
网页抓取数据
网页抓取数据( 广告网站数据采集工具用哪个好?300万+用户选择八抓鱼×)
网站优化 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2022-04-15 07:18
广告网站数据采集工具用哪个好?300万+用户选择八抓鱼×)
广告网站数据采集哪个工具最好用?300+用户选择霸主语
×
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从 Wikipedia 表中获取数据。在之前的一篇文章 文章(关于 Python 中的探索性数据分析)中,我们还使用 Pandas 从 HTML 表中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 时,对于数据分析和可视化,我们通常从练习导入数据开始。在前面的文章中,我们已经看到可以在Python中直接输入值(例如,从Python字典创建Pandas数据框)。但是,通过从可用来源导入数据来获取数据肯定更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用该方法的快速示例,但请务必查看有关该主题的博客文章 以获取更多信息。
现在,只有当我们已经拥有合适格式的数据(如 csv 或 JSON)时,上述方法才有用(请参阅 文章,了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人使用维基百科来获取我们感兴趣的主题的信息。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用 pandas 在 Python 中获取这些表,我们可以将它们剪切并粘贴到电子表格中,然后,例如,使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤来完成:我们可以通过网络抓取来自动化它。请务必查看什么是网络抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 来安装 Python 包,例如 Pandas,或者安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法: pip install pandas。
请注意,如果有更新版本的 pip 可用的消息,请查看此 文章 以了解如何升级 pip。注意我们还需要安装lxml或者BeautifulSoup4,当然这些包也可以使用pip安装:pip install lxml。
熊猫 read_html 语法
下面是关于如何使用 Pandas read_html 从 HTML 表中抓取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看一些 read_html 示例。
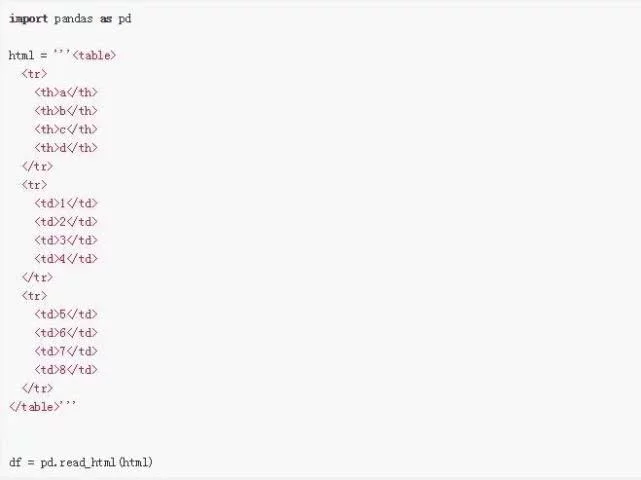
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas 的 read_html 方法,我们将从字符串中读取 HTML 表格。
广告大数据获取客户——精准客源,同行客户就是你的客户
×
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。也就是说,如果我们使用 type() 函数,我们可以看到:
如果我们想得到那个表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
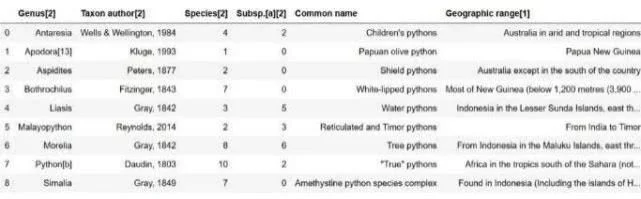
在第二个 Pandas read_html 示例中,我们将从 Wikipedia 中抓取数据。实际上,我们将获得一个 Python(也称为 pythons)的 HTML 表。
现在,我们得到一个收录 7 个表的列表 (len(df))。如果我们去维基百科页面,我们可以看到第一个表是右边的那个。但是,在这种情况下,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 病例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在这之后,我们还需要对数据进行清洗,最后,我们会做一些简单的数据可视化操作。
使用 Pandas read_html 抓取数据并匹配参数:
如上所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
广告精准大数据采集神器一键式采集精准客户,覆盖全网,轻松获客
×
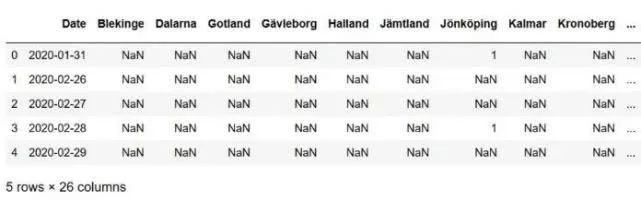
这样我们只能得到这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请务必查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了这个数据框的副本。
在下一节中,我们将学习如何将多索引列名称更改为单个索引。
将多索引更改为单索引并删除不需要的字符
现在,我们要摆脱多索引列。也就是说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取了一些注释。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,让我们继续使用 Pandas set_index 将日期列转换为索引。这使我们可以在以后轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用 0 填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累积值:
广告一小时搭建数据分析平台
×
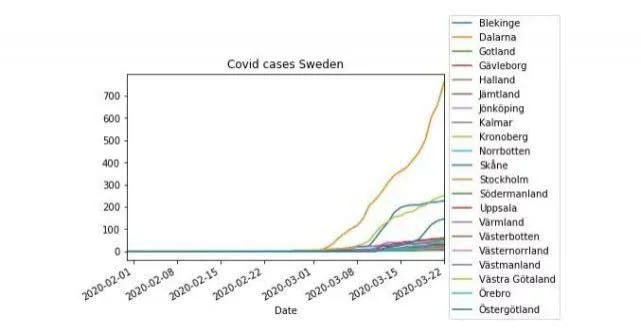
来自 HTML 表的时间序列图
在最后一个示例中,我们使用 Pandas read_html 来获取我们抓取的数据并创建时间序列图。现在,我们还导入 matplotlib 以便我们可以更改 Pandas 图例标题的位置:
广告数据采集从进入到放弃【简介】
×
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自 Wikipedia文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:一会儿 查看全部
网页抓取数据(
广告网站数据采集工具用哪个好?300万+用户选择八抓鱼×)

广告网站数据采集哪个工具最好用?300+用户选择霸主语
×
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从 Wikipedia 表中获取数据。在之前的一篇文章 文章(关于 Python 中的探索性数据分析)中,我们还使用 Pandas 从 HTML 表中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 时,对于数据分析和可视化,我们通常从练习导入数据开始。在前面的文章中,我们已经看到可以在Python中直接输入值(例如,从Python字典创建Pandas数据框)。但是,通过从可用来源导入数据来获取数据肯定更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用该方法的快速示例,但请务必查看有关该主题的博客文章 以获取更多信息。
现在,只有当我们已经拥有合适格式的数据(如 csv 或 JSON)时,上述方法才有用(请参阅 文章,了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人使用维基百科来获取我们感兴趣的主题的信息。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用 pandas 在 Python 中获取这些表,我们可以将它们剪切并粘贴到电子表格中,然后,例如,使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤来完成:我们可以通过网络抓取来自动化它。请务必查看什么是网络抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 来安装 Python 包,例如 Pandas,或者安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法: pip install pandas。
请注意,如果有更新版本的 pip 可用的消息,请查看此 文章 以了解如何升级 pip。注意我们还需要安装lxml或者BeautifulSoup4,当然这些包也可以使用pip安装:pip install lxml。
熊猫 read_html 语法
下面是关于如何使用 Pandas read_html 从 HTML 表中抓取数据的最简单语法:

现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看一些 read_html 示例。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas 的 read_html 方法,我们将从字符串中读取 HTML 表格。
广告大数据获取客户——精准客源,同行客户就是你的客户
×
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。也就是说,如果我们使用 type() 函数,我们可以看到:
如果我们想得到那个表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从 Wikipedia 中抓取数据。实际上,我们将获得一个 Python(也称为 pythons)的 HTML 表。
现在,我们得到一个收录 7 个表的列表 (len(df))。如果我们去维基百科页面,我们可以看到第一个表是右边的那个。但是,在这种情况下,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 病例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在这之后,我们还需要对数据进行清洗,最后,我们会做一些简单的数据可视化操作。
使用 Pandas read_html 抓取数据并匹配参数:
如上所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:

广告精准大数据采集神器一键式采集精准客户,覆盖全网,轻松获客
×
这样我们只能得到这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请务必查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了这个数据框的副本。
在下一节中,我们将学习如何将多索引列名称更改为单个索引。
将多索引更改为单索引并删除不需要的字符
现在,我们要摆脱多索引列。也就是说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取了一些注释。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,让我们继续使用 Pandas set_index 将日期列转换为索引。这使我们可以在以后轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用 0 填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累积值:

广告一小时搭建数据分析平台
×
来自 HTML 表的时间序列图
在最后一个示例中,我们使用 Pandas read_html 来获取我们抓取的数据并创建时间序列图。现在,我们还导入 matplotlib 以便我们可以更改 Pandas 图例标题的位置:

广告数据采集从进入到放弃【简介】
×
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自 Wikipedia文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:一会儿
网页抓取数据(网页抓取频率对SEO有哪些重要重要意义?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-13 13:31
每天都有数以万计的网址被搜索引擎抓取和抓取,它们通过相互链接构成了我们现有的互联网关系。对于SEO人员,我们经常讲一个名词:网站爬取频率。
它在SEO的日常工作中发挥着重要作用,为网站优化提供了宝贵的建议。
那么,网站爬取频率对SEO有什么意义呢?
根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上只要是外部链接,无论其质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,目录层次简化,URL过长,动态参数过多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候其实有个方便的小技巧:那就是主动将URL添加到sitemap中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当你有一个页面需要排名时,你有必要将它放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定好。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面已经很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,可以使用百度官方后台爬虫诊断查看具体原因。
总结:页面爬取频率在索引、收录、排名、二级排名中起着至关重要的作用。作为SEO人员,您可能需要适当注意。以上内容仅供参考。 查看全部
网页抓取数据(网页抓取频率对SEO有哪些重要重要意义?(图))
每天都有数以万计的网址被搜索引擎抓取和抓取,它们通过相互链接构成了我们现有的互联网关系。对于SEO人员,我们经常讲一个名词:网站爬取频率。
它在SEO的日常工作中发挥着重要作用,为网站优化提供了宝贵的建议。
那么,网站爬取频率对SEO有什么意义呢?
根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上只要是外部链接,无论其质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,目录层次简化,URL过长,动态参数过多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候其实有个方便的小技巧:那就是主动将URL添加到sitemap中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当你有一个页面需要排名时,你有必要将它放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定好。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面已经很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,可以使用百度官方后台爬虫诊断查看具体原因。
总结:页面爬取频率在索引、收录、排名、二级排名中起着至关重要的作用。作为SEO人员,您可能需要适当注意。以上内容仅供参考。
网页抓取数据(发送的最原始的请求就是GET请求(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-09 02:17
发送 GET 请求
当我们用浏览器打开豆瓣首页时,发送的最原创的请求其实是一个GET请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
如您所见,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用text或者content属性来获取
text:以字符串的形式返回数据
内容:以二进制形式返回数据
print(type(res.text))
print(res.text)
>>>
.....
发送 POST 请求
对于 POST 请求,一般是提交表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
数据中有需要传递的表单信息,是字典类型的数据。
标题增强
对于一些网站,没有headers的请求会被拒绝,所以需要做一些header的增强。例如:UA、Cookie、主机等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
res = requests.get('http://www.xxx.com', headers=header)
解析 HTML
既然我们已经获得了网页返回的数据,也就是HTML代码,我们就需要对HTML进行解析,提取出有效信息。
美丽汤
BeautifulSoup 是一个 Python 库,其主要功能是从网页中解析数据。
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。
BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list
具体用法和效果会在后面的实战中详细讲解。
XPath 定位
XPath 是 XML 的路径语言,用于通过元素和属性进行导航和定位。几种常用的表达方式
表达式含义 node 选择节点node的所有子节点/从根节点中选择//选择所有当前节点。当前节点..父节点@property select text() 当前路径下的文本内容
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点
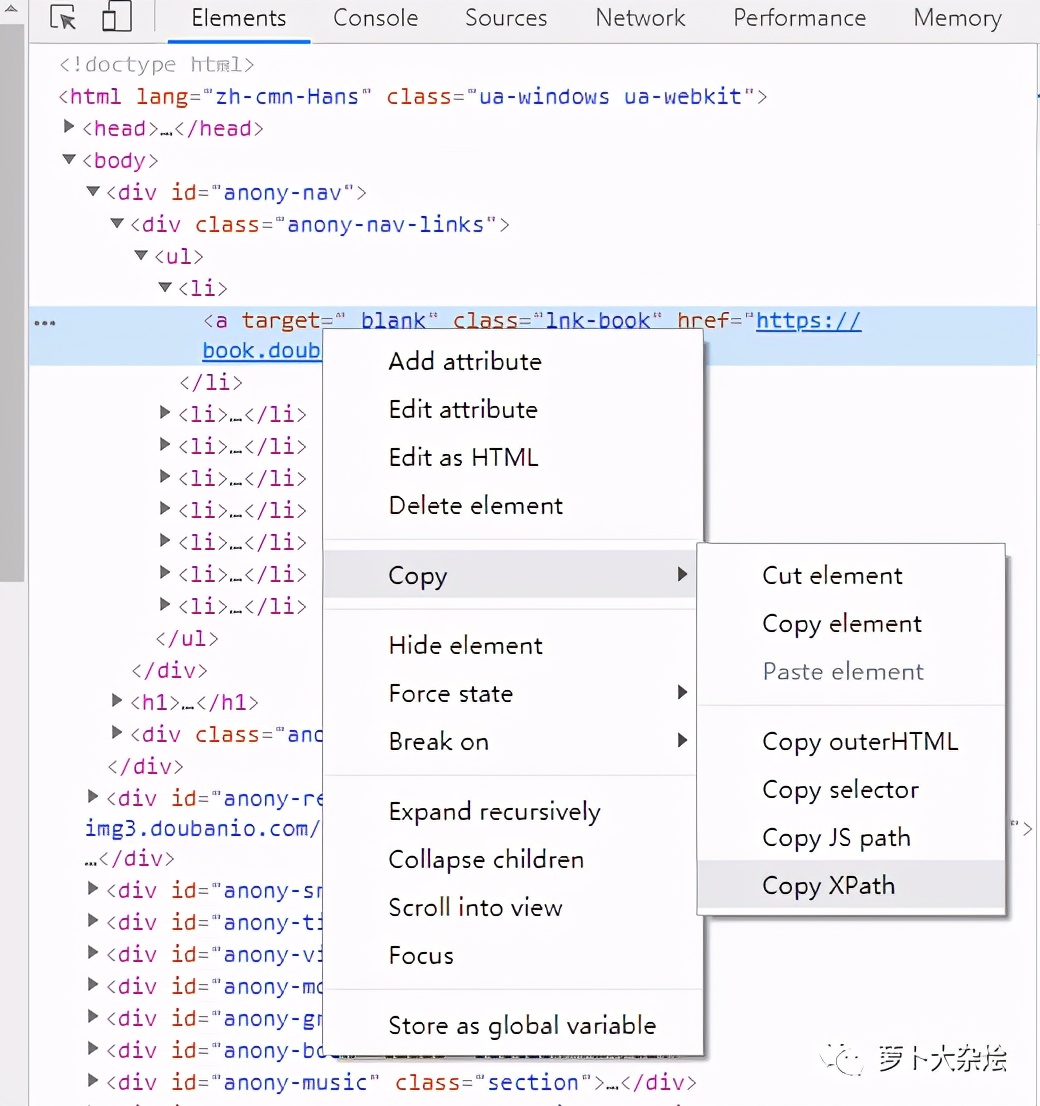
当然XPath很强大,但是语法比较复杂,但是我们可以通过Chrome的开发者工具快速定位一个元素的xpath,如下图
生成的 xpath 是
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在实际使用过程中,到底是用BeautifulSoup还是XPath,完全看个人喜好,用哪个更熟练、更方便,就用哪个。
爬虫实战:爬虫豆瓣海报
从豆瓣映人页面,我们可以进入到对应的独映人映人图片页面。例如,以刘涛为例,她的英仁图片页地址是:
让我们分析一下这个页面
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:721195303
目标网站页面分析
注意:网络上网站页面的构成会一直变化,所以这里需要学习分析,其他的网站等等。俗话说,授人以鱼不如授人以渔。
Chrome 开发者工具
Chrome开发者工具(按F12打开)是分析网页的优秀工具,一定要好好使用。
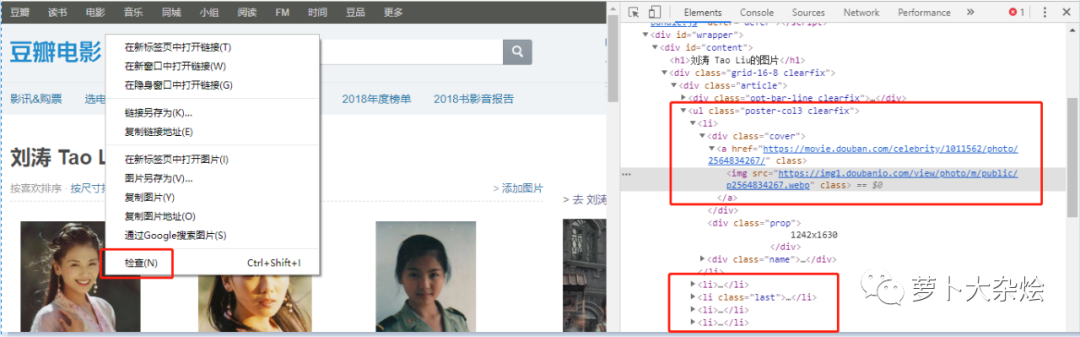
我们在任意一张图片上右击选择“Inspect”,可以看到“开发者工具”也打开了,图片的位置自动定位了。
可以清楚的看到每张图片都存放在li标签中,图片的地址存放在li标签中的img中。
知道了这些规则之后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,获取图片地址。
代码编写
我们只需要几行代码就可以完成图片url的提取
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/celeb ... 39%3B
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B]
如您所见,这是一个非常干净的列表,其中存储了海报地址。
但这里只是一页海报的数据。我们观察了页面,发现它有很多分页。如何处理分页。
寻呼
我们点击第二页,看看浏览器url的变化
发现浏览器url加了几个参数
再次点击第三页,继续观察url
通过观察我们可以看到,这里的参数中,只有start发生了变化,也就是变量,其余的参数都可以按常理处理。
同时也可以知道这个start参数应该起到类似于page的作用,start=30是第二页,start=60是第三页,以此类推,最后一页就是start=420。
所以我们处理分页的代码已经准备好了
首先将上面处理HTML页面的代码封装成一个函数
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list
然后我们在另一个函数中处理分页并调用上面的函数
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
page += 1
至此,我们所有的海报数据都存储在data变量中,现在我们需要一个下载器来保存海报
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
然后将下载器添加到fire函数中。此时为了防止豆瓣网的正常访问被请求过于频繁,将休眠时间设置为1秒。
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
fire函数在下面执行。程序运行完成后,会在当前目录下生成一个图片文件夹,里面保存着我们下载的所有海报。
核心代码说明
我们来看看完整的代码
import requests
from bs4 import BeautifulSoup
import time
import osdef fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_listdef download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)if __name__ == '__main__':
fire()
消防功能
这是使用 range 函数处理分页的主要执行函数。
get_poster_url 函数
这是解析 HTML 的函数,使用 BeautifulSoup
下载图片功能
简易图片下载器
总结
本节讲解爬虫的基本流程以及需要用到的Python库和方法,并通过一个实例完成从分析网页到数据存储的整个流程。其实爬虫无非就是模拟请求,解析数据,保存数据。
当然,有时候,网站也会设置各种反爬机制,比如cookie验证、请求频率检查、非浏览器访问限制、JS混淆等等。这个时候,反反爬技术是需要的。比如抓取cookie放到headers中,使用代理IP访问,使用Selenium模拟浏览器等待模式。
这里推荐一下我自己建的Python学习群:721195303。群里的每个人都在学习Python。如果您想学习或正在学习Python,欢迎您的加入。大家都是软件开发党,不定期分享干货(仅限Python软件开发相关),包括我自己整理的2021最新Python进阶资料和零基础教学,欢迎进阶有兴趣的小伙伴加入Python! 查看全部
网页抓取数据(发送的最原始的请求就是GET请求(二))
发送 GET 请求
当我们用浏览器打开豆瓣首页时,发送的最原创的请求其实是一个GET请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
如您所见,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用text或者content属性来获取
text:以字符串的形式返回数据
内容:以二进制形式返回数据
print(type(res.text))
print(res.text)
>>>
.....
发送 POST 请求
对于 POST 请求,一般是提交表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
数据中有需要传递的表单信息,是字典类型的数据。
标题增强
对于一些网站,没有headers的请求会被拒绝,所以需要做一些header的增强。例如:UA、Cookie、主机等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
res = requests.get('http://www.xxx.com', headers=header)
解析 HTML
既然我们已经获得了网页返回的数据,也就是HTML代码,我们就需要对HTML进行解析,提取出有效信息。
美丽汤
BeautifulSoup 是一个 Python 库,其主要功能是从网页中解析数据。
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。
BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list
具体用法和效果会在后面的实战中详细讲解。
XPath 定位
XPath 是 XML 的路径语言,用于通过元素和属性进行导航和定位。几种常用的表达方式
表达式含义 node 选择节点node的所有子节点/从根节点中选择//选择所有当前节点。当前节点..父节点@property select text() 当前路径下的文本内容
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点
当然XPath很强大,但是语法比较复杂,但是我们可以通过Chrome的开发者工具快速定位一个元素的xpath,如下图
生成的 xpath 是
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在实际使用过程中,到底是用BeautifulSoup还是XPath,完全看个人喜好,用哪个更熟练、更方便,就用哪个。
爬虫实战:爬虫豆瓣海报
从豆瓣映人页面,我们可以进入到对应的独映人映人图片页面。例如,以刘涛为例,她的英仁图片页地址是:
让我们分析一下这个页面
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:721195303
目标网站页面分析
注意:网络上网站页面的构成会一直变化,所以这里需要学习分析,其他的网站等等。俗话说,授人以鱼不如授人以渔。
Chrome 开发者工具
Chrome开发者工具(按F12打开)是分析网页的优秀工具,一定要好好使用。
我们在任意一张图片上右击选择“Inspect”,可以看到“开发者工具”也打开了,图片的位置自动定位了。
可以清楚的看到每张图片都存放在li标签中,图片的地址存放在li标签中的img中。
知道了这些规则之后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,获取图片地址。
代码编写
我们只需要几行代码就可以完成图片url的提取
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/celeb ... 39%3B
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B]
如您所见,这是一个非常干净的列表,其中存储了海报地址。
但这里只是一页海报的数据。我们观察了页面,发现它有很多分页。如何处理分页。
寻呼
我们点击第二页,看看浏览器url的变化
发现浏览器url加了几个参数
再次点击第三页,继续观察url
通过观察我们可以看到,这里的参数中,只有start发生了变化,也就是变量,其余的参数都可以按常理处理。
同时也可以知道这个start参数应该起到类似于page的作用,start=30是第二页,start=60是第三页,以此类推,最后一页就是start=420。
所以我们处理分页的代码已经准备好了
首先将上面处理HTML页面的代码封装成一个函数
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list
然后我们在另一个函数中处理分页并调用上面的函数
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
page += 1
至此,我们所有的海报数据都存储在data变量中,现在我们需要一个下载器来保存海报
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
然后将下载器添加到fire函数中。此时为了防止豆瓣网的正常访问被请求过于频繁,将休眠时间设置为1秒。
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
fire函数在下面执行。程序运行完成后,会在当前目录下生成一个图片文件夹,里面保存着我们下载的所有海报。
核心代码说明
我们来看看完整的代码
import requests
from bs4 import BeautifulSoup
import time
import osdef fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_listdef download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)if __name__ == '__main__':
fire()
消防功能
这是使用 range 函数处理分页的主要执行函数。
get_poster_url 函数
这是解析 HTML 的函数,使用 BeautifulSoup
下载图片功能
简易图片下载器
总结
本节讲解爬虫的基本流程以及需要用到的Python库和方法,并通过一个实例完成从分析网页到数据存储的整个流程。其实爬虫无非就是模拟请求,解析数据,保存数据。
当然,有时候,网站也会设置各种反爬机制,比如cookie验证、请求频率检查、非浏览器访问限制、JS混淆等等。这个时候,反反爬技术是需要的。比如抓取cookie放到headers中,使用代理IP访问,使用Selenium模拟浏览器等待模式。
这里推荐一下我自己建的Python学习群:721195303。群里的每个人都在学习Python。如果您想学习或正在学习Python,欢迎您的加入。大家都是软件开发党,不定期分享干货(仅限Python软件开发相关),包括我自己整理的2021最新Python进阶资料和零基础教学,欢迎进阶有兴趣的小伙伴加入Python!
网页抓取数据(网页抓取数据的主要有两种途径,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-06 13:09
网页抓取数据,主要有两种途径,一是爬虫程序对网页进行抓取,另一种是直接爬虫程序抓取。如果是爬虫程序,如果没有处理格式化的任务,将爬取到的网页格式化后,直接存储到自己的服务器上。另外就是有需要的时候,直接把网页传给程序。两种途径对业务对代码的要求也不一样。爬虫程序对于某些爬虫框架要求不高,直接用他的api就可以了,但对于某些比较复杂或处理格式化要求高的网页还是需要自己写解析api。
给你个传送门:利用python进行网页抓取
根据我个人对这个问题的经验来看,你需要准备几个软件(第一是python;第二是懂scrapy,logging,settings.py等工具;第三是你要学习一点html5和markdown的知识)如下:网站抓取、爬虫框架如pyspider、scrapy、euclid、symbolicbrowser等;页面解析后,存储在本地,或者直接使用mongodb服务;数据库你可以根据实际需要选用mysql、postgresql、mongodb等。
如果你需要做好用户分析和流量统计的话,就要买些数据抓取工具了,要那种什么“微多访问统计工具”或者“访问页面统计工具”。
有selenium不用学习编程。
初学,建议自己学习下python基础语法,
看你的做什么。如果是企业级网站,推荐scrapy框架;如果是个人站,用html2css吧。python比较适合做高性能的网站,非常适合有一定网站架构经验的人,所以如果不熟悉还是要熟悉scrapy框架。如果刚入门学python,只是想做一些测试网站,可以学下python的web开发库python3。 查看全部
网页抓取数据(网页抓取数据的主要有两种途径,你知道吗?)
网页抓取数据,主要有两种途径,一是爬虫程序对网页进行抓取,另一种是直接爬虫程序抓取。如果是爬虫程序,如果没有处理格式化的任务,将爬取到的网页格式化后,直接存储到自己的服务器上。另外就是有需要的时候,直接把网页传给程序。两种途径对业务对代码的要求也不一样。爬虫程序对于某些爬虫框架要求不高,直接用他的api就可以了,但对于某些比较复杂或处理格式化要求高的网页还是需要自己写解析api。
给你个传送门:利用python进行网页抓取
根据我个人对这个问题的经验来看,你需要准备几个软件(第一是python;第二是懂scrapy,logging,settings.py等工具;第三是你要学习一点html5和markdown的知识)如下:网站抓取、爬虫框架如pyspider、scrapy、euclid、symbolicbrowser等;页面解析后,存储在本地,或者直接使用mongodb服务;数据库你可以根据实际需要选用mysql、postgresql、mongodb等。
如果你需要做好用户分析和流量统计的话,就要买些数据抓取工具了,要那种什么“微多访问统计工具”或者“访问页面统计工具”。
有selenium不用学习编程。
初学,建议自己学习下python基础语法,
看你的做什么。如果是企业级网站,推荐scrapy框架;如果是个人站,用html2css吧。python比较适合做高性能的网站,非常适合有一定网站架构经验的人,所以如果不熟悉还是要熟悉scrapy框架。如果刚入门学python,只是想做一些测试网站,可以学下python的web开发库python3。
网页抓取数据( 一个基于新的异步库(aiohttp)的请求的代替品)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-10 17:07
一个基于新的异步库(aiohttp)的请求的代替品)
Python网页数据抓取全记录
在本文中,我将向您展示基于新异步库 (aiohttp) 的请求的替代方案。我已经用它编写了一些非常快速的小型数据采集器,我将在下面向您展示如何操作。中描述的方法如此多样化的原因是数据“抓取”实际上涉及很多问题:您不需要使用相同的工具从数千个页面中抓取数据,同时自动化一些 Web 工作流程(例如填写一些表单然后取回数据)。
异步的基本概念
asyncio是python3.4中引入的异步IO库。您也可以通过 python3.3 中的 pypi 安装它。这很复杂,我不会详细介绍。相反,我将解释使用它编写异步代码需要了解的内容。
协程和事件循环。
协程类似于方法,但它们可以在代码中的特定点暂停和恢复。可用于在等待 IO(例如 HTTP 请求)时暂停协程,同时执行另一个请求。我们使用关键字 yield from 来设置一个状态,表明我们想要一个协程的返回值。事件循环用于调度协程的执行。
关于 asyncio 的内容还有很多,但到目前为止我们需要知道的就是这些。可能你还有点不清楚,我们来看一段代码。
aiohttp 是一个利用 asyncio 的库,它的 API 看起来很像请求 API。到目前为止,其中介绍的相关文档还不完整。我们使用 asyncio.coroutine 将方法装饰为协程。aiohttp.request 是一个协程,所以它是一个可读的方法,我们需要使用 yield from 来调用它们。除此之外,以下代码看起来相当直观:
@asyncio.coroutine def print_page(url): response = yield from aiohttp.request('GET', url) body = yield from response.read_and_close(decode=True) print(body)
我们可以使用 yield from 从另一个协程调用一个协程。为了从同步代码中调用协程,我们需要一个事件循环。我们可以通过 asyncio.get_event_loop() 获得一个标准的事件循环,然后使用它的 run_until_complete() 方法来运行协程。所以,为了让前面的协程运行起来,我们只需要执行以下步骤:
loop = asyncio.get_event_loop() loop.run_until_complete(print_page('
一个有用的方法是 asyncio.wait,它接受一个协程列表并返回一个收录所有协程的协程,所以我们可以这样写:
loop.run_until_complete(asyncio.wait([print_page('#x27;),
打印页面('
另一个是 asyncio.as_completed,它接受一个协程列表,同时返回一个迭代器,它按照完成的顺序生成协程,所以当你用它迭代时,你会尽快得到每个可用的结果。
数据抓取
现在我们知道如何执行异步 HTTP 请求,我们可以编写一个数据抓取器。我们只需要一些工具来阅读html页面,我用beautifulsoup来做这个,其他的比如pyquery或者lxml也可以实现。
我们将编写一个小型数据抓取器,从海盗湾网站 抓取一些 linux 发行版的种子链接,并声称是“世界上最大的 BitTorrent 跟踪器(BT 种子服务器)”。除了采集免费的版权BT种子外,还有很多作者声称拥有版权的音频、视频、应用软件和视频游戏。等等,网络共享和下载的重要网站之一。译者注来自维基百科)
首先,需要一个辅助协程来获取请求:
@asyncio.coroutine def get(*args, **kwargs): response = yield from aiohttp.request('GET', *args, **kwargs) return (yield from response.read_and_close(decode=True))
解析部分。这篇文章不是关于beautifulsoup的,所以我将这部分缩写:我们得到了这个页面的第一个磁力链接。
def first_magnet(page): soup = bs4.BeautifulSoup(page) a = soup.find('a', title='使用磁铁下载这个种子') return a['href']
在这个协程中,url 的结果是按种子数排序的,所以第一个结果实际上是种子数最多的结果:
6 @asyncio.coroutine def print_magnet(query): url = ' page = yield from get(url, compress=True) magnet = first_magnet(page) print('{}: {}'.format(query, magnet))
使用以下代码调用上述所有方法。
distros = ['archlinux', 'ubuntu', 'debian'] loop = asyncio.get_event_loop() f = asyncio.wait([print_magnet(d) for d in distros]) loop.run_until_complete(f)
现在我们来到这一部分。你有一个异步工作的小抓取器。这意味着可以同时下载多个页面,因此这个示例比使用相同代码进行请求快 3 倍。现在你应该可以用同样的方式编写你自己的抓取器了。
一旦你熟悉了这一切,我建议你看一下 asyncio 文档和 aiohttp 示例,它们可以告诉你 asyncio 有多少潜力。
这种方法(实际上是所有手动方法)的一个限制是没有用于处理表单的单个库。机械方法有很多帮助提交表单非常容易,但如果你不使用它们,你将不得不自己处理这些事情。这可能会导致一些错误,所以同时我可能会编写一个这样的库(但现在不要担心)。
额外建议:不要向服务器要求太多
同时做3个请求很酷,但是同时做5000个就没那么好玩了。如果您计划同时执行太多请求,则链接可能会中断。您甚至可能被禁止连接到 Internet。
为了避免这些,您可以使用信号量。这是一个同步工具,可以用来限制同时工作的协程数量。我们只需要在构建循环之前创建一个信号量,并将我们希望允许的同时请求数作为参数传递给它:
sem = asyncio.Semaphore(5)
然后,我们只需要添加以下内容
页面 = 来自 get(url, compress=True)
替换为受信号量保护的相同事物。
with (yield from sem): page = yield from get(url, compress=True)
这保证了最多同时处理 5 个请求。
tqdm 是一个用于生成进度条的优秀库。这个协程就像 asyncio.wait 一样工作,但是会显示一个进度条来指示完成。
@asyncio.coroutine def wait_with_progress(coros): for f in tqdm.tqdm(asyncio.as_completed(coros), total=len(coros)): yield from f 查看全部
网页抓取数据(
一个基于新的异步库(aiohttp)的请求的代替品)
Python网页数据抓取全记录
在本文中,我将向您展示基于新异步库 (aiohttp) 的请求的替代方案。我已经用它编写了一些非常快速的小型数据采集器,我将在下面向您展示如何操作。中描述的方法如此多样化的原因是数据“抓取”实际上涉及很多问题:您不需要使用相同的工具从数千个页面中抓取数据,同时自动化一些 Web 工作流程(例如填写一些表单然后取回数据)。
异步的基本概念
asyncio是python3.4中引入的异步IO库。您也可以通过 python3.3 中的 pypi 安装它。这很复杂,我不会详细介绍。相反,我将解释使用它编写异步代码需要了解的内容。
协程和事件循环。
协程类似于方法,但它们可以在代码中的特定点暂停和恢复。可用于在等待 IO(例如 HTTP 请求)时暂停协程,同时执行另一个请求。我们使用关键字 yield from 来设置一个状态,表明我们想要一个协程的返回值。事件循环用于调度协程的执行。
关于 asyncio 的内容还有很多,但到目前为止我们需要知道的就是这些。可能你还有点不清楚,我们来看一段代码。
aiohttp 是一个利用 asyncio 的库,它的 API 看起来很像请求 API。到目前为止,其中介绍的相关文档还不完整。我们使用 asyncio.coroutine 将方法装饰为协程。aiohttp.request 是一个协程,所以它是一个可读的方法,我们需要使用 yield from 来调用它们。除此之外,以下代码看起来相当直观:
@asyncio.coroutine def print_page(url): response = yield from aiohttp.request('GET', url) body = yield from response.read_and_close(decode=True) print(body)
我们可以使用 yield from 从另一个协程调用一个协程。为了从同步代码中调用协程,我们需要一个事件循环。我们可以通过 asyncio.get_event_loop() 获得一个标准的事件循环,然后使用它的 run_until_complete() 方法来运行协程。所以,为了让前面的协程运行起来,我们只需要执行以下步骤:
loop = asyncio.get_event_loop() loop.run_until_complete(print_page('
一个有用的方法是 asyncio.wait,它接受一个协程列表并返回一个收录所有协程的协程,所以我们可以这样写:
loop.run_until_complete(asyncio.wait([print_page('#x27;),
打印页面('
另一个是 asyncio.as_completed,它接受一个协程列表,同时返回一个迭代器,它按照完成的顺序生成协程,所以当你用它迭代时,你会尽快得到每个可用的结果。
数据抓取
现在我们知道如何执行异步 HTTP 请求,我们可以编写一个数据抓取器。我们只需要一些工具来阅读html页面,我用beautifulsoup来做这个,其他的比如pyquery或者lxml也可以实现。
我们将编写一个小型数据抓取器,从海盗湾网站 抓取一些 linux 发行版的种子链接,并声称是“世界上最大的 BitTorrent 跟踪器(BT 种子服务器)”。除了采集免费的版权BT种子外,还有很多作者声称拥有版权的音频、视频、应用软件和视频游戏。等等,网络共享和下载的重要网站之一。译者注来自维基百科)
首先,需要一个辅助协程来获取请求:
@asyncio.coroutine def get(*args, **kwargs): response = yield from aiohttp.request('GET', *args, **kwargs) return (yield from response.read_and_close(decode=True))
解析部分。这篇文章不是关于beautifulsoup的,所以我将这部分缩写:我们得到了这个页面的第一个磁力链接。
def first_magnet(page): soup = bs4.BeautifulSoup(page) a = soup.find('a', title='使用磁铁下载这个种子') return a['href']
在这个协程中,url 的结果是按种子数排序的,所以第一个结果实际上是种子数最多的结果:
6 @asyncio.coroutine def print_magnet(query): url = ' page = yield from get(url, compress=True) magnet = first_magnet(page) print('{}: {}'.format(query, magnet))
使用以下代码调用上述所有方法。
distros = ['archlinux', 'ubuntu', 'debian'] loop = asyncio.get_event_loop() f = asyncio.wait([print_magnet(d) for d in distros]) loop.run_until_complete(f)
现在我们来到这一部分。你有一个异步工作的小抓取器。这意味着可以同时下载多个页面,因此这个示例比使用相同代码进行请求快 3 倍。现在你应该可以用同样的方式编写你自己的抓取器了。
一旦你熟悉了这一切,我建议你看一下 asyncio 文档和 aiohttp 示例,它们可以告诉你 asyncio 有多少潜力。
这种方法(实际上是所有手动方法)的一个限制是没有用于处理表单的单个库。机械方法有很多帮助提交表单非常容易,但如果你不使用它们,你将不得不自己处理这些事情。这可能会导致一些错误,所以同时我可能会编写一个这样的库(但现在不要担心)。
额外建议:不要向服务器要求太多
同时做3个请求很酷,但是同时做5000个就没那么好玩了。如果您计划同时执行太多请求,则链接可能会中断。您甚至可能被禁止连接到 Internet。
为了避免这些,您可以使用信号量。这是一个同步工具,可以用来限制同时工作的协程数量。我们只需要在构建循环之前创建一个信号量,并将我们希望允许的同时请求数作为参数传递给它:
sem = asyncio.Semaphore(5)
然后,我们只需要添加以下内容
页面 = 来自 get(url, compress=True)
替换为受信号量保护的相同事物。
with (yield from sem): page = yield from get(url, compress=True)
这保证了最多同时处理 5 个请求。
tqdm 是一个用于生成进度条的优秀库。这个协程就像 asyncio.wait 一样工作,但是会显示一个进度条来指示完成。
@asyncio.coroutine def wait_with_progress(coros): for f in tqdm.tqdm(asyncio.as_completed(coros), total=len(coros)): yield from f
网页抓取数据(腾讯云“新产品类型公有云”“最佳推荐方案团队”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-24 02:06
网页抓取数据可以用聚合数据网的爆火,助力小微企业快速获取互联网大数据源。聚合数据网联合腾讯云推出三星刷新机制,可以实现传统企业远程远程抓取网页数据,覆盖传统企业和互联网新贵等企业。在三星旗舰机与2018年主流手机之间,选择是否抓取三星数据将影响后续的口碑引爆和用户忠诚度,以及舆论导向。聚合数据网作为腾讯云“新产品类型公有云”“最佳推荐方案团队”,已入驻国内40多家领先的企业和互联网公司,正在逐步提供最佳解决方案,帮助客户获取更可靠的大数据源和视野变得更加可靠。
现在有分析平台可以抓取大数据,很多专门做数据分析的第三方公司,比如启飞云等等,题主可以关注他们。
据我所知,网站数据获取一般分为三种途径:网页抓取:大部分网站会有定期的页面抓取,可以借助一些分析工具(建议使用ueeshop,请点击下列链接查看详情)了解部分网站。这些抓取的页面数据是经过交互的,包括上传的图片。另外一些也会进行到页面内容抓取,转成数据库的形式存放于本地。站内搜索:通过站内搜索进行的抓取工作,因为排在搜索之前的页面具有重要的价值,所以搜索之后大部分也是可以抓取的。
官方应用:基于leancloud提供的微服务框架,一些有较大用户量级的大型网站会提供的paas平台服务。例如百度的搜索服务、京东的服务,会提供丰富的微服务。抓取难点:数据获取是分析研究的基础,有几个难点:1.客户端2.分析工具3.处理平台的选择4.数据源的选择有些网站会提供官方免费版的分析工具,大部分也都是外包出去的。
最近启飞云发布了爬虫管理工具superfily2.0,包括爬虫post-star.js、提交post-shutdown等。使用这些语言写好脚本,存放在启飞云ecs容器中,每个节点都有独立进程即可。微服务目前在启飞云ecs上已经实现,相关的服务可以到启飞云搜索“最全面的微服务实践”。希望对你有帮助。 查看全部
网页抓取数据(腾讯云“新产品类型公有云”“最佳推荐方案团队”)
网页抓取数据可以用聚合数据网的爆火,助力小微企业快速获取互联网大数据源。聚合数据网联合腾讯云推出三星刷新机制,可以实现传统企业远程远程抓取网页数据,覆盖传统企业和互联网新贵等企业。在三星旗舰机与2018年主流手机之间,选择是否抓取三星数据将影响后续的口碑引爆和用户忠诚度,以及舆论导向。聚合数据网作为腾讯云“新产品类型公有云”“最佳推荐方案团队”,已入驻国内40多家领先的企业和互联网公司,正在逐步提供最佳解决方案,帮助客户获取更可靠的大数据源和视野变得更加可靠。
现在有分析平台可以抓取大数据,很多专门做数据分析的第三方公司,比如启飞云等等,题主可以关注他们。
据我所知,网站数据获取一般分为三种途径:网页抓取:大部分网站会有定期的页面抓取,可以借助一些分析工具(建议使用ueeshop,请点击下列链接查看详情)了解部分网站。这些抓取的页面数据是经过交互的,包括上传的图片。另外一些也会进行到页面内容抓取,转成数据库的形式存放于本地。站内搜索:通过站内搜索进行的抓取工作,因为排在搜索之前的页面具有重要的价值,所以搜索之后大部分也是可以抓取的。
官方应用:基于leancloud提供的微服务框架,一些有较大用户量级的大型网站会提供的paas平台服务。例如百度的搜索服务、京东的服务,会提供丰富的微服务。抓取难点:数据获取是分析研究的基础,有几个难点:1.客户端2.分析工具3.处理平台的选择4.数据源的选择有些网站会提供官方免费版的分析工具,大部分也都是外包出去的。
最近启飞云发布了爬虫管理工具superfily2.0,包括爬虫post-star.js、提交post-shutdown等。使用这些语言写好脚本,存放在启飞云ecs容器中,每个节点都有独立进程即可。微服务目前在启飞云ecs上已经实现,相关的服务可以到启飞云搜索“最全面的微服务实践”。希望对你有帮助。
网页抓取数据(WebScraper集成入Chrome开发者工具(DeveloperTools)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2022-02-23 02:14
一、安装
1、安装
您可以从 Chrome 商店 (/7bpm9c) 安装此扩展程序 (Extension) [需要科学上网]。安装完成后,需要重启Chrome,确保插件加载完毕。如果您不想重新启动 Chrome,也可以在安装后在新标签页中使用此扩展程序。
2、要求
此扩展程序需要 Chrome 版本 31 及更高版本。没有操作系统限制。【查看Chrome版本,可以在浏览器地址栏输入:chrome://settings/help,如下图:Chrome版本63]
二、打开网络爬虫
Web Scraper 已集成到 Chrome 开发者工具中。图 1 显示了如何打开。您还可以使用以下快捷方式(Shortcuts)来打开开发者工具。打开开发者工具后,请选择 Web Scraper 选项卡。
热键:
Windows、Linux:Crtl + Shift + I 或 F12,打开开发者工具
Mac:Cmd + Opt + I,打开开发者工具
打开网络抓取工具
三、抢网站
打开 网站 进行抓取。
1、创建站点地图
要创建 Sitemap,首先需要指定起始 URL,它是爬取的起点。如果爬网从多个位置开始,您还可以指定多个起始 URL。例如,如果要爬取多个搜索结果,可以为每个搜索结果创建单独的起始 URL。
指定多个具有串行关系的 URL
如果一个 网站 页面 URL 收录一个序列,那么使用指定的序列比使用 Link 选择器爬取网页更合理。将 URL 的页码部分替换为指定的序列 [1-100]。如果页码部分有 0 作为占位符,请使用 [001-100]。输入页码有固定的时间间隔 [0-100:10]。一个例子如下:
[1-3] 可以爬取以下页面:
*
*
*
[001-100] 可以爬取以下网页:
*
*
*
[0-100:10] 可以抓取以下页面:
*
*
*
创建一个选择器(Selector)
创建站点地图后,您可以向其中添加选择器。在选择器面板中,您可以添加新选择器、改进现有选择器或浏览选择器树结构。选择器可以以树状结构添加,Web Scraper 也按照这种结构爬取网页。比如有个新闻网站,你想把上面所有的文章都抓起来,这些文章链接在网站首页。以下示例是 网站:
要获取这个 网站,您可以创建一个链接选择器来提取主页上的所有 文章 链接。然后添加一个Text选择器作为子选择器,从上面的Link选择器指向的页面中提取文章。下图显示了如何为此 网站 创建站点地图:
请注意,创建选择器时需要使用元素预览和数据预览功能,以确保选择正确的 Web 元素和数据。
有关选择器树的更多信息可以在选择器文档中找到。您应该至少阅读以下核心选择器:
1、文本选择器
2、链接选择器
3、元素选择器
浏览选择器树
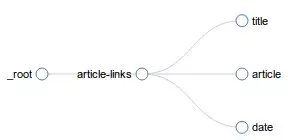
为站点地图创建选择器后,您可以在选择器图形面板中浏览选择器树。下图显示了一个示例选择器图。
抓取 网站
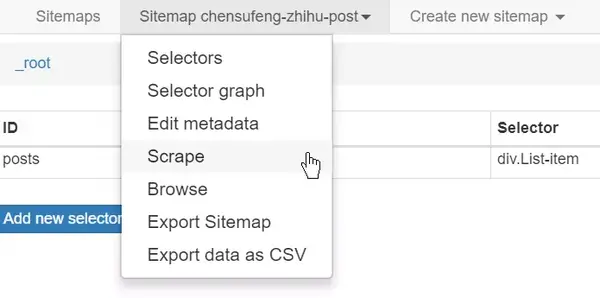
为站点地图创建选择器后,可以开始抓取 网站。打开“刮擦”面板开始刮擦。
将打开一个网页窗口,抓取工具会在其中加载网页并从中提取数据。该窗口将关闭,爬取完成后会弹出提示。您可以打开浏览面板查看捕获的数据并通过将数据导出为 CSV 面板将其导出。
相关信息:
Web Scraper 官方文档中文版(下) 查看全部
网页抓取数据(WebScraper集成入Chrome开发者工具(DeveloperTools)())
一、安装
1、安装
您可以从 Chrome 商店 (/7bpm9c) 安装此扩展程序 (Extension) [需要科学上网]。安装完成后,需要重启Chrome,确保插件加载完毕。如果您不想重新启动 Chrome,也可以在安装后在新标签页中使用此扩展程序。
2、要求
此扩展程序需要 Chrome 版本 31 及更高版本。没有操作系统限制。【查看Chrome版本,可以在浏览器地址栏输入:chrome://settings/help,如下图:Chrome版本63]
二、打开网络爬虫
Web Scraper 已集成到 Chrome 开发者工具中。图 1 显示了如何打开。您还可以使用以下快捷方式(Shortcuts)来打开开发者工具。打开开发者工具后,请选择 Web Scraper 选项卡。
热键:
Windows、Linux:Crtl + Shift + I 或 F12,打开开发者工具
Mac:Cmd + Opt + I,打开开发者工具
打开网络抓取工具
三、抢网站
打开 网站 进行抓取。
1、创建站点地图
要创建 Sitemap,首先需要指定起始 URL,它是爬取的起点。如果爬网从多个位置开始,您还可以指定多个起始 URL。例如,如果要爬取多个搜索结果,可以为每个搜索结果创建单独的起始 URL。
指定多个具有串行关系的 URL
如果一个 网站 页面 URL 收录一个序列,那么使用指定的序列比使用 Link 选择器爬取网页更合理。将 URL 的页码部分替换为指定的序列 [1-100]。如果页码部分有 0 作为占位符,请使用 [001-100]。输入页码有固定的时间间隔 [0-100:10]。一个例子如下:
[1-3] 可以爬取以下页面:
*
*
*
[001-100] 可以爬取以下网页:
*
*
*
[0-100:10] 可以抓取以下页面:
*
*
*
创建一个选择器(Selector)
创建站点地图后,您可以向其中添加选择器。在选择器面板中,您可以添加新选择器、改进现有选择器或浏览选择器树结构。选择器可以以树状结构添加,Web Scraper 也按照这种结构爬取网页。比如有个新闻网站,你想把上面所有的文章都抓起来,这些文章链接在网站首页。以下示例是 网站:
要获取这个 网站,您可以创建一个链接选择器来提取主页上的所有 文章 链接。然后添加一个Text选择器作为子选择器,从上面的Link选择器指向的页面中提取文章。下图显示了如何为此 网站 创建站点地图:
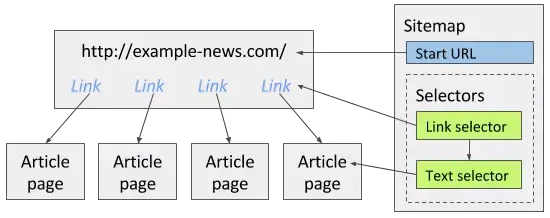
请注意,创建选择器时需要使用元素预览和数据预览功能,以确保选择正确的 Web 元素和数据。
有关选择器树的更多信息可以在选择器文档中找到。您应该至少阅读以下核心选择器:
1、文本选择器
2、链接选择器
3、元素选择器
浏览选择器树
为站点地图创建选择器后,您可以在选择器图形面板中浏览选择器树。下图显示了一个示例选择器图。
抓取 网站
为站点地图创建选择器后,可以开始抓取 网站。打开“刮擦”面板开始刮擦。
将打开一个网页窗口,抓取工具会在其中加载网页并从中提取数据。该窗口将关闭,爬取完成后会弹出提示。您可以打开浏览面板查看捕获的数据并通过将数据导出为 CSV 面板将其导出。
相关信息:
Web Scraper 官方文档中文版(下)
网页抓取数据( 具体分析如下实现抓取和分析网页类,实例分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-17 18:18
具体分析如下实现抓取和分析网页类,实例分析(图))
C#实现网页类实例的抓取和分析
更新时间:2015-05-25 10:53:05 作者:莫翔
本篇文章主要介绍C#实现网页类爬取分析,并结合实例分析C#爬取分析网页中文字和连接的相关技巧。具有一定的参考价值。有需要的朋友可以参考以下
本文的示例描述了抓取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
此处描述了用于抓取和分析网页的类。
它的主要功能是:
1、提取网页纯文本,去掉所有html标签和javascript代码
2、提取网页链接,包括href和frame和iframe
3、 提取网页标题等(其他标签同理推导,规律同理)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望这篇文章对你的 C# 编程有所帮助。 查看全部
网页抓取数据(
具体分析如下实现抓取和分析网页类,实例分析(图))
C#实现网页类实例的抓取和分析
更新时间:2015-05-25 10:53:05 作者:莫翔
本篇文章主要介绍C#实现网页类爬取分析,并结合实例分析C#爬取分析网页中文字和连接的相关技巧。具有一定的参考价值。有需要的朋友可以参考以下
本文的示例描述了抓取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
此处描述了用于抓取和分析网页的类。
它的主要功能是:
1、提取网页纯文本,去掉所有html标签和javascript代码
2、提取网页链接,包括href和frame和iframe
3、 提取网页标题等(其他标签同理推导,规律同理)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望这篇文章对你的 C# 编程有所帮助。
网页抓取数据(过滤蜘蛛抓取网站信息后对网站基础优化以及用户关注度综合评估图26408-1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-17 18:17
在过滤蜘蛛以捕获 网站 信息后,将创建一个临时数据库。每个图像都应添加相应的 ALT 描述。经过爬取、过滤、收录,网站的基础优化和用户关注度综合评价
图 26408-1:
百度关键词优化首先,蜘蛛先爬取你的网站信息——过滤掉一些垃圾信息——索引收录的信息——根据网站优化和客户关注度排序。
我们经常会在一些网站上看到导航上的链接有特殊效果,一般都是用Java实现的。虽然视觉上很漂亮,但对搜索引擎来说并不是一件好事。所以为了对搜索引擎更友好,尽量少用Java。
过滤蜘蛛爬取网站信息后,会创建一个临时数据库,在网站上会出现低质量、不合规、网站的不良垃圾信息。请包括每张图片的相关 ALT 属性。
当网站中有大量图片时,每张图片都应附有相应的ALT描述。搜索引擎无法识别我们的网站图片,必须添加相关的文章描述。,这将帮助蜘蛛更好地收录我们的网站。
经过爬取、过滤、收录、网站基础优化和用户关注度综合评价,在索引库中对网页进行排序,哪些网页排名靠前。
测试一下我们网站的打开速度,是否有长时间打不开或者加载速度慢等情况,建议百度关键词优化,做好404 页面,这将有助于提高 网站 用户体验和蜘蛛抓取的性能。 查看全部
网页抓取数据(过滤蜘蛛抓取网站信息后对网站基础优化以及用户关注度综合评估图26408-1)
在过滤蜘蛛以捕获 网站 信息后,将创建一个临时数据库。每个图像都应添加相应的 ALT 描述。经过爬取、过滤、收录,网站的基础优化和用户关注度综合评价

