
php如何抓取网页数据库
php如何抓取网页数据库(php如何抓取网页数据库——利用kibana了解一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-06 13:02
php如何抓取网页数据库——利用kibana了解一下
通过它抓取网页对apache而言是ok的
可以看看现在的知乎页面抓取程序,
知乎是一个结构庞大的网站,因此正常的开发人员是不会经常去写这样的程序的,而且,开发人员写代码很难保证自己技术水平的,经常性的出现各种坑。用apache+php的这种工具,一般用来解决问题,或者借助它获取解决目标网站有内容但是转化率低的需求。
要获取数据就要了解他的数据结构,
其实很简单在浏览器浏览知乎页面时,采用fiddler软件,会显示这个页面的源代码,随便找一个看看,主要就是看数据结构就行了。
apache自带功能抓取知乎数据
google直接抓取就可以了
用requests库就可以啊!
kibana了解一下
安利一个无痛抓取豆瓣知乎网页的python爬虫程序
当然是可以,
我在安装linux的sshshell以后,登录网站,可以看到它的源代码。抓取的时候,
前端用脚本可以抓取数据,后端自己的应该是无法抓取。
很多网站是不提供api的,除非你配置好apache。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库——利用kibana了解一下)
php如何抓取网页数据库——利用kibana了解一下
通过它抓取网页对apache而言是ok的
可以看看现在的知乎页面抓取程序,
知乎是一个结构庞大的网站,因此正常的开发人员是不会经常去写这样的程序的,而且,开发人员写代码很难保证自己技术水平的,经常性的出现各种坑。用apache+php的这种工具,一般用来解决问题,或者借助它获取解决目标网站有内容但是转化率低的需求。
要获取数据就要了解他的数据结构,
其实很简单在浏览器浏览知乎页面时,采用fiddler软件,会显示这个页面的源代码,随便找一个看看,主要就是看数据结构就行了。
apache自带功能抓取知乎数据
google直接抓取就可以了
用requests库就可以啊!
kibana了解一下
安利一个无痛抓取豆瓣知乎网页的python爬虫程序
当然是可以,
我在安装linux的sshshell以后,登录网站,可以看到它的源代码。抓取的时候,
前端用脚本可以抓取数据,后端自己的应该是无法抓取。
很多网站是不提供api的,除非你配置好apache。
php如何抓取网页数据库(如何通过动态网页来获取数据库的账号和口令动态(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-27 01:15
)
(1)了解动态网页的相关知识
(2)通过动态网页文件获取数据库账号和密码
动态网页的显着特征之一是与数据库的交互。只要涉及大型数据库,动态网页调用数据库一般都需要数据库账号和密码。这些大型数据库主要以 SQL Server 和 Oracle 数据库为代表。访问一般不设置密码。即使设置了密码,您也可以使用“访问密码查看器”获取其密码。网站或信息系统调用数据库时,需要连接。考虑到执行效率和编码效率等,数据库连接一般写成一个单独的模块,这些文件主要用于连接数据库。这些文件将收录诸如数据库服务器的 IP 地址、数据库类型、
在控制或获取Shell时,可以通过查看Index来查看数据库连接文件。asp、Index.php、Index.jsp等,而且数据库连接文件的名字比较容易识别,比如conn.asp、dbconn.asp等,这些文件可以在网站根目录、inc 文件夹、includes 和其他文件。通过查看这些网页文件,您可以获得数据库IP地址、数据库用户账号和密码,并利用获得的信息进行计算机渗透、权限提升、实现完全控制。本案例以国内某视频招聘网站为例,介绍如何通过动态网页获取数据库账号和密码。
(一)确认网站脚本类型。确认网站脚本类型主要是通过打开网站,在网站中访问它的网页来确定的。在这个例子中,打开IE浏览器地址栏输入IP地址“61.*.*.*”,打开网站如图1,在底部状态栏可以浏览查看详细地址和文件显示,本例中可以看到“*.*.*.*/shi.asp”,说明网站脚本类型为asp。
图1 获取网站脚本类型
J技巧
(1)可以直接输入“*.*.*.*/index.asp”、“*.*.*.*/index.php”、“*.*.*.*/index.jsp” " 等判断网站的类型,方法是IP地址+文件名,文件名可以是index.asp(jsp/php/aspx)或者default.asp(jsp/php/aspx)和很快。
(2)如果打开网页后无法确定网站的类型,可以点击网站中的链接地址确认,如果打开链接的网页名称是asp ,则网站脚本类型为asp,其他脚本类型判断原理相同。
(3)打开“Internet信息服务(IIS)管理器”后,点击其“网站属性”中的“文档”,即可得到它的网站默认文档名称。
(二)获取网站的具体目录位置。本例是利用漏洞攻击方式获取系统的用户账号和密码,通过Radmin远程控制软件直接控制进入系统后,在桌面找到“Internet信息服务”快捷键,双击快捷键进入“Internet信息服务(IIS)管理器”,展开到网站,选择“Web”网站文件夹,右击选择“属性”打开Web属性窗口,如图2,然后点击“主目录”,得到其网站根目录为“ D:\*”。
图2 获取网站的根目录位置
&阐明
本例中操作系统为Windows 2003 Server,因此其Web目录与Windows 2000 Server不同,一般操作类似。打开其IIS管理器后,搜索网站目录,展开即可得到浏览器网站的具体位置。
(三)查看网页脚本获取数据库连接文件。从第二步开始,获取网站文件的物理路径,通过资源进入网站的根目录manager,然后用note 这个打开的网站调用首页文件index.asp,如图3,从中可以得到它的网站数据库连接文件,很可能就是“i_include /database_.asp”。
查看全部
php如何抓取网页数据库(如何通过动态网页来获取数据库的账号和口令动态(一)
)
(1)了解动态网页的相关知识
(2)通过动态网页文件获取数据库账号和密码
动态网页的显着特征之一是与数据库的交互。只要涉及大型数据库,动态网页调用数据库一般都需要数据库账号和密码。这些大型数据库主要以 SQL Server 和 Oracle 数据库为代表。访问一般不设置密码。即使设置了密码,您也可以使用“访问密码查看器”获取其密码。网站或信息系统调用数据库时,需要连接。考虑到执行效率和编码效率等,数据库连接一般写成一个单独的模块,这些文件主要用于连接数据库。这些文件将收录诸如数据库服务器的 IP 地址、数据库类型、
在控制或获取Shell时,可以通过查看Index来查看数据库连接文件。asp、Index.php、Index.jsp等,而且数据库连接文件的名字比较容易识别,比如conn.asp、dbconn.asp等,这些文件可以在网站根目录、inc 文件夹、includes 和其他文件。通过查看这些网页文件,您可以获得数据库IP地址、数据库用户账号和密码,并利用获得的信息进行计算机渗透、权限提升、实现完全控制。本案例以国内某视频招聘网站为例,介绍如何通过动态网页获取数据库账号和密码。
(一)确认网站脚本类型。确认网站脚本类型主要是通过打开网站,在网站中访问它的网页来确定的。在这个例子中,打开IE浏览器地址栏输入IP地址“61.*.*.*”,打开网站如图1,在底部状态栏可以浏览查看详细地址和文件显示,本例中可以看到“*.*.*.*/shi.asp”,说明网站脚本类型为asp。

图1 获取网站脚本类型
J技巧
(1)可以直接输入“*.*.*.*/index.asp”、“*.*.*.*/index.php”、“*.*.*.*/index.jsp” " 等判断网站的类型,方法是IP地址+文件名,文件名可以是index.asp(jsp/php/aspx)或者default.asp(jsp/php/aspx)和很快。
(2)如果打开网页后无法确定网站的类型,可以点击网站中的链接地址确认,如果打开链接的网页名称是asp ,则网站脚本类型为asp,其他脚本类型判断原理相同。
(3)打开“Internet信息服务(IIS)管理器”后,点击其“网站属性”中的“文档”,即可得到它的网站默认文档名称。
