
php如何抓取网页数据库
php如何抓取网页数据库(php如何抓取网页数据库中已有的数据selenium抓取登录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-25 21:01
php如何抓取网页数据库中已有的数据selenium抓取网页模拟登录现在,有人问在什么网站上有很多在线视频教程,是不是可以采用抓包教程抓取视频资源,与网站数据对接,最后实现需求。
你可以去抓包,然后解析,不过楼上已经说得很好了。
我老婆php和python都有,php可以抓取百度搜索,python就是抓个某些机构数据。其实呢,跟采取什么方式是没关系的,当你有足够的数据的时候,爬虫抓取数据,数据清洗,怎么来想怎么来。爬虫抓取时需要考虑许多问题,加载慢速度不一定快,一些动态请求不好处理,可能还得用一些算法解析。另外服务器容量要足够,毕竟http能持续缓存长达若干秒。
php抓包,
php最快,web开发者大会,华云数据库峰会.
服务器没有直接推送后,也可以抓取页面的token,
php与python的话,最简单的就是基于web.py的document包进行抓取,
好像就是有一个网站叫500px,基于python开发的,一直在追踪数据,
php抓包工具-xxxspython抓包工具-xxxspy
php、python都是脚本语言,就python来说,可以搭配java编写api。在接触api2框架的时候,发现thequest这个库(get请求api),api2框架提供了一些基本的接口。所以抓取非常方便。总结一下,就是用php提供的json到restfulmessage的api可以抓取各种网站上的信息。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库中已有的数据selenium抓取登录)
php如何抓取网页数据库中已有的数据selenium抓取网页模拟登录现在,有人问在什么网站上有很多在线视频教程,是不是可以采用抓包教程抓取视频资源,与网站数据对接,最后实现需求。
你可以去抓包,然后解析,不过楼上已经说得很好了。
我老婆php和python都有,php可以抓取百度搜索,python就是抓个某些机构数据。其实呢,跟采取什么方式是没关系的,当你有足够的数据的时候,爬虫抓取数据,数据清洗,怎么来想怎么来。爬虫抓取时需要考虑许多问题,加载慢速度不一定快,一些动态请求不好处理,可能还得用一些算法解析。另外服务器容量要足够,毕竟http能持续缓存长达若干秒。
php抓包,
php最快,web开发者大会,华云数据库峰会.
服务器没有直接推送后,也可以抓取页面的token,
php与python的话,最简单的就是基于web.py的document包进行抓取,
好像就是有一个网站叫500px,基于python开发的,一直在追踪数据,
php抓包工具-xxxspython抓包工具-xxxspy
php、python都是脚本语言,就python来说,可以搭配java编写api。在接触api2框架的时候,发现thequest这个库(get请求api),api2框架提供了一些基本的接口。所以抓取非常方便。总结一下,就是用php提供的json到restfulmessage的api可以抓取各种网站上的信息。
php如何抓取网页数据库(自学Python爬虫有哪些步骤?自学爬虫的网页解析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-23 01:03
如何自学 Python 爬虫?在每个人学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫实际上是一个自动抓取页面信息的网络机器人。至于为什么要用 Python 作为爬虫,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬取技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者。它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引和模拟程序。其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫的功能就很好用了。
二、为什么python适合爬虫?
实现爬虫技术的编程环境有很多。 Java、Python、C++等都可以用于爬虫。但是为什么大家选择 Python 是因为 Python 真的很适合爬虫。丰富的第三方库功能非常强大,只需几行代码即可实现您想要的功能;跨平台,对Linux和windows都有很好的支持。 更重要的是,Python 还是数据挖掘和分析的好专家。这样一来,使用Python进行数据爬取和数据分析的一站式服务,真的很方便。
三、自学Python爬虫的步骤是什么?
1、先学习基本的 Python 语法
2、了解Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5、了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制
6、学习一些特殊的网站爬取解决登录、cookies、动态网页等问题
7、了解爬虫和数据库的结合,如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫、Scrapy、PySpider等框架
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备、HTTP和HTTPS的学习、requests模块的使用、重试模块的使用和cookie相关请求的处理、数据提取方法值json、data提取值xpath和lxml模块的学习,xpath和lxml模块的练习等等。完成本课程后,可以了解爬虫的原理,学习使用python进行网络请求,掌握抓取网页数据的方法。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动比心跳更糟糕。无论是视频还是其他学习资源,网上都可以轻松获取。 查看全部
php如何抓取网页数据库(自学Python爬虫有哪些步骤?自学爬虫的网页解析工具)
如何自学 Python 爬虫?在每个人学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫实际上是一个自动抓取页面信息的网络机器人。至于为什么要用 Python 作为爬虫,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬取技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者。它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引和模拟程序。其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫的功能就很好用了。
二、为什么python适合爬虫?
实现爬虫技术的编程环境有很多。 Java、Python、C++等都可以用于爬虫。但是为什么大家选择 Python 是因为 Python 真的很适合爬虫。丰富的第三方库功能非常强大,只需几行代码即可实现您想要的功能;跨平台,对Linux和windows都有很好的支持。 更重要的是,Python 还是数据挖掘和分析的好专家。这样一来,使用Python进行数据爬取和数据分析的一站式服务,真的很方便。
三、自学Python爬虫的步骤是什么?
1、先学习基本的 Python 语法
2、了解Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5、了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制
6、学习一些特殊的网站爬取解决登录、cookies、动态网页等问题
7、了解爬虫和数据库的结合,如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫、Scrapy、PySpider等框架
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备、HTTP和HTTPS的学习、requests模块的使用、重试模块的使用和cookie相关请求的处理、数据提取方法值json、data提取值xpath和lxml模块的学习,xpath和lxml模块的练习等等。完成本课程后,可以了解爬虫的原理,学习使用python进行网络请求,掌握抓取网页数据的方法。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动比心跳更糟糕。无论是视频还是其他学习资源,网上都可以轻松获取。
php如何抓取网页数据库(搜索引擎网站出现异常的原因有哪些呢?有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-21 14:19
部分网站内容质量高,用户可以访问,但搜索引擎无法抓取网站内容,导致搜索结果覆盖率低。都是亏本。
如果大量的网站内容无法爬取,搜索引擎会认为网站的用户体验不好,会降低网站的评价,从而有负面影响,从而影响 网站 排名和流量。
那么,搜索引擎爬取异常的原因是什么网站?
1、服务器连接异常
服务器连接异常有两种情况:
①网站不稳定,当搜索引擎蜘蛛连接到网站服务器时,会连接失败。
②搜索引擎蜘蛛一直无法连接到网站服务器。
服务器连接异常的原因通常是网站服务器太大或过载。
2、网络运营商
如果出现这种情况,需要联系网络运营商解决问题。
3、DNS 异常
当爬虫无法解析 网站IP 时,会发生 DNS 异常。可能是网站IP地址错误,此时需要更新IP地址。
4、IP 封锁
限制网络的导出IP地址,并禁止该IP段内的用户访问内容。这里指的是被屏蔽的爬虫的IP。您只需联系服务提供商更改设置即可。
5、UA 禁令
服务器通过UA识别用户。当网站异常返回一个页面或者跳转到另一个页面进行指定的UA访问,就是UAban。只有当网站不需要搜索引擎蜘蛛访问时才需要设置。
6、链接失效
网站无效页面或未向用户提供有价值信息的页面为死链接。
7、异常跳转
重定向到另一个位置的网络请求是一个跳转。 查看全部
php如何抓取网页数据库(搜索引擎网站出现异常的原因有哪些呢?有什么作用?)
部分网站内容质量高,用户可以访问,但搜索引擎无法抓取网站内容,导致搜索结果覆盖率低。都是亏本。
如果大量的网站内容无法爬取,搜索引擎会认为网站的用户体验不好,会降低网站的评价,从而有负面影响,从而影响 网站 排名和流量。

那么,搜索引擎爬取异常的原因是什么网站?
1、服务器连接异常
服务器连接异常有两种情况:
①网站不稳定,当搜索引擎蜘蛛连接到网站服务器时,会连接失败。
②搜索引擎蜘蛛一直无法连接到网站服务器。
服务器连接异常的原因通常是网站服务器太大或过载。
2、网络运营商
如果出现这种情况,需要联系网络运营商解决问题。
3、DNS 异常
当爬虫无法解析 网站IP 时,会发生 DNS 异常。可能是网站IP地址错误,此时需要更新IP地址。
4、IP 封锁
限制网络的导出IP地址,并禁止该IP段内的用户访问内容。这里指的是被屏蔽的爬虫的IP。您只需联系服务提供商更改设置即可。
5、UA 禁令
服务器通过UA识别用户。当网站异常返回一个页面或者跳转到另一个页面进行指定的UA访问,就是UAban。只有当网站不需要搜索引擎蜘蛛访问时才需要设置。
6、链接失效
网站无效页面或未向用户提供有价值信息的页面为死链接。
7、异常跳转
重定向到另一个位置的网络请求是一个跳转。
php如何抓取网页数据库(使用PHP的动态网页-Web概念-本课程演示PHP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2022-02-21 14:12
"。以下程序将“Hello World”输出到您的网络浏览器。.
PHP 仅收录在主页 URL 中,截至 2018 年 10 月,80% 的 网站 使用 PHP,其所有 PHP 代码仅在 Web 服务器上执行,而不是在本地机器上执行。将您的页脚链接更改为仅显示在主页上。在活动 WordPress 主题内的 footer.php 文件中,您需要添加此部分。最好的 PHP 例子,PHP 的语法比较简单。像往常一样对您的页面进行编码,但所有 PHP 代码必须用“”括起来。以下程序将“Hello World”输出到您的 Web 浏览器。php,当前显示在每个页面上。我希望它只出现在我的主页上 - 我必须认为有一个简单的代码片段可以 .
PHP动态内容
1. 动态内容和 Web,4-1:使用 PHP 的动态网页 - 一个简单(但很有帮助)的示例 从一个页面到另一个页面的唯一变化是介于两者之间的“主要内容”的内容它们之间的媒介使我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您必须在 . 4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入工作 服务动态内容 这种情况很容易解决通过使用 PHP 生成的动态网页。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一页到另一页的唯一变化是“
4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,动态内容是两者之间的快乐媒介,让我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您需要在 PHP - Web 概念 - 本课程中做的越多,它将演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。使用 PHP 显示动态数据库驱动的内容,使用 PHP 生成的动态网页可以轻松解决这种情况。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的 .
使用 PHP 显示动态数据库驱动的内容,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,可以立即清楚地看出它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。. 添加动态内容 | PHP Crash Course 使用服务器端脚本语言的主要原因是能够为网站用户提供动态内容。这是一个重要的如何用 PHP 和 Mysql 创建一个简单的动态 网站?
添加动态内容 | PHP Crash Course,这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的。PHP & MySQL 教程创建动态内容 3. 如何用 PHP 和 Mysql 创建一个简单的动态 网站?
如何在 PHP MySQL 中使用管理面板创建 网站
使用 Bootstrap 4 创建 PHP 管理仪表板模板,在本教程中,学习如何使用 PHP 和 MYSQL 以及 CRUD 操作构建管理面板。PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分)有一个 html 提示,您可以在根据需要进行一些更改后在 网站 上使用它。现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin: CREATE TABLE login_admin ( id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100), user_pass VARCHAR(200), PRIMARY KEY ( id) ) 现在使用以下命令在两个表中插入用户信息: . PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php 中在 My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。几乎每一个 网站 都提供注册和登录功能。因此,有必要使用 .
PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin:CREATE TABLE login_admin (id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100)@ > , user_pass VARCHAR( 200), PRIMARY KEY (id) ) 现在使用以下方法在表中插入两个用户信息:如何使用管理员面板在 PHP MySQL 中创建动态网站。在 php My Admin 中创建表和数据库并连接它们到网站..管理员和用户登录php和mysql数据库,如何使用PHP和MySQL创建注册和登录系统。这是使用PHP和MySQL构建登录系统的快速解决方案。现在几乎每个网站都提供注册和登录功能。因此有必要使用以下查询在数据库中添加登录系统 - .
管理员和用户登录到 php 和 mysql 数据库,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。现在几乎每个 网站 都提供注册和登录功能。因此,有必要使用 PHP、MySQL、HTML 和 CSS 设置管理面板,使用以下查询的数据库 -
使用 PHP、MySQL、HTML 和 CSS 设置管理面板,PHP 管理面板的 3 个简单步骤(包括源代码),
简单的 PHP 管理面板分 3 步(包括源代码),使用管理面板 PHP MYSQL 第 1 部分构建动态 网站,
更多问题 查看全部
php如何抓取网页数据库(使用PHP的动态网页-Web概念-本课程演示PHP)
"。以下程序将“Hello World”输出到您的网络浏览器。.
PHP 仅收录在主页 URL 中,截至 2018 年 10 月,80% 的 网站 使用 PHP,其所有 PHP 代码仅在 Web 服务器上执行,而不是在本地机器上执行。将您的页脚链接更改为仅显示在主页上。在活动 WordPress 主题内的 footer.php 文件中,您需要添加此部分。最好的 PHP 例子,PHP 的语法比较简单。像往常一样对您的页面进行编码,但所有 PHP 代码必须用“”括起来。以下程序将“Hello World”输出到您的 Web 浏览器。php,当前显示在每个页面上。我希望它只出现在我的主页上 - 我必须认为有一个简单的代码片段可以 .
PHP动态内容
1. 动态内容和 Web,4-1:使用 PHP 的动态网页 - 一个简单(但很有帮助)的示例 从一个页面到另一个页面的唯一变化是介于两者之间的“主要内容”的内容它们之间的媒介使我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您必须在 . 4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入工作 服务动态内容 这种情况很容易解决通过使用 PHP 生成的动态网页。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一页到另一页的唯一变化是“
4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,动态内容是两者之间的快乐媒介,让我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您需要在 PHP - Web 概念 - 本课程中做的越多,它将演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。使用 PHP 显示动态数据库驱动的内容,使用 PHP 生成的动态网页可以轻松解决这种情况。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的 .
使用 PHP 显示动态数据库驱动的内容,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,可以立即清楚地看出它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。. 添加动态内容 | PHP Crash Course 使用服务器端脚本语言的主要原因是能够为网站用户提供动态内容。这是一个重要的如何用 PHP 和 Mysql 创建一个简单的动态 网站?
添加动态内容 | PHP Crash Course,这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的。PHP & MySQL 教程创建动态内容 3. 如何用 PHP 和 Mysql 创建一个简单的动态 网站?
如何在 PHP MySQL 中使用管理面板创建 网站
使用 Bootstrap 4 创建 PHP 管理仪表板模板,在本教程中,学习如何使用 PHP 和 MYSQL 以及 CRUD 操作构建管理面板。PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分)有一个 html 提示,您可以在根据需要进行一些更改后在 网站 上使用它。现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin: CREATE TABLE login_admin ( id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100), user_pass VARCHAR(200), PRIMARY KEY ( id) ) 现在使用以下命令在两个表中插入用户信息: . PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php 中在 My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。几乎每一个 网站 都提供注册和登录功能。因此,有必要使用 .
PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin:CREATE TABLE login_admin (id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100)@ > , user_pass VARCHAR( 200), PRIMARY KEY (id) ) 现在使用以下方法在表中插入两个用户信息:如何使用管理员面板在 PHP MySQL 中创建动态网站。在 php My Admin 中创建表和数据库并连接它们到网站..管理员和用户登录php和mysql数据库,如何使用PHP和MySQL创建注册和登录系统。这是使用PHP和MySQL构建登录系统的快速解决方案。现在几乎每个网站都提供注册和登录功能。因此有必要使用以下查询在数据库中添加登录系统 - .
管理员和用户登录到 php 和 mysql 数据库,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。现在几乎每个 网站 都提供注册和登录功能。因此,有必要使用 PHP、MySQL、HTML 和 CSS 设置管理面板,使用以下查询的数据库 -
使用 PHP、MySQL、HTML 和 CSS 设置管理面板,PHP 管理面板的 3 个简单步骤(包括源代码),
简单的 PHP 管理面板分 3 步(包括源代码),使用管理面板 PHP MYSQL 第 1 部分构建动态 网站,
更多问题
php如何抓取网页数据库(php如何抓取网页数据库内部对应关系怎么变化呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-18 23:03
php如何抓取网页数据库内部对应关系怎么变化呢?简单的方法,可以在php里面做变量替换,将每个元素映射到php中的数据库键值对(key_value)对里面去。php里面数据的键值对比如下{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}看上去,应该跟python是一样的。
那么,用php抓取网页数据库内部对应关系不是应该也是可以成立的么?这个比较奇怪,难道php和python不是一个完整的语言么?我们是不是可以做一个新的语言?php是脚本语言,中间并没有用到语言的标准方言,php5.6(新型语言)来增加语言的标准方言,原先php3.0的模板里面增加函数common_content_script_method。
{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}发现这里面php5.6和php5.3没有变化,使用的标准模板函数一样。另外,php5.6是用于部署php5.6.4。这意味着可以通过vc6或vc6+的方式搭建php5.6的环境,下面是centos6的安装方法:在centos环境下安装方法是:bash-cpphp-5.6/bin/bash以上方法仅能部署到centos6+系统,后面会讲解怎么部署到centos7和centos7+系统。详情请参考安装hadoop。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库内部对应关系怎么变化呢?)
php如何抓取网页数据库内部对应关系怎么变化呢?简单的方法,可以在php里面做变量替换,将每个元素映射到php中的数据库键值对(key_value)对里面去。php里面数据的键值对比如下{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}看上去,应该跟python是一样的。
那么,用php抓取网页数据库内部对应关系不是应该也是可以成立的么?这个比较奇怪,难道php和python不是一个完整的语言么?我们是不是可以做一个新的语言?php是脚本语言,中间并没有用到语言的标准方言,php5.6(新型语言)来增加语言的标准方言,原先php3.0的模板里面增加函数common_content_script_method。
{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}发现这里面php5.6和php5.3没有变化,使用的标准模板函数一样。另外,php5.6是用于部署php5.6.4。这意味着可以通过vc6或vc6+的方式搭建php5.6的环境,下面是centos6的安装方法:在centos环境下安装方法是:bash-cpphp-5.6/bin/bash以上方法仅能部署到centos6+系统,后面会讲解怎么部署到centos7和centos7+系统。详情请参考安装hadoop。
php如何抓取网页数据库(web开发笔记php多线程!抓http请求,获取到对应的字符串)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-18 11:01
php如何抓取网页数据库中数据php的话,一般是通过反射的方式来实现。你首先需要手动抓取网页,然后根据格式来封装自己的http请求,进而调用合适的方法将结果返回到php代码中。最终达到你需要的效果。比如你的网页里会有类似请求参数和具体配置的内容。你就可以通过反射的方式来匹配,写个单例来实现,在同一个类中有2个变量,offset和class是相同的,则每次调用的是不同的方法获取数据。
应该调用php的malloc函数。
你可以手工写个单例然后调用他的.
