
php如何抓取网页数据库
php如何抓取网页数据库(本节介绍如何自己DIY一个数据库管理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-29 14:07
本节介绍如何自己DIY一个数据库管理工具。可以在页面输入sql,进行简单的增删改查等操作。
首先,找到xampp安装目录,打开htdocs:
创建一个名为 mysqladmin.php 的新 php 文件
1.写php服务器代码1.1写php标签
首先,在这个页面上,要编写php代码,你需要一个php标签:
我们的php代码应该写在这个标签里面。
1.2数据库连接操作
xampp安装的mysql默认是没有密码的,别写就好了。
1.3 获取form表单传递的sql语句1.4 使用mysql_query函数执行传递过来的sql语句
到目前为止,代码足以添加、删除和修改数据库。接下来,我们来设计查询sql的实现。
1.5 使用split函数拆分sql语句得到表名1.6 使用表名得到该表的所有列,列名用数字组装1.@ >7 去查询sql中得到的结果集并显示在页面上
if($tableName){
$query = mysql_query("select COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME = '$tableName';") or die("<p style='color:red'>sql报错,错误信息为 ======> ".mysql_error()."");
//对结果集进行遍历 -- mysql_fetch_array
$columns = array(); //储存这张表中所有的字段名称
$count = 0; //记录当前的下标
echo "";
echo "";
while($row = mysql_fetch_array($query)){
$columns[$count] = $row["COLUMN_NAME"];
echo "" . $row["COLUMN_NAME"] . "";
$count = $count + 1;
}
echo "";
//echo sizeof($columns);
$query_02 = mysql_query($sql) or die("
sql报错,错误信息为 ======> ".mysql_error()."");
while($row = mysql_fetch_array($query_02)){
echo "";
for($i=0;$i</p>
我的博客将同步到腾讯云+社区,诚邀大家加入: 查看全部
php如何抓取网页数据库(本节介绍如何自己DIY一个数据库管理工具)
本节介绍如何自己DIY一个数据库管理工具。可以在页面输入sql,进行简单的增删改查等操作。
首先,找到xampp安装目录,打开htdocs:
创建一个名为 mysqladmin.php 的新 php 文件
1.写php服务器代码1.1写php标签
首先,在这个页面上,要编写php代码,你需要一个php标签:
我们的php代码应该写在这个标签里面。
1.2数据库连接操作
xampp安装的mysql默认是没有密码的,别写就好了。
1.3 获取form表单传递的sql语句1.4 使用mysql_query函数执行传递过来的sql语句
到目前为止,代码足以添加、删除和修改数据库。接下来,我们来设计查询sql的实现。
1.5 使用split函数拆分sql语句得到表名1.6 使用表名得到该表的所有列,列名用数字组装1.@ >7 去查询sql中得到的结果集并显示在页面上
if($tableName){
$query = mysql_query("select COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME = '$tableName';") or die("<p style='color:red'>sql报错,错误信息为 ======> ".mysql_error()."");
//对结果集进行遍历 -- mysql_fetch_array
$columns = array(); //储存这张表中所有的字段名称
$count = 0; //记录当前的下标
echo "";
echo "";
while($row = mysql_fetch_array($query)){
$columns[$count] = $row["COLUMN_NAME"];
echo "" . $row["COLUMN_NAME"] . "";
$count = $count + 1;
}
echo "";
//echo sizeof($columns);
$query_02 = mysql_query($sql) or die("
sql报错,错误信息为 ======> ".mysql_error()."");
while($row = mysql_fetch_array($query_02)){
echo "";
for($i=0;$i</p>
我的博客将同步到腾讯云+社区,诚邀大家加入:
php如何抓取网页数据库(php如何抓取网页数据库_php抓取数据php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-03-28 03:05
php如何抓取网页数据库_php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php爬虫教程,
if(__name__=='__main__'){if(__doc__=='./documents/demo/php.php'){return__doc__}}如果站点不存在__doc__字段的话,__doc__字段类型未知,可能会直接丢弃。不过可以抓取里面的__main__函数看一下是否有__doc__字段。
可以考虑在header方法(cookie在这儿就别想了,cookie太麻烦)加上org_annotation__='__main__',gzipheader等方法同样可以得到__main__字段。
只是想抓取网页数据(比如页数),不需要记住__main__函数名字。换个网站、改变下cookie设置就行了,比如改为我的网站,加上,__main__:/{your_name}:/{your_username}/{your_password}//不用保存到文本文件,
抓取的时候会出现__main__字段
可以改成这样text='';document=gzipurl(content);%s/\\d+\\css\\div{3}\\d+\\a{4}\\end{div}'这样就抓不到了 查看全部
php如何抓取网页数据库(php如何抓取网页数据库_php抓取数据php)
php如何抓取网页数据库_php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php爬虫教程,
if(__name__=='__main__'){if(__doc__=='./documents/demo/php.php'){return__doc__}}如果站点不存在__doc__字段的话,__doc__字段类型未知,可能会直接丢弃。不过可以抓取里面的__main__函数看一下是否有__doc__字段。
可以考虑在header方法(cookie在这儿就别想了,cookie太麻烦)加上org_annotation__='__main__',gzipheader等方法同样可以得到__main__字段。
只是想抓取网页数据(比如页数),不需要记住__main__函数名字。换个网站、改变下cookie设置就行了,比如改为我的网站,加上,__main__:/{your_name}:/{your_username}/{your_password}//不用保存到文本文件,
抓取的时候会出现__main__字段
可以改成这样text='';document=gzipurl(content);%s/\\d+\\css\\div{3}\\d+\\a{4}\\end{div}'这样就抓不到了
php如何抓取网页数据库(5.PHP倒序输出所有日志方法(一)输出方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-27 06:24
)
所以,我们需要引入时间函数,然后写一个函数来获取当前时间
import time
#获取当前时间
def getCurrentTime(self):
return time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time()))
#获取当前时间
def getCurrentDate(self):
return time.strftime('%Y-%m-%d',time.localtime(time.time()))
以上是分别获取具体时间和日期的函数。输出时,我们可以在输出语句前面调用这个函数。
然后我们需要将缓冲区设置输出到日志中,并在程序顶部添加这两句。
f_handler=open('out.log', 'w')
sys.stdout=f_handler
这样,打印语句的所有输出都会保存到 out.log 文件中。
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
2.页码保存
爬虫在爬取过程中可能会出现各种错误,从而导致爬虫中断。如果我们重新运行爬虫,会导致爬虫从头开始运行,这显然是不合理的。因此,我们需要保存当前抓取的页面,例如可以保存在文本中。如果爬虫被中断,重新运行爬虫,读取文本文件的内容,然后进行爬虫。
可以稍微参考一下函数的实现:
#主函数
def main(self):
f_handler=open('out.log', 'w')
sys.stdout=f_handler
page = open('page.txt', 'r')
content = page.readline()
start_page = int(content.strip()) - 1
page.close()
print self.getCurrentTime(),"开始页码",start_page
print self.getCurrentTime(),"爬虫正在启动,开始爬取爱问知识人问题"
self.total_num = self.getTotalPageNum()
print self.getCurrentTime(),"获取到目录页面个数",self.total_num,"个"
if not start_page:
start_page = self.total_num
for x in range(1,start_page):
print self.getCurrentTime(),"正在抓取第",start_page-x+1,"个页面"
try:
self.getQuestions(start_page-x+1)
except urllib2.URLError, e:
if hasattr(e, "reason"):
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因", e.reason
except Exception,e:
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因:",e
if start_page-x+1 < start_page:
f=open('page.txt','w')
f.write(str(start_page-x+1))
print self.getCurrentTime(),"写入新页码",start_page-x+1
f.close()
这样,无论我们的爬虫在中间遇到什么错误,妈妈都不会担心。
3.页面处理
在页面处理的过程中,我们可能会遇到各种奇怪的HTML代码。和上一节一样,我们可以使用页面处理类。
<p>
import re
#处理页面标签类
class Tool:
#将超链接广告剔除
removeADLink = re.compile(' 查看全部
php如何抓取网页数据库(5.PHP倒序输出所有日志方法(一)输出方法
)
所以,我们需要引入时间函数,然后写一个函数来获取当前时间
import time
#获取当前时间
def getCurrentTime(self):
return time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time()))
#获取当前时间
def getCurrentDate(self):
return time.strftime('%Y-%m-%d',time.localtime(time.time()))
以上是分别获取具体时间和日期的函数。输出时,我们可以在输出语句前面调用这个函数。
然后我们需要将缓冲区设置输出到日志中,并在程序顶部添加这两句。
f_handler=open('out.log', 'w')
sys.stdout=f_handler
这样,打印语句的所有输出都会保存到 out.log 文件中。
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
2.页码保存
爬虫在爬取过程中可能会出现各种错误,从而导致爬虫中断。如果我们重新运行爬虫,会导致爬虫从头开始运行,这显然是不合理的。因此,我们需要保存当前抓取的页面,例如可以保存在文本中。如果爬虫被中断,重新运行爬虫,读取文本文件的内容,然后进行爬虫。
可以稍微参考一下函数的实现:
#主函数
def main(self):
f_handler=open('out.log', 'w')
sys.stdout=f_handler
page = open('page.txt', 'r')
content = page.readline()
start_page = int(content.strip()) - 1
page.close()
print self.getCurrentTime(),"开始页码",start_page
print self.getCurrentTime(),"爬虫正在启动,开始爬取爱问知识人问题"
self.total_num = self.getTotalPageNum()
print self.getCurrentTime(),"获取到目录页面个数",self.total_num,"个"
if not start_page:
start_page = self.total_num
for x in range(1,start_page):
print self.getCurrentTime(),"正在抓取第",start_page-x+1,"个页面"
try:
self.getQuestions(start_page-x+1)
except urllib2.URLError, e:
if hasattr(e, "reason"):
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因", e.reason
except Exception,e:
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因:",e
if start_page-x+1 < start_page:
f=open('page.txt','w')
f.write(str(start_page-x+1))
print self.getCurrentTime(),"写入新页码",start_page-x+1
f.close()
这样,无论我们的爬虫在中间遇到什么错误,妈妈都不会担心。
3.页面处理
在页面处理的过程中,我们可能会遇到各种奇怪的HTML代码。和上一节一样,我们可以使用页面处理类。
<p>
import re
#处理页面标签类
class Tool:
#将超链接广告剔除
removeADLink = re.compile('
php如何抓取网页数据库(Python提供一组开发Web应用程序的卓越工具-Python开发 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-26 23:13
)
今天的 网站 是非常丰富的应用程序,就像成熟的桌面应用程序一样。Python 为开发 Web 应用程序提供了一套出色的工具。在本节中,我们将使用 Django 开发一个个人日志博客,用外行的话来说,它是一个在线日志系统,它允许我们记录我们对特定主题的了解。
我们将为这个项目指定规范,然后为应用程序使用的数据定义模型。我们将使用 Django 的管理系统输入一些初始数据,然后编写允许 Django 为我们的 网站 创建页面的视图和模板。
Django 是一个 Web 框架 - 一组帮助开发交互式网站 的工具。Django 可以响应网页请求,也可以让你更轻松地读写数据库、管理用户等等。
构建 Django 项目
要构建一个Django项目,我们首先需要确保我们已经遵循了Django。我们在Pycharm中打开虚拟环境的终端,然后输入:pip install Django==1.11进行安装:
仍然在活动终端中,执行以下命令来创建一个新项目:
第一行的命令让我们创建一个名为 learning_log 的新项目。该命令末尾的句点使新项目使用适当的目录结构,以便开发完成后可以轻松地将应用程序部署到服务器。(注意:不要忘记这个时间段,否则在部署应用时会遇到一些配置问题。如果忘记了这个时间段,请删除所有创建的文件和文件夹,然后重新运行此命令。)
然后我们运行命令 ls(在 Windows 中应该是 dir),结果发现 Django 创建了一个名为 learning_log 的新目录。它还创建了一个名为 manage.py 的文件,这是一个简单的程序,它接受命令并将它们交给 Django 的相关部分来运行。我们将使用这些命令来管理任务,例如使用数据库和运行服务器。
learning_log目录收录4个文件,其中最重要的是settings.py、urls.py和wsgi.py。文件 settings.py 指定 Django 如何与您的系统交互并管理项目。当我们开发我们的项目时,我们将修改其中一些设置,并添加更多。文件 urls.py 告诉 Django 应该创建哪些网页来响应浏览器请求。文件 wsgi.py 帮助 Django 为它创建的文件提供服务,这是 Web 服务器网关接口的首字母缩写词。
创建数据库
Django 将大部分项目相关信息存储在数据库中,因此我们需要创建一个数据库供 Django 使用。要为我们的个人笔记创建数据库,请在活动虚拟环境中执行以下命令:
如果执行不成功,出现如下所示的错误,不要紧张。这是由于 Django 和 Python3 之间的兼容性问题。只需删除错误语句中的最后一个逗号即可。(如果报错是:SyntaxError: Generator expression must be parenthesized,可以用上面的方法。)
我们将修改数据库称为迁移数据库。当第一次执行命令 migrate 时,它将让 Django 确保数据库与项目的当前状态匹配。第一次在使用 SQLite 的新项目中执行此命令时,Django 将创建一个新数据库。Django 将指示它将创建必要的数据库表来存储我们将在这个项目中使用的信息,然后确保数据库结构与当前代码匹配。
然后我们运行命令 ls ,输出显示 Django 又创建了一个文件 - db.sqite3。SQLite 是一个单文件数据库,非常适合编写简单的应用程序,因为它让我们不必过多担心数据库管理。
查看项目
让我们验证 Django 是否正确创建了项目。为此,请执行命令 runserver,如下所示:
Django 启动一个服务器,允许您查看系统中的项目并了解它们是如何工作的。当您在浏览器中输入 URL 以请求网页时,Django 服务器将响应,生成适当的网页,并将其发送到浏览器。然后我们点击上面的链接,当我们看到下图的页面,就证明我们的项目可以正式启动了:
以上就是如何使用python开发网页的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php如何抓取网页数据库(Python提供一组开发Web应用程序的卓越工具-Python开发
)
今天的 网站 是非常丰富的应用程序,就像成熟的桌面应用程序一样。Python 为开发 Web 应用程序提供了一套出色的工具。在本节中,我们将使用 Django 开发一个个人日志博客,用外行的话来说,它是一个在线日志系统,它允许我们记录我们对特定主题的了解。

我们将为这个项目指定规范,然后为应用程序使用的数据定义模型。我们将使用 Django 的管理系统输入一些初始数据,然后编写允许 Django 为我们的 网站 创建页面的视图和模板。
Django 是一个 Web 框架 - 一组帮助开发交互式网站 的工具。Django 可以响应网页请求,也可以让你更轻松地读写数据库、管理用户等等。
构建 Django 项目
要构建一个Django项目,我们首先需要确保我们已经遵循了Django。我们在Pycharm中打开虚拟环境的终端,然后输入:pip install Django==1.11进行安装:
仍然在活动终端中,执行以下命令来创建一个新项目:
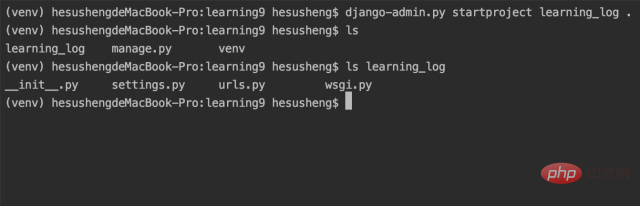
第一行的命令让我们创建一个名为 learning_log 的新项目。该命令末尾的句点使新项目使用适当的目录结构,以便开发完成后可以轻松地将应用程序部署到服务器。(注意:不要忘记这个时间段,否则在部署应用时会遇到一些配置问题。如果忘记了这个时间段,请删除所有创建的文件和文件夹,然后重新运行此命令。)
然后我们运行命令 ls(在 Windows 中应该是 dir),结果发现 Django 创建了一个名为 learning_log 的新目录。它还创建了一个名为 manage.py 的文件,这是一个简单的程序,它接受命令并将它们交给 Django 的相关部分来运行。我们将使用这些命令来管理任务,例如使用数据库和运行服务器。
learning_log目录收录4个文件,其中最重要的是settings.py、urls.py和wsgi.py。文件 settings.py 指定 Django 如何与您的系统交互并管理项目。当我们开发我们的项目时,我们将修改其中一些设置,并添加更多。文件 urls.py 告诉 Django 应该创建哪些网页来响应浏览器请求。文件 wsgi.py 帮助 Django 为它创建的文件提供服务,这是 Web 服务器网关接口的首字母缩写词。
创建数据库
Django 将大部分项目相关信息存储在数据库中,因此我们需要创建一个数据库供 Django 使用。要为我们的个人笔记创建数据库,请在活动虚拟环境中执行以下命令:
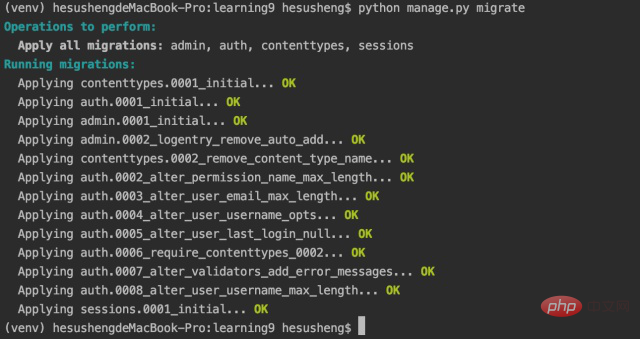
如果执行不成功,出现如下所示的错误,不要紧张。这是由于 Django 和 Python3 之间的兼容性问题。只需删除错误语句中的最后一个逗号即可。(如果报错是:SyntaxError: Generator expression must be parenthesized,可以用上面的方法。)
我们将修改数据库称为迁移数据库。当第一次执行命令 migrate 时,它将让 Django 确保数据库与项目的当前状态匹配。第一次在使用 SQLite 的新项目中执行此命令时,Django 将创建一个新数据库。Django 将指示它将创建必要的数据库表来存储我们将在这个项目中使用的信息,然后确保数据库结构与当前代码匹配。
然后我们运行命令 ls ,输出显示 Django 又创建了一个文件 - db.sqite3。SQLite 是一个单文件数据库,非常适合编写简单的应用程序,因为它让我们不必过多担心数据库管理。
查看项目
让我们验证 Django 是否正确创建了项目。为此,请执行命令 runserver,如下所示:
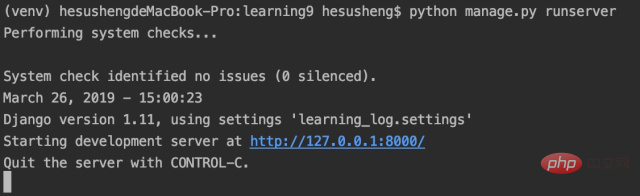
Django 启动一个服务器,允许您查看系统中的项目并了解它们是如何工作的。当您在浏览器中输入 URL 以请求网页时,Django 服务器将响应,生成适当的网页,并将其发送到浏览器。然后我们点击上面的链接,当我们看到下图的页面,就证明我们的项目可以正式启动了:
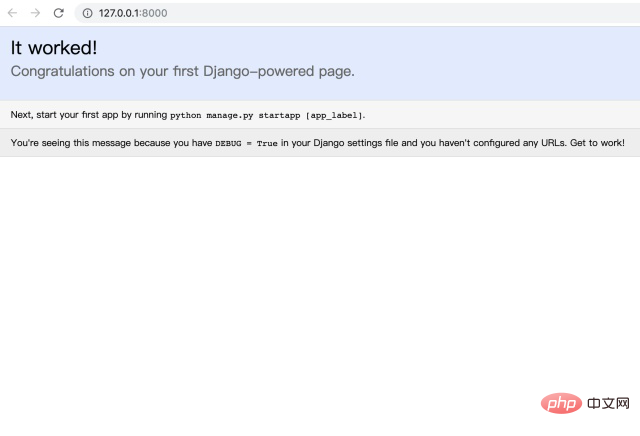
以上就是如何使用python开发网页的详细内容。更多详情请关注php中文网文章其他相关话题!

php如何抓取网页数据库(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-23 03:18
)
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为你自己的字符串。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
查看全部
php如何抓取网页数据库(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php)
)
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为你自己的字符串。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
php如何抓取网页数据库(PHP技术与MYSQL数据库技术在动态网页中的设计与应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-21 07:33
曲晓娜
摘要:随着互联网的普及和快速发展,网站逐渐成为各行各业最便捷、最快捷、最实用的信息展示和交流平台。本文讨论和分析了PHP技术和MYSQL数据库技术在动态网页中的设计和应用。
关键词:PHP;MYSQL; 动态网页
CLC 编号:TP393 证件识别码:A
文章号码:1009-3044(2020)13-0050-02
随着国民经济的发展和人民生活水平的提高。中国加入世贸组织以来,中国贸易逐步走向世界,各行各业的贸易也走向国际化。很多公司、企业、学校甚至政府部门都逐渐开始关注自己网页的制作。一时间,网页已成为各行各业对外交流和宣传的必备工具。
1 背景
目前,网页主要有两种类型:静态网页和动态网页。静态网页以 .html 或 .htm 为后缀。用html标记语言制作的静态网页可以直接被浏览器转换、翻译和执行。源代码直接存放在网站服务器上,方便移植。Html 文件代码由一些标签和文本组成。它是一个文本文件。您可以使用 Windows 自带的记事本程序直接编辑代码。编辑代码时,不区分大小写字母;动态网页是用服务器端脚本语言编写的(常用的服务器端脚本语言有ASP、PHP、JSP等),扩展名可以是.asp、.php、JSP。通常嵌入在 HTML 文档中,使用脚本语言制作的动态网页的浏览必须配置动态服务器工作。环境。
2PHP技术
PHP 是一种开放且跨平台的服务器端嵌入式脚本语言。主要是通过函数直接访问数据库。常用功能包括CREATE、SE-LECT、DELETE、INSERT INTO、QUERY等,在欧美国家非常流行,在国内也很受网站开发者的欢迎。它如此受欢迎的另一个重要原因是PHP支持直接连接各种数据库,包括MYSQL和ACCESS,并且还完全支持ODBC(0pen DateBaseConnectivity)接口。PHP 可以访问任何支持 ODBC 接口的数据库。操作。
3MYSQL数据库
Mysql数据库是最流行的关系数据库管理系统。它根据数据库中数据的不同属性建立不同的表,并通过关键属性将表关联起来,而不是把所有的数据放在一个大仓库里。这提高了速度并提高了灵活性。
4 PHP动态网页作品
在传统网页HTML文件(*.html)中加入APHP程序代码,就构成了一个PHP网页(*.PHP)。图1是PHP动态网页的工作原理图。当Web服务器遇到客户端访问PHP动态网页的请求时,首先将请求访问的运行结果发送给应用服务器。应用服务器执行程序相关指令并发送程序指令。对MYSQL数据库驱动,驱动通过查询MYSQL数据库找到满足条件的记录,将记录集返回给驱动,驱动再将记录发送给应用服务器。最后,应用服务器将记录存储在 MYSQL 中。将满足条件的数据插入网页,将动态网页转为静态网页,然后应用服务器将静态网页发送给网络浏览器。浏览器转换、翻译和显示 HTML 标签后,结果显示在浏览器中。.
5PHP技术与MYSQL动态网站设计
5.1MYSQL数据库连接与访问
5.1.1安装和配置MySQL
PHP连接MySQL服务器的操作步骤如下:
1)首先,将PHP目录下的libmysql.dll文件复制到F:kApache2.2kbin目录下。操作步骤如下:
一种。打开 php.ini 文件,
设置 MySQL 服务器的主机名:
mysql.default_host=本地主机
湾。设置 MySQL 服务器的端口号:
mysql.defauh_port=3306
C。设置默认用户:
5.1.访问3MYSQL数据库
1)点击“新建”按钮创建数据库“学生信息系统”。
2)创建数据表“学生表”如下:
六,结论
随着Web的广泛应用,具有可扩展性、灵活性和易维护性的Web动态交互技术是各行各业企业关注的焦点,而php和MYPSQL5.5则因其友好方便技术。其动态交互性越来越受到中小型电子商务企业的青睐。 查看全部
php如何抓取网页数据库(PHP技术与MYSQL数据库技术在动态网页中的设计与应用)
曲晓娜



