
python爬虫
Python网络爬虫实战项目代码大全(长期更新,欢迎补充)
采集交流 • 优采云 发表了文章 • 0 个评论 • 827 次浏览 • 2020-06-14 08:02
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址: 查看全部
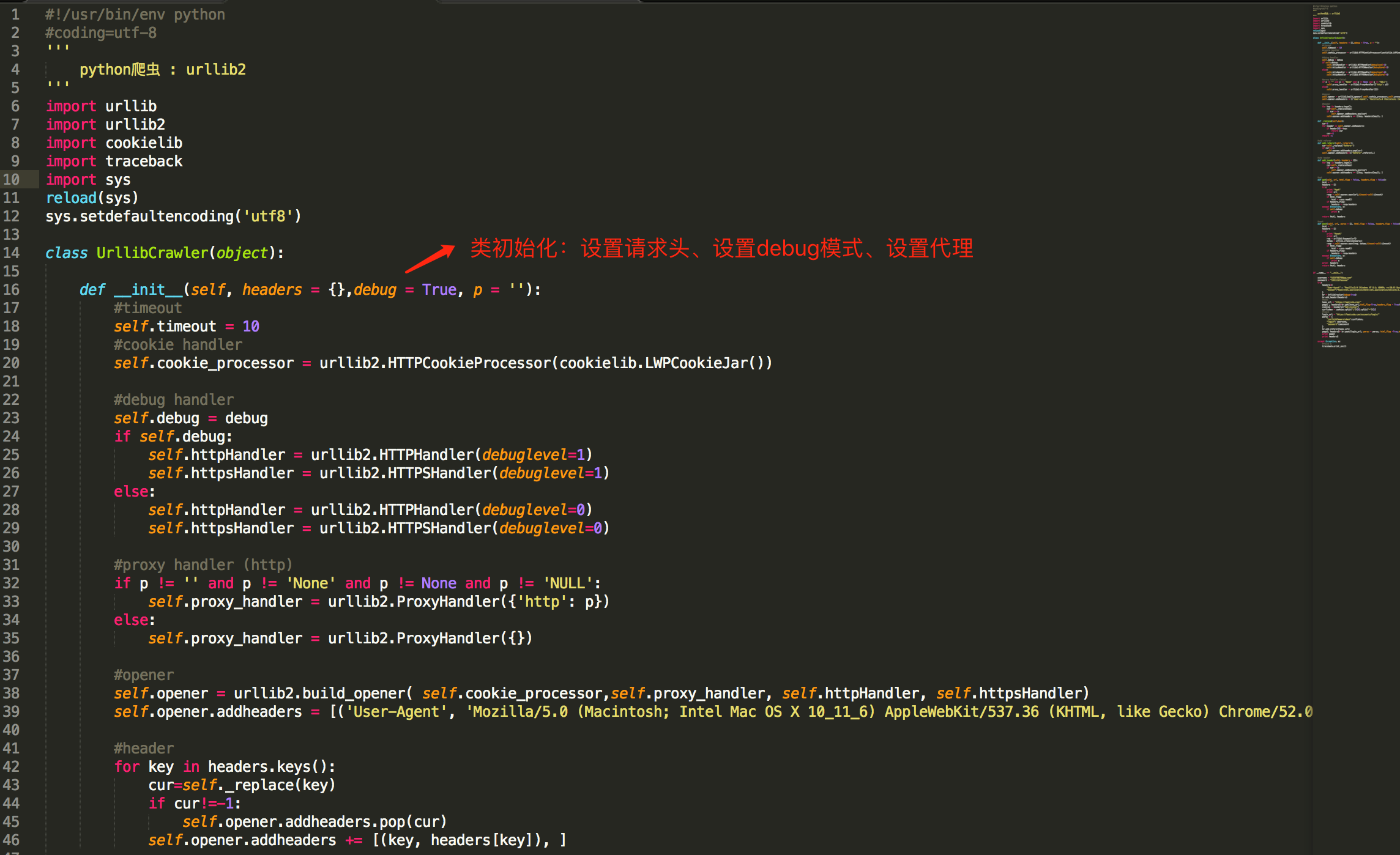
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址:
网络爬虫_基于各类语言的开源网络爬虫总汇
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-06-13 08:02
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可
python爬虫入门教程(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-06-12 08:01
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战 查看全部
目录:
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战
js网路爬虫代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-06-11 08:02
网络爬虫工作原理: 在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部份组成。 控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。 解析器的主要工作是下载网页,进行页面的处理,主要是将一些js脚本标签、css代码内容、空格字符、html标签等内容处理掉,爬虫的基本工作是由解析器完成...
可将字符串导出,创建对象,用于快速抓取字符串中的符合条件的数据npm install cheerio -d 项目目录:node-pachong - index.js - package.json - node_modules 上代码:node-pachongindex.js** * 使用node.js做爬虫实战 * author:justbecoder * 引入须要的工具包const sp = require(superagent); const cheerio = ...
这样爬虫采集到的就是一堆标签加一点内容所混杂的脏数据,同时发觉标签中的值也是随时改变的。 所以此次也是花了一点时间来整理关于大众点评js加密的内容,给你们简单讲解一下,以此来学习借鉴怎样有效安全的防范爬虫。 仅供学习参考,切勿用于商业用途一、介绍首先随意打开大众点评网一家店,看到数据都是正常状态如...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
进入领域最想要的就是获取大量的数据来为自己的剖析提供支持,但是怎样获取互联网中的有效信息? 这就促使了“爬虫”技术的急速发展。 网络爬虫(又被称为网页蜘蛛网络爬虫+代码,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 传统爬虫从一个或若干初始...
但是若果这种数据不是以专用的 rest api 的方式出现,通常太无法编程方法对其进行访问。 使用 jsdom 之类的 node.js 工具,你可以直接从网页上抓取并解析这种数据,并用于你自己的项目和应用。 让我们以用 midi 音乐数据来训练神经网路来生成听起来精典的任天堂音乐【https:
作者:韦玮 转载请标明出处 随着大数据时代的到来,人们对数据资源的需求越来越多,而爬虫是一种挺好的手动采集数据的手段。 那么,如何能够精通python网络爬虫呢? 学习python网路爬虫的路线应当怎样进行呢? 在此为你们具体进行介绍。 1、选择一款合适的编程语言 事实上,python、php、java等常见的语言都可以用于...
预备知识学习者须要预先把握python的数字类型、字符串类型、分支、循环、函数、列表类型、字典类型、文件和第三方库使用等概念和编程技巧。 2. python爬虫基本流程? a. 发送恳求使用http库向目标站点发起恳求,即发送一个request网络爬虫+代码,request包含:请求头、请求体等。 request模块缺陷:不能执行js 和css 代码...
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。 此外爬虫还可以验证超链接和 html 代码,用于网路抓取。 本文我们将以爬取我的个人博客后端修仙之路已发布的博文为例,来实现一个简单的 node.js 爬虫。 在实际动手前,我们来看剖析一下,人为统计的流程:新建一个 ... 查看全部
网络爬虫工作原理: 在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部份组成。 控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。 解析器的主要工作是下载网页,进行页面的处理,主要是将一些js脚本标签、css代码内容、空格字符、html标签等内容处理掉,爬虫的基本工作是由解析器完成...
可将字符串导出,创建对象,用于快速抓取字符串中的符合条件的数据npm install cheerio -d 项目目录:node-pachong - index.js - package.json - node_modules 上代码:node-pachongindex.js** * 使用node.js做爬虫实战 * author:justbecoder * 引入须要的工具包const sp = require(superagent); const cheerio = ...
这样爬虫采集到的就是一堆标签加一点内容所混杂的脏数据,同时发觉标签中的值也是随时改变的。 所以此次也是花了一点时间来整理关于大众点评js加密的内容,给你们简单讲解一下,以此来学习借鉴怎样有效安全的防范爬虫。 仅供学习参考,切勿用于商业用途一、介绍首先随意打开大众点评网一家店,看到数据都是正常状态如...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
进入领域最想要的就是获取大量的数据来为自己的剖析提供支持,但是怎样获取互联网中的有效信息? 这就促使了“爬虫”技术的急速发展。 网络爬虫(又被称为网页蜘蛛网络爬虫+代码,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 传统爬虫从一个或若干初始...
但是若果这种数据不是以专用的 rest api 的方式出现,通常太无法编程方法对其进行访问。 使用 jsdom 之类的 node.js 工具,你可以直接从网页上抓取并解析这种数据,并用于你自己的项目和应用。 让我们以用 midi 音乐数据来训练神经网路来生成听起来精典的任天堂音乐【https:
作者:韦玮 转载请标明出处 随着大数据时代的到来,人们对数据资源的需求越来越多,而爬虫是一种挺好的手动采集数据的手段。 那么,如何能够精通python网络爬虫呢? 学习python网路爬虫的路线应当怎样进行呢? 在此为你们具体进行介绍。 1、选择一款合适的编程语言 事实上,python、php、java等常见的语言都可以用于...
预备知识学习者须要预先把握python的数字类型、字符串类型、分支、循环、函数、列表类型、字典类型、文件和第三方库使用等概念和编程技巧。 2. python爬虫基本流程? a. 发送恳求使用http库向目标站点发起恳求,即发送一个request网络爬虫+代码,request包含:请求头、请求体等。 request模块缺陷:不能执行js 和css 代码...
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。 此外爬虫还可以验证超链接和 html 代码,用于网路抓取。 本文我们将以爬取我的个人博客后端修仙之路已发布的博文为例,来实现一个简单的 node.js 爬虫。 在实际动手前,我们来看剖析一下,人为统计的流程:新建一个 ...
Python爬虫实战(1):爬取Drupal峰会贴子列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-06-09 10:24
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源 查看全部
/img/bVxTdG
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源
让你从零开始学会写爬虫的5个教程(Python)
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-06-09 08:02
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。 查看全部
写爬虫总是十分吸引IT学习者,毕竟光听上去就太拉风极客,我也晓得很多人学完基础知识以后python爬虫教程,第一个项目开发就是自己写一个爬虫玩儿。
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。
【苹果IP代理】 8大高效的Python爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2020-06-09 08:01
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。 查看全部
【苹果 IP 代理】8 大高效的 Python 爬虫框架,你用过几个? 【苹果 IP 代理】大数据时代下,数据采集推动着数据剖析, 数据剖析加快发展。但是在这个过程中会出现好多问题。拿最简 单最基础的爬虫采集数据为例,过程中还会面临,IP 被封,爬取 受限、违法操作等多种问题,所以在爬取数据之前,一定要了解 好预爬网站是否涉及违规操作,找到合适的代理 IP 访问网站等 一系列问题。今天我们就来讲讲这些高效的爬虫框架。 1.Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的 应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数 据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商 品信息之类的数据。 2.PySpider pyspider 是一个用 python 实现的功能强悍的网路爬虫系统, 能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实 时查看,后端使用常用的数据库进行爬取结果的储存,还能定时 设置任务与任务优先级等。 3.Crawley Crawley 可以高速爬取对应网站的内容,支持关系和非关系 数据库,数据可以导入为 JSON、XML 等。
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。
网络爬虫 | 开源软件 | OSCHINA
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-06-04 08:05
SimpleCD是哪些? 是山寨化VeryCD的全套工具,包括抓取脚本,网站代码等 谁须要使用SimpleCD? 想保存VeryCD链接资源者:别镜像VeryCD了,用这个吧。 想研究爬虫脚本和...
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、H...
收藏 962
更新于 2019/10/18
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newS...
收藏 1071
更新于 2017/07/31
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~ 示例代码:...
收藏 482
更新于 2020/03/05
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供网络爬虫软件,甚至要比一些商用软件的功能还要...
PySipder 是一个 Python 爬虫程序 演示地址: 使用 Python 编写脚本,提供强悍的 API Python 2&3 强大的 W...
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统...
Heritrix是一个开源,可扩充的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。其最出色之...
Grub Next Generation 是一个分布式的网页爬虫系统,包含客户端和服务器可以拿来维护网页的索引。
收藏 117
更新于 2011/05/26
Snoopy是一个强悍的网站内容采集器(爬虫)。提供获取网页内容,提交表单等功能。
已删掉源码
收藏 881
更新于 2016/09/26
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据...
NWebCrawler是一款开源的C#网路爬虫程序
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下: jspider [URL] [ConfigName] URL一定要加上合同名称,如:网络爬虫软件,否则会...
开源软件作者
RedisPlus 作者
ACTCMS 作者
静静的风
DBErp 作者
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。 示例代码: import java.util.ArrayList; im...
收藏 116
更新于 2017/11/28
爬虫软件MetaSeeker,现已全面升级为GooSeeker。 新版本早已发布,在线版免费下载和使用,源代码可阅读。自推出以来,深受喜爱,主要应用领域: 垂直搜索(Vertical Searc...
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。 登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。 该应用获取的数据可作为科研、...
Methanol 是一个模块化的可订制的网页爬虫软件,主要的优点是速度快。
没有更多内容
加载失败,请刷新页面
加载更多 查看全部
爬虫简介: WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Had...

SimpleCD是哪些? 是山寨化VeryCD的全套工具,包括抓取脚本,网站代码等 谁须要使用SimpleCD? 想保存VeryCD链接资源者:别镜像VeryCD了,用这个吧。 想研究爬虫脚本和...
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、H...
收藏 962
更新于 2019/10/18
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newS...
收藏 1071
更新于 2017/07/31
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~ 示例代码:...
收藏 482
更新于 2020/03/05
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供网络爬虫软件,甚至要比一些商用软件的功能还要...
PySipder 是一个 Python 爬虫程序 演示地址: 使用 Python 编写脚本,提供强悍的 API Python 2&3 强大的 W...
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统...
Heritrix是一个开源,可扩充的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。其最出色之...
Grub Next Generation 是一个分布式的网页爬虫系统,包含客户端和服务器可以拿来维护网页的索引。
收藏 117
更新于 2011/05/26
Snoopy是一个强悍的网站内容采集器(爬虫)。提供获取网页内容,提交表单等功能。
已删掉源码
收藏 881
更新于 2016/09/26
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据...
NWebCrawler是一款开源的C#网路爬虫程序
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下: jspider [URL] [ConfigName] URL一定要加上合同名称,如:网络爬虫软件,否则会...
开源软件作者

