
python爬虫
广受欢迎的专业电子峰会!
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-05-11 08:02
0
刚接触爬虫的菜鸟常常会问,到底须要使用哪种语言做爬虫爬虫技术用什么语言,其实,我相信任何语言,只要他具备访问网路的标准库,都可以挺轻易的做到这一点。刚刚接触爬虫的时侯,我总是苦恼于用 Python 来做爬虫,现在想来大可不必,无论是 JAVA,PHP 还是其他更低级语言,都可以很方便的实现,静态语言可能更不容易出错,低级语言运行速率可能更快,Python 的优势在于库更丰富,框架愈发成熟,但是对于菜鸟来说,熟悉库和框架实际上也要耗费不少时间。
比如我接触的 Scrapy,配环境就配了三天,对于上面复杂的结构更是云里雾里,任何爬虫都可以只使用几个简单的库来实现,虽然花费了好多时间,但是对整个 HTTP 流程有了更深的理解。所以,在没有搞清楚设计优势的时侯盲目的学习框架是制约技术进步的。
新手总是有一种倾向,花费巨大的精力去找寻这些一劳永逸的方式,语言和框架,妄想只要学了这个,以后长时间就可以高枕无忧,面对各类挑战。如果要我重来一次爬虫技术用什么语言,我会选择看一两篇这些优质的比较文章,然后大胆的选用其中一种主流的框架,在不重要的学习项目中尝试其他的框架,用了几次自然而然都会发觉她们的利弊。
现在我还发觉这些倾向除了在菜鸟中存在,学了许久的人也有好多患有这些技术焦虑症。他们看见媒体宣扬 Go 语言和 Assembly,大家都在讨论微服务和 React Native,也不知所以的加入。但是有的人还是真心读懂了这种技术的优势,他们在合适的场景下进行试探性的尝试,然后步步为营,将这种新技术运用到了主要业务中,我真钦佩这些人,他们不焦不怕冷的推动着新技术,永远都不会被新技术推着走。
无论使用哪种爬虫手段爬取数据,同一个IP频繁操作,必然会导致IP受限,不过如今这也不算问题,因为市面上的代理IP基本都可以解决这个问题。所以只要选择自己适宜的语言就可以了。
亿牛云HTTP代理为您提供安全稳定、高效方便的爬虫代理IP服务,提供高匿代理IP资源的同时,还可以设置不同类型的HTTP代理,以及设置去重等等标准,简单一点说,亿牛云HTTP代理就似乎是一个中间桥梁,可以按照用户的需求设置HTTP代理类型,助您不间断获取行业数据
0 查看全部
0
刚接触爬虫的菜鸟常常会问,到底须要使用哪种语言做爬虫爬虫技术用什么语言,其实,我相信任何语言,只要他具备访问网路的标准库,都可以挺轻易的做到这一点。刚刚接触爬虫的时侯,我总是苦恼于用 Python 来做爬虫,现在想来大可不必,无论是 JAVA,PHP 还是其他更低级语言,都可以很方便的实现,静态语言可能更不容易出错,低级语言运行速率可能更快,Python 的优势在于库更丰富,框架愈发成熟,但是对于菜鸟来说,熟悉库和框架实际上也要耗费不少时间。
比如我接触的 Scrapy,配环境就配了三天,对于上面复杂的结构更是云里雾里,任何爬虫都可以只使用几个简单的库来实现,虽然花费了好多时间,但是对整个 HTTP 流程有了更深的理解。所以,在没有搞清楚设计优势的时侯盲目的学习框架是制约技术进步的。
新手总是有一种倾向,花费巨大的精力去找寻这些一劳永逸的方式,语言和框架,妄想只要学了这个,以后长时间就可以高枕无忧,面对各类挑战。如果要我重来一次爬虫技术用什么语言,我会选择看一两篇这些优质的比较文章,然后大胆的选用其中一种主流的框架,在不重要的学习项目中尝试其他的框架,用了几次自然而然都会发觉她们的利弊。
现在我还发觉这些倾向除了在菜鸟中存在,学了许久的人也有好多患有这些技术焦虑症。他们看见媒体宣扬 Go 语言和 Assembly,大家都在讨论微服务和 React Native,也不知所以的加入。但是有的人还是真心读懂了这种技术的优势,他们在合适的场景下进行试探性的尝试,然后步步为营,将这种新技术运用到了主要业务中,我真钦佩这些人,他们不焦不怕冷的推动着新技术,永远都不会被新技术推着走。
无论使用哪种爬虫手段爬取数据,同一个IP频繁操作,必然会导致IP受限,不过如今这也不算问题,因为市面上的代理IP基本都可以解决这个问题。所以只要选择自己适宜的语言就可以了。
亿牛云HTTP代理为您提供安全稳定、高效方便的爬虫代理IP服务,提供高匿代理IP资源的同时,还可以设置不同类型的HTTP代理,以及设置去重等等标准,简单一点说,亿牛云HTTP代理就似乎是一个中间桥梁,可以按照用户的需求设置HTTP代理类型,助您不间断获取行业数据
0
关于爬虫程序的合法性?
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-05-10 08:03
希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
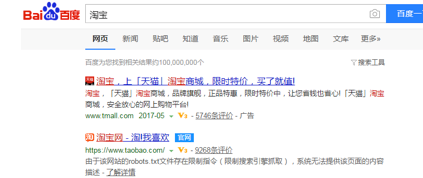
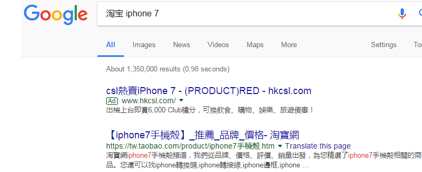
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗? 查看全部

希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗?
Python爬虫模拟登陆的黑魔法
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-05-10 08:02
大概思路是这样, 通过 selenium 打开浏览器, 模拟登陆。 获取cookies ,并将cookies以文件的方式保存到本地。 当我们使用requests打开页面的时侯就可以用本地的cookies。 由于 通过selenium打开浏览器的形式登录没有那么多限制,只须要模拟登陆流程( 输入账号密码python爬虫模拟登录, 点击登入即可登录)。 而且selenium可以模拟各类浏览器,亦可以在命令行下实现浏览器功能。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browser
通过seleum 模拟登录python爬虫模拟登录, 然后将cookie打包保存到本地
import requests
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)
cookies = browser.get_cookies()
# save the current cookies as a python object using pickle import selenium.webdriver
import pickle
pickle.dump( cookies , open("cookies.ini","wb"))
# add them back:browser = selenium.webdriver.Firefox()
browser.get("http://www.example.com")
cookies = pickle.load(open("cookies.pkl", "rb"))for cookie in cookies:
browser.add_cookie(cookie)
import pickleimport selenium.webdriver
import pickleimport requests
cookies = pickle.load(open("cookies.pkl", "rb"))
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value'])# 加载cookies后登录网站request.get("www.example.com")
import pickleimport requestsfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef setup():
browser = webdriver.Firefox() return browserdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browserdef set_sessions(browser):
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
}
request.headers.update(headers)
cookies = browser.get_cookies() for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value']) return requestif __name__ == "__main__":
browser = login("textusername", "tespassword", setup())
rq = set_sessiond(browser)
re.get("http://www.example.com")
由于selenium 下的phantomJS在使用过程中出现了不知缘由的各类坑。 所以在Python中我们可以用下边的方式,在命令行打开Chrome、FireFox。
from pyvirtualdisplay import Displayfrom selenium import webdriver
display = Display(visible=0, size=(1024, 768))
display.start()
chromedriver = "/root/project/driver/chromedriver"os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
作者:王独立
链接: 查看全部
今天用 requests + BeautifulSoup 抓取 aliexpress 的时侯, 在模拟登陆时侯出现了好多问题, 提交数据时会对密码等一些数组加密, 而且递交一大堆不知名的数组, 大概有二十多项。 看到那么多数组, 整个人就不好了, 作为一个懒人, 准备绕开这个坑。
大概思路是这样, 通过 selenium 打开浏览器, 模拟登陆。 获取cookies ,并将cookies以文件的方式保存到本地。 当我们使用requests打开页面的时侯就可以用本地的cookies。 由于 通过selenium打开浏览器的形式登录没有那么多限制,只须要模拟登陆流程( 输入账号密码python爬虫模拟登录, 点击登入即可登录)。 而且selenium可以模拟各类浏览器,亦可以在命令行下实现浏览器功能。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browser
通过seleum 模拟登录python爬虫模拟登录, 然后将cookie打包保存到本地
import requests
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)
cookies = browser.get_cookies()
# save the current cookies as a python object using pickle import selenium.webdriver
import pickle
pickle.dump( cookies , open("cookies.ini","wb"))
# add them back:browser = selenium.webdriver.Firefox()
browser.get("http://www.example.com")
cookies = pickle.load(open("cookies.pkl", "rb"))for cookie in cookies:
browser.add_cookie(cookie)
import pickleimport selenium.webdriver
import pickleimport requests
cookies = pickle.load(open("cookies.pkl", "rb"))
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value'])# 加载cookies后登录网站request.get("www.example.com")
import pickleimport requestsfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef setup():
browser = webdriver.Firefox() return browserdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browserdef set_sessions(browser):
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
}
request.headers.update(headers)
cookies = browser.get_cookies() for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value']) return requestif __name__ == "__main__":
browser = login("textusername", "tespassword", setup())
rq = set_sessiond(browser)
re.get("http://www.example.com")
由于selenium 下的phantomJS在使用过程中出现了不知缘由的各类坑。 所以在Python中我们可以用下边的方式,在命令行打开Chrome、FireFox。
from pyvirtualdisplay import Displayfrom selenium import webdriver
display = Display(visible=0, size=(1024, 768))
display.start()
chromedriver = "/root/project/driver/chromedriver"os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
作者:王独立
链接:
【Scrapy】走进成熟的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-10 08:02
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
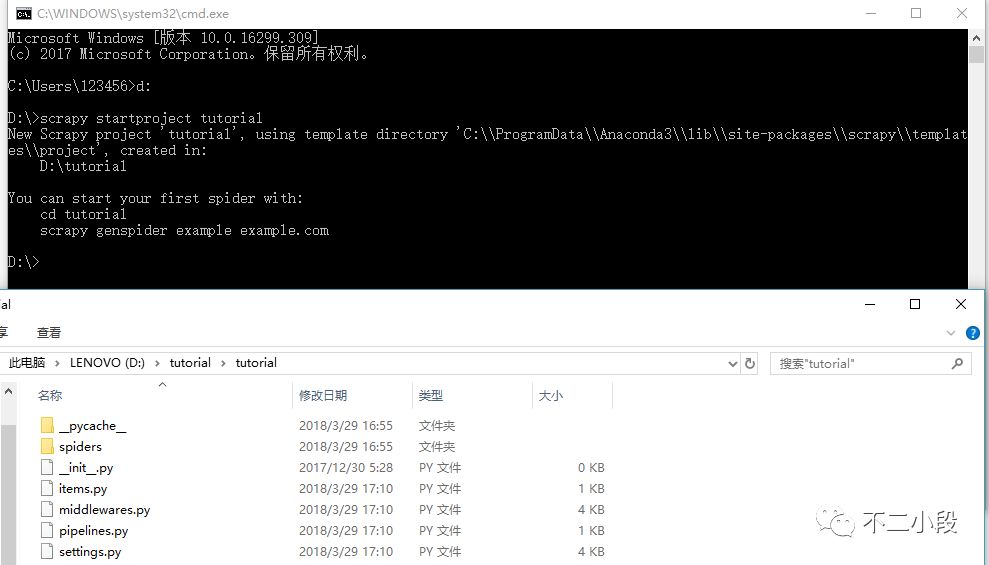
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录. 查看全部
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:

具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
Python爬虫形式抓取免费代理IP
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2020-05-10 08:01
由于个别网站对会对爬虫做限制,因此往往须要通过代理将爬虫的实际IP隐蔽上去,代理也有分类,如透明代理,高匿代理等。
本文主要述说怎么获取代理IP,并且怎么储存和使用。
某些网站会免费提供代理IP,如下边的几个
获取那些页面上的代理IP及端口也是通过爬虫抓取,下面以第一个网站xicidaili.com为例,解释怎样获取并储存这种代理IP。一般的流程为:解析当前页面–>存储当前页面的代理IP–>跳转到下一页面,重复该流程即可。
首先要解析页面,由于网页中显示代理IP时是在表格中显示的,因此只须要通过找出网页源码中相关的表格元素即可。下面是通过python中的requests和bs4获取页面xicidaili.com/nt/上显示的IP及端口。
import requestsfrom bs4 import BeautifulSoupuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text print proxy
输出如下:
36.235.1.189:3128219.141.225.149:80125.44.132.44:9999123.249.8.100:3128183.54.30.186:9999110.211.45.228:9000
上面代码获取的代理IP可以通过在代码一开始构建一个集合(set)来储存,这种情况适用于一次性使用这种代理IP,当程序发生异常或正常退出后,这些储存在显存中的代理IP也会遗失。但是爬虫中使用代理IP的情况又是十分多的,所以有必要把这种IP储存上去python爬虫抓超链接,从而可以使程序多次借助。
这里主要通过redis数据库储存这种代理IP,redis是一个NOSQL数据库,具体使用参照官方文档,这里不做详尽解释。
下面是ConnectRedis.py文件,用于联接redis
import redisHOST = 'XXX.XXX.XXX.XXX' # redis所在主机IPPORT = 6379 # redis服务监听的端口PASSWORD = 'XXXXXX' # 连接redis的密码DB = 0 # IP存储的DB编号def get_connection(): r = redis.Redis(host = HOST, port = PORT, password = PASSWORD, db= DB) return r
下面是在前面的代码基础中将IP储存到redis中,
import requestsfrom bs4 import BeautifulSoupfrom ConnectRedis import get_connection# 获取redis连接try: conn = get_connection()except Exception: print 'Error while connecting to redis' returnuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text conn.sadd("ip_set", proxy) print '%s added to ip set'%proxy
上面的conn.sadd(“ip_set”, proxy)将代理proxy加入到redis的集合”ip_set”,这个集合须要预先在redis中创建,否则会出错。
上面的代码获取的只是一个页面上显示的代理,显然这个数目不够,一般通过当前页面中的下一页的超链接可以跳转到下一页,但是我们测试的因为每页的的url都有规律,都是xicidaili.com/nt/page_number,其中的page_number表示当前在哪一页,省略时为第一页。因此,通过一个for循环嵌套里面的代码即可获取多个页面的代理。但是更通常的方式是通过在当前页面获取下一页的超链接而跳转到下一页。
当我们须要通过代理访问某一网站时,首先须要从redis中随机选出一个代理ip,然后尝试通过代理ip是否能连到我们须要访问的目标网站,因为这种代理IP是公共使用的,所以常常也会被封的很快python爬虫抓超链接,假如通过代理难以访问目标网站,那么就要从数据库中删掉这个代理IP。反之即可通过此代理访问目标网站
下面是实现里面所说流程的代码:
import requestsfrom ConnectRedis import get_connection# 判断IP是否能访问目标网站def is_valid(url, ip): proxy = { 'http': 'http://%s' %ip } user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36' headers = {'user-agent': user_agent} try: r = requests.get(url, headers = headers, proxies = proxy, timeout = 6) return True except Exception: return Falseif __name__ == '__main__': my_proxy, proxies, ip_set = None, None, 'amazon_ips' conn = get_connection() target = 'https://www.amazon.com/' while not is_valid(target, my_proxy): if my_proxy: conn.srem(ip_set, my_proxy) #删除无效的代理IP if proxies: my_proxy = proxies.pop() else: proxies = conn.srandmember(ip_set, 5) #从redis中随机抽5个代理ip my_proxy = proxies.pop() print 'valid proxy %s' %my_proxy
requests.get(url, headers = headers, proxies = proxy, timeout = 6)是通过代理去访问目标网站,超时时间设为6s,也就是说在6秒内网站没有回应或返回错误信息就觉得这个代理无效。
除此之外,在爬取免费提供代理的网站上的代理IP的时侯,爬取的速率不要很快,其中的一个缘由是爬取很快有可能会被封,另外一个缘由是假如每个人都无间隙地从这些网站上爬取,那么网站的负担会比较大,甚至有可能垮掉,因此采用一个可持续爬取的策略特别有必要,我爬取的时侯是没爬完一个页面后使程序sleep大约2分钟,这样出来不会被封并且爬取的代理的量也足够使用。实际中可以按照自己使用代理的频度来进行调整。
当然,免费代理ip虽然也只能用于练手,免费的ip代理在可用率,速度、安全性里面,都无法跟付费的IP代理对比,尤其是独享的IP代理,所以企业爬虫采集的话,为了更快更稳定的进行业务举办,建议你们订购付费的ip代理,比如快闪或则飞蚁,类似的付费代理具有并发高,单次提取200个IP,间隔一秒,所以短时间内可以获取大量IP进行数据采集。 查看全部
我们菜鸟在练手的时侯,常常须要一些代理ip进行爬虫抓取,但是由于学习阶段,对IP质量要求不高,主要是搞清原理,所以花钱订购就变得没必要(大款忽视),今天跟你们分享一下,如果使用爬虫抓取免费的代理IP。
由于个别网站对会对爬虫做限制,因此往往须要通过代理将爬虫的实际IP隐蔽上去,代理也有分类,如透明代理,高匿代理等。
本文主要述说怎么获取代理IP,并且怎么储存和使用。
某些网站会免费提供代理IP,如下边的几个
获取那些页面上的代理IP及端口也是通过爬虫抓取,下面以第一个网站xicidaili.com为例,解释怎样获取并储存这种代理IP。一般的流程为:解析当前页面–>存储当前页面的代理IP–>跳转到下一页面,重复该流程即可。
首先要解析页面,由于网页中显示代理IP时是在表格中显示的,因此只须要通过找出网页源码中相关的表格元素即可。下面是通过python中的requests和bs4获取页面xicidaili.com/nt/上显示的IP及端口。
import requestsfrom bs4 import BeautifulSoupuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text print proxy
输出如下:
36.235.1.189:3128219.141.225.149:80125.44.132.44:9999123.249.8.100:3128183.54.30.186:9999110.211.45.228:9000
上面代码获取的代理IP可以通过在代码一开始构建一个集合(set)来储存,这种情况适用于一次性使用这种代理IP,当程序发生异常或正常退出后,这些储存在显存中的代理IP也会遗失。但是爬虫中使用代理IP的情况又是十分多的,所以有必要把这种IP储存上去python爬虫抓超链接,从而可以使程序多次借助。
这里主要通过redis数据库储存这种代理IP,redis是一个NOSQL数据库,具体使用参照官方文档,这里不做详尽解释。
下面是ConnectRedis.py文件,用于联接redis
import redisHOST = 'XXX.XXX.XXX.XXX' # redis所在主机IPPORT = 6379 # redis服务监听的端口PASSWORD = 'XXXXXX' # 连接redis的密码DB = 0 # IP存储的DB编号def get_connection(): r = redis.Redis(host = HOST, port = PORT, password = PASSWORD, db= DB) return r
下面是在前面的代码基础中将IP储存到redis中,
import requestsfrom bs4 import BeautifulSoupfrom ConnectRedis import get_connection# 获取redis连接try: conn = get_connection()except Exception: print 'Error while connecting to redis' returnuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text conn.sadd("ip_set", proxy) print '%s added to ip set'%proxy
上面的conn.sadd(“ip_set”, proxy)将代理proxy加入到redis的集合”ip_set”,这个集合须要预先在redis中创建,否则会出错。
上面的代码获取的只是一个页面上显示的代理,显然这个数目不够,一般通过当前页面中的下一页的超链接可以跳转到下一页,但是我们测试的因为每页的的url都有规律,都是xicidaili.com/nt/page_number,其中的page_number表示当前在哪一页,省略时为第一页。因此,通过一个for循环嵌套里面的代码即可获取多个页面的代理。但是更通常的方式是通过在当前页面获取下一页的超链接而跳转到下一页。
当我们须要通过代理访问某一网站时,首先须要从redis中随机选出一个代理ip,然后尝试通过代理ip是否能连到我们须要访问的目标网站,因为这种代理IP是公共使用的,所以常常也会被封的很快python爬虫抓超链接,假如通过代理难以访问目标网站,那么就要从数据库中删掉这个代理IP。反之即可通过此代理访问目标网站
下面是实现里面所说流程的代码:
import requestsfrom ConnectRedis import get_connection# 判断IP是否能访问目标网站def is_valid(url, ip): proxy = { 'http': 'http://%s' %ip } user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36' headers = {'user-agent': user_agent} try: r = requests.get(url, headers = headers, proxies = proxy, timeout = 6) return True except Exception: return Falseif __name__ == '__main__': my_proxy, proxies, ip_set = None, None, 'amazon_ips' conn = get_connection() target = 'https://www.amazon.com/' while not is_valid(target, my_proxy): if my_proxy: conn.srem(ip_set, my_proxy) #删除无效的代理IP if proxies: my_proxy = proxies.pop() else: proxies = conn.srandmember(ip_set, 5) #从redis中随机抽5个代理ip my_proxy = proxies.pop() print 'valid proxy %s' %my_proxy
requests.get(url, headers = headers, proxies = proxy, timeout = 6)是通过代理去访问目标网站,超时时间设为6s,也就是说在6秒内网站没有回应或返回错误信息就觉得这个代理无效。
除此之外,在爬取免费提供代理的网站上的代理IP的时侯,爬取的速率不要很快,其中的一个缘由是爬取很快有可能会被封,另外一个缘由是假如每个人都无间隙地从这些网站上爬取,那么网站的负担会比较大,甚至有可能垮掉,因此采用一个可持续爬取的策略特别有必要,我爬取的时侯是没爬完一个页面后使程序sleep大约2分钟,这样出来不会被封并且爬取的代理的量也足够使用。实际中可以按照自己使用代理的频度来进行调整。
当然,免费代理ip虽然也只能用于练手,免费的ip代理在可用率,速度、安全性里面,都无法跟付费的IP代理对比,尤其是独享的IP代理,所以企业爬虫采集的话,为了更快更稳定的进行业务举办,建议你们订购付费的ip代理,比如快闪或则飞蚁,类似的付费代理具有并发高,单次提取200个IP,间隔一秒,所以短时间内可以获取大量IP进行数据采集。
《Python3网络爬虫开发实战》来了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-05-09 08:03
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!
本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁 查看全部
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!

本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁
爬虫常用库的安装(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-05-09 08:02
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快! 查看全部
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快!
网络爬虫简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-05-09 08:01
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
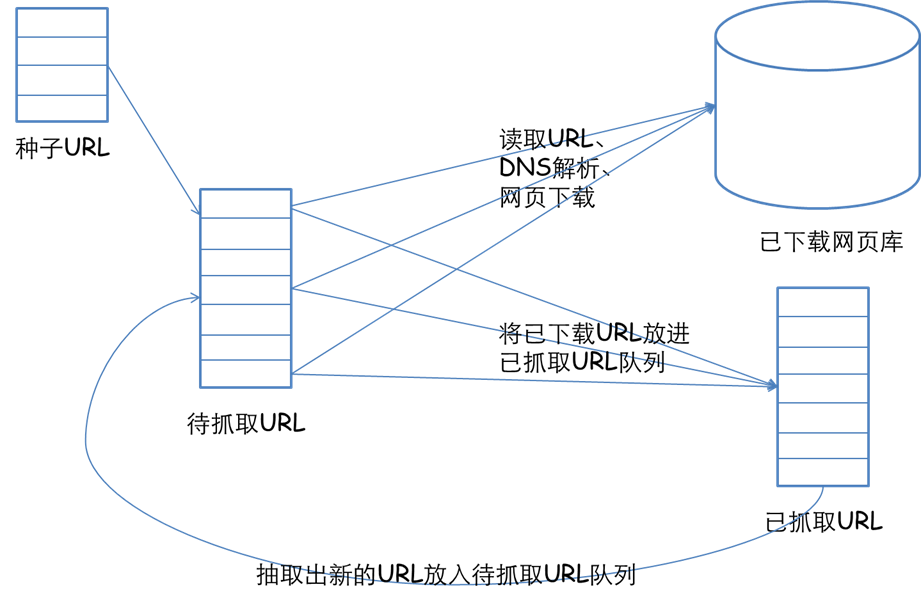
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:
初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:
而在爬虫眼中网络爬虫,这个网页是这样的:
因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:
最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:
Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。
,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器
BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:
首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:
查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:

初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:

而在爬虫眼中网络爬虫,这个网页是这样的:

因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:

最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:

Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。

,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器

BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:

首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:


Python爬虫代理池
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-05-09 08:01
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬爬虫代理软件,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
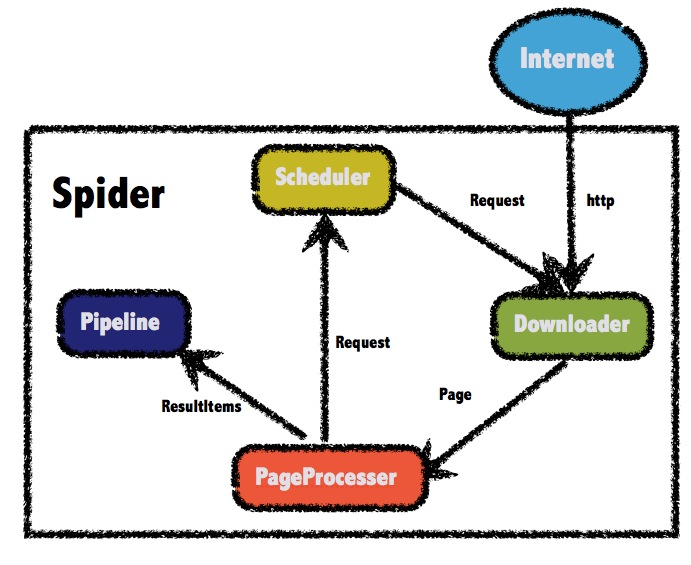
2、代理池设计
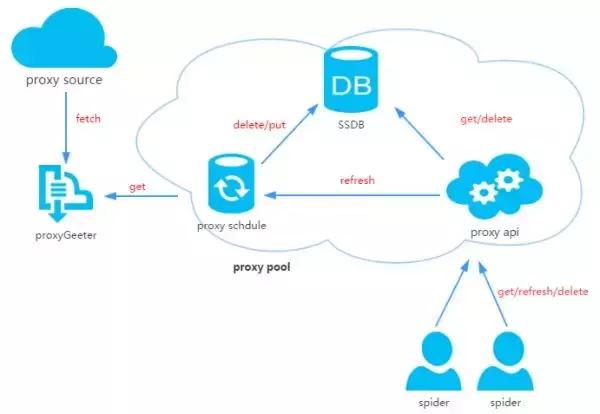
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数爬虫代理软件,包含GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
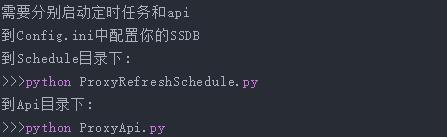
4、安装
下载代码:
安装依赖:
pip install -r requirements.txt
启动:
5、使用
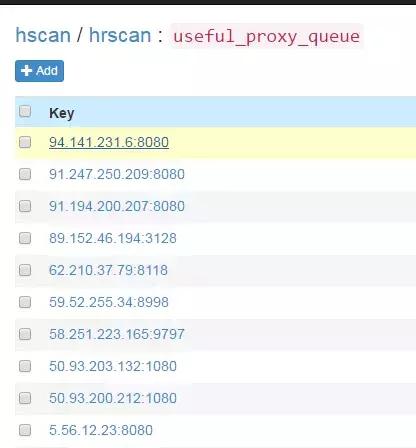
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
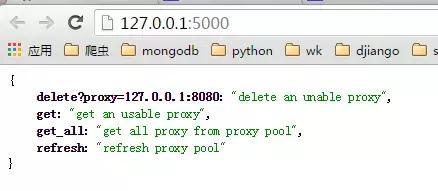
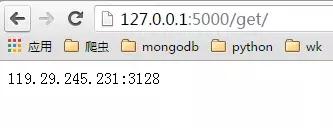
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:
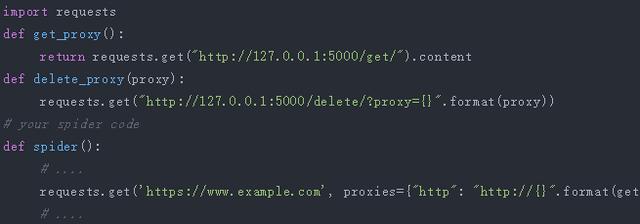
爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
6、最后 查看全部

