创建了一个简单的网页,现在你看见的所有网页都是这样设计的,只是比你的复杂一点而已,不信你去瞧瞧刚刚截图出来的网页源代码图片。
接下来,我们来看一下HTML语言的特性。最重要的一点是网页爬虫,文本都是被标签(h1标签 p标签)夹在中间的,而这种标签都是特定的,有专门用途的。比如<h1>就表示一级标题,包在上面的文本自然会被放大显示;而<p>标签则表示段落。
再看里面的源代码截图,head meta script title div li每一个都是标签,层层嵌套。我们完全不需要晓得总共有什么种标签,也不需要晓得这种标签都是拿来干哪些的,我们只要找到我们要的信息包含在哪些标签里就行了。比如使用正则表达式就直接用<p>(.*?)</p>就可以把上面的内容提取下来了。
但是事实似乎没有这么简单,看里面的截图标签如何是这样的<nav id="nav" class="clearfix">?其实这是一个<nav>标签,后面的id class是这个标签的属性。
为什么要给标签设置属性呢?我们先考虑这样一个问题:我们看见的网页千差万别,文字的颜色字体等都不一样,这是如何设置的呢?答案是使用css样式。
css句子类似这样
h1 {
color: white;
text-align: center;
}
p {
font-family: verdana;
font-size: 20px;
}
即设置对应标签的颜色、字体、大小、居中等。而当有的段落使用这个字体,有的段落使用哪个字体如何办呢?css这样设置
p.test1 {
font-size: 20px;
}
p.test2 {
font-size: 15px;
}
在HTML代码中则这样写
<p class="test1">20px大小的字</p>
<p class="test2">15px大小的字</p>
所以不同属性就是为了分辨相同标签用的,这相当于给标签进行了分类,在统一设计款式上更方便,同时对于我们依照属性定位我们想要内容的位置虽然也是更方便了。这里要说明一下,class id这两个属性比较特殊,用的也最多,所以各自弄了一个快捷键来表示,class用.,id用#。
做爬虫不需要了解刚才编撰的css代码内容放到那里之类的问题,也不需要了解css代码设置了哪些,我们只会和HTML打交道,所以只要理解HTML中属性的作用就可以了。
如果想要更进一步了解HTML和CSS,可以到w3school网站学习。
现在你就早已具备了解析网页须要的全部HTML知识了。我们通常就是依据标签名配合属性值来定位我们想要资源的位置的,其他的都不用管。这时,我们再来看爬虫的解析代码
把上面的代码再粘贴一遍如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
解释一下里面代码的过程
可以看见里面的代码十分简约,思路清晰,读者可以自己想一想假如要用正则表达式怎么匹配那些标签,会发觉代码冗长好多,虽然它也有更快的优势。
那么我们是如何晓得要找寻什么样属性的div标签,为什么要找h2 a标签而不是其他的呢?这就要去剖析网页的源代码了。而这个过程也十分简单。
我们如今用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-查看网页源代码,这时才会打开一个新的页面这个页面就是这个网站的HTML源代码了,我们可以通过这个页面来看我们要的信息在那里,但是觉得十分不便捷,因为有太多无用的信息做干扰,我们难以快速掌控网页的结构。所以我们可以用另一种形式查看源代码。
用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-检查,就会弹出一个框,如下图所示
(如果没有听到这个界面,注意要切换到Element中)
这个页面最大的用处是通过折叠来使人更快探求出网页的结构。
其中的这些代码就是HTML代码,该页面的一个个标题就存在这一个个li上面。点击li后面的三角就可以展开具体的代码内容,如下图所示
可以看见文章的标题(打造一个高性能、易落地的公链开发平台)就在这个源代码之中,也就是说在我们刚才获得的r.text字符串之中。而我们代码定位路径也一目了然了,因为每位li上面还会有一个<div class="title">而每一个div上面还会有一个h2 里面有一个a,a中包含我们要的标题名称。所以我们就用find_all找到所有这样的div标签,存储为一个list,再对list进行循环,对每一个元素提取h2 a 再提取标签中的内容。
当然我们也可以find_all最外边的li标签,再一层层往里找,都是一样的。只要找到定位信息的惟一标示(标签或则属性)就可以了。
虽然在这里看源代码可以折叠一些没用的代码,但是虽然还有一些更好用的工具来辅助我们找到我们要的信息在网页源码中的位置。比如下边这个键盘符号。
在所有代码都折叠上去的情况下,点击这个键盘,之后再去点击网页中的元素,浏览器都会手动帮你把你点击的元素选中下来,其实你键盘悬在一个元素前面的时侯,就早已帮你定位了,如下图所示
当我们要爬一个网页的时侯,只须要如下流程
现在,对于一些没有丝毫反爬举措的网站我们都可以游刃有余了。至于抓取多个数组的数据怎么组织在一起、抓取多页(URL有规律的情况下)的代码怎样设计,就不是爬虫知识范畴了,这是用python基础知识就可以解决的。下一系列文章就主要讲这一部分。接下来给几个当前可以练手的网站
如果使用BeautifulSoup的定位的过程中遇见困难,可以直接到网上搜教程,也可以等我们这个专题前面更新的BeautifulSoup详尽介绍。
如果你去抓取其他网站,最好先看一下r.text是不是和网站源代码一模一样,如果不是,说明你对方服务器没有把真正的信息给你,说明他可能看出你是爬虫了(进行网页恳求的时侯,浏览器和requests.get都相当于带着一堆资格证去敲门,对方会检测你这种资格证,浏览器的资格证通常是可以通过的,而代码的资格证就可能不合格,因为代码的资格证可能有一些比较固定的特征,对方服务器预先设定好,资格证是这样的恳求一律拒绝,因为她们一定是爬虫,这就是反爬虫机制),这时就须要懂一些反反爬举措就能获得真正的信息,反反爬方式的学习是一个积累的过程,我们前面再讲。读者假如遇见一些反爬机制,可以到网上查这个网站的爬虫,估计都能查到一些博客讲怎么破解,甚至直接贴出代码。
在这篇的基础上抓取多页以及代码设计的改进看下边这三篇续集
爬虫代码改进(一)
爬虫代码改进(二)
爬虫代码改进(三)
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明 查看全部
这篇文章的定位是,给有一些python基础,但是对爬虫一无所知的人写的。文中只会涉及到爬虫最核心的部份,完全避免莫名其妙的坑或概念,让读者认为爬虫是一件极其简单的事情,而事实上爬虫确实是一件极其简单的事情(如果你不是以爬虫为工作的话)。
本文分为如下几个部份
简单理解网路爬虫就是手动抓取网页信息的代码,可以简单理解成取代繁杂的复制粘贴操作的手段。
首先必须申明,爬虫的对象必须是你早已听到的网页,比如你不能说你想找到知乎上那个用户的关注人数最多,就希望通过写一个爬虫来帮你爬到答案。你必须明晰地晓得这个人,找到他的主页,然后才会用爬虫来抓取他页面上的信息。
下面我们用一个简单的事例来展示爬虫的工作流程。感觉多数教程第一篇都使用的是豆瓣top250,我们这儿换一个,抓取CSDN首页的文章标题,链接在这里,页面样子是这样的
抓取标题完整代码如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
这样才会复印出所有标题,展示一部分如下

上述过程是一个最简单的完整爬虫流程,可以看出它的功能就是把这些标题复制粘贴到一起,免不仅自动操作的冗长。其实爬虫通常就是做这些事的,比如我们须要用链家的数据进行剖析,看到链家的页面是这样的
我们想获取每位房屋的标题、几室几厅、多少平米、朝向、装修、价格等等数组(即指标),就可以通过爬虫进行定位,自动化抓取这100页所有房屋的那些数组信息。比如100页里有2000个房屋,总共抓取10个数组,爬虫运行结束就可以得到一个2000行10列的excel表格。
注:如果还没有安装里面两个库的读者可以在命令行下分别运行下边两行命令完成安装
pip install requests
pip install beautifulsoup4
知道了爬虫是拿来干哪些的以后,我们来介绍一些最常见到的概念
1.URL
URL英文称为统一资源定位符,其实可以理解成网页的链接,比如前面的就是一个URL。
但是更广义的URL不只是我们常听到的网页资源链接,而是资源在网页中的定位标示。我们一般说的网页是一个资源,网页中加载的每一张图片也是一个资源,它们在互联网中也有惟一的定位URL。比如我们从CSDN网页上随意找一张图片

这个链接就是这个图片资源的定位符,将这个链接输入浏览器中都会显示出这张图片网页爬虫,所以说这张图片也对应一个URL。
不过晓得如此回事就好,我们一般所说的传入URL指的就是把网页的链接传进去。上面代码中
r = requests.get('https://www.csdn.net/')
就是在将URL传入恳求函数。
2.网页恳求
说到网页恳求,就有必要讲一下我们平时浏览网页时,信息交互的模式大约是什么样的。我们平时用浏览器浏览网页的时侯,鼠标点了一个链接,比如你如今点击这儿,其实浏览器帮你向这个网页发送了恳求(request),维护网页的服务器(可以理解为CSDN公司里的一台笔记本,在维护这CSDN上的各个网页)收到了这个恳求,判定这个恳求是有效的,于是返回了一些响应信息(response)到浏览器,浏览器将这种信息进行渲染(可以理解成 处理成人能读懂的样子),就是你看见的网页的样子了。发送恳求与接收恳求的过程就和 发陌陌和收到回复的过程类似。
而如今我们要用代码来模拟滑鼠点击的过程。上面的requests.get就是使代码帮你向这个网页发送了这个恳求,如果恳求被判断为有效,网页的服务器也会把信息传送给你,传送回去的这种信息就被形参到变量r之中。所以这个变量r里就包含有我们想要的信息了,也包括这些我们想要提取的标题。
我们可以print(r.text)看一下上面有哪些东西
我们再看一下网页的源代码(如何读懂这个源码,以及这个源码如何查看下一节HTML会详尽提到)
源代码和r.text虽然是一模一样的东西。r.text虽然就是一个字符串,字符串中有我们刚才抓取到的所有标题,我们只要通过字符串匹配方式(比如正则表达式)将她们提取下来就可以了。这样说是不是觉得爬虫十分简单呢?只要这样傻蛋操作
r = requests.get('https://www.csdn.net/')
再直接从r.text字符串中提取信息即可。其实爬虫就是那么简单。
但是解析是如何回事呢,为什么刚才不直接用正则而要用bs4呢?因为便捷,但是正则也是完全可以的,只是相对麻烦一些、需要写更多的代码而已。
3.网页解析
网页解析虽然就从网页服务器返回给我们的信息中提取我们想要数据的过程。其实使用正则表达式提取我们要的标题的过程也可以称为网页解析。
因为当前绝大多数网页源代码都是用HTML语言写的,而HTML语言时特别有规律性的,比如我们要的所有文章标题都具有相同结构,也就是说它周围的字符串都是十分类似的,这样我们能够批量获取。所以就有大鳄专门封装了怎样从HTML代码中提取特定文本的库,也就是我们平常说的网页解析库,如bs4 lxml pyquery等,其实把她们当作处理字符串的就可以了。
为了更清楚地了解怎样对网页进行解析,我们须要先简略把握HTML代码的结构。
引用维基百科中的一段话来介绍HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被诸多网站用于设计令人赏心悦目的网页、网页应用程序以及移动应用程序的用户界面[1]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
为了使读者对HTML有更清楚的认识,我们来写一点简单的HTML代码。用文本编辑器(记事本也可以)创建一个名子为a.html的文件,在里面写下如下代码
<!DOCTYPE html>
<html>
<head>
<title>爬虫基本原理</title>
</head>
<body>
<h1>HTML介绍</h1>
<p>第一段</p>
<p>第二段</p>
</body>
</html>
保存,然后你双击这个文件,就会手动用浏览器打开,然后你还能见到下边这个样子的页面

你若果根据我的操作来做的话,你已然创建了一个简单的网页,现在你看见的所有网页都是这样设计的,只是比你的复杂一点而已,不信你去瞧瞧刚刚截图出来的网页源代码图片。
接下来,我们来看一下HTML语言的特性。最重要的一点是网页爬虫,文本都是被标签(h1标签 p标签)夹在中间的,而这种标签都是特定的,有专门用途的。比如<h1>就表示一级标题,包在上面的文本自然会被放大显示;而<p>标签则表示段落。
再看里面的源代码截图,head meta script title div li每一个都是标签,层层嵌套。我们完全不需要晓得总共有什么种标签,也不需要晓得这种标签都是拿来干哪些的,我们只要找到我们要的信息包含在哪些标签里就行了。比如使用正则表达式就直接用<p>(.*?)</p>就可以把上面的内容提取下来了。
但是事实似乎没有这么简单,看里面的截图标签如何是这样的<nav id="nav" class="clearfix">?其实这是一个<nav>标签,后面的id class是这个标签的属性。
为什么要给标签设置属性呢?我们先考虑这样一个问题:我们看见的网页千差万别,文字的颜色字体等都不一样,这是如何设置的呢?答案是使用css样式。
css句子类似这样
h1 {
color: white;
text-align: center;
}
p {
font-family: verdana;
font-size: 20px;
}
即设置对应标签的颜色、字体、大小、居中等。而当有的段落使用这个字体,有的段落使用哪个字体如何办呢?css这样设置
p.test1 {
font-size: 20px;
}
p.test2 {
font-size: 15px;
}
在HTML代码中则这样写
<p class="test1">20px大小的字</p>
<p class="test2">15px大小的字</p>
所以不同属性就是为了分辨相同标签用的,这相当于给标签进行了分类,在统一设计款式上更方便,同时对于我们依照属性定位我们想要内容的位置虽然也是更方便了。这里要说明一下,class id这两个属性比较特殊,用的也最多,所以各自弄了一个快捷键来表示,class用.,id用#。
做爬虫不需要了解刚才编撰的css代码内容放到那里之类的问题,也不需要了解css代码设置了哪些,我们只会和HTML打交道,所以只要理解HTML中属性的作用就可以了。
如果想要更进一步了解HTML和CSS,可以到w3school网站学习。
现在你就早已具备了解析网页须要的全部HTML知识了。我们通常就是依据标签名配合属性值来定位我们想要资源的位置的,其他的都不用管。这时,我们再来看爬虫的解析代码
把上面的代码再粘贴一遍如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
解释一下里面代码的过程
可以看见里面的代码十分简约,思路清晰,读者可以自己想一想假如要用正则表达式怎么匹配那些标签,会发觉代码冗长好多,虽然它也有更快的优势。
那么我们是如何晓得要找寻什么样属性的div标签,为什么要找h2 a标签而不是其他的呢?这就要去剖析网页的源代码了。而这个过程也十分简单。
我们如今用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-查看网页源代码,这时才会打开一个新的页面这个页面就是这个网站的HTML源代码了,我们可以通过这个页面来看我们要的信息在那里,但是觉得十分不便捷,因为有太多无用的信息做干扰,我们难以快速掌控网页的结构。所以我们可以用另一种形式查看源代码。
用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-检查,就会弹出一个框,如下图所示
(如果没有听到这个界面,注意要切换到Element中)
这个页面最大的用处是通过折叠来使人更快探求出网页的结构。
其中的这些代码就是HTML代码,该页面的一个个标题就存在这一个个li上面。点击li后面的三角就可以展开具体的代码内容,如下图所示
可以看见文章的标题(打造一个高性能、易落地的公链开发平台)就在这个源代码之中,也就是说在我们刚才获得的r.text字符串之中。而我们代码定位路径也一目了然了,因为每位li上面还会有一个<div class="title">而每一个div上面还会有一个h2 里面有一个a,a中包含我们要的标题名称。所以我们就用find_all找到所有这样的div标签,存储为一个list,再对list进行循环,对每一个元素提取h2 a 再提取标签中的内容。
当然我们也可以find_all最外边的li标签,再一层层往里找,都是一样的。只要找到定位信息的惟一标示(标签或则属性)就可以了。
虽然在这里看源代码可以折叠一些没用的代码,但是虽然还有一些更好用的工具来辅助我们找到我们要的信息在网页源码中的位置。比如下边这个键盘符号。
在所有代码都折叠上去的情况下,点击这个键盘,之后再去点击网页中的元素,浏览器都会手动帮你把你点击的元素选中下来,其实你键盘悬在一个元素前面的时侯,就早已帮你定位了,如下图所示
当我们要爬一个网页的时侯,只须要如下流程
现在,对于一些没有丝毫反爬举措的网站我们都可以游刃有余了。至于抓取多个数组的数据怎么组织在一起、抓取多页(URL有规律的情况下)的代码怎样设计,就不是爬虫知识范畴了,这是用python基础知识就可以解决的。下一系列文章就主要讲这一部分。接下来给几个当前可以练手的网站
如果使用BeautifulSoup的定位的过程中遇见困难,可以直接到网上搜教程,也可以等我们这个专题前面更新的BeautifulSoup详尽介绍。
如果你去抓取其他网站,最好先看一下r.text是不是和网站源代码一模一样,如果不是,说明你对方服务器没有把真正的信息给你,说明他可能看出你是爬虫了(进行网页恳求的时侯,浏览器和requests.get都相当于带着一堆资格证去敲门,对方会检测你这种资格证,浏览器的资格证通常是可以通过的,而代码的资格证就可能不合格,因为代码的资格证可能有一些比较固定的特征,对方服务器预先设定好,资格证是这样的恳求一律拒绝,因为她们一定是爬虫,这就是反爬虫机制),这时就须要懂一些反反爬举措就能获得真正的信息,反反爬方式的学习是一个积累的过程,我们前面再讲。读者假如遇见一些反爬机制,可以到网上查这个网站的爬虫,估计都能查到一些博客讲怎么破解,甚至直接贴出代码。
在这篇的基础上抓取多页以及代码设计的改进看下边这三篇续集
爬虫代码改进(一)
爬虫代码改进(二)
爬虫代码改进(三)
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明
网页爬虫及其用到的算法和数据结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-05-13 08:04
网络爬虫程序的好坏,很大程度上反映了一个搜索引擎的好差。不信,你可以随意拿一个网站去查询一下各家搜索对它的网页收录情况,爬虫强悍程度跟搜索引擎优劣基本成正比。
1.世界上最简单的爬虫——三行情诗
我们先来看一个最简单的最简单的爬虫,用python写成,只须要三行。
import requests url="http://www.cricode.com" r=requests.get(url)
上面这三行爬虫程序,就如下边这三行短诗通常,很干脆利落。
是好男人,
就应当在和妻子争吵时网络爬虫算法书籍,
抱着必输的态度。
2.一个正常的爬虫程序
上面哪个最简单的爬虫,是一个不完整的残障的爬虫。因为爬虫程序一般须要做的事情如下:
因此,一个完整的爬虫大约是这样子的:
import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
seds = ["http://www.hao123.com", #我们的种子
"http://www.csdn.net",
http://www.cricode.com]
sum = 0 #我们设定终止条件为:爬取到100000个页面时,就不玩了
while sum < 10000 :
if sum < len(seds):
r = requests.get(seds[sum])
sum = sum + 1
do_save_action(r)
soup = BeautifulSoup(r.content)
urls = soup.find_all("href",.....) //解析网页
for url in urls:
seds.append(url) else:
break
3.现在来找碴
上面哪个完整的爬虫,不足20行代码,相信你能找出20个茬来。因为它的缺点实在是太多。下面一一列出它的N宗罪:
4.找了这么多茬后,很有成就感,真正的问题来了,学挖掘机究竟哪家强?
现在我们就来一一讨论里面找碴找出的若干问题的解决方案。
1)并行爬起问题
我们可以有多重方式去实现并行。
多线程或则线程池形式,一个爬虫程序内部开启多个线程。同一台机器开启多个爬虫程序,如此,我们就有N多爬取线程在同时工作。能大大降低时间。
此外,当我们要爬取的任务非常多时,一台机器、一个网点肯定是不够的,我们必须考虑分布式爬虫。常见的分布式构架有:主从(Master——Slave)架构、点对点(PeertoPeer)架构,混合构架等。
说道分布式构架,那我们须要考虑的问题就有很多,我们须要分派任务,各个爬虫之间须要通讯合作,共同完成任务,不要重复爬取相同的网页。分派任务我们要做到公正公平,就须要考虑怎样进行负载均衡。负载均衡,我们第一个想到的就是Hash,比如按照网站域名进行hash。
负载均衡分派完任务以后,千万不要以为万事大吉了,万一哪台机器挂了呢?原先委派给死掉的哪台机器的任务委派给谁?又或则哪天要降低几台机器网络爬虫算法书籍,任务有该怎样进行重新分配呢?
一个比较好的解决方案是用一致性Hash算法。
2)待爬取网页队列
如何对待待抓取队列,跟操作系统怎么调度进程是类似的场景。
不同网站,重要程度不同,因此,可以设计一个优先级队列来储存待爬起的网页链接。如此一来,每次抓取时,我们都优先爬取重要的网页。
当然,你也可以仿效操作系统的进程调度策略之多级反馈队列调度算法。
3)DNS缓存
为了防止每次都发起DNS查询,我们可以将DNS进行缓存。DNS缓存其实是设计一个hash表来储存已有的域名及其IP。
4)网页去重
说到网页去重,第一个想到的是垃圾邮件过滤。垃圾邮件过滤一个精典的解决方案是BloomFilter(布隆过滤器)。布隆过滤器原理简单来说就是:建立一个大的位字段,然后用多个Hash函数对同一个url进行hash得到多个数字,然后将位字段中这种数字对应的位置为1。下次再来一个url时,同样是用多个Hash函数进行hash,得到多个数字,我们只须要判定位字段中这种数字对应的为是全为1,如果全为1,那么说明这个url早已出现过。如此,便完成了url去重的问题。当然,这种方式会有偏差,只要偏差在我们的容忍范围之类,比如1万个网页,我只爬取到了9999个,剩下那一个网页,whocares!
5)数据储存的问题
数据储存同样是个挺有技术浓度的问题。用关系数据库存取还是用NoSQL,抑或是自己设计特定的文件格式进行储存,都大有文章可做。
6)进程间通信
分布式爬虫,就必然离不开进程间的通讯。我们可以以规定的数据格式进行数据交互,完成进程间通信。
7)……
废话说了那么多,真正的问题来了,问题不是学挖掘机究竟哪家强?而是怎么实现里面那些东西!:)
实现的过程中,你会发觉,我们要考虑的问题远远不止里面那些。纸上得来终觉浅,觉知此事要笃行! 查看全部