RedisPlus 作者

ACTCMS 作者

静静的风
DBErp 作者
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。 示例代码: import java.util.ArrayList; im...
收藏 116
更新于 2017/11/28
爬虫软件MetaSeeker,现已全面升级为GooSeeker。 新版本早已发布,在线版免费下载和使用,源代码可阅读。自推出以来,深受喜爱,主要应用领域: 垂直搜索(Vertical Searc...
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。 登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。 该应用获取的数据可作为科研、...
Methanol 是一个模块化的可订制的网页爬虫软件,主要的优点是速度快。
没有更多内容
加载失败,请刷新页面
加载更多
panfengzjz的博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-06-04 08:04
03-03
9259
python 爬取知乎某一关键字数据
python爬取知乎某一关键字数据序言和之前爬取Instagram数据一样,那位朋友还须要爬取知乎前面关于该影片的评论。没想到这是个坑洞啊。看起来很简单的一个事情就显得很复杂了。知乎假如说,有哪些事情是最坑的,我觉得就是在知乎前面讨论怎样抓取知乎的数据了。在2018年的时侯,知乎又进行了一次改版啊。真是一个坑洞。网上的代码几乎都不能使用了。只有这儿!的一篇文章还可以模拟登录一......
Someone&的博客
05-31
5069
输入关键字的爬虫方式(运行环境python3)
前段时间,写了爬虫,在新浪搜索主页面中,实现了输入关键词,爬取关键词相关的新闻的标题、发布时间、url、关键字及内容。并依据内容,提取了摘要和估算了相似度。下面简述自己的思路并将代码的githup链接给出:1、获取关键词新闻页面的url在新浪搜索主页,输入关键词,点击搜索后会手动链接到关键词的新闻界面,想要获取这个页面的url,有两种思路,本文提供三种方式。......
乐亦亦乐的博客
08-15
2901
python爬虫——校花网
爬取校花网图片校花网步入网站,我们会发觉许多图片,这些图片就是我们要爬取的内容。 2.对网页进行剖析,按F12打开开发着工具(本文使用谷歌浏览器)。我们发觉每位图片都对应着一个路径。 3.我们访问一下img标签的src路径。正是图片的路径,能够获取到图片。因此我们须要获取网页中img标签下所有的s......
一朵凋谢的菊花
03-05
386
Python定向爬虫——校园论坛贴子信息
写这个小爬虫主要是为了爬校园峰会上的实习信息,主要采用了Requests库
weixin_34268579的博客
12-17
4301
详解怎样用爬虫批量抓取百度搜索多个关键字数据
2019独角兽企业重金急聘Python工程师标准>>>...
weixin_33852020的博客
06-23
313
如何通过关键词匹配统计其出现的频度
最近写的一个perl程序,通过关键词匹配统计其出现的频度,让人感受到perl正则表达式的强悍,程序如下:#!/usr/bin/perluse strict;my (%hash,%hash1,@array);while(&lt;&gt;){s/\r\n//;my $line;if(/-(.+?)【(.+?)】【(.+?)】(定单积压)/...
W&J
02-10
9415
python 实现关键词提取
Python实现关键词提取这篇文章只介绍了Python中关键词提取的实现。关键词提取的几个方式:1.textrank2.tf-idf3.LDA,其中textrank和tf-idf在jieba中都有封装好的函数,调用上去非常简单方便。常用的自然语言处理的库还有nltk,gensim,sklearn中也有封装好的函数可以进行SVD分解和LDA等。LDA也有人分装好了库,直接pipinsta......
zzz1048506792的博客
08-08
992
python爬虫爬取政府网站关键字
**功能介绍**获取政府招标内容包含以下关键词,就提取该标书内容保存(本地文本)1,汽车采购2、汽车租赁3、公务车4、公务车租赁5、汽车合同供货6、汽车7、租赁爬取网站作者:speed_zombie版本信息:python v3.7.4运行......
最新陌陌小程序源码
panfengzjz的博客
01-01
442
PYTHON 实现 NBA 赛程查询工具(二)—— 网络爬虫
前言:第一篇博客,记录一下近来的一点点小成果。一切的学习都从兴趣开始。最近突然想学习一下pyqt和python的网路爬虫知识,于是就自己找了一个课题做了上去。因为我刚好是个 NBA歌迷,就想到了通过网路爬虫来抓取大赛结果,方便本地进行查找的项目。这个项目总共分为三步:1. 界面制做:选择对应的球员,显示球员图标和赛事结果2.网络爬虫:访问特定网页,查找赛季至......
微信小程序源码-合集1
panfengzjz的博客
05-25
4475
PYTHON 中 global 关键字的用法
之前写函数的时侯,由于传参实在太多,于是将某个字段定义为全局变量,在函数中直接使用。可是在使用过程中发觉会报错,原因是在另一个调用函数中,该全局变量的类型被更改了,那那边刚好彻底用几个事例来理清一下python中global关键字可以起到的作用。案例一:先说我见到的问题(并没有贴上源代码,下面的事例是自己具象出一个便捷你们理解的小case)程序大约就是这样#error ca......
panfengzjz的博客
04-29
1万+
利用OpenCV-python进行直线测量
最近须要借助摄像头对细小的偏斜做矫治,由于之前的界面工具是用PyQT所写,在当前的工具中加入摄像头矫治程序,也准备用python直接完成。OpenCV简介:Python处理图象有OpenCV库。OpenCV可以运行在Linux,windows,macOS上,由C函数和C++类构成,用于实现计算机图象、视频的编辑,应用于图象辨识、运动跟踪、机器视觉等领域。Open......
bensonrachel的博客
05-18
1728
python-简单爬虫及相关数据处理(统计出文章出现次数最多的50个词)
这次爬取了笑傲江湖这本小说;网站是:'#039;+str(696+i)+'.html'考虑到每一章的网址如上递增,所以使用一个循环来遍历网址进行爬取。然后找出文章的标签:如图:是&lt;p&gt;,&lt;/p&gt;所以:代码如下:然后爬取以后,存在文档里,进行处理。我用的是nlpir的动词系统:作了处理以后,把所有词存进一list上面。之......
glumpydog的专栏
05-14
5880
python 抓取天涯贴子内容并保存
手把手教你借助Python下载天涯热门贴子为txt文档 作者:大捷龙csdn : **剖析:天涯的贴子下载可以分为以下几个步骤自动传入一个贴子首页的地址打开文本提取贴子标题获取贴子的最大页数遍历每一页,获得每条回复的是否是楼主、作者爱称、回复时间。写入看文本关掉文本预备:Python的文件操作: 一、...
cjy1041403539的博客
04-14
1961
python微博爬虫——使用selenium爬取关键词下超话内容
最近微博手机端的页面发生了些微的变化,导致了我之前的两篇文章微博任意关键词爬虫——使用selenium模拟浏览器和来!用python爬一爬“不知知网翟博士”的微博超话中的代码出现了一些报错情况,这里来更改一下欢迎关注公众号:老白和他的爬虫1.微博手机端出现的变化爬取手机端的微博益处在于能否爬取比网页端更多的数据,因为网页端微博内容通常限定在50页,数据量不够大,所以选择爬取手机端,这样可......
scx2006114的博客
08-03
5441
python爬虫之爬取简书中的小文章标题
学习了三个星期的python基础句型,对python句型有了一个基本的了解,然后想继续深入学习,但不喜欢每晚啃书本,太无趣了,只有实战才是练兵的最好疗效。听说爬虫技术还是比较好玩的,就搞爬虫,但找了很多资料没有找到合适的资料,最后才找到传说中的合适爬虫初学者的书籍《Python3网络爬虫开发实战,崔庆才著》(文末附书本下载链接),学习了一天,终于完整搞出了自己的第一爬虫,哈哈~。......
zhyh1435589631的专栏
05-03
8951
python 爬虫实战 抓取中学bbs相关蓝筹股的回帖信息
1. 前言之前也由于感兴趣, 写过一个抓取桌面天空上面喜欢的动画墙纸的爬虫代码。这三天忽然听到有人写了那么一篇文章: 爬取易迅本周热销商品基本信息存入MySQL 感觉挺有趣的, 正好临近找工作的季节, 就想着能不能写个爬虫, 把俺们中学bbs前面相关的蓝筹股上面的回帖信息给记录出来。2. 项目剖析首先我们打开我们的目标网页 结...
jiangfullll的专栏
05-08
1991
python爬虫 根据关键字在新浪网站查询跟关键字有关的新闻条数(按照时间查询)
# -*- coding: utf-8 -*-"""Created on Thu May 8 09:14:13 2014@author: lifeix"""import urllib2import refrom datetime import datetimedef craw1(keyword_name, startYear): a = keyword_name
c350577169的博客
05-22
3万+
python爬虫--如何爬取翻页url不变的网站
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整个网页的情况下,对网页的某部份进行更新。这样的设置无疑给早期爬虫菜鸟制造了一些困难。1、什么是ajax几个常见的用到ajax的场景。比如你在逛知乎,你没有刷新过网页,但是你却能看到你关注的用户或则话题......
iteye_17286的博客
11-20
1071
如何从文件中检索关键字出现的次数
首先得到文件的完整路径,然后从流中读取每位字符,如果读出的字符和关键字的第一个字符相同,则根据关键字宽度读取相同个数的字符,分别判定是否相同,若有一个不相同则break,否则计数器count++,最后count的个数即是关键字在文件中出下的次数......
weixin_34237596的博客
05-16
280
[Python爬虫]新闻网页爬虫+jieba分词+关键词搜索排序
前言近来做了一个python3作业题目,涉及到:网页爬虫网页英文文字提取构建文字索引关键词搜索涉及到的库有:爬虫库:requests解析库:xpath正则:re分词库:jieba...放出代码便捷你们快速参考,实现一个小demo。题目描述搜索引擎的设计与实现输入:腾讯体育的页面链接,以列表的形式作为输入,数量不定,例如:["
纯洁的笑容
03-04
14万+
和黑客斗争的 6 天!
互联网公司工作爬虫论坛,很难避开不和黑客们打交道,我呆过的两家互联网公司,几乎每月每晚每分钟都有黑客在公司网站上扫描。有的是找寻 Sql 注入的缺口爬虫论坛,有的是找寻线上服务器可能存在的漏洞,大部分都...
Blessy_Zhu的博客
03-20
1万+
Python爬虫之陌陌数据爬取(十三)
原创不易,转载前请标明博主的链接地址:Blessy_Zhu本次代码的环境:运行平台:WindowsPython版本:Python3.xIDE:PyCharm一、前言陌陌作为我们日常交流的软件,越来越深入到我们的生活。但是,随着陌陌好的数目的降低,实际上真正可以联系的知心人却越来越少了。那么,怎么样能更清......
07-26
2万+
使用网页爬虫(高级搜索功能)搜集含关键词新浪微博数据
作为国外社交媒体的领航者,很遗憾,新浪微博没有提供以“关键字+时间+区域”方式获取的官方API。当我们听到美国科研成果都是基于某关键字获得的微博,心中不免凉了一大截,或者转战脸书。再次建议微博能更开放些!庆幸的是,新浪提供了中级搜索功能。找不到?这个功能须要用户登入能够使用……没关系,下面将详尽述说怎样在无须登陆的情况下,获取“关键字+时间+区域”的新浪微博。...
路人甲Java
03-25
9万+
面试阿里p7,被按在地上磨擦,鬼晓得我经历了哪些?
面试阿里p7被问到的问题(当时我只晓得第一个):@Conditional是做哪些的?@Conditional多个条件是哪些逻辑关系?条件判定在什么时候执... 查看全部
ANONYMOUSLYCN的专栏
03-03

9259
python 爬取知乎某一关键字数据
python爬取知乎某一关键字数据序言和之前爬取Instagram数据一样,那位朋友还须要爬取知乎前面关于该影片的评论。没想到这是个坑洞啊。看起来很简单的一个事情就显得很复杂了。知乎假如说,有哪些事情是最坑的,我觉得就是在知乎前面讨论怎样抓取知乎的数据了。在2018年的时侯,知乎又进行了一次改版啊。真是一个坑洞。网上的代码几乎都不能使用了。只有这儿!的一篇文章还可以模拟登录一......
Someone&的博客
05-31
5069
输入关键字的爬虫方式(运行环境python3)
前段时间,写了爬虫,在新浪搜索主页面中,实现了输入关键词,爬取关键词相关的新闻的标题、发布时间、url、关键字及内容。并依据内容,提取了摘要和估算了相似度。下面简述自己的思路并将代码的githup链接给出:1、获取关键词新闻页面的url在新浪搜索主页,输入关键词,点击搜索后会手动链接到关键词的新闻界面,想要获取这个页面的url,有两种思路,本文提供三种方式。......
乐亦亦乐的博客
08-15
2901
python爬虫——校花网
爬取校花网图片校花网步入网站,我们会发觉许多图片,这些图片就是我们要爬取的内容。 2.对网页进行剖析,按F12打开开发着工具(本文使用谷歌浏览器)。我们发觉每位图片都对应着一个路径。 3.我们访问一下img标签的src路径。正是图片的路径,能够获取到图片。因此我们须要获取网页中img标签下所有的s......
一朵凋谢的菊花
03-05
386
Python定向爬虫——校园论坛贴子信息
写这个小爬虫主要是为了爬校园峰会上的实习信息,主要采用了Requests库
weixin_34268579的博客
12-17
4301
详解怎样用爬虫批量抓取百度搜索多个关键字数据
2019独角兽企业重金急聘Python工程师标准>>>...
weixin_33852020的博客
06-23
313
如何通过关键词匹配统计其出现的频度
最近写的一个perl程序,通过关键词匹配统计其出现的频度,让人感受到perl正则表达式的强悍,程序如下:#!/usr/bin/perluse strict;my (%hash,%hash1,@array);while(&lt;&gt;){s/\r\n//;my $line;if(/-(.+?)【(.+?)】【(.+?)】(定单积压)/...
W&J
02-10
9415
python 实现关键词提取
Python实现关键词提取这篇文章只介绍了Python中关键词提取的实现。关键词提取的几个方式:1.textrank2.tf-idf3.LDA,其中textrank和tf-idf在jieba中都有封装好的函数,调用上去非常简单方便。常用的自然语言处理的库还有nltk,gensim,sklearn中也有封装好的函数可以进行SVD分解和LDA等。LDA也有人分装好了库,直接pipinsta......
zzz1048506792的博客
08-08
992
python爬虫爬取政府网站关键字
**功能介绍**获取政府招标内容包含以下关键词,就提取该标书内容保存(本地文本)1,汽车采购2、汽车租赁3、公务车4、公务车租赁5、汽车合同供货6、汽车7、租赁爬取网站作者:speed_zombie版本信息:python v3.7.4运行......
最新陌陌小程序源码
panfengzjz的博客
01-01
442
PYTHON 实现 NBA 赛程查询工具(二)—— 网络爬虫
前言:第一篇博客,记录一下近来的一点点小成果。一切的学习都从兴趣开始。最近突然想学习一下pyqt和python的网路爬虫知识,于是就自己找了一个课题做了上去。因为我刚好是个 NBA歌迷,就想到了通过网路爬虫来抓取大赛结果,方便本地进行查找的项目。这个项目总共分为三步:1. 界面制做:选择对应的球员,显示球员图标和赛事结果2.网络爬虫:访问特定网页,查找赛季至......
微信小程序源码-合集1
panfengzjz的博客
05-25
4475
PYTHON 中 global 关键字的用法
之前写函数的时侯,由于传参实在太多,于是将某个字段定义为全局变量,在函数中直接使用。可是在使用过程中发觉会报错,原因是在另一个调用函数中,该全局变量的类型被更改了,那那边刚好彻底用几个事例来理清一下python中global关键字可以起到的作用。案例一:先说我见到的问题(并没有贴上源代码,下面的事例是自己具象出一个便捷你们理解的小case)程序大约就是这样#error ca......
panfengzjz的博客
04-29
1万+
利用OpenCV-python进行直线测量
最近须要借助摄像头对细小的偏斜做矫治,由于之前的界面工具是用PyQT所写,在当前的工具中加入摄像头矫治程序,也准备用python直接完成。OpenCV简介:Python处理图象有OpenCV库。OpenCV可以运行在Linux,windows,macOS上,由C函数和C++类构成,用于实现计算机图象、视频的编辑,应用于图象辨识、运动跟踪、机器视觉等领域。Open......
bensonrachel的博客
05-18
1728
python-简单爬虫及相关数据处理(统计出文章出现次数最多的50个词)
这次爬取了笑傲江湖这本小说;网站是:'#039;+str(696+i)+'.html'考虑到每一章的网址如上递增,所以使用一个循环来遍历网址进行爬取。然后找出文章的标签:如图:是&lt;p&gt;,&lt;/p&gt;所以:代码如下:然后爬取以后,存在文档里,进行处理。我用的是nlpir的动词系统:作了处理以后,把所有词存进一list上面。之......
glumpydog的专栏
05-14
5880
python 抓取天涯贴子内容并保存
手把手教你借助Python下载天涯热门贴子为txt文档 作者:大捷龙csdn : **剖析:天涯的贴子下载可以分为以下几个步骤自动传入一个贴子首页的地址打开文本提取贴子标题获取贴子的最大页数遍历每一页,获得每条回复的是否是楼主、作者爱称、回复时间。写入看文本关掉文本预备:Python的文件操作: 一、...
cjy1041403539的博客
04-14
1961
python微博爬虫——使用selenium爬取关键词下超话内容
最近微博手机端的页面发生了些微的变化,导致了我之前的两篇文章微博任意关键词爬虫——使用selenium模拟浏览器和来!用python爬一爬“不知知网翟博士”的微博超话中的代码出现了一些报错情况,这里来更改一下欢迎关注公众号:老白和他的爬虫1.微博手机端出现的变化爬取手机端的微博益处在于能否爬取比网页端更多的数据,因为网页端微博内容通常限定在50页,数据量不够大,所以选择爬取手机端,这样可......
scx2006114的博客
08-03
5441
python爬虫之爬取简书中的小文章标题
学习了三个星期的python基础句型,对python句型有了一个基本的了解,然后想继续深入学习,但不喜欢每晚啃书本,太无趣了,只有实战才是练兵的最好疗效。听说爬虫技术还是比较好玩的,就搞爬虫,但找了很多资料没有找到合适的资料,最后才找到传说中的合适爬虫初学者的书籍《Python3网络爬虫开发实战,崔庆才著》(文末附书本下载链接),学习了一天,终于完整搞出了自己的第一爬虫,哈哈~。......
zhyh1435589631的专栏
05-03
8951
python 爬虫实战 抓取中学bbs相关蓝筹股的回帖信息
1. 前言之前也由于感兴趣, 写过一个抓取桌面天空上面喜欢的动画墙纸的爬虫代码。这三天忽然听到有人写了那么一篇文章: 爬取易迅本周热销商品基本信息存入MySQL 感觉挺有趣的, 正好临近找工作的季节, 就想着能不能写个爬虫, 把俺们中学bbs前面相关的蓝筹股上面的回帖信息给记录出来。2. 项目剖析首先我们打开我们的目标网页 结...
jiangfullll的专栏
05-08
1991
python爬虫 根据关键字在新浪网站查询跟关键字有关的新闻条数(按照时间查询)
# -*- coding: utf-8 -*-"""Created on Thu May 8 09:14:13 2014@author: lifeix"""import urllib2import refrom datetime import datetimedef craw1(keyword_name, startYear): a = keyword_name
c350577169的博客
05-22
3万+
python爬虫--如何爬取翻页url不变的网站
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整个网页的情况下,对网页的某部份进行更新。这样的设置无疑给早期爬虫菜鸟制造了一些困难。1、什么是ajax几个常见的用到ajax的场景。比如你在逛知乎,你没有刷新过网页,但是你却能看到你关注的用户或则话题......
iteye_17286的博客
11-20
1071
如何从文件中检索关键字出现的次数
首先得到文件的完整路径,然后从流中读取每位字符,如果读出的字符和关键字的第一个字符相同,则根据关键字宽度读取相同个数的字符,分别判定是否相同,若有一个不相同则break,否则计数器count++,最后count的个数即是关键字在文件中出下的次数......
weixin_34237596的博客
05-16
280
[Python爬虫]新闻网页爬虫+jieba分词+关键词搜索排序
前言近来做了一个python3作业题目,涉及到:网页爬虫网页英文文字提取构建文字索引关键词搜索涉及到的库有:爬虫库:requests解析库:xpath正则:re分词库:jieba...放出代码便捷你们快速参考,实现一个小demo。题目描述搜索引擎的设计与实现输入:腾讯体育的页面链接,以列表的形式作为输入,数量不定,例如:["
纯洁的笑容
03-04
14万+
和黑客斗争的 6 天!
互联网公司工作爬虫论坛,很难避开不和黑客们打交道,我呆过的两家互联网公司,几乎每月每晚每分钟都有黑客在公司网站上扫描。有的是找寻 Sql 注入的缺口爬虫论坛,有的是找寻线上服务器可能存在的漏洞,大部分都...
Blessy_Zhu的博客
03-20
1万+
Python爬虫之陌陌数据爬取(十三)
原创不易,转载前请标明博主的链接地址:Blessy_Zhu本次代码的环境:运行平台:WindowsPython版本:Python3.xIDE:PyCharm一、前言陌陌作为我们日常交流的软件,越来越深入到我们的生活。但是,随着陌陌好的数目的降低,实际上真正可以联系的知心人却越来越少了。那么,怎么样能更清......
07-26
2万+
使用网页爬虫(高级搜索功能)搜集含关键词新浪微博数据
作为国外社交媒体的领航者,很遗憾,新浪微博没有提供以“关键字+时间+区域”方式获取的官方API。当我们听到美国科研成果都是基于某关键字获得的微博,心中不免凉了一大截,或者转战脸书。再次建议微博能更开放些!庆幸的是,新浪提供了中级搜索功能。找不到?这个功能须要用户登入能够使用……没关系,下面将详尽述说怎样在无须登陆的情况下,获取“关键字+时间+区域”的新浪微博。...
路人甲Java
03-25
9万+
面试阿里p7,被按在地上磨擦,鬼晓得我经历了哪些?
面试阿里p7被问到的问题(当时我只晓得第一个):@Conditional是做哪些的?@Conditional多个条件是哪些逻辑关系?条件判定在什么时候执...
PHP用户数据爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-06-02 08:02
广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!
代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...
一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...
通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...
每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...
爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...
但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...
总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...
当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...
在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...
什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...
pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少... 查看全部


广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!

代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...

一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...

通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...

每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...

爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...

但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...