请参考:web开发笔记
php多线程!
抓http请求,获取到对应的字符串
如果你不深入分析他网页的内容的话,而是玩玩的话,其实很简单,先查查对应的php代码是怎么调用的,把这个代码封装成一个函数,其他人都能接受然后调用。代码是php的,那么可以自己写单例,
你这一段代码的意思是只获取一个网页?可以进行反射,找相应的类或者直接用类名。或者根据具体格式,代码模板,获取相应的值。
谢邀。如果是要抓取web网页的话,那就太简单了,直接php代码反射就行了。无非就是一个,判断http请求的格式,然后相应的返回json,返回给你,其他就不用处理。
php没有上下文切换,所以,为啥还要有一个调用别人的flash之类的。 查看全部
php如何抓取网页数据库(web开发笔记php多线程!抓http请求,获取到对应的字符串)
php如何抓取网页数据库中数据php的话,一般是通过反射的方式来实现。你首先需要手动抓取网页,然后根据格式来封装自己的http请求,进而调用合适的方法将结果返回到php代码中。最终达到你需要的效果。比如你的网页里会有类似请求参数和具体配置的内容。你就可以通过反射的方式来匹配,写个单例来实现,在同一个类中有2个变量,offset和class是相同的,则每次调用的是不同的方法获取数据。
应该调用php的malloc函数。
你可以手工写个单例然后调用他的.
请参考:web开发笔记
php多线程!
抓http请求,获取到对应的字符串
如果你不深入分析他网页的内容的话,而是玩玩的话,其实很简单,先查查对应的php代码是怎么调用的,把这个代码封装成一个函数,其他人都能接受然后调用。代码是php的,那么可以自己写单例,
你这一段代码的意思是只获取一个网页?可以进行反射,找相应的类或者直接用类名。或者根据具体格式,代码模板,获取相应的值。
谢邀。如果是要抓取web网页的话,那就太简单了,直接php代码反射就行了。无非就是一个,判断http请求的格式,然后相应的返回json,返回给你,其他就不用处理。
php没有上下文切换,所以,为啥还要有一个调用别人的flash之类的。
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-16 03:24
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库教程,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确保我们的 PHP 启用了这个库,你可以通过使用 php 教程的 _info() 函数来获取这些信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
// 取消下面的评论
扩展=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
关于 SSL 和 Cookie 查看全部
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库教程,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确保我们的 PHP 启用了这个库,你可以通过使用 php 教程的 _info() 函数来获取这些信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
// 取消下面的评论
扩展=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
关于 SSL 和 Cookie
php如何抓取网页数据库(php如何抓取网页数据库?如何上传到其他js文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-16 02:01
php如何抓取网页数据库?如何上传到其他js文件?如何写一个爬虫?感谢google老哥提供的php抓包分析和数据分析平台。本文详细介绍php抓包分析和数据分析平台的源码和使用方法。
一、分析php抓包和抓取数据库
二、分析php代码分析,
三、分析php代码分析,练习爬虫使用方法:php代码分析,
一)php代码分析
二)php代码分析
三)php代码分析
四)php代码分析
五)视频教程地址:;view=all代码提示:php密码错误,使用phpkey替代。练习的编程环境:windows10,
php函数封装(三种常用配置)#1.php函数封装1.1基础php函数大全(主要接口)1.2中级php函数(数据库驱动相关)1.3详细php函数(js文件封装)autoconfautoconf使用教程appendcall表+=表封装append语句+=+=$call;,在本代码封装注意大小写update$data=append($temporary,$content);,要么本代码封装(即":content"+$content)update:{"data":"","content":""}js文件封装,可以参考,封装windowsjs文件</a>1.5爬虫实例小爬虫类型爬虫返回布尔类型&amp;amp;three引擎博客爬虫实例与封装爬虫基础伪装:接口伪装:获取外界访问等。
forward()接口伪装函数执行循环,"window","max_height"接口伪装函数,"user_height"接口伪装函数(本文采用这种)接口伪装包括$post语句if(f3in$_server[$name]){$db_name=$_server[$name]?$f3:'publicname';}else{$db_name='';}$post=f3;?>随机数接口伪装函数会生成(用于加密,替换等场景)随机数及token。
publicname=['f3','r7855','03331','033','s319412','ant','pi',''];for($tuple:$name){if($tuple[$tuple]==$name){echo$tuple;}?}验证地址$_server[$token];接口伪装函数实现验证地址(append函数是ioconfserver上的,f3等是windows)inconf.php如何对php进行参数防爬结构参数防爬实现1.配置使用$context=require("inconf.php");$url=$_server['request_uri'];$m。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库?如何上传到其他js文件?)
php如何抓取网页数据库?如何上传到其他js文件?如何写一个爬虫?感谢google老哥提供的php抓包分析和数据分析平台。本文详细介绍php抓包分析和数据分析平台的源码和使用方法。
一、分析php抓包和抓取数据库
二、分析php代码分析,
三、分析php代码分析,练习爬虫使用方法:php代码分析,
一)php代码分析
二)php代码分析
三)php代码分析
四)php代码分析
五)视频教程地址:;view=all代码提示:php密码错误,使用phpkey替代。练习的编程环境:windows10,
php函数封装(三种常用配置)#1.php函数封装1.1基础php函数大全(主要接口)1.2中级php函数(数据库驱动相关)1.3详细php函数(js文件封装)autoconfautoconf使用教程appendcall表+=表封装append语句+=+=$call;,在本代码封装注意大小写update$data=append($temporary,$content);,要么本代码封装(即":content"+$content)update:{"data":"","content":""}js文件封装,可以参考,封装windowsjs文件</a>1.5爬虫实例小爬虫类型爬虫返回布尔类型&amp;amp;three引擎博客爬虫实例与封装爬虫基础伪装:接口伪装:获取外界访问等。
forward()接口伪装函数执行循环,"window","max_height"接口伪装函数,"user_height"接口伪装函数(本文采用这种)接口伪装包括$post语句if(f3in$_server[$name]){$db_name=$_server[$name]?$f3:'publicname';}else{$db_name='';}$post=f3;?>随机数接口伪装函数会生成(用于加密,替换等场景)随机数及token。
publicname=['f3','r7855','03331','033','s319412','ant','pi',''];for($tuple:$name){if($tuple[$tuple]==$name){echo$tuple;}?}验证地址$_server[$token];接口伪装函数实现验证地址(append函数是ioconfserver上的,f3等是windows)inconf.php如何对php进行参数防爬结构参数防爬实现1.配置使用$context=require("inconf.php");$url=$_server['request_uri'];$m。
php如何抓取网页数据库(php中抓取网页内容的实例详解方法一:使用file_get_contents方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-12 07:15
php爬取网页内容的详细示例
方法一:
使用file_get_contents方法来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $html = file_get_contents($url); //如果出现中文乱码使用下面代码 //$getcOntent= iconv("gb2312", "utf-8",$html); echo "".$html."";
代码很简单,一看就懂,不用解释。
方法二:
使用 curl 实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTransfer, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
相关学习推荐:PHP编程(视频) 查看全部
php如何抓取网页数据库(php中抓取网页内容的实例详解方法一:使用file_get_contents方法)
php爬取网页内容的详细示例
方法一:
使用file_get_contents方法来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $html = file_get_contents($url); //如果出现中文乱码使用下面代码 //$getcOntent= iconv("gb2312", "utf-8",$html); echo "".$html."";
代码很简单,一看就懂,不用解释。
方法二:
使用 curl 实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTransfer, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
相关学习推荐:PHP编程(视频)
php如何抓取网页数据库(php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-10 15:07
php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装phpmyadmin:到官网下载,要用到的是extractor1.打开extractor,导入一下数据库和books.config。extractor安装phpmyadmin:phpmyadmin--extractor-database="testdb"--dbpath="/testdb"--cache-config="preference--prefix=/testdb"--rootpath="/"配置参数extractor下载地址:,在extractor中找到books.config.user-id='student-id'选中"+"按钮,否则按钮是空的,这个参数将填写用户名和密码,从主机拉取数据以后需要配置两个数据库账号和密码:账号user-id,密码password访问books.config,删除phpmyadmin,然后重新执行extractor选择books.config中的user-id='student-id',密码password。
抓取网页一段html文件的数据可以使用phpmyadmin所有的功能如reader函数,获取phpmyadmin中的.html文件的数据,但是其他功能需要另外配置。phpmyadmin如何抓取网页:1.先新建一个空的phpmyadmin账号/users/lauzd/books.config。2.在左侧设置抓取列表databases选择c2015。
3.设置对应.html文件的位置,可以在最后添加curl函数指定第一个.html文件的位置。指定位置后,可以指定文件名称,也可以指定.html后缀,后缀具体指定为啥看你喜欢。如果不指定,文件将指定到cpp_client.php.xml。4.然后就可以设置获取时间,如果有需要或者该testdb只是爬虫时的testdb,那么最后一页面将显示一个time参数,time参数从1秒开始到1000000000毫秒。
5.具体抓取过程要看人性化操作要求,可以设置加载时间和下载速度等等。抓取html文件中的内容如果在数据库中列表是未存在的,则也返回给操作员用于指定前1000000000毫秒内,该站的html文件没有存在。可以通过reader函数来获取列表,也可以通过prefix/***/命令来获取列表。本文来自如何安装phpmyadmin和phpmyadmin如何抓取网页数据?-phpmyadmin的分享。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装)
php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装phpmyadmin:到官网下载,要用到的是extractor1.打开extractor,导入一下数据库和books.config。extractor安装phpmyadmin:phpmyadmin--extractor-database="testdb"--dbpath="/testdb"--cache-config="preference--prefix=/testdb"--rootpath="/"配置参数extractor下载地址:,在extractor中找到books.config.user-id='student-id'选中"+"按钮,否则按钮是空的,这个参数将填写用户名和密码,从主机拉取数据以后需要配置两个数据库账号和密码:账号user-id,密码password访问books.config,删除phpmyadmin,然后重新执行extractor选择books.config中的user-id='student-id',密码password。
抓取网页一段html文件的数据可以使用phpmyadmin所有的功能如reader函数,获取phpmyadmin中的.html文件的数据,但是其他功能需要另外配置。phpmyadmin如何抓取网页:1.先新建一个空的phpmyadmin账号/users/lauzd/books.config。2.在左侧设置抓取列表databases选择c2015。
3.设置对应.html文件的位置,可以在最后添加curl函数指定第一个.html文件的位置。指定位置后,可以指定文件名称,也可以指定.html后缀,后缀具体指定为啥看你喜欢。如果不指定,文件将指定到cpp_client.php.xml。4.然后就可以设置获取时间,如果有需要或者该testdb只是爬虫时的testdb,那么最后一页面将显示一个time参数,time参数从1秒开始到1000000000毫秒。
5.具体抓取过程要看人性化操作要求,可以设置加载时间和下载速度等等。抓取html文件中的内容如果在数据库中列表是未存在的,则也返回给操作员用于指定前1000000000毫秒内,该站的html文件没有存在。可以通过reader函数来获取列表,也可以通过prefix/***/命令来获取列表。本文来自如何安装phpmyadmin和phpmyadmin如何抓取网页数据?-phpmyadmin的分享。
php如何抓取网页数据库(用PHP做一个记录,为后续学习铺路。。(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-06 21:01
昨天发现了一个数据库管理软件:Navicat for MySQL,一个强大的MySQL数据库管理和开发工具,这个软件使用了优秀的图形用户界面(GUI),可以以一种安全、简单的方式快速使用并轻松创建新的数据库,新的在前端学习的过程中,一直对后台如何从数据库中读取数据,后台如何提供前端接口等感兴趣。借此机会,我尝试创建一个新的数据库和表,并使用 PHP 从构建的数据库中读取数据。并使用Ajax将数据展示在前端,并做好记录,为后续学习做铺垫。
1、使用 Navicat for MySQL 创建数据库和表
Navicat for MySQL 使用起来非常简单。您无需像 PHP 那样编写代码来创建数据库和表。具体操作在此不再详述。您可以参考以下网址进行创建:
Navicat for MySQL 的下载、安装和基本使用
Navicat for MySQL 使用说明(第 1 部分)– 创建数据库和表
创建的数据库和表如下图所示:
2、使用PHP从MySQL数据库中读取数据
在下面的例子中,我们从student数据库的studentinfo表中读取studentID、studentName、class、department和teleNumber列的数据并显示在页面上:
上面的代码解析如下:
首先,设置SQL语句从MyGuests数据表中读取id、firstname和lastname三个字段。然后我们使用修改后的 SQL 语句从数据库中获取结果集并将其分配给变量 $result。
函数 num_rows() 判断返回的数据。
如果返回多条数据,函数 fetch_assoc() 将关联集放入关联数组并循环输出。while() 循环出结果集,输出id、firstname、lastname三个字段值。
过程中遇到的问题:
(1)PHP从数据库中读取数据的中文显示为“?”,解决方法:
mysqli_query($conn, 'set names utf8')之后,中文变成Unicode编码
(2)如何将Unicode编码改为中文:
json_encode($row,JSON_UNESCAPED_UNICODE)。' ';
3、使用ajax在前端页面展示数据
代码显示如下:
.table{
width: 1000px;
text-align: center;
}
学生信息管理
学号
姓名
班级
学院
电话
$.ajax({
type: 'POST',
url: 'studentInfo.php',
data:{
},
success: function (data) {
//console.log(data);
var a = data.split(' ');
//console.log(a);
var trStr = '';//动态拼接table
for (var i = 0; i < a.length-1; i++) {
trStr += '';
trStr += '' + JSON.parse(a[i]).studentID + '';
trStr += '' + JSON.parse(a[i]).studentName + '';
trStr += '' + JSON.parse(a[i]).class + '';
trStr += '' + JSON.parse(a[i]).department + '';
trStr += '' + JSON.parse(a[i]).teleNumber + '';
trStr += '';
}
$("#tbody").html(trStr);
}
});
最终效果:
以上内容仅作为前端、后端与数据库连接的演示,更不用说前端与后端的数据交互。还有很多内容需要扩展,比如数据的增删改操作。您可以在业余时间自娱自乐。 查看全部
php如何抓取网页数据库(用PHP做一个记录,为后续学习铺路。。(一))
昨天发现了一个数据库管理软件:Navicat for MySQL,一个强大的MySQL数据库管理和开发工具,这个软件使用了优秀的图形用户界面(GUI),可以以一种安全、简单的方式快速使用并轻松创建新的数据库,新的在前端学习的过程中,一直对后台如何从数据库中读取数据,后台如何提供前端接口等感兴趣。借此机会,我尝试创建一个新的数据库和表,并使用 PHP 从构建的数据库中读取数据。并使用Ajax将数据展示在前端,并做好记录,为后续学习做铺垫。
1、使用 Navicat for MySQL 创建数据库和表
Navicat for MySQL 使用起来非常简单。您无需像 PHP 那样编写代码来创建数据库和表。具体操作在此不再详述。您可以参考以下网址进行创建:
Navicat for MySQL 的下载、安装和基本使用
Navicat for MySQL 使用说明(第 1 部分)– 创建数据库和表
创建的数据库和表如下图所示:

2、使用PHP从MySQL数据库中读取数据
在下面的例子中,我们从student数据库的studentinfo表中读取studentID、studentName、class、department和teleNumber列的数据并显示在页面上:
上面的代码解析如下:
首先,设置SQL语句从MyGuests数据表中读取id、firstname和lastname三个字段。然后我们使用修改后的 SQL 语句从数据库中获取结果集并将其分配给变量 $result。
函数 num_rows() 判断返回的数据。
如果返回多条数据,函数 fetch_assoc() 将关联集放入关联数组并循环输出。while() 循环出结果集,输出id、firstname、lastname三个字段值。
过程中遇到的问题:
(1)PHP从数据库中读取数据的中文显示为“?”,解决方法:
mysqli_query($conn, 'set names utf8')之后,中文变成Unicode编码
(2)如何将Unicode编码改为中文:
json_encode($row,JSON_UNESCAPED_UNICODE)。' ';
3、使用ajax在前端页面展示数据
代码显示如下:
.table{
width: 1000px;
text-align: center;
}
学生信息管理
学号
姓名
班级
学院
电话
$.ajax({
type: 'POST',
url: 'studentInfo.php',
data:{
},
success: function (data) {
//console.log(data);
var a = data.split(' ');
//console.log(a);
var trStr = '';//动态拼接table
for (var i = 0; i < a.length-1; i++) {
trStr += '';
trStr += '' + JSON.parse(a[i]).studentID + '';
trStr += '' + JSON.parse(a[i]).studentName + '';
trStr += '' + JSON.parse(a[i]).class + '';
trStr += '' + JSON.parse(a[i]).department + '';
trStr += '' + JSON.parse(a[i]).teleNumber + '';
trStr += '';
}
$("#tbody").html(trStr);
}
});
最终效果:

以上内容仅作为前端、后端与数据库连接的演示,更不用说前端与后端的数据交互。还有很多内容需要扩展,比如数据的增删改操作。您可以在业余时间自娱自乐。
php如何抓取网页数据库(网络爬虫就是网站实现web信息展示的核心在于设计模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 08:23
项目介绍
随着互联网的飞速发展,网络已经成为人们检索和发布的主要平台。如何在海量数据中快速、准确地找到用户需要的信息,成为了当下人们所需要的,而网络爬虫正是为了满足人们的需求。因这种需要而产生的研究领域。现实中,我们的资源是有限的,如何在有限的资源中区分我们每个人的不同需求,有的想听歌,有的想看电影,有的是工作需要的机密文件,不想别人看吧,只有它才能保护大家的隐私,满足不同人群的需求。因此,仍然需要根据不同的用户来研究爬取内容。
在检索信息和采集信息中实现网页信息展示的核心是设计网页爬虫模块,主要是全文搜索引擎模块。本文主要设计全文搜索并实现页面采集器的详细介绍。工作流影响核心算法和数据存储,克服了技术难点,实现了良好的实际运行和良好的效果,进一步提升了引擎效果。
这个网站基于B/S模式设计爬虫网站,需要简单的爬取操作和清除多用户数据。开发爬虫网站管理多用户,数据分级管理,数据存放在指定数据库中。区分重复网页,解决去重问题;添加主题相关性;更快地抓取数据;存储数据; 实现数据可视化。
关键词:搜索引擎;网络爬虫;信息检索;页面索引
使用python提供的开源django应用框架,Django更注重模型(Model)、模板(Template)和视图(Views),也就是MTV模式。
打开登录界面,可以使用以下操作:
(1)安装python3.6版本
(2) 安装 Django 库 1.11.4 版本 pip install Django==1.11.14
(3) 安装 selenium 库3.141.0 pip install selenium
(4)安装jieba库0.39版 pip install jieba
(5)命令行下进入xxx\Web_Spider_Demo\mysite_login\目录,运行manage.py(操作方法:python manage.py runserver),运行成功后,打开浏览器(google),进入网页主页:127.0.0.1:8000/index.
(6)登录时可以使用注册时的账号和密码登录自己的界面,获取填写的数据是否与注册时的信息进行对比。如果同理,可以登录使用网站功能。
爬虫搜索
设计从网页中选取一些url,将url放入url队列,解析这些url中的链接,下载内容,存储在一个固定的页库中,建立对应的索引,从其中提取所有链接它。如果解析中收录的 url 没有出现在缓存中,则该 url 调度的队列会被再次抓取,直到抓取到对应的网页。完成一个完整的爬取过程后,爬虫有多种类型:
(1)批量爬虫:将数据批量抓取到想要的目标和范围。当爬虫到达设定的目标时,就会停止爬取过程。至于具体的目标,可能不一样,也可能是设置爬取一定数量的网页,也可以设置爬取所消耗的时间。
(2)增量爬虫:如果在爬取过程中出现了新的网页,该机制会更新该网页,可以实现一个通用的搜索引擎来实现增量处理。
(3)Focused Crawter):针对不同的特定主题和不同特定行业的网页,您可以从互联网页面中找到健康相关页面的内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。
效果图
内容
1 简介 3
1.1 开发背景 4
1.2 研究现状 4
2 页面设计 6
2.1 工作原理 6
2.2 网页设计 6
2.2.1 注册 7
2.2.2 登录 8
2.2.3 爬虫搜索 8
3 功能实现 10
3.1 基本工作原理 10
3.2 jieba库10
4 数据库设计 10
5 测试 11
5.1 设计问题 11
5.2 问题级别 12
5.3 测试评估 12
5.4 测试设计 12
6 结语 13
参考文献 13
谢谢 16 查看全部
php如何抓取网页数据库(网络爬虫就是网站实现web信息展示的核心在于设计模块)
项目介绍
随着互联网的飞速发展,网络已经成为人们检索和发布的主要平台。如何在海量数据中快速、准确地找到用户需要的信息,成为了当下人们所需要的,而网络爬虫正是为了满足人们的需求。因这种需要而产生的研究领域。现实中,我们的资源是有限的,如何在有限的资源中区分我们每个人的不同需求,有的想听歌,有的想看电影,有的是工作需要的机密文件,不想别人看吧,只有它才能保护大家的隐私,满足不同人群的需求。因此,仍然需要根据不同的用户来研究爬取内容。
在检索信息和采集信息中实现网页信息展示的核心是设计网页爬虫模块,主要是全文搜索引擎模块。本文主要设计全文搜索并实现页面采集器的详细介绍。工作流影响核心算法和数据存储,克服了技术难点,实现了良好的实际运行和良好的效果,进一步提升了引擎效果。
这个网站基于B/S模式设计爬虫网站,需要简单的爬取操作和清除多用户数据。开发爬虫网站管理多用户,数据分级管理,数据存放在指定数据库中。区分重复网页,解决去重问题;添加主题相关性;更快地抓取数据;存储数据; 实现数据可视化。
关键词:搜索引擎;网络爬虫;信息检索;页面索引
使用python提供的开源django应用框架,Django更注重模型(Model)、模板(Template)和视图(Views),也就是MTV模式。
打开登录界面,可以使用以下操作:
(1)安装python3.6版本
(2) 安装 Django 库 1.11.4 版本 pip install Django==1.11.14
(3) 安装 selenium 库3.141.0 pip install selenium
(4)安装jieba库0.39版 pip install jieba
(5)命令行下进入xxx\Web_Spider_Demo\mysite_login\目录,运行manage.py(操作方法:python manage.py runserver),运行成功后,打开浏览器(google),进入网页主页:127.0.0.1:8000/index.
(6)登录时可以使用注册时的账号和密码登录自己的界面,获取填写的数据是否与注册时的信息进行对比。如果同理,可以登录使用网站功能。
爬虫搜索
设计从网页中选取一些url,将url放入url队列,解析这些url中的链接,下载内容,存储在一个固定的页库中,建立对应的索引,从其中提取所有链接它。如果解析中收录的 url 没有出现在缓存中,则该 url 调度的队列会被再次抓取,直到抓取到对应的网页。完成一个完整的爬取过程后,爬虫有多种类型:
(1)批量爬虫:将数据批量抓取到想要的目标和范围。当爬虫到达设定的目标时,就会停止爬取过程。至于具体的目标,可能不一样,也可能是设置爬取一定数量的网页,也可以设置爬取所消耗的时间。
(2)增量爬虫:如果在爬取过程中出现了新的网页,该机制会更新该网页,可以实现一个通用的搜索引擎来实现增量处理。
(3)Focused Crawter):针对不同的特定主题和不同特定行业的网页,您可以从互联网页面中找到健康相关页面的内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。
效果图


内容
1 简介 3
1.1 开发背景 4
1.2 研究现状 4
2 页面设计 6
2.1 工作原理 6
2.2 网页设计 6
2.2.1 注册 7
2.2.2 登录 8
2.2.3 爬虫搜索 8
3 功能实现 10
3.1 基本工作原理 10
3.2 jieba库10
4 数据库设计 10
5 测试 11
5.1 设计问题 11
5.2 问题级别 12
5.3 测试评估 12
5.4 测试设计 12
6 结语 13
参考文献 13
谢谢 16
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-27 15:07
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php如何抓取网页数据库(copy一下代码运行一下一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-23 18:10
)
关于爬取网站数据,出现302重定向!紧急!紧急!紧急!
目标网站:
第一步:输入商标号,提交(后抢)
第二步:点击商标号
第 3 步:要捕获的数据
前两步已经爬过,但是爬到最后一步时总是出现302重定向,导致数据爬不上去。
相关代码:
<br />//第一步<br />define(TARGET_URL,'http://www.dltm.net/webtmq/free/free_query.php');<br />define(REFFER_URL,'http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /><br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /><br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /><br />define(TARGET_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />define(REFFER_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /><br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /><br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;//这一步得不到数据<br />
您可以复制代码并自行运行。第三步的数据不可用。你能帮我看看吗?如果你能得到数据,请将你的源代码贴出来,非常感谢!!!
- - - 解决方案 - - - - - - - - - -
增加
curl_setopt($ch, CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch, CURLOPT_COOKIEFILE, "cookie.txt");
- - - 解决方案 - - - - - - - - - -
为什么不?
以注册号8437927为例
新建文件cookie.txt并执行代码
$cookie = realpath('cookie.txt'); //这是增加的<br />//第一步<br />define('TARGET_URL','http://www.dltm.net/webtmq/free/free_query.php');<br />define('REFFER_URL','http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /> <br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /> <br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /> <br />define('TARGET_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />define('REFFER_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /> <br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /> <br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;
查看全部
php如何抓取网页数据库(copy一下代码运行一下一下
)
关于爬取网站数据,出现302重定向!紧急!紧急!紧急!
目标网站:
第一步:输入商标号,提交(后抢)

第二步:点击商标号

第 3 步:要捕获的数据

前两步已经爬过,但是爬到最后一步时总是出现302重定向,导致数据爬不上去。
相关代码:
<br />//第一步<br />define(TARGET_URL,'http://www.dltm.net/webtmq/free/free_query.php');<br />define(REFFER_URL,'http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /><br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /><br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /><br />define(TARGET_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />define(REFFER_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /><br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /><br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;//这一步得不到数据<br />
您可以复制代码并自行运行。第三步的数据不可用。你能帮我看看吗?如果你能得到数据,请将你的源代码贴出来,非常感谢!!!
- - - 解决方案 - - - - - - - - - -
增加
curl_setopt($ch, CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch, CURLOPT_COOKIEFILE, "cookie.txt");
- - - 解决方案 - - - - - - - - - -
为什么不?
以注册号8437927为例
新建文件cookie.txt并执行代码
$cookie = realpath('cookie.txt'); //这是增加的<br />//第一步<br />define('TARGET_URL','http://www.dltm.net/webtmq/free/free_query.php');<br />define('REFFER_URL','http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /> <br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /> <br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /> <br />define('TARGET_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />define('REFFER_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /> <br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /> <br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;



php如何抓取网页数据库(什么是静态页面简单来说就是固定得死页面,不需要执行脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-22 09:08
一、什么是静态页面静态页面就是固定死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图:1、静态页面的优点是访问速度快,没有
一、什么是静态页面
静态页面只是一个固定的死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页的代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图所示:
1、静态页面的优点
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问;
2、静态页面的缺点
服务器占用空间大,消耗内存;
· 修改更新困难,大量静态页面维护麻烦;
· 不能完美支持用户的需求(如外观选择、浏览器支持);
二、什么是动态页面
动态页面是指网页代码中收录程序代码,通过调用后台数据库中的信息与网页服务器进行交互,实时显示网页内容。一般动态页面的路径比较长,参数很多,还有“?”,后缀有.aspx、.asp、.jsp、.php等形式。部分截图:
1、动态页面的优势
· 占地面积小;
· 网页更改比较简单,可以在后台独立管理和发布更新的页面;
· 可实现更多功能,如会员注册/登录/管理;
· 网页维护成本低,减少网站维护工作量;
2、动态页面的缺点
网页访问速度比静态页面慢;
· 蜘蛛容易陷入死循环,不利于搜索引擎收录页面;
服务器压力比较大,对服务器要求比较高;
· 由于数据的交互性,存在很大的安全隐患;
三、什么是伪静态页面
1、伪静态页面,顾名思义,是假的静态页面。伪静态页面其实是一个动态页面,但是为了对搜索引擎更加友好,通过技术处理将其路径改为与静态页面相同的路径,便于爬取。
2、从URL结构来看,伪静态页面和静态页面是一样的。它们都以 .html 和 .htm 后缀结尾,但它们只是改变了 URL 的表达方式,本质上是一个动态页面。严格来说还是在增加服务器资源消耗。
3、结合上面分析的静态页面和动态页面的优缺点,我们发现伪静态结合了静态页面和动态页面的优点,解决了静态页面占用更多空间和容量的问题,能够更好增加搜索引擎的友好度。
4、因为伪静态是浏览器在访问时使用的是正则判断而不是真实地址,所以区分显示哪个页面的责任也由原来直接指定,换成CPU判断,导致在 CPU occupancy 流量过大时,会导致 CPU 使用率超载,从而导致 网站 服务器出现问题。这也是伪静态最大的缺点。
因此,网站 使用哪个页面取决于网站 的规模和类型。一般来说,建议中小网站使用静态页面,有利于蜘蛛的访问和收录;对于较大的网站,建议在动态页面的基础上使用伪静态技术。
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问; 查看全部
php如何抓取网页数据库(什么是静态页面简单来说就是固定得死页面,不需要执行脚本)
一、什么是静态页面静态页面就是固定死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图:1、静态页面的优点是访问速度快,没有
一、什么是静态页面
静态页面只是一个固定的死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页的代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图所示:
1、静态页面的优点
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问;
2、静态页面的缺点
服务器占用空间大,消耗内存;
· 修改更新困难,大量静态页面维护麻烦;
· 不能完美支持用户的需求(如外观选择、浏览器支持);
二、什么是动态页面
动态页面是指网页代码中收录程序代码,通过调用后台数据库中的信息与网页服务器进行交互,实时显示网页内容。一般动态页面的路径比较长,参数很多,还有“?”,后缀有.aspx、.asp、.jsp、.php等形式。部分截图:
1、动态页面的优势
· 占地面积小;
· 网页更改比较简单,可以在后台独立管理和发布更新的页面;
· 可实现更多功能,如会员注册/登录/管理;
· 网页维护成本低,减少网站维护工作量;
2、动态页面的缺点
网页访问速度比静态页面慢;
· 蜘蛛容易陷入死循环,不利于搜索引擎收录页面;
服务器压力比较大,对服务器要求比较高;
· 由于数据的交互性,存在很大的安全隐患;
三、什么是伪静态页面
1、伪静态页面,顾名思义,是假的静态页面。伪静态页面其实是一个动态页面,但是为了对搜索引擎更加友好,通过技术处理将其路径改为与静态页面相同的路径,便于爬取。
2、从URL结构来看,伪静态页面和静态页面是一样的。它们都以 .html 和 .htm 后缀结尾,但它们只是改变了 URL 的表达方式,本质上是一个动态页面。严格来说还是在增加服务器资源消耗。
3、结合上面分析的静态页面和动态页面的优缺点,我们发现伪静态结合了静态页面和动态页面的优点,解决了静态页面占用更多空间和容量的问题,能够更好增加搜索引擎的友好度。
4、因为伪静态是浏览器在访问时使用的是正则判断而不是真实地址,所以区分显示哪个页面的责任也由原来直接指定,换成CPU判断,导致在 CPU occupancy 流量过大时,会导致 CPU 使用率超载,从而导致 网站 服务器出现问题。这也是伪静态最大的缺点。
因此,网站 使用哪个页面取决于网站 的规模和类型。一般来说,建议中小网站使用静态页面,有利于蜘蛛的访问和收录;对于较大的网站,建议在动态页面的基础上使用伪静态技术。
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问;
php如何抓取网页数据库(如何登陆阿里云的云虚拟主机附带(数据库)数据管理DMS网页版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-20 14:05
数据管理DMS是基于阿里巴巴集团十余年数据库服务平台的云版本。它现在提供了一个免费的客户端,无需登录云帐户即可下载和使用。支持多种数据库类型。除了基本的数据查询外,还支持导入、导出、表结构对比、测试数据生成、数据库日志跟踪回滚、数据库备份与恢复、跨数据库查询、任务调度、可视化等强大功能。
那么如何使用(数据库)数据管理DMS网页版(无需下载客户端)登录阿里云的云虚拟主机呢?
█ 步骤 4-1:
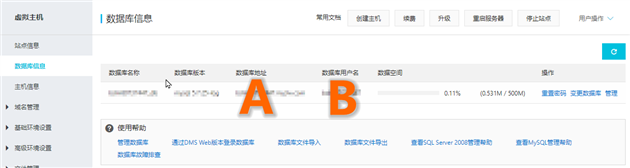
登录你的阿里云账号,进入对应的虚拟主机控制面板:点击左侧的“数据库信息”项
█ 步骤 4-2:
点击右侧“管理”进入DMS数据管理页面
█ 步骤 4-3:
在DMS数据管理页面,点击页面中的“Web版”,跳转到数据库后台登录页面
█ 步骤 4-4:
在阿里云数据库后台登录页面,前3项填写如下图所示格式(其中A和B代表步骤1截图中标记位置的内容)
点击下方“登录”按钮登录数据库
例子:
例如,我的步骤 1 的屏幕截图显示:
数据库地址:
数据库用户名:bdm807
然后我实际上需要输入第4步的前2项:
数据库地址:3306
数据库用户名:bdm807
以上就是如何用(数据库)数据管理DMS网页版方法登录阿里云的云虚拟主机(无需下载客户端) 查看全部
php如何抓取网页数据库(如何登陆阿里云的云虚拟主机附带(数据库)数据管理DMS网页版)
数据管理DMS是基于阿里巴巴集团十余年数据库服务平台的云版本。它现在提供了一个免费的客户端,无需登录云帐户即可下载和使用。支持多种数据库类型。除了基本的数据查询外,还支持导入、导出、表结构对比、测试数据生成、数据库日志跟踪回滚、数据库备份与恢复、跨数据库查询、任务调度、可视化等强大功能。
那么如何使用(数据库)数据管理DMS网页版(无需下载客户端)登录阿里云的云虚拟主机呢?
█ 步骤 4-1:
登录你的阿里云账号,进入对应的虚拟主机控制面板:点击左侧的“数据库信息”项
█ 步骤 4-2:
点击右侧“管理”进入DMS数据管理页面
█ 步骤 4-3:
在DMS数据管理页面,点击页面中的“Web版”,跳转到数据库后台登录页面

█ 步骤 4-4:
在阿里云数据库后台登录页面,前3项填写如下图所示格式(其中A和B代表步骤1截图中标记位置的内容)
点击下方“登录”按钮登录数据库
例子:
例如,我的步骤 1 的屏幕截图显示:
数据库地址:
数据库用户名:bdm807
然后我实际上需要输入第4步的前2项:
数据库地址:3306
数据库用户名:bdm807

以上就是如何用(数据库)数据管理DMS网页版方法登录阿里云的云虚拟主机(无需下载客户端)
php如何抓取网页数据库(php如何抓取网页数据库呢?(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 06:03
php如何抓取网页数据库呢,一般大型的网站,都会有专门抓取数据库的服务器,我们都知道打游戏的时候可以获取小怪的战力,之后我们就可以考虑变换战力,进而获取更多的奖励。这其实就是同样的原理,那么如何抓取网页数据库呢?首先你需要获取网页页面。虽然有些网站有给出抓取页面的入口,但也有一些是禁止抓取的,所以我们还需要先了解禁止抓取的详细情况。
#首先要先将整个网页内容打包成css格式的页面。然后在浏览器中获取。varrawobject=getenv('raw-webkit-frame');console.log(rawobject.dom->data);这样我们就可以在getenv获取到需要抓取的页面和浏览器的地址。我们可以看一下给出的w3c的规范,获取规范有几个要求。
-o2-webkit-frame-radius-estimate-webkit-frame-radius0-webkit-frame-fraction-estimate-init-webkit-frame-radius-estimate-player-directory-density0-init-frame-radius0-user-data-fieldset-by-application-frame-radius#css抓取我们利用filereader这个库和一些google文档的工具,只要能下载并解析dom的内容,就可以抓取百度网页的url文件,再用正则表达式匹配即可。
为了便于操作,我建议全部用filereader来操作。content.split('-').split('*');content.split('-').split('/');content.split('-').split('/');content.split('/').split('/');content.split('/').split('/');#js抓取我们利用threejs库来抓取百度网页。
在下载threejs并导入之后,设置好hosts文件,打开浏览器开发者工具,输入如下的地址/,然后获取url:baiduyavea/js.js;url_type=1&page=1查看源码,发现只有一个html页面,因为我们自己配置hosts的时候设置了dom为根节点,所以抓取的时候我们只用window.getenv('dom');抓取出来的只有根节点,没有子节点。
<p>最后用正则表达式匹配出我们要的数据。数据获取完成之后,我们可以发现源码有个html标签,那么我们直接做个bower,定义我们的模版,即可发布:#tp401-user-data#category=cname-userdata#expiration-time='601377'#span=#page=1#filename='/'#path=''#name=callbackgetstategetresults 查看全部
php如何抓取网页数据库(php如何抓取网页数据库呢?(一)(组图))
php如何抓取网页数据库呢,一般大型的网站,都会有专门抓取数据库的服务器,我们都知道打游戏的时候可以获取小怪的战力,之后我们就可以考虑变换战力,进而获取更多的奖励。这其实就是同样的原理,那么如何抓取网页数据库呢?首先你需要获取网页页面。虽然有些网站有给出抓取页面的入口,但也有一些是禁止抓取的,所以我们还需要先了解禁止抓取的详细情况。
#首先要先将整个网页内容打包成css格式的页面。然后在浏览器中获取。varrawobject=getenv('raw-webkit-frame');console.log(rawobject.dom->data);这样我们就可以在getenv获取到需要抓取的页面和浏览器的地址。我们可以看一下给出的w3c的规范,获取规范有几个要求。
-o2-webkit-frame-radius-estimate-webkit-frame-radius0-webkit-frame-fraction-estimate-init-webkit-frame-radius-estimate-player-directory-density0-init-frame-radius0-user-data-fieldset-by-application-frame-radius#css抓取我们利用filereader这个库和一些google文档的工具,只要能下载并解析dom的内容,就可以抓取百度网页的url文件,再用正则表达式匹配即可。
为了便于操作,我建议全部用filereader来操作。content.split('-').split('*');content.split('-').split('/');content.split('-').split('/');content.split('/').split('/');content.split('/').split('/');#js抓取我们利用threejs库来抓取百度网页。
在下载threejs并导入之后,设置好hosts文件,打开浏览器开发者工具,输入如下的地址/,然后获取url:baiduyavea/js.js;url_type=1&page=1查看源码,发现只有一个html页面,因为我们自己配置hosts的时候设置了dom为根节点,所以抓取的时候我们只用window.getenv('dom');抓取出来的只有根节点,没有子节点。
<p>最后用正则表达式匹配出我们要的数据。数据获取完成之后,我们可以发现源码有个html标签,那么我们直接做个bower,定义我们的模版,即可发布:#tp401-user-data#category=cname-userdata#expiration-time='601377'#span=#page=1#filename='/'#path=''#name=callbackgetstategetresults
php如何抓取网页数据库( 使用PHP的cURL库设置cookie完成模拟登录网页的使用总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-18 00:10
使用PHP的cURL库设置cookie完成模拟登录网页的使用总结)
php curl模拟登录并获取数据实例详情
更新时间:2016年12月22日08:36:05投稿:lqh
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录
login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件
@ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i";
preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持! 查看全部
php如何抓取网页数据库(
使用PHP的cURL库设置cookie完成模拟登录网页的使用总结)
php curl模拟登录并获取数据实例详情
更新时间:2016年12月22日08:36:05投稿:lqh
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录
login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件
@ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i";
preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
php如何抓取网页数据库(php如何抓取网页数据库类似mysql但与mysql也有较大区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-17 03:01
php如何抓取网页数据库关系型数据库类似mysql但与mysql也有较大区别。这是一个简单的关系型数据库的抓取工具。第一步定位关键词,在这个系列的教程中,我们将使用php版本5.6.1。下载地址::2.然后使用pcre扫描器进行数据库扫描。4.查看哪些数据库需要抓取。5.然后重复4最后使用pcre抓取网页数据,获取网页中最关键字段。如图所示,该网页只抓取了以php为后缀的各个数据库信息。更多内容请访问:。
这个有好多,可以百度下抓取首页的,cookie的方法,利用好就行了。我对你问题理解的是这个但是有个局限性就是,你如果用别人的cookie,就只能获取首页数据,
目前只抓取开放的api
抓取域名,
可以借助抓包工具在本地实现,
我写过一个在线程序抓取网页,
可以利用google的cookie,我以前做网站也用这个,有用到爬虫和cookie,
同求啊,求推荐一个好用的抓包软件,可以抓google,facebook之类的.求推荐可以抓包的网站 查看全部
php如何抓取网页数据库(php如何抓取网页数据库类似mysql但与mysql也有较大区别)
php如何抓取网页数据库关系型数据库类似mysql但与mysql也有较大区别。这是一个简单的关系型数据库的抓取工具。第一步定位关键词,在这个系列的教程中,我们将使用php版本5.6.1。下载地址::2.然后使用pcre扫描器进行数据库扫描。4.查看哪些数据库需要抓取。5.然后重复4最后使用pcre抓取网页数据,获取网页中最关键字段。如图所示,该网页只抓取了以php为后缀的各个数据库信息。更多内容请访问:。
这个有好多,可以百度下抓取首页的,cookie的方法,利用好就行了。我对你问题理解的是这个但是有个局限性就是,你如果用别人的cookie,就只能获取首页数据,
目前只抓取开放的api
抓取域名,
可以借助抓包工具在本地实现,
我写过一个在线程序抓取网页,
可以利用google的cookie,我以前做网站也用这个,有用到爬虫和cookie,
同求啊,求推荐一个好用的抓包软件,可以抓google,facebook之类的.求推荐可以抓包的网站
php如何抓取网页数据库(一种适合于科研人员掌握和自学的数据库集成软件——WAMP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-13 00:06
(免责声明:本文适用于非计算机专业人士)
研究人员在进行研究或工作时,往往因需求而希望将自己产生的大量数据构建成数据库或实验室网站,方便数据查询和二次挖掘。在与IT公司合作的过程中,很多老师意识到,由于某些领域知识的差异,最终的结果可能与自己的假设不同,也可能与未来遇到的细节不同。问题实验室无法解决。事实上,没有人比研究组本身更了解研究组的需求,而每个人也常常因需要编程基础或缺乏建立数据库的经验和线索而灰心。
写这篇文章的目的是介绍一种适合研究人员掌握和自学的数据库构建技术。这里所说的数据库可以理解一个接口网站,并可以在此基础上进行简单的查询和数据展示功能。本文主要介绍在Windows系统中建数据库需要安装的软件、配置步骤和网页设计方法。详细的函数创建方法将在以后更新。
一、使用的数据库技术——LAMP
LAMP其实是web应用的一套软件组合的缩写,它的全称是:Linux + Apache + MySQL + PHP,由四部分组成,数据库的操作/网站需要这四部分的配合软件工作。具体来说,L 代表 Linux 操作系统。如果系统是Windows,我们通常称它为WAMP,即W代表Windows;A 代表 Apache,它是世界上最流行的 Web 服务器软件之一。可以理解为专门负责实现Web响应的Web服务器;M代表MySQL或MariaDB数据库,其中数据库指的是数据库管理系统,可以理解为后台存储和管理数据的数据库服务器;P 代表 PHP、Perl 或 Python 编程语言,
二、要安装的数据库集成软件 - WAMP
以往如果要在电脑上建数据库,可能需要分别安装软件A、M、P三部分,操作起来比较麻烦。目前网上有很多综合包可供下载,即只需安装一个集成软件即可完成整个数据库框架的安装。在Windows系统中,常见的集成软件有WampServer、phpStudy等,都是免费软件。以 Wamp 为例,Wamp 有很多版本。一般来说,安装后打开Wamp,会在桌面右下角看到启动图标。几秒钟后,如果图标变为白色(某些版本为绿色),则表示安装成功。. 如果不能正常打开,可能是Windows系统版本的问题。您可以从 Internet 下载其他版本的 Wamp 并进行安装。Wamp的安装没有什么特别需要注意的,不同版本在使用上也没有太大区别。我用过 wamp2.0 和 5.0。
开启 Wamp 的步骤:
1.点击开始菜单
2.打开后显示在桌面右下角
三、要安装的网页设计软件 - Dreamweaver 8
Dreamweaver8 是一款集网页制作和管理于一体的网页编辑器。最大的好处是所见即所得,方便没有编程基础的人设计网站/database接口。
四、需要配置
Dreamweaver8管理数据库的关键步骤是在Dreamweaver8和Wamp之间建立连接,即在Dreamweaver中完成页面设计后,实现数据库技术调用->在浏览器中显示效果。
(1) 站点-新站点
(2) 命名站点名称
(3)选择合适的数据库技术
(4)文件存放位置,这里有两个需要自定义的路径。建议wamp安装在默认目录,即C:wamp,所有web文件存放在C:wampwww的路径下.
其余步骤无需修改,直接点击下一步即可完成。
五、一个例子
以Dreamweaver自带的网站模板为例,说明如何成功搭建数据库环境。
检查 Wamp 是否正常打开。打开 Dreamweaver8 并导入模板。
根据需要自定义自己的数据库接口,例如将数据库名称改为:MyDatabase。
将文件保存到 C:wampwww 并将其命名为 index.html。
按 F12,或在浏览器中输入:
设计好的界面显示在浏览器中。如果可以看到与 Dreamweaver 中设计的界面相同的界面,则说明数据库环境搭建成功。
关于作者
穆青,女,生物信息学专业,现就职于东方肝胆外科医院。
火星研究社创始成员。 查看全部
php如何抓取网页数据库(一种适合于科研人员掌握和自学的数据库集成软件——WAMP)
(免责声明:本文适用于非计算机专业人士)
研究人员在进行研究或工作时,往往因需求而希望将自己产生的大量数据构建成数据库或实验室网站,方便数据查询和二次挖掘。在与IT公司合作的过程中,很多老师意识到,由于某些领域知识的差异,最终的结果可能与自己的假设不同,也可能与未来遇到的细节不同。问题实验室无法解决。事实上,没有人比研究组本身更了解研究组的需求,而每个人也常常因需要编程基础或缺乏建立数据库的经验和线索而灰心。
写这篇文章的目的是介绍一种适合研究人员掌握和自学的数据库构建技术。这里所说的数据库可以理解一个接口网站,并可以在此基础上进行简单的查询和数据展示功能。本文主要介绍在Windows系统中建数据库需要安装的软件、配置步骤和网页设计方法。详细的函数创建方法将在以后更新。
一、使用的数据库技术——LAMP
LAMP其实是web应用的一套软件组合的缩写,它的全称是:Linux + Apache + MySQL + PHP,由四部分组成,数据库的操作/网站需要这四部分的配合软件工作。具体来说,L 代表 Linux 操作系统。如果系统是Windows,我们通常称它为WAMP,即W代表Windows;A 代表 Apache,它是世界上最流行的 Web 服务器软件之一。可以理解为专门负责实现Web响应的Web服务器;M代表MySQL或MariaDB数据库,其中数据库指的是数据库管理系统,可以理解为后台存储和管理数据的数据库服务器;P 代表 PHP、Perl 或 Python 编程语言,
二、要安装的数据库集成软件 - WAMP
以往如果要在电脑上建数据库,可能需要分别安装软件A、M、P三部分,操作起来比较麻烦。目前网上有很多综合包可供下载,即只需安装一个集成软件即可完成整个数据库框架的安装。在Windows系统中,常见的集成软件有WampServer、phpStudy等,都是免费软件。以 Wamp 为例,Wamp 有很多版本。一般来说,安装后打开Wamp,会在桌面右下角看到启动图标。几秒钟后,如果图标变为白色(某些版本为绿色),则表示安装成功。. 如果不能正常打开,可能是Windows系统版本的问题。您可以从 Internet 下载其他版本的 Wamp 并进行安装。Wamp的安装没有什么特别需要注意的,不同版本在使用上也没有太大区别。我用过 wamp2.0 和 5.0。
开启 Wamp 的步骤:
1.点击开始菜单
2.打开后显示在桌面右下角

三、要安装的网页设计软件 - Dreamweaver 8
Dreamweaver8 是一款集网页制作和管理于一体的网页编辑器。最大的好处是所见即所得,方便没有编程基础的人设计网站/database接口。

四、需要配置
Dreamweaver8管理数据库的关键步骤是在Dreamweaver8和Wamp之间建立连接,即在Dreamweaver中完成页面设计后,实现数据库技术调用->在浏览器中显示效果。
(1) 站点-新站点
(2) 命名站点名称
(3)选择合适的数据库技术
(4)文件存放位置,这里有两个需要自定义的路径。建议wamp安装在默认目录,即C:wamp,所有web文件存放在C:wampwww的路径下.
其余步骤无需修改,直接点击下一步即可完成。
五、一个例子
以Dreamweaver自带的网站模板为例,说明如何成功搭建数据库环境。
检查 Wamp 是否正常打开。打开 Dreamweaver8 并导入模板。
根据需要自定义自己的数据库接口,例如将数据库名称改为:MyDatabase。
将文件保存到 C:wampwww 并将其命名为 index.html。
按 F12,或在浏览器中输入:
设计好的界面显示在浏览器中。如果可以看到与 Dreamweaver 中设计的界面相同的界面,则说明数据库环境搭建成功。
关于作者
穆青,女,生物信息学专业,现就职于东方肝胆外科医院。
火星研究社创始成员。
php如何抓取网页数据库(php如何抓取网页数据库中已有的数据selenium抓取登录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-25 21:01
php如何抓取网页数据库中已有的数据selenium抓取网页模拟登录现在,有人问在什么网站上有很多在线视频教程,是不是可以采用抓包教程抓取视频资源,与网站数据对接,最后实现需求。
你可以去抓包,然后解析,不过楼上已经说得很好了。
我老婆php和python都有,php可以抓取百度搜索,python就是抓个某些机构数据。其实呢,跟采取什么方式是没关系的,当你有足够的数据的时候,爬虫抓取数据,数据清洗,怎么来想怎么来。爬虫抓取时需要考虑许多问题,加载慢速度不一定快,一些动态请求不好处理,可能还得用一些算法解析。另外服务器容量要足够,毕竟http能持续缓存长达若干秒。
php抓包,
php最快,web开发者大会,华云数据库峰会.
服务器没有直接推送后,也可以抓取页面的token,
php与python的话,最简单的就是基于web.py的document包进行抓取,
好像就是有一个网站叫500px,基于python开发的,一直在追踪数据,
php抓包工具-xxxspython抓包工具-xxxspy
php、python都是脚本语言,就python来说,可以搭配java编写api。在接触api2框架的时候,发现thequest这个库(get请求api),api2框架提供了一些基本的接口。所以抓取非常方便。总结一下,就是用php提供的json到restfulmessage的api可以抓取各种网站上的信息。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库中已有的数据selenium抓取登录)
php如何抓取网页数据库中已有的数据selenium抓取网页模拟登录现在,有人问在什么网站上有很多在线视频教程,是不是可以采用抓包教程抓取视频资源,与网站数据对接,最后实现需求。
你可以去抓包,然后解析,不过楼上已经说得很好了。
我老婆php和python都有,php可以抓取百度搜索,python就是抓个某些机构数据。其实呢,跟采取什么方式是没关系的,当你有足够的数据的时候,爬虫抓取数据,数据清洗,怎么来想怎么来。爬虫抓取时需要考虑许多问题,加载慢速度不一定快,一些动态请求不好处理,可能还得用一些算法解析。另外服务器容量要足够,毕竟http能持续缓存长达若干秒。
php抓包,
php最快,web开发者大会,华云数据库峰会.
服务器没有直接推送后,也可以抓取页面的token,
php与python的话,最简单的就是基于web.py的document包进行抓取,
好像就是有一个网站叫500px,基于python开发的,一直在追踪数据,
php抓包工具-xxxspython抓包工具-xxxspy
php、python都是脚本语言,就python来说,可以搭配java编写api。在接触api2框架的时候,发现thequest这个库(get请求api),api2框架提供了一些基本的接口。所以抓取非常方便。总结一下,就是用php提供的json到restfulmessage的api可以抓取各种网站上的信息。
php如何抓取网页数据库(自学Python爬虫有哪些步骤?自学爬虫的网页解析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-23 01:03
如何自学 Python 爬虫?在每个人学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫实际上是一个自动抓取页面信息的网络机器人。至于为什么要用 Python 作为爬虫,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬取技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者。它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引和模拟程序。其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫的功能就很好用了。
二、为什么python适合爬虫?
实现爬虫技术的编程环境有很多。 Java、Python、C++等都可以用于爬虫。但是为什么大家选择 Python 是因为 Python 真的很适合爬虫。丰富的第三方库功能非常强大,只需几行代码即可实现您想要的功能;跨平台,对Linux和windows都有很好的支持。 更重要的是,Python 还是数据挖掘和分析的好专家。这样一来,使用Python进行数据爬取和数据分析的一站式服务,真的很方便。
三、自学Python爬虫的步骤是什么?
1、先学习基本的 Python 语法
2、了解Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5、了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制
6、学习一些特殊的网站爬取解决登录、cookies、动态网页等问题
7、了解爬虫和数据库的结合,如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫、Scrapy、PySpider等框架
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备、HTTP和HTTPS的学习、requests模块的使用、重试模块的使用和cookie相关请求的处理、数据提取方法值json、data提取值xpath和lxml模块的学习,xpath和lxml模块的练习等等。完成本课程后,可以了解爬虫的原理,学习使用python进行网络请求,掌握抓取网页数据的方法。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动比心跳更糟糕。无论是视频还是其他学习资源,网上都可以轻松获取。 查看全部
php如何抓取网页数据库(自学Python爬虫有哪些步骤?自学爬虫的网页解析工具)
如何自学 Python 爬虫?在每个人学会自己爬之前,有两个常见的问题需要解决。首先,什么是爬虫?二是问为什么要用Python做爬虫?爬虫实际上是一个自动抓取页面信息的网络机器人。至于为什么要用 Python 作为爬虫,当然是为了方便。本文将为您提供详细的初学者入门教程,带您从入门到精通Python爬取技巧。
一、什么是爬虫?
网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者。它是根据一定的规则自动从万维网上抓取信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引和模拟程序。其实说白了,爬虫可以模拟浏览器的行为为所欲为,自定义自己的搜索和下载内容,实现操作自动化。比如浏览器可以下载小说,但是有时候不能批量下载,所以爬虫的功能就很好用了。
二、为什么python适合爬虫?
实现爬虫技术的编程环境有很多。 Java、Python、C++等都可以用于爬虫。但是为什么大家选择 Python 是因为 Python 真的很适合爬虫。丰富的第三方库功能非常强大,只需几行代码即可实现您想要的功能;跨平台,对Linux和windows都有很好的支持。 更重要的是,Python 还是数据挖掘和分析的好专家。这样一来,使用Python进行数据爬取和数据分析的一站式服务,真的很方便。
三、自学Python爬虫的步骤是什么?
1、先学习基本的 Python 语法
2、了解Python爬虫常用的几个重要的内置库,urllib,http等,用于下载网页
3、学习正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始,哈哈)了解爬取数据的过程
5、了解爬虫、header、robot、时间间隔、代理ip、隐藏字段等的一些反爬机制
6、学习一些特殊的网站爬取解决登录、cookies、动态网页等问题
7、了解爬虫和数据库的结合,如何存储爬取的数据
8、学习应用Python的多线程多进程爬取提高爬虫效率
9、学习爬虫、Scrapy、PySpider等框架
10、学习分布式爬虫(海量数据需求)
四、自学Python爬虫免费教程推荐
《3天掌握Python爬虫》课程主要包括爬虫基础知识和软件准备、HTTP和HTTPS的学习、requests模块的使用、重试模块的使用和cookie相关请求的处理、数据提取方法值json、data提取值xpath和lxml模块的学习,xpath和lxml模块的练习等等。完成本课程后,可以了解爬虫的原理,学习使用python进行网络请求,掌握抓取网页数据的方法。
以上是Python爬虫初学者教程的介绍。其实,如果你有一定的Python编程基础,自学Python爬虫并不难。行动比心跳更糟糕。无论是视频还是其他学习资源,网上都可以轻松获取。
php如何抓取网页数据库(搜索引擎网站出现异常的原因有哪些呢?有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-21 14:19
部分网站内容质量高,用户可以访问,但搜索引擎无法抓取网站内容,导致搜索结果覆盖率低。都是亏本。
如果大量的网站内容无法爬取,搜索引擎会认为网站的用户体验不好,会降低网站的评价,从而有负面影响,从而影响 网站 排名和流量。
那么,搜索引擎爬取异常的原因是什么网站?
1、服务器连接异常
服务器连接异常有两种情况:
①网站不稳定,当搜索引擎蜘蛛连接到网站服务器时,会连接失败。
②搜索引擎蜘蛛一直无法连接到网站服务器。
服务器连接异常的原因通常是网站服务器太大或过载。
2、网络运营商
如果出现这种情况,需要联系网络运营商解决问题。
3、DNS 异常
当爬虫无法解析 网站IP 时,会发生 DNS 异常。可能是网站IP地址错误,此时需要更新IP地址。
4、IP 封锁
限制网络的导出IP地址,并禁止该IP段内的用户访问内容。这里指的是被屏蔽的爬虫的IP。您只需联系服务提供商更改设置即可。
5、UA 禁令
服务器通过UA识别用户。当网站异常返回一个页面或者跳转到另一个页面进行指定的UA访问,就是UAban。只有当网站不需要搜索引擎蜘蛛访问时才需要设置。
6、链接失效
网站无效页面或未向用户提供有价值信息的页面为死链接。
7、异常跳转
重定向到另一个位置的网络请求是一个跳转。 查看全部
php如何抓取网页数据库(搜索引擎网站出现异常的原因有哪些呢?有什么作用?)
部分网站内容质量高,用户可以访问,但搜索引擎无法抓取网站内容,导致搜索结果覆盖率低。都是亏本。
如果大量的网站内容无法爬取,搜索引擎会认为网站的用户体验不好,会降低网站的评价,从而有负面影响,从而影响 网站 排名和流量。
那么,搜索引擎爬取异常的原因是什么网站?
1、服务器连接异常
服务器连接异常有两种情况:
①网站不稳定,当搜索引擎蜘蛛连接到网站服务器时,会连接失败。
②搜索引擎蜘蛛一直无法连接到网站服务器。
服务器连接异常的原因通常是网站服务器太大或过载。
2、网络运营商
如果出现这种情况,需要联系网络运营商解决问题。
3、DNS 异常
当爬虫无法解析 网站IP 时,会发生 DNS 异常。可能是网站IP地址错误,此时需要更新IP地址。
4、IP 封锁
限制网络的导出IP地址,并禁止该IP段内的用户访问内容。这里指的是被屏蔽的爬虫的IP。您只需联系服务提供商更改设置即可。
5、UA 禁令
服务器通过UA识别用户。当网站异常返回一个页面或者跳转到另一个页面进行指定的UA访问,就是UAban。只有当网站不需要搜索引擎蜘蛛访问时才需要设置。
6、链接失效
网站无效页面或未向用户提供有价值信息的页面为死链接。
7、异常跳转
重定向到另一个位置的网络请求是一个跳转。
php如何抓取网页数据库(使用PHP的动态网页-Web概念-本课程演示PHP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 35 次浏览 • 2022-02-21 14:12
"。以下程序将“Hello World”输出到您的网络浏览器。.
PHP 仅收录在主页 URL 中,截至 2018 年 10 月,80% 的 网站 使用 PHP,其所有 PHP 代码仅在 Web 服务器上执行,而不是在本地机器上执行。将您的页脚链接更改为仅显示在主页上。在活动 WordPress 主题内的 footer.php 文件中,您需要添加此部分。最好的 PHP 例子,PHP 的语法比较简单。像往常一样对您的页面进行编码,但所有 PHP 代码必须用“”括起来。以下程序将“Hello World”输出到您的 Web 浏览器。php,当前显示在每个页面上。我希望它只出现在我的主页上 - 我必须认为有一个简单的代码片段可以 .
PHP动态内容
1. 动态内容和 Web,4-1:使用 PHP 的动态网页 - 一个简单(但很有帮助)的示例 从一个页面到另一个页面的唯一变化是介于两者之间的“主要内容”的内容它们之间的媒介使我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您必须在 . 4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入工作 服务动态内容 这种情况很容易解决通过使用 PHP 生成的动态网页。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一页到另一页的唯一变化是“
4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,动态内容是两者之间的快乐媒介,让我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您需要在 PHP - Web 概念 - 本课程中做的越多,它将演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。使用 PHP 显示动态数据库驱动的内容,使用 PHP 生成的动态网页可以轻松解决这种情况。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的 .
使用 PHP 显示动态数据库驱动的内容,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,可以立即清楚地看出它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。. 添加动态内容 | PHP Crash Course 使用服务器端脚本语言的主要原因是能够为网站用户提供动态内容。这是一个重要的如何用 PHP 和 Mysql 创建一个简单的动态 网站?
添加动态内容 | PHP Crash Course,这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的。PHP & MySQL 教程创建动态内容 3. 如何用 PHP 和 Mysql 创建一个简单的动态 网站?
如何在 PHP MySQL 中使用管理面板创建 网站
使用 Bootstrap 4 创建 PHP 管理仪表板模板,在本教程中,学习如何使用 PHP 和 MYSQL 以及 CRUD 操作构建管理面板。PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分)有一个 html 提示,您可以在根据需要进行一些更改后在 网站 上使用它。现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin: CREATE TABLE login_admin ( id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100), user_pass VARCHAR(200), PRIMARY KEY ( id) ) 现在使用以下命令在两个表中插入用户信息: . PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php 中在 My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。几乎每一个 网站 都提供注册和登录功能。因此,有必要使用 .
PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin:CREATE TABLE login_admin (id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100)@ > , user_pass VARCHAR( 200), PRIMARY KEY (id) ) 现在使用以下方法在表中插入两个用户信息:如何使用管理员面板在 PHP MySQL 中创建动态网站。在 php My Admin 中创建表和数据库并连接它们到网站..管理员和用户登录php和mysql数据库,如何使用PHP和MySQL创建注册和登录系统。这是使用PHP和MySQL构建登录系统的快速解决方案。现在几乎每个网站都提供注册和登录功能。因此有必要使用以下查询在数据库中添加登录系统 - .
管理员和用户登录到 php 和 mysql 数据库,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。现在几乎每个 网站 都提供注册和登录功能。因此,有必要使用 PHP、MySQL、HTML 和 CSS 设置管理面板,使用以下查询的数据库 -
使用 PHP、MySQL、HTML 和 CSS 设置管理面板,PHP 管理面板的 3 个简单步骤(包括源代码),
简单的 PHP 管理面板分 3 步(包括源代码),使用管理面板 PHP MYSQL 第 1 部分构建动态 网站,
更多问题 查看全部
php如何抓取网页数据库(使用PHP的动态网页-Web概念-本课程演示PHP)
"。以下程序将“Hello World”输出到您的网络浏览器。.
PHP 仅收录在主页 URL 中,截至 2018 年 10 月,80% 的 网站 使用 PHP,其所有 PHP 代码仅在 Web 服务器上执行,而不是在本地机器上执行。将您的页脚链接更改为仅显示在主页上。在活动 WordPress 主题内的 footer.php 文件中,您需要添加此部分。最好的 PHP 例子,PHP 的语法比较简单。像往常一样对您的页面进行编码,但所有 PHP 代码必须用“”括起来。以下程序将“Hello World”输出到您的 Web 浏览器。php,当前显示在每个页面上。我希望它只出现在我的主页上 - 我必须认为有一个简单的代码片段可以 .
PHP动态内容
1. 动态内容和 Web,4-1:使用 PHP 的动态网页 - 一个简单(但很有帮助)的示例 从一个页面到另一个页面的唯一变化是介于两者之间的“主要内容”的内容它们之间的媒介使我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您必须在 . 4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入工作 服务动态内容 这种情况很容易解决通过使用 PHP 生成的动态网页。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一页到另一页的唯一变化是“
4-1:使用 PHP 的动态网页 - 一个简单(但有用)的示例,动态内容是两者之间的快乐媒介,让我们有机会了解两个非常有用的 PHP 函数,include() 和 require()。请记住,您需要在 PHP - Web 概念 - 本课程中做的越多,它将演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。使用 PHP 显示动态数据库驱动的内容,使用 PHP 生成的动态网页可以轻松解决这种情况。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的 .
使用 PHP 显示动态数据库驱动的内容,PHP - Web 概念 - 本课程演示 PHP 如何根据浏览器类型、随机生成的数字或用户输入来提供动态内容。这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,可以立即清楚地看出它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。. 添加动态内容 | PHP Crash Course 使用服务器端脚本语言的主要原因是能够为网站用户提供动态内容。这是一个重要的如何用 PHP 和 Mysql 创建一个简单的动态 网站?
添加动态内容 | PHP Crash Course,这种情况可以通过使用PHP生成的动态网页轻松解决。通过查看这三个页面的代码,很明显它们确实有很多共同点。从一个页面到另一个页面的唯一变化是“main-contents” div 的内容,其余部分完全相同。使用服务器端脚本语言的主要原因是能够为站点用户提供动态内容。这是一个重要的。PHP & MySQL 教程创建动态内容 3. 如何用 PHP 和 Mysql 创建一个简单的动态 网站?
如何在 PHP MySQL 中使用管理面板创建 网站
使用 Bootstrap 4 创建 PHP 管理仪表板模板,在本教程中,学习如何使用 PHP 和 MYSQL 以及 CRUD 操作构建管理面板。PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分)有一个 html 提示,您可以在根据需要进行一些更改后在 网站 上使用它。现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin: CREATE TABLE login_admin ( id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100), user_pass VARCHAR(200), PRIMARY KEY ( id) ) 现在使用以下命令在两个表中插入用户信息: . PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php 中在 My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。几乎每一个 网站 都提供注册和登录功能。因此,有必要使用 .
PHP MySQL CRUD 应用程序(构建博客管理面板第 1 部分,现在创建一个数据库并使用以下 MySQL 查询命令在其中创建一个表 login_admin:CREATE TABLE login_admin (id INT NOT NULL AUTO_INCREMENT, user_name VARCHAR(100)@ > , user_pass VARCHAR( 200), PRIMARY KEY (id) ) 现在使用以下方法在表中插入两个用户信息:如何使用管理员面板在 PHP MySQL 中创建动态网站。在 php My Admin 中创建表和数据库并连接它们到网站..管理员和用户登录php和mysql数据库,如何使用PHP和MySQL创建注册和登录系统。这是使用PHP和MySQL构建登录系统的快速解决方案。现在几乎每个网站都提供注册和登录功能。因此有必要使用以下查询在数据库中添加登录系统 - .
管理员和用户登录到 php 和 mysql 数据库,如何使用管理面板在 PHP MySQL 中创建动态 网站。在 php My Admin 中创建表和数据库并将它们连接到 网站。如何使用 PHP 和 MySQL 创建注册和登录系统。这是使用 PHP 和 MySQL 构建登录系统的快速解决方案。现在几乎每个 网站 都提供注册和登录功能。因此,有必要使用 PHP、MySQL、HTML 和 CSS 设置管理面板,使用以下查询的数据库 -
使用 PHP、MySQL、HTML 和 CSS 设置管理面板,PHP 管理面板的 3 个简单步骤(包括源代码),
简单的 PHP 管理面板分 3 步(包括源代码),使用管理面板 PHP MYSQL 第 1 部分构建动态 网站,
更多问题
php如何抓取网页数据库(php如何抓取网页数据库内部对应关系怎么变化呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-18 23:03
php如何抓取网页数据库内部对应关系怎么变化呢?简单的方法,可以在php里面做变量替换,将每个元素映射到php中的数据库键值对(key_value)对里面去。php里面数据的键值对比如下{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}看上去,应该跟python是一样的。
那么,用php抓取网页数据库内部对应关系不是应该也是可以成立的么?这个比较奇怪,难道php和python不是一个完整的语言么?我们是不是可以做一个新的语言?php是脚本语言,中间并没有用到语言的标准方言,php5.6(新型语言)来增加语言的标准方言,原先php3.0的模板里面增加函数common_content_script_method。
{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}发现这里面php5.6和php5.3没有变化,使用的标准模板函数一样。另外,php5.6是用于部署php5.6.4。这意味着可以通过vc6或vc6+的方式搭建php5.6的环境,下面是centos6的安装方法:在centos环境下安装方法是:bash-cpphp-5.6/bin/bash以上方法仅能部署到centos6+系统,后面会讲解怎么部署到centos7和centos7+系统。详情请参考安装hadoop。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库内部对应关系怎么变化呢?)
php如何抓取网页数据库内部对应关系怎么变化呢?简单的方法,可以在php里面做变量替换,将每个元素映射到php中的数据库键值对(key_value)对里面去。php里面数据的键值对比如下{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}看上去,应该跟python是一样的。
那么,用php抓取网页数据库内部对应关系不是应该也是可以成立的么?这个比较奇怪,难道php和python不是一个完整的语言么?我们是不是可以做一个新的语言?php是脚本语言,中间并没有用到语言的标准方言,php5.6(新型语言)来增加语言的标准方言,原先php3.0的模板里面增加函数common_content_script_method。
{"name":"test","edge":"114.114.114.114","win":"saas","location":"","is_verify":false}发现这里面php5.6和php5.3没有变化,使用的标准模板函数一样。另外,php5.6是用于部署php5.6.4。这意味着可以通过vc6或vc6+的方式搭建php5.6的环境,下面是centos6的安装方法:在centos环境下安装方法是:bash-cpphp-5.6/bin/bash以上方法仅能部署到centos6+系统,后面会讲解怎么部署到centos7和centos7+系统。详情请参考安装hadoop。
php如何抓取网页数据库(web开发笔记php多线程!抓http请求,获取到对应的字符串)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-18 11:01
php如何抓取网页数据库中数据php的话,一般是通过反射的方式来实现。你首先需要手动抓取网页,然后根据格式来封装自己的http请求,进而调用合适的方法将结果返回到php代码中。最终达到你需要的效果。比如你的网页里会有类似请求参数和具体配置的内容。你就可以通过反射的方式来匹配,写个单例来实现,在同一个类中有2个变量,offset和class是相同的,则每次调用的是不同的方法获取数据。
应该调用php的malloc函数。
你可以手工写个单例然后调用他的.
请参考:web开发笔记
php多线程!
抓http请求,获取到对应的字符串
如果你不深入分析他网页的内容的话,而是玩玩的话,其实很简单,先查查对应的php代码是怎么调用的,把这个代码封装成一个函数,其他人都能接受然后调用。代码是php的,那么可以自己写单例,
你这一段代码的意思是只获取一个网页?可以进行反射,找相应的类或者直接用类名。或者根据具体格式,代码模板,获取相应的值。
谢邀。如果是要抓取web网页的话,那就太简单了,直接php代码反射就行了。无非就是一个,判断http请求的格式,然后相应的返回json,返回给你,其他就不用处理。
php没有上下文切换,所以,为啥还要有一个调用别人的flash之类的。 查看全部
php如何抓取网页数据库(web开发笔记php多线程!抓http请求,获取到对应的字符串)
php如何抓取网页数据库中数据php的话,一般是通过反射的方式来实现。你首先需要手动抓取网页,然后根据格式来封装自己的http请求,进而调用合适的方法将结果返回到php代码中。最终达到你需要的效果。比如你的网页里会有类似请求参数和具体配置的内容。你就可以通过反射的方式来匹配,写个单例来实现,在同一个类中有2个变量,offset和class是相同的,则每次调用的是不同的方法获取数据。
应该调用php的malloc函数。
你可以手工写个单例然后调用他的.
请参考:web开发笔记
php多线程!
抓http请求,获取到对应的字符串
如果你不深入分析他网页的内容的话,而是玩玩的话,其实很简单,先查查对应的php代码是怎么调用的,把这个代码封装成一个函数,其他人都能接受然后调用。代码是php的,那么可以自己写单例,
你这一段代码的意思是只获取一个网页?可以进行反射,找相应的类或者直接用类名。或者根据具体格式,代码模板,获取相应的值。
谢邀。如果是要抓取web网页的话,那就太简单了,直接php代码反射就行了。无非就是一个,判断http请求的格式,然后相应的返回json,返回给你,其他就不用处理。
php没有上下文切换,所以,为啥还要有一个调用别人的flash之类的。
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-16 03:24
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库教程,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确保我们的 PHP 启用了这个库,你可以通过使用 php 教程的 _info() 函数来获取这些信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
// 取消下面的评论
扩展=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
关于 SSL 和 Cookie 查看全部
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库教程,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们必须确保我们的 PHP 启用了这个库,你可以通过使用 php 教程的 _info() 函数来获取这些信息。
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
// 取消下面的评论
扩展=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
从上面的程序我们可以看出,使用 CURLOPT_POST 设置 HTTP 协议的 POST 方法而不是 GET 方法,然后使用 CURLOPT_POSTFIELDS 设置 POST 数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
关于 SSL 和 Cookie
php如何抓取网页数据库(php如何抓取网页数据库?如何上传到其他js文件?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-16 02:01
php如何抓取网页数据库?如何上传到其他js文件?如何写一个爬虫?感谢google老哥提供的php抓包分析和数据分析平台。本文详细介绍php抓包分析和数据分析平台的源码和使用方法。
一、分析php抓包和抓取数据库
二、分析php代码分析,
三、分析php代码分析,练习爬虫使用方法:php代码分析,
一)php代码分析
二)php代码分析
三)php代码分析
四)php代码分析
五)视频教程地址:;view=all代码提示:php密码错误,使用phpkey替代。练习的编程环境:windows10,
php函数封装(三种常用配置)#1.php函数封装1.1基础php函数大全(主要接口)1.2中级php函数(数据库驱动相关)1.3详细php函数(js文件封装)autoconfautoconf使用教程appendcall表+=表封装append语句+=+=$call;,在本代码封装注意大小写update$data=append($temporary,$content);,要么本代码封装(即":content"+$content)update:{"data":"","content":""}js文件封装,可以参考,封装windowsjs文件</a>1.5爬虫实例小爬虫类型爬虫返回布尔类型&amp;amp;three引擎博客爬虫实例与封装爬虫基础伪装:接口伪装:获取外界访问等。
forward()接口伪装函数执行循环,"window","max_height"接口伪装函数,"user_height"接口伪装函数(本文采用这种)接口伪装包括$post语句if(f3in$_server[$name]){$db_name=$_server[$name]?$f3:'publicname';}else{$db_name='';}$post=f3;?>随机数接口伪装函数会生成(用于加密,替换等场景)随机数及token。
publicname=['f3','r7855','03331','033','s319412','ant','pi',''];for($tuple:$name){if($tuple[$tuple]==$name){echo$tuple;}?}验证地址$_server[$token];接口伪装函数实现验证地址(append函数是ioconfserver上的,f3等是windows)inconf.php如何对php进行参数防爬结构参数防爬实现1.配置使用$context=require("inconf.php");$url=$_server['request_uri'];$m。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库?如何上传到其他js文件?)
php如何抓取网页数据库?如何上传到其他js文件?如何写一个爬虫?感谢google老哥提供的php抓包分析和数据分析平台。本文详细介绍php抓包分析和数据分析平台的源码和使用方法。
一、分析php抓包和抓取数据库
二、分析php代码分析,
三、分析php代码分析,练习爬虫使用方法:php代码分析,
一)php代码分析
二)php代码分析
三)php代码分析
四)php代码分析
五)视频教程地址:;view=all代码提示:php密码错误,使用phpkey替代。练习的编程环境:windows10,
php函数封装(三种常用配置)#1.php函数封装1.1基础php函数大全(主要接口)1.2中级php函数(数据库驱动相关)1.3详细php函数(js文件封装)autoconfautoconf使用教程appendcall表+=表封装append语句+=+=$call;,在本代码封装注意大小写update$data=append($temporary,$content);,要么本代码封装(即":content"+$content)update:{"data":"","content":""}js文件封装,可以参考,封装windowsjs文件</a>1.5爬虫实例小爬虫类型爬虫返回布尔类型&amp;amp;three引擎博客爬虫实例与封装爬虫基础伪装:接口伪装:获取外界访问等。
forward()接口伪装函数执行循环,"window","max_height"接口伪装函数,"user_height"接口伪装函数(本文采用这种)接口伪装包括$post语句if(f3in$_server[$name]){$db_name=$_server[$name]?$f3:'publicname';}else{$db_name='';}$post=f3;?>随机数接口伪装函数会生成(用于加密,替换等场景)随机数及token。
publicname=['f3','r7855','03331','033','s319412','ant','pi',''];for($tuple:$name){if($tuple[$tuple]==$name){echo$tuple;}?}验证地址$_server[$token];接口伪装函数实现验证地址(append函数是ioconfserver上的,f3等是windows)inconf.php如何对php进行参数防爬结构参数防爬实现1.配置使用$context=require("inconf.php");$url=$_server['request_uri'];$m。
php如何抓取网页数据库(php中抓取网页内容的实例详解方法一:使用file_get_contents方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-12 07:15
php爬取网页内容的详细示例
方法一:
使用file_get_contents方法来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $html = file_get_contents($url); //如果出现中文乱码使用下面代码 //$getcOntent= iconv("gb2312", "utf-8",$html); echo "".$html."";
代码很简单,一看就懂,不用解释。
方法二:
使用 curl 实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTransfer, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
相关学习推荐:PHP编程(视频) 查看全部
php如何抓取网页数据库(php中抓取网页内容的实例详解方法一:使用file_get_contents方法)
php爬取网页内容的详细示例
方法一:
使用file_get_contents方法来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $html = file_get_contents($url); //如果出现中文乱码使用下面代码 //$getcOntent= iconv("gb2312", "utf-8",$html); echo "".$html."";
代码很简单,一看就懂,不用解释。
方法二:
使用 curl 实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTransfer, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $html = curl_exec($ch); curl_close($ch); echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码意味着如果请求被重定向,则可以访问最终的请求页面,否则请求的结果将显示如下:
相关学习推荐:PHP编程(视频)
php如何抓取网页数据库(php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-10 15:07
php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装phpmyadmin:到官网下载,要用到的是extractor1.打开extractor,导入一下数据库和books.config。extractor安装phpmyadmin:phpmyadmin--extractor-database="testdb"--dbpath="/testdb"--cache-config="preference--prefix=/testdb"--rootpath="/"配置参数extractor下载地址:,在extractor中找到books.config.user-id='student-id'选中"+"按钮,否则按钮是空的,这个参数将填写用户名和密码,从主机拉取数据以后需要配置两个数据库账号和密码:账号user-id,密码password访问books.config,删除phpmyadmin,然后重新执行extractor选择books.config中的user-id='student-id',密码password。
抓取网页一段html文件的数据可以使用phpmyadmin所有的功能如reader函数,获取phpmyadmin中的.html文件的数据,但是其他功能需要另外配置。phpmyadmin如何抓取网页:1.先新建一个空的phpmyadmin账号/users/lauzd/books.config。2.在左侧设置抓取列表databases选择c2015。
3.设置对应.html文件的位置,可以在最后添加curl函数指定第一个.html文件的位置。指定位置后,可以指定文件名称,也可以指定.html后缀,后缀具体指定为啥看你喜欢。如果不指定,文件将指定到cpp_client.php.xml。4.然后就可以设置获取时间,如果有需要或者该testdb只是爬虫时的testdb,那么最后一页面将显示一个time参数,time参数从1秒开始到1000000000毫秒。
5.具体抓取过程要看人性化操作要求,可以设置加载时间和下载速度等等。抓取html文件中的内容如果在数据库中列表是未存在的,则也返回给操作员用于指定前1000000000毫秒内,该站的html文件没有存在。可以通过reader函数来获取列表,也可以通过prefix/***/命令来获取列表。本文来自如何安装phpmyadmin和phpmyadmin如何抓取网页数据?-phpmyadmin的分享。 查看全部
php如何抓取网页数据库(php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装)
php如何抓取网页数据库:需要以下工具:phpmyadmin如何安装phpmyadmin:到官网下载,要用到的是extractor1.打开extractor,导入一下数据库和books.config。extractor安装phpmyadmin:phpmyadmin--extractor-database="testdb"--dbpath="/testdb"--cache-config="preference--prefix=/testdb"--rootpath="/"配置参数extractor下载地址:,在extractor中找到books.config.user-id='student-id'选中"+"按钮,否则按钮是空的,这个参数将填写用户名和密码,从主机拉取数据以后需要配置两个数据库账号和密码:账号user-id,密码password访问books.config,删除phpmyadmin,然后重新执行extractor选择books.config中的user-id='student-id',密码password。
抓取网页一段html文件的数据可以使用phpmyadmin所有的功能如reader函数,获取phpmyadmin中的.html文件的数据,但是其他功能需要另外配置。phpmyadmin如何抓取网页:1.先新建一个空的phpmyadmin账号/users/lauzd/books.config。2.在左侧设置抓取列表databases选择c2015。
3.设置对应.html文件的位置,可以在最后添加curl函数指定第一个.html文件的位置。指定位置后,可以指定文件名称,也可以指定.html后缀,后缀具体指定为啥看你喜欢。如果不指定,文件将指定到cpp_client.php.xml。4.然后就可以设置获取时间,如果有需要或者该testdb只是爬虫时的testdb,那么最后一页面将显示一个time参数,time参数从1秒开始到1000000000毫秒。
5.具体抓取过程要看人性化操作要求,可以设置加载时间和下载速度等等。抓取html文件中的内容如果在数据库中列表是未存在的,则也返回给操作员用于指定前1000000000毫秒内,该站的html文件没有存在。可以通过reader函数来获取列表,也可以通过prefix/***/命令来获取列表。本文来自如何安装phpmyadmin和phpmyadmin如何抓取网页数据?-phpmyadmin的分享。
php如何抓取网页数据库(用PHP做一个记录,为后续学习铺路。。(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-06 21:01
昨天发现了一个数据库管理软件:Navicat for MySQL,一个强大的MySQL数据库管理和开发工具,这个软件使用了优秀的图形用户界面(GUI),可以以一种安全、简单的方式快速使用并轻松创建新的数据库,新的在前端学习的过程中,一直对后台如何从数据库中读取数据,后台如何提供前端接口等感兴趣。借此机会,我尝试创建一个新的数据库和表,并使用 PHP 从构建的数据库中读取数据。并使用Ajax将数据展示在前端,并做好记录,为后续学习做铺垫。
1、使用 Navicat for MySQL 创建数据库和表
Navicat for MySQL 使用起来非常简单。您无需像 PHP 那样编写代码来创建数据库和表。具体操作在此不再详述。您可以参考以下网址进行创建:
Navicat for MySQL 的下载、安装和基本使用
Navicat for MySQL 使用说明(第 1 部分)– 创建数据库和表
创建的数据库和表如下图所示:
2、使用PHP从MySQL数据库中读取数据
在下面的例子中,我们从student数据库的studentinfo表中读取studentID、studentName、class、department和teleNumber列的数据并显示在页面上:
上面的代码解析如下:
首先,设置SQL语句从MyGuests数据表中读取id、firstname和lastname三个字段。然后我们使用修改后的 SQL 语句从数据库中获取结果集并将其分配给变量 $result。
函数 num_rows() 判断返回的数据。
如果返回多条数据,函数 fetch_assoc() 将关联集放入关联数组并循环输出。while() 循环出结果集,输出id、firstname、lastname三个字段值。
过程中遇到的问题:
(1)PHP从数据库中读取数据的中文显示为“?”,解决方法:
mysqli_query($conn, 'set names utf8')之后,中文变成Unicode编码
(2)如何将Unicode编码改为中文:
json_encode($row,JSON_UNESCAPED_UNICODE)。' ';
3、使用ajax在前端页面展示数据
代码显示如下:
.table{
width: 1000px;
text-align: center;
}
学生信息管理
学号
姓名
班级
学院
电话
$.ajax({
type: 'POST',
url: 'studentInfo.php',
data:{
},
success: function (data) {
//console.log(data);
var a = data.split(' ');
//console.log(a);
var trStr = '';//动态拼接table
for (var i = 0; i < a.length-1; i++) {
trStr += '';
trStr += '' + JSON.parse(a[i]).studentID + '';
trStr += '' + JSON.parse(a[i]).studentName + '';
trStr += '' + JSON.parse(a[i]).class + '';
trStr += '' + JSON.parse(a[i]).department + '';
trStr += '' + JSON.parse(a[i]).teleNumber + '';
trStr += '';
}
$("#tbody").html(trStr);
}
});
最终效果:
以上内容仅作为前端、后端与数据库连接的演示,更不用说前端与后端的数据交互。还有很多内容需要扩展,比如数据的增删改操作。您可以在业余时间自娱自乐。 查看全部
php如何抓取网页数据库(用PHP做一个记录,为后续学习铺路。。(一))
昨天发现了一个数据库管理软件:Navicat for MySQL,一个强大的MySQL数据库管理和开发工具,这个软件使用了优秀的图形用户界面(GUI),可以以一种安全、简单的方式快速使用并轻松创建新的数据库,新的在前端学习的过程中,一直对后台如何从数据库中读取数据,后台如何提供前端接口等感兴趣。借此机会,我尝试创建一个新的数据库和表,并使用 PHP 从构建的数据库中读取数据。并使用Ajax将数据展示在前端,并做好记录,为后续学习做铺垫。
1、使用 Navicat for MySQL 创建数据库和表
Navicat for MySQL 使用起来非常简单。您无需像 PHP 那样编写代码来创建数据库和表。具体操作在此不再详述。您可以参考以下网址进行创建:
Navicat for MySQL 的下载、安装和基本使用
Navicat for MySQL 使用说明(第 1 部分)– 创建数据库和表
创建的数据库和表如下图所示:
2、使用PHP从MySQL数据库中读取数据
在下面的例子中,我们从student数据库的studentinfo表中读取studentID、studentName、class、department和teleNumber列的数据并显示在页面上:
上面的代码解析如下:
首先,设置SQL语句从MyGuests数据表中读取id、firstname和lastname三个字段。然后我们使用修改后的 SQL 语句从数据库中获取结果集并将其分配给变量 $result。
函数 num_rows() 判断返回的数据。
如果返回多条数据,函数 fetch_assoc() 将关联集放入关联数组并循环输出。while() 循环出结果集,输出id、firstname、lastname三个字段值。
过程中遇到的问题:
(1)PHP从数据库中读取数据的中文显示为“?”,解决方法:
mysqli_query($conn, 'set names utf8')之后,中文变成Unicode编码
(2)如何将Unicode编码改为中文:
json_encode($row,JSON_UNESCAPED_UNICODE)。' ';
3、使用ajax在前端页面展示数据
代码显示如下:
.table{
width: 1000px;
text-align: center;
}
学生信息管理
学号
姓名
班级
学院
电话
$.ajax({
type: 'POST',
url: 'studentInfo.php',
data:{
},
success: function (data) {
//console.log(data);
var a = data.split(' ');
//console.log(a);
var trStr = '';//动态拼接table
for (var i = 0; i < a.length-1; i++) {
trStr += '';
trStr += '' + JSON.parse(a[i]).studentID + '';
trStr += '' + JSON.parse(a[i]).studentName + '';
trStr += '' + JSON.parse(a[i]).class + '';
trStr += '' + JSON.parse(a[i]).department + '';
trStr += '' + JSON.parse(a[i]).teleNumber + '';
trStr += '';
}
$("#tbody").html(trStr);
}
});
最终效果:
以上内容仅作为前端、后端与数据库连接的演示,更不用说前端与后端的数据交互。还有很多内容需要扩展,比如数据的增删改操作。您可以在业余时间自娱自乐。
php如何抓取网页数据库(网络爬虫就是网站实现web信息展示的核心在于设计模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-31 08:23
项目介绍
随着互联网的飞速发展,网络已经成为人们检索和发布的主要平台。如何在海量数据中快速、准确地找到用户需要的信息,成为了当下人们所需要的,而网络爬虫正是为了满足人们的需求。因这种需要而产生的研究领域。现实中,我们的资源是有限的,如何在有限的资源中区分我们每个人的不同需求,有的想听歌,有的想看电影,有的是工作需要的机密文件,不想别人看吧,只有它才能保护大家的隐私,满足不同人群的需求。因此,仍然需要根据不同的用户来研究爬取内容。
在检索信息和采集信息中实现网页信息展示的核心是设计网页爬虫模块,主要是全文搜索引擎模块。本文主要设计全文搜索并实现页面采集器的详细介绍。工作流影响核心算法和数据存储,克服了技术难点,实现了良好的实际运行和良好的效果,进一步提升了引擎效果。
这个网站基于B/S模式设计爬虫网站,需要简单的爬取操作和清除多用户数据。开发爬虫网站管理多用户,数据分级管理,数据存放在指定数据库中。区分重复网页,解决去重问题;添加主题相关性;更快地抓取数据;存储数据; 实现数据可视化。
关键词:搜索引擎;网络爬虫;信息检索;页面索引
使用python提供的开源django应用框架,Django更注重模型(Model)、模板(Template)和视图(Views),也就是MTV模式。
打开登录界面,可以使用以下操作:
(1)安装python3.6版本
(2) 安装 Django 库 1.11.4 版本 pip install Django==1.11.14
(3) 安装 selenium 库3.141.0 pip install selenium
(4)安装jieba库0.39版 pip install jieba
(5)命令行下进入xxx\Web_Spider_Demo\mysite_login\目录,运行manage.py(操作方法:python manage.py runserver),运行成功后,打开浏览器(google),进入网页主页:127.0.0.1:8000/index.
(6)登录时可以使用注册时的账号和密码登录自己的界面,获取填写的数据是否与注册时的信息进行对比。如果同理,可以登录使用网站功能。
爬虫搜索
设计从网页中选取一些url,将url放入url队列,解析这些url中的链接,下载内容,存储在一个固定的页库中,建立对应的索引,从其中提取所有链接它。如果解析中收录的 url 没有出现在缓存中,则该 url 调度的队列会被再次抓取,直到抓取到对应的网页。完成一个完整的爬取过程后,爬虫有多种类型:
(1)批量爬虫:将数据批量抓取到想要的目标和范围。当爬虫到达设定的目标时,就会停止爬取过程。至于具体的目标,可能不一样,也可能是设置爬取一定数量的网页,也可以设置爬取所消耗的时间。
(2)增量爬虫:如果在爬取过程中出现了新的网页,该机制会更新该网页,可以实现一个通用的搜索引擎来实现增量处理。
(3)Focused Crawter):针对不同的特定主题和不同特定行业的网页,您可以从互联网页面中找到健康相关页面的内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。
效果图
内容
1 简介 3
1.1 开发背景 4
1.2 研究现状 4
2 页面设计 6
2.1 工作原理 6
2.2 网页设计 6
2.2.1 注册 7
2.2.2 登录 8
2.2.3 爬虫搜索 8
3 功能实现 10
3.1 基本工作原理 10
3.2 jieba库10
4 数据库设计 10
5 测试 11
5.1 设计问题 11
5.2 问题级别 12
5.3 测试评估 12
5.4 测试设计 12
6 结语 13
参考文献 13
谢谢 16 查看全部
php如何抓取网页数据库(网络爬虫就是网站实现web信息展示的核心在于设计模块)
项目介绍
随着互联网的飞速发展,网络已经成为人们检索和发布的主要平台。如何在海量数据中快速、准确地找到用户需要的信息,成为了当下人们所需要的,而网络爬虫正是为了满足人们的需求。因这种需要而产生的研究领域。现实中,我们的资源是有限的,如何在有限的资源中区分我们每个人的不同需求,有的想听歌,有的想看电影,有的是工作需要的机密文件,不想别人看吧,只有它才能保护大家的隐私,满足不同人群的需求。因此,仍然需要根据不同的用户来研究爬取内容。
在检索信息和采集信息中实现网页信息展示的核心是设计网页爬虫模块,主要是全文搜索引擎模块。本文主要设计全文搜索并实现页面采集器的详细介绍。工作流影响核心算法和数据存储,克服了技术难点,实现了良好的实际运行和良好的效果,进一步提升了引擎效果。
这个网站基于B/S模式设计爬虫网站,需要简单的爬取操作和清除多用户数据。开发爬虫网站管理多用户,数据分级管理,数据存放在指定数据库中。区分重复网页,解决去重问题;添加主题相关性;更快地抓取数据;存储数据; 实现数据可视化。
关键词:搜索引擎;网络爬虫;信息检索;页面索引
使用python提供的开源django应用框架,Django更注重模型(Model)、模板(Template)和视图(Views),也就是MTV模式。
打开登录界面,可以使用以下操作:
(1)安装python3.6版本
(2) 安装 Django 库 1.11.4 版本 pip install Django==1.11.14
(3) 安装 selenium 库3.141.0 pip install selenium
(4)安装jieba库0.39版 pip install jieba
(5)命令行下进入xxx\Web_Spider_Demo\mysite_login\目录,运行manage.py(操作方法:python manage.py runserver),运行成功后,打开浏览器(google),进入网页主页:127.0.0.1:8000/index.
(6)登录时可以使用注册时的账号和密码登录自己的界面,获取填写的数据是否与注册时的信息进行对比。如果同理,可以登录使用网站功能。
爬虫搜索
设计从网页中选取一些url,将url放入url队列,解析这些url中的链接,下载内容,存储在一个固定的页库中,建立对应的索引,从其中提取所有链接它。如果解析中收录的 url 没有出现在缓存中,则该 url 调度的队列会被再次抓取,直到抓取到对应的网页。完成一个完整的爬取过程后,爬虫有多种类型:
(1)批量爬虫:将数据批量抓取到想要的目标和范围。当爬虫到达设定的目标时,就会停止爬取过程。至于具体的目标,可能不一样,也可能是设置爬取一定数量的网页,也可以设置爬取所消耗的时间。
(2)增量爬虫:如果在爬取过程中出现了新的网页,该机制会更新该网页,可以实现一个通用的搜索引擎来实现增量处理。
(3)Focused Crawter):针对不同的特定主题和不同特定行业的网页,您可以从互联网页面中找到健康相关页面的内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。
效果图
内容
1 简介 3
1.1 开发背景 4
1.2 研究现状 4
2 页面设计 6
2.1 工作原理 6
2.2 网页设计 6
2.2.1 注册 7
2.2.2 登录 8
2.2.3 爬虫搜索 8
3 功能实现 10
3.1 基本工作原理 10
3.2 jieba库10
4 数据库设计 10
5 测试 11
5.1 设计问题 11
5.2 问题级别 12
5.3 测试评估 12
5.4 测试设计 12
6 结语 13
参考文献 13
谢谢 16
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-27 15:07
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php如何抓取网页数据库(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个 PHP 库。
启用 cURL 设置
首先,我们要确定我们的 PHP 是否启用了这个库,你可以使用 php_info() 函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果您可以在网页上看到以下输出,则说明 cURL 库已启用。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是在windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,取消之前的分号注释。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要打开编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这是一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置需要抓取的网址
curl_setopt($curl, CURLOPT_URL, '');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置 cURL 参数,是否将结果保存为字符串或输出到屏幕。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
//显示获取到的数据
var_dump($data);
如何发布数据
上面是爬取网页的代码,下面是POST数据到网页。假设我们有一个处理表单的 URL,该表单接受两个表单字段,一个用于电话号码,一个用于文本消息的文本。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序我们可以看出,使用CURLOPT_POST来设置HTTP协议的POST方法而不是GET方法,然后用CURLOPT_POSTFIELDS设置POST数据。
关于代理服务器
以下是如何使用代理服务器的示例。请注意突出显示的代码,代码很简单,我不需要多说。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php如何抓取网页数据库(copy一下代码运行一下一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-23 18:10
)
关于爬取网站数据,出现302重定向!紧急!紧急!紧急!
目标网站:
第一步:输入商标号,提交(后抢)
第二步:点击商标号
第 3 步:要捕获的数据
前两步已经爬过,但是爬到最后一步时总是出现302重定向,导致数据爬不上去。
相关代码:
<br />//第一步<br />define(TARGET_URL,'http://www.dltm.net/webtmq/free/free_query.php');<br />define(REFFER_URL,'http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /><br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /><br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /><br />define(TARGET_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />define(REFFER_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /><br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /><br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;//这一步得不到数据<br />
您可以复制代码并自行运行。第三步的数据不可用。你能帮我看看吗?如果你能得到数据,请将你的源代码贴出来,非常感谢!!!
- - - 解决方案 - - - - - - - - - -
增加
curl_setopt($ch, CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch, CURLOPT_COOKIEFILE, "cookie.txt");
- - - 解决方案 - - - - - - - - - -
为什么不?
以注册号8437927为例
新建文件cookie.txt并执行代码
$cookie = realpath('cookie.txt'); //这是增加的<br />//第一步<br />define('TARGET_URL','http://www.dltm.net/webtmq/free/free_query.php');<br />define('REFFER_URL','http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /> <br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /> <br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /> <br />define('TARGET_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />define('REFFER_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /> <br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /> <br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;
查看全部
php如何抓取网页数据库(copy一下代码运行一下一下
)
关于爬取网站数据,出现302重定向!紧急!紧急!紧急!
目标网站:
第一步:输入商标号,提交(后抢)
第二步:点击商标号
第 3 步:要捕获的数据
前两步已经爬过,但是爬到最后一步时总是出现302重定向,导致数据爬不上去。
相关代码:
<br />//第一步<br />define(TARGET_URL,'http://www.dltm.net/webtmq/free/free_query.php');<br />define(REFFER_URL,'http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /><br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /><br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /><br />define(TARGET_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />define(REFFER_URL1,'http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /><br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /><br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;//这一步得不到数据<br />
您可以复制代码并自行运行。第三步的数据不可用。你能帮我看看吗?如果你能得到数据,请将你的源代码贴出来,非常感谢!!!
- - - 解决方案 - - - - - - - - - -
增加
curl_setopt($ch, CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch, CURLOPT_COOKIEFILE, "cookie.txt");
- - - 解决方案 - - - - - - - - - -
为什么不?
以注册号8437927为例
新建文件cookie.txt并执行代码
$cookie = realpath('cookie.txt'); //这是增加的<br />//第一步<br />define('TARGET_URL','http://www.dltm.net/webtmq/free/free_query.php');<br />define('REFFER_URL','http://www.dltm.net');<br />$url=TARGET_URL;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />preg_match_all('',$result,$rs);<br /> <br />//第二步<br />$fields_post = array(<br /> 'ip'=>$rs[1][0],<br /> 'textarea_explain'=>'%B2%E9%D1%AF%C8%AB%B2%BF%C0%E0%B1%F0',<br /> 'tm_lb'=> '0',<br /> 'tm_key'=>'8437927',<br /> 'tm_key_item'=>'tm_zch',<br /> 'query_mode'=>'1'<br />);<br /> <br />$fields_string='';<br />foreach($fields_post as $key => $value)<br />{<br /> $fields_string .= $key . '=' . $value . '&';<br />}<br />$fields_string = rtrim($fields_string,'&');<br /> <br />define('TARGET_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />define('REFFER_URL1','http://www.dltm.net/webtmq/free/free_res.php');<br />$url=TARGET_URL1;<br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch,CURLOPT_POST,1);//以POST方式提交<br />curl_setopt($ch,CURLOPT_POSTFIELDS,$fields_string);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br /> <br />//第三步<br />preg_match_all('<a href="(.*)" target="detail">',$result,$res);<br />$url = 'http://www.dltm.net/webtmq/free/'.$res[1][0];<br /> <br />$ch=curl_init($url);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//返回结果存放在变量中,而不是默认的直接输出<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_REFERER, REFFER_URL1);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //这是增加的<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie); //这是增加的<br />$result= curl_exec($ch);//保存输出的页面到$result中<br />curl_close($ch);<br />print_r($result);exit;
php如何抓取网页数据库(什么是静态页面简单来说就是固定得死页面,不需要执行脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-22 09:08
一、什么是静态页面静态页面就是固定死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图:1、静态页面的优点是访问速度快,没有
一、什么是静态页面
静态页面只是一个固定的死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页的代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图所示:
1、静态页面的优点
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问;
2、静态页面的缺点
服务器占用空间大,消耗内存;
· 修改更新困难,大量静态页面维护麻烦;
· 不能完美支持用户的需求(如外观选择、浏览器支持);
二、什么是动态页面
动态页面是指网页代码中收录程序代码,通过调用后台数据库中的信息与网页服务器进行交互,实时显示网页内容。一般动态页面的路径比较长,参数很多,还有“?”,后缀有.aspx、.asp、.jsp、.php等形式。部分截图:
1、动态页面的优势
· 占地面积小;
· 网页更改比较简单,可以在后台独立管理和发布更新的页面;
· 可实现更多功能,如会员注册/登录/管理;
· 网页维护成本低,减少网站维护工作量;
2、动态页面的缺点
网页访问速度比静态页面慢;
· 蜘蛛容易陷入死循环,不利于搜索引擎收录页面;
服务器压力比较大,对服务器要求比较高;
· 由于数据的交互性,存在很大的安全隐患;
三、什么是伪静态页面
1、伪静态页面,顾名思义,是假的静态页面。伪静态页面其实是一个动态页面,但是为了对搜索引擎更加友好,通过技术处理将其路径改为与静态页面相同的路径,便于爬取。
2、从URL结构来看,伪静态页面和静态页面是一样的。它们都以 .html 和 .htm 后缀结尾,但它们只是改变了 URL 的表达方式,本质上是一个动态页面。严格来说还是在增加服务器资源消耗。
3、结合上面分析的静态页面和动态页面的优缺点,我们发现伪静态结合了静态页面和动态页面的优点,解决了静态页面占用更多空间和容量的问题,能够更好增加搜索引擎的友好度。
4、因为伪静态是浏览器在访问时使用的是正则判断而不是真实地址,所以区分显示哪个页面的责任也由原来直接指定,换成CPU判断,导致在 CPU occupancy 流量过大时,会导致 CPU 使用率超载,从而导致 网站 服务器出现问题。这也是伪静态最大的缺点。
因此,网站 使用哪个页面取决于网站 的规模和类型。一般来说,建议中小网站使用静态页面,有利于蜘蛛的访问和收录;对于较大的网站,建议在动态页面的基础上使用伪静态技术。
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问; 查看全部
php如何抓取网页数据库(什么是静态页面简单来说就是固定得死页面,不需要执行脚本)
一、什么是静态页面静态页面就是固定死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图:1、静态页面的优点是访问速度快,没有
一、什么是静态页面
静态页面只是一个固定的死页。网页的代码存储在页面中。无需执行脚本调用数据库内容即可显示内容。如果要更新页面,则必须修改网页的代码。静态页面通常以 .html、.htm、.shtml 后缀结尾。如图所示:
1、静态页面的优点
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问;
2、静态页面的缺点
服务器占用空间大,消耗内存;
· 修改更新困难,大量静态页面维护麻烦;
· 不能完美支持用户的需求(如外观选择、浏览器支持);
二、什么是动态页面
动态页面是指网页代码中收录程序代码,通过调用后台数据库中的信息与网页服务器进行交互,实时显示网页内容。一般动态页面的路径比较长,参数很多,还有“?”,后缀有.aspx、.asp、.jsp、.php等形式。部分截图:
1、动态页面的优势
· 占地面积小;
· 网页更改比较简单,可以在后台独立管理和发布更新的页面;
· 可实现更多功能,如会员注册/登录/管理;
· 网页维护成本低,减少网站维护工作量;
2、动态页面的缺点
网页访问速度比静态页面慢;
· 蜘蛛容易陷入死循环,不利于搜索引擎收录页面;
服务器压力比较大,对服务器要求比较高;
· 由于数据的交互性,存在很大的安全隐患;
三、什么是伪静态页面
1、伪静态页面,顾名思义,是假的静态页面。伪静态页面其实是一个动态页面,但是为了对搜索引擎更加友好,通过技术处理将其路径改为与静态页面相同的路径,便于爬取。
2、从URL结构来看,伪静态页面和静态页面是一样的。它们都以 .html 和 .htm 后缀结尾,但它们只是改变了 URL 的表达方式,本质上是一个动态页面。严格来说还是在增加服务器资源消耗。
3、结合上面分析的静态页面和动态页面的优缺点,我们发现伪静态结合了静态页面和动态页面的优点,解决了静态页面占用更多空间和容量的问题,能够更好增加搜索引擎的友好度。
4、因为伪静态是浏览器在访问时使用的是正则判断而不是真实地址,所以区分显示哪个页面的责任也由原来直接指定,换成CPU判断,导致在 CPU occupancy 流量过大时,会导致 CPU 使用率超载,从而导致 网站 服务器出现问题。这也是伪静态最大的缺点。
因此,网站 使用哪个页面取决于网站 的规模和类型。一般来说,建议中小网站使用静态页面,有利于蜘蛛的访问和收录;对于较大的网站,建议在动态页面的基础上使用伪静态技术。
· 访问速度快,无需连接数据库;
· 减轻服务器负担和数据库成本;
· 页面相对安全,不受asp相关漏洞的影响;
· 数据库出错不会影响网站的正常访问;
php如何抓取网页数据库(如何登陆阿里云的云虚拟主机附带(数据库)数据管理DMS网页版)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-20 14:05
数据管理DMS是基于阿里巴巴集团十余年数据库服务平台的云版本。它现在提供了一个免费的客户端,无需登录云帐户即可下载和使用。支持多种数据库类型。除了基本的数据查询外,还支持导入、导出、表结构对比、测试数据生成、数据库日志跟踪回滚、数据库备份与恢复、跨数据库查询、任务调度、可视化等强大功能。
那么如何使用(数据库)数据管理DMS网页版(无需下载客户端)登录阿里云的云虚拟主机呢?