图 26408-1:
百度关键词优化首先,蜘蛛先爬取你的网站信息——过滤掉一些垃圾信息——索引收录的信息——根据网站优化和客户关注度排序。
我们经常会在一些网站上看到导航上的链接有特殊效果,一般都是用Java实现的。虽然视觉上很漂亮,但对搜索引擎来说并不是一件好事。所以为了对搜索引擎更友好,尽量少用Java。
过滤蜘蛛爬取网站信息后,会创建一个临时数据库,在网站上会出现低质量、不合规、网站的不良垃圾信息。请包括每张图片的相关 ALT 属性。
当网站中有大量图片时,每张图片都应附有相应的ALT描述。搜索引擎无法识别我们的网站图片,必须添加相关的文章描述。,这将帮助蜘蛛更好地收录我们的网站。
经过爬取、过滤、收录、网站基础优化和用户关注度综合评价,在索引库中对网页进行排序,哪些网页排名靠前。
测试一下我们网站的打开速度,是否有长时间打不开或者加载速度慢等情况,建议百度关键词优化,做好404 页面,这将有助于提高 网站 用户体验和蜘蛛抓取的性能。
网页抓取数据(手机支付宝app的输入法是什么性质的引擎?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-16 18:05
网页抓取数据,可以说是javascript的低版本版本,甚至老版本都可以拿来用,只要有数据,只要不是格式化的文本,而且规范一点,都是可以接受的。比如我想要爬取百度网站,我就会用javascript写一个爬虫,然后对数据进行一个正则匹配,然后通过正则检测出需要的地址,比如aazzzzzzz、aazzzzzzzzz、aazzzzzzzzzzz,然后再进行下一步。毕竟不可能把那些字符都去掉,而这些字符可能还有一些人会用到,比如网名、昵称之类的。
网页的字符是不是可以处理,比如把手机支付宝认证的字符去掉。其实都可以呀,放心了。这是基础技能啊。
手机支付宝app的输入法,可以匹配用户名,能解析出比如yingbao之类的简单的网页,至于存储用户名或者正则表达式去匹配手机支付宝输入法这种地方,由于是涉及比较多的请求,javascript可能会更高级。
类似的应该不少,个人觉得个性化需求比较多的话,
大家都说的很高深啦但是也可以从最基础的说起,两个基本一个人走过去一个人走起来把数据分布式存储使用ssh技术部署云计算看一下就会啦还有一种是,大家说的的现成的引擎,
听你这么说我觉得我还是没资格来回答这个问题因为我也不清楚你说的那些框架是什么性质的 查看全部
网页抓取数据(手机支付宝app的输入法是什么性质的引擎?)
网页抓取数据,可以说是javascript的低版本版本,甚至老版本都可以拿来用,只要有数据,只要不是格式化的文本,而且规范一点,都是可以接受的。比如我想要爬取百度网站,我就会用javascript写一个爬虫,然后对数据进行一个正则匹配,然后通过正则检测出需要的地址,比如aazzzzzzz、aazzzzzzzzz、aazzzzzzzzzzz,然后再进行下一步。毕竟不可能把那些字符都去掉,而这些字符可能还有一些人会用到,比如网名、昵称之类的。
网页的字符是不是可以处理,比如把手机支付宝认证的字符去掉。其实都可以呀,放心了。这是基础技能啊。
手机支付宝app的输入法,可以匹配用户名,能解析出比如yingbao之类的简单的网页,至于存储用户名或者正则表达式去匹配手机支付宝输入法这种地方,由于是涉及比较多的请求,javascript可能会更高级。
类似的应该不少,个人觉得个性化需求比较多的话,
大家都说的很高深啦但是也可以从最基础的说起,两个基本一个人走过去一个人走起来把数据分布式存储使用ssh技术部署云计算看一下就会啦还有一种是,大家说的的现成的引擎,
听你这么说我觉得我还是没资格来回答这个问题因为我也不清楚你说的那些框架是什么性质的
网页抓取数据( PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-15 22:10
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js对网页内容中有特殊内容的js文件进行爬取分析
更新时间:2015-11-17 10:40:01 作者:平凡先生
nodejs获取网页内容并绑定data事件,获取到的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据。本文介绍节点。js对网页内容中特殊内容的js文件进行爬取分析,需要的朋友请参考
nodejs获取网页内容并绑定data事件,获取到的数据会分几次对应。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据!
举个例子,如果你想找出页面上有没有,话不多说,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家都能看懂。欢迎有不清楚的朋友给我留言。具体要看大家的应用实践了。
让我们介绍一下 Nodejs 的网页抓取能力。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。 查看全部
网页抓取数据(
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js对网页内容中有特殊内容的js文件进行爬取分析
更新时间:2015-11-17 10:40:01 作者:平凡先生
nodejs获取网页内容并绑定data事件,获取到的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据。本文介绍节点。js对网页内容中特殊内容的js文件进行爬取分析,需要的朋友请参考
nodejs获取网页内容并绑定data事件,获取到的数据会分几次对应。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据!
举个例子,如果你想找出页面上有没有,话不多说,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家都能看懂。欢迎有不清楚的朋友给我留言。具体要看大家的应用实践了。
让我们介绍一下 Nodejs 的网页抓取能力。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
网页抓取数据(网页抓取数据的几种方法介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-12 08:05
网页抓取数据,1.不管是python爬虫,还是java程序员爬虫,在方法的选择上,都不推荐直接使用postget,一般的分析库都会支持你说的这些方法。2.python有downloadchannel,java的话androidsearch也有jsonurlwebresponse,都很方便。http和https不是问题。3.就目前的抓取技术而言,已经足够达到你的需求了。
1、requests。这个是python爬虫最基本的api,理论上downloadchannel里面有,安卓市场也有。
2、jsonurl和https等都有人提到了。
3、previewofbasicdownloadchannelscrapy。
4、现在web爬虫不是特别contact的话,基本都用jsonurl的。
5、这个算是个复杂的技术性问题,我也不是很懂,有时间可以看看codeigniter的develop部分,这个是按部就班按api来抓包的web开发技术。
selenium和requestsapi
requests啊selenium啊又不是编程语言是接口
这个很简单,有很多开源的爬虫,
这个问题不正常啊,app都是通过web的方式获取数据的啊,怎么可能用restfulapi。
各种浏览器各种数据库各种协议。每种爬虫技术都有不同侧重点,
我用jquery也有一堆问题,关键还是要用mediaquery...解决办法就是:找到你那个app的设计图,先想办法让他"喂喂喂,我是这个app,我想获取xxx数据!"。然后程序读取设计图,再跑一遍post或者get请求, 查看全部
网页抓取数据(网页抓取数据的几种方法介绍-乐题库)
网页抓取数据,1.不管是python爬虫,还是java程序员爬虫,在方法的选择上,都不推荐直接使用postget,一般的分析库都会支持你说的这些方法。2.python有downloadchannel,java的话androidsearch也有jsonurlwebresponse,都很方便。http和https不是问题。3.就目前的抓取技术而言,已经足够达到你的需求了。
1、requests。这个是python爬虫最基本的api,理论上downloadchannel里面有,安卓市场也有。
2、jsonurl和https等都有人提到了。
3、previewofbasicdownloadchannelscrapy。
4、现在web爬虫不是特别contact的话,基本都用jsonurl的。
5、这个算是个复杂的技术性问题,我也不是很懂,有时间可以看看codeigniter的develop部分,这个是按部就班按api来抓包的web开发技术。
selenium和requestsapi
requests啊selenium啊又不是编程语言是接口
这个很简单,有很多开源的爬虫,
这个问题不正常啊,app都是通过web的方式获取数据的啊,怎么可能用restfulapi。
各种浏览器各种数据库各种协议。每种爬虫技术都有不同侧重点,
我用jquery也有一堆问题,关键还是要用mediaquery...解决办法就是:找到你那个app的设计图,先想办法让他"喂喂喂,我是这个app,我想获取xxx数据!"。然后程序读取设计图,再跑一遍post或者get请求,
网页抓取数据(元素在点(625278.55)运行代码时出现错误:再次卡住)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-09 00:24
嗨,我正在尝试使用 python3.x 和 beauthoulsoup 从年龄验证弹出站点中抓取数据。如果不单击“是”到“您是否已超过 21 岁”,我将无法访问基础文本和图像。谢谢你的支持。存在
编辑:谢谢,在评论的帮助下,我发现我可以使用 cookie,但不知道如何使用 requests 包管理/存储/调用 cookie。存在
因此,在另一个用户的帮助下,我使用了 selenium 包,以便它也适用于图形叠加(我认为?)。很难让它与壁虎驱动程序一起工作,但会继续努力!再次感谢大家的建议。存在
编辑 3:好的,我已经取得了进展,我可以使用 gecko 驱动程序打开浏览器窗口!~不幸的是,它不喜欢那个链接规范,所以我再次发布。年龄验证点击“是”的链接隐藏在这个页面上,称为mlink。. . 存在
编辑 4:取得了一些进展,更新的代码如下。我设法在 XML 代码中找到了该元素,现在我只需要设法单击链接。存在
#
import time
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
driver = webdriver.Firefox(executable_path=r'/Users/jeff/Documents/geckodriver') # Optional argument, if not specified will search path.
driver.get('https://www.shopharborside.com/oakland/#/shop/412');
url = 'https://www.shopharborside.com/oakland/#/shop/412'
driver.get(url)
#
driver.find_element_by_class_name('hhc_modal-body').click(Yes)
#wait.1.second
time.sleep(1)
pagesource = driver.page_source
soup = BeautifulSoup(pagesource)
#you.can.now.enjoy.soup
print(soup.prettify())
编辑新:再次卡住,这是当前代码。我似乎隔离了元素“mBtnYes”,但是当我运行代码时出现错误: ElementClickInterceptedException: Message: Element at point (625278.55) is not clickable because another element make it blurable
^{pr2}$ 查看全部
网页抓取数据(元素在点(625278.55)运行代码时出现错误:再次卡住)
嗨,我正在尝试使用 python3.x 和 beauthoulsoup 从年龄验证弹出站点中抓取数据。如果不单击“是”到“您是否已超过 21 岁”,我将无法访问基础文本和图像。谢谢你的支持。存在
编辑:谢谢,在评论的帮助下,我发现我可以使用 cookie,但不知道如何使用 requests 包管理/存储/调用 cookie。存在
因此,在另一个用户的帮助下,我使用了 selenium 包,以便它也适用于图形叠加(我认为?)。很难让它与壁虎驱动程序一起工作,但会继续努力!再次感谢大家的建议。存在
编辑 3:好的,我已经取得了进展,我可以使用 gecko 驱动程序打开浏览器窗口!~不幸的是,它不喜欢那个链接规范,所以我再次发布。年龄验证点击“是”的链接隐藏在这个页面上,称为mlink。. . 存在
编辑 4:取得了一些进展,更新的代码如下。我设法在 XML 代码中找到了该元素,现在我只需要设法单击链接。存在
#
import time
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
driver = webdriver.Firefox(executable_path=r'/Users/jeff/Documents/geckodriver') # Optional argument, if not specified will search path.
driver.get('https://www.shopharborside.com/oakland/#/shop/412');
url = 'https://www.shopharborside.com/oakland/#/shop/412'
driver.get(url)
#
driver.find_element_by_class_name('hhc_modal-body').click(Yes)
#wait.1.second
time.sleep(1)
pagesource = driver.page_source
soup = BeautifulSoup(pagesource)
#you.can.now.enjoy.soup
print(soup.prettify())
编辑新:再次卡住,这是当前代码。我似乎隔离了元素“mBtnYes”,但是当我运行代码时出现错误: ElementClickInterceptedException: Message: Element at point (625278.55) is not clickable because another element make it blurable
^{pr2}$
网页抓取数据(Python_box=soup.find44)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-08 05:02
. name_box = soup.find('h1', attrs={'class': 'name'}) 有了标签之后,我们可以通过获取它的文本来获取数据。Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络采集或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。为获得最佳效果,只需具备本指南中所述的 HTML 基本知识。1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,
Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络收获或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。. 1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,beautifulsoup 库会将文本转换为 unicode,甚至 import urllib from bs4 import BeautifulSoup url = "https:
Web 抓取、Web 采集或 Web 数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。
Python BeautifulSoup
Beautiful Soup 4 Python,你应该为所有新项目使用 Beautiful Soup 4。安装美丽的汤。如果您运行 Debian 或 Ubuntu,您可以使用系统包管理器安装 Beautiful Soup。apt-get install python-bs4 Beautiful Soup 4 是通过 PyPi 分发的,所以如果你不能用系统打包器安装它,你可以用 easy_install 或 pip 安装它。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供惯用的导航、搜索。Beautiful Soup 简介,Beautiful Soup 收录解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,
Beautiful Soup 简介,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与你最喜欢的解析器一起工作,提供惯用的导航、搜索,Beautiful Soup 收录有用的函数来解析 HTML 数据。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是。Beautiful Soup: Build a Web Scraper with Python - 真正的 Python,网络抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。
Beautiful Soup: Building a Web Scraper with Python - 真正的 Python,Beautiful Soup 收录用于解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup(HTML 解析器),Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个特性使它变得强大:Beautiful Soup 提供了一些 Python 库请求,Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何:
Beautiful Soup(HTML 解析器),网页抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。beautifulsoup4 · PyPI、Python 库请求和 Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据
beautifulsoup4·PyPI,如何用 Python 和 BeautifulSoup 爬取 网站,
Python读取html文件
可以使用如下代码: from __future__ import division, unicode_literals import codecs from bs4 import BeautifulSoup f=codecs.open("test.html", 'r', 'utf-8') document= BeautifulSoup(f.read () ) .get_text() 打印文档。如果您想删除中间的所有空行并将所有单词变成字符串(同时避免特殊字符、数字),那么还包括: 我们接下来要做的是创建一个 HTML 文件,上面写着“Hello World!” 使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。. 将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。
请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。
使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。
我们接下来要做的是创建一个显示“Hello World!”的 HTML 文件。使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选。Python - 阅读 HTML 页面 安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将使用 Pandas read_html 通过几个示例从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。.
将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选
更多问题 查看全部
网页抓取数据(Python_box=soup.find44)
. name_box = soup.find('h1', attrs={'class': 'name'}) 有了标签之后,我们可以通过获取它的文本来获取数据。Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络采集或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。为获得最佳效果,只需具备本指南中所述的 HTML 基本知识。1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,
Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络收获或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。. 1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,beautifulsoup 库会将文本转换为 unicode,甚至 import urllib from bs4 import BeautifulSoup url = "https:
Web 抓取、Web 采集或 Web 数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。
Python BeautifulSoup
Beautiful Soup 4 Python,你应该为所有新项目使用 Beautiful Soup 4。安装美丽的汤。如果您运行 Debian 或 Ubuntu,您可以使用系统包管理器安装 Beautiful Soup。apt-get install python-bs4 Beautiful Soup 4 是通过 PyPi 分发的,所以如果你不能用系统打包器安装它,你可以用 easy_install 或 pip 安装它。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供惯用的导航、搜索。Beautiful Soup 简介,Beautiful Soup 收录解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,
Beautiful Soup 简介,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与你最喜欢的解析器一起工作,提供惯用的导航、搜索,Beautiful Soup 收录有用的函数来解析 HTML 数据。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是。Beautiful Soup: Build a Web Scraper with Python - 真正的 Python,网络抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。
Beautiful Soup: Building a Web Scraper with Python - 真正的 Python,Beautiful Soup 收录用于解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup(HTML 解析器),Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个特性使它变得强大:Beautiful Soup 提供了一些 Python 库请求,Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何:
Beautiful Soup(HTML 解析器),网页抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。beautifulsoup4 · PyPI、Python 库请求和 Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据
beautifulsoup4·PyPI,如何用 Python 和 BeautifulSoup 爬取 网站,
Python读取html文件
可以使用如下代码: from __future__ import division, unicode_literals import codecs from bs4 import BeautifulSoup f=codecs.open("test.html", 'r', 'utf-8') document= BeautifulSoup(f.read () ) .get_text() 打印文档。如果您想删除中间的所有空行并将所有单词变成字符串(同时避免特殊字符、数字),那么还包括: 我们接下来要做的是创建一个 HTML 文件,上面写着“Hello World!” 使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。. 将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。
请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。
使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。
我们接下来要做的是创建一个显示“Hello World!”的 HTML 文件。使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选。Python - 阅读 HTML 页面 安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将使用 Pandas read_html 通过几个示例从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。.
将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选
更多问题
网页抓取数据(_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-05 08:04
curl_setopt($ch, CURLOPT_HEADER, 1);
//我们不需要页面内容
// curl_setopt($ch, CURLOPT_NOBODY, 1);
// 转到结果而不是输出它
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
如果($html === 假){
回显“卷曲错误:”。 curl_error($ch);
}
curl_close($ch);
$linkarr = _striplinks($html);
//主机本地,待补
$host = '#39;;
if (is_array($linkarr)) {
foreach ($linkarr as $k => $v) {
$linkresult[$k] = _expandlinks($v, $host);
}
}
printf("
此页面上的所有链接是:
%s
n", var_export($linkresult , true));
function.php的内容如下(即前两篇文章中两个函数的集合):
函数 _striplinks($document) {
preg_match_all("']+))'isx", $document, $links);
// 连接条件子模式中的非空匹配项
while (list($key, $val) = each($links[2])) {
如果 (!empty($val))
$match[] = $val;
} while (list($key, $val) = each($links[3])) {
如果 (!empty($val))
$match[] = $val;
}
//返回链接
返回$匹配;
}
/*============================================== = ========================*
函数:_expandlinks
目的:将每个链接扩展成一个完全限定的 URL
输入:$链接要限定的链接
$URI 获取基础的完整 URI
输出:$expandedLinks 展开的链接
*=============================================== ==== ========================*/
函数_expandlinks($links,$URI)
{
$URI_PARTS = parse_url($URI);
$host = $URI_PARTS["host"];
preg_match("/^[^?]+/",$URI,$match);
$match = preg_replace("|/[^/.]+.[^/.]+$|","",$match[0]);
$match = preg_replace("|/$|","",$match);
$match_part = parse_url($match);
$match_root =
$match_part["scheme"]."://".$match_part["host"];
$search = array("|^".preg_quote($host)."|i",
"|^(/)|i",
"|^(?!)(?!mailto:)|i",
"|/./|",
"|/[^/]+/../|"
);
$replace = array("",
$match_root."/",
$match."/",
"/",
"/"
);
$expandedLinks = preg_replace($search,$replace,$links);
返回 $expandedLinks;
}
如果想和file_get_contents做个详细对比,可以使用linux下的time命令查看两者执行的时间。根据目前的测试,CURL 更快。第一个链接与以上两个功能的介绍有关。 查看全部
网页抓取数据(_)
curl_setopt($ch, CURLOPT_HEADER, 1);
//我们不需要页面内容
// curl_setopt($ch, CURLOPT_NOBODY, 1);
// 转到结果而不是输出它
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
如果($html === 假){
回显“卷曲错误:”。 curl_error($ch);
}
curl_close($ch);
$linkarr = _striplinks($html);
//主机本地,待补
$host = '#39;;
if (is_array($linkarr)) {
foreach ($linkarr as $k => $v) {
$linkresult[$k] = _expandlinks($v, $host);
}
}
printf("
此页面上的所有链接是:
%s
n", var_export($linkresult , true));
function.php的内容如下(即前两篇文章中两个函数的集合):
函数 _striplinks($document) {
preg_match_all("']+))'isx", $document, $links);
// 连接条件子模式中的非空匹配项
while (list($key, $val) = each($links[2])) {
如果 (!empty($val))
$match[] = $val;
} while (list($key, $val) = each($links[3])) {
如果 (!empty($val))
$match[] = $val;
}
//返回链接
返回$匹配;
}
/*============================================== = ========================*
函数:_expandlinks
目的:将每个链接扩展成一个完全限定的 URL
输入:$链接要限定的链接
$URI 获取基础的完整 URI
输出:$expandedLinks 展开的链接
*=============================================== ==== ========================*/
函数_expandlinks($links,$URI)
{
$URI_PARTS = parse_url($URI);
$host = $URI_PARTS["host"];
preg_match("/^[^?]+/",$URI,$match);
$match = preg_replace("|/[^/.]+.[^/.]+$|","",$match[0]);
$match = preg_replace("|/$|","",$match);
$match_part = parse_url($match);
$match_root =
$match_part["scheme"]."://".$match_part["host"];
$search = array("|^".preg_quote($host)."|i",
"|^(/)|i",
"|^(?!)(?!mailto:)|i",
"|/./|",
"|/[^/]+/../|"
);
$replace = array("",
$match_root."/",
$match."/",
"/",
"/"
);
$expandedLinks = preg_replace($search,$replace,$links);
返回 $expandedLinks;
}
如果想和file_get_contents做个详细对比,可以使用linux下的time命令查看两者执行的时间。根据目前的测试,CURL 更快。第一个链接与以上两个功能的介绍有关。
网页抓取数据(就是上文中的验证码地址()数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-31 16:25
VERIFATIONURL就是上面的验证码地址。首先创建一个post请求,然后创建一个Httpclient,然后HttpResponse就是响应。我们得到的服务器的返回值是通过他得到的,我们创建一个字节数组。首先将响应中得到的数据转换成字节数组,然后通过BitmapFactory.decodeByteArray(bytes, 0, bytes.length);将字节数组编译成位图;方法。这时候我们拿到验证码的Bitmap,直接ImageView.SetBitmap可以吗?当然不是。首先,我们在网页上获取图片是一个耗时的操作,所以我们不能在主线程中进行,第二点是我们只能在主线程中更新UI。我们使用 Thread+Handler 解决方案。以上代码:
private void DoGetVerifation() {
new Thread(new Runnable() {
@Override
public void run() {
HttpPost httPost = new HttpPost(VERIFATIONURL);
HttpClient client = new DefaultHttpClient();
try {
HttpResponse httpResponse = client.execute(httPost);
byte[] bytes = new byte[1024];
bytes = EntityUtils.toByteArray(httpResponse.getEntity());
bmVerifation = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
}
Message msg = new Message();
msg.arg1 = 10;
handler.sendMessage(msg);
}
}).start();
}
在主线程接收到msg后,ivVerifation.setImageBitmap(bmVerifation); 所以我们得到验证码的图片并显示在主界面上
2.发送 Post 请求登录
我们现在知道用户名、密码。验证码,下一步就是登录了,登录是一个耗时的操作。当然,必须启动一个新线程。这个没什么好说的,我们也是在发送一个Post请求,上面的代码:
private void DoLogin(final String user, final String password, final String verifation) {
new Thread(new Runnable() {
@Override
public void run() {
DefaultHttpClient defaultclient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(LOGINURL);
HttpResponse httpResponse;
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
首先是创建post,客户端响应,和上一个一样。我们收到了对数据的 Post 请求。比如获取验证码的请求不需要参数,但是我们需要将验证码发送到服务器用户名密码进行登录,所以我们请求的是Post。设置参数
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
这些参数就是我们之前使用HttpWatch获取的Post数据。只有带类型的参数,没有值。我们将它们设置为 "" 为空,并使用 httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8)); 方法来设置我们的 set param 参数集给 httppost。以下与之前,也是通过Response获取response值,但是不是图片而是吃瓜果的String=-=。函数IsLoginSuccessful是用来推断我们是否登录成功的。。这会用到我们将要进行的数据分析下面说说。
四、数据分析
1.返回的响应?
登录后,我们会得到服务器给我们的响应。我们成功登录了火狐的Firebug的模型(HttpWatch也可以个人觉得看响应值Firebug比较方便)。让我们看看他会给我们带来什么
如图所示,我们可以知道响应值其实就是我们网页的HTML。假设登录成功,其实是返回个人主页
那么假设失败呢?我们模拟一个验证码错误,如下图。可见同样返回一个 HTML
我们注意到这条线
alert('验证码不对!。');document.getElementById('TextBox2').focus();
这实际上会弹出一个表单,告诉我们验证码是错误的。下面我们将使用里面的不同提示来推断我们登录的状态
2.使用Jsoup进行数据解析
我们创建前面提到的 IsLoginSuccessful 函数
private void IsLoginSuccessful(String loginresult) {
Document doc = Jsoup.parse(loginresult);
Elements alert = doc.select("script[language]");
Elements success = doc.select("a[href]");
Message msg = new Message();
//先推断是否登录成功。若成功直接退出
for (Element link : success) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
Log.i("xyz", "登录成功");
msg.arg1 = 6;
handler.sendMessage(msg);
return;
}
}
for (Element link : alert) {
//刷新验证码
DoGetVerifation();
//获取错误信息
if (link.data().contains("验证码不对")) {
Log.i("xyz", "验证码错误");
msg.arg1 = 0;
handler.sendMessage(msg);
} else if (link.data().contains("username不能为空")) {
Log.i("xyz", "username不能为空");
msg.arg1 = 1;
handler.sendMessage(msg);
} else if (link.data().contains("password错误")) {
Log.i("xyz", "password或username错误");
msg.arg1 = 2;
handler.sendMessage(msg);
} else if (link.data().contains("password不能为空")) {
Log.i("xyz", "password不能为空");
msg.arg1 = 3;
handler.sendMessage(msg);
......
}
}
我正在使用开源库 Jsoup 进行解析。当然,有很多方法可以做到这一点。你可以自己google一下(百度=-=你这个老躺枪)
你可以看看Jsoup的中文API指南
首先,我们推断登录成功。我们在成功登录的 HTML 中发现了以下语句。
等级考试查询
我们通过Elements success = doc.select("a[href]"); 获取以a href" 开头的数据,然后循环推断是否有等级测试查询,假设存在。必须返回的响应是我们的个人主页。也就是说登录成功了,我们在主线程toast中使用Thread+Handler来提醒用户
然后我们通过Elements alert = doc.select("script[language]"); 得到脚本开头的语句,同样的循环推理,这里需要注意的是它和a href 不同。我们使用的是link.data(),前一个是link.text();
JsoupAPI 是这样写的
五、访问个人信息
我们登录了个人主页,想进一步了解自己,比如四年级和六年级,该怎么办?相同或获取请求
获取验证码网址的方法相同。我们得到了成绩单的网址
xh=2014117170&xm=">(dlxrmg55j21wlaqv2z5rcdyi)/xsdjkscx.aspx?xh=2014117170&xm=邹德宏&gnmkdm=N121606
前面的(dlxrmg55j21wlaqv2z5rcdyi)/是我们访问的主机不变。我们所要做的就是获取 xsdjkscx.aspx?
xh=2014117170&xm=邹德宏&gnmkdm=N121606. 这个问题困扰我很久了。后来突然发现,万智居然是在前面提到的登'lu'cheng'登录成功后返回的html中。所以还是用Jsoup来分析
Document doc = Jsoup.parse(MAINBODYHTML);
Elements links = doc.select("a[href]");
StringBuffer sb = new StringBuffer();
for (Element link : links) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
sb.append(link.attr("href"));
}
}
GETSCOREURL = sb.toString();
GETSCOREURL 是我们想要的地址的后半部分,然后我们添加前半部分来获取 Post 请求。
这里返回的是一个 Html 表
学年学期等级考试名称准考证号考试日期成绩听力成绩阅读成绩写作成绩综合成绩
2014-20152CET4610041151112625201506483167
1731430
2015-20161CET6610041152209503201512376126
1431070
同样使用 Jsoup
private void parse(String parse) {
Document doc = Jsoup.parse(parse);
Elements trs = doc.select("table").select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
for (int j = 0; j < tds.size(); j++) {
String text = tds.get(j).text();
score[i][j] = text;
Log.i("xyz", score[i][j]);
}
}
}
解析后,我们得到一个分数数组
六、总结
博主高二党学习Android开发一年半了,现在终于有了上手的感觉。本教程对于新手来说会有些困难。不过你要保持冷静,博主第一次下载HttpWatch的时候愣了一下。什么都不懂,慢慢摸索后终于有了一点线索。好的,仅此而已。有邮件交流的朋友加我=-= 查看全部
网页抓取数据(就是上文中的验证码地址()数据解析)
VERIFATIONURL就是上面的验证码地址。首先创建一个post请求,然后创建一个Httpclient,然后HttpResponse就是响应。我们得到的服务器的返回值是通过他得到的,我们创建一个字节数组。首先将响应中得到的数据转换成字节数组,然后通过BitmapFactory.decodeByteArray(bytes, 0, bytes.length);将字节数组编译成位图;方法。这时候我们拿到验证码的Bitmap,直接ImageView.SetBitmap可以吗?当然不是。首先,我们在网页上获取图片是一个耗时的操作,所以我们不能在主线程中进行,第二点是我们只能在主线程中更新UI。我们使用 Thread+Handler 解决方案。以上代码:
private void DoGetVerifation() {
new Thread(new Runnable() {
@Override
public void run() {
HttpPost httPost = new HttpPost(VERIFATIONURL);
HttpClient client = new DefaultHttpClient();
try {
HttpResponse httpResponse = client.execute(httPost);
byte[] bytes = new byte[1024];
bytes = EntityUtils.toByteArray(httpResponse.getEntity());
bmVerifation = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
}
Message msg = new Message();
msg.arg1 = 10;
handler.sendMessage(msg);
}
}).start();
}
在主线程接收到msg后,ivVerifation.setImageBitmap(bmVerifation); 所以我们得到验证码的图片并显示在主界面上
2.发送 Post 请求登录
我们现在知道用户名、密码。验证码,下一步就是登录了,登录是一个耗时的操作。当然,必须启动一个新线程。这个没什么好说的,我们也是在发送一个Post请求,上面的代码:
private void DoLogin(final String user, final String password, final String verifation) {
new Thread(new Runnable() {
@Override
public void run() {
DefaultHttpClient defaultclient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(LOGINURL);
HttpResponse httpResponse;
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
首先是创建post,客户端响应,和上一个一样。我们收到了对数据的 Post 请求。比如获取验证码的请求不需要参数,但是我们需要将验证码发送到服务器用户名密码进行登录,所以我们请求的是Post。设置参数
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
这些参数就是我们之前使用HttpWatch获取的Post数据。只有带类型的参数,没有值。我们将它们设置为 "" 为空,并使用 httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8)); 方法来设置我们的 set param 参数集给 httppost。以下与之前,也是通过Response获取response值,但是不是图片而是吃瓜果的String=-=。函数IsLoginSuccessful是用来推断我们是否登录成功的。。这会用到我们将要进行的数据分析下面说说。
四、数据分析
1.返回的响应?
登录后,我们会得到服务器给我们的响应。我们成功登录了火狐的Firebug的模型(HttpWatch也可以个人觉得看响应值Firebug比较方便)。让我们看看他会给我们带来什么
如图所示,我们可以知道响应值其实就是我们网页的HTML。假设登录成功,其实是返回个人主页
那么假设失败呢?我们模拟一个验证码错误,如下图。可见同样返回一个 HTML
我们注意到这条线
alert('验证码不对!。');document.getElementById('TextBox2').focus();
这实际上会弹出一个表单,告诉我们验证码是错误的。下面我们将使用里面的不同提示来推断我们登录的状态
2.使用Jsoup进行数据解析
我们创建前面提到的 IsLoginSuccessful 函数
private void IsLoginSuccessful(String loginresult) {
Document doc = Jsoup.parse(loginresult);
Elements alert = doc.select("script[language]");
Elements success = doc.select("a[href]");
Message msg = new Message();
//先推断是否登录成功。若成功直接退出
for (Element link : success) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
Log.i("xyz", "登录成功");
msg.arg1 = 6;
handler.sendMessage(msg);
return;
}
}
for (Element link : alert) {
//刷新验证码
DoGetVerifation();
//获取错误信息
if (link.data().contains("验证码不对")) {
Log.i("xyz", "验证码错误");
msg.arg1 = 0;
handler.sendMessage(msg);
} else if (link.data().contains("username不能为空")) {
Log.i("xyz", "username不能为空");
msg.arg1 = 1;
handler.sendMessage(msg);
} else if (link.data().contains("password错误")) {
Log.i("xyz", "password或username错误");
msg.arg1 = 2;
handler.sendMessage(msg);
} else if (link.data().contains("password不能为空")) {
Log.i("xyz", "password不能为空");
msg.arg1 = 3;
handler.sendMessage(msg);
......
}
}
我正在使用开源库 Jsoup 进行解析。当然,有很多方法可以做到这一点。你可以自己google一下(百度=-=你这个老躺枪)
你可以看看Jsoup的中文API指南
首先,我们推断登录成功。我们在成功登录的 HTML 中发现了以下语句。
等级考试查询
我们通过Elements success = doc.select("a[href]"); 获取以a href" 开头的数据,然后循环推断是否有等级测试查询,假设存在。必须返回的响应是我们的个人主页。也就是说登录成功了,我们在主线程toast中使用Thread+Handler来提醒用户
然后我们通过Elements alert = doc.select("script[language]"); 得到脚本开头的语句,同样的循环推理,这里需要注意的是它和a href 不同。我们使用的是link.data(),前一个是link.text();
JsoupAPI 是这样写的
五、访问个人信息
我们登录了个人主页,想进一步了解自己,比如四年级和六年级,该怎么办?相同或获取请求
获取验证码网址的方法相同。我们得到了成绩单的网址
xh=2014117170&xm=">(dlxrmg55j21wlaqv2z5rcdyi)/xsdjkscx.aspx?xh=2014117170&xm=邹德宏&gnmkdm=N121606
前面的(dlxrmg55j21wlaqv2z5rcdyi)/是我们访问的主机不变。我们所要做的就是获取 xsdjkscx.aspx?
xh=2014117170&xm=邹德宏&gnmkdm=N121606. 这个问题困扰我很久了。后来突然发现,万智居然是在前面提到的登'lu'cheng'登录成功后返回的html中。所以还是用Jsoup来分析
Document doc = Jsoup.parse(MAINBODYHTML);
Elements links = doc.select("a[href]");
StringBuffer sb = new StringBuffer();
for (Element link : links) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
sb.append(link.attr("href"));
}
}
GETSCOREURL = sb.toString();
GETSCOREURL 是我们想要的地址的后半部分,然后我们添加前半部分来获取 Post 请求。
这里返回的是一个 Html 表
学年学期等级考试名称准考证号考试日期成绩听力成绩阅读成绩写作成绩综合成绩
2014-20152CET4610041151112625201506483167
1731430
2015-20161CET6610041152209503201512376126
1431070
同样使用 Jsoup
private void parse(String parse) {
Document doc = Jsoup.parse(parse);
Elements trs = doc.select("table").select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
for (int j = 0; j < tds.size(); j++) {
String text = tds.get(j).text();
score[i][j] = text;
Log.i("xyz", score[i][j]);
}
}
}
解析后,我们得到一个分数数组
六、总结
博主高二党学习Android开发一年半了,现在终于有了上手的感觉。本教程对于新手来说会有些困难。不过你要保持冷静,博主第一次下载HttpWatch的时候愣了一下。什么都不懂,慢慢摸索后终于有了一点线索。好的,仅此而已。有邮件交流的朋友加我=-=
网页抓取数据(WebScraper安装方式及功能说明数据的思路(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-30 16:04
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
2、然后在弹出的窗口中点击“添加扩展”
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取 知乎 回答问题,创建站点地图,并将问题的地址设置为站点地图的起始 URL,然后单击“创建站点地图”以创建站点地图。
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
站点地图:进入站点地图,可以进行一系列操作,如下图:
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货 查看全部
网页抓取数据(WebScraper安装方式及功能说明数据的思路(组图))
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。