在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。

1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬爬虫代理软件,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数爬虫代理软件,包含GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:

安装依赖:
pip install -r requirements.txt
启动:
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:

爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
6、最后
Python和数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2020-05-08 08:03
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们! 查看全部
网络爬虫, Python和数据 分析王澎 中国科技大学哪些是网络爬虫?? 网络爬虫是一个手动提取网页的程序,它为搜索 引擎从万维网上下载网页,是搜索引擎的重要组 成。传统爬虫从一个或若干初始网页的URL开始, 获得初始网页上的URL,在抓取网页的过程中, 不断从当前页面上抽取新的URL装入队列,直到满 足系统的一定停止条件爬虫有哪些用?? 做为通用搜索引擎网页收集器。(google,baidu) ? 做垂直搜索引擎.(找工作的搜索引擎:,数据来源于: , , 等等) ? 科学研究:在线人类行为,在线社群演变,人类 动力学研究数据挖掘与网络爬虫,计量社会学,复杂网路,数据挖掘, 等领域的实证研究都须要大量数据,网络爬虫是 收集相关数据的神器。 ? 偷窥,hacking数据挖掘与网络爬虫,发垃圾邮件……(《google hack》….)爬虫是搜索引擎的第一步 也是最容易的一步? 网页收集 ? 建立索引 ? 查询排序用哪些语言写爬虫?? C,C++。高效率,快速,适合通用搜索引 擎做全网爬取。缺点,开发慢,写上去又 臭又长,例如:天网搜索源代码。? 脚本语言:Perl, Python, Java, Ruby。简单, 易学,良好的文本处理能便捷网页内容的 细致提取,但效率常常不高,适合对少量 网站的聚焦爬取? C#?(貌似信息管理的人比较喜欢的语言)我当初拿来写过爬虫的语言? Perl: 古老的脚本语言,hack 语言,被拿来写爬虫 有着悠久的历史,因此,书本支持相当丰富: 《spidering hacks》,《Perl & LWP》;强大的文 本处理能力,数据库支持能力。
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们!
了解网页结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2020-05-08 08:01
学习爬虫, 首先要懂的是网页. 支撑起各类光鲜亮丽的网页的不是别的, 全都是一些代码.这种代码我们称之为 HTML,HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这些语言转换成我们用肉眼见到的网页.所以 HTML 里面必将存在着好多规律, 我们的爬虫还能根据这样的规律来爬取你须要的信息.
其实不仅 HTML, 一同打造多彩/多功能网页的组件还有 CSS 和. 但是这个简单的爬虫教程,大部分时间会将会使用 HTML.CSS 和 JavaScript 会在后期简单介绍一下. 因为爬网页的时侯多多少少还是要和 CSS JavaScript 打交道的.
虽然莫烦Python主打的是机器学习的教程. 但是这个爬虫教程适用于任何想学爬虫的朋友们.从机器学习的角度看爬虫结构, 机器学习中的大量数据, 也是可以从这种网页中来, 使用爬虫来爬取各类网页里面的信息, 然后再装入各类机器学习的方式,这样的应用途径正在越来越多被采用. 所以假如你的数据也是分散在各个网页中, 爬虫是你降低人力劳动的必修课.
网页基本组成部分
在真正步入爬虫之前, 我们先来做一下热身运动, 弄明白网页的基础, HTML 有什么组成部分,是怎么样运作的. 如果你早已十分熟悉网页的构造了, 欢迎直接跳过这一节, 进入下边的学习.
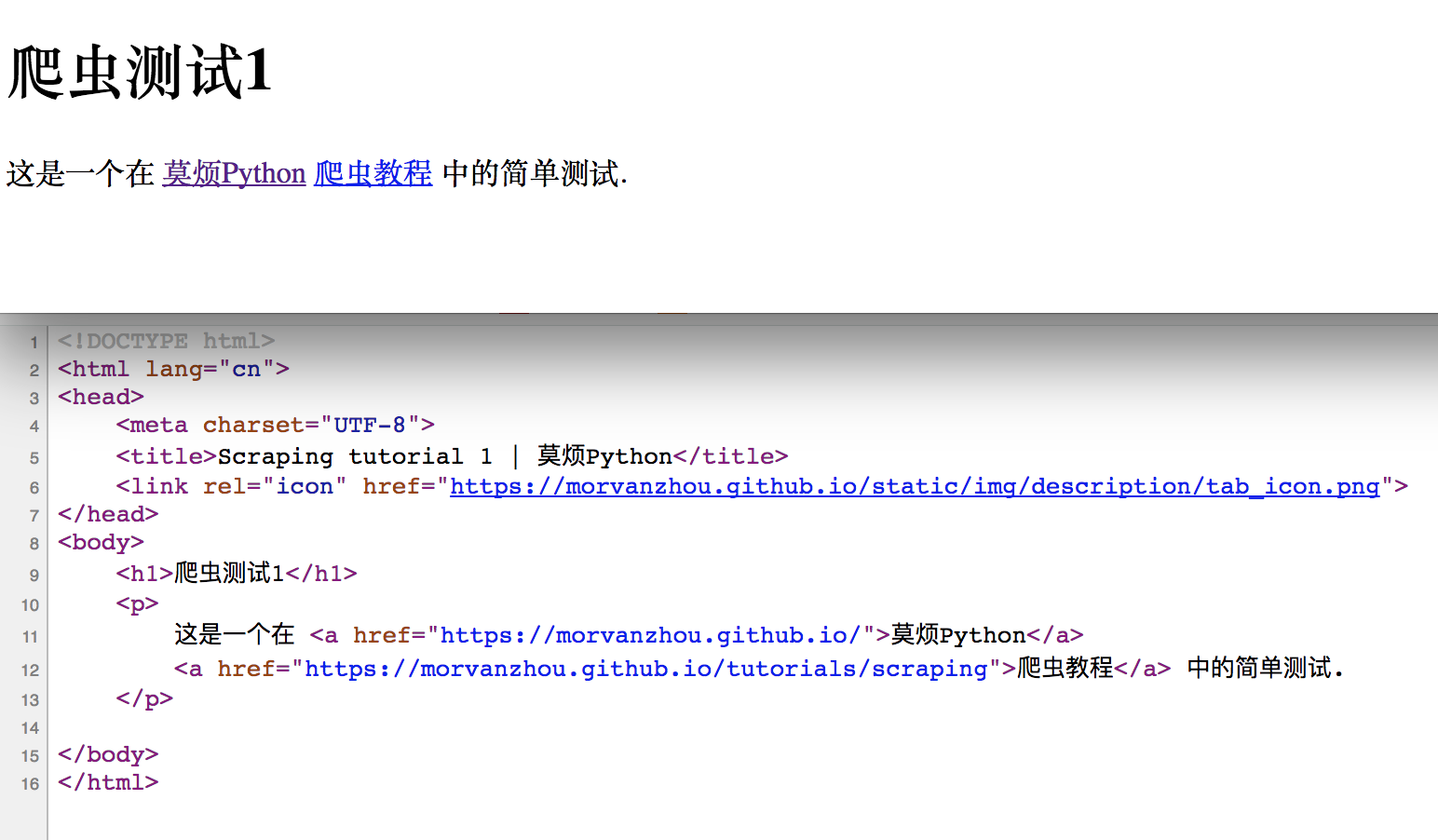
我制做了一个特别简易的网页, 给你们呈现以下最肉感的 HTML 结构.如果你点开它, 呈现在你眼前的, 就是下边这张图的上半部份. 而下半部份就是我们网页背后的 HTML code.
想问我是怎么见到 HTML 的 source code 的? 其实很简单, 在你的浏览器中 (我用的是 Google Chrome),显示网页的地方, 点击滑鼠右键,大多数浏览器就会有类似这样一个选项 “View Page Source”. 点击它能够看见页面的源码了.
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的方式, 或有不同的功能.主体的 tag 分成两部份, header 和 body. 在 header 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看见的网页中的.这些信息大多数时侯是给浏览器看, 或者是给搜索引擎的爬虫看.
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
HTML 的第二大块是 body, 这个部份才是你看见的网页信息. 网页中的 heading, 视频, 图片和文字等都储存在这里.这里的 <h1></h1> tag 就是主标题, 我们看见呈现下来的疗效就是大一号的文字. <p></p> 里面的文字就是一个段落.<a></a>里面都是一些链接. 所以好多情况, 东西都是置于这种 tag 中的.
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
爬虫想要做的就是按照这种 tag 来找到合适的信息.
用 Python 登录网页
好了, 对网页结构和 HTML 有了一些基本认识之后, 我们能够用 Python 来爬取这个网页的一些基本信息.首先要做的, 是使用 Python 来登入这个网页, 并复印出这个网页 HTML 的 source code.注意, 因为网页中存在英文, 为了正常显示英文, read() 完之后, 我们要对读下来的文字进行转换, decode() 成可以正常显示英文的方式.
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/s ... ot%3B
).read().decode('utf-8')
print(html)
print 出来就是下边这样啦. 这就证明了我们能否成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和借助.我们发觉, 想要提取一些方式的信息, 合理的借助 tag 的名子非常重要.
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
匹配网页内容
所以这儿我们使用 Python 的正则表达式 RegEx 进行匹配文字, 筛选信息的工作. 我有一个很不错的正则表达式的教程,如果是中级的网页匹配, 我们使用正则完全就可以了, 高级一点或则比较冗长的匹配, 我还是推荐使用 BeautifulSoup.不急不急, 我知道你想偷懒, 我然后马上还会教 beautiful soup 了. 但是如今我们还是使用正则来做几个简单的事例, 让你熟悉一下套路.
如果我们想用代码找到这个网页的 title, 我们能够这样写. 选好要使用的 tag 名称 <title>. 使用正则匹配.
import re
res = re.findall(r"<title>(.+?)</title>", html)
print("\nPage title is: ", res[0])
# Page title is: Scraping tutorial 1 | 莫烦Python
如果想要找到中间的那种段落 <p>, 我们使用下边方式, 因为这个段落在 HTML 中还参杂着 tab, new line, 所以我们给一个flags=re.DOTALL 来对那些 tab, new line 不敏感.
res = re.findall(r"<p>(.*?)</p>", html, flags=re.DOTALL) # re.DOTALL if multi line
print("\nPage paragraph is: ", res[0])
# Page paragraph is:
# 这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
# <a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
最后一个练习是找一找所有的链接, 这个比较有用, 有时候你想找到网页里的链接, 然后下载一些内容到笔记本里,就靠这样的途径了.
res = re.findall(r'href="(.*?)"', html)
print("\nAll links: ", res)
# All links:
['https://morvanzhou.github.io/static/img/description/tab_icon.png',
'https://morvanzhou.github.io/',
'https://morvanzhou.github.io/tutorials/scraping']
下次我们就来瞧瞧为了图方面爬虫结构, 我们怎样使用 BeautifulSoup.
相关教程 查看全部
学习资料:
学习爬虫, 首先要懂的是网页. 支撑起各类光鲜亮丽的网页的不是别的, 全都是一些代码.这种代码我们称之为 HTML,HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这些语言转换成我们用肉眼见到的网页.所以 HTML 里面必将存在着好多规律, 我们的爬虫还能根据这样的规律来爬取你须要的信息.
其实不仅 HTML, 一同打造多彩/多功能网页的组件还有 CSS 和. 但是这个简单的爬虫教程,大部分时间会将会使用 HTML.CSS 和 JavaScript 会在后期简单介绍一下. 因为爬网页的时侯多多少少还是要和 CSS JavaScript 打交道的.