(二)获取网站的具体目录位置。本例是利用漏洞攻击方式获取系统的用户账号和密码,通过Radmin远程控制软件直接控制进入系统后,在桌面找到“Internet信息服务”快捷键,双击快捷键进入“Internet信息服务(IIS)管理器”,展开到网站,选择“Web”网站文件夹,右击选择“属性”打开Web属性窗口,如图2,然后点击“主目录”,得到其网站根目录为“ D:\*”。

图2 获取网站的根目录位置
&阐明
本例中操作系统为Windows 2003 Server,因此其Web目录与Windows 2000 Server不同,一般操作类似。打开其IIS管理器后,搜索网站目录,展开即可得到浏览器网站的具体位置。
(三)查看网页脚本获取数据库连接文件。从第二步开始,获取网站文件的物理路径,通过资源进入网站的根目录manager,然后用note 这个打开的网站调用首页文件index.asp,如图3,从中可以得到它的网站数据库连接文件,很可能就是“i_include /database_.asp”。

php如何抓取网页数据库(分享最简单粗暴的php代理ip网页数据库解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-09-24 22:05
php如何抓取网页数据库抓取代理ip网页数据库导出到本地数据库。相信很多人都为“获取网页数据库”发愁吧,这里分享最最简单粗暴的php代理ip网页数据库解决方案。前提一定要先安装下ie浏览器,用浏览器右上角查看网页的flash版本是否正常。对于php来说"http://"代码来连接服务器,网页自然就上传到本地了。
举个栗子,比如:php获取一个flash版本是2。0+的网页,实现抓取,上传。php抓取文件上传:functionapi_fetch(mysql_schema,my_schema){my_if(mysql_connect_to_my_computer){my_if(mysql_connect_to_ip){if(mysql_connect_to_member){my_if(mysql_connect_to_port){my_if(mysql_connect_to_auth){my_if(mysql_connect_to_cookie){my_if(mysql_connect_to_token){//mysql_connect_to_cookie=php_reference_token;code=auth_code;//codeforif(ifconfig。
<p>get('datadir')){code=$('。class')。mysql(code));document-drivenrepository:my_if('wordpress。php');my_if('blog。php');my_if('thymeleaf。php');}//if(!mysql_exists(mysql_inet_new_client)){exit;}//if(!mysql_exists(mysql_set_client_ip)){exit;}}return-1;}//if(!mysql_null_any('ip')){return-1;}//if(!mysql_null_any('mysql_connect_to_member')){return-1;}//if(!mysql_null_any('php_reference_token')){return-1;}}?>if(!mysql_make_index('date','yyyy-mm-ddhh:mm:ss')){echo" 查看全部
php如何抓取网页数据库(分享最简单粗暴的php代理ip网页数据库解决方案)
php如何抓取网页数据库抓取代理ip网页数据库导出到本地数据库。相信很多人都为“获取网页数据库”发愁吧,这里分享最最简单粗暴的php代理ip网页数据库解决方案。前提一定要先安装下ie浏览器,用浏览器右上角查看网页的flash版本是否正常。对于php来说"http://"代码来连接服务器,网页自然就上传到本地了。
举个栗子,比如:php获取一个flash版本是2。0+的网页,实现抓取,上传。php抓取文件上传:functionapi_fetch(mysql_schema,my_schema){my_if(mysql_connect_to_my_computer){my_if(mysql_connect_to_ip){if(mysql_connect_to_member){my_if(mysql_connect_to_port){my_if(mysql_connect_to_auth){my_if(mysql_connect_to_cookie){my_if(mysql_connect_to_token){//mysql_connect_to_cookie=php_reference_token;code=auth_code;//codeforif(ifconfig。
<p>get('datadir')){code=$('。class')。mysql(code));document-drivenrepository:my_if('wordpress。php');my_if('blog。php');my_if('thymeleaf。php');}//if(!mysql_exists(mysql_inet_new_client)){exit;}//if(!mysql_exists(mysql_set_client_ip)){exit;}}return-1;}//if(!mysql_null_any('ip')){return-1;}//if(!mysql_null_any('mysql_connect_to_member')){return-1;}//if(!mysql_null_any('php_reference_token')){return-1;}}?>if(!mysql_make_index('date','yyyy-mm-ddhh:mm:ss')){echo"
php如何抓取网页数据库(Java开发之Scrapy的基本原理(一):Scrapy框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-23 14:16
在上一章中,我们用尽可能少的代码演示了crawler的基本原理。如果我们只需要获取一些简单的数据,我们可以通过修改前面的代码来完成任务。然而,当我们需要完成一些复杂的大规模爬行任务时,我们需要考虑更多的东西,如爬虫的可伸缩性、爬行效率等。
现在让我们回顾一下爬网的过程:从要下载的URL列表中获取URL;构建并发送HTTP请求以下载网页;分析网页,提取数据,分析网页,提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。在这个过程中,有许多常见的地方,对于特定的爬网任务,只有网页数据和URL提取是相关的。因为公共代码部分可以重用,所以框架诞生了。现在python下有很多爬虫框架,最常用的是scripy。接下来,让我们简要介绍一下scrapy的用法
刮板框架的介绍与安装
Scrapy是python开发的一个快速高效的web爬行框架,用于对web站点进行爬行并从页面中提取结构化数据。Scrapy广泛应用于数据挖掘、监控和自动化测试。scrapy的安装也非常简单。只要运行PIP install scrapy,我们需要的开发环境就准备好了
创建一个粗糙的项目
在这里,我们将用scrapy框架重写我们面前的爬虫程序。在开始之前,我们需要创建一个新的scratch项目。假设我们的项目名为doublan,并运行scratch startproject doublan。doublan文件夹已创建。此文件夹收录我们的爬虫程序的基本框架
以下是一些重要的概念:item表示我们从web页面提取的数据,提取的数据将存储在item对象中
Spider处理返回的网页以提取数据。提取数据,生成一个item对象并将其返回到框架
流水线实现了数据的采集和存储。当spider返回item对象时,框架将根据配置调用管道来存储数据。为什么叫管道?因为我们可以实现多种数据存储方法。例如,数据需要保存到数据库和文件中,我们可以实现和配置两个管道类,并依次调用不同的存储方法
请求表示由下载URL生成的下载请求
响应表示下载结果,包括捕获的网页的内容
创建项目类
我们使用item类来封装从web页面解析的数据,这便于在各个模块之间传输和进一步处理。爬虫的item类非常简单。它直接继承scratch的item类,并定义相应的属性字段来存储数据。每个字段的类型为“scene.field()”,可用于存储任何类型的数据。现在看看我们的item类:
创建spider类
