Python爬虫39-100天津市科技计划项目成果库(组图)
优采云 发布时间: 2021-08-18 03:29Python爬虫39-100天津市科技计划项目成果库(组图)
阿里巴巴云>云栖社区>主题图>W>网站page 数据抓取
推荐活动:
更多优惠>
当前主题:网站paged 数据捕获并添加到采集夹
相关主题:
网站Paging 数据抓取相关博客,查看更多博客
Python爬虫入门教程29-100手机APP数据抓取pyspider
作者:Dream Eraser 1318 次浏览和评论:02 年前
1.手机APP资料----写在前面,继续练习pyspider的使用。最近搜了一下这个框架的一些使用技巧,发现文档其实挺难懂的,不过暂时没有障碍使用,我猜想,大概写5个这个框架的教程吧。今天的教程增加了图片处理,大家可以专心学习。 2.
阅读全文
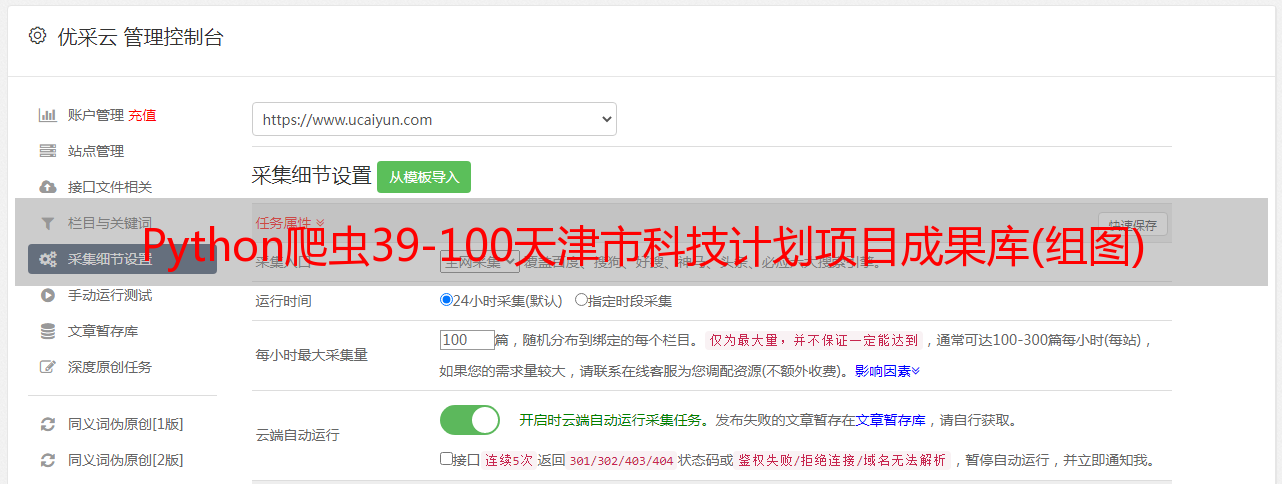
Python爬虫入门教程39-100天津市科技计划项目成果数据库数据采集scrapy
作者:Dream Eraser 766 次浏览和评论:02 年前
今天说爬之前爬的原因本来不打算抢这个网站的。无意中看到微信群里有人问这个网站。我想看看有什么特别复杂的。下来后发现这个网站,除了卡慢,经常宕机,好像没什么特别的……爬取网址
阅读全文
Python 捕获欧洲足球联赛数据用于大数据分析
作者:青山无名12610人查看评论:14年前
Background Web Scraping 在大数据时代,一切都必须用数据说话。大数据的处理过程一般需要以下几个步骤:数据的采集以及数据的清洗、提取、变形和加载。分析、探索和预测数据的呈现方式。首先要做的是获取数据,提取有效数据,用于下一步分析
阅读全文
使用 Scrapy 抓取数据
作者:于客 6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:嗯 99251585 浏览和评论:03 年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来我们看看如何将抓取到的内容保存在一个普通的m
阅读全文
Scrapy爬虫成长日记会将爬取到的内容写入mysql数据库
作者:无声胜有生 732人浏览评论:06年前
我尝试scrapy抓取博客园的博客(可以查看scrapy爬虫成长日记的创建项目-提取数据-保存为json格式数据),但是之前抓取的数据保存为json格式的文本文件这显然不能满足我们日常的实际应用。接下来,我们来看看常见的如何保存抓取到的内容
阅读全文
“全民K歌”的秘诀是什么? 网站数据采集的数据分析
作者:反向一睡2103人浏览评论:03年前
最近看到身边好几个朋友在手机上用“国民K歌”软件唱歌,使用频率还是很高的,所以想看看国民是个什么样的用户K歌平台都喜欢。用户?他们有什么样的特点。然后进行数据分析,加强你的分析思维和实践能力。这个过程我会分四个部分来写:数据采集、数据清洗、数据
阅读全文
使用MVCPager通过分页方式在博客园首页展示数据
作者:建筑师郭果940人浏览评论:08年前
在上一篇博客中,我们使用正则表达式来抓取博客园的列表数据。我用正则表达式抓取了博客园的部分数据作为测试数据。现在测试数据也可用了,数据应该分页显示。 NS。但是如何分页让我犹豫了几分钟。我应该写javascript自定义分页显示,还是用现成的控件来做分页
阅读全文