█ 步骤 4-1:
登录你的阿里云账号,进入对应的虚拟主机控制面板:点击左侧的“数据库信息”项
█ 步骤 4-2:
点击右侧“管理”进入DMS数据管理页面
█ 步骤 4-3:
在DMS数据管理页面,点击页面中的“Web版”,跳转到数据库后台登录页面
█ 步骤 4-4:
在阿里云数据库后台登录页面,前3项填写如下图所示格式(其中A和B代表步骤1截图中标记位置的内容)
点击下方“登录”按钮登录数据库
例子:
例如,我的步骤 1 的屏幕截图显示:
数据库地址:
数据库用户名:bdm807
然后我实际上需要输入第4步的前2项:
数据库地址:3306
数据库用户名:bdm807
以上就是如何用(数据库)数据管理DMS网页版方法登录阿里云的云虚拟主机(无需下载客户端) 查看全部
php如何抓取网页数据库(如何登陆阿里云的云虚拟主机附带(数据库)数据管理DMS网页版)
数据管理DMS是基于阿里巴巴集团十余年数据库服务平台的云版本。它现在提供了一个免费的客户端,无需登录云帐户即可下载和使用。支持多种数据库类型。除了基本的数据查询外,还支持导入、导出、表结构对比、测试数据生成、数据库日志跟踪回滚、数据库备份与恢复、跨数据库查询、任务调度、可视化等强大功能。
那么如何使用(数据库)数据管理DMS网页版(无需下载客户端)登录阿里云的云虚拟主机呢?
█ 步骤 4-1:
登录你的阿里云账号,进入对应的虚拟主机控制面板:点击左侧的“数据库信息”项
█ 步骤 4-2:
点击右侧“管理”进入DMS数据管理页面
█ 步骤 4-3:
在DMS数据管理页面,点击页面中的“Web版”,跳转到数据库后台登录页面
█ 步骤 4-4:
在阿里云数据库后台登录页面,前3项填写如下图所示格式(其中A和B代表步骤1截图中标记位置的内容)
点击下方“登录”按钮登录数据库
例子:
例如,我的步骤 1 的屏幕截图显示:
数据库地址:
数据库用户名:bdm807
然后我实际上需要输入第4步的前2项:
数据库地址:3306
数据库用户名:bdm807
以上就是如何用(数据库)数据管理DMS网页版方法登录阿里云的云虚拟主机(无需下载客户端)
php如何抓取网页数据库(php如何抓取网页数据库呢?(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-20 06:03
php如何抓取网页数据库呢,一般大型的网站,都会有专门抓取数据库的服务器,我们都知道打游戏的时候可以获取小怪的战力,之后我们就可以考虑变换战力,进而获取更多的奖励。这其实就是同样的原理,那么如何抓取网页数据库呢?首先你需要获取网页页面。虽然有些网站有给出抓取页面的入口,但也有一些是禁止抓取的,所以我们还需要先了解禁止抓取的详细情况。
#首先要先将整个网页内容打包成css格式的页面。然后在浏览器中获取。varrawobject=getenv('raw-webkit-frame');console.log(rawobject.dom->data);这样我们就可以在getenv获取到需要抓取的页面和浏览器的地址。我们可以看一下给出的w3c的规范,获取规范有几个要求。
-o2-webkit-frame-radius-estimate-webkit-frame-radius0-webkit-frame-fraction-estimate-init-webkit-frame-radius-estimate-player-directory-density0-init-frame-radius0-user-data-fieldset-by-application-frame-radius#css抓取我们利用filereader这个库和一些google文档的工具,只要能下载并解析dom的内容,就可以抓取百度网页的url文件,再用正则表达式匹配即可。
为了便于操作,我建议全部用filereader来操作。content.split('-').split('*');content.split('-').split('/');content.split('-').split('/');content.split('/').split('/');content.split('/').split('/');#js抓取我们利用threejs库来抓取百度网页。
在下载threejs并导入之后,设置好hosts文件,打开浏览器开发者工具,输入如下的地址/,然后获取url:baiduyavea/js.js;url_type=1&page=1查看源码,发现只有一个html页面,因为我们自己配置hosts的时候设置了dom为根节点,所以抓取的时候我们只用window.getenv('dom');抓取出来的只有根节点,没有子节点。
<p>最后用正则表达式匹配出我们要的数据。数据获取完成之后,我们可以发现源码有个html标签,那么我们直接做个bower,定义我们的模版,即可发布:#tp401-user-data#category=cname-userdata#expiration-time='601377'#span=#page=1#filename='/'#path=''#name=callbackgetstategetresults 查看全部
php如何抓取网页数据库(php如何抓取网页数据库呢?(一)(组图))
php如何抓取网页数据库呢,一般大型的网站,都会有专门抓取数据库的服务器,我们都知道打游戏的时候可以获取小怪的战力,之后我们就可以考虑变换战力,进而获取更多的奖励。这其实就是同样的原理,那么如何抓取网页数据库呢?首先你需要获取网页页面。虽然有些网站有给出抓取页面的入口,但也有一些是禁止抓取的,所以我们还需要先了解禁止抓取的详细情况。
#首先要先将整个网页内容打包成css格式的页面。然后在浏览器中获取。varrawobject=getenv('raw-webkit-frame');console.log(rawobject.dom->data);这样我们就可以在getenv获取到需要抓取的页面和浏览器的地址。我们可以看一下给出的w3c的规范,获取规范有几个要求。
-o2-webkit-frame-radius-estimate-webkit-frame-radius0-webkit-frame-fraction-estimate-init-webkit-frame-radius-estimate-player-directory-density0-init-frame-radius0-user-data-fieldset-by-application-frame-radius#css抓取我们利用filereader这个库和一些google文档的工具,只要能下载并解析dom的内容,就可以抓取百度网页的url文件,再用正则表达式匹配即可。
为了便于操作,我建议全部用filereader来操作。content.split('-').split('*');content.split('-').split('/');content.split('-').split('/');content.split('/').split('/');content.split('/').split('/');#js抓取我们利用threejs库来抓取百度网页。
在下载threejs并导入之后,设置好hosts文件,打开浏览器开发者工具,输入如下的地址/,然后获取url:baiduyavea/js.js;url_type=1&page=1查看源码,发现只有一个html页面,因为我们自己配置hosts的时候设置了dom为根节点,所以抓取的时候我们只用window.getenv('dom');抓取出来的只有根节点,没有子节点。
<p>最后用正则表达式匹配出我们要的数据。数据获取完成之后,我们可以发现源码有个html标签,那么我们直接做个bower,定义我们的模版,即可发布:#tp401-user-data#category=cname-userdata#expiration-time='601377'#span=#page=1#filename='/'#path=''#name=callbackgetstategetresults
php如何抓取网页数据库( 使用PHP的cURL库设置cookie完成模拟登录网页的使用总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-18 00:10
使用PHP的cURL库设置cookie完成模拟登录网页的使用总结)
php curl模拟登录并获取数据实例详情
更新时间:2016年12月22日08:36:05投稿:lqh
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录
login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件
@ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i";
preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持! 查看全部
php如何抓取网页数据库(
使用PHP的cURL库设置cookie完成模拟登录网页的使用总结)
php curl模拟登录并获取数据实例详情
更新时间:2016年12月22日08:36:05投稿:lqh
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录
login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件
@ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i";
preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
php如何抓取网页数据库(php如何抓取网页数据库类似mysql但与mysql也有较大区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-17 03:01
php如何抓取网页数据库关系型数据库类似mysql但与mysql也有较大区别。这是一个简单的关系型数据库的抓取工具。第一步定位关键词,在这个系列的教程中,我们将使用php版本5.6.1。下载地址::2.然后使用pcre扫描器进行数据库扫描。4.查看哪些数据库需要抓取。5.然后重复4最后使用pcre抓取网页数据,获取网页中最关键字段。如图所示,该网页只抓取了以php为后缀的各个数据库信息。更多内容请访问:。
这个有好多,可以百度下抓取首页的,cookie的方法,利用好就行了。我对你问题理解的是这个但是有个局限性就是,你如果用别人的cookie,就只能获取首页数据,
目前只抓取开放的api
抓取域名,
可以借助抓包工具在本地实现,
我写过一个在线程序抓取网页,
可以利用google的cookie,我以前做网站也用这个,有用到爬虫和cookie,
同求啊,求推荐一个好用的抓包软件,可以抓google,facebook之类的.求推荐可以抓包的网站 查看全部
php如何抓取网页数据库(php如何抓取网页数据库类似mysql但与mysql也有较大区别)
php如何抓取网页数据库关系型数据库类似mysql但与mysql也有较大区别。这是一个简单的关系型数据库的抓取工具。第一步定位关键词,在这个系列的教程中,我们将使用php版本5.6.1。下载地址::2.然后使用pcre扫描器进行数据库扫描。4.查看哪些数据库需要抓取。5.然后重复4最后使用pcre抓取网页数据,获取网页中最关键字段。如图所示,该网页只抓取了以php为后缀的各个数据库信息。更多内容请访问:。
这个有好多,可以百度下抓取首页的,cookie的方法,利用好就行了。我对你问题理解的是这个但是有个局限性就是,你如果用别人的cookie,就只能获取首页数据,
目前只抓取开放的api
抓取域名,
可以借助抓包工具在本地实现,
我写过一个在线程序抓取网页,
可以利用google的cookie,我以前做网站也用这个,有用到爬虫和cookie,
同求啊,求推荐一个好用的抓包软件,可以抓google,facebook之类的.求推荐可以抓包的网站
php如何抓取网页数据库(一种适合于科研人员掌握和自学的数据库集成软件——WAMP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-13 00:06
(免责声明:本文适用于非计算机专业人士)
研究人员在进行研究或工作时,往往因需求而希望将自己产生的大量数据构建成数据库或实验室网站,方便数据查询和二次挖掘。在与IT公司合作的过程中,很多老师意识到,由于某些领域知识的差异,最终的结果可能与自己的假设不同,也可能与未来遇到的细节不同。问题实验室无法解决。事实上,没有人比研究组本身更了解研究组的需求,而每个人也常常因需要编程基础或缺乏建立数据库的经验和线索而灰心。
写这篇文章的目的是介绍一种适合研究人员掌握和自学的数据库构建技术。这里所说的数据库可以理解一个接口网站,并可以在此基础上进行简单的查询和数据展示功能。本文主要介绍在Windows系统中建数据库需要安装的软件、配置步骤和网页设计方法。详细的函数创建方法将在以后更新。
一、使用的数据库技术——LAMP
LAMP其实是web应用的一套软件组合的缩写,它的全称是:Linux + Apache + MySQL + PHP,由四部分组成,数据库的操作/网站需要这四部分的配合软件工作。具体来说,L 代表 Linux 操作系统。如果系统是Windows,我们通常称它为WAMP,即W代表Windows;A 代表 Apache,它是世界上最流行的 Web 服务器软件之一。可以理解为专门负责实现Web响应的Web服务器;M代表MySQL或MariaDB数据库,其中数据库指的是数据库管理系统,可以理解为后台存储和管理数据的数据库服务器;P 代表 PHP、Perl 或 Python 编程语言,
二、要安装的数据库集成软件 - WAMP
以往如果要在电脑上建数据库,可能需要分别安装软件A、M、P三部分,操作起来比较麻烦。目前网上有很多综合包可供下载,即只需安装一个集成软件即可完成整个数据库框架的安装。在Windows系统中,常见的集成软件有WampServer、phpStudy等,都是免费软件。以 Wamp 为例,Wamp 有很多版本。一般来说,安装后打开Wamp,会在桌面右下角看到启动图标。几秒钟后,如果图标变为白色(某些版本为绿色),则表示安装成功。. 如果不能正常打开,可能是Windows系统版本的问题。您可以从 Internet 下载其他版本的 Wamp 并进行安装。Wamp的安装没有什么特别需要注意的,不同版本在使用上也没有太大区别。我用过 wamp2.0 和 5.0。
开启 Wamp 的步骤:
1.点击开始菜单
2.打开后显示在桌面右下角
三、要安装的网页设计软件 - Dreamweaver 8
Dreamweaver8 是一款集网页制作和管理于一体的网页编辑器。最大的好处是所见即所得,方便没有编程基础的人设计网站/database接口。
四、需要配置
Dreamweaver8管理数据库的关键步骤是在Dreamweaver8和Wamp之间建立连接,即在Dreamweaver中完成页面设计后,实现数据库技术调用->在浏览器中显示效果。
(1) 站点-新站点
(2) 命名站点名称
(3)选择合适的数据库技术
(4)文件存放位置,这里有两个需要自定义的路径。建议wamp安装在默认目录,即C:wamp,所有web文件存放在C:wampwww的路径下.
其余步骤无需修改,直接点击下一步即可完成。
五、一个例子
以Dreamweaver自带的网站模板为例,说明如何成功搭建数据库环境。
检查 Wamp 是否正常打开。打开 Dreamweaver8 并导入模板。
根据需要自定义自己的数据库接口,例如将数据库名称改为:MyDatabase。
将文件保存到 C:wampwww 并将其命名为 index.html。
按 F12,或在浏览器中输入:
设计好的界面显示在浏览器中。如果可以看到与 Dreamweaver 中设计的界面相同的界面,则说明数据库环境搭建成功。
关于作者
穆青,女,生物信息学专业,现就职于东方肝胆外科医院。
火星研究社创始成员。 查看全部
php如何抓取网页数据库(一种适合于科研人员掌握和自学的数据库集成软件——WAMP)
(免责声明:本文适用于非计算机专业人士)
研究人员在进行研究或工作时,往往因需求而希望将自己产生的大量数据构建成数据库或实验室网站,方便数据查询和二次挖掘。在与IT公司合作的过程中,很多老师意识到,由于某些领域知识的差异,最终的结果可能与自己的假设不同,也可能与未来遇到的细节不同。问题实验室无法解决。事实上,没有人比研究组本身更了解研究组的需求,而每个人也常常因需要编程基础或缺乏建立数据库的经验和线索而灰心。
写这篇文章的目的是介绍一种适合研究人员掌握和自学的数据库构建技术。这里所说的数据库可以理解一个接口网站,并可以在此基础上进行简单的查询和数据展示功能。本文主要介绍在Windows系统中建数据库需要安装的软件、配置步骤和网页设计方法。详细的函数创建方法将在以后更新。
一、使用的数据库技术——LAMP
LAMP其实是web应用的一套软件组合的缩写,它的全称是:Linux + Apache + MySQL + PHP,由四部分组成,数据库的操作/网站需要这四部分的配合软件工作。具体来说,L 代表 Linux 操作系统。如果系统是Windows,我们通常称它为WAMP,即W代表Windows;A 代表 Apache,它是世界上最流行的 Web 服务器软件之一。可以理解为专门负责实现Web响应的Web服务器;M代表MySQL或MariaDB数据库,其中数据库指的是数据库管理系统,可以理解为后台存储和管理数据的数据库服务器;P 代表 PHP、Perl 或 Python 编程语言,
二、要安装的数据库集成软件 - WAMP
以往如果要在电脑上建数据库,可能需要分别安装软件A、M、P三部分,操作起来比较麻烦。目前网上有很多综合包可供下载,即只需安装一个集成软件即可完成整个数据库框架的安装。在Windows系统中,常见的集成软件有WampServer、phpStudy等,都是免费软件。以 Wamp 为例,Wamp 有很多版本。一般来说,安装后打开Wamp,会在桌面右下角看到启动图标。几秒钟后,如果图标变为白色(某些版本为绿色),则表示安装成功。. 如果不能正常打开,可能是Windows系统版本的问题。您可以从 Internet 下载其他版本的 Wamp 并进行安装。Wamp的安装没有什么特别需要注意的,不同版本在使用上也没有太大区别。我用过 wamp2.0 和 5.0。
开启 Wamp 的步骤:
1.点击开始菜单
2.打开后显示在桌面右下角
三、要安装的网页设计软件 - Dreamweaver 8
Dreamweaver8 是一款集网页制作和管理于一体的网页编辑器。最大的好处是所见即所得,方便没有编程基础的人设计网站/database接口。
四、需要配置
Dreamweaver8管理数据库的关键步骤是在Dreamweaver8和Wamp之间建立连接,即在Dreamweaver中完成页面设计后,实现数据库技术调用->在浏览器中显示效果。
(1) 站点-新站点
(2) 命名站点名称
(3)选择合适的数据库技术
(4)文件存放位置,这里有两个需要自定义的路径。建议wamp安装在默认目录,即C:wamp,所有web文件存放在C:wampwww的路径下.
其余步骤无需修改,直接点击下一步即可完成。
五、一个例子
以Dreamweaver自带的网站模板为例,说明如何成功搭建数据库环境。
检查 Wamp 是否正常打开。打开 Dreamweaver8 并导入模板。
根据需要自定义自己的数据库接口,例如将数据库名称改为:MyDatabase。
将文件保存到 C:wampwww 并将其命名为 index.html。
按 F12,或在浏览器中输入:
设计好的界面显示在浏览器中。如果可以看到与 Dreamweaver 中设计的界面相同的界面,则说明数据库环境搭建成功。
关于作者
穆青,女,生物信息学专业,现就职于东方肝胆外科医院。
火星研究社创始成员。

