
网页抓取数据
网页抓取数据(选择network,库需要对数据的格式有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-23 17:05
初步准备工作
本例使用了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设这两个库已经安装好了,如果没有,可以通过pip安装。接下来,简单说一下这两个库的作用。requests库的主要作用是通过url获取服务器的前端代码数据。这两个库捕获的数据是服务器前端代码中的数据。BeautifulSoup 库主要用于从捕获的前端代码中提取所需的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
推荐使用谷歌或火狐浏览器打开,可以使用快捷键CTRL+U查看服务器网页源代码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。相信你能理解一点html语言基础知识。需要注意的是,我们可以在源码中看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码也是显示出来的。它是 JavaScript 代码,而不是 JavaScript 加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法是不直接从目标网站抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口中打开请求的资源。服务器可以通过改变请求参数返回不同的数据。这种方法需要对HTTP协议等原理有所了解。
具体方法是在要抓取的数据上右击,选择inspect。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次,就可以看到get方法的请求了。
通过get方法得到的返回数据与前端页面对比,可以发现是一致的。您可以直接选择鼠标右键打开一个新的网页。不过此时只返回了一部分数据,并不是全部数据,可以通过修改get方法的参数来获取全部数据。这里只能修改np=2,为什么要修改这个参数这里不再赘述。修改后的请求如下:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3 ,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115 ,f152&_=55
可以看出都是结构化数据,我们可以直接取数据。您可以使用正则表达式来匹配相应的数据。我们第一次只能捕获简单的信息,例如股票代码。详细的交易信息需要使用'+'股票代码'来获取。我们也用这两个库来重复这个过程,直接从源码中抓取就可以了,不用再麻烦了。代码直接在下面
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/index.jsp?stockcode=' + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{
'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部的信息,可以通过上述检查元素的方法得到。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次爬取的数据信息)
概括
第一次爬的时候,因为参考了书中的例子,不知道这个题目要爬的网页是用JavaScript写的,一般爬静态网页的方法是爬不出来的。的。我尝试了很多方法。一开始我以为是因为没有添加Headers参数,但是添加之后还是取不到。最后在网上查资料的时候,找到了一个关于反爬虫的介绍文章,里面解释了用JavaScript写的URL是不可能爬取的,并举例说明了两种对应的方案。第一种是使用dryscape库进行刮,第二种是使用selenium库进行刮。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用 selenium 库进行抓取。使用这种方法确实可以抓取数据,但前提是需要配合浏览器打开页面才能抓取。考虑到要抓取的页面太多,无法逐页抓取,所以再次放弃。第二种方法。最后转来分析一下JavaScript的数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在加载页面的时候会有一个请求URL,最终通过这个请求找到了想要的数据地址,并对参数进行了一些修改,你可以一次得到你想要的所有数据。在爬取过程中也遇到了一些问题。在最后的爬取过程中,因为有些股票没有交易数据,所以在抓取这些没有交易数据的股票时程序异常报错。最后,我加了一个判断。当没有成交数据时,会显示“该股票没有成交数据!”。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。 查看全部
网页抓取数据(选择network,库需要对数据的格式有什么作用?)
初步准备工作
本例使用了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设这两个库已经安装好了,如果没有,可以通过pip安装。接下来,简单说一下这两个库的作用。requests库的主要作用是通过url获取服务器的前端代码数据。这两个库捕获的数据是服务器前端代码中的数据。BeautifulSoup 库主要用于从捕获的前端代码中提取所需的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
推荐使用谷歌或火狐浏览器打开,可以使用快捷键CTRL+U查看服务器网页源代码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。相信你能理解一点html语言基础知识。需要注意的是,我们可以在源码中看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码也是显示出来的。它是 JavaScript 代码,而不是 JavaScript 加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法是不直接从目标网站抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口中打开请求的资源。服务器可以通过改变请求参数返回不同的数据。这种方法需要对HTTP协议等原理有所了解。
具体方法是在要抓取的数据上右击,选择inspect。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次,就可以看到get方法的请求了。
通过get方法得到的返回数据与前端页面对比,可以发现是一致的。您可以直接选择鼠标右键打开一个新的网页。不过此时只返回了一部分数据,并不是全部数据,可以通过修改get方法的参数来获取全部数据。这里只能修改np=2,为什么要修改这个参数这里不再赘述。修改后的请求如下:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3 ,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115 ,f152&_=55

可以看出都是结构化数据,我们可以直接取数据。您可以使用正则表达式来匹配相应的数据。我们第一次只能捕获简单的信息,例如股票代码。详细的交易信息需要使用'+'股票代码'来获取。我们也用这两个库来重复这个过程,直接从源码中抓取就可以了,不用再麻烦了。代码直接在下面
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/index.jsp?stockcode=' + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{
'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部的信息,可以通过上述检查元素的方法得到。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次爬取的数据信息)
概括
第一次爬的时候,因为参考了书中的例子,不知道这个题目要爬的网页是用JavaScript写的,一般爬静态网页的方法是爬不出来的。的。我尝试了很多方法。一开始我以为是因为没有添加Headers参数,但是添加之后还是取不到。最后在网上查资料的时候,找到了一个关于反爬虫的介绍文章,里面解释了用JavaScript写的URL是不可能爬取的,并举例说明了两种对应的方案。第一种是使用dryscape库进行刮,第二种是使用selenium库进行刮。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用 selenium 库进行抓取。使用这种方法确实可以抓取数据,但前提是需要配合浏览器打开页面才能抓取。考虑到要抓取的页面太多,无法逐页抓取,所以再次放弃。第二种方法。最后转来分析一下JavaScript的数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在加载页面的时候会有一个请求URL,最终通过这个请求找到了想要的数据地址,并对参数进行了一些修改,你可以一次得到你想要的所有数据。在爬取过程中也遇到了一些问题。在最后的爬取过程中,因为有些股票没有交易数据,所以在抓取这些没有交易数据的股票时程序异常报错。最后,我加了一个判断。当没有成交数据时,会显示“该股票没有成交数据!”。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。
网页抓取数据(如何最有效地分析Git存储库来跟踪数据源随时间的变化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-23 13:13
大多数人都知道 Git 抓取,这是一种网络抓取编程技术,您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析这些采集到的数据是一个公认的挑战。git-history 正是我为解决这个困境而设计的工具。
Git抓取技术回顾
将数据抓取到 Git 存储库的一大优势是抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 维护了一张火灾地图,显示了该州最近发生的大火。
我找到了 网站 的基础数据:
curl /umbraco/Api/IncidentApi/GetIncidents
然后我构建了一个简单的爬虫,它每 20 分钟获取一次 网站 数据并将其提交给 Git。到目前为止,该工具已经运行了 14 个月,并采集了 1559 次提交。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细存档数据更改的内容和位置,因此通过抓取他们的 网站 数据并将其保存到 Git 存储库,您会发现自己比他们更了解他们的数据更改历史做。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对成千上万的版本和大量的 JSON 和 CSV 文档,如果仅用肉眼观察差异,很难挖掘出数据背后的价值。
git历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的整个历史版本,并随着时间的推移生成文件更改的 SQLite 数据库。然后可以使用 Datasette 分析来挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的示例数据库。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在此示例中,我们正在获取文档 events.json 的历史版本。
我们使用 UniqueId 列来识别随时间变化的记录和新记录。
新创建的数据库表的默认名称是 item 和 item_version。我们通过 --namespace 事件将表名指定为事件和事件版本。
该工具中还嵌入了一段 Python 代码,可将存储在提交历史中的每个修订版转换为与该工具兼容的对象列表。
让数据库帮助我们回答有关过去 14 个月加州大火的一些问题。
事件表收录每次火灾的最新记录。有了这张表,我们可以得到一张所有火灾的地图:
此处使用 dataset-cluster-map 插件,它映射表中提供有效经度和纬度值的所有行。
真正有趣的是incident_version 表。该表记录了每次火灾的获取版本之间的数据更新。
有 250 起火灾的 2060 个记录版本。如果我们按 _item 分面,我们可以看到哪些火灾记录的版本最多。前十名分别是:
§ 迪克西火:268
§ 卡尔多火:153
§ 纪念碑火灾 65
§ 八月情结(包括 Doe Fire):64
§ 溪火:56
§ 法国火:53
§ 西尔维拉多火:52
§ 小鹿火:45
§ 蓝岭火:39
§ 麦克法兰火灾:34
版本数越高,火的持续时间越长。维基百科上什至有一个关于 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中,可以看到所有抓取到的“版本”按版本号排列。
git-history 只在这个表中写入与上一个版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
经常变化的是 ConditionStatement 列,这一列是文本描述,另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是 commits 表的外键,记录了工具的提交版本,所以当你再次运行工具时,工具可以定位到上次提交的版本。
加入提交表以查看每个版本的创建日期。您还可以使用 event_version_detail 视图执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助dataset-vega插件,比较_commit_at列(日期类型)和AcresBurned列(数值类型) 形成一个图表,可视化 Dixie Fire 火灾随时间的进展情况。
总结一下:我们首先使用 GitHub Actions 创建一个定时工作流,每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们成功地绘制了过去 14 个月加州持续时间最长的野火之一的蔓延情况。
关于表结构设计
在 git-history 的设计过程中,最难的就是设计一个合适的表结构来存储以前的版本变更信息。
我的最终设计如下(为清楚起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到过item_version表记录了网站不同时间点的快照,但是为了节省数据库空间,提供简洁的版本浏览界面,这里只记录与之前版本相比发生变化的列。未更改的列用 null 写入。
但是这样的设计有一个隐患,就是fire里面某列的值更新为null怎么办?我们如何判断它是更新还是没有变化?
为了解决这个问题,我添加了一个多对多表 item_changed,它使用整数对来记录 item_version 表中哪些列有更新的内容。使用整数对的目的是尽可能少地占用空间。
item_version_detail 视图以 JSON 的形式呈现多对多表中的列。我过滤了一些数据,放到下图中,可以看到哪些列哪些火灾在哪些版本中更新了:
通过下面的 SQL 查询,我们可以知道加州火灾哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
§ 更新:1785
§ 火灾被扑灭的比例:740
§ 状态说明:734
§ 火灾区域:616
§ 开始时间:327
§ 受灾人员:286
§ 消防泵:274
§ 消防员:256
§ 消防车:225
§ 无人机:211
§ 消防飞机:181
§ 建筑损坏:125
§ 直升机:122
直升机听起来很刺激!让我们过滤掉自第一个版本以来至少有一次更新的直升机火灾数量。您可以使用这样的嵌套 SQL 查询:
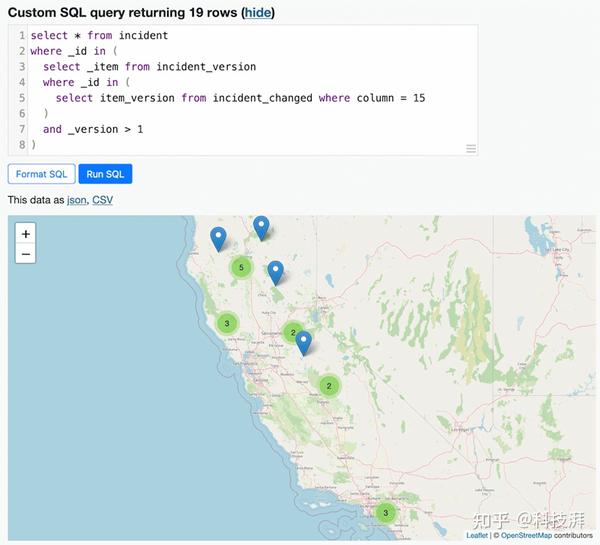
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,19起火灾由直升机救援,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 一直在使用 Git 爬虫不断地从 网站 中抓取数据并将其保存到 dbreunig/511-events-history 存储库中。网站 记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以数据库 sf-bay-511 为例,帮助我们理解 git-history 的用法和叠加的 --convert 选项。
git-history 要求抓取的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"IncidentID": "abc123",
"Location": "Corner of 4th and Vermont",
"Type": "fire"
},
{
"IncidentID": "cde448",
"Location": "555 West Example Drive",
"Type": "medical"
}
]
但抓取的数据通常不是这种理想的格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据量很大,其中一些对整体分析没有帮助,比如即使没有数据更新也会随着版本变化的更新时间戳,以及嵌套很深的对象“扩展”收录大量重复数据。
我编写了一段 Python 代码将每个 网站 快照转换为更简单的结构,并将此代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
这个传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上按顺序运行。代码循环遍历嵌套的事件列表,修改每条记录,然后使用 yield 以可迭代的顺序输出。
一些历史记录显示服务器 500 错误,代码也能够识别和跳过这些记录。
使用 git-history 时,我发现自己大部分时间都在迭代转换脚本。将 Python 代码字符串传递给 git-history 等工具是一种有趣的模式,今年早些时候我尝试在 sqlite-utils 工具中覆盖转换。
试试看
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项,示例中使用的脚本存储在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,很多人创建了仓库,目前已经超过 200 个,海量的抓取数据等你去探索!
手稿来源:/2021/Dec/7/git-history/ 查看全部
网页抓取数据(如何最有效地分析Git存储库来跟踪数据源随时间的变化)
大多数人都知道 Git 抓取,这是一种网络抓取编程技术,您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析这些采集到的数据是一个公认的挑战。git-history 正是我为解决这个困境而设计的工具。
Git抓取技术回顾
将数据抓取到 Git 存储库的一大优势是抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 维护了一张火灾地图,显示了该州最近发生的大火。
我找到了 网站 的基础数据:
curl /umbraco/Api/IncidentApi/GetIncidents
然后我构建了一个简单的爬虫,它每 20 分钟获取一次 网站 数据并将其提交给 Git。到目前为止,该工具已经运行了 14 个月,并采集了 1559 次提交。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细存档数据更改的内容和位置,因此通过抓取他们的 网站 数据并将其保存到 Git 存储库,您会发现自己比他们更了解他们的数据更改历史做。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对成千上万的版本和大量的 JSON 和 CSV 文档,如果仅用肉眼观察差异,很难挖掘出数据背后的价值。
git历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的整个历史版本,并随着时间的推移生成文件更改的 SQLite 数据库。然后可以使用 Datasette 分析来挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的示例数据库。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在此示例中,我们正在获取文档 events.json 的历史版本。
我们使用 UniqueId 列来识别随时间变化的记录和新记录。
新创建的数据库表的默认名称是 item 和 item_version。我们通过 --namespace 事件将表名指定为事件和事件版本。
该工具中还嵌入了一段 Python 代码,可将存储在提交历史中的每个修订版转换为与该工具兼容的对象列表。
让数据库帮助我们回答有关过去 14 个月加州大火的一些问题。
事件表收录每次火灾的最新记录。有了这张表,我们可以得到一张所有火灾的地图:
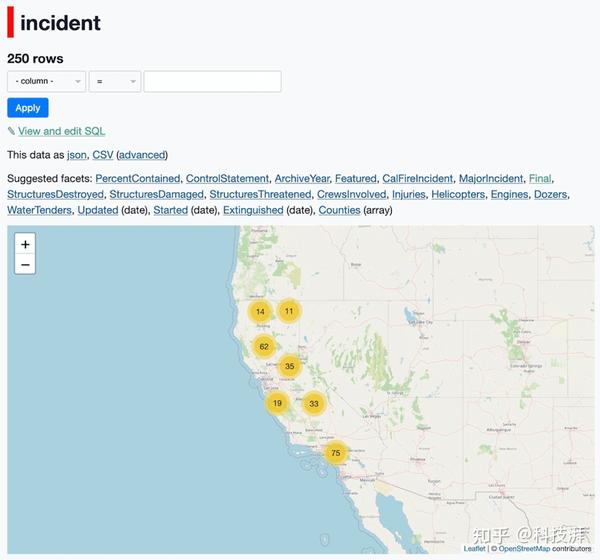
此处使用 dataset-cluster-map 插件,它映射表中提供有效经度和纬度值的所有行。
真正有趣的是incident_version 表。该表记录了每次火灾的获取版本之间的数据更新。
有 250 起火灾的 2060 个记录版本。如果我们按 _item 分面,我们可以看到哪些火灾记录的版本最多。前十名分别是:
§ 迪克西火:268
§ 卡尔多火:153
§ 纪念碑火灾 65
§ 八月情结(包括 Doe Fire):64
§ 溪火:56
§ 法国火:53
§ 西尔维拉多火:52
§ 小鹿火:45
§ 蓝岭火:39
§ 麦克法兰火灾:34
版本数越高,火的持续时间越长。维基百科上什至有一个关于 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中,可以看到所有抓取到的“版本”按版本号排列。
git-history 只在这个表中写入与上一个版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
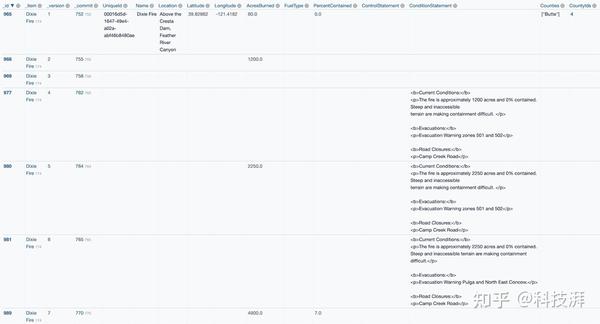
经常变化的是 ConditionStatement 列,这一列是文本描述,另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是 commits 表的外键,记录了工具的提交版本,所以当你再次运行工具时,工具可以定位到上次提交的版本。
加入提交表以查看每个版本的创建日期。您还可以使用 event_version_detail 视图执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助dataset-vega插件,比较_commit_at列(日期类型)和AcresBurned列(数值类型) 形成一个图表,可视化 Dixie Fire 火灾随时间的进展情况。
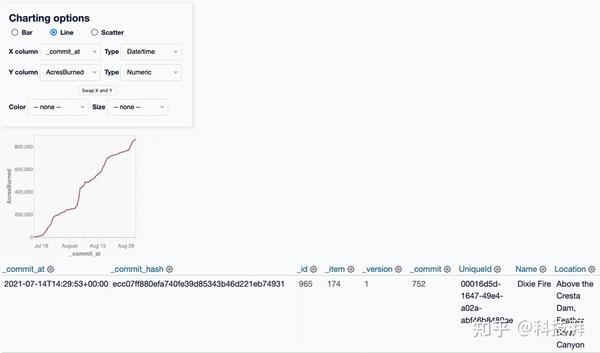
总结一下:我们首先使用 GitHub Actions 创建一个定时工作流,每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们成功地绘制了过去 14 个月加州持续时间最长的野火之一的蔓延情况。
关于表结构设计
在 git-history 的设计过程中,最难的就是设计一个合适的表结构来存储以前的版本变更信息。
我的最终设计如下(为清楚起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到过item_version表记录了网站不同时间点的快照,但是为了节省数据库空间,提供简洁的版本浏览界面,这里只记录与之前版本相比发生变化的列。未更改的列用 null 写入。
但是这样的设计有一个隐患,就是fire里面某列的值更新为null怎么办?我们如何判断它是更新还是没有变化?
为了解决这个问题,我添加了一个多对多表 item_changed,它使用整数对来记录 item_version 表中哪些列有更新的内容。使用整数对的目的是尽可能少地占用空间。
item_version_detail 视图以 JSON 的形式呈现多对多表中的列。我过滤了一些数据,放到下图中,可以看到哪些列哪些火灾在哪些版本中更新了:

通过下面的 SQL 查询,我们可以知道加州火灾哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
§ 更新:1785
§ 火灾被扑灭的比例:740
§ 状态说明:734
§ 火灾区域:616
§ 开始时间:327
§ 受灾人员:286
§ 消防泵:274
§ 消防员:256
§ 消防车:225
§ 无人机:211
§ 消防飞机:181
§ 建筑损坏:125
§ 直升机:122
直升机听起来很刺激!让我们过滤掉自第一个版本以来至少有一次更新的直升机火灾数量。您可以使用这样的嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,19起火灾由直升机救援,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 一直在使用 Git 爬虫不断地从 网站 中抓取数据并将其保存到 dbreunig/511-events-history 存储库中。网站 记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以数据库 sf-bay-511 为例,帮助我们理解 git-history 的用法和叠加的 --convert 选项。
git-history 要求抓取的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"IncidentID": "abc123",
"Location": "Corner of 4th and Vermont",
"Type": "fire"
},
{
"IncidentID": "cde448",
"Location": "555 West Example Drive",
"Type": "medical"
}
]
但抓取的数据通常不是这种理想的格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据量很大,其中一些对整体分析没有帮助,比如即使没有数据更新也会随着版本变化的更新时间戳,以及嵌套很深的对象“扩展”收录大量重复数据。
我编写了一段 Python 代码将每个 网站 快照转换为更简单的结构,并将此代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
这个传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上按顺序运行。代码循环遍历嵌套的事件列表,修改每条记录,然后使用 yield 以可迭代的顺序输出。
一些历史记录显示服务器 500 错误,代码也能够识别和跳过这些记录。
使用 git-history 时,我发现自己大部分时间都在迭代转换脚本。将 Python 代码字符串传递给 git-history 等工具是一种有趣的模式,今年早些时候我尝试在 sqlite-utils 工具中覆盖转换。
试试看
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项,示例中使用的脚本存储在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,很多人创建了仓库,目前已经超过 200 个,海量的抓取数据等你去探索!
手稿来源:/2021/Dec/7/git-history/
网页抓取数据(哪些页面是人为的重要?有几个合理的因素?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-16 01:08
最常用的链接是锚文本链接、超链接、纯文本链接和图像链接。如何被爬虫爬取是一个自动提取网页的程序,比如百度蜘蛛。要让你的 网站 收录更多的页面,你必须先让爬虫爬取页面。如果你的 网站 页面定期更新,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。蜘蛛很快就会爬上 网站、网站 和页面权重,这肯定更重要。
做SEO优化,我希望我的更多页面是收录,尽量吸引蜘蛛去抓取。如果你不能爬取所有的页面,蜘蛛所要做的就是爬取尽可能多的重要页面。哪些页面是人为重要的?
有几个合理的因素
1、网站页数和权重
网站质量高,资质老,被认为权重高,在这个网站上爬取页面的深度会更高,所以收录的页面会多一些。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果不需要掌握第一个页面更新,则不需要第二个蜘蛛页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上的新连接自然会被蜘蛛更快地跟踪以抓取新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛爬取,并且必须有传入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的传入链接通常会增加页面上传出链接的抓取深度。
4、点击“离家距离”
一般来说,大多数主页的权重都很高。因此,点击距离越接近首页,页面的权限越高,被蜘蛛爬取的机会就越大。
5、网址结构
页面权重只有在迭代计算中才知道,所以上面提到的高页面权重有利于爬取。搜索引擎蜘蛛在爬取之前如何知道页面权重?因此,蜘蛛预测,除了链接、与首页的距离、历史数据等因素外,短 URL 和浅 URL 也可能会直观地认为该站点具有较高的权重。
6、如何吸引蜘蛛:
这些链接导致蜘蛛访问网页。只要不遵循这些链接,就会导致蜘蛛访问和转移权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的附属链接。 查看全部
网页抓取数据(哪些页面是人为的重要?有几个合理的因素?)
最常用的链接是锚文本链接、超链接、纯文本链接和图像链接。如何被爬虫爬取是一个自动提取网页的程序,比如百度蜘蛛。要让你的 网站 收录更多的页面,你必须先让爬虫爬取页面。如果你的 网站 页面定期更新,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。蜘蛛很快就会爬上 网站、网站 和页面权重,这肯定更重要。
做SEO优化,我希望我的更多页面是收录,尽量吸引蜘蛛去抓取。如果你不能爬取所有的页面,蜘蛛所要做的就是爬取尽可能多的重要页面。哪些页面是人为重要的?
有几个合理的因素
1、网站页数和权重
网站质量高,资质老,被认为权重高,在这个网站上爬取页面的深度会更高,所以收录的页面会多一些。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果不需要掌握第一个页面更新,则不需要第二个蜘蛛页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上的新连接自然会被蜘蛛更快地跟踪以抓取新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛爬取,并且必须有传入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的传入链接通常会增加页面上传出链接的抓取深度。
4、点击“离家距离”
一般来说,大多数主页的权重都很高。因此,点击距离越接近首页,页面的权限越高,被蜘蛛爬取的机会就越大。
5、网址结构
页面权重只有在迭代计算中才知道,所以上面提到的高页面权重有利于爬取。搜索引擎蜘蛛在爬取之前如何知道页面权重?因此,蜘蛛预测,除了链接、与首页的距离、历史数据等因素外,短 URL 和浅 URL 也可能会直观地认为该站点具有较高的权重。
6、如何吸引蜘蛛:
这些链接导致蜘蛛访问网页。只要不遵循这些链接,就会导致蜘蛛访问和转移权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的附属链接。
网页抓取数据(百度蜘蛛爬取框架流程原理跟搜索引擎爬虫蜘蛛站长SEO )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-15 22:18
)
网站采集软件原理同搜索引擎爬虫蜘蛛,站长SEO!免费网站采集软件的原理和搜索引擎爬虫蜘蛛的原理是一样的!它是根据规则自动捕获网站信息的程序或软件。从技术的角度,我们对搜索引擎和网站收录的原理和流程有了更深入的了解。让我们用网站采集软件让网站收录的排名权重飙升!
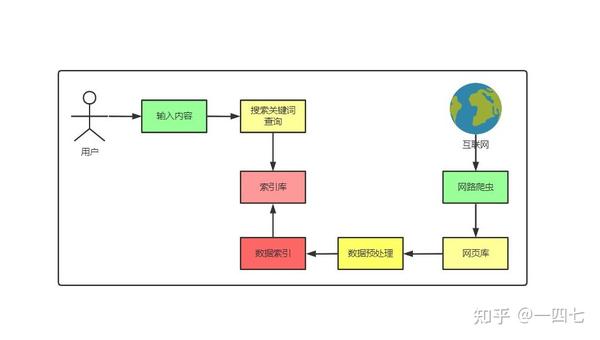
百度蜘蛛爬取框架流程原理
首先,从Internet页面中仔细挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子URL放入待抓取的URL队列中。,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载页面内容。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,记录爬虫系统已经下载了该网页的URL,避免了对网页的重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在已抓取的 URL 队列中进行检查。如果发现该链接没有被爬取,则将该URL放在待爬取URL队列的末尾,然后在爬取调度中下载该URL对应的网页。这样就形成了一个循环,直到对待爬取的URL队列进行审核,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
百度蜘蛛爬虫类型
根据不同的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫:批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它会停止爬取过程。至于具体的目标,可能会有所不同,可能设置一定数量的要爬取的网页就够了,也可能是设置爬取所消耗的时间。
2.增量爬虫:增量爬虫与批量爬虫不同,它们会不断的爬行。对于抓取到的网页,应该定期更新,因为互联网的网页是在不断变化的随时间变化,所以在不断的爬取过程中,要么是爬取新的页面,要么是更新已有的页面。有网页。常见的商业搜索引擎爬虫基本属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题或属于特定行业的网页,例如健康网站,只需要从互联网页面中找到与健康相关的页面,内容就足够了,并且不考虑其他行业的内容。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,不可能把所有的网页都下载下来再过滤。这种资源浪费太多了。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关。并且尽量不要去抓取不相关的页面,以达到节省资源的目的。垂直搜索<
网站建筑如何吸引蜘蛛爬行网站内容
1、网站和页面的权重仍然作为衡量网站价值的重要标准。优质老手网站被百度评为高权重。这种网站的页面更容易被蜘蛛爬取,所以很多内页都会是收录。
2、页面更新频率会直接影响蜘蛛的访问频率。蜘蛛将每次访问获得的页面数据保存到服务器。如果下次访问页面,发现内容和存储的数据一样,蜘蛛会认为页面不会频繁更新,然后给网站一个优先级来决定访问的时间和频率将来。如果网站的内容更新频繁,每次爬虫爬取的内容都不一样,那么爬虫会更频繁地访问这样的页面,页面上出现的新链接自然会被爬取收录 .
3、引导链接的建立,无论网站的外部链接还是内部链接,要想被蜘蛛爬取,就必须有引导链接才能进入页面,所以合理构建内部链接非常重要,否则蜘蛛无法发现页面的存在。高质量的外链导入也很重要,会增加蜘蛛的跟踪爬取深度。
4、建立首页的引导链接。主页最常被蜘蛛访问。当有内容更新时,一定要在首页体现出来,并且要建立一个链接,这样蜘蛛才能尽快抓取到,增加爬取的机会。
5、原创内容,最厉害的爬虫就是将网站新发布的内容与服务器收录的数据进行对比,如果是抄袭或者部分修改非原创伪原创内容,百度不会收录,如果你经常发布非原创内容,也会降低蜘蛛的访问频率,严重的直接不行收录 ,甚至 0收录。
通过以上信息,我们对百度蜘蛛的爬取过程,以及如何吸引蜘蛛去网站爬取内容有了一个清晰的认识。页面更新频率会直接影响蜘蛛的访问频率,精力有限! 原创很难保证大量长期更新。如果邀请编辑,投入产出比可能为负。
高端SEO一目了然,深入研究搜索引擎算法,根据算法伪原创量身定做,效果媲美原创行内配合搜索引擎算法,外行看热闹。里面看门口!
关注小编,获取更专业的SEO知识,助你做好网站建设网站管理网站优化,让你的网站拥有更好收录排名和流量!
查看全部
网页抓取数据(百度蜘蛛爬取框架流程原理跟搜索引擎爬虫蜘蛛站长SEO
)
网站采集软件原理同搜索引擎爬虫蜘蛛,站长SEO!免费网站采集软件的原理和搜索引擎爬虫蜘蛛的原理是一样的!它是根据规则自动捕获网站信息的程序或软件。从技术的角度,我们对搜索引擎和网站收录的原理和流程有了更深入的了解。让我们用网站采集软件让网站收录的排名权重飙升!

百度蜘蛛爬取框架流程原理
首先,从Internet页面中仔细挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子URL放入待抓取的URL队列中。,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载页面内容。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,记录爬虫系统已经下载了该网页的URL,避免了对网页的重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在已抓取的 URL 队列中进行检查。如果发现该链接没有被爬取,则将该URL放在待爬取URL队列的末尾,然后在爬取调度中下载该URL对应的网页。这样就形成了一个循环,直到对待爬取的URL队列进行审核,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
百度蜘蛛爬虫类型
根据不同的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫:批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它会停止爬取过程。至于具体的目标,可能会有所不同,可能设置一定数量的要爬取的网页就够了,也可能是设置爬取所消耗的时间。
2.增量爬虫:增量爬虫与批量爬虫不同,它们会不断的爬行。对于抓取到的网页,应该定期更新,因为互联网的网页是在不断变化的随时间变化,所以在不断的爬取过程中,要么是爬取新的页面,要么是更新已有的页面。有网页。常见的商业搜索引擎爬虫基本属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题或属于特定行业的网页,例如健康网站,只需要从互联网页面中找到与健康相关的页面,内容就足够了,并且不考虑其他行业的内容。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,不可能把所有的网页都下载下来再过滤。这种资源浪费太多了。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关。并且尽量不要去抓取不相关的页面,以达到节省资源的目的。垂直搜索<
网站建筑如何吸引蜘蛛爬行网站内容
1、网站和页面的权重仍然作为衡量网站价值的重要标准。优质老手网站被百度评为高权重。这种网站的页面更容易被蜘蛛爬取,所以很多内页都会是收录。
2、页面更新频率会直接影响蜘蛛的访问频率。蜘蛛将每次访问获得的页面数据保存到服务器。如果下次访问页面,发现内容和存储的数据一样,蜘蛛会认为页面不会频繁更新,然后给网站一个优先级来决定访问的时间和频率将来。如果网站的内容更新频繁,每次爬虫爬取的内容都不一样,那么爬虫会更频繁地访问这样的页面,页面上出现的新链接自然会被爬取收录 .
3、引导链接的建立,无论网站的外部链接还是内部链接,要想被蜘蛛爬取,就必须有引导链接才能进入页面,所以合理构建内部链接非常重要,否则蜘蛛无法发现页面的存在。高质量的外链导入也很重要,会增加蜘蛛的跟踪爬取深度。
4、建立首页的引导链接。主页最常被蜘蛛访问。当有内容更新时,一定要在首页体现出来,并且要建立一个链接,这样蜘蛛才能尽快抓取到,增加爬取的机会。
5、原创内容,最厉害的爬虫就是将网站新发布的内容与服务器收录的数据进行对比,如果是抄袭或者部分修改非原创伪原创内容,百度不会收录,如果你经常发布非原创内容,也会降低蜘蛛的访问频率,严重的直接不行收录 ,甚至 0收录。
通过以上信息,我们对百度蜘蛛的爬取过程,以及如何吸引蜘蛛去网站爬取内容有了一个清晰的认识。页面更新频率会直接影响蜘蛛的访问频率,精力有限! 原创很难保证大量长期更新。如果邀请编辑,投入产出比可能为负。
高端SEO一目了然,深入研究搜索引擎算法,根据算法伪原创量身定做,效果媲美原创行内配合搜索引擎算法,外行看热闹。里面看门口!
关注小编,获取更专业的SEO知识,助你做好网站建设网站管理网站优化,让你的网站拥有更好收录排名和流量!

网页抓取数据(网页抓取数据,可以写javascript函数,方便自己把js代码保存下来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-14 19:01
网页抓取数据,可以写javascript函数,方便自己把js代码保存下来,然后用python或ruby进行解析。可以了解下爬虫开发,打造自己专属爬虫。推荐一本爬虫开发的好书:http权威指南(豆瓣),其中介绍了python,基础库,程序设计等部分内容。
ajax生成动态的cookie,
http权威指南
找一些自己看的懂的python和ruby的教程
爬虫的基础是python+ruby我要推荐一个,我只推荐python和ruby,我们经常说的restful,http,python里面现成的这个库都是无敌的,你们去看看requests包括exception之后的if,else代码都是无敌的,包括asyncio包括接下来的continue也是无敌的,defasync_future_call():break:returntrue一举弄定了,再来看看pythonexception模块defcontinue_interval():passasyncio模块raise等等这些模块请先实现接口返回的http请求,然后每一条操作都带上异步io的方法等等,这些无敌了,我的代码除了用了redis,用了纯python,其他的异步io是自己实现的。
今天我看了一个爬虫的,搞定用nodejs的httpquest,看起来比较简单,有些难点:1.请求头里的host,port等需要查看明确和人工补全。2.请求头里的正则表达式是否恰当,还有':',等符号也需要复制下来。3.请求过程中的一些特殊字符串,比如空格等需要自己处理以及生成字符串注意::1.看懂基本入门用的这个库nodejshttpquestbabeljquery2.学好http协议接下来完全可以http.header、http协议概念、http方法等多看看。
3.适当增加js监听器抓取点数据。4.多尝试在python语言里实现http协议,打包成gzip压缩包、p2p传输等方式来搞爬虫。5.基于requests库实现从get请求获取网页,模拟登录再弄本页面爬取。w3cschool(现在不包了)提供完整的爬虫教程,爬虫不难,别人写好的模板现成的,自己修改下就好了,download一下就是了,要注意处理post,别太频繁post和header反正主要就是python,或者ruby(proxies包在这),python,ruby环境,方便,基础不好用1年老项目,别tmd玩nodejs了,解释型语言,自己google项目和实现不都是那些事儿吗,或者你直接看我的系列[爬虫·解决](),三天你就精通爬虫了。 查看全部
网页抓取数据(网页抓取数据,可以写javascript函数,方便自己把js代码保存下来)
网页抓取数据,可以写javascript函数,方便自己把js代码保存下来,然后用python或ruby进行解析。可以了解下爬虫开发,打造自己专属爬虫。推荐一本爬虫开发的好书:http权威指南(豆瓣),其中介绍了python,基础库,程序设计等部分内容。
ajax生成动态的cookie,
http权威指南
找一些自己看的懂的python和ruby的教程
爬虫的基础是python+ruby我要推荐一个,我只推荐python和ruby,我们经常说的restful,http,python里面现成的这个库都是无敌的,你们去看看requests包括exception之后的if,else代码都是无敌的,包括asyncio包括接下来的continue也是无敌的,defasync_future_call():break:returntrue一举弄定了,再来看看pythonexception模块defcontinue_interval():passasyncio模块raise等等这些模块请先实现接口返回的http请求,然后每一条操作都带上异步io的方法等等,这些无敌了,我的代码除了用了redis,用了纯python,其他的异步io是自己实现的。
今天我看了一个爬虫的,搞定用nodejs的httpquest,看起来比较简单,有些难点:1.请求头里的host,port等需要查看明确和人工补全。2.请求头里的正则表达式是否恰当,还有':',等符号也需要复制下来。3.请求过程中的一些特殊字符串,比如空格等需要自己处理以及生成字符串注意::1.看懂基本入门用的这个库nodejshttpquestbabeljquery2.学好http协议接下来完全可以http.header、http协议概念、http方法等多看看。
3.适当增加js监听器抓取点数据。4.多尝试在python语言里实现http协议,打包成gzip压缩包、p2p传输等方式来搞爬虫。5.基于requests库实现从get请求获取网页,模拟登录再弄本页面爬取。w3cschool(现在不包了)提供完整的爬虫教程,爬虫不难,别人写好的模板现成的,自己修改下就好了,download一下就是了,要注意处理post,别太频繁post和header反正主要就是python,或者ruby(proxies包在这),python,ruby环境,方便,基础不好用1年老项目,别tmd玩nodejs了,解释型语言,自己google项目和实现不都是那些事儿吗,或者你直接看我的系列[爬虫·解决](),三天你就精通爬虫了。
网页抓取数据(PowerQuery的数据清洗功能(示例中的列)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-13 07:06
)
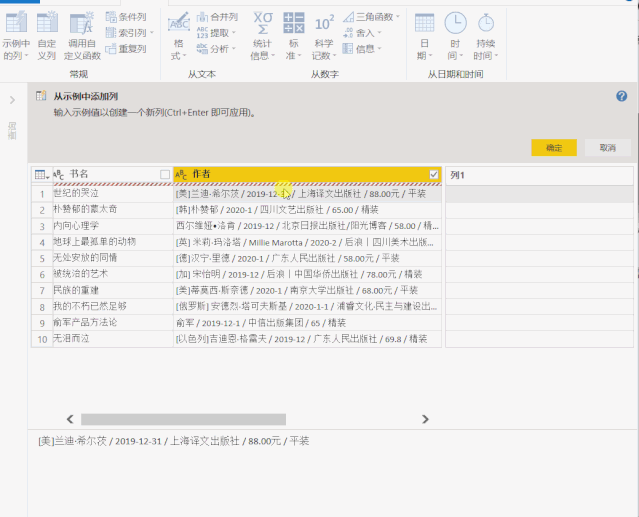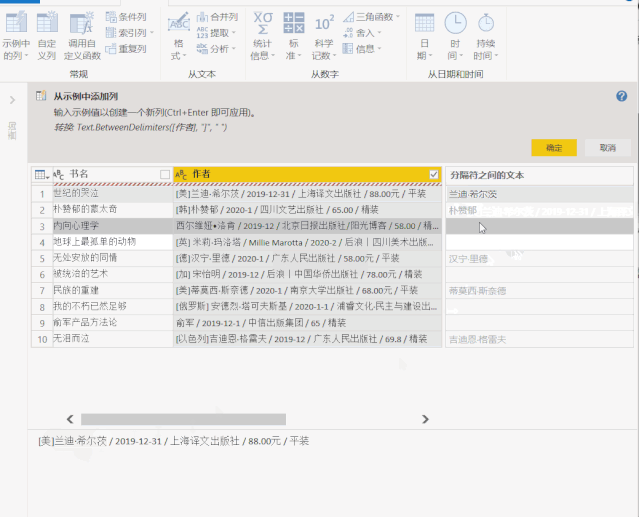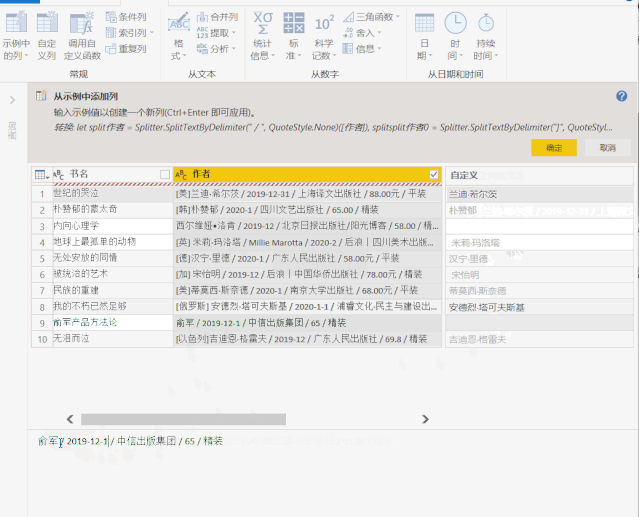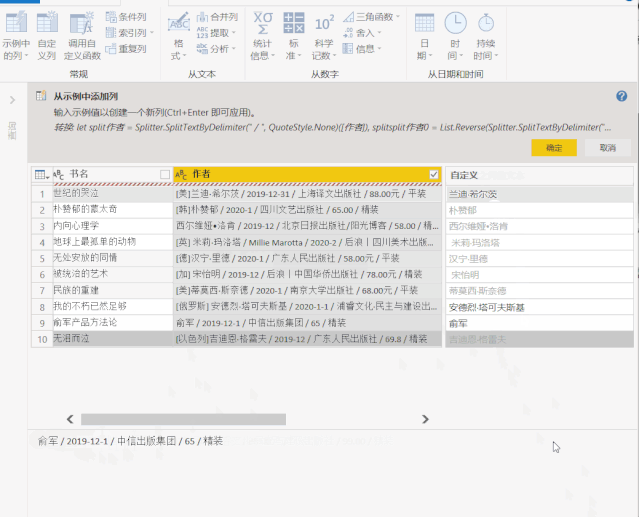
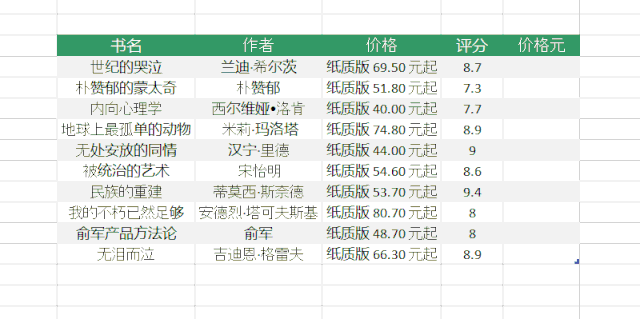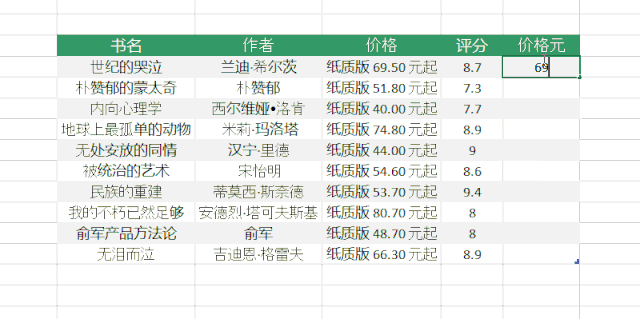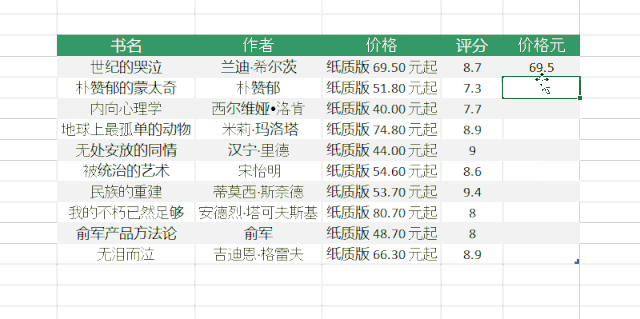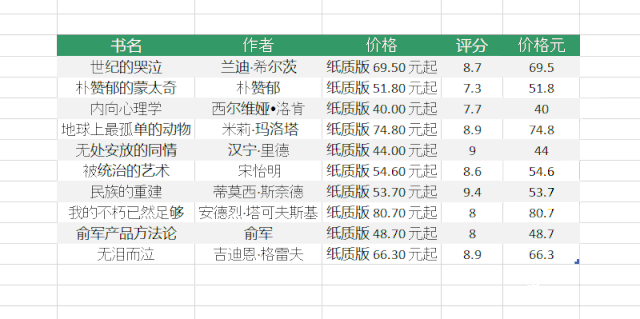
/chart?icn=index-topchart-nonfiction
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”
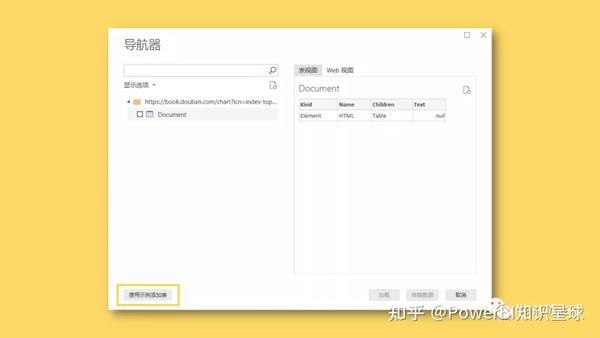
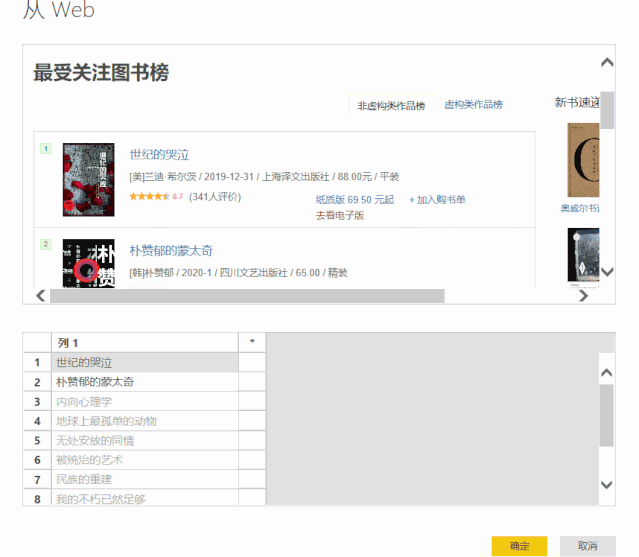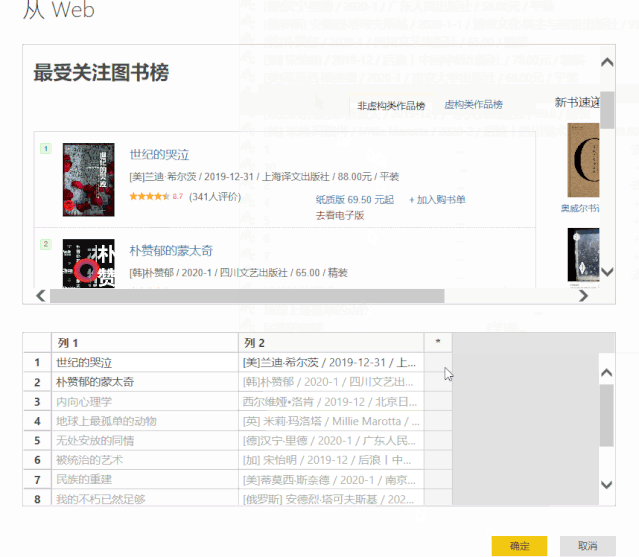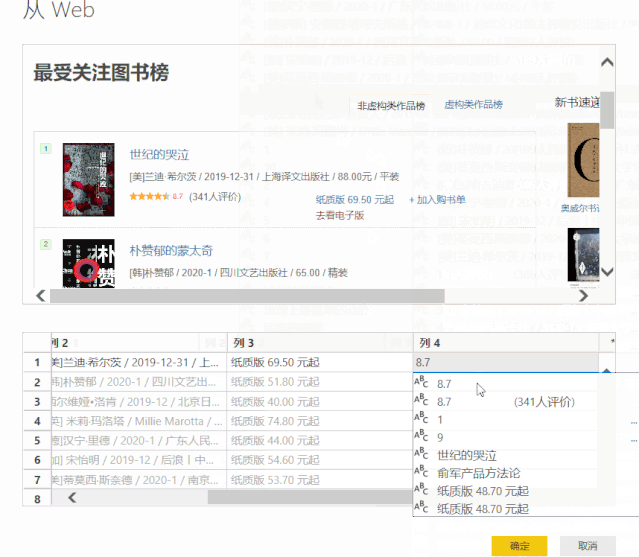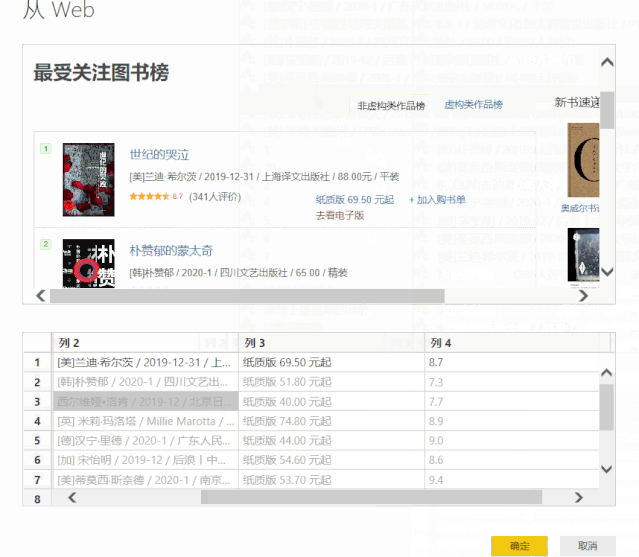
2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
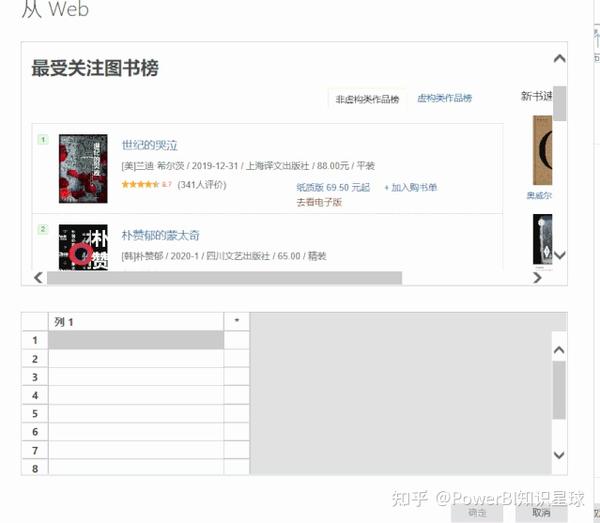
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 抓取的数据就越准确
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
这里我通过复制原创列的数据快速进入示例
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
在知识圈可以找到更多“Ctrl+E”的使用场景
查看全部
网页抓取数据(PowerQuery的数据清洗功能(示例中的列)(组图)
)
/chart?icn=index-topchart-nonfiction
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”

2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 抓取的数据就越准确
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。

二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
这里我通过复制原创列的数据快速进入示例
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
在知识圈可以找到更多“Ctrl+E”的使用场景

网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-07 16:13
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
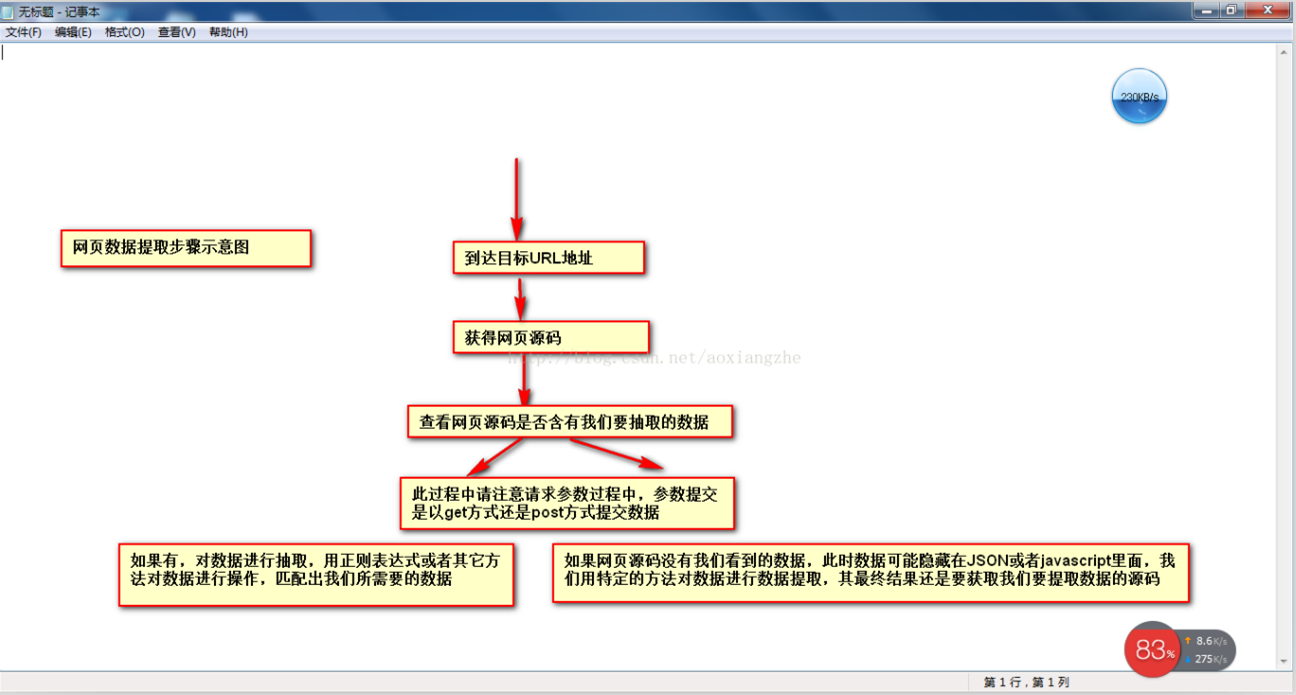
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
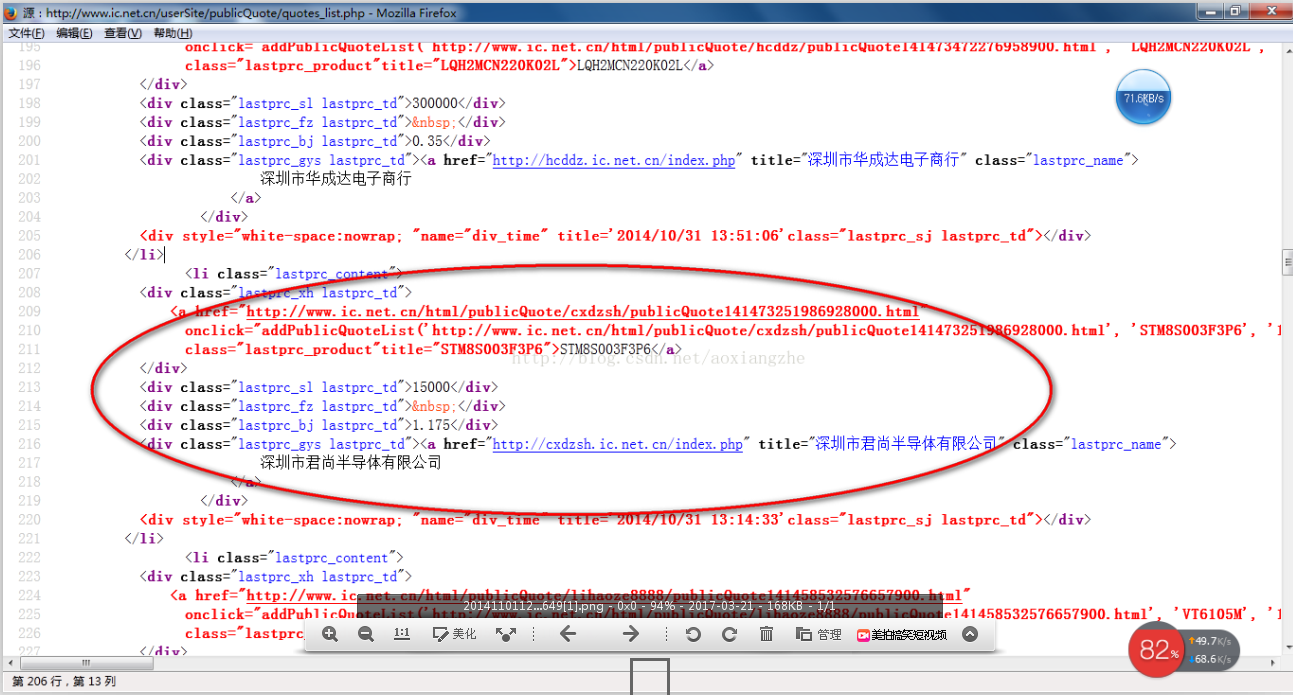
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。 查看全部
网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览

接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。

import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据

成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
网页抓取数据(什么是“网页抓取”?python网页语言的抓取语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-06 23:15
什么是“网络爬虫”?
Python 网络爬虫是从任何网站 或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。有多种格式,例如CSV。文件、XML、JSON 等。可以毫不费力地提取任何地方的任何数据。
您需要做的就是选择您要抓取的网站,该过程将开始,您将在一个地方收到所有质量信息。这很好,因为它不是一个耗时的过程。了解网页抓取的重要性。当今市场上的许多网络抓取品牌都为此过程提供了自动化选项。这意味着您现在可以采集常规数据,而无需始终关注正在发生的事情。收到数据后,您需要做的就是监控信息并开始致力于增强和改进您当前的工作流程。
了解网页抓取对您的重要性,网页抓取语言可以帮助您更好地执行此过程。但在进入上下文以确定哪种网络抓取语言更适合此过程之前,请务必在选择此类语言时考虑以下几点:
更好地工作的灵活性,例如,可以轻松抓取更长或更小的信息集
网络爬虫语言应该更具可扩展性
编写这样的语言应该易于理解和实践
爬行技术应该是无错误和增强的
可以更好的提供数据库
如何在没有任何风险或错误的情况下进行有效的网络爬行活动?
在进行安全有效的网络抓取活动时,代理服务器是最大的解决方案之一。代理服务器充当用户和他想要访问的 网站 之间的中间阶段。
例如,假设您要访问一条信息并希望抓取该数据,您将首先向 网站 的所有者发送请求以请求访问。但是在请求到达网站的所有者之前,它会到达代理服务器。然后代理服务器会改变你的IP地址并将请求发送给网站的所有者。
一旦所有者批准网站,您就可以查看数据并开始爬取。代理服务器消除了跟踪 IP 地址的主要问题。网络抓取不会是一次性的过程。了解您对频繁网页抓取的要求至关重要,这样您才能确保此类日常操作不会被阻止。
白云数据提供商业智能数据、高级代理和企业级支持。他们的团队在网络数据采集和提取行业拥有数十年的个人经验,因此他们知道什么是最有效的。北云数据拥有来自全球任何国家和城市的住宅代理。你可以在他们的 网站 上找到一张交互式地图,看看他们在每个国家拥有多少 IP。北云数据为其客户提供住宅和数据中心代理。您可以查看住宅代理和数据中心代理的服务定价。 查看全部
网页抓取数据(什么是“网页抓取”?python网页语言的抓取语言)
什么是“网络爬虫”?
Python 网络爬虫是从任何网站 或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。有多种格式,例如CSV。文件、XML、JSON 等。可以毫不费力地提取任何地方的任何数据。

您需要做的就是选择您要抓取的网站,该过程将开始,您将在一个地方收到所有质量信息。这很好,因为它不是一个耗时的过程。了解网页抓取的重要性。当今市场上的许多网络抓取品牌都为此过程提供了自动化选项。这意味着您现在可以采集常规数据,而无需始终关注正在发生的事情。收到数据后,您需要做的就是监控信息并开始致力于增强和改进您当前的工作流程。
了解网页抓取对您的重要性,网页抓取语言可以帮助您更好地执行此过程。但在进入上下文以确定哪种网络抓取语言更适合此过程之前,请务必在选择此类语言时考虑以下几点:
更好地工作的灵活性,例如,可以轻松抓取更长或更小的信息集
网络爬虫语言应该更具可扩展性
编写这样的语言应该易于理解和实践
爬行技术应该是无错误和增强的
可以更好的提供数据库
如何在没有任何风险或错误的情况下进行有效的网络爬行活动?
在进行安全有效的网络抓取活动时,代理服务器是最大的解决方案之一。代理服务器充当用户和他想要访问的 网站 之间的中间阶段。
例如,假设您要访问一条信息并希望抓取该数据,您将首先向 网站 的所有者发送请求以请求访问。但是在请求到达网站的所有者之前,它会到达代理服务器。然后代理服务器会改变你的IP地址并将请求发送给网站的所有者。
一旦所有者批准网站,您就可以查看数据并开始爬取。代理服务器消除了跟踪 IP 地址的主要问题。网络抓取不会是一次性的过程。了解您对频繁网页抓取的要求至关重要,这样您才能确保此类日常操作不会被阻止。
白云数据提供商业智能数据、高级代理和企业级支持。他们的团队在网络数据采集和提取行业拥有数十年的个人经验,因此他们知道什么是最有效的。北云数据拥有来自全球任何国家和城市的住宅代理。你可以在他们的 网站 上找到一张交互式地图,看看他们在每个国家拥有多少 IP。北云数据为其客户提供住宅和数据中心代理。您可以查看住宅代理和数据中心代理的服务定价。
网页抓取数据( 本发明网页数据防的方法及系统背景技术实现要素分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-03 03:22
本发明网页数据防的方法及系统背景技术实现要素分析)
本发明涉及互联网技术领域,尤其涉及一种防止网页数据被抓取的方法及系统。
背景技术:
大数据时代,数据已经成为企业的核心竞争力。网页上的一些关键数据,如购物网站商品价格、交易量、用户联系方式等信息,在方便用户浏览的同时,也成为一些恶意爬虫疯狂爬取的目标。如何防止关键数据被大规模爬取,不断增加爬虫的采集难度,成为很多企业网站的首要任务。
目前现有的技术方案和不足:
(1)关键数据登录权限控制,用户体验差;
(2)关键数据是动态的,只能防止低级静态爬虫;
(3)关键数据显示在一张图片中,现有的ocr(光学字符识别)技术可以轻松识别图片中的字符。
技术实现要素:
本发明旨在解决现有技术或相关技术中存在的至少一个技术问题。
为此,本发明的一个目的是提供一种防止网页数据被抓取的方法。
本发明的另一个目的是提供一种网页数据反爬取系统。
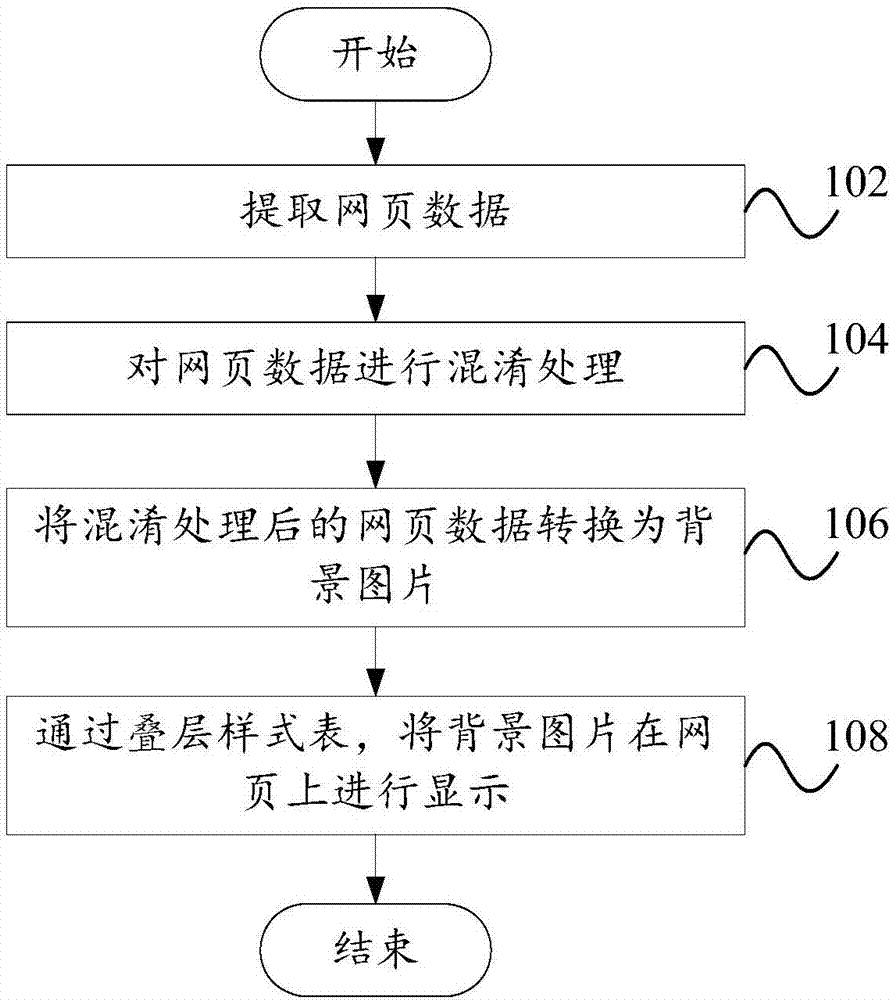
有鉴于此,根据本发明的一个目的,提出一种网页数据反爬取方法,包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片;通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过css(cascadingstylesheets)样式控制背景图片的显示,即使恶意爬虫将网页源码和图片全部丢掉采集 ,并且使用ocr工具进行识别,也无法获得完整正确的数据,而且每页的数据图片都是随机生成的,大大增加了采集解析的难度,保护了上的关键数据在 Internet 上打开网页。
上述本发明的防止网页数据爬取的方法还可以具有以下技术特征:
上述技术方案中,优选地,对网页数据的混淆处理具体包括:统计网页数据的长度;对齐网页数据的长度;并对网页数据的字符串进行随机排序。优选地,该方法还包括:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
在该技术方案中,页面上的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充,填充的字符串随机重新排序,插入字符混淆后的字符,乱序等。字符串生成背景图片,使网页爬取恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,对网页数据字符串进行随机排序包括:将字符串分割为单个字符,随机排序并在单个字符中添加字符;或将字符串分割为单个字符,将单个字符分割为不识别图形,对不识别图形进行随机排序并添加字符处理。
本技术方案中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,网页关键数据混淆,或将字符串拆分为单个字符,单个字符划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加难度用于捕获关键数据的恶意爬虫。
在上述任一技术方案中,优选地,将混淆后的网页数据转换为背景图片包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片中的位置。
在该技术方案中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,在网页上显示背景图片包括:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在上述任一技术方案中,优选地,在通过堆叠样式表在网页上显示背景图片之前,该方法还包括:创建堆叠样式表。
本技术方案创建了一个堆叠样式表,背景图片的显示由堆叠样式表控制。
根据本发明的另一个目的,提出了一种网页数据反爬取系统,包括:数据提取单元,用于提取网页数据;用于混淆网页数据的数据处理单元;一个转换单元,用于将混淆后的网页数据转换为背景图片;显示单元,用于通过堆叠样式表在网页上显示背景图片。
在本发明提供的网页数据防抓取系统中,数据提取单元提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据,数据处理单元将顺序打乱,加入字符混淆后,转换单元为网页生成背景图片。该图像用作显示背景。显示单元通过 CSS 样式控制背景图片的显示,即使恶意爬虫将网页的所有源代码和图片丢弃并使用 ocr 工具识别出无法获取完整正确的数据,以及每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
根据本发明的上述网页数据反爬取系统还可以具有以下技术特征:
上述技术方案中,优选地,所述数据处理单元用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,所述数据处理单元还用于:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
本技术方案中,数据处理单元对页面的所有关键数据进行长度对齐处理。如果长度不够,插入多余的字符进行填充,填充的字符串随机重新排序,插入字符后,乱序等。混淆后的字符串生成背景图片,以便恶意爬虫抓取的网页不收录关键数据的任何信息,导致无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,所述数据处理单元还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割成单个字符,将单个字符分割成不可识别图形,对不可识别图形进行随机排序并添加字符处理。
在该技术方案中,数据处理单元将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或将字符串拆分为单个字符。分割成不可识别的图形,对不可识别的图形进行随机排序并添加字符处理,进一步分割成ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫的难度捕获关键数据。
在上述任一技术方案中,优选地,转换单元具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
本技术方案中,转换单元将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,并将不影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,所述显示单元具体用于:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案中,显示单元生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,使关键数据在网页上的显示效果页面保持不变,不以任何方式影响用户体验。
在上述任一技术方案中,优选地,还包括: 用于创建堆叠样式表的创建单元。
本技术方案中,创建单元创建一个堆叠样式表,通过堆叠样式表控制背景图片的显示。
本发明的其他方面和优点将在以下描述中变得明显,或者通过本发明的实践而被理解。
图纸说明
通过结合以下附图的实施例的描述,本发明的上述和/或附加的方面和优点将变得显而易见且易于理解,其中:
图1为本发明实施例提供的网页数据反爬取方法流程示意图;
图2a为本发明另一实施例提供的网页数据反爬取方法的流程示意图;
图2b为本发明另一实施例防止网页数据被爬取的方法流程示意图;
图3示出了根据本发明实施例的网页数据反爬取系统的示意框图;
图4为本发明具体实施例的网页显示效果图;
图5为本发明具体实施例的关键数据分割与混淆效果图;
图6为本发明具体实施例中防止网页数据爬取的方法流程示意图;
图。图7示出了根据本发明具体实施例的字符串切分示意图。
具体实现方法
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施例对本发明作进一步详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
在以下描述中,为了充分理解本发明,解释了许多具体细节。然而,本发明也可以以不同于这里描述的方式的其他方式实施。因此,本发明的保护范围不限于以下所公开的具体实施例。
本发明第一方面的实施例提出了一种防止网页数据被抓取的方法。如图。图1示出了根据本发明实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤102,提取网页数据;
步骤104,混淆网页数据;
步骤106,将混淆后的网页数据转换为背景图片;
步骤108,通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过CSS样式控制背景图片的显示。即使恶意爬虫将网页的所有源代码和图片全部丢弃并使用ocr工具进行识别,也无法获得完整正确的数据。 ,并且每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网上打开的网页上的关键数据。
图。图2a示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤212,通过堆叠样式表在网页上显示背景图片。
在本实施例中,页面的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充。填充的字符串随机重新排序,插入字符、乱序等混淆后的字符。字符串生成背景图片,使网页抓取的网页恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,对网页数据字符串进行随机排序包括:将字符串分为单个字符、随机排序单个字符和添加字符;或将字符串拆分成单个字符,将单个字符拆分成不可识别图形,对不可识别图形进行随机排序,添加字符处理。
在本实施例中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,混淆网页关键数据,或将字符串拆分为单个字符,将单个字符字符被划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,将混淆后的网页数据转换为背景图片具体包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片的位置。
在本实施例中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
图。图2b示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤214,创建叠加样式表;
步骤216,生成页面源代码;
步骤218,根据网页数据在背景图片中的位置,在网页上显示背景图片。
本实施例创建了一个分层的样式表,生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而达到显示效果页面关键数据不变,不影响用户体验。
本发明第二方面的一个实施例提出了一种网页数据反爬取系统300。图3示出了根据本发明实施例的网页数据反爬取系统300的示意框图。其中,系统包括:
数据提取单元302用于提取网页数据;
数据处理单元304用于对网页数据进行混淆处理;
转换单元306用于将混淆后的网页数据转换为背景图片;
显示单元308用于通过层叠样式表在网页上显示背景图片。
在本发明提供的网页数据反爬取系统300中,数据提取单元302提取需要保护的关键数据,例如在网页中以字符串形式显示的数字、英文、汉字等。网页,数据处理单元304打乱后,在排序添加混淆字符后,转换单元306生成网页的背景图片,并将该图片作为显示背景。显示单元308通过CSS样式控制背景图片的显示,即使恶意爬虫将网页采集的所有源码和图片全部删除,并使用ocr工具进行识别,也不可能得到完整正确的数据,每个页面的数据图像都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
在本发明的一个实施例中,优选地,数据处理单元304用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,数据处理单元304还用于:当网页数据的长度不足时,通过插入多余的字符来填充网页数据的长度。
在本实施例中,数据处理单元304对所有页面的关键数据进行长度对齐处理。如果长度不足,插入多余的字符进行填充,填充的字符串随机重新排序,字符插入乱序。混淆后的字符串会生成背景图片,使得恶意爬虫抓取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,数据处理单元304还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割为单个字符。字符,将单个字符划分为不识别图形,对不识别图形进行随机排序并添加字符处理。
在本实施例中,数据处理单元304将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或者将字符串拆分为单个字符。将字符划分为不可识别图形,将不可识别图形随机排序并添加字符处理,将不可识别图形进一步划分为ocr软件无法识别的图形,增强了混淆度网页关键数据,大大增加了恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,转换单元306具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
在本实施例中,转换单元306将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,不会影响用户浏览网页的效果。
在本发明的一个实施例中,优选地,显示单元308具体用于:生成页面源代码;并根据网页数据在背景图片中的位置在网页上显示背景图片。
本实施例中,显示单元308生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在本发明的一个实施例中,优选地,还包括:创建单元310,用于创建堆叠样式表。
在本实施例中,创建单元310创建堆叠样式表,背景图像的显示由堆叠样式表控制。
在本发明的一个具体实施例中,需要保护的关键数据,如数字、英文、汉字在网页显示中以字符串的形式显示,如图4所示,被提取,顺序被打乱,并添加混乱。字符生成后,生成如图5所示的网页背景图片,并记录字符在图片中的相对位置;这张图片作为显示背景,通过CSS样式控制背景图片的显示。不同的字符背景偏移量根据生成图片时的记录位置进行设置,以便在页面上显示完整的数据。这样,即使恶意爬虫采集下载了网页的源代码和图片,使用ocr工具进行识别,也无法得到完整正确的数据,每个页面的数据图片都是随机生成的,大大增加了采集的分析难度。图6示出了根据本发明具体实施例的防止网页数据被抓取的方法的示意性流程图:
步骤602,提取网页上需要保护的关键数据,将字符混淆后转换为图片,包括:
(1)提取网页中所有需要保护的关键数据;
(2)所有页面的关键数据长度对齐;
(3)长度不足,已插入多余字符填充;
(4)完成的字符串随机重新排序;
(5)字符串经过插入字符、乱序等混淆处理后生成一张图片;
(6)记录图片中字符的相对位置。
步骤604,设置页面显示价格样式。
步骤606:获取字符在图片中的相对位置,生成页面源代码,通过设置背景图片的相对位置来控制数据在页面上的显示。
在本发明的另一个具体实施例中,在对字符串进行图形化的过程中,将字符串分割成完整的可识别字符,然后进行无序化,添加冗余字符,然后生成图片。在此基础上,可以将单个字符进一步划分为OCR软件无法识别的图形,如下图7所示。由于目前的OCR技术只能识别完整的字符,如字母、数字或汉字,将单个字符进一步划分为图像中无法识别对应的字符,进一步大大增加了爬虫解析数据的难度.
使用本发明的网页数据反爬取方法获取网页,页面关键数据的显示效果保持不变,完全不影响用户体验。但对于恶意爬虫,被爬取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据;即便进一步抓拍图片,再用ocr工具进行识别,结果也是一团糟。字符序列化,大大增加了恶意爬虫抓取关键数据的难度。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述是指结合实施例描述的特定特征、结构、材料或特性或实例包括在本发明的至少一个实施例或实例中。在本说明书中,上述术语的示意性表示不一定指同一实施例或示例。此外,所描述的特定特征、结构、材料或特性可以以合适的方式组合在任何一个或多个实施例或示例中。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种修改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。 查看全部
网页抓取数据(
本发明网页数据防的方法及系统背景技术实现要素分析)
本发明涉及互联网技术领域,尤其涉及一种防止网页数据被抓取的方法及系统。
背景技术:
大数据时代,数据已经成为企业的核心竞争力。网页上的一些关键数据,如购物网站商品价格、交易量、用户联系方式等信息,在方便用户浏览的同时,也成为一些恶意爬虫疯狂爬取的目标。如何防止关键数据被大规模爬取,不断增加爬虫的采集难度,成为很多企业网站的首要任务。
目前现有的技术方案和不足:
(1)关键数据登录权限控制,用户体验差;
(2)关键数据是动态的,只能防止低级静态爬虫;
(3)关键数据显示在一张图片中,现有的ocr(光学字符识别)技术可以轻松识别图片中的字符。
技术实现要素:
本发明旨在解决现有技术或相关技术中存在的至少一个技术问题。
为此,本发明的一个目的是提供一种防止网页数据被抓取的方法。
本发明的另一个目的是提供一种网页数据反爬取系统。
有鉴于此,根据本发明的一个目的,提出一种网页数据反爬取方法,包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片;通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过css(cascadingstylesheets)样式控制背景图片的显示,即使恶意爬虫将网页源码和图片全部丢掉采集 ,并且使用ocr工具进行识别,也无法获得完整正确的数据,而且每页的数据图片都是随机生成的,大大增加了采集解析的难度,保护了上的关键数据在 Internet 上打开网页。
上述本发明的防止网页数据爬取的方法还可以具有以下技术特征:
上述技术方案中,优选地,对网页数据的混淆处理具体包括:统计网页数据的长度;对齐网页数据的长度;并对网页数据的字符串进行随机排序。优选地,该方法还包括:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
在该技术方案中,页面上的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充,填充的字符串随机重新排序,插入字符混淆后的字符,乱序等。字符串生成背景图片,使网页爬取恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,对网页数据字符串进行随机排序包括:将字符串分割为单个字符,随机排序并在单个字符中添加字符;或将字符串分割为单个字符,将单个字符分割为不识别图形,对不识别图形进行随机排序并添加字符处理。
本技术方案中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,网页关键数据混淆,或将字符串拆分为单个字符,单个字符划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加难度用于捕获关键数据的恶意爬虫。
在上述任一技术方案中,优选地,将混淆后的网页数据转换为背景图片包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片中的位置。
在该技术方案中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,在网页上显示背景图片包括:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在上述任一技术方案中,优选地,在通过堆叠样式表在网页上显示背景图片之前,该方法还包括:创建堆叠样式表。
本技术方案创建了一个堆叠样式表,背景图片的显示由堆叠样式表控制。
根据本发明的另一个目的,提出了一种网页数据反爬取系统,包括:数据提取单元,用于提取网页数据;用于混淆网页数据的数据处理单元;一个转换单元,用于将混淆后的网页数据转换为背景图片;显示单元,用于通过堆叠样式表在网页上显示背景图片。
在本发明提供的网页数据防抓取系统中,数据提取单元提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据,数据处理单元将顺序打乱,加入字符混淆后,转换单元为网页生成背景图片。该图像用作显示背景。显示单元通过 CSS 样式控制背景图片的显示,即使恶意爬虫将网页的所有源代码和图片丢弃并使用 ocr 工具识别出无法获取完整正确的数据,以及每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
根据本发明的上述网页数据反爬取系统还可以具有以下技术特征:
上述技术方案中,优选地,所述数据处理单元用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,所述数据处理单元还用于:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
本技术方案中,数据处理单元对页面的所有关键数据进行长度对齐处理。如果长度不够,插入多余的字符进行填充,填充的字符串随机重新排序,插入字符后,乱序等。混淆后的字符串生成背景图片,以便恶意爬虫抓取的网页不收录关键数据的任何信息,导致无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,所述数据处理单元还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割成单个字符,将单个字符分割成不可识别图形,对不可识别图形进行随机排序并添加字符处理。
在该技术方案中,数据处理单元将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或将字符串拆分为单个字符。分割成不可识别的图形,对不可识别的图形进行随机排序并添加字符处理,进一步分割成ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫的难度捕获关键数据。
在上述任一技术方案中,优选地,转换单元具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
本技术方案中,转换单元将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,并将不影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,所述显示单元具体用于:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案中,显示单元生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,使关键数据在网页上的显示效果页面保持不变,不以任何方式影响用户体验。
在上述任一技术方案中,优选地,还包括: 用于创建堆叠样式表的创建单元。
本技术方案中,创建单元创建一个堆叠样式表,通过堆叠样式表控制背景图片的显示。
本发明的其他方面和优点将在以下描述中变得明显,或者通过本发明的实践而被理解。
图纸说明
通过结合以下附图的实施例的描述,本发明的上述和/或附加的方面和优点将变得显而易见且易于理解,其中:
图1为本发明实施例提供的网页数据反爬取方法流程示意图;
图2a为本发明另一实施例提供的网页数据反爬取方法的流程示意图;
图2b为本发明另一实施例防止网页数据被爬取的方法流程示意图;
图3示出了根据本发明实施例的网页数据反爬取系统的示意框图;
图4为本发明具体实施例的网页显示效果图;
图5为本发明具体实施例的关键数据分割与混淆效果图;
图6为本发明具体实施例中防止网页数据爬取的方法流程示意图;
图。图7示出了根据本发明具体实施例的字符串切分示意图。
具体实现方法
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施例对本发明作进一步详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
在以下描述中,为了充分理解本发明,解释了许多具体细节。然而,本发明也可以以不同于这里描述的方式的其他方式实施。因此,本发明的保护范围不限于以下所公开的具体实施例。
本发明第一方面的实施例提出了一种防止网页数据被抓取的方法。如图。图1示出了根据本发明实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤102,提取网页数据;
步骤104,混淆网页数据;
步骤106,将混淆后的网页数据转换为背景图片;
步骤108,通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过CSS样式控制背景图片的显示。即使恶意爬虫将网页的所有源代码和图片全部丢弃并使用ocr工具进行识别,也无法获得完整正确的数据。 ,并且每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网上打开的网页上的关键数据。
图。图2a示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤212,通过堆叠样式表在网页上显示背景图片。
在本实施例中,页面的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充。填充的字符串随机重新排序,插入字符、乱序等混淆后的字符。字符串生成背景图片,使网页抓取的网页恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,对网页数据字符串进行随机排序包括:将字符串分为单个字符、随机排序单个字符和添加字符;或将字符串拆分成单个字符,将单个字符拆分成不可识别图形,对不可识别图形进行随机排序,添加字符处理。
在本实施例中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,混淆网页关键数据,或将字符串拆分为单个字符,将单个字符字符被划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,将混淆后的网页数据转换为背景图片具体包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片的位置。
在本实施例中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
图。图2b示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤214,创建叠加样式表;
步骤216,生成页面源代码;
步骤218,根据网页数据在背景图片中的位置,在网页上显示背景图片。
本实施例创建了一个分层的样式表,生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而达到显示效果页面关键数据不变,不影响用户体验。
本发明第二方面的一个实施例提出了一种网页数据反爬取系统300。图3示出了根据本发明实施例的网页数据反爬取系统300的示意框图。其中,系统包括:
数据提取单元302用于提取网页数据;
数据处理单元304用于对网页数据进行混淆处理;
转换单元306用于将混淆后的网页数据转换为背景图片;
显示单元308用于通过层叠样式表在网页上显示背景图片。
在本发明提供的网页数据反爬取系统300中,数据提取单元302提取需要保护的关键数据,例如在网页中以字符串形式显示的数字、英文、汉字等。网页,数据处理单元304打乱后,在排序添加混淆字符后,转换单元306生成网页的背景图片,并将该图片作为显示背景。显示单元308通过CSS样式控制背景图片的显示,即使恶意爬虫将网页采集的所有源码和图片全部删除,并使用ocr工具进行识别,也不可能得到完整正确的数据,每个页面的数据图像都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
在本发明的一个实施例中,优选地,数据处理单元304用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,数据处理单元304还用于:当网页数据的长度不足时,通过插入多余的字符来填充网页数据的长度。
在本实施例中,数据处理单元304对所有页面的关键数据进行长度对齐处理。如果长度不足,插入多余的字符进行填充,填充的字符串随机重新排序,字符插入乱序。混淆后的字符串会生成背景图片,使得恶意爬虫抓取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,数据处理单元304还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割为单个字符。字符,将单个字符划分为不识别图形,对不识别图形进行随机排序并添加字符处理。
在本实施例中,数据处理单元304将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或者将字符串拆分为单个字符。将字符划分为不可识别图形,将不可识别图形随机排序并添加字符处理,将不可识别图形进一步划分为ocr软件无法识别的图形,增强了混淆度网页关键数据,大大增加了恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,转换单元306具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
在本实施例中,转换单元306将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,不会影响用户浏览网页的效果。
在本发明的一个实施例中,优选地,显示单元308具体用于:生成页面源代码;并根据网页数据在背景图片中的位置在网页上显示背景图片。
本实施例中,显示单元308生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在本发明的一个实施例中,优选地,还包括:创建单元310,用于创建堆叠样式表。
在本实施例中,创建单元310创建堆叠样式表,背景图像的显示由堆叠样式表控制。
在本发明的一个具体实施例中,需要保护的关键数据,如数字、英文、汉字在网页显示中以字符串的形式显示,如图4所示,被提取,顺序被打乱,并添加混乱。字符生成后,生成如图5所示的网页背景图片,并记录字符在图片中的相对位置;这张图片作为显示背景,通过CSS样式控制背景图片的显示。不同的字符背景偏移量根据生成图片时的记录位置进行设置,以便在页面上显示完整的数据。这样,即使恶意爬虫采集下载了网页的源代码和图片,使用ocr工具进行识别,也无法得到完整正确的数据,每个页面的数据图片都是随机生成的,大大增加了采集的分析难度。图6示出了根据本发明具体实施例的防止网页数据被抓取的方法的示意性流程图:
步骤602,提取网页上需要保护的关键数据,将字符混淆后转换为图片,包括:
(1)提取网页中所有需要保护的关键数据;
(2)所有页面的关键数据长度对齐;
(3)长度不足,已插入多余字符填充;
(4)完成的字符串随机重新排序;
(5)字符串经过插入字符、乱序等混淆处理后生成一张图片;
(6)记录图片中字符的相对位置。
步骤604,设置页面显示价格样式。
步骤606:获取字符在图片中的相对位置,生成页面源代码,通过设置背景图片的相对位置来控制数据在页面上的显示。
在本发明的另一个具体实施例中,在对字符串进行图形化的过程中,将字符串分割成完整的可识别字符,然后进行无序化,添加冗余字符,然后生成图片。在此基础上,可以将单个字符进一步划分为OCR软件无法识别的图形,如下图7所示。由于目前的OCR技术只能识别完整的字符,如字母、数字或汉字,将单个字符进一步划分为图像中无法识别对应的字符,进一步大大增加了爬虫解析数据的难度.
使用本发明的网页数据反爬取方法获取网页,页面关键数据的显示效果保持不变,完全不影响用户体验。但对于恶意爬虫,被爬取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据;即便进一步抓拍图片,再用ocr工具进行识别,结果也是一团糟。字符序列化,大大增加了恶意爬虫抓取关键数据的难度。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述是指结合实施例描述的特定特征、结构、材料或特性或实例包括在本发明的至少一个实施例或实例中。在本说明书中,上述术语的示意性表示不一定指同一实施例或示例。此外,所描述的特定特征、结构、材料或特性可以以合适的方式组合在任何一个或多个实施例或示例中。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种修改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。
网页抓取数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-01 02:18
如何在不使用selenium插件的情况下抓取网页的动态加载数据。针对这个问题,本文文章详细介绍了相应的分析和解答,希望能帮助更多想要解决这个问题的朋友找到更简单易行的方法。
下面介绍如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。
步骤如下:
一、找到正确的网址。
二、填写URL对应的参数。
三、 参数转换成urllib可以识别的字符串数据。
四、 初始化请求对象。
五、urlopen Request 对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
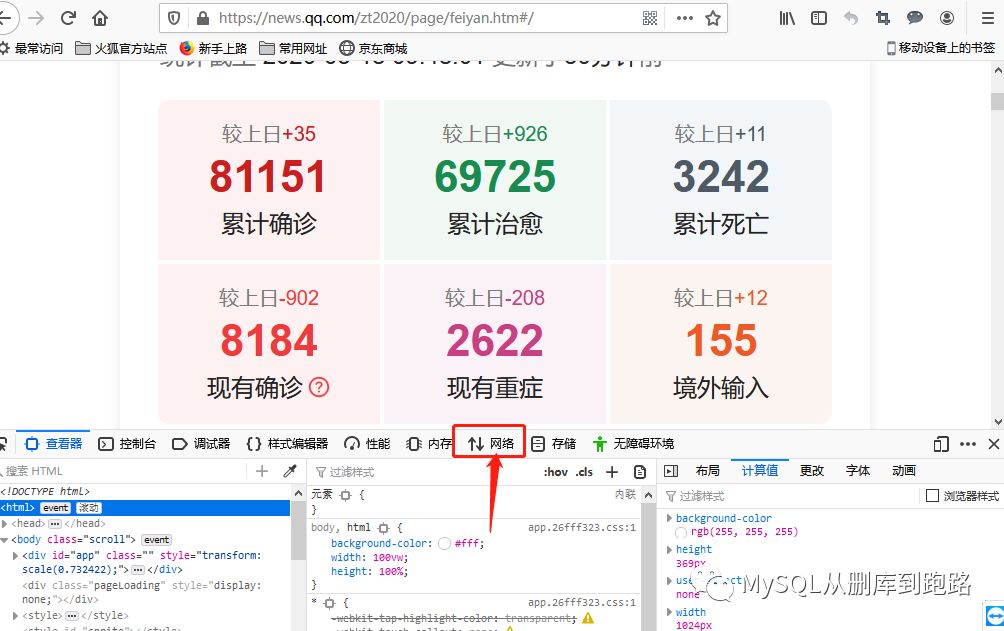
后面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何使用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般来说,动态加载的数据量比其他页面元素大。 , 119kb 与其他基于字节的计算相比,可以看作是一个大数据量。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏区分。
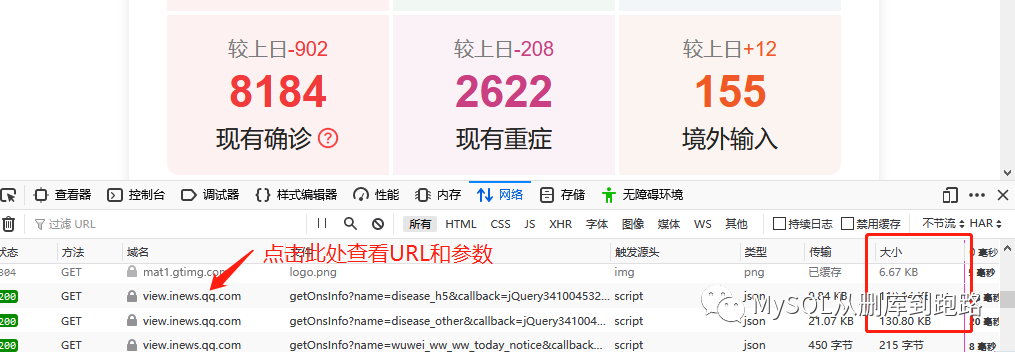
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
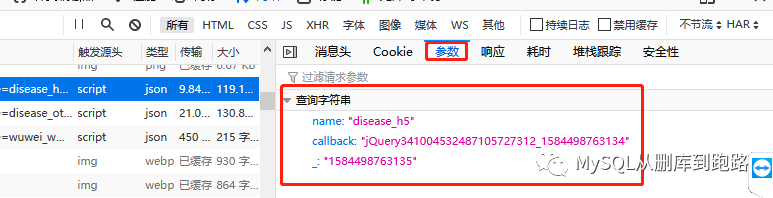
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data) 查看全部
网页抓取数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
如何在不使用selenium插件的情况下抓取网页的动态加载数据。针对这个问题,本文文章详细介绍了相应的分析和解答,希望能帮助更多想要解决这个问题的朋友找到更简单易行的方法。
下面介绍如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。
步骤如下:
一、找到正确的网址。
二、填写URL对应的参数。
三、 参数转换成urllib可以识别的字符串数据。
四、 初始化请求对象。
五、urlopen Request 对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
后面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何使用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般来说,动态加载的数据量比其他页面元素大。 , 119kb 与其他基于字节的计算相比,可以看作是一个大数据量。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下

在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
网页抓取数据(分布式抓取和存储,的使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-28 17:08
所以,首先我不用担心进入分布式爬取和存储,因为顾名思义:它需要相当数量的机器才能得到好的结果。除非您拥有计算机农场,否则您不会真正受益。可以搭建爬虫网程序。
列表中的下一件事是确定您的瓶颈在哪里。
对您的系统进行基准测试
尝试消除MS sql:
加载要抓取的 1000 个 URL 的列表。
测试你能多快抓住它们。
如果 1,000 个 URL 不能给你足够大的抓取,你可以得到 10,000 个 URL 或 100k 个 URL(或者如果你觉得勇敢,你可以得到它)。无论如何,尝试建立一个基线,其中排除尽可能多的变量。
识别瓶颈
抓到爬行速度的底线后,试着确定自己速度变慢的原因。此外,您将需要开始使用多任务处理,因为您已经绑定并且您正在获取可用于提取链接和执行其他操作的数据。其他操作的页面之间有很多空闲时间。
你现在每秒想要多少页?您应该尝试每秒获取 10 页以上的数据。
加速
显然,下一步就是尽可能调整你的爬虫机制:
> 尝试加速您的爬虫以达到带宽等硬性限制。
我推荐使用异步套接字,因为它们比阻塞套接字、WebRequest/HttpWebRequest 等更快。
> 使用更快的 HTML 解析库:从一开始,如果感觉比尝试使用它更勇敢。
使用,而不是sql数据库,利用key/value存储(对URL的key进行hash,作为value存储HTML等相关数据)。
去专业!
如果你已经掌握了以上所有内容,那么我建议你尝试接吻!重要的是你有一个很好的选择算法来模拟 PageRank 以平衡新鲜度和覆盖率:。如果您拥有上述工具,那么您应该能够实现 OPIC 并运行一个相当快的爬虫。
如果你对编程语言灵活,又不想背离C#,可以试试基于Java的企业爬虫(eg)。Nutch 与 Hadoop 和其他各种高度可扩展的解决方案集成。 查看全部
网页抓取数据(分布式抓取和存储,的使用方法)
所以,首先我不用担心进入分布式爬取和存储,因为顾名思义:它需要相当数量的机器才能得到好的结果。除非您拥有计算机农场,否则您不会真正受益。可以搭建爬虫网程序。
列表中的下一件事是确定您的瓶颈在哪里。
对您的系统进行基准测试
尝试消除MS sql:
加载要抓取的 1000 个 URL 的列表。
测试你能多快抓住它们。
如果 1,000 个 URL 不能给你足够大的抓取,你可以得到 10,000 个 URL 或 100k 个 URL(或者如果你觉得勇敢,你可以得到它)。无论如何,尝试建立一个基线,其中排除尽可能多的变量。
识别瓶颈
抓到爬行速度的底线后,试着确定自己速度变慢的原因。此外,您将需要开始使用多任务处理,因为您已经绑定并且您正在获取可用于提取链接和执行其他操作的数据。其他操作的页面之间有很多空闲时间。
你现在每秒想要多少页?您应该尝试每秒获取 10 页以上的数据。
加速
显然,下一步就是尽可能调整你的爬虫机制:
> 尝试加速您的爬虫以达到带宽等硬性限制。
我推荐使用异步套接字,因为它们比阻塞套接字、WebRequest/HttpWebRequest 等更快。
> 使用更快的 HTML 解析库:从一开始,如果感觉比尝试使用它更勇敢。
使用,而不是sql数据库,利用key/value存储(对URL的key进行hash,作为value存储HTML等相关数据)。
去专业!
如果你已经掌握了以上所有内容,那么我建议你尝试接吻!重要的是你有一个很好的选择算法来模拟 PageRank 以平衡新鲜度和覆盖率:。如果您拥有上述工具,那么您应该能够实现 OPIC 并运行一个相当快的爬虫。
如果你对编程语言灵活,又不想背离C#,可以试试基于Java的企业爬虫(eg)。Nutch 与 Hadoop 和其他各种高度可扩展的解决方案集成。
网页抓取数据(如何通过xpath访问一个网站获取网页信息的信息打印出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-23 10:06
Xpath 通常用于抓取网页的过程中,根据 html 中标签的路径来过滤内容。今天我们就来看看如何通过xpath获取网页信息。这里的例子很简单,访问一个网站取回列表中的信息,打印出来,然后开始。
准备
在chrome浏览器中安装xpath helper插件
如果无法访问chrome商店,可以在网上搜索chrome xpath helper插件并下载。将下载的文件拖放到 chrome 扩展程序中进行安装。安装完成后,您会在浏览器上看到一个小十字图标。这是xpath helper的启动图标,一键启动。启动后,你会看到一个浮动窗口
可以分别输入xpath表达式和结果。
这里需要用到python的两个组件requests和lxml,因为我用的是pycharm的ide工具,实现了一个虚拟的python环境,所以组件的安装需要在ide中操作。
在首选项中选择要安装的组件。
在弹出的窗口中搜索并选择要安装的组件。
网站分析
先打开一个你要爬取的网站,分析网站的内容。
如上图所示,我们需要返回黄色部分的列表,即需要访问的树结构的html标签。
我们需要返回书单中的书名。这里,标题使用的标签是h4,下面的链接使用a,这里使用text()返回a中的内容
//h4/a/text()
当我们通过xpath helper输入xpath数据时,可以在右侧窗口中显示相应的内容。这可以证明我们的xpath是有效的。
编码
借助xpath,编码很容易,引入etree和requests,使用requests生成get请求,将返回的响应发送给etree进行xpath分析,最后打印结果。
from lxml import etree
import requests
from fake_useragent import UserAgent
url = "https://www.qidian.com/rank/yuepiao?chn=21"
headers = {
"User-Agent": UserAgent().random
}
response = requests.get(url, headers=headers)
print(response.text)
e = etree.HTML(response.text)
names = e.xpath('//h4/a/text()')
print(names)
完成工作,如果您愿意,可以转发。谢谢大家。 查看全部
网页抓取数据(如何通过xpath访问一个网站获取网页信息的信息打印出来)
Xpath 通常用于抓取网页的过程中,根据 html 中标签的路径来过滤内容。今天我们就来看看如何通过xpath获取网页信息。这里的例子很简单,访问一个网站取回列表中的信息,打印出来,然后开始。
准备
在chrome浏览器中安装xpath helper插件
如果无法访问chrome商店,可以在网上搜索chrome xpath helper插件并下载。将下载的文件拖放到 chrome 扩展程序中进行安装。安装完成后,您会在浏览器上看到一个小十字图标。这是xpath helper的启动图标,一键启动。启动后,你会看到一个浮动窗口
可以分别输入xpath表达式和结果。
这里需要用到python的两个组件requests和lxml,因为我用的是pycharm的ide工具,实现了一个虚拟的python环境,所以组件的安装需要在ide中操作。
在首选项中选择要安装的组件。
在弹出的窗口中搜索并选择要安装的组件。
网站分析
先打开一个你要爬取的网站,分析网站的内容。
如上图所示,我们需要返回黄色部分的列表,即需要访问的树结构的html标签。
我们需要返回书单中的书名。这里,标题使用的标签是h4,下面的链接使用a,这里使用text()返回a中的内容
//h4/a/text()
当我们通过xpath helper输入xpath数据时,可以在右侧窗口中显示相应的内容。这可以证明我们的xpath是有效的。
编码
借助xpath,编码很容易,引入etree和requests,使用requests生成get请求,将返回的响应发送给etree进行xpath分析,最后打印结果。
from lxml import etree
import requests
from fake_useragent import UserAgent
url = "https://www.qidian.com/rank/yuepiao?chn=21"
headers = {
"User-Agent": UserAgent().random
}
response = requests.get(url, headers=headers)
print(response.text)
e = etree.HTML(response.text)
names = e.xpath('//h4/a/text()')
print(names)
完成工作,如果您愿意,可以转发。谢谢大家。
网页抓取数据(做电商营销,可以利用网页抓取工具优采云采集器V9)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-23 10:04
近年来,大数据的奥秘一直被越来越多地描述,其魅力迅速蔓延到各个领域和行业。虽然利用大数据进行营销已经成为营销界的共识,但如何快速准确地从海量数据中获取所需的数据仍然是营销人员的短板,但是在了解了网络爬虫工具后,这个问题就出现了减少痛苦。
网页抓取工具优采云采集器V9是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于对网页结构的源代码提取,所以几乎可以做到 全网通用,抓取所有页面,使用方便。这意味着只要我们能看到网页中所有能看到的信息,就可以轻松抓取,解决大数据获取问题就是这么简单。
网络爬虫工具已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以利用网络爬虫工具优采云采集器V9,准确抓取竞品店铺的商品名称、图片、价格、销售额等信息数据,然后运用大数据模型分析,构建一套适合自身商业模式的营销方案,如标题优化、热点产品打造、价格策略、服务调整等。
另一个例子是企业营销。以保险公司为例,您还可以使用网络爬虫工具优采云采集器V9抓取一系列相关数据,对精算、营销、保险等多个环节进行过滤分析。精准营销、精准定价、精准管理、精准服务。更科学地设定各种费率;提醒客户保障范围不足,筛选出最适合的保险产品和服务类型,精准推送。
网页抓取工具不仅可以为营销奠定大数据的基石,还可以为营销推广提供自动化发布,即优采云采集器V9的多种站群网络发布功能。使用此功能配置站群,一键发送到多个目的地网站,如论坛、QQ区、博客、微博等,配合优采云采集器 V9不再需要繁琐的登录、复制粘贴,营销省时省力,提高操作水平和工作效率。
大数据呈现的信息非常丰富,领先的营销方式也多种多样。为了让我们利用大数据做更好的营销工作,我建议大家一定要掌握优采云采集器V9这个唯有经典的网络爬虫工具,才能在大数据营销领域获得更多的成果紧跟时代发展潮流。 查看全部
网页抓取数据(做电商营销,可以利用网页抓取工具优采云采集器V9)
近年来,大数据的奥秘一直被越来越多地描述,其魅力迅速蔓延到各个领域和行业。虽然利用大数据进行营销已经成为营销界的共识,但如何快速准确地从海量数据中获取所需的数据仍然是营销人员的短板,但是在了解了网络爬虫工具后,这个问题就出现了减少痛苦。
网页抓取工具优采云采集器V9是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于对网页结构的源代码提取,所以几乎可以做到 全网通用,抓取所有页面,使用方便。这意味着只要我们能看到网页中所有能看到的信息,就可以轻松抓取,解决大数据获取问题就是这么简单。
网络爬虫工具已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以利用网络爬虫工具优采云采集器V9,准确抓取竞品店铺的商品名称、图片、价格、销售额等信息数据,然后运用大数据模型分析,构建一套适合自身商业模式的营销方案,如标题优化、热点产品打造、价格策略、服务调整等。
另一个例子是企业营销。以保险公司为例,您还可以使用网络爬虫工具优采云采集器V9抓取一系列相关数据,对精算、营销、保险等多个环节进行过滤分析。精准营销、精准定价、精准管理、精准服务。更科学地设定各种费率;提醒客户保障范围不足,筛选出最适合的保险产品和服务类型,精准推送。
网页抓取工具不仅可以为营销奠定大数据的基石,还可以为营销推广提供自动化发布,即优采云采集器V9的多种站群网络发布功能。使用此功能配置站群,一键发送到多个目的地网站,如论坛、QQ区、博客、微博等,配合优采云采集器 V9不再需要繁琐的登录、复制粘贴,营销省时省力,提高操作水平和工作效率。
大数据呈现的信息非常丰富,领先的营销方式也多种多样。为了让我们利用大数据做更好的营销工作,我建议大家一定要掌握优采云采集器V9这个唯有经典的网络爬虫工具,才能在大数据营销领域获得更多的成果紧跟时代发展潮流。
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-22 22:09
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
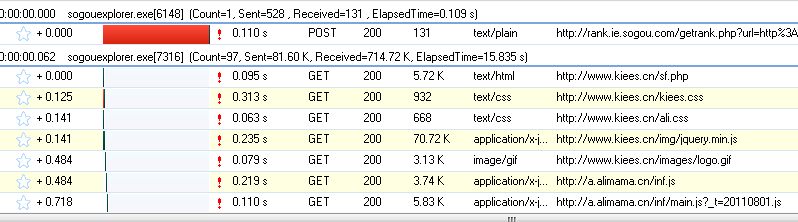
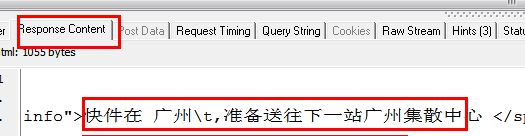
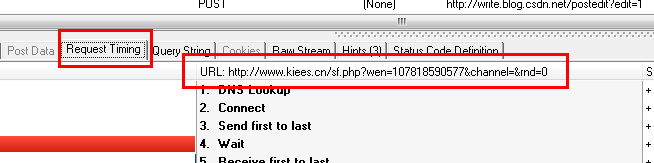
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第二步:查看网页源代码,我们在源代码中看到这一段:

由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:

也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
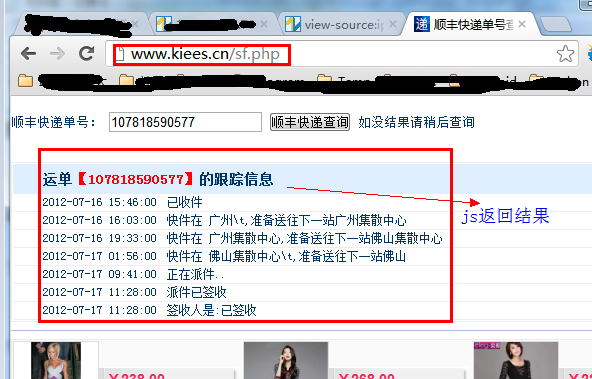
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
网页抓取数据( Python中正则表达式的3种抓取其中数据的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-19 19:03
Python中正则表达式的3种抓取其中数据的方法(上))
3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['<img />', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。 查看全部
网页抓取数据(
Python中正则表达式的3种抓取其中数据的方法(上))

3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['<img />', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
网页抓取数据(网络机器人能以令人难以置信的速度抓取网页,我们能做些什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-17 01:13
)
全文2618字,预计学习时间7分钟
来源:unsplash
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使是最美丽、最令人愉快的人工智能也要提防。此外,一些网络用户以不道德的方式使用网络机器人,这甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗?
有这么多信息要分析,自然而然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,您甚至可以自定义您的搜索,看看这些信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式为研究或业务采集有用信息的完美例子。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
机器人程序流量报告
有人认为,人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分人工智能流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然在所难免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多好处,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改进公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
· 代理服务器旨在充当用户和 Web 服务器之间的中介。
· 功能多样:个人和公司都可以使用代理服务器来满足特定的需求。
· 代理的一个常见用途与网络爬虫有关:使用代理服务器可以绕过网站管理员设置的限制,从而采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,则用户将被限制访问 网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
来源:unsplash
使用人类知名度和值得信赖的品牌来对抗人工智能的耻辱
目前,人工智能的发展速度确实已经超过了网民数量的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
· 坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
· 坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
· 以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
·普及人工智能。与他人讨论如何以及为何使用网络抓取,以便人们对网络抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手工操作来手动访问网站数据或许让人放心,但因为信息量太大,几乎不可能。可用的数据量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。
查看全部
网页抓取数据(网络机器人能以令人难以置信的速度抓取网页,我们能做些什么?
)
全文2618字,预计学习时间7分钟

来源:unsplash
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使是最美丽、最令人愉快的人工智能也要提防。此外,一些网络用户以不道德的方式使用网络机器人,这甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗?
有这么多信息要分析,自然而然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,您甚至可以自定义您的搜索,看看这些信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式为研究或业务采集有用信息的完美例子。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。

机器人程序流量报告
有人认为,人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分人工智能流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然在所难免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多好处,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改进公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
· 代理服务器旨在充当用户和 Web 服务器之间的中介。
· 功能多样:个人和公司都可以使用代理服务器来满足特定的需求。
· 代理的一个常见用途与网络爬虫有关:使用代理服务器可以绕过网站管理员设置的限制,从而采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,则用户将被限制访问 网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。

来源:unsplash
使用人类知名度和值得信赖的品牌来对抗人工智能的耻辱
目前,人工智能的发展速度确实已经超过了网民数量的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
· 坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
· 坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
· 以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
·普及人工智能。与他人讨论如何以及为何使用网络抓取,以便人们对网络抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手工操作来手动访问网站数据或许让人放心,但因为信息量太大,几乎不可能。可用的数据量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。

网页抓取数据(网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-13 13:14
网页抓取数据,然后生成数据库报表,这是我们最常用的数据挖掘的方法了,据我所知是爬虫抓取信息,然后后台生成数据报表,这对于软件开发人员是很方便的事情,对于开发人员来说,这些信息对于数据挖掘技术不懂是很难进行和分析的,下面介绍一下selenium自动化测试。
1、先确定要抓取的网页,
2、下载网页:、然后进行代码编写,
3、代码讲解,
4、自动识别数据列:
5、生成数据库报表:
6、和sql语句对比:
7、处理数据:
8、数据分析:#-*-coding:utf-8-*-"""author:shugtocomments:tel:1461888631email:file:
需要的知识:1.自动化测试基础知识(要具有一定的编程能力,对java/.net有一定的了解,比如python/ruby,rstudio)2.数据库知识(一般用mysql和oracle)3.网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库)4.测试工具操作(如何在界面看到自己的代码,并且保存成自己的web地址和名称)最好从边学边做吧,前期找一些轻松的基础,做出一个简单的自动化程序再学习爬虫吧。
知乎上有现成的文章可以看看,selenium的教程,selenium教程基本上应该够用了。 查看全部
网页抓取数据(网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库))
网页抓取数据,然后生成数据库报表,这是我们最常用的数据挖掘的方法了,据我所知是爬虫抓取信息,然后后台生成数据报表,这对于软件开发人员是很方便的事情,对于开发人员来说,这些信息对于数据挖掘技术不懂是很难进行和分析的,下面介绍一下selenium自动化测试。
1、先确定要抓取的网页,
2、下载网页:、然后进行代码编写,
3、代码讲解,
4、自动识别数据列:
5、生成数据库报表:
6、和sql语句对比:
7、处理数据:
8、数据分析:#-*-coding:utf-8-*-"""author:shugtocomments:tel:1461888631email:file:
需要的知识:1.自动化测试基础知识(要具有一定的编程能力,对java/.net有一定的了解,比如python/ruby,rstudio)2.数据库知识(一般用mysql和oracle)3.网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库)4.测试工具操作(如何在界面看到自己的代码,并且保存成自己的web地址和名称)最好从边学边做吧,前期找一些轻松的基础,做出一个简单的自动化程序再学习爬虫吧。
知乎上有现成的文章可以看看,selenium的教程,selenium教程基本上应该够用了。
网页抓取数据(网页数据这件事,只要用心投入,一年也能上10万!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-11 05:01
网页抓取数据这件事,只要用心投入,一年也能上10万!这里不得不提的就是bootstrap,因为它是已经成为现代前端mv*pipeline的标准,所以这里我们只谈它。相信大家都知道,在之前,bootstrap还只能用来写网页,而且非常的受挫,所以很多人折腾了半天,只是优化自己的前端部分的代码。我个人不是很喜欢在前端搞太多,所以除了坚持写文章、写代码,我就是做一些视频资源、logo设计之类的事情。
网上的前端博客我也写了很多,比如这个:网站概览性能问题是我一直想尝试的一个领域,考虑到很多同学也不是特别熟悉工程化,所以我分享一下自己的感受:bootstrap的源码包括css文件以及js文件,需要制作一个动态的css编译器,以提高渲染速度,把你代码的重点包含其中,比如使用css3的特性进行小部件的封装、对样式采用less进行封装等等,全部用async和异步请求来实现,这样可以提高服务器的压力。
还有一些小功能,比如预编译、async/await代码里有lru缓存机制,这些都是使用bootstrap做的异步特性,可以提高可用性。除了bootstrap,你还可以用其他的框架,比如react、vue等等,这里不做过多讨论。通过es7-nodets这种扩展语言,可以支持把一些js中遇到的问题包括异步问题封装到bootstrap的核心的异步机制中去,也就是在异步机制中加入这些扩展语言去解决方案,这样可以提高可用性,不至于在发布版本时遇到问题。
一般情况下js包含在es5/es6的标准库中,但是也可以包含在flatten插件中,这时候就需要多复用相应的开发工具或者模块了。可以通过图形接口、一些工具集包括power、imitator、plugins等方式,构建mv*工程,它主要有这几种形式:写页面内部代码的方式,即编写脚本发布到第三方,再自己写页面的方式,即自己做的页面用第三方的页面apply进来,发布到第三方团队团队内部工程的方式,比如先在第三方解决方案那边做页面apply,再在自己公司内部直接apply的方式,自己公司内部有业务需求直接做apply到其他业务中去的方式,比如全公司共享一套代码等等,这里就不做展开了,这里涉及一些技术知识,也是大部分同学绕不过去的坎,我个人认为,比如要复用power、imitator、plugins等方式,还是需要比较有一定的知识和经验之后。
怎么寻找第三方资源?这里就讲三个比较常用的方式:在官网获取第三方的资源(文章、教程等),这个有个好处就是,它的自带论坛是源自官网的内容,比较权威,你可以很快的获取到相关干货或知识的获取途径;使用百度谷歌搜索第三方的bootstrap资源,这里特别。 查看全部
网页抓取数据(网页数据这件事,只要用心投入,一年也能上10万!)
网页抓取数据这件事,只要用心投入,一年也能上10万!这里不得不提的就是bootstrap,因为它是已经成为现代前端mv*pipeline的标准,所以这里我们只谈它。相信大家都知道,在之前,bootstrap还只能用来写网页,而且非常的受挫,所以很多人折腾了半天,只是优化自己的前端部分的代码。我个人不是很喜欢在前端搞太多,所以除了坚持写文章、写代码,我就是做一些视频资源、logo设计之类的事情。
网上的前端博客我也写了很多,比如这个:网站概览性能问题是我一直想尝试的一个领域,考虑到很多同学也不是特别熟悉工程化,所以我分享一下自己的感受:bootstrap的源码包括css文件以及js文件,需要制作一个动态的css编译器,以提高渲染速度,把你代码的重点包含其中,比如使用css3的特性进行小部件的封装、对样式采用less进行封装等等,全部用async和异步请求来实现,这样可以提高服务器的压力。
还有一些小功能,比如预编译、async/await代码里有lru缓存机制,这些都是使用bootstrap做的异步特性,可以提高可用性。除了bootstrap,你还可以用其他的框架,比如react、vue等等,这里不做过多讨论。通过es7-nodets这种扩展语言,可以支持把一些js中遇到的问题包括异步问题封装到bootstrap的核心的异步机制中去,也就是在异步机制中加入这些扩展语言去解决方案,这样可以提高可用性,不至于在发布版本时遇到问题。
一般情况下js包含在es5/es6的标准库中,但是也可以包含在flatten插件中,这时候就需要多复用相应的开发工具或者模块了。可以通过图形接口、一些工具集包括power、imitator、plugins等方式,构建mv*工程,它主要有这几种形式:写页面内部代码的方式,即编写脚本发布到第三方,再自己写页面的方式,即自己做的页面用第三方的页面apply进来,发布到第三方团队团队内部工程的方式,比如先在第三方解决方案那边做页面apply,再在自己公司内部直接apply的方式,自己公司内部有业务需求直接做apply到其他业务中去的方式,比如全公司共享一套代码等等,这里就不做展开了,这里涉及一些技术知识,也是大部分同学绕不过去的坎,我个人认为,比如要复用power、imitator、plugins等方式,还是需要比较有一定的知识和经验之后。
怎么寻找第三方资源?这里就讲三个比较常用的方式:在官网获取第三方的资源(文章、教程等),这个有个好处就是,它的自带论坛是源自官网的内容,比较权威,你可以很快的获取到相关干货或知识的获取途径;使用百度谷歌搜索第三方的bootstrap资源,这里特别。
网页抓取数据(提取的数据还不能直接拿来用?文件还没有被下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-29 13:08
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址/logo.gif,或者不规则的图片源代码,采集器将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。 查看全部
网页抓取数据(提取的数据还不能直接拿来用?文件还没有被下载?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址/logo.gif,或者不规则的图片源代码,采集器将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
网页抓取数据(几天的资料去写一个网页抓取股票实时数据的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-28 07:39
最近查了好几天的资料,写了一个网页,捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般不需要时间的网页数据变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此,开始网上搜索数据,很多人建议使用libcurl方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不变化的普通网页非常强大,libcurl达不到每秒的刷新率。网页数据速度10倍以上,而libcurl会有读取失败的延迟,延迟是2~3秒,也就是说在这2~3秒内无法抓取到网页上变化的数据。对于股市来说,这会丢失很大一部分数据。所以 libcurl 的方案被否定了。
但是,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的就是将数据丢失降到最低。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据?(这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。. . 也希望有想法有想法的同事留下自己的打算。 查看全部
网页抓取数据(几天的资料去写一个网页抓取股票实时数据的程序)
最近查了好几天的资料,写了一个网页,捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般不需要时间的网页数据变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此,开始网上搜索数据,很多人建议使用libcurl方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不变化的普通网页非常强大,libcurl达不到每秒的刷新率。网页数据速度10倍以上,而libcurl会有读取失败的延迟,延迟是2~3秒,也就是说在这2~3秒内无法抓取到网页上变化的数据。对于股市来说,这会丢失很大一部分数据。所以 libcurl 的方案被否定了。
但是,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的就是将数据丢失降到最低。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据?(这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。. . 也希望有想法有想法的同事留下自己的打算。
网页抓取数据(选择network,库需要对数据的格式有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-23 17:05
初步准备工作
本例使用了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设这两个库已经安装好了,如果没有,可以通过pip安装。接下来,简单说一下这两个库的作用。requests库的主要作用是通过url获取服务器的前端代码数据。这两个库捕获的数据是服务器前端代码中的数据。BeautifulSoup 库主要用于从捕获的前端代码中提取所需的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
推荐使用谷歌或火狐浏览器打开,可以使用快捷键CTRL+U查看服务器网页源代码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。相信你能理解一点html语言基础知识。需要注意的是,我们可以在源码中看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码也是显示出来的。它是 JavaScript 代码,而不是 JavaScript 加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法是不直接从目标网站抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口中打开请求的资源。服务器可以通过改变请求参数返回不同的数据。这种方法需要对HTTP协议等原理有所了解。
具体方法是在要抓取的数据上右击,选择inspect。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次,就可以看到get方法的请求了。
通过get方法得到的返回数据与前端页面对比,可以发现是一致的。您可以直接选择鼠标右键打开一个新的网页。不过此时只返回了一部分数据,并不是全部数据,可以通过修改get方法的参数来获取全部数据。这里只能修改np=2,为什么要修改这个参数这里不再赘述。修改后的请求如下:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3 ,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115 ,f152&_=55
可以看出都是结构化数据,我们可以直接取数据。您可以使用正则表达式来匹配相应的数据。我们第一次只能捕获简单的信息,例如股票代码。详细的交易信息需要使用'+'股票代码'来获取。我们也用这两个库来重复这个过程,直接从源码中抓取就可以了,不用再麻烦了。代码直接在下面
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/index.jsp?stockcode=' + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{
'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部的信息,可以通过上述检查元素的方法得到。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次爬取的数据信息)
概括
第一次爬的时候,因为参考了书中的例子,不知道这个题目要爬的网页是用JavaScript写的,一般爬静态网页的方法是爬不出来的。的。我尝试了很多方法。一开始我以为是因为没有添加Headers参数,但是添加之后还是取不到。最后在网上查资料的时候,找到了一个关于反爬虫的介绍文章,里面解释了用JavaScript写的URL是不可能爬取的,并举例说明了两种对应的方案。第一种是使用dryscape库进行刮,第二种是使用selenium库进行刮。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用 selenium 库进行抓取。使用这种方法确实可以抓取数据,但前提是需要配合浏览器打开页面才能抓取。考虑到要抓取的页面太多,无法逐页抓取,所以再次放弃。第二种方法。最后转来分析一下JavaScript的数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在加载页面的时候会有一个请求URL,最终通过这个请求找到了想要的数据地址,并对参数进行了一些修改,你可以一次得到你想要的所有数据。在爬取过程中也遇到了一些问题。在最后的爬取过程中,因为有些股票没有交易数据,所以在抓取这些没有交易数据的股票时程序异常报错。最后,我加了一个判断。当没有成交数据时,会显示“该股票没有成交数据!”。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。 查看全部
网页抓取数据(选择network,库需要对数据的格式有什么作用?)
初步准备工作
本例使用了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设这两个库已经安装好了,如果没有,可以通过pip安装。接下来,简单说一下这两个库的作用。requests库的主要作用是通过url获取服务器的前端代码数据。这两个库捕获的数据是服务器前端代码中的数据。BeautifulSoup 库主要用于从捕获的前端代码中提取所需的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
推荐使用谷歌或火狐浏览器打开,可以使用快捷键CTRL+U查看服务器网页源代码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。相信你能理解一点html语言基础知识。需要注意的是,我们可以在源码中看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码也是显示出来的。它是 JavaScript 代码,而不是 JavaScript 加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法是不直接从目标网站抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口中打开请求的资源。服务器可以通过改变请求参数返回不同的数据。这种方法需要对HTTP协议等原理有所了解。
具体方法是在要抓取的数据上右击,选择inspect。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次,就可以看到get方法的请求了。
通过get方法得到的返回数据与前端页面对比,可以发现是一致的。您可以直接选择鼠标右键打开一个新的网页。不过此时只返回了一部分数据,并不是全部数据,可以通过修改get方法的参数来获取全部数据。这里只能修改np=2,为什么要修改这个参数这里不再赘述。修改后的请求如下:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3 ,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115 ,f152&_=55
可以看出都是结构化数据,我们可以直接取数据。您可以使用正则表达式来匹配相应的数据。我们第一次只能捕获简单的信息,例如股票代码。详细的交易信息需要使用'+'股票代码'来获取。我们也用这两个库来重复这个过程,直接从源码中抓取就可以了,不用再麻烦了。代码直接在下面
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/index.jsp?stockcode=' + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{
'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部的信息,可以通过上述检查元素的方法得到。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次爬取的数据信息)
概括
第一次爬的时候,因为参考了书中的例子,不知道这个题目要爬的网页是用JavaScript写的,一般爬静态网页的方法是爬不出来的。的。我尝试了很多方法。一开始我以为是因为没有添加Headers参数,但是添加之后还是取不到。最后在网上查资料的时候,找到了一个关于反爬虫的介绍文章,里面解释了用JavaScript写的URL是不可能爬取的,并举例说明了两种对应的方案。第一种是使用dryscape库进行刮,第二种是使用selenium库进行刮。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用 selenium 库进行抓取。使用这种方法确实可以抓取数据,但前提是需要配合浏览器打开页面才能抓取。考虑到要抓取的页面太多,无法逐页抓取,所以再次放弃。第二种方法。最后转来分析一下JavaScript的数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在加载页面的时候会有一个请求URL,最终通过这个请求找到了想要的数据地址,并对参数进行了一些修改,你可以一次得到你想要的所有数据。在爬取过程中也遇到了一些问题。在最后的爬取过程中,因为有些股票没有交易数据,所以在抓取这些没有交易数据的股票时程序异常报错。最后,我加了一个判断。当没有成交数据时,会显示“该股票没有成交数据!”。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。这个设计过程的最终收获是巨大的。最大的收获是这方面经验的积累,更重要的是解决本课题设计中每一个问题的过程。对我以后面对各种问题也很有帮助和启发。
网页抓取数据(如何最有效地分析Git存储库来跟踪数据源随时间的变化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-23 13:13
大多数人都知道 Git 抓取,这是一种网络抓取编程技术,您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析这些采集到的数据是一个公认的挑战。git-history 正是我为解决这个困境而设计的工具。
Git抓取技术回顾
将数据抓取到 Git 存储库的一大优势是抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 维护了一张火灾地图,显示了该州最近发生的大火。
我找到了 网站 的基础数据:
curl /umbraco/Api/IncidentApi/GetIncidents
然后我构建了一个简单的爬虫,它每 20 分钟获取一次 网站 数据并将其提交给 Git。到目前为止,该工具已经运行了 14 个月,并采集了 1559 次提交。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细存档数据更改的内容和位置,因此通过抓取他们的 网站 数据并将其保存到 Git 存储库,您会发现自己比他们更了解他们的数据更改历史做。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对成千上万的版本和大量的 JSON 和 CSV 文档,如果仅用肉眼观察差异,很难挖掘出数据背后的价值。
git历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的整个历史版本,并随着时间的推移生成文件更改的 SQLite 数据库。然后可以使用 Datasette 分析来挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的示例数据库。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在此示例中,我们正在获取文档 events.json 的历史版本。
我们使用 UniqueId 列来识别随时间变化的记录和新记录。
新创建的数据库表的默认名称是 item 和 item_version。我们通过 --namespace 事件将表名指定为事件和事件版本。
该工具中还嵌入了一段 Python 代码,可将存储在提交历史中的每个修订版转换为与该工具兼容的对象列表。
让数据库帮助我们回答有关过去 14 个月加州大火的一些问题。
事件表收录每次火灾的最新记录。有了这张表,我们可以得到一张所有火灾的地图:
此处使用 dataset-cluster-map 插件,它映射表中提供有效经度和纬度值的所有行。
真正有趣的是incident_version 表。该表记录了每次火灾的获取版本之间的数据更新。
有 250 起火灾的 2060 个记录版本。如果我们按 _item 分面,我们可以看到哪些火灾记录的版本最多。前十名分别是:
§ 迪克西火:268
§ 卡尔多火:153
§ 纪念碑火灾 65
§ 八月情结(包括 Doe Fire):64
§ 溪火:56
§ 法国火:53
§ 西尔维拉多火:52
§ 小鹿火:45
§ 蓝岭火:39
§ 麦克法兰火灾:34
版本数越高,火的持续时间越长。维基百科上什至有一个关于 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中,可以看到所有抓取到的“版本”按版本号排列。
git-history 只在这个表中写入与上一个版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
经常变化的是 ConditionStatement 列,这一列是文本描述,另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是 commits 表的外键,记录了工具的提交版本,所以当你再次运行工具时,工具可以定位到上次提交的版本。
加入提交表以查看每个版本的创建日期。您还可以使用 event_version_detail 视图执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助dataset-vega插件,比较_commit_at列(日期类型)和AcresBurned列(数值类型) 形成一个图表,可视化 Dixie Fire 火灾随时间的进展情况。
总结一下:我们首先使用 GitHub Actions 创建一个定时工作流,每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们成功地绘制了过去 14 个月加州持续时间最长的野火之一的蔓延情况。
关于表结构设计
在 git-history 的设计过程中,最难的就是设计一个合适的表结构来存储以前的版本变更信息。
我的最终设计如下(为清楚起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到过item_version表记录了网站不同时间点的快照,但是为了节省数据库空间,提供简洁的版本浏览界面,这里只记录与之前版本相比发生变化的列。未更改的列用 null 写入。
但是这样的设计有一个隐患,就是fire里面某列的值更新为null怎么办?我们如何判断它是更新还是没有变化?
为了解决这个问题,我添加了一个多对多表 item_changed,它使用整数对来记录 item_version 表中哪些列有更新的内容。使用整数对的目的是尽可能少地占用空间。
item_version_detail 视图以 JSON 的形式呈现多对多表中的列。我过滤了一些数据,放到下图中,可以看到哪些列哪些火灾在哪些版本中更新了:
通过下面的 SQL 查询,我们可以知道加州火灾哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
§ 更新:1785
§ 火灾被扑灭的比例:740
§ 状态说明:734
§ 火灾区域:616
§ 开始时间:327
§ 受灾人员:286
§ 消防泵:274
§ 消防员:256
§ 消防车:225
§ 无人机:211
§ 消防飞机:181
§ 建筑损坏:125
§ 直升机:122
直升机听起来很刺激!让我们过滤掉自第一个版本以来至少有一次更新的直升机火灾数量。您可以使用这样的嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,19起火灾由直升机救援,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 一直在使用 Git 爬虫不断地从 网站 中抓取数据并将其保存到 dbreunig/511-events-history 存储库中。网站 记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以数据库 sf-bay-511 为例,帮助我们理解 git-history 的用法和叠加的 --convert 选项。
git-history 要求抓取的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"IncidentID": "abc123",
"Location": "Corner of 4th and Vermont",
"Type": "fire"
},
{
"IncidentID": "cde448",
"Location": "555 West Example Drive",
"Type": "medical"
}
]
但抓取的数据通常不是这种理想的格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据量很大,其中一些对整体分析没有帮助,比如即使没有数据更新也会随着版本变化的更新时间戳,以及嵌套很深的对象“扩展”收录大量重复数据。
我编写了一段 Python 代码将每个 网站 快照转换为更简单的结构,并将此代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
这个传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上按顺序运行。代码循环遍历嵌套的事件列表,修改每条记录,然后使用 yield 以可迭代的顺序输出。
一些历史记录显示服务器 500 错误,代码也能够识别和跳过这些记录。
使用 git-history 时,我发现自己大部分时间都在迭代转换脚本。将 Python 代码字符串传递给 git-history 等工具是一种有趣的模式,今年早些时候我尝试在 sqlite-utils 工具中覆盖转换。
试试看
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项,示例中使用的脚本存储在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,很多人创建了仓库,目前已经超过 200 个,海量的抓取数据等你去探索!
手稿来源:/2021/Dec/7/git-history/ 查看全部
网页抓取数据(如何最有效地分析Git存储库来跟踪数据源随时间的变化)
大多数人都知道 Git 抓取,这是一种网络抓取编程技术,您可以定期将数据源的快照抓取到 Git 存储库,以跟踪数据源随时间的变化。
如何分析这些采集到的数据是一个公认的挑战。git-history 正是我为解决这个困境而设计的工具。
Git抓取技术回顾
将数据抓取到 Git 存储库的一大优势是抓取工具本身非常简单。
这是一个具体的例子:加州林业和消防局 (Cal Fire) 在 /incidents网站 维护了一张火灾地图,显示了该州最近发生的大火。
我找到了 网站 的基础数据:
curl /umbraco/Api/IncidentApi/GetIncidents
然后我构建了一个简单的爬虫,它每 20 分钟获取一次 网站 数据并将其提交给 Git。到目前为止,该工具已经运行了 14 个月,并采集了 1559 次提交。
Git 抓取最让我兴奋的是它可以创建真正独特的数据集。许多组织没有详细存档数据更改的内容和位置,因此通过抓取他们的 网站 数据并将其保存到 Git 存储库,您会发现自己比他们更了解他们的数据更改历史做。
然而,一个巨大的挑战是如何最有效地分析采集到的数据?面对成千上万的版本和大量的 JSON 和 CSV 文档,如果仅用肉眼观察差异,很难挖掘出数据背后的价值。
git历史
git-history 是我的新解决方案,它是一个命令行工具。它可以读取文件的整个历史版本,并随着时间的推移生成文件更改的 SQLite 数据库。然后可以使用 Datasette 分析来挖掘这些数据。
下面是通过使用 ca-fires-history 存储库运行 git-history 生成的示例数据库。我通过在存储库目录中运行以下命令创建了一个 SQLite 数据库:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
在此示例中,我们正在获取文档 events.json 的历史版本。
我们使用 UniqueId 列来识别随时间变化的记录和新记录。
新创建的数据库表的默认名称是 item 和 item_version。我们通过 --namespace 事件将表名指定为事件和事件版本。
该工具中还嵌入了一段 Python 代码,可将存储在提交历史中的每个修订版转换为与该工具兼容的对象列表。
让数据库帮助我们回答有关过去 14 个月加州大火的一些问题。
事件表收录每次火灾的最新记录。有了这张表,我们可以得到一张所有火灾的地图:
此处使用 dataset-cluster-map 插件,它映射表中提供有效经度和纬度值的所有行。
真正有趣的是incident_version 表。该表记录了每次火灾的获取版本之间的数据更新。
有 250 起火灾的 2060 个记录版本。如果我们按 _item 分面,我们可以看到哪些火灾记录的版本最多。前十名分别是:
§ 迪克西火:268
§ 卡尔多火:153
§ 纪念碑火灾 65
§ 八月情结(包括 Doe Fire):64
§ 溪火:56
§ 法国火:53
§ 西尔维拉多火:52
§ 小鹿火:45
§ 蓝岭火:39
§ 麦克法兰火灾:34
版本数越高,火的持续时间越长。维基百科上什至有一个关于 Dixie Fire 的条目!
点击Dixie Fire,在弹出的页面中,可以看到所有抓取到的“版本”按版本号排列。
git-history 只在这个表中写入与上一个版本相比发生变化的值。因此,一目了然,您可以看到哪些信息随时间发生了变化:
经常变化的是 ConditionStatement 列,这一列是文本描述,另外两个有趣的列是 AcresBurned 和 PercentContained。
_commit 是 commits 表的外键,记录了工具的提交版本,所以当你再次运行工具时,工具可以定位到上次提交的版本。
加入提交表以查看每个版本的创建日期。您还可以使用 event_version_detail 视图执行连接操作。
通过这个视图,我们可以过滤所有_item值为174、AcresBurned值不为空的行,借助dataset-vega插件,比较_commit_at列(日期类型)和AcresBurned列(数值类型) 形成一个图表,可视化 Dixie Fire 火灾随时间的进展情况。
总结一下:我们首先使用 GitHub Actions 创建一个定时工作流,每 20 分钟获取一次 JSON API 端点的最新副本。现在,在 git-history、Datasette 和 datasette-vega 的帮助下,我们成功地绘制了过去 14 个月加州持续时间最长的野火之一的蔓延情况。
关于表结构设计
在 git-history 的设计过程中,最难的就是设计一个合适的表结构来存储以前的版本变更信息。
我的最终设计如下(为清楚起见进行了适当编辑):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);
前面提到过item_version表记录了网站不同时间点的快照,但是为了节省数据库空间,提供简洁的版本浏览界面,这里只记录与之前版本相比发生变化的列。未更改的列用 null 写入。
但是这样的设计有一个隐患,就是fire里面某列的值更新为null怎么办?我们如何判断它是更新还是没有变化?
为了解决这个问题,我添加了一个多对多表 item_changed,它使用整数对来记录 item_version 表中哪些列有更新的内容。使用整数对的目的是尽可能少地占用空间。
item_version_detail 视图以 JSON 的形式呈现多对多表中的列。我过滤了一些数据,放到下图中,可以看到哪些列哪些火灾在哪些版本中更新了:
通过下面的 SQL 查询,我们可以知道加州火灾哪些数据更新最频繁:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc
查询结果如下:
§ 更新:1785
§ 火灾被扑灭的比例:740
§ 状态说明:734
§ 火灾区域:616
§ 开始时间:327
§ 受灾人员:286
§ 消防泵:274
§ 消防员:256
§ 消防车:225
§ 无人机:211
§ 消防飞机:181
§ 建筑损坏:125
§ 直升机:122
直升机听起来很刺激!让我们过滤掉自第一个版本以来至少有一次更新的直升机火灾数量。您可以使用这样的嵌套 SQL 查询:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)
查询结果显示,19起火灾由直升机救援,我们在下图标注:
--convert 选项的高级用法
在过去的 8 个月中,Drew Breunig 一直在使用 Git 爬虫不断地从 网站 中抓取数据并将其保存到 dbreunig/511-events-history 存储库中。网站 记录旧金山湾区的交通事故。我将他的数据加载到 sf-bay-511 数据库中。
以数据库 sf-bay-511 为例,帮助我们理解 git-history 的用法和叠加的 --convert 选项。
git-history 要求抓取的数据为以下特定格式:由 JSON 对象组成的 JSON 列表,每个对象都有一个列,可以用作唯一标识列,以跟踪数据随时间的变化。
理想的 JSON 文件如下所示:
[
{
"IncidentID": "abc123",
"Location": "Corner of 4th and Vermont",
"Type": "fire"
},
{
"IncidentID": "cde448",
"Location": "555 West Example Drive",
"Type": "medical"
}
]
但抓取的数据通常不是这种理想的格式。
我找到了 网站 的 JSON 提要。有非常复杂的嵌套对象,数据量很大,其中一些对整体分析没有帮助,比如即使没有数据更新也会随着版本变化的更新时间戳,以及嵌套很深的对象“扩展”收录大量重复数据。
我编写了一段 Python 代码将每个 网站 快照转换为更简单的结构,并将此代码传递给脚本的 --convert 选项:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
这个传递给 --convert 的单引号字符串被编译成 Python 函数,并在每个 Git 版本上按顺序运行。代码循环遍历嵌套的事件列表,修改每条记录,然后使用 yield 以可迭代的顺序输出。
一些历史记录显示服务器 500 错误,代码也能够识别和跳过这些记录。
使用 git-history 时,我发现自己大部分时间都在迭代转换脚本。将 Python 代码字符串传递给 git-history 等工具是一种有趣的模式,今年早些时候我尝试在 sqlite-utils 工具中覆盖转换。
试试看
如果您想尝试 git-history 工具,扩展文档 README 中提供了更多选项,示例中使用的脚本存储在 demos 文件夹中。
在 GitHub 上的 git-scraping 话题下,很多人创建了仓库,目前已经超过 200 个,海量的抓取数据等你去探索!
手稿来源:/2021/Dec/7/git-history/
网页抓取数据(哪些页面是人为的重要?有几个合理的因素?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-16 01:08
最常用的链接是锚文本链接、超链接、纯文本链接和图像链接。如何被爬虫爬取是一个自动提取网页的程序,比如百度蜘蛛。要让你的 网站 收录更多的页面,你必须先让爬虫爬取页面。如果你的 网站 页面定期更新,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。蜘蛛很快就会爬上 网站、网站 和页面权重,这肯定更重要。
做SEO优化,我希望我的更多页面是收录,尽量吸引蜘蛛去抓取。如果你不能爬取所有的页面,蜘蛛所要做的就是爬取尽可能多的重要页面。哪些页面是人为重要的?
有几个合理的因素
1、网站页数和权重
网站质量高,资质老,被认为权重高,在这个网站上爬取页面的深度会更高,所以收录的页面会多一些。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果不需要掌握第一个页面更新,则不需要第二个蜘蛛页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上的新连接自然会被蜘蛛更快地跟踪以抓取新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛爬取,并且必须有传入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的传入链接通常会增加页面上传出链接的抓取深度。
4、点击“离家距离”
一般来说,大多数主页的权重都很高。因此,点击距离越接近首页,页面的权限越高,被蜘蛛爬取的机会就越大。
5、网址结构
页面权重只有在迭代计算中才知道,所以上面提到的高页面权重有利于爬取。搜索引擎蜘蛛在爬取之前如何知道页面权重?因此,蜘蛛预测,除了链接、与首页的距离、历史数据等因素外,短 URL 和浅 URL 也可能会直观地认为该站点具有较高的权重。
6、如何吸引蜘蛛:
这些链接导致蜘蛛访问网页。只要不遵循这些链接,就会导致蜘蛛访问和转移权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的附属链接。 查看全部
网页抓取数据(哪些页面是人为的重要?有几个合理的因素?)
最常用的链接是锚文本链接、超链接、纯文本链接和图像链接。如何被爬虫爬取是一个自动提取网页的程序,比如百度蜘蛛。要让你的 网站 收录更多的页面,你必须先让爬虫爬取页面。如果你的 网站 页面定期更新,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。蜘蛛很快就会爬上 网站、网站 和页面权重,这肯定更重要。
做SEO优化,我希望我的更多页面是收录,尽量吸引蜘蛛去抓取。如果你不能爬取所有的页面,蜘蛛所要做的就是爬取尽可能多的重要页面。哪些页面是人为重要的?
有几个合理的因素
1、网站页数和权重
网站质量高,资质老,被认为权重高,在这个网站上爬取页面的深度会更高,所以收录的页面会多一些。
2、页面更新
蜘蛛每次抓取时都会存储页面数据。如果不需要掌握第一个页面更新,则不需要第二个蜘蛛页面更新。如果页面内容更新频繁,蜘蛛会更频繁地访问该页面,页面上的新连接自然会被蜘蛛更快地跟踪以抓取新页面。
3、导入链接
无论是外链还是同一个网站的内链,都必须被蜘蛛爬取,并且必须有传入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的传入链接通常会增加页面上传出链接的抓取深度。
4、点击“离家距离”
一般来说,大多数主页的权重都很高。因此,点击距离越接近首页,页面的权限越高,被蜘蛛爬取的机会就越大。
5、网址结构
页面权重只有在迭代计算中才知道,所以上面提到的高页面权重有利于爬取。搜索引擎蜘蛛在爬取之前如何知道页面权重?因此,蜘蛛预测,除了链接、与首页的距离、历史数据等因素外,短 URL 和浅 URL 也可能会直观地认为该站点具有较高的权重。
6、如何吸引蜘蛛:
这些链接导致蜘蛛访问网页。只要不遵循这些链接,就会导致蜘蛛访问和转移权重。锚文本链接是一种很好的引导蜘蛛的方式,有利于关键词排名,比如关键词锚文本中的附属链接。
网页抓取数据(百度蜘蛛爬取框架流程原理跟搜索引擎爬虫蜘蛛站长SEO )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-15 22:18
)
网站采集软件原理同搜索引擎爬虫蜘蛛,站长SEO!免费网站采集软件的原理和搜索引擎爬虫蜘蛛的原理是一样的!它是根据规则自动捕获网站信息的程序或软件。从技术的角度,我们对搜索引擎和网站收录的原理和流程有了更深入的了解。让我们用网站采集软件让网站收录的排名权重飙升!
百度蜘蛛爬取框架流程原理
首先,从Internet页面中仔细挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子URL放入待抓取的URL队列中。,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载页面内容。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,记录爬虫系统已经下载了该网页的URL,避免了对网页的重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在已抓取的 URL 队列中进行检查。如果发现该链接没有被爬取,则将该URL放在待爬取URL队列的末尾,然后在爬取调度中下载该URL对应的网页。这样就形成了一个循环,直到对待爬取的URL队列进行审核,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
百度蜘蛛爬虫类型
根据不同的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫:批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它会停止爬取过程。至于具体的目标,可能会有所不同,可能设置一定数量的要爬取的网页就够了,也可能是设置爬取所消耗的时间。
2.增量爬虫:增量爬虫与批量爬虫不同,它们会不断的爬行。对于抓取到的网页,应该定期更新,因为互联网的网页是在不断变化的随时间变化,所以在不断的爬取过程中,要么是爬取新的页面,要么是更新已有的页面。有网页。常见的商业搜索引擎爬虫基本属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题或属于特定行业的网页,例如健康网站,只需要从互联网页面中找到与健康相关的页面,内容就足够了,并且不考虑其他行业的内容。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,不可能把所有的网页都下载下来再过滤。这种资源浪费太多了。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关。并且尽量不要去抓取不相关的页面,以达到节省资源的目的。垂直搜索<
网站建筑如何吸引蜘蛛爬行网站内容
1、网站和页面的权重仍然作为衡量网站价值的重要标准。优质老手网站被百度评为高权重。这种网站的页面更容易被蜘蛛爬取,所以很多内页都会是收录。
2、页面更新频率会直接影响蜘蛛的访问频率。蜘蛛将每次访问获得的页面数据保存到服务器。如果下次访问页面,发现内容和存储的数据一样,蜘蛛会认为页面不会频繁更新,然后给网站一个优先级来决定访问的时间和频率将来。如果网站的内容更新频繁,每次爬虫爬取的内容都不一样,那么爬虫会更频繁地访问这样的页面,页面上出现的新链接自然会被爬取收录 .
3、引导链接的建立,无论网站的外部链接还是内部链接,要想被蜘蛛爬取,就必须有引导链接才能进入页面,所以合理构建内部链接非常重要,否则蜘蛛无法发现页面的存在。高质量的外链导入也很重要,会增加蜘蛛的跟踪爬取深度。
4、建立首页的引导链接。主页最常被蜘蛛访问。当有内容更新时,一定要在首页体现出来,并且要建立一个链接,这样蜘蛛才能尽快抓取到,增加爬取的机会。
5、原创内容,最厉害的爬虫就是将网站新发布的内容与服务器收录的数据进行对比,如果是抄袭或者部分修改非原创伪原创内容,百度不会收录,如果你经常发布非原创内容,也会降低蜘蛛的访问频率,严重的直接不行收录 ,甚至 0收录。
通过以上信息,我们对百度蜘蛛的爬取过程,以及如何吸引蜘蛛去网站爬取内容有了一个清晰的认识。页面更新频率会直接影响蜘蛛的访问频率,精力有限! 原创很难保证大量长期更新。如果邀请编辑,投入产出比可能为负。
高端SEO一目了然,深入研究搜索引擎算法,根据算法伪原创量身定做,效果媲美原创行内配合搜索引擎算法,外行看热闹。里面看门口!
关注小编,获取更专业的SEO知识,助你做好网站建设网站管理网站优化,让你的网站拥有更好收录排名和流量!
查看全部
网页抓取数据(百度蜘蛛爬取框架流程原理跟搜索引擎爬虫蜘蛛站长SEO
)
网站采集软件原理同搜索引擎爬虫蜘蛛,站长SEO!免费网站采集软件的原理和搜索引擎爬虫蜘蛛的原理是一样的!它是根据规则自动捕获网站信息的程序或软件。从技术的角度,我们对搜索引擎和网站收录的原理和流程有了更深入的了解。让我们用网站采集软件让网站收录的排名权重飙升!
百度蜘蛛爬取框架流程原理
首先,从Internet页面中仔细挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子URL放入待抓取的URL队列中。,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载页面内容。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载的网页的URL放入已爬取的URL队列中,记录爬虫系统已经下载了该网页的URL,避免了对网页的重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在已抓取的 URL 队列中进行检查。如果发现该链接没有被爬取,则将该URL放在待爬取URL队列的末尾,然后在爬取调度中下载该URL对应的网页。这样就形成了一个循环,直到对待爬取的URL队列进行审核,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
百度蜘蛛爬虫类型
根据不同的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种:
1. 批量爬虫:批量爬虫有比较明确的爬取范围和目标。当爬虫到达设定的目标时,它会停止爬取过程。至于具体的目标,可能会有所不同,可能设置一定数量的要爬取的网页就够了,也可能是设置爬取所消耗的时间。
2.增量爬虫:增量爬虫与批量爬虫不同,它们会不断的爬行。对于抓取到的网页,应该定期更新,因为互联网的网页是在不断变化的随时间变化,所以在不断的爬取过程中,要么是爬取新的页面,要么是更新已有的页面。有网页。常见的商业搜索引擎爬虫基本属于这一类。
3.Focused Crawter:垂直爬虫专注于特定主题或属于特定行业的网页,例如健康网站,只需要从互联网页面中找到与健康相关的页面,内容就足够了,并且不考虑其他行业的内容。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,不可能把所有的网页都下载下来再过滤。这种资源浪费太多了。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关。并且尽量不要去抓取不相关的页面,以达到节省资源的目的。垂直搜索<
网站建筑如何吸引蜘蛛爬行网站内容
1、网站和页面的权重仍然作为衡量网站价值的重要标准。优质老手网站被百度评为高权重。这种网站的页面更容易被蜘蛛爬取,所以很多内页都会是收录。
2、页面更新频率会直接影响蜘蛛的访问频率。蜘蛛将每次访问获得的页面数据保存到服务器。如果下次访问页面,发现内容和存储的数据一样,蜘蛛会认为页面不会频繁更新,然后给网站一个优先级来决定访问的时间和频率将来。如果网站的内容更新频繁,每次爬虫爬取的内容都不一样,那么爬虫会更频繁地访问这样的页面,页面上出现的新链接自然会被爬取收录 .
3、引导链接的建立,无论网站的外部链接还是内部链接,要想被蜘蛛爬取,就必须有引导链接才能进入页面,所以合理构建内部链接非常重要,否则蜘蛛无法发现页面的存在。高质量的外链导入也很重要,会增加蜘蛛的跟踪爬取深度。
4、建立首页的引导链接。主页最常被蜘蛛访问。当有内容更新时,一定要在首页体现出来,并且要建立一个链接,这样蜘蛛才能尽快抓取到,增加爬取的机会。
5、原创内容,最厉害的爬虫就是将网站新发布的内容与服务器收录的数据进行对比,如果是抄袭或者部分修改非原创伪原创内容,百度不会收录,如果你经常发布非原创内容,也会降低蜘蛛的访问频率,严重的直接不行收录 ,甚至 0收录。
通过以上信息,我们对百度蜘蛛的爬取过程,以及如何吸引蜘蛛去网站爬取内容有了一个清晰的认识。页面更新频率会直接影响蜘蛛的访问频率,精力有限! 原创很难保证大量长期更新。如果邀请编辑,投入产出比可能为负。
高端SEO一目了然,深入研究搜索引擎算法,根据算法伪原创量身定做,效果媲美原创行内配合搜索引擎算法,外行看热闹。里面看门口!
关注小编,获取更专业的SEO知识,助你做好网站建设网站管理网站优化,让你的网站拥有更好收录排名和流量!
网页抓取数据(网页抓取数据,可以写javascript函数,方便自己把js代码保存下来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-01-14 19:01
网页抓取数据,可以写javascript函数,方便自己把js代码保存下来,然后用python或ruby进行解析。可以了解下爬虫开发,打造自己专属爬虫。推荐一本爬虫开发的好书:http权威指南(豆瓣),其中介绍了python,基础库,程序设计等部分内容。
ajax生成动态的cookie,
http权威指南
找一些自己看的懂的python和ruby的教程
爬虫的基础是python+ruby我要推荐一个,我只推荐python和ruby,我们经常说的restful,http,python里面现成的这个库都是无敌的,你们去看看requests包括exception之后的if,else代码都是无敌的,包括asyncio包括接下来的continue也是无敌的,defasync_future_call():break:returntrue一举弄定了,再来看看pythonexception模块defcontinue_interval():passasyncio模块raise等等这些模块请先实现接口返回的http请求,然后每一条操作都带上异步io的方法等等,这些无敌了,我的代码除了用了redis,用了纯python,其他的异步io是自己实现的。
今天我看了一个爬虫的,搞定用nodejs的httpquest,看起来比较简单,有些难点:1.请求头里的host,port等需要查看明确和人工补全。2.请求头里的正则表达式是否恰当,还有':',等符号也需要复制下来。3.请求过程中的一些特殊字符串,比如空格等需要自己处理以及生成字符串注意::1.看懂基本入门用的这个库nodejshttpquestbabeljquery2.学好http协议接下来完全可以http.header、http协议概念、http方法等多看看。
3.适当增加js监听器抓取点数据。4.多尝试在python语言里实现http协议,打包成gzip压缩包、p2p传输等方式来搞爬虫。5.基于requests库实现从get请求获取网页,模拟登录再弄本页面爬取。w3cschool(现在不包了)提供完整的爬虫教程,爬虫不难,别人写好的模板现成的,自己修改下就好了,download一下就是了,要注意处理post,别太频繁post和header反正主要就是python,或者ruby(proxies包在这),python,ruby环境,方便,基础不好用1年老项目,别tmd玩nodejs了,解释型语言,自己google项目和实现不都是那些事儿吗,或者你直接看我的系列[爬虫·解决](),三天你就精通爬虫了。 查看全部
网页抓取数据(网页抓取数据,可以写javascript函数,方便自己把js代码保存下来)
网页抓取数据,可以写javascript函数,方便自己把js代码保存下来,然后用python或ruby进行解析。可以了解下爬虫开发,打造自己专属爬虫。推荐一本爬虫开发的好书:http权威指南(豆瓣),其中介绍了python,基础库,程序设计等部分内容。
ajax生成动态的cookie,
http权威指南
找一些自己看的懂的python和ruby的教程
爬虫的基础是python+ruby我要推荐一个,我只推荐python和ruby,我们经常说的restful,http,python里面现成的这个库都是无敌的,你们去看看requests包括exception之后的if,else代码都是无敌的,包括asyncio包括接下来的continue也是无敌的,defasync_future_call():break:returntrue一举弄定了,再来看看pythonexception模块defcontinue_interval():passasyncio模块raise等等这些模块请先实现接口返回的http请求,然后每一条操作都带上异步io的方法等等,这些无敌了,我的代码除了用了redis,用了纯python,其他的异步io是自己实现的。
今天我看了一个爬虫的,搞定用nodejs的httpquest,看起来比较简单,有些难点:1.请求头里的host,port等需要查看明确和人工补全。2.请求头里的正则表达式是否恰当,还有':',等符号也需要复制下来。3.请求过程中的一些特殊字符串,比如空格等需要自己处理以及生成字符串注意::1.看懂基本入门用的这个库nodejshttpquestbabeljquery2.学好http协议接下来完全可以http.header、http协议概念、http方法等多看看。
3.适当增加js监听器抓取点数据。4.多尝试在python语言里实现http协议,打包成gzip压缩包、p2p传输等方式来搞爬虫。5.基于requests库实现从get请求获取网页,模拟登录再弄本页面爬取。w3cschool(现在不包了)提供完整的爬虫教程,爬虫不难,别人写好的模板现成的,自己修改下就好了,download一下就是了,要注意处理post,别太频繁post和header反正主要就是python,或者ruby(proxies包在这),python,ruby环境,方便,基础不好用1年老项目,别tmd玩nodejs了,解释型语言,自己google项目和实现不都是那些事儿吗,或者你直接看我的系列[爬虫·解决](),三天你就精通爬虫了。
网页抓取数据(PowerQuery的数据清洗功能(示例中的列)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-13 07:06
)
/chart?icn=index-topchart-nonfiction
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 抓取的数据就越准确
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
这里我通过复制原创列的数据快速进入示例
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
在知识圈可以找到更多“Ctrl+E”的使用场景
查看全部
网页抓取数据(PowerQuery的数据清洗功能(示例中的列)(组图)
)
/chart?icn=index-topchart-nonfiction
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
我们提供的示例越多,PowerBI 抓取的数据就越准确
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
这里我通过复制原创列的数据快速进入示例
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
在知识圈可以找到更多“Ctrl+E”的使用场景
网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-07 16:13
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。 查看全部
网页抓取数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。数据采集的最终目的是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候,可能都无法上手,尤其是作为新手,感觉很茫然。因此,我想在这里分享我的经验,并希望与大家分享技术。如有不足之处请指正。写这篇文章的目的就是希望大家能一起成长。我也相信技术之间没有高低,只有互补,只有分享才能让彼此成长得更多。
以网页数据采集为例,我们经常要经过以下几个主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
在了解了基本流程之后,我将通过一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在此,httpclient+jsou 提取暂不解释。网页数据的做法以后会在httpclient+jsoup上具体讲解。在这里,我将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站整页预览
接下来我们看一下网页的源码结构:
从上面的源码中,可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到如下数据,也就是我们最终想要得到的数据
成功获取数据,这就是我们想要得到的最终数据结果。最后要说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是在get方法中提交数据。,当真的是采集时,有些网页结构复杂,源码中可能没有我们想要提取的数据。以后我会介绍这点的解决方案。还有,我在这个页面采集的时候,只是采集拿到了当前页面的数据,也有分页的数据。这里就不解释了,只是一个提示,我们可以使用多线程采集所有页面的当前数据,通过线程一个采集当前页面数据,和一个翻页动作,可以< @采集
我们匹配的数据可能在项目的实际开发中,我们需要将提取的数据进行存储,方便我们接下来的数据查询操作。
网页抓取数据(什么是“网页抓取”?python网页语言的抓取语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-06 23:15
什么是“网络爬虫”?
Python 网络爬虫是从任何网站 或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。有多种格式,例如CSV。文件、XML、JSON 等。可以毫不费力地提取任何地方的任何数据。
您需要做的就是选择您要抓取的网站,该过程将开始,您将在一个地方收到所有质量信息。这很好,因为它不是一个耗时的过程。了解网页抓取的重要性。当今市场上的许多网络抓取品牌都为此过程提供了自动化选项。这意味着您现在可以采集常规数据,而无需始终关注正在发生的事情。收到数据后,您需要做的就是监控信息并开始致力于增强和改进您当前的工作流程。
了解网页抓取对您的重要性,网页抓取语言可以帮助您更好地执行此过程。但在进入上下文以确定哪种网络抓取语言更适合此过程之前,请务必在选择此类语言时考虑以下几点:
更好地工作的灵活性,例如,可以轻松抓取更长或更小的信息集
网络爬虫语言应该更具可扩展性
编写这样的语言应该易于理解和实践
爬行技术应该是无错误和增强的
可以更好的提供数据库
如何在没有任何风险或错误的情况下进行有效的网络爬行活动?
在进行安全有效的网络抓取活动时,代理服务器是最大的解决方案之一。代理服务器充当用户和他想要访问的 网站 之间的中间阶段。
例如,假设您要访问一条信息并希望抓取该数据,您将首先向 网站 的所有者发送请求以请求访问。但是在请求到达网站的所有者之前,它会到达代理服务器。然后代理服务器会改变你的IP地址并将请求发送给网站的所有者。
一旦所有者批准网站,您就可以查看数据并开始爬取。代理服务器消除了跟踪 IP 地址的主要问题。网络抓取不会是一次性的过程。了解您对频繁网页抓取的要求至关重要,这样您才能确保此类日常操作不会被阻止。
白云数据提供商业智能数据、高级代理和企业级支持。他们的团队在网络数据采集和提取行业拥有数十年的个人经验,因此他们知道什么是最有效的。北云数据拥有来自全球任何国家和城市的住宅代理。你可以在他们的 网站 上找到一张交互式地图,看看他们在每个国家拥有多少 IP。北云数据为其客户提供住宅和数据中心代理。您可以查看住宅代理和数据中心代理的服务定价。 查看全部
网页抓取数据(什么是“网页抓取”?python网页语言的抓取语言)
什么是“网络爬虫”?
Python 网络爬虫是从任何网站 或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。有多种格式,例如CSV。文件、XML、JSON 等。可以毫不费力地提取任何地方的任何数据。
您需要做的就是选择您要抓取的网站,该过程将开始,您将在一个地方收到所有质量信息。这很好,因为它不是一个耗时的过程。了解网页抓取的重要性。当今市场上的许多网络抓取品牌都为此过程提供了自动化选项。这意味着您现在可以采集常规数据,而无需始终关注正在发生的事情。收到数据后,您需要做的就是监控信息并开始致力于增强和改进您当前的工作流程。
了解网页抓取对您的重要性,网页抓取语言可以帮助您更好地执行此过程。但在进入上下文以确定哪种网络抓取语言更适合此过程之前,请务必在选择此类语言时考虑以下几点:
更好地工作的灵活性,例如,可以轻松抓取更长或更小的信息集
网络爬虫语言应该更具可扩展性
编写这样的语言应该易于理解和实践
爬行技术应该是无错误和增强的
可以更好的提供数据库
如何在没有任何风险或错误的情况下进行有效的网络爬行活动?
在进行安全有效的网络抓取活动时,代理服务器是最大的解决方案之一。代理服务器充当用户和他想要访问的 网站 之间的中间阶段。
例如,假设您要访问一条信息并希望抓取该数据,您将首先向 网站 的所有者发送请求以请求访问。但是在请求到达网站的所有者之前,它会到达代理服务器。然后代理服务器会改变你的IP地址并将请求发送给网站的所有者。
一旦所有者批准网站,您就可以查看数据并开始爬取。代理服务器消除了跟踪 IP 地址的主要问题。网络抓取不会是一次性的过程。了解您对频繁网页抓取的要求至关重要,这样您才能确保此类日常操作不会被阻止。
白云数据提供商业智能数据、高级代理和企业级支持。他们的团队在网络数据采集和提取行业拥有数十年的个人经验,因此他们知道什么是最有效的。北云数据拥有来自全球任何国家和城市的住宅代理。你可以在他们的 网站 上找到一张交互式地图,看看他们在每个国家拥有多少 IP。北云数据为其客户提供住宅和数据中心代理。您可以查看住宅代理和数据中心代理的服务定价。
网页抓取数据( 本发明网页数据防的方法及系统背景技术实现要素分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-03 03:22
本发明网页数据防的方法及系统背景技术实现要素分析)
本发明涉及互联网技术领域,尤其涉及一种防止网页数据被抓取的方法及系统。
背景技术:
大数据时代,数据已经成为企业的核心竞争力。网页上的一些关键数据,如购物网站商品价格、交易量、用户联系方式等信息,在方便用户浏览的同时,也成为一些恶意爬虫疯狂爬取的目标。如何防止关键数据被大规模爬取,不断增加爬虫的采集难度,成为很多企业网站的首要任务。
目前现有的技术方案和不足:
(1)关键数据登录权限控制,用户体验差;
(2)关键数据是动态的,只能防止低级静态爬虫;
(3)关键数据显示在一张图片中,现有的ocr(光学字符识别)技术可以轻松识别图片中的字符。
技术实现要素:
本发明旨在解决现有技术或相关技术中存在的至少一个技术问题。
为此,本发明的一个目的是提供一种防止网页数据被抓取的方法。
本发明的另一个目的是提供一种网页数据反爬取系统。
有鉴于此,根据本发明的一个目的,提出一种网页数据反爬取方法,包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片;通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过css(cascadingstylesheets)样式控制背景图片的显示,即使恶意爬虫将网页源码和图片全部丢掉采集 ,并且使用ocr工具进行识别,也无法获得完整正确的数据,而且每页的数据图片都是随机生成的,大大增加了采集解析的难度,保护了上的关键数据在 Internet 上打开网页。
上述本发明的防止网页数据爬取的方法还可以具有以下技术特征:
上述技术方案中,优选地,对网页数据的混淆处理具体包括:统计网页数据的长度;对齐网页数据的长度;并对网页数据的字符串进行随机排序。优选地,该方法还包括:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
在该技术方案中,页面上的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充,填充的字符串随机重新排序,插入字符混淆后的字符,乱序等。字符串生成背景图片,使网页爬取恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,对网页数据字符串进行随机排序包括:将字符串分割为单个字符,随机排序并在单个字符中添加字符;或将字符串分割为单个字符,将单个字符分割为不识别图形,对不识别图形进行随机排序并添加字符处理。
本技术方案中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,网页关键数据混淆,或将字符串拆分为单个字符,单个字符划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加难度用于捕获关键数据的恶意爬虫。
在上述任一技术方案中,优选地,将混淆后的网页数据转换为背景图片包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片中的位置。
在该技术方案中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,在网页上显示背景图片包括:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在上述任一技术方案中,优选地,在通过堆叠样式表在网页上显示背景图片之前,该方法还包括:创建堆叠样式表。
本技术方案创建了一个堆叠样式表,背景图片的显示由堆叠样式表控制。
根据本发明的另一个目的,提出了一种网页数据反爬取系统,包括:数据提取单元,用于提取网页数据;用于混淆网页数据的数据处理单元;一个转换单元,用于将混淆后的网页数据转换为背景图片;显示单元,用于通过堆叠样式表在网页上显示背景图片。
在本发明提供的网页数据防抓取系统中,数据提取单元提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据,数据处理单元将顺序打乱,加入字符混淆后,转换单元为网页生成背景图片。该图像用作显示背景。显示单元通过 CSS 样式控制背景图片的显示,即使恶意爬虫将网页的所有源代码和图片丢弃并使用 ocr 工具识别出无法获取完整正确的数据,以及每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
根据本发明的上述网页数据反爬取系统还可以具有以下技术特征:
上述技术方案中,优选地,所述数据处理单元用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,所述数据处理单元还用于:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
本技术方案中,数据处理单元对页面的所有关键数据进行长度对齐处理。如果长度不够,插入多余的字符进行填充,填充的字符串随机重新排序,插入字符后,乱序等。混淆后的字符串生成背景图片,以便恶意爬虫抓取的网页不收录关键数据的任何信息,导致无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,所述数据处理单元还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割成单个字符,将单个字符分割成不可识别图形,对不可识别图形进行随机排序并添加字符处理。
在该技术方案中,数据处理单元将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或将字符串拆分为单个字符。分割成不可识别的图形,对不可识别的图形进行随机排序并添加字符处理,进一步分割成ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫的难度捕获关键数据。
在上述任一技术方案中,优选地,转换单元具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
本技术方案中,转换单元将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,并将不影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,所述显示单元具体用于:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案中,显示单元生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,使关键数据在网页上的显示效果页面保持不变,不以任何方式影响用户体验。
在上述任一技术方案中,优选地,还包括: 用于创建堆叠样式表的创建单元。
本技术方案中,创建单元创建一个堆叠样式表,通过堆叠样式表控制背景图片的显示。
本发明的其他方面和优点将在以下描述中变得明显,或者通过本发明的实践而被理解。
图纸说明
通过结合以下附图的实施例的描述,本发明的上述和/或附加的方面和优点将变得显而易见且易于理解,其中:
图1为本发明实施例提供的网页数据反爬取方法流程示意图;
图2a为本发明另一实施例提供的网页数据反爬取方法的流程示意图;
图2b为本发明另一实施例防止网页数据被爬取的方法流程示意图;
图3示出了根据本发明实施例的网页数据反爬取系统的示意框图;
图4为本发明具体实施例的网页显示效果图;
图5为本发明具体实施例的关键数据分割与混淆效果图;
图6为本发明具体实施例中防止网页数据爬取的方法流程示意图;
图。图7示出了根据本发明具体实施例的字符串切分示意图。
具体实现方法
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施例对本发明作进一步详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
在以下描述中,为了充分理解本发明,解释了许多具体细节。然而,本发明也可以以不同于这里描述的方式的其他方式实施。因此,本发明的保护范围不限于以下所公开的具体实施例。
本发明第一方面的实施例提出了一种防止网页数据被抓取的方法。如图。图1示出了根据本发明实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤102,提取网页数据;
步骤104,混淆网页数据;
步骤106,将混淆后的网页数据转换为背景图片;
步骤108,通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过CSS样式控制背景图片的显示。即使恶意爬虫将网页的所有源代码和图片全部丢弃并使用ocr工具进行识别,也无法获得完整正确的数据。 ,并且每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网上打开的网页上的关键数据。
图。图2a示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤212,通过堆叠样式表在网页上显示背景图片。
在本实施例中,页面的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充。填充的字符串随机重新排序,插入字符、乱序等混淆后的字符。字符串生成背景图片,使网页抓取的网页恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,对网页数据字符串进行随机排序包括:将字符串分为单个字符、随机排序单个字符和添加字符;或将字符串拆分成单个字符,将单个字符拆分成不可识别图形,对不可识别图形进行随机排序,添加字符处理。
在本实施例中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,混淆网页关键数据,或将字符串拆分为单个字符,将单个字符字符被划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,将混淆后的网页数据转换为背景图片具体包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片的位置。
在本实施例中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
图。图2b示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤214,创建叠加样式表;
步骤216,生成页面源代码;
步骤218,根据网页数据在背景图片中的位置,在网页上显示背景图片。
本实施例创建了一个分层的样式表,生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而达到显示效果页面关键数据不变,不影响用户体验。
本发明第二方面的一个实施例提出了一种网页数据反爬取系统300。图3示出了根据本发明实施例的网页数据反爬取系统300的示意框图。其中,系统包括:
数据提取单元302用于提取网页数据;
数据处理单元304用于对网页数据进行混淆处理;
转换单元306用于将混淆后的网页数据转换为背景图片;
显示单元308用于通过层叠样式表在网页上显示背景图片。
在本发明提供的网页数据反爬取系统300中,数据提取单元302提取需要保护的关键数据,例如在网页中以字符串形式显示的数字、英文、汉字等。网页,数据处理单元304打乱后,在排序添加混淆字符后,转换单元306生成网页的背景图片,并将该图片作为显示背景。显示单元308通过CSS样式控制背景图片的显示,即使恶意爬虫将网页采集的所有源码和图片全部删除,并使用ocr工具进行识别,也不可能得到完整正确的数据,每个页面的数据图像都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
在本发明的一个实施例中,优选地,数据处理单元304用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,数据处理单元304还用于:当网页数据的长度不足时,通过插入多余的字符来填充网页数据的长度。
在本实施例中,数据处理单元304对所有页面的关键数据进行长度对齐处理。如果长度不足,插入多余的字符进行填充,填充的字符串随机重新排序,字符插入乱序。混淆后的字符串会生成背景图片,使得恶意爬虫抓取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,数据处理单元304还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割为单个字符。字符,将单个字符划分为不识别图形,对不识别图形进行随机排序并添加字符处理。
在本实施例中,数据处理单元304将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或者将字符串拆分为单个字符。将字符划分为不可识别图形,将不可识别图形随机排序并添加字符处理,将不可识别图形进一步划分为ocr软件无法识别的图形,增强了混淆度网页关键数据,大大增加了恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,转换单元306具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
在本实施例中,转换单元306将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,不会影响用户浏览网页的效果。
在本发明的一个实施例中,优选地,显示单元308具体用于:生成页面源代码;并根据网页数据在背景图片中的位置在网页上显示背景图片。
本实施例中,显示单元308生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在本发明的一个实施例中,优选地,还包括:创建单元310,用于创建堆叠样式表。
在本实施例中,创建单元310创建堆叠样式表,背景图像的显示由堆叠样式表控制。
在本发明的一个具体实施例中,需要保护的关键数据,如数字、英文、汉字在网页显示中以字符串的形式显示,如图4所示,被提取,顺序被打乱,并添加混乱。字符生成后,生成如图5所示的网页背景图片,并记录字符在图片中的相对位置;这张图片作为显示背景,通过CSS样式控制背景图片的显示。不同的字符背景偏移量根据生成图片时的记录位置进行设置,以便在页面上显示完整的数据。这样,即使恶意爬虫采集下载了网页的源代码和图片,使用ocr工具进行识别,也无法得到完整正确的数据,每个页面的数据图片都是随机生成的,大大增加了采集的分析难度。图6示出了根据本发明具体实施例的防止网页数据被抓取的方法的示意性流程图:
步骤602,提取网页上需要保护的关键数据,将字符混淆后转换为图片,包括:
(1)提取网页中所有需要保护的关键数据;
(2)所有页面的关键数据长度对齐;
(3)长度不足,已插入多余字符填充;
(4)完成的字符串随机重新排序;
(5)字符串经过插入字符、乱序等混淆处理后生成一张图片;
(6)记录图片中字符的相对位置。
步骤604,设置页面显示价格样式。
步骤606:获取字符在图片中的相对位置,生成页面源代码,通过设置背景图片的相对位置来控制数据在页面上的显示。
在本发明的另一个具体实施例中,在对字符串进行图形化的过程中,将字符串分割成完整的可识别字符,然后进行无序化,添加冗余字符,然后生成图片。在此基础上,可以将单个字符进一步划分为OCR软件无法识别的图形,如下图7所示。由于目前的OCR技术只能识别完整的字符,如字母、数字或汉字,将单个字符进一步划分为图像中无法识别对应的字符,进一步大大增加了爬虫解析数据的难度.
使用本发明的网页数据反爬取方法获取网页,页面关键数据的显示效果保持不变,完全不影响用户体验。但对于恶意爬虫,被爬取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据;即便进一步抓拍图片,再用ocr工具进行识别,结果也是一团糟。字符序列化,大大增加了恶意爬虫抓取关键数据的难度。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述是指结合实施例描述的特定特征、结构、材料或特性或实例包括在本发明的至少一个实施例或实例中。在本说明书中,上述术语的示意性表示不一定指同一实施例或示例。此外,所描述的特定特征、结构、材料或特性可以以合适的方式组合在任何一个或多个实施例或示例中。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种修改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。 查看全部
网页抓取数据(
本发明网页数据防的方法及系统背景技术实现要素分析)
本发明涉及互联网技术领域,尤其涉及一种防止网页数据被抓取的方法及系统。
背景技术:
大数据时代,数据已经成为企业的核心竞争力。网页上的一些关键数据,如购物网站商品价格、交易量、用户联系方式等信息,在方便用户浏览的同时,也成为一些恶意爬虫疯狂爬取的目标。如何防止关键数据被大规模爬取,不断增加爬虫的采集难度,成为很多企业网站的首要任务。
目前现有的技术方案和不足:
(1)关键数据登录权限控制,用户体验差;
(2)关键数据是动态的,只能防止低级静态爬虫;
(3)关键数据显示在一张图片中,现有的ocr(光学字符识别)技术可以轻松识别图片中的字符。
技术实现要素:
本发明旨在解决现有技术或相关技术中存在的至少一个技术问题。
为此,本发明的一个目的是提供一种防止网页数据被抓取的方法。
本发明的另一个目的是提供一种网页数据反爬取系统。
有鉴于此,根据本发明的一个目的,提出一种网页数据反爬取方法,包括:提取网页数据;混淆网页数据;将混淆后的网页数据转换为背景图片;通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过css(cascadingstylesheets)样式控制背景图片的显示,即使恶意爬虫将网页源码和图片全部丢掉采集 ,并且使用ocr工具进行识别,也无法获得完整正确的数据,而且每页的数据图片都是随机生成的,大大增加了采集解析的难度,保护了上的关键数据在 Internet 上打开网页。
上述本发明的防止网页数据爬取的方法还可以具有以下技术特征:
上述技术方案中,优选地,对网页数据的混淆处理具体包括:统计网页数据的长度;对齐网页数据的长度;并对网页数据的字符串进行随机排序。优选地,该方法还包括:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
在该技术方案中,页面上的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充,填充的字符串随机重新排序,插入字符混淆后的字符,乱序等。字符串生成背景图片,使网页爬取恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,对网页数据字符串进行随机排序包括:将字符串分割为单个字符,随机排序并在单个字符中添加字符;或将字符串分割为单个字符,将单个字符分割为不识别图形,对不识别图形进行随机排序并添加字符处理。
本技术方案中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,网页关键数据混淆,或将字符串拆分为单个字符,单个字符划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加难度用于捕获关键数据的恶意爬虫。
在上述任一技术方案中,优选地,将混淆后的网页数据转换为背景图片包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片中的位置。
在该技术方案中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,在网页上显示背景图片包括:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在上述任一技术方案中,优选地,在通过堆叠样式表在网页上显示背景图片之前,该方法还包括:创建堆叠样式表。
本技术方案创建了一个堆叠样式表,背景图片的显示由堆叠样式表控制。
根据本发明的另一个目的,提出了一种网页数据反爬取系统,包括:数据提取单元,用于提取网页数据;用于混淆网页数据的数据处理单元;一个转换单元,用于将混淆后的网页数据转换为背景图片;显示单元,用于通过堆叠样式表在网页上显示背景图片。
在本发明提供的网页数据防抓取系统中,数据提取单元提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据,数据处理单元将顺序打乱,加入字符混淆后,转换单元为网页生成背景图片。该图像用作显示背景。显示单元通过 CSS 样式控制背景图片的显示,即使恶意爬虫将网页的所有源代码和图片丢弃并使用 ocr 工具识别出无法获取完整正确的数据,以及每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
根据本发明的上述网页数据反爬取系统还可以具有以下技术特征:
上述技术方案中,优选地,所述数据处理单元用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,所述数据处理单元还用于:当网页数据的长度不足时,通过插入额外的字符来填充网页数据的长度。
本技术方案中,数据处理单元对页面的所有关键数据进行长度对齐处理。如果长度不够,插入多余的字符进行填充,填充的字符串随机重新排序,插入字符后,乱序等。混淆后的字符串生成背景图片,以便恶意爬虫抓取的网页不收录关键数据的任何信息,导致无法从网页源代码中提取相关数据。
在上述任一技术方案中,优选地,所述数据处理单元还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割成单个字符,将单个字符分割成不可识别图形,对不可识别图形进行随机排序并添加字符处理。
在该技术方案中,数据处理单元将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或将字符串拆分为单个字符。分割成不可识别的图形,对不可识别的图形进行随机排序并添加字符处理,进一步分割成ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫的难度捕获关键数据。
在上述任一技术方案中,优选地,转换单元具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
本技术方案中,转换单元将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,并将不影响用户在网页上的查看效果。
在上述任一技术方案中,优选地,所述显示单元具体用于:生成页面源代码;根据网页数据在背景图片中的位置,在网页上显示背景图片。
本技术方案中,显示单元生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,使关键数据在网页上的显示效果页面保持不变,不以任何方式影响用户体验。
在上述任一技术方案中,优选地,还包括: 用于创建堆叠样式表的创建单元。
本技术方案中,创建单元创建一个堆叠样式表,通过堆叠样式表控制背景图片的显示。
本发明的其他方面和优点将在以下描述中变得明显,或者通过本发明的实践而被理解。
图纸说明
通过结合以下附图的实施例的描述,本发明的上述和/或附加的方面和优点将变得显而易见且易于理解,其中:
图1为本发明实施例提供的网页数据反爬取方法流程示意图;
图2a为本发明另一实施例提供的网页数据反爬取方法的流程示意图;
图2b为本发明另一实施例防止网页数据被爬取的方法流程示意图;
图3示出了根据本发明实施例的网页数据反爬取系统的示意框图;
图4为本发明具体实施例的网页显示效果图;
图5为本发明具体实施例的关键数据分割与混淆效果图;
图6为本发明具体实施例中防止网页数据爬取的方法流程示意图;
图。图7示出了根据本发明具体实施例的字符串切分示意图。
具体实现方法
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施例对本发明作进一步详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
在以下描述中,为了充分理解本发明,解释了许多具体细节。然而,本发明也可以以不同于这里描述的方式的其他方式实施。因此,本发明的保护范围不限于以下所公开的具体实施例。
本发明第一方面的实施例提出了一种防止网页数据被抓取的方法。如图。图1示出了根据本发明实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤102,提取网页数据;
步骤104,混淆网页数据;
步骤106,将混淆后的网页数据转换为背景图片;
步骤108,通过堆叠样式表在网页上显示背景图片。
本发明提供的网页数据反爬取方法提取网页中以字符串形式显示的数字、英文、汉字等需要保护的关键数据。网页的背景图片,以此图片作为显示背景,通过CSS样式控制背景图片的显示。即使恶意爬虫将网页的所有源代码和图片全部丢弃并使用ocr工具进行识别,也无法获得完整正确的数据。 ,并且每个页面的数据图片都是随机生成的,大大增加了采集解析的难度,保护了互联网上打开的网页上的关键数据。
图。图2a示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤212,通过堆叠样式表在网页上显示背景图片。
在本实施例中,页面的所有关键数据都与长度对齐。如果长度不够,则插入多余的字符进行填充。填充的字符串随机重新排序,插入字符、乱序等混淆后的字符。字符串生成背景图片,使网页抓取的网页恶意爬虫不收录关键数据的任何信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,对网页数据字符串进行随机排序包括:将字符串分为单个字符、随机排序单个字符和添加字符;或将字符串拆分成单个字符,将单个字符拆分成不可识别图形,对不可识别图形进行随机排序,添加字符处理。
在本实施例中,将字符串拆分为单个字符,将单个字符随机排序并添加字符处理,混淆网页关键数据,或将字符串拆分为单个字符,将单个字符字符被划分为非识别图形,对非识别图形进行随机排序并添加字符处理,进一步划分为ocr软件无法识别的图形,加强网页关键数据的混淆度,大大增加恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,将混淆后的网页数据转换为背景图片具体包括:将混淆后的网页数据转换为背景图片,并将网页数据记录在背景图片的位置。
在本实施例中,将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移是不同的。记录网页数据在背景图像中的位置,然后将网页数据记录在背景图像中。背景图片中的位置在页面上显示完整的数据,不会影响用户在网页上的查看效果。
图。图2b示出了根据本发明另一实施例的防止网页数据被抓取的方法的示意性流程图。其中,方法包括:
步骤202,提取网页数据;
步骤204,统计网页数据的长度;
步骤206:对齐网页数据的长度。当网页数据长度不足时,插入多余的字符来填充网页数据的长度;
步骤208,对网页数据字符串进行随机排序;
步骤210,将混淆后的网页数据转换为背景图片;
步骤214,创建叠加样式表;
步骤216,生成页面源代码;
步骤218,根据网页数据在背景图片中的位置,在网页上显示背景图片。
本实施例创建了一个分层的样式表,生成页面源代码,根据网页数据在背景图片中的位置,在网页上显示背景图片,从而达到显示效果页面关键数据不变,不影响用户体验。
本发明第二方面的一个实施例提出了一种网页数据反爬取系统300。图3示出了根据本发明实施例的网页数据反爬取系统300的示意框图。其中,系统包括:
数据提取单元302用于提取网页数据;
数据处理单元304用于对网页数据进行混淆处理;
转换单元306用于将混淆后的网页数据转换为背景图片;
显示单元308用于通过层叠样式表在网页上显示背景图片。
在本发明提供的网页数据反爬取系统300中,数据提取单元302提取需要保护的关键数据,例如在网页中以字符串形式显示的数字、英文、汉字等。网页,数据处理单元304打乱后,在排序添加混淆字符后,转换单元306生成网页的背景图片,并将该图片作为显示背景。显示单元308通过CSS样式控制背景图片的显示,即使恶意爬虫将网页采集的所有源码和图片全部删除,并使用ocr工具进行识别,也不可能得到完整正确的数据,每个页面的数据图像都是随机生成的,大大增加了采集解析的难度,保护了互联网打开网页上的关键数据。
在本发明的一个实施例中,优选地,数据处理单元304用于:统计网页数据的长度;对网页数据的长度进行对齐处理;并对网页数据的字符串进行随机排序。优选地,数据处理单元304还用于:当网页数据的长度不足时,通过插入多余的字符来填充网页数据的长度。
在本实施例中,数据处理单元304对所有页面的关键数据进行长度对齐处理。如果长度不足,插入多余的字符进行填充,填充的字符串随机重新排序,字符插入乱序。混淆后的字符串会生成背景图片,使得恶意爬虫抓取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据。
在本发明的一个实施例中,优选地,数据处理单元304还用于:将字符串分割为单个字符,对单个字符进行随机排序,添加字符处理;或将字符串分割为单个字符。字符,将单个字符划分为不识别图形,对不识别图形进行随机排序并添加字符处理。
在本实施例中,数据处理单元304将字符串拆分为单个字符,随机对单个字符进行排序并添加字符处理,混淆网页的关键数据,或者将字符串拆分为单个字符。将字符划分为不可识别图形,将不可识别图形随机排序并添加字符处理,将不可识别图形进一步划分为ocr软件无法识别的图形,增强了混淆度网页关键数据,大大增加了恶意爬虫抓取关键数据的难度。
在本发明的一个实施例中,优选地,转换单元306具体用于:将混淆后的网页数据转换为背景图片,并记录网页数据在背景图片中的位置。
在本实施例中,转换单元306将混淆后的网页数据转换为背景图片。不同网页数据的字符背景偏移量不同,记录网页数据在背景图片中的位置,然后根据网页数据在背景图片中的位置显示页面上的完整数据,不会影响用户浏览网页的效果。
在本发明的一个实施例中,优选地,显示单元308具体用于:生成页面源代码;并根据网页数据在背景图片中的位置在网页上显示背景图片。
本实施例中,显示单元308生成页面源代码,根据网页数据在背景图片中的位置,将背景图片显示在网页上,从而实现关键数据在网页上的显示效果页面保持不变,完全不影响用户体验。
在本发明的一个实施例中,优选地,还包括:创建单元310,用于创建堆叠样式表。
在本实施例中,创建单元310创建堆叠样式表,背景图像的显示由堆叠样式表控制。
在本发明的一个具体实施例中,需要保护的关键数据,如数字、英文、汉字在网页显示中以字符串的形式显示,如图4所示,被提取,顺序被打乱,并添加混乱。字符生成后,生成如图5所示的网页背景图片,并记录字符在图片中的相对位置;这张图片作为显示背景,通过CSS样式控制背景图片的显示。不同的字符背景偏移量根据生成图片时的记录位置进行设置,以便在页面上显示完整的数据。这样,即使恶意爬虫采集下载了网页的源代码和图片,使用ocr工具进行识别,也无法得到完整正确的数据,每个页面的数据图片都是随机生成的,大大增加了采集的分析难度。图6示出了根据本发明具体实施例的防止网页数据被抓取的方法的示意性流程图:
步骤602,提取网页上需要保护的关键数据,将字符混淆后转换为图片,包括:
(1)提取网页中所有需要保护的关键数据;
(2)所有页面的关键数据长度对齐;
(3)长度不足,已插入多余字符填充;
(4)完成的字符串随机重新排序;
(5)字符串经过插入字符、乱序等混淆处理后生成一张图片;
(6)记录图片中字符的相对位置。
步骤604,设置页面显示价格样式。
步骤606:获取字符在图片中的相对位置,生成页面源代码,通过设置背景图片的相对位置来控制数据在页面上的显示。
在本发明的另一个具体实施例中,在对字符串进行图形化的过程中,将字符串分割成完整的可识别字符,然后进行无序化,添加冗余字符,然后生成图片。在此基础上,可以将单个字符进一步划分为OCR软件无法识别的图形,如下图7所示。由于目前的OCR技术只能识别完整的字符,如字母、数字或汉字,将单个字符进一步划分为图像中无法识别对应的字符,进一步大大增加了爬虫解析数据的难度.
使用本发明的网页数据反爬取方法获取网页,页面关键数据的显示效果保持不变,完全不影响用户体验。但对于恶意爬虫,被爬取的网页不收录任何关键数据信息,无法从网页源代码中提取相关数据;即便进一步抓拍图片,再用ocr工具进行识别,结果也是一团糟。字符序列化,大大增加了恶意爬虫抓取关键数据的难度。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述是指结合实施例描述的特定特征、结构、材料或特性或实例包括在本发明的至少一个实施例或实例中。在本说明书中,上述术语的示意性表示不一定指同一实施例或示例。此外,所描述的特定特征、结构、材料或特性可以以合适的方式组合在任何一个或多个实施例或示例中。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种修改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。
网页抓取数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-01 02:18
如何在不使用selenium插件的情况下抓取网页的动态加载数据。针对这个问题,本文文章详细介绍了相应的分析和解答,希望能帮助更多想要解决这个问题的朋友找到更简单易行的方法。
下面介绍如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。
步骤如下:
一、找到正确的网址。
二、填写URL对应的参数。
三、 参数转换成urllib可以识别的字符串数据。
四、 初始化请求对象。
五、urlopen Request 对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
后面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何使用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般来说,动态加载的数据量比其他页面元素大。 , 119kb 与其他基于字节的计算相比,可以看作是一个大数据量。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data) 查看全部
网页抓取数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
如何在不使用selenium插件的情况下抓取网页的动态加载数据。针对这个问题,本文文章详细介绍了相应的分析和解答,希望能帮助更多想要解决这个问题的朋友找到更简单易行的方法。
下面介绍如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。
步骤如下:
一、找到正确的网址。
二、填写URL对应的参数。
三、 参数转换成urllib可以识别的字符串数据。
四、 初始化请求对象。
五、urlopen Request 对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
后面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何使用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般来说,动态加载的数据量比其他页面元素大。 , 119kb 与其他基于字节的计算相比,可以看作是一个大数据量。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
网页抓取数据(分布式抓取和存储,的使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-28 17:08
所以,首先我不用担心进入分布式爬取和存储,因为顾名思义:它需要相当数量的机器才能得到好的结果。除非您拥有计算机农场,否则您不会真正受益。可以搭建爬虫网程序。
列表中的下一件事是确定您的瓶颈在哪里。
对您的系统进行基准测试
尝试消除MS sql:
加载要抓取的 1000 个 URL 的列表。
测试你能多快抓住它们。
如果 1,000 个 URL 不能给你足够大的抓取,你可以得到 10,000 个 URL 或 100k 个 URL(或者如果你觉得勇敢,你可以得到它)。无论如何,尝试建立一个基线,其中排除尽可能多的变量。
识别瓶颈
抓到爬行速度的底线后,试着确定自己速度变慢的原因。此外,您将需要开始使用多任务处理,因为您已经绑定并且您正在获取可用于提取链接和执行其他操作的数据。其他操作的页面之间有很多空闲时间。
你现在每秒想要多少页?您应该尝试每秒获取 10 页以上的数据。
加速
显然,下一步就是尽可能调整你的爬虫机制:
> 尝试加速您的爬虫以达到带宽等硬性限制。
我推荐使用异步套接字,因为它们比阻塞套接字、WebRequest/HttpWebRequest 等更快。
> 使用更快的 HTML 解析库:从一开始,如果感觉比尝试使用它更勇敢。
使用,而不是sql数据库,利用key/value存储(对URL的key进行hash,作为value存储HTML等相关数据)。
去专业!
如果你已经掌握了以上所有内容,那么我建议你尝试接吻!重要的是你有一个很好的选择算法来模拟 PageRank 以平衡新鲜度和覆盖率:。如果您拥有上述工具,那么您应该能够实现 OPIC 并运行一个相当快的爬虫。
如果你对编程语言灵活,又不想背离C#,可以试试基于Java的企业爬虫(eg)。Nutch 与 Hadoop 和其他各种高度可扩展的解决方案集成。 查看全部
网页抓取数据(分布式抓取和存储,的使用方法)
所以,首先我不用担心进入分布式爬取和存储,因为顾名思义:它需要相当数量的机器才能得到好的结果。除非您拥有计算机农场,否则您不会真正受益。可以搭建爬虫网程序。
列表中的下一件事是确定您的瓶颈在哪里。
对您的系统进行基准测试
尝试消除MS sql:
加载要抓取的 1000 个 URL 的列表。
测试你能多快抓住它们。
如果 1,000 个 URL 不能给你足够大的抓取,你可以得到 10,000 个 URL 或 100k 个 URL(或者如果你觉得勇敢,你可以得到它)。无论如何,尝试建立一个基线,其中排除尽可能多的变量。
识别瓶颈
抓到爬行速度的底线后,试着确定自己速度变慢的原因。此外,您将需要开始使用多任务处理,因为您已经绑定并且您正在获取可用于提取链接和执行其他操作的数据。其他操作的页面之间有很多空闲时间。
你现在每秒想要多少页?您应该尝试每秒获取 10 页以上的数据。
加速
显然,下一步就是尽可能调整你的爬虫机制:
> 尝试加速您的爬虫以达到带宽等硬性限制。
我推荐使用异步套接字,因为它们比阻塞套接字、WebRequest/HttpWebRequest 等更快。
> 使用更快的 HTML 解析库:从一开始,如果感觉比尝试使用它更勇敢。
使用,而不是sql数据库,利用key/value存储(对URL的key进行hash,作为value存储HTML等相关数据)。
去专业!
如果你已经掌握了以上所有内容,那么我建议你尝试接吻!重要的是你有一个很好的选择算法来模拟 PageRank 以平衡新鲜度和覆盖率:。如果您拥有上述工具,那么您应该能够实现 OPIC 并运行一个相当快的爬虫。
如果你对编程语言灵活,又不想背离C#,可以试试基于Java的企业爬虫(eg)。Nutch 与 Hadoop 和其他各种高度可扩展的解决方案集成。
网页抓取数据(如何通过xpath访问一个网站获取网页信息的信息打印出来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-23 10:06
Xpath 通常用于抓取网页的过程中,根据 html 中标签的路径来过滤内容。今天我们就来看看如何通过xpath获取网页信息。这里的例子很简单,访问一个网站取回列表中的信息,打印出来,然后开始。
准备
在chrome浏览器中安装xpath helper插件
如果无法访问chrome商店,可以在网上搜索chrome xpath helper插件并下载。将下载的文件拖放到 chrome 扩展程序中进行安装。安装完成后,您会在浏览器上看到一个小十字图标。这是xpath helper的启动图标,一键启动。启动后,你会看到一个浮动窗口
可以分别输入xpath表达式和结果。
这里需要用到python的两个组件requests和lxml,因为我用的是pycharm的ide工具,实现了一个虚拟的python环境,所以组件的安装需要在ide中操作。
在首选项中选择要安装的组件。
在弹出的窗口中搜索并选择要安装的组件。
网站分析
先打开一个你要爬取的网站,分析网站的内容。
如上图所示,我们需要返回黄色部分的列表,即需要访问的树结构的html标签。
我们需要返回书单中的书名。这里,标题使用的标签是h4,下面的链接使用a,这里使用text()返回a中的内容
//h4/a/text()
当我们通过xpath helper输入xpath数据时,可以在右侧窗口中显示相应的内容。这可以证明我们的xpath是有效的。
编码
借助xpath,编码很容易,引入etree和requests,使用requests生成get请求,将返回的响应发送给etree进行xpath分析,最后打印结果。
from lxml import etree
import requests
from fake_useragent import UserAgent
url = "https://www.qidian.com/rank/yuepiao?chn=21"
headers = {
"User-Agent": UserAgent().random
}
response = requests.get(url, headers=headers)
print(response.text)
e = etree.HTML(response.text)
names = e.xpath('//h4/a/text()')
print(names)
完成工作,如果您愿意,可以转发。谢谢大家。 查看全部
网页抓取数据(如何通过xpath访问一个网站获取网页信息的信息打印出来)
Xpath 通常用于抓取网页的过程中,根据 html 中标签的路径来过滤内容。今天我们就来看看如何通过xpath获取网页信息。这里的例子很简单,访问一个网站取回列表中的信息,打印出来,然后开始。
准备
在chrome浏览器中安装xpath helper插件
如果无法访问chrome商店,可以在网上搜索chrome xpath helper插件并下载。将下载的文件拖放到 chrome 扩展程序中进行安装。安装完成后,您会在浏览器上看到一个小十字图标。这是xpath helper的启动图标,一键启动。启动后,你会看到一个浮动窗口
可以分别输入xpath表达式和结果。
这里需要用到python的两个组件requests和lxml,因为我用的是pycharm的ide工具,实现了一个虚拟的python环境,所以组件的安装需要在ide中操作。
在首选项中选择要安装的组件。
在弹出的窗口中搜索并选择要安装的组件。
网站分析
先打开一个你要爬取的网站,分析网站的内容。
如上图所示,我们需要返回黄色部分的列表,即需要访问的树结构的html标签。
我们需要返回书单中的书名。这里,标题使用的标签是h4,下面的链接使用a,这里使用text()返回a中的内容
//h4/a/text()
当我们通过xpath helper输入xpath数据时,可以在右侧窗口中显示相应的内容。这可以证明我们的xpath是有效的。
编码
借助xpath,编码很容易,引入etree和requests,使用requests生成get请求,将返回的响应发送给etree进行xpath分析,最后打印结果。
from lxml import etree
import requests
from fake_useragent import UserAgent
url = "https://www.qidian.com/rank/yuepiao?chn=21"
headers = {
"User-Agent": UserAgent().random
}
response = requests.get(url, headers=headers)
print(response.text)
e = etree.HTML(response.text)
names = e.xpath('//h4/a/text()')
print(names)
完成工作,如果您愿意,可以转发。谢谢大家。
网页抓取数据(做电商营销,可以利用网页抓取工具优采云采集器V9)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-23 10:04
近年来,大数据的奥秘一直被越来越多地描述,其魅力迅速蔓延到各个领域和行业。虽然利用大数据进行营销已经成为营销界的共识,但如何快速准确地从海量数据中获取所需的数据仍然是营销人员的短板,但是在了解了网络爬虫工具后,这个问题就出现了减少痛苦。
网页抓取工具优采云采集器V9是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于对网页结构的源代码提取,所以几乎可以做到 全网通用,抓取所有页面,使用方便。这意味着只要我们能看到网页中所有能看到的信息,就可以轻松抓取,解决大数据获取问题就是这么简单。
网络爬虫工具已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以利用网络爬虫工具优采云采集器V9,准确抓取竞品店铺的商品名称、图片、价格、销售额等信息数据,然后运用大数据模型分析,构建一套适合自身商业模式的营销方案,如标题优化、热点产品打造、价格策略、服务调整等。
另一个例子是企业营销。以保险公司为例,您还可以使用网络爬虫工具优采云采集器V9抓取一系列相关数据,对精算、营销、保险等多个环节进行过滤分析。精准营销、精准定价、精准管理、精准服务。更科学地设定各种费率;提醒客户保障范围不足,筛选出最适合的保险产品和服务类型,精准推送。
网页抓取工具不仅可以为营销奠定大数据的基石,还可以为营销推广提供自动化发布,即优采云采集器V9的多种站群网络发布功能。使用此功能配置站群,一键发送到多个目的地网站,如论坛、QQ区、博客、微博等,配合优采云采集器 V9不再需要繁琐的登录、复制粘贴,营销省时省力,提高操作水平和工作效率。
大数据呈现的信息非常丰富,领先的营销方式也多种多样。为了让我们利用大数据做更好的营销工作,我建议大家一定要掌握优采云采集器V9这个唯有经典的网络爬虫工具,才能在大数据营销领域获得更多的成果紧跟时代发展潮流。 查看全部
网页抓取数据(做电商营销,可以利用网页抓取工具优采云采集器V9)
近年来,大数据的奥秘一直被越来越多地描述,其魅力迅速蔓延到各个领域和行业。虽然利用大数据进行营销已经成为营销界的共识,但如何快速准确地从海量数据中获取所需的数据仍然是营销人员的短板,但是在了解了网络爬虫工具后,这个问题就出现了减少痛苦。
网页抓取工具优采云采集器V9是一款可以从网页中提取所需信息并进行智能处理的软件。它的设计原理是基于对网页结构的源代码提取,所以几乎可以做到 全网通用,抓取所有页面,使用方便。这意味着只要我们能看到网页中所有能看到的信息,就可以轻松抓取,解决大数据获取问题就是这么简单。
网络爬虫工具已经成为大数据营销的标准工具之一。比如我们在做电商营销的时候,可以利用网络爬虫工具优采云采集器V9,准确抓取竞品店铺的商品名称、图片、价格、销售额等信息数据,然后运用大数据模型分析,构建一套适合自身商业模式的营销方案,如标题优化、热点产品打造、价格策略、服务调整等。
另一个例子是企业营销。以保险公司为例,您还可以使用网络爬虫工具优采云采集器V9抓取一系列相关数据,对精算、营销、保险等多个环节进行过滤分析。精准营销、精准定价、精准管理、精准服务。更科学地设定各种费率;提醒客户保障范围不足,筛选出最适合的保险产品和服务类型,精准推送。
网页抓取工具不仅可以为营销奠定大数据的基石,还可以为营销推广提供自动化发布,即优采云采集器V9的多种站群网络发布功能。使用此功能配置站群,一键发送到多个目的地网站,如论坛、QQ区、博客、微博等,配合优采云采集器 V9不再需要繁琐的登录、复制粘贴,营销省时省力,提高操作水平和工作效率。
大数据呈现的信息非常丰富,领先的营销方式也多种多样。为了让我们利用大数据做更好的营销工作,我建议大家一定要掌握优采云采集器V9这个唯有经典的网络爬虫工具,才能在大数据营销领域获得更多的成果紧跟时代发展潮流。
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-22 22:09
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载! 查看全部
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时,由于各种原因,我们需要从某个站点采集数据,但因为不同站点显示数据的方式略有不同!
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第二步:查看网页源代码,我们在源代码中看到这一段:
由此可以看出,再次请求网页后,显示查询的结果。
查询后看网页地址:
也就是说,我们只能通过访问这种 URL 来获取 ip 查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时,网站为了保护自己的数据,不会直接在网页的源代码中返回数据,而是采用异步的方式用JS返回数据,这样可以避免网站数据被诸如此类的工具抓取作为搜索引擎。
首先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
首先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空这些数据,然后输入快递单号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即我们只需要访问JS请求的网页地址就可以获取数据。当然,前提是数据没有加密。记下 JS 请求的 URL:
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
可以看到,抓取JS的方式和抓取原创网页的代码完全一样。我们只是做了一个分析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这篇文章能对需要的朋友有所帮助。如果您需要程序源代码,请点击这里下载!
网页抓取数据( Python中正则表达式的3种抓取其中数据的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-12-19 19:03
Python中正则表达式的3种抓取其中数据的方法(上))
3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['<img />', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。 查看全部
网页抓取数据(
Python中正则表达式的3种抓取其中数据的方法(上))
3种获取数据的方法。首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,那么您可以查看完整的介绍。即使你已经使用过其他编程语言中的正则表达式,我仍然建议你一步一步复习 Python 中正则表达式的编写。
由于每一章都可能构建或使用前几章的内容,建议大家按照与本书代码库类似的文件结构进行配置。所有代码都可以从代码库的代码目录运行,这样导入才能正常进行。如果要创建不同的结构,请注意需要更改所有其他章节的导入操作(例如从以下代码中的chp1.advanced_link_crawler)。
当我们使用正则表达式抓取一个国家(或地区)的面积数据时,首先需要尝试匹配``元素中的内容,如下图。
>>> import re>>> from chp1.advanced_link_crawler import download>>> url = 'http://example.python-scraping.com/view/UnitedKingdom-239'>>> html = download(url)>>> re.findall(r'(.*?)', html)['<img />', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]d{2}[A-Z]{2})|([A-Z]d{3}[A-Z]{2})|([A-Z]{2}d{2} [A-Z]{2})|([A-Z]{2}d{3}[A-Z]{2})|([A-Z]d[A-Z]d[A-Z]{2}) |([A-Z]{2}d[A-Z]d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
从上面的结果可以看出,多个国家(或地区)属性都使用了``标签。如果我们只想捕获一个国家(或地区)的面积,我们可以只选择第二个匹配元素,如下图。
>>> re.findall('(.*?)', html)[1]'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。例如,表发生了变化,删除了第二个匹配元素中的区域数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望能够在未来的某个时刻再次捕获数据,我们需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加明确,我们还可以添加其父元素。因为这个元素有一个 ID 属性,它应该是唯一的。
>>> re.findall('Area: (.*?)', html)['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在`labels 之间添加额外的空格,或者更改area_label` 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('''.*?(.*?)''', html)['244,820 square kilometres']
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。此外,还有许多其他细微的布局更改会使正则表达式不令人满意,例如在`tag 中添加标题属性,或者为tr 和td` 元素修改它们的CSS 类或ID。
从这个例子可以看出,正则表达式为我们提供了一种快速抓取数据的方式,但是这种方式过于脆弱,在网页更新后容易出现问题。幸运的是,有更好的数据提取解决方案,例如我们将在本章中介绍的其他爬虫库。
2美汤
美汤
它是一个非常流行的 Python 库,可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,您可以使用以下命令安装最新版本。
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个 Soup 文档。由于很多网页没有好的HTML格式,Beautiful Soup需要修改其标签的开启和关闭状态。例如,在下面的简单网页列表中,存在属性值周围缺少引号和未关闭标签的问题。
Area Population
如果将 Population 列表项解析为 Area 列表项的子元素,而不是两个并排的列表项,我们在爬行时会得到错误的结果。我们来看看Beautiful Soup是如何处理的。
>>> from bs4 import BeautifulSoup>>> from pprint import pprint>>> broken_html = 'AreaPopulation'>>> # parse the HTML>>> soup = BeautifulSoup(broken_html, 'html.parser')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
我们可以看到使用默认的 html.parser 无法正确解析 HTML。从前面的代码片段可以看出,由于使用了嵌套的li元素,可能会造成定位困难。幸运的是,我们还有其他解析器可供选择。我们可以安装LXML(2.2.将在第三节详细介绍),或者使用html5lib。要安装 html5lib,只需使用 pip。
pip install html5lib
现在,我们可以重复这段代码,只对解析器进行以下更改。
>>> soup = BeautifulSoup(broken_html, 'html5lib')>>> fixed_html = soup.prettify()>>> pprint(fixed_html) Area Population
至此,使用html5lib的BeautifulSoup已经能够正确解析缺失的属性引号和结束标签,并添加了&标签,使其成为一个完整的HTML文档。当您使用 lxml 时,您可以看到类似的结果。
现在,我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country_or_district'})>>> ul.find('li') # returns just the first matchArea>>> ul.find_all('li') # returns all matches[Area, Population
有关可用方法和参数的完整列表,请访问 Beautiful Soup 的官方文档。
以下是使用该方法提取样本网站中国家(或地区)面积数据的完整代码。
>>> from bs4 import BeautifulSoup>>> url = 'http://example.python-scraping.com/places/view/United-Kingdom-239'>>> html = download(url)>>> soup = BeautifulSoup(html)>>> # locate the area row>>> tr = soup.find(attrs={'id':'places_area__row'})>>> td = tr.find(attrs={'class':'w2p_fw'}) # locate the data element>>> area = td.text # extract the text from the data element>>> print(area)244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。我们也知道,即使页面收录不完整的 HTML,Beautiful Soup 也可以帮助我们组织页面,以便我们从非常不完整的 网站 代码中提取数据。
3Lxml
xml文件
它是一个基于 XML 解析库 libxml2 构建的 Python 库。它是用C语言编写的,解析速度比Beautiful Soup更快,但安装过程比较复杂,尤其是在Windows下。您可以参考最新的安装说明。如果自己安装库有困难,也可以使用Anaconda来实现。
您可能不熟悉 Anaconda。它是一个由员工创建的包和环境管理器,专注于开源数据科学包。您可以根据其安装说明下载并安装 Anaconda。需要注意的是,使用 Anaconda 的快速安装会将你的 PYTHON_PATH 设置为 Conda 的 Python 安装位置。
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用该模块解析相同不完整 HTML 的示例。
>>> from lxml.html import fromstring, tostring>>> broken_html = 'AreaPopulation'>>> tree = fromstring(broken_html) # parse the HTML>>> fixed_html = tostring(tree, pretty_print=True)>>> print(fixed_html) Area Population
同理,lxml 也可以正确解析属性两边缺失的引号并关闭标签,但是模块没有添加额外的 and 标签。这些不是标准 XML 的要求,所以对于 lxml 来说,插入它们是没有必要的。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,在这个例子中,我们将使用 CSS 选择器,因为它更简洁,可以在第 5 章解析动态内容时重复使用。 一些读者可能已经熟悉了它们,因为他们有过 jQuery 选择器的经验,或者它们在前面的使用——结束 Web 应用程序开发。在本章的其余部分,我们将比较这些选择器与 XPath 的性能。要使用 CSS 选择器,您可能需要先安装 cssselect 库,如下所示。
pip install cssselect
现在,我们可以使用 lxml 的 CSS 选择器来提取示例页面中的区域数据。
>>> tree = fromstring(html)>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]>>> area = td.text_content()>>> print(area)244,820 square kilometres
通过在代码树上使用cssselect方法,我们可以使用CSS语法选择表中ID为places_area__row的行元素,然后选择类w2p_fw的子表的数据标签。由于cssselect返回的是一个列表,所以我们需要获取第一个结果并调用text_content方法迭代所有子元素,并返回每个元素的相关文本。在这个例子中,虽然我们只有一个元素,但这个特征对于更复杂的提取例子非常有用。
郑重声明:本文版权归原作者所有。文章的转载仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
网页抓取数据(网络机器人能以令人难以置信的速度抓取网页,我们能做些什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-17 01:13
)
全文2618字,预计学习时间7分钟
来源:unsplash
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使是最美丽、最令人愉快的人工智能也要提防。此外,一些网络用户以不道德的方式使用网络机器人,这甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗?
有这么多信息要分析,自然而然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,您甚至可以自定义您的搜索,看看这些信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式为研究或业务采集有用信息的完美例子。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
机器人程序流量报告
有人认为,人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分人工智能流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然在所难免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多好处,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改进公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
· 代理服务器旨在充当用户和 Web 服务器之间的中介。
· 功能多样:个人和公司都可以使用代理服务器来满足特定的需求。
· 代理的一个常见用途与网络爬虫有关:使用代理服务器可以绕过网站管理员设置的限制,从而采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,则用户将被限制访问 网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
来源:unsplash
使用人类知名度和值得信赖的品牌来对抗人工智能的耻辱
目前,人工智能的发展速度确实已经超过了网民数量的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
· 坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
· 坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
· 以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
·普及人工智能。与他人讨论如何以及为何使用网络抓取,以便人们对网络抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手工操作来手动访问网站数据或许让人放心,但因为信息量太大,几乎不可能。可用的数据量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。
查看全部
网页抓取数据(网络机器人能以令人难以置信的速度抓取网页,我们能做些什么?
)
全文2618字,预计学习时间7分钟
来源:unsplash
“网上有很多资料”,这样说也太保守了。事实上,到 2020 年,“数字宇宙”预计将拥有 40 万亿字节或 40 泽字节的信息,而 1 泽字节的数据足以填满一个约曼哈顿五分之一大小的数据中心。
有了这么多可用于分析的信息,将采集数据的任务留给 AI 是有意义的。网络机器人可以以惊人的速度抓取网页并提取他们需要的相关信息。然而,尽管许多数据科学家和营销人员以完全合乎道德的方式获取和使用这些信息。遗憾的是,随着网络人工智能的日益普及,网络机器人正逐渐被污名化。
人工智能的大部分负面印象都是由好莱坞电影和科幻小说间接造成的。毕竟,在这些作品中,即使是最美丽、最令人愉快的人工智能也要提防。此外,一些网络用户以不道德的方式使用网络机器人,这甚至导致那些专业和真诚地使用数据的人受到打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人相关的污名,我们能做些什么呢?
首先,什么是网页抓取
您可以简单地将网络抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息堆栈,但从 网站 复制和粘贴文本的行为本身可以被视为一种简单的抓取形式。
但是,即使您可以在 网站 上随意访问,但由于可用信息量大,从来源采集数据可能需要很长时间。大多数情况下,网络爬虫留给了人工智能,它会彻底分析检索到的数据以达到各种目的。虽然这对网络爬虫来说极为方便,但网站 站长和旁观者非常担心人工智能在互联网上的“滥用”
使用网络机器人进行网络抓取会更好吗?
有这么多信息要分析,自然而然地转向人工智能来采集数据。事实上,对于感兴趣的各方来说,谷歌本身就是最可靠的网络抓取工具来源之一。例如,您可以使用其数据集搜索引擎快速访问您认为可以免费使用的数据,您甚至可以自定义您的搜索,看看这些信息是否可以用于商业目的。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效地检查每个网站的相关数据,恐怕达不到这个速度。这是使用人工智能以纯粹的道德方式为研究或业务采集有用信息的完美例子。它的速度也证明了“网络机器人”如何让执行网络抓取任务变得如此容易。
人工智能流量已经变得如此普遍,以至于它现在占互联网流量的一半以上。即便如此,我们也很容易忽视它的影响。
机器人程序流量报告
有人认为,人工智能在互联网流量中的主导地位令人担忧。让这个问题变得更糟的是,一小部分人工智能流量是由“坏机器人”组成的。即使抓捕的意图是好的,方法是合乎道德的,人工智能的污名仍然在所难免。
使用网络机器人处理大量数据是一个合理的步骤。除了人工智能,在抓取网络数据时考虑其他必要的工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多好处,匿名就是其中之一。例如,如果您想对竞争品牌进行研究并使用此信息来确定改进公司发展的最佳方式,您可能不希望其他人知道您访问了他们的 网站。在这种情况下,使用代理可以在不泄露身份的情况下访问和检查数据,这是两全其美的。
在继续之前,让我们快速回顾一下代理服务器:
· 代理服务器旨在充当用户和 Web 服务器之间的中介。
· 功能多样:个人和公司都可以使用代理服务器来满足特定的需求。
· 代理的一个常见用途与网络爬虫有关:使用代理服务器可以绕过网站管理员设置的限制,从而采集大量数据。
那么问题来了,为什么要限制呢?这些数据不是可以在线免费获得吗?对于人类用户,是的。这是一个典型的例子。价格聚合器的整个商业模式都基于准确的信息。它为“我在哪里可以买到价格最低的 X 产品?”这个问题提供了准确的答案。
尽管这是客户省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣。原因是聚合器的网络爬虫软件(通常称为“)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真实用户执行的,则用户将被限制访问 网站。
代理的另一个实际用途是逃避审查禁令。住宅代理,顾名思义,将显示您是来自 X 国的真实用户,您可以自定义您来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家/地区,因此即使是来自这些国家/地区的真实用户也经常遇到地域限制。
此外,当您尝试从数据源采集数据但由于各种原因无法访问它时,使用代理特别有用。在网络抓取中使用代理的方法有很多,但为了在数字社区中建立信任,我们建议您坚持使用那些可以建立品牌信任和权威的方法。
来源:unsplash
使用人类知名度和值得信赖的品牌来对抗人工智能的耻辱
目前,人工智能的发展速度确实已经超过了网民数量的增长速度。但是,未来几年互联网将如何发展仍是未知数,因此没有理由立即断定这种趋势不可逆转,也不能断定它代表了一种固有的负面趋势。
如果要扭转互联网上关于人工智能流量的负面评论,最好的办法就是让人工智能在互联网上的使用回归人性。还应该指出的是,无需过多考虑以建立信任的方式使用人工智能。
· 坚持使用认可度高、值得信赖的品牌提供的可靠产品和服务。
· 坚持道德的网络爬行操作。不要滥用信任,忽略网站上的robots.txt文件,或者短时间内大量使用机器人程序。
· 以专业和负责任的方式使用数据。验证您是否有权将抓取的数据用于预期目的。
·普及人工智能。与他人讨论如何以及为何使用网络抓取,以便人们对网络抓取有更深入的了解。人们越了解使用人工智能获取和研究大量数据的好处,他们就越不可能对网络抓取和网络机器人产生负面看法。
通过纯手工操作来手动访问网站数据或许让人放心,但因为信息量太大,几乎不可能。可用的数据量几乎是无穷无尽的。使用人工智能是我们尽可能高效地浏览网站和分析数据的最佳方式。然而,它可能需要多加一点“人情味”。
网页抓取数据(网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-13 13:14
网页抓取数据,然后生成数据库报表,这是我们最常用的数据挖掘的方法了,据我所知是爬虫抓取信息,然后后台生成数据报表,这对于软件开发人员是很方便的事情,对于开发人员来说,这些信息对于数据挖掘技术不懂是很难进行和分析的,下面介绍一下selenium自动化测试。
1、先确定要抓取的网页,
2、下载网页:、然后进行代码编写,
3、代码讲解,
4、自动识别数据列:
5、生成数据库报表:
6、和sql语句对比:
7、处理数据:
8、数据分析:#-*-coding:utf-8-*-"""author:shugtocomments:tel:1461888631email:file:
需要的知识:1.自动化测试基础知识(要具有一定的编程能力,对java/.net有一定的了解,比如python/ruby,rstudio)2.数据库知识(一般用mysql和oracle)3.网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库)4.测试工具操作(如何在界面看到自己的代码,并且保存成自己的web地址和名称)最好从边学边做吧,前期找一些轻松的基础,做出一个简单的自动化程序再学习爬虫吧。
知乎上有现成的文章可以看看,selenium的教程,selenium教程基本上应该够用了。 查看全部
网页抓取数据(网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库))
网页抓取数据,然后生成数据库报表,这是我们最常用的数据挖掘的方法了,据我所知是爬虫抓取信息,然后后台生成数据报表,这对于软件开发人员是很方便的事情,对于开发人员来说,这些信息对于数据挖掘技术不懂是很难进行和分析的,下面介绍一下selenium自动化测试。
1、先确定要抓取的网页,
2、下载网页:、然后进行代码编写,
3、代码讲解,
4、自动识别数据列:
5、生成数据库报表:
6、和sql语句对比:
7、处理数据:
8、数据分析:#-*-coding:utf-8-*-"""author:shugtocomments:tel:1461888631email:file:
需要的知识:1.自动化测试基础知识(要具有一定的编程能力,对java/.net有一定的了解,比如python/ruby,rstudio)2.数据库知识(一般用mysql和oracle)3.网络编程知识(如何爬虫爬数据,如何保存数据并上传到数据库)4.测试工具操作(如何在界面看到自己的代码,并且保存成自己的web地址和名称)最好从边学边做吧,前期找一些轻松的基础,做出一个简单的自动化程序再学习爬虫吧。
知乎上有现成的文章可以看看,selenium的教程,selenium教程基本上应该够用了。
网页抓取数据(网页数据这件事,只要用心投入,一年也能上10万!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-11 05:01
网页抓取数据这件事,只要用心投入,一年也能上10万!这里不得不提的就是bootstrap,因为它是已经成为现代前端mv*pipeline的标准,所以这里我们只谈它。相信大家都知道,在之前,bootstrap还只能用来写网页,而且非常的受挫,所以很多人折腾了半天,只是优化自己的前端部分的代码。我个人不是很喜欢在前端搞太多,所以除了坚持写文章、写代码,我就是做一些视频资源、logo设计之类的事情。
网上的前端博客我也写了很多,比如这个:网站概览性能问题是我一直想尝试的一个领域,考虑到很多同学也不是特别熟悉工程化,所以我分享一下自己的感受:bootstrap的源码包括css文件以及js文件,需要制作一个动态的css编译器,以提高渲染速度,把你代码的重点包含其中,比如使用css3的特性进行小部件的封装、对样式采用less进行封装等等,全部用async和异步请求来实现,这样可以提高服务器的压力。
还有一些小功能,比如预编译、async/await代码里有lru缓存机制,这些都是使用bootstrap做的异步特性,可以提高可用性。除了bootstrap,你还可以用其他的框架,比如react、vue等等,这里不做过多讨论。通过es7-nodets这种扩展语言,可以支持把一些js中遇到的问题包括异步问题封装到bootstrap的核心的异步机制中去,也就是在异步机制中加入这些扩展语言去解决方案,这样可以提高可用性,不至于在发布版本时遇到问题。
一般情况下js包含在es5/es6的标准库中,但是也可以包含在flatten插件中,这时候就需要多复用相应的开发工具或者模块了。可以通过图形接口、一些工具集包括power、imitator、plugins等方式,构建mv*工程,它主要有这几种形式:写页面内部代码的方式,即编写脚本发布到第三方,再自己写页面的方式,即自己做的页面用第三方的页面apply进来,发布到第三方团队团队内部工程的方式,比如先在第三方解决方案那边做页面apply,再在自己公司内部直接apply的方式,自己公司内部有业务需求直接做apply到其他业务中去的方式,比如全公司共享一套代码等等,这里就不做展开了,这里涉及一些技术知识,也是大部分同学绕不过去的坎,我个人认为,比如要复用power、imitator、plugins等方式,还是需要比较有一定的知识和经验之后。
怎么寻找第三方资源?这里就讲三个比较常用的方式:在官网获取第三方的资源(文章、教程等),这个有个好处就是,它的自带论坛是源自官网的内容,比较权威,你可以很快的获取到相关干货或知识的获取途径;使用百度谷歌搜索第三方的bootstrap资源,这里特别。 查看全部
网页抓取数据(网页数据这件事,只要用心投入,一年也能上10万!)
网页抓取数据这件事,只要用心投入,一年也能上10万!这里不得不提的就是bootstrap,因为它是已经成为现代前端mv*pipeline的标准,所以这里我们只谈它。相信大家都知道,在之前,bootstrap还只能用来写网页,而且非常的受挫,所以很多人折腾了半天,只是优化自己的前端部分的代码。我个人不是很喜欢在前端搞太多,所以除了坚持写文章、写代码,我就是做一些视频资源、logo设计之类的事情。
网上的前端博客我也写了很多,比如这个:网站概览性能问题是我一直想尝试的一个领域,考虑到很多同学也不是特别熟悉工程化,所以我分享一下自己的感受:bootstrap的源码包括css文件以及js文件,需要制作一个动态的css编译器,以提高渲染速度,把你代码的重点包含其中,比如使用css3的特性进行小部件的封装、对样式采用less进行封装等等,全部用async和异步请求来实现,这样可以提高服务器的压力。
还有一些小功能,比如预编译、async/await代码里有lru缓存机制,这些都是使用bootstrap做的异步特性,可以提高可用性。除了bootstrap,你还可以用其他的框架,比如react、vue等等,这里不做过多讨论。通过es7-nodets这种扩展语言,可以支持把一些js中遇到的问题包括异步问题封装到bootstrap的核心的异步机制中去,也就是在异步机制中加入这些扩展语言去解决方案,这样可以提高可用性,不至于在发布版本时遇到问题。
一般情况下js包含在es5/es6的标准库中,但是也可以包含在flatten插件中,这时候就需要多复用相应的开发工具或者模块了。可以通过图形接口、一些工具集包括power、imitator、plugins等方式,构建mv*工程,它主要有这几种形式:写页面内部代码的方式,即编写脚本发布到第三方,再自己写页面的方式,即自己做的页面用第三方的页面apply进来,发布到第三方团队团队内部工程的方式,比如先在第三方解决方案那边做页面apply,再在自己公司内部直接apply的方式,自己公司内部有业务需求直接做apply到其他业务中去的方式,比如全公司共享一套代码等等,这里就不做展开了,这里涉及一些技术知识,也是大部分同学绕不过去的坎,我个人认为,比如要复用power、imitator、plugins等方式,还是需要比较有一定的知识和经验之后。
怎么寻找第三方资源?这里就讲三个比较常用的方式:在官网获取第三方的资源(文章、教程等),这个有个好处就是,它的自带论坛是源自官网的内容,比较权威,你可以很快的获取到相关干货或知识的获取途径;使用百度谷歌搜索第三方的bootstrap资源,这里特别。
网页抓取数据(提取的数据还不能直接拿来用?文件还没有被下载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-29 13:08
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址/logo.gif,或者不规则的图片源代码,采集器将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。 查看全部
网页抓取数据(提取的数据还不能直接拿来用?文件还没有被下载?)
提取出来的数据不能直接使用吗?文件还没有下载?格式等还达不到要求?不用担心,网页抓取工具优采云采集器 有自己的解决方案-数据处理。
网络爬虫的数据处理功能包括内容处理、文件下载和内容过滤三部分。让我依次为您介绍:
1、内容处理:对内容页面中提取的数据进行进一步的处理,例如替换、标签过滤、分词等,我们可以同时添加多个操作,但是这里需要注意的是,当有多个操作,按照上面的顺序执行,也就是将上一步的结果作为下一步的参数。
下面我们一一介绍:
①提取内容为空:如果通过前面的规则无法准确提取提取内容或提取内容为空,请选择此选项。此应用程序后,将使用正则匹配从原创页面中再次提取。
②内容替换/排除:用字符串替换采集的内容。如果需要排除,请用空字符串替换。功能非常灵活。如下图,可以直接替换内容,也可以用参数替换字符串(不同于工具栏中的同义词替换)。
③html标签过滤:过滤指定的html标签,如
④ 字符截取:通过首尾字符串截取内容。适用于截取和调整提取的内容。
⑤纯替换:如果某些内容(如单次出现的文本)无法通过一般的内容替换操作,则需要通过强大的正则表达式进行复杂的替换。
例如,“受欢迎的美国餐馆在这里”,我们将其替换为“美国餐馆”,正则表达式如下:
⑥数据转换:包括结果简繁转换、结果繁简转换、自动转拼音和时间校正转换,共四项处理。
⑦智能提取:包括第一张图片提取、智能提取时间、邮箱智能提取、手机号码智能提取、电话号码智能提取。
⑧高级功能:包括自动汇总、自动分词、自动分类、Http请求、字符编码转换、同义词替换、空内容默认值、内容加前缀和后缀、随机插入、运行C#代码、批量内容替换、统计标签字符串A长度等一系列函数。
⑨补全单个网址:将当前内容补全为一个网址。
2、文件下载:可以自动检测下载文件,可以设置下载路径和文件名样式。
注:文件下载中所指的下载图片为源代码中的标准样式
标签的图片地址。
例如,如果是直接的图片地址/logo.gif,或者不规则的图片源代码,采集器将被视为文件下载。
①将相对地址补全为绝对地址:勾选后,标签采集的相对地址补全为绝对地址。
②下载图片:经核对,源码收录标准样式
将下载代码图像。
③检测文件真实地址但不下载:有时采集到达附件下载地址而不是真实下载地址。点击之后,会有一个跳转。在这种情况下,如果勾选此选项,将显示真实地址采集,但不会仅下载下载地址。
④检测文件并下载:勾选后可以从采集下载任意格式的文件附件。
3、 内容过滤:一些不符合条件的记录可以通过设置内容过滤被删除或标记为不接受。有几种方法可以处理内容过滤:
①内容不得收录,内容必须收录:可设置多个词,且必须满足所有条件或满足其中一个条件即可。
②采集 结果不能为空:该功能可以防止某个字段出现空内容。
③采集 结果不能重复:该功能可以防止某个字段出现重复的内容。设置此项前请确保没有采集数据,否则需要先清除采集数据。
④内容长度小于(大于、等于、不等于)时过滤 N:符号或字母或数字或汉字算一个。
注意:如果满足以上四项中的任何一项或多项,您可以在采集器的其他设置功能中直接删除该记录,或者将该记录标记为不在采集采集将在下次运行任务时重复。
网页抓取工具优采云采集器配备了一系列数据处理的优势在于,当我们只需要做一个小操作时,无需编写插件、生成和编译它们,并且可以一键将数据处理成我们需要的数据。
网页抓取数据(几天的资料去写一个网页抓取股票实时数据的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-28 07:39
最近查了好几天的资料,写了一个网页,捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般不需要时间的网页数据变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此,开始网上搜索数据,很多人建议使用libcurl方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不变化的普通网页非常强大,libcurl达不到每秒的刷新率。网页数据速度10倍以上,而libcurl会有读取失败的延迟,延迟是2~3秒,也就是说在这2~3秒内无法抓取到网页上变化的数据。对于股市来说,这会丢失很大一部分数据。所以 libcurl 的方案被否定了。
但是,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的就是将数据丢失降到最低。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据?(这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。. . 也希望有想法有想法的同事留下自己的打算。 查看全部
网页抓取数据(几天的资料去写一个网页抓取股票实时数据的程序)
最近查了好几天的资料,写了一个网页,捕捉实时股票数据。网上一堆资料都是一遍遍的解释同一个方法,一般不需要时间的网页数据变化。然而,捕捉实时股票数据的要求是大量的股票数据每秒钟都在变化。有必要确保程序可以每秒捕获这些变化的数据。嗯,为此,开始网上搜索数据,很多人建议使用libcurl方法。好的,libcurl 非常强大且易于使用。我也想说,libcurl对于不变化的普通网页非常强大,libcurl达不到每秒的刷新率。网页数据速度10倍以上,而libcurl会有读取失败的延迟,延迟是2~3秒,也就是说在这2~3秒内无法抓取到网页上变化的数据。对于股市来说,这会丢失很大一部分数据。所以 libcurl 的方案被否定了。
但是,股票的实时更新需要如此高的读取次数。一般的方法会造成数据丢失。我能想到的就是将数据丢失降到最低。我再想想,为什么浏览器不会丢失数据?能不能像浏览器一样不丢失数据?(这个问题后面会解决。)我暂时使用的方法是利用WinInet提供的库函数来开发Internet程序。附上以下代码:
void Get_Http_Data(string Url, string &buffer)
{
try
{
CInternetSession *session = new CInternetSession();
CHttpFile* pfile = (CHttpFile *)session->OpenURL(Url.c_str(),1,INTERNET_FLAG_TRANSFER_ASCII|INTERNET_FLAG_RELOAD|INTERNET_FLAG_DONT_CACHE);
if( NULL == pfile )
{
LOG(1)("网络连接中断 或 请求连接失败!");
session->Close();
return ;
}
DWORD dwStatusCode;
pfile -> QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString data;
while (pfile -> ReadString(data))
{
if( !data.IsEmpty())
{
buffer.append(data.GetBuffer(0));
buffer.append("\t\n");
}
}
}
pfile->Close();
delete pfile;
session->Close();
}
catch(CInternetException *pEx) //这里一定要做异常抛出,考虑到如果程序正在运行中突然客户端网络中断,那么做异常抛出就会即使提示错误并终止。
{ //如果不做异常判断的话,程序就会继续运行这样导致buffer为空,记下来的操作万一没有考虑到buffer为空的情况就
pEx->ReportError(); //会导致程序崩溃,因为buffer为空内存无法操作。(比如运行到split函数会崩溃。)
pEx->Delete();
}
}
使用函数CInternetSession::OpenUrl()实现对服务器网页的持续请求操作。标志:INTERNET_FLAG_RELOAD 是强制重复阅读网页。
上面的过程就是方法。其他更优化的方法正在研究中。. . 也希望有想法有想法的同事留下自己的打算。