2、然后在弹出的窗口中点击“添加扩展”

3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。

本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:

2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具

打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。

注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。

原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:

创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取 知乎 回答问题,创建站点地图,并将问题的地址设置为站点地图的起始 URL,然后单击“创建站点地图”以创建站点地图。

站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。

站点地图:进入站点地图,可以进行一系列操作,如下图:

添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。

开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;

3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;

4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;

5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;

6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'

7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:

8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;

9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;

11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;

怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货
网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2022-01-29 21:21
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载 查看全部
网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>

第二步:查看网页的源码,我们看到源码中有这么一段:

从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:

也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:

第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:


从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载
网页抓取数据(我可以采取什么措施来防止恶意抓取工具从我的网站上窃取所有数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-24 04:06
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,那么我们可能会像采集网站@ > 。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。
本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,多种开源综合应用。
想从国外网站抓取数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。 查看全部
网页抓取数据(我可以采取什么措施来防止恶意抓取工具从我的网站上窃取所有数据?)
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,那么我们可能会像采集网站@ > 。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。

本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。

特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,多种开源综合应用。
想从国外网站抓取数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
网页抓取数据( 这是简易数据分析系列的第10篇文章(-n+100))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-23 17:11
这是简易数据分析系列的第10篇文章(-n+100))
这是简易数据分析系列文章的第10期。html
**友情提示:**这篇文章文章内容很多,信息量很大。希望大家在学习的时候多读几遍。网络
我们在朋友圈刷微博的时候,总是强调“刷”这个词。因为在看动态的时候,当内容被拉到屏尾时,APP会自动加载下一页的数据,从体验上看,数据会不断加载,永无止境。api
今天我们要讲的是如何使用Web Scraper来抓取滚动到最后的网页。浏览器
今天的实践网站是知乎的数据分析模块的精华,网址是:markdown
学习
这次要刮的内容是精英帖的标题、回答者和点赞数。下面是今天的教程。网站
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到网页底部加载数据。温泉
在这种情况下,所选元素被命名为 div.List-item。。网
为了复习上一节通过数据数控制记录数的方法,我们在元素名后面加上nth-of-type(-n+100),暂时只抓取前100个数据.3d
然后我们保存容器节点,选择该节点下要抓取的三种数据类型。
第一个是标题,我们命名为title,选中的元素命名为[itemprop='知乎:question'] a:
然后是响应者姓名和点赞数,选中元素名称为#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部被选中。我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径来抓取数据。等了十多秒才出来结果,内容让我们傻眼了:
数据呢?我要捕获哪些数据?为什么这一切都变成了空?
在计算机领域,null通常表示一个空值,表示什么都没有,如果放在Web Scraper中,则表示没有抓取到任何数据。
我们可以回想一下,网页上确实有数据。在整个操作过程中,唯一的变量就是选择元素的操作。因此,确定我们选择元素有误,导致内容匹配出现问题,无法正常获取数据。要解决这个问题,我们要看看页面的构成。
3.分析问题
要查看一个网页的构成,我们需要用到浏览器的另一个功能,就是选择视图元素。
**1.**我们点击控制面板左上角的箭头,此时箭头颜色会变为蓝色。
**2.** 然后我们将鼠标移到标题上,标题将被蓝色半透明蒙版覆盖。
**3.** 我们再次点击标题,会发现我们会跳转到Elements子面板,里面收录了一些难以理解的彩色代码
这里不要害怕,这些HTML代码不涉及任何逻辑,它们只是网页中的一个骨架,提供一些排版功能。如果你每天都在写markdown,你可以将HTML理解为具有更复杂功能的markdown。
结合HTML代码,我们先看一下[itemprop='知乎:question']的匹配规则a。
首先这是一个树结构:
从可视化的角度来看,上一句其实是一个嵌套结构。我提取了关键内容。内容结构是否清晰得多?
<a>如何快速成为数据分析师?</a>
让我们再分析一个标题 HTML 代码,它将标题作为空值。
我们可以很清楚的观察到,在这个标题的代码中,缺少属性itemprop='知乎:question'的名为div的标签!这样,当我们的匹配规则匹配到时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成了null。
找到原因后,我们就可以解决问题了。
4.解决问题
我们发现,在选择标题时,无论标题的嵌套关系如何变化,始终有一个标签保持不变,即包裹在最外层的h2标签,属性名称为class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清了关系,我们如何操作Web Scraper?这时候我们就可以使用上一篇文章中介绍的内容文章来使用键盘P键选择元素的父节点:
在今天的课程中,我们可以通过双击P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于被访者的名字也出现了null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面有很大的不同,大家可以试试。
个人的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape爬取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现数据的滚动加载很快就完成了,但是匹配元素要花很多时间。
这间接表明 知乎this网站 从代码的角度来看仍然写得不好。
如果多爬一点网站,你会发现大部分网页结构都比较“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20条记录,看看数据有没有问题。没有问题后,可以加一个大范围的正式捕获,可以在一定程度上减少返工时间。
6.下一期
本期内容很多,可以多看几遍消化一下。下一期我们会讲一些简单的内容,以及如何抓取表格内容。 查看全部
网页抓取数据(
这是简易数据分析系列的第10篇文章(-n+100))