摘要:随着互联网的普及和快速发展,网站逐渐成为各行各业最便捷、最快捷、最实用的信息展示和交流平台。本文讨论和分析了PHP技术和MYSQL数据库技术在动态网页中的设计和应用。
关键词:PHP;MYSQL; 动态网页
CLC 编号:TP393 证件识别码:A
文章号码:1009-3044(2020)13-0050-02
随着国民经济的发展和人民生活水平的提高。中国加入世贸组织以来,中国贸易逐步走向世界,各行各业的贸易也走向国际化。很多公司、企业、学校甚至政府部门都逐渐开始关注自己网页的制作。一时间,网页已成为各行各业对外交流和宣传的必备工具。
1 背景
目前,网页主要有两种类型:静态网页和动态网页。静态网页以 .html 或 .htm 为后缀。用html标记语言制作的静态网页可以直接被浏览器转换、翻译和执行。源代码直接存放在网站服务器上,方便移植。Html 文件代码由一些标签和文本组成。它是一个文本文件。您可以使用 Windows 自带的记事本程序直接编辑代码。编辑代码时,不区分大小写字母;动态网页是用服务器端脚本语言编写的(常用的服务器端脚本语言有ASP、PHP、JSP等),扩展名可以是.asp、.php、JSP。通常嵌入在 HTML 文档中,使用脚本语言制作的动态网页的浏览必须配置动态服务器工作。环境。
2PHP技术
PHP 是一种开放且跨平台的服务器端嵌入式脚本语言。主要是通过函数直接访问数据库。常用功能包括CREATE、SE-LECT、DELETE、INSERT INTO、QUERY等,在欧美国家非常流行,在国内也很受网站开发者的欢迎。它如此受欢迎的另一个重要原因是PHP支持直接连接各种数据库,包括MYSQL和ACCESS,并且还完全支持ODBC(0pen DateBaseConnectivity)接口。PHP 可以访问任何支持 ODBC 接口的数据库。操作。
3MYSQL数据库
Mysql数据库是最流行的关系数据库管理系统。它根据数据库中数据的不同属性建立不同的表,并通过关键属性将表关联起来,而不是把所有的数据放在一个大仓库里。这提高了速度并提高了灵活性。
4 PHP动态网页作品
在传统网页HTML文件(*.html)中加入APHP程序代码,就构成了一个PHP网页(*.PHP)。图1是PHP动态网页的工作原理图。当Web服务器遇到客户端访问PHP动态网页的请求时,首先将请求访问的运行结果发送给应用服务器。应用服务器执行程序相关指令并发送程序指令。对MYSQL数据库驱动,驱动通过查询MYSQL数据库找到满足条件的记录,将记录集返回给驱动,驱动再将记录发送给应用服务器。最后,应用服务器将记录存储在 MYSQL 中。将满足条件的数据插入网页,将动态网页转为静态网页,然后应用服务器将静态网页发送给网络浏览器。浏览器转换、翻译和显示 HTML 标签后,结果显示在浏览器中。.
5PHP技术与MYSQL动态网站设计
5.1MYSQL数据库连接与访问
5.1.1安装和配置MySQL
PHP连接MySQL服务器的操作步骤如下:
1)首先,将PHP目录下的libmysql.dll文件复制到F:kApache2.2kbin目录下。操作步骤如下:
一种。打开 php.ini 文件,
设置 MySQL 服务器的主机名:
mysql.default_host=本地主机
湾。设置 MySQL 服务器的端口号:
mysql.defauh_port=3306
C。设置默认用户:
5.1.访问3MYSQL数据库
1)点击“新建”按钮创建数据库“学生信息系统”。
2)创建数据表“学生表”如下:
六,结论
随着Web的广泛应用,具有可扩展性、灵活性和易维护性的Web动态交互技术是各行各业企业关注的焦点,而php和MYPSQL5.5则因其友好方便技术。其动态交互性越来越受到中小型电子商务企业的青睐。
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-18 06:24
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是Windows平台的话,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理一个表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是Windows平台的话,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理一个表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php如何抓取网页数据库(1.实现前的思考(图)评论系统的改版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 32 次浏览 • 2022-03-17 18:11
)
关于如何实现楼内评论系统的具体操作1. 实施前的思考
经过一番讨论和网易云话题,我终于下定决心自己写一个评论系统。
在我们使用的众多评论系统中,最流行的是楼内楼,如百度贴吧、wordpress等。在此之前,1、2、3层一般是按时间顺序展示的。如果要回复某人,请使用@符号标记用户名,然后回复内容。但是,这有一个很大的问题。讨论问题不集中,其他用户不知道你在讨论什么。原作者在一楼发表评论。当你进来回复这个用户的评论时,已经是10楼了。作者再次回复你到20楼。其他网友看到10楼的时候,已经忘记了原作者说了什么。
百度贴吧在改版之前就使用了这个方法,后来在新版本中启用了build方法里面的build。这样,就可以集中讨论某个话题。
同时,知乎也对自己的评论系统进行了修改,但并没有将其重新设计成楼中楼,而是在每条评论后添加了一个弹出链接,并带有一个对话来查看对话,并且点击链接后会弹出一个弹窗。可以看到关于这两个人互动的所有评论。
按时间倒序显示评论或按正序平铺很容易实现,但难以阅读。分门别类地显示评论对用户的阅读习惯很友好,但可能难以实现。不过最后还是决定采用楼内建房的方式。虽然我博客的评论数也很差,但我还是决定实现它。
2. 数据表设计
先说一下前后端使用的语言和框架。考虑到页面渲染和更多的事件调用,前端使用vue框架。应该说vue并不是最好的选择。毕竟,对于一个评论前端的部门来说,这可能有点矫枉过正。,但是为了快速发展,也选择了vue。后端使用php语言,数据库使用mysql。
数据库表的设计既考虑到了以前数据的导入能力,也方便以后添加新的评论。这里我创建了 3 个表:文章 表、用户表、评论表。
在网易云线程关闭之前,导出了自己的数据(我说的数据已经丢失,不知道导出的格式是什么),我们来看看网易云中导出的数据的格式线:
从上面的数据可以看出,每个文章都有一个title、url和comment,每个comment都有自己对应的id、reply的comment pid、content content、comment的user。用户名、昵称和头像。这里我只提取主要信息并输入到数据库中。
2.1 用户表
用户表比较简单。原来的userid也要保存为字段,以便在导入评论数据时可以找到对应的用户。评论数据也导入后,可以删除该字段。新添加的注册用户不使用该字段。用户表设计:
字段类型说明
ID
整数
自增,主键
宽
整数
用户的原创用户标识
昵称
varchar(50)
昵称
头像
varchar(100)
阿凡达
状态
整数
健康)状况
设计好用户表后,将原创数据中的所有用户分别取出,然后以userid为key存入数组,也可以起到去重的作用。将获取到的所有用户数据存储在用户表中
2.2 评论表
在设计意见表时,主要考虑以下因素:
评论必须依赖文章和用户才能存在,所以评论的外键是文章ID和userid,留言板是文章内容为空的评论表单;
我想以后新的评论可以使用自增id而不是跟随原评论的cid生成新的评论id,所以这次评论表的主键是id,原评论id是仅用作字段宽度之一。构建建筑物与建筑物的关系,这些旧评论插入数据表时会有新的评论id;
楼内楼的评论在某条评论下,同时楼内楼内有互动回复。因此,这条评论的pid(parentid)表示当前评论在哪条评论下,replyid表示正在回复的是哪条评论;如果直接回复父评论,则pid与replyid相同,都是父评论的id。不是父评论,pid是父评论的id,replyid是回复评论的id;当pid或replyid为0时,表示评论直接发到文章。
所以我们的评论表单是这样设计的:
字段类型说明
ID
整数
自增,主键
宽
整数
注释掉原来的主键 cid
uid
整数
用户身份
回复人
整数
评论回复的评论id,否则为0
PID
整数
评论的父 id,如果不是,则为 0
援助
varchar(100)
文章 的标志
内容
varchar(300)
注释
创建时间
整数
评论时间的时间戳
表中的aid(标识文章)可以是文章的url、文章的id或者其他任何可以唯一标识文章的东西。这里我们使用文章的uri作为唯一标识,比如上面数据中的文章,我们使用/node/2017/02/20/node-express-forum.html来标识文章. 其他 文章 也是如此。
在将这些评论写入表格时,我们还应该注意,在原创数据中,每条评论对应一个用户。在我设计的系统中,用户和评论是分开的,只有uid用来关联他们。新用户和新评论都使用自己的自增主键。因此,在将原创评论存入数据库时,需要将原创userid转换为新用户表中的主键id,并统一新旧数据。
文章表不解释。
3. 具体实现
前端部分主要负责展示每个文章的评论,同时允许登录用户添加评论。
3.1 显示评论
我们为每条评论添加了一个文章标志,前端可以根据辅助获取当前所有的文章评论。但是,我们的评论要以逐栋建筑的方式显示,我们不能简单地将数据平铺在页面上。我们在2.2中也说过,pid为0的评论都是直接发给文章的评论,这些评论应该显示为一级评论;如果pid是其他数据,则必须是属于注释的,应该显示为建筑物内的建筑物。
同时,无论是一级评论还是楼内楼的评论,都可能有分页,所以分页也要在这里处理。
所以最后我们在前端得到的结构应该大致是这样的:
前端拿到接口返回的数据后,就可以渲染页面了。在头像的处理中,也考虑了https环境,所以返回的头像链接都是以//开头的形式。
3.2 参与评论
如果用户对 文章 或评论产生共鸣,需要留言讨论,我们需要用户能够添加自己的评论。
评论的类型,如果细分的话,可以分为3类:
我这里的前端实现参考oschina(Open Source China)的comment方法。直接评论文章就是直接在顶部的评论窗口中输入;回复其他评论时,使用弹窗回复。弹窗回复的好处是页面不需要滚动,用户对评论的感知也可以停留在这个位置;同时,用户输入评论也无需添加各种不必要的小输入框。
3.3 登录
在登录问题上,我也纠结了很久,是使用自己的登录系统,还是使用第三方登录,还是用户无需注册登录,输入邮箱和昵称即可评论?
如果使用自己的评论系统,需要自己开发注册登录流程,比较麻烦,对于想要回复一句话的用户,可以干脆放弃注册;如果您只需要输入您的电子邮件地址和昵称即可发表评论,我会考虑到可能从用户那里引出的无限评论,无法控制。所以最后还是考虑接入第三方登录。这里我们选择使用微博作为第三方登录入口,以后会考虑添加github账号登录。
关于如何访问微博第三方登录,我们下一篇文章再讲。文档齐全。对于不熟悉的开发者来说,一开始可能会有些迷惑,但应该问题不大。
3.4 添加邮箱功能
用户登录第三方成功后,名字旁边有一个小输入框,可以让用户输入邮箱地址来接收回复提醒。此输入完全是自愿的,您仍然可以在不输入电子邮件地址的情况下发表评论。也被认为是这个站点是一个流量极低的小站点。用户可能会心血来潮发表评论,然后想到这个网站,但我不知道如何找到它。于是想到了增加邮件提醒功能,防止大神评论沉入海中。
3.5 特别注意
前端部门引入了vue框架,每一个文章页面都加载了评论模块。为了防止评论模块中的vue库影响外部资源(比如版本冲突等),我先把全局变量给了wzVue,然后注销了vue:
同时,在评论功能完成之初,只要用户进入这个页面,评论就会被加载。但是有一个问题,用户不一定能看到你的文章到底部,不一定能看到你的评论。因此,文章 改为按需加载。只有当用户滚动到底部并有阅读评论的意图时,才会加载评论。
最终结果是这样的:
4. 摘要
作为前端开发者,只用后端知识开发一个博客评论系统似乎很简单,整个框架的设计也很粗糙。同时缓存系统不熟练,无法立即更新评论信息。这个系统还有很大的改进空间。欢迎大家对蚊子(邵兵)提出更多的意见和建议。
写这个文章的时候,想着以后版本修改的时候,可以通过同步加载评论的方式来完成。生成文章后,更新频率极低,甚至变化不大,然后缓存评论的内容。每当有新评论时,当前 文章 的缓存将被删除并重新加载新评论。数据,然后缓存新的数据,这样在评论数据更新量比较低的时候,可以缓存更长的时间,同时也有利于搜索评论内容的爬取。
查看全部
php如何抓取网页数据库(1.实现前的思考(图)评论系统的改版
)
关于如何实现楼内评论系统的具体操作1. 实施前的思考
经过一番讨论和网易云话题,我终于下定决心自己写一个评论系统。
在我们使用的众多评论系统中,最流行的是楼内楼,如百度贴吧、wordpress等。在此之前,1、2、3层一般是按时间顺序展示的。如果要回复某人,请使用@符号标记用户名,然后回复内容。但是,这有一个很大的问题。讨论问题不集中,其他用户不知道你在讨论什么。原作者在一楼发表评论。当你进来回复这个用户的评论时,已经是10楼了。作者再次回复你到20楼。其他网友看到10楼的时候,已经忘记了原作者说了什么。
百度贴吧在改版之前就使用了这个方法,后来在新版本中启用了build方法里面的build。这样,就可以集中讨论某个话题。
同时,知乎也对自己的评论系统进行了修改,但并没有将其重新设计成楼中楼,而是在每条评论后添加了一个弹出链接,并带有一个对话来查看对话,并且点击链接后会弹出一个弹窗。可以看到关于这两个人互动的所有评论。
按时间倒序显示评论或按正序平铺很容易实现,但难以阅读。分门别类地显示评论对用户的阅读习惯很友好,但可能难以实现。不过最后还是决定采用楼内建房的方式。虽然我博客的评论数也很差,但我还是决定实现它。
2. 数据表设计
先说一下前后端使用的语言和框架。考虑到页面渲染和更多的事件调用,前端使用vue框架。应该说vue并不是最好的选择。毕竟,对于一个评论前端的部门来说,这可能有点矫枉过正。,但是为了快速发展,也选择了vue。后端使用php语言,数据库使用mysql。
数据库表的设计既考虑到了以前数据的导入能力,也方便以后添加新的评论。这里我创建了 3 个表:文章 表、用户表、评论表。
在网易云线程关闭之前,导出了自己的数据(我说的数据已经丢失,不知道导出的格式是什么),我们来看看网易云中导出的数据的格式线:
从上面的数据可以看出,每个文章都有一个title、url和comment,每个comment都有自己对应的id、reply的comment pid、content content、comment的user。用户名、昵称和头像。这里我只提取主要信息并输入到数据库中。
2.1 用户表
用户表比较简单。原来的userid也要保存为字段,以便在导入评论数据时可以找到对应的用户。评论数据也导入后,可以删除该字段。新添加的注册用户不使用该字段。用户表设计:
字段类型说明
ID
整数
自增,主键
宽
整数
用户的原创用户标识
昵称
varchar(50)
昵称
头像
varchar(100)
阿凡达
状态
整数
健康)状况
设计好用户表后,将原创数据中的所有用户分别取出,然后以userid为key存入数组,也可以起到去重的作用。将获取到的所有用户数据存储在用户表中
2.2 评论表
在设计意见表时,主要考虑以下因素:
评论必须依赖文章和用户才能存在,所以评论的外键是文章ID和userid,留言板是文章内容为空的评论表单;
我想以后新的评论可以使用自增id而不是跟随原评论的cid生成新的评论id,所以这次评论表的主键是id,原评论id是仅用作字段宽度之一。构建建筑物与建筑物的关系,这些旧评论插入数据表时会有新的评论id;
楼内楼的评论在某条评论下,同时楼内楼内有互动回复。因此,这条评论的pid(parentid)表示当前评论在哪条评论下,replyid表示正在回复的是哪条评论;如果直接回复父评论,则pid与replyid相同,都是父评论的id。不是父评论,pid是父评论的id,replyid是回复评论的id;当pid或replyid为0时,表示评论直接发到文章。
所以我们的评论表单是这样设计的:
字段类型说明
ID
整数
自增,主键
宽
整数
注释掉原来的主键 cid
uid
整数
用户身份
回复人
整数
评论回复的评论id,否则为0
PID
整数
评论的父 id,如果不是,则为 0
援助
varchar(100)
文章 的标志
内容
varchar(300)
注释
创建时间
整数
评论时间的时间戳
表中的aid(标识文章)可以是文章的url、文章的id或者其他任何可以唯一标识文章的东西。这里我们使用文章的uri作为唯一标识,比如上面数据中的文章,我们使用/node/2017/02/20/node-express-forum.html来标识文章. 其他 文章 也是如此。
在将这些评论写入表格时,我们还应该注意,在原创数据中,每条评论对应一个用户。在我设计的系统中,用户和评论是分开的,只有uid用来关联他们。新用户和新评论都使用自己的自增主键。因此,在将原创评论存入数据库时,需要将原创userid转换为新用户表中的主键id,并统一新旧数据。
文章表不解释。
3. 具体实现
前端部分主要负责展示每个文章的评论,同时允许登录用户添加评论。
3.1 显示评论
我们为每条评论添加了一个文章标志,前端可以根据辅助获取当前所有的文章评论。但是,我们的评论要以逐栋建筑的方式显示,我们不能简单地将数据平铺在页面上。我们在2.2中也说过,pid为0的评论都是直接发给文章的评论,这些评论应该显示为一级评论;如果pid是其他数据,则必须是属于注释的,应该显示为建筑物内的建筑物。
同时,无论是一级评论还是楼内楼的评论,都可能有分页,所以分页也要在这里处理。
所以最后我们在前端得到的结构应该大致是这样的:
前端拿到接口返回的数据后,就可以渲染页面了。在头像的处理中,也考虑了https环境,所以返回的头像链接都是以//开头的形式。
3.2 参与评论
如果用户对 文章 或评论产生共鸣,需要留言讨论,我们需要用户能够添加自己的评论。
评论的类型,如果细分的话,可以分为3类:
我这里的前端实现参考oschina(Open Source China)的comment方法。直接评论文章就是直接在顶部的评论窗口中输入;回复其他评论时,使用弹窗回复。弹窗回复的好处是页面不需要滚动,用户对评论的感知也可以停留在这个位置;同时,用户输入评论也无需添加各种不必要的小输入框。
3.3 登录
在登录问题上,我也纠结了很久,是使用自己的登录系统,还是使用第三方登录,还是用户无需注册登录,输入邮箱和昵称即可评论?
如果使用自己的评论系统,需要自己开发注册登录流程,比较麻烦,对于想要回复一句话的用户,可以干脆放弃注册;如果您只需要输入您的电子邮件地址和昵称即可发表评论,我会考虑到可能从用户那里引出的无限评论,无法控制。所以最后还是考虑接入第三方登录。这里我们选择使用微博作为第三方登录入口,以后会考虑添加github账号登录。
关于如何访问微博第三方登录,我们下一篇文章再讲。文档齐全。对于不熟悉的开发者来说,一开始可能会有些迷惑,但应该问题不大。
3.4 添加邮箱功能
用户登录第三方成功后,名字旁边有一个小输入框,可以让用户输入邮箱地址来接收回复提醒。此输入完全是自愿的,您仍然可以在不输入电子邮件地址的情况下发表评论。也被认为是这个站点是一个流量极低的小站点。用户可能会心血来潮发表评论,然后想到这个网站,但我不知道如何找到它。于是想到了增加邮件提醒功能,防止大神评论沉入海中。
3.5 特别注意
前端部门引入了vue框架,每一个文章页面都加载了评论模块。为了防止评论模块中的vue库影响外部资源(比如版本冲突等),我先把全局变量给了wzVue,然后注销了vue:
同时,在评论功能完成之初,只要用户进入这个页面,评论就会被加载。但是有一个问题,用户不一定能看到你的文章到底部,不一定能看到你的评论。因此,文章 改为按需加载。只有当用户滚动到底部并有阅读评论的意图时,才会加载评论。
最终结果是这样的:
4. 摘要
作为前端开发者,只用后端知识开发一个博客评论系统似乎很简单,整个框架的设计也很粗糙。同时缓存系统不熟练,无法立即更新评论信息。这个系统还有很大的改进空间。欢迎大家对蚊子(邵兵)提出更多的意见和建议。
写这个文章的时候,想着以后版本修改的时候,可以通过同步加载评论的方式来完成。生成文章后,更新频率极低,甚至变化不大,然后缓存评论的内容。每当有新评论时,当前 文章 的缓存将被删除并重新加载新评论。数据,然后缓存新的数据,这样在评论数据更新量比较低的时候,可以缓存更长的时间,同时也有利于搜索评论内容的爬取。
php如何抓取网页数据库(Google新闻抓取工具如何知道新网站何时出现?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-16 00:25
您有一些我将回答的关键问题,但首先您应该了解什么是爬虫。
什么是爬虫?
爬虫的工作是通过阅读页面扫描互联网,获取他收录的所有链接,然后阅读这些页面。此操作的主要目的是自动查找新内容。一个好的爬虫会开始爬取几个大的、熟悉的、更新频繁的网站,这样他就可以对这些网站进行更新和索引,快速获取新的内容和新的网站(因为大的 网站s 经常收录指向其他 网站s 的链接)。
关于你的问题:
googlenews 是否可以访问所有这些 网站 数据库?
不,如果您有权访问数据库,则不需要使用爬虫。
爬虫如何知道 网站 中添加了新链接?
Google 偶尔会抓取每个 网站 并在 网站 中搜索新链接。通常,新页面或 文章 将通过已存储在 Google 数据库中的主页链接。
Google 新闻抓取工具如何知道新的 网站 何时可用?
简单的答案是:爬虫找到新的 网站 的链接,检查 网站 是否在系统中,如果没有,则添加它。
他们如何获得旧版 文章 的链接?
很简单,他们将这些链接保存在一个巨大的数据库中。谷歌几年前开始抓取网络。如果谷歌今天再次开始抓取互联网,旧链接可能不会出现。
我如何获得时间网站发布文章?
这取决于您要抓取的 网站。如果每篇文章 文章 都有一个日期,则需要解析页面并提取该日期。这篇文章的顶部有一个日期,通过搜索日期类很容易找到 HTML dom:2014 年 6 月 6 日。如果没有出现日期,你无法知道他们什么时候会发布日期。
作为开发人员,您可以让 Google 的生活更轻松,并要求 Google 通过 Google 网站管理员工具抓取您的新 网站。
在抓取网页时,Google 还会统计指向页面的链接数量,这会影响页面的排名。许多指向您的链接 网站 表明您拥有有价值的内容,并且您应该在搜索结果中出现更高的位置。
编写一个简单的爬虫很容易。您使用 php cURL 或 file_get_contents 获取页面内容,对其进行解析,选择并保存所需的数据,提取此页面中的所有链接,并递归地抓取您找到的链接。</p> 查看全部
php如何抓取网页数据库(Google新闻抓取工具如何知道新网站何时出现?(组图))
您有一些我将回答的关键问题,但首先您应该了解什么是爬虫。
什么是爬虫?
爬虫的工作是通过阅读页面扫描互联网,获取他收录的所有链接,然后阅读这些页面。此操作的主要目的是自动查找新内容。一个好的爬虫会开始爬取几个大的、熟悉的、更新频繁的网站,这样他就可以对这些网站进行更新和索引,快速获取新的内容和新的网站(因为大的 网站s 经常收录指向其他 网站s 的链接)。
关于你的问题:
googlenews 是否可以访问所有这些 网站 数据库?
不,如果您有权访问数据库,则不需要使用爬虫。
爬虫如何知道 网站 中添加了新链接?
Google 偶尔会抓取每个 网站 并在 网站 中搜索新链接。通常,新页面或 文章 将通过已存储在 Google 数据库中的主页链接。
Google 新闻抓取工具如何知道新的 网站 何时可用?
简单的答案是:爬虫找到新的 网站 的链接,检查 网站 是否在系统中,如果没有,则添加它。
他们如何获得旧版 文章 的链接?
很简单,他们将这些链接保存在一个巨大的数据库中。谷歌几年前开始抓取网络。如果谷歌今天再次开始抓取互联网,旧链接可能不会出现。
我如何获得时间网站发布文章?
这取决于您要抓取的 网站。如果每篇文章 文章 都有一个日期,则需要解析页面并提取该日期。这篇文章的顶部有一个日期,通过搜索日期类很容易找到 HTML dom:2014 年 6 月 6 日。如果没有出现日期,你无法知道他们什么时候会发布日期。
作为开发人员,您可以让 Google 的生活更轻松,并要求 Google 通过 Google 网站管理员工具抓取您的新 网站。
在抓取网页时,Google 还会统计指向页面的链接数量,这会影响页面的排名。许多指向您的链接 网站 表明您拥有有价值的内容,并且您应该在搜索结果中出现更高的位置。
编写一个简单的爬虫很容易。您使用 php cURL 或 file_get_contents 获取页面内容,对其进行解析,选择并保存所需的数据,提取此页面中的所有链接,并递归地抓取您找到的链接。</p>
php如何抓取网页数据库(使用scrapy来抓取数据创建项目配置信息制作信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-14 06:08
简介
OMIM的全称是Online Mendelian Inheritance in Man,是一个不断更新的人类孟德尔遗传病数据库,重点关注人类遗传变异与表型性状的关系。
OMIM官网网址为:
呲牙
OMIM的注册用户可以下载或使用API获取数据。这里我们尝试使用爬虫来爬取Phenotype-Gene Relationships数据。
使用scrapy创建项目来抓取数据
scrapy startproject omimScrapy
cd omimScrapy
scrapy genspider omim omim.org
配置物品信息
import scrapy
class OmimscrapyItem(scrapy.Item):
# define the fields for your item here like:
geneSymbol = scrapy.Field()
mimNumber = scrapy.Field()
location = scrapy.Field()
phenotype = scrapy.Field()
phenotypeMimNumber = scrapy.Field()
nheritance = scrapy.Field()
mappingKey = scrapy.Field()
descriptionFold = scrapy.Field()
diagnosisFold = scrapy.Field()
inheritanceFold = scrapy.Field()
populationGeneticsFold = scrapy.Field()
做一个爬虫
我们依次抓取文件mim2gene.txt的内容,所以需要解析文件。
'''
解析omim mim2gene.txt的文件
'''
def readMim2Gene(self,filename):
filelist = []
with open(filename,"r") as f:
for line in f.readlines():
tempList = []
strs = line.split()
mimNumber = strs[0]
mimEntryType = strs[1]
geneSymbol = "."
if(len(strs)>=4):
geneSymbol = strs[3]
if(mimEntryType in ["gene","gene/phenotype"]):
tempList.append(mimNumber)
tempList.append(mimEntryType)
tempList.append(geneSymbol)
filelist.append(tempList)
return filelist
解析文件后,需要动态生成爬虫爬取的入口。我们需要通过 start_requests 方法动态生成抓取的 url。然后根据url爬取对应的内容。
注意:此阶段可以同时解析html内容,提取需要的内容,也可以先保存html内容,供后续统一处理。抓取到的html内容这里不解析,而是直接将html内容保存为html文件。文件名以mimNumber命名,后缀为.html。
爬虫设置
OMIM robots.txt 设置了爬虫策略,只允许微软 Bingbot 和谷歌 googlebot 爬虫获取指定路径的内容。主要注意几个方面的配置。
BOT_NAME = 'bingbot'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'bingbot (+https://www.bing.com/bingbot.htm)'
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 4
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
执行
然后就可以进行爬取操作了。这个过程比较慢,估计要一天。之后,所有的html页面都保存为本地html页面。
scrapy crawl omim
后续提取
基于本地html的提取操作非常简单,可以使用BeautifulSoup进行提取。提取的核心操作如下:
'''
解析Phenotype-Gene Relationships表格
'''
def parseHtmlTable(html):
soup = BeautifulSoup(html,"html.parser")
table = soup.table
location,phenotype,mimNumber,nheritance,mappingKey,descriptionFold,diagnosisFold,inheritanceFold,populationGeneticsFold="","","","","","","","",""
if not table:
result = "ERROR"
else:
result = "SUCCESS"
trs = table.find_all('tr')
for tr in trs:
tds = tr.find_all('td')
if len(tds)==0:
continue
elif len(tds)==4:
phenotype = phenotype + "|" + (tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.' )
mimNumber = mimNumber + "|" + (tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.')
nheritance = nheritance + "|" + (tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.')
mappingKey = mappingKey + "|" + (tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.')
elif len(tds)==5:
location = tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.'
phenotype = tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.'
mimNumber = tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.'
nheritance = tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.'
mappingKey = tds[4].get_text().strip() if tds[4].get_text().strip()!='' else '.'
else:
result = "ERROR"
descriptionFoldList = soup.select("#descriptionFold")
descriptionFold = "." if len(descriptionFoldList)==0 else descriptionFoldList[0].get_text().strip()
diagnosisFoldList = soup.select("#diagnosisFold")
diagnosisFold = "." if len(diagnosisFoldList)==0 else diagnosisFoldList[0].get_text().strip()
inheritanceFoldList = soup.select("#inheritanceFold")
inheritanceFold = "." if len(inheritanceFoldList)==0 else inheritanceFoldList[0].get_text().strip()
populationGeneticsFoldList = soup.select("#populationGeneticsFold")
populationGeneticsFold = "." if len(populationGeneticsFoldList)==0 else populationGeneticsFoldList[0].get_text().strip()
至于最终的格式,就看个人需求了。 查看全部
php如何抓取网页数据库(使用scrapy来抓取数据创建项目配置信息制作信息)
简介
OMIM的全称是Online Mendelian Inheritance in Man,是一个不断更新的人类孟德尔遗传病数据库,重点关注人类遗传变异与表型性状的关系。
OMIM官网网址为:

呲牙
OMIM的注册用户可以下载或使用API获取数据。这里我们尝试使用爬虫来爬取Phenotype-Gene Relationships数据。
使用scrapy创建项目来抓取数据
scrapy startproject omimScrapy
cd omimScrapy
scrapy genspider omim omim.org
配置物品信息
import scrapy
class OmimscrapyItem(scrapy.Item):
# define the fields for your item here like:
geneSymbol = scrapy.Field()
mimNumber = scrapy.Field()
location = scrapy.Field()
phenotype = scrapy.Field()
phenotypeMimNumber = scrapy.Field()
nheritance = scrapy.Field()
mappingKey = scrapy.Field()
descriptionFold = scrapy.Field()
diagnosisFold = scrapy.Field()
inheritanceFold = scrapy.Field()
populationGeneticsFold = scrapy.Field()
做一个爬虫
我们依次抓取文件mim2gene.txt的内容,所以需要解析文件。
'''
解析omim mim2gene.txt的文件
'''
def readMim2Gene(self,filename):
filelist = []
with open(filename,"r") as f:
for line in f.readlines():
tempList = []
strs = line.split()
mimNumber = strs[0]
mimEntryType = strs[1]
geneSymbol = "."
if(len(strs)>=4):
geneSymbol = strs[3]
if(mimEntryType in ["gene","gene/phenotype"]):
tempList.append(mimNumber)
tempList.append(mimEntryType)
tempList.append(geneSymbol)
filelist.append(tempList)
return filelist
解析文件后,需要动态生成爬虫爬取的入口。我们需要通过 start_requests 方法动态生成抓取的 url。然后根据url爬取对应的内容。
注意:此阶段可以同时解析html内容,提取需要的内容,也可以先保存html内容,供后续统一处理。抓取到的html内容这里不解析,而是直接将html内容保存为html文件。文件名以mimNumber命名,后缀为.html。
爬虫设置
OMIM robots.txt 设置了爬虫策略,只允许微软 Bingbot 和谷歌 googlebot 爬虫获取指定路径的内容。主要注意几个方面的配置。
BOT_NAME = 'bingbot'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'bingbot (+https://www.bing.com/bingbot.htm)'
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 4
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
执行
然后就可以进行爬取操作了。这个过程比较慢,估计要一天。之后,所有的html页面都保存为本地html页面。
scrapy crawl omim
后续提取
基于本地html的提取操作非常简单,可以使用BeautifulSoup进行提取。提取的核心操作如下:
'''
解析Phenotype-Gene Relationships表格
'''
def parseHtmlTable(html):
soup = BeautifulSoup(html,"html.parser")
table = soup.table
location,phenotype,mimNumber,nheritance,mappingKey,descriptionFold,diagnosisFold,inheritanceFold,populationGeneticsFold="","","","","","","","",""
if not table:
result = "ERROR"
else:
result = "SUCCESS"
trs = table.find_all('tr')
for tr in trs:
tds = tr.find_all('td')
if len(tds)==0:
continue
elif len(tds)==4:
phenotype = phenotype + "|" + (tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.' )
mimNumber = mimNumber + "|" + (tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.')
nheritance = nheritance + "|" + (tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.')
mappingKey = mappingKey + "|" + (tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.')
elif len(tds)==5:
location = tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.'
phenotype = tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.'
mimNumber = tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.'
nheritance = tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.'
mappingKey = tds[4].get_text().strip() if tds[4].get_text().strip()!='' else '.'
else:
result = "ERROR"
descriptionFoldList = soup.select("#descriptionFold")
descriptionFold = "." if len(descriptionFoldList)==0 else descriptionFoldList[0].get_text().strip()
diagnosisFoldList = soup.select("#diagnosisFold")
diagnosisFold = "." if len(diagnosisFoldList)==0 else diagnosisFoldList[0].get_text().strip()
inheritanceFoldList = soup.select("#inheritanceFold")
inheritanceFold = "." if len(inheritanceFoldList)==0 else inheritanceFoldList[0].get_text().strip()
populationGeneticsFoldList = soup.select("#populationGeneticsFold")
populationGeneticsFold = "." if len(populationGeneticsFoldList)==0 else populationGeneticsFoldList[0].get_text().strip()
至于最终的格式,就看个人需求了。
php如何抓取网页数据库(搜索引擎不要禁止所有搜索引擎访问网站的任何部分2、禁止 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-13 22:29
)
方法一:设置robots.txt方法
搜索引擎默认遵循robots.txt协议,创建一个robots.txt文本文件放在网站根目录下,编辑代码如下:
User-agent:*
Disallow:/
通过上面的代码,告诉搜索引擎不要抓取,获取,收录this网站.
注意:如果使用上述代码,它将阻止所有搜索引擎访问网站的任何部分。
以下常见用法示例:
1、禁止所有搜索引擎访问网站的所有部分
User-agent:*
Disallow:/
2、百度收录网站所有版块
User-agent:Baiduspider
Disallow:/
3、禁止谷歌收录全站
User-agent:Googlebot
Disallow:/
4、禁止除谷歌以外的所有搜索引擎搜索整个网站
4、禁止除百度以外的所有搜索引擎搜索全站
User-agent:Baiduspider
Disallow:
User-agent:*
allow:/
5、禁止所有搜索引擎访问某个目录(如禁止根目录下的admin和css)
User-agent:*
Disallow:/css/
Disallow:/admin/
方法二:设置页面代码方法
在网站主页代码之间,添加以下代码禁用收录和索引
按搜索引擎
## 禁止所有搜索引擎的收录和索引
## 禁止百度搜索引擎和索引
## 禁止Google搜索引擎和索引 查看全部
php如何抓取网页数据库(搜索引擎不要禁止所有搜索引擎访问网站的任何部分2、禁止
)
方法一:设置robots.txt方法
搜索引擎默认遵循robots.txt协议,创建一个robots.txt文本文件放在网站根目录下,编辑代码如下:
User-agent:*
Disallow:/
通过上面的代码,告诉搜索引擎不要抓取,获取,收录this网站.
注意:如果使用上述代码,它将阻止所有搜索引擎访问网站的任何部分。
以下常见用法示例:
1、禁止所有搜索引擎访问网站的所有部分
User-agent:*
Disallow:/
2、百度收录网站所有版块
User-agent:Baiduspider
Disallow:/
3、禁止谷歌收录全站
User-agent:Googlebot
Disallow:/
4、禁止除谷歌以外的所有搜索引擎搜索整个网站
4、禁止除百度以外的所有搜索引擎搜索全站
User-agent:Baiduspider
Disallow:
User-agent:*
allow:/
5、禁止所有搜索引擎访问某个目录(如禁止根目录下的admin和css)
User-agent:*
Disallow:/css/
Disallow:/admin/
方法二:设置页面代码方法
在网站主页代码之间,添加以下代码禁用收录和索引
按搜索引擎
## 禁止所有搜索引擎的收录和索引
## 禁止百度搜索引擎和索引
## 禁止Google搜索引擎和索引
php如何抓取网页数据库(网站seo需要优化哪些html代码(30/4)? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-13 22:26
)
相关话题
网站优化的标准HTML代码
2007 年 5 月 31 日 09:16:00
规范化的 Html 代码对于 网站 有很多好处,例如:易于修改、易于代码维护、代码量大
增长知识!网站哪些html代码需要针对seo进行优化?
24/11/202012:05:45
关于seo,大部分人看到的界面都是用html代码组织的。优化网站html代码的目的是为了让网站更适合搜索引擎。精致的网站一端适合用户,另一端适合
如何在html中直接显示html代码
30/4/202109:53:59
本文文章将介绍在html中直接显示html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。百度做了很多实践,感觉很多都没有测试过就废话了。
如何优化 HTML网站 代码
2018 年 5 月 12 日 14:20:51
一个高质量的网站,网站代码的优化是非常重要的。对于一个好的SEO人来说,虽然不需要精通代码,但是一些简单的基本代码还是需要懂的。要想成为优秀的SEO人眼,需要有不断学习的精神。我们的网站 中的某个页面需要网站 代码优化。如果想看懂代码,可以给网站的添加附加值,有利于蜘蛛爬网
如何编写html换行代码
2021 年 2 月 2 日 18:05:55
html换行代码是“
",在要换行的行末尾,添加"
《代码可以实现换行操作.html》
”标签用于插入简单的换行符,实现换行。本教程运行环境:win
html中的空格代码是什么
15/12/202015:20:52
HTML空格码就是HTML空格字符码,由“&+n+b+s+p+;”组成,记住最后一个分号不要忘记。在 CSS 中,当 white-space 属性的值为 pre 时,浏览器会在文本中保留空格和换行符,例如:
如何在vscode中运行html代码
30/4/202109:54:00
本文文章将介绍在vscode中运行html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。如何在vscode中运行html代码:点击vscode软件左侧的扩展
html常用代码
2018 年 4 月 3 日 01:10:52
1:粗斜体代码 ◆粗体代码为:Hello ◆斜体代码为:Hello!◆底线字:2:文本链接代码 如果你想点击某个文本连接到另一个网页,这是一个超链接,代码如下: 如果你在共享空间中点击这个文本并重新打开一个窗口,代码是:
如何在html中注释代码
2021 年 12 月 4 日 18:13:35
html中注释代码的方法:先修改文件名,完善代码;然后创建三个div层,并使用“”进行注释;最后刷新网页。本教程的运行环境:windows7系统,html5版本,DELLG3电脑。用于注释的 html 中的代码
jquery如何输出html代码
17/11/202018:04:57
jquery输出html代码的方法:1、直接输出tag元素,代码为[varform1=""];2、 输出带有变量的标签元素,代码为[varcountry=....]。杰克
为什么html看不到php代码
24/6/202109:16:35
html看不到php代码,因为所有的php代码都是在网站发送到浏览器之前在服务器上执行的,而浏览器接收到的一切都是php嵌入到html中的结果。本文运行环境:windows7系统,PHP7.第1版,DELLG3
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站代码应该如何优化?
2014 年 11 月 3 日 17:19:00
网站是由代码组成的,所以一定要优化网站网站的代码,代码的优化也是网站优化中的一个优化措施。@> 优化很重要。虽然HTML代码是程序员应该精通的语言,但是HTML代码的优化应该是SEO专家应该精通的技能。作为一名合格的SEOer,我们不需要精通HTML代码,但我们要知道如何优化 网站 代码,...
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
查看全部
php如何抓取网页数据库(网站seo需要优化哪些html代码(30/4)?
)
相关话题
网站优化的标准HTML代码
2007 年 5 月 31 日 09:16:00
规范化的 Html 代码对于 网站 有很多好处,例如:易于修改、易于代码维护、代码量大

增长知识!网站哪些html代码需要针对seo进行优化?
24/11/202012:05:45
关于seo,大部分人看到的界面都是用html代码组织的。优化网站html代码的目的是为了让网站更适合搜索引擎。精致的网站一端适合用户,另一端适合
如何在html中直接显示html代码
30/4/202109:53:59
本文文章将介绍在html中直接显示html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。百度做了很多实践,感觉很多都没有测试过就废话了。
如何优化 HTML网站 代码
2018 年 5 月 12 日 14:20:51
一个高质量的网站,网站代码的优化是非常重要的。对于一个好的SEO人来说,虽然不需要精通代码,但是一些简单的基本代码还是需要懂的。要想成为优秀的SEO人眼,需要有不断学习的精神。我们的网站 中的某个页面需要网站 代码优化。如果想看懂代码,可以给网站的添加附加值,有利于蜘蛛爬网
如何编写html换行代码
2021 年 2 月 2 日 18:05:55
html换行代码是“
",在要换行的行末尾,添加"
《代码可以实现换行操作.html》
”标签用于插入简单的换行符,实现换行。本教程运行环境:win
html中的空格代码是什么
15/12/202015:20:52
HTML空格码就是HTML空格字符码,由“&+n+b+s+p+;”组成,记住最后一个分号不要忘记。在 CSS 中,当 white-space 属性的值为 pre 时,浏览器会在文本中保留空格和换行符,例如:
如何在vscode中运行html代码
30/4/202109:54:00
本文文章将介绍在vscode中运行html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。如何在vscode中运行html代码:点击vscode软件左侧的扩展
html常用代码
2018 年 4 月 3 日 01:10:52
1:粗斜体代码 ◆粗体代码为:Hello ◆斜体代码为:Hello!◆底线字:2:文本链接代码 如果你想点击某个文本连接到另一个网页,这是一个超链接,代码如下: 如果你在共享空间中点击这个文本并重新打开一个窗口,代码是:
如何在html中注释代码
2021 年 12 月 4 日 18:13:35
html中注释代码的方法:先修改文件名,完善代码;然后创建三个div层,并使用“”进行注释;最后刷新网页。本教程的运行环境:windows7系统,html5版本,DELLG3电脑。用于注释的 html 中的代码
jquery如何输出html代码
17/11/202018:04:57
jquery输出html代码的方法:1、直接输出tag元素,代码为[varform1=""];2、 输出带有变量的标签元素,代码为[varcountry=....]。杰克
为什么html看不到php代码
24/6/202109:16:35
html看不到php代码,因为所有的php代码都是在网站发送到浏览器之前在服务器上执行的,而浏览器接收到的一切都是php嵌入到html中的结果。本文运行环境:windows7系统,PHP7.第1版,DELLG3
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站代码应该如何优化?
2014 年 11 月 3 日 17:19:00
网站是由代码组成的,所以一定要优化网站网站的代码,代码的优化也是网站优化中的一个优化措施。@> 优化很重要。虽然HTML代码是程序员应该精通的语言,但是HTML代码的优化应该是SEO专家应该精通的技能。作为一名合格的SEOer,我们不需要精通HTML代码,但我们要知道如何优化 网站 代码,...
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
php如何抓取网页数据库(windows10系统、AdobeDreamweaveHtml代码seo优化最佳布局实例讲解(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-11 01:20
)
相关话题
如何在html中居中网页
18/1/202112:07:17
html居中网页的方法:首先在Dreamweaver中打开html页面文件;然后直接在页面高度后面加上[align="center"]代码。本教程运行环境:windows10系统、Adobe Dreamweave
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
高质量网页设计:示例和提示
2018 年 14 月 5 日 09:08:43
接下来,我会给大家一些重点,并附上相应的例子,和大家分享一下我在别人的网页设计中寻找“高品质”的过程。
html是网页文件吗?
25/11/202012:05:42
HTML是网页文件,而Html文件就是我们通常所说的静态网页文件。此方法适用于所有品牌的电脑Htm
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
实现网站(网页)跳转并可以隐藏跳转后URL的代码
2/3/2018 01:10:32
实现网站(网页)跳转的代码,跳转后隐藏URL Chengzi 2017-04-0423:44:01 浏览304条评论0 阿里云域名根目录http网页设计UIhtdocscharsetindexhtml总结:实现网站(网页)跳转可以隐藏跳转后的URL代码1.实现网站(网页)跳转并隐藏跳转后URL的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
提高网页和博客设计质量的一些示例和技巧
21/5/2009 11:27:00
“高品质”是每个人都在追求的,在网页设计界也不例外。但是什么是“质量”,你如何判断一个设计的质量好坏?我碰巧有一种方法可以找到网页设计中质量的重点。一旦你知道如何判断一个高质量的设计真正擅长什么,你就会有很多技巧来完善你自己的。
响应式网页设计和 SEO
20/6/2013 14:47:00
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站上,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难,网页中的功能也越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Adobe 发布网页设计软件 Muse
17/5/2012 13:24:00
Adobe 今天宣布推出其网页设计软件 Muse。Adobe 表示,使用 Muse 软件,网页设计师无需编写代码即可创建 网站。Adobe 此前曾进行过 Musebeta 公开测试版。
起床!网页设计师的网页设计简史
2014 年 9 月 12 日 11:08:00
这是一部网页设计发展的简史,我们可以看到技术、设计和思想的演变,看到无数有识之士改变世界的剪影。
查看全部
php如何抓取网页数据库(windows10系统、AdobeDreamweaveHtml代码seo优化最佳布局实例讲解(组图)
)
相关话题
如何在html中居中网页
18/1/202112:07:17
html居中网页的方法:首先在Dreamweaver中打开html页面文件;然后直接在页面高度后面加上[align="center"]代码。本教程运行环境:windows10系统、Adobe Dreamweave
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
高质量网页设计:示例和提示
2018 年 14 月 5 日 09:08:43
接下来,我会给大家一些重点,并附上相应的例子,和大家分享一下我在别人的网页设计中寻找“高品质”的过程。
html是网页文件吗?
25/11/202012:05:42
HTML是网页文件,而Html文件就是我们通常所说的静态网页文件。此方法适用于所有品牌的电脑Htm
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
实现网站(网页)跳转并可以隐藏跳转后URL的代码
2/3/2018 01:10:32
实现网站(网页)跳转的代码,跳转后隐藏URL Chengzi 2017-04-0423:44:01 浏览304条评论0 阿里云域名根目录http网页设计UIhtdocscharsetindexhtml总结:实现网站(网页)跳转可以隐藏跳转后的URL代码1.实现网站(网页)跳转并隐藏跳转后URL的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
提高网页和博客设计质量的一些示例和技巧
21/5/2009 11:27:00
“高品质”是每个人都在追求的,在网页设计界也不例外。但是什么是“质量”,你如何判断一个设计的质量好坏?我碰巧有一种方法可以找到网页设计中质量的重点。一旦你知道如何判断一个高质量的设计真正擅长什么,你就会有很多技巧来完善你自己的。
响应式网页设计和 SEO
20/6/2013 14:47:00
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站上,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难,网页中的功能也越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Adobe 发布网页设计软件 Muse
17/5/2012 13:24:00
Adobe 今天宣布推出其网页设计软件 Muse。Adobe 表示,使用 Muse 软件,网页设计师无需编写代码即可创建 网站。Adobe 此前曾进行过 Musebeta 公开测试版。
起床!网页设计师的网页设计简史
2014 年 9 月 12 日 11:08:00
这是一部网页设计发展的简史,我们可以看到技术、设计和思想的演变,看到无数有识之士改变世界的剪影。
php如何抓取网页数据库(8.根据数据集大小下载数据匹配的所有数据摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-08 09:06
8. 根据数据集大小下载数据集。
9. 根据与之关联的机器学习任务下载数据集。
案例(搜索并下载数据集)
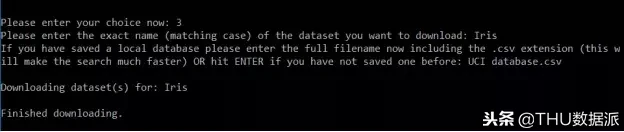
例如,如果您想下载著名的鸢尾花数据集,只需从菜单中选择选项 3,然后输入存储它的本地数据库的名称(以便更快地搜索)。只需下载 Iris 数据集并将其存储在名为“Iris”的文件夹中!
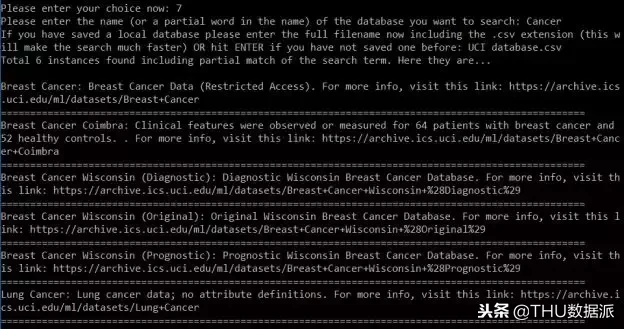
案例(搜索收录 关键词 的数据集)
如果选择了选项 7,将使用关键字搜索来获取名称与搜索字符串匹配的所有数据集(甚至部分)的简短摘要。您还可以获得每个结果的 Web 链接,以便根据需要进一步探索数据。下面的截图是使用 关键词Cancer 搜索的结果。
如果你想另辟蹊径
如果你想避开这个简单的用户API,使用基本功能,也是可以的。大致流程如下,先导入必要的包。
从 UCI_ML_Functions 导入 *import pandas as pd
read_dataset_table():从url读取数据集并进一步处理,用于后续的数据清洗和分类。
网址:
clean_dataset_table():清理原创数据集(DataFrame)并返回数据。处理后的数据会删除收录缺失值的观测值。还移除了 Default Tasks 列,该列用于显示与数据集关联的主机学习任务。
build_local_table(filename=None, msg_flag=True):读取UCI ML网站,构建本地表,收录名称、大小、ML任务、数据类型等信息。
build_dataset_list():从 UCI ML 数据集页面获取信息并构建收录所有数据集信息的列表。
build_dataset_dictionary():从 UCI ML 数据集页面获取信息并构建收录所有数据集名称和描述的字典。此外,还会生成一个与数据集对应的唯一标识符,下载器需要这个标识符字符串来下载数据文件。在这种情况下,通用名称无效。
build_full_dataframe():构建一个收录所有信息的 DataFrame,包括用于下载数据的 URL 链接。
build_local_database(filename=None, msg_flag=True):读取 UCI ML网站 并使用以下信息构建本地数据库:名称、摘要、数据页 URL。
return_abstract(name,local_database=None,msg_flag=False):通过搜索给定的名称返回特定数据集的单行描述(以及指向更多信息的 Web 链接)。
describe_all_dataset(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的描述。
print_all_datasets_names(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的名称。
extract_url_dataset(dataset,msg_flag=False):给定一个数据集标识符,该函数提取实际原创数据所在页面的URL。
download_dataset_url(url,directory,msg_flag=False,download_flag=True):从给定 url 中的链接下载所有文件。
download_datasets(num=10,local_database=None,msg_flag=True,download_flag=True):下载数据集并将其放在以数据集命名的本地目录中。默认情况下,仅下载前 10 个数据集。用户可以选择要下载的数据集数量。
download_dataset_name(name,local_database=None,msg_flag=True,download_flag=True):下载指定名称的数据集。
download_datasets_size(size='Small',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载所有符合“大小”标准的数据集。
download_datasets_task(task='Classification',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载用户想要满足 ML 任务条件的所有数据集。
原标题:
为 UCI 机器学习存储库引入简单直观的 Python API
原文链接:
关于译者
UIUC统计学硕士王雨桐,主修统计学,目前专注于编码能力的提升。在从理论到应用的转化中,我们尊重数据,不断进化。
——结束——
关注清华-青岛数据科学研究所官方微信公众平台“THU数据学院”及其姊妹号“数据学院THU”,获取更多讲座福利和优质内容。 查看全部
php如何抓取网页数据库(8.根据数据集大小下载数据匹配的所有数据摘要)
8. 根据数据集大小下载数据集。
9. 根据与之关联的机器学习任务下载数据集。
案例(搜索并下载数据集)
例如,如果您想下载著名的鸢尾花数据集,只需从菜单中选择选项 3,然后输入存储它的本地数据库的名称(以便更快地搜索)。只需下载 Iris 数据集并将其存储在名为“Iris”的文件夹中!
案例(搜索收录 关键词 的数据集)
如果选择了选项 7,将使用关键字搜索来获取名称与搜索字符串匹配的所有数据集(甚至部分)的简短摘要。您还可以获得每个结果的 Web 链接,以便根据需要进一步探索数据。下面的截图是使用 关键词Cancer 搜索的结果。
如果你想另辟蹊径
如果你想避开这个简单的用户API,使用基本功能,也是可以的。大致流程如下,先导入必要的包。
从 UCI_ML_Functions 导入 *import pandas as pd
read_dataset_table():从url读取数据集并进一步处理,用于后续的数据清洗和分类。
网址:
clean_dataset_table():清理原创数据集(DataFrame)并返回数据。处理后的数据会删除收录缺失值的观测值。还移除了 Default Tasks 列,该列用于显示与数据集关联的主机学习任务。
build_local_table(filename=None, msg_flag=True):读取UCI ML网站,构建本地表,收录名称、大小、ML任务、数据类型等信息。
build_dataset_list():从 UCI ML 数据集页面获取信息并构建收录所有数据集信息的列表。
build_dataset_dictionary():从 UCI ML 数据集页面获取信息并构建收录所有数据集名称和描述的字典。此外,还会生成一个与数据集对应的唯一标识符,下载器需要这个标识符字符串来下载数据文件。在这种情况下,通用名称无效。
build_full_dataframe():构建一个收录所有信息的 DataFrame,包括用于下载数据的 URL 链接。
build_local_database(filename=None, msg_flag=True):读取 UCI ML网站 并使用以下信息构建本地数据库:名称、摘要、数据页 URL。
return_abstract(name,local_database=None,msg_flag=False):通过搜索给定的名称返回特定数据集的单行描述(以及指向更多信息的 Web 链接)。
describe_all_dataset(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的描述。
print_all_datasets_names(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的名称。
extract_url_dataset(dataset,msg_flag=False):给定一个数据集标识符,该函数提取实际原创数据所在页面的URL。
download_dataset_url(url,directory,msg_flag=False,download_flag=True):从给定 url 中的链接下载所有文件。
download_datasets(num=10,local_database=None,msg_flag=True,download_flag=True):下载数据集并将其放在以数据集命名的本地目录中。默认情况下,仅下载前 10 个数据集。用户可以选择要下载的数据集数量。
download_dataset_name(name,local_database=None,msg_flag=True,download_flag=True):下载指定名称的数据集。
download_datasets_size(size='Small',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载所有符合“大小”标准的数据集。
download_datasets_task(task='Classification',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载用户想要满足 ML 任务条件的所有数据集。
原标题:
为 UCI 机器学习存储库引入简单直观的 Python API
原文链接:
关于译者

