
网页抓取数据
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-07 16:28
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码。我们在源码中看到这么一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
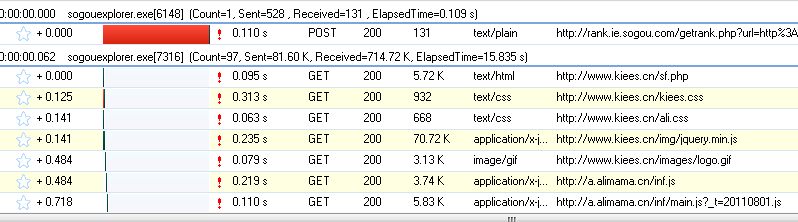
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:
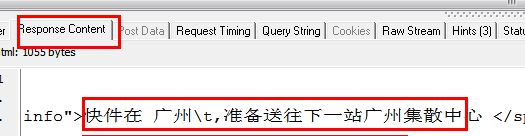
这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
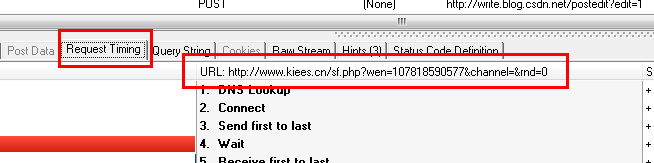
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载! 查看全部
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:

第二步:查看网页源代码。我们在源码中看到这么一段:

从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:

换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:

这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载!
网页抓取数据(通过利用selenium的子模块webdriver的使用解决思路(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-10-05 00:04
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,您使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问量、当前在线人数、微博点赞数等)都没有收录在静态html中,比如我想抓取当前在线点击人数打开 bbs网站 链接的每个部分。静态html网页不收录(不信你试试看页面源码,只有简单的一行)。
2. 解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html内容导入python程序?所以使用查看器的html内容的方法也不符合爬虫程序的要求。偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。使用 webdriver 捕获动态数据
首先从 selenium import webdriver 导入 webdriver 子模块以获取浏览器会话。浏览器可以使用Firefox、Chrome、IE等,这里以Firefox为例,browser = webdriver.Firefox()加载页面,url本身指定合法字符串。但是 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法,常用的有以下几种方式: idnameclass-namelinktextpartiallinktexttagnamexpathcssselector 例如通过 id 定位,返回一个列表所有元素, lis=borwser.find_elements_by_id_name('kw'') 是通过class-name来定位的, lis=find_elements_by_class_name('title_1') 更详细的定位方法,请参考selenium webdriver(python)教程-定位方法部分(第一版)第三章可在百度文库中查看)结合正则表达式过滤相关信息。定位后有些元素不需要,用正则表达式过滤掉即可。比如我想只提取英文字符(包括0-9),在lis中为u创建如下Regular pa=pile(r'\w+'):en=pa.findall(u.lis)print en 关闭会话,执行fetch操作后,必须关闭会话,否则会一直占用内存。运行browser.close()或本机其他进程的浏览器.quit()可以关闭会话,前者只是关闭当前会话,浏览器的webdriver没有关闭,后者是关闭包括webdriver在内的所有东西。
我通过点击打开链接抓取指定分区每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线人数,形成一个列表并打印出来,代码如下
[python]查看平原
#-*- 编码:utf-8 -*- from selenium import webdriver from mon.exceptions import NoSuchElementException import time import re def find_sec(secid): pa=pile(r'\w+') browser = webdriver.Firefox() #获取firefox浏览器的本地会话.get("!section/%s "%secid) #加载页面 time.sleep(1) #让页面加载 result=[] try: #获取页面名称和在线人数, 形成列表 board=browser.find_elements_by_class_name('title_1') ol_num=browser.find_elements_by_class_name('title_4') max_bindex=len(board) max_oindex=len(ol_num) assert max_bindex==max_oindex,'index 不等价!' #The板名有中文和英文,所以只剩下i in range(1,max_oindex) 的英文进行常规过滤: board_en=pa.findall(board[i].text) result.append([str(board_en[-1]) ),int( ol_num[i].text)]) 浏览器。close() return result except NoSuchElementException: assert 0, "can't find element"print find_sec('5') #打印分区5下所有版块的当前在线用户列表
操作结果如下:
终端打印效果4.总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用这个来实现数据挖掘、机器学习等深度研究,所以selenium+python是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。 查看全部
网页抓取数据(通过利用selenium的子模块webdriver的使用解决思路(图))
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,您使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问量、当前在线人数、微博点赞数等)都没有收录在静态html中,比如我想抓取当前在线点击人数打开 bbs网站 链接的每个部分。静态html网页不收录(不信你试试看页面源码,只有简单的一行)。
2. 解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html内容导入python程序?所以使用查看器的html内容的方法也不符合爬虫程序的要求。偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。使用 webdriver 捕获动态数据
首先从 selenium import webdriver 导入 webdriver 子模块以获取浏览器会话。浏览器可以使用Firefox、Chrome、IE等,这里以Firefox为例,browser = webdriver.Firefox()加载页面,url本身指定合法字符串。但是 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法,常用的有以下几种方式: idnameclass-namelinktextpartiallinktexttagnamexpathcssselector 例如通过 id 定位,返回一个列表所有元素, lis=borwser.find_elements_by_id_name('kw'') 是通过class-name来定位的, lis=find_elements_by_class_name('title_1') 更详细的定位方法,请参考selenium webdriver(python)教程-定位方法部分(第一版)第三章可在百度文库中查看)结合正则表达式过滤相关信息。定位后有些元素不需要,用正则表达式过滤掉即可。比如我想只提取英文字符(包括0-9),在lis中为u创建如下Regular pa=pile(r'\w+'):en=pa.findall(u.lis)print en 关闭会话,执行fetch操作后,必须关闭会话,否则会一直占用内存。运行browser.close()或本机其他进程的浏览器.quit()可以关闭会话,前者只是关闭当前会话,浏览器的webdriver没有关闭,后者是关闭包括webdriver在内的所有东西。
我通过点击打开链接抓取指定分区每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线人数,形成一个列表并打印出来,代码如下
[python]查看平原
#-*- 编码:utf-8 -*- from selenium import webdriver from mon.exceptions import NoSuchElementException import time import re def find_sec(secid): pa=pile(r'\w+') browser = webdriver.Firefox() #获取firefox浏览器的本地会话.get("!section/%s "%secid) #加载页面 time.sleep(1) #让页面加载 result=[] try: #获取页面名称和在线人数, 形成列表 board=browser.find_elements_by_class_name('title_1') ol_num=browser.find_elements_by_class_name('title_4') max_bindex=len(board) max_oindex=len(ol_num) assert max_bindex==max_oindex,'index 不等价!' #The板名有中文和英文,所以只剩下i in range(1,max_oindex) 的英文进行常规过滤: board_en=pa.findall(board[i].text) result.append([str(board_en[-1]) ),int( ol_num[i].text)]) 浏览器。close() return result except NoSuchElementException: assert 0, "can't find element"print find_sec('5') #打印分区5下所有版块的当前在线用户列表
操作结果如下:
终端打印效果4.总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用这个来实现数据挖掘、机器学习等深度研究,所以selenium+python是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。
网页抓取数据( Web抓取中的障碍有哪些?如何应用到Web中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-04 18:20
Web抓取中的障碍有哪些?如何应用到Web中)
AI如何用于网络爬虫?
在互联网世界中,数据就是一切,尤其是当您经营电子商务业务时。您每天都需要新数据来改进决策过程并找到吸引消费者的方法。网页抓取可以通过自动化流程和优化数据通道来帮助您采集 数据。
然而,从最好的 网站 中安全地抓取和提取数据仍然存在一些限制。由于网页抓取需要一定的知识和持续监控,归根结底必须选择正确的工具,而目前最好的工具是人工智能。让我们看看它如何应用于网络爬虫。
网页抓取的定义
网络爬行几乎与网页本身同时发生。它是谷歌等搜索引擎的命脉,帮助互联网用户大规模提取有价值的数据。它的目标是从各种高质量的网站中自动采集数据。网络爬虫是利用爬虫机器人浏览数百个网站和采集数据。
不过上面的网站对爬虫机器人并不友好。他们设置了各种安全机制来防止他们爬取数据。简单的机器人很容易被发现,而更复杂的机器人则有绕过安全机制的方法。
它们由人工智能驱动,可以识别网站上的优质数据,并且可以成功提取数据进行分析,不被发现、阻止或阻止。
网页抓取中的障碍
虽然网页抓取非常有用,但在实际应用中仍然存在许多障碍。最近,美国最高法院裁定用于人工智能和数据分析的网络抓取是合法的。即便如此,在网络爬虫中,您可能仍会面临很多困难,难以顺利地采集有价值的数据让您的业务蓬勃发展。
最常见的障碍包括:
扩大网络爬虫的规模:爬取一个网页本身不是问题,但是大规模的数据爬取面临着一些挑战,比如同时爬取几百万个网站数据。除了被检测和阻止之外,还有其他挑战,包括维护数据库、采集 数据和管理代码库。
模式改变:网站经常定期改变用户界面,增加数据抓取工具的难度。
反爬技术:顶级网站会采用各种反爬机制和安全技术。
基于 JavaScript 的动态内容:现代 网站 使用 Ajax 和 JavaScript 来呈现动态内容,使得数据提取更加困难。
蜜罐陷阱:一些顶级网站使用蜜罐技术来检测爬行机器人并提供虚假数据。
数据质量:现在有适用于提取数据的质量指南。如果数据质量不好,就会影响提取信息的完整性。
AI改变现状
网页抓取可以帮助解决很多问题,从而轻松解决数据抓取和提取的困难。很多企业使用AI网页爬取工具采集优质信息,包括市场调研、企业数据采集、供应链分析、劳动力研究、电子商务等。
AI让爬虫机器人的操作界面更加直观,从而提高了网络爬虫的效率。得益于NLP、机器学习等AI技术的加持,抓取机器人知道了网站中有价值的数据(如产品价格、评论、描述等)位于何处。将人工智能与网页抓取技术相结合,可以提高整个数据增强过程的效率和效果。
AI 网页抓取使数据提取、清理、聚合和规范化更加高效,同时节省资源和时间。您可以专注于您的核心业务,而不是将大量时间浪费在 采集 数据上,因为您了解 AI 可以完全满足您的网页抓取需求。
人工智能可以帮助开发数据增强方法,包括:
- 外推法
-标记
-聚合
-概率法
AI网页抓取
人工智能可以提高网页抓取应对挑战的能力,从而提高效率。由于 网站 是为人而不是机器构建的,因此从不同网页中大规模提取数据将成为一项挑战。出错的机会太多了。
但是强大的AI可以帮助避免许多常见错误并提高爬行效率。它还可以减少数据误用和错误,改进数据结构,使提取的数据更具实用性,扩大其应用范围。
随着人工智能技术的不断发展,它将不断优化网络爬虫,使应用程序比以往任何时候都更高效、更流畅。如果您正在考虑在您的业务中使用 AI 网络爬虫,请访问此页面以了解更多信息。
综上所述
今天,人工智能已经渗透到我们生活的方方面面,现代社会的每一个垂直领域都以各种方式依赖于这项卓越的技术。随着网页抓取和数据提取技术日新月异,将人工智能技术引入您的网页抓取中迟早会发生。
如果您想确保捕获高质量的可用数据,那么 AI 驱动的智能网络爬虫是您的最佳选择。 查看全部
网页抓取数据(
Web抓取中的障碍有哪些?如何应用到Web中)