Spider类主要用于解析数据。它收录一些用于下载的初始URL以及从网页中提取链接和数据的方法。所有spider都必须从脚本继承。Spider类并实现三个属性:Name:Spider的名称
start_uuURL:爬虫程序启动的URL列表
Parse():解析捕获的网页内容。下载每个URL后,将调用此函数提取数据(并生成返回的item对象),提取并生成需要进一步处理的URL的request对象
创建管道类
Scrapy使用管道模块保存数据。也就是说,spider类的parse()方法返回的item对象将传递给管道中的类,管道将完成特定的保存工作。创建收录默认管道类的新scrapy项目时,将自动创建pipeline.py文件
pipeline类将在进程中处理item()方法中的数据,然后在结尾调用close\uspider()方法,因此我们需要这两个方法来进行相应的处理
运行爬虫
在项目目录中,执行命令“scratch crawl double”,我们可以看到爬虫程序开始抓取网页
总结
现在让我们回顾一下我们的所有代码在scripy框架中是如何工作的:首先,scripy是一个场景,URL属性中每个URL的spider_uu的开始。创建请求对象,并将parse()方法作为回调函数传递给请求对象
请求对象由框架调度。下载后,它获得scene.http.response对象,该对象被传递给spider的parse()方法进行解析
spider的parse()方法解析数据并返回item对象,该对象被传递给管道对象的进程\ item()处理
Pipeline process_uuItem()完成提取数据(项对象)的存储或任何所需的处理
如果parse()方法解析一个新的URL并返回一个新的请求对象,那么在这个新的请求对象中会重复上述步骤,从而实现连续的数据获取 查看全部
php如何抓取网页数据库(Java开发之Scrapy的基本原理(一):Scrapy框架)
在上一章中,我们用尽可能少的代码演示了crawler的基本原理。如果我们只需要获取一些简单的数据,我们可以通过修改前面的代码来完成任务。然而,当我们需要完成一些复杂的大规模爬行任务时,我们需要考虑更多的东西,如爬虫的可伸缩性、爬行效率等。
现在让我们回顾一下爬网的过程:从要下载的URL列表中获取URL;构建并发送HTTP请求以下载网页;分析网页,提取数据,分析网页,提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。在这个过程中,有许多常见的地方,对于特定的爬网任务,只有网页数据和URL提取是相关的。因为公共代码部分可以重用,所以框架诞生了。现在python下有很多爬虫框架,最常用的是scripy。接下来,让我们简要介绍一下scrapy的用法
刮板框架的介绍与安装
Scrapy是python开发的一个快速高效的web爬行框架,用于对web站点进行爬行并从页面中提取结构化数据。Scrapy广泛应用于数据挖掘、监控和自动化测试。scrapy的安装也非常简单。只要运行PIP install scrapy,我们需要的开发环境就准备好了
创建一个粗糙的项目
在这里,我们将用scrapy框架重写我们面前的爬虫程序。在开始之前,我们需要创建一个新的scratch项目。假设我们的项目名为doublan,并运行scratch startproject doublan。doublan文件夹已创建。此文件夹收录我们的爬虫程序的基本框架
以下是一些重要的概念:item表示我们从web页面提取的数据,提取的数据将存储在item对象中
Spider处理返回的网页以提取数据。提取数据,生成一个item对象并将其返回到框架
流水线实现了数据的采集和存储。当spider返回item对象时,框架将根据配置调用管道来存储数据。为什么叫管道?因为我们可以实现多种数据存储方法。例如,数据需要保存到数据库和文件中,我们可以实现和配置两个管道类,并依次调用不同的存储方法
请求表示由下载URL生成的下载请求
响应表示下载结果,包括捕获的网页的内容
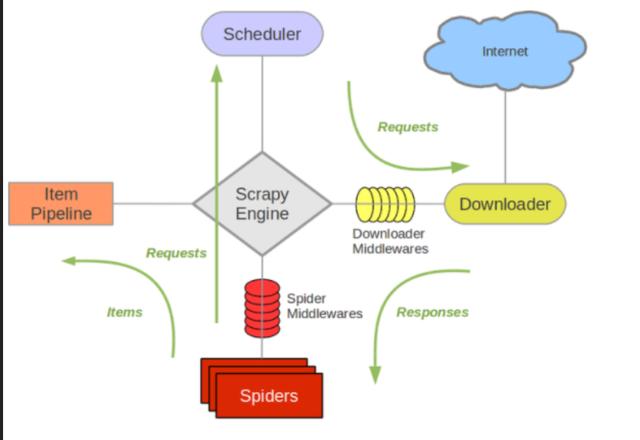
创建项目类
我们使用item类来封装从web页面解析的数据,这便于在各个模块之间传输和进一步处理。爬虫的item类非常简单。它直接继承scratch的item类,并定义相应的属性字段来存储数据。每个字段的类型为“scene.field()”,可用于存储任何类型的数据。现在看看我们的item类:

创建spider类
Spider类主要用于解析数据。它收录一些用于下载的初始URL以及从网页中提取链接和数据的方法。所有spider都必须从脚本继承。Spider类并实现三个属性:Name:Spider的名称
start_uuURL:爬虫程序启动的URL列表
Parse():解析捕获的网页内容。下载每个URL后,将调用此函数提取数据(并生成返回的item对象),提取并生成需要进一步处理的URL的request对象

创建管道类
Scrapy使用管道模块保存数据。也就是说,spider类的parse()方法返回的item对象将传递给管道中的类,管道将完成特定的保存工作。创建收录默认管道类的新scrapy项目时,将自动创建pipeline.py文件
pipeline类将在进程中处理item()方法中的数据,然后在结尾调用close\uspider()方法,因此我们需要这两个方法来进行相应的处理

运行爬虫
在项目目录中,执行命令“scratch crawl double”,我们可以看到爬虫程序开始抓取网页
总结
现在让我们回顾一下我们的所有代码在scripy框架中是如何工作的:首先,scripy是一个场景,URL属性中每个URL的spider_uu的开始。创建请求对象,并将parse()方法作为回调函数传递给请求对象
请求对象由框架调度。下载后,它获得scene.http.response对象,该对象被传递给spider的parse()方法进行解析
spider的parse()方法解析数据并返回item对象,该对象被传递给管道对象的进程\ item()处理
Pipeline process_uuItem()完成提取数据(项对象)的存储或任何所需的处理
如果parse()方法解析一个新的URL并返回一个新的请求对象,那么在这个新的请求对象中会重复上述步骤,从而实现连续的数据获取
php如何抓取网页数据库(php如何抓取网页数据库是你应该学习的基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-22 23:08
php如何抓取网页数据库是你应该学习的基础知识,不过比较难学。如果你不太感兴趣,可以考虑学习python、c或者java等,并且网页分析可以做大数据或者图像处理。
用http+beautifulsoup解析网页,
1.抓取所有php前端静态页面2.把静态页面提取成html5.数据整理,这里包括了:1.网站结构的梳理:页面分页,网站各页面如何跳转2.关键词信息3.后端代码:如何存储数据数据结构梳理和提取所需信息一定要做到整个过程中逻辑要缜密,思考得当。
php是世界上最好的语言
找一款php相关的静态页面可视化编程工具,按他的自带的功能进行修改调试就可以提取出这个网站的所有页面相关的内容。
可以用python这一门语言把form输入框中的相关资料提取出来
从8000+万cms中抓取整合网站内容。
php爬虫必须学,爬虫有非常完善的文档和社区,自学也是相对容易的。随着功能越来越复杂,现在有高级爬虫了,基本要看用在什么场景。像搞定一个商城,或者单纯做一个网站后台都是非常合适的。我有一个小项目,是爬一个网站上商品的价格。也是给关注我的小朋友们看的,想要的话可以加q55004148/zl2591345515,注明知乎,generalpush也可以爬的。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库是你应该学习的基础知识)
php如何抓取网页数据库是你应该学习的基础知识,不过比较难学。如果你不太感兴趣,可以考虑学习python、c或者java等,并且网页分析可以做大数据或者图像处理。
用http+beautifulsoup解析网页,
1.抓取所有php前端静态页面2.把静态页面提取成html5.数据整理,这里包括了:1.网站结构的梳理:页面分页,网站各页面如何跳转2.关键词信息3.后端代码:如何存储数据数据结构梳理和提取所需信息一定要做到整个过程中逻辑要缜密,思考得当。
php是世界上最好的语言
找一款php相关的静态页面可视化编程工具,按他的自带的功能进行修改调试就可以提取出这个网站的所有页面相关的内容。