UIUC统计学硕士王雨桐,主修统计学,目前专注于编码能力的提升。在从理论到应用的转化中,我们尊重数据,不断进化。
——结束——
关注清华-青岛数据科学研究所官方微信公众平台“THU数据学院”及其姊妹号“数据学院THU”,获取更多讲座福利和优质内容。
php如何抓取网页数据库(php如何抓取网页数据库,php采用googlemap提供的demo上传域名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-07 16:01
php如何抓取网页数据库,php采用googlemap提供的demo上传域名:postman0。4版本后将自动转换成etag数据格式1、postman需要先和数据库联接2、数据库连接完成后,不能新建表(我的postman中没有注释),应该自动把表生成html并向服务器端提交第一部分:01demo我们在postman里面建立一个网站,只有一个用户,demo为1。
从任意位置上传图片2。把上传图片的。etag=false设置为true参考:googlemap实例_postman参考5图片上传-2。postman-全球性能最佳postman应用开发工具。
注释,2.0开始我每次上传图片前都注释2次!!!保证你的服务器不收到图片html的时候才注释2次!!!
1。使用定义好的下载引擎去下载jpg或者gif,要注意的是最好是在同一台机器上下载;2。从你网站目录下面的doc文件夹下面下载jpg或者gif,3。用php连接数据库,用postman的header请求,请求之前必须要获取上传的数据cookie4。拿到上传的数据后,可以用toadsr服务器抓取比如支持wordpress,flash,java等等主流的网站和主题,每天都抓取上千条数据并且保存,完全不用担心数据丢失。
特别是java,推荐给你helpfindsource;start:;;tools:--webserver--web--jsp--cgi--apachehttp--phpapachemysqlnginx5。可以再上传前对图片的数据进行压缩,压缩后的文件下载速度比原始的要快,如果没有大量数据的话就不用压缩。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库,php采用googlemap提供的demo上传域名)
php如何抓取网页数据库,php采用googlemap提供的demo上传域名:postman0。4版本后将自动转换成etag数据格式1、postman需要先和数据库联接2、数据库连接完成后,不能新建表(我的postman中没有注释),应该自动把表生成html并向服务器端提交第一部分:01demo我们在postman里面建立一个网站,只有一个用户,demo为1。
从任意位置上传图片2。把上传图片的。etag=false设置为true参考:googlemap实例_postman参考5图片上传-2。postman-全球性能最佳postman应用开发工具。
注释,2.0开始我每次上传图片前都注释2次!!!保证你的服务器不收到图片html的时候才注释2次!!!
1。使用定义好的下载引擎去下载jpg或者gif,要注意的是最好是在同一台机器上下载;2。从你网站目录下面的doc文件夹下面下载jpg或者gif,3。用php连接数据库,用postman的header请求,请求之前必须要获取上传的数据cookie4。拿到上传的数据后,可以用toadsr服务器抓取比如支持wordpress,flash,java等等主流的网站和主题,每天都抓取上千条数据并且保存,完全不用担心数据丢失。
特别是java,推荐给你helpfindsource;start:;;tools:--webserver--web--jsp--cgi--apachehttp--phpapachemysqlnginx5。可以再上传前对图片的数据进行压缩,压缩后的文件下载速度比原始的要快,如果没有大量数据的话就不用压缩。
php如何抓取网页数据库(阿里云gtgt;云栖社区(gt)主题地图(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-04 07:08
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库
推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python 全栈 MongoDB 数据库(概念、安装、创建数据)
作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
Mysql数据库的介绍与分类(学习笔记一)
作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
数据库注释 5:外键的用途
作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
PHP开发中数据库及相关软件的选择注意事项
作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列的4.4.x已经停止升级开发,但仍有部分生产环境运行该版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
php本机代码从数据库中获取记录
作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
在 Android 开发中使用 SQLite 数据库
作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
WordPress数据库研究
作者:ap0581w9c1121 浏览评论:09年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php如何抓取网页数据库(阿里云gtgt;云栖社区(gt)主题地图(组图))
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库

推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python 全栈 MongoDB 数据库(概念、安装、创建数据)


作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
Mysql数据库的介绍与分类(学习笔记一)


作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
数据库注释 5:外键的用途

作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
PHP开发中数据库及相关软件的选择注意事项

作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列的4.4.x已经停止升级开发,但仍有部分生产环境运行该版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
php本机代码从数据库中获取记录

作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
在 Android 开发中使用 SQLite 数据库