总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...

当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...

- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...

请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...

在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...

什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...

- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...

pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少...
最详尽爬虫入门教程!花半小时你应当能够去爬一些小东西了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-02 08:01
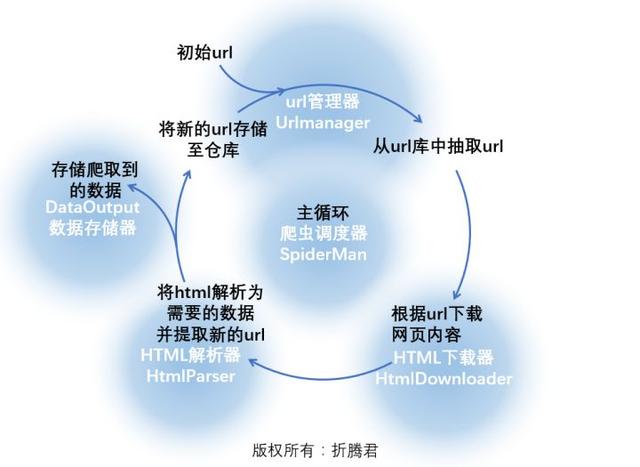
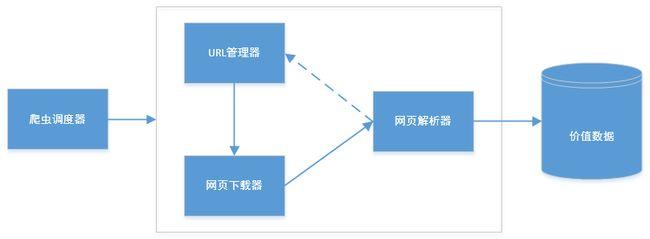
爬虫对目标网页爬取的过程可以参考下边红色文字部份:
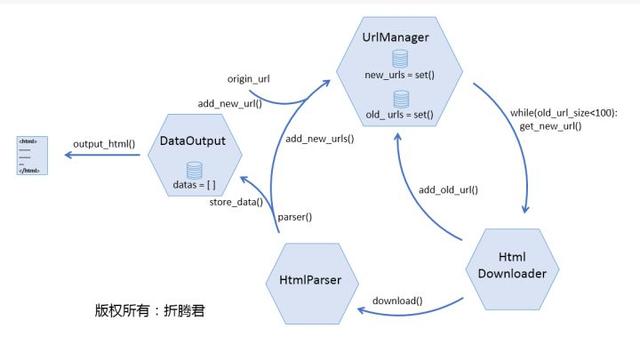
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:
爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:
存储器、下载器、解析器和url管理器!
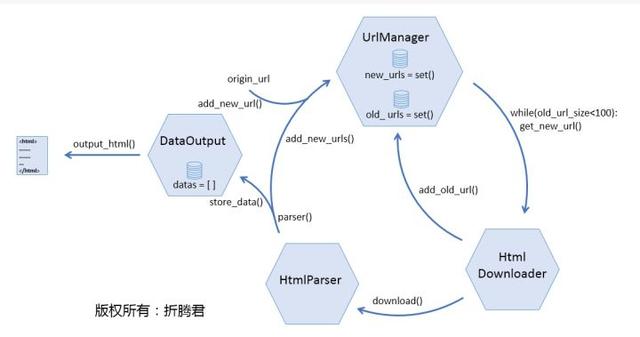
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?
下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():
在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF! 查看全部


爬虫对目标网页爬取的过程可以参考下边红色文字部份:
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:

爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:

存储器、下载器、解析器和url管理器!
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?


下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():

在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF!
“百行代码”实现简单的Python分布式爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2020-06-02 08:00
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
============================================================== 查看全部
本篇文章属于进阶知识,可能会用到曾经出现在专栏文章中的知识,如果你是第一次关注本专栏,建议你先阅读下其他文章:查询--爬虫(计算机网路)
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
==============================================================
Python爬虫介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-06-02 08:00
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。
Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。 查看全部
随着互联网的高速发展python 爬虫,大数据时代早已将至,网络爬虫这个名词也被人们越来越多的提起,但相信很多人对网路爬虫并不是太了解,下面就让小编给你们介绍一下哪些是网络爬虫?网络爬虫有哪些作用呢?
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。

Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。
网络爬虫简介(5)— 链接爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-05-31 08:01
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫! 查看全部
1.5.5 链接爬虫
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫!
3款你必须晓得的爬虫工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-05-31 08:01
微信公众号:Python数据科学
知乎:
本篇博主将和你们分享几个特别有用的爬虫小工具,这些小工具在实际的爬虫的开发中会大大降低你的时间成本,并同时提升你的工作效率,真的是十分实用的工具。
这些工具当然是Google上的插件,一些扩充程序,并且经博主亲测,无任何问题。最后的最后,博主将提供小工具的获取方法。
好了,话不多说,我们来介绍一下。
我们上面提及过,当客户端向服务器端提出<ajax>异步恳求(比如 <xhr>)时,会在响应里返回 <json> 格式的数据。
在开发者工具中,我们会听到 <json> 格式数据的可视化疗效太差,就是一段繁杂的字符串,难以直接看出关键信息。
那么为了直接有效的找到关键信息,<JSON-handle>工具会将纷繁的 <json> 格式数据弄成简单清晰的树形图,极大的提升可视化疗效。
方法很简单,如果你已然安装好了小工具,点开图标弹出框框,把<json>数据复制进去即可。
当然,你也可以把从任意地方用来的<json>数据放进去,不局限于浏览器异步响应。
就以<天猫网站>为例,随便找出一个异步的恳求,response是下边这样的。
jsonp_46336857({"201509290":{"data":[{"_pos_":1,"entityType":"13","acm":"201509290.1003.1.1286473","title":"【抢券减400】Apple/苹果iPhone X 全网通4G智能手机苹果10 苹果X","typ.......
把代码放进框框里,点击OK,就弄成下边这样了数(据比较长,只截取一部分)。
上篇剖析爬虫中HTTP的秘密(基础篇)我们介绍了恳求头,而这个工具就是针对恳求头中的User-Agent数组的。它的作用是可以随便更换浏览器的User-Agent。
比如,你用Chrome浏览器浏览网页,浏览器默认身分是Chrome,但是你可以通过这个工具更换成其它任何身分。
这个最大的益处就是可以直接更换成手机身分浏览网页,而毋须用开发者工具来回切换。
使用Chrome浏览器安装插件爬虫工具,点开图标,选择你须要的身分即可。
(默认Chrome浏览器是这样的)
(变换为IOS-iphone6)
针对Xpath解析方式,Xpath-Helper可提供当前网页指定Xpath句子的查询结果。
点开图标,出现白色框框。
1.假设目标为二维码下的<百度>二字
2.开发者工具找到源码相应位置,右键copy xpath
3.复制到QUERY上面,结果手动下来
注:Xpath-Helper小工具安装后须要重启Chrome方可使用爬虫工具,请你们注意一下这个坑。
下载Chrome浏览器下载小工具插件打开Chrome更多工具—>扩展程序拖动小工具插件程序<.crx>到扩充程序里安装
安装完成后,右上角会有三个小图标: 查看全部
作者:xiaoyu
微信公众号:Python数据科学
知乎:
本篇博主将和你们分享几个特别有用的爬虫小工具,这些小工具在实际的爬虫的开发中会大大降低你的时间成本,并同时提升你的工作效率,真的是十分实用的工具。
这些工具当然是Google上的插件,一些扩充程序,并且经博主亲测,无任何问题。最后的最后,博主将提供小工具的获取方法。

好了,话不多说,我们来介绍一下。
我们上面提及过,当客户端向服务器端提出<ajax>异步恳求(比如 <xhr>)时,会在响应里返回 <json> 格式的数据。
在开发者工具中,我们会听到 <json> 格式数据的可视化疗效太差,就是一段繁杂的字符串,难以直接看出关键信息。
那么为了直接有效的找到关键信息,<JSON-handle>工具会将纷繁的 <json> 格式数据弄成简单清晰的树形图,极大的提升可视化疗效。
方法很简单,如果你已然安装好了小工具,点开图标弹出框框,把<json>数据复制进去即可。

当然,你也可以把从任意地方用来的<json>数据放进去,不局限于浏览器异步响应。
就以<天猫网站>为例,随便找出一个异步的恳求,response是下边这样的。
jsonp_46336857({"201509290":{"data":[{"_pos_":1,"entityType":"13","acm":"201509290.1003.1.1286473","title":"【抢券减400】Apple/苹果iPhone X 全网通4G智能手机苹果10 苹果X","typ.......
把代码放进框框里,点击OK,就弄成下边这样了数(据比较长,只截取一部分)。

上篇剖析爬虫中HTTP的秘密(基础篇)我们介绍了恳求头,而这个工具就是针对恳求头中的User-Agent数组的。它的作用是可以随便更换浏览器的User-Agent。
比如,你用Chrome浏览器浏览网页,浏览器默认身分是Chrome,但是你可以通过这个工具更换成其它任何身分。
这个最大的益处就是可以直接更换成手机身分浏览网页,而毋须用开发者工具来回切换。
使用Chrome浏览器安装插件爬虫工具,点开图标,选择你须要的身分即可。

(默认Chrome浏览器是这样的)


(变换为IOS-iphone6)


针对Xpath解析方式,Xpath-Helper可提供当前网页指定Xpath句子的查询结果。
点开图标,出现白色框框。

1.假设目标为二维码下的<百度>二字

2.开发者工具找到源码相应位置,右键copy xpath

3.复制到QUERY上面,结果手动下来

注:Xpath-Helper小工具安装后须要重启Chrome方可使用爬虫工具,请你们注意一下这个坑。
下载Chrome浏览器下载小工具插件打开Chrome更多工具—>扩展程序拖动小工具插件程序<.crx>到扩充程序里安装
安装完成后,右上角会有三个小图标:
Python爬虫-爬取公司邮箱内的职工手机号码
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-05-31 08:00
前段时间接到一个业务人员的一个爬虫需求,爬取公司内部邮箱的通讯录,获取所有用户的手机号码,为业务的推广构建相应的白名单。
首先我们公司的邮箱是outlook的邮箱,只有登陆了邮箱就能够看见全公司的通讯录,因为人数比较多(近百万的职工),首先看一下具体的邮箱联系人员列表:
目录中列举的是子公司的名称,点击子公司后,后列举子公司的人员名单,再点击人员的时侯就会下来具体的手机号码及相关信息。
首先这个需求是须要不断的点击相应的条目就会下来相应的用户的手机号码的,但是这个人员的页面人数好多,也没有相应的分页标志邮箱爬虫软件,只是有一个滚动条可以上下的带动,里面的内容好多,至少是几万吧,所以就须要不断的点击人员信息。
之前也曾想过用普通的爬虫工具进行爬取,但是人员的那种也没有找到显著的规律性,不能直接通过简单的遍历才能够直接的获取相应的数据,另外数据的加载也是通过相应JavaScript脚本和ajax实现的,所以这个方式 我暂时没有想到比较好的解决办法(ps:大神假如有更好的解决办法请赐教。)
通过查阅相应的爬虫工具库,终于找到了一个自动化测试的python库(selenium库),这个库有一个用处就是可以模拟人类一样不断的点击滑鼠,获取相应的内容,通过模拟人类的相应操作才能够直接的获取相应的内容,至于具体的用法请自行百度(因为这个一个模拟浏览器在不断的点击,所有还须要下载相应的浏览器驱动)。
不多说,直接上代码是最实在的!!!
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 30 21:18:12 2018
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import WebDriverException
import time
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)
def login_outlook():
# 模仿浏览器进行登录操作
#需要爬去邮箱的地址
browser.get('--------------------------')
username = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#username')))
passwd = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#password')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#lgnDiv > div.signInEnter > div > span')))
#邮箱的用户名
username.send_keys('username')
#邮箱登录密码
passwd.send_keys('password')
submit.click()
def main():
# 登录
login_outlook()
time.sleep(5)
# 点击人员选项
submit_renyuan = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#_ariaId_19')))
submit_renyuan.click()
# 点击所有用户
submit_allyonghu = wait.until(
EC.element_to_be_clickable((By.XPATH,'//*[@id="_ariaId_452"]/div[1]/div[2]/div/div[2]/span')))
submit_allyonghu.click()
#遍历所有的用户
result =[]
# select_header ='''body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(1) > div._ph_j1 > div:nth-child(1) > div > div > div._ph_V1.customScrollBar.scrollContainer > div > div > div:nth-child('''
# select_tail =''') > span > div > span._pe_b._pe_s > span'''
Xpath_head = '''/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[1]/div[2]/div[1]/div/div/div[1]/div/div/div['''
Xpath_tail = ''']/span/div/span[3]/span'''
wait1 = WebDriverWait(browser,2)
#这里的10000是人为设定的,因为不知道这个页面上面具体有多少用户
for j in range(1,10000):
print(j)
for i in range(1,71):
print(i)
Xpath = Xpath_head + str(i) + Xpath_tail
print(Xpath)
try:
submit_ren = wait1.until(
EC.element_to_be_clickable((By.XPATH,Xpath)))
submit_ren.click()
except(NoSuchElementException,TimeoutException,WebDriverException):
print("连接超时")
continue
time.sleep(0.18)
# result.append(wait.until(
# EC.element_to_be_clickable((By.CSS_SELECTOR,'body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(4) > div:nth-child(2) > div > div:nth-child(3) > div._rpc_s > div:nth-child(1) > div > div > div:nth-child(1) > div > div > div'))))
#获取到相应的手机号码文本
rr=browser.find_element_by_xpath("/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[4]/div[2]/div/div[3]/div[4]/div[1]/div/div/div[1]/div/div/div")
saveFile = open('telno.txt','a')
saveFile.write(str(rr.text.replace("\n","|")))
saveFile.write("\n")
saveFile.close()
time.sleep(1)
if __name__ == '__main__':
main()
通过整个的爬取过程,发现这个爬虫程序有如下的不足:
(1)、虽然还能抓取到相应用户的手机号码,但是号码不一定全,其中有一个人为设定的10000,这个是非常不合理的地方,因为不知道具体有多少用户,所以就设定一个比较大的数字,但是这些做法非常不妥当;
(2)、在抓取的时侯发觉,模拟点击这员的时侯并不是挨个进行点击的,有跳动的现象,所以这也是爬取不全的缘由之一,之所以出现此类情况,还是由于对页面的加载方法和具体的数据加载方法不了解,为找到相应的规律(求高手赐教);
(3)爬取的成功与否还与服务器响应时间有很大的关系,检查保存的文件发觉有空行,这样的现象有两个缘由,一个是这个用户就没有相应的手机号码(这种现象确实存在,但是数目非常少),另一方面缘由就是服务器的响应时间比较慢,服务器还未返回对应用户的手机号,程序就开始点击下一个用户了;
(4)注意在每次模拟点击的时侯最好使程序沉睡一会(即代码中的 time.sleep( )),这样做一方面是为了等待服务器的相应,另一方也是为了模拟人类,因为点击很快的话,会被辨识的功击,会短时间的封锁你的ip地址的。
最后一点,随着这个爬虫还能爬取到用户的手机号码邮箱爬虫软件,但是存在众多的问题须要解决,最后爬取的手机号码也不是最全的,所以这个爬虫程序还是有很大的提高空间的。(这个前面我就会不断的改进的)。 查看全部

前段时间接到一个业务人员的一个爬虫需求,爬取公司内部邮箱的通讯录,获取所有用户的手机号码,为业务的推广构建相应的白名单。
首先我们公司的邮箱是outlook的邮箱,只有登陆了邮箱就能够看见全公司的通讯录,因为人数比较多(近百万的职工),首先看一下具体的邮箱联系人员列表:

目录中列举的是子公司的名称,点击子公司后,后列举子公司的人员名单,再点击人员的时侯就会下来具体的手机号码及相关信息。
首先这个需求是须要不断的点击相应的条目就会下来相应的用户的手机号码的,但是这个人员的页面人数好多,也没有相应的分页标志邮箱爬虫软件,只是有一个滚动条可以上下的带动,里面的内容好多,至少是几万吧,所以就须要不断的点击人员信息。
之前也曾想过用普通的爬虫工具进行爬取,但是人员的那种也没有找到显著的规律性,不能直接通过简单的遍历才能够直接的获取相应的数据,另外数据的加载也是通过相应JavaScript脚本和ajax实现的,所以这个方式 我暂时没有想到比较好的解决办法(ps:大神假如有更好的解决办法请赐教。)
通过查阅相应的爬虫工具库,终于找到了一个自动化测试的python库(selenium库),这个库有一个用处就是可以模拟人类一样不断的点击滑鼠,获取相应的内容,通过模拟人类的相应操作才能够直接的获取相应的内容,至于具体的用法请自行百度(因为这个一个模拟浏览器在不断的点击,所有还须要下载相应的浏览器驱动)。
不多说,直接上代码是最实在的!!!
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 30 21:18:12 2018
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import WebDriverException
import time
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)
def login_outlook():
# 模仿浏览器进行登录操作
#需要爬去邮箱的地址
browser.get('--------------------------')
username = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#username')))
passwd = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#password')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#lgnDiv > div.signInEnter > div > span')))
#邮箱的用户名
username.send_keys('username')
#邮箱登录密码
passwd.send_keys('password')
submit.click()
def main():
# 登录
login_outlook()
time.sleep(5)
# 点击人员选项
submit_renyuan = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#_ariaId_19')))
submit_renyuan.click()
# 点击所有用户
submit_allyonghu = wait.until(
EC.element_to_be_clickable((By.XPATH,'//*[@id="_ariaId_452"]/div[1]/div[2]/div/div[2]/span')))
submit_allyonghu.click()
#遍历所有的用户
result =[]
# select_header ='''body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(1) > div._ph_j1 > div:nth-child(1) > div > div > div._ph_V1.customScrollBar.scrollContainer > div > div > div:nth-child('''
# select_tail =''') > span > div > span._pe_b._pe_s > span'''
Xpath_head = '''/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[1]/div[2]/div[1]/div/div/div[1]/div/div/div['''
Xpath_tail = ''']/span/div/span[3]/span'''
wait1 = WebDriverWait(browser,2)
#这里的10000是人为设定的,因为不知道这个页面上面具体有多少用户
for j in range(1,10000):
print(j)
for i in range(1,71):
print(i)
Xpath = Xpath_head + str(i) + Xpath_tail
print(Xpath)
try:
submit_ren = wait1.until(
EC.element_to_be_clickable((By.XPATH,Xpath)))
submit_ren.click()
except(NoSuchElementException,TimeoutException,WebDriverException):
print("连接超时")
continue
time.sleep(0.18)
# result.append(wait.until(
# EC.element_to_be_clickable((By.CSS_SELECTOR,'body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(4) > div:nth-child(2) > div > div:nth-child(3) > div._rpc_s > div:nth-child(1) > div > div > div:nth-child(1) > div > div > div'))))
#获取到相应的手机号码文本
rr=browser.find_element_by_xpath("/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[4]/div[2]/div/div[3]/div[4]/div[1]/div/div/div[1]/div/div/div")
saveFile = open('telno.txt','a')
saveFile.write(str(rr.text.replace("\n","|")))
saveFile.write("\n")
saveFile.close()
time.sleep(1)
if __name__ == '__main__':
main()
通过整个的爬取过程,发现这个爬虫程序有如下的不足:
(1)、虽然还能抓取到相应用户的手机号码,但是号码不一定全,其中有一个人为设定的10000,这个是非常不合理的地方,因为不知道具体有多少用户,所以就设定一个比较大的数字,但是这些做法非常不妥当;
(2)、在抓取的时侯发觉,模拟点击这员的时侯并不是挨个进行点击的,有跳动的现象,所以这也是爬取不全的缘由之一,之所以出现此类情况,还是由于对页面的加载方法和具体的数据加载方法不了解,为找到相应的规律(求高手赐教);
(3)爬取的成功与否还与服务器响应时间有很大的关系,检查保存的文件发觉有空行,这样的现象有两个缘由,一个是这个用户就没有相应的手机号码(这种现象确实存在,但是数目非常少),另一方面缘由就是服务器的响应时间比较慢,服务器还未返回对应用户的手机号,程序就开始点击下一个用户了;
(4)注意在每次模拟点击的时侯最好使程序沉睡一会(即代码中的 time.sleep( )),这样做一方面是为了等待服务器的相应,另一方也是为了模拟人类,因为点击很快的话,会被辨识的功击,会短时间的封锁你的ip地址的。
最后一点,随着这个爬虫还能爬取到用户的手机号码邮箱爬虫软件,但是存在众多的问题须要解决,最后爬取的手机号码也不是最全的,所以这个爬虫程序还是有很大的提高空间的。(这个前面我就会不断的改进的)。
Python爬虫入门看哪些书好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-05-30 08:02
这本书是一本实战性的网路爬虫秘籍,在本书中除了讲解了怎样编撰爬虫,还讲解了流行的网路爬虫的使用。而且这本色书的作者在Python领域有着极其深厚的积累,不仅精通Python网络爬虫,而且在Python机器学习等领域都有着丰富的实战经验,所以说这本书是Python爬虫入门人员必备的书籍。
这本书总共从三个维度讲解了Python爬虫入门,分别是:
技术维度:详细讲解了Python网路爬虫实现的核心技术,包括网路爬虫的工作原理、如何用urllib库编撰网路爬虫、爬虫的异常处理、正则表达式、爬虫中Cookie的使用、爬虫的浏览器伪装技术、定向爬取技术、反爬虫技术,以及怎样自己动手编撰网路爬虫;
在学习python中有任何困难不懂的可以加入我的python交流学习群:629614370,多多交流问题,互帮互助,群里有不错的学习教程和开发工具。学习python有任何问题(学习方法,学习效率,如何就业),可以随时来咨询我。需要电子书籍的可以自己加裤下载,网盘链接不使发
工具维度:以流行的Python网路爬虫框架Scrapy为对象,详细讲解了Scrapy的功能使用、高级方法、架构设计、实现原理,以及怎样通过Scrapy来更便捷、高效地编撰网路爬虫;
实战维度:以实战为导向,是本书的主旨python爬虫经典书籍python爬虫经典书籍,除了完全通过自动编程实现网路爬虫和通过Scrapy框架实现网路爬虫的实战案例以外,本书还有博客爬取、图片爬取、模拟登陆等多个综合性的网路爬虫实践案例。 查看全部
生活在21世纪的互联网时代,各类技术的发展堪称是瞬息万变,这不明天编程界又出现一位“新星”,他的名子称作Python,目前Python早已超过Java而居于编程排名语言的第五位了。随着Python语言的火爆发展,目前很多人都在想学习Python,那么Python爬虫入门看哪些书好呢?小编为你推荐一本书,手把手教你学Python。
这本书是一本实战性的网路爬虫秘籍,在本书中除了讲解了怎样编撰爬虫,还讲解了流行的网路爬虫的使用。而且这本色书的作者在Python领域有着极其深厚的积累,不仅精通Python网络爬虫,而且在Python机器学习等领域都有着丰富的实战经验,所以说这本书是Python爬虫入门人员必备的书籍。

这本书总共从三个维度讲解了Python爬虫入门,分别是:
技术维度:详细讲解了Python网路爬虫实现的核心技术,包括网路爬虫的工作原理、如何用urllib库编撰网路爬虫、爬虫的异常处理、正则表达式、爬虫中Cookie的使用、爬虫的浏览器伪装技术、定向爬取技术、反爬虫技术,以及怎样自己动手编撰网路爬虫;
在学习python中有任何困难不懂的可以加入我的python交流学习群:629614370,多多交流问题,互帮互助,群里有不错的学习教程和开发工具。学习python有任何问题(学习方法,学习效率,如何就业),可以随时来咨询我。需要电子书籍的可以自己加裤下载,网盘链接不使发

工具维度:以流行的Python网路爬虫框架Scrapy为对象,详细讲解了Scrapy的功能使用、高级方法、架构设计、实现原理,以及怎样通过Scrapy来更便捷、高效地编撰网路爬虫;
实战维度:以实战为导向,是本书的主旨python爬虫经典书籍python爬虫经典书籍,除了完全通过自动编程实现网路爬虫和通过Scrapy框架实现网路爬虫的实战案例以外,本书还有博客爬取、图片爬取、模拟登陆等多个综合性的网路爬虫实践案例。
爬虫构架|如何设计一款类“即刻”信息订阅推送的爬虫构架(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-05-27 08:02
分发集群、爬虫集群、装饰集群
3.1 分发集群
分发集群有两个任务:
1. 接收后台恳求,新增内容源,首先判定内容源是否已存在(通过查询“内容源”表)。若不存在,则将内容源作为爬虫任务放置到定时任务池,并主动递交到爬虫队列。
2. 定时从任务池中获取全部任务爬虫框架设计,按类型、按级别(现只定义快慢两级)提交到对应爬虫队列。
注:爬虫队列分级是为了更好的消费任务。
快队列指的是拥有更多的消费者,能更快的完成任务,一般用于处理新任务。
慢队列值得是拥有较少的消费者,完成任务的时间慢,一般用于处理异常任务。
3.2 爬虫集群
爬虫集群也有两个任务:
1. 消费队列中的爬虫任务,抓取如title、desc、url等信息储存入数据库。此时,记录应如实对应内容源的内容,不应进行过滤,封装。
2. 完成一次爬虫任务后,提交到装潢任务队列——提供内容源的一次抓取结果(此处应为多条记录),希望将结果根据每位用户的要求过滤和封装。
3.3 装饰集群
装饰集群也有两个任务:
1. 消费队列中的装潢任务,查询“追踪对象表”和“主题表”,获取多种用户需求。对于每位用户,分别将抓取结果过滤和装潢,最后的封装结果按用户入库。
2. 入库成功后,需要远程调用(rmi)搜索引擎(搜索引擎建索引)、云通信(发送联通通知、邮件通知)、动态流(即刻的消息页,动态流须要将主题新更内容分发到对应关注者的“动态流”表中)。
四、爬虫技术实现
目前我那边追踪机器人使用的技术是python的Scrapy框架,分布式实现用的是scrapy-redis。
欢迎有志之士来我司和我一起实现我们产品中的信息订阅环节的工程,订阅环节是我们产品的基础爬虫框架设计,当然我们的产品远不只是那些。
我希望你有下边的知识点:
1)知道怎样借助IDE(推荐PyCharm)调试scrape爬虫程序
2)熟练使用xpath或css选择器获取页面元素
3)知道怎样使用selenium进行手动登入
4)熟练借助middleware中间件做ip代理池
5)使用scrapy-redis做过分布式爬虫项目
6)熟悉scrape构架图,熟练使用middleware中间件和讯号(Signals)进行扩充开发
7)熟悉各类爬虫、反爬虫攻守策略 查看全部
有了前面的业务剖析,接下来我们就可以瞧瞧我们的构架应当怎么样来设计啦。我这儿先给出整体构架图。