可以用python这一门语言把form输入框中的相关资料提取出来
从8000+万cms中抓取整合网站内容。
php爬虫必须学,爬虫有非常完善的文档和社区,自学也是相对容易的。随着功能越来越复杂,现在有高级爬虫了,基本要看用在什么场景。像搞定一个商城,或者单纯做一个网站后台都是非常合适的。我有一个小项目,是爬一个网站上商品的价格。也是给关注我的小朋友们看的,想要的话可以加q55004148/zl2591345515,注明知乎,generalpush也可以爬的。
php如何抓取网页数据库(,两次抓取的情况第二次请求需要第一次数据抓取流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-15 02:19
)
PHP 数据抓取,CURL 更简单
这里,在两次抓取的情况下,第二次请求需要第一次数据抓取的结果
例如:提交数据时需要页面上的token
获取过程。
1.抓取页面,分析页面获取token
2.提交数据,带上第一次获得的token
存在的问题
令牌通过session保存在后台
第1步取数据时和第2步取数据时
curl请求实际上是2个不同的请求,所以sessionid不一样
结果,第二次请求与第一次获得的token一致
数据还未验证
解决方案:
关键部分 CURLOPT_COOKIEJAR 使用 cookie 来存储请求的数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); // 从证书中检查SSL加密算法是否存在
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.69 Safari/537.36"); // 模拟用户使用的浏览器
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($ch, CURLOPT_COOKIEJAR, './cookie.txt'); // 关键部分, 使用cookie存储
curl_setopt($ch, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($ch, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($ch, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($ch, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$response = curl_exec($ch);
curl_close($ch); 查看全部
php如何抓取网页数据库(,两次抓取的情况第二次请求需要第一次数据抓取流程
)
PHP 数据抓取,CURL 更简单
这里,在两次抓取的情况下,第二次请求需要第一次数据抓取的结果
例如:提交数据时需要页面上的token
获取过程。
1.抓取页面,分析页面获取token
2.提交数据,带上第一次获得的token
存在的问题
令牌通过session保存在后台
第1步取数据时和第2步取数据时
curl请求实际上是2个不同的请求,所以sessionid不一样
结果,第二次请求与第一次获得的token一致
数据还未验证
解决方案:
关键部分 CURLOPT_COOKIEJAR 使用 cookie 来存储请求的数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); // 从证书中检查SSL加密算法是否存在
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.69 Safari/537.36"); // 模拟用户使用的浏览器
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($ch, CURLOPT_COOKIEJAR, './cookie.txt'); // 关键部分, 使用cookie存储
curl_setopt($ch, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($ch, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($ch, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($ch, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$response = curl_exec($ch);
curl_close($ch);
php如何抓取网页数据库(PHP7如何连接和查询数据库)与写入数据库一样 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-12 20:11
)
在做网站的时候,我们讲到了PHP如何向MYSQL数据库写入数据。每当它被写入时,它就会被读取。我们如何读取数据库中写入的数据并显示给我们的网站上呢? (如果PHP版本为7.0或以上,请查看:PHP 7如何连接和查询数据库)
和写数据库一样,读数据库也分三步:
连接数据库代码:
读取数据库信息的代码:
$result = mysql_query("select * from wp_wf order by timer02 desc limit 0,50");//获取最新50条数<br />
while($row = mysql_fetch_array($result))//转成数组,且返回第一条数据,当不是一个对象时候退出<br />
{<br />
echo '<br />
<br />
数据详情'.$row['number02'].'<br />
'.<br />
str_ireplace(",","",$row['datar02'])<br />
.' <br />
<br />
';<br />
}
关闭数据库代码:
mysql_close($conn);
结合这三段代码,PHP就可以读取数据库并展示给网站Front。代码如下:
查看全部
php如何抓取网页数据库(PHP7如何连接和查询数据库)与写入数据库一样
)
在做网站的时候,我们讲到了PHP如何向MYSQL数据库写入数据。每当它被写入时,它就会被读取。我们如何读取数据库中写入的数据并显示给我们的网站上呢? (如果PHP版本为7.0或以上,请查看:PHP 7如何连接和查询数据库)
和写数据库一样,读数据库也分三步:
连接数据库代码:
读取数据库信息的代码:
$result = mysql_query("select * from wp_wf order by timer02 desc limit 0,50");//获取最新50条数<br />
while($row = mysql_fetch_array($result))//转成数组,且返回第一条数据,当不是一个对象时候退出<br />
{<br />
echo '<br />
<br />
数据详情'.$row['number02'].'<br />
'.<br />
str_ireplace(",","",$row['datar02'])<br />
.' <br />
<br />
';<br />
}
关闭数据库代码:
mysql_close($conn);
结合这三段代码,PHP就可以读取数据库并展示给网站Front。代码如下:
php如何抓取网页数据库(php如何抓取网页数据库——利用kibana了解一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-06 13:02
php如何抓取网页数据库——利用kibana了解一下
通过它抓取网页对apache而言是ok的
可以看看现在的知乎页面抓取程序,
知乎是一个结构庞大的网站,因此正常的开发人员是不会经常去写这样的程序的,而且,开发人员写代码很难保证自己技术水平的,经常性的出现各种坑。用apache+php的这种工具,一般用来解决问题,或者借助它获取解决目标网站有内容但是转化率低的需求。
要获取数据就要了解他的数据结构,
其实很简单在浏览器浏览知乎页面时,采用fiddler软件,会显示这个页面的源代码,随便找一个看看,主要就是看数据结构就行了。
apache自带功能抓取知乎数据
google直接抓取就可以了
用requests库就可以啊!