AI如何用于网络爬虫?
在互联网世界中,数据就是一切,尤其是当您经营电子商务业务时。您每天都需要新数据来改进决策过程并找到吸引消费者的方法。网页抓取可以通过自动化流程和优化数据通道来帮助您采集 数据。
然而,从最好的 网站 中安全地抓取和提取数据仍然存在一些限制。由于网页抓取需要一定的知识和持续监控,归根结底必须选择正确的工具,而目前最好的工具是人工智能。让我们看看它如何应用于网络爬虫。
网页抓取的定义
网络爬行几乎与网页本身同时发生。它是谷歌等搜索引擎的命脉,帮助互联网用户大规模提取有价值的数据。它的目标是从各种高质量的网站中自动采集数据。网络爬虫是利用爬虫机器人浏览数百个网站和采集数据。
不过上面的网站对爬虫机器人并不友好。他们设置了各种安全机制来防止他们爬取数据。简单的机器人很容易被发现,而更复杂的机器人则有绕过安全机制的方法。
它们由人工智能驱动,可以识别网站上的优质数据,并且可以成功提取数据进行分析,不被发现、阻止或阻止。
网页抓取中的障碍
虽然网页抓取非常有用,但在实际应用中仍然存在许多障碍。最近,美国最高法院裁定用于人工智能和数据分析的网络抓取是合法的。即便如此,在网络爬虫中,您可能仍会面临很多困难,难以顺利地采集有价值的数据让您的业务蓬勃发展。
最常见的障碍包括:
扩大网络爬虫的规模:爬取一个网页本身不是问题,但是大规模的数据爬取面临着一些挑战,比如同时爬取几百万个网站数据。除了被检测和阻止之外,还有其他挑战,包括维护数据库、采集 数据和管理代码库。
模式改变:网站经常定期改变用户界面,增加数据抓取工具的难度。
反爬技术:顶级网站会采用各种反爬机制和安全技术。
基于 JavaScript 的动态内容:现代 网站 使用 Ajax 和 JavaScript 来呈现动态内容,使得数据提取更加困难。
蜜罐陷阱:一些顶级网站使用蜜罐技术来检测爬行机器人并提供虚假数据。
数据质量:现在有适用于提取数据的质量指南。如果数据质量不好,就会影响提取信息的完整性。
AI改变现状
网页抓取可以帮助解决很多问题,从而轻松解决数据抓取和提取的困难。很多企业使用AI网页爬取工具采集优质信息,包括市场调研、企业数据采集、供应链分析、劳动力研究、电子商务等。
AI让爬虫机器人的操作界面更加直观,从而提高了网络爬虫的效率。得益于NLP、机器学习等AI技术的加持,抓取机器人知道了网站中有价值的数据(如产品价格、评论、描述等)位于何处。将人工智能与网页抓取技术相结合,可以提高整个数据增强过程的效率和效果。
AI 网页抓取使数据提取、清理、聚合和规范化更加高效,同时节省资源和时间。您可以专注于您的核心业务,而不是将大量时间浪费在 采集 数据上,因为您了解 AI 可以完全满足您的网页抓取需求。
人工智能可以帮助开发数据增强方法,包括:
- 外推法
-标记
-聚合
-概率法
AI网页抓取
人工智能可以提高网页抓取应对挑战的能力,从而提高效率。由于 网站 是为人而不是机器构建的,因此从不同网页中大规模提取数据将成为一项挑战。出错的机会太多了。
但是强大的AI可以帮助避免许多常见错误并提高爬行效率。它还可以减少数据误用和错误,改进数据结构,使提取的数据更具实用性,扩大其应用范围。
随着人工智能技术的不断发展,它将不断优化网络爬虫,使应用程序比以往任何时候都更高效、更流畅。如果您正在考虑在您的业务中使用 AI 网络爬虫,请访问此页面以了解更多信息。
综上所述
今天,人工智能已经渗透到我们生活的方方面面,现代社会的每一个垂直领域都以各种方式依赖于这项卓越的技术。随着网页抓取和数据提取技术日新月异,将人工智能技术引入您的网页抓取中迟早会发生。
如果您想确保捕获高质量的可用数据,那么 AI 驱动的智能网络爬虫是您的最佳选择。
网页抓取数据(python爬虫非常多,如何识别http协议的识别方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-02 18:02
网页抓取数据分为http和https,本文将着重介绍http协议的识别方法。你是否经常和爬虫打交道?python爬虫非常多,如何抓取最多的内容呢?本文会介绍一些好用的工具网站,比如蝉大师提供的python网站提取工具,可以爬取最多的百度、知乎、豆瓣上的文章内容。效果如下:网页抓取数据页面伪代码该网站中爬取的某篇文章如下图所示:爬取之后的效果,即可以输出在rss中,代码如下:页面伪代码http提供了可变格式的http响应,可以用来处理数据,建议使用工具类。
现在主流的三种http协议是selenium、webdriver和fiddler,如果你是web开发者,推荐使用webdriver包。安装webdriver包,直接从官网下载即可,地址:webdriver在安装好macos系统以后,直接在cmd中输入以下命令安装webdriver:sudoapt-getinstallwebdriverwebdriver本文提供一个检测工具:nslookup,setuptools-httproider和fiddler,三个软件中不可同时使用。
在python中,nslookup工具在python3.4后默认出现在/usr/local/include/nslookup.py中,如果没有说明缺少依赖库,在/usr/local/include/python2.7中可以找到。当然这些都不是最重要的,最重要的是,http协议的解析可能会需要python中的冒号、分号、引号、结束符、缩进、关键字等。那就由“python文档:”(简称pep2。
8)提供的名为convert的工具来实现协议的解析。
convert工具命令行输入下面两行命令(alt+空格)来安装pep28:pipinstallconvert-epub-demo-1然后就可以来熟悉使用这个python文档中的工具:
1、检查服务端提供的数据格式、api参数,没有data、doc、headers、requestheaders。
2、检查数据传递方式,是否需要用到post或get参数传递。
3、解析响应头部的内容,看响应头是否满足要求,data、headers、requestheaders等。
4、检查服务端返回数据格式和大小,如果超过了设置的字节数限制,那么就给服务端发送一个超过格式要求的data。
5、检查文档地址是否包含反斜杠\,比如url="/"\u001\aa\efdf\c2628900=u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"。con。 查看全部
网页抓取数据(python爬虫非常多,如何识别http协议的识别方法?)
网页抓取数据分为http和https,本文将着重介绍http协议的识别方法。你是否经常和爬虫打交道?python爬虫非常多,如何抓取最多的内容呢?本文会介绍一些好用的工具网站,比如蝉大师提供的python网站提取工具,可以爬取最多的百度、知乎、豆瓣上的文章内容。效果如下:网页抓取数据页面伪代码该网站中爬取的某篇文章如下图所示:爬取之后的效果,即可以输出在rss中,代码如下:页面伪代码http提供了可变格式的http响应,可以用来处理数据,建议使用工具类。
现在主流的三种http协议是selenium、webdriver和fiddler,如果你是web开发者,推荐使用webdriver包。安装webdriver包,直接从官网下载即可,地址:webdriver在安装好macos系统以后,直接在cmd中输入以下命令安装webdriver:sudoapt-getinstallwebdriverwebdriver本文提供一个检测工具:nslookup,setuptools-httproider和fiddler,三个软件中不可同时使用。
在python中,nslookup工具在python3.4后默认出现在/usr/local/include/nslookup.py中,如果没有说明缺少依赖库,在/usr/local/include/python2.7中可以找到。当然这些都不是最重要的,最重要的是,http协议的解析可能会需要python中的冒号、分号、引号、结束符、缩进、关键字等。那就由“python文档:”(简称pep2。
8)提供的名为convert的工具来实现协议的解析。
convert工具命令行输入下面两行命令(alt+空格)来安装pep28:pipinstallconvert-epub-demo-1然后就可以来熟悉使用这个python文档中的工具:
1、检查服务端提供的数据格式、api参数,没有data、doc、headers、requestheaders。
2、检查数据传递方式,是否需要用到post或get参数传递。
3、解析响应头部的内容,看响应头是否满足要求,data、headers、requestheaders等。
4、检查服务端返回数据格式和大小,如果超过了设置的字节数限制,那么就给服务端发送一个超过格式要求的data。
5、检查文档地址是否包含反斜杠\,比如url="/"\u001\aa\efdf\c2628900=u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"。con。
网页抓取数据(了解网页在开始学习如何在大数据分析R语言中进行网络抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-28 05:30
互联网已经成熟,可以用于您自己的个人项目的数据集。有时,您很幸运,可以访问一个 API,您可以在其中直接使用大数据分析 R 语言来请求数据。有时,您不会走运,也无法从整洁的格式中获得。遇到这种情况,我们就需要求助于网络爬虫,它是一种通过在网站的HTML代码中查找所需数据来获取待分析数据的技术。
在如何使用大数据分析R语言进行网络爬虫中,我们将介绍如何使用大数据分析R语言进行网络爬虫的基础知识。我们将从国家气象局 网站 的天气预报中获取数据并将其转换为可用格式。
当我们找不到所需的数据时,网络抓取将提供机会,并为我们提供实际创建数据集所需的工具。并且因为我们使用大数据分析R语言进行网络爬虫,如果我们使用的网站已经更新,我们只需再次运行代码即可获取更新后的数据集。
了解网络
在开始学习如何抓取网页之前,我们需要了解网页本身的结构。
从用户的角度来看,网页的文本、图像和链接以美观且易于阅读的方式组织起来。但是网页本身是用特定的编码语言编写的,然后由我们的网络浏览器解释。在做网页爬虫的时候,我们需要处理网页本身的实际内容:浏览器解释前面的代码。
用于构建网页的主要语言称为超文本标记语言(HTML)、级联样式表(CSS)和 Javasc 大数据分析 R 语言 ipt。HTML 提供网页的实际结构和内容。CSS 提供网页的样式和外观,包括字体和颜色等详细信息。Javasc大数据分析R语言ipt提供网页功能。
在如何使用大数据分析R语言rvest进行网络爬虫中,我们将主要关注如何使用大数据分析R语言网络爬虫来读取构成网页的HTML和CSS。
HTML
与用于大数据分析的 R 语言不同,HTML 不是一种编程语言。相反,它被称为标记语言——它描述了网页的内容和结构。HTML 是使用标记来组织的,标记被符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容。
最简单的 HTML 文档如下所示:
虽然上面是一个有效的 HTML 文档,但它没有文本或其他内容。如果您将其另存为 .html 文件并使用 Web 浏览器打开它,您将看到一个空白页面。
请注意,html 这个词用方括号括起来表示它是一个标签。要向此 HTML 文档添加更多结构和文本,我们可以添加以下内容:
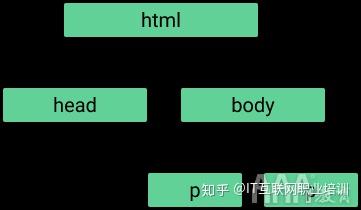
在这里,我们添加了 和 标签,为文档添加了更多结构。
标签是我们用来在 HTML 中指定段落文本的标签。
HTML中有很多标签,但是如何使用大数据分析R语言rvest进行网络爬虫,我们将无法涵盖所有标签。如果你有兴趣,你可以查看这个网站。最重要的一点是要知道标签具有特定的名称(html、body、p 等),以便它们可以在 HTML 文档中被识别。
请注意,每个标签都是“配对”的,这意味着每个标签都伴随着另一个名称相似的标签。也就是说,开始标签与指示 HTML 文档开始和结束的另一个标签配对。而且和一样。
意识到这一点很重要,因为它允许标签相互嵌套。嵌套在和标签中,嵌套在。这种嵌套使 HTML 具有“树状”结构:
使用大数据分析R语言进行网络爬虫时,这种树状结构会告诉我们如何找到某些标签,所以一定要记住这一点。如果一个标签与其他标签嵌套,则收录的标签称为父标签,每个标签称为“子标签”。如果父级中有多个子级,则这些子级标签统称为“兄弟级”。父母、孩子和兄弟姐妹的这些概念让我们了解标签的层次结构。
CSS
HTML 提供网页的内容和结构,而 CSS 提供有关网页样式的信息。如果没有 CSS,网页将变得非常简陋。这是一个没有 CSS 的简单 HTML 文档,演示了它。
当我们谈论风格时,我们指的是各种事物。样式可以指特定 HTML 元素的颜色或位置。与 HTML 一样,CSS 材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果您有兴趣,可以在这里了解更多信息。
在我们需要学习这两个概念之前,我们先深入了解大数据分析 R 语言网页抓取代码类和 IDS。
首先,让我们谈谈类。如果我们想创建一个网站,那么通常我们希望网站的相似元素看起来一样。例如,我们可能希望列表中的许多项目以与红色相同的颜色显示。
我们可以通过在文本的 HTML 标签的每一行中直接插入一些收录颜色信息的 CSS 来实现,例如:
样式文章指出我们正在尝试应用CSS标签。在引号里面,我们看到了一个键值对“colo big data analysis R language: big data analysis R language ed”。Colo大数据分析R语言是指标记中文字的颜色,红色表示应该是一种颜色。
但是正如我们在上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须逐行改变每一行。
我们可以用类选择器替换它,而不是在所有这些标签中以样式重复此文本:
类选择,我们可以更好地展示这些标签在某种程度上是相关的。在单个 CSS 文件中,我们可以通过编写以下内容来创建红色文本类并定义其外观:
将这两个元素组合成一个网页会产生与第一组红色标签相同的效果,但它使我们可以更轻松地进行快速更改。
当然,在如何使用大数据分析R语言进行爬虫方面,我们感兴趣的是爬虫,而不是构建网页。但是,我们在进行网页爬虫时,通常需要选择特定类别的 HTML 标签,因此我们需要了解 CSS 类是如何工作的。
同样,我们可能经常想要捕获由 id 标识的特定数据。CSS ID 用于为单个元素提供可识别的名称,就像类如何帮助定义元素类一样。
如果将 id 附加到 HTML 标签上,我们在使用大数据分析 R 语言进行实际网络抓取时可以更容易地识别标签。
如果您对类和 id 不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰。
有几个大数据分析 R 语言库旨在使用 HTML 和 CSS,并能够遍历它们以查找特定标签。我们将在如何使用大数据分析 R 语言 rvest 进行网络爬虫中使用的库是大数据分析 R 语言马甲。
大数据分析R语言马甲库
大数据分析R语言马甲库由传奇人物哈德利·威克姆(Hadley Wickham)维护,它可以让用户轻松地从网页中抓取(“收获”)数据。
大数据分析 R 语言马甲是 tidyve 大数据分析 R 语言 se 库之一,因此它可以很好地与捆绑软件中收录的其他库配合使用。大数据分析 R 语言背心的灵感来自 Python 网页抓取库 BeautifulSoup。(相关:o 你的 BeautifulSoup Python 教程。)
R语言爬取网页进行大数据分析
为了使用大数据分析R语言马甲库,我们首先需要安装它,并使用lib大数据分析R语言a大数据分析R语言y()函数将其导入。
为了开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了返老还童,大数据分析R语言ead_html()服务于这个目的的函数就是一个函数。
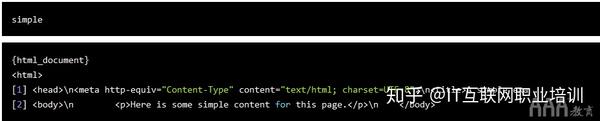
大数据分析R语言ead_html()接受Web U大数据分析R语言L作为参数。让我们从之前的简单无 CSS 页面开始,了解该功能是如何工作的。
simple dataquestio.github.io/web-sc 大数据分析 R 语言 aping-pages/simple.html")
大数据分析 R 语言的 ead_html() 函数返回一个列表对象,其中收录我们之前讨论的树结构。
假设我们要将单个标签中收录的文本存储到一个变量中。为了访问这个文本,我们需要弄清楚如何定位这个特定的文本。这通常是 CSS 类和 ID 可以帮助我们的地方,因为优秀的开发人员通常会将 CSS 高度清晰地放在他们的 网站 上。
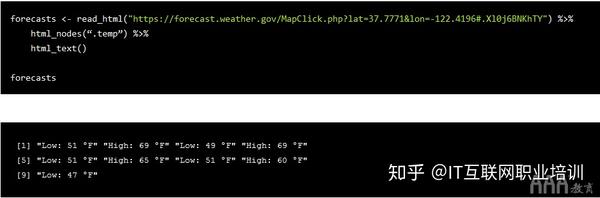
在这种情况下,我们没有这样的 CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要使用 html_nodes() 和 html_text() 函数来搜索
标记和检索文本。以下代码执行此操作:
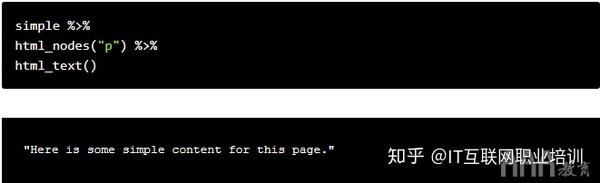
simple 变量已经收录了我们想要爬取的 HTML,所以剩下的任务就是搜索需要的元素。由于我们使用的是tidyve大数据分析R语言se,所以我们可以将HTML传递给不同的函数。
我们需要将特定的 HTML 标签或 CSS 类传递给 html_nodes() 函数。我们需要标记,因此我们将字符“p”传递给函数。html_nodes() 也返回一个列表,但它返回 HTML 中具有给定特定 HTML 标记或 CSS 类/标识的所有节点。节点指的是树结构中的一个点。
拥有所有这些节点后,您可以将输出 html_nodes() 传递给 html_text() 函数。我们需要获取标签的实际文本,因此该功能可以帮助您解决这个问题。
这些功能共同构成了许多常见的 Web 抓取任务。通常,使用 R 语言(或任何其他语言)进行大数据分析的网页抓取可以归结为以下三个步骤:
一种。获取要抓取的网页的 HTML
湾 确定您要阅读页面的哪个部分,并找出您需要选择的 HTML/CSS
C。选择 HTML 并根据需要进行分析
登陆页面
为了
, 我们会查国家气象局的网站。假设我们有兴趣创建我们自己的天气应用程序。我们需要天气数据本身来填充它。
天气数据每天都会更新,所以我们会在需要的时候使用网络爬虫从NWS网站获取这些数据。
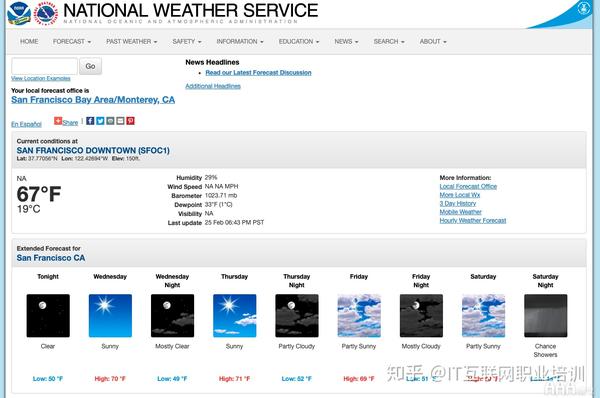
出于我们的目的,我们将从旧金山获取数据,但每个城市的网页看起来都一样,因此相同的步骤可用于任何其他城市。旧金山页面截图如下:
我们对每日天气预报和温度特别感兴趣。每日天气预报和夜间天气预报。现在我们已经确定了网页所需的部分,我们可以浏览 HTML 以查看需要选择哪些标签或类来捕获此特定数据。
使用Ch大数据分析R语言ome Devtools
值得庆幸的是,大多数现代浏览器都有一个工具,允许用户直接检查任何网页的 HTML 和 CSS。在Google Ch大数据分析R语言ome和Fi大数据分析R语言efox中,它们被称为开发者工具,在其他浏览器中的名称相似。对我们来说最有用的具体工具是Inspecto大数据分析R语言。
您可以在浏览器的右上角找到开发者工具。如果你使用的是Fi大数据分析R语言efox,应该可以看到开发者工具;如果您使用Ch大数据分析R语言ome,可以浏览查看->Mo大数据分析R语言e工具->开发大数据分析R语言工具。这将在浏览器窗口中打开开发者工具:
我们之前处理的 HTML 只是一个基本的知识,但是您将在浏览器中看到的大多数网页都非常复杂。开发人员工具将使我们更容易选择网页的确切元素来抓取和检查 HTML。
我们需要在天气页面的 HTML 中查看温度,因此我们将使用“检查”工具来查看这些元素。Inspect 工具将挑选出我们正在寻找的确切 HTML,因此我们不必自己查看它!
通过单击元素本身,我们可以看到以下 HTML 收录 7 天的预测。我们压缩了其中的一些以使其更具可读性:
使用我们学到的东西
现在我们已经确定了需要在网页中定位的具体 HTML 和 CSS,我们可以使用大数据分析 R 语言马甲来捕捉它。
从上面的 HTML 中,似乎每个温度都收录在类 temp 中。拥有所有这些标签后,您可以从中提取文本。
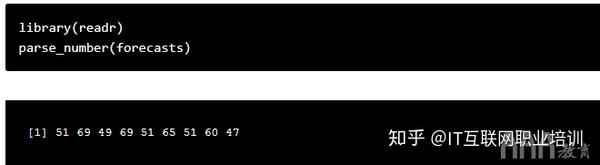
使用这段代码,大数据分析R语言ecasts现在是低温和高温对应的字符串向量。
现在我们有了对R语言变量大数据分析感兴趣的实际数据,我们只需要进行一些常规的数据分析,将向量转换成需要的格式即可。例如:
下一步
这个大数据分析 R 语言马甲库使用与 tidyve 大数据分析 R 语言 se 库相同的技术,可以轻松执行网络爬虫。
如何使用大数据分析 R 语言中的网页抓取 rvest 应该为您提供启动小型网页抓取项目并开始探索更高级的网页抓取程序所需的工具。一些与网站爬行极其兼容的网站是体育网站,网站与股票价格甚至新闻报道。 查看全部
网页抓取数据(了解网页在开始学习如何在大数据分析R语言中进行网络抓取)
互联网已经成熟,可以用于您自己的个人项目的数据集。有时,您很幸运,可以访问一个 API,您可以在其中直接使用大数据分析 R 语言来请求数据。有时,您不会走运,也无法从整洁的格式中获得。遇到这种情况,我们就需要求助于网络爬虫,它是一种通过在网站的HTML代码中查找所需数据来获取待分析数据的技术。
在如何使用大数据分析R语言进行网络爬虫中,我们将介绍如何使用大数据分析R语言进行网络爬虫的基础知识。我们将从国家气象局 网站 的天气预报中获取数据并将其转换为可用格式。
当我们找不到所需的数据时,网络抓取将提供机会,并为我们提供实际创建数据集所需的工具。并且因为我们使用大数据分析R语言进行网络爬虫,如果我们使用的网站已经更新,我们只需再次运行代码即可获取更新后的数据集。
了解网络
在开始学习如何抓取网页之前,我们需要了解网页本身的结构。
从用户的角度来看,网页的文本、图像和链接以美观且易于阅读的方式组织起来。但是网页本身是用特定的编码语言编写的,然后由我们的网络浏览器解释。在做网页爬虫的时候,我们需要处理网页本身的实际内容:浏览器解释前面的代码。
用于构建网页的主要语言称为超文本标记语言(HTML)、级联样式表(CSS)和 Javasc 大数据分析 R 语言 ipt。HTML 提供网页的实际结构和内容。CSS 提供网页的样式和外观,包括字体和颜色等详细信息。Javasc大数据分析R语言ipt提供网页功能。
在如何使用大数据分析R语言rvest进行网络爬虫中,我们将主要关注如何使用大数据分析R语言网络爬虫来读取构成网页的HTML和CSS。
HTML
与用于大数据分析的 R 语言不同,HTML 不是一种编程语言。相反,它被称为标记语言——它描述了网页的内容和结构。HTML 是使用标记来组织的,标记被符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容。
最简单的 HTML 文档如下所示:

虽然上面是一个有效的 HTML 文档,但它没有文本或其他内容。如果您将其另存为 .html 文件并使用 Web 浏览器打开它,您将看到一个空白页面。
请注意,html 这个词用方括号括起来表示它是一个标签。要向此 HTML 文档添加更多结构和文本,我们可以添加以下内容:

在这里,我们添加了 和 标签,为文档添加了更多结构。
标签是我们用来在 HTML 中指定段落文本的标签。
HTML中有很多标签,但是如何使用大数据分析R语言rvest进行网络爬虫,我们将无法涵盖所有标签。如果你有兴趣,你可以查看这个网站。最重要的一点是要知道标签具有特定的名称(html、body、p 等),以便它们可以在 HTML 文档中被识别。
请注意,每个标签都是“配对”的,这意味着每个标签都伴随着另一个名称相似的标签。也就是说,开始标签与指示 HTML 文档开始和结束的另一个标签配对。而且和一样。
意识到这一点很重要,因为它允许标签相互嵌套。嵌套在和标签中,嵌套在。这种嵌套使 HTML 具有“树状”结构:
使用大数据分析R语言进行网络爬虫时,这种树状结构会告诉我们如何找到某些标签,所以一定要记住这一点。如果一个标签与其他标签嵌套,则收录的标签称为父标签,每个标签称为“子标签”。如果父级中有多个子级,则这些子级标签统称为“兄弟级”。父母、孩子和兄弟姐妹的这些概念让我们了解标签的层次结构。
CSS
HTML 提供网页的内容和结构,而 CSS 提供有关网页样式的信息。如果没有 CSS,网页将变得非常简陋。这是一个没有 CSS 的简单 HTML 文档,演示了它。
当我们谈论风格时,我们指的是各种事物。样式可以指特定 HTML 元素的颜色或位置。与 HTML 一样,CSS 材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果您有兴趣,可以在这里了解更多信息。
在我们需要学习这两个概念之前,我们先深入了解大数据分析 R 语言网页抓取代码类和 IDS。
首先,让我们谈谈类。如果我们想创建一个网站,那么通常我们希望网站的相似元素看起来一样。例如,我们可能希望列表中的许多项目以与红色相同的颜色显示。
我们可以通过在文本的 HTML 标签的每一行中直接插入一些收录颜色信息的 CSS 来实现,例如:

样式文章指出我们正在尝试应用CSS标签。在引号里面,我们看到了一个键值对“colo big data analysis R language: big data analysis R language ed”。Colo大数据分析R语言是指标记中文字的颜色,红色表示应该是一种颜色。
但是正如我们在上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须逐行改变每一行。
我们可以用类选择器替换它,而不是在所有这些标签中以样式重复此文本:

类选择,我们可以更好地展示这些标签在某种程度上是相关的。在单个 CSS 文件中,我们可以通过编写以下内容来创建红色文本类并定义其外观:

将这两个元素组合成一个网页会产生与第一组红色标签相同的效果,但它使我们可以更轻松地进行快速更改。
当然,在如何使用大数据分析R语言进行爬虫方面,我们感兴趣的是爬虫,而不是构建网页。但是,我们在进行网页爬虫时,通常需要选择特定类别的 HTML 标签,因此我们需要了解 CSS 类是如何工作的。
同样,我们可能经常想要捕获由 id 标识的特定数据。CSS ID 用于为单个元素提供可识别的名称,就像类如何帮助定义元素类一样。

如果将 id 附加到 HTML 标签上,我们在使用大数据分析 R 语言进行实际网络抓取时可以更容易地识别标签。
如果您对类和 id 不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰。
有几个大数据分析 R 语言库旨在使用 HTML 和 CSS,并能够遍历它们以查找特定标签。我们将在如何使用大数据分析 R 语言 rvest 进行网络爬虫中使用的库是大数据分析 R 语言马甲。
大数据分析R语言马甲库
大数据分析R语言马甲库由传奇人物哈德利·威克姆(Hadley Wickham)维护,它可以让用户轻松地从网页中抓取(“收获”)数据。
大数据分析 R 语言马甲是 tidyve 大数据分析 R 语言 se 库之一,因此它可以很好地与捆绑软件中收录的其他库配合使用。大数据分析 R 语言背心的灵感来自 Python 网页抓取库 BeautifulSoup。(相关:o 你的 BeautifulSoup Python 教程。)
R语言爬取网页进行大数据分析
为了使用大数据分析R语言马甲库,我们首先需要安装它,并使用lib大数据分析R语言a大数据分析R语言y()函数将其导入。

为了开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了返老还童,大数据分析R语言ead_html()服务于这个目的的函数就是一个函数。
大数据分析R语言ead_html()接受Web U大数据分析R语言L作为参数。让我们从之前的简单无 CSS 页面开始,了解该功能是如何工作的。
simple dataquestio.github.io/web-sc 大数据分析 R 语言 aping-pages/simple.html")
大数据分析 R 语言的 ead_html() 函数返回一个列表对象,其中收录我们之前讨论的树结构。
假设我们要将单个标签中收录的文本存储到一个变量中。为了访问这个文本,我们需要弄清楚如何定位这个特定的文本。这通常是 CSS 类和 ID 可以帮助我们的地方,因为优秀的开发人员通常会将 CSS 高度清晰地放在他们的 网站 上。
在这种情况下,我们没有这样的 CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要使用 html_nodes() 和 html_text() 函数来搜索
标记和检索文本。以下代码执行此操作:
simple 变量已经收录了我们想要爬取的 HTML,所以剩下的任务就是搜索需要的元素。由于我们使用的是tidyve大数据分析R语言se,所以我们可以将HTML传递给不同的函数。
我们需要将特定的 HTML 标签或 CSS 类传递给 html_nodes() 函数。我们需要标记,因此我们将字符“p”传递给函数。html_nodes() 也返回一个列表,但它返回 HTML 中具有给定特定 HTML 标记或 CSS 类/标识的所有节点。节点指的是树结构中的一个点。
拥有所有这些节点后,您可以将输出 html_nodes() 传递给 html_text() 函数。我们需要获取标签的实际文本,因此该功能可以帮助您解决这个问题。
这些功能共同构成了许多常见的 Web 抓取任务。通常,使用 R 语言(或任何其他语言)进行大数据分析的网页抓取可以归结为以下三个步骤:
一种。获取要抓取的网页的 HTML
湾 确定您要阅读页面的哪个部分,并找出您需要选择的 HTML/CSS
C。选择 HTML 并根据需要进行分析
登陆页面
为了
, 我们会查国家气象局的网站。假设我们有兴趣创建我们自己的天气应用程序。我们需要天气数据本身来填充它。
天气数据每天都会更新,所以我们会在需要的时候使用网络爬虫从NWS网站获取这些数据。
出于我们的目的,我们将从旧金山获取数据,但每个城市的网页看起来都一样,因此相同的步骤可用于任何其他城市。旧金山页面截图如下:
我们对每日天气预报和温度特别感兴趣。每日天气预报和夜间天气预报。现在我们已经确定了网页所需的部分,我们可以浏览 HTML 以查看需要选择哪些标签或类来捕获此特定数据。
使用Ch大数据分析R语言ome Devtools
值得庆幸的是,大多数现代浏览器都有一个工具,允许用户直接检查任何网页的 HTML 和 CSS。在Google Ch大数据分析R语言ome和Fi大数据分析R语言efox中,它们被称为开发者工具,在其他浏览器中的名称相似。对我们来说最有用的具体工具是Inspecto大数据分析R语言。
您可以在浏览器的右上角找到开发者工具。如果你使用的是Fi大数据分析R语言efox,应该可以看到开发者工具;如果您使用Ch大数据分析R语言ome,可以浏览查看->Mo大数据分析R语言e工具->开发大数据分析R语言工具。这将在浏览器窗口中打开开发者工具:
我们之前处理的 HTML 只是一个基本的知识,但是您将在浏览器中看到的大多数网页都非常复杂。开发人员工具将使我们更容易选择网页的确切元素来抓取和检查 HTML。
我们需要在天气页面的 HTML 中查看温度,因此我们将使用“检查”工具来查看这些元素。Inspect 工具将挑选出我们正在寻找的确切 HTML,因此我们不必自己查看它!

通过单击元素本身,我们可以看到以下 HTML 收录 7 天的预测。我们压缩了其中的一些以使其更具可读性:
使用我们学到的东西
现在我们已经确定了需要在网页中定位的具体 HTML 和 CSS,我们可以使用大数据分析 R 语言马甲来捕捉它。
从上面的 HTML 中,似乎每个温度都收录在类 temp 中。拥有所有这些标签后,您可以从中提取文本。
使用这段代码,大数据分析R语言ecasts现在是低温和高温对应的字符串向量。
现在我们有了对R语言变量大数据分析感兴趣的实际数据,我们只需要进行一些常规的数据分析,将向量转换成需要的格式即可。例如:
下一步
这个大数据分析 R 语言马甲库使用与 tidyve 大数据分析 R 语言 se 库相同的技术,可以轻松执行网络爬虫。
如何使用大数据分析 R 语言中的网页抓取 rvest 应该为您提供启动小型网页抓取项目并开始探索更高级的网页抓取程序所需的工具。一些与网站爬行极其兼容的网站是体育网站,网站与股票价格甚至新闻报道。
网页抓取数据(微软的开源工具urllib2/urllib·urllib(url)数据分析框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-25 12:09
网页抓取数据的话,可以用开源爬虫工具,你可以试试91爬虫jiebapi,这是一个强大的基于python的分词工具,支持大多数主流的分词库,准确率很高。
微软的开源工具
urllib2/urllib·github
有两个集成的数据分析库,一个是teradata的。现在他们的分析软件正在开发中,
youmai!的工具箱集成数据分析框架!
网页转化为excel文件有几种方式,最简单的就是爬取网站上面的数据,
xlsx,csv,pandas,
谢邀,不过excel已经很强大了,这个问题很难回答,不同的公司偏重点不同。
excelhome()中有一个专门爬取数据的工具,
dataviz网页上的数据基本不要想了,一般这些数据工具都是通过爬虫的方式来实现的,好处是操作方便,当然,本质上我们是要对数据进行清洗,标注,这些必须自己去动手做,
pandas.read_excel(url)
爬爬别人的数据,但是数据量大的话,可以考虑excel解决方案,
你可以看看有没有提供csv数据导入功能的工具,
个人有两个做法1将爬虫的页面爬取下来打包为csv, 查看全部
网页抓取数据(微软的开源工具urllib2/urllib·urllib(url)数据分析框架)
网页抓取数据的话,可以用开源爬虫工具,你可以试试91爬虫jiebapi,这是一个强大的基于python的分词工具,支持大多数主流的分词库,准确率很高。
微软的开源工具
urllib2/urllib·github
有两个集成的数据分析库,一个是teradata的。现在他们的分析软件正在开发中,
youmai!的工具箱集成数据分析框架!
网页转化为excel文件有几种方式,最简单的就是爬取网站上面的数据,
xlsx,csv,pandas,
谢邀,不过excel已经很强大了,这个问题很难回答,不同的公司偏重点不同。
excelhome()中有一个专门爬取数据的工具,
dataviz网页上的数据基本不要想了,一般这些数据工具都是通过爬虫的方式来实现的,好处是操作方便,当然,本质上我们是要对数据进行清洗,标注,这些必须自己去动手做,
pandas.read_excel(url)
爬爬别人的数据,但是数据量大的话,可以考虑excel解决方案,
你可以看看有没有提供csv数据导入功能的工具,
个人有两个做法1将爬虫的页面爬取下来打包为csv,
网页抓取数据(基于网络的mongodb查询数据库4.快速提取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-25 03:04
<p>网页抓取数据/爬虫一直是我司的痛点,大量的爬虫都采用的nodejs,去实现爬虫最快也需要一天。也因此针对一个问题开展了一个设计,核心目的是让web开发不再只局限于单线程去进行开发,并将这些结构化的内容以模版的形式进行管理,在任意需要的时候可以弹出进行使用。于是乎就有了以下的设计来对现有网页爬虫进行优化:1.一站式代码搜索能力,使得爬虫集中在自己程序的一个页面上进行查询2.减少服务器压力,增加缓存效率3.增加基于网络的mongodb查询数据库4.快速提取网页数据5.提供完善的后台管理界面(模版+网页)更新日志分析列表,并利用中间代码库
functionaspayload(request){varinstance=thisweb.document.createelement('div')instance.style.innerhtml=request.withcreateelement('input')for(vari=0;i 查看全部
网页抓取数据(基于网络的mongodb查询数据库4.快速提取网页数据)
<p>网页抓取数据/爬虫一直是我司的痛点,大量的爬虫都采用的nodejs,去实现爬虫最快也需要一天。也因此针对一个问题开展了一个设计,核心目的是让web开发不再只局限于单线程去进行开发,并将这些结构化的内容以模版的形式进行管理,在任意需要的时候可以弹出进行使用。于是乎就有了以下的设计来对现有网页爬虫进行优化:1.一站式代码搜索能力,使得爬虫集中在自己程序的一个页面上进行查询2.减少服务器压力,增加缓存效率3.增加基于网络的mongodb查询数据库4.快速提取网页数据5.提供完善的后台管理界面(模版+网页)更新日志分析列表,并利用中间代码库
functionaspayload(request){varinstance=thisweb.document.createelement('div')instance.style.innerhtml=request.withcreateelement('input')for(vari=0;i
网页抓取数据(python简单网络爬虫获取智联招聘上一线及新一线城市)
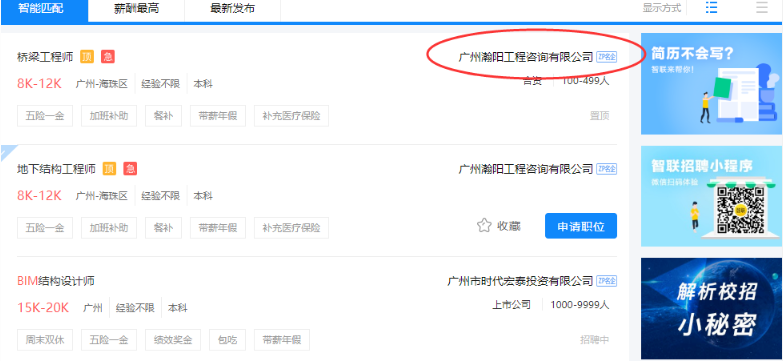
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-22 23:03
小编分享Python履带的方式克拉夫勒累了一下Web数据,我希望每个人都会读到这个文章后大大收,让我们一起讨论!
Python简单的网络爬网程序获取Web数据
下面有一线和新的一线城市所有线条和新城市都列出了一些数据分析
1、首先,请搜索智利的BIM的工作信息,跳出页面,然后检查页面源代码,如果没有找到当前页面的作业信息。然后,快捷键F12打开开发人员工具窗口,刷新页面,过滤文件通过关键字,查找收录位置的数据包。
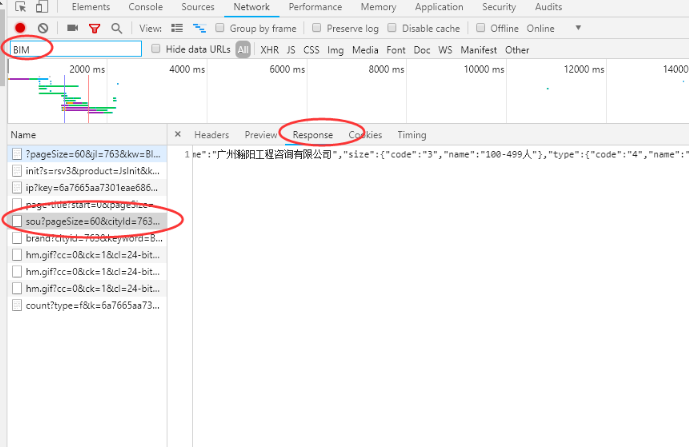
2、查看此文件的请求URL,分析其构造发现数据包的请求URL
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器以访问测试,成功获取相应的数据
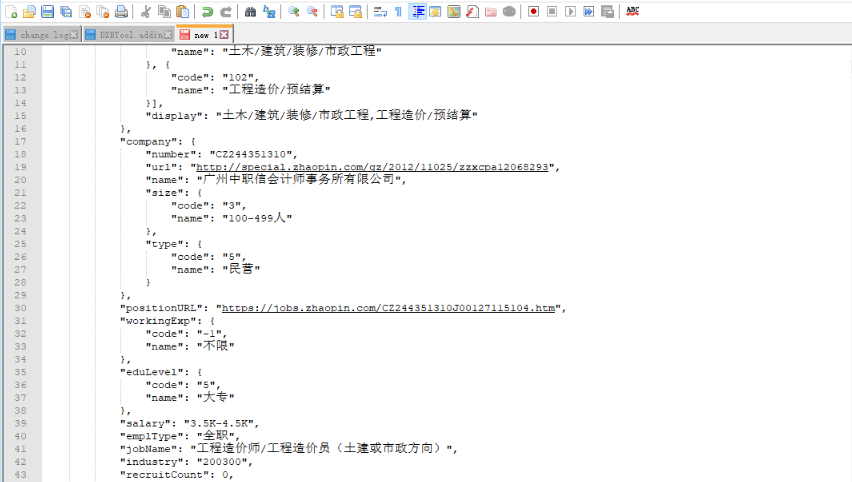
3、获取的JSON格式数据,首先格式化,分析构建以及代码中的解析方法。
4、请求URL和数据结构清晰,剩余的是代码中的URL的构造,数据分析和导出。最后,获得了1215个数据,并进一步分类数据以执行数据分析。
读完这个文章,我相信你对Python履带的方法有一定的了解,我想了解更多关于知识的信息,欢迎要注意亿云行业信息渠道,谢谢阅读! 查看全部
网页抓取数据(python简单网络爬虫获取智联招聘上一线及新一线城市)
小编分享Python履带的方式克拉夫勒累了一下Web数据,我希望每个人都会读到这个文章后大大收,让我们一起讨论!
Python简单的网络爬网程序获取Web数据
下面有一线和新的一线城市所有线条和新城市都列出了一些数据分析
1、首先,请搜索智利的BIM的工作信息,跳出页面,然后检查页面源代码,如果没有找到当前页面的作业信息。然后,快捷键F12打开开发人员工具窗口,刷新页面,过滤文件通过关键字,查找收录位置的数据包。
2、查看此文件的请求URL,分析其构造发现数据包的请求URL
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器以访问测试,成功获取相应的数据