分发集群、爬虫集群、装饰集群
3.1 分发集群
分发集群有两个任务:
1. 接收后台恳求,新增内容源,首先判定内容源是否已存在(通过查询“内容源”表)。若不存在,则将内容源作为爬虫任务放置到定时任务池,并主动递交到爬虫队列。
2. 定时从任务池中获取全部任务爬虫框架设计,按类型、按级别(现只定义快慢两级)提交到对应爬虫队列。
注:爬虫队列分级是为了更好的消费任务。
快队列指的是拥有更多的消费者,能更快的完成任务,一般用于处理新任务。
慢队列值得是拥有较少的消费者,完成任务的时间慢,一般用于处理异常任务。
3.2 爬虫集群
爬虫集群也有两个任务:
1. 消费队列中的爬虫任务,抓取如title、desc、url等信息储存入数据库。此时,记录应如实对应内容源的内容,不应进行过滤,封装。
2. 完成一次爬虫任务后,提交到装潢任务队列——提供内容源的一次抓取结果(此处应为多条记录),希望将结果根据每位用户的要求过滤和封装。
3.3 装饰集群
装饰集群也有两个任务:
1. 消费队列中的装潢任务,查询“追踪对象表”和“主题表”,获取多种用户需求。对于每位用户,分别将抓取结果过滤和装潢,最后的封装结果按用户入库。
2. 入库成功后,需要远程调用(rmi)搜索引擎(搜索引擎建索引)、云通信(发送联通通知、邮件通知)、动态流(即刻的消息页,动态流须要将主题新更内容分发到对应关注者的“动态流”表中)。
四、爬虫技术实现
目前我那边追踪机器人使用的技术是python的Scrapy框架,分布式实现用的是scrapy-redis。
欢迎有志之士来我司和我一起实现我们产品中的信息订阅环节的工程,订阅环节是我们产品的基础爬虫框架设计,当然我们的产品远不只是那些。
我希望你有下边的知识点:
1)知道怎样借助IDE(推荐PyCharm)调试scrape爬虫程序
2)熟练使用xpath或css选择器获取页面元素
3)知道怎样使用selenium进行手动登入
4)熟练借助middleware中间件做ip代理池
5)使用scrapy-redis做过分布式爬虫项目
6)熟悉scrape构架图,熟练使用middleware中间件和讯号(Signals)进行扩充开发
7)熟悉各类爬虫、反爬虫攻守策略
Python爬虫视频教程全集下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-05-27 08:02
强大的编程语言,你一定会认为很难学吧?但事 实上,Python 是十分容易入门的。 因为它有丰富的标准库,不仅语言简练易懂,可读性强python爬虫高级教程,代码还具有太强的 可拓展性,比起 C 语言、Java 等编程语言要简单得多: C 语言可能须要写 1000 行代码,Java 可能须要写几百行代码python爬虫高级教程,而 Python 可能仅仅只需几十行代码能够搞定。Python 应用非常广泛的场景就是爬虫,很 多菜鸟刚入门 Python,也是由于爬虫。 网络爬虫是 Python 极其简单、基本、实用的技术之一,它的编撰也十分简 单,无许把握网页信息怎样呈现和形成。掌握了 Python 的基本句型后,是才能 轻易写出一个爬虫程序的。还没想好去哪家机构学习 Python 爬虫技术?千锋 Python 讲师风格奇特, 深入浅出, 常以简单的视角解决复杂的开发困局, 注重思维培养, 授课富于激情,做真实的自己-用良心做教育千锋教育 Python 培训擅长理论结合实际、提高中学生项目开发实战的能力。 当然了,千锋 Python 爬虫培训更重视就业服务:开设有就业指导课,设有 专门的就业指导老师,在结业前期,就业之际,就业老师会手把手地教中学生笔试 着装、面试礼仪、面试对话等基本的就业素质的培训。做到更有针对性和目标性 的笔试,提高就业率。做真实的自己-用良心做教育 查看全部
千锋教育 Python 培训Python 爬虫视频教程全集下载 python 作为一门中级编程语言,在编程中应用十分的广泛,近年来随着人 工智能的发展 python 人才的需求更大。当然,这也吸引了很多人选择自学 Python 爬虫。Python 爬虫视频教程全集在此分享给你们。 千锋 Python 课程教学前辈晋级视频总目录: Python 课程 windows 知识点: Python 课程 linux 知识点: Python 课程 web 知识点: Python 课程机器学习: 看完 Python 爬虫视频教程全集,来瞧瞧 Python 爬虫到底是什么。 Python 的市场需求每年都在大规模扩充。网络爬虫又被称为网页蜘蛛,是 一种根据一定的规则, 自动的抓取万维网信息的程序或则脚本, 已被广泛应用于 互联网领域。搜索引擎使用网路爬虫抓取 Web 网页、文档甚至图片、音频、视 频等资源,通过相应的索引技术组织这种信息,提供给搜索用户进行查询。做真实的自己-用良心做教育千锋教育 Python 培训Python 如此受欢迎,主要是它可以做的东西十分多,小到一个网页、一个 网站的建设,大到人工智能 AI、大数据剖析、机器学习、云计算等尖端技术, 都是基于 Python 来实现的。
强大的编程语言,你一定会认为很难学吧?但事 实上,Python 是十分容易入门的。 因为它有丰富的标准库,不仅语言简练易懂,可读性强python爬虫高级教程,代码还具有太强的 可拓展性,比起 C 语言、Java 等编程语言要简单得多: C 语言可能须要写 1000 行代码,Java 可能须要写几百行代码python爬虫高级教程,而 Python 可能仅仅只需几十行代码能够搞定。Python 应用非常广泛的场景就是爬虫,很 多菜鸟刚入门 Python,也是由于爬虫。 网络爬虫是 Python 极其简单、基本、实用的技术之一,它的编撰也十分简 单,无许把握网页信息怎样呈现和形成。掌握了 Python 的基本句型后,是才能 轻易写出一个爬虫程序的。还没想好去哪家机构学习 Python 爬虫技术?千锋 Python 讲师风格奇特, 深入浅出, 常以简单的视角解决复杂的开发困局, 注重思维培养, 授课富于激情,做真实的自己-用良心做教育千锋教育 Python 培训擅长理论结合实际、提高中学生项目开发实战的能力。 当然了,千锋 Python 爬虫培训更重视就业服务:开设有就业指导课,设有 专门的就业指导老师,在结业前期,就业之际,就业老师会手把手地教中学生笔试 着装、面试礼仪、面试对话等基本的就业素质的培训。做到更有针对性和目标性 的笔试,提高就业率。做真实的自己-用良心做教育
Python做爬虫到底比其他语言好在哪儿呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-25 08:02
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f... 查看全部
07-22
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f...
Python网络爬虫实战项目代码大全(长期更新,欢迎补充)
采集交流 • 优采云 发表了文章 • 0 个评论 • 827 次浏览 • 2020-06-14 08:02
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址: 查看全部
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址:
网络爬虫_基于各类语言的开源网络爬虫总汇
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-06-13 08:02
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
nodejs可以爬虫。Node.js出现后,爬虫便不再是后台语言如PHP,Python的专利了,尽管在处理大量数据时的表现依然不如后台语言,但是Node.js异步编程的特点可以使我们在最少的cpu开支下轻松完成高并发的爬取。
你了解爬虫是哪些吗?你晓得爬虫的爬取流程吗?你晓得如何处理爬取中出现的问题吗?如果你回答不下来,或许你真的要好好瞧瞧这篇文章了!网络爬虫(Web crawler),是一种根据一定的规则
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下,程序没问题,可以正常的把这个网站的数据给抓取出来
很多同学不知道Python爬虫如何入门,怎么学习,到底要学习什么内容。今天我来给你们谈谈学习爬虫,我们必须把握的一些第三方库。废话不多说,直接上干货。
Scrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。pyspider 是一个用python实现的功能强悍的网路爬虫系统网络爬虫开源,能在浏览器界面上进行脚本的编撰
node可以做爬虫,下面我们来看一下怎样使用node来做一个简单的爬虫。node做爬虫的优势:第一个就是他的驱动语言是JavaScript。JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言,其优势就是对网页上的dom元素进行操作
网络爬虫 (又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。随着web2.0时代的到来,数据的价值更加彰显下来。
Puppeteer是微软官方出品的一个通过DevTools合同控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或则作为爬虫访问页面来搜集数据
本文适宜无论是否有爬虫以及 Node.js 基础的同事观看~如果你是一名技术人员,那么可以看我接下来的文章,否则网络爬虫开源,请直接移步到我的 github 仓库,直接看文档使用即可
python爬虫入门教程(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-06-12 08:01
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战 查看全部
目录:
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战
js网路爬虫代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2020-06-11 08:02
网络爬虫工作原理: 在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部份组成。 控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。 解析器的主要工作是下载网页,进行页面的处理,主要是将一些js脚本标签、css代码内容、空格字符、html标签等内容处理掉,爬虫的基本工作是由解析器完成...
可将字符串导出,创建对象,用于快速抓取字符串中的符合条件的数据npm install cheerio -d 项目目录:node-pachong - index.js - package.json - node_modules 上代码:node-pachongindex.js** * 使用node.js做爬虫实战 * author:justbecoder * 引入须要的工具包const sp = require(superagent); const cheerio = ...
这样爬虫采集到的就是一堆标签加一点内容所混杂的脏数据,同时发觉标签中的值也是随时改变的。 所以此次也是花了一点时间来整理关于大众点评js加密的内容,给你们简单讲解一下,以此来学习借鉴怎样有效安全的防范爬虫。 仅供学习参考,切勿用于商业用途一、介绍首先随意打开大众点评网一家店,看到数据都是正常状态如...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
进入领域最想要的就是获取大量的数据来为自己的剖析提供支持,但是怎样获取互联网中的有效信息? 这就促使了“爬虫”技术的急速发展。 网络爬虫(又被称为网页蜘蛛网络爬虫+代码,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 传统爬虫从一个或若干初始...
但是若果这种数据不是以专用的 rest api 的方式出现,通常太无法编程方法对其进行访问。 使用 jsdom 之类的 node.js 工具,你可以直接从网页上抓取并解析这种数据,并用于你自己的项目和应用。 让我们以用 midi 音乐数据来训练神经网路来生成听起来精典的任天堂音乐【https:
作者:韦玮 转载请标明出处 随着大数据时代的到来,人们对数据资源的需求越来越多,而爬虫是一种挺好的手动采集数据的手段。 那么,如何能够精通python网络爬虫呢? 学习python网路爬虫的路线应当怎样进行呢? 在此为你们具体进行介绍。 1、选择一款合适的编程语言 事实上,python、php、java等常见的语言都可以用于...
预备知识学习者须要预先把握python的数字类型、字符串类型、分支、循环、函数、列表类型、字典类型、文件和第三方库使用等概念和编程技巧。 2. python爬虫基本流程? a. 发送恳求使用http库向目标站点发起恳求,即发送一个request网络爬虫+代码,request包含:请求头、请求体等。 request模块缺陷:不能执行js 和css 代码...
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。 此外爬虫还可以验证超链接和 html 代码,用于网路抓取。 本文我们将以爬取我的个人博客后端修仙之路已发布的博文为例,来实现一个简单的 node.js 爬虫。 在实际动手前,我们来看剖析一下,人为统计的流程:新建一个 ... 查看全部
网络爬虫工作原理: 在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部份组成。 控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。 解析器的主要工作是下载网页,进行页面的处理,主要是将一些js脚本标签、css代码内容、空格字符、html标签等内容处理掉,爬虫的基本工作是由解析器完成...
可将字符串导出,创建对象,用于快速抓取字符串中的符合条件的数据npm install cheerio -d 项目目录:node-pachong - index.js - package.json - node_modules 上代码:node-pachongindex.js** * 使用node.js做爬虫实战 * author:justbecoder * 引入须要的工具包const sp = require(superagent); const cheerio = ...
这样爬虫采集到的就是一堆标签加一点内容所混杂的脏数据,同时发觉标签中的值也是随时改变的。 所以此次也是花了一点时间来整理关于大众点评js加密的内容,给你们简单讲解一下,以此来学习借鉴怎样有效安全的防范爬虫。 仅供学习参考,切勿用于商业用途一、介绍首先随意打开大众点评网一家店,看到数据都是正常状态如...
一、前言 在你心中哪些是网络爬虫? 在网线里钻来钻去的虫子? 先看一下百度百科的解释:网络爬虫(又被称为网页蜘蛛,网络机器人,在foaf社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。 看完以后...
进入领域最想要的就是获取大量的数据来为自己的剖析提供支持,但是怎样获取互联网中的有效信息? 这就促使了“爬虫”技术的急速发展。 网络爬虫(又被称为网页蜘蛛网络爬虫+代码,网络机器人,在foaf社区中间,更时常的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。 传统爬虫从一个或若干初始...
但是若果这种数据不是以专用的 rest api 的方式出现,通常太无法编程方法对其进行访问。 使用 jsdom 之类的 node.js 工具,你可以直接从网页上抓取并解析这种数据,并用于你自己的项目和应用。 让我们以用 midi 音乐数据来训练神经网路来生成听起来精典的任天堂音乐【https:
作者:韦玮 转载请标明出处 随着大数据时代的到来,人们对数据资源的需求越来越多,而爬虫是一种挺好的手动采集数据的手段。 那么,如何能够精通python网络爬虫呢? 学习python网路爬虫的路线应当怎样进行呢? 在此为你们具体进行介绍。 1、选择一款合适的编程语言 事实上,python、php、java等常见的语言都可以用于...
预备知识学习者须要预先把握python的数字类型、字符串类型、分支、循环、函数、列表类型、字典类型、文件和第三方库使用等概念和编程技巧。 2. python爬虫基本流程? a. 发送恳求使用http库向目标站点发起恳求,即发送一个request网络爬虫+代码,request包含:请求头、请求体等。 request模块缺陷:不能执行js 和css 代码...
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览万维网的网路机器人。 此外爬虫还可以验证超链接和 html 代码,用于网路抓取。 本文我们将以爬取我的个人博客后端修仙之路已发布的博文为例,来实现一个简单的 node.js 爬虫。 在实际动手前,我们来看剖析一下,人为统计的流程:新建一个 ...
Python爬虫实战(1):爬取Drupal峰会贴子列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-06-09 10:24
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源 查看全部
/img/bVxTdG
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源
让你从零开始学会写爬虫的5个教程(Python)
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-06-09 08:02
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。 查看全部
写爬虫总是十分吸引IT学习者,毕竟光听上去就太拉风极客,我也晓得很多人学完基础知识以后python爬虫教程,第一个项目开发就是自己写一个爬虫玩儿。
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。
【苹果IP代理】 8大高效的Python爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2020-06-09 08:01
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。 查看全部
【苹果 IP 代理】8 大高效的 Python 爬虫框架,你用过几个? 【苹果 IP 代理】大数据时代下,数据采集推动着数据剖析, 数据剖析加快发展。但是在这个过程中会出现好多问题。拿最简 单最基础的爬虫采集数据为例,过程中还会面临,IP 被封,爬取 受限、违法操作等多种问题,所以在爬取数据之前,一定要了解 好预爬网站是否涉及违规操作,找到合适的代理 IP 访问网站等 一系列问题。今天我们就来讲讲这些高效的爬虫框架。 1.Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的 应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数 据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商 品信息之类的数据。 2.PySpider pyspider 是一个用 python 实现的功能强悍的网路爬虫系统, 能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实 时查看,后端使用常用的数据库进行爬取结果的储存,还能定时 设置任务与任务优先级等。 3.Crawley Crawley 可以高速爬取对应网站的内容,支持关系和非关系 数据库,数据可以导入为 JSON、XML 等。
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。
网络爬虫 | 开源软件 | OSCHINA
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-06-04 08:05
SimpleCD是哪些? 是山寨化VeryCD的全套工具,包括抓取脚本,网站代码等 谁须要使用SimpleCD? 想保存VeryCD链接资源者:别镜像VeryCD了,用这个吧。 想研究爬虫脚本和...
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、H...
收藏 962
更新于 2019/10/18
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newS...
收藏 1071
更新于 2017/07/31
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~ 示例代码:...
收藏 482
更新于 2020/03/05
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供网络爬虫软件,甚至要比一些商用软件的功能还要...
PySipder 是一个 Python 爬虫程序 演示地址: 使用 Python 编写脚本,提供强悍的 API Python 2&3 强大的 W...
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统...
Heritrix是一个开源,可扩充的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。其最出色之...
Grub Next Generation 是一个分布式的网页爬虫系统,包含客户端和服务器可以拿来维护网页的索引。
收藏 117
更新于 2011/05/26
Snoopy是一个强悍的网站内容采集器(爬虫)。提供获取网页内容,提交表单等功能。
已删掉源码
收藏 881
更新于 2016/09/26
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据...
NWebCrawler是一款开源的C#网路爬虫程序
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下: jspider [URL] [ConfigName] URL一定要加上合同名称,如:网络爬虫软件,否则会...
开源软件作者
RedisPlus 作者
ACTCMS 作者
静静的风
DBErp 作者
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。 示例代码: import java.util.ArrayList; im...
收藏 116
更新于 2017/11/28
爬虫软件MetaSeeker,现已全面升级为GooSeeker。 新版本早已发布,在线版免费下载和使用,源代码可阅读。自推出以来,深受喜爱,主要应用领域: 垂直搜索(Vertical Searc...
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。 登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。 该应用获取的数据可作为科研、...
Methanol 是一个模块化的可订制的网页爬虫软件,主要的优点是速度快。
没有更多内容
加载失败,请刷新页面
加载更多 查看全部
爬虫简介: WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Had...
SimpleCD是哪些? 是山寨化VeryCD的全套工具,包括抓取脚本,网站代码等 谁须要使用SimpleCD? 想保存VeryCD链接资源者:别镜像VeryCD了,用这个吧。 想研究爬虫脚本和...
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、H...
收藏 962
更新于 2019/10/18
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newS...
收藏 1071
更新于 2017/07/31
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~ 示例代码:...
收藏 482
更新于 2020/03/05
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供网络爬虫软件,甚至要比一些商用软件的功能还要...
PySipder 是一个 Python 爬虫程序 演示地址: 使用 Python 编写脚本,提供强悍的 API Python 2&3 强大的 W...
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统...
Heritrix是一个开源,可扩充的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格依照robots.txt文件的排除指示和META robots标签。其最出色之...
Grub Next Generation 是一个分布式的网页爬虫系统,包含客户端和服务器可以拿来维护网页的索引。
收藏 117
更新于 2011/05/26
Snoopy是一个强悍的网站内容采集器(爬虫)。提供获取网页内容,提交表单等功能。
已删掉源码
收藏 881
更新于 2016/09/26
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据...
NWebCrawler是一款开源的C#网路爬虫程序