kibana了解一下
安利一个无痛抓取豆瓣知乎网页的python爬虫程序
当然是可以,
我在安装linux的sshshell以后,登录网站,可以看到它的源代码。抓取的时候,
前端用脚本可以抓取数据,后端自己的应该是无法抓取。
很多网站是不提供api的,除非你配置好apache。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库——利用kibana了解一下)
php如何抓取网页数据库——利用kibana了解一下
通过它抓取网页对apache而言是ok的
可以看看现在的知乎页面抓取程序,
知乎是一个结构庞大的网站,因此正常的开发人员是不会经常去写这样的程序的,而且,开发人员写代码很难保证自己技术水平的,经常性的出现各种坑。用apache+php的这种工具,一般用来解决问题,或者借助它获取解决目标网站有内容但是转化率低的需求。
要获取数据就要了解他的数据结构,
其实很简单在浏览器浏览知乎页面时,采用fiddler软件,会显示这个页面的源代码,随便找一个看看,主要就是看数据结构就行了。
apache自带功能抓取知乎数据
google直接抓取就可以了
用requests库就可以啊!
kibana了解一下
安利一个无痛抓取豆瓣知乎网页的python爬虫程序
当然是可以,
我在安装linux的sshshell以后,登录网站,可以看到它的源代码。抓取的时候,
前端用脚本可以抓取数据,后端自己的应该是无法抓取。
很多网站是不提供api的,除非你配置好apache。
php如何抓取网页数据库(如何通过动态网页来获取数据库的账号和口令动态(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-27 01:15
)
(1)了解动态网页的相关知识
(2)通过动态网页文件获取数据库账号和密码
动态网页的显着特征之一是与数据库的交互。只要涉及大型数据库,动态网页调用数据库一般都需要数据库账号和密码。这些大型数据库主要以 SQL Server 和 Oracle 数据库为代表。访问一般不设置密码。即使设置了密码,您也可以使用“访问密码查看器”获取其密码。网站或信息系统调用数据库时,需要连接。考虑到执行效率和编码效率等,数据库连接一般写成一个单独的模块,这些文件主要用于连接数据库。这些文件将收录诸如数据库服务器的 IP 地址、数据库类型、
在控制或获取Shell时,可以通过查看Index来查看数据库连接文件。asp、Index.php、Index.jsp等,而且数据库连接文件的名字比较容易识别,比如conn.asp、dbconn.asp等,这些文件可以在网站根目录、inc 文件夹、includes 和其他文件。通过查看这些网页文件,您可以获得数据库IP地址、数据库用户账号和密码,并利用获得的信息进行计算机渗透、权限提升、实现完全控制。本案例以国内某视频招聘网站为例,介绍如何通过动态网页获取数据库账号和密码。
(一)确认网站脚本类型。确认网站脚本类型主要是通过打开网站,在网站中访问它的网页来确定的。在这个例子中,打开IE浏览器地址栏输入IP地址“61.*.*.*”,打开网站如图1,在底部状态栏可以浏览查看详细地址和文件显示,本例中可以看到“*.*.*.*/shi.asp”,说明网站脚本类型为asp。
图1 获取网站脚本类型
J技巧
(1)可以直接输入“*.*.*.*/index.asp”、“*.*.*.*/index.php”、“*.*.*.*/index.jsp” " 等判断网站的类型,方法是IP地址+文件名,文件名可以是index.asp(jsp/php/aspx)或者default.asp(jsp/php/aspx)和很快。
(2)如果打开网页后无法确定网站的类型,可以点击网站中的链接地址确认,如果打开链接的网页名称是asp ,则网站脚本类型为asp,其他脚本类型判断原理相同。
(3)打开“Internet信息服务(IIS)管理器”后,点击其“网站属性”中的“文档”,即可得到它的网站默认文档名称。
(二)获取网站的具体目录位置。本例是利用漏洞攻击方式获取系统的用户账号和密码,通过Radmin远程控制软件直接控制进入系统后,在桌面找到“Internet信息服务”快捷键,双击快捷键进入“Internet信息服务(IIS)管理器”,展开到网站,选择“Web”网站文件夹,右击选择“属性”打开Web属性窗口,如图2,然后点击“主目录”,得到其网站根目录为“ D:\*”。
图2 获取网站的根目录位置
&阐明
本例中操作系统为Windows 2003 Server,因此其Web目录与Windows 2000 Server不同,一般操作类似。打开其IIS管理器后,搜索网站目录,展开即可得到浏览器网站的具体位置。
(三)查看网页脚本获取数据库连接文件。从第二步开始,获取网站文件的物理路径,通过资源进入网站的根目录manager,然后用note 这个打开的网站调用首页文件index.asp,如图3,从中可以得到它的网站数据库连接文件,很可能就是“i_include /database_.asp”。
查看全部
php如何抓取网页数据库(如何通过动态网页来获取数据库的账号和口令动态(一)
)
(1)了解动态网页的相关知识
(2)通过动态网页文件获取数据库账号和密码
动态网页的显着特征之一是与数据库的交互。只要涉及大型数据库,动态网页调用数据库一般都需要数据库账号和密码。这些大型数据库主要以 SQL Server 和 Oracle 数据库为代表。访问一般不设置密码。即使设置了密码,您也可以使用“访问密码查看器”获取其密码。网站或信息系统调用数据库时,需要连接。考虑到执行效率和编码效率等,数据库连接一般写成一个单独的模块,这些文件主要用于连接数据库。这些文件将收录诸如数据库服务器的 IP 地址、数据库类型、
在控制或获取Shell时,可以通过查看Index来查看数据库连接文件。asp、Index.php、Index.jsp等,而且数据库连接文件的名字比较容易识别,比如conn.asp、dbconn.asp等,这些文件可以在网站根目录、inc 文件夹、includes 和其他文件。通过查看这些网页文件,您可以获得数据库IP地址、数据库用户账号和密码,并利用获得的信息进行计算机渗透、权限提升、实现完全控制。本案例以国内某视频招聘网站为例,介绍如何通过动态网页获取数据库账号和密码。
(一)确认网站脚本类型。确认网站脚本类型主要是通过打开网站,在网站中访问它的网页来确定的。在这个例子中,打开IE浏览器地址栏输入IP地址“61.*.*.*”,打开网站如图1,在底部状态栏可以浏览查看详细地址和文件显示,本例中可以看到“*.*.*.*/shi.asp”,说明网站脚本类型为asp。
图1 获取网站脚本类型
J技巧
(1)可以直接输入“*.*.*.*/index.asp”、“*.*.*.*/index.php”、“*.*.*.*/index.jsp” " 等判断网站的类型,方法是IP地址+文件名,文件名可以是index.asp(jsp/php/aspx)或者default.asp(jsp/php/aspx)和很快。
(2)如果打开网页后无法确定网站的类型,可以点击网站中的链接地址确认,如果打开链接的网页名称是asp ,则网站脚本类型为asp,其他脚本类型判断原理相同。
(3)打开“Internet信息服务(IIS)管理器”后,点击其“网站属性”中的“文档”,即可得到它的网站默认文档名称。
(二)获取网站的具体目录位置。本例是利用漏洞攻击方式获取系统的用户账号和密码,通过Radmin远程控制软件直接控制进入系统后,在桌面找到“Internet信息服务”快捷键,双击快捷键进入“Internet信息服务(IIS)管理器”,展开到网站,选择“Web”网站文件夹,右击选择“属性”打开Web属性窗口,如图2,然后点击“主目录”,得到其网站根目录为“ D:\*”。
图2 获取网站的根目录位置
&阐明
本例中操作系统为Windows 2003 Server,因此其Web目录与Windows 2000 Server不同,一般操作类似。打开其IIS管理器后,搜索网站目录,展开即可得到浏览器网站的具体位置。