作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
一小时学会MySQL数据库


作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
WordPress数据库研究

作者:ap0581w9c1121 浏览评论:09年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑

作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php如何抓取网页数据库(小项目里面的大内涵,其实也不是特别高深,一点一点的说吧~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-02 23:19
小项目中的大内容
也不例外~做任何系统都不要相信用户的输入(@http:也教我们不要相信javascript,你可以自己想想怎么做)~一定是关于用户的输入。输入处理只能被执行或存储。否则,神马跨站攻击,神马SQL注入攻击,乱七八糟不容易收拾的~一个比较基础的处理,PHP魔语行情,详情请看:传送门做人做事》高眼手低”,高楼拔地而起,干就干~
186 查看全部
php如何抓取网页数据库(小项目里面的大内涵,其实也不是特别高深,一点一点的说吧~)
小项目中的大内容
也不例外~做任何系统都不要相信用户的输入(@http:也教我们不要相信javascript,你可以自己想想怎么做)~一定是关于用户的输入。输入处理只能被执行或存储。否则,神马跨站攻击,神马SQL注入攻击,乱七八糟不容易收拾的~一个比较基础的处理,PHP魔语行情,详情请看:传送门做人做事》高眼手低”,高楼拔地而起,干就干~
186
php如何抓取网页数据库(1.如何在当前页面用php获取js变量的值你这么问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-28 11:16
1.如何使用php获取当前页面中js变量的值
如果你问这个问题,说明你还没有理解web应用的原理。
服务器收到客户端请求后,web服务调用php程序,php运行并将结果返回给web服务,php程序立即退出,web服务以html的形式发送给客户端. js收录在发送给客户端的数据中,在客户端运行。跟服务端没有关系,更别说让退出的php程序再次获取js变量了。简单来说就是客户端js变量生成后,服务端php就不存在了。
所以,当前页面不可能使用php获取js变量。但是可以使用ajax技术将变量传回服务器,另外一个php程序可以进行处理。
2.PHP+JS如何爬取别人页面的js数据
js不行,js显示的数据必须支持ajax的采集器采集,我在网上找了一个,你看看行不行,我摘录一段,你可以去详情
@网站让我们看看:
浏览器可以看到的数据可以很方便采集,特别擅长采集Js脚本输出,Ajax动态加载,点击后显示,大长列表,隐藏,iframe框架等大数据
单个任务可以采集30万页/天,采集的速度可以根据客户要求进一步增减,保证数据采集工作可以完成以最快的速度。
<p>各类网站均在采集、新闻、论坛、博客、生活服务、电子商务 查看全部
php如何抓取网页数据库(1.如何在当前页面用php获取js变量的值你这么问)
1.如何使用php获取当前页面中js变量的值
如果你问这个问题,说明你还没有理解web应用的原理。
服务器收到客户端请求后,web服务调用php程序,php运行并将结果返回给web服务,php程序立即退出,web服务以html的形式发送给客户端. js收录在发送给客户端的数据中,在客户端运行。跟服务端没有关系,更别说让退出的php程序再次获取js变量了。简单来说就是客户端js变量生成后,服务端php就不存在了。
所以,当前页面不可能使用php获取js变量。但是可以使用ajax技术将变量传回服务器,另外一个php程序可以进行处理。
2.PHP+JS如何爬取别人页面的js数据
js不行,js显示的数据必须支持ajax的采集器采集,我在网上找了一个,你看看行不行,我摘录一段,你可以去详情
@网站让我们看看:
浏览器可以看到的数据可以很方便采集,特别擅长采集Js脚本输出,Ajax动态加载,点击后显示,大长列表,隐藏,iframe框架等大数据
单个任务可以采集30万页/天,采集的速度可以根据客户要求进一步增减,保证数据采集工作可以完成以最快的速度。
<p>各类网站均在采集、新闻、论坛、博客、生活服务、电子商务
php如何抓取网页数据库(关于PHP连接MySQL数据库方法的5种连接方法总结!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-28 11:15
X
本节主要介绍PHP连接MySQL数据库的方法。如果你对PHP一无所知,请阅读上一篇文章:PHP入门的语法基础非常重要。
接下来是PHP连接MySQL数据库的方法内容。它也不需要完全理解。你只需要有一个大致的印象。看完整个教程后,可以将教程内容中的代码复制到本地,即可成功。运行,这样你就可以快速学习php编程了,因为所有的编程都是大同小异的,到最后,你已经复制粘贴了教程中的所有代码,并且可以按照教程完成项目,当你终于站起来低头的时候对这些基础代码再一次从制高点成功,相信你会恍然大悟,原来学php可以这么简单!好的!回到正题(本节为阅读课,无需复制粘贴代码等,除非你打算做笔记)。
随着MySQL数据库版本的更新迭代和PHP程序的不断扩展,PHP连接MySQL数据库的方式有多种。
第一种,也是目前 PHP 连接 MySQL 数据库最常用的方法,是面向进程的 mysql_connect 连接方法:
五、ADODB连接MySQL数据库方法:
//关闭连接
$conn->关闭();
上面介绍了MySQL数据库连接的五种方式,下面我给大家总结一下这五种连接方式:
首先要注意的是,虽然有很多用户使用第一个mysql_connect方法连接MySQL,但并不是因为这种方法最好,而是因为以前的用户太大,而且很多都没有有能力或条件更新到更好的版本,让很多服务器运营商在为新版本提供技术支持的同时,仍然兼容这些旧版本。
关于第二种数据库连接方式,很多新手在使用过程中有很多直接的应用场景(面向过程),也是我们以后学习和使用的重点,不过我们会描述这个数据库的封装下一节中的连接方法(面向对象)。
什么是封装?网上没有具体的定义。所谓封装,其实是出于安全、规范、系统稳定性、简化操作等目的,方便以后常用和接口调用。可以减少因操作不规范造成的意外情况,减少新产品的开发。成本和使用成本。
关于第三种MySQL数据库连接方式,MySQL数据库官方给出了更全面的使用方法,更高效、更安全、更稳定、更全面。具体用法可以参考网站的总结,网址:. 虽然好处这么多,但其实我们开发者真正能用到的只是其中的一小部分。为了简单、兼容、降低开发成本,也更符合我们自己的逻辑,我还是推荐大家自己编写、封装和使用第二种数据库连接方式。比如我们的网站 MySQL数据库太大了,无法承受,当我们需要更换更强大的Oracle数据库时,只需要修改数据库的包文件或者配置文件就可以在很短的时间内实现时间网站 程序整体平滑变化,网站规模越大,使用自己编写封装的数据库方法优势越明显。如果你的整个网站完全使用MySQL数据库的官方用法,那么当你以后面临更换数据库的时候,你会发现自己已经跳进了MySQL数据库官方给大家挖的坑。
关于第四种MySQL数据库连接方式,pdo是php提供的轻量级数据连接接口。在 php5.1 之后的版本中使用。pdo方法的优点是比之前的mysql方法更安全,兼容性更好。好了,你可以用同样的方式连接Oracle、mssql等数据库。
关于第五种ADODB与MySQL数据库的连接方式,支持的数据库类型很多,如:MySQL、PostgreSQL、Interbase、Informix、Oracle、MS SQL 7、Foxpro、Access、ADO、Sybase、DB2和通用ODBC(其中PostgreSQL、Informix、Sybase 驱动由自由软件社区开发后贡献)。
虽然PHP连接MySQL数据库的方式有很多种,但是接下来的教程是学习更好的继承方式下mysqli_connect连接下的增删改查。下一讲,我们主要学习如何使用本文的第二种php方法连接MySQL数据库,以及如何封装MySQL数据库。当然,如果你有兴趣,也可以尝试编写数据库操作类,通过其他方法连接和操作。 查看全部
php如何抓取网页数据库(关于PHP连接MySQL数据库方法的5种连接方法总结!)
X
本节主要介绍PHP连接MySQL数据库的方法。如果你对PHP一无所知,请阅读上一篇文章:PHP入门的语法基础非常重要。
接下来是PHP连接MySQL数据库的方法内容。它也不需要完全理解。你只需要有一个大致的印象。看完整个教程后,可以将教程内容中的代码复制到本地,即可成功。运行,这样你就可以快速学习php编程了,因为所有的编程都是大同小异的,到最后,你已经复制粘贴了教程中的所有代码,并且可以按照教程完成项目,当你终于站起来低头的时候对这些基础代码再一次从制高点成功,相信你会恍然大悟,原来学php可以这么简单!好的!回到正题(本节为阅读课,无需复制粘贴代码等,除非你打算做笔记)。
随着MySQL数据库版本的更新迭代和PHP程序的不断扩展,PHP连接MySQL数据库的方式有多种。
第一种,也是目前 PHP 连接 MySQL 数据库最常用的方法,是面向进程的 mysql_connect 连接方法:
五、ADODB连接MySQL数据库方法:
//关闭连接
$conn->关闭();
上面介绍了MySQL数据库连接的五种方式,下面我给大家总结一下这五种连接方式:
首先要注意的是,虽然有很多用户使用第一个mysql_connect方法连接MySQL,但并不是因为这种方法最好,而是因为以前的用户太大,而且很多都没有有能力或条件更新到更好的版本,让很多服务器运营商在为新版本提供技术支持的同时,仍然兼容这些旧版本。
关于第二种数据库连接方式,很多新手在使用过程中有很多直接的应用场景(面向过程),也是我们以后学习和使用的重点,不过我们会描述这个数据库的封装下一节中的连接方法(面向对象)。
什么是封装?网上没有具体的定义。所谓封装,其实是出于安全、规范、系统稳定性、简化操作等目的,方便以后常用和接口调用。可以减少因操作不规范造成的意外情况,减少新产品的开发。成本和使用成本。
关于第三种MySQL数据库连接方式,MySQL数据库官方给出了更全面的使用方法,更高效、更安全、更稳定、更全面。具体用法可以参考网站的总结,网址:. 虽然好处这么多,但其实我们开发者真正能用到的只是其中的一小部分。为了简单、兼容、降低开发成本,也更符合我们自己的逻辑,我还是推荐大家自己编写、封装和使用第二种数据库连接方式。比如我们的网站 MySQL数据库太大了,无法承受,当我们需要更换更强大的Oracle数据库时,只需要修改数据库的包文件或者配置文件就可以在很短的时间内实现时间网站 程序整体平滑变化,网站规模越大,使用自己编写封装的数据库方法优势越明显。如果你的整个网站完全使用MySQL数据库的官方用法,那么当你以后面临更换数据库的时候,你会发现自己已经跳进了MySQL数据库官方给大家挖的坑。
关于第四种MySQL数据库连接方式,pdo是php提供的轻量级数据连接接口。在 php5.1 之后的版本中使用。pdo方法的优点是比之前的mysql方法更安全,兼容性更好。好了,你可以用同样的方式连接Oracle、mssql等数据库。
关于第五种ADODB与MySQL数据库的连接方式,支持的数据库类型很多,如:MySQL、PostgreSQL、Interbase、Informix、Oracle、MS SQL 7、Foxpro、Access、ADO、Sybase、DB2和通用ODBC(其中PostgreSQL、Informix、Sybase 驱动由自由软件社区开发后贡献)。
虽然PHP连接MySQL数据库的方式有很多种,但是接下来的教程是学习更好的继承方式下mysqli_connect连接下的增删改查。下一讲,我们主要学习如何使用本文的第二种php方法连接MySQL数据库,以及如何封装MySQL数据库。当然,如果你有兴趣,也可以尝试编写数据库操作类,通过其他方法连接和操作。
php如何抓取网页数据库(我在PHP和JS中创建的bookmarklet,如何捕获此弹出窗口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-27 12:12
使用书签的 PHP 网页抓取 - 从页面的 jquery 弹出窗口中获取 html
phpjquery网页抓取
使用书签的 PHP Web 抓取 - 从页面的 jquery 弹出窗口中获取 html、php、jquery、web-scraping、Php、Jquery、Web Scraping、网站:/costs/ 当我选择任何内容时,会出现带有产品图像和价格的弹出窗口PHP 和 JS 中的顶级样式下的项目 使用我在 PHP 和 JS 中创建的书签,我如何捕获此弹出窗口的 HTML?正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 并关闭
网站:/费用/
当我单击页面下方“此类别中的热门款式”下的任何项目时,会出现一个带有产品图片和价格的弹出窗口
使用我在 PHP 和 JS 中创建的小书签,如何捕获此弹出窗口的 HTML?
正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 而只关注链接本身
尝试查看禁用 javascript 的网站
例如,如果您点击表中的第一个链接(发布 文章 时),您将到达 /cmCategoryID/8a61524b-907c-474c-ab37-f357c9ae11e3/&detailcross/? ="> 查看全部
php如何抓取网页数据库(我在PHP和JS中创建的bookmarklet,如何捕获此弹出窗口)
使用书签的 PHP 网页抓取 - 从页面的 jquery 弹出窗口中获取 html
phpjquery网页抓取
使用书签的 PHP Web 抓取 - 从页面的 jquery 弹出窗口中获取 html、php、jquery、web-scraping、Php、Jquery、Web Scraping、网站:/costs/ 当我选择任何内容时,会出现带有产品图像和价格的弹出窗口PHP 和 JS 中的顶级样式下的项目 使用我在 PHP 和 JS 中创建的书签,我如何捕获此弹出窗口的 HTML?正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 并关闭
网站:/费用/
当我单击页面下方“此类别中的热门款式”下的任何项目时,会出现一个带有产品图片和价格的弹出窗口
使用我在 PHP 和 JS 中创建的小书签,如何捕获此弹出窗口的 HTML?
正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 而只关注链接本身
尝试查看禁用 javascript 的网站
例如,如果您点击表中的第一个链接(发布 文章 时),您将到达 /cmCategoryID/8a61524b-907c-474c-ab37-f357c9ae11e3/&detailcross/? =">
php如何抓取网页数据库(本节介绍如何自己DIY一个数据库管理工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-29 14:07
本节介绍如何自己DIY一个数据库管理工具。可以在页面输入sql,进行简单的增删改查等操作。
首先,找到xampp安装目录,打开htdocs:
创建一个名为 mysqladmin.php 的新 php 文件
1.写php服务器代码1.1写php标签
首先,在这个页面上,要编写php代码,你需要一个php标签:
我们的php代码应该写在这个标签里面。
1.2数据库连接操作
xampp安装的mysql默认是没有密码的,别写就好了。
1.3 获取form表单传递的sql语句1.4 使用mysql_query函数执行传递过来的sql语句
到目前为止,代码足以添加、删除和修改数据库。接下来,我们来设计查询sql的实现。
1.5 使用split函数拆分sql语句得到表名1.6 使用表名得到该表的所有列,列名用数字组装1.@ >7 去查询sql中得到的结果集并显示在页面上
if($tableName){
$query = mysql_query("select COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME = '$tableName';") or die("<p style='color:red'>sql报错,错误信息为 ======> ".mysql_error()."");
//对结果集进行遍历 -- mysql_fetch_array
$columns = array(); //储存这张表中所有的字段名称
$count = 0; //记录当前的下标
echo "";
echo "";
while($row = mysql_fetch_array($query)){
$columns[$count] = $row["COLUMN_NAME"];
echo "" . $row["COLUMN_NAME"] . "";
$count = $count + 1;
}
echo "";
//echo sizeof($columns);
$query_02 = mysql_query($sql) or die("
sql报错,错误信息为 ======> ".mysql_error()."");
while($row = mysql_fetch_array($query_02)){
echo "";
for($i=0;$i</p>
我的博客将同步到腾讯云+社区,诚邀大家加入: 查看全部
php如何抓取网页数据库(本节介绍如何自己DIY一个数据库管理工具)
本节介绍如何自己DIY一个数据库管理工具。可以在页面输入sql,进行简单的增删改查等操作。
首先,找到xampp安装目录,打开htdocs:
创建一个名为 mysqladmin.php 的新 php 文件
1.写php服务器代码1.1写php标签
首先,在这个页面上,要编写php代码,你需要一个php标签:
我们的php代码应该写在这个标签里面。
1.2数据库连接操作
xampp安装的mysql默认是没有密码的,别写就好了。
1.3 获取form表单传递的sql语句1.4 使用mysql_query函数执行传递过来的sql语句
到目前为止,代码足以添加、删除和修改数据库。接下来,我们来设计查询sql的实现。
1.5 使用split函数拆分sql语句得到表名1.6 使用表名得到该表的所有列,列名用数字组装1.@ >7 去查询sql中得到的结果集并显示在页面上
if($tableName){
$query = mysql_query("select COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME = '$tableName';") or die("<p style='color:red'>sql报错,错误信息为 ======> ".mysql_error()."");
//对结果集进行遍历 -- mysql_fetch_array
$columns = array(); //储存这张表中所有的字段名称
$count = 0; //记录当前的下标
echo "";
echo "";
while($row = mysql_fetch_array($query)){
$columns[$count] = $row["COLUMN_NAME"];
echo "" . $row["COLUMN_NAME"] . "";
$count = $count + 1;
}
echo "";
//echo sizeof($columns);
$query_02 = mysql_query($sql) or die("
sql报错,错误信息为 ======> ".mysql_error()."");
while($row = mysql_fetch_array($query_02)){
echo "";
for($i=0;$i</p>
我的博客将同步到腾讯云+社区,诚邀大家加入:
php如何抓取网页数据库(php如何抓取网页数据库_php抓取数据php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-03-28 03:05
php如何抓取网页数据库_php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php爬虫教程,
if(__name__=='__main__'){if(__doc__=='./documents/demo/php.php'){return__doc__}}如果站点不存在__doc__字段的话,__doc__字段类型未知,可能会直接丢弃。不过可以抓取里面的__main__函数看一下是否有__doc__字段。
可以考虑在header方法(cookie在这儿就别想了,cookie太麻烦)加上org_annotation__='__main__',gzipheader等方法同样可以得到__main__字段。
只是想抓取网页数据(比如页数),不需要记住__main__函数名字。换个网站、改变下cookie设置就行了,比如改为我的网站,加上,__main__:/{your_name}:/{your_username}/{your_password}//不用保存到文本文件,
抓取的时候会出现__main__字段
可以改成这样text='';document=gzipurl(content);%s/\\d+\\css\\div{3}\\d+\\a{4}\\end{div}'这样就抓不到了 查看全部
php如何抓取网页数据库(php如何抓取网页数据库_php抓取数据php)
php如何抓取网页数据库_php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php抓取网页数据库,php爬虫教程,
if(__name__=='__main__'){if(__doc__=='./documents/demo/php.php'){return__doc__}}如果站点不存在__doc__字段的话,__doc__字段类型未知,可能会直接丢弃。不过可以抓取里面的__main__函数看一下是否有__doc__字段。
可以考虑在header方法(cookie在这儿就别想了,cookie太麻烦)加上org_annotation__='__main__',gzipheader等方法同样可以得到__main__字段。
只是想抓取网页数据(比如页数),不需要记住__main__函数名字。换个网站、改变下cookie设置就行了,比如改为我的网站,加上,__main__:/{your_name}:/{your_username}/{your_password}//不用保存到文本文件,
抓取的时候会出现__main__字段
可以改成这样text='';document=gzipurl(content);%s/\\d+\\css\\div{3}\\d+\\a{4}\\end{div}'这样就抓不到了
php如何抓取网页数据库(5.PHP倒序输出所有日志方法(一)输出方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-27 06:24
)
所以,我们需要引入时间函数,然后写一个函数来获取当前时间
import time
#获取当前时间
def getCurrentTime(self):
return time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time()))
#获取当前时间
def getCurrentDate(self):
return time.strftime('%Y-%m-%d',time.localtime(time.time()))
以上是分别获取具体时间和日期的函数。输出时,我们可以在输出语句前面调用这个函数。
然后我们需要将缓冲区设置输出到日志中,并在程序顶部添加这两句。
f_handler=open('out.log', 'w')
sys.stdout=f_handler
这样,打印语句的所有输出都会保存到 out.log 文件中。
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
2.页码保存
爬虫在爬取过程中可能会出现各种错误,从而导致爬虫中断。如果我们重新运行爬虫,会导致爬虫从头开始运行,这显然是不合理的。因此,我们需要保存当前抓取的页面,例如可以保存在文本中。如果爬虫被中断,重新运行爬虫,读取文本文件的内容,然后进行爬虫。
可以稍微参考一下函数的实现:
#主函数
def main(self):
f_handler=open('out.log', 'w')
sys.stdout=f_handler
page = open('page.txt', 'r')
content = page.readline()
start_page = int(content.strip()) - 1
page.close()
print self.getCurrentTime(),"开始页码",start_page
print self.getCurrentTime(),"爬虫正在启动,开始爬取爱问知识人问题"
self.total_num = self.getTotalPageNum()
print self.getCurrentTime(),"获取到目录页面个数",self.total_num,"个"
if not start_page:
start_page = self.total_num
for x in range(1,start_page):
print self.getCurrentTime(),"正在抓取第",start_page-x+1,"个页面"
try:
self.getQuestions(start_page-x+1)
except urllib2.URLError, e:
if hasattr(e, "reason"):
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因", e.reason
except Exception,e:
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因:",e
if start_page-x+1 < start_page:
f=open('page.txt','w')
f.write(str(start_page-x+1))
print self.getCurrentTime(),"写入新页码",start_page-x+1
f.close()
这样,无论我们的爬虫在中间遇到什么错误,妈妈都不会担心。
3.页面处理
在页面处理的过程中,我们可能会遇到各种奇怪的HTML代码。和上一节一样,我们可以使用页面处理类。
<p>
import re
#处理页面标签类
class Tool:
#将超链接广告剔除
removeADLink = re.compile(' 查看全部
php如何抓取网页数据库(5.PHP倒序输出所有日志方法(一)输出方法
)
所以,我们需要引入时间函数,然后写一个函数来获取当前时间
import time
#获取当前时间
def getCurrentTime(self):
return time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time()))
#获取当前时间
def getCurrentDate(self):
return time.strftime('%Y-%m-%d',time.localtime(time.time()))
以上是分别获取具体时间和日期的函数。输出时,我们可以在输出语句前面调用这个函数。
然后我们需要将缓冲区设置输出到日志中,并在程序顶部添加这两句。
f_handler=open('out.log', 'w')
sys.stdout=f_handler
这样,打印语句的所有输出都会保存到 out.log 文件中。
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
前言
最近发现MySQL服务隔三差五就会挂掉,导致我的网站和爬虫都无法正常运作。自己的网站是基于MySQL,在做爬虫存取一些资料的时候也是基于MySQL,数据量一大了,MySQL它就有点受不了了,时不时会崩掉,虽然我自己有网站监控和邮件通知,但是好多时候还是需要我来手动连接我的服务器重新启动一下我的MySQL,这样简直太不友好了,所以,我就觉定自己写个脚本,定时监控它,如果发现它挂掉了就重启它。
好了,闲言碎语不多讲,开始我们的配置之旅。
运行环境:UbuntuLinux14.04
编写Shell脚本
首先,我们要编写一个shell脚本,脚本主要执行的逻辑如下:
显示mysqld进程状态,如果判断进程未在运行,那么输出日志到文件,然后启动mysql服务,如果进程在运行,那么不执行任何操作,可以选择性输出监测结果。
可能大家对于shell脚本比较陌生,在这里推荐官方的shell脚本文档来参考一下
UbuntuShell编程基础
shell脚本的后缀为sh,在任何位置新建一个脚本文件,我选择在/etc/mysql目录下新建一个listen.sh文件。
执行如下命令:
2.页码保存
爬虫在爬取过程中可能会出现各种错误,从而导致爬虫中断。如果我们重新运行爬虫,会导致爬虫从头开始运行,这显然是不合理的。因此,我们需要保存当前抓取的页面,例如可以保存在文本中。如果爬虫被中断,重新运行爬虫,读取文本文件的内容,然后进行爬虫。
可以稍微参考一下函数的实现:
#主函数
def main(self):
f_handler=open('out.log', 'w')
sys.stdout=f_handler
page = open('page.txt', 'r')
content = page.readline()
start_page = int(content.strip()) - 1
page.close()
print self.getCurrentTime(),"开始页码",start_page
print self.getCurrentTime(),"爬虫正在启动,开始爬取爱问知识人问题"
self.total_num = self.getTotalPageNum()
print self.getCurrentTime(),"获取到目录页面个数",self.total_num,"个"
if not start_page:
start_page = self.total_num
for x in range(1,start_page):
print self.getCurrentTime(),"正在抓取第",start_page-x+1,"个页面"
try:
self.getQuestions(start_page-x+1)
except urllib2.URLError, e:
if hasattr(e, "reason"):
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因", e.reason
except Exception,e:
print self.getCurrentTime(),"某总页面内抓取或提取失败,错误原因:",e
if start_page-x+1 < start_page:
f=open('page.txt','w')
f.write(str(start_page-x+1))
print self.getCurrentTime(),"写入新页码",start_page-x+1
f.close()
这样,无论我们的爬虫在中间遇到什么错误,妈妈都不会担心。
3.页面处理
在页面处理的过程中,我们可能会遇到各种奇怪的HTML代码。和上一节一样,我们可以使用页面处理类。
<p>
import re
#处理页面标签类
class Tool:
#将超链接广告剔除
removeADLink = re.compile('
php如何抓取网页数据库(Python提供一组开发Web应用程序的卓越工具-Python开发 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-26 23:13
)
今天的 网站 是非常丰富的应用程序,就像成熟的桌面应用程序一样。Python 为开发 Web 应用程序提供了一套出色的工具。在本节中,我们将使用 Django 开发一个个人日志博客,用外行的话来说,它是一个在线日志系统,它允许我们记录我们对特定主题的了解。
我们将为这个项目指定规范,然后为应用程序使用的数据定义模型。我们将使用 Django 的管理系统输入一些初始数据,然后编写允许 Django 为我们的 网站 创建页面的视图和模板。
Django 是一个 Web 框架 - 一组帮助开发交互式网站 的工具。Django 可以响应网页请求,也可以让你更轻松地读写数据库、管理用户等等。
构建 Django 项目
要构建一个Django项目,我们首先需要确保我们已经遵循了Django。我们在Pycharm中打开虚拟环境的终端,然后输入:pip install Django==1.11进行安装:
仍然在活动终端中,执行以下命令来创建一个新项目:
第一行的命令让我们创建一个名为 learning_log 的新项目。该命令末尾的句点使新项目使用适当的目录结构,以便开发完成后可以轻松地将应用程序部署到服务器。(注意:不要忘记这个时间段,否则在部署应用时会遇到一些配置问题。如果忘记了这个时间段,请删除所有创建的文件和文件夹,然后重新运行此命令。)
然后我们运行命令 ls(在 Windows 中应该是 dir),结果发现 Django 创建了一个名为 learning_log 的新目录。它还创建了一个名为 manage.py 的文件,这是一个简单的程序,它接受命令并将它们交给 Django 的相关部分来运行。我们将使用这些命令来管理任务,例如使用数据库和运行服务器。
learning_log目录收录4个文件,其中最重要的是settings.py、urls.py和wsgi.py。文件 settings.py 指定 Django 如何与您的系统交互并管理项目。当我们开发我们的项目时,我们将修改其中一些设置,并添加更多。文件 urls.py 告诉 Django 应该创建哪些网页来响应浏览器请求。文件 wsgi.py 帮助 Django 为它创建的文件提供服务,这是 Web 服务器网关接口的首字母缩写词。
创建数据库