虽然莫烦Python主打的是机器学习的教程. 但是这个爬虫教程适用于任何想学爬虫的朋友们.从机器学习的角度看爬虫结构, 机器学习中的大量数据, 也是可以从这种网页中来, 使用爬虫来爬取各类网页里面的信息, 然后再装入各类机器学习的方式,这样的应用途径正在越来越多被采用. 所以假如你的数据也是分散在各个网页中, 爬虫是你降低人力劳动的必修课.
网页基本组成部分
在真正步入爬虫之前, 我们先来做一下热身运动, 弄明白网页的基础, HTML 有什么组成部分,是怎么样运作的. 如果你早已十分熟悉网页的构造了, 欢迎直接跳过这一节, 进入下边的学习.
我制做了一个特别简易的网页, 给你们呈现以下最肉感的 HTML 结构.如果你点开它, 呈现在你眼前的, 就是下边这张图的上半部份. 而下半部份就是我们网页背后的 HTML code.
想问我是怎么见到 HTML 的 source code 的? 其实很简单, 在你的浏览器中 (我用的是 Google Chrome),显示网页的地方, 点击滑鼠右键,大多数浏览器就会有类似这样一个选项 “View Page Source”. 点击它能够看见页面的源码了.
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的方式, 或有不同的功能.主体的 tag 分成两部份, header 和 body. 在 header 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看见的网页中的.这些信息大多数时侯是给浏览器看, 或者是给搜索引擎的爬虫看.
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
HTML 的第二大块是 body, 这个部份才是你看见的网页信息. 网页中的 heading, 视频, 图片和文字等都储存在这里.这里的 <h1></h1> tag 就是主标题, 我们看见呈现下来的疗效就是大一号的文字. <p></p> 里面的文字就是一个段落.<a></a>里面都是一些链接. 所以好多情况, 东西都是置于这种 tag 中的.
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
爬虫想要做的就是按照这种 tag 来找到合适的信息.
用 Python 登录网页
好了, 对网页结构和 HTML 有了一些基本认识之后, 我们能够用 Python 来爬取这个网页的一些基本信息.首先要做的, 是使用 Python 来登入这个网页, 并复印出这个网页 HTML 的 source code.注意, 因为网页中存在英文, 为了正常显示英文, read() 完之后, 我们要对读下来的文字进行转换, decode() 成可以正常显示英文的方式.
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/s ... ot%3B
).read().decode('utf-8')
print(html)
print 出来就是下边这样啦. 这就证明了我们能否成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和借助.我们发觉, 想要提取一些方式的信息, 合理的借助 tag 的名子非常重要.
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
匹配网页内容
所以这儿我们使用 Python 的正则表达式 RegEx 进行匹配文字, 筛选信息的工作. 我有一个很不错的正则表达式的教程,如果是中级的网页匹配, 我们使用正则完全就可以了, 高级一点或则比较冗长的匹配, 我还是推荐使用 BeautifulSoup.不急不急, 我知道你想偷懒, 我然后马上还会教 beautiful soup 了. 但是如今我们还是使用正则来做几个简单的事例, 让你熟悉一下套路.
如果我们想用代码找到这个网页的 title, 我们能够这样写. 选好要使用的 tag 名称 <title>. 使用正则匹配.
import re
res = re.findall(r"<title>(.+?)</title>", html)
print("\nPage title is: ", res[0])
# Page title is: Scraping tutorial 1 | 莫烦Python
如果想要找到中间的那种段落 <p>, 我们使用下边方式, 因为这个段落在 HTML 中还参杂着 tab, new line, 所以我们给一个flags=re.DOTALL 来对那些 tab, new line 不敏感.
res = re.findall(r"<p>(.*?)</p>", html, flags=re.DOTALL) # re.DOTALL if multi line
print("\nPage paragraph is: ", res[0])
# Page paragraph is:
# 这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
# <a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
最后一个练习是找一找所有的链接, 这个比较有用, 有时候你想找到网页里的链接, 然后下载一些内容到笔记本里,就靠这样的途径了.
res = re.findall(r'href="(.*?)"', html)
print("\nAll links: ", res)
# All links:
['https://morvanzhou.github.io/static/img/description/tab_icon.png',
'https://morvanzhou.github.io/',
'https://morvanzhou.github.io/tutorials/scraping']
下次我们就来瞧瞧为了图方面爬虫结构, 我们怎样使用 BeautifulSoup.
相关教程
33款可用来抓数据的开源爬虫软件工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2020-05-07 08:02
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。 查看全部
要玩大数据,没有数据如何玩?这里推荐一些33款开源爬虫软件给你们。
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签

heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。

webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
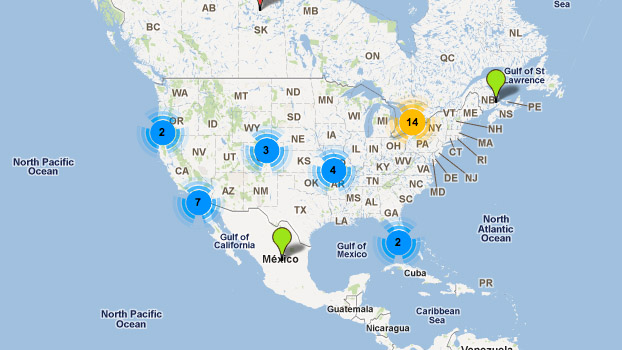
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。
通俗的讲,网络爬虫到底是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-05-06 08:03
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,
以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。
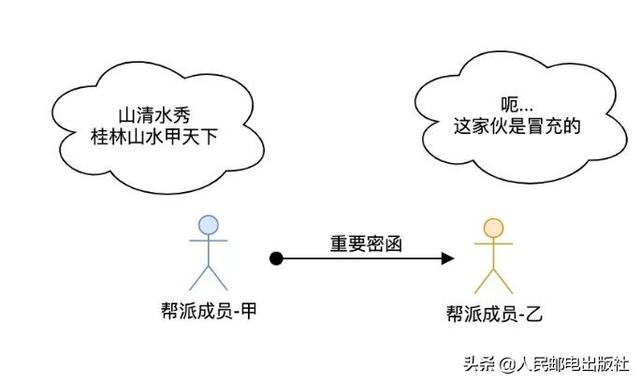
假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
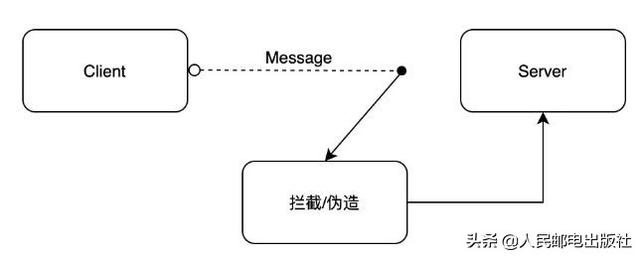
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:
那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
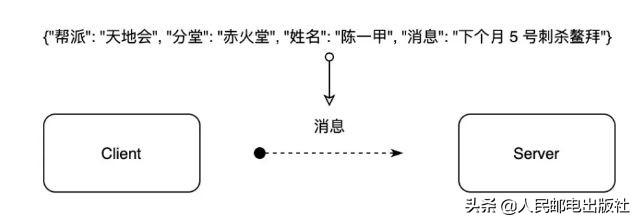
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
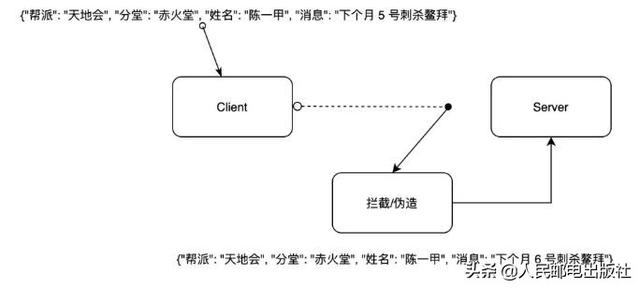
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功? 查看全部
爬虫的起源
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。

爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
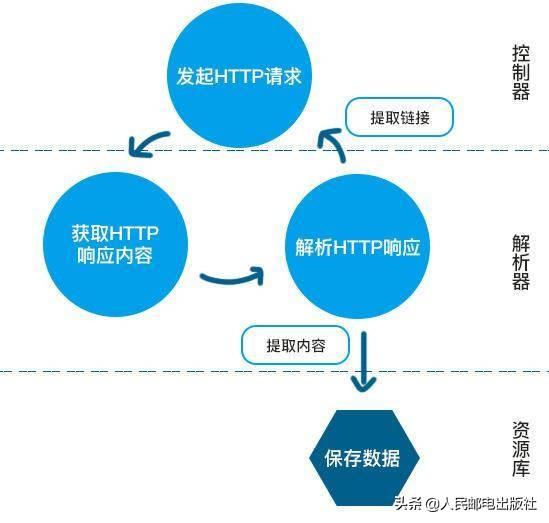
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,

以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。

假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
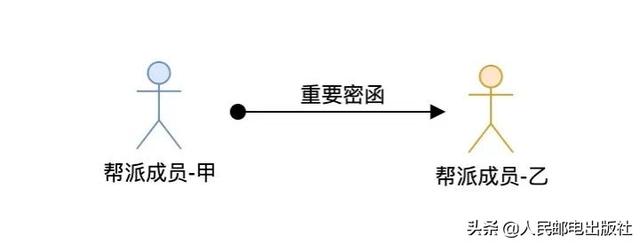
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
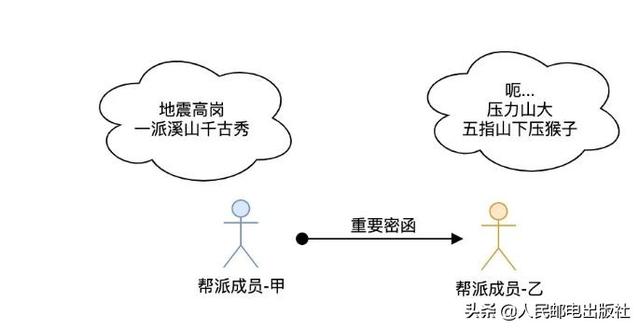
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:

那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功?
老司机带你学爬虫——Python爬虫技术分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-05-06 08:01
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心 查看全部
什么是“爬虫”?
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心
设计和实现一款轻量级的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-05-05 08:05
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。
关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图
整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图
项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献 查看全部
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。

关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图

整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图

项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献
Scrapy爬虫框架:抓取天猫淘宝数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-05-05 08:05
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。 查看全部
有了前两篇的基础,接下来通过抓取天猫和淘宝的数据来详尽说明,如何通过Scrapy爬取想要的内容。完整的代码:[不带数据库版本][ 数据库版本]。
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。
网络爬虫:使用Scrapy框架编撰一个抓取书籍信息的爬虫服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-05-04 08:06
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) 查看全部
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总),
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:

虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)
开源爬虫框架各有哪些优缺点
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-05-04 08:06
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。 查看全部
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。
一般公司做爬虫采集的话常用哪些语言
采集交流 • 优采云 发表了文章 • 0 个评论 • 555 次浏览 • 2020-05-03 08:09
其实我不太同意做了DHT爬虫这位的说法。
不同语言自然会有不同害处。离开环境谈那个好网络爬虫用什么语言写,哪个不好都是耍流氓。
1,如果是自己做着玩的话,定向爬几个页面网络爬虫用什么语言写,效率不是核心要求的话,问题不会大,什么语言都行的,性能差别不会大。当然,如果遇到极其复杂的页面,正则写的很复杂的话,爬虫的可维护性都会增长。
2,如果是做定向爬取,而目标又要解析动态js。
那么这个时侯,用普通的恳求页面,然后得到内容的方式肯定不行了,就要一个类似firfox,chrome的js引擎来对js代码做动态解析。这个时侯推荐casperJS+phantomjs或slimerJS+phantomjs
3,如果是大规模的网站爬取
这个时侯就要考虑到,效率,扩展性,可维护性,等等了。
大规模的爬取涉及的方面好多,比如分布式爬取,判重机制,任务调度。这些问题深入下去哪一个简单了?
语言选定这个时侯很重要。
NodeJs:做爬虫效率很高。高并发,多线程编程弄成了简单的遍历和callback,内存cpu占用小,要处理好callback。
PHP:各种框架四处有,随便拉个来用都行。但是,PHP的效率真的有问题…不多说
Python:我用python写的比较多,对各类问题都有比较好的支持。scrapy框架挺好用,优点多。
我认为js也不是太适宜写…效率问题。没写过,估计会有麻烦一堆。
据我晓得的,大公司也有用c++的,总之大多数都是在开源框架上改建。真重新造个轮子的不多吧。
不值。
随手凭印象写的,欢迎见谅。 查看全部