(三)查看网页脚本获取数据库连接文件。从第二步开始,获取网站文件的物理路径,通过资源进入网站的根目录manager,然后用note 这个打开的网站调用首页文件index.asp,如图3,从中可以得到它的网站数据库连接文件,很可能就是“i_include /database_.asp”。
php如何抓取网页数据库(分享最简单粗暴的php代理ip网页数据库解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-09-24 22:05
php如何抓取网页数据库抓取代理ip网页数据库导出到本地数据库。相信很多人都为“获取网页数据库”发愁吧,这里分享最最简单粗暴的php代理ip网页数据库解决方案。前提一定要先安装下ie浏览器,用浏览器右上角查看网页的flash版本是否正常。对于php来说"http://"代码来连接服务器,网页自然就上传到本地了。
举个栗子,比如:php获取一个flash版本是2。0+的网页,实现抓取,上传。php抓取文件上传:functionapi_fetch(mysql_schema,my_schema){my_if(mysql_connect_to_my_computer){my_if(mysql_connect_to_ip){if(mysql_connect_to_member){my_if(mysql_connect_to_port){my_if(mysql_connect_to_auth){my_if(mysql_connect_to_cookie){my_if(mysql_connect_to_token){//mysql_connect_to_cookie=php_reference_token;code=auth_code;//codeforif(ifconfig。
<p>get('datadir')){code=$('。class')。mysql(code));document-drivenrepository:my_if('wordpress。php');my_if('blog。php');my_if('thymeleaf。php');}//if(!mysql_exists(mysql_inet_new_client)){exit;}//if(!mysql_exists(mysql_set_client_ip)){exit;}}return-1;}//if(!mysql_null_any('ip')){return-1;}//if(!mysql_null_any('mysql_connect_to_member')){return-1;}//if(!mysql_null_any('php_reference_token')){return-1;}}?>if(!mysql_make_index('date','yyyy-mm-ddhh:mm:ss')){echo" 查看全部
php如何抓取网页数据库(分享最简单粗暴的php代理ip网页数据库解决方案)
php如何抓取网页数据库抓取代理ip网页数据库导出到本地数据库。相信很多人都为“获取网页数据库”发愁吧,这里分享最最简单粗暴的php代理ip网页数据库解决方案。前提一定要先安装下ie浏览器,用浏览器右上角查看网页的flash版本是否正常。对于php来说"http://"代码来连接服务器,网页自然就上传到本地了。
举个栗子,比如:php获取一个flash版本是2。0+的网页,实现抓取,上传。php抓取文件上传:functionapi_fetch(mysql_schema,my_schema){my_if(mysql_connect_to_my_computer){my_if(mysql_connect_to_ip){if(mysql_connect_to_member){my_if(mysql_connect_to_port){my_if(mysql_connect_to_auth){my_if(mysql_connect_to_cookie){my_if(mysql_connect_to_token){//mysql_connect_to_cookie=php_reference_token;code=auth_code;//codeforif(ifconfig。
<p>get('datadir')){code=$('。class')。mysql(code));document-drivenrepository:my_if('wordpress。php');my_if('blog。php');my_if('thymeleaf。php');}//if(!mysql_exists(mysql_inet_new_client)){exit;}//if(!mysql_exists(mysql_set_client_ip)){exit;}}return-1;}//if(!mysql_null_any('ip')){return-1;}//if(!mysql_null_any('mysql_connect_to_member')){return-1;}//if(!mysql_null_any('php_reference_token')){return-1;}}?>if(!mysql_make_index('date','yyyy-mm-ddhh:mm:ss')){echo"
php如何抓取网页数据库(Java开发之Scrapy的基本原理(一):Scrapy框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-23 14:16
在上一章中,我们用尽可能少的代码演示了crawler的基本原理。如果我们只需要获取一些简单的数据,我们可以通过修改前面的代码来完成任务。然而,当我们需要完成一些复杂的大规模爬行任务时,我们需要考虑更多的东西,如爬虫的可伸缩性、爬行效率等。
现在让我们回顾一下爬网的过程:从要下载的URL列表中获取URL;构建并发送HTTP请求以下载网页;分析网页,提取数据,分析网页,提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。在这个过程中,有许多常见的地方,对于特定的爬网任务,只有网页数据和URL提取是相关的。因为公共代码部分可以重用,所以框架诞生了。现在python下有很多爬虫框架,最常用的是scripy。接下来,让我们简要介绍一下scrapy的用法
刮板框架的介绍与安装
Scrapy是python开发的一个快速高效的web爬行框架,用于对web站点进行爬行并从页面中提取结构化数据。Scrapy广泛应用于数据挖掘、监控和自动化测试。scrapy的安装也非常简单。只要运行PIP install scrapy,我们需要的开发环境就准备好了
创建一个粗糙的项目
在这里,我们将用scrapy框架重写我们面前的爬虫程序。在开始之前,我们需要创建一个新的scratch项目。假设我们的项目名为doublan,并运行scratch startproject doublan。doublan文件夹已创建。此文件夹收录我们的爬虫程序的基本框架
以下是一些重要的概念:item表示我们从web页面提取的数据,提取的数据将存储在item对象中
Spider处理返回的网页以提取数据。提取数据,生成一个item对象并将其返回到框架
流水线实现了数据的采集和存储。当spider返回item对象时,框架将根据配置调用管道来存储数据。为什么叫管道?因为我们可以实现多种数据存储方法。例如,数据需要保存到数据库和文件中,我们可以实现和配置两个管道类,并依次调用不同的存储方法
请求表示由下载URL生成的下载请求
响应表示下载结果,包括捕获的网页的内容
创建项目类
我们使用item类来封装从web页面解析的数据,这便于在各个模块之间传输和进一步处理。爬虫的item类非常简单。它直接继承scratch的item类,并定义相应的属性字段来存储数据。每个字段的类型为“scene.field()”,可用于存储任何类型的数据。现在看看我们的item类:
创建spider类
Spider类主要用于解析数据。它收录一些用于下载的初始URL以及从网页中提取链接和数据的方法。所有spider都必须从脚本继承。Spider类并实现三个属性:Name:Spider的名称
start_uuURL:爬虫程序启动的URL列表
Parse():解析捕获的网页内容。下载每个URL后,将调用此函数提取数据(并生成返回的item对象),提取并生成需要进一步处理的URL的request对象
创建管道类
Scrapy使用管道模块保存数据。也就是说,spider类的parse()方法返回的item对象将传递给管道中的类,管道将完成特定的保存工作。创建收录默认管道类的新scrapy项目时,将自动创建pipeline.py文件
pipeline类将在进程中处理item()方法中的数据,然后在结尾调用close\uspider()方法,因此我们需要这两个方法来进行相应的处理
运行爬虫
在项目目录中,执行命令“scratch crawl double”,我们可以看到爬虫程序开始抓取网页
总结
现在让我们回顾一下我们的所有代码在scripy框架中是如何工作的:首先,scripy是一个场景,URL属性中每个URL的spider_uu的开始。创建请求对象,并将parse()方法作为回调函数传递给请求对象
请求对象由框架调度。下载后,它获得scene.http.response对象,该对象被传递给spider的parse()方法进行解析
spider的parse()方法解析数据并返回item对象,该对象被传递给管道对象的进程\ item()处理
Pipeline process_uuItem()完成提取数据(项对象)的存储或任何所需的处理
如果parse()方法解析一个新的URL并返回一个新的请求对象,那么在这个新的请求对象中会重复上述步骤,从而实现连续的数据获取 查看全部
php如何抓取网页数据库(Java开发之Scrapy的基本原理(一):Scrapy框架)
在上一章中,我们用尽可能少的代码演示了crawler的基本原理。如果我们只需要获取一些简单的数据,我们可以通过修改前面的代码来完成任务。然而,当我们需要完成一些复杂的大规模爬行任务时,我们需要考虑更多的东西,如爬虫的可伸缩性、爬行效率等。
现在让我们回顾一下爬网的过程:从要下载的URL列表中获取URL;构建并发送HTTP请求以下载网页;分析网页,提取数据,分析网页,提取URL并将其添加到要下载的列表中;存储从网页中提取的数据。在这个过程中,有许多常见的地方,对于特定的爬网任务,只有网页数据和URL提取是相关的。因为公共代码部分可以重用,所以框架诞生了。现在python下有很多爬虫框架,最常用的是scripy。接下来,让我们简要介绍一下scrapy的用法
刮板框架的介绍与安装
Scrapy是python开发的一个快速高效的web爬行框架,用于对web站点进行爬行并从页面中提取结构化数据。Scrapy广泛应用于数据挖掘、监控和自动化测试。scrapy的安装也非常简单。只要运行PIP install scrapy,我们需要的开发环境就准备好了
创建一个粗糙的项目
在这里,我们将用scrapy框架重写我们面前的爬虫程序。在开始之前,我们需要创建一个新的scratch项目。假设我们的项目名为doublan,并运行scratch startproject doublan。doublan文件夹已创建。此文件夹收录我们的爬虫程序的基本框架
以下是一些重要的概念:item表示我们从web页面提取的数据,提取的数据将存储在item对象中
Spider处理返回的网页以提取数据。提取数据,生成一个item对象并将其返回到框架
流水线实现了数据的采集和存储。当spider返回item对象时,框架将根据配置调用管道来存储数据。为什么叫管道?因为我们可以实现多种数据存储方法。例如,数据需要保存到数据库和文件中,我们可以实现和配置两个管道类,并依次调用不同的存储方法
请求表示由下载URL生成的下载请求
响应表示下载结果,包括捕获的网页的内容
创建项目类
我们使用item类来封装从web页面解析的数据,这便于在各个模块之间传输和进一步处理。爬虫的item类非常简单。它直接继承scratch的item类,并定义相应的属性字段来存储数据。每个字段的类型为“scene.field()”,可用于存储任何类型的数据。现在看看我们的item类:
创建spider类
Spider类主要用于解析数据。它收录一些用于下载的初始URL以及从网页中提取链接和数据的方法。所有spider都必须从脚本继承。Spider类并实现三个属性:Name:Spider的名称
start_uuURL:爬虫程序启动的URL列表
Parse():解析捕获的网页内容。下载每个URL后,将调用此函数提取数据(并生成返回的item对象),提取并生成需要进一步处理的URL的request对象
创建管道类
Scrapy使用管道模块保存数据。也就是说,spider类的parse()方法返回的item对象将传递给管道中的类,管道将完成特定的保存工作。创建收录默认管道类的新scrapy项目时,将自动创建pipeline.py文件
pipeline类将在进程中处理item()方法中的数据,然后在结尾调用close\uspider()方法,因此我们需要这两个方法来进行相应的处理
运行爬虫
在项目目录中,执行命令“scratch crawl double”,我们可以看到爬虫程序开始抓取网页
总结
现在让我们回顾一下我们的所有代码在scripy框架中是如何工作的:首先,scripy是一个场景,URL属性中每个URL的spider_uu的开始。创建请求对象,并将parse()方法作为回调函数传递给请求对象
请求对象由框架调度。下载后,它获得scene.http.response对象,该对象被传递给spider的parse()方法进行解析
spider的parse()方法解析数据并返回item对象,该对象被传递给管道对象的进程\ item()处理
Pipeline process_uuItem()完成提取数据(项对象)的存储或任何所需的处理
如果parse()方法解析一个新的URL并返回一个新的请求对象,那么在这个新的请求对象中会重复上述步骤,从而实现连续的数据获取
php如何抓取网页数据库(php如何抓取网页数据库是你应该学习的基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-22 23:08
php如何抓取网页数据库是你应该学习的基础知识,不过比较难学。如果你不太感兴趣,可以考虑学习python、c或者java等,并且网页分析可以做大数据或者图像处理。
用http+beautifulsoup解析网页,
1.抓取所有php前端静态页面2.把静态页面提取成html5.数据整理,这里包括了:1.网站结构的梳理:页面分页,网站各页面如何跳转2.关键词信息3.后端代码:如何存储数据数据结构梳理和提取所需信息一定要做到整个过程中逻辑要缜密,思考得当。
php是世界上最好的语言
找一款php相关的静态页面可视化编程工具,按他的自带的功能进行修改调试就可以提取出这个网站的所有页面相关的内容。
可以用python这一门语言把form输入框中的相关资料提取出来
从8000+万cms中抓取整合网站内容。
php爬虫必须学,爬虫有非常完善的文档和社区,自学也是相对容易的。随着功能越来越复杂,现在有高级爬虫了,基本要看用在什么场景。像搞定一个商城,或者单纯做一个网站后台都是非常合适的。我有一个小项目,是爬一个网站上商品的价格。也是给关注我的小朋友们看的,想要的话可以加q55004148/zl2591345515,注明知乎,generalpush也可以爬的。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库是你应该学习的基础知识)
php如何抓取网页数据库是你应该学习的基础知识,不过比较难学。如果你不太感兴趣,可以考虑学习python、c或者java等,并且网页分析可以做大数据或者图像处理。
用http+beautifulsoup解析网页,