Django 将大部分项目相关信息存储在数据库中,因此我们需要创建一个数据库供 Django 使用。要为我们的个人笔记创建数据库,请在活动虚拟环境中执行以下命令:
如果执行不成功,出现如下所示的错误,不要紧张。这是由于 Django 和 Python3 之间的兼容性问题。只需删除错误语句中的最后一个逗号即可。(如果报错是:SyntaxError: Generator expression must be parenthesized,可以用上面的方法。)
我们将修改数据库称为迁移数据库。当第一次执行命令 migrate 时,它将让 Django 确保数据库与项目的当前状态匹配。第一次在使用 SQLite 的新项目中执行此命令时,Django 将创建一个新数据库。Django 将指示它将创建必要的数据库表来存储我们将在这个项目中使用的信息,然后确保数据库结构与当前代码匹配。
然后我们运行命令 ls ,输出显示 Django 又创建了一个文件 - db.sqite3。SQLite 是一个单文件数据库,非常适合编写简单的应用程序,因为它让我们不必过多担心数据库管理。
查看项目
让我们验证 Django 是否正确创建了项目。为此,请执行命令 runserver,如下所示:
Django 启动一个服务器,允许您查看系统中的项目并了解它们是如何工作的。当您在浏览器中输入 URL 以请求网页时,Django 服务器将响应,生成适当的网页,并将其发送到浏览器。然后我们点击上面的链接,当我们看到下图的页面,就证明我们的项目可以正式启动了:
以上就是如何使用python开发网页的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php如何抓取网页数据库(Python提供一组开发Web应用程序的卓越工具-Python开发
)
今天的 网站 是非常丰富的应用程序,就像成熟的桌面应用程序一样。Python 为开发 Web 应用程序提供了一套出色的工具。在本节中,我们将使用 Django 开发一个个人日志博客,用外行的话来说,它是一个在线日志系统,它允许我们记录我们对特定主题的了解。
我们将为这个项目指定规范,然后为应用程序使用的数据定义模型。我们将使用 Django 的管理系统输入一些初始数据,然后编写允许 Django 为我们的 网站 创建页面的视图和模板。
Django 是一个 Web 框架 - 一组帮助开发交互式网站 的工具。Django 可以响应网页请求,也可以让你更轻松地读写数据库、管理用户等等。
构建 Django 项目
要构建一个Django项目,我们首先需要确保我们已经遵循了Django。我们在Pycharm中打开虚拟环境的终端,然后输入:pip install Django==1.11进行安装:
仍然在活动终端中,执行以下命令来创建一个新项目:
第一行的命令让我们创建一个名为 learning_log 的新项目。该命令末尾的句点使新项目使用适当的目录结构,以便开发完成后可以轻松地将应用程序部署到服务器。(注意:不要忘记这个时间段,否则在部署应用时会遇到一些配置问题。如果忘记了这个时间段,请删除所有创建的文件和文件夹,然后重新运行此命令。)
然后我们运行命令 ls(在 Windows 中应该是 dir),结果发现 Django 创建了一个名为 learning_log 的新目录。它还创建了一个名为 manage.py 的文件,这是一个简单的程序,它接受命令并将它们交给 Django 的相关部分来运行。我们将使用这些命令来管理任务,例如使用数据库和运行服务器。
learning_log目录收录4个文件,其中最重要的是settings.py、urls.py和wsgi.py。文件 settings.py 指定 Django 如何与您的系统交互并管理项目。当我们开发我们的项目时,我们将修改其中一些设置,并添加更多。文件 urls.py 告诉 Django 应该创建哪些网页来响应浏览器请求。文件 wsgi.py 帮助 Django 为它创建的文件提供服务,这是 Web 服务器网关接口的首字母缩写词。
创建数据库
Django 将大部分项目相关信息存储在数据库中,因此我们需要创建一个数据库供 Django 使用。要为我们的个人笔记创建数据库,请在活动虚拟环境中执行以下命令:
如果执行不成功,出现如下所示的错误,不要紧张。这是由于 Django 和 Python3 之间的兼容性问题。只需删除错误语句中的最后一个逗号即可。(如果报错是:SyntaxError: Generator expression must be parenthesized,可以用上面的方法。)
我们将修改数据库称为迁移数据库。当第一次执行命令 migrate 时,它将让 Django 确保数据库与项目的当前状态匹配。第一次在使用 SQLite 的新项目中执行此命令时,Django 将创建一个新数据库。Django 将指示它将创建必要的数据库表来存储我们将在这个项目中使用的信息,然后确保数据库结构与当前代码匹配。
然后我们运行命令 ls ,输出显示 Django 又创建了一个文件 - db.sqite3。SQLite 是一个单文件数据库,非常适合编写简单的应用程序,因为它让我们不必过多担心数据库管理。
查看项目
让我们验证 Django 是否正确创建了项目。为此,请执行命令 runserver,如下所示:
Django 启动一个服务器,允许您查看系统中的项目并了解它们是如何工作的。当您在浏览器中输入 URL 以请求网页时,Django 服务器将响应,生成适当的网页,并将其发送到浏览器。然后我们点击上面的链接,当我们看到下图的页面,就证明我们的项目可以正式启动了:
以上就是如何使用python开发网页的详细内容。更多详情请关注php中文网文章其他相关话题!
php如何抓取网页数据库(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-23 03:18
)
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为你自己的字符串。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
查看全部
php如何抓取网页数据库(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php)
)
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); //$str 替换为你自己的字符串。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
php如何抓取网页数据库(PHP技术与MYSQL数据库技术在动态网页中的设计与应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-21 07:33
曲晓娜
摘要:随着互联网的普及和快速发展,网站逐渐成为各行各业最便捷、最快捷、最实用的信息展示和交流平台。本文讨论和分析了PHP技术和MYSQL数据库技术在动态网页中的设计和应用。
关键词:PHP;MYSQL; 动态网页
CLC 编号:TP393 证件识别码:A
文章号码:1009-3044(2020)13-0050-02
随着国民经济的发展和人民生活水平的提高。中国加入世贸组织以来,中国贸易逐步走向世界,各行各业的贸易也走向国际化。很多公司、企业、学校甚至政府部门都逐渐开始关注自己网页的制作。一时间,网页已成为各行各业对外交流和宣传的必备工具。
1 背景
目前,网页主要有两种类型:静态网页和动态网页。静态网页以 .html 或 .htm 为后缀。用html标记语言制作的静态网页可以直接被浏览器转换、翻译和执行。源代码直接存放在网站服务器上,方便移植。Html 文件代码由一些标签和文本组成。它是一个文本文件。您可以使用 Windows 自带的记事本程序直接编辑代码。编辑代码时,不区分大小写字母;动态网页是用服务器端脚本语言编写的(常用的服务器端脚本语言有ASP、PHP、JSP等),扩展名可以是.asp、.php、JSP。通常嵌入在 HTML 文档中,使用脚本语言制作的动态网页的浏览必须配置动态服务器工作。环境。
2PHP技术
PHP 是一种开放且跨平台的服务器端嵌入式脚本语言。主要是通过函数直接访问数据库。常用功能包括CREATE、SE-LECT、DELETE、INSERT INTO、QUERY等,在欧美国家非常流行,在国内也很受网站开发者的欢迎。它如此受欢迎的另一个重要原因是PHP支持直接连接各种数据库,包括MYSQL和ACCESS,并且还完全支持ODBC(0pen DateBaseConnectivity)接口。PHP 可以访问任何支持 ODBC 接口的数据库。操作。
3MYSQL数据库
Mysql数据库是最流行的关系数据库管理系统。它根据数据库中数据的不同属性建立不同的表,并通过关键属性将表关联起来,而不是把所有的数据放在一个大仓库里。这提高了速度并提高了灵活性。
4 PHP动态网页作品
在传统网页HTML文件(*.html)中加入APHP程序代码,就构成了一个PHP网页(*.PHP)。图1是PHP动态网页的工作原理图。当Web服务器遇到客户端访问PHP动态网页的请求时,首先将请求访问的运行结果发送给应用服务器。应用服务器执行程序相关指令并发送程序指令。对MYSQL数据库驱动,驱动通过查询MYSQL数据库找到满足条件的记录,将记录集返回给驱动,驱动再将记录发送给应用服务器。最后,应用服务器将记录存储在 MYSQL 中。将满足条件的数据插入网页,将动态网页转为静态网页,然后应用服务器将静态网页发送给网络浏览器。浏览器转换、翻译和显示 HTML 标签后,结果显示在浏览器中。.
5PHP技术与MYSQL动态网站设计
5.1MYSQL数据库连接与访问
5.1.1安装和配置MySQL
PHP连接MySQL服务器的操作步骤如下:
1)首先,将PHP目录下的libmysql.dll文件复制到F:kApache2.2kbin目录下。操作步骤如下:
一种。打开 php.ini 文件,
设置 MySQL 服务器的主机名:
mysql.default_host=本地主机
湾。设置 MySQL 服务器的端口号:
mysql.defauh_port=3306
C。设置默认用户:
5.1.访问3MYSQL数据库
1)点击“新建”按钮创建数据库“学生信息系统”。
2)创建数据表“学生表”如下:
六,结论
随着Web的广泛应用,具有可扩展性、灵活性和易维护性的Web动态交互技术是各行各业企业关注的焦点,而php和MYPSQL5.5则因其友好方便技术。其动态交互性越来越受到中小型电子商务企业的青睐。 查看全部
php如何抓取网页数据库(PHP技术与MYSQL数据库技术在动态网页中的设计与应用)
曲晓娜
摘要:随着互联网的普及和快速发展,网站逐渐成为各行各业最便捷、最快捷、最实用的信息展示和交流平台。本文讨论和分析了PHP技术和MYSQL数据库技术在动态网页中的设计和应用。
关键词:PHP;MYSQL; 动态网页
CLC 编号:TP393 证件识别码:A
文章号码:1009-3044(2020)13-0050-02
随着国民经济的发展和人民生活水平的提高。中国加入世贸组织以来,中国贸易逐步走向世界,各行各业的贸易也走向国际化。很多公司、企业、学校甚至政府部门都逐渐开始关注自己网页的制作。一时间,网页已成为各行各业对外交流和宣传的必备工具。
1 背景
目前,网页主要有两种类型:静态网页和动态网页。静态网页以 .html 或 .htm 为后缀。用html标记语言制作的静态网页可以直接被浏览器转换、翻译和执行。源代码直接存放在网站服务器上,方便移植。Html 文件代码由一些标签和文本组成。它是一个文本文件。您可以使用 Windows 自带的记事本程序直接编辑代码。编辑代码时,不区分大小写字母;动态网页是用服务器端脚本语言编写的(常用的服务器端脚本语言有ASP、PHP、JSP等),扩展名可以是.asp、.php、JSP。通常嵌入在 HTML 文档中,使用脚本语言制作的动态网页的浏览必须配置动态服务器工作。环境。
2PHP技术
PHP 是一种开放且跨平台的服务器端嵌入式脚本语言。主要是通过函数直接访问数据库。常用功能包括CREATE、SE-LECT、DELETE、INSERT INTO、QUERY等,在欧美国家非常流行,在国内也很受网站开发者的欢迎。它如此受欢迎的另一个重要原因是PHP支持直接连接各种数据库,包括MYSQL和ACCESS,并且还完全支持ODBC(0pen DateBaseConnectivity)接口。PHP 可以访问任何支持 ODBC 接口的数据库。操作。
3MYSQL数据库
Mysql数据库是最流行的关系数据库管理系统。它根据数据库中数据的不同属性建立不同的表,并通过关键属性将表关联起来,而不是把所有的数据放在一个大仓库里。这提高了速度并提高了灵活性。
4 PHP动态网页作品
在传统网页HTML文件(*.html)中加入APHP程序代码,就构成了一个PHP网页(*.PHP)。图1是PHP动态网页的工作原理图。当Web服务器遇到客户端访问PHP动态网页的请求时,首先将请求访问的运行结果发送给应用服务器。应用服务器执行程序相关指令并发送程序指令。对MYSQL数据库驱动,驱动通过查询MYSQL数据库找到满足条件的记录,将记录集返回给驱动,驱动再将记录发送给应用服务器。最后,应用服务器将记录存储在 MYSQL 中。将满足条件的数据插入网页,将动态网页转为静态网页,然后应用服务器将静态网页发送给网络浏览器。浏览器转换、翻译和显示 HTML 标签后,结果显示在浏览器中。.
5PHP技术与MYSQL动态网站设计
5.1MYSQL数据库连接与访问
5.1.1安装和配置MySQL
PHP连接MySQL服务器的操作步骤如下:
1)首先,将PHP目录下的libmysql.dll文件复制到F:kApache2.2kbin目录下。操作步骤如下:
一种。打开 php.ini 文件,
设置 MySQL 服务器的主机名:
mysql.default_host=本地主机
湾。设置 MySQL 服务器的端口号:
mysql.defauh_port=3306
C。设置默认用户:
5.1.访问3MYSQL数据库
1)点击“新建”按钮创建数据库“学生信息系统”。
2)创建数据表“学生表”如下:
六,结论
随着Web的广泛应用,具有可扩展性、灵活性和易维护性的Web动态交互技术是各行各业企业关注的焦点,而php和MYPSQL5.5则因其友好方便技术。其动态交互性越来越受到中小型电子商务企业的青睐。
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-18 06:24
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是Windows平台的话,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理一个表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是Windows平台的话,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理一个表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php如何抓取网页数据库(1.实现前的思考(图)评论系统的改版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 32 次浏览 • 2022-03-17 18:11
)
关于如何实现楼内评论系统的具体操作1. 实施前的思考
经过一番讨论和网易云话题,我终于下定决心自己写一个评论系统。
在我们使用的众多评论系统中,最流行的是楼内楼,如百度贴吧、wordpress等。在此之前,1、2、3层一般是按时间顺序展示的。如果要回复某人,请使用@符号标记用户名,然后回复内容。但是,这有一个很大的问题。讨论问题不集中,其他用户不知道你在讨论什么。原作者在一楼发表评论。当你进来回复这个用户的评论时,已经是10楼了。作者再次回复你到20楼。其他网友看到10楼的时候,已经忘记了原作者说了什么。
百度贴吧在改版之前就使用了这个方法,后来在新版本中启用了build方法里面的build。这样,就可以集中讨论某个话题。
同时,知乎也对自己的评论系统进行了修改,但并没有将其重新设计成楼中楼,而是在每条评论后添加了一个弹出链接,并带有一个对话来查看对话,并且点击链接后会弹出一个弹窗。可以看到关于这两个人互动的所有评论。
按时间倒序显示评论或按正序平铺很容易实现,但难以阅读。分门别类地显示评论对用户的阅读习惯很友好,但可能难以实现。不过最后还是决定采用楼内建房的方式。虽然我博客的评论数也很差,但我还是决定实现它。
2. 数据表设计
先说一下前后端使用的语言和框架。考虑到页面渲染和更多的事件调用,前端使用vue框架。应该说vue并不是最好的选择。毕竟,对于一个评论前端的部门来说,这可能有点矫枉过正。,但是为了快速发展,也选择了vue。后端使用php语言,数据库使用mysql。
数据库表的设计既考虑到了以前数据的导入能力,也方便以后添加新的评论。这里我创建了 3 个表:文章 表、用户表、评论表。
在网易云线程关闭之前,导出了自己的数据(我说的数据已经丢失,不知道导出的格式是什么),我们来看看网易云中导出的数据的格式线:
从上面的数据可以看出,每个文章都有一个title、url和comment,每个comment都有自己对应的id、reply的comment pid、content content、comment的user。用户名、昵称和头像。这里我只提取主要信息并输入到数据库中。
2.1 用户表
用户表比较简单。原来的userid也要保存为字段,以便在导入评论数据时可以找到对应的用户。评论数据也导入后,可以删除该字段。新添加的注册用户不使用该字段。用户表设计:
字段类型说明
ID
整数
自增,主键
宽
整数
用户的原创用户标识
昵称
varchar(50)
昵称
头像
varchar(100)
阿凡达
状态
整数
健康)状况
设计好用户表后,将原创数据中的所有用户分别取出,然后以userid为key存入数组,也可以起到去重的作用。将获取到的所有用户数据存储在用户表中
2.2 评论表
在设计意见表时,主要考虑以下因素:
评论必须依赖文章和用户才能存在,所以评论的外键是文章ID和userid,留言板是文章内容为空的评论表单;
我想以后新的评论可以使用自增id而不是跟随原评论的cid生成新的评论id,所以这次评论表的主键是id,原评论id是仅用作字段宽度之一。构建建筑物与建筑物的关系,这些旧评论插入数据表时会有新的评论id;
楼内楼的评论在某条评论下,同时楼内楼内有互动回复。因此,这条评论的pid(parentid)表示当前评论在哪条评论下,replyid表示正在回复的是哪条评论;如果直接回复父评论,则pid与replyid相同,都是父评论的id。不是父评论,pid是父评论的id,replyid是回复评论的id;当pid或replyid为0时,表示评论直接发到文章。
所以我们的评论表单是这样设计的:
字段类型说明
ID
整数
自增,主键
宽
整数
注释掉原来的主键 cid
uid
整数
用户身份
回复人
整数
评论回复的评论id,否则为0
PID
整数
评论的父 id,如果不是,则为 0
援助
varchar(100)
文章 的标志
内容
varchar(300)
注释
创建时间
整数
评论时间的时间戳
表中的aid(标识文章)可以是文章的url、文章的id或者其他任何可以唯一标识文章的东西。这里我们使用文章的uri作为唯一标识,比如上面数据中的文章,我们使用/node/2017/02/20/node-express-forum.html来标识文章. 其他 文章 也是如此。
在将这些评论写入表格时,我们还应该注意,在原创数据中,每条评论对应一个用户。在我设计的系统中,用户和评论是分开的,只有uid用来关联他们。新用户和新评论都使用自己的自增主键。因此,在将原创评论存入数据库时,需要将原创userid转换为新用户表中的主键id,并统一新旧数据。
文章表不解释。
3. 具体实现
前端部分主要负责展示每个文章的评论,同时允许登录用户添加评论。
3.1 显示评论
我们为每条评论添加了一个文章标志,前端可以根据辅助获取当前所有的文章评论。但是,我们的评论要以逐栋建筑的方式显示,我们不能简单地将数据平铺在页面上。我们在2.2中也说过,pid为0的评论都是直接发给文章的评论,这些评论应该显示为一级评论;如果pid是其他数据,则必须是属于注释的,应该显示为建筑物内的建筑物。
同时,无论是一级评论还是楼内楼的评论,都可能有分页,所以分页也要在这里处理。
所以最后我们在前端得到的结构应该大致是这样的:
前端拿到接口返回的数据后,就可以渲染页面了。在头像的处理中,也考虑了https环境,所以返回的头像链接都是以//开头的形式。
3.2 参与评论
如果用户对 文章 或评论产生共鸣,需要留言讨论,我们需要用户能够添加自己的评论。
评论的类型,如果细分的话,可以分为3类:
我这里的前端实现参考oschina(Open Source China)的comment方法。直接评论文章就是直接在顶部的评论窗口中输入;回复其他评论时,使用弹窗回复。弹窗回复的好处是页面不需要滚动,用户对评论的感知也可以停留在这个位置;同时,用户输入评论也无需添加各种不必要的小输入框。
3.3 登录
在登录问题上,我也纠结了很久,是使用自己的登录系统,还是使用第三方登录,还是用户无需注册登录,输入邮箱和昵称即可评论?
如果使用自己的评论系统,需要自己开发注册登录流程,比较麻烦,对于想要回复一句话的用户,可以干脆放弃注册;如果您只需要输入您的电子邮件地址和昵称即可发表评论,我会考虑到可能从用户那里引出的无限评论,无法控制。所以最后还是考虑接入第三方登录。这里我们选择使用微博作为第三方登录入口,以后会考虑添加github账号登录。
关于如何访问微博第三方登录,我们下一篇文章再讲。文档齐全。对于不熟悉的开发者来说,一开始可能会有些迷惑,但应该问题不大。
3.4 添加邮箱功能
用户登录第三方成功后,名字旁边有一个小输入框,可以让用户输入邮箱地址来接收回复提醒。此输入完全是自愿的,您仍然可以在不输入电子邮件地址的情况下发表评论。也被认为是这个站点是一个流量极低的小站点。用户可能会心血来潮发表评论,然后想到这个网站,但我不知道如何找到它。于是想到了增加邮件提醒功能,防止大神评论沉入海中。
3.5 特别注意
前端部门引入了vue框架,每一个文章页面都加载了评论模块。为了防止评论模块中的vue库影响外部资源(比如版本冲突等),我先把全局变量给了wzVue,然后注销了vue:
同时,在评论功能完成之初,只要用户进入这个页面,评论就会被加载。但是有一个问题,用户不一定能看到你的文章到底部,不一定能看到你的评论。因此,文章 改为按需加载。只有当用户滚动到底部并有阅读评论的意图时,才会加载评论。
最终结果是这样的:
4. 摘要
作为前端开发者,只用后端知识开发一个博客评论系统似乎很简单,整个框架的设计也很粗糙。同时缓存系统不熟练,无法立即更新评论信息。这个系统还有很大的改进空间。欢迎大家对蚊子(邵兵)提出更多的意见和建议。
写这个文章的时候,想着以后版本修改的时候,可以通过同步加载评论的方式来完成。生成文章后,更新频率极低,甚至变化不大,然后缓存评论的内容。每当有新评论时,当前 文章 的缓存将被删除并重新加载新评论。数据,然后缓存新的数据,这样在评论数据更新量比较低的时候,可以缓存更长的时间,同时也有利于搜索评论内容的爬取。
查看全部
php如何抓取网页数据库(1.实现前的思考(图)评论系统的改版
)
关于如何实现楼内评论系统的具体操作1. 实施前的思考
经过一番讨论和网易云话题,我终于下定决心自己写一个评论系统。
在我们使用的众多评论系统中,最流行的是楼内楼,如百度贴吧、wordpress等。在此之前,1、2、3层一般是按时间顺序展示的。如果要回复某人,请使用@符号标记用户名,然后回复内容。但是,这有一个很大的问题。讨论问题不集中,其他用户不知道你在讨论什么。原作者在一楼发表评论。当你进来回复这个用户的评论时,已经是10楼了。作者再次回复你到20楼。其他网友看到10楼的时候,已经忘记了原作者说了什么。
百度贴吧在改版之前就使用了这个方法,后来在新版本中启用了build方法里面的build。这样,就可以集中讨论某个话题。
同时,知乎也对自己的评论系统进行了修改,但并没有将其重新设计成楼中楼,而是在每条评论后添加了一个弹出链接,并带有一个对话来查看对话,并且点击链接后会弹出一个弹窗。可以看到关于这两个人互动的所有评论。
按时间倒序显示评论或按正序平铺很容易实现,但难以阅读。分门别类地显示评论对用户的阅读习惯很友好,但可能难以实现。不过最后还是决定采用楼内建房的方式。虽然我博客的评论数也很差,但我还是决定实现它。
2. 数据表设计
先说一下前后端使用的语言和框架。考虑到页面渲染和更多的事件调用,前端使用vue框架。应该说vue并不是最好的选择。毕竟,对于一个评论前端的部门来说,这可能有点矫枉过正。,但是为了快速发展,也选择了vue。后端使用php语言,数据库使用mysql。
数据库表的设计既考虑到了以前数据的导入能力,也方便以后添加新的评论。这里我创建了 3 个表:文章 表、用户表、评论表。
在网易云线程关闭之前,导出了自己的数据(我说的数据已经丢失,不知道导出的格式是什么),我们来看看网易云中导出的数据的格式线:
从上面的数据可以看出,每个文章都有一个title、url和comment,每个comment都有自己对应的id、reply的comment pid、content content、comment的user。用户名、昵称和头像。这里我只提取主要信息并输入到数据库中。
2.1 用户表
用户表比较简单。原来的userid也要保存为字段,以便在导入评论数据时可以找到对应的用户。评论数据也导入后,可以删除该字段。新添加的注册用户不使用该字段。用户表设计:
字段类型说明
ID
整数
自增,主键
宽
整数
用户的原创用户标识
昵称
varchar(50)
昵称
头像
varchar(100)
阿凡达
状态
整数
健康)状况
设计好用户表后,将原创数据中的所有用户分别取出,然后以userid为key存入数组,也可以起到去重的作用。将获取到的所有用户数据存储在用户表中
2.2 评论表
在设计意见表时,主要考虑以下因素:
评论必须依赖文章和用户才能存在,所以评论的外键是文章ID和userid,留言板是文章内容为空的评论表单;
我想以后新的评论可以使用自增id而不是跟随原评论的cid生成新的评论id,所以这次评论表的主键是id,原评论id是仅用作字段宽度之一。构建建筑物与建筑物的关系,这些旧评论插入数据表时会有新的评论id;
楼内楼的评论在某条评论下,同时楼内楼内有互动回复。因此,这条评论的pid(parentid)表示当前评论在哪条评论下,replyid表示正在回复的是哪条评论;如果直接回复父评论,则pid与replyid相同,都是父评论的id。不是父评论,pid是父评论的id,replyid是回复评论的id;当pid或replyid为0时,表示评论直接发到文章。
所以我们的评论表单是这样设计的:
字段类型说明
ID
整数
自增,主键
宽
整数
注释掉原来的主键 cid
uid
整数
用户身份
回复人
整数
评论回复的评论id,否则为0
PID
整数
评论的父 id,如果不是,则为 0
援助
varchar(100)
文章 的标志
内容
varchar(300)
注释
创建时间
整数
评论时间的时间戳
表中的aid(标识文章)可以是文章的url、文章的id或者其他任何可以唯一标识文章的东西。这里我们使用文章的uri作为唯一标识,比如上面数据中的文章,我们使用/node/2017/02/20/node-express-forum.html来标识文章. 其他 文章 也是如此。
在将这些评论写入表格时,我们还应该注意,在原创数据中,每条评论对应一个用户。在我设计的系统中,用户和评论是分开的,只有uid用来关联他们。新用户和新评论都使用自己的自增主键。因此,在将原创评论存入数据库时,需要将原创userid转换为新用户表中的主键id,并统一新旧数据。
文章表不解释。
3. 具体实现
前端部分主要负责展示每个文章的评论,同时允许登录用户添加评论。
3.1 显示评论
我们为每条评论添加了一个文章标志,前端可以根据辅助获取当前所有的文章评论。但是,我们的评论要以逐栋建筑的方式显示,我们不能简单地将数据平铺在页面上。我们在2.2中也说过,pid为0的评论都是直接发给文章的评论,这些评论应该显示为一级评论;如果pid是其他数据,则必须是属于注释的,应该显示为建筑物内的建筑物。
同时,无论是一级评论还是楼内楼的评论,都可能有分页,所以分页也要在这里处理。
所以最后我们在前端得到的结构应该大致是这样的:
前端拿到接口返回的数据后,就可以渲染页面了。在头像的处理中,也考虑了https环境,所以返回的头像链接都是以//开头的形式。
3.2 参与评论
如果用户对 文章 或评论产生共鸣,需要留言讨论,我们需要用户能够添加自己的评论。
评论的类型,如果细分的话,可以分为3类:
我这里的前端实现参考oschina(Open Source China)的comment方法。直接评论文章就是直接在顶部的评论窗口中输入;回复其他评论时,使用弹窗回复。弹窗回复的好处是页面不需要滚动,用户对评论的感知也可以停留在这个位置;同时,用户输入评论也无需添加各种不必要的小输入框。
3.3 登录
在登录问题上,我也纠结了很久,是使用自己的登录系统,还是使用第三方登录,还是用户无需注册登录,输入邮箱和昵称即可评论?
如果使用自己的评论系统,需要自己开发注册登录流程,比较麻烦,对于想要回复一句话的用户,可以干脆放弃注册;如果您只需要输入您的电子邮件地址和昵称即可发表评论,我会考虑到可能从用户那里引出的无限评论,无法控制。所以最后还是考虑接入第三方登录。这里我们选择使用微博作为第三方登录入口,以后会考虑添加github账号登录。
关于如何访问微博第三方登录,我们下一篇文章再讲。文档齐全。对于不熟悉的开发者来说,一开始可能会有些迷惑,但应该问题不大。
3.4 添加邮箱功能
用户登录第三方成功后,名字旁边有一个小输入框,可以让用户输入邮箱地址来接收回复提醒。此输入完全是自愿的,您仍然可以在不输入电子邮件地址的情况下发表评论。也被认为是这个站点是一个流量极低的小站点。用户可能会心血来潮发表评论,然后想到这个网站,但我不知道如何找到它。于是想到了增加邮件提醒功能,防止大神评论沉入海中。
3.5 特别注意
前端部门引入了vue框架,每一个文章页面都加载了评论模块。为了防止评论模块中的vue库影响外部资源(比如版本冲突等),我先把全局变量给了wzVue,然后注销了vue:
同时,在评论功能完成之初,只要用户进入这个页面,评论就会被加载。但是有一个问题,用户不一定能看到你的文章到底部,不一定能看到你的评论。因此,文章 改为按需加载。只有当用户滚动到底部并有阅读评论的意图时,才会加载评论。
最终结果是这样的:
4. 摘要
作为前端开发者,只用后端知识开发一个博客评论系统似乎很简单,整个框架的设计也很粗糙。同时缓存系统不熟练,无法立即更新评论信息。这个系统还有很大的改进空间。欢迎大家对蚊子(邵兵)提出更多的意见和建议。
写这个文章的时候,想着以后版本修改的时候,可以通过同步加载评论的方式来完成。生成文章后,更新频率极低,甚至变化不大,然后缓存评论的内容。每当有新评论时,当前 文章 的缓存将被删除并重新加载新评论。数据,然后缓存新的数据,这样在评论数据更新量比较低的时候,可以缓存更长的时间,同时也有利于搜索评论内容的爬取。
php如何抓取网页数据库(Google新闻抓取工具如何知道新网站何时出现?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-16 00:25
您有一些我将回答的关键问题,但首先您应该了解什么是爬虫。
什么是爬虫?
爬虫的工作是通过阅读页面扫描互联网,获取他收录的所有链接,然后阅读这些页面。此操作的主要目的是自动查找新内容。一个好的爬虫会开始爬取几个大的、熟悉的、更新频繁的网站,这样他就可以对这些网站进行更新和索引,快速获取新的内容和新的网站(因为大的 网站s 经常收录指向其他 网站s 的链接)。
关于你的问题:
googlenews 是否可以访问所有这些 网站 数据库?
不,如果您有权访问数据库,则不需要使用爬虫。
爬虫如何知道 网站 中添加了新链接?
Google 偶尔会抓取每个 网站 并在 网站 中搜索新链接。通常,新页面或 文章 将通过已存储在 Google 数据库中的主页链接。
Google 新闻抓取工具如何知道新的 网站 何时可用?
简单的答案是:爬虫找到新的 网站 的链接,检查 网站 是否在系统中,如果没有,则添加它。
他们如何获得旧版 文章 的链接?
很简单,他们将这些链接保存在一个巨大的数据库中。谷歌几年前开始抓取网络。如果谷歌今天再次开始抓取互联网,旧链接可能不会出现。
我如何获得时间网站发布文章?
这取决于您要抓取的 网站。如果每篇文章 文章 都有一个日期,则需要解析页面并提取该日期。这篇文章的顶部有一个日期,通过搜索日期类很容易找到 HTML dom:2014 年 6 月 6 日。如果没有出现日期,你无法知道他们什么时候会发布日期。
作为开发人员,您可以让 Google 的生活更轻松,并要求 Google 通过 Google 网站管理员工具抓取您的新 网站。
在抓取网页时,Google 还会统计指向页面的链接数量,这会影响页面的排名。许多指向您的链接 网站 表明您拥有有价值的内容,并且您应该在搜索结果中出现更高的位置。
编写一个简单的爬虫很容易。您使用 php cURL 或 file_get_contents 获取页面内容,对其进行解析,选择并保存所需的数据,提取此页面中的所有链接,并递归地抓取您找到的链接。</p> 查看全部
php如何抓取网页数据库(Google新闻抓取工具如何知道新网站何时出现?(组图))
您有一些我将回答的关键问题,但首先您应该了解什么是爬虫。
什么是爬虫?
爬虫的工作是通过阅读页面扫描互联网,获取他收录的所有链接,然后阅读这些页面。此操作的主要目的是自动查找新内容。一个好的爬虫会开始爬取几个大的、熟悉的、更新频繁的网站,这样他就可以对这些网站进行更新和索引,快速获取新的内容和新的网站(因为大的 网站s 经常收录指向其他 网站s 的链接)。
关于你的问题:
googlenews 是否可以访问所有这些 网站 数据库?
不,如果您有权访问数据库,则不需要使用爬虫。
爬虫如何知道 网站 中添加了新链接?
Google 偶尔会抓取每个 网站 并在 网站 中搜索新链接。通常,新页面或 文章 将通过已存储在 Google 数据库中的主页链接。
Google 新闻抓取工具如何知道新的 网站 何时可用?
简单的答案是:爬虫找到新的 网站 的链接,检查 网站 是否在系统中,如果没有,则添加它。
他们如何获得旧版 文章 的链接?