网络爬虫程序的好坏,很大程度上反映了一个搜索引擎的好差。不信,你可以随意拿一个网站去查询一下各家搜索对它的网页收录情况,爬虫强悍程度跟搜索引擎优劣基本成正比。
1.世界上最简单的爬虫——三行情诗
我们先来看一个最简单的最简单的爬虫,用python写成,只须要三行。
import requests url="http://www.cricode.com" r=requests.get(url)
上面这三行爬虫程序,就如下边这三行短诗通常,很干脆利落。
是好男人,
就应当在和妻子争吵时网络爬虫算法书籍,
抱着必输的态度。
2.一个正常的爬虫程序
上面哪个最简单的爬虫,是一个不完整的残障的爬虫。因为爬虫程序一般须要做的事情如下:
因此,一个完整的爬虫大约是这样子的:
import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
seds = ["http://www.hao123.com", #我们的种子
"http://www.csdn.net",
http://www.cricode.com]
sum = 0 #我们设定终止条件为:爬取到100000个页面时,就不玩了
while sum < 10000 :
if sum < len(seds):
r = requests.get(seds[sum])
sum = sum + 1
do_save_action(r)
soup = BeautifulSoup(r.content)
urls = soup.find_all("href",.....) //解析网页
for url in urls:
seds.append(url) else:
break
3.现在来找碴
上面哪个完整的爬虫,不足20行代码,相信你能找出20个茬来。因为它的缺点实在是太多。下面一一列出它的N宗罪:
4.找了这么多茬后,很有成就感,真正的问题来了,学挖掘机究竟哪家强?
现在我们就来一一讨论里面找碴找出的若干问题的解决方案。
1)并行爬起问题
我们可以有多重方式去实现并行。
多线程或则线程池形式,一个爬虫程序内部开启多个线程。同一台机器开启多个爬虫程序,如此,我们就有N多爬取线程在同时工作。能大大降低时间。
此外,当我们要爬取的任务非常多时,一台机器、一个网点肯定是不够的,我们必须考虑分布式爬虫。常见的分布式构架有:主从(Master——Slave)架构、点对点(PeertoPeer)架构,混合构架等。
说道分布式构架,那我们须要考虑的问题就有很多,我们须要分派任务,各个爬虫之间须要通讯合作,共同完成任务,不要重复爬取相同的网页。分派任务我们要做到公正公平,就须要考虑怎样进行负载均衡。负载均衡,我们第一个想到的就是Hash,比如按照网站域名进行hash。
负载均衡分派完任务以后,千万不要以为万事大吉了,万一哪台机器挂了呢?原先委派给死掉的哪台机器的任务委派给谁?又或则哪天要降低几台机器网络爬虫算法书籍,任务有该怎样进行重新分配呢?
一个比较好的解决方案是用一致性Hash算法。
2)待爬取网页队列
如何对待待抓取队列,跟操作系统怎么调度进程是类似的场景。
不同网站,重要程度不同,因此,可以设计一个优先级队列来储存待爬起的网页链接。如此一来,每次抓取时,我们都优先爬取重要的网页。
当然,你也可以仿效操作系统的进程调度策略之多级反馈队列调度算法。
3)DNS缓存
为了防止每次都发起DNS查询,我们可以将DNS进行缓存。DNS缓存其实是设计一个hash表来储存已有的域名及其IP。
4)网页去重
说到网页去重,第一个想到的是垃圾邮件过滤。垃圾邮件过滤一个精典的解决方案是BloomFilter(布隆过滤器)。布隆过滤器原理简单来说就是:建立一个大的位字段,然后用多个Hash函数对同一个url进行hash得到多个数字,然后将位字段中这种数字对应的位置为1。下次再来一个url时,同样是用多个Hash函数进行hash,得到多个数字,我们只须要判定位字段中这种数字对应的为是全为1,如果全为1,那么说明这个url早已出现过。如此,便完成了url去重的问题。当然,这种方式会有偏差,只要偏差在我们的容忍范围之类,比如1万个网页,我只爬取到了9999个,剩下那一个网页,whocares!
5)数据储存的问题
数据储存同样是个挺有技术浓度的问题。用关系数据库存取还是用NoSQL,抑或是自己设计特定的文件格式进行储存,都大有文章可做。
6)进程间通信
分布式爬虫,就必然离不开进程间的通讯。我们可以以规定的数据格式进行数据交互,完成进程间通信。
7)……
废话说了那么多,真正的问题来了,问题不是学挖掘机究竟哪家强?而是怎么实现里面那些东西!:)
实现的过程中,你会发觉,我们要考虑的问题远远不止里面那些。纸上得来终觉浅,觉知此事要笃行!
python爬虫入门书籍
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-13 08:03
广告
云服务器1核2G首年99年,还有多款热门云产品满足您的上云需求
如果你想获得文章中实战的源代码,可以点击对应文章中【阅读文章】来获取。 学爬虫之道解读 python3 urllibpython 正则表达式内容提取利器 beautiful soup的用法爬虫实战一:爬取当当网所有 python 书籍python 多进程与多线程解读 requests库的用法“干将莫邪” —— xpath 与 lxml 库爬虫实战二:爬取影片天堂的最新...
点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫介绍----网络爬虫,英译为 web crawler ,是一种自动化程序,现在我们很幸运,生处互联网时代,有大量的信息在...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,都放到了文章结尾,欢迎前来发放!? 最近闲的无趣,想爬点书瞧瞧。 于是我选择了这个网站雨枫轩(http:)step1. 分析网站----一开始我想通过一篇文章引用的...
学习应用python的多线程、多进程进行爬取,提高爬虫效率; 学习爬虫的框架,scrapy、pyspider等; 学习分布式爬虫(数据量庞大的需求); 以上便是一个整体的学习概况,好多内容博主也须要继续学习,关于提及的每位步骤的细节,博主会在后续内容中以实战的事例逐渐与你们分享,当然中间也会穿插一些关于爬虫的好玩 3. ...
v站笔记 爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip install...
爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip installpymysql须要...
简单点书,python爬虫就是一个机械化的为你查询网页内容,并且按照你制订的规则返回你须要的资源的一类程序,也是目前大数据常用的一种形式,所以昨晚来进行爬虫扫盲,高端用户请回避,或者可以私戳,容我来膜拜下。 我的学习动机近来对简书中毒太深,所以想要写一个爬虫,放到服务器上,自己帮我随时查看简书的主页...
点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 今天我就来找一个简单的网页进行爬取,就当是给之前的兵书做一个实践。 不然不就是纸上谈兵的赵括了吗。 好了,我们...
编程对于任何一个菜鸟来说都不是一件容易的事情,python对于任何一个想学习的编程的人来说的确是一个福音,阅读python代码象是在阅读文章,源于python语言提供了十分典雅的句型,被称为最高贵的语言之一。? python入门时用得最多的还是各种爬虫脚本,写过抓代理本机验证的脚本、写过峰会中手动登入手动发帖的脚本写过...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! “入门”是良好的动机,但是可能作用平缓。 如果你手里或则脑袋里有一个项目,那么实践上去你会被目标驱动,而不会象学习模块一样渐渐学习。 另外假如说...
如果你是跟随实战的书敲代码的,很多时侯项目都不会一遍运行成功数据挖掘爬虫书籍,那么你就要按照各类报错去找寻缘由,这也是一个学习的过程。 总结上去从python入门跳出来的过程分为三步:照抄、照抄以后的理解、重新自己实现。 (八)python爬虫入门第一:python爬虫学习系列教程python版本:3.6整体目录:一、爬虫入门 python爬虫...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着他人的爬虫代码学,弄懂每一...
python中有许多种操作简单且高效的工具可以协助我们来解析html或则xml,学会这种工具抓取数据是很容易了。 说到爬虫的htmlxml解析(现在网页大部分都是html)数据挖掘爬虫书籍,可使用的方式实在有很多种,如:正则表达式beautifulsouplxmlpyquerycssselector似乎也不止这几种,还有好多,那么究竟哪一种最好呢? 这个很难说,萝卜...
zhuanlan.zhihu.comp28865834(简介:这本书主要内容是python入门,以及python爬虫入门和python爬虫进阶)2. 问题:求大神们推荐python入门书籍https:(简介:python爬虫方面入门书籍推荐教程:系列教程:1.python爬虫学习系列教程https:zhuanlan.zhihu.comp25949099...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫是哪些? 如果我们把互联网称作一张大的蜘蛛网,数据便是储存于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网路抓取自己的猎物(数据)爬虫指的是...
获取某个答案的所有点赞者名单? 知乎上有一个问题是怎样写个爬虫程序扒下知乎某个回答所有点赞用户名单? 我参考了段草儿的这个答案怎么入门python爬虫,然后有了下边的这个函数。 这里先来大约的剖析一下整个流程。 我们要知道,知乎上的每一个问题都有一个惟一id,这个可以从地址中看下来,例如问题2015 年有什么书...
工具:xmind▍思维导图1 爬虫基础知识 ? 2 requests 库 ? 3 beautifulsoup & urllib ? 4 scrapy 爬虫框架 ? ▍参考资料假如你希望进一步学习表单递交,js 处理,验证码等更高阶的话题,可以继续深入学习本文附上的参考资料哦:mooc:python 网络爬虫与信息提取 书籍:《python 网络数据采集》若发觉本篇 python 笔记...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 在常见的几个音乐网站里,酷狗可以说是最好爬取的啦,什么弯都没有,也没加密啥的,所以最适宜小白入门爬虫本篇针对爬虫零基础的小白,所以每一步骤我都...
同时,自己是一名中级python开发工程师,从基础的python脚本到web开发、爬虫、django、数据挖掘等,零基础到项目实战的资料都有整理。 送给每一位python的...而这个网路恳求背后的技术就是基于 http 协议。 作为入门爬虫来说,你须要了解 http合同的基本原理,虽然 http 规范用一本书都写不完,但深入的内容可以放...
并非开始都是最容易的刚开始对爬虫不是太了解,又没有任何的计算机、编程基础,确实有点懵逼。 从那里开始,哪些是最开始应当学的,哪些应当等到有一定基础以后再学,也没个清晰的概念。 因为是 python 爬虫嘛,python 就是必备的咯,那先从 python 开始吧。 于是看了一些教程和书籍,了解基本的数据结构,然后是列表... 查看全部


广告
云服务器1核2G首年99年,还有多款热门云产品满足您的上云需求
如果你想获得文章中实战的源代码,可以点击对应文章中【阅读文章】来获取。 学爬虫之道解读 python3 urllibpython 正则表达式内容提取利器 beautiful soup的用法爬虫实战一:爬取当当网所有 python 书籍python 多进程与多线程解读 requests库的用法“干将莫邪” —— xpath 与 lxml 库爬虫实战二:爬取影片天堂的最新...

点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫介绍----网络爬虫,英译为 web crawler ,是一种自动化程序,现在我们很幸运,生处互联网时代,有大量的信息在...

前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,都放到了文章结尾,欢迎前来发放!? 最近闲的无趣,想爬点书瞧瞧。 于是我选择了这个网站雨枫轩(http:)step1. 分析网站----一开始我想通过一篇文章引用的...
学习应用python的多线程、多进程进行爬取,提高爬虫效率; 学习爬虫的框架,scrapy、pyspider等; 学习分布式爬虫(数据量庞大的需求); 以上便是一个整体的学习概况,好多内容博主也须要继续学习,关于提及的每位步骤的细节,博主会在后续内容中以实战的事例逐渐与你们分享,当然中间也会穿插一些关于爬虫的好玩 3. ...
v站笔记 爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip install...
爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip installpymysql须要...

简单点书,python爬虫就是一个机械化的为你查询网页内容,并且按照你制订的规则返回你须要的资源的一类程序,也是目前大数据常用的一种形式,所以昨晚来进行爬虫扫盲,高端用户请回避,或者可以私戳,容我来膜拜下。 我的学习动机近来对简书中毒太深,所以想要写一个爬虫,放到服务器上,自己帮我随时查看简书的主页...

点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 今天我就来找一个简单的网页进行爬取,就当是给之前的兵书做一个实践。 不然不就是纸上谈兵的赵括了吗。 好了,我们...
编程对于任何一个菜鸟来说都不是一件容易的事情,python对于任何一个想学习的编程的人来说的确是一个福音,阅读python代码象是在阅读文章,源于python语言提供了十分典雅的句型,被称为最高贵的语言之一。? python入门时用得最多的还是各种爬虫脚本,写过抓代理本机验证的脚本、写过峰会中手动登入手动发帖的脚本写过...

前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! “入门”是良好的动机,但是可能作用平缓。 如果你手里或则脑袋里有一个项目,那么实践上去你会被目标驱动,而不会象学习模块一样渐渐学习。 另外假如说...
如果你是跟随实战的书敲代码的,很多时侯项目都不会一遍运行成功数据挖掘爬虫书籍,那么你就要按照各类报错去找寻缘由,这也是一个学习的过程。 总结上去从python入门跳出来的过程分为三步:照抄、照抄以后的理解、重新自己实现。 (八)python爬虫入门第一:python爬虫学习系列教程python版本:3.6整体目录:一、爬虫入门 python爬虫...

前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着他人的爬虫代码学,弄懂每一...

python中有许多种操作简单且高效的工具可以协助我们来解析html或则xml,学会这种工具抓取数据是很容易了。 说到爬虫的htmlxml解析(现在网页大部分都是html)数据挖掘爬虫书籍,可使用的方式实在有很多种,如:正则表达式beautifulsouplxmlpyquerycssselector似乎也不止这几种,还有好多,那么究竟哪一种最好呢? 这个很难说,萝卜...
zhuanlan.zhihu.comp28865834(简介:这本书主要内容是python入门,以及python爬虫入门和python爬虫进阶)2. 问题:求大神们推荐python入门书籍https:(简介:python爬虫方面入门书籍推荐教程:系列教程:1.python爬虫学习系列教程https:zhuanlan.zhihu.comp25949099...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫是哪些? 如果我们把互联网称作一张大的蜘蛛网,数据便是储存于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网路抓取自己的猎物(数据)爬虫指的是...
获取某个答案的所有点赞者名单? 知乎上有一个问题是怎样写个爬虫程序扒下知乎某个回答所有点赞用户名单? 我参考了段草儿的这个答案怎么入门python爬虫,然后有了下边的这个函数。 这里先来大约的剖析一下整个流程。 我们要知道,知乎上的每一个问题都有一个惟一id,这个可以从地址中看下来,例如问题2015 年有什么书...
工具:xmind▍思维导图1 爬虫基础知识 ? 2 requests 库 ? 3 beautifulsoup & urllib ? 4 scrapy 爬虫框架 ? ▍参考资料假如你希望进一步学习表单递交,js 处理,验证码等更高阶的话题,可以继续深入学习本文附上的参考资料哦:mooc:python 网络爬虫与信息提取 书籍:《python 网络数据采集》若发觉本篇 python 笔记...

前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 在常见的几个音乐网站里,酷狗可以说是最好爬取的啦,什么弯都没有,也没加密啥的,所以最适宜小白入门爬虫本篇针对爬虫零基础的小白,所以每一步骤我都...
同时,自己是一名中级python开发工程师,从基础的python脚本到web开发、爬虫、django、数据挖掘等,零基础到项目实战的资料都有整理。 送给每一位python的...而这个网路恳求背后的技术就是基于 http 协议。 作为入门爬虫来说,你须要了解 http合同的基本原理,虽然 http 规范用一本书都写不完,但深入的内容可以放...