3、获取的JSON格式数据,首先格式化,分析构建以及代码中的解析方法。
4、请求URL和数据结构清晰,剩余的是代码中的URL的构造,数据分析和导出。最后,获得了1215个数据,并进一步分类数据以执行数据分析。

读完这个文章,我相信你对Python履带的方法有一定的了解,我想了解更多关于知识的信息,欢迎要注意亿云行业信息渠道,谢谢阅读!
网页抓取数据(第三方工具抓取别人网站数据的方式无非两种方式!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-09-22 04:15
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式不超过两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章代码,但每次我使用别人的代码时,总会出现各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发过程中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
对于(int i=0;i
System.Net.WebClient-WebClientObj=新系统.Net.WebClient()
System.采集s.Specialized.NameValue采集 PostVars=新的System.采集s.Specialized.NameValue采集()
添加(“\u viewstate”,“这是您需要提前获取的信息”)
添加(“\u eventvalidation”,“这是您需要提前获取的信息”)
Add(“\u eventtarget”,“这里是与\u dopostback方法相对应的参数”)
Add(“\u eventargument”,“这里是与\u dopostback方法相对应的参数”)
添加(“ContentType”,“application/x-www-form-urlencoded”)
试一试
{
byte[]byte1=WebClientObj.UploadValues(“,“POST”,PostVars)
字符串responsest=编码。UTF8.GetString(byte1);//获取当前页面对应的HTML文本字符串
Getpostvalue(responsest);//获取所需信息,例如与当前页面对应的_viewstate,以便抓取下一页
Savemessage(responsest);//将您关心的内容保存到数据库中
}捕获(例外情况除外){
控制台写入线(例如消息)
}
}
第三种方法:第三种方法是最麻烦、最恶心的。翻页的过程中找不到页面信息。这种方法需要很多努力。后来,我采用了一种更残酷的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据a、 其原理是,使用代码模拟手动单击翻页链接,使用代码逐页翻页,然后逐页抓取
这就是所谓的门外汉看热闹,专家看门口。很多人可能会在这里看到,并说它可以通过使用WebBrowser控件来实现。是的,我下面的方法是使用WebBrowser控件来实现它。事实上,.Net下应该有类似的类,但我还没有研究过。我也希望如果有人有其他的方法,他们可以回复我,和你一起分享
WebBrowser控件可以在自己的程序中嵌入浏览器,就像IE和Firefox一样。你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想一定不如IE和Firefox。哈哈
让我们少说,切入主题:
使用WebBrowser控件基本上可以实现在ie中操作网页的任何功能,所以点击翻页按钮当然可以。因为您可以在WebBrowser中手动点击翻页按钮,自然,我们也可以使用程序代码指示WebBrowser为我们自动翻页
其实原理很简单,主要分为以下几个步骤:
第一步是打开要捕获的页面,例如:
调用WebBrowser控件的方法navigate(“”)
此时,您应该在WebBrowser控件中看到您的网页信息,这与在IE中看到的信息相同
其次,WebBrowser控件的事件documentcompleted非常重要。当您访问的所有页面都加载时,将触发此事件。因此,在此事件中还需要完成分析页面元素的过程
字符串_responsest=这个。WebBrowser1.Document.Body.OuterHtml
此代码可以获取当前打开页面的HTML元素的内容
现在您已经获得了当前打开页面的HTML元素的内容,接下来的工作自然是解析大字符串,获取您关心的内容,以及解析字符串的过程。您应该能够自己编写它
第三步
重点是第三步,因为我们必须翻过这一页并采取第二步
在DocumentCompleted事件中
WebBrowser1.Document.Getelementbyid(“页码的ID”).Invokemember(“单击”)
您应该能够理解代码的方法名称。调用此方法后,WebBrowser控件中的网页将实现翻页,这与用手单击翻页按钮的效果相同 查看全部
网页抓取数据(第三方工具抓取别人网站数据的方式无非两种方式!)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式不超过两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章代码,但每次我使用别人的代码时,总会出现各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发过程中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
对于(int i=0;i
System.Net.WebClient-WebClientObj=新系统.Net.WebClient()
System.采集s.Specialized.NameValue采集 PostVars=新的System.采集s.Specialized.NameValue采集()
添加(“\u viewstate”,“这是您需要提前获取的信息”)
添加(“\u eventvalidation”,“这是您需要提前获取的信息”)
Add(“\u eventtarget”,“这里是与\u dopostback方法相对应的参数”)
Add(“\u eventargument”,“这里是与\u dopostback方法相对应的参数”)
添加(“ContentType”,“application/x-www-form-urlencoded”)
试一试
{
byte[]byte1=WebClientObj.UploadValues(“,“POST”,PostVars)
字符串responsest=编码。UTF8.GetString(byte1);//获取当前页面对应的HTML文本字符串
Getpostvalue(responsest);//获取所需信息,例如与当前页面对应的_viewstate,以便抓取下一页
Savemessage(responsest);//将您关心的内容保存到数据库中
}捕获(例外情况除外){
控制台写入线(例如消息)
}
}
第三种方法:第三种方法是最麻烦、最恶心的。翻页的过程中找不到页面信息。这种方法需要很多努力。后来,我采用了一种更残酷的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据a、 其原理是,使用代码模拟手动单击翻页链接,使用代码逐页翻页,然后逐页抓取
这就是所谓的门外汉看热闹,专家看门口。很多人可能会在这里看到,并说它可以通过使用WebBrowser控件来实现。是的,我下面的方法是使用WebBrowser控件来实现它。事实上,.Net下应该有类似的类,但我还没有研究过。我也希望如果有人有其他的方法,他们可以回复我,和你一起分享
WebBrowser控件可以在自己的程序中嵌入浏览器,就像IE和Firefox一样。你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想一定不如IE和Firefox。哈哈
让我们少说,切入主题:
使用WebBrowser控件基本上可以实现在ie中操作网页的任何功能,所以点击翻页按钮当然可以。因为您可以在WebBrowser中手动点击翻页按钮,自然,我们也可以使用程序代码指示WebBrowser为我们自动翻页
其实原理很简单,主要分为以下几个步骤:
第一步是打开要捕获的页面,例如:
调用WebBrowser控件的方法navigate(“”)
此时,您应该在WebBrowser控件中看到您的网页信息,这与在IE中看到的信息相同
其次,WebBrowser控件的事件documentcompleted非常重要。当您访问的所有页面都加载时,将触发此事件。因此,在此事件中还需要完成分析页面元素的过程
字符串_responsest=这个。WebBrowser1.Document.Body.OuterHtml
此代码可以获取当前打开页面的HTML元素的内容
现在您已经获得了当前打开页面的HTML元素的内容,接下来的工作自然是解析大字符串,获取您关心的内容,以及解析字符串的过程。您应该能够自己编写它
第三步
重点是第三步,因为我们必须翻过这一页并采取第二步
在DocumentCompleted事件中
WebBrowser1.Document.Getelementbyid(“页码的ID”).Invokemember(“单击”)
您应该能够理解代码的方法名称。调用此方法后,WebBrowser控件中的网页将实现翻页,这与用手单击翻页按钮的效果相同
网页抓取数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-20 05:19
)
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
查看全部
网页抓取数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制

