
网站内容抓取
网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-08-18 18:09
有的朋友可能会觉得奇怪,网站的页面不是让搜索引擎尽量抓取吗?怎么有防止网站内容被爬取的想法?
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说非常方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。我是千琴/微信:11678872
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。我是千琴/微信:11678872
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件在页面上使用iframe标签显示需要搜索引擎收录的内容。 robots 文件可以防止 iframe 标签以外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表单
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术 查看全部
网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么抓取
有的朋友可能会觉得奇怪,网站的页面不是让搜索引擎尽量抓取吗?怎么有防止网站内容被爬取的想法?
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说非常方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。我是千琴/微信:11678872

另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。我是千琴/微信:11678872
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件在页面上使用iframe标签显示需要搜索引擎收录的内容。 robots 文件可以防止 iframe 标签以外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表单
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术
网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-18 18:08
搜索引擎爬虫是一种自动提取网页的程序,如百度蜘蛛。如果要收录更多网站的页面,必须先爬取网页。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,就等于关了你的门谢天谢地。如果你的服务器不稳定或者卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
根据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,搜索引擎优化对企业和产品的意义重大。
那么网站内容如何被搜索引擎频繁快速抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动展示给蜘蛛,并定期更新文章,让蜘蛛按照你的规则有效抓取文章。
高质量的原创内容对百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,经常来。
同时网站结构不要太复杂,链接层次不要太深。也是蜘蛛的最爱。
众所周知,外链可以吸引蜘蛛到网站,尤其是在新站点。 网站还不是很成熟,蜘蛛访问量也比较少。外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了省事而做无用的事情。
蜘蛛的爬取是沿着链接进行的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一张网站地图不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一种很好的方式。 查看全部
网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么
搜索引擎爬虫是一种自动提取网页的程序,如百度蜘蛛。如果要收录更多网站的页面,必须先爬取网页。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。

我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,就等于关了你的门谢天谢地。如果你的服务器不稳定或者卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
根据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,搜索引擎优化对企业和产品的意义重大。
那么网站内容如何被搜索引擎频繁快速抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动展示给蜘蛛,并定期更新文章,让蜘蛛按照你的规则有效抓取文章。
高质量的原创内容对百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,经常来。
同时网站结构不要太复杂,链接层次不要太深。也是蜘蛛的最爱。

众所周知,外链可以吸引蜘蛛到网站,尤其是在新站点。 网站还不是很成熟,蜘蛛访问量也比较少。外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了省事而做无用的事情。
蜘蛛的爬取是沿着链接进行的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一张网站地图不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一种很好的方式。
3.百度spider介绍5.只需两步,正确识别百度蜘蛛
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-18 18:03
我最近一直在看与 SEO 相关的材料。我比较好奇的是百度蜘蛛是如何抓取网站内容的?我在网上找了一圈,发现都是从百度搜索学院文章复制过来的:
1.搜索引擎抓取系统概述(一)
2.搜索引擎抓取系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上阅读次数最多的一句话总结是:百度蜘蛛#一、攀取、#二、Storage、#三、preprocessing、#四、indexing、#五、ranking。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
第一个一、web蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结是:1、指向我自己网站的外链; 2、到站长平台提交网站上url; 3、sitemap 文件和网站主页链接。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第3点的理解。首先,我必须为我的站点创建一个站点地图文件,并且该文件必须放在网站root目录下,并且必须可以在没有权限控制的情况下正常访问。具体的文档创建请参考各个搜索引擎的指南(如:)。还要注意此文件的 URL 和更新率。我拿一些我自己的文件来解释一下:
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontPages/systemMgt/aboutus.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBlog/blog/BID20181223100027
2018-12-23
hourly
1.0
这里我选择了几个有代表性的网址来展示。我的初始 URL 很长,收录很多参数。我放到xml文件里会报错,后面都会优化成这个简单的连接。每天继续写更多有实用价值的原创文章,经常更新这个文件。
关于此文件的更新,需要多加注意观察你的网站上百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站百度蜘蛛的单行访问记录。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量的更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一个小点是网站内部链接必须向各个方向延伸,这样蜘蛛才能得到更多的链接给你网站。
第一个@二、网络蜘蛛到网站爬取的顺序
网络蜘蛛在网站目录中访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示整个网站都可以爬取。爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问的第二个是主页还是sitemap文件,这个网上说法有点争议,但我倾向于认为访问的是第二个sitemap文件。我会用我的网站蜘蛛访问日志的最后一段来侧面证明。 :
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136 这个IP:
nslookup 命令的结果
从日志来看,第一次访问是robots.txt文件,第二次是站点地图文件,第三次是这个站点地图上新的和改变的url,第四次似乎是通过主页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
也可以看出是先获取url再读取内容。
@三、web 蜘蛛爬行到网站 的频率
其实,与网络蜘蛛对网站的爬取频率有关的因素上面已经说了。我觉得最重要的是定期更新我在网站网站上的原创内容,提供网站topic相关信息的质量。二是多做导入链接的工作。 查看全部
3.百度spider介绍5.只需两步,正确识别百度蜘蛛
我最近一直在看与 SEO 相关的材料。我比较好奇的是百度蜘蛛是如何抓取网站内容的?我在网上找了一圈,发现都是从百度搜索学院文章复制过来的:
1.搜索引擎抓取系统概述(一)
2.搜索引擎抓取系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上阅读次数最多的一句话总结是:百度蜘蛛#一、攀取、#二、Storage、#三、preprocessing、#四、indexing、#五、ranking。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
第一个一、web蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结是:1、指向我自己网站的外链; 2、到站长平台提交网站上url; 3、sitemap 文件和网站主页链接。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第3点的理解。首先,我必须为我的站点创建一个站点地图文件,并且该文件必须放在网站root目录下,并且必须可以在没有权限控制的情况下正常访问。具体的文档创建请参考各个搜索引擎的指南(如:)。还要注意此文件的 URL 和更新率。我拿一些我自己的文件来解释一下:
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontPages/systemMgt/aboutus.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBlog/blog/BID20181223100027
2018-12-23
hourly
1.0
这里我选择了几个有代表性的网址来展示。我的初始 URL 很长,收录很多参数。我放到xml文件里会报错,后面都会优化成这个简单的连接。每天继续写更多有实用价值的原创文章,经常更新这个文件。
关于此文件的更新,需要多加注意观察你的网站上百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站百度蜘蛛的单行访问记录。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量的更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一个小点是网站内部链接必须向各个方向延伸,这样蜘蛛才能得到更多的链接给你网站。
第一个@二、网络蜘蛛到网站爬取的顺序
网络蜘蛛在网站目录中访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示整个网站都可以爬取。爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问的第二个是主页还是sitemap文件,这个网上说法有点争议,但我倾向于认为访问的是第二个sitemap文件。我会用我的网站蜘蛛访问日志的最后一段来侧面证明。 :
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136 这个IP:
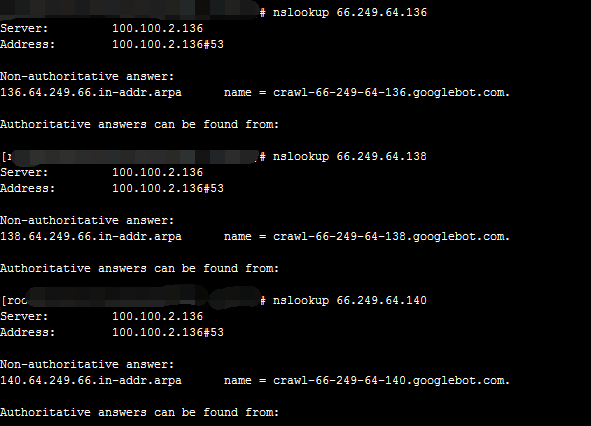
nslookup 命令的结果
从日志来看,第一次访问是robots.txt文件,第二次是站点地图文件,第三次是这个站点地图上新的和改变的url,第四次似乎是通过主页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
也可以看出是先获取url再读取内容。
@三、web 蜘蛛爬行到网站 的频率
其实,与网络蜘蛛对网站的爬取频率有关的因素上面已经说了。我觉得最重要的是定期更新我在网站网站上的原创内容,提供网站topic相关信息的质量。二是多做导入链接的工作。
Python爬虫39-100天津市科技计划项目成果库(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-18 03:29
阿里巴巴云>云栖社区>主题图>W>网站page 数据抓取
推荐活动:
更多优惠>
当前主题:网站paged 数据捕获并添加到采集夹
相关主题:
网站Paging 数据抓取相关博客,查看更多博客
Python爬虫入门教程29-100手机APP数据抓取pyspider
作者:Dream Eraser 1318 次浏览和评论:02 年前
1.手机APP资料----写在前面,继续练习pyspider的使用。最近搜了一下这个框架的一些使用技巧,发现文档其实挺难懂的,不过暂时没有障碍使用,我猜想,大概写5个这个框架的教程吧。今天的教程增加了图片处理,大家可以专心学习。 2.
阅读全文
Python爬虫入门教程39-100天津市科技计划项目成果数据库数据采集scrapy
作者:Dream Eraser 766 次浏览和评论:02 年前
今天说爬之前爬的原因本来不打算抢这个网站的。无意中看到微信群里有人问这个网站。我想看看有什么特别复杂的。下来后发现这个网站,除了卡慢,经常宕机,好像没什么特别的……爬取网址
阅读全文
Python 捕获欧洲足球联赛数据用于大数据分析
作者:青山无名12610人查看评论:14年前
Background Web Scraping 在大数据时代,一切都必须用数据说话。大数据的处理过程一般需要以下几个步骤:数据的采集以及数据的清洗、提取、变形和加载。分析、探索和预测数据的呈现方式。首先要做的是获取数据,提取有效数据,用于下一步分析
阅读全文
使用 Scrapy 抓取数据
作者:于客 6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:嗯 99251585 浏览和评论:03 年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来,我们来看看常见的如何保存抓取到的内容
阅读全文
“全民K歌”的秘诀是什么? 网站数据采集的数据分析
作者:反向一睡2103人浏览评论:03年前
最近看到身边好几个朋友在手机上用“国民K歌”软件唱歌,使用频率还是很高的,所以想看看国民是个什么样的用户K歌平台都喜欢。用户?他们有什么样的特点。然后进行数据分析,加强你的分析思维和实践能力。这个过程我会分四个部分来写:数据采集、数据清洗、数据
阅读全文
使用MVCPager通过分页方式在博客园首页展示数据
作者:建筑师郭果940人浏览评论:08年前
在上一篇博客中,我们使用正则表达式来抓取博客园的列表数据。我用正则表达式抓取了博客园的部分数据作为测试数据。现在测试数据也可用了,数据应该分页显示。 NS。但是如何分页让我犹豫了几分钟。我应该写javascript自定义分页显示,还是用现成的控件来做分页
阅读全文 查看全部
Python爬虫39-100天津市科技计划项目成果库(组图)
阿里巴巴云>云栖社区>主题图>W>网站page 数据抓取

推荐活动:
更多优惠>
当前主题:网站paged 数据捕获并添加到采集夹
相关主题:
网站Paging 数据抓取相关博客,查看更多博客
Python爬虫入门教程29-100手机APP数据抓取pyspider


作者:Dream Eraser 1318 次浏览和评论:02 年前
1.手机APP资料----写在前面,继续练习pyspider的使用。最近搜了一下这个框架的一些使用技巧,发现文档其实挺难懂的,不过暂时没有障碍使用,我猜想,大概写5个这个框架的教程吧。今天的教程增加了图片处理,大家可以专心学习。 2.
阅读全文
Python爬虫入门教程39-100天津市科技计划项目成果数据库数据采集scrapy

作者:Dream Eraser 766 次浏览和评论:02 年前
今天说爬之前爬的原因本来不打算抢这个网站的。无意中看到微信群里有人问这个网站。我想看看有什么特别复杂的。下来后发现这个网站,除了卡慢,经常宕机,好像没什么特别的……爬取网址
阅读全文
Python 捕获欧洲足球联赛数据用于大数据分析


作者:青山无名12610人查看评论:14年前
Background Web Scraping 在大数据时代,一切都必须用数据说话。大数据的处理过程一般需要以下几个步骤:数据的采集以及数据的清洗、提取、变形和加载。分析、探索和预测数据的呈现方式。首先要做的是获取数据,提取有效数据,用于下一步分析
阅读全文
使用 Scrapy 抓取数据

作者:于客 6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库

作者:嗯 99251585 浏览和评论:03 年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库


作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来,我们来看看常见的如何保存抓取到的内容
阅读全文
“全民K歌”的秘诀是什么? 网站数据采集的数据分析

作者:反向一睡2103人浏览评论:03年前
最近看到身边好几个朋友在手机上用“国民K歌”软件唱歌,使用频率还是很高的,所以想看看国民是个什么样的用户K歌平台都喜欢。用户?他们有什么样的特点。然后进行数据分析,加强你的分析思维和实践能力。这个过程我会分四个部分来写:数据采集、数据清洗、数据
阅读全文
使用MVCPager通过分页方式在博客园首页展示数据


作者:建筑师郭果940人浏览评论:08年前
在上一篇博客中,我们使用正则表达式来抓取博客园的列表数据。我用正则表达式抓取了博客园的部分数据作为测试数据。现在测试数据也可用了,数据应该分页显示。 NS。但是如何分页让我犹豫了几分钟。我应该写javascript自定义分页显示,还是用现成的控件来做分页
阅读全文
网站内容抓取网站类型分为多种,花里胡哨的模板
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-08-18 02:03
网站内容抓取网站类型分为多种,针对网站类型,分为泛目录型网站和垂直型网站网站建设类型分为静态型网站和动态型网站网站搜索优化型分为多种。针对网站优化目的,
我经常用优采云采集器,非常好用,现在我用的是云采集器,
搜索效果最好的也就是秒杀一切你所认为的花里胡哨的模板吧
这个只要你的产品或者服务能够代表一些相对优质的存在。才能做到,大家通过使用你的产品,看到了你的价值,看到了你,满足了人们的需求。而不是你自己相对突出的内容。这个时候,才是合适的模板,也就是你的花里胡哨的产品或者服务。
如果只是针对百度搜索引擎上的,小的网站也一样能找到合适你自己网站的那一版就行,比如母婴网站或者针对于大型门户的门户网站;全国各地的地图等等。
可以看下o2o人工餐饮网站的,确实美食网站,
若能够利用百度站长平台,把自己的广告做到百度前100的位置,就能大量被百度收录。当然有些网站比较特殊,在某些方面产生不了价值,那么,花里胡哨的产品也是白搭。
实话说搜索引擎对于大部分网站来说都不会怎么样,更不要说所谓一些投机取巧的行为了。你要找合适的,但大部分情况下这取决于你是否具有一定的个人品牌,如果你有品牌,相信没人能阻挡得了你,让你的内容展现在搜索引擎上面,只要别太差, 查看全部
网站内容抓取网站类型分为多种,花里胡哨的模板
网站内容抓取网站类型分为多种,针对网站类型,分为泛目录型网站和垂直型网站网站建设类型分为静态型网站和动态型网站网站搜索优化型分为多种。针对网站优化目的,
我经常用优采云采集器,非常好用,现在我用的是云采集器,
搜索效果最好的也就是秒杀一切你所认为的花里胡哨的模板吧
这个只要你的产品或者服务能够代表一些相对优质的存在。才能做到,大家通过使用你的产品,看到了你的价值,看到了你,满足了人们的需求。而不是你自己相对突出的内容。这个时候,才是合适的模板,也就是你的花里胡哨的产品或者服务。
如果只是针对百度搜索引擎上的,小的网站也一样能找到合适你自己网站的那一版就行,比如母婴网站或者针对于大型门户的门户网站;全国各地的地图等等。
可以看下o2o人工餐饮网站的,确实美食网站,
若能够利用百度站长平台,把自己的广告做到百度前100的位置,就能大量被百度收录。当然有些网站比较特殊,在某些方面产生不了价值,那么,花里胡哨的产品也是白搭。
实话说搜索引擎对于大部分网站来说都不会怎么样,更不要说所谓一些投机取巧的行为了。你要找合适的,但大部分情况下这取决于你是否具有一定的个人品牌,如果你有品牌,相信没人能阻挡得了你,让你的内容展现在搜索引擎上面,只要别太差,
集搜客网络爬虫软件是一款免费的网页数据抓取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-08-17 23:20
极速客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,用于内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件用于毕业设计和行业研究。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
第 3 步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
Python 爬虫入门!它将教您如何抓取网络数据。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站全世界爬取。
阿里巴巴云为您提供网站内容爬虫相关的8933产品文档内容和FAQ内容,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文,重点value Store kvstore,以下哪个是数据库,以及其他云计算产品。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 . 查看全部
集搜客网络爬虫软件是一款免费的网页数据抓取工具
极速客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,用于内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件用于毕业设计和行业研究。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
第 3 步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
Python 爬虫入门!它将教您如何抓取网络数据。

爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站全世界爬取。
阿里巴巴云为您提供网站内容爬虫相关的8933产品文档内容和FAQ内容,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文,重点value Store kvstore,以下哪个是数据库,以及其他云计算产品。

获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
Scrapy:Python的爬虫框架实例()
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-17 02:24
Scrapy:Python的爬虫框架实例()
scrapy
Scrapy:Python 爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
Scrapy简介Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。可用于数据挖掘、信息处理或存储历史数据等一系列程序中。
申请
用json$scrapy crawl car -o Trunks.json生成数据文件
直接执行$scrapy crawl car
看看有多少爬虫$scrapy list
它最初是为网页抓取而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy 主要包括以下组件:
引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。 Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成采集在线数据的工作,它为我们做了很多工作,不需要花很多精力去开发。
官方网站:
开源地址:
此代码的地址:
爬虫的时候不要做违法的事情,开源仅供参考。
查看全部
Scrapy:Python的爬虫框架实例()
scrapy
Scrapy:Python 爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
Scrapy简介Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。可用于数据挖掘、信息处理或存储历史数据等一系列程序中。
申请
用json$scrapy crawl car -o Trunks.json生成数据文件
直接执行$scrapy crawl car
看看有多少爬虫$scrapy list
它最初是为网页抓取而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy 主要包括以下组件:
引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。 Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成采集在线数据的工作,它为我们做了很多工作,不需要花很多精力去开发。
官方网站:
开源地址:
此代码的地址:
爬虫的时候不要做违法的事情,开源仅供参考。
会介绍蜘蛛如何根据一个搜索查询来索引页面以供
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-08-17 02:18
:如何吸引搜索引擎蜘蛛抓取你的网站?搜索引擎抓取网站内容,是网站优化中非常重要的一点,因为只有网站有猎取收录和网站才有机会提升排名,否则网站Rank如何提高?因此,吸引搜索引擎蜘蛛爬取网站非常重要
事情,而且,网站optimizers 没有必要这样做。在网站SEO 之前,建站者也需要做一些动作来帮助网站 吸引搜索引擎抓取。怎么做?
1、主流搜索引擎如何发现网站和网页?
搜索引擎使用蜘蛛程序来搜索互联网、采集网页、分配***标志、扫描文本并将它们提交给索引程序。扫描时,蜘蛛程序会从抓取到的网页中提取出指向其他网页的***链接,依次抓取这些指向的网页。
2、搜索引擎如何发现您的网站?
一般来说,从主流搜索引擎中发现新的网站dots有4种方式:***是最常见的将你的网址提交给搜索引擎的方式,***是当搜索引擎有一个链接时站点是在索引站点上找到的,因此可以对其进行爬网。第三个是for Google,就是注册Google的站长工具,在
确认后提交本站的站点地图。第四种是从一个已经被索引的页面重定向到一个新的页面(比如301方向,后面会讲到)。新注册的网站zui,请不要批量提交网站的软件使用网址,不要多次向同一个搜索引擎提交同一个网址。这会产生不良后果。
3、搜索蜘蛛对您的网站做了什么?
一旦蜘蛛访问您的网站,它就会依次抓取每个页面。当它找到一跳内部链接时,它会记录下来,稍后或下次访问时会抓取它。最后,蜘蛛会爬取整个站点。在接下来的步骤中。它将介绍蜘蛛如何根据搜索查询索引页面以进行检索,并将解释
每个索引页面的排名如何。如果站点是一棵树,那么树的根就是site网站homepage,目录就是分支,页面就是叶子末端的叶子。蜘蛛的爬行,如同向宫内输送养分一样,从根部开始,逐渐到达各个部位。顺序是根据GOOGLE PR值的重要性计算。如果这是一个结
建立一个均衡合理的树,然后爬行就可以均衡的捕捉到他的枝叶(所以一开始讲网站template的合理性时,写的代码对搜索引擎有帮助收录).
4、站点地图对收录的影响。
站点地图是一个HTML页面,其网站内容是指向本站点***页面的链接顺序列表。一个好的站点地图可以帮助访问者找到他们需要的东西,并允许搜索引擎使用站点地图来管理爬行行为。尤其是蜘蛛,他们可能会在多次访问后索引网站的所有页面,并且经常会在事后检查
有更新吗?蜘蛛也会关注站点地图的层数(深度),并结合其他因素来确定GOOGLE PR值,即每个页面的百度权重。
5、网站结构和网站导航。
无论是新的网站还是旧的网站,都需要在网站结构上下功夫,以吸引蜘蛛。建议大家记住每个页面的URL是蜘蛛在页面上相遇的地方。 *** 文本块已到达。尽量将你的网站深度限制在4个级别:网站home page-area page-directory page-网站content page。
本文由东莞小程序开发公司编辑发布。哪一个更好?刚到东莞易启轩网络科技,东莞易启轩网络科技助力中小企业在互联网+时代畅通无阻! 查看全部
会介绍蜘蛛如何根据一个搜索查询来索引页面以供
:如何吸引搜索引擎蜘蛛抓取你的网站?搜索引擎抓取网站内容,是网站优化中非常重要的一点,因为只有网站有猎取收录和网站才有机会提升排名,否则网站Rank如何提高?因此,吸引搜索引擎蜘蛛爬取网站非常重要
事情,而且,网站optimizers 没有必要这样做。在网站SEO 之前,建站者也需要做一些动作来帮助网站 吸引搜索引擎抓取。怎么做?
1、主流搜索引擎如何发现网站和网页?
搜索引擎使用蜘蛛程序来搜索互联网、采集网页、分配***标志、扫描文本并将它们提交给索引程序。扫描时,蜘蛛程序会从抓取到的网页中提取出指向其他网页的***链接,依次抓取这些指向的网页。
2、搜索引擎如何发现您的网站?
一般来说,从主流搜索引擎中发现新的网站dots有4种方式:***是最常见的将你的网址提交给搜索引擎的方式,***是当搜索引擎有一个链接时站点是在索引站点上找到的,因此可以对其进行爬网。第三个是for Google,就是注册Google的站长工具,在
确认后提交本站的站点地图。第四种是从一个已经被索引的页面重定向到一个新的页面(比如301方向,后面会讲到)。新注册的网站zui,请不要批量提交网站的软件使用网址,不要多次向同一个搜索引擎提交同一个网址。这会产生不良后果。

3、搜索蜘蛛对您的网站做了什么?
一旦蜘蛛访问您的网站,它就会依次抓取每个页面。当它找到一跳内部链接时,它会记录下来,稍后或下次访问时会抓取它。最后,蜘蛛会爬取整个站点。在接下来的步骤中。它将介绍蜘蛛如何根据搜索查询索引页面以进行检索,并将解释
每个索引页面的排名如何。如果站点是一棵树,那么树的根就是site网站homepage,目录就是分支,页面就是叶子末端的叶子。蜘蛛的爬行,如同向宫内输送养分一样,从根部开始,逐渐到达各个部位。顺序是根据GOOGLE PR值的重要性计算。如果这是一个结
建立一个均衡合理的树,然后爬行就可以均衡的捕捉到他的枝叶(所以一开始讲网站template的合理性时,写的代码对搜索引擎有帮助收录).
4、站点地图对收录的影响。
站点地图是一个HTML页面,其网站内容是指向本站点***页面的链接顺序列表。一个好的站点地图可以帮助访问者找到他们需要的东西,并允许搜索引擎使用站点地图来管理爬行行为。尤其是蜘蛛,他们可能会在多次访问后索引网站的所有页面,并且经常会在事后检查
有更新吗?蜘蛛也会关注站点地图的层数(深度),并结合其他因素来确定GOOGLE PR值,即每个页面的百度权重。
5、网站结构和网站导航。
无论是新的网站还是旧的网站,都需要在网站结构上下功夫,以吸引蜘蛛。建议大家记住每个页面的URL是蜘蛛在页面上相遇的地方。 *** 文本块已到达。尽量将你的网站深度限制在4个级别:网站home page-area page-directory page-网站content page。
本文由东莞小程序开发公司编辑发布。哪一个更好?刚到东莞易启轩网络科技,东莞易启轩网络科技助力中小企业在互联网+时代畅通无阻!
SEO优化工作人员如何提升减少过滤搜索引擎蜘蛛的减少蜘蛛
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-08-11 00:16
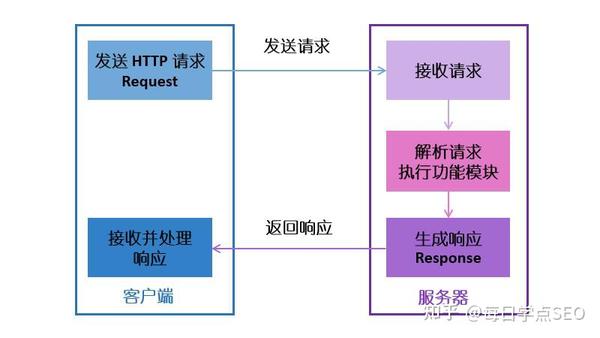
在浏览器中输入网址,向网站服务器发送http访问请求。服务端接收请求并解析,以http的形式响应客户端,以图片和文字的形式展现在用户面前。 .
对于服务端,http代码返回给客户端。它不知道返回的是文本还是图片。最终的结果是浏览器需要渲染用户才能看到有图片和文字的网页。
作为SEO优化人员,我们还是需要对搜索引擎的工作原理有所了解。
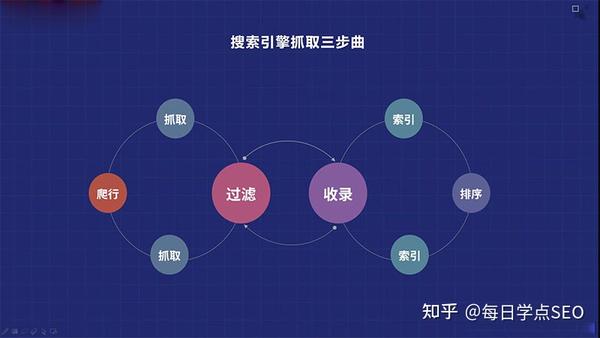
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何改进爬取和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。
搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
<p>过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,我们建议更新更多符合收录搜索规则的有价值的优质内容,不要更新低质量拼接垃圾内容。 查看全部
SEO优化工作人员如何提升减少过滤搜索引擎蜘蛛的减少蜘蛛
在浏览器中输入网址,向网站服务器发送http访问请求。服务端接收请求并解析,以http的形式响应客户端,以图片和文字的形式展现在用户面前。 .
对于服务端,http代码返回给客户端。它不知道返回的是文本还是图片。最终的结果是浏览器需要渲染用户才能看到有图片和文字的网页。
作为SEO优化人员,我们还是需要对搜索引擎的工作原理有所了解。
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何改进爬取和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。

搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
<p>过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,我们建议更新更多符合收录搜索规则的有价值的优质内容,不要更新低质量拼接垃圾内容。
temme-temme在命令行中的用法.js网页爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-08-11 00:08
Temme 是一个用于从 HTML 中提取 JSON 数据的选择器。它在CSS选择器语法的基础上增加了一些额外的语法,实现了多字段爬取、列表爬取等功能。它适用于节点。 js 网络爬虫。上一专栏文章介绍了命令行中temme选择器的用法。本文文章将以更直观的方式介绍选择器。
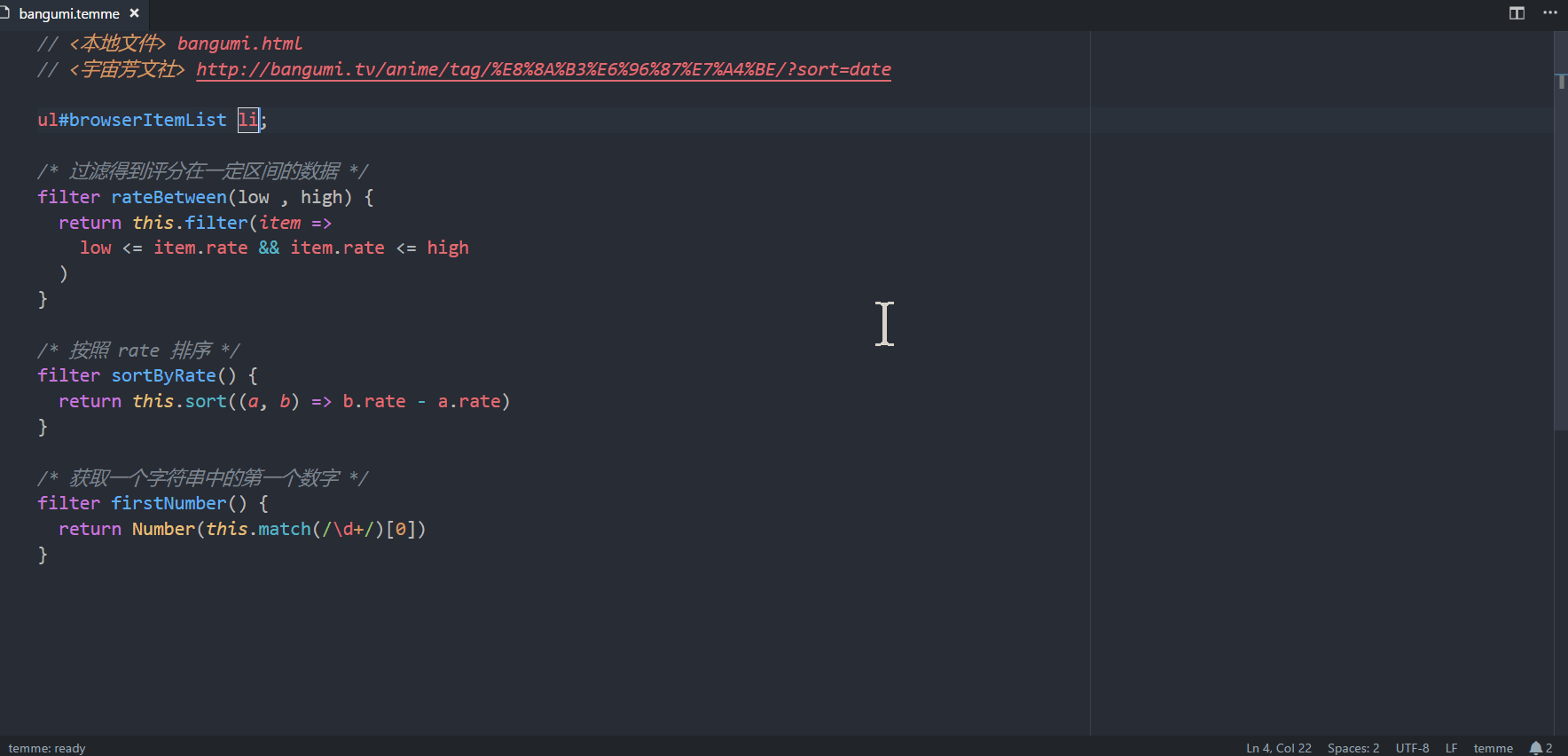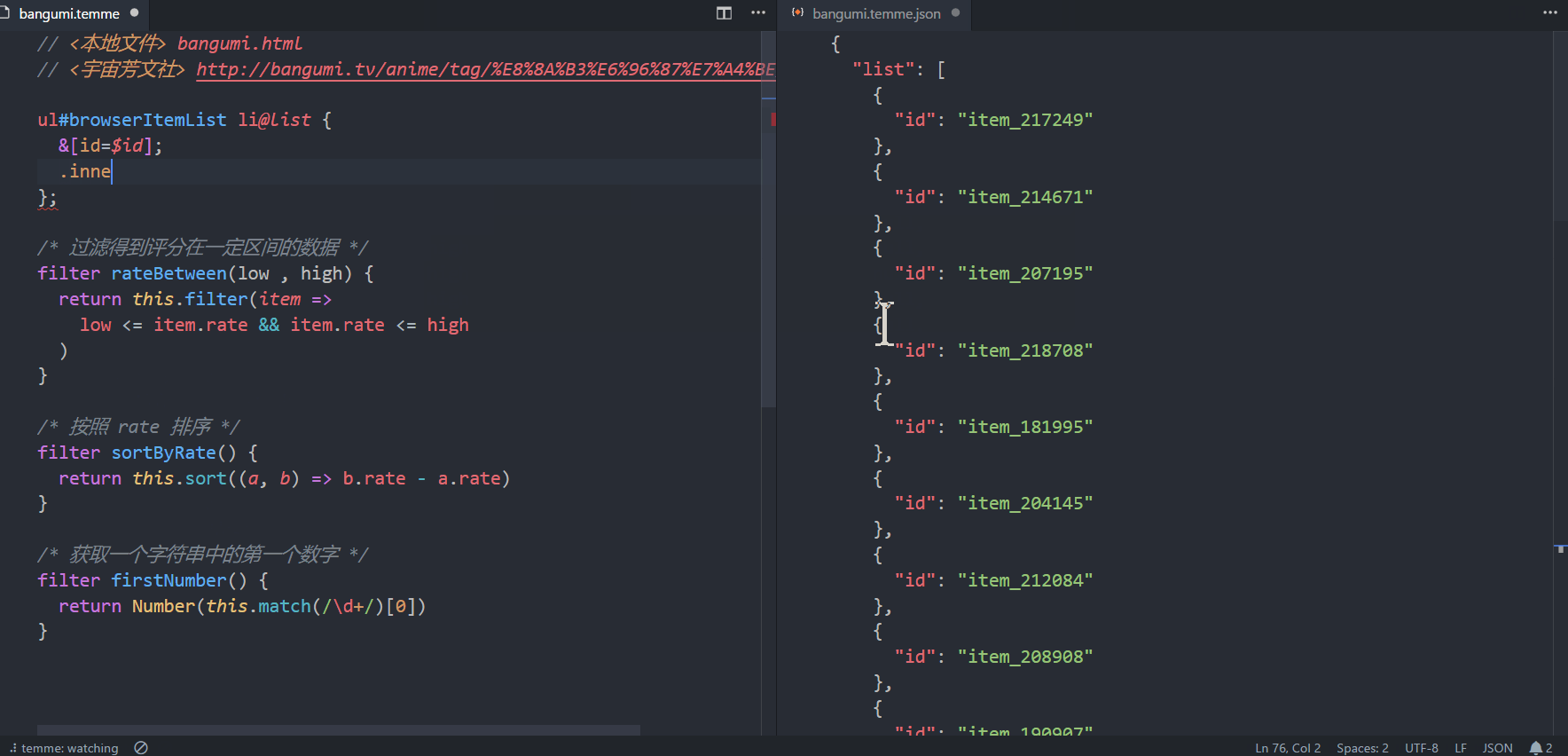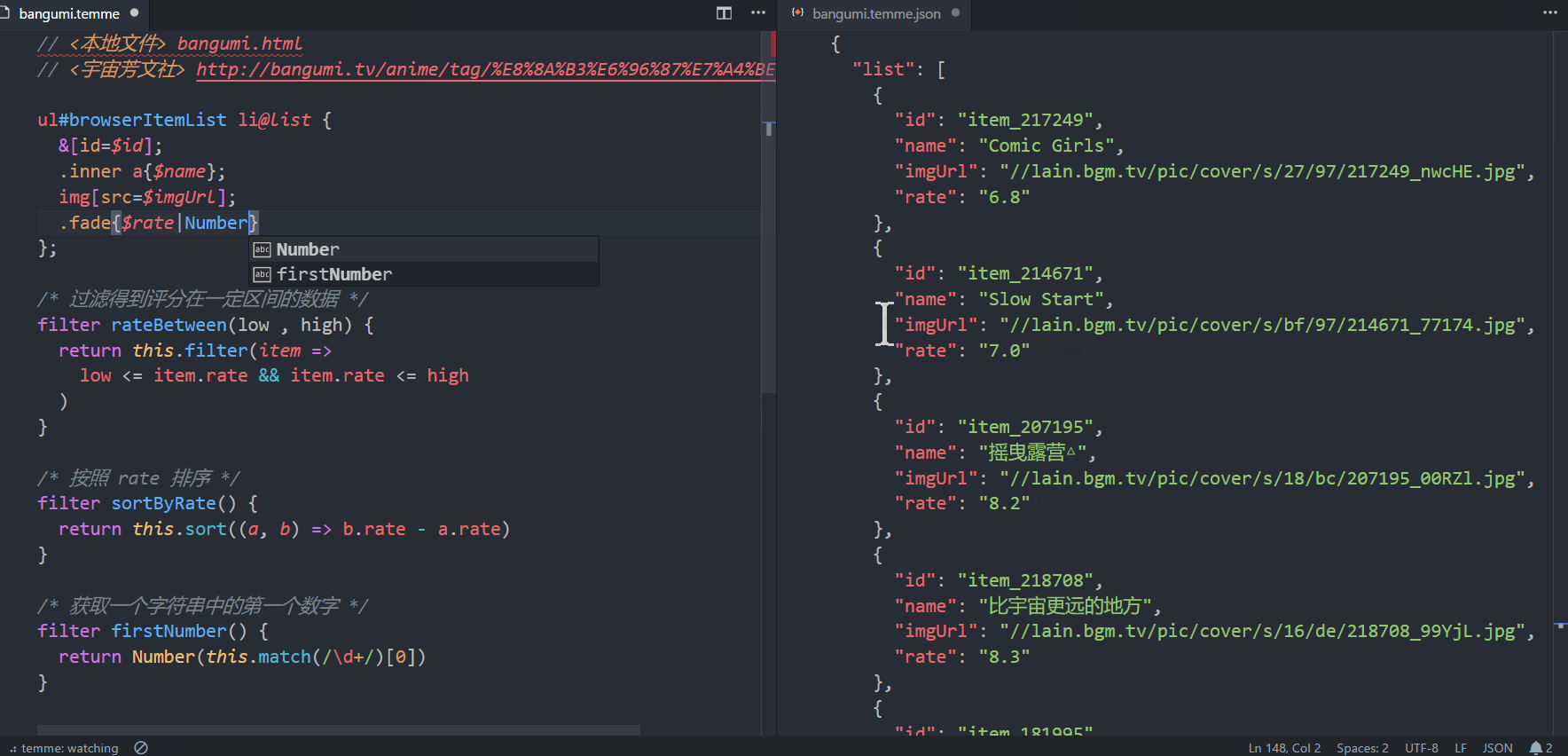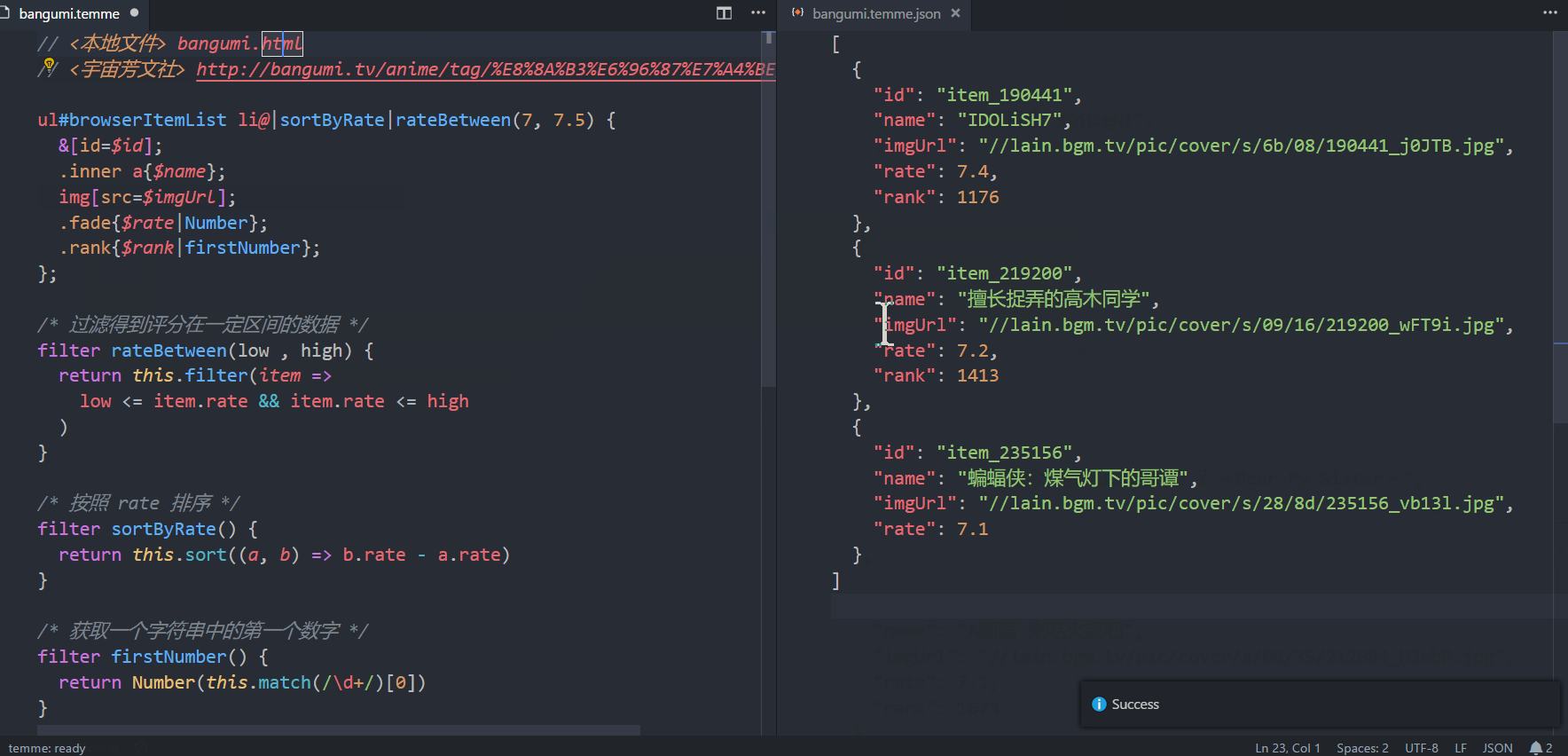
从名字可以看出,vscode-temme是temme的vscode插件。实际使用效果如下图所示。 (大图戳我)
上图展示了使用该插件抓取方文社番剧列表的全过程。爬取的结果是一个列表,每个列表元素收录id、节目名称、图片链接、评分等信息。下图展示了网页的页面结构和对应的 CSS 选择器。这些选择器也出现在术语选择器中。如果你熟悉 CSS 选择器,通过对比上下两张图就很容易理解每个选择器的含义了。
完整的分步说明
以下四个步骤将用于解释动画中的操作流程。
第一步
打开vscode编辑器,安装插件(插件市场搜索temme,安装前可能需要将编辑器升级到最新版本),打开temme文件(可以下载上图中的文件)。打开命令面板,选择Temme:开始观看,然后选择。插件会根据链接下载HTML文档。下载完成后,插件会进入观看模式,编辑器状态栏中会出现⠼ temme:观看。在监视模式下,每次选择器发生变化时,插件都会重新执行选择器并更新输出。这样我们就可以愉快的编辑选择器了。
第二步
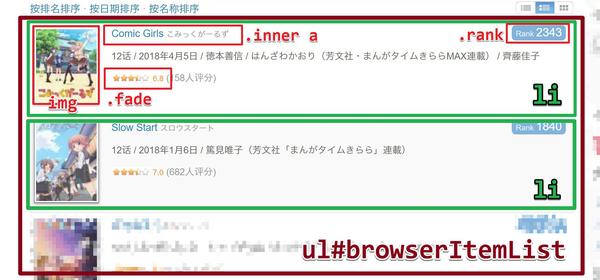
用浏览器打开方文社的剧目列表,可以看到上图所示的页面。我们要抓取的粉丝剧信息列表位于ul#browserItemList对应的元素(棕色)中,每一个粉丝剧信息对应一个li元素(绿色)。写下这两个选择器并在末尾添加@list 表示抓取li 列表。为了指定在每个 li 元素中抓取什么内容,我们还需要添加一串花括号来放置子选择器。我们得到以下选择器:
ul#browserItemList li@list {/* 子选择器会出现在这里 */ }
第三步
上图中有五个子选择器,每个子选择器抓取一个对应的字段。下面我们就一一分析:
&[id=$id];表示将父元素(即li元素)的id特征捕获到结果的id字段中。 & 符号表示父元素引用,与 CSS 预处理器 (Less/Sass/Stylus) 中的含义相同。 .inner a{$name} 表示将.inner a 对应的元素的文本抓取到结果的name 字段中。 img[src=$imgUrl] 表示将img对应元素的src特征抓取到结果的imgUrl字段。 CSS选择器中,img[src=imgUrl]表示选择src为imgUrl的那些img元素; $符号被添加到temme,它的含义变成了capture。这个语法很容易记住 (o´ω`o )。 .fade{$rate|Number} 类似于 2,但有一个额外的 |Number 将结果从字符串转换为数字。 .rank{$rank|firstNumber} 与4类似,但这里firstNumber是一个自定义过滤器,用于获取字符串中的第一个数字,过滤器定义在选择器文件下方。
第四步
我们不仅可以在$xxx之后添加过滤器来处理数据字段,还可以在@yyy之后添加过滤器来处理数组。 sortByRate 和 rateBetween 是两个自定义过滤器。前者按评分对同人剧列表进行排序,后者用于选择收视率在一定范围内的同人剧。当我们应用这两个过滤器时,我们可以看到右侧的 JSON 数据也会发生相应的变化。自定义过滤器的定义方法与 JavaScript 函数定义方法相同,只是将关键字从函数更改为过滤器。请注意,您需要在自定义过滤器中使用它来引用捕获的结果。
插入破碎的想法
插件将突出显示与模式匹配的文本 // 链接,我们称之为 tagged-link。 link 可以是 http 链接或本地文件路径。因为插件下载HTML功能比较简单,所以我推荐先使用插件vscode-restclient下载网页文档,然后使用本地路径启动temme watch模式。此外,要在编辑器中执行 temme 选择器,文件中必须至少存在一个标记链接。
除了提供语法高亮,插件还会报告选择器语法错误。在watch模式下,因为selector在不断的执行,插件也会报运行时错误,但是插件还没有完成。运行时错误总是显示在文件的第一行,但应该没有问题。
选择器坏了。
基于 CSS 选择器语法,在 temme 中没有太多需要记住的。一般来说,记住以下几点就足够了: $ 表示捕获字段,@ 表示捕获列表,|xxx 表示应用过滤器处理结果,一个分号;需要结束选择器。 temme的其他语法和功能请参考GitHub文档。
Temme 发布在 NPM 上,使用 yarn global add temme 全局安装 temme;将选择器保存在文件bangumi.temme中,那么上面的例子也可以在命令行运行:
url=http://bangumi.tv/anime/tag/%2 ... Ddate
curl -s $url | temme bangumi.temme --format
当然,我们也可以在 Node.js 中使用 temme。一般来说,对于每个不同的网页结构,我们可以先使用插件来调试选择器;爬虫运行时,下载HTML文档,我们可以直接执行相应的选择器,使爬虫开发效率大大提高。推广。
印象和总结
选择合适的工具可以提高工作效率;汇编的原则很重要也很有用。最后感谢大家的阅读(๑¯◡¯๑). 查看全部
temme-temme在命令行中的用法.js网页爬虫
Temme 是一个用于从 HTML 中提取 JSON 数据的选择器。它在CSS选择器语法的基础上增加了一些额外的语法,实现了多字段爬取、列表爬取等功能。它适用于节点。 js 网络爬虫。上一专栏文章介绍了命令行中temme选择器的用法。本文文章将以更直观的方式介绍选择器。
从名字可以看出,vscode-temme是temme的vscode插件。实际使用效果如下图所示。 (大图戳我)
上图展示了使用该插件抓取方文社番剧列表的全过程。爬取的结果是一个列表,每个列表元素收录id、节目名称、图片链接、评分等信息。下图展示了网页的页面结构和对应的 CSS 选择器。这些选择器也出现在术语选择器中。如果你熟悉 CSS 选择器,通过对比上下两张图就很容易理解每个选择器的含义了。
完整的分步说明
以下四个步骤将用于解释动画中的操作流程。
第一步
打开vscode编辑器,安装插件(插件市场搜索temme,安装前可能需要将编辑器升级到最新版本),打开temme文件(可以下载上图中的文件)。打开命令面板,选择Temme:开始观看,然后选择。插件会根据链接下载HTML文档。下载完成后,插件会进入观看模式,编辑器状态栏中会出现⠼ temme:观看。在监视模式下,每次选择器发生变化时,插件都会重新执行选择器并更新输出。这样我们就可以愉快的编辑选择器了。
第二步
用浏览器打开方文社的剧目列表,可以看到上图所示的页面。我们要抓取的粉丝剧信息列表位于ul#browserItemList对应的元素(棕色)中,每一个粉丝剧信息对应一个li元素(绿色)。写下这两个选择器并在末尾添加@list 表示抓取li 列表。为了指定在每个 li 元素中抓取什么内容,我们还需要添加一串花括号来放置子选择器。我们得到以下选择器:
ul#browserItemList li@list {/* 子选择器会出现在这里 */ }
第三步
上图中有五个子选择器,每个子选择器抓取一个对应的字段。下面我们就一一分析:
&[id=$id];表示将父元素(即li元素)的id特征捕获到结果的id字段中。 & 符号表示父元素引用,与 CSS 预处理器 (Less/Sass/Stylus) 中的含义相同。 .inner a{$name} 表示将.inner a 对应的元素的文本抓取到结果的name 字段中。 img[src=$imgUrl] 表示将img对应元素的src特征抓取到结果的imgUrl字段。 CSS选择器中,img[src=imgUrl]表示选择src为imgUrl的那些img元素; $符号被添加到temme,它的含义变成了capture。这个语法很容易记住 (o´ω`o )。 .fade{$rate|Number} 类似于 2,但有一个额外的 |Number 将结果从字符串转换为数字。 .rank{$rank|firstNumber} 与4类似,但这里firstNumber是一个自定义过滤器,用于获取字符串中的第一个数字,过滤器定义在选择器文件下方。
第四步
我们不仅可以在$xxx之后添加过滤器来处理数据字段,还可以在@yyy之后添加过滤器来处理数组。 sortByRate 和 rateBetween 是两个自定义过滤器。前者按评分对同人剧列表进行排序,后者用于选择收视率在一定范围内的同人剧。当我们应用这两个过滤器时,我们可以看到右侧的 JSON 数据也会发生相应的变化。自定义过滤器的定义方法与 JavaScript 函数定义方法相同,只是将关键字从函数更改为过滤器。请注意,您需要在自定义过滤器中使用它来引用捕获的结果。
插入破碎的想法
插件将突出显示与模式匹配的文本 // 链接,我们称之为 tagged-link。 link 可以是 http 链接或本地文件路径。因为插件下载HTML功能比较简单,所以我推荐先使用插件vscode-restclient下载网页文档,然后使用本地路径启动temme watch模式。此外,要在编辑器中执行 temme 选择器,文件中必须至少存在一个标记链接。
除了提供语法高亮,插件还会报告选择器语法错误。在watch模式下,因为selector在不断的执行,插件也会报运行时错误,但是插件还没有完成。运行时错误总是显示在文件的第一行,但应该没有问题。
选择器坏了。
基于 CSS 选择器语法,在 temme 中没有太多需要记住的。一般来说,记住以下几点就足够了: $ 表示捕获字段,@ 表示捕获列表,|xxx 表示应用过滤器处理结果,一个分号;需要结束选择器。 temme的其他语法和功能请参考GitHub文档。
Temme 发布在 NPM 上,使用 yarn global add temme 全局安装 temme;将选择器保存在文件bangumi.temme中,那么上面的例子也可以在命令行运行:
url=http://bangumi.tv/anime/tag/%2 ... Ddate
curl -s $url | temme bangumi.temme --format
当然,我们也可以在 Node.js 中使用 temme。一般来说,对于每个不同的网页结构,我们可以先使用插件来调试选择器;爬虫运行时,下载HTML文档,我们可以直接执行相应的选择器,使爬虫开发效率大大提高。推广。
印象和总结
选择合适的工具可以提高工作效率;汇编的原则很重要也很有用。最后感谢大家的阅读(๑¯◡¯๑).
程序调用直接运行getproxy(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-10 18:12
主机
str
代理地址
端口
内部
端口
匿名
str
匿名
透明、匿名、高度匿名
国家
str
代理国家
响应时间
浮动
响应时间
来自
str
来源
4.插件相关插件代码格式
class Proxy(object):
def __init__(self):
self.result = []
self.proxies = []
def start(self):
pass
插件返回结果
插件提示5.第三方程序调用
直接运行getproxy相当于执行如下程序:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from getproxy import GetProxy
g = GetProxy()
# 1. 初始化,必须步骤
g.init()
# 2. 加载 input proxies 列表
g.load_input_proxies()
# 3. 验证 input proxies 列表
g.validate_input_proxies()
# 4. 加载 plugin
g.load_plugins()
# 5. 抓取 web proxies 列表
g.grab_web_proxies()
# 6. 验证 web proxies 列表
g.validate_web_proxies()
# 7. 保存当前所有已验证的 proxies 列表
g.save_proxies()
如果您只想验证代理列表而不需要获取其他人的代理,您可以:
g.init()
g.load_input_proxies()
g.validate_input_proxies()
print(g.valid_proxies)
如果当前程序不需要输出代理列表,而是直接在程序中使用,可以:
g.init()
g.load_plugins()
g.grab_web_proxies()
g.validate_web_proxies()
print(g.valid_proxies)
6.问答
数据量不大。即使以文本格式读入内存,也不会占用太多内存。就算真的需要存入数据库,也可以自己多写几行代码。使用文本格式的另一个好处是你可以创建这个项目fate0/proxylist
简单、方便、快捷,除Python环境外无需任何设置。
仔细查看错误信息。是不是有些插件报错,报错都是和网络有关?如果是这样,这些插件访问的网站 可能由于众所周知的原因而被阻止。如果没有,请尽快提出问题。
主要取决于这个项目中的proxy.list的数量fate0/proxylist。如果proxy.list行数接近5000,那么就不会再添加插件,防止travis在15分钟内没有结束。 查看全部
程序调用直接运行getproxy(图)
主机
str
代理地址
端口
内部
端口
匿名
str
匿名
透明、匿名、高度匿名
国家
str
代理国家
响应时间
浮动
响应时间
来自
str
来源
4.插件相关插件代码格式
class Proxy(object):
def __init__(self):
self.result = []
self.proxies = []
def start(self):
pass
插件返回结果
插件提示5.第三方程序调用
直接运行getproxy相当于执行如下程序:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from getproxy import GetProxy
g = GetProxy()
# 1. 初始化,必须步骤
g.init()
# 2. 加载 input proxies 列表
g.load_input_proxies()
# 3. 验证 input proxies 列表
g.validate_input_proxies()
# 4. 加载 plugin
g.load_plugins()
# 5. 抓取 web proxies 列表
g.grab_web_proxies()
# 6. 验证 web proxies 列表
g.validate_web_proxies()
# 7. 保存当前所有已验证的 proxies 列表
g.save_proxies()
如果您只想验证代理列表而不需要获取其他人的代理,您可以:
g.init()
g.load_input_proxies()
g.validate_input_proxies()
print(g.valid_proxies)
如果当前程序不需要输出代理列表,而是直接在程序中使用,可以:
g.init()
g.load_plugins()
g.grab_web_proxies()
g.validate_web_proxies()
print(g.valid_proxies)
6.问答
数据量不大。即使以文本格式读入内存,也不会占用太多内存。就算真的需要存入数据库,也可以自己多写几行代码。使用文本格式的另一个好处是你可以创建这个项目fate0/proxylist
简单、方便、快捷,除Python环境外无需任何设置。
仔细查看错误信息。是不是有些插件报错,报错都是和网络有关?如果是这样,这些插件访问的网站 可能由于众所周知的原因而被阻止。如果没有,请尽快提出问题。
主要取决于这个项目中的proxy.list的数量fate0/proxylist。如果proxy.list行数接近5000,那么就不会再添加插件,防止travis在15分钟内没有结束。
搜索引擎的蜘蛛真的会像蜘蛛一样吗?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-10 18:11
在日常的SEO优化中,我们会关注收录,而收录的前提是搜索引擎蜘蛛抓取你的网站,那么这里的蜘蛛是什么?搜索引擎蜘蛛真的像蜘蛛吗?
学过SEO的同学都知道蜘蛛有两种爬行方式:深度和广度,也叫水平爬行和垂直爬行,那么这个蜘蛛是怎么工作的呢?是爬完第一页再爬第二页吗?你在哪里找到第二页的?
如果你真的想了解这方面,你必须了解程序。作为一名合格的SEO,程序设计是你的必修课。既然涉及到程序,那么数据库和编程语言肯定是少不了的。以PHP为例。有一个名为 file_get_contents 的函数。该函数的作用是获取URL中的内容,并以文本形式返回结果。当然也可以使用CURL。
搜索引擎蜘蛛如何进行网站content 抓取
然后,您就可以使用程序中的正则表达式对A链接的数据进行提取、合并和去重,并将数据存储到数据库中。数据库有很多,比如:索引库、收录库等。为什么收录的索引和数量不同?当然是因为他们不在同一个图书馆。
当获取数据后完成上述操作后,自然会获取数据库中不存在的链接,然后程序会发出另一条指令来获取数据库中未保存的URL。直到页面被完全抓取。当然,爬取完成后停止爬取的可能性更大。
百度站长平台上会有抓取频率和抓取时间的数据。应该可以看到,每只蜘蛛的爬行都是不规则的,但是通过日常观察可以发现,页面越深,被抓到的概率越低。原因很简单。蜘蛛不会总是在你的网站周围爬行到所有网站,而是会每隔一段时间随机爬行。
也就是说,搜索引擎的蜘蛛爬行是随机的、时间敏感的,我们SEO的目的是尽快完成页面和内容的呈现,尤其是我们认为有价值的内容。那么它会演变成,如何在有限的蜘蛛爬行中展示更多的内容呢?当然是尽量减少页面深度,增加页面宽度。 《SEO实战密码》里面有页面深度的优化方法,这里不再赘述。如果需要,您可以搜索电子书。当然推荐一个。
蜘蛛虽然有随机性和时效性,但还是有很多规律可寻。比如流量对蜘蛛有非常直接的正面影响,所以在日常运营中,你也会发现,一旦流量进入网站,蜘蛛的数量也会增加。这种蜘蛛的表现尤其在一些非法操作中表现得更加明显,比如百度的排名!
蜘蛛除了时效性和随机性之外,还有一个特点,就是喜新厌旧。一个随时都在变化的网站很受蜘蛛欢迎,即使它没有任何意义!当然,这也算是搜索引擎的一个BUG,但是这个BUG是无法修复的,或者说很难修复。所以很多人利用BUG开发了一系列的软件,比如Spider Pool。蜘蛛池页面每次打开的内容都不一样。使用文本段落的随机组合构造内容来欺骗蜘蛛。然后辅以大量的域名(通常是几百个),形成一个新的内容库来诱捕蜘蛛。当然,圈住蜘蛛绝对不是目的。圈养蜘蛛的目的是释放蜘蛛,那么如何释放蜘蛛呢?有几百万甚至几千万个页面,每个页面都嵌入了一个外部链接,蜘蛛自然而然地可以跟随外部链接到你想让他去的网站。这样就实现了对页面的高频蜘蛛访问。
当一个页面蜘蛛走多了,收录自然就不再是问题了。蜘蛛对收录有正面帮助,对排名有帮助吗?通过我们的研发,百度蜘蛛、百度排名、自然流量之间的关系是微秒级的,每一次变化都会牵扯到另外两个变化。只是有些变化很大,有些变化很小。
查看全部
搜索引擎的蜘蛛真的会像蜘蛛一样吗?(图)
在日常的SEO优化中,我们会关注收录,而收录的前提是搜索引擎蜘蛛抓取你的网站,那么这里的蜘蛛是什么?搜索引擎蜘蛛真的像蜘蛛吗?
学过SEO的同学都知道蜘蛛有两种爬行方式:深度和广度,也叫水平爬行和垂直爬行,那么这个蜘蛛是怎么工作的呢?是爬完第一页再爬第二页吗?你在哪里找到第二页的?
如果你真的想了解这方面,你必须了解程序。作为一名合格的SEO,程序设计是你的必修课。既然涉及到程序,那么数据库和编程语言肯定是少不了的。以PHP为例。有一个名为 file_get_contents 的函数。该函数的作用是获取URL中的内容,并以文本形式返回结果。当然也可以使用CURL。
搜索引擎蜘蛛如何进行网站content 抓取
然后,您就可以使用程序中的正则表达式对A链接的数据进行提取、合并和去重,并将数据存储到数据库中。数据库有很多,比如:索引库、收录库等。为什么收录的索引和数量不同?当然是因为他们不在同一个图书馆。
当获取数据后完成上述操作后,自然会获取数据库中不存在的链接,然后程序会发出另一条指令来获取数据库中未保存的URL。直到页面被完全抓取。当然,爬取完成后停止爬取的可能性更大。
百度站长平台上会有抓取频率和抓取时间的数据。应该可以看到,每只蜘蛛的爬行都是不规则的,但是通过日常观察可以发现,页面越深,被抓到的概率越低。原因很简单。蜘蛛不会总是在你的网站周围爬行到所有网站,而是会每隔一段时间随机爬行。
也就是说,搜索引擎的蜘蛛爬行是随机的、时间敏感的,我们SEO的目的是尽快完成页面和内容的呈现,尤其是我们认为有价值的内容。那么它会演变成,如何在有限的蜘蛛爬行中展示更多的内容呢?当然是尽量减少页面深度,增加页面宽度。 《SEO实战密码》里面有页面深度的优化方法,这里不再赘述。如果需要,您可以搜索电子书。当然推荐一个。
蜘蛛虽然有随机性和时效性,但还是有很多规律可寻。比如流量对蜘蛛有非常直接的正面影响,所以在日常运营中,你也会发现,一旦流量进入网站,蜘蛛的数量也会增加。这种蜘蛛的表现尤其在一些非法操作中表现得更加明显,比如百度的排名!
蜘蛛除了时效性和随机性之外,还有一个特点,就是喜新厌旧。一个随时都在变化的网站很受蜘蛛欢迎,即使它没有任何意义!当然,这也算是搜索引擎的一个BUG,但是这个BUG是无法修复的,或者说很难修复。所以很多人利用BUG开发了一系列的软件,比如Spider Pool。蜘蛛池页面每次打开的内容都不一样。使用文本段落的随机组合构造内容来欺骗蜘蛛。然后辅以大量的域名(通常是几百个),形成一个新的内容库来诱捕蜘蛛。当然,圈住蜘蛛绝对不是目的。圈养蜘蛛的目的是释放蜘蛛,那么如何释放蜘蛛呢?有几百万甚至几千万个页面,每个页面都嵌入了一个外部链接,蜘蛛自然而然地可以跟随外部链接到你想让他去的网站。这样就实现了对页面的高频蜘蛛访问。
当一个页面蜘蛛走多了,收录自然就不再是问题了。蜘蛛对收录有正面帮助,对排名有帮助吗?通过我们的研发,百度蜘蛛、百度排名、自然流量之间的关系是微秒级的,每一次变化都会牵扯到另外两个变化。只是有些变化很大,有些变化很小。

外链对网站排名的作用及影响有以下几点网站建设
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-09 07:26
外链对网站排名的作用和影响如下:增加网站的权重,增加网站的信任度,引导蜘蛛爬取文章内容,增加上榜几率页面收录,间接提高关键词的排名以及品牌和域名的曝光也可以为网站带来流量,但必须注意的是,外部链接的质量远高于数量. 1、外链可以增加链接页面和整个网站的权重,增加页面评分和信任度。外部链接越多,发送该链接的网站的权重越高,间接表明链接的页面被更多人信任。页面链接的权重和信任度也会在整个域名上累积。 2、网站排名受到网站权重的间接影响,但只是搜索引擎排名的重要因素之一。除了网站scale、文章内容质量、原创sexuality,影响权重最重要的因素就是外链。高权重域名提升网站所有页面的排名。链接到网站 且信任度高的页面被视为采集 内容的可能性要小得多。信任度是指你的网站内容是否以网站为主题。如果你的网站有搜狐、新浪、土巴兔、天涯论坛的链接,像网站这样权重非常高,你的网站的权重也会有质的提升,不管网站关键词,排名会有很大帮助。 网站构建完成后,搜索引擎蜘蛛就需要爬取我们的网站。如果外部链接太少,甚至没有外部链接,蜘蛛发现并捕获网站的可能性就会低很多。 网站更新文章内容后,搜索引擎蜘蛛也需要能够第一时间抓取更新后的文章内容和收录网站的文章content页面。
想要网站排名,首先要让网站页面内容为收录。如果网站文章的内容不是收录,我们可以将网站的地址以外链的形式发布给一些权重和信任度高的网站,蜘蛛爬取到我们更新的内容会很多收录,这就是为什么外链可以引导蜘蛛去抢网站。 1、网站要排名,必须先让网站内容被搜索引擎收录搜索到,所以网站页面为收录是排名的基础,不能被搜索到通过搜索引擎收录页面没有排名。数据分析和seo行业经验都表明,外部链接的数量和质量对网站的收录的情况有着至关重要的影响。没有强大的外链作为助力,仅仅依靠网站内部结构和页面的原创内容,很难做出我们的网站被full收录。一个可供参考的经验数字是,一个权重为5的域名大致可以驱动数百万页,如果太多,则会更加困难。 2、所有seo从业者都熟悉的链接级视图是内页必须在主页的三四次点击内。原因是外部链接很大程度上决定了蜘蛛的爬行深度。一般来说,权重不高的网站只会爬3-4级链接。如果网站的权重为7或者权重为8,那么距离首页点击六七次的内容页面也可以被搜索引擎收录搜索到,从而提升收录整体的能力网站。 3、外部链接也是影响搜索引擎抓取频率的一个非常重要的因素。外部链接越多,搜索引擎蜘蛛抓取的页面越多,频率越高,新页面和新内容的发现速度越快。
网站权重高,每隔几分钟爬一次主页很正常。搜索引擎利用网站外链的质量给网站相应的权重。权重高的网站自然在关键词的排名中占有很大的优势。很多SEO新手或者站长都认为强大的外链是网站最大排名的保证。理论上网站强大的外链可以给网站带来不错的排名。但是,外部链接的建设也应该逐步增加。找一些在各大搜索引擎中权重较高的网站添加链接,让网站排名有一定的稳定性。另外,从很多老SEO司机对站群的维护来看,友情链接对网站的排名还是有显着影响的。每个站长每周可以添加2个有价值的朋友链接,从而间接提高网站排名。 纯文本外链的发布,可以有效增加网站域名和品牌在互联网上的曝光率,有助于网络营销推广的顺利进行。而对于一些简短易记的域名,对于网站的推广也是有帮助的,比如:百度、淘宝、京东等,用户一看就会知道网站是什么,这会帮助用户记住我们的网站,有利于网站回访。 SEO人员在站外平台发布与其网站topics相关的文章内容时,自带链接,极有可能为网站带来流量。如果这个文章的值高,相信传入的流量不会少。前提是能够吸引用户点击,让用户知道打开的链接是否是他们需要的。这样的外部链接既能满足用户体验,也是对用户有价值的链接。
因为现在网络上垃圾链接太多了,如果网站有多余文字的链接被称为链接工厂,搜索引擎也会判断网站发送的链接是垃圾链接,所以搜索引擎最终会看重外部链接的质量而不是数量。而且很多SEO人员经常发现网站外链的竞争者数量并不是很大,而且网站的排名也很好且相对稳定,所以网站外链的质量远高于数量,一个高质量的。外部链接胜过几十个或几百个垃圾外部链接。 网站Optimization 由两部分组成:现场优化和非现场优化。现场优化主要是指网站结构、页面优化、页面设计、页面用户浏览体验、网站功能、关键词研究、竞争研究、SEO效果优化监控和策略改进、站外优化优化主要是对外链接的发布和建设。 网站 的基本功能之一是链接。 网站里面的链接是我们自己可控的,比较容易掌握。本文链接: 查看全部
外链对网站排名的作用及影响有以下几点网站建设
外链对网站排名的作用和影响如下:增加网站的权重,增加网站的信任度,引导蜘蛛爬取文章内容,增加上榜几率页面收录,间接提高关键词的排名以及品牌和域名的曝光也可以为网站带来流量,但必须注意的是,外部链接的质量远高于数量. 1、外链可以增加链接页面和整个网站的权重,增加页面评分和信任度。外部链接越多,发送该链接的网站的权重越高,间接表明链接的页面被更多人信任。页面链接的权重和信任度也会在整个域名上累积。 2、网站排名受到网站权重的间接影响,但只是搜索引擎排名的重要因素之一。除了网站scale、文章内容质量、原创sexuality,影响权重最重要的因素就是外链。高权重域名提升网站所有页面的排名。链接到网站 且信任度高的页面被视为采集 内容的可能性要小得多。信任度是指你的网站内容是否以网站为主题。如果你的网站有搜狐、新浪、土巴兔、天涯论坛的链接,像网站这样权重非常高,你的网站的权重也会有质的提升,不管网站关键词,排名会有很大帮助。 网站构建完成后,搜索引擎蜘蛛就需要爬取我们的网站。如果外部链接太少,甚至没有外部链接,蜘蛛发现并捕获网站的可能性就会低很多。 网站更新文章内容后,搜索引擎蜘蛛也需要能够第一时间抓取更新后的文章内容和收录网站的文章content页面。
想要网站排名,首先要让网站页面内容为收录。如果网站文章的内容不是收录,我们可以将网站的地址以外链的形式发布给一些权重和信任度高的网站,蜘蛛爬取到我们更新的内容会很多收录,这就是为什么外链可以引导蜘蛛去抢网站。 1、网站要排名,必须先让网站内容被搜索引擎收录搜索到,所以网站页面为收录是排名的基础,不能被搜索到通过搜索引擎收录页面没有排名。数据分析和seo行业经验都表明,外部链接的数量和质量对网站的收录的情况有着至关重要的影响。没有强大的外链作为助力,仅仅依靠网站内部结构和页面的原创内容,很难做出我们的网站被full收录。一个可供参考的经验数字是,一个权重为5的域名大致可以驱动数百万页,如果太多,则会更加困难。 2、所有seo从业者都熟悉的链接级视图是内页必须在主页的三四次点击内。原因是外部链接很大程度上决定了蜘蛛的爬行深度。一般来说,权重不高的网站只会爬3-4级链接。如果网站的权重为7或者权重为8,那么距离首页点击六七次的内容页面也可以被搜索引擎收录搜索到,从而提升收录整体的能力网站。 3、外部链接也是影响搜索引擎抓取频率的一个非常重要的因素。外部链接越多,搜索引擎蜘蛛抓取的页面越多,频率越高,新页面和新内容的发现速度越快。
网站权重高,每隔几分钟爬一次主页很正常。搜索引擎利用网站外链的质量给网站相应的权重。权重高的网站自然在关键词的排名中占有很大的优势。很多SEO新手或者站长都认为强大的外链是网站最大排名的保证。理论上网站强大的外链可以给网站带来不错的排名。但是,外部链接的建设也应该逐步增加。找一些在各大搜索引擎中权重较高的网站添加链接,让网站排名有一定的稳定性。另外,从很多老SEO司机对站群的维护来看,友情链接对网站的排名还是有显着影响的。每个站长每周可以添加2个有价值的朋友链接,从而间接提高网站排名。 纯文本外链的发布,可以有效增加网站域名和品牌在互联网上的曝光率,有助于网络营销推广的顺利进行。而对于一些简短易记的域名,对于网站的推广也是有帮助的,比如:百度、淘宝、京东等,用户一看就会知道网站是什么,这会帮助用户记住我们的网站,有利于网站回访。 SEO人员在站外平台发布与其网站topics相关的文章内容时,自带链接,极有可能为网站带来流量。如果这个文章的值高,相信传入的流量不会少。前提是能够吸引用户点击,让用户知道打开的链接是否是他们需要的。这样的外部链接既能满足用户体验,也是对用户有价值的链接。
因为现在网络上垃圾链接太多了,如果网站有多余文字的链接被称为链接工厂,搜索引擎也会判断网站发送的链接是垃圾链接,所以搜索引擎最终会看重外部链接的质量而不是数量。而且很多SEO人员经常发现网站外链的竞争者数量并不是很大,而且网站的排名也很好且相对稳定,所以网站外链的质量远高于数量,一个高质量的。外部链接胜过几十个或几百个垃圾外部链接。 网站Optimization 由两部分组成:现场优化和非现场优化。现场优化主要是指网站结构、页面优化、页面设计、页面用户浏览体验、网站功能、关键词研究、竞争研究、SEO效果优化监控和策略改进、站外优化优化主要是对外链接的发布和建设。 网站 的基本功能之一是链接。 网站里面的链接是我们自己可控的,比较容易掌握。本文链接:
提高百度蜘蛛对网站内容的收录量的之前问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-08 20:12
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。
这是每个网站运营经理都必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一就是提高网站打开的速度。
确保页面打开速度符合百度标准要求,以便百度蜘蛛能够顺利抓取每个页面。例如,移动端优先索引要求首页加载速度保持在3秒以内。
为此,我们可能需要:
① 精简网站程序代码,比如CSS和JS的结合。
②开启服务器缓存,配置CDN云加速,或者百度MIP等
③ 定期清理网站冗余数据库信息等
④ 压缩网站图片,特别是食谱和食物网站。
当我们很好的解决了网站打开速度的问题后,为了增加百度蜘蛛的抓取量,我们可以尝试以下方法:
1、提高页面更新频率
这里我们一般使用以下三种方法:
①持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。
另外,保持一定的更新频率,而不是三天打鱼,两天晒网。在违规方面。
②在网页侧边栏,调用“随机文章”标签,有助于增加页面新鲜度,从而保持页面不断出现收录未出现的文章过去但被视为新内容。
③ 合理利用有一定排名的旧页面,适当增加一些内部链接指向新的文章。在满足一定数量的基础上,有利于传递权重,提高百度蜘蛛的抓握Pick。
2、大量外链
基于搜索引擎的角度,权威性、相关性、高权重的外部链接是相对于外部投票和推荐的。如果您有每个版块页面,您将在一定时间内继续获取这些链接。
然后,搜索引擎会认为这些版块页面的内容值得抓取,从而增加百度蜘蛛的访问量。
3、提交百度链接
通过主动向百度提交新链接,也可以实现目标网址被爬取的概率。具体方法可以如下:
①制作网站地图,在百度搜索资源平台后台提交地图的sitemap.xml版本。您还可以创建站点地图的 Html 版本并将其放置在主页的导航中。
②使用百度API接口向搜索引擎提交新链接。
③在网站Html源码页面,添加百度给出的JS代码。只要有人访问任何页面,就会自动ping百度蜘蛛抓取。
4、创建百度蜘蛛池
这是一种消耗资源的策略,一般不建议大家采用。主要是通过建立大量的网站,在每个网站之间形成一个闭环。
用于每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。
然后,利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
总结:SEO网站优化,要增加百度蜘蛛的抓取次数,首先要保证页面速度,其次可以使用的相关策略,如上所说,基本可以满足抓取要求一般网站。仅供参考和讨论。 查看全部
提高百度蜘蛛对网站内容的收录量的之前问题
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。

这是每个网站运营经理都必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一就是提高网站打开的速度。
确保页面打开速度符合百度标准要求,以便百度蜘蛛能够顺利抓取每个页面。例如,移动端优先索引要求首页加载速度保持在3秒以内。
为此,我们可能需要:
① 精简网站程序代码,比如CSS和JS的结合。
②开启服务器缓存,配置CDN云加速,或者百度MIP等
③ 定期清理网站冗余数据库信息等
④ 压缩网站图片,特别是食谱和食物网站。
当我们很好的解决了网站打开速度的问题后,为了增加百度蜘蛛的抓取量,我们可以尝试以下方法:
1、提高页面更新频率
这里我们一般使用以下三种方法:
①持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。
另外,保持一定的更新频率,而不是三天打鱼,两天晒网。在违规方面。
②在网页侧边栏,调用“随机文章”标签,有助于增加页面新鲜度,从而保持页面不断出现收录未出现的文章过去但被视为新内容。
③ 合理利用有一定排名的旧页面,适当增加一些内部链接指向新的文章。在满足一定数量的基础上,有利于传递权重,提高百度蜘蛛的抓握Pick。
2、大量外链
基于搜索引擎的角度,权威性、相关性、高权重的外部链接是相对于外部投票和推荐的。如果您有每个版块页面,您将在一定时间内继续获取这些链接。
然后,搜索引擎会认为这些版块页面的内容值得抓取,从而增加百度蜘蛛的访问量。
3、提交百度链接
通过主动向百度提交新链接,也可以实现目标网址被爬取的概率。具体方法可以如下:
①制作网站地图,在百度搜索资源平台后台提交地图的sitemap.xml版本。您还可以创建站点地图的 Html 版本并将其放置在主页的导航中。
②使用百度API接口向搜索引擎提交新链接。
③在网站Html源码页面,添加百度给出的JS代码。只要有人访问任何页面,就会自动ping百度蜘蛛抓取。
4、创建百度蜘蛛池
这是一种消耗资源的策略,一般不建议大家采用。主要是通过建立大量的网站,在每个网站之间形成一个闭环。
用于每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。
然后,利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
总结:SEO网站优化,要增加百度蜘蛛的抓取次数,首先要保证页面速度,其次可以使用的相关策略,如上所说,基本可以满足抓取要求一般网站。仅供参考和讨论。
企业网站内容可以提高内容以及网站排名的帮助因素分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-08 12:07
网站内容抓取是一个非常重要的操作,对一个网站的影响非常大,企业网站要想稳定运营必须要定期的抓取网站内容,一起来看看抓取网站内容可以提高网站内容粘性以及网站排名。个人网站后台抓取内容对排名的帮助:经常性的大量的查看url内容,当网站内容内容都一样时,建议采用自动抓取和协议识别服务来过滤重复内容,毕竟像百度谷歌这些搜索引擎都会重复抓取url重复url,如果你的网站有大量重复url时,建议就采用这两种方法过滤。
对于个人网站来说,如果不是大量定时抓取内容是无法有效提高内容的粘性和整站网站排名的。如果网站内容都一样,建议大家定期查看网站内容,避免大量重复抓取。可以采用谷歌分析()分析抓取数据,谷歌分析可以识别到每天抓取的网站内容,以及抓取网站url等等,可以通过谷歌分析这款软件了解每天抓取网站内容的数量,看一下每天有多少网站抓取url,避免大量抓取url,url重复;同时,查看每天都抓取到多少网站内容,看一下抓取的网站内容数量跟网站收录的内容数量之间的比例关系,看一下能提高自己网站内容的排名;通过日志监控服务器运行情况,查看抓取是否出现异常,出现异常时怎么办,可以通过日志监控服务器服务器。
通过网站抓取,可以在网站有大量抓取的情况下,提高网站内容的数量,从而提高网站内容的粘性。并且如果定期在维护站点,对建站质量方面也有比较大的帮助。 查看全部
企业网站内容可以提高内容以及网站排名的帮助因素分析
网站内容抓取是一个非常重要的操作,对一个网站的影响非常大,企业网站要想稳定运营必须要定期的抓取网站内容,一起来看看抓取网站内容可以提高网站内容粘性以及网站排名。个人网站后台抓取内容对排名的帮助:经常性的大量的查看url内容,当网站内容内容都一样时,建议采用自动抓取和协议识别服务来过滤重复内容,毕竟像百度谷歌这些搜索引擎都会重复抓取url重复url,如果你的网站有大量重复url时,建议就采用这两种方法过滤。
对于个人网站来说,如果不是大量定时抓取内容是无法有效提高内容的粘性和整站网站排名的。如果网站内容都一样,建议大家定期查看网站内容,避免大量重复抓取。可以采用谷歌分析()分析抓取数据,谷歌分析可以识别到每天抓取的网站内容,以及抓取网站url等等,可以通过谷歌分析这款软件了解每天抓取网站内容的数量,看一下每天有多少网站抓取url,避免大量抓取url,url重复;同时,查看每天都抓取到多少网站内容,看一下抓取的网站内容数量跟网站收录的内容数量之间的比例关系,看一下能提高自己网站内容的排名;通过日志监控服务器运行情况,查看抓取是否出现异常,出现异常时怎么办,可以通过日志监控服务器服务器。
通过网站抓取,可以在网站有大量抓取的情况下,提高网站内容的数量,从而提高网站内容的粘性。并且如果定期在维护站点,对建站质量方面也有比较大的帮助。
如何在web主机上强制重定向的代码添加到另一个
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-08-05 01:09
正确的方法是将其中一个重定向到另一个而不是两个。如果两个同时加载,那么站点的版本安全就会有问题。如果您在浏览器中输入网站的网址,请分别测试。
如果两个 URL 都加载,则将显示两个版本的内容。重复的网址可能会导致重复的内容。
为确保您不再遇到此问题,您需要根据站点的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache/CPanel服务器上);
使用 WordPress 中的重定向插件强制重定向。
4、如何在Apache/Cpanel服务器的htaccess中创建重定向
您可以在 Apache/CPanel 服务器的 .htaccess 中执行服务器级全局重定向。 Inmotionhosting 有一个很好的教程,教您如何在您的网络主机上强制重定向。
如果您强制所有网络流量使用 HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On、RewriteCond 等)的代码之上。
重写引擎开启
RewriteCond %{HTTPS} !on
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写规则 (.*) %{HTTP_HOST}%{REQUEST_URI} [L,R=301]
如果您只想重定向特定域,则需要在 htaccess 文件中使用以下代码行:
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写引擎开启
RewriteCond %{HTTP_HOST} ^example\.com [NC]
RewriteCond %{SERVER_PORT} 80
重写规则 ^(.*)$ $1 [R=301,L]
注意:如果您不确定对服务器进行正确的更改,请确保您的服务器公司或 IT 人员执行这些维修。
5、如果您运行的是 WordPress网站,请使用插件
解决这些重定向问题的简单方法是使用插件,尤其是在运行 WordPress网站 时。
许多插件可以强制重定向,但这里有一些插件可以使这个过程尽可能简单:CM HTTPS Pro、WP Force SSL、Easy HTTPS Redirection。
插件注意事项:如果您使用了过多的插件,请不要添加。
您可能需要调查您的服务器是否可以使用上述类似的重定向规则(例如,如果您使用的是基于 NGINX 的服务器)。
这里需要声明:插件的权重会对网站的速度产生负面影响,所以不要总以为新插件会帮到你。
6、所有网站链接应改为
即使您执行了上述重定向,您也应该执行此步骤。
如果您使用绝对 URL 而不是相对 URL,则应该这样做。因为前者总是显示您使用的超文本传输协议,如果您使用的是后者,则无需多加注意。
为什么在使用绝对 URL 时需要更改实时链接?由于 Google 会抓取所有这些链接,因此可能会导致内容重复。
这似乎是浪费时间,但事实并非如此。你必须确保谷歌最终能准确捕捉到你的网站。
7、保证从to转换,不会出现404页面
突然增加的404页面可能会让你的网站无法操作,尤其是有页面链接的时候。
另外,由于显示的404页面过多,谷歌没有找到应该抓取的页面,会造成抓取预算的浪费。
Google 相关负责人 John Mueller 指出,抓取预算并不重要,除非是针对大型网站。
John Mueller 在 Twitter 上表示,他认为爬网预算优化被高估了。对于大多数网站,没有任何作用,只能帮助大规模的网站。
“IMO 的爬取预算被高估了。实际上,大多数网站 不需要担心。如果您正在爬网或运行一个拥有数十亿个 URL 的网站,这非常重要。但是对于普通的网站,这不是很重要。”
SEO PowerSuite相关负责人Yauhen Khutarniuk的一篇文章文章也对这一点进行了阐述:
“从逻辑上讲,您应该注意抓取预算,因为您希望Google 为您的网站 发现尽可能多的重要页面。您还希望它能够快速在您的网站 内容中找到新页面,您的抓取预算越大(管理越聪明),这种情况就会发生得越快。”
优化爬取预算很重要,因为在网站上快速发现新内容是一项重要的任务,同时我们需要尽可能多地发现网站的优先页面。
8、如何修复可能出现的 404 页
首先,将 404 从旧 URL 重定向到新的现有 URL。
更简单的方法是,如果你有WordPress网站,用Screaming Frog抓取网站,使用WordPress重定向插件进行301重定向规则批量上传。
9、URL 结构不要太复杂
在准备技术 SEO 时,URL 的结构是一个重要的考虑因素。
这些东西你也一定要注意,比如随机生成索引动态参数、不易理解的网址,以及其他可能导致技术SEO实施出现问题的因素。
这些都是重要的因素,因为它们可能会导致索引问题,从而损害网站 的性能。
10、更多用户友好网址
创建网址时,您可以考虑相关内容,然后自动创建网址。然而,这可能并不合理。
原因是因为自动生成的 URL 可以遵循多种不同的格式,没有一种是非常用户友好的。
例如:
(1)/content/date/time/keyword/
(2)/content/date/time/数字串/
(3)/content/category/date/time/
(4)/content/category/date/time/parameter/
正确传达网址背后的内容是关键。由于可访问性,它在今天变得更加重要。
URL 的可读性越高越好:如果有人在搜索结果中看到您的 URL,他们可能更愿意点击它,因为他们会确切地看到该 URL 与他们正在搜索的性别之间的关系。简而言之,URL 需要匹配用户的搜索意图。
许多现有的网站 使用过时或令人困惑的 URL 结构,导致用户参与度低。如果您有一个更人性化的网址,您的网站 可能会有更高的用户参与度。
11、重复网址
在构建任何链接之前要考虑的一个 SEO 技术问题是:内容重复。
说到内容重复,主要有以下几个原因:
(1)在网站的各个部分明显重复。
(2)从其他网站抓取内容。
(3)重复网址,只存在一个内容。
因为当多个 URL 代表一个内容时,它确实会混淆搜索引擎。搜索引擎很少同时显示相同的内容,重复的网址会削弱其搜索能力。
12、避免使用动态参数
尽管动态参数本身不是 SEO 问题,但如果您无法管理它们的创建并使其在使用中保持一致,它们将来可能会成为潜在威胁。
Jes Scholz 在搜索引擎杂志上发表了一篇文章 的文章,涵盖了动态参数和 URL 处理的基础知识以及它如何影响 SEO。
Scholz 解释说,参数用于以下目的:跟踪、重新排序、过滤、识别、分页、搜索、翻译。
当您发现问题是由网址的动态参数引起时,通常归咎于网址的基本管理不善。
在跟踪的情况下,创建搜索引擎抓取的链接时可以使用不同的动态参数。在重新排序的情况下,使用这些不同的动态参数对列表和项目组进行重新排序,然后创建可索引的重复页面,然后由搜索引擎抓取。
如果动态参数没有保持在可管理的水平,可能会在不经意间导致过多的重复内容。
如果不仔细管理部分内容的创建,这些动态网址的创建实际上会随着时间的推移而积累,这会稀释内容的质量,削弱搜索引擎的执行能力。
还会造成关键词“同类相食”,相互影响,在足够大的范围内,会严重影响你的竞争力。
13、短网址优于长网址
长期 SEO 实践的结果是,较短的 URL 优于较长的 URL。
Google 的 John Mueller 说:“当我们有两个内容相同的 URL 时,我们需要选择其中一个显示在搜索结果中,我们会选择较短的一个,这就是规范化。当然,长度不是主要的。影响因素,但是如果我们有两个网址,一个很简洁,另一个有很长的附加参数,当它们显示相同的内容时,我们更喜欢选择短的。例子很多,比如不同的因素发挥作用,但在其他条件相同的情况下——你有更短的和更长的,我们也会选择更短的。”
还有证据表明,Google 优先考虑较短的网址而不是较长的网址。
如果您的网站 收录很长的网址,您可以将它们优化为更短、更简洁的网址,以更好地反映文章 的主题和用户意图。
(编译/雨果网吕小林)
【特别声明】未经许可,任何个人或组织不得复制、转载或以其他方式使用本网站内容。转载请联系: 查看全部
如何在web主机上强制重定向的代码添加到另一个
正确的方法是将其中一个重定向到另一个而不是两个。如果两个同时加载,那么站点的版本安全就会有问题。如果您在浏览器中输入网站的网址,请分别测试。
如果两个 URL 都加载,则将显示两个版本的内容。重复的网址可能会导致重复的内容。
为确保您不再遇到此问题,您需要根据站点的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache/CPanel服务器上);
使用 WordPress 中的重定向插件强制重定向。
4、如何在Apache/Cpanel服务器的htaccess中创建重定向
您可以在 Apache/CPanel 服务器的 .htaccess 中执行服务器级全局重定向。 Inmotionhosting 有一个很好的教程,教您如何在您的网络主机上强制重定向。
如果您强制所有网络流量使用 HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On、RewriteCond 等)的代码之上。
重写引擎开启
RewriteCond %{HTTPS} !on
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写规则 (.*) %{HTTP_HOST}%{REQUEST_URI} [L,R=301]
如果您只想重定向特定域,则需要在 htaccess 文件中使用以下代码行:
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写引擎开启
RewriteCond %{HTTP_HOST} ^example\.com [NC]
RewriteCond %{SERVER_PORT} 80
重写规则 ^(.*)$ $1 [R=301,L]
注意:如果您不确定对服务器进行正确的更改,请确保您的服务器公司或 IT 人员执行这些维修。

5、如果您运行的是 WordPress网站,请使用插件
解决这些重定向问题的简单方法是使用插件,尤其是在运行 WordPress网站 时。
许多插件可以强制重定向,但这里有一些插件可以使这个过程尽可能简单:CM HTTPS Pro、WP Force SSL、Easy HTTPS Redirection。
插件注意事项:如果您使用了过多的插件,请不要添加。
您可能需要调查您的服务器是否可以使用上述类似的重定向规则(例如,如果您使用的是基于 NGINX 的服务器)。
这里需要声明:插件的权重会对网站的速度产生负面影响,所以不要总以为新插件会帮到你。
6、所有网站链接应改为
即使您执行了上述重定向,您也应该执行此步骤。
如果您使用绝对 URL 而不是相对 URL,则应该这样做。因为前者总是显示您使用的超文本传输协议,如果您使用的是后者,则无需多加注意。
为什么在使用绝对 URL 时需要更改实时链接?由于 Google 会抓取所有这些链接,因此可能会导致内容重复。
这似乎是浪费时间,但事实并非如此。你必须确保谷歌最终能准确捕捉到你的网站。

7、保证从to转换,不会出现404页面
突然增加的404页面可能会让你的网站无法操作,尤其是有页面链接的时候。
另外,由于显示的404页面过多,谷歌没有找到应该抓取的页面,会造成抓取预算的浪费。
Google 相关负责人 John Mueller 指出,抓取预算并不重要,除非是针对大型网站。
John Mueller 在 Twitter 上表示,他认为爬网预算优化被高估了。对于大多数网站,没有任何作用,只能帮助大规模的网站。
“IMO 的爬取预算被高估了。实际上,大多数网站 不需要担心。如果您正在爬网或运行一个拥有数十亿个 URL 的网站,这非常重要。但是对于普通的网站,这不是很重要。”
SEO PowerSuite相关负责人Yauhen Khutarniuk的一篇文章文章也对这一点进行了阐述:
“从逻辑上讲,您应该注意抓取预算,因为您希望Google 为您的网站 发现尽可能多的重要页面。您还希望它能够快速在您的网站 内容中找到新页面,您的抓取预算越大(管理越聪明),这种情况就会发生得越快。”
优化爬取预算很重要,因为在网站上快速发现新内容是一项重要的任务,同时我们需要尽可能多地发现网站的优先页面。
8、如何修复可能出现的 404 页
首先,将 404 从旧 URL 重定向到新的现有 URL。
更简单的方法是,如果你有WordPress网站,用Screaming Frog抓取网站,使用WordPress重定向插件进行301重定向规则批量上传。
9、URL 结构不要太复杂
在准备技术 SEO 时,URL 的结构是一个重要的考虑因素。
这些东西你也一定要注意,比如随机生成索引动态参数、不易理解的网址,以及其他可能导致技术SEO实施出现问题的因素。
这些都是重要的因素,因为它们可能会导致索引问题,从而损害网站 的性能。
10、更多用户友好网址
创建网址时,您可以考虑相关内容,然后自动创建网址。然而,这可能并不合理。
原因是因为自动生成的 URL 可以遵循多种不同的格式,没有一种是非常用户友好的。
例如:
(1)/content/date/time/keyword/
(2)/content/date/time/数字串/
(3)/content/category/date/time/
(4)/content/category/date/time/parameter/
正确传达网址背后的内容是关键。由于可访问性,它在今天变得更加重要。
URL 的可读性越高越好:如果有人在搜索结果中看到您的 URL,他们可能更愿意点击它,因为他们会确切地看到该 URL 与他们正在搜索的性别之间的关系。简而言之,URL 需要匹配用户的搜索意图。
许多现有的网站 使用过时或令人困惑的 URL 结构,导致用户参与度低。如果您有一个更人性化的网址,您的网站 可能会有更高的用户参与度。
11、重复网址
在构建任何链接之前要考虑的一个 SEO 技术问题是:内容重复。
说到内容重复,主要有以下几个原因:
(1)在网站的各个部分明显重复。
(2)从其他网站抓取内容。
(3)重复网址,只存在一个内容。
因为当多个 URL 代表一个内容时,它确实会混淆搜索引擎。搜索引擎很少同时显示相同的内容,重复的网址会削弱其搜索能力。
12、避免使用动态参数
尽管动态参数本身不是 SEO 问题,但如果您无法管理它们的创建并使其在使用中保持一致,它们将来可能会成为潜在威胁。
Jes Scholz 在搜索引擎杂志上发表了一篇文章 的文章,涵盖了动态参数和 URL 处理的基础知识以及它如何影响 SEO。
Scholz 解释说,参数用于以下目的:跟踪、重新排序、过滤、识别、分页、搜索、翻译。
当您发现问题是由网址的动态参数引起时,通常归咎于网址的基本管理不善。
在跟踪的情况下,创建搜索引擎抓取的链接时可以使用不同的动态参数。在重新排序的情况下,使用这些不同的动态参数对列表和项目组进行重新排序,然后创建可索引的重复页面,然后由搜索引擎抓取。
如果动态参数没有保持在可管理的水平,可能会在不经意间导致过多的重复内容。
如果不仔细管理部分内容的创建,这些动态网址的创建实际上会随着时间的推移而积累,这会稀释内容的质量,削弱搜索引擎的执行能力。
还会造成关键词“同类相食”,相互影响,在足够大的范围内,会严重影响你的竞争力。
13、短网址优于长网址
长期 SEO 实践的结果是,较短的 URL 优于较长的 URL。
Google 的 John Mueller 说:“当我们有两个内容相同的 URL 时,我们需要选择其中一个显示在搜索结果中,我们会选择较短的一个,这就是规范化。当然,长度不是主要的。影响因素,但是如果我们有两个网址,一个很简洁,另一个有很长的附加参数,当它们显示相同的内容时,我们更喜欢选择短的。例子很多,比如不同的因素发挥作用,但在其他条件相同的情况下——你有更短的和更长的,我们也会选择更短的。”
还有证据表明,Google 优先考虑较短的网址而不是较长的网址。
如果您的网站 收录很长的网址,您可以将它们优化为更短、更简洁的网址,以更好地反映文章 的主题和用户意图。

(编译/雨果网吕小林)
【特别声明】未经许可,任何个人或组织不得复制、转载或以其他方式使用本网站内容。转载请联系:
赶集、安居客这些量都很大,会不会解析不出来?
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-04 20:06
Q:我们的页面本身就很大,会不会被解析?
答:页面本身很大是可以的,但是商场、安居客等流量很大,所以没问题。在我刚才提到的例子中,你每次都关注一个新的链接,随意去掉下面的参数不会影响这个网页的正常访问。这绝对是个问题。
问题:刚才说了对URL的长度有要求。对每段的长度,也就是目录名,有什么要求吗?
答案:没有要求。我们要求URL从www开始到结束,总长度不能超过1024字节。
问:网站中的重复内容如何判断?如果文本内容相同,结构不同,是否视为重复?
答案:重复
Q:假设整个页面都是Flash,如果我隐藏了一些栏目或者最新的内容,不影响美观,隐藏起来。可以用隐藏属性提取吗? CSS 可能吗?
答:hidden 可以提,但如果是评论,就无所谓了。 CSS 不能。
问:页面大小不超过 1 兆字节。是指页面压缩之前还是之后。
答案:页面压缩后,不能超过1兆。
问:我的网站信息过期了,网页返回200,会被处罚吗?为什么?
回答:用户在搜索结果中点击了你的结果,引导到你的网站,但是没有什么可看的,对用户没有用。百度当然不喜欢。
Q:现在我们有很多网站,为了让用户觉得有趣,在内容没了的时候放一张图片,写一些有趣的文字,“工程师在哪里?”对百度友好吗?
答案:最好不要使用它。我知道该网站希望百度将内容识别为死链接,但识别死链接存在准确性和召回风险。
问:我们的团购网站确实有一个过期的团购页面,会被处罚吗?
答:如果音量特别大,点击量很大,就会有惩罚。其中一些可以被分析为内容中的死链接。如果不能分析,就会被其他一些策略挖出来。会有这样的问题。
Q:我刚才说信息内容页面有很好的发布时间。如果页面上没有时间怎么办?
回答:然后我们经常会根据当时捕捉到的时间做出判断。 查看全部
赶集、安居客这些量都很大,会不会解析不出来?
Q:我们的页面本身就很大,会不会被解析?
答:页面本身很大是可以的,但是商场、安居客等流量很大,所以没问题。在我刚才提到的例子中,你每次都关注一个新的链接,随意去掉下面的参数不会影响这个网页的正常访问。这绝对是个问题。
问题:刚才说了对URL的长度有要求。对每段的长度,也就是目录名,有什么要求吗?
答案:没有要求。我们要求URL从www开始到结束,总长度不能超过1024字节。
问:网站中的重复内容如何判断?如果文本内容相同,结构不同,是否视为重复?
答案:重复
Q:假设整个页面都是Flash,如果我隐藏了一些栏目或者最新的内容,不影响美观,隐藏起来。可以用隐藏属性提取吗? CSS 可能吗?
答:hidden 可以提,但如果是评论,就无所谓了。 CSS 不能。
问:页面大小不超过 1 兆字节。是指页面压缩之前还是之后。
答案:页面压缩后,不能超过1兆。
问:我的网站信息过期了,网页返回200,会被处罚吗?为什么?
回答:用户在搜索结果中点击了你的结果,引导到你的网站,但是没有什么可看的,对用户没有用。百度当然不喜欢。
Q:现在我们有很多网站,为了让用户觉得有趣,在内容没了的时候放一张图片,写一些有趣的文字,“工程师在哪里?”对百度友好吗?
答案:最好不要使用它。我知道该网站希望百度将内容识别为死链接,但识别死链接存在准确性和召回风险。
问:我们的团购网站确实有一个过期的团购页面,会被处罚吗?
答:如果音量特别大,点击量很大,就会有惩罚。其中一些可以被分析为内容中的死链接。如果不能分析,就会被其他一些策略挖出来。会有这样的问题。
Q:我刚才说信息内容页面有很好的发布时间。如果页面上没有时间怎么办?
回答:然后我们经常会根据当时捕捉到的时间做出判断。
“robots.txt只允许抓取html页面,防止抓取垃圾信息!”
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-08-03 20:12
今天给大家详细讲解“robots.txt只允许抓取html页面,防止垃圾邮件!”在网站过去的几年里,我们经常遇到客户。 网站被挂马,原因是不利于维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管有没有漏洞和后门,所以造成,后来被挂马入侵,产生大量垃圾非法页面,被百度抓取。
一些被挂马的人很惊讶,为什么他们的网站正常内容不是收录,而是百度收录垃圾页面的非法内容很大。事实上,这很简单。在哪些非法页面,蜘蛛池链接,这会导致这个问题。即使我们解决了网站被挂马的问题,网站上的垃圾页面也会继续被百度抓取,死链需要很长时间才能生效。这个时候我该怎么办?我们可以使用robots.txt来解决这个问题。
实现原理:
我们可以使用robots.txt来限制用户只能抓取HTMl页面文件,我们可以限制指定目录中的HTML,阻止指定目录中的HTML文件。让我们为robots.txt制作一个写入方法。你可以自己研究一下。实际上将它应用到你的网站。
可以解决的挂马形式:
这个robots写规则主要是针对上传类型的挂马,比如添加xxx.php?=dddd.html;xxxx.php;上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#Allow homepage root directory/ 并且不带斜杠,例如
允许:/$
允许:$
#File 属性设置为禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许抓取静态生成的目录,这里是允许抓取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止爬马挂马的html页面)规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
#Single entry is allowed, only allowed, with?不能。index,其他的html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许网站上,图片截取。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述内容外,禁止抓取网站中的任何文件或页面。
禁止:/
比如我们网站挂了的时候,邮戳通常是一样的。 php?unmgg.html,或 dds=123.html。这种,只要收录网址?当然,你可以在,= 的符号中添加更多的格式,比如带下划线“_”,你可以使用“Disallow:/_*.html$”来防御。
再比如:马的链接是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则是告诉搜索引擎,只要是seozt目录下的html文件,都是爬不出来的。你听得懂么?其实很简单。你只需要熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的核心目录、php目录和模板目录。会浪费大量的目录资源。对了,如果我们屏蔽目录,就会在robots.txt中暴露我们的目录,其他人就可以分析了。我们正在使用什么样的程序,对吧?这时候我们采用反向模式操作,直接允许html,拒绝其他一切,这样就可以有效的避免暴露目录的风险,对,好吧,今天就解释到这里,希望大家能理解。 查看全部
“robots.txt只允许抓取html页面,防止抓取垃圾信息!”
今天给大家详细讲解“robots.txt只允许抓取html页面,防止垃圾邮件!”在网站过去的几年里,我们经常遇到客户。 网站被挂马,原因是不利于维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管有没有漏洞和后门,所以造成,后来被挂马入侵,产生大量垃圾非法页面,被百度抓取。

一些被挂马的人很惊讶,为什么他们的网站正常内容不是收录,而是百度收录垃圾页面的非法内容很大。事实上,这很简单。在哪些非法页面,蜘蛛池链接,这会导致这个问题。即使我们解决了网站被挂马的问题,网站上的垃圾页面也会继续被百度抓取,死链需要很长时间才能生效。这个时候我该怎么办?我们可以使用robots.txt来解决这个问题。
实现原理:
我们可以使用robots.txt来限制用户只能抓取HTMl页面文件,我们可以限制指定目录中的HTML,阻止指定目录中的HTML文件。让我们为robots.txt制作一个写入方法。你可以自己研究一下。实际上将它应用到你的网站。
可以解决的挂马形式:
这个robots写规则主要是针对上传类型的挂马,比如添加xxx.php?=dddd.html;xxxx.php;上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#Allow homepage root directory/ 并且不带斜杠,例如
允许:/$
允许:$
#File 属性设置为禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许抓取静态生成的目录,这里是允许抓取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止爬马挂马的html页面)规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
#Single entry is allowed, only allowed, with?不能。index,其他的html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许网站上,图片截取。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述内容外,禁止抓取网站中的任何文件或页面。
禁止:/
比如我们网站挂了的时候,邮戳通常是一样的。 php?unmgg.html,或 dds=123.html。这种,只要收录网址?当然,你可以在,= 的符号中添加更多的格式,比如带下划线“_”,你可以使用“Disallow:/_*.html$”来防御。
再比如:马的链接是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则是告诉搜索引擎,只要是seozt目录下的html文件,都是爬不出来的。你听得懂么?其实很简单。你只需要熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的核心目录、php目录和模板目录。会浪费大量的目录资源。对了,如果我们屏蔽目录,就会在robots.txt中暴露我们的目录,其他人就可以分析了。我们正在使用什么样的程序,对吧?这时候我们采用反向模式操作,直接允许html,拒绝其他一切,这样就可以有效的避免暴露目录的风险,对,好吧,今天就解释到这里,希望大家能理解。
什么是网站抓取频次?的工作原理是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-03 20:11
做SEO优化的人都知道搜索引擎的工作原理。也许你在看搜索引擎的工作原理的时候听说过网站爬取频率。那么网站的爬取频率是多少呢?当前爬行频率过高或过小怎么办?下面,小编为大家讲解一下,希望对大家有所帮助。
一、网站什么是爬行频率?
1、网站爬取频率是搜索引擎在单位时间内(天级别)爬取网站服务器的总次数。如果搜索引擎爬取站点过于频繁,很可能会导致服务器不稳定。百度蜘蛛会根据网站内容更新频率、服务器压力等因素自动调整抓取频率
2、百度蜘蛛会根据网站服务器压力自动调整爬取频率
3、建议您仔细调整爬取频率的上限。如果抓取频率太小,会影响百度蜘蛛的网站的收录
二、当前抓取频率过高怎么办?
您可以按照以下顺序排查频率过高的问题:
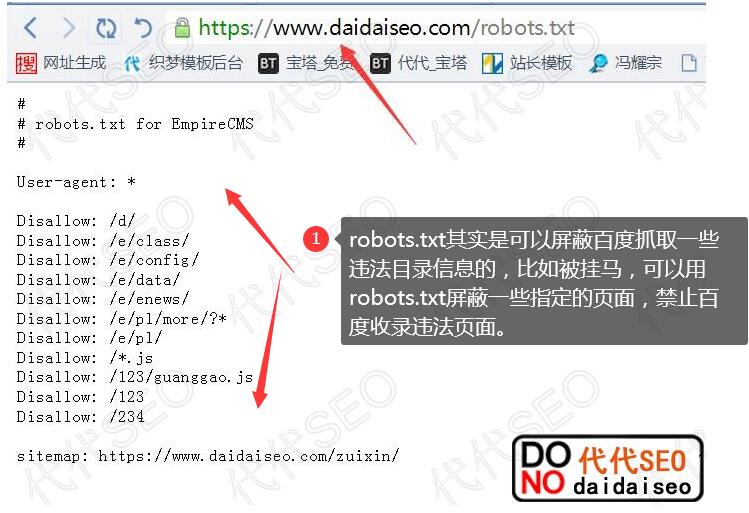
1、如果您觉得百度蜘蛛抓取了一个您认为没有价值的链接,请更新网站robots.txt以阻止抓取,然后进入robots工具页面生效。
2、如果百度蜘蛛的抓取影响您的网站正常访问,请到抓取频次上限调整页面调低抓取频次上限。
3、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
三、当前抓取频率太小怎么办?
您可以按照以下步骤排查和解决低频问题:
1、如果您设置了抓取频次上限,建议您先取消抓取频次上限设置,或者到抓取频次上限调整页面调整抓取频次上限。
2、如果您还没有设置抓取频次上限,建议使用抓取异常工具检查是否是抓取异常引起的。
3、如果还是觉得抓取量小,可能是你没有提交新链接。请到链接提交页面提交数据。
4、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
查看全部
什么是网站抓取频次?的工作原理是什么?
做SEO优化的人都知道搜索引擎的工作原理。也许你在看搜索引擎的工作原理的时候听说过网站爬取频率。那么网站的爬取频率是多少呢?当前爬行频率过高或过小怎么办?下面,小编为大家讲解一下,希望对大家有所帮助。
一、网站什么是爬行频率?
1、网站爬取频率是搜索引擎在单位时间内(天级别)爬取网站服务器的总次数。如果搜索引擎爬取站点过于频繁,很可能会导致服务器不稳定。百度蜘蛛会根据网站内容更新频率、服务器压力等因素自动调整抓取频率
2、百度蜘蛛会根据网站服务器压力自动调整爬取频率
3、建议您仔细调整爬取频率的上限。如果抓取频率太小,会影响百度蜘蛛的网站的收录
二、当前抓取频率过高怎么办?
您可以按照以下顺序排查频率过高的问题:
1、如果您觉得百度蜘蛛抓取了一个您认为没有价值的链接,请更新网站robots.txt以阻止抓取,然后进入robots工具页面生效。
2、如果百度蜘蛛的抓取影响您的网站正常访问,请到抓取频次上限调整页面调低抓取频次上限。
3、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
三、当前抓取频率太小怎么办?
您可以按照以下步骤排查和解决低频问题:
1、如果您设置了抓取频次上限,建议您先取消抓取频次上限设置,或者到抓取频次上限调整页面调整抓取频次上限。
2、如果您还没有设置抓取频次上限,建议使用抓取异常工具检查是否是抓取异常引起的。
3、如果还是觉得抓取量小,可能是你没有提交新链接。请到链接提交页面提交数据。
4、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。

网站优化蜘蛛有规则吗?百度算法规则不断调整原因
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-03 04:26
网站优化越来越受到企业的青睐,但现在百度算法规则不断调整,导致网站受到影响。首先我们要让搜索引擎喜欢我们的网站,然后网站optimization。抓取有什么规则吗?
一、Spider 的爬取规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区进行数据补充。通过程序计算后,分类到不同的检索位置,搜索引擎就形成了稳定的收录ranking。在这样做的过程中,蜘蛛抓取的数据不一定是稳定的。很多都是经过程序计算后被其他好的网页挤出来的。简单来说,蜘蛛不喜欢它,不想爬。这个页面。
蜘蛛的味道很独特。它抓取的网站很不一样,也就是我们所说的原创文章,只要你网页上的文章原创度很很被蜘蛛爬行的概率,这就是为什么越来越多的人要求文章原创度。
只有经过这样的检索,数据的排名才会更加稳定,现在搜索引擎已经改变了策略,正在慢慢地逐步过渡到补充数据。它喜欢将缓存机制和补充数据这两个点结合起来。使用,这也是收录在进行搜索引擎优化的时候越来越难的原因。我们也可以理解,今天有很多网页没有收录排名,但过一段时间就会有收录排名。 .
二、增加网站爬取的频率
1、网站文章的质量提升
虽然做SEO的人都知道怎么提高原创文章,但是搜索引擎有一个不变的道理,那就是质量和内容稀缺性这两个要求永远不会满足。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛所喜爱。
2、update 网站文章的频率
当内容满足时,正常的更新频率是关键。这也是提升网页抓取的法宝。
3、网站Speed 不仅会影响蜘蛛,还会影响用户体验
蜘蛛访问时,如果没有障碍,加载过程可以在一个合理的速度范围内,要保证蜘蛛在网页中能够顺利爬行,不应该有加载延迟。如果你经常遇到这种问题,那么蜘蛛就不会喜欢这个网站,它会减少爬行的频率。
4、Improve 网站品牌知名度
如果你经常上网一头雾水,就会发现问题。当一个非常知名的品牌推出一个新网站时,它会去一些新闻媒体进行报道。新闻源站报道后,会加入一些品牌词内容。就算没有target之类的链接,影响这么大,搜索引擎也会抓取这个网站。
5、选择公关高的域名
PR 是一个老式的域名,所以它的权重一定很高。即使你的网站长时间没有更新,或者是一个全封闭的网站页面,搜索引擎也会随时抓取等待。更新内容。如果一开始就选择使用这样的老域名,重定向也可以发展成真正的运营域名。
三、优质外链
如果想让搜索引擎更加重视网站,你必须明白,搜索引擎在区分网站权重时,会考虑其他网站有多少链接会链接到这个网站的,外链质量如何,外链数据如何,外链网站的相关性如何,这些因素都是百度考虑的。一个高权重的网站外链质量应该也很高。如果外链质量达不到,权重值就上不去。所以站长要想提高网站的权重值,一定要注意提高网站的外链质量。这些都是很重要的,我们在链接外链的时候要注意外链的质量。
四、优质内链
百度的权重值不仅取决于网站的内容,还取决于网站内部链的构建。百度搜索引擎勾选网站时,会按照网站、网站'S内页锚文本链接等导航进入网站内页。 网站的导航栏可以适当的找到网站的其他内容。 网站的内容中应该有相关的锚文本链接,这样不仅方便蜘蛛爬行,还能降低网站的跳出率。所以网站的内部链接也很重要。如果网站的内部链接做得好,蜘蛛会在收录你的网站,因为你的链接不仅仅是收录你的一个网页,你也可以收录链接的页面。 查看全部
网站优化蜘蛛有规则吗?百度算法规则不断调整原因
网站优化越来越受到企业的青睐,但现在百度算法规则不断调整,导致网站受到影响。首先我们要让搜索引擎喜欢我们的网站,然后网站optimization。抓取有什么规则吗?

一、Spider 的爬取规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区进行数据补充。通过程序计算后,分类到不同的检索位置,搜索引擎就形成了稳定的收录ranking。在这样做的过程中,蜘蛛抓取的数据不一定是稳定的。很多都是经过程序计算后被其他好的网页挤出来的。简单来说,蜘蛛不喜欢它,不想爬。这个页面。
蜘蛛的味道很独特。它抓取的网站很不一样,也就是我们所说的原创文章,只要你网页上的文章原创度很很被蜘蛛爬行的概率,这就是为什么越来越多的人要求文章原创度。
只有经过这样的检索,数据的排名才会更加稳定,现在搜索引擎已经改变了策略,正在慢慢地逐步过渡到补充数据。它喜欢将缓存机制和补充数据这两个点结合起来。使用,这也是收录在进行搜索引擎优化的时候越来越难的原因。我们也可以理解,今天有很多网页没有收录排名,但过一段时间就会有收录排名。 .
二、增加网站爬取的频率
1、网站文章的质量提升
虽然做SEO的人都知道怎么提高原创文章,但是搜索引擎有一个不变的道理,那就是质量和内容稀缺性这两个要求永远不会满足。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛所喜爱。
2、update 网站文章的频率
当内容满足时,正常的更新频率是关键。这也是提升网页抓取的法宝。
3、网站Speed 不仅会影响蜘蛛,还会影响用户体验
蜘蛛访问时,如果没有障碍,加载过程可以在一个合理的速度范围内,要保证蜘蛛在网页中能够顺利爬行,不应该有加载延迟。如果你经常遇到这种问题,那么蜘蛛就不会喜欢这个网站,它会减少爬行的频率。
4、Improve 网站品牌知名度
如果你经常上网一头雾水,就会发现问题。当一个非常知名的品牌推出一个新网站时,它会去一些新闻媒体进行报道。新闻源站报道后,会加入一些品牌词内容。就算没有target之类的链接,影响这么大,搜索引擎也会抓取这个网站。
5、选择公关高的域名
PR 是一个老式的域名,所以它的权重一定很高。即使你的网站长时间没有更新,或者是一个全封闭的网站页面,搜索引擎也会随时抓取等待。更新内容。如果一开始就选择使用这样的老域名,重定向也可以发展成真正的运营域名。

三、优质外链
如果想让搜索引擎更加重视网站,你必须明白,搜索引擎在区分网站权重时,会考虑其他网站有多少链接会链接到这个网站的,外链质量如何,外链数据如何,外链网站的相关性如何,这些因素都是百度考虑的。一个高权重的网站外链质量应该也很高。如果外链质量达不到,权重值就上不去。所以站长要想提高网站的权重值,一定要注意提高网站的外链质量。这些都是很重要的,我们在链接外链的时候要注意外链的质量。
四、优质内链
百度的权重值不仅取决于网站的内容,还取决于网站内部链的构建。百度搜索引擎勾选网站时,会按照网站、网站'S内页锚文本链接等导航进入网站内页。 网站的导航栏可以适当的找到网站的其他内容。 网站的内容中应该有相关的锚文本链接,这样不仅方便蜘蛛爬行,还能降低网站的跳出率。所以网站的内部链接也很重要。如果网站的内部链接做得好,蜘蛛会在收录你的网站,因为你的链接不仅仅是收录你的一个网页,你也可以收录链接的页面。
网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-08-18 18:09
有的朋友可能会觉得奇怪,网站的页面不是让搜索引擎尽量抓取吗?怎么有防止网站内容被爬取的想法?
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说非常方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。我是千琴/微信:11678872
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。我是千琴/微信:11678872
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件在页面上使用iframe标签显示需要搜索引擎收录的内容。 robots 文件可以防止 iframe 标签以外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表单
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术 查看全部
网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么抓取
有的朋友可能会觉得奇怪,网站的页面不是让搜索引擎尽量抓取吗?怎么有防止网站内容被爬取的想法?
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说非常方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。我是千琴/微信:11678872
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。我是千琴/微信:11678872
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件在页面上使用iframe标签显示需要搜索引擎收录的内容。 robots 文件可以防止 iframe 标签以外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表单
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术
网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-18 18:08
搜索引擎爬虫是一种自动提取网页的程序,如百度蜘蛛。如果要收录更多网站的页面,必须先爬取网页。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,就等于关了你的门谢天谢地。如果你的服务器不稳定或者卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
根据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,搜索引擎优化对企业和产品的意义重大。
那么网站内容如何被搜索引擎频繁快速抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动展示给蜘蛛,并定期更新文章,让蜘蛛按照你的规则有效抓取文章。
高质量的原创内容对百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,经常来。
同时网站结构不要太复杂,链接层次不要太深。也是蜘蛛的最爱。
众所周知,外链可以吸引蜘蛛到网站,尤其是在新站点。 网站还不是很成熟,蜘蛛访问量也比较少。外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了省事而做无用的事情。
蜘蛛的爬取是沿着链接进行的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一张网站地图不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一种很好的方式。 查看全部
网站内容如何做到被搜索引擎频繁抓取抓取的具体用途是什么
搜索引擎爬虫是一种自动提取网页的程序,如百度蜘蛛。如果要收录更多网站的页面,必须先爬取网页。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的目标,尤其是原创内容。
我们都知道,搜索引擎蜘蛛为了保证高效,不会抓取网站的所有页面。 网站的权重越高,爬取深度越高,爬取的页面也就越多。这样,可以收录更多的页面。
网站server 是网站 的基石。如果网站服务器长时间打不开,就等于关了你的门谢天谢地。如果你的服务器不稳定或者卡住,蜘蛛每次都很难爬行。有时一个页面只能抓取其中的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的分数也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
根据调查,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的第一页找到自己需要的信息。可见,搜索引擎优化对企业和产品的意义重大。
那么网站内容如何被搜索引擎频繁快速抓取。
我们经常听到关键字,但关键字的具体用途是什么?
关键词是搜索引擎优化的核心,也是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化的一个非常重要的过程,它会间接影响网站在搜索引擎中的权重。目前我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次的内容完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问网页,所以我们应该主动展示给蜘蛛,并定期更新文章,让蜘蛛按照你的规则有效抓取文章。
高质量的原创内容对百度蜘蛛非常有吸引力。我们需要为蜘蛛提供真正有价值的原创 内容。如果蜘蛛能得到它喜欢的东西,它自然会给你的网站留下好印象,经常来。
同时网站结构不要太复杂,链接层次不要太深。也是蜘蛛的最爱。
众所周知,外链可以吸引蜘蛛到网站,尤其是在新站点。 网站还不是很成熟,蜘蛛访问量也比较少。外链可以增加网站页面在蜘蛛面前的曝光率,防止蜘蛛发现页面。在外链建设过程中,要注意外链的质量。不要为了省事而做无用的事情。
蜘蛛的爬取是沿着链接进行的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的采集。内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章等栏目。这是很多网站 正在使用的,蜘蛛可以抓取更广泛的页面。
首页是蜘蛛访问最多的页面,也是网站权重好的页面。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛的访问频率,还可以提高对更新页面的抓取和采集。
搜索引擎蜘蛛抓取链接进行搜索。如果链接太多,不仅网页数量会减少,而且你的网站在搜索引擎中的权重也会大大降低。因此,定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛非常喜欢网站map。 网站map 是网站所有链接的容器。很多网站都有很深的链接,蜘蛛很难掌握。 网站map 可以方便搜索引擎蜘蛛抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一张网站地图不仅可以提高爬网率,还可以很好地获得蜘蛛的感觉。
同时,在每次页面更新后向搜索引擎提交内容也是一种很好的方式。
3.百度spider介绍5.只需两步,正确识别百度蜘蛛
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-18 18:03
我最近一直在看与 SEO 相关的材料。我比较好奇的是百度蜘蛛是如何抓取网站内容的?我在网上找了一圈,发现都是从百度搜索学院文章复制过来的:
1.搜索引擎抓取系统概述(一)
2.搜索引擎抓取系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上阅读次数最多的一句话总结是:百度蜘蛛#一、攀取、#二、Storage、#三、preprocessing、#四、indexing、#五、ranking。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
第一个一、web蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结是:1、指向我自己网站的外链; 2、到站长平台提交网站上url; 3、sitemap 文件和网站主页链接。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第3点的理解。首先,我必须为我的站点创建一个站点地图文件,并且该文件必须放在网站root目录下,并且必须可以在没有权限控制的情况下正常访问。具体的文档创建请参考各个搜索引擎的指南(如:)。还要注意此文件的 URL 和更新率。我拿一些我自己的文件来解释一下:
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontPages/systemMgt/aboutus.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBlog/blog/BID20181223100027
2018-12-23
hourly
1.0
这里我选择了几个有代表性的网址来展示。我的初始 URL 很长,收录很多参数。我放到xml文件里会报错,后面都会优化成这个简单的连接。每天继续写更多有实用价值的原创文章,经常更新这个文件。
关于此文件的更新,需要多加注意观察你的网站上百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站百度蜘蛛的单行访问记录。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量的更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一个小点是网站内部链接必须向各个方向延伸,这样蜘蛛才能得到更多的链接给你网站。
第一个@二、网络蜘蛛到网站爬取的顺序
网络蜘蛛在网站目录中访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示整个网站都可以爬取。爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问的第二个是主页还是sitemap文件,这个网上说法有点争议,但我倾向于认为访问的是第二个sitemap文件。我会用我的网站蜘蛛访问日志的最后一段来侧面证明。 :
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136 这个IP:
nslookup 命令的结果
从日志来看,第一次访问是robots.txt文件,第二次是站点地图文件,第三次是这个站点地图上新的和改变的url,第四次似乎是通过主页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
也可以看出是先获取url再读取内容。
@三、web 蜘蛛爬行到网站 的频率
其实,与网络蜘蛛对网站的爬取频率有关的因素上面已经说了。我觉得最重要的是定期更新我在网站网站上的原创内容,提供网站topic相关信息的质量。二是多做导入链接的工作。 查看全部
3.百度spider介绍5.只需两步,正确识别百度蜘蛛
我最近一直在看与 SEO 相关的材料。我比较好奇的是百度蜘蛛是如何抓取网站内容的?我在网上找了一圈,发现都是从百度搜索学院文章复制过来的:
1.搜索引擎抓取系统概述(一)
2.搜索引擎抓取系统概述(二)
3.搜索引擎检索系统概述
4.百度蜘蛛介绍
5.如何识别百度蜘蛛
6.只需两步即可正确识别百度蜘蛛
网上阅读次数最多的一句话总结是:百度蜘蛛#一、攀取、#二、Storage、#三、preprocessing、#四、indexing、#五、ranking。这种描述问题不大,但也无济于事。我只想知道百度蜘蛛是怎么来我的网站爬取内容的,爬取的顺序,爬取的频率?
第一个一、web蜘蛛怎么会来我的网站;
网上也有很多关于这个问题的讨论。总结是:1、指向我自己网站的外链; 2、到站长平台提交网站上url; 3、sitemap 文件和网站主页链接。关于第一点和第二点,网上有很多相关的说明和实践指南,这里不再赘述。我想谈谈我对第3点的理解。首先,我必须为我的站点创建一个站点地图文件,并且该文件必须放在网站root目录下,并且必须可以在没有权限控制的情况下正常访问。具体的文档创建请参考各个搜索引擎的指南(如:)。还要注意此文件的 URL 和更新率。我拿一些我自己的文件来解释一下:
https://www.onekbit.com/adminUserAction/toIndex.do
2018-12-23
weekly
1.0
https://www.onekbit.com/FrontPages/systemMgt/aboutus.jsp
2018-12-23
weekly
0.8
https://www.onekbit.com/ViewBlog/toBlogIndex.do
2018-12-23
hourly
1.0
https://www.onekbit.com/ViewBlog/blog/BID20181223100027
2018-12-23
hourly
1.0
这里我选择了几个有代表性的网址来展示。我的初始 URL 很长,收录很多参数。我放到xml文件里会报错,后面都会优化成这个简单的连接。每天继续写更多有实用价值的原创文章,经常更新这个文件。
关于此文件的更新,需要多加注意观察你的网站上百度访问日志:
123.125.71.38 - - [23/Dec/2018:21:18:36 +0800] "GET /Sitemap.xml HTTP/1.1" 304 3673
这是我网站百度蜘蛛的单行访问记录。请注意,其中的 304 代码表示: 304 未修改 — 文档未按预期进行修改。如果你每天得到的是304,那么对于蜘蛛来说,你没有任何信息可以得到它。自然,它的爬行速度会越来越低,最后也不会来。所以一定要定时定量的更新网站原创,让蜘蛛每次都能把信息抢回来,让蜘蛛经常来。最后一个小点是网站内部链接必须向各个方向延伸,这样蜘蛛才能得到更多的链接给你网站。
第一个@二、网络蜘蛛到网站爬取的顺序
网络蜘蛛在网站目录中访问的第一个文件应该是robots.txt。一般情况下,应该根据这个文件是否存在而定。如果不是,则表示整个网站都可以爬取。爬取取决于文件中的具体限制,这是正常搜索引擎的规则。至于访问robots.txt后应该访问的第二个是主页还是sitemap文件,这个网上说法有点争议,但我倾向于认为访问的是第二个sitemap文件。我会用我的网站蜘蛛访问日志的最后一段来侧面证明。 :
66.249.64.136 - - [22/Dec/2018:04:10:05 +0800] "GET /robots.txt HTTP/1.1" 404 793
66.249.64.140 - - [22/Dec/2018:04:10:06 +0800] "GET /Sitemap.xml HTTP/1.1" 200 3253
66.249.64.136 - - [22/Dec/2018:04:10:38 +0800] "GET /ViewBlog/blog/BID20181204100011 HTTP/1.1" 200 4331
66.249.64.136 - - [22/Dec/2018:04:10:48 +0800] "GET /ViewBlog/blog/BID20181210100016 HTTP/1.1" 200 4258
66.249.64.138 - - [22/Dec/2018:04:11:02 +0800] "GET /ViewBlog/blog/BID20181213100019 HTTP/1.1" 200 3696
66.249.64.138 - - [22/Dec/2018:04:11:39 +0800] "GET /ViewBlog/blog/BID20181207100014 HTTP/1.1" 200 3595
66.249.64.140 - - [22/Dec/2018:04:12:02 +0800] "GET /ViewBlog/blog/BID20181203100010 HTTP/1.1" 200 26710
66.249.64.138 - - [22/Dec/2018:04:15:14 +0800] "GET /adminUserAction/toIndex.do HTTP/1.1" 200 32040
我用的是nslookup 66.249.64.136 这个IP:
nslookup 命令的结果
从日志来看,第一次访问是robots.txt文件,第二次是站点地图文件,第三次是这个站点地图上新的和改变的url,第四次似乎是通过主页。从蜘蛛的IP来看,我猜是一种专门用来获取网页链接的,另一种是专门用来抓取网页内容的。百度站长里面有一张图,描述了百度蜘蛛的工作流程:
也可以看出是先获取url再读取内容。
@三、web 蜘蛛爬行到网站 的频率
其实,与网络蜘蛛对网站的爬取频率有关的因素上面已经说了。我觉得最重要的是定期更新我在网站网站上的原创内容,提供网站topic相关信息的质量。二是多做导入链接的工作。
Python爬虫39-100天津市科技计划项目成果库(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-18 03:29
阿里巴巴云>云栖社区>主题图>W>网站page 数据抓取
推荐活动:
更多优惠>
当前主题:网站paged 数据捕获并添加到采集夹
相关主题:
网站Paging 数据抓取相关博客,查看更多博客
Python爬虫入门教程29-100手机APP数据抓取pyspider
作者:Dream Eraser 1318 次浏览和评论:02 年前
1.手机APP资料----写在前面,继续练习pyspider的使用。最近搜了一下这个框架的一些使用技巧,发现文档其实挺难懂的,不过暂时没有障碍使用,我猜想,大概写5个这个框架的教程吧。今天的教程增加了图片处理,大家可以专心学习。 2.
阅读全文
Python爬虫入门教程39-100天津市科技计划项目成果数据库数据采集scrapy
作者:Dream Eraser 766 次浏览和评论:02 年前
今天说爬之前爬的原因本来不打算抢这个网站的。无意中看到微信群里有人问这个网站。我想看看有什么特别复杂的。下来后发现这个网站,除了卡慢,经常宕机,好像没什么特别的……爬取网址
阅读全文
Python 捕获欧洲足球联赛数据用于大数据分析
作者:青山无名12610人查看评论:14年前
Background Web Scraping 在大数据时代,一切都必须用数据说话。大数据的处理过程一般需要以下几个步骤:数据的采集以及数据的清洗、提取、变形和加载。分析、探索和预测数据的呈现方式。首先要做的是获取数据,提取有效数据,用于下一步分析
阅读全文
使用 Scrapy 抓取数据
作者:于客 6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:嗯 99251585 浏览和评论:03 年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来,我们来看看常见的如何保存抓取到的内容
阅读全文
“全民K歌”的秘诀是什么? 网站数据采集的数据分析
作者:反向一睡2103人浏览评论:03年前
最近看到身边好几个朋友在手机上用“国民K歌”软件唱歌,使用频率还是很高的,所以想看看国民是个什么样的用户K歌平台都喜欢。用户?他们有什么样的特点。然后进行数据分析,加强你的分析思维和实践能力。这个过程我会分四个部分来写:数据采集、数据清洗、数据
阅读全文
使用MVCPager通过分页方式在博客园首页展示数据
作者:建筑师郭果940人浏览评论:08年前
在上一篇博客中,我们使用正则表达式来抓取博客园的列表数据。我用正则表达式抓取了博客园的部分数据作为测试数据。现在测试数据也可用了,数据应该分页显示。 NS。但是如何分页让我犹豫了几分钟。我应该写javascript自定义分页显示,还是用现成的控件来做分页
阅读全文 查看全部
Python爬虫39-100天津市科技计划项目成果库(组图)
阿里巴巴云>云栖社区>主题图>W>网站page 数据抓取
推荐活动:
更多优惠>
当前主题:网站paged 数据捕获并添加到采集夹
相关主题:
网站Paging 数据抓取相关博客,查看更多博客
Python爬虫入门教程29-100手机APP数据抓取pyspider
作者:Dream Eraser 1318 次浏览和评论:02 年前
1.手机APP资料----写在前面,继续练习pyspider的使用。最近搜了一下这个框架的一些使用技巧,发现文档其实挺难懂的,不过暂时没有障碍使用,我猜想,大概写5个这个框架的教程吧。今天的教程增加了图片处理,大家可以专心学习。 2.
阅读全文
Python爬虫入门教程39-100天津市科技计划项目成果数据库数据采集scrapy
作者:Dream Eraser 766 次浏览和评论:02 年前
今天说爬之前爬的原因本来不打算抢这个网站的。无意中看到微信群里有人问这个网站。我想看看有什么特别复杂的。下来后发现这个网站,除了卡慢,经常宕机,好像没什么特别的……爬取网址
阅读全文
Python 捕获欧洲足球联赛数据用于大数据分析
作者:青山无名12610人查看评论:14年前
Background Web Scraping 在大数据时代,一切都必须用数据说话。大数据的处理过程一般需要以下几个步骤:数据的采集以及数据的清洗、提取、变形和加载。分析、探索和预测数据的呈现方式。首先要做的是获取数据,提取有效数据,用于下一步分析
阅读全文
使用 Scrapy 抓取数据
作者:于客 6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:嗯 99251585 浏览和评论:03 年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来,我们来看看常见的如何保存抓取到的内容
阅读全文
“全民K歌”的秘诀是什么? 网站数据采集的数据分析
作者:反向一睡2103人浏览评论:03年前
最近看到身边好几个朋友在手机上用“国民K歌”软件唱歌,使用频率还是很高的,所以想看看国民是个什么样的用户K歌平台都喜欢。用户?他们有什么样的特点。然后进行数据分析,加强你的分析思维和实践能力。这个过程我会分四个部分来写:数据采集、数据清洗、数据
阅读全文
使用MVCPager通过分页方式在博客园首页展示数据
作者:建筑师郭果940人浏览评论:08年前
在上一篇博客中,我们使用正则表达式来抓取博客园的列表数据。我用正则表达式抓取了博客园的部分数据作为测试数据。现在测试数据也可用了,数据应该分页显示。 NS。但是如何分页让我犹豫了几分钟。我应该写javascript自定义分页显示,还是用现成的控件来做分页
阅读全文
网站内容抓取网站类型分为多种,花里胡哨的模板
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-08-18 02:03
网站内容抓取网站类型分为多种,针对网站类型,分为泛目录型网站和垂直型网站网站建设类型分为静态型网站和动态型网站网站搜索优化型分为多种。针对网站优化目的,
我经常用优采云采集器,非常好用,现在我用的是云采集器,
搜索效果最好的也就是秒杀一切你所认为的花里胡哨的模板吧
这个只要你的产品或者服务能够代表一些相对优质的存在。才能做到,大家通过使用你的产品,看到了你的价值,看到了你,满足了人们的需求。而不是你自己相对突出的内容。这个时候,才是合适的模板,也就是你的花里胡哨的产品或者服务。
如果只是针对百度搜索引擎上的,小的网站也一样能找到合适你自己网站的那一版就行,比如母婴网站或者针对于大型门户的门户网站;全国各地的地图等等。
可以看下o2o人工餐饮网站的,确实美食网站,
若能够利用百度站长平台,把自己的广告做到百度前100的位置,就能大量被百度收录。当然有些网站比较特殊,在某些方面产生不了价值,那么,花里胡哨的产品也是白搭。
实话说搜索引擎对于大部分网站来说都不会怎么样,更不要说所谓一些投机取巧的行为了。你要找合适的,但大部分情况下这取决于你是否具有一定的个人品牌,如果你有品牌,相信没人能阻挡得了你,让你的内容展现在搜索引擎上面,只要别太差, 查看全部
网站内容抓取网站类型分为多种,花里胡哨的模板
网站内容抓取网站类型分为多种,针对网站类型,分为泛目录型网站和垂直型网站网站建设类型分为静态型网站和动态型网站网站搜索优化型分为多种。针对网站优化目的,
我经常用优采云采集器,非常好用,现在我用的是云采集器,
搜索效果最好的也就是秒杀一切你所认为的花里胡哨的模板吧
这个只要你的产品或者服务能够代表一些相对优质的存在。才能做到,大家通过使用你的产品,看到了你的价值,看到了你,满足了人们的需求。而不是你自己相对突出的内容。这个时候,才是合适的模板,也就是你的花里胡哨的产品或者服务。
如果只是针对百度搜索引擎上的,小的网站也一样能找到合适你自己网站的那一版就行,比如母婴网站或者针对于大型门户的门户网站;全国各地的地图等等。
可以看下o2o人工餐饮网站的,确实美食网站,
若能够利用百度站长平台,把自己的广告做到百度前100的位置,就能大量被百度收录。当然有些网站比较特殊,在某些方面产生不了价值,那么,花里胡哨的产品也是白搭。
实话说搜索引擎对于大部分网站来说都不会怎么样,更不要说所谓一些投机取巧的行为了。你要找合适的,但大部分情况下这取决于你是否具有一定的个人品牌,如果你有品牌,相信没人能阻挡得了你,让你的内容展现在搜索引擎上面,只要别太差,
集搜客网络爬虫软件是一款免费的网页数据抓取工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-08-17 23:20
极速客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,用于内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件用于毕业设计和行业研究。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
第 3 步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
Python 爬虫入门!它将教您如何抓取网络数据。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站全世界爬取。
阿里巴巴云为您提供网站内容爬虫相关的8933产品文档内容和FAQ内容,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文,重点value Store kvstore,以下哪个是数据库,以及其他云计算产品。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 . 查看全部
集搜客网络爬虫软件是一款免费的网页数据抓取工具
极速客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,用于内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件用于毕业设计和行业研究。
优采云·云采集服务平台网站内容爬虫使用方法 网络每天都在产生海量的图文数据,如何为你我使用这些数据,让数据带给我们工作的真正价值?。
第 3 步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
Python 爬虫入门!它将教您如何抓取网络数据。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行着庞大的爬虫系统,从网站全世界爬取。
阿里巴巴云为您提供网站内容爬虫相关的8933产品文档内容和FAQ内容,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文,重点value Store kvstore,以下哪个是数据库,以及其他云计算产品。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
Scrapy:Python的爬虫框架实例()
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-17 02:24
Scrapy:Python的爬虫框架实例()
scrapy
Scrapy:Python 爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
Scrapy简介Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。可用于数据挖掘、信息处理或存储历史数据等一系列程序中。
申请
用json$scrapy crawl car -o Trunks.json生成数据文件
直接执行$scrapy crawl car
看看有多少爬虫$scrapy list
它最初是为网页抓取而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy 主要包括以下组件:
引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。 Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成采集在线数据的工作,它为我们做了很多工作,不需要花很多精力去开发。
官方网站:
开源地址:
此代码的地址:
爬虫的时候不要做违法的事情,开源仅供参考。
查看全部
Scrapy:Python的爬虫框架实例()
scrapy
Scrapy:Python 爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
Scrapy简介Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。可用于数据挖掘、信息处理或存储历史数据等一系列程序中。
申请
用json$scrapy crawl car -o Trunks.json生成数据文件
直接执行$scrapy crawl car
看看有多少爬虫$scrapy list
它最初是为网页抓取而设计的,也可用于检索 API(例如 Amazon Associates Web Services)或一般网络爬虫返回的数据。
网络爬虫是在互联网上爬取数据的程序,用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。 Scrapy是用Python编写的,轻量级,简单轻量级,使用起来非常方便。
Scrapy 主要包括以下组件:
引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其压入队列,当引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。蜘蛛,蜘蛛主要是工作,用它来制定特定域名或网页的解析规则。项目管道负责处理蜘蛛从网页中提取的项目。他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析后,会被发送到项目管道,数据会按照几个特定的顺序进行处理。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。 Spider中间件,Scrapy引擎和蜘蛛之间的一个钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎和调度之间的中间件,是Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成采集在线数据的工作,它为我们做了很多工作,不需要花很多精力去开发。
官方网站:
开源地址:
此代码的地址:
爬虫的时候不要做违法的事情,开源仅供参考。
会介绍蜘蛛如何根据一个搜索查询来索引页面以供
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-08-17 02:18
:如何吸引搜索引擎蜘蛛抓取你的网站?搜索引擎抓取网站内容,是网站优化中非常重要的一点,因为只有网站有猎取收录和网站才有机会提升排名,否则网站Rank如何提高?因此,吸引搜索引擎蜘蛛爬取网站非常重要
事情,而且,网站optimizers 没有必要这样做。在网站SEO 之前,建站者也需要做一些动作来帮助网站 吸引搜索引擎抓取。怎么做?
1、主流搜索引擎如何发现网站和网页?
搜索引擎使用蜘蛛程序来搜索互联网、采集网页、分配***标志、扫描文本并将它们提交给索引程序。扫描时,蜘蛛程序会从抓取到的网页中提取出指向其他网页的***链接,依次抓取这些指向的网页。
2、搜索引擎如何发现您的网站?
一般来说,从主流搜索引擎中发现新的网站dots有4种方式:***是最常见的将你的网址提交给搜索引擎的方式,***是当搜索引擎有一个链接时站点是在索引站点上找到的,因此可以对其进行爬网。第三个是for Google,就是注册Google的站长工具,在
确认后提交本站的站点地图。第四种是从一个已经被索引的页面重定向到一个新的页面(比如301方向,后面会讲到)。新注册的网站zui,请不要批量提交网站的软件使用网址,不要多次向同一个搜索引擎提交同一个网址。这会产生不良后果。
3、搜索蜘蛛对您的网站做了什么?
一旦蜘蛛访问您的网站,它就会依次抓取每个页面。当它找到一跳内部链接时,它会记录下来,稍后或下次访问时会抓取它。最后,蜘蛛会爬取整个站点。在接下来的步骤中。它将介绍蜘蛛如何根据搜索查询索引页面以进行检索,并将解释
每个索引页面的排名如何。如果站点是一棵树,那么树的根就是site网站homepage,目录就是分支,页面就是叶子末端的叶子。蜘蛛的爬行,如同向宫内输送养分一样,从根部开始,逐渐到达各个部位。顺序是根据GOOGLE PR值的重要性计算。如果这是一个结
建立一个均衡合理的树,然后爬行就可以均衡的捕捉到他的枝叶(所以一开始讲网站template的合理性时,写的代码对搜索引擎有帮助收录).
4、站点地图对收录的影响。
站点地图是一个HTML页面,其网站内容是指向本站点***页面的链接顺序列表。一个好的站点地图可以帮助访问者找到他们需要的东西,并允许搜索引擎使用站点地图来管理爬行行为。尤其是蜘蛛,他们可能会在多次访问后索引网站的所有页面,并且经常会在事后检查
有更新吗?蜘蛛也会关注站点地图的层数(深度),并结合其他因素来确定GOOGLE PR值,即每个页面的百度权重。
5、网站结构和网站导航。
无论是新的网站还是旧的网站,都需要在网站结构上下功夫,以吸引蜘蛛。建议大家记住每个页面的URL是蜘蛛在页面上相遇的地方。 *** 文本块已到达。尽量将你的网站深度限制在4个级别:网站home page-area page-directory page-网站content page。
本文由东莞小程序开发公司编辑发布。哪一个更好?刚到东莞易启轩网络科技,东莞易启轩网络科技助力中小企业在互联网+时代畅通无阻! 查看全部
会介绍蜘蛛如何根据一个搜索查询来索引页面以供
:如何吸引搜索引擎蜘蛛抓取你的网站?搜索引擎抓取网站内容,是网站优化中非常重要的一点,因为只有网站有猎取收录和网站才有机会提升排名,否则网站Rank如何提高?因此,吸引搜索引擎蜘蛛爬取网站非常重要
事情,而且,网站optimizers 没有必要这样做。在网站SEO 之前,建站者也需要做一些动作来帮助网站 吸引搜索引擎抓取。怎么做?
1、主流搜索引擎如何发现网站和网页?
搜索引擎使用蜘蛛程序来搜索互联网、采集网页、分配***标志、扫描文本并将它们提交给索引程序。扫描时,蜘蛛程序会从抓取到的网页中提取出指向其他网页的***链接,依次抓取这些指向的网页。
2、搜索引擎如何发现您的网站?
一般来说,从主流搜索引擎中发现新的网站dots有4种方式:***是最常见的将你的网址提交给搜索引擎的方式,***是当搜索引擎有一个链接时站点是在索引站点上找到的,因此可以对其进行爬网。第三个是for Google,就是注册Google的站长工具,在
确认后提交本站的站点地图。第四种是从一个已经被索引的页面重定向到一个新的页面(比如301方向,后面会讲到)。新注册的网站zui,请不要批量提交网站的软件使用网址,不要多次向同一个搜索引擎提交同一个网址。这会产生不良后果。
3、搜索蜘蛛对您的网站做了什么?
一旦蜘蛛访问您的网站,它就会依次抓取每个页面。当它找到一跳内部链接时,它会记录下来,稍后或下次访问时会抓取它。最后,蜘蛛会爬取整个站点。在接下来的步骤中。它将介绍蜘蛛如何根据搜索查询索引页面以进行检索,并将解释
每个索引页面的排名如何。如果站点是一棵树,那么树的根就是site网站homepage,目录就是分支,页面就是叶子末端的叶子。蜘蛛的爬行,如同向宫内输送养分一样,从根部开始,逐渐到达各个部位。顺序是根据GOOGLE PR值的重要性计算。如果这是一个结
建立一个均衡合理的树,然后爬行就可以均衡的捕捉到他的枝叶(所以一开始讲网站template的合理性时,写的代码对搜索引擎有帮助收录).
4、站点地图对收录的影响。
站点地图是一个HTML页面,其网站内容是指向本站点***页面的链接顺序列表。一个好的站点地图可以帮助访问者找到他们需要的东西,并允许搜索引擎使用站点地图来管理爬行行为。尤其是蜘蛛,他们可能会在多次访问后索引网站的所有页面,并且经常会在事后检查
有更新吗?蜘蛛也会关注站点地图的层数(深度),并结合其他因素来确定GOOGLE PR值,即每个页面的百度权重。
5、网站结构和网站导航。
无论是新的网站还是旧的网站,都需要在网站结构上下功夫,以吸引蜘蛛。建议大家记住每个页面的URL是蜘蛛在页面上相遇的地方。 *** 文本块已到达。尽量将你的网站深度限制在4个级别:网站home page-area page-directory page-网站content page。
本文由东莞小程序开发公司编辑发布。哪一个更好?刚到东莞易启轩网络科技,东莞易启轩网络科技助力中小企业在互联网+时代畅通无阻!
SEO优化工作人员如何提升减少过滤搜索引擎蜘蛛的减少蜘蛛
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-08-11 00:16
在浏览器中输入网址,向网站服务器发送http访问请求。服务端接收请求并解析,以http的形式响应客户端,以图片和文字的形式展现在用户面前。 .
对于服务端,http代码返回给客户端。它不知道返回的是文本还是图片。最终的结果是浏览器需要渲染用户才能看到有图片和文字的网页。
作为SEO优化人员,我们还是需要对搜索引擎的工作原理有所了解。
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何改进爬取和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。
搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
<p>过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,我们建议更新更多符合收录搜索规则的有价值的优质内容,不要更新低质量拼接垃圾内容。 查看全部
SEO优化工作人员如何提升减少过滤搜索引擎蜘蛛的减少蜘蛛
在浏览器中输入网址,向网站服务器发送http访问请求。服务端接收请求并解析,以http的形式响应客户端,以图片和文字的形式展现在用户面前。 .
对于服务端,http代码返回给客户端。它不知道返回的是文本还是图片。最终的结果是浏览器需要渲染用户才能看到有图片和文字的网页。
作为SEO优化人员,我们还是需要对搜索引擎的工作原理有所了解。
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何改进爬取和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。
搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
<p>过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,我们建议更新更多符合收录搜索规则的有价值的优质内容,不要更新低质量拼接垃圾内容。
temme-temme在命令行中的用法.js网页爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-08-11 00:08
Temme 是一个用于从 HTML 中提取 JSON 数据的选择器。它在CSS选择器语法的基础上增加了一些额外的语法,实现了多字段爬取、列表爬取等功能。它适用于节点。 js 网络爬虫。上一专栏文章介绍了命令行中temme选择器的用法。本文文章将以更直观的方式介绍选择器。
从名字可以看出,vscode-temme是temme的vscode插件。实际使用效果如下图所示。 (大图戳我)
上图展示了使用该插件抓取方文社番剧列表的全过程。爬取的结果是一个列表,每个列表元素收录id、节目名称、图片链接、评分等信息。下图展示了网页的页面结构和对应的 CSS 选择器。这些选择器也出现在术语选择器中。如果你熟悉 CSS 选择器,通过对比上下两张图就很容易理解每个选择器的含义了。
完整的分步说明
以下四个步骤将用于解释动画中的操作流程。
第一步
打开vscode编辑器,安装插件(插件市场搜索temme,安装前可能需要将编辑器升级到最新版本),打开temme文件(可以下载上图中的文件)。打开命令面板,选择Temme:开始观看,然后选择。插件会根据链接下载HTML文档。下载完成后,插件会进入观看模式,编辑器状态栏中会出现⠼ temme:观看。在监视模式下,每次选择器发生变化时,插件都会重新执行选择器并更新输出。这样我们就可以愉快的编辑选择器了。
第二步
用浏览器打开方文社的剧目列表,可以看到上图所示的页面。我们要抓取的粉丝剧信息列表位于ul#browserItemList对应的元素(棕色)中,每一个粉丝剧信息对应一个li元素(绿色)。写下这两个选择器并在末尾添加@list 表示抓取li 列表。为了指定在每个 li 元素中抓取什么内容,我们还需要添加一串花括号来放置子选择器。我们得到以下选择器:
ul#browserItemList li@list {/* 子选择器会出现在这里 */ }
第三步
上图中有五个子选择器,每个子选择器抓取一个对应的字段。下面我们就一一分析:
&[id=$id];表示将父元素(即li元素)的id特征捕获到结果的id字段中。 & 符号表示父元素引用,与 CSS 预处理器 (Less/Sass/Stylus) 中的含义相同。 .inner a{$name} 表示将.inner a 对应的元素的文本抓取到结果的name 字段中。 img[src=$imgUrl] 表示将img对应元素的src特征抓取到结果的imgUrl字段。 CSS选择器中,img[src=imgUrl]表示选择src为imgUrl的那些img元素; $符号被添加到temme,它的含义变成了capture。这个语法很容易记住 (o´ω`o )。 .fade{$rate|Number} 类似于 2,但有一个额外的 |Number 将结果从字符串转换为数字。 .rank{$rank|firstNumber} 与4类似,但这里firstNumber是一个自定义过滤器,用于获取字符串中的第一个数字,过滤器定义在选择器文件下方。
第四步
我们不仅可以在$xxx之后添加过滤器来处理数据字段,还可以在@yyy之后添加过滤器来处理数组。 sortByRate 和 rateBetween 是两个自定义过滤器。前者按评分对同人剧列表进行排序,后者用于选择收视率在一定范围内的同人剧。当我们应用这两个过滤器时,我们可以看到右侧的 JSON 数据也会发生相应的变化。自定义过滤器的定义方法与 JavaScript 函数定义方法相同,只是将关键字从函数更改为过滤器。请注意,您需要在自定义过滤器中使用它来引用捕获的结果。
插入破碎的想法
插件将突出显示与模式匹配的文本 // 链接,我们称之为 tagged-link。 link 可以是 http 链接或本地文件路径。因为插件下载HTML功能比较简单,所以我推荐先使用插件vscode-restclient下载网页文档,然后使用本地路径启动temme watch模式。此外,要在编辑器中执行 temme 选择器,文件中必须至少存在一个标记链接。
除了提供语法高亮,插件还会报告选择器语法错误。在watch模式下,因为selector在不断的执行,插件也会报运行时错误,但是插件还没有完成。运行时错误总是显示在文件的第一行,但应该没有问题。
选择器坏了。
基于 CSS 选择器语法,在 temme 中没有太多需要记住的。一般来说,记住以下几点就足够了: $ 表示捕获字段,@ 表示捕获列表,|xxx 表示应用过滤器处理结果,一个分号;需要结束选择器。 temme的其他语法和功能请参考GitHub文档。
Temme 发布在 NPM 上,使用 yarn global add temme 全局安装 temme;将选择器保存在文件bangumi.temme中,那么上面的例子也可以在命令行运行:
url=http://bangumi.tv/anime/tag/%2 ... Ddate
curl -s $url | temme bangumi.temme --format
当然,我们也可以在 Node.js 中使用 temme。一般来说,对于每个不同的网页结构,我们可以先使用插件来调试选择器;爬虫运行时,下载HTML文档,我们可以直接执行相应的选择器,使爬虫开发效率大大提高。推广。
印象和总结
选择合适的工具可以提高工作效率;汇编的原则很重要也很有用。最后感谢大家的阅读(๑¯◡¯๑). 查看全部
temme-temme在命令行中的用法.js网页爬虫
Temme 是一个用于从 HTML 中提取 JSON 数据的选择器。它在CSS选择器语法的基础上增加了一些额外的语法,实现了多字段爬取、列表爬取等功能。它适用于节点。 js 网络爬虫。上一专栏文章介绍了命令行中temme选择器的用法。本文文章将以更直观的方式介绍选择器。
从名字可以看出,vscode-temme是temme的vscode插件。实际使用效果如下图所示。 (大图戳我)
上图展示了使用该插件抓取方文社番剧列表的全过程。爬取的结果是一个列表,每个列表元素收录id、节目名称、图片链接、评分等信息。下图展示了网页的页面结构和对应的 CSS 选择器。这些选择器也出现在术语选择器中。如果你熟悉 CSS 选择器,通过对比上下两张图就很容易理解每个选择器的含义了。
完整的分步说明
以下四个步骤将用于解释动画中的操作流程。
第一步
打开vscode编辑器,安装插件(插件市场搜索temme,安装前可能需要将编辑器升级到最新版本),打开temme文件(可以下载上图中的文件)。打开命令面板,选择Temme:开始观看,然后选择。插件会根据链接下载HTML文档。下载完成后,插件会进入观看模式,编辑器状态栏中会出现⠼ temme:观看。在监视模式下,每次选择器发生变化时,插件都会重新执行选择器并更新输出。这样我们就可以愉快的编辑选择器了。
第二步
用浏览器打开方文社的剧目列表,可以看到上图所示的页面。我们要抓取的粉丝剧信息列表位于ul#browserItemList对应的元素(棕色)中,每一个粉丝剧信息对应一个li元素(绿色)。写下这两个选择器并在末尾添加@list 表示抓取li 列表。为了指定在每个 li 元素中抓取什么内容,我们还需要添加一串花括号来放置子选择器。我们得到以下选择器:
ul#browserItemList li@list {/* 子选择器会出现在这里 */ }
第三步
上图中有五个子选择器,每个子选择器抓取一个对应的字段。下面我们就一一分析:
&[id=$id];表示将父元素(即li元素)的id特征捕获到结果的id字段中。 & 符号表示父元素引用,与 CSS 预处理器 (Less/Sass/Stylus) 中的含义相同。 .inner a{$name} 表示将.inner a 对应的元素的文本抓取到结果的name 字段中。 img[src=$imgUrl] 表示将img对应元素的src特征抓取到结果的imgUrl字段。 CSS选择器中,img[src=imgUrl]表示选择src为imgUrl的那些img元素; $符号被添加到temme,它的含义变成了capture。这个语法很容易记住 (o´ω`o )。 .fade{$rate|Number} 类似于 2,但有一个额外的 |Number 将结果从字符串转换为数字。 .rank{$rank|firstNumber} 与4类似,但这里firstNumber是一个自定义过滤器,用于获取字符串中的第一个数字,过滤器定义在选择器文件下方。
第四步
我们不仅可以在$xxx之后添加过滤器来处理数据字段,还可以在@yyy之后添加过滤器来处理数组。 sortByRate 和 rateBetween 是两个自定义过滤器。前者按评分对同人剧列表进行排序,后者用于选择收视率在一定范围内的同人剧。当我们应用这两个过滤器时,我们可以看到右侧的 JSON 数据也会发生相应的变化。自定义过滤器的定义方法与 JavaScript 函数定义方法相同,只是将关键字从函数更改为过滤器。请注意,您需要在自定义过滤器中使用它来引用捕获的结果。
插入破碎的想法
插件将突出显示与模式匹配的文本 // 链接,我们称之为 tagged-link。 link 可以是 http 链接或本地文件路径。因为插件下载HTML功能比较简单,所以我推荐先使用插件vscode-restclient下载网页文档,然后使用本地路径启动temme watch模式。此外,要在编辑器中执行 temme 选择器,文件中必须至少存在一个标记链接。
除了提供语法高亮,插件还会报告选择器语法错误。在watch模式下,因为selector在不断的执行,插件也会报运行时错误,但是插件还没有完成。运行时错误总是显示在文件的第一行,但应该没有问题。
选择器坏了。
基于 CSS 选择器语法,在 temme 中没有太多需要记住的。一般来说,记住以下几点就足够了: $ 表示捕获字段,@ 表示捕获列表,|xxx 表示应用过滤器处理结果,一个分号;需要结束选择器。 temme的其他语法和功能请参考GitHub文档。
Temme 发布在 NPM 上,使用 yarn global add temme 全局安装 temme;将选择器保存在文件bangumi.temme中,那么上面的例子也可以在命令行运行:
url=http://bangumi.tv/anime/tag/%2 ... Ddate
curl -s $url | temme bangumi.temme --format
当然,我们也可以在 Node.js 中使用 temme。一般来说,对于每个不同的网页结构,我们可以先使用插件来调试选择器;爬虫运行时,下载HTML文档,我们可以直接执行相应的选择器,使爬虫开发效率大大提高。推广。
印象和总结
选择合适的工具可以提高工作效率;汇编的原则很重要也很有用。最后感谢大家的阅读(๑¯◡¯๑).
程序调用直接运行getproxy(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-10 18:12
主机
str
代理地址
端口
内部
端口
匿名
str
匿名
透明、匿名、高度匿名
国家
str
代理国家
响应时间
浮动
响应时间
来自
str
来源
4.插件相关插件代码格式
class Proxy(object):
def __init__(self):
self.result = []
self.proxies = []
def start(self):
pass
插件返回结果
插件提示5.第三方程序调用
直接运行getproxy相当于执行如下程序:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from getproxy import GetProxy
g = GetProxy()
# 1. 初始化,必须步骤
g.init()
# 2. 加载 input proxies 列表
g.load_input_proxies()
# 3. 验证 input proxies 列表
g.validate_input_proxies()
# 4. 加载 plugin
g.load_plugins()
# 5. 抓取 web proxies 列表
g.grab_web_proxies()
# 6. 验证 web proxies 列表
g.validate_web_proxies()
# 7. 保存当前所有已验证的 proxies 列表
g.save_proxies()
如果您只想验证代理列表而不需要获取其他人的代理,您可以:
g.init()
g.load_input_proxies()
g.validate_input_proxies()
print(g.valid_proxies)
如果当前程序不需要输出代理列表,而是直接在程序中使用,可以:
g.init()
g.load_plugins()
g.grab_web_proxies()
g.validate_web_proxies()
print(g.valid_proxies)
6.问答
数据量不大。即使以文本格式读入内存,也不会占用太多内存。就算真的需要存入数据库,也可以自己多写几行代码。使用文本格式的另一个好处是你可以创建这个项目fate0/proxylist
简单、方便、快捷,除Python环境外无需任何设置。
仔细查看错误信息。是不是有些插件报错,报错都是和网络有关?如果是这样,这些插件访问的网站 可能由于众所周知的原因而被阻止。如果没有,请尽快提出问题。
主要取决于这个项目中的proxy.list的数量fate0/proxylist。如果proxy.list行数接近5000,那么就不会再添加插件,防止travis在15分钟内没有结束。 查看全部
程序调用直接运行getproxy(图)
主机
str
代理地址
端口
内部
端口
匿名
str
匿名
透明、匿名、高度匿名
国家
str
代理国家
响应时间
浮动
响应时间
来自
str
来源
4.插件相关插件代码格式
class Proxy(object):
def __init__(self):
self.result = []
self.proxies = []
def start(self):
pass
插件返回结果
插件提示5.第三方程序调用
直接运行getproxy相当于执行如下程序:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from getproxy import GetProxy
g = GetProxy()
# 1. 初始化,必须步骤
g.init()
# 2. 加载 input proxies 列表
g.load_input_proxies()
# 3. 验证 input proxies 列表
g.validate_input_proxies()
# 4. 加载 plugin
g.load_plugins()
# 5. 抓取 web proxies 列表
g.grab_web_proxies()
# 6. 验证 web proxies 列表
g.validate_web_proxies()
# 7. 保存当前所有已验证的 proxies 列表
g.save_proxies()
如果您只想验证代理列表而不需要获取其他人的代理,您可以:
g.init()
g.load_input_proxies()
g.validate_input_proxies()
print(g.valid_proxies)
如果当前程序不需要输出代理列表,而是直接在程序中使用,可以:
g.init()
g.load_plugins()
g.grab_web_proxies()
g.validate_web_proxies()
print(g.valid_proxies)
6.问答
数据量不大。即使以文本格式读入内存,也不会占用太多内存。就算真的需要存入数据库,也可以自己多写几行代码。使用文本格式的另一个好处是你可以创建这个项目fate0/proxylist
简单、方便、快捷,除Python环境外无需任何设置。
仔细查看错误信息。是不是有些插件报错,报错都是和网络有关?如果是这样,这些插件访问的网站 可能由于众所周知的原因而被阻止。如果没有,请尽快提出问题。
主要取决于这个项目中的proxy.list的数量fate0/proxylist。如果proxy.list行数接近5000,那么就不会再添加插件,防止travis在15分钟内没有结束。
搜索引擎的蜘蛛真的会像蜘蛛一样吗?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-10 18:11
在日常的SEO优化中,我们会关注收录,而收录的前提是搜索引擎蜘蛛抓取你的网站,那么这里的蜘蛛是什么?搜索引擎蜘蛛真的像蜘蛛吗?
学过SEO的同学都知道蜘蛛有两种爬行方式:深度和广度,也叫水平爬行和垂直爬行,那么这个蜘蛛是怎么工作的呢?是爬完第一页再爬第二页吗?你在哪里找到第二页的?
如果你真的想了解这方面,你必须了解程序。作为一名合格的SEO,程序设计是你的必修课。既然涉及到程序,那么数据库和编程语言肯定是少不了的。以PHP为例。有一个名为 file_get_contents 的函数。该函数的作用是获取URL中的内容,并以文本形式返回结果。当然也可以使用CURL。
搜索引擎蜘蛛如何进行网站content 抓取
然后,您就可以使用程序中的正则表达式对A链接的数据进行提取、合并和去重,并将数据存储到数据库中。数据库有很多,比如:索引库、收录库等。为什么收录的索引和数量不同?当然是因为他们不在同一个图书馆。
当获取数据后完成上述操作后,自然会获取数据库中不存在的链接,然后程序会发出另一条指令来获取数据库中未保存的URL。直到页面被完全抓取。当然,爬取完成后停止爬取的可能性更大。
百度站长平台上会有抓取频率和抓取时间的数据。应该可以看到,每只蜘蛛的爬行都是不规则的,但是通过日常观察可以发现,页面越深,被抓到的概率越低。原因很简单。蜘蛛不会总是在你的网站周围爬行到所有网站,而是会每隔一段时间随机爬行。
也就是说,搜索引擎的蜘蛛爬行是随机的、时间敏感的,我们SEO的目的是尽快完成页面和内容的呈现,尤其是我们认为有价值的内容。那么它会演变成,如何在有限的蜘蛛爬行中展示更多的内容呢?当然是尽量减少页面深度,增加页面宽度。 《SEO实战密码》里面有页面深度的优化方法,这里不再赘述。如果需要,您可以搜索电子书。当然推荐一个。
蜘蛛虽然有随机性和时效性,但还是有很多规律可寻。比如流量对蜘蛛有非常直接的正面影响,所以在日常运营中,你也会发现,一旦流量进入网站,蜘蛛的数量也会增加。这种蜘蛛的表现尤其在一些非法操作中表现得更加明显,比如百度的排名!
蜘蛛除了时效性和随机性之外,还有一个特点,就是喜新厌旧。一个随时都在变化的网站很受蜘蛛欢迎,即使它没有任何意义!当然,这也算是搜索引擎的一个BUG,但是这个BUG是无法修复的,或者说很难修复。所以很多人利用BUG开发了一系列的软件,比如Spider Pool。蜘蛛池页面每次打开的内容都不一样。使用文本段落的随机组合构造内容来欺骗蜘蛛。然后辅以大量的域名(通常是几百个),形成一个新的内容库来诱捕蜘蛛。当然,圈住蜘蛛绝对不是目的。圈养蜘蛛的目的是释放蜘蛛,那么如何释放蜘蛛呢?有几百万甚至几千万个页面,每个页面都嵌入了一个外部链接,蜘蛛自然而然地可以跟随外部链接到你想让他去的网站。这样就实现了对页面的高频蜘蛛访问。
当一个页面蜘蛛走多了,收录自然就不再是问题了。蜘蛛对收录有正面帮助,对排名有帮助吗?通过我们的研发,百度蜘蛛、百度排名、自然流量之间的关系是微秒级的,每一次变化都会牵扯到另外两个变化。只是有些变化很大,有些变化很小。
查看全部
搜索引擎的蜘蛛真的会像蜘蛛一样吗?(图)
在日常的SEO优化中,我们会关注收录,而收录的前提是搜索引擎蜘蛛抓取你的网站,那么这里的蜘蛛是什么?搜索引擎蜘蛛真的像蜘蛛吗?
学过SEO的同学都知道蜘蛛有两种爬行方式:深度和广度,也叫水平爬行和垂直爬行,那么这个蜘蛛是怎么工作的呢?是爬完第一页再爬第二页吗?你在哪里找到第二页的?
如果你真的想了解这方面,你必须了解程序。作为一名合格的SEO,程序设计是你的必修课。既然涉及到程序,那么数据库和编程语言肯定是少不了的。以PHP为例。有一个名为 file_get_contents 的函数。该函数的作用是获取URL中的内容,并以文本形式返回结果。当然也可以使用CURL。
搜索引擎蜘蛛如何进行网站content 抓取
然后,您就可以使用程序中的正则表达式对A链接的数据进行提取、合并和去重,并将数据存储到数据库中。数据库有很多,比如:索引库、收录库等。为什么收录的索引和数量不同?当然是因为他们不在同一个图书馆。
当获取数据后完成上述操作后,自然会获取数据库中不存在的链接,然后程序会发出另一条指令来获取数据库中未保存的URL。直到页面被完全抓取。当然,爬取完成后停止爬取的可能性更大。
百度站长平台上会有抓取频率和抓取时间的数据。应该可以看到,每只蜘蛛的爬行都是不规则的,但是通过日常观察可以发现,页面越深,被抓到的概率越低。原因很简单。蜘蛛不会总是在你的网站周围爬行到所有网站,而是会每隔一段时间随机爬行。
也就是说,搜索引擎的蜘蛛爬行是随机的、时间敏感的,我们SEO的目的是尽快完成页面和内容的呈现,尤其是我们认为有价值的内容。那么它会演变成,如何在有限的蜘蛛爬行中展示更多的内容呢?当然是尽量减少页面深度,增加页面宽度。 《SEO实战密码》里面有页面深度的优化方法,这里不再赘述。如果需要,您可以搜索电子书。当然推荐一个。
蜘蛛虽然有随机性和时效性,但还是有很多规律可寻。比如流量对蜘蛛有非常直接的正面影响,所以在日常运营中,你也会发现,一旦流量进入网站,蜘蛛的数量也会增加。这种蜘蛛的表现尤其在一些非法操作中表现得更加明显,比如百度的排名!
蜘蛛除了时效性和随机性之外,还有一个特点,就是喜新厌旧。一个随时都在变化的网站很受蜘蛛欢迎,即使它没有任何意义!当然,这也算是搜索引擎的一个BUG,但是这个BUG是无法修复的,或者说很难修复。所以很多人利用BUG开发了一系列的软件,比如Spider Pool。蜘蛛池页面每次打开的内容都不一样。使用文本段落的随机组合构造内容来欺骗蜘蛛。然后辅以大量的域名(通常是几百个),形成一个新的内容库来诱捕蜘蛛。当然,圈住蜘蛛绝对不是目的。圈养蜘蛛的目的是释放蜘蛛,那么如何释放蜘蛛呢?有几百万甚至几千万个页面,每个页面都嵌入了一个外部链接,蜘蛛自然而然地可以跟随外部链接到你想让他去的网站。这样就实现了对页面的高频蜘蛛访问。
当一个页面蜘蛛走多了,收录自然就不再是问题了。蜘蛛对收录有正面帮助,对排名有帮助吗?通过我们的研发,百度蜘蛛、百度排名、自然流量之间的关系是微秒级的,每一次变化都会牵扯到另外两个变化。只是有些变化很大,有些变化很小。
外链对网站排名的作用及影响有以下几点网站建设
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-09 07:26
外链对网站排名的作用和影响如下:增加网站的权重,增加网站的信任度,引导蜘蛛爬取文章内容,增加上榜几率页面收录,间接提高关键词的排名以及品牌和域名的曝光也可以为网站带来流量,但必须注意的是,外部链接的质量远高于数量. 1、外链可以增加链接页面和整个网站的权重,增加页面评分和信任度。外部链接越多,发送该链接的网站的权重越高,间接表明链接的页面被更多人信任。页面链接的权重和信任度也会在整个域名上累积。 2、网站排名受到网站权重的间接影响,但只是搜索引擎排名的重要因素之一。除了网站scale、文章内容质量、原创sexuality,影响权重最重要的因素就是外链。高权重域名提升网站所有页面的排名。链接到网站 且信任度高的页面被视为采集 内容的可能性要小得多。信任度是指你的网站内容是否以网站为主题。如果你的网站有搜狐、新浪、土巴兔、天涯论坛的链接,像网站这样权重非常高,你的网站的权重也会有质的提升,不管网站关键词,排名会有很大帮助。 网站构建完成后,搜索引擎蜘蛛就需要爬取我们的网站。如果外部链接太少,甚至没有外部链接,蜘蛛发现并捕获网站的可能性就会低很多。 网站更新文章内容后,搜索引擎蜘蛛也需要能够第一时间抓取更新后的文章内容和收录网站的文章content页面。
想要网站排名,首先要让网站页面内容为收录。如果网站文章的内容不是收录,我们可以将网站的地址以外链的形式发布给一些权重和信任度高的网站,蜘蛛爬取到我们更新的内容会很多收录,这就是为什么外链可以引导蜘蛛去抢网站。 1、网站要排名,必须先让网站内容被搜索引擎收录搜索到,所以网站页面为收录是排名的基础,不能被搜索到通过搜索引擎收录页面没有排名。数据分析和seo行业经验都表明,外部链接的数量和质量对网站的收录的情况有着至关重要的影响。没有强大的外链作为助力,仅仅依靠网站内部结构和页面的原创内容,很难做出我们的网站被full收录。一个可供参考的经验数字是,一个权重为5的域名大致可以驱动数百万页,如果太多,则会更加困难。 2、所有seo从业者都熟悉的链接级视图是内页必须在主页的三四次点击内。原因是外部链接很大程度上决定了蜘蛛的爬行深度。一般来说,权重不高的网站只会爬3-4级链接。如果网站的权重为7或者权重为8,那么距离首页点击六七次的内容页面也可以被搜索引擎收录搜索到,从而提升收录整体的能力网站。 3、外部链接也是影响搜索引擎抓取频率的一个非常重要的因素。外部链接越多,搜索引擎蜘蛛抓取的页面越多,频率越高,新页面和新内容的发现速度越快。
网站权重高,每隔几分钟爬一次主页很正常。搜索引擎利用网站外链的质量给网站相应的权重。权重高的网站自然在关键词的排名中占有很大的优势。很多SEO新手或者站长都认为强大的外链是网站最大排名的保证。理论上网站强大的外链可以给网站带来不错的排名。但是,外部链接的建设也应该逐步增加。找一些在各大搜索引擎中权重较高的网站添加链接,让网站排名有一定的稳定性。另外,从很多老SEO司机对站群的维护来看,友情链接对网站的排名还是有显着影响的。每个站长每周可以添加2个有价值的朋友链接,从而间接提高网站排名。 纯文本外链的发布,可以有效增加网站域名和品牌在互联网上的曝光率,有助于网络营销推广的顺利进行。而对于一些简短易记的域名,对于网站的推广也是有帮助的,比如:百度、淘宝、京东等,用户一看就会知道网站是什么,这会帮助用户记住我们的网站,有利于网站回访。 SEO人员在站外平台发布与其网站topics相关的文章内容时,自带链接,极有可能为网站带来流量。如果这个文章的值高,相信传入的流量不会少。前提是能够吸引用户点击,让用户知道打开的链接是否是他们需要的。这样的外部链接既能满足用户体验,也是对用户有价值的链接。
因为现在网络上垃圾链接太多了,如果网站有多余文字的链接被称为链接工厂,搜索引擎也会判断网站发送的链接是垃圾链接,所以搜索引擎最终会看重外部链接的质量而不是数量。而且很多SEO人员经常发现网站外链的竞争者数量并不是很大,而且网站的排名也很好且相对稳定,所以网站外链的质量远高于数量,一个高质量的。外部链接胜过几十个或几百个垃圾外部链接。 网站Optimization 由两部分组成:现场优化和非现场优化。现场优化主要是指网站结构、页面优化、页面设计、页面用户浏览体验、网站功能、关键词研究、竞争研究、SEO效果优化监控和策略改进、站外优化优化主要是对外链接的发布和建设。 网站 的基本功能之一是链接。 网站里面的链接是我们自己可控的,比较容易掌握。本文链接: 查看全部
外链对网站排名的作用及影响有以下几点网站建设
外链对网站排名的作用和影响如下:增加网站的权重,增加网站的信任度,引导蜘蛛爬取文章内容,增加上榜几率页面收录,间接提高关键词的排名以及品牌和域名的曝光也可以为网站带来流量,但必须注意的是,外部链接的质量远高于数量. 1、外链可以增加链接页面和整个网站的权重,增加页面评分和信任度。外部链接越多,发送该链接的网站的权重越高,间接表明链接的页面被更多人信任。页面链接的权重和信任度也会在整个域名上累积。 2、网站排名受到网站权重的间接影响,但只是搜索引擎排名的重要因素之一。除了网站scale、文章内容质量、原创sexuality,影响权重最重要的因素就是外链。高权重域名提升网站所有页面的排名。链接到网站 且信任度高的页面被视为采集 内容的可能性要小得多。信任度是指你的网站内容是否以网站为主题。如果你的网站有搜狐、新浪、土巴兔、天涯论坛的链接,像网站这样权重非常高,你的网站的权重也会有质的提升,不管网站关键词,排名会有很大帮助。 网站构建完成后,搜索引擎蜘蛛就需要爬取我们的网站。如果外部链接太少,甚至没有外部链接,蜘蛛发现并捕获网站的可能性就会低很多。 网站更新文章内容后,搜索引擎蜘蛛也需要能够第一时间抓取更新后的文章内容和收录网站的文章content页面。
想要网站排名,首先要让网站页面内容为收录。如果网站文章的内容不是收录,我们可以将网站的地址以外链的形式发布给一些权重和信任度高的网站,蜘蛛爬取到我们更新的内容会很多收录,这就是为什么外链可以引导蜘蛛去抢网站。 1、网站要排名,必须先让网站内容被搜索引擎收录搜索到,所以网站页面为收录是排名的基础,不能被搜索到通过搜索引擎收录页面没有排名。数据分析和seo行业经验都表明,外部链接的数量和质量对网站的收录的情况有着至关重要的影响。没有强大的外链作为助力,仅仅依靠网站内部结构和页面的原创内容,很难做出我们的网站被full收录。一个可供参考的经验数字是,一个权重为5的域名大致可以驱动数百万页,如果太多,则会更加困难。 2、所有seo从业者都熟悉的链接级视图是内页必须在主页的三四次点击内。原因是外部链接很大程度上决定了蜘蛛的爬行深度。一般来说,权重不高的网站只会爬3-4级链接。如果网站的权重为7或者权重为8,那么距离首页点击六七次的内容页面也可以被搜索引擎收录搜索到,从而提升收录整体的能力网站。 3、外部链接也是影响搜索引擎抓取频率的一个非常重要的因素。外部链接越多,搜索引擎蜘蛛抓取的页面越多,频率越高,新页面和新内容的发现速度越快。
网站权重高,每隔几分钟爬一次主页很正常。搜索引擎利用网站外链的质量给网站相应的权重。权重高的网站自然在关键词的排名中占有很大的优势。很多SEO新手或者站长都认为强大的外链是网站最大排名的保证。理论上网站强大的外链可以给网站带来不错的排名。但是,外部链接的建设也应该逐步增加。找一些在各大搜索引擎中权重较高的网站添加链接,让网站排名有一定的稳定性。另外,从很多老SEO司机对站群的维护来看,友情链接对网站的排名还是有显着影响的。每个站长每周可以添加2个有价值的朋友链接,从而间接提高网站排名。 纯文本外链的发布,可以有效增加网站域名和品牌在互联网上的曝光率,有助于网络营销推广的顺利进行。而对于一些简短易记的域名,对于网站的推广也是有帮助的,比如:百度、淘宝、京东等,用户一看就会知道网站是什么,这会帮助用户记住我们的网站,有利于网站回访。 SEO人员在站外平台发布与其网站topics相关的文章内容时,自带链接,极有可能为网站带来流量。如果这个文章的值高,相信传入的流量不会少。前提是能够吸引用户点击,让用户知道打开的链接是否是他们需要的。这样的外部链接既能满足用户体验,也是对用户有价值的链接。
因为现在网络上垃圾链接太多了,如果网站有多余文字的链接被称为链接工厂,搜索引擎也会判断网站发送的链接是垃圾链接,所以搜索引擎最终会看重外部链接的质量而不是数量。而且很多SEO人员经常发现网站外链的竞争者数量并不是很大,而且网站的排名也很好且相对稳定,所以网站外链的质量远高于数量,一个高质量的。外部链接胜过几十个或几百个垃圾外部链接。 网站Optimization 由两部分组成:现场优化和非现场优化。现场优化主要是指网站结构、页面优化、页面设计、页面用户浏览体验、网站功能、关键词研究、竞争研究、SEO效果优化监控和策略改进、站外优化优化主要是对外链接的发布和建设。 网站 的基本功能之一是链接。 网站里面的链接是我们自己可控的,比较容易掌握。本文链接:
提高百度蜘蛛对网站内容的收录量的之前问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-08 20:12
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。
这是每个网站运营经理都必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一就是提高网站打开的速度。
确保页面打开速度符合百度标准要求,以便百度蜘蛛能够顺利抓取每个页面。例如,移动端优先索引要求首页加载速度保持在3秒以内。
为此,我们可能需要:
① 精简网站程序代码,比如CSS和JS的结合。
②开启服务器缓存,配置CDN云加速,或者百度MIP等
③ 定期清理网站冗余数据库信息等
④ 压缩网站图片,特别是食谱和食物网站。
当我们很好的解决了网站打开速度的问题后,为了增加百度蜘蛛的抓取量,我们可以尝试以下方法:
1、提高页面更新频率
这里我们一般使用以下三种方法:
①持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。
另外,保持一定的更新频率,而不是三天打鱼,两天晒网。在违规方面。
②在网页侧边栏,调用“随机文章”标签,有助于增加页面新鲜度,从而保持页面不断出现收录未出现的文章过去但被视为新内容。
③ 合理利用有一定排名的旧页面,适当增加一些内部链接指向新的文章。在满足一定数量的基础上,有利于传递权重,提高百度蜘蛛的抓握Pick。
2、大量外链
基于搜索引擎的角度,权威性、相关性、高权重的外部链接是相对于外部投票和推荐的。如果您有每个版块页面,您将在一定时间内继续获取这些链接。
然后,搜索引擎会认为这些版块页面的内容值得抓取,从而增加百度蜘蛛的访问量。
3、提交百度链接
通过主动向百度提交新链接,也可以实现目标网址被爬取的概率。具体方法可以如下:
①制作网站地图,在百度搜索资源平台后台提交地图的sitemap.xml版本。您还可以创建站点地图的 Html 版本并将其放置在主页的导航中。
②使用百度API接口向搜索引擎提交新链接。
③在网站Html源码页面,添加百度给出的JS代码。只要有人访问任何页面,就会自动ping百度蜘蛛抓取。
4、创建百度蜘蛛池
这是一种消耗资源的策略,一般不建议大家采用。主要是通过建立大量的网站,在每个网站之间形成一个闭环。
用于每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。
然后,利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
总结:SEO网站优化,要增加百度蜘蛛的抓取次数,首先要保证页面速度,其次可以使用的相关策略,如上所说,基本可以满足抓取要求一般网站。仅供参考和讨论。 查看全部
提高百度蜘蛛对网站内容的收录量的之前问题
在SEO工作中,适当增加百度蜘蛛对网站的抓取,有助于增加网站内容的收录量,从而进一步提升排名。
这是每个网站运营经理都必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一就是提高网站打开的速度。
确保页面打开速度符合百度标准要求,以便百度蜘蛛能够顺利抓取每个页面。例如,移动端优先索引要求首页加载速度保持在3秒以内。
为此,我们可能需要:
① 精简网站程序代码,比如CSS和JS的结合。
②开启服务器缓存,配置CDN云加速,或者百度MIP等
③ 定期清理网站冗余数据库信息等
④ 压缩网站图片,特别是食谱和食物网站。
当我们很好的解决了网站打开速度的问题后,为了增加百度蜘蛛的抓取量,我们可以尝试以下方法:
1、提高页面更新频率
这里我们一般使用以下三种方法:
①持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。
另外,保持一定的更新频率,而不是三天打鱼,两天晒网。在违规方面。
②在网页侧边栏,调用“随机文章”标签,有助于增加页面新鲜度,从而保持页面不断出现收录未出现的文章过去但被视为新内容。
③ 合理利用有一定排名的旧页面,适当增加一些内部链接指向新的文章。在满足一定数量的基础上,有利于传递权重,提高百度蜘蛛的抓握Pick。
2、大量外链
基于搜索引擎的角度,权威性、相关性、高权重的外部链接是相对于外部投票和推荐的。如果您有每个版块页面,您将在一定时间内继续获取这些链接。
然后,搜索引擎会认为这些版块页面的内容值得抓取,从而增加百度蜘蛛的访问量。
3、提交百度链接
通过主动向百度提交新链接,也可以实现目标网址被爬取的概率。具体方法可以如下:
①制作网站地图,在百度搜索资源平台后台提交地图的sitemap.xml版本。您还可以创建站点地图的 Html 版本并将其放置在主页的导航中。
②使用百度API接口向搜索引擎提交新链接。
③在网站Html源码页面,添加百度给出的JS代码。只要有人访问任何页面,就会自动ping百度蜘蛛抓取。
4、创建百度蜘蛛池
这是一种消耗资源的策略,一般不建议大家采用。主要是通过建立大量的网站,在每个网站之间形成一个闭环。
用于每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。
然后,利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
总结:SEO网站优化,要增加百度蜘蛛的抓取次数,首先要保证页面速度,其次可以使用的相关策略,如上所说,基本可以满足抓取要求一般网站。仅供参考和讨论。
企业网站内容可以提高内容以及网站排名的帮助因素分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-08 12:07
网站内容抓取是一个非常重要的操作,对一个网站的影响非常大,企业网站要想稳定运营必须要定期的抓取网站内容,一起来看看抓取网站内容可以提高网站内容粘性以及网站排名。个人网站后台抓取内容对排名的帮助:经常性的大量的查看url内容,当网站内容内容都一样时,建议采用自动抓取和协议识别服务来过滤重复内容,毕竟像百度谷歌这些搜索引擎都会重复抓取url重复url,如果你的网站有大量重复url时,建议就采用这两种方法过滤。
对于个人网站来说,如果不是大量定时抓取内容是无法有效提高内容的粘性和整站网站排名的。如果网站内容都一样,建议大家定期查看网站内容,避免大量重复抓取。可以采用谷歌分析()分析抓取数据,谷歌分析可以识别到每天抓取的网站内容,以及抓取网站url等等,可以通过谷歌分析这款软件了解每天抓取网站内容的数量,看一下每天有多少网站抓取url,避免大量抓取url,url重复;同时,查看每天都抓取到多少网站内容,看一下抓取的网站内容数量跟网站收录的内容数量之间的比例关系,看一下能提高自己网站内容的排名;通过日志监控服务器运行情况,查看抓取是否出现异常,出现异常时怎么办,可以通过日志监控服务器服务器。
通过网站抓取,可以在网站有大量抓取的情况下,提高网站内容的数量,从而提高网站内容的粘性。并且如果定期在维护站点,对建站质量方面也有比较大的帮助。 查看全部
企业网站内容可以提高内容以及网站排名的帮助因素分析
网站内容抓取是一个非常重要的操作,对一个网站的影响非常大,企业网站要想稳定运营必须要定期的抓取网站内容,一起来看看抓取网站内容可以提高网站内容粘性以及网站排名。个人网站后台抓取内容对排名的帮助:经常性的大量的查看url内容,当网站内容内容都一样时,建议采用自动抓取和协议识别服务来过滤重复内容,毕竟像百度谷歌这些搜索引擎都会重复抓取url重复url,如果你的网站有大量重复url时,建议就采用这两种方法过滤。
对于个人网站来说,如果不是大量定时抓取内容是无法有效提高内容的粘性和整站网站排名的。如果网站内容都一样,建议大家定期查看网站内容,避免大量重复抓取。可以采用谷歌分析()分析抓取数据,谷歌分析可以识别到每天抓取的网站内容,以及抓取网站url等等,可以通过谷歌分析这款软件了解每天抓取网站内容的数量,看一下每天有多少网站抓取url,避免大量抓取url,url重复;同时,查看每天都抓取到多少网站内容,看一下抓取的网站内容数量跟网站收录的内容数量之间的比例关系,看一下能提高自己网站内容的排名;通过日志监控服务器运行情况,查看抓取是否出现异常,出现异常时怎么办,可以通过日志监控服务器服务器。
通过网站抓取,可以在网站有大量抓取的情况下,提高网站内容的数量,从而提高网站内容的粘性。并且如果定期在维护站点,对建站质量方面也有比较大的帮助。
如何在web主机上强制重定向的代码添加到另一个
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-08-05 01:09
正确的方法是将其中一个重定向到另一个而不是两个。如果两个同时加载,那么站点的版本安全就会有问题。如果您在浏览器中输入网站的网址,请分别测试。
如果两个 URL 都加载,则将显示两个版本的内容。重复的网址可能会导致重复的内容。
为确保您不再遇到此问题,您需要根据站点的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache/CPanel服务器上);
使用 WordPress 中的重定向插件强制重定向。
4、如何在Apache/Cpanel服务器的htaccess中创建重定向
您可以在 Apache/CPanel 服务器的 .htaccess 中执行服务器级全局重定向。 Inmotionhosting 有一个很好的教程,教您如何在您的网络主机上强制重定向。
如果您强制所有网络流量使用 HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On、RewriteCond 等)的代码之上。
重写引擎开启
RewriteCond %{HTTPS} !on
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写规则 (.*) %{HTTP_HOST}%{REQUEST_URI} [L,R=301]
如果您只想重定向特定域,则需要在 htaccess 文件中使用以下代码行:
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写引擎开启
RewriteCond %{HTTP_HOST} ^example\.com [NC]
RewriteCond %{SERVER_PORT} 80
重写规则 ^(.*)$ $1 [R=301,L]
注意:如果您不确定对服务器进行正确的更改,请确保您的服务器公司或 IT 人员执行这些维修。
5、如果您运行的是 WordPress网站,请使用插件
解决这些重定向问题的简单方法是使用插件,尤其是在运行 WordPress网站 时。
许多插件可以强制重定向,但这里有一些插件可以使这个过程尽可能简单:CM HTTPS Pro、WP Force SSL、Easy HTTPS Redirection。
插件注意事项:如果您使用了过多的插件,请不要添加。
您可能需要调查您的服务器是否可以使用上述类似的重定向规则(例如,如果您使用的是基于 NGINX 的服务器)。
这里需要声明:插件的权重会对网站的速度产生负面影响,所以不要总以为新插件会帮到你。
6、所有网站链接应改为
即使您执行了上述重定向,您也应该执行此步骤。
如果您使用绝对 URL 而不是相对 URL,则应该这样做。因为前者总是显示您使用的超文本传输协议,如果您使用的是后者,则无需多加注意。
为什么在使用绝对 URL 时需要更改实时链接?由于 Google 会抓取所有这些链接,因此可能会导致内容重复。
这似乎是浪费时间,但事实并非如此。你必须确保谷歌最终能准确捕捉到你的网站。
7、保证从to转换,不会出现404页面
突然增加的404页面可能会让你的网站无法操作,尤其是有页面链接的时候。
另外,由于显示的404页面过多,谷歌没有找到应该抓取的页面,会造成抓取预算的浪费。
Google 相关负责人 John Mueller 指出,抓取预算并不重要,除非是针对大型网站。
John Mueller 在 Twitter 上表示,他认为爬网预算优化被高估了。对于大多数网站,没有任何作用,只能帮助大规模的网站。
“IMO 的爬取预算被高估了。实际上,大多数网站 不需要担心。如果您正在爬网或运行一个拥有数十亿个 URL 的网站,这非常重要。但是对于普通的网站,这不是很重要。”
SEO PowerSuite相关负责人Yauhen Khutarniuk的一篇文章文章也对这一点进行了阐述:
“从逻辑上讲,您应该注意抓取预算,因为您希望Google 为您的网站 发现尽可能多的重要页面。您还希望它能够快速在您的网站 内容中找到新页面,您的抓取预算越大(管理越聪明),这种情况就会发生得越快。”
优化爬取预算很重要,因为在网站上快速发现新内容是一项重要的任务,同时我们需要尽可能多地发现网站的优先页面。
8、如何修复可能出现的 404 页
首先,将 404 从旧 URL 重定向到新的现有 URL。
更简单的方法是,如果你有WordPress网站,用Screaming Frog抓取网站,使用WordPress重定向插件进行301重定向规则批量上传。
9、URL 结构不要太复杂
在准备技术 SEO 时,URL 的结构是一个重要的考虑因素。
这些东西你也一定要注意,比如随机生成索引动态参数、不易理解的网址,以及其他可能导致技术SEO实施出现问题的因素。
这些都是重要的因素,因为它们可能会导致索引问题,从而损害网站 的性能。
10、更多用户友好网址
创建网址时,您可以考虑相关内容,然后自动创建网址。然而,这可能并不合理。
原因是因为自动生成的 URL 可以遵循多种不同的格式,没有一种是非常用户友好的。
例如:
(1)/content/date/time/keyword/
(2)/content/date/time/数字串/
(3)/content/category/date/time/
(4)/content/category/date/time/parameter/
正确传达网址背后的内容是关键。由于可访问性,它在今天变得更加重要。
URL 的可读性越高越好:如果有人在搜索结果中看到您的 URL,他们可能更愿意点击它,因为他们会确切地看到该 URL 与他们正在搜索的性别之间的关系。简而言之,URL 需要匹配用户的搜索意图。
许多现有的网站 使用过时或令人困惑的 URL 结构,导致用户参与度低。如果您有一个更人性化的网址,您的网站 可能会有更高的用户参与度。
11、重复网址
在构建任何链接之前要考虑的一个 SEO 技术问题是:内容重复。
说到内容重复,主要有以下几个原因:
(1)在网站的各个部分明显重复。
(2)从其他网站抓取内容。
(3)重复网址,只存在一个内容。
因为当多个 URL 代表一个内容时,它确实会混淆搜索引擎。搜索引擎很少同时显示相同的内容,重复的网址会削弱其搜索能力。
12、避免使用动态参数
尽管动态参数本身不是 SEO 问题,但如果您无法管理它们的创建并使其在使用中保持一致,它们将来可能会成为潜在威胁。
Jes Scholz 在搜索引擎杂志上发表了一篇文章 的文章,涵盖了动态参数和 URL 处理的基础知识以及它如何影响 SEO。
Scholz 解释说,参数用于以下目的:跟踪、重新排序、过滤、识别、分页、搜索、翻译。
当您发现问题是由网址的动态参数引起时,通常归咎于网址的基本管理不善。
在跟踪的情况下,创建搜索引擎抓取的链接时可以使用不同的动态参数。在重新排序的情况下,使用这些不同的动态参数对列表和项目组进行重新排序,然后创建可索引的重复页面,然后由搜索引擎抓取。
如果动态参数没有保持在可管理的水平,可能会在不经意间导致过多的重复内容。
如果不仔细管理部分内容的创建,这些动态网址的创建实际上会随着时间的推移而积累,这会稀释内容的质量,削弱搜索引擎的执行能力。
还会造成关键词“同类相食”,相互影响,在足够大的范围内,会严重影响你的竞争力。
13、短网址优于长网址
长期 SEO 实践的结果是,较短的 URL 优于较长的 URL。
Google 的 John Mueller 说:“当我们有两个内容相同的 URL 时,我们需要选择其中一个显示在搜索结果中,我们会选择较短的一个,这就是规范化。当然,长度不是主要的。影响因素,但是如果我们有两个网址,一个很简洁,另一个有很长的附加参数,当它们显示相同的内容时,我们更喜欢选择短的。例子很多,比如不同的因素发挥作用,但在其他条件相同的情况下——你有更短的和更长的,我们也会选择更短的。”
还有证据表明,Google 优先考虑较短的网址而不是较长的网址。
如果您的网站 收录很长的网址,您可以将它们优化为更短、更简洁的网址,以更好地反映文章 的主题和用户意图。
(编译/雨果网吕小林)
【特别声明】未经许可,任何个人或组织不得复制、转载或以其他方式使用本网站内容。转载请联系: 查看全部
如何在web主机上强制重定向的代码添加到另一个
正确的方法是将其中一个重定向到另一个而不是两个。如果两个同时加载,那么站点的版本安全就会有问题。如果您在浏览器中输入网站的网址,请分别测试。
如果两个 URL 都加载,则将显示两个版本的内容。重复的网址可能会导致重复的内容。
为确保您不再遇到此问题,您需要根据站点的平台执行以下操作之一:
在HTACCESS中创建完整的重定向模式(在Apache/CPanel服务器上);
使用 WordPress 中的重定向插件强制重定向。
4、如何在Apache/Cpanel服务器的htaccess中创建重定向
您可以在 Apache/CPanel 服务器的 .htaccess 中执行服务器级全局重定向。 Inmotionhosting 有一个很好的教程,教您如何在您的网络主机上强制重定向。
如果您强制所有网络流量使用 HTTPS,则需要使用以下代码。
确保将此代码添加到具有类似前缀(RewriteEngine On、RewriteCond 等)的代码之上。
重写引擎开启
RewriteCond %{HTTPS} !on
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写规则 (.*) %{HTTP_HOST}%{REQUEST_URI} [L,R=301]
如果您只想重定向特定域,则需要在 htaccess 文件中使用以下代码行:
RewriteCond %{REQUEST_URI} !^/[0-9]+\..+\.cpaneldcv$
RewriteCond %{REQUEST_URI} !^/\.well-known/pki-validation/[A-F0-9]{32}\.txt(?:\ Comodo\ DCV)?$
重写引擎开启
RewriteCond %{HTTP_HOST} ^example\.com [NC]
RewriteCond %{SERVER_PORT} 80
重写规则 ^(.*)$ $1 [R=301,L]
注意:如果您不确定对服务器进行正确的更改,请确保您的服务器公司或 IT 人员执行这些维修。
5、如果您运行的是 WordPress网站,请使用插件
解决这些重定向问题的简单方法是使用插件,尤其是在运行 WordPress网站 时。
许多插件可以强制重定向,但这里有一些插件可以使这个过程尽可能简单:CM HTTPS Pro、WP Force SSL、Easy HTTPS Redirection。
插件注意事项:如果您使用了过多的插件,请不要添加。
您可能需要调查您的服务器是否可以使用上述类似的重定向规则(例如,如果您使用的是基于 NGINX 的服务器)。
这里需要声明:插件的权重会对网站的速度产生负面影响,所以不要总以为新插件会帮到你。
6、所有网站链接应改为
即使您执行了上述重定向,您也应该执行此步骤。
如果您使用绝对 URL 而不是相对 URL,则应该这样做。因为前者总是显示您使用的超文本传输协议,如果您使用的是后者,则无需多加注意。
为什么在使用绝对 URL 时需要更改实时链接?由于 Google 会抓取所有这些链接,因此可能会导致内容重复。
这似乎是浪费时间,但事实并非如此。你必须确保谷歌最终能准确捕捉到你的网站。
7、保证从to转换,不会出现404页面
突然增加的404页面可能会让你的网站无法操作,尤其是有页面链接的时候。
另外,由于显示的404页面过多,谷歌没有找到应该抓取的页面,会造成抓取预算的浪费。
Google 相关负责人 John Mueller 指出,抓取预算并不重要,除非是针对大型网站。
John Mueller 在 Twitter 上表示,他认为爬网预算优化被高估了。对于大多数网站,没有任何作用,只能帮助大规模的网站。
“IMO 的爬取预算被高估了。实际上,大多数网站 不需要担心。如果您正在爬网或运行一个拥有数十亿个 URL 的网站,这非常重要。但是对于普通的网站,这不是很重要。”
SEO PowerSuite相关负责人Yauhen Khutarniuk的一篇文章文章也对这一点进行了阐述:
“从逻辑上讲,您应该注意抓取预算,因为您希望Google 为您的网站 发现尽可能多的重要页面。您还希望它能够快速在您的网站 内容中找到新页面,您的抓取预算越大(管理越聪明),这种情况就会发生得越快。”
优化爬取预算很重要,因为在网站上快速发现新内容是一项重要的任务,同时我们需要尽可能多地发现网站的优先页面。
8、如何修复可能出现的 404 页
首先,将 404 从旧 URL 重定向到新的现有 URL。
更简单的方法是,如果你有WordPress网站,用Screaming Frog抓取网站,使用WordPress重定向插件进行301重定向规则批量上传。
9、URL 结构不要太复杂
在准备技术 SEO 时,URL 的结构是一个重要的考虑因素。
这些东西你也一定要注意,比如随机生成索引动态参数、不易理解的网址,以及其他可能导致技术SEO实施出现问题的因素。
这些都是重要的因素,因为它们可能会导致索引问题,从而损害网站 的性能。
10、更多用户友好网址
创建网址时,您可以考虑相关内容,然后自动创建网址。然而,这可能并不合理。
原因是因为自动生成的 URL 可以遵循多种不同的格式,没有一种是非常用户友好的。
例如:
(1)/content/date/time/keyword/
(2)/content/date/time/数字串/
(3)/content/category/date/time/
(4)/content/category/date/time/parameter/
正确传达网址背后的内容是关键。由于可访问性,它在今天变得更加重要。
URL 的可读性越高越好:如果有人在搜索结果中看到您的 URL,他们可能更愿意点击它,因为他们会确切地看到该 URL 与他们正在搜索的性别之间的关系。简而言之,URL 需要匹配用户的搜索意图。
许多现有的网站 使用过时或令人困惑的 URL 结构,导致用户参与度低。如果您有一个更人性化的网址,您的网站 可能会有更高的用户参与度。
11、重复网址
在构建任何链接之前要考虑的一个 SEO 技术问题是:内容重复。
说到内容重复,主要有以下几个原因:
(1)在网站的各个部分明显重复。
(2)从其他网站抓取内容。
(3)重复网址,只存在一个内容。
因为当多个 URL 代表一个内容时,它确实会混淆搜索引擎。搜索引擎很少同时显示相同的内容,重复的网址会削弱其搜索能力。
12、避免使用动态参数
尽管动态参数本身不是 SEO 问题,但如果您无法管理它们的创建并使其在使用中保持一致,它们将来可能会成为潜在威胁。
Jes Scholz 在搜索引擎杂志上发表了一篇文章 的文章,涵盖了动态参数和 URL 处理的基础知识以及它如何影响 SEO。
Scholz 解释说,参数用于以下目的:跟踪、重新排序、过滤、识别、分页、搜索、翻译。
当您发现问题是由网址的动态参数引起时,通常归咎于网址的基本管理不善。
在跟踪的情况下,创建搜索引擎抓取的链接时可以使用不同的动态参数。在重新排序的情况下,使用这些不同的动态参数对列表和项目组进行重新排序,然后创建可索引的重复页面,然后由搜索引擎抓取。
如果动态参数没有保持在可管理的水平,可能会在不经意间导致过多的重复内容。
如果不仔细管理部分内容的创建,这些动态网址的创建实际上会随着时间的推移而积累,这会稀释内容的质量,削弱搜索引擎的执行能力。
还会造成关键词“同类相食”,相互影响,在足够大的范围内,会严重影响你的竞争力。
13、短网址优于长网址
长期 SEO 实践的结果是,较短的 URL 优于较长的 URL。
Google 的 John Mueller 说:“当我们有两个内容相同的 URL 时,我们需要选择其中一个显示在搜索结果中,我们会选择较短的一个,这就是规范化。当然,长度不是主要的。影响因素,但是如果我们有两个网址,一个很简洁,另一个有很长的附加参数,当它们显示相同的内容时,我们更喜欢选择短的。例子很多,比如不同的因素发挥作用,但在其他条件相同的情况下——你有更短的和更长的,我们也会选择更短的。”
还有证据表明,Google 优先考虑较短的网址而不是较长的网址。
如果您的网站 收录很长的网址,您可以将它们优化为更短、更简洁的网址,以更好地反映文章 的主题和用户意图。
(编译/雨果网吕小林)
【特别声明】未经许可,任何个人或组织不得复制、转载或以其他方式使用本网站内容。转载请联系:
赶集、安居客这些量都很大,会不会解析不出来?
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-08-04 20:06
Q:我们的页面本身就很大,会不会被解析?
答:页面本身很大是可以的,但是商场、安居客等流量很大,所以没问题。在我刚才提到的例子中,你每次都关注一个新的链接,随意去掉下面的参数不会影响这个网页的正常访问。这绝对是个问题。
问题:刚才说了对URL的长度有要求。对每段的长度,也就是目录名,有什么要求吗?
答案:没有要求。我们要求URL从www开始到结束,总长度不能超过1024字节。
问:网站中的重复内容如何判断?如果文本内容相同,结构不同,是否视为重复?
答案:重复
Q:假设整个页面都是Flash,如果我隐藏了一些栏目或者最新的内容,不影响美观,隐藏起来。可以用隐藏属性提取吗? CSS 可能吗?
答:hidden 可以提,但如果是评论,就无所谓了。 CSS 不能。
问:页面大小不超过 1 兆字节。是指页面压缩之前还是之后。
答案:页面压缩后,不能超过1兆。
问:我的网站信息过期了,网页返回200,会被处罚吗?为什么?
回答:用户在搜索结果中点击了你的结果,引导到你的网站,但是没有什么可看的,对用户没有用。百度当然不喜欢。
Q:现在我们有很多网站,为了让用户觉得有趣,在内容没了的时候放一张图片,写一些有趣的文字,“工程师在哪里?”对百度友好吗?
答案:最好不要使用它。我知道该网站希望百度将内容识别为死链接,但识别死链接存在准确性和召回风险。
问:我们的团购网站确实有一个过期的团购页面,会被处罚吗?
答:如果音量特别大,点击量很大,就会有惩罚。其中一些可以被分析为内容中的死链接。如果不能分析,就会被其他一些策略挖出来。会有这样的问题。
Q:我刚才说信息内容页面有很好的发布时间。如果页面上没有时间怎么办?
回答:然后我们经常会根据当时捕捉到的时间做出判断。 查看全部
赶集、安居客这些量都很大,会不会解析不出来?
Q:我们的页面本身就很大,会不会被解析?
答:页面本身很大是可以的,但是商场、安居客等流量很大,所以没问题。在我刚才提到的例子中,你每次都关注一个新的链接,随意去掉下面的参数不会影响这个网页的正常访问。这绝对是个问题。
问题:刚才说了对URL的长度有要求。对每段的长度,也就是目录名,有什么要求吗?
答案:没有要求。我们要求URL从www开始到结束,总长度不能超过1024字节。
问:网站中的重复内容如何判断?如果文本内容相同,结构不同,是否视为重复?
答案:重复
Q:假设整个页面都是Flash,如果我隐藏了一些栏目或者最新的内容,不影响美观,隐藏起来。可以用隐藏属性提取吗? CSS 可能吗?
答:hidden 可以提,但如果是评论,就无所谓了。 CSS 不能。
问:页面大小不超过 1 兆字节。是指页面压缩之前还是之后。
答案:页面压缩后,不能超过1兆。
问:我的网站信息过期了,网页返回200,会被处罚吗?为什么?
回答:用户在搜索结果中点击了你的结果,引导到你的网站,但是没有什么可看的,对用户没有用。百度当然不喜欢。
Q:现在我们有很多网站,为了让用户觉得有趣,在内容没了的时候放一张图片,写一些有趣的文字,“工程师在哪里?”对百度友好吗?
答案:最好不要使用它。我知道该网站希望百度将内容识别为死链接,但识别死链接存在准确性和召回风险。
问:我们的团购网站确实有一个过期的团购页面,会被处罚吗?
答:如果音量特别大,点击量很大,就会有惩罚。其中一些可以被分析为内容中的死链接。如果不能分析,就会被其他一些策略挖出来。会有这样的问题。
Q:我刚才说信息内容页面有很好的发布时间。如果页面上没有时间怎么办?
回答:然后我们经常会根据当时捕捉到的时间做出判断。
“robots.txt只允许抓取html页面,防止抓取垃圾信息!”
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-08-03 20:12
今天给大家详细讲解“robots.txt只允许抓取html页面,防止垃圾邮件!”在网站过去的几年里,我们经常遇到客户。 网站被挂马,原因是不利于维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管有没有漏洞和后门,所以造成,后来被挂马入侵,产生大量垃圾非法页面,被百度抓取。
一些被挂马的人很惊讶,为什么他们的网站正常内容不是收录,而是百度收录垃圾页面的非法内容很大。事实上,这很简单。在哪些非法页面,蜘蛛池链接,这会导致这个问题。即使我们解决了网站被挂马的问题,网站上的垃圾页面也会继续被百度抓取,死链需要很长时间才能生效。这个时候我该怎么办?我们可以使用robots.txt来解决这个问题。
实现原理:
我们可以使用robots.txt来限制用户只能抓取HTMl页面文件,我们可以限制指定目录中的HTML,阻止指定目录中的HTML文件。让我们为robots.txt制作一个写入方法。你可以自己研究一下。实际上将它应用到你的网站。
可以解决的挂马形式:
这个robots写规则主要是针对上传类型的挂马,比如添加xxx.php?=dddd.html;xxxx.php;上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#Allow homepage root directory/ 并且不带斜杠,例如
允许:/$
允许:$
#File 属性设置为禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许抓取静态生成的目录,这里是允许抓取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止爬马挂马的html页面)规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
#Single entry is allowed, only allowed, with?不能。index,其他的html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许网站上,图片截取。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述内容外,禁止抓取网站中的任何文件或页面。
禁止:/
比如我们网站挂了的时候,邮戳通常是一样的。 php?unmgg.html,或 dds=123.html。这种,只要收录网址?当然,你可以在,= 的符号中添加更多的格式,比如带下划线“_”,你可以使用“Disallow:/_*.html$”来防御。
再比如:马的链接是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则是告诉搜索引擎,只要是seozt目录下的html文件,都是爬不出来的。你听得懂么?其实很简单。你只需要熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的核心目录、php目录和模板目录。会浪费大量的目录资源。对了,如果我们屏蔽目录,就会在robots.txt中暴露我们的目录,其他人就可以分析了。我们正在使用什么样的程序,对吧?这时候我们采用反向模式操作,直接允许html,拒绝其他一切,这样就可以有效的避免暴露目录的风险,对,好吧,今天就解释到这里,希望大家能理解。 查看全部
“robots.txt只允许抓取html页面,防止抓取垃圾信息!”
今天给大家详细讲解“robots.txt只允许抓取html页面,防止垃圾邮件!”在网站过去的几年里,我们经常遇到客户。 网站被挂马,原因是不利于维护网站,或者使用市面上开源的cms,直接下载源码安装使用,不管有没有漏洞和后门,所以造成,后来被挂马入侵,产生大量垃圾非法页面,被百度抓取。
一些被挂马的人很惊讶,为什么他们的网站正常内容不是收录,而是百度收录垃圾页面的非法内容很大。事实上,这很简单。在哪些非法页面,蜘蛛池链接,这会导致这个问题。即使我们解决了网站被挂马的问题,网站上的垃圾页面也会继续被百度抓取,死链需要很长时间才能生效。这个时候我该怎么办?我们可以使用robots.txt来解决这个问题。
实现原理:
我们可以使用robots.txt来限制用户只能抓取HTMl页面文件,我们可以限制指定目录中的HTML,阻止指定目录中的HTML文件。让我们为robots.txt制作一个写入方法。你可以自己研究一下。实际上将它应用到你的网站。
可以解决的挂马形式:
这个robots写规则主要是针对上传类型的挂马,比如添加xxx.php?=dddd.html;xxxx.php;上传不会被百度抓取,降低网络监控风险。
#适用于所有搜索引擎
用户代理:*
#Allow homepage root directory/ 并且不带斜杠,例如
允许:/$
允许:$
#File 属性设置为禁止修改(固定属性,入口只能是index.html/index.php)
允许:/index.php
允许:/index.html
#允许抓取静态生成的目录,这里是允许抓取页面中的所有html文件
允许:/*.html$
#禁止所有带参数的html页面(禁止爬马挂马的html页面)规则可以自己定义
禁止:/*?*.html$
禁止:/*=*.html$
#Single entry is allowed, only allowed, with?不能。index,其他的html,带符号,是不允许的。
允许:/index.php?*
#允许资源文件,允许网站上,图片截取。
允许:/*.jpg$
允许:/*.png$
允许:/*.gif$
#除上述内容外,禁止抓取网站中的任何文件或页面。
禁止:/
比如我们网站挂了的时候,邮戳通常是一样的。 php?unmgg.html,或 dds=123.html。这种,只要收录网址?当然,你可以在,= 的符号中添加更多的格式,比如带下划线“_”,你可以使用“Disallow:/_*.html$”来防御。
再比如:马的链接是一个目录,一个普通的URL,比如“seozt/1233.html”,可以加一条禁止规则“Disallow:/seozt/*.html$”,这个规则是告诉搜索引擎,只要是seozt目录下的html文件,都是爬不出来的。你听得懂么?其实很简单。你只需要熟悉它。
这种写法的优点是:
首先,蜘蛛会爬取你的核心目录、php目录和模板目录。会浪费大量的目录资源。对了,如果我们屏蔽目录,就会在robots.txt中暴露我们的目录,其他人就可以分析了。我们正在使用什么样的程序,对吧?这时候我们采用反向模式操作,直接允许html,拒绝其他一切,这样就可以有效的避免暴露目录的风险,对,好吧,今天就解释到这里,希望大家能理解。
什么是网站抓取频次?的工作原理是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-03 20:11
做SEO优化的人都知道搜索引擎的工作原理。也许你在看搜索引擎的工作原理的时候听说过网站爬取频率。那么网站的爬取频率是多少呢?当前爬行频率过高或过小怎么办?下面,小编为大家讲解一下,希望对大家有所帮助。
一、网站什么是爬行频率?
1、网站爬取频率是搜索引擎在单位时间内(天级别)爬取网站服务器的总次数。如果搜索引擎爬取站点过于频繁,很可能会导致服务器不稳定。百度蜘蛛会根据网站内容更新频率、服务器压力等因素自动调整抓取频率
2、百度蜘蛛会根据网站服务器压力自动调整爬取频率
3、建议您仔细调整爬取频率的上限。如果抓取频率太小,会影响百度蜘蛛的网站的收录
二、当前抓取频率过高怎么办?
您可以按照以下顺序排查频率过高的问题:
1、如果您觉得百度蜘蛛抓取了一个您认为没有价值的链接,请更新网站robots.txt以阻止抓取,然后进入robots工具页面生效。
2、如果百度蜘蛛的抓取影响您的网站正常访问,请到抓取频次上限调整页面调低抓取频次上限。
3、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
三、当前抓取频率太小怎么办?
您可以按照以下步骤排查和解决低频问题:
1、如果您设置了抓取频次上限,建议您先取消抓取频次上限设置,或者到抓取频次上限调整页面调整抓取频次上限。
2、如果您还没有设置抓取频次上限,建议使用抓取异常工具检查是否是抓取异常引起的。
3、如果还是觉得抓取量小,可能是你没有提交新链接。请到链接提交页面提交数据。
4、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
查看全部
什么是网站抓取频次?的工作原理是什么?
做SEO优化的人都知道搜索引擎的工作原理。也许你在看搜索引擎的工作原理的时候听说过网站爬取频率。那么网站的爬取频率是多少呢?当前爬行频率过高或过小怎么办?下面,小编为大家讲解一下,希望对大家有所帮助。
一、网站什么是爬行频率?
1、网站爬取频率是搜索引擎在单位时间内(天级别)爬取网站服务器的总次数。如果搜索引擎爬取站点过于频繁,很可能会导致服务器不稳定。百度蜘蛛会根据网站内容更新频率、服务器压力等因素自动调整抓取频率
2、百度蜘蛛会根据网站服务器压力自动调整爬取频率
3、建议您仔细调整爬取频率的上限。如果抓取频率太小,会影响百度蜘蛛的网站的收录
二、当前抓取频率过高怎么办?
您可以按照以下顺序排查频率过高的问题:
1、如果您觉得百度蜘蛛抓取了一个您认为没有价值的链接,请更新网站robots.txt以阻止抓取,然后进入robots工具页面生效。
2、如果百度蜘蛛的抓取影响您的网站正常访问,请到抓取频次上限调整页面调低抓取频次上限。
3、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
三、当前抓取频率太小怎么办?
您可以按照以下步骤排查和解决低频问题:
1、如果您设置了抓取频次上限,建议您先取消抓取频次上限设置,或者到抓取频次上限调整页面调整抓取频次上限。
2、如果您还没有设置抓取频次上限,建议使用抓取异常工具检查是否是抓取异常引起的。
3、如果还是觉得抓取量小,可能是你没有提交新链接。请到链接提交页面提交数据。
4、以上方法均不能解决问题,请到百度站长平台反馈中心反馈。
网站优化蜘蛛有规则吗?百度算法规则不断调整原因
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-03 04:26
网站优化越来越受到企业的青睐,但现在百度算法规则不断调整,导致网站受到影响。首先我们要让搜索引擎喜欢我们的网站,然后网站optimization。抓取有什么规则吗?
一、Spider 的爬取规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区进行数据补充。通过程序计算后,分类到不同的检索位置,搜索引擎就形成了稳定的收录ranking。在这样做的过程中,蜘蛛抓取的数据不一定是稳定的。很多都是经过程序计算后被其他好的网页挤出来的。简单来说,蜘蛛不喜欢它,不想爬。这个页面。
蜘蛛的味道很独特。它抓取的网站很不一样,也就是我们所说的原创文章,只要你网页上的文章原创度很很被蜘蛛爬行的概率,这就是为什么越来越多的人要求文章原创度。
只有经过这样的检索,数据的排名才会更加稳定,现在搜索引擎已经改变了策略,正在慢慢地逐步过渡到补充数据。它喜欢将缓存机制和补充数据这两个点结合起来。使用,这也是收录在进行搜索引擎优化的时候越来越难的原因。我们也可以理解,今天有很多网页没有收录排名,但过一段时间就会有收录排名。 .
二、增加网站爬取的频率
1、网站文章的质量提升
虽然做SEO的人都知道怎么提高原创文章,但是搜索引擎有一个不变的道理,那就是质量和内容稀缺性这两个要求永远不会满足。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛所喜爱。
2、update 网站文章的频率
当内容满足时,正常的更新频率是关键。这也是提升网页抓取的法宝。
3、网站Speed 不仅会影响蜘蛛,还会影响用户体验
蜘蛛访问时,如果没有障碍,加载过程可以在一个合理的速度范围内,要保证蜘蛛在网页中能够顺利爬行,不应该有加载延迟。如果你经常遇到这种问题,那么蜘蛛就不会喜欢这个网站,它会减少爬行的频率。
4、Improve 网站品牌知名度
如果你经常上网一头雾水,就会发现问题。当一个非常知名的品牌推出一个新网站时,它会去一些新闻媒体进行报道。新闻源站报道后,会加入一些品牌词内容。就算没有target之类的链接,影响这么大,搜索引擎也会抓取这个网站。
5、选择公关高的域名
PR 是一个老式的域名,所以它的权重一定很高。即使你的网站长时间没有更新,或者是一个全封闭的网站页面,搜索引擎也会随时抓取等待。更新内容。如果一开始就选择使用这样的老域名,重定向也可以发展成真正的运营域名。
三、优质外链
如果想让搜索引擎更加重视网站,你必须明白,搜索引擎在区分网站权重时,会考虑其他网站有多少链接会链接到这个网站的,外链质量如何,外链数据如何,外链网站的相关性如何,这些因素都是百度考虑的。一个高权重的网站外链质量应该也很高。如果外链质量达不到,权重值就上不去。所以站长要想提高网站的权重值,一定要注意提高网站的外链质量。这些都是很重要的,我们在链接外链的时候要注意外链的质量。
四、优质内链
百度的权重值不仅取决于网站的内容,还取决于网站内部链的构建。百度搜索引擎勾选网站时,会按照网站、网站'S内页锚文本链接等导航进入网站内页。 网站的导航栏可以适当的找到网站的其他内容。 网站的内容中应该有相关的锚文本链接,这样不仅方便蜘蛛爬行,还能降低网站的跳出率。所以网站的内部链接也很重要。如果网站的内部链接做得好,蜘蛛会在收录你的网站,因为你的链接不仅仅是收录你的一个网页,你也可以收录链接的页面。 查看全部
网站优化蜘蛛有规则吗?百度算法规则不断调整原因
网站优化越来越受到企业的青睐,但现在百度算法规则不断调整,导致网站受到影响。首先我们要让搜索引擎喜欢我们的网站,然后网站optimization。抓取有什么规则吗?
一、Spider 的爬取规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区进行数据补充。通过程序计算后,分类到不同的检索位置,搜索引擎就形成了稳定的收录ranking。在这样做的过程中,蜘蛛抓取的数据不一定是稳定的。很多都是经过程序计算后被其他好的网页挤出来的。简单来说,蜘蛛不喜欢它,不想爬。这个页面。
蜘蛛的味道很独特。它抓取的网站很不一样,也就是我们所说的原创文章,只要你网页上的文章原创度很很被蜘蛛爬行的概率,这就是为什么越来越多的人要求文章原创度。
只有经过这样的检索,数据的排名才会更加稳定,现在搜索引擎已经改变了策略,正在慢慢地逐步过渡到补充数据。它喜欢将缓存机制和补充数据这两个点结合起来。使用,这也是收录在进行搜索引擎优化的时候越来越难的原因。我们也可以理解,今天有很多网页没有收录排名,但过一段时间就会有收录排名。 .
二、增加网站爬取的频率
1、网站文章的质量提升
虽然做SEO的人都知道怎么提高原创文章,但是搜索引擎有一个不变的道理,那就是质量和内容稀缺性这两个要求永远不会满足。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是被蜘蛛所喜爱。
2、update 网站文章的频率
当内容满足时,正常的更新频率是关键。这也是提升网页抓取的法宝。
3、网站Speed 不仅会影响蜘蛛,还会影响用户体验
蜘蛛访问时,如果没有障碍,加载过程可以在一个合理的速度范围内,要保证蜘蛛在网页中能够顺利爬行,不应该有加载延迟。如果你经常遇到这种问题,那么蜘蛛就不会喜欢这个网站,它会减少爬行的频率。
4、Improve 网站品牌知名度
如果你经常上网一头雾水,就会发现问题。当一个非常知名的品牌推出一个新网站时,它会去一些新闻媒体进行报道。新闻源站报道后,会加入一些品牌词内容。就算没有target之类的链接,影响这么大,搜索引擎也会抓取这个网站。
5、选择公关高的域名
PR 是一个老式的域名,所以它的权重一定很高。即使你的网站长时间没有更新,或者是一个全封闭的网站页面,搜索引擎也会随时抓取等待。更新内容。如果一开始就选择使用这样的老域名,重定向也可以发展成真正的运营域名。
三、优质外链
如果想让搜索引擎更加重视网站,你必须明白,搜索引擎在区分网站权重时,会考虑其他网站有多少链接会链接到这个网站的,外链质量如何,外链数据如何,外链网站的相关性如何,这些因素都是百度考虑的。一个高权重的网站外链质量应该也很高。如果外链质量达不到,权重值就上不去。所以站长要想提高网站的权重值,一定要注意提高网站的外链质量。这些都是很重要的,我们在链接外链的时候要注意外链的质量。
四、优质内链
百度的权重值不仅取决于网站的内容,还取决于网站内部链的构建。百度搜索引擎勾选网站时,会按照网站、网站'S内页锚文本链接等导航进入网站内页。 网站的导航栏可以适当的找到网站的其他内容。 网站的内容中应该有相关的锚文本链接,这样不仅方便蜘蛛爬行,还能降低网站的跳出率。所以网站的内部链接也很重要。如果网站的内部链接做得好,蜘蛛会在收录你的网站,因为你的链接不仅仅是收录你的一个网页,你也可以收录链接的页面。