很简单,他们将这些链接保存在一个巨大的数据库中。谷歌几年前开始抓取网络。如果谷歌今天再次开始抓取互联网,旧链接可能不会出现。
我如何获得时间网站发布文章?
这取决于您要抓取的 网站。如果每篇文章 文章 都有一个日期,则需要解析页面并提取该日期。这篇文章的顶部有一个日期,通过搜索日期类很容易找到 HTML dom:2014 年 6 月 6 日。如果没有出现日期,你无法知道他们什么时候会发布日期。
作为开发人员,您可以让 Google 的生活更轻松,并要求 Google 通过 Google 网站管理员工具抓取您的新 网站。
在抓取网页时,Google 还会统计指向页面的链接数量,这会影响页面的排名。许多指向您的链接 网站 表明您拥有有价值的内容,并且您应该在搜索结果中出现更高的位置。
编写一个简单的爬虫很容易。您使用 php cURL 或 file_get_contents 获取页面内容,对其进行解析,选择并保存所需的数据,提取此页面中的所有链接,并递归地抓取您找到的链接。</p>
php如何抓取网页数据库(使用scrapy来抓取数据创建项目配置信息制作信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-14 06:08
简介
OMIM的全称是Online Mendelian Inheritance in Man,是一个不断更新的人类孟德尔遗传病数据库,重点关注人类遗传变异与表型性状的关系。
OMIM官网网址为:
呲牙
OMIM的注册用户可以下载或使用API获取数据。这里我们尝试使用爬虫来爬取Phenotype-Gene Relationships数据。
使用scrapy创建项目来抓取数据
scrapy startproject omimScrapy
cd omimScrapy
scrapy genspider omim omim.org
配置物品信息
import scrapy
class OmimscrapyItem(scrapy.Item):
# define the fields for your item here like:
geneSymbol = scrapy.Field()
mimNumber = scrapy.Field()
location = scrapy.Field()
phenotype = scrapy.Field()
phenotypeMimNumber = scrapy.Field()
nheritance = scrapy.Field()
mappingKey = scrapy.Field()
descriptionFold = scrapy.Field()
diagnosisFold = scrapy.Field()
inheritanceFold = scrapy.Field()
populationGeneticsFold = scrapy.Field()
做一个爬虫
我们依次抓取文件mim2gene.txt的内容,所以需要解析文件。
'''
解析omim mim2gene.txt的文件
'''
def readMim2Gene(self,filename):
filelist = []
with open(filename,"r") as f:
for line in f.readlines():
tempList = []
strs = line.split()
mimNumber = strs[0]
mimEntryType = strs[1]
geneSymbol = "."
if(len(strs)>=4):
geneSymbol = strs[3]
if(mimEntryType in ["gene","gene/phenotype"]):
tempList.append(mimNumber)
tempList.append(mimEntryType)
tempList.append(geneSymbol)
filelist.append(tempList)
return filelist
解析文件后,需要动态生成爬虫爬取的入口。我们需要通过 start_requests 方法动态生成抓取的 url。然后根据url爬取对应的内容。
注意:此阶段可以同时解析html内容,提取需要的内容,也可以先保存html内容,供后续统一处理。抓取到的html内容这里不解析,而是直接将html内容保存为html文件。文件名以mimNumber命名,后缀为.html。
爬虫设置
OMIM robots.txt 设置了爬虫策略,只允许微软 Bingbot 和谷歌 googlebot 爬虫获取指定路径的内容。主要注意几个方面的配置。
BOT_NAME = 'bingbot'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'bingbot (+https://www.bing.com/bingbot.htm)'
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 4
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
执行
然后就可以进行爬取操作了。这个过程比较慢,估计要一天。之后,所有的html页面都保存为本地html页面。
scrapy crawl omim
后续提取
基于本地html的提取操作非常简单,可以使用BeautifulSoup进行提取。提取的核心操作如下:
'''
解析Phenotype-Gene Relationships表格
'''
def parseHtmlTable(html):
soup = BeautifulSoup(html,"html.parser")
table = soup.table
location,phenotype,mimNumber,nheritance,mappingKey,descriptionFold,diagnosisFold,inheritanceFold,populationGeneticsFold="","","","","","","","",""
if not table:
result = "ERROR"
else:
result = "SUCCESS"
trs = table.find_all('tr')
for tr in trs:
tds = tr.find_all('td')
if len(tds)==0:
continue
elif len(tds)==4:
phenotype = phenotype + "|" + (tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.' )
mimNumber = mimNumber + "|" + (tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.')
nheritance = nheritance + "|" + (tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.')
mappingKey = mappingKey + "|" + (tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.')
elif len(tds)==5:
location = tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.'
phenotype = tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.'
mimNumber = tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.'
nheritance = tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.'
mappingKey = tds[4].get_text().strip() if tds[4].get_text().strip()!='' else '.'
else:
result = "ERROR"
descriptionFoldList = soup.select("#descriptionFold")
descriptionFold = "." if len(descriptionFoldList)==0 else descriptionFoldList[0].get_text().strip()
diagnosisFoldList = soup.select("#diagnosisFold")
diagnosisFold = "." if len(diagnosisFoldList)==0 else diagnosisFoldList[0].get_text().strip()
inheritanceFoldList = soup.select("#inheritanceFold")
inheritanceFold = "." if len(inheritanceFoldList)==0 else inheritanceFoldList[0].get_text().strip()
populationGeneticsFoldList = soup.select("#populationGeneticsFold")
populationGeneticsFold = "." if len(populationGeneticsFoldList)==0 else populationGeneticsFoldList[0].get_text().strip()
至于最终的格式,就看个人需求了。 查看全部
php如何抓取网页数据库(使用scrapy来抓取数据创建项目配置信息制作信息)
简介
OMIM的全称是Online Mendelian Inheritance in Man,是一个不断更新的人类孟德尔遗传病数据库,重点关注人类遗传变异与表型性状的关系。
OMIM官网网址为:
呲牙
OMIM的注册用户可以下载或使用API获取数据。这里我们尝试使用爬虫来爬取Phenotype-Gene Relationships数据。
使用scrapy创建项目来抓取数据
scrapy startproject omimScrapy
cd omimScrapy
scrapy genspider omim omim.org
配置物品信息
import scrapy
class OmimscrapyItem(scrapy.Item):
# define the fields for your item here like:
geneSymbol = scrapy.Field()
mimNumber = scrapy.Field()
location = scrapy.Field()
phenotype = scrapy.Field()
phenotypeMimNumber = scrapy.Field()
nheritance = scrapy.Field()
mappingKey = scrapy.Field()
descriptionFold = scrapy.Field()
diagnosisFold = scrapy.Field()
inheritanceFold = scrapy.Field()
populationGeneticsFold = scrapy.Field()
做一个爬虫
我们依次抓取文件mim2gene.txt的内容,所以需要解析文件。
'''
解析omim mim2gene.txt的文件
'''
def readMim2Gene(self,filename):
filelist = []
with open(filename,"r") as f:
for line in f.readlines():
tempList = []
strs = line.split()
mimNumber = strs[0]
mimEntryType = strs[1]
geneSymbol = "."
if(len(strs)>=4):
geneSymbol = strs[3]
if(mimEntryType in ["gene","gene/phenotype"]):
tempList.append(mimNumber)
tempList.append(mimEntryType)
tempList.append(geneSymbol)
filelist.append(tempList)
return filelist
解析文件后,需要动态生成爬虫爬取的入口。我们需要通过 start_requests 方法动态生成抓取的 url。然后根据url爬取对应的内容。
注意:此阶段可以同时解析html内容,提取需要的内容,也可以先保存html内容,供后续统一处理。抓取到的html内容这里不解析,而是直接将html内容保存为html文件。文件名以mimNumber命名,后缀为.html。
爬虫设置
OMIM robots.txt 设置了爬虫策略,只允许微软 Bingbot 和谷歌 googlebot 爬虫获取指定路径的内容。主要注意几个方面的配置。
BOT_NAME = 'bingbot'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'bingbot (+https://www.bing.com/bingbot.htm)'
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 4
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
执行
然后就可以进行爬取操作了。这个过程比较慢,估计要一天。之后,所有的html页面都保存为本地html页面。
scrapy crawl omim
后续提取
基于本地html的提取操作非常简单,可以使用BeautifulSoup进行提取。提取的核心操作如下:
'''
解析Phenotype-Gene Relationships表格
'''
def parseHtmlTable(html):
soup = BeautifulSoup(html,"html.parser")
table = soup.table
location,phenotype,mimNumber,nheritance,mappingKey,descriptionFold,diagnosisFold,inheritanceFold,populationGeneticsFold="","","","","","","","",""
if not table:
result = "ERROR"
else:
result = "SUCCESS"
trs = table.find_all('tr')
for tr in trs:
tds = tr.find_all('td')
if len(tds)==0:
continue
elif len(tds)==4:
phenotype = phenotype + "|" + (tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.' )
mimNumber = mimNumber + "|" + (tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.')
nheritance = nheritance + "|" + (tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.')
mappingKey = mappingKey + "|" + (tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.')
elif len(tds)==5:
location = tds[0].get_text().strip() if tds[0].get_text().strip()!='' else '.'
phenotype = tds[1].get_text().strip() if tds[1].get_text().strip()!='' else '.'
mimNumber = tds[2].get_text().strip() if tds[2].get_text().strip()!='' else '.'
nheritance = tds[3].get_text().strip() if tds[3].get_text().strip()!='' else '.'
mappingKey = tds[4].get_text().strip() if tds[4].get_text().strip()!='' else '.'
else:
result = "ERROR"
descriptionFoldList = soup.select("#descriptionFold")
descriptionFold = "." if len(descriptionFoldList)==0 else descriptionFoldList[0].get_text().strip()
diagnosisFoldList = soup.select("#diagnosisFold")
diagnosisFold = "." if len(diagnosisFoldList)==0 else diagnosisFoldList[0].get_text().strip()
inheritanceFoldList = soup.select("#inheritanceFold")
inheritanceFold = "." if len(inheritanceFoldList)==0 else inheritanceFoldList[0].get_text().strip()
populationGeneticsFoldList = soup.select("#populationGeneticsFold")
populationGeneticsFold = "." if len(populationGeneticsFoldList)==0 else populationGeneticsFoldList[0].get_text().strip()
至于最终的格式,就看个人需求了。
php如何抓取网页数据库(搜索引擎不要禁止所有搜索引擎访问网站的任何部分2、禁止 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-13 22:29
)
方法一:设置robots.txt方法
搜索引擎默认遵循robots.txt协议,创建一个robots.txt文本文件放在网站根目录下,编辑代码如下:
User-agent:*
Disallow:/
通过上面的代码,告诉搜索引擎不要抓取,获取,收录this网站.
注意:如果使用上述代码,它将阻止所有搜索引擎访问网站的任何部分。
以下常见用法示例:
1、禁止所有搜索引擎访问网站的所有部分
User-agent:*
Disallow:/
2、百度收录网站所有版块
User-agent:Baiduspider
Disallow:/
3、禁止谷歌收录全站
User-agent:Googlebot
Disallow:/
4、禁止除谷歌以外的所有搜索引擎搜索整个网站
4、禁止除百度以外的所有搜索引擎搜索全站
User-agent:Baiduspider
Disallow:
User-agent:*
allow:/
5、禁止所有搜索引擎访问某个目录(如禁止根目录下的admin和css)
User-agent:*
Disallow:/css/
Disallow:/admin/
方法二:设置页面代码方法
在网站主页代码之间,添加以下代码禁用收录和索引
按搜索引擎
## 禁止所有搜索引擎的收录和索引
## 禁止百度搜索引擎和索引
## 禁止Google搜索引擎和索引 查看全部
php如何抓取网页数据库(搜索引擎不要禁止所有搜索引擎访问网站的任何部分2、禁止
)
方法一:设置robots.txt方法
搜索引擎默认遵循robots.txt协议,创建一个robots.txt文本文件放在网站根目录下,编辑代码如下:
User-agent:*
Disallow:/
通过上面的代码,告诉搜索引擎不要抓取,获取,收录this网站.
注意:如果使用上述代码,它将阻止所有搜索引擎访问网站的任何部分。
以下常见用法示例:
1、禁止所有搜索引擎访问网站的所有部分
User-agent:*
Disallow:/
2、百度收录网站所有版块
User-agent:Baiduspider
Disallow:/
3、禁止谷歌收录全站
User-agent:Googlebot
Disallow:/
4、禁止除谷歌以外的所有搜索引擎搜索整个网站
4、禁止除百度以外的所有搜索引擎搜索全站
User-agent:Baiduspider
Disallow:
User-agent:*
allow:/
5、禁止所有搜索引擎访问某个目录(如禁止根目录下的admin和css)
User-agent:*
Disallow:/css/
Disallow:/admin/
方法二:设置页面代码方法
在网站主页代码之间,添加以下代码禁用收录和索引
按搜索引擎
## 禁止所有搜索引擎的收录和索引
## 禁止百度搜索引擎和索引
## 禁止Google搜索引擎和索引
php如何抓取网页数据库(网站seo需要优化哪些html代码(30/4)? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-13 22:26
)
相关话题
网站优化的标准HTML代码
2007 年 5 月 31 日 09:16:00
规范化的 Html 代码对于 网站 有很多好处,例如:易于修改、易于代码维护、代码量大
增长知识!网站哪些html代码需要针对seo进行优化?
24/11/202012:05:45
关于seo,大部分人看到的界面都是用html代码组织的。优化网站html代码的目的是为了让网站更适合搜索引擎。精致的网站一端适合用户,另一端适合
如何在html中直接显示html代码
30/4/202109:53:59
本文文章将介绍在html中直接显示html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。百度做了很多实践,感觉很多都没有测试过就废话了。
如何优化 HTML网站 代码
2018 年 5 月 12 日 14:20:51
一个高质量的网站,网站代码的优化是非常重要的。对于一个好的SEO人来说,虽然不需要精通代码,但是一些简单的基本代码还是需要懂的。要想成为优秀的SEO人眼,需要有不断学习的精神。我们的网站 中的某个页面需要网站 代码优化。如果想看懂代码,可以给网站的添加附加值,有利于蜘蛛爬网
如何编写html换行代码
2021 年 2 月 2 日 18:05:55
html换行代码是“
",在要换行的行末尾,添加"
《代码可以实现换行操作.html》
”标签用于插入简单的换行符,实现换行。本教程运行环境:win
html中的空格代码是什么
15/12/202015:20:52
HTML空格码就是HTML空格字符码,由“&+n+b+s+p+;”组成,记住最后一个分号不要忘记。在 CSS 中,当 white-space 属性的值为 pre 时,浏览器会在文本中保留空格和换行符,例如:
如何在vscode中运行html代码
30/4/202109:54:00
本文文章将介绍在vscode中运行html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。如何在vscode中运行html代码:点击vscode软件左侧的扩展
html常用代码
2018 年 4 月 3 日 01:10:52
1:粗斜体代码 ◆粗体代码为:Hello ◆斜体代码为:Hello!◆底线字:2:文本链接代码 如果你想点击某个文本连接到另一个网页,这是一个超链接,代码如下: 如果你在共享空间中点击这个文本并重新打开一个窗口,代码是:
如何在html中注释代码
2021 年 12 月 4 日 18:13:35
html中注释代码的方法:先修改文件名,完善代码;然后创建三个div层,并使用“”进行注释;最后刷新网页。本教程的运行环境:windows7系统,html5版本,DELLG3电脑。用于注释的 html 中的代码
jquery如何输出html代码
17/11/202018:04:57
jquery输出html代码的方法:1、直接输出tag元素,代码为[varform1=""];2、 输出带有变量的标签元素,代码为[varcountry=....]。杰克
为什么html看不到php代码
24/6/202109:16:35
html看不到php代码,因为所有的php代码都是在网站发送到浏览器之前在服务器上执行的,而浏览器接收到的一切都是php嵌入到html中的结果。本文运行环境:windows7系统,PHP7.第1版,DELLG3
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站代码应该如何优化?
2014 年 11 月 3 日 17:19:00
网站是由代码组成的,所以一定要优化网站网站的代码,代码的优化也是网站优化中的一个优化措施。@> 优化很重要。虽然HTML代码是程序员应该精通的语言,但是HTML代码的优化应该是SEO专家应该精通的技能。作为一名合格的SEOer,我们不需要精通HTML代码,但我们要知道如何优化 网站 代码,...
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
查看全部
php如何抓取网页数据库(网站seo需要优化哪些html代码(30/4)?
)
相关话题
网站优化的标准HTML代码
2007 年 5 月 31 日 09:16:00
规范化的 Html 代码对于 网站 有很多好处,例如:易于修改、易于代码维护、代码量大
增长知识!网站哪些html代码需要针对seo进行优化?
24/11/202012:05:45
关于seo,大部分人看到的界面都是用html代码组织的。优化网站html代码的目的是为了让网站更适合搜索引擎。精致的网站一端适合用户,另一端适合
如何在html中直接显示html代码
30/4/202109:53:59
本文文章将介绍在html中直接显示html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。百度做了很多实践,感觉很多都没有测试过就废话了。
如何优化 HTML网站 代码
2018 年 5 月 12 日 14:20:51
一个高质量的网站,网站代码的优化是非常重要的。对于一个好的SEO人来说,虽然不需要精通代码,但是一些简单的基本代码还是需要懂的。要想成为优秀的SEO人眼,需要有不断学习的精神。我们的网站 中的某个页面需要网站 代码优化。如果想看懂代码,可以给网站的添加附加值,有利于蜘蛛爬网
如何编写html换行代码
2021 年 2 月 2 日 18:05:55
html换行代码是“
",在要换行的行末尾,添加"
《代码可以实现换行操作.html》
”标签用于插入简单的换行符,实现换行。本教程运行环境:win
html中的空格代码是什么
15/12/202015:20:52
HTML空格码就是HTML空格字符码,由“&+n+b+s+p+;”组成,记住最后一个分号不要忘记。在 CSS 中,当 white-space 属性的值为 pre 时,浏览器会在文本中保留空格和换行符,例如:
如何在vscode中运行html代码
30/4/202109:54:00
本文文章将介绍在vscode中运行html代码的方式。有一定的参考价值,有需要的朋友可以参考,希望对大家有所帮助。如何在vscode中运行html代码:点击vscode软件左侧的扩展
html常用代码
2018 年 4 月 3 日 01:10:52
1:粗斜体代码 ◆粗体代码为:Hello ◆斜体代码为:Hello!◆底线字:2:文本链接代码 如果你想点击某个文本连接到另一个网页,这是一个超链接,代码如下: 如果你在共享空间中点击这个文本并重新打开一个窗口,代码是:
如何在html中注释代码
2021 年 12 月 4 日 18:13:35
html中注释代码的方法:先修改文件名,完善代码;然后创建三个div层,并使用“”进行注释;最后刷新网页。本教程的运行环境:windows7系统,html5版本,DELLG3电脑。用于注释的 html 中的代码
jquery如何输出html代码
17/11/202018:04:57
jquery输出html代码的方法:1、直接输出tag元素,代码为[varform1=""];2、 输出带有变量的标签元素,代码为[varcountry=....]。杰克
为什么html看不到php代码
24/6/202109:16:35
html看不到php代码,因为所有的php代码都是在网站发送到浏览器之前在服务器上执行的,而浏览器接收到的一切都是php嵌入到html中的结果。本文运行环境:windows7系统,PHP7.第1版,DELLG3
如何善用博客或网站上的标签?
28/1/2010 08:55:00
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
网站代码应该如何优化?
2014 年 11 月 3 日 17:19:00
网站是由代码组成的,所以一定要优化网站网站的代码,代码的优化也是网站优化中的一个优化措施。@> 优化很重要。虽然HTML代码是程序员应该精通的语言,但是HTML代码的优化应该是SEO专家应该精通的技能。作为一名合格的SEOer,我们不需要精通HTML代码,但我们要知道如何优化 网站 代码,...
网站优化:TAG标签更有益。你用过网站吗?
15/7/2013 14:20:00
一些随处可见的大型网站已经熟练使用了TAG标签,今天想和大家讨论这个话题,因为很多中小型网站往往忽略了TAG标签的作用TAG标签我什至不知道TAG标签能给网站带来什么好处,所以今天给大家详细分享一下。
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
php如何抓取网页数据库(windows10系统、AdobeDreamweaveHtml代码seo优化最佳布局实例讲解(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-11 01:20
)
相关话题
如何在html中居中网页
18/1/202112:07:17
html居中网页的方法:首先在Dreamweaver中打开html页面文件;然后直接在页面高度后面加上[align="center"]代码。本教程运行环境:windows10系统、Adobe Dreamweave
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
高质量网页设计:示例和提示
2018 年 14 月 5 日 09:08:43
接下来,我会给大家一些重点,并附上相应的例子,和大家分享一下我在别人的网页设计中寻找“高品质”的过程。
html是网页文件吗?
25/11/202012:05:42
HTML是网页文件,而Html文件就是我们通常所说的静态网页文件。此方法适用于所有品牌的电脑Htm
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
实现网站(网页)跳转并可以隐藏跳转后URL的代码
2/3/2018 01:10:32
实现网站(网页)跳转的代码,跳转后隐藏URL Chengzi 2017-04-0423:44:01 浏览304条评论0 阿里云域名根目录http网页设计UIhtdocscharsetindexhtml总结:实现网站(网页)跳转可以隐藏跳转后的URL代码1.实现网站(网页)跳转并隐藏跳转后URL的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
提高网页和博客设计质量的一些示例和技巧
21/5/2009 11:27:00
“高品质”是每个人都在追求的,在网页设计界也不例外。但是什么是“质量”,你如何判断一个设计的质量好坏?我碰巧有一种方法可以找到网页设计中质量的重点。一旦你知道如何判断一个高质量的设计真正擅长什么,你就会有很多技巧来完善你自己的。
响应式网页设计和 SEO
20/6/2013 14:47:00
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站上,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难,网页中的功能也越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Adobe 发布网页设计软件 Muse
17/5/2012 13:24:00
Adobe 今天宣布推出其网页设计软件 Muse。Adobe 表示,使用 Muse 软件,网页设计师无需编写代码即可创建 网站。Adobe 此前曾进行过 Musebeta 公开测试版。
起床!网页设计师的网页设计简史
2014 年 9 月 12 日 11:08:00
这是一部网页设计发展的简史,我们可以看到技术、设计和思想的演变,看到无数有识之士改变世界的剪影。
查看全部
php如何抓取网页数据库(windows10系统、AdobeDreamweaveHtml代码seo优化最佳布局实例讲解(组图)
)
相关话题
如何在html中居中网页
18/1/202112:07:17
html居中网页的方法:首先在Dreamweaver中打开html页面文件;然后直接在页面高度后面加上[align="center"]代码。本教程运行环境:windows10系统、Adobe Dreamweave
html代码seo优化最佳布局实例讲解
21/5/2018 11:45:46
html代码seo优化最佳布局示例说明搜索引擎对html代码的优化非常好,所以html优化是推广的第一步。符合 seo 规则的代码一般看起来像下面的界面。1、这东西是一些页面评论,你可以在这里添加我的“木庄互联网博客”,但是关键字太多可能会被搜索引擎惩罚!2、这是代码的开头和结尾以及对应的。3、4、(木庄网博客-....
高质量网页设计:示例和提示
2018 年 14 月 5 日 09:08:43
接下来,我会给大家一些重点,并附上相应的例子,和大家分享一下我在别人的网页设计中寻找“高品质”的过程。
html是网页文件吗?
25/11/202012:05:42
HTML是网页文件,而Html文件就是我们通常所说的静态网页文件。此方法适用于所有品牌的电脑Htm