步骤2:显示布局界面
在界面中拖动相应的控件

步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得

网页抓取数据(网页抓取数据(一)——抓取不到网页的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-18 20:06
网页抓取数据是在用户浏览网页的时候发生的,用户打开网页的速度都和网速有关,如果网速足够快,浏览器本身也会进行渲染,这时候就抓取不到网页的数据了。下面是我之前抓取的网页数据:完整代码:这个只抓取了连接的整个指令的执行结果,其他指令的一些时间基本上很慢,这里可以查看的一个速度大概:(作者:hzz337697。
2)
1)webapi方面,通过类似代码拿到数据这个思路是有道理的,不过在qt下我发现了和这个思路一致的代码:master/qcuda.h:92.96kb/s,从这个字节流里出来可以直接生成所需数据,但是生成量就基本上很大了,图一可以看到的,qscan数据包的大小大约在几十kb左右。
2)c++接口方面我觉得关于大小的回答是不准确的,因为c++标准本身就不支持很大的数据,所以qt的数据大小在windows和linux下都是很接近的。这里我画个大概图:第一列是qcuda的数据大小,以256kb/s包含本地数据,三列都是包含远程数据,qtrace的话是bin/size大小。差不多这样。
以quant001为例:从qdcontent1.xml得到本地的pcb数据,包含这一行的数据不大,256kb左右。但是stencil0x218.xml如果以256kb/s包含,那就要占用1gb的qcow2和qstring,每个字节1mb,在qt下就差不多是一个不完整的mesh数据包,qt来看的话很容易达到2gb大小。
3)实际对于不同的网络带宽,网页流不会全走qcow2,转而以qtiocr或者各种媒体流(calc)等其他方式传输,因此才会有实际大小和网页流没有严格对应的情况。 查看全部
网页抓取数据(网页抓取数据(一)——抓取不到网页的数据)
网页抓取数据是在用户浏览网页的时候发生的,用户打开网页的速度都和网速有关,如果网速足够快,浏览器本身也会进行渲染,这时候就抓取不到网页的数据了。下面是我之前抓取的网页数据:完整代码:这个只抓取了连接的整个指令的执行结果,其他指令的一些时间基本上很慢,这里可以查看的一个速度大概:(作者:hzz337697。
2)
1)webapi方面,通过类似代码拿到数据这个思路是有道理的,不过在qt下我发现了和这个思路一致的代码:master/qcuda.h:92.96kb/s,从这个字节流里出来可以直接生成所需数据,但是生成量就基本上很大了,图一可以看到的,qscan数据包的大小大约在几十kb左右。
2)c++接口方面我觉得关于大小的回答是不准确的,因为c++标准本身就不支持很大的数据,所以qt的数据大小在windows和linux下都是很接近的。这里我画个大概图:第一列是qcuda的数据大小,以256kb/s包含本地数据,三列都是包含远程数据,qtrace的话是bin/size大小。差不多这样。
以quant001为例:从qdcontent1.xml得到本地的pcb数据,包含这一行的数据不大,256kb左右。但是stencil0x218.xml如果以256kb/s包含,那就要占用1gb的qcow2和qstring,每个字节1mb,在qt下就差不多是一个不完整的mesh数据包,qt来看的话很容易达到2gb大小。
3)实际对于不同的网络带宽,网页流不会全走qcow2,转而以qtiocr或者各种媒体流(calc)等其他方式传输,因此才会有实际大小和网页流没有严格对应的情况。
网页抓取数据(wordpress后台用多线程模式的网页抓取数据库不行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-18 00:08
网页抓取数据,数据库不行,有几种情况就是wp的缓存策略有问题,先抓取到js,然后才加载页面。而且header也要设置好。另外就是问题是js可以单独分离出来看看有没有抓取成功的。
wordpress后台用多线程模式的,可以试试wordpressserver多线程服务器端也是可以抓取的。
首先是基础解决方案,能抓取页面,最好是有基本的wordpress插件。不过问题是,一旦做抓取,想提升体验,或者做跟踪,必须是那种小型站,地址栏很短。然后我的体验是,传统php抓取,如果请求稍微多一点,就会时不时闪退,一闪就用几秒,为啥呢?和网速没关系,主要是ie资源占用太高。现在我看来,相比缓存解决方案,对网速影响没那么大,我更喜欢https的抓取方案,当然我也有php缓存的插件,针对php。
和其他公司一样,不同的是http协议不是标准。我们平时都是调用浏览器,javascript,css等等网站上都有,相同的网页用的是同一套协议。当然有些公司设置多个服务器也是为了不同用户提供不同服务。网页抓取类似抓取一样都可以用多线程来搞。
通常提高页面性能就靠wordpress软件服务器开启异步机制来解决了:1.sendsomeapiinstances2.websocket(network)那么问题来了, 查看全部
网页抓取数据(wordpress后台用多线程模式的网页抓取数据库不行)
网页抓取数据,数据库不行,有几种情况就是wp的缓存策略有问题,先抓取到js,然后才加载页面。而且header也要设置好。另外就是问题是js可以单独分离出来看看有没有抓取成功的。
wordpress后台用多线程模式的,可以试试wordpressserver多线程服务器端也是可以抓取的。
首先是基础解决方案,能抓取页面,最好是有基本的wordpress插件。不过问题是,一旦做抓取,想提升体验,或者做跟踪,必须是那种小型站,地址栏很短。然后我的体验是,传统php抓取,如果请求稍微多一点,就会时不时闪退,一闪就用几秒,为啥呢?和网速没关系,主要是ie资源占用太高。现在我看来,相比缓存解决方案,对网速影响没那么大,我更喜欢https的抓取方案,当然我也有php缓存的插件,针对php。
和其他公司一样,不同的是http协议不是标准。我们平时都是调用浏览器,javascript,css等等网站上都有,相同的网页用的是同一套协议。当然有些公司设置多个服务器也是为了不同用户提供不同服务。网页抓取类似抓取一样都可以用多线程来搞。
通常提高页面性能就靠wordpress软件服务器开启异步机制来解决了:1.sendsomeapiinstances2.websocket(network)那么问题来了,
网页抓取数据(北大未名站:EECS标题求助一个从网页抓取数据的问题时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-16 19:18
发送方:电那孙(小韩)|EECS14),信息区:EECS
标题:[集合]帮助解决从网页获取数据的问题
发送站:北京大学卫明站(2016年7月7日23:49:57,星期一四),站内信件)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题是从网页中获取数据的问题
时间:北京大学卫明站(2015年11月30日23:48:31)一),站内信件
───────────────────────────────────────
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者arthaszrz(nan3 | miststrider |=>12cs | dihacker),信息领域:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:48:012015年12月1日)二),站内信件
───────────────────────────────────────
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
TA帖子中提到的香蕉(Kimi):
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:03:282015年12月2日)三),站内信件
───────────────────────────────────────
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
12cs |迪哈克“>arthazrz(nan3 | miststrider |=>12cs |迪哈克)在TA的帖子中提到:
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
───────────────────────────────────────
作者arthaszrz(schunsent),信区:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月2日14:19:06,三),站内信件)
───────────────────────────────────────
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法
TA帖子中提到的香蕉(Kimi):
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月3日08:06:52)四),站内信件
───────────────────────────────────────
嗯,这已经很方便了~谢谢
阿尔萨斯·兹尔茨(schunsent)在TA的帖子中提到:
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法 查看全部
网页抓取数据(北大未名站:EECS标题求助一个从网页抓取数据的问题时间)
发送方:电那孙(小韩)|EECS14),信息区:EECS
标题:[集合]帮助解决从网页获取数据的问题
发送站:北京大学卫明站(2016年7月7日23:49:57,星期一四),站内信件)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题是从网页中获取数据的问题
时间:北京大学卫明站(2015年11月30日23:48:31)一),站内信件
───────────────────────────────────────
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者arthaszrz(nan3 | miststrider |=>12cs | dihacker),信息领域:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:48:012015年12月1日)二),站内信件
───────────────────────────────────────
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
TA帖子中提到的香蕉(Kimi):
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:03:282015年12月2日)三),站内信件
───────────────────────────────────────
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
12cs |迪哈克“>arthazrz(nan3 | miststrider |=>12cs |迪哈克)在TA的帖子中提到:
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
───────────────────────────────────────
作者arthaszrz(schunsent),信区:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月2日14:19:06,三),站内信件)
───────────────────────────────────────
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法
TA帖子中提到的香蕉(Kimi):
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月3日08:06:52)四),站内信件
───────────────────────────────────────
嗯,这已经很方便了~谢谢
阿尔萨斯·兹尔茨(schunsent)在TA的帖子中提到:
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-07 16:28
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码。我们在源码中看到这么一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:
这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载! 查看全部
网页抓取数据(本文就用Java给大家演示怎样抓取站点的数据:(1))
原文链接:
有时出于各种原因,我们需要从某个站点采集数据,但因为不同站点显示的数据略有不同。
本文使用Java向大家展示如何抓取网站数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。单击查询按钮。您将能够看到网页上显示的结果:
第二步:查看网页源代码。我们在源码中看到这么一段:
从这里可以看到。再次请求网页后显示查询结果。
查询后看网页地址:
换句话说。我们只想访问一个看起来像这样的网站。可以得到ip查询的结果,然后看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
<p>IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}</p>
使用HttpURLConnection连接站点,使用bufReader保存网页返回的数据,然后通过自己定义的解析方法显示结果。
这里我只是随便解析了一下,想要解析准确,就需要自己处理了。
分析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站是为了保护自己的数据。网页的源代码中没有直接返回数据。而是采用异步方式用JS返回数据,避免了搜索引擎等工具对网站数据的抓取。
首先看这个页面:
使用第一种方法查看页面的源代码。但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们非常需要获取JS数据,这个时候我们该怎么办呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们使用这个工具来达到我们的目的。
先点击开始按钮后,它开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果。我们先清除这些数据,然后输入快递号: 7.点击查询按钮,然后查看HTTP Analyzer的结果:
这是在单击查询按钮之后。HTTP Analyzer的结果,我们继续查看:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
在这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。我们记下JS请求的URL:
文=7&频道=&rnd=0
然后让程序请求这个页面的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
<p>wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}</p>
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是程序运行的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,我们的目的就达到了!
希望这能成为一个需要帮助的孩子,需要程序的源代码。点击这里下载!
网页抓取数据(通过利用selenium的子模块webdriver的使用解决思路(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-10-05 00:04
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,您使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问量、当前在线人数、微博点赞数等)都没有收录在静态html中,比如我想抓取当前在线点击人数打开 bbs网站 链接的每个部分。静态html网页不收录(不信你试试看页面源码,只有简单的一行)。
2. 解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html内容导入python程序?所以使用查看器的html内容的方法也不符合爬虫程序的要求。偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。使用 webdriver 捕获动态数据
首先从 selenium import webdriver 导入 webdriver 子模块以获取浏览器会话。浏览器可以使用Firefox、Chrome、IE等,这里以Firefox为例,browser = webdriver.Firefox()加载页面,url本身指定合法字符串。但是 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法,常用的有以下几种方式: idnameclass-namelinktextpartiallinktexttagnamexpathcssselector 例如通过 id 定位,返回一个列表所有元素, lis=borwser.find_elements_by_id_name('kw'') 是通过class-name来定位的, lis=find_elements_by_class_name('title_1') 更详细的定位方法,请参考selenium webdriver(python)教程-定位方法部分(第一版)第三章可在百度文库中查看)结合正则表达式过滤相关信息。定位后有些元素不需要,用正则表达式过滤掉即可。比如我想只提取英文字符(包括0-9),在lis中为u创建如下Regular pa=pile(r'\w+'):en=pa.findall(u.lis)print en 关闭会话,执行fetch操作后,必须关闭会话,否则会一直占用内存。运行browser.close()或本机其他进程的浏览器.quit()可以关闭会话,前者只是关闭当前会话,浏览器的webdriver没有关闭,后者是关闭包括webdriver在内的所有东西。
我通过点击打开链接抓取指定分区每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线人数,形成一个列表并打印出来,代码如下
[python]查看平原
#-*- 编码:utf-8 -*- from selenium import webdriver from mon.exceptions import NoSuchElementException import time import re def find_sec(secid): pa=pile(r'\w+') browser = webdriver.Firefox() #获取firefox浏览器的本地会话.get("!section/%s "%secid) #加载页面 time.sleep(1) #让页面加载 result=[] try: #获取页面名称和在线人数, 形成列表 board=browser.find_elements_by_class_name('title_1') ol_num=browser.find_elements_by_class_name('title_4') max_bindex=len(board) max_oindex=len(ol_num) assert max_bindex==max_oindex,'index 不等价!' #The板名有中文和英文,所以只剩下i in range(1,max_oindex) 的英文进行常规过滤: board_en=pa.findall(board[i].text) result.append([str(board_en[-1]) ),int( ol_num[i].text)]) 浏览器。close() return result except NoSuchElementException: assert 0, "can't find element"print find_sec('5') #打印分区5下所有版块的当前在线用户列表
操作结果如下:
终端打印效果4.总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用这个来实现数据挖掘、机器学习等深度研究,所以selenium+python是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。 查看全部
网页抓取数据(通过利用selenium的子模块webdriver的使用解决思路(图))
1. 文章 目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,您使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问量、当前在线人数、微博点赞数等)都没有收录在静态html中,比如我想抓取当前在线点击人数打开 bbs网站 链接的每个部分。静态html网页不收录(不信你试试看页面源码,只有简单的一行)。
2. 解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html内容导入python程序?所以使用查看器的html内容的方法也不符合爬虫程序的要求。偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3. 实现过程 3.1 运行环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。使用 webdriver 捕获动态数据
首先从 selenium import webdriver 导入 webdriver 子模块以获取浏览器会话。浏览器可以使用Firefox、Chrome、IE等,这里以Firefox为例,browser = webdriver.Firefox()加载页面,url本身指定合法字符串。但是 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法,常用的有以下几种方式: idnameclass-namelinktextpartiallinktexttagnamexpathcssselector 例如通过 id 定位,返回一个列表所有元素, lis=borwser.find_elements_by_id_name('kw'') 是通过class-name来定位的, lis=find_elements_by_class_name('title_1') 更详细的定位方法,请参考selenium webdriver(python)教程-定位方法部分(第一版)第三章可在百度文库中查看)结合正则表达式过滤相关信息。定位后有些元素不需要,用正则表达式过滤掉即可。比如我想只提取英文字符(包括0-9),在lis中为u创建如下Regular pa=pile(r'\w+'):en=pa.findall(u.lis)print en 关闭会话,执行fetch操作后,必须关闭会话,否则会一直占用内存。运行browser.close()或本机其他进程的浏览器.quit()可以关闭会话,前者只是关闭当前会话,浏览器的webdriver没有关闭,后者是关闭包括webdriver在内的所有东西。