其实我不太同意做了DHT爬虫这位的说法。
不同语言自然会有不同害处。离开环境谈那个好网络爬虫用什么语言写,哪个不好都是耍流氓。
1,如果是自己做着玩的话,定向爬几个页面网络爬虫用什么语言写,效率不是核心要求的话,问题不会大,什么语言都行的,性能差别不会大。当然,如果遇到极其复杂的页面,正则写的很复杂的话,爬虫的可维护性都会增长。
2,如果是做定向爬取,而目标又要解析动态js。
那么这个时侯,用普通的恳求页面,然后得到内容的方式肯定不行了,就要一个类似firfox,chrome的js引擎来对js代码做动态解析。这个时侯推荐casperJS+phantomjs或slimerJS+phantomjs
3,如果是大规模的网站爬取
这个时侯就要考虑到,效率,扩展性,可维护性,等等了。
大规模的爬取涉及的方面好多,比如分布式爬取,判重机制,任务调度。这些问题深入下去哪一个简单了?
语言选定这个时侯很重要。
NodeJs:做爬虫效率很高。高并发,多线程编程弄成了简单的遍历和callback,内存cpu占用小,要处理好callback。
PHP:各种框架四处有,随便拉个来用都行。但是,PHP的效率真的有问题…不多说
Python:我用python写的比较多,对各类问题都有比较好的支持。scrapy框架挺好用,优点多。
我认为js也不是太适宜写…效率问题。没写过,估计会有麻烦一堆。
据我晓得的,大公司也有用c++的,总之大多数都是在开源框架上改建。真重新造个轮子的不多吧。
不值。
随手凭印象写的,欢迎见谅。
[ Python爬虫实战 ] 爬虫简介与作用
采集交流 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2020-05-03 08:02
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。
广受欢迎的专业电子峰会!
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-05-11 08:02
0
刚接触爬虫的菜鸟常常会问,到底须要使用哪种语言做爬虫爬虫技术用什么语言,其实,我相信任何语言,只要他具备访问网路的标准库,都可以挺轻易的做到这一点。刚刚接触爬虫的时侯,我总是苦恼于用 Python 来做爬虫,现在想来大可不必,无论是 JAVA,PHP 还是其他更低级语言,都可以很方便的实现,静态语言可能更不容易出错,低级语言运行速率可能更快,Python 的优势在于库更丰富,框架愈发成熟,但是对于菜鸟来说,熟悉库和框架实际上也要耗费不少时间。
比如我接触的 Scrapy,配环境就配了三天,对于上面复杂的结构更是云里雾里,任何爬虫都可以只使用几个简单的库来实现,虽然花费了好多时间,但是对整个 HTTP 流程有了更深的理解。所以,在没有搞清楚设计优势的时侯盲目的学习框架是制约技术进步的。
新手总是有一种倾向,花费巨大的精力去找寻这些一劳永逸的方式,语言和框架,妄想只要学了这个,以后长时间就可以高枕无忧,面对各类挑战。如果要我重来一次爬虫技术用什么语言,我会选择看一两篇这些优质的比较文章,然后大胆的选用其中一种主流的框架,在不重要的学习项目中尝试其他的框架,用了几次自然而然都会发觉她们的利弊。
现在我还发觉这些倾向除了在菜鸟中存在,学了许久的人也有好多患有这些技术焦虑症。他们看见媒体宣扬 Go 语言和 Assembly,大家都在讨论微服务和 React Native,也不知所以的加入。但是有的人还是真心读懂了这种技术的优势,他们在合适的场景下进行试探性的尝试,然后步步为营,将这种新技术运用到了主要业务中,我真钦佩这些人,他们不焦不怕冷的推动着新技术,永远都不会被新技术推着走。
无论使用哪种爬虫手段爬取数据,同一个IP频繁操作,必然会导致IP受限,不过如今这也不算问题,因为市面上的代理IP基本都可以解决这个问题。所以只要选择自己适宜的语言就可以了。
亿牛云HTTP代理为您提供安全稳定、高效方便的爬虫代理IP服务,提供高匿代理IP资源的同时,还可以设置不同类型的HTTP代理,以及设置去重等等标准,简单一点说,亿牛云HTTP代理就似乎是一个中间桥梁,可以按照用户的需求设置HTTP代理类型,助您不间断获取行业数据
0 查看全部
0
刚接触爬虫的菜鸟常常会问,到底须要使用哪种语言做爬虫爬虫技术用什么语言,其实,我相信任何语言,只要他具备访问网路的标准库,都可以挺轻易的做到这一点。刚刚接触爬虫的时侯,我总是苦恼于用 Python 来做爬虫,现在想来大可不必,无论是 JAVA,PHP 还是其他更低级语言,都可以很方便的实现,静态语言可能更不容易出错,低级语言运行速率可能更快,Python 的优势在于库更丰富,框架愈发成熟,但是对于菜鸟来说,熟悉库和框架实际上也要耗费不少时间。
比如我接触的 Scrapy,配环境就配了三天,对于上面复杂的结构更是云里雾里,任何爬虫都可以只使用几个简单的库来实现,虽然花费了好多时间,但是对整个 HTTP 流程有了更深的理解。所以,在没有搞清楚设计优势的时侯盲目的学习框架是制约技术进步的。
新手总是有一种倾向,花费巨大的精力去找寻这些一劳永逸的方式,语言和框架,妄想只要学了这个,以后长时间就可以高枕无忧,面对各类挑战。如果要我重来一次爬虫技术用什么语言,我会选择看一两篇这些优质的比较文章,然后大胆的选用其中一种主流的框架,在不重要的学习项目中尝试其他的框架,用了几次自然而然都会发觉她们的利弊。
现在我还发觉这些倾向除了在菜鸟中存在,学了许久的人也有好多患有这些技术焦虑症。他们看见媒体宣扬 Go 语言和 Assembly,大家都在讨论微服务和 React Native,也不知所以的加入。但是有的人还是真心读懂了这种技术的优势,他们在合适的场景下进行试探性的尝试,然后步步为营,将这种新技术运用到了主要业务中,我真钦佩这些人,他们不焦不怕冷的推动着新技术,永远都不会被新技术推着走。
无论使用哪种爬虫手段爬取数据,同一个IP频繁操作,必然会导致IP受限,不过如今这也不算问题,因为市面上的代理IP基本都可以解决这个问题。所以只要选择自己适宜的语言就可以了。
亿牛云HTTP代理为您提供安全稳定、高效方便的爬虫代理IP服务,提供高匿代理IP资源的同时,还可以设置不同类型的HTTP代理,以及设置去重等等标准,简单一点说,亿牛云HTTP代理就似乎是一个中间桥梁,可以按照用户的需求设置HTTP代理类型,助您不间断获取行业数据
0
关于爬虫程序的合法性?
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-05-10 08:03
希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗? 查看全部
希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗?
Python爬虫模拟登陆的黑魔法
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-05-10 08:02
大概思路是这样, 通过 selenium 打开浏览器, 模拟登陆。 获取cookies ,并将cookies以文件的方式保存到本地。 当我们使用requests打开页面的时侯就可以用本地的cookies。 由于 通过selenium打开浏览器的形式登录没有那么多限制,只须要模拟登陆流程( 输入账号密码python爬虫模拟登录, 点击登入即可登录)。 而且selenium可以模拟各类浏览器,亦可以在命令行下实现浏览器功能。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browser
通过seleum 模拟登录python爬虫模拟登录, 然后将cookie打包保存到本地
import requests
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)
cookies = browser.get_cookies()
# save the current cookies as a python object using pickle import selenium.webdriver
import pickle
pickle.dump( cookies , open("cookies.ini","wb"))
# add them back:browser = selenium.webdriver.Firefox()
browser.get("http://www.example.com")
cookies = pickle.load(open("cookies.pkl", "rb"))for cookie in cookies:
browser.add_cookie(cookie)
import pickleimport selenium.webdriver
import pickleimport requests
cookies = pickle.load(open("cookies.pkl", "rb"))
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value'])# 加载cookies后登录网站request.get("www.example.com")
import pickleimport requestsfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef setup():
browser = webdriver.Firefox() return browserdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browserdef set_sessions(browser):
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
}
request.headers.update(headers)
cookies = browser.get_cookies() for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value']) return requestif __name__ == "__main__":
browser = login("textusername", "tespassword", setup())
rq = set_sessiond(browser)
re.get("http://www.example.com")
由于selenium 下的phantomJS在使用过程中出现了不知缘由的各类坑。 所以在Python中我们可以用下边的方式,在命令行打开Chrome、FireFox。
from pyvirtualdisplay import Displayfrom selenium import webdriver
display = Display(visible=0, size=(1024, 768))
display.start()
chromedriver = "/root/project/driver/chromedriver"os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
作者:王独立
链接: 查看全部
今天用 requests + BeautifulSoup 抓取 aliexpress 的时侯, 在模拟登陆时侯出现了好多问题, 提交数据时会对密码等一些数组加密, 而且递交一大堆不知名的数组, 大概有二十多项。 看到那么多数组, 整个人就不好了, 作为一个懒人, 准备绕开这个坑。
大概思路是这样, 通过 selenium 打开浏览器, 模拟登陆。 获取cookies ,并将cookies以文件的方式保存到本地。 当我们使用requests打开页面的时侯就可以用本地的cookies。 由于 通过selenium打开浏览器的形式登录没有那么多限制,只须要模拟登陆流程( 输入账号密码python爬虫模拟登录, 点击登入即可登录)。 而且selenium可以模拟各类浏览器,亦可以在命令行下实现浏览器功能。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browser
通过seleum 模拟登录python爬虫模拟登录, 然后将cookie打包保存到本地
import requests
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)
cookies = browser.get_cookies()
# save the current cookies as a python object using pickle import selenium.webdriver
import pickle
pickle.dump( cookies , open("cookies.ini","wb"))
# add them back:browser = selenium.webdriver.Firefox()
browser.get("http://www.example.com")
cookies = pickle.load(open("cookies.pkl", "rb"))for cookie in cookies:
browser.add_cookie(cookie)
import pickleimport selenium.webdriver
import pickleimport requests
cookies = pickle.load(open("cookies.pkl", "rb"))
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
request.headers.update(headers)for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value'])# 加载cookies后登录网站request.get("www.example.com")
import pickleimport requestsfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef setup():
browser = webdriver.Firefox() return browserdef login(username, password browser=None):
browser.get("https://login.example.com/")
pwd_btn = browser.find_element_by_name("password")
act_btn = browser.find_element_by_name("loginId")
submit_btn = browser.find_element_by_name("submit-btn")
act_but.send_keys(username)
pwd_btn.send_keys(password)
submint_btn.send_keys(Keys.ENTER) return browserdef set_sessions(browser):
request = requests.Session()
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
}
request.headers.update(headers)
cookies = browser.get_cookies() for cookie in cookies:
request.cookies.set(cookie['name'], cookie['value']) return requestif __name__ == "__main__":
browser = login("textusername", "tespassword", setup())
rq = set_sessiond(browser)
re.get("http://www.example.com")
由于selenium 下的phantomJS在使用过程中出现了不知缘由的各类坑。 所以在Python中我们可以用下边的方式,在命令行打开Chrome、FireFox。
from pyvirtualdisplay import Displayfrom selenium import webdriver
display = Display(visible=0, size=(1024, 768))
display.start()
chromedriver = "/root/project/driver/chromedriver"os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
作者:王独立
链接:
【Scrapy】走进成熟的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-10 08:02
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录. 查看全部
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
Python爬虫形式抓取免费代理IP
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2020-05-10 08:01
由于个别网站对会对爬虫做限制,因此往往须要通过代理将爬虫的实际IP隐蔽上去,代理也有分类,如透明代理,高匿代理等。
本文主要述说怎么获取代理IP,并且怎么储存和使用。
某些网站会免费提供代理IP,如下边的几个
获取那些页面上的代理IP及端口也是通过爬虫抓取,下面以第一个网站xicidaili.com为例,解释怎样获取并储存这种代理IP。一般的流程为:解析当前页面–>存储当前页面的代理IP–>跳转到下一页面,重复该流程即可。
首先要解析页面,由于网页中显示代理IP时是在表格中显示的,因此只须要通过找出网页源码中相关的表格元素即可。下面是通过python中的requests和bs4获取页面xicidaili.com/nt/上显示的IP及端口。
import requestsfrom bs4 import BeautifulSoupuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text print proxy
输出如下:
36.235.1.189:3128219.141.225.149:80125.44.132.44:9999123.249.8.100:3128183.54.30.186:9999110.211.45.228:9000
上面代码获取的代理IP可以通过在代码一开始构建一个集合(set)来储存,这种情况适用于一次性使用这种代理IP,当程序发生异常或正常退出后,这些储存在显存中的代理IP也会遗失。但是爬虫中使用代理IP的情况又是十分多的,所以有必要把这种IP储存上去python爬虫抓超链接,从而可以使程序多次借助。
这里主要通过redis数据库储存这种代理IP,redis是一个NOSQL数据库,具体使用参照官方文档,这里不做详尽解释。
下面是ConnectRedis.py文件,用于联接redis
import redisHOST = 'XXX.XXX.XXX.XXX' # redis所在主机IPPORT = 6379 # redis服务监听的端口PASSWORD = 'XXXXXX' # 连接redis的密码DB = 0 # IP存储的DB编号def get_connection(): r = redis.Redis(host = HOST, port = PORT, password = PASSWORD, db= DB) return r
下面是在前面的代码基础中将IP储存到redis中,
import requestsfrom bs4 import BeautifulSoupfrom ConnectRedis import get_connection# 获取redis连接try: conn = get_connection()except Exception: print 'Error while connecting to redis' returnuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text conn.sadd("ip_set", proxy) print '%s added to ip set'%proxy
上面的conn.sadd(“ip_set”, proxy)将代理proxy加入到redis的集合”ip_set”,这个集合须要预先在redis中创建,否则会出错。
上面的代码获取的只是一个页面上显示的代理,显然这个数目不够,一般通过当前页面中的下一页的超链接可以跳转到下一页,但是我们测试的因为每页的的url都有规律,都是xicidaili.com/nt/page_number,其中的page_number表示当前在哪一页,省略时为第一页。因此,通过一个for循环嵌套里面的代码即可获取多个页面的代理。但是更通常的方式是通过在当前页面获取下一页的超链接而跳转到下一页。
当我们须要通过代理访问某一网站时,首先须要从redis中随机选出一个代理ip,然后尝试通过代理ip是否能连到我们须要访问的目标网站,因为这种代理IP是公共使用的,所以常常也会被封的很快python爬虫抓超链接,假如通过代理难以访问目标网站,那么就要从数据库中删掉这个代理IP。反之即可通过此代理访问目标网站
下面是实现里面所说流程的代码:
import requestsfrom ConnectRedis import get_connection# 判断IP是否能访问目标网站def is_valid(url, ip): proxy = { 'http': 'http://%s' %ip } user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36' headers = {'user-agent': user_agent} try: r = requests.get(url, headers = headers, proxies = proxy, timeout = 6) return True except Exception: return Falseif __name__ == '__main__': my_proxy, proxies, ip_set = None, None, 'amazon_ips' conn = get_connection() target = 'https://www.amazon.com/' while not is_valid(target, my_proxy): if my_proxy: conn.srem(ip_set, my_proxy) #删除无效的代理IP if proxies: my_proxy = proxies.pop() else: proxies = conn.srandmember(ip_set, 5) #从redis中随机抽5个代理ip my_proxy = proxies.pop() print 'valid proxy %s' %my_proxy
requests.get(url, headers = headers, proxies = proxy, timeout = 6)是通过代理去访问目标网站,超时时间设为6s,也就是说在6秒内网站没有回应或返回错误信息就觉得这个代理无效。
除此之外,在爬取免费提供代理的网站上的代理IP的时侯,爬取的速率不要很快,其中的一个缘由是爬取很快有可能会被封,另外一个缘由是假如每个人都无间隙地从这些网站上爬取,那么网站的负担会比较大,甚至有可能垮掉,因此采用一个可持续爬取的策略特别有必要,我爬取的时侯是没爬完一个页面后使程序sleep大约2分钟,这样出来不会被封并且爬取的代理的量也足够使用。实际中可以按照自己使用代理的频度来进行调整。
当然,免费代理ip虽然也只能用于练手,免费的ip代理在可用率,速度、安全性里面,都无法跟付费的IP代理对比,尤其是独享的IP代理,所以企业爬虫采集的话,为了更快更稳定的进行业务举办,建议你们订购付费的ip代理,比如快闪或则飞蚁,类似的付费代理具有并发高,单次提取200个IP,间隔一秒,所以短时间内可以获取大量IP进行数据采集。 查看全部
我们菜鸟在练手的时侯,常常须要一些代理ip进行爬虫抓取,但是由于学习阶段,对IP质量要求不高,主要是搞清原理,所以花钱订购就变得没必要(大款忽视),今天跟你们分享一下,如果使用爬虫抓取免费的代理IP。
由于个别网站对会对爬虫做限制,因此往往须要通过代理将爬虫的实际IP隐蔽上去,代理也有分类,如透明代理,高匿代理等。
本文主要述说怎么获取代理IP,并且怎么储存和使用。
某些网站会免费提供代理IP,如下边的几个
获取那些页面上的代理IP及端口也是通过爬虫抓取,下面以第一个网站xicidaili.com为例,解释怎样获取并储存这种代理IP。一般的流程为:解析当前页面–>存储当前页面的代理IP–>跳转到下一页面,重复该流程即可。
首先要解析页面,由于网页中显示代理IP时是在表格中显示的,因此只须要通过找出网页源码中相关的表格元素即可。下面是通过python中的requests和bs4获取页面xicidaili.com/nt/上显示的IP及端口。
import requestsfrom bs4 import BeautifulSoupuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text print proxy
输出如下:
36.235.1.189:3128219.141.225.149:80125.44.132.44:9999123.249.8.100:3128183.54.30.186:9999110.211.45.228:9000
上面代码获取的代理IP可以通过在代码一开始构建一个集合(set)来储存,这种情况适用于一次性使用这种代理IP,当程序发生异常或正常退出后,这些储存在显存中的代理IP也会遗失。但是爬虫中使用代理IP的情况又是十分多的,所以有必要把这种IP储存上去python爬虫抓超链接,从而可以使程序多次借助。
这里主要通过redis数据库储存这种代理IP,redis是一个NOSQL数据库,具体使用参照官方文档,这里不做详尽解释。
下面是ConnectRedis.py文件,用于联接redis
import redisHOST = 'XXX.XXX.XXX.XXX' # redis所在主机IPPORT = 6379 # redis服务监听的端口PASSWORD = 'XXXXXX' # 连接redis的密码DB = 0 # IP存储的DB编号def get_connection(): r = redis.Redis(host = HOST, port = PORT, password = PASSWORD, db= DB) return r
下面是在前面的代码基础中将IP储存到redis中,
import requestsfrom bs4 import BeautifulSoupfrom ConnectRedis import get_connection# 获取redis连接try: conn = get_connection()except Exception: print 'Error while connecting to redis' returnuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'referer = 'http://www.xicidaili.com/'headers = {'user-agent': user_agent, 'referer': referer}target = 'http://www.xicidaili.com/nt/'# 获取页面源码r = requests.get(target, headers = headers)# 解析页面源码soup = BeautifulSoup(r.text, 'lxml')for tr in soup.find_all('tr')[1:]: tds = tr.find_all('td') proxy = tds[1].text+':'+tds[2].text conn.sadd("ip_set", proxy) print '%s added to ip set'%proxy
上面的conn.sadd(“ip_set”, proxy)将代理proxy加入到redis的集合”ip_set”,这个集合须要预先在redis中创建,否则会出错。
上面的代码获取的只是一个页面上显示的代理,显然这个数目不够,一般通过当前页面中的下一页的超链接可以跳转到下一页,但是我们测试的因为每页的的url都有规律,都是xicidaili.com/nt/page_number,其中的page_number表示当前在哪一页,省略时为第一页。因此,通过一个for循环嵌套里面的代码即可获取多个页面的代理。但是更通常的方式是通过在当前页面获取下一页的超链接而跳转到下一页。
当我们须要通过代理访问某一网站时,首先须要从redis中随机选出一个代理ip,然后尝试通过代理ip是否能连到我们须要访问的目标网站,因为这种代理IP是公共使用的,所以常常也会被封的很快python爬虫抓超链接,假如通过代理难以访问目标网站,那么就要从数据库中删掉这个代理IP。反之即可通过此代理访问目标网站
下面是实现里面所说流程的代码:
import requestsfrom ConnectRedis import get_connection# 判断IP是否能访问目标网站def is_valid(url, ip): proxy = { 'http': 'http://%s' %ip } user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36' headers = {'user-agent': user_agent} try: r = requests.get(url, headers = headers, proxies = proxy, timeout = 6) return True except Exception: return Falseif __name__ == '__main__': my_proxy, proxies, ip_set = None, None, 'amazon_ips' conn = get_connection() target = 'https://www.amazon.com/' while not is_valid(target, my_proxy): if my_proxy: conn.srem(ip_set, my_proxy) #删除无效的代理IP if proxies: my_proxy = proxies.pop() else: proxies = conn.srandmember(ip_set, 5) #从redis中随机抽5个代理ip my_proxy = proxies.pop() print 'valid proxy %s' %my_proxy
requests.get(url, headers = headers, proxies = proxy, timeout = 6)是通过代理去访问目标网站,超时时间设为6s,也就是说在6秒内网站没有回应或返回错误信息就觉得这个代理无效。
除此之外,在爬取免费提供代理的网站上的代理IP的时侯,爬取的速率不要很快,其中的一个缘由是爬取很快有可能会被封,另外一个缘由是假如每个人都无间隙地从这些网站上爬取,那么网站的负担会比较大,甚至有可能垮掉,因此采用一个可持续爬取的策略特别有必要,我爬取的时侯是没爬完一个页面后使程序sleep大约2分钟,这样出来不会被封并且爬取的代理的量也足够使用。实际中可以按照自己使用代理的频度来进行调整。
当然,免费代理ip虽然也只能用于练手,免费的ip代理在可用率,速度、安全性里面,都无法跟付费的IP代理对比,尤其是独享的IP代理,所以企业爬虫采集的话,为了更快更稳定的进行业务举办,建议你们订购付费的ip代理,比如快闪或则飞蚁,类似的付费代理具有并发高,单次提取200个IP,间隔一秒,所以短时间内可以获取大量IP进行数据采集。
《Python3网络爬虫开发实战》来了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 299 次浏览 • 2020-05-09 08:03
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!
本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁 查看全部
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!
本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁
爬虫常用库的安装(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2020-05-09 08:02
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快! 查看全部
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快!
网络爬虫简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-05-09 08:01
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:
初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:
而在爬虫眼中网络爬虫,这个网页是这样的:
因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:
最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:
Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。
,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器
BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:
首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:
查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:
初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:
而在爬虫眼中网络爬虫,这个网页是这样的:
因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:
最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:
Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。
,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器
BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:
首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:
Python爬虫代理池
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-05-09 08:01
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬爬虫代理软件,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数爬虫代理软件,包含GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:
安装依赖:
pip install -r requirements.txt
启动:
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:
爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
6、最后 查看全部
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫领到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源下来。不过呢,闲暇时间手痒,所以就想借助一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而至?
刚自学爬虫的时侯没有代理IP就去西刺、快代理之类有免费代理的网站去爬爬虫代理软件,还是有某些代理能用。当然,如果你有更好的代理插口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然他人为何还提供付费的(不过事实是好多代理商的付费IP也不稳定,也有好多是不能用)。所以采集回来的代理IP不能直接使用,可以写检查程序不断的去用这种代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方法,因为测量代理是个太慢的过程。
采集回来的代理怎么储存?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫挺好中间储存工具。
如何使爬虫更简单的使用这种代理?
答案肯定是弄成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多用处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检查程序愈加靠谱。
2、代理池设计
代理池由四部份组成:
ProxyGetter:
代理获取插口,目前有5个免费代理源,每调用一次都会抓取这个5个网站的最新代理装入DB,可自行添加额外的代理获取插口;
DB:
用于储存代理IP,现在暂时只支持SSDB。至于为何选择SSDB,大家可以参考这篇文章,个人认为SSDB是个不错的Redis取代方案,如果你没有用过SSDB,安装上去也很简单,可以参考这儿;
Schedule:
计划任务用户定时去检查DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理装入DB;
ProxyApi:
代理池的外部插口,由于现今如此代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等插口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它特别适合于快速应用开发,也适合于作为胶带语言联接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api插口相关代码,目前api是由Flask实现,代码也十分简单。客户端恳求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩充其他类型数据库;
Manager:
get/delete/refresh/get_all等插口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和帐号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩充代理插口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程形式;
Util:
存放一些公共的模块方式或函数爬虫代理软件,包含GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重画ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性估算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取插口配置,可以在GetFreeProxy中添加新的代理获取方式,并在Config.ini中注册即可使用;
4、安装
下载代码:
安装依赖:
pip install -r requirements.txt
启动:
5、使用
定时任务启动后,会通过代理获取方式fetch所有代理装入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大约一两分钟后,便可在SSDB中见到刷新下来的可用的代理:
启动ProxyApi.py后即可在浏览器中使用插口获取代理,一下是浏览器中的截图:
index页面:
get页面:
get_all页面:
爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
6、最后
Python和数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2020-05-08 08:03
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们! 查看全部
网络爬虫, Python和数据 分析王澎 中国科技大学哪些是网络爬虫?? 网络爬虫是一个手动提取网页的程序,它为搜索 引擎从万维网上下载网页,是搜索引擎的重要组 成。传统爬虫从一个或若干初始网页的URL开始, 获得初始网页上的URL,在抓取网页的过程中, 不断从当前页面上抽取新的URL装入队列,直到满 足系统的一定停止条件爬虫有哪些用?? 做为通用搜索引擎网页收集器。(google,baidu) ? 做垂直搜索引擎.(找工作的搜索引擎:,数据来源于: , , 等等) ? 科学研究:在线人类行为,在线社群演变,人类 动力学研究数据挖掘与网络爬虫,计量社会学,复杂网路,数据挖掘, 等领域的实证研究都须要大量数据,网络爬虫是 收集相关数据的神器。 ? 偷窥,hacking数据挖掘与网络爬虫,发垃圾邮件……(《google hack》….)爬虫是搜索引擎的第一步 也是最容易的一步? 网页收集 ? 建立索引 ? 查询排序用哪些语言写爬虫?? C,C++。高效率,快速,适合通用搜索引 擎做全网爬取。缺点,开发慢,写上去又 臭又长,例如:天网搜索源代码。? 脚本语言:Perl, Python, Java, Ruby。简单, 易学,良好的文本处理能便捷网页内容的 细致提取,但效率常常不高,适合对少量 网站的聚焦爬取? C#?(貌似信息管理的人比较喜欢的语言)我当初拿来写过爬虫的语言? Perl: 古老的脚本语言,hack 语言,被拿来写爬虫 有着悠久的历史,因此,书本支持相当丰富: 《spidering hacks》,《Perl & LWP》;强大的文 本处理能力,数据库支持能力。
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们!
了解网页结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2020-05-08 08:01