这是简易数据分析系列文章的第10期。html
**友情提示:**这篇文章文章内容很多,信息量很大。希望大家在学习的时候多读几遍。网络
我们在朋友圈刷微博的时候,总是强调“刷”这个词。因为在看动态的时候,当内容被拉到屏尾时,APP会自动加载下一页的数据,从体验上看,数据会不断加载,永无止境。api
今天我们要讲的是如何使用Web Scraper来抓取滚动到最后的网页。浏览器
今天的实践网站是知乎的数据分析模块的精华,网址是:markdown
学习
这次要刮的内容是精英帖的标题、回答者和点赞数。下面是今天的教程。网站
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到网页底部加载数据。温泉
在这种情况下,所选元素被命名为 div.List-item。。网
为了复习上一节通过数据数控制记录数的方法,我们在元素名后面加上nth-of-type(-n+100),暂时只抓取前100个数据.3d
然后我们保存容器节点,选择该节点下要抓取的三种数据类型。
第一个是标题,我们命名为title,选中的元素命名为[itemprop='知乎:question'] a:
然后是响应者姓名和点赞数,选中元素名称为#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部被选中。我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径来抓取数据。等了十多秒才出来结果,内容让我们傻眼了:
数据呢?我要捕获哪些数据?为什么这一切都变成了空?
在计算机领域,null通常表示一个空值,表示什么都没有,如果放在Web Scraper中,则表示没有抓取到任何数据。
我们可以回想一下,网页上确实有数据。在整个操作过程中,唯一的变量就是选择元素的操作。因此,确定我们选择元素有误,导致内容匹配出现问题,无法正常获取数据。要解决这个问题,我们要看看页面的构成。
3.分析问题
要查看一个网页的构成,我们需要用到浏览器的另一个功能,就是选择视图元素。
**1.**我们点击控制面板左上角的箭头,此时箭头颜色会变为蓝色。
**2.** 然后我们将鼠标移到标题上,标题将被蓝色半透明蒙版覆盖。
**3.** 我们再次点击标题,会发现我们会跳转到Elements子面板,里面收录了一些难以理解的彩色代码
这里不要害怕,这些HTML代码不涉及任何逻辑,它们只是网页中的一个骨架,提供一些排版功能。如果你每天都在写markdown,你可以将HTML理解为具有更复杂功能的markdown。
结合HTML代码,我们先看一下[itemprop='知乎:question']的匹配规则a。
首先这是一个树结构:
从可视化的角度来看,上一句其实是一个嵌套结构。我提取了关键内容。内容结构是否清晰得多?
<a>如何快速成为数据分析师?</a>
让我们再分析一个标题 HTML 代码,它将标题作为空值。
我们可以很清楚的观察到,在这个标题的代码中,缺少属性itemprop='知乎:question'的名为div的标签!这样,当我们的匹配规则匹配到时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成了null。
找到原因后,我们就可以解决问题了。
4.解决问题
我们发现,在选择标题时,无论标题的嵌套关系如何变化,始终有一个标签保持不变,即包裹在最外层的h2标签,属性名称为class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清了关系,我们如何操作Web Scraper?这时候我们就可以使用上一篇文章中介绍的内容文章来使用键盘P键选择元素的父节点:
在今天的课程中,我们可以通过双击P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于被访者的名字也出现了null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面有很大的不同,大家可以试试。
个人的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape爬取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现数据的滚动加载很快就完成了,但是匹配元素要花很多时间。
这间接表明 知乎this网站 从代码的角度来看仍然写得不好。
如果多爬一点网站,你会发现大部分网页结构都比较“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20条记录,看看数据有没有问题。没有问题后,可以加一个大范围的正式捕获,可以在一定程度上减少返工时间。
6.下一期
本期内容很多,可以多看几遍消化一下。下一期我们会讲一些简单的内容,以及如何抓取表格内容。
网页抓取数据( 广告网站数据采集工具用哪个好?300万+用户选择八抓鱼×)
网站优化 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2022-04-15 07:18
广告网站数据采集工具用哪个好?300万+用户选择八抓鱼×)
广告网站数据采集哪个工具最好用?300+用户选择霸主语
×
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从 Wikipedia 表中获取数据。在之前的一篇文章 文章(关于 Python 中的探索性数据分析)中,我们还使用 Pandas 从 HTML 表中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 时,对于数据分析和可视化,我们通常从练习导入数据开始。在前面的文章中,我们已经看到可以在Python中直接输入值(例如,从Python字典创建Pandas数据框)。但是,通过从可用来源导入数据来获取数据肯定更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用该方法的快速示例,但请务必查看有关该主题的博客文章 以获取更多信息。
现在,只有当我们已经拥有合适格式的数据(如 csv 或 JSON)时,上述方法才有用(请参阅 文章,了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人使用维基百科来获取我们感兴趣的主题的信息。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用 pandas 在 Python 中获取这些表,我们可以将它们剪切并粘贴到电子表格中,然后,例如,使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤来完成:我们可以通过网络抓取来自动化它。请务必查看什么是网络抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 来安装 Python 包,例如 Pandas,或者安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法: pip install pandas。
请注意,如果有更新版本的 pip 可用的消息,请查看此 文章 以了解如何升级 pip。注意我们还需要安装lxml或者BeautifulSoup4,当然这些包也可以使用pip安装:pip install lxml。
熊猫 read_html 语法
下面是关于如何使用 Pandas read_html 从 HTML 表中抓取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看一些 read_html 示例。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas 的 read_html 方法,我们将从字符串中读取 HTML 表格。
广告大数据获取客户——精准客源,同行客户就是你的客户
×
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。也就是说,如果我们使用 type() 函数,我们可以看到:
如果我们想得到那个表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从 Wikipedia 中抓取数据。实际上,我们将获得一个 Python(也称为 pythons)的 HTML 表。
现在,我们得到一个收录 7 个表的列表 (len(df))。如果我们去维基百科页面,我们可以看到第一个表是右边的那个。但是,在这种情况下,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 病例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在这之后,我们还需要对数据进行清洗,最后,我们会做一些简单的数据可视化操作。
使用 Pandas read_html 抓取数据并匹配参数:
如上所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
广告精准大数据采集神器一键式采集精准客户,覆盖全网,轻松获客
×
这样我们只能得到这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请务必查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了这个数据框的副本。
在下一节中,我们将学习如何将多索引列名称更改为单个索引。
将多索引更改为单索引并删除不需要的字符
现在,我们要摆脱多索引列。也就是说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取了一些注释。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,让我们继续使用 Pandas set_index 将日期列转换为索引。这使我们可以在以后轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用 0 填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累积值:
广告一小时搭建数据分析平台
×
来自 HTML 表的时间序列图
在最后一个示例中,我们使用 Pandas read_html 来获取我们抓取的数据并创建时间序列图。现在,我们还导入 matplotlib 以便我们可以更改 Pandas 图例标题的位置:
广告数据采集从进入到放弃【简介】
×
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自 Wikipedia文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:一会儿 查看全部
网页抓取数据(
广告网站数据采集工具用哪个好?300万+用户选择八抓鱼×)
广告网站数据采集哪个工具最好用?300+用户选择霸主语
×
在本 Pandas 教程中,我们将详细介绍如何使用 Pandas read_html 方法从 HTML 中获取数据。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例使用 Pandas read_html 从 Wikipedia 表中获取数据。在之前的一篇文章 文章(关于 Python 中的探索性数据分析)中,我们还使用 Pandas 从 HTML 表中读取数据。
在 Python 中导入数据
在开始学习 Python 和 Pandas 时,对于数据分析和可视化,我们通常从练习导入数据开始。在前面的文章中,我们已经看到可以在Python中直接输入值(例如,从Python字典创建Pandas数据框)。但是,通过从可用来源导入数据来获取数据肯定更为常见。这通常通过从 CSV 文件或 Excel 文件中读取数据来完成。例如,要从 .csv 文件导入数据,我们可以使用 Pandas read_csv 方法。这是如何使用该方法的快速示例,但请务必查看有关该主题的博客文章 以获取更多信息。
现在,只有当我们已经拥有合适格式的数据(如 csv 或 JSON)时,上述方法才有用(请参阅 文章,了解如何使用 Python 和 Pandas 解析 JSON 文件)。
我们大多数人使用维基百科来获取我们感兴趣的主题的信息。此外,这些 Wikipedia文章 通常收录 HTML 表格。
要使用 pandas 在 Python 中获取这些表,我们可以将它们剪切并粘贴到电子表格中,然后,例如,使用 read_excel 将它们读入 Python。现在,这个任务当然可以用更少的步骤来完成:我们可以通过网络抓取来自动化它。请务必查看什么是网络抓取。
先决条件
当然,这个 Pandas 阅读 HTML 教程需要我们安装 Pandas 及其依赖项。例如,我们可以使用 pip 来安装 Python 包,例如 Pandas,或者安装 Python 发行版(例如,Anaconda、ActivePython)。以下是使用 pip 安装 Pandas 的方法: pip install pandas。
请注意,如果有更新版本的 pip 可用的消息,请查看此 文章 以了解如何升级 pip。注意我们还需要安装lxml或者BeautifulSoup4,当然这些包也可以使用pip安装:pip install lxml。
熊猫 read_html 语法
下面是关于如何使用 Pandas read_html 从 HTML 表中抓取数据的最简单语法:
现在我们知道了使用 Pandas 读取 HTML 表格的简单语法,我们可以看一些 read_html 示例。
熊猫 read_html 示例 1:
第一个例子是关于如何使用 Pandas 的 read_html 方法,我们将从字符串中读取 HTML 表格。
广告大数据获取客户——精准客源,同行客户就是你的客户
×
现在,我们得到的结果不是 Pandas DataFrame,而是 Python 列表。也就是说,如果我们使用 type() 函数,我们可以看到:
如果我们想得到那个表,我们可以使用列表的第一个索引(0)
熊猫 read_html 示例 2:
在第二个 Pandas read_html 示例中,我们将从 Wikipedia 中抓取数据。实际上,我们将获得一个 Python(也称为 pythons)的 HTML 表。
现在,我们得到一个收录 7 个表的列表 (len(df))。如果我们去维基百科页面,我们可以看到第一个表是右边的那个。但是,在这种情况下,我们可能对第二个表更感兴趣。
熊猫 read_html 示例 3:
在第三个示例中,我们将从瑞典的 covid-19 病例中读取 HTML 表格。在这里,我们将使用 read_html 方法的一些附加参数。具体来说,我们将使用 match 参数。在这之后,我们还需要对数据进行清洗,最后,我们会做一些简单的数据可视化操作。
使用 Pandas read_html 抓取数据并匹配参数:
如上所示,表格的标题是:“瑞典各县的新 COVID-19 病例”。现在,我们可以使用 match 参数并将其作为字符串输入:
广告精准大数据采集神器一键式采集精准客户,覆盖全网,轻松获客
×
这样我们只能得到这个表,但它仍然是一个数据框列表。现在,如上图所示,在底部,我们需要删除三行。因此,我们要删除最后三行。
使用 Pandas iloc 删除最后一行
现在,我们将使用 Pandas iloc 删除最后 3 行。请注意,我们使用 -3 作为第二个参数(请务必查看此 Panda iloc 教程以获取更多信息)。最后,我们还创建了这个数据框的副本。
在下一节中,我们将学习如何将多索引列名称更改为单个索引。
将多索引更改为单索引并删除不需要的字符
现在,我们要摆脱多索引列。也就是说,我们将把 2 列索引(名称)变成一个唯一的列名。在这里,我们将使用 DataFrame.columns 和 DataFrame.columns,get_level_values():
最后,正如您在“日期”列中看到的,我们使用 Pandas read_html 从 WikiPedia 表中获取了一些注释。接下来,我们将使用 str.replace 方法和正则表达式来删除它们:
使用 Pandas set_index 更改索引
现在,让我们继续使用 Pandas set_index 将日期列转换为索引。这使我们可以在以后轻松创建时间序列图。
现在,为了能够绘制这个时间序列图,我们需要用 0 填充缺失值并将这些列的数据类型更改为数字。这里我们也使用了apply方法。最后,我们使用 cumsum() 方法获取列中每个新值的累积值:
广告一小时搭建数据分析平台
×
来自 HTML 表的时间序列图
在最后一个示例中,我们使用 Pandas read_html 来获取我们抓取的数据并创建时间序列图。现在,我们还导入 matplotlib 以便我们可以更改 Pandas 图例标题的位置:
广告数据采集从进入到放弃【简介】
×
结论:如何将 HTML 读入 Pandas DataFrame
在本 Pandas 教程中,我们学习了如何使用 Pandas read_html 方法从 HTML 中抓取数据。此外,我们使用来自 Wikipedia文章 的数据来创建时间序列图。最后,我们还可以使用 Pandas read_html 通过参数 index_col 将 'Date' 列设置为索引列。
英文原文:
译者:一会儿
网页抓取数据(网页抓取频率对SEO有哪些重要重要意义?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-13 13:31
每天都有数以万计的网址被搜索引擎抓取和抓取,它们通过相互链接构成了我们现有的互联网关系。对于SEO人员,我们经常讲一个名词:网站爬取频率。
它在SEO的日常工作中发挥着重要作用,为网站优化提供了宝贵的建议。
那么,网站爬取频率对SEO有什么意义呢?
根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上只要是外部链接,无论其质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,目录层次简化,URL过长,动态参数过多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候其实有个方便的小技巧:那就是主动将URL添加到sitemap中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当你有一个页面需要排名时,你有必要将它放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定好。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面已经很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,可以使用百度官方后台爬虫诊断查看具体原因。
总结:页面爬取频率在索引、收录、排名、二级排名中起着至关重要的作用。作为SEO人员,您可能需要适当注意。以上内容仅供参考。 查看全部
网页抓取数据(网页抓取频率对SEO有哪些重要重要意义?(图))
每天都有数以万计的网址被搜索引擎抓取和抓取,它们通过相互链接构成了我们现有的互联网关系。对于SEO人员,我们经常讲一个名词:网站爬取频率。
它在SEO的日常工作中发挥着重要作用,为网站优化提供了宝贵的建议。
那么,网站爬取频率对SEO有什么意义呢?
根据以往的工作经验,我们知道网页收录的一个基本流程主要是:
爬取 URL -> 内容质量评估 -> 索引库筛选 -> 网页 收录(显示在搜索结果中)
其中,如果你的内容质量比较低,会直接放入低质量索引库,那么百度就难了收录,从这个过程不难看出,网站的catch选择频率将直接影响网站的收录率和内容质量评估。
影响 网站 抓取频率的因素:
①入站链接:理论上只要是外部链接,无论其质量、形状如何,都会起到引导蜘蛛爬行的作用。
② 网站结构:建站首选短域名,目录层次简化,URL过长,动态参数过多。
③ 页面速度:百度不止一次提到移动优先索引。最重要的指标是页面的首次加载,控制在3秒以内。
④ 主动提交:网站map、官方API提交、JS访问提交等。
⑤ 内容更新:优质内容的更新频率,大规模网站排名的核心因素。
⑥ 百度熊掌号:如果你的网站配置了熊掌号,只要内容够高,爬取率几乎可以达到100%。
如何查看 网站 抓取频率:
① cms系统自带的“百度蜘蛛”分析插件。
② 定期做“网站日志分析”比较方便。
页面爬取对网站的影响:
1、网站修订
如果您的网站针对某些网址进行了更新和修改,可能急需搜索引擎对页面内容进行抓取和重新评估。
这时候其实有个方便的小技巧:那就是主动将URL添加到sitemap中,并在百度后台更新,并第一时间通知搜索引擎其变化。
2、网站排名
大部分站长认为,百度熊掌上推出以来,解决了收录的问题。实际上,只有不断爬取目标网址,才能不断重新评估权重,提升排名。
因此,当你有一个页面需要排名时,你有必要将它放在爬取频率较高的列中。
3、压力控制
页面爬取频率高不一定好。它来自恶意的采集爬虫,往往会造成服务器资源的严重浪费甚至停机,尤其是一些外链分析爬虫。
如有必要,可能需要使用 Robots.txt 进行有效屏蔽。
4、异常诊断
如果你发现一个页面已经很久没有收录了,那么你有必要了解一下:百度蜘蛛的可访问性,可以使用百度官方后台爬虫诊断查看具体原因。
总结:页面爬取频率在索引、收录、排名、二级排名中起着至关重要的作用。作为SEO人员,您可能需要适当注意。以上内容仅供参考。
网页抓取数据(发送的最原始的请求就是GET请求(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-09 02:17
发送 GET 请求
当我们用浏览器打开豆瓣首页时,发送的最原创的请求其实是一个GET请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
如您所见,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用text或者content属性来获取
text:以字符串的形式返回数据
内容:以二进制形式返回数据
print(type(res.text))
print(res.text)
>>>
.....
发送 POST 请求
对于 POST 请求,一般是提交表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
数据中有需要传递的表单信息,是字典类型的数据。
标题增强
对于一些网站,没有headers的请求会被拒绝,所以需要做一些header的增强。例如:UA、Cookie、主机等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
res = requests.get('http://www.xxx.com', headers=header)
解析 HTML
既然我们已经获得了网页返回的数据,也就是HTML代码,我们就需要对HTML进行解析,提取出有效信息。
美丽汤
BeautifulSoup 是一个 Python 库,其主要功能是从网页中解析数据。
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。
BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list
具体用法和效果会在后面的实战中详细讲解。
XPath 定位
XPath 是 XML 的路径语言,用于通过元素和属性进行导航和定位。几种常用的表达方式
表达式含义 node 选择节点node的所有子节点/从根节点中选择//选择所有当前节点。当前节点..父节点@property select text() 当前路径下的文本内容
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点
当然XPath很强大,但是语法比较复杂,但是我们可以通过Chrome的开发者工具快速定位一个元素的xpath,如下图
生成的 xpath 是
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在实际使用过程中,到底是用BeautifulSoup还是XPath,完全看个人喜好,用哪个更熟练、更方便,就用哪个。
爬虫实战:爬虫豆瓣海报
从豆瓣映人页面,我们可以进入到对应的独映人映人图片页面。例如,以刘涛为例,她的英仁图片页地址是:
让我们分析一下这个页面
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:721195303
目标网站页面分析
注意:网络上网站页面的构成会一直变化,所以这里需要学习分析,其他的网站等等。俗话说,授人以鱼不如授人以渔。
Chrome 开发者工具
Chrome开发者工具(按F12打开)是分析网页的优秀工具,一定要好好使用。
我们在任意一张图片上右击选择“Inspect”,可以看到“开发者工具”也打开了,图片的位置自动定位了。
可以清楚的看到每张图片都存放在li标签中,图片的地址存放在li标签中的img中。
知道了这些规则之后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,获取图片地址。
代码编写
我们只需要几行代码就可以完成图片url的提取
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/celeb ... 39%3B
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B]
如您所见,这是一个非常干净的列表,其中存储了海报地址。
但这里只是一页海报的数据。我们观察了页面,发现它有很多分页。如何处理分页。
寻呼
我们点击第二页,看看浏览器url的变化
发现浏览器url加了几个参数
再次点击第三页,继续观察url
通过观察我们可以看到,这里的参数中,只有start发生了变化,也就是变量,其余的参数都可以按常理处理。
同时也可以知道这个start参数应该起到类似于page的作用,start=30是第二页,start=60是第三页,以此类推,最后一页就是start=420。
所以我们处理分页的代码已经准备好了
首先将上面处理HTML页面的代码封装成一个函数
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list
然后我们在另一个函数中处理分页并调用上面的函数
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
page += 1
至此,我们所有的海报数据都存储在data变量中,现在我们需要一个下载器来保存海报
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
然后将下载器添加到fire函数中。此时为了防止豆瓣网的正常访问被请求过于频繁,将休眠时间设置为1秒。
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
fire函数在下面执行。程序运行完成后,会在当前目录下生成一个图片文件夹,里面保存着我们下载的所有海报。
核心代码说明
我们来看看完整的代码
import requests
from bs4 import BeautifulSoup
import time
import osdef fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_listdef download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)if __name__ == '__main__':
fire()
消防功能
这是使用 range 函数处理分页的主要执行函数。
get_poster_url 函数
这是解析 HTML 的函数,使用 BeautifulSoup
下载图片功能
简易图片下载器
总结
本节讲解爬虫的基本流程以及需要用到的Python库和方法,并通过一个实例完成从分析网页到数据存储的整个流程。其实爬虫无非就是模拟请求,解析数据,保存数据。
当然,有时候,网站也会设置各种反爬机制,比如cookie验证、请求频率检查、非浏览器访问限制、JS混淆等等。这个时候,反反爬技术是需要的。比如抓取cookie放到headers中,使用代理IP访问,使用Selenium模拟浏览器等待模式。
这里推荐一下我自己建的Python学习群:721195303。群里的每个人都在学习Python。如果您想学习或正在学习Python,欢迎您的加入。大家都是软件开发党,不定期分享干货(仅限Python软件开发相关),包括我自己整理的2021最新Python进阶资料和零基础教学,欢迎进阶有兴趣的小伙伴加入Python! 查看全部
网页抓取数据(发送的最原始的请求就是GET请求(二))
发送 GET 请求
当我们用浏览器打开豆瓣首页时,发送的最原创的请求其实是一个GET请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
如您所见,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用text或者content属性来获取
text:以字符串的形式返回数据
内容:以二进制形式返回数据
print(type(res.text))
print(res.text)
>>>
.....
发送 POST 请求
对于 POST 请求,一般是提交表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
数据中有需要传递的表单信息,是字典类型的数据。
标题增强
对于一些网站,没有headers的请求会被拒绝,所以需要做一些header的增强。例如:UA、Cookie、主机等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
res = requests.get('http://www.xxx.com', headers=header)
解析 HTML
既然我们已经获得了网页返回的数据,也就是HTML代码,我们就需要对HTML进行解析,提取出有效信息。
美丽汤
BeautifulSoup 是一个 Python 库,其主要功能是从网页中解析数据。
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。
BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list
具体用法和效果会在后面的实战中详细讲解。
XPath 定位
XPath 是 XML 的路径语言,用于通过元素和属性进行导航和定位。几种常用的表达方式
表达式含义 node 选择节点node的所有子节点/从根节点中选择//选择所有当前节点。当前节点..父节点@property select text() 当前路径下的文本内容
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点
当然XPath很强大,但是语法比较复杂,但是我们可以通过Chrome的开发者工具快速定位一个元素的xpath,如下图
生成的 xpath 是
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在实际使用过程中,到底是用BeautifulSoup还是XPath,完全看个人喜好,用哪个更熟练、更方便,就用哪个。
爬虫实战:爬虫豆瓣海报
从豆瓣映人页面,我们可以进入到对应的独映人映人图片页面。例如,以刘涛为例,她的英仁图片页地址是:
让我们分析一下这个页面
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!
QQ群:721195303
目标网站页面分析
注意:网络上网站页面的构成会一直变化,所以这里需要学习分析,其他的网站等等。俗话说,授人以鱼不如授人以渔。
Chrome 开发者工具
Chrome开发者工具(按F12打开)是分析网页的优秀工具,一定要好好使用。
我们在任意一张图片上右击选择“Inspect”,可以看到“开发者工具”也打开了,图片的位置自动定位了。
可以清楚的看到每张图片都存放在li标签中,图片的地址存放在li标签中的img中。
知道了这些规则之后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,获取图片地址。
代码编写
我们只需要几行代码就可以完成图片url的提取
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/celeb ... 39%3B
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img3.doubanio.com/view ... 39%3B, 'https://img1.doubanio.com/view ... 39%3B]
如您所见,这是一个非常干净的列表,其中存储了海报地址。
但这里只是一页海报的数据。我们观察了页面,发现它有很多分页。如何处理分页。
寻呼
我们点击第二页,看看浏览器url的变化
发现浏览器url加了几个参数
再次点击第三页,继续观察url
通过观察我们可以看到,这里的参数中,只有start发生了变化,也就是变量,其余的参数都可以按常理处理。
同时也可以知道这个start参数应该起到类似于page的作用,start=30是第二页,start=60是第三页,以此类推,最后一页就是start=420。
所以我们处理分页的代码已经准备好了
首先将上面处理HTML页面的代码封装成一个函数
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list
然后我们在另一个函数中处理分页并调用上面的函数
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
page += 1
至此,我们所有的海报数据都存储在data变量中,现在我们需要一个下载器来保存海报
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
然后将下载器添加到fire函数中。此时为了防止豆瓣网的正常访问被请求过于频繁,将休眠时间设置为1秒。
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
fire函数在下面执行。程序运行完成后,会在当前目录下生成一个图片文件夹,里面保存着我们下载的所有海报。
核心代码说明
我们来看看完整的代码
import requests
from bs4 import BeautifulSoup
import time
import osdef fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celeb ... rt%3D{}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_listdef download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)if __name__ == '__main__':
fire()
消防功能
这是使用 range 函数处理分页的主要执行函数。
get_poster_url 函数
这是解析 HTML 的函数,使用 BeautifulSoup
下载图片功能
简易图片下载器
总结
本节讲解爬虫的基本流程以及需要用到的Python库和方法,并通过一个实例完成从分析网页到数据存储的整个流程。其实爬虫无非就是模拟请求,解析数据,保存数据。
当然,有时候,网站也会设置各种反爬机制,比如cookie验证、请求频率检查、非浏览器访问限制、JS混淆等等。这个时候,反反爬技术是需要的。比如抓取cookie放到headers中,使用代理IP访问,使用Selenium模拟浏览器等待模式。
这里推荐一下我自己建的Python学习群:721195303。群里的每个人都在学习Python。如果您想学习或正在学习Python,欢迎您的加入。大家都是软件开发党,不定期分享干货(仅限Python软件开发相关),包括我自己整理的2021最新Python进阶资料和零基础教学,欢迎进阶有兴趣的小伙伴加入Python!
