网络爬虫 c++
优采云 发布时间: 2020-05-22 08:01
广告
提供包括云服务器,云数据库在内的50+款云计算产品。打造一站式的云产品试用服务,助力开发者和企业零门槛上云。
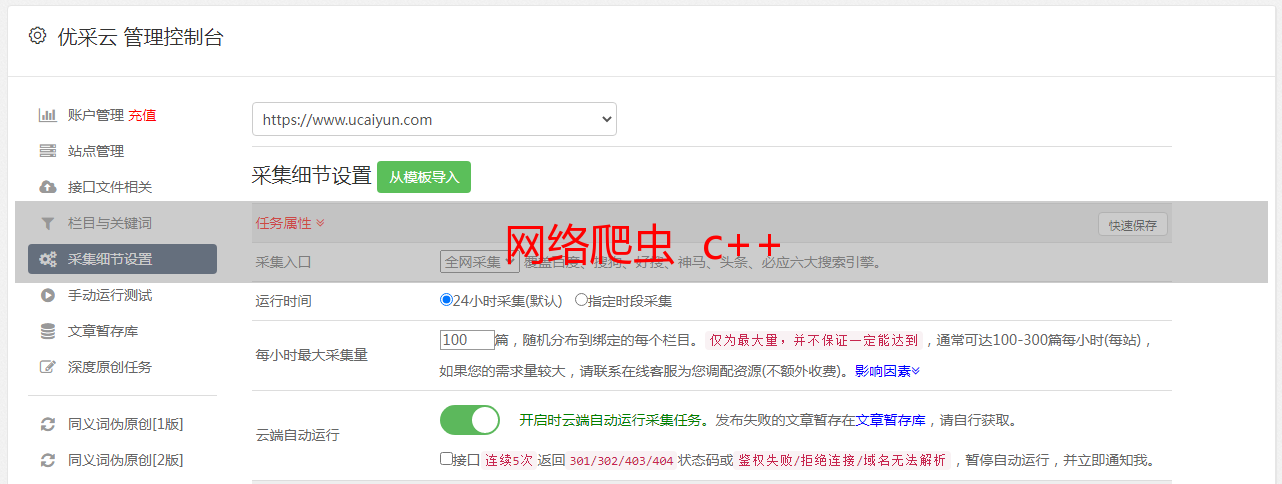
c++写的socket网络爬虫,代码会在最后一次讲解中提供给你们,同时我也会在写的同时不断的对代码进行建立与更改我首先向你们讲解怎样将网页中的内容,文本,图片等下载到笔记本中。? 我会教你们怎样将百度首页上的这个百度标志图片(http:)抓取下载到笔记本中。? 程序的部份代码如下,讲解在...
互联网初期,公司内部都设有好多的‘网站编辑’岗位,负责内容的整理和发布,纵然是高级动物人类,也只有两只手,无法通过复制、粘贴手工去维护,所以我们须要一种可以手动的步入网页提炼内容的程序技术,这就是‘爬虫’,网络爬虫工程师又被亲切的称之为‘虫师’。网络爬虫概述 网络爬虫(又被称为网页蜘蛛,网络...
这款框架作为java的爬虫框架基本上早已囊括了所有我们须要的功能,今天我们就来详尽了解这款爬虫框架,webmagic我会分为两篇文章介绍,今天主要写webmagic的入门,明天会写一些爬取指定内容和一些特点介绍,下面请看正文; 先了解下哪些是网路爬虫简介: 网络爬虫(web crawler) 也称作网路机器人,可以取代人们手动地在...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
rec 5.1 网络爬虫概述:网络爬虫(web spider)又称网路蜘蛛、网络机器人,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 网络爬虫根据系统结构和实现技术,大致可分为以下集中类型:通用网路爬虫:就是尽可能大的网路覆盖率,如 搜索引擎(百度、雅虎和微软等...)。 聚焦网路爬虫:有目标性,选择性地...
b. 网络爬虫的法律风险服务器上的数据有产权归属,网络爬虫获取数据敛财将带来法律风险c.网络爬虫的隐私泄漏网路爬虫可能具备突破简单控制访问的能力,获取被保护的数据因而外泄个人隐私。 4.2 网络爬虫限制a. 来源审查:判断user-agent进行限制检测来访http合同头的user-agent域,只响应浏览器或友好爬虫的访问b. ...
curl简介php的curl可以实现模拟http的各类恳求,这也是php做网路爬虫的基础,也多用于插口api的调用。 php 支持 daniel stenberg 创建的 libcurl 库,能够联接通信各类服务器、使用各类合同。 libcurl 目前支持的合同有 http、https、ftp、gopher、telnet、dict、file、ldap。 libcurl 同时支持 https 证书、http ...
说起网路爬虫,大家想起的恐怕都是 python ,诚然爬虫早已是 python 的代名词之一,相比 java 来说就要逊色不少。 有不少人都不知道 java 可以做网路爬虫,其实 java 也能做网路爬虫并且能够做的非常好,在开源社区中有不少优秀的 java 网络爬虫框架,例如 webmagic 。 我的第一份即将工作就是使用 webmagic 编写数据...
所以假如对爬虫有一定基础,上手框架是一种好的选择。 本书主要介绍的爬虫框架有pyspider和scrapy,本节我们来介绍一下 pyspider、scrapy 以及它们的一些扩充库的安装方法。 pyspider的安装pyspider 是国人 binux 编写的强悍的网路爬虫框架,它带有强悍的 webui、脚本编辑器、任务*敏*感*词*、项目管理器以及结果处理器...
介绍: 所谓网路爬虫,就是一个在网上四处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的html数据。 不过因为一个网站的网页好多,而我们又不可能事先晓得所有网页的url地址,所以,如何保证我们抓取到了网站的所有html页面就是一个有待考究的问题了。 一般的方式是,定义一个...
政府部门可以爬虫新闻类的网站,爬虫评论查看舆论; 还有的网站从别的网站爬虫下来在自己网站上展示。 等等 爬虫分类: 1. 全网爬虫(爬取所有的网站) 2. 垂直爬虫(爬取某类网站) 网络爬虫开源框架 nutch; webmagic 爬虫技术剖析: 1. 数据下载 模拟浏览器访问网站就是request恳求response响应 可是使用httpclient...
nodejs实现为什么忽然会选择nodejs来实现,刚好近来在看node书籍,里面有提及node爬虫,解析爬取的内容,书中提及借助cheerio模块,遂果断浏览其api文档...前言上周借助java爬取的网路文章,一直无法借助java实现html转化md,整整一周时间才得以解决。 虽然本人的博客文章数量不多,但是绝不齿于自动转换,毕竟...
很多小型的网路搜索引擎系统都被称为基于 web数据采集的搜索引擎系统,比如 google、baidu。 由此可见 web 网络爬虫系统在搜索引擎中的重要性。 网页中不仅包含供用户阅读的文字信息外,还包含一些超链接信息。 web网路爬虫系统正是通过网页中的超联接信息不断获得网路上的其它网页。 正是由于这些采集过程象一个爬虫...
requests-bs4 定向爬虫:仅对输入url进行爬取网络爬虫 c++,不拓展爬取 程序的结构设计:步骤1:从网路上获取学院排行网页内容 gethtmltext() 步骤2:提取网页内容中...列出工程中所有爬虫 scrapy list shell 启动url调试命令行 scrapy shellscrapy框架的基本使用步骤1:建立一个scrapy爬虫工程#打开命令提示符-win+r 输入...
twisted介绍twisted是用python实现的基于风波驱动的网路引擎框架,scrapy正是依赖于twisted,从而基于风波循环机制实现爬虫的并发。 scrapy的pipeline文件和items文件这两个文件有哪些作用先瞧瞧我们下篇的示例:# -*- coding: utf-8 -*-import scrapy class choutispider(scrapy.spider):爬去抽屉网的贴子信息 name ...
总算有时间动手用所学的python知识编撰一个简单的网路爬虫了,这个反例主要实现用python爬虫从百度图库中下载美眉的图片,并保存在本地,闲话少说,直接贴出相应的代码如下:----------#coding=utf-8#导出urllib和re模块importurllibimportre#定义获取百度图库url的类; classgethtml:def__init__(self,url):self.url...
读取页面与下载页面须要用到def gethtml(url): #定义gethtml()函数,用来获取页面源代码page = urllib.urlopen(url)#urlopen()根据url来获取页面源代码html = page.read()#从获取的对象中读取内容return htmldef getimage(html): #定义getimage()函数,用来获取图片地址并下载reg = rsrc=(.*?.jpg) width#定义匹配...
《python3 网络爬虫开发实战(崔庆才著)》redis 命令参考:http:redisdoc.com 、http:doc.redisfans.com----【16.3】key(键)操作 方法 作用 参数说明 示例 示例说明示例结果 exists(name) 判断一个键是否存在 name:键名 redis.exists(‘name’) 是否存在 name 这个键 true delete(name) 删除一个键name...
data=kw)res =session.get(http:)print(demo + res.text)总结本篇介绍了爬虫中有关网路恳求的相关知识,通过阅读,你将了解到urllib和...查看完整url地址print(response.url) with open(cunyu.html, w, encoding=utf-8 )as cy:cy.write(response.content.decode(utf-8))# 查看cookiesprint...
本文的实战内容有:网络小说下载(静态网站) 优美墙纸下载(动态网站) 爱奇艺vip视频下载二、网络爬虫简介 网络爬虫,也叫网路蜘蛛(web spider)。 它依据网页地址(url)爬取网页内容,而网页地址(url)就是我们在浏览器中输入的网站链接。 比如:https:,它就是一个url。 在讲解爬虫内容之前网络爬虫 c++,我们须要先...