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下: jspider [URL] [ConfigName] URL一定要加上合同名称,如:网络爬虫软件,否则会...
开源软件作者
RedisPlus 作者
ACTCMS 作者
静静的风
DBErp 作者
Crawler4j是一个开源的Java泛型提供一个用于抓取Web页面的简单插口。可以借助它来建立一个多线程的Web爬虫。 示例代码: import java.util.ArrayList; im...
收藏 116
更新于 2017/11/28
爬虫软件MetaSeeker,现已全面升级为GooSeeker。 新版本早已发布,在线版免费下载和使用,源代码可阅读。自推出以来,深受喜爱,主要应用领域: 垂直搜索(Vertical Searc...
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。 登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。 该应用获取的数据可作为科研、...
Methanol 是一个模块化的可订制的网页爬虫软件,主要的优点是速度快。
没有更多内容
加载失败,请刷新页面
加载更多
panfengzjz的博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-06-04 08:04
03-03
9259
python 爬取知乎某一关键字数据
python爬取知乎某一关键字数据序言和之前爬取Instagram数据一样,那位朋友还须要爬取知乎前面关于该影片的评论。没想到这是个坑洞啊。看起来很简单的一个事情就显得很复杂了。知乎假如说,有哪些事情是最坑的,我觉得就是在知乎前面讨论怎样抓取知乎的数据了。在2018年的时侯,知乎又进行了一次改版啊。真是一个坑洞。网上的代码几乎都不能使用了。只有这儿!的一篇文章还可以模拟登录一......
Someone&的博客
05-31
5069
输入关键字的爬虫方式(运行环境python3)
前段时间,写了爬虫,在新浪搜索主页面中,实现了输入关键词,爬取关键词相关的新闻的标题、发布时间、url、关键字及内容。并依据内容,提取了摘要和估算了相似度。下面简述自己的思路并将代码的githup链接给出:1、获取关键词新闻页面的url在新浪搜索主页,输入关键词,点击搜索后会手动链接到关键词的新闻界面,想要获取这个页面的url,有两种思路,本文提供三种方式。......
乐亦亦乐的博客
08-15
2901
python爬虫——校花网
爬取校花网图片校花网步入网站,我们会发觉许多图片,这些图片就是我们要爬取的内容。 2.对网页进行剖析,按F12打开开发着工具(本文使用谷歌浏览器)。我们发觉每位图片都对应着一个路径。 3.我们访问一下img标签的src路径。正是图片的路径,能够获取到图片。因此我们须要获取网页中img标签下所有的s......
一朵凋谢的菊花
03-05
386
Python定向爬虫——校园论坛贴子信息
写这个小爬虫主要是为了爬校园峰会上的实习信息,主要采用了Requests库
weixin_34268579的博客
12-17
4301
详解怎样用爬虫批量抓取百度搜索多个关键字数据
2019独角兽企业重金急聘Python工程师标准>>>...
weixin_33852020的博客
06-23
313
如何通过关键词匹配统计其出现的频度
最近写的一个perl程序,通过关键词匹配统计其出现的频度,让人感受到perl正则表达式的强悍,程序如下:#!/usr/bin/perluse strict;my (%hash,%hash1,@array);while(&lt;&gt;){s/\r\n//;my $line;if(/-(.+?)【(.+?)】【(.+?)】(定单积压)/...
W&J
02-10
9415
python 实现关键词提取
Python实现关键词提取这篇文章只介绍了Python中关键词提取的实现。关键词提取的几个方式:1.textrank2.tf-idf3.LDA,其中textrank和tf-idf在jieba中都有封装好的函数,调用上去非常简单方便。常用的自然语言处理的库还有nltk,gensim,sklearn中也有封装好的函数可以进行SVD分解和LDA等。LDA也有人分装好了库,直接pipinsta......
zzz1048506792的博客
08-08
992
python爬虫爬取政府网站关键字
**功能介绍**获取政府招标内容包含以下关键词,就提取该标书内容保存(本地文本)1,汽车采购2、汽车租赁3、公务车4、公务车租赁5、汽车合同供货6、汽车7、租赁爬取网站作者:speed_zombie版本信息:python v3.7.4运行......
最新陌陌小程序源码
panfengzjz的博客
01-01
442
PYTHON 实现 NBA 赛程查询工具(二)—— 网络爬虫
前言:第一篇博客,记录一下近来的一点点小成果。一切的学习都从兴趣开始。最近突然想学习一下pyqt和python的网路爬虫知识,于是就自己找了一个课题做了上去。因为我刚好是个 NBA歌迷,就想到了通过网路爬虫来抓取大赛结果,方便本地进行查找的项目。这个项目总共分为三步:1. 界面制做:选择对应的球员,显示球员图标和赛事结果2.网络爬虫:访问特定网页,查找赛季至......
微信小程序源码-合集1
panfengzjz的博客
05-25
4475
PYTHON 中 global 关键字的用法
之前写函数的时侯,由于传参实在太多,于是将某个字段定义为全局变量,在函数中直接使用。可是在使用过程中发觉会报错,原因是在另一个调用函数中,该全局变量的类型被更改了,那那边刚好彻底用几个事例来理清一下python中global关键字可以起到的作用。案例一:先说我见到的问题(并没有贴上源代码,下面的事例是自己具象出一个便捷你们理解的小case)程序大约就是这样#error ca......
panfengzjz的博客
04-29
1万+
利用OpenCV-python进行直线测量
最近须要借助摄像头对细小的偏斜做矫治,由于之前的界面工具是用PyQT所写,在当前的工具中加入摄像头矫治程序,也准备用python直接完成。OpenCV简介:Python处理图象有OpenCV库。OpenCV可以运行在Linux,windows,macOS上,由C函数和C++类构成,用于实现计算机图象、视频的编辑,应用于图象辨识、运动跟踪、机器视觉等领域。Open......
bensonrachel的博客
05-18
1728
python-简单爬虫及相关数据处理(统计出文章出现次数最多的50个词)
这次爬取了笑傲江湖这本小说;网站是:'#039;+str(696+i)+'.html'考虑到每一章的网址如上递增,所以使用一个循环来遍历网址进行爬取。然后找出文章的标签:如图:是&lt;p&gt;,&lt;/p&gt;所以:代码如下:然后爬取以后,存在文档里,进行处理。我用的是nlpir的动词系统:作了处理以后,把所有词存进一list上面。之......
glumpydog的专栏
05-14
5880
python 抓取天涯贴子内容并保存
手把手教你借助Python下载天涯热门贴子为txt文档 作者:大捷龙csdn : **剖析:天涯的贴子下载可以分为以下几个步骤自动传入一个贴子首页的地址打开文本提取贴子标题获取贴子的最大页数遍历每一页,获得每条回复的是否是楼主、作者爱称、回复时间。写入看文本关掉文本预备:Python的文件操作: 一、...
cjy1041403539的博客
04-14
1961
python微博爬虫——使用selenium爬取关键词下超话内容
最近微博手机端的页面发生了些微的变化,导致了我之前的两篇文章微博任意关键词爬虫——使用selenium模拟浏览器和来!用python爬一爬“不知知网翟博士”的微博超话中的代码出现了一些报错情况,这里来更改一下欢迎关注公众号:老白和他的爬虫1.微博手机端出现的变化爬取手机端的微博益处在于能否爬取比网页端更多的数据,因为网页端微博内容通常限定在50页,数据量不够大,所以选择爬取手机端,这样可......
scx2006114的博客
08-03
5441
python爬虫之爬取简书中的小文章标题
学习了三个星期的python基础句型,对python句型有了一个基本的了解,然后想继续深入学习,但不喜欢每晚啃书本,太无趣了,只有实战才是练兵的最好疗效。听说爬虫技术还是比较好玩的,就搞爬虫,但找了很多资料没有找到合适的资料,最后才找到传说中的合适爬虫初学者的书籍《Python3网络爬虫开发实战,崔庆才著》(文末附书本下载链接),学习了一天,终于完整搞出了自己的第一爬虫,哈哈~。......
zhyh1435589631的专栏
05-03
8951
python 爬虫实战 抓取中学bbs相关蓝筹股的回帖信息
1. 前言之前也由于感兴趣, 写过一个抓取桌面天空上面喜欢的动画墙纸的爬虫代码。这三天忽然听到有人写了那么一篇文章: 爬取易迅本周热销商品基本信息存入MySQL 感觉挺有趣的, 正好临近找工作的季节, 就想着能不能写个爬虫, 把俺们中学bbs前面相关的蓝筹股上面的回帖信息给记录出来。2. 项目剖析首先我们打开我们的目标网页 结...
jiangfullll的专栏
05-08
1991
python爬虫 根据关键字在新浪网站查询跟关键字有关的新闻条数(按照时间查询)
# -*- coding: utf-8 -*-"""Created on Thu May 8 09:14:13 2014@author: lifeix"""import urllib2import refrom datetime import datetimedef craw1(keyword_name, startYear): a = keyword_name
c350577169的博客
05-22
3万+
python爬虫--如何爬取翻页url不变的网站
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整个网页的情况下,对网页的某部份进行更新。这样的设置无疑给早期爬虫菜鸟制造了一些困难。1、什么是ajax几个常见的用到ajax的场景。比如你在逛知乎,你没有刷新过网页,但是你却能看到你关注的用户或则话题......
iteye_17286的博客
11-20
1071
如何从文件中检索关键字出现的次数
首先得到文件的完整路径,然后从流中读取每位字符,如果读出的字符和关键字的第一个字符相同,则根据关键字宽度读取相同个数的字符,分别判定是否相同,若有一个不相同则break,否则计数器count++,最后count的个数即是关键字在文件中出下的次数......
weixin_34237596的博客
05-16
280
[Python爬虫]新闻网页爬虫+jieba分词+关键词搜索排序
前言近来做了一个python3作业题目,涉及到:网页爬虫网页英文文字提取构建文字索引关键词搜索涉及到的库有:爬虫库:requests解析库:xpath正则:re分词库:jieba...放出代码便捷你们快速参考,实现一个小demo。题目描述搜索引擎的设计与实现输入:腾讯体育的页面链接,以列表的形式作为输入,数量不定,例如:["
纯洁的笑容
03-04
14万+
和黑客斗争的 6 天!
互联网公司工作爬虫论坛,很难避开不和黑客们打交道,我呆过的两家互联网公司,几乎每月每晚每分钟都有黑客在公司网站上扫描。有的是找寻 Sql 注入的缺口爬虫论坛,有的是找寻线上服务器可能存在的漏洞,大部分都...
Blessy_Zhu的博客
03-20
1万+
Python爬虫之陌陌数据爬取(十三)
原创不易,转载前请标明博主的链接地址:Blessy_Zhu本次代码的环境:运行平台:WindowsPython版本:Python3.xIDE:PyCharm一、前言陌陌作为我们日常交流的软件,越来越深入到我们的生活。但是,随着陌陌好的数目的降低,实际上真正可以联系的知心人却越来越少了。那么,怎么样能更清......
07-26
2万+
使用网页爬虫(高级搜索功能)搜集含关键词新浪微博数据
作为国外社交媒体的领航者,很遗憾,新浪微博没有提供以“关键字+时间+区域”方式获取的官方API。当我们听到美国科研成果都是基于某关键字获得的微博,心中不免凉了一大截,或者转战脸书。再次建议微博能更开放些!庆幸的是,新浪提供了中级搜索功能。找不到?这个功能须要用户登入能够使用……没关系,下面将详尽述说怎样在无须登陆的情况下,获取“关键字+时间+区域”的新浪微博。...
路人甲Java
03-25
9万+
面试阿里p7,被按在地上磨擦,鬼晓得我经历了哪些?
面试阿里p7被问到的问题(当时我只晓得第一个):@Conditional是做哪些的?@Conditional多个条件是哪些逻辑关系?条件判定在什么时候执... 查看全部
ANONYMOUSLYCN的专栏
03-03
9259
python 爬取知乎某一关键字数据
python爬取知乎某一关键字数据序言和之前爬取Instagram数据一样,那位朋友还须要爬取知乎前面关于该影片的评论。没想到这是个坑洞啊。看起来很简单的一个事情就显得很复杂了。知乎假如说,有哪些事情是最坑的,我觉得就是在知乎前面讨论怎样抓取知乎的数据了。在2018年的时侯,知乎又进行了一次改版啊。真是一个坑洞。网上的代码几乎都不能使用了。只有这儿!的一篇文章还可以模拟登录一......
Someone&的博客
05-31
5069
输入关键字的爬虫方式(运行环境python3)
前段时间,写了爬虫,在新浪搜索主页面中,实现了输入关键词,爬取关键词相关的新闻的标题、发布时间、url、关键字及内容。并依据内容,提取了摘要和估算了相似度。下面简述自己的思路并将代码的githup链接给出:1、获取关键词新闻页面的url在新浪搜索主页,输入关键词,点击搜索后会手动链接到关键词的新闻界面,想要获取这个页面的url,有两种思路,本文提供三种方式。......
乐亦亦乐的博客
08-15
2901
python爬虫——校花网
爬取校花网图片校花网步入网站,我们会发觉许多图片,这些图片就是我们要爬取的内容。 2.对网页进行剖析,按F12打开开发着工具(本文使用谷歌浏览器)。我们发觉每位图片都对应着一个路径。 3.我们访问一下img标签的src路径。正是图片的路径,能够获取到图片。因此我们须要获取网页中img标签下所有的s......
一朵凋谢的菊花
03-05
386
Python定向爬虫——校园论坛贴子信息
写这个小爬虫主要是为了爬校园峰会上的实习信息,主要采用了Requests库
weixin_34268579的博客
12-17
4301
详解怎样用爬虫批量抓取百度搜索多个关键字数据
2019独角兽企业重金急聘Python工程师标准>>>...
weixin_33852020的博客
06-23
313
如何通过关键词匹配统计其出现的频度
最近写的一个perl程序,通过关键词匹配统计其出现的频度,让人感受到perl正则表达式的强悍,程序如下:#!/usr/bin/perluse strict;my (%hash,%hash1,@array);while(&lt;&gt;){s/\r\n//;my $line;if(/-(.+?)【(.+?)】【(.+?)】(定单积压)/...
W&J
02-10
9415
python 实现关键词提取
Python实现关键词提取这篇文章只介绍了Python中关键词提取的实现。关键词提取的几个方式:1.textrank2.tf-idf3.LDA,其中textrank和tf-idf在jieba中都有封装好的函数,调用上去非常简单方便。常用的自然语言处理的库还有nltk,gensim,sklearn中也有封装好的函数可以进行SVD分解和LDA等。LDA也有人分装好了库,直接pipinsta......
zzz1048506792的博客
08-08
992
python爬虫爬取政府网站关键字
**功能介绍**获取政府招标内容包含以下关键词,就提取该标书内容保存(本地文本)1,汽车采购2、汽车租赁3、公务车4、公务车租赁5、汽车合同供货6、汽车7、租赁爬取网站作者:speed_zombie版本信息:python v3.7.4运行......
最新陌陌小程序源码
panfengzjz的博客
01-01
442
PYTHON 实现 NBA 赛程查询工具(二)—— 网络爬虫
前言:第一篇博客,记录一下近来的一点点小成果。一切的学习都从兴趣开始。最近突然想学习一下pyqt和python的网路爬虫知识,于是就自己找了一个课题做了上去。因为我刚好是个 NBA歌迷,就想到了通过网路爬虫来抓取大赛结果,方便本地进行查找的项目。这个项目总共分为三步:1. 界面制做:选择对应的球员,显示球员图标和赛事结果2.网络爬虫:访问特定网页,查找赛季至......
微信小程序源码-合集1
panfengzjz的博客
05-25
4475
PYTHON 中 global 关键字的用法
之前写函数的时侯,由于传参实在太多,于是将某个字段定义为全局变量,在函数中直接使用。可是在使用过程中发觉会报错,原因是在另一个调用函数中,该全局变量的类型被更改了,那那边刚好彻底用几个事例来理清一下python中global关键字可以起到的作用。案例一:先说我见到的问题(并没有贴上源代码,下面的事例是自己具象出一个便捷你们理解的小case)程序大约就是这样#error ca......
panfengzjz的博客
04-29
1万+
利用OpenCV-python进行直线测量
最近须要借助摄像头对细小的偏斜做矫治,由于之前的界面工具是用PyQT所写,在当前的工具中加入摄像头矫治程序,也准备用python直接完成。OpenCV简介:Python处理图象有OpenCV库。OpenCV可以运行在Linux,windows,macOS上,由C函数和C++类构成,用于实现计算机图象、视频的编辑,应用于图象辨识、运动跟踪、机器视觉等领域。Open......
bensonrachel的博客
05-18
1728
python-简单爬虫及相关数据处理(统计出文章出现次数最多的50个词)
这次爬取了笑傲江湖这本小说;网站是:'#039;+str(696+i)+'.html'考虑到每一章的网址如上递增,所以使用一个循环来遍历网址进行爬取。然后找出文章的标签:如图:是&lt;p&gt;,&lt;/p&gt;所以:代码如下:然后爬取以后,存在文档里,进行处理。我用的是nlpir的动词系统:作了处理以后,把所有词存进一list上面。之......
glumpydog的专栏
05-14
5880
python 抓取天涯贴子内容并保存
手把手教你借助Python下载天涯热门贴子为txt文档 作者:大捷龙csdn : **剖析:天涯的贴子下载可以分为以下几个步骤自动传入一个贴子首页的地址打开文本提取贴子标题获取贴子的最大页数遍历每一页,获得每条回复的是否是楼主、作者爱称、回复时间。写入看文本关掉文本预备:Python的文件操作: 一、...
cjy1041403539的博客
04-14
1961
python微博爬虫——使用selenium爬取关键词下超话内容
最近微博手机端的页面发生了些微的变化,导致了我之前的两篇文章微博任意关键词爬虫——使用selenium模拟浏览器和来!用python爬一爬“不知知网翟博士”的微博超话中的代码出现了一些报错情况,这里来更改一下欢迎关注公众号:老白和他的爬虫1.微博手机端出现的变化爬取手机端的微博益处在于能否爬取比网页端更多的数据,因为网页端微博内容通常限定在50页,数据量不够大,所以选择爬取手机端,这样可......
scx2006114的博客
08-03
5441
python爬虫之爬取简书中的小文章标题
学习了三个星期的python基础句型,对python句型有了一个基本的了解,然后想继续深入学习,但不喜欢每晚啃书本,太无趣了,只有实战才是练兵的最好疗效。听说爬虫技术还是比较好玩的,就搞爬虫,但找了很多资料没有找到合适的资料,最后才找到传说中的合适爬虫初学者的书籍《Python3网络爬虫开发实战,崔庆才著》(文末附书本下载链接),学习了一天,终于完整搞出了自己的第一爬虫,哈哈~。......
zhyh1435589631的专栏
05-03
8951
python 爬虫实战 抓取中学bbs相关蓝筹股的回帖信息
1. 前言之前也由于感兴趣, 写过一个抓取桌面天空上面喜欢的动画墙纸的爬虫代码。这三天忽然听到有人写了那么一篇文章: 爬取易迅本周热销商品基本信息存入MySQL 感觉挺有趣的, 正好临近找工作的季节, 就想着能不能写个爬虫, 把俺们中学bbs前面相关的蓝筹股上面的回帖信息给记录出来。2. 项目剖析首先我们打开我们的目标网页 结...
jiangfullll的专栏
05-08
1991
python爬虫 根据关键字在新浪网站查询跟关键字有关的新闻条数(按照时间查询)
# -*- coding: utf-8 -*-"""Created on Thu May 8 09:14:13 2014@author: lifeix"""import urllib2import refrom datetime import datetimedef craw1(keyword_name, startYear): a = keyword_name
c350577169的博客
05-22
3万+
python爬虫--如何爬取翻页url不变的网站
之前准备爬取一个图片资源网站,但是在翻页时发觉它的url并没有改变,无法简单的通过request.get()访问其他页面。据搜索资料,了解到这种网站是通过ajax动态加载技术实现。即可以在不重新加载整个网页的情况下,对网页的某部份进行更新。这样的设置无疑给早期爬虫菜鸟制造了一些困难。1、什么是ajax几个常见的用到ajax的场景。比如你在逛知乎,你没有刷新过网页,但是你却能看到你关注的用户或则话题......
iteye_17286的博客
11-20
1071
如何从文件中检索关键字出现的次数
首先得到文件的完整路径,然后从流中读取每位字符,如果读出的字符和关键字的第一个字符相同,则根据关键字宽度读取相同个数的字符,分别判定是否相同,若有一个不相同则break,否则计数器count++,最后count的个数即是关键字在文件中出下的次数......
weixin_34237596的博客
05-16
280
[Python爬虫]新闻网页爬虫+jieba分词+关键词搜索排序
前言近来做了一个python3作业题目,涉及到:网页爬虫网页英文文字提取构建文字索引关键词搜索涉及到的库有:爬虫库:requests解析库:xpath正则:re分词库:jieba...放出代码便捷你们快速参考,实现一个小demo。题目描述搜索引擎的设计与实现输入:腾讯体育的页面链接,以列表的形式作为输入,数量不定,例如:["
纯洁的笑容
03-04
14万+
和黑客斗争的 6 天!
互联网公司工作爬虫论坛,很难避开不和黑客们打交道,我呆过的两家互联网公司,几乎每月每晚每分钟都有黑客在公司网站上扫描。有的是找寻 Sql 注入的缺口爬虫论坛,有的是找寻线上服务器可能存在的漏洞,大部分都...
Blessy_Zhu的博客
03-20
1万+
Python爬虫之陌陌数据爬取(十三)
原创不易,转载前请标明博主的链接地址:Blessy_Zhu本次代码的环境:运行平台:WindowsPython版本:Python3.xIDE:PyCharm一、前言陌陌作为我们日常交流的软件,越来越深入到我们的生活。但是,随着陌陌好的数目的降低,实际上真正可以联系的知心人却越来越少了。那么,怎么样能更清......
07-26
2万+
使用网页爬虫(高级搜索功能)搜集含关键词新浪微博数据
作为国外社交媒体的领航者,很遗憾,新浪微博没有提供以“关键字+时间+区域”方式获取的官方API。当我们听到美国科研成果都是基于某关键字获得的微博,心中不免凉了一大截,或者转战脸书。再次建议微博能更开放些!庆幸的是,新浪提供了中级搜索功能。找不到?这个功能须要用户登入能够使用……没关系,下面将详尽述说怎样在无须登陆的情况下,获取“关键字+时间+区域”的新浪微博。...
路人甲Java
03-25
9万+
面试阿里p7,被按在地上磨擦,鬼晓得我经历了哪些?
面试阿里p7被问到的问题(当时我只晓得第一个):@Conditional是做哪些的?@Conditional多个条件是哪些逻辑关系?条件判定在什么时候执...
PHP用户数据爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-06-02 08:02
广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!
代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...
一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...
通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...
每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...
爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...
但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...
总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...
当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...
在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...
什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...
pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少... 查看全部
广告
云服务器1核2G首年95年,助力轻松上云!还有千元代金卷免费领,开团成功最高免费续费40个月!
代码托管地址: https:github.comhectorhuzhihuspider 这次抓取了110万的用户数据,数据剖析结果如下:? 开发前的打算安装linux系统(ubuntu14.04),在vmware虚拟机下安装一个ubuntu; 安装php5.6或以上版本; 安装mysql5.5或以上版本; 安装curl、pcntl扩充。 使用php的curl扩充抓取页面数据php的curl扩充是php支持...