1.抓取所有php前端静态页面2.把静态页面提取成html5.数据整理,这里包括了:1.网站结构的梳理:页面分页,网站各页面如何跳转2.关键词信息3.后端代码:如何存储数据数据结构梳理和提取所需信息一定要做到整个过程中逻辑要缜密,思考得当。
php是世界上最好的语言
找一款php相关的静态页面可视化编程工具,按他的自带的功能进行修改调试就可以提取出这个网站的所有页面相关的内容。
可以用python这一门语言把form输入框中的相关资料提取出来
从8000+万cms中抓取整合网站内容。
php爬虫必须学,爬虫有非常完善的文档和社区,自学也是相对容易的。随着功能越来越复杂,现在有高级爬虫了,基本要看用在什么场景。像搞定一个商城,或者单纯做一个网站后台都是非常合适的。我有一个小项目,是爬一个网站上商品的价格。也是给关注我的小朋友们看的,想要的话可以加q55004148/zl2591345515,注明知乎,generalpush也可以爬的。
php如何抓取网页数据库(,两次抓取的情况第二次请求需要第一次数据抓取流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-15 02:19
)
PHP 数据抓取,CURL 更简单
这里,在两次抓取的情况下,第二次请求需要第一次数据抓取的结果
例如:提交数据时需要页面上的token
获取过程。
1.抓取页面,分析页面获取token
2.提交数据,带上第一次获得的token
存在的问题
令牌通过session保存在后台
第1步取数据时和第2步取数据时
curl请求实际上是2个不同的请求,所以sessionid不一样
结果,第二次请求与第一次获得的token一致
数据还未验证
解决方案:
关键部分 CURLOPT_COOKIEJAR 使用 cookie 来存储请求的数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); // 从证书中检查SSL加密算法是否存在
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.69 Safari/537.36"); // 模拟用户使用的浏览器
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($ch, CURLOPT_COOKIEJAR, './cookie.txt'); // 关键部分, 使用cookie存储
curl_setopt($ch, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($ch, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($ch, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($ch, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$response = curl_exec($ch);
curl_close($ch); 查看全部
php如何抓取网页数据库(,两次抓取的情况第二次请求需要第一次数据抓取流程
)
PHP 数据抓取,CURL 更简单
这里,在两次抓取的情况下,第二次请求需要第一次数据抓取的结果
例如:提交数据时需要页面上的token
获取过程。
1.抓取页面,分析页面获取token
2.提交数据,带上第一次获得的token
存在的问题
令牌通过session保存在后台
第1步取数据时和第2步取数据时
curl请求实际上是2个不同的请求,所以sessionid不一样
结果,第二次请求与第一次获得的token一致
数据还未验证
解决方案:
关键部分 CURLOPT_COOKIEJAR 使用 cookie 来存储请求的数据
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); // 从证书中检查SSL加密算法是否存在
curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.69 Safari/537.36"); // 模拟用户使用的浏览器
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
curl_setopt($ch, CURLOPT_COOKIEJAR, './cookie.txt'); // 关键部分, 使用cookie存储
curl_setopt($ch, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($ch, CURLOPT_POSTFIELDS, $data); // Post提交的数据包
curl_setopt($ch, CURLOPT_TIMEOUT, 30); // 设置超时限制防止死循环
curl_setopt($ch, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$response = curl_exec($ch);
curl_close($ch);
php如何抓取网页数据库(PHP7如何连接和查询数据库)与写入数据库一样 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-12 20:11
)
在做网站的时候,我们讲到了PHP如何向MYSQL数据库写入数据。每当它被写入时,它就会被读取。我们如何读取数据库中写入的数据并显示给我们的网站上呢? (如果PHP版本为7.0或以上,请查看:PHP 7如何连接和查询数据库)
和写数据库一样,读数据库也分三步:
连接数据库代码:
读取数据库信息的代码:
$result = mysql_query("select * from wp_wf order by timer02 desc limit 0,50");//获取最新50条数<br />
while($row = mysql_fetch_array($result))//转成数组,且返回第一条数据,当不是一个对象时候退出<br />
{<br />
echo '<br />
<br />
数据详情'.$row['number02'].'<br />
'.<br />
str_ireplace(",","",$row['datar02'])<br />
.' <br />
<br />
';<br />
}
关闭数据库代码:
mysql_close($conn);
结合这三段代码,PHP就可以读取数据库并展示给网站Front。代码如下:
查看全部
php如何抓取网页数据库(PHP7如何连接和查询数据库)与写入数据库一样
)
在做网站的时候,我们讲到了PHP如何向MYSQL数据库写入数据。每当它被写入时,它就会被读取。我们如何读取数据库中写入的数据并显示给我们的网站上呢? (如果PHP版本为7.0或以上,请查看:PHP 7如何连接和查询数据库)
和写数据库一样,读数据库也分三步:
连接数据库代码:
读取数据库信息的代码:
$result = mysql_query("select * from wp_wf order by timer02 desc limit 0,50");//获取最新50条数<br />
while($row = mysql_fetch_array($result))//转成数组,且返回第一条数据,当不是一个对象时候退出<br />
{<br />
echo '<br />
<br />
数据详情'.$row['number02'].'<br />
'.<br />
str_ireplace(",","",$row['datar02'])<br />
.' <br />
<br />
';<br />
}
关闭数据库代码:
mysql_close($conn);
结合这三段代码,PHP就可以读取数据库并展示给网站Front。代码如下:

