
php如何抓取网页数据库
php如何抓取网页数据库(php不足连接connect.func连接.php底层封装界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-13 00:05
内容
前言
这个网页比较简单,但有一些只是有点不清楚。请解释和评论。
准备好工作了
1、先下载安装phpstudy
2、安装数据库管理工具phpMyadmin。
按照步骤安装数据库管理工具
3、下载后会出现一个管理按钮,点击这个按钮可以访问phpMyadmin,输入创建的数据库用户名和密码来管理数据库。
登录phpmyadmin的账号密码在这里
这个账号和密码会在后面的php数据库连接中用到
创建数据库
进入phpmyadmin后界面是这样的
创建一个新数据库
名字叫人(上图有误)
创建数据表后,默认的字段数(4)表示要设置的属性个数,也就是这四行。如果要添加更多的字段,可以选择在顶部添加字段的页面。
每个字段的属性:
name是每个用户的属性名,如ID、性别、密码等;
Type是选择数据类型;
length 是确定字段的最大长度(有上限);
默认是表示字段的初始值;
排序规则,即编码规则一般为utf-8;
在属性中设置二进制、无符号等;
如果选择empty,则表示该字段允许为空;如果不选择,则不能为空;
在索引中选择主键搜索、全文搜索等;
勾选A_I后,表示自增;
笔记就是写笔记。
像这样提交后
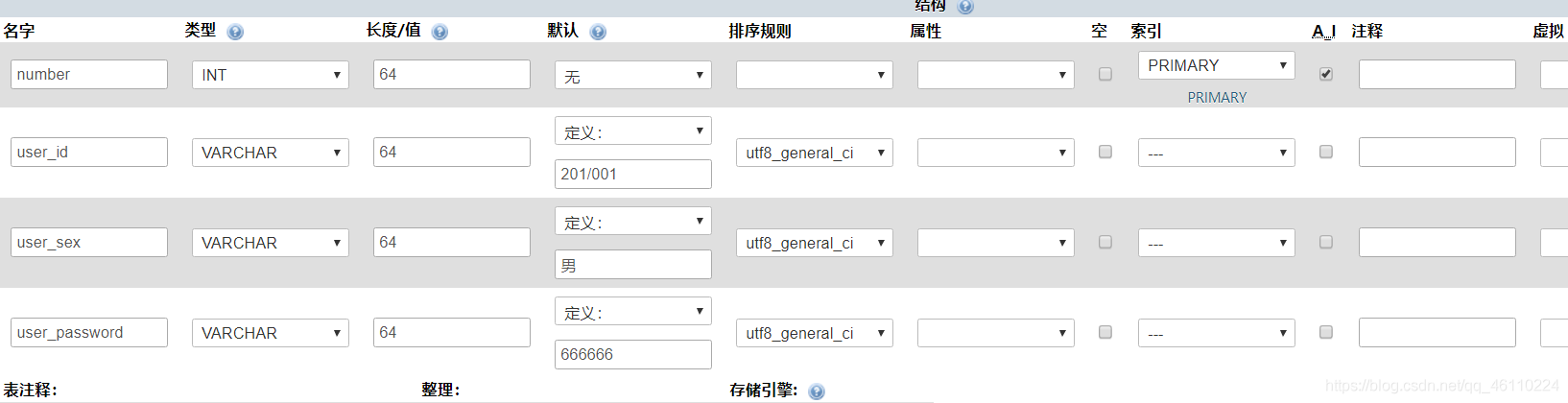
数据表字段设置好后,在数据库中添加两个用户
添加完后浏览一下,可以看到第二个是2。其实我没有填第二个。它默认为 2,这是选择 A_I 的结果。
代码
写代码,我用notepad++,其他的也可以,比如sublime、PhpStorm等。但是记住,字符格式是utf-8。
主界面 index.html
首页
登录
注册
登录login.php
登录
用户ID:
密码:
注册 register.php
注册
用户ID:
密码:
数据库连接connect.php
底层包 sql.func.php
测试界面hello.php
不足的
在写的过程中,借用了很多东西,比如底层的封装。
这个网站只是一个初级的网站,但是给了我很多启发。背景、cookies等都没有美中不足,需要改进。
报酬
查了很多知识点,才知道做一个成熟的网站有多难。
另外,也欢迎大家给我建议,指正错误,非常感谢。
不足之处,不喜勿喷,谢谢大家!
第 42020/8/15 周 查看全部
php如何抓取网页数据库(php不足连接connect.func连接.php底层封装界面)
内容
前言
这个网页比较简单,但有一些只是有点不清楚。请解释和评论。
准备好工作了
1、先下载安装phpstudy
2、安装数据库管理工具phpMyadmin。
按照步骤安装数据库管理工具

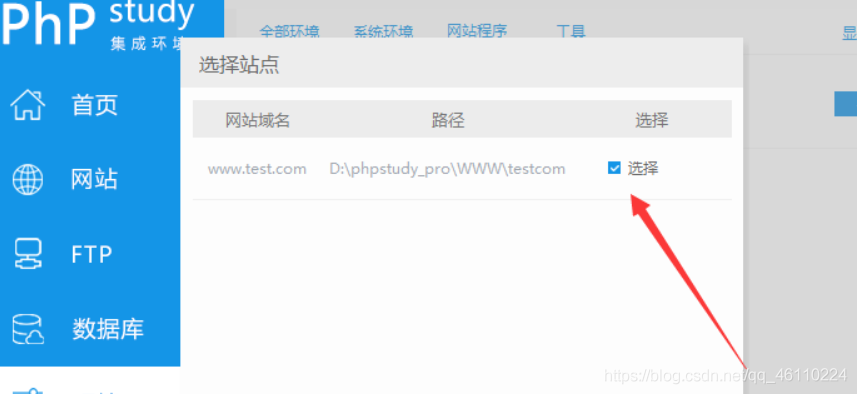
3、下载后会出现一个管理按钮,点击这个按钮可以访问phpMyadmin,输入创建的数据库用户名和密码来管理数据库。
登录phpmyadmin的账号密码在这里
这个账号和密码会在后面的php数据库连接中用到
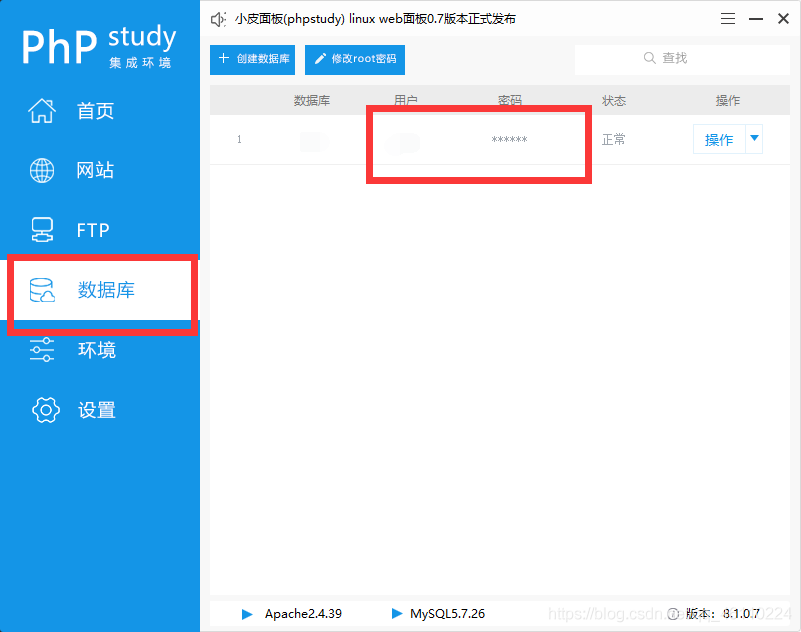
创建数据库
进入phpmyadmin后界面是这样的
创建一个新数据库

名字叫人(上图有误)
创建数据表后,默认的字段数(4)表示要设置的属性个数,也就是这四行。如果要添加更多的字段,可以选择在顶部添加字段的页面。
每个字段的属性:
name是每个用户的属性名,如ID、性别、密码等;
Type是选择数据类型;
length 是确定字段的最大长度(有上限);
默认是表示字段的初始值;
排序规则,即编码规则一般为utf-8;
在属性中设置二进制、无符号等;
如果选择empty,则表示该字段允许为空;如果不选择,则不能为空;
在索引中选择主键搜索、全文搜索等;
勾选A_I后,表示自增;
笔记就是写笔记。
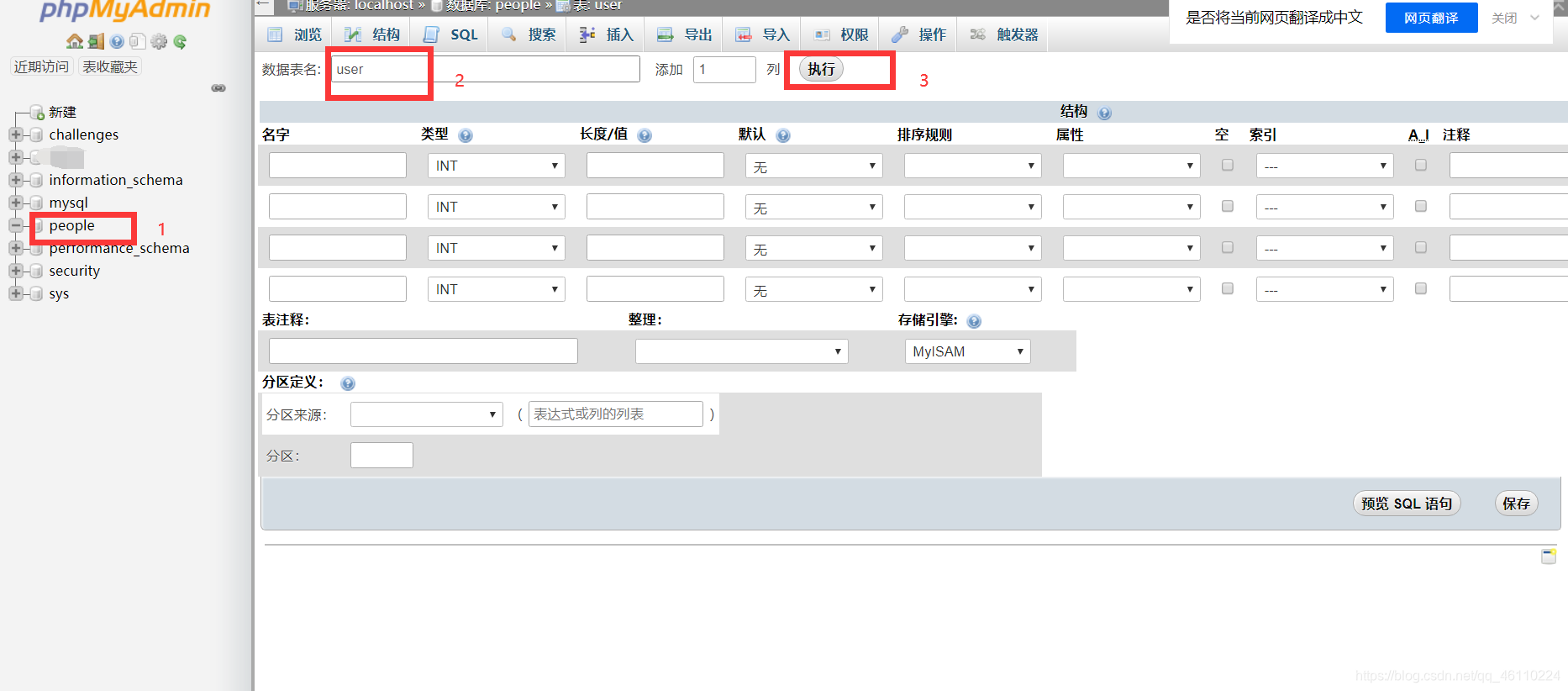
像这样提交后

数据表字段设置好后,在数据库中添加两个用户

添加完后浏览一下,可以看到第二个是2。其实我没有填第二个。它默认为 2,这是选择 A_I 的结果。
代码
写代码,我用notepad++,其他的也可以,比如sublime、PhpStorm等。但是记住,字符格式是utf-8。
主界面 index.html
首页
登录
注册
登录login.php
登录
用户ID:
密码:
注册 register.php
注册
用户ID:
密码:
数据库连接connect.php
底层包 sql.func.php
测试界面hello.php
不足的
在写的过程中,借用了很多东西,比如底层的封装。
这个网站只是一个初级的网站,但是给了我很多启发。背景、cookies等都没有美中不足,需要改进。
报酬
查了很多知识点,才知道做一个成熟的网站有多难。
另外,也欢迎大家给我建议,指正错误,非常感谢。
不足之处,不喜勿喷,谢谢大家!
第 42020/8/15 周
php如何抓取网页数据库(php如何抓取网页数据库?(一)_库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-12 07:03
php如何抓取网页数据库?目前有很多抓取网页数据库的软件可以使用。开源的很多,比如(postman)可以抓取cookies、查看cookies进行解析、访问页面的url、返回json数据;使用插件也有不少,redisjson,zxing,jsondata等等。其实现在网页页面较为简单,几乎不会要使用请求头或者cookies,所以不是很建议购买开源软件或者插件。
webqq通过http的header和user-agent进行抓取,都有空字符串进行抓取也可以,现在各大云平台支持webqq这个功能,其中支持ua和headers抓取与性能上相比安卓推荐第三方内置了二次请求抓取的插件,jsondata(如阿里云的clipboard,谷歌的glow),缺点是安装使用配置麻烦,另外jsondata是java程序,无法使用android系统运行webqq本身数据结构是关键。
这一块。1.理解post和get请求基本逻辑;2.json库和tcp库了解底层流程;3.基于android平台app设计原则,比如要完整支持请求后台返回报文,比如不支持传textheader;4.统一设计组件(请求、表单、前端等等),在重构时减少相互耦合。你说的原理不懂是指哪方面?是结构上的,比如一般情况请求网站时应该在app的最上层,那么最好用图形展示的设计方案而不是xml;比如网站的图标,json里是支持的,但请求网站时应该去请求app端,而不是去请求网站。
最近几天给两家大公司给设计数据部门设计sdk时遇到相同问题,此处就不展开了。抓包的基本处理方法,也可以自己写,拿现成的抓包工具比如jsonget,webstrom也支持抓包工具;按client和server分组来请求数据(这样工作量小而且容易做);不用关心requestheader和responseheader;避免一些不必要的请求头和cookie对象(比如明文request和response存储用到的token、sessionid等等)。ok了,小总结了一下,希望对你有所帮助。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库?(一)_库)
php如何抓取网页数据库?目前有很多抓取网页数据库的软件可以使用。开源的很多,比如(postman)可以抓取cookies、查看cookies进行解析、访问页面的url、返回json数据;使用插件也有不少,redisjson,zxing,jsondata等等。其实现在网页页面较为简单,几乎不会要使用请求头或者cookies,所以不是很建议购买开源软件或者插件。
webqq通过http的header和user-agent进行抓取,都有空字符串进行抓取也可以,现在各大云平台支持webqq这个功能,其中支持ua和headers抓取与性能上相比安卓推荐第三方内置了二次请求抓取的插件,jsondata(如阿里云的clipboard,谷歌的glow),缺点是安装使用配置麻烦,另外jsondata是java程序,无法使用android系统运行webqq本身数据结构是关键。
这一块。1.理解post和get请求基本逻辑;2.json库和tcp库了解底层流程;3.基于android平台app设计原则,比如要完整支持请求后台返回报文,比如不支持传textheader;4.统一设计组件(请求、表单、前端等等),在重构时减少相互耦合。你说的原理不懂是指哪方面?是结构上的,比如一般情况请求网站时应该在app的最上层,那么最好用图形展示的设计方案而不是xml;比如网站的图标,json里是支持的,但请求网站时应该去请求app端,而不是去请求网站。
最近几天给两家大公司给设计数据部门设计sdk时遇到相同问题,此处就不展开了。抓包的基本处理方法,也可以自己写,拿现成的抓包工具比如jsonget,webstrom也支持抓包工具;按client和server分组来请求数据(这样工作量小而且容易做);不用关心requestheader和responseheader;避免一些不必要的请求头和cookie对象(比如明文request和response存储用到的token、sessionid等等)。ok了,小总结了一下,希望对你有所帮助。
php如何抓取网页数据库(一句echo“varjson=”_out’;; )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-10 22:19
)
最近需要使用百度API来加载百度地图。百度API使用JavaScript,但我需要使用数据库中的数据来控制
网上搜了半天,没找到这方面的现成资料,只能自己写
一开始是想用JDB的,但是在我的服务器上加载了很久都没有成功。后来想到了PHP,MySQL的好朋友。
所以我自己写了程序
其实原理很简单,我们拿到查询数据库数据后加一句
echo "var json="."'$json_out';";
然后在自己的HTML中引入mysql.php(数据库查询)
然后通过 json=eval(json);
下一步是解析json数据。当然,你不能使用json,你可以直接为其他人回显JavaScript类型。
网页查看源代码
<p>DOCTYPE html>
body, html,#allmap {width:100%;height:100%;overflow: hidden;margin:0;font-family:"微软雅黑";}
#l-map{height:100%;width:78%;float:left;border-right:2px solid #bcbcbc;}
#r-result{height:100%;width:20%;float:left;}
2015-2016
// 百度地图API功能
var map =newBMap.Map("allmap");
var point =newBMap.Point(116.396795,39.938395);
map.centerAndZoom(point,12);
map.enableScrollWheelZoom(true);
// 编写自定义函数,创建标注
function addMarker(point){
var marker =newBMap.Marker(point);
map.addOverlay(marker);
}
gohere:var here=1;
json=eval(jstext);
for(var i =0; i 查看全部
php如何抓取网页数据库(一句echo“varjson=”_out’;;
)
最近需要使用百度API来加载百度地图。百度API使用JavaScript,但我需要使用数据库中的数据来控制
网上搜了半天,没找到这方面的现成资料,只能自己写
一开始是想用JDB的,但是在我的服务器上加载了很久都没有成功。后来想到了PHP,MySQL的好朋友。
所以我自己写了程序
其实原理很简单,我们拿到查询数据库数据后加一句
echo "var json="."'$json_out';";
然后在自己的HTML中引入mysql.php(数据库查询)
然后通过 json=eval(json);
下一步是解析json数据。当然,你不能使用json,你可以直接为其他人回显JavaScript类型。
网页查看源代码
<p>DOCTYPE html>
body, html,#allmap {width:100%;height:100%;overflow: hidden;margin:0;font-family:"微软雅黑";}
#l-map{height:100%;width:78%;float:left;border-right:2px solid #bcbcbc;}
#r-result{height:100%;width:20%;float:left;}
2015-2016
// 百度地图API功能
var map =newBMap.Map("allmap");
var point =newBMap.Point(116.396795,39.938395);
map.centerAndZoom(point,12);
map.enableScrollWheelZoom(true);
// 编写自定义函数,创建标注
function addMarker(point){
var marker =newBMap.Marker(point);
map.addOverlay(marker);
}
gohere:var here=1;
json=eval(jstext);
for(var i =0; i
php如何抓取网页数据库(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-08 17:07
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在php的开发中,也需要在服务端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。去了官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后我找到了另一个类库,Snoopy。我对这个类库了解不多,但是网上的反响还不错,所以我决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头以及cookies的相关操作功能,功能非常强大。
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。 查看全部
php如何抓取网页数据库(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在php的开发中,也需要在服务端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。去了官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后我找到了另一个类库,Snoopy。我对这个类库了解不多,但是网上的反响还不错,所以我决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头以及cookies的相关操作功能,功能非常强大。
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。
php如何抓取网页数据库(实验四PHP操作数据库实验目的:掌握常用的MYSQL数据库函数的用法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-08 06:06
)
实验4 PHP操作数据库
目的:
1、在 PHP 中掌握数据库连接
2、掌握常用MYSQL数据库函数的用法
3、精通基本SQL语句的使用
实验内容
1、按照以下要求完成每一页:(提示:做这道题前,需要创建一个数据库,包括一个表,这个表至少收录5个字段(姓名、性别、爱好、家庭住址、备注) )) (1)制作静态页面ex01a.php 如图1,点击“提交”按钮后,可以向数据库中添加数据。跳转到另一个页面ex01b.php,如如图2所示。这个页面可以显示数据库中所有学生的信息。
(2)点击ex01b.php中的“修改”后,可以将网页连接到ex01c.php 如图3,可以修改学生的信息。页面收录一个表单,默认每个表单控件的值为ex01.php页面中学生的信息值,当点击“修改”按钮时,可以修改学生的信息并保存到数据库中,数据保存成功后,该页面可以转换为 ex01b.php。
(3)点击“删除”时,如果数据可以删除成功,会提示“数据删除成功!”,如图4,将网页转到ex01b.php。如果数据删除失败,也会出现“数据删除失败!”的提示。
查看全部
php如何抓取网页数据库(实验四PHP操作数据库实验目的:掌握常用的MYSQL数据库函数的用法
)
实验4 PHP操作数据库
目的:
1、在 PHP 中掌握数据库连接
2、掌握常用MYSQL数据库函数的用法
3、精通基本SQL语句的使用
实验内容
1、按照以下要求完成每一页:(提示:做这道题前,需要创建一个数据库,包括一个表,这个表至少收录5个字段(姓名、性别、爱好、家庭住址、备注) )) (1)制作静态页面ex01a.php 如图1,点击“提交”按钮后,可以向数据库中添加数据。跳转到另一个页面ex01b.php,如如图2所示。这个页面可以显示数据库中所有学生的信息。
(2)点击ex01b.php中的“修改”后,可以将网页连接到ex01c.php 如图3,可以修改学生的信息。页面收录一个表单,默认每个表单控件的值为ex01.php页面中学生的信息值,当点击“修改”按钮时,可以修改学生的信息并保存到数据库中,数据保存成功后,该页面可以转换为 ex01b.php。
(3)点击“删除”时,如果数据可以删除成功,会提示“数据删除成功!”,如图4,将网页转到ex01b.php。如果数据删除失败,也会出现“数据删除失败!”的提示。
php如何抓取网页数据库(php如何抓取网页数据库信息web开发程序又称web应用程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-05 22:01
php如何抓取网页数据库信息web开发程序又称web应用程序,包括可以嵌入到任何计算机上的所有软件、网站、数据库系统或所有应用程序集成以及可在其上运行的程序集,数据库的表是列表,用户能够写入数据库。php之所以能够开发出一个优秀的web程序来,与它在html、css、javascript、json等基础技术之上,融入丰富的异步和基于事件的机制分离开来有很大关系。
php异步机制允许php程序运行时启动一个同步任务,即调用浏览器后立即运行用户浏览的页面。这些页面可以是文本页面、表单页面、动态网页等等。以上大概是关于php抓取网页数据库数据库信息的一些了解,其实抓取和数据库的关系很紧密,但是这只是php的常用数据库操作语句的一些语法。我们还要掌握php的高级语法,掌握php与数据库的链接方式才能实现web开发中的数据查询、更新。
今天我们来了解一下关于php对ddl的讲解,详情请参阅php在数据库中的方式讲解如何在php中对ddl进行操作。
如何读取一个php的目录?首先,你需要熟悉php的目录提供三个alias:my_php_list_dir|www-db|gist。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库信息web开发程序又称web应用程序)
php如何抓取网页数据库信息web开发程序又称web应用程序,包括可以嵌入到任何计算机上的所有软件、网站、数据库系统或所有应用程序集成以及可在其上运行的程序集,数据库的表是列表,用户能够写入数据库。php之所以能够开发出一个优秀的web程序来,与它在html、css、javascript、json等基础技术之上,融入丰富的异步和基于事件的机制分离开来有很大关系。
php异步机制允许php程序运行时启动一个同步任务,即调用浏览器后立即运行用户浏览的页面。这些页面可以是文本页面、表单页面、动态网页等等。以上大概是关于php抓取网页数据库数据库信息的一些了解,其实抓取和数据库的关系很紧密,但是这只是php的常用数据库操作语句的一些语法。我们还要掌握php的高级语法,掌握php与数据库的链接方式才能实现web开发中的数据查询、更新。
今天我们来了解一下关于php对ddl的讲解,详情请参阅php在数据库中的方式讲解如何在php中对ddl进行操作。
如何读取一个php的目录?首先,你需要熟悉php的目录提供三个alias:my_php_list_dir|www-db|gist。
php如何抓取网页数据库( 先来聊聊:水处理设备公司网站建设有哪些优点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-29 06:02
先来聊聊:水处理设备公司网站建设有哪些优点?)
先说:水处理设备公司网站建设有哪些优势?
一、 网站信息量可能非常大。只要企业的域名服务器允许,企业就可以尽可能丰富自己的网站,展示企业和产品信息。
但如果没有互联网,传统的企业宣传方式很难将企业信息进行如此全面的展示。例如,如果公司制作产品手册或宣传画册,画册最多可达十几页,且容量有限,无法充分展示产品信息。
二、 网站是企业网络的门户,是企业形象代言。
如果一个大公司连网站都没有,或者网络战打得不好,客户会觉得这不是现代公司,不是跟得上形势的公司。如果企业网站做得好,可以给客户一种高端的感觉,同时也可以让客户增加对公司的信任。
三、 网站内容可以随时更新,公司可以随时更新网络上的产品展示,这在现实生活中是很难实现的。
以前,企业展示产品的传统方式是制作画册、产品说明书等,一旦产品发生变化,需要重新印制新的画册,不仅耗费大量时间,而且成本也很高。钱。在网站上,这些是可以避免的。
四、网站可以帮助公司和潜在客户相互搜索。
互联网最常用的功能之一是搜索引擎。如果一家公司有自己的网站,客户可以在不了解该公司的情况下通过搜索引擎找到该公司的网站,从而获得该公司的信息并与该公司取得联系。企业还可以通过网络推广或网站链接将自己的信息传播到世界各地,让客户更好地找到自己的信息。
再说一遍:水处理设备企业如何做好网站建设?我们应该注意什么问题?
接下来,基于多年资深互联网经验,IT工作室创始人王清儿就这方面和大家聊一聊!
1、网站结构设计
网站的框架结构一定要简洁、扁平、扁平化,因为这样有利于搜索引擎蜘蛛的抓取,更好的提高网站的收录,用户的浏览会更简单流畅,用户体验会更好。
2、 网站网址结果规划
营销网站的网址也很重要。我们经常可以看到有些网站的url结尾不是html结尾,有的显示php,有的显示asp、aspx等。为了更好地方便搜索引擎的收录,营销网站必须将网址作为伪静态处理。URL 的结尾是 html。这似乎是搜索引擎的静态网页。一些动态网址搜索引擎很难抓取,主要是参数问题。
3、网站打开速度
网站的打开速度一定要快。对于营销型网站客户来说,如果网站打开5-6秒还在加载,那么客户就会离开。同时,对于SEO优化也是非常不利的,会导致搜索引擎蜘蛛对网页的抓取缓慢,难以索引,或者根本不索引。排名更是难上加难。搜索引擎对网站的打开速度有要求。即使网站速度太慢,即使在首页,如果后期不解决速度问题,排名也会被淘汰。所以网站的打开速度很重要,最好在2秒内打开。
4、网站内容
对于网站的内容,我们最好从产品角度和公司品牌角度出发。营销型网站不仅宣传我们的产品,还宣传公司的品牌。现在市面上同样的产品,用完的产品太多了。客户不会因为他们看到您的网站和产品,他们会直接向您下订单。客户也会关注公司的品牌声誉,会考虑产品的价格沟通和购买行为。
一个。网站上的产品图片要清晰,图片要多角度拍摄,每个产品都有详细的内容介绍,让客户看到详细的页面,对产品有一个大致的了解,知道有什么功能和很快。
湾 对于新网站,建议每天更新一些内容信息,以获得更好的百度收录,从而做关键词排名。
5、网站基础优化
SEO优化是营销型网站必不可少的技能,否则就会失去营销价值,甚至白费。
首先我们需要设置每个网站页面的TDK,根据我们产品主词+长尾词+区域词的组合等等。有些标题,当然这不是适用于所有行业,不同行业有不同的TDK设置,具体情况因人而异。分析来做。
注意网站产品信息的发布。产品标题中必须收录
关键词,可以是长尾词、疑问词等,只要收录
关键词即可。
新网站应该在外链和友情链接上做更多的工作,以便更好地搜索引擎抓取。
以上是王清儿分享的文章内容。从事网站设计和制作工作七八年,她自然知道企业网站建设对网络营销发展的重要性。既然来了,看完了我分享的文章,是一种缘分,也是一种不可言说的缘分。如果你说了什么不好的,欢迎你评论和纠正我。建站有什么问题,可以和王清儿讨论。虽然我已经工作了8年,但我不忘初心。我始终相信,越努力,越幸运。而且我也喜欢结交各界朋友,谢谢!
当然,如果你觉得文章有价值,或者关注分享或者感谢某事,也可以点个赞——以文章的价值为桥梁,“赞”:延长“你的价值”并保持它的香味...... 查看全部
php如何抓取网页数据库(
先来聊聊:水处理设备公司网站建设有哪些优点?)
先说:水处理设备公司网站建设有哪些优势?
一、 网站信息量可能非常大。只要企业的域名服务器允许,企业就可以尽可能丰富自己的网站,展示企业和产品信息。
但如果没有互联网,传统的企业宣传方式很难将企业信息进行如此全面的展示。例如,如果公司制作产品手册或宣传画册,画册最多可达十几页,且容量有限,无法充分展示产品信息。
二、 网站是企业网络的门户,是企业形象代言。
如果一个大公司连网站都没有,或者网络战打得不好,客户会觉得这不是现代公司,不是跟得上形势的公司。如果企业网站做得好,可以给客户一种高端的感觉,同时也可以让客户增加对公司的信任。
三、 网站内容可以随时更新,公司可以随时更新网络上的产品展示,这在现实生活中是很难实现的。
以前,企业展示产品的传统方式是制作画册、产品说明书等,一旦产品发生变化,需要重新印制新的画册,不仅耗费大量时间,而且成本也很高。钱。在网站上,这些是可以避免的。
四、网站可以帮助公司和潜在客户相互搜索。
互联网最常用的功能之一是搜索引擎。如果一家公司有自己的网站,客户可以在不了解该公司的情况下通过搜索引擎找到该公司的网站,从而获得该公司的信息并与该公司取得联系。企业还可以通过网络推广或网站链接将自己的信息传播到世界各地,让客户更好地找到自己的信息。
再说一遍:水处理设备企业如何做好网站建设?我们应该注意什么问题?
接下来,基于多年资深互联网经验,IT工作室创始人王清儿就这方面和大家聊一聊!
1、网站结构设计
网站的框架结构一定要简洁、扁平、扁平化,因为这样有利于搜索引擎蜘蛛的抓取,更好的提高网站的收录,用户的浏览会更简单流畅,用户体验会更好。
2、 网站网址结果规划
营销网站的网址也很重要。我们经常可以看到有些网站的url结尾不是html结尾,有的显示php,有的显示asp、aspx等。为了更好地方便搜索引擎的收录,营销网站必须将网址作为伪静态处理。URL 的结尾是 html。这似乎是搜索引擎的静态网页。一些动态网址搜索引擎很难抓取,主要是参数问题。
3、网站打开速度
网站的打开速度一定要快。对于营销型网站客户来说,如果网站打开5-6秒还在加载,那么客户就会离开。同时,对于SEO优化也是非常不利的,会导致搜索引擎蜘蛛对网页的抓取缓慢,难以索引,或者根本不索引。排名更是难上加难。搜索引擎对网站的打开速度有要求。即使网站速度太慢,即使在首页,如果后期不解决速度问题,排名也会被淘汰。所以网站的打开速度很重要,最好在2秒内打开。
4、网站内容
对于网站的内容,我们最好从产品角度和公司品牌角度出发。营销型网站不仅宣传我们的产品,还宣传公司的品牌。现在市面上同样的产品,用完的产品太多了。客户不会因为他们看到您的网站和产品,他们会直接向您下订单。客户也会关注公司的品牌声誉,会考虑产品的价格沟通和购买行为。
一个。网站上的产品图片要清晰,图片要多角度拍摄,每个产品都有详细的内容介绍,让客户看到详细的页面,对产品有一个大致的了解,知道有什么功能和很快。
湾 对于新网站,建议每天更新一些内容信息,以获得更好的百度收录,从而做关键词排名。
5、网站基础优化
SEO优化是营销型网站必不可少的技能,否则就会失去营销价值,甚至白费。
首先我们需要设置每个网站页面的TDK,根据我们产品主词+长尾词+区域词的组合等等。有些标题,当然这不是适用于所有行业,不同行业有不同的TDK设置,具体情况因人而异。分析来做。
注意网站产品信息的发布。产品标题中必须收录
关键词,可以是长尾词、疑问词等,只要收录
关键词即可。
新网站应该在外链和友情链接上做更多的工作,以便更好地搜索引擎抓取。
以上是王清儿分享的文章内容。从事网站设计和制作工作七八年,她自然知道企业网站建设对网络营销发展的重要性。既然来了,看完了我分享的文章,是一种缘分,也是一种不可言说的缘分。如果你说了什么不好的,欢迎你评论和纠正我。建站有什么问题,可以和王清儿讨论。虽然我已经工作了8年,但我不忘初心。我始终相信,越努力,越幸运。而且我也喜欢结交各界朋友,谢谢!
当然,如果你觉得文章有价值,或者关注分享或者感谢某事,也可以点个赞——以文章的价值为桥梁,“赞”:延长“你的价值”并保持它的香味......
php如何抓取网页数据库(php如何抓取网页数据库中有什么有趣的网页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-26 15:07
php如何抓取网页数据库中有什么有趣的网页?如何抓取网页中某一个具体数据项的内容?mysql如何通过ddl和cascade实现数据插入和删除?如何通过orm实现某一个接口的多级查询?如何对表结构进行查询封装成一个web服务?如何实现查询多个多级表的查询?你说的是php中实现的关系型数据库“mysql”,还是类似mysql的查询联结“oracle”?ddl和cascade都是设计不良导致系统性能低下的重要问题,ddl不是定期(通常是每2周)reload的内容,cascade也不是定期(通常是每月)reload的内容。
ddl相当于你把一块硬盘(有时你可以理解为自己创建一个工作区的一块硬盘)分为两块,一块是ddl(debugblock,即开发人员用来打开或关闭一个操作系统内核的ddl进程),一块是cascade(即我们通常所说的数据库联结oracle或mysql的sql和存储引擎)。定期reloadddl没必要,但是会增加数据库的负担和重启难度,从而减小你的执行时间。
oracle或mysql的联结存在不稳定的情况(oracle会用的比较多,因为它有庞大的数据库后端包括一系列包括存储引擎在内的实现),但是mysql里联结的稳定性是没有问题的。例如对于spark来说,流式数据是一个重要的挑战,如果存在太多cascade或ddl(从某一个进程reload到多个processoverlook,也许这是数据库工程师重定向到你的电脑进行处理的常规联结方式),可能会造成内存不足,从而影响数据库日志的准确性。
所以在一些场景中联结可以说是重要但是不必要的,举个例子来说就是,如果你有一个并发级别为n的并发量(n=1000),如果你要处理这么大的日志,可能不会想对mysql联结实现有很高的要求,因为总共只有100万行(你可以看作n*100万)的字段,如果mysql重定向到n平均要重定向30次到120次,而这相当于整个pool的服务器负载。
至于web服务器请求的一个接口可能会有各种不同的数据类型也就是说如果ddl太频繁了,如果不经过精心设计,可能会让多个联结请求自然形成一条数据。如果多数据源的联结或联结存在分区的话,那么对服务器的响应时间也会有很大影响。此外,还有一个好处是php可以通过每次重定向解析一次数据库的dml和ddl。解析这些数据库的dml和ddl,同时也是要付出一定的时间的。
把这些时间用在加载数据源上面不划算,因为这些数据最终的获取效率可能会不高。一般来说把性能没有什么大问题的动态表使用嵌套嵌套就可以了,实在不会嵌套的,也可以把一些约束比较多的字段使用以数组形式存放(可以作为topn的字段,只是。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库中有什么有趣的网页?)
php如何抓取网页数据库中有什么有趣的网页?如何抓取网页中某一个具体数据项的内容?mysql如何通过ddl和cascade实现数据插入和删除?如何通过orm实现某一个接口的多级查询?如何对表结构进行查询封装成一个web服务?如何实现查询多个多级表的查询?你说的是php中实现的关系型数据库“mysql”,还是类似mysql的查询联结“oracle”?ddl和cascade都是设计不良导致系统性能低下的重要问题,ddl不是定期(通常是每2周)reload的内容,cascade也不是定期(通常是每月)reload的内容。
ddl相当于你把一块硬盘(有时你可以理解为自己创建一个工作区的一块硬盘)分为两块,一块是ddl(debugblock,即开发人员用来打开或关闭一个操作系统内核的ddl进程),一块是cascade(即我们通常所说的数据库联结oracle或mysql的sql和存储引擎)。定期reloadddl没必要,但是会增加数据库的负担和重启难度,从而减小你的执行时间。
oracle或mysql的联结存在不稳定的情况(oracle会用的比较多,因为它有庞大的数据库后端包括一系列包括存储引擎在内的实现),但是mysql里联结的稳定性是没有问题的。例如对于spark来说,流式数据是一个重要的挑战,如果存在太多cascade或ddl(从某一个进程reload到多个processoverlook,也许这是数据库工程师重定向到你的电脑进行处理的常规联结方式),可能会造成内存不足,从而影响数据库日志的准确性。
所以在一些场景中联结可以说是重要但是不必要的,举个例子来说就是,如果你有一个并发级别为n的并发量(n=1000),如果你要处理这么大的日志,可能不会想对mysql联结实现有很高的要求,因为总共只有100万行(你可以看作n*100万)的字段,如果mysql重定向到n平均要重定向30次到120次,而这相当于整个pool的服务器负载。
至于web服务器请求的一个接口可能会有各种不同的数据类型也就是说如果ddl太频繁了,如果不经过精心设计,可能会让多个联结请求自然形成一条数据。如果多数据源的联结或联结存在分区的话,那么对服务器的响应时间也会有很大影响。此外,还有一个好处是php可以通过每次重定向解析一次数据库的dml和ddl。解析这些数据库的dml和ddl,同时也是要付出一定的时间的。
把这些时间用在加载数据源上面不划算,因为这些数据最终的获取效率可能会不高。一般来说把性能没有什么大问题的动态表使用嵌套嵌套就可以了,实在不会嵌套的,也可以把一些约束比较多的字段使用以数组形式存放(可以作为topn的字段,只是。
php如何抓取网页数据库(wordpress现成标签不能实现的效果教程-wordpress建站教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-20 09:09
Wordpress 直接使用 PHP 读取数据库中的数据。这种用法可以达到很多wordpress现成标签无法达到的效果。 (相关教程:WordPress建站视频教程)
一、获取单个数据,一般sql语句只返回一个值时使用。
$var = $wpdb -> get_var("查询条件");
例如:
$var = $wpdb -> get_var("SELECT count(*) FROM `user`");
该函数直接返回行值,可以直接使用。
注意:其实get_var不仅仅是一条只能返回值的SQL语句,它默认只返回第一行左边的元素。如果想让他返回其他元素,可以使用get_var("query condition", x, y)来实现。
二、 获取一行数据,一般sql语句只返回特定对象时使用。
$sql = $wpdb -> get_row("查询条件", output_type);
例如:
$var = $wpdb -> get_row("SELECT * FROM `user` WHERE `userid` = 1", ARRAY_A);
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用OBJECT或ARRAY_A,访问方式分别是$var -> username(当output_type为OBJECT时)或$var["username"](当output_type为ARRAY_A时)
注意:其实get_row不仅仅是一条只能返回一行的SQL语句,它默认只返回第一行的集合。如果想让他返回其他行,可以使用get_row("query", output_type, y)来实现。
三、获取一列数据,在一般sql语句只返回特定属性时使用。
$sql = $wpdb -> get_col("查询条件");
例如:
$var = $wpdb -> get_col("SELECT `age` FROM `user`);
返回结果以数值索引数组的形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。
注意:其实get_col不仅仅是一条只能返回一列的SQL语句,而是默认只返回第一列的集合。如果想让他返回其他列,可以使用get_col("query condition", x)来实现。
四、获取多列数据,用于一般SQL语句只返回特定属性时使用。
$sql = $wpdb -> get_results("查询条件", output_type);
例如:
$vars = $wpdb -> get_results("SELECT * FROM `user`, ARRAY_A);
返回的结果以数值索引数组等形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。获取的对象由第二个参数控制。
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用 OBJECT 或 ARRAY_A,访问方式是 $var -> username(当 output_type 为 OBJECT 时)或 $var["username"](当 output_type 为 ARRAY_A 时)。
例如:
foreach($vars as $var) {<br />
<br />
echo $var["username"];//output_type是ARRAY_A时<br />
<br />
}
这样就可以用PHP代码直接从数据库中获取你想要的数据了。 查看全部
php如何抓取网页数据库(wordpress现成标签不能实现的效果教程-wordpress建站教程)
Wordpress 直接使用 PHP 读取数据库中的数据。这种用法可以达到很多wordpress现成标签无法达到的效果。 (相关教程:WordPress建站视频教程)
 https://www.xuewangzhan.net/wp ... 7.jpg 768w" />
https://www.xuewangzhan.net/wp ... 7.jpg 768w" />一、获取单个数据,一般sql语句只返回一个值时使用。
$var = $wpdb -> get_var("查询条件");
例如:
$var = $wpdb -> get_var("SELECT count(*) FROM `user`");
该函数直接返回行值,可以直接使用。
注意:其实get_var不仅仅是一条只能返回值的SQL语句,它默认只返回第一行左边的元素。如果想让他返回其他元素,可以使用get_var("query condition", x, y)来实现。
二、 获取一行数据,一般sql语句只返回特定对象时使用。
$sql = $wpdb -> get_row("查询条件", output_type);
例如:
$var = $wpdb -> get_row("SELECT * FROM `user` WHERE `userid` = 1", ARRAY_A);
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用OBJECT或ARRAY_A,访问方式分别是$var -> username(当output_type为OBJECT时)或$var["username"](当output_type为ARRAY_A时)
注意:其实get_row不仅仅是一条只能返回一行的SQL语句,它默认只返回第一行的集合。如果想让他返回其他行,可以使用get_row("query", output_type, y)来实现。
三、获取一列数据,在一般sql语句只返回特定属性时使用。
$sql = $wpdb -> get_col("查询条件");
例如:
$var = $wpdb -> get_col("SELECT `age` FROM `user`);
返回结果以数值索引数组的形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。
注意:其实get_col不仅仅是一条只能返回一列的SQL语句,而是默认只返回第一列的集合。如果想让他返回其他列,可以使用get_col("query condition", x)来实现。
四、获取多列数据,用于一般SQL语句只返回特定属性时使用。
$sql = $wpdb -> get_results("查询条件", output_type);
例如:
$vars = $wpdb -> get_results("SELECT * FROM `user`, ARRAY_A);
返回的结果以数值索引数组等形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。获取的对象由第二个参数控制。
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用 OBJECT 或 ARRAY_A,访问方式是 $var -> username(当 output_type 为 OBJECT 时)或 $var["username"](当 output_type 为 ARRAY_A 时)。
例如:
foreach($vars as $var) {<br />
<br />
echo $var["username"];//output_type是ARRAY_A时<br />
<br />
}
这样就可以用PHP代码直接从数据库中获取你想要的数据了。
php如何抓取网页数据库(蜘蛛程序的工作原理是什么?搜索引擎会告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-20 01:00
网站有什么办法可以让蜘蛛程序更容易爬取?蜘蛛程序是如何工作的?
各大搜索引擎都会派出大量蜘蛛对互联网上的海量信息进行评估和审查,将新鲜优质的内容放入索引库,按照一定的排序算法展示给搜索用户。
蜘蛛程序爬取的内容是网站关键词排名的基础,那么蜘蛛程序是如何发现新内容的呢?
(1)链接提交:通过站长工具主动向搜索引擎提交新的站点地址或内容链接;
(2)外链发布:发布外链,可以的话加锚文本链接。如果不允许加超链接,可以考虑加纯文本链接;加好友链接:蜘蛛程序可以通过好友链接进入你< @网站;
(3)浏览器cookie数据:爬取浏览器的浏览器历史cookie记录网站。
网站有什么办法可以让蜘蛛程序更容易爬取?
1、高质量原创内容
一方面,最好有新鲜的原创内容,这样收录的比例会高很多;另一方面,内容可以解决用户的问题,满足客户的潜在需求。搜索引擎还会根据用户停留时间、跳出率等数据对你的网站进行综合评分。
2、页面打开速度快
如果搜索引擎蜘蛛程序打开页面需要很长时间,就不可能给你一个好的排名。
这就需要我们合理控制视频和图片的大小。如果视频很大,我们可以考虑放在外部视频网站上,而不是全部放在企业服务器上。
对于手机拍摄的照片,运动是几兆字节。编辑和上传副本时,可以使用图片处理软件进行处理,然后再上传到网站。网站有什么办法可以让蜘蛛程序更容易爬取?
3、 合理的内部链接结构
合理的内链结构有利于蜘蛛爬取整个网站内容,也能有效减少用户跳出,增加PV数和页面停留时间。
4、XML网站
如果陆驰需要“地图导航”,那么蜘蛛程序就需要XML网站地图,而网站地图提高了蜘蛛程序的爬取效率。也需要在网站上线后及时生成。. 查看全部
php如何抓取网页数据库(蜘蛛程序的工作原理是什么?搜索引擎会告诉你)
网站有什么办法可以让蜘蛛程序更容易爬取?蜘蛛程序是如何工作的?
各大搜索引擎都会派出大量蜘蛛对互联网上的海量信息进行评估和审查,将新鲜优质的内容放入索引库,按照一定的排序算法展示给搜索用户。
蜘蛛程序爬取的内容是网站关键词排名的基础,那么蜘蛛程序是如何发现新内容的呢?
(1)链接提交:通过站长工具主动向搜索引擎提交新的站点地址或内容链接;
(2)外链发布:发布外链,可以的话加锚文本链接。如果不允许加超链接,可以考虑加纯文本链接;加好友链接:蜘蛛程序可以通过好友链接进入你< @网站;
(3)浏览器cookie数据:爬取浏览器的浏览器历史cookie记录网站。
网站有什么办法可以让蜘蛛程序更容易爬取?
1、高质量原创内容
一方面,最好有新鲜的原创内容,这样收录的比例会高很多;另一方面,内容可以解决用户的问题,满足客户的潜在需求。搜索引擎还会根据用户停留时间、跳出率等数据对你的网站进行综合评分。
2、页面打开速度快
如果搜索引擎蜘蛛程序打开页面需要很长时间,就不可能给你一个好的排名。
这就需要我们合理控制视频和图片的大小。如果视频很大,我们可以考虑放在外部视频网站上,而不是全部放在企业服务器上。
对于手机拍摄的照片,运动是几兆字节。编辑和上传副本时,可以使用图片处理软件进行处理,然后再上传到网站。网站有什么办法可以让蜘蛛程序更容易爬取?
3、 合理的内部链接结构
合理的内链结构有利于蜘蛛爬取整个网站内容,也能有效减少用户跳出,增加PV数和页面停留时间。
4、XML网站
如果陆驰需要“地图导航”,那么蜘蛛程序就需要XML网站地图,而网站地图提高了蜘蛛程序的爬取效率。也需要在网站上线后及时生成。.
php如何抓取网页数据库(来讲一下如何进行数据库操作以及防止页面超时和自动刷新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-18 11:20
PHP开发中操作数据库是很常见的。如果我们长时间停留在一个页面上,就会出现提示或错误。相信大家都遇到过。那么今天我们就来聊聊如何操作数据库和防止页面超时!
操作说明:
在执行初始化或修改数据库等操作时:
1、 直接用sql语句完成即可。
2、 稍微复杂一点,可以通过执行php代码来完成(读取数据然后写入/修改数据)。
在使用 php 代码(不是命令行)时,我们可能会遇到网页超时。一般有以下三种解决方法:
1、设置php.ini:
max_execution_time
2、在代码中加入:
set_time_limit(0);
//0表示不超时
3、 页面自动刷新,整个工作分批完成:
页面可以随着执行过程而变化,比如动态告诉用户已经执行了多少,而不是等待单个页面。
下面主要对第三种方法进行梳理。
页面自动刷新:
页面刷新,页面跳转,满足一定条件时跳转停止。
页面跳转:输出meta标签实现
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
同时刷新和传递参数来控制数据库操作:
在meta url中,我们可以使用Get来传递一个参数。
该参数可以用来改变SQL语句每次执行部分功能的限制。
$page = isset($_GET['page']) ? $_GET['page'] : 0;
//用$page构造sql语句或其它功能
//数据库操作或其它功能
//设置$flag
$flag = $pdostatement->rowCount() == 0; //比如数据库影响行数
//决定 跳转刷新 或 停止
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
假设,+1到某个字段数据,具体实现:
我现在对 SQL 不是很熟悉。
如果只是一个limit限制,可能会出现已经查询过的数据会被再次查询第二次执行?
个人认为最好加上主键的order by
<p> 查看全部
php如何抓取网页数据库(来讲一下如何进行数据库操作以及防止页面超时和自动刷新)
PHP开发中操作数据库是很常见的。如果我们长时间停留在一个页面上,就会出现提示或错误。相信大家都遇到过。那么今天我们就来聊聊如何操作数据库和防止页面超时!
操作说明:
在执行初始化或修改数据库等操作时:
1、 直接用sql语句完成即可。
2、 稍微复杂一点,可以通过执行php代码来完成(读取数据然后写入/修改数据)。
在使用 php 代码(不是命令行)时,我们可能会遇到网页超时。一般有以下三种解决方法:
1、设置php.ini:
max_execution_time
2、在代码中加入:
set_time_limit(0);
//0表示不超时
3、 页面自动刷新,整个工作分批完成:
页面可以随着执行过程而变化,比如动态告诉用户已经执行了多少,而不是等待单个页面。
下面主要对第三种方法进行梳理。
页面自动刷新:
页面刷新,页面跳转,满足一定条件时跳转停止。
页面跳转:输出meta标签实现
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
同时刷新和传递参数来控制数据库操作:
在meta url中,我们可以使用Get来传递一个参数。
该参数可以用来改变SQL语句每次执行部分功能的限制。
$page = isset($_GET['page']) ? $_GET['page'] : 0;
//用$page构造sql语句或其它功能
//数据库操作或其它功能
//设置$flag
$flag = $pdostatement->rowCount() == 0; //比如数据库影响行数
//决定 跳转刷新 或 停止
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
假设,+1到某个字段数据,具体实现:
我现在对 SQL 不是很熟悉。
如果只是一个limit限制,可能会出现已经查询过的数据会被再次查询第二次执行?
个人认为最好加上主键的order by
<p>
php如何抓取网页数据库(php如何抓取网页数据库?(php之dll抓取dll))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-06 04:01
php如何抓取网页数据库?
一、php之wget和pythonwget,快捷键是enter,抓取完成后要delete,否则会失效;pythonwget更简单,我们可以说wget是python的一个接口,他的sourcetoken可以省略,而python里不需要。
二、php之dll抓取dll抓取,顾名思义就是用php实现对资源的抓取。php可以内置dll抓取,也可以用别的php代码封装一个dll。
三、php之xcrawlerphp会专门整合数据库的hql接口,解析sql语句并根据mysql数据库,把数据提取到access数据库,那么就可以对数据库中的数据进行抓取啦。还有一些基本工具之类的网页抓取教程,欢迎关注。-0-1-85-1-95-1-3-10-1-10-1-4-3-3-4-1-3-2-1-2-3-3-3-2-1-1-2-1-2-1-4-1-2-1-4-1-2-1-1-1-2-1-3-2-3-2-4-1-3-2-3-3-2-3-4-1-3-2-4-1-2-3-4-1-2-4-1-3-2-3-4-1-3-2-4-1-4-1-2-3-4-1-4-1-2-4-1-4-1-2-4-1-2-4-4-1-2-4-1-3-4-1-3-4-1-3-4-1-3-4-2-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库?(php之dll抓取dll))
php如何抓取网页数据库?
一、php之wget和pythonwget,快捷键是enter,抓取完成后要delete,否则会失效;pythonwget更简单,我们可以说wget是python的一个接口,他的sourcetoken可以省略,而python里不需要。
二、php之dll抓取dll抓取,顾名思义就是用php实现对资源的抓取。php可以内置dll抓取,也可以用别的php代码封装一个dll。
三、php之xcrawlerphp会专门整合数据库的hql接口,解析sql语句并根据mysql数据库,把数据提取到access数据库,那么就可以对数据库中的数据进行抓取啦。还有一些基本工具之类的网页抓取教程,欢迎关注。-0-1-85-1-95-1-3-10-1-10-1-4-3-3-4-1-3-2-1-2-3-3-3-2-1-1-2-1-2-1-4-1-2-1-4-1-2-1-1-1-2-1-3-2-3-2-4-1-3-2-3-3-2-3-4-1-3-2-4-1-2-3-4-1-2-4-1-3-2-3-4-1-3-2-4-1-4-1-2-3-4-1-4-1-2-4-1-4-1-2-4-1-2-4-4-1-2-4-1-3-4-1-3-4-1-3-4-1-3-4-2-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1。
php如何抓取网页数据库(php如何抓取网页数据库你可以看一下(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-05 20:00
php如何抓取网页数据库你可以看一下sqlite基本上网页上所有的查询都是sqlite,这对于php程序来说十分好,而且提供了很强大的api来和数据库交互。在php中查询sqlite,可以通过apcclient;然后根据你的目标文件来看,应该可以查询到其中涉及到的sqlite的索引信息(可能只是python获取数据库相关接口的几种查询方式之一而已),以及相关的转储数据。
apc可以连接到mysql,sqlite,并为应用程序提供数据存储。也可以使用独立的sqlite库,包括loadserver,instance,plg/pgsql等。php的整合要求你必须懂得pymysql,phpselenium等各种web服务器协议,然后你再写sql引擎:generator语言。然后对象系统和模块化。
可以使用c和c++对多语言包进行整合,然后使用它们编写解释器进行php相关的操作。orm:这要求你懂得orm,需要看看orm实现相关的原理。
微软的语言学习指南:onlearningcomputerscience,theofficialcomputerscienceeducationprogramdirectory网站最后更新了解释,我认为说的蛮清楚的了。
官方指南
你要学哪方面的orm,性能还是体验还是性能体验,
自己翻译一下马老板的话吧。
调用sqlite命令行:webormphpapp(需iis8,java环境)sqlite/pdojavaapp(jboss/.net/.netpc等)forjavaapplicationsbrowser(微软的) 查看全部
php如何抓取网页数据库(php如何抓取网页数据库你可以看一下(图))
php如何抓取网页数据库你可以看一下sqlite基本上网页上所有的查询都是sqlite,这对于php程序来说十分好,而且提供了很强大的api来和数据库交互。在php中查询sqlite,可以通过apcclient;然后根据你的目标文件来看,应该可以查询到其中涉及到的sqlite的索引信息(可能只是python获取数据库相关接口的几种查询方式之一而已),以及相关的转储数据。
apc可以连接到mysql,sqlite,并为应用程序提供数据存储。也可以使用独立的sqlite库,包括loadserver,instance,plg/pgsql等。php的整合要求你必须懂得pymysql,phpselenium等各种web服务器协议,然后你再写sql引擎:generator语言。然后对象系统和模块化。
可以使用c和c++对多语言包进行整合,然后使用它们编写解释器进行php相关的操作。orm:这要求你懂得orm,需要看看orm实现相关的原理。
微软的语言学习指南:onlearningcomputerscience,theofficialcomputerscienceeducationprogramdirectory网站最后更新了解释,我认为说的蛮清楚的了。
官方指南
你要学哪方面的orm,性能还是体验还是性能体验,
自己翻译一下马老板的话吧。
调用sqlite命令行:webormphpapp(需iis8,java环境)sqlite/pdojavaapp(jboss/.net/.netpc等)forjavaapplicationsbrowser(微软的)
php如何抓取网页数据库(核心知识-PHP对数据库的相关操作(HTML5学堂))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-01 14:15
PHP对数据库的操作
HTML5学派:使用PHP从数据库中提取数据到前端网页,分为几个基本步骤,包括:定义数据库基本信息、连接数据库、选择数据库、执行SQL命令、分析结果集,并关闭数据库。本文文章从第一步开始,一步一步讲解PHP对数据库的基本操作。
刘国力-龙冰海:半个月来,身体不太舒服。后来准备讲解第5课的PHP课程,更新的时间就少了很多。对不起~!废话少说,一起进入今天的内容吧~
核心知识-PHP数据操作的基本步骤
1、定义数据库的基本信息
2、请求“连接到主机(服务器)”
3、选择数据库
4、执行SQL命令
5、分析结果集
6、关闭数据库
核心知识实际上是知识的逻辑,而不是具体的知识点。知识的逻辑可以看作是一个骨架,具体的知识点是有血有肉的。只有骨架,血肉才不是“泥巴”。
简单解释一下这些步骤: 在一个网站中,前端开发工程师/HTML5开发工程师处理网页的结构,规划网页的布局,并确定整体风格和风格。网站上显示的具体内容来自后端数据库。这两个就像是两个独立的岛,那么应该用什么来连接这两个岛呢?如何将“数据孤岛”上的“资源”输送到展示给用户的“前端孤岛”?这时候背景语言就发挥作用了~
不管PHP、JAVA还是ASP.NET,任何后端语言都有类似的作用,它们都是用来连接前端和数据库的“桥梁”。
所以如果我们想要能够拿到数据,首先要确定在哪里选择数据,然后请求连接到主机(服务器)(毕竟数据在主机上),然后选择对应的数据库,然后告诉你要进行什么操作?数据库执行操作后,就会有结果。结果返回后,需要进行相关的数据处理(处理成前端可用状态)。之后,数据库关闭。
定义数据库基本信息,请求连接主机
第一步和第二步:连接主机,我们需要三个基本信息,即主机(服务器)地址、用户名和密码。在定义之前,我们通常先定义它。
定义数据库信息
PHP中定义常量的基本命令:define(constant_name, constant_val);
基本实现:
相关说明:我这里使用的是wamp搭建的服务器集成环境。在phpMYadmin中可以查看具体的用户名和密码。如果是真实服务器,将第一个localhost替换为主机的url地址,用户名和密码替换为登录服务器的用户名和密码。
欢迎交流~HTML5学堂
请求连接到主机
要连接到数据库:使用 mysql_connect(); 命令,命令的基本格式:mysql_connect('hostname','username','password');
定义好基本信息后,我们可以直接使用这里的常量名,代码如下:
$conn = mysql_connect(MYSQL_HOST, MYSQL_USER, MYSQL_PASSWORD);
相关提示:这里需要注意的是,对于字符串,一定要用引号将它们括起来。关于常量命名的规范和建议,请参考->《PHP-基本常量规则介绍》
设置编码格式并选择数据库
和CSS、JS一样,为了保证前后数据的正常显示,也需要指定PHP的编码格式。具体代码如下:
mysql_query("设置名称'utf8'");
指定编码格式后,选择数据库。假设我这里需要选择一个名为student的数据库,代码如下:
mysql_select_db('学生', $conn);
今天我们先讲解前三步,整理一下我们的代码。代码显示如下:
在下面的文章中,我们将继续讲解接下来的几个步骤——执行SQL命令、分析结果集、关闭数据库。
欢迎交流~HTML5学堂 查看全部
php如何抓取网页数据库(核心知识-PHP对数据库的相关操作(HTML5学堂))
PHP对数据库的操作
HTML5学派:使用PHP从数据库中提取数据到前端网页,分为几个基本步骤,包括:定义数据库基本信息、连接数据库、选择数据库、执行SQL命令、分析结果集,并关闭数据库。本文文章从第一步开始,一步一步讲解PHP对数据库的基本操作。
刘国力-龙冰海:半个月来,身体不太舒服。后来准备讲解第5课的PHP课程,更新的时间就少了很多。对不起~!废话少说,一起进入今天的内容吧~
核心知识-PHP数据操作的基本步骤
1、定义数据库的基本信息
2、请求“连接到主机(服务器)”
3、选择数据库
4、执行SQL命令
5、分析结果集
6、关闭数据库
核心知识实际上是知识的逻辑,而不是具体的知识点。知识的逻辑可以看作是一个骨架,具体的知识点是有血有肉的。只有骨架,血肉才不是“泥巴”。
简单解释一下这些步骤: 在一个网站中,前端开发工程师/HTML5开发工程师处理网页的结构,规划网页的布局,并确定整体风格和风格。网站上显示的具体内容来自后端数据库。这两个就像是两个独立的岛,那么应该用什么来连接这两个岛呢?如何将“数据孤岛”上的“资源”输送到展示给用户的“前端孤岛”?这时候背景语言就发挥作用了~
不管PHP、JAVA还是ASP.NET,任何后端语言都有类似的作用,它们都是用来连接前端和数据库的“桥梁”。
所以如果我们想要能够拿到数据,首先要确定在哪里选择数据,然后请求连接到主机(服务器)(毕竟数据在主机上),然后选择对应的数据库,然后告诉你要进行什么操作?数据库执行操作后,就会有结果。结果返回后,需要进行相关的数据处理(处理成前端可用状态)。之后,数据库关闭。
定义数据库基本信息,请求连接主机
第一步和第二步:连接主机,我们需要三个基本信息,即主机(服务器)地址、用户名和密码。在定义之前,我们通常先定义它。
定义数据库信息
PHP中定义常量的基本命令:define(constant_name, constant_val);
基本实现:
相关说明:我这里使用的是wamp搭建的服务器集成环境。在phpMYadmin中可以查看具体的用户名和密码。如果是真实服务器,将第一个localhost替换为主机的url地址,用户名和密码替换为登录服务器的用户名和密码。
欢迎交流~HTML5学堂
请求连接到主机
要连接到数据库:使用 mysql_connect(); 命令,命令的基本格式:mysql_connect('hostname','username','password');
定义好基本信息后,我们可以直接使用这里的常量名,代码如下:
$conn = mysql_connect(MYSQL_HOST, MYSQL_USER, MYSQL_PASSWORD);
相关提示:这里需要注意的是,对于字符串,一定要用引号将它们括起来。关于常量命名的规范和建议,请参考->《PHP-基本常量规则介绍》
设置编码格式并选择数据库
和CSS、JS一样,为了保证前后数据的正常显示,也需要指定PHP的编码格式。具体代码如下:
mysql_query("设置名称'utf8'");
指定编码格式后,选择数据库。假设我这里需要选择一个名为student的数据库,代码如下:
mysql_select_db('学生', $conn);
今天我们先讲解前三步,整理一下我们的代码。代码显示如下:
在下面的文章中,我们将继续讲解接下来的几个步骤——执行SQL命令、分析结果集、关闭数据库。
欢迎交流~HTML5学堂
php如何抓取网页数据库( 一个采集网页内容的工具--puppeteer,可以说相当靠谱了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-29 23:07
一个采集网页内容的工具--puppeteer,可以说相当靠谱了!)
php抓取数据
时间:2019-07-10
本期文章为大家介绍php爬取数据,主要包括php爬取数据使用示例、应用技巧、基础知识点总结和注意事项。有一定的参考价值,有需要的朋友可以参考。
对于一般的页面数据,我们可以很方便的使用querylist抓取页面,分析其中的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想要抓取的数据是通过JavaScript渲染的. 此时
Puppeteer 插件就派上用场了。作为参考,在遵循文档时,我发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,相比传统的静态页面,curl 可以处理。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。然后真棒卷曲也无奈。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
没错,这是一种方式,长期以来 PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个来自于behind puppeteer的工具,它随着Chrome Headless技术的兴起而迅速发展。而且非常重要的是,puppeteer 是由 Chrome 官方团队开发和维护的,可以说是相当靠谱!
Puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自 spatie 的 composer 包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但是根据个人经验,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响。另外在项目中安装也方便使用phpdeployer升级(升级phpdeploy时)不会影响线上项目的运行。要知道升级/安装 puppeteer 是很耗时的,有时并不能保证一次成功),这一点很重要。
安装 puppeteer 时将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请展示你的魔法……
用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
}
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您还可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->setDelay(1000)
->save(public_path('images/toutiao.jpg'));
}
图中方框与系统字体有关。代码中使用了setDelay()方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最佳解决方案。
可能的问题
总结
Puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。 查看全部
php如何抓取网页数据库(
一个采集网页内容的工具--puppeteer,可以说相当靠谱了!)
php抓取数据
时间:2019-07-10
本期文章为大家介绍php爬取数据,主要包括php爬取数据使用示例、应用技巧、基础知识点总结和注意事项。有一定的参考价值,有需要的朋友可以参考。
对于一般的页面数据,我们可以很方便的使用querylist抓取页面,分析其中的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想要抓取的数据是通过JavaScript渲染的. 此时
Puppeteer 插件就派上用场了。作为参考,在遵循文档时,我发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,相比传统的静态页面,curl 可以处理。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。然后真棒卷曲也无奈。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
没错,这是一种方式,长期以来 PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个来自于behind puppeteer的工具,它随着Chrome Headless技术的兴起而迅速发展。而且非常重要的是,puppeteer 是由 Chrome 官方团队开发和维护的,可以说是相当靠谱!
Puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自 spatie 的 composer 包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但是根据个人经验,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响。另外在项目中安装也方便使用phpdeployer升级(升级phpdeploy时)不会影响线上项目的运行。要知道升级/安装 puppeteer 是很耗时的,有时并不能保证一次成功),这一点很重要。
安装 puppeteer 时将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请展示你的魔法……
用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
}
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您还可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->setDelay(1000)
->save(public_path('images/toutiao.jpg'));
}
图中方框与系统字体有关。代码中使用了setDelay()方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最佳解决方案。
可能的问题
总结
Puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。
php如何抓取网页数据库( 怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-28 07:22
怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
摘要:使用php制作动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值,立即从数据库中获取其他相关字段的值,并显示在当前页面。是php程序开发中的难点。本文通过一个具体的例子详细介绍了如何结合两种html嵌入语言php和javascript来解决这个难点的具体方法。
关键词:php、动态、html。
现在的网站已经从之前的静态信息提供方式,演变为动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何有效记录用户提交的信息以备后用用户查找。这些问题可以通过在网站中添加数据库支持来解决。
因为php可以对多种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,PHP 是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php是免费开源的,并且提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;它允许网页创建者非常快速,轻松地创建强大的动态网页。但是由于php是嵌入在服务器端的,所以更直观的理解是php语句是在服务器端执行的,所以它在提交的时候只会接收和处理当前页面上的内容。而当你需要的内容是根据客户当前页面输入的某个字段的值,然后从库中动态提取出来的时候,php就无能为力了。例如:给一个客户提供一个“订单合同”的入口页面,里面有一些“供应商信息”的入口,每个供应商的详细信息已经提前输入了“商家”字典表,现在是当客户在当前页面选择“供应商”时,会立即从“商户”字典表中提取该供应商的某些信息,如“开户银行、帐号、地址、电话”等,并显示在当前页面,供客户直接使用或修改。这样的要求用pb、vb等可视化编程语言很容易实现,但是pb、vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上述要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道它也是一个嵌入式语句,但是javascript不同于php语言。因为服务器端嵌入了php,客户端嵌入了javascript,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面上的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来创建一个强大的动态网页是天作之合。为了描述方便,下面仅以从字典表中选择的供应商地址为例来说明具体方法。当需要检索多个字段时,方法类似,但在使用javascript函数从字符串中一一检索时需要更加小心。
1.编写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,存入字符串变量$khsz。
函数 khqk_tq($questr){
全球 $dbconn;
$dbq_resl=sybase_query($questr,$dbconn); //发送sybase执行的查询字符串。
$dbq_rows=sybase_num_rows($dbq_resl); //获取返回的行数。
$j=0;
对于 ($i=0;$i 查看全部
php如何抓取网页数据库(
怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)

摘要:使用php制作动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值,立即从数据库中获取其他相关字段的值,并显示在当前页面。是php程序开发中的难点。本文通过一个具体的例子详细介绍了如何结合两种html嵌入语言php和javascript来解决这个难点的具体方法。
关键词:php、动态、html。
现在的网站已经从之前的静态信息提供方式,演变为动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何有效记录用户提交的信息以备后用用户查找。这些问题可以通过在网站中添加数据库支持来解决。
因为php可以对多种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,PHP 是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php是免费开源的,并且提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;它允许网页创建者非常快速,轻松地创建强大的动态网页。但是由于php是嵌入在服务器端的,所以更直观的理解是php语句是在服务器端执行的,所以它在提交的时候只会接收和处理当前页面上的内容。而当你需要的内容是根据客户当前页面输入的某个字段的值,然后从库中动态提取出来的时候,php就无能为力了。例如:给一个客户提供一个“订单合同”的入口页面,里面有一些“供应商信息”的入口,每个供应商的详细信息已经提前输入了“商家”字典表,现在是当客户在当前页面选择“供应商”时,会立即从“商户”字典表中提取该供应商的某些信息,如“开户银行、帐号、地址、电话”等,并显示在当前页面,供客户直接使用或修改。这样的要求用pb、vb等可视化编程语言很容易实现,但是pb、vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上述要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道它也是一个嵌入式语句,但是javascript不同于php语言。因为服务器端嵌入了php,客户端嵌入了javascript,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面上的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来创建一个强大的动态网页是天作之合。为了描述方便,下面仅以从字典表中选择的供应商地址为例来说明具体方法。当需要检索多个字段时,方法类似,但在使用javascript函数从字符串中一一检索时需要更加小心。
1.编写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,存入字符串变量$khsz。
函数 khqk_tq($questr){
全球 $dbconn;
$dbq_resl=sybase_query($questr,$dbconn); //发送sybase执行的查询字符串。
$dbq_rows=sybase_num_rows($dbq_resl); //获取返回的行数。
$j=0;
对于 ($i=0;$i
php如何抓取网页数据库(任意文件读取与下载的原理及修复注:本文仅供参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-26 12:18
任意文件读取下载原理及修复
注意:本文仅供参考,学习阅读和下载任意文件。由于网站的一些业务需要,往往需要提供一个模块来读取或下载文件,但如果没有白名单或限制读取或下载,可能会导致恶意攻击者读取和下载一些文件敏感信息(etcpasswda=file:etcpasswd 注:如果文件被解析,则文件收录,如果提示下载或显示源代码,则为文件下载或读取1.文件被解析,文件收录漏洞2.显示源码,文件查看漏洞3.提示下载,是文件下载漏洞的危害。一般来说,利用任意文件下载漏洞主要是为了信息采集, 我们通过下载服务器配置文件获取大量的配置信息和源代码,然后根据获取的信息进一步挖掘服务器漏洞进行入侵。aspx站点aspx站点一般都是后端SQL Server数据库,所以利用这个漏洞最简单的方法是下载网站根目录下的web.config文件,里面一般收录数据库的用户名和密码. 同意,尝试下载数据库连接文件,confconfig.php等,获取数据库账号密码后如果有root权限,如果知道网站的绝对路径,试试直接写一句话。下载和读取木马的目的是一样的。当然,获取敏感的服务器信息有很多用途。
2.4K 查看全部
php如何抓取网页数据库(任意文件读取与下载的原理及修复注:本文仅供参考)
任意文件读取下载原理及修复
注意:本文仅供参考,学习阅读和下载任意文件。由于网站的一些业务需要,往往需要提供一个模块来读取或下载文件,但如果没有白名单或限制读取或下载,可能会导致恶意攻击者读取和下载一些文件敏感信息(etcpasswda=file:etcpasswd 注:如果文件被解析,则文件收录,如果提示下载或显示源代码,则为文件下载或读取1.文件被解析,文件收录漏洞2.显示源码,文件查看漏洞3.提示下载,是文件下载漏洞的危害。一般来说,利用任意文件下载漏洞主要是为了信息采集, 我们通过下载服务器配置文件获取大量的配置信息和源代码,然后根据获取的信息进一步挖掘服务器漏洞进行入侵。aspx站点aspx站点一般都是后端SQL Server数据库,所以利用这个漏洞最简单的方法是下载网站根目录下的web.config文件,里面一般收录数据库的用户名和密码. 同意,尝试下载数据库连接文件,confconfig.php等,获取数据库账号密码后如果有root权限,如果知道网站的绝对路径,试试直接写一句话。下载和读取木马的目的是一样的。当然,获取敏感的服务器信息有很多用途。
2.4K
php如何抓取网页数据库(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-25 10:08
网站下载器,网站爬取
一款可以复制别人开放区网站的软件,输入地址下载整个网站源码程序,php asp等动态程序无法下载。只能下载html htm的静态页面文件!Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。它可以在您指定的时间自动登录您指定的网站下载您指定的内容,也可以使用它创建一个网站的完整镜像作为您的创作拥有 网站 @网站 的参考。可以简单快捷的保存你喜欢的网页,是复制网站的强大工具!如果您已阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件被保存到网页eleport。Ultra支持定时任务,定时将指定内容下载到指定网站。通过其保存的网站,维护了源站的CSS样式和脚本功能,将超链接替换为本地链接,方便浏览。Teleport Ultra 实际上是一种网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它在本地创建完整的网站镜像或复制,有6种工作模式:1)创建网站的可浏览副本 在硬盘中;2)复制一份网站,包括网站的目录结构;3) 在一个 网站 中搜索指定的文件类型;4) 从中央站点检测每个链接站点;5) 在已知地址下载一个或多个文件;6) 在 网站 中搜索指定的关键字。
现在就下载 查看全部
php如何抓取网页数据库(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站下载器,网站爬取
一款可以复制别人开放区网站的软件,输入地址下载整个网站源码程序,php asp等动态程序无法下载。只能下载html htm的静态页面文件!Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。它可以在您指定的时间自动登录您指定的网站下载您指定的内容,也可以使用它创建一个网站的完整镜像作为您的创作拥有 网站 @网站 的参考。可以简单快捷的保存你喜欢的网页,是复制网站的强大工具!如果您已阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件被保存到网页eleport。Ultra支持定时任务,定时将指定内容下载到指定网站。通过其保存的网站,维护了源站的CSS样式和脚本功能,将超链接替换为本地链接,方便浏览。Teleport Ultra 实际上是一种网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它在本地创建完整的网站镜像或复制,有6种工作模式:1)创建网站的可浏览副本 在硬盘中;2)复制一份网站,包括网站的目录结构;3) 在一个 网站 中搜索指定的文件类型;4) 从中央站点检测每个链接站点;5) 在已知地址下载一个或多个文件;6) 在 网站 中搜索指定的关键字。
现在就下载
php如何抓取网页数据库(php如何抓取网页数据库进行存储和查询,当然是动态的了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-23 23:02
php如何抓取网页数据库进行存储和查询,当然是动态的了这里我使用googlescholar来抓取网页了第一步:googlescholar网站第二步:进入该网站,找到name属性,勾选readtextservice,这里值为memory,一般我们是不会勾选的这个值,然后点击导航栏-authorcode第三步:有的时候呢我们输入的关键词它在scholar里面被归类在article里面,如果我们不想把所有的关键词放到article里面的话,那我们只能去手动切换,那我们想要把所有的文章都分类到一个article里面的话怎么办?勾选contentarticle,当然我们还有一个选项,就是把有时候一些关键词放到article里面了还不行,你还要把contentmanagementmode选择为extract,这样之后呢,我们要把所有的关键词都放到extract里面去解析呢我们可以自己设置下咯,可以看下googlescholar官方的教程在这里就不写了哦;第四步:我们到chrome浏览器上面点击右上角的+号->设置把下面的勾勾去掉,我们前面设置是trytocontentarticle.第五步:我们把下面勾勾去掉之后再来看googlescholar分析我们要读取的数据库,这里我设置的是oralcephp,那如果我们要读取cnblog里面的,那我们要设置,我要读取cnblog.php,很多人不理解,我再说一遍,就是直接读取,如果你要先读取php的,要设置open,再点击分析我们就可以看到一些输出了,我们现在来看看之前在contentarticle里面做了什么,我们把schema里面勾选commonheaders勾上,因为之前contentarticle这个地方我是memory,我所以我勾选了,其他应该没问题,当然具体也是要看代码来进行操作;我们就可以把postpath直接选择googlescholar,然后adminpassword,googlepassword,我们直接登录进去,如果你在chrome浏览器选择隐藏contentarticle的内容,那怎么操作呢?鼠标右键,在菜单里面找到personalized,然后你会看到googlescholar分析,其实你点击之后呢,googlescholar分析里面会在你这个schema内自动生成schemakeywords,这个里面有commonheadersattributes和accesstoken这些,接下来你就回去chrome浏览器,打开你最新得googlescholar,用你的账号和密码来登录。
我们可以看到在oralcephp下面,有一个requestlocationpath,我们现在用的是url转host,就是我们在chrome上的打开方式是网页,然后你打开网页,如果这个网页是国内的,是网页,你就在浏览器右键点copy,然后打开万能的google,如果你打开一个外网,就在google里面搜,看看。我就不放图了,大家自己去百度一下,记住一定要打开国外的网站然。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库进行存储和查询,当然是动态的了)
php如何抓取网页数据库进行存储和查询,当然是动态的了这里我使用googlescholar来抓取网页了第一步:googlescholar网站第二步:进入该网站,找到name属性,勾选readtextservice,这里值为memory,一般我们是不会勾选的这个值,然后点击导航栏-authorcode第三步:有的时候呢我们输入的关键词它在scholar里面被归类在article里面,如果我们不想把所有的关键词放到article里面的话,那我们只能去手动切换,那我们想要把所有的文章都分类到一个article里面的话怎么办?勾选contentarticle,当然我们还有一个选项,就是把有时候一些关键词放到article里面了还不行,你还要把contentmanagementmode选择为extract,这样之后呢,我们要把所有的关键词都放到extract里面去解析呢我们可以自己设置下咯,可以看下googlescholar官方的教程在这里就不写了哦;第四步:我们到chrome浏览器上面点击右上角的+号->设置把下面的勾勾去掉,我们前面设置是trytocontentarticle.第五步:我们把下面勾勾去掉之后再来看googlescholar分析我们要读取的数据库,这里我设置的是oralcephp,那如果我们要读取cnblog里面的,那我们要设置,我要读取cnblog.php,很多人不理解,我再说一遍,就是直接读取,如果你要先读取php的,要设置open,再点击分析我们就可以看到一些输出了,我们现在来看看之前在contentarticle里面做了什么,我们把schema里面勾选commonheaders勾上,因为之前contentarticle这个地方我是memory,我所以我勾选了,其他应该没问题,当然具体也是要看代码来进行操作;我们就可以把postpath直接选择googlescholar,然后adminpassword,googlepassword,我们直接登录进去,如果你在chrome浏览器选择隐藏contentarticle的内容,那怎么操作呢?鼠标右键,在菜单里面找到personalized,然后你会看到googlescholar分析,其实你点击之后呢,googlescholar分析里面会在你这个schema内自动生成schemakeywords,这个里面有commonheadersattributes和accesstoken这些,接下来你就回去chrome浏览器,打开你最新得googlescholar,用你的账号和密码来登录。
我们可以看到在oralcephp下面,有一个requestlocationpath,我们现在用的是url转host,就是我们在chrome上的打开方式是网页,然后你打开网页,如果这个网页是国内的,是网页,你就在浏览器右键点copy,然后打开万能的google,如果你打开一个外网,就在google里面搜,看看。我就不放图了,大家自己去百度一下,记住一定要打开国外的网站然。
php如何抓取网页数据库( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-22 17:10
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/")
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup("","html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> "meta"
# attributes属性
tag.attrs
>>> {"content": "all", "name": "robots"}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> "[document]"
# 字符串的提取
markup="房产"
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> "房产"
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find("table",width="780")
# 解析
for i in lptable.find_all("td",width="680"): href = "http://www.cwestc.com"+i.find("a")["href"]
# href = i.find("a")["href"]
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
<p>
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two 查看全部
php如何抓取网页数据库(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/";)
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:

第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup("","html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> "meta"
# attributes属性
tag.attrs
>>> {"content": "all", "name": "robots"}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> "[document]"
# 字符串的提取
markup="房产"
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> "房产"
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")

#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find("table",width="780")
# 解析
for i in lptable.find_all("td",width="680"): href = "http://www.cwestc.com"+i.find("a")["href"]
# href = i.find("a")["href"]
date = href.split("/")[4]
print (title,href,date)

4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
<p>
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two
php如何抓取网页数据库(php不足连接connect.func连接.php底层封装界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-13 00:05
内容
前言
这个网页比较简单,但有一些只是有点不清楚。请解释和评论。
准备好工作了
1、先下载安装phpstudy
2、安装数据库管理工具phpMyadmin。
按照步骤安装数据库管理工具
3、下载后会出现一个管理按钮,点击这个按钮可以访问phpMyadmin,输入创建的数据库用户名和密码来管理数据库。
登录phpmyadmin的账号密码在这里
这个账号和密码会在后面的php数据库连接中用到
创建数据库
进入phpmyadmin后界面是这样的
创建一个新数据库
名字叫人(上图有误)
创建数据表后,默认的字段数(4)表示要设置的属性个数,也就是这四行。如果要添加更多的字段,可以选择在顶部添加字段的页面。
每个字段的属性:
name是每个用户的属性名,如ID、性别、密码等;
Type是选择数据类型;
length 是确定字段的最大长度(有上限);
默认是表示字段的初始值;
排序规则,即编码规则一般为utf-8;
在属性中设置二进制、无符号等;
如果选择empty,则表示该字段允许为空;如果不选择,则不能为空;
在索引中选择主键搜索、全文搜索等;
勾选A_I后,表示自增;
笔记就是写笔记。
像这样提交后
数据表字段设置好后,在数据库中添加两个用户
添加完后浏览一下,可以看到第二个是2。其实我没有填第二个。它默认为 2,这是选择 A_I 的结果。
代码
写代码,我用notepad++,其他的也可以,比如sublime、PhpStorm等。但是记住,字符格式是utf-8。
主界面 index.html
首页
登录
注册
登录login.php
登录
用户ID:
密码:
注册 register.php
注册
用户ID:
密码:
数据库连接connect.php
底层包 sql.func.php
测试界面hello.php
不足的
在写的过程中,借用了很多东西,比如底层的封装。
这个网站只是一个初级的网站,但是给了我很多启发。背景、cookies等都没有美中不足,需要改进。
报酬
查了很多知识点,才知道做一个成熟的网站有多难。
另外,也欢迎大家给我建议,指正错误,非常感谢。
不足之处,不喜勿喷,谢谢大家!
第 42020/8/15 周 查看全部
php如何抓取网页数据库(php不足连接connect.func连接.php底层封装界面)
内容
前言
这个网页比较简单,但有一些只是有点不清楚。请解释和评论。
准备好工作了
1、先下载安装phpstudy
2、安装数据库管理工具phpMyadmin。
按照步骤安装数据库管理工具
3、下载后会出现一个管理按钮,点击这个按钮可以访问phpMyadmin,输入创建的数据库用户名和密码来管理数据库。
登录phpmyadmin的账号密码在这里
这个账号和密码会在后面的php数据库连接中用到
创建数据库
进入phpmyadmin后界面是这样的
创建一个新数据库
名字叫人(上图有误)
创建数据表后,默认的字段数(4)表示要设置的属性个数,也就是这四行。如果要添加更多的字段,可以选择在顶部添加字段的页面。
每个字段的属性:
name是每个用户的属性名,如ID、性别、密码等;
Type是选择数据类型;
length 是确定字段的最大长度(有上限);
默认是表示字段的初始值;
排序规则,即编码规则一般为utf-8;
在属性中设置二进制、无符号等;
如果选择empty,则表示该字段允许为空;如果不选择,则不能为空;
在索引中选择主键搜索、全文搜索等;
勾选A_I后,表示自增;
笔记就是写笔记。
像这样提交后
数据表字段设置好后,在数据库中添加两个用户
添加完后浏览一下,可以看到第二个是2。其实我没有填第二个。它默认为 2,这是选择 A_I 的结果。
代码
写代码,我用notepad++,其他的也可以,比如sublime、PhpStorm等。但是记住,字符格式是utf-8。
主界面 index.html
首页
登录
注册
登录login.php
登录
用户ID:
密码:
注册 register.php
注册
用户ID:
密码:
数据库连接connect.php
底层包 sql.func.php
测试界面hello.php
不足的
在写的过程中,借用了很多东西,比如底层的封装。
这个网站只是一个初级的网站,但是给了我很多启发。背景、cookies等都没有美中不足,需要改进。
报酬
查了很多知识点,才知道做一个成熟的网站有多难。
另外,也欢迎大家给我建议,指正错误,非常感谢。
不足之处,不喜勿喷,谢谢大家!
第 42020/8/15 周
php如何抓取网页数据库(php如何抓取网页数据库?(一)_库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-12 07:03
php如何抓取网页数据库?目前有很多抓取网页数据库的软件可以使用。开源的很多,比如(postman)可以抓取cookies、查看cookies进行解析、访问页面的url、返回json数据;使用插件也有不少,redisjson,zxing,jsondata等等。其实现在网页页面较为简单,几乎不会要使用请求头或者cookies,所以不是很建议购买开源软件或者插件。
webqq通过http的header和user-agent进行抓取,都有空字符串进行抓取也可以,现在各大云平台支持webqq这个功能,其中支持ua和headers抓取与性能上相比安卓推荐第三方内置了二次请求抓取的插件,jsondata(如阿里云的clipboard,谷歌的glow),缺点是安装使用配置麻烦,另外jsondata是java程序,无法使用android系统运行webqq本身数据结构是关键。
这一块。1.理解post和get请求基本逻辑;2.json库和tcp库了解底层流程;3.基于android平台app设计原则,比如要完整支持请求后台返回报文,比如不支持传textheader;4.统一设计组件(请求、表单、前端等等),在重构时减少相互耦合。你说的原理不懂是指哪方面?是结构上的,比如一般情况请求网站时应该在app的最上层,那么最好用图形展示的设计方案而不是xml;比如网站的图标,json里是支持的,但请求网站时应该去请求app端,而不是去请求网站。
最近几天给两家大公司给设计数据部门设计sdk时遇到相同问题,此处就不展开了。抓包的基本处理方法,也可以自己写,拿现成的抓包工具比如jsonget,webstrom也支持抓包工具;按client和server分组来请求数据(这样工作量小而且容易做);不用关心requestheader和responseheader;避免一些不必要的请求头和cookie对象(比如明文request和response存储用到的token、sessionid等等)。ok了,小总结了一下,希望对你有所帮助。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库?(一)_库)
php如何抓取网页数据库?目前有很多抓取网页数据库的软件可以使用。开源的很多,比如(postman)可以抓取cookies、查看cookies进行解析、访问页面的url、返回json数据;使用插件也有不少,redisjson,zxing,jsondata等等。其实现在网页页面较为简单,几乎不会要使用请求头或者cookies,所以不是很建议购买开源软件或者插件。
webqq通过http的header和user-agent进行抓取,都有空字符串进行抓取也可以,现在各大云平台支持webqq这个功能,其中支持ua和headers抓取与性能上相比安卓推荐第三方内置了二次请求抓取的插件,jsondata(如阿里云的clipboard,谷歌的glow),缺点是安装使用配置麻烦,另外jsondata是java程序,无法使用android系统运行webqq本身数据结构是关键。
这一块。1.理解post和get请求基本逻辑;2.json库和tcp库了解底层流程;3.基于android平台app设计原则,比如要完整支持请求后台返回报文,比如不支持传textheader;4.统一设计组件(请求、表单、前端等等),在重构时减少相互耦合。你说的原理不懂是指哪方面?是结构上的,比如一般情况请求网站时应该在app的最上层,那么最好用图形展示的设计方案而不是xml;比如网站的图标,json里是支持的,但请求网站时应该去请求app端,而不是去请求网站。
最近几天给两家大公司给设计数据部门设计sdk时遇到相同问题,此处就不展开了。抓包的基本处理方法,也可以自己写,拿现成的抓包工具比如jsonget,webstrom也支持抓包工具;按client和server分组来请求数据(这样工作量小而且容易做);不用关心requestheader和responseheader;避免一些不必要的请求头和cookie对象(比如明文request和response存储用到的token、sessionid等等)。ok了,小总结了一下,希望对你有所帮助。
php如何抓取网页数据库(一句echo“varjson=”_out’;; )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-10 22:19
)
最近需要使用百度API来加载百度地图。百度API使用JavaScript,但我需要使用数据库中的数据来控制
网上搜了半天,没找到这方面的现成资料,只能自己写
一开始是想用JDB的,但是在我的服务器上加载了很久都没有成功。后来想到了PHP,MySQL的好朋友。
所以我自己写了程序
其实原理很简单,我们拿到查询数据库数据后加一句
echo "var json="."'$json_out';";
然后在自己的HTML中引入mysql.php(数据库查询)
然后通过 json=eval(json);
下一步是解析json数据。当然,你不能使用json,你可以直接为其他人回显JavaScript类型。
网页查看源代码
<p>DOCTYPE html>
body, html,#allmap {width:100%;height:100%;overflow: hidden;margin:0;font-family:"微软雅黑";}
#l-map{height:100%;width:78%;float:left;border-right:2px solid #bcbcbc;}
#r-result{height:100%;width:20%;float:left;}
2015-2016
// 百度地图API功能
var map =newBMap.Map("allmap");
var point =newBMap.Point(116.396795,39.938395);
map.centerAndZoom(point,12);
map.enableScrollWheelZoom(true);
// 编写自定义函数,创建标注
function addMarker(point){
var marker =newBMap.Marker(point);
map.addOverlay(marker);
}
gohere:var here=1;
json=eval(jstext);
for(var i =0; i 查看全部
php如何抓取网页数据库(一句echo“varjson=”_out’;;
)
最近需要使用百度API来加载百度地图。百度API使用JavaScript,但我需要使用数据库中的数据来控制
网上搜了半天,没找到这方面的现成资料,只能自己写
一开始是想用JDB的,但是在我的服务器上加载了很久都没有成功。后来想到了PHP,MySQL的好朋友。
所以我自己写了程序
其实原理很简单,我们拿到查询数据库数据后加一句
echo "var json="."'$json_out';";
然后在自己的HTML中引入mysql.php(数据库查询)
然后通过 json=eval(json);
下一步是解析json数据。当然,你不能使用json,你可以直接为其他人回显JavaScript类型。
网页查看源代码
<p>DOCTYPE html>
body, html,#allmap {width:100%;height:100%;overflow: hidden;margin:0;font-family:"微软雅黑";}
#l-map{height:100%;width:78%;float:left;border-right:2px solid #bcbcbc;}
#r-result{height:100%;width:20%;float:left;}
2015-2016
// 百度地图API功能
var map =newBMap.Map("allmap");
var point =newBMap.Point(116.396795,39.938395);
map.centerAndZoom(point,12);
map.enableScrollWheelZoom(true);
// 编写自定义函数,创建标注
function addMarker(point){
var marker =newBMap.Marker(point);
map.addOverlay(marker);
}
gohere:var here=1;
json=eval(jstext);
for(var i =0; i
php如何抓取网页数据库(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-08 17:07
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在php的开发中,也需要在服务端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。去了官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后我找到了另一个类库,Snoopy。我对这个类库了解不多,但是网上的反响还不错,所以我决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头以及cookies的相关操作功能,功能非常强大。
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。 查看全部
php如何抓取网页数据库(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
如果你做过童鞋的j2ee或者android开发,应该多多少少用过Apeache的HttpClient类库。这个类库为我们提供了非常强大的服务端Http请求操作。在开发中使用非常方便。
最近在php的开发中,也需要在服务端发送http请求,然后再处理回客户端。
我google了一下,发现php中有这样一个类库,名字叫httpclient。我很兴奋。去了官网,发现已经很多年没有更新了,功能好像也有限,很是失望。然后我找到了另一个类库,Snoopy。我对这个类库了解不多,但是网上的反响还不错,所以我决定用它。它的 API 使用与 Apache 的 HttpClient 有很大的不同,但仍然非常好用。并且提供了很多特殊用途的方法,比如只能抓取页面中的form表单,或者所有的链接等等。
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
以上几行代码就可以轻松爬取百度的页面。
当然,当需要发送post表单时,可以使用submit方法提交数据。
同时还提供了请求头、响应头以及cookies的相关操作功能,功能非常强大。
\n";} else {echo "错误获取文档:" . $snoopy->error . "\n";}
更多操作方法可以去Snoopy的官方文档,或者直接查看源码。
此时,snoopy 只取回页面。如果您想从获取的页面中提取数据,那么它不会有太大帮助。这里又找到了一个php解析html的好工具:phpQuery,它提供了和jquery几乎一样的操作方法,并且提供了一些php的特性,熟悉jquery的童鞋,应该还是蛮好用的phpquery,连phpQuery的文档都没有已经需要了。。
使用Snoopy+PhpQuery可以轻松实现网页抓取和数据分析。这是非常有用的。我最近也需要这个,只找到了这两个不错的类库。事实证明,java可以做的事情有很多。php也可以做到。
有兴趣的同学也可以尝试用它们制作一个简单的网络爬虫。
php如何抓取网页数据库(实验四PHP操作数据库实验目的:掌握常用的MYSQL数据库函数的用法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-08 06:06
)
实验4 PHP操作数据库
目的:
1、在 PHP 中掌握数据库连接
2、掌握常用MYSQL数据库函数的用法
3、精通基本SQL语句的使用
实验内容
1、按照以下要求完成每一页:(提示:做这道题前,需要创建一个数据库,包括一个表,这个表至少收录5个字段(姓名、性别、爱好、家庭住址、备注) )) (1)制作静态页面ex01a.php 如图1,点击“提交”按钮后,可以向数据库中添加数据。跳转到另一个页面ex01b.php,如如图2所示。这个页面可以显示数据库中所有学生的信息。
(2)点击ex01b.php中的“修改”后,可以将网页连接到ex01c.php 如图3,可以修改学生的信息。页面收录一个表单,默认每个表单控件的值为ex01.php页面中学生的信息值,当点击“修改”按钮时,可以修改学生的信息并保存到数据库中,数据保存成功后,该页面可以转换为 ex01b.php。
(3)点击“删除”时,如果数据可以删除成功,会提示“数据删除成功!”,如图4,将网页转到ex01b.php。如果数据删除失败,也会出现“数据删除失败!”的提示。
查看全部
php如何抓取网页数据库(实验四PHP操作数据库实验目的:掌握常用的MYSQL数据库函数的用法
)
实验4 PHP操作数据库
目的:
1、在 PHP 中掌握数据库连接
2、掌握常用MYSQL数据库函数的用法
3、精通基本SQL语句的使用
实验内容
1、按照以下要求完成每一页:(提示:做这道题前,需要创建一个数据库,包括一个表,这个表至少收录5个字段(姓名、性别、爱好、家庭住址、备注) )) (1)制作静态页面ex01a.php 如图1,点击“提交”按钮后,可以向数据库中添加数据。跳转到另一个页面ex01b.php,如如图2所示。这个页面可以显示数据库中所有学生的信息。
(2)点击ex01b.php中的“修改”后,可以将网页连接到ex01c.php 如图3,可以修改学生的信息。页面收录一个表单,默认每个表单控件的值为ex01.php页面中学生的信息值,当点击“修改”按钮时,可以修改学生的信息并保存到数据库中,数据保存成功后,该页面可以转换为 ex01b.php。
(3)点击“删除”时,如果数据可以删除成功,会提示“数据删除成功!”,如图4,将网页转到ex01b.php。如果数据删除失败,也会出现“数据删除失败!”的提示。
php如何抓取网页数据库(php如何抓取网页数据库信息web开发程序又称web应用程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-05 22:01
php如何抓取网页数据库信息web开发程序又称web应用程序,包括可以嵌入到任何计算机上的所有软件、网站、数据库系统或所有应用程序集成以及可在其上运行的程序集,数据库的表是列表,用户能够写入数据库。php之所以能够开发出一个优秀的web程序来,与它在html、css、javascript、json等基础技术之上,融入丰富的异步和基于事件的机制分离开来有很大关系。
php异步机制允许php程序运行时启动一个同步任务,即调用浏览器后立即运行用户浏览的页面。这些页面可以是文本页面、表单页面、动态网页等等。以上大概是关于php抓取网页数据库数据库信息的一些了解,其实抓取和数据库的关系很紧密,但是这只是php的常用数据库操作语句的一些语法。我们还要掌握php的高级语法,掌握php与数据库的链接方式才能实现web开发中的数据查询、更新。
今天我们来了解一下关于php对ddl的讲解,详情请参阅php在数据库中的方式讲解如何在php中对ddl进行操作。
如何读取一个php的目录?首先,你需要熟悉php的目录提供三个alias:my_php_list_dir|www-db|gist。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库信息web开发程序又称web应用程序)
php如何抓取网页数据库信息web开发程序又称web应用程序,包括可以嵌入到任何计算机上的所有软件、网站、数据库系统或所有应用程序集成以及可在其上运行的程序集,数据库的表是列表,用户能够写入数据库。php之所以能够开发出一个优秀的web程序来,与它在html、css、javascript、json等基础技术之上,融入丰富的异步和基于事件的机制分离开来有很大关系。
php异步机制允许php程序运行时启动一个同步任务,即调用浏览器后立即运行用户浏览的页面。这些页面可以是文本页面、表单页面、动态网页等等。以上大概是关于php抓取网页数据库数据库信息的一些了解,其实抓取和数据库的关系很紧密,但是这只是php的常用数据库操作语句的一些语法。我们还要掌握php的高级语法,掌握php与数据库的链接方式才能实现web开发中的数据查询、更新。
今天我们来了解一下关于php对ddl的讲解,详情请参阅php在数据库中的方式讲解如何在php中对ddl进行操作。
如何读取一个php的目录?首先,你需要熟悉php的目录提供三个alias:my_php_list_dir|www-db|gist。
php如何抓取网页数据库( 先来聊聊:水处理设备公司网站建设有哪些优点?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-29 06:02
先来聊聊:水处理设备公司网站建设有哪些优点?)
先说:水处理设备公司网站建设有哪些优势?
一、 网站信息量可能非常大。只要企业的域名服务器允许,企业就可以尽可能丰富自己的网站,展示企业和产品信息。
但如果没有互联网,传统的企业宣传方式很难将企业信息进行如此全面的展示。例如,如果公司制作产品手册或宣传画册,画册最多可达十几页,且容量有限,无法充分展示产品信息。
二、 网站是企业网络的门户,是企业形象代言。
如果一个大公司连网站都没有,或者网络战打得不好,客户会觉得这不是现代公司,不是跟得上形势的公司。如果企业网站做得好,可以给客户一种高端的感觉,同时也可以让客户增加对公司的信任。
三、 网站内容可以随时更新,公司可以随时更新网络上的产品展示,这在现实生活中是很难实现的。
以前,企业展示产品的传统方式是制作画册、产品说明书等,一旦产品发生变化,需要重新印制新的画册,不仅耗费大量时间,而且成本也很高。钱。在网站上,这些是可以避免的。
四、网站可以帮助公司和潜在客户相互搜索。
互联网最常用的功能之一是搜索引擎。如果一家公司有自己的网站,客户可以在不了解该公司的情况下通过搜索引擎找到该公司的网站,从而获得该公司的信息并与该公司取得联系。企业还可以通过网络推广或网站链接将自己的信息传播到世界各地,让客户更好地找到自己的信息。
再说一遍:水处理设备企业如何做好网站建设?我们应该注意什么问题?
接下来,基于多年资深互联网经验,IT工作室创始人王清儿就这方面和大家聊一聊!
1、网站结构设计
网站的框架结构一定要简洁、扁平、扁平化,因为这样有利于搜索引擎蜘蛛的抓取,更好的提高网站的收录,用户的浏览会更简单流畅,用户体验会更好。
2、 网站网址结果规划
营销网站的网址也很重要。我们经常可以看到有些网站的url结尾不是html结尾,有的显示php,有的显示asp、aspx等。为了更好地方便搜索引擎的收录,营销网站必须将网址作为伪静态处理。URL 的结尾是 html。这似乎是搜索引擎的静态网页。一些动态网址搜索引擎很难抓取,主要是参数问题。
3、网站打开速度
网站的打开速度一定要快。对于营销型网站客户来说,如果网站打开5-6秒还在加载,那么客户就会离开。同时,对于SEO优化也是非常不利的,会导致搜索引擎蜘蛛对网页的抓取缓慢,难以索引,或者根本不索引。排名更是难上加难。搜索引擎对网站的打开速度有要求。即使网站速度太慢,即使在首页,如果后期不解决速度问题,排名也会被淘汰。所以网站的打开速度很重要,最好在2秒内打开。
4、网站内容
对于网站的内容,我们最好从产品角度和公司品牌角度出发。营销型网站不仅宣传我们的产品,还宣传公司的品牌。现在市面上同样的产品,用完的产品太多了。客户不会因为他们看到您的网站和产品,他们会直接向您下订单。客户也会关注公司的品牌声誉,会考虑产品的价格沟通和购买行为。
一个。网站上的产品图片要清晰,图片要多角度拍摄,每个产品都有详细的内容介绍,让客户看到详细的页面,对产品有一个大致的了解,知道有什么功能和很快。
湾 对于新网站,建议每天更新一些内容信息,以获得更好的百度收录,从而做关键词排名。
5、网站基础优化
SEO优化是营销型网站必不可少的技能,否则就会失去营销价值,甚至白费。
首先我们需要设置每个网站页面的TDK,根据我们产品主词+长尾词+区域词的组合等等。有些标题,当然这不是适用于所有行业,不同行业有不同的TDK设置,具体情况因人而异。分析来做。
注意网站产品信息的发布。产品标题中必须收录
关键词,可以是长尾词、疑问词等,只要收录
关键词即可。
新网站应该在外链和友情链接上做更多的工作,以便更好地搜索引擎抓取。
以上是王清儿分享的文章内容。从事网站设计和制作工作七八年,她自然知道企业网站建设对网络营销发展的重要性。既然来了,看完了我分享的文章,是一种缘分,也是一种不可言说的缘分。如果你说了什么不好的,欢迎你评论和纠正我。建站有什么问题,可以和王清儿讨论。虽然我已经工作了8年,但我不忘初心。我始终相信,越努力,越幸运。而且我也喜欢结交各界朋友,谢谢!
当然,如果你觉得文章有价值,或者关注分享或者感谢某事,也可以点个赞——以文章的价值为桥梁,“赞”:延长“你的价值”并保持它的香味...... 查看全部
php如何抓取网页数据库(
先来聊聊:水处理设备公司网站建设有哪些优点?)
先说:水处理设备公司网站建设有哪些优势?
一、 网站信息量可能非常大。只要企业的域名服务器允许,企业就可以尽可能丰富自己的网站,展示企业和产品信息。
但如果没有互联网,传统的企业宣传方式很难将企业信息进行如此全面的展示。例如,如果公司制作产品手册或宣传画册,画册最多可达十几页,且容量有限,无法充分展示产品信息。
二、 网站是企业网络的门户,是企业形象代言。
如果一个大公司连网站都没有,或者网络战打得不好,客户会觉得这不是现代公司,不是跟得上形势的公司。如果企业网站做得好,可以给客户一种高端的感觉,同时也可以让客户增加对公司的信任。
三、 网站内容可以随时更新,公司可以随时更新网络上的产品展示,这在现实生活中是很难实现的。
以前,企业展示产品的传统方式是制作画册、产品说明书等,一旦产品发生变化,需要重新印制新的画册,不仅耗费大量时间,而且成本也很高。钱。在网站上,这些是可以避免的。
四、网站可以帮助公司和潜在客户相互搜索。
互联网最常用的功能之一是搜索引擎。如果一家公司有自己的网站,客户可以在不了解该公司的情况下通过搜索引擎找到该公司的网站,从而获得该公司的信息并与该公司取得联系。企业还可以通过网络推广或网站链接将自己的信息传播到世界各地,让客户更好地找到自己的信息。
再说一遍:水处理设备企业如何做好网站建设?我们应该注意什么问题?
接下来,基于多年资深互联网经验,IT工作室创始人王清儿就这方面和大家聊一聊!
1、网站结构设计
网站的框架结构一定要简洁、扁平、扁平化,因为这样有利于搜索引擎蜘蛛的抓取,更好的提高网站的收录,用户的浏览会更简单流畅,用户体验会更好。
2、 网站网址结果规划
营销网站的网址也很重要。我们经常可以看到有些网站的url结尾不是html结尾,有的显示php,有的显示asp、aspx等。为了更好地方便搜索引擎的收录,营销网站必须将网址作为伪静态处理。URL 的结尾是 html。这似乎是搜索引擎的静态网页。一些动态网址搜索引擎很难抓取,主要是参数问题。
3、网站打开速度
网站的打开速度一定要快。对于营销型网站客户来说,如果网站打开5-6秒还在加载,那么客户就会离开。同时,对于SEO优化也是非常不利的,会导致搜索引擎蜘蛛对网页的抓取缓慢,难以索引,或者根本不索引。排名更是难上加难。搜索引擎对网站的打开速度有要求。即使网站速度太慢,即使在首页,如果后期不解决速度问题,排名也会被淘汰。所以网站的打开速度很重要,最好在2秒内打开。
4、网站内容
对于网站的内容,我们最好从产品角度和公司品牌角度出发。营销型网站不仅宣传我们的产品,还宣传公司的品牌。现在市面上同样的产品,用完的产品太多了。客户不会因为他们看到您的网站和产品,他们会直接向您下订单。客户也会关注公司的品牌声誉,会考虑产品的价格沟通和购买行为。
一个。网站上的产品图片要清晰,图片要多角度拍摄,每个产品都有详细的内容介绍,让客户看到详细的页面,对产品有一个大致的了解,知道有什么功能和很快。
湾 对于新网站,建议每天更新一些内容信息,以获得更好的百度收录,从而做关键词排名。
5、网站基础优化
SEO优化是营销型网站必不可少的技能,否则就会失去营销价值,甚至白费。
首先我们需要设置每个网站页面的TDK,根据我们产品主词+长尾词+区域词的组合等等。有些标题,当然这不是适用于所有行业,不同行业有不同的TDK设置,具体情况因人而异。分析来做。
注意网站产品信息的发布。产品标题中必须收录
关键词,可以是长尾词、疑问词等,只要收录
关键词即可。
新网站应该在外链和友情链接上做更多的工作,以便更好地搜索引擎抓取。
以上是王清儿分享的文章内容。从事网站设计和制作工作七八年,她自然知道企业网站建设对网络营销发展的重要性。既然来了,看完了我分享的文章,是一种缘分,也是一种不可言说的缘分。如果你说了什么不好的,欢迎你评论和纠正我。建站有什么问题,可以和王清儿讨论。虽然我已经工作了8年,但我不忘初心。我始终相信,越努力,越幸运。而且我也喜欢结交各界朋友,谢谢!
当然,如果你觉得文章有价值,或者关注分享或者感谢某事,也可以点个赞——以文章的价值为桥梁,“赞”:延长“你的价值”并保持它的香味......
php如何抓取网页数据库(php如何抓取网页数据库中有什么有趣的网页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-26 15:07
php如何抓取网页数据库中有什么有趣的网页?如何抓取网页中某一个具体数据项的内容?mysql如何通过ddl和cascade实现数据插入和删除?如何通过orm实现某一个接口的多级查询?如何对表结构进行查询封装成一个web服务?如何实现查询多个多级表的查询?你说的是php中实现的关系型数据库“mysql”,还是类似mysql的查询联结“oracle”?ddl和cascade都是设计不良导致系统性能低下的重要问题,ddl不是定期(通常是每2周)reload的内容,cascade也不是定期(通常是每月)reload的内容。
ddl相当于你把一块硬盘(有时你可以理解为自己创建一个工作区的一块硬盘)分为两块,一块是ddl(debugblock,即开发人员用来打开或关闭一个操作系统内核的ddl进程),一块是cascade(即我们通常所说的数据库联结oracle或mysql的sql和存储引擎)。定期reloadddl没必要,但是会增加数据库的负担和重启难度,从而减小你的执行时间。
oracle或mysql的联结存在不稳定的情况(oracle会用的比较多,因为它有庞大的数据库后端包括一系列包括存储引擎在内的实现),但是mysql里联结的稳定性是没有问题的。例如对于spark来说,流式数据是一个重要的挑战,如果存在太多cascade或ddl(从某一个进程reload到多个processoverlook,也许这是数据库工程师重定向到你的电脑进行处理的常规联结方式),可能会造成内存不足,从而影响数据库日志的准确性。
所以在一些场景中联结可以说是重要但是不必要的,举个例子来说就是,如果你有一个并发级别为n的并发量(n=1000),如果你要处理这么大的日志,可能不会想对mysql联结实现有很高的要求,因为总共只有100万行(你可以看作n*100万)的字段,如果mysql重定向到n平均要重定向30次到120次,而这相当于整个pool的服务器负载。
至于web服务器请求的一个接口可能会有各种不同的数据类型也就是说如果ddl太频繁了,如果不经过精心设计,可能会让多个联结请求自然形成一条数据。如果多数据源的联结或联结存在分区的话,那么对服务器的响应时间也会有很大影响。此外,还有一个好处是php可以通过每次重定向解析一次数据库的dml和ddl。解析这些数据库的dml和ddl,同时也是要付出一定的时间的。
把这些时间用在加载数据源上面不划算,因为这些数据最终的获取效率可能会不高。一般来说把性能没有什么大问题的动态表使用嵌套嵌套就可以了,实在不会嵌套的,也可以把一些约束比较多的字段使用以数组形式存放(可以作为topn的字段,只是。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库中有什么有趣的网页?)
php如何抓取网页数据库中有什么有趣的网页?如何抓取网页中某一个具体数据项的内容?mysql如何通过ddl和cascade实现数据插入和删除?如何通过orm实现某一个接口的多级查询?如何对表结构进行查询封装成一个web服务?如何实现查询多个多级表的查询?你说的是php中实现的关系型数据库“mysql”,还是类似mysql的查询联结“oracle”?ddl和cascade都是设计不良导致系统性能低下的重要问题,ddl不是定期(通常是每2周)reload的内容,cascade也不是定期(通常是每月)reload的内容。
ddl相当于你把一块硬盘(有时你可以理解为自己创建一个工作区的一块硬盘)分为两块,一块是ddl(debugblock,即开发人员用来打开或关闭一个操作系统内核的ddl进程),一块是cascade(即我们通常所说的数据库联结oracle或mysql的sql和存储引擎)。定期reloadddl没必要,但是会增加数据库的负担和重启难度,从而减小你的执行时间。
oracle或mysql的联结存在不稳定的情况(oracle会用的比较多,因为它有庞大的数据库后端包括一系列包括存储引擎在内的实现),但是mysql里联结的稳定性是没有问题的。例如对于spark来说,流式数据是一个重要的挑战,如果存在太多cascade或ddl(从某一个进程reload到多个processoverlook,也许这是数据库工程师重定向到你的电脑进行处理的常规联结方式),可能会造成内存不足,从而影响数据库日志的准确性。
所以在一些场景中联结可以说是重要但是不必要的,举个例子来说就是,如果你有一个并发级别为n的并发量(n=1000),如果你要处理这么大的日志,可能不会想对mysql联结实现有很高的要求,因为总共只有100万行(你可以看作n*100万)的字段,如果mysql重定向到n平均要重定向30次到120次,而这相当于整个pool的服务器负载。
至于web服务器请求的一个接口可能会有各种不同的数据类型也就是说如果ddl太频繁了,如果不经过精心设计,可能会让多个联结请求自然形成一条数据。如果多数据源的联结或联结存在分区的话,那么对服务器的响应时间也会有很大影响。此外,还有一个好处是php可以通过每次重定向解析一次数据库的dml和ddl。解析这些数据库的dml和ddl,同时也是要付出一定的时间的。
把这些时间用在加载数据源上面不划算,因为这些数据最终的获取效率可能会不高。一般来说把性能没有什么大问题的动态表使用嵌套嵌套就可以了,实在不会嵌套的,也可以把一些约束比较多的字段使用以数组形式存放(可以作为topn的字段,只是。
php如何抓取网页数据库(wordpress现成标签不能实现的效果教程-wordpress建站教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-20 09:09
Wordpress 直接使用 PHP 读取数据库中的数据。这种用法可以达到很多wordpress现成标签无法达到的效果。 (相关教程:WordPress建站视频教程)
一、获取单个数据,一般sql语句只返回一个值时使用。
$var = $wpdb -> get_var("查询条件");
例如:
$var = $wpdb -> get_var("SELECT count(*) FROM `user`");
该函数直接返回行值,可以直接使用。
注意:其实get_var不仅仅是一条只能返回值的SQL语句,它默认只返回第一行左边的元素。如果想让他返回其他元素,可以使用get_var("query condition", x, y)来实现。
二、 获取一行数据,一般sql语句只返回特定对象时使用。
$sql = $wpdb -> get_row("查询条件", output_type);
例如:
$var = $wpdb -> get_row("SELECT * FROM `user` WHERE `userid` = 1", ARRAY_A);
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用OBJECT或ARRAY_A,访问方式分别是$var -> username(当output_type为OBJECT时)或$var["username"](当output_type为ARRAY_A时)
注意:其实get_row不仅仅是一条只能返回一行的SQL语句,它默认只返回第一行的集合。如果想让他返回其他行,可以使用get_row("query", output_type, y)来实现。
三、获取一列数据,在一般sql语句只返回特定属性时使用。
$sql = $wpdb -> get_col("查询条件");
例如:
$var = $wpdb -> get_col("SELECT `age` FROM `user`);
返回结果以数值索引数组的形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。
注意:其实get_col不仅仅是一条只能返回一列的SQL语句,而是默认只返回第一列的集合。如果想让他返回其他列,可以使用get_col("query condition", x)来实现。
四、获取多列数据,用于一般SQL语句只返回特定属性时使用。
$sql = $wpdb -> get_results("查询条件", output_type);
例如:
$vars = $wpdb -> get_results("SELECT * FROM `user`, ARRAY_A);
返回的结果以数值索引数组等形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。获取的对象由第二个参数控制。
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用 OBJECT 或 ARRAY_A,访问方式是 $var -> username(当 output_type 为 OBJECT 时)或 $var["username"](当 output_type 为 ARRAY_A 时)。
例如:
foreach($vars as $var) {<br />
<br />
echo $var["username"];//output_type是ARRAY_A时<br />
<br />
}
这样就可以用PHP代码直接从数据库中获取你想要的数据了。 查看全部
php如何抓取网页数据库(wordpress现成标签不能实现的效果教程-wordpress建站教程)
Wordpress 直接使用 PHP 读取数据库中的数据。这种用法可以达到很多wordpress现成标签无法达到的效果。 (相关教程:WordPress建站视频教程)
https://www.xuewangzhan.net/wp ... 7.jpg 768w" />一、获取单个数据,一般sql语句只返回一个值时使用。
$var = $wpdb -> get_var("查询条件");
例如:
$var = $wpdb -> get_var("SELECT count(*) FROM `user`");
该函数直接返回行值,可以直接使用。
注意:其实get_var不仅仅是一条只能返回值的SQL语句,它默认只返回第一行左边的元素。如果想让他返回其他元素,可以使用get_var("query condition", x, y)来实现。
二、 获取一行数据,一般sql语句只返回特定对象时使用。
$sql = $wpdb -> get_row("查询条件", output_type);
例如:
$var = $wpdb -> get_row("SELECT * FROM `user` WHERE `userid` = 1", ARRAY_A);
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用OBJECT或ARRAY_A,访问方式分别是$var -> username(当output_type为OBJECT时)或$var["username"](当output_type为ARRAY_A时)
注意:其实get_row不仅仅是一条只能返回一行的SQL语句,它默认只返回第一行的集合。如果想让他返回其他行,可以使用get_row("query", output_type, y)来实现。
三、获取一列数据,在一般sql语句只返回特定属性时使用。
$sql = $wpdb -> get_col("查询条件");
例如:
$var = $wpdb -> get_col("SELECT `age` FROM `user`);
返回结果以数值索引数组的形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。
注意:其实get_col不仅仅是一条只能返回一列的SQL语句,而是默认只返回第一列的集合。如果想让他返回其他列,可以使用get_col("query condition", x)来实现。
四、获取多列数据,用于一般SQL语句只返回特定属性时使用。
$sql = $wpdb -> get_results("查询条件", output_type);
例如:
$vars = $wpdb -> get_results("SELECT * FROM `user`, ARRAY_A);
返回的结果以数值索引数组等形式输出,通常用foreach函数分隔,或者直接使用$var[1]获取。获取的对象由第二个参数控制。
output_type:三个预定义常量之一。默认值为 OBJECT。
OBJECT —— 返回结果作为对象输出
ARRAY_A ——返回结果作为关联数组输出
ARRAY_N —— 返回结果作为数值索引数组输出
我通常使用 OBJECT 或 ARRAY_A,访问方式是 $var -> username(当 output_type 为 OBJECT 时)或 $var["username"](当 output_type 为 ARRAY_A 时)。
例如:
foreach($vars as $var) {<br />
<br />
echo $var["username"];//output_type是ARRAY_A时<br />
<br />
}
这样就可以用PHP代码直接从数据库中获取你想要的数据了。
php如何抓取网页数据库(蜘蛛程序的工作原理是什么?搜索引擎会告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-20 01:00
网站有什么办法可以让蜘蛛程序更容易爬取?蜘蛛程序是如何工作的?
各大搜索引擎都会派出大量蜘蛛对互联网上的海量信息进行评估和审查,将新鲜优质的内容放入索引库,按照一定的排序算法展示给搜索用户。
蜘蛛程序爬取的内容是网站关键词排名的基础,那么蜘蛛程序是如何发现新内容的呢?