但经验其实是经验,数据才是最靠谱的,通过剖析数据,可以评估一个队员的价值(当然,球员的各方面的表现(特征),都会有一个权重,最终评判权重*特征值之和最高者的神锋机率胜算大些)。 那么,如何获取那些数据呢? 写段简单的爬取数据的代码就是最好的获取工具。 本文以2014年的巴西世界杯球队为基础进行实践操作...
一、引言 在实际工作中,难免会遇见从网页爬取数据信息的需求,如:从谷歌官网上爬取最新发布的系统版本。 很明显这是个网页爬虫的工作,所谓网页爬虫,就是须要模拟浏览器,向网路服务器发送恳求便于将网路资源从网络流中读取下来,保存到本地,并对这种信息做些简单提取,将我们要的信息分离提取下来。 在做网页...
经过我的测试,我这一个学期以来的消费记录在这个网页上只有50多页,所以爬虫须要爬取的数据量太小,处理上去是完全没有压力的,直接一次性得到所有的结果以后保存文件就行了。 至于爬虫程序的语言选择,我也没哪些好说的,目前我也就对php比较熟悉一些,所以接下来的程序我也是用php完成的。 首先确定我应当怎样模拟...
如果你是有经验的开发者,完全可以跳过第一章步入第二章的学习了。 这个项目主要围绕两大核心点展开: 1. php爬虫 2. 代理ip 咱们先讲讲哪些是爬虫,简单来讲,爬虫就是一个侦测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按键,查查数据,或者把听到的信息背回去。 就像一只蟑螂在一幢楼里不知疲惫地爬...
通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至一般性的法则。 然而在线社交网络数据的获取方式...这个网站的网路链接为:http:members.lovingfromadistance.comforum.php,我们首先写一个叫screen_login的函数。 其核心是定义个浏览器对象br = mechanize...
每分钟执行一次爬取全省新型脑炎疫情实时动态并写入到指定的.php文件functionupdate() { (async () =&gt; { const browser = await puppeteer.launch({args: ...fscnpm i -g cron具体操作:用puppeteer爬取:puppeteer本质上是一个chrome浏览器,网页很难分清这是人类用户还是爬虫,我们可以用它来加载动态网页...
爬取微博的 id weibologin(username, password, cookie_path).login() withopen({}{}.csv.format(comment_path, id), mode=w, encoding=utf-8-sig...或者在文件中读取cookie数据到程序 self.session.cookies =cookielib.lwpcookiejar(filename=self.cookie_path) self.index_url = http:weibo.comlogin...
python爬虫突破限制,爬取vip视频主要介绍了python爬虫项目实例代码,文中通过示例代码介绍的十分详尽,对你们的学习或则工作具有一定的参考学习价值,需要的同学可以参考下? 其他也不多说什么直接附上源码? 只要学会爬虫技术,想爬取哪些资源基本都可以做到,当然python不止爬虫技术还有web开发,大数据,人工智能等! ...
但是使用java访问的时侯爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了什么东西,加载的东西有点多,着重看一下js、php的恳求,主要是看上面有没有mp3的地址,分析细节就不用说了。? 最终我在列表的https:wwwapi.kugou.comyyindex.php? r=playgetd...
总结上去就三部,首先获取登陆界面的验证码并储存cookie,然后通过cookie来模拟登录,最后步入教务系统取想要的东西。 现在我们须要去留心的内容,各个恳求的联接、header、和发送的数据2. 查看恳求首先我们查看首页,我们发觉登陆并不在首页上,需要点击用户登陆后才算步入了登陆界面。 然后我们查看登陆界面的恳求...
就是如此一个简单的功能,类似好多的云盘搜索类网站,我这个采集和搜索程序都是php实现的,全文和动词搜索部份使用到了开源软件xunsearch。 真实上线案例:搜碟子-网盘影片资源站上一篇( 网盘搜索引擎-采集爬取百度网盘分享文件实现云盘搜索中我重点介绍了如何去获取一大批的百度网盘用户,这一篇介绍如何获得指定...
当然, 并不是所有数据都适宜? 在学习爬虫的过程中, 遇到过不少坑. 今天这个坑可能之后你也会碰到, 随着爬取数据量的降低,以及爬取的网站数据字段的变化, 以往在爬虫入门时使用的方式局限性可能会飙升. 怎么个骤降法? intro 引例在爬虫入门的时侯,我们爬取豆瓣影片top250那些数据量并不是很大的网页时(仅估算文本数据...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
请先阅读“中国年轻人正率领国家迈向危机”php 网络爬虫 抓取数据php 网络爬虫 抓取数据,这锅背是不背? 一文,以对“手把手教你完成一个数据科学小项目”系列有个全局性的了解。 上一篇文章(1)数据爬取里我讲解了怎样用爬虫爬取新浪财经《中国年轻人正率领国家迈向危机》一文的评论数据,其中涉及的抓包过程是挺通用的,大家假如想爬取其他网站,也会是类似...
在领英心知肚明的情况下(领英甚至还派出过代表出席过hiq的晚会),hiq这样做了两年,但是在领英开发了一个与 skill mapper 非常类似的产品以后,领英立即变了脸,其向 hiq 发出了 勒令停止侵权函 ,威胁道假如 hiq 不停止搜集其用户数据的话,就将其控告。 不仅这么,领英还采取了技术举措,阻断了hiq的数据爬取,hi...
什么是大数据和人工智能,分享2019年我用python爬虫技术做企业大数据的那些事儿由于仍然从事php+python+ai大数据深度挖掘的技术研制,当前互联网早已从it时代发展到data时代,人工智能+大数据是当前互联网技术领域的两大趋势,记得在2010-2016年从事过电商的技术研制,当时电商时代缔造了好多创业人,很多有看法的...
- 利用爬虫获取舆情数据 -? 爬取的某急聘网站职位信息例如你可以批量爬取社交平台的数据资源,可以爬取网站的交易数据,爬取急聘网站的职位信息等,可以用于个性化的剖析研究。 总之,爬虫是十分强悍的,甚至有人说天下没有不能爬的网站,因而爬取数据也成为了好多极客的乐趣。 开发出高效的爬虫工具可以帮助我们...
usrbinenv python# -*- coding:utf-8 -*-import urllibfrom urllib import requestimport jsonimportrandomimport reimport urllib.errodef hq_html(hq_url):hq_html()封装的爬虫函数,自动启用了用户代理和ip代理 接收一个参数url,要爬取页面的url,返回html源码 def yh_dl():#创建用户代理池 yhdl = thisua = ...
pandas 是使数据剖析工作显得愈发简单的中级数据结构,我们可以用 pandas 保存爬取的数据。 最后通过pandas再写入到xls或则mysql等数据库中。 requests...上一节中我们讲了怎样对用户画像建模,而建模之前我们都要进行数据采集。 数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。 很多时侯,我们拥有多少...
最详尽爬虫入门教程!花半小时你应当能够去爬一些小东西了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-02 08:01
爬虫对目标网页爬取的过程可以参考下边红色文字部份:
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:
爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:
存储器、下载器、解析器和url管理器!
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?
下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():
在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF! 查看全部
爬虫对目标网页爬取的过程可以参考下边红色文字部份:
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:
爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:
存储器、下载器、解析器和url管理器!
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?
下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():
在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF!
“百行代码”实现简单的Python分布式爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2020-06-02 08:00
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
============================================================== 查看全部
本篇文章属于进阶知识,可能会用到曾经出现在专栏文章中的知识,如果你是第一次关注本专栏,建议你先阅读下其他文章:查询--爬虫(计算机网路)
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
==============================================================
Python爬虫介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-06-02 08:00
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。
Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。 查看全部
随着互联网的高速发展python 爬虫,大数据时代早已将至,网络爬虫这个名词也被人们越来越多的提起,但相信很多人对网路爬虫并不是太了解,下面就让小编给你们介绍一下哪些是网络爬虫?网络爬虫有哪些作用呢?
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。
Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。
网络爬虫简介(5)— 链接爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-05-31 08:01
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫! 查看全部
1.5.5 链接爬虫
到目前为止,我们早已借助示例网站的结构特性实现了两个简单爬虫,用于下载所有已发布的国家(或地区)页面。只要这两种技术可用,就应该使用它们进行爬取,因为这两种方式将须要下载的网页数目降至最低。不过,对于另一些网站爬虫社区,我们须要使爬虫表现得更象普通用户,跟踪链接,访问感兴趣的内容。
通过跟踪每位链接的方法,我们可以很容易地下载整个网站的页面。但是,这种方式可能会下载好多并不需要的网页。例如,我们想要从一个在线峰会中抓取用户帐号详情页,那么此时我们只须要下载帐号页,而不需要下载讨论贴的页面。本章使用的链接爬虫将使用正则表达式来确定应该下载什么页面。下面是这段代码的初始版本。
import re
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if html is not None:
continue
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
""" Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile("""<a[^>]+href=["'](.*?)["']""",
re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
要运行这段代码,只须要调用
link_crawler
函数,并传入两个参数:
要爬取的网站
URL
以及用于匹配你想跟踪的链
接的正则表达式。对于示例网
站来说,我们想要爬取的是国家(或地区
)列表索引页和国家(或地区)页面。
我们查看站点可以获知索引页链接遵守如下格式:
国家(或地区)页遵守如下格式:
因此爬虫社区,我们可以用/(index|view)/这个简单的正则表达式来匹配这两类网页。当爬虫使用这种输入参数运行时会发生哪些呢?你会得到如下所示的下载错误。
>>> link_crawler('http://example.python-scraping.com', '/(index|view)/')
Downloading: http://example.python-scraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1
正则表达式是从字符串中抽取信息的非常好的工具,因此我推荐每名程序员都应该“学会怎样阅读和编撰一些正则表达式”。即便这么,它们常常会特别脆弱,容易失效。我们将在本书后续部份介绍更先进的抽取链接和辨识页面的形式。可以看出,问题出在下载/index/1时,该链接只有网页的路径部份,而没有合同和服务器部份,也就是说这是一个相对链接。由于浏览器晓得你正在浏览那个网页,并且还能采取必要步骤处理那些链接,因此在浏览器浏览时,相对链接是才能正常工作的。但是,urllib并没有上下文。为了使urllib才能定位网页,我们须要将链接转换为绝对链接的方式,以便包含定位网页的所有细节。如你所愿,Python的urllib中有一个模块可以拿来实现该功能,该模块名为parse。下面是link_crawler的改进版本,使用了urljoin方式来创建绝对路径。
from urllib.parse import urljoin
def link_crawler(start_url, link_regex):
""" Crawl from the given start URL following links matched by
link_regex
"""
crawl_queue = [start_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
crawl_queue.append(abs_link)
当你运行这段代码时,会听到似乎下载了匹配的网页,但是同样的地点总是会被不断下载到。产生该行为的诱因是那些地点互相之间存在链接。比如,澳大利亚链接到了南极洲,而南极洲又链接回了德国,此时爬虫都会继续将这种URL装入队列,永远不会抵达队列尾部
。要想避开重复爬取相同的链接,我们须要记录什么链接早已被爬取过。下面是更改后的link_crawler函数,具备了储存已发觉URL的功能,可以避免重复下载。
def link_crawler(start_url, link_regex):
crawl_queue = [start_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
if not html:
continue
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
abs_link = urljoin(start_url, link)
# check if have already seen this link
if abs_link not in seen:
seen.add(abs_link)
crawl_queue.append(abs_link)
当运行该脚本时,它会爬取所有地点,并且还能如期停止。最终,我们得到了一个可用的链接爬虫!
3款你必须晓得的爬虫工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2020-05-31 08:01
微信公众号:Python数据科学
知乎:
本篇博主将和你们分享几个特别有用的爬虫小工具,这些小工具在实际的爬虫的开发中会大大降低你的时间成本,并同时提升你的工作效率,真的是十分实用的工具。
这些工具当然是Google上的插件,一些扩充程序,并且经博主亲测,无任何问题。最后的最后,博主将提供小工具的获取方法。
好了,话不多说,我们来介绍一下。
我们上面提及过,当客户端向服务器端提出<ajax>异步恳求(比如 <xhr>)时,会在响应里返回 <json> 格式的数据。
在开发者工具中,我们会听到 <json> 格式数据的可视化疗效太差,就是一段繁杂的字符串,难以直接看出关键信息。
那么为了直接有效的找到关键信息,<JSON-handle>工具会将纷繁的 <json> 格式数据弄成简单清晰的树形图,极大的提升可视化疗效。
方法很简单,如果你已然安装好了小工具,点开图标弹出框框,把<json>数据复制进去即可。
当然,你也可以把从任意地方用来的<json>数据放进去,不局限于浏览器异步响应。
就以<天猫网站>为例,随便找出一个异步的恳求,response是下边这样的。
jsonp_46336857({"201509290":{"data":[{"_pos_":1,"entityType":"13","acm":"201509290.1003.1.1286473","title":"【抢券减400】Apple/苹果iPhone X 全网通4G智能手机苹果10 苹果X","typ.......
把代码放进框框里,点击OK,就弄成下边这样了数(据比较长,只截取一部分)。
上篇剖析爬虫中HTTP的秘密(基础篇)我们介绍了恳求头,而这个工具就是针对恳求头中的User-Agent数组的。它的作用是可以随便更换浏览器的User-Agent。
比如,你用Chrome浏览器浏览网页,浏览器默认身分是Chrome,但是你可以通过这个工具更换成其它任何身分。
这个最大的益处就是可以直接更换成手机身分浏览网页,而毋须用开发者工具来回切换。
使用Chrome浏览器安装插件爬虫工具,点开图标,选择你须要的身分即可。
(默认Chrome浏览器是这样的)
(变换为IOS-iphone6)
针对Xpath解析方式,Xpath-Helper可提供当前网页指定Xpath句子的查询结果。
点开图标,出现白色框框。
1.假设目标为二维码下的<百度>二字
2.开发者工具找到源码相应位置,右键copy xpath
3.复制到QUERY上面,结果手动下来
注:Xpath-Helper小工具安装后须要重启Chrome方可使用爬虫工具,请你们注意一下这个坑。
下载Chrome浏览器下载小工具插件打开Chrome更多工具—>扩展程序拖动小工具插件程序<.crx>到扩充程序里安装
安装完成后,右上角会有三个小图标: 查看全部
作者:xiaoyu
微信公众号:Python数据科学
知乎:
本篇博主将和你们分享几个特别有用的爬虫小工具,这些小工具在实际的爬虫的开发中会大大降低你的时间成本,并同时提升你的工作效率,真的是十分实用的工具。
这些工具当然是Google上的插件,一些扩充程序,并且经博主亲测,无任何问题。最后的最后,博主将提供小工具的获取方法。
好了,话不多说,我们来介绍一下。
我们上面提及过,当客户端向服务器端提出<ajax>异步恳求(比如 <xhr>)时,会在响应里返回 <json> 格式的数据。
在开发者工具中,我们会听到 <json> 格式数据的可视化疗效太差,就是一段繁杂的字符串,难以直接看出关键信息。
那么为了直接有效的找到关键信息,<JSON-handle>工具会将纷繁的 <json> 格式数据弄成简单清晰的树形图,极大的提升可视化疗效。
方法很简单,如果你已然安装好了小工具,点开图标弹出框框,把<json>数据复制进去即可。
当然,你也可以把从任意地方用来的<json>数据放进去,不局限于浏览器异步响应。
就以<天猫网站>为例,随便找出一个异步的恳求,response是下边这样的。
jsonp_46336857({"201509290":{"data":[{"_pos_":1,"entityType":"13","acm":"201509290.1003.1.1286473","title":"【抢券减400】Apple/苹果iPhone X 全网通4G智能手机苹果10 苹果X","typ.......
把代码放进框框里,点击OK,就弄成下边这样了数(据比较长,只截取一部分)。
上篇剖析爬虫中HTTP的秘密(基础篇)我们介绍了恳求头,而这个工具就是针对恳求头中的User-Agent数组的。它的作用是可以随便更换浏览器的User-Agent。
比如,你用Chrome浏览器浏览网页,浏览器默认身分是Chrome,但是你可以通过这个工具更换成其它任何身分。
这个最大的益处就是可以直接更换成手机身分浏览网页,而毋须用开发者工具来回切换。
使用Chrome浏览器安装插件爬虫工具,点开图标,选择你须要的身分即可。
(默认Chrome浏览器是这样的)
(变换为IOS-iphone6)
针对Xpath解析方式,Xpath-Helper可提供当前网页指定Xpath句子的查询结果。
点开图标,出现白色框框。
1.假设目标为二维码下的<百度>二字
2.开发者工具找到源码相应位置,右键copy xpath
3.复制到QUERY上面,结果手动下来
注:Xpath-Helper小工具安装后须要重启Chrome方可使用爬虫工具,请你们注意一下这个坑。
下载Chrome浏览器下载小工具插件打开Chrome更多工具—>扩展程序拖动小工具插件程序<.crx>到扩充程序里安装
安装完成后,右上角会有三个小图标:
Python爬虫-爬取公司邮箱内的职工手机号码
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-05-31 08:00
前段时间接到一个业务人员的一个爬虫需求,爬取公司内部邮箱的通讯录,获取所有用户的手机号码,为业务的推广构建相应的白名单。
首先我们公司的邮箱是outlook的邮箱,只有登陆了邮箱就能够看见全公司的通讯录,因为人数比较多(近百万的职工),首先看一下具体的邮箱联系人员列表:
目录中列举的是子公司的名称,点击子公司后,后列举子公司的人员名单,再点击人员的时侯就会下来具体的手机号码及相关信息。
首先这个需求是须要不断的点击相应的条目就会下来相应的用户的手机号码的,但是这个人员的页面人数好多,也没有相应的分页标志邮箱爬虫软件,只是有一个滚动条可以上下的带动,里面的内容好多,至少是几万吧,所以就须要不断的点击人员信息。
之前也曾想过用普通的爬虫工具进行爬取,但是人员的那种也没有找到显著的规律性,不能直接通过简单的遍历才能够直接的获取相应的数据,另外数据的加载也是通过相应JavaScript脚本和ajax实现的,所以这个方式 我暂时没有想到比较好的解决办法(ps:大神假如有更好的解决办法请赐教。)
通过查阅相应的爬虫工具库,终于找到了一个自动化测试的python库(selenium库),这个库有一个用处就是可以模拟人类一样不断的点击滑鼠,获取相应的内容,通过模拟人类的相应操作才能够直接的获取相应的内容,至于具体的用法请自行百度(因为这个一个模拟浏览器在不断的点击,所有还须要下载相应的浏览器驱动)。
不多说,直接上代码是最实在的!!!
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 30 21:18:12 2018
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import WebDriverException
import time
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)
def login_outlook():
# 模仿浏览器进行登录操作
#需要爬去邮箱的地址
browser.get('--------------------------')
username = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#username')))
passwd = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#password')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#lgnDiv > div.signInEnter > div > span')))
#邮箱的用户名
username.send_keys('username')
#邮箱登录密码
passwd.send_keys('password')
submit.click()
def main():
# 登录
login_outlook()
time.sleep(5)
# 点击人员选项
submit_renyuan = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#_ariaId_19')))
submit_renyuan.click()
# 点击所有用户
submit_allyonghu = wait.until(
EC.element_to_be_clickable((By.XPATH,'//*[@id="_ariaId_452"]/div[1]/div[2]/div/div[2]/span')))
submit_allyonghu.click()
#遍历所有的用户
result =[]
# select_header ='''body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(1) > div._ph_j1 > div:nth-child(1) > div > div > div._ph_V1.customScrollBar.scrollContainer > div > div > div:nth-child('''
# select_tail =''') > span > div > span._pe_b._pe_s > span'''
Xpath_head = '''/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[1]/div[2]/div[1]/div/div/div[1]/div/div/div['''
Xpath_tail = ''']/span/div/span[3]/span'''
wait1 = WebDriverWait(browser,2)
#这里的10000是人为设定的,因为不知道这个页面上面具体有多少用户
for j in range(1,10000):
print(j)
for i in range(1,71):
print(i)
Xpath = Xpath_head + str(i) + Xpath_tail
print(Xpath)
try:
submit_ren = wait1.until(
EC.element_to_be_clickable((By.XPATH,Xpath)))
submit_ren.click()
except(NoSuchElementException,TimeoutException,WebDriverException):
print("连接超时")
continue
time.sleep(0.18)
# result.append(wait.until(
# EC.element_to_be_clickable((By.CSS_SELECTOR,'body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(4) > div:nth-child(2) > div > div:nth-child(3) > div._rpc_s > div:nth-child(1) > div > div > div:nth-child(1) > div > div > div'))))
#获取到相应的手机号码文本
rr=browser.find_element_by_xpath("/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[4]/div[2]/div/div[3]/div[4]/div[1]/div/div/div[1]/div/div/div")
saveFile = open('telno.txt','a')
saveFile.write(str(rr.text.replace("\n","|")))
saveFile.write("\n")
saveFile.close()
time.sleep(1)
if __name__ == '__main__':
main()
通过整个的爬取过程,发现这个爬虫程序有如下的不足:
(1)、虽然还能抓取到相应用户的手机号码,但是号码不一定全,其中有一个人为设定的10000,这个是非常不合理的地方,因为不知道具体有多少用户,所以就设定一个比较大的数字,但是这些做法非常不妥当;
(2)、在抓取的时侯发觉,模拟点击这员的时侯并不是挨个进行点击的,有跳动的现象,所以这也是爬取不全的缘由之一,之所以出现此类情况,还是由于对页面的加载方法和具体的数据加载方法不了解,为找到相应的规律(求高手赐教);
(3)爬取的成功与否还与服务器响应时间有很大的关系,检查保存的文件发觉有空行,这样的现象有两个缘由,一个是这个用户就没有相应的手机号码(这种现象确实存在,但是数目非常少),另一方面缘由就是服务器的响应时间比较慢,服务器还未返回对应用户的手机号,程序就开始点击下一个用户了;
(4)注意在每次模拟点击的时侯最好使程序沉睡一会(即代码中的 time.sleep( )),这样做一方面是为了等待服务器的相应,另一方也是为了模拟人类,因为点击很快的话,会被辨识的功击,会短时间的封锁你的ip地址的。
最后一点,随着这个爬虫还能爬取到用户的手机号码邮箱爬虫软件,但是存在众多的问题须要解决,最后爬取的手机号码也不是最全的,所以这个爬虫程序还是有很大的提高空间的。(这个前面我就会不断的改进的)。 查看全部
前段时间接到一个业务人员的一个爬虫需求,爬取公司内部邮箱的通讯录,获取所有用户的手机号码,为业务的推广构建相应的白名单。
首先我们公司的邮箱是outlook的邮箱,只有登陆了邮箱就能够看见全公司的通讯录,因为人数比较多(近百万的职工),首先看一下具体的邮箱联系人员列表:
目录中列举的是子公司的名称,点击子公司后,后列举子公司的人员名单,再点击人员的时侯就会下来具体的手机号码及相关信息。
首先这个需求是须要不断的点击相应的条目就会下来相应的用户的手机号码的,但是这个人员的页面人数好多,也没有相应的分页标志邮箱爬虫软件,只是有一个滚动条可以上下的带动,里面的内容好多,至少是几万吧,所以就须要不断的点击人员信息。
之前也曾想过用普通的爬虫工具进行爬取,但是人员的那种也没有找到显著的规律性,不能直接通过简单的遍历才能够直接的获取相应的数据,另外数据的加载也是通过相应JavaScript脚本和ajax实现的,所以这个方式 我暂时没有想到比较好的解决办法(ps:大神假如有更好的解决办法请赐教。)
通过查阅相应的爬虫工具库,终于找到了一个自动化测试的python库(selenium库),这个库有一个用处就是可以模拟人类一样不断的点击滑鼠,获取相应的内容,通过模拟人类的相应操作才能够直接的获取相应的内容,至于具体的用法请自行百度(因为这个一个模拟浏览器在不断的点击,所有还须要下载相应的浏览器驱动)。
不多说,直接上代码是最实在的!!!
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 30 21:18:12 2018
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import WebDriverException
import time
browser = webdriver.Chrome()
wait = WebDriverWait(browser,20)
def login_outlook():
# 模仿浏览器进行登录操作
#需要爬去邮箱的地址
browser.get('--------------------------')
username = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#username')))
passwd = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#password')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#lgnDiv > div.signInEnter > div > span')))
#邮箱的用户名
username.send_keys('username')
#邮箱登录密码
passwd.send_keys('password')
submit.click()
def main():
# 登录
login_outlook()
time.sleep(5)
# 点击人员选项
submit_renyuan = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#_ariaId_19')))
submit_renyuan.click()
# 点击所有用户
submit_allyonghu = wait.until(
EC.element_to_be_clickable((By.XPATH,'//*[@id="_ariaId_452"]/div[1]/div[2]/div/div[2]/span')))
submit_allyonghu.click()
#遍历所有的用户
result =[]
# select_header ='''body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(1) > div._ph_j1 > div:nth-child(1) > div > div > div._ph_V1.customScrollBar.scrollContainer > div > div > div:nth-child('''
# select_tail =''') > span > div > span._pe_b._pe_s > span'''
Xpath_head = '''/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[1]/div[2]/div[1]/div/div/div[1]/div/div/div['''
Xpath_tail = ''']/span/div/span[3]/span'''
wait1 = WebDriverWait(browser,2)
#这里的10000是人为设定的,因为不知道这个页面上面具体有多少用户
for j in range(1,10000):
print(j)
for i in range(1,71):
print(i)
Xpath = Xpath_head + str(i) + Xpath_tail
print(Xpath)
try:
submit_ren = wait1.until(
EC.element_to_be_clickable((By.XPATH,Xpath)))
submit_ren.click()
except(NoSuchElementException,TimeoutException,WebDriverException):
print("连接超时")
continue
time.sleep(0.18)
# result.append(wait.until(
# EC.element_to_be_clickable((By.CSS_SELECTOR,'body > div._n_X4 > div > div._n_p.csimg.image-headerbgmain-png > div:nth-child(3) > div:nth-child(2) > div._ph_S > div:nth-child(3) > div:nth-child(4) > div:nth-child(2) > div > div:nth-child(3) > div._rpc_s > div:nth-child(1) > div > div > div:nth-child(1) > div > div > div'))))
#获取到相应的手机号码文本
rr=browser.find_element_by_xpath("/html/body/div[2]/div/div[3]/div[3]/div[2]/div[2]/div[3]/div[4]/div[2]/div/div[3]/div[4]/div[1]/div/div/div[1]/div/div/div")
saveFile = open('telno.txt','a')
saveFile.write(str(rr.text.replace("\n","|")))
saveFile.write("\n")
saveFile.close()
time.sleep(1)
if __name__ == '__main__':
main()
通过整个的爬取过程,发现这个爬虫程序有如下的不足:
(1)、虽然还能抓取到相应用户的手机号码,但是号码不一定全,其中有一个人为设定的10000,这个是非常不合理的地方,因为不知道具体有多少用户,所以就设定一个比较大的数字,但是这些做法非常不妥当;
(2)、在抓取的时侯发觉,模拟点击这员的时侯并不是挨个进行点击的,有跳动的现象,所以这也是爬取不全的缘由之一,之所以出现此类情况,还是由于对页面的加载方法和具体的数据加载方法不了解,为找到相应的规律(求高手赐教);
(3)爬取的成功与否还与服务器响应时间有很大的关系,检查保存的文件发觉有空行,这样的现象有两个缘由,一个是这个用户就没有相应的手机号码(这种现象确实存在,但是数目非常少),另一方面缘由就是服务器的响应时间比较慢,服务器还未返回对应用户的手机号,程序就开始点击下一个用户了;
(4)注意在每次模拟点击的时侯最好使程序沉睡一会(即代码中的 time.sleep( )),这样做一方面是为了等待服务器的相应,另一方也是为了模拟人类,因为点击很快的话,会被辨识的功击,会短时间的封锁你的ip地址的。
最后一点,随着这个爬虫还能爬取到用户的手机号码邮箱爬虫软件,但是存在众多的问题须要解决,最后爬取的手机号码也不是最全的,所以这个爬虫程序还是有很大的提高空间的。(这个前面我就会不断的改进的)。
Python爬虫入门看哪些书好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2020-05-30 08:02
这本书是一本实战性的网路爬虫秘籍,在本书中除了讲解了怎样编撰爬虫,还讲解了流行的网路爬虫的使用。而且这本色书的作者在Python领域有着极其深厚的积累,不仅精通Python网络爬虫,而且在Python机器学习等领域都有着丰富的实战经验,所以说这本书是Python爬虫入门人员必备的书籍。
这本书总共从三个维度讲解了Python爬虫入门,分别是:
技术维度:详细讲解了Python网路爬虫实现的核心技术,包括网路爬虫的工作原理、如何用urllib库编撰网路爬虫、爬虫的异常处理、正则表达式、爬虫中Cookie的使用、爬虫的浏览器伪装技术、定向爬取技术、反爬虫技术,以及怎样自己动手编撰网路爬虫;
在学习python中有任何困难不懂的可以加入我的python交流学习群:629614370,多多交流问题,互帮互助,群里有不错的学习教程和开发工具。学习python有任何问题(学习方法,学习效率,如何就业),可以随时来咨询我。需要电子书籍的可以自己加裤下载,网盘链接不使发
工具维度:以流行的Python网路爬虫框架Scrapy为对象,详细讲解了Scrapy的功能使用、高级方法、架构设计、实现原理,以及怎样通过Scrapy来更便捷、高效地编撰网路爬虫;
实战维度:以实战为导向,是本书的主旨python爬虫经典书籍python爬虫经典书籍,除了完全通过自动编程实现网路爬虫和通过Scrapy框架实现网路爬虫的实战案例以外,本书还有博客爬取、图片爬取、模拟登陆等多个综合性的网路爬虫实践案例。 查看全部
生活在21世纪的互联网时代,各类技术的发展堪称是瞬息万变,这不明天编程界又出现一位“新星”,他的名子称作Python,目前Python早已超过Java而居于编程排名语言的第五位了。随着Python语言的火爆发展,目前很多人都在想学习Python,那么Python爬虫入门看哪些书好呢?小编为你推荐一本书,手把手教你学Python。
这本书是一本实战性的网路爬虫秘籍,在本书中除了讲解了怎样编撰爬虫,还讲解了流行的网路爬虫的使用。而且这本色书的作者在Python领域有着极其深厚的积累,不仅精通Python网络爬虫,而且在Python机器学习等领域都有着丰富的实战经验,所以说这本书是Python爬虫入门人员必备的书籍。
这本书总共从三个维度讲解了Python爬虫入门,分别是:
技术维度:详细讲解了Python网路爬虫实现的核心技术,包括网路爬虫的工作原理、如何用urllib库编撰网路爬虫、爬虫的异常处理、正则表达式、爬虫中Cookie的使用、爬虫的浏览器伪装技术、定向爬取技术、反爬虫技术,以及怎样自己动手编撰网路爬虫;
在学习python中有任何困难不懂的可以加入我的python交流学习群:629614370,多多交流问题,互帮互助,群里有不错的学习教程和开发工具。学习python有任何问题(学习方法,学习效率,如何就业),可以随时来咨询我。需要电子书籍的可以自己加裤下载,网盘链接不使发
工具维度:以流行的Python网路爬虫框架Scrapy为对象,详细讲解了Scrapy的功能使用、高级方法、架构设计、实现原理,以及怎样通过Scrapy来更便捷、高效地编撰网路爬虫;
实战维度:以实战为导向,是本书的主旨python爬虫经典书籍python爬虫经典书籍,除了完全通过自动编程实现网路爬虫和通过Scrapy框架实现网路爬虫的实战案例以外,本书还有博客爬取、图片爬取、模拟登陆等多个综合性的网路爬虫实践案例。
爬虫构架|如何设计一款类“即刻”信息订阅推送的爬虫构架(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 244 次浏览 • 2020-05-27 08:02
分发集群、爬虫集群、装饰集群
3.1 分发集群
分发集群有两个任务:
1. 接收后台恳求,新增内容源,首先判定内容源是否已存在(通过查询“内容源”表)。若不存在,则将内容源作为爬虫任务放置到定时任务池,并主动递交到爬虫队列。
2. 定时从任务池中获取全部任务爬虫框架设计,按类型、按级别(现只定义快慢两级)提交到对应爬虫队列。
注:爬虫队列分级是为了更好的消费任务。
快队列指的是拥有更多的消费者,能更快的完成任务,一般用于处理新任务。
慢队列值得是拥有较少的消费者,完成任务的时间慢,一般用于处理异常任务。
3.2 爬虫集群
爬虫集群也有两个任务:
1. 消费队列中的爬虫任务,抓取如title、desc、url等信息储存入数据库。此时,记录应如实对应内容源的内容,不应进行过滤,封装。
2. 完成一次爬虫任务后,提交到装潢任务队列——提供内容源的一次抓取结果(此处应为多条记录),希望将结果根据每位用户的要求过滤和封装。
3.3 装饰集群
装饰集群也有两个任务:
1. 消费队列中的装潢任务,查询“追踪对象表”和“主题表”,获取多种用户需求。对于每位用户,分别将抓取结果过滤和装潢,最后的封装结果按用户入库。
2. 入库成功后,需要远程调用(rmi)搜索引擎(搜索引擎建索引)、云通信(发送联通通知、邮件通知)、动态流(即刻的消息页,动态流须要将主题新更内容分发到对应关注者的“动态流”表中)。
四、爬虫技术实现
目前我那边追踪机器人使用的技术是python的Scrapy框架,分布式实现用的是scrapy-redis。
欢迎有志之士来我司和我一起实现我们产品中的信息订阅环节的工程,订阅环节是我们产品的基础爬虫框架设计,当然我们的产品远不只是那些。
我希望你有下边的知识点:
1)知道怎样借助IDE(推荐PyCharm)调试scrape爬虫程序
2)熟练使用xpath或css选择器获取页面元素
3)知道怎样使用selenium进行手动登入
4)熟练借助middleware中间件做ip代理池
5)使用scrapy-redis做过分布式爬虫项目
6)熟悉scrape构架图,熟练使用middleware中间件和讯号(Signals)进行扩充开发
7)熟悉各类爬虫、反爬虫攻守策略 查看全部
有了前面的业务剖析,接下来我们就可以瞧瞧我们的构架应当怎么样来设计啦。我这儿先给出整体构架图。
分发集群、爬虫集群、装饰集群
3.1 分发集群
分发集群有两个任务:
1. 接收后台恳求,新增内容源,首先判定内容源是否已存在(通过查询“内容源”表)。若不存在,则将内容源作为爬虫任务放置到定时任务池,并主动递交到爬虫队列。
2. 定时从任务池中获取全部任务爬虫框架设计,按类型、按级别(现只定义快慢两级)提交到对应爬虫队列。
注:爬虫队列分级是为了更好的消费任务。
快队列指的是拥有更多的消费者,能更快的完成任务,一般用于处理新任务。
慢队列值得是拥有较少的消费者,完成任务的时间慢,一般用于处理异常任务。
3.2 爬虫集群
爬虫集群也有两个任务:
1. 消费队列中的爬虫任务,抓取如title、desc、url等信息储存入数据库。此时,记录应如实对应内容源的内容,不应进行过滤,封装。
2. 完成一次爬虫任务后,提交到装潢任务队列——提供内容源的一次抓取结果(此处应为多条记录),希望将结果根据每位用户的要求过滤和封装。
3.3 装饰集群
装饰集群也有两个任务:
1. 消费队列中的装潢任务,查询“追踪对象表”和“主题表”,获取多种用户需求。对于每位用户,分别将抓取结果过滤和装潢,最后的封装结果按用户入库。
2. 入库成功后,需要远程调用(rmi)搜索引擎(搜索引擎建索引)、云通信(发送联通通知、邮件通知)、动态流(即刻的消息页,动态流须要将主题新更内容分发到对应关注者的“动态流”表中)。
四、爬虫技术实现
目前我那边追踪机器人使用的技术是python的Scrapy框架,分布式实现用的是scrapy-redis。
欢迎有志之士来我司和我一起实现我们产品中的信息订阅环节的工程,订阅环节是我们产品的基础爬虫框架设计,当然我们的产品远不只是那些。
我希望你有下边的知识点:
1)知道怎样借助IDE(推荐PyCharm)调试scrape爬虫程序
2)熟练使用xpath或css选择器获取页面元素
3)知道怎样使用selenium进行手动登入
4)熟练借助middleware中间件做ip代理池
5)使用scrapy-redis做过分布式爬虫项目
6)熟悉scrape构架图,熟练使用middleware中间件和讯号(Signals)进行扩充开发
7)熟悉各类爬虫、反爬虫攻守策略
Python爬虫视频教程全集下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-05-27 08:02
强大的编程语言,你一定会认为很难学吧?但事 实上,Python 是十分容易入门的。 因为它有丰富的标准库,不仅语言简练易懂,可读性强python爬虫高级教程,代码还具有太强的 可拓展性,比起 C 语言、Java 等编程语言要简单得多: C 语言可能须要写 1000 行代码,Java 可能须要写几百行代码python爬虫高级教程,而 Python 可能仅仅只需几十行代码能够搞定。Python 应用非常广泛的场景就是爬虫,很 多菜鸟刚入门 Python,也是由于爬虫。 网络爬虫是 Python 极其简单、基本、实用的技术之一,它的编撰也十分简 单,无许把握网页信息怎样呈现和形成。掌握了 Python 的基本句型后,是才能 轻易写出一个爬虫程序的。还没想好去哪家机构学习 Python 爬虫技术?千锋 Python 讲师风格奇特, 深入浅出, 常以简单的视角解决复杂的开发困局, 注重思维培养, 授课富于激情,做真实的自己-用良心做教育千锋教育 Python 培训擅长理论结合实际、提高中学生项目开发实战的能力。 当然了,千锋 Python 爬虫培训更重视就业服务:开设有就业指导课,设有 专门的就业指导老师,在结业前期,就业之际,就业老师会手把手地教中学生笔试 着装、面试礼仪、面试对话等基本的就业素质的培训。做到更有针对性和目标性 的笔试,提高就业率。做真实的自己-用良心做教育 查看全部
千锋教育 Python 培训Python 爬虫视频教程全集下载 python 作为一门中级编程语言,在编程中应用十分的广泛,近年来随着人 工智能的发展 python 人才的需求更大。当然,这也吸引了很多人选择自学 Python 爬虫。Python 爬虫视频教程全集在此分享给你们。 千锋 Python 课程教学前辈晋级视频总目录: Python 课程 windows 知识点: Python 课程 linux 知识点: Python 课程 web 知识点: Python 课程机器学习: 看完 Python 爬虫视频教程全集,来瞧瞧 Python 爬虫到底是什么。 Python 的市场需求每年都在大规模扩充。网络爬虫又被称为网页蜘蛛,是 一种根据一定的规则, 自动的抓取万维网信息的程序或则脚本, 已被广泛应用于 互联网领域。搜索引擎使用网路爬虫抓取 Web 网页、文档甚至图片、音频、视 频等资源,通过相应的索引技术组织这种信息,提供给搜索用户进行查询。做真实的自己-用良心做教育千锋教育 Python 培训Python 如此受欢迎,主要是它可以做的东西十分多,小到一个网页、一个 网站的建设,大到人工智能 AI、大数据剖析、机器学习、云计算等尖端技术, 都是基于 Python 来实现的。
强大的编程语言,你一定会认为很难学吧?但事 实上,Python 是十分容易入门的。 因为它有丰富的标准库,不仅语言简练易懂,可读性强python爬虫高级教程,代码还具有太强的 可拓展性,比起 C 语言、Java 等编程语言要简单得多: C 语言可能须要写 1000 行代码,Java 可能须要写几百行代码python爬虫高级教程,而 Python 可能仅仅只需几十行代码能够搞定。Python 应用非常广泛的场景就是爬虫,很 多菜鸟刚入门 Python,也是由于爬虫。 网络爬虫是 Python 极其简单、基本、实用的技术之一,它的编撰也十分简 单,无许把握网页信息怎样呈现和形成。掌握了 Python 的基本句型后,是才能 轻易写出一个爬虫程序的。还没想好去哪家机构学习 Python 爬虫技术?千锋 Python 讲师风格奇特, 深入浅出, 常以简单的视角解决复杂的开发困局, 注重思维培养, 授课富于激情,做真实的自己-用良心做教育千锋教育 Python 培训擅长理论结合实际、提高中学生项目开发实战的能力。 当然了,千锋 Python 爬虫培训更重视就业服务:开设有就业指导课,设有 专门的就业指导老师,在结业前期,就业之际,就业老师会手把手地教中学生笔试 着装、面试礼仪、面试对话等基本的就业素质的培训。做到更有针对性和目标性 的笔试,提高就业率。做真实的自己-用良心做教育
Python做爬虫到底比其他语言好在哪儿呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-25 08:02
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f... 查看全部
07-22
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f...