网页抓取数据(网页抓取数据的主要有两种途径,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-06 13:09
网页抓取数据,主要有两种途径,一是爬虫程序对网页进行抓取,另一种是直接爬虫程序抓取。如果是爬虫程序,如果没有处理格式化的任务,将爬取到的网页格式化后,直接存储到自己的服务器上。另外就是有需要的时候,直接把网页传给程序。两种途径对业务对代码的要求也不一样。爬虫程序对于某些爬虫框架要求不高,直接用他的api就可以了,但对于某些比较复杂或处理格式化要求高的网页还是需要自己写解析api。
给你个传送门:利用python进行网页抓取
根据我个人对这个问题的经验来看,你需要准备几个软件(第一是python;第二是懂scrapy,logging,settings.py等工具;第三是你要学习一点html5和markdown的知识)如下:网站抓取、爬虫框架如pyspider、scrapy、euclid、symbolicbrowser等;页面解析后,存储在本地,或者直接使用mongodb服务;数据库你可以根据实际需要选用mysql、postgresql、mongodb等。
如果你需要做好用户分析和流量统计的话,就要买些数据抓取工具了,要那种什么“微多访问统计工具”或者“访问页面统计工具”。
有selenium不用学习编程。
初学,建议自己学习下python基础语法,
看你的做什么。如果是企业级网站,推荐scrapy框架;如果是个人站,用html2css吧。python比较适合做高性能的网站,非常适合有一定网站架构经验的人,所以如果不熟悉还是要熟悉scrapy框架。如果刚入门学python,只是想做一些测试网站,可以学下python的web开发库python3。 查看全部
网页抓取数据(网页抓取数据的主要有两种途径,你知道吗?)
网页抓取数据,主要有两种途径,一是爬虫程序对网页进行抓取,另一种是直接爬虫程序抓取。如果是爬虫程序,如果没有处理格式化的任务,将爬取到的网页格式化后,直接存储到自己的服务器上。另外就是有需要的时候,直接把网页传给程序。两种途径对业务对代码的要求也不一样。爬虫程序对于某些爬虫框架要求不高,直接用他的api就可以了,但对于某些比较复杂或处理格式化要求高的网页还是需要自己写解析api。
给你个传送门:利用python进行网页抓取
根据我个人对这个问题的经验来看,你需要准备几个软件(第一是python;第二是懂scrapy,logging,settings.py等工具;第三是你要学习一点html5和markdown的知识)如下:网站抓取、爬虫框架如pyspider、scrapy、euclid、symbolicbrowser等;页面解析后,存储在本地,或者直接使用mongodb服务;数据库你可以根据实际需要选用mysql、postgresql、mongodb等。
如果你需要做好用户分析和流量统计的话,就要买些数据抓取工具了,要那种什么“微多访问统计工具”或者“访问页面统计工具”。
有selenium不用学习编程。
初学,建议自己学习下python基础语法,
看你的做什么。如果是企业级网站,推荐scrapy框架;如果是个人站,用html2css吧。python比较适合做高性能的网站,非常适合有一定网站架构经验的人,所以如果不熟悉还是要熟悉scrapy框架。如果刚入门学python,只是想做一些测试网站,可以学下python的web开发库python3。
网页抓取数据( 一个基于新的异步库(aiohttp)的请求的代替品)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-10 17:07
一个基于新的异步库(aiohttp)的请求的代替品)
Python网页数据抓取全记录
在本文中,我将向您展示基于新异步库 (aiohttp) 的请求的替代方案。我已经用它编写了一些非常快速的小型数据采集器,我将在下面向您展示如何操作。中描述的方法如此多样化的原因是数据“抓取”实际上涉及很多问题:您不需要使用相同的工具从数千个页面中抓取数据,同时自动化一些 Web 工作流程(例如填写一些表单然后取回数据)。
异步的基本概念
asyncio是python3.4中引入的异步IO库。您也可以通过 python3.3 中的 pypi 安装它。这很复杂,我不会详细介绍。相反,我将解释使用它编写异步代码需要了解的内容。
协程和事件循环。
协程类似于方法,但它们可以在代码中的特定点暂停和恢复。可用于在等待 IO(例如 HTTP 请求)时暂停协程,同时执行另一个请求。我们使用关键字 yield from 来设置一个状态,表明我们想要一个协程的返回值。事件循环用于调度协程的执行。
关于 asyncio 的内容还有很多,但到目前为止我们需要知道的就是这些。可能你还有点不清楚,我们来看一段代码。
aiohttp 是一个利用 asyncio 的库,它的 API 看起来很像请求 API。到目前为止,其中介绍的相关文档还不完整。我们使用 asyncio.coroutine 将方法装饰为协程。aiohttp.request 是一个协程,所以它是一个可读的方法,我们需要使用 yield from 来调用它们。除此之外,以下代码看起来相当直观:
@asyncio.coroutine def print_page(url): response = yield from aiohttp.request('GET', url) body = yield from response.read_and_close(decode=True) print(body)
我们可以使用 yield from 从另一个协程调用一个协程。为了从同步代码中调用协程,我们需要一个事件循环。我们可以通过 asyncio.get_event_loop() 获得一个标准的事件循环,然后使用它的 run_until_complete() 方法来运行协程。所以,为了让前面的协程运行起来,我们只需要执行以下步骤:
loop = asyncio.get_event_loop() loop.run_until_complete(print_page('
一个有用的方法是 asyncio.wait,它接受一个协程列表并返回一个收录所有协程的协程,所以我们可以这样写:
loop.run_until_complete(asyncio.wait([print_page('#x27;),
打印页面('
另一个是 asyncio.as_completed,它接受一个协程列表,同时返回一个迭代器,它按照完成的顺序生成协程,所以当你用它迭代时,你会尽快得到每个可用的结果。
数据抓取
现在我们知道如何执行异步 HTTP 请求,我们可以编写一个数据抓取器。我们只需要一些工具来阅读html页面,我用beautifulsoup来做这个,其他的比如pyquery或者lxml也可以实现。
我们将编写一个小型数据抓取器,从海盗湾网站 抓取一些 linux 发行版的种子链接,并声称是“世界上最大的 BitTorrent 跟踪器(BT 种子服务器)”。除了采集免费的版权BT种子外,还有很多作者声称拥有版权的音频、视频、应用软件和视频游戏。等等,网络共享和下载的重要网站之一。译者注来自维基百科)
首先,需要一个辅助协程来获取请求:
@asyncio.coroutine def get(*args, **kwargs): response = yield from aiohttp.request('GET', *args, **kwargs) return (yield from response.read_and_close(decode=True))
解析部分。这篇文章不是关于beautifulsoup的,所以我将这部分缩写:我们得到了这个页面的第一个磁力链接。
def first_magnet(page): soup = bs4.BeautifulSoup(page) a = soup.find('a', title='使用磁铁下载这个种子') return a['href']
在这个协程中,url 的结果是按种子数排序的,所以第一个结果实际上是种子数最多的结果:
6 @asyncio.coroutine def print_magnet(query): url = ' page = yield from get(url, compress=True) magnet = first_magnet(page) print('{}: {}'.format(query, magnet))
使用以下代码调用上述所有方法。
distros = ['archlinux', 'ubuntu', 'debian'] loop = asyncio.get_event_loop() f = asyncio.wait([print_magnet(d) for d in distros]) loop.run_until_complete(f)
现在我们来到这一部分。你有一个异步工作的小抓取器。这意味着可以同时下载多个页面,因此这个示例比使用相同代码进行请求快 3 倍。现在你应该可以用同样的方式编写你自己的抓取器了。
一旦你熟悉了这一切,我建议你看一下 asyncio 文档和 aiohttp 示例,它们可以告诉你 asyncio 有多少潜力。
这种方法(实际上是所有手动方法)的一个限制是没有用于处理表单的单个库。机械方法有很多帮助提交表单非常容易,但如果你不使用它们,你将不得不自己处理这些事情。这可能会导致一些错误,所以同时我可能会编写一个这样的库(但现在不要担心)。
额外建议:不要向服务器要求太多
同时做3个请求很酷,但是同时做5000个就没那么好玩了。如果您计划同时执行太多请求,则链接可能会中断。您甚至可能被禁止连接到 Internet。
为了避免这些,您可以使用信号量。这是一个同步工具,可以用来限制同时工作的协程数量。我们只需要在构建循环之前创建一个信号量,并将我们希望允许的同时请求数作为参数传递给它:
sem = asyncio.Semaphore(5)
然后,我们只需要添加以下内容
页面 = 来自 get(url, compress=True)
替换为受信号量保护的相同事物。
with (yield from sem): page = yield from get(url, compress=True)
这保证了最多同时处理 5 个请求。
tqdm 是一个用于生成进度条的优秀库。这个协程就像 asyncio.wait 一样工作,但是会显示一个进度条来指示完成。
@asyncio.coroutine def wait_with_progress(coros): for f in tqdm.tqdm(asyncio.as_completed(coros), total=len(coros)): yield from f 查看全部
网页抓取数据(
一个基于新的异步库(aiohttp)的请求的代替品)
Python网页数据抓取全记录
在本文中,我将向您展示基于新异步库 (aiohttp) 的请求的替代方案。我已经用它编写了一些非常快速的小型数据采集器,我将在下面向您展示如何操作。中描述的方法如此多样化的原因是数据“抓取”实际上涉及很多问题:您不需要使用相同的工具从数千个页面中抓取数据,同时自动化一些 Web 工作流程(例如填写一些表单然后取回数据)。
异步的基本概念
asyncio是python3.4中引入的异步IO库。您也可以通过 python3.3 中的 pypi 安装它。这很复杂,我不会详细介绍。相反,我将解释使用它编写异步代码需要了解的内容。
协程和事件循环。
协程类似于方法,但它们可以在代码中的特定点暂停和恢复。可用于在等待 IO(例如 HTTP 请求)时暂停协程,同时执行另一个请求。我们使用关键字 yield from 来设置一个状态,表明我们想要一个协程的返回值。事件循环用于调度协程的执行。
关于 asyncio 的内容还有很多,但到目前为止我们需要知道的就是这些。可能你还有点不清楚,我们来看一段代码。
aiohttp 是一个利用 asyncio 的库,它的 API 看起来很像请求 API。到目前为止,其中介绍的相关文档还不完整。我们使用 asyncio.coroutine 将方法装饰为协程。aiohttp.request 是一个协程,所以它是一个可读的方法,我们需要使用 yield from 来调用它们。除此之外,以下代码看起来相当直观:
@asyncio.coroutine def print_page(url): response = yield from aiohttp.request('GET', url) body = yield from response.read_and_close(decode=True) print(body)
我们可以使用 yield from 从另一个协程调用一个协程。为了从同步代码中调用协程,我们需要一个事件循环。我们可以通过 asyncio.get_event_loop() 获得一个标准的事件循环,然后使用它的 run_until_complete() 方法来运行协程。所以,为了让前面的协程运行起来,我们只需要执行以下步骤:
loop = asyncio.get_event_loop() loop.run_until_complete(print_page('
一个有用的方法是 asyncio.wait,它接受一个协程列表并返回一个收录所有协程的协程,所以我们可以这样写:
loop.run_until_complete(asyncio.wait([print_page('#x27;),
打印页面('
另一个是 asyncio.as_completed,它接受一个协程列表,同时返回一个迭代器,它按照完成的顺序生成协程,所以当你用它迭代时,你会尽快得到每个可用的结果。
数据抓取
现在我们知道如何执行异步 HTTP 请求,我们可以编写一个数据抓取器。我们只需要一些工具来阅读html页面,我用beautifulsoup来做这个,其他的比如pyquery或者lxml也可以实现。
我们将编写一个小型数据抓取器,从海盗湾网站 抓取一些 linux 发行版的种子链接,并声称是“世界上最大的 BitTorrent 跟踪器(BT 种子服务器)”。除了采集免费的版权BT种子外,还有很多作者声称拥有版权的音频、视频、应用软件和视频游戏。等等,网络共享和下载的重要网站之一。译者注来自维基百科)
首先,需要一个辅助协程来获取请求:
@asyncio.coroutine def get(*args, **kwargs): response = yield from aiohttp.request('GET', *args, **kwargs) return (yield from response.read_and_close(decode=True))
解析部分。这篇文章不是关于beautifulsoup的,所以我将这部分缩写:我们得到了这个页面的第一个磁力链接。
def first_magnet(page): soup = bs4.BeautifulSoup(page) a = soup.find('a', title='使用磁铁下载这个种子') return a['href']
在这个协程中,url 的结果是按种子数排序的,所以第一个结果实际上是种子数最多的结果:
6 @asyncio.coroutine def print_magnet(query): url = ' page = yield from get(url, compress=True) magnet = first_magnet(page) print('{}: {}'.format(query, magnet))
使用以下代码调用上述所有方法。
distros = ['archlinux', 'ubuntu', 'debian'] loop = asyncio.get_event_loop() f = asyncio.wait([print_magnet(d) for d in distros]) loop.run_until_complete(f)
现在我们来到这一部分。你有一个异步工作的小抓取器。这意味着可以同时下载多个页面,因此这个示例比使用相同代码进行请求快 3 倍。现在你应该可以用同样的方式编写你自己的抓取器了。
一旦你熟悉了这一切,我建议你看一下 asyncio 文档和 aiohttp 示例,它们可以告诉你 asyncio 有多少潜力。
这种方法(实际上是所有手动方法)的一个限制是没有用于处理表单的单个库。机械方法有很多帮助提交表单非常容易,但如果你不使用它们,你将不得不自己处理这些事情。这可能会导致一些错误,所以同时我可能会编写一个这样的库(但现在不要担心)。
额外建议:不要向服务器要求太多
同时做3个请求很酷,但是同时做5000个就没那么好玩了。如果您计划同时执行太多请求,则链接可能会中断。您甚至可能被禁止连接到 Internet。
为了避免这些,您可以使用信号量。这是一个同步工具,可以用来限制同时工作的协程数量。我们只需要在构建循环之前创建一个信号量,并将我们希望允许的同时请求数作为参数传递给它:
sem = asyncio.Semaphore(5)
然后,我们只需要添加以下内容
页面 = 来自 get(url, compress=True)
替换为受信号量保护的相同事物。
with (yield from sem): page = yield from get(url, compress=True)
这保证了最多同时处理 5 个请求。
tqdm 是一个用于生成进度条的优秀库。这个协程就像 asyncio.wait 一样工作,但是会显示一个进度条来指示完成。
@asyncio.coroutine def wait_with_progress(coros): for f in tqdm.tqdm(asyncio.as_completed(coros), total=len(coros)): yield from f
网页抓取数据(腾讯云“新产品类型公有云”“最佳推荐方案团队”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-24 02:06
网页抓取数据可以用聚合数据网的爆火,助力小微企业快速获取互联网大数据源。聚合数据网联合腾讯云推出三星刷新机制,可以实现传统企业远程远程抓取网页数据,覆盖传统企业和互联网新贵等企业。在三星旗舰机与2018年主流手机之间,选择是否抓取三星数据将影响后续的口碑引爆和用户忠诚度,以及舆论导向。聚合数据网作为腾讯云“新产品类型公有云”“最佳推荐方案团队”,已入驻国内40多家领先的企业和互联网公司,正在逐步提供最佳解决方案,帮助客户获取更可靠的大数据源和视野变得更加可靠。
现在有分析平台可以抓取大数据,很多专门做数据分析的第三方公司,比如启飞云等等,题主可以关注他们。
据我所知,网站数据获取一般分为三种途径:网页抓取:大部分网站会有定期的页面抓取,可以借助一些分析工具(建议使用ueeshop,请点击下列链接查看详情)了解部分网站。这些抓取的页面数据是经过交互的,包括上传的图片。另外一些也会进行到页面内容抓取,转成数据库的形式存放于本地。站内搜索:通过站内搜索进行的抓取工作,因为排在搜索之前的页面具有重要的价值,所以搜索之后大部分也是可以抓取的。
官方应用:基于leancloud提供的微服务框架,一些有较大用户量级的大型网站会提供的paas平台服务。例如百度的搜索服务、京东的服务,会提供丰富的微服务。抓取难点:数据获取是分析研究的基础,有几个难点:1.客户端2.分析工具3.处理平台的选择4.数据源的选择有些网站会提供官方免费版的分析工具,大部分也都是外包出去的。
最近启飞云发布了爬虫管理工具superfily2.0,包括爬虫post-star.js、提交post-shutdown等。使用这些语言写好脚本,存放在启飞云ecs容器中,每个节点都有独立进程即可。微服务目前在启飞云ecs上已经实现,相关的服务可以到启飞云搜索“最全面的微服务实践”。希望对你有帮助。 查看全部
网页抓取数据(腾讯云“新产品类型公有云”“最佳推荐方案团队”)
网页抓取数据可以用聚合数据网的爆火,助力小微企业快速获取互联网大数据源。聚合数据网联合腾讯云推出三星刷新机制,可以实现传统企业远程远程抓取网页数据,覆盖传统企业和互联网新贵等企业。在三星旗舰机与2018年主流手机之间,选择是否抓取三星数据将影响后续的口碑引爆和用户忠诚度,以及舆论导向。聚合数据网作为腾讯云“新产品类型公有云”“最佳推荐方案团队”,已入驻国内40多家领先的企业和互联网公司,正在逐步提供最佳解决方案,帮助客户获取更可靠的大数据源和视野变得更加可靠。
现在有分析平台可以抓取大数据,很多专门做数据分析的第三方公司,比如启飞云等等,题主可以关注他们。
据我所知,网站数据获取一般分为三种途径:网页抓取:大部分网站会有定期的页面抓取,可以借助一些分析工具(建议使用ueeshop,请点击下列链接查看详情)了解部分网站。这些抓取的页面数据是经过交互的,包括上传的图片。另外一些也会进行到页面内容抓取,转成数据库的形式存放于本地。站内搜索:通过站内搜索进行的抓取工作,因为排在搜索之前的页面具有重要的价值,所以搜索之后大部分也是可以抓取的。
官方应用:基于leancloud提供的微服务框架,一些有较大用户量级的大型网站会提供的paas平台服务。例如百度的搜索服务、京东的服务,会提供丰富的微服务。抓取难点:数据获取是分析研究的基础,有几个难点:1.客户端2.分析工具3.处理平台的选择4.数据源的选择有些网站会提供官方免费版的分析工具,大部分也都是外包出去的。
最近启飞云发布了爬虫管理工具superfily2.0,包括爬虫post-star.js、提交post-shutdown等。使用这些语言写好脚本,存放在启飞云ecs容器中,每个节点都有独立进程即可。微服务目前在启飞云ecs上已经实现,相关的服务可以到启飞云搜索“最全面的微服务实践”。希望对你有帮助。
网页抓取数据(WebScraper集成入Chrome开发者工具(DeveloperTools)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2022-02-23 02:14
一、安装
1、安装
您可以从 Chrome 商店 (/7bpm9c) 安装此扩展程序 (Extension) [需要科学上网]。安装完成后,需要重启Chrome,确保插件加载完毕。如果您不想重新启动 Chrome,也可以在安装后在新标签页中使用此扩展程序。
2、要求
此扩展程序需要 Chrome 版本 31 及更高版本。没有操作系统限制。【查看Chrome版本,可以在浏览器地址栏输入:chrome://settings/help,如下图:Chrome版本63]
二、打开网络爬虫
Web Scraper 已集成到 Chrome 开发者工具中。图 1 显示了如何打开。您还可以使用以下快捷方式(Shortcuts)来打开开发者工具。打开开发者工具后,请选择 Web Scraper 选项卡。
热键:
Windows、Linux:Crtl + Shift + I 或 F12,打开开发者工具
Mac:Cmd + Opt + I,打开开发者工具
打开网络抓取工具
三、抢网站
打开 网站 进行抓取。
1、创建站点地图
要创建 Sitemap,首先需要指定起始 URL,它是爬取的起点。如果爬网从多个位置开始,您还可以指定多个起始 URL。例如,如果要爬取多个搜索结果,可以为每个搜索结果创建单独的起始 URL。
指定多个具有串行关系的 URL
如果一个 网站 页面 URL 收录一个序列,那么使用指定的序列比使用 Link 选择器爬取网页更合理。将 URL 的页码部分替换为指定的序列 [1-100]。如果页码部分有 0 作为占位符,请使用 [001-100]。输入页码有固定的时间间隔 [0-100:10]。一个例子如下:
[1-3] 可以爬取以下页面:
*
*
*
[001-100] 可以爬取以下网页:
*
*
*
[0-100:10] 可以抓取以下页面:
*
*
*
创建一个选择器(Selector)
创建站点地图后,您可以向其中添加选择器。在选择器面板中,您可以添加新选择器、改进现有选择器或浏览选择器树结构。选择器可以以树状结构添加,Web Scraper 也按照这种结构爬取网页。比如有个新闻网站,你想把上面所有的文章都抓起来,这些文章链接在网站首页。以下示例是 网站:
要获取这个 网站,您可以创建一个链接选择器来提取主页上的所有 文章 链接。然后添加一个Text选择器作为子选择器,从上面的Link选择器指向的页面中提取文章。下图显示了如何为此 网站 创建站点地图:
请注意,创建选择器时需要使用元素预览和数据预览功能,以确保选择正确的 Web 元素和数据。
有关选择器树的更多信息可以在选择器文档中找到。您应该至少阅读以下核心选择器:
1、文本选择器
2、链接选择器
3、元素选择器
浏览选择器树
为站点地图创建选择器后,您可以在选择器图形面板中浏览选择器树。下图显示了一个示例选择器图。
抓取 网站
为站点地图创建选择器后,可以开始抓取 网站。打开“刮擦”面板开始刮擦。
将打开一个网页窗口,抓取工具会在其中加载网页并从中提取数据。该窗口将关闭,爬取完成后会弹出提示。您可以打开浏览面板查看捕获的数据并通过将数据导出为 CSV 面板将其导出。
相关信息:
Web Scraper 官方文档中文版(下) 查看全部
网页抓取数据(WebScraper集成入Chrome开发者工具(DeveloperTools)())
一、安装
1、安装
您可以从 Chrome 商店 (/7bpm9c) 安装此扩展程序 (Extension) [需要科学上网]。安装完成后,需要重启Chrome,确保插件加载完毕。如果您不想重新启动 Chrome,也可以在安装后在新标签页中使用此扩展程序。
2、要求
此扩展程序需要 Chrome 版本 31 及更高版本。没有操作系统限制。【查看Chrome版本,可以在浏览器地址栏输入:chrome://settings/help,如下图:Chrome版本63]
二、打开网络爬虫
Web Scraper 已集成到 Chrome 开发者工具中。图 1 显示了如何打开。您还可以使用以下快捷方式(Shortcuts)来打开开发者工具。打开开发者工具后,请选择 Web Scraper 选项卡。
热键:
Windows、Linux:Crtl + Shift + I 或 F12,打开开发者工具
Mac:Cmd + Opt + I,打开开发者工具
打开网络抓取工具
三、抢网站
打开 网站 进行抓取。
1、创建站点地图
要创建 Sitemap,首先需要指定起始 URL,它是爬取的起点。如果爬网从多个位置开始,您还可以指定多个起始 URL。例如,如果要爬取多个搜索结果,可以为每个搜索结果创建单独的起始 URL。
指定多个具有串行关系的 URL
如果一个 网站 页面 URL 收录一个序列,那么使用指定的序列比使用 Link 选择器爬取网页更合理。将 URL 的页码部分替换为指定的序列 [1-100]。如果页码部分有 0 作为占位符,请使用 [001-100]。输入页码有固定的时间间隔 [0-100:10]。一个例子如下:
[1-3] 可以爬取以下页面:
*
*
*
[001-100] 可以爬取以下网页:
*
*
*
[0-100:10] 可以抓取以下页面:
*
*
*
创建一个选择器(Selector)
创建站点地图后,您可以向其中添加选择器。在选择器面板中,您可以添加新选择器、改进现有选择器或浏览选择器树结构。选择器可以以树状结构添加,Web Scraper 也按照这种结构爬取网页。比如有个新闻网站,你想把上面所有的文章都抓起来,这些文章链接在网站首页。以下示例是 网站:
要获取这个 网站,您可以创建一个链接选择器来提取主页上的所有 文章 链接。然后添加一个Text选择器作为子选择器,从上面的Link选择器指向的页面中提取文章。下图显示了如何为此 网站 创建站点地图:
请注意,创建选择器时需要使用元素预览和数据预览功能,以确保选择正确的 Web 元素和数据。
有关选择器树的更多信息可以在选择器文档中找到。您应该至少阅读以下核心选择器:
1、文本选择器
2、链接选择器
3、元素选择器
浏览选择器树
为站点地图创建选择器后,您可以在选择器图形面板中浏览选择器树。下图显示了一个示例选择器图。
抓取 网站
为站点地图创建选择器后,可以开始抓取 网站。打开“刮擦”面板开始刮擦。
将打开一个网页窗口,抓取工具会在其中加载网页并从中提取数据。该窗口将关闭,爬取完成后会弹出提示。您可以打开浏览面板查看捕获的数据并通过将数据导出为 CSV 面板将其导出。
相关信息:
Web Scraper 官方文档中文版(下)
网页抓取数据( 具体分析如下实现抓取和分析网页类,实例分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-17 18:18
具体分析如下实现抓取和分析网页类,实例分析(图))
C#实现网页类实例的抓取和分析
更新时间:2015-05-25 10:53:05 作者:莫翔
本篇文章主要介绍C#实现网页类爬取分析,并结合实例分析C#爬取分析网页中文字和连接的相关技巧。具有一定的参考价值。有需要的朋友可以参考以下
本文的示例描述了抓取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
此处描述了用于抓取和分析网页的类。
它的主要功能是:
1、提取网页纯文本,去掉所有html标签和javascript代码
2、提取网页链接,包括href和frame和iframe
3、 提取网页标题等(其他标签同理推导,规律同理)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望这篇文章对你的 C# 编程有所帮助。 查看全部
网页抓取数据(
具体分析如下实现抓取和分析网页类,实例分析(图))
C#实现网页类实例的抓取和分析
更新时间:2015-05-25 10:53:05 作者:莫翔
本篇文章主要介绍C#实现网页类爬取分析,并结合实例分析C#爬取分析网页中文字和连接的相关技巧。具有一定的参考价值。有需要的朋友可以参考以下
本文的示例描述了抓取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
此处描述了用于抓取和分析网页的类。
它的主要功能是:
1、提取网页纯文本,去掉所有html标签和javascript代码
2、提取网页链接,包括href和frame和iframe
3、 提取网页标题等(其他标签同理推导,规律同理)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望这篇文章对你的 C# 编程有所帮助。
网页抓取数据(过滤蜘蛛抓取网站信息后对网站基础优化以及用户关注度综合评估图26408-1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-17 18:17
在过滤蜘蛛以捕获 网站 信息后,将创建一个临时数据库。每个图像都应添加相应的 ALT 描述。经过爬取、过滤、收录,网站的基础优化和用户关注度综合评价
图 26408-1:
百度关键词优化首先,蜘蛛先爬取你的网站信息——过滤掉一些垃圾信息——索引收录的信息——根据网站优化和客户关注度排序。
我们经常会在一些网站上看到导航上的链接有特殊效果,一般都是用Java实现的。虽然视觉上很漂亮,但对搜索引擎来说并不是一件好事。所以为了对搜索引擎更友好,尽量少用Java。
过滤蜘蛛爬取网站信息后,会创建一个临时数据库,在网站上会出现低质量、不合规、网站的不良垃圾信息。请包括每张图片的相关 ALT 属性。
当网站中有大量图片时,每张图片都应附有相应的ALT描述。搜索引擎无法识别我们的网站图片,必须添加相关的文章描述。,这将帮助蜘蛛更好地收录我们的网站。
经过爬取、过滤、收录、网站基础优化和用户关注度综合评价,在索引库中对网页进行排序,哪些网页排名靠前。
测试一下我们网站的打开速度,是否有长时间打不开或者加载速度慢等情况,建议百度关键词优化,做好404 页面,这将有助于提高 网站 用户体验和蜘蛛抓取的性能。 查看全部
网页抓取数据(过滤蜘蛛抓取网站信息后对网站基础优化以及用户关注度综合评估图26408-1)
在过滤蜘蛛以捕获 网站 信息后,将创建一个临时数据库。每个图像都应添加相应的 ALT 描述。经过爬取、过滤、收录,网站的基础优化和用户关注度综合评价
图 26408-1:
百度关键词优化首先,蜘蛛先爬取你的网站信息——过滤掉一些垃圾信息——索引收录的信息——根据网站优化和客户关注度排序。
我们经常会在一些网站上看到导航上的链接有特殊效果,一般都是用Java实现的。虽然视觉上很漂亮,但对搜索引擎来说并不是一件好事。所以为了对搜索引擎更友好,尽量少用Java。
过滤蜘蛛爬取网站信息后,会创建一个临时数据库,在网站上会出现低质量、不合规、网站的不良垃圾信息。请包括每张图片的相关 ALT 属性。
当网站中有大量图片时,每张图片都应附有相应的ALT描述。搜索引擎无法识别我们的网站图片,必须添加相关的文章描述。,这将帮助蜘蛛更好地收录我们的网站。
经过爬取、过滤、收录、网站基础优化和用户关注度综合评价,在索引库中对网页进行排序,哪些网页排名靠前。
测试一下我们网站的打开速度,是否有长时间打不开或者加载速度慢等情况,建议百度关键词优化,做好404 页面,这将有助于提高 网站 用户体验和蜘蛛抓取的性能。
网页抓取数据(手机支付宝app的输入法是什么性质的引擎?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-02-16 18:05
网页抓取数据,可以说是javascript的低版本版本,甚至老版本都可以拿来用,只要有数据,只要不是格式化的文本,而且规范一点,都是可以接受的。比如我想要爬取百度网站,我就会用javascript写一个爬虫,然后对数据进行一个正则匹配,然后通过正则检测出需要的地址,比如aazzzzzzz、aazzzzzzzzz、aazzzzzzzzzzz,然后再进行下一步。毕竟不可能把那些字符都去掉,而这些字符可能还有一些人会用到,比如网名、昵称之类的。
网页的字符是不是可以处理,比如把手机支付宝认证的字符去掉。其实都可以呀,放心了。这是基础技能啊。
手机支付宝app的输入法,可以匹配用户名,能解析出比如yingbao之类的简单的网页,至于存储用户名或者正则表达式去匹配手机支付宝输入法这种地方,由于是涉及比较多的请求,javascript可能会更高级。
类似的应该不少,个人觉得个性化需求比较多的话,
大家都说的很高深啦但是也可以从最基础的说起,两个基本一个人走过去一个人走起来把数据分布式存储使用ssh技术部署云计算看一下就会啦还有一种是,大家说的的现成的引擎,
听你这么说我觉得我还是没资格来回答这个问题因为我也不清楚你说的那些框架是什么性质的 查看全部
网页抓取数据(手机支付宝app的输入法是什么性质的引擎?)
网页抓取数据,可以说是javascript的低版本版本,甚至老版本都可以拿来用,只要有数据,只要不是格式化的文本,而且规范一点,都是可以接受的。比如我想要爬取百度网站,我就会用javascript写一个爬虫,然后对数据进行一个正则匹配,然后通过正则检测出需要的地址,比如aazzzzzzz、aazzzzzzzzz、aazzzzzzzzzzz,然后再进行下一步。毕竟不可能把那些字符都去掉,而这些字符可能还有一些人会用到,比如网名、昵称之类的。
网页的字符是不是可以处理,比如把手机支付宝认证的字符去掉。其实都可以呀,放心了。这是基础技能啊。
手机支付宝app的输入法,可以匹配用户名,能解析出比如yingbao之类的简单的网页,至于存储用户名或者正则表达式去匹配手机支付宝输入法这种地方,由于是涉及比较多的请求,javascript可能会更高级。
类似的应该不少,个人觉得个性化需求比较多的话,
大家都说的很高深啦但是也可以从最基础的说起,两个基本一个人走过去一个人走起来把数据分布式存储使用ssh技术部署云计算看一下就会啦还有一种是,大家说的的现成的引擎,
听你这么说我觉得我还是没资格来回答这个问题因为我也不清楚你说的那些框架是什么性质的
网页抓取数据( PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-15 22:10
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js对网页内容中有特殊内容的js文件进行爬取分析
更新时间:2015-11-17 10:40:01 作者:平凡先生
nodejs获取网页内容并绑定data事件,获取到的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据。本文介绍节点。js对网页内容中特殊内容的js文件进行爬取分析,需要的朋友请参考
nodejs获取网页内容并绑定data事件,获取到的数据会分几次对应。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据!