并非开始都是最容易的刚开始对爬虫不是太了解,又没有任何的计算机、编程基础,确实有点懵逼。 从那里开始,哪些是最开始应当学的,哪些应当等到有一定基础以后再学,也没个清晰的概念。 因为是 python 爬虫嘛,python 就是必备的咯,那先从 python 开始吧。 于是看了一些教程和书籍,了解基本的数据结构,然后是列表...
java爬虫gecco
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-05-13 08:02
java爬虫gecco 相关的博客
教您使用java爬虫gecco抓取JD全部商品信息教您使用DynamicGecco抓取JD全部商品信息 Gecco+Spring+Mybatis完整事例,下载美女图美眉图片 结合spring的插件gecco-spring 结合htmlunit的插件gecco
互联网编程1年前 505
Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫java爬虫框架gecco,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。
互联网编程2年前 596
一、Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。 主题爬虫通常关注的是:下载、内容抽取、灵活的业务
互联网编程1年前 1069
补充基础知识 爬虫,毋庸置疑就是爬去互联网的网页java爬虫框架gecco,理论上,只要是互联网中存在的web页面,都可以爬取。用来做数据采集非常合适,尤其是现今大数据领域,爬虫必不可少。 爬虫种类有很多,了解概念可以参考百度百科 这里采用Java语言做爬虫,没有哪些非常的缘由,第一
互联网编程1年前 707
整理了Node.js、PHP、Go、JAVA、Ruby、Python等语言的爬虫框架。不知道读者们都用过哪些爬虫框架?爬虫框架的什么点你感觉好?哪些点认为不好? Node.js node-crawler
seancheney1年前 952 查看全部
java爬虫gecco 相关的博客

教您使用java爬虫gecco抓取JD全部商品信息教您使用DynamicGecco抓取JD全部商品信息 Gecco+Spring+Mybatis完整事例,下载美女图美眉图片 结合spring的插件gecco-spring 结合htmlunit的插件gecco

互联网编程1年前 505

Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫java爬虫框架gecco,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。
互联网编程2年前 596

一、Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。 主题爬虫通常关注的是:下载、内容抽取、灵活的业务
互联网编程1年前 1069

补充基础知识 爬虫,毋庸置疑就是爬去互联网的网页java爬虫框架gecco,理论上,只要是互联网中存在的web页面,都可以爬取。用来做数据采集非常合适,尤其是现今大数据领域,爬虫必不可少。 爬虫种类有很多,了解概念可以参考百度百科 这里采用Java语言做爬虫,没有哪些非常的缘由,第一
互联网编程1年前 707

整理了Node.js、PHP、Go、JAVA、Ruby、Python等语言的爬虫框架。不知道读者们都用过哪些爬虫框架?爬虫框架的什么点你感觉好?哪些点认为不好? Node.js node-crawler

seancheney1年前 952
利用 scrapy 集成社区爬虫功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-05-13 08:00
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:
代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:
scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:
在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键
填写社交帐号,点击更新按键
爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:) 查看全部
社区活跃度或则贡献越来越遭到注重,往往会作为获得工作或则承接项目的加分项。为了便捷用户展示自己的社区资料,中降低了一个社区爬虫功能。
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:

代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:

scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:

在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键

填写社交帐号,点击更新按键

爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:)
Python爬虫能做哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-05-12 08:03
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言! 查看全部
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言!
python网络爬虫书籍推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-05-11 08:02
Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载 查看全部
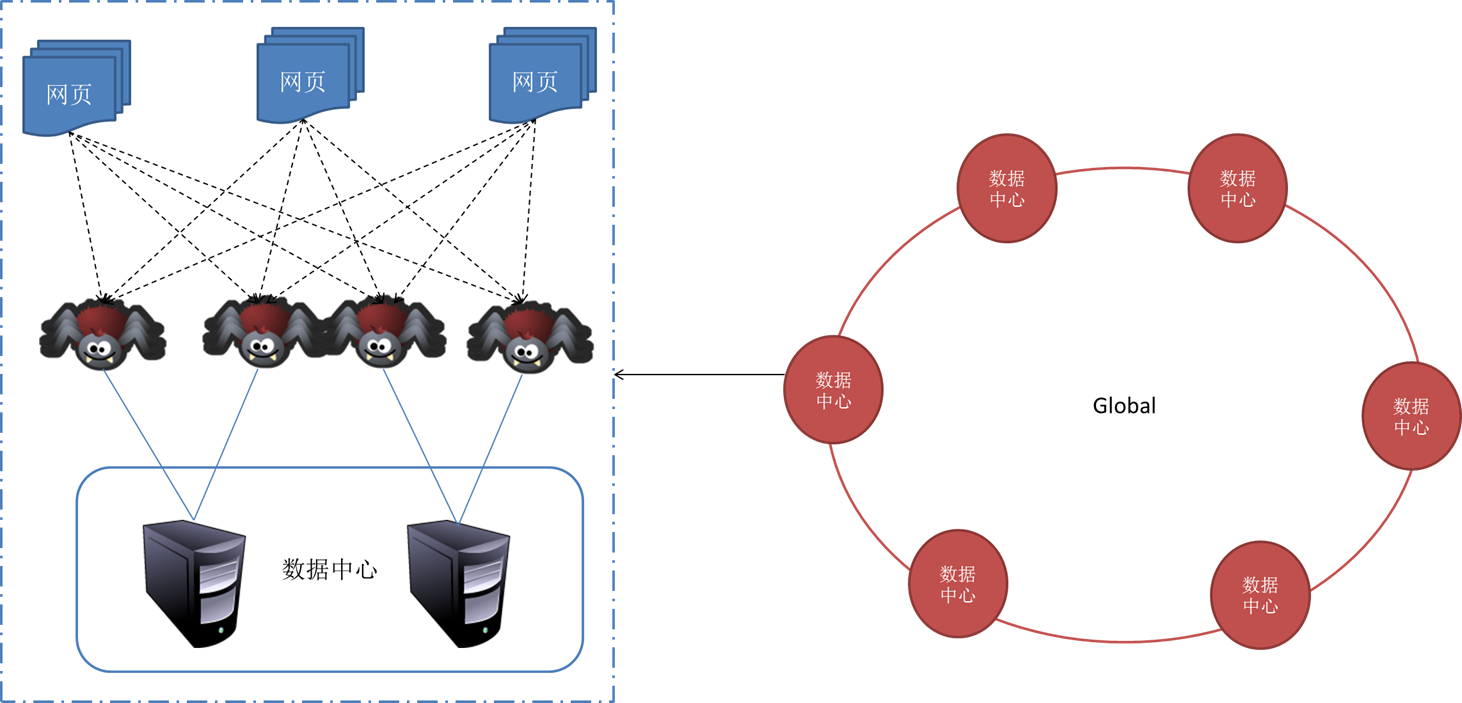

Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载
python爬虫js加密篇—搜狗微信公号文章的爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-05-24 08:01
微信公众号的上一个版本中的反爬机制中并没有涉及到js加密,仅通过监控用户ip,单个ip访问很频繁会面临被封的风险;在新的版本中加入了js加密反爬机制,接下来我们来逐渐剖析一下文章爬取过程
打开搜狗页面搜狗陌陌页面,在输入框中输入任意关键词比如列车隧洞大火,搜下来的都是涉及关键词的公号文章列表
私信小编01 获取全套学习教程!
这里根据平时套路,直接借助开发者工具的选择工具,查看源码中列表中整篇文章的url,就是下边这个 href属性 标签
看到这个url,按照正常思路的话,就是直接做url拼接:搜狗主域名 + href 就是陌陌主要内容的url,形式如下
https
:
//weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS_yBZajb90fWf-LwgFP7QmnFtbELADqFzFqXa8Fplpd9nrYbnf-BG6fJQmhdTDKRUQC_zVYwjAHQRnKwtfQUOD-aNBz2bhtCuShQywQb837B12cBkYFsYkKXir7Y9WqlRBcZIrhUAYmFlBSVIg7YGFbBdu4rXklGlRslEFpw0lTmIX8pHfpQ9x6clCHaA92qoA9YOaIV2yOyrE-focNFXq7wdVqCwyPdzA..&type=2&query=%E7%81%AB%E8%BD%A6%E9%9A%A7%E9%81%93%E8%B5%B7%E7%81%AB
但是直接点这个链接返回的是402页面,需要输入验证码进行验证,而且验证码通过后仍然进不去;很明显这个url并不是文章的访问入口
经过测试,这篇文章的真实url是下边这些方式(直接通过点击页面标签打开即可):
https
:
//mp.weixin.qq.com/s?src=11×tamp=1567073292&ver=1820&signature=z2h7E*HznopGFidmtUA4PmXgi3ioRqV7XiYIqn9asMT3RCMKss6Y2nPUh7RG63nrwmRii77cL9LyDNJIVp1qpo5LHvQ8s754Q9HtCgbp5EPUP9HjosY7HWDwze6A2Qi7&new=1
是不是太太意外;这里开始就须要转变思路:不管怎样最好先抓一下包,这里我借助的工具是Fidder,关于Fidder怎样使用,可以参照这篇文章:
先从搜索页面的文章列表中步入文章的详情页,我们须要通过Fidder来监控一下文章的跳转情况:
看到没,惊奇地发觉有个 /link?url 开头的url跳转成功了,深入一下,我们再看一下这个链接返回的是哪些,点一下response部份的TextView;
返回的text文本是一串字符串组成的,即使不懂javascript,但上面大约意思就是构造一个url,格式与后面那种真实的url有一些相像呢,经测试以后发觉,返回的这个url就是获取文章内容的真实url
把这个访问成功的而且以link?url开头的url完整复制出来,与源码中的那种 link?url 放在一起,发现这个访问成功的url中多了两个参数一个是k一个是h
# 访问成功的:https://weixin.sogou.com/link% ... h%3Df
# 访问失败的:https://weixin.sogou.com/link% ... %25AB
现在基本爬取核心思路早已晓得了,主要就是破解这两个参数k和h,拼接成'真'的url( 以/cl.gif开头的 ),然后获取真url; 关于这两个参数的破解就是涉及到了js加密,需要进行调试,不懂的可以参考这篇文章:Chrome DevTools 中调试 JavaScript 入门;
第一步,回到源码中 link?url 位置的地方,因为前面两个参数的降低是因为我们触发了这个假的url,所以这儿须要对假的url进行窃听:
开发者工具[Elements] -> 右上角处的[Event Listeners] -> [click] -> 你须要监控的元素标签;
第二步,按流程浏览完前面所有过程时下边会有个js文件,点进去,并对js代码进行低格,发现参数k与h的构造方式:
其实还有一种参数定位的方式,在Google开发者选项中借助全局搜索[Search]就能快速定位,但是并不适用于这儿,因为这儿我们定位的参数都是单个元素,定位的准确度非常低
定位以后,参数k与h的定义十分清楚,没有过多函数嵌套,就是在一个简单的函数中,一个是生成一个随机数字,另一个在这个href标签的链接中获取其中的某一个字符,这里我们可以直python把这个功能实现:
url_list11
=
pq
(
res
.
text
)(
'.news-list li'
).
items
()
for
i
in
url_list11
:
url_list12
=
pq
(
i
(
'.img-box a'
).
attr
(
'href'
))
url_list12
=
str
(
url_list12
).
replace
(
'
'
,
''
).
replace
(
'
'
,
''
).
replace
(
'amp;'
,
''
)
(
url_list12
)
b
=
int
(
random
.
random
()
*
100
)
+
1
a
=
url_list12
.
find
(
"url="
)
result_link
=
url_list12
+
"&k="
+
str
(
b
)
+
"&h="
+
url_list12
[
a
+
4
+
21
+
b
:
a
+
4
+
21
+
b
+
1
]
a_url
=
"https://weixin.sogou.com"
+
result_link
好了,‘真’url也就能构造成功了,通过访问‘真’url来获取 真url(访问时记得加上headers),然后再获取我们须要的信息;然而结果却是下边这样的:
经测试发觉,原因是因为Cookie中最为核心的两个参数SUV和SUNID搜狗微信 反爬虫,而这两个参数在不断地发生改变
其中SUNID有固定得访问次数/时间限制,超过了限制直接变为无效,并且当访问网页恳求失败后,SUNID与SUV须要更换能够再度正常访问
SUV参数是在 ‘真’url 过度到 真url 中某个网页中Response里的Set-Cookie中生成的,也就是下边这个网页:
需要我们恳求这个链接,通过这个链接返回的Cookie,我们领到这个Cookie装入恳求头上面,再访问拼接好的 * ‘真’ url*
最后能够获取到真url最后恳求这个链接,解析出我们想要的数据( 注意用恳求头的时侯最好不要加Cookies搜狗微信 反爬虫,否则会导致访问失败 ) 当解决以上所有问题了,这里再测试一下,已经才能成功地领到我们想要的数据: 查看全部
今天这篇文章主要介绍的是关于微信公众号文章的爬取,其中上面主要涉及的反爬机制就是 js加密与cookies的设置 ;
微信公众号的上一个版本中的反爬机制中并没有涉及到js加密,仅通过监控用户ip,单个ip访问很频繁会面临被封的风险;在新的版本中加入了js加密反爬机制,接下来我们来逐渐剖析一下文章爬取过程
打开搜狗页面搜狗陌陌页面,在输入框中输入任意关键词比如列车隧洞大火,搜下来的都是涉及关键词的公号文章列表
私信小编01 获取全套学习教程!
这里根据平时套路,直接借助开发者工具的选择工具,查看源码中列表中整篇文章的url,就是下边这个 href属性 标签
看到这个url,按照正常思路的话,就是直接做url拼接:搜狗主域名 + href 就是陌陌主要内容的url,形式如下
https
:
//weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS_yBZajb90fWf-LwgFP7QmnFtbELADqFzFqXa8Fplpd9nrYbnf-BG6fJQmhdTDKRUQC_zVYwjAHQRnKwtfQUOD-aNBz2bhtCuShQywQb837B12cBkYFsYkKXir7Y9WqlRBcZIrhUAYmFlBSVIg7YGFbBdu4rXklGlRslEFpw0lTmIX8pHfpQ9x6clCHaA92qoA9YOaIV2yOyrE-focNFXq7wdVqCwyPdzA..&type=2&query=%E7%81%AB%E8%BD%A6%E9%9A%A7%E9%81%93%E8%B5%B7%E7%81%AB
但是直接点这个链接返回的是402页面,需要输入验证码进行验证,而且验证码通过后仍然进不去;很明显这个url并不是文章的访问入口
经过测试,这篇文章的真实url是下边这些方式(直接通过点击页面标签打开即可):
https
:
//mp.weixin.qq.com/s?src=11×tamp=1567073292&ver=1820&signature=z2h7E*HznopGFidmtUA4PmXgi3ioRqV7XiYIqn9asMT3RCMKss6Y2nPUh7RG63nrwmRii77cL9LyDNJIVp1qpo5LHvQ8s754Q9HtCgbp5EPUP9HjosY7HWDwze6A2Qi7&new=1
是不是太太意外;这里开始就须要转变思路:不管怎样最好先抓一下包,这里我借助的工具是Fidder,关于Fidder怎样使用,可以参照这篇文章:
先从搜索页面的文章列表中步入文章的详情页,我们须要通过Fidder来监控一下文章的跳转情况:
看到没,惊奇地发觉有个 /link?url 开头的url跳转成功了,深入一下,我们再看一下这个链接返回的是哪些,点一下response部份的TextView;
返回的text文本是一串字符串组成的,即使不懂javascript,但上面大约意思就是构造一个url,格式与后面那种真实的url有一些相像呢,经测试以后发觉,返回的这个url就是获取文章内容的真实url
把这个访问成功的而且以link?url开头的url完整复制出来,与源码中的那种 link?url 放在一起,发现这个访问成功的url中多了两个参数一个是k一个是h
# 访问成功的:https://weixin.sogou.com/link% ... h%3Df
# 访问失败的:https://weixin.sogou.com/link% ... %25AB
现在基本爬取核心思路早已晓得了,主要就是破解这两个参数k和h,拼接成'真'的url( 以/cl.gif开头的 ),然后获取真url; 关于这两个参数的破解就是涉及到了js加密,需要进行调试,不懂的可以参考这篇文章:Chrome DevTools 中调试 JavaScript 入门;
第一步,回到源码中 link?url 位置的地方,因为前面两个参数的降低是因为我们触发了这个假的url,所以这儿须要对假的url进行窃听:
开发者工具[Elements] -> 右上角处的[Event Listeners] -> [click] -> 你须要监控的元素标签;
第二步,按流程浏览完前面所有过程时下边会有个js文件,点进去,并对js代码进行低格,发现参数k与h的构造方式:
其实还有一种参数定位的方式,在Google开发者选项中借助全局搜索[Search]就能快速定位,但是并不适用于这儿,因为这儿我们定位的参数都是单个元素,定位的准确度非常低
定位以后,参数k与h的定义十分清楚,没有过多函数嵌套,就是在一个简单的函数中,一个是生成一个随机数字,另一个在这个href标签的链接中获取其中的某一个字符,这里我们可以直python把这个功能实现:
url_list11
=
pq
(
res
.
text
)(
'.news-list li'
).
items
()
for
i
in
url_list11
:
url_list12
=
pq
(
i
(
'.img-box a'
).
attr
(
'href'
))
url_list12
=
str
(
url_list12
).
replace
(
'
'
,
''
).
replace
(
'
'
,
''
).
replace
(
'amp;'
,
''
)
(
url_list12
)
b
=
int
(
random
.
random
()
*
100
)
+
1
a
=
url_list12
.
find
(
"url="
)
result_link
=
url_list12
+
"&k="
+
str
(
b
)
+
"&h="
+
url_list12
[
a
+
4
+
21
+
b
:
a
+
4
+
21
+
b
+
1
]
a_url
=
"https://weixin.sogou.com"
+
result_link
好了,‘真’url也就能构造成功了,通过访问‘真’url来获取 真url(访问时记得加上headers),然后再获取我们须要的信息;然而结果却是下边这样的:
经测试发觉,原因是因为Cookie中最为核心的两个参数SUV和SUNID搜狗微信 反爬虫,而这两个参数在不断地发生改变
其中SUNID有固定得访问次数/时间限制,超过了限制直接变为无效,并且当访问网页恳求失败后,SUNID与SUV须要更换能够再度正常访问
SUV参数是在 ‘真’url 过度到 真url 中某个网页中Response里的Set-Cookie中生成的,也就是下边这个网页:
需要我们恳求这个链接,通过这个链接返回的Cookie,我们领到这个Cookie装入恳求头上面,再访问拼接好的 * ‘真’ url*
最后能够获取到真url最后恳求这个链接,解析出我们想要的数据( 注意用恳求头的时侯最好不要加Cookies搜狗微信 反爬虫,否则会导致访问失败 ) 当解决以上所有问题了,这里再测试一下,已经才能成功地领到我们想要的数据:
干货丨推荐八款高效率的爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 421 次浏览 • 2020-05-24 08:01
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。 查看全部
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。
PySpider
pyspider 是一个用python实现的功能强悍的网路爬虫系统,能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的储存,还能定时设置任务与任务优先级等。
开源地址:
Crawley
Crawley可以高速爬取对应网站的内容爬虫软件 推荐爬虫软件 推荐,支持关系和非关系数据库,数据可以导入为JSON、XML等。
Portia
Portia是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。
Newspaper
Newspaper可以拿来提取新闻、文章和内容剖析。使用多线程,支持10多种语言等。
Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它还能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方法.Beautiful Soup会帮你节约数小时甚至数天的工作时间。
Grab
Grab是一个用于建立Web刮板的Python框架。借助Grab,您可以建立各类复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网路恳求和处理接收到的内容,例如与HTML文档的DOM树进行交互。
Cola
Cola是一个分布式的爬虫框架,对于用户来说,只需编撰几个特定的函数,而无需关注分布式运行的细节。任务会手动分配到多台机器上,整个过程对用户是透明的。
网络爬虫 c++
采集交流 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2020-05-22 08:01
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先... 查看全部
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务监控器、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先...
Python爬虫必备工具汇总,并为你深析,为什么你应当要学爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-05-20 08:01
网络爬虫又称网路蜘蛛、网络机器人等爬虫软件 性能要求,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据所拟定的相应规则进行,即网络爬虫算法。
注意:如果须要Python爬虫的资料,就在文章底部哦
为什么要学Python爬虫?
原因很简单,我们可以借助爬虫技术,自动地从互联网中获取我们感兴趣的内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
在大数据时代,这一技能是必不可少的。
掌握Python技术,你应必备什么高效工具?
一、Xpath
Python中关于爬虫的包好多,推荐从Xpath开始爬虫软件 性能要求,Xpath的主要作用是用于解析网页,便于从中抽取数据。
这样出来,像豆瓣、腾讯新闻这类的网站就可以上手开始爬了。
二、抓包工具
可以用傲游,用傲游中的插件,可以便捷地查看网站收包分包信息。
三、基本的http抓取工具:scrapy
掌握后面的工具与技术后通常量级的数据基本没有问题了,但碰到十分复杂的情况时,你可能须要用到强悍的scrapy工具。
scrapy是十分强悍的爬虫框架,能轻松方便地建立request,还有强悍的selector才能便捷解析response,性能还超高,你可以将爬虫工程化、模块化。
学会scrapy你基本具备了爬虫工程师思维,可以自己搭建一些爬虫框架了。 查看全部
网络爬虫又称网路蜘蛛、网络机器人等爬虫软件 性能要求,可以自动化浏览网路中的信息,当然浏览信息的时侯须要根据所拟定的相应规则进行,即网络爬虫算法。
注意:如果须要Python爬虫的资料,就在文章底部哦
为什么要学Python爬虫?
原因很简单,我们可以借助爬虫技术,自动地从互联网中获取我们感兴趣的内容,并将这种数据内容爬取回去,作为我们的数据源,从而进行更深层次的数据剖析,并获得更多有价值的信息。
在大数据时代,这一技能是必不可少的。
掌握Python技术,你应必备什么高效工具?
一、Xpath
Python中关于爬虫的包好多,推荐从Xpath开始爬虫软件 性能要求,Xpath的主要作用是用于解析网页,便于从中抽取数据。
这样出来,像豆瓣、腾讯新闻这类的网站就可以上手开始爬了。
二、抓包工具
可以用傲游,用傲游中的插件,可以便捷地查看网站收包分包信息。
三、基本的http抓取工具:scrapy
掌握后面的工具与技术后通常量级的数据基本没有问题了,但碰到十分复杂的情况时,你可能须要用到强悍的scrapy工具。
scrapy是十分强悍的爬虫框架,能轻松方便地建立request,还有强悍的selector才能便捷解析response,性能还超高,你可以将爬虫工程化、模块化。
学会scrapy你基本具备了爬虫工程师思维,可以自己搭建一些爬虫框架了。
Java做爬虫也太牛
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-05-20 08:00
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb 查看全部
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb
初学者的爬虫日志(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-05-19 08:02
言归正传,在接触网路爬虫这个名词,我的第一反应是它是啥东东百度爬虫日志,它能干啥,该如何做(。。。怎么觉得象在读书时在写论文。。。)。当然你可以百度,想了下还是不要贴百度的定义(不要打我),先说下自己对这个专业术语的理解吧,由于博主也才学几天理解十分狭隘,希望诸位读者理解,我个人觉得:网络爬虫就是个多样化的互联网信息采集程序(当然,以后可能有不同的理解,认知总不断变化地。)。它还能针对性对各网站的信息进行提取和分类(比如我要想知道天猫有多少家店面,各店家都是些谁如何办,你就运用爬虫技术爬取整个淘宝网)。说了这么多屁话,主要是希望你们对新事物有自己的看法,也希望读者老爷们多点耐心(这个话痨。。。。)
这次是真的“言归正传”,作为一个目标驱动型的学习者,我非常喜欢在学习一个新东西前制订“作战计划”,在做的过程中去学习,而不是学完后在做。比如我想去爬取糗事百科所有用户的用户名,我该如何做呢?有人说,先把python句型会用后,在学urllib或requests之类的库学会http请求的啥,然后去学正则抒发或BeautifulSoup,lxml 之类的库去解析啥,可能你还有去学一些后端的一些东西,比如html css,xml 之类的东东,接着还要去学一些mysql 或oracle,sqlite ,sqlserver之类数据库操作一些东东,我的天啊 ,我只是想知道晓得如何爬糗事百科网的用户名,怎么还要学这么多,许多人看着这长长的学习路线惊呆了,然后就gg了。所以,让我们回到最初的起点,从实际问题出发。首先,不去好使啥语言,会啥句型,不要去学啥urllib,lxml,xml,mysql 之类的东东,先仔细剖析下怎样去爬取糗事百科所有用户的用户名这个实际问题。
先想一下你是怎么晓得糗事百科网的他人的用户名,有人说,那还不简单,百度搜下糗事百科,打开糗事百科官网,不就听到了吗。对!就是这样简单,所有爬虫程序所干的事情都是这样的,它也是打开一个网站,然后按照所设规则提取出我们所须要的信息,然后保存出来 ,只不过一个是通过人眼看见,一个是爬虫程序手动提取信息,一个是记在头脑里(可能过下就忘了),一个是保存在c盘中(你只要不删掉,估计大约可能能保持20,30年)。虽然形式有所不同,但是她们的思想是共通的。简单来讲,就三步,打开网页-提取信息-保存信息。
那么,如何使程序能打开我们想要的网站呢?你可以试着通过百度搜下,比如哪些“如何用python打开网站之类的”,"python 打开网站的几种形式“ 之类的关键字,当然,你也可以去峰会csdn,知乎等峰会提问。我当时试着搜索下,搜到了这个网站。这个网站介绍了四种方式,这里就第一种为反例 ,代码如下:
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
在运行之前 ,先简单说下,我的python版本是2.7.12,所用的ide(集成开发环境)是pycharm,至于怎样下载这两软件可以参考下边两个网站:一个是python的官网: ;一个是pycharm的官网:,下载教程链接:
好了。运行开始。。。。。。,怎么运行不起!,这不科学啊!
先别急,看一下ide提示啥(哈 都是e文,和我一样英语弱的朋友快去背单词吧,你会利润终生),大概意思是这个文件不是 ascii,没有设置文件编码 。打开百度 ,输入如下关键字”如何为python设置文件编码“之类,你就可以晓得在文件开头原先还须要设置这一句”# -*- coding: utf-8 -*-“
让我们加上这一句开始运行,代码如下:
# -*- coding: utf-8 -*-
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
坑啊 ,怎么还是运行不上去 。。。我了个搽
冷静,冷静, 冷静啊 ,看一下ide提示啥 AttributeError: 'module' object has no attribute 'open' ,大概意思是说属性错误:“模块”对象没有属性“open” ,这他喵的啥意思。这个时侯你应当想这还不简单百度爬虫日志,直接把这句话复制到百度里搜下不就行了,我当时就是这样想在,然后浪费了10几分钟一无所获,最后只能自己解决了。 我又是如何解决的呢?首先 ,通过这个ide提示我晓得了错误出在这一句代码上content=urllib.open(url).read() , 然后我开始重新考量这端代码 ,从字面上看,这句话的意思是用urlib这个东西打开这个网站 ,然后在读取这个网站的内容,所以问题要么出在打开这个网站 上,要么是在读取上。接着 ,我就自动输入urllib. ,神奇的事情发生了(后来才晓得是代码手动补全),出现了如下界面,我看了这个urlopen 想了想, 试不试可以用这个来试下,果然成功了!(兴奋了)