学习爬虫, 首先要懂的是网页. 支撑起各类光鲜亮丽的网页的不是别的, 全都是一些代码.这种代码我们称之为 HTML,HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这些语言转换成我们用肉眼见到的网页.所以 HTML 里面必将存在着好多规律, 我们的爬虫还能根据这样的规律来爬取你须要的信息.
其实不仅 HTML, 一同打造多彩/多功能网页的组件还有 CSS 和. 但是这个简单的爬虫教程,大部分时间会将会使用 HTML.CSS 和 JavaScript 会在后期简单介绍一下. 因为爬网页的时侯多多少少还是要和 CSS JavaScript 打交道的.
虽然莫烦Python主打的是机器学习的教程. 但是这个爬虫教程适用于任何想学爬虫的朋友们.从机器学习的角度看爬虫结构, 机器学习中的大量数据, 也是可以从这种网页中来, 使用爬虫来爬取各类网页里面的信息, 然后再装入各类机器学习的方式,这样的应用途径正在越来越多被采用. 所以假如你的数据也是分散在各个网页中, 爬虫是你降低人力劳动的必修课.
网页基本组成部分
在真正步入爬虫之前, 我们先来做一下热身运动, 弄明白网页的基础, HTML 有什么组成部分,是怎么样运作的. 如果你早已十分熟悉网页的构造了, 欢迎直接跳过这一节, 进入下边的学习.
我制做了一个特别简易的网页, 给你们呈现以下最肉感的 HTML 结构.如果你点开它, 呈现在你眼前的, 就是下边这张图的上半部份. 而下半部份就是我们网页背后的 HTML code.
想问我是怎么见到 HTML 的 source code 的? 其实很简单, 在你的浏览器中 (我用的是 Google Chrome),显示网页的地方, 点击滑鼠右键,大多数浏览器就会有类似这样一个选项 “View Page Source”. 点击它能够看见页面的源码了.
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的方式, 或有不同的功能.主体的 tag 分成两部份, header 和 body. 在 header 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看见的网页中的.这些信息大多数时侯是给浏览器看, 或者是给搜索引擎的爬虫看.
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
HTML 的第二大块是 body, 这个部份才是你看见的网页信息. 网页中的 heading, 视频, 图片和文字等都储存在这里.这里的 <h1></h1> tag 就是主标题, 我们看见呈现下来的疗效就是大一号的文字. <p></p> 里面的文字就是一个段落.<a></a>里面都是一些链接. 所以好多情况, 东西都是置于这种 tag 中的.
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
爬虫想要做的就是按照这种 tag 来找到合适的信息.
用 Python 登录网页
好了, 对网页结构和 HTML 有了一些基本认识之后, 我们能够用 Python 来爬取这个网页的一些基本信息.首先要做的, 是使用 Python 来登入这个网页, 并复印出这个网页 HTML 的 source code.注意, 因为网页中存在英文, 为了正常显示英文, read() 完之后, 我们要对读下来的文字进行转换, decode() 成可以正常显示英文的方式.
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/s ... ot%3B
).read().decode('utf-8')
print(html)
print 出来就是下边这样啦. 这就证明了我们能否成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和借助.我们发觉, 想要提取一些方式的信息, 合理的借助 tag 的名子非常重要.
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
匹配网页内容
所以这儿我们使用 Python 的正则表达式 RegEx 进行匹配文字, 筛选信息的工作. 我有一个很不错的正则表达式的教程,如果是中级的网页匹配, 我们使用正则完全就可以了, 高级一点或则比较冗长的匹配, 我还是推荐使用 BeautifulSoup.不急不急, 我知道你想偷懒, 我然后马上还会教 beautiful soup 了. 但是如今我们还是使用正则来做几个简单的事例, 让你熟悉一下套路.
如果我们想用代码找到这个网页的 title, 我们能够这样写. 选好要使用的 tag 名称 <title>. 使用正则匹配.
import re
res = re.findall(r"<title>(.+?)</title>", html)
print("\nPage title is: ", res[0])
# Page title is: Scraping tutorial 1 | 莫烦Python
如果想要找到中间的那种段落 <p>, 我们使用下边方式, 因为这个段落在 HTML 中还参杂着 tab, new line, 所以我们给一个flags=re.DOTALL 来对那些 tab, new line 不敏感.
res = re.findall(r"<p>(.*?)</p>", html, flags=re.DOTALL) # re.DOTALL if multi line
print("\nPage paragraph is: ", res[0])
# Page paragraph is:
# 这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
# <a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
最后一个练习是找一找所有的链接, 这个比较有用, 有时候你想找到网页里的链接, 然后下载一些内容到笔记本里,就靠这样的途径了.
res = re.findall(r'href="(.*?)"', html)
print("\nAll links: ", res)
# All links:
['https://morvanzhou.github.io/static/img/description/tab_icon.png',
'https://morvanzhou.github.io/',
'https://morvanzhou.github.io/tutorials/scraping']
下次我们就来瞧瞧为了图方面爬虫结构, 我们怎样使用 BeautifulSoup.
相关教程 查看全部
学习资料:
学习爬虫, 首先要懂的是网页. 支撑起各类光鲜亮丽的网页的不是别的, 全都是一些代码.这种代码我们称之为 HTML,HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这些语言转换成我们用肉眼见到的网页.所以 HTML 里面必将存在着好多规律, 我们的爬虫还能根据这样的规律来爬取你须要的信息.
其实不仅 HTML, 一同打造多彩/多功能网页的组件还有 CSS 和. 但是这个简单的爬虫教程,大部分时间会将会使用 HTML.CSS 和 JavaScript 会在后期简单介绍一下. 因为爬网页的时侯多多少少还是要和 CSS JavaScript 打交道的.
虽然莫烦Python主打的是机器学习的教程. 但是这个爬虫教程适用于任何想学爬虫的朋友们.从机器学习的角度看爬虫结构, 机器学习中的大量数据, 也是可以从这种网页中来, 使用爬虫来爬取各类网页里面的信息, 然后再装入各类机器学习的方式,这样的应用途径正在越来越多被采用. 所以假如你的数据也是分散在各个网页中, 爬虫是你降低人力劳动的必修课.
网页基本组成部分
在真正步入爬虫之前, 我们先来做一下热身运动, 弄明白网页的基础, HTML 有什么组成部分,是怎么样运作的. 如果你早已十分熟悉网页的构造了, 欢迎直接跳过这一节, 进入下边的学习.
我制做了一个特别简易的网页, 给你们呈现以下最肉感的 HTML 结构.如果你点开它, 呈现在你眼前的, 就是下边这张图的上半部份. 而下半部份就是我们网页背后的 HTML code.
想问我是怎么见到 HTML 的 source code 的? 其实很简单, 在你的浏览器中 (我用的是 Google Chrome),显示网页的地方, 点击滑鼠右键,大多数浏览器就会有类似这样一个选项 “View Page Source”. 点击它能够看见页面的源码了.
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的方式, 或有不同的功能.主体的 tag 分成两部份, header 和 body. 在 header 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看见的网页中的.这些信息大多数时侯是给浏览器看, 或者是给搜索引擎的爬虫看.
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
HTML 的第二大块是 body, 这个部份才是你看见的网页信息. 网页中的 heading, 视频, 图片和文字等都储存在这里.这里的 <h1></h1> tag 就是主标题, 我们看见呈现下来的疗效就是大一号的文字. <p></p> 里面的文字就是一个段落.<a></a>里面都是一些链接. 所以好多情况, 东西都是置于这种 tag 中的.
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
爬虫想要做的就是按照这种 tag 来找到合适的信息.
用 Python 登录网页
好了, 对网页结构和 HTML 有了一些基本认识之后, 我们能够用 Python 来爬取这个网页的一些基本信息.首先要做的, 是使用 Python 来登入这个网页, 并复印出这个网页 HTML 的 source code.注意, 因为网页中存在英文, 为了正常显示英文, read() 完之后, 我们要对读下来的文字进行转换, decode() 成可以正常显示英文的方式.
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/s ... ot%3B
).read().decode('utf-8')
print(html)
print 出来就是下边这样啦. 这就证明了我们能否成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和借助.我们发觉, 想要提取一些方式的信息, 合理的借助 tag 的名子非常重要.
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/s ... gt%3B
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
匹配网页内容
所以这儿我们使用 Python 的正则表达式 RegEx 进行匹配文字, 筛选信息的工作. 我有一个很不错的正则表达式的教程,如果是中级的网页匹配, 我们使用正则完全就可以了, 高级一点或则比较冗长的匹配, 我还是推荐使用 BeautifulSoup.不急不急, 我知道你想偷懒, 我然后马上还会教 beautiful soup 了. 但是如今我们还是使用正则来做几个简单的事例, 让你熟悉一下套路.
如果我们想用代码找到这个网页的 title, 我们能够这样写. 选好要使用的 tag 名称 <title>. 使用正则匹配.
import re
res = re.findall(r"<title>(.+?)</title>", html)
print("\nPage title is: ", res[0])
# Page title is: Scraping tutorial 1 | 莫烦Python
如果想要找到中间的那种段落 <p>, 我们使用下边方式, 因为这个段落在 HTML 中还参杂着 tab, new line, 所以我们给一个flags=re.DOTALL 来对那些 tab, new line 不敏感.
res = re.findall(r"<p>(.*?)</p>", html, flags=re.DOTALL) # re.DOTALL if multi line
print("\nPage paragraph is: ", res[0])
# Page paragraph is:
# 这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
# <a href="https://morvanzhou.github.io/t ... gt%3B爬虫教程</a> 中的简单测试.
最后一个练习是找一找所有的链接, 这个比较有用, 有时候你想找到网页里的链接, 然后下载一些内容到笔记本里,就靠这样的途径了.
res = re.findall(r'href="(.*?)"', html)
print("\nAll links: ", res)
# All links:
['https://morvanzhou.github.io/static/img/description/tab_icon.png',
'https://morvanzhou.github.io/',
'https://morvanzhou.github.io/tutorials/scraping']
下次我们就来瞧瞧为了图方面爬虫结构, 我们怎样使用 BeautifulSoup.
相关教程
33款可用来抓数据的开源爬虫软件工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2020-05-07 08:02
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。 查看全部
要玩大数据,没有数据如何玩?这里推荐一些33款开源爬虫软件给你们。
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。
通俗的讲,网络爬虫到底是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-05-06 08:03
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,
以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。
假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:
那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功? 查看全部
爬虫的起源
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,
以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。
假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:
那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功?
老司机带你学爬虫——Python爬虫技术分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-05-06 08:01
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心 查看全部
什么是“爬虫”?
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心
设计和实现一款轻量级的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-05-05 08:05
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。
关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图
整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图
项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献 查看全部
说起爬虫,大家能否想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步剖析爬虫框架的诞生过程。
我把这个爬虫框架的源码置于 github上,里面有几个事例可以运行。
关于爬虫的一切
下面我们来介绍哪些是爬虫?以及爬虫框架的设计和碰到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网路蜘蛛(spider),是一种拿来手动浏览网路上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不容许被爬虫抓取(这就是你遇见过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫须要考虑到规划、负载,还须要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也未能作出完整的索引。因此在公元2000年之前的万维网出现早期,搜索引擎常常找不到多少相关结果。 现在的搜索引擎在这方面早已进步好多,能够即刻给出高质量结果。
网络爬虫会碰到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会碰到一些阻挠,在业内称之为 反爬虫策略 我们来列举一些常见的。
这些是传统的反爬虫手段,当然未来也会愈加先进,技术的革新永远会推动多个行业的发展,毕竟 AI 的时代早已到来, 爬虫和反爬虫的斗争仍然持续进行。
爬虫框架要考虑哪些
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来瞧瞧在没有爬虫框架的时侯我们是怎样抓取页面信息的。 一个常见的事例是使用 HttpClient 包或则 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时侯抓取页面的代码,这是我在网路上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从这么丰富的注释中我感受到了作者的耐心,我们来剖析一下这个爬虫在干哪些?
大概就是这样的步骤,代码也十分简约,我们设计框架的目的是将这种流程统一化,把通用的功能进行具象,减少重复工作。 还有一些没考虑到的诱因添加进去爬虫框架,那么设计爬虫框架要有什么组成呢?
分别来解释一下每位组成的作用是哪些。
URL管理器
爬虫框架要处理好多的URL,我们须要设计一个队列储存所有要处理的URL,这种先进先出的数据结构十分符合这个需求。 将所有要下载的URL存贮在待处理队列中,每次下载会取出一个,队列中还会少一个。我们晓得有些URL的下载会有反爬虫策略, 所以针对那些恳求须要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在上面的简单事例中可以看出,如果没有网页下载器,用户就要编撰网路恳求的处理代码,这无疑对每位URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用哪些库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网路恳求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再度的传输给下载器,这样才会使各个组件有条不紊的进行工作。
网页解析器
我们晓得当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还须要提取出真正须要的数据, 以前的做法是通过 String 的 API 或者正则表达式的形式在 DOM 中搜救,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方法来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应当是各司其职的,我们先通过解析器将须要的数据解析下来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是储存到数据库,也可能通过插口发送给老王。
基本特点
上面说了这么多,我们设计的爬虫框架有以下几个特点,没有做到大而全,可以称得上轻量迷你很好用。
架构图
整个流程和 Scrapy 是一致的,但简化了一些操作
执行流程图
项目结构
该项目使用 Maven3、Java8 进行完善,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白以后,编程不过是顺手之作,至于写的怎么审视的是程序员对编程语言的使用熟练度以及构架上的思索, 优秀的代码是经验和优化而至的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于风波驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来储存所有风波,提供两个方式:注册一个风波、执行某个风波。
阻塞队列储存恳求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL恳求,result 存储下载成功的响应,调度器负责恳求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个事例我们来爬取豆瓣影片的标题。豆瓣影片中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