举个例子,如果你想找出页面上有没有,话不多说,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家都能看懂。欢迎有不清楚的朋友给我留言。具体要看大家的应用实践了。
让我们介绍一下 Nodejs 的网页抓取能力。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。 查看全部
网页抓取数据(
PHPNodejs获取网页内容绑定data事件,获取到的数据会分几次)
node.js对网页内容中有特殊内容的js文件进行爬取分析
更新时间:2015-11-17 10:40:01 作者:平凡先生
nodejs获取网页内容并绑定data事件,获取到的数据会分几次。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据。本文介绍节点。js对网页内容中特殊内容的js文件进行爬取分析,需要的朋友请参考
nodejs获取网页内容并绑定data事件,获取到的数据会分几次对应。如果要匹配全局内容,需要等待请求结束,在end事件中操作累积的全局数据!
举个例子,如果你想找出页面上有没有,话不多说,直接放代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
上面的代码大家都能看懂。欢迎有不清楚的朋友给我留言。具体要看大家的应用实践了。
让我们介绍一下 Nodejs 的网页抓取能力。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
网页抓取数据(网页抓取数据的几种方法介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-12 08:05
网页抓取数据,1.不管是python爬虫,还是java程序员爬虫,在方法的选择上,都不推荐直接使用postget,一般的分析库都会支持你说的这些方法。2.python有downloadchannel,java的话androidsearch也有jsonurlwebresponse,都很方便。http和https不是问题。3.就目前的抓取技术而言,已经足够达到你的需求了。
1、requests。这个是python爬虫最基本的api,理论上downloadchannel里面有,安卓市场也有。
2、jsonurl和https等都有人提到了。
3、previewofbasicdownloadchannelscrapy。
4、现在web爬虫不是特别contact的话,基本都用jsonurl的。
5、这个算是个复杂的技术性问题,我也不是很懂,有时间可以看看codeigniter的develop部分,这个是按部就班按api来抓包的web开发技术。
selenium和requestsapi
requests啊selenium啊又不是编程语言是接口
这个很简单,有很多开源的爬虫,
这个问题不正常啊,app都是通过web的方式获取数据的啊,怎么可能用restfulapi。
各种浏览器各种数据库各种协议。每种爬虫技术都有不同侧重点,
我用jquery也有一堆问题,关键还是要用mediaquery...解决办法就是:找到你那个app的设计图,先想办法让他"喂喂喂,我是这个app,我想获取xxx数据!"。然后程序读取设计图,再跑一遍post或者get请求, 查看全部
网页抓取数据(网页抓取数据的几种方法介绍-乐题库)
网页抓取数据,1.不管是python爬虫,还是java程序员爬虫,在方法的选择上,都不推荐直接使用postget,一般的分析库都会支持你说的这些方法。2.python有downloadchannel,java的话androidsearch也有jsonurlwebresponse,都很方便。http和https不是问题。3.就目前的抓取技术而言,已经足够达到你的需求了。
1、requests。这个是python爬虫最基本的api,理论上downloadchannel里面有,安卓市场也有。
2、jsonurl和https等都有人提到了。
3、previewofbasicdownloadchannelscrapy。
4、现在web爬虫不是特别contact的话,基本都用jsonurl的。
5、这个算是个复杂的技术性问题,我也不是很懂,有时间可以看看codeigniter的develop部分,这个是按部就班按api来抓包的web开发技术。
selenium和requestsapi
requests啊selenium啊又不是编程语言是接口
这个很简单,有很多开源的爬虫,
这个问题不正常啊,app都是通过web的方式获取数据的啊,怎么可能用restfulapi。
各种浏览器各种数据库各种协议。每种爬虫技术都有不同侧重点,
我用jquery也有一堆问题,关键还是要用mediaquery...解决办法就是:找到你那个app的设计图,先想办法让他"喂喂喂,我是这个app,我想获取xxx数据!"。然后程序读取设计图,再跑一遍post或者get请求,
网页抓取数据(元素在点(625278.55)运行代码时出现错误:再次卡住)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-09 00:24
嗨,我正在尝试使用 python3.x 和 beauthoulsoup 从年龄验证弹出站点中抓取数据。如果不单击“是”到“您是否已超过 21 岁”,我将无法访问基础文本和图像。谢谢你的支持。存在
编辑:谢谢,在评论的帮助下,我发现我可以使用 cookie,但不知道如何使用 requests 包管理/存储/调用 cookie。存在
因此,在另一个用户的帮助下,我使用了 selenium 包,以便它也适用于图形叠加(我认为?)。很难让它与壁虎驱动程序一起工作,但会继续努力!再次感谢大家的建议。存在
编辑 3:好的,我已经取得了进展,我可以使用 gecko 驱动程序打开浏览器窗口!~不幸的是,它不喜欢那个链接规范,所以我再次发布。年龄验证点击“是”的链接隐藏在这个页面上,称为mlink。. . 存在
编辑 4:取得了一些进展,更新的代码如下。我设法在 XML 代码中找到了该元素,现在我只需要设法单击链接。存在
#
import time
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
driver = webdriver.Firefox(executable_path=r'/Users/jeff/Documents/geckodriver') # Optional argument, if not specified will search path.
driver.get('https://www.shopharborside.com/oakland/#/shop/412');
url = 'https://www.shopharborside.com/oakland/#/shop/412'
driver.get(url)
#
driver.find_element_by_class_name('hhc_modal-body').click(Yes)
#wait.1.second
time.sleep(1)
pagesource = driver.page_source
soup = BeautifulSoup(pagesource)
#you.can.now.enjoy.soup
print(soup.prettify())
编辑新:再次卡住,这是当前代码。我似乎隔离了元素“mBtnYes”,但是当我运行代码时出现错误: ElementClickInterceptedException: Message: Element at point (625278.55) is not clickable because another element make it blurable
^{pr2}$ 查看全部
网页抓取数据(元素在点(625278.55)运行代码时出现错误:再次卡住)
嗨,我正在尝试使用 python3.x 和 beauthoulsoup 从年龄验证弹出站点中抓取数据。如果不单击“是”到“您是否已超过 21 岁”,我将无法访问基础文本和图像。谢谢你的支持。存在
编辑:谢谢,在评论的帮助下,我发现我可以使用 cookie,但不知道如何使用 requests 包管理/存储/调用 cookie。存在
因此,在另一个用户的帮助下,我使用了 selenium 包,以便它也适用于图形叠加(我认为?)。很难让它与壁虎驱动程序一起工作,但会继续努力!再次感谢大家的建议。存在
编辑 3:好的,我已经取得了进展,我可以使用 gecko 驱动程序打开浏览器窗口!~不幸的是,它不喜欢那个链接规范,所以我再次发布。年龄验证点击“是”的链接隐藏在这个页面上,称为mlink。. . 存在
编辑 4:取得了一些进展,更新的代码如下。我设法在 XML 代码中找到了该元素,现在我只需要设法单击链接。存在
#
import time
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
driver = webdriver.Firefox(executable_path=r'/Users/jeff/Documents/geckodriver') # Optional argument, if not specified will search path.
driver.get('https://www.shopharborside.com/oakland/#/shop/412');
url = 'https://www.shopharborside.com/oakland/#/shop/412'
driver.get(url)
#
driver.find_element_by_class_name('hhc_modal-body').click(Yes)
#wait.1.second
time.sleep(1)
pagesource = driver.page_source
soup = BeautifulSoup(pagesource)
#you.can.now.enjoy.soup
print(soup.prettify())
编辑新:再次卡住,这是当前代码。我似乎隔离了元素“mBtnYes”,但是当我运行代码时出现错误: ElementClickInterceptedException: Message: Element at point (625278.55) is not clickable because another element make it blurable
^{pr2}$
网页抓取数据(Python_box=soup.find44)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-08 05:02
. name_box = soup.find('h1', attrs={'class': 'name'}) 有了标签之后,我们可以通过获取它的文本来获取数据。Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络采集或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。为获得最佳效果,只需具备本指南中所述的 HTML 基本知识。1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,
Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络收获或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。. 1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,beautifulsoup 库会将文本转换为 unicode,甚至 import urllib from bs4 import BeautifulSoup url = "https:
Web 抓取、Web 采集或 Web 数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。
Python BeautifulSoup
Beautiful Soup 4 Python,你应该为所有新项目使用 Beautiful Soup 4。安装美丽的汤。如果您运行 Debian 或 Ubuntu,您可以使用系统包管理器安装 Beautiful Soup。apt-get install python-bs4 Beautiful Soup 4 是通过 PyPi 分发的,所以如果你不能用系统打包器安装它,你可以用 easy_install 或 pip 安装它。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供惯用的导航、搜索。Beautiful Soup 简介,Beautiful Soup 收录解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,
Beautiful Soup 简介,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与你最喜欢的解析器一起工作,提供惯用的导航、搜索,Beautiful Soup 收录有用的函数来解析 HTML 数据。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是。Beautiful Soup: Build a Web Scraper with Python - 真正的 Python,网络抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。
Beautiful Soup: Building a Web Scraper with Python - 真正的 Python,Beautiful Soup 收录用于解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup(HTML 解析器),Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个特性使它变得强大:Beautiful Soup 提供了一些 Python 库请求,Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何:
Beautiful Soup(HTML 解析器),网页抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。beautifulsoup4 · PyPI、Python 库请求和 Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据
beautifulsoup4·PyPI,如何用 Python 和 BeautifulSoup 爬取 网站,
Python读取html文件
可以使用如下代码: from __future__ import division, unicode_literals import codecs from bs4 import BeautifulSoup f=codecs.open("test.html", 'r', 'utf-8') document= BeautifulSoup(f.read () ) .get_text() 打印文档。如果您想删除中间的所有空行并将所有单词变成字符串(同时避免特殊字符、数字),那么还包括: 我们接下来要做的是创建一个 HTML 文件,上面写着“Hello World!” 使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。. 将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。
请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。
使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。
我们接下来要做的是创建一个显示“Hello World!”的 HTML 文件。使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选。Python - 阅读 HTML 页面 安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将使用 Pandas read_html 通过几个示例从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。.
将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选
更多问题 查看全部
网页抓取数据(Python_box=soup.find44)
. name_box = soup.find('h1', attrs={'class': 'name'}) 有了标签之后,我们可以通过获取它的文本来获取数据。Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络采集或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。为获得最佳效果,只需具备本指南中所述的 HTML 基本知识。1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,
Beautiful Soup 位于流行的 Python 解析器(如 lxml 和 html5lib)之上,允许您尝试不同的解析策略或以速度换取灵活性。基本上,BeautifulSoup 可以解析您提供给它的网络上的任何内容。这是 BeautifulSoup 的一个简单示例:网络抓取、网络收获或网络数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。. 1.如何将 unicode("") 转换为普通字符串作为网页中的文本?因为当我只提取“p”标签时,beautifulsoup 库会将文本转换为 unicode,甚至 import urllib from bs4 import BeautifulSoup url = "https:
Web 抓取、Web 采集或 Web 数据提取是用于从 网站 中提取数据的数据抓取。BeautifulSoup 是 Python 提供的一个流行的库,用于从网络上抓取数据。要充分利用它,您需要的只是 HTML 的基本知识,这在指南中有所介绍。
Python BeautifulSoup
Beautiful Soup 4 Python,你应该为所有新项目使用 Beautiful Soup 4。安装美丽的汤。如果您运行 Debian 或 Ubuntu,您可以使用系统包管理器安装 Beautiful Soup。apt-get install python-bs4 Beautiful Soup 4 是通过 PyPi 分发的,所以如果你不能用系统打包器安装它,你可以用 easy_install 或 pip 安装它。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与您最喜欢的解析器一起工作,以提供惯用的导航、搜索。Beautiful Soup 简介,Beautiful Soup 收录解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,
Beautiful Soup 简介,Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它与你最喜欢的解析器一起工作,提供惯用的导航、搜索,Beautiful Soup 收录有用的函数来解析 HTML 数据。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是。Beautiful Soup: Build a Web Scraper with Python - 真正的 Python,网络抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。
Beautiful Soup: Building a Web Scraper with Python - 真正的 Python,Beautiful Soup 收录用于解析 HTML 数据的有用函数。对于您的网络抓取冒险,它是值得信赖且有用的伴侣。它的文档是网页抓取,允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup(HTML 解析器),Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个特性使它变得强大:Beautiful Soup 提供了一些 Python 库请求,Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何:
Beautiful Soup(HTML 解析器),网页抓取允许我们从网页中提取信息。在本教程中,您将学习如何使用 Python 和 BeautifulSoup 执行网页抓取。Beautiful Soup 是一个 Python 库,专为屏幕抓取等快速周转项目而设计。三个功能使它强大: Beautiful Soup 提供了一些功能。beautifulsoup4 · PyPI、Python 库请求和 Beautiful Soup 是完成这项工作的强大工具。如果您喜欢通过动手示例进行学习并且对 Python 和 HTML 有基本的了解,那么本教程适合您。在本教程中,您将学习如何: 使用请求和 Beautiful Soup 从 Web 抓取和解析数据
beautifulsoup4·PyPI,如何用 Python 和 BeautifulSoup 爬取 网站,
Python读取html文件
可以使用如下代码: from __future__ import division, unicode_literals import codecs from bs4 import BeautifulSoup f=codecs.open("test.html", 'r', 'utf-8') document= BeautifulSoup(f.read () ) .get_text() 打印文档。如果您想删除中间的所有空行并将所有单词变成字符串(同时避免特殊字符、数字),那么还包括: 我们接下来要做的是创建一个 HTML 文件,上面写着“Hello World!” 使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。. 将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。
请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选 Python - 阅读 HTML 页面安装 Beautifulsoup。
使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。我们可以。
我们接下来要做的是创建一个显示“Hello World!”的 HTML 文件。使用 Python。我们将通过将 HTML 标记存储在多行 Python 字符串中并将内容保存到新文件中来实现此目的。此文件将以 .html 扩展名而不是 .txt 扩展名保存。通常,HTML 文件以 doctype 声明开头。您在上一课中编写 HTML“Hello World”程序时看到了这一点。将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选。Python - 阅读 HTML 页面 安装 Beautifulsoup。使用 Anaconda 包管理器安装所需的包及其依赖项。读取 HTML 文件。在下面的示例中,我们向要加载到 python 环境中的 url 发出请求。然后提取标签值。首先,在最简单的示例中,我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将使用 Pandas read_html 通过几个示例从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。. 我们将使用 Pandas 从字符串中读取 HTML。其次,我们将通过几个示例,使用 Pandas read_html 从 Wikipedia 表中抓取数据。在之前的一篇文章 文章 中,关于 Python 中的探索性数据分析,我们还使用 Pandas 从 HTML 表中读取数据。.
将 HTML 表读入 DataFrame 对象列表。参数 io str、路径对象或类文件对象。URL、类似文件的对象或收录 HTML 的原创字符串。请注意,lxml 仅接受 http、ftp 和文件 url 协议。如果您有一个以“https”开头的 URL,您可以尝试删除“s”。匹配 str 或编译的正则表达式,可选
更多问题
网页抓取数据(_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-05 08:04
curl_setopt($ch, CURLOPT_HEADER, 1);
//我们不需要页面内容
// curl_setopt($ch, CURLOPT_NOBODY, 1);
// 转到结果而不是输出它
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
如果($html === 假){
回显“卷曲错误:”。 curl_error($ch);
}
curl_close($ch);
$linkarr = _striplinks($html);
//主机本地,待补
$host = '#39;;
if (is_array($linkarr)) {
foreach ($linkarr as $k => $v) {
$linkresult[$k] = _expandlinks($v, $host);
}
}
printf("
此页面上的所有链接是:
%s
n", var_export($linkresult , true));
function.php的内容如下(即前两篇文章中两个函数的集合):
函数 _striplinks($document) {
preg_match_all("']+))'isx", $document, $links);
// 连接条件子模式中的非空匹配项
while (list($key, $val) = each($links[2])) {
如果 (!empty($val))
$match[] = $val;
} while (list($key, $val) = each($links[3])) {
如果 (!empty($val))
$match[] = $val;
}
//返回链接
返回$匹配;
}
/*============================================== = ========================*
函数:_expandlinks
目的:将每个链接扩展成一个完全限定的 URL
输入:$链接要限定的链接
$URI 获取基础的完整 URI
输出:$expandedLinks 展开的链接
*=============================================== ==== ========================*/
函数_expandlinks($links,$URI)
{
$URI_PARTS = parse_url($URI);
$host = $URI_PARTS["host"];
preg_match("/^[^?]+/",$URI,$match);
$match = preg_replace("|/[^/.]+.[^/.]+$|","",$match[0]);
$match = preg_replace("|/$|","",$match);
$match_part = parse_url($match);
$match_root =
$match_part["scheme"]."://".$match_part["host"];
$search = array("|^".preg_quote($host)."|i",
"|^(/)|i",
"|^(?!)(?!mailto:)|i",
"|/./|",
"|/[^/]+/../|"
);
$replace = array("",
$match_root."/",
$match."/",
"/",
"/"
);
$expandedLinks = preg_replace($search,$replace,$links);
返回 $expandedLinks;
}
如果想和file_get_contents做个详细对比,可以使用linux下的time命令查看两者执行的时间。根据目前的测试,CURL 更快。第一个链接与以上两个功能的介绍有关。 查看全部
网页抓取数据(_)
curl_setopt($ch, CURLOPT_HEADER, 1);
//我们不需要页面内容
// curl_setopt($ch, CURLOPT_NOBODY, 1);
// 转到结果而不是输出它
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
如果($html === 假){
回显“卷曲错误:”。 curl_error($ch);
}
curl_close($ch);
$linkarr = _striplinks($html);
//主机本地,待补
$host = '#39;;
if (is_array($linkarr)) {
foreach ($linkarr as $k => $v) {
$linkresult[$k] = _expandlinks($v, $host);
}
}
printf("
此页面上的所有链接是:
%s
n", var_export($linkresult , true));
function.php的内容如下(即前两篇文章中两个函数的集合):
函数 _striplinks($document) {
preg_match_all("']+))'isx", $document, $links);
// 连接条件子模式中的非空匹配项
while (list($key, $val) = each($links[2])) {
如果 (!empty($val))
$match[] = $val;
} while (list($key, $val) = each($links[3])) {
如果 (!empty($val))
$match[] = $val;
}
//返回链接
返回$匹配;
}
/*============================================== = ========================*
函数:_expandlinks
目的:将每个链接扩展成一个完全限定的 URL
输入:$链接要限定的链接
$URI 获取基础的完整 URI
输出:$expandedLinks 展开的链接
*=============================================== ==== ========================*/
函数_expandlinks($links,$URI)
{
$URI_PARTS = parse_url($URI);
$host = $URI_PARTS["host"];
preg_match("/^[^?]+/",$URI,$match);
$match = preg_replace("|/[^/.]+.[^/.]+$|","",$match[0]);
$match = preg_replace("|/$|","",$match);
$match_part = parse_url($match);
$match_root =
$match_part["scheme"]."://".$match_part["host"];
$search = array("|^".preg_quote($host)."|i",
"|^(/)|i",
"|^(?!)(?!mailto:)|i",
"|/./|",
"|/[^/]+/../|"
);
$replace = array("",
$match_root."/",
$match."/",
"/",
"/"
);
$expandedLinks = preg_replace($search,$replace,$links);
返回 $expandedLinks;
}
如果想和file_get_contents做个详细对比,可以使用linux下的time命令查看两者执行的时间。根据目前的测试,CURL 更快。第一个链接与以上两个功能的介绍有关。
网页抓取数据(就是上文中的验证码地址()数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-31 16:25
VERIFATIONURL就是上面的验证码地址。首先创建一个post请求,然后创建一个Httpclient,然后HttpResponse就是响应。我们得到的服务器的返回值是通过他得到的,我们创建一个字节数组。首先将响应中得到的数据转换成字节数组,然后通过BitmapFactory.decodeByteArray(bytes, 0, bytes.length);将字节数组编译成位图;方法。这时候我们拿到验证码的Bitmap,直接ImageView.SetBitmap可以吗?当然不是。首先,我们在网页上获取图片是一个耗时的操作,所以我们不能在主线程中进行,第二点是我们只能在主线程中更新UI。我们使用 Thread+Handler 解决方案。以上代码:
private void DoGetVerifation() {
new Thread(new Runnable() {
@Override
public void run() {
HttpPost httPost = new HttpPost(VERIFATIONURL);
HttpClient client = new DefaultHttpClient();
try {
HttpResponse httpResponse = client.execute(httPost);
byte[] bytes = new byte[1024];
bytes = EntityUtils.toByteArray(httpResponse.getEntity());
bmVerifation = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
}
Message msg = new Message();
msg.arg1 = 10;
handler.sendMessage(msg);
}
}).start();
}
在主线程接收到msg后,ivVerifation.setImageBitmap(bmVerifation); 所以我们得到验证码的图片并显示在主界面上
2.发送 Post 请求登录
我们现在知道用户名、密码。验证码,下一步就是登录了,登录是一个耗时的操作。当然,必须启动一个新线程。这个没什么好说的,我们也是在发送一个Post请求,上面的代码:
private void DoLogin(final String user, final String password, final String verifation) {
new Thread(new Runnable() {
@Override
public void run() {
DefaultHttpClient defaultclient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(LOGINURL);
HttpResponse httpResponse;
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
首先是创建post,客户端响应,和上一个一样。我们收到了对数据的 Post 请求。比如获取验证码的请求不需要参数,但是我们需要将验证码发送到服务器用户名密码进行登录,所以我们请求的是Post。设置参数
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
这些参数就是我们之前使用HttpWatch获取的Post数据。只有带类型的参数,没有值。我们将它们设置为 "" 为空,并使用 httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8)); 方法来设置我们的 set param 参数集给 httppost。以下与之前,也是通过Response获取response值,但是不是图片而是吃瓜果的String=-=。函数IsLoginSuccessful是用来推断我们是否登录成功的。。这会用到我们将要进行的数据分析下面说说。
四、数据分析
1.返回的响应?
登录后,我们会得到服务器给我们的响应。我们成功登录了火狐的Firebug的模型(HttpWatch也可以个人觉得看响应值Firebug比较方便)。让我们看看他会给我们带来什么
如图所示,我们可以知道响应值其实就是我们网页的HTML。假设登录成功,其实是返回个人主页
那么假设失败呢?我们模拟一个验证码错误,如下图。可见同样返回一个 HTML
我们注意到这条线
alert('验证码不对!。');document.getElementById('TextBox2').focus();
这实际上会弹出一个表单,告诉我们验证码是错误的。下面我们将使用里面的不同提示来推断我们登录的状态
2.使用Jsoup进行数据解析
我们创建前面提到的 IsLoginSuccessful 函数
private void IsLoginSuccessful(String loginresult) {
Document doc = Jsoup.parse(loginresult);
Elements alert = doc.select("script[language]");
Elements success = doc.select("a[href]");
Message msg = new Message();
//先推断是否登录成功。若成功直接退出
for (Element link : success) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
Log.i("xyz", "登录成功");
msg.arg1 = 6;
handler.sendMessage(msg);
return;
}
}
for (Element link : alert) {
//刷新验证码
DoGetVerifation();
//获取错误信息
if (link.data().contains("验证码不对")) {
Log.i("xyz", "验证码错误");
msg.arg1 = 0;
handler.sendMessage(msg);
} else if (link.data().contains("username不能为空")) {
Log.i("xyz", "username不能为空");
msg.arg1 = 1;
handler.sendMessage(msg);
} else if (link.data().contains("password错误")) {
Log.i("xyz", "password或username错误");
msg.arg1 = 2;
handler.sendMessage(msg);
} else if (link.data().contains("password不能为空")) {
Log.i("xyz", "password不能为空");
msg.arg1 = 3;
handler.sendMessage(msg);
......
}
}
我正在使用开源库 Jsoup 进行解析。当然,有很多方法可以做到这一点。你可以自己google一下(百度=-=你这个老躺枪)
你可以看看Jsoup的中文API指南
首先,我们推断登录成功。我们在成功登录的 HTML 中发现了以下语句。
等级考试查询
我们通过Elements success = doc.select("a[href]"); 获取以a href" 开头的数据,然后循环推断是否有等级测试查询,假设存在。必须返回的响应是我们的个人主页。也就是说登录成功了,我们在主线程toast中使用Thread+Handler来提醒用户
然后我们通过Elements alert = doc.select("script[language]"); 得到脚本开头的语句,同样的循环推理,这里需要注意的是它和a href 不同。我们使用的是link.data(),前一个是link.text();
JsoupAPI 是这样写的
五、访问个人信息
我们登录了个人主页,想进一步了解自己,比如四年级和六年级,该怎么办?相同或获取请求
获取验证码网址的方法相同。我们得到了成绩单的网址
xh=2014117170&xm=">(dlxrmg55j21wlaqv2z5rcdyi)/xsdjkscx.aspx?xh=2014117170&xm=邹德宏&gnmkdm=N121606
前面的(dlxrmg55j21wlaqv2z5rcdyi)/是我们访问的主机不变。我们所要做的就是获取 xsdjkscx.aspx?
xh=2014117170&xm=邹德宏&gnmkdm=N121606. 这个问题困扰我很久了。后来突然发现,万智居然是在前面提到的登'lu'cheng'登录成功后返回的html中。所以还是用Jsoup来分析
Document doc = Jsoup.parse(MAINBODYHTML);
Elements links = doc.select("a[href]");
StringBuffer sb = new StringBuffer();
for (Element link : links) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
sb.append(link.attr("href"));
}
}
GETSCOREURL = sb.toString();
GETSCOREURL 是我们想要的地址的后半部分,然后我们添加前半部分来获取 Post 请求。
这里返回的是一个 Html 表
学年学期等级考试名称准考证号考试日期成绩听力成绩阅读成绩写作成绩综合成绩
2014-20152CET4610041151112625201506483167
1731430
2015-20161CET6610041152209503201512376126
1431070
同样使用 Jsoup
private void parse(String parse) {
Document doc = Jsoup.parse(parse);
Elements trs = doc.select("table").select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
for (int j = 0; j < tds.size(); j++) {
String text = tds.get(j).text();
score[i][j] = text;
Log.i("xyz", score[i][j]);
}
}
}
解析后,我们得到一个分数数组
六、总结
博主高二党学习Android开发一年半了,现在终于有了上手的感觉。本教程对于新手来说会有些困难。不过你要保持冷静,博主第一次下载HttpWatch的时候愣了一下。什么都不懂,慢慢摸索后终于有了一点线索。好的,仅此而已。有邮件交流的朋友加我=-= 查看全部
网页抓取数据(就是上文中的验证码地址()数据解析)
VERIFATIONURL就是上面的验证码地址。首先创建一个post请求,然后创建一个Httpclient,然后HttpResponse就是响应。我们得到的服务器的返回值是通过他得到的,我们创建一个字节数组。首先将响应中得到的数据转换成字节数组,然后通过BitmapFactory.decodeByteArray(bytes, 0, bytes.length);将字节数组编译成位图;方法。这时候我们拿到验证码的Bitmap,直接ImageView.SetBitmap可以吗?当然不是。首先,我们在网页上获取图片是一个耗时的操作,所以我们不能在主线程中进行,第二点是我们只能在主线程中更新UI。我们使用 Thread+Handler 解决方案。以上代码:
private void DoGetVerifation() {
new Thread(new Runnable() {
@Override
public void run() {
HttpPost httPost = new HttpPost(VERIFATIONURL);
HttpClient client = new DefaultHttpClient();
try {
HttpResponse httpResponse = client.execute(httPost);
byte[] bytes = new byte[1024];
bytes = EntityUtils.toByteArray(httpResponse.getEntity());
bmVerifation = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
}
Message msg = new Message();
msg.arg1 = 10;
handler.sendMessage(msg);
}
}).start();
}
在主线程接收到msg后,ivVerifation.setImageBitmap(bmVerifation); 所以我们得到验证码的图片并显示在主界面上
2.发送 Post 请求登录
我们现在知道用户名、密码。验证码,下一步就是登录了,登录是一个耗时的操作。当然,必须启动一个新线程。这个没什么好说的,我们也是在发送一个Post请求,上面的代码:
private void DoLogin(final String user, final String password, final String verifation) {
new Thread(new Runnable() {
@Override
public void run() {
DefaultHttpClient defaultclient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(LOGINURL);
HttpResponse httpResponse;
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
首先是创建post,客户端响应,和上一个一样。我们收到了对数据的 Post 请求。比如获取验证码的请求不需要参数,但是我们需要将验证码发送到服务器用户名密码进行登录,所以我们请求的是Post。设置参数
//设置post參数
List params = new ArrayList();
params.add(new BasicNameValuePair("__VIEWSTATE", "dDwyODE2NTM0OTg7Oz6ZmvWn7xzjizifHN9MgLoDNTRtjQ=="));
params.add(new BasicNameValuePair("Button1", ""));
params.add(new BasicNameValuePair("hidPdrs", ""));
params.add(new BasicNameValuePair("hidsc", ""));
params.add(new BasicNameValuePair("lbLanguage", ""));
params.add(new BasicNameValuePair("RadioButtonList1", "%D1%A7%C9%FA"));
params.add(new BasicNameValuePair("TextBox2", password));
params.add(new BasicNameValuePair("txtSecretCode", verifation));
params.add(new BasicNameValuePair("txtUserName", user));
//获得个人主界面的HTML
try {
httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
httpResponse = defaultclient.execute(httpPost);
Log.i("xyz", String.valueOf(httpResponse.getStatusLine().getStatusCode()));
if (httpResponse.getStatusLine().getStatusCode() == 200) {
StringBuffer sb = new StringBuffer();
HttpEntity entity = httpResponse.getEntity();
MAINBODYHTML = EntityUtils.toString(entity);
IsLoginSuccessful(MAINBODYHTML);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
这些参数就是我们之前使用HttpWatch获取的Post数据。只有带类型的参数,没有值。我们将它们设置为 "" 为空,并使用 httpPost.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8)); 方法来设置我们的 set param 参数集给 httppost。以下与之前,也是通过Response获取response值,但是不是图片而是吃瓜果的String=-=。函数IsLoginSuccessful是用来推断我们是否登录成功的。。这会用到我们将要进行的数据分析下面说说。
四、数据分析
1.返回的响应?
登录后,我们会得到服务器给我们的响应。我们成功登录了火狐的Firebug的模型(HttpWatch也可以个人觉得看响应值Firebug比较方便)。让我们看看他会给我们带来什么
如图所示,我们可以知道响应值其实就是我们网页的HTML。假设登录成功,其实是返回个人主页
那么假设失败呢?我们模拟一个验证码错误,如下图。可见同样返回一个 HTML
我们注意到这条线
alert('验证码不对!。');document.getElementById('TextBox2').focus();
这实际上会弹出一个表单,告诉我们验证码是错误的。下面我们将使用里面的不同提示来推断我们登录的状态
2.使用Jsoup进行数据解析
我们创建前面提到的 IsLoginSuccessful 函数
private void IsLoginSuccessful(String loginresult) {
Document doc = Jsoup.parse(loginresult);
Elements alert = doc.select("script[language]");
Elements success = doc.select("a[href]");
Message msg = new Message();
//先推断是否登录成功。若成功直接退出
for (Element link : success) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
Log.i("xyz", "登录成功");
msg.arg1 = 6;
handler.sendMessage(msg);
return;
}
}
for (Element link : alert) {
//刷新验证码
DoGetVerifation();
//获取错误信息
if (link.data().contains("验证码不对")) {
Log.i("xyz", "验证码错误");
msg.arg1 = 0;
handler.sendMessage(msg);
} else if (link.data().contains("username不能为空")) {
Log.i("xyz", "username不能为空");
msg.arg1 = 1;
handler.sendMessage(msg);
} else if (link.data().contains("password错误")) {
Log.i("xyz", "password或username错误");
msg.arg1 = 2;
handler.sendMessage(msg);
} else if (link.data().contains("password不能为空")) {
Log.i("xyz", "password不能为空");
msg.arg1 = 3;
handler.sendMessage(msg);
......
}
}
我正在使用开源库 Jsoup 进行解析。当然,有很多方法可以做到这一点。你可以自己google一下(百度=-=你这个老躺枪)
你可以看看Jsoup的中文API指南
首先,我们推断登录成功。我们在成功登录的 HTML 中发现了以下语句。
等级考试查询
我们通过Elements success = doc.select("a[href]"); 获取以a href" 开头的数据,然后循环推断是否有等级测试查询,假设存在。必须返回的响应是我们的个人主页。也就是说登录成功了,我们在主线程toast中使用Thread+Handler来提醒用户
然后我们通过Elements alert = doc.select("script[language]"); 得到脚本开头的语句,同样的循环推理,这里需要注意的是它和a href 不同。我们使用的是link.data(),前一个是link.text();
JsoupAPI 是这样写的
五、访问个人信息
我们登录了个人主页,想进一步了解自己,比如四年级和六年级,该怎么办?相同或获取请求
获取验证码网址的方法相同。我们得到了成绩单的网址
xh=2014117170&xm=">(dlxrmg55j21wlaqv2z5rcdyi)/xsdjkscx.aspx?xh=2014117170&xm=邹德宏&gnmkdm=N121606
前面的(dlxrmg55j21wlaqv2z5rcdyi)/是我们访问的主机不变。我们所要做的就是获取 xsdjkscx.aspx?
xh=2014117170&xm=邹德宏&gnmkdm=N121606. 这个问题困扰我很久了。后来突然发现,万智居然是在前面提到的登'lu'cheng'登录成功后返回的html中。所以还是用Jsoup来分析
Document doc = Jsoup.parse(MAINBODYHTML);
Elements links = doc.select("a[href]");
StringBuffer sb = new StringBuffer();
for (Element link : links) {
//获取所要查询的URL,这里相应地址button的名字叫成绩查询
if (link.text().equals("等级考试查询")) {
sb.append(link.attr("href"));
}
}
GETSCOREURL = sb.toString();
GETSCOREURL 是我们想要的地址的后半部分,然后我们添加前半部分来获取 Post 请求。
这里返回的是一个 Html 表
学年学期等级考试名称准考证号考试日期成绩听力成绩阅读成绩写作成绩综合成绩
2014-20152CET4610041151112625201506483167
1731430
2015-20161CET6610041152209503201512376126
1431070
同样使用 Jsoup
private void parse(String parse) {
Document doc = Jsoup.parse(parse);
Elements trs = doc.select("table").select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
for (int j = 0; j < tds.size(); j++) {
String text = tds.get(j).text();
score[i][j] = text;
Log.i("xyz", score[i][j]);
}
}
}
解析后,我们得到一个分数数组
六、总结
博主高二党学习Android开发一年半了,现在终于有了上手的感觉。本教程对于新手来说会有些困难。不过你要保持冷静,博主第一次下载HttpWatch的时候愣了一下。什么都不懂,慢慢摸索后终于有了一点线索。好的,仅此而已。有邮件交流的朋友加我=-=
网页抓取数据(WebScraper安装方式及功能说明数据的思路(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-30 16:04
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
2、然后在弹出的窗口中点击“添加扩展”
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取 知乎 回答问题,创建站点地图,并将问题的地址设置为站点地图的起始 URL,然后单击“创建站点地图”以创建站点地图。
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
站点地图:进入站点地图,可以进行一系列操作,如下图:
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货 查看全部
网页抓取数据(WebScraper安装方式及功能说明数据的思路(组图))
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。比如知乎答案列表、微博热门、微博评论、电商网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
2、然后在弹出的窗口中点击“添加扩展”
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
2、安装完成后在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你要获取 知乎 回答问题,创建站点地图,并将问题的地址设置为站点地图的起始 URL,然后单击“创建站点地图”以创建站点地图。
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
站点地图:进入站点地图,可以进行一系列操作,如下图:
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明一下,一个sitemap可以有多个选择器,每个选择器可以收录子选择器,一个选择器可以只对应一个标题,也可以对应整个区域,这个区域可以收录标题、副标题、作者信息、内容等. 和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
开始
1、假设我们打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后don'
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建站点地图会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货
网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2022-01-29 21:21
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载 查看全部
网页抓取数据(本文就用Java给大家演示如何抓取网站的数据:(1))
原文链接:
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
搜索结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市移动
二、抓取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然,前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章能对需要的人有所帮助。如需程序源代码,请点击此处下载
网页抓取数据(我可以采取什么措施来防止恶意抓取工具从我的网站上窃取所有数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-24 04:06
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,那么我们可能会像采集网站@ > 。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。
本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,多种开源综合应用。
想从国外网站抓取数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。 查看全部
网页抓取数据(我可以采取什么措施来防止恶意抓取工具从我的网站上窃取所有数据?)
如何防止恶意爬虫窃取我的 网站 上的所有数据?我不太关心 SEO,虽然我不想阻止合法的抓取。
大家都会使用网页抓取工具优采云采集器来采集网页数据,但是如果有很多朋友还没有,那么我们可能会像采集网站@ > 。
OctoparseOctoparse 是一个免费且强大的网站爬虫工具,用于从网站中提取各种类型的数据。它有两种学习方式。
30款流行的大数据分析工具推荐(最新) Mozenda是一款网页抓取软件,同时也提供商业级数据抓取的定制化服务。它可以。
呵呵,楼上说的很清楚了,你先看看你要在哪里抓数据,如果是一般用途,随便找个免费的就行了。如果说的是专业的网页数据抓取,比如最近流行的网络信息采集,监控等商业用途,可以使用乐思数据抓取系统,可以搜索详情,它们是国内信息的采集 的创始人。
本软件可以帮助想要研究代码或者嫁接别人前端代码文件的开发者网站爬虫网站爬虫详解相关用法。
不再有手写爬虫!推荐5个自动爬取数据的神器!_c-CSDN博客。
特点:网页抓取,信息抽取,数据抽取工具包,操作简单 11、Playfishplayfish是Java技术,多种开源综合应用。
想从国外网站抓取数据,有什么好的数据抓取工具推荐吗?.
33个用于抓取数据的开源爬虫软件工具 每个人都是产品经理。
网页抓取数据( 这是简易数据分析系列的第10篇文章(-n+100))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-23 17:11
这是简易数据分析系列的第10篇文章(-n+100))
这是简易数据分析系列文章的第10期。html
**友情提示:**这篇文章文章内容很多,信息量很大。希望大家在学习的时候多读几遍。网络
我们在朋友圈刷微博的时候,总是强调“刷”这个词。因为在看动态的时候,当内容被拉到屏尾时,APP会自动加载下一页的数据,从体验上看,数据会不断加载,永无止境。api
今天我们要讲的是如何使用Web Scraper来抓取滚动到最后的网页。浏览器
今天的实践网站是知乎的数据分析模块的精华,网址是:markdown
学习
这次要刮的内容是精英帖的标题、回答者和点赞数。下面是今天的教程。网站
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到网页底部加载数据。温泉
在这种情况下,所选元素被命名为 div.List-item。。网
为了复习上一节通过数据数控制记录数的方法,我们在元素名后面加上nth-of-type(-n+100),暂时只抓取前100个数据.3d
然后我们保存容器节点,选择该节点下要抓取的三种数据类型。
第一个是标题,我们命名为title,选中的元素命名为[itemprop='知乎:question'] a:
然后是响应者姓名和点赞数,选中元素名称为#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部被选中。我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径来抓取数据。等了十多秒才出来结果,内容让我们傻眼了:
数据呢?我要捕获哪些数据?为什么这一切都变成了空?
在计算机领域,null通常表示一个空值,表示什么都没有,如果放在Web Scraper中,则表示没有抓取到任何数据。
我们可以回想一下,网页上确实有数据。在整个操作过程中,唯一的变量就是选择元素的操作。因此,确定我们选择元素有误,导致内容匹配出现问题,无法正常获取数据。要解决这个问题,我们要看看页面的构成。
3.分析问题
要查看一个网页的构成,我们需要用到浏览器的另一个功能,就是选择视图元素。
**1.**我们点击控制面板左上角的箭头,此时箭头颜色会变为蓝色。
**2.** 然后我们将鼠标移到标题上,标题将被蓝色半透明蒙版覆盖。
**3.** 我们再次点击标题,会发现我们会跳转到Elements子面板,里面收录了一些难以理解的彩色代码
这里不要害怕,这些HTML代码不涉及任何逻辑,它们只是网页中的一个骨架,提供一些排版功能。如果你每天都在写markdown,你可以将HTML理解为具有更复杂功能的markdown。
结合HTML代码,我们先看一下[itemprop='知乎:question']的匹配规则a。
首先这是一个树结构:
从可视化的角度来看,上一句其实是一个嵌套结构。我提取了关键内容。内容结构是否清晰得多?
<a>如何快速成为数据分析师?</a>
让我们再分析一个标题 HTML 代码,它将标题作为空值。
我们可以很清楚的观察到,在这个标题的代码中,缺少属性itemprop='知乎:question'的名为div的标签!这样,当我们的匹配规则匹配到时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成了null。
找到原因后,我们就可以解决问题了。
4.解决问题
我们发现,在选择标题时,无论标题的嵌套关系如何变化,始终有一个标签保持不变,即包裹在最外层的h2标签,属性名称为class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清了关系,我们如何操作Web Scraper?这时候我们就可以使用上一篇文章中介绍的内容文章来使用键盘P键选择元素的父节点:
在今天的课程中,我们可以通过双击P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于被访者的名字也出现了null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面有很大的不同,大家可以试试。
个人的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape爬取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现数据的滚动加载很快就完成了,但是匹配元素要花很多时间。
这间接表明 知乎this网站 从代码的角度来看仍然写得不好。
如果多爬一点网站,你会发现大部分网页结构都比较“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20条记录,看看数据有没有问题。没有问题后,可以加一个大范围的正式捕获,可以在一定程度上减少返工时间。
6.下一期
本期内容很多,可以多看几遍消化一下。下一期我们会讲一些简单的内容,以及如何抓取表格内容。 查看全部
网页抓取数据(
这是简易数据分析系列的第10篇文章(-n+100))
这是简易数据分析系列文章的第10期。html
**友情提示:**这篇文章文章内容很多,信息量很大。希望大家在学习的时候多读几遍。网络
我们在朋友圈刷微博的时候,总是强调“刷”这个词。因为在看动态的时候,当内容被拉到屏尾时,APP会自动加载下一页的数据,从体验上看,数据会不断加载,永无止境。api
今天我们要讲的是如何使用Web Scraper来抓取滚动到最后的网页。浏览器
今天的实践网站是知乎的数据分析模块的精华,网址是:markdown
学习
这次要刮的内容是精英帖的标题、回答者和点赞数。下面是今天的教程。网站
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到网页底部加载数据。温泉
在这种情况下,所选元素被命名为 div.List-item。。网
为了复习上一节通过数据数控制记录数的方法,我们在元素名后面加上nth-of-type(-n+100),暂时只抓取前100个数据.3d
然后我们保存容器节点,选择该节点下要抓取的三种数据类型。
第一个是标题,我们命名为title,选中的元素命名为[itemprop='知乎:question'] a:
然后是响应者姓名和点赞数,选中元素名称为#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部被选中。我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径来抓取数据。等了十多秒才出来结果,内容让我们傻眼了:
数据呢?我要捕获哪些数据?为什么这一切都变成了空?
在计算机领域,null通常表示一个空值,表示什么都没有,如果放在Web Scraper中,则表示没有抓取到任何数据。
我们可以回想一下,网页上确实有数据。在整个操作过程中,唯一的变量就是选择元素的操作。因此,确定我们选择元素有误,导致内容匹配出现问题,无法正常获取数据。要解决这个问题,我们要看看页面的构成。
3.分析问题
要查看一个网页的构成,我们需要用到浏览器的另一个功能,就是选择视图元素。
**1.**我们点击控制面板左上角的箭头,此时箭头颜色会变为蓝色。
**2.** 然后我们将鼠标移到标题上,标题将被蓝色半透明蒙版覆盖。
**3.** 我们再次点击标题,会发现我们会跳转到Elements子面板,里面收录了一些难以理解的彩色代码
这里不要害怕,这些HTML代码不涉及任何逻辑,它们只是网页中的一个骨架,提供一些排版功能。如果你每天都在写markdown,你可以将HTML理解为具有更复杂功能的markdown。
结合HTML代码,我们先看一下[itemprop='知乎:question']的匹配规则a。
首先这是一个树结构:
从可视化的角度来看,上一句其实是一个嵌套结构。我提取了关键内容。内容结构是否清晰得多?
<a>如何快速成为数据分析师?</a>
让我们再分析一个标题 HTML 代码,它将标题作为空值。
我们可以很清楚的观察到,在这个标题的代码中,缺少属性itemprop='知乎:question'的名为div的标签!这样,当我们的匹配规则匹配到时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成了null。
找到原因后,我们就可以解决问题了。
4.解决问题
我们发现,在选择标题时,无论标题的嵌套关系如何变化,始终有一个标签保持不变,即包裹在最外层的h2标签,属性名称为class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就不能完美匹配标题内容了?
逻辑上理清了关系,我们如何操作Web Scraper?这时候我们就可以使用上一篇文章中介绍的内容文章来使用键盘P键选择元素的父节点:
在今天的课程中,我们可以通过双击P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于被访者的名字也出现了null,我们分析HTML结构,选择名字的父标签span.AuthorInfo-name。具体的分析操作和上面有很大的不同,大家可以试试。
个人的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape爬取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现数据的滚动加载很快就完成了,但是匹配元素要花很多时间。
这间接表明 知乎this网站 从代码的角度来看仍然写得不好。
如果多爬一点网站,你会发现大部分网页结构都比较“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20条记录,看看数据有没有问题。没有问题后,可以加一个大范围的正式捕获,可以在一定程度上减少返工时间。
6.下一期
本期内容很多,可以多看几遍消化一下。下一期我们会讲一些简单的内容,以及如何抓取表格内容。