完整代码: 查看全部
博主本人在先前就很好奇知乎那群答主的答案数据从那儿的, 别人说是从网上爬的(搞安全的朋友例外)。由于本人近来比较闲的,所以就起了学习写网路爬虫的心思(所以兴趣很重要!)。打开浏览器,百度了下网络爬虫,什么用python写网路爬虫的的比较多,所以就用它了(好随意的感觉). 然后我开始搜索有关用python写的网路爬虫的网路博客(主要是入门的教程指导类 ),看了下博客,怎么说呢,网上各博客主个个实力都不错,知识结构都十分的清晰,讲解的都十分细致,非常肤浅易懂,但总觉得少了点哪些,仔细想了下应当是大部分博客都重视知识本身,而漠视获取知识的过程(我认为这个最有意思),没啥成就感,自我觉得很无趣(总觉得有天朝教育的影子,我写你抄)。所以打算换个角度,从学习者角度写一些自觉得有意思的东西。
言归正传,在接触网路爬虫这个名词,我的第一反应是它是啥东东百度爬虫日志,它能干啥,该如何做(。。。怎么觉得象在读书时在写论文。。。)。当然你可以百度,想了下还是不要贴百度的定义(不要打我),先说下自己对这个专业术语的理解吧,由于博主也才学几天理解十分狭隘,希望诸位读者理解,我个人觉得:网络爬虫就是个多样化的互联网信息采集程序(当然,以后可能有不同的理解,认知总不断变化地。)。它还能针对性对各网站的信息进行提取和分类(比如我要想知道天猫有多少家店面,各店家都是些谁如何办,你就运用爬虫技术爬取整个淘宝网)。说了这么多屁话,主要是希望你们对新事物有自己的看法,也希望读者老爷们多点耐心(这个话痨。。。。)
这次是真的“言归正传”,作为一个目标驱动型的学习者,我非常喜欢在学习一个新东西前制订“作战计划”,在做的过程中去学习,而不是学完后在做。比如我想去爬取糗事百科所有用户的用户名,我该如何做呢?有人说,先把python句型会用后,在学urllib或requests之类的库学会http请求的啥,然后去学正则抒发或BeautifulSoup,lxml 之类的库去解析啥,可能你还有去学一些后端的一些东西,比如html css,xml 之类的东东,接着还要去学一些mysql 或oracle,sqlite ,sqlserver之类数据库操作一些东东,我的天啊 ,我只是想知道晓得如何爬糗事百科网的用户名,怎么还要学这么多,许多人看着这长长的学习路线惊呆了,然后就gg了。所以,让我们回到最初的起点,从实际问题出发。首先,不去好使啥语言,会啥句型,不要去学啥urllib,lxml,xml,mysql 之类的东东,先仔细剖析下怎样去爬取糗事百科所有用户的用户名这个实际问题。
先想一下你是怎么晓得糗事百科网的他人的用户名,有人说,那还不简单,百度搜下糗事百科,打开糗事百科官网,不就听到了吗。对!就是这样简单,所有爬虫程序所干的事情都是这样的,它也是打开一个网站,然后按照所设规则提取出我们所须要的信息,然后保存出来 ,只不过一个是通过人眼看见,一个是爬虫程序手动提取信息,一个是记在头脑里(可能过下就忘了),一个是保存在c盘中(你只要不删掉,估计大约可能能保持20,30年)。虽然形式有所不同,但是她们的思想是共通的。简单来讲,就三步,打开网页-提取信息-保存信息。
那么,如何使程序能打开我们想要的网站呢?你可以试着通过百度搜下,比如哪些“如何用python打开网站之类的”,"python 打开网站的几种形式“ 之类的关键字,当然,你也可以去峰会csdn,知乎等峰会提问。我当时试着搜索下,搜到了这个网站。这个网站介绍了四种方式,这里就第一种为反例 ,代码如下:
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
在运行之前 ,先简单说下,我的python版本是2.7.12,所用的ide(集成开发环境)是pycharm,至于怎样下载这两软件可以参考下边两个网站:一个是python的官网: ;一个是pycharm的官网:,下载教程链接:
好了。运行开始。。。。。。,怎么运行不起!,这不科学啊!
先别急,看一下ide提示啥(哈 都是e文,和我一样英语弱的朋友快去背单词吧,你会利润终生),大概意思是这个文件不是 ascii,没有设置文件编码 。打开百度 ,输入如下关键字”如何为python设置文件编码“之类,你就可以晓得在文件开头原先还须要设置这一句”# -*- coding: utf-8 -*-“
让我们加上这一句开始运行,代码如下:
# -*- coding: utf-8 -*-
import urllib
url="http://www.baidu.com" #这里是需要获取的网页
content=urllib.open(url).read() #使用urllib模块获取网页内容
print content #输出网页的内容 功能相当于查看网页源代码
坑啊 ,怎么还是运行不上去 。。。我了个搽
冷静,冷静, 冷静啊 ,看一下ide提示啥 AttributeError: 'module' object has no attribute 'open' ,大概意思是说属性错误:“模块”对象没有属性“open” ,这他喵的啥意思。这个时侯你应当想这还不简单百度爬虫日志,直接把这句话复制到百度里搜下不就行了,我当时就是这样想在,然后浪费了10几分钟一无所获,最后只能自己解决了。 我又是如何解决的呢?首先 ,通过这个ide提示我晓得了错误出在这一句代码上content=urllib.open(url).read() , 然后我开始重新考量这端代码 ,从字面上看,这句话的意思是用urlib这个东西打开这个网站 ,然后在读取这个网站的内容,所以问题要么出在打开这个网站 上,要么是在读取上。接着 ,我就自动输入urllib. ,神奇的事情发生了(后来才晓得是代码手动补全),出现了如下界面,我看了这个urlopen 想了想, 试不试可以用这个来试下,果然成功了!(兴奋了)
完整代码:
八爪鱼采集器能代替python爬虫吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 913 次浏览 • 2020-05-19 08:02
44 人赞成了该回答
作为同时使用八爪鱼采集器和写爬虫的非技术的莫名其妙喜欢自己寻思技术的互联网营运喵。。。我来说说心得看法。
八爪鱼有一些优势,比如学习成本低,可视化流程,快速搭建采集系统。能直接导入excel文件和导入到数据库中。降低采集成本,云采集提供10个节点,也能省事不少。
不好的地方就是,即使看似很简单了,而且还有更傻瓜化的smart模式,但是上面的坑只有用的多的人才清楚。关于这个我在我的博客里简单写了写,不过说实话心得太多,还没仔细整理。
首先上面的循环都是xpath元素定位,如果用单纯的傻瓜化点击定位的话,很生硬,大批量采集页面的时侯很容易出错。另外用这个工具的,因为便捷,小白太多,成天有人问普通问题,他们都不会看页面结构,也不懂xpath,很容易出现采集不全,无限翻页等问题。
但是八爪鱼采集器的ajax加载,模拟手机页面,过滤广告,滚动至页面底端等功能堪比利器,一个勾选才能搞定。写代码很麻烦的,实现这种功能费力。
八爪鱼虽然只是工具,自由度肯定完败编程。胜在便捷,快速,低成本。
八爪鱼判定语录较弱,无法进行复杂判定,也未能执行复杂逻辑。还有就是八爪鱼只有企业版能够解决验证码问题,一般版本未能接入打码平台。
还有一点就是没有ocr功能,58同城和赶集网采集的电话号码都是图片格式,python可以用开源图象辨识库解决,对接进去辨识便可。
这里更新一下:
之前写的觉得有片面性,毕竟是那个时代我的心境下写下来的。一段时间以后,思考了一下,数据采集的需求才是决定最终使用哪些工具的。如果我是大量数据采集需求的话,爬虫一定是不可避开的,因为代码的自由度更高。八爪鱼的目标我感觉也不是代替python,而是实现人人都能上手的采集器这个目标。
另一点就是python学习容易,部署简单,开源免费。即使只学了scrapy也能解决一些问题了,不过麻烦的就是原本一些工具里很简单选择能够搞定的功能八爪鱼采集器高级模式,必须靠自己写或则拷贝他人的代码能够实现,如果不是专职写爬虫的话,很快就想从入门到舍弃了……
综合写了一下对比和坑,放在知乎专栏里了八爪鱼采集器高级模式,有兴趣的可以去瞧瞧:
浅谈一下近来使用八爪鱼采集器碰到的坑(还有对比其他采集软件和爬虫) - 知乎专栏
编辑于 2017-12-17
深圳视界信息技术有限公司 CEO
10 人赞成了该回答
八爪鱼是工具,python是代码,八爪鱼的目标是使有须要采集网页的人都可以使用工具轻松达到目的,就这个目的来讲,八爪鱼就是要代替诸多公司自己爬虫工程师团队开发的python爬虫程序,我认为完全替代有点困难,总有些人就是一定要求自己开发的,这种就没办法了,但是从成本,效率,响应需求变化的能力,通用性,易用性,IP资源,防封能力,智能化程度,对使用人员的要求等等审视爬虫做的好不好的指标来看的话,八爪鱼目前所达到的技术和产品能力,一般的技术团队用python是难以达到的。
发布于 2017-07-04 查看全部
44 人赞成了该回答
作为同时使用八爪鱼采集器和写爬虫的非技术的莫名其妙喜欢自己寻思技术的互联网营运喵。。。我来说说心得看法。
八爪鱼有一些优势,比如学习成本低,可视化流程,快速搭建采集系统。能直接导入excel文件和导入到数据库中。降低采集成本,云采集提供10个节点,也能省事不少。
不好的地方就是,即使看似很简单了,而且还有更傻瓜化的smart模式,但是上面的坑只有用的多的人才清楚。关于这个我在我的博客里简单写了写,不过说实话心得太多,还没仔细整理。
首先上面的循环都是xpath元素定位,如果用单纯的傻瓜化点击定位的话,很生硬,大批量采集页面的时侯很容易出错。另外用这个工具的,因为便捷,小白太多,成天有人问普通问题,他们都不会看页面结构,也不懂xpath,很容易出现采集不全,无限翻页等问题。
但是八爪鱼采集器的ajax加载,模拟手机页面,过滤广告,滚动至页面底端等功能堪比利器,一个勾选才能搞定。写代码很麻烦的,实现这种功能费力。
八爪鱼虽然只是工具,自由度肯定完败编程。胜在便捷,快速,低成本。
八爪鱼判定语录较弱,无法进行复杂判定,也未能执行复杂逻辑。还有就是八爪鱼只有企业版能够解决验证码问题,一般版本未能接入打码平台。
还有一点就是没有ocr功能,58同城和赶集网采集的电话号码都是图片格式,python可以用开源图象辨识库解决,对接进去辨识便可。
这里更新一下:
之前写的觉得有片面性,毕竟是那个时代我的心境下写下来的。一段时间以后,思考了一下,数据采集的需求才是决定最终使用哪些工具的。如果我是大量数据采集需求的话,爬虫一定是不可避开的,因为代码的自由度更高。八爪鱼的目标我感觉也不是代替python,而是实现人人都能上手的采集器这个目标。
另一点就是python学习容易,部署简单,开源免费。即使只学了scrapy也能解决一些问题了,不过麻烦的就是原本一些工具里很简单选择能够搞定的功能八爪鱼采集器高级模式,必须靠自己写或则拷贝他人的代码能够实现,如果不是专职写爬虫的话,很快就想从入门到舍弃了……
综合写了一下对比和坑,放在知乎专栏里了八爪鱼采集器高级模式,有兴趣的可以去瞧瞧:
浅谈一下近来使用八爪鱼采集器碰到的坑(还有对比其他采集软件和爬虫) - 知乎专栏
编辑于 2017-12-17
深圳视界信息技术有限公司 CEO
10 人赞成了该回答
八爪鱼是工具,python是代码,八爪鱼的目标是使有须要采集网页的人都可以使用工具轻松达到目的,就这个目的来讲,八爪鱼就是要代替诸多公司自己爬虫工程师团队开发的python爬虫程序,我认为完全替代有点困难,总有些人就是一定要求自己开发的,这种就没办法了,但是从成本,效率,响应需求变化的能力,通用性,易用性,IP资源,防封能力,智能化程度,对使用人员的要求等等审视爬虫做的好不好的指标来看的话,八爪鱼目前所达到的技术和产品能力,一般的技术团队用python是难以达到的。
发布于 2017-07-04
【黑马程序员】Python爬虫是哪些?爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2020-05-19 08:01
【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708 查看全部
【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708
python爬虫有哪些用
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-05-18 08:03
一:python爬虫是哪些意思
python是多种语言实现的程序,爬虫又称网页机器人,也有人称为蚂蚁,python是可以根据规则去进行抓取网站上的所有有价值的信息,并且保存到本地,其实好多爬虫都是使用python开发的。
二:python爬虫有哪些用?爬虫可以做哪些?
网络爬虫是一种程序,可以抓取网路上的一切数据,比如网站上的图片和文字视频,只要我们能访问的数据都是可以获取到的,使用python爬虫去抓取而且下载到本地。
三:如何学习爬虫
学习爬虫之前,首先我们要学习一门语言,一般建议是学习Python,Python可以跨平台,相比其它语言来说,Python的爬虫库都是比较丰富的,其次就是要学习html知识,和抓包等相关知识,清楚爬虫的知识体系,新手在学习的时侯,首先要基础开始,在学习完基础以后,然后再去使用框架,其实更好的方式就是实战练习。
四:爬虫的简单原理
首先要先获得url,把url装入在队列中,等待抓取,然后进行解析dns,获得主机的ippython爬虫有啥用,就可以把网站给下载出来,保存到本地。
以上就是对python爬虫有什么用的全部介绍,如果你想了解更多有关Python教程,请关注php英文网。
以上就是python爬虫有什么用的详尽内容,更多请关注php中文网其它相关文章! 查看全部
python爬虫是哪些意思?python爬虫有哪些用?一些刚才python入门的菜鸟python爬虫有啥用,可能对这种问题并不是太熟悉,下面小编就为您整理关于python爬虫,希望对您有所帮助。
一:python爬虫是哪些意思
python是多种语言实现的程序,爬虫又称网页机器人,也有人称为蚂蚁,python是可以根据规则去进行抓取网站上的所有有价值的信息,并且保存到本地,其实好多爬虫都是使用python开发的。
二:python爬虫有哪些用?爬虫可以做哪些?
网络爬虫是一种程序,可以抓取网路上的一切数据,比如网站上的图片和文字视频,只要我们能访问的数据都是可以获取到的,使用python爬虫去抓取而且下载到本地。
三:如何学习爬虫
学习爬虫之前,首先我们要学习一门语言,一般建议是学习Python,Python可以跨平台,相比其它语言来说,Python的爬虫库都是比较丰富的,其次就是要学习html知识,和抓包等相关知识,清楚爬虫的知识体系,新手在学习的时侯,首先要基础开始,在学习完基础以后,然后再去使用框架,其实更好的方式就是实战练习。
四:爬虫的简单原理
首先要先获得url,把url装入在队列中,等待抓取,然后进行解析dns,获得主机的ippython爬虫有啥用,就可以把网站给下载出来,保存到本地。
以上就是对python爬虫有什么用的全部介绍,如果你想了解更多有关Python教程,请关注php英文网。
以上就是python爬虫有什么用的详尽内容,更多请关注php中文网其它相关文章!
网络爬虫的原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 809 次浏览 • 2020-05-18 08:02
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。 查看全部
互联网上,公开数据(各种网页)都是以http(或加密的http即https)协议传输的。所以,我们这儿介绍的爬虫技术都是基于http(https)协议的爬虫。
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'the_password@www.yuanrenxue.com/user/info?page=2'" rel="nofollow" target="_blank">http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。
python网络爬虫源代码(可直接抓取图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-05-18 08:01
在开始制做爬虫前,我们应当做好前期打算工作,找到要爬的网站,然后查看它的源代码我们此次爬豆瓣美眉网站,网址为:用到的工具:pycharm,这是它的图标...博文来自:zhang740000的博客
Python菜鸟写出漂亮的爬虫代码1初到大数据学习圈子的朋友可能对爬虫都有所耳闻,会认为是一个高大上的东西,仿佛九阳神功和乾坤大挪移一样,和他人说“老子会爬虫”,就觉得非常有颜值,但是又不知从何入手,...博文来自:夏洛克江户川
互联网是由一个个站点和网路设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前。网络爬虫,也叫网路蜘蛛(We...博文来自:阎松的博客
从链家网站爬虫广州符合条件的房源信息,并保存到文件,房源信息包括名称、建筑面积、总价、所在区域、套内面积等。其中所在区域、套内面积须要在详情页获取估算。主要使用了requests+Beautiful...博文
###写在题外的话爬虫,我还是大三的时侯,第一次据说网络爬虫 源码,当时我的学姐给我找的一个勤工俭学的项目,要求是在微博上爬出感兴趣的信息,结果很遗憾,第一次邂逅只是搽肩而过。然后,时间来到4年后的研二,在做信息检...博文来自:wsbxzz1的专栏
WechatSogou[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。DouBanSpider[2]-豆...博文来自:perry_Fan
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimportht...博文来自:程松
前几天,刘若英的《后来》电影版——《后来的我们》上映了,我身边也有小伙伴去看了,问了以后,他们说虽然这个影片对没有多少故事的我们代入感不够强,我没去看,一是因为独身猫一只,去电影院看影片纯属找虐,另一...博文来自:weixin_41032076的博客
本篇是在学习Python基础知识以后的一次小小尝试,这次将会爬取熊猫TV网页上的王者荣耀主播排行,在不依靠第三方框架的情况下演示一个爬虫的原理。一、实现Python爬虫的思路第一步:明确目的1.找到想...博文来自:梧雨北辰的博客
问题的来历前几天,在微信公众号(Python爬虫及算法)上有个人问了笔者一个问题,如何借助爬虫来实现如下的需求,需要爬取的网页如下(网址为:博文来自:但盼风雨来
首先要导出模块,然后输入须要爬虫的网址,接着打开一个文件(接收器)然后将网址中的东西缓冲到你的接收器中这样就可以实现简单的爬虫fromurllibimportrequestr=request.urlo...博文来自:xuanyugang的博客
爬虫是封装在WebCrawler类中的,Test.py调用爬虫的craw函数达到下载网页的功能。运用的算法:广度遍历关于网路爬虫的详尽信息请参考百度百科Test.py----------------...博文来自:Cashey1991的专栏
今天小编给你们分享一下怎样借助Python网络爬虫抓取微信朋友圈的动态信息,实际上假如单独的去爬取朋友圈的话,难度会特别大,因为陌陌没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌...博文来自:weixin_34252090的博客
来源:程序猿本文宽度为2863字,建议阅读5分钟本文为你分享零基础开始写爬虫的经验。刚开始接触爬虫的时侯,简直惊为天人,十几行代码,就可以将无数网页的信息全部获取出来,自动选定网页元素,自动整理成结构...博文来自:THU数据派
概述:第一次接触爬虫,从简单一点的爬取百度图片开始,话不多说,直接上手。前期打算:首先要配置环境,这里使用到的是requests第三方库,相比Beautifulsoup而言req...博文来自:heart__gx的博客
1、任务简介前段时间仍然在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方式,只有将网页源码抓取出来能够从...博文来自:罗思洋的博客
对职友集急聘网站的爬虫一、对职友集的python爬虫代码如下:输出结果:headers错误信息处理一、对职友集的python爬虫学习python那就要对自己将来的工作有一个研究网络爬虫 源码,现在就来瞧瞧,职友集上...博文来自:Prodigal
最近学习了一下python的基础知识,大家通常对“爬虫”这个词,一听就比较熟悉,都晓得是爬一些网站上的数据,然后做一些操作整理,得到人们想要的数据,但是如何写一个爬虫程序代码呢?相信很多人是不会的,今...博文来自:rmkloveme
爬虫:爬取全书网,获取数据,存到数据库工具:mysql,python3,MySQLdb模块:requests(pipinstallrequests),re(不需要安装)网址:博文来自:乐亦亦乐的博客
python作为人工智能或则大数据的宠儿,我自然要学习,作为一个小白,第一个实现的工能就是爬虫,爬数据,收集数据,我以我爬csdn博客的事情为反例,附上代码,大家一起学习这儿还使用了ip代理基数,一起...博文来自:Mr小颜朋友的博客
环境:Windows7+python3.6+Pycharm2017目标:抓取易迅商品列表页面信息:售价、评论数、商品名称-----以手机为例---全部文章:京东爬虫、链家爬虫、美团爬虫、微信公众号爬虫...博文来自:老王の博客
本文介绍两种爬取形式:1.正则表达式2.bs4解析Html以下为正则表达式爬虫,面向对象封装后的代码如下:以下为使用bs4爬取的代码:bs4面向对象封装后代码:......博文来自:python学习者的博客
2018年3月27日,继开学以来,开了软件工程和信息系统设计,想来想去也没哪些好的题目,干脆就想弄一个实用点的,于是形成了做“学生服务系统”想法。相信各大院校应当都有本校APP或超级课程表之类的...博文来自:跬步至以千里的博客
本文参考IMMOC中的python”开发简单爬虫“:。如果不足,希望见谅本文为原创,转载请标明出处:博文来自:014技术库房
python小白群交流:861480019手机笔记本挂机赚零钱群:一毛一毛挣903271585(每天手机登入之后不用管,一天有不到一块钱的收入,大部分软件可以一块钱提现一次)注意,申请时说明加入缘由...博文来自:chq1005613740的博客
(一)百度贴吧贴子用户与评论信息(二)豆瓣登陆脚本博文来自:PANGHAIFEI的博客
文章地址:在我们日常上网浏览网页的时侯,经常会见到一些好看的图片,我们就希望把那些图片保存下载,或者用户拿来做桌面壁...博文来自:不如缺钙的博客
大数据下的简单网路爬虫使用代码进行实现(本博文对易迅网站的某手机的评论进行爬取)...博文来自:data_bug的博客
以下总结的全是单机爬取的应对反爬策略1、设置爬取速率,由于爬虫发送恳求的速率比较快,会对服务器引起一定的影响,尽可能控制爬取速率,做到文明爬取2、重启路由器。并不是指化学上的拔插路由器,而是指模拟路...博文来自:菜到怀疑人生的博客
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整...博文来自:c350577169的博客
Python开发爬虫完整代码解析移除python一天时间,总算开发完了。说道爬虫,我认为有几个东西须要非常注意,一个是队列,告诉程序,有什么url要爬,第二个就是爬页面,肯定有元素缺位的,这个究其...博文来自:大壮的博客
这段时间公司要求抓全省的一类网站,网站虽然都是一类的,但是结构也是各有不同,目前是抓了几十个上百个测试,我使用的是scrapy多爬虫爬取,感觉也不是非常好,所以在找寻更好的方式或则框架,看看有没有一些峰会
本文主要囊括了Python编程的核心知识(暂不包括标准库及第三方库,后续会发布相应专题的文章)。首先,按次序依次展示了以下内容的一系列思维导图:基础知识,数据类型(数字,字符串,列表,元组,字典,集合...博文来自:的博客 查看全部
2019-8-3 18:5:0 | 作者:老铁SEO | | 人浏览
在开始制做爬虫前,我们应当做好前期打算工作,找到要爬的网站,然后查看它的源代码我们此次爬豆瓣美眉网站,网址为:用到的工具:pycharm,这是它的图标...博文来自:zhang740000的博客
