
python爬虫
爬虫技术浅析
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-05-02 08:09
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
 谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
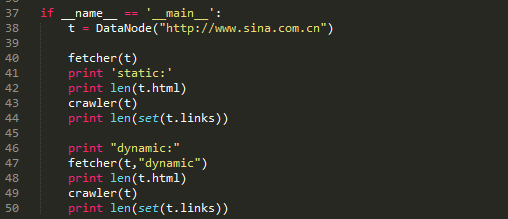
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。

在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
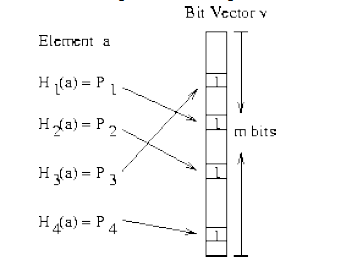
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
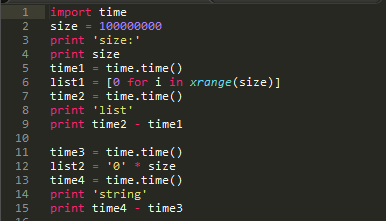
上面这段代码简单验证了生成容器的运行时间。
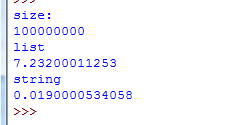
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
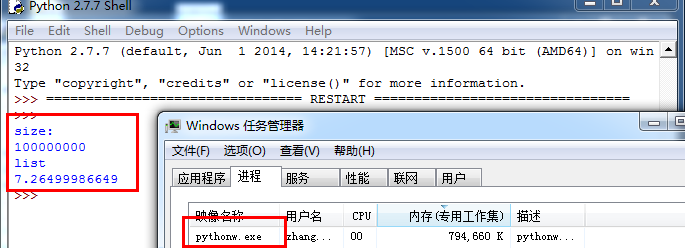
如果构建1亿的列表占用了794660k显存。
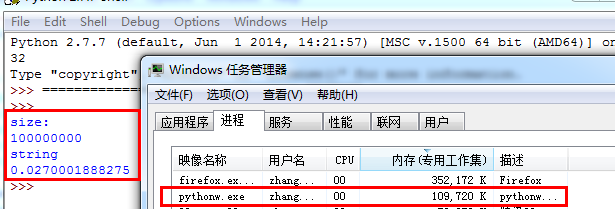
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
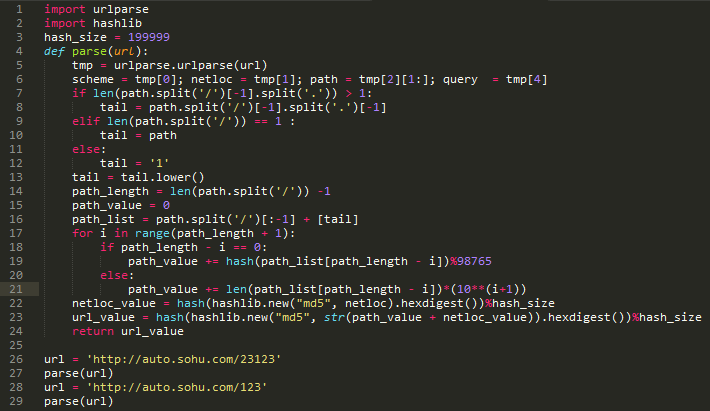
算法本身太菜,各位一看才能懂。
实际疗效:
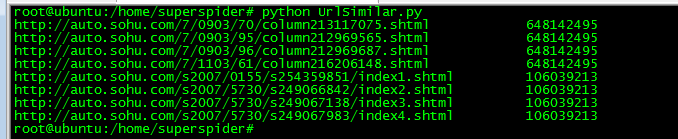
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型

目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。
爬虫框架是哪些?常见的Python爬虫框架有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-05-02 08:09
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。 查看全部
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。
爬虫技术浅析
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-05-02 08:09
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。
爬虫框架是哪些?常见的Python爬虫框架有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-05-02 08:09
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。 查看全部
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。