}
@Override
public void onStart(Config config) {
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个风波,会在启动该爬虫的时侯执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管线中只进行了输出,你也可以储存。
在 parse 方法中做了两件事,首先解析当前抓取到的所有影片标题,将标题数据搜集为 List 传递给 Pipeline; 其次按照当前页面继续抓取下一页,将下一页恳求传递给调度器爬虫框架,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中早已论述,要做的更好还有好多细节须要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves 中递交你的意见。
参考文献
Scrapy爬虫框架:抓取天猫淘宝数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2020-05-05 08:05
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。 查看全部
有了前两篇的基础,接下来通过抓取天猫和淘宝的数据来详尽说明,如何通过Scrapy爬取想要的内容。完整的代码:[不带数据库版本][ 数据库版本]。
通过天猫的搜索,获取搜索下来的每件商品的销量、收藏数、价格。
所以,最终的目的是通过获取两个页面的内容,一个是搜索结果,从上面找下来每一个商品的详尽地址,然后第二个是商品详尽内容,从上面获取到销量、价格等。
有了思路如今我们先下载搜索结果页面,然后再下载页面中每一项详尽信息页面。
def _parse_handler(self, response):
''' 下载页面 """
self.driver.get(response.url)
pass
很简单,通过self.driver.get(response.url)就能使用selenium下载内容,如果直接使用response中的网页内容是静态的。
上面说了怎样下载内容,当我们下载好内容后,需要从上面去获取我们想要的有用信息,这里就要用到选择器,选择器构造方法比较多,只介绍一种,这里看详尽信息:
>>> body = '<html><body><span>good</span></body></html>'
>>> Selector(text=body).xpath('//span/text()').extract()
[u'good']
这样就通过xpath取下来了good这个词组,更详尽的xpath教程点击这儿。
Selector 提供了好多形式出了xpath,还有css选择器,正则表达式,中文教程看这个,具体内容就不多说,只须要晓得这样可以快速获取我们须要的内容。
简单的介绍了如何获取内容后,现在我们从第一个搜索结果中获取我们想要的商品详尽链接,通过查看网页源代码可以看见,商品的链接在这里:
...
<p class="title">
<a class="J_ClickStat" data-nid="523242229702" href="//detail.tmall.com/item.htm?spm=a230r.1.14.46.Mnbjq5&id=523242229702&ns=1&abbucket=14" target="_blank" trace="msrp_auction" traceidx="5" trace-pid="" data-spm-anchor-id="a230r.1.14.46">WD/西部数据 WD30EZRZ台式机3T电脑<span class="H">硬盘</span> 西数蓝盘3TB 替绿盘</a>
</p>
...
使用之前的规则来获取到a元素的href属性就是须要的内容:
selector = Selector(text=self.driver.page_source) # 这里不要省略text因为省略后Selector使用的是另外一个构造函数,self.driver.page_source是这个网页的html内容
selector.css(".title").css(".J_ClickStat").xpath("./@href").extract()
简单说一下,这里通过css工具取了class叫title的p元素,然后又获取了class是J_ClickStat的a元素,最后通过xpath规则获取a元素的href中的内容。啰嗦一句css中若果是取id则应当是selector.css("#title"),这个和css中的选择器是一致的。
同理,我们获取到商品详情后,以获取销量为例,查看源代码:
<ul class="tm-ind-panel">
<li class="tm-ind-item tm-ind-sellCount" data-label="月销量"><div class="tm-indcon"><span class="tm-label">月销量</span><span class="tm-count">881</span></div></li>
<li class="tm-ind-item tm-ind-reviewCount canClick tm-line3" id="J_ItemRates"><div class="tm-indcon"><span class="tm-label">累计评价</span><span class="tm-count">4593</span></div></li>
<li class="tm-ind-item tm-ind-emPointCount" data-spm="1000988"><div class="tm-indcon"><a href="//vip.tmall.com/vip/index.htm" target="_blank"><span class="tm-label">送天猫积分</span><span class="tm-count">55</span></a></div></li>
</ul>
获取月销量:
selector.css(".tm-ind-sellCount").xpath("./div/span[@class='tm-count']/text()").extract_first()
获取累计评价:
selector.css(".tm-ind-reviewCount").xpath("./div[@class='tm-indcon']/span[@class='tm-count']/text()").extract_first()
最后把获取下来的数据包装成Item返回。淘宝或则淘宝她们的页面内容不一样,所以规则也不同,需要分开去获取想要的内容。
Item是scrapy中获取下来的结果,后面可以处理这种结果。
Item通常是放在items.py中
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
>>> product = Product(name='Desktop PC', price=1000)
>>> print product
Product(name='Desktop PC', price=1000)
>>> product['name']
Desktop PC
>>> product.get('name')
Desktop PC
>>> product['price']
1000
>>> product['last_updated']
Traceback (most recent call last):
...
KeyError: 'last_updated'
>>> product.get('last_updated', 'not set')
not set
>>> product['lala'] # getting unknown field
Traceback (most recent call last):
...
KeyError: 'lala'
>>> product.get('lala', 'unknown field')
'unknown field'
>>> 'name' in product # is name field populated?
True
>>> 'last_updated' in product # is last_updated populated?
False
>>> 'last_updated' in product.fields # is last_updated a declared field?
True
>>> 'lala' in product.fields # is lala a declared field?
False
>>> product['last_updated'] = 'today'
>>> product['last_updated']
today
>>> product['lala'] = 'test' # setting unknown field
Traceback (most recent call last):
...
KeyError: 'Product does not support field: lala'
这里只须要注意一个地方,不能通过product.name的方法获取,也不能通过product.name = "name"的形式设置值。
当Item在Spider中被搜集以后,它将会被传递到Item Pipeline,一些组件会根据一定的次序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方式的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被遗弃而不再进行处理。
以下是item pipeline的一些典型应用:
现在实现一个Item过滤器,我们把获取下来若果是None的数据形参为0,如果Item对象是None则丢弃这条数据。
pipeline通常是放在pipelines.py中
def process_item(self, item, spider):
if item is not None:
if item["p_standard_price"] is None:
item["p_standard_price"] = item["p_shop_price"]
if item["p_shop_price"] is None:
item["p_shop_price"] = item["p_standard_price"]
item["p_collect_count"] = text_utils.to_int(item["p_collect_count"])
item["p_comment_count"] = text_utils.to_int(item["p_comment_count"])
item["p_month_sale_count"] = text_utils.to_int(item["p_month_sale_count"])
item["p_sale_count"] = text_utils.to_int(item["p_sale_count"])
item["p_standard_price"] = text_utils.to_string(item["p_standard_price"], "0")
item["p_shop_price"] = text_utils.to_string(item["p_shop_price"], "0")
item["p_pay_count"] = item["p_pay_count"] if item["p_pay_count"] is not "-" else "0"
return item
else:
raise DropItem("Item is None %s" % item)
最后须要在settings.py中添加这个pipeline
ITEM_PIPELINES = {
'TaoBao.pipelines.TTDataHandlerPipeline': 250,
'TaoBao.pipelines.MysqlPipeline': 300,
}
后面那种数字越小,则执行的次序越靠前,这里先过滤处理数据,获取到正确的数据后,再执行TaoBao.pipelines.MysqlPipeline添加数据到数据库。
完整的代码:[不带数据库版本][ 数据库版本]。
之前说的方法都是直接通过命令scrapy crawl tts来启动。怎么用IDE的调试功能呢?很简单通过main函数启动爬虫:
# 写到Spider里面
if __name__ == "__main__":
settings = get_project_settings()
process = CrawlerProcess(settings)
spider = TmallAndTaoBaoSpider
process.crawl(spider)
process.start()
在获取数据的时侯,很多时侯会碰到网页重定向的问题,scrapy会返回302之后不会手动重定向后继续爬取新地址,在scrapy的设置中,可以通过配置来开启重定向,这样虽然域名是重定向的scrapy也会手动到最终的地址获取内容。
解决方案:settings.py中添加REDIRECT_ENABLED = True
很多时侯爬虫都有自定义数据,比如之前写的是硬碟关键字,现在通过参数的方法如何传递呢?
解决方案:
大部分时侯,我们可以取到完整的网页信息,如果网页的ajax恳求太多,网速很慢的时侯,selenium并不知道什么时候ajax恳求完成,这个时侯假如通过self.driver.get(response.url)获取页面天猫反爬虫,然后通过Selector取数据天猫反爬虫,很可能还没加载完成取不到数据。
解决方案:通过selenium提供的工具来延后获取内容,直到获取到数据,或者超时。
网络爬虫:使用Scrapy框架编撰一个抓取书籍信息的爬虫服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-05-04 08:06
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) 查看全部
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总),
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)
开源爬虫框架各有哪些优缺点
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-05-04 08:06
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。 查看全部
分布式爬虫:Nutch
JAVA单机爬虫:Crawler4j,WebMagic,WebCollector
非JAVA单机爬虫:scrapy
海量URL管理
网速快
Nutch是为搜索引擎设计的爬虫,大多数用户是须要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有很大的意义。
用Nutch做数据抽取,会浪费好多的时间在不必要的估算上。而且假如你企图通过对Nutch进行二次开发,来促使它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非。
Nutch依赖hadoop运行,hadoop本身会消耗好多的时间。如果集群机器数目较少,爬取速率反倒不如单机爬虫。
Nutch似乎有一套插件机制,而且作为亮点宣传。可以看见一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都晓得,Nutch的插件系统有多拙劣。利用反射的机制来加载和调用插件,使得程序的编撰和调试都显得异常困难,更别说在里面开发一套复杂的精抽取系统了。
Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的开源爬虫框架,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点虽然是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text)
用Nutch进行爬虫的二次开发,爬虫的编撰和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要使一个团队的人都看懂Nutch源码。调试过程中会出现除程序本身之外的各类问题(hadoop的问题、hbase的问题)。
Nutch2的版本目前并不适宜开发。官方如今稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。Nutch2.3之前、Nutch2.2.1以后的一个版本,这个版本在官方的SVN中不断更新。而且十分不稳定(一e799bee5baa6e997aee7ad94e78988e69d8331333363396465直在更改)。
支持多线程。
支持代理。
能过滤重复URL的。
负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。
先说python爬虫,python可以用30行代码,完成JAVA
50行代码干的任务。python写代码的确快开源爬虫框架,但是在调试代码的阶段,python代码的调试常常会花费远远少于编码阶段市下的时间。
使用python开发,要保证程序的正确性和稳定性,就须要写更多的测试模块。当然若果爬取规模不大、爬取业务不复杂,使用scrapy这些爬虫也是挺不错的,可以轻松完成爬取任务。
bug较多,不稳定。
网页上有一些异步加载的数据,爬取这种数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
爬虫常常都是设计成广度遍历或则深度遍历的模式,去遍历静态或则动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速率,都太可以。
一般公司做爬虫采集的话常用哪些语言
采集交流 • 优采云 发表了文章 • 0 个评论 • 555 次浏览 • 2020-05-03 08:09
其实我不太同意做了DHT爬虫这位的说法。
不同语言自然会有不同害处。离开环境谈那个好网络爬虫用什么语言写,哪个不好都是耍流氓。
1,如果是自己做着玩的话,定向爬几个页面网络爬虫用什么语言写,效率不是核心要求的话,问题不会大,什么语言都行的,性能差别不会大。当然,如果遇到极其复杂的页面,正则写的很复杂的话,爬虫的可维护性都会增长。
2,如果是做定向爬取,而目标又要解析动态js。
那么这个时侯,用普通的恳求页面,然后得到内容的方式肯定不行了,就要一个类似firfox,chrome的js引擎来对js代码做动态解析。这个时侯推荐casperJS+phantomjs或slimerJS+phantomjs
3,如果是大规模的网站爬取
这个时侯就要考虑到,效率,扩展性,可维护性,等等了。
大规模的爬取涉及的方面好多,比如分布式爬取,判重机制,任务调度。这些问题深入下去哪一个简单了?
语言选定这个时侯很重要。
NodeJs:做爬虫效率很高。高并发,多线程编程弄成了简单的遍历和callback,内存cpu占用小,要处理好callback。
PHP:各种框架四处有,随便拉个来用都行。但是,PHP的效率真的有问题…不多说
Python:我用python写的比较多,对各类问题都有比较好的支持。scrapy框架挺好用,优点多。
我认为js也不是太适宜写…效率问题。没写过,估计会有麻烦一堆。
据我晓得的,大公司也有用c++的,总之大多数都是在开源框架上改建。真重新造个轮子的不多吧。
不值。
随手凭印象写的,欢迎见谅。 查看全部
其实我不太同意做了DHT爬虫这位的说法。
不同语言自然会有不同害处。离开环境谈那个好网络爬虫用什么语言写,哪个不好都是耍流氓。
1,如果是自己做着玩的话,定向爬几个页面网络爬虫用什么语言写,效率不是核心要求的话,问题不会大,什么语言都行的,性能差别不会大。当然,如果遇到极其复杂的页面,正则写的很复杂的话,爬虫的可维护性都会增长。
2,如果是做定向爬取,而目标又要解析动态js。
那么这个时侯,用普通的恳求页面,然后得到内容的方式肯定不行了,就要一个类似firfox,chrome的js引擎来对js代码做动态解析。这个时侯推荐casperJS+phantomjs或slimerJS+phantomjs
3,如果是大规模的网站爬取
这个时侯就要考虑到,效率,扩展性,可维护性,等等了。
大规模的爬取涉及的方面好多,比如分布式爬取,判重机制,任务调度。这些问题深入下去哪一个简单了?
语言选定这个时侯很重要。
NodeJs:做爬虫效率很高。高并发,多线程编程弄成了简单的遍历和callback,内存cpu占用小,要处理好callback。
PHP:各种框架四处有,随便拉个来用都行。但是,PHP的效率真的有问题…不多说
Python:我用python写的比较多,对各类问题都有比较好的支持。scrapy框架挺好用,优点多。
我认为js也不是太适宜写…效率问题。没写过,估计会有麻烦一堆。
据我晓得的,大公司也有用c++的,总之大多数都是在开源框架上改建。真重新造个轮子的不多吧。
不值。
随手凭印象写的,欢迎见谅。
[ Python爬虫实战 ] 爬虫简介与作用
采集交流 • 优采云 发表了文章 • 0 个评论 • 606 次浏览 • 2020-05-03 08:02
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。