(1)链接提交:通过站长工具主动向搜索引擎提交新的站点地址或内容链接;
(2)外链发布:发布外链,可以的话加锚文本链接。如果不允许加超链接,可以考虑加纯文本链接;加好友链接:蜘蛛程序可以通过好友链接进入你< @网站;
(3)浏览器cookie数据:爬取浏览器的浏览器历史cookie记录网站。
网站有什么办法可以让蜘蛛程序更容易爬取?
1、高质量原创内容
一方面,最好有新鲜的原创内容,这样收录的比例会高很多;另一方面,内容可以解决用户的问题,满足客户的潜在需求。搜索引擎还会根据用户停留时间、跳出率等数据对你的网站进行综合评分。
2、页面打开速度快
如果搜索引擎蜘蛛程序打开页面需要很长时间,就不可能给你一个好的排名。
这就需要我们合理控制视频和图片的大小。如果视频很大,我们可以考虑放在外部视频网站上,而不是全部放在企业服务器上。
对于手机拍摄的照片,运动是几兆字节。编辑和上传副本时,可以使用图片处理软件进行处理,然后再上传到网站。网站有什么办法可以让蜘蛛程序更容易爬取?
3、 合理的内部链接结构
合理的内链结构有利于蜘蛛爬取整个网站内容,也能有效减少用户跳出,增加PV数和页面停留时间。
4、XML网站
如果陆驰需要“地图导航”,那么蜘蛛程序就需要XML网站地图,而网站地图提高了蜘蛛程序的爬取效率。也需要在网站上线后及时生成。. 查看全部
php如何抓取网页数据库(蜘蛛程序的工作原理是什么?搜索引擎会告诉你)
网站有什么办法可以让蜘蛛程序更容易爬取?蜘蛛程序是如何工作的?
各大搜索引擎都会派出大量蜘蛛对互联网上的海量信息进行评估和审查,将新鲜优质的内容放入索引库,按照一定的排序算法展示给搜索用户。
蜘蛛程序爬取的内容是网站关键词排名的基础,那么蜘蛛程序是如何发现新内容的呢?
(1)链接提交:通过站长工具主动向搜索引擎提交新的站点地址或内容链接;
(2)外链发布:发布外链,可以的话加锚文本链接。如果不允许加超链接,可以考虑加纯文本链接;加好友链接:蜘蛛程序可以通过好友链接进入你< @网站;
(3)浏览器cookie数据:爬取浏览器的浏览器历史cookie记录网站。
网站有什么办法可以让蜘蛛程序更容易爬取?
1、高质量原创内容
一方面,最好有新鲜的原创内容,这样收录的比例会高很多;另一方面,内容可以解决用户的问题,满足客户的潜在需求。搜索引擎还会根据用户停留时间、跳出率等数据对你的网站进行综合评分。
2、页面打开速度快
如果搜索引擎蜘蛛程序打开页面需要很长时间,就不可能给你一个好的排名。
这就需要我们合理控制视频和图片的大小。如果视频很大,我们可以考虑放在外部视频网站上,而不是全部放在企业服务器上。
对于手机拍摄的照片,运动是几兆字节。编辑和上传副本时,可以使用图片处理软件进行处理,然后再上传到网站。网站有什么办法可以让蜘蛛程序更容易爬取?
3、 合理的内部链接结构
合理的内链结构有利于蜘蛛爬取整个网站内容,也能有效减少用户跳出,增加PV数和页面停留时间。
4、XML网站
如果陆驰需要“地图导航”,那么蜘蛛程序就需要XML网站地图,而网站地图提高了蜘蛛程序的爬取效率。也需要在网站上线后及时生成。.
php如何抓取网页数据库(来讲一下如何进行数据库操作以及防止页面超时和自动刷新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-18 11:20
PHP开发中操作数据库是很常见的。如果我们长时间停留在一个页面上,就会出现提示或错误。相信大家都遇到过。那么今天我们就来聊聊如何操作数据库和防止页面超时!
操作说明:
在执行初始化或修改数据库等操作时:
1、 直接用sql语句完成即可。
2、 稍微复杂一点,可以通过执行php代码来完成(读取数据然后写入/修改数据)。
在使用 php 代码(不是命令行)时,我们可能会遇到网页超时。一般有以下三种解决方法:
1、设置php.ini:
max_execution_time
2、在代码中加入:
set_time_limit(0);
//0表示不超时
3、 页面自动刷新,整个工作分批完成:
页面可以随着执行过程而变化,比如动态告诉用户已经执行了多少,而不是等待单个页面。
下面主要对第三种方法进行梳理。
页面自动刷新:
页面刷新,页面跳转,满足一定条件时跳转停止。
页面跳转:输出meta标签实现
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
同时刷新和传递参数来控制数据库操作:
在meta url中,我们可以使用Get来传递一个参数。
该参数可以用来改变SQL语句每次执行部分功能的限制。
$page = isset($_GET['page']) ? $_GET['page'] : 0;
//用$page构造sql语句或其它功能
//数据库操作或其它功能
//设置$flag
$flag = $pdostatement->rowCount() == 0; //比如数据库影响行数
//决定 跳转刷新 或 停止
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
假设,+1到某个字段数据,具体实现:
我现在对 SQL 不是很熟悉。
如果只是一个limit限制,可能会出现已经查询过的数据会被再次查询第二次执行?
个人认为最好加上主键的order by
<p> 查看全部
php如何抓取网页数据库(来讲一下如何进行数据库操作以及防止页面超时和自动刷新)
PHP开发中操作数据库是很常见的。如果我们长时间停留在一个页面上,就会出现提示或错误。相信大家都遇到过。那么今天我们就来聊聊如何操作数据库和防止页面超时!
操作说明:
在执行初始化或修改数据库等操作时:
1、 直接用sql语句完成即可。
2、 稍微复杂一点,可以通过执行php代码来完成(读取数据然后写入/修改数据)。
在使用 php 代码(不是命令行)时,我们可能会遇到网页超时。一般有以下三种解决方法:
1、设置php.ini:
max_execution_time
2、在代码中加入:
set_time_limit(0);
//0表示不超时
3、 页面自动刷新,整个工作分批完成:
页面可以随着执行过程而变化,比如动态告诉用户已经执行了多少,而不是等待单个页面。
下面主要对第三种方法进行梳理。
页面自动刷新:
页面刷新,页面跳转,满足一定条件时跳转停止。
页面跳转:输出meta标签实现
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
同时刷新和传递参数来控制数据库操作:
在meta url中,我们可以使用Get来传递一个参数。
该参数可以用来改变SQL语句每次执行部分功能的限制。
$page = isset($_GET['page']) ? $_GET['page'] : 0;
//用$page构造sql语句或其它功能
//数据库操作或其它功能
//设置$flag
$flag = $pdostatement->rowCount() == 0; //比如数据库影响行数
//决定 跳转刷新 或 停止
if ($flag) {
//跳转页面,xxx为该php文件的文件名
echo '';
} else {
//刷新停止
}
假设,+1到某个字段数据,具体实现:
我现在对 SQL 不是很熟悉。
如果只是一个limit限制,可能会出现已经查询过的数据会被再次查询第二次执行?
个人认为最好加上主键的order by
<p>
php如何抓取网页数据库(php如何抓取网页数据库?(php之dll抓取dll))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-06 04:01
php如何抓取网页数据库?
一、php之wget和pythonwget,快捷键是enter,抓取完成后要delete,否则会失效;pythonwget更简单,我们可以说wget是python的一个接口,他的sourcetoken可以省略,而python里不需要。
二、php之dll抓取dll抓取,顾名思义就是用php实现对资源的抓取。php可以内置dll抓取,也可以用别的php代码封装一个dll。
三、php之xcrawlerphp会专门整合数据库的hql接口,解析sql语句并根据mysql数据库,把数据提取到access数据库,那么就可以对数据库中的数据进行抓取啦。还有一些基本工具之类的网页抓取教程,欢迎关注。-0-1-85-1-95-1-3-10-1-10-1-4-3-3-4-1-3-2-1-2-3-3-3-2-1-1-2-1-2-1-4-1-2-1-4-1-2-1-1-1-2-1-3-2-3-2-4-1-3-2-3-3-2-3-4-1-3-2-4-1-2-3-4-1-2-4-1-3-2-3-4-1-3-2-4-1-4-1-2-3-4-1-4-1-2-4-1-4-1-2-4-1-2-4-4-1-2-4-1-3-4-1-3-4-1-3-4-1-3-4-2-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库?(php之dll抓取dll))
php如何抓取网页数据库?
一、php之wget和pythonwget,快捷键是enter,抓取完成后要delete,否则会失效;pythonwget更简单,我们可以说wget是python的一个接口,他的sourcetoken可以省略,而python里不需要。
二、php之dll抓取dll抓取,顾名思义就是用php实现对资源的抓取。php可以内置dll抓取,也可以用别的php代码封装一个dll。
三、php之xcrawlerphp会专门整合数据库的hql接口,解析sql语句并根据mysql数据库,把数据提取到access数据库,那么就可以对数据库中的数据进行抓取啦。还有一些基本工具之类的网页抓取教程,欢迎关注。-0-1-85-1-95-1-3-10-1-10-1-4-3-3-4-1-3-2-1-2-3-3-3-2-1-1-2-1-2-1-4-1-2-1-4-1-2-1-1-1-2-1-3-2-3-2-4-1-3-2-3-3-2-3-4-1-3-2-4-1-2-3-4-1-2-4-1-3-2-3-4-1-3-2-4-1-4-1-2-3-4-1-4-1-2-4-1-4-1-2-4-1-2-4-4-1-2-4-1-3-4-1-3-4-1-3-4-1-3-4-2-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-4-1-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1-3-4-1。
php如何抓取网页数据库(php如何抓取网页数据库你可以看一下(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-05 20:00
php如何抓取网页数据库你可以看一下sqlite基本上网页上所有的查询都是sqlite,这对于php程序来说十分好,而且提供了很强大的api来和数据库交互。在php中查询sqlite,可以通过apcclient;然后根据你的目标文件来看,应该可以查询到其中涉及到的sqlite的索引信息(可能只是python获取数据库相关接口的几种查询方式之一而已),以及相关的转储数据。
apc可以连接到mysql,sqlite,并为应用程序提供数据存储。也可以使用独立的sqlite库,包括loadserver,instance,plg/pgsql等。php的整合要求你必须懂得pymysql,phpselenium等各种web服务器协议,然后你再写sql引擎:generator语言。然后对象系统和模块化。
可以使用c和c++对多语言包进行整合,然后使用它们编写解释器进行php相关的操作。orm:这要求你懂得orm,需要看看orm实现相关的原理。
微软的语言学习指南:onlearningcomputerscience,theofficialcomputerscienceeducationprogramdirectory网站最后更新了解释,我认为说的蛮清楚的了。
官方指南
你要学哪方面的orm,性能还是体验还是性能体验,
自己翻译一下马老板的话吧。
调用sqlite命令行:webormphpapp(需iis8,java环境)sqlite/pdojavaapp(jboss/.net/.netpc等)forjavaapplicationsbrowser(微软的) 查看全部
php如何抓取网页数据库(php如何抓取网页数据库你可以看一下(图))
php如何抓取网页数据库你可以看一下sqlite基本上网页上所有的查询都是sqlite,这对于php程序来说十分好,而且提供了很强大的api来和数据库交互。在php中查询sqlite,可以通过apcclient;然后根据你的目标文件来看,应该可以查询到其中涉及到的sqlite的索引信息(可能只是python获取数据库相关接口的几种查询方式之一而已),以及相关的转储数据。
apc可以连接到mysql,sqlite,并为应用程序提供数据存储。也可以使用独立的sqlite库,包括loadserver,instance,plg/pgsql等。php的整合要求你必须懂得pymysql,phpselenium等各种web服务器协议,然后你再写sql引擎:generator语言。然后对象系统和模块化。
可以使用c和c++对多语言包进行整合,然后使用它们编写解释器进行php相关的操作。orm:这要求你懂得orm,需要看看orm实现相关的原理。
微软的语言学习指南:onlearningcomputerscience,theofficialcomputerscienceeducationprogramdirectory网站最后更新了解释,我认为说的蛮清楚的了。
官方指南
你要学哪方面的orm,性能还是体验还是性能体验,
自己翻译一下马老板的话吧。
调用sqlite命令行:webormphpapp(需iis8,java环境)sqlite/pdojavaapp(jboss/.net/.netpc等)forjavaapplicationsbrowser(微软的)
php如何抓取网页数据库(核心知识-PHP对数据库的相关操作(HTML5学堂))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-01 14:15
PHP对数据库的操作
HTML5学派:使用PHP从数据库中提取数据到前端网页,分为几个基本步骤,包括:定义数据库基本信息、连接数据库、选择数据库、执行SQL命令、分析结果集,并关闭数据库。本文文章从第一步开始,一步一步讲解PHP对数据库的基本操作。
刘国力-龙冰海:半个月来,身体不太舒服。后来准备讲解第5课的PHP课程,更新的时间就少了很多。对不起~!废话少说,一起进入今天的内容吧~
核心知识-PHP数据操作的基本步骤
1、定义数据库的基本信息
2、请求“连接到主机(服务器)”
3、选择数据库
4、执行SQL命令
5、分析结果集
6、关闭数据库
核心知识实际上是知识的逻辑,而不是具体的知识点。知识的逻辑可以看作是一个骨架,具体的知识点是有血有肉的。只有骨架,血肉才不是“泥巴”。
简单解释一下这些步骤: 在一个网站中,前端开发工程师/HTML5开发工程师处理网页的结构,规划网页的布局,并确定整体风格和风格。网站上显示的具体内容来自后端数据库。这两个就像是两个独立的岛,那么应该用什么来连接这两个岛呢?如何将“数据孤岛”上的“资源”输送到展示给用户的“前端孤岛”?这时候背景语言就发挥作用了~
不管PHP、JAVA还是ASP.NET,任何后端语言都有类似的作用,它们都是用来连接前端和数据库的“桥梁”。
所以如果我们想要能够拿到数据,首先要确定在哪里选择数据,然后请求连接到主机(服务器)(毕竟数据在主机上),然后选择对应的数据库,然后告诉你要进行什么操作?数据库执行操作后,就会有结果。结果返回后,需要进行相关的数据处理(处理成前端可用状态)。之后,数据库关闭。
定义数据库基本信息,请求连接主机
第一步和第二步:连接主机,我们需要三个基本信息,即主机(服务器)地址、用户名和密码。在定义之前,我们通常先定义它。
定义数据库信息
PHP中定义常量的基本命令:define(constant_name, constant_val);
基本实现:
相关说明:我这里使用的是wamp搭建的服务器集成环境。在phpMYadmin中可以查看具体的用户名和密码。如果是真实服务器,将第一个localhost替换为主机的url地址,用户名和密码替换为登录服务器的用户名和密码。
欢迎交流~HTML5学堂
请求连接到主机
要连接到数据库:使用 mysql_connect(); 命令,命令的基本格式:mysql_connect('hostname','username','password');
定义好基本信息后,我们可以直接使用这里的常量名,代码如下:
$conn = mysql_connect(MYSQL_HOST, MYSQL_USER, MYSQL_PASSWORD);
相关提示:这里需要注意的是,对于字符串,一定要用引号将它们括起来。关于常量命名的规范和建议,请参考->《PHP-基本常量规则介绍》
设置编码格式并选择数据库
和CSS、JS一样,为了保证前后数据的正常显示,也需要指定PHP的编码格式。具体代码如下:
mysql_query("设置名称'utf8'");
指定编码格式后,选择数据库。假设我这里需要选择一个名为student的数据库,代码如下:
mysql_select_db('学生', $conn);
今天我们先讲解前三步,整理一下我们的代码。代码显示如下:
在下面的文章中,我们将继续讲解接下来的几个步骤——执行SQL命令、分析结果集、关闭数据库。
欢迎交流~HTML5学堂 查看全部
php如何抓取网页数据库(核心知识-PHP对数据库的相关操作(HTML5学堂))
PHP对数据库的操作
HTML5学派:使用PHP从数据库中提取数据到前端网页,分为几个基本步骤,包括:定义数据库基本信息、连接数据库、选择数据库、执行SQL命令、分析结果集,并关闭数据库。本文文章从第一步开始,一步一步讲解PHP对数据库的基本操作。
刘国力-龙冰海:半个月来,身体不太舒服。后来准备讲解第5课的PHP课程,更新的时间就少了很多。对不起~!废话少说,一起进入今天的内容吧~
核心知识-PHP数据操作的基本步骤
1、定义数据库的基本信息
2、请求“连接到主机(服务器)”
3、选择数据库
4、执行SQL命令
5、分析结果集
6、关闭数据库
核心知识实际上是知识的逻辑,而不是具体的知识点。知识的逻辑可以看作是一个骨架,具体的知识点是有血有肉的。只有骨架,血肉才不是“泥巴”。
简单解释一下这些步骤: 在一个网站中,前端开发工程师/HTML5开发工程师处理网页的结构,规划网页的布局,并确定整体风格和风格。网站上显示的具体内容来自后端数据库。这两个就像是两个独立的岛,那么应该用什么来连接这两个岛呢?如何将“数据孤岛”上的“资源”输送到展示给用户的“前端孤岛”?这时候背景语言就发挥作用了~
不管PHP、JAVA还是ASP.NET,任何后端语言都有类似的作用,它们都是用来连接前端和数据库的“桥梁”。
所以如果我们想要能够拿到数据,首先要确定在哪里选择数据,然后请求连接到主机(服务器)(毕竟数据在主机上),然后选择对应的数据库,然后告诉你要进行什么操作?数据库执行操作后,就会有结果。结果返回后,需要进行相关的数据处理(处理成前端可用状态)。之后,数据库关闭。
定义数据库基本信息,请求连接主机
第一步和第二步:连接主机,我们需要三个基本信息,即主机(服务器)地址、用户名和密码。在定义之前,我们通常先定义它。
定义数据库信息
PHP中定义常量的基本命令:define(constant_name, constant_val);
基本实现:
相关说明:我这里使用的是wamp搭建的服务器集成环境。在phpMYadmin中可以查看具体的用户名和密码。如果是真实服务器,将第一个localhost替换为主机的url地址,用户名和密码替换为登录服务器的用户名和密码。
欢迎交流~HTML5学堂
请求连接到主机
要连接到数据库:使用 mysql_connect(); 命令,命令的基本格式:mysql_connect('hostname','username','password');
定义好基本信息后,我们可以直接使用这里的常量名,代码如下:
$conn = mysql_connect(MYSQL_HOST, MYSQL_USER, MYSQL_PASSWORD);
相关提示:这里需要注意的是,对于字符串,一定要用引号将它们括起来。关于常量命名的规范和建议,请参考->《PHP-基本常量规则介绍》
设置编码格式并选择数据库
和CSS、JS一样,为了保证前后数据的正常显示,也需要指定PHP的编码格式。具体代码如下:
mysql_query("设置名称'utf8'");
指定编码格式后,选择数据库。假设我这里需要选择一个名为student的数据库,代码如下:
mysql_select_db('学生', $conn);
今天我们先讲解前三步,整理一下我们的代码。代码显示如下:
在下面的文章中,我们将继续讲解接下来的几个步骤——执行SQL命令、分析结果集、关闭数据库。
欢迎交流~HTML5学堂
php如何抓取网页数据库( 一个采集网页内容的工具--puppeteer,可以说相当靠谱了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-11-29 23:07
一个采集网页内容的工具--puppeteer,可以说相当靠谱了!)
php抓取数据
时间:2019-07-10
本期文章为大家介绍php爬取数据,主要包括php爬取数据使用示例、应用技巧、基础知识点总结和注意事项。有一定的参考价值,有需要的朋友可以参考。
对于一般的页面数据,我们可以很方便的使用querylist抓取页面,分析其中的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想要抓取的数据是通过JavaScript渲染的. 此时
Puppeteer 插件就派上用场了。作为参考,在遵循文档时,我发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,相比传统的静态页面,curl 可以处理。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。然后真棒卷曲也无奈。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
没错,这是一种方式,长期以来 PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个来自于behind puppeteer的工具,它随着Chrome Headless技术的兴起而迅速发展。而且非常重要的是,puppeteer 是由 Chrome 官方团队开发和维护的,可以说是相当靠谱!
Puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自 spatie 的 composer 包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但是根据个人经验,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响。另外在项目中安装也方便使用phpdeployer升级(升级phpdeploy时)不会影响线上项目的运行。要知道升级/安装 puppeteer 是很耗时的,有时并不能保证一次成功),这一点很重要。
安装 puppeteer 时将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请展示你的魔法……
用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
}
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您还可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->setDelay(1000)
->save(public_path('images/toutiao.jpg'));
}
图中方框与系统字体有关。代码中使用了setDelay()方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最佳解决方案。
可能的问题
总结
Puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。 查看全部
php如何抓取网页数据库(
一个采集网页内容的工具--puppeteer,可以说相当靠谱了!)
php抓取数据
时间:2019-07-10
本期文章为大家介绍php爬取数据,主要包括php爬取数据使用示例、应用技巧、基础知识点总结和注意事项。有一定的参考价值,有需要的朋友可以参考。
对于一般的页面数据,我们可以很方便的使用querylist抓取页面,分析其中的dom树,抓取我们需要的数据,存入数据库,但是有时候我们会遇到我们想要抓取的数据是通过JavaScript渲染的. 此时
Puppeteer 插件就派上用场了。作为参考,在遵循文档时,我发现
错误:无法下载 Chromium r672088!设置“PUPPETEER_SKIP_CHROMIUM_DOWNLOAD”环境变量以跳过下载。错误,
解决方案
采集 Web 内容是一个很常见的需求,相比传统的静态页面,curl 可以处理。但是如果页面中有动态加载的内容,比如有些页面通过ajax加载的文章 body内容,如果有些页面经过一些额外的处理(图片地址替换等...)而你想要采集这些处理过的内容。然后真棒卷曲也无奈。
做过类似需求的人可能会说,老铁,去PhantomJS吧!
没错,这是一种方式,长期以来 PhantomJS 是少数可以解决这种需求的工具之一。
但是今天我要介绍一个来自于behind puppeteer的工具,它随着Chrome Headless技术的兴起而迅速发展。而且非常重要的是,puppeteer 是由 Chrome 官方团队开发和维护的,可以说是相当靠谱!
Puppeteer 是一个 js 包,如果你想在 Laravel 中使用它,你必须求助于另一个神器 spatie/browsershot。
安装
安装 spatie/browsershot
browsershot 是来自 spatie 的 composer 包
$ composer require spatie/browsershot
安装 puppeteer
$ npm i puppeteer --save
也可以全局保护puppeteer,但是根据个人经验,建议安装在项目中,因为不同的项目不会同时受到全局安装的puppeteer的影响。另外在项目中安装也方便使用phpdeployer升级(升级phpdeploy时)不会影响线上项目的运行。要知道升级/安装 puppeteer 是很耗时的,有时并不能保证一次成功),这一点很重要。
安装 puppeteer 时将下载 Chromium-Browser。由于我们特殊的国情,很可能无法下载。为此,请展示你的魔法……
用
以采集今日头条移动版页面文章的内容为例。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
$html = Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->bodyHtml();
\Log::info($html);
}
运行后可以在日志中看到如下内容(截图只是其中的一部分)
此外,您还可以将页面另存为图片或 PDF 文件。
use Spatie\Browsershot\Browsershot;
public function getBodyHtml()
{
$newsUrl = 'https://m.toutiao.com/i6546884151050502660/';
Browsershot::url($newsUrl)
->windowSize(480, 800)
->userAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36')
->mobile()
->touch()
->setDelay(1000)
->save(public_path('images/toutiao.jpg'));
}
图中方框与系统字体有关。代码中使用了setDelay()方法,用于在内容加载后进行截图。它既简单又粗鲁,可能不是最佳解决方案。
可能的问题
总结
Puppeteer 用于测试、采集 等场景。这是一个非常强大的工具。对于轻量的采集任务,就足够了,比如Laravel(php)中的这篇文章使用采集一些小页面,但是如果你需要快速采集很多内容,或者Python什么的。
php如何抓取网页数据库( 怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-28 07:22
怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
摘要:使用php制作动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值,立即从数据库中获取其他相关字段的值,并显示在当前页面。是php程序开发中的难点。本文通过一个具体的例子详细介绍了如何结合两种html嵌入语言php和javascript来解决这个难点的具体方法。
关键词:php、动态、html。
现在的网站已经从之前的静态信息提供方式,演变为动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何有效记录用户提交的信息以备后用用户查找。这些问题可以通过在网站中添加数据库支持来解决。
因为php可以对多种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,PHP 是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php是免费开源的,并且提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;它允许网页创建者非常快速,轻松地创建强大的动态网页。但是由于php是嵌入在服务器端的,所以更直观的理解是php语句是在服务器端执行的,所以它在提交的时候只会接收和处理当前页面上的内容。而当你需要的内容是根据客户当前页面输入的某个字段的值,然后从库中动态提取出来的时候,php就无能为力了。例如:给一个客户提供一个“订单合同”的入口页面,里面有一些“供应商信息”的入口,每个供应商的详细信息已经提前输入了“商家”字典表,现在是当客户在当前页面选择“供应商”时,会立即从“商户”字典表中提取该供应商的某些信息,如“开户银行、帐号、地址、电话”等,并显示在当前页面,供客户直接使用或修改。这样的要求用pb、vb等可视化编程语言很容易实现,但是pb、vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上述要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道它也是一个嵌入式语句,但是javascript不同于php语言。因为服务器端嵌入了php,客户端嵌入了javascript,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面上的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来创建一个强大的动态网页是天作之合。为了描述方便,下面仅以从字典表中选择的供应商地址为例来说明具体方法。当需要检索多个字段时,方法类似,但在使用javascript函数从字符串中一一检索时需要更加小心。
1.编写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,存入字符串变量$khsz。
函数 khqk_tq($questr){
全球 $dbconn;
$dbq_resl=sybase_query($questr,$dbconn); //发送sybase执行的查询字符串。
$dbq_rows=sybase_num_rows($dbq_resl); //获取返回的行数。
$j=0;
对于 ($i=0;$i 查看全部
php如何抓取网页数据库(
怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
摘要:使用php制作动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值,立即从数据库中获取其他相关字段的值,并显示在当前页面。是php程序开发中的难点。本文通过一个具体的例子详细介绍了如何结合两种html嵌入语言php和javascript来解决这个难点的具体方法。
关键词:php、动态、html。
现在的网站已经从之前的静态信息提供方式,演变为动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何有效记录用户提交的信息以备后用用户查找。这些问题可以通过在网站中添加数据库支持来解决。
因为php可以对多种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,PHP 是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php是免费开源的,并且提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;它允许网页创建者非常快速,轻松地创建强大的动态网页。但是由于php是嵌入在服务器端的,所以更直观的理解是php语句是在服务器端执行的,所以它在提交的时候只会接收和处理当前页面上的内容。而当你需要的内容是根据客户当前页面输入的某个字段的值,然后从库中动态提取出来的时候,php就无能为力了。例如:给一个客户提供一个“订单合同”的入口页面,里面有一些“供应商信息”的入口,每个供应商的详细信息已经提前输入了“商家”字典表,现在是当客户在当前页面选择“供应商”时,会立即从“商户”字典表中提取该供应商的某些信息,如“开户银行、帐号、地址、电话”等,并显示在当前页面,供客户直接使用或修改。这样的要求用pb、vb等可视化编程语言很容易实现,但是pb、vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上述要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道它也是一个嵌入式语句,但是javascript不同于php语言。因为服务器端嵌入了php,客户端嵌入了javascript,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面上的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来创建一个强大的动态网页是天作之合。为了描述方便,下面仅以从字典表中选择的供应商地址为例来说明具体方法。当需要检索多个字段时,方法类似,但在使用javascript函数从字符串中一一检索时需要更加小心。
1.编写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,存入字符串变量$khsz。
函数 khqk_tq($questr){
全球 $dbconn;
$dbq_resl=sybase_query($questr,$dbconn); //发送sybase执行的查询字符串。
$dbq_rows=sybase_num_rows($dbq_resl); //获取返回的行数。
$j=0;
对于 ($i=0;$i
php如何抓取网页数据库(任意文件读取与下载的原理及修复注:本文仅供参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-26 12:18
任意文件读取下载原理及修复
注意:本文仅供参考,学习阅读和下载任意文件。由于网站的一些业务需要,往往需要提供一个模块来读取或下载文件,但如果没有白名单或限制读取或下载,可能会导致恶意攻击者读取和下载一些文件敏感信息(etcpasswda=file:etcpasswd 注:如果文件被解析,则文件收录,如果提示下载或显示源代码,则为文件下载或读取1.文件被解析,文件收录漏洞2.显示源码,文件查看漏洞3.提示下载,是文件下载漏洞的危害。一般来说,利用任意文件下载漏洞主要是为了信息采集, 我们通过下载服务器配置文件获取大量的配置信息和源代码,然后根据获取的信息进一步挖掘服务器漏洞进行入侵。aspx站点aspx站点一般都是后端SQL Server数据库,所以利用这个漏洞最简单的方法是下载网站根目录下的web.config文件,里面一般收录数据库的用户名和密码. 同意,尝试下载数据库连接文件,confconfig.php等,获取数据库账号密码后如果有root权限,如果知道网站的绝对路径,试试直接写一句话。下载和读取木马的目的是一样的。当然,获取敏感的服务器信息有很多用途。
2.4K 查看全部
php如何抓取网页数据库(任意文件读取与下载的原理及修复注:本文仅供参考)
任意文件读取下载原理及修复
注意:本文仅供参考,学习阅读和下载任意文件。由于网站的一些业务需要,往往需要提供一个模块来读取或下载文件,但如果没有白名单或限制读取或下载,可能会导致恶意攻击者读取和下载一些文件敏感信息(etcpasswda=file:etcpasswd 注:如果文件被解析,则文件收录,如果提示下载或显示源代码,则为文件下载或读取1.文件被解析,文件收录漏洞2.显示源码,文件查看漏洞3.提示下载,是文件下载漏洞的危害。一般来说,利用任意文件下载漏洞主要是为了信息采集, 我们通过下载服务器配置文件获取大量的配置信息和源代码,然后根据获取的信息进一步挖掘服务器漏洞进行入侵。aspx站点aspx站点一般都是后端SQL Server数据库,所以利用这个漏洞最简单的方法是下载网站根目录下的web.config文件,里面一般收录数据库的用户名和密码. 同意,尝试下载数据库连接文件,confconfig.php等,获取数据库账号密码后如果有root权限,如果知道网站的绝对路径,试试直接写一句话。下载和读取木马的目的是一样的。当然,获取敏感的服务器信息有很多用途。
2.4K
php如何抓取网页数据库(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-25 10:08
网站下载器,网站爬取
一款可以复制别人开放区网站的软件,输入地址下载整个网站源码程序,php asp等动态程序无法下载。只能下载html htm的静态页面文件!Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。它可以在您指定的时间自动登录您指定的网站下载您指定的内容,也可以使用它创建一个网站的完整镜像作为您的创作拥有 网站 @网站 的参考。可以简单快捷的保存你喜欢的网页,是复制网站的强大工具!如果您已阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件被保存到网页eleport。Ultra支持定时任务,定时将指定内容下载到指定网站。通过其保存的网站,维护了源站的CSS样式和脚本功能,将超链接替换为本地链接,方便浏览。Teleport Ultra 实际上是一种网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它在本地创建完整的网站镜像或复制,有6种工作模式:1)创建网站的可浏览副本 在硬盘中;2)复制一份网站,包括网站的目录结构;3) 在一个 网站 中搜索指定的文件类型;4) 从中央站点检测每个链接站点;5) 在已知地址下载一个或多个文件;6) 在 网站 中搜索指定的关键字。
现在就下载 查看全部
php如何抓取网页数据库(网站下载器,网站爬取一款可以复制别人开区网站的软件)
网站下载器,网站爬取
一款可以复制别人开放区网站的软件,输入地址下载整个网站源码程序,php asp等动态程序无法下载。只能下载html htm的静态页面文件!Teleport Ultra 可以做的不仅仅是离线浏览网页,它还可以从互联网上的任何地方检索您想要的任何文件。它可以在您指定的时间自动登录您指定的网站下载您指定的内容,也可以使用它创建一个网站的完整镜像作为您的创作拥有 网站 @网站 的参考。可以简单快捷的保存你喜欢的网页,是复制网站的强大工具!如果您已阻止浏览器保存网页,那么使用网站下载器是一种理想的方式。使用网站下载器保存网页要容易得多。软件会自动保存所有页面,但有时因为软件功能太强大,会导致很多不必要的代码、图片、js文件被保存到网页eleport。Ultra支持定时任务,定时将指定内容下载到指定网站。通过其保存的网站,维护了源站的CSS样式和脚本功能,将超链接替换为本地链接,方便浏览。Teleport Ultra 实际上是一种网络蜘蛛(网络机器人),可以自动从互联网上检索特定信息。使用它在本地创建完整的网站镜像或复制,有6种工作模式:1)创建网站的可浏览副本 在硬盘中;2)复制一份网站,包括网站的目录结构;3) 在一个 网站 中搜索指定的文件类型;4) 从中央站点检测每个链接站点;5) 在已知地址下载一个或多个文件;6) 在 网站 中搜索指定的关键字。
现在就下载
php如何抓取网页数据库(php如何抓取网页数据库进行存储和查询,当然是动态的了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-23 23:02
php如何抓取网页数据库进行存储和查询,当然是动态的了这里我使用googlescholar来抓取网页了第一步:googlescholar网站第二步:进入该网站,找到name属性,勾选readtextservice,这里值为memory,一般我们是不会勾选的这个值,然后点击导航栏-authorcode第三步:有的时候呢我们输入的关键词它在scholar里面被归类在article里面,如果我们不想把所有的关键词放到article里面的话,那我们只能去手动切换,那我们想要把所有的文章都分类到一个article里面的话怎么办?勾选contentarticle,当然我们还有一个选项,就是把有时候一些关键词放到article里面了还不行,你还要把contentmanagementmode选择为extract,这样之后呢,我们要把所有的关键词都放到extract里面去解析呢我们可以自己设置下咯,可以看下googlescholar官方的教程在这里就不写了哦;第四步:我们到chrome浏览器上面点击右上角的+号->设置把下面的勾勾去掉,我们前面设置是trytocontentarticle.第五步:我们把下面勾勾去掉之后再来看googlescholar分析我们要读取的数据库,这里我设置的是oralcephp,那如果我们要读取cnblog里面的,那我们要设置,我要读取cnblog.php,很多人不理解,我再说一遍,就是直接读取,如果你要先读取php的,要设置open,再点击分析我们就可以看到一些输出了,我们现在来看看之前在contentarticle里面做了什么,我们把schema里面勾选commonheaders勾上,因为之前contentarticle这个地方我是memory,我所以我勾选了,其他应该没问题,当然具体也是要看代码来进行操作;我们就可以把postpath直接选择googlescholar,然后adminpassword,googlepassword,我们直接登录进去,如果你在chrome浏览器选择隐藏contentarticle的内容,那怎么操作呢?鼠标右键,在菜单里面找到personalized,然后你会看到googlescholar分析,其实你点击之后呢,googlescholar分析里面会在你这个schema内自动生成schemakeywords,这个里面有commonheadersattributes和accesstoken这些,接下来你就回去chrome浏览器,打开你最新得googlescholar,用你的账号和密码来登录。
我们可以看到在oralcephp下面,有一个requestlocationpath,我们现在用的是url转host,就是我们在chrome上的打开方式是网页,然后你打开网页,如果这个网页是国内的,是网页,你就在浏览器右键点copy,然后打开万能的google,如果你打开一个外网,就在google里面搜,看看。我就不放图了,大家自己去百度一下,记住一定要打开国外的网站然。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库进行存储和查询,当然是动态的了)
php如何抓取网页数据库进行存储和查询,当然是动态的了这里我使用googlescholar来抓取网页了第一步:googlescholar网站第二步:进入该网站,找到name属性,勾选readtextservice,这里值为memory,一般我们是不会勾选的这个值,然后点击导航栏-authorcode第三步:有的时候呢我们输入的关键词它在scholar里面被归类在article里面,如果我们不想把所有的关键词放到article里面的话,那我们只能去手动切换,那我们想要把所有的文章都分类到一个article里面的话怎么办?勾选contentarticle,当然我们还有一个选项,就是把有时候一些关键词放到article里面了还不行,你还要把contentmanagementmode选择为extract,这样之后呢,我们要把所有的关键词都放到extract里面去解析呢我们可以自己设置下咯,可以看下googlescholar官方的教程在这里就不写了哦;第四步:我们到chrome浏览器上面点击右上角的+号->设置把下面的勾勾去掉,我们前面设置是trytocontentarticle.第五步:我们把下面勾勾去掉之后再来看googlescholar分析我们要读取的数据库,这里我设置的是oralcephp,那如果我们要读取cnblog里面的,那我们要设置,我要读取cnblog.php,很多人不理解,我再说一遍,就是直接读取,如果你要先读取php的,要设置open,再点击分析我们就可以看到一些输出了,我们现在来看看之前在contentarticle里面做了什么,我们把schema里面勾选commonheaders勾上,因为之前contentarticle这个地方我是memory,我所以我勾选了,其他应该没问题,当然具体也是要看代码来进行操作;我们就可以把postpath直接选择googlescholar,然后adminpassword,googlepassword,我们直接登录进去,如果你在chrome浏览器选择隐藏contentarticle的内容,那怎么操作呢?鼠标右键,在菜单里面找到personalized,然后你会看到googlescholar分析,其实你点击之后呢,googlescholar分析里面会在你这个schema内自动生成schemakeywords,这个里面有commonheadersattributes和accesstoken这些,接下来你就回去chrome浏览器,打开你最新得googlescholar,用你的账号和密码来登录。
我们可以看到在oralcephp下面,有一个requestlocationpath,我们现在用的是url转host,就是我们在chrome上的打开方式是网页,然后你打开网页,如果这个网页是国内的,是网页,你就在浏览器右键点copy,然后打开万能的google,如果你打开一个外网,就在google里面搜,看看。我就不放图了,大家自己去百度一下,记住一定要打开国外的网站然。
php如何抓取网页数据库( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-22 17:10
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/")
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup("","html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> "meta"
# attributes属性
tag.attrs
>>> {"content": "all", "name": "robots"}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> "[document]"
# 字符串的提取
markup="房产"
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> "房产"
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find("table",width="780")
# 解析
for i in lptable.find_all("td",width="680"): href = "http://www.cwestc.com"+i.find("a")["href"]
# href = i.find("a")["href"]
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
<p>
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two 查看全部
php如何抓取网页数据库(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/";)
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup("","html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> "meta"
# attributes属性
tag.attrs
>>> {"content": "all", "name": "robots"}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> "[document]"
# 字符串的提取
markup="房产"
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> "房产"
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests
from bs4 import BeautifulSoup
url = "http://www.cwestc.com/MroeNews.aspx?gd=2"
html = requests.get(url)
soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find("table",width="780")
# 解析
for i in lptable.find_all("td",width="680"): href = "http://www.cwestc.com"+i.find("a")["href"]
# href = i.find("a")["href"]
date = href.split("/")[4]
print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
<p>
from lxml import etree
html="""
test
NO.1
NO.2
NO.3
one
two