Python菜鸟写出漂亮的爬虫代码1初到大数据学习圈子的朋友可能对爬虫都有所耳闻,会认为是一个高大上的东西,仿佛九阳神功和乾坤大挪移一样,和他人说“老子会爬虫”,就觉得非常有颜值,但是又不知从何入手,...博文来自:夏洛克江户川
互联网是由一个个站点和网路设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前。网络爬虫,也叫网路蜘蛛(We...博文来自:阎松的博客
从链家网站爬虫广州符合条件的房源信息,并保存到文件,房源信息包括名称、建筑面积、总价、所在区域、套内面积等。其中所在区域、套内面积须要在详情页获取估算。主要使用了requests+Beautiful...博文
###写在题外的话爬虫,我还是大三的时侯,第一次据说网络爬虫 源码,当时我的学姐给我找的一个勤工俭学的项目,要求是在微博上爬出感兴趣的信息,结果很遗憾,第一次邂逅只是搽肩而过。然后,时间来到4年后的研二,在做信息检...博文来自:wsbxzz1的专栏
WechatSogou[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。DouBanSpider[2]-豆...博文来自:perry_Fan
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimportht...博文来自:程松
前几天,刘若英的《后来》电影版——《后来的我们》上映了,我身边也有小伙伴去看了,问了以后,他们说虽然这个影片对没有多少故事的我们代入感不够强,我没去看,一是因为独身猫一只,去电影院看影片纯属找虐,另一...博文来自:weixin_41032076的博客
本篇是在学习Python基础知识以后的一次小小尝试,这次将会爬取熊猫TV网页上的王者荣耀主播排行,在不依靠第三方框架的情况下演示一个爬虫的原理。一、实现Python爬虫的思路第一步:明确目的1.找到想...博文来自:梧雨北辰的博客
问题的来历前几天,在微信公众号(Python爬虫及算法)上有个人问了笔者一个问题,如何借助爬虫来实现如下的需求,需要爬取的网页如下(网址为:博文来自:但盼风雨来
首先要导出模块,然后输入须要爬虫的网址,接着打开一个文件(接收器)然后将网址中的东西缓冲到你的接收器中这样就可以实现简单的爬虫fromurllibimportrequestr=request.urlo...博文来自:xuanyugang的博客
爬虫是封装在WebCrawler类中的,Test.py调用爬虫的craw函数达到下载网页的功能。运用的算法:广度遍历关于网路爬虫的详尽信息请参考百度百科Test.py----------------...博文来自:Cashey1991的专栏
今天小编给你们分享一下怎样借助Python网络爬虫抓取微信朋友圈的动态信息,实际上假如单独的去爬取朋友圈的话,难度会特别大,因为陌陌没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌...博文来自:weixin_34252090的博客
来源:程序猿本文宽度为2863字,建议阅读5分钟本文为你分享零基础开始写爬虫的经验。刚开始接触爬虫的时侯,简直惊为天人,十几行代码,就可以将无数网页的信息全部获取出来,自动选定网页元素,自动整理成结构...博文来自:THU数据派
概述:第一次接触爬虫,从简单一点的爬取百度图片开始,话不多说,直接上手。前期打算:首先要配置环境,这里使用到的是requests第三方库,相比Beautifulsoup而言req...博文来自:heart__gx的博客
1、任务简介前段时间仍然在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方式,只有将网页源码抓取出来能够从...博文来自:罗思洋的博客
对职友集急聘网站的爬虫一、对职友集的python爬虫代码如下:输出结果:headers错误信息处理一、对职友集的python爬虫学习python那就要对自己将来的工作有一个研究网络爬虫 源码,现在就来瞧瞧,职友集上...博文来自:Prodigal
最近学习了一下python的基础知识,大家通常对“爬虫”这个词,一听就比较熟悉,都晓得是爬一些网站上的数据,然后做一些操作整理,得到人们想要的数据,但是如何写一个爬虫程序代码呢?相信很多人是不会的,今...博文来自:rmkloveme
爬虫:爬取全书网,获取数据,存到数据库工具:mysql,python3,MySQLdb模块:requests(pipinstallrequests),re(不需要安装)网址:博文来自:乐亦亦乐的博客
python作为人工智能或则大数据的宠儿,我自然要学习,作为一个小白,第一个实现的工能就是爬虫,爬数据,收集数据,我以我爬csdn博客的事情为反例,附上代码,大家一起学习这儿还使用了ip代理基数,一起...博文来自:Mr小颜朋友的博客
环境:Windows7+python3.6+Pycharm2017目标:抓取易迅商品列表页面信息:售价、评论数、商品名称-----以手机为例---全部文章:京东爬虫、链家爬虫、美团爬虫、微信公众号爬虫...博文来自:老王の博客
本文介绍两种爬取形式:1.正则表达式2.bs4解析Html以下为正则表达式爬虫,面向对象封装后的代码如下:以下为使用bs4爬取的代码:bs4面向对象封装后代码:......博文来自:python学习者的博客
2018年3月27日,继开学以来,开了软件工程和信息系统设计,想来想去也没哪些好的题目,干脆就想弄一个实用点的,于是形成了做“学生服务系统”想法。相信各大院校应当都有本校APP或超级课程表之类的...博文来自:跬步至以千里的博客
本文参考IMMOC中的python”开发简单爬虫“:。如果不足,希望见谅本文为原创,转载请标明出处:博文来自:014技术库房
python小白群交流:861480019手机笔记本挂机赚零钱群:一毛一毛挣903271585(每天手机登入之后不用管,一天有不到一块钱的收入,大部分软件可以一块钱提现一次)注意,申请时说明加入缘由...博文来自:chq1005613740的博客
(一)百度贴吧贴子用户与评论信息(二)豆瓣登陆脚本博文来自:PANGHAIFEI的博客
文章地址:在我们日常上网浏览网页的时侯,经常会见到一些好看的图片,我们就希望把那些图片保存下载,或者用户拿来做桌面壁...博文来自:不如缺钙的博客
大数据下的简单网路爬虫使用代码进行实现(本博文对易迅网站的某手机的评论进行爬取)...博文来自:data_bug的博客
以下总结的全是单机爬取的应对反爬策略1、设置爬取速率,由于爬虫发送恳求的速率比较快,会对服务器引起一定的影响,尽可能控制爬取速率,做到文明爬取2、重启路由器。并不是指化学上的拔插路由器,而是指模拟路...博文来自:菜到怀疑人生的博客
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整...博文来自:c350577169的博客
Python开发爬虫完整代码解析移除python一天时间,总算开发完了。说道爬虫,我认为有几个东西须要非常注意,一个是队列,告诉程序,有什么url要爬,第二个就是爬页面,肯定有元素缺位的,这个究其...博文来自:大壮的博客
这段时间公司要求抓全省的一类网站,网站虽然都是一类的,但是结构也是各有不同,目前是抓了几十个上百个测试,我使用的是scrapy多爬虫爬取,感觉也不是非常好,所以在找寻更好的方式或则框架,看看有没有一些峰会
本文主要囊括了Python编程的核心知识(暂不包括标准库及第三方库,后续会发布相应专题的文章)。首先,按次序依次展示了以下内容的一系列思维导图:基础知识,数据类型(数字,字符串,列表,元组,字典,集合...博文来自:的博客
用PYTHON爬取车辆之家街车报价数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-05-16 08:07
用PYTHON爬虫—汽车之家街车报价爬取—斑点虾/数据咨询师爬 虫 的 价 值 爬 虫 的 原 理 爬 虫 的 实 例01爬 虫 的 价 值01 爬虫的价值? 爬取数据,进行市场督查和商业剖析知乎:爬取优质答案,为你筛选出各话题下最优质的内容。 淘宝、京东:抓取商品、评论及销量数据,对各类商品及用户 的消费场景进行剖析。 安居客、链家:抓取房产买卖及租售信息爬虫之家,分析楼市变化趋势、 做不同区域的楼价剖析。 智联:爬取各种职位信息,分析各行业人才需求情况及工资水 平。 雪球网:抓取雪球高回报用户的行为爬虫之家,对股票进行剖析和预测。01爬虫的价值? 作为机器学习、数据挖掘的原始数据? ? 比如你要做一个推荐系统,那么你可以去爬取更多维度的数据,做出更好的模型。 比如你要做图象辨识,你可以先去爬取大量的图片作为训练集进行训练。01爬虫的价值? 爬取优质的资源: 图片、文本、视频? 爬取知乎钓鱼贴\图片网站,获得福利图片。 ? 爬取微信公众号文章,分析新媒体内容营运策略。这些事情,原本我们也是可以自动完成的,但若果是单纯地复制粘贴,非常花费时间,比如你想获取100万行的数据,大 约需忘寝废食重复工作五年。而爬虫可以在一天之内帮你完成,而且完全不需要任何干预。02爬 虫 的 原 理02 爬虫的原理? 通用爬虫的框架02 爬虫的原理? 从爬虫角度对互联网进行界定02 爬虫的原理? 爬虫的基本流程解析页面发送恳求获得页面requests抽取并储存内容02 爬虫的原理? Requests 库的使用方式02 爬虫的原理? 爬取页面的通用代码框架03爬 虫 的 实 例03 爬虫的实例—汽车之家街车的报价找到街车的车型名称和价钱所在位置的Html03 爬虫的实例—汽车之家街车的报价导出模块定义街车的车型名称和价钱03 爬虫的实例—汽车之家街车的报价下载网页、解析网页、循环页数、获取列表03 爬虫的实例—汽车之家街车的报价保存数据至EXCELTHANKS!
基于Scrapy框架的分布式网路爬虫实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-05-14 08:09
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art 查看全部
龙源期刊网 基于 Scrapy 框架的分布式网路爬虫实现 作者:陶兴海 来源:《电子技术与软件工程》2017 年第 11 期 摘 要按照互联网实际情况,提出分布式爬虫模型,基于 Scrapy 框架,进行代码实现,且 该开发方法可以迅速进行对不同主题的数据爬取的移植,满足不同专业方向的基于互联网大数 据剖析须要。 【关键词】网络爬虫 Scrapy-redis 分布式 1 基本概念 分布式爬虫:分布式方法是以共同爬取为目标,形成多爬虫协同工作的模式,每个爬虫需 要独立完成单项爬取任务,下载网页并保存。 Scrapy-redis:一个三方的基于 redis 数据库实现的分布式方法,配合 scrapy 爬虫框架让 用,让 scrapy 具有了分布式爬取的功能。 2 分布式爬虫技术方案 Scrapy-redis 分布式爬虫的基本设计理念为主从模式,由作为主控端负责所有网络子爬虫 的管理,子爬虫只须要从主控端那儿接收任务分布式爬虫框架,并把新生成任务递交给主控端,在整个爬取的 过程中毋须与其他爬虫通讯。 主要有几个技术关键点: 2.1 子爬虫爬取任务的分发 通过在主控端安装一个 redis 数据库,维护统一的任务列表,子爬虫每次联接 redis 库调用 lpop()方法,生成一个任务,并生成一个 request,接下去就是就像通常爬虫工作。
2.2 用户登入 由于网站对于旅客的访问有限制,为了爬取所需信息,必须在程序中实现用户登陆,其原 理就是能获取到有效的本地 cookie,并借助该 cookie 进行网站访问,除了通常还能用第三方库 进行图象辨识的验证方法外,一般采用浏览器中自动登入,通过网路工具截取有效的 cookie, 然后在爬虫生成 request 时附送上 cookie。 2.3 url 的去重 龙源期刊网 scrapy_redis 有一个 dupefilter 文件中包含 RFPDupeFilter 类用于过滤新增的 url,可以在该 类 request_seen 中借助 redis 的 key 的查找功能,如果所爬取的任务数以亿计则建议 Bloomfilter 去重的方法对于 URL 的储存和操作方法进行优化,虽然该方法会导致大于万分之一的过滤遗 失率。 2.4 数据写入 选择非关系性数据库 MongoDB 作为硬碟数据库与 scrapy 进行搭配使用,在 pipeline 中对 item 数据进行 MongoDB 的写入操作。 3 基本实现步骤 配置:Windows7 64-bit、Python:2.7.11、 Anaconda 4.0.0 (64-bit)、IDE:Pycharm 3.4.1、Scrapy:1.3.2Redis:X64-3.2、MongoDB:3.2.12 代码实现须要对几个文件进行设置和编撰:items、settings、spiders、pipelines。
Items:这是一个爬取数据的基础数据结构类,由其来储存爬虫爬取的键值性数据,关键 的就是这条句子:_id = Field() _id 表示的生成一个数据对象,在 Items 中可以按照须要设定 多个数据对象。 Settings:ITEM_PIPELINES 该参数决定了 item 的处理方式;DOWNLOAD_DELAY 这个 是下载的间隔时间;SCHEDULER 指定作为总的任务协调器的类; SCHEDULER_QUEUE_CLASS 这个参数是设定处理 URL 的队列的工作模式一共有四种,一般 选用 SpiderSimpleQueue 即可。 spiders:该文件就是爬虫主要功能的实现,首先设定该爬虫的基本信息:name、domain、 redis_key、start_urls。爬虫的第一步都是执行方式 start_requests,其中核心句子 yield Request (url,callback)用以按照 url 产生一个 request 并且将 response 结果回传给 callback 方法。 callback 的方式中通常借助 xpath 或者正则表达式对 response 中包含的 html 代码进行解析,产 生所须要的数据以及新的任务 url。
pipelines:该文件作为数据处理、存储的代码段分布式爬虫框架,将在 items 数据被创建后被调用,其中 process_item 的方式就是被调用的方式,所以一定要将其重画,根据实际须要把数据借助方式 dict()转化为字典数据,最后写入 MongoDB。 完成编撰后,在布署的时侯,start_url 的队列只能是第一个运行的爬虫进行初始化,后续 运行的爬虫只能是把新的 url 进行写入不能对其进行再度初始化,部署爬虫的步骤也很简单, 只须要把相关的代码拷贝到目标笔记本上,让后 cmd 命令步入 spiders 的文件夹,运行命令 scrapy crawl XXXX,其中 XXXX 就是爬虫的名子,就完成了爬虫的布署和运行了。 龙源期刊网 4 结语 爬虫的实现,除了基本的步骤和参数设置之外,需要开发者按照实际网站以及数据情况, 针对性的对爬取的策略、数据的去重、数据筛选进行处理,对于爬虫的性能进行有效优化,为 之后的数据剖析做好良好的数据打算。同时,根据须要可以考虑时间的诱因加入到数据结构 中,这就要求爬虫还能通过数据的时间去进行增量爬取。 参考文献 [1]使用 redis 如何实现一个网络分布式爬虫[OL].http: //www.oschina.net/code/snippet_209440_20495/. [2]scrapy_redis 的使用解读[OL].http://www.cnblogs.com/kylinlin/p/5198233.html.http: //blog.csdn.net/u012150179/art
爬虫基本原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-05-14 08:08
本文分为如下几个部份
简单理解网路爬虫就是手动抓取网页信息的代码,可以简单理解成取代繁杂的复制粘贴操作的手段。
首先必须申明,爬虫的对象必须是你早已听到的网页,比如你不能说你想找到知乎上那个用户的关注人数最多,就希望通过写一个爬虫来帮你爬到答案。你必须明晰地晓得这个人,找到他的主页,然后才会用爬虫来抓取他页面上的信息。
下面我们用一个简单的事例来展示爬虫的工作流程。感觉多数教程第一篇都使用的是豆瓣top250,我们这儿换一个,抓取CSDN首页的文章标题,链接在这里,页面样子是这样的
抓取标题完整代码如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
这样才会复印出所有标题,展示一部分如下
上述过程是一个最简单的完整爬虫流程,可以看出它的功能就是把这些标题复制粘贴到一起,免不仅自动操作的冗长。其实爬虫通常就是做这些事的,比如我们须要用链家的数据进行剖析,看到链家的页面是这样的
我们想获取每位房屋的标题、几室几厅、多少平米、朝向、装修、价格等等数组(即指标),就可以通过爬虫进行定位,自动化抓取这100页所有房屋的那些数组信息。比如100页里有2000个房屋,总共抓取10个数组,爬虫运行结束就可以得到一个2000行10列的excel表格。
注:如果还没有安装里面两个库的读者可以在命令行下分别运行下边两行命令完成安装
pip install requests
pip install beautifulsoup4
知道了爬虫是拿来干哪些的以后,我们来介绍一些最常见到的概念
1.URL
URL英文称为统一资源定位符,其实可以理解成网页的链接,比如前面的就是一个URL。
但是更广义的URL不只是我们常听到的网页资源链接,而是资源在网页中的定位标示。我们一般说的网页是一个资源,网页中加载的每一张图片也是一个资源,它们在互联网中也有惟一的定位URL。比如我们从CSDN网页上随意找一张图片
这个链接就是这个图片资源的定位符,将这个链接输入浏览器中都会显示出这张图片网页爬虫,所以说这张图片也对应一个URL。
不过晓得如此回事就好,我们一般所说的传入URL指的就是把网页的链接传进去。上面代码中
r = requests.get('https://www.csdn.net/')
就是在将URL传入恳求函数。
2.网页恳求
说到网页恳求,就有必要讲一下我们平时浏览网页时,信息交互的模式大约是什么样的。我们平时用浏览器浏览网页的时侯,鼠标点了一个链接,比如你如今点击这儿,其实浏览器帮你向这个网页发送了恳求(request),维护网页的服务器(可以理解为CSDN公司里的一台笔记本,在维护这CSDN上的各个网页)收到了这个恳求,判定这个恳求是有效的,于是返回了一些响应信息(response)到浏览器,浏览器将这种信息进行渲染(可以理解成 处理成人能读懂的样子),就是你看见的网页的样子了。发送恳求与接收恳求的过程就和 发陌陌和收到回复的过程类似。
而如今我们要用代码来模拟滑鼠点击的过程。上面的requests.get就是使代码帮你向这个网页发送了这个恳求,如果恳求被判断为有效,网页的服务器也会把信息传送给你,传送回去的这种信息就被形参到变量r之中。所以这个变量r里就包含有我们想要的信息了,也包括这些我们想要提取的标题。
我们可以print(r.text)看一下上面有哪些东西
我们再看一下网页的源代码(如何读懂这个源码,以及这个源码如何查看下一节HTML会详尽提到)
源代码和r.text虽然是一模一样的东西。r.text虽然就是一个字符串,字符串中有我们刚才抓取到的所有标题,我们只要通过字符串匹配方式(比如正则表达式)将她们提取下来就可以了。这样说是不是觉得爬虫十分简单呢?只要这样傻蛋操作
r = requests.get('https://www.csdn.net/')
再直接从r.text字符串中提取信息即可。其实爬虫就是那么简单。
但是解析是如何回事呢,为什么刚才不直接用正则而要用bs4呢?因为便捷,但是正则也是完全可以的,只是相对麻烦一些、需要写更多的代码而已。
3.网页解析
网页解析虽然就从网页服务器返回给我们的信息中提取我们想要数据的过程。其实使用正则表达式提取我们要的标题的过程也可以称为网页解析。
因为当前绝大多数网页源代码都是用HTML语言写的,而HTML语言时特别有规律性的,比如我们要的所有文章标题都具有相同结构,也就是说它周围的字符串都是十分类似的,这样我们能够批量获取。所以就有大鳄专门封装了怎样从HTML代码中提取特定文本的库,也就是我们平常说的网页解析库,如bs4 lxml pyquery等,其实把她们当作处理字符串的就可以了。
为了更清楚地了解怎样对网页进行解析,我们须要先简略把握HTML代码的结构。
引用维基百科中的一段话来介绍HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被诸多网站用于设计令人赏心悦目的网页、网页应用程序以及移动应用程序的用户界面[1]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
为了使读者对HTML有更清楚的认识,我们来写一点简单的HTML代码。用文本编辑器(记事本也可以)创建一个名子为a.html的文件,在里面写下如下代码
<!DOCTYPE html>
<html>
<head>
<title>爬虫基本原理</title>
</head>
<body>
<h1>HTML介绍</h1>
<p>第一段</p>
<p>第二段</p>
</body>
</html>
保存,然后你双击这个文件,就会手动用浏览器打开,然后你还能见到下边这个样子的页面
你若果根据我的操作来做的话,你已然创建了一个简单的网页,现在你看见的所有网页都是这样设计的,只是比你的复杂一点而已,不信你去瞧瞧刚刚截图出来的网页源代码图片。
接下来,我们来看一下HTML语言的特性。最重要的一点是网页爬虫,文本都是被标签(h1标签 p标签)夹在中间的,而这种标签都是特定的,有专门用途的。比如<h1>就表示一级标题,包在上面的文本自然会被放大显示;而<p>标签则表示段落。
再看里面的源代码截图,head meta script title div li每一个都是标签,层层嵌套。我们完全不需要晓得总共有什么种标签,也不需要晓得这种标签都是拿来干哪些的,我们只要找到我们要的信息包含在哪些标签里就行了。比如使用正则表达式就直接用<p>(.*?)</p>就可以把上面的内容提取下来了。
但是事实似乎没有这么简单,看里面的截图标签如何是这样的<nav id="nav" class="clearfix">?其实这是一个<nav>标签,后面的id class是这个标签的属性。
为什么要给标签设置属性呢?我们先考虑这样一个问题:我们看见的网页千差万别,文字的颜色字体等都不一样,这是如何设置的呢?答案是使用css样式。
css句子类似这样
h1 {
color: white;
text-align: center;
}
p {
font-family: verdana;
font-size: 20px;
}
即设置对应标签的颜色、字体、大小、居中等。而当有的段落使用这个字体,有的段落使用哪个字体如何办呢?css这样设置
p.test1 {
font-size: 20px;
}
p.test2 {
font-size: 15px;
}
在HTML代码中则这样写
<p class="test1">20px大小的字</p>
<p class="test2">15px大小的字</p>
所以不同属性就是为了分辨相同标签用的,这相当于给标签进行了分类,在统一设计款式上更方便,同时对于我们依照属性定位我们想要内容的位置虽然也是更方便了。这里要说明一下,class id这两个属性比较特殊,用的也最多,所以各自弄了一个快捷键来表示,class用.,id用#。
做爬虫不需要了解刚才编撰的css代码内容放到那里之类的问题,也不需要了解css代码设置了哪些,我们只会和HTML打交道,所以只要理解HTML中属性的作用就可以了。
如果想要更进一步了解HTML和CSS,可以到w3school网站学习。
现在你就早已具备了解析网页须要的全部HTML知识了。我们通常就是依据标签名配合属性值来定位我们想要资源的位置的,其他的都不用管。这时,我们再来看爬虫的解析代码
把上面的代码再粘贴一遍如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
解释一下里面代码的过程
可以看见里面的代码十分简约,思路清晰,读者可以自己想一想假如要用正则表达式怎么匹配那些标签,会发觉代码冗长好多,虽然它也有更快的优势。
那么我们是如何晓得要找寻什么样属性的div标签,为什么要找h2 a标签而不是其他的呢?这就要去剖析网页的源代码了。而这个过程也十分简单。
我们如今用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-查看网页源代码,这时才会打开一个新的页面这个页面就是这个网站的HTML源代码了,我们可以通过这个页面来看我们要的信息在那里,但是觉得十分不便捷,因为有太多无用的信息做干扰,我们难以快速掌控网页的结构。所以我们可以用另一种形式查看源代码。
用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-检查,就会弹出一个框,如下图所示
(如果没有听到这个界面,注意要切换到Element中)
这个页面最大的用处是通过折叠来使人更快探求出网页的结构。
其中的这些代码就是HTML代码,该页面的一个个标题就存在这一个个li上面。点击li后面的三角就可以展开具体的代码内容,如下图所示
可以看见文章的标题(打造一个高性能、易落地的公链开发平台)就在这个源代码之中,也就是说在我们刚才获得的r.text字符串之中。而我们代码定位路径也一目了然了,因为每位li上面还会有一个<div class="title">而每一个div上面还会有一个h2 里面有一个a,a中包含我们要的标题名称。所以我们就用find_all找到所有这样的div标签,存储为一个list,再对list进行循环,对每一个元素提取h2 a 再提取标签中的内容。
当然我们也可以find_all最外边的li标签,再一层层往里找,都是一样的。只要找到定位信息的惟一标示(标签或则属性)就可以了。
虽然在这里看源代码可以折叠一些没用的代码,但是虽然还有一些更好用的工具来辅助我们找到我们要的信息在网页源码中的位置。比如下边这个键盘符号。
在所有代码都折叠上去的情况下,点击这个键盘,之后再去点击网页中的元素,浏览器都会手动帮你把你点击的元素选中下来,其实你键盘悬在一个元素前面的时侯,就早已帮你定位了,如下图所示
当我们要爬一个网页的时侯,只须要如下流程
现在,对于一些没有丝毫反爬举措的网站我们都可以游刃有余了。至于抓取多个数组的数据怎么组织在一起、抓取多页(URL有规律的情况下)的代码怎样设计,就不是爬虫知识范畴了,这是用python基础知识就可以解决的。下一系列文章就主要讲这一部分。接下来给几个当前可以练手的网站
如果使用BeautifulSoup的定位的过程中遇见困难,可以直接到网上搜教程,也可以等我们这个专题前面更新的BeautifulSoup详尽介绍。
如果你去抓取其他网站,最好先看一下r.text是不是和网站源代码一模一样,如果不是,说明你对方服务器没有把真正的信息给你,说明他可能看出你是爬虫了(进行网页恳求的时侯,浏览器和requests.get都相当于带着一堆资格证去敲门,对方会检测你这种资格证,浏览器的资格证通常是可以通过的,而代码的资格证就可能不合格,因为代码的资格证可能有一些比较固定的特征,对方服务器预先设定好,资格证是这样的恳求一律拒绝,因为她们一定是爬虫,这就是反爬虫机制),这时就须要懂一些反反爬举措就能获得真正的信息,反反爬方式的学习是一个积累的过程,我们前面再讲。读者假如遇见一些反爬机制,可以到网上查这个网站的爬虫,估计都能查到一些博客讲怎么破解,甚至直接贴出代码。
在这篇的基础上抓取多页以及代码设计的改进看下边这三篇续集
爬虫代码改进(一)
爬虫代码改进(二)
爬虫代码改进(三)
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明 查看全部
这篇文章的定位是,给有一些python基础,但是对爬虫一无所知的人写的。文中只会涉及到爬虫最核心的部份,完全避免莫名其妙的坑或概念,让读者认为爬虫是一件极其简单的事情,而事实上爬虫确实是一件极其简单的事情(如果你不是以爬虫为工作的话)。
本文分为如下几个部份
简单理解网路爬虫就是手动抓取网页信息的代码,可以简单理解成取代繁杂的复制粘贴操作的手段。
首先必须申明,爬虫的对象必须是你早已听到的网页,比如你不能说你想找到知乎上那个用户的关注人数最多,就希望通过写一个爬虫来帮你爬到答案。你必须明晰地晓得这个人,找到他的主页,然后才会用爬虫来抓取他页面上的信息。
下面我们用一个简单的事例来展示爬虫的工作流程。感觉多数教程第一篇都使用的是豆瓣top250,我们这儿换一个,抓取CSDN首页的文章标题,链接在这里,页面样子是这样的
抓取标题完整代码如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
这样才会复印出所有标题,展示一部分如下
上述过程是一个最简单的完整爬虫流程,可以看出它的功能就是把这些标题复制粘贴到一起,免不仅自动操作的冗长。其实爬虫通常就是做这些事的,比如我们须要用链家的数据进行剖析,看到链家的页面是这样的
我们想获取每位房屋的标题、几室几厅、多少平米、朝向、装修、价格等等数组(即指标),就可以通过爬虫进行定位,自动化抓取这100页所有房屋的那些数组信息。比如100页里有2000个房屋,总共抓取10个数组,爬虫运行结束就可以得到一个2000行10列的excel表格。
注:如果还没有安装里面两个库的读者可以在命令行下分别运行下边两行命令完成安装
pip install requests
pip install beautifulsoup4
知道了爬虫是拿来干哪些的以后,我们来介绍一些最常见到的概念
1.URL
URL英文称为统一资源定位符,其实可以理解成网页的链接,比如前面的就是一个URL。
但是更广义的URL不只是我们常听到的网页资源链接,而是资源在网页中的定位标示。我们一般说的网页是一个资源,网页中加载的每一张图片也是一个资源,它们在互联网中也有惟一的定位URL。比如我们从CSDN网页上随意找一张图片
这个链接就是这个图片资源的定位符,将这个链接输入浏览器中都会显示出这张图片网页爬虫,所以说这张图片也对应一个URL。
不过晓得如此回事就好,我们一般所说的传入URL指的就是把网页的链接传进去。上面代码中
r = requests.get('https://www.csdn.net/')
就是在将URL传入恳求函数。
2.网页恳求
说到网页恳求,就有必要讲一下我们平时浏览网页时,信息交互的模式大约是什么样的。我们平时用浏览器浏览网页的时侯,鼠标点了一个链接,比如你如今点击这儿,其实浏览器帮你向这个网页发送了恳求(request),维护网页的服务器(可以理解为CSDN公司里的一台笔记本,在维护这CSDN上的各个网页)收到了这个恳求,判定这个恳求是有效的,于是返回了一些响应信息(response)到浏览器,浏览器将这种信息进行渲染(可以理解成 处理成人能读懂的样子),就是你看见的网页的样子了。发送恳求与接收恳求的过程就和 发陌陌和收到回复的过程类似。
而如今我们要用代码来模拟滑鼠点击的过程。上面的requests.get就是使代码帮你向这个网页发送了这个恳求,如果恳求被判断为有效,网页的服务器也会把信息传送给你,传送回去的这种信息就被形参到变量r之中。所以这个变量r里就包含有我们想要的信息了,也包括这些我们想要提取的标题。
我们可以print(r.text)看一下上面有哪些东西
我们再看一下网页的源代码(如何读懂这个源码,以及这个源码如何查看下一节HTML会详尽提到)
源代码和r.text虽然是一模一样的东西。r.text虽然就是一个字符串,字符串中有我们刚才抓取到的所有标题,我们只要通过字符串匹配方式(比如正则表达式)将她们提取下来就可以了。这样说是不是觉得爬虫十分简单呢?只要这样傻蛋操作
r = requests.get('https://www.csdn.net/')
再直接从r.text字符串中提取信息即可。其实爬虫就是那么简单。
但是解析是如何回事呢,为什么刚才不直接用正则而要用bs4呢?因为便捷,但是正则也是完全可以的,只是相对麻烦一些、需要写更多的代码而已。
3.网页解析
网页解析虽然就从网页服务器返回给我们的信息中提取我们想要数据的过程。其实使用正则表达式提取我们要的标题的过程也可以称为网页解析。
因为当前绝大多数网页源代码都是用HTML语言写的,而HTML语言时特别有规律性的,比如我们要的所有文章标题都具有相同结构,也就是说它周围的字符串都是十分类似的,这样我们能够批量获取。所以就有大鳄专门封装了怎样从HTML代码中提取特定文本的库,也就是我们平常说的网页解析库,如bs4 lxml pyquery等,其实把她们当作处理字符串的就可以了。
为了更清楚地了解怎样对网页进行解析,我们须要先简略把握HTML代码的结构。
引用维基百科中的一段话来介绍HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被诸多网站用于设计令人赏心悦目的网页、网页应用程序以及移动应用程序的用户界面[1]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
为了使读者对HTML有更清楚的认识,我们来写一点简单的HTML代码。用文本编辑器(记事本也可以)创建一个名子为a.html的文件,在里面写下如下代码
<!DOCTYPE html>
<html>
<head>
<title>爬虫基本原理</title>
</head>
<body>
<h1>HTML介绍</h1>
<p>第一段</p>
<p>第二段</p>
</body>
</html>
保存,然后你双击这个文件,就会手动用浏览器打开,然后你还能见到下边这个样子的页面
你若果根据我的操作来做的话,你已然创建了一个简单的网页,现在你看见的所有网页都是这样设计的,只是比你的复杂一点而已,不信你去瞧瞧刚刚截图出来的网页源代码图片。
接下来,我们来看一下HTML语言的特性。最重要的一点是网页爬虫,文本都是被标签(h1标签 p标签)夹在中间的,而这种标签都是特定的,有专门用途的。比如<h1>就表示一级标题,包在上面的文本自然会被放大显示;而<p>标签则表示段落。
再看里面的源代码截图,head meta script title div li每一个都是标签,层层嵌套。我们完全不需要晓得总共有什么种标签,也不需要晓得这种标签都是拿来干哪些的,我们只要找到我们要的信息包含在哪些标签里就行了。比如使用正则表达式就直接用<p>(.*?)</p>就可以把上面的内容提取下来了。
但是事实似乎没有这么简单,看里面的截图标签如何是这样的<nav id="nav" class="clearfix">?其实这是一个<nav>标签,后面的id class是这个标签的属性。
为什么要给标签设置属性呢?我们先考虑这样一个问题:我们看见的网页千差万别,文字的颜色字体等都不一样,这是如何设置的呢?答案是使用css样式。
css句子类似这样
h1 {
color: white;
text-align: center;
}
p {
font-family: verdana;
font-size: 20px;
}
即设置对应标签的颜色、字体、大小、居中等。而当有的段落使用这个字体,有的段落使用哪个字体如何办呢?css这样设置
p.test1 {
font-size: 20px;
}
p.test2 {
font-size: 15px;
}
在HTML代码中则这样写
<p class="test1">20px大小的字</p>
<p class="test2">15px大小的字</p>
所以不同属性就是为了分辨相同标签用的,这相当于给标签进行了分类,在统一设计款式上更方便,同时对于我们依照属性定位我们想要内容的位置虽然也是更方便了。这里要说明一下,class id这两个属性比较特殊,用的也最多,所以各自弄了一个快捷键来表示,class用.,id用#。
做爬虫不需要了解刚才编撰的css代码内容放到那里之类的问题,也不需要了解css代码设置了哪些,我们只会和HTML打交道,所以只要理解HTML中属性的作用就可以了。
如果想要更进一步了解HTML和CSS,可以到w3school网站学习。
现在你就早已具备了解析网页须要的全部HTML知识了。我们通常就是依据标签名配合属性值来定位我们想要资源的位置的,其他的都不用管。这时,我们再来看爬虫的解析代码
把上面的代码再粘贴一遍如下
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get('https://www.csdn.net/')
# 解析URL
soup = BeautifulSoup(r.text, 'html.parser')
content_list = soup.find_all('div', attrs = {'class': 'title'})
for content in content_list:
print(content.h2.a.text)
解释一下里面代码的过程
可以看见里面的代码十分简约,思路清晰,读者可以自己想一想假如要用正则表达式怎么匹配那些标签,会发觉代码冗长好多,虽然它也有更快的优势。
那么我们是如何晓得要找寻什么样属性的div标签,为什么要找h2 a标签而不是其他的呢?这就要去剖析网页的源代码了。而这个过程也十分简单。
我们如今用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-查看网页源代码,这时才会打开一个新的页面这个页面就是这个网站的HTML源代码了,我们可以通过这个页面来看我们要的信息在那里,但是觉得十分不便捷,因为有太多无用的信息做干扰,我们难以快速掌控网页的结构。所以我们可以用另一种形式查看源代码。
用谷歌浏览器打开CSDN这个网站,找一个空白的位置右键-检查,就会弹出一个框,如下图所示
(如果没有听到这个界面,注意要切换到Element中)
这个页面最大的用处是通过折叠来使人更快探求出网页的结构。
其中的这些代码就是HTML代码,该页面的一个个标题就存在这一个个li上面。点击li后面的三角就可以展开具体的代码内容,如下图所示
可以看见文章的标题(打造一个高性能、易落地的公链开发平台)就在这个源代码之中,也就是说在我们刚才获得的r.text字符串之中。而我们代码定位路径也一目了然了,因为每位li上面还会有一个<div class="title">而每一个div上面还会有一个h2 里面有一个a,a中包含我们要的标题名称。所以我们就用find_all找到所有这样的div标签,存储为一个list,再对list进行循环,对每一个元素提取h2 a 再提取标签中的内容。
当然我们也可以find_all最外边的li标签,再一层层往里找,都是一样的。只要找到定位信息的惟一标示(标签或则属性)就可以了。
虽然在这里看源代码可以折叠一些没用的代码,但是虽然还有一些更好用的工具来辅助我们找到我们要的信息在网页源码中的位置。比如下边这个键盘符号。
在所有代码都折叠上去的情况下,点击这个键盘,之后再去点击网页中的元素,浏览器都会手动帮你把你点击的元素选中下来,其实你键盘悬在一个元素前面的时侯,就早已帮你定位了,如下图所示
当我们要爬一个网页的时侯,只须要如下流程
现在,对于一些没有丝毫反爬举措的网站我们都可以游刃有余了。至于抓取多个数组的数据怎么组织在一起、抓取多页(URL有规律的情况下)的代码怎样设计,就不是爬虫知识范畴了,这是用python基础知识就可以解决的。下一系列文章就主要讲这一部分。接下来给几个当前可以练手的网站
如果使用BeautifulSoup的定位的过程中遇见困难,可以直接到网上搜教程,也可以等我们这个专题前面更新的BeautifulSoup详尽介绍。
如果你去抓取其他网站,最好先看一下r.text是不是和网站源代码一模一样,如果不是,说明你对方服务器没有把真正的信息给你,说明他可能看出你是爬虫了(进行网页恳求的时侯,浏览器和requests.get都相当于带着一堆资格证去敲门,对方会检测你这种资格证,浏览器的资格证通常是可以通过的,而代码的资格证就可能不合格,因为代码的资格证可能有一些比较固定的特征,对方服务器预先设定好,资格证是这样的恳求一律拒绝,因为她们一定是爬虫,这就是反爬虫机制),这时就须要懂一些反反爬举措就能获得真正的信息,反反爬方式的学习是一个积累的过程,我们前面再讲。读者假如遇见一些反爬机制,可以到网上查这个网站的爬虫,估计都能查到一些博客讲怎么破解,甚至直接贴出代码。
在这篇的基础上抓取多页以及代码设计的改进看下边这三篇续集
爬虫代码改进(一)
爬虫代码改进(二)
爬虫代码改进(三)
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明
网页爬虫及其用到的算法和数据结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-05-13 08:04
网络爬虫程序的好坏,很大程度上反映了一个搜索引擎的好差。不信,你可以随意拿一个网站去查询一下各家搜索对它的网页收录情况,爬虫强悍程度跟搜索引擎优劣基本成正比。
1.世界上最简单的爬虫——三行情诗
我们先来看一个最简单的最简单的爬虫,用python写成,只须要三行。
import requests url="http://www.cricode.com" r=requests.get(url)
上面这三行爬虫程序,就如下边这三行短诗通常,很干脆利落。
是好男人,
就应当在和妻子争吵时网络爬虫算法书籍,
抱着必输的态度。
2.一个正常的爬虫程序
上面哪个最简单的爬虫,是一个不完整的残障的爬虫。因为爬虫程序一般须要做的事情如下:
因此,一个完整的爬虫大约是这样子的:
import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
seds = ["http://www.hao123.com", #我们的种子
"http://www.csdn.net",
http://www.cricode.com]
sum = 0 #我们设定终止条件为:爬取到100000个页面时,就不玩了
while sum < 10000 :
if sum < len(seds):
r = requests.get(seds[sum])
sum = sum + 1
do_save_action(r)
soup = BeautifulSoup(r.content)
urls = soup.find_all("href",.....) //解析网页
for url in urls:
seds.append(url) else:
break
3.现在来找碴
上面哪个完整的爬虫,不足20行代码,相信你能找出20个茬来。因为它的缺点实在是太多。下面一一列出它的N宗罪:
4.找了这么多茬后,很有成就感,真正的问题来了,学挖掘机究竟哪家强?
现在我们就来一一讨论里面找碴找出的若干问题的解决方案。
1)并行爬起问题
我们可以有多重方式去实现并行。
多线程或则线程池形式,一个爬虫程序内部开启多个线程。同一台机器开启多个爬虫程序,如此,我们就有N多爬取线程在同时工作。能大大降低时间。
此外,当我们要爬取的任务非常多时,一台机器、一个网点肯定是不够的,我们必须考虑分布式爬虫。常见的分布式构架有:主从(Master——Slave)架构、点对点(PeertoPeer)架构,混合构架等。
说道分布式构架,那我们须要考虑的问题就有很多,我们须要分派任务,各个爬虫之间须要通讯合作,共同完成任务,不要重复爬取相同的网页。分派任务我们要做到公正公平,就须要考虑怎样进行负载均衡。负载均衡,我们第一个想到的就是Hash,比如按照网站域名进行hash。
负载均衡分派完任务以后,千万不要以为万事大吉了,万一哪台机器挂了呢?原先委派给死掉的哪台机器的任务委派给谁?又或则哪天要降低几台机器网络爬虫算法书籍,任务有该怎样进行重新分配呢?
一个比较好的解决方案是用一致性Hash算法。
2)待爬取网页队列
如何对待待抓取队列,跟操作系统怎么调度进程是类似的场景。
不同网站,重要程度不同,因此,可以设计一个优先级队列来储存待爬起的网页链接。如此一来,每次抓取时,我们都优先爬取重要的网页。
当然,你也可以仿效操作系统的进程调度策略之多级反馈队列调度算法。
3)DNS缓存
为了防止每次都发起DNS查询,我们可以将DNS进行缓存。DNS缓存其实是设计一个hash表来储存已有的域名及其IP。
4)网页去重
说到网页去重,第一个想到的是垃圾邮件过滤。垃圾邮件过滤一个精典的解决方案是BloomFilter(布隆过滤器)。布隆过滤器原理简单来说就是:建立一个大的位字段,然后用多个Hash函数对同一个url进行hash得到多个数字,然后将位字段中这种数字对应的位置为1。下次再来一个url时,同样是用多个Hash函数进行hash,得到多个数字,我们只须要判定位字段中这种数字对应的为是全为1,如果全为1,那么说明这个url早已出现过。如此,便完成了url去重的问题。当然,这种方式会有偏差,只要偏差在我们的容忍范围之类,比如1万个网页,我只爬取到了9999个,剩下那一个网页,whocares!
5)数据储存的问题
数据储存同样是个挺有技术浓度的问题。用关系数据库存取还是用NoSQL,抑或是自己设计特定的文件格式进行储存,都大有文章可做。
6)进程间通信
分布式爬虫,就必然离不开进程间的通讯。我们可以以规定的数据格式进行数据交互,完成进程间通信。
7)……
废话说了那么多,真正的问题来了,问题不是学挖掘机究竟哪家强?而是怎么实现里面那些东西!:)
实现的过程中,你会发觉,我们要考虑的问题远远不止里面那些。纸上得来终觉浅,觉知此事要笃行! 查看全部
网络爬虫程序的好坏,很大程度上反映了一个搜索引擎的好差。不信,你可以随意拿一个网站去查询一下各家搜索对它的网页收录情况,爬虫强悍程度跟搜索引擎优劣基本成正比。
1.世界上最简单的爬虫——三行情诗
我们先来看一个最简单的最简单的爬虫,用python写成,只须要三行。
import requests url="http://www.cricode.com" r=requests.get(url)
上面这三行爬虫程序,就如下边这三行短诗通常,很干脆利落。
是好男人,
就应当在和妻子争吵时网络爬虫算法书籍,
抱着必输的态度。
2.一个正常的爬虫程序
上面哪个最简单的爬虫,是一个不完整的残障的爬虫。因为爬虫程序一般须要做的事情如下:
因此,一个完整的爬虫大约是这样子的:
import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
seds = ["http://www.hao123.com", #我们的种子
"http://www.csdn.net",
http://www.cricode.com]
sum = 0 #我们设定终止条件为:爬取到100000个页面时,就不玩了
while sum < 10000 :
if sum < len(seds):
r = requests.get(seds[sum])
sum = sum + 1
do_save_action(r)
soup = BeautifulSoup(r.content)
urls = soup.find_all("href",.....) //解析网页
for url in urls:
seds.append(url) else:
break
3.现在来找碴
上面哪个完整的爬虫,不足20行代码,相信你能找出20个茬来。因为它的缺点实在是太多。下面一一列出它的N宗罪:
4.找了这么多茬后,很有成就感,真正的问题来了,学挖掘机究竟哪家强?
现在我们就来一一讨论里面找碴找出的若干问题的解决方案。
1)并行爬起问题
我们可以有多重方式去实现并行。
多线程或则线程池形式,一个爬虫程序内部开启多个线程。同一台机器开启多个爬虫程序,如此,我们就有N多爬取线程在同时工作。能大大降低时间。
此外,当我们要爬取的任务非常多时,一台机器、一个网点肯定是不够的,我们必须考虑分布式爬虫。常见的分布式构架有:主从(Master——Slave)架构、点对点(PeertoPeer)架构,混合构架等。
说道分布式构架,那我们须要考虑的问题就有很多,我们须要分派任务,各个爬虫之间须要通讯合作,共同完成任务,不要重复爬取相同的网页。分派任务我们要做到公正公平,就须要考虑怎样进行负载均衡。负载均衡,我们第一个想到的就是Hash,比如按照网站域名进行hash。
负载均衡分派完任务以后,千万不要以为万事大吉了,万一哪台机器挂了呢?原先委派给死掉的哪台机器的任务委派给谁?又或则哪天要降低几台机器网络爬虫算法书籍,任务有该怎样进行重新分配呢?
一个比较好的解决方案是用一致性Hash算法。
2)待爬取网页队列
如何对待待抓取队列,跟操作系统怎么调度进程是类似的场景。
不同网站,重要程度不同,因此,可以设计一个优先级队列来储存待爬起的网页链接。如此一来,每次抓取时,我们都优先爬取重要的网页。
当然,你也可以仿效操作系统的进程调度策略之多级反馈队列调度算法。
3)DNS缓存
为了防止每次都发起DNS查询,我们可以将DNS进行缓存。DNS缓存其实是设计一个hash表来储存已有的域名及其IP。
4)网页去重
说到网页去重,第一个想到的是垃圾邮件过滤。垃圾邮件过滤一个精典的解决方案是BloomFilter(布隆过滤器)。布隆过滤器原理简单来说就是:建立一个大的位字段,然后用多个Hash函数对同一个url进行hash得到多个数字,然后将位字段中这种数字对应的位置为1。下次再来一个url时,同样是用多个Hash函数进行hash,得到多个数字,我们只须要判定位字段中这种数字对应的为是全为1,如果全为1,那么说明这个url早已出现过。如此,便完成了url去重的问题。当然,这种方式会有偏差,只要偏差在我们的容忍范围之类,比如1万个网页,我只爬取到了9999个,剩下那一个网页,whocares!
5)数据储存的问题
数据储存同样是个挺有技术浓度的问题。用关系数据库存取还是用NoSQL,抑或是自己设计特定的文件格式进行储存,都大有文章可做。
6)进程间通信
分布式爬虫,就必然离不开进程间的通讯。我们可以以规定的数据格式进行数据交互,完成进程间通信。
7)……
废话说了那么多,真正的问题来了,问题不是学挖掘机究竟哪家强?而是怎么实现里面那些东西!:)
实现的过程中,你会发觉,我们要考虑的问题远远不止里面那些。纸上得来终觉浅,觉知此事要笃行!
python爬虫入门书籍
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-13 08:03
广告
云服务器1核2G首年99年,还有多款热门云产品满足您的上云需求
如果你想获得文章中实战的源代码,可以点击对应文章中【阅读文章】来获取。 学爬虫之道解读 python3 urllibpython 正则表达式内容提取利器 beautiful soup的用法爬虫实战一:爬取当当网所有 python 书籍python 多进程与多线程解读 requests库的用法“干将莫邪” —— xpath 与 lxml 库爬虫实战二:爬取影片天堂的最新...
点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫介绍----网络爬虫,英译为 web crawler ,是一种自动化程序,现在我们很幸运,生处互联网时代,有大量的信息在...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,都放到了文章结尾,欢迎前来发放!? 最近闲的无趣,想爬点书瞧瞧。 于是我选择了这个网站雨枫轩(http:)step1. 分析网站----一开始我想通过一篇文章引用的...
学习应用python的多线程、多进程进行爬取,提高爬虫效率; 学习爬虫的框架,scrapy、pyspider等; 学习分布式爬虫(数据量庞大的需求); 以上便是一个整体的学习概况,好多内容博主也须要继续学习,关于提及的每位步骤的细节,博主会在后续内容中以实战的事例逐渐与你们分享,当然中间也会穿插一些关于爬虫的好玩 3. ...
v站笔记 爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip install...
爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip installpymysql须要...
简单点书,python爬虫就是一个机械化的为你查询网页内容,并且按照你制订的规则返回你须要的资源的一类程序,也是目前大数据常用的一种形式,所以昨晚来进行爬虫扫盲,高端用户请回避,或者可以私戳,容我来膜拜下。 我的学习动机近来对简书中毒太深,所以想要写一个爬虫,放到服务器上,自己帮我随时查看简书的主页...
点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 今天我就来找一个简单的网页进行爬取,就当是给之前的兵书做一个实践。 不然不就是纸上谈兵的赵括了吗。 好了,我们...
编程对于任何一个菜鸟来说都不是一件容易的事情,python对于任何一个想学习的编程的人来说的确是一个福音,阅读python代码象是在阅读文章,源于python语言提供了十分典雅的句型,被称为最高贵的语言之一。? python入门时用得最多的还是各种爬虫脚本,写过抓代理本机验证的脚本、写过峰会中手动登入手动发帖的脚本写过...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! “入门”是良好的动机,但是可能作用平缓。 如果你手里或则脑袋里有一个项目,那么实践上去你会被目标驱动,而不会象学习模块一样渐渐学习。 另外假如说...
如果你是跟随实战的书敲代码的,很多时侯项目都不会一遍运行成功数据挖掘爬虫书籍,那么你就要按照各类报错去找寻缘由,这也是一个学习的过程。 总结上去从python入门跳出来的过程分为三步:照抄、照抄以后的理解、重新自己实现。 (八)python爬虫入门第一:python爬虫学习系列教程python版本:3.6整体目录:一、爬虫入门 python爬虫...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着他人的爬虫代码学,弄懂每一...
python中有许多种操作简单且高效的工具可以协助我们来解析html或则xml,学会这种工具抓取数据是很容易了。 说到爬虫的htmlxml解析(现在网页大部分都是html)数据挖掘爬虫书籍,可使用的方式实在有很多种,如:正则表达式beautifulsouplxmlpyquerycssselector似乎也不止这几种,还有好多,那么究竟哪一种最好呢? 这个很难说,萝卜...
zhuanlan.zhihu.comp28865834(简介:这本书主要内容是python入门,以及python爬虫入门和python爬虫进阶)2. 问题:求大神们推荐python入门书籍https:(简介:python爬虫方面入门书籍推荐教程:系列教程:1.python爬虫学习系列教程https:zhuanlan.zhihu.comp25949099...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫是哪些? 如果我们把互联网称作一张大的蜘蛛网,数据便是储存于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网路抓取自己的猎物(数据)爬虫指的是...
获取某个答案的所有点赞者名单? 知乎上有一个问题是怎样写个爬虫程序扒下知乎某个回答所有点赞用户名单? 我参考了段草儿的这个答案怎么入门python爬虫,然后有了下边的这个函数。 这里先来大约的剖析一下整个流程。 我们要知道,知乎上的每一个问题都有一个惟一id,这个可以从地址中看下来,例如问题2015 年有什么书...
工具:xmind▍思维导图1 爬虫基础知识 ? 2 requests 库 ? 3 beautifulsoup & urllib ? 4 scrapy 爬虫框架 ? ▍参考资料假如你希望进一步学习表单递交,js 处理,验证码等更高阶的话题,可以继续深入学习本文附上的参考资料哦:mooc:python 网络爬虫与信息提取 书籍:《python 网络数据采集》若发觉本篇 python 笔记...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 在常见的几个音乐网站里,酷狗可以说是最好爬取的啦,什么弯都没有,也没加密啥的,所以最适宜小白入门爬虫本篇针对爬虫零基础的小白,所以每一步骤我都...
同时,自己是一名中级python开发工程师,从基础的python脚本到web开发、爬虫、django、数据挖掘等,零基础到项目实战的资料都有整理。 送给每一位python的...而这个网路恳求背后的技术就是基于 http 协议。 作为入门爬虫来说,你须要了解 http合同的基本原理,虽然 http 规范用一本书都写不完,但深入的内容可以放...
并非开始都是最容易的刚开始对爬虫不是太了解,又没有任何的计算机、编程基础,确实有点懵逼。 从那里开始,哪些是最开始应当学的,哪些应当等到有一定基础以后再学,也没个清晰的概念。 因为是 python 爬虫嘛,python 就是必备的咯,那先从 python 开始吧。 于是看了一些教程和书籍,了解基本的数据结构,然后是列表... 查看全部
广告
云服务器1核2G首年99年,还有多款热门云产品满足您的上云需求
如果你想获得文章中实战的源代码,可以点击对应文章中【阅读文章】来获取。 学爬虫之道解读 python3 urllibpython 正则表达式内容提取利器 beautiful soup的用法爬虫实战一:爬取当当网所有 python 书籍python 多进程与多线程解读 requests库的用法“干将莫邪” —— xpath 与 lxml 库爬虫实战二:爬取影片天堂的最新...
点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫介绍----网络爬虫,英译为 web crawler ,是一种自动化程序,现在我们很幸运,生处互联网时代,有大量的信息在...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,都放到了文章结尾,欢迎前来发放!? 最近闲的无趣,想爬点书瞧瞧。 于是我选择了这个网站雨枫轩(http:)step1. 分析网站----一开始我想通过一篇文章引用的...
学习应用python的多线程、多进程进行爬取,提高爬虫效率; 学习爬虫的框架,scrapy、pyspider等; 学习分布式爬虫(数据量庞大的需求); 以上便是一个整体的学习概况,好多内容博主也须要继续学习,关于提及的每位步骤的细节,博主会在后续内容中以实战的事例逐渐与你们分享,当然中间也会穿插一些关于爬虫的好玩 3. ...
v站笔记 爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip install...
爬取这个网上的书籍http:然后价位等信息在亚马逊上爬取:https: url=search-alias%3daps&field-keywords=xxx #xxx表示的是下边爬取的isbn用的是python3.6微博、小程序查看代码混乱,请查看原文~准备安装的包$ pip install scrapy$ pip installpymysql须要...
简单点书,python爬虫就是一个机械化的为你查询网页内容,并且按照你制订的规则返回你须要的资源的一类程序,也是目前大数据常用的一种形式,所以昨晚来进行爬虫扫盲,高端用户请回避,或者可以私戳,容我来膜拜下。 我的学习动机近来对简书中毒太深,所以想要写一个爬虫,放到服务器上,自己帮我随时查看简书的主页...
点击绿字“python教程”关注我们哟! 前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 今天我就来找一个简单的网页进行爬取,就当是给之前的兵书做一个实践。 不然不就是纸上谈兵的赵括了吗。 好了,我们...
编程对于任何一个菜鸟来说都不是一件容易的事情,python对于任何一个想学习的编程的人来说的确是一个福音,阅读python代码象是在阅读文章,源于python语言提供了十分典雅的句型,被称为最高贵的语言之一。? python入门时用得最多的还是各种爬虫脚本,写过抓代理本机验证的脚本、写过峰会中手动登入手动发帖的脚本写过...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! “入门”是良好的动机,但是可能作用平缓。 如果你手里或则脑袋里有一个项目,那么实践上去你会被目标驱动,而不会象学习模块一样渐渐学习。 另外假如说...
如果你是跟随实战的书敲代码的,很多时侯项目都不会一遍运行成功数据挖掘爬虫书籍,那么你就要按照各类报错去找寻缘由,这也是一个学习的过程。 总结上去从python入门跳出来的过程分为三步:照抄、照抄以后的理解、重新自己实现。 (八)python爬虫入门第一:python爬虫学习系列教程python版本:3.6整体目录:一、爬虫入门 python爬虫...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着他人的爬虫代码学,弄懂每一...
python中有许多种操作简单且高效的工具可以协助我们来解析html或则xml,学会这种工具抓取数据是很容易了。 说到爬虫的htmlxml解析(现在网页大部分都是html)数据挖掘爬虫书籍,可使用的方式实在有很多种,如:正则表达式beautifulsouplxmlpyquerycssselector似乎也不止这几种,还有好多,那么究竟哪一种最好呢? 这个很难说,萝卜...
zhuanlan.zhihu.comp28865834(简介:这本书主要内容是python入门,以及python爬虫入门和python爬虫进阶)2. 问题:求大神们推荐python入门书籍https:(简介:python爬虫方面入门书籍推荐教程:系列教程:1.python爬虫学习系列教程https:zhuanlan.zhihu.comp25949099...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 爬虫是哪些? 如果我们把互联网称作一张大的蜘蛛网,数据便是储存于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网路抓取自己的猎物(数据)爬虫指的是...
获取某个答案的所有点赞者名单? 知乎上有一个问题是怎样写个爬虫程序扒下知乎某个回答所有点赞用户名单? 我参考了段草儿的这个答案怎么入门python爬虫,然后有了下边的这个函数。 这里先来大约的剖析一下整个流程。 我们要知道,知乎上的每一个问题都有一个惟一id,这个可以从地址中看下来,例如问题2015 年有什么书...
工具:xmind▍思维导图1 爬虫基础知识 ? 2 requests 库 ? 3 beautifulsoup & urllib ? 4 scrapy 爬虫框架 ? ▍参考资料假如你希望进一步学习表单递交,js 处理,验证码等更高阶的话题,可以继续深入学习本文附上的参考资料哦:mooc:python 网络爬虫与信息提取 书籍:《python 网络数据采集》若发觉本篇 python 笔记...
前言python如今十分火,语法简单但是功能强悍,很多朋友都想学python! 所以小的给诸位看官们打算了高价值python学习视频教程及相关电子版书籍,欢迎前来发放! 在常见的几个音乐网站里,酷狗可以说是最好爬取的啦,什么弯都没有,也没加密啥的,所以最适宜小白入门爬虫本篇针对爬虫零基础的小白,所以每一步骤我都...
同时,自己是一名中级python开发工程师,从基础的python脚本到web开发、爬虫、django、数据挖掘等,零基础到项目实战的资料都有整理。 送给每一位python的...而这个网路恳求背后的技术就是基于 http 协议。 作为入门爬虫来说,你须要了解 http合同的基本原理,虽然 http 规范用一本书都写不完,但深入的内容可以放...
并非开始都是最容易的刚开始对爬虫不是太了解,又没有任何的计算机、编程基础,确实有点懵逼。 从那里开始,哪些是最开始应当学的,哪些应当等到有一定基础以后再学,也没个清晰的概念。 因为是 python 爬虫嘛,python 就是必备的咯,那先从 python 开始吧。 于是看了一些教程和书籍,了解基本的数据结构,然后是列表...
java爬虫gecco
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-05-13 08:02
java爬虫gecco 相关的博客
教您使用java爬虫gecco抓取JD全部商品信息教您使用DynamicGecco抓取JD全部商品信息 Gecco+Spring+Mybatis完整事例,下载美女图美眉图片 结合spring的插件gecco-spring 结合htmlunit的插件gecco
互联网编程1年前 505
Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫java爬虫框架gecco,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。
互联网编程2年前 596
一、Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。 主题爬虫通常关注的是:下载、内容抽取、灵活的业务
互联网编程1年前 1069
补充基础知识 爬虫,毋庸置疑就是爬去互联网的网页java爬虫框架gecco,理论上,只要是互联网中存在的web页面,都可以爬取。用来做数据采集非常合适,尤其是现今大数据领域,爬虫必不可少。 爬虫种类有很多,了解概念可以参考百度百科 这里采用Java语言做爬虫,没有哪些非常的缘由,第一
互联网编程1年前 707
整理了Node.js、PHP、Go、JAVA、Ruby、Python等语言的爬虫框架。不知道读者们都用过哪些爬虫框架?爬虫框架的什么点你感觉好?哪些点认为不好? Node.js node-crawler
seancheney1年前 952 查看全部
java爬虫gecco 相关的博客
教您使用java爬虫gecco抓取JD全部商品信息教您使用DynamicGecco抓取JD全部商品信息 Gecco+Spring+Mybatis完整事例,下载美女图美眉图片 结合spring的插件gecco-spring 结合htmlunit的插件gecco
互联网编程1年前 505
Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫java爬虫框架gecco,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。
互联网编程2年前 596
一、Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫,不同于Nutch这样的面向搜索引擎的通用爬虫,Gecco是面向主题的爬虫。 通用爬虫通常关注三个主要的问题:下载、排序、索引。 主题爬虫通常关注的是:下载、内容抽取、灵活的业务
互联网编程1年前 1069
补充基础知识 爬虫,毋庸置疑就是爬去互联网的网页java爬虫框架gecco,理论上,只要是互联网中存在的web页面,都可以爬取。用来做数据采集非常合适,尤其是现今大数据领域,爬虫必不可少。 爬虫种类有很多,了解概念可以参考百度百科 这里采用Java语言做爬虫,没有哪些非常的缘由,第一
互联网编程1年前 707
整理了Node.js、PHP、Go、JAVA、Ruby、Python等语言的爬虫框架。不知道读者们都用过哪些爬虫框架?爬虫框架的什么点你感觉好?哪些点认为不好? Node.js node-crawler
seancheney1年前 952
利用 scrapy 集成社区爬虫功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-05-13 08:00
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:
代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:
scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:
在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键
填写社交帐号,点击更新按键
爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:) 查看全部
社区活跃度或则贡献越来越遭到注重,往往会作为获得工作或则承接项目的加分项。为了便捷用户展示自己的社区资料,中降低了一个社区爬虫功能。
当前只爬取了用户主页上一些简单的信息,如果有需求请讲到我们的
:
代码放到了github上,源码
如图所示,在之前的构架上(),我降低了黑色实线框内的部份,包括:
scrapy是一个python爬虫框架,想要快速实现爬虫推荐使用这个。
可以参考如下资料自行学习:
官方文档和官方事例
一个简单明了的入门博客,注意:博客中scrapy的安装步骤可以简化,直接使用 pip install scrapy,安装过程中可能会缺乏几个lib,ubuntu使用 apt-get install libffi-dev libxml2-dev libxslt1-dev -y
mongo特别适宜储存爬虫数据,支持异构数据。这意味着你可以随时改变爬虫策略抓取不同的数据,而不用害怕会和先前的数据冲突(使用sql就须要操蛋的更改表结构了)。
通过scrapy的pipline来集成mongo,非常便捷。
安装mongo
apt-get install mongodb
pip install pymongo
在编撰爬虫的过程中须要使用xpath表达式来提取页面数据,在chrome中可以使用XPath Helper来定位元素,非常便捷。使用方式:
打开XPath Helper插件
鼠标点击一下页面,按住shift键,把键盘联通到须要选定的元素上,插件会将该元素标记为红色,并给出对应的xpath表达式,如下图:
在爬虫程序中使用这个表达式selector.xpath(..../text()").extract()
编写好爬虫后,我门可以通过执行scrapy crawl spidername命令来运行爬虫程序,但这还不够。
通常我们通过自动或则定时任务(cron)来执行爬虫爬虫社区,而这儿我们须要通过web应用来触发爬虫。即,当用户更新绑定的社交帐号时,去执行一次爬虫。来剖析一下:
爬虫执行过程中会阻塞当前进程,为了不阻塞用户恳求,必须通过异步的方法来运行爬虫。
可能有多个用户同时更新资料,这就要求才能同时执行多个爬虫,并且要保证系统不会超员。
可以扩充成分布式的爬虫。
鉴于项目当前的构架,准备使用celery来执行异步爬虫。但是遇到了两个问题:
scrapy框架下,需要在scrapy目录下执行爬虫,否则难以获取到settings,这个用上去有点别扭,不过能够解决。
celery中反复运行scrapy的爬虫会报错:raise error.ReactorNotRestartable()。原因是scrapy用的twisted调度框架,不可以在进程中重启。
stackoverflow上有讨论过这个问题,尝试了一下,搞不定,放弃这个方案。如果你有解决这个问题的方式,期待分享:)
scrapy文档中提及了可以使用scrapyd来布署,scrapyd是一个用于运行scrapy爬虫的webservice,使用者才能通过http请求来运行爬虫。
你只须要使用scrapyd-client将爬虫发布到scrapyd中,然后通过如下命令就可以运行爬虫程序。
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=spider2
{"status": "ok", "jobid": "26d1b1a6d6f111e0be5c001e648c57f8"}
这意味哪些:
爬虫应用和自己的web应用完全前馈,只有一个http插口。
由于使用http插口,爬虫可以放到任何还能被访问的主机上运行。一个简易的分布式爬虫,不是吗?
scrapyd使用sqlite队列来保存爬虫任务,实现异步执行。
scrapyd可以同时执行多个爬虫,最大进程数可配,防止系统过载。
欢迎使用我们的爬虫功能来搜集社交资料。
成为雨点儿网用户爬虫社区,进入用户主页,点击编辑按键
填写社交帐号,点击更新按键
爬虫会在几秒内完成工作,刷新个人主页能够看见你的社区资料了,你也可以把个人主页链接附在电子简历中哟:)
Python爬虫能做哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-05-12 08:03
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言! 查看全部
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言!
python网络爬虫书籍推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-05-11 08:02
Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载 查看全部
Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载