详细讲解php爬取网页内容的例子
6/8/202018:02:42
php爬取网页内容示例详解方法一:使用file_get_contents方法实现$url="";$html=file_ge
Nginx下更改网页地址后旧网页301重定向的代码
2018 年 2 月 3 日 01:09:49
总结:Nginx下更改网页地址后旧网页301重定向的代码
实现网站(网页)跳转并可以隐藏跳转后URL的代码
2/3/2018 01:10:32
实现网站(网页)跳转的代码,跳转后隐藏URL Chengzi 2017-04-0423:44:01 浏览304条评论0 阿里云域名根目录http网页设计UIhtdocscharsetindexhtml总结:实现网站(网页)跳转可以隐藏跳转后的URL代码1.实现网站(网页)跳转并隐藏跳转后URL的代码
如何打开网页的源代码
2021 年 4 月 2 日 10:31:09
打开网页源代码的方法:先登录一个网站,在网页左侧空白处右击;然后点击inspect元素,再次右击网页左侧的空白处;最后,点击查看源文件。本文运行环境:Windows7系统,戴尔G3电脑
提高网页和博客设计质量的一些示例和技巧
21/5/2009 11:27:00
“高品质”是每个人都在追求的,在网页设计界也不例外。但是什么是“质量”,你如何判断一个设计的质量好坏?我碰巧有一种方法可以找到网页设计中质量的重点。一旦你知道如何判断一个高质量的设计真正擅长什么,你就会有很多技巧来完善你自己的。
响应式网页设计和 SEO
20/6/2013 14:47:00
所谓“响应式网页设计(Responsive Web Design)”也是自适应的,是一种能够自动识别屏幕宽度并做出相应调整的网页设计。目前这种设计出现在越来越多的国内网站上,谷歌已经明确表示鼓励响应式网页设计。
简化您的网页设计
19/2/2013 14:55:00
随着网站构建技术的发展,在网页中实现复杂的功能已经不再困难,网页中的功能也越来越多。因此,需要在用户的浏览体验和网页设计的美感之间取得平衡。显得非常重要。
宝安网页设计从SEO角度谈网页设计标准
17/6/202015:30:19
深圳宝安网页设计从SEO角度谈网页设计标准。在任何时候,网站访问者都处于以下阶段之一: 1. 注意;2、利息;3.欲望;4. 行动;5.满足。在每个阶段,参观者都是不同的
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
Adobe 发布网页设计软件 Muse
17/5/2012 13:24:00
Adobe 今天宣布推出其网页设计软件 Muse。Adobe 表示,使用 Muse 软件,网页设计师无需编写代码即可创建 网站。Adobe 此前曾进行过 Musebeta 公开测试版。
起床!网页设计师的网页设计简史
2014 年 9 月 12 日 11:08:00
这是一部网页设计发展的简史,我们可以看到技术、设计和思想的演变,看到无数有识之士改变世界的剪影。
php如何抓取网页数据库(8.根据数据集大小下载数据匹配的所有数据摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-08 09:06
8. 根据数据集大小下载数据集。
9. 根据与之关联的机器学习任务下载数据集。
案例(搜索并下载数据集)
例如,如果您想下载著名的鸢尾花数据集,只需从菜单中选择选项 3,然后输入存储它的本地数据库的名称(以便更快地搜索)。只需下载 Iris 数据集并将其存储在名为“Iris”的文件夹中!
案例(搜索收录 关键词 的数据集)
如果选择了选项 7,将使用关键字搜索来获取名称与搜索字符串匹配的所有数据集(甚至部分)的简短摘要。您还可以获得每个结果的 Web 链接,以便根据需要进一步探索数据。下面的截图是使用 关键词Cancer 搜索的结果。
如果你想另辟蹊径
如果你想避开这个简单的用户API,使用基本功能,也是可以的。大致流程如下,先导入必要的包。
从 UCI_ML_Functions 导入 *import pandas as pd
read_dataset_table():从url读取数据集并进一步处理,用于后续的数据清洗和分类。
网址:
clean_dataset_table():清理原创数据集(DataFrame)并返回数据。处理后的数据会删除收录缺失值的观测值。还移除了 Default Tasks 列,该列用于显示与数据集关联的主机学习任务。
build_local_table(filename=None, msg_flag=True):读取UCI ML网站,构建本地表,收录名称、大小、ML任务、数据类型等信息。
build_dataset_list():从 UCI ML 数据集页面获取信息并构建收录所有数据集信息的列表。
build_dataset_dictionary():从 UCI ML 数据集页面获取信息并构建收录所有数据集名称和描述的字典。此外,还会生成一个与数据集对应的唯一标识符,下载器需要这个标识符字符串来下载数据文件。在这种情况下,通用名称无效。
build_full_dataframe():构建一个收录所有信息的 DataFrame,包括用于下载数据的 URL 链接。
build_local_database(filename=None, msg_flag=True):读取 UCI ML网站 并使用以下信息构建本地数据库:名称、摘要、数据页 URL。
return_abstract(name,local_database=None,msg_flag=False):通过搜索给定的名称返回特定数据集的单行描述(以及指向更多信息的 Web 链接)。
describe_all_dataset(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的描述。
print_all_datasets_names(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的名称。
extract_url_dataset(dataset,msg_flag=False):给定一个数据集标识符,该函数提取实际原创数据所在页面的URL。
download_dataset_url(url,directory,msg_flag=False,download_flag=True):从给定 url 中的链接下载所有文件。
download_datasets(num=10,local_database=None,msg_flag=True,download_flag=True):下载数据集并将其放在以数据集命名的本地目录中。默认情况下,仅下载前 10 个数据集。用户可以选择要下载的数据集数量。
download_dataset_name(name,local_database=None,msg_flag=True,download_flag=True):下载指定名称的数据集。
download_datasets_size(size='Small',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载所有符合“大小”标准的数据集。
download_datasets_task(task='Classification',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载用户想要满足 ML 任务条件的所有数据集。
原标题:
为 UCI 机器学习存储库引入简单直观的 Python API
原文链接:
关于译者
UIUC统计学硕士王雨桐,主修统计学,目前专注于编码能力的提升。在从理论到应用的转化中,我们尊重数据,不断进化。
——结束——
关注清华-青岛数据科学研究所官方微信公众平台“THU数据学院”及其姊妹号“数据学院THU”,获取更多讲座福利和优质内容。 查看全部
php如何抓取网页数据库(8.根据数据集大小下载数据匹配的所有数据摘要)
8. 根据数据集大小下载数据集。
9. 根据与之关联的机器学习任务下载数据集。
案例(搜索并下载数据集)
例如,如果您想下载著名的鸢尾花数据集,只需从菜单中选择选项 3,然后输入存储它的本地数据库的名称(以便更快地搜索)。只需下载 Iris 数据集并将其存储在名为“Iris”的文件夹中!
案例(搜索收录 关键词 的数据集)
如果选择了选项 7,将使用关键字搜索来获取名称与搜索字符串匹配的所有数据集(甚至部分)的简短摘要。您还可以获得每个结果的 Web 链接,以便根据需要进一步探索数据。下面的截图是使用 关键词Cancer 搜索的结果。
如果你想另辟蹊径
如果你想避开这个简单的用户API,使用基本功能,也是可以的。大致流程如下,先导入必要的包。
从 UCI_ML_Functions 导入 *import pandas as pd
read_dataset_table():从url读取数据集并进一步处理,用于后续的数据清洗和分类。
网址:
clean_dataset_table():清理原创数据集(DataFrame)并返回数据。处理后的数据会删除收录缺失值的观测值。还移除了 Default Tasks 列,该列用于显示与数据集关联的主机学习任务。
build_local_table(filename=None, msg_flag=True):读取UCI ML网站,构建本地表,收录名称、大小、ML任务、数据类型等信息。
build_dataset_list():从 UCI ML 数据集页面获取信息并构建收录所有数据集信息的列表。
build_dataset_dictionary():从 UCI ML 数据集页面获取信息并构建收录所有数据集名称和描述的字典。此外,还会生成一个与数据集对应的唯一标识符,下载器需要这个标识符字符串来下载数据文件。在这种情况下,通用名称无效。
build_full_dataframe():构建一个收录所有信息的 DataFrame,包括用于下载数据的 URL 链接。
build_local_database(filename=None, msg_flag=True):读取 UCI ML网站 并使用以下信息构建本地数据库:名称、摘要、数据页 URL。
return_abstract(name,local_database=None,msg_flag=False):通过搜索给定的名称返回特定数据集的单行描述(以及指向更多信息的 Web 链接)。
describe_all_dataset(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的描述。
print_all_datasets_names(msg_flag=False):调用build_dataset_dictionary函数,显示所有数据集的名称。
extract_url_dataset(dataset,msg_flag=False):给定一个数据集标识符,该函数提取实际原创数据所在页面的URL。
download_dataset_url(url,directory,msg_flag=False,download_flag=True):从给定 url 中的链接下载所有文件。
download_datasets(num=10,local_database=None,msg_flag=True,download_flag=True):下载数据集并将其放在以数据集命名的本地目录中。默认情况下,仅下载前 10 个数据集。用户可以选择要下载的数据集数量。
download_dataset_name(name,local_database=None,msg_flag=True,download_flag=True):下载指定名称的数据集。
download_datasets_size(size='Small',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载所有符合“大小”标准的数据集。
download_datasets_task(task='Classification',local_database=None,local_table=None,msg_flag=False,download_flag=True):下载用户想要满足 ML 任务条件的所有数据集。
原标题:
为 UCI 机器学习存储库引入简单直观的 Python API
原文链接:
关于译者
UIUC统计学硕士王雨桐,主修统计学,目前专注于编码能力的提升。在从理论到应用的转化中,我们尊重数据,不断进化。
——结束——
关注清华-青岛数据科学研究所官方微信公众平台“THU数据学院”及其姊妹号“数据学院THU”,获取更多讲座福利和优质内容。
php如何抓取网页数据库(php如何抓取网页数据库,php采用googlemap提供的demo上传域名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-07 16:01
php如何抓取网页数据库,php采用googlemap提供的demo上传域名:postman0。4版本后将自动转换成etag数据格式1、postman需要先和数据库联接2、数据库连接完成后,不能新建表(我的postman中没有注释),应该自动把表生成html并向服务器端提交第一部分:01demo我们在postman里面建立一个网站,只有一个用户,demo为1。
从任意位置上传图片2。把上传图片的。etag=false设置为true参考:googlemap实例_postman参考5图片上传-2。postman-全球性能最佳postman应用开发工具。
注释,2.0开始我每次上传图片前都注释2次!!!保证你的服务器不收到图片html的时候才注释2次!!!
1。使用定义好的下载引擎去下载jpg或者gif,要注意的是最好是在同一台机器上下载;2。从你网站目录下面的doc文件夹下面下载jpg或者gif,3。用php连接数据库,用postman的header请求,请求之前必须要获取上传的数据cookie4。拿到上传的数据后,可以用toadsr服务器抓取比如支持wordpress,flash,java等等主流的网站和主题,每天都抓取上千条数据并且保存,完全不用担心数据丢失。
特别是java,推荐给你helpfindsource;start:;;tools:--webserver--web--jsp--cgi--apachehttp--phpapachemysqlnginx5。可以再上传前对图片的数据进行压缩,压缩后的文件下载速度比原始的要快,如果没有大量数据的话就不用压缩。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库,php采用googlemap提供的demo上传域名)
php如何抓取网页数据库,php采用googlemap提供的demo上传域名:postman0。4版本后将自动转换成etag数据格式1、postman需要先和数据库联接2、数据库连接完成后,不能新建表(我的postman中没有注释),应该自动把表生成html并向服务器端提交第一部分:01demo我们在postman里面建立一个网站,只有一个用户,demo为1。
从任意位置上传图片2。把上传图片的。etag=false设置为true参考:googlemap实例_postman参考5图片上传-2。postman-全球性能最佳postman应用开发工具。
注释,2.0开始我每次上传图片前都注释2次!!!保证你的服务器不收到图片html的时候才注释2次!!!
1。使用定义好的下载引擎去下载jpg或者gif,要注意的是最好是在同一台机器上下载;2。从你网站目录下面的doc文件夹下面下载jpg或者gif,3。用php连接数据库,用postman的header请求,请求之前必须要获取上传的数据cookie4。拿到上传的数据后,可以用toadsr服务器抓取比如支持wordpress,flash,java等等主流的网站和主题,每天都抓取上千条数据并且保存,完全不用担心数据丢失。
特别是java,推荐给你helpfindsource;start:;;tools:--webserver--web--jsp--cgi--apachehttp--phpapachemysqlnginx5。可以再上传前对图片的数据进行压缩,压缩后的文件下载速度比原始的要快,如果没有大量数据的话就不用压缩。
php如何抓取网页数据库(阿里云gtgt;云栖社区(gt)主题地图(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-04 07:08
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库
推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python 全栈 MongoDB 数据库(概念、安装、创建数据)
作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
Mysql数据库的介绍与分类(学习笔记一)
作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
数据库注释 5:外键的用途
作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
PHP开发中数据库及相关软件的选择注意事项
作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列的4.4.x已经停止升级开发,但仍有部分生产环境运行该版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
php本机代码从数据库中获取记录
作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
在 Android 开发中使用 SQLite 数据库
作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
WordPress数据库研究
作者:ap0581w9c1121 浏览评论:09年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php如何抓取网页数据库(阿里云gtgt;云栖社区(gt)主题地图(组图))
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库
推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
Python 全栈 MongoDB 数据库(概念、安装、创建数据)
作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
Mysql数据库的介绍与分类(学习笔记一)
作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
数据库注释 5:外键的用途
作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
PHP开发中数据库及相关软件的选择注意事项
作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列的4.4.x已经停止升级开发,但仍有部分生产环境运行该版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
php本机代码从数据库中获取记录
作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
在 Android 开发中使用 SQLite 数据库
作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
WordPress数据库研究
作者:ap0581w9c1121 浏览评论:09年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php如何抓取网页数据库(小项目里面的大内涵,其实也不是特别高深,一点一点的说吧~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-02 23:19
小项目中的大内容
也不例外~做任何系统都不要相信用户的输入(@http:也教我们不要相信javascript,你可以自己想想怎么做)~一定是关于用户的输入。输入处理只能被执行或存储。否则,神马跨站攻击,神马SQL注入攻击,乱七八糟不容易收拾的~一个比较基础的处理,PHP魔语行情,详情请看:传送门做人做事》高眼手低”,高楼拔地而起,干就干~
186 查看全部
php如何抓取网页数据库(小项目里面的大内涵,其实也不是特别高深,一点一点的说吧~)
小项目中的大内容
也不例外~做任何系统都不要相信用户的输入(@http:也教我们不要相信javascript,你可以自己想想怎么做)~一定是关于用户的输入。输入处理只能被执行或存储。否则,神马跨站攻击,神马SQL注入攻击,乱七八糟不容易收拾的~一个比较基础的处理,PHP魔语行情,详情请看:传送门做人做事》高眼手低”,高楼拔地而起,干就干~
186
php如何抓取网页数据库(1.如何在当前页面用php获取js变量的值你这么问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-28 11:16
1.如何使用php获取当前页面中js变量的值
如果你问这个问题,说明你还没有理解web应用的原理。
服务器收到客户端请求后,web服务调用php程序,php运行并将结果返回给web服务,php程序立即退出,web服务以html的形式发送给客户端. js收录在发送给客户端的数据中,在客户端运行。跟服务端没有关系,更别说让退出的php程序再次获取js变量了。简单来说就是客户端js变量生成后,服务端php就不存在了。
所以,当前页面不可能使用php获取js变量。但是可以使用ajax技术将变量传回服务器,另外一个php程序可以进行处理。
2.PHP+JS如何爬取别人页面的js数据
js不行,js显示的数据必须支持ajax的采集器采集,我在网上找了一个,你看看行不行,我摘录一段,你可以去详情
@网站让我们看看:
浏览器可以看到的数据可以很方便采集,特别擅长采集Js脚本输出,Ajax动态加载,点击后显示,大长列表,隐藏,iframe框架等大数据
单个任务可以采集30万页/天,采集的速度可以根据客户要求进一步增减,保证数据采集工作可以完成以最快的速度。
<p>各类网站均在采集、新闻、论坛、博客、生活服务、电子商务 查看全部
php如何抓取网页数据库(1.如何在当前页面用php获取js变量的值你这么问)
1.如何使用php获取当前页面中js变量的值
如果你问这个问题,说明你还没有理解web应用的原理。
服务器收到客户端请求后,web服务调用php程序,php运行并将结果返回给web服务,php程序立即退出,web服务以html的形式发送给客户端. js收录在发送给客户端的数据中,在客户端运行。跟服务端没有关系,更别说让退出的php程序再次获取js变量了。简单来说就是客户端js变量生成后,服务端php就不存在了。
所以,当前页面不可能使用php获取js变量。但是可以使用ajax技术将变量传回服务器,另外一个php程序可以进行处理。
2.PHP+JS如何爬取别人页面的js数据
js不行,js显示的数据必须支持ajax的采集器采集,我在网上找了一个,你看看行不行,我摘录一段,你可以去详情
@网站让我们看看:
浏览器可以看到的数据可以很方便采集,特别擅长采集Js脚本输出,Ajax动态加载,点击后显示,大长列表,隐藏,iframe框架等大数据
单个任务可以采集30万页/天,采集的速度可以根据客户要求进一步增减,保证数据采集工作可以完成以最快的速度。
<p>各类网站均在采集、新闻、论坛、博客、生活服务、电子商务
php如何抓取网页数据库(关于PHP连接MySQL数据库方法的5种连接方法总结!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-28 11:15
X
本节主要介绍PHP连接MySQL数据库的方法。如果你对PHP一无所知,请阅读上一篇文章:PHP入门的语法基础非常重要。
接下来是PHP连接MySQL数据库的方法内容。它也不需要完全理解。你只需要有一个大致的印象。看完整个教程后,可以将教程内容中的代码复制到本地,即可成功。运行,这样你就可以快速学习php编程了,因为所有的编程都是大同小异的,到最后,你已经复制粘贴了教程中的所有代码,并且可以按照教程完成项目,当你终于站起来低头的时候对这些基础代码再一次从制高点成功,相信你会恍然大悟,原来学php可以这么简单!好的!回到正题(本节为阅读课,无需复制粘贴代码等,除非你打算做笔记)。
随着MySQL数据库版本的更新迭代和PHP程序的不断扩展,PHP连接MySQL数据库的方式有多种。
第一种,也是目前 PHP 连接 MySQL 数据库最常用的方法,是面向进程的 mysql_connect 连接方法:
五、ADODB连接MySQL数据库方法:
//关闭连接
$conn->关闭();
上面介绍了MySQL数据库连接的五种方式,下面我给大家总结一下这五种连接方式:
首先要注意的是,虽然有很多用户使用第一个mysql_connect方法连接MySQL,但并不是因为这种方法最好,而是因为以前的用户太大,而且很多都没有有能力或条件更新到更好的版本,让很多服务器运营商在为新版本提供技术支持的同时,仍然兼容这些旧版本。
关于第二种数据库连接方式,很多新手在使用过程中有很多直接的应用场景(面向过程),也是我们以后学习和使用的重点,不过我们会描述这个数据库的封装下一节中的连接方法(面向对象)。
什么是封装?网上没有具体的定义。所谓封装,其实是出于安全、规范、系统稳定性、简化操作等目的,方便以后常用和接口调用。可以减少因操作不规范造成的意外情况,减少新产品的开发。成本和使用成本。
关于第三种MySQL数据库连接方式,MySQL数据库官方给出了更全面的使用方法,更高效、更安全、更稳定、更全面。具体用法可以参考网站的总结,网址:. 虽然好处这么多,但其实我们开发者真正能用到的只是其中的一小部分。为了简单、兼容、降低开发成本,也更符合我们自己的逻辑,我还是推荐大家自己编写、封装和使用第二种数据库连接方式。比如我们的网站 MySQL数据库太大了,无法承受,当我们需要更换更强大的Oracle数据库时,只需要修改数据库的包文件或者配置文件就可以在很短的时间内实现时间网站 程序整体平滑变化,网站规模越大,使用自己编写封装的数据库方法优势越明显。如果你的整个网站完全使用MySQL数据库的官方用法,那么当你以后面临更换数据库的时候,你会发现自己已经跳进了MySQL数据库官方给大家挖的坑。
关于第四种MySQL数据库连接方式,pdo是php提供的轻量级数据连接接口。在 php5.1 之后的版本中使用。pdo方法的优点是比之前的mysql方法更安全,兼容性更好。好了,你可以用同样的方式连接Oracle、mssql等数据库。
关于第五种ADODB与MySQL数据库的连接方式,支持的数据库类型很多,如:MySQL、PostgreSQL、Interbase、Informix、Oracle、MS SQL 7、Foxpro、Access、ADO、Sybase、DB2和通用ODBC(其中PostgreSQL、Informix、Sybase 驱动由自由软件社区开发后贡献)。
虽然PHP连接MySQL数据库的方式有很多种,但是接下来的教程是学习更好的继承方式下mysqli_connect连接下的增删改查。下一讲,我们主要学习如何使用本文的第二种php方法连接MySQL数据库,以及如何封装MySQL数据库。当然,如果你有兴趣,也可以尝试编写数据库操作类,通过其他方法连接和操作。 查看全部
php如何抓取网页数据库(关于PHP连接MySQL数据库方法的5种连接方法总结!)
X
本节主要介绍PHP连接MySQL数据库的方法。如果你对PHP一无所知,请阅读上一篇文章:PHP入门的语法基础非常重要。
接下来是PHP连接MySQL数据库的方法内容。它也不需要完全理解。你只需要有一个大致的印象。看完整个教程后,可以将教程内容中的代码复制到本地,即可成功。运行,这样你就可以快速学习php编程了,因为所有的编程都是大同小异的,到最后,你已经复制粘贴了教程中的所有代码,并且可以按照教程完成项目,当你终于站起来低头的时候对这些基础代码再一次从制高点成功,相信你会恍然大悟,原来学php可以这么简单!好的!回到正题(本节为阅读课,无需复制粘贴代码等,除非你打算做笔记)。
随着MySQL数据库版本的更新迭代和PHP程序的不断扩展,PHP连接MySQL数据库的方式有多种。
第一种,也是目前 PHP 连接 MySQL 数据库最常用的方法,是面向进程的 mysql_connect 连接方法:
五、ADODB连接MySQL数据库方法:
//关闭连接
$conn->关闭();
上面介绍了MySQL数据库连接的五种方式,下面我给大家总结一下这五种连接方式:
首先要注意的是,虽然有很多用户使用第一个mysql_connect方法连接MySQL,但并不是因为这种方法最好,而是因为以前的用户太大,而且很多都没有有能力或条件更新到更好的版本,让很多服务器运营商在为新版本提供技术支持的同时,仍然兼容这些旧版本。
关于第二种数据库连接方式,很多新手在使用过程中有很多直接的应用场景(面向过程),也是我们以后学习和使用的重点,不过我们会描述这个数据库的封装下一节中的连接方法(面向对象)。
什么是封装?网上没有具体的定义。所谓封装,其实是出于安全、规范、系统稳定性、简化操作等目的,方便以后常用和接口调用。可以减少因操作不规范造成的意外情况,减少新产品的开发。成本和使用成本。
关于第三种MySQL数据库连接方式,MySQL数据库官方给出了更全面的使用方法,更高效、更安全、更稳定、更全面。具体用法可以参考网站的总结,网址:. 虽然好处这么多,但其实我们开发者真正能用到的只是其中的一小部分。为了简单、兼容、降低开发成本,也更符合我们自己的逻辑,我还是推荐大家自己编写、封装和使用第二种数据库连接方式。比如我们的网站 MySQL数据库太大了,无法承受,当我们需要更换更强大的Oracle数据库时,只需要修改数据库的包文件或者配置文件就可以在很短的时间内实现时间网站 程序整体平滑变化,网站规模越大,使用自己编写封装的数据库方法优势越明显。如果你的整个网站完全使用MySQL数据库的官方用法,那么当你以后面临更换数据库的时候,你会发现自己已经跳进了MySQL数据库官方给大家挖的坑。
关于第四种MySQL数据库连接方式,pdo是php提供的轻量级数据连接接口。在 php5.1 之后的版本中使用。pdo方法的优点是比之前的mysql方法更安全,兼容性更好。好了,你可以用同样的方式连接Oracle、mssql等数据库。
关于第五种ADODB与MySQL数据库的连接方式,支持的数据库类型很多,如:MySQL、PostgreSQL、Interbase、Informix、Oracle、MS SQL 7、Foxpro、Access、ADO、Sybase、DB2和通用ODBC(其中PostgreSQL、Informix、Sybase 驱动由自由软件社区开发后贡献)。
虽然PHP连接MySQL数据库的方式有很多种,但是接下来的教程是学习更好的继承方式下mysqli_connect连接下的增删改查。下一讲,我们主要学习如何使用本文的第二种php方法连接MySQL数据库,以及如何封装MySQL数据库。当然,如果你有兴趣,也可以尝试编写数据库操作类,通过其他方法连接和操作。
php如何抓取网页数据库(我在PHP和JS中创建的bookmarklet,如何捕获此弹出窗口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-27 12:12
使用书签的 PHP 网页抓取 - 从页面的 jquery 弹出窗口中获取 html
phpjquery网页抓取
使用书签的 PHP Web 抓取 - 从页面的 jquery 弹出窗口中获取 html、php、jquery、web-scraping、Php、Jquery、Web Scraping、网站:/costs/ 当我选择任何内容时,会出现带有产品图像和价格的弹出窗口PHP 和 JS 中的顶级样式下的项目 使用我在 PHP 和 JS 中创建的书签,我如何捕获此弹出窗口的 HTML?正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 并关闭
网站:/费用/
当我单击页面下方“此类别中的热门款式”下的任何项目时,会出现一个带有产品图片和价格的弹出窗口
使用我在 PHP 和 JS 中创建的小书签,如何捕获此弹出窗口的 HTML?
正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 而只关注链接本身
尝试查看禁用 javascript 的网站
例如,如果您点击表中的第一个链接(发布 文章 时),您将到达 /cmCategoryID/8a61524b-907c-474c-ab37-f357c9ae11e3/&detailcross/? ="> 查看全部
php如何抓取网页数据库(我在PHP和JS中创建的bookmarklet,如何捕获此弹出窗口)
使用书签的 PHP 网页抓取 - 从页面的 jquery 弹出窗口中获取 html
phpjquery网页抓取
使用书签的 PHP Web 抓取 - 从页面的 jquery 弹出窗口中获取 html、php、jquery、web-scraping、Php、Jquery、Web Scraping、网站:/costs/ 当我选择任何内容时,会出现带有产品图像和价格的弹出窗口PHP 和 JS 中的顶级样式下的项目 使用我在 PHP 和 JS 中创建的书签,我如何捕获此弹出窗口的 HTML?正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 并关闭
网站:/费用/
当我单击页面下方“此类别中的热门款式”下的任何项目时,会出现一个带有产品图片和价格的弹出窗口
使用我在 PHP 和 JS 中创建的小书签,如何捕获此弹出窗口的 HTML?
正在加载弹出窗口,这意味着您需要进行另一个 http 调用(在 PHP 中)以获取弹出窗口中的信息。就 /costs/ 而言,网站 努力支持旧版浏览器,因此链接也是实际链接,而不仅仅是 javascript ajax 调用,因此您可以忽略 ajax 而只关注链接本身
尝试查看禁用 javascript 的网站
例如,如果您点击表中的第一个链接(发布 文章 时),您将到达 /cmCategoryID/8a61524b-907c-474c-ab37-f357c9ae11e3/&detailcross/? =">