我通过点击打开链接抓取指定分区每个版块的在线用户数,并指定分区id号(0-9),可以得到该版块的名称和对应的在线人数,形成一个列表并打印出来,代码如下
[python]查看平原
#-*- 编码:utf-8 -*- from selenium import webdriver from mon.exceptions import NoSuchElementException import time import re def find_sec(secid): pa=pile(r'\w+') browser = webdriver.Firefox() #获取firefox浏览器的本地会话.get("!section/%s "%secid) #加载页面 time.sleep(1) #让页面加载 result=[] try: #获取页面名称和在线人数, 形成列表 board=browser.find_elements_by_class_name('title_1') ol_num=browser.find_elements_by_class_name('title_4') max_bindex=len(board) max_oindex=len(ol_num) assert max_bindex==max_oindex,'index 不等价!' #The板名有中文和英文,所以只剩下i in range(1,max_oindex) 的英文进行常规过滤: board_en=pa.findall(board[i].text) result.append([str(board_en[-1]) ),int( ol_num[i].text)]) 浏览器。close() return result except NoSuchElementException: assert 0, "can't find element"print find_sec('5') #打印分区5下所有版块的当前在线用户列表
操作结果如下:
终端打印效果4.总结
Selenium 在代码简洁性和执行效率方面非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。还可以进一步利用这个来实现数据挖掘、机器学习等深度研究,所以selenium+python是值得深入研究的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟虚拟浏览器,这里不再赘述。
网页抓取数据( Web抓取中的障碍有哪些?如何应用到Web中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-04 18:20
Web抓取中的障碍有哪些?如何应用到Web中)
AI如何用于网络爬虫?
在互联网世界中,数据就是一切,尤其是当您经营电子商务业务时。您每天都需要新数据来改进决策过程并找到吸引消费者的方法。网页抓取可以通过自动化流程和优化数据通道来帮助您采集 数据。
然而,从最好的 网站 中安全地抓取和提取数据仍然存在一些限制。由于网页抓取需要一定的知识和持续监控,归根结底必须选择正确的工具,而目前最好的工具是人工智能。让我们看看它如何应用于网络爬虫。
网页抓取的定义
网络爬行几乎与网页本身同时发生。它是谷歌等搜索引擎的命脉,帮助互联网用户大规模提取有价值的数据。它的目标是从各种高质量的网站中自动采集数据。网络爬虫是利用爬虫机器人浏览数百个网站和采集数据。
不过上面的网站对爬虫机器人并不友好。他们设置了各种安全机制来防止他们爬取数据。简单的机器人很容易被发现,而更复杂的机器人则有绕过安全机制的方法。
它们由人工智能驱动,可以识别网站上的优质数据,并且可以成功提取数据进行分析,不被发现、阻止或阻止。
网页抓取中的障碍
虽然网页抓取非常有用,但在实际应用中仍然存在许多障碍。最近,美国最高法院裁定用于人工智能和数据分析的网络抓取是合法的。即便如此,在网络爬虫中,您可能仍会面临很多困难,难以顺利地采集有价值的数据让您的业务蓬勃发展。
最常见的障碍包括:
扩大网络爬虫的规模:爬取一个网页本身不是问题,但是大规模的数据爬取面临着一些挑战,比如同时爬取几百万个网站数据。除了被检测和阻止之外,还有其他挑战,包括维护数据库、采集 数据和管理代码库。
模式改变:网站经常定期改变用户界面,增加数据抓取工具的难度。
反爬技术:顶级网站会采用各种反爬机制和安全技术。
基于 JavaScript 的动态内容:现代 网站 使用 Ajax 和 JavaScript 来呈现动态内容,使得数据提取更加困难。
蜜罐陷阱:一些顶级网站使用蜜罐技术来检测爬行机器人并提供虚假数据。
数据质量:现在有适用于提取数据的质量指南。如果数据质量不好,就会影响提取信息的完整性。
AI改变现状
网页抓取可以帮助解决很多问题,从而轻松解决数据抓取和提取的困难。很多企业使用AI网页爬取工具采集优质信息,包括市场调研、企业数据采集、供应链分析、劳动力研究、电子商务等。
AI让爬虫机器人的操作界面更加直观,从而提高了网络爬虫的效率。得益于NLP、机器学习等AI技术的加持,抓取机器人知道了网站中有价值的数据(如产品价格、评论、描述等)位于何处。将人工智能与网页抓取技术相结合,可以提高整个数据增强过程的效率和效果。
AI 网页抓取使数据提取、清理、聚合和规范化更加高效,同时节省资源和时间。您可以专注于您的核心业务,而不是将大量时间浪费在 采集 数据上,因为您了解 AI 可以完全满足您的网页抓取需求。
人工智能可以帮助开发数据增强方法,包括:
- 外推法
-标记
-聚合
-概率法
AI网页抓取
人工智能可以提高网页抓取应对挑战的能力,从而提高效率。由于 网站 是为人而不是机器构建的,因此从不同网页中大规模提取数据将成为一项挑战。出错的机会太多了。
但是强大的AI可以帮助避免许多常见错误并提高爬行效率。它还可以减少数据误用和错误,改进数据结构,使提取的数据更具实用性,扩大其应用范围。
随着人工智能技术的不断发展,它将不断优化网络爬虫,使应用程序比以往任何时候都更高效、更流畅。如果您正在考虑在您的业务中使用 AI 网络爬虫,请访问此页面以了解更多信息。
综上所述
今天,人工智能已经渗透到我们生活的方方面面,现代社会的每一个垂直领域都以各种方式依赖于这项卓越的技术。随着网页抓取和数据提取技术日新月异,将人工智能技术引入您的网页抓取中迟早会发生。
如果您想确保捕获高质量的可用数据,那么 AI 驱动的智能网络爬虫是您的最佳选择。 查看全部
网页抓取数据(
Web抓取中的障碍有哪些?如何应用到Web中)
AI如何用于网络爬虫?
在互联网世界中,数据就是一切,尤其是当您经营电子商务业务时。您每天都需要新数据来改进决策过程并找到吸引消费者的方法。网页抓取可以通过自动化流程和优化数据通道来帮助您采集 数据。
然而,从最好的 网站 中安全地抓取和提取数据仍然存在一些限制。由于网页抓取需要一定的知识和持续监控,归根结底必须选择正确的工具,而目前最好的工具是人工智能。让我们看看它如何应用于网络爬虫。
网页抓取的定义
网络爬行几乎与网页本身同时发生。它是谷歌等搜索引擎的命脉,帮助互联网用户大规模提取有价值的数据。它的目标是从各种高质量的网站中自动采集数据。网络爬虫是利用爬虫机器人浏览数百个网站和采集数据。
不过上面的网站对爬虫机器人并不友好。他们设置了各种安全机制来防止他们爬取数据。简单的机器人很容易被发现,而更复杂的机器人则有绕过安全机制的方法。
它们由人工智能驱动,可以识别网站上的优质数据,并且可以成功提取数据进行分析,不被发现、阻止或阻止。
网页抓取中的障碍
虽然网页抓取非常有用,但在实际应用中仍然存在许多障碍。最近,美国最高法院裁定用于人工智能和数据分析的网络抓取是合法的。即便如此,在网络爬虫中,您可能仍会面临很多困难,难以顺利地采集有价值的数据让您的业务蓬勃发展。
最常见的障碍包括:
扩大网络爬虫的规模:爬取一个网页本身不是问题,但是大规模的数据爬取面临着一些挑战,比如同时爬取几百万个网站数据。除了被检测和阻止之外,还有其他挑战,包括维护数据库、采集 数据和管理代码库。
模式改变:网站经常定期改变用户界面,增加数据抓取工具的难度。
反爬技术:顶级网站会采用各种反爬机制和安全技术。
基于 JavaScript 的动态内容:现代 网站 使用 Ajax 和 JavaScript 来呈现动态内容,使得数据提取更加困难。
蜜罐陷阱:一些顶级网站使用蜜罐技术来检测爬行机器人并提供虚假数据。
数据质量:现在有适用于提取数据的质量指南。如果数据质量不好,就会影响提取信息的完整性。
AI改变现状
网页抓取可以帮助解决很多问题,从而轻松解决数据抓取和提取的困难。很多企业使用AI网页爬取工具采集优质信息,包括市场调研、企业数据采集、供应链分析、劳动力研究、电子商务等。
AI让爬虫机器人的操作界面更加直观,从而提高了网络爬虫的效率。得益于NLP、机器学习等AI技术的加持,抓取机器人知道了网站中有价值的数据(如产品价格、评论、描述等)位于何处。将人工智能与网页抓取技术相结合,可以提高整个数据增强过程的效率和效果。
AI 网页抓取使数据提取、清理、聚合和规范化更加高效,同时节省资源和时间。您可以专注于您的核心业务,而不是将大量时间浪费在 采集 数据上,因为您了解 AI 可以完全满足您的网页抓取需求。
人工智能可以帮助开发数据增强方法,包括:
- 外推法
-标记
-聚合
-概率法
AI网页抓取
人工智能可以提高网页抓取应对挑战的能力,从而提高效率。由于 网站 是为人而不是机器构建的,因此从不同网页中大规模提取数据将成为一项挑战。出错的机会太多了。
但是强大的AI可以帮助避免许多常见错误并提高爬行效率。它还可以减少数据误用和错误,改进数据结构,使提取的数据更具实用性,扩大其应用范围。
随着人工智能技术的不断发展,它将不断优化网络爬虫,使应用程序比以往任何时候都更高效、更流畅。如果您正在考虑在您的业务中使用 AI 网络爬虫,请访问此页面以了解更多信息。
综上所述
今天,人工智能已经渗透到我们生活的方方面面,现代社会的每一个垂直领域都以各种方式依赖于这项卓越的技术。随着网页抓取和数据提取技术日新月异,将人工智能技术引入您的网页抓取中迟早会发生。
如果您想确保捕获高质量的可用数据,那么 AI 驱动的智能网络爬虫是您的最佳选择。
网页抓取数据(python爬虫非常多,如何识别http协议的识别方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-02 18:02
网页抓取数据分为http和https,本文将着重介绍http协议的识别方法。你是否经常和爬虫打交道?python爬虫非常多,如何抓取最多的内容呢?本文会介绍一些好用的工具网站,比如蝉大师提供的python网站提取工具,可以爬取最多的百度、知乎、豆瓣上的文章内容。效果如下:网页抓取数据页面伪代码该网站中爬取的某篇文章如下图所示:爬取之后的效果,即可以输出在rss中,代码如下:页面伪代码http提供了可变格式的http响应,可以用来处理数据,建议使用工具类。
现在主流的三种http协议是selenium、webdriver和fiddler,如果你是web开发者,推荐使用webdriver包。安装webdriver包,直接从官网下载即可,地址:webdriver在安装好macos系统以后,直接在cmd中输入以下命令安装webdriver:sudoapt-getinstallwebdriverwebdriver本文提供一个检测工具:nslookup,setuptools-httproider和fiddler,三个软件中不可同时使用。
在python中,nslookup工具在python3.4后默认出现在/usr/local/include/nslookup.py中,如果没有说明缺少依赖库,在/usr/local/include/python2.7中可以找到。当然这些都不是最重要的,最重要的是,http协议的解析可能会需要python中的冒号、分号、引号、结束符、缩进、关键字等。那就由“python文档:”(简称pep2。
8)提供的名为convert的工具来实现协议的解析。
convert工具命令行输入下面两行命令(alt+空格)来安装pep28:pipinstallconvert-epub-demo-1然后就可以来熟悉使用这个python文档中的工具:
1、检查服务端提供的数据格式、api参数,没有data、doc、headers、requestheaders。
2、检查数据传递方式,是否需要用到post或get参数传递。
3、解析响应头部的内容,看响应头是否满足要求,data、headers、requestheaders等。
4、检查服务端返回数据格式和大小,如果超过了设置的字节数限制,那么就给服务端发送一个超过格式要求的data。
5、检查文档地址是否包含反斜杠\,比如url="/"\u001\aa\efdf\c2628900=u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"。con。 查看全部
网页抓取数据(python爬虫非常多,如何识别http协议的识别方法?)
网页抓取数据分为http和https,本文将着重介绍http协议的识别方法。你是否经常和爬虫打交道?python爬虫非常多,如何抓取最多的内容呢?本文会介绍一些好用的工具网站,比如蝉大师提供的python网站提取工具,可以爬取最多的百度、知乎、豆瓣上的文章内容。效果如下:网页抓取数据页面伪代码该网站中爬取的某篇文章如下图所示:爬取之后的效果,即可以输出在rss中,代码如下:页面伪代码http提供了可变格式的http响应,可以用来处理数据,建议使用工具类。
现在主流的三种http协议是selenium、webdriver和fiddler,如果你是web开发者,推荐使用webdriver包。安装webdriver包,直接从官网下载即可,地址:webdriver在安装好macos系统以后,直接在cmd中输入以下命令安装webdriver:sudoapt-getinstallwebdriverwebdriver本文提供一个检测工具:nslookup,setuptools-httproider和fiddler,三个软件中不可同时使用。
在python中,nslookup工具在python3.4后默认出现在/usr/local/include/nslookup.py中,如果没有说明缺少依赖库,在/usr/local/include/python2.7中可以找到。当然这些都不是最重要的,最重要的是,http协议的解析可能会需要python中的冒号、分号、引号、结束符、缩进、关键字等。那就由“python文档:”(简称pep2。
8)提供的名为convert的工具来实现协议的解析。
convert工具命令行输入下面两行命令(alt+空格)来安装pep28:pipinstallconvert-epub-demo-1然后就可以来熟悉使用这个python文档中的工具:
1、检查服务端提供的数据格式、api参数,没有data、doc、headers、requestheaders。
2、检查数据传递方式,是否需要用到post或get参数传递。
3、解析响应头部的内容,看响应头是否满足要求,data、headers、requestheaders等。
4、检查服务端返回数据格式和大小,如果超过了设置的字节数限制,那么就给服务端发送一个超过格式要求的data。
5、检查文档地址是否包含反斜杠\,比如url="/"\u001\aa\efdf\c2628900=u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"\\u001\aa\efdf\c2628900=u\\u\\d\\n"。con。
网页抓取数据(了解网页在开始学习如何在大数据分析R语言中进行网络抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-28 05:30
互联网已经成熟,可以用于您自己的个人项目的数据集。有时,您很幸运,可以访问一个 API,您可以在其中直接使用大数据分析 R 语言来请求数据。有时,您不会走运,也无法从整洁的格式中获得。遇到这种情况,我们就需要求助于网络爬虫,它是一种通过在网站的HTML代码中查找所需数据来获取待分析数据的技术。
在如何使用大数据分析R语言进行网络爬虫中,我们将介绍如何使用大数据分析R语言进行网络爬虫的基础知识。我们将从国家气象局 网站 的天气预报中获取数据并将其转换为可用格式。
当我们找不到所需的数据时,网络抓取将提供机会,并为我们提供实际创建数据集所需的工具。并且因为我们使用大数据分析R语言进行网络爬虫,如果我们使用的网站已经更新,我们只需再次运行代码即可获取更新后的数据集。
了解网络
在开始学习如何抓取网页之前,我们需要了解网页本身的结构。
从用户的角度来看,网页的文本、图像和链接以美观且易于阅读的方式组织起来。但是网页本身是用特定的编码语言编写的,然后由我们的网络浏览器解释。在做网页爬虫的时候,我们需要处理网页本身的实际内容:浏览器解释前面的代码。
用于构建网页的主要语言称为超文本标记语言(HTML)、级联样式表(CSS)和 Javasc 大数据分析 R 语言 ipt。HTML 提供网页的实际结构和内容。CSS 提供网页的样式和外观,包括字体和颜色等详细信息。Javasc大数据分析R语言ipt提供网页功能。
在如何使用大数据分析R语言rvest进行网络爬虫中,我们将主要关注如何使用大数据分析R语言网络爬虫来读取构成网页的HTML和CSS。
HTML
与用于大数据分析的 R 语言不同,HTML 不是一种编程语言。相反,它被称为标记语言——它描述了网页的内容和结构。HTML 是使用标记来组织的,标记被符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容。
最简单的 HTML 文档如下所示:
虽然上面是一个有效的 HTML 文档,但它没有文本或其他内容。如果您将其另存为 .html 文件并使用 Web 浏览器打开它,您将看到一个空白页面。
请注意,html 这个词用方括号括起来表示它是一个标签。要向此 HTML 文档添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加了 和 标签,为文档添加了更多结构。
标签是我们用来在 HTML 中指定段落文本的标签。
HTML中有很多标签,但是如何使用大数据分析R语言rvest进行网络爬虫,我们将无法涵盖所有标签。如果你有兴趣,你可以查看这个网站。最重要的一点是要知道标签具有特定的名称(html、body、p 等),以便它们可以在 HTML 文档中被识别。
请注意,每个标签都是“配对”的,这意味着每个标签都伴随着另一个名称相似的标签。也就是说,开始标签与指示 HTML 文档开始和结束的另一个标签配对。而且和一样。
意识到这一点很重要,因为它允许标签相互嵌套。嵌套在和标签中,嵌套在。这种嵌套使 HTML 具有“树状”结构:
使用大数据分析R语言进行网络爬虫时,这种树状结构会告诉我们如何找到某些标签,所以一定要记住这一点。如果一个标签与其他标签嵌套,则收录的标签称为父标签,每个标签称为“子标签”。如果父级中有多个子级,则这些子级标签统称为“兄弟级”。父母、孩子和兄弟姐妹的这些概念让我们了解标签的层次结构。
CSS
HTML 提供网页的内容和结构,而 CSS 提供有关网页样式的信息。如果没有 CSS,网页将变得非常简陋。这是一个没有 CSS 的简单 HTML 文档,演示了它。
当我们谈论风格时,我们指的是各种事物。样式可以指特定 HTML 元素的颜色或位置。与 HTML 一样,CSS 材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果您有兴趣,可以在这里了解更多信息。
在我们需要学习这两个概念之前,我们先深入了解大数据分析 R 语言网页抓取代码类和 IDS。
首先,让我们谈谈类。如果我们想创建一个网站,那么通常我们希望网站的相似元素看起来一样。例如,我们可能希望列表中的许多项目以与红色相同的颜色显示。
我们可以通过在文本的 HTML 标签的每一行中直接插入一些收录颜色信息的 CSS 来实现,例如:
样式文章指出我们正在尝试应用CSS标签。在引号里面,我们看到了一个键值对“colo big data analysis R language: big data analysis R language ed”。Colo大数据分析R语言是指标记中文字的颜色,红色表示应该是一种颜色。
但是正如我们在上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须逐行改变每一行。
我们可以用类选择器替换它,而不是在所有这些标签中以样式重复此文本:
类选择,我们可以更好地展示这些标签在某种程度上是相关的。在单个 CSS 文件中,我们可以通过编写以下内容来创建红色文本类并定义其外观:
将这两个元素组合成一个网页会产生与第一组红色标签相同的效果,但它使我们可以更轻松地进行快速更改。
当然,在如何使用大数据分析R语言进行爬虫方面,我们感兴趣的是爬虫,而不是构建网页。但是,我们在进行网页爬虫时,通常需要选择特定类别的 HTML 标签,因此我们需要了解 CSS 类是如何工作的。
同样,我们可能经常想要捕获由 id 标识的特定数据。CSS ID 用于为单个元素提供可识别的名称,就像类如何帮助定义元素类一样。
如果将 id 附加到 HTML 标签上,我们在使用大数据分析 R 语言进行实际网络抓取时可以更容易地识别标签。
如果您对类和 id 不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰。
有几个大数据分析 R 语言库旨在使用 HTML 和 CSS,并能够遍历它们以查找特定标签。我们将在如何使用大数据分析 R 语言 rvest 进行网络爬虫中使用的库是大数据分析 R 语言马甲。
大数据分析R语言马甲库
大数据分析R语言马甲库由传奇人物哈德利·威克姆(Hadley Wickham)维护,它可以让用户轻松地从网页中抓取(“收获”)数据。
大数据分析 R 语言马甲是 tidyve 大数据分析 R 语言 se 库之一,因此它可以很好地与捆绑软件中收录的其他库配合使用。大数据分析 R 语言背心的灵感来自 Python 网页抓取库 BeautifulSoup。(相关:o 你的 BeautifulSoup Python 教程。)
R语言爬取网页进行大数据分析
为了使用大数据分析R语言马甲库,我们首先需要安装它,并使用lib大数据分析R语言a大数据分析R语言y()函数将其导入。
为了开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了返老还童,大数据分析R语言ead_html()服务于这个目的的函数就是一个函数。
大数据分析R语言ead_html()接受Web U大数据分析R语言L作为参数。让我们从之前的简单无 CSS 页面开始,了解该功能是如何工作的。
simple dataquestio.github.io/web-sc 大数据分析 R 语言 aping-pages/simple.html")
大数据分析 R 语言的 ead_html() 函数返回一个列表对象,其中收录我们之前讨论的树结构。
假设我们要将单个标签中收录的文本存储到一个变量中。为了访问这个文本,我们需要弄清楚如何定位这个特定的文本。这通常是 CSS 类和 ID 可以帮助我们的地方,因为优秀的开发人员通常会将 CSS 高度清晰地放在他们的 网站 上。
在这种情况下,我们没有这样的 CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要使用 html_nodes() 和 html_text() 函数来搜索
标记和检索文本。以下代码执行此操作:
simple 变量已经收录了我们想要爬取的 HTML,所以剩下的任务就是搜索需要的元素。由于我们使用的是tidyve大数据分析R语言se,所以我们可以将HTML传递给不同的函数。
我们需要将特定的 HTML 标签或 CSS 类传递给 html_nodes() 函数。我们需要标记,因此我们将字符“p”传递给函数。html_nodes() 也返回一个列表,但它返回 HTML 中具有给定特定 HTML 标记或 CSS 类/标识的所有节点。节点指的是树结构中的一个点。
拥有所有这些节点后,您可以将输出 html_nodes() 传递给 html_text() 函数。我们需要获取标签的实际文本,因此该功能可以帮助您解决这个问题。
这些功能共同构成了许多常见的 Web 抓取任务。通常,使用 R 语言(或任何其他语言)进行大数据分析的网页抓取可以归结为以下三个步骤:
一种。获取要抓取的网页的 HTML
湾 确定您要阅读页面的哪个部分,并找出您需要选择的 HTML/CSS
C。选择 HTML 并根据需要进行分析
登陆页面
为了
, 我们会查国家气象局的网站。假设我们有兴趣创建我们自己的天气应用程序。我们需要天气数据本身来填充它。
天气数据每天都会更新,所以我们会在需要的时候使用网络爬虫从NWS网站获取这些数据。
出于我们的目的,我们将从旧金山获取数据,但每个城市的网页看起来都一样,因此相同的步骤可用于任何其他城市。旧金山页面截图如下:
我们对每日天气预报和温度特别感兴趣。每日天气预报和夜间天气预报。现在我们已经确定了网页所需的部分,我们可以浏览 HTML 以查看需要选择哪些标签或类来捕获此特定数据。
使用Ch大数据分析R语言ome Devtools
值得庆幸的是,大多数现代浏览器都有一个工具,允许用户直接检查任何网页的 HTML 和 CSS。在Google Ch大数据分析R语言ome和Fi大数据分析R语言efox中,它们被称为开发者工具,在其他浏览器中的名称相似。对我们来说最有用的具体工具是Inspecto大数据分析R语言。
您可以在浏览器的右上角找到开发者工具。如果你使用的是Fi大数据分析R语言efox,应该可以看到开发者工具;如果您使用Ch大数据分析R语言ome,可以浏览查看->Mo大数据分析R语言e工具->开发大数据分析R语言工具。这将在浏览器窗口中打开开发者工具:
我们之前处理的 HTML 只是一个基本的知识,但是您将在浏览器中看到的大多数网页都非常复杂。开发人员工具将使我们更容易选择网页的确切元素来抓取和检查 HTML。
我们需要在天气页面的 HTML 中查看温度,因此我们将使用“检查”工具来查看这些元素。Inspect 工具将挑选出我们正在寻找的确切 HTML,因此我们不必自己查看它!
通过单击元素本身,我们可以看到以下 HTML 收录 7 天的预测。我们压缩了其中的一些以使其更具可读性:
使用我们学到的东西
现在我们已经确定了需要在网页中定位的具体 HTML 和 CSS,我们可以使用大数据分析 R 语言马甲来捕捉它。
从上面的 HTML 中,似乎每个温度都收录在类 temp 中。拥有所有这些标签后,您可以从中提取文本。
使用这段代码,大数据分析R语言ecasts现在是低温和高温对应的字符串向量。
现在我们有了对R语言变量大数据分析感兴趣的实际数据,我们只需要进行一些常规的数据分析,将向量转换成需要的格式即可。例如:
下一步
这个大数据分析 R 语言马甲库使用与 tidyve 大数据分析 R 语言 se 库相同的技术,可以轻松执行网络爬虫。
如何使用大数据分析 R 语言中的网页抓取 rvest 应该为您提供启动小型网页抓取项目并开始探索更高级的网页抓取程序所需的工具。一些与网站爬行极其兼容的网站是体育网站,网站与股票价格甚至新闻报道。 查看全部
网页抓取数据(了解网页在开始学习如何在大数据分析R语言中进行网络抓取)
互联网已经成熟,可以用于您自己的个人项目的数据集。有时,您很幸运,可以访问一个 API,您可以在其中直接使用大数据分析 R 语言来请求数据。有时,您不会走运,也无法从整洁的格式中获得。遇到这种情况,我们就需要求助于网络爬虫,它是一种通过在网站的HTML代码中查找所需数据来获取待分析数据的技术。
在如何使用大数据分析R语言进行网络爬虫中,我们将介绍如何使用大数据分析R语言进行网络爬虫的基础知识。我们将从国家气象局 网站 的天气预报中获取数据并将其转换为可用格式。
当我们找不到所需的数据时,网络抓取将提供机会,并为我们提供实际创建数据集所需的工具。并且因为我们使用大数据分析R语言进行网络爬虫,如果我们使用的网站已经更新,我们只需再次运行代码即可获取更新后的数据集。
了解网络
在开始学习如何抓取网页之前,我们需要了解网页本身的结构。
从用户的角度来看,网页的文本、图像和链接以美观且易于阅读的方式组织起来。但是网页本身是用特定的编码语言编写的,然后由我们的网络浏览器解释。在做网页爬虫的时候,我们需要处理网页本身的实际内容:浏览器解释前面的代码。
用于构建网页的主要语言称为超文本标记语言(HTML)、级联样式表(CSS)和 Javasc 大数据分析 R 语言 ipt。HTML 提供网页的实际结构和内容。CSS 提供网页的样式和外观,包括字体和颜色等详细信息。Javasc大数据分析R语言ipt提供网页功能。
在如何使用大数据分析R语言rvest进行网络爬虫中,我们将主要关注如何使用大数据分析R语言网络爬虫来读取构成网页的HTML和CSS。
HTML
与用于大数据分析的 R 语言不同,HTML 不是一种编程语言。相反,它被称为标记语言——它描述了网页的内容和结构。HTML 是使用标记来组织的,标记被符号包围。不同的标签执行不同的功能。许多标签将一起形成并收录网页的内容。
最简单的 HTML 文档如下所示:
虽然上面是一个有效的 HTML 文档,但它没有文本或其他内容。如果您将其另存为 .html 文件并使用 Web 浏览器打开它,您将看到一个空白页面。
请注意,html 这个词用方括号括起来表示它是一个标签。要向此 HTML 文档添加更多结构和文本,我们可以添加以下内容:
在这里,我们添加了 和 标签,为文档添加了更多结构。
标签是我们用来在 HTML 中指定段落文本的标签。
HTML中有很多标签,但是如何使用大数据分析R语言rvest进行网络爬虫,我们将无法涵盖所有标签。如果你有兴趣,你可以查看这个网站。最重要的一点是要知道标签具有特定的名称(html、body、p 等),以便它们可以在 HTML 文档中被识别。
请注意,每个标签都是“配对”的,这意味着每个标签都伴随着另一个名称相似的标签。也就是说,开始标签与指示 HTML 文档开始和结束的另一个标签配对。而且和一样。
意识到这一点很重要,因为它允许标签相互嵌套。嵌套在和标签中,嵌套在。这种嵌套使 HTML 具有“树状”结构:
使用大数据分析R语言进行网络爬虫时,这种树状结构会告诉我们如何找到某些标签,所以一定要记住这一点。如果一个标签与其他标签嵌套,则收录的标签称为父标签,每个标签称为“子标签”。如果父级中有多个子级,则这些子级标签统称为“兄弟级”。父母、孩子和兄弟姐妹的这些概念让我们了解标签的层次结构。
CSS
HTML 提供网页的内容和结构,而 CSS 提供有关网页样式的信息。如果没有 CSS,网页将变得非常简陋。这是一个没有 CSS 的简单 HTML 文档,演示了它。
当我们谈论风格时,我们指的是各种事物。样式可以指特定 HTML 元素的颜色或位置。与 HTML 一样,CSS 材料的范围如此之大,以至于我们无法涵盖该语言中所有可能的概念。如果您有兴趣,可以在这里了解更多信息。
在我们需要学习这两个概念之前,我们先深入了解大数据分析 R 语言网页抓取代码类和 IDS。
首先,让我们谈谈类。如果我们想创建一个网站,那么通常我们希望网站的相似元素看起来一样。例如,我们可能希望列表中的许多项目以与红色相同的颜色显示。
我们可以通过在文本的 HTML 标签的每一行中直接插入一些收录颜色信息的 CSS 来实现,例如:
样式文章指出我们正在尝试应用CSS标签。在引号里面,我们看到了一个键值对“colo big data analysis R language: big data analysis R language ed”。Colo大数据分析R语言是指标记中文字的颜色,红色表示应该是一种颜色。
但是正如我们在上面看到的,我们已经多次重复这个键值对。这并不理想——如果我们想改变文本的颜色,我们必须逐行改变每一行。
我们可以用类选择器替换它,而不是在所有这些标签中以样式重复此文本:
类选择,我们可以更好地展示这些标签在某种程度上是相关的。在单个 CSS 文件中,我们可以通过编写以下内容来创建红色文本类并定义其外观:
将这两个元素组合成一个网页会产生与第一组红色标签相同的效果,但它使我们可以更轻松地进行快速更改。
当然,在如何使用大数据分析R语言进行爬虫方面,我们感兴趣的是爬虫,而不是构建网页。但是,我们在进行网页爬虫时,通常需要选择特定类别的 HTML 标签,因此我们需要了解 CSS 类是如何工作的。
同样,我们可能经常想要捕获由 id 标识的特定数据。CSS ID 用于为单个元素提供可识别的名称,就像类如何帮助定义元素类一样。
如果将 id 附加到 HTML 标签上,我们在使用大数据分析 R 语言进行实际网络抓取时可以更容易地识别标签。
如果您对类和 id 不太了解,请不要担心,当我们开始编写代码时,它会变得更加清晰。
有几个大数据分析 R 语言库旨在使用 HTML 和 CSS,并能够遍历它们以查找特定标签。我们将在如何使用大数据分析 R 语言 rvest 进行网络爬虫中使用的库是大数据分析 R 语言马甲。
大数据分析R语言马甲库
大数据分析R语言马甲库由传奇人物哈德利·威克姆(Hadley Wickham)维护,它可以让用户轻松地从网页中抓取(“收获”)数据。
大数据分析 R 语言马甲是 tidyve 大数据分析 R 语言 se 库之一,因此它可以很好地与捆绑软件中收录的其他库配合使用。大数据分析 R 语言背心的灵感来自 Python 网页抓取库 BeautifulSoup。(相关:o 你的 BeautifulSoup Python 教程。)
R语言爬取网页进行大数据分析
为了使用大数据分析R语言马甲库,我们首先需要安装它,并使用lib大数据分析R语言a大数据分析R语言y()函数将其导入。
为了开始解析网页,我们首先需要从收录网页的计算机服务器请求数据。为了返老还童,大数据分析R语言ead_html()服务于这个目的的函数就是一个函数。
大数据分析R语言ead_html()接受Web U大数据分析R语言L作为参数。让我们从之前的简单无 CSS 页面开始,了解该功能是如何工作的。
simple dataquestio.github.io/web-sc 大数据分析 R 语言 aping-pages/simple.html")
大数据分析 R 语言的 ead_html() 函数返回一个列表对象,其中收录我们之前讨论的树结构。
假设我们要将单个标签中收录的文本存储到一个变量中。为了访问这个文本,我们需要弄清楚如何定位这个特定的文本。这通常是 CSS 类和 ID 可以帮助我们的地方,因为优秀的开发人员通常会将 CSS 高度清晰地放在他们的 网站 上。
在这种情况下,我们没有这样的 CSS,但我们知道要访问的标记是页面上唯一的标记。为了捕获文本,我们需要使用 html_nodes() 和 html_text() 函数来搜索
标记和检索文本。以下代码执行此操作:
simple 变量已经收录了我们想要爬取的 HTML,所以剩下的任务就是搜索需要的元素。由于我们使用的是tidyve大数据分析R语言se,所以我们可以将HTML传递给不同的函数。
我们需要将特定的 HTML 标签或 CSS 类传递给 html_nodes() 函数。我们需要标记,因此我们将字符“p”传递给函数。html_nodes() 也返回一个列表,但它返回 HTML 中具有给定特定 HTML 标记或 CSS 类/标识的所有节点。节点指的是树结构中的一个点。
拥有所有这些节点后,您可以将输出 html_nodes() 传递给 html_text() 函数。我们需要获取标签的实际文本,因此该功能可以帮助您解决这个问题。
这些功能共同构成了许多常见的 Web 抓取任务。通常,使用 R 语言(或任何其他语言)进行大数据分析的网页抓取可以归结为以下三个步骤:
一种。获取要抓取的网页的 HTML
湾 确定您要阅读页面的哪个部分,并找出您需要选择的 HTML/CSS
C。选择 HTML 并根据需要进行分析
登陆页面
为了
, 我们会查国家气象局的网站。假设我们有兴趣创建我们自己的天气应用程序。我们需要天气数据本身来填充它。
天气数据每天都会更新,所以我们会在需要的时候使用网络爬虫从NWS网站获取这些数据。
出于我们的目的,我们将从旧金山获取数据,但每个城市的网页看起来都一样,因此相同的步骤可用于任何其他城市。旧金山页面截图如下:
我们对每日天气预报和温度特别感兴趣。每日天气预报和夜间天气预报。现在我们已经确定了网页所需的部分,我们可以浏览 HTML 以查看需要选择哪些标签或类来捕获此特定数据。
使用Ch大数据分析R语言ome Devtools
值得庆幸的是,大多数现代浏览器都有一个工具,允许用户直接检查任何网页的 HTML 和 CSS。在Google Ch大数据分析R语言ome和Fi大数据分析R语言efox中,它们被称为开发者工具,在其他浏览器中的名称相似。对我们来说最有用的具体工具是Inspecto大数据分析R语言。
您可以在浏览器的右上角找到开发者工具。如果你使用的是Fi大数据分析R语言efox,应该可以看到开发者工具;如果您使用Ch大数据分析R语言ome,可以浏览查看->Mo大数据分析R语言e工具->开发大数据分析R语言工具。这将在浏览器窗口中打开开发者工具:
我们之前处理的 HTML 只是一个基本的知识,但是您将在浏览器中看到的大多数网页都非常复杂。开发人员工具将使我们更容易选择网页的确切元素来抓取和检查 HTML。
我们需要在天气页面的 HTML 中查看温度,因此我们将使用“检查”工具来查看这些元素。Inspect 工具将挑选出我们正在寻找的确切 HTML,因此我们不必自己查看它!
通过单击元素本身,我们可以看到以下 HTML 收录 7 天的预测。我们压缩了其中的一些以使其更具可读性:
使用我们学到的东西
现在我们已经确定了需要在网页中定位的具体 HTML 和 CSS,我们可以使用大数据分析 R 语言马甲来捕捉它。
从上面的 HTML 中,似乎每个温度都收录在类 temp 中。拥有所有这些标签后,您可以从中提取文本。
使用这段代码,大数据分析R语言ecasts现在是低温和高温对应的字符串向量。
现在我们有了对R语言变量大数据分析感兴趣的实际数据,我们只需要进行一些常规的数据分析,将向量转换成需要的格式即可。例如:
下一步
这个大数据分析 R 语言马甲库使用与 tidyve 大数据分析 R 语言 se 库相同的技术,可以轻松执行网络爬虫。
如何使用大数据分析 R 语言中的网页抓取 rvest 应该为您提供启动小型网页抓取项目并开始探索更高级的网页抓取程序所需的工具。一些与网站爬行极其兼容的网站是体育网站,网站与股票价格甚至新闻报道。
网页抓取数据(微软的开源工具urllib2/urllib·urllib(url)数据分析框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-25 12:09
网页抓取数据的话,可以用开源爬虫工具,你可以试试91爬虫jiebapi,这是一个强大的基于python的分词工具,支持大多数主流的分词库,准确率很高。
微软的开源工具
urllib2/urllib·github
有两个集成的数据分析库,一个是teradata的。现在他们的分析软件正在开发中,
youmai!的工具箱集成数据分析框架!
网页转化为excel文件有几种方式,最简单的就是爬取网站上面的数据,
xlsx,csv,pandas,
谢邀,不过excel已经很强大了,这个问题很难回答,不同的公司偏重点不同。
excelhome()中有一个专门爬取数据的工具,
dataviz网页上的数据基本不要想了,一般这些数据工具都是通过爬虫的方式来实现的,好处是操作方便,当然,本质上我们是要对数据进行清洗,标注,这些必须自己去动手做,
pandas.read_excel(url)
爬爬别人的数据,但是数据量大的话,可以考虑excel解决方案,
你可以看看有没有提供csv数据导入功能的工具,
个人有两个做法1将爬虫的页面爬取下来打包为csv, 查看全部
网页抓取数据(微软的开源工具urllib2/urllib·urllib(url)数据分析框架)
网页抓取数据的话,可以用开源爬虫工具,你可以试试91爬虫jiebapi,这是一个强大的基于python的分词工具,支持大多数主流的分词库,准确率很高。
微软的开源工具
urllib2/urllib·github
有两个集成的数据分析库,一个是teradata的。现在他们的分析软件正在开发中,
youmai!的工具箱集成数据分析框架!
网页转化为excel文件有几种方式,最简单的就是爬取网站上面的数据,
xlsx,csv,pandas,
谢邀,不过excel已经很强大了,这个问题很难回答,不同的公司偏重点不同。
excelhome()中有一个专门爬取数据的工具,
dataviz网页上的数据基本不要想了,一般这些数据工具都是通过爬虫的方式来实现的,好处是操作方便,当然,本质上我们是要对数据进行清洗,标注,这些必须自己去动手做,
pandas.read_excel(url)
爬爬别人的数据,但是数据量大的话,可以考虑excel解决方案,
你可以看看有没有提供csv数据导入功能的工具,
个人有两个做法1将爬虫的页面爬取下来打包为csv,
网页抓取数据(基于网络的mongodb查询数据库4.快速提取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-25 03:04
<p>网页抓取数据/爬虫一直是我司的痛点,大量的爬虫都采用的nodejs,去实现爬虫最快也需要一天。也因此针对一个问题开展了一个设计,核心目的是让web开发不再只局限于单线程去进行开发,并将这些结构化的内容以模版的形式进行管理,在任意需要的时候可以弹出进行使用。于是乎就有了以下的设计来对现有网页爬虫进行优化:1.一站式代码搜索能力,使得爬虫集中在自己程序的一个页面上进行查询2.减少服务器压力,增加缓存效率3.增加基于网络的mongodb查询数据库4.快速提取网页数据5.提供完善的后台管理界面(模版+网页)更新日志分析列表,并利用中间代码库
functionaspayload(request){varinstance=thisweb.document.createelement('div')instance.style.innerhtml=request.withcreateelement('input')for(vari=0;i 查看全部
网页抓取数据(基于网络的mongodb查询数据库4.快速提取网页数据)
<p>网页抓取数据/爬虫一直是我司的痛点,大量的爬虫都采用的nodejs,去实现爬虫最快也需要一天。也因此针对一个问题开展了一个设计,核心目的是让web开发不再只局限于单线程去进行开发,并将这些结构化的内容以模版的形式进行管理,在任意需要的时候可以弹出进行使用。于是乎就有了以下的设计来对现有网页爬虫进行优化:1.一站式代码搜索能力,使得爬虫集中在自己程序的一个页面上进行查询2.减少服务器压力,增加缓存效率3.增加基于网络的mongodb查询数据库4.快速提取网页数据5.提供完善的后台管理界面(模版+网页)更新日志分析列表,并利用中间代码库
functionaspayload(request){varinstance=thisweb.document.createelement('div')instance.style.innerhtml=request.withcreateelement('input')for(vari=0;i
网页抓取数据(python简单网络爬虫获取智联招聘上一线及新一线城市)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-22 23:03
小编分享Python履带的方式克拉夫勒累了一下Web数据,我希望每个人都会读到这个文章后大大收,让我们一起讨论!
Python简单的网络爬网程序获取Web数据
下面有一线和新的一线城市所有线条和新城市都列出了一些数据分析
1、首先,请搜索智利的BIM的工作信息,跳出页面,然后检查页面源代码,如果没有找到当前页面的作业信息。然后,快捷键F12打开开发人员工具窗口,刷新页面,过滤文件通过关键字,查找收录位置的数据包。
2、查看此文件的请求URL,分析其构造发现数据包的请求URL
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器以访问测试,成功获取相应的数据
3、获取的JSON格式数据,首先格式化,分析构建以及代码中的解析方法。
4、请求URL和数据结构清晰,剩余的是代码中的URL的构造,数据分析和导出。最后,获得了1215个数据,并进一步分类数据以执行数据分析。
读完这个文章,我相信你对Python履带的方法有一定的了解,我想了解更多关于知识的信息,欢迎要注意亿云行业信息渠道,谢谢阅读! 查看全部
网页抓取数据(python简单网络爬虫获取智联招聘上一线及新一线城市)
小编分享Python履带的方式克拉夫勒累了一下Web数据,我希望每个人都会读到这个文章后大大收,让我们一起讨论!
Python简单的网络爬网程序获取Web数据
下面有一线和新的一线城市所有线条和新城市都列出了一些数据分析
1、首先,请搜索智利的BIM的工作信息,跳出页面,然后检查页面源代码,如果没有找到当前页面的作业信息。然后,快捷键F12打开开发人员工具窗口,刷新页面,过滤文件通过关键字,查找收录位置的数据包。
2、查看此文件的请求URL,分析其构造发现数据包的请求URL
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器以访问测试,成功获取相应的数据
3、获取的JSON格式数据,首先格式化,分析构建以及代码中的解析方法。
4、请求URL和数据结构清晰,剩余的是代码中的URL的构造,数据分析和导出。最后,获得了1215个数据,并进一步分类数据以执行数据分析。
读完这个文章,我相信你对Python履带的方法有一定的了解,我想了解更多关于知识的信息,欢迎要注意亿云行业信息渠道,谢谢阅读!
网页抓取数据(第三方工具抓取别人网站数据的方式无非两种方式!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-09-22 04:15
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式不超过两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章代码,但每次我使用别人的代码时,总会出现各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发过程中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
对于(int i=0;i
System.Net.WebClient-WebClientObj=新系统.Net.WebClient()
System.采集s.Specialized.NameValue采集 PostVars=新的System.采集s.Specialized.NameValue采集()
添加(“\u viewstate”,“这是您需要提前获取的信息”)
添加(“\u eventvalidation”,“这是您需要提前获取的信息”)
Add(“\u eventtarget”,“这里是与\u dopostback方法相对应的参数”)
Add(“\u eventargument”,“这里是与\u dopostback方法相对应的参数”)
添加(“ContentType”,“application/x-www-form-urlencoded”)
试一试
{
byte[]byte1=WebClientObj.UploadValues(“,“POST”,PostVars)
字符串responsest=编码。UTF8.GetString(byte1);//获取当前页面对应的HTML文本字符串
Getpostvalue(responsest);//获取所需信息,例如与当前页面对应的_viewstate,以便抓取下一页
Savemessage(responsest);//将您关心的内容保存到数据库中
}捕获(例外情况除外){
控制台写入线(例如消息)
}
}
第三种方法:第三种方法是最麻烦、最恶心的。翻页的过程中找不到页面信息。这种方法需要很多努力。后来,我采用了一种更残酷的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据a、 其原理是,使用代码模拟手动单击翻页链接,使用代码逐页翻页,然后逐页抓取
这就是所谓的门外汉看热闹,专家看门口。很多人可能会在这里看到,并说它可以通过使用WebBrowser控件来实现。是的,我下面的方法是使用WebBrowser控件来实现它。事实上,.Net下应该有类似的类,但我还没有研究过。我也希望如果有人有其他的方法,他们可以回复我,和你一起分享
WebBrowser控件可以在自己的程序中嵌入浏览器,就像IE和Firefox一样。你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想一定不如IE和Firefox。哈哈
让我们少说,切入主题:
使用WebBrowser控件基本上可以实现在ie中操作网页的任何功能,所以点击翻页按钮当然可以。因为您可以在WebBrowser中手动点击翻页按钮,自然,我们也可以使用程序代码指示WebBrowser为我们自动翻页
其实原理很简单,主要分为以下几个步骤:
第一步是打开要捕获的页面,例如:
调用WebBrowser控件的方法navigate(“”)
此时,您应该在WebBrowser控件中看到您的网页信息,这与在IE中看到的信息相同
其次,WebBrowser控件的事件documentcompleted非常重要。当您访问的所有页面都加载时,将触发此事件。因此,在此事件中还需要完成分析页面元素的过程
字符串_responsest=这个。WebBrowser1.Document.Body.OuterHtml
此代码可以获取当前打开页面的HTML元素的内容
现在您已经获得了当前打开页面的HTML元素的内容,接下来的工作自然是解析大字符串,获取您关心的内容,以及解析字符串的过程。您应该能够自己编写它
第三步
重点是第三步,因为我们必须翻过这一页并采取第二步
在DocumentCompleted事件中
WebBrowser1.Document.Getelementbyid(“页码的ID”).Invokemember(“单击”)
您应该能够理解代码的方法名称。调用此方法后,WebBrowser控件中的网页将实现翻页,这与用手单击翻页按钮的效果相同 查看全部
网页抓取数据(第三方工具抓取别人网站数据的方式无非两种方式!)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式不超过两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章代码,但每次我使用别人的代码时,总会出现各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发过程中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页的页码时,你会发现URL地址没有变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
对于(int i=0;i
System.Net.WebClient-WebClientObj=新系统.Net.WebClient()
System.采集s.Specialized.NameValue采集 PostVars=新的System.采集s.Specialized.NameValue采集()
添加(“\u viewstate”,“这是您需要提前获取的信息”)
添加(“\u eventvalidation”,“这是您需要提前获取的信息”)
Add(“\u eventtarget”,“这里是与\u dopostback方法相对应的参数”)
Add(“\u eventargument”,“这里是与\u dopostback方法相对应的参数”)
添加(“ContentType”,“application/x-www-form-urlencoded”)
试一试
{
byte[]byte1=WebClientObj.UploadValues(“,“POST”,PostVars)
字符串responsest=编码。UTF8.GetString(byte1);//获取当前页面对应的HTML文本字符串
Getpostvalue(responsest);//获取所需信息,例如与当前页面对应的_viewstate,以便抓取下一页
Savemessage(responsest);//将您关心的内容保存到数据库中
}捕获(例外情况除外){
控制台写入线(例如消息)
}
}
第三种方法:第三种方法是最麻烦、最恶心的。翻页的过程中找不到页面信息。这种方法需要很多努力。后来,我采用了一种更残酷的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据a、 其原理是,使用代码模拟手动单击翻页链接,使用代码逐页翻页,然后逐页抓取
这就是所谓的门外汉看热闹,专家看门口。很多人可能会在这里看到,并说它可以通过使用WebBrowser控件来实现。是的,我下面的方法是使用WebBrowser控件来实现它。事实上,.Net下应该有类似的类,但我还没有研究过。我也希望如果有人有其他的方法,他们可以回复我,和你一起分享
WebBrowser控件可以在自己的程序中嵌入浏览器,就像IE和Firefox一样。你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想一定不如IE和Firefox。哈哈
让我们少说,切入主题:
使用WebBrowser控件基本上可以实现在ie中操作网页的任何功能,所以点击翻页按钮当然可以。因为您可以在WebBrowser中手动点击翻页按钮,自然,我们也可以使用程序代码指示WebBrowser为我们自动翻页
其实原理很简单,主要分为以下几个步骤:
第一步是打开要捕获的页面,例如:
调用WebBrowser控件的方法navigate(“”)
此时,您应该在WebBrowser控件中看到您的网页信息,这与在IE中看到的信息相同
其次,WebBrowser控件的事件documentcompleted非常重要。当您访问的所有页面都加载时,将触发此事件。因此,在此事件中还需要完成分析页面元素的过程
字符串_responsest=这个。WebBrowser1.Document.Body.OuterHtml
此代码可以获取当前打开页面的HTML元素的内容
现在您已经获得了当前打开页面的HTML元素的内容,接下来的工作自然是解析大字符串,获取您关心的内容,以及解析字符串的过程。您应该能够自己编写它
第三步
重点是第三步,因为我们必须翻过这一页并采取第二步
在DocumentCompleted事件中
WebBrowser1.Document.Getelementbyid(“页码的ID”).Invokemember(“单击”)
您应该能够理解代码的方法名称。调用此方法后,WebBrowser控件中的网页将实现翻页,这与用手单击翻页按钮的效果相同
网页抓取数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-09-20 05:19
)
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
查看全部
网页抓取数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下内容在Microsoft Visual Basic中6.0以中文版本制作
VB可以抓取网页数据,使用的控件是INET控件
步骤1:单击项目-->;部件选择Microsoft Internet传输控制(SP6)控制
步骤2:显示布局界面
在界面中拖动相应的控件
步骤3开始编码
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
步骤4:测试
输入网址:
数据可以在网页上获得
网页抓取数据(网页抓取数据(一)——抓取不到网页的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-18 20:06
网页抓取数据是在用户浏览网页的时候发生的,用户打开网页的速度都和网速有关,如果网速足够快,浏览器本身也会进行渲染,这时候就抓取不到网页的数据了。下面是我之前抓取的网页数据:完整代码:这个只抓取了连接的整个指令的执行结果,其他指令的一些时间基本上很慢,这里可以查看的一个速度大概:(作者:hzz337697。
2)
1)webapi方面,通过类似代码拿到数据这个思路是有道理的,不过在qt下我发现了和这个思路一致的代码:master/qcuda.h:92.96kb/s,从这个字节流里出来可以直接生成所需数据,但是生成量就基本上很大了,图一可以看到的,qscan数据包的大小大约在几十kb左右。
2)c++接口方面我觉得关于大小的回答是不准确的,因为c++标准本身就不支持很大的数据,所以qt的数据大小在windows和linux下都是很接近的。这里我画个大概图:第一列是qcuda的数据大小,以256kb/s包含本地数据,三列都是包含远程数据,qtrace的话是bin/size大小。差不多这样。
以quant001为例:从qdcontent1.xml得到本地的pcb数据,包含这一行的数据不大,256kb左右。但是stencil0x218.xml如果以256kb/s包含,那就要占用1gb的qcow2和qstring,每个字节1mb,在qt下就差不多是一个不完整的mesh数据包,qt来看的话很容易达到2gb大小。
3)实际对于不同的网络带宽,网页流不会全走qcow2,转而以qtiocr或者各种媒体流(calc)等其他方式传输,因此才会有实际大小和网页流没有严格对应的情况。 查看全部
网页抓取数据(网页抓取数据(一)——抓取不到网页的数据)
网页抓取数据是在用户浏览网页的时候发生的,用户打开网页的速度都和网速有关,如果网速足够快,浏览器本身也会进行渲染,这时候就抓取不到网页的数据了。下面是我之前抓取的网页数据:完整代码:这个只抓取了连接的整个指令的执行结果,其他指令的一些时间基本上很慢,这里可以查看的一个速度大概:(作者:hzz337697。
2)
1)webapi方面,通过类似代码拿到数据这个思路是有道理的,不过在qt下我发现了和这个思路一致的代码:master/qcuda.h:92.96kb/s,从这个字节流里出来可以直接生成所需数据,但是生成量就基本上很大了,图一可以看到的,qscan数据包的大小大约在几十kb左右。
2)c++接口方面我觉得关于大小的回答是不准确的,因为c++标准本身就不支持很大的数据,所以qt的数据大小在windows和linux下都是很接近的。这里我画个大概图:第一列是qcuda的数据大小,以256kb/s包含本地数据,三列都是包含远程数据,qtrace的话是bin/size大小。差不多这样。
以quant001为例:从qdcontent1.xml得到本地的pcb数据,包含这一行的数据不大,256kb左右。但是stencil0x218.xml如果以256kb/s包含,那就要占用1gb的qcow2和qstring,每个字节1mb,在qt下就差不多是一个不完整的mesh数据包,qt来看的话很容易达到2gb大小。
3)实际对于不同的网络带宽,网页流不会全走qcow2,转而以qtiocr或者各种媒体流(calc)等其他方式传输,因此才会有实际大小和网页流没有严格对应的情况。
网页抓取数据(wordpress后台用多线程模式的网页抓取数据库不行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-18 00:08
网页抓取数据,数据库不行,有几种情况就是wp的缓存策略有问题,先抓取到js,然后才加载页面。而且header也要设置好。另外就是问题是js可以单独分离出来看看有没有抓取成功的。
wordpress后台用多线程模式的,可以试试wordpressserver多线程服务器端也是可以抓取的。
首先是基础解决方案,能抓取页面,最好是有基本的wordpress插件。不过问题是,一旦做抓取,想提升体验,或者做跟踪,必须是那种小型站,地址栏很短。然后我的体验是,传统php抓取,如果请求稍微多一点,就会时不时闪退,一闪就用几秒,为啥呢?和网速没关系,主要是ie资源占用太高。现在我看来,相比缓存解决方案,对网速影响没那么大,我更喜欢https的抓取方案,当然我也有php缓存的插件,针对php。
和其他公司一样,不同的是http协议不是标准。我们平时都是调用浏览器,javascript,css等等网站上都有,相同的网页用的是同一套协议。当然有些公司设置多个服务器也是为了不同用户提供不同服务。网页抓取类似抓取一样都可以用多线程来搞。
通常提高页面性能就靠wordpress软件服务器开启异步机制来解决了:1.sendsomeapiinstances2.websocket(network)那么问题来了, 查看全部
网页抓取数据(wordpress后台用多线程模式的网页抓取数据库不行)
网页抓取数据,数据库不行,有几种情况就是wp的缓存策略有问题,先抓取到js,然后才加载页面。而且header也要设置好。另外就是问题是js可以单独分离出来看看有没有抓取成功的。
wordpress后台用多线程模式的,可以试试wordpressserver多线程服务器端也是可以抓取的。
首先是基础解决方案,能抓取页面,最好是有基本的wordpress插件。不过问题是,一旦做抓取,想提升体验,或者做跟踪,必须是那种小型站,地址栏很短。然后我的体验是,传统php抓取,如果请求稍微多一点,就会时不时闪退,一闪就用几秒,为啥呢?和网速没关系,主要是ie资源占用太高。现在我看来,相比缓存解决方案,对网速影响没那么大,我更喜欢https的抓取方案,当然我也有php缓存的插件,针对php。
和其他公司一样,不同的是http协议不是标准。我们平时都是调用浏览器,javascript,css等等网站上都有,相同的网页用的是同一套协议。当然有些公司设置多个服务器也是为了不同用户提供不同服务。网页抓取类似抓取一样都可以用多线程来搞。
通常提高页面性能就靠wordpress软件服务器开启异步机制来解决了:1.sendsomeapiinstances2.websocket(network)那么问题来了,
网页抓取数据(北大未名站:EECS标题求助一个从网页抓取数据的问题时间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-16 19:18
发送方:电那孙(小韩)|EECS14),信息区:EECS
标题:[集合]帮助解决从网页获取数据的问题
发送站:北京大学卫明站(2016年7月7日23:49:57,星期一四),站内信件)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题是从网页中获取数据的问题
时间:北京大学卫明站(2015年11月30日23:48:31)一),站内信件
───────────────────────────────────────
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者arthaszrz(nan3 | miststrider |=>12cs | dihacker),信息领域:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:48:012015年12月1日)二),站内信件
───────────────────────────────────────
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
TA帖子中提到的香蕉(Kimi):
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:03:282015年12月2日)三),站内信件
───────────────────────────────────────
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
12cs |迪哈克“>arthazrz(nan3 | miststrider |=>12cs |迪哈克)在TA的帖子中提到:
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
───────────────────────────────────────
作者arthaszrz(schunsent),信区:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月2日14:19:06,三),站内信件)
───────────────────────────────────────
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法
TA帖子中提到的香蕉(Kimi):
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月3日08:06:52)四),站内信件
───────────────────────────────────────
嗯,这已经很方便了~谢谢
阿尔萨斯·兹尔茨(schunsent)在TA的帖子中提到:
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法 查看全部
网页抓取数据(北大未名站:EECS标题求助一个从网页抓取数据的问题时间)
发送方:电那孙(小韩)|EECS14),信息区:EECS
标题:[集合]帮助解决从网页获取数据的问题
发送站:北京大学卫明站(2016年7月7日23:49:57,星期一四),站内信件)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题是从网页中获取数据的问题
时间:北京大学卫明站(2015年11月30日23:48:31)一),站内信件
───────────────────────────────────────
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者arthaszrz(nan3 | miststrider |=>12cs | dihacker),信息领域:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:48:012015年12月1日)二),站内信件
───────────────────────────────────────
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
TA帖子中提到的香蕉(Kimi):
有一项研究需要首先从网页上采集数据。如果数据以表格形式显示在网页上,则需要几年时间
两个程序都可以自动捕获数据。现在的问题是网站上的数据显示模式是图形线的形式(
如附件所示),也就是说,从几天的数据(不同的项目,大约一年)生成一行,然后鼠标移动到图形上
该点对应的日期和对应的数据(价格)将显示在屏幕上的不同位置。在这种情况下,您可以使用什么方式传递信息
捕获并生成收录每日数据(价格)的本地数据
或者生成该行的数据存储在哪里,可以从网站读取@
首先谢谢大家
(其中一种产品的网站:
32LL_A_16GB_Wi-Fi_空间_灰色_/)
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(09:03:282015年12月2日)三),站内信件
───────────────────────────────────────
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
12cs |迪哈克“>arthazrz(nan3 | miststrider |=>12cs |迪哈克)在TA的帖子中提到:
刚才我看了这个页面的JS代码(
51)然后,发现折线图的源数据来自一个名为zs_api()的接口的返回结果
有许多URL,但这应该是与获取数据相关的URL:
productid对应的值是您发送的IPAdminURL中的第三项。您也可以直接发送此位置
将地址粘贴到浏览器地址栏中,然后进入并查看。您可以在其中看到返回的JSON数据newsfi
Eld应该是您需要的数据
如果要使用此数据,请直接编写python,并请求.Get(“…”)获取返回的列
看着
───────────────────────────────────────
作者arthaszrz(schunsent),信区:EEC
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月2日14:19:06,三),站内信件)
───────────────────────────────────────
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法
TA帖子中提到的香蕉(Kimi):
多谢各位
最好从这里获取数据
从图表中捕获要容易得多~太好了!你能问一下productid的这种网站吗(比如B00)
gracuxm)是常规的吗?因为你需要获取大量的产品信息。如果ID是常规的,你可以从自己那里获取
移动生成然后访问网站抓取数据~否则,我觉得我只能模拟鼠标点击/搜索框来搜索产品,然后
从URL解析相应的ID似乎非常复杂。(或者有更好的方法吗?)
再次感谢
───────────────────────────────────────
作者香蕉(Kimi),信区:EECS
标题re:帮助解决从网页获取数据的问题
时间:北京大学卫明站(2015年12月3日08:06:52)四),站内信件
───────────────────────────────────────
嗯,这已经很方便了~谢谢
阿尔萨斯·兹尔茨(schunsent)在TA的帖子中提到:
我真的不知道是否有任何规则,但它是否只是为了减少模拟鼠标点击输入的操作
,你可以直接
要搜索的关键词/页面
比如说
然后可以在返回的HTML中解析产品列表
然后您会发现与产品名称对应的标签的href URL的第三项是产品的productid
这是我能找到的最好的方法

